- 投稿日:2020-09-19T23:51:54+09:00
【Golang】Go言語の配列の基礎
最近Go言語の勉強を初めました!
今回は配列の基礎について復習したので備忘録として簡単にまとめさせていただきます。
書き方
1. var 変数名 [長さ]データ型 2. var 変数名 [長さ]データ型 = [長さ]データ型{初期値A, 初期値B} 3. 変数名 := [...]データ型{初期値A, 初期値B}例
package main import "fmt" func main() { var a [3]int a[0] = 100 a[1] = 200 a[2] = 300 fmt.Println(a) //=> [100 200 300] var b [3]int = [3]int{100, 200, 300} b = append(b, 400) //=> ERROR fmt.Println(b) //=> [100 200 300] c := [...]int{100, 200, 300} fmt.Println(c) //=> [100 200 300] }配列は長さが決められており、appendなどを用いて要素を追加しようとするとエラーになります。
実際は次に説明するスライスを使いことが多いようです。スライスは配列の長さを変更することができます。スライスの書き方
1.var 変数名 []型 2.var 変数名 []型 = []型{初期値1, ..., 初期値n} 3.変数名 := 配列[start:end]package main import "fmt" func main() { n := []int{1, 2, 3, 4, 5, 6} fmt.Println(n) //=> [1 2 3 4 5 6] fmt.Println(n[2]) //=> 3 fmt.Println(n[2:4]) //=> [3 4] fmt.Println(n[:2]) //=> [1 2] fmt.Println(n[2:]) //=> [3 4 5 6] fmt.Println(n[:]) //=> [1 2 3 4 5 6] n[2] = 100 fmt.Println(n) //=> [1 2 100 4 5 6] var board = [][]int{ []int{0, 1, 2}, []int{3, 4, 5}, []int{6, 7, 8}, } //入れ子 fmt.Println(board) //=> [[0 1 2] [3 4 5] [6 7 8]] n = append(n, 100) fmt.Println(n) //=> [1 2 100 4 5 6 100] }↑のようにスライスの要素を変更すると、その元となる入れるの要素も変更されている。
- 投稿日:2020-09-19T23:28:58+09:00
子プロセス、スレッドそして、goroutineの違い
はじめに
普段goroutineを使っている人も、Java.Threadとの違いや、そもそもプロセスやOSがどのような仕組みで並列処理をサポートしているかについて知らない人も多いと思うので、それについて自分の理解を話し口調でわかりやすくまとめました。
UnixOSに限定された挙動を一般的なOSの挙動のように扱っている箇所や、厳密な言葉の定義に外れたりしている箇所がございましたら、コメントでご指摘いただけると幸いです。そもそもプロセスとは何か
皆さんのパソコンでも複数のプロセスが起動していると思いますが、そもそもプロセスとは何なのか。
基本的には、プログラム実行の単位として、プロセスを定義しています。
というのも、マルチプログラミングにおいては、1つのCPUは特定のプログラムを実行することしかできない(PCをインクリメントすることによって一行ずつメモリから命令を読み込み、レジスタが実行するというコンピュータアーキテクチャの性質)という性質を克服するためには、実行したい複数のプログラムを管理する必要があったのです。
具体的には、どのプログラムを実行中で、どのプログラムはどこの行で中断していて、プログラムはどこのメモリ領域に退避させたのか。
という内容をOSが管理する必要があります。
この時に、それぞれのプログラムを区別する必要があったので、プロセス(またはタスク)という概念を導入しました。
それと同時に、プログラム側は、これらの仕組みを意識せず、自分専用のプロセッサが与えられたように振る舞って欲しいという設計から、Unixを含む多くのOSにおいて、プロセスに対して、ページを割り当てるという挙動をします。※ もっと厳密に言えば、デファクトスタンダートなっている「demand paging」というスケジューリングアルゴリズムにおいては、プロセスを立ち上げた時には実メモリは確保せずに、仮想メモリ領域のみを確保します。実メモリが存在するかどうかの存在ビットというのを作ることによっています。
プログラムが存在ビットが0であるようなメモリ領域を参照したときに、page faultが起きることで、割り込みルーチンが走り、空きメモリ領域を割り当てるという挙動が走ります。
仮想ページングテーブルによって、こういった実メモリの節約や、補助記憶装置を用いたスワップの挙動を実現しています。
厳密には、実メモリが確保されるのはプログラム参照されるタイミングですが、メモリ領域自体が、プロセスごとに管理されています。
プロセスがkillされれば、そのプロセスに対応するようなメモリ領域も全て解放されます。プロセスを構成するもの
- プロセッサ
- メモリ領域
- 開かれているプログラムファイル
- 親プロセスの情報
- 使用しているユーザーの情報
- プロセスの状態
プロセススケジューラは、プロセスの状態を確認することで、どのプロセスが実行中でどのプロセスが実行待ちかを管理することができるようになっている。
ここでは、プロセスの状態について、少しだけ説明を補足する。Unix系のシステムでは、プロセスディスクリプターと呼ばれていて、特にその ステートメンバには、以下のような識別子を用いて管理されている。
- TASK_RUNNING: 実行可能な状態。CPUが空いていれば実行できる。
- TASK_UNINTERRUPTABLE: 割り込み不能な待ち状態。ディスクI/O待ちなど、短時間で復帰するもの。
- TASK_INTERRUPTABLE: 割り込み可能な待ち状態。ユーザの入力待ちなど、復帰時間が予測できないもの。
- TASK_STOPPED: 実行中断になった状態。リジュームされるまでスケジューリングされない。
- TASK_ZOMBIE: ゾンビプロセス。子プロセスがexitして親プロセスにwaitされていないもの。
ちなみに、一般にサーバーの負荷の指標として用いられているload_averageの定義は、
ready queueに入っているプロセスのうち、TASK_INTERRUPTABLE と TASK_UNINTERRUPTABLE のステートが割り振られているプロセスの数を物理CPUの数で割ったものである。並列にプログラムを動かすために
親プロセスをforkすることで、並列に動く別のプロセスを生成する方法が提案された。
これが、子プロセスと呼ばれるプロセスである。
子プロセスを生成する際には、親プロセスをforkする。
forkという関数の挙動は、子プロセスようのメモリ領域を確保したのちに、親プロセスのデータセグメントに書き込まれた変数などをコピーして、同じものにする。
fork関数から復帰した時から、別々にプログラムが走るようにすることで、並列に動作させることができるようになる。ただし、全く個々のプロセスではなく、子プロセスは親プロセスを把握しているし、プログラム領域はコピーせず同じ番地を参照する。
要点をまとめると、
- 親子で同じプログラムセグメントのプログラムを参照している
- データセグメントはコピーすることで生成され、それぞれ別のメモリを参照している。子プロセスの課題
Unixなどの多くのOSにおけるプロセスでは、いくつかのパフォーマンス的なオーバーヘッドが課題として挙げられている。
- プロセスを生成する際に上記の構成を確保するために、メモリ領域を確保する必要がある。
- アドレス空間が別物であるので、メモリを共有することで、変数の受け渡しができない。プロセス間通信が必要になる。
- プロセスを切り替える際には仮想アドレスと物理アドレスのマッピングをしているMMU(Memory Management Unit)のキャッシュをクリアする必要があるこのような課題を解決するために、一つのプロセスが複数の処理を制御できるような仕組みであるスレッドが作られた。
スレッドの仕組み
一つのプロセスの中で動く仕組みがプロセスである。
そのために、プロセスもつメモリ領域の中に、スレッドのメモリ領域を作成する必要があるので、
- プログラムカウンタ
- スタックポインタ
- スタック領域のデータ
はスレッドに割り振られるのだが、
すでにプロセスによって、確保されているメモリの中に作成するので、新たに確保する必要がなく、
プロセス切り替えの必要もないので、コンテキストスイッチにかかるオーバーヘッドがとても小さくすむ。
また、プロセス間通信を用いなくても、メモリを共有することで通信を行うことができる。
これは、同一プロセス内に複数のスレッドを立てることで、プロセスのもつヒープ領域の変数には、全てのスレッドがアクセスできることに起因する。
その代わり、全ての変数がスレッドセーフであるように工夫しないと、意図しない変更が他のプロセスによって加えられることがあるので、注意が必要である。スレッドの課題
スタックサイズが固定長
超大規模な並列処理を行いたいとすると、全てのスレッドに対して、スタック領域が必要になる。
スタック領域というのは、ローカル変数や、サブルーチン情報が書かれる領域で、普遍的なプログラムでは大きなメモリを消費しないのだが、固定長なものとして実装されている。
Linuxでは、デフォルトで、スレッド一つあたり2MBと設定されていて、変更することが可能であるが、減らしすぎると、スタックオーバーフローを起こしてしまう可能性が高くなってしまうので、減らすことも難しい。
仮に、2MBと仮定すると、たかが2000のスレッドで4GBのRAMを消費することになる。スレッドの切り替えにコストがかかる
新たにスレッドを生成するのは、プロセスを生成するのに比べ、メモリ領域を割り当てる必要がないから、コストが低いという話をしたが、大規模な並列処理を行う場合は話が大きく変わる。
スレッドはOSの仕組みであり、OSカーネル上で動作するため、システムコール関数を発行する、完全なコンテキストスイッチが必要で、ここにコストがかかるため、スレッドの切り替えにもコストがかかりる。
仮に、スレッドの切り替えにかかるのが、100msだとすれば、一秒間に10万回しか切り替えが行えないことになる。
これが意味することは、10万のスレッドを動作させるのに、秒単位の遅れがでてしまうことだ。goroutineの解決策
動的なスタックサイズ
スレッドでは、2MBで固定していた、スタックサイズであるが、goでは、動的に変わるため、最小のスタックサイズは2KBに設定されている。
これによって、単純計算で1000倍のメモリ効率でgoroutineは生成できることになる。
(参考)
https://medium.com/a-journey-with-go/go-how-does-the-goroutine-stack-size-evolve-447fc02085e5
https://blog.cloudflare.com/how-stacks-are-handled-in-go/独自のスケジューラを持っている
goroutineのスケジューラはm:nスレッドを用いているため、ユーザーモードのまま、goroutineの切り替えができ、コンテキストスイッチの必要が無いので、
スレッドの再スケジュールより低コストにスケジューリング可能です。
また、gotoutineスケジューラはチャネルと統合されていて、待ち状態のgoroutineに対して、実行することはなく、最適にプロセッサを割り当てるような工夫がプログラムレベルで行われています。結果
goroutineでは、これまでのスレッドによる並行処理では絶対に出せないようなパフォーマンスを実現しています。
goroutineと仲良くなれるように勉強を頑張ります。(補足) メモリ領域の説明
スタック領域
一般にコールスタック・制御スタックと呼ばれている。LIFO方式で構成されプログラムの実行中サブルーチンの情報を記憶しておくメモリ領域。
サブルーチン終了後の戻りアドレスや局所変数などを保持する。ヒープ領域
mallock関数によって、動的に確保することができる領域で、プロセスがメモリが足りない場合などに、必要に応じて新たにメモリを確保することができる。
動的にメモリ取得・解放を繰り返すことによりメモリ上にどこからも参照されない領域(ガベージ)が発生する。テキストセグメント
プログラムファイルがオンメモリに乗っかる必要があるので、その領域。
プログラムカウンタの指し示す行をフェッチしてきて実行しするような挙動をとる。データセグメント
プロセッサのデータエリア。
上記のプログラムカウンタや、アキュミュレータ上のメモリでは演算が遂行できない場合に用いられるスタックポインタなどが主に該当する。(補足) コンテキストスイッチの挙動
コンテキストスイッチでは、実行中のプロセスの状態を何らかの方法で保存し、後にそのプロセスを再開する際にその状態を復元して、正常に実行を継続できるようにしなければならない。
プロセスの状態には、そのプロセスが使用し得る全てのレジスタ(特にプログラムカウンタ)や、プロセスの実行に必要となるオペレーティングシステム固有の情報が含まれる。多くの場合、これらのデータは1つのデータ構造として保存される。
プロセスを切り替えるためには、実行中のプロセスの状態を表すデータ構造を作成し、保存しなければならない。このデータは、カーネルメモリ上にあるプロセスごとに割り当てられるスタックか、あるいはオペレーティングシステムによって定義された固有のデータ構造に保存される。
- 投稿日:2020-09-19T23:11:35+09:00
「Goの静的解析ツール開発」を支える技術
はじめに
タイトル大きく出過ぎたかな…と本編を書く前から感じてます。さんぽしです
最近、先日のインターンをきっかけにGoの静的解析ツールの開発を行っています。
これは「えっ、静的解析ツール開発って難しくない?」「どうやって作ったの?」という記事です
- Goの静的解析ツール開発の流れ
- 具体的に開発したGoの静的解析ツールを元に解説
という流れで進めていきます。
いくつかの静的解析ツールを作成しましたが、今回は以下の
wastedassignという静的解析ツールを例にしていきますそもそもどういうツールなの
題材にする静的解析ツールを軽く紹介します
wastedassignは無駄な代入を発見してくれる静的解析ツールです。
wastedassignでは主に
- 代入されたけどreturnまでその代入された値が使用されることはなかった
- 代入されたけど代入された値が用いられることなく、別の値に変更された
と言った二種類の無駄な代入を検出します。
Golangは完全な未使用変数は教えてくれるけど、「定義されてから一度使われている変数に対する再代入&その後未使用なもの」は教えてくれないよね。というモチベです
以下サンプルです
sample.gopackage a func f() { useOutOfIf := 0 // "wasted assignment" err := doHoge() if err != nil { useOutOfIf = 10 // "reassigned, but never used afterwards" return } err = doFuga() // "reassigned, but never used afterwards" useOutOfIf = 12 println(useOutOfIf) return }コメントのように、このコードに対しては3回ツールによる警告が行われます。
- 一つ目はどのルートを通っても
useOutOfIfがもう一度定義されるので1行目で定義する必要性がない- 二つ目は
useOutOfIfに対して再代入が行われているが、その後すぐにreturnされているので再代入の必要性がない- 三つ目は
doHoge()の返り値として受け取った変数errを使いまわしてdoFuga()のエラーを受け取っているが、その後使用されていないので再代入の必要性がない以下のようなケースに役立ちます
- 無駄な代入文を省くことによる可読性アップ
- 無駄な再代入を検出することによる使用忘れの確認
前者に関しては必ずしも可読性がアップするかというと議論の余地はあるかもしれませんが、個人的には使用しないのであればブランク変数で受け取るなりした方が読む方としては明示的に使わないということがわかり、読みやすいと思います。
また、使用しないことが明示的にわかることで、
- なぜ使用しないのか
- 関数の返り値として返す必要がそもそもないのではないか(上記Sampleで言うと、doFuga()はそもそもエラーを返す必要がないのではないか
などの議論が生まれるきっかけとなることを期待します
Goの静的解析について
と言ったツールの宣伝はさておき…
他の言語の静的解析事情に詳しいわけではないですが、Goは静的解析の環境がかなり充実しています。
詳しくはインターンでも使用された資料(14章)や、インターンで講師を務めていただいた@tenntennさんの以下の記事をみるのが早いです(丸投げ
goパッケージで簡単に静的解析して世界を広げよう #golangそのためかなり静的解析ツールを作成する敷居は低いです。
本当に簡単なものを雑に作るだけであれば後述のskeletonを用いれば1時間もかからないと思いますskeletonを使用した静的解析ツールの開発の流れ
やっと本題です
そう言ったGoの充実したライブラリ達を用いて具体的にどのように実装して行ったのかを説明しつつ、Goにおける静的解析ツールの開発の流れを紹介します
skeletonという静的解析ツールの雛形を用意してくれる便利ライブラリがあります。
READMEを見てもらうのが正確ですが
$ skeleton sample sample ├── cmd │ └── sample │ └── main.go ├── go.mod ├── sample.go ├── sample_test.go ├── plugin │ └── main.go └── testdata └── src └── a ├── a.go └── go.modこのようにツールの雛形を作成してくれます
実際に静的解析のコードを書いていくのは以下の
sample.goになります、少し内容を覗いてみますsample.gopackage sample import ( "go/ast" "golang.org/x/tools/go/analysis" "golang.org/x/tools/go/analysis/passes/inspect" "golang.org/x/tools/go/ast/inspector" ) const doc = "sample is ..." // Analyzer is ... var Analyzer = &analysis.Analyzer{ Name: "sample", Doc: doc, Run: run, Requires: []*analysis.Analyzer{ inspect.Analyzer, }, } func run(pass *analysis.Pass) (interface{}, error) { inspect := pass.ResultOf[inspect.Analyzer].(*inspector.Inspector) nodeFilter := []ast.Node{ (*ast.Ident)(nil), } inspect.Preorder(nodeFilter, func(n ast.Node) { switch n := n.(type) { case *ast.Ident: if n.Name == "gopher" { pass.Reportf(n.Pos(), "identifier is gopher") } } }) return nil, nil }skeletonによって作成されるテンプレートでははじめに「
gophorという変数が使用されている箇所を見つける静的解析のコード」が入っていますまた、
testdata/src/a/a.goには以下のファイルが入っていますtestdata/src/a/a.gopackage a func f() { // The pattern can be written in regular expression. var gopher int // want "pattern" print(gopher) // want "identifier is gopher" }こちらはテストで静的解析の対象となるファイルです
コメントで// The pattern can be written in regular expression.とあるように、静的解析ツールの出力を期待する文字列を
want "pattern"という形で記述できます試しにテストを回してみましょう、skeletonで生成されたコードは何もいじらずともテストが回るようになっています
$ go test --- FAIL: TestAnalyzer (0.03s) analysistest.go:419: a/a.go:5:6: diagnostic "identifier is gopher" does not match pattern "pattern" analysistest.go:483: a/a.go:5: no diagnostic was reported matching "pattern" FAIL exit status 1 FAIL github.com/sanposhiho/sample 0.437sテストは落ちます、理由はテストファイルに
var gopher int // want "pattern"となっている行があるからですね
var gopher int // want "identifier is gopher"このように書き直すことでテストを通すことができます
$ go test PASS ok github.com/sanposhiho/sample 0.303s実際にskeletonを元にした静的解析ツールを開発する際は
sample.goをいじるgo testを回してみるを繰り返して開発していくことになります
他のファイルはほとんど触らずに開発が進められるので、skeletonに感謝です
「ソースコードから不要な代入を発見する静的解析ツール」を支える技術
ここから実際に開発した静的解析ツールの仕組みに触れていきます
ソースコードから†完全に理解した†状態になるには、先に前述の資料を読み、尚且つ僕のクソコードを読み解く読解力が必要になります。
なのでここではざっくりと雰囲気で説明していきます。再三の説明になりますが、このツールが発見する対象は
- 代入されたけどreturnまでその代入された値が使用されることはなかった
- 代入されたけど代入された値が用いられることなく、別の値に変更された
の二種類です。
ツールでは主に静的単一代入形式(ssa)での解析を行いました
大まかな流れとしては以下の仕組みになります
ssa.Storeの命令を探す- 見つかった箇所から飛びうるBlockへその変数が次に使用される箇所を探す
- 遷移の可能性があるBlockのいずれかで使用されている場合、「必要な代入」である
- 遷移の可能性があるどのBlockでも使用されることなく再代入されている場合、「不要な代入である」である
- 遷移の可能性があるどのBlockでも使用されることなく関数が終了(return)する場合、「不要な代入」である
急に難しくなりましたね、これらのパターンに関しては後半に図を用いた説明があるのでさらっと読み飛ばして頂いて構いません。
用語を簡単に補足します
ssa.Storeの命令
ssaパッケージの型の内の一つですごく噛み砕くと 変数への代入 です(ここでいう変数は実際にソースコードに定義されている変数とは異なり、詳しくは前述の資料を…)
Block
Wikipediaより引用
上記のようなグラフでソースコードを扱っていると考えるとわかりやすいです。Blockは↑でいうところのそれぞれの四角形です
具体的に実装を覗いてみよう
説明に戻り、上記の大まかな流れがどのように実装されているかをみていきます
ここからの説明は以下のソースコード全体を閲覧した方がわかりやすいと思います
ssa.Storeの命令を探す
こちらはシンプルにループとtype-switchを使用して探していきます
該当のコードは以下ですwastedassign.gofor _, sf := range s.SrcFuncs { for _, bl := range sf.Blocks { blCopy := *bl for _, ist := range bl.Instrs { blCopy.Instrs = rmInstrFromInstrs(blCopy.Instrs, ist) switch ist.(type) { case *ssa.Store: var buf [10]*ssa.Value for _, op := range ist.Operands(buf[:0]) { if (*op) != nil && opInLocals(sf.Locals, op) { if reason := isNextOperationToOpIsStore([]*ssa.BasicBlock{&blCopy}, op, nil); reason != notWasted { if ist.Pos() != 0 && !typeSwitchPos[pass.Fset.Position(ist.Pos()).Line] { wastedAssignMap = append(wastedAssignMap, wastedAssignStruct{ pos: ist.Pos(), reason: reason.String(), }) } } } } } } } }for文がネストしまくってます。
最終的にブロックのInstrsをtype-switchして*ssa.Storeを探していることがわかります細かい処理を説明していると長くなるので色々省略し、
isNextOperationToOpIsStoreが次の見つかった箇所から飛びうるBlockへその変数が次に使用される箇所を探すを行う関数です見つかった箇所から飛びうるBlockへその変数が次に使用される箇所を探す
isNextOperationToOpIsStoreの目的は
- 見つかった箇所から飛びうるBlockへその変数が次に使用される箇所を探す
- 探した結果に応じて適切なwastedReasonを返すです
大まかにこの関数の流れを説明します
- blsで渡ってきたBlockを一つ一つ見ていき、指定の変数(Store命令が発生していた変数)に対する命令を探す
- そのBlock内に命令がなかった場合はそのBlockの遷移先のBlock(
bl.Succs)をisNextOperationToOpIsStoreに渡して再帰的に調べるここからは以下の条件に別れます
- 遷移の可能性があるBlockのいずれかで使用されている場合、「必要な代入」である
- 遷移の可能性があるどのBlockでも使用されることなく再代入されている場合、「不要な代入である」である
- 遷移の可能性があるどのBlockでも使用されることなく関数が終了(return)する場合、「不要な代入」である
1. いずれかで使用
図で表現すると以下のようになります
この場合はt0に対するstore命令は必要なため報告の対象になりません
2. 再代入されてる
図で表現すると以下のようになります
この場合はどのルートを通っても使用されることはなく再代入が発生しているので「不要な代入である」であると報告されます
3. どこでも使用されず関数が終了
図で表現すると以下のようになります
returnまで探索してもt0は使用されないため、「不要な代入である」であると報告されます
※「あれ、Goって使われないのに代入されていたらエラー出してくれなかったっけ?」と思われた方もいるかと思いますが、以下のような再代入の場合にはGoは教えてくれません
コーナーケースへの対応が大変
Goはある程度シンプルな言語だとは思いますが、いくつかのコーナーケースが見つかり、一筋縄では行きませんでした
具体的には以下のコーナーケースに対応しました
終わりに
Goに標準で備わる静的解析に関する豊富なライブラリに加えてSkeletonを用いるとかなり簡単に静的解析ツールを行える
後半は少しややこしい実装の話になってしまいました。
実際のコードを覗くと少し難しく見えるかもしれないですが、本質的には再帰でフィールドを追っているだけであり、リファレンスなどを覗きながら実装をやってみるとかなり簡単に開発が行えることに気が付く…はず!です!静的解析ツールって敷居高く見えるけどそんなことないやん!となれば嬉しいです
記事内で何か間違っているところなりありましたらコメントやTwitterでそっと優しく教えてください
役立つサイト集
「プログラミング言語Go完全入門」の「完全」公開のお知らせ
→ こちらの14章が静的解析の回になりますgoパッケージで簡単に静的解析して世界を広げよう #golang
GoAst Viewer
→ wastedassignではメインでは使用しませんでしたが、Goのコードを入力すると、対応する抽象構文木(AST)を確認できますGo SSA Viewer
→ 上記のSSA版になります[番外編]紹介しなかった別の静的解析ツール
以下番外編です
Golangのソースに対して、さくっとデバッグ文を追加してくれるツールを公開しましたhttps://t.co/fdL3Vl2PEn
— さんぽし (@sanpo_shiho) September 5, 2020
全ての変数への代入文の後にデバッグ用の文が追加され、追加した全てのデバック文の削除も行うことができます#mercari_intern pic.twitter.com/x39JXzRUiy静的解析ツールというよりは静的解析を利用したツールというのが正しいかもしれません
ツイートにあるように変数の代入文の後にその変数をデバックする関数を入れてくれるというツールです。軽く仕組みを紹介
かなりシンプルな仕組みです。
こちらはSSA形式ではなくASTの形式で解析を行いました。wastedassignと似たような感じで変数の代入文を探して、その次の行にデバックの関数を差し込むという処理になります。
なぜSSAではなくAST?
- SSAまでの解析を必要としなかった
- ASTだと、
format.Nodeを使用してさくっとAST→ソースコードの変換ができると言った理由でした





- 投稿日:2020-09-19T19:51:22+09:00
簡易LISP処理系の実装例(Go言語版)
【他言語版へのリンク記事】簡易LISP処理系の実装例【各言語版まとめ】
この記事は,下記拙作記事のGo言語版を抜粋・修正したものを利用した,簡易LISP処理系("McCarthy's Original Lisp")の実装例をまとめたものです.
最低限の機能をもったLISP処理系の実装の場合,本体である評価器(eval)実装はとても簡単であり,むしろ,字句・構文解析を行うS式入出力やリスト処理実装の方が開発言語ごとの手間が多く,それが敷居になっている人向けにまとめています.
処理系の概要
実行例は次の通り.Go 1.11.6にて確認.
$ go run jmclisp.go (car (cdr '(10 20 30))) 20 $ go run jmclisp.go ((lambda (x) (car (cdr x))) '(abc def ghi)) def $ go run jmclisp.go ((lambda (f x y) (f x (f y '()))) 'cons '10 '20) (10 20) $ go run jmclisp.go ((lambda (f x y) (f x (f y '()))) '(lambda (x y) (cons x (cons y '()))) '10 '20) (10 (20 ())) $ go run jmclisp.go ((lambda (assoc k v) (assoc k v)) '(lambda (k v) (cond ((eq v '()) nil) ((eq (car (car v)) k) (car v)) (t (assoc k (cdr v))))) 'Orange '((Apple . 120) (Orange . 210) (Lemmon . 180))) (Orange . 210)実装内容は次の通り.
- "McCarthy's Original Lisp"をベースにした評価器
- 数字を含むアトムは全てシンボルとし,変数の値とする場合は
quote(')を使用- 構文として
quoteの他,condとlambdaが使用可能- 組込関数:
atomeqconscarcdr(内部でコンスセルを作成)- 真偽値は
t(真)およびnil(偽)=空リスト=Go言語自身のnil- エラーチェックなし,モジュール化なし,ガーベジコレクションなし
"McCarthy's Original Lisp"の詳細についてはまとめ記事を参照.ダイナミックスコープということもあり,実行例ではlambda式を
letrec(Scheme)やlabels(Common Lisp)などの代わりに使用しています.実装例
ソースコード一式
jmclisp.go// // JMC Lisp: defined in McCarthy's 1960 paper, // with S-expression input/output and basic list processing // package main import ( "fmt" "bufio" "os" "strings" ) // basic list processing: cons, car, cdr, eq, atom type NODE interface{}; type CONS struct { x NODE; y NODE; }; func cons(x NODE, y NODE) NODE { var r CONS; r.x = x; r.y = y; return NODE(r); } func car(s NODE) NODE { return s.(CONS).x; } func cdr(s NODE) NODE { return s.(CONS).y; } func eq(s1 NODE, s2 NODE) bool { return s1 == s2; } func atom(s NODE) bool { if (s == nil) { return true; } else { switch s.(type) { case string: return true; case bool: return true; default: return false; } } } // S-expression input: s_lex, s_syn func s_lex(s string) []string { for _, k := range "()'" { ks := string(k); s = strings.Replace(s, ks, " " + ks + " ", -1); } r := []string{}; for _, w := range strings.Split(s, " ") { if (w != "") { r = append(r, w); } } return r; } func s_syn(s []string, pos *int) NODE { t := s[*pos]; *pos = *pos - 1; if t == ")" { var r NODE = nil; for s[*pos] != "(" { if s[*pos] == "." { *pos = *pos - 1; r = cons(s_syn(s, pos), car(r)); } else { r = cons(s_syn(s, pos), r); } } *pos = *pos - 1; if *pos != -1 && s[*pos] == "'" { *pos = *pos - 1; return cons("quote", cons(r, nil)); } else { return r; } } else { if *pos != -1 && s[*pos] == "'" { *pos = *pos - 1; return cons("quote", cons(t, nil)); } else { return t; } } } // S-expression output: s_display func s_strcons(s NODE) { s_display(car(s)); sd := cdr(s); if sd == nil { fmt.Print(""); } else if atom(sd) { fmt.Print(" . ", sd); } else { fmt.Print(" "); s_strcons(sd); } } func s_display(s NODE) { if s == nil { fmt.Print("()"); } else if atom(s) { fmt.Print(s); } else { fmt.Print("("); s_strcons(s); fmt.Print(")"); } } // JMC Lisp evaluator: s_eval func caar(x NODE) NODE { return car(car(x)); } func cadr(x NODE) NODE { return car(cdr(x)); } func cadar(x NODE) NODE { return car(cdr(car(x))); } func caddr(x NODE) NODE { return car(cdr(cdr(x))); } func caddar(x NODE) NODE { return car(cdr(cdr(car(x)))); } func s_null(x NODE) bool { if eq(x, nil) { return true; } else { return false; } } func s_append(x NODE, y NODE) NODE { if s_null(x) { return y; } else { return cons(car(x), s_append(cdr(x), y)); } } func s_list(x NODE, y NODE) NODE { return cons(x, cons(y, nil)); } func s_pair(x NODE, y NODE) NODE { if s_null(x) && s_null(y) { return nil; } else if !atom(x) && !atom(y) { return cons(s_list(car(x), car(y)), s_pair(cdr(x), cdr(y))); } else { return nil; } } func s_assoc(x NODE, y NODE) NODE { if s_null(y) { return false; } else if eq(caar(y), x) { return cadar(y); } else { return s_assoc(x, cdr(y)); } } func s_eval(e NODE, a NODE) NODE { if eq(e, "t") { return true; } else if eq(e, "nil") { return false; } else if atom(e) { return s_assoc(e, a); } else if atom(car(e)) { if eq(car(e), "quote") { return cadr(e); } else if eq(car(e), "atom") { return atom(s_eval(cadr(e), a)); } else if eq(car(e), "eq") { return eq(s_eval(cadr(e), a), s_eval(caddr(e), a)); } else if eq(car(e), "car") { return car(s_eval(cadr(e), a)); } else if eq(car(e), "cdr") { return cdr(s_eval(cadr(e), a)); } else if eq(car(e), "cons") { return cons(s_eval(cadr(e), a), s_eval(caddr(e), a)); } else if eq(car(e), "cond") { return evcon(cdr(e), a); } else { return s_eval(cons(s_assoc(car(e), a), cdr(e)), a); } } else if eq(caar(e), "lambda") { return s_eval(caddar(e), s_append(s_pair(cadar(e), evlis(cdr(e), a)), a)); } else { fmt.Println("Error"); return nil; } } func evcon(c NODE, a NODE) NODE { r := s_eval(caar(c), a); switch r.(type) { case string: return s_eval(cadar(c), a); default: if r.(bool) { return s_eval(cadar(c), a); } else { return evcon(cdr(c), a); } } } func evlis(m NODE, a NODE) NODE { if s_null(m) { return nil; } else { return cons(s_eval(car(m), a), evlis(cdr(m), a)); } } // REP (no Loop): s_rep func s_rep(s string) { lr_s := s_lex(s); s_len := len(lr_s) - 1; rs := s_syn(lr_s, &s_len); r := s_eval(rs, nil); s_display(r); fmt.Println(); } func main() { i := bufio.NewScanner(os.Stdin); r := ""; i.Scan(); for i.Text() != "" { r = r + i.Text() i.Scan(); } s_rep(r); }解説
リスト処理:
conscarcdreqatom
先の記事よりそのまま抜粋.Go言語版については,S式入出力の元記事でも使用しています.S式字句解析:
s_lex,S式抽象構文木生成:s_syn
先の記事から,字句解析部を()および'の識別に変更.抽象構文木生成部については,元記事でもリスト処理関数でコンスセルによる構文木を生成しており,そこに,ドット対とクォート記号に対応するための記述を追加.S式出力:
s_display
S式出力部はs_displayとして新規に作成.処理結果のS式抽象構文木を表示するだけのものとして実装.評価器:
s_eval+ユーティリティ関数
"McCarthy's Original Lisp"をベースにs_eval関数およびユーティリティ関数を作成.オリジナルおよび他言語実装版との大きな違いは,『0以外のあらゆるデータ』を真として扱うことができないため,条件式から文字列が返ってきたら真とみなすよう,cond本体の処理を調整していること.REP (no Loop):
s_repおよびmain関数
s_lex→s_syn→s_eval→s_displayをまとめたs_repを定義.プログラム記述やbufio等を用いた入力の場合,二重引用符で囲んだ(LISP記述としての)文字列を複数行に分けて入力・記述することができないため,空行を入力するまで行単位の文字列入力を行い,結合してs_repに渡すよう記述.備考
記事に関する補足
- 評価器のみで約100行/2400バイトほど.全体で約240行/4800バイトほどなので,評価器部は半分程度といったところ.Go言語の場合,if文などで中括弧や改行が省略できないところがあるのと,今回はセミコロンをほぼ全て省略せずに記載したため,特に条件分岐が多い評価器で字数を稼いでしまってるという話が.
更新履歴
- 2020-09-19:初版公開
- 投稿日:2020-09-19T19:10:11+09:00
Go言語初心者がGo言語をさわってみた
Windowsユーザー&Goに初めて触れるor久々に触れる人が流し読む用のメモです。
使用しているGoのバージョンはgo1.15.2 windows/amd64で、エディタはAtomを使っています。・プログラミング言語「Go」
「Go」は2009年に発表されたGoogle発のプログラミング言語で、バージョン1.0が2012年に公開された、比較的最近登場した言語です。「Golang」や「Go言語」などと呼ばれていますが、正式名称は「Go」だそうです。Googleが開発しているだけあって、YouTubeなどのシステムはGoで構築されています。
Goは以下のような特長を備えています。
- 静的型付け
- コンパイルが速い
- タイプセーフかつメモリセーフ
- 並列処理が得意 (など...)
Goはモバイル向けのアプリ開発や、Webサーバー構築などの用途で採用されることの多い言語です。CやC++に迫る高速処理がウリで、GoroutineやChannelなどの機能を使えば同時並行で処理を進める(並列処理)ことができます。
なお、GoのデメリットについてはQiita内外の各所で議論されていますので、興味のある方は探してみて下さい。私はGo言語初心者なので、取り敢えず動けばOK、のスタンスです。
Goの文法については後で詳しく見ていきますが、C言語Likeに記述でき、あまり自由な書き方が許されていないことから、ソフトウェア等の共同開発に向いている言語と評価されています。Cを知らないPythonエンジニアなどにとっては習得に時間が掛かりそうですが、Cに慣れていればそれほど苦労せずコーディングできるようになると思います。
今回はテキストエディタ「Atom」でGoを動かしてみます。Atomは公式サイトからダウンロードできます。この記事ではAtomについては深く立ち入りません。Atomの詳しい使い方や設定方法については「ATOM Editor をそろそろ始めようか」に掲載されているブックマーク等を参考にしてみて下さい。
今回の主な目的はWindowsユーザーが手早くGoを使える環境を作ることです。書いて保存してコンパイルして実行...という手順を楽しみたい方はご自由にどうぞ...。Ubuntuをご利用の方は「Ubuntuに最新のGolangをインストールする」などをご覧下さい。
・Goを導入する手順
主にWindows向けに紹介します。
まずGoの公式サイトから、PCの環境に合った Go installer をダウンロードします。当方のPCの環境は Windows 10 Pro (バージョン 1903) なので、私は go1.15.2.windows-amd64.msi (116 MB) をダウンロードしました。
ダウンロードした.msiファイルを実行すると以下のような画面が出てきますので、[Next] を押しまくってデフォルトの設定のままインストールします。
Macなら.pkgファイルを開いてインストールする、もしくは
brew install goでインストールする。(詳しくは「他言語から来た人がGoを使い始めてすぐハマったこととその答え」を参照)
Linuxならtar -C /usr/local -xzf go1.15.2.linux-amd64.tar.gzとして.tar.gzファイルを解凍する。[finish] を押せば、以上でGoのインストールは完了です。コマンドプロンプトで
go versionと叩けば、go version go1.15.2 windows/amd64などと返ってきます。
あとはGoのパスを通せばAtom上で使えるようになります…が、デフォルト設定でインストールした場合は既にユーザー環境変数に「GOPATH」が追加されているはずです(不慮の事故を防止するため、GOPATHは普通は1つだけ指定しておきます)。デフォルトでは
C:\Users\name\goにパスが通っています。環境変数の確認方法は以下の通りです。
① コントロールパネルを開く(プログラム → Windowsシステムツール から選択できる)
② システムとセキュリティ → システム に移動
③ システムの詳細設定 をクリックしてプロパティを開く
④「環境設定」をクリック →「環境変数」をクリック以上でGoのパスが通ったので、Atom上でGoのスクリプトが動かせるようになりました。
Goをインストールしていない状態、もしくは、GoのPathが通っていない状態でGoのスクリプトを実行すると以下のようなエラーが出てきます。
'go' �́A�����R�}���h�܂��͊O���R�}���h�A ����”\�ȃv���O�����܂��̓o�b�` �t�@�C���Ƃ��ĔF������Ă��܂���BこれはAtomがGoの実行ファイルの場所を見つけられない時に出てくるエラーですが、上記の手順を踏む限り、このエラーには遭遇しないはずです。
・Goを使ってみる
テキストエディタとしてAtomを使う場合は「script」パッケージをインストールしておくと、[Ctrl + Shift + B] でスクリプトを実行することができるので便利です。冒頭でも述べましたがGoはコンパイラ型言語です。Atom上でGoスクリプトを実行する際はコンパイルする手間が掛かるので、レスポンスは多少遅くなります(プログラム自体が遅い訳ではありません)。
以下、Goの使用例とTipsを紹介していきます。
・ご挨拶 (Println関数, Print関数)
package main import "fmt" func main() { fmt.Println("Hello, world") } // Print 改行なし出力 // Println 改行あり出力fmt は入出力を制御するパッケージで、Print関数やPrintln関数によって文字列を表示できます。このとき
package main import "fmt" func main() { fmt.Print("Hello, "); fmt.Print("world!") } // 出力結果は Hello, world!セミコロンで繋げば出力を1行で表示することができます。C言語と似たような仕様です。
・Printf関数の取り扱い
package main import "fmt" func main() { fmt.Printf("%v\n", "apple") fmt.Printf("%v\n", 2020) fmt.Printf("%v\n", uint(2020)) fmt.Printf("%v\n", 12.345) fmt.Printf("%v\n", 2 + 1i) // 複素数 fmt.Printf("%v\n", "ぴえん?") fmt.Printf("%v\n", make(chan bool)) fmt.Printf("%v\n", new(int)) }出力結果apple 2020 2020 12.345 (2+1i) ぴえん? 0xc000014120 0xc000010098書式指定子がCと少し異なりますが、Printfが使えます。詳しい使い方については以下の記事をご参照ください。
・「fmt.Printfなんかこわくない」
・「【Go】print系関数の違い」・for文、if文の取り扱い
FizzBuzzpackage main import "fmt" func main() { var i = 1 for i < 16 { switch { // Cと同様にswitch文が利用可能 case i % 15 == 0: fmt.Println("FizzBuzz") case i % 3 == 0: fmt.Println("Fizz") case i % 5 == 0: fmt.Println("Buzz") default: fmt.Println(i) } i++ } }
var i = 1という変数の定義の仕方はi := 1のような型を省略した変数宣言に置き換えることができます。いわゆる「セイウチ演算子」です。
また、GoではCやJavaと異なりif文の条件を丸括弧で囲む必要はありません。1行for文package main import "fmt" func main() { for i := 1; i <= 10; i++ {fmt.Printf("%d\n", i)} }無限ループpackage main import "fmt" func main() { i := 1 for { // <-- 条件を書かない if i > 10 { break // ループを抜ける } fmt.Printf("%d\n", i) i++ } }Goにはwhile文が無く、すべてのloop処理はfor文で書きます。他の言語から来た方や久し振りにGoを触る方は、whileを使おうと頑張らないで下さい...。
・文字列の取り扱い
文字列の結合package main import "fmt" func main() { a := "ABCDEF" b := "abcdef" fmt.Println(a + b) // ABCDEFabcdef c := a + b fmt.Println(c) // ABCDEFabcdef }文字列の分割(インデックス指定)package main import "fmt" func main() { a := "ABCDEF" fmt.Println(a[:3]) // ABC fmt.Println(a[3:]) // DEF }大文字化・小文字化package main import ("fmt"; "strings") func main() { a := "ABCdef" fmt.Println(strings.ToUpper(a)) // ABCDEF fmt.Println(strings.ToLower(a)) // abcdef }変数型の変換については「golang 文字列→数値、数値→文字列変換」などの記事を参考にして下さい。
・配列(Arrays)とスライス(Slices)の取り扱い
Goの配列(Arrays)の宣言には以下の3タイプがあります。
①var 変数名 [長さ]型
②var 変数名 [長さ]型 = [大きさ]型{初期値1, 初期値n}
③変数名 := [...]型{初期値1, 初期値n}③の記法は要素数の指定が不要でシンプルに書けるため、よく使われているようです。
package main import "fmt" func main(){ arr := [...] string{"apple", "banana", "cherry"} fmt.Println(arr[0], arr[1]) fmt.Println(arr, len(arr)) } /* 出力結果 apple banana [apple banana cherry] 3 */len関数で配列の長さ(要素数)を取得できます。
配列(Arrays)は長さ(要素数)が固定されているのに対して、スライス(Slices)は長さ(要素数)が可変です。Goの「配列」はCの配列と似ており、Goの「スライス」はPythonのリストやRubyの配列に近いイメージでしょうか。
スライスの宣言方法も何通りか知られています。
①var 変数名 []型
②var 変数名 []型 = []型{初期値1, ..., 初期値n}
③変数名 := []型{初期値1, ..., 初期値n}
④変数名 := 配列[start:end]④は既に存在する配列をスライスにする方法です。例えば以下のようにします。
package main import "fmt" func main(){ arr := [...] string{"apple", "banana", "cherry"} slice := arr[0:2] fmt.Println(slice) fmt.Println(arr) } /* 出力結果 [apple banana] [apple banana cherry] */参考:
「【Go】基本文法④(配列・スライス)」
「Go言語のスライスで勘違いしやすいこところ」
「Go言語の基本 — array と slice の違い」
「Goのarrayとsliceを理解するときがきた」・配列は要素数を増やせない
配列(要素数指定)だと怒られるpackage main import "fmt" func main(){ numbers := [3]int{1, 2, 3} numbers = append(numbers, 4) fmt.Println(numbers) // first argument to append must be slice; have [3]int }要素数を指定しなければ動く...?package main import "fmt" func main(){ numbers := []int{1, 2, 3} numbers = append(numbers, 4) fmt.Println(numbers) // [1 2 3 4] }実は後者の
testは配列ではなく、スライスとして宣言されています。そのため、appendで要素の追加が可能です。・2次元配列、多次元配列
中括弧
{ }で二重に囲めば、2次元配列・2次元スライス(行列)になります。2次元スライスへの行追加package main import "fmt" func main() { numbers := [][]int{{1, 1}, {1, 2}, {1, 3}, {1, 4}} numbers = append(numbers, []int{1, 5}) fmt.Println(numbers) // [[1 1] [1 2] [1 3] [1 4] [1 5]] }これは以下の操作に該当します。
\left[\begin{array}{ll} 1 & 1 \\ 1 & 2 \\ 1 & 3 \\ 1 & 4 \end{array}\right] \to \left[\begin{array}{ll} 1 & 1 \\ 1 & 2 \\ 1 & 3 \\ 1 & 4 \\ 1 & 5 \end{array}\right]なお、多次元配列は以下のように生成可能です。
多次元配列の生成package main import "fmt" func main() { multiDimArray := [2][4][3][2]string{} fmt.Println(multiDimArray) } // 以下のような多次元「配列」が作成されます。 // [[[[ ] [ ] [ ]] [[ ] [ ] [ ]] [[ ] [ ] [ ]] [[ ] [ ] [ ]]] [[[ ] [ ] [ ]] [[ ] [ ] [ ]] [[ ] [ ] [ ]] [[ ] [ ] [ ]]]]要素数を指定したくないからといって
[][][][]型{}のように書いても多次元配列は生成されません。・関数(例:ニュートン法による平方根の計算)
ニュートン法による平方根の計算package main import ( "fmt" "math" ) func mySqrt(x float64) (float64) { z := 1.0 for i := 0; i < 10; i++ { // 10回最適化する calculation := z - (z*z-x)/(2*z) if calculation == z { break } z = calculation } return z } func main() { a := [4]float64{0, 0.25, 0.999, 2020} // この4点について平方根を求める for i := 0; i < 4; i++ { mySqrt := mySqrt(a[i]) mathSqrt := math.Sqrt(a[i]) fmt.Println("自作Sqrt関数 = ", mySqrt, "(x =", a[i], "のとき)") fmt.Println("math.Sqrt関数 = ", mathSqrt, "(x =", a[i], "のとき)") fmt.Println("自作Sqrt関数とmath.Sqrt関数の差 = ", math.Abs(mySqrt-mathSqrt), "\n") } }出力結果自作Sqrt関数 = 0.0009765625 (x = 0 のとき) math.Sqrt関数 = 0 (x = 0 のとき) 自作Sqrt関数とmath.Sqrt関数の差 = 0.0009765625 自作Sqrt関数 = 0.5 (x = 0.25 のとき) math.Sqrt関数 = 0.5 (x = 0.25 のとき) 自作Sqrt関数とmath.Sqrt関数の差 = 0 自作Sqrt関数 = 0.999499874937461 (x = 0.999 のとき) math.Sqrt関数 = 0.999499874937461 (x = 0.999 のとき) 自作Sqrt関数とmath.Sqrt関数の差 = 0 自作Sqrt関数 = 44.94441010848846 (x = 2020 のとき) math.Sqrt関数 = 44.94441010848846 (x = 2020 のとき) 自作Sqrt関数とmath.Sqrt関数の差 = 0・ファイル処理
osパッケージを利用してファイルの読み書きが可能です。
例として以下のようなテキストファイル(test.txt)を読み込んでみます。test.txtapple banana cherryバイト型スライスを利用すると以下のようにファイルの読み込みが可能です。
ファイルの読み込みpackage main import( "fmt" "os" ) func main(){ f, err := os.Open("test.txt") // ファイルを開く if err != nil{ // 読み取り時の例外処理 fmt.Println("error") } defer f.Close() // 関数終了時にファイルを閉じる buf := make([]byte, 1024) // バイト型スライスを用意する for { n, err := f.Read(buf) // n = バイト数 if n == 0{ // バイト数が 0 になれば読み取り終了 break } if err != nil{ // 読み取り時の例外処理 break } fmt.Println(string(buf[:n])) // バイト型スライスを文字列型に変換して出力 } }ファイルへの書き出しは次のようにします。
ファイルへの書き出しpackage main import( "fmt" "os" ) func writeByres(filename string) error { file, err := os.Create(filename) // 新規ファイルの作成 if err != nil { // ファイル作成時の例外処理 return err } defer file.Close() // 関数終了時にファイルを閉じる for _, line := range lines { // インデックスの値は変数 _ に逃がす b := []byte(line) // バイト型スライスを用意する _, err := file.Write(b) // ファイル書き込み if err != nil { // ファイル書き込み時の例外処理 return err } } return nil } var ( // ファイルに書き込む文字列 lines = []string{"apple\n", "banana\n", "cherry\n"} ) func main() { if err := writeByres("write.txt"); err != nil { // write.txt に書き込む fmt.Println(os.Stderr, err) os.Exit(1) } }os.Create は既に同じ名前のファイルがある場合でも新規作成(上書き)するので使い方には要注意です。
・コメントアウト
// 一行ずつコメントアウト // apple // banana // cherry /* 複数行コメントアウト apple banana cherry */C言語と同じです。
・日本語文字列の取り扱い
文字列はバイト列になっているので、マルチバイト文字を含む文字列をインデックス指定で取り出そうとしても、文字単位での指定はできません。
stringのスライスはバイト単位package main import "fmt" func main() { var s = "あいうえお" fmt.Println(s[:3]) //-> あ fmt.Printf("%x\n", s[:3]) //-> e38182 fmt.Println(s[:4]) //-> あ� fmt.Printf("%x\n", s[:4]) //-> e38182e3 }「ルーン (rune)」型のスライスを使えば、文字数ごとに文字列をインデックス指定で取り出すことができます。(rune型文字とはUnicode文字のことを指しています)
runeのスライスを使うpackage main import "fmt" func main() { var str = "あいうえお" rstr := []rune(str) fmt.Println(string(rstr[:3])) //-> あいう }for文の条件文でのインデックス指定もバイト単位なので、マルチバイト文字を使っている場合はハマる危険性があり、注意が必要です。日本語を含む文字列の文字数を取得したい場合はunicode/utf8パッケージのRuneCountInString関数を使うこともできます。
RuneCountInString関数によるカウントpackage main import ( "fmt" "unicode/utf8" ) func main() { str := "ゼロから始めるGo言語生活" fmt.Println(utf8.RuneCountInString(str)) //-> 13 }因みに、rangeで取り出すとrune単位で取り出すことができます。
日本語文字列を1文字ずつ抜き出すpackage main import ( "fmt" ) func main() { str := "ゼロから始めるGo言語生活" for _, letter := range str { // rune単位での切り出し fmt.Println(string(letter)) } }参考:
「Go言語 - 日本語文字列の操作」
「Go で UTF-8 の文字列を扱う」
「Goのruneを理解するためのUnicode知識」・for文でのrangeの取り扱い(インデックスの値を逃がす)
上手く動かないrangepackage main import "fmt" func main() { words := []string{"ABC", "DEF", "abc", "def"} for str := range words { fmt.Println(str) } } /* 出力結果 0 1 2 3 */こうなってしまう理由は、インデックスの値が
strに代入されているためです。この問題は以下のようにダミーの使い捨て変数を用意することで解消可能です。意図した通りのrangepackage main import "fmt" func main() { words := []string{"ABC", "DEF", "abc", "def"} for _, str := range words { // <-- インデックスの値を変数 _ に逃がす fmt.Println(str) } }初心者のハマりやすいポイントみたいです。「Goのfor rangeで思った値が取れなかった話」などをご参考に。
・Goにおける整数&小数の取り扱い
「Better C - Goと整数」や「Better C - Goと小数」などの記事に詳しくまとめられていますので参考にして下さい。
・使用しない変数は宣言しないこと
未使用変数がある場合package main import "fmt" func main() { a := "apple" b := "banana" fmt.Println(a) } /* 出力結果(エラー) b declared but not used */変数の型によらず、使用されていない変数があると怒られます。importしたのに使っていないパッケージがある場合も怒られます。
・
:=による再代入は可能宣言済みの変数に再び値を代入する際は以下のようにします。
varを用いた再代入の例package main import "fmt" func main() { var str = "apple" str = "banana" fmt.Println(str) } /* 出力結果 banana */しかし以下のように書くと
no new variables on left side of :=などと怒られてコンパイルエラーとなります。ダメな代入例package main import "fmt" func main() { str := "apple" str := "banana" fmt.Println(str) }ただし、新しい変数を含む複数の変数の宣言を同時に行えば、既存の変数への再代入が可能です。
許容される代入例package main import "fmt" func main() { str1 := "apple" fmt.Println(str1) str1, str2 := "banana", "cherry" fmt.Println(str1, str2) } /* 出力結果 apple banana cherry */・Goで並列処理(GoroutineとChannelの取り扱い)
Goのウリでもある並列処理は、大量のcsvファイルを同時に読み込んで処理するとか、大量のhtmlをダウンロードするとかいう場合に用いられます。Goではプログラマがスレッドやプロセスのことをあまり考えていなくても、自動でうまい具合に処理を振り分けてくれます。
GoではGoroutineを使えば簡単に並列処理を書くことができます。
Goroutineの使用例package main import ( "fmt" "time" ) func printnumbers() { // 100ミリ秒ごとに数字を表示 for i := 1; i <= 5; i++ { time.Sleep(100 * time.Millisecond) fmt.Printf("%d ", i) } } func printletters() { // 140ミリ秒ごとにアルファベットを表示 for i := 'a'; i <= 'e'; i++ { time.Sleep(140 * time.Millisecond) fmt.Printf("%c ", i) } } func main() { go printnumbers() // goroutine その1 go printletters() // goroutine その2 time.Sleep(1000 * time.Millisecond) // 1秒待機する } /* 出力結果 1 a 2 b 3 4 c 5 d e */このコードではGoroutineを2つ動かして同時並行で処理を行っています。プログラムの挙動は以下のようなイメージです。
赤色の打刻はprintnumbers関数が、青色の打刻はprintletters関数が、それぞれ行っています。これを並列で実行しているため1 a 2 b 3 4 c 5 d eという順で出力されます。
それから、最後に待ち時間を確保しているのはgoroutineが終わる前にmain関数自体が終わるのを防止するためです(この1行はChannelを利用すれば不要になります)。Goroutineの出力結果はChannelを介することで値をやり取りできます。
Channelの使用例package main import ( "fmt" "time" ) func print1(ch chan bool) { fmt.Println("print1") ch <- true } func print2(ch chan bool) { // 時間が掛かる処理 time.Sleep(1000 * time.Millisecond) fmt.Println("print2") ch <- true } func main() { ch1 := make(chan bool) // bool型のchannelその1を作成 ch2 := make(chan bool) // bool型のchannelその2を作成 go print1(ch1) // 並列処理 go print2(ch2) <-ch1 // bool型の要素を受信するまで待機(順不同) <-ch2 fmt.Println("処理終了") }並列する処理ごとにChannelを用意しておけば処理が終わるまで待機してくれます。
<-ch1と<-ch2で受信待ちをしていますが、これらを入れ替えても(どっちの処理の方が時間が掛かるか分からなくても)ちゃんと待ってくれます。意外と簡単に並列処理が書けるんですね。Goroutine(ゴルーチン)やChannel(チャネル)の使い方は公式にはこちらのページで紹介されています。並列処理の例:
「Goで実装する並列処理(Hello, world!を10000回出力してみる)」参考:
「並行処理、並列処理のあれこれ」
「GoのChannelを使いこなせるようになるための手引」
「Goのgoroutine, channelをちょっと攻略!」
「Goのテストを並列で実行する」・Goは速い?
当然ですが、PythonやRubyなどのインタプリタ型言語に比べて、コンパイラ型言語であるGoは数段速く動きます。探してみるとベンチマークの報告が色々とヒットします。
「RubyからGoの関数をつかう → はやい」
「C++, Go, Julia, Kotlin, Rust, Swift5 で競争」
「言語別int64素因数分解(試し割り法)処理時間比較」
などなど...ただ、下手に言語間のベンチマーク結果を公開すると宗教戦争に発展することが間々あります。どんな言語にも一長一短はありますので、少なくとも個人開発の範囲では目的・用途に応じて改宗?(良いトコ取り)すれば良いと思います。平和主義ですね。
・リンク集
「Go 言語に関するブックマーク」(← Goを使うならブックマーク推奨です)
「Go言語の初心者が見ると幸せになれる場所」
「他言語から来た人がGoを使い始めてすぐハマったこととその答え」
「何故Go言語を私は使いたいのか? 良い点と悪い点を雑にまとめる」


- 投稿日:2020-09-19T16:31:37+09:00
Go(Echo)×MySQL×Docker×Clean ArchitectureでAPIサーバー構築してみた
はじめに
タイトルにもある通り、Go×MySQL×DockerでAPIサーバーを作ってみました。
はじめは、・Goで簡単なREST APIを作ってみる
・Dockerで開発環境を立てるを目的として作っていたのですが、ディレクトリ構成をどうしようか悩んでいろいろ調べているとGo×クリーンアーキテクチャでAPIサーバーを作っている記事をたくさん発見したので、クリーンアーキテクチャやってみよう、ということでやってみました。
ということでこの記事は、
・GoでAPIを書いてみたい
・Dockerで開発環境をたてたい
・その際にクリーンアーキテクチャを採用してみたいぐらいの温度感の方におすすめです。
逆に、がっつりクリーンアーキテクチャを勉強したいという方にはあまり参考にならないかもしれません。。
なお、
フレームワークにEcho (https://echo.labstack.com/)
DBへのアクセスにはGorm (https://github.com/go-gorm/gorm)
を使用しています。リポジトリはこちら↓
準備編
開発環境
Dockerで開発環境を構築しました。
Dockerfile
基本的なDockerfileの書き方は Dockerfile 公式リファレンス が参考になります。
では、さらっとですが順番に見ていきます。
まずはGoです。
docker/api/DockerfileFROM golang:1.14 # go moduleを使用 ENV GO111MODULE=on # アプリケーションを実行するディレクトリを指定 WORKDIR /go/src/github.com/Le0tk0k/go-rest-api # 上記のディレクトリにgo.modとgo.sumをコピー COPY go.mod go.sum ./ # 上記のファイルに変更がなければキャッシュ利用できる RUN go mod download COPY . . RUN go build . RUN go get github.com/pilu/fresh EXPOSE 8080 # freshコマンドでサーバーを起動 CMD ["fresh"]github.com/pilu/fresh でホットリロードできるようにしました。
他は特に変わったところはありません。参考
・Using go mod download to speed up Golang Docker builds
・Go v1.11 + Docker + fresh でホットリロード開発環境を作って愉快なGo言語生活次にMySQLです。
docker/mysql/DockerfileFROM mysql EXPOSE 3306 # MySQL設定ファイルをイメージ内にコピー COPY ./docker/mysql/my.cnf /etc/mysql/conf.d/my.cnf CMD ["mysqld"]MySQLの設定ファイルは以下のようになりました。
MySQL8.0以降では接続時の認証方式が変更になっているため、2行目の記述が必要になるらしい。
あと、文字化けを防ぐために文字コードを変更しています。docker/mysql/my.cnf[mysqld] default_authentication_plugin=mysql_native_password character-set-server=utf8mb4 [client] default-character-set=utf8mb4/docker-entrypoint-initdb.d/ というディレクトリ内に初期化用のSQLやスクリプトを置いておくと、最初にimageを起動したときにデータの初期化を自動的に行えます。
ということで、テーブルを作成します。
docker/mysql/db/init.sqlCREATE DATABASE IF NOT EXISTS go_rest_api; USE go_rest_api; CREATE TABLE IF NOT EXISTS users ( id INT PRIMARY KEY NOT NULL AUTO_INCREMENT, name VARCHAR(256) NOT NULL, age INT NOT NULL, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, updated_at TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) ENGINE=InnoDB DEFAULT CHARSET=utf8;docker-compose.yml
こちらも Compose ファイル・公式リファレンス が参考になります。
docker-compose.ymlversion: '3' services: db: build: # Dockerfileのあるディレクトリのパスを指定 context: . dockerfile: ./docker/mysql/Dockerfile ports: # 公開ポートを指定 - "3306:3306" volumes: # 起動時にデータの初期化を行う - ./docker/mysql/db:/docker-entrypoint-initdb.d # mysqlの永続化 - ./docker/mysql/db/mysql_data:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: go_rest_api MYSQL_USER: user MYSQL_PASSWORD: password api: build: context: . dockerfile: ./docker/api/Dockerfile volumes: - ./:/go/src/github.com/Le0tk0k/go-rest-api ports: - "8080:8080" depends_on: # dbが先に起動する - dbmysqlの永続化をしているので、コンテナを立ち上げ直した場合も、以前のデータが残ったままになります。
また、apiにdepend_onを指定することで、先にdbが起動し、その次にapiが起動するようになります。
しかし、depend_onは起動する順番を指定するだけで、出来上がるまでは待ってくれないので、別で対策が必要です。
なお、対策については実装編で紹介しています。参考
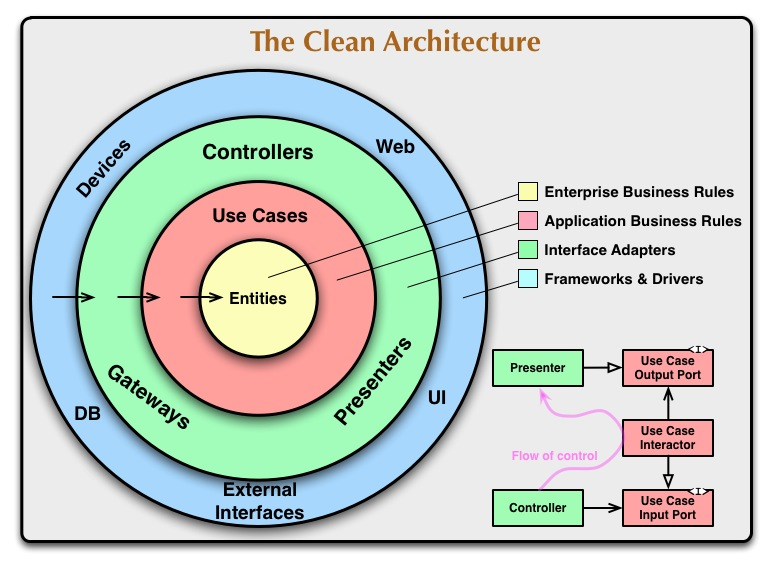
クリーンアーキテクチャ
クリーンアーキテクチャは、The Clean Architecture で提唱されているアーキテクチャです。
僕はそもそも、アーキテクチャ?何それ?状態だったのですが、以下の記事を読んで
上澄み1mmぐらいは理解できた気がします。他にもたくさん記事があるのでぜひ調べてみてください!参考 (クリーンアーキテクチャ以外の記事もあります)
- クリーンアーキテクチャの書籍を読んだのでAPIサーバを実装してみた
- 今すぐ「レイヤードアーキテクチャ+DDD」を理解しよう。(golang)
- Clean ArchitectureでAPI Serverを構築してみる
- 【Golang + レイヤードアーキテクチャー】DDD を意識して Web API を実装してみる
実装編
ディレクトリ構成
ディレクトリ構成は以下の通りです。
├── docker │ ├── api │ │ └── Dockerfile │ └── mysql │ ├── Dockerfile │ ├── db │ │ ├── init.sql │ │ └── mysql_data │ └── my.cnf ├── docker-compose.yml ├── domain │ └── user.go ├── infrastructure │ ├── router.go │ └── sqlhandler.go ├── interfaces │ ├── controllers │ │ ├── context.go │ │ ├── error.go │ │ └── user_controller.go │ └── database │ ├── sql_handler.go │ └── user_repository.go |── usecase │ ├── user_interactor.go │ └── user_repository.go ├── server.go ├── go.mod ├── go.sumdomain → Entities層
infrastructure → Frameworks & Drivers層
interfaces → Interface層
usecase → Use cases層に対応しています。
Domain ( Entities層 )
最も内側にある層で、どこにも依存しない層となります。
Userモデルを定義していきます。なお、
json:"-"については、- と書くと出力されなくなります。domain/user.gopackage domain import "time" type User struct { ID int `gorm:"primary_key" json:"id"` Name string `json:"name"` Age int `json:"age"` CreatedAt time.Time `json:"-"` UpdatedAt time.Time `json:"-"` } type Users []UserInterfaces/database, Infrastructure (Interface層, Frameworks & Driver層)
次に、データベース周辺を実装していきます。
データベースの接続は外部との接続となるので、一番外側のInfrastructure層に定義します。infrastructure/sqlhandler.gopackage infrastructure import ( "fmt" "time" "github.com/Le0tk0k/go-rest-api/interfaces/database" "github.com/jinzhu/gorm" _ "github.com/jinzhu/gorm/dialects/mysql" ) type SqlHandler struct { Conn *gorm.DB } func NewMySqlDb() database.SqlHandler { connectionString := fmt.Sprintf( "%s:%s@tcp(%s:%s)/%s?charset=utf8mb4&parseTime=true&loc=Local", "user", "password", "db", "3306", "go_rest_api", ) conn, err := open(connectionString, 30) if err != nil { panic(err) } //接続できているか確認 err = conn.DB().Ping() if err != nil { panic(err) } // ログの詳細を出力 conn.LogMode(true) // DBのエンジンを設定 conn.Set("gorm:table_options", "ENGINE=InnoDB") sqlHandler := new(SqlHandler) sqlHandler.Conn = conn return sqlHandler } // MySQLの立ち上がりを確認してからapiコンテナが立ち上がるようにする func open(path string, count uint) (*gorm.DB, error) { db, err := gorm.Open("mysql", path) if err != nil { if count == 0 { return nil, fmt.Errorf("Retry count over") } time.Sleep(time.Second) count-- return open(path, count) } return db, nil } func (handler *SqlHandler) Find(out interface{}, where ...interface{}) *gorm.DB { return handler.Conn.Find(out, where...) } func (handler *SqlHandler) Create(value interface{}) *gorm.DB { return handler.Conn.Create(value) } func (handler *SqlHandler) Save(value interface{}) *gorm.DB { return handler.Conn.Save(value) } func (handler *SqlHandler) Delete(value interface{}) *gorm.DB { return handler.Conn.Delete(value) }opan()では、dbコンテナが立ち上がるまで待ってからapiコンテナが立ち上がるように設定しています。
今回は、Goのコードでこの機能を実装しましたが、シェルスクリプトで実装する方がいいのでしょうか?ベストプラクティスがわかりません、、
参考
- docker-compose upでMySQLが起動するまで待つ方法(2種類紹介)なお、infrastructure層はdb接続のみにして、実際の処理はinterfaces/database層に実装します。
interfaces/database/user_repository.gopackage database import ( "github.com/Le0tk0k/go-rest-api/domain" ) type UserRepository struct { SqlHandler } func (userRepository *UserRepository) FindByID(id int) (user domain.User, err error) { if err = userRepository.Find(&user, id).Error; err != nil { return } return } func (userRepository *UserRepository) Store(u domain.User) (user domain.User, err error) { if err = userRepository.Create(&u).Error; err != nil { return } user = u return } func (userRepository *UserRepository) Update(u domain.User) (user domain.User, err error) { if err = userRepository.Save(&u).Error; err != nil { return } user = u return } func (userRepository *UserRepository) DeleteByID(user domain.User) (err error) { if err = userRepository.Delete(&user).Error; err != nil { return } return } func (userRepository *UserRepository) FindAll() (users domain.Users, err error) { if err = userRepository.Find(&users).Error; err != nil { return } return }UserRepositoryにSqlHandlerを埋め込んでいます。
domain層をインポートしていますが、これは最も内側にある層なので、依存関係は守れています。しかし、SqlHandlerは1番外側のInfrastructure層に定義したので、依存関係が内から外に向いており、ルールを守れていないのでは?という疑問が生まれますが、実はここで呼んでいるSqlHandlerはInfrastructure層に定義した構造体ではなく、同階層であるinterface/database層に定義したインターフェースなのです。
これをDIP(依存関係逆転の原則)といいます。どういうことかといいますと、interfaces/database/user_repository.goでは、Infrastructure層で定義されている処理を呼んでしまうと依存関係が内→外になってしまい依存関係を守れていないことになります。それを避けるために同階層にDBとのやりとりをinterfaceで定義しておき、それを呼び出しましょうということです。
これで、実際にはInfrastructure層で処理を行っているが、interfaces/database/user_repository.goではSqlHandlerインターフェースを呼び出しているので依存関係は守れていることになります。そしてGoでは、型TがインターフェースIで定義されているメソッドを全て持つとき、インターフェースIを実装していることになるので、Infrastructure.SqlHandler構造体にinterfaces/databases/sql_handerのSqlHandlerインターフェースで定義されているメソッドを定義しています。
interfaces/database/sql_handler.gopackage database import "github.com/jinzhu/gorm" type SqlHandler interface { Find(interface{}, ...interface{}) *gorm.DB Create(interface{}) *gorm.DB Save(interface{}) *gorm.DB Delete(interface{}) *gorm.DB }Usecase ( Use Case層 )
Usecase層では、interfaces/database層から情報を受け取り、interfaces/controller層へと情報を渡す役割を持ちます。
usecase/user_interactor.gopackage usecase import "github.com/Le0tk0k/go-rest-api/domain" type UserInteractor struct { UserRepository UserRepository } func (interactor *UserInteractor) UserById(id int) (user domain.User, err error) { user, err = interactor.UserRepository.FindByID(id) return } func (interactor *UserInteractor) Users() (users domain.Users, err error) { users, err = interactor.UserRepository.FindAll() return } func (interactor *UserInteractor) Add(u domain.User) (user domain.User, err error) { user, err = interactor.UserRepository.Store(u) return } func (interactor *UserInteractor) Update(u domain.User) (user domain.User, err error) { user, err = interactor.UserRepository.Update(u) return } func (interactor *UserInteractor) DeleteById(user domain.User) (err error) { err = interactor.UserRepository.DeleteByID(user) return }UserInteractorはUserRepositoryを呼び出していますが、これもInterfase層から呼び出してしまうと内→外への依存となり依存関係を守れなくなってしまうので、同階層にuser_repository.goを作成し、インターフェースを実装してDIP(依存関係逆転の原則)を利用して依存関係を守ります。
usecase/user_repository.gopackage usecase import "github.com/Le0tk0k/go-rest-api/domain" type UserRepository interface { FindByID(id int) (domain.User, error) Store(domain.User) (domain.User, error) Update(domain.User) (domain.User, error) DeleteByID(domain.User) error FindAll() (domain.Users, error) }Interfaces/controllers, Infrastructure (Interface層, Frameworks & Driver層)
そして、コントローラーとルーターを実装していきます。
interfaces/controllers/user_controller.gopackage controllers import ( "strconv" "github.com/Le0tk0k/go-rest-api/domain" "github.com/Le0tk0k/go-rest-api/interfaces/database" "github.com/Le0tk0k/go-rest-api/usecase" ) type UserController struct { Interactor usecase.UserInteractor } func NewUserController(sqlHandler database.SqlHandler) *UserController { return &UserController{ Interactor: usecase.UserInteractor{ UserRepository: &database.UserRepository{ SqlHandler: sqlHandler, }, }, } } func (controller *UserController) CreateUser(c Context) (err error) { u := domain.User{} c.Bind(&u) user, err := controller.Interactor.Add(u) if err != nil { c.JSON(500, NewError(err)) return } c.JSON(201, user) return } func (controller *UserController) GetUsers(c Context) (err error) { users, err := controller.Interactor.Users() if err != nil { c.JSON(500, NewError(err)) return } c.JSON(200, users) return } func (controller *UserController) GetUser(c Context) (err error) { id, _ := strconv.Atoi(c.Param("id")) user, err := controller.Interactor.UserById(id) if err != nil { c.JSON(500, NewError(err)) return } c.JSON(200, user) return } func (controller *UserController) UpdateUser(c Context) (err error) { id, _ := strconv.Atoi(c.Param("id")) u := domain.User{ID: id} c.Bind(&u) user, err := controller.Interactor.Update(u) if err != nil { c.JSON(500, NewError(err)) return } c.JSON(201, user) return } func (controller *UserController) DeleteUser(c Context) (err error) { id, _ := strconv.Atoi(c.Param("id")) user := domain.User{ID: id} err = controller.Interactor.DeleteById(user) if err != nil { c.JSON(500, NewError(err)) return } c.JSON(200, user) return }echoはecho.Contextを使用するので、今回利用するメソッドのインターフェイスを定義します。
interfaces/controllers/context.gopackage controllers type Context interface { Param(string) string Bind(interface{}) error JSON(int, interface{}) error }interfaces/controllers/error.gopackage controllers type Error struct { Message string } func NewError(err error) *Error { return &Error{ Message: err.Error(), } }ルーティングはechoを使用している (外部パッケージを使用している)ので、Infrastructure層に実装します。
なお、uesrController.関数(c)で引数にecho.Context型を渡せているのは、echo.Contextがinterfaces/controllers/context.goのcontextインターフェースを満たしているからです。
(つまり、echo.Context型はcontextインターフェースのメソッドをすべて持っている。)infrastructure/router.gopackage infrastructure import ( "github.com/Le0tk0k/go-rest-api/interfaces/controllers" "github.com/labstack/echo" "github.com/labstack/echo/middleware" ) func Init() { e := echo.New() userController := controllers.NewUserController(NewMySqlDb()) // アクセスログのようなリクエスト単位のログを出力する e.Use(middleware.Logger()) // アプリケーションのどこかで予期せずにpanicを起こしてしまっても、サーバは落とさずにエラーレスポンスを返せるようにリカバリーする e.Use(middleware.Recover()) e.GET("/users", func(c echo.Context) error { return userController.GetUsers(c) }) e.GET("/users/:id", func(c echo.Context) error { return userController.GetUser(c) }) e.POST("/users", func(c echo.Context) error { return userController.CreateUser(c) }) e.PUT("/users/:id", func(c echo.Context) error { return userController.UpdateUser(c) }) e.DELETE("/users/:id", func(c echo.Context) error { return userController.DeleteUser(c) }) e.Logger.Fatal(e.Start(":8080")) }最後に、server.goから呼び出します。
server.gopackage main import "github.com/Le0tk0k/go-rest-api/infrastructure" func main() { infrastructure.Init() }実行編
では、完成したAPIを叩いてみましょう。
今回はPostmanを使用してみたいと思います。 (https://www.postman.com/downloads/)まずHeadersのContent-Typeをapplication/jsonにします。
GetUsers
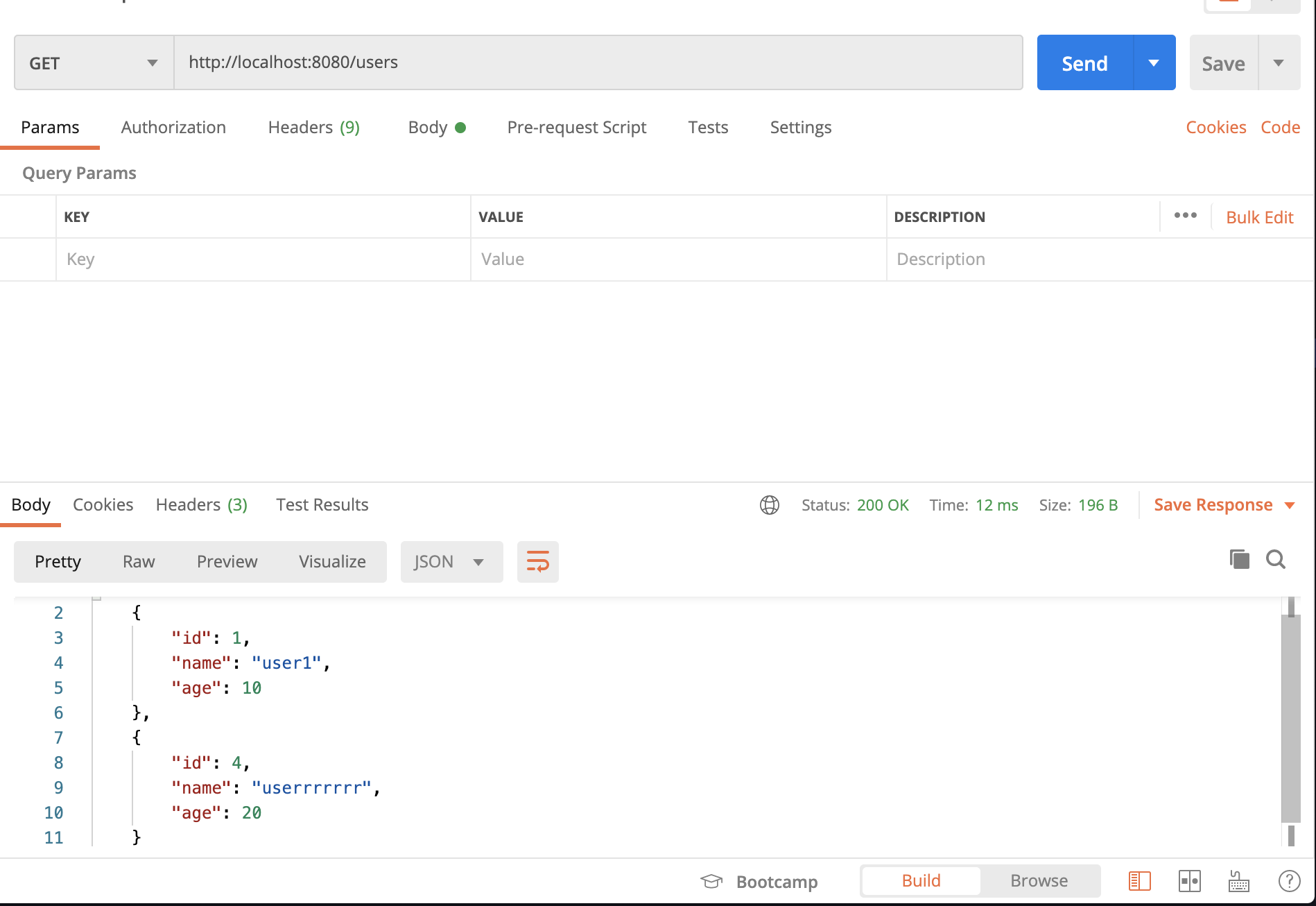
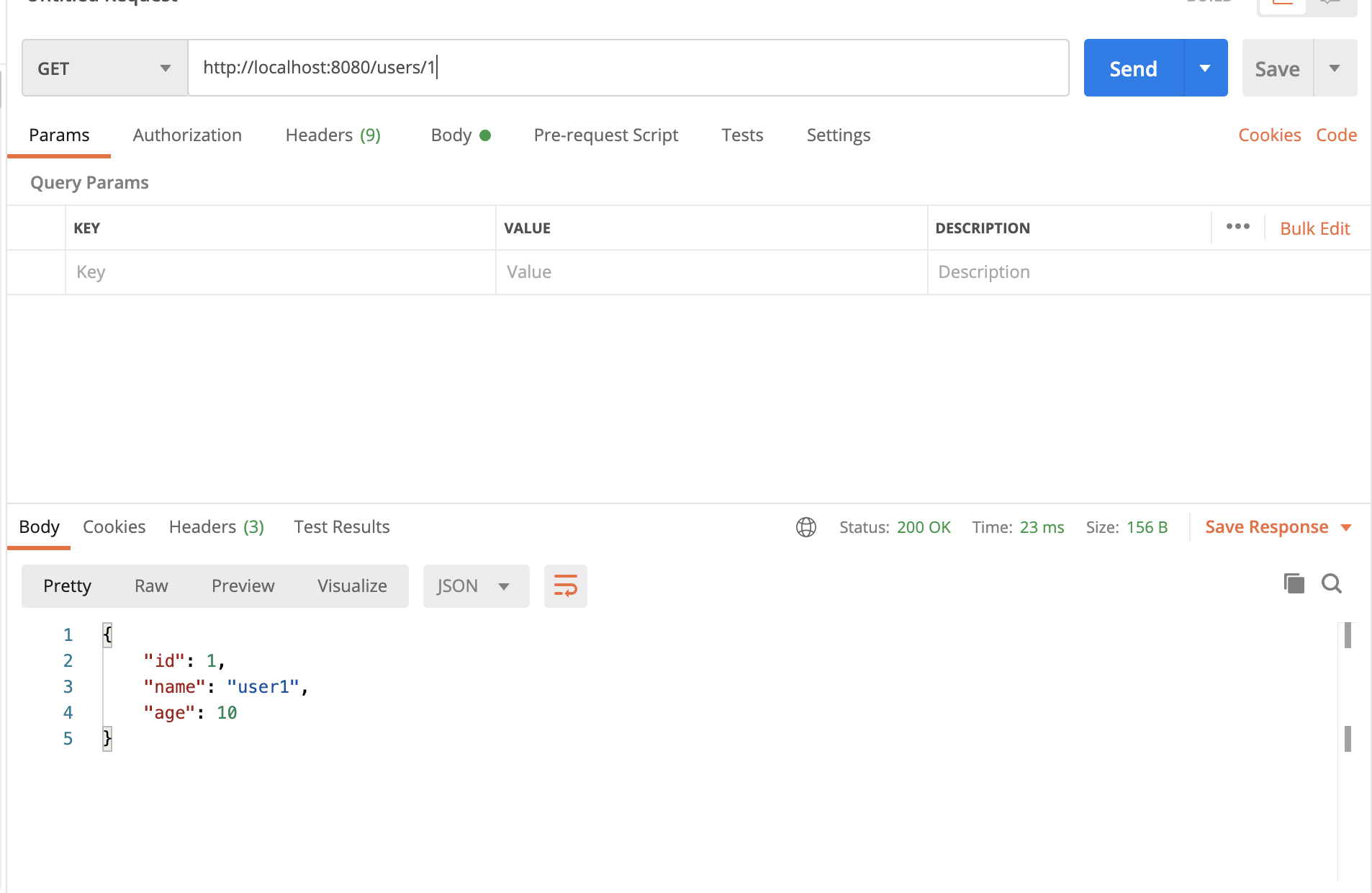
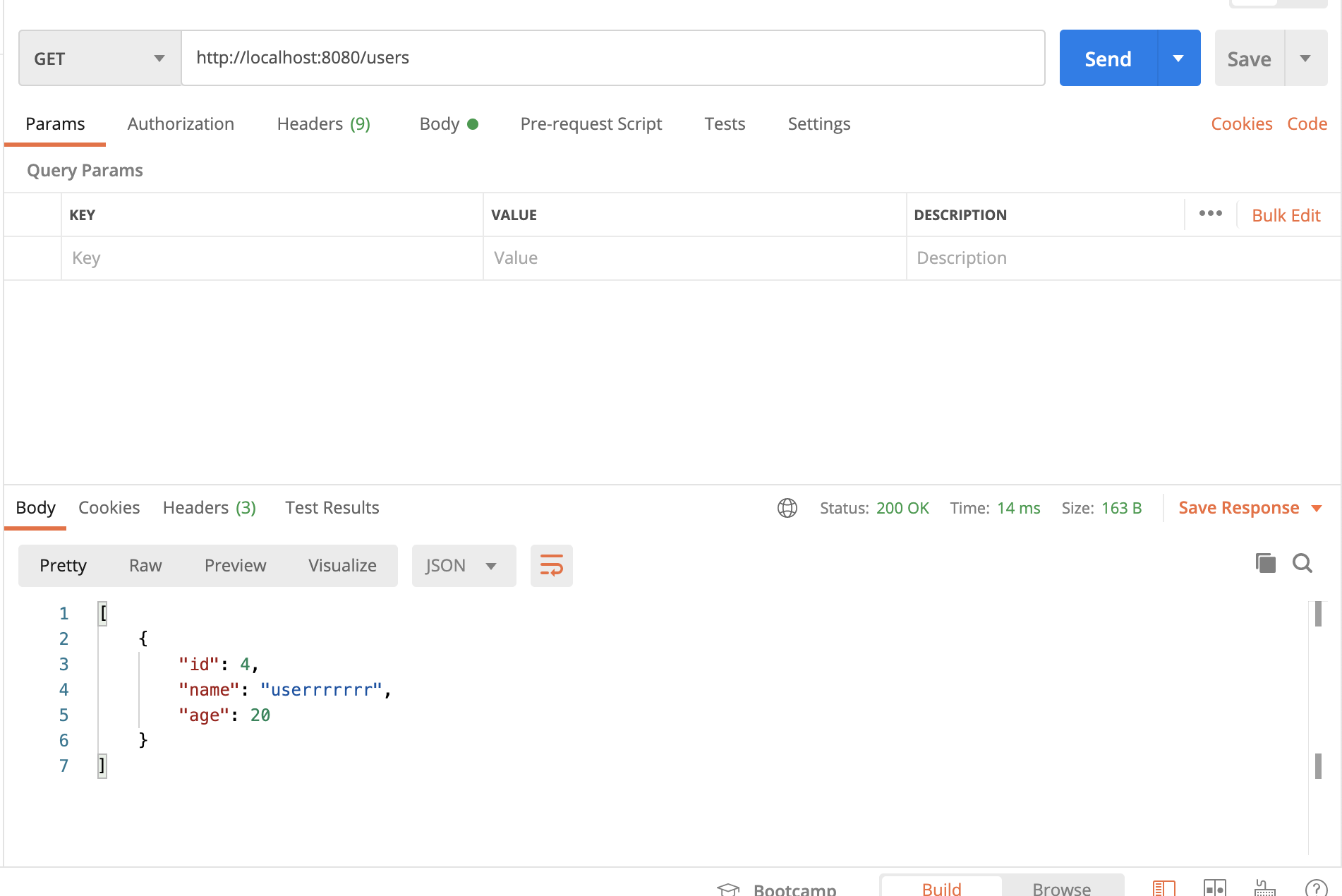
全ユーザーを取得してみます。
/usersにGETリクエストを送ります。
Getuser
任意のユーザーを取得してみます。
/users/:idにGETリクエストを送ります。
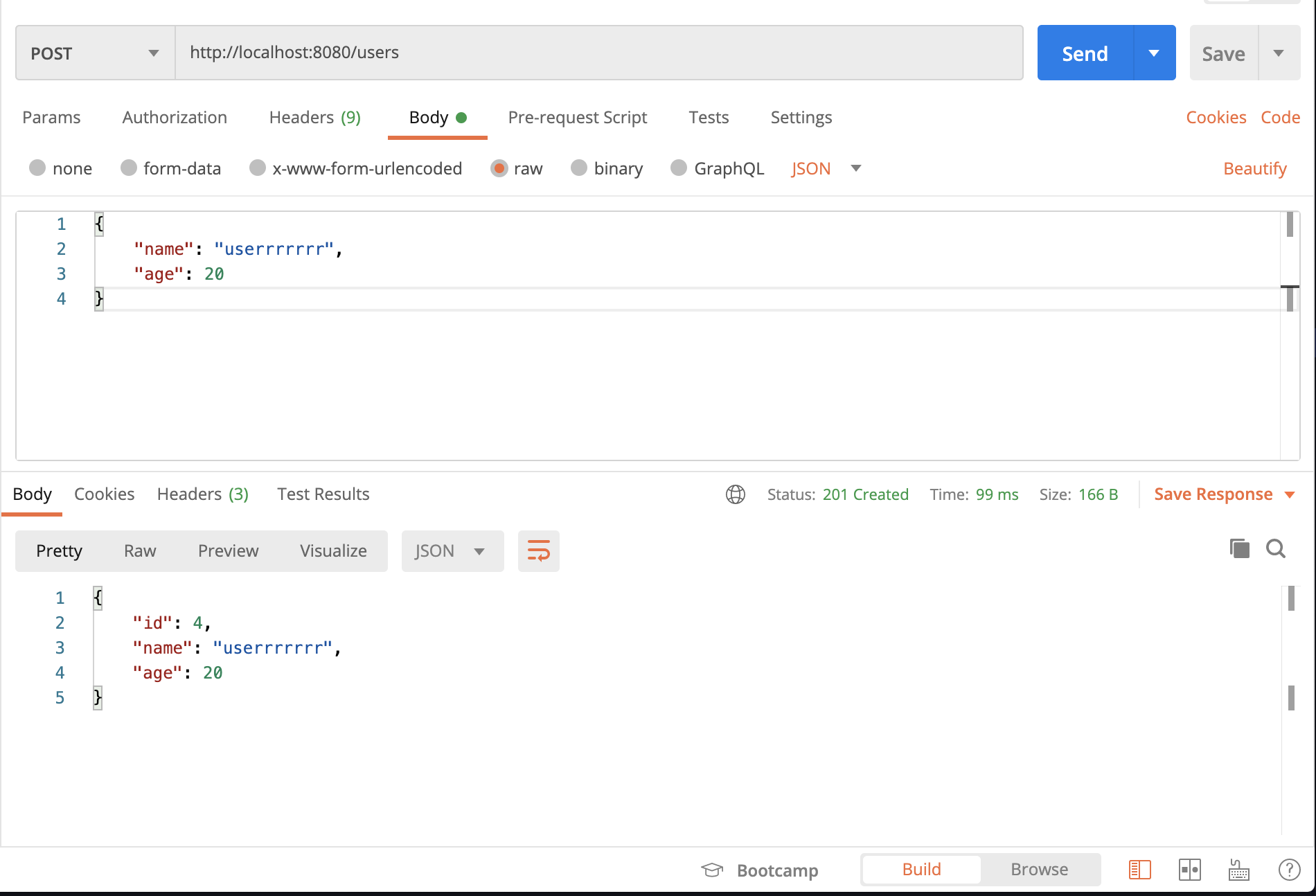
CreateUser
まずはUserを作成してみます。
/usersにPOSTリクエストを送ります。
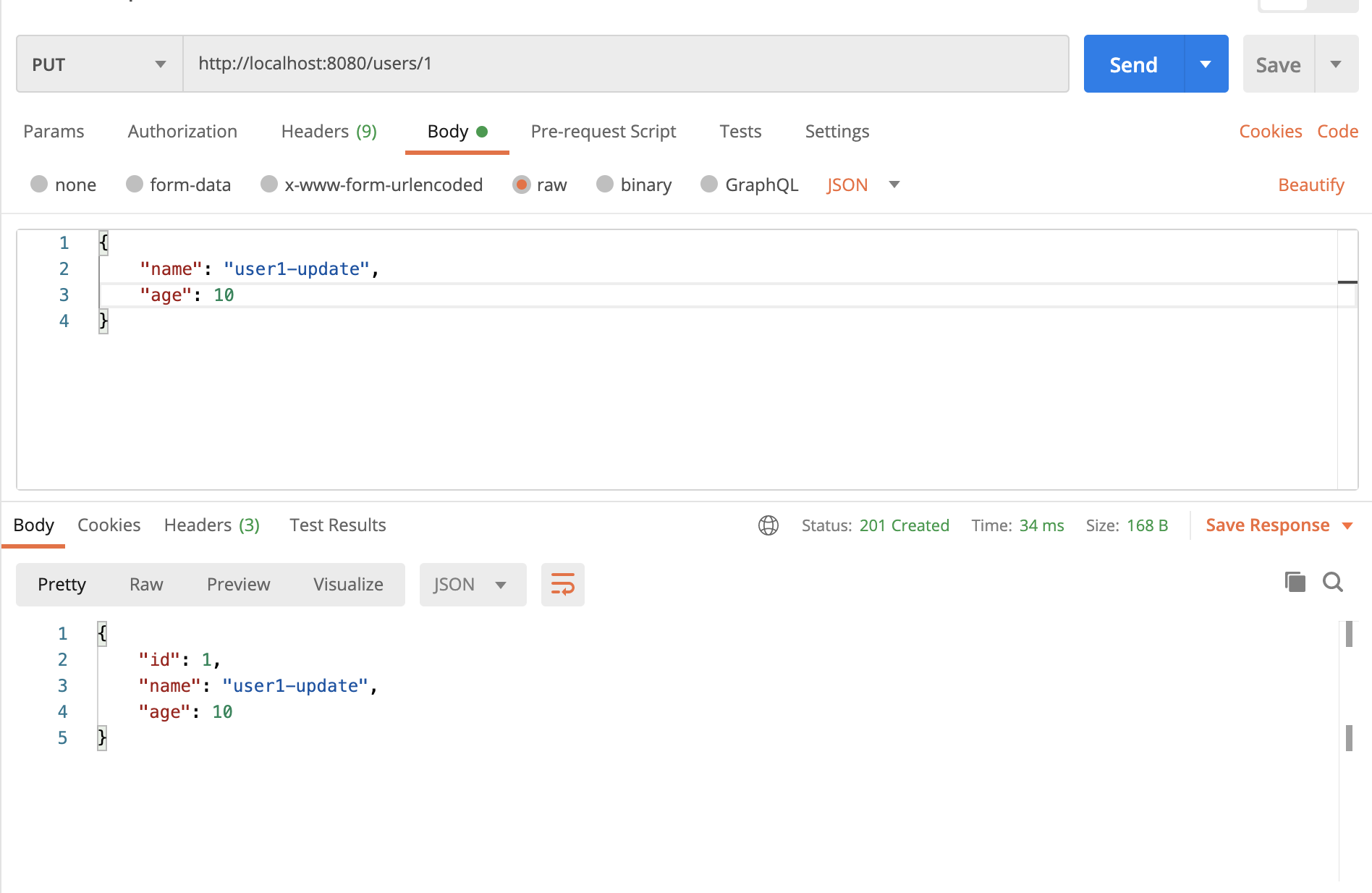
UpdateUser
任意のユーザーを更新してみます。
/users/:idにPUTリクエストを送ります。
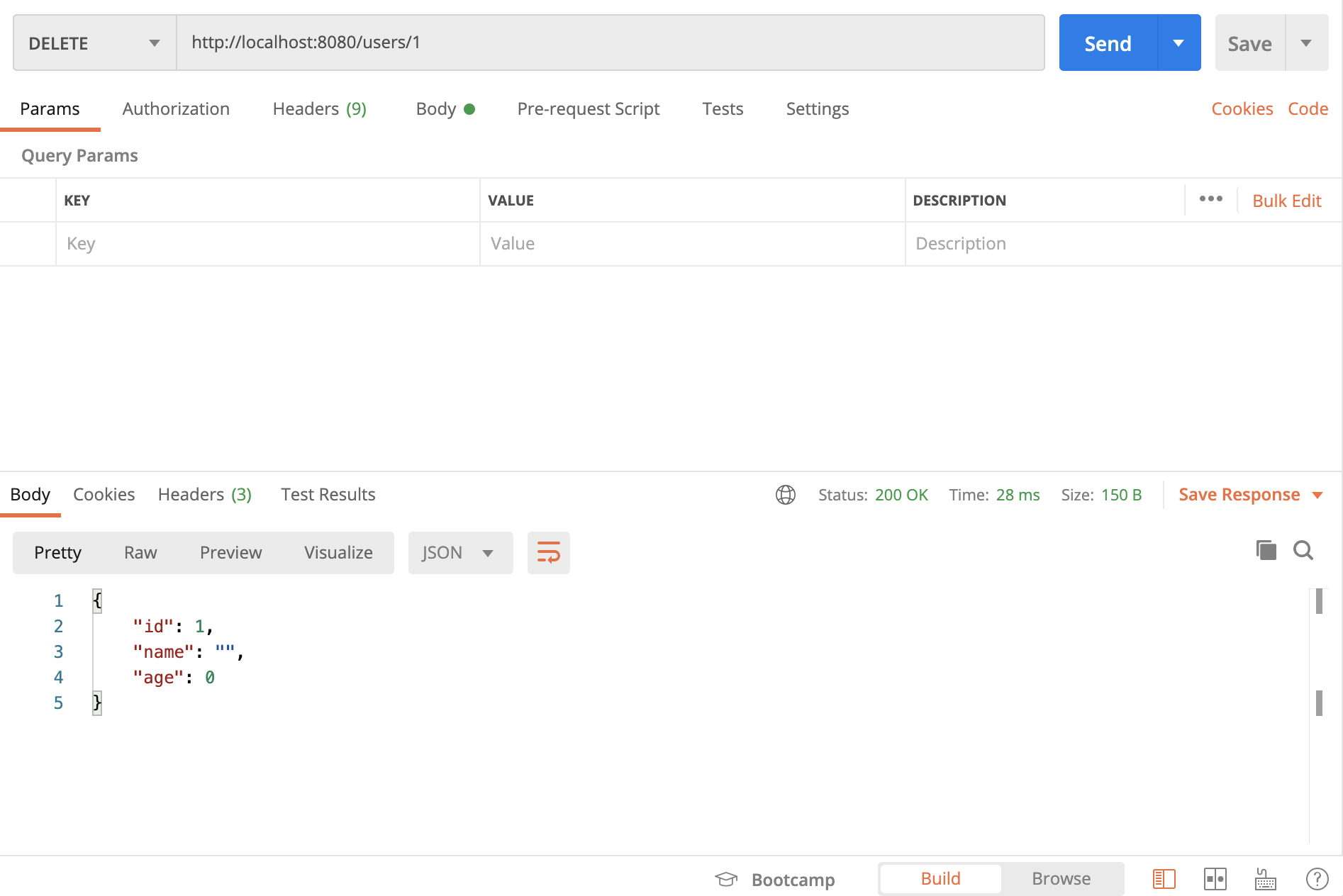
DeleteUser
任意のユーザーを削除してみます。
/users/:idにDELETEリクエストを送ります。
GETで確認してみると、しっかり削除されています。
しっかり機能してます!
さいごに
Dockerで開発環境を立ててREST APIを作るだけだったはずが、クリーンアーキテクチャまで勉強することになり大変でしたが、アーキテクチャを知るとても良い機会になったと思います。
今回ぐらいの小さいAPIだと逆に複雑になった感はありますが、大規模だったら良さが発揮されるのかなといった感想を持ちました。
(実際のところ、あまり理解できていないので)また設計についても勉強していきたいと思います!
- 投稿日:2020-09-19T13:17:16+09:00
Go(Gin)+MySQLなDocker環境でpanic: dial tcp 127.0.0.1:3306: connect: connection refusedに苛まれた
症状
タイトルの通り。
解決策
こちらに見事なまでにおんなじ症状の方がいて、言われるがままにMySQLの接続情報を修正したところ無事直りました。以下Before/Afterです。
Before
docker-compose.ymlversion: "3" services: app: build: . depends_on: - db volumes: - ./:/go/src/app ports: - 3000:3000 environment: MYSQL_DATABASE: go_app_dev MYSQL_USER: docker MYSQL_PASSWORD: password db: image: mysql:5.7 container_name: dockerMySQL volumes: - ./storage/mysql_data:/var/lib/mysql ports: - 3306:3306 environment: MYSQL_DATABASE: go_app_dev MYSQL_USER: docker MYSQL_PASSWORD: password MYSQL_ROOT_PASSWORD: passworddb/db.gopackage db import ( "fmt" "os" "github.com/jinzhu/gorm" _ "github.com/jinzhu/gorm/dialects/mysql" ) var ( db *gorm.DB err error ) func Init() { user = os.Getenv("MySQL_USER") pass = os.Getenv("MYSQL_PASSWORD") dbname := os.Getenv("MYSQL_DATABASE") connection := fmt.Sprintf("%s:%s@/%s?charset=utf8&parseTime=True&loc=Local", user, pass, dbname) db, err := gorm.Open("mysql", connection) if err != nil { panic(err) } }After
docker-compose.ymlversion: "3" services: app: build: . depends_on: - db volumes: - ./:/go/src/app ports: - 3000:3000 environment: MYSQL_DATABASE: go_app_dev MYSQL_HOST: dockerMySQL # 追加!! MYSQL_USER: docker MYSQL_PASSWORD: password db: image: mysql:5.7 container_name: dockerMySQL # 追加!! volumes: - ./storage/mysql_data:/var/lib/mysql ports: - 3306:3306 environment: MYSQL_DATABASE: go_app_dev MYSQL_USER: docker MYSQL_PASSWORD: password MYSQL_ROOT_PASSWORD: passworddb/db.go// ...略 func Init() { user = os.Getenv("MySQL_USER") pass = os.Getenv("MYSQL_PASSWORD") host = os.Getenv("MYSQL_HOST") // ココ!! dbname := os.Getenv("MYSQL_DATABASE") connection := fmt.Sprintf("%s:%s@tcp(%s)/%s?charset=utf8&parseTime=True&loc=Local", user, pass, host, dbname) // 修正!! db, err := gorm.Open("mysql", connection) if err != nil { panic(err) } }決め手はgorm.Openの第二引数で接続情報を指定する際に、MySQLを動かしているDockerコンテナのコンテナ名で接続するという点でした。そもそもBeforeのコードでMySQLに接続できなかったのはMySQLがlocalhost,あるいはTCPの3306番ポートでListenしていなかったからです。そしてdocker-composeで起動しているコンテナ達はdocker networkを介して通信しているため、ネットワーク名の代わりにコンテナ名で接続することが可能であり、Afterに載せたような接続情報でappコンテナからdbコンテナに接続できるということらしいです。このような理解で合っているかは少々自信がありませんがw
参考
- 投稿日:2020-09-19T13:14:11+09:00
【Go】インターフェースを学ぶ
内容
- インターフェース
- Goでのインターフェースの書き方
- サンプル
- インタフェースを使う
参考記事
初心者に送りたいinterfaceの使い方[Golang]. # Intro | by Takahito Yamada | Since I want to start “blog” that looks like men do, I do start. | Medium
A Tour of Go
A Tour of Go 練習問題を解く - Qiitaインターフェース
インターフェースって?
ソフトウェアの振る舞いは、既存の成果物を変更せずに拡張できるようにすべし!
特徴
- 実態を持つ
- 疎結合するのに用いられる
- ユニットテスト書く時に便利
実装パターン
インタフェースの実装パターン #golang - Qiita
サンプル実装
typeは型を宣言するために使う- レシーバーに実装したい構造体を渡す
既存の interface を使用する場合
- interfaceで定義されている(
Stringer)関数と同じ名前の関数を作る- 引数の型、返り値の型を合わせる
type Person struct { Name string Age int } // Stringer という interface と同じ名前、引数、返り値を宣言する func (p Person) String() string { return fmt.Sprintf("%v (%v years)", p.Name, p.Age) } func main() { a := Person{"Arthur Dent", 42} z := Person{"Zaphod Beeblebrox", 9001} fmt.Println(a, z) }Sortの Interface の場合
もう一例書いておきます。
下記に記事のように Interface を修正することで幅広い実装が可能になります。
ソートを使う — プログラミング言語 Go | text.Baldanders.infoSortの Interface
type Interface interface { // Len is the number of elements in the collection. Len() int // Less returns whether the element with index i should sort // before the element with index j. Less(i, j int) bool // Swap swaps the elements with indexes i and j. Swap(i, j int) }テストを書く場合
- テストしたい関数は、
interfaceで定義しておくtype UserAccessor interface { ListTree() (*[]repository.User, error) }空のインターフェース
interface{}のような空のインターフェースは、どんな型にでも対応できるようになります。func main() { // 空のインターフェース を宣言する var i interface{} describe(i) i = 42 describe(i) i = "hello" describe(i) } func describe(i interface{}) { fmt.Printf("(%v, %T)\n", i, i) }
- 投稿日:2020-09-19T13:14:11+09:00
【Go】インターフェースっす!
参考記事
初心者に送りたいinterfaceの使い方[Golang]. # Intro | by Takahito Yamada | Since I want to start “blog” that looks like men do, I do start. | Medium
A Tour of Go
A Tour of Go 練習問題を解く - Qiitaインターフェース
インターフェースって?
ソフトウェアの振る舞いは、既存の成果物を変更せずに拡張できるようにすべし!
特徴
- 実態を持つ
- 疎結合するのに用いられる
- ユニットテスト書く時に便利
実装パターン
インタフェースの実装パターン #golang - Qiita
サンプル実装
typeは型を宣言するために使う- レシーバーに実装したい構造体を渡す
既存の interface を使用する場合(Stringer)
- interfaceで定義されている(
Stringer)関数と同じ名前の関数を作る- 引数の型、返り値の型を合わせる
type Person struct { Name string Age int } // Stringer という interface と同じ名前、引数、返り値を宣言する func (p Person) String() string { return fmt.Sprintf("%v (%v years)", p.Name, p.Age) } func main() { a := Person{"Arthur Dent", 42} z := Person{"Zaphod Beeblebrox", 9001} fmt.Println(a, z) }既存の interface を使用する場合(Sort)
もう一例書いておきます。
下記に記事のように Interface を修正することで幅広い実装が可能になります。
ソートを使う — プログラミング言語 Go | text.Baldanders.infoSortの Interface
下記の Interface を持つ型であればsort.Sort()関数でソートが可能ということになります。type Interface interface { // Len is the number of elements in the collection. Len() int // Less returns whether the element with index i should sort // before the element with index j. Less(i, j int) bool // Swap swaps the elements with indexes i and j. Swap(i, j int) }もし一部の Interface が実装されていない場合は、下記のようなエラーが出ます。
does not implement sort.Interface (missing Swap method)テストを書く場合
- テストしたい関数は、
interfaceで定義しておくtype UserAccessor interface { ListTree() (*[]repository.User, error) }空のインターフェース
interface{}のような空のインターフェースは、どんな型にでも対応できるようになります。func main() { // 空のインターフェース を宣言する var i interface{} describe(i) i = 42 describe(i) i = "hello" describe(i) } func describe(i interface{}) { fmt.Printf("(%v, %T)\n", i, i) }