- 投稿日:2020-09-16T23:26:22+09:00
【Firebase】deployがうまくいかない時の対処方法
はじめに
本記事は初の投稿になります。わかりづらい点や間違ってる点がありましたら、コメントの程よろしくお願い致します。
- 対象者
- Firabaseの初心者向け
- 大まかな流れ
- Firebaseのデプロイコマンドである「firebase deploy」 を実施時のエラーの解決方法を記載する
目次
1. 背景
2. エラー内容
3. 解決概要
4. 解決方法
5. 参考記事1. 背景
ReactとFirebaseの学習時で、「create-react-app」で作成したアプリをFirebaseにデプロイを実施。
※「firebase init」はfirestore / functions / hostingを選択2. エラー内容
「firebase deploy」コマンドでデプロイを実施した時、以下のエラーがターミナルで発生
ターミナル✔ functions: Finished running predeploy script. i firestore: reading indexes from firestore.indexes.json... i cloud.firestore: checking firestore.rules for compilation errors... ✔ cloud.firestore: rules file firestore.rules compiled successfully i functions: ensuring required API cloudfunctions.googleapis.com is enabled... i functions: ensuring required API cloudbuild.googleapis.com is enabled... ⚠ functions: missing required API cloudbuild.googleapis.com. Enabling now... ✔ functions: required API cloudfunctions.googleapis.com is enabled Error: HTTP Error: 400, Billing account for project 'xxxxxxxxxxxx' is not found. Billing must be enabled for activation of service(s) 'cloudbuild.googleapis.com,containerregistry.googleapis.com' to proceed.3. 解決概要
Cloud FunctionsのNode.js対応バージョンは10 or 12(Blaze従量課金生)
そのため、現時点の解決方法はNode.jsのバージョンを下げる必要がある。
しかし、今後は使用できなくなる為、暫定的な対応になる。公式引用
Node.js 8(2020 年 6 月 8 日に非推奨) Node.js 8 関数は、2020 年 2 月 15 日以降はデプロイできなくなります。すでにデプロイされている Node.js 8 関数は、2021 年 3 月 15 日をもって実行できなくなります。Node.js 8 ランタイムに関数をデプロイしている場合は、Node.js 10 ランタイムにアップグレードすることをおすすめします。
4. 解決方法
functions/package.jsonを修正する。functions/package.json"engines": { "node": "8" }5. 参考記事
- 投稿日:2020-09-16T21:31:05+09:00
第7回:ニュースフィード取得サーバIFを作る
第7回:ニュースフィード取得サーバIFを作る
今回はバックエンドにREST APIを実装していきます。
まずニュースフィードのIFを取得するGET /newsfeedsを作成します。REST APIのモジュールを利用する
REST APIのクライアント側、サーバ側の実装は在り物のモジュールを利用するのが一般的です。
OSSに色々なモジュールがありますが、今回はexpressを利用します。
下記のコマンドでバックエンドにexpressモジュールをインストールします。$ npm install express $ npm install @types/expressREST APIを処理するためのファイルをapp/rest.tsとして用意します。
下記のように空のクラスを作成してください。export class Rest { constructor() { } start() { console.log('start()'); } stop() { } }main.tsからRestクラスのstart()を呼び出します。
main.tsの内容を下記のように書き換えてください。import {Rest} from './rest'; const rest = new Rest(); rest.start();実行すると、下記のログが出力され、Restクラスのstart()メソッドが呼び出されていることが確認できます。
$ npm start > tsc && node build/main.js start()ニュースフィードの取得IFを作成する
Expressを初期化する
下記のようにapp/rest.tsを書き換えます。
import * as core from "express-serve-static-core"; import * as http from "http"; import express = require('express'); import bodyParser = require('body-parser'); export class Rest { app: core.Express; server: http.Server; constructor() { } start() { const app = express(); app.use(bodyParser.urlencoded({extended: true})); app.use(bodyParser.json()); this.server = app.listen(4300, () => { console.log('listening to port: 4300'); }); app.use((request, response, next) => { response.header('Access-Control-Allow-Origin', '*'); response.header('Access-Control-Allow-Headers', 'Origin, X-Requested-With, Content-Type, Accept'); response.header('Access-Control-Allow-Methods', 'GET, POST, PUT, DELETE'); }); } stop() { } }実行すると下記のログが出力され、REST APIの待ち受けが開始されます。
listening to port: 4300一つずつ解説します。
const app = express();ここでexpressを生成しています。
app.use(bodyParser.urlencoded({extended: true})); app.use(bodyParser.json());生成したexpressに、利用するボディパーサーを登録しています。
HTTPプロトコルはテキストデータをやりとりしますが、ボディパーサーを利用することで、
テキスト→JSONへ自動変換され、プログラム上ではJSONオブジェクトとして扱うことができるようになります。this.server = app.listen(4300, () => { console.log('listening to port: 4300'); });ここでサーバの待ち受けを開始しています。4300はポート番号です。
wikiなどで空いているポート番号を調べて利用しましょう。
() => {}の部分は、サーバの待ち受けが開始したタイミングで呼び出されます。ラムダ式について
先ほどの
() => {}はラムダ式と呼ばれます。関数をクロージャ登録するときに利用されます。
以前はfunction() {}形式で書いていましたが、簡略化するため上記の記法が利用できるようになりました。
クロージャとは、呼び出し先のモジュールにイベントを通知してもらうための仕組みです。
いつ呼ばれるかはモジュール次第なのでモジュールの仕様を確認しましょう。
目的の処理が完了したタイミングで呼ばれることが多いです。
app.listen()のクロージャはサーバの待ち受けが開始したタイミングで呼び出されます。
rest.tsはサーバの待ち受けが開始したタイミングで動く処理を実装することができます。環境変数ファイルを作成する
environment.tsを下記の内容で作成します。export const environment = { restServer: { port: 4300 } }
app/rest.tsに修正を加えます。・・・ import bodyParser = require('body-parser'); import {environment} from '../environment'; export class Rest { ・・・ this.server = app.listen(environment.restServer.port, () => { console.log(`listening to port: ${environment.restServer.port}`); }); ・・・環境変数ファイルを利用することで、作成したプログラムのユーザは環境に合わせて何を書き換えればいいかわかるため、使い勝手がよくなります。
ニュースフィードの一覧を取得するAPIを登録する
下記のように
app/rest.tsを修正し、expressにGET /newsfeedsを追加します。}); app.get('/newsfeeds', (request, response, next) => { try { const newsfeeds = [ { message: 'あけましておめでとう!', createdAt: new Date('2020-01-01T02:23:30'), }, { message: 'メリークリスマス!', createdAt: new Date('2019-12-25T10:52:02'), }, { message: 'ハッピーハロウィーン!', createdAt: new Date('2019-10-31T20:13:55'), }, ]; response.send(newsfeeds); } catch (error) { response.sendStatus(500); } }); } stop() {
app.get()で登録したクロージャはGET /newsfeedsを受信した時に呼び出されます。作成したIFをクライアントから呼んでみる
RESTクライアントソフトを使って、作成した
GET /newsfeedsを呼び出してみます。Postmanをインストール
RESTクライアントソフトは今回はPostmanを利用します。
公式サイトからインストールしてください。
無料アカウント登録し、サインインすると画像のダイアログが表示されるので、Download desktop agentからデスクトップアプリをインストールしてください。
PostmanでサーバIFを呼んでみる
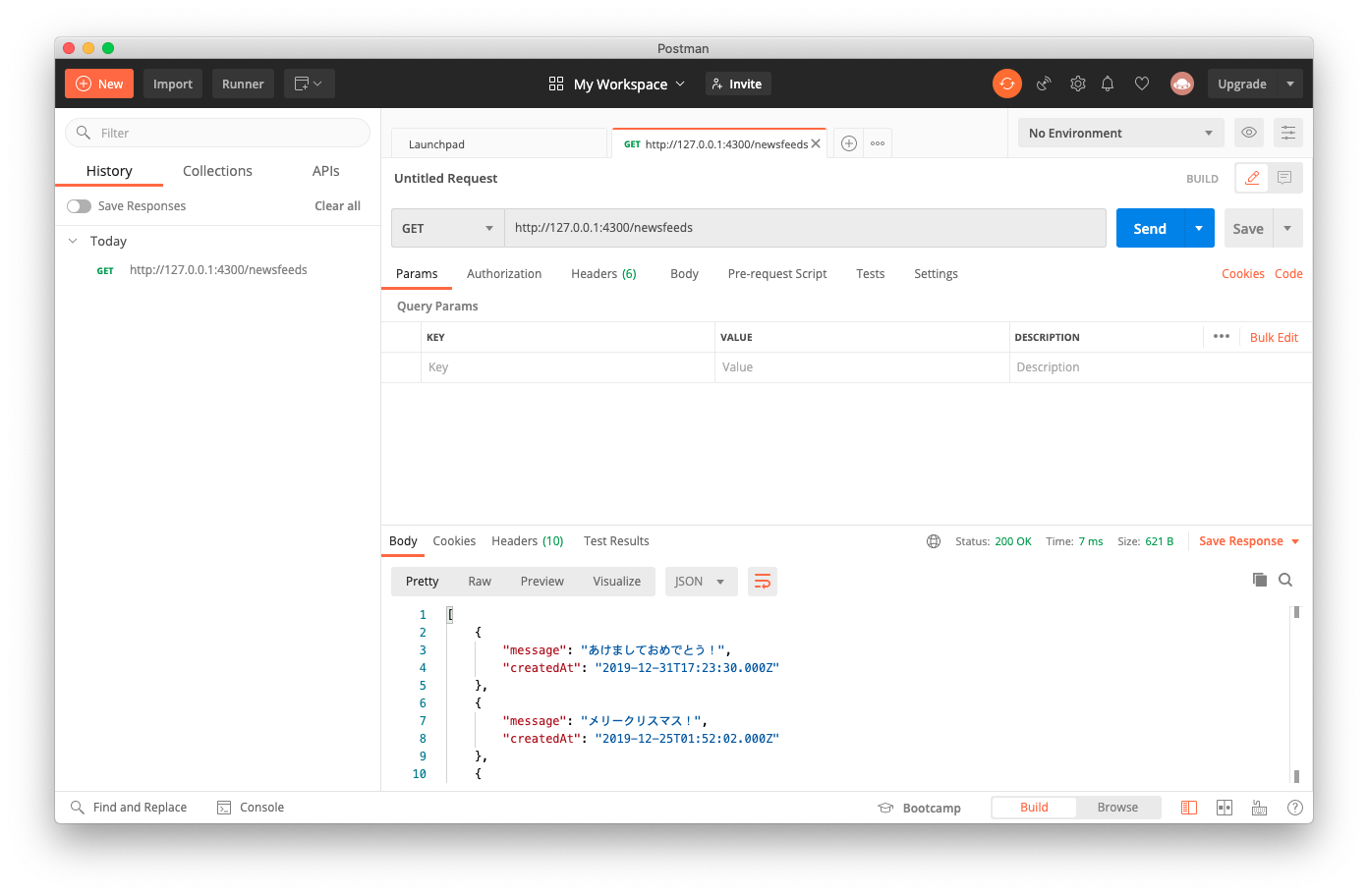
画像のように
GET http://127.0.0.1:4300/newsfeedsを作成し送信するとレスポンスが受信できていることが確認できます。
1) 画面上部のタブ(+)をクリックし、新規のタブを追加します。
2) メソッドにGETを選択します。
3) request URLにhttp://127.0.0.1:4200/newsfeedsを入力します。
4) Sendボタンをクリックします。
REST APIについて
最後に簡単にREST APIについて説明します。
GET http://xxxx.com/newsfeeds/{id}?a=1&b=2プロトコル
http://の部分をプロトコルと言います。クライアント-サーバ間での通信方式を指定することができます。
プロトコルは通信のデータフォーマットや遣り取りを行うシーケンスの方式などが規定されています。
仕様はRFCに記載されているので詳しくはそちらを参照しましょう。
httpは暗号化しないHTTPでの通信で、httpsは暗号化するHTTPでの通信です。
一般的にはhttpsを利用しますが、証明書を作成する必要があるので今回は割愛しました。
REST APIで利用するのはhttp,httpsの二種類ですが、
プロトコルとしては他にファイルを遣り取りするftp/ftps、メールを送信するsmtpなど様々なものがあります。ドメイン
xxxx.comの部分をドメインと言います。ドメインはコンピュータへたどり着くための場所を示します。
コンピュータはまず最初にDNS(Domain Name System)というサーバへ通信し、xxxx.comに対応しているIPアドレスを問い合わせます。次にそのIPアドレスへ通信を行います。
コマンドラインでDNSへの問い合わせを行うこともできます。$ nslookup xxxx.comパス
/newsfeeds/{id}の部分をパスと言います。
パスは、データへのパスを示します。
また、複数形・単数形の名詞で返すデータの種類を示します。
- GET /newsfeeds: newsfeedの一覧を返す
- GET /newsfeeds/{id}: 複数あるnewsfeedのうちの一つの詳細を返す
パスパラメータ
/{id}の部分をパスパラメータと呼びます。
左のパスに書かれている/newsfeedsの中の一つのnewsfeedを指定するためのidを渡すことができます。クエリパラメータ
?a=1&b=2の部分をクエリパラメータと呼びます。
?はパスとの区切り文字、&は複数のクエリパラメータの区切り文字として利用します。
a=1でaというパラメータに1を設定していることになります。
主に取得するデータが複数ある場合に、フィルタをかける役割で利用します。リクエストボディ
POSTメソッドやPUTメソッドではリクエストボディを設定することができます。
POST /newsfeedsとして場合、リクエストボディには投稿する記事のデータを設定することになります。
リクエストボディには一つの種類のデータを入れることができ、REST APIではJSONオブジェクトを送信することが多いです。
ボディに指定しているデータの種類を指定するContent-TypeやMIME-Typeはまたの機会に記載します。メソッド
メソッド 説明 GET パスやクエリで指定したデータを取得します。 POST パスで指定したデータを新規追加します。 PUT パスで指定したデータを変更します。 DELETE パスで指定したデータを削除します。 最後に
今回はREST APIのGETを一つ作成してみました。
次回はフロントエンドからこのAPIを呼び出してみます。
今回開発したソースコードはGitHubに入っています。
- 投稿日:2020-09-16T20:18:26+09:00
コロナ渦に Node.js, Angular.js, MongoDB などを勉強してサービスをリリースした感想文
はじめに
今年、16年勤めた上場企業を辞め、ベトナム拠点のスタートアップ(日系)に転職しました。退職時に有給休暇がたくさん残っており、こういう滅多にない節目の長期休暇では、リフレッシュのため、自分探しの旅に出るんだろうなと想像していましたが、生憎のコロナ渦、ということで自宅に。細々とあれやこれややっていましたが、基本的には暇を持て余していました。
旅行することも出来ず、暇なので、勉強することにしました。Manager として長らく実装からは離れていましたが、スタートアップでは実装も求められるし。
という訳で、まずはこれまでほぼ担当することがなかったフロントエンドのリハビリから。YouTube で、html, css, js(vanilla) をやってみました。次に Python。そして Node.js、TypeScript と。そして AWS ばかりだったので GCP。時間だけはたくさんあるので、色々できました。教材は、YouTube と Udemy と書籍。
で、こういうの作れませんか?と相談を受け、実践の場を得て、先日リリースしたんですが、あちこち躓き、色々な学びがあったので、その反省文。
作ったもの
- 様々なサービスを大量に毎日巡回してスクレイピングし、データを貯めるバッチ
- そのデータをあれこれ加工して表示する Web サイト
最初は Python で作り始めたけど、最終的には、
- バッチ: Node.js
- サイト: Angular.js
- DB: MongoDB(AWS DocumentDB)
- サーバ: AWS EC2
の構成に。EC2 以外は、Production は初めて。
Python から Node.js へ
スクレイピングと言えば、Python。と BeautifulSoup でせっせと作っていましたが、GeoIP 問題。スクレイピングするものが、グローバルに展開しているサービスで、日本からだとアメリカのサイトが取得できないとか。まぁ、なんか解決方法あるんだろうけど、面倒くさいなーと、ネットを彷徨っていたところ、いい感じにやってくれるライブラリを発見。
だいたいいい感じにやってくれるんだけど、ちょっとだけ足らない。やりたいことが全部できない!そんな中、同様のライブラリを Node.js で発見。こちらはやりたいことが全部できる(その時点ではそう思っていた)。という訳で、Python を捨て、Node.js に変更。
学び1: スクレイピング、本当に自分でするの?
特に有名なサービスは、誰かが既にやってて、しかも公開されてるからそれを使った方が良い。Python コミュニティや Node.js コミュニティの Assets は検討の上、極力活用すべき。
MongoDB という罠
Local で開発する分には、Docker で MongoDB 公式の Image から立ち上げてしまえば、超簡単にできるし、今回利用したライブラリは、取得した値が JSON 形式で返ってくるので、(ほぼ)そのままぶっ込める MongoDB は使い勝手が良かったので、軽い気持ちで採用した。いいじゃん、NoSQL くらいの気持ちで。
Node.js から MongoDB への接続には、mongoose を使ったのだけど、mongoose のトップページに書いてあるコードをコピペしてちょっと変更したものが動かない!なんでやねん!とググったところ…
学び2: MongoDB 関連はドキュメントや記事が少ない。特に日本語。
MySQL 等の RDB に比べ、NoSQL は参考にできるものが極端に少ない。Stack Overflow 様がいなければ詰んでました。英語が読めて良かったよ。ついでに言うと、エラーメッセージ見てもサッパリ。
無事使えるようになって、さぁ Production!となった時に、問題発生。
学び3: AWS, GCP で MongoDB は MySQL ほど気軽に使えない
GCP では、MongoDB Atlas を使うか、コンテナ等で立ち上げるか、なのかな?なんだけど、ちょっと高すぎない?それにあちこちに支払いが発生するのも嫌だなと。コンテナでも良いんだけど、バックアップだの何だのやってられないので、GCP はやめました。
一方 AWS は?というと、こちらもちょっと高いんだけど、DocumentDB という MongoDB 互換の NoSQL が使えて、Node.js 側は何も変えなくても使えるので、こちらに。EC2 内とかコンテナで MongoDB を立ち上げるのは、前述の通り面倒でやってられなので、却下。DocumentDB も安くはないんだけど、個人で払うわけじゃないし、起業レベルで考えれば、まぁ良いかということで、相談の上、採用。立ち上げようとして問題発生
学び4: AWS DocumentDB はインスタンス数が1つでも、Multi AZ じゃないとダメ
(重要だけど)社内ツールなので、スケーリングもしないし、ロード・バランシングもしないし、Single AZ で良いやと VPC を構築していたので、作り直し。変なところで手を抜かなきゃ良かった。
なお、AWS と GCP は思想というか哲学というかが全然違う。AWS でよくやることは、GCP では… みたいな使い方は、すべきでない。
果たされない Promise
学び5: Node.js の非同期処理は1日にしてならず
Node.js って、他の言語に比べると、非同期処理の扱いがなかなか理解し難く、今回作ったバッチは、基本逐次処理したいものだったので、Promise ってなんやねん!Sleep ないのかよ!などと四苦八苦。async/await しまくって、かなり非効率なプログラムになってるんだろうなと思う。
また、Local では問題なかったものが、スペックの高いサーバで実行した結果、問題になることも。全然処理終わってないのに、じゃんじゃか進んじゃって、メモリが溢れるなど。初心者丸出しを痛感。
言語ごとの特徴をこれほど強烈に感じる言語も、他にはあんまりないのかなと思った。
メモリが足らない!
バッチは前述の理由で、メモリが足らなくなるので、処理を分割するのと、減らすのと。急遽仕様変更。何に時間がかかってるかは分かりやすかったので、まぁなんとか。チームひとりだったので良かったけど、Go Live 直前の仕様変更とか嫌ですね。
一方で、Angular.js の Build が通らなかった時は、もうどうしようかと。
学び6: Angular.js は AWS 無料枠の t2.micro では build できない?
Build 済みのものを持っていくとか、そういう風にするのが良いのかも知れないけど。社内ツールで、トラフィックもそんなにないし、インスタンスサイズはしょぼくても良いやと思ってたけど、ダメだった。最終的には、インスタンスサイズを上げ、
$ node --max_old_space_size=1069 (path_to_ng)/ng build --prodなどとして実行。メモリ増やしてもそのまま実行するとエラーになる。なった。Node.js でなにかを作る時は、メモリサイズをしっかり気にしないといけないんですね。
SPA で作るべきだったのか?
Angular.js を選んだ理由は、SPA(Single Page Application)やってみたかったから、ですが、最初は、うぉぉぉぉ!超速い!!!すげえええええ!!!!と感動していましたが、今回作ったサービスは、画像やビデオを大量に扱うため、Angular.js の assets ディレクトリが肥大化しがち。
で、案の定コンパイルできなくなり、まじかーと。
他にも、Creative Tim のテンプレート持ってきてそのまま使ったら、コンパイルできなくなった。そんなことあんの?と思ったが、コンパイルできなかった。学び7: どこまで Single Page であるべきかは要検討
Webサービスにおいて、レスポンス速度は非常に重要な要素であり、SPA は1つの解ではあるものの、レスポンス速度改善の本質は別の所にあることが多い。
また、Creative Tim で配布されているようなリッチなコンテンツを実現したり、コンテンツがどんどん増えていったりなどの場合、Angular.json の budgets のサイズを変更することで、コンパイルはできるようになるが、SPA の利点が失われていくし、限度がある。
規模の大きなサービスを作る(そうなる可能性がある)場合は、よくよく考えてから使うようにしないと、後で泣くことになるかも知れない。ただ、Angular.js による SPA は感動するほど速かった。フロントエンドからバックエンドまで一気通貫で、JavaScript/TypeScript で作れるのも、非常に良い。今後続けて勉強していくかは悩ましい。
なお、大量の画像やビデオは、S3 に置いて、https アクセスするようにした。Creative Tim は使うのを止めた。全体的に Bootstrap を使ったけど、使わなくても良かったなと、出来上がったものを見て思った。コピペでサクっと出来ちゃうのは良いけど、Bootstrap と相性悪いライブラリもあるし、大したデザインじゃないし、flex box の万能感。
スクレイピングにおけるページロードの待ち時間
結局、どうしても独自でスクレイピングしないといけないものがあって、Puppeteer を使いました。待ち時間の設定はいくつかあるんだけど、どうにも思った通りに動かない。
やりたかったことは、2つあって、ページをスクロールして読み込まれるものを全部待ってからスクレイピングするのと、画像を並べて(直リンクで表示)スクリーンショットを撮るというもの。
Puppeteer の待ちオプションだと、うまく行かないケースがあって、仕方がないので、ロード状況等は無視して、一定時間必ず待つようにした。他にも、スクレイピング先に迷惑をかけないように、ちょいちょい待たせているので、時間がかかる。
遅いなーと思って、電卓叩いて全ての処理が終わる最小時間を計算したら、もう全然無理じゃんとなったので、スクリーンショットの方は止めることに。スクロールの方は、対象が増えると破綻するはずなので、なんか考えないといけない。
学び8: スクレイピングできることと、運用に耐えうるかは別問題
本番で失敗する前に電卓叩いた私は偉いと思うけど、デイリーで大量のスクレイピングを伴うサービスって難しいんだなと思った。Python でやる場合、言語自体のパフォーマンスも含め、実装は簡単でも実運用できる設計は難しいのかな。
Puppeteer は他にも、スクリーンショットでブラウザ幅がうまく変更できないとか、Chrome Headless Browser を Amazon Linux2 で動かすのに一手間いるとか、読み方が分からないとか色々つまづき所がある。ぴゅーぺてぃあー
終わりに
今回、Node.js, Angular.js + MongoDB を AWS で動かすサービスを、フロントエンドからバックエンド、インフラまで全て一人で作って Production にリリースしてみた。大量のトラフィックをさばく必要はなかったので、その点は楽だったが、初めてのものが多く、あれこれ躓いた。が、ぶっちゃけ楽しかったし、学びもたくさんあった。今後改善すべき点も、実務でバリバリやっている人にとっては、バカじゃねーの?ってレベルだとは思うが、明確なので、次のモチベーションにもなった。
大企業では分業化が進んでいて、サービスの全てを担当することなんてほぼないし、まして技術選定を全て決められることなんてない。基本的には枯れた技術を使って安定運用することの方が重要だったりするし。そういう意味で、スタートアップはエンジニアとして面白い。辛い点としては、助けてくれる人も聞ける人も近くにいないというのがあるが、インターネット上にいくらでもいるので、たいした問題ではなかった。できなきゃいつでもクビみたいな緊張感も、刺激的だ。
枯れた技術の運用ばっかりやっていても面白くもなんともないし、自身の技術力の向上感を感じることは少ないと思うが、今回新しい言語でも、久しぶりの実作業でも、割とすんなり対応できたのは、そうしたつまらん期間に基礎をみっちりやってきたからに他ならないと思う。16年もいる必要はないと思うが、つまらん期間も大事だ。
エンジニアの採用を長らくやってきて、ベンチャー思考、新しいもの(だけ)好きなエンジニアの薄っぺらさ、応用の効かなさ、基礎のなってなさみたいなものはさんざん見てきているので、まぁやっぱり大事で間違いないんじゃないかと思う。前職は16年前は現職より小さな会社で、あれよあれよと言う間に大きくなったが、会社が成長する過程で、上が詰まってなかったので、私自身も色々なことに挑戦できたというのは、ラッキーだったかも知れない。
終わりの最後に、途中で「チームひとり」と書いたが、いま本当にひとりだ。他にもエンジニアはいるが、もっとプリミティブな部分だったり、アプリだったり領域が違う。で、今後作っていくサービスのブループリントを描いて、おおまかな方針は決めたが、かなり壮大なサービスをスクラッチから作ることになる。特にトラフィックとレスポンス要件が、え?そんなにシビアなの??って感じで、当然、ひとりでは作れない。震える。ちなみに、Angular.js や Node.js は Plan B のオプションではあるものの、使わない。"ベトナム"のスタートアップで、壮大な VISION を技術面から一緒に追いかけたい、という人がいたらTwitterか何かでご連絡ください。いまが一番熱い時。
- 投稿日:2020-09-16T18:08:18+09:00
zoom-sdk-electron でできることを調べるまでのアレコレ
概要
zoomが提供しているElectronのAPIでできそうなことがリファレンスだとちょっとわかりにくいのでデモアプリを起動しようと思ったが、案外ハマりどころが多かったのでそれについて。
参考資料
非常にわかりやすかったのですが、具体的なコードの変更内容が例示されていなくて詰まってしまったのでその補足をしたい。当時と若干バージョンが異なる関係で行数のところがずれてしまうので...
記事を読む限り、この方のときはむしろ私が書いているように SDK Key/Secretによる認証が基本だったように見えるのですが...(https://github.com/zoom/zoom-sdk-electron/commit/dbdff5a65dff40c1bccb7a1b269391ea72d8f6b5#diff-3b4cc93c41d4067694a6d9ff6ae923efL643 このコミットで大規模に改修が入ってますね)
※ CHANGELOG 見る限りでは開発用途ではJWT Tokenのほうが、
more secure, more convenient, and more versatile.ということのようです。SDK Key/Secret認証のメソッド消さなくてもいいのに...まずは必要なものの準備
※ 前提としてMac版で実施しています
こちらのページから必要な事項を確認します。
- ソースコード(Gitでcloneする)
- A device with Mac OS or Windows OS
- Mac OS: MacOS 10.10 or later. とのこと
- node.js 12.0.0 version と書いてある
- nvmで用意しておこう
- zoomのアカウント(またMarketplaceでのAPIキー、トークン等の生成)
- あとでやります
基本の準備〜ビルド
node 12.0.0.0 (マイナーバージョンまであわせる必要はないかも)
$ nvm install 12.0.0 $ node -v v12.0.0ソースコード
$ git clone https://github.com/zoom/zoom-sdk-electron手順通りに必要なものを入れて、ビルドします
$ npm install --save-dev electron@5.0.2 -g $ npm install node-gyp -g $ npm install bindings -g $ cd zoom-sdk-electron $ sh build_nodeaddon_mac.sh手元の環境ではめっちゃwarningが出ました。
gyp info ok cp: ../../../../../../Bin/Mac/Release: No such file or directory cp: ./build/Release/zoomsdk.node.dSYM: unable to copy extended attributes to ../../../../../../Bin/Mac/Release: No such file or directory cp: ../../../../../../Bin/Mac/Release/Contents: No such file or directory cp: ./build/Release/zoomsdk.node.dSYM/Contents: unable to copy extended attributes to ../../../../../../Bin/Mac/Release/Contents: No such file or directory cp: ../../../../../../Bin/Mac/Release/Contents/Resources: No such file or directory cp: ./build/Release/zoomsdk.node.dSYM/Contents/Resources: unable to copy extended attributes to ../../../../../../Bin/Mac/Release/Contents/Resources: No such file or directory cp: ../../../../../../Bin/Mac/Release/Contents/Resources/DWARF: No such file or directory cp: ./build/Release/zoomsdk.node.dSYM/Contents/Resources/DWARF: unable to copy extended attributes to ../../../../../../Bin/Mac/Release/Contents/Resources/DWARF: No such file or directory cp: ../../../../../../Bin/Mac/Release/Contents/Resources/DWARF/zoomsdk.node: No such file or directory cp: ../../../../../../Bin/Mac/Release/Contents/Info.plist: No such file or directory結果的に失敗しているようにも見えますが、大丈夫っぽいので突き進みます。
デモの起動
$ sh run_demo_mac.sh run_demo_mac.sh: line 12: cd: ./demo: No such file or directoryこちらもエラーか?!と思いますがそういうもんです。このあといろいろ生成してくれます。
無事起動しました...が...
objc[43150]: Class ZoomLauncher3rdSdkIPCReciever is implemented in both /Users/tetsunosuke/work/zoom/electron/zoom-sdk-electron/demo/node_modules/electron/dist/Electron.app/Contents/Frameworks/ZoomSDKChatUI.framework/Versions/A/ZoomSDKChatUI (0x10d2e6b30) and /Users/tetsunosuke/work/zoom/electron/zoom-sdk-electron/demo/node_modules/electron/dist/Electron.app/Contents/Frameworks/zChatApp.bundle/Contents/MacOS/zChatApp (0x115173560). One of the two will be used. Which one is undefined. InitSDK 0 Error: Send error, 60 Operation timed out Error: Send error, 60 Operation timed out Error: Send error, 60 Operation timed outエラーっぽいなにかが出ています・・・。気にしなくても動作はしているので一旦無視します。
で?
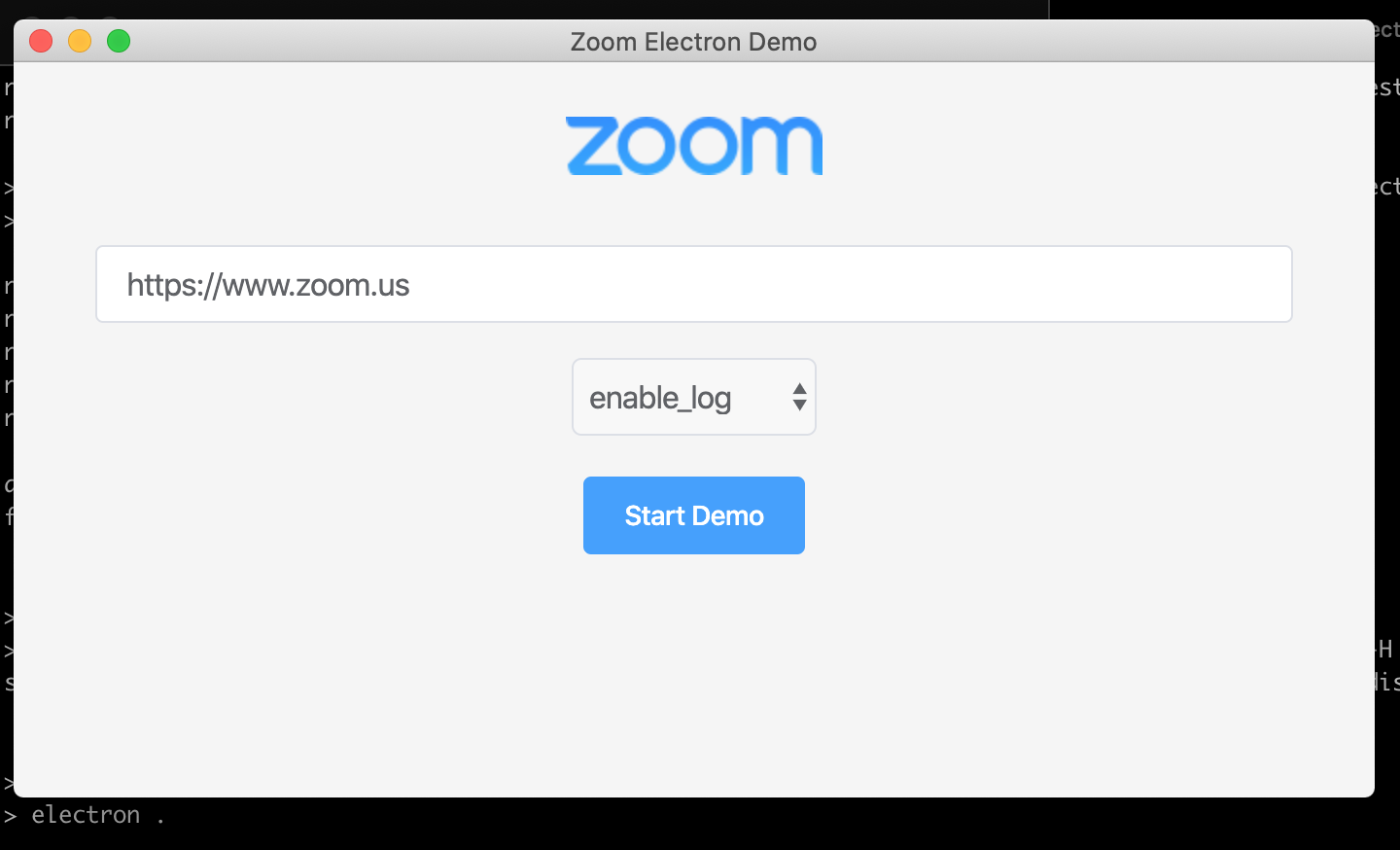
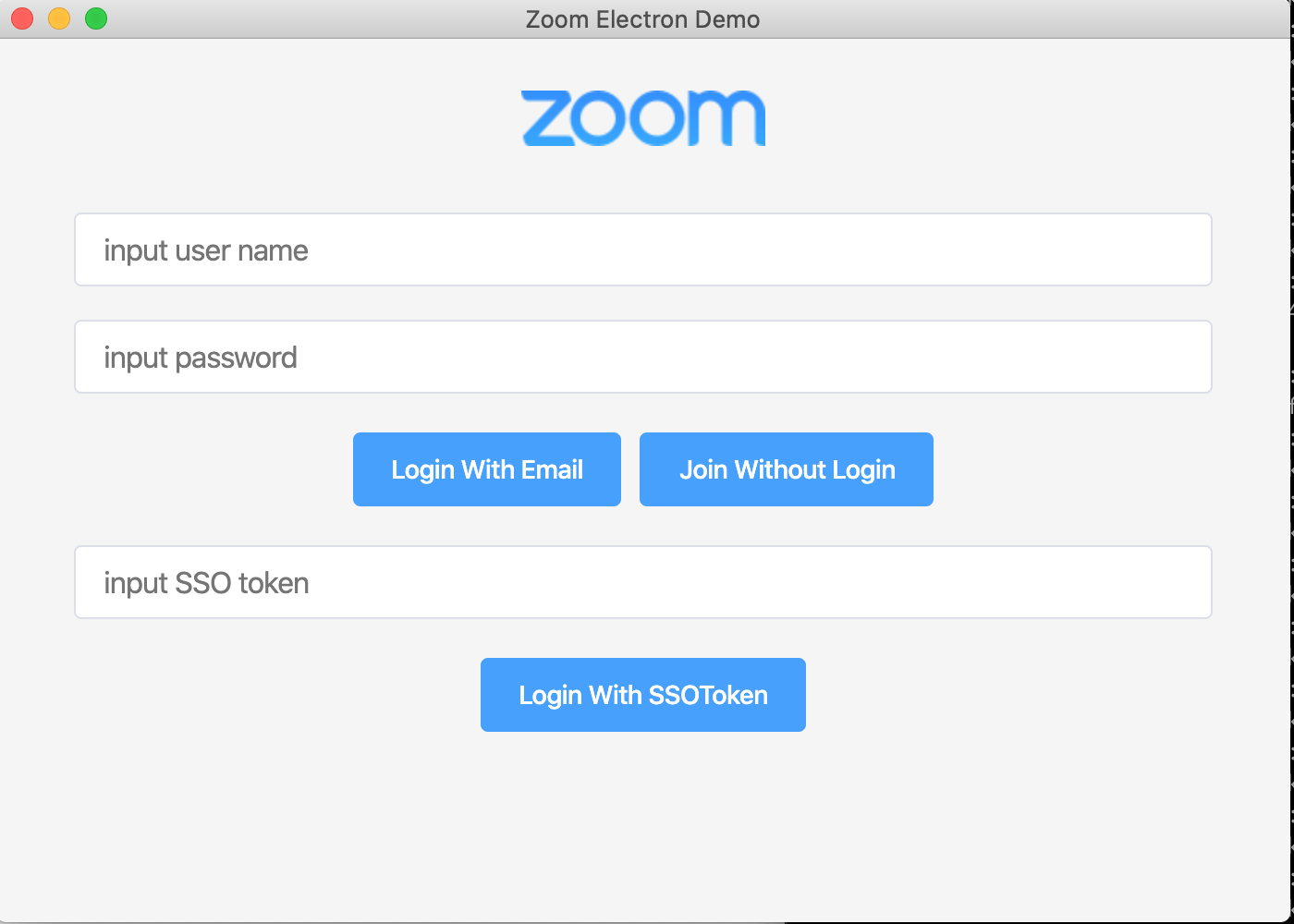
このままStart Demo を押すと
というように
jwt tokenを求められますが、jwt token の有効期限のことを考えると、 とりあえずのお試しには、SDK Key/SDK Secretのほうがいいんじゃないかなと思います。以後、その前提で手を入れていきます。参考記事の
Zoom Electron SDK 入門とはここからがやや異なります。手を加えていきます
その前にSDKで Key/Secret を発行しておく
https://marketplace.zoom.us/ よりサインアップして、
Develop → Build App と選択します。 Choose your app type から SDK を選択しましょう。
各種情報を入力してアプリを作成すると
SDK Key、 SDK Secret が払い出されるので控えておきます。
アプリの起動を簡略化します。
こちらも参考記事と同様に内部フローを把握しておくと
- main.js: createWindow() -> showDomainWindow() -> pages/domain.html が開かれる
- dmain.html: doinit() -> senddomainmsg() -> asynchronous-message で "setDomain", 画面で選ばれたdomain, enable_logがメインプロセスに送られる
- main:js は asynchronous-messageを受け取って
functionObj[arg1](arg2, arg3, arg4, arg5);を呼び出すという流れになっており、「ボタンを押す」操作は
function createWindow() { // Create the browser window. - showDomainwindow(); + // showDomainwindow(); + functionObj["setDomain"]( + "https://www.zoom.us", /* domain */ + true /* enable_log */ + ); }こうしたのと同じと言えます。
※ ところでこのdomainって一体何・・・?
また、 jwt tokenを要求する画面は
pages/index.htmlが呼び出されます。
これは、 ProcSDKReady() が呼ばれたときに、 showAuthWindow() が呼ばれているからですね。ここから先の処理は
- index.html: ボタンクリックで dosdkauth() が呼ばれる -> authWithJwtToken が asynchronous-messageで呼び出される
となっているので、ここを一気にスキップします。
今回は認証をSDKのKey/Secretで行うので、
zoomauth.AuthWithJwtToken(sdk_context);の代わりに、zoomauth.SDKAuth(key, secret);を使うようにします。つまり
+ sdkLogin: function(key, secret) { + let ret = zoomauth.SDKAuth(key, secret); + if (ret == 0) { + showWaitingWindow(); + } }このように新しい関数を main.js に実装して、
function ProcSDKReady() { - showAuthwindow() var options = { authcb: sdkauthCB, logincb: loginretCB, logoutcb: null } zoomauth = zoomsdk.GetAuth(options); + functionObj["sdkLogin"]( + "ここに取得していた SDK Keyを", /* key */ + "ここに取得していた SDK Secretを" /* secret */ + ); }と書くことで、sdkLoginが呼ばれ、コールバック(sdkauthCB)以降が動き出します。
これと、言語を日本語化する処理(ZoomSDK_LANGUAGE_ID.LANGUAGE_English→ZoomSDK_LANGUAGE_ID.LANGUAGE_Japanese)を加えて、差分は以下のようになりました。
main.js@@ -489,13 +489,16 @@ function showStartJoinWindow() { } function ProcSDKReady() { - showAuthwindow() var options = { authcb: sdkauthCB, logincb: loginretCB, logoutcb: null } zoomauth = zoomsdk.GetAuth(options); + functionObj["sdkLogin"]( + "<省略>", /* key */ + "<省略>" /* secret */ + ); } function apicallresultcb(apiname, ret) { @@ -625,7 +628,7 @@ let functionObj = { path: '', // win require absolute path, mac require '' domain: domain, enable_log: enable_log, - langid: ZoomSDK_LANGUAGE_ID.LANGUAGE_English, + langid: ZoomSDK_LANGUAGE_ID.LANGUAGE_Japanese, locale: ZoomAPPLocale.ZNSDK_APP_Locale_Default, logfilesize: 5 } @@ -2613,6 +2616,12 @@ let functionObj = { } let ret = zoomsms.SetDefaultCellPhoneInfo(opts); console.log('SetDefaultCellPhoneInfo', ret); + }, + sdkLogin: function(key, secret) { + let ret = zoomauth.SDKAuth(key, secret); + if (ret == 0) { + showWaitingWindow(); + } } } @@ -2629,7 +2638,10 @@ app.on('window-all-closed', function () { function createWindow() { // Create the browser window. - showDomainwindow(); + functionObj["setDomain"]( + "https://www.zoom.us", /* domain */ + true /* enable_log */ + ); }
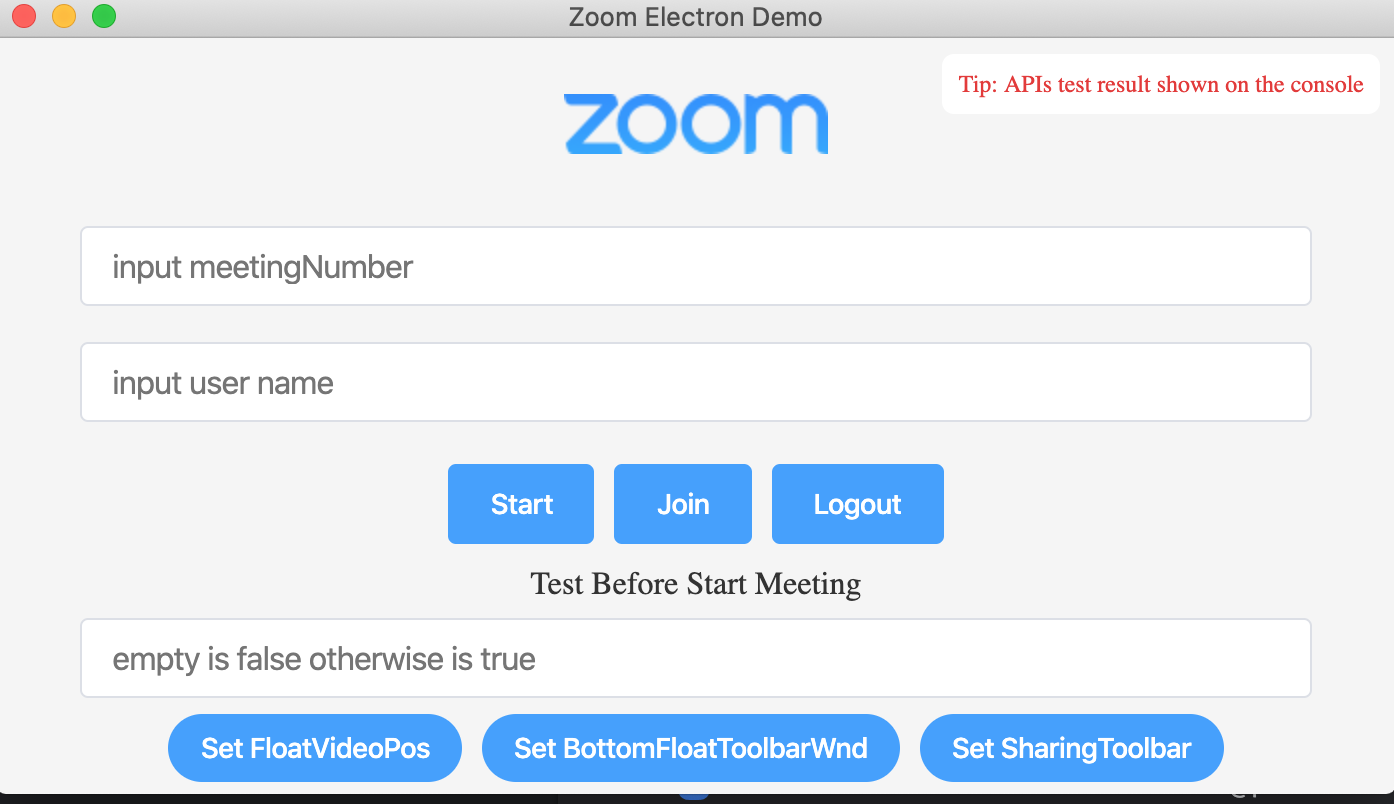
これでzoomクライアントとしてのメインの実装は完了です!
あとはデモ用の用途をお楽しみください



- 投稿日:2020-09-16T17:33:20+09:00
WindowsでNode.jsを更新する
Node.jsのバージョン管理ツール「
n」はWindowsには対応していません(Note: n is not supported natively on Windows.)
ので、Chocolateyを使いましょう
choco upgrade nodejsChocolatey経由でインストールしていなくても更新できます。
- 投稿日:2020-09-16T17:31:52+09:00
Warning: ENOSPC: System limit for number of file watchers reached (memo)
It’s hitting your system's file watchers limit
Try echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p
- 投稿日:2020-09-16T17:04:56+09:00
M5StackでLINE Beaconを作成する手順を久々にまとめてみる 2020年9月版
最近LINE Beaconを触ってみているので久々に少しまとめてみます。
調べると出てくる記事はもう結構古いと思うので改めて自分用にも。
必要なソフトウェアなどは省略せずに書いてるつもりですが、完全初心者向けハンズオン記事とかではないのでご留意下さい。
何よりも登録のこのURLをいつも忘れるので記録です。(後述)
LINE Beaconとは
LINEが提供するLINEと連携できるビーコンの仕組みです。詳細は参考記事へ。
選択肢として公式デバイスもありますが、今回はLINE Simple Beaconを利用します。
M5Stack
M5Atom Liteが安いかつコンパクトかつケース個人的にオススメです。1000円で買えます。
必要な要素
ざっくり言うとサーバーサイド実装+マイコンボード実装が必要です。
- STEP0. [下準備] LINE BOT作成
- LINE BeaconはLINE BOTに紐づく仕組みです。LINE BOT開発が必要になります。
- サーバーサイドの言語ならなんでもOKですが、ここではNode.jsで進めます。
- STEP1. マイコンボードのLINE Beacon化
- LINE Simple Beaconを利用してESP32などのマイコンボードに書き込みます。
- STEP2. LINE BOT開発
- 作成したLINE BOTをLINE Beaconのイベントに対応させます
ちなみに筆者環境は、macOS Catalina / Arduino IDE 1.8.12 / Node.js v14.10.1です
実際に作ってみる
STEP0. [下準備] LINE BOTを作成
Node.jsでLINE BOTを作成します。Node.jsのインストールなどは事前に済ませておきましょう。
1時間でLINE BOTを作るハンズオンを元にLINE BOTを作成しましょう。
STEP1. マイコンボードのLINE Beacon化
この記事ではM5Atom Liteを利用しますが、M5Atom MatrixやM5Stack Basic、M5Core2などでも試せました。
1.1 マイコンボードへの書き込みまで
- Arduino IDEの準備
Arduino IDEで開発をしていきます。準備しましょう。
- Arduino IDEにESP32ボードライブラリの追加
Arduino IDEでESP32系のボードの書き込みが出来るようにします。
Arduino IDEの設定から、追加のボードマネージャのURLに以下のURLを追加
https://dl.espressif.com/dl/package_esp32_index.json
ボードマネージャでESP32と検索し,espressif/arduino-esp32をインストール
- Arduino IDEにLINE Beacon用ライブラリのGreen Beaconを追加
ライブラリマネージャ(ライブラリを管理)でGreen Beaconと検索しgreen-beacon-esp32をインストール
- シンプルなコードを書き込む
PCとマイコンボードをケーブルで接続して書き込みを行います。
hello.inovoid setup() { Serial.begin(115200); Serial.println("start"); } void loop() { }書き込み時の設定はこんな感じ。
M5Atom系の場合、ボードはESP32 Pico Kitを選択、Upload Speedを115200に変更しましょう。
Upload Speedをそのままにすると
A fatal error occurred: Timed out waiting for packet headerというエラーになります。...ちなみに同じエラーでもこんな事象(↓)が発生することもあるので気をつけましょう。
1.2 LINE Simple BeaconのID発行
LINE Simple BeaconのID発行のページへ行きます。このページのURLがいつもどこにあるか分からなくなる......
line simple BeaconのハードウェアIDを発行を選択 -> 利用するLINE Botのアカウントを選択 -> ハードウェアIDを発行と進んでIDを発行します。
123456abczのような10桁のIDが発行されると思います。1.3 マイコンボードへ書き込む
以下のようなコードで実装できます。
beacon.ino#include "GreenBeacon.h" void setup() { GreenBeacon beacon = GreenBeacon("123456abcz"); // 取得したIDを指定 beacon.start("Hello!"); } void loop() {}これを書き込みます。
無事に書き込まれたらマイコンボードがLINE Beacon化してビーコン電波を発信してくれます。
STEP2. LINE BOT開発
1時間でLINE BOTを作るハンズオンの記事を元に作ったコードのhandleEventの関数を差し替えます。
//省略 async function handleEvent(event) { //BOTが生きてるか確認用のおうむ返し if (event.type === 'message' && event.message.type === 'text') { return client.replyMessage(event.replyToken, { type: 'text', text: event.message.text //実際に返信の言葉を入れる箇所 }); } //ビーコン反応 else if(event.type === 'beacon') { console.log(`beacon enter`); // ここに処理を書いていく return Promise.resolve(null); } } //省略実際に試すと、LINE Beaconの反応があった際にターミナルに
beacon enterと表示されます。あとは
// ここに処理を書いていくとコメントした箇所を中心に処理を書いていきましょう。動かない場合
- 基本
- LINE BOTと友達になっているか確認
- スマートフォンでBluetoothがオンになっているか確認
- LINEアプリでLINE Beaconがオンになってるか確認
- Arduino IDEで書き込みエラーは出てないか確認
- それでもダメなら
- おうむ返しが帰ってくるか確認
- LINEアプリを一度落としてから再起動
- LINE BOTを一度友達削除してから再度友達に
こんな手順で確認しましょう。
おまけ: マイコンボードからビーコンでメッセージを送る
LINE Simple BeaconではDMというパラメータでマイコンボードからLINE BOT側にメッセージを送ることができます。
センサーデータをLINE BOT経由でユーザーに送ったり、その値によってLINE BOTがユーザーに話しかける内容を変えたり出来ます。
beacon: { hwid: '000000000', dm: '48656c6c6f', type: 'enter' }
- Arduino側のコード
beacon.ino#include "GreenBeacon.h" const String hwid = "xxxxxxxxx"; GreenBeacon beacon; // Require in case using globally void setup() { beacon = GreenBeacon(hwid, "MyBeacon"); // "MyBeacon" is optional beacon.start(); // start advertising } void loop() { // String mes = String(millis()); String mes = "Hello"; log_i("setMessage(%s)", mes.c_str()); beacon.setMessage(mes); delay(1000); }
- Node.js側のコード
マイコンボードからのメッセージが
event.beacon.dmに格納されています。このままだと16進数の文字列で送信されてくるので変換してあげましょう。
const dmHexStr = event.beacon.dm; //16進数文字列 const dmStr = Buffer.from(dmHexStr, 'hex').toString('utf-8'); console.log(dmStr); //マイコンボードからのメッセージ以下、handleEventの関数をまるっと置き換えられるようにしてます。
//省略 async function handleEvent(event) { //おうむ返し if (event.type === 'message' && event.message.type === 'text') { return client.replyMessage(event.replyToken, { type: 'text', text: event.message.text //実際に返信の言葉を入れる箇所 }); } //ビーコン反応 else if(event.type === 'beacon') { console.log(`beacon enter`); // ここに処理 const dmHexStr = event.beacon.dm; //16進数文字列 const dmStr = Buffer.from(dmHexStr, 'hex').toString('utf-8'); console.log(dmStr); //マイコンボードからのメッセージ return client.replyMessage(event.replyToken, { type: 'text', text: `マイコンボードからのメッセージ: ` + dmStr //実際に返信の言葉を入れる箇所 }); } }
まとめ
一旦一通り使えるようにまとめてみました。
何よりもこのビーコンのID払い出しURLがいつも忘れてしまう問題がデカいのでこの記事にまた戻ってこれるようにしたい。
ドキュメントやBOT管理画面からの導線がいつも分からないんだよなぁ......



- 投稿日:2020-09-16T17:02:51+09:00
ホロライブの動画情報・チャンネル情報を収集するサイト「LisVir.holo」の開発メモ
概要
LisVir.holoを作ろうと考えた経緯や開発環境、公開までのざっくりとした流れや公開後の話のメモ。
なぜ作ろうと思ったのか
- 時間がそこそこあった
- 何か作って最近の技術に触れないと腐りそうという危機感
- 最近VTuberにハマったので関連したものを作りたい
作るにあたっての検討
何で作るか
仕事ではあまり触らないSPAに挑戦したい。→Node.js, express, Vue.js
DBはNoSQLに触っときたい。→MongoDB開発環境
OSは何でもよいがUbuntuを使う(遊びで触ったことがあった)。
ソース管理はGitHub(初めてちゃんと使う)公開環境
過去にさくらのレンタルサーバーでWebを公開したことがあるので今回も検討したが、折角なので従量課金のクラウド系を試したい。
→Google Cloud Platformざっくり設計
バック
YouTube Data APIでチャンネル・スケジュールを取得しMongoDBに保存
フロントからのリクエストでMongoDBのデータを返却フロント
バックへのリクエストでチャンネル・スケジュール情報を取得し画面表示開発中につまったこと
YouTube Data APIの利用制限
執筆時点(2020年9月15日)では1日のクォータ数(Quota)が10,000となっている。
検索リクエスト(search)が1リクエストで100なので、1日100回が限界。
直近スケジュールの収集タイミングを1日3回に制限。
(動画のスケジュール動画情報を収集する対象が32チャンネルなので、それだけで9,600)
チャンネル情報取集用のリクエスト(channels)は1クォータなので制限は気にせず実行できる。
動画単体の情報収集用リクエスト(videos)も1クォータ。
クォータ数の制限を増やす申請は行い、現在対応中(後述)フロントの見た目
デザイン能力の欠片もないので、見た目は誰かのテンプレートを頂戴することに。
ライセンス的に問題ないVue.jsのテンプレートのCoPilotを使用。
そのテンプレート内でJavaScript Standard Styleに触れて、いつもの記法で書いていたらコンパイルがなかなか通らない。
JavaScriptでセミコロンが不要なのを知れて良かった。公開に向けての作業
ドメイン
お名前.comで取得。
Whois情報公開代行で住所は隠したけど登録者名は非公開にならないのが、少しだけ嫌だったが仕方がない。
他のドメイン登録サービスではやってる場所もあるみたいだが、これはもうこのままでGo。サーバー、SSL証明書
初のGoogle Cloud Platform。ネットで調べながら作業。
最初、Compute EngineからVMインスタンスを作ったが、
後にSSLが必要(APIの利用規約にはSSLで、とあった)となるので、これは削除。
ネットワークサービスの負荷分散からロードバランサ作成、バックエンドとしてのインスタンスグループを作った。
SSL証明書を新規に取得するほどでもなかったので、GoogleマネージドSSL証明書を使うこととして、そのためにロードバランサでうんたらかんたら。
VM(Ubuntu、東京リージョン)にアプリケーションをインストールして公開。公開後の課題と展望
クォータ数が足りない
前述のとおり、動画情報の収集に用いる検索クエリ(search)が1回100コストかかるので、頻繁にスケジュール情報を更新できない。
そのため、YouTube APIのクォータ数の増加申請を行い、現在審査待ち
(申請に関する詳細情報は別途書く)
直近全然足りないので、スケジュール情報の収集回数を減らし、チャンネル量を増やす。
(2020/09/16時点で増やした)同系の別サイトも作りたい
ホロライブだけでなく、にじさんじ、個人勢、切り抜きチャンネルに関する情報まとめも作りたい。
そのためにはクォータ数の上限を何とか増やしたい。
※APIのプロジェクト単位でクォータ数は管理されている。1つのサイトの複数のプロジェクトのキー・クォータ数を割り当てるのは規約違反なので最悪BANされる可能性あり。少なくともクォータ数上限増加の申請はできない。詳細な環境構築手順やGoogle Cloud Platformでの作業の詳細は別途書く。
- 投稿日:2020-09-16T16:49:08+09:00
Node.jsで16進数文字列を文字列に変換メモ
Arduinoなどのマイコンボードなどのから情報送るときにたまに使うやつです。
Bufferでシンプルに書く
今のところこれがシンプルな感じです。 Bufferを使うのでNode.js環境のみですが
const string = Buffer.from(hexStr, 'hex').toString('utf-8');これでOK。
実際に書くときはこんな感じです。
app.jsconst hexStr = `48656c6c6f`; //16進数文字列 const string = Buffer.from(hexStr, 'hex').toString('utf-8'); console.log(string);その他
- もう少し丁寧に
const buf = Buffer.from(hexStr, 'hex'); //16進数文字列 -> Buffer const string = buf.toString('utf-8'); //Buffer -> 文字列
- バイト配列指定
const buf = new Buffer.from([0x48, 0x65, 0x6c, 0x6c, 0x6f]); //48656c6c6f const string = buf.toString('utf-8');
- ブラウザでも使える版
const string = (new TextDecoder).decode(Uint8Array.of(0x48, 0x65, 0x6c, 0x6c, 0x6f)); //48656c6c6fちなみに
48656c6c6fは?変換するとstringの値は
Helloになります。$ node app.js Hello
- 投稿日:2020-09-16T14:44:32+09:00
Twitter広告APIを利用してキャンペーンを作ってみる その3~TwitterAPIでツイート編~
経緯
私が所属している会社では待ラノという小説投稿サイトを運営しています。
待ラノではオススメ小説のランキング上位5作を定期的にTwitterの公式アカウントで紹介しています。
紹介された小説をTwitter広告のキャンペーンを利用してプロモーションをしようってなりました。そもそもTwitter広告のキャンペーンって何?
Twitter広告のキャンペーンですが、簡単いうと1日にかける予算や期間内にかける総予算を指定して、Twitterに広告を出す機能です。
Twitter広告APIでキャンペーンを作る理由
1つのキャンペーンで複数のツイートをプロモーションする場合、1日にかける予算を一気に消化されてしまいます。
しかもどのツイートにどれだけ予算が消化されているかがわかりません。
そのため、1つのツイートに1キャンペーンを紐付けることで消化される予算の見える化を行うことになりました。ただ手動でTwitterの広告コンソールから、1ツイートに1キャンペーンを毎回作ることになると結構手間です。
というわけで、Twitter広告APIを利用して動的にキャンペーンを作成することになりました。Twitter広告APIでキャンペーンを作成するためには
以下の手順が必要です。
- Tiwtterアカウントを作成する(省略)
- Tiwtterアカウントにメールアドレスと電話番号を設定する(省略)
- TiwtterAPIの利用申請をする
- TiwtterAPIのAPIキーとトークンを取得する
- TiwtterAPIを利用してツイートをする ←イマココ
- Tiwtter広告APIの利用申請をする
- Tiwtter広告APIでを利用してツイートを使ったキャンペーンを作る
今回は5の【TiwtterAPIを利用してツイートをする】について説明していきます。
動作環境
- 使用端末:Mac
- Node.js:v12.18.2
- yarn:v1.22.4
使用するライブラリ
仕様
サーバーのURLにアクセスすると自動で定型文をツイートする。
1.package.jsonを作成する
以下のコマンドでpackage.jsonを作成します。
対話式で質問を聞かれるので基本的に全てEnterで問題ありません。$ yarn init question name (twitter-api-post-tweet): question version (1.0.0): question description: question entry point (index.js): question repository url: question author: question license (MIT): question private:2.ライブラリをインストールする
以下のコマンドでライブラリをインストールする
$ yarn add express twitter3.ソースファイルを作成する
$ touch index.js4.ソースコードを書く
index.js// Server settings const express = require('express') const server = express() const port = 3000 // Twitter settings const Twitter = require('twitter') // 【その2】で取得したAPIキーとトークン const API_KEY = 'AAAAAAAAAA' const API_SECRET_KEY = 'BBBBBBBBBB' const ACCESS_TOKEN = 'CCCCCCCCCC' const ACCESS_TOKEN_SECRET = 'DDDDDDDDDD' const twitterClient = new Twitter({ consumer_key: API_KEY, consumer_secret: API_SECRET_KEY, access_token_key: ACCESS_TOKEN, access_token_secret: ACCESS_TOKEN_SECRET }) // Routes server.get('/', (req, res, next) => { res.send('server is up') }) server.get('/post', async (req, res, next) => { try { // http://localhost:3000/post にアクセスすると自動でTweetする const tweetText = 'tweet内容' const response = await twitterClient.post('statuses/update', { status: tweetText }) // TwitterAPIの結果をそのまま返す res.send(response) } catch (error) { res.send(error) } }) server.listen(port, function () { console.log('Listening on port ' + port) })5.サーバーを立ち上げる
以下のコマンドを叩いてサーバーを起動させる。
$ node index.jp
6.自動ツイートするURLにアクセスする。
ブラウザで「http://localhost:3000/post」にアクセスする。
アクセスするするとツイートが投稿されます。
■「Twitter広告APIを利用してキャンペーンを作ってみる 」シリーズ
- その1~TwitterAPI申請編~
- その2~TiwtterAPIのAPIキーとトークンの取得編~
- その3~TwitterAPIでツイート編~ ←イマココ
- その4~Tiwtter広告APIのAPI申請編~
- その5~Twitter広告APIでキャンペーン作成編~
- 投稿日:2020-09-16T14:00:00+09:00
Firebase Storageの複数ファイルをダウンロード&アップロード
はじめに
Firebaseのプロジェクトを作り直した際、元のプロジェクトから新しいプロジェクトへStorageの中身を全てコピーする必要がありました。調べたけど複数ファイルを一括で扱う方法が見つからなかったので、forEachで1ファイルずつ処理しました。
Google Cloud Storageからのダウンロード
Storage直下にあるファイルをローカルのworkディレクトリへダウンロードします。
download-storage.jsconst admin = require('firebase-admin'); const serviceAccount = require("path/to/serviceAccountKey.json"); admin.initializeApp({ credential: admin.credential.cert(serviceAccount), storageBucket: "<BUCKET_NAME>.appspot.com" }); const bucket = admin.storage().bucket(); async function main() { const files = await bucket.getFiles(); files[0].forEach((file) => { const filePath = `./work/${file.name}`; console.log(filePath); file.download({destination: filePath}); }); } main().then();Google Cloud Storageへのアップロード
ローカルのworkディレクトリにあるファイルをStorage直下へアップロードします。
upload-storage.jsconst fs = require('fs'); const admin = require('firebase-admin'); const serviceAccount = require("path/to/serviceAccountKey.json"); admin.initializeApp({ credential: admin.credential.cert(serviceAccount), storageBucket: "<BUCKET_NAME>.appspot.com" }); const bucket = admin.storage().bucket(); async function main() { const files = await fs.readdirSync('./work'); files.forEach((file) => { const filePath = `./work/${file}`; console.log(filePath); bucket.upload(filePath); }); } main().then();
- 投稿日:2020-09-16T13:54:44+09:00
OrientJSとOrientDBの併用方法
このチュートリアルでは、Alibaba Cloud上でOrientDBを設定し、OrientDBと一緒にOrientJSの使い方を探っていきます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
前提条件
このチュートリアルは中程度の難易度と言えます。そのため、このチュートリアルでは、いくつかの関連する背景知識が必要となります。また、このチュートリアルを進める前に、いくつかの設定をしておくことも大前提となります。具体的には、以下のものが必要です。
1、Linuxのコマンドラインインターフェースの機能についての一般的な理解。
2、Alibaba Cloud の ECS セキュリティグループの一般的な理解。
3、Java(具体的には1.7以降)がインストールされており、関連する環境変数も設定されていること。
4、JavaScriptの一般的な理解。Alibaba Cloud ECSへのOrientDBのインストール
このチュートリアルの最初のステップとして、Alibaba Cloud Elastic Compute Service (ECS) インスタンスを作成する必要があります。このチュートリアルでは、Ubuntuがインストールされ、ワンコアプロセッサと512MBのメモリを持つECSインスタンスを作成します。次に、SSHを使用するか、Alibaba Cloudコンソールを介してインスタンスにログオンします。その方法については、まだ知らない場合は、このガイドをチェックしてください。
次に、適切なバイナリパッケージをインストールする必要があります。まず、OrientDBの最新の安定版リリースをダウンロードします。あるいは、ウェブサイトから手動でダウンロードするのではなく、以下のコマンドを使って OrientDB 3.0.21 をダウンロードしてみることもできます。
curl https://s3.us-east-2.amazonaws.com/orientdb3/releases/3.0.21/orientdb-3.0.21.tar.gzダウンロードが完了すると、最初に curl コマンドを入力したディレクトリに
orientdb-3.0.21.tar.gzという名前の zip ファイルが存在します。その後、zip ファイルの内容を展開し、環境変数ORIENTDB_HOMEの下の適切なディレクトリに移動します。現在のバージョンに応じた対応するコマンドは以下の通りです。
tar -xvzf orientdb-3.0.21.tar.gz: フォルダを解凍します。cp -r orientdb-3.0.21 /opt: フォルダ全体を/optディレクトリにコピーするために使用します。/etc/environmentの内容は以下のようにします。JAVA_HOME=/usr/lib/jvm/java-8-oracle ORIENTDB_HOME=/opt/orientdb-3.0.21 PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games :$ORIENTDB_HOME/bin"このチュートリアルの前提条件であるJava 1.7以降がインストールされていること、およびUbuntuでインストールされたインスタンスにスワップ領域が追加されていること、つまり、新しいインスタンスサーバーであり、まだインストールされていない場合です。
注: OrientDB を更新した後、必要であれば、このファイルをソースにして、新しい OrientDB の実行ファイルがターミナルで利用できるようにする必要があります。これに使用するコマンドは次のとおりです: source /etc/environment.
ここで、
ORIENTDB_DIRの代わりにORIENTDB_HOMEの OrientDB ディレクトリの場所(もちろんORIENTDB_HOME)と、USER_YOU_WANT_ORIENTDB_RUN_WITHの代わりに使用したいシステムユーザを入力して、ORIENTDB_HOME/binにあるorientdb.shファイルを編集する必要があります。OrientDBのインストールが完全に機能している状態で、以下のコマンドでOirentDBサーバを制御することができます。
orientdb.sh status: サーバが稼働しているかどうかをチェックするために使用します。orientdb.sh start: OrientDB サーバを起動するために使用します。orientdb.sh stop: OrientDB をシャットダウンするために使用します。ほとんどの場合、本番環境では非常に安全なインストールが必要です。つまり、どのユーザーも自分の意思でデータベースを起動したり停止したりする権限を持たないような、安全なOrientDBのインストールが必要になります。そのため、
OrientDB bin/orientdb.shファイルでは、USER_YOU_WANT_ORIENTDB_RUN_WITHの代わりに管理ユーザーを入力することができます。そうすることで、管理者としてOriendDBの最も賢明なコマンドの完全な権利を持つ唯一のユーザーになることを意味します。この種のことをもっと知りたい方は、OrientDBのドキュメントを見てください。
さて、これでこれらのことはすべて完了しましたので、次に進みましょう。
orientdb.sh startコマンドを実行してインストールをテストすることができます。次のスクリーンショットに示すように、ポータル、特にOrientDB Studioには、http://our_ecs_ip:2480またはhttp://localhost:2480のいずれかのアドレスからアクセスすることができます。
OrientDB に接続してダッシュボードにアクセスするためには、ここで説明したように
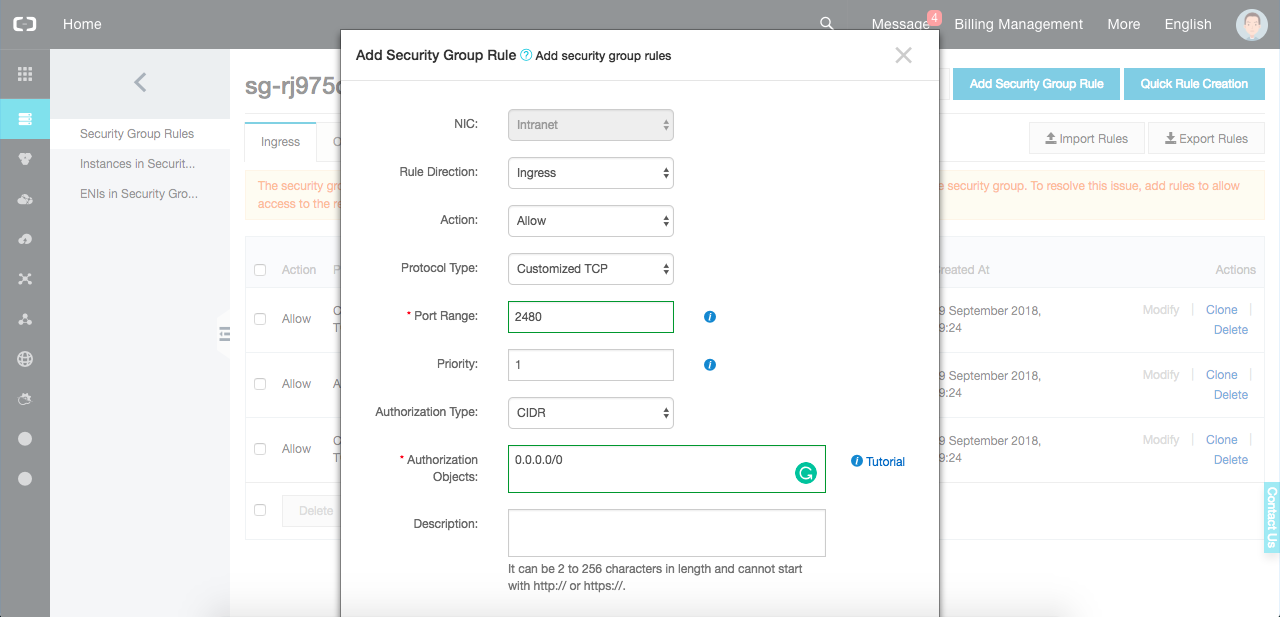
$ORIENTDB_HOME/config/oritdenb-server-config.xmlファイルの最後にユーザーを定義する必要があります。次に、2480番ポート(OrientDB Studioのポート)にインスタンスセキュリティグループを設定することを忘れないでください。
注: 外部からアクセスできるように設定する必要があります。
以下は、テスト用インスタンスの設定の出力です。
OrientJsの設定
OrientDBのOrientJSモジュールは、JavaScriptプロジェクトのための公式のOrientDBドライバとして記述することができます。これは、NodeJSの開発者の間で広く使われています。もちろん、他のパッケージと同様に、node package managerを使ってインストールするには、たった一つのコマンドが必要です。具体的には、ローカルにインストールするには、
npm install orientjsコマンドを実行します。そして、OrientJSがインストールされて初期化されると、以下のようなことができるようになります。
OrientJSの初期化
OrientJSとOrientDBを相互に連携させるための最初のステップは、サーバーAPIを初期化することです。これを行うことは、OreintJSがOrientDBのサーバーAPIと対話できるようにするために重要です。なぜなら、OrientDBサーバーのホストとそのポートにデータベースユーザーが接続されている必要があるからです。
// Initializing the Server API var server = OrientDB({ host: 'localhost', port: 2424, username: 'admin', password: 'admin' });注: この場合、ユーザー資格情報には
admin:adminを使用しています。しかし、これはOrientDB設定ファイルに設定した対応する資格情報に変更する必要があります。データベースのリスト
このチュートリアルの次のステップは、OrientJSを使って単一のクエリを実行して、ここまでに作成したすべてのデータベースを一覧表示することです。これに続いて、通常はDBオブジェクトを返すように、各データベースの名前とタイプを表示しています。
// Databases listing server.list() .then(list => { console.log(list.length + ' databases created so far'); list.forEach(db => { console.log(db.name + ' - ' + db.type); }); });データベースの作成
それでは、サーバーAPIからデータベースを作成する作業に移りましょう。これは比較的簡単です。この操作は、先ほど作成したデータベースオブジェクトとの約束を返す単一のコマンドでも行うことができます。
以下は、Create関数に関連するOrientJsの型の内容です。
/** * Create a database with the given name / config. * * @param config The database name or configuration object. * @promise {Db} The database instance */ create(name: string | DbConfig): Promise<Db>;この関数にコンフィギュレーション・オブジェクトまたは単にデータベース名を提供することで作成操作が完了することが明記されています。しかし、以下に示す2つ目のケースでは、デフォルト値は欠落しているフィールドのために選択されることになります。ここでは、設定オブジェクトを使ってデータベースを作成する方法を説明します。
// Creating a database server.create({ name: 'NewDatabase', type: 'graph', storage: 'plocal', }).then(dbCreated => { console.log('Database ' + dbCreated.name + ' created successfully'); });既存のデータベースを使用
データベースが作成された後は、後からインスタンスを取得して、より多くの操作を行うことができます。データベースのインスタンスを初期化するには、以下のメソッドを使用します。
var db = server.use('NewDatabase');バージョン2.1.11からは、ODatabaseクラスを使ってServer APIを初期化し、すぐにデータベースに接続することも可能になりました。そのための構文は以下の通りです。
var ODatabase = require('orientjs').ODatabase; var db = new ODatabase({ host: 'localhost', port: 2424, username: 'admin', password: 'admin', name: 'NewDatabase' }); console.log('Connected to: ' + db.name);レコードAPI
データベースインスタンスが初期化されると、保存されたレコード、つまりデータベースに保存された情報を、データベースのレコードID(RID)を使用して取得したり操作したりすることができます。
注意: レコード ID は一意の値なので、一般的な SQL ベースのリレーショナル・データベースのように、主キーを参照するフィールドをもう 1 つ作成する必要はありません。
レコードIDの構文は以下の通りです。
#<cluster>:<position>となります。このコードの場合
cluster:クラスタ識別子として機能します。これはクラスタが属するクラスタレコードを直接参照します。このパラメータの値は、正の値は永続的なレコードを示し、負の値は一時的なレコードを示します。position:クラスタへのレコードの絶対位置を指定します。 ここでは、レコードのRIDを指定して 1 つのレコードを取得してみましょう。db.record.get('#1:1') .then( function(article) { console.log('Loaded article:', article); } );レコードを取得したので、いくつかの操作について説明します。まず、削除操作です。一般的には、レコードの削除は比較的簡単で、以下のコードで行うことができます。
db.record.delete('#1:1');次に、更新操作です。レコードの更新は少し複雑ですが、それでも私の中では問題ありません。更新したい対応するデータが読み込まれた後に行うことができます。以下に、更新関数の実装方法を示します。
db.record.get('#1:1') .then(function(article) { article.title = 'New Title'; db.record.update(article) .then(function() { console.log("Article updated successfully"); }); });注意:このコードを使用する際には、以下のことを考慮してください。
- The an asterisk (#) prefix is required to recognize a Record ID. - When creating a new record, OrientDB selects the cluster to store it using a configurable strategy, which can be the default strategy, the round-robin one, or a balanced or local strategy. - Also, note that, in our example, #1:1 represents the RID.クラスAPI
データベースの派生オブジェクトは、クラスにアクセスしたり、作成したり、操作したりするために特別に使用されます。具体的には、"クラス "と言うと
db.classのことを指します。例えば、ここにクラスを作成するためのメソッドがあります。// Creating a new class(Article) using the Class API var Article = db.class.create('Article');既存のクラスを取得するには、以下のようにします。
var Article = db.class.get('Article');これらはすべてプロミスを返していることに注意しましょう。プロミスが解決したら、さらにアクションを実行することを意識したスタイルになります。現在接続しているデータベースに保存されているすべてのクラスのリストを返すには、次のコードを適用します。
// List all the database classes db.class.list() .then( function(classes){ console.log(classes.length + ' existing classes into ' + db.name); classes.forEach(cl => { console.log(cl.name); }); } );次に、作成操作があります。クラスを作成することは、データベース構造を完全に設計する前に知っておいた方が良いことです。私たちは、プロパティを操作する前に作業するクラスを正しくロードしなければなりません。
Articleのクラスのプロパティのリストは次のようになります。
db.class.get('Article').then(function(Article) { Article.property.list() .then( function(properties) { console.log(Article.name + ' has the properties: ', properties); } ); });プロパティの作成は、ほぼ同じ構文で行われます。
db.class.get('Article').then(function(Article) { Article.property.create([{ name: 'title', type: 'String' },{ name: 'content', type: 'String' }]).then( function(properties) { console.log("Successfully created properties"); } ); });クラスには1つのプロパティを設定するだけです。多くのプロパティを設定する必要はありません。では、いくつかのアクションを実行してみましょう。
まず、プロパティを名前で削除してみましょう。
db.class.get('Article').then(function(Article) { Article.property.drop('peroperty_to_drop').then(function(){ console.log('Property deleted successfully.'); }); });続いて、プロパティ名を変更してみましょう。
db.class.get('Article').then(function(Article) { Article.property.rename('old_name', 'new_name').then(function(p) { console.log('Property renamed successfully'); }); });Class API の詳細については、こちらのドキュメントを参照してください。
OrientDB でのクエリ
クエリは、データをより良く管理するために、データベースエンジンが提供する最も重要な操作の一つであり、OrientDBでは2つの方法のいずれかでクエリを実行することができます。直接SQLリクエストを発行するか、Query Builderを使用してNodeJsで暗黙的にクエリを構築するかのどちらかです。
// Find articles viewed 200 times var numberViews = 200; db.query( 'SELECT title, content FROM Article ' + 'WHERE number_views = :numberViews, { params: { numberViews: numberViews, } } ).then(function(articles) { console.log(articles); });上のクエリでは、200回閲覧された記事を探しています。このクエリは比較的簡単に実行できます。この可能性を利用してエンジンに命令を出す方法は、AND, OR, LIKEなどの演算子を使って、より面白いSQL構文を使うことができます。リクエストのサブストリングとパラメータを連結してSQL文字列を完全に構築するのではなく、パラメトリック化されたリクエストを使用するこの可能性(より簡単)。OrientDBのSQL構文についての詳細はこちらを参照してください。
SQL クエリを完全に記述する代わりに、代わりに Query Builder を使用することができます。クエリビルダは、データベースAPIアクションを通じて内部的にクエリを実行している特定のメソッドを呼び出すことができるように機能します。ここでは、SQL で行ったのと同じクエリを Query Builder で実行しています。
var numberViews = 200; var query = db.select('title, content').from('Article') .where({ "number_views": numberViews }) .all();イベント情報
OrientDBでは、イベントはコールバックメソッドとして機能し、クエリの終了時や開始時に実行することができます。イベントは、クエリのデバッグや、ログの記録、プロファイリング、データを調整するための特別なタスクの実行に便利です。イベントはデータベースに依存します。つまり、各イベントは単一のデータベースにアタッチされ、その作成には Database API を使用する必要があります。このAPIを使用する場合は、
db.on()関数を使用します。以下の例では、BeginQueryイベントを使用して、OrientDBサーバに送信された全てのクエリをログに記録しています。(クエリの終了にはendQueryを使用することもできます)。db.on("beginQuery", function(queryObj) { console.log('DEBUG: ', queryObj); });結論
このチュートリアルでは、Alibaba Cloud ECSインスタンス上でOrientDBを設定する方法を見てきましたが、OrientDBと一緒にOrientJSを使用する方法も探ってきました。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-16T11:47:11+09:00
Node.jsの特徴
プログラミング勉強日記
2020年9月16日
JSには色々なフレームワークがあって、開発の用途によって使用するフレームワークが違うと思うので、まとめてみようと思う。ReactについてとAngularについて、Vue.jsについて、Next.jsについて、Riot.jsについてまとめたので、今回はNode.jsについてまとめる。Node.jsとは
Node.js(読み方:ノードジェーエス)は、2009年に作成されたGoogle Chromeのために開発されたもので、JSアプリケーションのプラットフォーム。なので、ライブラリでもフレームワークでもない。
サーバーサイドJavaScriptで、PHPやRuby、Python、Javaと同様にサーバで動作を行う。軽量で効率よく作業できるので人気のJSライブラリ。特徴
- 大規模開発に向いている(大量接続を同時処理できる)
- C10K問題を解決できる
- フロントエンドのJSでも処理上の互換性がない
大規模開発に向いている(大量接続を同時処理できる)
軽量であるので、リアルタイムで複数人が使用する場合でも動作がもたつかない。Webアプリやスマホアプリの作成もNode.jsはしやすく、複数人が同時に接続する場合でも処理のパフォーマンスは落ちにくい。
つまり、多くのアクセスがあるアプリに向いている。C10K問題を解決する
サーバへの接続台数が1万台以上になると処理が遅くなってしまうのがC10K問題であり、この問題をNode.jsを使うだけで解決できるので、技術液なことに時間やコストを割かなくていい。
フロントエンドのJSでも処理上の互換性がない
Node.jsとフロントエンドのJavaScriptには、同じJSでも処理上の互換性がない。ただ、JSなのでプログラミング言語の基礎的な書き方や知識は活かせる。
参考文献
「.js」選びに迷った時に役立つ!人気のJavaScriptライブラリ&フレームワークまとめ!
初めてでもわかる!Node.jsの特徴やできることとは?
- 投稿日:2020-09-16T10:29:59+09:00
Trelloも要らない? Exmentでカンバンボードを運用してみる
BacklogやRedmineが要らないとか煽り記事書いてしまった筆者です。どうもです。
さて、Exmentでガントチャートを作ってしまったら、どうせならカンバンボードもやってみたくなるのが人情ではないでしょうか?
というわけで、やってみました。
Expressでフロントを作る
簡易原価計算の時や、ガントチャートの時と同じく、Express + Pugでフロント画面を作ります。
今回、フロントではSortable.jsというライブラリを用いました。HTMLの要素を自由にドラッグアンドドロップできるようになる魔法のようなライブラリです。
まずは、タスク表示のGET部分です。
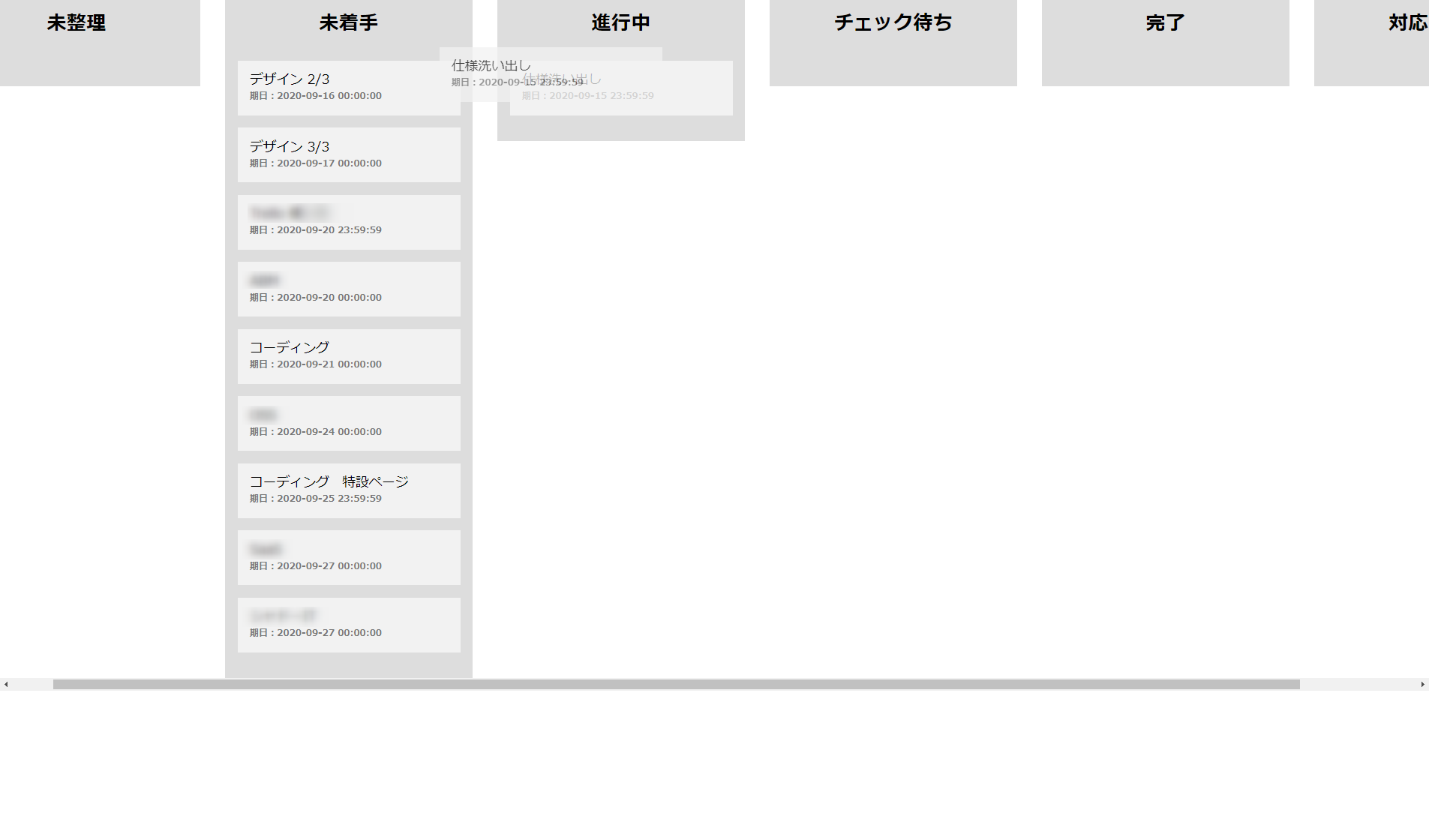
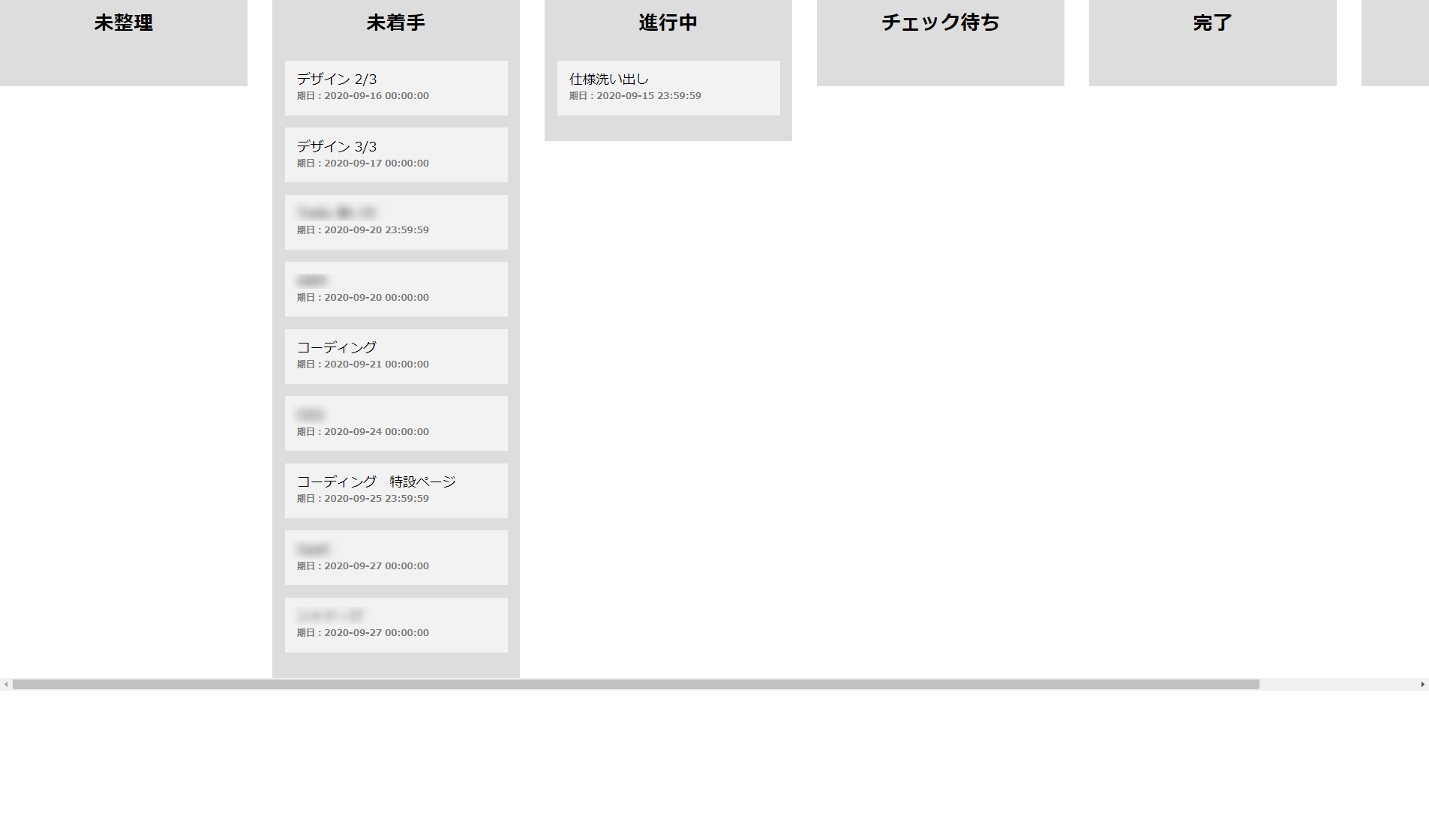
app.jsapp.get('/kanban', async(req,res) => { ;(async () => { const exmentToken = JSON.parse(await fs.readFileSync('./exment_tokens.txt')).access_token let tasksData = await axios.get('https://example.com/api/data/tasks/?orderby=start_at', { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { return res.data.data }) .catch(err => { console.error(err) }) let tasksArray = [] tasksData.forEach(item => { const id = item.id const name = item.value.title const status = item.value.status tasksArray.push({ id: String(id), name: name, status: status, endAt: item.value.end_at }) }) let statuses = await axios.get('https://example.com/api/column/86', { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { return res.data.options.select_item_valtext }) .catch(err => { console.error(err) }) statuses = statuses.split('\r\n') let statusData = [] statuses.forEach(status => { status = status.split(',') statusData.push({ id: status[0], title: status[1] }) }) // console.log(statusData) let payload = [] let i = 1 statusData.forEach(item => { const tasks = _.filter(tasksArray, { status: item.id }) let j = 1 const taskItems = () => { let taskItems = [] tasks.forEach(item => { taskItems.push({ id: `item-id-${j}`, exmentId: item.id, title: item.name, endAt: item.endAt }) j++ }) return taskItems } payload.push({ id: `board-id-${i}`, title: item.title, item: taskItems() }) i++ }) // console.log(payload) res.render('kanban', { payload }) })() })今回も、Exment側からデータを取得して、Sortableのデータ形式に整形しています。なんというか、JSONコネコネ屋さんって感じですね…
続いて、viewです。
kanban.pug<!DOCTYPE html> html(lang="ja") head meta(charset="UTF-8") meta(name="viewport", content="width=device-width, initial-scale=1.0") title Document . <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.min.css" integrity="sha512-NhSC1YmyruXifcj/KFRWoC561YpHpc5Jtzgvbuzx5VozKpWvQ+4nXhPdFgmx8xqexRcpAglTj9sIBWINXa8x5w==" crossorigin="anonymous" /> style. * { box-sizing: border-box; } [class^="wrapper-"] { background: #ddd; padding: 0; width: 300px; margin-right: 30px; flex: 0 0 auto; height: 100%; } [id^="board-id-"] { padding-left: 0; padding: 15px; } #boards { width: 100vw; overflow-x: scroll; display: flex; height: 100%; } .title { margin-top: 15px; text-align: center; margin-bottom: 0; } .item { background: #f2f2f2; list-style-type: none; padding: 15px; margin-bottom: 15px; margin-left: 0; } .item:last-child { margin-bottom: 0; } .due { font-size: 11px; color: #777; font-weight: bold; } body #boards each board in payload div(class="wrapper-" + board.id) h2.title=board.title ul(id=board.id).sortable if board.item each item in board.item li.item(data-exmentid=item.exmentId) =item.title br span.due=`期日:${item.endAt}` . <script src="https://cdnjs.cloudflare.com/ajax/libs/Sortable/1.10.2/Sortable.min.js" integrity="sha512-ELgdXEUQM5x+vB2mycmnSCsiDZWQYXKwlzh9+p+Hff4f5LA+uf0w2pOp3j7UAuSAajxfEzmYZNOOLQuiotrt9Q==" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/axios/0.20.0/axios.min.js" integrity="sha512-quHCp3WbBNkwLfYUMd+KwBAgpVukJu5MncuQaWXgCrfgcxCJAq/fo+oqrRKOj+UKEmyMCG3tb8RB63W+EmrOBg==" crossorigin="anonymous"></script> script. var boards = document.querySelectorAll('.sortable') var i = 1 boards.forEach(function(board) { new Sortable(board, { group: 'status', onEnd: function(event) { var newStatus = event.to.id.replace(/[^0-9]/g, '') var itemId = event.item.dataset.exmentid axios.put('/kanban', { id: itemId, status: newStatus }) } }) })これで
http://localhost:3000/kanbanにアクセスしてみましょう。
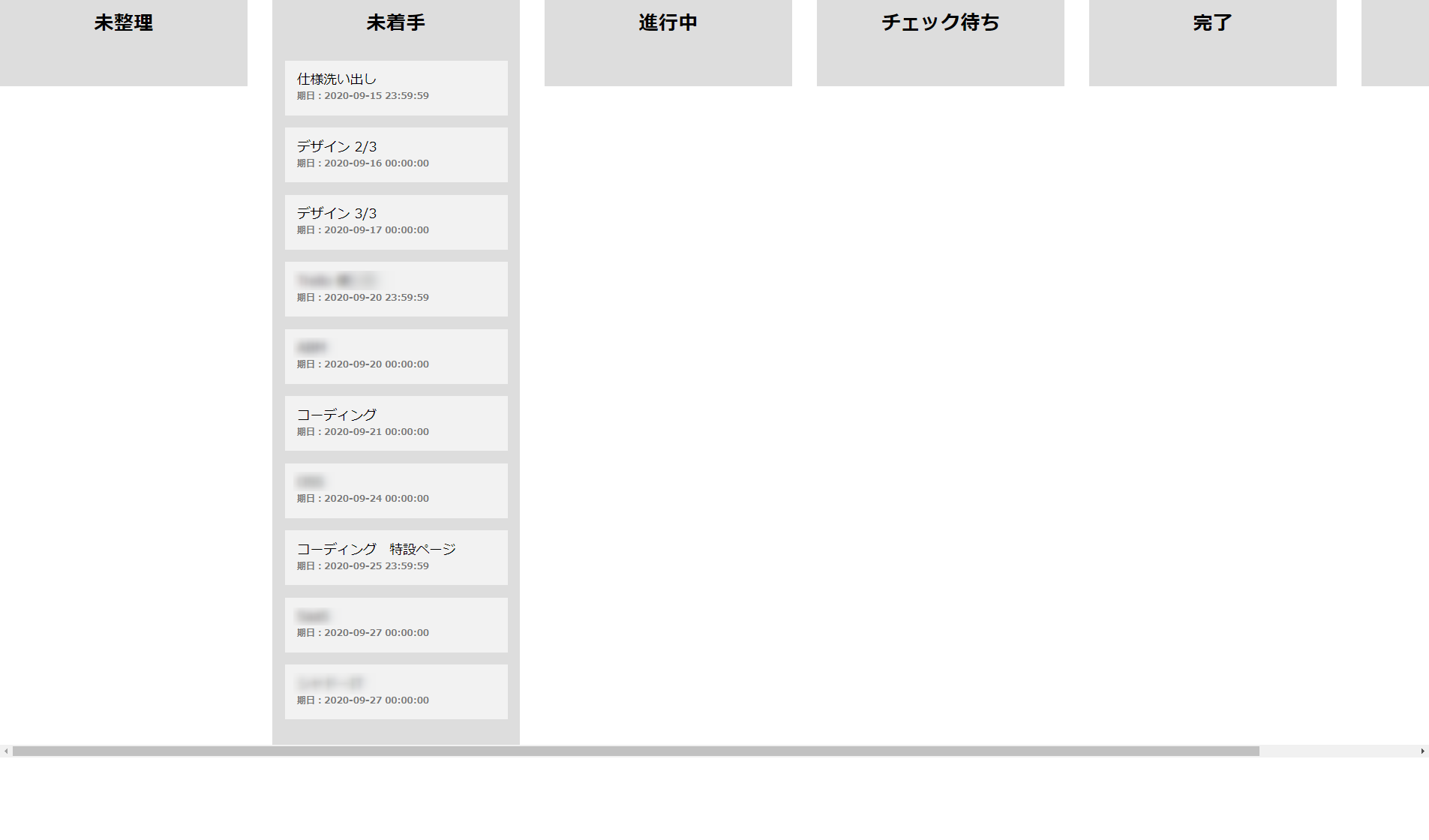
こんな感じになっていれば成功です!
なお、Trello風のUIを実現するCSSは、以下の記事を参考にしました。
カンバン間を移動したらステータスが変更されるようにPUTしよう
ガントチャートの時もそうでしたが、フロントで弄った時に、きちんとバックエンドに通信が飛んでデータが上書きされてほしいですよね。
Sortable.jsにもコールバックの仕組みがきちんと用意されているので、以下の技術を追記します。
kanban.pugscript. var boards = document.querySelectorAll('.sortable') var i = 1 boards.forEach(function(board) { new Sortable(board, { group: 'status', onEnd: function(event) { var newStatus = event.to.id.replace(/[^0-9]/g, '') var itemId = event.item.dataset.exmentid axios.put('/kanban', { id: itemId, status: newStatus }) } }) })オプションのプロパティ
onEndが、ドラッグアンドドロップを完了した時のコールバックです。
ここにExment側のAPIから持ってきたExmentのタスクのIDと、ボードのIDを取り込みます。SortableのボードのIDは、
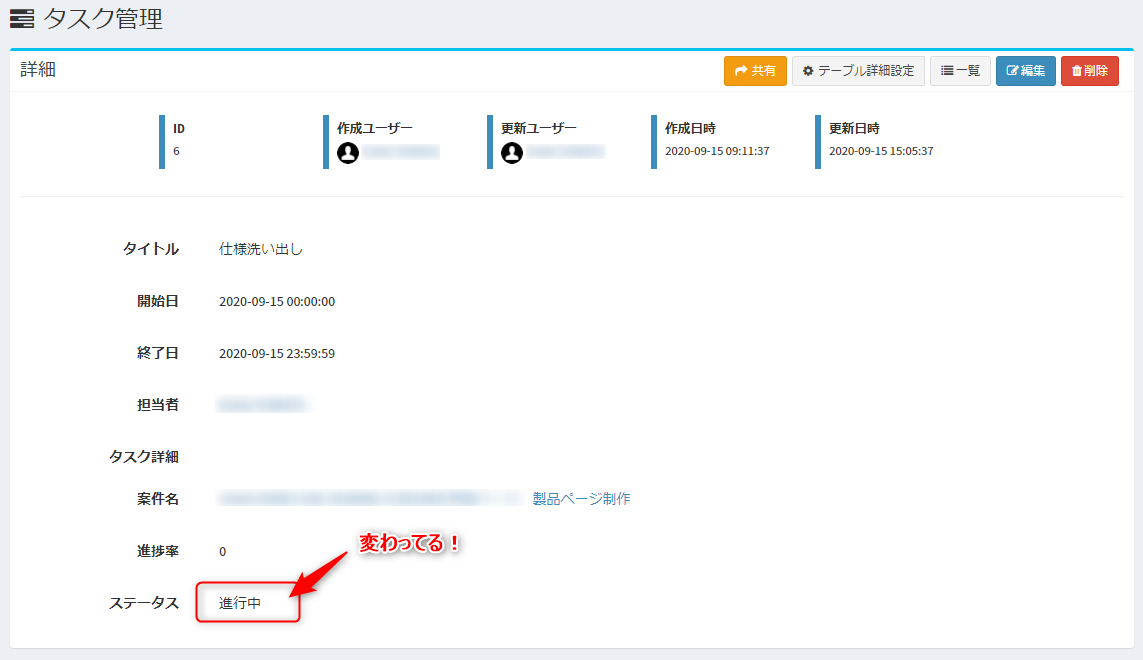
board-id-1みたいな感じなので、数字以外を取り払ってあげます。Exmentで設定した列設定では、enum型で値は数字を列挙しているので、ID番号=Exment側の値となります。最後にaxiosで、Express側にデータを投げます。
Express側はこんな感じです。
app.jsapp.put('/kanban', async (req, res) => { ;(async () => { const exmentToken = JSON.parse(await fs.readFileSync('./exment_tokens.txt')).access_token // console.log(req.body) await axios.put('https://example.com/api/data/tasks/' + req.body.id, { value: { status: req.body.status } }, { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { return res }) .catch(err => { console.error(err.response.data) }) })() })シンプルですね。タスクのIDをエンドポイントに付加して、PUTします。statusも、先程のボードのID番号を指定してあげれば、ステータスの状態と連動します。
動作確認してみよう
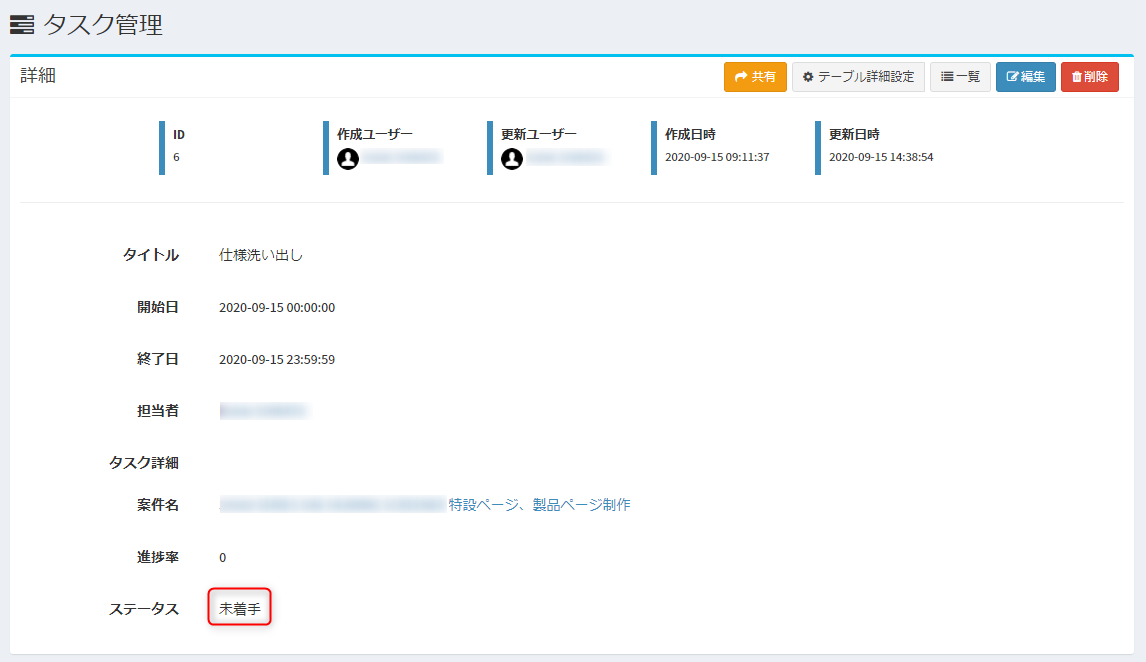
Exmentにアクセスし、カンバン上で動かす予定のタスクを確認しておきます。未着手になってますね。
カンバン上でドラッグ&ドロップしてみます。
ドロップ後、リロードしてみましょう。
また、Exment側もリロードして確認してみましょう。
きちんとステータスが変わっているのを確認できました!
課題もあります
まあ、ガントチャートの時ほどではないのですが、課題はあります。
縦方向の並びを変えるのが難しい
無理じゃないとは思うんですが、今回はExment側に並び順のフィールドを作ってないので、並べ替えられません。並べ替えも、並べ替えごとに番号を全部のタスクで書き換えないといけないので、API的にも負荷は大きそうです。
まとめ
というわけで、いかがでしたでしょうか。
この実装ではTrelloほど高機能な実装はしませんでしたが、簡易とはいえ、Exmentでガントチャートも、そしてカンバンも出来るとなると、これでタスク管理したくなってきませんか? もちろん、もっと作り込めば、Backlog/Redmine/Trelloに負けないタスク管理サービスを作ることも可能です。
興味持った方は、ぜひトライしてみてください!
- 投稿日:2020-09-16T07:29:24+09:00
ReactとWebRTCでZoomのようなビデオチャットアプリを作ってデータフローを図解してみた
はじめに
ご無沙汰しています。
約2年ぶりの投稿です?
早速本題から外れて自分のお話になってしまうのですが、
僕はとある会社にて約1年半ほどReactとWebRTCを用いて映像配信のアプリケーション開発を行ってきました。そこでは開発をスムーズに進める為にWebRTCのSDKを利用していて、
本来学習コストが高いとされているWebRTCをカジュアルに利用することができています。
しかし、より入り組んだ実装をしたり映像配信特有の問題(後述)を解決するとなると以下3つのWebAPIの理解は避けて通れません。詳しくは文中に記載しますがこれらの理解を深めないと開発の進行に大きな影響があると思ったので、WebRTC関連のライブラリ等を利用せずに映像配信のアプリケーションを作って学習しようという考えになり、実際に作ってみました。
それがこれです!
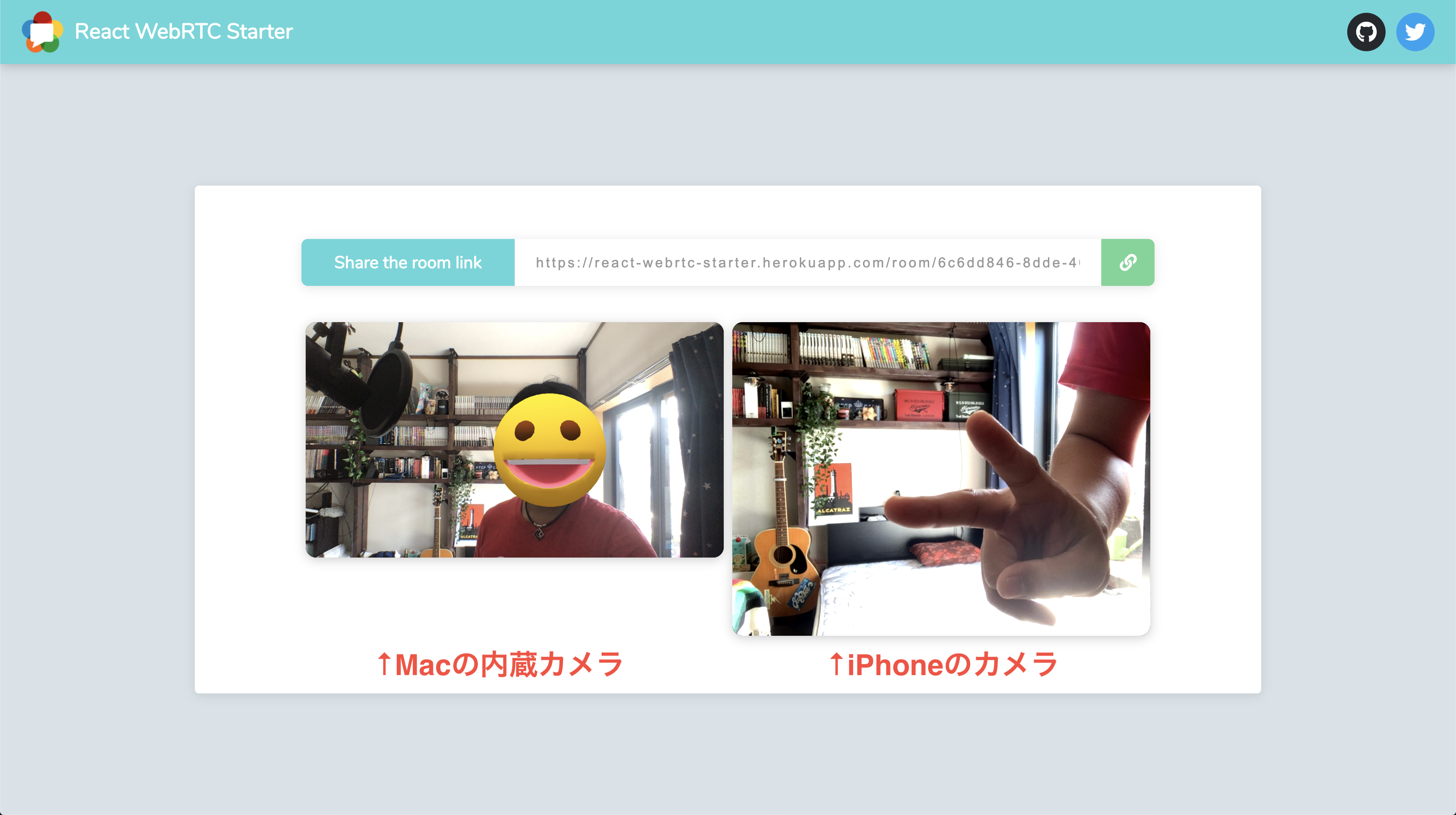
リンク: https://react-webrtc-starter.herokuapp.com※ Herokuに上げたので初回起動の場合コンテンツレンダリングが遅めです?
このスクショでは何をやっているのか端的に説明しますと、まずMacで上記リンクにアクセスして部屋を作成します。
続いてその部屋にiPhoneからアクセスをすると、既に部屋に入っているユーザー(Mac)と映像や音声(MediaStream)を交換することで相手と会話をすることが可能となります。これはSFU(後述)と呼ばれる仕組みを使った双方向通信といわれるもので、別々のデバイスから流す映像や音声を特定のサーバーを経由して送り合うということをやっています。
この記事で話す内容
表題の通り、別々のデバイスで映像と音声のやり取りを行う上でのデータフローについて自分なりの解釈を述べていきたいと思っています。
アプリケーションの技術スタックであったり実際のコードについて興味がある方は、公開リポジトリを用意してるのでそちらを見てもらえればよいのかなと思うので、今回はWebRTCに焦点を当ててこんなハマりどころがあるとか、こんなところが歯痒いとかそういう使用感について取り上げていきたいと思います。※ 本文では後述するSFUという通信方式である前提で執筆しているので、一部偏った表現があるかもしれませんが予めご了承くださいまし。
リポジトリ: https://github.com/yuyake0084/react-webrtc-starter
WebRTCについて
1. そもそもWebRTCって何?
アカデミックな話はできないし知らないので端的かつ自分の理解で言ってしまうと、Webブラウザというツールを介して音声や映像を相互に送り合ってリアルタイムコミュニケーションをWebで実現することができる仕組みのことを指します。
※ WebRTCとはWeb Real-Time Communicationの略称WebRTC以外でWebというプラットフォームを使ってリアルタイムコミュニケーションをするとなれば、WebSocketを用いてのテキストチャット等が挙げられますね。
そのテキストチャットと明確に異なるのは、MediaStream(音声・映像)を用いてのリアルタイムコミュニケーションが実現可能になるということです。2. リアルタイム通信を行うにあたって必要な情報
Webを介しているとはいえお互いの情報を交換し合わなければMediaStreamを送り合うことができないので、
RTCPeerConnection(以下、PC)から提供されているAPIを利用して、通信している人同士で特定のデータを送り合う必要があります。
それが以下2つで、どちらもWebSocketを介して相手に送る。⭐️ SDP(Session Description Protocol)
利用しているブラウザで配信可能なコーデックの種類だったり、セッション情報、通信相手の情報等が記載されている文字列。
PCのcreateOfferやcreateAnswerというものを行って以下のオブジェクトを作成する。
かなり長いのでDevToolのconsoleで読むのはちょっと辛い。{ type: "offer", // or answer sdp: "v=0↵o=- 7548328979379926014 2 IN IP4 127.0.0.1↵s=-↵t=0 0↵a=group:BUNDLE 0 1↵a=msid-semantic: WMS HLYst9oarpp0MHhOHH47iyqzgQypSVIAM3Zq↵m=audio 9 UDP/TLS/RTP/SAVPF 111 103 104 9 0 8 106 105 13 110 112 113 126↵c=IN IP4 0.0.0.0↵a=rtcp:9 IN IP4 0.0.0.0↵a=ice-ufrag:uJVj↵a=ice-pwd:iDqHChd7qahzFuRfZMiAdnN5↵a=ice-options:trickle....." // まだまだ続く }⭐️ ICE(Interactive Connectivity Establishment)
相手との通信経路が記載された文字列。
SDPをsetLocalDescriptionを使って自身が保持しているPCに格納すると、
そのPCでicecandidateイベントが発火するのでそのイベント内に格納されているのが以下オブジェクト。{ type: "candidate", candidate: "candidate:669691712 1 udp 2122260223 172.16.100.225 63152 typ host generation 0 ufrag xLmL network-id 1 network-cost 10" }3. 通信方式は主に3種類
特定の相手と通信するにあたってお互いの
WebRTCを用いてサービス開発をする方にとってはその要件次第で以下の3つから通信方式を選定すると思います。
- P2P(Peer-to-peer)
- MCU(Multipoint Control Unit)
- SFU(Selective Forwarding Unit)
? P2P(Peer-to-peer)
サーバーを介さず直接端末(ブラウザ)同士で接続する通信方式。
高解像度で視聴できるがそれ故にモバイル端末に於いてはデコードにかかるCPUへの負荷が高い。? MCU(Multipoint Control Unit)
音声と映像(ストリーム)をサーバーで結合してそれをクライアントに提供する通信方式。
PCのコネクションが1本しか無い為クライアントサイドの負荷は低いが、
サーバーサイドは音声と映像を結合する為のエンコード処理が走る為負荷が高い。(それに付随して遅延が発生するリスクがある)⭐ SFU(Selective Forwarding Unit)
MCUと同じくサーバーを介してストリームを提供し合う通信方式。
しかしMCUと異なるのは、サーバーはクライアントから送られたストリームを結合せずに他の配信者に流す役割を持っている。冒頭にも記載しましたが、本記事で紹介したアプリケーションはSFUを採用しています。
理由は単純で、チームでSFUを利用しているので同じ仕組みを使った上で挙動を把握したかった為です。複数人でビデオチャットをするにあたってのデータフロー
ここまででビデオチャットを行う上で必要最低限の前提知識は紹介させて頂いたので、
実際にお互いの映像が映るまでのデータフローを追いかけてみましょう。1. 部屋の作成
特定の人同士でクローズドなチャットを行うにはまず最初に部屋の作成を行う必要があります。
下記図ではAさんが「XXXX-XXX-XXXX」というRoomIdの部屋を作成しました。2. Bさんが入室
続いてBさんはAさんが作成したXXXX-XXX-XXXXの部屋に入室します。
前提として、この時のBさんはWebSocketに接続しているけれどAさんの映像は写っていない状態です。
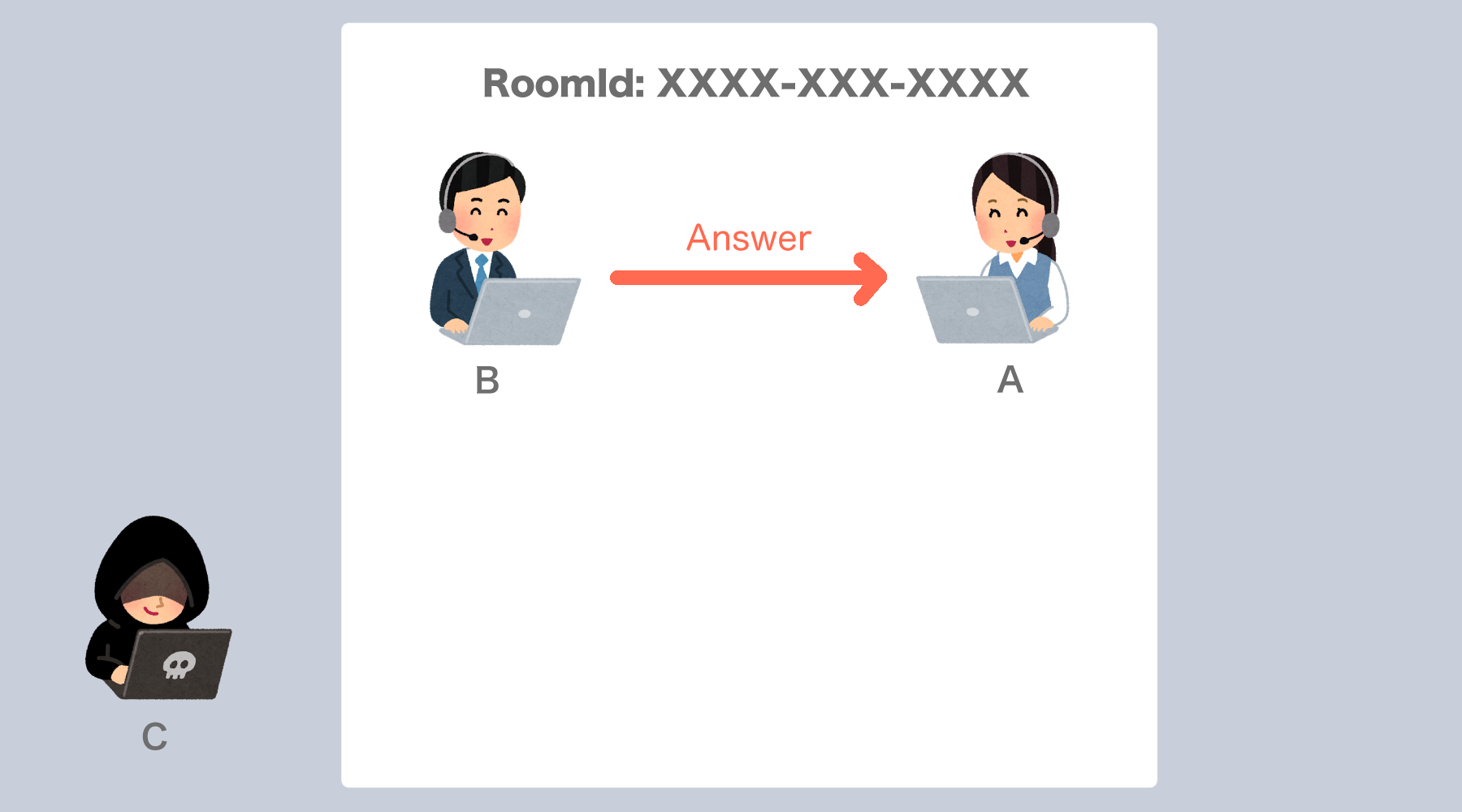
なのでBさんはまず、「入室しましたよ!」という旨をWebSocketを介して入室中のユーザーに伝えます。3. AさんからBさんへOfferを送る
ちょっとここはやや複雑なので最初にここでやってることを簡潔に述べると、 「私(Aさん)はこういう者ですけれど、あなたはどちら様ですか??」 という質問を新しく入室してきたユーザーに対して投げかける、ということをやっています。Callが届いたAさんはまず最初に
pc.createOffer()でSDPを作成します。
作成されたSDPはCall主であるBさんに返すのですが、Bさんとの通信経路を確立する必要があります。
ここでいう通信経路とは互いの映像と音声を送る上でのPC上でのMediaStreamの通り道をイメージしてもらうと良いと思います。
簡易的なコードを用いて説明すると以下の通り。const pc = new RTCPeerConnection(...) // 接続するクライアントごとにPCを生成。引数にはSTUNサーバーの情報とか色々渡す const sessionDescription = await pc.createOffer() // SDP生成 // setLocalDescriptionが実行されると発火 pc.onicecandidate = (e: RTCPeerConnectionIceEvent): void => { console.log(e.candidate) // イベント経由で得られる経路情報。これをWebSocketを使って相手に送る } await pc.setLocalDescription(sessionDescription)具体的に説明すると、まず最初に
pc.setLocalDescription(SDP)を実行します。
引数のSDPは上記のpc.createOffer()で生成されたSDPと同一のものです。
pc.setLocalDescription(SDP)が実行されると該当するpcから通信経路が確定するまでicecandidateイベントが発火され続けます。
このイベントを契機に通信相手に対してSDPを送るのですが、方法としては以下の2種類があります。⭐ Trickle ICE
上記のicecandidateイベントは経路情報が確定するまで何度か発火するのですが、発火される度に収集した経路情報があればWebSocketで即座にサーバに送りつけるのがTrickle ICEです。pc.onicecandidate = (e: RTCPeerConnectionIceEvent): void => { if (!!e.candidate) { const data = { toId: clientId, roomId: this.roomId, sdp: { type: 'candidate', ice: e.candidate, }, } this.socket?.emit(types.CANDIDATE, data) } }⭕ メリット
Vanilla ICEと比較して部屋にいるユーザーとの通信確立の時間が短い❌ デメリット
イベントが発火される度に小出しで送る為、仮にネットワーク不安定等の理由でうまく送れなかった場合経路情報に欠損があるとうまく通信ができなくなる可能性がある⭐ Vanilla ICE
経路情報が確立するとpc内部にlocalDescriptionが用意されるので、それを1度だけ送るようにするのがVanilla ICEです。pc.onicecandidate = (e: RTCPeerConnectionIceEvent): void => { if (this.pc?.localDescription) { this.sendSDP(this.pc.localDescription) } }⭕ メリット
Trickle ICEと比較して安定した通信経路の送信が可能❌ デメリット
Trickle ICEと比較して通信経路確立までの時間が長い今回僕が作ったアプリケーションではTrickle ICEを採用していますが、どちらが良いかは作成するアプリケーションの性質によって異なると思うので適宜使い分けると良いのかなと思います。
4. BさんからAさんに対してAnswerを返す
AさんからSDPが送られたらBさんの手元にもAさんとのPCが作成され、
Aさんに対してBさんのSDPを乗せてAnswerを返します。
また、3同様Aさんとの通信経路を確立します。
5. AさんとBさんのコネクションが確立?
SDPの交換が成立した時点で、PCの
addstreamイベントが発火し、相手のMediaStreamを受け取ることができます。
MediaStreamを受け取ったタイミングで新たにvideoタグを生成し、srcObject属性に受け取ったMediaStreamを渡すことで自身のブラウザ上で相手の映像と音声を再生することができる為、ここでようやくコネクションが確立したと言えるのかなと思います。
長くなってしまいましたがデータフローの説明については以上です。
厳密には異なりますが、Cさんが入室した場合でも上記の入室フローとほぼ一緒の挙動となります。(記事の尺的な都合上Cさんの出番無くなってしまった。。。)
映像配信特有の問題とは?
例を上げると、配信映像が意図しないタイミングで切断してしまったり、音声は聴こえるが映像が固まったままの状態になってしまうことが稀にあって、要因については様々です。
ネットワーク帯域幅が低かったり、利用しているブラウザとそのバージョン、果てには利用している端末でWebRTCとの相性なんてものもあったりしますし、これら以外にも存在するあらゆる問題全てを網羅的にカバーするのはほぼ不可能です。
しかし、映像系のサービスに対して課金を行なったが、映像が止まってしまったことによって課金額に見合うだけのサービスが提供されなかったエンドユーザーにとっては、そんなことは関係ないですし、まともに動作しないサービスとして不信感を持たれてしまうことになります。
網羅的にカバーすることは不可能であるにしても、エンドユーザーからお問い合わせがあった際にどこに原因があったのかを特定できるようにログを残して根気強くその調査を行って、そのログから得られた知見を基に映像停止の発生を抑制できるような方法を模索し続けていく努力を怠ってはいけないので、手探りしながらでも改善の糸口を掴んでいきたいと思っています。
まとめ
最後の方は映像配信特有の問題のところでマイナスな表現をしてしまいましたが、その仕組自体はとてもおもしろいものですし、コロナ時代で他者と円滑なコミュニケーションを取るにあたってWebRTCという技術はなくてはならない存在だと思うので、引き続き情報をキャッチアップしていきたいと思います。
ではでは✋大変参考になった記事