- 投稿日:2020-09-16T23:31:08+09:00
intelijでファイル保存時にコマンドを実行する
blackとpylintを使った快適なPython開発
の補足みたいな記事です。File Watchersのインストール
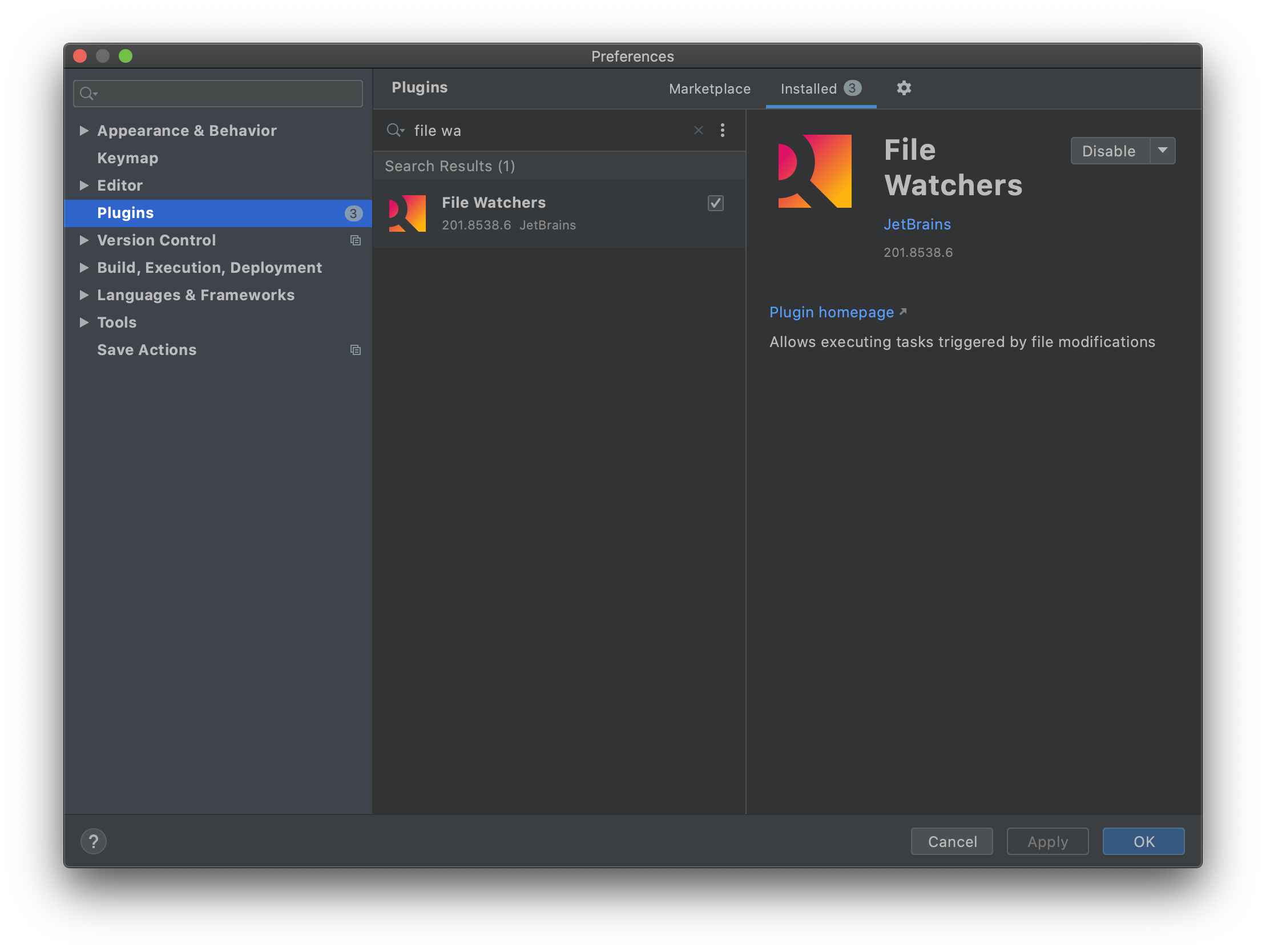
Preferences > Plugins
からFile Watchersをインストールする(インストール後にintelijの再起動が必要)
File Watchersの設定
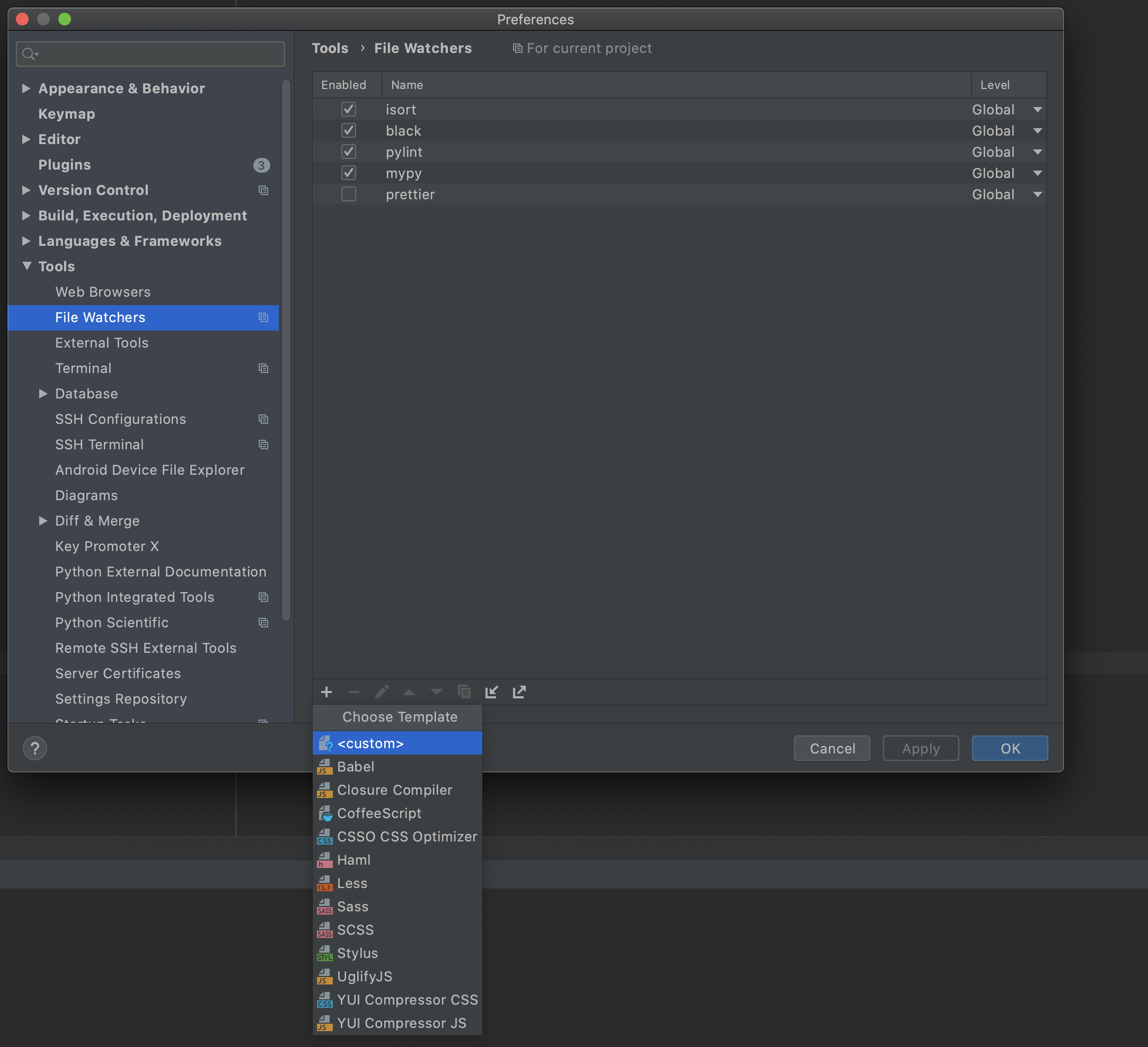
Preferences > Tools > File Watchers
+><custom>からファイル保存時に実行したいコマンドを追加できる
開いたWindowに実行したいコマンドを入力してOKを押せば保存される
項目名 説明 Name 任意の名前 FileType どの拡張子ファイルを保存した時にコマンドを実行するか Scope 基本的にCurrentFIleでOK Program 実行したいコマンドの最初のワード Arguments 実行したいコマンドの二つ目以降のワード Working directory コマンドを実行する際のカレントディレトリ Advanced Options 自動保存時にもコマンドを実行するかなど チェックを外しておくのが無難 以下はPythonファイル保存時にpoetryでpylintを実行する場合の例
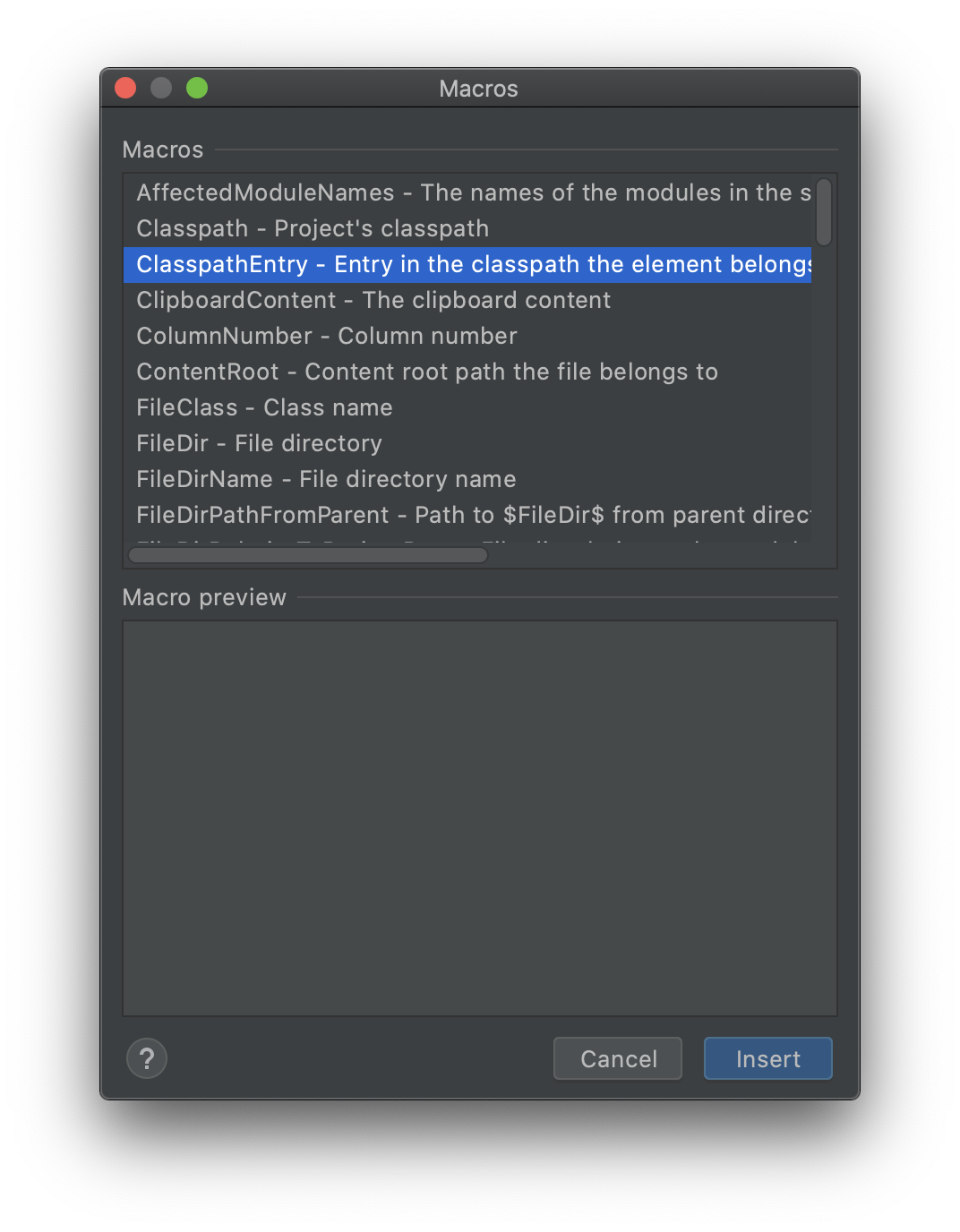
$FilePath$は保存したファイルのパスのマクロ
$FileDir$は保存したファイルののディレクトリパスのマクロ
入力欄の+からマクロ一覧が見れる
プロジェクト間での設定の共有
複数のリポジトリで使いたい時はLevelをGlobalに設定すると、
他のプロジェクトでもFile Watchers設定画面で表示される
デフォルトでEnabledのチェックは外れてるので使用したい場合はチェックを入れる必要あり


- 投稿日:2020-09-16T23:09:06+09:00
OpenCVでエッジを抜き出す(ラプラシアン、ソーベル、キャニー)
機械学習に使う画像の前処理
コンピュータに「その画像に何が写っているか」を理解させるためには検出対象の輪郭を描き、そこから特徴を見つけ出すというプロセスが多く取られます。
その輪郭を描く部分をPython+OpenCVで3つの方法で行った結果をこの記事では掲載します。
元画像
加工元となる画像は2つ用意しました。
自然と人間です。
コード
この程度です。
edge.pyimport cv2 img = cv2.imread('xxxxxxx.jpg') # エッジ検出 edge_laplacian = cv2.Laplacian(img, -1)#ラプラシアン edge_sobel = cv2.Sobel(img, -1, 0, 1)#ソーベル edge_canny = cv2.Canny(img, 10.0, 200.0)#キャニー # ファイル書き出し cv2.imwrite('laplacian.jpg', edge_laplacian) cv2.imwrite('sobel.jpg', edge_sobel) cv2.imwrite('canny.jpg', edge_canny)出力結果
自然
ラプラシアン↓
ソーベル↓
キャニー↓
人間
ラプラシアン↓
ソーベル↓
キャニー↓








- 投稿日:2020-09-16T21:39:21+09:00
pythonによるword2vec等によるテキストマイニング(【高等学校情報科 情報Ⅱ】教員研修用教材)
はじめに
過去の記事で青空文庫の作品を題材に簡単なテキストマイニングを行いました。
https://qiita.com/ereyester/items/7c220a49c15073809c33
今回は、Word2vecを使って、単語の類似度を探りたいと思います。
Word2vecについては、ほかにたくさん記事がありますので具体的な説明は省略します。
Word2Vecを理解する
【Python】Word2Vecの使い方
今回は、gensimのgensim.models 内のword2vec.Word2Vec()の関数を中心にまとめていきたいと思います。
絵で理解するWord2vecの仕組み教材
高等学校情報科「情報Ⅱ」教員研修用教材(本編):文部科学省
第3章 情報とデータサイエンス 後半 (PDF:7.6MB)環境
- ipython
- Colaboratory - Google Colab
教材内で取り上げる箇所
学習18 テキストマイニングと画像認識:「2.MeCabを利用したテキストマイニング」
pythonでの実装例と結果
準備
pythonにて、Word2vecで機械学習を行うために、gensimというパッケージを読み込みます。
!pip install gensim次に後で行う感情分析のための感情辞書をダウンロードしておきます。
感情分析の際にWord2vecで感情を示す用語の主な用語との距離を求めることにより感情分析が可能ですが、ここでは日本語辞書として,東京工業大学のPN Tableを使用して感情分析を行います。import urllib.request import pandas as pd #PN tableのリンク url = 'http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic' #ファイル保存名 file_path = 'pn_ja.dic' with urllib.request.urlopen(url) as dl_file: with open(file_path, 'wb') as out_file: out_file.write(dl_file.read()) # 辞書を読み込みます dic = pd.read_csv('/content/pn_ja.dic', sep = ':', encoding= 'shift_jis', names = ('word','reading','Info1', 'PN')) print(dic)実行結果は以下になります。
word reading Info1 PN 0 優れる すぐれる 動詞 1.000000 1 良い よい 形容詞 0.999995 2 喜ぶ よろこぶ 動詞 0.999979 3 褒める ほめる 動詞 0.999979 4 めでたい めでたい 形容詞 0.999645 ... ... ... ... ... 55120 ない ない 助動詞 -0.999997 55121 酷い ひどい 形容詞 -0.999997 55122 病気 びょうき 名詞 -0.999998 55123 死ぬ しぬ 動詞 -0.999999 55124 悪い わるい 形容詞 -1.000000 [55125 rows x 4 columns]次に、Mecabをインストールしておきます。
!apt install aptitude !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3 !pip install unidic-liteWord2vecによるモデル構築とテキストの分析
word2vecで学習をさせるために、分析対象の文章を分かち書きのテキストに変換して保存します。
以下のステップで処理を行います。
①夏目漱石の「坊ちゃん」に対してテキスト分析を行うため「坊ちゃん」のテキストデータをダウンロードし読み込みを行います。
②ルビ、注釈などの除去を行います。
③「坊ちゃん」の本文から、名詞、形容詞、動詞を取り出し、数や非自立語等を取り除き、「分かち書き」に変換して、tf.txtというファイルに変換する。from collections import Counter import MeCab #MeCabを読み出す import zipfile import os.path,glob import re #「坊ちゃん」のURLを指定 url = 'https://www.aozora.gr.jp/cards/000148/files/752_ruby_2438.zip' #zipファイル保存名 file_path = 'temp.zip' # 坊ちゃんのファイルを開き、読み込んだファイルは削除する with urllib.request.urlopen(url) as dl_file: with open(file_path, 'wb') as out_file: out_file.write(dl_file.read()) with zipfile.ZipFile(file_path) as zf: listfiles = zf.namelist() zf.extractall() os.remove(file_path) # shift_jisで読み込み with open(listfiles[0], 'rb') as f: text = f.read().decode('shift_jis') # ルビ、注釈などの除去 text = re.split(r'\-{5,}', text)[2] text = re.split(r'底本:', text)[0] text = re.sub(r'《.+?》', '', text) text = re.sub(r'[#.+?]', '', text) text = text.strip() #MeCabを使えるように準備 tagger = MeCab.Tagger() # 初期化しないとエラーになる tagger.parse("") # NMeCabで形態素解析 node = tagger.parseToNode(text) word_list_raw = [] result_dict_raw = {} # 名詞、形容詞、動詞は取り出す wordclass_list = ['名詞','形容詞','動詞'] # 数、非自立、代名詞、接尾は除外 not_fine_word_class_list = ["数", "非自立", "代名詞","接尾"] while node: #詳細情報を取得 word_feature = node.feature.split(",") #単語を取得(原則、基本形) word = node.surface #品詞を取得 word_class = word_feature[0] fine_word_class = word_feature[1] #品詞から取り出すものと除外するものを指定する if ((word not in ['', ' ','\r', '\u3000']) \ and (word_class in wordclass_list) \ and (fine_word_class not in not_fine_word_class_list)): #wordリスト word_list_raw.append(word) result_dict_raw[word] = [word_class, fine_word_class] #次の単語に進める node = node.next print(word_list_raw) wakachi_text = ' '.join(word_list_raw); #wakachiファイル保存名 file2_path = 'tf.txt' with open(file2_path, 'w') as out_file: out_file.write(wakachi_text) print(wakachi_text)実行結果は以下になります。
['一', '親譲り', '無鉄砲', '小供', '時', '損', 'し', 'いる', '学校',… 一 親譲り 無鉄砲 小供 時 損 し いる 学校 居る 時分 学校 二 階 飛び降り…次に、今回の記事のメインであるword2vecによるモデルの構築です。
from gensim.models import word2vec import logging logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentence_data = word2vec.LineSentence('tf.txt') model_bochan = word2vec.Word2Vec(sentence_data, sg=1, # Skip-gram size=100, # 次元数 min_count=5, # min_count回未満の単語を破棄 window=12, # 文脈の最大単語数 hs=0, # 階層ソフトマックス(ネガティブサンプリングするなら0) negative=5, # ネガティブサンプリング iter=10 # Epoch数 ) model_bochan.save('test.model')gensimモジュールのword2vecをインポートし、Word2Vecでモデルの構築を行います。
word2vecでは、二つの学習モデルが使用できます。
- CBOW(continuous bag-of-words)
- skip-gramこの二つの説明は割愛しますが、教材ではskip-gramを使用しているので、そちらにあわせてskip-gramを使用しています。(一般的には、CBOWとskip-gramでは、skip-gramのほうがよい性能を示すとのこと)
単語ベクトルの次元数は、デフォルトと同じですが100にしています。
単語を破棄条件は、出現回数が5回未満の単語は無視して処理するようにしています。
コンテクストとして認識する前後の最大単語数は12としています。学習を高速化するアルゴリズムとして二つあります。
-Hierarchical Softmax
-Negative Sampling
この二つの説明も割愛します。ここでは、Negative Samplingを使用しています。この説明は、
http://tkengo.github.io/blog/2016/05/09/understand-how-to-learn-word2vec/
が詳しいです。コーパスの反復回数は10を指定しています。これは、一つの訓練データをニューラルネットワークで何回学習させるかを示すエポック数のことです。
これにより、モデルを構築することができました。
次に教材同様、単語の類似度をみてみます。
赤という単語で調べてみましょう。model = word2vec.Word2Vec.load('/content/test.model') results = model.most_similar(positive=['赤'], topn=100) for result in results: print(result[0], '\t', result[1])実行結果は以下になりました。
: 2020-09-16 12:30:12,986 : INFO : precomputing L2-norms of word weight vectors シャツ 0.9854607582092285 迷惑 0.9401918053627014 名 0.9231084585189819 ゴルキ 0.9050831198692322 知っ 0.8979452252388 優しい 0.897865891456604 賛成 0.8932155966758728 露西亜 0.8931306004524231 マドンナ 0.890703558921814 :上記のように、登場人物の赤シャツなどが上位に来ることがわかりました。
次に、モデルの要素の引き算の例として、「マドンナ」から「シャツ」を引いてみます。model = word2vec.Word2Vec.load('/content/test.model') results = model.most_similar(positive=['マドンナ'], negative=['シャツ'], topn=100) for result in results: print(result[0], '\t', result[1])実行結果は以下になりました。
: INFO : precomputing L2-norms of word weight vectors 声 0.2074282020330429 芸者 0.1831434667110443 団子 0.13945674896240234 娯楽 0.13744047284126282 天麩羅 0.11241232603788376 バッタ 0.10779635608196259 先生 0.08393052220344543 精神 0.08120302855968475 親切 0.0712042897939682 :マドンナからシャツという要素を引くと、声や先生、芸者、親切などの要素を抽出できました。
word2vecによる要素の足し引きについて、以下が詳しいです。
https://www.pc-koubou.jp/magazine/9905PN tableによる簡単な感情分析
感情分析は、Word2Vecでも感情の主要用語との距離を求めることにより、感情分析が可能であるが、ここでは教材通り前述で読み込んだ感情辞書(PN Table)で分析を行ってみたいと思います。
まず、辞書をdataframe型からdict型に変換し扱いやすい形にしておきます。
dic2 = dic[['word', 'PN']].rename(columns={'word': 'TERM'}) # PN Tableをデータフレームからdict型に変換しておく word_list = list(dic2['TERM']) pn_list = list(dic2['PN']) # 中身の型はnumpy.float64 pn_dict = dict(zip(word_list, pn_list)) print(pn_dict)実行結果は以下になりました。
{'優れる': 1.0, '良い': 0.9999950000000001, '喜ぶ': 0.9999790000000001, '褒める': 0.9999790000000001, 'めでたい': 0.9996450000000001,…ポジティブな用語は1に近い値が設定され、ネガティブな用語については-1に近い値が設定されています。
次に、「坊ちゃん」から名詞と形容詞を取り出し、数や接尾語を取り除きます。単語の頻度表と感情辞書を組み合わせて、ポジティブな言葉とネガティブな言葉を表示してみます。
#MeCabを使えるように準備 tagger = MeCab.Tagger() # 初期化しないとエラーになる tagger.parse("") # NMeCabで形態素解析 node = tagger.parseToNode(text) word_list_raw = [] extra_result_list = [] # 名詞、形容詞、動詞は取り出す wordclass_list = ['名詞','形容詞'] # 数、非自立、代名詞、接尾は除外 not_fine_word_class_list = ["数","接尾", "非自立"] while node: #詳細情報を取得 word_feature = node.feature.split(",") #単語を取得(原則、基本形) word = node.surface #品詞を取得 word_class = word_feature[0] fine_word_class = word_feature[1] #品詞から取り出すものと除外するものを指定する if ((word not in ['', ' ','\r', '\u3000']) \ and (word_class in wordclass_list) \ and (fine_word_class not in not_fine_word_class_list)): #wordリスト word_list_raw.append(word) #次の単語に進める node = node.next freq_counterlist_raw = Counter(word_list_raw) dict_freq_raw = dict(freq_counterlist_raw) extra_result_list = [] for k, v in dict_freq_raw.items(): if k in pn_dict: extra_result_list.append([k, v, pn_dict[k]]) extra_result_pn_sorted_list = sorted(extra_result_list, key=lambda x:x[2], reverse=True) print("ポジティブな単語") display(extra_result_pn_sorted_list[:10]) print("ネガティブな単語") display(extra_result_pn_sorted_list[-10:-1])実行結果は以下になりました。
ポジティブな単語 [['めでたい', 1, 0.9996450000000001], ['善い', 2, 0.9993139999999999], ['嬉しい', 1, 0.998871], ['仕合せ', 1, 0.998208], ['手柄', 2, 0.997308], ['正義', 1, 0.9972780000000001], ['感心', 10, 0.997201], ['恐悦', 1, 0.9967889999999999], ['奨励', 1, 0.9959040000000001], ['剴切', 1, 0.995553]] ネガティブな単語 [['乱暴', 13, -0.9993340000000001], ['狭い', 7, -0.999342], ['寒い', 1, -0.999383], ['罰', 5, -0.9994299999999999], ['敵', 3, -0.9995790000000001], ['苦しい', 1, -0.9997879999999999], ['下手', 6, -0.9998309999999999], ['ない', 338, -0.9999969999999999], ['病気', 6, -0.9999979999999999]]listの要素の2つ目が出現頻度(回数)、3つ目がポジティブかネガティブかわかる値となっております。
最後に、「坊ちゃん」全体としては、ポジティブ・ネガティブどちらの単語がよく使われているかをみてみる。(ただし、教材通り単語の出現頻度は使用していない)pos_n = sum(x[2] > 0 for x in extra_result_pn_sorted_list) print(pos_n) neg_n = sum(x[2] < 0 for x in extra_result_pn_sorted_list) print(neg_n)実行結果は以下になりました。
182 1914「坊ちゃん」ではネガティブな単語がよくつかわれていることがわかりました。
コメント
word2vecに関する処理に関してはpythonとRで似たような結果が出なかったので、今後余裕があったら原因を探っていこうと思います。
ソースコード
https://gist.github.com/ereyester/101ae0da17e747b701b67fe9fe137b84
- 投稿日:2020-09-16T21:20:55+09:00
Django + Docker
はじめに
この記事ではDjango + Dockerのアプリ開発でおきたエラーとその対処法を書いていきます。
ERROR: No container found for web_1
いろいろ試してみてたのですが、一向に対処法がわからなかったのですが、次のようにターミナルに打ち込めば解決しました。
terminal$ docker-compose up -d参考記事
ERROR: No container found for web_1 #11045TypeError: Field 'id' expected a number but got datetime.datetime(2020, 9, 16, 2, 52, 51, 44897, tzinfo=).
models.pyのForignkeyがあるところに次のように追記しました。
models.pyuser = models.OneToOneField( User, verbose_name='ユーザー', on_delete=models.CASCADE, default=1 #追記 )これで解決しました。
django.db.utils.OperationalError: could not translate host name "db" to address: Name or service not known
sqlite3を使っていたのですが、このエラーが頻繁に出るので、Postgresqlを導入しました。
手順としてはこちらを参照してください。
ERROR: yaml.scanner.ScannerError: while scanning for the next token
このエラーでは「docker-compose.yml」のインデントを確認してみてください。
コメントアウトしているものでも、インデントがずれていると怒られるので注意してください。yaml.parser.ParserError: while parsing a block mapping
このエラーでも「docker-compose.yml」のインデントを確認してみてください。
- 投稿日:2020-09-16T19:59:34+09:00
swagger-codegenを使ってpython-flaskのモックサーバーを秒で立てたい。
はじめに
業務の中でWebサーバーなんぞ詳しくないのに、
PoC用にWebサーバーを立てろ(しかも秒で)と言われた経験がある方にswagger-codegenをご紹介します。
(秒では立てられないかもしれませんが、API仕様さえyamlで書ければ簡単にサーバーまで立てられます。)swagger-codegenについて
swagger-codegenはYAML(or JSON)でAPI仕様を定義すると、
そのAPI定義通りにモックサーバーを作り、
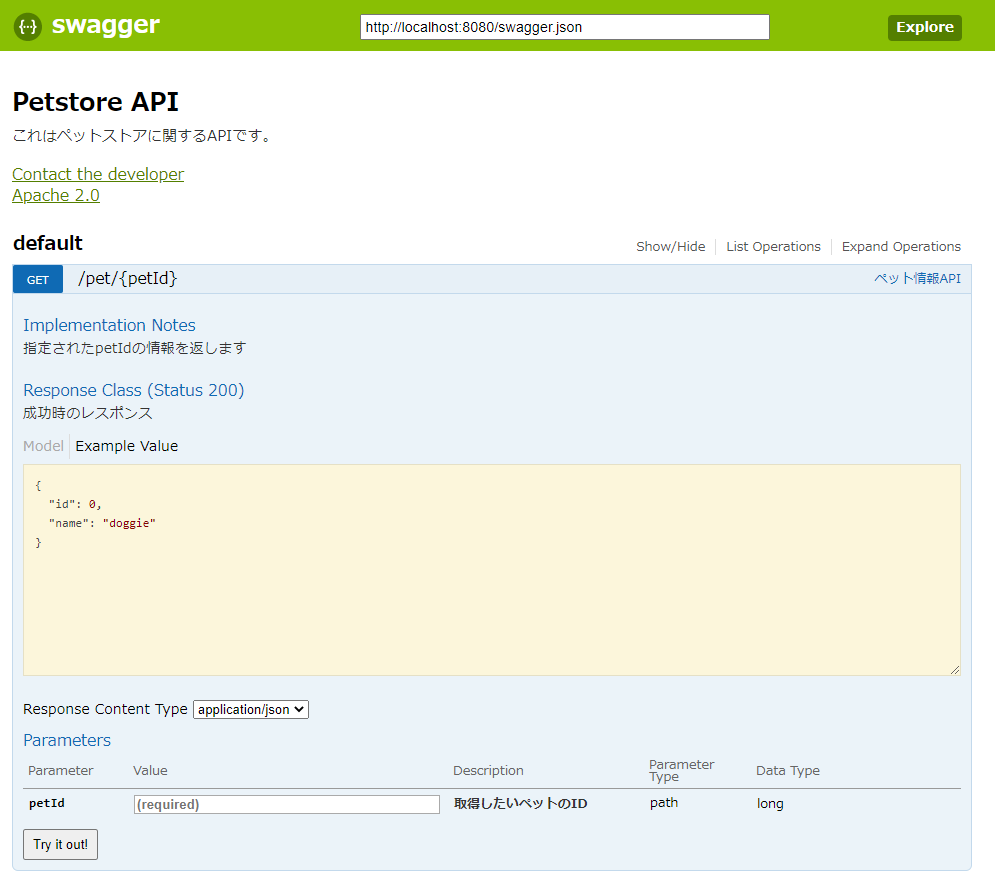
さらに、以下のようにそのAPIを叩けるブラウザUI画面を作成できます。
使用環境
- OS ... Windows 10 Home(64bit)
- Python ... conda環境
- その他、JREが必要
JREのインストール
JREがない場合は以下よりダウンロード&インストールをする。
- https://www.java.com/ja/download/manual.jspswagger-codegen-cli.jarの取得
mavenのレポジトリから取得する。
- https://repo1.maven.org/maven2/io/swagger/今回は以下の2.4.15を使用した。
- https://repo1.maven.org/maven2/io/swagger/swagger-codegen-cli/2.4.15API仕様をswagger.yamlに定義
API仕様を定義してあげると、その定義に沿ってモックサーバーができます。
以下のようなファイルをどこか適当に作成します。swagger.yamlswagger: "2.0" info: description: "これはペットストアに関するAPIです。" version: "1.0.0" title: "Petstore API" termsOfService: "http://swagger.io/terms/" contact: email: "apiteam@swagger.io" license: name: "Apache 2.0" url: "http://www.apache.org/licenses/LICENSE-2.0.html" paths: /pet/{petId}: get: summary: "ペット情報API" description: "指定されたpetIdの情報を返します" parameters: - name: "petId" in: "path" description: "取得したいペットのID" required: true type: "integer" format: "int64" responses: 200: description: "成功時のレスポンス" schema: type: "object" properties: id: type: "integer" format: "int64" name: type: "string" example: "doggie"swagger.yml内の記述の意味は以下をご参考にしてください。
- https://qiita.com/rllllho/items/53a0023b32f4c0f8eabbモックサーバーを作成
今回は慣れ親しんだpythonを使いたいので、pytoh-flaskでモックサーバーを作成します。
> java -jar {ダウンロードしたjarファイル} generate -i swagger.yaml -l python-flask -o test-server
-lオプションを変えればGoでもNode.jsでもRuby on Railsでもなんでも作れます。
他に-lオプションに何があるかは以下を参考にしてください。
- https://github.com/swagger-api/swagger-codegen/wiki/Server-stub-generator-HOWTO作成されたフォルダ構成
python-flaskの場合、こんな感じでモックサーバーができます。
Dockerfileもできていますので、Dockerコンテナにすることも可能です。> tree server server ├── Dockerfile ├── README.md ├── git_push.sh ├── requirements.txt ├── setup.py ├── swagger_server │ ├── __init__.py │ ├── __main__.py │ ├── controllers │ │ ├── __init__.py │ │ └── default_controller.py │ ├── encoder.py │ ├── models │ │ ├── __init__.py │ │ ├── base_model_.py │ │ └── inline_response200.py │ ├── swagger │ │ └── swagger.yaml │ ├── test │ │ ├── __init__.py │ │ └── test_default_controller.py │ └── util.py ├── test-requirements.txt └── tox.iniこの中で、実際の処理を記載するのは、
default_controller.pyのpet_pet_id_getの部分になります。default_controller.pyimport connexion import six from swagger_server.models.inline_response200 import InlineResponse200 # noqa: E501 from swagger_server import util def pet_pet_id_get(petId): # noqa: E501 """ペット情報API 指定されたpetIdの情報を返します # noqa: E501 :param petId: 取得したいペットのID :type petId: int :rtype: InlineResponse200 """ return 'do some magic!'Windows上のconda環境で動かしてみる。
必要なパッケージをインストールします。
swagger-codegenによって作られた環境にはpipのrequirements.txtしか書いていませんが、
conda環境では以下をインストールすれば動かすことができます。> conda install connexion > conda install swagger-ui-bundle起動します。
> cd test-server > python -m swagger_server以下にブラウザからアクセスして画面が見えたら起動できています。
- http://localhost:8080/ui/以上、お疲れさまでした!
- 投稿日:2020-09-16T19:52:11+09:00
Python参照ページ
Pythonを扱う上で参考にしたWebページの一覧
Pythonリスト内包表記
https://note.nkmk.me/python-list-comprehension/
基本型
[式 for 任意の変数名 in イテラブルオブジェクト]!!ファイルを読み込んだものから改行コードを取りたいときはf.read().splitlines()でいい!!
https://qiita.com/suzuki-hoge/items/8eac60f7b68044eea6c1pythonでのファイルの読み込み、書き込み
https://note.nkmk.me/python-file-io-open-with/python 辞書のfor文
https://note.nkmk.me/python-dict-keys-values-items/python strip系
https://note.nkmk.me/python-str-remove-strip/python 配列の初期化
https://www.javadrive.jp/python/list/index12.htmlpython 文字列の扱い
https://qiita.com/tomotaka_ito/items/594ee1396cf982ba9887python if not
https://www.sejuku.net/blog/65070pythonで冪乗を扱う
https://www.sejuku.net/blog/71405
- 投稿日:2020-09-16T18:41:54+09:00
Python × GISの基礎(その2)
その1はこちら
ヘルシンキ大学の教材のWeek3-Week4の解答と補足をまとめていきます。Week3
3-1 ショッピングセンターのジオコーディング
ヘルシンキにある大型ショッピングモールの周囲1.5kmに住んでいる住民の数、すなわち商圏人口を求めることが目標です。自分でネットで検索してモールの住所を調べる必要があります。
住所から座標に変換するジオコーディングが登場します。日本では東京大学が提供しているCSVアドレスマッチングサービスが有名ですね。
またバッファリング・空間結合といったQGISでお馴染みの操作も登場します。import geopandas as gpd import pandas as pd import matplotlib.pyplot as plt import requests import geojson from shapely.geometry import Polygon, LineString, Point from pyproj import CRS import os #データ読み込み data = pd.read_table('shopping_centers.txt', sep=';', header=None) data.index.name = 'id' data.columns=['name', 'addr'] #ジオコーディング geo = geocode(data['addr'], provider='nominatim', user_agent='autogis_xx', timeout=4) #データの結合 geo = geo.to_crs(CRS.from_epsg(3879)) geodata = geo.join(data) #バッファリング geodata['buffer']=None geodata['buffer'] = geodata['geometry'].buffer(distance=1500) geodata['geometry'] = geodata['buffer'] #人口のグリッドデータの取得 url = 'https://kartta.hsy.fi/geoserver/wfs' params = dict(service='WFS',version='2.0.0',request='GetFeature', typeName='asuminen_ja_maankaytto:Vaestotietoruudukko_2018',outputFormat='json') r = requests.get(url, params=params) pop = gpd.GeoDataFrame.from_features(geojson.loads(r.content)) #座標系変換 pop = pop[['geometry', 'asukkaita']] pop.crs = CRS.from_epsg(3879).to_wkt() geodata = geodata.to_crs(pop.crs) #空間結合 join = gpd.sjoin(geodata, pop, how="inner", op="intersects") #商圏人口の計算 grouped = join.groupby('name') for key, group in grouped: print('store: ', key,"\n", 'population:', sum(group['asukkaita']))3-2 最寄りのショッピングセンター
自分の家と職場から最寄りのショッピングセンターを求めます。フィンランドに住んでいる方は別ですが、適当なヘルシンキのスポットを基点の住所として置きましょう。
(以下ライブラリのインポートは省略しています。)#データの読み込み home = pd.read_table('activity_locations.txt', sep=';', header=None) home.index.name='id' home.columns = ['name', 'addr'] shop = pd.read_table('shopping_centers.txt', sep=';', header=None) shop.index.name = 'id' shop.columns=['name', 'addr'] #ジオコーディング geo_home = geocode(home['addr'], provider='nominatim', user_agent='autogis_xx', timeout=4) geo_shop = geocode(shop['addr'], provider='nominatim', user_agent='autogis_xx', timeout=4) #最寄り店を求める destinations = MultiPoint(list(geo_shop['geometry'])) for home in geo_home['geometry']: nearest_geoms = nearest_points(home, destinations) print(nearest_geoms[1])Week4
4-1 アクセシビリティデータの可視化
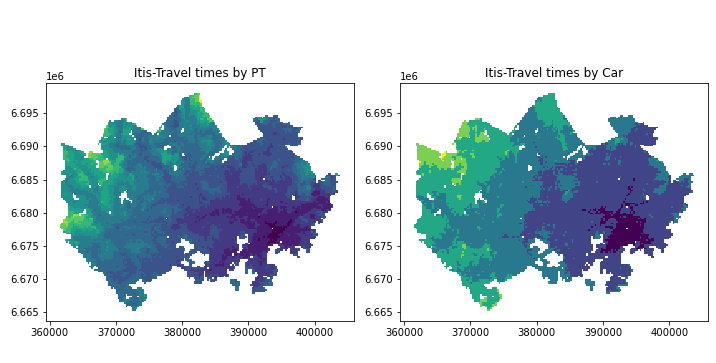
移動時間データと地下鉄網のデータを組み合わせて、アクセシビリティを可視化します。
#データの読み込み grid = gpd.read_file('data/MetropAccess_YKR_grid_EurefFIN.shp') data = pd.read_table('data/TravelTimes_to_5944003_Itis.txt', sep=';') data = data[["pt_r_t", "car_r_t", "from_id", "to_id"]] #データ結合 data_geo = grid.merge(data, left_on='YKR_ID', right_on='from_id') #無効データ(-1)の除外 import numpy as np data_geo = data_geo.replace(-1, np.nan) data_geo = data_geo.dropna() #データの階層化 import mapclassify bins = [15, 30, 45, 60, 75, 90, 105, 120, 135, 150, 165, 180] classifier = mapclassify.UserDefined.make(bins = bins) data_geo['pt_r_t_cl'] = data_geo[['pt_r_t']].apply(classifier) data_geo['car_r_t_cl'] = data_geo[['car_r_t']].apply(classifier) #可視化 fig = plt.figure(figsize=(10,10)) ax1 = fig.add_subplot(1, 2, 1) #公共交通 data_geo.plot(ax=ax1, column='pt_r_t_cl') ax1.set_title("Itis-Travel times by PT") ax2 = fig.add_subplot(1, 2, 2) #自家用車 data_geo.plot(ax=ax2, column='car_r_t_cl') ax2.set_title("Itis-Travel times by Car") plt.tight_layout() plt.show() fig.savefig('itis_accessibility.png')こんな感じで表示されます。
4-2ショッピングモールの勢力圏
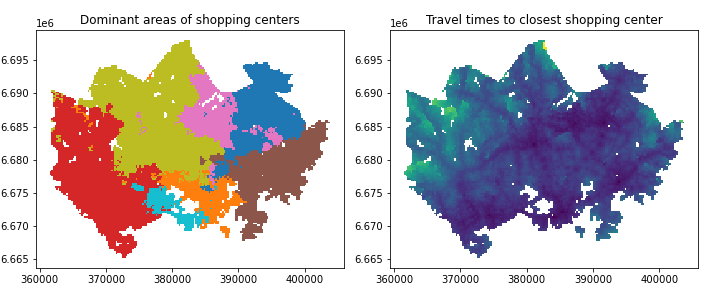
4-1で得たアクセシビリティのデータをもとに、各グリッドの最寄りのショッピングモールを求めることで勢力圏の可視化を目指します。
#データの読み込み filepaths = glob.glob('data/TravelTimes*.txt') for path in filepaths: data = pd.read_table(path, sep=';') data = data[['from_id', 'pt_r_t']] data = data.rename(columns={'from_id':'YKR_ID'}) #カラム名を'pt_r_t_{store}'に変更 newname = path.replace('data/TravelTimes_to_', '') newname = newname.replace('.txt', '') newname = re.sub('\d{7}_', '', newname) data = data.rename(columns={'pt_r_t':'pt_r_t_'+newname}) grid = grid.merge(data) #データの結合 grid = gpd.read_file('data/MetropAccess_YKR_grid_EurefFIN.shp') #無効データ(-1)の除外 import numpy as np grid = grid.replace(-1, np.nan) grid = grid.dropna() #各グリッドのモールへの最短距離・モール名 grid['min_t'] = None grid['dominant_service'] = None columns = ['pt_r_t_Ruoholahti', 'pt_r_t_Myyrmanni','pt_r_t_Itis', 'pt_r_t_Jumbo', 'pt_r_t_IsoOmena', 'pt_r_t_Dixi','pt_r_t_Forum'] mini = lambda row:row[columns].min() idx = lambda row:row[columns].astype(float).idxmin() grid['min_t'] = grid.apply(mini, axis=1) grid['dominant_service'] = grid.apply(idx, axis=1)
4-3 ショッピングモールの勢圏人口
グリッドデータに対してディゾルブを使い集約化しインターセクションで勢圏人口を求める、というベタなものです。
4-2と重複する箇所は省略します。#4-2のステップを進め, 勢圏を含むpopデータを作成 #ディゾルブしてインターセクション dissolved = grid.dissolve(by = 'dominant_service') pop = pop[['geometry', 'asukkaita']] #必要なデータに限定 intersection = gpd.overlay(grid, pop, how='intersection') #勢圏でグルーピングして勢圏人口を求める grouped = intersection.groupby('dominant_service') for key, group in grouped: print(key, ':', sum(group['asukkaita']))
- 投稿日:2020-09-16T18:07:04+09:00
tensorflow==2.0.0でDQNを学習したらmemory-leakが発生した
はじめに
最近研究で使うDQNをそこそこ苦労しながら実装し、それの学習を回したところ異常な程Memoryを食っており、原因究明に1週間もかかってしまいました。
自分のような人が現れないように、簡単に記録を残していきたいと思います。環境
python==3.7
Tensorflow==2.0.0
Ubuntu 18.04実際に発生した現象
私が使っていたのは、研究室に設置されたDeepStationと呼ばれる学習用サーバです。
これは、GTX1080ti * 4と RAMが64GBあるので、少々無理やり動作させても変なことは起きたことがありませんでした。
しかし、環境を更新して普通にEnd-to-Endの識別モデルの学習を行っている時には発生していませんでした。しかし、DQNで学習を行っていた際に問題が発生しました。
今回のDQNの実装に参考にしたのは以下の記事になります。https://qiita.com/sugulu_Ogawa_ISID/items/bc7c70e6658f204f85f9
このソースコードを実行して放置していると、三時間ぐらいで64GBをオーバーしてmemory-overでクラッシュしてしまいました。
最初はソースコードに問題があると思い、一行ずつソースコードを確認していましたが特に問題が見つからず苦労していました。
もともと、Pythonはmemory-leakが起きにくいというのもあり、あまり意識したことがなかったためです。このソースコードを見ればわかりますが、episideが閾値を超えると毎回model.fit()を呼び出して少しずつ学習を行っています。
問題はここにありました。
以下をみてもらえれば、似たような症状が見つかります。https://github.com/tensorflow/tensorflow/issues/33030
これをみてみると、一回model.fitやmodel.predictをしているのは大きな問題ではなく、コレを複数回行うことでmemory-leakが発生したようです。
おそらくですが、model.fitやmodel.predictで呼び出されたmodelがreleaseされずに保持されていたんじゃないかなーと思います。解決方法
基本的には、tensorflowのversionをupdateすればOKです。
私は、tenosorflow==2.3.0をインストールすることで、解決しました。このせいで、一週間も時間を取られるとは思いませんでした。
memory leakって本当に起きるんだーって思いました。
jupyter-labで実行していると、メモリをエラーで開放してくれるわけではなかったためPCにもなかなかログインできずかなり焦りました。
大きくメモリを持っていても過信せずに、pythonのメモリ使用に制限しておくと安心ですね。今は私もそうしています。
以下の記事を参考すると良いでしょう。https://blog.imind.jp/entry/2019/08/10/022501
最後に
DQNで学習していても似たような情報があんまり出ていなかったので、よくわからず苦労しました。
これがみんさんの参考に慣れば幸いです。
- 投稿日:2020-09-16T17:58:44+09:00
for文で使える関数
for文で使える関数
Python では繰り返し処理を行うために for 文が使用されます。
回数を指定して繰り返すなどの処理を行いたい場合には range 関数と組み合わせる。range()関数
0から始まり、1(デフォルト)で増減する一連の数値を返し、指定した数値の前で停止します。
range(開始, 終了, ステップ)
使い方 説明 開始 開始位置を指定する整数。デフォルトは0です。 終了 終了後位置を指定する整数。 ステップ インクリメント、デクリメントを指定する整数。デフォルトは1である。 開始 開始位置を指定する整数。デフォルトは0です。
終了 終了後位置を指定する整数。
ステップ インクリメント、デクリメントを指定する整数。デフォルトは1である。range(開始, 終了, ステップ)
for f in renge(5)
※この場合は、開始=「デフォルトの0」ステップ=「デフォルトの1」が適用される。print (f, end = ‘ ’)
01234
「終了」に指定した値は含まれないので4が返される。仮に5まで取得可能したい場合は、6を指定すればいいです。range(1, 5, 2)
※この場合は1から4まで2づつ増えるrange(10, 5, -2)
※この場合は10から6まで2づつ減るprint(list(range(3)))
この形にすると、リスト型で取得することができるらしいです。ループカウンタ
恥ずかしながら、ループカウンタの意味を知らなかったので調べてきました。
ループを制御する変数で、繰り返し処理の終了条件が処理回数の場合に使用して、処理を1回行うたびに、ループカウンターを1加算し、何回処理が行われたかをカウントして制御する。
上記の意味をループカウンタと言うそうです。Python、でループカウンタを使用したい場合はenumerate()関数を使用する。
enumerate()
l = [‘kokugo’, ‘suugaku’, ‘eigo’]
for i, subject in enumerate(l):
print(i, subject)
0 kokugo
1 suugaku
2 eigo※enumerate()の第2引数を指定しない場合は0からになる
以下のように、第2引数を指定した場合は、指定した数値からループカウンタが返される。
l = [‘kokugo’, ‘suugaku’, ‘eigo’]
for i, subject in enumerate(l, 11):
print(i, subject)
11 kokugo
12 suugaku
13 eigozip()
ループカウンタはzip()関数を使用して定義することも可能ですfor i , w in zip(['kokugo', 'suugaku', 'eigo'], [78, 82, 54]):
print(subject, number)
kokugo 78
suugaku 82
eigo 54以下のように、ループ内容を変数で定義することも可能です
subject = ['kokugo', 'suugaku', 'eigo']
number = [78, 82, 54]for i , w in zip(subject, number):
print(subject, number)
kokugo 78
suugaku 82
eigo 54
- 投稿日:2020-09-16T17:21:09+09:00
pyautoGUIでopencvを入れたらエラーになる
概要
pythonでRPAを行うために、
pyautoguiを使っているとき、
許容誤差や、グレースケール認識などを行いたいときがあります。
その時にopencvを入れる必要が出てきます。ところが、結局使えませんでした。
エラー内容と回避策を載せておきます。エラー内容
pos = pyautogui.locateCenterOnScreen(GetImage(imgname), region=inputregion)
このコードが、これまで動いていたのに、急に動かなくなりました。
pip opencv-pythonして、
pos = pyautogui.locateCenterOnScreen(GetImage(imgname), region=inputregion, grayscale=True)
と書き換えてグレースケールに対応させようとしました。output============================= test session starts ============================= platform win32 -- Python 3.8.5, pytest-6.0.2, py-1.9.0, pluggy-0.13.1 ================================== FAILURES =================================== pos = pyautogui.locateCenterOnScreen(GetImage(imgname), region=inputregion,grayscale=True) C:\tools\miniconda3\envs\rpa2\lib\site-packages\pyautogui\__init__.py:175: in wrapper return wrappedFunction(*args, **kwargs) C:\tools\miniconda3\envs\rpa2\lib\site-packages\pyautogui\__init__.py:207: in locateCenterOnScreen return pyscreeze.locateCenterOnScreen(*args, **kwargs) C:\tools\miniconda3\envs\rpa2\lib\site-packages\pyscreeze\__init__.py:400: in locateCenterOnScreen coords = locateOnScreen(image, **kwargs) C:\tools\miniconda3\envs\rpa2\lib\site-packages\pyscreeze\__init__.py:360: in locateOnScreen retVal = locate(image, screenshotIm, **kwargs) C:\tools\miniconda3\envs\rpa2\lib\site-packages\pyscreeze\__init__.py:340: in locate points = tuple(locateAll(needleImage, haystackImage, **kwargs)) _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ needleImage = array([[31, 31, 31, ..., 31, 31, 31], [31, 31, 31, ..., 31, 31, 31], [31, 31, 31, ..., 31, 31, 31], ...31, 31, 31, ..., 31, 31, 31], [31, 31, 31, ..., 31, 31, 31], [31, 31, 31, ..., 31, 31, 31]], dtype=uint8) haystackImage = array([[60, 60, 60, ..., 60, 60, 60], [60, 60, 60, ..., 60, 60, 60], [60, 60, 60, ..., 60, 60, 60], ...16, 16, 16, ..., 16, 16, 16], [16, 16, 16, ..., 16, 16, 16], [16, 16, 16, ..., 16, 16, 16]], dtype=uint8) grayscale = True, limit = 1, region = (0, 945.0, 240.0, 135.0), step = 1 confidence = 0.999 def _locateAll_opencv(needleImage, haystackImage, grayscale=None, limit=10000, region=None, step=1, confidence=0.999): """ TODO - rewrite this faster but more memory-intensive than pure python step 2 skips every other row and column = ~3x faster but prone to miss; to compensate, the algorithm automatically reduces the confidence threshold by 5% (which helps but will not avoid all misses). limitations: - OpenCV 3.x & python 3.x not tested - RGBA images are treated as RBG (ignores alpha channel) """ if grayscale is None: grayscale = GRAYSCALE_DEFAULT confidence = float(confidence) needleImage = _load_cv2(needleImage, grayscale) needleHeight, needleWidth = needleImage.shape[:2] haystackImage = _load_cv2(haystackImage, grayscale) if region: > haystackImage = haystackImage[region[1]:region[1]+region[3], region[0]:region[0]+region[2]] E TypeError: slice indices must be integers or None or have an __index__ method C:\tools\miniconda3\envs\rpa2\lib\site-packages\pyscreeze\__init__.py:202: TypeError =========================== short test summary info =========================== FAILED test_iqctrl.py::test_iqcreate - TypeError: slice indices must be integ... ============================== 1 failed in 2.03s ==============================環境
使用しているpythonモジュールの一覧です。
conda install python pip install pyautogui pip install rope yapf black autopep8 pylint pytest pip install tqdm pip install pyperclip pip install pyodbc pip install cx_Oracleここにopencv-pythonを追加しました。
OSはWindows10です。
結論
_locateAll_opencv関数がpython3.xではテストされておらず、発展途上とのこと。
「配列をスライスするインデックスは整数にしなきゃダメだよ」などのエラーが出ていますが、
pyautoguiモジュールの中の話なので関与できませんでした。回避策
現状は2.Xで我慢するか、opencvをあきらめるかどちらか。
どちらも受け入れられない場合にはグレースケールと曖昧画像検索をあきらめる必要がありそう。_locateAll_opencv関数そのものを書き換えられる人は、Githubにプルリクしていただけると助かります。
関係資料
- 投稿日:2020-09-16T16:44:08+09:00
写真から3Dモデルを作る方法を思いついた その04ポリゴンの生成
どーもKsukeです。
写真から3Dモデルを作る方法を思いついたその04で、ポリゴンの生成をやっていきます。
その3はこちらhttps://qiita.com/Ksuke/items/8b7f2dc840126753b4e9※注意※
この記事は思いついて試した事の末路を載せているだけなので、唐突なネタやBad Endで終わる可能性があります。やってみる
手順
1.点群の境界の点を取得
2.点群の境界の内側の点を取得
3.ポリゴン生成ところどころにあるコードは、最後にまとめたものを載せてあります。
1.点群の境界の点を取得
今のところオブジェクトが点群で表されていますが、その点はオブジェクトの内側にも敷き詰められています。内側の点はいらないので、境界部分の点のみを取り出します。
各点が境界かを判定するために、各座標の隣接6方向(上下右左前後)にある点の数を数えます。隣接点の数が0でない点を境界の点として取り出しました。点群の境界の点を取得#境界部分の点群を返す関数 def genBorderPointSpace(imgProjectSpace): # 空間に6方向(上下左右前後)の加算フィルタに相当する処理をして、各地点の周囲の点の数のmapを作る locationPointMap = np.stack([ imgProjectSpace[2:,1:-1,1:-1], imgProjectSpace[:-2,1:-1,1:-1], imgProjectSpace[1:-1,2:,1:-1], imgProjectSpace[1:-1,:-2,1:-1], imgProjectSpace[1:-1,1:-1,2:], imgProjectSpace[1:-1,1:-1,:-2], ]).sum(axis=0,dtype=np.int8) #空間の大きさをもとに戻しておく locationPointMap = np.insert(locationPointMap, (0,-1), 0, axis=0) locationPointMap = np.insert(locationPointMap, (0,-1), 0, axis=1) locationPointMap = np.insert(locationPointMap, (0,-1), 0, axis=2) #各地点ごとの周囲の点の数のmapから、周囲の点の数が0でも6でもない(周囲に点が存在し、かつ点に囲まれていない)点を残した空間を作る borderPointSpace = np.where((0<locationPointMap)&(locationPointMap<6)&(imgProjectSpace==1),1,0).astype(np.int8) #周りを点で囲まれていない点を残した空間を返す return borderPointSpace #重ねた空間の点群のうち、外部と接している境界部分の点を取り出す borderPointSpace = genBorderPointSpace(imgProjectSpace) #空間から点の座標を取り出す borderCoords = binary2coords(borderPointSpace)2.点群の境界の内側の点を取得
ポリゴンの表示は境界部分の点だけで充分ですが、のちのポリゴンの自動生成の都合で、境界の点の内側の点も取得します。
点群の境界の内側の点を取得#境界部分のすぐ内側の点群を返す関数 def genInsidePointSpace(imgProjectSpace,borderPointSpace): #境界付近の点を残した空間を作成(境界部分は残さない) nearBorderPointSpace = np.stack([ borderPointSpace[2:,1:-1,1:-1], borderPointSpace[:-2,1:-1,1:-1], borderPointSpace[1:-1,2:,1:-1], borderPointSpace[1:-1,:-2,1:-1], borderPointSpace[1:-1,1:-1,2:], borderPointSpace[1:-1,1:-1,:-2], borderPointSpace[1:-1,1:-1,1:-1]*-6 ]).sum(axis=0,dtype=np.int8) #大きさを戻す nearBorderPointSpace = np.insert(nearBorderPointSpace, (0,-1), 0, axis=0) nearBorderPointSpace = np.insert(nearBorderPointSpace, (0,-1), 0, axis=1) nearBorderPointSpace = np.insert(nearBorderPointSpace, (0,-1), 0, axis=2) #境界付近で、元の点群の内側の点を残した空間を作成 insidePointSpace = np.where(((0<nearBorderPointSpace)&(imgProjectSpace==1)),1,0) return insidePointSpace #重ねた空間の点群のうち、境界部分のすぐ内側の点を取り出す insidePointSpace = genInsidePointSpace(imgProjectSpace,borderPointSpace) #空間から点の座標を取り出す insideCoords = binary2coords(insidePointSpace)3.ポリゴン生成
2種類の点を取得したら、いよいよポリゴンの生成をしていきます。この処理でやっていることは他の処理に比べ説明しずらいので、2次元の画像で説明します(ここだけめっちゃ時間かかった。。。)。
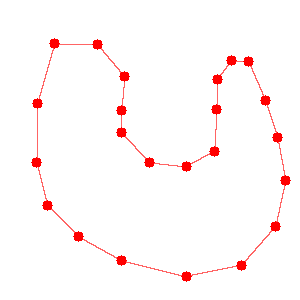
まずこの処理の目的を確認しなおすと、オブジェクトの境界部分の点から、オブジェクトを囲う面を決定することです。2次元の画像上でいうと、オブジェクトの境界部分の点(図1)から領域を囲う線(図2)を決定することになります。
図1.境界部分の点 ↓
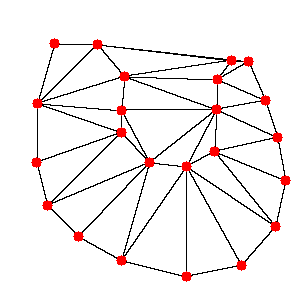
図2.最終的に欲しい境界線 このような処理を行うために、Delaunayというメソッドを利用しました。これは、点で表された領域を三角形で分割する、というものです。画像の赤い点でDelaunayをそのままを試した結果が下の図3です。御覧の通りほしい境界部分に線を引けてはいますが、それ以外の部分にも線が引かれてしまっています。
図3.境界部分の点の三角分割結果 さーて困ったと悩んだ末に、境界部分の点とは別に、境界部分の内側の点を加えてDelaunayを行うことにしました。境界部分の内側の点とは、境界部分の点に近く、かつオブジェクトの領域の内側にある点のことです。下の図4でいうところの、追加された青い点です。
図4.境界部分の点と境界部分の内側の点 この境界部分の内側の点を含めてDelaunayをするとどうなるかというと、下の図5のようになります。
図5.境界部分の点と境界部分の内側の点の三角分割結果 一見赤い点だけでDelaunayした時より少し複雑になっただけに見えるかもしれませんが、実はこれなら分割した三角形を3種類に分類することができます。
どう分類するかというと、
・境界部分の点だけで構成された三角形(薄い赤で塗られているもの)
・境界部分の内側の点だけで構成された三角形(薄い青で塗られているもの)
・境界部分の点と境界部分の内側の点両方で構成された三角形(薄い紫で塗られているもの)
という具合です。実際に塗り分けてみると図6のようになります。
図6.三角分割分類結果 3種類の三角形を見てみると、最終的に欲しい境界線はすべて薄い紫の三角形に含まれていることがわかります。そこで薄い紫の三角形以外を除くと図7のようになります。
図7.境界線を含む三角形 ここまで三角形が減ったところで、次は線に注目してみていきます。線に注目すると、こちらも3種類に分類することができます。
どう分類するかというと、
・境界部分の点をつないだ線(薄い赤で塗られているもの)
・境界部分の内側の点をつないだ線(薄い青で塗られているもの)
・境界部分の点と境界部分の内側の点をつないだ線(薄い紫で塗られているもの)
という具合です。実際に塗り分けてみると図8のようになります。
図8.線分類結果 ここまでくればあとは見た通りです。薄い赤で塗り分けた線が、まさに図2で書かれた最終的に欲しい境界線そのまんまですよね?てなわけで薄い赤の線以外を除くと図9のようになります。
図9.取得できた境界線 このようにして、点群からそれを囲う線(3次元の点群対象であれば面)を取得することができます。この処理を、3次元の点群を対象として実装したのがこちらです。
ポリゴン生成#座標群からポリゴンの面を決定する関数 def genPolygon(borderCoords,insideCoords): #2種類の頂点を結合(図4の処理に相当) coords = np.concatenate([borderCoords,insideCoords]) #頂点ごとの種別を表すmapを生成(0はborderで、1はinside) coordStat = np.zeros((len(coords)),dtype=np.uint8) coordStat[len(borderCoords):len(borderCoords)+len(insideCoords)] = 1 #頂点群から4点からなる三角錐群を生成(図5の処理に相当) triPyramids = Delaunay(coords).simplices #三角錐ごとに、insideの頂点がいくつ含まれているか確認(図6の処理に相当) triPyramidsStat = coordStat[triPyramids].sum(axis=1) #三角錐のうち、insideの頂点とborderの頂点を両方含んでいるものを取り出して、有効な三角錐とする(図7の処理に相当) #(ここでborderの頂点のみで構成されたオブジェクトの外部の余白の空間の三角錐と、insideの頂点のみで構成されたオブジェクトの内部の余白の空間の三角錐を取り除く) effectiveTriPyramids = triPyramids[np.where((triPyramidsStat!=0)&(triPyramidsStat!=4))[0]] #オブジェクトの面の候補(頂点のindex3つ)を入れるlist(余分なものは後々取り除く) faces = [] #有効な三角錐の面を、オブジェクトの面の候補をして取り出す(記事の画像の説明でいう、線に注目している部分に該当) for coordIndexs in effectiveTriPyramids: faces.append([coordIndexs[0],coordIndexs[1],coordIndexs[2]]) faces.append([coordIndexs[0],coordIndexs[1],coordIndexs[3]]) faces.append([coordIndexs[0],coordIndexs[2],coordIndexs[3]]) faces.append([coordIndexs[1],coordIndexs[2],coordIndexs[3]]) #オブジェクトの面の候補の、頂点のindexを並び替え、重複を取り除く faces = np.array(faces) faces.sort(axis=1) faces = np.unique(faces,axis=0) #面ごとに、insideの頂点をいくつ含んでいるのか確認(図8の処理に相当) faceStat = coordStat[faces].sum(axis=1) #insideの頂点を1つも含んでいない面を取り出し(図9の処理に相当) faces = faces[np.where(faceStat==0)] #頂点と面を返す return borderCoords,faces #2種類の座標からポリゴン(正確にはポリゴンとなる頂点と頂点を結ぶ面の定義)を生成 coords,faces = genPolygon(borderCoords,insideCoords) #facesをblenderに渡す形式に変更 faces = [[face[0],face[1],face[2],face[0]] for face in faces]動作確認
最後にコードが問題なく動くか確認。
1.全部まとめて
ポリゴン生成のところで力尽きたので動確はまとめて。。。
下のコードをblenderで実行して、動確用1#頂点とポリゴンを描画 addObj(coords=coords,faces=faces,name = "porigon",offset=[-125,-50,-50]) addObj(coords=borderCoords,name = "borderCoords",offset=[-50,-85,-50]) addObj(coords=insideCoords,name = "insideCoords",offset=[-50,-15,-50])こんな感じのオブジェクトが表示されれば成功。オブジェクトのうち下2つをよくよく見比べると、右のほうが少し小さい(境界の内側の点だから)。
次は?
やっとポリゴンが表示されたけど、ポリゴン数がめちゃくちゃ多い・・・。ので、blenderの機能を使ってポリゴン数の削減を行っていきます。
コードまとめ
前回のコードの後ろに追加すれば動くはずです。
関数編
コードまとめ(関数編)#境界部分の点群を返す関数 def genBorderPointSpace(imgProjectSpace): # 空間に6方向(上下左右前後)の加算フィルタに相当する処理をして、各地点の周囲の点の数のmapを作る locationPointMap = np.stack([ imgProjectSpace[2:,1:-1,1:-1], imgProjectSpace[:-2,1:-1,1:-1], imgProjectSpace[1:-1,2:,1:-1], imgProjectSpace[1:-1,:-2,1:-1], imgProjectSpace[1:-1,1:-1,2:], imgProjectSpace[1:-1,1:-1,:-2], ]).sum(axis=0,dtype=np.int8) #空間の大きさをもとに戻しておく locationPointMap = np.insert(locationPointMap, (0,-1), 0, axis=0) locationPointMap = np.insert(locationPointMap, (0,-1), 0, axis=1) locationPointMap = np.insert(locationPointMap, (0,-1), 0, axis=2) #各地点ごとの周囲の点の数のmapから、周囲の点の数が0でも6でもない(周囲に点が存在し、かつ点に囲まれていない)点を残した空間を作る borderPointSpace = np.where((0<locationPointMap)&(locationPointMap<6)&(imgProjectSpace==1),1,0).astype(np.int8) #周りを点で囲まれていない点を残した空間を返す return borderPointSpace #境界部分のすぐ内側の点群を返す関数 def genInsidePointSpace(imgProjectSpace,borderPointSpace): #境界付近の点を残した空間を作成(境界部分は残さない) nearBorderPointSpace = np.stack([ borderPointSpace[2:,1:-1,1:-1], borderPointSpace[:-2,1:-1,1:-1], borderPointSpace[1:-1,2:,1:-1], borderPointSpace[1:-1,:-2,1:-1], borderPointSpace[1:-1,1:-1,2:], borderPointSpace[1:-1,1:-1,:-2], borderPointSpace[1:-1,1:-1,1:-1]*-6 ]).sum(axis=0,dtype=np.int8) #大きさを戻す nearBorderPointSpace = np.insert(nearBorderPointSpace, (0,-1), 0, axis=0) nearBorderPointSpace = np.insert(nearBorderPointSpace, (0,-1), 0, axis=1) nearBorderPointSpace = np.insert(nearBorderPointSpace, (0,-1), 0, axis=2) #境界付近で、元の点群の内側の点を残した空間を作成 insidePointSpace = np.where(((0<nearBorderPointSpace)&(imgProjectSpace==1)),1,0) return insidePointSpace #座標群からポリゴンの面を決定する関数 def genPolygon(borderCoords,insideCoords): #2種類の頂点を結合(図4の処理に相当) coords = np.concatenate([borderCoords,insideCoords]) #頂点ごとの種別を表すmapを生成(0はborderで、1はinside) coordStat = np.zeros((len(coords)),dtype=np.uint8) coordStat[len(borderCoords):len(borderCoords)+len(insideCoords)] = 1 #頂点群から4点からなる三角錐群を生成(図5の処理に相当) triPyramids = Delaunay(coords).simplices #三角錐ごとに、insideの頂点がいくつ含まれているか確認(図6の処理に相当) triPyramidsStat = coordStat[triPyramids].sum(axis=1) #三角錐のうち、insideの頂点とborderの頂点を両方含んでいるものを取り出して、有効な三角錐とする(図7の処理に相当) #(ここでborderの頂点のみで構成されたオブジェクトの外部の余白の空間の三角錐と、insideの頂点のみで構成されたオブジェクトの内部の余白の空間の三角錐を取り除く) effectiveTriPyramids = triPyramids[np.where((triPyramidsStat!=0)&(triPyramidsStat!=4))[0]] #オブジェクトの面の候補(頂点のindex3つ)を入れるlist(余分なものは後々取り除く) faces = [] #有効な三角錐の面を、オブジェクトの面の候補をして取り出す(記事の画像の説明でいう、線に注目している部分に該当) for coordIndexs in effectiveTriPyramids: faces.append([coordIndexs[0],coordIndexs[1],coordIndexs[2]]) faces.append([coordIndexs[0],coordIndexs[1],coordIndexs[3]]) faces.append([coordIndexs[0],coordIndexs[2],coordIndexs[3]]) faces.append([coordIndexs[1],coordIndexs[2],coordIndexs[3]]) #オブジェクトの面の候補の、頂点のindexを並び替え、重複を取り除く faces = np.array(faces) faces.sort(axis=1) faces = np.unique(faces,axis=0) #面ごとに、insideの頂点をいくつ含んでいるのか確認(図8の処理に相当) faceStat = coordStat[faces].sum(axis=1) #insideの頂点を1つも含んでいない面を取り出し(図9の処理に相当) faces = faces[np.where(faceStat==0)] #頂点と面を返す return borderCoords,faces実行コード編
コードまとめ(実行コード編)#重ねた空間の点群のうち、外部と接している境界部分の点を取り出す borderPointSpace = genBorderPointSpace(imgProjectSpace) #重ねた空間の点群のうち、境界部分のすぐ内側の点を取り出す insidePointSpace = genInsidePointSpace(imgProjectSpace,borderPointSpace) #空間から点の座標を取り出す borderCoords = binary2coords(borderPointSpace) insideCoords = binary2coords(insidePointSpace) #2種類の座標からポリゴン(正確にはポリゴンとなる頂点と頂点を結ぶ面の定義)を生成 coords,faces = genPolygon(borderCoords,insideCoords) #facesをblenderに渡す形式に変更 faces = [[face[0],face[1],face[2],face[0]] for face in faces] print("step04:porigon generate success\n") #以下確認表示用(メインの流れと関係ないので、次の回では多分消えてる) #頂点を描画 addObj(coords=coords,faces=faces,name = "porigon",offset=[-125,-50,-50]) addObj(coords=borderCoords,name = "borderCoords",offset=[-50,-85,-50]) addObj(coords=insideCoords,name = "insideCoords",offset=[-50,-15,-50])






- 投稿日:2020-09-16T16:35:37+09:00
Pandas DataFrame を .csv.gz として Amazon S3 に保存する
Pandas DataFrame を gzip 圧縮しつつ CSV ファイルとして Amazon S3 バケットに保存しようとしたときに少しハマったので備忘録。
import gzip from io import BytesIO import pandas as pd import boto3 def save_to_s3(df: pd.DataFrame, bucket: str, key: str): """Pandas DataFrame を .csv.gz として Amazon S3 に保存する""" buf = BytesIO() with gzip.open(buf, mode="wt") as f: df.to_csv(f) s3 = boto3.client("s3") s3.put_object(Bucket=bucket, Key=key, Body=buf.getvalue())ポイントとしては以下。
gzip.openの第一引数は gzip フォーマットを表す file-like オブジェクトなのでBytesIO()を入力するpandas.DataFrame.to_csvの出力は文字列なので、gzip.openのmodeは「テキスト書き込み (wt)」を指定する最初
pandas.DataFrame.to_csvにcompression="gzip"を指定すれば明示的に圧縮しなくてもいけるかと思って試したが、to_csvに file-like オブジェクトを入力した場合はcompressionオプションは無視されるらしく、使えなかった。
- 投稿日:2020-09-16T16:30:51+09:00
diagrams の nodes の一覧
はじめに
diagrams を使い始めたのですがアイコン画像がよくわからず、一覧を探したところみつからなかったので、自分で一覧を作成しました。
一覧
コード
ココ
list.pyfrom diagrams import Diagram, Cluster # onprem from diagrams.onprem.analytics import Beam, Databricks, Dbt, Flink, Hadoop, Hive, Metabase, Norikra, Singer, Spark, Storm, Tableau from diagrams.onprem.cd import Spinnaker, TektonCli, Tekton from diagrams.onprem.ci import Circleci, Concourseci, Droneci, Gitlabci, Jenkins, Teamcity, Travisci, Zuulci from diagrams.onprem.client import Client, User, Users from diagrams.onprem.compute import Nomad, Server from diagrams.onprem.container import Rkt, Docker from diagrams.onprem.database import Scylla, Postgresql, Oracle, Neo4J, Mysql, Mssql, Mongodb, Mariadb, Janusgraph, Influxdb, Hbase, Druid, Dgraph, Couchdb, Couchbase, Cockroachdb, Clickhouse, Cassandra from diagrams.onprem.etl import Embulk from diagrams.onprem.gitops import Flux, Flagger, Argocd from diagrams.onprem.iac import Terraform, Awx, Atlantis, Ansible from diagrams.onprem.inmemory import Redis, Memcached, Hazelcast, Aerospike from diagrams.onprem.logging import SyslogNg, Rsyslog, Loki, Graylog, Fluentd, Fluentbit from diagrams.onprem.mlops import Polyaxon from diagrams.onprem.monitoring import Thanos, Splunk, Sentry, Prometheus, PrometheusOperator, Grafana, Datadog from diagrams.onprem.network import Zookeeper, Vyos, Traefik, Tomcat, Pomerium, Pfsense, Nginx, Linkerd, Kong, Istio, Internet, Haproxy, Etcd, Envoy, Consul, Caddy, Apache from diagrams.onprem.queue import Zeromq, Rabbitmq, Kafka, Celery, Activemq from diagrams.onprem.search import Solr from diagrams.onprem.security import Vault, Trivy from diagrams.onprem.vcs import Gitlab, Github, Git from diagrams.onprem.workflow import Nifi, Kubeflow, Digdag, Airflow # aws from diagrams.aws.analytics import Analytics, Athena, Cloudsearch, CloudsearchSearchDocuments, DataPipeline, EMR, EMRCluster, EMRHdfsCluster, ElasticsearchService, Glue, GlueCrawlers, GlueDataCatalog, Kinesis, KinesisDataAnalytics, KinesisDataFirehose, KinesisDataStreams, KinesisVideoStreams, LakeFormation, ManagedStreamingForKafka, Quicksight, RedshiftDenseComputeNode, RedshiftDenseStorageNode, Redshift from diagrams.aws.ar import Sumerian from diagrams.aws.blockchain import QuantumLedgerDatabaseQldb, ManagedBlockchain from diagrams.aws.business import Workmail, Chime, AlexaForBusiness from diagrams.aws.compute import VmwareCloudOnAWS, ThinkboxXmesh, ThinkboxStoke, ThinkboxSequoia, ThinkboxKrakatoa, ThinkboxFrost, ThinkboxDraft, ThinkboxDeadline, ServerlessApplicationRepository, Outposts, Lightsail, Lambda, Fargate, ElasticKubernetesService, ElasticContainerService, ElasticBeanstalk, EC2, EC2ContainerRegistry, Compute, Batch, ApplicationAutoScaling from diagrams.aws.cost import SavingsPlans, ReservedInstanceReporting, CostExplorer, CostAndUsageReport, Budgets from diagrams.aws.database import Timestream, Redshift, RDS, RDSOnVmware, QuantumLedgerDatabaseQldb, Neptune, Elasticache, Dynamodb, DynamodbTable, DynamodbGlobalSecondaryIndex, DynamodbDax, DocumentdbMongodbCompatibility, Database, DatabaseMigrationService, Aurora from diagrams.aws.devtools import XRay, ToolsAndSdks, DeveloperTools, CommandLineInterface, Codestar, Codepipeline, Codedeploy, Codecommit, Codebuild, Cloud9, CloudDevelopmentKit from diagrams.aws.enablement import Support, ProfessionalServices, ManagedServices, Iq from diagrams.aws.enduser import Workspaces, Worklink, Workdocs, Appstream20 from diagrams.aws.engagement import SimpleEmailServiceSes, Pinpoint, Connect from diagrams.aws.game import Gamelift from diagrams.aws.general import Users, User, TradicionalServer, Marketplace, GenericSDK, GenericSamlToken, GenericOfficeBuilding, GenericFirewall, GenericDatabase, General, Disk from diagrams.aws.integration import StepFunctions, SimpleQueueServiceSqs, SimpleNotificationServiceSns, MQ, Eventbridge, ConsoleMobileApplication, Appsync, ApplicationIntegration from diagrams.aws.iot import IotTopic, IotThingsGraph, IotSitewise, IotShadow, IotRule, IotPolicy, IotPolicyEmergency, IotMqtt, IotLambda, IotJobs, IotHttp2, IotHttp, IotHardwareBoard, IotGreengrass, IotGreengrassConnector, IotEvents, IotDeviceManagement, IotDeviceDefender, IotCore, IotCertificate, IotCamera, IotButton, IotAnalytics, IotAlexaSkill, IotAlexaEcho, IotAction, Iot1Click, InternetOfThings, Freertos from diagrams.aws.management import WellArchitectedTool, TrustedAdvisor, SystemsManager, SystemsManagerParameterStore, ServiceCatalog, Organizations, Opsworks, ManagementConsole, ManagedServices, LicenseManager, ControlTower, Config, CommandLineInterface, Codeguru, Cloudwatch, Cloudtrail, Cloudformation, AutoScaling from diagrams.aws.media import ElementalServer, ElementalMediatailor, ElementalMediastore, ElementalMediapackage, ElementalMedialive, ElementalMediaconvert, ElementalMediaconnect, ElementalLive, ElementalDelta, ElementalConductor, ElasticTranscoder from diagrams.aws.migration import TransferForSftp, Snowmobile, Snowball, SnowballEdge, ServerMigrationService, MigrationHub, MigrationAndTransfer, Datasync, DatabaseMigrationService, CloudendureMigration, ApplicationDiscoveryService from diagrams.aws.ml import Translate, Transcribe, Textract, TensorflowOnAWS, Sagemaker, SagemakerTrainingJob, SagemakerNotebook, SagemakerModel, SagemakerGroundTruth, Rekognition, Polly, Personalize, MachineLearning, Lex, Forecast, ElasticInference, Deepracer, Deeplens, DeepLearningContainers, DeepLearningAmis, Comprehend, ApacheMxnetOnAWS from diagrams.aws.mobile import Pinpoint, DeviceFarm, Appsync, APIGateway, APIGatewayEndpoint, Amplify from diagrams.aws.network import VPC, VPCRouter, VPCPeering, TransitGateway, SiteToSiteVpn, RouteTable, Route53, PublicSubnet, Privatelink, PrivateSubnet, NetworkingAndContentDelivery, NATGateway, Nacl, InternetGateway, GlobalAccelerator, Endpoint, ElasticLoadBalancing, DirectConnect, CloudFront, CloudMap, ClientVpn, AppMesh, APIGateway from diagrams.aws.quantum import Braket from diagrams.aws.robotics import Robotics, Robomaker, RobomakerSimulator from diagrams.aws.satellite import GroundStation from diagrams.aws.security import WAF, SingleSignOn, Shield, SecurityIdentityAndCompliance, SecurityHub, SecretsManager, ResourceAccessManager, Macie, KeyManagementService, Inspector, IdentityAndAccessManagementIam, IdentityAndAccessManagementIamRole, IdentityAndAccessManagementIamPermissions, IdentityAndAccessManagementIamAWSSts, IdentityAndAccessManagementIamAccessAnalyzer, Guardduty, FirewallManager, DirectoryService, Detective, Cognito, Cloudhsm, CloudDirectory, CertificateManager, Artifact from diagrams.aws.storage import Storage, StorageGateway, Snowmobile, Snowball, SnowballEdge, SimpleStorageServiceS3, S3Glacier, Fsx, FsxForWindowsFileServer, FsxForLustre, ElasticFileSystemEFS, ElasticBlockStoreEBS, EFSStandardPrimaryBg, EFSInfrequentaccessPrimaryBg, CloudendureDisasterRecovery, Backup # azure from diagrams.azure.analytics import StreamAnalyticsJobs, LogAnalyticsWorkspaces, Hdinsightclusters, EventHubs, EventHubClusters, Databricks, DataLakeStoreGen1, DataLakeAnalytics, DataFactories, DataExplorerClusters, AnalysisServices from diagrams.azure.compute import VM, VMWindows, VMLinux, VMImages, VMClassic, ServiceFabricClusters, SAPHANAOnAzure, MeshApplications, KubernetesServices, FunctionApps, Disks, DiskSnapshots, ContainerRegistries, ContainerInstances, CloudsimpleVirtualMachines, CloudServices, CloudServicesClassic, CitrixVirtualDesktopsEssentials, BatchAccounts, AvailabilitySets from diagrams.azure.database import VirtualDatacenter, VirtualClusters, SQLServers, SQLServerStretchDatabases, SQLManagedInstances, SQLDatawarehouse, SQLDatabases, ManagedDatabases, ElasticJobAgents, ElasticDatabasePools, DatabaseForPostgresqlServers, DatabaseForMysqlServers, DatabaseForMariadbServers, DataLake, CosmosDb, CacheForRedis, BlobStorage from diagrams.azure.devops import TestPlans, Repos, Pipelines, DevtestLabs, Devops, Boards, Artifacts, ApplicationInsights from diagrams.azure.general import Whatsnew, Userresource, Userprivacy, Usericon, Userhealthicon, Twousericon, Templates, Tags, Tag, Supportrequests, Support, Subscriptions, Shareddashboard, Servicehealth, Resourcegroups, Resource, Reservations, Recent, Quickstartcenter, Marketplace, Managementgroups, Information, Helpsupport, Developertools, Azurehome, Allresources from diagrams.azure.identity import ManagedIdentities, InformationProtection, IdentityGovernance, EnterpriseApplications, ConditionalAccess, AppRegistrations, ADPrivilegedIdentityManagement, ADIdentityProtection, ADDomainServices, ADB2C, ActiveDirectory, ActiveDirectoryConnectHealth, AccessReview from diagrams.azure.integration import StorsimpleDeviceManagers, SoftwareAsAService, ServiceCatalogManagedApplicationDefinitions, ServiceBus, ServiceBusRelays, SendgridAccounts, LogicApps, LogicAppsCustomConnector, IntegrationServiceEnvironments, IntegrationAccounts, EventGridTopics, EventGridSubscriptions, EventGridDomains, DataCatalog, AppConfiguration, APIManagement, APIForFhir from diagrams.azure.iot import Windows10IotCoreServices, TimeSeriesInsightsEventsSources, TimeSeriesInsightsEnvironments, Sphere, Maps, IotHub, IotHubSecurity, IotCentralApplications, DigitalTwins, DeviceProvisioningServices from diagrams.azure.migration import RecoveryServicesVaults, MigrationProjects, DatabaseMigrationServices from diagrams.azure.ml import MachineLearningStudioWorkspaces, MachineLearningStudioWebServices, MachineLearningStudioWebServicePlans, MachineLearningServiceWorkspaces, GenomicsAccounts, CognitiveServices, BotServices, BatchAI from diagrams.azure.mobile import NotificationHubs, MobileEngagement, AppServiceMobile from diagrams.azure.network import VirtualWans, VirtualNetworks, VirtualNetworkGateways, VirtualNetworkClassic, TrafficManagerProfiles, ServiceEndpointPolicies, RouteTables, RouteFilters, ReservedIpAddressesClassic, PublicIpAddresses, OnPremisesDataGateways, NetworkWatcher, NetworkSecurityGroupsClassic, NetworkInterfaces, LocalNetworkGateways, LoadBalancers, FrontDoors, Firewall, ExpressrouteCircuits, DNSZones, DNSPrivateZones, DDOSProtectionPlans, Connections, CDNProfiles, ApplicationSecurityGroups, ApplicationGateway from diagrams.azure.security import Sentinel, SecurityCenter, KeyVaults from diagrams.azure.storage import TableStorage, StorsimpleDeviceManagers, StorsimpleDataManagers, StorageSyncServices, StorageExplorer, StorageAccounts, StorageAccountsClassic, QueuesStorage, NetappFiles, GeneralStorage, DataLakeStorage, DataBox, DataBoxEdgeDataBoxGateway, BlobStorage, Azurefxtedgefiler, ArchiveStorage from diagrams.azure.web import Signalr, Search, NotificationHubNamespaces, MediaServices, AppServices, AppServicePlans, AppServiceEnvironments, AppServiceDomains, AppServiceCertificates, APIConnections # Programming from diagrams.programming.framework import Vue, Spring, React, Rails, Laravel, Flutter, Flask, Ember, Django, Backbone, Angular from diagrams.programming.language import Typescript, Swift, Rust, Ruby, R, Python, Php, Nodejs, Matlab, Kotlin, Javascript, Java, Go, Dart, Csharp, Cpp, C, Bash # Saas from diagrams.saas.alerting import Pushover, Opsgenie from diagrams.saas.analytics import Stitch, Snowflake from diagrams.saas.cdn import Cloudflare from diagrams.saas.chat import Telegram, Slack from diagrams.saas.identity import Okta, Auth0 from diagrams.saas.logging import Papertrail, Datadog from diagrams.saas.media import Cloudinary from diagrams.saas.recommendation import Recombee from diagrams.saas.social import Twitter, Facebook # Generic from diagrams.generic.database import SQL from diagrams.generic.device import Tablet, Mobile from diagrams.generic.network import VPN, Switch, Router, Firewall from diagrams.generic.os import Windows, Ubuntu, Suse, LinuxGeneral, IOS, Centos, Android from diagrams.generic.place import Datacenter from diagrams.generic.storage import Storage from diagrams.generic.virtualization import XEN, Vmware, Virtualbox # Elastic from diagrams.elastic.elasticsearch import Sql, SecuritySettings, Monitoring, Maps, MachineLearning, Logstash, Kibana, Elasticsearch, Beats, Alerting from diagrams.elastic.enterprisesearch import WorkplaceSearch, SiteSearch, EnterpriseSearch, AppSearch from diagrams.elastic.observability import Uptime, Observability, Metrics, Logs, APM from diagrams.elastic.orchestration import ECK, ECE from diagrams.elastic.saas import Elastic, Cloud from diagrams.elastic.security import SIEM, Security, Endpoint # # Outscale # from diagrams.outscale.compute import DirectConnect, Compute # from diagrams.outscale.network import SiteToSiteVpng, Net, NatService, LoadBalancer, InternetService, ClientVpn # from diagrams.outscale.security import IdentityAndAccessManagement, Firewall # from diagrams.outscale.storage import Storage, SimpleStorageService # Firebase from diagrams.firebase.base import Firebase from diagrams.firebase.develop import Storage, RealtimeDatabase, MLKit, Hosting, Functions, Firestore, Authentication from diagrams.firebase.extentions import Extensions from diagrams.firebase.grow import RemoteConfig, Predictions, Messaging, Invites, InAppMessaging, DynamicLinks, AppIndexing, ABTesting from diagrams.firebase.quality import TestLab, PerformanceMonitoring, Crashlytics, CrashReporting, AppDistribution # OpenStack from diagrams.openstack.apiproxies import EC2API from diagrams.openstack.applicationlifecycle import Solum, Murano, Masakari, Freezer from diagrams.openstack.baremetal import Ironic, Cyborg from diagrams.openstack.billing import Cloudkitty from diagrams.openstack.compute import Zun, Qinling, Nova from diagrams.openstack.containerservices import Kuryr from diagrams.openstack.deployment import Tripleo, Kolla, Helm, Chef, Charms, Ansible from diagrams.openstack.frontend import Horizon from diagrams.openstack.monitoring import Telemetry, Monasca from diagrams.openstack.multiregion import Tricircle from diagrams.openstack.networking import Octavia, Neutron, Designate from diagrams.openstack.nfv import Tacker from diagrams.openstack.optimization import Watcher, Vitrage, Rally, Congress from diagrams.openstack.orchestration import Zaqar, Senlin, Mistral, Heat, Blazar from diagrams.openstack.packaging import RPM, Puppet, LOCI from diagrams.openstack.sharedservices import Searchlight, Keystone, Karbor, Glance, Barbican from diagrams.openstack.storage import Swift, Manila, Cinder from diagrams.openstack.user import Openstackclient from diagrams.openstack.workloadprovisioning import Trove, Sahara, Magnum # OCI from diagrams.oci.compute import VM, VMWhite, OKE, OKEWhite, OCIR, OCIRWhite, InstancePools, InstancePoolsWhite, Functions, FunctionsWhite, Container, ContainerWhite, BM, BMWhite, Autoscale, AutoscaleWhite from diagrams.oci.connectivity import VPN, VPNWhite, NATGateway, NATGatewayWhite, FastConnect, FastConnectWhite, DNS, DNSWhite, DisconnectedRegions, DisconnectedRegionsWhite, CustomerPremise, CustomerPremiseWhite, CustomerDatacntrWhite, CustomerDatacenter, CDN, CDNWhite, Backbone, BackboneWhite # from diagrams.oci.database import Stream, StreamWhite, Science, ScienceWhite, DMS, DMSWhite, Dis, DisWhite, Dcat, DcatWhite, DataflowApache, DataflowApacheWhite, DatabaseService, DatabaseServiceWhite, BigdataService, BigdataServiceWhite, Autonomous, AutonomousWhite from diagrams.oci.devops import ResourceMgmt, ResourceMgmtWhite, APIService, APIServiceWhite, APIGateway, APIGatewayWhite from diagrams.oci.governance import Tagging, TaggingWhite, Policies, PoliciesWhite, OCID, OCIDWhite, Logging, LoggingWhite, Groups, GroupsWhite, Compartments, CompartmentsWhite, Audit, AuditWhite from diagrams.oci.monitoring import Workflow, WorkflowWhite, Telemetry, TelemetryWhite, Search, SearchWhite, Queue, QueueWhite, Notifications, NotificationsWhite, HealthCheck, HealthCheckWhite, Events, EventsWhite, Email, EmailWhite, Alarm, AlarmWhite from diagrams.oci.network import Vcn, VcnWhite, ServiceGateway, ServiceGatewayWhite, SecurityLists, SecurityListsWhite, RouteTable, RouteTableWhite, LoadBalancer, LoadBalancerWhite, InternetGateway, InternetGatewayWhite, Firewall, FirewallWhite, Drg, DrgWhite from diagrams.oci.security import WAF, WAFWhite, Vault, VaultWhite, MaxSecurityZone, MaxSecurityZoneWhite, KeyManagement, KeyManagementWhite, IDAccess, IDAccessWhite, Encryption, EncryptionWhite, DDOS, DDOSWhite, CloudGuard, CloudGuardWhite from diagrams.oci.storage import StorageGateway, StorageGatewayWhite, ObjectStorage, ObjectStorageWhite, FileStorage, FileStorageWhite, ElasticPerformance, ElasticPerformanceWhite, DataTransfer, DataTransferWhite, Buckets, BucketsWhite, BlockStorage, BlockStorageWhite, BlockStorageClone, BlockStorageCloneWhite, BackupRestore, BackupRestoreWhite # AlibabaCloud from diagrams.alibabacloud.analytics import OpenSearch, ElaticMapReduce, DataLakeAnalytics, ClickHouse, AnalyticDb from diagrams.alibabacloud.application import Yida, SmartConversationAnalysis, RdCloud, PerformanceTestingService, OpenSearch, NodeJsPerformancePlatform, MessageNotificationService, LogService, DirectMail, CodePipeline, CloudCallCenter, BlockchainAsAService, BeeBot, ApiGateway from diagrams.alibabacloud.communication import MobilePush, DirectMail from diagrams.alibabacloud.compute import WebAppService, SimpleApplicationServer, ServerlessAppEngine, ServerLoadBalancer, ResourceOrchestrationService, OperationOrchestrationService, FunctionCompute, ElasticSearch, ElasticHighPerformanceComputing, ElasticContainerInstance, ElasticComputeService, ContainerService, ContainerRegistry, BatchCompute, AutoScaling from diagrams.alibabacloud.database import RelationalDatabaseService, HybriddbForMysql, GraphDatabaseService, DisributeRelationalDatabaseService, DatabaseBackupService, DataTransmissionService, DataManagementService, ApsaradbSqlserver, ApsaradbRedis, ApsaradbPpas, ApsaradbPostgresql, ApsaradbPolardb, ApsaradbOceanbase, ApsaradbMongodb, ApsaradbMemcache, ApsaradbHbase, ApsaradbCassandra from diagrams.alibabacloud.iot import IotPlatform, IotMobileConnectionPackage, IotLinkWan, IotInternetDeviceId from diagrams.alibabacloud.network import VpnGateway, VirtualPrivateCloud, SmartAccessGateway, ServerLoadBalancer, NatGateway, ExpressConnect, ElasticIpAddress, CloudEnterpriseNetwork, Cdn from diagrams.alibabacloud.security import WebApplicationFirewall, SslCertificates, ServerGuard, SecurityCenter, ManagedSecurityService, IdVerification, GameShield, DbAudit, DataEncryptionService, CrowdsourcedSecurityTesting, ContentModeration, CloudSecurityScanner, CloudFirewall, BastionHost, AntifraudService, AntiDdosPro, AntiDdosBasic, AntiBotService from diagrams.alibabacloud.storage import ObjectTableStore, ObjectStorageService, Imm, HybridCloudDisasterRecovery, HybridBackupRecovery, FileStorageNas, FileStorageHdfs, CloudStorageGateway from diagrams.alibabacloud.web import Domain, Dns # K8S from diagrams.k8s.clusterconfig import Quota, Limits, HPA from diagrams.k8s.compute import STS, RS, Pod, Job, DS, Deploy, Cronjob from diagrams.k8s.controlplane import Sched, Kubelet, KProxy, CM, CCM, API from diagrams.k8s.ecosystem import Kustomize, Krew, Helm from diagrams.k8s.group import NS from diagrams.k8s.infra import Node, Master, ETCD from diagrams.k8s.network import SVC, Netpol, Ing, Ep from diagrams.k8s.others import PSP, CRD from diagrams.k8s.podconfig import Secret, CM from diagrams.k8s.rbac import User, SA, Role, RB, Group, CRB, CRole from diagrams.k8s.storage import Vol, SC, PVC, PV # GCP from diagrams.gcp.analytics import Pubsub, Genomics, Dataproc, Dataprep, Datalab, Dataflow, DataFusion, DataCatalog, Composer, Bigquery from diagrams.gcp.compute import Run, KubernetesEngine, GPU, GKEOnPrem, Functions, ContainerOptimizedOS, ComputeEngine, AppEngine from diagrams.gcp.database import SQL, Spanner, Memorystore, Firestore, Datastore, Bigtable from diagrams.gcp.devtools import ToolsForVisualStudio, ToolsForPowershell, ToolsForEclipse, TestLab, Tasks, SourceRepositories, SDK, Scheduler, MavenAppEnginePlugin, IdePlugins, GradleAppEnginePlugin, ContainerRegistry, Code, CodeForIntellij, Build from diagrams.gcp.iot import IotCore from diagrams.gcp.migration import TransferAppliance from diagrams.gcp.ml import VisionAPI, VideoIntelligenceAPI, TranslationAPI, TPU, TextToSpeech, SpeechToText, RecommendationsAI, NaturalLanguageAPI, JobsAPI, InferenceAPI, DialogFlowEnterpriseEdition, Automl, AutomlVision, AutomlVideoIntelligence, AutomlTranslation, AutomlTables, AutomlNaturalLanguage, AIPlatform, AIPlatformDataLabelingService, AIHub, AdvancedSolutionsLab from diagrams.gcp.network import VPN, VirtualPrivateCloud, TrafficDirector, StandardNetworkTier, Routes, Router, PremiumNetworkTier, PartnerInterconnect, Network, NAT, LoadBalancing, FirewallRules, ExternalIpAddresses, DNS, DedicatedInterconnect, CDN, Armor from diagrams.gcp.security import SecurityScanner, SecurityCommandCenter, ResourceManager, KeyManagementService, IAP, Iam from diagrams.gcp.storage import Storage, PersistentDisk, Filestore node_list_all = { 'OnPrem': { 'analytics': ['Beam', 'Databricks', 'Dbt', 'Flink', 'Hadoop', 'Hive', 'Metabase', 'Norikra', 'Singer', 'Spark', 'Storm', 'Tableau'], 'cd': ['Spinnaker', 'TektonCli', 'Tekton'], 'ci': ['Circleci', 'Concourseci', 'Droneci', 'Gitlabci', 'Jenkins', 'Teamcity', 'Travisci', 'Zuulci'], 'client': ['Client', 'User', 'Users'], 'compute': ['Nomad', 'Server'], 'container': ['Rkt', 'Docker', ], 'database': ['Scylla', 'Postgresql', 'Oracle', 'Neo4J', 'Mysql', 'Mssql', 'Mongodb', 'Mariadb', 'Janusgraph', 'Influxdb', 'Hbase', 'Druid', 'Dgraph', 'Couchdb', 'Couchbase', 'Cockroachdb', 'Clickhouse', 'Cassandra', ], 'etl': ['Embulk', ], 'gitops': ['Flux', 'Flagger', 'Argocd', ], 'iac': ['Terraform', 'Awx', 'Atlantis', 'Ansible', ], 'inmemory': ['Redis', 'Memcached', 'Hazelcast', 'Aerospike', ], 'logging': ['SyslogNg', 'Rsyslog', 'Loki', 'Graylog', 'Fluentd', 'Fluentbit', ], 'mlops': ['Polyaxon', ], 'monitoring': ['Thanos', 'Splunk', 'Sentry', 'Prometheus', 'PrometheusOperator', 'Grafana', 'Datadog', ], 'network': ['Zookeeper', 'Vyos', 'Traefik', 'Tomcat', 'Pomerium', 'Pfsense', 'Nginx', 'Linkerd', 'Kong', 'Istio', 'Internet', 'Haproxy', 'Etcd', 'Envoy', 'Consul', 'Caddy', 'Apache', ], 'queue': ['Zeromq', 'Rabbitmq', 'Kafka', 'Celery', 'Activemq', ], 'search': ['Solr'], 'security': ['Vault', 'Trivy', ], 'vcs': ['Gitlab', 'Github', 'Git', ], 'workflow': ['Nifi', 'Kubeflow', 'Digdag', 'Airflow', ] }, 'AWS': { 'analytics': ['Analytics', 'Athena', 'Cloudsearch', 'CloudsearchSearchDocuments', 'DataPipeline', 'EMR', 'EMRCluster', 'EMRHdfsCluster', 'ElasticsearchService', 'Glue', 'GlueCrawlers', 'GlueDataCatalog', 'Kinesis', 'KinesisDataAnalytics', 'KinesisDataFirehose', 'KinesisDataStreams', 'KinesisVideoStreams', 'LakeFormation', 'ManagedStreamingForKafka', 'Quicksight', 'RedshiftDenseComputeNode', 'RedshiftDenseStorageNode', 'Redshift'], 'ar': ['Sumerian', ], 'blockchain': ['QuantumLedgerDatabaseQldb', 'ManagedBlockchain', ], 'business': ['Workmail', 'Chime', 'AlexaForBusiness', ], 'compute': ['VmwareCloudOnAWS', 'ThinkboxXmesh', 'ThinkboxStoke', 'ThinkboxSequoia', 'ThinkboxKrakatoa', 'ThinkboxFrost', 'ThinkboxDraft', 'ThinkboxDeadline', 'ServerlessApplicationRepository', 'Outposts', 'Lightsail', 'Lambda', 'Fargate', 'ElasticKubernetesService', 'ElasticContainerService', 'ElasticBeanstalk', 'EC2', 'EC2ContainerRegistry', 'Compute', 'Batch', 'ApplicationAutoScaling', ], 'cost': ['SavingsPlans', 'ReservedInstanceReporting', 'CostExplorer', 'CostAndUsageReport', 'Budgets', ], 'database': ['Timestream', 'Redshift', 'RDS', 'RDSOnVmware', 'QuantumLedgerDatabaseQldb', 'Neptune', 'Elasticache', 'Dynamodb', 'DynamodbTable', 'DynamodbGlobalSecondaryIndex', 'DynamodbDax', 'DocumentdbMongodbCompatibility', 'Database', 'DatabaseMigrationService', 'Aurora', ], 'devtools': ['XRay', 'ToolsAndSdks', 'DeveloperTools', 'CommandLineInterface', 'Codestar', 'Codepipeline', 'Codedeploy', 'Codecommit', 'Codebuild', 'Cloud9', 'CloudDevelopmentKit', ], 'enablement': ['Support', 'ProfessionalServices', 'ManagedServices', 'Iq', ], 'enduser': ['Workspaces', 'Worklink', 'Workdocs', 'Appstream20', ], 'engagement': ['SimpleEmailServiceSes', 'Pinpoint', 'Connect', ], 'game': ['Gamelift', ], 'general': ['Users', 'User', 'TradicionalServer', 'Marketplace', 'GenericSDK', 'GenericSamlToken', 'GenericOfficeBuilding', 'GenericFirewall', 'GenericDatabase', 'General', 'Disk', ], 'integration': ['StepFunctions', 'SimpleQueueServiceSqs', 'SimpleNotificationServiceSns', 'MQ', 'Eventbridge', 'ConsoleMobileApplication', 'Appsync', 'ApplicationIntegration', ], 'iot': ['IotTopic', 'IotThingsGraph', 'IotSitewise', 'IotShadow', 'IotRule', 'IotPolicy', 'IotPolicyEmergency', 'IotMqtt', 'IotLambda', 'IotJobs', 'IotHttp2', 'IotHttp', 'IotHardwareBoard', 'IotGreengrass', 'IotGreengrassConnector', 'IotEvents', 'IotDeviceManagement', 'IotDeviceDefender', 'IotCore', 'IotCertificate', 'IotCamera', 'IotButton', 'IotAnalytics', 'IotAlexaSkill', 'IotAlexaEcho', 'IotAction', 'Iot1Click', 'InternetOfThings', 'Freertos', ], 'management': ['WellArchitectedTool', 'TrustedAdvisor', 'SystemsManager', 'SystemsManagerParameterStore', 'ServiceCatalog', 'Organizations', 'Opsworks', 'ManagementConsole', 'ManagedServices', 'LicenseManager', 'ControlTower', 'Config', 'CommandLineInterface', 'Codeguru', 'Cloudwatch', 'Cloudtrail', 'Cloudformation', 'AutoScaling', ], 'media': ['ElementalServer', 'ElementalMediatailor', 'ElementalMediastore', 'ElementalMediapackage', 'ElementalMedialive', 'ElementalMediaconvert', 'ElementalMediaconnect', 'ElementalLive', 'ElementalDelta', 'ElementalConductor', 'ElasticTranscoder', ], 'migration': ['TransferForSftp', 'Snowmobile', 'Snowball', 'SnowballEdge', 'ServerMigrationService', 'MigrationHub', 'MigrationAndTransfer', 'Datasync', 'DatabaseMigrationService', 'CloudendureMigration', 'ApplicationDiscoveryService', ], 'ml': ['Translate', 'Transcribe', 'Textract', 'TensorflowOnAWS', 'Sagemaker', 'SagemakerTrainingJob', 'SagemakerNotebook', 'SagemakerModel', 'SagemakerGroundTruth', 'Rekognition', 'Polly', 'Personalize', 'MachineLearning', 'Lex', 'Forecast', 'ElasticInference', 'Deepracer', 'Deeplens', 'DeepLearningContainers', 'DeepLearningAmis', 'Comprehend', 'ApacheMxnetOnAWS', ], 'mobile': ['Pinpoint', 'DeviceFarm', 'Appsync', 'APIGateway', 'APIGatewayEndpoint', 'Amplify', ], 'network': ['VPC', 'VPCRouter', 'VPCPeering', 'TransitGateway', 'SiteToSiteVpn', 'RouteTable', 'Route53', 'PublicSubnet', 'Privatelink', 'PrivateSubnet', 'NetworkingAndContentDelivery', 'NATGateway', 'Nacl', 'InternetGateway', 'GlobalAccelerator', 'Endpoint', 'ElasticLoadBalancing', 'DirectConnect', 'CloudFront', 'CloudMap', 'ClientVpn', 'AppMesh', 'APIGateway', ], 'quantum': ['Braket', ], 'robotics': ['Robotics', 'Robomaker', 'RobomakerSimulator', ], 'satellite': ['GroundStation', ], 'security': ['WAF', 'SingleSignOn', 'Shield', 'SecurityIdentityAndCompliance', 'SecurityHub', 'SecretsManager', 'ResourceAccessManager', 'Macie', 'KeyManagementService', 'Inspector', 'IdentityAndAccessManagementIam', 'IdentityAndAccessManagementIamRole', 'IdentityAndAccessManagementIamPermissions', 'IdentityAndAccessManagementIamAWSSts', 'IdentityAndAccessManagementIamAccessAnalyzer', 'Guardduty', 'FirewallManager', 'DirectoryService', 'Detective', 'Cognito', 'Cloudhsm', 'CloudDirectory', 'CertificateManager', 'Artifact', ], 'storage': ['Storage', 'StorageGateway', 'Snowmobile', 'Snowball', 'SnowballEdge', 'SimpleStorageServiceS3', 'S3Glacier', 'Fsx', 'FsxForWindowsFileServer', 'FsxForLustre', 'ElasticFileSystemEFS', 'ElasticBlockStoreEBS', 'EFSStandardPrimaryBg', 'EFSInfrequentaccessPrimaryBg', 'CloudendureDisasterRecovery', 'Backup', ], }, 'Azure': { 'analytics': ['StreamAnalyticsJobs', 'LogAnalyticsWorkspaces', 'Hdinsightclusters', 'EventHubs', 'EventHubClusters', 'Databricks', 'DataLakeStoreGen1', 'DataLakeAnalytics', 'DataFactories', 'DataExplorerClusters', 'AnalysisServices', ], 'compute': ['VM', 'VMWindows', 'VMLinux', 'VMImages', 'VMClassic', 'ServiceFabricClusters', 'SAPHANAOnAzure', 'MeshApplications', 'KubernetesServices', 'FunctionApps', 'Disks', 'DiskSnapshots', 'ContainerRegistries', 'ContainerInstances', 'CloudsimpleVirtualMachines', 'CloudServices', 'CloudServicesClassic', 'CitrixVirtualDesktopsEssentials', 'BatchAccounts', 'AvailabilitySets', ], 'database': ['VirtualDatacenter', 'VirtualClusters', 'SQLServers', 'SQLServerStretchDatabases', 'SQLManagedInstances', 'SQLDatawarehouse', 'SQLDatabases', 'ManagedDatabases', 'ElasticJobAgents', 'ElasticDatabasePools', 'DatabaseForPostgresqlServers', 'DatabaseForMysqlServers', 'DatabaseForMariadbServers', 'DataLake', 'CosmosDb', 'CacheForRedis', 'BlobStorage', ], 'devops': ['TestPlans', 'Repos', 'Pipelines', 'DevtestLabs', 'Devops', 'Boards', 'Artifacts', 'ApplicationInsights', ], 'general': ['Whatsnew', 'Userresource', 'Userprivacy', 'Usericon', 'Userhealthicon', 'Twousericon', 'Templates', 'Tags', 'Tag', 'Supportrequests', 'Support', 'Subscriptions', 'Shareddashboard', 'Servicehealth', 'Resourcegroups', 'Resource', 'Reservations', 'Recent', 'Quickstartcenter', 'Marketplace', 'Managementgroups', 'Information', 'Helpsupport', 'Developertools', 'Azurehome', 'Allresources', ], 'identity': ['ManagedIdentities', 'InformationProtection', 'IdentityGovernance', 'EnterpriseApplications', 'ConditionalAccess', 'AppRegistrations', 'ADPrivilegedIdentityManagement', 'ADIdentityProtection', 'ADDomainServices', 'ADB2C', 'ActiveDirectory', 'ActiveDirectoryConnectHealth', 'AccessReview', ], 'integration': ['StorsimpleDeviceManagers', 'SoftwareAsAService', 'ServiceCatalogManagedApplicationDefinitions', 'ServiceBus', 'ServiceBusRelays', 'SendgridAccounts', 'LogicApps', 'LogicAppsCustomConnector', 'IntegrationServiceEnvironments', 'IntegrationAccounts', 'EventGridTopics', 'EventGridSubscriptions', 'EventGridDomains', 'DataCatalog', 'AppConfiguration', 'APIManagement', 'APIForFhir', ], 'iot': ['Windows10IotCoreServices', 'TimeSeriesInsightsEventsSources', 'TimeSeriesInsightsEnvironments', 'Sphere', 'Maps', 'IotHub', 'IotHubSecurity', 'IotCentralApplications', 'DigitalTwins', 'DeviceProvisioningServices', ], 'migration': ['RecoveryServicesVaults', 'MigrationProjects', 'DatabaseMigrationServices', ], 'ml': ['MachineLearningStudioWorkspaces', 'MachineLearningStudioWebServices', 'MachineLearningStudioWebServicePlans', 'MachineLearningServiceWorkspaces', 'GenomicsAccounts', 'CognitiveServices', 'BotServices', 'BatchAI', ], 'mobile': ['NotificationHubs', 'MobileEngagement', 'AppServiceMobile', ], 'network': ['VirtualWans', 'VirtualNetworks', 'VirtualNetworkGateways', 'VirtualNetworkClassic', 'TrafficManagerProfiles', 'ServiceEndpointPolicies', 'RouteTables', 'RouteFilters', 'ReservedIpAddressesClassic', 'PublicIpAddresses', 'OnPremisesDataGateways', 'NetworkWatcher', 'NetworkSecurityGroupsClassic', 'NetworkInterfaces', 'LocalNetworkGateways', 'LoadBalancers', 'FrontDoors', 'Firewall', 'ExpressrouteCircuits', 'DNSZones', 'DNSPrivateZones', 'DDOSProtectionPlans', 'Connections', 'CDNProfiles', 'ApplicationSecurityGroups', 'ApplicationGateway', ], 'security': ['Sentinel', 'SecurityCenter', 'KeyVaults', ], 'storage': ['TableStorage', 'StorsimpleDeviceManagers', 'StorsimpleDataManagers', 'StorageSyncServices', 'StorageExplorer', 'StorageAccounts', 'StorageAccountsClassic', 'QueuesStorage', 'NetappFiles', 'GeneralStorage', 'DataLakeStorage', 'DataBox', 'DataBoxEdgeDataBoxGateway', 'BlobStorage', 'Azurefxtedgefiler', 'ArchiveStorage', ], 'web': ['Signalr', 'Search', 'NotificationHubNamespaces', 'MediaServices', 'AppServices', 'AppServicePlans', 'AppServiceEnvironments', 'AppServiceDomains', 'AppServiceCertificates', 'APIConnections', ] }, 'Saas': { 'alerting': ['Pushover', 'Opsgenie', ], 'analytics': ['Stitch', 'Snowflake', ], 'cdn': ['Cloudflare', ], 'chat': ['Telegram', 'Slack', ], 'identity': ['Okta', 'Auth0', ], 'logging': ['Papertrail', 'Datadog', ], 'media': ['Cloudinary', ], 'recommendation': ['Recombee', ], 'social': ['Twitter', 'Facebook', ] }, 'Programming': { 'framework': ['Vue', 'Spring', 'React', 'Rails', 'Laravel', 'Flutter', 'Flask', 'Ember', 'Django', 'Backbone', 'Angular', ], 'language': ['Typescript', 'Swift', 'Rust', 'Ruby', 'R', 'Python', 'Php', 'Nodejs', 'Matlab', 'Kotlin', 'Javascript', 'Java', 'Go', 'Dart', 'Csharp', 'Cpp', 'C', 'Bash', ] }, 'Generic': { # 'blank': ['Blank', ], # 'compute': ['Rack', ], 'database': ['SQL', ], 'device': ['Tablet', 'Mobile', ], 'network': ['VPN', 'Switch', 'Router', 'Firewall', ], 'os': ['Windows', 'Ubuntu', 'Suse', 'LinuxGeneral', 'IOS', 'Centos', 'Android', ], 'place': ['Datacenter', ], 'storage': ['Storage', ], 'virtualization': ['XEN', 'Vmware', 'Virtualbox', ], }, 'Elastic': { 'elasticsearch': ['Sql', 'SecuritySettings', 'Monitoring', 'Maps', 'MachineLearning', 'Logstash', 'Kibana', 'Elasticsearch', 'Beats', 'Alerting', ], 'enterprisesearch': ['WorkplaceSearch', 'SiteSearch', 'EnterpriseSearch', 'AppSearch', ], 'observability': ['Uptime', 'Observability', 'Metrics', 'Logs', 'APM', ], 'orchestration': ['ECK', 'ECE', ], 'saas': ['Elastic', 'Cloud', ], 'security': ['SIEM', 'Security', 'Endpoint', ], }, 'GCP': { 'analytics': ['Pubsub', 'Genomics', 'Dataproc', 'Dataprep', 'Datalab', 'Dataflow', 'DataFusion', 'DataCatalog', 'Composer', 'Bigquery', ], 'compute': ['Run', 'KubernetesEngine', 'GPU', 'GKEOnPrem', 'Functions', 'ContainerOptimizedOS', 'ComputeEngine', 'AppEngine', ], 'database': ['SQL', 'Spanner', 'Memorystore', 'Firestore', 'Datastore', 'Bigtable', ], 'devtools': ['ToolsForVisualStudio', 'ToolsForPowershell', 'ToolsForEclipse', 'TestLab', 'Tasks', 'SourceRepositories', 'SDK', 'Scheduler', 'MavenAppEnginePlugin', 'IdePlugins', 'GradleAppEnginePlugin', 'ContainerRegistry', 'Code', 'CodeForIntellij', 'Build', ], 'iot': ['IotCore', ], 'migration': ['TransferAppliance', ], 'ml': ['VisionAPI', 'VideoIntelligenceAPI', 'TranslationAPI', 'TPU', 'TextToSpeech', 'SpeechToText', 'RecommendationsAI', 'NaturalLanguageAPI', 'JobsAPI', 'InferenceAPI', 'DialogFlowEnterpriseEdition', 'Automl', 'AutomlVision', 'AutomlVideoIntelligence', 'AutomlTranslation', 'AutomlTables', 'AutomlNaturalLanguage', 'AIPlatform', 'AIPlatformDataLabelingService', 'AIHub', 'AdvancedSolutionsLab', ], 'network': ['VPN', 'VirtualPrivateCloud', 'TrafficDirector', 'StandardNetworkTier', 'Routes', 'Router', 'PremiumNetworkTier', 'PartnerInterconnect', 'Network', 'NAT', 'LoadBalancing', 'FirewallRules', 'ExternalIpAddresses', 'DNS', 'DedicatedInterconnect', 'CDN', 'Armor', ], 'security': ['SecurityScanner', 'SecurityCommandCenter', 'ResourceManager', 'KeyManagementService', 'IAP', 'Iam', ], 'storage': ['Storage', 'PersistentDisk', 'Filestore', ], }, 'K8S': { 'clusterconfig': ['Quota', 'Limits', 'HPA', ], 'compute': ['STS', 'RS', 'Pod', 'Job', 'DS', 'Deploy', 'Cronjob', ], 'controlplane': ['Sched', 'Kubelet', 'KProxy', 'CM', 'CCM', 'API', ], 'ecosystem': ['Kustomize', 'Krew', 'Helm', ], 'group': ['NS', ], 'infra': ['Node', 'Master', 'ETCD', ], 'network': ['SVC', 'Netpol', 'Ing', 'Ep', ], 'others': ['PSP', 'CRD', ], 'podconfig': ['Secret', 'CM', ], 'rbac': ['User', 'SA', 'Role', 'RB', 'Group', 'CRB', 'CRole', ], 'storage': ['Vol', 'SC', 'PVC', 'PV', ], }, 'AlibabaCloud': { 'analytics': ['OpenSearch', 'ElaticMapReduce', 'DataLakeAnalytics', 'ClickHouse', 'AnalyticDb', ], 'application': ['Yida', 'SmartConversationAnalysis', 'RdCloud', 'PerformanceTestingService', 'OpenSearch', 'NodeJsPerformancePlatform', 'MessageNotificationService', 'LogService', 'DirectMail', 'CodePipeline', 'CloudCallCenter', 'BlockchainAsAService', 'BeeBot', 'ApiGateway', ], 'communication': ['MobilePush', 'DirectMail', ], 'compute': ['WebAppService', 'SimpleApplicationServer', 'ServerlessAppEngine', 'ServerLoadBalancer', 'ResourceOrchestrationService', 'OperationOrchestrationService', 'FunctionCompute', 'ElasticSearch', 'ElasticHighPerformanceComputing', 'ElasticContainerInstance', 'ElasticComputeService', 'ContainerService', 'ContainerRegistry', 'BatchCompute', 'AutoScaling', ], 'database': ['RelationalDatabaseService', 'HybriddbForMysql', 'GraphDatabaseService', 'DisributeRelationalDatabaseService', 'DatabaseBackupService', 'DataTransmissionService', 'DataManagementService', 'ApsaradbSqlserver', 'ApsaradbRedis', 'ApsaradbPpas', 'ApsaradbPostgresql', 'ApsaradbPolardb', 'ApsaradbOceanbase', 'ApsaradbMongodb', 'ApsaradbMemcache', 'ApsaradbHbase', 'ApsaradbCassandra', ], 'iot': ['IotPlatform', 'IotMobileConnectionPackage', 'IotLinkWan', 'IotInternetDeviceId', ], 'network': ['VpnGateway', 'VirtualPrivateCloud', 'SmartAccessGateway', 'ServerLoadBalancer', 'NatGateway', 'ExpressConnect', 'ElasticIpAddress', 'CloudEnterpriseNetwork', 'Cdn', ], 'security': ['WebApplicationFirewall', 'SslCertificates', 'ServerGuard', 'SecurityCenter', 'ManagedSecurityService', 'IdVerification', 'GameShield', 'DbAudit', 'DataEncryptionService', 'CrowdsourcedSecurityTesting', 'ContentModeration', 'CloudSecurityScanner', 'CloudFirewall', 'BastionHost', 'AntifraudService', 'AntiDdosPro', 'AntiDdosBasic', 'AntiBotService', ], 'storage': ['ObjectTableStore', 'ObjectStorageService', 'Imm', 'HybridCloudDisasterRecovery', 'HybridBackupRecovery', 'FileStorageNas', 'FileStorageHdfs', 'CloudStorageGateway', ], 'web': ['Domain', 'Dns', ], }, 'OCI': { 'compute': ['VM', 'VMWhite', 'OKE', 'OKEWhite', 'OCIR', 'OCIRWhite', 'InstancePools', 'InstancePoolsWhite', 'Functions', 'FunctionsWhite', 'Container', 'ContainerWhite', 'BM', 'BMWhite', 'Autoscale', 'AutoscaleWhite', ], 'connectivity': ['VPN', 'VPNWhite', 'NATGateway', 'NATGatewayWhite', 'FastConnect', 'FastConnectWhite', 'DNS', 'DNSWhite', 'DisconnectedRegions', 'DisconnectedRegionsWhite', 'CustomerPremise', 'CustomerPremiseWhite', 'CustomerDatacntrWhite', 'CustomerDatacenter', 'CDN', 'CDNWhite', 'Backbone', 'BackboneWhite', ], # 'database': ['Stream', 'StreamWhite', 'Science', 'ScienceWhite', 'DMS', 'DMSWhite', 'Dis', 'DisWhite', 'Dcat', 'DcatWhite', 'DataflowApache', 'DataflowApacheWhite', 'DatabaseService', 'DatabaseServiceWhite', 'BigdataService', 'BigdataServiceWhite', 'Autonomous', 'AutonomousWhite', ], 'devops': ['ResourceMgmt', 'ResourceMgmtWhite', 'APIService', 'APIServiceWhite', 'APIGateway', 'APIGatewayWhite', ], 'governance': ['Tagging', 'TaggingWhite', 'Policies', 'PoliciesWhite', 'OCID', 'OCIDWhite', 'Logging', 'LoggingWhite', 'Groups', 'GroupsWhite', 'Compartments', 'CompartmentsWhite', 'Audit', 'AuditWhite', ], 'monitoring': ['Workflow', 'WorkflowWhite', 'Telemetry', 'TelemetryWhite', 'Search', 'SearchWhite', 'Queue', 'QueueWhite', 'Notifications', 'NotificationsWhite', 'HealthCheck', 'HealthCheckWhite', 'Events', 'EventsWhite', 'Email', 'EmailWhite', 'Alarm', 'AlarmWhite', ], 'network': ['Vcn', 'VcnWhite', 'ServiceGateway', 'ServiceGatewayWhite', 'SecurityLists', 'SecurityListsWhite', 'RouteTable', 'RouteTableWhite', 'LoadBalancer', 'LoadBalancerWhite', 'InternetGateway', 'InternetGatewayWhite', 'Firewall', 'FirewallWhite', 'Drg', 'DrgWhite', ], 'security': ['WAF', 'WAFWhite', 'Vault', 'VaultWhite', 'MaxSecurityZone', 'MaxSecurityZoneWhite', 'KeyManagement', 'KeyManagementWhite', 'IDAccess', 'IDAccessWhite', 'Encryption', 'EncryptionWhite', 'DDOS', 'DDOSWhite', 'CloudGuard', 'CloudGuardWhite', ], 'storage': ['StorageGateway', 'StorageGatewayWhite', 'ObjectStorage', 'ObjectStorageWhite', 'FileStorage', 'FileStorageWhite', 'ElasticPerformance', 'ElasticPerformanceWhite', 'DataTransfer', 'DataTransferWhite', 'Buckets', 'BucketsWhite', 'BlockStorage', 'BlockStorageWhite', 'BlockStorageClone', 'BlockStorageCloneWhite', 'BackupRestore', 'BackupRestoreWhite', ], }, 'OpenStack': { 'apiproxies': ['EC2API', ], 'applicationlifecycle': ['Solum', 'Murano', 'Masakari', 'Freezer', ], 'baremetal': ['Ironic', 'Cyborg', ], 'billing': ['Cloudkitty', ], 'compute': ['Zun', 'Qinling', 'Nova', ], 'containerservices': ['Kuryr', ], 'deployment': ['Tripleo', 'Kolla', 'Helm', 'Chef', 'Charms', 'Ansible', ], 'frontend': ['Horizon', ], 'monitoring': ['Telemetry', 'Monasca', ], 'multiregion': ['Tricircle', ], 'networking': ['Octavia', 'Neutron', 'Designate', ], 'nfv': ['Tacker', ], 'optimization': ['Watcher', 'Vitrage', 'Rally', 'Congress', ], 'orchestration': ['Zaqar', 'Senlin', 'Mistral', 'Heat', 'Blazar', ], 'packaging': ['RPM', 'Puppet', 'LOCI', ], 'sharedservices': ['Searchlight', 'Keystone', 'Karbor', 'Glance', 'Barbican', ], 'storage': ['Swift', 'Manila', 'Cinder', ], 'user': ['Openstackclient', ], 'workloadprovisioning': ['Trove', 'Sahara', 'Magnum', ], }, 'Firebase': { 'base': ['Firebase', ], 'develop': ['Storage', 'RealtimeDatabase', 'MLKit', 'Hosting', 'Functions', 'Firestore', 'Authentication', ], 'extentions': ['Extensions', ], 'grow': ['RemoteConfig', 'Predictions', 'Messaging', 'Invites', 'InAppMessaging', 'DynamicLinks', 'AppIndexing', 'ABTesting', ], 'quality': ['TestLab', 'PerformanceMonitoring', 'Crashlytics', 'CrashReporting', 'AppDistribution', ], }, # 'Outscale': { # 'compute':['Compute','DirectConnect'], # 'network': ['SiteToSiteVpng', 'Net', 'NatService', 'LoadBalancer', 'InternetService', 'ClientVpn', ], # 'security': ['IdentityAndAccessManagement', 'Firewall', ], # 'storage': ['Storage', 'SimpleStorageService', ], # } } graph_attr_node_resource = { "fontsize": "45" } graph_attr_node_class = { "fontsize": "30" } with Diagram('Nodes list', direction="LR"): for node_resource, node_resourcs_list in node_list_all.items(): with Cluster(node_resource, graph_attr=graph_attr_node_resource): for node_class, node_class_list in node_resourcs_list.items(): with Cluster(node_resource + '.' + node_class, graph_attr=graph_attr_node_class): node_list = node_class_list for n in range(len(node_list)): node_name = node_list[n] exec("{} = {}".format( node_class + "_" + node_name, node_name + "('" + node_name + "')")) for n in range(len(node_list)): node_left = node_class + "_" + node_list[n] if n != len(node_list)-1: node_right = node_class + "_" + node_list[n+1] exec("{} >> {}".format(node_left, node_right))
※これを実行すると凄く小さい画像になります…
アイコン画像一覧
onprem
AWS
Azure
GCP
Generic
Programming
Saas
Elastic
Firebase
OpenStack
なぜか出ないものがあります
OCI
AlibabaCloud
K8S










- 投稿日:2020-09-16T16:06:12+09:00
簡易LISP処理系の実装例【各言語版まとめ】
この記事は,様々なプログラミング言語でS式入出力および基本リスト処理を実装した上で,John McCarthy氏の原初のLISPインタプリタ記述をPaul Graham氏がCommon Lispで実装した"McCarthy's Original Lisp"(
jmc.lisp)について,各言語向けに移植・動作確認してみた記述例のリンク集および共通解説をまとめたものです.
- Python版
- Scheme版(
jmc.lispの書き直し)- C言語版
- Ruby版
- JavaScript版
- Common Lisp版(
jmc.lispをjmc.lispで動作確認した例)- Haskell版
なお,複数の種類の括弧を用いた記述の簡易パーサ,基本リスト処理のみを実装した例をまとめた記事もあり,こちらの記述から抜粋・修正して組み込んでいる場合もあります.
この記事の方が新しく,少しずつ整理していますが,各リンク先記事との整合性が合っていなかったり,記述や説明が重複していたりする箇所があるかもしれません.御了解いただけますと幸いです.
実装例の趣旨
LISP系言語については,開発当初より『LISP自身でそのLISP処理系を記述する』という,超循環評価器(meta-circular evaluator)としての実装が行われています.最低限の機能をもったLISP処理系であればそのような実装は可能であり,しかも,その評価器の仕組みはとても簡単です.McCarthy's Original Lispの他,SICP 4.1など,Webでも多くの記述例が公開されています.
これらを参照すれば,LISP系以外の他のプログラミング言語でも,超循環評価器としての性質をもつ同じLISP処理系が容易に実装でき,言語処理系実装の入門用として最適…のはずなのですが,LISP処理系ならば標準で装備している,字句・構文を規定する『S式』の入出力処理,および,S式に基づく基本リスト処理(car,cdr,cons,eq,atom)の実装の方が開発言語ごとの手間が圧倒的にかかり,それが敷居になっているところがあります.
そこで,各プログラミング言語で簡単なS式入出力および基本リスト処理の実装例を別途作成し,"McCarthy's Original Lisp"を可能な限りそのまま移植・動作確認することで,言語処理系実装の最初の敷居を下げてみよう,というのが,今回の各実装例の趣旨です.
処理系の概要
次のサンプルの通り,名前付けや関数定義の記述方法がなく,ひとつのまとまったS式のみの処理を行うものですが,ダイナミックスコープということもあり,lambda式を用いて再帰関数を定義して利用することも可能です(Schemeの
letrecやCommon Lispのlabelsなどの代わり).(car (cdr '(10 20 30))) => 20 ((lambda (x) (car (cdr x))) '(abc def ghi)) => def ((lambda (f x y) (f x (f y '()))) 'cons '10 '20) => (10 20) ((lambda (f x y) (f x (f y '()))) '(lambda (x y) (cons x (cons y '()))) '10 '20) => (10 (20 ())) ((lambda (assoc k v) (assoc k v)) '(lambda (k v) (cond ((eq v '()) nil) ((eq (car (car v)) k) (car v)) ('t (assoc k (cdr v))))) 'Orange '((Apple . 120) (Orange . 210) (Lemmon . 180))) => (Orange . 210)評価器本体の実装内容は次の通り.
- "McCarthy's Original Lisp"を基にした,超循環評価器としての性質をもつLISP処理系
- 数字を含むアトムは全てシンボルとし,変数の値とする場合は
quote(')を使用- 構文として
quoteの他,condとlambdaが使用可能- 組込関数:
conscarcdreqatom(内部でコンスセルを作成)- 真偽値は
t(真),および,nil(偽)=空リスト(+内部用記号)- 評価器実装専用として,
caarやassocなどのユーティリティ関数を定義- エラーチェックなし,モジュール化なし,ガーベジコレクションなし
また,S式入出力およびリスト処理実装の構成は次の通り.
- 基本リスト処理:
conscarcdreqatom- S式字句解析:1行の文字列から
()'を字句として,空白を区切り記号として,文字列配列を生成- S式構文解析:
()の括りをconsでリスト化,'は(quote ...)を挿入,.はコンスセルを生成- S式出力:ドット対簡略その他の表現に基づくリスト構造などを表示,または,文字列として出力
- REP (no Loop):文字列1行読み込み→S式抽象構文木生成→評価→S式出力をまとめた関数を定義
評価器の解説
s_evalの処理内容を箇条書きにすると,次のようになります.
- 引数としてS式
eと環境変数をとる.eが真偽値を示す文字列ならば所定の真偽値を返す.eがリスト構造ではないならば束縛変数とみなし,対応する値を環境変数から取得して返す.eがリスト構造であり,先頭の要素e1がリスト構造ではないならば,次の処理を行う.
e1がquoteならば,eの2番目の要素をそのまま値として返す.e1がatomeqcarcdrconsならば,引数要素を評価した後に関数適用を行い,その結果を返す.e1がcondならば,条件式と処理を組にしたリストをevconに渡し,その結果を返す.- それ以外の場合は,
e1をlambda式の束縛変数とみなし,対応するlambda式を環境変数から取得してeの先頭要素として置き換え,あらためて評価した結果を返す.e1もリスト構造であり先頭の要素がlambdaならば,lambda式の値適用とみなし,次の処理を行う.
- 適用する値要素をリストにしたものを
evlisに渡し,それぞれの要素が評価された結果を再度リストとして受け取る.- lambda式の各引数と評価済の各値要素を対応付けたリストを作り,環境変数に追加する.
- lambda式の処理本体を,更新後の環境変数を用いて評価した結果を返す.
eが上記以外の構成の場合は,エラーとして()を返す.肝となるのは,lambda式を別のlambda式の引数に束縛した後の,lambda式の値適用,たとえば,
(s_eval '((lambda (f) (f '(a b c))) '(lambda (x) (cdr x))) '())) => (s_eval '(f '(a b c)) '((f (lambda (x) (cdr x))) . ())) => (s_eval '((lambda (x) (cdr x)) '(a b c)) '((f (lambda (x) (cdr x))) . ())) => (s_eval '(cdr x) '((x (a b c)) (f (lambda (x) (cdr x))) . ())) => (cdr (s_eval 'x '((x (a b c)) (f (lambda (x) (cdr x))) . ()))) => (cdr '(a b c)) => (b c)のように実行されていく処理でしょうか.環境変数内でlambda式に名前が付くことによって,その名前で自分自身を呼び出す再帰処理が定義可能です.
環境変数は,引数持ち回りとはいえ,ひとつのみです.ですのでダイナミックスコープとなるのですが,今回の評価器は,lambda式のみのS式はエラーとし(というよりも,真偽値およびクォートされた記述以外は値としてそのまま返さない),lambda式の処理本体としてlambda式を記述する,すなわち,lambda式を返すlambda式は処理できません.高階関数機能としては,いわゆる第二級オブジェクト相当となります.
実のところ,真偽値のように,lambda式のみの場合はそのまま返すこともできなくはないのですが,lambda式内にローカル環境変数を保持する,クロージャ機能を実装したレキシカルスコープとしないと,名前衝突(funarg)の問題が起きます.そして,レキシカルスコープでは別のlambda式内のローカル環境変数の値を適用できませんから,再帰処理定義のためには,グローバルな環境変数に変数束縛を直接追加する構文や,Yコンビネータのような不動点コンビネータが必要となってきます.
備考
記事に関する補足
趣旨としては他にも,簡易処理系とはいえ,ホスト言語の様々な機能を活用しないと実装できないことから,その言語を本格的に学ぶための題材としても適切な種類と規模,というのもあります.とりあえず,Haskellのリストモナドの妙なクセは一通りわかった(えっ).
実行サンプルのScheme版,Common Lisp版はそれぞれ次の通り.
sample.scm(car (cdr '(10 20 30))) => 20 ((lambda (x) (car (cdr x))) '(abc def ghi)) => def ((lambda (f x y) (f x (f y '()))) cons '10 '20) ; 引数として渡された関数名はクォートする必要がない => (10 20) ((lambda (f x y) (f x (f y '()))) (lambda (x y) (cons x (cons y '()))) ; 引数として渡されたlambda式もクォートする必要がない '10 '20) => (10 (20 ())) (letrec ((assoc_ (lambda (k v) (cond ((eq? v '()) '()) ((eq? (car (car v)) k) (car v)) (else (assoc_ k (cdr v))))))) (assoc_ 'Orange '((Apple . 120) (Orange . 210) (Lemmon . 180)))) => (Orange . 210)sample.lsp(car (cdr '(10 20 30))) => 20 ((lambda (x) (car (cdr x))) '(abc def ghi)) => DEF ; シンボルとしてのアルファベット表示は全て大文字となる ((lambda (f x y) (funcall f x (funcall f y '()))) 'cons '10 '20) ; 引数として渡された関数はfuncallを用いて実行 => (10 20) ((lambda (f x y) (funcall f x (funcall f y '()))) ; 引数として渡されたlambda式はfuncallを用いて実行 (lambda (x y) (cons x (cons y '()))) ; lambda式はクォートする必要がない '10 '20) => (10 (20 NIL)) (labels ((assoc_ (k v) (cond ((eq v '()) '()) ((eq (car (car v)) k) (car v)) (t (assoc_ k (cdr v)))))) (assoc_ 'Orange '((Apple . 120) (Orange . 210) (Lemmon . 180)))) => (ORANGE . 210)更新履歴
2020-09-16:評価器の解説を追加
2020-09-16:初版公開
- 投稿日:2020-09-16T16:00:17+09:00
備忘録(csv.reader とcsv.dictreaderの違い)
pythonで自動化とかできるんでしょ~?よろしく~、って言われたので頑張る記録 その2
記録その1(https://qiita.com/wellwell3176/items/8e9a31d1595cdde89498 )で使った
「csv.dictreader」が良く分からなかったので調べて、何となく分かったという話。というか、辞書形式という言葉に問題がある気がする・・・検索性悪い・・・検索性悪くない・・・?
調べた限り、要するに、1行目に書かれた情報を「データとして扱うか」「見出しとして扱うか」の差ということらしい。
図に落とし込まないと何も分からないマンなのでポンチ絵を作ってみたが、下図であっているはず。
<図1:readerとdictreaderの差>CSVデータの1行目にデータではなく見出し("No."とか、"年齢"とかそういうの)が入っているのであれば、
dictreaderの方が扱いやすそう。「年齢列の1~70行目のデータの平均値を出す」という書き方ができるはずなので。一方、見出しが入っているCSVに対してreaderを使った場合は、「2列目の2~71行目のデータの平均値」というように、
「何列目に何の情報が格納されているか?」「1行目はデータに含まない」の2点を常に考慮しないと行けないから大変、と。ざっくりだが、この理解で次に進もう。
とても独立記事を作るような内容ではないが、備忘録だし、一件一テーマで残しておくこととする。
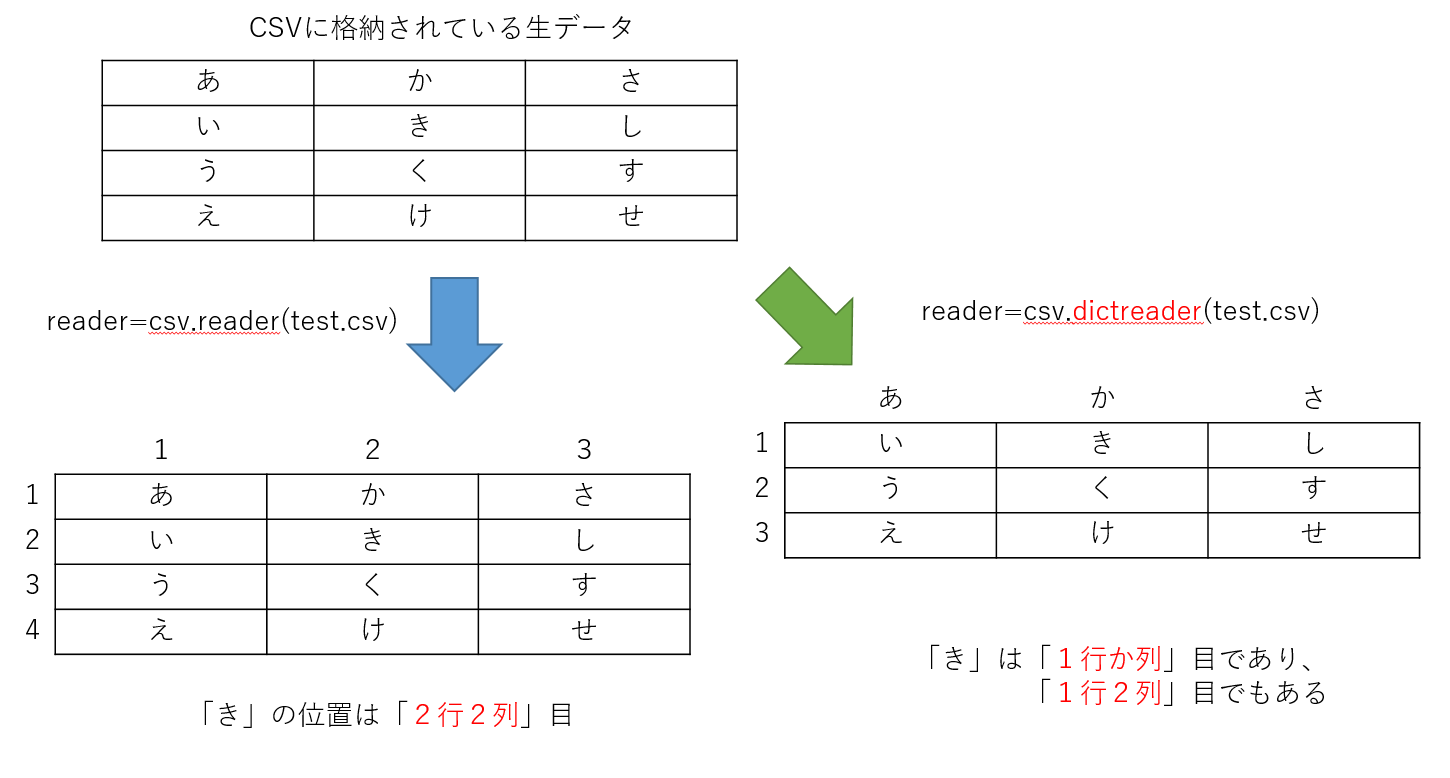
- 投稿日:2020-09-16T15:41:32+09:00
「ゼロから作るDeep Learning」自習メモ(その9)MultiLayerNet クラス
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その8 ←
5章でニューラルネットワークの構成要素をレイヤとして実装し、6章でそれを使っています。
個々のレイヤについては5章で説明がありますが、実装した MultiLayerNet クラスは、本の中では説明されていません。ソースは、フォルダcommon の multi_layer_net.py にあります。ということで、MultiLayerNet クラスの中身を見ていきます。
6.1.8 MNIST データセットによる更新手法の比較 で使っているソースコードch06/optimizer_compare_mnist.py でMultiLayerNet クラスを参照しています。
from common.multi_layer_net import MultiLayerNet #クラスのインポート ・ ・ batch_size = 128 ・ ・ # 1:実験の設定========== optimizers = {} optimizers['SGD'] = SGD() optimizers['Momentum'] = Momentum() optimizers['AdaGrad'] = AdaGrad() optimizers['Adam'] = Adam() # MultiLayerNetクラスから networksオブジェクトを作成 networks = {} train_loss = {} for key in optimizers.keys(): networks[key] = MultiLayerNet( input_size=784, hidden_size_list=[100, 100, 100, 100], output_size=10) train_loss[key] = [] ・ ・MNISTデータセットを使うので、
input_size=784 入力は784 列(元は28 × 28)の画像データ
output_size=10 出力は0~9のどれであるかの予測確率
hidden_size_list=[100, 100, 100, 100] 隠れ層が4層あり、ニューロンの数が各100個
weight_init_std=weight_type 重みの初期値の設定この設定で全結合による多層ニューラルネットワークを作成するから、
こんな感じで、配列が作られる。
以下、networksオブジェクトの中にある配列やオブジェクトを参照したときのものです。
networks{'SGD': common.multi_layer_net.MultiLayerNet at 0x8800d50,
'Momentum': common.multi_layer_net.MultiLayerNet at 0x8800a50,
'AdaGrad': common.multi_layer_net.MultiLayerNet at 0x8800710,
'Adam': common.multi_layer_net.MultiLayerNet at 0x88003d0}networks['SGD']common.multi_layer_net.MultiLayerNet at 0x8800d50
networks['SGD'].layersOrderedDict([('Affine1', common.layers.Affine at 0x8800c30),
('Activation_function1', common.layers.Relu at 0x8800c70),
('Affine2', common.layers.Affine at 0x8800bf0),
('Activation_function2', common.layers.Relu at 0x8800bd0),
('Affine3', common.layers.Affine at 0x8800b90),
('Activation_function3', common.layers.Relu at 0x8800b70),
('Affine4', common.layers.Affine at 0x8800ab0),
('Activation_function4', common.layers.Relu at 0x8800b30),
('Affine5', common.layers.Affine at 0x8800af0)])networks['SGD'].layers['Affine1'].xarray([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32)networks['SGD'].layers['Affine1'].x.shape(128, 784)
networks['SGD'].layers['Affine1'].Warray([[-0.04430735, -0.00916858, -0.05385046, ..., -0.01356, 0.0366878, -0.04629992],
[-0.0974915 , 0.01896 , 0.0016755 , ..., 0.00820512, -0.01012246, -0.04869024],
...,
[ 0.03065034, -0.02653425, -0.00433941, ..., -0.06933382, 0.03986452, 0.06821553],
[ 0.01673732, 0.04850334, -0.0291053 , ..., -0.05045292, 0.00599257, 0.08265754]])networks['SGD'].layers['Affine1'].W.shape(784, 100)
networks['SGD'].layers['Affine1'].barray([ 0.01646891, 0.01467293, 0.02892796, 0.02414651, 0.02259769,
-0.00919552, -0.01567924, 0.0039934 , 0.00693527, 0.03932801,
...,
-0.00536202, 0.00508444, 0.00204647, 0.01040528, 0.00355356,
-0.00960685, 0.06204312, 0.02886584, 0.06678846, 0.0186539 ])networks['SGD'].layers['Affine1'].b.shape(100,)
networks['SGD'].layers['Activation_function1']common.layers.Relu at 0x8800c70
networks['SGD'].layers['Affine2'].x.shape(128, 100)
networks['SGD'].layers['Affine2'].W.shape(100, 100)
networks['SGD'].layers['Affine2'].b.shape(100,)
networks['SGD'].layers['Activation_function2']common.layers.Relu at 0x8800bd0
networks['SGD'].layers['Affine3'].x.shape(128, 100)
networks['SGD'].layers['Affine3'].W.shape(100, 100)
networks['SGD'].layers['Affine3'].b.shape(100,)
networks['SGD'].layers['Activation_function3']common.layers.Relu at 0x8800b70
networks['SGD'].layers['Affine4'].x.shape(128, 100)
networks['SGD'].layers['Affine4'].W.shape(100, 100)
networks['SGD'].layers['Affine4'].b.shape(100,)
networks['SGD'].layers['Activation_function4']common.layers.Relu at 0x8800b30
指定した中間層の数は4だが、その後に出力層として5番目の層を作っている。
networks['SGD'].layers['Affine5'].x.shape(128, 100)
networks['SGD'].layers['Affine5'].W.shape(100, 10)
networks['SGD'].layers['Affine5'].b.shape(10,)
出力層の活性化関数は、last_layer に定義されている。
ここではソフトマックス関数を使っている。networks['SGD'].last_layercommon.layers.SoftmaxWithLoss at 0x8800770
networks['SGD'].last_layer.yarray([[2.08438091e-05, 2.66555051e-09, 1.29436456e-03, ...,
1.83391350e-07, 9.98317338e-01, 6.77137764e-05],
[5.68871828e-04, 1.59787427e-06, 3.60265866e-03, ...,
7.25385216e-05, 1.80220134e-03, 4.95014520e-02],
...,
[3.01731618e-03, 5.57601184e-03, 1.40908372e-02, ...,
8.49627989e-02, 5.44208078e-03, 2.32114245e-01],
[9.82201047e-07, 3.01213101e-07, 1.05657504e-03, ...,
1.03584551e-05, 9.92242677e-01, 5.06642654e-03]])networks['SGD'].last_layer.y.shape(128, 10)
その8 ←
- 投稿日:2020-09-16T14:57:47+09:00
【Python】自分の好きなデスクトップ画像を元に、自動で良い感じに合うターミナル/Vim/VSCodeのテーマを1コマンドで作ろう
例えばこんな感じ
好きなデスクトップ画像さえあれば、1コマンドですぐに反映できます。
これらは実際に私のデスクトップ画像を元に、自動であうテーマを1コマンドで生成/反映したテーマです。
(私の他のテーマはこちらに10種類ほど置いています。 https://github.com/ryuta69/dotfiles)
やり方
1: Python3をインストール
Macであれば標準でPythonがインストールされていますが、そうでない場合はこちらからPython3をインストールしてください。
https://www.python.org/downloads/2: imagemagickをインストール
## MacOS brew install imagemagick ## Windows https://imagemagick.org/script/download.php#windows からダウンロード ## Linux系 https://imagemagick.org/script/download.php#unix からダウンロード3: Pywalをインストール
git clone https://github.com/dylanaraps/pywal cd pywal pip3 install .4: Pywalを実行してみる
まず、実行したあと反映されたかどうかがわかりやすいように、ターミナルやvimを開いた状態にしておくことをオススメします。準備ができたら、下記のコマンドを実行してみてください。
wal -i xxxxx(デスクトップ画像)実行した瞬間、 下のgifのように、ターミナルもvimもテーマが反映されましたでしょうか?
5: Pywalは既存設定を上書きしないようにできてるので(安心)、ターミナル起動時に常時読み込むようにする
Pywalは既存のiTermの設定やvimのテーマが上書きしているわけではなく、~/.cache/wal配下にキャッシュが保存されてここからカラーセットを読み込むようになっています(だから安全)。
なので、反映させたあとにiTermを終了して再起動すると、もともとのテーマに戻っていることがわかります。
この状態からもう一度pywalで生成したテーマを読み込むには下記のコマンドを実行します。
wal -Rこのコマンドを、.bashrcや.zshrcに追記しておくとターミナルが起動するたびに自動でテーマを読み込んでくれます。
VimやVSCodeにも、Pywalで作成したテーマを自動で反映させる
Vimはwal.vimをインストールする
下記の文を、.vimrcに追記してください
.vimrc"" vim-plugを使っている場合 Plug 'dylanaraps/wal.vim' "" deinを使っている場合 call dein#add('dylanaraps/wal.vim') "" neobundleを使っている場合 NeoBundle 'dylanaraps/wal.vim' set notermguicolors colorscheme walこれ以外に設定はいりません。これだけで自動反映されます。
VSCodeはWal Themeをインストールする
こちらからインストールしてください。これだけで自動反映されます。
https://marketplace.visualstudio.com/items?itemName=dlasagno.wal-theme発展1:fzfを介して、いつでも1コマンドでテーマを切り替える
fzfについてはこちらの記事が詳しいです。
おい、peco もいいけど fzf 使えよ# ~/.theme配下に、自作のテーマフォルダが何個もある想定 # 例:https://github.com/ryuta69/dotfiles/tree/master/dotfiles/.themes alias swtm='wal -i `ls -d ~/.theme/* | fzf`'
swtmと打てば、テーマ一覧を選択する状態となり、選択すればそのテーマに即時変更してくれます。(previewにranger入れるのもアリ。imgcatは動かない。)発展2:themerを介して、SlackやChromeやFirefox用テーマを作る
themerについてはこちらの記事が詳しいです。
VSCode、Vim、iTerm、Slackなどのカラーテーマが簡単に作れるWebサイト 「themer.dev」themerはそのままの状態では対応色が少ない為(Accent9がcursorとtextで被っちゃうなど)、vimやvscodeなどはpywalの方がオススメです。しかし、対応アプリの幅が非常に広いため「pywalで色生成→themerで魔合成」するコンボで様々なアプリにカラーセットを反映できます。
その方法ですが、
~/.cache/wal/colorsからカラーセット16色を確認して、https://themer.dev/ にアクセスして、ポチポチ色を入れていく・・・といった手段が必要になりこれは非常に面倒です。ということで簡素なpywal→themerの変換PRを作成しました。まだマージされてませんが、このブランチのpywalを用いればcolors-themer.jsというCUI版themer用設定ファイルが生成されます。これを用いて
npm install -g themer @themer/slack @themer/chrome @themer/firefox-addon @themer/vim @themer/vscode themer -c colors-themer.js \ -t @themer/slack \ -t @themer/chrome \ -t @themer/firefox-addon \ -t @themer/vim -t @themer/vscodeとすれば各テーマファイルが生成されます。
まとめ(一番書きたかったこと)
余談ですが、こういった「活かした開発環境の見た目を作る」カテゴリを海外では「UnixPorn / VimPorn」と呼んでいます。
ちょっとだけこちらの、色々な人が自分のUnixPornを投稿してる、Redditのサイトを見てみてください。
https://www.reddit.com/r/unixporn/
・・・・・最高じゃないですか!?いやもう本当大好きすぎて(ry
あとこのPinterestも見てみてください。
https://www.pinterest.jp/pin/333196072430758602/
いや本っっっっ当最高じゃないですか!!??
・・・・って感じで自分は完全にハマってしまいまして、「自分も作りたいなぁ」と今年は色々自作テーマを試行錯誤して作ってました。でもやはりデザインセンスがなくってどれも全然ハマらなかったんですね・・・そんなときにこのpywalに出会いました。pywalのおかげでベースとなる配色をすぐに作ることができて、発見がたくさんあったりデザインの参考を作ることができました。そしてついに、
冒頭にあげた画像の1枚目は憧れだったUnixPornのHot1位を
https://www.reddit.com/r/unixporn/comments/irl7i5/rectangle_ubersicht_orange_sunset_theme/冒頭にあげた画像の2枚目はVimPornのHot1位を獲得することができました。
https://www.reddit.com/r/vimporn/comments/imlyg6/cowboy_bebop_brown_original_theme/「日本でもUnixPorn流行れ!お願いします!めっちゃ他の人のも見たい!めっちゃ開発環境いい感じにしたい!」という、強い強い思いを込めて記事を締めたいと思います。
(なにか質問あればコメントにてお願いします。Requirementsはこちらの公式ドキュメントを参照してください。)





- 投稿日:2020-09-16T14:12:15+09:00
PythonでModuleNotFoundError: No module namedした話
問題
pip install flaskしたflaskがimportするとタイトルのエラーを吐く。
何なら、pandasもimportするとエラーを吐く。逃げろジャイローーッ!!これはスタンド攻撃だァァーーーッ!!!
ネタバレ
Inkscapeくんのせいでした。
(ここでInkscape関係なさそうな人はおまけへ)原因究明
まずは焦らず慌てずちゃんとインストールできているか調べる。
ターミナルで以下のコードをポチッとな。pip list結果
ふむふむ。
インストールはちゃんとできている。では、次。
Pythonがモジュールのインポートで探してるディレクトリはどこか、確認する。
Pythonコンソールを開いて以下のコードを実行する。import sys import pprint pprint.pprint(sys.path)結果はこう
( ゚д゚) ・・・
(つд⊂)ゴシゴシ
(;゚д゚) ・・・
(つд⊂)ゴシゴシゴシ(;;゚ Д゚) …!?
Inkscape!?
そ、そういえば、この間Inskcapeをインストールしたとき、環境変数PATHに追加にチェックしたような……
Inkscape、お前絶対許さねえからな!!!(責任転嫁)
(ここでInkscape関係なかった人はおまけへ)対処
Pythonくんが変なところを参照しているのは、環境変数の
PATHがトチ狂ったから。
これをまともなように編集し直してあげればよい。環境変数の設定は
コントロールパネル→システムとセキュリティ→システム→(左欄の)システムの詳細設定→環境変数から行える。
今回、問題となっているのはユーザー環境変数ではなく、下欄のシステム環境変数のPATH(環境によっては小文字かも)。
これを選択して編集。
Inkscapeなんたらってなっているパスを消す。
消したら保存して再起動。
チェックしてみると…
ktkr~~~~~~!!!!!
一件落着。まとめ
変なものをホイホイと環境変数
PATHに追加しない!おまけ (Inkscape関係なかった人たちへ)
原因究明の項のモジュールをインストールできているかの確認をまずしてほしい。
インストールがミスっているならもう1回インストール、できていたならば次のコードを。pip show [importできなくて困ってるモジュール名]このコードはモジュールの場所を教えてくれる。
そして、Pythonコンソールを開いてPythonがどこを参照してインポートしようとしているかの確認する。
手順は原因究明にある(コンソールで、sysをなんたらってやつ)。Pythonの参照先とモジュールの場所は一致しているだろうか。おそらく一致していないと思う。
であれば、対処の項の環境変数の設定の仕方を参考に、Pythonがインストールされたフォルダを環境変数PATHに追加する。
Pythonのインストールフォルダは人によって違うだろうが、筆者の環境ではC:\Users\[筆者の名前]\AppData\Local\Programs\Python\Python38にあった。見つからない場合は、スタートメニューからPythonを探して、右クリックメニューの
その他→ファイルの場所を開く、
開いたフォルダで選択されているもの(おそらくPythonのショートカット)の右クリックメニューからファイルの場所を開く。
これでpythonがインストールされたフォルダにたどり着く。そもそもスタートメニューにPythonがないって人は諦めてPythonを再インストールしよう。
その際、インストール画面をじっくり見て、環境変数PATHに追加にチェックを入れること。
そうすれば解決するはずだ。それでは、よいPythonライフを!
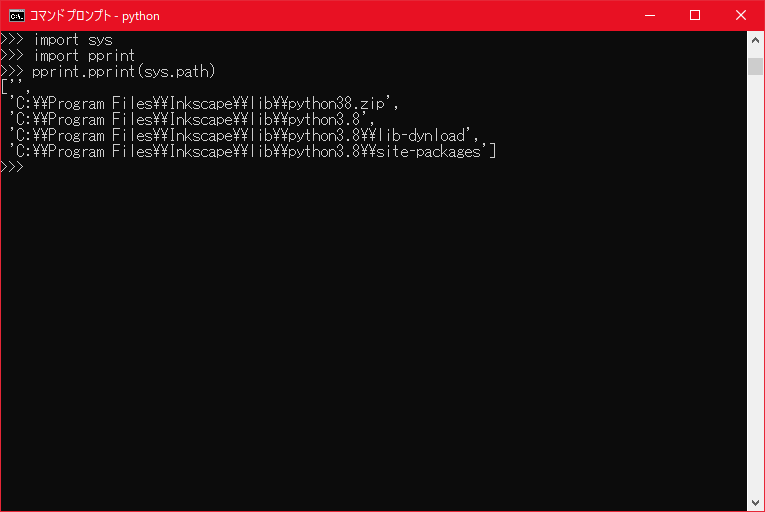
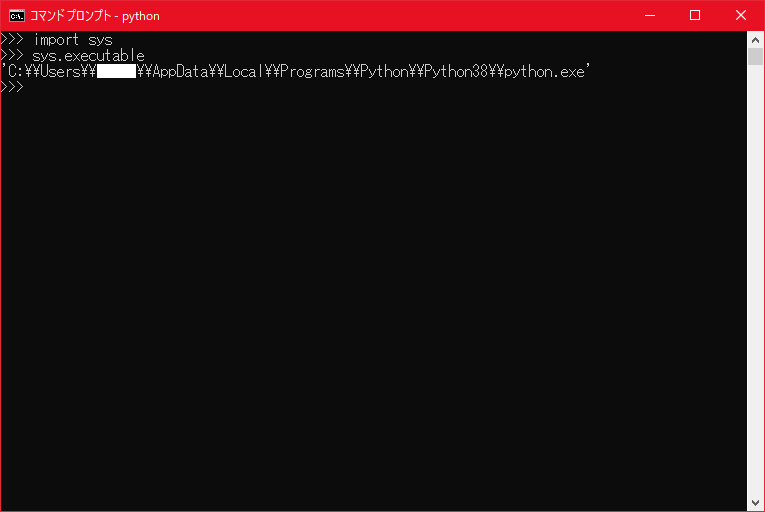
- 投稿日:2020-09-16T14:04:26+09:00
備忘録(CSVファイル読み込み時のUnicodeDecodeError対策)
pythonで自動化とかできるんでしょ~?よろしく~、って言われたので頑張る記録 その1
~~結論だけ先に書いておく~~
open(CSVファイル,encoding =文字コード)で指定する時、
文字コードには「CSVファイルに使われている文字コード」を使えば大丈夫。
今回は日本語を含むファイルだったのでShift-jisで指定が必要だった。
~~どうでもいい日記~~
社内のソフトでデータをCSVに出力する
→担当者がいい感じにエクセルファイル上で成形する
→エクセルファイルをメールで先方に送る
pythonを使って上記作業をうまいこと自動化するように言われたのでゼロスタートで頑張ることになった。
pythonについては完全に素人だが、VBAの知識が多少あるなら何とかなるらしい。本当かよ。
~~ここまで日記~~~~主題~~
・CSVファイルを読み込んだらUnicodeDecodeErrorが出たので直したい~~ここから状況説明~~
Google Colaboratoryを使ってpythonの基本機能を確認から開始した。
適当なCSVファイルをグーグルドライブ直下に置く。
google Colaboratoryから新しいNotebookを作成する。
csvを読み込んで出力するサンプルプログラムを試す。
Ref:https://note.com/092i034i/n/n76f2c2de197testimport csv #これを書いておくとCSVファイルが扱えるっぽい csvfile = open('/content/drive/My Drive/test.csv') #csvファイルをpythonの変数csvfileに取り込んだ reader = csv.DictReader(csvfile) #csvfileの情報を何らかの形でreaderという変数に放り込んだ for row in reader: #まだ良く分かってない。繰り返し処理っぽいけど・・・。 print(row) #変数rowの中身を出力するやつしかし、コンパイルが通らない。エラーが出る。
error-messageUnicodeDecodeError Traceback (most recent call last) <ipython-input-30-e6400dcd8fdb> in <module>() 4 reader = csv.DictReader(csvfile) 5 ----> 6 for row in reader: 7 print(row)英語の成績が致命を通り越して落命レベルであり、スマブラの「Break the target!」のアナウンスさえ異界の言語と思っていた身としては、この時点で既に気分がどんよりしてきているが、まあ一個ずつ取り組むしか無い。
見たところ、変数readerの中身をrowに代入するときのデコード(復号化)に失敗しているのだが、
csvfile=open(test.csv)の処理では何もエラーが出ていない。
この結果から考えたプログラム処理の流れ
1.ドライブ上のCSVファイルをエンコード(暗号化)してpythonの変数csvfileに取り込む
2.変数csvfileの中身を、エンコードされたままcsv.dictreaderという法則で変数Readerに代入
3.変数readerの中身を復号化して変数row に移し替える(ここで復号に失敗してエラーが出た)
4.変数Rowの中身を1行目から最後まで出力する
よってreaderの中身をrowに移すときの復号方式に何か問題がある・・・と、思っていたのだが、
エラーメッセージをネットで調べるとどうも違うらしい。
正しい処理の流れっぽいもの
1.ドライブ上のCSVファイルは日本語を含むのでShift-jisでエンコードされていた
2.しかし、特に何も指定がないと、pythonはCSVファイルの中身をUTF-8でエンコードして変数csvfileに取り込む
3.この時、変数csvfileの中身は「Shift-jisのファイルをUTF-8で無理矢理エンコードした文字化け状態」になっている
4.しかし、なぜかこの状態でもcsv.dictreaderという法則で変数csvfileから変数Readerに代入することはできる
5.変数readerの中身を復号化して変数row に移し替える(ここでデコードできないことで初めて文字化けが分かるらしい)
6.変数Rowの中身を1行目から最後まで出力する
何故csv.dictreaderではOKなのか分からないが、
直したらコンパイルが通ってしまったのでひとまずはそういうものだと割り切ることにする。エンコードの時点で問題が発生していても、pythonの処理でそれが発覚するのはデコード時らしい。
これは多分、俺のエンコード・デコードに関する知識が不十分なせいで意味が分からない点なんだけど・・・メインの自動化の話からは逸れるので今回は追うのを諦める。しかし、初日が終わってまだCSVファイルの読み取りしか出来ていないが本当に大丈夫か。
俺がオリマーならホコタテ星から出られず土に還るペースだぞ。
VBAの知識あれば大丈夫って本当に本当か。不安。補足:直したらコンパイルが通ったときのコードimport csv csvfile = open('/content/drive/My Drive/test.csv',encoding="shift-jis") #日本語csvファイルをshift-jisで取り込み reader = csv.DictReader(csvfile) for row in reader: print(row)
- 投稿日:2020-09-16T13:33:35+09:00
深さ優先探索をPythonで書く
概要
- 勉強のため深さ優先探索をPythonで書いてみます。
- ごく簡単な迷路のようなもののルート算出を深さ優先探索で対応します。
- 元々デザイン方面の学校卒なので、コンピューターサイエンス方面で知識的に雑な点などはご容赦ください。
深さ優先探索とは?
深さ優先探索とは「とにかく行けるとこまで行ってそれ以上進めなくなったら一歩戻ってそこから探索する」という探索方法。
深さ優先探索と幅優先探索たとえばグリッド上の迷路で考えてみます。上端のグリッドに迷路の入口があり、下端のグリッドに迷路の出口があるとします。
途中途中に通路の分岐や行き止まりもあるとします。
こういった際に進めるだけ先に進んで(深さ優先)、もし行き止まりで進めなくなったら直前の通路の分岐まで戻ってその分岐を進んで出口を目指すような探索方法です。
英語だとdepth-first search、略してDFSなどと表記されます。
解くべき問題のための迷路を作るスクリプトを書く
まずはグリッド上のランダムな迷路を生成するためのスクリプトを書いていきます。
セルの状態の定義
各グリッドの位置1つ分をセルとして、セルには「入口」「通路」「壁」「出口」という状態があるとします。また、探索で算出されたルートが分かるようにするための状態も保持するようにします。
これらの状態を定数として持っておきます。定数の値は半角の文字で持ち、グリッド表示の際にこの文字を表示するようにします。
# 入口用の定数値。 CELL_TYPE_START: str = 'S' # 通路用の定数値。 CELL_TYPE_PASSAGE: str = ' ' # 壁の定数値。 CELL_TYPE_WALL: str = 'W' # 出口の定数値。 CELL_TYPE_GOAL: str = 'G' # 算出されたルートのパス用の定数値。 CELL_TYPE_PATH: str = '*'入口と出口は、ENTRANCEやEXITとすると両方Eで分かりづらいのでSTARTとGOALとしてあります。
通路部分は空文字、通ったパスはアスタリスクの記号を設定するようにしてあります。
迷路のグリッドの位置情報を扱うクラスの定義
迷路のグリッドの位置情報単体を扱うためのクラスを定義しておきます。左上の位置で0からスタートする値で、右下にいくほど1増加する形で行と列の属性が設定されるようにします。
class Location: def __init__(self, row: int, column: int) -> None: """ 迷路のグリッドの位置情報単体を扱うクラス。 Parameters ---------- row : int 位置の行番号。0からスタートし、上から下に向かって1ずつ 加算される。 column : int 位置の列番号。0からスタートし、左から右に向かって1ずつ 加算される。 """ self.row: int = row self.column: int = columnランダムな迷路を生成するクラスの定義
インスタンス化する度にランダムな迷路を生成するためのクラスを追加していきます。
from typing import List import random ... class Maze: # 生成する迷路のグリッドの縦の件数。 _ROW_NUM: int = 7 # 生成する迷路のグリッドの横の件数。 _COLUMN_NUM: int = 15 # 生成する壁の比率。1.0に近いほど壁が多くなる。 _WALL_SPARSENESS: float = 0.3 def __init__(self) -> None: """ ランダムな迷路のグリッドの生成・制御などを扱うクラス。 Notes ----- ランダムに各セルタイプが設定されるため、必ずしもスタートから ゴールに到達できるものができるわけではない点には注意。 """ self._set_start_and_goal_location() self._grid: List[List[str]] = [] self._fill_grid_by_passage_cell() self._set_wall_type_to_cells_randomly() self._set_start_and_goal_type_to_cell() def _set_start_and_goal_location(self) -> None: """ 開始地点(入口)とゴール(出口)の座標の属性を設定する。 """ self.start_loc: Location = Location(row=0, column=0) self.goal_loc: Location = Location( row=self._ROW_NUM - 1, column=self._COLUMN_NUM - 1) def _fill_grid_by_passage_cell(self) -> None: """ 全てのセルに対してセルの追加を行い、通路のセルタイプを設定する。 """ for row in range(self._ROW_NUM): row_cells: List[str] = [] for column in range(self._COLUMN_NUM): row_cells.append(CELL_TYPE_PASSAGE) self._grid.append(row_cells) def _set_wall_type_to_cells_randomly(self) -> None: """ グリッドの各セルへ、ランダムに壁のセルタイプを設定する。 """ for row in range(self._ROW_NUM): for column in range(self._COLUMN_NUM): probability = random.uniform(0.0, 1.0) if probability >= self._WALL_SPARSENESS: continue self._grid[row][column] = CELL_TYPE_WALL def _set_start_and_goal_type_to_cell(self) -> None: """ 開始(入口)とゴール(出口)の位置にそれぞれの セルタイプを設定する。 """ self._grid[self.start_loc.row][self.start_loc.column] = \ CELL_TYPE_START self._grid[self.goal_loc.row][self.goal_loc.column] = \ CELL_TYPE_GOAL def __str__(self) -> str: """ グリッドの各セルのタイプの文字列を取得する。 Returns ------- grid_str : str グリッドの各セルのタイプの文字列。 """ grid_str: str = '' for row_cells in self._grid: grid_str += '-' * self._COLUMN_NUM * 2 grid_str += '\n' for cell_type in row_cells: grid_str += cell_type grid_str += '|' grid_str += '\n' return grid_strコンストラクタで順番にグリッドの行列のセル数の定数を定義したり、2次元のリストにセルタイプの文字列を格納する属性を追加したり、ランダムに壁のセルタイプを配置したり、入口と出口の位置をセルに設定したりしています。
__str__メソッドではprint関数などに渡された際に、見やすいように境界の線の文字などを追加するようにしています。試しにインスタンス化してみて、print関数で出力してみると以下のようなものが出力されます。
if __name__ == '__main__': maze = Maze() print(maze)
左上に入口(スタート)のS、右下に出口(ゴール)のGが設定されます。
また、各セルにはランダムに壁(W)が配置されます。空のセルは通路です。注意点として、単純にランダムに壁を生成しているだけなので、壁の生成具合によっては壁に阻まれてスタートからゴールまでのルートが存在しないケースも発生します(今回は何度か実行すれば問題ないと判断してこのまま進めます)。
ゴールに到達したかの判定用のメソッドの追加
Mazeクラスに、指定の位置がゴールの位置かどうかの判定を行うためのメソッドを追加しておきます。後で探索を実行した際に、ゴールに達しているのかの判定に使います。
def is_goal_loc(self, location: Location) -> bool: """ 指定された位置がゴールの位置かどうかの真偽値を取得する。 Parameters ---------- location : Location 判定用の位置。 Returns ------- result : bool ゴールの位置であればTrueが設定される。 """ if (location.row == self.goal_loc.row and location.column == self.goal_loc.column): return True return False移動可能な位置を取得するメソッドの追加
引き続きMazeクラスに、指定された位置を起点に移動可能な位置のリストを取得するメソッドを追加していきます。移動の処理はグリッド内で上下左右の1マスのみ、且つ壁のセルには移動できないようにします。
本当はパラメーターで奥方向を優先するなどの制御を色々入れたりといったところですが長くなりそうなので今回は割愛します(本当はそこが大切な気がしないでもないですが、参考にした本も読んだところでは割愛され気味だったので、別の記事などで機会があれば深堀りしようと思います)。
def get_movable_locations(self, location: Location) -> List[Location]: """ 指定された位置から、移動が可能な位置のリストを取得する。 Parameters ---------- location : Location 基準となる位置のインスタンス。 Returns ------- movable_locations : list of Location 移動可能な位置のインスタンスを格納したリスト。 """ movable_locations: List[Location] = [] # 上に移動可能かどうかの判定処理。 if location.row + 1 < self._ROW_NUM: is_wall: bool = self._grid[location.row + 1][location.column] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row + 1, column=location.column)) # 下に移動可能かどうかの判定処理。 if location.row - 1 >= 0: is_wall = self._grid[location.row - 1][location.column] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row - 1, column=location.column)) # 右に移動可能かどうかの判定処理。 if location.column + 1 < self._COLUMN_NUM: is_wall = self._grid[location.row][location.column + 1] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row, column=location.column + 1)) # 左に移動可能かどうかの判定処理。 if location.column - 1 >= 0: is_wall = self._grid[location.row][location.column - 1] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row, column=location.column - 1)) return movable_locationsスタックの制御のためのクラスの定義
深さ優先探索では、スタックと呼ばれるデータ構造のものを使っていきます。スタックはLast-In-First-Out(LIFO・後入れ先出し)と呼ばれる挙動をします。つまり後に追加したデータの方が、取り出す際には先に対象になります。
積み上げられている新聞をイメージすると分かりやすいかもしれません。どんどん上に積み重ねて(スタックして)いきますが、それらを手に取る際には上から(後から積み上げた方から)手に取る形になります。
collectionsパッケージ内のPython標準モジュールを使えばスタックの制御を扱えますが、ここでは勉強目的なので自前でクラスを用意していきます。
class Stack: def __init__(self) -> None: """ スタックの制御を扱うためのクラス。 """ self._container: list = [] @property def empty(self) -> bool: """ スタックの内容が空かどうかの真偽値を取得する。 """ return not self._container def push(self, item: Any) -> None: """ スタックへ要素を追加する。 Parameters ---------- item : * 追加する要素。 """ self._container.append(item) def pop(self) -> Any: """ スタック内から要素を取り出す。 Returns ------- item : * 取り出された要素。最後に追加されたものが対象となる。 """ item = self._container.pop() return item def __repr__(self) -> str: """ リスト内容を文字列で返却する。 Returns ------- output : str リスト内容を変換した文字列。 """ return repr(self._container)読んでいた書籍で出てきて思いましたが、今更ながら
__repr__とかreprの制御ってなんのためにあるのだろう?__str__などとの使いわけはどうなのだろう?ということで調べてみました。どうやらreprなどの方はPythonのコードとして使える(コンストラクタを実行するような形)での文字列として出力されるそうです。str()がJavaのクラスでオーバーライドするtoString()メソッド(C#のToString()メソッド)のイメージです。repr()は引数付きのコンストラクタ(または初期化子)を文字列で返してくれる関数と解釈できます。
Pythonのstr( )とrepr( )の使い分け少しコードを動かして試してみます。
__repr__部分の動作確認としてprint(stack)とインスタンス自体を出力しているのと、popさせた際にLIFOになっていることを確認します。if __name__ == '__main__': stack = Stack() stack.push(100) stack.push(200) print(stack) last_value = stack.pop() print('last_value:', last_value)[100, 200] last_value: 200移動の位置情報を保持するクラスの追加
移動してきた情報を格納するためのNodeクラスを追加します。該当の位置情報とどのグリッド位置から移動してきたのかをparentという属性名で保持します。
なお、クラスの引数自体にそのクラスの型のアノテーションをしたい場合には利用するPythonのバージョン次第(3.7や3.8では恐らく必要になります)で
from __future__ import annotationsの記述が必要になります(そうしないとPylanceなどでエラーで引っかかります)。詳細は少々まだ読めていませんが、PEP 563 -- Postponed Evaluation of Annotationsなどに書かれているそうです。
from __future__ import annotations from typing import Optional ... class Node: def __init__(self, location: Location, parent: Optional[Node]): """ 迷路の位置や推移の情報などを保持するためのノード単体のデータを 扱うクラス。 Parameters ---------- location : Location 対象の位置情報を扱うインスタンス。 parent : Node or None 移動前の位置情報を扱うノードのインスタンス。探索開始時 などにはNoneとなる。 """ self.location: Location = location self.parent: Optional[Node] = parentスタックではこのNodeクラスのインスタンスを格納して扱っていきます。
深さ優先探索の関数の定義
実際に深さ優先探索のコードを書いていきます。DFSの略名から関数名もdfsとします。
from typing import Callable from typing import Set ... def dfs( initial_loc: Location, is_goal_loc_method: Callable[[Location], bool], get_movable_locations_method: Callable[[Location], List[Location]] ) -> Optional[Node]: """ 深さ優先探索(depth-first search)による、迷路のゴールの 探索を行う。 Parameters ---------- initial_loc : Location 探索の開始位置。 is_goal_loc_method : callable 対象の位置がゴールかどうかを判定するためのメソッド。 get_movable_locations_method : callable 対象の位置から移動可能な位置のリストを取得するための メソッド。 Returns ------- goal_node : Node or None ゴールに達した場合にはその位置のNodeクラスのインスタンスが 設定され、迷路の構造的にもしゴールにたどり着けない場合には Noneが設定される。 """ frontier_loc_stack: Stack = Stack() frontier_loc_stack.push( item=Node(location=initial_loc, parent=None)) explored_set: Set[Location] = {initial_loc} while not frontier_loc_stack.empty: current_node: Node = frontier_loc_stack.pop() current_location: Location = current_node.location print('current_location', current_location.row, current_location.column) if is_goal_loc_method(current_location): return current_node movable_locations = get_movable_locations_method(current_location) for movable_location in movable_locations: is_explored_loc = _is_explored_loc( location=movable_location, explored_set=explored_set) if is_explored_loc: continue explored_set.add(movable_location) frontier_loc_stack.push( Node(location=movable_location, parent=current_node)) return None def _is_explored_loc( location: Location, explored_set: Set[Location]) -> bool: """ 既に探索済みの位置かどうかの真偽値を返す。 Parameters ---------- location : Location チェック対象の位置。 explored_set : set 探索済みの位置を格納したセット。 Returns ------- result : bool 探索済みの位置であればTrueが設定される。 """ for explored_location in explored_set: if (location.row == explored_location.row and location.column == explored_location.column): return True return Falseまずは引数説明からですが、initial_locは基本的に入口の位置のインスタンスが指定されます。
is_goal_loc_methodとget_movable_locations_methodに関しては、対象の生成されたMazeクラスのインスタンスが持っている各メソッドが対象となります。
Callableで型アノテーションしておくと、Pylanceなどを使っているとちゃんとそのメソッド(や関数など)で実行箇所で引数の型の説明などが出るようで良いですね。
frontier_loc_stackは探索先となる位置を格納するスタックです。このスタックでLIFOの方式で最後に追加された位置に対して、ゴールかどうかの判定と移動可能な位置のスタックへの追加が実行されます。
explored_setに関しては同じ箇所を複数回探索しないようにするための制御に使われます。frontier_loc_stackのスタックに追加されたものはこちらのSetにも追加され、同じ探索を繰り返さないように制御しています。以下の部分で探索済みの箇所をスキップするようにしています。
is_explored_loc = _is_explored_loc( location=movable_location, explored_set=explored_set) if is_explored_loc: continue出口(ゴール)のノードから入口 → 出口のパス情報を取得する処理の追加
dfs関数で出口の位置のノードが(算出できる条件であれば)算出できる形になりました。
ただし出口のノードのインスタンスだけではなく、入口から出口までどのような経路を辿るのかを算出しておきたい(後でセルタイプとしてアスタリスクの表示を反映したい)ので、入口から出口までのパスを取得する関数を追加しておきます。
Nodeクラスは移動元となるparent属性を持っているので、出口のノードさえ参照できればparent属性のノードを辿っていって、最後にそれらのノードのリストを逆順にすれば、入口のノードから出口のノードまでのノードを格納したリスト(探索で得られたパス)を取得することができます。
def get_path_from_goal_node(goal_node: Node) -> List[Location]: """ 出口のノードから、探索で取得できた入口 → 出口までのパスを 取得する。 Parameters ---------- goal_node : Node 対象の出口(ゴール)のノードのインスタンス。 Returns ------- path : list of Location 入口から出口までの各位置のインスタンスを格納したリスト。 """ path: List[Location] = [goal_node.location] node: Node = goal_node while node.parent is not None: node = node.parent path.append(node.location) path.reverse() return path最終的に入口のノードまで辿れたら、parent属性はNoneになるのでwhileのループを終了しています。
算出したパスを各セルへ反映するためのメソッドの追加
パスの取得処理を追加したので、今度はそのパスの各セルをアスタリスクの表示になるように設定していきます。
入口や壁などと同様にパスはセルタイプの定数として
CELL_TYPE_PATH: str = '*'と定義してあるのでそちらを反映し、迷路の可視化時にアスタリスクで表示されるようにします。メソッドとしてMazeクラスに追加していきます。
def set_path_type_to_cells(self, path: List[Location]) -> None: """ 入口と出口までの指定されたパス内に含まれるセルに対して、 パスのセルタイプを設定する。 Parameters ---------- path : list of Location 探索で得られた入口から出口までの各セルの位置情報を 格納したリスト。 """ for location in path: self._grid[location.row][location.column] = CELL_TYPE_PATH # パス内に含まれている入口と出口の部分は、それぞれ元の # セルタイプを反映する。 self._grid[self.start_loc.row][self.start_loc.column] = \ CELL_TYPE_START self._grid[self.goal_loc.row][self.goal_loc.column] = \ CELL_TYPE_GOAL実行してみる
これで準備ができたのでコードを実行してみます。
if __name__ == '__main__': maze = Maze() print('-' * 20) print('生成された迷路 :') print(maze) print('-' * 20) goal_node: Optional[Node] = dfs( initial_loc=maze.start_loc, is_goal_loc_method=maze.is_goal_loc, get_movable_locations_method=maze.get_movable_locations) if goal_node is None: print('出口に到達できない迷路です。') else: path: List[Location] = get_path_from_goal_node( goal_node=goal_node) maze.set_path_type_to_cells(path=path) print('算出されたパス :') print(maze)まずは最初に生成された迷路の内容を出力しています。
続いて深さ優先探索(dfs)を実行しています。
実行結果で返却されるノードは、出口に到達できない迷路の場合はNoneとなるのでNoneかどうかで分岐しています。もしNone以外が返却されていれば、パスの取得(get_path_from_goal_node)とセルへの探索のパスの反映(set_path_type_to_cells)をしています。
迷路は毎回ランダムに生成されるので出力結果の一例として以下のようになります。
算出されたパス : ------------------------------ S|W| |W|W| | | |W| | |W| | |W| ------------------------------ *|*|W| | | |W|W| |W| |W| | |W| ------------------------------ |*|*|W| |W|W|W| | | | |W| | | ------------------------------ | |*|*|*|*|*|W| | | | | | | | ------------------------------ W| | |W|W|W|*|*|W|W| | |W|W| | ------------------------------ |W| | | | |W|*|*|*|*|*|*|*|W| ------------------------------ |W|W| | | |W|W| | |W| | |*|G|入口(S)からアスタリスクのセルを辿っていくと出口(G)までちゃんと到達できていることが確認できます。
迷路はランダムなので、例えば以下のように壁(W)に阻まれて出口に到達できないケースも発生します。
生成された迷路 : ------------------------------ S| |W| |W|W| |W| | |W| |W| | | ------------------------------ |W|W| | | | | | |W| | |W| |W| ------------------------------ | | | | | | | |W|W| | | |W|W| ------------------------------ |W| | |W| | |W| | |W| |W|W| | ------------------------------ | |W|W|W|W|W| | | | | |W| |W| ------------------------------ |W|W|W| | | |W| | |W| | | | | ------------------------------ W| |W|W| |W|W| | | | | | |W|G| -------------------- 出口に到達できない迷路です。コード全体
from __future__ import annotations from typing import Optional from typing import List import random from typing import Any from typing import Callable from typing import Set # 入口用の定数値。 CELL_TYPE_START: str = 'S' # 通路用の定数値。 CELL_TYPE_PASSAGE: str = ' ' # 壁の定数値。 CELL_TYPE_WALL: str = 'W' # 出口の定数値。 CELL_TYPE_GOAL: str = 'G' # 算出されたルートのパス用の定数値。 CELL_TYPE_PATH: str = '*' class Location: def __init__(self, row: int, column: int) -> None: """ 迷路のグリッドの位置情報単体を扱うクラス。 Parameters ---------- row : int 位置の行番号。0からスタートし、上から下に向かって1ずつ 加算される。 column : int 位置の列番号。0からスタートし、左から右に向かって1ずつ 加算される。 """ self.row: int = row self.column: int = column class Maze: # 生成する迷路のグリッドの縦の件数。 _ROW_NUM: int = 7 # 生成する迷路のグリッドの横の件数。 _COLUMN_NUM: int = 15 # 生成する壁の比率。1.0に近いほど壁が多くなる。 _WALL_SPARSENESS: float = 0.3 def __init__(self) -> None: """ ランダムな迷路のグリッドの生成・制御などを扱うクラス。 Notes ----- ランダムに各セルタイプが設定されるため、必ずしもスタートから ゴールに到達できるものができるわけではない点には注意。 """ self._set_start_and_goal_location() self._grid: List[List[str]] = [] self._fill_grid_by_passage_cell() self._set_wall_type_to_cells_randomly() self._set_start_and_goal_type_to_cell() def _set_start_and_goal_location(self) -> None: """ 開始地点(入口)とゴール(出口)の座標の属性を設定する。 """ self.start_loc: Location = Location(row=0, column=0) self.goal_loc: Location = Location( row=self._ROW_NUM - 1, column=self._COLUMN_NUM - 1) def _fill_grid_by_passage_cell(self) -> None: """ 全てのセルに対してセルの追加を行い、通路のセルタイプを設定する。 """ for row in range(self._ROW_NUM): row_cells: List[str] = [] for column in range(self._COLUMN_NUM): row_cells.append(CELL_TYPE_PASSAGE) self._grid.append(row_cells) def _set_wall_type_to_cells_randomly(self) -> None: """ グリッドの各セルへ、ランダムに壁のセルタイプを設定する。 """ for row in range(self._ROW_NUM): for column in range(self._COLUMN_NUM): probability = random.uniform(0.0, 1.0) if probability >= self._WALL_SPARSENESS: continue self._grid[row][column] = CELL_TYPE_WALL def _set_start_and_goal_type_to_cell(self) -> None: """ 開始(入口)とゴール(出口)の位置にそれぞれの セルタイプを設定する。 """ self._grid[self.start_loc.row][self.start_loc.column] = \ CELL_TYPE_START self._grid[self.goal_loc.row][self.goal_loc.column] = \ CELL_TYPE_GOAL def is_goal_loc(self, location: Location) -> bool: """ 指定された位置がゴールの位置かどうかの真偽値を取得する。 Parameters ---------- location : Location 判定用の位置。 Returns ------- result : bool ゴールの位置であればTrueが設定される。 """ if (location.row == self.goal_loc.row and location.column == self.goal_loc.column): return True return False def get_movable_locations(self, location: Location) -> List[Location]: """ 指定された位置から、移動が可能な位置のリストを取得する。 Parameters ---------- location : Location 基準となる位置のインスタンス。 Returns ------- movable_locations : list of Location 移動可能な位置のインスタンスを格納したリスト。 """ movable_locations: List[Location] = [] # 上に移動可能かどうかの判定処理。 if location.row + 1 < self._ROW_NUM: is_wall: bool = self._grid[location.row + 1][location.column] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row + 1, column=location.column)) # 下に移動可能かどうかの判定処理。 if location.row - 1 >= 0: is_wall = self._grid[location.row - 1][location.column] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row - 1, column=location.column)) # 右に移動可能かどうかの判定処理。 if location.column + 1 < self._COLUMN_NUM: is_wall = self._grid[location.row][location.column + 1] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row, column=location.column + 1)) # 左に移動可能かどうかの判定処理。 if location.column - 1 >= 0: is_wall = self._grid[location.row][location.column - 1] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row, column=location.column - 1)) return movable_locations def set_path_type_to_cells(self, path: List[Location]) -> None: """ 入口と出口までの指定されたパス内に含まれるセルに対して、 パスのセルタイプを設定する。 Parameters ---------- path : list of Location 探索で得られた入口から出口までの各セルの位置情報を 格納したリスト。 """ for location in path: self._grid[location.row][location.column] = CELL_TYPE_PATH # パス内に含まれている入口と出口の部分は、それぞれ元の # セルタイプを反映する。 self._grid[self.start_loc.row][self.start_loc.column] = \ CELL_TYPE_START self._grid[self.goal_loc.row][self.goal_loc.column] = \ CELL_TYPE_GOAL def __str__(self) -> str: """ グリッドの各セルのタイプの文字列を取得する。 Returns ------- grid_str : str グリッドの各セルのタイプの文字列。 """ grid_str: str = '' for row_cells in self._grid: grid_str += '-' * self._COLUMN_NUM * 2 grid_str += '\n' for cell_type in row_cells: grid_str += cell_type grid_str += '|' grid_str += '\n' return grid_str class Stack: def __init__(self) -> None: """ スタックの制御を扱うためのクラス。 """ self._container: list = [] @property def empty(self) -> bool: """ スタックの内容が空かどうかの真偽値を取得する。 """ return not self._container def push(self, item: Any) -> None: """ スタックへ要素を追加する。 Parameters ---------- item : * 追加する要素。 """ self._container.append(item) def pop(self) -> Any: """ スタック内から要素を取り出す。 Returns ------- item : * 取り出された要素。最後に追加されたものが対象となる。 """ item = self._container.pop() return item def __repr__(self) -> str: """ リスト内容を文字列で返却する。 Returns ------- output : str リスト内容を変換した文字列。 """ return repr(self._container) class Node: def __init__(self, location: Location, parent: Optional[Node]): """ 迷路の位置や推移の情報などを保持するためのノード単体のデータを 扱うクラス。 Parameters ---------- location : Location 対象の位置情報を扱うインスタンス。 parent : Node or None 移動前の位置情報を扱うノードのインスタンス。探索開始時 などにはNoneとなる。 """ self.location: Location = location self.parent: Optional[Node] = parent def dfs( initial_loc: Location, is_goal_loc_method: Callable[[Location], bool], get_movable_locations_method: Callable[[Location], List[Location]] ) -> Optional[Node]: """ 深さ優先探索(depth-first search)による、迷路のゴールの 探索を行う。 Parameters ---------- initial_loc : Location 探索の開始位置。 is_goal_loc_method : callable 対象の位置がゴールかどうかを判定するためのメソッド。 get_movable_locations_method : callable 対象の位置から移動可能な位置のリストを取得するための メソッド。 Returns ------- goal_node : Node or None ゴールに達した場合にはその位置のNodeクラスのインスタンスが 設定され、迷路の構造的にもしゴールにたどり着けない場合には Noneが設定される。 """ frontier_loc_stack: Stack = Stack() frontier_loc_stack.push( item=Node(location=initial_loc, parent=None)) explored_set: Set[Location] = {initial_loc} while not frontier_loc_stack.empty: current_node: Node = frontier_loc_stack.pop() current_location: Location = current_node.location if is_goal_loc_method(current_location): return current_node movable_locations = get_movable_locations_method(current_location) for movable_location in movable_locations: is_explored_loc = _is_explored_loc( location=movable_location, explored_set=explored_set) if is_explored_loc: continue explored_set.add(movable_location) frontier_loc_stack.push( Node(location=movable_location, parent=current_node)) return None def _is_explored_loc( location: Location, explored_set: Set[Location]) -> bool: """ 既に探索済みの位置かどうかの真偽値を返す。 Parameters ---------- location : Location チェック対象の位置。 explored_set : set 探索済みの位置を格納したセット。 Returns ------- result : bool 探索済みの位置であればTrueが設定される。 """ for explored_location in explored_set: if (location.row == explored_location.row and location.column == explored_location.column): return True return False def get_path_from_goal_node(goal_node: Node) -> List[Location]: """ 出口のノードから、探索で取得できた入口 → 出口までのパスを 取得する。 Parameters ---------- goal_node : Node 対象の出口(ゴール)のノードのインスタンス。 Returns ------- path : list of Location 入口から出口までの各位置のインスタンスを格納したリスト。 """ path: List[Location] = [goal_node.location] node: Node = goal_node while node.parent is not None: node = node.parent path.append(node.location) path.reverse() return path if __name__ == '__main__': maze = Maze() print('-' * 20) print('生成された迷路 :') print(maze) print('-' * 20) goal_node: Optional[Node] = dfs( initial_loc=maze.start_loc, is_goal_loc_method=maze.is_goal_loc, get_movable_locations_method=maze.get_movable_locations) if goal_node is None: print('出口に到達できない迷路です。') else: path: List[Location] = get_path_from_goal_node( goal_node=goal_node) maze.set_path_type_to_cells(path=path) print('算出されたパス :') print(maze)参考文献・サイトまとめ

- 投稿日:2020-09-16T13:32:20+09:00
Python を学習するなら 無料クラウドサービス 『python anywhere』 が最適! (2020年9月)
Python 初学者必見?
Pythonの無料クラウドサービス『python anywhere』は、
環境構築不要!!
最速!!
5分でデプロイ可能!!
その場で、
Webアプリケーションを作成することができます
ブログサイトや、ToDoリスト、プレビューサイトなど?公式サイト ➡️ https://www.pythonanywhere.com/
(2020年9月現在)⬇️
デプロイ方法は、近日公開?
必要スキルDjango(web フレームワーク)
基本的なコマンド(ls,cd,mkdirなど)
- 投稿日:2020-09-16T11:35:35+09:00
Python × GIS の基礎(その1)
なぜPythonを使う?
GISだけで大量の空間データを処理するには時間がかかり、研究を進めていく上でコード処理の必要を感じていました。またQGISに存在するプラグインではネットワーク解析や図形単純化を十分に行えず, Pythonの豊富なライブラリは有効な手段となります。
今回はヘルシンキ大学が提供しているAutomating GIS processesを勉強の素材として用います。
7週構成になっており、GeoPnadasやmatplotlibを用いた可視化について特に充実して学ぶことができます。また各週に受講者向けの宿題(練習問題)が付けられており, 本記事では主にその解答例を載せます。
その1:Week1-Week2
その2:Week3-Week4
その3(作成中):Week5-Week6(Week7は課題なし)
その4(作成中):Final Assignment下記は週毎の教材の内容の一部です。
週 内容 Week1 ポイント, ライン, ポリゴンの描画 Week2 Geopandasの導入, CRS設定, 距離計算 Week3 空間結合, 近傍点分析 Week4 空間結合2, データ階層化 Week5 静的・動的な地図の描画, Week6 OSMの分析, ネットワーク解析 Week7 QGISプラグイン Week 1
1-1 ポイント, ライン, ポリゴンを作る関数の作成
問題の条件として関数が正常に機能するよういくつかの要件が求められています。
from shapely.geometry import Point, LineString, Polygon #ポイント def create_point_geom(x, y): point = Point(x, y) return point #ライン リストを引数に取ります def create_line_geom(points): assert type(points)=="list", "Input should be a list!" assert len(points)>=2, "LineString object requires at least two Points!" line = LineString([points[0], points[1]]) return line #ポリゴン リストを引数に取ります def create_poly_geom(coords): assert type(coords) is list, "Input should be a list!" assert len(coords)>=3, "Polygon object requires at least three Points!" for i in coords: assert type(i) is tuple, "All list values should be coordinate tuples!" poly = Polygon(coords) return poly1-2 重心, ポリゴン面積, 距離の取得
assert文は本質的ではないので一部省略しています。
#重心 引数はポイントorラインorポリゴン def get_centroid(gem): assert type(gem) == 'shapely', "Input should be a Shapely geometry!" assert gem.geom_type in ['Point', 'LineString', 'Polygon'], "Input should be a Shapely geometry!" centroid = gem.centroid return centroid #面積 def get_area(poly): return poly.area #距離 def get_length(geom): if geom.geom_type == 'LineString': return geom.length elif geom.geom_type == 'Polygon': return geom.exterior.length1-3 テキストデータの取得と表示
ヘルシンキの移動データを用いた簡単なデータ加工の練習問題です。
from_x, from_y は出発点, to_x, to_y は到着点を示しており, これらのデータから総移動距離を求めるというのが目標です。import pandas as pd #データ読み込み data = pd.read_table("data/travelTimes_2015_Helsinki.txt", sep=";",) data = data[['from_x','from_y', 'to_x', 'to_y', 'total_route_time',]] #座標データの作成 orig_points = [] dest_points = [] from shapely.geometry import Point for index, row in data.iterrows(): orig = Point(row['from_x'], row['from_y']) dest = Point(row['to_x'], row['to_y']) orig_points.append(orig) dest_points.append(dest) #移動ラインの作成 from shapely.geometry import LineString lines = [] for orig, dest in zip(orig_points, dest_points): line = LineString([orig, dest]) lines.append(line) #総移動距離の取得 total_length = 0 for line in lines: total_length += line.lengthWeek2
Pandasの拡張形であるGeopandasというライブラリを学びます。Pandas同様非常に使いやすく、空間操作も簡単に行えます。
2-1 座標データのGeoDataFrameへの変換
import geopandas as gpd import matplotlib.pyplot as plt from shapely.geometry import Polygon #使う座標データ longitudes = [29.99671173095703, 31.58196258544922, 27.738052368164062, 26.50013542175293, 26.652359008789062, 25.921663284301758, 22.90027618408203, 23.257217407226562, 23.335693359375, 22.87444305419922, 23.08465003967285, 22.565473556518555, 21.452774047851562, 21.66388702392578, 21.065969467163086, 21.67659568786621, 21.496871948242188, 22.339998245239258, 22.288192749023438, 24.539581298828125, 25.444232940673828, 25.303749084472656, 24.669166564941406, 24.689163208007812, 24.174999237060547, 23.68471908569336, 24.000761032104492, 23.57332992553711, 23.76513671875, 23.430830001831055, 23.6597900390625, 20.580928802490234, 21.320831298828125, 22.398330688476562, 23.97638702392578, 24.934917449951172, 25.7611083984375, 25.95930290222168, 26.476804733276367, 27.91069221496582, 29.1027774810791, 29.29846954345703, 28.4355525970459, 28.817358016967773, 28.459857940673828, 30.028610229492188, 29.075136184692383, 30.13492774963379, 29.818885803222656, 29.640830993652344, 30.57735824584961, 29.99671173095703] latitudes = [63.748023986816406, 62.90789794921875, 60.511383056640625, 60.44499588012695, 60.646385192871094, 60.243743896484375, 59.806800842285156, 59.91944122314453, 60.02395248413086, 60.14555358886719, 60.3452033996582, 60.211936950683594, 60.56249237060547, 61.54027557373047, 62.59798049926758, 63.02013397216797, 63.20353698730469, 63.27652359008789, 63.525691986083984, 64.79915618896484, 64.9533920288086, 65.51513671875, 65.65470886230469, 65.89610290527344, 65.79151916503906, 66.26332092285156, 66.80228424072266, 67.1570053100586, 67.4168701171875, 67.47978210449219, 67.94589233398438, 69.060302734375, 69.32611083984375, 68.71110534667969, 68.83248901367188, 68.580810546875, 68.98916625976562, 69.68568420410156, 69.9363784790039, 70.08860778808594, 69.70597076416016, 69.48533630371094, 68.90263366699219, 68.84700012207031, 68.53485107421875, 67.69471740722656, 66.90360260009766, 65.70887756347656, 65.6533203125, 64.92096710205078, 64.22373962402344, 63.748023986816406] #ポリゴン化 coordpairs = list(zip(longitudes, latitudes)) poly = Polygon(coordpairs) #GeoDataFrameの作成 geo = gpd.GeoDataFrame(index=[0], columns=['geometry']) geo['geometry'] = poly #図示 import matplotlib.pyplot as plt geo.plot() #shpファイルの保存 fp = 'polygon.shp' geo.to_file(fp)2-2 csvに格納された座標データのプロット
憎らしいCRSが登場します。apply関数はpandasとの相性が良く, 短いコードで加工ができます。
#ライブラリ import pandas as pd from shapely.geometry import Point, LineString, Polygon from pyproj import CRS import matplotlib.pyplot as plt #csv読み込み data = pd.read_csv('data/some_posts.csv') #ポイントデータ作成 data = pd.read_csv('data/some_posts.csv') make_point = lambda row:Point(row['lat'],row['lon']) data['geometry'] = data.apply(make_point, axis=1) #GeoDataFrameへの変換 geometryと座標系を指定する必要があります. geo = gpd.GeoDataFrame(data, geometry='geometry',crs=CRS.from_epsg(4326).to_wkt()) #プロット geo.plot()2-3 移動距離の計算
SNSの投稿の座標データから各ユーザーの移動距離を計算します。
座標系の変換が登場しますが、以下の点に注意が必要です。CRSはどこでも厄介。。。・座標系の定義(ex. data.crs=CRS.from_espg(4276) )だけではGeoDataFrameのデータは変換しないため, 座標系の変換(ex. data=data.to_crs(epsg=4276) ) が必要
・GeoDataFrameの座標系が定義されていない場合は, 座標系変換の前に座標系定義を行うimport geopandas as gpd import pandas as pd from pyproj import CRS from shapely.geometry import Point, LineString, Polygon #データ読み込み data = gpd.read_file('Kruger_posts.shp') #座標系変換 data = data.to_crs(epsg=32735) #idごとに分類して移動ラインを作成(投稿が一つのみの場合移動していないため, None値を入れる) grouped = data.groupby('userid') movements = gpd.GeoDataFrame(columns=['userid', 'geometry']) for key, group in grouped: group = group.sort_values('timestamp') if len(group['geometry'])>=2: line = (LineString(list(group['geometry']))) else: line=None movements.at[count, 'userid'] = key movements.at[count, 'geometry'] = line movements.crs = CRS.from_epsg(32735) #移動距離の計算 def cal_distance(x): if x['geometry'] is None: return None else: return x['geometry'].length movements['distance'] = movements.apply(cal_distance, axis=1) #移動距離の平均, 最大値, 最小値 print(mean(movements['distance'])) #138871.14194459998 print(max(movements['distance'].dropna())) #8457917.497356484 print(min(movements['distance'])) #0.0
- 投稿日:2020-09-16T11:27:49+09:00
Python | Pythonでできること
はじめに
- 機械学習
- データ分析・可視化
- WEBアプリケーション開発
Pythonでできることは主にこの3つです。
一つ一つ解説していきます。機械学習
- 機械学習とはなにか
- 機械学習におけるPython
- 機械学習の学び方
機械学習とはなにか
機械学習を簡単に説明すると、課題をこなすのに一番コスパがいい方法はどれかをデータから発見するというものです。
よくAIと混同されがちですが、一部はあっています。AIという大きな枠組みの中に機械学習が有る、というものです。ジュースのという大きな枠組みの中に炭酸という分野が存在するようなものです。
具体的に、機械学習を用いると、言語間の翻訳やECサイトでのレコメンデーション(おすすめ機能)ができます。
機械学習におけるPython
Pythonには機械学習のためのライブラリ・モジュールが豊富です。
代表的には
- NumPy
- scikit-learn
- TensorFlow
などがあります。それぞれの特徴は以下のとおりです。
特徴 NumPy 数学的計算を高速にできる scikit-learn アルゴリズムやデータセットが豊富 TensorFlow Googleが開発・ニューラルネットワークの構築ができる 機械学習の学び方3選
- ゼロから作るDeep Learning
- DL4US 東京大学松尾研究室
- Cousera 機械学習 スタンフォード大学
ゼロから作るDeep Learning
書籍で機械学習、特にディープラーニングを学ぶならこの1冊です。Pythonをある程度学んでから取り組むのがベストです。しかし、本自体が分厚いので書籍での勉強が苦手の人には、挫折率が高いかと思われます。
DL4US 東京大学松尾研究室
日本ディープラーニング協会理事長、ソフトバンクグループ社外取締役である、東京大学の松尾豊教授を中心に作成された、授業で使われている実際のコンテンツです。すべて無償でダウンロードすることができます。
本コンテンツは、エンジニア向けDeep Learning講座「DL4US」のコンテンツです。高度な数学的知識を必要とせず、Deep Learningの新しいモデルを構築したり、高度な研究・開発を行うために重要な知識が基礎から学べるように設計されています。
- https://weblab.t.u-tokyo.ac.jp/dl4us/ | 松尾研究室 DL4USコンテンツ 公開ページより引用Cousera 機械学習 スタンフォード大学
名門大学やGoogle,IBMなどの優良企業の一流講師によるオンライン講座であるCouseraにある、スタンフォード大学の機械学習コースです。言語は英語ですが、日本語字幕があります。機械学習を網羅的に学ぶことができます。
このコースでは、機械学習、データマイニング、統計的パターン認識について幅広く紹介します。トピックは以下の通りです。(i) 教師あり学習(パラメトリック/ノンパラメトリックアルゴリズム、サポートベクターマシン、カーネル、ニューラルネットワーク)。(ii) 教師なし学習(クラスタリング、次元削減、推薦システム、ディープラーニング)。(iii) 機械学習のベストプラクティス(バイアス/分散理論、機械学習とAIのイノベーションプロセス)。また、多数のケーススタディやアプリケーションから学習アルゴリズムを引き出し、スマートロボットの構築(知覚、制御)、テキスト理解(ウェブ検索、スパム対策)、コンピュータビジョン、医療情報学、オーディオ、データベースマイニングなどの分野への応用方法も学びます。
- https://www.coursera.org/learn/machine-learning Coursera 機械学習 Stanford より引用(https://www.deepl.com/ja/translator DeepLにて翻訳)データ分析・可視化
- データ分析・可視化とはなにか
- データ分析・可視化におけるPython
- データ分析・可視化の学び方
データ分析・可視化とはなにか
データ分析とは、数字や文字などを収集し、各要素に分類・削除・付加などを行い、データの価値をつけることです。データ分析をすることで、傾向やそこからみつかる問題点を改善し、事業の発展に役立てることができます。
また、同時にデータ可視化を行い、グラフや表にすることで、さらにデータの本質・価値が見えてきます。
データ分析・可視化におけるPython
Pythonにはデータを扱うのためのライブラリもあります。
代表的には
- Pandas
- SciPy
- Matplotlib など
特徴 Pandas データのグラフ化・データ分析・データの読み込み Scipy 科学技術計算ライブラリ(微分積分・統計学など) Matplotlib グラフ描画ライブラリ WEBアプリケーション開発
- WEBアプリケーションとはなにか
- WEBアプリケーションにおけるPython
WEBアプリケーションとはなにか
WEBアプリケーションとは、サーバとクライアントを連携させて稼働するアプリケーションです。簡単に言うと、YoutubeやTwitterなどの個々人がアカウントを持っているようなアプリケーションです。
WEBアプリケーションにおけるPython
PythonのフレームワークにはDjango,Flaskといったものがあります。
特徴 Django 豊富な機能、高品質・短時間でのアプリ開発 Flask 機能がシンプルで扱いやすい、小規模向け Bottle 必要最低限の機能を搭載 まとめ
Pythonには、これ以外にもPygameを使ったゲームの開発やコードが明快でわかりやすいため
教育の現場にも用いられています。Pythonでできることを最大限活用して、楽しくプログラミングをしましょう!

- 投稿日:2020-09-16T10:54:30+09:00
Psychopy から Psychtoolbox を使う (Audio)
神経生理学において視聴覚刺激を行う際の選択肢は大体,
- Psychtoolbox
- Psychopy
である(筆者は最近はPsychopy を愛用している).
これらのライブラリは排他的ではなく,Psychopy において聴覚刺激については Psychtoolbox (以下PTB) のバックエンドの使用がレイテンシの面から推奨されている.PsychoPy currently supports a choice of sound engines: PTB, pyo, sounddevice or pygame. You can select which will be used via the audioLib preference. sound.Sound() will then refer to one of SoundPTB, SoundDevice, SoundPyo or SoundPygame. This preference can be set on a per-experiment basis by importing preferences, and setting the audioLib option to use.
The PTB library has by far the lowest latencies and is strongly recommended (requires 64 bit Python3)https://psychopy.org/api/sound.html
インストール手順は下記の通り (Windows10 + Anaconda).
pip install psychopy pip install git+https://github.com/Psychtoolbox-3/Psychtoolbox-3この状態でSound のサンプルコード
mport psychtoolbox as ptb from psychopy import sound mySound = sound.Sound('A') now = ptb.GetSecs() mySound.play(when=now+0.5) # play in EXACTLY 0.5sを実行するとおそらくインポートのエラーが発生する.
そこで,
- libusb-1.0.dll
- libusb-1.0.dll.a
- portaudio_x64.dllをPsychtoolbox のリポジトリから探し,コピーする.
筆者の場合はC:\Users\username\anaconda3\envs\psypy3\Lib\site-packages\psychtoolbox
にコピーした.
これで上記サンプルコードが動作する.
- 投稿日:2020-09-16T10:54:30+09:00
Psychopy から 低レイテンシ聴覚刺激のための Psychtoolbox を使う (Audio)
神経生理学において視聴覚刺激を行う際の選択肢は大体,
- Psychtoolbox
- Psychopy
である(筆者は最近はPsychopy を愛用している).
これらのライブラリは排他的ではなく,Psychopy において聴覚刺激については Psychtoolbox (以下PTB) のバックエンドの使用がレイテンシの面から推奨されている.PsychoPy currently supports a choice of sound engines: PTB, pyo, sounddevice or pygame. You can select which will be used via the audioLib preference. sound.Sound() will then refer to one of SoundPTB, SoundDevice, SoundPyo or SoundPygame. This preference can be set on a per-experiment basis by importing preferences, and setting the audioLib option to use.
The PTB library has by far the lowest latencies and is strongly recommended (requires 64 bit Python3)https://psychopy.org/api/sound.html
インストール手順は下記の通り (Windows10 + Anaconda).
pip install psychopy pip install git+https://github.com/Psychtoolbox-3/Psychtoolbox-3この状態でSound のサンプルコード
import psychtoolbox as ptb from psychopy import sound mySound = sound.Sound('A') now = ptb.GetSecs() mySound.play(when=now+0.5) # play in EXACTLY 0.5sを実行するとおそらくインポートのエラーが発生する.
そこで,
- libusb-1.0.dll
- libusb-1.0.dll.a
- portaudio_x64.dllをPsychtoolbox のリポジトリから探し,コピーする.
筆者の場合はC:\Users\username\anaconda3\envs\psypy3\Lib\site-packages\psychtoolbox
にコピーした.
これで上記サンプルコードが動作する.実際に低レイテンシかどうかは,手元では未検証.
追記:
git と VS build tool が必要
- https://anaconda.org/anaconda/git
- https://visualstudio.microsoft.com/ja/downloads/
- 投稿日:2020-09-16T10:23:23+09:00
Google_images_downloadで画像をダウンロードできない
今回は画像認識を行いたいなーと思っていたので、google_images_downloadを使って画像を収集することにしました。
実行環境
MacOS
Google Chrome詰まったところ
Googleから画像を一括でダウンロードするツール「google-images-download」
こちらの記事を参考にして、画像を収集できるようにしようとしていました。pip install google_images_downloadこのコードを実行して、google_images_downloadのインストールは完了したと思ったのですが、いざ画像を収集しようと思ったら、エラーが発生するという状況
なんでかな〜、と思い調べてみたら
google image downloadが動かなかったのでその対応
google-images-download フォルダーはできるけどダウンロードされない
こちらの記事がありましたので、git clone https://github.com/Joeclinton1/google-images-download.git gid-joeclinton pip install -e gid-joeclintonコードを実行して、再びgoogle_images_downloadを使って、画像を収集したら、上手くいきました!
まとめ
なんでgitでクローンしたやつを実行する必要があったのかは、自分もわかりませんが、今回は動くようになったので、良かったかなと思います!
とりあえずは画像認識をやっていきたいと思います。
- 投稿日:2020-09-16T07:38:45+09:00
stereo depth estimationの基礎理解(Deep Learning編)
Depth Estimationのプロセス
- Feature Extraction =>左右同じNetwork,同じweightを使って特徴取り出す(WxHxC)。ex)intensity, shape, .....etc
- Cost Volume =>Pixelをshiftする事でDisparity Channelを作る(DxWxHxC)。 Dは任意の値で、取り得る最大Disparity(pixel)を自分で決める。大きすぎると重くなるし、小さすぎると近い物体のマッチングがされない。
- 3D Feature Matching =>求めた特徴量を(DxWxHxC)を畳み込む事で右と左の特徴量が近い所に大きな値が出るよう学習する(DxWxHx1)
- Disparity Regression =>(DxWxH)から(1xWxH)に変換して最終的なDisparityを求める
- Lossを計算する =>Ground TruthにLiDARを使うか左と右の画像をwarpすることでLossを計算する。最近では画像のみで学習するのが多く見られる。
Computing the Stereo Matching Cost with a Convolutional Neural Network(2015)
右と左の画像の特徴量をintensityの代わりにconvolutionすることによって、多チャンネルの特徴量に代替することによって精度を向上
Spatial Pyramid Pooling in Deep Convolutional
Networks for Visual Recognition(2015)近くの物体をmatchingさせるためにはより広範囲のpixelを参照しなければいけない。その解決方法として特徴量マップの解像度を細かいものと粗いものを結合させることにより解決
End-to-End Learning of Geometry and Context for Deep Stereo Regression(2017)
今までと同じように右と左の画像をそれぞれに同じweightを使って畳込み特徴量マップ(WxHxC)を生成。右の画像に対して左の画像のpixelを0~maxDisparity(任意)まで横にshiftさせた特徴量マップ(DxWxHxC)を作る。単純にpixelを横(width方向)にシフトするだけ。3D Convolutionと3D Deconvolutionを1/2,1/4,1/8,1/16,1/32で行う事によって大まかな特徴と細かい特徴を学習できる。ここでの出力が(DxHxW)となる。1次元になったmatchingの値にDisparityを掛けて重み付け平均を取ることで最終的なDisparityを出力する。softArgMinによりsub-pixel accuracyでDisparityを求めることが可能になった。
Self-Supervised Learning for Stereo Matching with Self-Improving Ability(2017)
今までLossを求めるのにDisparityまたはDepthをLiDARから得ていた。LiDARの密度は画像よりも粗く、LiDARを用いないシステムでもTrainingをする為、右の画像を推定した右のDisparityだけpixelをshiftすることによって、左の画像を擬似的に生成する。生成された左の画像と、元の左の画像をSAD(intensityまたはRGBの差)やSSIM(構造的類似性)を見ることで、Lossを定義出来る。Disparityが正しく推定出来ているのであれば、warpをした画像はほぼ反対の画像と同じになる。


- 投稿日:2020-09-16T07:32:34+09:00
Django ログイン画面を作成する
前回、ユーザ情報を取得していないことでStaffの新規登録ができない感じだったので、ログイン画面を作成していきます。
スタッフのログインということで、staffアプリに作成していきます。
urls.pyにログイン用のテンプレートを読み込みするようにします。staff.urls.pyfrom django.urls import path, include from .views import StaffCreate, loginfunc urlpatterns = [ path('login/', loginfunc, name='login'), path('create/', StaffCreate.as_view(), name = "staffcreate"), ]loginfuncを追加しました。次は、Viewsにログインファンクを作成します。
staff.views.pydef loginfunc(request): if request.method == 'POST': user_name = request.POST['username'] user_password = request.POST['password'] user = authenticate(request, username=user_name, password=user_password) if user is not None: login(request, user) return redirect('staff:staffcreate') else: return render(request, 'staff/login.html', {'error':'社員名かパスワードが間違っています'}) return render(request, 'staff/login.html')これでいけてるかな?
htmlのログイン画面から、入力されたusernameとpasswordを変数、user_name user_passwordにいれて、同一のユーザがあるか確認。
もしユーザーがないことではなかったら(わかりにくいですが(笑))ログインさせて、staffアプリのurslでstaffcreateっていう名前のページを呼び出しなさい。という感じでいくはずもしユーザーが見つからなかったら、ログイン画面に戻すが、その時、error でメッセージを受け渡すようにする。
templates/staff/login.html{% extends 'staff/base.html' %} {% load static %} {% block customcss %} <link rel='stylesheet' type='text/css' href="{% static 'style.css' %}"> {% endblock customcss %} {% block header %} {% endblock header %} {% block content %} <form class="form-signin" method="POST" action="">{% csrf_token %} <img class="mb-4" src="/docs/4.5/assets/brand/bootstrap-solid.svg" alt="" width="72" height="72"> <h1 class="h3 mb-3 font-weight-normal">ログインページ</h1> {{ error }} <label for="text" class="sr-only">社員ID</label> <input type="text" name="username" placeholder="username" required autofocus> <label for="inputPassword" class="sr-only">Password</label> <input type="password" name="password" placeholder="Password" required> <button class="btn btn-lg btn-primary btn-block" type="submit">ログイン</button> <p class="mt-5 mb-3 text-muted">© 合同会社 縁家</p> </form> {% endblock content %}bootstrapのテンプレから一部修正しただけです。
staticファイルを呼び込みできるようにsettings.pyに設定を追加しますconfig/settings.pySTATIC_URL = '/static/' STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')]templatesと同じ階層にstaticフォルダを作成します
整理するため、staffフォルダを作成しその中にloginstyle.css を作成して、ここにcssを記載します。これも、bootstrapのテンプレからコピペなので自分では一から書くのはまだ無理ですstatic/staff/loginstylecsshtml, body { height: 100%; } body { display: -ms-flexbox; display: flex; -ms-flex-align: center; align-items: center; padding-top: 40px; padding-bottom: 40px; background-color: #f5f5f5; } .form-signin { width: 100%; max-width: 330px; padding: 15px; margin: auto; } .form-signin .checkbox { font-weight: 400; } .form-signin .form-control { position: relative; box-sizing: border-box; height: auto; padding: 10px; font-size: 16px; } .form-signin .form-control:focus { z-index: 2; } .form-signin input[type="email"] { margin-bottom: -1px; border-bottom-right-radius: 0; border-bottom-left-radius: 0; } .form-signin input[type="password"] { margin-bottom: 10px; border-top-left-radius: 0; border-top-right-radius: 0; }これでいちよできるかな。
保存してサーバーを起動してみます。
だめでしたねー
staaff/login.html???なんだこれaが多い…viewsを修正
staff/login.views.pydef loginfunc(request): if request.method == 'POST': user_name = request.POST['username'] user_password = request.POST['password'] user = authenticate(request, username=user_name, password=user_password) if user is not None: login(request, user) return redirect('staff:staffcreate') else: return render(request, 'staff/login.html', {'error':'社員名かパスワードが間違っています'}) return render(request, 'staff/login.html')これでもう一度トライしてみます
なんじゃこりゃー!!!!
表示がおかしい…
bootstarpから触らない方が無難なんだろうか…全然だめ色々修正したり、過去に作成したものを引用したりしたりすること2時間…
結局、まだわからず…
CSSファイルが呼び込まれていないようです
現状こんな状態…
config.settings.pySTATIC_URL = '/staic/' STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')]追加して、urlsも
config.urls.pyfrom django.contrib import admin from django.urls import path, include from django.conf import settings from django.conf.urls.static import static urlpatterns = [ path('staff/',include('staff.urls') ), path('admin/', admin.site.urls), ] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)に変更して、staticフォルダをtemplatesと同じ階層に作成して、その直下にstyle.cssを作成しました。
static/style.csshtml, body { height: 100%; } body { display: -ms-flexbox; display: flex; -ms-flex-align: center; align-items: center; padding-top: 40px; padding-bottom: 40px; background-color: #f5f5f5; } .form-signin { width: 100%; max-width: 330px; padding: 15px; margin: auto; } .form-signin .checkbox { font-weight: 400; } .form-signin .form-control { position: relative; box-sizing: border-box; height: auto; padding: 10px; font-size: 16px; } .form-signin .form-control:focus { z-index: 2; } .form-signin input[type="email"] { margin-bottom: -1px; border-bottom-right-radius: 0; border-bottom-left-radius: 0; } .form-signin input[type="password"] { margin-bottom: 10px; border-top-left-radius: 0; border-top-right-radius: 0; }これが読み込みされていないので幅が全然変わらない状態…
ちょっとあきらめて、create機能をやり始めようかな



- 投稿日:2020-09-16T07:26:41+09:00
3Dグラフのインタラクティブなプロット
Jupyter Notebookでインタラクティブなプロット
シンプルな例を見つけられなかったので、メモとして作成。
詳細な説明やセットアップは下記を参照のこと。
import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ipywidgets import interact, FloatSlider import numpy as np x = y = np.arange(-20, 20, 0.5) X, Y = np.meshgrid(x, y) Z = X*X + 2 * Y*Y @interact(elev=FloatSlider(min=-180, max=180, step=10, value=30), azim=FloatSlider(min=-180, max=180, step=10, value=30)) def plot_3d(elev, azim): # Figureの設定 fig = plt.figure(figsize=(10, 10)) ax = fig.add_subplot(111, projection='3d') # 3Dグラフを表示 ax.plot_surface(X, Y, Z) # 3Dグラフの見る方向の初期値を設定 ax.view_init(elev=elev, azim=azim) plt.show()
- 投稿日:2020-09-16T04:09:28+09:00
Django 認証機能がうまく反映されない
はじめに
この記事ではDjango + Dockerでユーザー認証機能を盛り込む際に出たエラーの対処法について書いていきます。
ModuleNotFoundError: No module named 'allauth'
このエラー文にめちゃくちゃ悩まされました。
どうしたら良いのかわからずあきらめかけていましたが、対処法はいとも簡単でした...。まず「Docker」ファイルに次のように追記してください。
DockerfileRUN pip install django-allauth次に「requirements.txt」にも追記していきます。
requirements.txtdjango-allauth>=0.32.0最後にターミナルに次のように打ち込みます。
terminal$ docker-compose build最後にお決まりの作業をしていきます。
terminal$ docker-compose run --rm web python3 manage.py makemigrations $ docker-compose run --rm web python3 manage.py migrate $ docker-compose upこれで完了です。
最後に
このエラーに何時間もかけてしまったので、同じようにつまずいている人の助けになれば幸いです。
コマンドについてはこちらにまとめておいたので、参考になれば幸いです。