- 投稿日:2020-09-08T23:10:12+09:00
【Rails】本番環境でのデータベースをリセット
はじめに
【前提】
・Railsを使用してアプリケーションを開発
・AWSを使用
・EC2(AWSが提供する仮想サーバ)にてWebサーバを作成既存のデータベースをリセット
今まで私自身ローカル環境にて開発を行うにあたり、DBをリセットしたいことがあった場合
rails db:risetを使用し、DBの再作成を行なっておりました。今回デプロイ後ですが、マイグレーションファイル等に変更を色々と加えたため、
一度本番環境でもリセットし、再構築しようと考えました。本番環境でのデータベースリセット
RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rails db:dropこのコマンドで本番時でのDBをリセットすることができます
(本番環境でのDBリセットは、実務ではありえるのでしょうか・・)再度データベースの内容を反映させる
rails db:migrate RAILS_ENV=productionおそらくデータベースが無いですよ?とエラーが帰ってくる方がいると思いますので、再度createしてあげます。
rails db:create RAILS_ENV=production rails db:migrate RAILS_ENV=production rails db:seed RAILS_ENV=production※シードに情報を記載していない方は、最後の1行は不要です
上記コマンドを使用すれば本番環境へ無事変更点等が反映されているはず・・・上記記載内容では、こういったリスクがあるのでは等の改善案や提案がございましたら、
コメント等にてお伝えいただければありがたいです。以上、ご参考になれば幸いです。
- 投稿日:2020-09-08T22:48:18+09:00
Serverlessで複数の関数をどう管理できるか検証した時のメモ
前提
AWS LambdaでPythonを動かします。個人開発用ではなく、複数人で複数の関数を複数の環境で実行するユースケースを想定しています。
調べたこと
- プロジェクトの作成(入門)
- デプロイ
- Pythonパッケージ管理周りの設定
- 環境ごとに設定を管理する方法
- 1つのリポジトリで複数種類のfunctionを管理する時の構成
- その他所感
$ python -V Python 3.8.1 $ serverless -v Framework Core: 1.82.0 Plugin: 3.8.3 SDK: 2.3.1 Components: 2.34.9プロジェクトの作成
公式のQuickStartで入門しました。
AWS認証設定のやり方はいくつか方法がありますが、今回の用なユースケースだとserverless.ymlを以下のように設定する形になります。
serverless.ymlprovider: name: aws runtime: python3.8 region: ap-northeast-1 profile: ${self:custom.profiles.${opt:stage, self:provider.stage, 'stg'}} stage: ${opt:stage, self:custom.defaultStage} custom: defaultStage: stg profiles: # 環境ごとの設定を書く stg: [[プロファイル名]] prd: [[プロファイル名]]deployコマンド実行時に
--stage stgのように書くことで、指定した環境の設定が参照されます。プロファイルだけではなく、環境変数なども上記のような書き方で定義します(後述)。認証設定後の流れは
serverless createコマンドでプロジェクトを作成して、serverless deployコマンドでデプロイするだけでした。コマンド2つで必要なリソース(Lambdaで使うCloudWatch Logsなども)も作れてHelloWorldできてしまうので0→1で実装したい時はこれほど楽なものはないなと感動しました。プロジェクトの最小構成は以下のようになります。
├── my-service │ ├── handler.py # Lambdaで実行するファイル │ └── serverless.yml # それ以外の設定全般を記した設定ファイルデプロイ
大きく分けて2つデプロイのやり方があるようでした。
-vは詳細なログを表示しますサービス全体のデプロイ
serverless deploy -v一番最初にデプロイする時や、serverless.ymlで管理している設定の変更を反映させる時はこのコマンドを実行します。
初回デプロイの流れとして以下のようなことが行われていました。
- CFnを実行
- S3バケットとポリシーを作成
- ソースコードをzipで固めてS3にアップロード
- CFnを実行
- CloudWatch Logs ロググループ作成
- IAM roleの作成
- Lambda functionの作成
2回目以降のデプロイでは上記の流れに沿いつつもserverless.ymlファイルで変更があった箇所だけアップロードされていきました。
単体のfunctionのデプロイ
serverless deploy function -f hello -vやっていることはローカルでzipファイルを作成し、s3バケットに上げているだけです。
なので変更範囲がソースコードのみの時はこの関数でデプロイする方が圧倒的に早いです。また前者のデプロイは変更の差分関係なくアップロード処理が走りますが、
deploy functionコマンドの方は差分のチェックを行い、差分がなければdeployパートはskipされるという違いもありました。Pythonパッケージ管理周りの設定
外部のパッケージをLambda関数の中で使いたい場合、パッケージのソースコードも一緒にアップロードする必要があります。そのあたりでやらないといけない処理は
serverless-python-packagingというプラグインを使って行うやり方が紹介されていました。How to Handle your Python packaging in Lambda with Serverless plugins | Serverless blog
上記のブログではnumpyを使うソースコードのデプロイのチュートリアルが載っています。
やることとしては、pipで上記のプラグインをインストールして、serverless.ymlにプラグイン用の設定を追記するだけでした。
serverless.ymlplugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: non-linux useStaticCache: false
dockerizePip:では、パッケージのソースコードを落とす際にLambdaのDockerコンテナ(lambci/lambda:build-python3.8)を起動してpip installを行うようにしています。Lambda実行環境でパッケージインストールを行わないと、一部のパッケージが使えないということがあります。non-linuxをfalseにすると、Docker環境を使わずにパッケージのソースコードを落とすこともできます。
# 実行ログの一部 Running docker run --rm -v /Users/-/Desktop/pra_serverless_for_lambda/numpy-test/.serverless/requirements\:/var/task\:z -v /Users/-/Library/Caches/serverless-python-requirements/downloadCacheslspyc\:/var/useDownloadCache\:z -u 0 lambci/lambda\:build-python3.8 python3.8 -m pip install -t /var/task/ -r /var/task/requirements.txt --cache-dir /var/useDownloadCache...不具合に気づいた
serverless-python-requirementsを使うと、serverless deploy functionコマンドが使えないという不具合があるみたいです、、余談: serverless-python-requirementsチュートリアルではまった話
一番最初にデプロイを行った時に、誤った設定で行なってしまったため(dockerizePipを有効にしていなかった)案の定Lambdaでnumpyが読み込まれませんでした。
dockerizePipの設定を書いた後も改善されなかったのですが、その原因がcacheでした。検証時のserverlessではcacheの読み込みがデフォルトでtrueになっているので、設定ファイルを変更した後も古いパッケージのデータが参照され続けていました。
useStaticCache: falseでstaticCacheの参照をしないようにすることで解決しました。1つのリポジトリで複数種類のfunctionを管理する時の構成
- function1
- stg用
- prd用
- function2
- stg用
- prd用
のようなものを同じリポジトリで管理したいケースは、よくあるかと思います。
2パターンやり方が考えられそうでした。案1. functionごとにserverless.ymlファイルを作る
├── function1 │ ├── .serverless │ ├── env_prd.yml │ ├── env_stg.yml │ ├── handler.py │ ├── requirements.txt │ └── serverless.yml ├── function2 │ ├── .serverless │ ├── env_prd.yml │ ├── env_stg.yml │ ├── handler.py │ ├── requirements.txt │ └── serverless.yml ├── .git ├── node_modules ├── package-lock.json └── package.json案2. 1つのserverlss.ymlで全functionを管理する
├── function │ ├── .serverless │ ├── env_prd.yml │ ├── env_stg.yml │ ├── function1.py │ ├── function2.py │ ├── requirements.txt │ └── serverless.yml ├── node_modules ├── package-lock.json └── package.json案1のメリットとしては、設定ファイルが一つの関数のものだけしか書かれていないから見やすく、デメリットはデプロイを関数ごとに行わなければならなくなります。
案2はその逆で、メリットは1回のデプロイで複数の関数への反映を行えること、デメリットは設定ファイルが混ざるので分かりにくくなることかと思います。案2に関しては、例えば後からfunctionを追加するようなケースがあった場合、変更のない他の関数でもデプロイが走ってしまいます。
deploy functionコマンドはインフラは作らないので初回デプロイでは使えないため。もちろんソースコードに変更がなければ何回デプロイしようと冪等性は担保されるはずですが...とはいえそうであればdry-runや、もしくはTerraformみたいに適用前に差分を確認してくれる機能が欲しくなりました。意図しない差分が混じってしまう可能性は考えられるので。
本当に簡単な検証しかしていないので、より設定が複雑になってくるとまた違ったメリデメが出てくるかもしれません。
既存リソースからインポートはできるのか
importみたいなコマンドやそれができるpluginを探してみましたが、見つけられませんでした。
最初からServerlessで作る分にはいいけれど、デプロイツールを他のものから乗り換えたいような場合、乗り換えコストはそこそこかかるかもしれません。
その他所感
- dry-runがなかった
SLS_DEBUG=* serverless deploy -vでより詳細なログを見れる- ソースコードを上げるS3バケットにライフサイクルポリシーがないのが気になったが、何度かデプロイを繰り返す中でつど5個前のソースコードは削除されていることに気づいた。デフォルトでこの設定がされているなんて気が利いているなと感心した
- 他にもログの保存期間などもserverless.ymlで設定できるようになっている
- KMSの設定やLambda Layerの設定も行える機能が提供されていて、Lambdaで設定できる一通りのものはServerlessで集約できそうな印象を持った(検証はしていないので使い勝手までは分からない)
Serverless removeコマンドで片付けも簡単
- ただしこれも同じ設定ファイルで複数関数を管理している場合、関数単位で実行させることはできなかった
- pluginで必要な機能は補っていく思想らしいので、便利なプラグインが色々あるかもしれない
まとめ
何もない状態から作る分には、爆速でデプロイできる手軽さが良かった?
Pythonの場合だとserverless-python-requirementsプラグインは欲しいので、function単位でデプロイできないバグがあるのは辛かったです。
また複数ファンクションを管理する時の構成は、他の事例も聞いてみたいなと思いました。(個人的にはfunctionごとにserverless.yml作った方がいいと思うけれど、それが辛いという声もあったので..)
- 投稿日:2020-09-08T22:30:13+09:00
AWS Summit Online 2020 Tokyoメモ
AWS-21:モダンアプリケーションのためのアーキテクチャデザインパターンと実装
https://resources.awscloud.com/aws-summit-online-japan-2020-on-demand-aws-sessions-1-82341
モダンアプリケーションをどう実装するか
- ゲートウェイパターン
- バックエンドサービスへの呼び出しが多い場合
- アプリケーションのエンドポイントはロールベースアクセス制御で保護
- AWSではAPI GatewayとCognitoを使う
- バックエンドサービス
- バックエンドサービスをアタッチされたリソースとして扱い、アプリケーションを再デプロイしなくても切り替えられるようにする
- ポリグロットパーシステンス
- 用途に応じたデータストアや、開発者のスキルセットを考慮して選択する
- サービス間の安定性を高めるデザイン
- カスケード障害防止する
- タイムアウト
- スロットリング
- リトライ
- サーキットブレーカー
- サービス感の呼び出しを規制して段階的に機能低下させる
- 発生した障害の回数をカウントし、上限を超えるとオープン状態に移行して切断
- バルクヘッド
- アプリケーションの要素を分離
- 1つの要素で障害が発生しても他の要素に障害が波及しないようにする
- サービスディスカバリ
- 伸縮性・弾力性を高めるデザイン
- アプリケーションを構成するサービスやコンポーネントがスケールできるように設計する
- コマンドクエリ責任分離(CQRS)
- 更新と参照のクエリを分離することで、それぞれスケールすることが可能になる(結果整合性を許容する必要がある
- AWSでは更新がDynamoDB -> Lambda -> Aurora。参照はAurora
- イベントソーシング
- データストアを直接更新するのではなく、イベントを記録することで状態を再生する
- AWSではイベントログをKinesis, SQLを用いる。処理はLambda
- ログ集約とモニタリング
- ログはイベントストリームとして集約して、パフォーマンス・ビジネス分析データ・ほかメトリクスをモニタリング
- AWSではCloudWatchとX-Ray
- CI/CDモダンアプリケーションのデリバリー
- 制作
- Cloud9, IDE toolkits
- ソース
- CodeCommit
- ビルド
- CodeBuild
- テスト
- CodeBuild
- デプロイ
- CodeDeploy
- モニタリング
- X-Ray
- CloudWatch
- モデルとしてはCloudFormation, Cloud Development Kit, SAM
良いアーキテクチャを作るために、物事を観測する謙虚さとバランス感覚が必要。
AWS-26:AWSの継続的インテグレーション/デリバリー総まとめ!モダンアプリケーション構築のための CI / CD ベストプラクティス!
https://resources.awscloud.com/aws-summit-online-japan-2020-on-demand-aws-sessions-1-82341
継続的インテグレーションのゴール
- コードがチェックインされた時に自動的にリリースを開始
- 一貫性のある繰り返し可能な環境でコードのビルドとテストを実施
- デプロイの準備ができているアーティファクトを常に保持
- ビルドが失敗した時のフィードバックループが常に回せる
-> AWS CodeBuild
- AWS Lambdaをビルド
- npm ci
- npm test
- aws cloudformation package --template-file template.yml --output-template template-output.yml --s3_bucket $BUCKET
- Dockerをビルド
- $(aws ecr get-login --no-include-email)
- docker build -t $IMAGE_REPO_NAME:$IMAGE_TAG .
- docker tag $IMAGE_REPO_NAME:$IMAGE_TAG $ECR_REPO:$IMAGE_TAG
- docker push $ECR_REPO:$IMAGE_TAG
- 更新された変更をテスト用のステージ環境に自動的にデプロイ
- 顧客に影響を与えることなく安全に本番環境にデプロイ
- デプロイメントの頻度向上、変更によるリードタイムと失敗率の削減
-> AWS CodePipeline
ソース
- CodeCommit
- GitHub
- S3
- ECR
ターゲット
- EC2
- CodeDeploy
- Elastic Beanstalk
- OpsWorks stacks(Chef)
- コンテナ
- CodeDeploy
- ECS/Fargate
- ECS/Fargate (blue/green)
- サーバーレス
- CloudFormation (SAM)
- Lambda (CodeDeploy)
- S3
- Service Catalog
- Alexa Skills Kit
サポートトリガー
- CloudWatch Events
- スケジュール
- AWSサービスのイベント
- Webhooks
- GitHub
- Quay
- Artifactory
-> CodeDeploy
- 設定ファイルに基づく複雑なアップデート
- ダウンタイム削減
- 一括、カナリア、blue/green
- エラー検知時に自動的にロールバックを実行
- EC2, Lambda, オンプレミス、コンテナへデプロイ
CodeDeploy Lambdaデプロイメント
- 関数重み付けエイリアスを利用したトラフィックのシフト
- カナリアデプロイ(10分間10%のトラフィックをシフト)、リニアデプロイ(毎10分毎に10%ずつ)
- Validation Hook
- 迅速なロールバック
SAMを使っても良い
CodeDeploy ECS blue/greenデプロイメント
- greenタスクをプロビジョニングし、ロードバランサーのトラフィックを切り替え
- 検証Hookによって各ステージのデプロイメントでテストを有効化
- Hookが失敗した場合はCloudWatchアラームを検死した場合は数秒でblueタスクに迅速にロールバック
Infrastructure as Codeのゴール
- インフラストラクチャの変更を繰り返し予測可能にする
- インフラストラクチャの変更のリリースにコードの変更と同じツールを利用する
- 本番環境をステージング環境に複製し継続的テストを有効化する
継続的テスト
成果物の検証と環境の検証
- LambdaのデプロイにはAWS SAMが利用可能
- AWS上のサーバーレスアプリケーションを構築するためのオープンソースフレームワーク
- 関数、API、データベース、イベントソースマッピングを表現する簡易な文法
- デプロイ時にCloudFormationに変換、展開
- 同一テンプレート内にSAM以外のCloudFormationテンプレートの混在が可能
- FargateのデプロイはCDKが利用可能
- インフラをTypeScriptで定義
- ハイレベルリソースタイプ
- AWS CloudFormationでプロビジョニングされる
- 投稿日:2020-09-08T22:27:45+09:00
AWSを使ってアプリケーションを公開する方法(3)EC2インスタンスの環境構築
はじめに
AWSを使ってアプリケーションを公開する手順を記載していく。
この記事ではEC2インスタンスの環境構築を行う。必要なツールのインストール
EC2インスタンスの環境構築を行うために様々なツールをインストールする。
「.ssh」ディレクトリに移動する
下記コマンドを実行し「.ssh」ディレクトリに移動する。
cd ~/.ssh/ssh接続
以下のコマンドを実行してEC2インスタンスにsshでアクセスする。
(ダウンロードしたpemファイル名が「xxx.pem」、ElasticIPが123.456.789の場合)ssh -i xxx.pem ec2-user@123.456.789yumコマンドを実行しパッケージをアップデート
以下のコマンドを実行してパッケージをアップデートする。
sudo yum -y updateパッケージとは
- パッケージはLinuxOSの動作に必要な各種プログラムやファイルをまとめたもの。
- バイナリ型式のプログラムおよびそのプログラムを動作させるのに必要なライブラリや設定ファイル、手順書のようなドキュメントで構成される。
yumコマンドとは
- CentOSなどのLinuxディストリビューションでは、基本的にRPM(Red Hat Package Manager)と呼ばれるパッケージ管理システムが使われている。RPMパッケージであれば、「rpm」コマンドで手軽にインストールしたり、アップデートやアンインストールしたりすることができる。
- 「あるソフトウェアを使うにはこのソフトウェアが必要」といった依存関係をチェックして必要なソフトウェアを自動でインストールするなど、RPMをより便利に活用できるようにしたのがYUM(Yellowdog Updater Modified)で、YUMのパッケージ操作はyumコマンドで行う。
- yumコマンドで使えるコマンドやオプションには様々なものがあり、上で行っている「yum -y update」は全ての問い合わせに「yes」で応答しシステムのパッケージを更新するというコマンドである。
yumコマンドを実行し各種パッケージをインストール
以下のコマンドを実行し、その他環境構築に必要なパッケージを諸々インストールする。
sudo yum -y install git make gcc-c++ patch libyaml-devel libffi-develsudo yum -y install libicu-devel zlib-devel readline-devel libxml2-develsudo yum -y install libxslt-devel ImageMagick ImageMagick-develsudo yum -y install openssl-devel libcurl libcurl-devel curlNode.jsをインストール
Node.jsとは、サーバサイドでJavascriptを動かすためのもの。詳しくは別の記事にまとめたい。
今後の作業でcssや画像を圧縮するためにインストールする。以下のコマンドを実行し、Node.jsをインストールする。
sudo curl -sL https://rpm.nodesource.com/setup_6.x | sudo bash -sudo yum -y install nodejscurlコマンドとは
サーバとデータのやりとりを行うコマンド。
よく使うオプションは以下らしい。こちらもあとで詳しくまとめたい。-L -- リダイレクトがあったらリダイレクト先の情報を取る -s -- 余計な出力をしない -o -- レスポンスボディの出力先を指定するbashコマンドとは
bashとはシェルの一種で、ユーザの入力をコンピュータに伝えるもの。
ここではbashを起動している。rbenvとruby-buildをインストールする
以下はRubyを使ってサーバサイドを実装する場合に行う。
以下のコマンドを実行してgitからrbenvをクローンする。
#rbenvのインストール git clone https://github.com/sstephenson/rbenv.git ~/.rbenv以下のコマンドを実行してパスを通す。
パスを通すとは、どのディレクトリからもアプリケーションを呼び出せる状態にすること。#パスを通す echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile #rbenvを呼び出すための記述 echo 'eval "$(rbenv init -)"' >> ~/.bash_profile以下のコマンドを実行して設定したパスを読み込む。
#.bash_profileの読み込み source .bash_profile以下のコマンドを実行してgitからruby-buildをクローンする。
#ruby-buildのインストール git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build以下のコマンドを実行して、rehashを行う。
つまり、rubyやgemをインストールして使えるコマンド(irb, gem, rake, rails, rubyなど)をバージョン毎に振り分け、使用できるようにする。#rehashを行う rbenv rehashRubyをインストールする
今回はバージョン2.5.1をインストールする。
以下のコマンドを実行して、Rubyの2.5.1のバージョンをインストールする。
rbenv install 2.5.1以下のコマンドを実行して、EC2インスタンス内で使用するRubyのバージョンを決める。
rbenv global 2.5.1以下のコマンドを実行して、サイドrehashを行う。
#rehashを行う rbenv rehash最後に以下のコマンドできちんとインストールができているか確認する。
#バージョンを確認 ruby -v参考
- 投稿日:2020-09-08T18:23:29+09:00
ELBを経由したリクエストでCSRF対策エラーが起こったのでデバッグと解決まで
背景
AWSで Proxy ELB -> Nginx -> ELB -> Taget Group -> ECS でリクエストを飛ばしてRailsのサービスを動かしたところ、 CSRFトークン対策でエラーになったのでそのデバッグと解決策までの道のり。
CSRFトークン対策でエラーになる
エラー概要
起こっていたエラーは
ActionController::InvalidAuthenticityToken。CSRFトークン対策とは
https://railsguides.jp/security.html#クロスサイトリクエストフォージェリ-csrf
Railsが標準搭載しているセキュリティ対策です。
セッションに保存されてるtokenとPOST時のauthencity_tokenが一致しているかを検証し、一致していない場合にエラーを吐く。解決策
nginx.confに
proxy_set_header X-Forwarded-SSL on;を追加する。nginx.conf# もっと本当は書いてあるけど省略 server { listen 80; server_name hoge.jp; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto https; # これを追加する proxy_set_header X-Forwarded-SSL on; }エラー検証
tokenが異なっている?
セッションに保存されてるtokenとPOST時の
authencity_tokenが一致しているかを検証し、一致していない場合にエラーを吐くならセッションに保存されているtokenと
authencity_tokenが異なっているのか、通常の操作でそうなることがあるのだろうか、ということで実際に検証しているRailsのコードをみてみた。rails/actionpack/lib/action_controller/metal/request_forgery_protection.rbdef verified_request? # :doc: !protect_against_forgery? || request.get? || request.head? || (valid_request_origin? && any_authenticity_token_valid?) endこの
verified_request?がfalseの時にInvalidAuthenticityTokenのエラーが投げられる。
tokenが異なるということはany_authenticity_token_valid?がfalseということになるので、その予想でデバッグをしてみた。が、any_authenticity_token_valid?はtrueだった。
valid_request_origin?がfalseになっている?上のコードを見ると、
valid_request_origin?がfalseの時にもverified_request?がfalseになる可能性があるので、確認してみた。
すると確かに、valid_request_origin?がfalseだった。
valid_request_origin?の中身を見てみる。rails/actionpack/lib/action_controller/metal/request_forgery_protection.rbdef valid_request_origin? # :doc: if forgery_protection_origin_check # We accept blank origin headers because some user agents don't send it. raise InvalidAuthenticityToken, NULL_ORIGIN_MESSAGE if request.origin == "null" request.origin.nil? || request.origin == request.base_url else true end end
valid_request_origin?がfalseになるにはrequest.originとrequest.base_urlの中身がわかれば理由が分りそうなので出力してみた。
するとrequest.originはhttps://〜なのに対しrequest.base_urlがhttp://〜となっていた。つまり上のコードの
request.origin == request.base_urlの検証部分でfalseになっていることがわかった。NginxのconfでX-Forwarded-Protoを設定する?
この時点でいろいろ調べると、「NginxからRailsにリクエストが渡される時にHTTPSでNginxにアクセスしてもHTTPとしてRailsに渡されてしまうらしく、これを防ぐために Nginxのconfで
X-Forwarded-Protoを使ってRailsにHTTPSであることを知らせる」、という方法がすぐ出てくる。やってみた。nginx.conf# もっと本当は書いてあるけど省略 server { listen 80; server_name hoge.jp; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # これを追加 proxy_set_header X-Forwarded-Proto https; }けどダメだった。
試しにRailsでリクエストヘッダを出力してみると"X-Forwarded-Proto": "http"となっていた。どこかでhttpsからhttpに上書きされている?
その通りで、これはELBの性質上でした。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/userguide/how-elastic-load-balancing-works.html
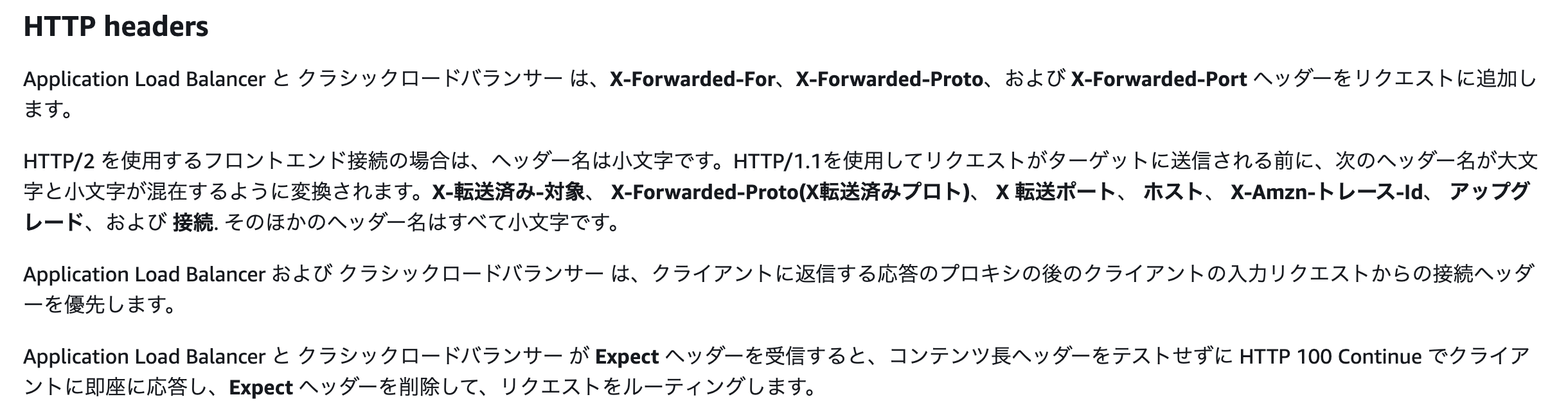
今回、ProxyとなるELBから動かしているRailsのサービスに紐づくELBに対してリクエストが送られてくるが、ここはHTTPで送られてくる。
Application Load Balancer および クラシックロードバランサー は、クライアントに返信する応答のプロキシの後のクライアントの入力リクエストからの接続ヘッダーを優先します
とのことで、NginxからELB間のHTTP通信が優先されてリクエストヘッダの
X-Forwarded-For、X-Forwarded-Proto、X-Forwarded-Portが書き換えられてしまっていた。じゃあどうする
requestオブジェクトはRackで作られているらしいのでそこのコードを見てみた。
rack/lib/rack/request.rbdef scheme if get_header(HTTPS) == 'on' 'https' elsif get_header(HTTP_X_FORWARDED_SSL) == 'on' 'https' elsif forwarded_scheme forwarded_scheme else get_header(RACK_URL_SCHEME) end end # 省略 def base_url "#{scheme}://#{host_with_port}" endhttps://github.com/rack/rack/blob/649c72bab9e7b50d657b5b432d0c205c95c2be07/lib/rack/request.rb
base_urlの作られ方から、schemeがhttpsになれば良い。
schemaがhttpsになるにはいくつか条件があるけれど 、今回はget_header(HTTP_X_FORWARDED_SSL) == 'on'になるようにすればいけそう!
(HTTP_X_FORWARDED_SSLはELBに書き換えられる心配もない)
ということで、NginxのリクエストヘッダにX_Forwarded_SSLを追加してみた。nginx.conf# もっと本当は書いてあるけど省略 server { listen 80; server_name hoge.jp; proxy_set_header Host $host; # この下2つはELBに書き換えられちゃう proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto https; # これを追加する proxy_set_header X-Forwarded-SSL on; }結果
エラーが出なくなった!
デバッグしてみたらちゃんとリクエストヘッダにX_Forwarded_SSLが追加されてschemeはhttpsになっていた。

- 投稿日:2020-09-08T16:51:58+09:00
Amazon ECS Workshop #4 ~コンテナのスケーリング~
概要
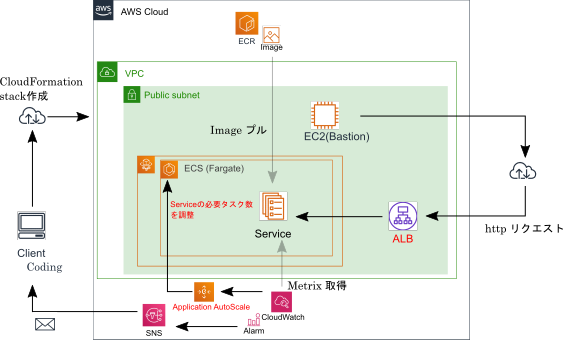
今回の投稿における達成目標と構成図を記載します。
達成目標
本投稿は#3 ~コンテナのモニタリング~編の続きになります。
下記ができることを確認します。
- リソースの高騰に合わせて、タスク起動数を増加できること
- リソースが定常に戻った際に、タスク起動数を定常数に戻せること
環境構成図
本投稿では下記構成図の赤字のリソースを新規に作成します。
今回の目的のタスク起動数のスケーリング自体はLBが無くても実現できますが、スケールした際のロードテストをIP単位で実施すると面倒だったため、作成しています。(というか今までサボっていました)
ALBの作成
下記を実施前提で進めていきます。
Subnetの追加
ALBは2以上のAZが必要となるので、AZ-cのsubnetを追加するため、VPC関連を構築したスタックを更新します。
Subnet追加 更新用テンプレート
vpc-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: VPC and Subnet Create Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix - Label: default: "Network Configuration" Parameters: - VPCCIDR - PublicSubnetACIDR - PublicSubnetCCIDR ParameterLabels: VPCCIDR: default: "VPC CIDR" PublicSubnetACIDR: default: "PublicSubnetA CIDR" PublicSubnetCCIDR: default: "PublicSubnetC CIDR" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String VPCCIDR: Type: String Default: "10.65.0.0/16" PublicSubnetACIDR: Type: String Default: "10.65.1.0/24" PublicSubnetCCIDR: Type: String Default: "10.65.2.0/24" Resources: # ------------------------------------------------------------# # VPC # ------------------------------------------------------------# # VPC Create VPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: !Ref VPCCIDR EnableDnsSupport: "true" EnableDnsHostnames: "true" InstanceTenancy: default Tags: - Key: Name Value: !Sub "${PJPrefix}-vpc" # InternetGateway Create InternetGateway: Type: "AWS::EC2::InternetGateway" Properties: Tags: - Key: Name Value: !Sub "${PJPrefix}-igw" # IGW Attach InternetGatewayAttachment: Type: "AWS::EC2::VPCGatewayAttachment" Properties: InternetGatewayId: !Ref InternetGateway VpcId: !Ref VPC # ------------------------------------------------------------# # Subnet # ------------------------------------------------------------# # Public SubnetA Create PublicSubnetA: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: "ap-northeast-1a" CidrBlock: !Ref PublicSubnetACIDR VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public-subnet-a" # Public SubnetC Create PublicSubnetC: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: "ap-northeast-1c" CidrBlock: !Ref PublicSubnetCCIDR VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public-subnet-c" # ------------------------------------------------------------# # RouteTable # ------------------------------------------------------------# # Public RouteTableA Create PublicRouteTableA: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public-route-a" # Public RouteTableC Create PublicRouteTableC: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public-route-c" # ------------------------------------------------------------# # Routing # ------------------------------------------------------------# # PublicRouteA Create PublicRouteA: Type: "AWS::EC2::Route" Properties: RouteTableId: !Ref PublicRouteTableA DestinationCidrBlock: "0.0.0.0/0" GatewayId: !Ref InternetGateway # PublicRouteC Create PublicRouteC: Type: "AWS::EC2::Route" Properties: RouteTableId: !Ref PublicRouteTableC DestinationCidrBlock: "0.0.0.0/0" GatewayId: !Ref InternetGateway # ------------------------------------------------------------# # RouteTable Associate # ------------------------------------------------------------# # PublicRouteTable Associate SubnetA PublicSubnetARouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref PublicSubnetA RouteTableId: !Ref PublicRouteTableA # PublicRouteTable Associate SubnetC PublicSubnetCRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref PublicSubnetC RouteTableId: !Ref PublicRouteTableC # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: # VPC VPC: Value: !Ref VPC Export: Name: !Sub "${PJPrefix}-vpc" VPCCIDR: Value: !Ref VPCCIDR Export: Name: !Sub "${PJPrefix}-vpc-cidr" # Subnet PublicSubnetA: Value: !Ref PublicSubnetA Export: Name: !Sub "${PJPrefix}-public-subnet-a" PublicSubnetC: Value: !Ref PublicSubnetC Export: Name: !Sub "${PJPrefix}-public-subnet-c" PublicSubnetACIDR: Value: !Ref PublicSubnetACIDR Export: Name: !Sub "${PJPrefix}-public-subnet-a-cidr" PublicSubnetCCIDR: Value: !Ref PublicSubnetCCIDR Export: Name: !Sub "${PJPrefix}-public-subnet-c-cidr" # Route PublicRouteTableA: Value: !Ref PublicRouteTableA Export: Name: !Sub "${PJPrefix}-public-route-a" PublicRouteTableC: Value: !Ref PublicRouteTableC Export: Name: !Sub "${PJPrefix}-public-route-c"ALB用SecurityGroup作成
ALB用のSecurityGroupを作成します。
「Client→コンテナ」の構成から「Client→ALB→コンテナ」の構成に変更したことで、コンテナのSecurityGroupは外部から通信許可が不要になり、ALBから通信できるように変更する必要があります。
前段ではECS作成のスタックの中で、ECSのSecurityGroupを定義してましたが、SecurityGroup構築用のスタックに切り出しておきます。下記テンプレートでALB用とECS用のSecurityGroupを構築します。
前段のECSのスタックを削除していない場合、論理名重複で失敗するため、ECSのスタックは一度削除してください。
SG 構築用テンプレート
AWSTemplateFormatVersion: "2010-09-09" Description: Create SG Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix - Label: default: "ECS Configuration" Parameters: - HTTPLocation ParameterLabels: HTTPLocation: default: "Permit HTTP Src IP Address" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String HTTPLocation: Default: 127.0.0.0/32 Type: String MinLength: 9 MaxLength: 18 AllowedPattern: (\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3})/(\d{1,2}) # ------------------------------------------------------------# # SG Create # ------------------------------------------------------------# Resources: ## SecurityGroup Create ALBSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: !Sub "${PJPrefix}-alb-http-permit" GroupDescription: Allow HTTP access only MyIP VpcId: { "Fn::ImportValue": !Sub "${PJPrefix}-vpc" } SecurityGroupIngress: # - IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: !Ref HTTPLocation ECSSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: !Sub "${PJPrefix}-ecs-internal-permit" GroupDescription: Allow AllProtocol from ALB VpcId: { "Fn::ImportValue": !Sub "${PJPrefix}-vpc" } SecurityGroupIngress: # - IpProtocol: -1 SourceSecurityGroupId: !Ref ALBSG # ------------------------------------------------------------# # Output Parameter # ------------------------------------------------------------# Outputs: ALBSG: Value: !Ref ALBSG Description: SG-ID for ALB Export: Name: !Sub "${PJPrefix}-sgid-alb" ECSSG: Value: !Ref ECSSG Description: SG-ID for ECS Export: Name: !Sub "${PJPrefix}-sgid-ecs"ALB(インスタンス&ターゲットグループ&リスナー)の作成
適当なLBを作成します。ヘルスチェックの通信コストを小さくするため、ヘルスチェック間隔を大きくしたり、多少設計はしてますが、適当です。
実運用だとルーティングやドレーニングなどなど、業務を意識した設計が必要になります。1点だけ注意するポイントはターゲットグループのターゲットタイプをipにしておかなければ、後段のターゲットにFargateを使用したServiceの指定ができなくなります。
ALB構築用テンプレート
alb-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create ALB Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String # ------------------------------------------------------------# # ALB Create # ------------------------------------------------------------# Resources: ## LBInstance: Type: AWS::ElasticLoadBalancingV2::LoadBalancer Properties: IpAddressType: ipv4 Name: !Sub "${PJPrefix}-alb" Scheme: internet-facing SecurityGroups: - { "Fn::ImportValue": !Sub "${PJPrefix}-sgid-alb" } Subnets: - { "Fn::ImportValue": !Sub "${PJPrefix}-public-subnet-a" } - { "Fn::ImportValue": !Sub "${PJPrefix}-public-subnet-c" } Type: application TargetGroup: Type: AWS::ElasticLoadBalancingV2::TargetGroup Properties: HealthCheckIntervalSeconds: 180 HealthCheckPath: "/" HealthCheckTimeoutSeconds: 2 HealthyThresholdCount: 2 Name: !Sub "${PJPrefix}-alb-target" Port: 80 Protocol: HTTP TargetType: ip UnhealthyThresholdCount: 2 VpcId: { "Fn::ImportValue": !Sub "${PJPrefix}-vpc" } Listener: Type: AWS::ElasticLoadBalancingV2::Listener Properties: DefaultActions: - TargetGroupArn: !Ref TargetGroup Type: forward LoadBalancerArn: !Ref LBInstance Port: 80 Protocol: HTTP # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: # ALB TargetGroup: Value: !Ref TargetGroup Export: Name: !Sub "${PJPrefix}-alb-target"ServiceをLBのターゲットに設定
Service部分の設定に下記を追加し、LB→Serviceの紐づけを行います。
LBをInternetfacingな前段に挟むことでタスクに外部アクセスする際にパブリックIPは不要となります。ただし、現構成ではパブリックIPの払い出しを無効化した場合、Imageのpullができなくなります。実運用ではNATGatewayを構築することでInternet経由でのpullを可能にし、実行コンテナ環境をよりセキュアにできるはずです。LoadBalancers: - ContainerName: !Sub ${PJPrefix}-ecscontainer ContainerPort: 80 TargetGroupArn: { "Fn::ImportValue": !Sub "${PJPrefix}-alb-target" }上記を追記した下記テンプレートでECSのスタックを更新します。
LB紐付け追加 ECS更新用スタック
ecs-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create Container with ECS on Fargate Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix - Label: default: "ECS Configuration" Parameters: - ECSTaskCPUUnit - ECSTaskMemory - IAMRoleParameter ParameterLabels: ECSTaskCPUUnit: default: "ECSTaskCPUUnit" ECSTaskMemory: default: "ECSTaskMemory" IAMRoleParameter: default: "IAM Role" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String ECSTaskCPUUnit: AllowedValues: [ 256, 512, 1024, 2048, 4096 ] Type: String Default: "256" ECSTaskMemory: AllowedValues: [ 512, 1024, 2048, 4096 ] Type: String Default: "512" IAMRoleParameter: Type: String # ------------------------------------------------------------# # ECS Create # ------------------------------------------------------------# Resources: ## ECS Cluster ECSCluster: Type: AWS::ECS::Cluster Properties: ClusterName: !Sub ${PJPrefix}-Cluster ### Enable CloudWatch Container Insights ClusterSettings: - Name: containerInsights Value: enabled ## ECS LogGroup ECSLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: !Sub /ecs/logs/${PJPrefix} ## ECS TaskDefinition ECSTaskDefinition: Type: AWS::ECS::TaskDefinition Properties: Cpu: !Ref ECSTaskCPUUnit ExecutionRoleArn: !Ref IAMRoleParameter Family: !Sub ${PJPrefix}-task Memory: !Ref ECSTaskMemory NetworkMode: awsvpc RequiresCompatibilities: - FARGATE ContainerDefinitions: - Name: !Sub ${PJPrefix}-ecscontainer Image: !Sub ${AWS::AccountId}.dkr.ecr.ap-northeast-1.amazonaws.com/myrepository LogConfiguration: LogDriver: awslogs Options: awslogs-group: !Ref ECSLogGroup awslogs-region: !Ref "AWS::Region" awslogs-stream-prefix: !Ref PJPrefix MemoryReservation: 128 PortMappings: - HostPort: 80 Protocol: tcp ContainerPort: 80 ## ECS Service ECSService: Type: AWS::ECS::Service Properties: Cluster: !Ref ECSCluster DesiredCount: 1 LaunchType: FARGATE LoadBalancers: - ContainerName: !Sub ${PJPrefix}-ecscontainer ContainerPort: 80 TargetGroupArn: { "Fn::ImportValue": !Sub "${PJPrefix}-alb-target" } NetworkConfiguration: AwsvpcConfiguration: AssignPublicIp: ENABLED SecurityGroups: - { "Fn::ImportValue": !Sub "${PJPrefix}-sgid-ecs" } Subnets: - { "Fn::ImportValue": !Sub "${PJPrefix}-public-subnet-a" } ServiceName: !Sub ${PJPrefix}-ecsservice TaskDefinition: !Ref ECSTaskDefinition # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: # ECS Cluster ECSCluster: Value: !Ref ECSCluster Export: Name: !Sub "${PJPrefix}-ecs-cluster" # ECS Service ECSService: Value: !GetAtt ECSService.Name Export: Name: !Sub "${PJPrefix}-ecs-service"疎通確認
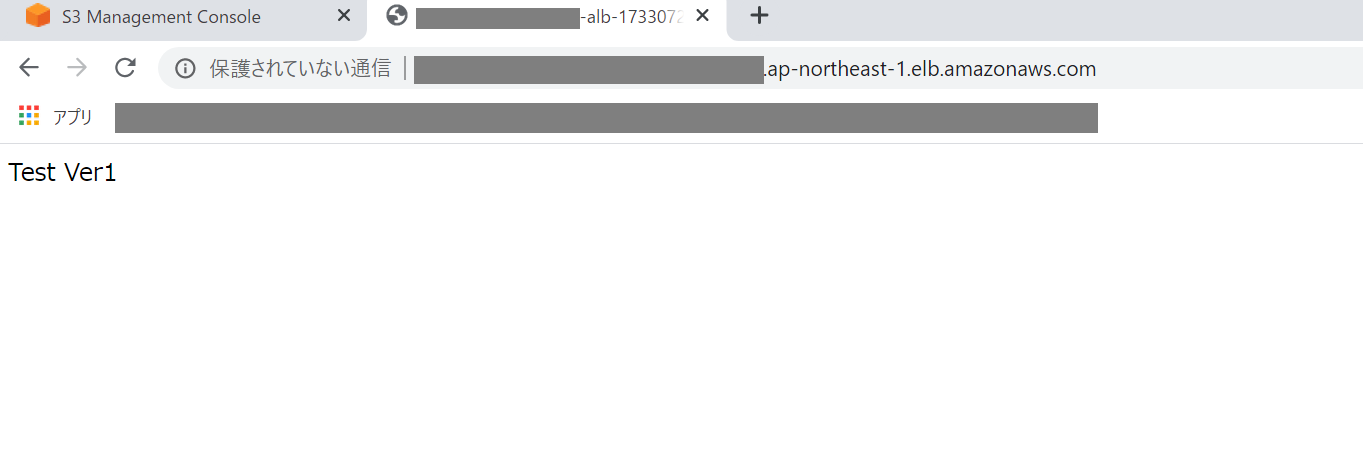
構築したALBのDNS名をコンソールから確認し、ブラウザアクセスしてみます。
ECRにプッシュしているイメージがデプロイされたタスクにアクセスできていることがわかります。
Application Autoscalingの設定
AutoscalingターゲットとAutoscalingポリシー作成
ECSのServiceのAutoscalingするにはApplication Autoscalingというサービスを利用します。
Application Autoscalingはターゲットとポリシーに分かれており、下記のような設定ができるコンポーネントです。
- Autoscalingターゲット:
どのリソース(今回はECSサービス)をどの範囲でスケール(今回は最小タスク数と最大タスク数)させるのか、を設定- Autoscalingポリシー:
イベントを検知した際に、どのようにスケール(今回であれば、何タスクずつ起動させる?起動させた後次のスケールまで何分待つ?(起動のオーバヘッド時間に誤検知して大量にリソースを作らないため)など)、などを設定私がはまったポイントはAutoscalingターゲットに紐づけるIAMRoleについて、
IAMRole側でApplication Autoscalingから呼び出せるよう、エンティティの設定が必要です。下記が構築用テンプレートとなります。
ApplicationAutoScaling構築用スタック
appas-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create ALB Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix - Label: default: "AS Configuration" Parameters: - MAXCapacity - MINCapacity - IAMRoleParameter ParameterLabels: MAXCapacity: default: "MAXCapacity" MINCapacity: default: "MINCapacity" IAMRoleParameter: default: "IAM Role" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String MAXCapacity: Type: String Default: "4" MINCapacity: Type: String Default: "1" IAMRoleParameter: Type: String # ------------------------------------------------------------# # Application AutoScaling Create # ------------------------------------------------------------# Resources: ## ScalableTarget: Type: AWS::ApplicationAutoScaling::ScalableTarget Properties: MaxCapacity: !Sub ${MAXCapacity} MinCapacity: !Sub ${MINCapacity} ResourceId: !Join - / - - service - { "Fn::ImportValue": !Sub "${PJPrefix}-ecs-cluster" } - { "Fn::ImportValue": !Sub "${PJPrefix}-ecs-service" } RoleARN: !Sub arn:aws:iam::${AWS::AccountId}:role/${IAMRoleParameter} ScalableDimension: ecs:service:DesiredCount ServiceNamespace: ecs ## ScalingPolicy: Type: AWS::ApplicationAutoScaling::ScalingPolicy Properties: PolicyName: ServiceAlarm PolicyType: StepScaling ScalableDimension: ecs:service:DesiredCount ScalingTargetId: !Ref ScalableTarget ServiceNamespace: ecs StepScalingPolicyConfiguration: AdjustmentType: ChangeInCapacity Cooldown: 180 MetricAggregationType: Average StepAdjustments: - MetricIntervalLowerBound: 0 ScalingAdjustment: 1 - MetricIntervalUpperBound: 0 ScalingAdjustment: -1 # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: # Autoscalingpolicy ScalingPolicy: Value: !Ref ScalingPolicy Export: Name: !Sub "${PJPrefix}-as-policy"Cloudwatch→ApplicationAutoScalingポリシーの紐づけ
次に何のイベントでApplicationAutoScalingを呼び出すかの紐づけです。
イベントとして、サービス毎にプレ定義されているメトリクスかCloudwatchAlarmのアクションで呼び出す2パターンがあります。
ECSでは、下記のメトリクスがプレ定義されています。
- ECSサービスの全体CPU使用率
- ECSサービスの全体メモリ使用率
- ALB→ECSタスクへの1タスクあたりのリクエスト数
今回は前段でCloudwatchAlarmを設定していたので、せっかくなので、そちらのアクションでApplicationAutoScalingを呼び出すような形にしました。
下記のような記載を追記して、CloudwatchAlarmのスタックを更新します。
AlarmActions: - Fn::ImportValue: !Sub "${PJPrefix}-topic" - Fn::ImportValue: !Sub "${PJPrefix}-as-policy" ~~~~ OKActions: - Fn::ImportValue: !Sub "${PJPrefix}-as-policy"
CloudwatchAlarm更新用テンプレート
cwalarm-cfn-template.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create CloudwatchAlarm of ecs-resource Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - PJPrefix - Label: default: "Alarm Configuration" Parameters: - Threshold # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String Threshold: Type: String Default: "10" # ------------------------------------------------------------# # CloudWatchAlarm of ECS-Resource # ------------------------------------------------------------# Resources: ## CloudwatchAlarm of ECS Resource CloudWatchAlarmECSResource: Type: 'AWS::CloudWatch::Alarm' Properties: AlarmActions: - Fn::ImportValue: !Sub "${PJPrefix}-topic" - Fn::ImportValue: !Sub "${PJPrefix}-as-policy" AlarmDescription: !Sub ${PJPrefix}-ecsresource-alarm AlarmName: !Sub ${PJPrefix}-ecsresource-alarm ComparisonOperator: GreaterThanOrEqualToThreshold EvaluationPeriods: 1 Dimensions: - Name: ServiceName Value: !Sub "${PJPrefix}-ecsservice" - Name: ClusterName Value: !Sub "${PJPrefix}-Cluster" MetricName: "CpuUtilized" Namespace: "ECS/ContainerInsights" OKActions: - Fn::ImportValue: !Sub "${PJPrefix}-as-policy" Period: 300 Statistic: Average Threshold: !Sub ${Threshold} TreatMissingData: ignore挙動確認
負荷掛け
#3 ~コンテナのモニタリング~で構築しているBastionサーバから一定量の負荷を掛け、
「ECSサービスの負荷高騰→ECSタスクのスケールアウト→ECSサービスの負荷軽減→ECSタスクのスケールイン」を確認してみます。今回は
・130 Transaction/s程度を50分間
・20 Transaction/s程度を10分間
掛けてみて、確認しました。「130 Transaction/s程度を50分間」かけた際のコマンドは下記の通りです。
※ rオプションがレートのはずですが、いまいちここを変動させてもトランザクションが変わりません… 詳しい方教えてください…siege --time=3000S -c 3 -r 5 -d 0.2 http://{ALBのDNS名}コンソール確認
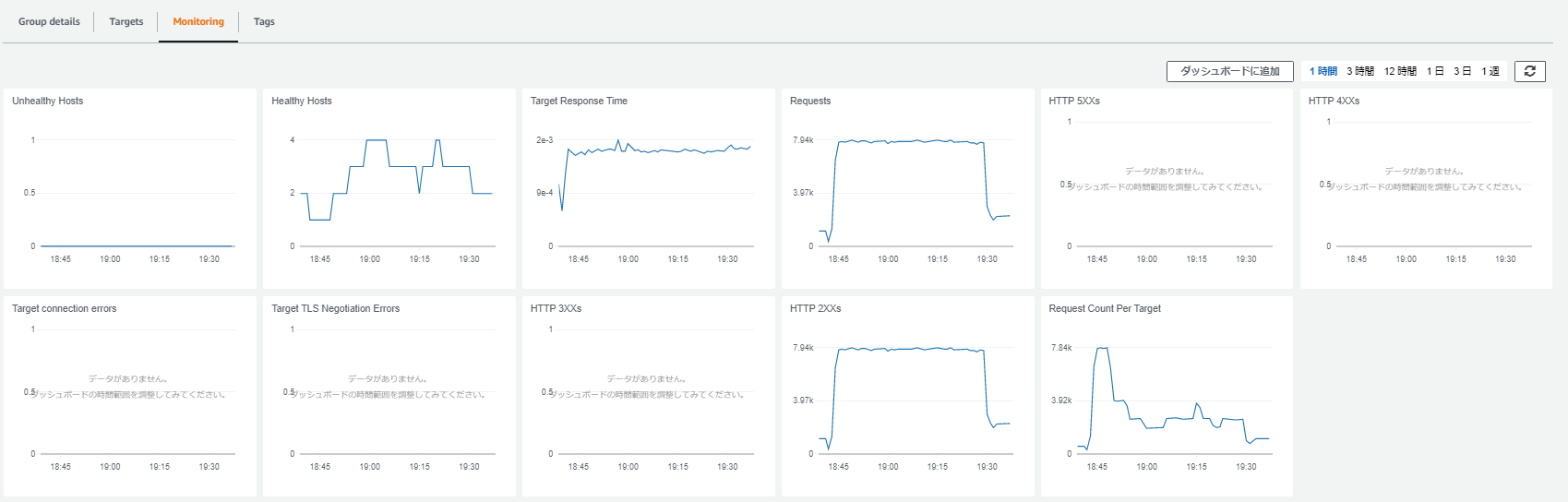
1時間負荷を掛けた後、ALBのメトリクスから状況を確認してみました。
まず、Requestsのメトリクスから一定量のアクセスが流入し続けられていることが分かります。
負荷を掛け始めより、下記のことが分かります。
- HealthyHostsの台数が5分間隔で1→4までタスクが増えていること
→時間軸のメモリが見にくく申し訳ありませんが、5分間隔である理由は、CloudwatchAlarmの間隔やAutoscalingポリシーのクールダウンあたりの設定によるものです。- Request Count Per Targetのメトリクスから、タスクの増加に伴い1台当たりのアクセス量を分散できていること
- 台数が増えた後、スケールイン/スケールアウトを繰り返していること
→これはcloudwatchalarmで設定した閾値が今回の負荷量だと3 or 4タスクで処理するギリギリであったためです。- スケールインする際にも500エラー等を返していないこと
→新規リクエストは振らずに処理中のレスポンスは返却してからタスクをドレーニングする機能が働いているのだと推察しています。 今回の処理はただhtmlを返すだけで処理時間が短すぎたのでキチンと確認はできていません。まとめ
cloudwatchのメトリクス状況から、
- リソースの高騰に合わせて、タスク起動数を増加できること
- リソースが定常に戻った際に、タスク起動数を定常数に戻せること
を確認できました。
コンソール上でECSのAutoscalingを設定するにはサービスの設定時にできますが、CFnで構築しようとすると、ApplicationAutoScalingというサービスであり、ECSとは別サービスであることが良く分かりました。コンソールでは2,3項目で完了する設定もCFnのパラメータを確認すると大量の項目があり、コンソール作業ではデフォルト設定で隠れていることがあります。
試しに感覚をつかむにはコンソール操作も良いですが、サービスを深く知る際にはCFnのドキュメントを見ることが個人的にはおすすめです。次はイメージのリリースでB/GリリースやカナリアリリースをCode系サービス使いながら、体験したいと思いますが、業務が繁忙してきたので投稿空きそうです。
- 投稿日:2020-09-08T16:17:07+09:00
sFlowによるクラウドパフォーマンス管理
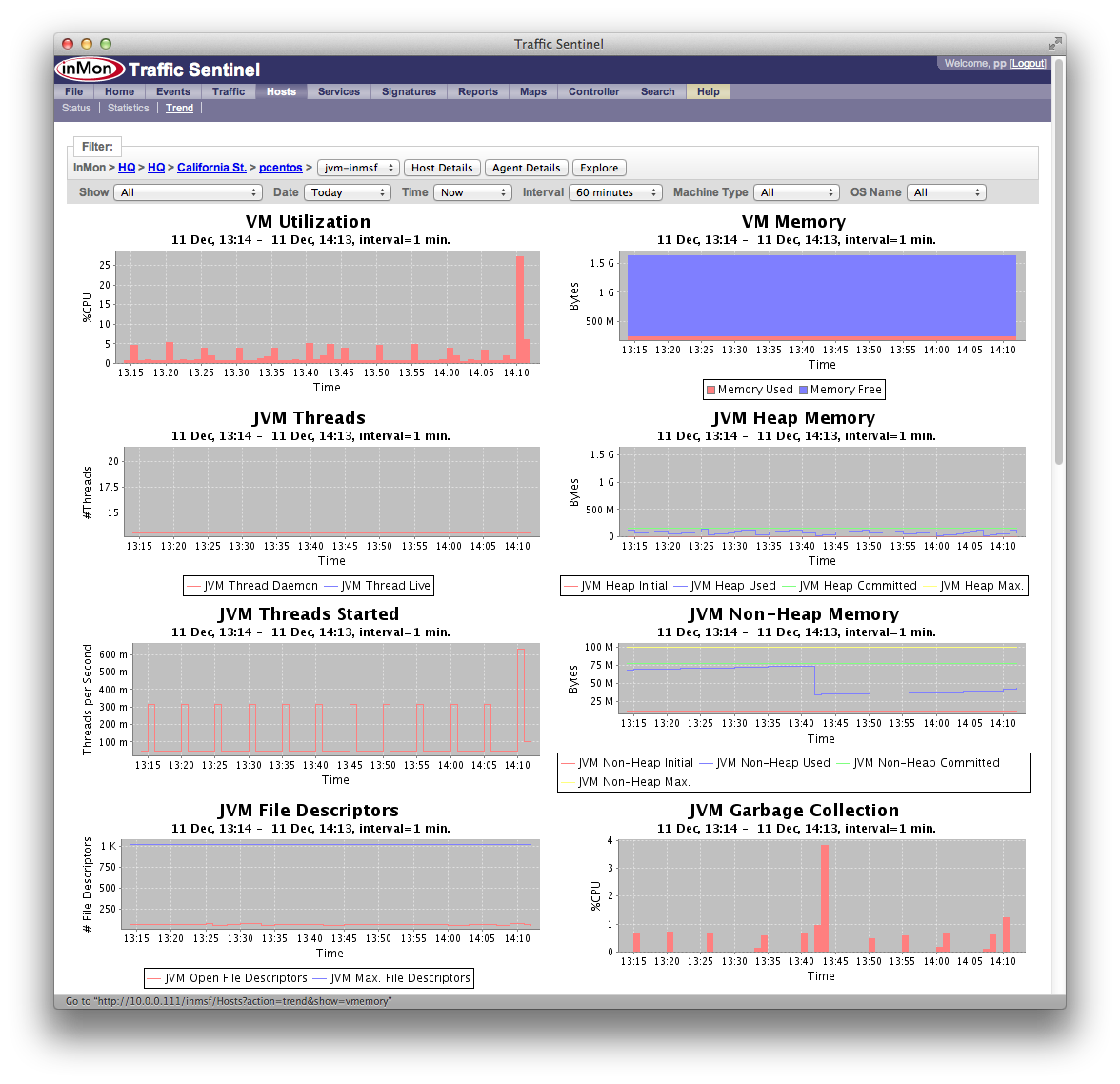
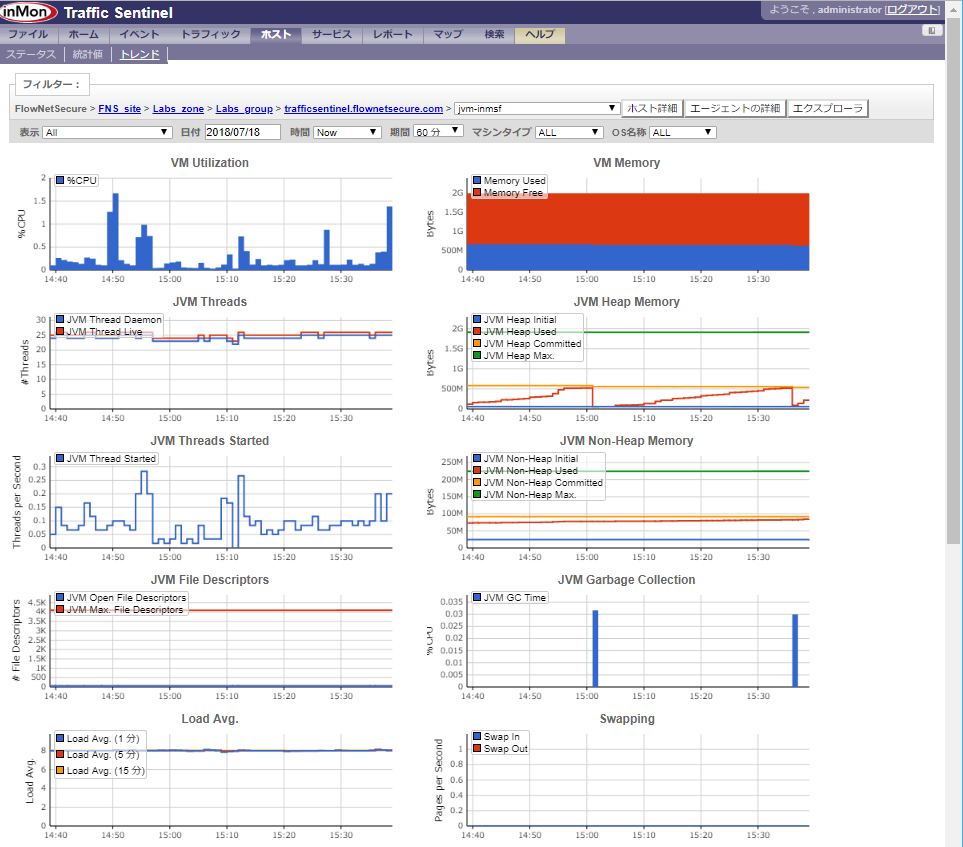
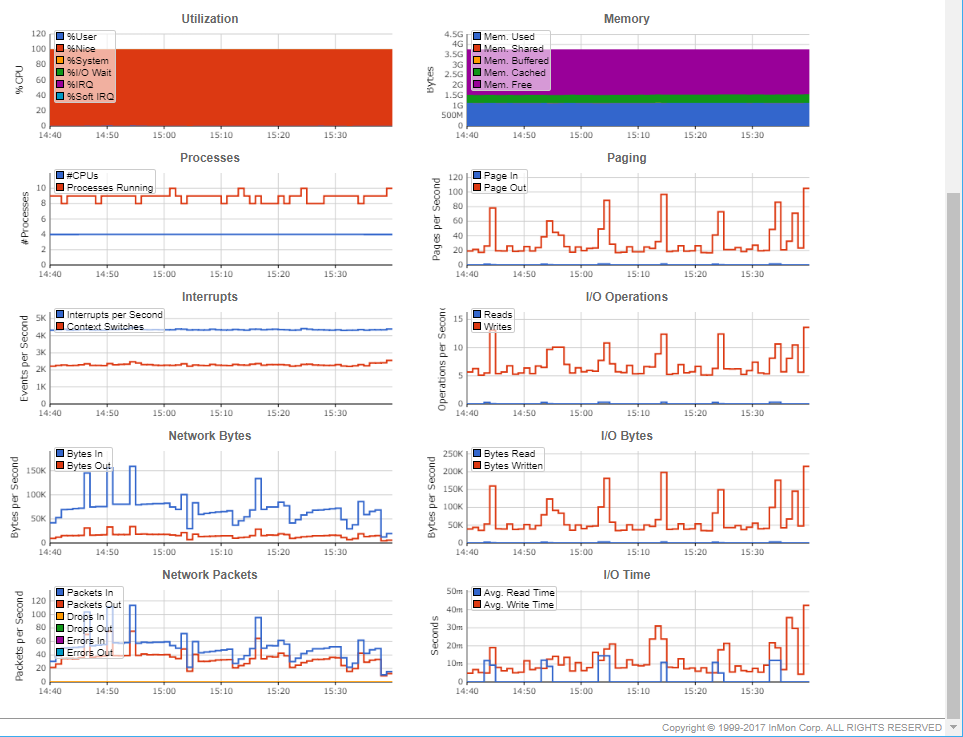
sFlowによるクラウドパフォーマンス管理
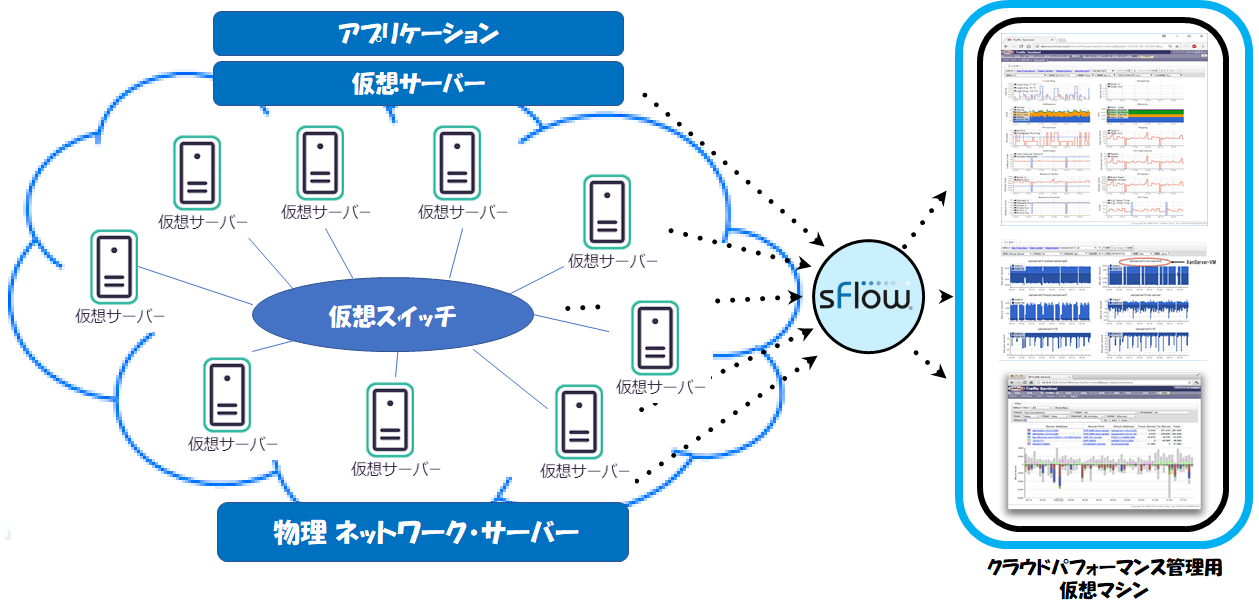
sFlow技術を用いて、フリー(無償)のsFlowエージェント及びフリー(無償)のsFlowCollector(あるいは商用Collector)により、Amazon Web Services(AWS)、Google Cloud Platform(GCP)、Microsoft Azure、各種国産クラウドなどのクラウド環境や各種データセンター内のパフォーマンス管理やモニタリングを実現出来ます。
管理対象は、
・仮想サーバーパフォーマンス
・仮想サーバーインターフェーストラフィック
・仮想スイッチトラフィック
・ホスト・ハイパーバイザー パフォーマンス
・アプリケーション・パフォーマンス
などになります。
クラウドパフォーマンス管理を導入することによって、管理しているクラウド環境内で以下の情報を取得できます。
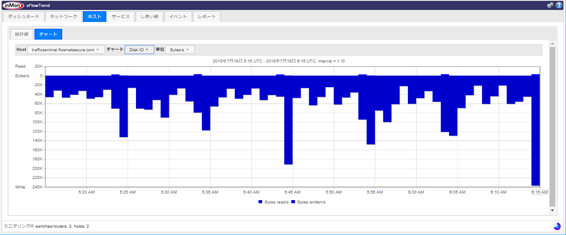
仮想サーバー・物理サーバー:
CPU、Memory、Disk IO、Network IO、TCP/IP etc
CPU Utilization:
Memory Usage:
Disk I/O:
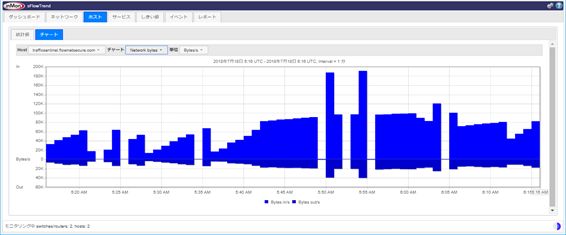
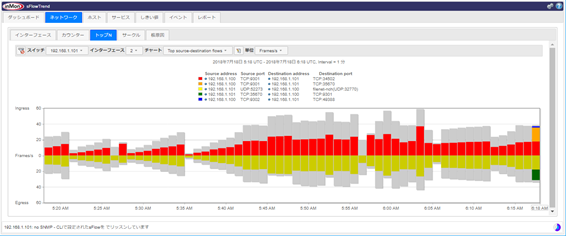
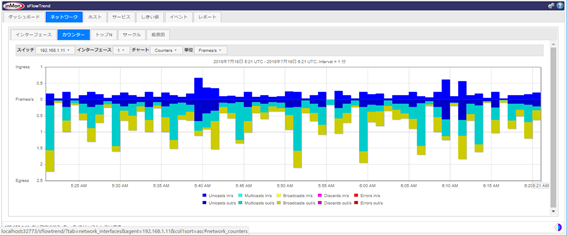
仮想スイッチ・物理スイッチ/ルーター:
MIB-2 ifTable、Flow Information
Network Bytes:
トップN(フロー情報):
Network Counter(SNMP):
アプリケーション・パフォーマンス:
HTTP、Memcache、Java VM etc
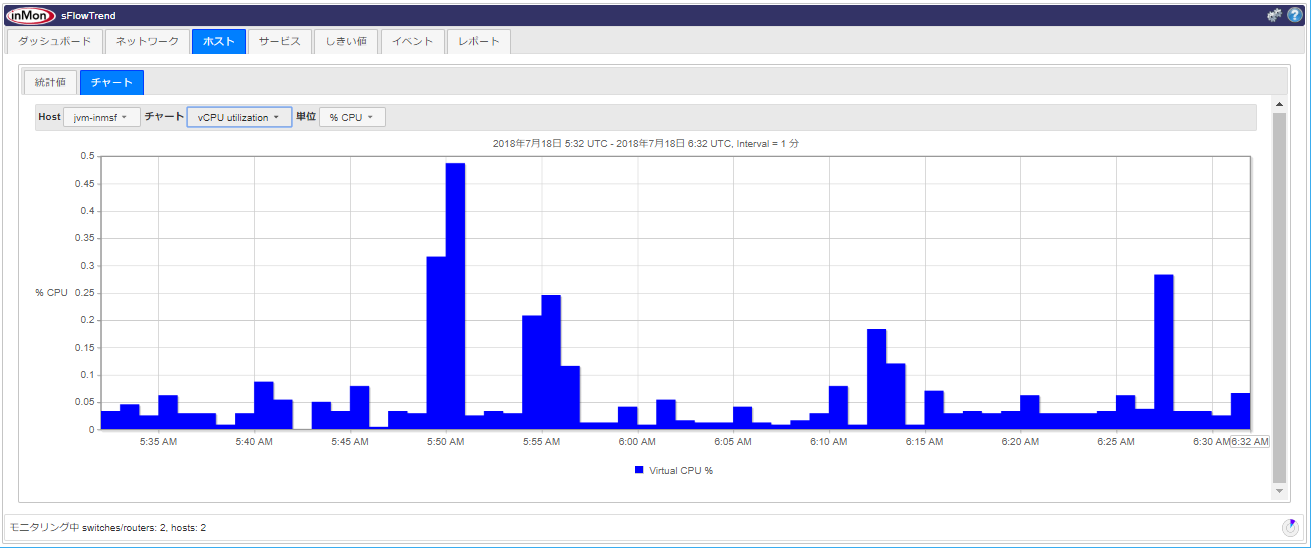
Java(JVM) vCPU Utilization:
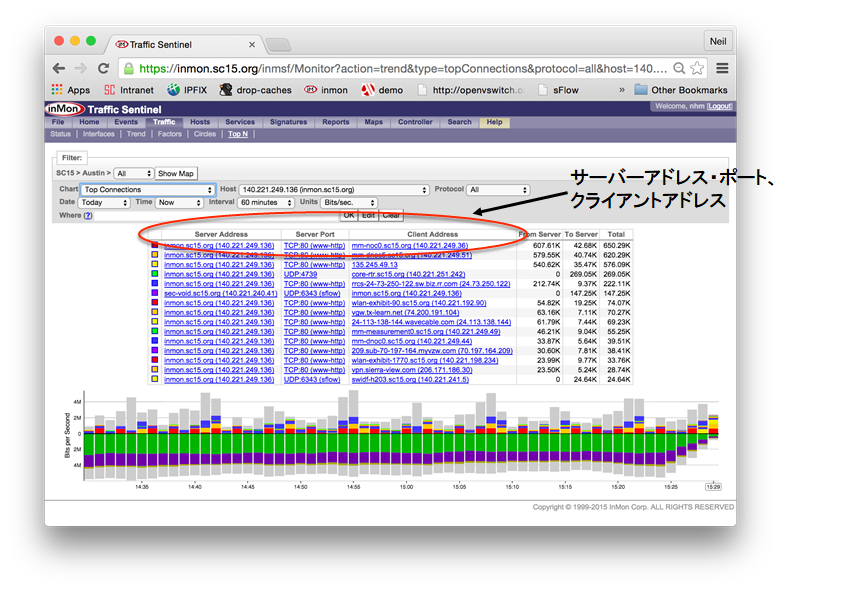
特に、フロープロトコルであるsFlowを使用することにより、一般的なSNMPなどによるサーバー管理では実現できない、フロー情報(送信元/送信先アドレス、送信元/送信先ポート、プロトコル、VLANなど)を把握することが出来、
仮想/物理ネットワーク、サーバーインターフェースでのトラフィックの内容を可視化出来ることが、最大の利点になります。sFlowエージェント
この管理を実現するためには、管理対象にsFlowエージェントを導入する必要があります。
管理対象が以下の場合は、Host sFlowをインストールします。
Host sFlowについては、Host sFlow のご紹介 を参照ください。Operating systems:
AIX
FreeBSD
Linux
Solaris
WindowsLinux containers:
Docker
Systemdhypervisors:
Hyper-V
KVM/libvirt
Nutanix AHV
Xen/XCP/XenServerSwitches:
Arista EOS
Cumulus Linux
Dell OS10
OpenSwitchOther (Application etc):
Open vSwitch, exports network flows and counters
jmx-sflow-agent, exports Java virtual machine metrics
mod-sflow, exports HTTP metrics from Apache
nginx-sflow-module, exports HTTP metrics from NGINX
tomcat-sflow-valve, exports HTTP metrics from Tomcat
node-sflow-module, exports HTTP metrics from node.js
sflow/haproxy, exports HTTP metrics from HAProxy
sflow/memcached, exports Memcache metrics from Memcached
sflow/sflowtool, command line utility for printing binary sFlow
sflow2graphite, utility to push metrics into GraphiteHost sFlowのダウンロード・インストールは、
https://sflow.net/downloads.php
より行ってください。
その他の物理的なルーター・スイッチなどのネットワーク機器は、製品にsFlowの機能が実装されていれば管理モニタリングが可能です。
sFlow実装機器の一覧は、
https://sflow.org/products/network.php
を参照ください。
sFlow以外のNetFlow / J-Flow / IPFIX / XRMON / LFAPなどのフロープロトコルが実装されている場合は、商用Collector(InMon Traffic Seentinel)で管理モニタリングが可能です。
sFlow コレクター
Host sFlowに対応したsFlowコレクターは、下記の3システムになります。
1.sFlowTrend(無償)
sFlow / Host sFlowに対応したフリー(無償)のsFlowコレクターです。
無償版としての機能制限は、5エージェント程度の管理対象と1時間のデータ保持期間になります。
まずは、sFlowTrendにて検証ください。
詳細は、sFlowTrendのインストール を参照ください。
インストール方法の記載もありますので、OS別にダウンロードしインストールし下さい。Dockerイメージ版もあります。2.sFlowTrend-Pro(商用)
sFlowTrendの機能制限なし商用sFlowコレクターです。
数十エージェントのモニタリングや長期分析データ保持が必要であれば、こちらを利用ください。3.InMon Traffic Sentinel(商用)
sFlowのみではなく、NetFlow / IPFIX / J-Flow / XRMON / LFAP に対応した高機能で大規模環境を管理する総合フロー運用管理システムです。
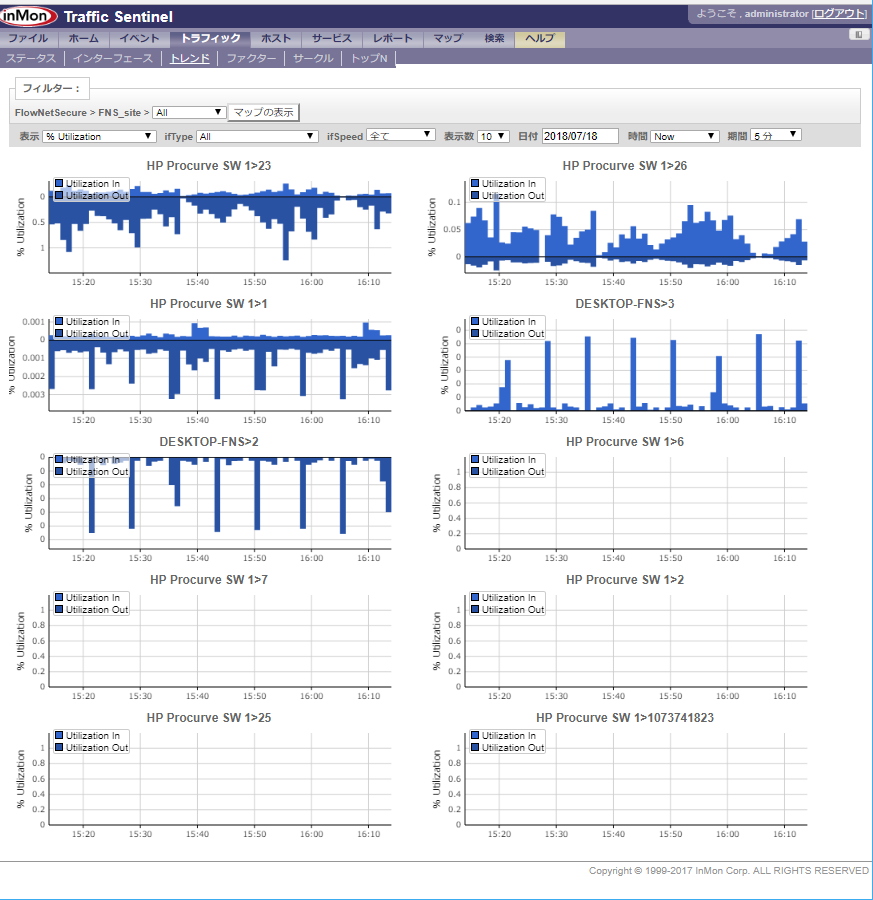
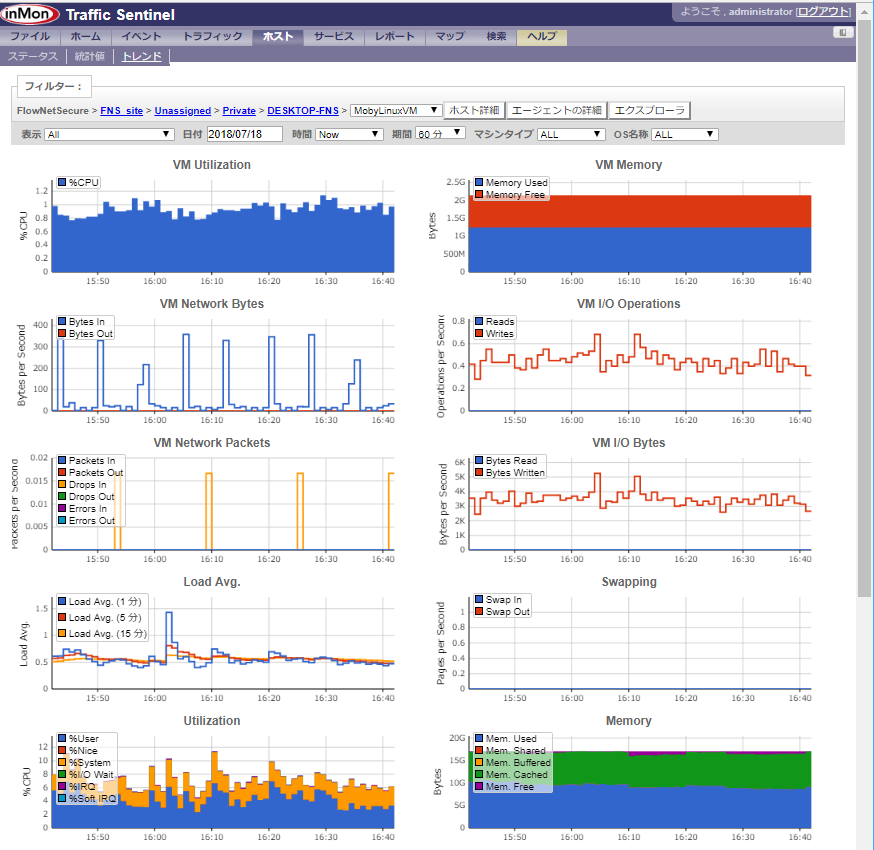
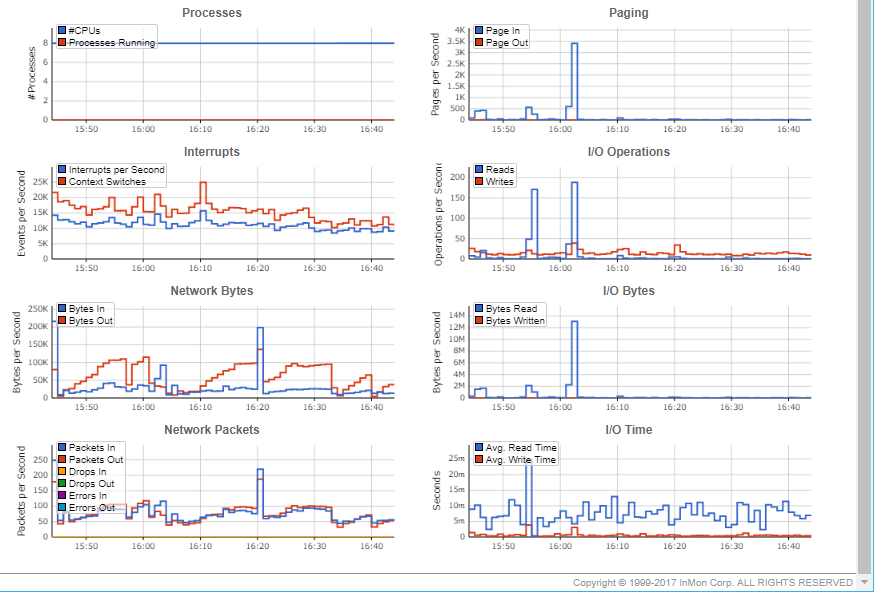
InMon Traffic Sentinelでのパフォーマンス管理
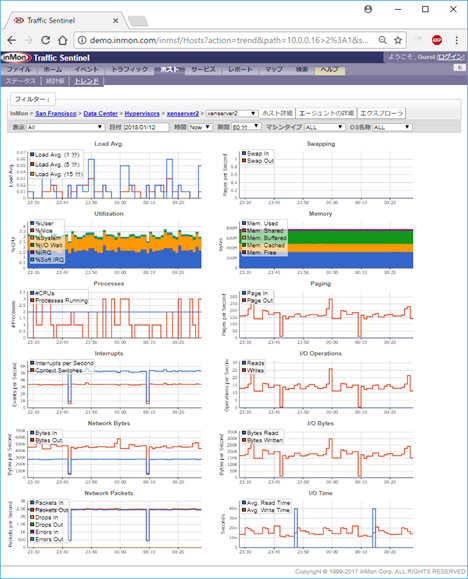
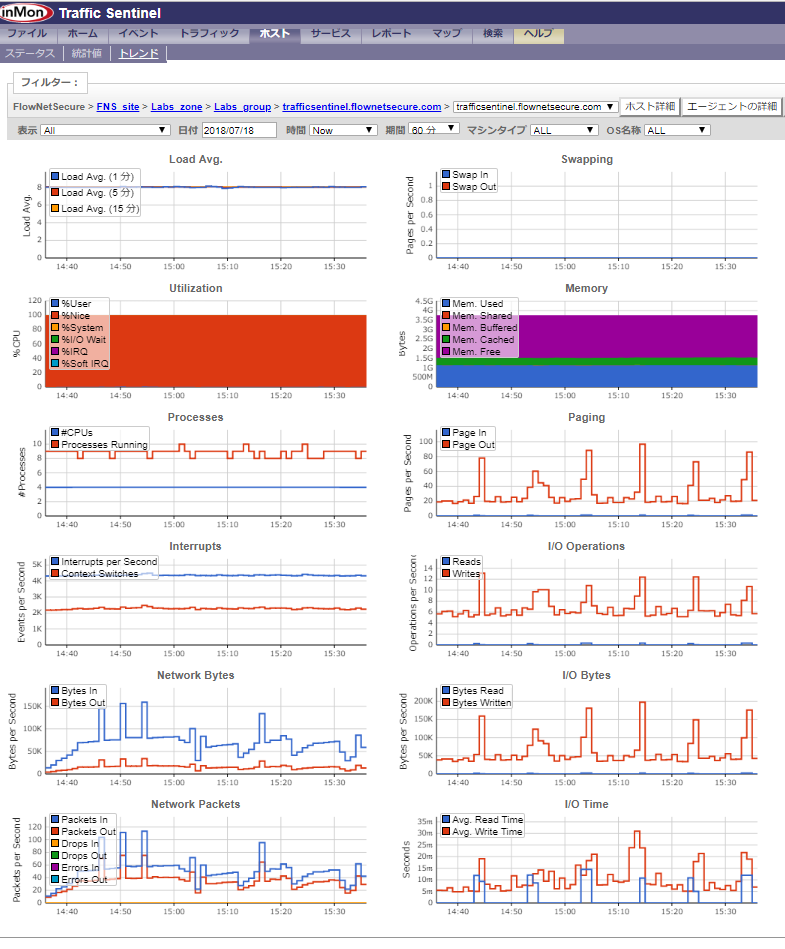
Host sFlow (サーバー・パフォーマンスの測定)
仮想スイッチ
物理スイッチ
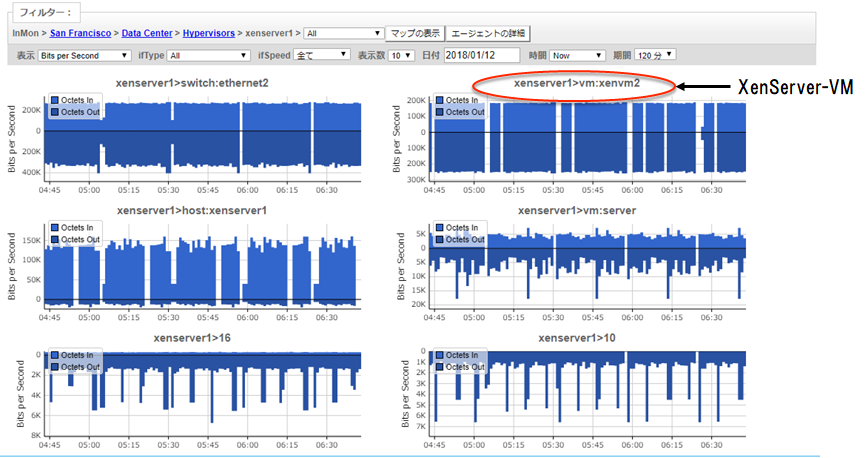
仮想マシン(MobyLinuxVM(Docker/Hyper-V)):
トラフィック・フロー
Hyper-V
アプリケーション(Java virtual machine)
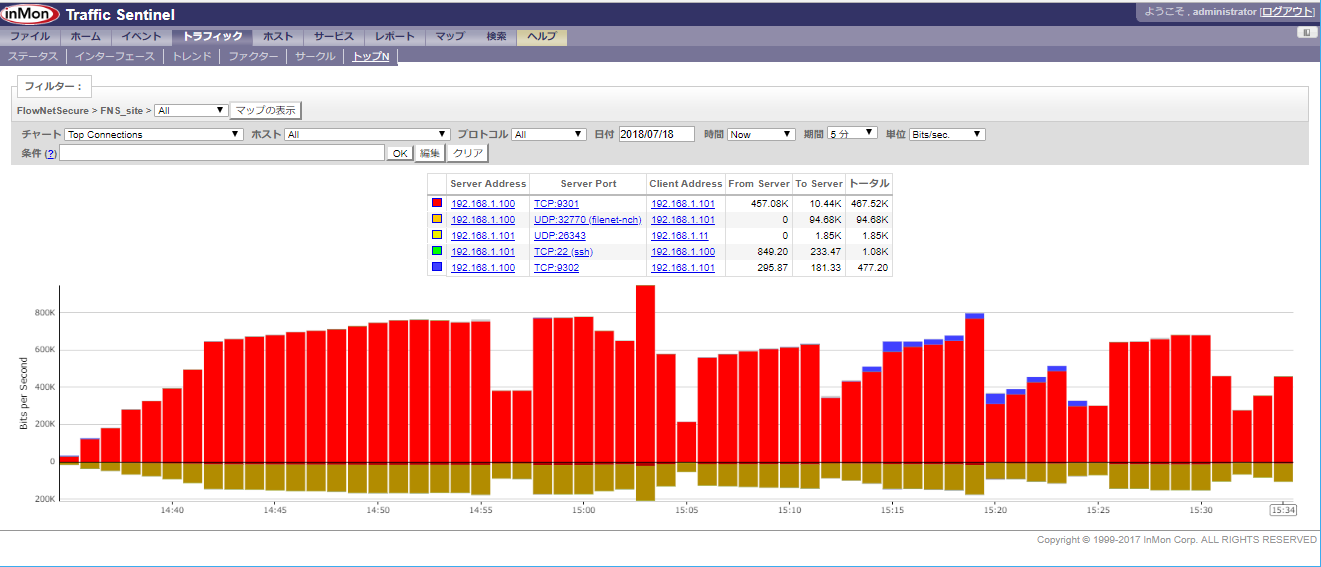
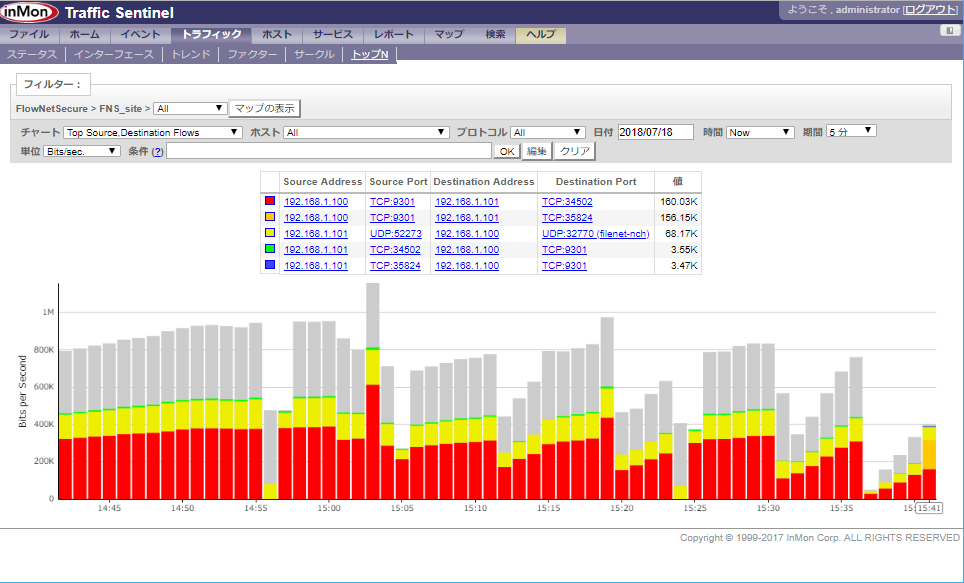
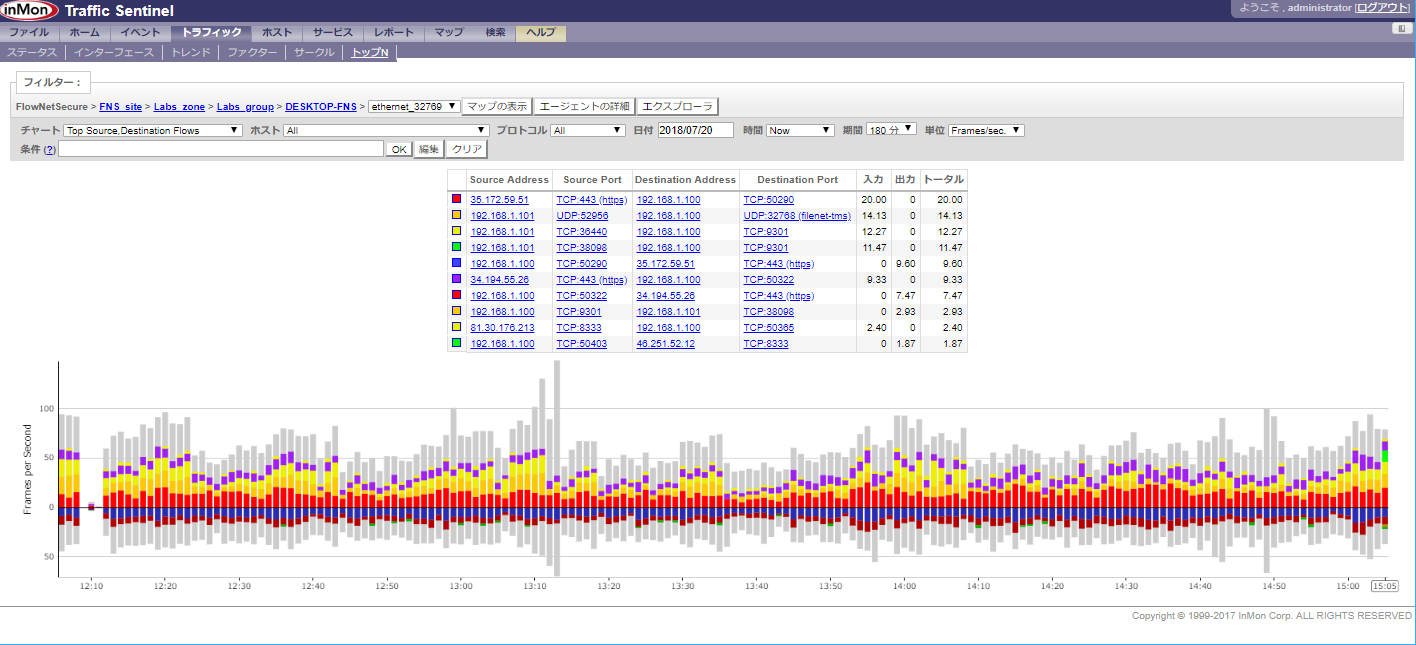
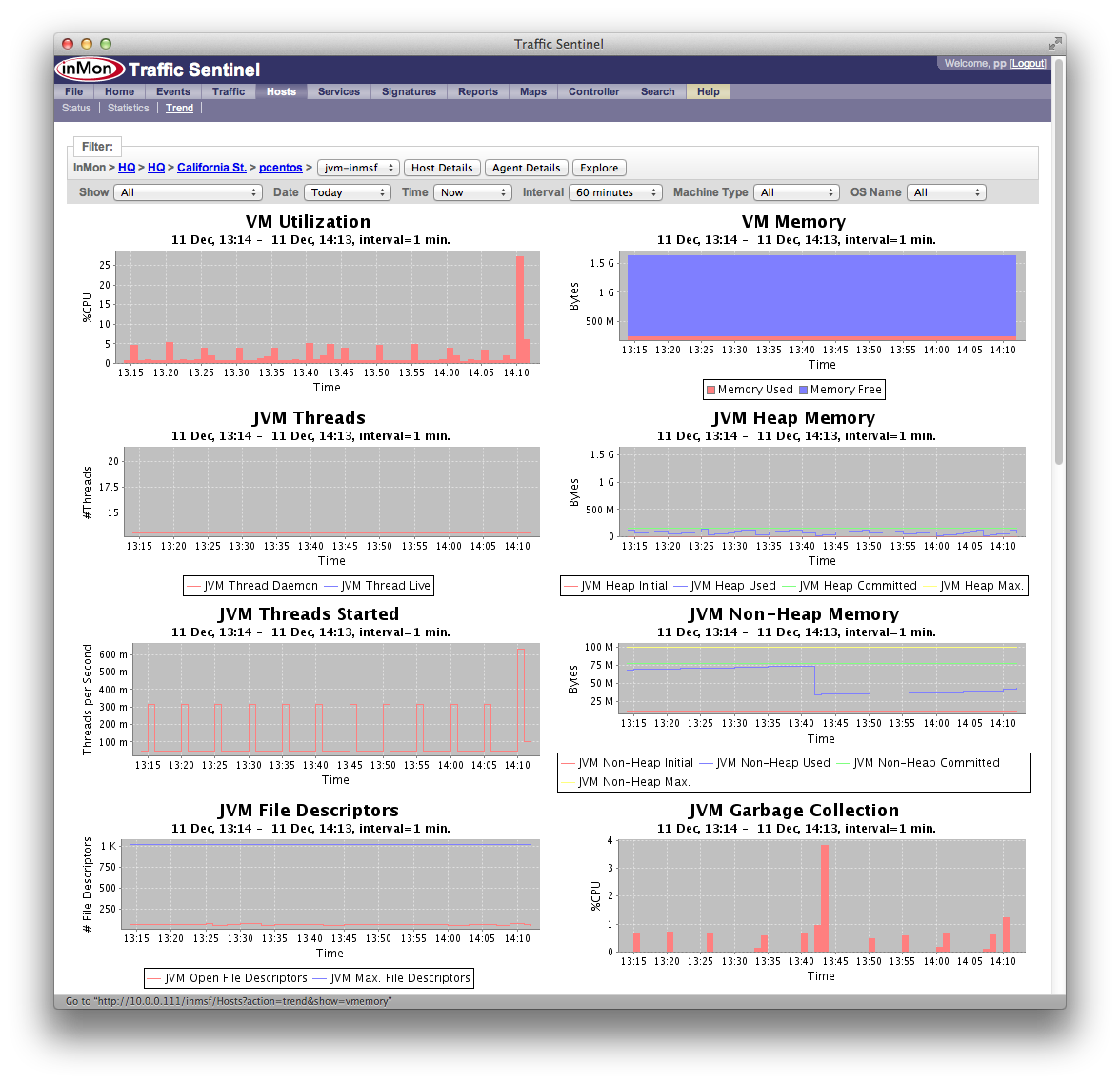
- 投稿日:2020-09-08T15:47:02+09:00
ウサギでもできるWindowsServer上でのAWS Systems ManagerによるRun Commandの実行
前回の記事では、AWSコンソール上でRun Commandを実行するところまでを書きましたが、実際にプロジェクトで実行しようと思っていることはこれではまだ中途半端な状態でした。
実際にお客様がサーバーを運用していくために、VSS Snapshotの取得を実施するたびにWebコンソールで実施するわけにはいかないので、CloudWatchEventなどで定期実行をすることが考えられますが、今回の要件ではとあるシステム管理ツールを利用する前提となっていたのです。そのため、WindowsServer上のコマンドプロンプト(バッチ)か、PowerShellで実行できるようにするところがゴールとなります。今回実施したこと
今回も以下のようなことをやりました。
・WindowsServer上のコマンドプロンプト上でCLIからSSMを実行できるか調べる
・Windowsはないことがわかる
・とりあえずLinuxコマンドでやってみる
・エラー出る(JSON関連)
・解決する
・エラー出る(ポリシー関連)
・解決する
今回はSSMのコンソールと、同僚に教えてもらったこちらのドキュメント、また、ググって見つけたQiitaを参考にして解決することができました。
やったぜ!これぞ集合知!インターネットの醍醐味ですね。
早速行ってみましょう。WindowsServer上のコマンドプロンプト上でCLIからSSMを実行できるか調べる
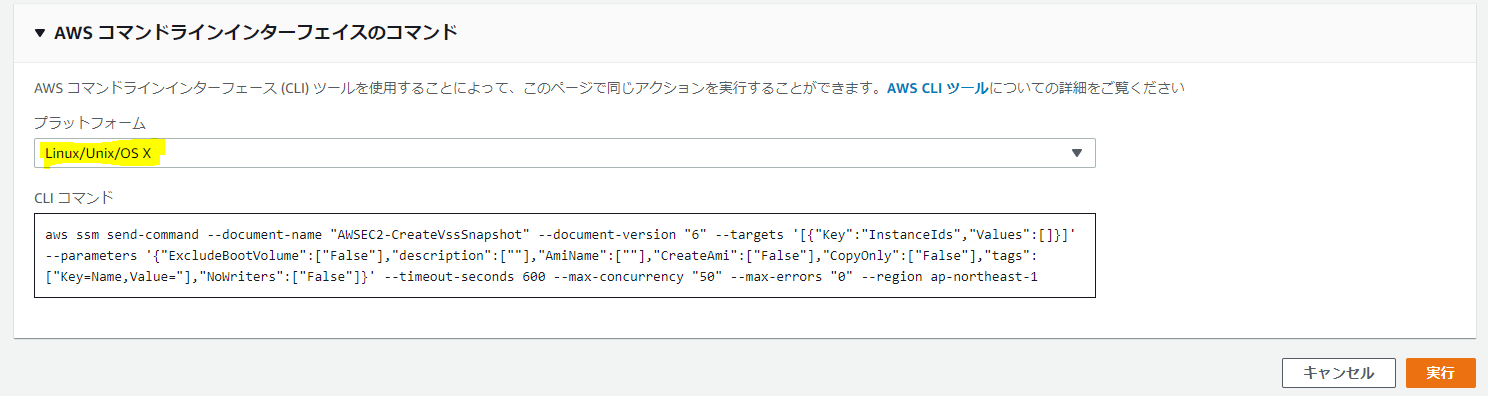
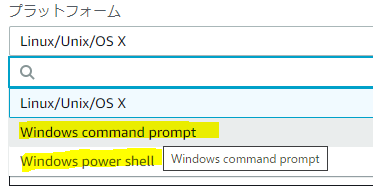
SSMコンソールのRun Commandを実行する画面の一番下に、CLIで今実行しようとすることと同じコマンドを表示する機能があります。それをまずは参考にしてみましょう。
↓これこれ、こんな感じで見ることができます。これはLinuxやMacの場合ですね。
次にWindowsを見てみましょう。
これこれ。これです。
ちゃんと「Windwows command prompt」「Windows Power shell」の二パターンが用意されていますね。
見てみましょう。
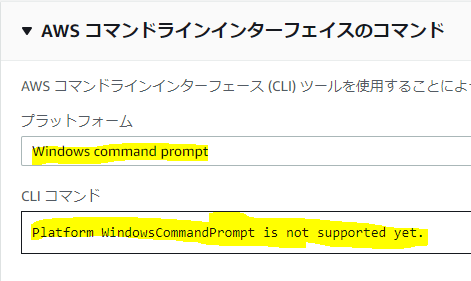
・・・ぉ、ぉぅ。ドンマイ。
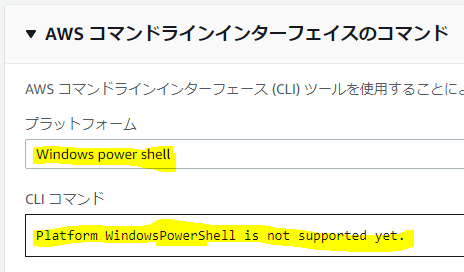
そういうこともあるよね~。「not yet」だからそのうち対応するのかな~?気を取り直して、Power Shellは?
ブルータス、お前もか。Windowsはないことがわかる
トホホ。
途方にくれますね。
うーん、ないなら仕方ない。出来ないのであれば素直に諦らめましょうかね。
と、同僚に愚痴ったら、「Linuxのコマンドそのまま打ったら行けないかな?」とのお言葉。おおっ?!確かに!
基本的にAWS CLIはどのプラットフォームでも同じ使い方のはずなので、いけるかもしれない。とりあえずLinuxコマンドでやってみる
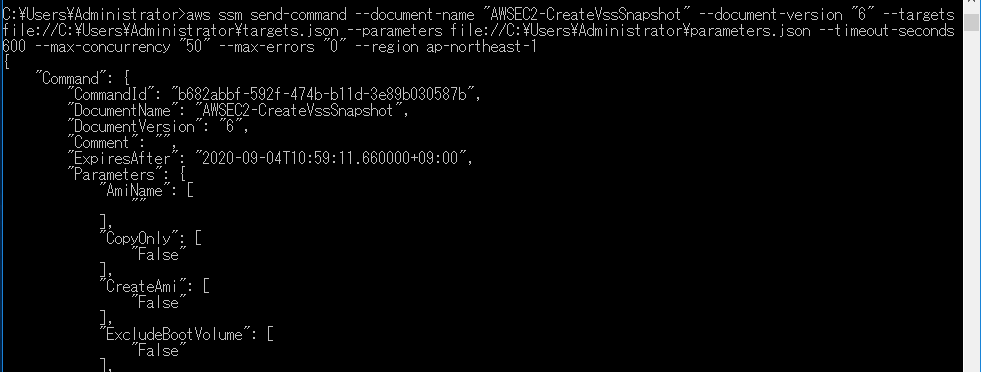
そのままLinuxコマンドでやってみました。
C:\Users\Administrator>aws ssm send-command --document-name "AWSEC2-CreateVssSnapshot" --document-version "6" --targets '[{"Key":"InstanceIds","Values":["i-017d77c8973d7c953"]}]' --parameters '{"ExcludeBootVolume":["False"],"description":[""],"AmiName":[""],"CreateAmi":["False"],"CopyOnly":["False"],"tags":["Key=Name,Value="],"NoWriters":["False"]}' --timeout-seconds 600 --max-concurrency "50" --max-errors "0" --region ap-northeast-1 Error parsing parameter '--targets': Expected: '=', received: ''' for input: '[{Key:InstanceIds,Values:[i-017d77c8973d7c953]}]' ^エラー出る(JSON関連)
はい、エラーが出ましたね。
いや、まだだ、まだ慌てるときじゃない。
とりあえずよくわかりませんが、JSONの表示に関わるエラーみたいですね。「'」が悪さをしている?
よくわからないまま「'」を外して実行してみましょう。C:\Users\Administrator>aws ssm send-command --document-name "AWSEC2-CreateVssSnapshot" --document-version "6" --targets [{"Key":"InstanceIds","Values":["i-017d77c8973d7c953"]}] --parameters '{"ExcludeBootVolume":["False"],"description":[""],"AmiName":[""],"CreateAmi":["False"],"CopyOnly":["False"],"tags":["Key=Name,Value="],"NoWriters":["False"]}' --timeout-seconds 600 --max-concurrency "50" --max-errors "0" --region ap-northeast-1 Expecting property name enclosed in double quotes: line 1 column 3 (char 2)はい、エラーが出ましたね。
いやいや、まだだ、まだ慌てるときじゃない。まぁよくわからないまま「'」を外して実行してみちゃうのはよくないですね。基本的にアホなので。
このエラーメッセージでググってみたところ、JSONの記法に関することでエラーが出ているみたいですね。
困った。
コマンドプロンプト上では「'」を含めて、JSON記法がうまく認識されない呪いにでもかかっているのでしょう。
これは無理だなあ。。。と、また同僚にぼやいたところ「じゃ、パラメーターを別ファイルで渡すこともできるから試してみたら?」と、また蜘蛛の糸的な助言をいただきました!
やってみましょう。解決する
とりあえず、「--targets」と「--parameters」のオプションパラメーターがJSONになっているようなので、こちらのAWSドキュメントを参考に記述しなおしてみました。
それぞれのファイルの中身は以下の通りです。targets.json[{"Key":"InstanceIds","Values":["i-*****************"]}]parameters.json{"ExcludeBootVolume":["False"],"description":[""],"AmiName":[""],"CreateAmi":["False"],"CopyOnly":["False"],"tags":["Key=Name,Value="],"NoWriters":["False"]}実行してみましょう。
エラー出る(ポリシー関連)
C:\Users\Administrator>aws ssm send-command --document-name "AWSEC2-CreateVssSnapshot" --document-version "6" --targets file://C:\Users\Administrator\targets.json --parameters file://C:\Users\Administrator\parameters.json --timeout-seconds 600 --max-concurrency "50" --max-errors "0" --region ap-northeast-1 An error occurred (AccessDeniedException) when calling the SendCommand operation: User: arn:aws:sts::************:assumed-role/TEST-SSM-ROLE/i-***************** is not authorized to perform: ssm:SendCommand on resource: arn:aws:ec2:ap-northeast-1:************:instance/i-*****************はい、エラーが出ましたね。
いやいやいや、まだだ、まだ慌てるときじゃない。とりあえず「not authorized to perform: ssm:SendCommand」って書いてあるので、SSMコマンドの権限がないってことは想像できます。なるほど、ロールが足りていないのかと想像できたところが、何となく自分が成長している気がします。解決はしていませんけど。
ググったところ、Lambdaで実行しようとしているという点は異なりますが、参考にできそうな素晴らしいQiita記事を発見しました。
早速ロールにポリシーを追加してみましょう。解決する
「AmazonSSMMaintenanceWindowRole 」という、Windows上でSSM Run Commandを実行するのに必要なポリシーが当然必要になるので、アタッチします。
ポリシーがアタッチできました!
これでどうでしょうか。
実行!
お???
おおおお?
何かいろいろJSONっぽいのが画面に出てきました。
これは実行結果ですね。
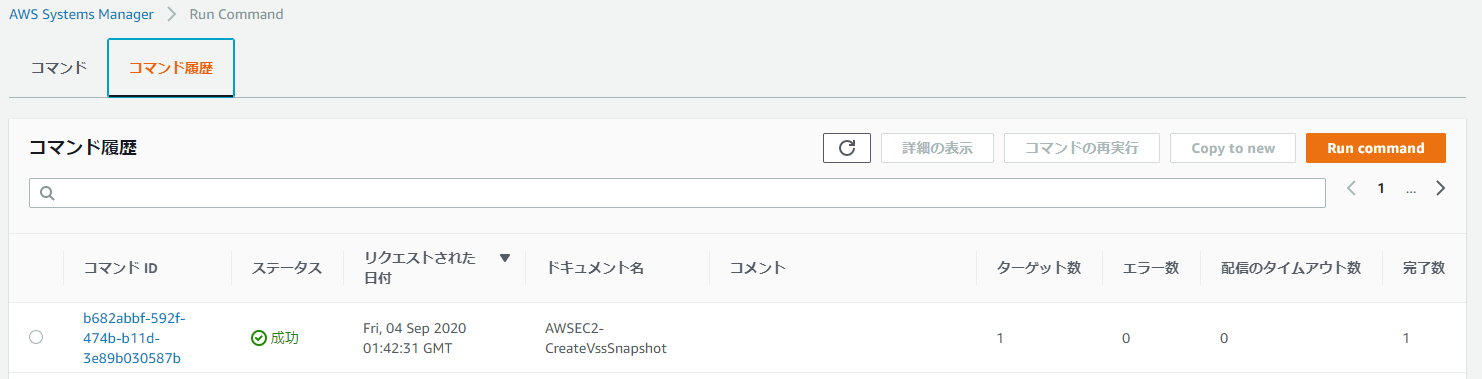
Systems Managerのコンソール画面でRun Commandの実行結果を確認してみましょう。
ヨシ!
成功しています。
これで、WindowsServer上のコマンドプロンプトからVSS Snapshotの取得を実行するというゴールを達成することができました。


- 投稿日:2020-09-08T15:23:19+09:00
ちょっと自分のメモ書き
AWS
基本的にLinuxコマンド
sudo vim とは
super user do
つまり管理者権限を持った人間がやりますよ
という意味のLinuxコマンドvimはvimEditor
使い方はLinuxとはまた別環境変数
.zshrc 内に記述してconfig/secrets.ymlで呼び出す。
それによって公開を防ぐ。
※ただしrailsの5.2以降はcredentials.ymlを使用する。credentials.ymlとは
まだよくわからん
rails でキャッシュのクリア
ブラウザでクリア
spring stopでクリア
webpackerでクリア
railsの再起動でクリア
vs-codeの再起動でクリア※webpackerがよくわからん
- 投稿日:2020-09-08T12:50:43+09:00
CircleCI でプライベートイメージを使用する際に必要なポリシー
プライベートイメージを利用する際の設定方法は以下。
https://circleci.com/docs/2.0/private-images/すべてのリソースに対して
ecr:GetAuthorizationToken対象のECRに対して
ecr:GetDownloadUrlForLayerecr:BatchGetImageTerraform
data "aws_iam_policy_document" "circle_ci_policy_full_resource" { statement { actions = [ "ecr:GetAuthorizationToken", ] resources = ["*"] effect = "Allow" } } data "aws_iam_policy_document" "circle_ci_policy_ecr" { statement { actions = [ "ecr:BatchGetImage", "ecr:GetDownloadUrlForLayer", ] resources = [ "{対象のECR ARN}", ] effect = "Allow" } } resource "aws_iam_user" "circle_ci" { name = "circle_ci" } resource "aws_iam_user_policy" "circle_ci_full_resource" { user = aws_iam_user.circle_ci.name policy = data.aws_iam_policy_document.circle_ci_policy_full_resource.json } resource "aws_iam_user_policy" "circle_ci_ecr" { user = aws_iam_user.circle_ci.name policy = data.aws_iam_policy_document.circle_ci_policy_ecr.json }
- 投稿日:2020-09-08T09:41:27+09:00
ドメイン駆動設計における5層アーキテクチャの全体図とソースの実装例
今回の記事では、過去に記述した以下のバックエンドに関する記事を一つに統合した内容となっている。
従来のドメイン駆動設計の4層アーキテクチャにDCIアーキテクチャを組み込んでいく過程で、様々なパラダイムが発生し、
最終的に4層アーキテクチャにミッション層を追加した5層アーキテクチャという形に落ち着いた。
今回の記事では、投稿した過去の記事の内容を5層アーキテクチャによって概念を整理し、整合性を担保している。投稿した過去の記事一覧
・ドメイン駆動設計のユースケース層(アプリケーション層)を軍事思想(作戦術)でドーピング
https://qiita.com/aLtrh3IpQEnXKN7/items/853ecb3cd109dd016476・OOUI(オブジェクト指向設計)によるバックエンド設計のパラダイムシフト
https://qiita.com/aLtrh3IpQEnXKN7/items/3aa05f9628544c43f279・DCIアーキテクチャの活用方法を紹介
https://qiita.com/aLtrh3IpQEnXKN7/items/355ad12f82ac424abea3・エリック・エヴァンスが提唱したアーキテクチャの4層モデルを拡張する
https://qiita.com/aLtrh3IpQEnXKN7/items/b7fe2014ccefcbb9e458・ドメイン駆動設計のミッション層を設計する手法を紹介
https://qiita.com/aLtrh3IpQEnXKN7/items/98e0c2d2ee0776e0e039・5層アーキテクチャモデルにおけるドメイン分析
https://qiita.com/aLtrh3IpQEnXKN7/items/e5d1a276c07f1fe140be各レイヤーの説明
レイヤーの全体図
1.コントロール層
アプリ外からアクセスの入り口となるインターフェースを主にRestApiで提供する。アプリ外からのアクセスがWeb、iOS、Androidと増加するたびにインターフェースを追加する必要がある。
インターフェース以外の機能として、コントロール層からユースケース層へデータを受け渡す際のデータ変換、コントロール層からアクセス元へのデータ変換(JSON化)を行う。データの受け渡し、データ変換機能をメインに担当する。2.ユースケース層
ビジネスロジックで実現したい目的を記載するための層。ミッション層のメソッドの呼び出しのみを行う。
ユースケース層では、フロントエンドから取得したデータを格納するためのBeanクラスを必ず用意する。
Beanクラスをミッション層へ引数として渡し、ミッション層内で具体的なロジック内容を実装する。ユースケース層のビジネスロジックは以下の種類で実装する。
偵察・・・画面に表示するデータを取得する
順次・・・ビジネスのワークフローを順番通りに進める
ゲリラ・・・不定期に行われるイベント処理を実施する
監視・・・DB内部の情報を監視し、アプリの規約に違反したユーザーの発見などを行う
エスカレーション・・・アプリのルールに違反しているユーザーへの通知、警告などを行う
エマージェンシ・・・緊急事態に対応する
相対・・・キャンセル処理などビジネスのワークフローから外れる例外処理3.ミッション層
具体的なビジネスロジックを記述するための層。ビジネスロジックはDCIアーキテクチャによって実装が行われる。
この層では、ユースケース層で実現したい目的をドメイン層のメソッドを組み合わせて実現する。
以下の観点で、ドメイン層のメソッドを組み合わせロジックを作成する。イベント・・・DBへデータを書き込む事象
リソース・・・企業が取り扱うサービス or 商品
ルール・・・イベントに紐づく運用ルール
テクノロジー・・外部ライブラリを使用して実装されるメールの転送やファイルアップロード
エージェント・・・ミッション層のロジックを統率する。イベント、リソース、テクノロジーのメソッドが全て集約する。4.ドメイン層
ミッション層のロジックを構成する層。ミッション層内でメソッドの呼び出しが行われる。
ドメイン層では、アプリ全体で共通するデータ構造の取得、共通するデータ構造に依存した業務ルールの提供、データ集約に基づいたデータ登録 or 更新 or 削除処理を取り扱う。5.インフラ層
外部ライブラリを使用したロジックを記述し、全レイヤーに外部ライブラリの機能を提供する。例としてメールの送信、ログの出力などが該当する。
ライブラリはバージョンアップや使用するライブラリ変更されるなど、頻繁に発生する箇所する。そのため、DIP(依存関係逆転の原則)に従って、
ドメイン層にインターフェースを配置し、実際のロジックはインフラ層に記述する。インターフェースをデータインジェクション(依存性注入)機能を利用してインタンス生成を行う。実装するクラス一覧
各レイヤー層に記述するクラス一覧について記載
1.コントロール層
Controller・・・REST APIの提供、Convetクラスのメソッドの呼び出し、ユースケース層の画面レベルのメソッドの呼び出し、
Web用、Andoroid、iOSへ引数を返却する際の値変換(JSON化)など
Coverter・・・REST APIから取得した画面の入力値の値をユースケース層へ引き渡す際の値の変換2.ユースケース層
Bean・・・コントロール層から取得した入力値を格納して、ユースケース層へ引き渡す際のクラス。getter setterでメソッドを構成。表示画面と1対1の関係にある。
SearchOperation・・・検索したデータを画面表示することを目的としたビジネスロジック
RegularOperation・・・ビジネスのワークフローを次状態に進めるデータ登録、更新処理を目的としたビジネスロジック
GuerrillaOperation・・・ゲリライベントで発生するデータ登録、更新、削除処理を目的としたビジネスロジック
MonitoringOperation・・・DBのデータを監視し、規約違反が発見した場合、規約違反のデータ登録、更新、削除処理を目的としたビジネスロジック
EscalationOperation・・・エスカレーションラダーを設定し、規約違反を起こしているユーザーに各エスカレーションに応じた通知処理を目的としたビジネスロジック
EmergencyOperation・・・緊急事態対応を目的としたビジネスロジック
IrregularOperation・・・従来のビジネスのワークフローから外れるデータ登録、更新、削除処理を目的としたビジネスロジック3.ミッション層
Mission ・・・Beanクラスを引数として受け取り、Beanクラスに対応したActorクラスのインスタンス、Actorクラスの型となるRoleインターフェスの選択、Roleメソッドの実行を行う。
Actor・・・Roleインターフェースを実装するクラス。Mixinを使用して多重継承を実施。
Role・・・インターフェース。ミッション層のEvent、Resource、Rule、Technologyのメソッドを集約する。ミッション層のロジックを組み合わせ ユースケース層で実現したいロジックを実装する。
Event・・・DBの登録 or 更新 or 削除に関する事象を実装するクラス。ドメイン層の、Aggregates、Servicesの組み合わせで実装される。
Resource・・・企業が取り扱う商品 or サービスのデータをDBから取得するクラス。ドメイン層の、Value Objects、Factories、Entities、Repositoriesの組み合わせで実装される。
Rule・・・運用ルールを実現するクラス。ドメイン層の、Specification、Value Objects、Factories、Entities、Repositoriesなどのメソッドの組み合わせで運用ルールを実現する。
Technology・・・技術的なビジネスロジックを実装するクラス。インフラ層のメソッドとインフラ層のメソッドを組み合わせて実現する。4.ドメイン層
Factorys・・・DTOクラスを引数とし、ValueObjectインスタンスを生成
ValueObject・・・共通構造クラス。DTOをフィールド変数として持ち、getterメソッドとisメソッドのみで構成されている。DTOのデータを加工して提供、DTOのデータに応じたif分の提供などを行う。
Specifications・・・ビジネスルール or 入力値チェックなどのビジネスロジックを提供する
Repositorys・・・DBからデータ検索処理を行うクラス。
Aggregates・・・特定のデータ範囲に応じて、データの登録、更新、削除を行うクラス。
Services・・・上記で上げたドメイン層のロジックに分類できない処理を取り扱うクラス。5.ドメイン層
Mail・・・メール送信を行う。
SFTP・・・SFTPによるデータ送受信を行う。
FileUpload・・・ファイルアップロードを行う。

- 投稿日:2020-09-08T02:49:38+09:00
AWS Client VPNをLinuxでも使いたい
AWS Client VPNはWindowsとmacOS向けにはクライアントが用意されているのですが、Linuxにはなく、UbuntuとかDebianとかopenSUSEを使いたい私はちょっと悲しかったのですが、プロファイル見たらOpenVPNのプロファイルだったのでオッと思ったのでした。
tl;dr
プロファイルを作ったらOpenVPNを使って接続しよう。
前提
- AWS VPCが構築去れていること
- AWS Client VPNの用意ができていること
How
CentOSやopenSUSEなどでもできると思うけれど、手元に構築してあったUbuntuで話します。
バージョンは 18.04LTS。
- OpenVPNをインストール
apt install openvpn- OpenVPNサービスを有効にする
systemctl enable openvpn- OpenVPNサービスを起動する
systemctl start openvpn(不要かもしれない)- opvnファイルを用意する。
- ここでファイル名は
file.ovpnとする。- プロファイルの作成マニュアルは https://docs.aws.amazon.com/ja_jp/vpn/latest/clientvpn-admin/cvpn-getting-started.html を参照のこと。
- rootで接続する
sudo openvpn --config file.ovpn- ユーザー名とパスワードを入力して
Initialization Sequence Completedがログで確認出来たら接続完了。所感
意外にLinuxでClient VPNしたい人はいないのかなと思いました。
- 投稿日:2020-09-08T01:17:46+09:00
AWS S3 アクセスログの集約化
前提
AWSのS3のアクセスログは1回のアクセスにつき、指定したバケットに1個のアクセスログファイルを作成するとします。
感覚的には1回につき1個のファイルではなく、同時間に発行されたログを1つのファイルにまとめて吐いているようです。細かいことはAmazon S3 サーバーアクセスのログ記録を見て下さい。
つまり「1時間毎に1回、1日で計24回のアクセスがあったとすると作成されるログファイルの数は24個」としてこの記事を読んで下さい。何がしたいか
前提で述べたように1回のアクセスで1個のログファイルが作成されるので、1000回アクセスされると1000個のログファイルが作成されてしまいます。「1日に発行されたログを全てまとめて見たい」という時に全てのログファイルをローカルにダウンロードするなんて事はしたくありません。S3の仕様上、それなりにコストがかかります。よってこれらのログファイルを1日毎にまとめてしまいます。1日毎ではなく1週間毎や1ヶ月毎にまとめてしまってもいいかもしれません。ただこの後に使用するAWSのLambdaの仕様上ファイルが大きくなりすぎると無理かもしれないので1日毎にしました。
Direction
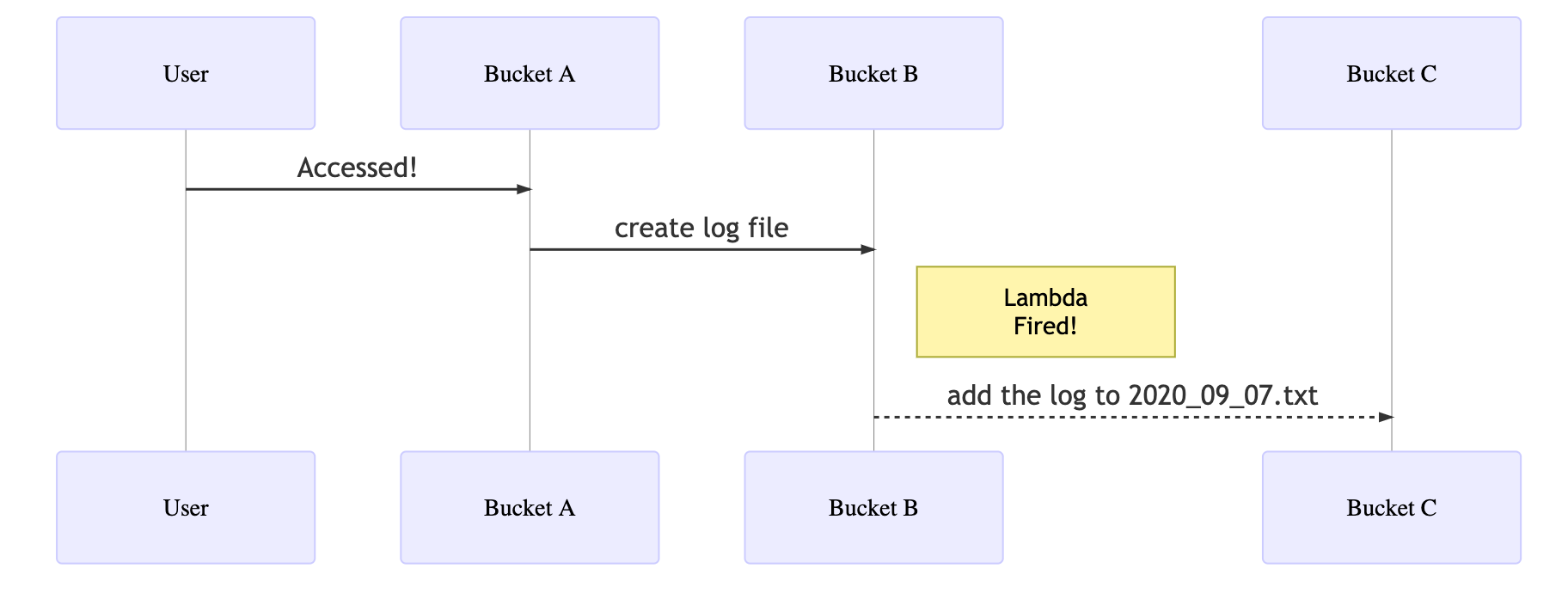
上の図のような流れで処理を実行します。
1. 左から「User」が「Bucket A」にアクセスする(2020-09-07-14-30)。
2. 「Bucket A」はアクセスされるとログを「Bucket B」に書き込む。
3. 「Bucket B」はログを書き込まれたら「Bucket C」においてある、「2020_09_07.txt」にそのログを追記する。これらの処理の内、1と2の処理はAmazon S3 サーバーアクセスのログ記録の設定で自動で行われるので割愛します。
前準備
3の処理をするためにLambdaより関数を作成します。今回私はNode.jsのデプロイパッケージを作成することで関数を作成しました。
Node.js の Lambda デプロイパッケージを作成するには、どうすればよいですか?作成する際には、アクセス権限に「S3FullAccess」をもつロールを与えておいて下さい。
作成した関数の名前を「sum_logs」とします。sum_logsの設定、「トリガーを追加」より、「Bucket B」に新しいオブジェクトが作成されたらsum_logsが実行されるようにしておきます。
また「Bucket C」に「2020_09_07.txt」というファイルを準備しておいて下さい。
「Bucket B」や「Bucket C」と書いていますが実際のBucketの名前は"B"や"C"として以下のコードを扱って下さい。
index.js
var AWS = require("aws-sdk"); const moment = require("moment"); const s3 = new AWS.S3({ region: "ap-northeast-1", }); exports.handler = async (event, context, callback) => { try { //this means Bucket "C" const dest_bucket = "C"; var uploaded_params = { // event.Records[0].s3.bucket.name means Bucket "B" Bucket: event.Records[0].s3.bucket.name, Key: event.Records[0].s3.object.key, }; var uploaded_obj = await s3.getObject(uploaded_params).promise(); var uploaded_body = uploaded_obj.Body.toString(); var dest_params = { Bucket: dest_bucket, Key: moment().format("YYYY-MM-DD") + ".txt", }; var dest_obj = await s3.getObject(dest_params).promise(); var dest_body = dest_obj.Body.toString(); dest_body += uploaded_body; var new_params = { Bucket: dest_bucket, Key: moment().format("YYYY-MM-DD") + ".txt", Body: dest_body, }; var put_obj = await s3.putObject(new_params).promise(); // delete uploaded logs in Bucket "B" var deleted = await s3.deleteObject(uploaded_params).promise(); return; } catch (e) { console.log(e); return; } };解説
内容は大体読めば分かるでしょう。
今回デプロイパッケージにしたのはMoment.jsを使用したかったからです。個人的には扱いやすいのでおすすめします。注意点とまとめ
今回、日付毎にファイルをまとめていますが、そのベースとなるファイル(今回は2020_09_07.txt)は前もって特定のバケット(今回はBucket "C")に作成しておく必要があります。
このベースになるファイルも手動で作成するなんて馬鹿らしいことはしないので、無論自動で行わせるわけですが疲れたので気が向けば書きます。処理は同様にLambdaを使用しますが、トリガーはEventBridgeを使用します。とっても簡単です。コストについて
「Logが吐かれる度にS3にファイルをPutしてたら、データ転送料は相当かかるんじゃないの?」とか思われるかもしれませんが、僕はAWS Lambda 料金に書かれている
同じ AWS リージョン内における Amazon S3、Amazon Glacier、Amazon DynamoDB、Amazon SES、Amazon SQS、Amazon Kinesis、Amazon ECR、Amazon SNS、Amazon EFS、または Amazon SimpleDB と AWS Lambda 関数の間でのデータ転送は無料です。
という文章を信じています。参考
S3
Amazon S3 サーバーアクセスのログ記録
Lambda
EventBridge
AWS Lambda 料金
mermaid.js