- 投稿日:2020-09-16T22:14:28+09:00
【Rails】エラーメッセージを日本語化してみよう
ユーザー作成とか、ログインとか、何か投稿するときのエラー文をカッコよく英語のままにするのもありですが、分かりやすく日本語にしたいときありますよね?
そんなあなたにGemを使った解決法でお伝えしていきます。
Gemをインストール
Gemfilegem 'rails-i18n'$ bundle installエラーメッセージを日本語に設定
config/application.rbmodule SampleApp class Application < Rails::Application config.i18n.default_locale = :ja config.i18n.load_path += Dir[Rails.root.join('config', 'locales', '**', '*.{rb,yml}').to_s] end endどのコードが、どの日本語に対応させるのかを設定
専用のファイルを使って設定していきます。
$ mkdir config/locales/models $ touch config/locales/models/ja.ymlja.ymlja: activerecord: models: user: ユーザ attributes: user: name: 名前 email: メールアドレス password: パスワード password_confirmation: パスワード(再入力)エラーメッセージを手動追加 errors.add
user.errors.add(:base, "追加エラー")もちろんエラーを生成してから出ないと、追加できないので、流れとしては以下の通り。
> user = User.new > user.errors > user.errors.add(:base, "追加エラー") > user.errors.full_messages => ["追加エラー"]
- 投稿日:2020-09-16T22:06:57+09:00
《未経験→webエンジニア》実務3日目
この記事の目的
自分がやったこと、知らなかったこと、やるべきことを明確にし
1日あたりの成長速度を速める。【今日やったこと】
Dockerを使用したローカル環境構築
postmanを使用したAPIテスト【知らなかったこと】
- postmanを使用してAPIテストをしている理由
今回の案件では、フロント側とバックエンド側の製作チームが
完全に別れている。そのため、バックエンド側だけでテストが出来る様にしている
- ログインフォームについて
Device
シンプルに作るには良い。
スクールでも使った!・Authlogic
https://qiita.com/zaru/items/a451de2b165a9e422d62メリット
カスタマイズをしやすい!
欲しいところだけ入れるなど。デメリット
日本語の記事が少ないのが難点。https://qiita.com/zaru/items/a451de2b165a9e422d62
3.トークンについて
・perishable_token
一時的トークン仮登録など、一時的に付与するトークン。
・persistence_token
永続的トークン会員登録後など、永続的に使用するトークン。
パスワードリセットの際には変わるので、そこだけ注意!Cromは情報を多く覚えているので、
検証時には注意すること!
- yarn JSやNPMなど、色々とパッケージになっている フロントをいい感じにしてくれるソフトを、まとめてインストールできる
【明日】やるべきこと、読みたい記事など
Sql文の勉強が必要そう
- 投稿日:2020-09-16T20:36:29+09:00
Rails フォロー機能
①Model(3ステップ)
○必要なモデル(2つ)を作成
1. USER (deviseで作成)
2. Relationships
rails g model Relationship follower_id:integer followed_id:integercreate_table "relationships", force: :cascade do |t| t.integer "follower_id" t.integer "followed_id" t.datetime "created_at", null: false t.datetime "updated_at", null: false end○アソシエーション
各モデルに追記。
Relationshipモデル [ Relationships.rb ]
belongs_to :follower, class_name: "User" belongs_to :followed, class_name: "User"*class_name: "モデル名" で、指定したモデルを参照した際のモデル名を変更できる。
Userモデルを「Follower」と「Followed」に分けるイメージ。
Userモデル [ User.rb ]
# フォローしている has_many :follower, class_name: "Relationship", foreign_key: "follower_id", dependent: :destroy # フォローされてる has_many :followed, class_name: "Relationship", foreign_key: "followed_id", dependent: :destroy #フォローしている人 has_many :follower_user, through: :followed, source: :follower #フォローされている人 has_many :following_user, through: :follower, source: :followed
*through: :モデル名 指定したモデルを通して取得する
*source: :モデル名 関連するモデルを指定する○メソッド定義(3つ) [ User.rb ]
# 1. followメソッド = フォローする def follow(user_id) follower.create(followed_id: user_id) end # 2. unfollowメソッド = フォローを外す def unfollow(user_id) follower.find_by(followed_id: user_id).destroy end # 3. followingメソッド = 既にフォローしているかの確認 def following?(user) following_user.include?(user) end
引数にuserが含まれていた場合、trueを返す=trueのときは「フォローを外す」を表示
*.include?(引数)メソッド: 対象の文字列に引数で指定した文字列が含まれているか検索して真偽値を返す②Controller
○メソッド定義: Relationships Controller
def create #フォローする Userモデルで定義したfollowメソッド current_user.follow(params[:user_id]) redirect_to request.referer #遷移前のURLを取得してリダイレクト end def destroy #フォローを外す Userモデルで定義したunfollowメソッド current_user.unfollow(params[:user_id]) redirect_back(fallback_location: root_path) end def follower #follower一覧 user = User.find(params[:user_id]) @users = user.following_user # .follower_userメソッド :Userモデルで定義済 end def followed #followed一覧 user = User.find(params[:user_id]) @users = user.follower_user # .follower_userメソッド :Userモデルで定義済 end③Routing
create(follow)、destroy(unfollow)とfollows,followersの一覧用を追加
resources :users resource :relationships, only:[:create, :destroy] get 'follows' => 'relationships#follower' get 'followers' => 'relationships#followed' end④View
・フォローボタン(follow/unfollow)
フォローボタンを表示させたい部分にリンクを追加
<% if current_user != user %> <% if current_user.following?(user) %> <%= link_to 'フォロー外す', user_relationships_path(user.id), method: :delete, class: "btn btn-default" %> <% else %> <%= link_to 'フォローする', user_relationships_path(user.id), method: :POST , class: "btn btn-primary"%> <% end %> <% end %>・follower.follows一覧
relationshipsのなかに、follower.html.erb と follows.html.erbファイルを作成し、
各ファイルに下記の通り記載<% if @users.count > 0 %> の条件分岐でUserがいる場合はeach文で表示し、
いない場合は ユーザーはいません を表示<% if @users.count > 0 %> <table class="table"> <thead> <tr> <th>name</th> </tr> </thead> <tbody> <% @users.each do |user| %> <tr> <td><%= @user.name %></td> <td>フォロー数:<%= @user.follower.count %></td> <td>フォロワー数:<%= @user.followed.count %></td> <td> <% if current_user != @user %> <% if current_user.following?(@user) %> <%= link_to 'フォロー外す', user_relationships_path(@user.id), method: :delete, class: "btn btn-default" %> <% else %> <%= link_to 'フォローする', user_relationships_path(@user.id), method: :POST , class: "btn btn-primary"%> <% end %> <% end %> </td> <td><%= link_to "Show", @user %></td> </tr> <% end %> </tbody> </table> <% else %> <p>ユーザーはいません</p> <% end %>
- 投稿日:2020-09-16T19:17:40+09:00
[Rails]複数行データの標準入力の取得する
- 投稿日:2020-09-16T18:51:22+09:00
デフォルトで今日の日付日時を秒以下を省いて表示する方法
【概要】
1.結論
2.どのように記載するか
3.ここから学んだこと
1.結論
(任意の変数).toISOString().slice(0, -8)を使用する
2.どのように記載するか
前提として、
new.html.erb<%= f.datetime_field :study_date ,id:"datetime_field"%>で設定しています。
datetime_fieldメソッドは
=***.toISOString().slice(0, -8);をすることにより、
今日の年、月、時間、分までをデフォルトに表記することができます。***.html.erb<script> var today_time = new Date(); now.setMinutes(today_time.getMinutes() - now.getTimezoneOffset()); #----❶ document.getElementById('datetime_field').value = today_time.toISOString().slice(0, -8); #----❷ </script>と記載しました。
html.erbに記述しておりますので"script"で囲み、更新するとconsoleで変数の定義がされているとエラーがでたのでvarにしています。❶❷までについては下記のURLで触れられている通り表示される時刻はUTC表記(❷)になるので、前もってUTCの差分(❶)に合わせています。参考にしたURL:
HTML5 に現在時刻を設定するには
3.ここから学んだこと
自分は最初に
****.html.erb<f.date_field :****, value:Time.now.strftime("%Y-%m-%d")>を使用していました。value:Time.now.strftime("%Y-%m-%d")を入れてあげるとページが表示された段階で現在の日付が自動で入力されます。
かなり参考にしたURL:
Railsのdate_fieldにてデフォルト値を設定するしかし、f.datetime_fieldの場合は、valueに上記のものを入れたり、Time.nowにすると
The specified value "2020 9/16 12:05" does not conform to the required format. The format is "yyyy-MM-ddThh:mm" followed by optional ":ss" or ":ss.SSS".と出てしまいました。
基準通りの記述を満たせていないということで、認識されていないということでした。なので上記の方法で行いましたが、slice(0,-1)をあまり理解できていないことに気づきました。slice(start,end)はstartから始まる文字~endの手前の数分だけを取り出すので、上記のように書くことで”ss.SSS(秒以下の時間)”を省くことができました。参考にしたURL:
sliceメソッド
- 投稿日:2020-09-16T18:51:22+09:00
デフォルトで今日の日付日時を表示する方法:秒以下を除去
【概要】
1.結論
2.どのように記載するか
3.ここから学んだこと
1.結論
(任意の変数).toISOString().slice(0, -8)を使用する
2.どのように記載するか
前提として、
new.html.erb<%= f.datetime_field :study_date ,id:"datetime_field"%>で設定しています。
datetime_fieldメソッドは
=***.toISOString().slice(0, -8);をすることにより、
今日の年、月、時間、分までをデフォルトに表記することができます。***.html.erb<script> var today_time = new Date(); now.setMinutes(today_time.getMinutes() - now.getTimezoneOffset()); #----❶ document.getElementById('datetime_field').value = today_time.toISOString().slice(0, -8); #----❷ </script>と記載しました。
html.erbに記述しておりますので"script"で囲み、更新するとconsoleで変数の定義がされているとエラーがでたのでvarにしています。❶❷までについては下記のURLで触れられている通り表示される時刻はUTC表記(❷)になるので、前もってUTCの差分(❶)に合わせています。参考にしたURL:
HTML5 に現在時刻を設定するには
3.ここから学んだこと
自分は最初に
****.html.erb<f.date_field :****, value:Time.now.strftime("%Y-%m-%d")>を使用していました。value:Time.now.strftime("%Y-%m-%d")を入れてあげるとページが表示された段階で現在の日付が自動で入力されます。
かなり参考にしたURL:
Railsのdate_fieldにてデフォルト値を設定するしかし、f.datetime_fieldの場合は、valueに上記のものを入れたり、Time.nowにすると
The specified value "2020 9/16 12:05" does not conform to the required format. The format is "yyyy-MM-ddThh:mm" followed by optional ":ss" or ":ss.SSS".と出てしまいました。
基準通りの記述を満たせていないということで、認識されていないということでした。なので上記の方法で行いましたが、slice(0,-1)をあまり理解できていないことに気づきました。slice(start,end)はstartから始まる文字~endの手前の数分だけを取り出すので、上記のように書くことで”ss.SSS(秒以下の時間)”を省くことができました。参考にしたURL:
sliceメソッド
- 投稿日:2020-09-16T18:21:04+09:00
herokuデプロイについて(初学者向け)
初めに
- 今回は
herokuのデプロイについて自分が学んだことを備忘録として記載いたします。素人が書いたものなので、仮に相違点があった場合、ご容赦いただけると幸いです。
それでは初めていきましょう!!
herokuをデプロイするのに必要な準備
1. 以下のサイトで会員登録をする
https://signup.heroku.com/jp2. クレジットカードの登録
- クレジットカードを登録しなくてもある程度herokuを使うことができるが、クレジットカードを登録するとアプリの起動可能時間が550時間から1000時間になるので登録することをおすすめ!!
登録方法
ダッシュボード右上の忍者みたいなアイコンをクリック
Account Settingをクリック最初に
profileを記入し、その後、billingをクリックし、Add Credit Cardをクリック住所、クレジットカードを入力する(住所は英語で記入する)
次にターミナルから直接Herokuアプリを作成および管理するために、Herokuコマンドラインインターフェイス(CLI)を使用する
その方法
- ターミナルに以下を入力する
brew tap heroku/brew && brew install heroku heroku login
- これでメールアドレスとパスワードを入力できたらOKです!!
次にアプリの準備をする
- (今回はアプリがある前提で話を進めていきます)
自前のアプリをアップする時の注意事項
トップページを設定していること
routes.rbの中にroot to 'コントローラー名/アクション名'を設定すればOKDBは
PostgreSQLになっているか確認
config/database.ymlを確認し、adapterがPostgreSQLになっているか確認公開したいアプリをGitのmasterブランチにコミット済であること
もしコミットしてない場合は、コミットする
Github連携、自動デプロイを行いたい方は、Githubにリポジトリを作り、プッシュする。herokuのデフォルトDBは
PostgreSQLである。デプロイの準備
herokuでアプリを公開するには、herokuアプリを作成する必要がある。
以下をターミナルに入力する
heroku create 自分が作ったアプリ名【注意事項】
アプリ名は小文字・数字・ダッシュ(-)のみ入力可能。また、世界で誰も使用していない必要がある
アプリ名を指定していない場合、自動で決まる
- ここで使用したアプリ名はURLで使用される
herokuにデプロイする
(ここでは最も単純な方法を紹介)
- 以下をターミナルに入力
git push heroku master
- 上記が問題なく終わったら、以下をターミナルに入力する
heroku openここで
We're sorry, but something went wrongというエラーが出たら、
次のコードをターミナルに入力したらどうだろうか。heroku run rails db:migrate(ちなみに自分も上記のようなエラーが出た時、こちらを入力したら、エラーがなくなった)
(参考)自動デプロイ方法
(参照URL)
https://qiita.com/sho7650/items/ebd87c5dc2c4c7abb8f0#%E8%87%AA%E5%8B%95deploy%E3%81%A3%E3%81%A6
herokuのダッシュボードの
deployをクリック
deployment methodのgithubのマークをクリック少しすると、
Connect to GitHubというのが出てくるので、これをクリックそうしたらGitHubの許可画面が出てくるので、
Authorize herokuをクリックこれで問題がなければ、検索画面へと移行する
reponameには自分のアプリのリポジトリ名を入力し、入力完了したら、Searchボタンをクリックするそうしたら、自分のアプリのリポジトリ名が検索欄の下に出るのでその右にある
Connectボタンをクリックする
Automatic deploysとManual deproyが表示されたら成功
Automatic deploysのところに、Wait for CI to pass before deployという項目があり、そこにチェックマークを付けて、Enable Automatic Deploysを押すと、自動デプロイ設定が完了する最後に
今回herokuのデプロイについて簡単な流れを書いたが、ミスがなければ、比較的容易にデプロイできると感じた。
ただし、git pushすることを忘れたりすると、エラーでデプロイできないなどするので、git push heroku masterを行う際は、ちゃんとgit pushを忘れずにした方がいいと思った。
- 投稿日:2020-09-16T17:54:32+09:00
【Rails】この記事を「devise 名前 ログイン」で調べたあなたへ贈る
この記事を「devise 名前 ログイン」で調べたあなたへ贈る
はじめに
yukiと申します。DMMWEBCAMPにお世話になって、今はWEBエンジニアをしつつ、自分で仲間を集めてサービス開発したり、プログラミングの家庭教師したり毎日エンジニアライフをエンジョイしています。
きっとあなたは「devise 名前 ログイン」でRailsのgem、Deviseをを用いて名前とパスワードを使ってログインする方法を調べに来てくれたんだと思います。
そんなあなたのために、今日はできるだけ関連記事の中で一番わかりやすく、そしてあなたにとってプラスになるように「なぜそれをやるのか」という部分まで解説します。
よければ最後まで頑張ってご覧ください。
なぜなら、あなたは過去の私なのだから・・・
記事の対象者
- deviseを使ってログインする方法が知りたい方
- Railsの環境構築は終わっており、deviseでmailとpasswordでのログイン実装をした経験がある方
修正方法
それでは、早速方法と理由について述べます。
順番通りに、かつ見落としがないように気をつけてください。
また、名前とパスワードでログインすることを以下「名前ログイン」と呼びます。Deviseをインストールして、初期設定をする
まずは、大前提としてdeviseの設定をしていきましょう。
Gemfileにdeviseを追記し、インストールする
Gemfileの一番下に以下の記述をして
gem 'devise'
bundle installを実行してください。
これでプロジェクトの中でdeviseを扱えるようになりました。deviseの初期設定
bundle installが終わったのちに、deviseをセットアップしていきます。
rails g devise:installを実行してください。この初期設定はデバイスの設定をするファイルを作るために必要です。
これを作っておけば、後で名前ログインするために必要な設定をできるようになります。ログインするために必要なUserテーブルを作成する
次に、そもそも名前ログインに必要なユーザーのデータを保存するテーブルを作成します。
rails g devise Userを実行してください。これは、
rails g model Userとはちょっと違っていて、deviseの機能を通じてUserのモデルやらマイグレーションファイルやらを作ってくれます。
なぜそんなことをするかというと、必要なカラム(emailなどの情報を入れる場所)を自動的に作ってくれるからです。Userのモデルを作るマイグレーションファイルに、nameカラムを追加する
先程のコマンドを実行すると、db/migrate/のなかに、マイグレーションファイルができていると思います。
rails db:migrateを行えばdeviseの機能でログインする際に最低限必要なUserテーブルができるのですが、今回は「名前ログイン」をできるようにしたいので、nameカラムを追加していきます。
理由は単純で、ユーザーの名前を入れておく場所が初期設定のままだと存在していないからです。こんな感じで追記してあげてください。
※ファイル名は若干各々で作成日時によって変わります。db/migrate/2020......devise_create_users.rb# 中略 ## Lockable # t.integer :failed_attempts, default: 0, null: false # Only if lock strategy is :failed_attempts # t.string :unlock_token # Only if unlock strategy is :email or :both # t.datetime :locked_at t.string :name # ここに追加したよ!!!!!!! t.timestamps null: false # 中略
rails db:migrateを実行これでnameカラムを持つUserテーブルが作成できました。
新規登録の際に、名前を登録できるように必要なviewファイルを可視化させる
これで保存する準備はできたので、新規登録画面でnameの情報を送れるようにしていきます。
しかし、今の状態だとdeviseの新規登録やログインに使う画面を編集することができません。なぜなら、ファイルが見えないからです。実際に編集できるようにするために
rails rails g devise:viewsこれで、app/views以下にdeviseのフォルダ一式が作成され、deviseの新規登録やログイン画面を書き換えられるようになりました。
肝心のファイルはどれかといいますと、
- 登録はregistrationsの中のnew.html.erb
- ログインはsessionsの中のnew.html.erb
です。
新規登録の画面に、nameを贈るフォームを追加する
現在、新規登録の画面からはemailしか送れない状態になっています。
app/views/users/registrations/new.html.erb<h2>Sign up</h2> <%= form_for(resource, as: resource_name, url: registration_path(resource_name)) do |f| %> <%= render "users/shared/error_messages", resource: resource %> <!-- ここから追加 --!> <div class="field"> <%= f.label :name %><br /> <%= f.text_field :name, autofocus: true, autocomplete: "name" %> </div> <!-- ここまで追加 --!> <div class="field"> <%= f.label :email %><br /> <%= f.email_field :email, autofocus: true, autocomplete: "email" %> </div> <--! これより下は省略 !-->ここまでできたら
rails sを実行して、localhost:3000/users/sign_upにアクセスしてください。名前のフォームもできていたらOKです。ただし・・・
新規登録の際に、nameの情報を送って良いように許可する
上の手順を行った際に、多分新規登録には成功してRailsの初期画面が現れますが、コマンドラインにこのような不穏な文字が出ているはずです。
Unpermittted parameter: :nameこれは:nameという値が送信を許可されていないよ。という意味です。
この記事を読んでいる人はきっと「ストロングパラメーター」という言葉を聞いたことがあると思いますが、まさにそれです。標準では、:nameの値を贈ることが許可されていないので、これを許可してあげましょう。
app/controllers/application_controller.rbapplication_controller.rb class ApplicationController < ActionController::Base before_action :configure_permitted_parameters, if: :devise_controller? private def configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up,keys:[:email]) end endこちらのファイルは、アプリケーション全体に関わるコントローラーだと思っていただいて大丈夫です。ここに書いたものがアプリケーションの処理を実行する際に適用されます。
before_action :configure_permitted_parameters, if: :devise_controller?は、わかりやすくいいますと、「もし、deviseの処理を行う場合、configure_permitted_parametersというものを実行してね」という意味です。じゃあ
configure_permitted_parametersとは何かというと、その下に定義されているメソッドです。devise_parameter_sanitizer.permit(:sign_up,keys:[:name])というやつですね。こちらもわかりやすくざっくり解説すると、「deviseゥ、sign_upする時は:nameという値を送信するのも許可しろォ!だが、その他不正な値だけは許可しないィ!」という意味です。
※emailとかはデフォルトで許可されているので大丈夫です。
もう、コマンドラインにさっきのエラーメッセージは出ていないはずです。ログアウトできねえよ!って方は、cookieを削除するとできます。
MACの場合、URLの横の「i」ボタンを押してみてください。ログインの画面の、emailを送るフォームを、nameを送るフォームに変更する
app/views/users/sessions/new.html.erb<h2>Log in</h2> <%= form_for(resource, as: resource_name, url: registration_path(resource_name)) do |f| %> <%= render "users/shared/error_messages", resource: resource %> <!-- ここから追加 --!> <div class="field"> <%= f.label :name %><br /> <%= f.text_field :name, autofocus: true, autocomplete: "name" %> </div> <!-- ここまで追加 --!> <!-- ここから削除 --!> <div class="field"> <%= f.label :email %><br /> <%= f.email_field :email, autofocus: true, autocomplete: "email" %> </div> <!-- ここまで削除 --!> <--! これより下は省略 !-->emailに関するフォームを削除して、nameのフォームを追加しました。
−−−
−−
−
はい、できません。いらっとしますね。
コマンドラインを見てみると、またUnpermitted parameters: :nameが出ています。
では、こちらを修正していきましょう。ログインに使う値をemailからnameに変更する
今回は、新規登録の時と同様にapplication_controllerに何かを登録すれば良いかというと、実は違います。今回ここで弾かれる要因を直すには、deviseの設定をしているファイルを見に行く必要があります。
思い出してください。
rails g devise:installした時に作ったファイルですね。
VSCcodeを使っている方は、cmd(ctrl) + pを押すとファイル名で検索できますよ。
ウジャウジャといろんな設定が書いてあるファイルが開きますが、大丈夫です。
cmd + fで文字列を検索できるのですが、config.auまで入力してみてください。
# config.authentication_keys = [:email]という記述が見つかるはずです。
deviseはここで、オーセンティケーションに使う鍵(つまりは認証ですね、ログインに使う値だと思ってください)を設定しているので、ここのコメントアウトを外して、emailをnameに変えてあげましょう。
# config.authentication_keys = [:name]ということですね。では、これでログインできるか試してみましょう!
きっと、エラーが出ずに成功できると思います。まとめ
- deviseのインストールと設定をしっかりしよう
- userのマイグレーションファイルにnameカラムを追加しよう
- 新規登録時nameの値が送れるように許可しよう
- ログイン時nameを使ってログイン(正式には認証してもらえるように)できるようにdeviseを設定しよう
といった感じです。
これからも勉強する際は、ぜひ「なんでその記述を書くと思い通りに動くのか」突き詰めて考えてみてください。
応援しています。何か困ったことがあれば、DM待っています〜。
こんな記事も書いてますという紹介
【卒業生】DMMWEBCAMPに通おうと思っている人に伝えたいこと
会社の紹介
私は現在、株式会社ダイアログという物流×ITの会社に勤務しております。
2020年9月現在、エンジニアの募集はしていませんが、他にも様々な職種を募集しているので、Wantedlyのページをご覧ください。いつか自分のQiitaきっかけで応募してくださる方がいたら、嬉しいなと思います。
- 投稿日:2020-09-16T16:52:50+09:00
リーダブルコード読んだのでメモ
未経験エンジニアとして実務に入ったので、リーダブルコードを読んだのでそのメモ。
1章 理解しやすいコード
Point
コードは理解しやすくしなければならない。
コードは他の人が最短時間で理解できるように書かなければいけない。
6ヶ月後の自分がみて、理解しやすいコードかが大事!
コードは短くした方がいいけど、理解するまでにかかる時間を短くすることが大事。
このコードは理解しやすいか?
を一歩下がって自問自答することが大事!
2章 名前に情報を詰め込む
Point
名前に情報を詰め込む
名前を見ただけで情報を読み取るようにすること
・明確な単語を選ぶ
→空虚な単語は避けるべき。「get」とかはあまり明確な単語ではない。
どこからのget?とわからなくなる。例えば、getではなく、状況に応じてfetch/downloadなどを使う。
汎用的な名前を避ける
→tmpやfooなどの空虚な名前は避けよう。
具体的な目的や値を表す名前をつけよう。
戻り値retval×
sum_squares○なので、tmp/it/retvalなどの汎用的な名前を使うときはそれ相応の理由を用意しよう!
単なる怠慢でこれを使うのはナンセンス!「命名力」!抽象的な名前よりも具体的名前を使う
→より適切な名前を使う
接尾辞を使って情報を追加する
→絶対に知らせないといけない大切な情報の場合「変数名」に追加すればいい。
値の単位など、delay→delay_secsなどより明確に。
セキュリティの面でもそうだ。
password→plaintext_password(passwordはプレインテキストなので、処理前に暗号化すべき)変数の意味を理解してもらわないといけないところに属性を追加しておく。
名前の長さを決める
→単純に覚えにくいし、画面占領してしまう、コードの量が増える。
スコープが小さければ短い名前でもいい。
識別子のスコープが大きければ、名前に十分な情報を詰め込んで明確にする必要がある。
省略も行いがちだが、プロジェクト固有の省略形はダメ。新しいメンバーは理解できない。名前のフォーマットで情報を伝える
→アンダースコア・ダッシュ・大文字を使って名前に情報を詰め込むこともできる。
どんな規約を使うかどうかはチームで決める。一貫性が大事。例えば、クラスのメンバ変数にアンダースコアを付けてローカル変数と区別する。
3章 誤解されない名前
名前が「他の意味と間違えられることはないだろうか?」と自問自答する。
積極的に誤解を探しにいく。限界値を含めるときは、minとmaxを使う。
範囲を指定するとくはfirstとlastを使う。
包含・排他的範囲にはbeginとendを使う。
ブール値の変数やブール値を返す関数の名前を選ぶ時には、trueとfalseの意味を明確に。
危険な例
bool read_password = true;
2つの解釈がある
・パスワードをこれから読み取る必要がある
・パスワードをすでに読み取ってる。ここでは、readの代わりにneed_passwordを使った方がいい。
まとめ
最前の名前とは、コード読んでいる人が君の意図を正しく理解できること。
名前を決める前に、反対意見を考えるなどして誤解されない名前かどうかを確認。
単語に対するユーザーの期待にも注意。例:get()やsize()には軽量なメソッドが期待されている。4章 美しさ
優れたコードは「目に優しい」物でなければならない。
3つの原則
・読み手が慣れているパターンと一貫性のあるレイアウトを使う。
・似ているコードは似ているように見せる。
・関連するコードをまとめてブロックにする。見た目の美しいコードの方が使いやすいのは明らか。
さっと流し読みできれば、誰にとって読みやすいコードができる。コードの見た目をよくすれば、表面上の改善だけではなくコードの構造も改善できる。
縦の線を真っ直ぐにしておく
列を整列させれば、コードを読みやすくなることがある。
これをしておけば、タイプミスが見つけやすくなる。宣言をブロックにまとめる
→コードの概要を素早く把握してもらうために、グループに分け「単位」を作ればいい。理解しやすいコード。
ただし、重要なのは一貫性のあるスタイルは「正しい」スタイルよりも重要ということ。
正しく読みやすく書いていても、全体的にバラバラのスタイルで書いていれば見にくく読みにくくなる。まとめ
一貫性と意味のあるやり方でコードを「整形」すれば素早く簡単にコードを読むことができる。
・複数のコードブロックで同じようなことをしていたら、シルエットも同じような者にする
・コードの「列」を整列すれば、概要が把握しやすくなる
・ある場所でA/B/Cのように並んでいたものを、他の場所でB/C/Aのように並べてはいけない。意味のある順番を選んで常にその順番を守る
・空行を使って大きなブロックを論理的な「段落」に分ける。5章 コメントすべきことを知る
価値のあるコメントと価値のないコメント
コードからすぐにわかる情報は書かない。
コメントのためのコメントを書かない。
ひどい名前は、コメントをつけずに名前を変える
→コメントはひどい名前の埋め合わせに使うものではない。それなら、より明確な名前に変える。では、何をコメントとして書くべきか?
→優れたコメントは「考えを記録する」ためのもの。コードを書いているときの「大切な考え」を書くべきコードが汚い理由をコメントに書いてもいい。
誰かに修正を促すようなコメント。コードの欠陥にコメントをつけよう。
→これからコードをどうしたいのかを自由にコメントに書くこと。
→コードの品質を知らせたり、改善の方向を示すことができる。定数にコメントを付ける。
→定数を定義するときには、その定数が何を意味するのか?なぜその「値」を持っているのかという背景が存在する場合が多い。
→定数の名前を決めた時に頭の中で考えていたことをコメントで記録することが大切。読み手の立つ場になって考える
質問されそうなことを想像する。
そこにコメントをつけて回答を明示しておく。
ハマりそうな罠を告知する。
→コードを使うときに直面する問題を前もって予測し、コメントで告知しておく。
全体像のコメント
新しいチームメンバにはコードを理解してもらわないといけない。
クラスはどのように連携しているのか?など
これは、コードに書くべきコメントだ。短い適切な文書でいい。何もないよりマシ。
要約コメント
低レベルのコードをうまく要約したコメントも大事。
優れたコード > ひどいコード+優れたコメント
コードを理解するのに役立つものなら何でもいいから書こう!
ライターズブロックを乗り越える
ライターズブロック=行き詰まってしまって文章が書けないこと
これを乗り越えるためには、とにかく書き始めるしかない。
自分の考えていることを書き出してみて、そのままコメントにする。
コメントを書く作業3ステップ
1、頭の中にあるコメントをとにかく書き出す。
2、コメントを読んで、改善が必要なものを見つける。
3、改善する。まとめ
コメントの目的は、コードの意図を読み手に理解してもらうこと。
コメントすべきではないこと
・コードから抽出できること
・ひどいコードを補う「補助的なコメント」→コメントを書くのではなく、コードを修正するコメントすべきこと
記録すべき自分の考え
・なぜコードが他のやり方ではなくこうなっているのかをかく
・コードの欠陥をTODO:、XXX:などの記法を使って示す
・定数の値にまつわる背景読み手の立場になって考える
・コードを読んだ人が「え?」と思うところを予想してコメントを付ける
・平均的な読み手が驚くような動作は文書化しておく
・ファイルやクラスには「全体像」のコメントを書く
・読み手が細部にとらわれないように、コードブロックにコメントをつけて概要をまとめる。6章 コメントは正確で簡潔に
- 投稿日:2020-09-16T16:31:58+09:00
ページ遷移後はJSが読まれず、ロードするとJSが読み込まれるという不具合に直面した件
状況
Railsを利用しフリマアプリ開発中に体験したエラーです。商品出品機能実装中、価格入力でイベント発火し出品する商品の手数料を自動計算し表示する機能を実装しました。
自動表示されることを確認後、トップページから商品出品ページのリンクに飛び商品出品機能が動作しているか確認していると、価格を入力しても手数料が表示されないという不具合を発見しました。
コードの記述等のチェックをしていると、いつの間にか手数料の自動表示機能が復活しているという現象に見舞われパニックを起こしました。
解決の糸口
色々やっていて、いつの間にか機能が復活なんてありえないので、コードを1つずつ書き換えたりボタンを1つ押す毎に挙動がどう変化するのか試したところ、どうやらページ遷移した直後のページではJavaScriptが読み込まれず、リンク先に飛んだ後にもう1度ページ更新をするとJavaScriptが読み込まれているということが発覚しました。
window.addEventListener('load',function(){ この中に手数料表示のコード });ページ読み込みが全てのJavaScriptのイベント発火に必要なので、ページを飛んだ時にはloadが読み込まれない仕様なのかと考えました。しかし、調べていくと、loadはページ遷移しただけでも読み込まれるイベントであるとのことで、ますますJSが動かないことに混乱することになりました。
解決
結局JavaScriptのコード自体には何も問題はありませんでした。そこで、そもそもJavaScriptがどのように読み込まれているか確認をすることにしました。railsでJavaScriptを読み込む流れとしては以下のような感じです。
application.html.erbの共通のビューのheadタグの中で読み込んでいます。
<head> <title>Furima</title> <%= csrf_meta_tags %> <%= csp_meta_tag %> <script type="text/javascript" src="https://js.pay.jp/v1/"></script> <%= stylesheet_link_tag 'application', media: 'all'%> <%= javascript_pack_tag 'application' %> ←この記述でapplication.jsを読み込んでいます。 </head>app/javascript/packs/application.jsでrailsで使うJavaScriptをまとめて読み込んでいます。
中略 require("@rails/ujs").start() require("turbolinks").start() ←不具合の原因(下記で説明) require("@rails/activestorage").start() require("channels") require("../fee.js") require("../card.js") 中略読み込んでいるものを1つずつ調べていくと、ようやく原因が判明しました。
不具合の原因はturbolinksをapplication.jsで読み込んでいることでした。turbolinksは大規模な開発等では読み込むJavaScriptが多くなるので、それを効率よく読み込めるようにする為のものみたいです。しかし、悪い部分もあってページ遷移した直後にloadのイベント発火を読み込んでくれない現象を起こすことがあるようです。
railsではアプリを作成するとapplication.jsでturbolinksを読み込む記述が自動で記述されてしまいます。turbolinksは大規模サイトでJavaScriptがすぐ読まれるようにする為のもので個人でポートフォリオを作るような場合は不要であるので、こちらをコメントアウトして読まれなくすると、ページ遷移後にJavaScriptが起動しないという不具合を解消することができました。
大規模な開発だとデフォルトで読み込んでいるturbolinks等も別のものに書き換えたりして使うこともあるらしいです。
まだまだ初学者で間違えた知識を書いている可能性もあるので、過ちがあれば教えていただけると嬉しいです。
拙い文章であったかと思いますが、ありがとうございました。
- 投稿日:2020-09-16T15:31:19+09:00
ストロングパラメーターを設定する際のrequireについて
動作環境
Ruby 2.6.5
Rails 6.0.3.2ストロングパラメーターを設定する際にrequireが必要な場合と必要でない場合の違いについて、理解するのに時間がかかってしまったので投稿してみました。
requireが必要な場合
new.html.erb<%= form_with model:@hoge, local: true do |f| %> <%= f.text_area :fuga %> <%= f.submit "投稿する" %>hoges_controller.rbdef create @hoge = Hoge.create(hoge_params) end private def hoge_params params.require(:hoge).permit(:fuga) end上記の場合、ストロングパラメーターにrequire(:hoge)が必要となります。なぜなら、投稿するをクリックした際に送信されるparamsのhogeの中にfugaが含まれているためです。
実際に、binding.pryを使ってcreateアクション内でparamsを確認すると、以下のようになります。fugaには「例」と入力しているとします。{"authenticity_token"=>"+wXNK4Z3C0wrq4AfslPS5zl/2LSUE6BvV+23hQpkHryrsVzPb0siDIkarIsNYLK2R502fuXlqQ==", "hoge">={"fuga"=>"例"},"commit"=>"投稿する", "controller"=>"hoges", "action"=>"create"}
requireが必要でない場合
new.html.erb<%= form_with url:hoge_path, local: true do |f| %> <%= f.text_area :fuga %> <%= f.submit "投稿する" %>hoges_controller.rbdef create @hoge = Hoge.create(hoge_params) end private def hoge_params params.permit(:fuga) end上記の場合、ストロングパラメーターにrequireが必要ないです。なぜなら、投稿するをクリックした際に送信されるparamsの中にhogeが存在せず、直接fugaが含まれているためです。
実際に、binding.pryを使ってcreateアクション内でparamsを確認すると、以下のようになります。fugaには「例」と入力しているとします。{"authenticity_token"=>"+wXNK4Z3C0wrq4AfslPS5zl/2LSUE6BvV+23hQpkHryrsVzPb0siDIkarIsNYLK2R502fuXlqQ==", "fuga"=>"例","commit"=>"投稿する", "controller"=>"hoges", "action"=>"create"}
上記の通り、先ほどと違ってhogeが存在しないことがわかります。
まとめ
つまり、ストロングパラメーターのrequireとは、paramsの中にある入力したもの(今回の場合はfuga)をある要素(今回の場合はhoge)から引っ張り出すために使われていることがわかりました。
雑にまとめると、form_withでmodelを指定している時はrequireが必要。指定していない時はrequireが必要でないと言えると思います。
- 投稿日:2020-09-16T15:06:09+09:00
Rails - Jquery でEXCELシート情報取得
下記のソースで取得できるはず!!!
{
①include script
src="" class="autolink">https://cdnjs.cloudflare.com/ajax/libs/jqueryui/1.12.1/jquery-ui.min.js">
src="" class="autolink">https://cdnjs.cloudflare.com/ajax/libs/xlsx/0.8.0/jszip.js">
src="" class="autolink">https://cdnjs.cloudflare.com/ajax/libs/xlsx/0.8.0/xlsx.js">②自分作るScript:
var ExcelToJSON = function() {
this.parseExcel = function(file) {
var reader = new FileReader();
reader.onload = function(e) {
var data = e.target.result;
var workbook = XLSX.read(data, {
type: 'binary'
});
console.log(workbook)
$('#sheet_name').empty()
$('.txt_sheet').empty()
var itemHtml = ''
workbook.Workbook.Sheets.forEach(function(sheet) {
itemHtml = itemHtml + '' + sheet.name + ''
})
$('#sheet_name').html(itemHtml)
$('.txt_sheet').html(itemHtml)
};
reader.onerror = function(ex) {
console.log(ex);
};
reader.readAsBinaryString(file);
};
};function handleFileSelect(evt) {
var files = evt.target.files;
var xl2json = new ExcelToJSON();
xl2json.parseExcel(files[0]);
$('#template_file').val($(this).val().replace(/^.*\/, ""));
}③ファイルコントロールChangeイベント追加
document.getElementById('upload_file').addEventListener('change', handleFileSelect, false);
}
※upload_file →file_field_tag
- 投稿日:2020-09-16T14:49:41+09:00
【Rails】SentryへPOSTリクエストのBody部分を送るようにする
デフォルトでは POSTリクエストのBody部分は送信しません。
以下の設定をすることで、Body部分も送るようになります。
Raven.configure do |config| config.processors -= [Raven::Processor::PostData] end参考
https://docs.sentry.io/platforms/ruby/configuration/options/
- 投稿日:2020-09-16T12:53:26+09:00
railsのバージョン指定について
該当箇所
現場で使えるRuby on Rails5 速習実践ガイドChapter3-1-3
$ rails _5.2.1_ new taskleaf -d postgresqlでバージョン指定してアプリを作成したのにサーバを起動するとrails のバージョンが5.2.4.4になってしまいました。
期待する動作
GemfileとGemfile.lockのバージョンを一致させて、サーバを起動するとrails のバージョンが5.2.1になること
取り組んだこと
バージョンはGemfile.lockに記述されているため、見てみるとやはりrails のバージョンが5.2.4.4になっていました。それに対し、Gemfileは
Gemfilegem 'rails', '~> 5.2.1'とあり、なんでGemfileとGemfile.lockでバージョンが違うんだろう?と思いました。
調べていくうちに、原因はGemfileの中のgem ‘rails’, ‘~> 5.2.1’の部分だとわかりました。
gem ‘rails’, ‘~> 5.2.1’はgem ‘rails’, ‘>= 5.2.1’, < 5.3.0'を表すためGemfile.lockのバージョンが5.2.4.4になってしまっていたのです。
Gemfile.lockも5.2.1にするためにはGemfileでgem ‘rails’, ‘5.2.1’でがっちり指定する必要がありました。Gemfilegem 'rails', '5.2.1'に修正して、
$ bundle updateこれで正しくバージョンが指定されました!
- 投稿日:2020-09-16T12:31:49+09:00
rails new アプリ名でアプリが作成されない
該当箇所
Railsチュートリアル第3章
$ rails _6.0.3_ new sample_app
を実行すると、エラーが起こりアプリが作成されない。期待する動作
$ rails _6.0.3_ new sample_appコマンドが正常に動作し、アプリが作成されること。取り組んだこと
$ rails _6.0.3_ new sample_app Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/Yarnがインストールされていないようです。Yarnをインストールしてくださいと言われました。
なので、HomebrewのbrewコマンドでYarnをインストールします。$ brew install yarn bash: brew: command not found次は、brewコマンドなんてないよと言われました。
ということはHomebrewがないのだと思い、Homebrewをインストールします。$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" Warning: /home/linuxbrew/.linuxbrew/bin is not in your PATH.PATHが通っていませんよ、と言われました。
なので、PATHを通らせます。$ echo 'export PATH="/home/linuxbrew/.linuxbrew/bin:$PATH"' >> ~/.bashrc source ~/.bashrcこれでHomebrewがインストールされYarnもインストールされました。
$ rails _6.0.3_ new sample_appちゃんとアプリが作成されました!!
結論
$ rails new アプリ名コマンドでアプリを作成するためには、Yarnをインストールする必要がある。
また、Yarnをインストールするためにはnpmでインストールする方法などもありますが、Homebrewでインストールできる。参考
- 投稿日:2020-09-16T11:48:29+09:00
現場で使えるRuby on Rails5速習実践ガイド まとめ
現場で使えるRuby on Rails5速習実践ガイド一冊を一通り習い終えたので、なるほど!と思ったことをメモしました。
用語整理
rbenv:
Rubyのバージョン管理を簡単にしてくれるツール。
開発においてプロジェクトに合わせてバージョンを使い分ける必要があるため、バージョン管理は重要。動作の速さやBundlerによるgem管理の使い勝手の良さが評価されている。rbenvのインストールにはHomebrewが便利で、Homebrewの利用にはXcodeが必要。
つまり、Xcode -> Homebrew -> rbenvの順でインストールを行う。RDB:
Relational DataBaseの略。
データを表で管理してわかりやすく関連性を示すデータベースのこと。
普段使うMysqlやPostgresqlなども含まれる。アセットパイプライン:
記述したCSSやJavaScriptをブラウザにとって最適な形にする処理のこと。
production環境では処理速度や通信量を重視する点からアセットの連結・最小化が行われるのに対し、devlopment環境ではデバックのしやすさを追求するためアセットの連結・最小化が行われない。app/views/layouts/application.html.slim= stylesheet_link_tag 'application', media: 'all' = javascript_include_tag 'application'共通ビューでのヘルパーメソッドstylesheet_link_tag, javascript_include_tagの記述によってブラウザがCSSやJavaScriptのアセットを読み込んでいる。
Yarn:
JavaScriptのパッケージマネージャ(RailsでいうGemのパッケージマネージャはBundler)のこと。
RailsがサポートするWebpack,Vue.js,React.jsなどのフロントエンドのモジュールをRailsから管理する役割を担っている。Yarnはデフォルトで入っていないため、自分でインストールしなければいけない。
Webpacker:
Railsのgemの一つで、Webpackを使ったアセットの管理を簡単にする。
WebpackerはYarnをインストールしていなければ使えない。〇〇と△△の違い
<renderとredirect_toの違い>
renderはアクション直後にviewを返すのに対し、redirect_toはアクション後に別のURLへとブラウザがリクエストし直す。
アクション内でrenderやredirect_toを記述しなくてもviewが表示されるのはRailsが勝手にアクション名と同じ名前のviewを返してくれるからである。<saveとsave!の違い>
saveメソッドは検証エラーがあればfalseを返し、そのエラーの中身はerrorsメソッドで見ることができる。
save!メソッドは検証エラーがあればfalseでなく例外を発生させるため、絶対保存できるはず!という時に使うのが妥当。
つまり、if文の分岐処理として使う場合はエラーでなくtrueかfalseを返したいため、!はつけない。<findとfind_byの違い>
findメソッドはデータがない時にエラーActiveRecord::RecordNotFoundを発生する。
find_byメソッドはデータがない時にnilを返す。よってログイン処理ではログインしていない状態、すなわちsession[:user_id]がない時にエラーでなくnilを返したいのでfind_byメソッドを使う。
その他のメモ
ルーティングについて
URLとHTTPメソッドの組み合わせからコントローラのアクションを繋げる役目だけでなく、
一つのルートはrails routesと打った時に出てくるPrefix部分に記述されているURLパターン名を用いてURLを簡単に作成するためのヘルパーメソッドを作り出している
link_toメソッドの第2引数の(URLパターン名)_pathはルーティングで生成されたURLヘルパーメソッドである。マイグレーションについて
マイグレーションファイルはバージョンの上げる記述だけでなく、上げ下げどちらの記述もしたほうがいい。
changeメソッドではバージョンを上げるコードだけの記述から、Railsが勝手にバージョンを下げるロールバック処理も行ってくれるようになっている。
$ rails db:migrate:redoコマンドはバージョンを一回下げてまた戻す処理をしてくれるためロールバックができるか確認することができる。これを常に確認する癖をつけておいたほうがチーム開発では特にトラブルへの対応が楽になる。Cookieの仕組みについて
まず、ブラウザの初めてのリクエストに対して、サーバはCookie情報を含めたレスポンスを返すことでブラウザはサーバのドメイン情報とそのCookie情報を保存する。
次回以降、サーバはブラウザからのリクエストに含まれるCookie情報から以前の情報を取得して更新する。更新したCookie情報はブラウザに渡され保存される。
この繰り返しでブラウザ側で情報を更新し続けている。学び終えた全体の感想
とにかくRailsが勝手にやってくれていることが多いな!というのが印象的でした。便利であるからこそその裏側は知っておくべきだと改めて感じました。また、学んでいてRuby on Railsの勉強というよりRuby on Railsによる開発の勉強というような感覚でした。実践的な開発の流れであったり仕組みが細かく記述されていたためとても勉強になりました。基礎学習としておすすめです!
- 投稿日:2020-09-16T11:30:02+09:00
チームで共有するための『Rails 6 x MySQL 8』Docker環境構築手順
今回はRails 6とMySQL 8を組み合わせたWebアプリケーションのDocker環境を構築する手順について紹介します。
Rails 6からwebpackerが標準でインストールされるようになったり、MySQL 8からユーザー認証の方式が変わったりと環境構築でつまる部分がいろいろとあったため参考になればと思います。
複数人でもスムーズに開発ができるようにするためリモートリポジトリからcloneしてきたらdocker-compose upするだけでアプリケーションが立ち上がるという環境をゴールにします。
各種バージョンは以下の通りです。
- Ruby on Rails: 6.0.3.2
- Ruby: 2.7.1
- MySQL: 8.0.21
実行環境はDocker Desktop for Mac(バージョン 2.3.0.4)を利用しています。
Railsアプリケーションの準備
ディレクトリの作成・移動をします。
今回作成するRailsアプリケーション名はsample_appとします。$ mkdir sample_app && cd $_rubyイメージを利用してローカル環境にGemfileを作成します。
-vはバインドマウント(ホストとコンテナのディレクトリの同期)のオプションです。ホストのカレントディレクトリとコンテナのワークディレクトリを同期させることで、コンテナ上で作成されるファイルをホストに配置します。
$ docker run --rm -v `pwd`:/sample_app -w /sample_app ruby:2.7.1 bundle init作成されたGemfileの
gem "rails"の部分をアンコメントし、railsのバージョンを指定します。Gemfile# frozen_string_literal: true source "https://rubygems.org" git_source(:github) {|repo_name| "https://github.com/#{repo_name}" } - # gem "rails" + gem "rails", '~> 6.0.3.2'
rails newを実行するDocker環境を構築するためDockerfileを作成します。Rails 6ではアプリケーションを作成する際に
rails webpacker:installも実行されるのでyarnのインストールを忘れずにしましょう。
今回はnpmを利用してyarnをインストールします。DockerfileFROM ruby:2.7.1 RUN apt-get update -qq && \ apt-get install -y nodejs \ npm && \ npm install -g yarn # 作業ディレクトリを/sample_appに指定 WORKDIR /sample_app # ローカルのGemfileをDokcerにコピー COPY Gemfile /sample_app/Gemfile # /sample_appディレクトリ上でbundle install RUN bundle installDockerfileをビルドして作成されたイメージを利用してコンテナを起動し、コンテナ上で
rails newをします。$ docker build -t sample_app . $ docker run --rm -v `pwd`:/sample_app sample_app rails new . –skip-bundle --database=mysql
docker-compose.ymlを作成します。今回は説明を簡略化するため、rootユーザーでMySQLに接続しています。
一般ユーザーで接続をする場合はMySQLのイメージに対して以下の環境変数を設定する必要があります。
環境変数 内容 MYSQL_USER ユーザー名 MYSQL_PASSWORD ユーザーパスワード データベースの情報は
mysql_dataという名前付きボリュームを作成して永続化します。docker-compose.ymlversion: '3' services: web: # Ruby on Railsが起動するコンテナ build: . ports: - '3000:3000' # localhostの3000ポートでアクセスできるようにする volumes: - .:/sample_app # アプリケーションファイルの同期 depends_on: - db command: ["rails", "server", "-b", "0.0.0.0"] db: # MySQLが起動するコンテナ image: mysql:8.0.21 volumes: - mysql_data:/var/lib/mysql # データの永続化 command: --default-authentication-plugin=mysql_native_password # 認証方式を8系以前のものにする。 environment: MYSQL_ROOT_PASSWORD: 'pass' MYSQL_DATABASE: 'sample_app_development' volumes: mysql_data: # データボリュームの登録上記の
docker-compose.ymlの補足説明をします。MySQLのDockerイメージでは
MYSQL_DATABASEに設定された名前のデータベースを作成してくれます。
Ruby on Railsのdevelopment環境では[アプリケーション名]_developmentというデータベースを利用するため、sample_app_developmentをMYSQL_DATABASEに登録しています。
これでrails db:createを実行しなくてもdevelopment環境のデータベースを用意できます。MySQL 8からは認証方式が
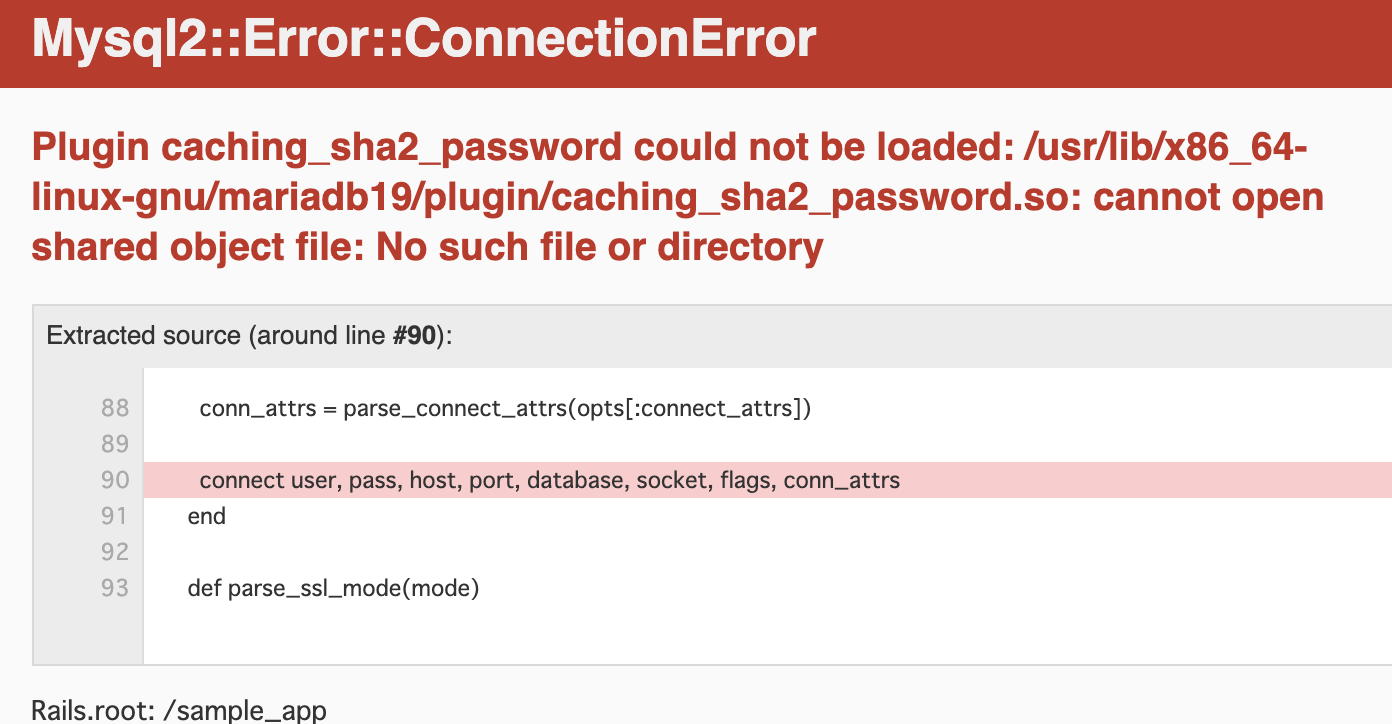
mysql_native_passwordからcaching_sha2_passwordに変更されました。
MySQL 8標準のcaching_sha2_passwordの認証方式だとデータベースへ接続できず、Railsアプリケーション起動時に以下のようなエラーメッセージが表示されてしまいます。Mysql2::Error::ConnectionError Plugin caching_sha2_password could not be loaded: /usr/lib/x86_64-linux-gnu/mariadb19/plugin/caching_sha2_password.so: cannot open shared object file: No such file or directory
そこで、
--default-authentication-plugin=mysql_native_passwordで以前のmysql_native_passwordの認証方式を利用するようにしています。次にRuby on Railsのデータベース接続設定を行います。
config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: pass # (今回はrootなので)MYSQL_ROOT_PASSWORDと一致させる host: db # データベースのコンテナ名を設定するRailsアプリケーションの起動確認
Ruby on Rails 6とMySQL 8を組み合わせたDocker環境ができあがったので起動をしてみます。
$ docker-compose up
localhost:3000にアクセスして以下の画面が表示されればOKです。
データベースのデータの永続化についても確認をしてみます。
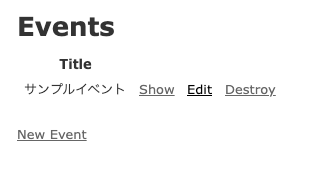
例としてscaffoldでeventに関する機能を作成します。$ docker-compose exec web rails g scaffold event title:string $ docker-compose exec web rails db:migrate
localhost:3000/events/newにアクセスし、例として『サンプルイベント』というレコードを登録してみます。
コンテナを削除・起動してもデータが残っていればOKです。
$ docker-compose down $ docker-compose up $ docker-compose exec web rails c > Event.last.title => "サンプルイベント"テスト環境用のデータベースの作成
MYSQL_DATABASEを利用してdevelopment環境のデータベースを作成することでdb:createを実行することなくRailsアプリケーションを起動できるようにしました。しかし、テストコードで利用するtest環境のデータベース(
[アプリケーション名]_test)が作られていないためこれだけでは開発環境としては不十分です。MySQLのDockerイメージでは
/docker-entrypoint-initdb.dにスクリプト(.sql、.sh、.sql.gz)を配置しておくとコンテナ起動時に実行してくれるという機能があります。1
この機能を活用してtest環境用のデータベースを作成します。スクリプトはアルファベット順で実行されるため、スクリプト間に依存関係がある場合はファイル名も意識してつけるようにしておきましょう。
$ mkdir docker-entrypoint-initdb.d && cd $_ $ vim 00_create.sql00_create.sql-- test環境用のデータベースを作成する CREATE DATABASE sample_app_test;なお、一般ユーザーのデータベースアクセス権は
MYSQL_DATABASEに設定したデータベースのみとなっています。
ですので、一般ユーザーでデータベースに接続する場合はデータベースの作成だけでなく、以下のようなアクセス権の付与も実行する必要があります。01_grant.sql-- webappという名前の一般ユーザーを利用する場合 GRANT ALL ON `sample_app_test`.* TO webapp@'%';作成したスクリプトをコンテナ上で読み取れるようにするためバインドマウントを追加します。
docker-compose.ymlversion: '3' services: web: build: . ports: - '3000:3000' volumes: - .:/sample_app depends_on: - db command: ["rails", "server", "-b", "0.0.0.0"] db: image: mysql:8.0.21 volumes: - mysql_data:/var/lib/mysql + - ./docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d command: --default-authentication-plugin=mysql_native_password environment: MYSQL_ROOT_PASSWORD: 'pass' MYSQL_DATABASE: 'sample_app_development' volumes: mysql_data:データベースが自動作成されることを確認
dbコンテナを削除・起動し、自動でデータベースが作られるか確認をしてみます。
[アプリケーション名]_developmentと[アプリケーション名]_testのデータベースが存在していればOKです。# データベースの永続化情報も削除して0からデータベースを作成する $ docker-compose down --volumes $ docker-compose up $ docker-compose exec db mysql -uroot -ppass -D sample_app_development mysql> show databases; +------------------------+ | Database | +------------------------+ | information_schema | | mysql | | performance_schema | | sample_app_development | | sample_app_test | ← test用のdbが作成されている | sys | +------------------------+ 6 rows in set (0.00 sec)Railsアプリケーションからも正常に接続できます。
$ docker-compose exec web rails c > ENV['RAILS_ENV'] => "development $ docker-compose exec web rails c -e test > ENV['RAILS_ENV'] => "test"『clone → docker-compose up』だけで環境が立ち上がるようにする
DockerでRailsの開発環境を構築する方法としてよく見かけるのが以下のようなパターンです。
# コンテナを立ち上げる $ docker-compose up # データベースの作成 $ docker-compose exec web rails db:create # テーブルのマイグレーション $ docker-compose exec web rails db:migrateRailsアプリケーションとデータベースをdocker-composeで連携させ、アプリケーションで利用するデータベースはコンテナ上で構築するという方法です。
上記の方法でも問題はないのですが、この場合だと初回起動時にデータベースとテーブルの作成をコンテナ上で手動実行する手間がかかります。
複数人でDocker環境を共有する時のことを考えると、リモートリポジトリからアプリケーションファイルをcloneしてきたら
docker-compose upをするだけで環境が立ち上がるのが理想です。共有メンバーに対して「初回起動時はデータベースの作成をコンテナ上で実施してね」とわざわざ伝えないといけない状況はできれば避けたいです。
ここからはリモートリポジトリからcloneしたら
docker-compose upするだけでRailsアプリケーションが起動できるようにするための設定を行います。yarn installをコンテナ起動時に実行する
開発環境ではバインドマウト(ホストとコンテナのディレクトリの同期)を利用したソースコードの同期がよく利用されます。
リモートリポジトリからcloneしてきたアプリケーションファイルは
package.jsonはありますが、node_modulesディレクトリはありません。
そのため、cloneしたあとdocker-compose upをするとnode_modulesがない状態のディレクトリがバインドマウントされます。その結果yarn installの実行を促すエラーが発生し、アプリケーションが起動できません。======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ======================================== To disable this check, please change `check_yarn_integrity` to `false` in your webpacker config file (config/webpacker.yml). yarn check v1.22.5 info Visit https://yarnpkg.com/en/docs/cli/check for documentation about this command.これを防ぐにはコンテナ起動時に
yarn installを実行する必要があります。
たとえば以下のようにすることでコンテナ起動時にyarn installを実行できます。docker-compose.ymlversion: '3' services: web: build: . + command: ["./start.sh"] - command: ["rails", "server", "-b", "0.0.0.0"] ports: - '3000:3000' volumes: - .:/sample_app depends_on: - db db: image: mysql:8.0.21 command: --default-authentication-plugin=mysql_native_password environment: MYSQL_ROOT_PASSWORD: 'pass' MYSQL_DATABASE: 'sample_app_development'start.sh#!/bin/bash -eu yarn rails server -b '0.0.0.0'シェルのパーミッションを変更します。
$ chmod 755 start.shコンテナを起動する際のコマンドでシェルを呼び出し、シェルの中で
yarn installを実行するようにしています。
yarn install実行後、rails serverでRailsアプリケーションが起動するため先ほどのエラーが解消されます。マイグレーションを自動実行できるようにする
テーブルのマイグレーションも
yarn installと同様、コンテナ起動時に呼び出されるシェルスクリプトで実行するようにします。start.sh#!/bin/bash -eu yarn + rails db:migrate rails server -b '0.0.0.0'しかし、
docker-compose.ymlのdepends_onを利用することでコンテナの起動順は制御できますが、コンテナの起動を待つということはできないため2、dbコンテナの起動準備が終わる前にdb:migrateが実行されるとマイグレーションが正常に行われません。マイグレーションの自動化をするにはdbコンテナの起動を待ってから
db:migrateが実行されるようにする必要があります。データベースの準備を待つ方法にはいくつかありますが、今回はwait-for-itを利用する方法を紹介します。
wait-for-it.shをカレントディレクトリに配置し、docker-compose.ymlを以下のようにするとデータベースの起動を待ってからスクリプトが実行されます。docker-compose.ymlversion: '3' services: web: build: . - command: [""./start.sh"] + command: ["./wait-for-it.sh", "db:3306", "--", "./start.sh"] ports: - '3000:3000' volumes: - .:/sample_app depends_on: - db db: image: mysql:8.0.21 command: --default-authentication-plugin=mysql_native_password environment: MYSQL_ROOT_PASSWORD: 'pass' MYSQL_DATABASE: 'sample_app_development'まとめ
以上でRails 6 + MySQL 8のDocker環境の構築手順の紹介を終わります。
コンテナ起動時にシェルを実行することで、複数人でDocker環境を利用する場合でもスムーズに開発環境を構築できるようにしました。
なお、今回はコンテナ起動時にシェルを呼び出すことでyarn installやdb:migrationを確実に実行するようにしましたが、コンテナ起動時のコマンドの制御はEntrykitと呼ばれるツールでも行えます。EntrykitについてはRailsのDocker環境にEntrykitを導入し、bundle installを自動実行させる方法で紹介していますので、興味のある方はご覧になってください。
- 今回のまとめ
- Rails 6からはyarnのインストールも事前に行う必要がある
- MySQL 8の認証エラーが発生した場合は標準の認証に戻すことで解決する
- コンテナ起動時にシェルを実行することでテーブル作成等の自動化が可能になる
さいごに
Twitter(@nishina555)やってます。フォローしてもらえるとうれしいです!
参考記事

- 投稿日:2020-09-16T09:36:41+09:00
EC2 + Rails「No space left on device @ io_write」のエラー対応手順
EC2 + Rails で発生したエラー「No space left on device @ io_write」の対応手順をまとめます。
環境
- AWS EC2
- Nginx
- Rails 5.2.3
背景
AWS EC2 で動いている Rails アプリにて、バックグラウンド処理が失敗していました。
アプリ自体は普通に動いてそうなので、SSH接続して
rails cしてみると、次のエラーが発生。No space left on device @ io_write - /tmp/execjs20200915-2847-13rxgx0js (Errno::ENOSPC)原因
エラーメッセージの内容は「ディスク容量に十分な空きがない」ということです。
容量を確認すると確かに空きがありませんでした。
df -h Filesystem Size Used Avail Use% Mounted on /dev/xvda1 7.7G 7.7G 72M 100% /「どうせログを消せば直るだろう」と思い、Rails のログを消してみましたが、引き続きエラーが出ます。EC2のインスタンスを再起動してみてもダメでした。
対応
原因ファイルの特定
何が悪さをしているかを突き止めるために、容量が大きいログファイルを探してみます。
sudo du -x -h / | sort -r -h | head -40 | grep log 802M /var/log 793M /var/log/journal/1d2e862128444912a1ce241cbc50a0b6 793M /var/log/journalすると
/var/log/journalが怪しいことがわかりました。journal とは
journal は systemd のログなので、消してしまっても問題ありません。
以下、systemd/ジャーナル より一部抜粋:
systemd/ジャーナル
systemd は、バージョン 38 から自前のログシステムである journal を搭載しています。
デフォルトで (/etc/systemd/journald.conf 内で Storage= が auto に設定されているとき)、journal は /var/log/journal/ へ書き込みを行います。journalctl で削除
systemd ジャーナルは
journalctlで操作できます。次のコマンドで、3日分のログを残し、それ以外は全て削除します。
sudo journalctl --vacuum-time=3days再度、ディスク容量を確認してみます。
df -h Filesystem Size Used Avail Use% Mounted on /dev/xvda1 7.7G 6.9G 835M 90% /10%削減でき、アプリも正常に動くようになりました。
journal の容量制限
今回のように journal の容量が膨れ上がらないように、設定ファイルを更新して容量を制限します。
sudo vi /etc/systemd/journald.conf/etc/systemd/journald.confSystemMaxUse=200M再起動して設定を反映させます。
sudo systemctl restart systemd-journaldこれで同じ問題は起きないでしょう!
References
- 投稿日:2020-09-16T09:36:41+09:00
EC2 + Rails `No space left on device @ io_write` のエラー対応手順
EC2 + Rails で発生したエラー「No space left on device @ io_write」の対応手順をまとめます。
環境
- AWS EC2
- Nginx
- Rails 5.2.3
背景
AWS EC2 で動いている Rails アプリにて、バックグラウンド処理が失敗していました。
アプリ自体は普通に動いてそうなので、SSH接続して
rails cしてみると、次のエラーが発生。No space left on device @ io_write - /tmp/execjs20200915-2847-13rxgx0js (Errno::ENOSPC)原因
エラーメッセージの内容は「ディスク容量に十分な空きがない」ということです。
容量を確認すると確かに空きがありませんでした。
df -h Filesystem Size Used Avail Use% Mounted on /dev/xvda1 7.7G 7.7G 72M 100% /「どうせログを消せば直るだろう」と思い、Rails のログを消してみましたが、引き続きエラーが出ます。EC2のインスタンスを再起動してみてもダメでした。
対応
原因ファイルの特定
何が悪さをしているかを突き止めるために、容量が大きいログファイルを探してみます。
sudo du -x -h / | sort -r -h | head -40 | grep log 802M /var/log 793M /var/log/journal/1d2e862128444912a1ce241cbc50a0b6 793M /var/log/journalすると
/var/log/journalが怪しいことがわかりました。journal とは
journal は systemd のログなので、消してしまっても問題ありません。
以下、systemd/ジャーナル より一部抜粋:
systemd/ジャーナル
systemd は、バージョン 38 から自前のログシステムである journal を搭載しています。
デフォルトで (/etc/systemd/journald.conf 内で Storage= が auto に設定されているとき)、journal は /var/log/journal/ へ書き込みを行います。journalctl で削除
systemd ジャーナルは
journalctlで操作できます。次のコマンドで、3日分のログを残し、それ以外は全て削除します。
sudo journalctl --vacuum-time=3days再度、ディスク容量を確認してみます。
df -h Filesystem Size Used Avail Use% Mounted on /dev/xvda1 7.7G 6.9G 835M 90% /10%削減でき、アプリも正常に動くようになりました。
journal の容量制限
今回のように journal の容量が膨れ上がらないように、設定ファイルを更新して容量を制限します。
sudo vi /etc/systemd/journald.conf/etc/systemd/journald.confSystemMaxUse=200M再起動して設定を反映させます。
sudo systemctl restart systemd-journaldこれで同じ問題は起きないでしょう!
References
- 投稿日:2020-09-16T09:00:31+09:00
Rails 6で認証認可入り掲示板APIを構築する #11 userモデルのテストとバリデーション追加
←Rails 6で認証認可入り掲示板APIを構築する #10 devise_token_auth導入
テストの準備
userにバリデーションとテストを実装します。
テストファーストではなくなってしまっていますが、deviseは特殊なので、ちゃんと動くところまで実装を済ませたかったため、順番が前後しています。まずはテストに必要なファイルを準備します。
userモデルはdevise_token_authで生成されたため、rspecとfactoryBotのファイルがありません。
以下コマンドで生成します。$ rails g rspec:model user create spec/models/user_spec.rb invoke factory_bot create spec/factories/users.rbfactoryを先に作ります。
spec/factories/users.rb# frozen_string_literal: true FactoryBot.define do factory :user do provider { "email" } sequence(:email) { |n| "test#{n}@example.com" } uid { email } password { "password" } remember_created_at { nil } name { "MyString" } tokens { nil } end enduserテーブルのカラムは何があったっけ?となったら、db/schema.rbを見ると出力結果が確認できます。
factoryファイルで注目すべきは3点。
sequence(:email) { |n| "test#{n}@example.com" }
uid { email }
password { "password" }
この3つです。
sequence(:email) { |n| "test#{n}@example.com" }
この処理のnには連番が入ってきます。1レコード目はtest1@example.com, 2レコード目はtest2@example.com, …となります。わざわざこうやっているのは、emailカラムがunique制約がかかっており、同一文字列だと登録できないためです。
例えばここを定数でemail { "test@example.com" }とすると、create_list(:user, 10)で該当メールアドレスが2個以上になってコケちゃうわけですね。
uid { email }
ここはシンプルに、uidにemailの変数を入れているだけです。
deviseの挙動として、providerがemailの場合はuid=emailとなります。
password { "password" }
DBのカラム上はencrypted_passwordですが、そこにはハッシュ化された文字列が保存されます。
パスワード設定時はpasswordに値を入れる必要があるため、schema.rbとカラム名が一致しないのです。userモデルのテスト
postと似たテストを実行したいので、spec/models/post_spec.rbをコピー。
PostをUser、subjectをname、bodyをspec/models/user_spec.rb# frozen_string_literal: true require "rails_helper" RSpec.describe User, type: :model do describe "name" do context "blankの時に" do let(:user) do build(:user, name: "") end it "invalidになる" do expect(user).not_to be_valid end end context "maxlengthにより" do context "30文字の場合に" do let(:user) do build(:user, name: "あ" * 30) end it "validになる" do expect(user).to be_valid end end context "31文字の場合に" do let(:user) do build(:user, name: "あ" * 31) end it "invalidになる" do expect(user).not_to be_valid end end end end describe "email" do context "blankの時に" do let(:user) do build(:user, email: "") end it "invalidになる" do expect(user).not_to be_valid end end context "maxlengthにより" do context "100文字の場合に" do let(:user) do build(:user, email: "@example.com".rjust(100, "a")) end it "validになる" do expect(user).to be_valid end end context "101文字の場合に" do let(:user) do build(:user, email: "@example.com".rjust(101, "a")) end it "invalidになる" do expect(user).not_to be_valid end end end context "email形式により" do context "正しい文字列の場合に" do let(:user) do build(:user, email: "test@example.com") end it "validになる" do expect(user).to be_valid end end context "正しくない文字列の場合に" do let(:user) do build(:user, email: "test@example") end it "invalidになる" do expect(user).not_to be_valid end end end end end以下箇所は、postからのコピーではなく独自に置き換えてます。
build(:user, email: "@example.com".rjust(100, "a")) build(:user, email: "@example.com".rjust(101, "a"))rjustは文字列が右詰めになるように指定文字で埋めるメソッドです。
rails cで実行してみます。$ rails c [1] pry(main)> "@example.com".rjust(100, "a") => "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa@example.com" [2] pry(main)> "@example.com".rjust(100, "a").length => 100こうすることによって、100文字ピッタリのダミーデータを生成できます。
userモデルのバリデーション実装
app/models/user.rb# frozen_string_literal: true # # ユーザークラス # class User < ActiveRecord::Base # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable and :omniauthable devise :database_authenticatable, :registerable, :rememberable, :validatable include DeviseTokenAuth::Concerns::User + validates :name, presence: true, length: { maximum: 30 } + validates :email, presence: true, length: { maximum: 100 } endこれでrspecのテストを通過するようになります。
あれ?メールアドレスのフォーマットバリデーション書いてないけどなんでOKなの?と感じたら鋭いです。
実はdeviseの:validatableでemailのフォーマットチェックは行われているので、email形式確認バリデーションはdevise依存モデルの場合特に指定不要です。authのrequest specを書く
今回のチュートリアルの中では、登録とログインだけの簡易的なテストを書いて終わりにします。
$ rails g rspec:request v1/auth create spec/requests/v1/auths_spec.rb $ mv spec/requests/v1/auths_spec.rb spec/requests/v1/auth_spec.rbauthsが気持ち悪いのでauthにrenameしておきます。
基本的にはspec/requests/v1/posts_spec.rbを参考にしながら、auth_spec.rbを書いていきます。spec/requests/v1/auth_spec.rb# frozen_string_literal: true require "rails_helper" RSpec.describe "V1::Auth", type: :request do describe "POST /v1/auth#create" do let(:user) do attributes_for(:user, email: "signup@example.com", name: "signupテスト") end it "正常レスポンスコードが返ってくる" do post v1_user_registration_url, params: user expect(response.status).to eq 200 end it "1件増えて返ってくる" do expect do post v1_user_registration_url, params: user end.to change { User.count }.by(1) end it "nameが正しく返ってくる" do post v1_user_registration_url, params: user json = JSON.parse(response.body) expect(json["data"]["name"]).to eq("signupテスト") end it "不正パラメータの時にerrorsが返ってくる" do post v1_user_registration_url, params: {} json = JSON.parse(response.body) expect(json.key?("errors")).to be true end end describe "POST /v1/auth/sign_in#create" do let(:user) do create(:user, email: "signin@example.com", name: "signinテスト") { email: "signin@example.com", password: "password" } end it "正常レスポンスコードが返ってくる" do post v1_user_session_url, params: user, as: :json expect(response.status).to eq 200 end it "nameが正しく返ってくる" do post v1_user_session_url, params: user json = JSON.parse(response.body) expect(json["data"]["name"]).to eq("signinテスト") end it "不正パラメータの時にerrorsが返ってくる" do post v1_user_session_url, params: {} json = JSON.parse(response.body) expect(json.key?("errors")).to be true end end endここまで書いて、rubocopとrspecが正常に通ればcommitします。
続き
→
【連載目次へ】
- 投稿日:2020-09-16T08:37:46+09:00
railsの中間テーブルでデータの組み合わせを一意にする方法
はじめに
Twitterのように、1人のユーザーは複数のツイートにいいね!ができて、1つのツイートは複数のユーザーにいいね
!されるような多対多の関係をよく実装することはあると思います。
あるユーザーは1つのツイートに対して1回しかいいね!はしないので組み合わせは一意である必要があります。
今回は中間テーブルのデータの組み合わせを一意にする方法を説明します。開発環境
Rails 6.0.3
Ruby 2.7.1
テスト: Rspec, FactoryBot, shoulda-matchers1. テーブル
今回使用するテーブルは下記の3つです。
Userテーブル
id name 1 ユーザー1 a@a.a 2 ユーザー2 b@b.b Tweetテーブル
id content 1 tweet1 2 tweet2 Likeテーブル(中間テーブル)
id user_id tweet_id 1 1 2 2 1 3 多対多の関係
多対多の説明に関しては今回は省略します。
user.rbclass User < ApplicationRecord has_many :likes, dependent: :destroy endtweet.rbclass Tweet < ApplicationRecord has_many_to :likes endlike.rbclass Like < ApplicationRecord belongs_to :user belongs_to :tweet end2. 組み合わせを一意にする方法
そして今回のメインに実装です。
やることは2つです。
- migrationファイルにadd_indexでunique制約をつける (DBに制約をつける)
- 中間テーブルのmodelにvalidationを追加する (アプリ側でバリデーションを追加)
2.1 migrationファイルにadd_indexでunique制約をつける
add_index :likes, [:user_id, :tweet_id], unique: trueを中間テーブルのmigrationファイルに追加します。
追加した後はmigrateを忘れないように!class CreateLikes < ActiveRecord::Migration[6.0] def change create_table :likes do |t| t.references :user, null: false, foreign_key: true t.references :tweet, null: false, foreign_key: true t.timestamps end add_index :likes, [:user_id, :tweet_id], unique: true #ここを追加 end end2.2 中間テーブルのmodelにvalidationを追加する
validates :hotel_id, uniqueness: { scope: :staff_id }を中間テーブルのモデルに追加します。like.rbclass Like < ApplicationRecord belongs_to :user belongs_to :tweet validates :user_id, uniqueness: { scope: :tweet_id } #ここを追加 end必要な実装は以上です。
コンソールで同一の組み合わせは一度しか登録できないことを確認してみてください。3. 一意であることを確認するRspecテスト
参考までにテストもご紹介します。
Rspec, FactoryBot, shoulda-matchersの設定はできているものとします。like_spec.rbrequire 'rails_helper' RSpec.describe Like, type: :model do let(:user) { create(:user) } let(:tweet) { create(:tweet) } before { create(:like, user: user, tweet: tweet) } it { should belong_to(:user) } # この行と下の行で多対多の関係を確認 it { should belong_to(:tweet) } it { is_expected.to validate_uniqueness_of(:user_id).scoped_to(:tweet_id) } # ここで一意であることを確認 endおわりに
ちゃんと組み合わせを一意にできましたでしょうか?
今回のような実装はよく使われると思うので参考になれば幸いです。
- 投稿日:2020-09-16T08:23:21+09:00
(アンチパターン)Railsの本番環境でローカル環境と同じエラー画面を表示させる
アンチパターン
ソフトウェア開発におけるアンチパターン (英: anti-pattern) とは、必ず否定的な結果に導く、しかも一般的に良く見られる開発方式を記述する文献形式を言う。はじめに
ローカル環境(開発環境)でRuby on Railsアプリケーションの開発をするとき、エラー(例外)が発生すると以下のようなエラー画面が表示されます。
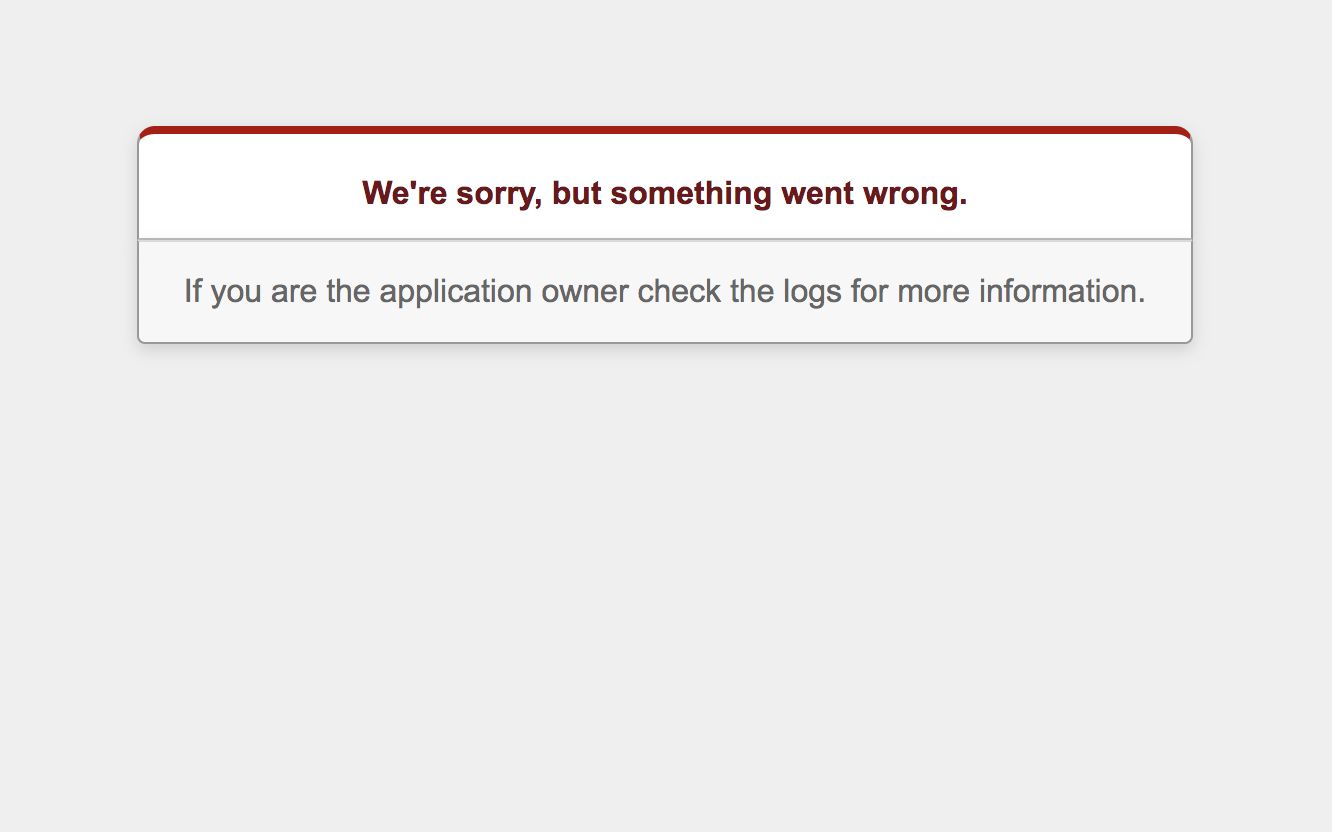
しかし、本番環境にRailsアプリをデプロイすると、ローカル環境のようなエラー画面は表示されず、デフォルトでは"We're sorry, but something went wrong."というようなエラーメッセージが表示されます。
ローカル環境のエラー画面では、エラーが発生した行やスタックトレース等の情報が豊富に表示されるので、デバッグに役立ちます。
一方、本番環境ではそういった情報がまったく表示されないため、どこでどんなエラーが発生したのかわかりません。では、こんなときはどうしたらよいでしょうか?
この記事では本番環境でエラーが発生した場合の(よくある)間違った方法と、適切な対処方法についてまとめます。間違った対処方法☠️
"rails 本番環境 エラー画面"のようなキーワードでネットを検索すると、次のように、「
config/environments/production.rbのconfig.consider_all_requests_localをtrueに変更してデプロイすればOK」と書いてある記事が上位に表示されます。しかし、 この対応はNG です。(つまりアンチパターン)config/environments/production.rb# falseからtrueに変更する、はNG!! config.consider_all_requests_local = trueたしかに、こうすると本番環境でローカル環境と同じエラー画面が表示されます。しかし、これだと本来は開発者以外知る必要がないソースコードや実行環境の情報が不特定多数の人々に公開されてしまいます。これはセキュリティ上の深刻なリスクになります。(この点については本記事の後半で詳しく議論します)
ですので、安易に
consider_all_requests_localをtrueに変更することはやめましょう!適切な対処方法?
前述の通り、本番環境でローカル環境と同じエラー画面を表示させるのはセキュリティ上のリスクが高いのでいさぎよく諦めましょう。
本番環境で発生したエラーを確認する場合は、以下のような方法が考えられます。
ログを見る
本番環境でエラーを確認する一番の正攻法はログを見ることです。検索するならエラー画面を表示する方法ではなく、ログを確認する方法にしてください。
たとえば、Heroku環境であれば以下のようなコマンドでログを確認できます。
# Heroku上のログを確認する $ heroku logsHerokuでログを確認する場合の詳しい情報は公式ドキュメントを参照してください。
もしくは、Papertrailのようなアドオンを入れて、ブラウザ上でログを確認することもできます。以下はPapertrailアドオンを使った場合のログの表示例です。
Heroku以外の環境(AWS等)でもログを確認する方法は必ずあるはずです。
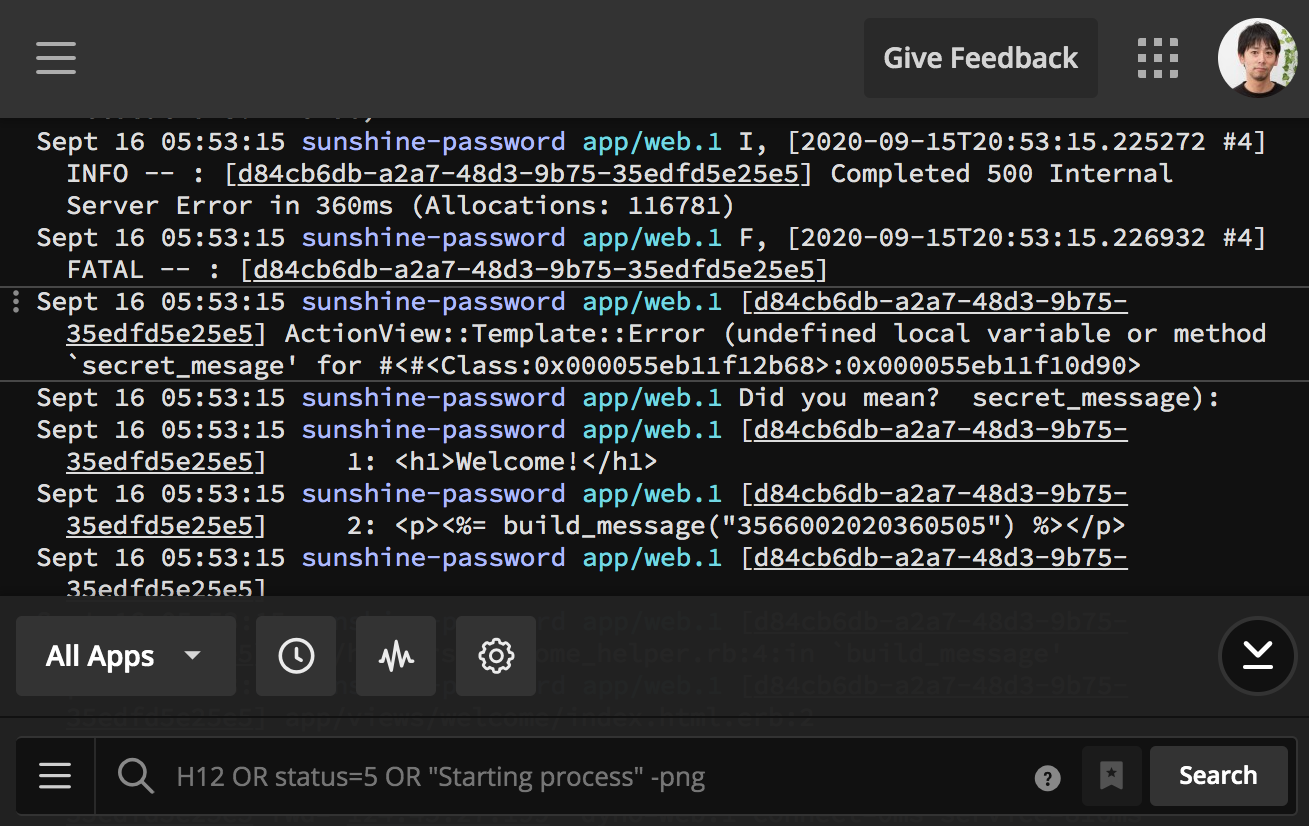
一般的な方法としてはsshなどを使って本番サーバーに接続し、tailコマンド等でログを確認する方法があります。# sshでサーバーに接続し、tailコマンドでログを確認する $ cd /path/to/your/rails/application $ tail -f log/production.logログを見るとエラーが発生したタイミングでバックトレース(スタックトレース)が出力されているはずです。この情報を元にデバッグを進めてください。
以下はエラー発生時のログの出力例です。
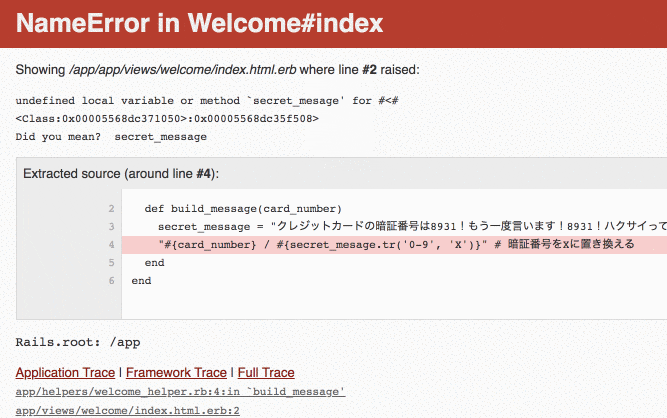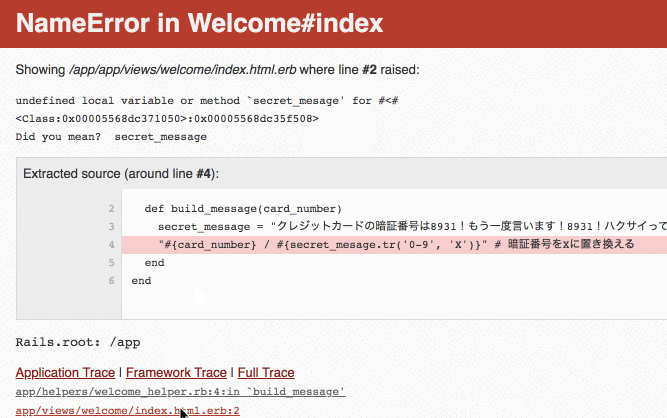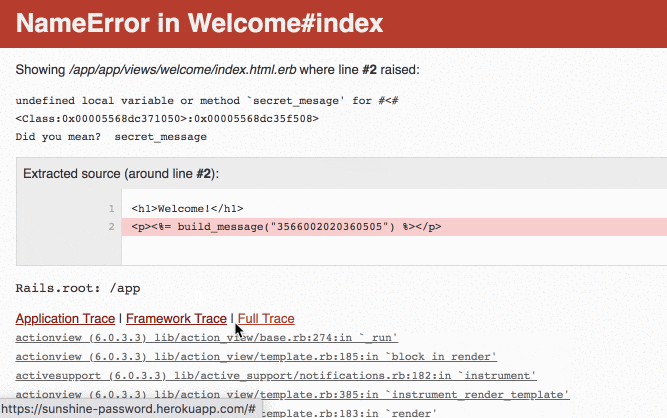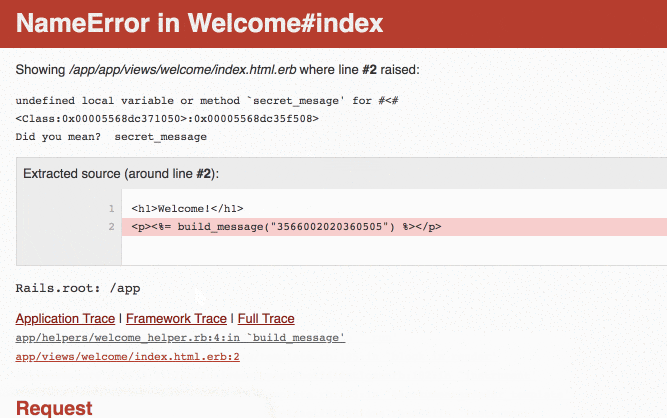
I, [2020-09-15T21:55:25.471329 #4] INFO -- : [2bc2421a-7441-46ef-8632-a205e72c03e0] Started GET "/" for 124.45.27.199 at 2020-09-15 21:55:25 +0000 I, [2020-09-15T21:55:25.473285 #4] INFO -- : [2bc2421a-7441-46ef-8632-a205e72c03e0] Processing by WelcomeController#index as HTML I, [2020-09-15T21:55:25.480425 #4] INFO -- : [2bc2421a-7441-46ef-8632-a205e72c03e0] Rendering welcome/index.html.erb within layouts/application I, [2020-09-15T21:55:25.705386 #4] INFO -- : [2bc2421a-7441-46ef-8632-a205e72c03e0] Rendered welcome/index.html.erb within layouts/application (Duration: 224.8ms | Allocations: 115496) I, [2020-09-15T21:55:25.705619 #4] INFO -- : [2bc2421a-7441-46ef-8632-a205e72c03e0] Completed 500 Internal Server Error in 232ms (Allocations: 116781) F, [2020-09-15T21:55:25.706575 #4] FATAL -- : [2bc2421a-7441-46ef-8632-a205e72c03e0] [2bc2421a-7441-46ef-8632-a205e72c03e0] ActionView::Template::Error (undefined local variable or method `secret_mesage' for #<#<Class:0x0000557c00d75308>:0x0000557c00d6f4f8> Did you mean? secret_message): [2bc2421a-7441-46ef-8632-a205e72c03e0] 1: <h1>Welcome!</h1> [2bc2421a-7441-46ef-8632-a205e72c03e0] 2: <p><%= build_message("3566 0020 2036 0505") %></p> [2bc2421a-7441-46ef-8632-a205e72c03e0] [2bc2421a-7441-46ef-8632-a205e72c03e0] app/helpers/welcome_helper.rb:4:in `build_message' [2bc2421a-7441-46ef-8632-a205e72c03e0] app/views/welcome/index.html.erb:2「英語ばっかりでわけがわかんない!」「何から手を付けていいかさっぱりわからん!」という方は、僕が以前書いたこちらの記事を参考にしてみてください。
プログラミング初心者歓迎!「エラーが出ました。どうすればいいですか?」から卒業するための基本と極意(解説動画付き) - Qiita
エラートラッキングツールを導入する
他にもエラートラッキングツールを導入する方法も考えられます。
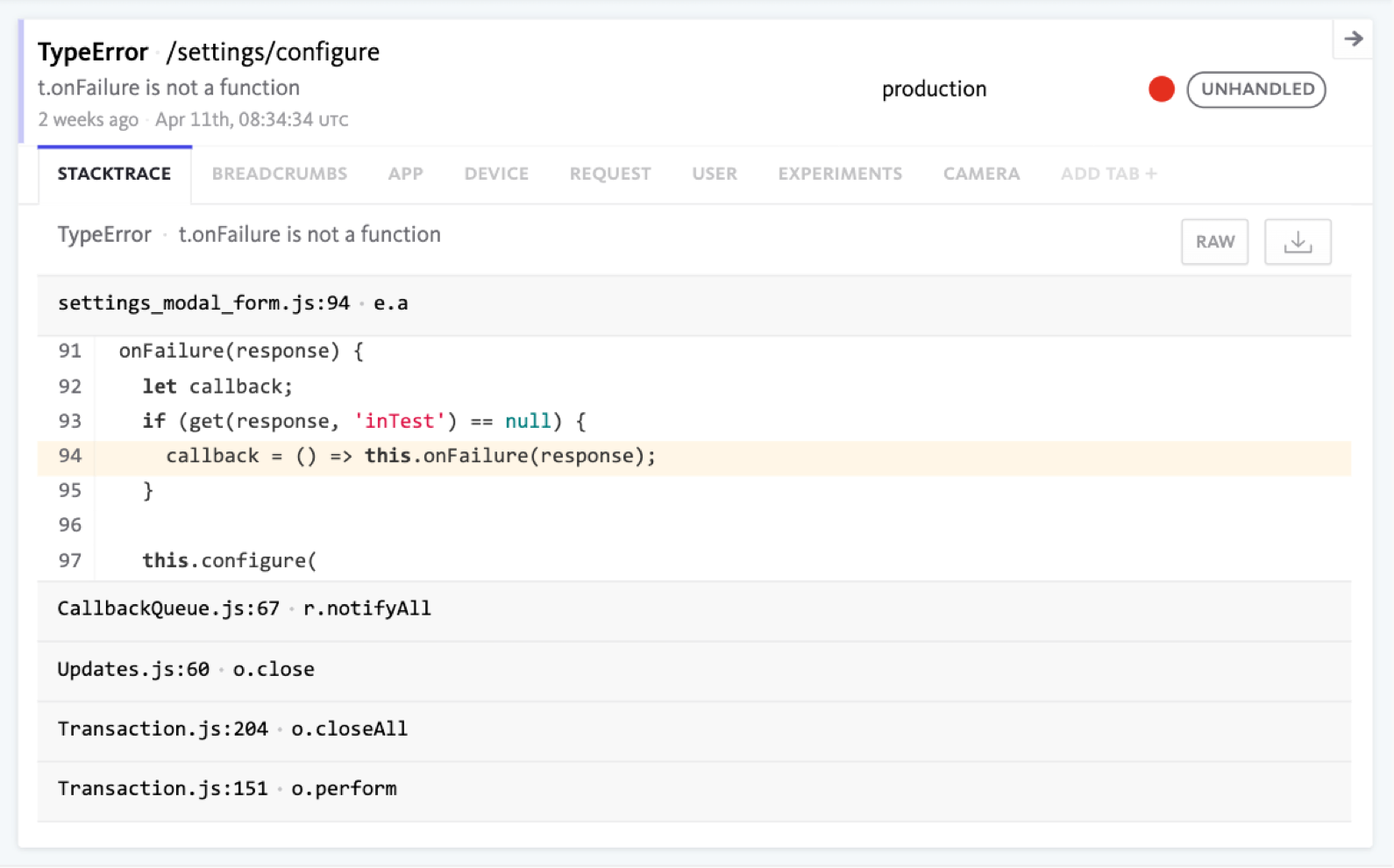
エラートラッキングツールを導入すると、エラー発生時に自動的にエラーに関する詳細情報がツールの専用サーバーに保存され、さらに開発者にメール等で通知されます。
通知メール等に記載されたリンクを開くと、バックトレースをはじめとした、エラーに関する詳細情報をブラウザ上で確認できます。以下はBugsnagの画面表示例です。(画像の出典:https://www.bugsnag.com/product)
代表的なエラートラッキングツールには以下のようなものがあります。
ただしエラートラッキングツールは有料のものが多いため、個人で利用するのは若干敷居が高いかもしれません。ですので、まずは本番環境でログを確認する方法を習得するのがベストだと思います。
本番環境でローカル環境と同じエラー画面を表示させるリスクについて、もっと詳しく
まだ実際の業務に就いたことがないプログラミング初心者の方は、「ログを見るなんて面倒くさい!本番環境でローカル環境と同じエラー画面を表示させたって別にいいじゃん!」って思っているかもしれません。
しかし、ソースコードはオープンソースソフトウェアではない限り、開発者以外の目に触れさせるべきではありません。
場合によっては次のように見えてはいけない情報が表示されてしまう可能性があります。
また、Railsのエラー画面ではリンクを使ってスタックトレース上のコードを確認していくことができます。
このリンクを使うと、エラーが発生した行以外のコードも見えてしまいます。以下の例は、Railsのエラー画面から
index.html.erbのリンクをクリックした場合の表示例です。
↓ リンクをクリック
さらに、"Framework Trace"や"Full Trace"といったリンクを開くと、gemのコードも含めたバックトレースが表示されます。このバックトレースを見ると、そのRailsアプリが利用しているgemのバージョンがわかります。セキュリティ上の脆弱性を抱えたバージョンを使っていた場合は、悪意のある第三者によってgemの脆弱性を突いた攻撃が行われるかもしれません。
たとえば、以下の表示例ではこのRailsアプリケーションがRails 6.0.3.3を使っていることがわかります。
本記事の執筆時点ではRails 6.0.3.3は最新バージョンですが、将来的にRailsに新たな脆弱性が発見されると、それがセキュリティ上のリスクになり得ます。
実際に動かしてリスクを確認してみる
上で見せた表示例は、筆者がHeroku上で公開しているデモアプリケーションです。
consider_all_requests_localをtrueに設定したので、みなさんのブラウザ上でもローカル環境と同じエラー画面が表示されます。以下のURLを開き、ソースコードやRailsのバージョンが任意の第三者に公開されてしまうリスクを確認してみてください。
https://sunshine-password.herokuapp.com/
想定される反論「誰も見に来ないから大丈夫です」「すぐに戻すから大丈夫です」
しかし、プログラミング初心者の方の中には「なるほど」と思いつつ、「まだどこにも公表してないから誰もアクセスしてこないはず」とか、「設定はすぐに戻すから大丈夫!」と考えている人がいるかもしれません。ですが、筆者はその考え自体がすでに危険だと考えます。
本番環境でローカル環境と同じエラー画面を表示させることは、技術上の問題だけでなく、 「習慣の問題」 という側面も大きいと思います。
すなわち、「いちいち本番サーバーに接続してログを見るなんて面倒くさい」とか、「何か困ったら本番環境でもローカル環境と同じエラー画面を表示させればいいや」と考えてしまう、その習慣に問題があるということです。そういう習慣が身体に染みついていると、業務に入ったときも同じような方法でデバッグしたくなるかもしれません。
その誘惑に負けてしまったときに限って、「すぐに戻したはずなのに、悪意のあるユーザーがアクセスしてきてコードを盗み見された!」とか、「問題が解決したらホッとしてしまって、設定を戻し忘れた!」という大問題が発生するかもしれません。だから、常日頃から「本番環境では必ずログを見に行く。安易に
production.rbの設定を変えるのはダメ!!」と自分に言い聞かせておくのです。
そういう正しい習慣を身に付けておけば、本番環境のログを見に行くことにも心理的な抵抗がなくなるはずです。参考:情報処理機構(IPA)の資料にも同じ話が載っています
情報処理機構(IPA)が提供している「安全なウェブサイトの作り方」という資料にも、ほぼ同じ話が載っています。
1-(iii)
エラーメッセージをそのままブラウザに表示しない。エラーメッセージの内容に、データベースの種類やエラーの原因、実行エラーを起こしたSQL文等の情報が含まれる場合、これらはSQLインジェクション攻撃につながる有用な情報となりえます。また、エラーメッセージは、攻撃の手がかりを与えるだけでなく、実際に攻撃された結果を表示する情報源として悪用される場合があります。データベースに関連するエラーメッセージは、利用者のブラウザ上に表示させないことをお勧めします。
https://www.ipa.go.jp/security/vuln/websecurity-HTML-1_1.html
上記の資料では議論の対象がデータベースに限定されていますが、「エラーメッセージは、攻撃の手がかりを与える」という点はデータベースに限らず、Webアプリケーションの仕組み全般に適用できるはずです。
まとめ
というわけで、本記事ではRailsの本番環境でローカル環境と同じエラー画面を表示させることのリスクと、本番環境でエラーが発生した場合の適切な対処方法について説明しました。
冒頭にも述べたとおり、ネット上には(というかこのQiita上にも!)「
config/environments/production.rbのconfig.consider_all_requests_localをtrueに変更してデプロイすればOK」と説明している記事はとても多いです。「セキュリティ上のリスクがありますよ」とか「すぐに戻しましょう」と、ひとこと注意書きが添えてあるならまだしも、何の注意書きもなく「これでOKです。以上!」で終わっている記事もよく見かけます。
もしみなさんの周りでそういった記事を鵜呑みにしている初心者さんがいたら、ぜひ本記事のリンクと一緒に「その設定、危険だよ!」と教えてあげてください。




- 投稿日:2020-09-16T08:22:13+09:00
RSpecの実行結果を分かりやすくするGitHub Actionを作った
はじめに
CI/CDのサービスとして最近はGitHub Actionsを利用しているのですが、CircleCIと比較した時にRSpecが失敗した時の実行結果が分かりにくいのが不満でした。
そんなストレスを解消するために社内ハッカソンで作った以下のGitHub Actionを紹介します。RSpec Report · Actions · GitHub Marketplace · GitHub
何が出来るの?
PRイベントの場合は失敗結果がコメントされます。
またコメントされることで同様の内容がメールでも通知されるので、失敗したテストの内容がGitHubにアクセスしなくても把握できるようになります。
PRイベント以外の場合はChecks API経由で通知されます。
使い方
test.ymlname: Build on: pull_request: jobs: rspec: steps: # RSpec実行の為の事前準備は省略しています - name: Test run: bundle exec rspec -f j -o tmp/rspec_results.json -f p - name: RSpec Report uses: SonicGarden/rspec-report-action@v1 with: token: ${{ secrets.GITHUB_TOKEN }} json-path: tmp/rspec_results.json if: always()その他
ポイント
- JSONフォーマットで出力したRSpecの実行結果を解析してコメントしています
rspecコマンドの-f j -o tmp/rspec_results.jsonオプションは必須です(保存先は任意)- テストが全て通ればコメントは削除されます
- 繰り返し同じコメントが投稿されることはありません
- テストの並列実行にも対応しています
- その場合は以下のようにタイトルがユニークになるように調整してください
with: token: ${{ secrets.GITHUB_TOKEN }} json-path: tmp/rspec_results.json title: "# :cold_sweat: RSpec failure ${{ matrix.ci_node_index }}"リポジトリ
GitHub - SonicGarden/rspec-report-action: A GitHub Action that report RSpec failure.
良かったら使ってみてください。

- 投稿日:2020-09-16T00:52:23+09:00
instagramのクローンアプリを作る③
はじめに
タイトルの通り、簡易版instagramのアプリを作っていきます。
下記の工程に分けて記事を執筆していきますので、順を追って読んでいただけたらなと思います。①アプリ作成〜ログイン機能の実装
②写真投稿機能の実装
③ユーザーページの実装 ←イマココ
④いいね機能の実装
⑤投稿削除機能の実装Users Controllerを作成・編集する
今更ですが、命名規則としてモデル名は単数形、コントローラ名は複数形です。
今回はコントローラ名なのでusersと複数形にしています。
※以下、アプリケーションのディレクトリでrails g controller usersルーティングの設定も忘れずに行います。
routes.rbRails.application.routes.draw do root 'homes#index' devise_for :users resources :photos resources :users # ←ここ end設定できたら、
users_controller.rbを編集します。users_controller.rbclass UsersController < ApplicationController def show @user = User.find(params[:id]) end end
showアクションでユーザーを一覧表示するようにしました。viewファイルを編集する
前回の記事で、ホーム画面で投稿された画像とテキストを見られるようにしていましたが、
今回は各ユーザーのページ内で投稿内容が見られるように編集していきます。ます、ユーザーページの作成から。
app/views/usersにshow.html.erbを作成し編集します。app/views/users/show.html.erb<h3><%= @user.email %></h3> <% @user.photos.each do |photo| %> <div> <p><%= photo.caption %></p> <%= image_tag photo.image %> </div> <% end %>
@user.emailはユーザー名の代わりです。
そして、前回 投稿内容の表示を
<% current_user.photos.each do |photo| %>
としていたところを
<% @user.photos.each do |photo| %>
としました。もちろん、ホーム画面に表示させていた投稿内容は削除します。
app/views/homes/index.html.erb<h3>home</h3> <div> <%= link_to 'logout', destroy_user_session_path, method: :delete %> </div> <div> <%= link_to '写真投稿', new_photo_path %> </div> # ↓↓↓↓↓↓↓↓↓↓↓↓↓↓ ここから下を削除 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓ <% current_user.photos.each do |photo| %> <div> <p><%= photo.caption %></p> <%= image_tag photo.image %> </div> <% end %>削除したら、各ユーザーのページへのリンクを表示させます。
app/views/homes/index.html.erb<h3>home</h3> <div> <%= link_to 'logout', destroy_user_session_path, method: :delete %> </div> <div> <%= link_to '写真投稿', new_photo_path %> </div> # ↓↓↓↓↓↓↓↓↓↓↓↓↓↓ ここから下を追加 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓ <% User.all.each do |user| %> <div> <%= link_to user.email, user_path(user) %> </div> <% end %>メールアドレスをユーザー名の代わりにしています。
user_path(user)の部分はrails routesのPrefixを確認。
今回はuserのidも識別する必要があるので、(user)が必要です。
※user_path(user)の部分を[user]としても同じです。
ホーム画面が以下のようになっていれば成功です。
実際の挙動はこのようになっています。
sample@gmail.comのページへアクセスすると、
一番上にユーザー名、続いて投稿内容が表示されています。
example@gmail.comのページへアクセスすると、
まだ投稿されていないのでユーザー名のみ表示されています。ちなみに、ログインしていない状態でも各ユーザーのページにアクセスできるように、
users_controllerにbefore_actionを設定していません。
以上です。お疲れ様でした。



- 投稿日:2020-09-16T00:47:24+09:00
Railsのルーティングにid以外を設定する
RailsでscaffoldするとURLの形式は
example.com/posts/:idになります。
しかし、パラメータにidを使用したくない場合もあります。
今回はexample.com/posts/:uuidの様な形式でidの代わりにuuidを設定してみました。カラムを追加
テーブル作成時にuuidのカラムを追加します。
$ rails g scaffold post uuid:string body:textclass CreatePosts < ActiveRecord::Migration[6.0] def change create_table :posts do |t| t.string :uuid, null: false t.text :body t.timestamps end add_index :posts, :uuid end end$ rails db:migrateルーティングを設定
config/routes.rbresources :posts, param: :uuid # 詳細画面のみ設定する場合 # get '/posts/:uuid', to: 'posts#show'uuidを設定
データを保存する前にuuidを設定する処理を追加します。
app/models/application_record.rbclass ApplicationRecord < ActiveRecord::Base self.abstract_class = true private # 追加 def set_uuid if self.has_attribute?(:uuid) && self.uuid.blank? self.uuid = SecureRandom.hex(10) end end endapp/models/post.rbclass Post < ApplicationRecord # 追加 before_create :set_uuid endコントローラを修正
このまま画面にアクセスするとエラーになるためコントローラを修正します。
app/controllers/posts_controller.rbdef set_post @post = Post.find_by(uuid: params[:uuid]) endこれで
example.com/posts/:uuidの形式への設定ができました。
- 投稿日:2020-09-16T00:00:19+09:00
リポジトリをコピーして初回bundle installでmysql2のエラーが発生
環境
Ruby 2.5.7
Rails 5.2.4経緯
自分のメモ用記事ですが、今回のエラーを解説している記事が見つからなかったので。どなたかの参考になれば幸いです。
学習のため、現在作成中のRailsアプリケーションのテンプレートエンジンを、erbからslimに変更しようとした。
重めの改修になりそうだったので既存のアプリケーションはそのままに、コピーを作成してそれをslim化させる。Qiita - cloneしたリポジトリを別リポジトリとしてリモートにpushする
GitHubのリポジトリやアプリケーションのコピーは完了し、コピーしたslim用のappディレクトリでbundle installを試みたところ下記のようなエラーが発生した。
(この時点でコピー元のアプリケーションではエラーは発生していません。)$ bundle install The dependency tzinfo-data (>= 0) will be unused by any of the platforms Bundler is installing for. Bundler is installing for ruby but the dependency is only for x86-mingw32, x86-mswin32, x64-mingw32, java. To add those platforms to the bundle, run `bundle lock --add-platform x86-mingw32 x86-mswin32 x64-mingw32 java`. Fetching gem metadata from https://rubygems.org/......... ... Using gem一覧 ... Fetching mysql2 0.5.3 Installing mysql2 0.5.3 with native extensions Gem::Ext::BuildError: ERROR: Failed to build gem native extension. current directory: /home/vagrant/.rbenv/versions/2.5.7/lib/ruby/gems/2.5.0/gems/mysql2-0.5.3/ext/mysql2 /home/vagrant/.rbenv/versions/2.5.7/bin/ruby -r ./siteconf20200915-19570-14xz74g.rb extconf.rb checking for rb_absint_size()... yes checking for rb_absint_singlebit_p()... yes checking for rb_wait_for_single_fd()... yes checking for -lmysqlclient... no ----- mysql client is missing. You may need to 'sudo apt-get install libmariadb-dev', 'sudo apt-get install libmysqlclient-dev' or 'sudo yum install mysql-devel', and try again. ----- *** extconf.rb failed *** Could not create Makefile due to some reason, probably lack of necessary libraries and/or headers. Check the mkmf.log file for more details. You may need configuration options. Provided configuration options: --with-opt-dir --without-opt-dir --with-opt-include --without-opt-include=${opt-dir}/include --with-opt-lib --without-opt-lib=${opt-dir}/lib --with-make-prog --without-make-prog --srcdir=. --curdir --ruby=/home/vagrant/.rbenv/versions/2.5.7/bin/$(RUBY_BASE_NAME) --with-mysql-dir --without-mysql-dir --with-mysql-include --without-mysql-include=${mysql-dir}/include --with-mysql-lib --without-mysql-lib=${mysql-dir}/lib --with-mysql-config --without-mysql-config --with-mysql-dir --without-mysql-dir --with-mysql-include --without-mysql-include=${mysql-dir}/include --with-mysql-lib --without-mysql-lib=${mysql-dir}/lib --with-mysqlclientlib --without-mysqlclientlib To see why this extension failed to compile, please check the mkmf.log which can be found here: /home/vagrant/.rbenv/versions/2.5.7/lib/ruby/gems/2.5.0/extensions/x86_64-linux/2.5.0/mysql2-0.5.3/mkmf.log extconf failed, exit code 1 Gem files will remain installed in /home/vagrant/.rbenv/versions/2.5.7/lib/ruby/gems/2.5.0/gems/mysql2-0.5.3 for inspection. Results logged to /home/vagrant/.rbenv/versions/2.5.7/lib/ruby/gems/2.5.0/extensions/x86_64-linux/2.5.0/mysql2-0.5.3/gem_make.out An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling. In Gemfile: mysql2解決策
mysql client is missing. You may need to 'sudo apt-get install libmariadb-dev', 'sudo apt-get install libmysqlclient-dev' or 'sudo yum install mysql-devel', and try again.エラーのこの一文、3パターンのコマンドを試してみてねとあるので、順番にやってみる。
$ sudo apt-get install libmariadb-dev sudo: apt-get: command not found
apt-getコマンドが見つからないと言われたので、2つ目の'sudo apt-get install libmysqlclient-dev'は飛ばして3つ目の'sudo yum install mysql-devel'を試す。$ sudo yum install mysql-devel Failed to set locale, defaulting to C Loaded plugins: fastestmirror Determining fastest mirrors * base: ftp.tsukuba.wide.ad.jp * extras: ftp.tsukuba.wide.ad.jp * updates: ftp.tsukuba.wide.ad.jp base | 3.6 kB 00:00:00 extras | 2.9 kB 00:00:00 nodesource | 2.5 kB 00:00:00 updates | 2.9 kB 00:00:00 (1/3): extras/7/x86_64/primary_db | 206 kB 00:00:00 (2/3): updates/7/x86_64/primary_db | 4.5 MB 00:00:00 (3/3): nodesource/x86_64/primary_db | 43 kB 00:00:01 Resolving Dependencies --> Running transaction check ---> Package mariadb-devel.x86_64 1:5.5.65-1.el7 will be installed --> Finished Dependency Resolution Dependencies Resolved ============================================================================================================================================================================================== Package Arch Version Repository Size ============================================================================================================================================================================================== Installing: mariadb-devel x86_64 1:5.5.65-1.el7 base 756 k Transaction Summary ============================================================================================================================================================================================== Install 1 Package Total download size: 756 k Installed size: 3.3 M Is this ok [y/d/N]: y Downloading packages: mariadb-devel-5.5.65-1.el7.x86_64.rpm | 756 kB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction Installing : 1:mariadb-devel-5.5.65-1.el7.x86_64 1/1 Verifying : 1:mariadb-devel-5.5.65-1.el7.x86_64 1/1 Installed: mariadb-devel.x86_64 1:5.5.65-1.el7 Complete!途中でパッケージのダウンロードを行うか聞かれるので
yを入力しEnter。コマンドに入力した
mysql-develと言うのはサーバ上でmysqlを動作させるために必要なパッケージ管理システムで、今回はその中で不足していたmariadb-develをダウンロードした形です。ダウンロードが正常に終わり、再度
$bundle installを行うと正常に完了しました。
まとめ
パッケージ管理システムは理解できたのですが、mariadb-develが今回のエラーにどのように関わっていたのか、いまいち理解ができなかったので、詳しい方はコメント等でご教授いただけると幸いです。
また質問や解釈の違い、記述方法に違和感ありましたら、コメント等でご指摘いただけると幸いです。
最後まで読んでいただきありがとうございました。
参考サイト
Qiita - cloneしたリポジトリを別リポジトリとしてリモートにpushする
Hatena Blog - CentOSにMySQLをインストール