- 投稿日:2020-09-17T23:59:18+09:00
試験の数理 その4(問題paramter推定の実装)
試験の数理 その3(3PL modelの最適化) の続きです。
前回は、「3PL modelの最適化の数理について」でした。
今回は、「3PL modelの問題paramter推定の実装について」です。用いた環境は、
- python 3.8
- numpy 1.19.2
- scipy 1.5.2
です。
データ生成
試験の数理 その1(問題設定とデータの生成)で行ったように実験のために各種パラメータや項目反応行列を生成します。
import numpy as np from functools import partial # 数値計算で発散させないように小さなεをおいておく epsilon = 0.0001 # 3 parameter logistic model の定義 def L3P(a, b, c, x): return c + (1 - epsilon - c) / (1 + np.exp(- a * (x - b))) # 2 parameter logistic model の定義。処理の統一のためにcも引数に取ることとする。 def L2P(a, b, c, x): return (1 - epsilon) / (1 + np.exp(- a * (x - b))) # model parameterの定義 # aは正の実数, bは実数, cは0より大きく1未満であれば良い a_min = 0.7 a_max = 4 b_min = -2 b_max = 2 c_min = 0 c_max = .4 # 何問、何人にするか、下なら10問4000人 num_items = 10 num_users = 4_000 # 問題parameterの生成 item_params = np.array( [np.random.uniform(a_min, a_max, num_items), np.random.uniform(b_min, b_max, num_items), np.random.uniform(c_min, c_max, num_items)] ).T # 受験者parameterの生成 user_params = np.random.normal(size=num_users) # 項目反応行列の作成、 要素は1(正答)か0(誤答) # i行j列は問iに受験者jがどう反応したか ir_matrix_ij = np.vectorize(int)( np.array( [partial(L3P, *ip)(user_params) > np.random.uniform(0, 1, num_users) for ip in item_params] ) )今までと同様に、問題を表す添字として$i$、受験者を表す添字として$j$を用います。
受験者を1000人以上に大きくとります。これは、経験的に1PLの推定には100人以上、2PLの推定には300人以上、3PLの推定には1000人以上あるとある程度推定が安定することが知られているからです。気になる方はここを変更して実験してみてください。ここでは、問題parameterとして
a / 識別力 b / 困難度 c / 当て推量 問 1 3.34998814 0.96567682 0.33289520 問 2 1.78741502 1.09887666 0.22340858 問 3 1.33657604 -0.97455532 0.21594273 問 4 1.05624284 0.84572140 0.11501424 問 5 1.21345944 1.24370213 0.32661421 問 6 3.22726757 -0.95479962 0.33023057 問 7 1.73090248 1.46742090 0.21991115 問 8 2.16403443 1.66529355 0.10403063 問 9 2.35283349 1.78746377 0.22301869 問 10 1.77976105 -0.06035497 0.29241184 を得ました。これを推定するのが目的となります。
データの前処理
推定を行う前に推定の精度を安定させるために、
- 正答率が高すぎる問題
- 正答率が低すぎる問題
- 素点との相関が低い問題
を推定対象から除去します。具体的には
# 推定しづらい問題を除去する。 # 正答率が高すぎたり(> 0.9)、低すぎたり(0.1 <)、素点との相関があまりにもない(< 0.3)問題は外す filter_a = ir_matrix_ij.sum(axis=1) / num_users < 0.9 filter_b = ir_matrix_ij.sum(axis=1) / num_users > 0.1 filter_c = np.corrcoef(np.vstack((ir_matrix_ij, ir_matrix_ij.sum(axis=0))))[num_items][:-1] >= 0.3 filter_total = filter_a & filter_b & filter_c # 項目反応行列を再定義する irm_ij = ir_matrix_ij[filter_total] num_items, num_users = irm_ij.shape推定用の関数と定数の準備
前回見たように問題$i$毎に
\begin{align} r_{i\theta} &:= \sum_{j}u_{ij} \Pr\{\theta| U_j = u_j, a^{old}, b^{old}, c^{old}\} \\ f_\theta &= \sum_{j} \Pr\{\theta| U_j = u_j, a^{old}, b^{old}, c^{old}\} \end{align}を計算するのがE stepであり、
\begin{align} R_{i\theta} :=\frac{r_{i\theta}}{P_{i\theta}} - f_\theta \end{align}を計算して、
\begin{align} \partial^a\mathcal{\tilde{L}}(a, b, c) &= \int R_{i\theta}(\theta - b_i)P_{i\theta}^*d\theta\\ \partial^b\mathcal{\tilde{L}}(a, b, c) &= -a_i \int R_{i\theta}P_{i\theta}^*d\theta\\ \partial^c\mathcal{\tilde{L}}(a, b, c) &= \frac{1}{(1 - c_i)} \int R_{i\theta} d\theta \end{align}を0にするのが、M stepになります。
ここで、周辺化や上の積分は区分求積的に解くこととして、$\theta$の代表点として$X_k$や$g_k = g(X_k)$を用意します。そのため、次を用意します。
# 受験者パラメータの取りうる範囲を定義する。 X_k = np.linspace(-4, 4, 41) # 受験者パラメータの分布を定義する。ここでは、scipyの正規分布を使う。 from scipy.stats import norm g_k = norm.pdf(X_k) # E stepの関数 def get_exp_params(irm_ij, g_k, P3_ik): Lg_jk = np.exp(irm_ij.T.dot(np.log(P3_ik)) + (1 - irm_ij).T.dot(np.log(1 - P3_ik)))* g_k n_Lg_jk = Lg_jk / Lg_jk.sum(axis=1)[:, np.newaxis] f_k = n_Lg_jk.sum(axis=0) r_ik = irm_ij.dot(n_Lg_jk) return f_k, r_ik # M step用のスコア関数 def score_(param, f_k, r_k, X_k): a, b, c = param P3_k = partial(L3P, a, b, c)(X_k) P2_k = partial(L2P, a, b, c)(X_k) R_k = r_k / P3_k - f_k v = [ ((X_k - b) * R_k * P2_k).sum(), - a * (R_k * P2_k).sum(), R_k.sum() / (1 - c) ] return np.linalg.norm(v)推定の実行
では、推定を実行します。推定は初期parameterに依存し、安定性もそこまで良くないことが予想されるので、初期parameterをランダムにいくつか用意して、安定したものの中の中央値を推定結果として採用します。M stepの最適化はscipyのminimizeを用いることとします。
from scipy.optimize import minimize # minimize用の制約条件を定義する。 cons_ = { 'type': 'ineq', 'fun': lambda x:[ x[0] - a_min, a_max - x[0], x[1] - b_min, b_max - x[1], x[2] - c_min, c_max - x[2], ] } # 初期parameter生成用のparameterを用意する。 a_min, a_max = 0.1, 8.0 b_min, b_max = -4.0, 4.0 c_min, c_max = epsilon, 0.6 # 推定実行用のoarameter # EM algorithmの繰り返し終了条件 delta = 0.001 # EM algorithmの繰り返し最大回数 max_num_of_itr = 1000 # 数値安定のために何度か計算して、安定したものの中の中央値を採用する p_data = [] for n_try in range(10): # 推定の初期値を定義する。 item_params_ = np.array( [np.random.uniform(a_min, a_max, num_items), np.random.uniform(b_min, b_max, num_items), np.random.uniform(c_min, c_max, num_items)] ).T prev_item_params_ = item_params_ for itr in range(max_num_of_itr): # E step : exp paramの計算 P3_ik = np.array([partial(L3P, *ip)(X_k) for ip in item_params_]) f_k, r_ik = get_exp_params(irm_ij, g_k, P3_ik) ip_n = [] # 各問題ごとに最適化問題をとく for item_id in range(num_items): target = partial(score_, f_k=f_k, r_k=r_ik[item_id], X_k=X_k) result = minimize(target, x0=item_params_[item_id], constraints=cons_, method="slsqp") ip_n.append(list(result.x)) item_params_ = np.array(ip_n) # 前回との平均差分が一定値を下回ったら計算終了 mean_diff = abs(prev_item_params_ - item_params_).sum() / item_params_.size if mean_diff < delta: break prev_item_params_ = item_params_ p_data.append(item_params_) p_data_ = np.array(p_data) result_ = [] for idx in range(p_data_.shape[1]): t_ = np.array(p_data)[:, idx, :] # 計算結果で極端なものを排除 filter_1 = t_[:, 1] < b_max - epsilon filter_2 = t_[:, 1] > b_min + epsilon # 残った中のmedianを計算結果とする。 result_.append(np.median(t_[filter_1 & filter_2], axis=0)) result = np.array(result_)実験結果
今回は計算の結果次を得ました。
計算結果(目的)
a / 識別力 b / 困難度 c / 当て推量 問 1 3.49633348(3.34998814) 1.12766137(0.96567682) 0.35744497(0.33289520) 問 2 2.06354365(1.78741502) 1.03621881(1.09887666) 0.20507606(0.22340858) 問 3 1.64406087(1.33657604) -0.39145998(-0.97455532) 0.48094315(0.21594273) 問 4 1.47999466(1.05624284) 0.95923840(0.84572140) 0.18384673(0.11501424) 問 5 1.44474336(1.21345944) 1.12406269(1.24370213) 0.31475672(0.32661421) 問 6 3.91285332(3.22726757) -1.09218709(-0.95479962) 0.18379076(0.33023057) 問 7 1.44498535(1.73090248) 1.50705016(1.46742090) 0.20601461(0.21991115) 問 8 2.37497907(2.16403443) 1.61937999(1.66529355) 0.10503096(0.10403063) 問 9 3.10840278(2.35283349) 1.69962392(1.78746377) 0.22051818(0.22301869) 問 10 1.79969976(1.77976105) 0.06053145(-0.06035497) 0.29944448(0.29241184) 問3のb(困難度)など若干おかしな数値になっているところもありますが、おおよそ良い精度で推定できています。
次回
次回は問題のparameterの結果を用いて受験者の能力parameter $\theta_j$の推定を行います。
参考文献
- 投稿日:2020-09-17T23:29:47+09:00
Pythonによる画像処理100本ノック#2 グレースケール化
はじめに
どうも、らむです。
画像処理ではお馴染みのグレースケール化を実装します。2本目:グレースケール化
グレースケールは様々な画像処理の前処理として使われる事が多いです。画像処理を学ぶならば必ず知っておきましょう。
グレースケール化とは画像を黒色、白色、及びその中間色である灰色の濃淡を用いて画像を表現する手法です。
モノクロ画像は白黒2色のみであるのに対し、グレースケール画像では通常256色を用います。なお、各画素は以下の式によって算出されます。
$$
P = 0.2126 R + 0.7152 G + 0.0722 B
$$grayscale.pyimport cv2 import matplotlib.pyplot as plt import numpy as np plt.gray() def grayscale(img): # グレースケール画像用配列作成 dst = np.zeros((img.shape[0], img.shape[1])) # グレースケール化 dst[:,:] = (0.2126*img[:,:,2] + 0.7152*img[:,:,1] + 0.0722*img[:,:,0]).astype(np.uint8) return dst # 画像読込 img = cv2.imread('image.jpg') # グレースケール化 gray = grayscale(img) # 画像保存 cv2.imwrite('result.jpg', gray) # 画像表示 plt.imshow(gray) plt.show()

画像左は入力画像、画像右は出力画像です。
しっかりグレースケール画像が作成できていますね。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。

- 投稿日:2020-09-17T23:04:15+09:00
Pythonで数値を扱う
はじめに
今回の記事ではPythonを使ってコンピューターで扱う数値について書いていきたいと思います。
10進数
主に僕たちが使っているもの。
「0, 1, 2, 3, 4, 5, 6, 7, 8, 9」の10種類の数字を扱う。2進数
主にコンピューターが使っているもの。
「0, 1」の2種類だけ。16進数
色とかで使われる。
「0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F」の16種類。重み
1000(10の3乗)や100(10の2乗)や1(10の0乗)など、10の何乗であるかで表せるもの。
また、このように10を基準にして表せるため、10進数では10を基数または底と呼ぶ。
2進数では「2」、16進数では「16」が基数。基数変換
10進数を2進数に、16進数を10進数のように基数を違う数値に変換してくこと。
10進数に変換
python#int('変更したい値', 基数) int('0b1010', 2) #10 int('0xa', 16) #102進数に変換
bin()関数を使います。
python#bin(2進数に変換したい値) bin(10) #0b1010 bin(-10) #-0b101016進数に変換
hex()関数を使います。
python#hex(16進数に変換したい値) hex(0b1010) #0xa1ビットと1バイト
1ビット=2進数の1桁でコンピューターで扱う最小の単位
1バイト=8ビットコンピューターでは、「10」を次のように表す。
python[00000010] #[11111111]に「1」を足す [0000000100000000]このように基本的に1バイト=8ビット塊であることを頭に入れておきましょう。
また、0は「その桁に値が何もない」ということを表している。補数
「-」を表すときに使われるもの。
python#[00000001]の補数は? [11111111]全ての「0」と「1」を反対にして、「1」を足すと表せます。
符号ビット
1バイトの8桁目は正の数か負の数かを表します。
0が正の数で、1が負の数です。python#正の数 [00000000] #負の数 [1000000]1バイトで正の数128種類、負の数128種類の合計256種類を扱うことができます。
最後に
今回はPythonを使ってコンピューターの数値について書いてきました。
今後追記していくです。
- 投稿日:2020-09-17T22:49:52+09:00
mono cameraによるdepth estimation基礎理解(Deep Learning編)
うまく説明出来てないかもしれませんが、ざっくりとニュアンスを組み取って頂けたら嬉しいです。
stereo depthについてもまとめたので、気になる方はどうぞ
https://qiita.com/minh33/items/55717aa1ace9d7f7e7dd
https://qiita.com/minh33/items/6b8d37ce08f85d3a3479目次
- Depth Estimation
- Image warp
- Loss
Depth Estimation
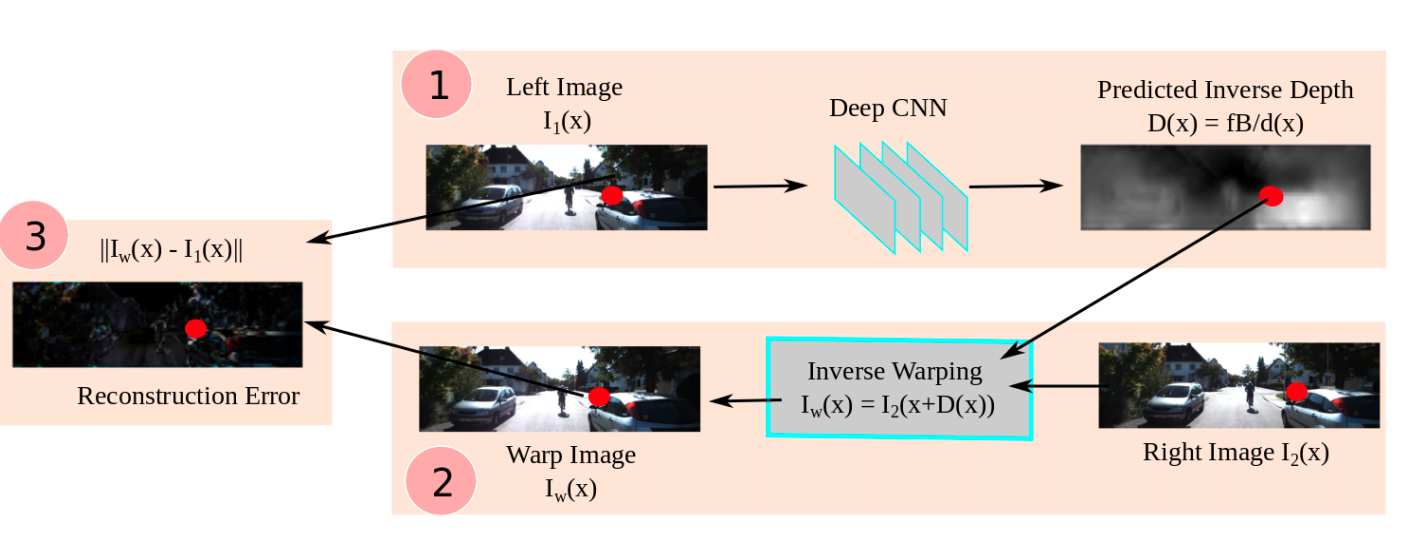
人が片目で物体の大まかな位置が分かるように単眼のカメラでも位置を推定することが出来ます。例えば、カメラの角度を固定しておけば、近い物は画像のしたの方に位置していて、遠いものは画像の上の方に位置しています。基本的に物体は地面の上にあるので、接地面の距離がわかれば物体の位置も推定出来ます。他には物体間の相対位置や物体の大きさなども情報として使えます。CNNを用いて学習しているので、実際どんな情報を得てモデルが推定してるかはわかりにくいのですが、実験をしたという面白い論文があったので興味のある人は是非
Image warp
単眼の場合
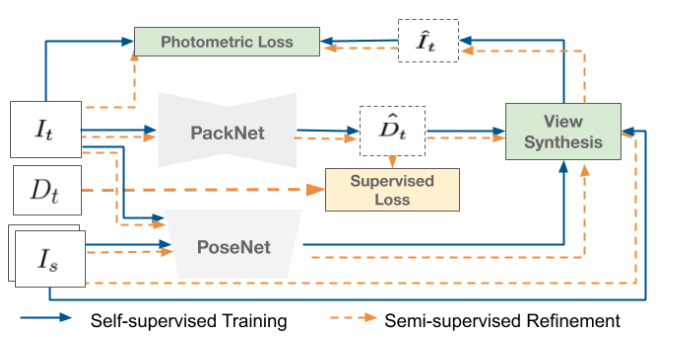
カメラを載せた車が動く事によって、一つ前のフレームに変換することが出来ます。まずt=tの時の画像の距離をネットワークで推定します。距離を推定出来たので3次元のポイントクラウドを計算する事が出来ます。カメラを載せた車の移動量を自己位置推定を使い求めます。自己位置推定はVSLAM、オドメトリー、GPS、IMUなどが使えます。x,y,z,roll,pitch,yawの1フレームの変化量を先程計算した3次元ポイントクラウドをTransfomationする事によって、t=t-1の3次元ポイントクラウドを推測する事が出来ました。それをImage Viewに変換する事で、t=tの画像をt=t-1の画像にwarpさせる事が出来ます。ただし自分が動いていいないと学習出来ないのと、相手の物体が動いているとwarpしてもずれてしまうというデメリットもあります。
It=>target Image(t=t)
Is=>source Image(t=t-1)
Dt=>target Depth(LiDARを用いた距離のGround Truth)
D^t=>Estimated target Depth
I^t=>Estimated target Image
View Synthesis=>画像のReconstruction
Photometric Loss=>推定画像と実際の画像の比較3番でLossを計算する為に使われるのですが、求めたDepthをDisparityに変換し、右の画像を左の画像にワープさせることが出来ます。ちなみにmono depthなのに双眼なのって?って思う人もいると思うんですが、距離推定は単眼で行い、学習のGround Truthとして反対のレンズを使います。
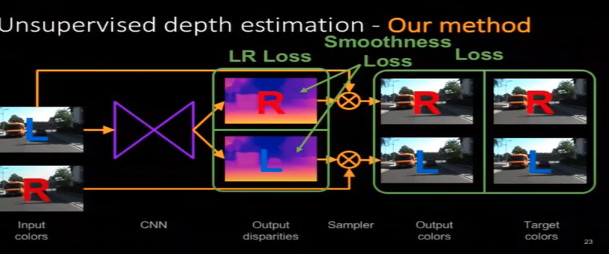
Lossの定義
Unsupervised Monocular Depth Estimation with Left-Right Consistency(2017)
monodepthで多分この論文が一番有名
・ Reconstruction Loss
右の画像を推定した左のDisparityを用いてwarpする事によって左のReconstruction画像が出来る。その画像と左の入力画像のSADとSSIMを計算する。逆も行う・LR Consistency Loss
右のDisparity Mapを左のDisparity MapへとwarpさせてDisparityの絶対値の差を計算する。逆も行う・Smoothness Loss
近傍のPixelのDisparity(Depth)は同一物体であればほぼ同じであるはずなので、Laplacian Smoothnessなどを用いてDisparityのSmoothnessを計算する。右と左のDisparityMapそれぞれで行う。
- 投稿日:2020-09-17T22:42:02+09:00
matplotlib.pyplot で積分区間をに色をつける
先日グラフの積分によって求められる面積に色をつけたいと考えた時に使用した関数が便利だったのでメモします。
matplotlib.pyplot.fill_between
matplotlib.pyplot.fill_between(x, y1, y2=0, where=None, interpolate=False, step=None, \*, data=None, **kwargs)今回私が使った関数はこれです。
今回私はグラフの下を塗りつぶしたかっただけなので使用するのはmatplotlib.pyplot.fill_between(x, y1, color='color',alpha=(float))のみのパラメータです。
基本的なplotと同じように最初の2つはx軸とy軸のデータを入れます
そして**kwargsで指定できる他のパラメータからcolor='色'と、alpha='透過度'で指定しています。実装
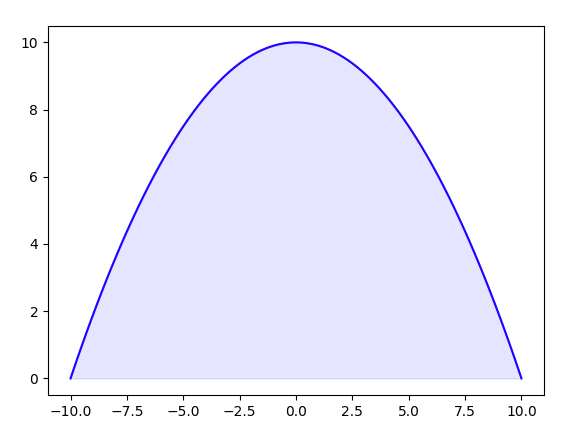
実装して見ました
ex_fill_between.pyimport numpy as np import matplotlib.pyplot as plt x = np.linspace(-10,10,100) y = -0.1*(x**2)+10 plt.plot(x,y,'blue') plt.fill_between(x,y,color='blue',alpha=0.1) plt.show()結果
こんな感じです。
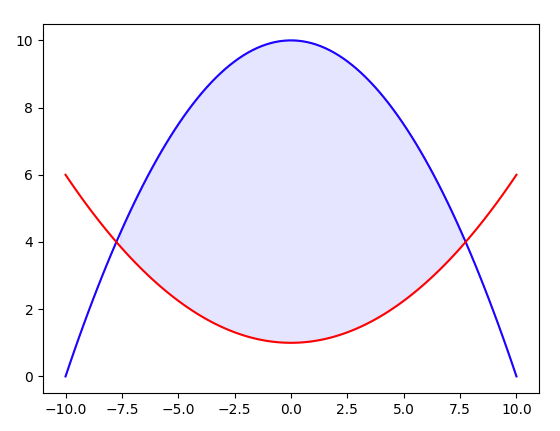
もし二つの曲線に挟まれたエリアを塗りつぶしたいならy2の値を入れればいいのでex_fill_between2.pyimport numpy as np import matplotlib.pyplot as plt x = np.linspace(-10,10,100) y = -0.1*(x**2)+10 y2 = 0.05*(x**2)+1 plt.plot(x,y,'blue') plt.plot(x,y2,'red') plt.fill_between(x,y,y2,where = y>y2,color='blue',alpha=0.1) plt.show() ~結果
となります。ここでwhereを使っていますが、これは適応する場所を選択するようでboolで指定するようです。
これによって赤線と青線で囲まれた場所(青線>赤線)のみ場所だけに適応しています。余談ーーー
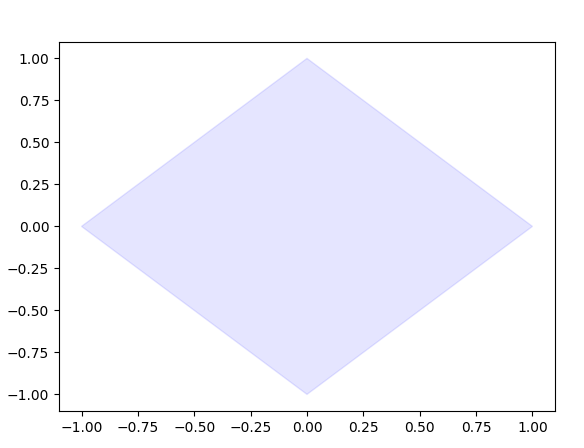
これとは別に図形を塗りたいならfill関数を使うのがいいみたいです。ex_fill.pyimport matplotlib.pyplot as plt x = [-1,0,1,0] y = [0,-1,0,1] plt.fill(x,y,color='blue',alpha=0.1) plt.show()結果
ーーーーー
終わりに
もしかしたらこの程度は常識かもしれませんが個人的に便利だと思いました。
小さなことをコツコツアウトプットすることも大事かと思うのでこういうものも書いていこうかと思います。[参考]
http://cranethree.hatenablog.com/entry/2015/07/25/204608 matplotlibで領域の図示
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.fill_between.html matplotlib公式
https://sabopy.com/py/matplotlib-28/ [matplotlibの使い方] 28. 折れ線グラフの下を塗りつぶしたグラフ
- 投稿日:2020-09-17T22:29:09+09:00
開発備忘録的覚え書き~pandasとかforelseとかデータ構造とか~
概要
最近、業務上の仕事を自動化する機会に恵まれました。内容としては、
- gspreadライブラリを使い、Googleスプレッドシート上のスケジュールを抜き出す
- 簡単な集計と再配置を含む操作を行い、pandasのデータフレームにまとめ直す
- まとめたデータフレームをGoogleスプレッドシートに再出力する
という比較的単純なものでした。現状の完成度は8割程度です。思った以上に手こずり、非常に得るものが多かったので、今後のためにまとめておこうと思いたちこの記事を作成しています。若干散らかっているかもしれませんが、温かい目で見ていただければ幸いです。
知識編
以下は主にライブラリだったり、プログラムの仕様だったりと、知識面に関する学びをまとめたものです。
1.)pandas.DataFrameの代入は同じオブジェクトを指す
これはデータフレームの扱いになれていらっしゃる方からすれば、当たり前のことなのだと思います。私も以前にリストを扱っているときに、同じ過ちを犯したことがあるのですが、思い至らず再びやらかしました。
状況としては、以下のようなdatetime型をキーとした辞書を空のデータフレームで初期化しようとしている場面です。「日付ごとにセクションを使っている人をまとめたいから、とりあえず空のデータフレームを登録したろ!」って感じで作りました。
import pandas as pd import datetime empty_user = dict(Section1=['', '', ''], Section2=['', '', ''], Section3=['', '', '']) hour = ['9:00', '10:00', '11:00'] df = pd.DataFrame(data=empty_user, index=hour) five_days_list = [(datetime.datetime(2020, 9, 1) + datetime.timedelta(days=1) * i) for i in range(5)] dict_of_dataframe = {date_key : df for date_key in five_days_list}出来上がった辞書はこんな感じです。
date_key : 2020-09-01 00:00:00 value : Section1 Section2 Section3 9:00 10:00 11:00 date_key : 2020-09-02 00:00:00 # 以下省略1週間くらい前の私はこれに何の疑問も抱かず次の作業に進みました。が、いざ集計したデータを登録し始めると、全く上手くいきません。1ヶ月分くらいのスケジュールのうち、3日目以降はぐっちゃぐちゃのもちゃもちゃです。
今思うと理由は単純。この作成方法は同じデータフレームを何度も使い回しているだけです。id()を使って出力すればより顕著になるでしょう。
for date_key, dataframe in dict_of_dataframe.items(): print(f"date_key : {date_key}") print(f"dataframe_id : {id(dataframe)}")date_key : 2020-09-01 00:00:00 dataframe_id : 2124838088520 date_key : 2020-09-02 00:00:00 dataframe_id : 2124838088520 date_key : 2020-09-03 00:00:00 # 以下省略正しくは、pandas.DataFrameのメソッドであるcopy()を使わなければなりませんでした。
dict_of_dataframe = {date_key : df.copy() for date_key in five_days_list}date_key : 2020-09-01 00:00:00 dataframe_id : 2124838588936 date_key : 2020-09-02 00:00:00 dataframe_id : 2124838590152 date_key : 2020-09-03 00:00:00pandasの公式ドキュメントにばっちり記載してあるのですが、データフレームのcopy()メソッドはデフォルトでdeep=True,つまり深いコピーになっています。あくまでテンプレートとして利用したいだけなら、オブジェクトとしては別になっていないとダメですよね。気づいたときはぶん殴られるような衝撃を感じました。
なお、後述しますが、この作業には結構深めのデータの構造、およびそれに伴う多重ループ構造というカルマまで付随していました。
当初はそちらの方ばかりを気にしていたため、途中経過を出力したりpandasのドキュメントを読んだり、ループ構造を紙に書き出したりと、アレやコレやの悪戦苦闘で2日くらい苦しんでいたと思います。2.)for:else:はとっても便利
Pythonの基礎文法をちょっとは知ったつもりになっていましたが、この子とは開発中に初めて出会いました。あるいは知っていたのに忘れていました。for文とセットでelse文を使うと、for文のループをbreakで抜けなかった時だけelse文を実行してくれます。
使い道は無数にあると思いますが、私は以下のように空きセクションが存在しないときにログで通知してもらうために利用しました。
client_salesman_dict = {datetime.datetime(2020, 9, 1, 9, 0) : [('山田様', '高橋'), ('吉沢様', '伊藤')], datetime.datetime(2020, 9, 1, 10, 0) : [('佐々木様', '桃山')], datetime.datetime(2020, 9, 1, 11, 0) : [('横田様', '高橋'), ('福地様', '大木'), ('中山様', '伊藤'), ('権田様', '小沢')],} section_list = ['Section1', 'Section2', 'Section3',] for date_dt, client_salesman_tuples in client_salesman_dict.items(): date_str = f"{date_dt.hour}:{date_dt.minute:02}" for client_salesman_tuple in client_salesman_tuples: client = client_salesman_tuple[0] salesman = client_salesman_tuple[1] for section in section_list: section_status = df.loc[date_str, section] print(f"client : {client}, salesman : {salesman}") print(f"time is {date_str}") print(f"section is {section}") print(f"section_status is {section_status}") if section_status: print(f"bool of section_status is {bool(section_status)}.") print("I will skip writing phase.") continue print(f"I have applied {client},{salesman} to {section}") df.loc[date_str, section] = f"{client} {salesman}" break else: print(f"There is no empty section for{client}, {salesman}.Please recheck schedule.")client : 山田様, salesman : 高橋 time is 9:00 section is Section1 section_status is I have applied 山田様,高橋 to Section1 client : 吉沢様, salesman : 伊藤 time is 9:00 section is Section1 section_status is 山田様 高橋 bool of section_status is True. I will skip writing phase. # 中略 There is no empty section for権田様, 小沢.Please recheck schedule.むかーしC言語だかJavaだかで似たような処理をしていたときは、確かフラグを内部に立てて頑張っていたと思うのですが、Pythonなら不要のようです。地味ですが、for文自体の利用機会が多いので、今後も適宜活用していきたいところ。
3.)属性の前に_を1個で慣習的なprivate宣言、2個だと通常の方法でアクセスできなくする
前々から存在は知っていたのですが、特に意識して自分で使うことはありませんでした。振る舞いについて適当にテストすると、こんな感じになると思います。
class TestClass: def __init__(self): self.hoge = 1 self._fuga = 2 self.__monge = 3 def _foo1(self): print("_foo1 is called") def __foo2(self): print("__foo2 is called") t = TestClass() # インスタンス変数 print(t.hoge) print(t._fuga) # print(t.__monge) ←呼べない print(t._TestClass__monge) # クラスメソッド t._foo1() # t.__foo2() ←呼べない t._TestClass__foo2()1 2 3 _foo1 is called __foo2 is calledアンダースコアを先頭に2つ付けた場合は、インスタンス変数もクラスメソッドもいつものようには呼べなくなります。かといってJavaにあるようなガチガチのPrivate属性というわけではなく、
instance.__ClassName_AttributeNameで呼ぶこと自体は可能です。
また、アンダースコアを先頭に1つ付けた場合は……こちらも呼べちゃうんですよね。しかも普通に。「え、じゃあ何のためにあるの?」と思って調べたところ、以下のようなサイトが見つかりました。
【Python】アンダースコア( _ )の使い方(特殊属性、dunders)
こちらによると、どうやら
- 1個の時は内部用だということを示唆するだけで、特に動作が変わったりはしない。ただし、モジュールとしてワイルドカードを使って呼び出すときに限り、読み込まれなくなる。
- 2個の時は名前のマングリング(名前修飾)を起こすので、そのままアクセスすることはできなくなる。ただ、privateにすることが目的ではなく、親子関係にあるクラス間で名前の衝突を避けるために利用される。
らしいです。そもそもprivateを作るためのものだという認識がおかしかったんですね。今回はクラスの継承を行わずにプログラムを作成したので、アンダースコア1個の利用で十分でした。
4.)docstringは良い文化
こちらも存在だけは何となく知っていたのですが、利用したのは今回が初めてでした。作成の際には以下の記事を参考にさせていただいています。
[Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル)
今回のプログラムは、自分による自分のための開発だったので「必要あるかな?」と思いつつ書いていましたが、結果としては「何を使って」「何のために」「何をするのか」をしっかりと考える切っ掛けになりました。これまでは何となく書き始めて、いったん動かしてから修正する場当たり的なやり方でしたが、docstringを書くことで少しはマシになったと思います。
考え方編
以下は知識というよりも、経験的に「こうした方が良さそうだな」と学んだ点になります。
1.)深すぎるデータ構造はアウト
最初にスケジュールをまとめ始めた時、私は以下のような辞書にデータをまとめていました。
from datetime import datetime from datetime import datetime schedule_dict = {'1week': {datetime(2020, 9, 1) : {datetime(2020, 9, 1, 9, 0): [('山田様', '寺田'),('吉木様', '遠藤'),], datetime(2020, 9, 1, 10, 0): [('工藤様', '山下'),],}, datetime(2020, 9, 2) : {datetime(2020, 9, 2, 10, 0): [('鶴川様', '本田'),], datetime(2020, 9, 2, 11, 0): [('遠藤様', '相澤'),],}, datetime(2020, 9, 2) : {datetime(2020, 9, 3, 9, 0): [('下田様', '寺田'), ('吉川様', '郷田')], } } '2week': ....}アクセスする際はこんな感じです。
schedule_dict['2week'][datetime(2020, 9, 8)][datetime(2020, 9, 8, 10, 0)]スプレッドシート側のデータが1週間ごとに横並びになっていたので、特に何も考えず合わせたのですが、とにかく無用に深い。アクセスする際もまだるっこしいし、利用する際にfor文なんかで展開するときにもループの階層がどんどん深くなる。
結局作業途中で根を上げて、週のキーを無くし、一階層だけ浅くしました。今あらためて見直してみると、0時の日付キーもいらない気がします。必要になったらdatetime.datetime型のyear,month,dayの属性それぞれにアクセスして、作り直せば良いですからね。
よく、「無駄に深いループは避けるべき」とは言われますが、それを引き起こす「無駄に深い階層のデータを作るのも避けるべき」だということが身にしみました。体感的には、階層を一回深くなるごとに処理あたりの負担が2倍になっている気がします。脳のおメモリがガンガン吸われるんですよね……
2.)多少長くなってもきちんとした名前をつける
開発当初、部分部分をテストした時の名前をそのまま変数名に使っていました。処理を対象ごとにクラス分けしていたので、名前が衝突することもありません。データフレームならdf,日付ならdate、辞書ならdctといった具合に、なるべく短く書こうと心がけていました。
が、すぐに壁にぶち当たりました。プログラムの仕様上の問題というより、脳のメモリの方の問題です。処理が複雑化するに連れて、「あれ、この辞書って中身はなんだっけ?」「エラー吐いてるけど、この日付は文字列型じゃないの?」「index out of range???想定していた要素数のリストが来ていないの?」などの問題が多発しました。
今までは仕様を軽く理解するためのサンプルプログラムくらいしか書いていなかったので、そこまで気にすることはありませんでしが、名前はどこから飛んできてもわかるようにつけるべきなのですね。言葉にすれば当然のようで、あまり本気で考えたことがありませんでした。
datetime型の日付ならdate_dtで、str型の日付ならdate_str。あとは、何を格納しているのかを示すためにclient_salesman_tuples_listという名前を付けたり、for文での展開時に使用する名前をfor client_salesman_tuple in client_salesman_tuples_list:のように、単数形と複数形を意識して使い分けるようにしました。
おかげさまで、最初の頃よりはいくぶんわかりやすくなりました。そもそも脳が混乱するような処理をしないのが理想なのでしょうが、そのための技量が足りないなら足りないなりに、名前の方で工夫するというのは今後も意識しておきたいところです。
3.)オブジェクト指向はお役所や会社を想像する
これは本当に正しいのかよくわかりません。ただ、2週間ほど前に部分から全体へとまとめる時に、100行くらい平書きして我に帰りました。この調子だと大変なことになるよねと。ちょっと調べて出てきた以下のサイトからプチ天啓を得ました。
オブジェクト指向とは、 クラスを通して self という名前空間を適切に分割していく作業じゃないかなと感じています。
適切に分割、という言葉を眺めてしばらくボーッとしていましたが、ふと「これってお役所と同じじゃない?」という発想に至りました。
少し前に市役所に住民票を取りに行って、ちょっとだけ待たなければならないことがありました。待っている間何とは無しにお役所のサイトを見ていたのですが、実に細かく別れています。市民、商工観光、建設、都市計画etcetc...
ぱっと見、「建設と都市計画って同じじゃないの?」なんてことを見てる側は思ったりするのですが、実際は○○部の△△課ということで区分けされているわけです。お仕事の中身までは知りませんが、しっかりと分担されているのでしょう。これは「クラス分け」と同じ。時には部署ごとの連携が必要になることもあるでしょうが、全ての情報を渡したりはしないでしょう。紙とデータが氾濫してしまいます。その仕事に必要なだけの情報を担当者が持っていって話し合うほうが合理的です。これが「継承より合成」と同じ。
さらに住民票の取得を申請した"私"は、中でどんな処理が行われているのかは全く知りません。担当の方がなんかこう、パソコンに色々入力して書類に記入しているのは何となく想像がつきますが、やってることは申請書を書いて、お金を払っているだけです。それで問題なく住民票は受け取れます。多分窓口業務をしている方も、具体的に書いた書類や入力されたデータが何に使われて、どう保管されているのか、その全ては把握されていないでしょう。これが「情報の隠蔽」と同じ。
そんな感じで、頭の中にお役所を想像したら何とかクラス分けを行うことができました。自分で書いてても、本当にこの理解で合っているのかは今ひとつ自身がないのですが、曲がりなりにも書けたので暫定的にOKとしています。
と思っていたら、Qiitaの方にタイムリーな記事が上がっていました。こちらの方がずっとわかりやすい説明だと思いますので、参照してみて下さい。
オブジェクト指向歴25年のオブジェクト指向おじさんが語るオブジェクト指向設計の処方箋
今後ここは習得していきたいよね編
最後に、知識や考え方としてはあったけど、結局上手に使えなかったことを書いていきます。
for文を浅くするためのitertoolsの活用
またまた知らなかったのですが、Pythonの標準ライブラリにはitertoolsなるライブラリがあります。わかりやすい解説はこちらの投稿を参考していただくとして、私がここで注目したのは、itertoolsの中にあるproductなるメソッドです。
このproductは、公式ドキュメントに記載のある通り、一般的な多重ループと同じような出力を行ってくれます。
import itertools section_list = ['Section1', 'Section2', 'Section3'] time_list = ['9:00', '10:00', '11:00'] for section in section_list: for time in time_list: print(section, time) print("------------") for section, time in list(itertools.product(section_list, time_list)): print(section, time)出力は同じです。
Section1 9:00 Section1 10:00 Section1 11:00 Section2 9:00 Section2 10:00 Section2 11:00 Section3 9:00 Section3 10:00 Section3 11:00 ------------ Section1 9:00 Section1 10:00 Section1 11:00 Section2 9:00 Section2 10:00 Section2 11:00 Section3 9:00 Section3 10:00 Section3 11:00タプルとして受け取ることも可能です。
for tpl in list(itertools.product(section_list, time_list)): print(tpl)('Section1', '9:00') ('Section1', '10:00') ('Section1', '11:00') ('Section2', '9:00') ('Section2', '10:00') ('Section2', '11:00') ('Section3', '9:00') ('Section3', '10:00') ('Section3', '11:00')本当はこれをループの階層削減に利用したかったのですが、どうにも上手く行きませんでした。上で述べたように、ループの階層の増加は脳の負担の増加に直結することを痛いほどに理解したので、今後はデータ構造の考え方と共に、itertoolsの利用も行っていきたいです。
まとめ
よくプログラミング初級者へのアドバイスとして、「とりあえずなにか作ってみたら?」というのを聞きますが、これが実に理に適った助言であることが理解できました。想像の10倍くらい苦労しましたが、それだけ得るものも多かったと感じています。
なにかご意見、アドバイス等ありましたらコメント欄によろしくお願いします。
- 投稿日:2020-09-17T22:12:34+09:00
Pythonによる画像処理100本ノック#1 チャネル入れ替え
はじめに
どうも、らむです。
突然ですが私は画像処理系の研究室に所属しています。私の研究室では来月から後輩にゼミで画像処理手法について教えていかなければなりません。正直最近勉強不足で基本的な画像処理の実装や説明ができない気がします。そこでimori_imoriさんの画像処理100本ノックをやってみることにしました。
ここでは1本ずつ画像処理を実装し軽く解説していこうと思います。なお、pythonは最近始めたばかりなのでコーディング力はお察しください。
1本目:チャネル入れ替え
記念すべき1本目の画像処理はチャンネル入れ替えです。
カラー画像には赤・青・緑の3色成分、つまり3チャネルの成分が存在します。
openCVを用いて読み込むと青・緑・赤の順番になりますが、今回はこれを赤・緑・青の順番に入れ替えます。reverseChannel.pyimport cv2 import matplotlib.pyplot as plt def reverseChannel(img): # 画像コピー dst = img.copy() # チャネル入れ替え dst[:, :, 0] = img[:, :, 2] dst[:, :, 2] = img[:, :, 0] return dst # 画像読込 img = cv2.imread('image.jpg') # チャネル入れ替え img = reverseChannel(img) # 画像保存 cv2.imwrite("result.jpg", img) # 画像表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.show()
画像左は入力画像、画像右は出力画像です。
赤成分と青成分が入れ替わったことによって刺し身の赤色が青色に変わっています。おわりに
このような感じでアウトプットしていこうと思います。もし、質問がある方がいらっしゃれば気軽にどうぞ。
ちなみに、画像処理100本ノック公式サイトのGithubに公式の解答が載っているので是非そちらも確認してみてください。

- 投稿日:2020-09-17T21:23:31+09:00
ポケモンと旅する特徴量エンジニアリング-カテゴリー変数編-
機械学習において、カテゴリーデータなど文字列のデータは数値データへ直さなければ機械学習モデルに入れることができません。また、数値データでも順序尺度でないデータはカテゴリー変数として扱うべきです。本記事では、カテゴリー変数を機械が理解できる形に直す手法を紹介します。
今回はポケモンと旅する特徴量エンジニアリング-数値編-の時と同様にポケモンのデータセットを利用します。
ライブラリーの読み込み
import pandas as pd from sklearn.feature_extraction import FeatureHasherデータ読み込み
df = pd.read_csv('./data/121_280_bundle_archive.zip') df.head()データ
# Name Type 1 Type 2 Total HP Attack Defense Sp. Atk Sp. Def Speed Generation Legendary 1 Bulbasaur Grass Poison 318 45 49 49 65 65 45 1 False 2 Ivysaur Grass Poison 405 60 62 63 80 80 60 1 False 3 Venusaur Grass Poison 525 80 82 83 100 100 80 1 False 3 VenusaurMega Venusaur Grass Poison 625 80 100 123 122 120 80 1 False 4 Charmander Fire NaN 309 39 52 43 60 50 65 1 False ダミーエンコーディング
ダミーエンコーディングは特徴量エンジニアリングにおいて、カテゴリー変数を扱う時、最も人気&頻繁に登場する手法です。各カテゴリー変数を0, 1のビットで表現します。カテゴリー値をが該当する部分のビットは1となり、該当しない部分のビットは0となります。
pandasにはダミーエンコーディングを簡単に関数があります。コードを見ていきましょう。
# One-hot Encoding gdm = pd.get_dummies(df['Type 1']) gdm = pd.concat([df['Name'], gdm], axis=1)Bulbasaur(フシギダネ)のGrass(草)タイプに該当するビットが1になっている事を確認できます。
Name Bug Dark Dragon Electric Fairy Fighting Fire Flying Ghost Grass Ground Ice Normal Poison Psychic Rock Steel Water Bulbasaur 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 Ivysaur 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 Venusaur 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 VenusaurMega Venusaur 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 Charmander 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 ラベルエンコーディング
ダミーエンコーディングは0, 1のビットで表現してたのですが、ラベルエンコーディングは整数で表現します。
特徴量ハッシング
特徴量ハッシングと今までの変換の違いは、特徴量ハッシングは変換後のカテゴリー数が少なくなることです。ハッシュ関数という魔法の関数を利用することで、入力された特徴数を減らすイメージして頂ければ問題ないです。
どんな勉強もイメージで覚えたほうが頭に入りやすいですからね。
コードを見ていきましょう。sklearnにはFeatureHasherモジュールがありますので、これを利用しましょう。ポケモンのタイプを特徴量ハッシングで5つに絞っていきます。
「こんなのどんな時に使うんや!」と思うかもしれませんね。通常はカテゴリー変数が多すぎる時に使うと覚えてください。
fh = FeatureHasher(n_features=5, input_type='string') hash_table = pd.DataFrame(fh.transform(df['Type 1']).todense())変換後の特徴量
0 1 2 3 4 2 0 0 0 -1 2 0 0 0 -1 2 0 0 0 -1 2 0 0 0 -1 1 -1 0 -1 1 さいごに
これらの手法はどんな時にどれを選べば良いでしょうか?一つの答えとして、分析用の計算機のスペックによって手法を使い分ける事があります。ダミーエンコーディングやラベルエンコーディングはシンプルな一方、カテゴリー変数が多すぎるとメモリーエラーを起こしたり可能性があります。その時は特徴量を圧縮する特徴量ハッシングを検討しても良いかもしれません。
ただし、最近は高スペックの計算機が無料で利用できるようになってきていますし、Kaggleで多く利用されている決定木モデルであるGBDTはラベルエンコーディングを処理できます。特徴量ハッシングの出番はそこまで大きくないと考えられます。
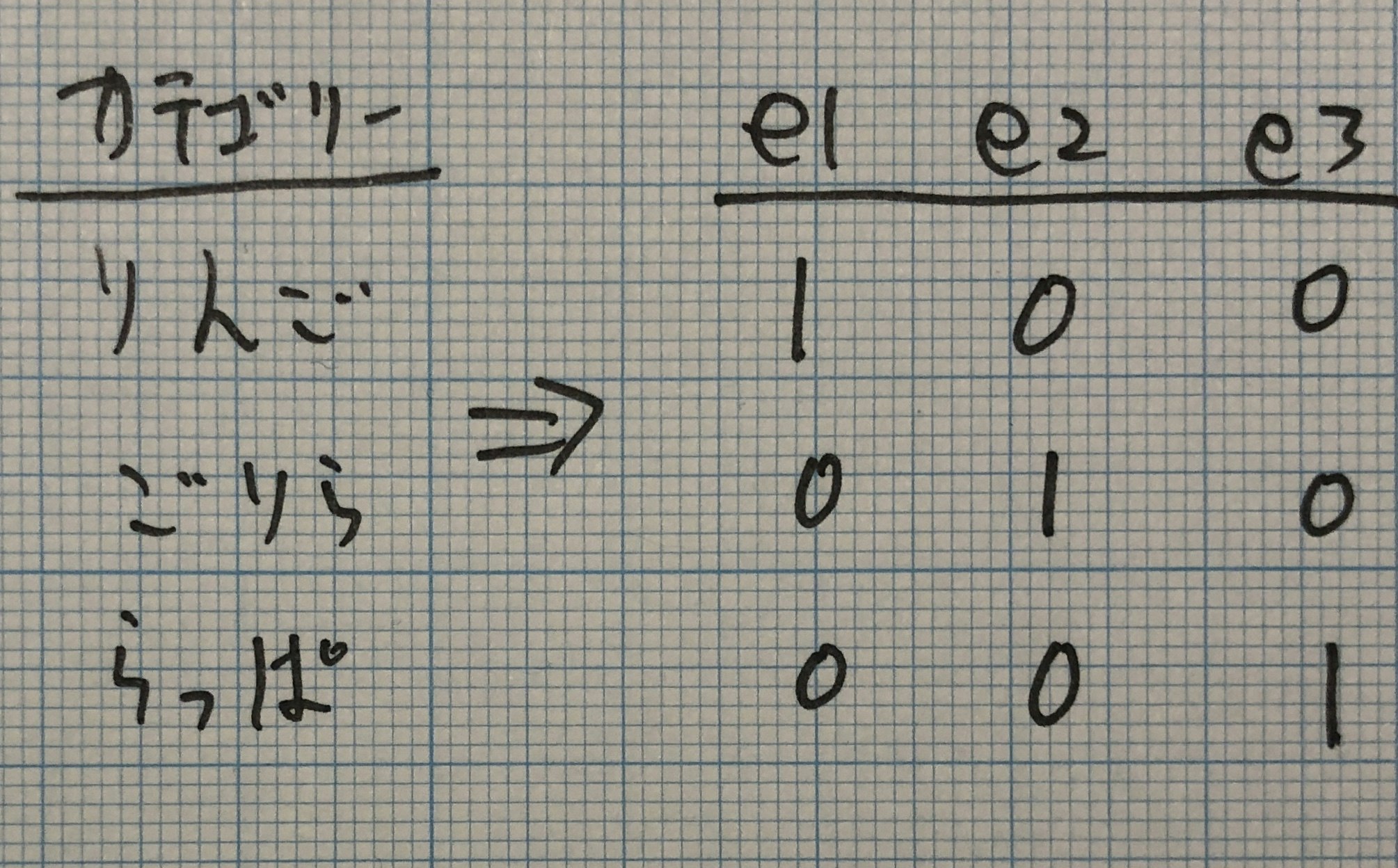
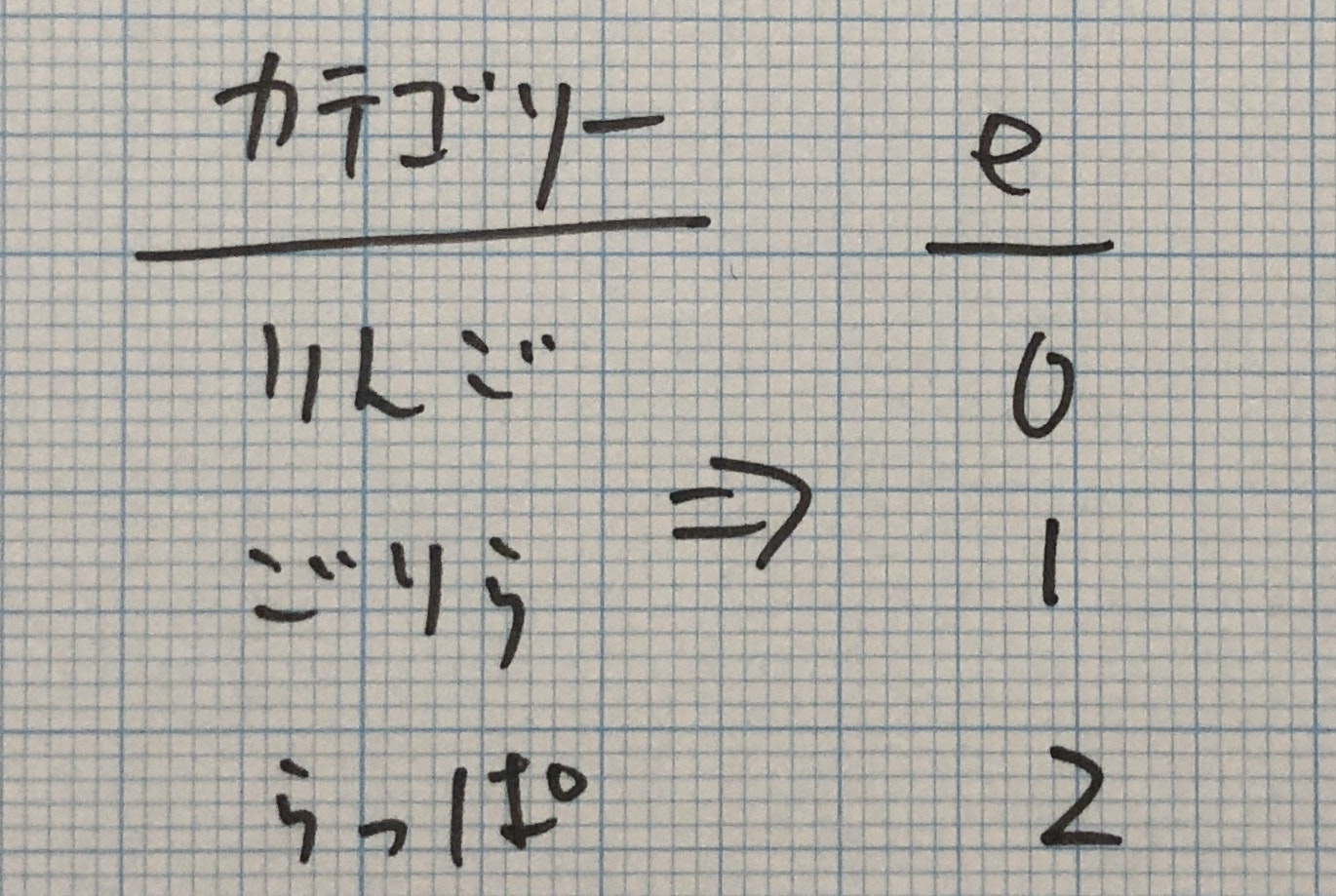

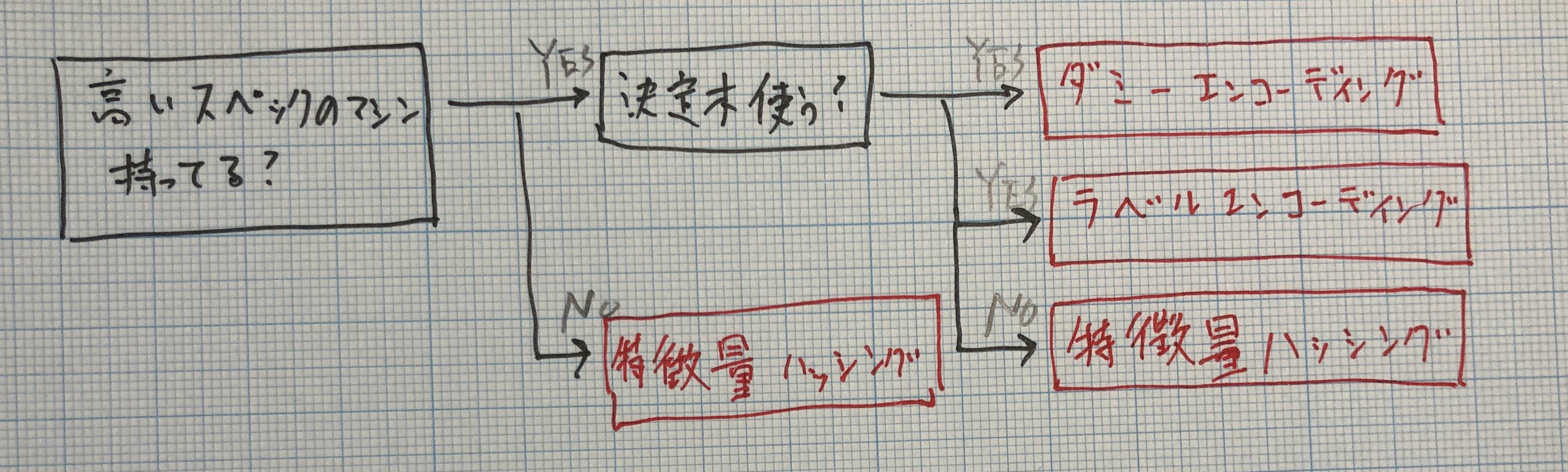
- 投稿日:2020-09-17T20:00:27+09:00
pythonでBrainf*ckのコードを書くコードを書いた
はじめに
Brainfuckでコードを書いてみたいな〜と思いましたが、コードを書くのがめんどくさそうだったので代わりにpythonに書いてもらうことにしました。
とはいえ、そんなに難しいものは作れないので、文字列を入力したらそれをそのまま出力するプログラムを作りました。環境
- python 3.6.9
実践
愚直な方法
最初に考えたのは、入力で受け取った文字列の各文字をASCIIに変換してその分愚直にポインタをインクリメントして出力しようと思いました。
コードで言うとこんな感じです。makebf0.pyimport os #すでにhoge.bfというファイルがあれば削除 if os.path.exists("/hoge.bf"): os.remove("hoge.bf") s = input() array = [] #各文字のASCIIを取得 for si in s: array.append(ord(si)) f = open("hoge.bf", "w") for ai in array: for i in range(ai): f.write("+") f.write(".>") #改行 f.write("++++++++++++.") f.close()これを実行すると
$ python makebf0.py brainf*ck $ cat hoge.bfhoge.bf++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.>++++++ ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ++.>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.>+++ ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.>++ ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ++.>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ .>++++++++++++++++++++++++++++++++++++++++++.>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++++++++++++++++++++.>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ++++++++++++++++++++++++++++++++++++++++++.>++++++++++++.このようなコードが生成されます。
これではコードが長いし、面白くもないので生成されるコードを圧縮してみようと思います。
コードの改善
コードを圧縮するために考えたのはループを使って+の数を減らすことを考えました。
アルゴリズムとしてはループを回す回数をn、文字列のi番目の文字のASCIIをsiとすれば、min(si/n, si/n+1)をループの中でインクリメントして、端数をループの外でインクリメントまたはデクリメントしました。そのうち+の数が最小であるコードを生成するようにしました。
コードとしてはこんな感じです。makebf1.pyimport os import math if os.path.exists("./hoge2.bf"): os.remove("hoge2.bf") s = input() array= [] #文字siのascii for si in s: array.append(ord(si)) f = open("hoge2.bf", "w") MAX = 0 for ai in array: if MAX < ai: MAX = ai list = [] #差分 #iの決め打ち for i in range(MAX): if i == 0: continue sum = i for ai in array: r1 = ai // i r2 = (ai + i) // i if ai - r1 * i > r2 * i - ai: r = r2 * i - ai sum += r2 else : r = ai - r1 * i sum += r1 sum = sum + r list.append(sum) m = 10000000000 for i in range(len(list)): #print(li) li = list[i] if m > li: #print(li) m = li std = i #ループを回す回数 for i in range(m): f.write('+') flag = [] #ループ中身 f.write('[') for ai in array: r1 = ai // m r2 = (ai + m) // m f.write('>') if ai - r1 * m > r2 * m - ai: flag.append(-(r2 * m - ai)) for j in range(r2): f.write('+') else: flag.append(ai - r1 * m) for j in range(r1): f.write('+') #ポインタをループカウンタに戻す for i in range(len(array)): f.write('<') f.write('-') f.write(']') #端数を処理する for i in range(len(array)) f.write('>') if flag[i] < 0: for j in range(-flag[i]): f.write('-') else: for j in range(flag[i]): f.write('+') f.write('.') #改行する f.write('>++++++++++++.') f.close()実行すると
$ python makebf1.py brainf*ck $ cat hoge2.bfhoge2.bf+++++++++++++++++++++[>+++++>+++++>+++++>+++++>+++++>+++++>++>+++++>+++++ <<<<<<<<<-]>-------.>+++++++++.>--------.>.>+++++.>---.>.>------.>++.>++++++++++++.かなりコードが圧縮されました。愚直なコードでは921byteだったのに対し、圧縮されたコードでは158byteでコードを生成することができました。やったね。
終わりに
いかがでしたか
筆者はpythonについて書き慣れていなかったため、このコードを書いて少しpythonについて慣れることができました。またBrainfuckについても、おもしろい言語なのでもっと複雑なことができるようにしたいと思います。
もっと良いアルゴリズムや、コードについて良くない点などがありましたらぜひ教えていただきたいです。
ここまで読んでいただき、ありがとうございました。参考にした記事
https://qiita.com/TomoShiozawa/items/25dcce1540085df71053
https://qiita.com/saba383810/items/39e20b11c71b3dfd2589
- 投稿日:2020-09-17T19:27:38+09:00
ヤフーニュースやはてなブックマークみたいな、コメント付きニュースサイトを作りたい
コメントを集めるには?
コメントを集めるのって、至難の業ですよね。
少し考えたのですが、Twitterからニュースをツイートしているコメントから、
抜き取ればいいんじゃないかと閃きました?
PythonでTwitterのニュースに対する、コメントを抽出しました。import tweepy import re from collections import Counter import unicodedata import string consumer_key = "twitterapiのconsumer_key" consumer_secret = "twitterapiのconsumer_secret" auth = tweepy.AppAuthHandler(consumer_key, consumer_secret) api = tweepy.API(auth) title = "ニュースのタイトル" url = "ニュースのURL" site_domain_name = "配信元" title1 = r"" + re.escape(title) + r"(.|\s)*#\S+(\s|$)" title2 = r"" + re.escape(title) + r"\s(.{0,40})https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" title3 = r"" + re.escape(title) + r"(.{0,40})https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" title4 = r"" + re.escape(title) tweets = api.search(url, count=100, exclude='retweets', tweet_mode='extended', lang = 'ja', result_type='recent') for tweet in tweets: text = re.sub(title1, "", tweet.full_text) text = re.sub(title2, "", text) text = re.sub(title3, "", text) text = re.sub(title4, "", text) text = re.sub(r'((.*?))', "", text) text = re.sub(r'\((.*?)\)', "", text) text = re.sub(r'【(.*?)】', "", text) text = re.sub(r'\[(.*?)\]', "", text) text = re.sub(r'〔(.*?)〕', "", text) text = re.sub(r'#\S+(\s|$)', "", text) text = re.sub(r'#\S+(\s|$)', "", text) text = re.sub(r'@[a-zA-Z0-9_]+さんから', "", text) text = re.sub(r'@[a-zA-Z0-9_]+さん', "", text) text = re.sub(r'@[a-zA-Z0-9_]+から', "", text) text = re.sub(r'@[a-zA-Z0-9_]+より', "", text) text = re.sub(r'|(.*)(\s|$)', "", text) text = re.sub(r'\|(.*)(\s|$)', "", text) text = re.sub(r'-\s(.*)(\s|$)', "", text) text = re.sub(r'■(.*)(\s|$)', "", text) text = re.sub(r'@[a-zA-Z0-9_]+', "", text) text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', "", text) text = text.replace("【","").replace("】","").replace(">","").replace("/","").replace(":","").replace(":","").replace("/","").replace("|","").replace(".","").replace("“","").replace("”","") text = text.replace("via","") text = text.replace(site_domain_name,"") lists = title.split(" ") for list in lists: text = text.replace(list,"") text = text.lstrip() text = text.rstrip() comp_a = unicodedata.normalize("NFKC", text) table = str.maketrans("", "", string.punctuation + "「」、。・!") comp_a = comp_a.translate(table) comp_b = unicodedata.normalize("NFKC", title) table = str.maketrans("", "", string.punctuation + "「」、。・!") comp_b = comp_b.translate(table) if text != "" and len(text) > 1 and comp_a not in comp_b: print(text)完成したニュースアプリ
NewsTweet(ニューズツイート)
https://apps.apple.com/jp/app/newstweet-ニューズツイート/id1531315934

- 投稿日:2020-09-17T18:55:34+09:00
Educational Codeforces Round 86 バチャ復習(9/17)
今回の成績
今回の感想
今回もいつもと同じように焦ってしまいましたが、切り替えてDをギリギリで通せたので及第点です。やはり、焦ってしまう問題のときは問題が整理できておらず、メモが乱雑になってしまう傾向があるので、できるだけ綺麗にメモすることと本当にわからない場合は清書するようにしたいと思います。
A問題
ABCでも以前に類題があったと思います。
$x,y$の符号は同じであり、$x<y$とします。このとき、いずれも単調に減らすのが最適であり、②の操作では同時に動いてしまうので①の操作で$y$を$x$まで減らします。さらに、$y=x$なので、操作①と②の最適な操作を選べばよく、求める最小値は$(y-x) \times a + min(x \times b,2 \times x \times a)$となります。
A.pyfor _ in range(int(input())): x,y=map(int,input().split()) a,b=map(int,input().split()) if x>y: x,y=y,x print((y-x)*a+min(x*b,2*x*a))B問題
最近コドフォの構築系の問題を高速に通せるようになってきた気がします。ABCでも出てくれると嬉しいです(この前のABC-Fはそうだったのでとても悔しい…)。
$S_i=S_{i+k}$が任意の$i$で成り立つとき周期$k$とよび、この周期を最大化するような文字列$s$を求めます。また、$s$は与えられた$t$を部分列として持ち、$|s| \leqq 2|t|$が成り立ちます。
まず、周期はかなり小さくすることができるのではと思いました。なぜなら、$0101…$または$1010…$となるような文字列を作ることができれば周期は2になるからです。この方針を元に考察を行えば以下のようになります。
まず、$s$が$k=1$となるのは$t$の要素が全て同じ時のみです。また、$t$の要素が異なる際の最小の$k$は2とすることができます。なぜなら、$01$が$|t|$回連続する文字列を作れば、$t$のそれぞれの文字が$0$か$1$かのいずれかなので、一致させられるからです。
B.pyfor _ in range(int(input())): t=input() if all(i=="0" for i in t) or all(i=="1" for i in t): print(t) else: print(len(t)*"01")C問題
初めの方針を立てる際に自分で書いた$i,j$を見間違えたせいで焦ってしまい、正答にたどり着くことができませんでした。また、その後も典型的な問題にもかかわらず変に解析的に解こうとしてしまいました。
まず、クエリ内で計算をすると間に合わないのは明らかなので、事前計算を行います。この時、ありうる数を全て書き出すと$10^9$なので明らかに間に合いません。
そこで、$ (x \ mod \ a) \ mod \ b \neq(x \ mod \ b) \ mod \ a$に注目すると、$i= x \ mod \ a,j= x \ mod \ b$がわかれば先ほどの式を考えられるので、$i,j$の組み合わせの$ab$通りを考えましたが、中国剰余定理のイメージを持てば$ab$の余りがわかれば良いとわかりました。これは、$x=ab+k(0 \leqq k <ab)$とおけば、$ (x \ mod \ a) \ mod \ b \neq (x \ mod \ b) \ mod \ a \leftrightarrow (k \ mod \ a) \ mod \ b \neq (k \ mod \ b) \ mod \ a $となることから言えます。
したがって、事前計算として$pre[i]:=$($ab$で割った余りが$0$~$i$のときに$(i \ mod \ a) \ mod \ b \neq (i \ mod \ b) \ mod \ a $となる数の個数)を求めておきます(後で必要になるので累積和にしています。)。
また、クエリにおいては$i \in [l,r]$で$(i \ mod \ a) \ mod \ b \neq (i \ mod \ b) \ mod \ a $となる数の個数を求めますが、$i \in [0,r]$における個数から$i \in [0,l-1]$における個数を引くことで求められます。また、$i \in [0,x]$における個数を$f(x)$とすれば、$f(r)-f(l-1)$で求められます。
この元で$f(x)$を事前計算を用いて求めることを考えますが、$ab$で割った余りが$0$~$ab-1$である数が0から順にループとしていると考えるとそのループの数に注目すればよく、$f(x)=[\frac{x}{a \times b}] \times pre[ab-1] + pre[x \ mod \ (a \times b)]$として求めることができます。
よって、それぞれのクエリは$O(1)$で求められるので、全体として$O(t \times (a \times b +q))$の十分間に合うプログラムを開くことができます。
C.pyfrom itertools import accumulate def f(i): global a,b,pre x=i//(a*b) y=i%(a*b) return x*pre[-1]+pre[y] for _ in range(int(input())): a,b,q=map(int,input().split()) pre=[int((i%a)%b!=(i%b)%a) for i in range(a*b)] pre=list(accumulate(pre)) ans=[] for i in range(q): l,r=map(int,input().split()) ans.append(str(f(r)-f(l-1))) #print(f(r),f(l-1)) print(" ".join(map(str,ans)))D問題
個人的にはC問題より直感的で解きやすい問題でした。30分ほど詰まったら解く問題を変えるのもかなり有効かもしれません。ただ、問題文は少し読みにくかったです。
(以下では、テストケースへと分配するために与えられた配列を$m$とします。これらは降順ソートされているものとします。)
それぞれのテストケースはある長さの配列がいくつか集まったものです(←長さにのみ興味があるのでいくつか数が集まったものという解釈で以下では問題を解きます)。また、いずれのテストケースにおいても$i$は$c_i$個以下しか含まれないという条件を満たしながら、テストケースの数が少なくなるように数を分配する場合のテストケースの数を考えます。また、$n \geqq c_1 \geqq c_2 \geqq … \geqq c_k \geqq 1$を満たすので、必ず最小のテストケースの数は存在することが保証されます。
ここで、より制約のきつい大きい数から順にどのテストケースに含めるかを貪欲法で決めることにしました。また、これによりある数を決めた時点でそれ以降の制約を常に満たすことが言えます。
まず、テストケース全体(それぞれのテストケースには複数の要素が含まれる)を管理する配列$ans$を用意します。さらに、$ans$の長さを$l$、$ans$のテストケースで今見ているインデックスを$now$とします。そして、$ans$に一つ目のテストケースとして$[m[0]]$を追加し、$now$を0,$l$を1で初期化します。
この元で、$m[1],…,m[n-1]$の順にテストケースに追加していきます。今見ているのが$m[i]$のとき、$m[i-1]>m[i]$の時は$c[m[i]-1]>c[m[i-1]-1]$となる可能性があります。このときは$now$を0に更新して$ans[now]$に$m[i]$を代入すれば良いです。また、この判定は$len(ans[0])<c[m[i]-1]$か$c[m[i-1]-1]<c[m[i]-1]$によって行うことができます。
次に$c[m[i]-1]=c[m[i-1]-1]$の時は$now$で見ている要素以降に追加できる可能性があるので、$len(ans[now])<c[m[i]-1]$となる要素が見つかるまで$now+=1$をして、見つかった場合は$ans[now]$に追加します。また、見つからなかった場合はテストケースが足りないので、$ans$に$[m[i]]$を追加します。
これを繰り返すことでできるだけテストケースが少なくなるように貪欲に決めていくことができます。あとは最終的に決まったテストケースを問題の指示に従って出力すれば良いです。
以上を言葉で説明すると難しいですが、貪欲法の正当性がわかりさえすれば意外と実装はすんなりできる気がします。
D.pyn,k=map(int,input().split()) m=sorted(list(map(int,input().split())),reverse=True) c=list(map(int,input().split())) ans=[[m[0]]] #ansの長さ l=1 #どのansの配列に入れられるか(更新に注意)(空いているように) now=0 for i in range(1,n): if len(ans[0])<c[m[i]-1]: now=0 ans[now].append(m[i]) else: while now!=l: if len(ans[now])<c[m[i]-1]: break now+=1 if now==l: ans.append([m[i]]) l+=1 else: ans[now].append(m[i]) print(len(ans)) for i in range(len(ans)): print(len(ans[i]),end=" ") print(" ".join(map(str,ans[i])))E問題以降
今回は飛ばします

- 投稿日:2020-09-17T18:45:24+09:00
pydanticでキーがCamelCaseのjsonをsnake_caseのクラスにキャストする
外部APIを使って実装するとき、REST APIの戻り値がCamelCaseなjsonであることもあります。例えば、PythonでAWSを
boto3で操作するとき頻発します。それではPythonのコーディング規約などを考えると少し困ったことになるのですが、
pydanticのalias_generatorという機能を使うと簡単にsnake_caseをキーにした型にキャストできます。ドキュメントでは
to_camelという関数を自作していますが、私はAWSの操作で様々なクラスで利用するために外部ライブラリのinflectionを利用しています。from pydantic import BaseModel from inflection import camelize class Voice(BaseModel): name: str language_code: str class Config: alias_generator = camelize voice = Voice(**{'Name': 'Filiz', 'LanguageCode': 'tr-TR'}) print(voice.language_code) #> tr-TR print(voice.dict(by_alias=True)) #> {'Name': 'Filiz', 'LanguageCode': 'tr-TR'}参考
- 投稿日:2020-09-17T17:59:39+09:00
Pythonの文字列
Pythonの文字列
Pythonではcodecsという仕組を使用して、マルチバイト文字をさまざまなエンコードに変換しています。
日本語だけでなく、韓国語、中国語にも対応しているようです。
- マルチバイト文字
2バイト以上のデータで表現する。
1バイトでは表現できない文字のこと[a] 1バイトで表現できる
[あ] 1バイトで表現できない
- 文字コード
代表的なものを調べて以下にまとめました
ASCII
アルファベットや数字、記号などをまとめた文字コード。最も基本的な文字コードとして世界的に普及しており、他の多くの文字コードがASCIIの拡張になるよう実装されていて、
文字を7ビットの値(0~127)で表し、128文字が収録されている。
「A」はASCIIでは0x41(0xは16進数を表す)。イメージしづらかったので以下に小文字を英字部分を抜粋しました。
16進 文字 0x61 a 0x62 b 0x63 c 0x64 d 0x65 e 0x66 f 0x67 g 0x68 h 0x69 i 0x6a j 0x6b k 0x6c l 0x6d m 0x6e n 0x6f o 0x70 p 0x71 q 0x72 r 0x73 s 0x74 t 0x75 u 0x76 v 0x77 w 0x78 x 0x79 y 0x7a z
Shift_JIS
日本工業標準調査会で標準化された日本語を含む様々な文字をまとめている、日本語を表すために多く用いられていた文字コードです。
全ての文字を2バイトで表します。
「あ」はShift_JISでは0x82E0です。
UTF-8
現在最も広く使われている標準的な文字コードです。全ての文字を1〜4バイトで表します。世界中の文字を扱えるため、標準的に使われるようになりました。
ASCIIと同じ部分は1バイトで表現し、そのほかの部分を2〜6バイトで表現する可変長の符号化方式となっています。
UTF-8は、ASCIIコードとの互換性が高く、世界中の多くのソフトウェアが使用しています。
「あ」はUTF-8では0xe38182です。
Pythonのバージョン2.xでは、標準の文字コードは ASCII でした。
Python のバージョン3.xでは、標準の文字コードはUTF-8となったため、文字コードを宣言することなく、日本語を扱えるようになっています。ユニコード
国際標準化機構(ISO)でISO/IEC 10646の一部として標準化された文字コードです
目的としては、すべての国で、共通して利用できるエンコード目指して作られたそうです。文字列をバイト型に変換するには
encode()
記載方法
'文字列'.encode('文字コード名’) ※文字コード=「utf-8」などdecode()
記載方法
b'バイト列'.decode('文字コード名')
- 投稿日:2020-09-17T16:30:33+09:00
Rstudioでpythonを書く (reticulate)
Rユーザーの皆さんこんにちは。
Rって便利ですよね。
機械学習や様々な統計手法を使うのに便利なRですが、たまには「これpythonで書きたい!!」なんてこともあるかと思います。そこで、今日は備忘録的な意味も含め、Rstudioでpythonを書く(実行する)方法などを書いていきたいと思います。
reticulateとは
reticulateはRのパッケージの1つになります。
・Rstudioでpythonを実行
・pythonパッケージ(モジュール)のインストール
・Rのオブジェクトをpythonで呼び出し
・pythonのオブジェクトをRで呼び出し主にできることは上記の4つになりますが、下2つが強烈です。
これを使うと「pythonでクローリング(データ収集)してデータフレーム化」>>「Rで分析・可視化」なんてこともできちゃいます。また、Rの「View」関数は大きな利点で、pythonのデメリットである見づらいpandasデータフレームを一時的にRで目視確認することもできますね。
そして何よりも重要なのが「わざわざgoogle colabやannacondaを起動しなくてよい !!!!」ということです。
reticulateのインストール/実行(R側)
パッケージのインストール、呼び出しはRの他のものと同じです。
> install.packages("reticulate") > library(reticulate) > #python起動 > repl_python() >>> #pythonが起動されました >>>※注意点
reticulateの実行にはpythonのインストールが必要(なはず)です。
reticulate::use_python()で指定するそうなのですが、僕はうまくいきませんでした。。確認してみると、自分でインストールしたpythonとは別のバージョンが使われているようなのですが、ちょっとよくわかりません。。(記事書いときながらごめんなさい!!)
上の時点でエラーが出てしまう人は教えてください。。pythonを使ってみよう!
準備はたったこれだけです。それではpythonを使っていきましょう。
Rとpythonどちらが使われているのかわかりづらいですが、コンソール画面が、
・Rは「>」(1つ)
・pythonは「>>>」(3つ)
になっています>repl_python() >>> >>> 1 + 1 2 >>> print("python3") python3 >>> [i for i in range(4)] [0, 1, 2, 3] >>> #pythonを抜けるにはquitを使います >>> quit > > #Rに戻っています完璧です。
オブジェクト名や関数などの入力補完(?)もRと同様、問題なく行われます。(((どっかの誰かさんとは大違い。pythonパッケージ(モジュール)のインストール
pythonを組み込み関数だけで使いこなすのは至難の技です(というか不可能)。
早速パッケージをインストールしてみましょう。>>> import pandas as pd ModuleNotFoundError: No module named 'pandas'おやおや。エラーが出てしまいます。「as pd」なんて一言も触れられてません。
reticulateのpythonでパッケージやモジュールを使うには、
・reticulateにインストール
・pythonでインポート
を行う必要があります。
ややこしい。一度、pythonを出てからインストールを行いましょう。
>>> quit > > #py_install()を使います > py_install("pandas")完了メッセージが出たら成功です。これで、pythonで使えるようになります。
> repl_python() >>> >>> import pandas as pd >>> >>> #これで読み込みが完了しましたしかし、、、
これでもうまくいかない場合があります。たとえば言語処理に使われる「MeCab」です。
> #R側 > py_install("mecab") エラー: one or more Python packages failed to install [error code 1]このエラーが出た場合は、ちょっと厄介ですが次の方法をとりましょう。
condaからのインストール方法をとります。
まず、https://anaconda.orgで自分の欲しいパッケージを検索しましょう。
そしてplatformsが自分の環境にあっているものを選んで開き、次のようなコマンドを探してください。conda install -c temporary-recipes mecab-python3これはターミナルから実行する時のコマンドになりますが、これを利用します。
conda install -c (チャネル名) (パッケージ名)
というようになっているので、> conda_install(channel = "temporary-recipes", packages = "mecab-python3") > # All requested packages already installed.これで、無事インストールが終わりました。
> repl_python() >>> >>> import MeCab >>>読み込みも問題ありません。
あまり深いところに詳しくないのでわからないのですが、パッケージ名がcondaとpythonで異なっているので、注意してください。reticulateを活用
reticulateの本領発揮はここからになります。
Rのオブジェクトを呼び出し
Rで作成したオブジェクトをpythonで利用します。
> a <- 1 > repl_python() >>> >>> #「r.」で呼び出しが可能 >>> r.a 1.0 >>> r.a + 1 2.0Rはnumeric、pythonではint型とfloat型が使われており、データ型が異なるので、何らかの変換が行われているようです。
もちろんデータフレームも使えます。
>>> r.iris Sepal.Length Sepal.Width Petal.Length Petal.Width Species 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa .. ... ... ... ... ... 145 6.7 3.0 5.2 2.3 virginica 146 6.3 2.5 5.0 1.9 virginica 147 6.5 3.0 5.2 2.0 virginica 148 6.2 3.4 5.4 2.3 virginica 149 5.9 3.0 5.1 1.8 virginica [150 rows x 5 columns] >>>pythonのオブジェクトをRで呼び出し
今度は逆をやってみましょう。こちらの方が利用頻度は高いかもしれないです。
>>> b = 1 >>> quit > > #「py$」で呼び出し > py$b [1] 1python > R でデータフレームを呼び出す場合、indexの情報が失われることもあるようですが、工夫次第でいくらでも活用できるでしょう。
まとめ
こんなに便利なreticulateパッケージですが、まとめられているサイトが少なかったので、簡単にまとめてみました。
環境によって使えない、、!!などあるかもしれませんが、その際はコメントしてください。僕もあまりわからないので一緒に勉強しましょう笑
冒頭でも書きましたが、R、pythonそれぞれの利点を活かして、
「pythonでクローリング、データ収集/加工したものをRに渡して分析/可視化」
なんてことも簡単にできます。Rstudioさえあればどっかのよくわかんないヘビさんをインストールして毎回起動する必要もないので、Rを利用している人、これからpythonを初めてみたい人にはとてもいいツールになるでしょう。
- 投稿日:2020-09-17T16:20:05+09:00
Pythonで特定の条件を満たす要素だけ抽出
忘れがちなのでメモ
コード
import pandas as pd data = [ {"name": "Taro Tanaka", "organization": "Example1", "age": 18}, {"name": "Hanako Yamada", "organization": "Example1", "age": 20}, {"name": "Ichiro Suzuki", "organization": "Example2", "age": 33}, {"name": "Michiko Sato", "organization": "Example2", "age": 50}, ... ] # オーソドックスな方法 arr = [ r for r in data if r["organization"] == "Example1" and r["age"] > 18 ] ## sort sorted_arr = sorted(arr, key=lambda x: x["age"]) # pandasを利用 df = pd.DataFrame(data) arr2 = df[(df["organization"] == "Example2") & (df["age"] > 18)] ## sort sorted_arr = df[(df["organization"] == "Example2") & (df["age"] > 18)].sort_values('age')
- 投稿日:2020-09-17T16:16:13+09:00
Python + Unity 強化学習(学習編)
前回の環境構築後に実際にUnityで強化学習を行っていく!
前回の記事はこちら、https://qiita.com/nol_miryuu/items/32cda0f5b7172197bb09前提条件
Unityの基礎知識が多少必要です(オブジェクトの作り方・名前の付け方)
目的
青い球(AI Agent)が床から落ちずに黄色い箱(Target)に素早く近づくことができるようにAIを学習させる構成
状態:Vector Observation(サイズ=8)
・ TargetのX,Y,Z座標の3つ
・ RollerAgentのX,Y,Z座標の3つ
・ RollerAgentのX,Z方向速度の2つ(Y方向には移動しないので除外)行動:Continuous(サイズ=2)
・ 0:RollerAgentのX方向に加える力
・ 1:RollerAgentのZ方向に加える力報酬:
・ RollerAgentがTargetに近づいた(RollerAgentとTargetとの距離が0に近づいた)場合,報酬(+1.0)を与え、エピソード完成
・ RollerAgentが床から落ちた(RollerAgentのY方向の位置が0未満になったら)場合、報酬を与えずにエピソード完了決定:
・ 10ステップごと強化学習サイクル(1ステップごとに実行されるプロセス)
状態取得 → 行動決定 → 行動実行と報酬取得 → ポリシー更新学習環境の準備
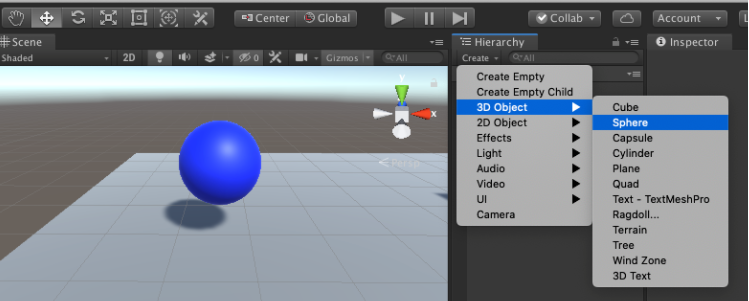
1.青い球、名前=RollerAgentを配置する
2.黄色い箱 名前=Target を配置する
3.床 名前=Floor を配置する
4.Main Camera : カメラの位置・角度を赤丸のように設定(全体がよく見える位置に調整するため)
5.各オブジェクトに色を付けるためにMaterialを作成(Asset>create)
6.メニューのWindowからPackage Managerを選択(ML-Agentをインポートする)
左上の「+」ぼたんを押してAdd package from diskを選択
前回作成したディレクトリに行き、ml-agents/com.unity.ml-agents/package.jsonを選択する
7.RollerAgent(青い球)にコンポーネント(機能)を追加する
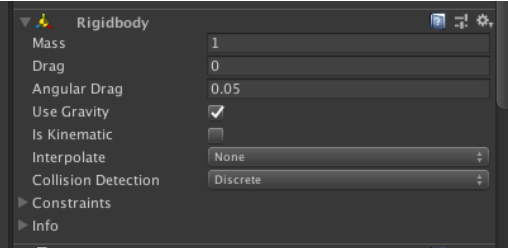
・ Rigidbody : 物理シミュレーションの仕組み
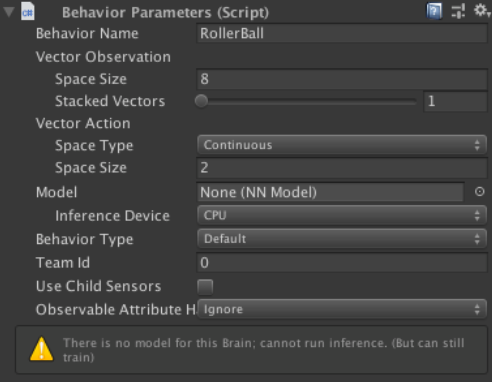
・ Behavior Parameters : RollerAgentの状態と行動のデータを設定
・ Decision Requester : 何ステップごとに「決定」を要求するかを設定
基本的にステップは0.02秒ごとに実行される。Decision Periodが「5」の場合は5 x 0.02 = 0.1秒ごと、
「10」の場合は10 x 0.02 = 0.2秒ごとに「決定」が実行されるRollerAgentに対しては最終的に下図のように設定する
Rigidbody
Behavior Paramenters
・Behavior Name:RollerBall(この名前でモデルが生成される)
・Vector ObservationのSpace Size:8(観察する状態の種類)
・Space Type:Continuous(行動の種別)
・Vector ActionのSpace Size:2(行動の種類)
Decision Requester
8.RollerAgents.csスクリプトを作成
・void Initialize()・・・エージェントのゲームオブジェクト生成時に1回だけ呼ばれる
・OnEpisodeBegin()・・・エピソード開始時に呼ばれる
・CollectObservations(VectorSensor sensor)・・・エージェントに渡す状態データを設定する
・OnActionReceived(float[] vactorAction)・・・決定された行動を実行し、報酬取得とエピソード完了を行うRollerActionusing System.Collections; using System.Collections.Generic; using UnityEngine; using Unity.MLAgents; using Unity.MLAgents.Sensors; public class RollerAgent : Agent { public Transform target; Rigidbody rBody; public override void Initialize() { this.rBody = GetComponent<Rigidbody>(); } // エピソード開始時に呼ばれる public override void OnEpisodeBegin() { if (this.transform.position.y < 0) // RollerAgent(球)が床から落下している時に以下をリセット { this.rBody.angularVelocity = Vector3.zero; // 回転加速度をリセット this.rBody.velocity = Vector3.zero; // 速度をリセット this.transform.position = new Vector3(0.0f, 0.5f, 0.0f); // 位置をリセット } // Target(キューブ)の位置をリセット target.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4); } // エージェントに渡す観察データ(8項目)を設定する public override void CollectObservations(VectorSensor sensor) { sensor.AddObservation(target.position); // Target(キューブ)のXYZ座標 sensor.AddObservation(this.transform.position); // RollerAgentのXYZ座標 sensor.AddObservation(rBody.velocity.x); // RollerAgentのX軸方向の速度 sensor.AddObservation(rBody.velocity.z); // RollerAgentのZ軸方向の速度 } // 行動実行時に呼ばれる public override void OnActionReceived(float[] vectorAction) { // RollerAgentに力を加える Vector3 controlSignal = Vector3.zero; controlSignal.x = vectorAction[0]; // ポリシーによって決定された行動データをセットする // vectorAction[0]は X方向 に加える力(-1.0 〜 +1.0) controlSignal.z = vectorAction[1]; // ポリシーによって決定された行動データをセットする // vectorAction[1]は Y方向 に加える力(-1.0 〜 +1.0) rBody.AddForce(controlSignal * 10); // RollerAgentとTargetとの距離を測定 float distanceToTarget = Vector3.Distance(this.transform.position, target.position); // RollerAgentがTargetの位置に到着したとき if(distanceToTarget < 1.42f) { AddReward(1.0f); // 報酬を与える EndEpisode(); // エピソードを完了する } // RollerAgentが床から落下したとき if(this.transform.position.y < 0) { EndEpisode(); // 報酬を与えずにエピソードを完了する } } }9.RollerAgentのプロパティを設定
Max Step:エピソードの最大ステップ数、エピソードのステップ数が設定値を超えるとエピソード完了となる
Max Stepを1000、Target欄に黄色の箱「Target」を選択10.ハイパラメータ設定ファイルの作成
・ml-agents/config/にsampleディレクトリ作成
・その中にRollerBall.yamlファイルを作成、ファイル内容は以下のとおり
ハイパーパラメータ(訓練設定ファイル 拡張子.yaml[ヤムルと読む] )
- 学習に利用するパラメータ
- 人間が調整する必要がある
- 強化学習アルゴリズム(PPO/SAC)ごとに設定項目が異なる
RollerBall.yamlbehaviors: RollerBall: trainer_type: ppo summary_freq: 1000 hyperparameters: batch_size: 10 buffer_size: 100 learning_rate: 0.0003 learning_rate_schedule: linear beta: 0.005 epsilon: 0.2 lambd: 0.95 num_epoch: 3 network_settings: normalize: true hidden_units: 128 num_layers: 2 vis_encode_type: simple reward_signals: extrinsic: gamma: 0.99 strength: 1.0 keep_checkpoints: 5RollerAgentの学習開始
前回のQittaで作成した仮想環境を動かす
terminalpoetry shellml-agentsディレクトリで以下のコマンドを実行する
terminal:terminal
mlagents-learn config/sample/RollerBall.yaml --run-id=model01
最後のmodel01は新たに訓練するたびに別名をつけるterminalStart training by pressing the Play button in the in the Unity Editor.上のコードがterminalに表記されたらUnityに戻って再生ボタンを押すと実行されます
1.Unityの再生ボタンを押すと訓練が始まる。
Stepが50000ごとにターミナルに情報が表示される。
Mean Reward:平均報酬ポイント・・・値が高くなれば精度が上がる. 1.0になったら訓練終了してしましょう。


- 投稿日:2020-09-17T16:13:56+09:00
Pythonanywhere で簡単デプロイ!! python 初心者向け(2020年9月)
まず、アカウントを作成します!
PythonAnywhereのDashboardから操作を進めます!
?
右上にある[Web]をクリックしましょう!
??
[add a new web app] をクリックした後、[Next>>] をクリックします!
???
[Django]を選択します!これらは、Python Web framework の一覧です!
学習済み?のものがあれば、そちらを選択してもかまいません!
????
[Python 3.8]を選択します!これらは、Python version の一覧です!
?????
プロジェクト名を入力します!
お好みのプロジェクト名で大丈夫?これでDjangoのプロジェクトの作成が完了???
??????
Configuraton for の下の行のリンク(URL)をクリックしてみましょう!
??? 完成 ???
「保護されていない通信」の解決方は、pythonanywhere に戻って
1、Force HTTPS をEnabledに変更する。(ページの下の方にあります。)
2、Reloadをクリックする。
3、URLをクリックすれば、解決?
ファイル構成などは、consoles から見れます?
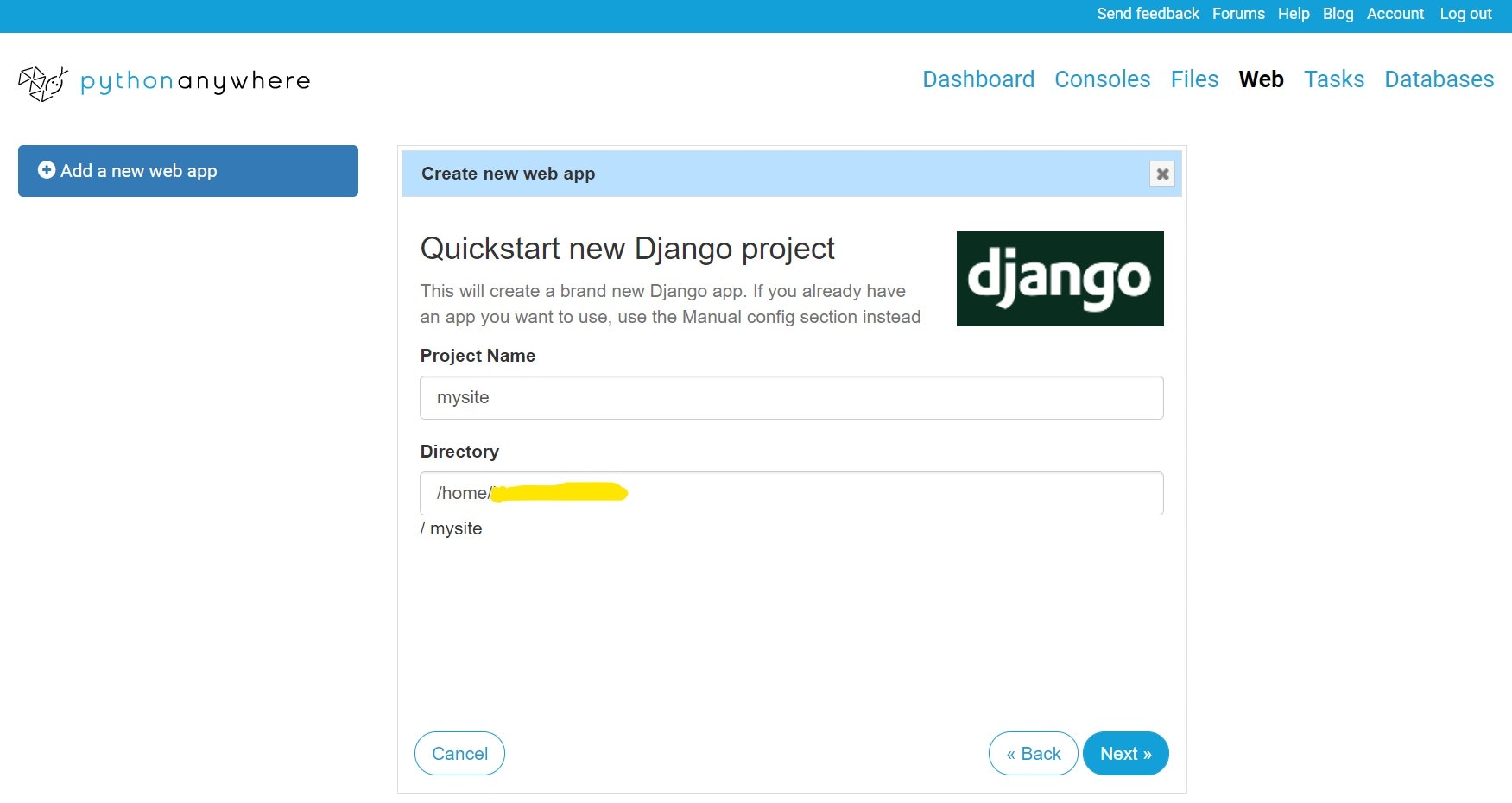
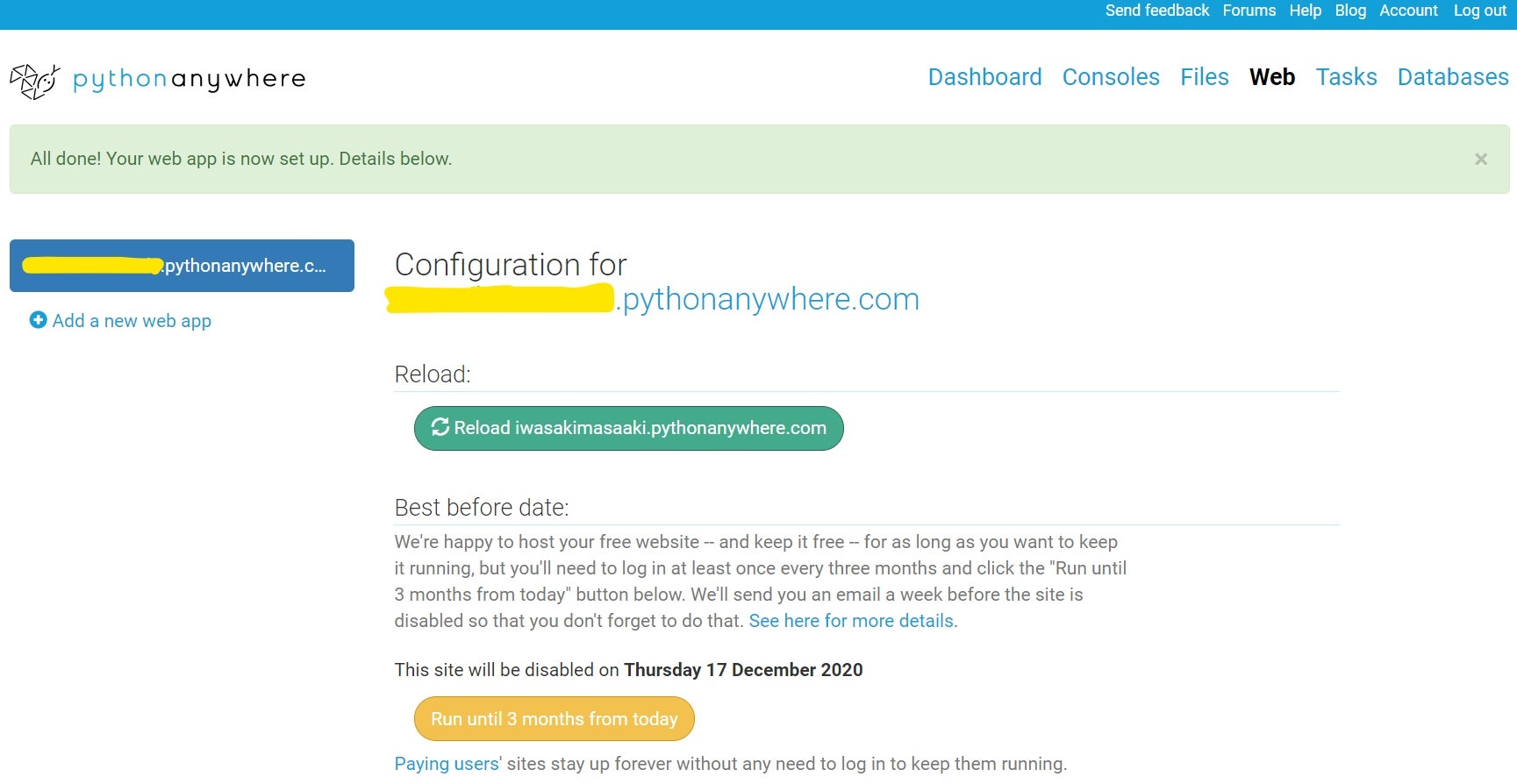
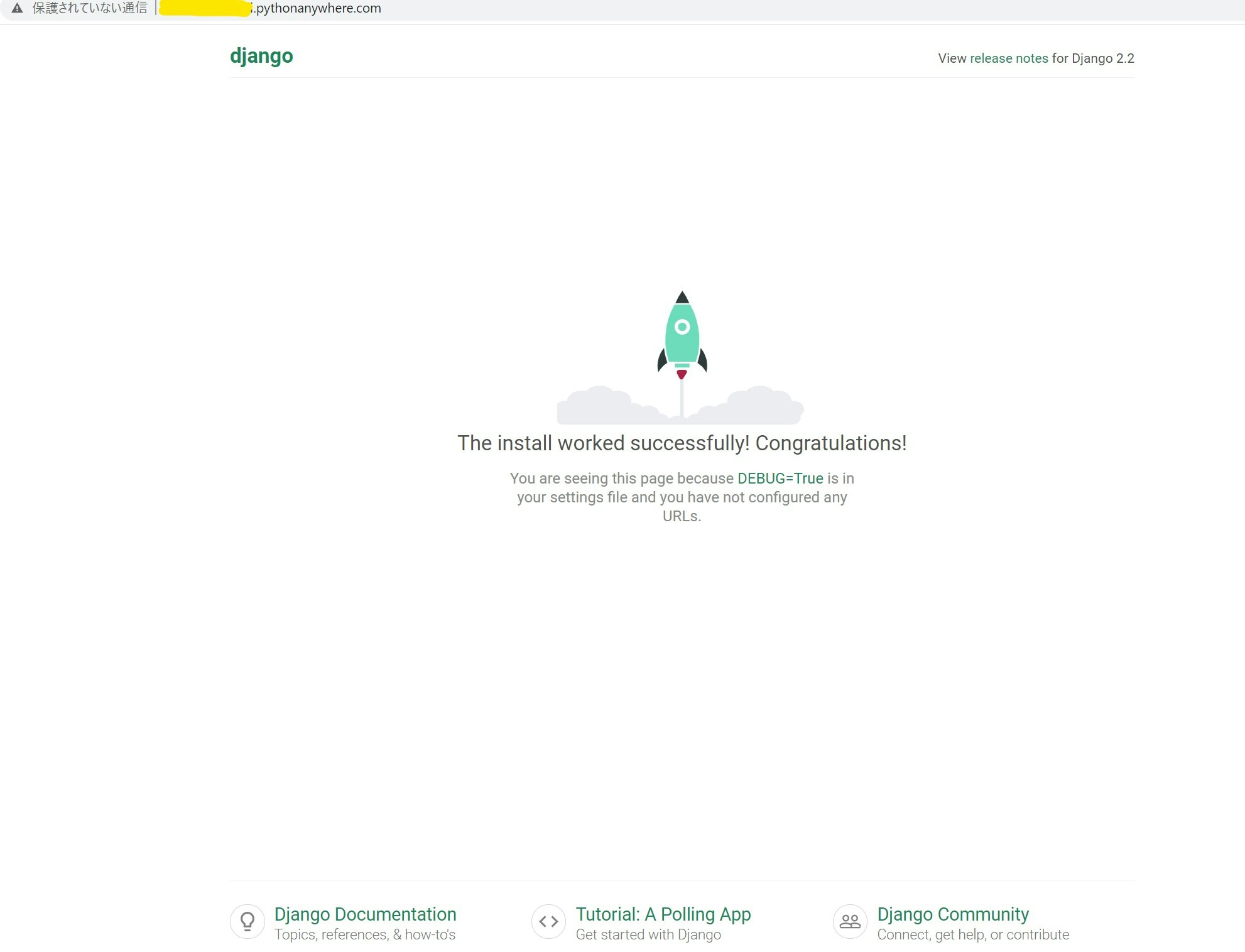

- 投稿日:2020-09-17T16:13:11+09:00
[python] 日付から文字列に変換
やりたいこと
- 日付を取得して文字列に変換
- ファイル名などによく使うため整理
ライブラリ
datetime日付から文字列に変換してみる
実行日付
- 現在の日付を出力
実行日付# yyyymmdd yyyymmdd = datetime.date.today().strftime('%Y%m%d') print(yyyymmdd) # yyyy/mm/dd yyyymmdd = datetime.date.today().strftime('%Y/%m/%d') print(yyyymmdd) # yyyy-mm-dd yyyymmdd = datetime.date.today().strftime('%Y-%m-%d') print(yyyymmdd)結果20200917 2020/09/17 2020-09-17実行日時
- 実行日時に時間を追加して出力
- 表示形式は
yyyymmddhhmmss実行日付yyyymmdd_hms = datetime.date.now().strftime('%Y%m%d%H%M%S') print(yyyymmdd_hms)結果20200917155026日付フォーマット
strftime()を使う
書式コードはこちら strftime() と strptime() の書式コード
- 投稿日:2020-09-17T16:04:52+09:00
Python × GIS の基礎(その3)
その1はこちら
その2はこちら
ヘルシンキ大学の教材のWeek5-Week6の解答と補足をまとめていきます。Week5
5-1 静的な地図の作成
Week5では元のnotebookが存在せず、GithubのREADMEを読んだ上で、自身で適当な題材を選び地図をビジュアライズすることが求められます。
5-2 動的な地図の作成
Week6
6-1 店の場所を推測する
Week6の前半ではOSM(オープンストリートマップ)を活用して、あらかじめ与えられた移動データの出発地点・到着地点を推測するという作業を行います。
mplleafletライブラリによってmatplotlibで作成した図形をインタラクティブ地図上にプロットできます。(mplleafletについてはこちらの記事が詳しいです。)mplleaflet単体では画像の保存ができないため、スクリーンショットなどを用いて画像保存する必要があります。#データの読み込み origin = pd.read_csv('data/origins.csv') #出発地 dest = pd.read_csv('data/destinations.csv') #到着地 #ポイント化 make_point = lambda row:Point(row['x'], row['y']) origin['geometry'] = origin.apply(make_point, axis=1) dest['geometry'] = dest.apply(make_point, axis=1) origin_geo = gpd.GeoDataFrame(origin, geometry='geometry') dest_geo = gpd.GeoDataFrame(dest, geometry='geometry') #座標系の定義と変換 rigin_geo.crs = CRS.from_epsg(3857) dest_geo.crs = CRS.from_epsg(3857) origin_geo = origin_geo.to_crs(CRS.from_epsg(3857)) dest_geo = dest_geo.to_crs(CRS.from_epsg(3857)) #プロット fig, ax = plt.subplots(figsize=(12,8)) origin_geo.plot(ax=ax) dest_geo.plot(ax=ax) mplleaflet.show() #地図と合成させる
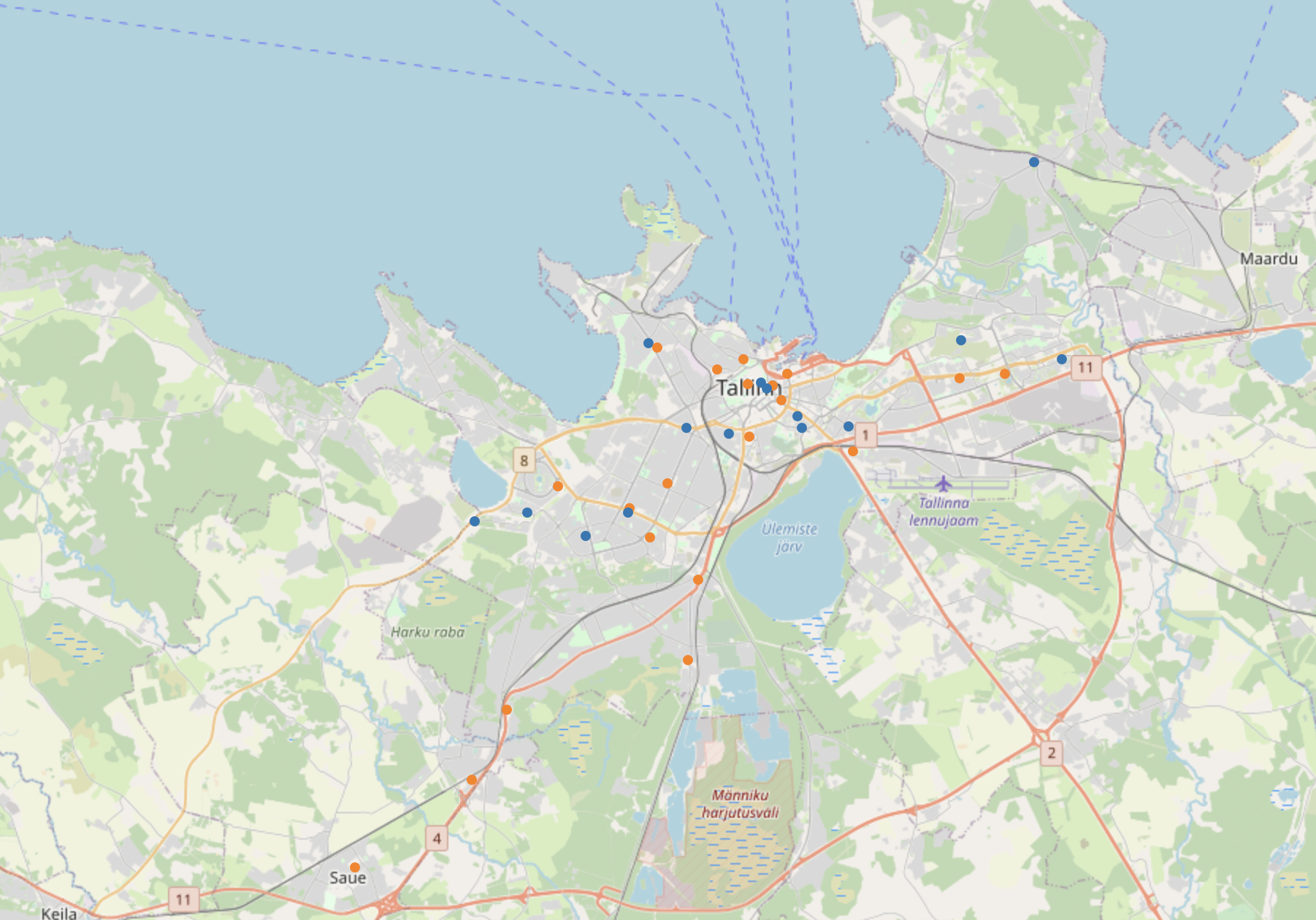
エストニアの首都タリン近辺にポイントが集まっていることが分かります。ジオコーディングによって確認しましょう。6-2 タリンのネットワーク解析
6-1で得た出発点、到着点の間のルート・道のり距離を求めるのが目標です。
①OSMの道路データを基に、osmxライブラリを用いてグラフに変換
②出発点・到着店をグラフの最寄りのノードに近似
③networkxでノード間最短ルートを作成し、その長さを求める
という順で作業を行います。#全てのポイントを包含する凸包の作成 merged = pd.concat([origin, dest]) make_p = lambda row: (row['geometry'].x, row['geometry'].y) merged['p'] = merged.apply(make_p, axis=1) list_point = merged['p'].values.tolist() multi = MultiPoint(list_point) extent = multi.convex_hull #グラフの抽出 import osmnx as ox graph = ox.graph_from_polygon(extent, network_type='drive') #グラフからノードとリンクを作成 nodes_proj, edges_proj = ox.graph_to_gdfs(graph_proj, nodes=True, edges=True) #ポイントのノードへの近似 graph_proj = ox.project_graph(graph) orig_nodes = [] for orig in origin_geo['geometry']: orig_xy = (orig.y, orig.x) orig_node = ox.get_nearest_node(graph, orig_xy) orig_nodes.append(orig_node) dest_nodes = [] for des in dest_geo['geometry']: dest_xy = (des.y, des.x) dest_node = ox.get_nearest_node(graph, dest_xy) dest_nodes.append(dest_node) #最小パスの作成 route_lines = [] route_lengths=[] for i in orig_nodes: for j in dest_nodes: if i==j: #出発点と到着点が同じ点に近似された場合は除外 continue route = nx.shortest_path(G=graph, source=i, target=j, weight='length') route_nodes = nodes_proj.loc[route] route_line = LineString(list(route_nodes.geometry.values)) route_lines.append(route_line) route_lengths.append(route_line.length) route_geom = pd.DataFrame([route_lines, route_lengths]).T route_geom.columns = ['geometry', 'route_dist'] route_geom = gpd.GeoDataFrame(route_geom,geometry='geometry', crs=edges_proj.crs) #最短距離と最長距離 mini = route_geom['route_dist'].min() maxx = route_geom['route_dist'].max() #ビジュアル化 fig, ax = plt.subplots(figsize=(12,8)) route_geom.plot(ax=ax, color='red') edges_proj.plot(ax=ax, color='gray', alpha=0.5, linewidth=0.7) fig.savefig('network.png')
全てのルートを塗ると上図のようになります。ネットワーク解析については、GISで行うよりもPythonを使った方が様々なことが試せそうです。
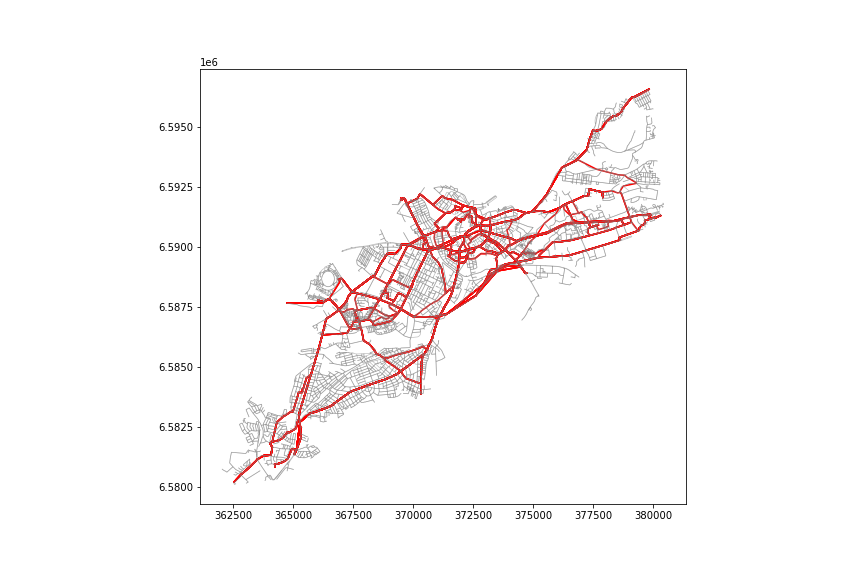
- 投稿日:2020-09-17T15:59:09+09:00
Pytorchで日経平均の予測2
どうもです。
つい先日後輩と銭湯に行く約束をしたものの、「すいません、女の子といて終電逃しました…」と断られ、怒りの余り作業が進み記事が完成しました。ということで前回記事、Pytorchで日経平均の予測~幕間~で紹介した
Using Deep Learning Neural Networks and Candlestick Chart Representation to Predict Stock Market
についてのデータセットの作成、コーディング、学習を行ったので備忘録として残しておきます。
データセット作成
こちらで使われるデータセットはチャートのようなものですがちょっと特殊な画像です。(詳しくは論文をどうぞ!!)
論文を参考にして作成したものは
このように48×48で上下が赤と緑によって表現されている画像になります。
以下にコードを紹介します。candle_make.ipynb#!/usr/bin/env python3 # -*- coding: utf-8 -*- import csv import glob import pandas as pd import numpy as np import sys import matplotlib.pyplot as plt import datetime import openpyxl # ローソク足描写 import matplotlib.pyplot as plt import matplotlib.dates as mdates path = "/content/drive/My Drive/Colab/pytorch_pre/" sys.path.append("/content/drive/My Drive/Colab/pytorch_pre") import mpl_financeライブラリ関係のインポートです。google colaboratoryを使用しているためpathなどはドライブのファイルをおいている場所を表しています。
おそらく珍しいのはmpl_financeだと思います。これはgit hubからダウンロードすることが出来ます。ローソク足を描写するために使える便利なやつです。
mlp_financecandle_make.ipynbfuture_num = 1 fname = path + "data/nikkei_heikin_x3.csv" flist = glob.glob(fname) for file in flist: dt = pd.read_csv(file, header=0, encoding="utf-8_sig", index_col='Datetime') dt = dt.sort_values('Datetime') print(dt) future_price = dt.iloc[future_num:-18]['終値'].values curr_price = dt.iloc[:-18-future_num]['終値'].values #future_num日後との比較した価格を正解ラベルとして扱う y_data_tmp = future_price / curr_price #正解ラベル用のlistを用意 y_data = np.zeros_like(y_data_tmp) y_data_nam = np.zeros(len(y_data_tmp)+1, dtype=object) Y_data = np.zeros((len(y_data_tmp)+1, 2), dtype=object) Y_columns = ["label","ImageName"] #予測するfuture_num日後が上昇なら正解 for i in range(len(y_data_tmp)): Y_data[i,0] = 0 if y_data_tmp[i] >= 1.0: y_data[i] = 1 Y_data[i,0] = 1 count = 0 for i in y_data: if i == 1: count += 1 print(count) for i in range(1,len(y_data_tmp)+1): y_data_nam[i] = "{:04}.png".format(i-1) Y_data[i,1] = y_data_nam[i] Y_data[0,0] = "label" Y_data[0,1] = "ImageName" dn = pd.DataFrame(Y_data) dn.columns = Y_columns np.savetxt(path+"debug/y_data.csv", dn, delimiter=",", fmt='%s') # csvファイルに書き込この辺でラベル付けに関することをしていきます。読み込んで来たデータを整理して当日の価格が前日よりも高い場合1、低い場合は0で二値分類していきます。
あとあと画像名からラベルを呼び出せるようにするためにcsvにファイルネーム(imagename)とラベルを同じ行に並べてテーブルのようにしておきます。candle_make.ipynbimg_create = 1 if img_create == 1: seq_len = 20 df = pd.read_csv(fname, parse_dates=True, index_col=0) df = df.sort_values('Datetime') df = df.rename(columns={'始値':'Open','高値':'High','安値':'Low','終値':'Close','出来高':'Volume'}) df.fillna(0) plt.style.use('dark_background') df.reset_index(inplace=True) df['Datetime'] = df['Datetime'].map(mdates.date2num) for i in range(0, len(df)): c = df.iloc[i:i + int(seq_len) - 1, :] if len(c) == int(seq_len-1): # Date,Open,High,Low,Adj Close,Volume ohlc = zip(c['Datetime'], c['Open'], c['High'], c['Low'], c['Close'], c['Volume']) my_dpi = 96 fig = plt.figure(figsize=(48 / my_dpi, 48 / my_dpi), dpi=my_dpi) ax1 = plt.subplot2grid((1, 1), (0, 0)) # candlestick2_ohlc(ax1, c['Open'],c['High'],c['Low'],c['Close'], width=0.4, colorup='#77d879', colordown='#db3f3f') mpl_finance.candlestick_ohlc(ax1, ohlc, width=0.4, colorup='#77d879', colordown='#db3f3f') ax1.grid(False) ax1.set_xticklabels([]) ax1.set_yticklabels([]) ax1.xaxis.set_visible(False) ax1.yaxis.set_visible(False) ax1.axis('off') # pngfile = 'datasets/{}_{}_{}.png'.format( # i, seq_len, fname[11:-4]) pngfile = 'datasets/{:04}.png'.format(i) fig.savefig(path+pngfile, pad_inches=0, transparent=False) plt.close(fig) print("Converting olhc to candlestik finished.")ここは論文とほぼ同じです。出来高表示は出来ていません。出来たら教えてください。
論文と同じ形の数値データではないので形を合わせています。自分が使用したデータです。
renameすることで形を合わせます。これでデータセットの画像が完成します。
学習
学習を行うモデルはResNetを使用します。論文では独自のモデル構造を使用してSOTAを記録していましたが、ResNetでも十分な結果が得られていたのでこちらを使用します。
resnet.ipynbclass MyDataSet(Dataset): def __init__(self, csv_path, root_dir): self.train_df = pd.read_csv(csv_path) self.root_dir = root_dir self.images = os.listdir(self.root_dir) self.transform = transforms.Compose([transforms.ToTensor()]) self.y_columns = ["label","ImageName"] def __len__(self): return len(self.images) def __getitem__(self, idx): # 画像読み込み # print(self.images) image_name = self.images[idx] image = Image.open(os.path.join(self.root_dir, image_name) ) image = image.convert('RGB') # PyTorch 0.4以降 # label (0 or 1) self.train_df.columns = self.y_columns label = self.train_df.query('ImageName=="'+image_name+'"')['label'].iloc[0] return self.transform(image), int(label) def conv3x3(in_channels, out_channels, stride=1, groups=1, dilation=1): return nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=dilation, groups=groups, bias=True, dilation=dilation) def conv1x1(in_channels, out_channels, stride=1): return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=True) class BasicBlock(nn.Module): # Implementation of Basic Building Block def __init__(self, in_channels, out_channels, stride=1, downsample=None): super(BasicBlock, self).__init__() self.conv1 = conv3x3(in_channels, out_channels, stride) self.bn1 = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(out_channels, out_channels) self.bn2 = nn.BatchNorm2d(out_channels) self.downsample = downsample def forward(self, x): identity_x = x # hold input for shortcut connection out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample is not None: identity_x = self.downsample(x) out += identity_x # shortcut connection return self.relu(out) class ResidualLayer(nn.Module): def __init__(self, num_blocks, in_channels, out_channels, block=BasicBlock): super(ResidualLayer, self).__init__() downsample = None if in_channels != out_channels: downsample = nn.Sequential( conv1x1(in_channels, out_channels), nn.BatchNorm2d(out_channels) ) self.first_block = block(in_channels, out_channels, downsample=downsample) self.blocks = nn.ModuleList(block(out_channels, out_channels) for _ in range(num_blocks)) def forward(self, x): out = self.first_block(x) for block in self.blocks: out = block(out) return out class ResNet18(nn.Module): def __init__(self, num_classes): super(ResNet18, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = ResidualLayer(2, in_channels=64, out_channels=64) self.layer2 = ResidualLayer(2, in_channels=64, out_channels=128) self.layer3 = ResidualLayer( 2, in_channels=128, out_channels=256) self.layer4 = ResidualLayer( 2, in_channels=256, out_channels=512) self.avg_pool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Linear(512, num_classes) def forward(self, x): out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.maxpool(out) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = self.avg_pool(out) out = out.view(out.size(0), -1) out = self.fc(out) return out class Trainer: def __init__(self, model, optimizer, criterion): self.device = 'cuda' if torch.cuda.is_available() else 'cpu' self.model = model.to(self.device) self.optimizer = optimizer self.criterion = criterion def epoch_train(self, train_loader): self.model.train() epoch_loss = 0 correct = 0 total = 0 for batch_idx, (inputs, targets) in enumerate(train_loader): inputs = inputs.to(self.device) targets = targets.to(self.device).long() self.optimizer.zero_grad() outputs = self.model(inputs) loss = self.criterion(outputs, targets) loss.backward() self.optimizer.step() epoch_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += targets.size(0) correct += predicted.eq(targets.data).cpu().sum().item() epoch_loss /= len(train_loader) acc = 100 * correct / total return epoch_loss, acc def epoch_valid(self, valid_loader): self.model.eval() epoch_loss = 0 correct = 0 total = 0 for batch_idx, (inputs, targets) in enumerate(valid_loader): inputs = inputs.to(self.device) targets = targets.to(self.device).long() outputs = self.model(inputs) loss = self.criterion(outputs, targets) epoch_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += targets.size(0) correct += predicted.eq(targets.data).cpu().sum().item() epoch_loss /= len(valid_loader) acc = 100 * correct / total return epoch_loss, acc @property def params(self): return self.model.state_dict()ResNetの定義、データセットの読み込みなどをしています。MyDataSetでラベルとファイルネームを読み込んでラベル付けをしています。
resnet.ipynbif __name__ == '__main__': model = ResNet18(2) epoch_n = 100 optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) criterion = nn.CrossEntropyLoss() trainer = Trainer(model, optimizer, criterion) transform = transforms.Compose([ transforms.Resize((50, 50)), transforms.ToTensor(), ]) tmp_data = MyDataSet(path+'debug/y_data.csv', path+'datasets/') dtrain, dtest = train_test_split(tmp_data, test_size=0.2)#出力が4つないとだめ?? # x_train, y_train, x_test, y_test = train_test_split(tmp_data) train_loader = torch.utils.data.DataLoader(dtrain, batch_size=43, shuffle=True, drop_last=True) valid_loader = torch.utils.data.DataLoader(dtest, batch_size=43, shuffle=True, drop_last=True) best_acc = -1 for epoch in range(1, 1 + epoch_n): train_loss, train_acc = trainer.epoch_train(train_loader) valid_loss, valid_acc = trainer.epoch_valid(valid_loader) if valid_acc > best_acc: best_acc = valid_acc best_params = trainer.params print(f'EPOCH: {epoch} / {epoch_n}') print(f'TRAIN LOSS: {train_loss:.3f}, TRAIN ACC: {train_acc:.3f}') print(f'VALID LOSS: {valid_loss:.3f}, VALID ACC: {valid_acc:.3f}') torch.save(best_params, path + 'models/resnet.pth')学習を行う部分です。普通のResNetとほぼ変わらないと思います。
学習結果です。EPOCH: 1 / 100 TRAIN LOSS: 0.700, TRAIN ACC: 62.114 VALID LOSS: 1.145, VALID ACC: 52.442 EPOCH: 2 / 100 TRAIN LOSS: 0.502, TRAIN ACC: 76.391 VALID LOSS: 0.476, VALID ACC: 78.023 EPOCH: 3 / 100 TRAIN LOSS: 0.426, TRAIN ACC: 81.248 VALID LOSS: 0.467, VALID ACC: 77.907 EPOCH: 4 / 100 TRAIN LOSS: 0.368, TRAIN ACC: 83.633 VALID LOSS: 0.357, VALID ACC: 85.000 EPOCH: 5 / 100 TRAIN LOSS: 0.324, TRAIN ACC: 86.488 VALID LOSS: 0.648, VALID ACC: 76.395 EPOCH: 6 / 100 TRAIN LOSS: 0.305, TRAIN ACC: 87.018 VALID LOSS: 0.365, VALID ACC: 84.884 EPOCH: 7 / 100 TRAIN LOSS: 0.277, TRAIN ACC: 88.284 VALID LOSS: 0.480, VALID ACC: 79.884 . . . EPOCH: 92 / 100 TRAIN LOSS: 0.006, TRAIN ACC: 99.853 VALID LOSS: 0.874, VALID ACC: 85.349 EPOCH: 93 / 100 TRAIN LOSS: 0.025, TRAIN ACC: 99.058 VALID LOSS: 0.960, VALID ACC: 78.953 EPOCH: 94 / 100 TRAIN LOSS: 0.028, TRAIN ACC: 99.058 VALID LOSS: 0.992, VALID ACC: 85.698 EPOCH: 95 / 100 TRAIN LOSS: 0.021, TRAIN ACC: 99.264 VALID LOSS: 0.744, VALID ACC: 84.884 EPOCH: 96 / 100 TRAIN LOSS: 0.007, TRAIN ACC: 99.735 VALID LOSS: 1.000, VALID ACC: 85.349 EPOCH: 97 / 100 TRAIN LOSS: 0.008, TRAIN ACC: 99.735 VALID LOSS: 0.834, VALID ACC: 86.279 EPOCH: 98 / 100 TRAIN LOSS: 0.020, TRAIN ACC: 99.470 VALID LOSS: 0.739, VALID ACC: 85.930 EPOCH: 99 / 100 TRAIN LOSS: 0.005, TRAIN ACC: 99.853 VALID LOSS: 0.846, VALID ACC: 86.395 EPOCH: 100 / 100 TRAIN LOSS: 0.016, TRAIN ACC: 99.382 VALID LOSS: 1.104, VALID ACC: 83.953trainデータでは100%、testデータでも87%を記録しました。前回のLSTMを使用して約60%を考えると遥かに精度が良くなっています。
結論考察
画像を使用することで上下を当てるだけならば、精度は向上しうることがあるというのがわかりました。実際に使って儲かるのかはわかりませんが…
ここまでは論文の後追い実験なのでここから、深層距離学習を取り入れて3%上昇の予想をして行こうかと思っています。ちなみに約4300のデータで前日比で3%上昇しているのは70しかありませんでした。全体の5%となっていてかなり不均衡なデータセットといえるでしょう。
次回はこれをなんとかしたいと思います。
- 投稿日:2020-09-17T15:58:27+09:00
Pytorchで日経平均の予測~幕間~
どうもお久しぶりです。
下宿先が火事になったり、バイト先を首になったり、コロナの影響で麻雀にびっくりするぐらいハマってしまったりでやる気が出ずまったく触っていなかったですが備忘録として、久々に更新することにしました。
まず色々触っていた上で前回の記事Pytorchで日経平均の予測で書いたコードではあまりよろしくないのではないかという結論に至ったので記事にしてみました。
参考、引用した記事
大体前回記事とおなじです。
追加で以下のものを参考にしました。Using Deep Learning Neural Networks and Candlestick Chart Representation to Predict Stock Market
Affinity LossをCIFAR-10で精度を求めてひたすら頑張った話
問題点、考察
上記の記事からLSTMでの予想というのはかなり精度が悪そうということです。
予想と実際の株価の予想から外れている図がプロットされています。ネットを調べているとこういった記事が散見されますが、いまいちパッとしないことが多いです。根拠は全くないです。感覚的にです。本当に理系なのでしょうか。
そして、前回の記事Pytorchで日経平均の予測で目標にしていた3%上がる時を予想する。といったものですが、これにはデータの不均衡により、厳しいと感じました。
+3%の壁
データ数が約4300(20年分)の日経平均のデータを扱っていたのですが上下だけでいうなら1:1の比率でデータに偏りがありませんでした。しかし、騰落率+3%という条件をつけると、上昇:下落の比率が1:10ほどの偏りになります。この場合では全て下落と予想するモデルが出来てしまい、予想もへったくれもありません。
これは、精度67%のディープラーニング株価予測モデル_1の記事でも言及されていることです。この問題をDataAugmentation(こちらの記事、データが足りないなら増やせば良いじゃない。
を参考にしました)によってクリアしている旨が書かれていました。DataAugmentation
なので。データ数が4300しかないので、アップサンプリングを行いました。
つまりデータを増やしたということです。
時系列データなので画像のようにcsvファイルで管理をしていました。ここからLSTMで20日分(20行)を読み込ませて学習させるという流れです。
アップサンプリングをすると、データが追加される時、少ない方(この場合上昇するというデータとラベル)がまとめて追加されます。なので、データ数を1:1にするため上昇するという予想されたものが連続で4000行近く追加されるわけです。
こうなってしまうと20行ごとに学習していたので後半4000行でまったく信頼性のないデータになってしまうと考えました(実際予想がまともにできていなかった)。ここで時系列データへのDataAugmentationは問題がありそうと考え使うことは諦めました。
画像を用いた予想
そういった時に、ディープラーニングが注目され始めたのはAlexNet使用された画像分類コンペであることを思い出しました。なので画像を使った予想について考えてみました。
実際、上昇下落の2値分類を当てるだけであるならば画像での予想は高い精度を誇っているっぽいです。Using Deep Learning Neural Networks and Candlestick Chart Representation to Predict Stock Marketこちらの論文では株価をチャート上から読み取ることで、accuracy97%でSOTA。とのことです。
こちらの記事のコードがgit hubに落ちていたので、使って予想することにしました。
データ不均衡の問題解決
画像データであるならばデータ不均衡はDataAugmentationによって解決できるかもしれないと考えました。さらに最近では、深層距離学習というのも取り入れることでよりデータの不均衡につよい学習を行えるみたいです。
Affinity LossをCIFAR-10で精度を求めてひたすら頑張った話
上記記事が時系列データを使ったLSTMに適応できるかがわからなかったため、画像での学習を行おうと考えました。
次回の記事
こういったことを踏まえて、現在コーディング中です。乞うご期待。
次回の記事
Pytorchで日経平均の予測2
- 投稿日:2020-09-17T13:59:49+09:00
備忘録(①csv.readerのAttributeError、②get_sheet_by_nameのDeprecationWarning、③.delete_colsが機能しない)
・今日の進捗
基本機能の確認として下図の処理を全部できるようにした。相変わらず細かいエラーが多い。
発生したミスを忘れないように書いておく
①大文字小文字はキッチリと。入力import csv csvfile = open('/content/drive/My Drive/Colab Notebooks/testB.csv',encoding="shift-jis") reader = csv.Reader(csvfile) for row in reader: print(row)出力AttributeError Traceback (most recent call last) <ipython-input-14-bb1b8be4844f> in <module>() 3 csvfile = open('/content/drive/My Drive/Colab Notebooks/testB.csv',encoding="shift-jis") ----> 4 reader = csv.Reader(csvfile) 5 for row in reader: AttributeError: module 'csv' has no attribute 'Reader'csv.reader() と csv.Reader() 、大文字小文字を間違えたのでAttribute Errorが発生。
csv.DictReaderから書き換えた時に頻発しそうなので覚えておく②get_sheet_by_nameは使わないほうがいい
入力import openpyxl wb=openpyxl.load_workbook('/content/drive/My Drive/Colab Notebooks/testB.xlsx') wb.get_sheet_names()出力/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:3: DeprecationWarning: Call to deprecated function get_sheet_names (Use wb.sheetnames). This is separate from the ipykernel package so we can avoid doing imports until ['Sheet1']Deprecationは非推奨という意味。機能はするけどあんま良くないので使うなってことらしく、更に推奨の関数も書いてある。
言われてみれば分かりやすいが、バーっと出てきた文字列を見て「は?なんで?」ってなって無駄に時間を使った。
ちゃんと英語は読まないとダメだね、本当に・・・。③ hogehoge.delete_cols コマンドのhogehogeの部分は変数名である
入力(修正前)import openpyxl wb=openpyxl.load_workbook('/content/drive/My Drive/Colab Notebooks/testB.xlsx') ws = wb.worksheets[0] sheet.delete_cols(2) wb.save('/content/drive/My Drive/Colab Notebooks/testC.xlsx')ファイルは出力されたが、エクセルの2列目が削除できていなかった。
今見ると、色々なサイトをツマミ食いして完全におかしくなっている。入力(修正後)import openpyxl wb=openpyxl.load_workbook('/content/drive/My Drive/Colab Notebooks/testB.xlsx') ws = wb.worksheets[0] ws.delete_cols(2) wb.save('/content/drive/My Drive/Colab Notebooks/testC.xlsx')wb=openpyxl.load_workbook() で、xlsxのデータを変数wbに詰め込む
ws=wb.worksheets[0] で、wbの中のxlsxのデータから引数(0)頁目のワークシートのデータを変数wsに詰め込む
ws.delete.cols(2) で、ワークシートのデータwsに対し、列数2列目(引数)を削除する
wb.save() で保存して成功・・・あれ?最終的に出力されたtestC.xlsxはちゃんと2列めが消えたデータになるのだが、何故だろう?
wsのデータはwbからコピーしてきたものなので、wb.saveをする前に、wbにwsのデータを戻さないと本当はダメな気がする。
ws=wb.worksheets[]を使った時点で、wsとwbのデータが同期しているんだろうか・・・?
調べて分からなければ、質問を書いてみるか・・・?
- 投稿日:2020-09-17T13:15:26+09:00
mixhostサーバーにPython3をインストール【未確認】
- 投稿日:2020-09-17T11:38:28+09:00
犬でもわかるLeetCode「200. Number of Islands」
概要
外資系では、エンジニアの面接でコーディングテストを行う企業が多いらしいです
そのコーディングテストの過去問のサイトがLeetCodeです
受ける予定はありませんが、勉強のために毎日1問解いています問題
200. Number of Islands
難易度はMediumです以下のような入力が与えられます
地図みたいなイメージで、1が陸、0が海を表します
隣接した陸で1つの島が作られます
求められる出力は、島の数です
以下の例では、左上、真ん中、右下に3つの島があるので、3が出力ですInput: grid = [ ["1","1","0","0","0"], ["1","1","0","0","0"], ["0","0","1","0","0"], ["0","0","0","1","1"] ] Output: 3解法
端から順に見ていって、以下を繰り返します
1. 島を見つけたら、その島の陸を、全て訪問済みにする
2. 島カウンターを1足すclass Solution: def numIslands(self, grid: List[List[str]]) -> int: #島の陸を全て訪問済みにする def check(i,j): if grid[i][j]=="1": #訪問済みにする grid[i][j]="2" #上下左右の隣接した陸を、再帰的に訪問済みにする if i-1>=0: check(i-1,j) if j-1>=0: check(i,j-1) if i+1<=len(grid)-1: check(i+1,j) if j+1<=len(grid[0])-1: check(i,j+1) #島カウンター count=0 #grid[0][0]から順に見ていく for i in range(len(grid)): for j in range(len(grid[0])): #陸だったら if grid[i][j]=="1": #島の陸を全て訪問済みにする check(i,j) #島カウンター1足す count+=1 return count
- 投稿日:2020-09-17T11:19:01+09:00
「知らぬ間によくわからないDBスキーマが追加されてるんだけど・・・」みたいなレガシー環境でDBテーブル定義をバージョン管理したい
やりたかったこと
- DBテーブル定義をバージョン管理したい
- 修正用をレビューしたい
(今時の新規サービスですと少ないかと思いますが)
テーブル定義のマスターがDBにあるのみで定義の変更を各々の開発者が行う(他の開発者は認識しづらい)という運用になってしまっているサービスだと便利かと思います※MySQL系でのみ動作確認済みです、最低限になるので必要に応じてカスタマイズしてください
エクスポートコード
こちらは初回のみ実行することを想定してます
以後のテーブル定義変更は、出力されたファイルを変更していく形です"""export_database_schema.py データベースからCREATE TABLE文をエクスポートするのに利用します optional arguments: -h, --help show this help message and exit --user USER データベースのユーザ名 --password PASSWORD データベースのパスワード --host HOST データベースのホスト名 --port PORT データベースのポート番号 --charset CHARSET データベースの文字コード --target TARGET [TARGET ...] エクスポート対象のDBリスト(スペース区切り) """ import os import sys import shutil import pymysql import argparse ROOT_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 引数の設定 parser = argparse.ArgumentParser() parser.add_argument("--user", help="データベースのユーザ名", default="root") parser.add_argument("--password", help="データベースのパスワード", default="password") parser.add_argument("--host", help="データベースのホスト名", default="127.0.0.1") parser.add_argument("--port", help="データベースのポート番号", default=3306) parser.add_argument("--charset", help="データベースの文字コード", default="utf8mb4") parser.add_argument("--target", help="エクスポート対象のDBリスト(スペース区切り)", default=["users", "shops"], nargs="+") args = parser.parse_args() print("Connection: mysql://%s:%s@%s:%s?charset=%s" % ( args.user, args.password, args.host, args.port, args.charset)) con = pymysql.connect( user=args.user, password=args.password, host=args.host, port=args.port, charset=args.charset) with con.cursor() as cursor: sql = "SHOW DATABASES" cursor.execute(sql) databases = cursor.fetchall() # 指定されたDBが存在する場合のみエクスポート処理を行う for d in databases: if d[0] not in args.target: continue # DBごとにディレクトリ作成(存在していたら一度削除) currentDirName = "%s/%s" % (ROOT_DIR, d[0]) if os.path.isdir(currentDirName): shutil.rmtree(currentDirName) os.mkdir(currentDirName) dirname = "%s/schemas" % (currentDirName) os.mkdir(dirname) print("Export database: ", d[0]) sql = "USE %s" % d[0] cursor.execute(sql) sql = "SHOW TABLES" cursor.execute(sql) tables = cursor.fetchall() for t in tables: print("\tExporting ", t[0]) sql = "SHOW CREATE TABLE %s" % t cursor.execute(sql) schema = cursor.fetchone() filename = "%s/%s.sql" % (dirname, t[0]) with open(filename, mode="w") as f: f.write(schema[1] + ";\n\n") con.close()例として、
python export_database_schema.py --target users shops
を実行することで下記のようなディレクトリ構成でCREATE文ファイルが設置されます├── users │ └── schemas # users DB内のテーブルのCREATE文が格納 └── shops └── schemas # shops DB内のテーブルのCREATE文が格納インポートコード
#!/bin/bash usage() { cat << EOS Usage: $0 [option] -t TARGET 対象のテーブル定義ディレクトリ -d DATABASE インポート先データベース名 -H HOST データベースのホスト名 -u USER データベースのユーザ名 -p PASSWORD データベースのパスワード -P PORT データベースのポート番号 -y 実行確認をプロンプト省略 EOS exit 1 } TARGET="" DATABASE_NAME="" HOST="127.0.0.1" USER="root" PASSWORD="" PORT="3306" AUTO_YES=false while getopts d:t:H:u:p:P:yh OPT do case $OPT in d) DATABASE_NAME=$OPTARG ;; t) TARGET=$OPTARG ;; H) HOST=$OPTARG ;; u) USER=$OPTARG ;; p) PASSWORD=$OPTARG ;; P) PORT=$OPTARG ;; y) AUTO_YES=true ;; h) usage ;; esac done ROOT_PATH=$(dirname "$(cd "$(dirname "${BASH_SOURCE:-$0}")" && pwd)") if [ "${DATABASE_NAME}" == "" ]; then echo "インポート対象のデータベースを指定してください。" echo " ./$0 -d DATABASE_NAME" exit 1 fi if [ ! -d $ROOT_PATH/$TARGET/schemas ]; then echo "指定されたテーブル定義ディレクトリが存在しません" echo "${ROOT_PATH}下にディレクトリが存在するか確認してください" echo " ./$0 -t TARGET" exit 1 fi echo "パラメータ -------------------------" echo "TARGET: $TARGET" echo "DATABASE_NAME: $DATABASE_NAME" echo "HOST: $HOST" echo "USER: $USER" echo "PASSWORD: $PASSWORD" echo "PORT: $PORT" echo "------------------------------------" # 確認 if ! "${AUTO_YES}"; then read -p "\"$DATABASE_NAME\" データベースを初期化していいですか?(y/N)" yn case "$yn" in [yY]*) ;; *) exit 1;; esac fi echo "データベース初期化中..." CMD="mysql -h$HOST" if [ "$USER" != "" ]; then CMD="$CMD -u$USER" fi if [ "$PASSWORD" != "" ]; then CMD="$CMD -p$PASSWORD" fi if [ "$PORT" != "" ]; then CMD="$CMD -P$PORT" fi echo 'SET FOREIGN_KEY_CHECKS = 0;' > "${ROOT_PATH}/tmp.sql" cat $ROOT_PATH/$TARGET/schemas/*.sql >> "${ROOT_PATH}/tmp.sql" `$CMD -e "set FOREIGN_KEY_CHECKS=0; DROP DATABASE IF EXISTS $DATABASE_NAME;"` `$CMD -e "CREATE DATABASE $DATABASE_NAME;"` `$CMD -t $DATABASE_NAME < "${ROOT_PATH}/tmp.sql"` rm "${ROOT_PATH}/tmp.sql" echo "完了" # テスト用に初期データを入れたい場合は下記のような形でファイルを配置し、一緒にインポートする # echo "初期データ作成中..." # `$CMD -t $DATABASE_NAME < "${ROOT_PATH}/${TARGET}/testdata/dump.sql"` # echo "完了" exit 0インポートは
例として、./scripts/import_database_schema.sh -t users -d users -y
という形で行います。実運用の際は、下記のようにテストデータを設置し、インポート時にテストデータも一緒にインポートするような形にしてgithub actionsでテストを回すような運用をしています
├── users │ ├── testdata # users DBのテストデータを格納 │ └── schemas # users DB内のテーブルのCREATE文が格納 └── shops ├── testdata # shops DBのテストデータを格納 └── schemas # shops DB内のテーブルのCREATE文が格納
- 投稿日:2020-09-17T10:24:45+09:00
xlwingsでアドインが有効なExcelインスタンスを生成する
ニッチすぎるけど、xlwingsでExcelインスタンスを生成するときの問題点とその解決方法を紹介。
0. 環境
以下で確認しています。
- OS: Windows 10 (1809)
- Office 2016
- xlwings 0.20.71. 問題点
xlwingsでExcelインスタンスを生成するには、
xw.apps.add()やxw.App()を使用する。しかし、この方法の場合、以下の問題点がある。
- なぜかアドインが読み込まれない。
- そのインスタンを閉じた後、エクスプローラーからブックを開いてもアドインが読み込まれない。
なお、ブックを開かずにExcelだけを開けば(スタートメニューから起動)、アドインは正常に読み込まれるようになる。
2. 解決方法
xw.apps.add()やxw.App()を使わずに、シェルからExcelインスタンスを生成し、xlwingsに渡す。import re import subprocess import time from pathlib import Path import xlwings as xw def get_xl_path() -> Path: #Excelのインストール先パスを返す関数 subprocess_rtn = ( subprocess .run(['assoc','.xlsx'], shell=True, stdout = subprocess.PIPE, stderr = subprocess.PIPE) .stdout.decode("utf8") ) assoc_to = re.search('Excel.Sheet.[0-9]+', subprocess_rtn).group() subprocess_rtn = ( subprocess .run(['ftype', assoc_to], shell=True, stdout = subprocess.PIPE, stderr = subprocess.PIPE) .stdout.decode('utf-8') ) xl_path = re.search('C:.*EXCEL.EXE', subprocess_rtn).group() return Path(xl_path) def xw_apps_add_fixed() -> xw.App: #Excelインスタンスを生成する関数 xl_path = get_xl_path() num = xw.apps.count pid = subprocess.Popen([str(xl_path),'/e']).pid #xlwingsから認識できるまで待つ while xw.apps.count == num: time.sleep(1) #xlwingsから使用できるようになるまで待つ while True: try: xw.apps[pid].activate() break except: time.sleep(1) return xw.apps[pid] app = xw_apps_add_fixed()参考
- 投稿日:2020-09-17T10:22:08+09:00
【PythonのORM】SQLAlchemyでIN句にサブクエリを用いたSQLを書くときの記法
ORM? SQLAlchemy?
既に下記のようなQiita記事でもまとめているため、省略して本題のみ
https://qiita.com/tomo0/items/a762b1bc0f192a55eae8
https://qiita.com/ariku/items/75799665acd09520bed2コード
url = 'mysql+pymysql://%s:%s@%s:%s/%s?charset=%s' % ( self.user, self.password, self.host, int(self.port), self.db, self.charset ) self.engine = create_engine(url) self.session = sessionmaker(bind=self.engine, autocommit=False, autoflush=True)()` # IN句にサブクエリを含める rows = db.session.query(User).filter( User.id.in_( db.session.query(UserItem.user_id).filter( UserItem.item_id == 1, UserItem.numbers > 10 ) ) ).all()下記のような
SELECT * FROM users WHERE id IN ( SELECT user_id FROM user_items WHERE item_id = 1 AND numbers > 10 )まとめ
SQLAlchemyではIN句にサブクエリを用いるSQLなどの複雑なSQLも表現可能
注意点として、ORMでは裏側でどういったSQLが発行されるかがブラックボックスであるため、微妙なSQLになっていないかデバッグ時は
create_engine時に下記のようなオプションを追加しSQLを出力するようにしてチェックすることをオススメしますecho_option = 'DEBUG' in os.environ and os.environ['DEBUG'] == 'on' self.engine = create_engine(url, echo=echo_option) self.session = sessionmaker(bind=self.engine, autocommit=False, autoflush=True)()`
- 投稿日:2020-09-17T09:47:30+09:00
3. Pythonによる自然言語処理 1-2. コーパスの作成方法 : 青空文庫
- 自然言語処理の試行につけてはコーパス(まとまった量のテキスト)が必要になります。
- しばしば利用させていただく『青空文庫』は、近代文学など著作権が切れた作品のテキストを公開しているインターネット上の図書館です。
- 自然言語処理の素材として『青空文庫』から作品を取得し、コーパス用に加工する手順を整理しておきます。
1. ファイルを取得して本文のみ抽出
⑴ 各種モジュールのインポート
import re import zipfile import urllib.request import os.path import glob
re:Regular Expressionの略で、正規表現の操作をするためのモジュールzipfile:zipファイルを操作するためのモジュールurllib.request:インターネット上のリソースを取得するためのモジュールos.path:パス名を操作するためのモジュールglob:ファイルパス名を取得するためのモジュール⑵ ファイルパスの取得
ここでは、宮沢賢治の『銀河鉄道の夜』を素材とします。
- 『青空文庫』のトップページ右上の検索ボックスに「宮沢賢治」を入力して検索。
- 検索結果の最上位に挙がる「作家別作品リスト:宮沢 賢治」から当該ページに遷移。
- リストの中から「59. 銀河鉄道の夜(新字新仮名、作品ID:43737)」を選択。
- 遷移先の「図書カード:No.43737」を下へ「ファイルのダウンロード」までスクロール。
- ファイル名(リンク)欄のzipファイル名を右クリックして「リンクのアドレスをコピー」を選択。
URL = 'https://www.aozora.gr.jp/cards/000081/files/43737_ruby_19028.zip'⑶ zipファイルを取得・解凍するメソッド
def download(URL): zip_file = re.split(r'/', URL)[-1] #➀ urllib.request.urlretrieve(URL, zip_file) #➁ dir = os.path.splitext(zip_file)[0] #➂ with zipfile.ZipFile(zip_file) as zip_object: #➃ zip_object.extractall(dir) #➄ os.remove(zip_file) #➅ path = os.path.join(dir,'*.txt') #➆ list = glob.glob(path) #➇ return list[0] #➈1) zipファイルのダウンロード
- ➀
re.split():URLの文字列を/で区切り、末尾のzipファイル名「43737_ruby_19028.zip」を取得。- ➁
urllib.request.urlretrieve(URL, 保存名):当該サイトから直接ファイルをダウンロードし、zipファイル名「43737_ruby_19028.zip」で保存。- ➂
os.path.splitext():zipファイル名をドット「.」で分割し、拡張子なしのファイル名dirを取得。2) zipファイルの解凍と保存
- ➃
zipfile.ZipFile():先に保存したzipファイルを読み込んで、zipオブジェクトを作成し、- ➄
extractall():zipオブジェクトの中身をすべて、ディレクトリdirに展開。- ➅
os.remove():解凍前のzipファイルを削除。3) 保存したファイルのパスを取得
- ➆
os.path.join():dirのパス文字列を生成。- ➇
glob.glob(): ディレクトリ内のテキストファイル名をすべて出力してリスト化。- ➈
list[0]: リスト内の一番目のファイルのパスを返す。⑷ ファイル読み込み・本文を抽出するメソッド
def convert(download_text): data = open(download_text, 'rb').read() #➀ text = data.decode('shift_jis') #➁ # 本文抽出 text = re.split(r'\-{5,}', text)[2] #➂ text = re.split(r'底本:', text)[0] #➃ text = re.split(r'[#改ページ]', text)[0] #➄ # ノイズ削除 text = re.sub(r'《.+?》', '', text) #➅ text = re.sub(r'[#.+?]', '', text) #➆ text = re.sub(r'|', '', text) #➇ text = re.sub(r'\r\n', '', text) #➈ text = re.sub(r'\u3000', '', text) #➉ return text1) ファイルの読み込み
- ①
open(ファイル名, 'rb').read():当該ファイルを'rb'(バイナリモード)で読み込む。- ②
decode('shift_jis'):shift_jisに従ってデコードし、テキストを取得。2)
re.split()による本文の抽出
- ➂
(r'\-{5,}', text)[2]:ハイフン「-」を5回以上くり返す部分を削除し、これを区切り文字として分割されたうちの3番目の要素を取り出す。- ④
(r'底本:', text)[0]:「底本:」を削除し、これを区切り文字として分割されたうちの1番目の要素を取り出す。- ➄
(r'[#改ページ]', text)[0]:「[#改ページ]」を削除し、これを区切り文字として分割されたうちの1番目の要素を取り出す。3)
re.sub()によるノイズの削除(置換)
- ➅
'《.+?》':《ルビ》- ➆
'[#.+?]':[注記]- ➇
'|':ルビ付き文字列の開始位置- ➈
'\r\n':改行コード- ➉
'\u3000':全角スペース⑸ ファイル取得と本文抽出の実行
download_file = download(URL) text = convert(download_file) print(text)
2. MeCabによる「分かち書き」
⑹ MeCabのインストール、分かち書き
!apt install aptitude !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3==0.7
MeCab.Tagger()というクラスに引数を-Owakatiとしてインスタンスを生成し、さらにparse()というメソッドを呼ぶことで結果が文字列として取得できます。import MeCab mecab = MeCab.Tagger("-Owakati") text = mecab.parse(text) print(text)
- さらに
split()で、空白を区切り文字として文字列を分割します。separated_text = text.split() print(separated_text)
3. ローカルPCにダウンロードするなら
⑺ ファイル化してローカルPCに取得
- 分かち書きにした状態のテキストを、ローカルPCにダウンロードします。
with open('output.txt', 'w') as f: f.write(text)
textを'output.txt'というファイルに書き出します。引数の'w'は書き込みモードの指定です。from google.colab import files files.download('output.txt')
filesは、ColaboratoryとローカルPCとの間でファイルをアップロードないしダウンロードするためのモジュールです。- ダウンロード後のテキストファイルを示します。文中のルビや脚注などの不要部分は取り除かれ、分かち書きにした本文のみとなっています。



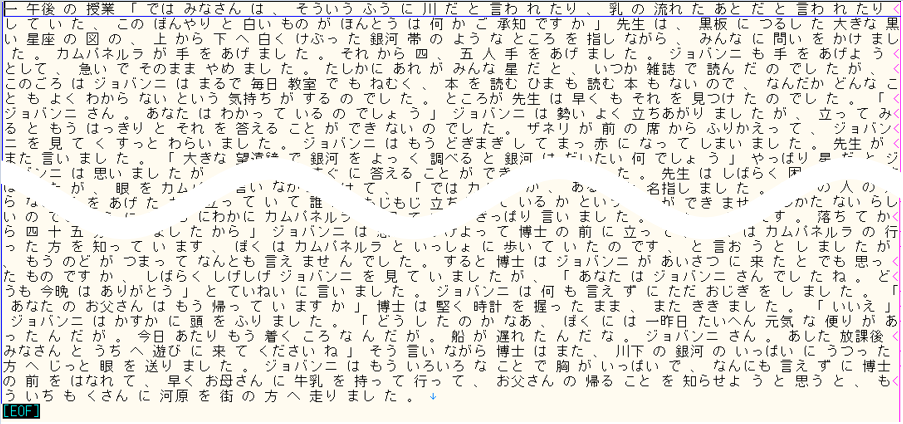
- 投稿日:2020-09-17T09:17:31+09:00
Pipenv+VSCodeで外部ライブラリのインテリセンスを有効にする
検証した環境



概要
VSCodeでPythonの開発をする際に特に設定を行わないと
標準ライブラリしかインテリセンスが有効になっていないので開発スピードが下がってしまう。
標準ライブラリだけではなく外部ライブラリを使用した場合でもインテリセンスが有効になるように設定を行う。手順
1. Pipenvで作成した仮想環境を調べる
pipenv --venvコマンド実行結果イメージ# 仮想環境のパスが表示される /Users/xxx/work/fastapi-demo/.venv2. 外部ライブラリがあるパスを調べる
.venv配下にあるsite-packagesに外部ライブラリがあるパス/Users/xxx/work/fastapi-demo/.venv/lib/python3.8/site-packages/3. VSCodeの基本設定で2のパスを設定する
python.autoComplete.extraPathsに2のパスを設定する
4. インテリセンスが有効になっていること確認する
参考


- 投稿日:2020-09-17T08:20:06+09:00
Selenium Python VBA プルダウンで選択されている値を取得する
Selenium Python Vba プルダウン(Select)で選択されている値を取得する
検索しても、Selectに値を設定するものばかりで、みつけるのに多少時間がかかったのでこちらでもメモします。
前提
Windows
Python 3.8
Selenium は既に使えていて、 driver の変数で扱うものとするSelenium Python プルダウンで選択されている値を取得する
Selectクラスを使います。
なのでSelectクラスをインポートする必要があります。
Select要素を参照するWebElementをSelect型にすると、様々なことができます。Select要素を操作する詳しい説明公式サイト
https://www.selenium.dev/documentation/ja/support_packages/working_with_select_elements/プルダウンから選択されている値を取得するfrom selenium.webdriver.support.select import Select #Select要素を操作するにはSelectクラスをインポートする AA = driver.find_element_by_id("A") #IDがAのSelect要素を取得する AAA=Select(AA) #Selectオブジェクトを作成 このオブジェクトから様々な操作ができます。 #プルダウンで選択されている値は print(AAA.first_selected_option.text) #複数選択できるプルダウンの場合リストで取得できます。 all_selected = AAA.all_selected_options #all_selectedはリストになります。SeleniumBasic VBA プルダウンで選択されている値を取得する
こちらは簡単
プルダウンで選択されている値を取得するDim AA As WebElement 'WebElement型で宣言 ’IDがAのSelect要素を取得 Set AA = driver.FindElementById("A").AsSelect.SelectedOption Debug.Print (A.Text) ’選択されている値が出力されました。できたー今日のつぶやき
そういえばテキストボックスやチェックボックスの値取得ばかりで
Selectの選択値をスクレイピングで取得することは久しぶりです。
最近また依頼が増えてきたので、スピードをもって取得していこう。
もっと考える暇がほしいです。