- 投稿日:2020-09-17T23:12:04+09:00
AspectJ の機嫌の取り方の本質 - あなたの `@Transactional` はどうして無視されてしまうのか
Aspect-oriented programming (AOP) ライブラリである AspectJ は JVM 環境においてメソッド呼び出しを横取りして任意の処理を挿入するために有用であり、フレームワークの実装としてもしばしば利用されています。
例えば Spring Framework の利用現場においても AspectJ (CGLIB proxy1) を利用して
@Transactionalアノテーションによるトランザクションを実現している事例が少なからずあります 2。広く使われている AspectJ は実際便利なのですが、それが有効なプロジェクトにおいて 「何時間も試行錯誤しても俺の
@Transactionalが無視される...何故だ...!」 という悲痛な叫びを筆者はさまざまな現場で幾度となく聞きました。Spring においては公式ドキュメント Chapter 6. Aspect Oriented Programming with Spring のチャプターを一通り読めばその背景も動作原理も取りうる選択肢も全てが分かるのですが、 「そんなことより俺の AOP を今すぐ動かしたい!!」 とお困りの方は以下をご参照ください:
あなたの AOP はどうして無視されるのか
1) Override 出来ないメソッド
以下の条件を満たす場合には AOP が効かないという症状が現れます:
- クラスまたはメソッドが
finalであるstaticメソッドoverride できるようにしてあげましょう。
2) AspectJ によって生成されるラッパーのインスタンスを参照していない
ありがちなパターン:
this.メソッド()で呼び出しているreturn this;したものに対してメソッド呼び出しが行われているnew あなたのクラス()しているなぜそうなるのか - AspectJ の動作原理
AspectJ は以下のステップによって AOP を実現しています:
- 元のインスタンスの class を継承する class を動的に生成、全てのメソッドを override する
- 上記の class を new してインスタンスを生成(元のインスタンスをラップするインスタンス)
- ラッパーのメソッドは、AOP の処理を実行した上で、元のインスタンスのメソッドを呼び出す 3
重要なのは、 AspectJ はあなたの書いた class を継承する別の class とそのインスタンス(ラッパー)を生成している という点です。
そのため、ラッパーのインスタンスに対してメソッド呼び出しをすれば AOP が働きますが、元の class のインスタンスのメソッドを呼び出してしまうと AOP は一切働きません。
対処法は、メソッドを呼び出す対象のインスタンスをフレームワーク(AspectJ をケアしている)から取得するようにすることです。
例えば、先述の
2)のありがちなパターンの具体的対処法は以下:
this.メソッド()で呼び出している
- あなたの書いた class のメソッドにおける
thisはラッパーではなく、元のインスタンスですthisではなく DI などで フレームワークから自分(のラッパー)のインスタンス を取得してそちらを呼び出しましょう (= AspectJ のラッパーが得られる)return this;したものに対してメソッド呼び出しが行われている
- フレームワークから DI などで取得したインスタンスを使うようにし、
thisを露出するのはやめましょうnew あなたのクラス()している
- インスタンスの生成をフレームワークに行わせましょう (Spring であれば Bean/Component として定義する)
まとめ
ここまでの説明を全て読んでいただいた方は既にご存知のように、 AspectJ が継承・override で生成したラッパーを経由しないでメソッドを呼び出すからダメ というシンプルな原理に帰着します。
世の中の記事などでは「あのケースでもこんなケースでもそんなケースでも AspectJ がうまく動かない」という説明・羅列の仕方がされていることがあり、それを見て「なんという複雑怪奇意味不明なライブラリなんだ...」と絶望されてしまっている人を幾度となく筆者は見たことがあるのですが、本質的にはただそれだけの問題です (ということを今後も説明することがありそうなので文章にまとめました)。
ここまでに触れた具体例そのものに直接該当しない場合も、本稿で触れました AspectJ の動作原理を思い浮かべていただけばきっと原因にたどり着けるのではないでしょうか。
おまけ: Spring の
@TransactionalのrollbackForBy default, a transaction will be rolling back on RuntimeException and Error but not on checked exceptions (business exceptions). See DefaultTransactionAttribute.rollbackOn(Throwable) for a detailed explanation.
本稿の主題とは無関係ですが、Spring の
@Transactionalではチェック例外(e.g.IOException)がデフォルトではロールバック対象にはなっていないため、「例外が発生したのにトランザクションが commit されてしまった!」という話もよくあります。
そのため、明示的にrollbackForを指定するほうが混乱しない、というノウハウもあります。
Spring 系の公式ドキュメントでは "CGLIB proxy" と表現されていますが、指しているのは AspectJ です (GCLIB は AspectJ が内部で使っているコード生成ライブラリ名)。 ↩
Spring がデフォルトで使う java.lang.reflect.Proxy は interface のみに対する AOP が可能であり、その制約を嫌って AspectJ を使っている事例が少なからずあります ↩
対象メソッドが override できる必要があるというのはこのため ↩
- 投稿日:2020-09-17T22:13:38+09:00
STSをセットアップしたときにハマった話
概要
タイトルの通り、STSのセットアップについて備忘録を書いておきます。
また自分がハマらないために。STSとは
STSとはeclipseベースのIDEで、
Springの各プロダクトを使いやすくするために
カスタマイズされています。ちなみに
STS = Spring Tool Suite
「Springトッピング全部乗せ」みたいな
ニュアンスです。セットアップしてみる
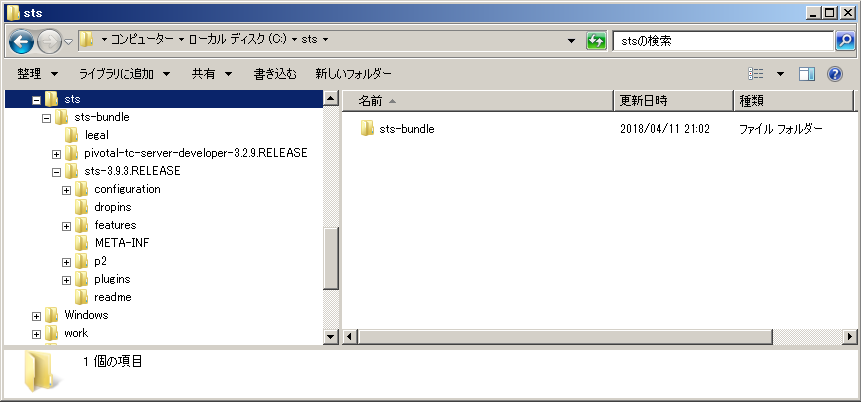
まずSTSをダウンロードします。
zipの方をダウンロードします。ダウンロードしたらzipを展開します。
c:\stsに展開してみました。
20分ほどかかりました。
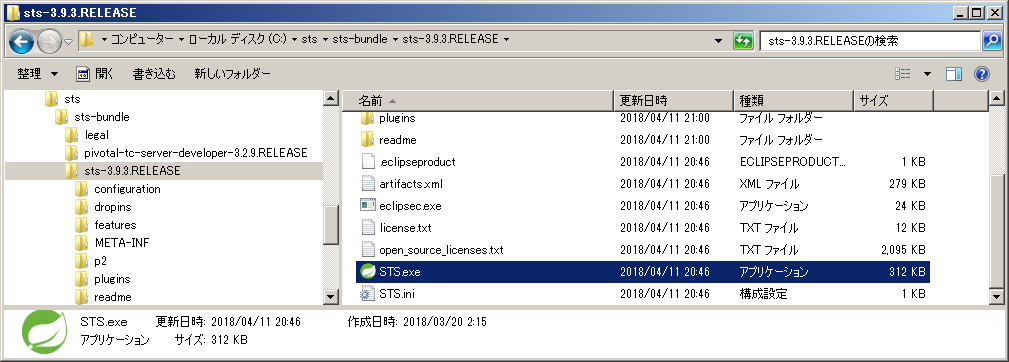
C:\sts\sts-bundle\sts-(バージョン番号).RELEASEに移動、
sts.exeを起動します。
ハマった箇所
起動しようとして
Error: Failed to load the JNI shared library
で起動しない。
このエラーメッセージはアプリケーションとOSのbitが
合っていないときに発生します。
例えばWindowsとJavaが64bit、でもSTSが32bit。
この記事を書いたとき、STSのトップページに32bitのzipが置いてあります。
私には罠でした。無事解決
というわけでSTSを起動しました。
- 投稿日:2020-09-17T22:05:50+09:00
【Java】アクセス修飾子publicと無指定のフィールドアクセスを試したみた【Eclipse】
クラスに使用するアクセス修飾子
アクセス修飾子 説明 public どこからでもアクセス可能 無指定 同パッケージ内からのアクセスのみ可能 メンバ(フィールド・メソッド)に使用するアクセス修飾子
アクセス修飾子 説明 public どこからでもアクセス可能 protected 同パッケージ内とサブクラスからアクセス可能 無指定 同パッケージ内からのアクセスのみ可能 private 同クラス内からのアクセスのみ可能 クラスに無指定でメンバにprivateならどうなる?
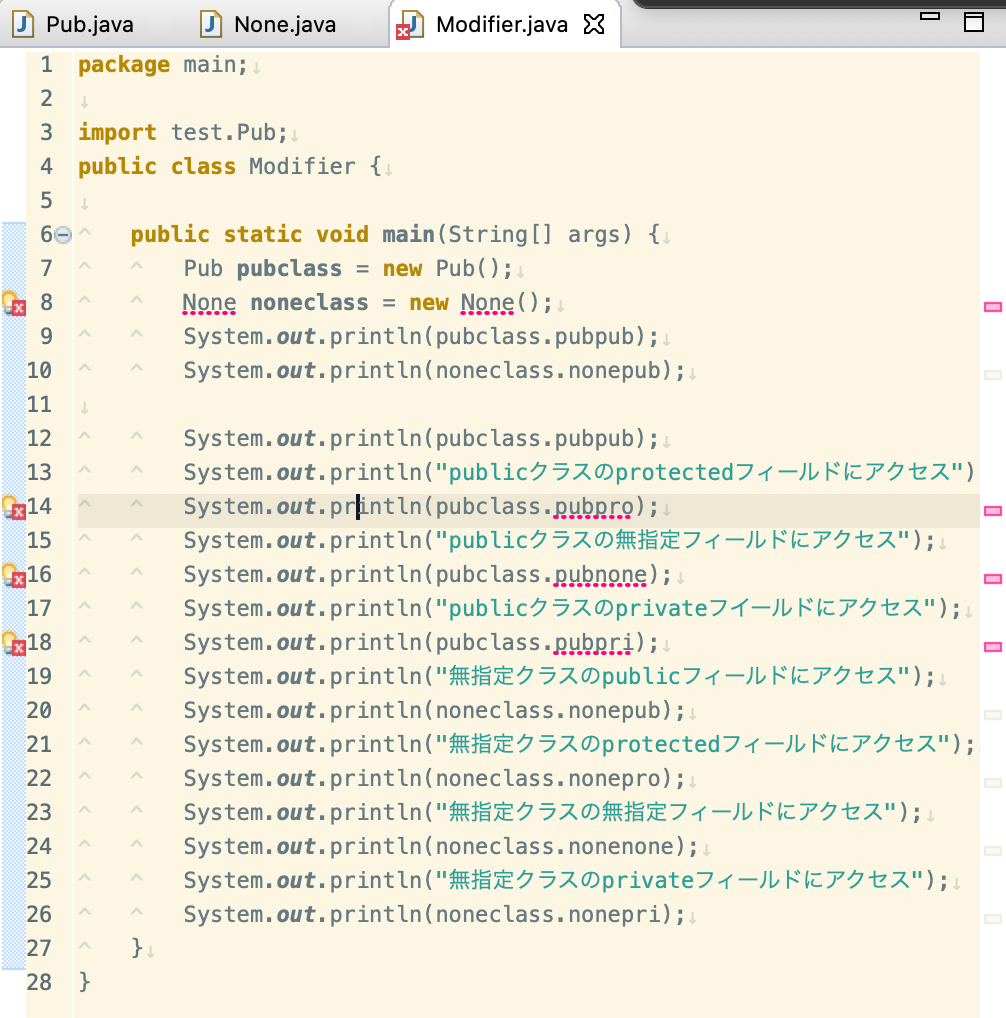
作成したファイルは下記の通り。
クラス ファイル名 mainクラス Modifier.java(mainフォルダ) publicクラス Pub.java(testフォルダ) 無指定クラス None.java(testフォルダ) Modifier.java(メインメソッドを記載)package main; import test.None; // Eclipseで実行時に削除されました import test.Pub; public class Modifier { public static void main(String[] args) { Pub pubclass = new Pub(); None noneclass = new None(); System.out.println(pubclass.pubpub); System.out.println("publicクラスのprotectedフィールドにアクセス"); System.out.println(pubclass.pubpro); System.out.println("publicクラスの無指定フィールドにアクセス"); System.out.println(pubclass.pubnone); System.out.println("publicクラスのprivateフイールドにアクセス"); System.out.println(pubclass.pubpri); System.out.println("無指定クラスのpublicフィールドにアクセス"); System.out.println(noneclass.nonepub); System.out.println("無指定クラスのprotectedフィールドにアクセス"); System.out.println(noneclass.nonepro); System.out.println("無指定クラスの無指定フィールドにアクセス"); System.out.println(noneclass.nonenone); System.out.println("無指定クラスのprivateフィールドにアクセス"); System.out.println(noneclass.nonepri); } }Pub.javapackage test; public class Pub { public String pubpub = "pubpub"; protected String pubpro = "public proteced"; String pubnone = "public none"; private String pubpri = "pubpri"; }None.javapackage test; class None { public String nonepub = "nonepub"; protected String nonepro = "nonepro"; String none = "nonenone"; private String nonepri = "nonepri"; }無名クラスはインポートできない!
上でもコメントで書いた通り、Modifier.javaの中に
import test.None;と書いてたのに、Eclipseで実行すると削除されました。コンソールのエラ〜メッセージは
Exception in thread "main" java.lang.Error: Unresolved compilation problems: None を型に解決できません None を型に解決できません フィールド Pub.pubpro は不可視です フィールド Pub.pubnone は不可視です フィールド Pub.pubpri は不可視です at main.Modifier.main(Modifier.java:8)public-publicなら問題なし
Pub.java// public以外をコメントアウトしました package test; public class Pub { public String pubpub = "pubpub"; // protected String pubpro = "public proteced"; // String pubnone = "public none"; // private String pubpri = "pubpri"; }None.java// public修飾子をクラスに追加しました // public以外をコメントアウトしました package test; public class None { public String nonepub = "nonepub"; // protected String nonepro = "nonepro"; // String none = "nonenone"; // private String nonepri = "nonepri"; }Modifier.java// 出力を全部コメントアウトにしました // パッケージのpublic修飾子のフィールドだけ呼び出すように追加しました package main; import test.None; // publicクラスにしたので消されずインポートできるようになりました import test.Pub; public class Modifier { public static void main(String[] args) { Pub pubclass = new Pub(); None noneclass = new None(); System.out.println(pubclass.pubpub); System.out.println(noneclass.nonepub); // System.out.println(pubclass.pubpub); // System.out.println("publicクラスのprotectedフィールドにアクセス"); // System.out.println(pubclass.pubpro); // System.out.println("publicクラスの無指定フィールドにアクセス"); // System.out.println(pubclass.pubnone); // System.out.println("publicクラスのprivateフイールドにアクセス"); // System.out.println(pubclass.pubpri); // System.out.println("無指定クラスのpublicフィールドにアクセス"); // System.out.println(noneclass.nonepub); // System.out.println("無指定クラスのprotectedフィールドにアクセス"); // System.out.println(noneclass.nonepro); // System.out.println("無指定クラスの無指定フィールドにアクセス"); // System.out.println(noneclass.nonenone); // System.out.println("無指定クラスのprivateフィールドにアクセス"); // System.out.println(noneclass.nonepri); } }実行結果pubpub nonepubエラーが出ることなく実行できるようになりました。
結論
- アクセス修飾子無指定クラスはimportできない
- publicクラスのpublicのみアクセスできる
ということになるかと思います。
無指定クラスは鉄壁の守り
publicクラスでもpublic以外のメンバは鉄壁の守りということでいいんでしょうかね?
無指定クラスはパッケージの外では使えないので、パッケージ内でのみ使えるということですから、抽象クラスとかで継承などで使うものでしょうかね。その辺りがまだ曖昧ですが、、、
そもそもEclipseで書いているとその都度赤い波線でエラーを知らせてくれました。その便利さに気づけただけでも書いてみた価値はありましたね。
とりあえず
初心者の方の参考に慣れば幸いです!
- 投稿日:2020-09-17T21:43:54+09:00
Processingを用いて、エディタ・コンソール・プレビュー画面を備えた自作ライブコーディング言語の実行環境を実装する
はじめに
これは2020年9月17日に明治大学FMS学科のEP演習内で発表されたやつです。まあそんなことどうでもいいんで適当に見てってください。ソースコードはgithubに置きました。
概要
プログラム自体はProcessingというjavaに皮を被せたみたいな言語を使って実装しています。実行画面はテキストエディタ、コンソール、プレビュー画面で構成されています。
言語文法
基本的にはjavaと同じような構文で書くことが出来ます。いくつかjavaとは異なる部分があるのでそこの説明を少し。
変数宣言
変数宣言は以下のような構文となります。
let a = 10; println(a); // -> 10 println(typeof(a)); // -> int let b: float = 10; println(typeof(b)); // -> float現在使用可能な組み込み型は
intfloatboolstringの4種類とその配列です。気が向いたらそのうち増やしていきたい。
配列の宣言は以下のように書けます。let arr1 = {0, 1, 2}; let arr2 = {{0, 1}, {1, 2}}; let arr3 = int[2][2]; // make {{0, 0}, {0, 0}}また、似た文法の言語にRustがありますが、Rustの場合
letで宣言すると定数に、mutを付けると変数になるのに対し、この言語ではletで変数が宣言されます。定数の宣言はまだ作ってないけど、JavaScriptみたいにconst文にしようかなと思ってます。さらに、以下のような書き方をすることもできます。
let c, d = 10, 20; println(c, d); // -> 10 20 c, d = d, c; // swap println(c, d); // -> 20 10関数定義
関数は以下の構文で定義することが出来ます。
fn add(a: int, b: int) -> int { return a + b; }補足
かなり突貫工事で作っているので、他の言語と比べてサポート出来ていない組み込み関数が多かったり、そもそもオブジェクト指向をサポート出来ていないなどの問題が山積みだったりします。許してください...
使用方法
次に、このプログラムをどう動かすのか見ていきましょう。
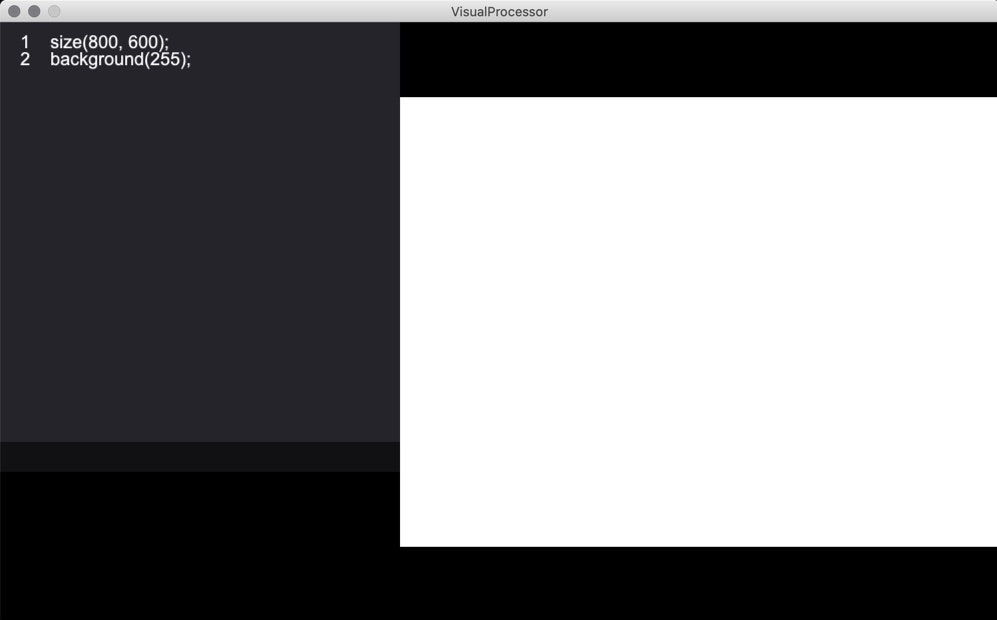
ウィンドウの生成
プレビュー画面内にウィンドウ(に対応する画面)を生成します。これはProcessingと同じような書き方で行えます。
この例では、800×600のウィンドウに対応する比率の画面をプレビュー画面に表示しています。
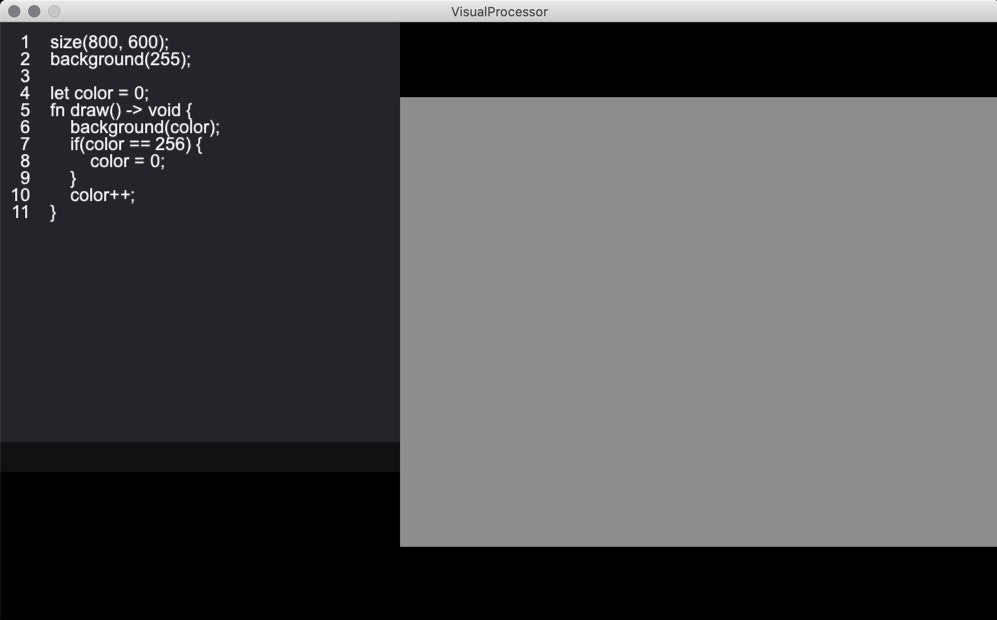
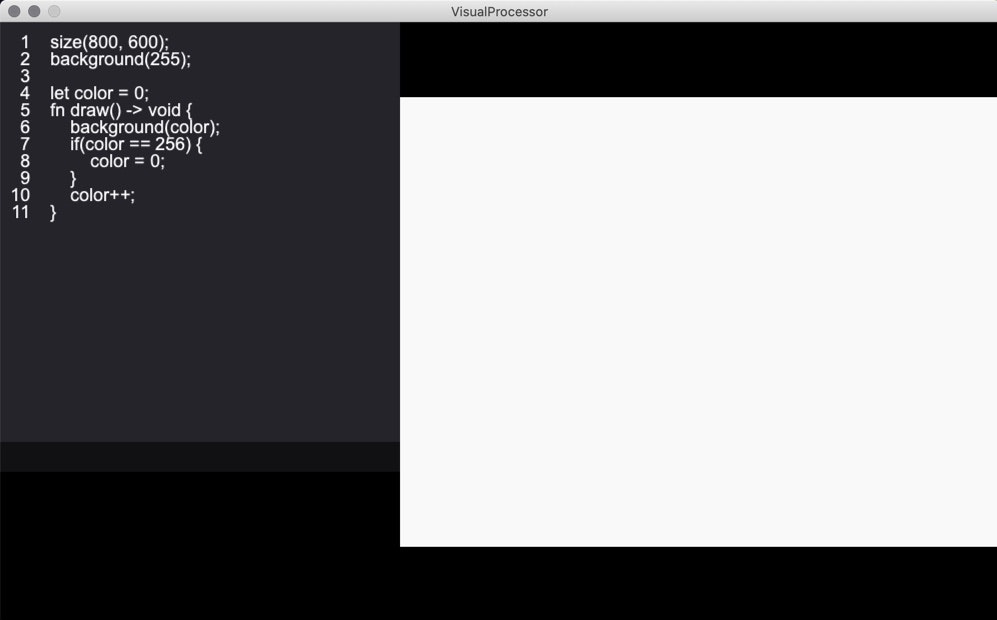
また、Processingと同じように、background()関数を使用して背景色を指定できます。コンソールの使用
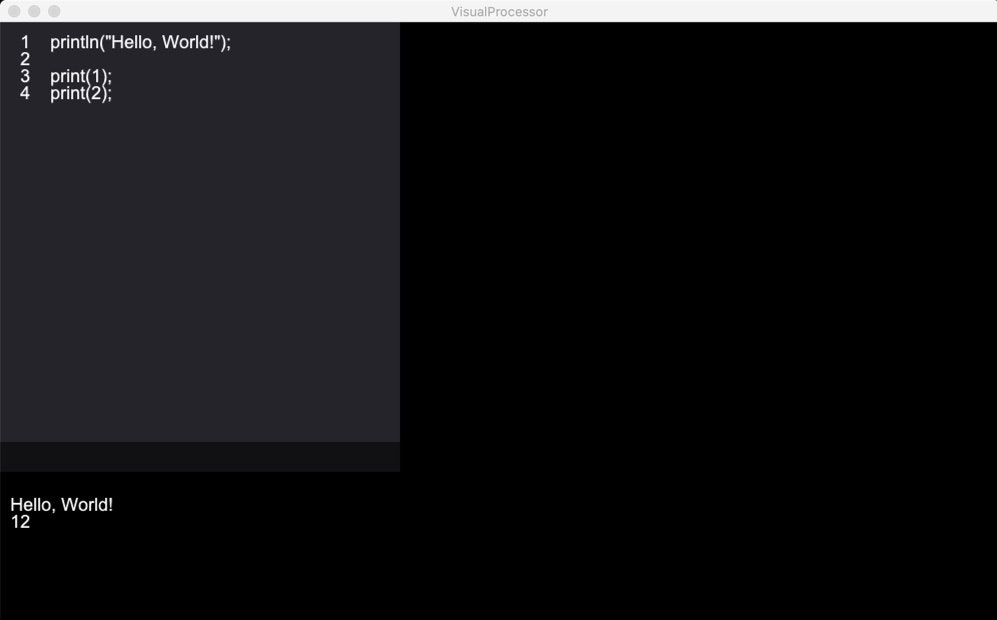
コンソールに文字列を出力するには、
println()関数を使用します。
行末に改行を出力しない場合、print()関数を使用することもできます。
コンソールに入力する機能はまだ未実装です。ごめんね。
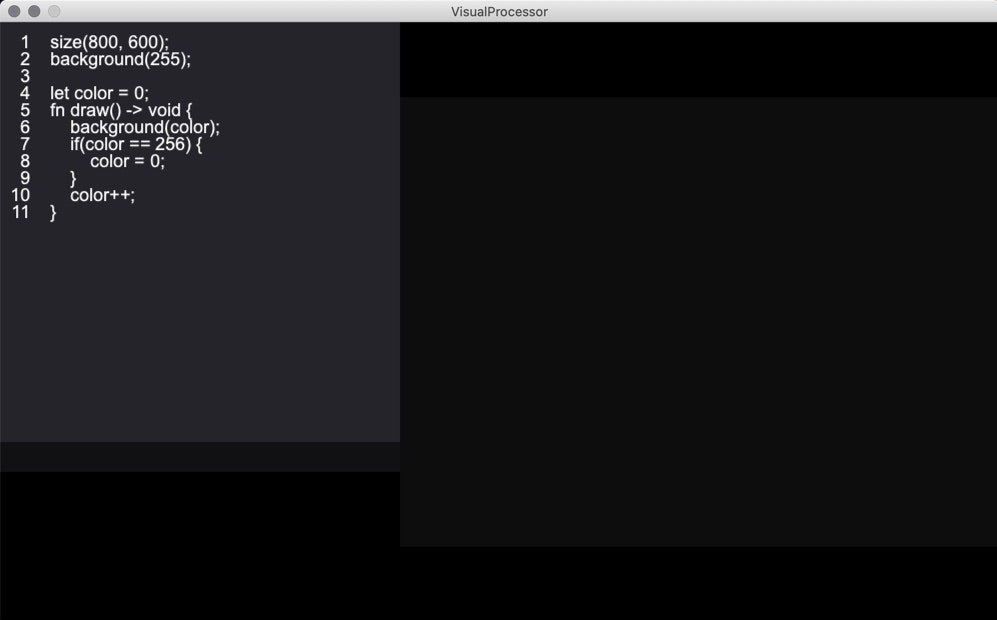
フレームごとの処理
Processingと同じように、
draw()関数を定義することでフレームごとの処理を書くことができます。
次の例では、だんだんと背景色を黒から白に変化させていく挙動を実装しています。
マウスに対する処理
マウスの座標を示す
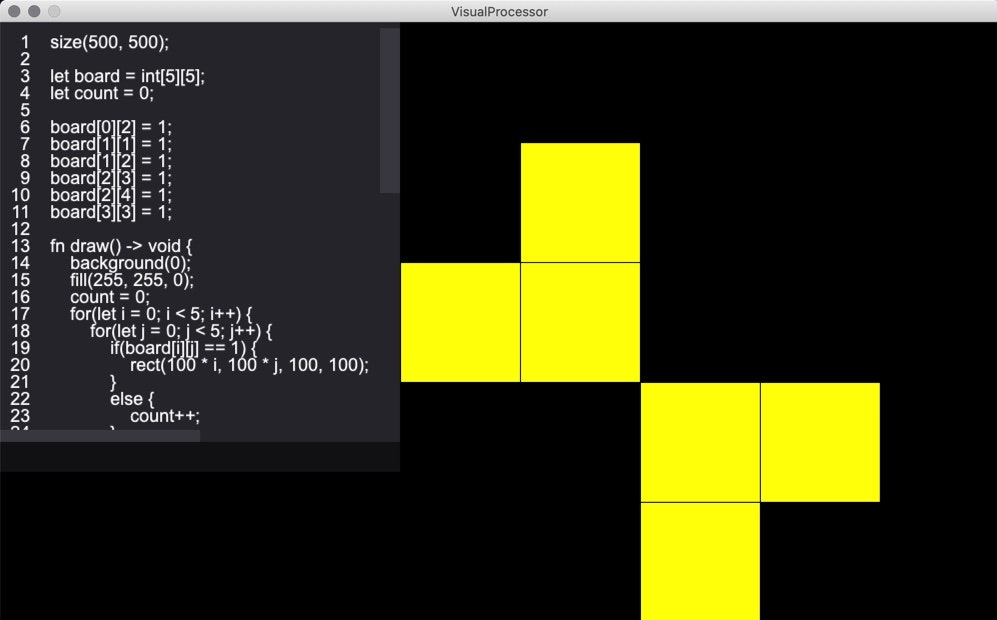
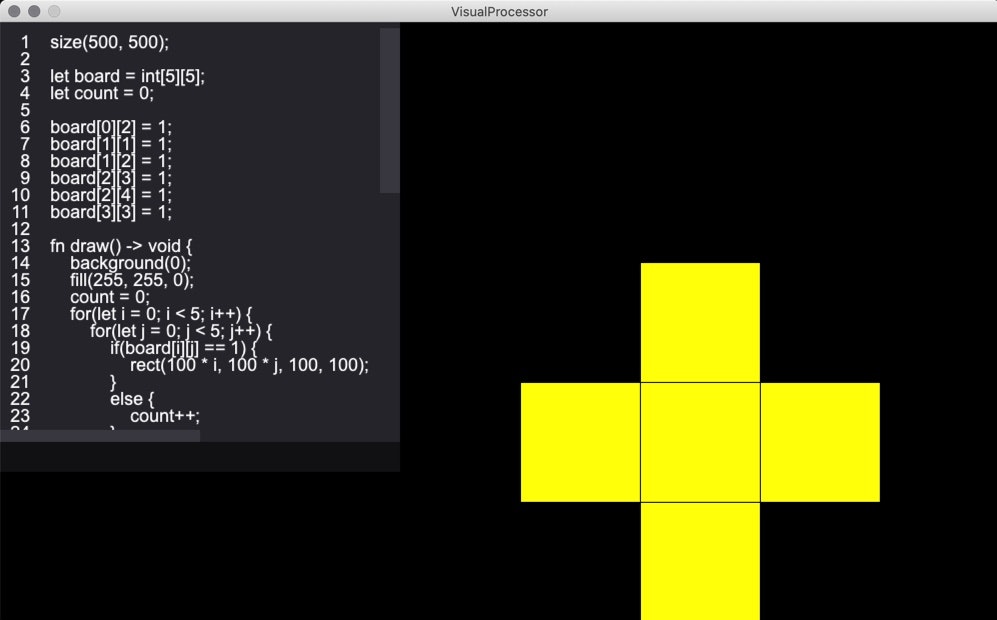
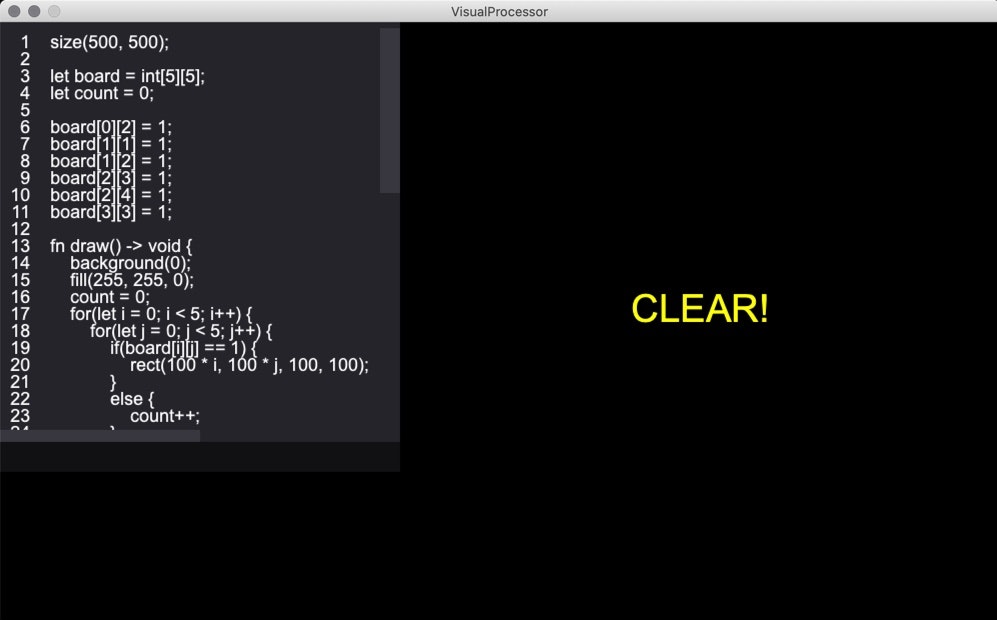
mouseX,mouseYと、mousePressed()関数を定義しておくとマウスクリック時に呼び出す機能を実装しました。なので、以下のようなクリックした部分とその上下左右のマスを反転させるこんな感じの処理を書けます。
コードが見切れているので、別に載せておきます。
size(500, 500); let board = int[5][5]; let count = 0; board[0][2] = 1; board[1][1] = 1; board[1][2] = 1; board[2][3] = 1; board[2][4] = 1; board[3][3] = 1; fn draw() -> void { background(0); fill(255, 255, 0); count = 0; for(let i = 0; i < 5; i++) { for(let j = 0; j < 5; j++) { if(board[i][j] == 1) { rect(100 * i, 100 * j, 100, 100); } else { count++; } } } if(count == 25) { textSize(32); textAlign(CENTER); text("CLEAR!", width / 2, height / 2); } } fn mousePressed() -> void { let x = mouseX / 100; let y = mouseY / 100; for(let i = max(0, x - 1); i <= min(4, x + 1); i++) { board[i][y] = 1 - board[i][y]; } for(let i = max(0, y - 1); i <= min(4, y + 1); i++) { board[x][i] = 1 - board[x][i]; } board[x][y] = 1 - board[x][y]; }使用できる組み込み関数
上のプログラムで、Processingで見慣れた関数がいくつか登場しましたね。Processingで使用できる関数のいくつかは、この自作言語でも使用できるように実装されています。現在使用できる組み込み関数は、Processingにあるのもないのも含めて以下の全てです。
size()background()fill()stroke()strokeWeight()textSize()textAlign()text()circle()rect()ellipse()println()print()typeof()(変数の型を調べる)millis()wait()(wait(ms) => msミリ秒間処理を停止する)random()min()(複数の引数の中で最小の値を返す)max()(複数の引数の中で最大の値を返す)range()(指定された範囲の整数値が順に並んだ配列を返す)内部の実装
では、内部の詳しい実装の話に移りましょう。ここから先は、Processingに関する知識が不十分な方やプログラミングの経験があまり多くない方には少し難しいかもしれません。
エディタの実装
文字の入力
keyPressed,keyPressed()関数、keyTyped()関数などを駆使して実装しています。
まず、draw()関数内にある以下のコードを見てみましょう。if(keyPressed) { if(prevKey.equals(String.valueOf(key))) { if(keyt < dur) keyt++; else { keyt = dur / 2; if(key != CODED) keyTyped(); } } else { keyt = 0; if(key != CODED) keyTyped(); } } else { keyt = 0; prevKey = ""; }
prevKeyは前回入力されたキーを保持しておく変数です。keytはキーが入力されてから何フレームが経過したかを表します。durはkeytの閾値として設定された値です。
前回と同じキーが入力されている間、keytが閾値durを超えたらkeytにdur / 2を代入し、keyがShiftやControlなどの符号化されたキーではないとき、keyTyped()関数を呼び出しています。前回とは異なるキーが入力されていたら、keytのチェックはせずkeytに0を代入します。
また、keyPressed()関数は以下のような実装になっています。void keyPressed() { if(key == CODED) { if(keyCode == LEFT) { cursor.prev(); beforeCursor.prev(); } else if(keyCode == RIGHT) { cursor.next(); beforeCursor.next(); } else if(keyCode == UP) { cursor.up(); beforeCursor.up(); } else if(keyCode == DOWN) { cursor.down(); beforeCursor.down(); } else { keyFlags.put(keyCode, true); } } }
cursor,beforeCursorはCursor型オブジェクトであり、行と列を表すメソッドline,rowを持っています。cursorは現在のカーソル位置を表しています。beforeCursorは範囲選択を実装するために使っているものなのでまた後ほど説明します。また、keyFlagsはHashMap<Integer, Boolean>型オブジェクトであり、十字キー以外の符号化されたキーを示すkeyCodeが入力されているかどうかを表します。
このkeyPressed()関数では、十字キーが押されたときカーソルを動かし、それ以外の符号化されたキーが入力されたときkeyFlagsを変更する、といった処理を行っています。また、keyFlagsがtrueになっているキーが離された時にkeyFlagsを変更するため、以下のようにkeyReleased()関数を定義しました。void keyReleased() { if(key == CODED) { if(keyFlags.get(keyCode) != null) { keyFlags.put(keyCode, false); } } keyPressed = false; }
keyPressedをfalseにする処理は、本来する必要がない処理のはずなのですが、なぜか書かないとkeyPressedの挙動がおかしくなるので書いておきます。
keyTyped()関数では、それぞれ入力されたキーに対応する挙動を記述しています。ここに書くと長くなるので、見たい方はソースコードのリンクから確認してみるといいかもです。文字列の表示
入力された文字列は、行ごとに
ArrayList<String>型オブジェクトに格納されています。それを順に表示していくだけですね。
行数がエディタの表示範囲を超えているとき、エディタの右側にスクロールバーを表示しています。スクロールバーの位置にしたがって文字列を出力する高さを変化させます。機能の実装
エディタを名乗るには、さすがに文字を入力できるだけだとメモ帳となんら変わりないので、いくつか機能が必要になります。現在実装しているエディタの機能として以下が挙げられます。
- マウスを用いた範囲選択
- 選択されている範囲の文字列をクリップボードへコピー
- クリップボードからのペースト
- 全選択
(に対する)や{に対する}などの簡易な補完- コードブロック内での自動インデント
- 行数の表示 など
範囲の選択を実装するにあたって、
beforeCursorとcursorの一方を範囲の始端、他方を範囲の終端とすることで実現しています。あとはまあkeyTyped()関数のなかにごちゃごちゃ書いているので興味があれば見てみてください。コンソールの実装
コンソールも同じように
ArrayList<String>型オブジェクトに文字列を格納しています。表示もエディタと同じようにしています。言語処理系の実装
今回実装した言語は簡易な動的型付けのインタプリンタ言語です。ただし、僕は動的型付け言語が好きでは無いので、コードの見た目は型推論を行っている静的型付け言語のような見た目になっています。
処理の流れは少し特殊で、本来行われる字句解析と構文解析をして、その抽象構文木に対して解釈・実行を行うのですが、今回実装したものは諸々を省いた雑な実装になっています。
例えば、以下のコードを実行することを考えてみましょう。let a = 10;このとき、
Lexerクラスは以下のような計算結果を生成します。[ Token("let", "let"), Token("id", "a"), Token("expr", "expr"), Token("int", "10"), Token("endExpr", "endExpr"), Token("endLet", "endLet") ]これは、
ArrayList<Token>型のオブジェクトです。Token型のオブジェクトは、kindとvalueの2つのフィールドを持っています。Token(a, b)と書いてあるのは、kindの値がa,valueの値がbのToken型オブジェクトを表していると思ってください。
そして、この配列を命令列として解釈し、実行します。let文の実行は以下のコードにより行われます。. . . else if(res.get(i).kind.equals("let")) { ArrayList<String> vars = new ArrayList<String>(); ArrayList<String> values = new ArrayList<String>(); i++; String type = "", exprType = ""; if(res.get(i).kind.equals("type")) { type = res.get(i).value; i++; } while(!res.get(i).kind.equals("endLet")) { if(res.get(i).kind.equals("id")) { vars.add(res.get(i).value); varNames.add(loc + "$" + res.get(i).value); } else if(res.get(i).kind.equals("expr")) { ArrayList<Token> expr = new ArrayList<Token>(); i++; int exprNum = 0; while(exprNum > 0 || !res.get(i).kind.equals("endExpr")) { if(res.get(i).kind.equals("expr")) exprNum++; if(res.get(i).kind.equals("endExpr")) exprNum--; expr.add(res.get(i)); i++; } exprType = calc(expr, loc); values.add(expr.get(0).value); } i++; } int vs = values.size(); for(int j = 0; j < vars.size(); j++) { if(j < vs) { if(type.isEmpty()) { variables.put(loc + "$" + vars.get(j), new Variable(exprType, vars.get(j), values.get(j))); } else { variables.put(loc + "$" + vars.get(j), new Variable(type, vars.get(j), values.get(j))); } } else { if(type.isEmpty()) { variables.put(loc + "$" + vars.get(j), new Variable(exprType, vars.get(j), values.get(vs - 1))); } else { variables.put(loc + "$" + vars.get(j), new Variable(type, vars.get(j), values.get(vs - 1))); } } } }
resはLexerの計算結果を受け取るArrayList<Token>型の変数です。variablesは変数を保存しておく、HashMap<String, Variable>型の変数です。varNamesはスコープも考慮した変数の名前を保存しているArrayList<String>型の変数です。変数のスコープ管理は、$を用いています。具体的には、グローバル領域にある変数aのスコープを考慮した名前はmain$aであり、グローバル領域にある関数func()内で定義された変数aのスコープを考慮した名前はmain$func$aとなります。
exprからendExprは式を表しているので、exprからendExprのToken列をcalc()関数に渡してあげることで、式を計算することができます。
このようにして、let文を実行することができます。他の文についても同じように
Token列を生成して実行することを行っていますので、それぞれの詳しい実装はstatement()関数の実装を参照してください。おしまい
他にも実装について解説できる部分は多くあるのですが、ネタは鮮度が命ですので、この作品を発表した当日中に記事を投稿したいということでここら辺で解説を終わらせたいと思います。解説を追加して欲しいなどの要望や質問、提案、指摘、罵倒、嘲笑などがありましたら、この記事にコメントするなり僕のTwitterアカウントに直接リプライやDMを送るなりしてください。
雑な実装、雑な解説、雑の終わらせ方と全てにおいて雑であったことを深くお詫びします。ごめんね。
より詳しく丁寧な言語処理系の実装についての解説が聞きたい人はこちらの記事をご覧ください。
- 投稿日:2020-09-17T18:25:16+09:00
Chain Of Responsibilityパターン
Chain of Responsibilityパターンとは
複数のオブジェクトを鎖のように繋いでおき、
そのオブジェクトの鎖を順次渡り歩いて目的のオブジェクトを決定する方法。
要求に対し、処理できるものなら処理し、処理できない場合は
次にたらい回しする。その次もまたたらい回していく…といったパターン。Handler(処理者)の役
要求を処理するインターフェースを定める役。
次の人を保持しておき、自分が処理できない要求がきたら、その人にたらい回しする。
次の人もHandler役。package chainOfResponsibility; public abstract class Support { private String name; private Support next; public Support(String name) { this.name = name; } public Support setNext(Support next) { this.next = next; return next; } public final void support(Trouble trouble) { if (resolve(trouble)) { done(trouble); } else if (next != null) { next.support(trouble); } else { fail(trouble); } } @Override public String toString() { return "[" + name + "]"; } protected abstract boolean resolve(Trouble trouble); protected void done(Trouble trouble) { System.out.println(trouble + "is resolved by " + this + "."); } protected void fail(Trouble trouble) { System.out.println(trouble + " cannot be resolved."); } }ConcreteHandler(具体的処理者)の役
要求を処理する具体的な役。
package chainOfResponsibility; public class NoSupport extends Support{ public NoSupport(String name) { super(name); } @Override protected boolean resolve(Trouble trouble) { return false; } }package chainOfResponsibility; public class LimitSupport extends Support{ private int limit; public LimitSupport(String name, int limit) { super(name); this.limit = limit; } @Override protected boolean resolve(Trouble trouble) { return trouble.getNumber() < limit; } }package chainOfResponsibility; public class SpecialSupport extends Support{ private int number; public SpecialSupport(String name, int number) { super(name); this.number = number; } @Override protected boolean resolve(Trouble trouble) { return trouble.getNumber() == number; } }package chainOfResponsibility; public class OddSupport extends Support{ public OddSupport(String name) { super(name); } @Override protected boolean resolve(Trouble trouble) { return trouble.getNumber() % 2 == 0; } }Client(要求者)の役
最初のConcreteHandler役に要求をだす役。
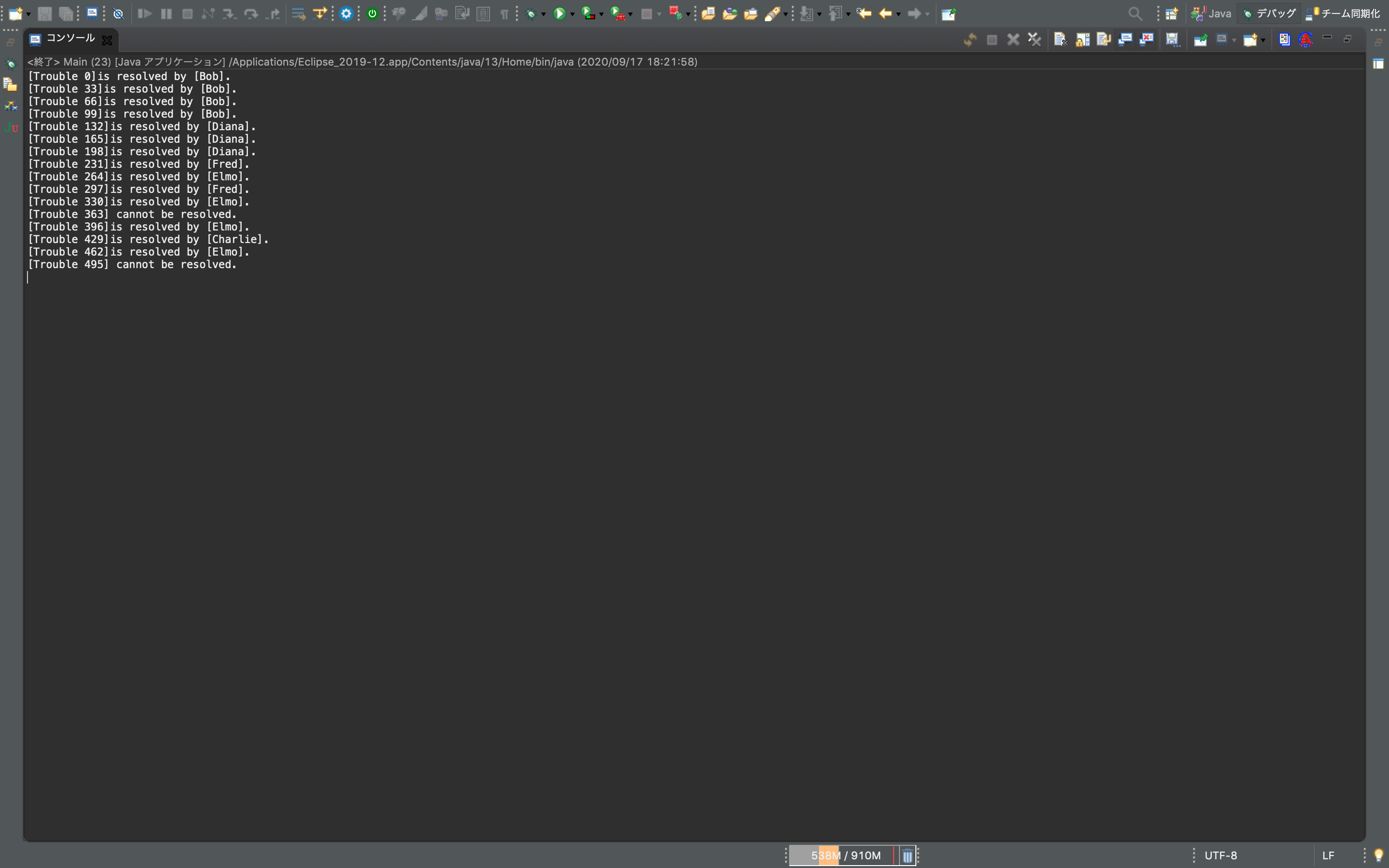
package chainOfResponsibility; public class Main { public static void main(String[] args) { Support alice = new NoSupport("Alice"); Support bob = new LimitSupport("Bob", 100); Support charlie = new SpecialSupport("Charlie", 429); Support diana = new LimitSupport("Diana", 200); Support elmo = new OddSupport("Elmo"); Support fred = new LimitSupport("Fred", 300); // 連鎖の形成 alice.setNext(bob).setNext(charlie).setNext(diana).setNext(elmo).setNext(fred); // 様々なトラブル発生 for (int i = 0; i < 500; i += 33) { alice.support(new Trouble(i)); } } }トラブルを表すクラス
package chainOfResponsibility; public class Trouble { private int number; public Trouble(int number) { this.number = number; } public int getNumber() { return number; } @Override public String toString() { return "[Trouble " + number + "]"; } }実行結果
https://github.com/aki0207/chainOfResponsibility
こちらを参考にさせていただきました。
増補改訂版Java言語で学ぶデザインパターン入門
- 投稿日:2020-09-17T16:44:16+09:00
Java Stringクラスについて
勘違いしていたので整理するために投稿しています。
String name = "田中君";
String name = new String("田中君");
これら2つは同じ意味であり、文字列は多く使う事があるため特別に
String name = "田中君";での入力が可能である。つまり文字列オブジェクトとなり変数nameに田中君が代入されている訳ではなくnameには参照データが格納されている。
- 投稿日:2020-09-17T16:06:25+09:00
Javaのプリミティブ型、参照型、Immutable、Mutable
Javaのプリミティブ型、参照型、Immutable、Mutableをまとめて理解する
Java Silverの勉強をしていますが、この辺りがバラバラに出てきて混乱したので、自分自身の理解をまとめてみました。
プリミティブ型
Type Value Bit boolean 真偽値 1 byte 整数 8 short 整数 16 char 文字 16 int 整数 32 float 浮動小数点 32 long 整数 64 double 浮動小数点 64 参照型
こちらは主にクラスやString、StringBuilderが含まれます。
Let's try
では実際に確認してみましょう。
Main.javaclass Codechef { public static void main (String[] args) throws java.lang.Exception { StringBuilder sb = new StringBuilder("apple"); sample(sb); System.out.println(sb); // "apple orange" StringBuilder ssb = new StringBuilder("apple"); sample5(ssb); System.out.println(ssb); // "apple" String s = "apple"; String t = sample2(s); System.out.println(s); // "apple" System.out.println(t); // "apple orange" int i = 1; sample3(i); System.out.println(i); //1 } public static StringBuilder sample(StringBuilder sb) { return sb.append(" orange"); } public static String sample2(String s) { return s+" orange"; } public static int sample3(int i) { return i+10; } public static StringBuilder sample5(StringBuilder sb) { return new StringBuilder(sb+" orange"); } }Immutable vs Mutable
ここで確認しておきたいのは、同じ参照型でもImmutableなStringとMutableなStringBuilderの違いです。
以下のコードでは、"apple orange"がsbに対して入っており、つまりは引数に渡されたStringBuilderはその値である"apple"ではなく、sbのアドレスが参照として渡されているため、参照先であるsbの値そのものが変わっています。
StringBuilder sb = new StringBuilder("apple"); sample(sb); System.out.println(sb); // "apple orange" public static String sample2(String s) { return s+" orange"; }対してStringの方はこちらも参照型ですが、引数に渡されたStringの値そのものは変わっていません。なぜか。これはStringBuilderがMutableでStringがImmutableだからです。Stringの方は一度初期化時に割り当てた値はその後変更できない為、
+などでStringの元の値を変更しようとした場合は内部では新しいインスタンスが返されており、最初に割り当てた参照先の値は変わりません。変更後の値を使用したい場合は、以下のように新たにString変数を作成して、そちらに割り当てるしかありません。String s = "apple"; String t = sample2(s); System.out.println(s); // "apple" System.out.println(t); // "apple orange" public static String sample2(String s) { return s+" orange"; }intの方は先に書いたとおりプリミティブ型なのでいわずもがなですね。引数に渡されているのは参照先のアドレスではなく、実値なので引数に渡された値に対して値が返ってきているだけですので、元の値が変わることはありません。
- 投稿日:2020-09-17T15:35:46+09:00
Dubboベースのマイクロサービスが保険会社のアーキテクチャをどのように変えるか
チャイナライフのXiaobin氏は、Dubboがどのようにアーキテクチャを変更したのか、Alibaba Cloudへの移行を検討しているのかについて共有しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Dubboについて
2013年、中国生命保険では、ビジネスデータベース全体を変革するためのRPCフレームワークを探していました。当時、市場には成熟した製品はほとんどなく、Spring CloudやDubboなど数多くの製品が出回っていました。私たちが探していたのは、実運用環境で大規模に適用されているフレームワークでした。Dubboはタオバオでも以前から導入されており、アリババのビジネスモデルは当社のビジネスモデルに匹敵するものでした。例えば、当社のビジネスモデルでは、海外の複数の地域からの依頼に対応する必要があり、それぞれに業務要件があります。
そういったことを考慮して、2013年にもDubboの利用を開始しました。2016年には香港とマカオ、2019年5月にはインドネシアでも業務システムを開始しました。今後は、Dubboを利用していることもあり、シンガポールをはじめとする東南アジア全域にも業務システムを急速に展開していく予定です。
展開の効率化とコスト削減という点で、Dubboのおかげでかなり助けられています。この記事では、多くの伝統的な保険会社に共通するDubbo以前のアーキテクチャについて説明した上で、Dubboをどのように利用したか、そしてアーキテクチャがどのように変化したかについてお話したいと思います。
保険会社が過去にしてきたこと
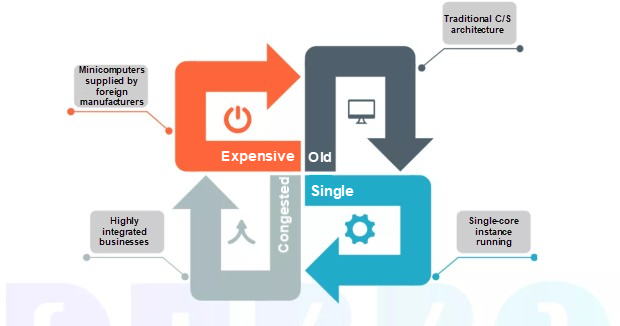
サーバーのハードウェアに関しては、他の多くの伝統的な保険業務システムが使用しているように、私たちが使用していたのは、通常IBMやHPのミニコンピュータでした。当時利用可能だったのはこの2つのシステムだけで、どちらもUNIXベースのOSが動作していました。
ビジネスアーキテクチャについては、これまでのソフトウェア開発では、主にクライアント/サーバアーキテクチャが用いられていました。このようなアーキテクチャの下では、Tuxedoという強力なミドルウェアが分散トランザクション管理に利用されており、優れた一貫性と高カレンシー性能を提供していました。では、そもそもなぜTuxedoをリプレースする必要があるのでしょうか?第一の理由は価格が高いこと、第二の理由は関連するO&M要員が不足していること、第三の理由は業務の統合性が高くなり、分散型やクロスプラットフォームのシナリオではパフォーマンスやスケジューリングが悪くなることです。第四の理由は、Tuxedo がモノリシックなアプリケーション向けに設計されていることです。その結果、あえて分割することはありません。
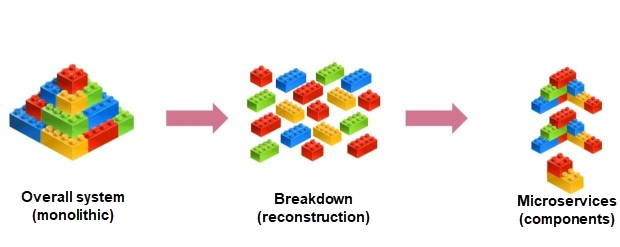
基幹業務システムをどのように変革するか
この図は、モノリシックアプリケーションと比較した場合のマイクロサービスの利点を示しています。Dubboは、異なるコンポーネント間の相互作用のための役割を果たし、これはレゴのおもちゃの凸部と凹部に似ています。これは、通信管理とサービスガバナンスを実装しています。この設計に支えられて、大型の伝統的なコアアーキテクチャを打破します。
OneLifeは、当社のビジネス支援プラットフォームです。その名の通り、1つのプラットフォームですべての保険業務を処理し、社内エコシステムを形成し、画像、新サービス、保存、クレーム決済など、いくつかの異なる領域をサポートすることができます。また、ワークフロー、商品エンジン、引受エンジン、メッセージエンジンなどのエンジンも提供しています。これらの業務機能は、どの保険会社にとっても必要不可欠なものです。
Dubboで開発された保険業務処理プラットフォーム
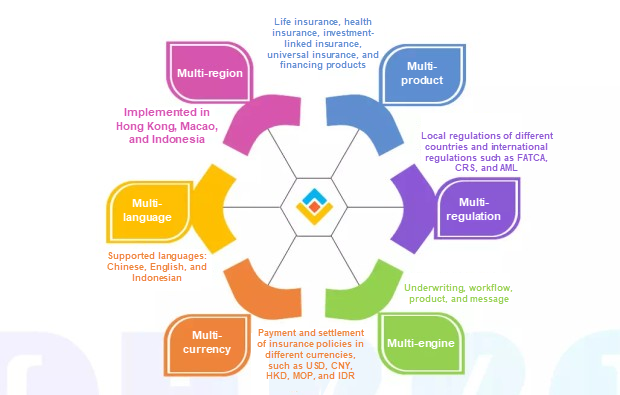
Dubboの支援を受け、「シックスマルチ」の保険業務処理を実現するための新しい保険業務処理プラットフォームを構築しました。シックスマルチとは、複数の業務システム、商品ラインアップ、従うべき規制、エンジン、通貨言語を持つという考え方を表しています。例えば、保険証券を生成するには、英語で生成するのか、中国語で生成するのか、インドネシア語で生成するのかを判断する必要があります。もちろんそのためには、各事業部との連携も必要ですし、適切な処理プラットフォームの設計・開発も必要になります。
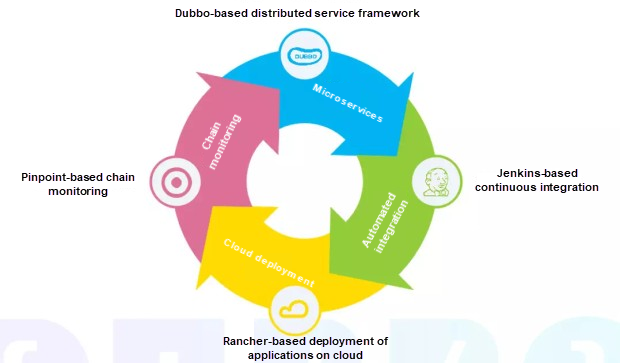
OneLife分散システムの形成
図に示すように、以下の4つの部分でクローズドループを形成することができます。Dubboベースのマイクロサービスコール、Jenkinsベースの継続的インテグレーション、Rancherベースのクラウド展開アプリケーション、Pinpointベースのチェーン監視です。インドネシア版のクラウド展開については、アリババクラウドと協議を重ねてきました。将来的には、インドネシアのシステムが真っ先にAlibaba Cloudに移行する可能性があります。ピンポイントチェーンの監視という点では、表示されているトポロジーが非常にわかりやすいのですが、このトポロジーをベースにすると、フォーメーションが途切れたり、通話が失敗したりと、いくつかの問題点が見えてきます。今年は、Pinpoint chain monitoringの助けを借りて、100以上のバグを確認することができました。Pinpointチェーン監視とDubboの組み合わせは秀逸です。
香港とマカオでのDubboの分散方法
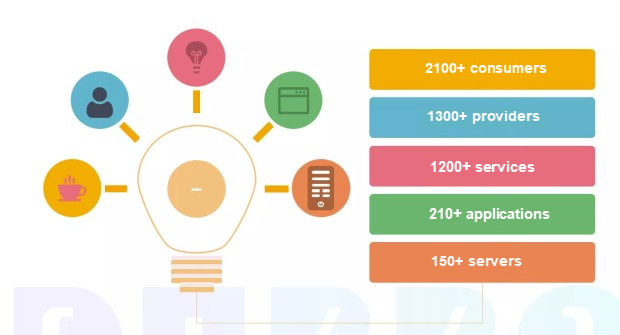
Dubboは150以上のサーバー、210以上のアプリケーション、2,100以上の消費者、1,300以上のプロバイダーが香港とマカオに分散しています。保険会社、特に自社の業務システムでは、高頻度の取引はあまりありません。高頻度取引のほとんどはフロントエンドで発生します。業務システムが常に高頻度な状態にあるわけではありませんが、それでもすべての業務システムが安定して正確に出力されることが重要です。これがDubboを選んだ理由の一つです。
Dubboの仕組み 中国生命保険(海外)有限公司
弊社の業務の約7割は初期のDubboバージョン(具体的には2.4.9)を使用しています。以前、分散トランザクションの補償など、Dubboをベースにいくつかのコード修正を行っていました。その後、大幅なコード修正を行ったため、バージョンアップができないことがわかりました。では、残りの3割の業務に使われているフレームワークは何なのか、と思われるかもしれません。あえて最新版を周辺機器で試しているだけなのですが。また、このバージョンは、実用化して実現可能であることが証明されてから、基幹業務アーキテクチャに適用しています。現在、中国生命保険(海外)有限公司のDubboは1日に2100万回以上の呼び出しを受けており、Dubboを導入してからシステムクラッシュが発生したことはありません。
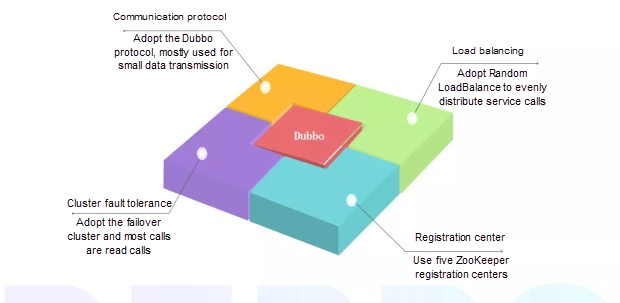
Dubboの構成構造
ここでは構成を共有します。2つの問題点が強調されています。第1の問題点は、リトライ機構である。これの問題点は、サービスが中断した場合、制御プラットフォームを利用して手動で介入したり、サービスが重要なものであればトランザクションを繰り返すことで代替的に補償したりすることです。第二の課題は、ZooKeeper登録センターを利用すると、ピーク時のネットワーク消費量が膨大になるため、デメリットがあることです。Dubboバージョン2.7のメタデータコンセプトは有望です。今後、Dubboのバージョン2.7以降を利用して、ZooKeeperの欠点を克服できるか、あるいはZooKeeperを最適化できるかを試してみたいと思います。
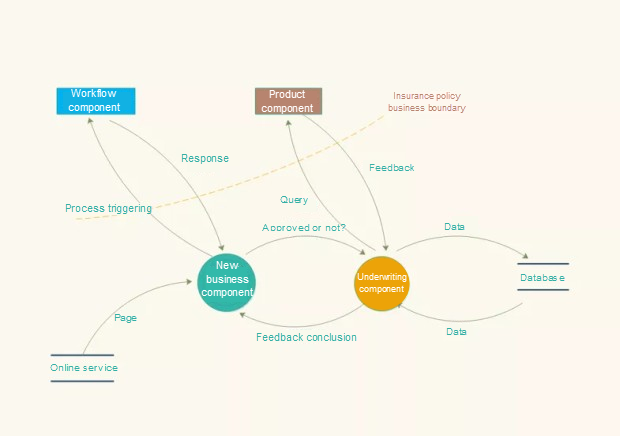
Dubboマイクロサービスの応用シナリオ
上図は、Dubboマイクロサービスのアプリケーションを示しています。アプリケーションは、オンライン・サービス・ページから始まり、新しいサービス・コンポーネントに移動します。その後、ワークフローが起動し、引受結果が照会されます。引受結果に基づいて、保険料計算結果が自動的に照会され、フロントエンドに戻される。インドネシアで基幹業務システムと営業システムを導入する場合、低コストは必須条件です。また、事業単位を分離する必要があります。これには、Base開発モデルが関わってきます。Base開発モデルとはなんでしょうか?
ビジネスが複数の地域に分散している場合、地域ごとに固有のバージョンを持つ必要があります。公開されている基本バージョンが同じであれば、業務の効率化を図ることができます。例えば、本社には基本的なサービスがありますが、インドネシアには独自の規制があります。将来的に香港にもこのような需要があれば、基本版がある一定の審査を通過したら、基本版をロールバックして、地域ごとに異なる基本版をリリースします。つまり、複雑な状況では、基本版は異なるビジネスロジックの階層的な分離、階層的なコード管理、階層的・地域的なサービスガバナンスをサポートしています。
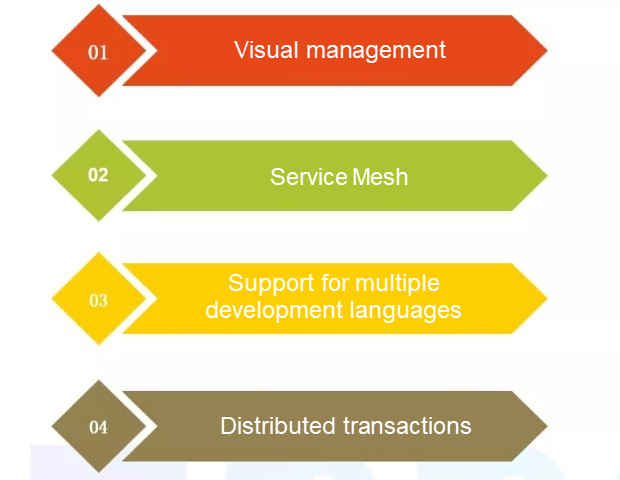
提案
第一に、視覚的な管理を強化します。
第二に、サービスグリッドを導入してパッケージ化し、ネットワーク呼び出し、トラフィック制限、回線遮断、サービス間の監視など、マイクロサービスシステムでより多くの機能を提供します。
第三に、複数の言語をサポートすることです。Dubboは現在、PHP、Node.js、Python、Goクライアントを提供していますが、将来的にはさらに多くのクライアントをサポートする予定です。
4つ目は、Dubboが分散トランザクション管理をサポートすることを推奨しないことです。最初にDubboを使用したとき、分散トランザクションをサポートする必要があると判断しました。そのため、Dubboをベースにコードを変更しました。アプリケーションの処理はスムーズで、コードはプラットフォームをまたいでもトランザクションの一貫性を確保することができました。しかし、サービスに障害が発生すると、送信するトランザクションがすべて崩れてしまい、データベースに致命的なリスクをもたらしました。
そこで、Dubboにメッセージ機構のサポートを増やしてもらい、分散トランザクションを補償しながらビジネス開発をしていくことが望ましいと考えています。以上が実用化を通じて思いついたいくつかのアイデアと提案です。
よくある質問
Q1: モノリシックアプリケーションをマイクロサービスコンポーネントに置き換えるプロセスは、ステップバイステップなのか、それとも一括して行うのか?また、置き換えプロセスを完了させるためには、どのくらいの人手とリソースが必要ですか?
A1: まず、既存の構造はモジュール化されており、モジュール同士は独立しています。最も重要なデータ構造については、ビジネスロジックを分離する必要があります。その後、データベースのシャードやパーミッションを設定し、モジュールを段階的に置き換えていきます。開発前には、全体の置き換えプロセスをしっかりと計画しておく必要があります。最初のモジュールを立ち上げたときは5人しかいませんでしたが、全員が技術力があり、それぞれの業務分野に精通していました。経営陣の支持を得ることが最優先でした。
Q2:システム内で分散トランザクション制御が利用できない場合、データの不整合をどのようにして検出することができるのでしょうか?また、この問題はどのように解決できるのでしょうか?
A2: ピンポイントベースのチェーン監視により、O&M担当者は問題を迅速に検出し、障害を修正した後、手動介入を行うことができます。キーサービスにはMQの仕組みを利用しています。しかし、このメカニズムは多くの時間とマンパワーを消費します。大規模な分散トランザクション制御は避けた方が良いと考えています。
Q3:社内のデータ量が多い場合、旧システムから新システムへデータを移行する際に、Oracleデータベースをどのようにリプレースすればよいでしょうか?この質問にお答えいただけますか?
A3:データベースレベルでは、Oracleデータベースのテーブル構造やデータが他のデータベースと一致していることを確認する必要があります。比較にはETLなどのツールを利用することができます。アプリケーションレベルでは、2つのステップを踏むことができます。最初のステップは、処理を自動化することです。セルフコンパイルツールを使用して、両方のデータベース上でアプリケーションのSQL文を実行し、タイムリーにエラーを修正することができます。3回目の実行では、ほぼすべてのSQL文が正常に実行できるようになります。次のステップでは、キーとなるアルゴリズムやインターフェースをスポットチェックし、新しいインターフェースが出力するデータと業務データを比較します。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ


- 投稿日:2020-09-17T15:20:34+09:00
JavaはExcelの数式を追加して読み取ります
Excelテーブルではデータを計算や処理する場合、仕事の効率を上げるために、様々なExcel関数式を使うことがよくあります。この記事では、Free Spire.XLS for Javaを使用してExcelセルに数式を追加する方法と、セル内の数式を読み取る方法を紹介します。
JARパッケージのインポート
方法1: Free Spire.XLS for Javaをダウンロードして解凍したら、libフォルダーのSpire.Xls.jarパッケージを依存関係としてJavaアプリケーションにインポートします。方法2: Mavenリポジトリから直接にJARパッケージをインストールしたら、pom.xmlファイルを次のように構成します。
<repositories> <repository> <id>com.e-iceblue</id> <name>e-iceblue</name> <url>http://repo.e-iceblue.com/nexus/content/groups/public/</url> </repository> </repositories> <dependencies> <dependency> <groupId>e-iceblue</groupId> <artifactId>spire.xls.free</artifactId> <version>2.2.0</version> </dependency> </dependencies>数式を追加する
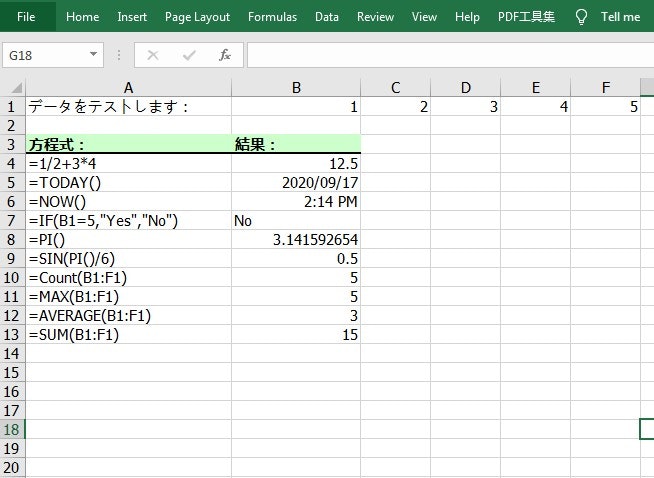
import com.spire.xls.*; public class InsertFormulas { public static void main(String[] args) { //Workbookオブジェクトを作成します Workbook workbook = new Workbook(); //最初目のワークシートを取得します Worksheet sheet = workbook.getWorksheets().get(0); //2つの変数を宣言します int currentRow = 1; String currentFormula = null; //列の幅を設定します sheet.setColumnWidth(1, 26); sheet.setColumnWidth(2, 16); //テスト用のデータをセルに書き込みます sheet.getCellRange(currentRow,1).setValue("データをテストします:"); sheet.getCellRange(currentRow,2).setNumberValue(1); sheet.getCellRange(currentRow,3).setNumberValue(2); sheet.getCellRange(currentRow,4).setNumberValue(3); sheet.getCellRange(currentRow,5).setNumberValue(4); sheet.getCellRange(currentRow,6).setNumberValue(5); //テキストへ書き込みます currentRow += 2; sheet.getCellRange(currentRow,1).setValue("方程式:") ; ; sheet.getCellRange(currentRow,2).setValue("結果:"); //セルのフォーマットを設定します CellRange range = sheet.getCellRange(currentRow,1,currentRow,2); range.getStyle().getFont().isBold(true); range.getStyle().setKnownColor(ExcelColors.LightGreen1); range.getStyle().setFillPattern(ExcelPatternType.Solid); range.getStyle().getBorders().getByBordersLineType(BordersLineType.EdgeBottom).setLineStyle(LineStyleType.Medium); //算術演算 currentFormula = "=1/2+3*4"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); //日付関数 currentFormula = "=TODAY()"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); sheet.getCellRange(currentRow,2).getStyle().setNumberFormat("YYYY/MM/DD"); //時間関数 currentFormula = "=NOW()"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); sheet.getCellRange(currentRow,2).getStyle().setNumberFormat("H:MM AM/PM"); //IF関数 currentFormula = "=IF(B1=5,\"Yes\",\"No\")"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); //PI関数 currentFormula = "=PI()"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); //三角関数 currentFormula = "=SIN(PI()/6)"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); //COUNT関数 currentFormula = "=Count(B1:F1)"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); //MAX関数 currentFormula = "=MAX(B1:F1)"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); //AVERAGE関数 currentFormula = "=AVERAGE(B1:F1)"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); //SUM関数 currentFormula = "=SUM(B1:F1)"; sheet.getCellRange(++currentRow,1).setText(currentFormula); sheet.getCellRange(currentRow,2).setFormula(currentFormula); //ドキュメントを保存します workbook.saveToFile("InsertFormulas.xlsx",FileFormat.Version2013); } }
数式を読み取る
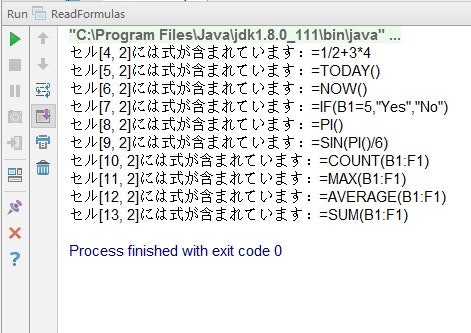
import com.spire.xls.*; public class ReadFormulas { public static void main(String[] args) { //Workbookオブジェクトを作成します Workbook workbook = new Workbook(); //Excelドキュメントをロードします workbook.loadFromFile("InsertFormulas.xlsx"); //最初目のワークシートを取得します Worksheet sheet = workbook.getWorksheets().get(0); //B1からB13までのセルをトラバースします for (Object cell : sheet.getCellRange("B1:B13") ) { CellRange cellRange = (CellRange) cell; //セルに数式が含まれるかどうかを判定します if (cellRange.hasFormula()) { //セルと数式を印刷します String certainCell = String.format("セル[%d, %d]には式が含まれています:", cellRange.getRow(), cellRange.getColumn()); System.out.println(certainCell + cellRange.getFormula()); } } } }
- 投稿日:2020-09-17T14:40:11+09:00
MaxComputeで異なる日付のアクティブユーザIDのビットマップをエンコードして計算する方法
この記事では、MaxComputeのMapReduceモジュールを使って、異なる日付のアクティブユーザーIDのビットマップをエンコードして計算する方法を示すコード例を紹介しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Qu Ning氏より
Bitmap(ビットマップ)は、データ開発者がユーザーデータをエンコードして圧縮するために一般的に使用する技術です。ビットマップのAND、OR、NOT演算の高速な処理速度により、開発者はプロファイルタグなどのユーザー情報でユーザーをフィルタリングしたり、週間アクティビティを分析したりすることができます。
以下のコード例で考えてみてください。
import com.aliyun.odps.OdpsException; import com.aliyun.odps.data.Record; import com.aliyun.odps.data.TableInfo; import com.aliyun.odps.mapred.JobClient; import com.aliyun.odps.mapred.MapperBase; import com.aliyun.odps.mapred.ReducerBase; import com.aliyun.odps.mapred.conf.JobConf; import com.aliyun.odps.mapred.utils.InputUtils; import com.aliyun.odps.mapred.utils.OutputUtils; import com.aliyun.odps.mapred.utils.SchemaUtils; import org.roaringbitmap.RoaringBitmap; import org.roaringbitmap.buffer.ImmutableRoaringBitmap; import java.io.DataOutputStream; import java.io.IOException; import java.io.OutputStream; import java.nio.ByteBuffer; import java.util.Base64; import java.util.Iterator; public class bitmapDemo2 { public static class BitMapper extends MapperBase { Record key; Record value; @Override public void setup(TaskContext context) throws IOException { key = context.createMapOutputKeyRecord(); value = context.createMapOutputValueRecord(); } @Override public void map(long recordNum, Record record, TaskContext context) throws IOException { RoaringBitmap mrb=new RoaringBitmap(); long AID=0; { { { { AID=record.getBigint("id"); mrb.add((int) AID); //获取key key.set(new Object[] {record.getString("active_date")}); } } } } ByteBuffer outbb = ByteBuffer.allocate(mrb.serializedSizeInBytes()); mrb.serialize(new DataOutputStream(new OutputStream(){ ByteBuffer mBB; OutputStream init(ByteBuffer mbb) {mBB=mbb; return this;} public void close() {} public void flush() {} public void write(int b) { mBB.put((byte) b);} public void write(byte[] b) {mBB.put(b);} public void write(byte[] b, int off, int l) {mBB.put(b,off,l);} }.init(outbb))); String serializedstring = Base64.getEncoder().encodeToString(outbb.array()); value.set(new Object[] {serializedstring}); context.write(key, value); } } public static class BitReducer extends ReducerBase { private Record result = null; public void setup(TaskContext context) throws IOException { result = context.createOutputRecord(); } public void reduce(Record key, Iterator<Record> values, TaskContext context) throws IOException { long fcount = 0; RoaringBitmap rbm=new RoaringBitmap(); while (values.hasNext()) { Record val = values.next(); ByteBuffer newbb = ByteBuffer.wrap(Base64.getDecoder().decode((String)val.get(0))); ImmutableRoaringBitmap irb = new ImmutableRoaringBitmap(newbb); RoaringBitmap p= new RoaringBitmap(irb); rbm.or(p); } ByteBuffer outbb = ByteBuffer.allocate(rbm.serializedSizeInBytes()); rbm.serialize(new DataOutputStream(new OutputStream(){ ByteBuffer mBB; OutputStream init(ByteBuffer mbb) {mBB=mbb; return this;} public void close() {} public void flush() {} public void write(int b) { mBB.put((byte) b);} public void write(byte[] b) {mBB.put(b);} public void write(byte[] b, int off, int l) {mBB.put(b,off,l);} }.init(outbb))); String serializedstring = Base64.getEncoder().encodeToString(outbb.array()); result.set(0, key.get(0)); result.set(1, serializedstring); context.write(result); } } public static void main( String[] args ) throws OdpsException { System.out.println("begin........."); JobConf job = new JobConf(); job.setMapperClass(BitMapper.class); job.setReducerClass(BitReducer.class); job.setMapOutputKeySchema(SchemaUtils.fromString("active_date:string")); job.setMapOutputValueSchema(SchemaUtils.fromString("id:string")); InputUtils.addTable(TableInfo.builder().tableName("bitmap_source").cols(new String[] {"id","active_date"}).build(), job); // +------------+-------------+ // | id | active_date | // +------------+-------------+ // | 1 | 20190729 | // | 2 | 20190729 | // | 3 | 20190730 | // | 4 | 20190801 | // | 5 | 20190801 | // +------------+-------------+ OutputUtils.addTable(TableInfo.builder().tableName("bitmap_target").build(), job); // +-------------+------------+ // | active_date | bit_map | // +-------------+------------+ // 20190729,OjAAAAEAAAAAAAEAEAAAAAEAAgA=3D // 20190730,OjAAAAEAAAAAAAAAEAAAAAMA // 20190801,OjAAAAEAAAAAAAEAEAAAAAQABQA=3D JobClient.runJob(job); } }では、このコードについて説明しましょう。Javaアプリケーションをパッケージ化してMaxComputeプロジェクトにアップロードした後、開発者はMaxComputeでこのMapReduceジョブ上で与えられたものを呼び出すことができます。入力テーブルのデータについては、日付をキーにしてユーザIDをエンコードし、同じ日付のビットマップでエンコードされたユーザIDに対してOR演算を行います。あるいは、必要に応じて、例えばリテンションの場合などにAND演算を行っても良いです。その後、処理されたデータは、さらなる処理のために、対象の構造テーブルに書き込まれます。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-17T13:40:33+09:00
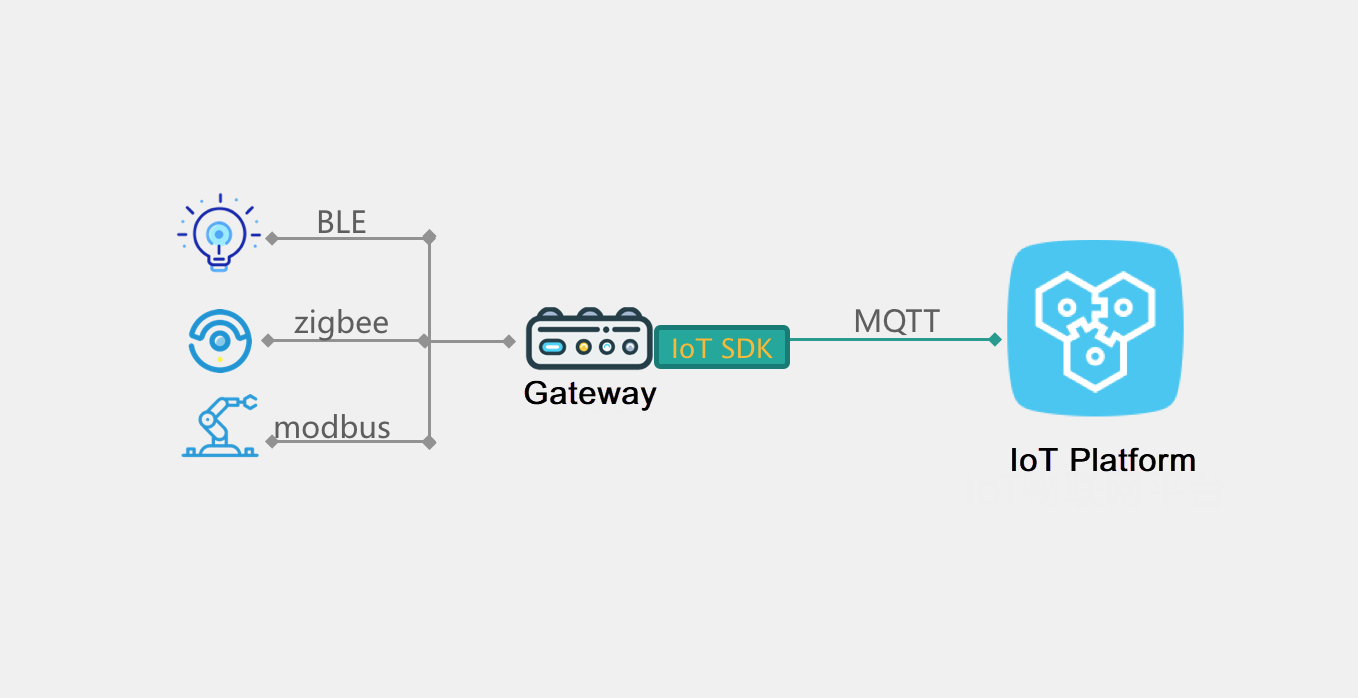
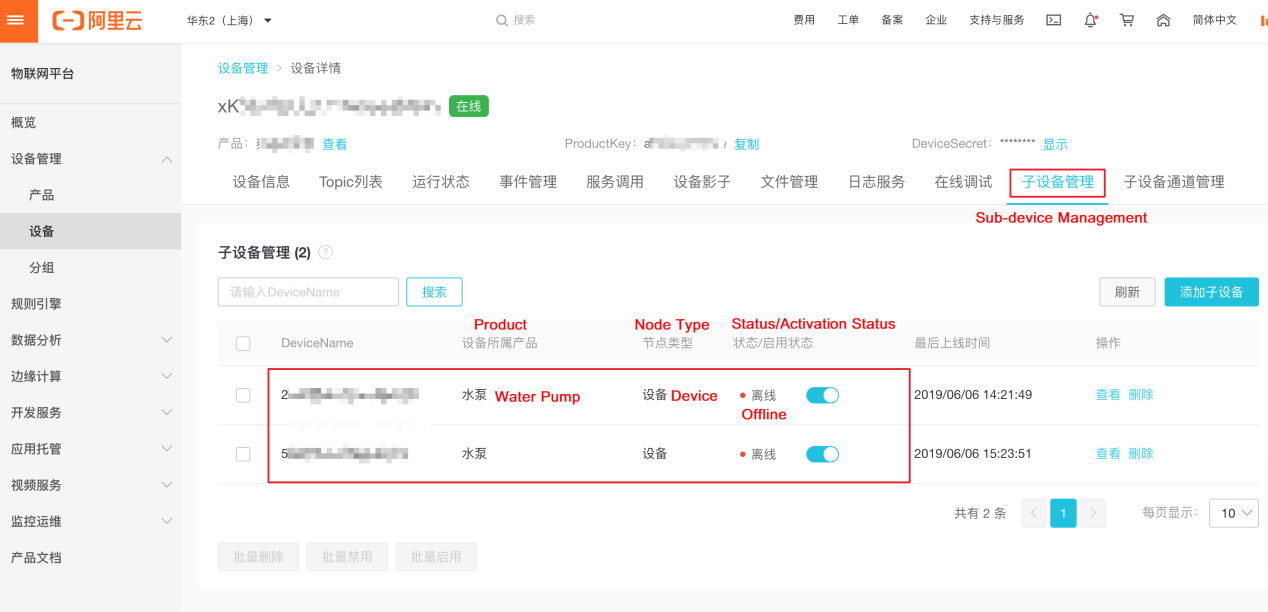
ゲートウェイとサブデバイスのシナリオを使用してIoTデバイスをクラウドに接続
今回は、IoTデバイスをクラウドに接続するためのゲートウェイとサブデバイスのシナリオを見ていきます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
多くのIoTシナリオでは、端末機器自体がインターネットにアクセスすることはありません。では、データをクラウドに移行するにはどうすればいいのだろうか、と疑問に思うかもしれません。
クラウドのIoTプラットフォームは、MQTTと呼ばれる特殊なプロトコルを使用したデバイス上での直接接続をサポートしています。
興味深いことに、この種の接続プロトコルは、ゲートウェイのサブデバイスとして機能するようにデバイスをゲートウェイにマウントすることもサポートしており、ゲートウェイのプロキシがデバイスをIoTプラットフォームに接続することができます。その後、ゲートウェイデバイス自体がIoTゲートウェイデバイスとして機能し、IoTプラットフォームへのMQTT接続を確立してデータを送受信します。さらに、このデバイスはサブデバイスの管理も担当しています。このように、このすべては、したがって、以下の操作も含みます。
- ゲートウェイは、サブデバイスのネットワーク・トポロジ・リレーションシップを追加します。
- サブデバイスはゲートウェイのMQTT接続チャネルを再利用して接続を実装します。
- ゲートウェイはサブデバイスのデータをクラウドに報告します。
- ゲートウェイは指令を受信し、サブデバイスに転送します。
- ゲートウェイはサブデバイスの切断を報告します。
- ゲートウェイは、サブデバイスのネットワークトポロジ関係を削除します。
また、ローカルネットワークに応じて、ゲートウェイとサブデバイス間の通信プロトコルは、HTTP、MQTT、ZigBee、Modbus、BLE、OPC-UAなどがあります。このロジックは、ゲートウェイによって実装されます。しかし、これらの接続機能はIoT SDKでは提供できません。
さて、上で説明したシナリオ、具体的にはゲートウェイとサブデバイスのシナリオを設定する方法を見てみましょう。そのためには、以下の手順に従う必要があります。
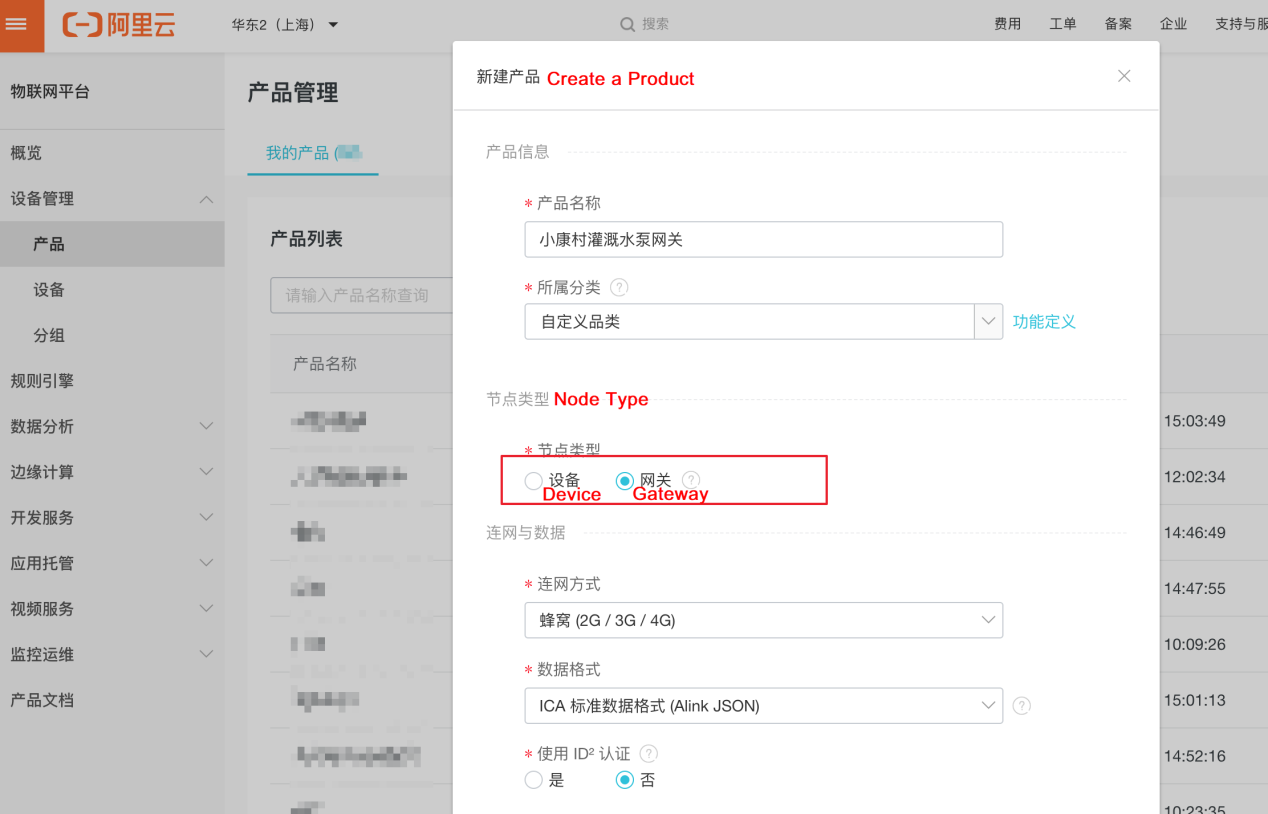
ネットワーク製品の作成
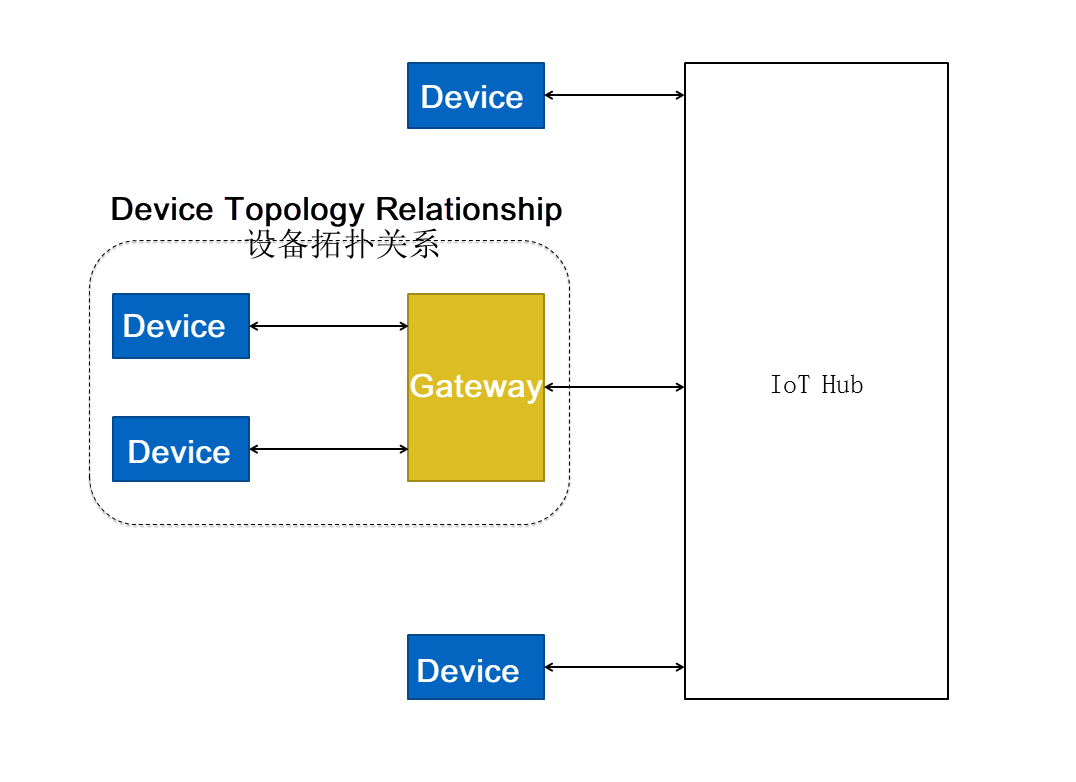
ネットワーク製品を作成するには、ノードタイプを選択する必要があります(このチュートリアルではゲートウェイとします)。ゲートウェイは、サブデバイスを管理し、サブデバイスに存在するトポロジカルな関係を維持し、これらのトポロジカルな関係をクラウドに同期させることができます。
参考までに、ゲートウェイとそのサブデバイス間に存在するトポロジカルな関係を下図に示します。
ゲートウェイを接続
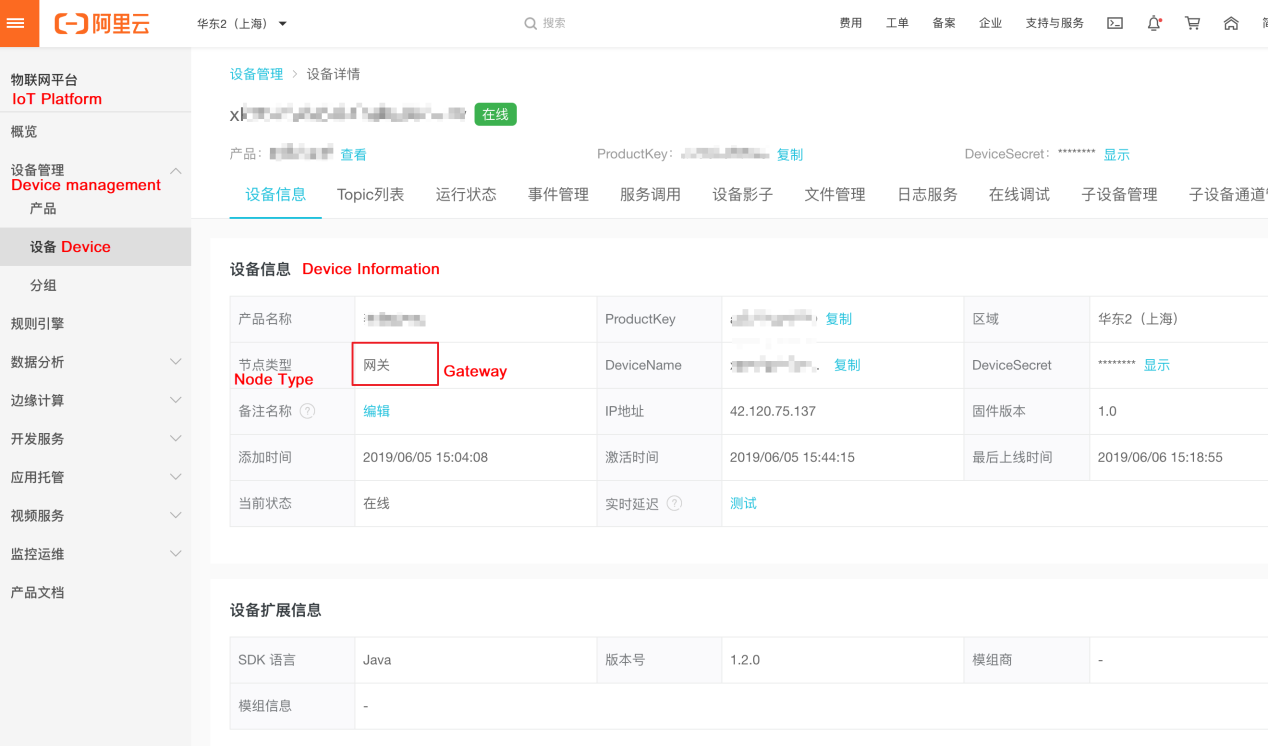
以下のパラメータを設定することで、ゲートウェイ装置を接続することができます。
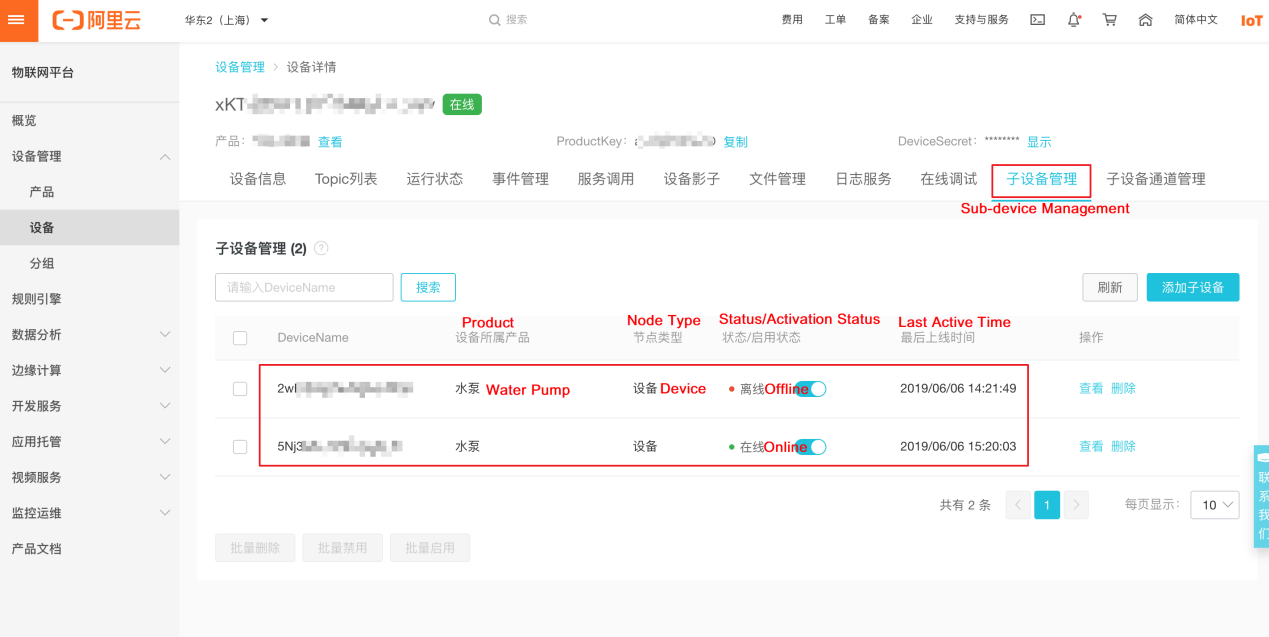
LinkKitInitParams params = new LinkKitInitParams(); DeviceInfo gatewayInfo = new DeviceInfo(); gatewayInfo.productKey = gateway.productKey; gatewayInfo.deviceName = gateway.deviceName; gatewayInfo.deviceSecret = gateway.deviceSecret; params.deviceInfo = gatewayInfo; LinkKit.getInstance().init(params, ILinkKitConnectListener)ゲートウェイデバイスが接続されると、コンソールに "Online "のステータスで表示されます。
ネットワーク トポロジの追加
以下のパラメータを設定して、ネットワークトポロジを追加することができます。
DeviceInfo deviceInfo = new DeviceInfo(); deviceInfo.productKey = productKey; deviceInfo.deviceName = deviceName; deviceInfo.deviceSecret = deviceSecret; LinkKit.getInstance().getGateway().gatewayAddSubDevice( deviceInfo, // the ID of the sub-device SubDeviceConnectListener)代わりにコンソールで行うことができます。
サブデバイスを接続する
以下のパラメータを設定することで、サブデバイスを接続することができます。
DeviceInfo deviceInfo = new DeviceInfo(); deviceInfo.productKey = productKey; deviceInfo.deviceName = deviceName; deviceInfo.deviceSecret = deviceSecret; LinkKit.getInstance().getGateway().gatewaySubDeviceLogin( deviceInfo, // the ID of the sub-device ISubDeviceActionListener)代わりにコンソールで行うことができます。
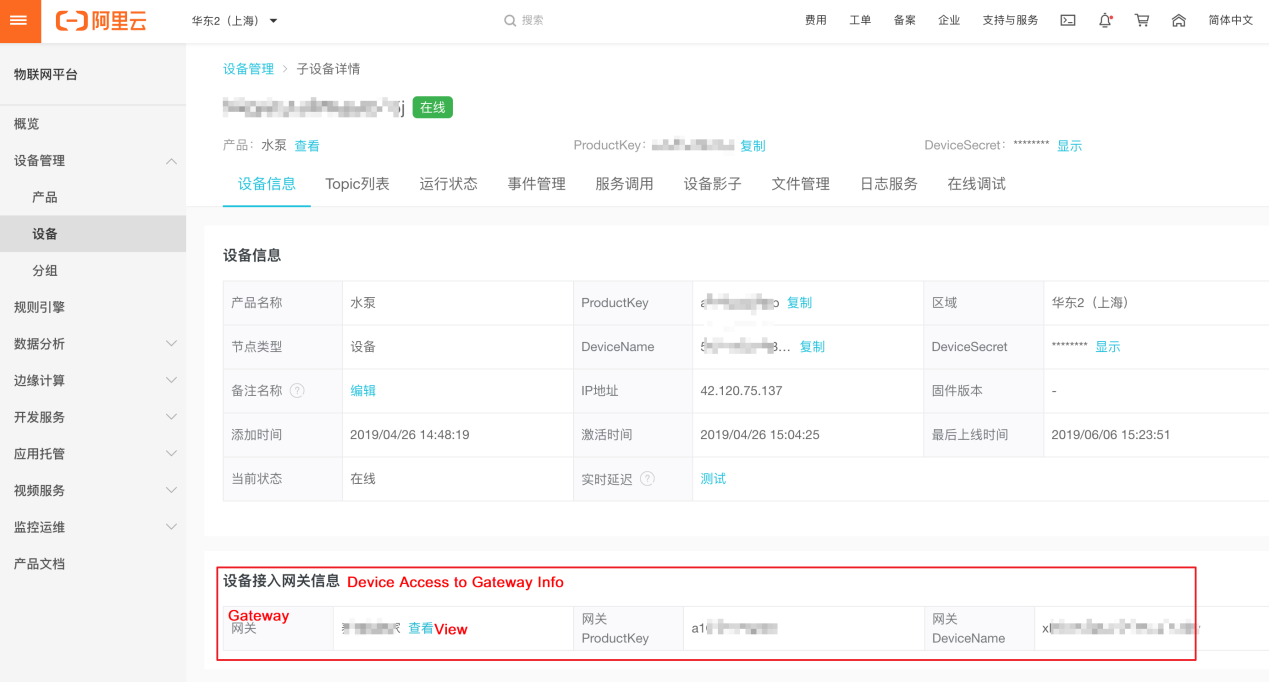
そして、サブデバイスの接続情報をコンソール上で確認することができます。
サブデバイスのデータを報告する
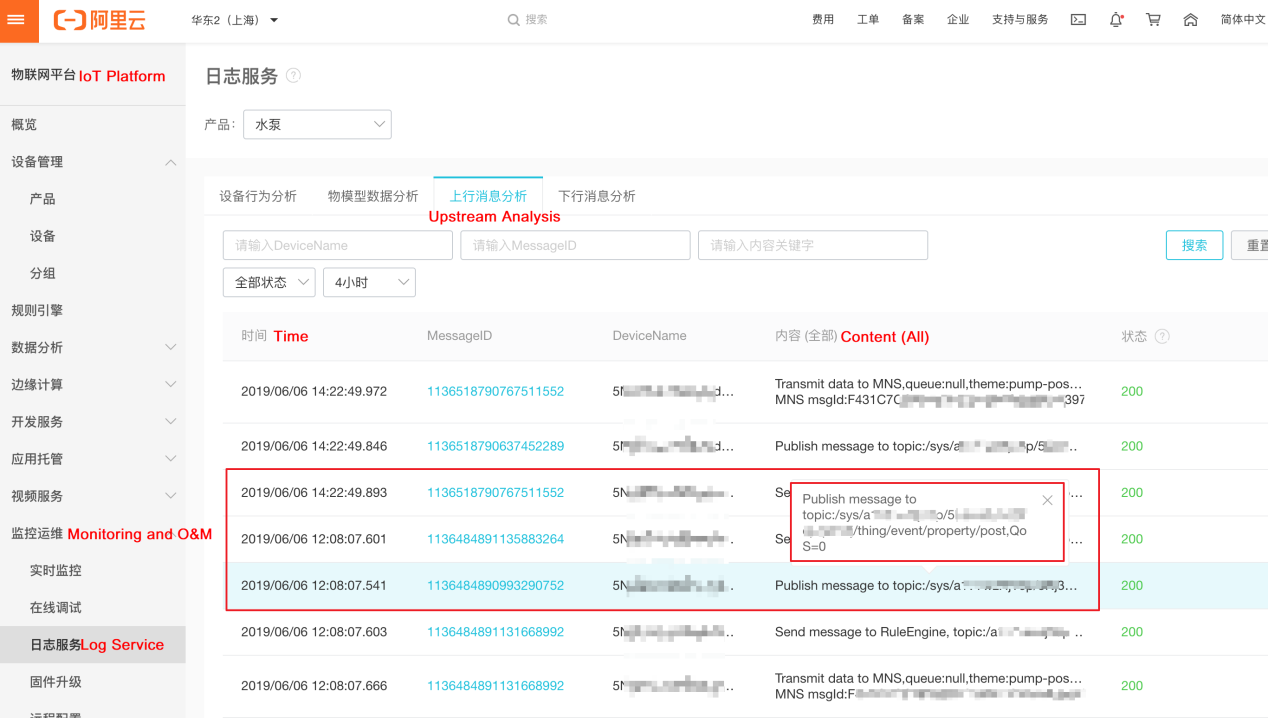
以下のパラメータを設定することで、サブデバイスのデータをレポートすることができます。
DeviceInfo deviceInfo = new DeviceInfo(); deviceInfo.productKey = productKey; deviceInfo.deviceName = deviceName; deviceInfo.deviceSecret = deviceSecret; LinkKit.getInstance().getGateway().gatewaySubDevicePublish( topic, // sub-device topic data, // the data deviceInfo, // the ID of the sub-device ISubDeviceActionListener)代わりにコンソールを使用することができます。
サブデバイスにトピックを購読させる
以下のパラメータを設定することで、サブデバイスにトピックを購読させることができます。
DeviceInfo deviceInfo = new DeviceInfo(); deviceInfo.productKey = productKey; deviceInfo.deviceName = deviceName; deviceInfo.deviceSecret = deviceSecret; LinkKit.getInstance().getGateway().gatewaySubDeviceSubscribe( topic, // sub-device subscription topic deviceInfo, // the ID of the sub-device ISubDeviceActionListener)サブデバイスの接続を解除する
DeviceInfo deviceInfo = new DeviceInfo(); deviceInfo.productKey = productKey; deviceInfo.deviceName = deviceName; deviceInfo.deviceSecret = deviceSecret; LinkKit.getInstance().getGateway().gatewaySubDeviceLogout( deviceInfo, // the ID of the sub-device ISubDeviceActionListener)サブデバイスのネットワークトポロジの削除
DeviceInfo deviceInfo = new DeviceInfo(); deviceInfo.productKey = productKey; deviceInfo.deviceName = deviceName; deviceInfo.deviceSecret = deviceSecret; LinkKit.getInstance().getGateway().gatewayDeleteSubDevice( deviceInfo, // the ID of the sub-device ISubDeviceRemoveListener)アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-17T13:24:09+09:00
[Java]MinecraftのModを作成しよう 1.16.1【木の追加と生成】
(この記事は一連の解説記事の一つになります)
注意事項
ここまで連続記事という体をとって、特記のない事項についてはそれまでと同じとしてきましたが、今回の記事から環境を変えたので特に注意してください。
環境
Minecraft Forgeのバージョンを上げました。開発中のバージョンであり未整備な部分が多かったためです。また、更新後も同様に開発中のバージョンであり、日々更新版が出ているのでご注意ください。
version OS Winsows 10 Home Oracle JDK 8u212 Minecraft 1.16.1 Minecraft Forge 1.16.1 (32.0.108) -> 1.16.1 (33.0.22) InteliJ IDEA 2020.1.3 (CE) 各ブロック・アイテムの追加
ブロックの追加を参考に原木・葉・苗ブロックを追加します。
Blocks.javapackage jp.koteko.liveinwater.block; import jp.koteko.liveinwater.LiveInWater; import jp.koteko.liveinwater.block.trees.WaterTree; import net.minecraft.block.*; import net.minecraft.block.material.Material; import net.minecraft.block.material.MaterialColor; import net.minecraft.client.renderer.RenderType; import net.minecraft.client.renderer.RenderTypeLookup; import net.minecraft.world.FoliageColors; import net.minecraft.world.biome.BiomeColors; import net.minecraftforge.client.event.ColorHandlerEvent; import net.minecraftforge.event.RegistryEvent; import net.minecraftforge.eventbus.api.SubscribeEvent; import net.minecraftforge.fml.common.Mod; import java.util.ArrayList; import java.util.List; @Mod.EventBusSubscriber(modid = LiveInWater.MOD_ID, bus = Mod.EventBusSubscriber.Bus.MOD) public class Blocks { public static List<Block> blockList = new ArrayList<Block>(); public static Block WATERTREE_ROOT_BLOCK = register("watertree_root_block", new Block(AbstractBlock.Properties.create(Material.WOOD).hardnessAndResistance(2.5F).sound(SoundType.WOOD))); public static Block WATERTREE_LOG = register("watertree_log", new RotatedPillarBlock(AbstractBlock.Properties.create(Material.WOOD, MaterialColor.WOOD).hardnessAndResistance(2.0F).sound(SoundType.WOOD))); public static Block WATERTREE_LEAVES = register("watertree_leaves", new LeavesBlock(AbstractBlock.Properties.create(Material.LEAVES).hardnessAndResistance(0.2F).tickRandomly().sound(SoundType.PLANT).notSolid())); public static Block WATERTREE_SAPLING = register("watertree_sapling", new SaplingBlock(new WaterTree(), AbstractBlock.Properties.create(Material.PLANTS).doesNotBlockMovement().tickRandomly().zeroHardnessAndResistance().sound(SoundType.PLANT))); private static Block register(String key, Block blockIn){ blockList.add(blockIn); return blockIn.setRegistryName(LiveInWater.MOD_ID, key); } @SubscribeEvent public static void registerBlocks(RegistryEvent.Register<Block> event) { for (Block block : blockList) { event.getRegistry().register(block); if (block instanceof SaplingBlock) { RenderTypeLookup.setRenderLayer(block, RenderType.getCutout()); } } } @SubscribeEvent public static void registerBlockColors(ColorHandlerEvent.Block event) { event.getBlockColors().register((p_210229_0_, p_210229_1_, p_210229_2_, p_210229_3_) -> { return p_210229_1_ != null && p_210229_2_ != null ? BiomeColors.getFoliageColor(p_210229_1_, p_210229_2_) : FoliageColors.getDefault(); }, WATERTREE_LEAVES); } }原木は
RotatedPillarBlock、葉はLeavesBlock、苗はSaplingBlockクラスで作ります。細かな設定はBlockに共通するもの(たとえば.hardnessAndResistance()で硬さや耐性を設定)なので適宜変更してください。上述のものはそれぞれに標準的な値(のはず)です。
SaplingBlockのコンストラクタに渡す第一引数は、苗が生成する木のインスタンスになります。まだ定義していませんが後述します。
また、ブロック登録部分に記述が追加されています。これは苗ブロックのテクスチャ表示を正しく行うためにレンダータイプの設定を行っています。これを行わないと透過されるべき部分が黒塗り状態になってしまいました。参考
最後に、葉ブロックの色をバイオームカラーに応じて変更するよう設定しています。1.14.4のときの記述をそのまま持ってきたので深く中は見てません。BlockColorsクラスを観察するともっといろいろ分かると思います。バイオームカラーについては参考ページを参照してください。これを設定しない場合、全バイオームでテクスチャの色がそのまま使われるので、省略可能です。
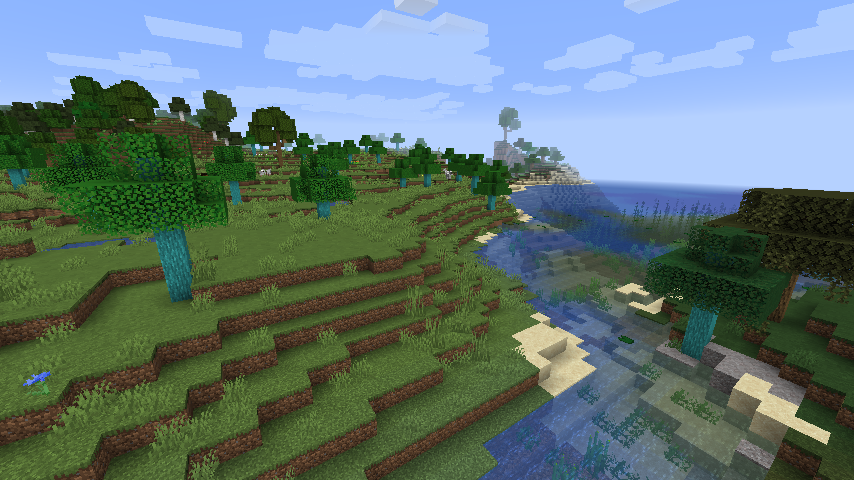
バイオームに応じて葉の色が変わる様子(記事末尾の自然生成まで実装後の様子なのでこの時点ではワールドに木は生成されません)
Items.javapackage jp.koteko.liveinwater.item; import jp.koteko.liveinwater.LiveInWater; import jp.koteko.liveinwater.block.Blocks; import net.minecraft.block.Block; import net.minecraft.item.BlockItem; import net.minecraft.item.Item; import net.minecraft.item.ItemGroup; import net.minecraftforge.event.RegistryEvent; import net.minecraftforge.eventbus.api.SubscribeEvent; import net.minecraftforge.fml.common.Mod; import java.util.ArrayList; import java.util.List; @Mod.EventBusSubscriber(modid = LiveInWater.MOD_ID, bus = Mod.EventBusSubscriber.Bus.MOD) public class Items { public static List<Item> itemList = new ArrayList<Item>(); public static final Item WATERTREE_ROOT = register("watertree_root", new Item((new Item.Properties()).group(LiwItemGroup.DEFAULT))); public static final Item WATERTREE_ROOT_BLOCK = register("watertree_root_block", Blocks.WATERTREE_ROOT_BLOCK, LiwItemGroup.DEFAULT); public static final Item WATERTREE_LOG = register("watertree_log", Blocks.WATERTREE_LOG, LiwItemGroup.DEFAULT); public static final Item WATERTREE_LEAVES = register("watertree_leaves", Blocks.WATERTREE_LEAVES, LiwItemGroup.DEFAULT); public static final Item WATERTREE_SAPLING = register("watertree_sapling", Blocks.WATERTREE_SAPLING, LiwItemGroup.DEFAULT); private static Item register(String key, Item itemIn) { itemList.add(itemIn); return itemIn.setRegistryName(LiveInWater.MOD_ID, key); } private static Item register(String key, Block blockIn, ItemGroup itemGroupIn) { return register(key, new BlockItem(blockIn, (new Item.Properties()).group(itemGroupIn))); } @SubscribeEvent public static void registerItems(RegistryEvent.Register<Item> event) { for (Item item : itemList) { event.getRegistry().register(item); } } }
BlockItemを宣言・登録します。アイテムの追加も参照してください。
resourcesの設定をします。\src\main\resources ├ assets │ └ example_mod │ ├ blockstates │ │ ├ watertree_leaves.json │ │ ├ watertree_log.json │ │ └ watertree_sapling.json │ ├ lang │ │ └ en_us.json │ │ └ ja_jp.json │ ├ models │ │ ├ block │ │ │ ├ watertree_leaves.json │ │ │ ├ watertree_log.json │ │ │ └ watertree_sapling.json │ │ └ item │ │ ├ example_leaves.json │ │ ├ example_log.json │ │ └ example_sapling.json │ └ textures │ ├ block │ │ ├ watertree_leaves.json │ │ ├ watertree_log.json │ │ └ watertree_sapling.json │ └ item │ └ watertree_sapling.json └ data └ liveinwater └ loot_tables └ blocks ├ example_leaves.json ├ example_log.json └ example_sapling.json
blockstates\watertree_leaves.json{ "variants": { "": { "model": "liveinwater:block/watertree_leaves" } } }blockstates\watertree_log.json{ "variants": { "axis=y": { "model": "liveinwater:block/watertree_log" }, "axis=z": { "model": "liveinwater:block/watertree_log", "x": 90 }, "axis=x": { "model": "liveinwater:block/watertree_log", "x": 90, "y": 90 } } }設置方向によってモデルを回転させます。
blockstates\watertree_sapling.json{ "variants": { "": { "model": "liveinwater:block/watertree_sapling" } } }
en_us.jp{ "item.liveinwater.watertree_log": "WaterTree Log", "item.liveinwater.watertree_leaves": "WaterTree Leaves", "item.liveinwater.watertree_sapling": "WaterTree Sapling", "block.liveinwater.watertree_log": "WaterTree Log", "block.liveinwater.watertree_leaves": "WaterTree Leaves", "block.liveinwater.watertree_sapling": "WaterTree Sapling" }ja_jp.json{ "item.liveinwater.watertree_log": "ウォーターツリーの原木", "item.liveinwater.watertree_leaves": "ウォーターツリーの葉", "item.liveinwater.watertree_sapling": "ウォーターツリーの苗", "block.liveinwater.watertree_log": "ウォーターツリーの原木", "block.liveinwater.watertree_leaves": "ウォーターツリーの葉", "block.liveinwater.watertree_sapling": "ウォーターツリーの苗" }
models\block\watertree_leaves.json{ "parent": "block/leaves", "textures": { "all": "liveinwater:block/watertree_leaves" } }models\block\watertree_log.json{ "parent": "block/cube_column", "textures": { "end": "liveinwater:block/watertree_log_top", "side": "liveinwater:block/watertree_log" } }
parentにblock/cube_columnを指定し、立方体型で上下面と側面で区別したテクスチャを適用します。それぞれのテクスチャファイルへのパスを指定しましょう。models\block\watertree_sapling.json{ "parent": "block/cross", "textures": { "cross": "liveinwater:block/watertree_sapling" } }
models\item\watertree_leaves.json{ "parent": "liveinwater:block/watertree_leaves" }models\item\watertree_log.json{ "parent": "liveinwater:block/watertree_log" }models\item\watertree_sapling.json{ "parent": "item/generated", "textures": { "layer0": "liveinwater:item/watertree_sapling" } }
\loot_table\blocks\watertree_leaves.json{ "type": "minecraft:block", "pools": [ { "rolls": 1, "entries": [ { "type": "minecraft:alternatives", "children": [ { "type": "minecraft:item", "conditions": [ { "condition": "minecraft:alternative", "terms": [ { "condition": "minecraft:match_tool", "predicate": { "item": "minecraft:shears" } }, { "condition": "minecraft:match_tool", "predicate": { "enchantments": [ { "enchantment": "minecraft:silk_touch", "levels": { "min": 1 } } ] } } ] } ], "name": "liveinwater:watertree_leaves" }, { "type": "minecraft:item", "conditions": [ { "condition": "minecraft:survives_explosion" }, { "condition": "minecraft:table_bonus", "enchantment": "minecraft:fortune", "chances": [ 0.05, 0.0625, 0.083333336, 0.1 ] } ], "name": "liveinwater:watertree_sapling" } ] } ] } ] }詳しくは参考ページを参照のこと。
\loot_table\blocks\watertree_log.json{ "type": "minecraft:block", "pools": [ { "rolls": 1, "entries": [ { "type": "minecraft:item", "name": "liveinwater:watertree_log" } ] } ] }\loot_table\blocks\watertree_sapling.json{ "type": "minecraft:block", "pools": [ { "rolls": 1, "entries": [ { "type": "minecraft:item", "name": "liveinwater:watertree_sapling" } ] } ] }タグへの追加
追加した原木ブロックを
minecraft:logsのタグに追加します。(他の部分でも活用されているかもしれませんが)これは葉ブロックの消滅判定に用いられるので、これを行わないと生成した木の葉ブロックがすぐに消滅を開始してしまいます。\src\main\resources ├ assets └ data ├ liveinwater └ minecraft └ tags └ blocks └ logs.json自分のプロジェクトフォルダ内に
\src\main\resources\data\minecraft\tags\blocksフォルダを作り、そこにlogs.jsonを配置します。この名前は必ず同じにしてください。logs.json{ "replace": false, "values": [ "liveinwater:watertree_log" ] }
replaceにfalseを与えることにより、同名のminecraft:logsにこのファイルでの記述が統合されます。valuesの中でブロックを指定しましょう。
同様に葉ブロックも
minecraft:leavesのタグに追加します。これは苗から木が成長する際に葉ブロックを障害物判定しないために必要です(leavesのタグにない場合木が生成される際に上書きされない)。\src\main\resources ├ assets └ data ├ liveinwater └ minecraft └ tags └ blocks ├ leaves.json └ logs.jsonleaves.json{ "replace": false, "values": [ "liveinwater:watertree_leaves" ] }
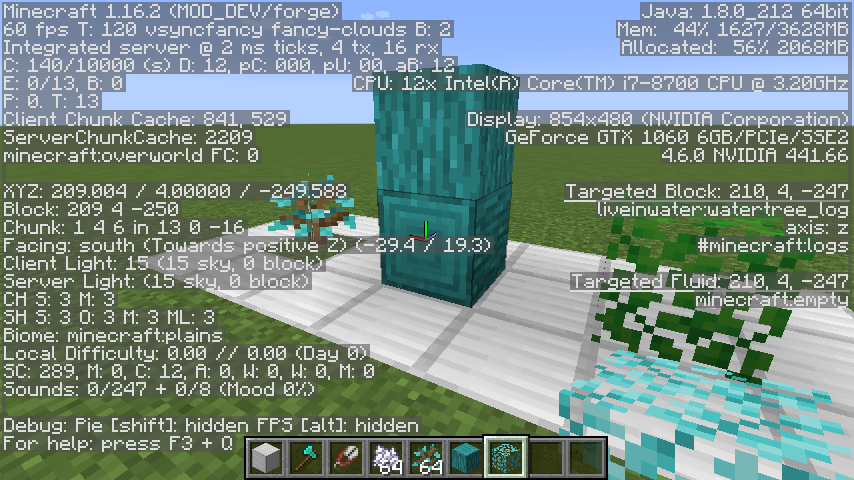
ゲーム内でF3を押してデバッグ表示をしブロックにカーソルを合わせた際に、画面右中央あたりにタグ(例えば#mineraft:logs)の表示が出ていることを確認します。TreeFeatureクラスとTreeクラスの追加
これらは違いを言葉で説明するのが難しいですが、ともに木を管理するクラスです。
Treeクラスは木自体を管理するクラスで、この後で追加する苗に関連して必要になります。一方で、TreeFeatureクラスは木の生成に関することを管理しており、Treeクラスから該当するTreeFeatureを取得することもできます。\src\main\java\jp\koteko\liveinwater\ ├ block │ └ trees │ └ WaterTree.java ├ item ├ world │ └ gen │ └ feature │ └ WaterTreeFeature.java └ LiveInWater.java
WaterTree.javapackage jp.koteko.liveinwater.block.trees; import jp.koteko.liveinwater.world.gen.TreeGenerator; import net.minecraft.block.trees.Tree; import net.minecraft.world.gen.feature.BaseTreeFeatureConfig; import net.minecraft.world.gen.feature.ConfiguredFeature; import javax.annotation.Nullable; import java.util.Random; public class WaterTree extends Tree { @Nullable protected ConfiguredFeature<BaseTreeFeatureConfig, ?> getTreeFeature(Random randomIn, boolean p_225546_2_) { return TreeGenerator.WATERTREE.setConfiguration(); } }
Tree抽象クラスをextendsしてクラスを定義します。抽象メソッドgetTreeFeatureを、後述するWaterTreeFeatureにコンフィグを与えた状態のBaseTreeFeatureConfigクラスのインスタンスを返すように定義しましょう(TreeGeneratorについては後の項で示します)。乱数を受け取るようになっていますが、これは木が確率で巨大種に成長する場合などに用いるので、必要であれば乱数に応じて返す値を変えましょう。
WaterTreeFeature.javapackage jp.koteko.liveinwater.world.gen.feature; import com.google.common.collect.ImmutableList; import com.mojang.serialization.Codec; import jp.koteko.liveinwater.block.Blocks; import net.minecraft.world.gen.blockstateprovider.SimpleBlockStateProvider; import net.minecraft.world.gen.feature.*; import net.minecraft.world.gen.foliageplacer.BlobFoliagePlacer; import net.minecraft.world.gen.placement.AtSurfaceWithExtraConfig; import net.minecraft.world.gen.placement.Placement; import net.minecraft.world.gen.treedecorator.BeehiveTreeDecorator; import net.minecraft.world.gen.trunkplacer.StraightTrunkPlacer; public class WaterTreeFeature extends TreeFeature { public WaterTreeFeature(Codec<BaseTreeFeatureConfig> codec) { super(codec); } public ConfiguredFeature<?, ?> configure() { return this.setConfiguration().withPlacement(Placement.field_242902_f.configure(new AtSurfaceWithExtraConfig(10, 0.1F, 1)).func_242728_a()); } public ConfiguredFeature<BaseTreeFeatureConfig, ?> setConfiguration() { return this.withConfiguration( new BaseTreeFeatureConfig.Builder( new SimpleBlockStateProvider(Blocks.WATERTREE_LOG.getDefaultState()), new SimpleBlockStateProvider(Blocks.WATERTREE_LEAVES.getDefaultState()), new BlobFoliagePlacer(FeatureSpread.func_242252_a(2), FeatureSpread.func_242252_a(0), 3), new StraightTrunkPlacer(5, 2, 0), new TwoLayerFeature(1, 0, 1) ).func_236700_a_().func_236703_a_(ImmutableList.of(new BeehiveTreeDecorator(0.002F))).build()); } }
TreeFeatureクラスをextendsしてクラスを定義します。
他のクラスからFeatureを用いる際のgenericsによる制限(<BaseTreeFeatureConfig, ?>の部分)に対応するため、2つのメソッドを定義します。まず下の
setConfiguration()では、この木がどのような形を持つかということを設定しています(withConfiguration())。
コンフィグにはビルダーが用意されており、引数は順に、幹となるブロックのプロバイダ、葉となるブロックのプロバイダ、葉の配置形状、幹の配置形状、(用途不明な引数AbstractFeatureSizeType)、です。名前が分かりづらいですが、func_236700_a_()はignore_vinesをtrueにする関数、func_236703_a_()は引数(今回の例では0.002の確率でハチの巣を生成するもの)をデコレーターとして与える関数、としてそれぞれビルダーに定義されています。最後にbuild()を呼ぶことでBaseTreeFeatureConfigを作成し、withConfiguration()の引数に渡します。次に
configure()では、setConfiguration()したFeatureにさらに配置場所の設定を与えます(withPlacement())。
Placementには沢山の種類が用いられており、また複数を重ねて使うようなこともされることがわかっています。そのため好みの配置を作るにはPlacementの中身を深く観察する必要があるでしょう。今回は私が確認し一例のみを示しました。例えば、Placement.field_242902_fで抽選回数を決定し、func_242728_a()が最終的にSquarePlacementを適用してgetPosisionsのメソッドでチャンク内のランダム座標のリストを返す、といった風なふるまいをしているようです。この辺りのことはもう少し深く理解したら別記事にまとめるかもしれません。木の生成
最後に、実装した木をワールド生成時に自動で生成されるようにしましょう。
\src\main\java\jp\koteko\liveinwater\ ├ block ├ item ├ world │ └ gen │ ├ feture │ └ TreeGenerator.java └ LiveInWater.java
WorldGenOres.javapackage jp.koteko.liveinwater.world.gen; import com.google.common.collect.Lists; import jp.koteko.liveinwater.world.gen.feature.WaterTreeFeature; import net.minecraft.util.RegistryKey; import net.minecraft.util.registry.Registry; import net.minecraft.util.registry.WorldGenRegistries; import net.minecraft.world.biome.Biome; import net.minecraft.world.biome.BiomeGenerationSettings; import net.minecraft.world.gen.GenerationStage; import net.minecraft.world.gen.feature.BaseTreeFeatureConfig; import net.minecraft.world.gen.feature.ConfiguredFeature; import net.minecraftforge.fml.common.ObfuscationReflectionHelper; import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.function.Supplier; public class TreeGenerator { public static WaterTreeFeature WATERTREE; public static ConfiguredFeature<?, ?> CONFIGURED_WATERTREE; public static void init() { WATERTREE = Registry.register(Registry.FEATURE, "liveinwater:watertree", new WaterTreeFeature(BaseTreeFeatureConfig.field_236676_a_)); CONFIGURED_WATERTREE = Registry.register(WorldGenRegistries.field_243653_e, "liveinwater:watertree", WATERTREE.configure()); } public static void setup() { addTreeToOverworld(CONFIGURED_WATERTREE); } private static void addTreeToOverworld(ConfiguredFeature<?, ?> featureIn){ for(Map.Entry<RegistryKey<Biome>, Biome> biome : WorldGenRegistries.field_243657_i.func_239659_c_()) { if(!biome.getValue().getCategory().equals(Biome.Category.NETHER) && !biome.getValue().getCategory().equals(Biome.Category.THEEND)) { addFeatureToBiome(biome.getValue(), GenerationStage.Decoration.VEGETAL_DECORATION, featureIn); } } } public static void addFeatureToBiome(Biome biome, GenerationStage.Decoration decoration, ConfiguredFeature<?, ?> configuredFeature) { List<List<Supplier<ConfiguredFeature<?, ?>>>> biomeFeatures = new ArrayList<>(biome.func_242440_e().func_242498_c()); while (biomeFeatures.size() <= decoration.ordinal()) { biomeFeatures.add(Lists.newArrayList()); } List<Supplier<ConfiguredFeature<?, ?>>> features = new ArrayList<>(biomeFeatures.get(decoration.ordinal())); features.add(() -> configuredFeature); biomeFeatures.set(decoration.ordinal(), features); ObfuscationReflectionHelper.setPrivateValue(BiomeGenerationSettings.class, biome.func_242440_e(), biomeFeatures, "field_242484_f"); } }全部を理解するのは難しい部分なので、必要に応じて変える部分を判断してください(実際私もそうしたので)。1.16.1版では、以前のような方法でBiomeにFeatureを登録することができなくなっていました。そのため参考になるコードを探し、BluePower様のコードを参考にさせていただきました。
最下部の
addFeatureToBiomeを定義することによって、今までと似たような方法でBiomeにFeatureを登録することを可能にしています。簡単に説明すると、BiomeGenerationSettingsクラスのメンバ変数field_242484_fがFeatureのリストを持っているようなので、上書きして追加するという作業をしているようです。
addFeatureToBiomeが定義されたら、あとは以前の方法に近い形で実装ができます。OverworldのBiomeに登録を行うaddTreeToOverworldメソッドを定義し、setupメソッド内で呼び出すようにしました。また、各Featureらはあらかじめ宣言し、initメソッドで登録を行うようにします。この時、上記のようにFeatureの登録とConfiguredFeatureの登録をそれぞれ行っておかないと上手くいかないようです(かなり詰まったけれど完全には理解できませんでした)。
最後に、今定義した
TreeGenerator.init()TreeGenerator.setup()をメインファイル内で呼びます。LiveInWater.javapackage jp.koteko.liveinwater; import jp.koteko.liveinwater.world.gen.TreeGenerator; import net.minecraftforge.common.MinecraftForge; import net.minecraftforge.eventbus.api.SubscribeEvent; import net.minecraftforge.fml.common.Mod; import net.minecraftforge.fml.event.lifecycle.FMLClientSetupEvent; import net.minecraftforge.fml.event.lifecycle.FMLCommonSetupEvent; import net.minecraftforge.fml.event.lifecycle.InterModEnqueueEvent; import net.minecraftforge.fml.event.lifecycle.InterModProcessEvent; import net.minecraftforge.fml.event.server.FMLServerStartingEvent; import net.minecraftforge.fml.javafmlmod.FMLJavaModLoadingContext; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; @Mod(LiveInWater.MOD_ID) public class LiveInWater { public static final String MOD_ID = "liveinwater"; private static final Logger LOGGER = LogManager.getLogger(); public LiveInWater() { FMLJavaModLoadingContext.get().getModEventBus().addListener(this::setup); FMLJavaModLoadingContext.get().getModEventBus().addListener(this::enqueueIMC); FMLJavaModLoadingContext.get().getModEventBus().addListener(this::processIMC); FMLJavaModLoadingContext.get().getModEventBus().addListener(this::doClientStuff); TreeGenerator.init(); MinecraftForge.EVENT_BUS.register(this); } private void setup(final FMLCommonSetupEvent event) { LOGGER.info("SETUP START"); TreeGenerator.setup(); LOGGER.info("SETUP END"); } private void doClientStuff(final FMLClientSetupEvent event) { // do something that can only be done on the client } private void enqueueIMC(final InterModEnqueueEvent event) { // some example code to dispatch IMC to another mod } private void processIMC(final InterModProcessEvent event) { // some example code to receive and process InterModComms from other mods } @SubscribeEvent public void onServerStarting(FMLServerStartingEvent event) { LOGGER.info("server starting"); } }ゲームを起動して新たにワールドを生成します。
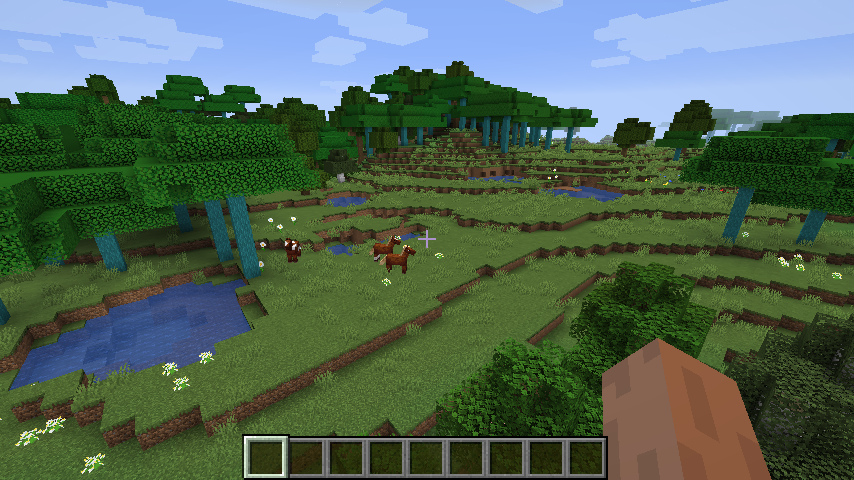
木が生成されている様子(ここまでの記述通りの場合)
木が生成されている様子(PlacementやConfigを変化させた場合)参考
[Java]MinecraftのModを作成しよう 1.14.4【9. 木の追加と生成】 - Qiita
BluePower/BPWorldGen.java at master · Qmunity/BluePower · GitHub
1.14.3 Tags help - Modder Support - Forge Forums
バイオーム - Minecraft Wiki
ルートテーブル - Minecraft Wiki
[SOLVED] [1.15.2] A texture issue with cross models? - Modder Support - Forge ForumsForge 1.16.1 32.0.108 での実装記録
Forgeのバージョンアップ前で取り敢えず動くレベルにまで実装した例を参考までに記録しておきます。
折り畳み
仮のレベルで木の追加生成までを描いたコード群です(苗や木を構成するブロックなどは追加してません)。\src\main\java\jp\koteko\liveinwater\ ├ block ├ item ├ world │ └ gen │ ├ feature │ │ └ WaterTreeFeature.java │ └ TreeGenerator.java └ LiveInWater.javaWaterTreeFeature.javapackage jp.koteko.liveinwater.world.gen.feature; import com.mojang.serialization.Codec; import net.minecraft.world.gen.feature.BaseTreeFeatureConfig; import net.minecraft.world.gen.feature.TreeFeature; public class WaterTreeFeature extends TreeFeature { public WaterTreeFeature(Codec<BaseTreeFeatureConfig> codec) { super(codec); } }実際まだ親クラスと何ら変わらないのでこれは今の時点では無意味です。1.14の頃と異なり、
Codecというインターフェースが導入されているようです。なんとなく眺めてみた感じでは、色んなクラスのオブジェクトを汎用的に扱うためのもののようです。TreeGenerator.javapackage jp.koteko.liveinwater.world.gen; import com.google.common.collect.ImmutableList; import jp.koteko.liveinwater.world.gen.feature.WaterTreeFeature; import net.minecraft.block.Blocks; import net.minecraft.world.biome.Biome; import net.minecraft.world.gen.GenerationStage; import net.minecraft.world.gen.blockstateprovider.SimpleBlockStateProvider; import net.minecraft.world.gen.feature.BaseTreeFeatureConfig; import net.minecraft.world.gen.feature.ConfiguredFeature; import net.minecraft.world.gen.feature.TwoLayerFeature; import net.minecraft.world.gen.foliageplacer.BlobFoliagePlacer; import net.minecraft.world.gen.placement.AtSurfaceWithExtraConfig; import net.minecraft.world.gen.placement.Placement; import net.minecraft.world.gen.treedecorator.BeehiveTreeDecorator; import net.minecraft.world.gen.trunkplacer.StraightTrunkPlacer; import net.minecraftforge.registries.ForgeRegistries; import java.util.OptionalInt; public class TreeGenerator { public static void setup() { addTreeToOverworld( new WaterTreeFeature(BaseTreeFeatureConfig.field_236676_a_) .withConfiguration( (new BaseTreeFeatureConfig.Builder( new SimpleBlockStateProvider(Blocks.ACACIA_WOOD.getDefaultState()), new SimpleBlockStateProvider(Blocks.BLUE_WOOL.getDefaultState()), new BlobFoliagePlacer(2, 0, 0, 0, 3), new StraightTrunkPlacer(5, 2, 0), new TwoLayerFeature(0, 0, 0, OptionalInt.of(4))) ).func_236700_a_().func_236703_a_(ImmutableList.of(new BeehiveTreeDecorator(0.002F))).build()) .withPlacement(Placement.COUNT_EXTRA_HEIGHTMAP.configure(new AtSurfaceWithExtraConfig(10, 0.1F, 1))) ); } private static void addTreeToOverworld(ConfiguredFeature<?, ?> featureIn) { for(Biome biome : ForgeRegistries.BIOMES) { if (!biome.getCategory().equals(Biome.Category.NETHER) && !biome.getCategory().equals(Biome.Category.THEEND)) { biome.addFeature(GenerationStage.Decoration.VEGETAL_DECORATION, featureIn); } } } }基本的に1.14の時と同じで
Biome#addFeatureによって生成したいバイオームに木のFeatureを追加することで生成させます。名前が分かりづらい状態のものが多く、またFeatureやConfiguredFeatureの扱いが変わったらしく、Biome#createDecoratedFeatureも見当たらなくなっていました。バニラのコードを観察して書いたのが上記のコードです。
ConfiguredFeature(new WaterTreeFeature())に対して、withConfiguration()とwithPlacement()でコンフィグ(この場合では木の構成ブロックや形状)とプレースメント(自然生成時の抽選される場所)を設定します。
コンフィグはビルダーが用意されていたので、これを用います。順に、幹となるブロック(のプロバイダ)、葉となるブロック(のプロバイダ)、葉の配置形状、幹の配置形状、最小サイズのタイプ(詳細不明)です。プロバイダは特別なことをしない限りSimpleBlockStateProviderクラスのインスタンスを渡せばよいでしょう。ブロックの種類だけ適宜変更します。葉と幹の配置形状については、バニラでもいくつかの種類が用いられているので適したものを用います。FoliagePlacer,AbstractTrunkPlacerのサブクラスを観察しましょう。引数で高さ等を指定します。ビルダー第5引数についてはminimum_sizeという名前で管理されるAbstractFeatureSizeTypeクラスのオブジェクトのようですが、どのようにはたらくか不明だったため、他のコードに合わせておきます。ビルダーに対してbuild()を呼ぶことでコンフィグのインスタンスを返します。func_236700_a_()はツタの生成をしない指定、func_236703_a_()はこのように引数を渡すことでハチの巣を生成するよう指定しています。
プレースメントは適当な種類(Placementクラスを参照)を選択し、configure()で設定します。次の記事

- 投稿日:2020-09-17T12:52:44+09:00
メモ Eclipsとgit(github)の連携 参考リンク
- 投稿日:2020-09-17T12:38:50+09:00
Eclipse MicroProfileのJAX-RS実装
MicroProfile実装で使われているJAX-RS実装の調査。今Jersey+Grizzlyを利用しているので、Jersey採用のプロダクトを触ってみようかなというところ。
プロダクト JAX-RS Helidon Jersey Quarkus RESTEasy Payara MicroProfile Jersey WildFly RESTEasy Thorntail v2 RESTEasy KumuluzEE Jersey
- 投稿日:2020-09-17T09:59:57+09:00
Javaでcronのプログラムを作ろう!!(TaskScheduler)
Java(cron4j)
・cronとは、多くのUNIX系OSで標準的に利用される常駐プログラム(デーモン)の一種で、利用者の設定したスケジュールに従って指定されたプログラムを定期的に起動してくれるもの。(*IT用語辞典参照)
jar
下記リンクからjarファイルをダウンロードしてIDEに設定しよう!!
https://www.sauronsoftware.it/projects/cron4j/download.phpTaskクラス
まず、実行したい処理を書くクラスを作ろう!!
CronTaskimport java.util.Date; public class CronTask implements Runnable{ @Override public void run() { System.out.println(new Date()+": Hiiiii! cron4j!"); } }Schedulerクラス
MyCronAppTestimport it.sauronsoftware.cron4j.Scheduler; public class MyCronAppTest { public static void main(String[] args) { MyCronAppTest app = new MyCronAppTest(); try { app.schedulerSimple(); System.out.println("Press Ctrl+C to stop."); Thread.sleep(100000000); } catch (InterruptedException e) { e.printStackTrace(); } } public void schedulerSimple() { Scheduler scheduler = new Scheduler(); // every minute. scheduler.schedule("* * * * *", new CronTask()); // start cron4j scheduler. scheduler.start(); } }おまけ(Servletを使ったScheduler)
HelloServletimport java.io.IOException; import java.util.Date; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import it.sauronsoftware.cron4j.Scheduler; public class HelloServlet extends HttpServlet { private static final long serialVersionUID = 1L; public void schedulerSimple() { Scheduler scheduler = new Scheduler(); // every minute. scheduler.schedule("* * * * *", new CronTask()); // start cron4j scheduler. scheduler.start(); } protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { MyCronApp app = new MyCronApp(); try { app.schedulerSimple(); System.out.println("Press Ctrl+C to stop."); Thread.sleep(100000000); } catch (InterruptedException e) { e.printStackTrace(); } response.getWriter().append("Hello Servlet"); } protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { doGet(request, response); } }
- 投稿日:2020-09-17T09:59:57+09:00
Javaでcronのプログラムを作ろう!!(タスクスケジューラー)
Java(cron4j)
・cronとは、多くのUNIX系OSで標準的に利用される常駐プログラム(デーモン)の一種で、利用者の設定したスケジュールに従って指定されたプログラムを定期的に起動してくれるもの。(*IT用語辞典参照)
jar
下記リンクからjarファイルをダウンロードしてIDEに設定しよう!!
https://www.sauronsoftware.it/projects/cron4j/download.phpTaskクラス
まず、実行したい処理を書くクラスを作ろう!!
CronTaskimport java.util.Date; public class CronTask implements Runnable{ @Override public void run() { System.out.println(new Date()+": Hiiiii! cron4j!"); } }Schedulerクラス
MyCronAppTestimport it.sauronsoftware.cron4j.Scheduler; public class MyCronAppTest { public static void main(String[] args) { MyCronAppTest app = new MyCronAppTest(); try { app.schedulerSimple(); System.out.println("Press Ctrl+C to stop."); Thread.sleep(100000000); } catch (InterruptedException e) { e.printStackTrace(); } } public void schedulerSimple() { Scheduler scheduler = new Scheduler(); // every minute. scheduler.schedule("* * * * *", new CronTask()); // start cron4j scheduler. scheduler.start(); } }おまけ(Servletを使ったScheduler)
HelloServletimport java.io.IOException; import java.util.Date; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import it.sauronsoftware.cron4j.Scheduler; public class HelloServlet extends HttpServlet { private static final long serialVersionUID = 1L; public void schedulerSimple() { Scheduler scheduler = new Scheduler(); // every minute. scheduler.schedule("* * * * *", new CronTask()); // start cron4j scheduler. scheduler.start(); } protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { MyCronApp app = new MyCronApp(); try { app.schedulerSimple(); System.out.println("Press Ctrl+C to stop."); Thread.sleep(100000000); } catch (InterruptedException e) { e.printStackTrace(); } response.getWriter().append("Hello Servlet"); } protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { doGet(request, response); } }