- 投稿日:2020-09-08T23:53:00+09:00
フォロー機能の実装
環境
Rails 6.0.3.2
ruby 2.6.5p114 (2019-10-01 revision 67812)
vscode参考記事
https://qiita.com/Kaisyou/items/86869db6345c9cc1413f
https://qiita.com/search?sort=&q=%E3%83%95%E3%82%A9%E3%83%AD%E3%83%BC%E6%A9%9F%E8%83%BDエラー
フォローボタンを押すと、
やはりエラーと遭遇。解決の糸口・・・
followingsをfollowingと変更したり、細かな記述を変更しても、エラーから抜けられない。
どこを直せばいいのか分からなかったので、沼にはまってしまう。(実際、このエラーを解決するのに2日費やすことになる。)解決方法
app/models/relationship.rbclass Relationship < ApplicationRecord belongs_to :user belongs_to :follower, class_name: 'User' belongs_to :following, class_name: "User" validates :follower_id, presence: true validates :following_id, presence: true endこの中に今回の沼の元凶があるのだが分かるだろうか?
それはbelongs_to :userである。
belongs_to を記述することで、userを要求することになってしまった。
今回のfollow機能の場合、followerとfollowerとで事足りるため、belongs_toでuserを要求する必要はないのである。1つのRelationshipにつき、一人のuserを割り当てる必要はないため、今回の場合は2行目は不要となる。belongs_toの詳細についてはhttps://railsguides.jp/association_basics.html#belongs-to%E9%96%A2%E9%80%A3%E4%BB%98%E3%81%91
結論
基本は重要であることを学びました。
対応してくれたメンターの方、ありがとうございました。
- 投稿日:2020-09-08T23:34:53+09:00
administrate で refileを使ってファイルを読み込めるようにしたい【rails6】
ハードはMacBook Air, 開発環境はVScodeを用いています。
ruby2.6.5
rails6.0.3.2rails6で管理者gemにadministrate, 画像読み込みgemにrefileを用いた時に, administrateとrefileの連携でハマってしまったので, その詳細と解決方法を紹介します.
ちなみに、administrate_field_refileはrails6に対応していなかったので、使わない方向で頑張りました!
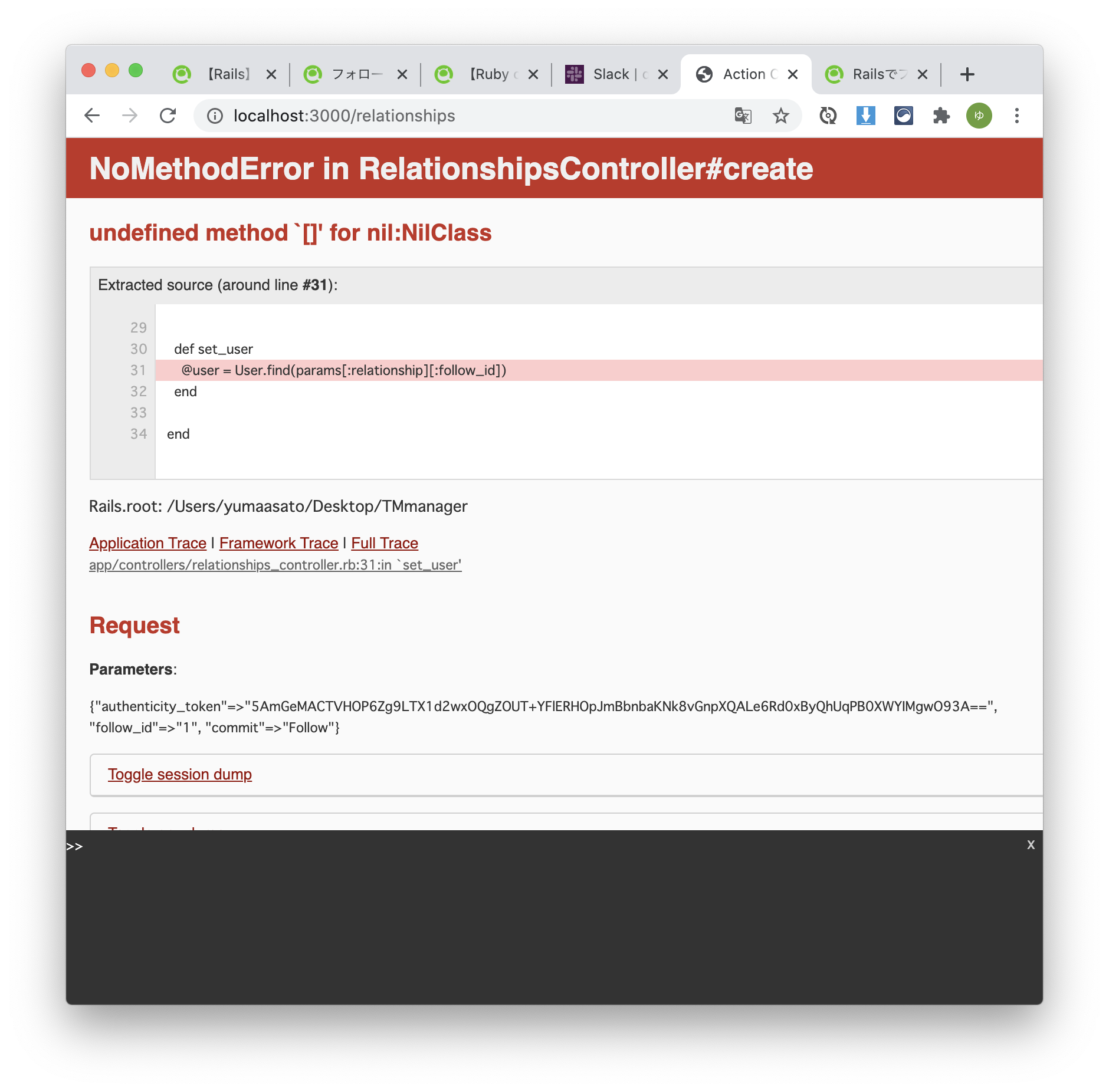
管理者画面(localhost:3000/admin)で, 新しいデータを追加しようとすると, 画像の入力部分がファイル選択ではなく, テキストボックスになってしまっている
localhost:3000/admin へ移動し, 新規Userを作製しようとすると, profile_imageの部分がテキストボックスになっています。(二枚目の画像の一番下)
そこでこれを解決するために, いろいろ調べてみるとadministrate_field_refileというgemがあるらしいのですが、こちらはrails6に未対応だったので、administrateをカスタムする方向で進めることにしました。
administrateをカスタムする
まず先にadministrate内部のコード、カスタムするであろう部分をローカルで表示できるようにします。administrateのドキュメントを参考に、dashbordのコントローラ, views, fieldを追加していきます。
$ rails generate administrate:dashboard User $ rails generate administrate:views User $ rails generate administrate:field refile次に、dashbordの profile_image_id: Field::String, となっているところを次のように書き換えます。参考;http://administrate-prototype.herokuapp.com/adding_custom_field_types
app/dashboards/user_dashboard.rbATTRIBUTE_TYPES = { ~省略~ profile_image_id: RefileField, }.freeze次にフォームのviewsをテキストボックスからファイルを選択に変更します.
app/views/fields/refile_field/_form.html.erb<div class="field-unit__label"> <%= f.label field.attribute %> </div> <div class="field-unit__field"> <%= f.attachment_field :profile_image, direct: field.direct, presigned: field.presigned, multiple: field.multiple %> </div>次に, app/fields/refile_field.rbを次のように書き換えます.
app/fields/refile_field.rbrequire "administrate/field/base" class RefileField < Administrate::Field::Base def to_s data end def direct options.fetch(:direct, false) end def presigned options.fetch(:presigned, false) end def multiple options.fetch(:multiple, false) end endこのままだと、Unpermitted parameters:という赤い文字がコンソールに表示されて画像を設定できないと思うので、以下で許可します。(~~~には, 登録する要素を入れておく。抜けがあると、ターミナルに赤く表示されるので、その都度確認して追加する)
def resource_params params.require(:user).permit(:profile_image,:~~~,:~~~,:~~~) end恐らくこれでadministrateから画像データを登録できるようになると思います。
パスワードとかも設定できるようにしたい、もっと登録画面を見やすくしたいという人は、以下を参考にしてみてください。
http://blog.319ring.net/2016/05/14/custom_view_administrate/
役に立ったら是非LGTMボタンをポチッと押していただけると嬉しいです
- 投稿日:2020-09-08T23:10:12+09:00
【Rails】本番環境でのデータベースをリセット
はじめに
【前提】
・Railsを使用してアプリケーションを開発
・AWSを使用
・EC2(AWSが提供する仮想サーバ)にてWebサーバを作成既存のデータベースをリセット
今まで私自身ローカル環境にて開発を行うにあたり、DBをリセットしたいことがあった場合
rails db:risetを使用し、DBの再作成を行なっておりました。今回デプロイ後ですが、マイグレーションファイル等に変更を色々と加えたため、
一度本番環境でもリセットし、再構築しようと考えました。本番環境でのデータベースリセット
RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rails db:dropこのコマンドで本番時でのDBをリセットすることができます
(本番環境でのDBリセットは、実務ではありえるのでしょうか・・)再度データベースの内容を反映させる
rails db:migrate RAILS_ENV=productionおそらくデータベースが無いですよ?とエラーが帰ってくる方がいると思いますので、再度createしてあげます。
rails db:create RAILS_ENV=production rails db:migrate RAILS_ENV=production rails db:seed RAILS_ENV=production※シードに情報を記載していない方は、最後の1行は不要です
上記コマンドを使用すれば本番環境へ無事変更点等が反映されているはず・・・上記記載内容では、こういったリスクがあるのでは等の改善案や提案がございましたら、
コメント等にてお伝えいただければありがたいです。以上、ご参考になれば幸いです。
- 投稿日:2020-09-08T22:54:45+09:00
Railsのformを素のJavaScriptで送信する
やりたかったこと
form送信後にJS側で何かしらの処理をしたい。
方法
fetchAPIのコールバックチェーンで行うことができる。
turbolinksやrails-ujsは使用しないので、remote: trueを使ったAjax通信とも異なるやり方。「form送信後のJS処理」を、
当初form.submit() ~ setTimeout()のような感じで書いたが、実行順序が担保されなかったので書き直した。ポイント
fetchでは
1.credentialsに'same-origin'
2.bodyにnew FormData(form)
を指定。
= f.submitや%button{ type: 'submit' }を使うと Railsによってリクエストが飛ばされてしまうので、%button{ type: 'button' }を使って送信ボタンをクリックしたときにJavaScriptを呼び出すようにしている。サンプル
あまりサンプルがなかった気がするのでさらっと残す。
送信ボタンを押した後に二度押せないようにする処理も入れてるが、もっとちゃんとした書き方はあるのかも。const userForm = document.getElementById('user-form'); const submitBtn = document.getElementById('submit-btn'); submitBtn.addEventListener('click', () => { submitBtn.textContent = '送信中...'; submitBtn.disabled = true; fetch('/users', { method: 'POST', credentials: 'same-origin', body: new FormData(userForm), }).then(response => { // 送信後の処理があればここに書く }).catch(error => { // 例外処理 }); });= form_with(model: @user, id: 'user-form') do |f| = f.text_field :name = f.text_field :mail %button{ type: 'button', id: 'submit-btn' } 送信追記
コントローラ側でリクエストを受け取るアクションに、
protect_from_forgeryを適切に使わないとうまくいかないかも。参考リンク
他の参考リンクは忘れてしまったので思い出したら書く。
- 投稿日:2020-09-08T22:16:07+09:00
今更ながら graphql-code-generator の便利さを痛感する
はじめに
今日も今日とて、フロントReact + バックRailsのSPA + APIのアプリ開発していたところ
TypeScriptのReact側で、react-apolloの型宣言がめんどくさいと思っていました。
バックエンド側はGraphQLを使用しているので、いろんなところに型宣言をしているようにも感じて、微妙。。
そこでgraphql-code-generatorを使っていろいろ気持ち悪い部分を解消していこうという話をします。
今回の構成
フロントエンド
- React(SPAで)
- TypeScript
- create-react-app
- React Apollo
バックエンド
- Ruby
- Rails(APIで)
- GraphQL
※上記2つのリポジトリはこちらのリポジトリから連動させる仕組みとしました。(開発環境として)
とりあえずApolloの公式通りにやってみる
バックエンド側に
todosという、Todoモデルにあるデータを全て取得するAPIを作成しておきました。これをフロントエンド側で取得し、表示します。
src/App.tsx+import { gql, useQuery } from "@apollo/client"; import React from "react"; import logo from "./logo.svg"; import "./App.css"; +const TODOS_QUERY = gql` + query { + todos { + name + } + } +`; const App = () => { + const { loading, data } = useQuery(TODOS_QUERY); + return ( <div className="App"> <header className="App-header"> <img src={logo} className="App-logo" alt="logo" /> <p> Edit <code>src/App.tsx</code> and save to reload. </p> - <a - className="App-link" - href="https://reactjs.org" - target="_blank" - rel="noopener noreferrer" - > - Learn React - </a> + {loading ? ( + <p>Loading ...</p> + ) : ( + <ul> + {data && data.todos.map(({ name }, i) => <li key={i}>{name}</li>)} + </ul> + )} </header> </div> ); }; export default App;型宣言していないので、エラーが出ましたね。
型宣言してあげます。
用意する型は、
Todoモデルの型と、レスポンス値の型です。レスポンスは
{"data":{"todos": []}という値が返るようにしています。interface Todo { name: string; } interface TodosData { todos: Todo[]; }
TodosDataを以下のように使います。- const { loading, data } = useQuery(TODOS_QUERY); + const { loading, data } = useQuery<TodosData>(TODOS_QUERY);エラーなく実行できました。
では、
GraphQL Code Generatorが入っていたらどうなるか試してみます。GraphQL Code Generatorを使う
公式の手順通り、インストールとセットアップ
https://graphql-code-generator.com/docs/getting-started/codegen-config
$ yarn add -D @graphql-codegen/cli @graphql-codegen/typescript @graphql-codegen/typescript-operationspackage.json"scripts": { "generate": "graphql-codegen" }バックエンド側に用意しているエンドボインとは
http://localhost:5000/graphqlなので、schemaにこれを使います。codegen.ymlschema: http://localhost:5000/graphql documents: ./graphql/queries/*.graphql generates: ./src/types.d.ts: plugins: - typescript - typescript-operations※
documentsオプションを使用する場合に、@graphql-codegen/typescript-operationsが必要みたいです。
documentsに指定した場所に、todosのクエリを記載します。graphql/queries/todos.graphqlquery { todos { name } }バックエンドを起動してある状態で、用意した
generateコマンドを実行してみます。$ yarn generate
src/types.d.tsファイルが生成されました。src/types.d.ts...省略... export type Unnamed_1_QueryVariables = Exact<{ [key: string]: never; }>; export type Unnamed_1_Query = ( { __typename?: 'Query' } & { todos: Array<( { __typename?: 'Todo' } & Pick<Todo, 'name'> )> } );
Unnamedとなってしまっているので、クエリに名前をつけて再度実行します。graphql/queries/todos.graphql-query { +query todos { todos { name } }
src/types.d.tsファイルにTodosQueryというTypeが定義されました。これを
useQueryの型に利用してみます。src/App.tsx+ import { TodosQuery } from "./types.d"; - const { loading, data } = useQuery<TodosData>(TODOS_QUERY); + const { loading, data } = useQuery<TodosQuery>(TODOS_QUERY);同じように動作が確認できました。
src/App.tsxにTodoモデルの型と、レスポンス値の型を定義しなくて良くなりました。でも、TODOデータを取得する為のクエリを
src/App.tsxとgraphql/queries/todos.graphqlの2箇所に書いているのが気持ち悪いですよね。
todosを取得する為の専用のuseQueryがあれば型もクエリも渡さなく済むのに。。。@graphql-codegen/typescript-react-apolloを導入する
todosを取得する為の専用のuseQueryがあれば型もクエリも渡さなく済むのに。。。ということで、この気持ち悪いを解消していきます。
まずはインストール
$ yarn add -D @graphql-codegen/typescript-react-apollo
typescript-react-apolloを追加します。codegen.ymlschema: http://localhost:5000/graphql documents: ./graphql/queries/*.graphql generates: ./src/types.d.ts: plugins: - typescript - typescript-operations + - typescript-react-apollo生成コマンドを実行
$ yarn generate
src/types.d.tsにuseTodosQueryという関数が生成されたので使ってみます。src/App.tsx- import { TodosQuery } from "./types.d"; + import { useTodosQuery } from "./types.d"; - const { loading, data } = useQuery<TodosQuery>(TODOS_QUERY); + const { loading, data } = useTodosQuery();ちゃんと動きましたね。
GraphQLの便利なところとして、同じAPIでも、必要なフィールドのみを取得することができる特徴があります。
先ほど、
todosのデータを取得する際、nameのみ指定し取得、一覧表示のような機能を実現しました。これを個別に、編集、削除といった機能を実現するには、
nameがユニークでない限り、idのようなもので、
todoを特定する必要があります。別の画面等で、
nameに加え、idも必要な場面があった場合、以下のようなクエリを別で作成したくなってきます。query todos { todos { id name } }しかし、
graphql-code-generatorで生成する関数は全て、src/types.d.tsに入るように設定しています。ここには既に、
nameのみを指定したtodosを取得するクエリの関数が存在しているので、以下のようなファイルを作成し、
yarn generateを実行すると、Not all operations have an unique nameというエラーが発生します。graphql/queries/todosIncludeId.graphqlquery todos { todos { id name } }
queryの右に記載している名前が、ユニークでないといけないってことですね。graphql/queries/todosIncludeId.graphql-query todos { +query todosIncludeId { todos { id name } }
queryの名前をユニークな名前に変更してみました。すると、
src/types.d.tsにuseTodosQueryとは別に、useTodosIncludeIdQuery関数が生成されました。GraphQLの便利な特性を潰すことなく利用できますね。

参考文献



- 投稿日:2020-09-08T21:59:15+09:00
rails + vue.js でテンプレートインジェクション対策をする
テンプレートインジェクションって?
テンプレートエンジンやjsのフレームワークを使用しているアプリケーションに対して、文字列展開される記法を利用して、santizeの漏れをつき任意のプログラムを実行させる攻撃方法の一つです。
広義のxssに近いような攻撃ですね。
例えばサーバーサイドをrails、フロントエンドをvue.jsという構成でアプリケーションが作成され、
一般ユーザーから入力を受け付けて表示する機能があるとします。ここで悪意のあるユーザーが、攻撃対象のwebサイトが使用しているフロントエンドフレームワークをvue.jsだと仮定して攻撃します。
文字列の展開に使われる{{を使用して以下の文字列を入力してきました。{{constructor.constructor('alert(1111111111)')()}}現状のrailsの仕様だと、
部分的に文字列表示をrailsで行っている箇所で {{ マスタッシュがエスケープの対象になっていません。
なので、vue.jsのテンプレートと解釈されて中の文字列がjsとして実行されてしまいます。なぜ、これが怖いのか?
という説明を今さらしてもあれなのですが、この中で任意のjsを実行できると訪問したユーザーの情報を他サーバーに送信するなどなんでもできちゃいますよね。
対応
でどうやって対応したの?
まあセキュリティ対策の基本で入力で弾く&出力で置き換えるをやっていきます。入力部分での対応
入力時にマスタッシュ文字がある場合弾いてあげます。
controllerがパラメーターを受け取る前後で対応するか、modelの保存直前で対応するか迷ったのですが、
railsのstrong parameterをいじるのが難しかったので、modelで対応しています。class BaseModel < ApplicationRecord self.abstract_class = true def delete_vue_template string_value_keys = self.attributes.map do |key, value| key if value.class == String end string_value_keys.compact!.each do key self[key].replace('{{', '{ {').replace('}}', '} }') end end end該当のmodelに
before_validation :delete_vue_templateを記載してあげています。
出力部分での対応
大体のrailsアプリケーションでsanitizeが使われていたり、simple_formatで内部的に呼ばれているかなと思いますので、そこに手を入れて行こうとと思います。
ApplicationHelperにsanitizeメソッドを作成して、オーバーライドしてあげます。
simple_formatを使っている方も多いと思いますのでそちらでも自動で適用されるよう工夫していますdef simple_format(string, options = {}) super(sanitize(string, tags: %w[p br strong]), options) end def sanitize(html, options = {}) html.replace('{{', '{ {') if html.class == String super(html, options) end感想&追記
セキュリティ検査を会社で行い、対応しようと思った際にあまり資料がなかったのでrails&vue.jsのアプリケーション向けに資料に致しました。
もっとこうやった方いいとか、記載に誤りや視点に抜け漏れがあった際にはコメント等頂けると嬉しいです。
編集リクエストでも助かります。他の対応方法
angular.jsのドキュメントには一部記載があります。
https://angular.jp/guide/security#offline-template-compilerオフライン・テンプレート・コンパイラはテンプレートインジェクションと呼ばれる脆弱性を確実に防止し アプリケーションのパフォーマンスを大幅に向上させます。プロダクション環境ではオフラインテンプレートコンパイラを使い、 動的にテンプレートを生成しないようにしましょう。Angularはテンプレートコードを信頼するので、 テンプレート、特にユーザーデータを含むテンプレートを生成すると、Angularの組み込みの保護が回避されます。 Angularはテンプレート文字列を全面的に信頼するため、動的なテンプレート生成は常にXSSの危険性を有します。フォームを安全に動的に構築する方法については Dynamic Forms のガイドを参照してください。
既にリリースしていてこの機能を使っているなら変更する手間がかなり大きいですが、動的テンプレートを生成しないようにしておくのもいいかなと思います。
- 投稿日:2020-09-08T21:58:57+09:00
rails + mysql5.7で"Mysql2::Error: Expression #1 of ORDER BY clause is not in SELECT list, references column 'テーブル名.カラム名' which is not in SELECT list "
環境
ruby 2.5.1
rails 5.2.4
mysql 5.7背景
railsのDBをmysqlに変えて、rspecを実行したら、見慣れぬエラーが発生
ActionView::Template::Error: Mysql2::Error: Expression #1 of ORDER BY clause is not in SELECT list, references column 'portfolio1_test.users.name' which is not in SELECT list; this is incompatible with DISTINCT: SELECT DISTINCT `communities`.* FROM `communities` LEFT OUTER JOIN `community_users` ON `community_users`.`community_id` = `communities`.`id` LEFT OUTER JOIN `users` ON `users`.`id` = `community_users`.`user_id` ORDER BY `users`.`name` DESC, created_at DESC LIMIT 15 OFFSET 0原因
Mysqlから以下の設定が追加されたために問題が発生していたらしい
sql_mode,'ONLY_FULL_GROUP_BY解決策1
上記の設定が影響するSQL文を変える
MySQL5.7にアップデートしたらonly_full_group_byでエラーになった解決策2
Mysqlの設定を変える
Ransack の sort_link が MySQL で動作しない( incompatible with DISTINCT)今回はMysqlの設定を変えることにした
変更する箇所が多すぎるので、Mysql の設定を変えることにした。
ローカルでは設定を変えることで、問題が解決するが、Docker 環境でもこの設定変更を実行させたい。docker-compose.yml にて command を使って、設定を変更できるはず。
コンテナを構築する際に、Mysqlの設定を反映させたい
MySQL 5.7 のONLY_FULL_GROUP_BY が出た時にDockerでやった対処
docker-compose.ymlversion: '3' services: web: build: context: . dockerfile: Dockerfile command: bundle exec rails s -p 3000 -b '0.0.0.0' tty: true stdin_open: true depends_on: - db ports: - "3000:3000" volumes: - .:/myapp:delegated db: image: mysql:5.7 command: - --sql-mode=NO_ENGINE_SUBSTITUTION #追加!! environment: MYSQL_USER: root MYSQL_ROOT_PASSWORD: password ports: - '3316:3306' volumes: - ./db/mysql/volumes:/var/lib/mysql
- 投稿日:2020-09-08T20:05:00+09:00
(ギリ)20代の地方公務員がRailsチュートリアルに取り組みます【第5章】
前提
・Railsチュートリアルは第4版
・今回の学習は3周目(9章以降は2周目)
・著者はProgate一通りやったぐらいの初学者基本方針
・読んだら分かることは端折る。
・意味がわからない用語は調べてまとめる(記事最下段・用語集)。
・理解できない内容を掘り下げる。
・演習はすべて取り組む。
・コードコピペは極力しない。さて第5章。こっから本格的な開発フェーズですね。
本日の一曲はこちら。
Luby Sparks "Pop.1979"
ルビー違い。この初期衝動たっぷりのサウンドがたまらん。第1章で予告した通り、ProgateのSassコースやってなかったので、さくっと終わらせてきました。コードの重複を無くして記述を楽に、そして変更にも対応しやすくするための記法ですね。
【5.1.1 ナビゲーション メモと演習】
Bootstrapが登場しました。概要はこの記事が分かりやすいかも。
要するに、あらかじめ動作が定義されたものを呼び出すことで、Web開発を楽にするためのもの。レスポンシブデザインにも難なく対応。1. Webページと言ったらネコ画像、というぐらいにはWebにはネコ画像が溢れていますよね。リスト 5.4のコマンドを使って、図 5.3のネコ画像をダウンロードしてきましょう8 。
→ 下記コマンドでダウンロードするだけ。(猫かわいいですよね)$ curl -OL cdn.learnenough.com/kitten.jpg
2. mvコマンドを使って、ダウンロードしたkitten.jpgファイルを適切なアセットディレクトリに移動してください (参考: 5.2.1)。
→ 下記コマンドでimagesディレクトリへ$ mv kitten.jpg app/assets/images3. image_tagを使って、kitten.jpg画像を表示してみてください (図 5.4)。
→ 下記をhomeの一番最後に追記すればOK。home.html.erb<%= link_to image_tag("kitten.jpg", alt: "cute kitten") %>
【5.1.2 BootstrapとカスタムCSS メモと演習】
まだまだCSSもおぼつかないので、時間がかかるけど、一つ入力するごとに動作を確認していこう。全コピしていちいちコメントアウトするよりこっちのが楽でしょ。
そして、うっとおしいのでこの時点でネストできるもんはしていきます。たしかこの後どっかでネストしてたと思うけど。先にやっといて、あとで答え合わせと行こうか。1. リスト 5.10を参考にして、5.1.1.1で使ったネコ画像をコメントアウトしてみてください。また、ブラウザのHTMLインスペクタ機能を使って、コメントアウトするとHTMLのソースからも消えていることを確認してみてください。
→ 指示通りやるだけ。消えろキトゥン!!!!!
2. リスト 5.11のコードをcustom.scssに追加し、すべての画像を非表示にしてみてください。うまくいけば、Railsのロゴ画像がHomeページから消えるはずです。先ほどと同様にインスペクタ機能を使って、今度はHTMLのソースコードは残ったままで、画像だけが表示されなくなっていることを確認してみてください。
→ そらっそすよね。CSSで非表示にしてるだけだし。これもやるだけなので細かいことは割愛。
【5.1.3 パーシャル(partial) メモと演習】
パーシャル=部分的な といった意味。冷蔵庫のパーシャルをイメージすると分かりやすいかも。あそこにガシャコンと分けて収納するイメージ。他のページでも使う部分や、すべてのページで共通して使うものを、切り出して個別保存すると。必要に応じて呼び出す(render)わけか。
1. Railsがデフォルトで生成するheadタグの部分を、リスト 5.18のようにrenderに置き換えてみてください。ヒント: 単純に削除してしまうと後でパーシャルを1から書き直す必要が出てくるので、削除する前にどこかに退避しておきましょう。
→ とりあえず適当に避難しといて指示どおり記入。
2. リスト 5.18のようなパーシャルはまだ作っていないので、現時点ではテストは redになっているはずです。実際にテストを実行して確認してみましょう。
→ そらREDです。
3. layoutsディレクトリにheadタグ用のパーシャルを作成し、先ほど退避しておいたコードを書き込み、最後にテストが green に戻ることを確認しましょう。
→ 下記ファイルを作成してパーシャル!(テストもGREENです)_rails_default.html.erb<%= csrf_meta_tags %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %>
【5.2.1 アセットパイプライン メモ】
今一つ分かりにくいなあと思うアセットパイプライン。重要なのはこの一文か。「『開発効率と読み込み時間のどちらを重視するか』という問題について悩む必要がなくなります。開発環境ではプログラマにとって読みやすいように整理しておき、本番環境ではAsset Pipelineを使ってファイルを最小化すればよいのです。」
要は、散らばったものを一つの細い管に通してやるイメージでしょうか。その過程でファイルを整理して無駄なものを省き、最小化してくれると。
【5.2.2 素晴らしい構文を備えたスタイルシート メモと演習】
LESS変数一覧をみると、@gray-lightが#777じゃなくて、lighten(@gray-base, 46.7%)になってるんですが、バージョンの違いでしょうか?実際の色は変わっていないようにみえるのでいいんですが(他の既定の色も同じか)
。1. 5.2.2で提案したように、footerのCSSを手作業で変換してみましょう。具体的には、リスト 5.17の内容を1つずつ変換していき、リスト 5.20のようにしてみてください。
→ はじめに書いたときから実践済みです。合ってました。(見やすいかと思ったのでネストに改行入れてます)custom.scss/* footer */ footer { margin-top: 45px; padding-top: 5px; border-top: 1px solid $gray-medium-light; color: $gray-light; a { color: $gray; &:hover { color: $gray-darker; } } small { float: left; } ul { float: right; li { float: left; margin-left: 15px; } } }
【5.3 レイアウトとリンク】
最初、名前付きルート(〇〇_path)ってのがしっくりこなかったけど、慣習としてこう書くっていうのと、そういう機能がrailsに備わっていて、変更にも対応しやすいからこうしましょってことと理解。ルーティングを設定することで使えるようになると。
【5.3.2 RailsのルートURL メモと演習】
〇〇_path:ルートURL以下の文字列を返す。基本はこっちを使用
〇〇_url :完全なURLの文字列を返す。リダイレクトの場合のみ使用。1. 実は名前付きルートは、as:オプションを使って変更することができます。有名なFar Sideの漫画に倣って、Helpページの名前付きルートをhelfに変更してみてください (リスト 5.29)。
→ リスト5.29のとおりas: 'helf'を追記。
2. 先ほどの変更により、テストが redになっていることを確認してください。リスト 5.28を参考にルーティングを更新して、テストを greenにして見てください。
→ 当然RED。テストをhelf_pathに変更するとGREENになります。
3. 比較演算子==を使って、上記2つの課題で作ったそれぞれのオブジェクトが同じであることを確認してみてください。
→ 戻しときましょう。
【5.3.3 名前付きルート 演習】
1. リスト 5.29のようにhelfルーティングを作成し、レイアウトのリンクを更新してみてください。
2. 前回の演習と同様に、エディタのUndo機能を使ってこの演習で行った変更を元に戻してみてください。
→ helf好きやな。ルートにas: 'helf'つけて、ヘッダーのhelp_pathをhelf_pathにして終わり!そして戻す!(この演習要る?)
【5.3.4 リンクのテスト メモと演習】
統合テスト(integration test)が登場。「統合テストを使うと、アプリケーションの動作を端から端まで (end-to-end) シミュレートしてテストすることができます。」ということです。動作の流れを考えながら書きましょう。
テストについては、Railsドキュメントが分かりやすいかも?(リンク先はRails6のものです)
assert_selectは柔軟な機能があるが、レイアウト内で頻繁に変更されるHTML要素 (リンクなど) をテストするぐらいに抑えておく方が賢明と。第3章の用語集でも取り上げてましたね。
おっと、ここでエラーが?調べると、リンク先を'root_path'のようにしていました。〇〇_pathはメソッドなので''は不要とのこと。単純な見落としでした。1. footerパーシャルのabout_pathをcontact_pathに変更してみて、テストが正しくエラーを捕まえてくれるかどうか確認してみてください。
→ /aboutにマッチする要素が一つもないよーと教えてくれます。
2. リスト 5.35で示すように、Applicationヘルパーで使っているfull_titleヘルパーを、test環境でも使えるようにすると便利です。こうしておくと、リスト 5.36のようなコードを使って、正しいタイトルをテストすることができます。ただし、これは完璧なテストではありません。例えばベースタイトルに「Ruby on Rails Tutoial」といった誤字があったとしても、このテストでは発見することができないでしょう。この問題を解決するためには、full_titleヘルパーに対するテストを書く必要があります。そこで、Applicationヘルパーをテストするファイルを作成し、リスト 5.37のFILL_INの部分を適切なコードに置き換えてみてください。ヒント: リスト 5.37ではassert_equal <期待される値>, <実際の値>といった形で使っていましたが、内部では==演算子で期待される値と実際の値を比較し、正しいかどうかのテストをしています。
→ 3周目でやっと内容についてこれた感があります。まずtest環境でApplicationヘルパー(のfull_titleメソッド)を使えるようにincludeする。そうすっとレイアウトの統合テストでページタイトルが合ってるかどうかテストできる。ただ誤字とかは発見できないから、Applicationヘルパー自体をテストしてやろうというわけか。FILL_INの部分は下記のとおり。テストはGREENです。test/helpers/application_helper_test.rbrequire 'test_helper' class ApplicationHelperTest < ActionView::TestCase test "full title helper" do assert_equal full_title, "Ruby on Rails Tutorial Sample App" assert_equal full_title("Help"), "Help | Ruby on Rails Tutorial Sample App" end end
【5.4.1 Usersコントローラ 演習】
1. 表 5.1を参考にしながらリスト 5.41を変更し、users_new_urlではなくsignup_pathを使えるようにしてみてください。
2. 先ほどの変更を加えたことにより、テストが redになったことを確認してください。なお、この演習はテスト駆動開発 (コラム 3.3) で説明した red/green のリズムを作ることを目的としています。このテストは次の5.4.2で greenになるよう修正します。
→ users_controller_test.rbのusers_new_urlをsignup_pathに変更するだけ。当然REDになります。
フライングですが、signup_pathを使えるようにするにはどうするか。ルーティングを設定する必要がありますね。以下で合ってるはず。テストはGREENになりました。routes.rbRails.application.routes.draw do get 'users/new' root 'static_pages#home' get '/help', to: 'static_pages#help' get '/about', to: 'static_pages#about' get '/contact', to: 'static_pages#contact' get '/signup', to: 'users#new' end次読むと、合ってましたね。
【5.4.2 ユーザー登録用URL 演習】
1. もしまだ5.4.1.1の演習に取り掛かっていなければ、まずはリスト 5.41のように変更し、名前付きルートsignup_pathを使えるようにしてください。また、リスト 5.43で名前付きルートが使えるようになったので、現時点でテストが greenになっていることを確認してください。
→ さっきやりました。
2. 先ほどのテストが正しく動いていることを確認するため、signupルートの部分をコメントアウトし、テスト redになることを確認してください。確認できたら、コメントアウトを解除して greenの状態に戻してください。
→ 試すだけー。
3. リスト 5.32の統合テストにsignupページにアクセスするコードを追加してください (getメソッドを使います)。コードを追加したら実際にテストを実行し、結果が正しいことを確認してください。ヒント: リスト 5.36で紹介したfull_titleヘルパーを使ってみてください。
→ たぶんいらんけど、ついでにSing upリンクがあるか確かめるテストも追記してみました。自分の知識を確かめるために要らんこともしていきます。site_layout_test.rbrequire 'test_helper' class SiteLayoutTest < ActionDispatch::IntegrationTest test "layout links" do get root_path assert_template 'static_pages/home' assert_select "a[href=?]", root_path, count: 2 assert_select "a[href=?]", help_path assert_select "a[href=?]", about_path assert_select "a[href=?]", contact_path assert_select "a[href=?]", signup_path get contact_path assert_select "title", full_title("Contact") get signup_path assert_select "title", full_title("Sign up") end end
第5章まとめ
・Bootstrapは便利やけど、使われすぎておもんないとも聞く。
・猫は万国共通でかわいい。
・Sassは便利ですね。コードがスッキリする。
・パーシャルでまとめて見た目スッキリ。
・Asset Pipelineが勝手にassets(画像とかCSSとかJSとか)を最適化してくれる。
・ルーティングを設定すると〇〇_pathと〇〇_urlが使えるようになる。
・統合テストはページ間移動とかの動作をテストできる。動作をシミュレートしよう。
第5章はわりとさっくり終了。3周目にして内容がやっと掴めるようになってきました。嬉しい。第6章ではユーザーモデルを作成していきます。
⇦第4章はこちら
学習にあたっての前提・著者ステータスはこちら
なんとなくイメージを掴む用語集
・条件付きコメント
Microsoft Internet Explorerに対して、コードを渡したり隠したりするのに使用できるHTMLソースコード中にある条件付きのステートメントのこと。IE10以降は廃止されている。・レスポンシブ(ウェブ)デザイン
表示する端末・ブラウザによって表示形式が変わるデザインのこと。同じwebサイトでも、スマホとPCでは文字やコンテンツの大きさが変わったりするアレ。レスポンシブ対応とかよく言われるやつ。・assert_template
そのアクションで指定されたテンプレートが描写されているかをテスト。・assert_equal
assert_equal <期待される値>, <実際の値> の形で、両者の値が等しいかテスト。
- 投稿日:2020-09-08T20:01:26+09:00
ERROR: In file ./.env: environment variable name 'THOR_SILENCE_DEPRECATION ' may not contain whitespace. への対処法
タイトルの通りですが、今回は
.envERROR: In file ./.env: environment variable name 'THOR_SILENCE_DEPRECATION ' may not contain whitespace.というエラーが出た際の対処法について、私の環境下でのソリューションを共有したいと思います。
私はRuby on Railsでプログラミング学習を開始して1ヶ月ほどの初学者ですので、至らない点や説明不足の点等もあるかと思います。
お気づきの点等ございましたらご指摘いただけると幸いです。※できるだけ初学者の方にも分かりやすく説明する事を心がけているため、やや冗長に感じる部分もあるかもしれませんがご了承くださいませ。
環境
・Ruby 2.6.5
・Rails 5.2.3
・MySQL 5.7
・Docker
・Dokcer-compose version: '3'まずは解決した方法から
早速ですが解決方法から述べたいと思います。
私の環境下では、ルートディレクトリ
(DockerfileやGemfile等のファイルと同じ階層)
に存在する.envファイルの記述が間違っていた事が原因でした。.env#こちらがエラーが出てしまう記述 THOR_SILENCE_DEPRECATION = true #以下の記述に修正すればエラーは解消される THOR_SILENCE_DEPRECATION=trueエラーが出てしまう記述では、余計な空白が入ってしまっていますね。
空白を除去する事で、上記エラーは解消されます。エラーの深掘り
エラーの内容を再度見てみましょう。
.envERROR: In file ./.env: environment variable name 'THOR_SILENCE_DEPRECATION ' may not contain whitespace.こちらの文章をGoogle翻訳で日本語に修正してみると、
エラー:ファイル./.env:環境変数名 'THOR_SILENCE_DEPRECATION'に空白が含まれていない可能性があります。
と変換されます。
日本語としては若干分かりづらいのですが、なんとなく
「空白の関係でエラーが出ているのだな」
とアタリをつける事ができます。
エラー文本文でググってみると、完全に同じエラー文が出てきた方はいらっしゃいませんでしたが、解決にあたっては以下のブログを参考にさせていただきました。
Composerで.env内のスペースはクォートで囲む必要があるエラーが発生
https://awesome-linus.com/2019/04/07/composer-install-error-need-quotes/エラー文でググったところ情報が少なかったため、おそらくそう頻繁に出るエラーではないのだと予測できますが、初学者の方がエラーに遭遇した際の一つのソリューションとして参考になれば幸いです。
エラーが起きた背景を詳しく
エラーが起きた背景について、もう少し詳しく記述していきます。
このエラーは「.envファイル」の記述が間違えているのが原因なのですが、そもそも.envファイルを触った事がないという方もいらっしゃるかも知れません。
私も約1ヶ月ほどRailsを勉強してきた中で、.envファイルを触る機会というのは一度もなかったのですが、ログイン機能を実装するGem「sorcery」を導入する過程で、以下のエラーを解決するために.envファイルを触る必要が出てきました。
Deprecation warning: Expected string default value for '--test-framework'; got false (boolean). This will be rejected in the future unless you explicitly pass the options `check_default_type: false` or call `allow_incompatible_default_type!` in your code You can silence deprecations warning by setting the environment variable THOR_SILENCE_DEPRECATION.こちらのエラーは、
・Gemfileにsorceryを追加
・bundle install
・sorceryを使用するためのコマンド「rails g sorcery:install」を実行という過程の中で発生したものです。
エラーの詳細については私もよく分かってはいないのですが、どうやらシェルスクリプトを生成するためのGemからエラーが出ているらしいとのこと。
このエラーを解決するための方法として、.envファイルに
.env#正しい記述 THOR_SILENCE_DEPRECATION=trueの記述を追加する必要があり、
誤って以下のコードを記述。.env#不要な空白があるためエラーが出る記述 THOR_SILENCE_DEPRECATION = trueそして、rails g controller ~~
を実行しようとしたところ、タイトルのエラーが発生したという経緯です。ちなみに、「Deprecation warning〜〜〜」のエラーに関しては、以下の記事
[Ruby on Rails]環境変数の設定方法(.bash_profile、Dotenv-rails)
https://qiita.com/yuichir43705457/items/7cfcae6546876086b849RSpecを導入する
https://qiita.com/d0ne1s/items/1ecd114b33e80058215fを参考に解決する事ができました。
ありがとうございました。おしまい
以上が、今回のエラーの解決方法と周辺情報です。
あまり情報が多くないエラーでしたので、もし遭遇して困っている方は参考にしていただけると幸いです。
また、説明が分かりづらい点等があれば、ご指摘いただければと思います。それでは、最後までお付き合いいただきありがとうございました。
- 投稿日:2020-09-08T18:54:24+09:00
問題です! ①と②が同じだって分かりますか?(クラス・インスタンス・メソッド・引数を実践で理解しよう!)
はじめに
突然ですが、質問です。
書き方は違いますが、①と②が同じだって分かりますか?User.rb(某アプリのモデルと仮定してください)# Userのアソシエーションはこのようになっています # has_many :posts, dependent: :destroy # has_many :active_relationships, class_name: 'Relationship', # foreign_key: 'follower_id', # dependent: :destroy # has_many :passive_relationships, class_name: 'Relationship', # foreign_key: 'followed_id', # dependent: :destroy # has_many :following, through: :active_relationships, source: :followed # has_many :followers, through: :passive_relationships, source: :follower # Userモデルのメソッドです def feed Post.where(user_id: following_ids << id) #=> ① end def feed return Post.where(:user_id => self.following_ids.<<(self.id)) #=> ② end分からない方は、読んで勉強になることがあるかもしれません。
よければ読んでいただけると幸いです。書くに至った経緯について
はじめまして。みけたと申します。
3月末で公務員を辞めて、Railsなどの勉強を始めて5ヶ月近く経過します。主にMENTAというサービスでだいそんさんという方にお世話になっており、
スパルタコースというコースを受講しながら、日々勉強に励んでおります。様々な課題が課されるのですが、その課題の1つがインスタクローンの実装です。
現在、私はこの実装に取り組んでいるところです。先日、後発で受講を始めたメンティーからトップ画面にフィードを表示させる機能について、
コミュニティ内で質問がありました。私はその範囲の実装を既に終えており、勉強がてらに質問に答えてみようと思ったのですが、
実力不足で答えられるほどの力がなかったので、改めて調べて、全力で答えてみることにしました。それなりに気合を入れて答えたので、コミュニティ外の初学者の方にも何か役に立てばと思い、
Qiitaという形で公開してみることにしました。前提条件について
自身の投稿とフォローしているユーザーの投稿がトップページに表示される仕様となっています。
Userモデルに
feedというメソッドを実装して、posts_controller.rbの
indexアクションにて該当の投稿を取得し、Viewにその投稿を渡すようなコードを書くのですが、
このfeedメソッドについて質問がありました。アソシエーションについて
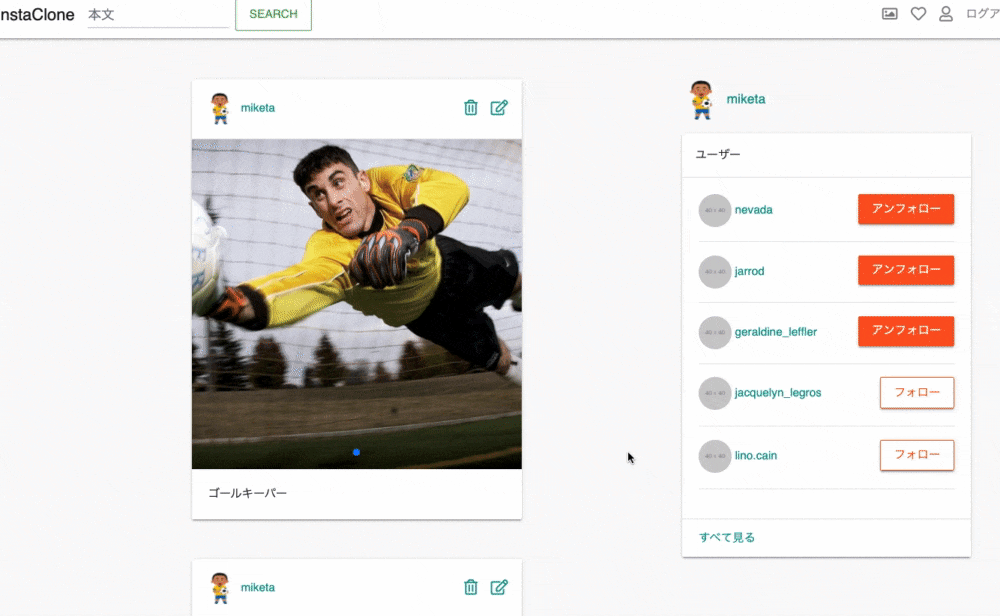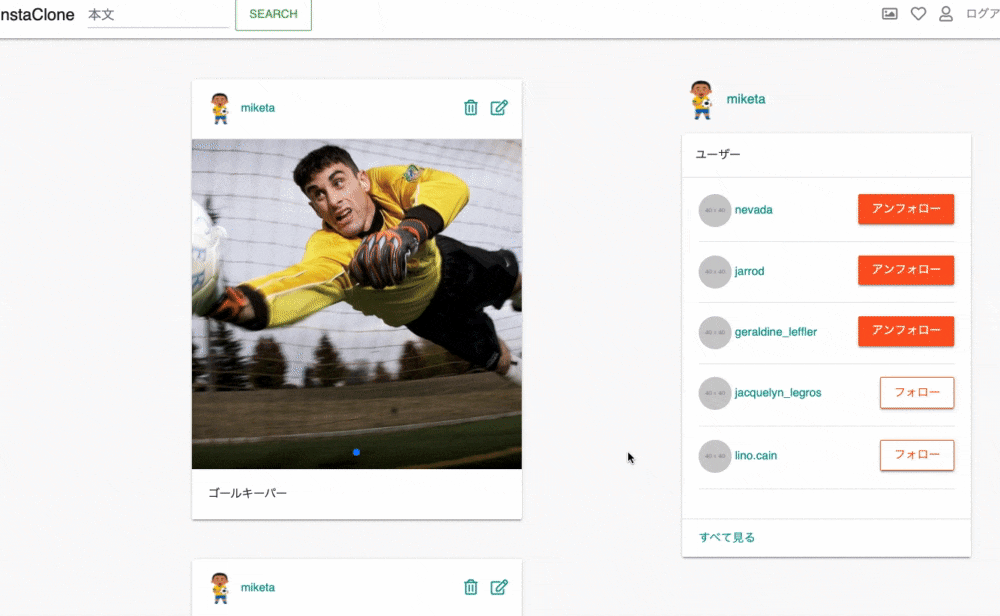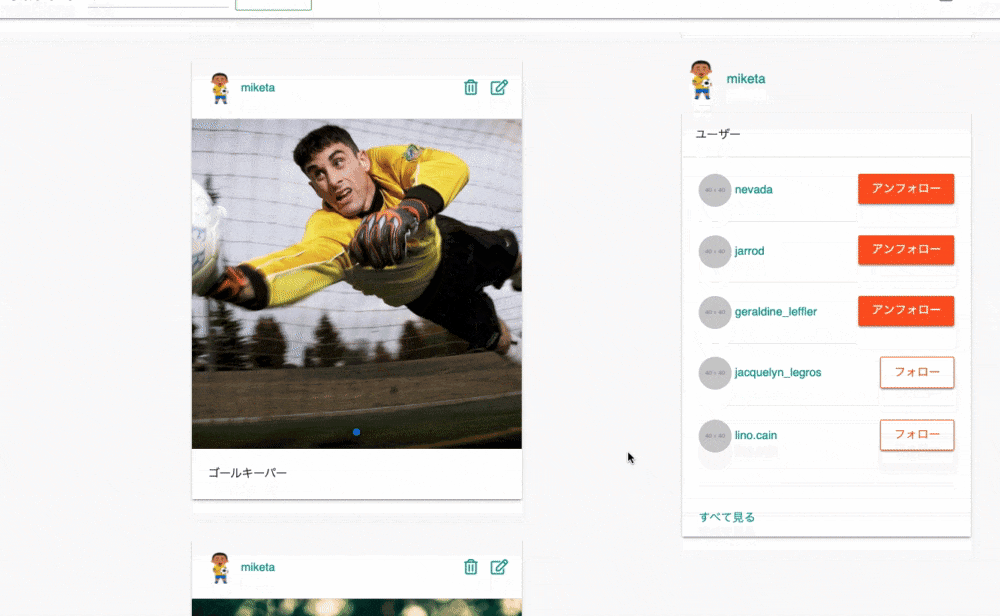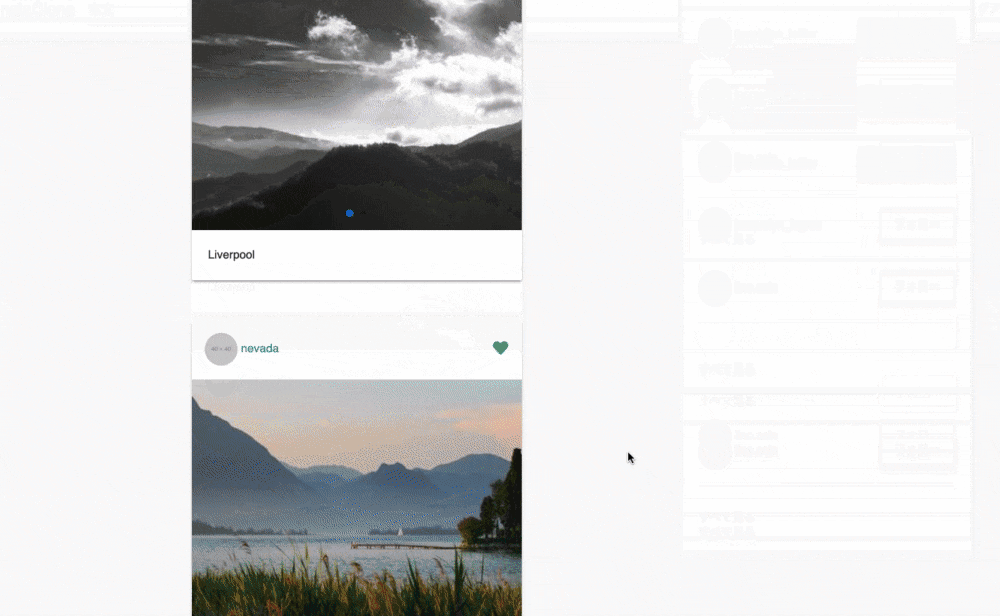
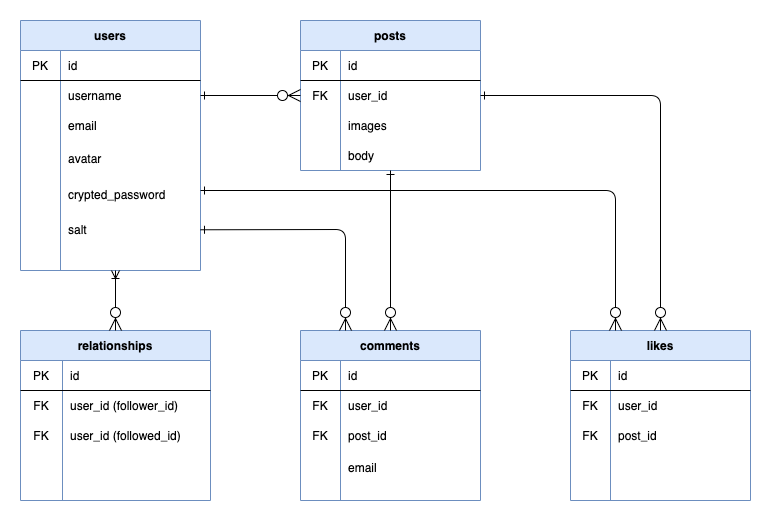
以上のような構成図となっています。なお、タイムスタンプ(created_atとupdated_atのカラム)は省略しています。
また、ER図の書き方は勉強不足のため、誤りがある可能性が高いです。。。とりあえず、
usersはたくさんのpostsを持っていて、@user.followingと書けばフォローしている
ユーザーが取得できることが分かれば、今回の記事は十分に理解できるかと思います。なお、アソシエーションについては、この記事では説明しません。
以下の記事などを参考にするとよいかと思います。
- 【初心者向け】丁寧すぎるRails『アソシエーション』チュートリアル【幾ら何でも】【完璧にわかる】? - Qiita
- 【Rails】アソシエーションを図解形式で徹底的に理解しよう! | Pikawaka - ピカ1わかりやすいプログラミング用語サイト
質問
current_user.feedで何をやっているのか分からない!!!該当のコードについて
posts_controller.rbdef index @posts = if current_user # このcurrent_user.feedが分からない!!! # feedメソッドについては、user.rbを参照してください current_user.feed.includes(:user).page(params[:page]).order(created_at: :desc) # 以下、省略user.rb# == Schema Information # # Table name: users # # id :bigint not null, primary key # avatar :string(255) # crypted_password :string(255) # email :string(255) not null # salt :string(255) # username :string(255) not null # created_at :datetime not null # updated_at :datetime not null # # Indexes # # index_users_on_email (email) UNIQUE # class User < ApplicationRecord authenticates_with_sorcery! # sorceryというgemを使っています mount_uploader :avatar, AvatarUploader # carrierwaveを使っています(今回の説明では関係ない) # validationは関係ないので省略します # post.rbやcomment.rbなどで適切にアソシエーションが設定されていると仮定してください has_many :posts, dependent: :destroy has_many :comments, dependent: :destroy has_many :likes, dependent: :destroy has_many :like_posts, through: :likes, source: :post has_many :active_relationships, class_name: 'Relationship', foreign_key: 'follower_id', dependent: :destroy has_many :passive_relationships, class_name: 'Relationship', foreign_key: 'followed_id', dependent: :destroy has_many :following, through: :active_relationships, source: :followed has_many :followers, through: :passive_relationships, source: :follower # 色々とメソッドがあるんですが、関係ないので省略します # このfollowing_idsとか<<とか、何なの!? def feed Post.where(user_id: following_ids << id) end endなお、
includes(:user).page(params[:page]).order(created_at: :desc)
についてはこの記事で取り扱いませんが、気になる方は適宜調べてください。補足をしておくと、
page(params[:page])と書けるのはkaminari
というgemを導入しているからです。クラス・インスタンスの概念を把握する
まず、クラスとインスタンスの関係について自分なりに説明します。
これは個人的な理解なので、誤った解釈を導く可能性があります。
参考程度にお聞きください。誤解を恐れずに言いますと、こんな感じです。
クッキーの型取りする銀色のやつと、実際に型取りされたクッキーの関係に似てますかね笑
- クラス: 抽象的な概念としての型
- インスタンス: 型から縁取られて出てきた具体的な個体
例えば、概念として「犬」という言葉を私たちは理解してますけど、
その時点で理解している「犬」というのは、すごいふわふわしたものです。別に柴犬でもダックスフンドでも犬ですし、同じ柴犬でも大きさが微妙に違います。
けど、概念としての犬であることには違いないわけで、それを私たちは全て犬として認識しています。この認識している概念としての犬こそが、クラスとしての犬です。
(便宜的に、犬クラスは犬種と長さという属性を持つクラスだと定義しましょう。)ただ、この世界に存在するのは、全て具体的な犬です。
犬インスタンスです! 犬オブジェクトです!犬インスタンスは、属性(attributesというやつです)を持っています。
犬インスタインス(id:1)は、犬種:柴犬、長さ:1mという属性を持っているかもしれませんが、
犬インスタンス(id:2)は、犬種:ダックス、長さ:50cmという属性かもしれません。ちなみに、英語が多少できる人なら、インスタンスの意味から覚えるといいかもしれません。
インスタンスは、for example と同じ意味の for instance の instance です。
クラスの具体例なので、インスタンスって言うんですね!・・・きっと笑メソッドについて考える
クラスとインスタンスについて把握して上で、メソッドについて考えてみましょう。
メソッドというのは「できることリスト」みたいなものです。便宜的に、犬クラスは「走る」というメソッドを持っている、ということにしましょう。
犬クラスというのは概念的なものなので、走ることはできません。
走らせるとエラーになります。走れるのは犬インスタンスだけです。
(User.saveなどと書いてエラーになったとき、犬クラスは走れないことを思い出しましょう)逆に犬オブジェクトから、犬種(という属性)が柴犬である犬を探すことはできません。
柴犬を見つけてきたい場合、犬クラスから探しましょう。
(@user.whereなどと書いてエラーになったとき、あなたはペットのゴン太という柴犬から、
柴犬を探そうとしているなんだか残念な人だという自覚を持ちましょう)
current_userって何?かなり冗長に説明しましたが、そろそろ具体的に考えていきましょう。
まず、current_userから考えてみましょう。
current_userは、sorceryというgemを導入することにより使えるメソッドです。公式GitHubに書いています。
え、メソッドなの!? と思われたあなた!
その発想が出てくるのは非常によいと思います!(初学者のくせに偉そう・・・)GitHubで辿っていくと分かりますが、sessionの
user_idを使って、
Userクラスから該当のユーザーを取得すると書いています。なので、まあ結果として、
current_userは、Userクラスのインスタンス
として考えてほぼ差し支えありません。ただ、正確には
current_userはメソッドであって、その返り値がUserクラスの
インスタンスになるように設計されていることを覚えておいてください。
feedって何クラスの何メソッド?
feedというメソッドですが、Userモデル(Userクラス)のインスタンスメソッドです。
インスタンスメソッドなので、userインスタンスのみ実行できます。先ほど言ったとおり、
current_userはメソッドではあるのですが、
そのメソッドを実行した結果として、Userクラスから該当のログインユーザーを取得します。
(面倒なので、以後このログインユーザーをcurrent_userと呼びます)この
current_userは、userインスタンスであるため、
Userモデルのインスタンスメソッドであるfeedというメソッドが使ます。
クラス インスタンス メソッド User current_userfeed
current_userはfeedメソッドを実行すると、
Post.where(user_id: following_ids << id)の返り値を取得します。current_user.feed #=> `Post.where(user_id: following_ids << id)`の返り値を取得
feedメソッドの中身を見ていく(following_idsとは)続いて、
Post.where(user_id: following_ids << id)を見ていきます。特に見慣れない部分が
following_ids << idの箇所だと思います。
私もこれを見て、「え、あ、えと、分からない、ごめんなさい」ってなりました 笑
おそらく、多くの初学者にとって、ここが1番のつまづきポイントだと思います。
following_idsですが、これはアソシエーションでhas_many書くと使えるメソッドです。
「え、メソッド!」と思ったかもしれませんが、Railsガイドに書いてます。collection_singular_idsメソッドは、そのコレクションに含まれるオブジェクトの
idを配列にしたものを返します。ちなみに、
@user.commentsと書くときのcommentsも実はメソッドです。
collectionメソッドは、関連付けられたすべてのオブジェクトのリレーションを返します。
関連付けられたオブジェクトがない場合は、空のリレーションを1つ返します。
@books = @author.books
@user.commentsと書くとき、.commentsと続けると@userに紐づくコレクションを
取得できるという覚えゲーでもあまり問題ありません。むしろ、そう覚えても問題ないよう設計されているRailsが素晴らしいんです。
ただ、実はこれもメソッドだと知っておくと、理解がより深まっていくのではないでしょうか。
binding.pryを使ってみようでは、
binding.pryを使って、following_idsの挙動を確認しましょう。まず、
posts_controller.rbのindexアクションにbinding.pryって書きます。
書く場所は、ここにします。
gem 'pry-rails'は導入しておいてください。
導入方法や使い方は、この記事などを参考にするとよいでしょう。def index binding.pry @posts = if current_user current_user.feed.includes(:user).page(params[:page]).order(created_at: :desc) # 省略
binding.pryと書いた後、ブラウザでトップ画面をリロードしましょう。
すると、リロードしている状態で画面が止まるはずです。ターミナルで確認してみると、
rails cの時と同じような形でデバッグができます。デバッグを始める前に、しつこいですが、クラスとインスタンスとメソッドのことを思い出しましょう。
following_idsは何ですか。そう、メソッドですよね。では、何のメソッドでしょう。そう、インスタンスのメソッドですよね。
具体的なコレクション(複数のオブジェクト)がコレクションの各IDを返すメソッドなので、
これはインスタンスメソッドです。なので、いきなり
following_idsと書くとエラーになります。今回はログインしているユーザーがフォローしているユーザーたちのID、つまり
following_idsを
取得したいので、current_user.following_idsと入力してみましょう。フォローしているユーザーがいれば、配列が返ってくるはずです。
binding.pryを使った際のターミナルの画面Processing by PostsController#index as HTML From: 〜〜〜/app/controllers/posts_controller.rb @ line 5 PostsController#index: 3: def index 4: binding.pry => 5: @posts = if current_user 6: current_user.feed.includes(:user).page(params[:page]).order(created_at: :desc) [1] pry(#<PostsController>)> current_user.following_ids User Load (1.0ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 7 LIMIT 1 ↳ (pry):6 (1.6ms) SELECT `users`.`id` FROM `users` INNER JOIN `relationships` ON `users`.`id` = `relationships`.`followed_id` WHERE `relationships`.`follower_id` = 7 ↳ (pry):6 => [3, 10]ここで、もしかしたら疑問に思ったかもしれません。
「あれ、
feedメソッドではcurrent_userなんて書かずにfollowing_idsと
入力していたような気がするけど、なんでだろう???」と。
selfは省略されているモデルで書くインスタンスメソッドですが、ここでは
selfが省略されています。
つまり、こういうことです。# ①と②は同じ Post.where(user_id: following_ids << id) #=> ① Post.where(user_id: self.following_ids << self.id) #=> ②どうですか?
分かりやすくなったと感じた方もいるかと思います。では、
current_user.feedと書いた場合について考えてみましょうか。
要はこういうことが起きています。Post.where(user_id: current_user.following_ids << current_user.id)続いて、
id: 1であるユーザーについて考えみましょう。
要はこういうことです。Post.where(user_id: User.find(1).following_ids << User.find(1).id)だいたい分かってきたんじゃないでしょうか。
ここでは
selfが省略されていますが、インスタンスが持っているメソッドが使用されていたり、
インスタンスが持っている属性の取得が行われているのです。奥さん、
<<ってメソッドなんですってタイトルのとおりですが、「<<」はメソッドなんです。
え、メソッドって文字じゃなくていいんですか。。。 これはさすがにビビりますよね。
(私だけですかね。。。)これは、Array(配列)クラスのインスタンスメソッドなんです。
ary = [1] ary << 2 p ary # [1, 2]では、振り返っていきましょう。
current_user.feedと書く場合、following_ids << idがどういう挙動になるか確認します。# current_user(id: 1)が、`id: 4`と`id: 6`のユーザーを2人フォローしていると仮定 current_user.follwing_ids << current_user.id [4, 6] << [1] [4, 6, 1]分かりましたか。
つまり、フォローしているユーザーのidの配列に対して、自分のユーザーidを加えているのです。そういえば、引数って分かりますか?
先ほどの事例の場合、難しいところがなかったので、すっと理解できたかと思います。
ただ、重要になってくるので、ary << 2と書く時、2は引数であると覚えてください。抽象的に説明しても分かりづらいので、まず引数があるメソッドと引数がないメソッドを見てみましょう。
大して犬好きでもないんですけど、犬の例で説明してしまっているので、初志貫徹したいと思います。Class Dog # 本当はここに色々なくちゃいけないと思いますが、とりあえずスルーします def bark "わんわん" end def run(speed) "#{speed}キロでダッシュした!" end endちゃんとした方々に怒られそうですが、Dogというクラス、つまりDogという抽象的な概念があって、
その型から生み出されたdogインスタンスには、barkとrunというメソッドがあると想定してください。じゃあ、dogインスタンスを誕生させましょう。
本当は
dogという変数にすることが一般的なんでしょうけど、
せっかくなので愛着を持って、wankoという変数にしましょう。wanko = Dog.newこのwankoですが、
barkとrunができます。wanko.bark #=> "わんわん" wanko.run(100) #=> "100キロでダッシュした!"無理させて100キロでダッシュさせてしまいましたが、この100というのが引数です。
メソッド内で変数を扱いたい場合、・・・と言うと分かりづらいので言い換えます。
引数を使うと走る速度に幅を持たすことができて、それはなぜかというと、
引数という「?」な速度をメソッド内に仮で書いておくことで、後から代入させる設計にできるからです。この引数ですが、Rubyだと括弧を省略してこのように書くこともできます。
この書き方、個人的には気持ち悪いですが、この自由な感じこそがRubyの特徴らしいです。wanko.run 100 #=> "100キロでダッシュした!"
following_ids.<<(id)って書いてもいいんですよさて、冗長な引数の説明にイラだった方もいるかもしれないですが、
それは<<がメソッドであり、idが引数だっていうことを改めてよく知ってほしいからです。だって、メソッドって多くの場合どうやって書きますか?
そう、wanko.run(100)っていうのがよく見る形ですよね。それにもかかわらず、
following_ids << idの<<がメソッドだって言われてもしっくりこないのは、
<<のインパクトもさることながら、書き方がよく見る形ではないからだと思うんです。ということで、書き換えてみましょう。
こんな感じで。following_ids.<<(id)これまでと雰囲気が一転したので、すごく気持ち悪い感じになってしまいましたが、
<<はメソッドであって、idは引数なので、これでいいんです!!!・・・これで動くのか疑問に思った方、いるかと思います。
私も理論専攻で先走ってこの文章を書いていたので、動くのかちょっと不安でした。。。
ただ、書き換えてみたら、やっぱりちゃんと動きました! よかった!ちなみに、
<<と似たappendやpushといった似たメソッドがあります。
なので、こんな感じで書き換えることが可能です。
(<<は単一の要素、appendやpushは複数の要素を追加できるメソッドという違いがあります)# ①と②と③は同じ # following_ids << id の書き換え following_ids.<<(id) #=> ① following_ids.append(id) #=> ② following_ids.push(id) #=> ③
user_id: following_ids << idについて考えようさて、徐々に範囲を拡大しましょう。
user_id: following_ids << idについて考えましょう。これは、ハッシュというやつです。
ハッシュは、キーと値の組み合わせでデータを管理するオブジェクトのことです。(チェリー本のP147)
キー 値 :user_id following_ids と current_user.id
:user_idというシンボル形式のキーがあって、
その値がfollowing_idsとcurrent_user.idです。
(フォローしているユーザーのids + ログインユーザーのid)このハッシュが、whereというメソッドの引数になっていると認識しましょう。
:user_idがどこから出てきたのか分からないあなた、
さらっとでよいので、ハッシュやシンボルについて勉強しましょう!勉強をすると、以下のとおり書き換えができることも分かるはずです。
Post.where(user_id: following_ids << id) Post.where(:user_id => following_ids << id)ちなみに、
=>を使う書き方は、ハッシュロケット記法といいます。
ハッシュロケット記法は、古い記法です。未だにアプリなんかで使っていると古いコードをコピペしたのがバレます笑
=>が出てきたら、書き換えをするのを怠らないようにしましょう。
whereメソッドについて考えようさて、そろそろ全体を理解することができそうですね。
次は、whereメソッドについて理解しましょう。
whereメソッドですが、これはPostというクラスに対して実行するクラスメソッドです。
(若干不安ですが、たぶんクラスメソッドと言い切って良いと思います)
whereメソッドには引数があり、様々な形で書くことができます。# 文字列で検索 Post.where("body = 'みけたさんカッコイイですね'") # ハッシュ形式で検索 Post.where(body: 'みけたさんカッコイイですね')さて、
Post.where(user_id: following_ids << id)の場合において、
whereメソッドの引数が何になるのか考えましょう。
user_id: following_ids << idはどのような形式になるのでしょうか。既に考察したとおり、
user_id: following_ids << idはハッシュ形式になります。
そのことを踏まえて、また順を追って、具体的な事例に即して理解していきます。# Post.where(user_id: following_ids << id)について # current_user(id: 1)が、`id: 4`と`id: 6`のユーザーを2人フォローしていると仮定 Post.where(user_id: current_user.follwing_ids << current_user.id) Post.where(user_id: [4, 6] << [1]) Post.where(user_id: [4, 6, 1])Railsガイドでは、この事例の場合においてどのようなSQLが発行されるか説明しています。
そう、発行されるSQLは、以下のとおりですね。
whereメソッドは、Post全体の中からuser_idが条件に合致するものを探しているのです。SELECT * FROM post WHERE (posts.orders_count IN (4,6,1))まとめ
さて、冒頭から最後まで流れを追って確認しましょう。
すんなりと理解できるようになっていないでしょうか。# Postクラスのオブジェクトであるcurrent_userがfeedメソッドを実行し、返り値を取得 current_user.feed # では、feedメソッドの中身を見ていきましょう def feed Post.where(user_id: following_ids << id) end # feedメソッドをcurrent_userが使ったので、①と②は同じ current_user.feed #=> ① Post.where(user_id: current_user.following_ids << current_user.id) #=> ② # current_user(id: 1)が、`id: 4`と`id: 6`のユーザーを2人フォローしていると仮定する Post.where(user_id: [4, 6] << [1]) Post.where(user_id: [4, 6, 1])【蛇足】 アソシエーションしている場合の
<<メソッドもあります!話の流れ上、完全に話の腰を折るので最後に付け足すように書きましたが、
実は<<メソッドには違うものがあります。
(とはいっても、その違いを意識することなく使えるよう設計されていますが)まずRailsガイドを見てください。
collection<<メソッドは、1つ以上のオブジェクトをコレクションに追加します。
このとき、追加されるオブジェクトの外部キーは、呼び出し側モデルの主キーに設定されます。
@author.books << @book1つまり、アソシエーションしている場合に使える
<<メソッドというのがRailsで定義されていて、
この<<メソッドを使う場合、オブジェクト自体を追加することができるんです。# current_user(id: 1)が、`id: 4`と`id: 6`のユーザーを2人フォローしていると仮定 # 表現が難しいので、イメージで書きます current_user.following << current_user [User.find(4), User.find(6)] << User.find(1) [User.find(4), User.find(6), User.find(1)] # 各userオブジェクトには、ユーザーの属性であるusernameやemailなどが保管されているとイメージしてくださいなお、もし英語が苦手でなければ、こちらを参照してもよいかもしれません。
事例つきで、挙動について紹介してくれています。【蛇足】 dashはいいぞ!
私はdashを愛用しています。
メソッドについて調べる時に、非常に便利です。
さくっと調べることができて、使い方や引数も分かります。
英語なのがネックですが、日本語だと情報量が限られるのでそこは我慢しましょう。
Google検索だと調べるの時間がかかりるところ、数秒で調べられるのはメリットです。
気軽に調べられると、調べる回数が増えます!!また、英語が苦手な方は、翻訳機能が使えるようなカスタマイズをしてみてはどうでしょう。
試せていないですが、こんなQiita記事を上げている方がいました。Qiita等でも結構紹介されているので、Dashの導入を検討してみてください。
私は無料版でしか使っていないですが、これは本当に便利です!
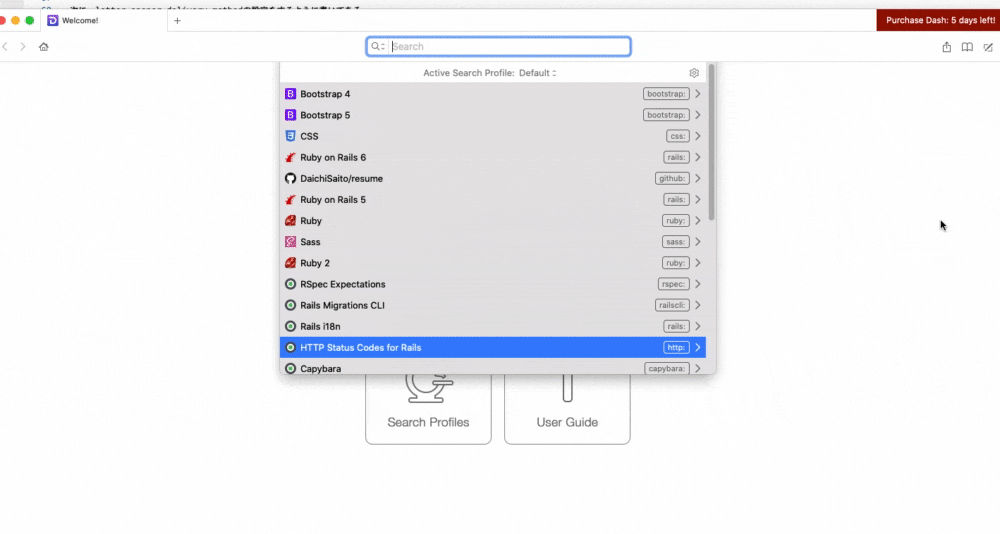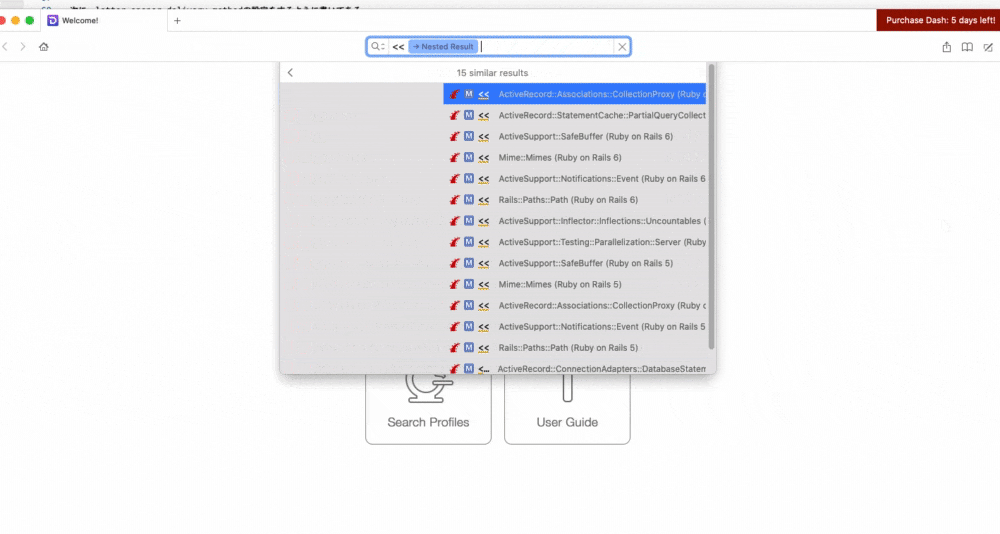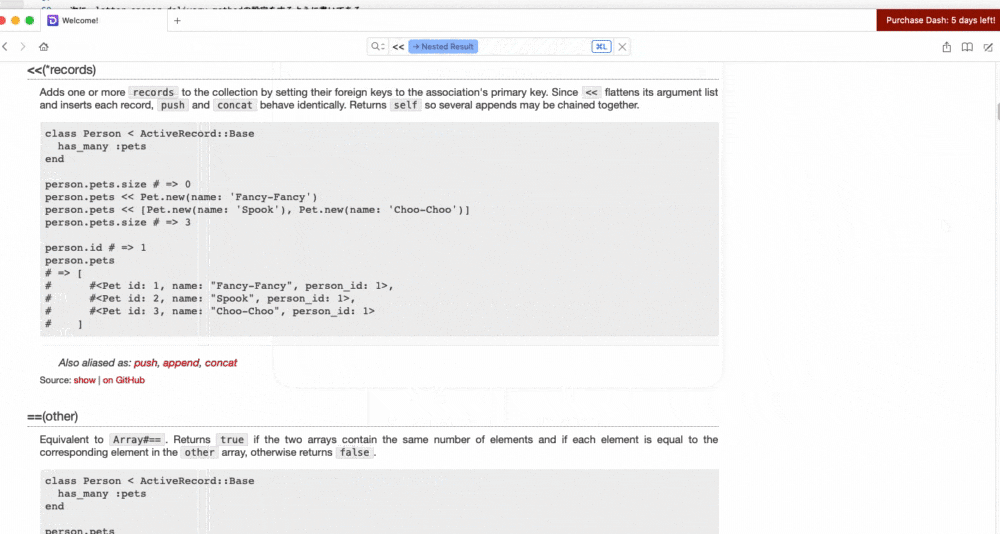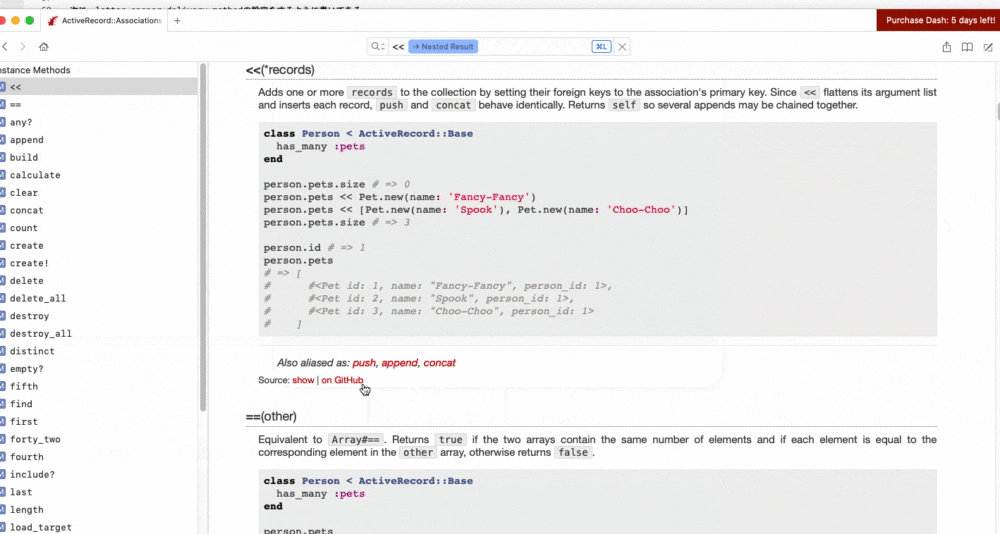
- 投稿日:2020-09-08T18:23:29+09:00
ELBを経由したリクエストでCSRF対策エラーが起こったのでデバッグと解決まで
背景
AWSで Proxy ELB -> Nginx -> ELB -> Taget Group -> ECS でリクエストを飛ばしてRailsのサービスを動かしたところ、 CSRFトークン対策でエラーになったのでそのデバッグと解決策までの道のり。
CSRFトークン対策でエラーになる
エラー概要
起こっていたエラーは
ActionController::InvalidAuthenticityToken。CSRFトークン対策とは
https://railsguides.jp/security.html#クロスサイトリクエストフォージェリ-csrf
Railsが標準搭載しているセキュリティ対策です。
セッションに保存されてるtokenとPOST時のauthencity_tokenが一致しているかを検証し、一致していない場合にエラーを吐く。解決策
nginx.confに
proxy_set_header X-Forwarded-SSL on;を追加する。nginx.conf# もっと本当は書いてあるけど省略 server { listen 80; server_name hoge.jp; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto https; # これを追加する proxy_set_header X-Forwarded-SSL on; }エラー検証
tokenが異なっている?
セッションに保存されてるtokenとPOST時の
authencity_tokenが一致しているかを検証し、一致していない場合にエラーを吐くならセッションに保存されているtokenと
authencity_tokenが異なっているのか、通常の操作でそうなることがあるのだろうか、ということで実際に検証しているRailsのコードをみてみた。rails/actionpack/lib/action_controller/metal/request_forgery_protection.rbdef verified_request? # :doc: !protect_against_forgery? || request.get? || request.head? || (valid_request_origin? && any_authenticity_token_valid?) endこの
verified_request?がfalseの時にInvalidAuthenticityTokenのエラーが投げられる。
tokenが異なるということはany_authenticity_token_valid?がfalseということになるので、その予想でデバッグをしてみた。が、any_authenticity_token_valid?はtrueだった。
valid_request_origin?がfalseになっている?上のコードを見ると、
valid_request_origin?がfalseの時にもverified_request?がfalseになる可能性があるので、確認してみた。
すると確かに、valid_request_origin?がfalseだった。
valid_request_origin?の中身を見てみる。rails/actionpack/lib/action_controller/metal/request_forgery_protection.rbdef valid_request_origin? # :doc: if forgery_protection_origin_check # We accept blank origin headers because some user agents don't send it. raise InvalidAuthenticityToken, NULL_ORIGIN_MESSAGE if request.origin == "null" request.origin.nil? || request.origin == request.base_url else true end end
valid_request_origin?がfalseになるにはrequest.originとrequest.base_urlの中身がわかれば理由が分りそうなので出力してみた。
するとrequest.originはhttps://〜なのに対しrequest.base_urlがhttp://〜となっていた。つまり上のコードの
request.origin == request.base_urlの検証部分でfalseになっていることがわかった。NginxのconfでX-Forwarded-Protoを設定する?
この時点でいろいろ調べると、「NginxからRailsにリクエストが渡される時にHTTPSでNginxにアクセスしてもHTTPとしてRailsに渡されてしまうらしく、これを防ぐために Nginxのconfで
X-Forwarded-Protoを使ってRailsにHTTPSであることを知らせる」、という方法がすぐ出てくる。やってみた。nginx.conf# もっと本当は書いてあるけど省略 server { listen 80; server_name hoge.jp; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # これを追加 proxy_set_header X-Forwarded-Proto https; }けどダメだった。
試しにRailsでリクエストヘッダを出力してみると"X-Forwarded-Proto": "http"となっていた。どこかでhttpsからhttpに上書きされている?
その通りで、これはELBの性質上でした。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/userguide/how-elastic-load-balancing-works.html
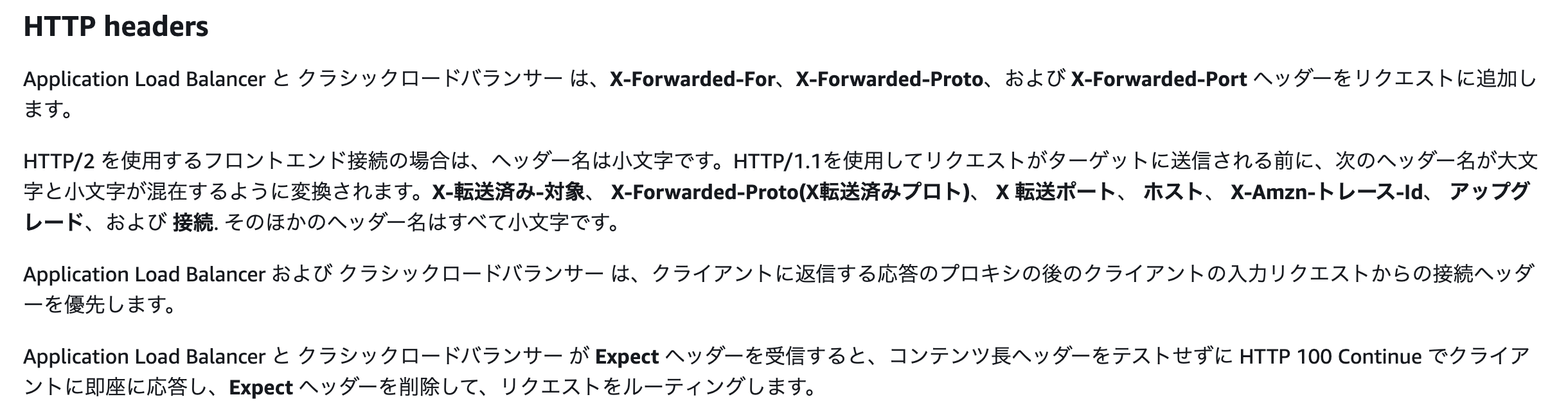
今回、ProxyとなるELBから動かしているRailsのサービスに紐づくELBに対してリクエストが送られてくるが、ここはHTTPで送られてくる。
Application Load Balancer および クラシックロードバランサー は、クライアントに返信する応答のプロキシの後のクライアントの入力リクエストからの接続ヘッダーを優先します
とのことで、NginxからELB間のHTTP通信が優先されてリクエストヘッダの
X-Forwarded-For、X-Forwarded-Proto、X-Forwarded-Portが書き換えられてしまっていた。じゃあどうする
requestオブジェクトはRackで作られているらしいのでそこのコードを見てみた。
rack/lib/rack/request.rbdef scheme if get_header(HTTPS) == 'on' 'https' elsif get_header(HTTP_X_FORWARDED_SSL) == 'on' 'https' elsif forwarded_scheme forwarded_scheme else get_header(RACK_URL_SCHEME) end end # 省略 def base_url "#{scheme}://#{host_with_port}" endhttps://github.com/rack/rack/blob/649c72bab9e7b50d657b5b432d0c205c95c2be07/lib/rack/request.rb
base_urlの作られ方から、schemeがhttpsになれば良い。
schemaがhttpsになるにはいくつか条件があるけれど 、今回はget_header(HTTP_X_FORWARDED_SSL) == 'on'になるようにすればいけそう!
(HTTP_X_FORWARDED_SSLはELBに書き換えられる心配もない)
ということで、NginxのリクエストヘッダにX_Forwarded_SSLを追加してみた。nginx.conf# もっと本当は書いてあるけど省略 server { listen 80; server_name hoge.jp; proxy_set_header Host $host; # この下2つはELBに書き換えられちゃう proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto https; # これを追加する proxy_set_header X-Forwarded-SSL on; }結果
エラーが出なくなった!
デバッグしてみたらちゃんとリクエストヘッダにX_Forwarded_SSLが追加されてschemeはhttpsになっていた。

- 投稿日:2020-09-08T18:01:12+09:00
Rails バリデーションとは
RailsでDBに値を保存する際、無意味なデータや想定外のデータの登録を防ぐ「バリデーション」。備忘録として、書き方や例をまとめます。
バリデーションとは
先にも書きましたが、データを保存する前に、無効なデータでないことを検証する機能のこと。門番みたいなものです。
空のデータが保存されないようにしたり、数字以外は保存できないようにしたり、文字数に制限を設けたり……保存するデータに制限をかける時に使います。基本的な書き方
Railsではモデルクラスに、validatesメソッドで指定します。validates :カラム名(シンボルで指定),検証ルール(こちらもシンボルで指定)これだけでは理解しづらいので、次から例を用いて書いていきます。
ユーザーモデルにname,age,email,genderのデータを追加していく例になります。空データを登録できないようにする→presence
user.rbclass User < ApplicationRecord validates :name, presence: true end文字数の制限を設ける→length
user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 50 } endここでは名前の長さの上限を50文字にしました。下限や範囲の指定もできます。
#長さの下限を2文字に設定→minimum validates :name, length: { minimum: 2 } #長さの範囲を2-50文字→in .. validates :name, length: { in: 2..50 } #長さを5文字に指定→is validates :name, length: { is: 5 }数値のみを許可する→numericality、空を許可するallow_blank
ageカラムは数字のみ、空でも構わない例です。user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 50 } validates :age, numericality: { only_integer: true }, allow_blank: true endnumericalityは、デフォルトでは小数も許容してしまいます。ageカラムでは整数のみ許可したいので、 only_integerを。
また、numericalityは空を許可しないため、空を許可する場合はallow_blank: trueを追加します。(空を許可せず、数値のみを許可する場合はnumericalityのみ、 presence: trueは無くても良い。)同一データは一つのみ許可する→uniqueness
emailカラムには同じデータを登録できないようにします。user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 50 } validates :age, numericality: { only_integer: true }, allow_blank: true validates :email, presence: true, uniqueness: true, format: { with: /\A([^@\s]+)@((?:[-a-z0-9]+\.)+[a-z]{2,})\Z/i} endここではuniqueness: trueを用いました。format:では、文字列が条件に適しているかの検証を行います(ここでは割愛させていただきます)。
特定の値が含まれているか確認する→inclusion
genderカラムに、1~3(1:male, 2:female, 3:other)のいずれかの数字が保存されるとします。user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 50 } validates :age, numericality: { only_integer: true }, allow_blank: true validates :email, presence: true, uniqueness: true, format: { with: /\A([^@\s]+)@((?:[-a-z0-9]+\.)+[a-z]{2,})\Z/i} validates :gender, presence: true, inclusion: { in: 1..3 } endおわりに
ほんの一部ではありますが、validationについてまとめてみました。
まだまだ知らないことだらけですが、日々勉強していきます!初心者ですので、間違っている点等あればご指摘いただけますと幸いです。
- 投稿日:2020-09-08T17:42:50+09:00
【Rails DM】DMが送信された時の通知機能を作ろう!
【Rails DM】通知機能を作ろう!
ステップ
1:DM機能を実装しよう
2:通知機能を実装しよう
2−1:モデルを作成しよう
rubyrails g model Notification visitor_id:integer visited_id:integer room_id:integer message_id:integer action:string checked:boolean2−2:作成した通知モデルを、User、Post、Commentと紐付け
UserモデルとNotificationモデルとの関連付け
app/models/user.rbhas_many :active_notifications, class_name: 'Notification', foreign_key: 'visitor_id', dependent: :destroy has_many :passive_notifications, class_name: 'Notification', foreign_key: 'visited_id', dependent: :destroyRoomモデルとNotificationモデルとの関連付け
app/models/room.rbhas_many :notifications, dependent: :destroyMessageモデルとNotificationモデルとの関連付け
app/models/message.rbhas_many :notifications, dependent: :destroyNotificationモデルとUser,Room,Messageモデルとの関連付け
app/models/notification.rbdefault_scope -> { order(created_at: :desc) } belongs_to :room, optional: true belongs_to :message, optional: true belongs_to :visitor, class_name: 'User', foreign_key: 'visitor_id', optional: true belongs_to :visited, class_name: 'User', foreign_key: 'visited_id', optional: true2−3:DM通知の作成メソッド
messages_controller.rbclass MessagesController < ApplicationController def create if Entry.where(user_id: current_user.id, room_id: params[:message][:room_id]).present? @message = Message.new(message_params) # ここから @room=@message.room # ここまでを追加 if @message.save # ここから @roommembernotme=Entry.where(room_id: @room.id).where.not(user_id: current_user.id) @theid=@roommembernotme.find_by(room_id: @room.id) notification = current_user.active_notifications.new( room_id: @room.id, message_id: @message.id, visited_id: @theid.user_id, visitor_id: current_user.id, action: 'dm' ) # 自分の投稿に対するコメントの場合は、通知済みとする if notification.visitor_id == notification.visited_id notification.checked = true end notification.save if notification.valid? # ここまでを追加 redirect_to "/rooms/#{@message.room_id}" end else redirect_back(fallback_location: root_path) end end private def message_params params.require(:message).permit(:user_id, :body, :room_id).merge(user_id: current_user.id) end end2−4:通知の一覧画面の作成
terminalrails g controller notifications indexcontroller/notifications_controller.rbclass NotificationsController < ApplicationController def index @notifications = current_user.passive_notifications @notifications.where(checked: false).each do |notification| notification.update_attributes(checked: true) end end endviews/notifications/index.html.erb<% notifications = @notifications.where.not(visitor_id: current_user.id) %> <% if notifications.exists? %> <%= render notifications %> <% else %> <p>通知はございません</p> <% end %>views/notifications/_notificastion.html.erb<% visitor = notification.visitor %> <% visited = notification.visited %> <div> <%= link_to user_path(visitor) do %> <%= visitor.name %>さんが <% end %> <% if notification.action=='dm' %> あなたにDMを送りました <% end %> </div>参考記事
- 投稿日:2020-09-08T16:14:57+09:00
特定のコントローラー#アクションのフィルター(コールバック関数)の実行時間をNew Relicにレポートするためのinitializerファイルを書いた
- コントローラのbefore_actionとかで指定されているfilter(callback関数)の実行時間をNew Relicに送信するためのinitializerファイル
- callback関数がProcで指定されている場合の処理がキツかった。(結局ProcをProcで挟み込むことで対応)
- 黒魔術に黒魔術を重ねてます。動作確認はしていますが、正確な保証はないです。
config/initializers/trace_controller_filters.rb# This initializer is to make a configuration to report the execution time of filters(callbacks) # for all actions of specified Controller class. # # Controller(s) to be traced can be configurable by environment variable 'FILTER_TRACED_CONTROLLERS' # Set it this way, say in .env file: # (Ex) FILTER_TRACED_CONTROLLERS="ProjectsController Api::V2::ProjectsController UsersController" Rails.application.config.after_initialize do if ENV['NEW_RELIC_ENABLED'] && ENV['FILTER_TRACED_CONTROLLERS'].present? traced_controllers = [] ENV['FILTER_TRACED_CONTROLLERS'].split.each do |controller_str| begin traced_controllers << controller_str.constantize rescue puts "===== #{controller_str} in FILTER_TRACED_CONTROLLERS has not been found =====" end end traced_controllers.each do |controller| begin controller.class_eval do self.include ::NewRelic::Agent::MethodTracer self._process_action_callbacks().send(:chain).each do |callback| case callback.raw_filter when Symbol self.add_method_tracer callback.raw_filter when Proc unless callback.instance_variable_get(:@_already_wrapped) callback.instance_variable_set(:@_already_wrapped, true) original_filter = callback.raw_filter wrapped_filter = Proc.new{ # execution time of 'original_filter' should be traced only if 'self' (= a Controller instance # which is executing current Proc) is an instance of one of FILTER_TRACED_CONTROLLERS. if traced_controllers.include? self.class self.class.trace_execution_scoped("Custom/ProcFilter/Proc_#{original_filter.source_location[0].gsub('/', ':')}}") do # execute 'original_filter' in the context of 'self' (= a Controller instance which is executing current proc), # which is not in the context of current 'wrapped_filter' Proc. # just as is done originally in ActiveSupport::Callbacks#run_callbacks. # See: https://github.com/rails/rails/blob/master/activesupport/lib/active_support/callbacks.rb#L645-L647 self.instance_exec(&original_filter) end else self.instance_exec(&original_filter) end } callback.instance_variable_set(:@filter, wrapped_filter) callback.instance_variable_set(:@key, callback.send(:compute_identifier, callback.raw_filter)) end end end end puts "===== Filters of actions for #{controller} will be reported to New Relic =====" rescue puts "===== #{controller} in FILTER_TRACED_CONTROLLERS has not been found =====" end end end end
- 投稿日:2020-09-08T16:05:58+09:00
特定のコントローラーのアクションのフィルター(コールバック関数)の実行時間をNew Relicにレポートするためのinitializerファイルを書いた
- コントローラのbefore_actionとかで指定されているfilter(callback関数)の実行時間をNew Relicに送信するためのinitializerファイル
- callback関数がProcで指定されている場合の処理がキツかった。(結局ProcをProcで挟み込むことで対応)
- 黒魔術に黒魔術を重ねてます。動作確認はしていますが、正確な保証はないです。
config/initializers/trace_controller_filters.rb# This initializer is to make a configuration to report the execution time of filters(callbacks) # for all actions of specified Controller class. # # Controller(s) to be traced can be configurable by environment variable 'FILTER_TRACED_CONTROLLERS' # Set it this way, say in .env file: # (Ex) FILTER_TRACED_CONTROLLERS="ProjectsController Api::V2::ProjectsController UsersController" # # Also, make sure that you set [config.eager_load = true] for your Rails environment to use this initializer. Rails.application.config.after_initialize do if ENV['NEW_RELIC_ENABLED'] && ENV['FILTER_TRACED_CONTROLLERS'].present? traced_controllers = [] ENV['FILTER_TRACED_CONTROLLERS'].split.each do |controller_str| begin traced_controllers << controller_str.constantize rescue puts "===== #{controller_str} in FILTER_TRACED_CONTROLLERS has not been found =====" end end traced_controllers.each do |controller| begin controller.class_eval do self.include ::NewRelic::Agent::MethodTracer self._process_action_callbacks().send(:chain).each do |callback| case callback.raw_filter when Symbol self.add_method_tracer callback.raw_filter when Proc unless callback.instance_variable_get(:@_wantedly_already_wrapped) callback.instance_variable_set(:@_wantedly_already_wrapped, true) original_filter = callback.raw_filter wrapped_filter = Proc.new{ # execution time of 'original_filter' should be traced only if 'self' (= a Controller instance # which is executing current Proc) is an instance of one of FILTER_TRACED_CONTROLLERS. if traced_controllers.include? self.class self.class.trace_execution_scoped("Custom/ProcFilter/Proc_#{original_filter.source_location[0].gsub('/', ':')}}") do # execute 'original_filter' in the context of 'self' (= a Controller instance which is executing current proc), # which is not in the context of current 'wrapped_filter' Proc. # just as is done originally in ActiveSupport::Callbacks#run_callbacks. # See: https://github.com/rails/rails/blob/master/activesupport/lib/active_support/callbacks.rb#L645-L647 self.instance_exec(&original_filter) end else self.instance_exec(&original_filter) end } callback.instance_variable_set(:@filter, wrapped_filter) callback.instance_variable_set(:@key, callback.send(:compute_identifier, callback.raw_filter)) end end end end puts "===== Filters of actions for #{controller} will be reported to New Relic =====" rescue puts "===== #{controller} in FILTER_TRACED_CONTROLLERS has not been found =====" end end end end
- 投稿日:2020-09-08T13:33:00+09:00
RSpec導入時のエラー[NameError: uninitialized constant FactoryBot]
エラー内容
某スクールでフリマアプリの開発中。RSpecを用いてテストを行った際のエラーです。
ターミナルで
bundle exec rspec spec/models/user_spec.rbを行ったところエラーが発生しました。An error occurred while loading ./spec/models/user_spec.rb. Failure/Error: config.include FactoryBot::Syntax::Methods NameError: uninitialized constant FactoryBot # ./spec/rails_helper.rb:35:in `block in <top (required)>' # ./spec/rails_helper.rb:32:in `<top (required)>' # ./spec/models/user_spec.rb:1:in `require' # ./spec/models/user_spec.rb:1:in `<top (required)>' # ------------------ # --- Caused by: --- # NameError: # uninitialized constant FactoryBot # ./spec/rails_helper.rb:35:in `block in <top (required)>' No examples found. Finished in 0.00007 seconds (files took 5.52 seconds to load) 0 examples, 0 failures, 1 error occurred outside of examples行ったこと
①
gem'rspec-rails'、gem 'factory_bot_rails'をGemfileに追記し、ターミナルでbundle installgroup :development, :test do #中略 gem 'rspec-rails' gem 'factory_bot_rails end②
rails g rspec:installでファイルを生成#ターミナル create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb③ .rspecに以下を追加
--format documentation④ spec/modelsディレクトリを追加し、その中にmodelsディテクトリ下に「user_spec.rb」をという名前で作成し、テストコードを記述
describe User do describe '#create' do it "必須項目が入力してあれば登録できること" do user = build(:user) expect(user).to be_valid end #省略⑤ spec/factoriesディレクトリを追加し、その中に「users.rb」という名前でファイルを生成し、インスタンスを作成
FactoryBot.define do factory :user do nickname {"yamada"} email {"yamada@gmail.com"} password {"00000000"} password_confirmation {"00000000"} familyname_kanji {"山田"} firstname_kanji {"太郎"} familyname_kana {"ヤマダ"} firstname_kana {"タロウ"} birthday {"2020-01-01"} end end⑥factory_botの記法の省略のため、spec/rails_helper.rbを以下のように編集
#省略 RSpec.configure do |config| #下記の記述を追加 config.include FactoryBot::Syntax::Methods #省略 end⑦ テストコードを確認するために、
bundle exec rspec spec/models/user_spec.rbを実行したところエラーが発生An error occurred while loading ./spec/models/user_spec.rb. Failure/Error: config.include FactoryBot::Syntax::Methods NameError: uninitialized constant FactoryBot # ./spec/rails_helper.rb:35:in `block in <top (required)>' # ./spec/rails_helper.rb:32:in `<top (required)>' # ./spec/models/user_spec.rb:1:in `require' # ./spec/models/user_spec.rb:1:in `<top (required)>' # ------------------ # --- Caused by: --- # NameError: # uninitialized constant FactoryBot # ./spec/rails_helper.rb:35:in `block in <top (required)>' No examples found. Finished in 0.00007 seconds (files took 5.52 seconds to load) 0 examples, 0 failures, 1 error occurred outside of examples⑦ RSpecを導入した時、詰まったこと(NameError: uninitialized constant FactoryBot)を参考に
config.include FactoryBot::Syntax::Methodsの配置を変えてみたが、解決できず…エラーの原因
factory_bot_railsのバージョンが原因。バージョンが違ったので読み込まれず、エラーが発生していたようです。gem 'factory_bot_rails', '5.2.0'さいごに
初歩的なミスでしたが、前例が見つからず手間取ったので、同じエラーに遭遇した方の参考になれば幸いです。
- 投稿日:2020-09-08T11:40:07+09:00
heroku run rails db:migrate ができないエラー
【概要】
1.結論
2.なぜ起きるのか
3.どのように解決するのか
5.ここから学んだこと
1.結論
migrateファイルを整理する!
2.なぜ起きるのか
実は、% rails db:rollbackをする前に、
upしているファイルのカラム名を変更してしまったんです。
なので、migrateファイルが噛み合っていなかったんです。
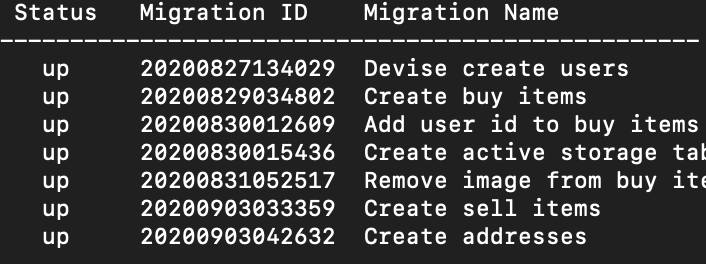
上記の画像では全て"up"になっていますが、この状態でカラム名を変更するための操作をしてしまいました。
具体的には % rails generate migration rename_”変更前カラム名”column_to”モデル名” です。ターミナル% heroku run rails db:migrate上を実行した際に文字や数字の中にとある一文がありまして”migrateファイルのorders(私が作ったmigrateファイル名です)がないよ”とも言われましたし、
ターミナル% rails db:migrate上を実行した際にも+αでこのカラム名がないよということを言われました。
3.どのように解決するのか
ただやることは明確で、migrateファイルの食違いをなくすために整理しました。
今回はとにかく早くエラーを解消したかったために、画像を用意し忘れました。
この時は必ず削除が発生する (=DBをいじる)ので% rails db:rollback を必ず行いました。
(rollbackするとDBのテーブルの中身は消えますが開発段階では特に問題はないと思います。)% rails db:migrate:statusでも"down"してることを確認しました。
自分は該当テーブルのカラム名のRenameやAdd、テーブルのDropを行っていたので順を追って何が必要で何が消しても問題ないかを慎重に行いながら整理しました。
% rails db:migrate を行うとうまく機能したのでherokuでも試してみるとうまく行きました。
4.ここから学んだこと(エラーの時に使用)
今思い返してみるとrollbackせずに、勝手にDB上でテーブルを削除したり、ロールバックしているけど違うファイルでカラム名を追加したりいろんなことたくさんやっていました。その時にmigrateしてもなぜかエラーが出るので勝手に削除等を行った結果このような自体になってしまいました。
実は自分がこの記事を書いたエラー(git push heroku masterする際のエラー解消方法)の前に起きたことだったので、migrateファイルを改善したのになぜherokuのmasterにpushできないのかと焦っていました。migrateファイルやDB関係は特に注意して扱わないと修正が本当に大変になることを実感しました。またrollbackする際は% rails db:rollback STEP="数字"をすることでupの箇所からし上方向”数字”番目までロールバックしてくれます。手間とミスを省ける記述です。
- 投稿日:2020-09-08T11:40:07+09:00
heroku run rails db:migrate ができないエラーの解消方法
【概要】
1.結論
2.なぜ起きるのか
3.どのように解決するのか
4.ここから学んだこと
1.結論
migrateファイルを整理する!
2.なぜ起きるのか
migrateファイルが噛み合っていなかったことが原因でした。実は、% rails db:rollbackをする前に、
upしているファイルのカラム名を変更してしまいました。
上記の画像では全て"up"になっていますが、この状態でカラム名を変更するための操作をしてしまいました。
具体的には % rails generate migration rename_”変更前カラム名”column_to”モデル名” です。AddやDropもしておりました。ターミナル% heroku run rails db:migrate上を実行した際に文字や数字の中にとある一文がありまして”migrateファイルのorders(私が作ったmigrateファイル名です)がないよ”とも言われましたし、
ターミナル% rails db:migrate上を実行した際にもordersに+αで”このカラム名がないよ”ということを言われました。
3.どのように解決するのか
ただやることは明確で、migrateファイルの食違いをなくすために整理しました。
今回はとにかく早くエラーを解消したかったために、画像を用意し忘れました。
この時は必ず削除が発生する (=migrateファイルの削除ですが結果的にはDBをいじることになる)ので% rails db:rollback を必ず行いました。
(rollbackするとDBのテーブルの中身は消えますが開発段階では特に問題はないと思います。)% rails db:migrate:statusでも"down"してることを確認しました。
自分は該当テーブルのカラム名のRenameやAdd、テーブルのDropを行っていたので順を追って何が必要で何が消しても問題ないかを慎重に行いながら整理しました。
% rails db:migrate を行うとうまく機能したのでherokuでも試してみるとうまく行きました。
4.ここから学んだこと(エラーの時に使用)
今思い返してみるとrollbackせずに、勝手にDB上でテーブルを削除したり、ロールバックしているけど違うファイルでカラム名を追加したりいろんなことたくさんやっていました。その時にmigrateしてもなぜかエラーが出るので勝手に削除等を行ってうまくいってしまってたので、ツケが回って1日も費やす形になってしまいました。
実は自分がこの記事を書いたエラー(git push heroku masterする際のエラー解消方法)の前に起きたことだったので、migrateファイルを改善したのになぜherokuのmasterにpushできないのかと焦っていました。migrateファイルやDB関係は特に注意して扱わないと修正が本当に大変になることを実感しました。またrollbackする際は% rails db:rollback STEP="数字"をすることでupの箇所から上方向”数字”番目までロールバックしてくれます。手間とミスを省ける記述です。
- 投稿日:2020-09-08T10:29:09+09:00
link_toの文字列部分にHTMLタグを挿入する方法
文字列部分にfontawesomeを使用したいときなどにすぐ思い出せるように自分用に残しておきます。
index.html.erb<%= link_to new_user_session_path, class: "new-post__btn" do%> <i class="fas fa-edit"></i> ///fontawesomeでコピーしたHTMLタグ <%end%>
無料で使う場合はproとついているフォントは使えない。
- 投稿日:2020-09-08T10:21:47+09:00
PG::ConnectionBad: could not connect to server: No such file or directory
PG::ConnectionBad: could not connect to server: No such file or directoryというエラーがでた
解決法
1,ターミナルでdesktopの前に行く。
2,
$ cd /usr/local/var/log/
3,
$ cat postgres.log
そうすると以下のようなエラーがでる
dyld: Library not loaded: /usr/local/opt/icu4c/lib/libicui18n.62.dylib
Referenced from: /usr/local/bin/postgres
4,以下の記事を参考に実行
https://qiita.com/eightfoursix/items/bf11693b085eced95e294-1
$ brew upgrade
4-2
$ brew postgresql-upgrade-database
自分の場合は、これで解決しました。
- 投稿日:2020-09-08T10:14:54+09:00
【RSpec】 Factory Botを使いこなそう
FactoryBotの基本のキ
bin/rails g factory_bot:model userのようにFactoryBotでデータを作成するファイルが生成されます。今回は
spec/factories/users.rbに以下のようなファイルが生成されると思います。spec/factories/users.rbFactoryBot.define do factory :user do end endこのなかに作りたいデータを詰め込んでいきます。
spec/factories/users.rbFactoryBot.define do factory :user do name {"佐藤"} age {20} height {170} end end実際に使ってみよう。
spec/models/user.rbrequire 'rails_helper' RSpec.describe User, type: :model do it "is valid with a name, age and height" do expect(FactoryBot.build(:user)).to be_valid end endこんな感じで簡潔に書くことができます。ちなみに、FactoryBotを使わない場合は下記のようになります。
spec/models/user.rbrequire 'rails_helper' RSpec.describe User, type: :model do it "is valid with a name, age and height" do user = User.new( name: "佐藤", age: 20, height: 170, ) expect(user).to be_valid end endこんな感じになってしまい、行数が多くなってしまいます。
とはいえ読みやすくなるとはいえ、FactoryBot内にデータの内容が隠されてしまうため、ユースケースによって使うか使わないか選択して行きましょう。
オーバーライド
スペックを書くファイルの中で、データをオーバーライド(上書き)することができます。
spec/models/user.rbrequire 'rails_helper' RSpec.describe User, type: :model do it "is invalid without a name" do user = FactoryBot.build(:user, name: nil) user.vaild? expect(user.errors[:name]).to include("can't be blank") end endFactoryBotの内容に上書きして、
nameをnilにしています。シーケンスを使ってユニークなデータを
例えば、「メアド」はユニークな値であるべきです。しかし、FactoryBotをそのまま使ってしまうと毎回同じ値が入るため、バリデーションに引っかかってしまいます。(意図せず。)
その問題に対処するために、「シーケンス」が用意されています。
spec/factories/users.rbFactoryBot.define do factory :user do name {"佐藤"} age {20} height {170} #emailにシーケンスが使われています。 sequence(:email) {|n| "test#{n}@example.com"} end endこうするとで新しいユーザーが作成されるたびに
test1@example.com,test2@example.comと常にユニークな値を入れることができます。ファクトリーをもっと多様化する
例えば、高齢者の場合をテストしたい、身長が高い人をテストしたい、みたいなことが出たとします。その細かい問題をファクトリー内で吸収することができます。主に二つの方法があります。
継承を使う
spec/factories/users.rbFactoryBot.define do factory :user do name {"佐藤"} age {20} height {170} sequence(:email) {|n| "test#{n}@example.com"} # 高齢者を対象とするデータ factory :senior do age {75} end # 高身長が対象とするデータ factory :tall do height {190} end end end
FactoryBot.build(:user, :senior)やFactoryBot.build(:user, :tall)みたいに使うことができます。traitを使う。
僕はこっちの方が好きです。理由はFactoryBot内に書くことで短縮できる,何が「違う」のかわかるからです。とにかく見て行きましょう!
spec/factories/users.rbFactoryBot.define do factory :user do name {"佐藤"} age {20} height {170} sequence(:email) {|n| "test#{n}@example.com"} trait :senior do age {75} end trait :tall do height {190} end end end
FactoryBot.build(:user, :senior)のように書くことで呼び出すことができます。こうすることで、そのデータの特徴が明示されているので、可読性が高いですよね。
コールバック
FactoryBotでは動的な動きも表現することができます。下記のコードをみてください。
spec/factories/users.rbFactoryBot.define do factory :user do name {"佐藤"} age {20} height {170} sequence(:email) {|n| "test#{n}@example.com"} trait :with_tasks do after(:create) { |user| create_list(:task, 5, user: user) } end end end
FactoryBot.build(:user, :with_tasks)とすることでuserに関連したtaskを作ることができます。
- 投稿日:2020-09-08T08:38:38+09:00
rails tutorial 第6章
はじめに
独学でrails tutorialを進めていく過程を投稿していきます。
進めていく上でわからなかった単語、詰まったエラーなどに触れています。
個人の学習のアウトプットなので間違いなどあればご指摘ください。
初めての投稿なので読みにくいところも多々あるかと思いますがご容赦ください。
第6章 ユーザーのモデルを作成する
6.2.2 存在性を検証する
存在性の検証は:presenceで行うようです。
tutorialではよく省略されたコードが示されていますのでしっかり理解するまでは自分でフォローもしておこうかと思います。validates :name, presence: true #すべて括弧をつけると validates(:name, {presence: true}) #第一引数には検証するカラム名を、第二引数には検証する内容
問題発生!!
リスト6.13のtestを実行するとRuntimeError: RuntimeError: database is lockedと表示されエラーになってしまう。
解決のために試したこと
参考記事1
https://qiita.com/kambe0331/items/1eaf2383b39c721e7283
こちらの記事を参考にし、dbファイル下のtest.sqlite3というファイルの名前を一旦変更し再度元の名前に戻しました。結果
上手くいかず、、、次に
参考記事2
https://stackoverflow.com/questions/7154664/ruby-sqlite3busyexception-database-is-locked/62730905#62730905
こちらの記事を参考にし、DB Browser for SQlite、サーバー、プロンプトなどを一度全て終了して、改めて起動。結果
テストをクリア出来ました。余談
一時的にテストをクリアできましたが、どうやら根本的には解決出来ていなかったようで、こちらのエラーこれからも頻発します。エラーの解決方法は別の記事にまとめました。
https://qiita.com/shun_study_p/items/fbb4cb2d4c392063c9a96.2.3 長さを検証する
長さの検証は:lengthで行うようです。
validates :name, presence: true, length: { maximum: 50 } #わかりやすく括弧をつけると validates(:name, {presence: true, length: { maximum: 50 }})先程と同様、慣れるまでは括弧を自分でフォローしておきます。
6.2.5 一意性を検証する
一意性の検証は:uniquenessで行うようです。
:case_sensitiveというオプションを使うことで、大文字小文字を区別するか指定が出来るようです。case_sensitive: falseとすることで:uniquenessの値が一意かどうかの検証で大文字と小文字を区別しないというオプションを追加しています。
問題発生!!
最後にrails testを実行したところMigrations are pending. To resolve this issue, run: bin/rails db:migrate RAILS_ENV=testとのエラーが発生しました。
素直に表示されたコマンド実行するとmigrateできないとのエラーが、、、解決
以下の記事を参考にし
http://kzlog.picoaccel.com/post-995/rails db:rollback RAILS_ENV=test rails db:migrate RAILS_ENV=test上記のコマンドを実行すると正常に動作しました。
終わりに
今回は少しエラーに躓きました。
しかし、6章の内容はしっかり理解が出来ました。
- 投稿日:2020-09-08T08:14:25+09:00
Rails 6で認証認可入り掲示板APIを構築する #3 RSpec, FactoryBot導入しpostモデルを作る
←Rails 6で認証認可入り掲示板APIを構築する #2 gitとrubocop導入
RSpec, FactoryBotのインストール
前回の続きから。
テストに使うRSpecとFactoryBotを入れます。Gemfilegroup :development, :test do + gem "rspec-rails" + gem "factory_bot_rails" end$ bundleインストールできたので初期化をします。
$ rails g rspec:install ... Running via Spring preloader in process 6770 create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb今後modelやcontrollerを生成した時に、一緒に自動生成されるRSpecの制御をします。
最低限のテストに収めるためmodelとrequestのみでいこうと思うので、それ以外を使わないよう設定します。config/application.rbclass Application < Rails::Application ... + config.generators do |g| + g.test_framework :rspec, + view_specs: false, + helper_specs: false, + controller_specs: false, + routing_specs: false + end end ...ついでにFactoryBotをRSpecの中でクラスを書かなくてもメソッドが使える設定をします。
spec/rails_helper.rbRSpec.configure do |config| + config.include FactoryBot::Syntax::Methods ...参考:RailsアプリへのRspecとFactory_botの導入手順
ここまでいったらrubocop動かしてエラー潰し、エラーがゼロになったらgit commitしておきましょう。
なおrubocop -aの-aは自動修正可能なものを自動修正するコマンドなので、1回目大量のエラーが出て場合、もう1回動かすと自動修正後で数が一気に減るはずです。postモデルの生成
前準備が非常に長かったですが、これでようやく準備が整ったのでmodelを作っていきます。
$ rails g model Post subject:string body:textこちらのコマンドを実行するとmodel, migration, spec, factory_botの4ファイルが
生成されます。$ rails db:migrateもし実行時に以下エラーが出たら、postgresが止まっているので起動します
rails aborted! PG::ConnectionBad: could not connect to server: No such file or directory Is the server running locally and accepting connections on Unix domain socket "/var/run/postgresql ... $ sudo service postgresql95 startpryを入れる
rails consoleコマンドを実行時、標準のirbよりもpryの方ができることが増えます。
Gemfilegroup :development, :test do + gem "pry-rails" + gem "pry-byebug" ... end$ bundlerails consoleでpostの保存ができるか試す
controllerまで実装して動作確認だと手間がかかるので、rails consoleでmodelがDBに保存・読み込みができるか試します。
$ rails c ... [1] pry(main)> Post.create!(subject: "hoge", body: "fuga") [2] pry(main)> posts = Post.all Post Load (0.6ms) SELECT "posts".* FROM "posts" => [#<Post:0x0000000006e89850 id: 1, subject: "hoge", body: "fuga", created_at: Sat, 05 Sep 2020 13:50:01 UTC +00:00, updated_at: Sat, 05 Sep 2020 13:50:01 UTC +00:00>][1]でpostを1件保存し、[2]で全件取得しました。
どうやら正常にcreate, readができていそうですね。続きは次回。
【連載目次へ】
- 投稿日:2020-09-08T02:03:02+09:00
理解されやすいコードの書き方
コードレビューしていて、結構ヤバイな...ってなるコード多いので、やばそうなポイントをまとめました。
一応Railsを用いて説明していますが、web系だとほかの言語でも当てはまると思います。
ざっくりいうと「CUIを整えよう」です。ぜひ気をつけてください。全コード共通
rescueを多用しない
一番大事。ほかの言語だとtry~catchですね。
hoge.rb# BAD def hoge raise 'hogehoge' rescue => e # エラーの握りつぶしは臭いものへの蓋と同じです。絶対やめてください。 endちゃんとprivateを使う
初歩的だが、例えば以下。
washing_machine.rb# BAD class WashingMachine def wash locking do inject_water # puts 注水します rolling # puts 洗濯槽を回します eject_water # puts 排水します ventilate # puts 乾燥します end end def dry locking do ventilate end end def locking puts "扉をロックします" yield puts "扉のロックを解除します" end def inject_water puts "注水します" end ... end適当に洗濯機モデルを作った。実用的な例が浮かばなかったから許してほしい。
このモデルの推奨の使い方はこう。> WashingMachine.new.wash 扉をロックします 注水します 洗濯槽を回します 排水します 乾燥します 扉のロックを解除しますだが、例えばこのモデルをこういう呼び出し方もできる。
> WashingMachine.new.inject_water 注水します扉のロックなしに注水を始めている。あたり一面水浸しになるかもしれない。クレームもんである。
「安易に使ってはいけないメソッド」の意味も込めて、しっかりprivate宣言はしましょう。washing_machine.rb# GOOD class WashingMachine def wash ... end def dry ... end private # これ以降は内部仕様なので隠す def locking ... end def inject_water ... end ...controller編
controllerでインスタンス変数を多用しない
例えば以下。
hoge_controller.rb# BAD class HogeController < ApplicationController def hoge @hoge = Hoge.new @data = @hoge.data @result = @hoge.result end ...インスタンス変数を使っているviewに値を共有する例である。
この例はview側から見るとviews/hoge/hoge.html.erb<%= @hoge %> <%= @data %> <%= @result %>となる。
@hogeはいいとして、@dataや@resultはデータや結果であることはわかるが、なんの結果なのか分からない。また、controllerには複数のactionが記述されるため、他のactionで同じ変数が使われる可能性もある。使われた場合、それらが同じ@dataなのか、異なる@dataなのか見分けるのは難しい。
よって以下のように書くのが好まれる。hoge_controller.rb# GOOD class HogeController < ApplicationController def hoge @hoge = Hoge.new end ...views/hoge/hoge.html.erb<%= @hoge %> <%= @hoge.data %> <%= @hoge.result %>これであれば、
@hogeにはHogeのインスタンスが入ってそうだし、view側から見ると@hoge.dataは@hogeのデータであることが直感的に理解できる。actionメソッド以外ではインスタンス変数で値の共有を行わない
例えば以下。
hoge_controller.rb# BAD class HogeController < ApplicationController before_action :set_main_hoge def set_main_hoge @main_hoge = Hoge.first end ...views/hoge/hoge.html.erb<%= @main_hoge %>複数のviewをまたいで共通の値をセットする場合によく見る。
この例は例えばhoge_controller.rb# BAD class HogeController < ApplicationController before_action :set_main_hoge def index @main_hoge = Fuga.first end def set_main_hoge @main_hoge = Hoge.first end ...とされると挙動がおかしくなる。なにかのはずみでこういうコードを書かれた場合、発見がしづらいし、こういうコードに怯えながらコードを書きたくはない。あと普通にviewで
@main_hogeが必要かどうかをcontrollerが知ってないといけないのは面倒すぎる。
よって以下のように書くと好ましい。hoge_controller.rb# GOOD class HogeController < ApplicationController helper_method :main_hoge def main_hoge @main_hoge ||= Hoge.first end ...views/hoge/hoge.html.erb<%= main_hoge %>これだと
main_hogeにある定義が全てだし、@main_hogeが改変される心配も少ない。改変された場合はよっぽど悪意があるか名前が悪いかの二択である。これでよく使われるのはcurrent_userとかだろう。もっとたくさん使っていい。modelに書けるロジックはmodelに書く
例えば以下。
hoge_controller.rb# BAD class HogeController < ApplicationController def new @hoge = Hoge.new @hoge.fuga = 'fuga' @hoge.piyo = 'piyo' end ...
Hogeの初期値をセットする、などの場合である。
Railsの場合、開発が進んでくると色々なcontrollerであるいはactionで似たようなことを行うことになるが、そのたびにこれらを呼び出すのはいささか面倒である。
以下のように書くのが望ましい。hoge_coontroller.rb# GOOD class HogeController < ApplicationController def new @hoge = Hoge.new @hoge.set_deafult end ...Hoge.rb# GOOD class Hoge < ApplicationModel def set_default self.fuga = 'fuga' self.piyo = 'piyo' end ...そもそもcontrollerは使い回しに向いていない。controller以外に居所がないロジックは仕方がないが、それ以外はcontrollerから切り離してmodelに入れるよう心がけるべきである。
要は「ファットコントローラーは避けましょう。」ということだ。余談 ActiveRecord::Base#read_attribute/write_attribute/[ ]/[ ]=を避ける
例えば以下。
hoge_controller.rbclass HogeController < ApplicationController def hoge @hoge = Hoge.new fuga = @hoge.read_attribute(:fuga) @hoge.write_attribute(:fuga, :fuga) fuga = @hoge[:fuga] # read_attribute(:fuga) と等価 @hoge[:fuga] = :fuga # write_attribute(:fuga) と等価 endこれらの正確な挙動は
- #read_attribute / #[] ... recordの値をtypecastしたものを取得
- #write_attribute / #[]= ... 値をtypecastしたものをrecordに書き込み
である。
ここで大事なのが、modelの値を取得/書き込み、とは異なる。例えばhoge.rbclass Hoge < ApplicationRecord def fuga super.to_s # read_attribute(:fuga).to_s と等価 end ...とされた場合に、
Hoge#fugaとHoge#read_attribute(:fuga)の結果は異なる。
正直思うんだが、このコードを見た人の100人に99人くらいはそんな認識持たないと思うし、このコードを書いた人の100人に99人はそんなこと知らずに書いていると思う。そういう意味で大変紛らわしいし危険なコードである。
よって以下のように書くのが望ましい。hoge_controller.rbclass HogeController < ApplicationController def hoge @hoge = Hoge.new # read_attribute/write_attributeはmodel外では使わない fuga = @hoge.fuga @hoge.fuga = :fuga endhoge.rbclass Hoge < ApplicationRecord def fuga super.to_s # read_attribute(:fuga).to_s と等価 end # どうしても生の値が必要なら専用のメソッドを用意する def fuga_raw read_attribute(:fuga) end ...model編
大きすぎるロジックは適度に分割する
例えば以下。
hoge# BAD class Hoge def fetch_fuga ready_fetch_fuga start_fetch_fuga finalize_fetch_fuga end def ready_fetch_fuga # そこそこに重めの処理 end def start_fetch_fuga # そこそこに重めのsy(ry end def finalize_fetch_fuga # そこそk(ry end
fetch_fugaを実行するためには3つの処理を実行するなどのような場合。
このような場合、ロジックとして大きいため、分割したほうがいい場合がある。例えば以下。hoge# GOOD class Hoge def fetch_fuga FetchFuga.run end ...hoge/fetch_fuga.rb# GOOD class Hoge class FetchFuga class << self def run(hoge) new(hoge).tap(&:run) end end def initialize(hoge) @hoge = hoge end def run ready start finalize end ...railsだとServiceパターンって名前で浸透してたりもするが、正直Commandパターンの焼き直しだし腹たつので、普通にCommandパターンということで紹介する。
ロジックが探しにくくならないようにする
例えば以下。
washing_machine.rb# BAD class WashingMachine < Machine include DoorModule include ValveModule include AirValveModule def run locking do inject_water ventilate end end endこのクラスを見せられたときに、送風する部分を改修して欲しいと言われたら、あなたはどこを探すだろうか?
送風(ventilate)ということは、ventilateメソッドを探せばいいのだろう。ということはventilateメソッドを定義している場所を探せばいいのだな。と、ここであなたはventilateでプロジェクト内を検索するだろう。このクラスはventilateが探しにくい。もしかしたらAirValveModuleの中に入っているかもしれないし、ValveModuleの中に入っているかもしれないし、DoorModuleの中に入っているかもしれないし、Machineクラスの中に入っているかもしれない。
なんでもかんでもincludeしているが故に、探さなければならない場所が多すぎるのだ。そして最終手段・全検索に走る。
一度や二度ならいいがそうなんどもやってるとコードを書くスピードも下がる。士気が下がる。呪いのコードである。まあ場合にはよるのだが、以下のように書くのがおすすめである。
waching_machine.rb# GOOD class WashingMachine < Machine def initialize @door = Door.new @valve = Valve.new @air_valve = AirValve.new end def run @door.locking do @valve.inject_water @air_valve.ventilate end end # delegate :locking, to: :@door # などでメソッド定義しても良い。とにかくメソッドの定義がファイル内に明示されている endこれで、
ventilateを定義しているのはValve内であることが圧倒的確証を持って明言できる。コーディングも捗るだろう。余談 複数のインスタンスにまたがる処理の場合
例えば以下。
hoge.rbclass Hoge < ApplicationModel attr_reader :fuga ...hoge_controller.rb# BAD class HogeController < ApplicationController def index @hoges = Hoge.all fugas = fetch_fugas(@hoges.pluck(:id)) @hoges.zip(fugas) { |hoge, fuga| hoge.fuga = fuga } end def fetch_fugas(ids) # hogeのidの配列を渡すと対応するfugaの配列を返す。例えばAPI経由で取得してくる。 end ...この場合、controllerに処理を書いてしまう人をよく見かけるが、これもmodelに入れた方がいい。
以下のように書くのが望ましい。hoge.rb# GOOD class Hoge < ApplicationModel attr_reader :fuga class << self def set_fugas(hoges) fugas = fetch_fugas(hoges.pluck(:id)) hoges.zip(fugas) { |hoge, fuga| hoge.fuga = fuga } end def self.fetch_fugas(ids) # hogeのidの配列を渡すと対応するfugaの配列を返す。例えばAPI経由で取得してくる。 end end ...hoge_controller.rb# GOOD class HogeController < ApplicationController def index @hoges = Hoge.all.tap(&:set_fugas) end ...あるいは extending などを用いて、自動で展開されるようにしてもいいかもしれない
view編
パーツごとに分けて作る。パーツ間は改行多めにする。
htmlは関数がない分コードのメリハリがつきにくい。例えばヘッダーとメインとフッター、あるいはコンテンツの説明と中身など、それぞれの項目に意味付けしてパーツとみなし、そのパーツ間は改行を少し多めに入れておくと胃もたれしない。コードを見る人の心と身体に優しくなる。
難しいjsをhtml上に書かない
超大事。
例えば以下。hoge.html.erb<!-- BAD --> <div class='hoge'> ここをクリック </div> <script> var hoge = <%= j(@hoge.data.to_json) %>; $('.hoge').click(function() { // クリックされたらajax通信して結果を表示するとか、結構分量のあるやつ。 }) </script>erbの性質上、コードの行数が変わりやすいので、これだとデバッグが大変になる。たまにscript内でerbのeach回してるのとか見かけるけど論外である。
以下のようにするのが望ましい。hoge.html.erb<!-- GOOD --> <div class='hoge' data-data='<%= j(@hoge.data.to_json) %>'> ここをクリック </div> <script> setupHoge($('.hoge')); </script>hoge.js// GOOD function setupHoge(el) { const hoge = $(el).data('data'); $('.hoge').click(function() { // クリックされたらajax通信して結果を表示するとか、結構分量のあるやつ。 }) }こうすればデバッグがしやすい。あと個人的にデータを渡すときはscriptに直接渡すのではなくて、datasetで渡す方がそのエレメントに関係するデータだってことがわかるのでいいと思う。
js編
パーツなどの初期化関数は通常、第一引数にElementを指定する
セレクタの検索を何度も行わない例えば以下。
hoge.html<!-- BAD --> <div class='hoge'> <div class='fuga'> <span class='hoge-fuga-text'> ほげふが </span> </div> </div> <script> setupHoge(); // この定義から見て、setupHogeがどのElementに依存するかがわからない。 </script>hoge.js// BAD function setupHoge() { // 毎回Elementを全検索している。かなりパフォーマンスが悪い。 $('.hoge').click(function() { $('.hoge-fuga-text').text('ほげ'); }); $('.fuga').click(function() { $('.hoge-fuga-text').text('ふが'); }); }こうすると、script上のsetupHogeからは、この関数がどのElementに依存するものなのかがわからない。この依存というのは非常に大事で、関数スコープみたいなものと考えれば良い。この例は、globalスコープを使うのと同じようなものだ。変更に弱く非常に危険である。
あとついでに言うと、hoge.js内のセレクタは全部、全てのエレメントから検索しており、パフォーマンスの低下にも繋がるので避けるべきである。
以下のようにするのが望ましい。hoge.html<!-- GOOD --> <div class='hoge'> <div class='fuga'> <span class='hoge-fuga-text'> ほげふが </span> </div> </div> <script> setupHoge($('.hoge')); // $('.hoge')に依存していることがわかりやすい。 </script>hoge.js// GOOD function setupHoge(el) { // hogeをrootとして、hoge以下のものを使う。もしくはdocument,window,bodyなどを使う。 // 何度もSelectorの検索を行わない。 const $hoge = $(el); const $fuga = $hoge.find('.fuga'); const $hogeFugaText = $hoge.find('.hoge-fuga-text'); $hoge.click(function() { $hogeFugaText.text('ほげ'); }); $fuga.click(function() { $hogeFugaText.text('ふが'); }); }こうすると
setupHogeが$('.hoge')に依存してそうなことは直感的にわかる。
もちろんsetupHogeの中で.hoge以下のエレメント、またはdocument,window,bodyなどのglobalなElement以外は使わないことも留意しなければならない。じゃないと無意味だからね。
setupHogeだから普通.hogeに依存するだろ、と言う場合は、// GOOD function setupHoge(el=$('.hoge')[0]) { ...までなら許されると思う。それ以上はコードの中身を読まなきゃいけないので許されない。
おわり
レビュワーの人と引き継ぎの人に優しいコードづくりを心がけましょう。
- 投稿日:2020-09-08T01:19:57+09:00
Ruby on RailsにおけるServiceクラスのススメ
こんにちは、@hairgaiです。
今回は、賛否両論あるServiceクラスについての自分的な使い方を書いていこうと思います。Serviceクラスとは
DDD(ドメイン駆動設計)でのサービスから派生している(と勝手に認識している)、ある一つの機能を記述するクラス郡です。
詳しくは説明している人がたくさんいらっしゃるので割愛しますが、ビジネスロジックをモデルとコントローラーの中間でキレイに書けるので、僕はよく使っています。
今回は(僕の使い方は間違ってるかもしれませんが)、自分的な使い方及びそのメリットと思われる部分を書いていきます。基本的な使い方
まず、基本的な使い方を、コード例と共に紹介しようかなと思います。(これが正解かどうかは正直わかりませんが、見やすいのでいいかなと思ってます)
例えば、SNSなどで「フォローをする」という機能をService層として1ファイルに記述すると、こんな感じにになるかと思います。
※重ねていいますが、これが正解とかじゃないです。class FollowService attr_reader :user, :target_user attr_accessor :follow def initialize(user, target_user) @user = user @target_user = target_user end def perform check! create_follow! run_after_worker! end private def check! check_following! check_blocking! end def check_following! return true unless user.following?(target_user) raise ArgumentError, 'User following target user' end def check_blocking! return true unless user.blocking?(target_user) raise ArgumentError, 'User blocking target user' end def create_follow! self.follow = user.follows.create!(target_user: target_user) end def run_after_worker! AfterFollowWorker.perform_in(0.2.seconds, follow.id) end endピュアなRubyのクラスで作る
基本的に何かGem等を使って作ることは、僕はしていないです。
ピュアRubyでの実装にすることで「実装の理解に対する障壁を下げる」効果を狙っています。
Serviceクラスは(重い機能になると)ロジックが複雑になりがちなので、なるべくシンプルに作成し、誰が見てもすぐに理解できるように心がけています。クラス名を定める
命名に好みがあると思いますが、機能を象徴するクラスであるので
[動詞]([目的語])Serviceで統一しています。
命名規則をつけることで機能が推論しやすくなるというメリットがあります。publicなメソッドはperformのみにする
ここらへんも好みがあると思います(
callとかにしたりする人も多いです)が、基本的にはpublicなメソッドを一つだけ生やし、それ以外は呼べないものとします。
これは、Serviceクラスは単一の機能を象徴するクラスであり、それを使用することで実現できる機能を単一のものと限定するためです。
この単一のpublicメソッドは結構いろいろな方が言っていますが、僕も設計時点において迷いが全くなくなり実装スピードが格段に上がったので採用しています。publicなメソッドで呼ぶのはprivateメソッドのみ
これも見通しが良くなる + 1メソッドごとの責務が軽くなり、ガード節が使いやすくなったりするので採用しています。
ここらへんは好みの分かれるところだと思います。後処理等へのアプローチを単一にする
上のFollowServiceでも書いていますが、業務で使用する以上はユーザさんに対するレスポンスを一番に考えます。
そういった場合のアプローチとしては「1レスポンス中には必要な処理のみを行う」というものがあり、後続処理などはジョブとしてキューに格納し、ジョブサーバ等に処理させることになります。
その際に、ControllerやModel等色々な場所にジョブをコールする処理が散らばると、プロジェクト全体での見通しが悪くなります。そこで、
HogeServiceの後処理のジョブはAfterHogeJobにする、というような命名規則にし、Serviceクラスでのみコールするという決まりにすることで、全体の見通しを良くすることができます。Controllerの肥大化の解消
言うまでもないですね。
class FollowsController < ApplicationController def create target_user = user.find(params[:target_user_id]) service = FollowService.new(current_user, target_user) service.perform redirect_to user_path(target_user) end endModelの肥大化の解消
こちらも言うまでもないですね。
Modelに書いていたものを全部Serviceクラスに持っていき、モデルがデータの関連付けやバリデーション、その他単一モデルに関するメソッド等のみになります。
そのため、モデルからロジックの多いメソッドがなくなり、肥大化した見づらいモデルというものがなくなります。あとがき
こうして改めて書いてみると、僕は色々と責任をServiceクラスに負わせている書き方をしているんだなぁ、と思います。
Serviceクラスは必要ない、等々議論の余地はあると思いますが、こういった設計等の話はあくまで手法の一つなので、自分たちのビジネスに合わせて適切に使用できると良いですね。