- 投稿日:2020-09-08T23:38:24+09:00
DjangoアプリケーションをDockerコンテナ上で動かす方法(開発および本番環境)
記事の概要
Djangoで作成したWEBアプリケーションを開発・本番環境で動作させる際はいくつかの方法があります。
最近では、Kubernetesが人気となりアプリケーションをコンテナ化する場面も多いです。本記事では開発・本番環境でどのようにDjangoアプリケーションをのせたDockerコンテナを作るかについて記載します。
前提条件・環境
本記事で使用する環境はCentOS7、Docker、Django2系です。
Dockerさえ動けばDockerコンテナは動くため、OSがWindowsでも問題ありません。
開発環境用Dockerコンテナ作成
使用するDockerファイル
開発環境用に使用するDockerファイルは以下になります。
このDockerファイルではdebian:10をベースにして、Pythonをソースコードからインストールしています。
公式PythonのDockerイメージもあるためそちらを使っても問題ないのですが、勉強のためにこのような構成になっています。FROM debian:10 # Install Python3.7.7 WORKDIR /work ADD ./Python-3.7.7.tar.xz . WORKDIR Python-3.7.7 RUN apt-get update && apt-get install -y \ gcc \ libbz2-dev \ libssl-dev \ libffi-dev \ libsqlite3-dev \ make \ tk-dev \ zlib1g-dev \ apache2-dev \ python3-dev \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* RUN ./configure --enable-shared && \ make && \ make install && \ make distclean && \ ./configure && \ make && \ make altbininstall # Install with pip COPY ./requirements.txt . RUN pip3 install --upgrade pip setuptools RUN pip3 install --upgrade wheel RUN pip3 install -r requirements.txt # Deploy App WORKDIR / ADD ./deployfiles.tar.xz . WORKDIR /myapp CMD ["python3", "manage.py", "runserver", "0.0.0.0:80"]Dockerファイルの説明
FROM debian:10まず、Dockerファイルを記載するときはベースとして何を使うか指定します。ここではdebian:10を指定しています。
# Install Python3.7.7 WORKDIR /work ADD ./Python-3.7.7.tar.xz . WORKDIR Python-3.7.7次にPythonのインストールです。
WORKDIRはOSのカレントディレクトリを移動させるような構文です。WORKDIR /workとすればルートディレクトリ(/)直下にworkというディレクトリが作られ(指定したディレクトリがなければ作られます)、そこがカレントディレクトリとなります。
ADDはADD ホストOS上のパス Dockerコンテナ上のパスとすることで指定したホストOS上にあるファイルをDockerコンテナ上のパスへコピー・展開することができます。
ADDはCOPYと異なり、圧縮されたファイルを展開することができます。そのためtarやxzなどのファイルはADDを使ってDockerコンテナ上へコピーすると良いと思います。RUN apt-get update && apt-get install -y \ gcc \ libbz2-dev \ libssl-dev \ libffi-dev \ libsqlite3-dev \ make \ tk-dev \ zlib1g-dev \ apache2-dev \ python3-dev \ && apt-get clean \ && rm -rf /var/lib/apt/lists/*RUNはDockerコンテナ上でコマンドを実行することが出来ます。apt-getを使用し、Pythonのインストールに必要な依存パッケージをインストールしています。
apt-get clean、rm -rf /var/lib/apt/lists/*は不必要なキャッシュやファイルを削除するために実行しています。これを削除することで、作成されるDockerイメージの容量を小さく保てます。
RUN ./configure --enable-shared && \ make && \ make install && \ make distclean && \ ./configure && \ make && \ make altbininstall後は./configure、make、make installです。4行ほど余分なものがありますが、これはエラー対応のためにつけています。
※何らかの組み合わせの問題だとは思うのですが、私が実行したときはこのようにしなければなりませんでした。もしかすると不要かもしれません。
# Install with pip COPY ./requirements.txt . RUN pip3 install --upgrade pip setuptools RUN pip3 install --upgrade wheel RUN pip3 install -r requirements.txtPythonのインストールが終わったら、Pythonパッケージのインストールを行います。ここではpipコマンドを使用してrequirements.txtに記載されているパッケージをインストールします。
COPYはADDと似ていて、COPY ホストOS上のパス Dockerコンテナ上のパスとすることでホストOS上にあるファイルをDockerコンテナ上のパスへコピーできます。こちらは文字通りコピーしかしません。
後はRUNでpipのアップグレードを行い、requirements.txtに基づいてPythonパッケージをインストールします。
# Deploy App WORKDIR / ADD ./deployfiles.tar.xz . WORKDIR /myapp CMD ["python3", "manage.py", "runserver", "0.0.0.0:80"]最後に自分が作ったアプリケーションをDockerコンテナへ加えます。
deployfiles.tar.xzはmyappというディレクトリを圧縮したもので、myapp直下にmanage.pyがあります。
CMDはDockerコンテナが起動するときに実行するコマンドを設定する構文です。これはPythonのリスト形式のように記載でき、各要素は半角スペースで結合されます。つまり、以下のようなコマンドになります。
CMD ["python3", "manage.py", "runserver", "0.0.0.0:80"] ↓ python3 manage.py runserver 0.0.0.0:80Dockerイメージのビルド
Dockerイメージをビルドするには以下のコマンドを実行します。
docker build -t test/myapp .-tオプションはDockerイメージへタグを付けるために使用します。タグを付ければ管理がしやすくなります。
コマンドの最後にはDockerファイルのパスを入れます。ここではカレントディレクトリ(.)を指定しています。
デフォルトではDockerfileという名前のファイルを指定されたパスから探すため、上記で作成したファイル名はDockerfileとしておきます。
作成したイメージを確認するには以下のコマンドを実行します。
docker image lsDockerコンテナの起動
DockerイメージからDockerコンテナを起動するには以下のコマンドを実行します。
docker run --name myapp -d -p 80:80 -v /work/db.sqlite3:/myapp/db.sqlite3 test/myapp:latest--nameオプションはDockerコンテナへ名前をつけます。これは後でこのDockerコンテナを停止、起動、削除したくなったりしたときに便利です。名前は一意なものになるため、名前をつけておけば名前を指定するだけで停止、起動、削除が出来ます。名前がない場合はコンテナIDを指定します。
-dオプションはバックグラウンドでコンテナを実行します。これをつけなかった場合は、Dockerコンテナの標準出力がコンソール上に表示されます。Ctrl + cで抜けられます。ほとんどの場合はバックグラウンドで動かすと思うのでつけておきます。
-pオプションはホストOSのポートとDockerコンテナのポートを紐付けます。ホストOSのポート:Dockerコンテナのポートとします。今回はDjangoのプロセスをDockerコンテナの80番ポートを使用して公開しているため80を指定します。
-vオプションはホストOSのボリューム(DockerボリュームまたはホストOS上のファイルパス)とDockerコンテナのファイルパスを紐付けます。コンテナは終了したときにデータを保持しません。そのため、残しておきたいデータは外部に保管する必要があります。推奨はDockerボリュームですが開発環境のためホスト上OSのファイルパスへデータを保存させます。ここではdb.sqlite3をホストOSからDockerコンテナへ紐付けています。
test/myappは元になるDockerイメージの指定です。latestというのはバージョン名でDockerイメージをビルドしたときに何も指定しなければlatestになります。docker image lsで出力されるTAG列を参照することで確認できます。
正常に起動されているかどうかを確認するには以下のコマンドを実行します。
docker psSTATUS列がUPになっていれば正常に起動しています。
何も出力されない場合は-aをつけて停止中のプロセスも確認します。もしDockerコンテナのログを確認したい場合は以下のコマンドを実行します。
docker logs [コンテナ名またはコンテナID]エラーを確認して対応します。
Djangoアプリケーションへの接続
Dockerを起動しているホストOS上のIPアドレスの公開したポート番号へアクセスします。
本番環境用Dockerコンテナ作成
使用するDockerファイル
本番環境用に使用するDockerファイルは以下になります。
開発環境と違い、python3 manage.py runserverでプロセスを立ち上げるわけにはいきません。Apacheなどの上で動作させるほうが安定します。
ここではベースとしてhttpd:2.4を使用しています。Apache Web サーバの公式Dockerイメージです。
ApacheでDjangoを実行するためにはmod_wsgiというモジュールをApacheへ組み込む必要があります。そのためPython、mod_wsgiをインストールしています。
FROM httpd:2.4 # Install Python3.7.7 WORKDIR /work ADD ./Python-3.7.7.tar.xz . WORKDIR Python-3.7.7 RUN apt-get update && apt-get install -y \ gcc \ libbz2-dev \ libssl-dev \ libffi-dev \ libsqlite3-dev \ make \ tk-dev \ zlib1g-dev \ apache2-dev \ python3-dev \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* RUN ./configure --enable-shared && \ make && \ make install && \ make distclean && \ ./configure && \ make && \ make altbininstall # Install with pip COPY ./requirements.txt . RUN pip3 install --upgrade pip setuptools RUN pip3 install --upgrade wheel RUN pip3 install -r requirements.txt # install ModWsgi WORKDIR /work ADD ./mod_wsgi-4.7.1.tar.gz . WORKDIR mod_wsgi-4.7.1 RUN ./configure \ --with-apxs=/usr/local/apache2/bin/apxs \ --with-python=/usr/local/bin/python3.7 && \ make && \ make install # Set Apache WORKDIR /usr/local/apache2/conf COPY ./httpd.conf . COPY ./server.crt . COPY ./server.key . COPY ./wsgi.conf ./extra COPY ./httpd-ssl.conf ./extraDockerファイルの説明
FROM httpd:2.4ベースとしてhttpd:2.4を指定しています。
# Install Python3.7.7 WORKDIR /work ADD ./Python-3.7.7.tar.xz . WORKDIR Python-3.7.7 RUN apt-get update && apt-get install -y \ gcc \ libbz2-dev \ libssl-dev \ libffi-dev \ libsqlite3-dev \ make \ tk-dev \ zlib1g-dev \ apache2-dev \ python3-dev \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* RUN ./configure --enable-shared && \ make && \ make install && \ make distclean && \ ./configure && \ make && \ make altbininstall開発環境と同様にPythonをインストールします。
# Install with pip COPY ./requirements.txt . RUN pip3 install --upgrade pip setuptools RUN pip3 install --upgrade wheel RUN pip3 install -r requirements.txt開発環境と同様にpipでrequirements.txtに基づいたPythonパッケージをインストールします。
# install ModWsgi WORKDIR /work ADD ./mod_wsgi-4.7.1.tar.gz . WORKDIR mod_wsgi-4.7.1 RUN ./configure \ --with-apxs=/usr/local/apache2/bin/apxs \ --with-python=/usr/local/bin/python3.7 && \ make && \ make installApacheでDjangoを動作させるためにmod_wsgiをインストールします。
# Set Apache WORKDIR /usr/local/apache2/conf COPY ./httpd.conf . COPY ./server.crt . COPY ./server.key . COPY ./wsgi.conf ./extra COPY ./httpd-ssl.conf ./extra最後にApacheの各種configファイル、証明書関連ファイルをコピーします。
Dockerイメージのビルド
開発環境と同様です。
Dockerボリュームの作成
Dockerボリュームを作成するには以下のコマンドを実行します。
docker volume create --name volume-name--nameで指定した名前でDockerボリュームが作成されます。このボリュームはDockerコンテナと紐付けます。
Dockerボリュームの寿命はDockerコンテナと異なります。DockerコンテナがなくなってもDockerボリュームは存在し続けるため、データを永続化できます。
Dockerコンテナの起動
DockerイメージからDockerコンテナを起動するには以下のコマンドを実行します。
docker run --name myapp -d -p 443:443 -v vlume-name:/myapp test/myapp-vオプションだけ開発環境とは異なります。ここではホストOS上のファイルパスではなく、Dockerボリュームを指定しています。volume-nameという名前のDockerボリュームがDockerコンテナ上の/myappと紐付きます。これで/myapp上にあるデータがDockerボリュームへ保存されます。
Djangoアプリケーションへの接続
開発環境と同様です。
使用したソースファイル
- 投稿日:2020-09-08T23:26:36+09:00
PDF のページ番号を振りなおす
PDF のページ番号を振りなおす必要性
報告書や書籍などのページ番号について、目次にはローマ数字 (i, ii, iii...)、本編はまた 1 から始まるアラビア数字 (1, 2, 3...) を振ることが一般的です。
しかし、その PDF 版はそうなっておらず、PDF のページ目から単純な連番のページ番号が振られていることが多いです。その場合、目次に n ページと書いてあっても、PDF 版では目次の総ページ数 m を足した (m + n) ページに飛ばなければなりません。
こうした不便さを解消するために、書籍と同様のページ番号を PDF に振る方法を紹介します。
環境
- Python
- pagelabels (python パッケージ)
pagelabes をインストールするには、
pip install pagelabelsを実行してください。実行
python -m pagelabels --startpage 1 --type "roman lowercase" --outfile out.pdf in.pdf python -m pagelabels --startpage 9 --type "arabic" out.pdfpagelabels のオプション
startpage: PDF全体の何ページ目から、このスキームでページを振るか。style: 数字のスタイル。arabicアラビア数字 (1, 2, 3, ...),roman uppercase大文字のローマ数字 (I, II, III, ...),roman lowercase小文字のローマ数字 (i, ii, iii, iii),letters uppercase大文字 (A, B, ..., Z, AA, BB, ...),letters lowercase小文字 (a, b, ..., z, aa, bb, ...)prefix: ページ番号の前に付ける文字列。"page - " とか。firstpagenum: 割り振るページ番号の最初の番号。指定しない時は 1 からページ番号が振られる。Adobe Acrobat Reader での見栄え、操作性
- ページサムネイルでは、きちんと i, ii, iii, ..., 1, 2, 3, と表示されます
- ページ番号は、i (1/140), ii (2/140), ..., viii (8/140), 1 (9/140) というように表示されます。
- ページ番号を直接入力して所望のページにジャンプするときは、ページ番号のところに ii と入れたり、1 と入れたりします。

- 投稿日:2020-09-08T23:05:30+09:00
AtCoder記(2020/09/08)
AtCoder Beginner Contest 006
ということで、さっそくAtCoder Beginner Contestの006から始めていきましょう!
(「001から始めないんかい」という気持ちは胸にしまっておいてください、、、)問題-A
数字Nが与えられます。Nに3が含まれる、もしくは3で割り切れる場合はYES、それ以外はNOと出力してください。
A.pyN = int(input()) if N % 3 == 0: print("YES") else: print("NO")FizzBuzz問題の少し簡単版でしょうか。答える際に改行を入れることを忘れずに。
問題-B
トリボナッチ数列というものがあります。この数列は3つ前までの数字を足したものです。
厳密には、a_1=0, a_2=0, a_3=1 \\ a_n=a_{n-1}+a_{n−2}+a_{n−3}と定義されています。この数列の第n項、$a_n$を10007で割った余りを求めてください。
B.pyn = int(input()) a, b, c = 0, 0, 1 for i in range(n-1): a, b, c = (b % 10007), (c % 10007), ((a+b+c) % 10007) print(a)この手の大きな数(10^7とか)で割って余りを表示する問題に弱いんです、、最近は最終的な答えを大きな数で割るのではなくてその都度計算するように対策しています。
この問題のほかの考え方としては、$a_1$と$a_2$の場合は0を出力するように分岐してそれ以外の場合はループ回数をn-3としたfor文を回すくらいかなと思います。(gitに上げようと思います。)問題-C
「この街には人間がN人いる。人間は、大人、老人、赤ちゃんの3通りだ。この街にいる人間の、足の数の合計はM本で、大人の足は2本、老人の足は3本、赤ちゃんの足は4本と仮定した場合、存在する人間の組み合わせとしてあり得るものを1つ答えよ。」
C.pyn, m = map(int, input().split()) for a in range(n+1): b = 4*n -2*a - m c = n -a -b if b >= 0 and c >= 0: print(a, " ", b, " ", c) break else: print("-1 -1 -1")何かいろいろ書いてありますが
a+b+c=N \\ 2a+3b+4c=Mの連立方程式を解くということと同値ですね。意外と数学の知識を使うことがあるので、頭の中から抜け落ちないように気を付けておきたいところです。
ところで、解法を参考にしているとrange関数ではなくxrange関数というものを見かけました。初めて見かけたので調べるとこのような記事を発見しました。
なるほど、知らぬ間に廃止されていたわけですね。python3から使用してきた身としては全く知らないものでした。これを機にイテレータなどを勉強するのもよいかもしれませんね。
問題-D
数字が書かれたカードがN枚あります。このカードの束(山札)に対して以下の操作が可能です。
山札からカードを1枚抜き取り、任意の場所に挿入する。
山札の上から下に向けて、カードを昇順に並べ替えるために必要な、最小の操作回数を求めてください。D.pyimport bisect n = int(input()) cards = [int(input()) for i in range(n)] sort_after_cards = [0] for card in cards: if sort_after_cards[-1] < card: sort_after_cards.append(card) else: index = bisect.bisect_left(sort_after_cards, card) sort_after_cards[index] = card print(n - len(sort_after_cards) +1)イメージ的には山札の上にあるカードを一枚引き別の山札を作る感じです。そして昇順にするためには、山札の下に本来元々あるカードよりも大きな数字がこなければならないため、もし小さい数字が来た場合は二分探索で本愛の位置に戻してあげましょう。最終的には交換したカードが除外された昇順の山札リストが作成されます。昇順にするだけならsortやsortedを使えばすぐですね。
おわりに
初回としてはなかなか理解に苦しみながら進めました。特にC問題やD問題は数学的思考やアルゴリズムを駆使して、いかに計算量を抑えて効率化することが求められているかというのを感じます。
最近のコンテスト的には調子が良くてC問題までしか解けないので、たくさん練習していろんなか発想が思いつくように努力します。
- 投稿日:2020-09-08T22:48:18+09:00
Serverlessで複数の関数をどう管理できるか検証した時のメモ
前提
AWS LambdaでPythonを動かします。個人開発用ではなく、複数人で複数の関数を複数の環境で実行するユースケースを想定しています。
調べたこと
- プロジェクトの作成(入門)
- デプロイ
- Pythonパッケージ管理周りの設定
- 環境ごとに設定を管理する方法
- 1つのリポジトリで複数種類のfunctionを管理する時の構成
- その他所感
$ python -V Python 3.8.1 $ serverless -v Framework Core: 1.82.0 Plugin: 3.8.3 SDK: 2.3.1 Components: 2.34.9プロジェクトの作成
公式のQuickStartで入門しました。
AWS認証設定のやり方はいくつか方法がありますが、今回の用なユースケースだとserverless.ymlを以下のように設定する形になります。
serverless.ymlprovider: name: aws runtime: python3.8 region: ap-northeast-1 profile: ${self:custom.profiles.${opt:stage, self:provider.stage, 'stg'}} stage: ${opt:stage, self:custom.defaultStage} custom: defaultStage: stg profiles: # 環境ごとの設定を書く stg: [[プロファイル名]] prd: [[プロファイル名]]deployコマンド実行時に
--stage stgのように書くことで、指定した環境の設定が参照されます。プロファイルだけではなく、環境変数なども上記のような書き方で定義します(後述)。認証設定後の流れは
serverless createコマンドでプロジェクトを作成して、serverless deployコマンドでデプロイするだけでした。コマンド2つで必要なリソース(Lambdaで使うCloudWatch Logsなども)も作れてHelloWorldできてしまうので0→1で実装したい時はこれほど楽なものはないなと感動しました。プロジェクトの最小構成は以下のようになります。
├── my-service │ ├── handler.py # Lambdaで実行するファイル │ └── serverless.yml # それ以外の設定全般を記した設定ファイルデプロイ
大きく分けて2つデプロイのやり方があるようでした。
-vは詳細なログを表示しますサービス全体のデプロイ
serverless deploy -v一番最初にデプロイする時や、serverless.ymlで管理している設定の変更を反映させる時はこのコマンドを実行します。
初回デプロイの流れとして以下のようなことが行われていました。
- CFnを実行
- S3バケットとポリシーを作成
- ソースコードをzipで固めてS3にアップロード
- CFnを実行
- CloudWatch Logs ロググループ作成
- IAM roleの作成
- Lambda functionの作成
2回目以降のデプロイでは上記の流れに沿いつつもserverless.ymlファイルで変更があった箇所だけアップロードされていきました。
単体のfunctionのデプロイ
serverless deploy function -f hello -vやっていることはローカルでzipファイルを作成し、s3バケットに上げているだけです。
なので変更範囲がソースコードのみの時はこの関数でデプロイする方が圧倒的に早いです。また前者のデプロイは変更の差分関係なくアップロード処理が走りますが、
deploy functionコマンドの方は差分のチェックを行い、差分がなければdeployパートはskipされるという違いもありました。Pythonパッケージ管理周りの設定
外部のパッケージをLambda関数の中で使いたい場合、パッケージのソースコードも一緒にアップロードする必要があります。そのあたりでやらないといけない処理は
serverless-python-packagingというプラグインを使って行うやり方が紹介されていました。How to Handle your Python packaging in Lambda with Serverless plugins | Serverless blog
上記のブログではnumpyを使うソースコードのデプロイのチュートリアルが載っています。
やることとしては、pipで上記のプラグインをインストールして、serverless.ymlにプラグイン用の設定を追記するだけでした。
serverless.ymlplugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: non-linux useStaticCache: false
dockerizePip:では、パッケージのソースコードを落とす際にLambdaのDockerコンテナ(lambci/lambda:build-python3.8)を起動してpip installを行うようにしています。Lambda実行環境でパッケージインストールを行わないと、一部のパッケージが使えないということがあります。non-linuxをfalseにすると、Docker環境を使わずにパッケージのソースコードを落とすこともできます。
# 実行ログの一部 Running docker run --rm -v /Users/-/Desktop/pra_serverless_for_lambda/numpy-test/.serverless/requirements\:/var/task\:z -v /Users/-/Library/Caches/serverless-python-requirements/downloadCacheslspyc\:/var/useDownloadCache\:z -u 0 lambci/lambda\:build-python3.8 python3.8 -m pip install -t /var/task/ -r /var/task/requirements.txt --cache-dir /var/useDownloadCache...不具合に気づいた
serverless-python-requirementsを使うと、serverless deploy functionコマンドが使えないという不具合があるみたいです、、余談: serverless-python-requirementsチュートリアルではまった話
一番最初にデプロイを行った時に、誤った設定で行なってしまったため(dockerizePipを有効にしていなかった)案の定Lambdaでnumpyが読み込まれませんでした。
dockerizePipの設定を書いた後も改善されなかったのですが、その原因がcacheでした。検証時のserverlessではcacheの読み込みがデフォルトでtrueになっているので、設定ファイルを変更した後も古いパッケージのデータが参照され続けていました。
useStaticCache: falseでstaticCacheの参照をしないようにすることで解決しました。1つのリポジトリで複数種類のfunctionを管理する時の構成
- function1
- stg用
- prd用
- function2
- stg用
- prd用
のようなものを同じリポジトリで管理したいケースは、よくあるかと思います。
2パターンやり方が考えられそうでした。案1. functionごとにserverless.ymlファイルを作る
├── function1 │ ├── .serverless │ ├── env_prd.yml │ ├── env_stg.yml │ ├── handler.py │ ├── requirements.txt │ └── serverless.yml ├── function2 │ ├── .serverless │ ├── env_prd.yml │ ├── env_stg.yml │ ├── handler.py │ ├── requirements.txt │ └── serverless.yml ├── .git ├── node_modules ├── package-lock.json └── package.json案2. 1つのserverlss.ymlで全functionを管理する
├── function │ ├── .serverless │ ├── env_prd.yml │ ├── env_stg.yml │ ├── function1.py │ ├── function2.py │ ├── requirements.txt │ └── serverless.yml ├── node_modules ├── package-lock.json └── package.json案1のメリットとしては、設定ファイルが一つの関数のものだけしか書かれていないから見やすく、デメリットはデプロイを関数ごとに行わなければならなくなります。
案2はその逆で、メリットは1回のデプロイで複数の関数への反映を行えること、デメリットは設定ファイルが混ざるので分かりにくくなることかと思います。案2に関しては、例えば後からfunctionを追加するようなケースがあった場合、変更のない他の関数でもデプロイが走ってしまいます。
deploy functionコマンドはインフラは作らないので初回デプロイでは使えないため。もちろんソースコードに変更がなければ何回デプロイしようと冪等性は担保されるはずですが...とはいえそうであればdry-runや、もしくはTerraformみたいに適用前に差分を確認してくれる機能が欲しくなりました。意図しない差分が混じってしまう可能性は考えられるので。
本当に簡単な検証しかしていないので、より設定が複雑になってくるとまた違ったメリデメが出てくるかもしれません。
既存リソースからインポートはできるのか
importみたいなコマンドやそれができるpluginを探してみましたが、見つけられませんでした。
最初からServerlessで作る分にはいいけれど、デプロイツールを他のものから乗り換えたいような場合、乗り換えコストはそこそこかかるかもしれません。
その他所感
- dry-runがなかった
SLS_DEBUG=* serverless deploy -vでより詳細なログを見れる- ソースコードを上げるS3バケットにライフサイクルポリシーがないのが気になったが、何度かデプロイを繰り返す中でつど5個前のソースコードは削除されていることに気づいた。デフォルトでこの設定がされているなんて気が利いているなと感心した
- 他にもログの保存期間などもserverless.ymlで設定できるようになっている
- KMSの設定やLambda Layerの設定も行える機能が提供されていて、Lambdaで設定できる一通りのものはServerlessで集約できそうな印象を持った(検証はしていないので使い勝手までは分からない)
Serverless removeコマンドで片付けも簡単
- ただしこれも同じ設定ファイルで複数関数を管理している場合、関数単位で実行させることはできなかった
- pluginで必要な機能は補っていく思想らしいので、便利なプラグインが色々あるかもしれない
まとめ
何もない状態から作る分には、爆速でデプロイできる手軽さが良かった?
Pythonの場合だとserverless-python-requirementsプラグインは欲しいので、function単位でデプロイできないバグがあるのは辛かったです。
また複数ファンクションを管理する時の構成は、他の事例も聞いてみたいなと思いました。(個人的にはfunctionごとにserverless.yml作った方がいいと思うけれど、それが辛いという声もあったので..)
- 投稿日:2020-09-08T22:39:23+09:00
ABC127 A,B,C 解説(python)
A問題
https://atcoder.jp/contests/abc127/tasks/abc127_a
a,b = map(int,input().split()) if 13 <= a: print(b) elif 6 <= a <= 12: print(b//2) else: print(0)if文にて年齢ゾーンを判別、金額を出力する。
B問題
https://atcoder.jp/contests/abc127/tasks/abc127_b
r,d,x = map(int,input().split()) for i in range(10): print(r*x-d) x = r*x-d漸化式(前の計算結果を次の計算結果に当てはめる)問題
C問題
https://atcoder.jp/contests/abc127/tasks/abc127_c
n,m = map(int,input().split()) l = [0]*m r = [0]*m for i in range(m): l[i],r[i] = map(int,input().split()) if min(r)-max(l) < 0: print(0) else: print(min(r)-max(l)+1)全てにおいて重なっている区間と言うことで
もっとも大きいlと最も小さいrの間のキーが該当する。
- 投稿日:2020-09-08T22:01:34+09:00
Signate_第1回Beginner限定コンペの振り返り
はじめに
SIGNATEで8月に開催されていた第1回Beginner限定コンペ( https://signate.jp/competitions/292 )に参加してみました。
しっかりやりきったコンペは今回が初めてでしたが、最終スコアはAUC=0.8588949で、13位でした(すごく中途半端な結果ですが...)。
このコンペでは、ある値よりもスコアが大きいとBeginnerからIntermediateに昇格することができ、無事に昇格しました。やったこと、振り返ってみてやればよかったことを今後の自分のためにもまとめておこうと思います。
なお、本コンペのモデルと分析結果については、情報公開ポリシーに則って公開しています。
コンペの概要
データは金融機関における定期預金のキャンペーンデータになっています。
データのもとはこちらですが、若干加工されていると思います。
評価の指標はAUCとなります。
詳細は上記リンクを参照してください。環境
$sw_vers ProductName: Mac OS X ProductVersion: 10.13.6 BuildVersion: 17G14019$python --version Python 3.7.3やったこと
0. random_seedを決める
料理の前に手を洗うようなものですが、あとで再現しなくなることもあるので大事。
結果が必ず再現するように、random_seedあるいはrandom_stateの引数をもつ関数を使うときに、必ず代入していきます。1. 一旦どんなものか見てみる(H2O)
H2Oに入れて、データの情報やAutoMLで回したときにどのようなアルゴリズムが上位に来るのか確認しました。
H2Oについては過去の記事をご覧ください。
ここでパーっとデータみつつ、AutoMLで走らせた結果、決定木系のアルゴリズムが上位に来たので、今後LightGBMを使って行こうと決めました。2.データ取得〜機械学習モデル構築〜予測までの流れを作る(JupyterNotebook)
Notebookファイルはデータ加工と、モデル構築で分けて用意しました(一つのファイルにすると見通しが悪くなったり、毎回不要な処理を流してしまうことがあるため)。
2-1. データ加工部分
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import category_encoders as ce %matplotlib inline pd.set_option('display.max_columns', None) random_state = 1234 df = pd.read_csv('./0_rawdata/train.csv')データ確認用のコードをいくつか書いていきます。
データの型や、nullの有無の確認↓df.info() df.describe()数値データの可視化↓
df.hist( figsize=(14, 10), bins=20)
文字列データの可視化↓
plt.figure( figsize = (20, 15)) cols = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome'] for i, col in enumerate(cols): plt.subplot(3,3,i+1) df[col].value_counts().plot.bar() plt.title(col)
上記の可視化で、
idはもちろんですが、balance,pdaysは一様分布担っているように見えたので、この後学習に用いるデータから削除します。
defaultについてもほとんどのデータがnoだったため、削除します。
また、文字列やカテゴリデータを数値化する処理を入れて、学習に用いるデータを作成しました。df2 = df.copy() df2 = df2.drop( columns=['id', 'balance', 'pdays', 'default']) # month month_map={ 'jan':1, 'feb':2, 'mar':3, 'apr':4, 'may':5, 'jun':6, 'jul':7, 'aug':8, 'sep':9, 'oct':10, 'nov':11} df2['month'] = df2['month'].fillna(0) df2['month'] = df2['month'].map(month_map) # job, marital, education, housing, loan, contact, poutcome cols = ['job', 'marital', 'education', 'housing', 'loan', 'contact', 'poutcome'] ce_onehot = ce.OneHotEncoder(cols=cols,handle_unknown='impute') ce_onehot.fit( df2 ) df2 = ce_onehot.transform( df2 ) df2['duration'] = df2['duration'] / 3600 df2.to_csv('mytrain.csv', index=False)2-2. モデル構築・予測部分
import pandas as pd import numpy as np import category_encoders as ce import lightgbm as lgb #import optuna from optuna.integration import lightgbm as lgb_optuna from sklearn import preprocessing from sklearn.model_selection import train_test_split,StratifiedKFold,cross_validate from sklearn.metrics import roc_auc_score pd.set_option('display.max_columns', None) random_state = 1234 version = 'v1'データを学習用、検証用に分割します(8:2)。
df_train = pd.read_csv('mytrain.csv') X = df_train.drop( columns=['y'] ) y = df_train['y'] X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.2, random_state=random_state)モデル構築・精度検証として以下の方法を取りました。
- 学習用データを層化抽出で5分割し、Cross Validation
- ハイパーパラメタ(以下、ハイパラ)チューニングはoptunaに任せる
- 最適化に用いる指標はloglossとする
- 学習用データ全体でモデルを再学習して、検証用データを用いてAUC算出
def build(): kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=random_state) lgb_train = lgb_optuna.Dataset(X_train, y_train) lgbm_params = { 'objective': 'binary', 'metric': 'binary_logloss', 'random_state':random_state, 'verbosity': 0 } tunecv = lgb_optuna.LightGBMTunerCV( lgbm_params, lgb_train, num_boost_round=100, early_stopping_rounds=20, seed = random_state, verbose_eval=20, folds=kf ) tunecv.run() print( 'Best score = ',tunecv.best_score) print( 'Best params= ',tunecv.best_params) return tunecv tunecv = build()学習用データ全体でモデルを再学習して、検証用データを用いてAUC算出↓
train_data = lgb.Dataset( X_train, y_train ) eval_data = lgb.Dataset(X_holdout, label=y_holdout, reference= train_data) clf = lgb.train( tunecv.best_params, train_data, valid_sets=eval_data, num_boost_round=50, verbose_eval=0 ) y_pred = clf.predict( X_holdout ) print('AUC: ', roc_auc_score(y_holdout, y_pred)) # AUC: 0.84864298107970913. データ・精度を見つつ試行錯誤
# やったこと AUC submit スコア 感想 00 上記の処理をデフォルトとする 0.8486 --- --- 01 job,marital,education,poutcomeのエンコーディングをtarget encodingへ変更0.8458 --- 微妙に下がったが、一旦これでいく 02 num_boost_round=200 (学習曲線を出したらもう少しスコアがよくなりそうだったので) 0.8536 --- 上がった。これでいく 03 学習用データ全体でモデルを再学習する部分の学習パラメタがハイパラチューニング用のパラメタと違うことに気がつく。num_boost_round=200、early_stopping_rounds = 20で統一。 0.8585 --- これでいく 04 最適化指標をAUCにしてみる 0.8557 --- 下がった。loglossのままにする 05 loan, housing, contactをordinal encodingへ変更 0.8593 0.8556 AUCは上がっているのでこれでいく。ただし、submitのスコアはちょい低い。 06 テストデータと学習データの違いを確認。可視化で比較しても大きな違いはない。テストデータを予測するモデルを作成してみたが、AUC=0.5程度なので、テストデータと学習データの違いはないと判断 --- --- --- 07 monthのエンコーディングを変更(データ数が少ないいくつかの月を合体) 0.8583 0.8585 03のAUCとほぼ変わらず。却下。 08 monthのエンコーディングを変更(データ数が少ないいくつかの月を合体) 0.8583 0.8585 05からAUCが下がった。却下。 09 時系列のラグ変数のように先月のyの平均を列として追加 0.8629 0.8559 学習用データではスコアが改善したが、テストスコアが下がったため、却下 10 ageをカテゴライズ(行数の少ないageを合体)0.8599 0.8588 微妙に改善。これでいく。 11 PCAにつっこんでみる 0.8574 --- 下がった 12 他のアルゴリズムを試してみる(SVM, RandomForest, LogisticRegression) --- --- 下がった 上記以外にも細かいところを変更してみたりしたものの、精度は改善されず。
また、いちいち記録するのもめんどくさくなり...コンペ期間終了という感じです。やればよかったと思うこと
- データ加工系
- もう少しクロス集計も含め、データをよく眺めてみれば何か発見できたかも
- 元データ(UCI)とマージしてみる(おそらく一部加工されているので、工夫は必要)
- 交互作用項の考慮
- モデル系
- random_stateを変えたLightGBMとのアンサンブルはやってみてもよかった
- 解釈系
- 精度が悪かったところを深掘って調べればよかった(それで
ageのカテゴライズなどできた部分もありましたが、もう少しできれば)- ツール、その他系
- Gitでもいいですが、コード管理のツールを活用すればよかった
- 同じく、実験管理系のツールを入れればよかった(MLOpsでもあるようなやつ)
さいごに
他にもやったほうがよいことはいくらでもありそうです。よければコメントいただければと思います。
次回コンペに出るときに今回の反省と、kaggleのカーネルなど参考にしながらテクニックを取り入れていきたいと思います。

- 投稿日:2020-09-08T21:53:04+09:00
Raspberry PiとOpenCVでWEB監視カメラを作成する
Raspberry PiとOpenCVでWEB監視カメラを作成する
はじめに
Mac環境の記事ですが、Windows環境も同じ手順になります。環境依存の部分は読み替えてお試しください。目的
ブラウザにストリーミング動画を表示します。
この記事を最後まで読むと、次のことができるようになります。
No. 概要 キーワード 1 REST API Flask 2 OpenCV cv2 完成イメージ
ストリーミング 実行環境
環境 Ver. macOS Catalina 10.15.6 Raspberry Pi 4 Model B 4GB RAM - Raspberry Pi OS (Raspbian) 10 Python 3.7.3 Flask 1.1.2 opencv-python 4.4.0.42 ソースコード
実際に実装内容やソースコードを追いながら読むとより理解が深まるかと思います。是非ご活用ください。
関連する記事
- Raspberry PiのセットアップからPython環境のインストールまで
- Raspberry PiとPythonでリモコンカーを作成する
- Raspberry PiとPythonでLCD(16x2)ゲームを作成する
Camera設定
Raspberry Pi Software Configuration Tool起動
command.sh~$ sudo raspi-configCamera有効化
5 Interfacing Optionsを選択P1 Cameraを選択再起動
command.sh~$ sudo rebootOpenCV依存関係
HDF5
HDF5 is a file format and library for storing scientific data.
command.sh~$ sudo apt-get install -y libhdf5-dev libhdf5-serial-dev libhdf5-103ATLAS
ATLAS is an approach for the automatic generation and optimization of numerical software.
command.sh~$ sudo apt-get install -y libatlas-base-devJasPer
JasPer is a collection of software (i.e., a library and application programs) for the coding and manipulation of images.
command.sh~$ sudo apt-get install -y libjasper-devハンズオン
ダウンロード
command.sh~$ git clone https://github.com/nsuhara/raspi-streaming.git -b masterセットアップ
command.sh~$ cd raspi-streaming ~$ python -m venv .venv ~$ source .venv/bin/activate ~$ pip install -r requirements.txt ~$ source configサービス起動
command.sh~$ flask run --host=0.0.0.0 --port=5000アクセス
command.sh~$ open "http://{host}:5000/raspi-streaming/api?process=front_end&request=app_form&secret_key=M7XvWE9fSFg3"サービス終了
command.sh~$ Control Key + Cアプリ構成
target.sh/app ├── __init__.py ├── apis │ ├── templates │ │ └── app_form.html │ └── views │ ├── __init__.py │ ├── back_end_handler.py │ ├── camera.py │ ├── front_end_handler.py │ └── main_handler.py ├── common │ ├── __init__.py │ └── utility.py ├── config │ ├── __init__.py │ ├── localhost.py │ └── production.py └── run.pyfront-end
target.sh/app └── apis ├── templates │ └── app_form.html └── views └── front_end_handler.pyfront-end制御
front_end_handler.py"""app/apis/views/front_end_handler.py """ from flask import jsonify, render_template from app import secret_key def handler(req): """handler """ param1 = req.get('param1') param2 = req.get('param2') if param1 == 'app_form': return _app_form(req=param2) return jsonify({'message': 'no route matched with those values'}), 200 def _app_form(req): """_app_form """ if req.get('secret_key', '') != secret_key: return jsonify({'message': 'no route matched with those values'}), 200 return render_template('app_form.html', secret_key=req.get('secret_key', ''))front-endレイアウト
app_form.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>raspi-streaming</title> <style type="text/css"> html, body { -webkit-user-select: none; width: 100%; height: 100%; } table { width: 100%; height: 100%; } table, td { border: 1px gray solid; padding: 10px; } img.img-option { width: 100%; /* height: 100%; */ } </style> <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script> <script type="text/javascript"> // nothing to do </script> </head> <body> <table> <tr height="5%"> <td> <h1>raspi-streaming</h1> </td> </tr> <tr> <td> <img class="img-option" src="{{ url_for('raspi-streaming.api', process='back_end', request='video_feed', secret_key=secret_key) }}"> </td> </tr> </table> </body> </html>back-end
target.sh/app └── apis └── views ├── back_end_handler.py └── camera.pyback-end制御
back_end_handler.py"""app/apis/views/back_end_handler.py """ from flask import Response, jsonify from app import secret_key from app.apis.views.camera import Camera def handler(req): """handler """ param1 = req.get('param1') param2 = req.get('param2') if param1 == 'video_feed': return _video_feed(req=param2) return jsonify({'message': 'no route matched with those values'}), 200 def _video_feed(req): """_video_feed """ if req.get('secret_key', '') != secret_key: return jsonify({'message': 'no route matched with those values'}), 200 return Response(_generator(Camera()), mimetype='multipart/x-mixed-replace; boundary=frame') def _generator(camera): """_generator """ while True: frame = camera.frame() yield b'--frame\r\n' yield b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n\r\n'カメラ制御
camera.py"""app/apis/views/camera.py """ import cv2 class Camera(): """Camera """ def __init__(self): self.video_capture = cv2.VideoCapture(-1) def __del__(self): self.video_capture.release() def frame(self): """frame """ _, frame = self.video_capture.read() _, image = cv2.imencode('.jpeg', frame) return image.tobytes()

- 投稿日:2020-09-08T21:31:49+09:00
matplotlibを使ってみる
matplotlibはLinux環境で手軽に使えるデータビジュアライゼーションのライブラリです。公式のチュートリアルに紹介されている最もシンプルなパターンのグラフは例えば以下のようなコードで記述することができます。
import matplotlib.pyplot as plt fig, ax = plt.subplots() # Create a figure containing a single axes. ax.plot([1, 2, 3, 4], [1, 4, 2, 3]) # Plot some data on the axes. plt.show()モジュールが見つからないなどのエラーが出る場合は、以下のような手順(pipなど)を使ってインストールします。
sudo pip3 install matplotlibnumpyやpandasも一緒に使うことが多いので入れておくと便利かもしれません。
import numpy as np import pandas as pd
- 投稿日:2020-09-08T20:38:01+09:00
GCP:Pub/SubからCloud Functions、Cloud Functions からPub/Sub、を繰り返す
以下今回のアーキテクチャイメージです。
用意するモノ
・Pub/SubでTopic2つ
┗「topic_1」と「topic_2」という名前とする・Cloud Scheduler
┗トピックに「topic_1」を設定し、ペイロードは「hello」とする・Cloud FunctionsでFunctionを2つ
┗「function_1」と「function_2」という名前とする
「function_1」のトリガーはPub/Subの「topic_1」を設定する
「function_2」のトリガーはPub/Subの「topic_2」を設定するfunction_1の中身
以下の「event_message」ではtopic_1を経由したCloud Schedulerで設定したペイロード「hello」とかの文字列が格納されている。
N個のCloud Schedulerをペイロードだけ変えてほか同じ設定にすると、function_1 内で event_message を判定させて後続処理をごにょごにょできる
def main(event, context): event_message = base64.b64decode(event['data']).decode('utf-8')次に、function_2にリストを渡すと仮定する
Pub/Subではテキストのみが渡せるのでencodeさせる必要があるfrom google.cloud import pubsub_v1 PROJECT_ID = os.getenv('GCP_PROJECT') client = pubsub_v1.PublisherClient() topic_id = "topic_2" # 次にパスするトピックを設定 topic_path = client.topic_path(PROJECT_ID, topic_id) pub_text = ["りんご", "ゴリラ", "ラッパ"] data = pub_text.encode() # ここでエンコード client.publish(topic_path, data=data) # これでtopic_2にpub_textがpushされる上記の最終行でtopic_2へ'["りんご", "ゴリラ", "ラッパ"]'が渡されてfunction_2が発火している。
function_2の中身
以下 event_message では'["りんご", "ゴリラ", "ラッパ"]'が入っているのでevalしてpythonのリストに戻す。
後続処理はよしなにdef main(event, context): event_message = base64.b64decode(event['data']).decode('utf-8') fruit_lst = eval(event_message)function_2を並列起動させてみる
Cloud Functionsは以下公式ドキュメントの通り、並列起動ができる
https://cloud.google.com/functions/quotas?hl=ja#scalabilityそのためfunction_1を以下のようにループさせながらPub/Subへpublishさせると、function_2では3つのフルーツを取得することになる
function_1.pyfrom google.cloud import pubsub_v1 PROJECT_ID = os.getenv('GCP_PROJECT') client = pubsub_v1.PublisherClient() topic_id = "topic_2" topic_path = client.topic_path(PROJECT_ID, topic_id) fruit_lst = ["りんご", "ゴリラ", "ラッパ"] for fruit in fruit_lst: data = fruit.encode() client.publish(topic_path, data=data)参考文献
https://cloud.google.com/solutions/streaming-data-from-cloud-storage-into-bigquery-using-cloud-functions?hl=ja
https://cloud.google.com/functions/quotas?hl=ja#scalability余談
list や dict も encode() して Pub/Sub へ渡して受け取った側で eval すれば元通りなので、複数の軽い処理を定期的に実行する、という場合に便利でした。

- 投稿日:2020-09-08T18:40:21+09:00
新しいMacでなるべく環境を汚さずに最短でJupyterでPandasが使えるように
概要
タイトルにある通り、新しい Mac でなるべく環境を汚さずに Jupter Notebook で Pandas(ついでに numpy) も使えるようにする。細かい流派の違いなどはあるかもしれませんが、これがまあ簡単だし、ちょっと使うには最短かなという手順をまとめました。基本的には以下の流れで必要なものをインストールするだけです。
- homebrew
- anyenv
- pyenv(by anyenv)
- miniconda(by pyenv)
- numpy(by conda)
- pandas(by conda)
- jupyter notebook(by conda)
手順
brew のインストールは他にも色々あるので割愛。brew がある前提で以下の手順を。
brew install anyenv anyenv init mkdir -p ~/.anyenv/plugins git clone https://github.com/znz/anyenv-update.git ~/.anyenv/plugins/anyenv-update anyenv update anyenv install pyenv pyenv install miniconda3-4.7.12 pyenv global miniconda3-4.7.12 conda install numpy conda install pandas conda install jupyter何も考えず上から順に愚直にやっていけばOK
動作確認
こんな感じの test.csv を作っておく
date,id,value 2020-08-01,1,123 2020-08-02,2,456jupyter notebook を起動
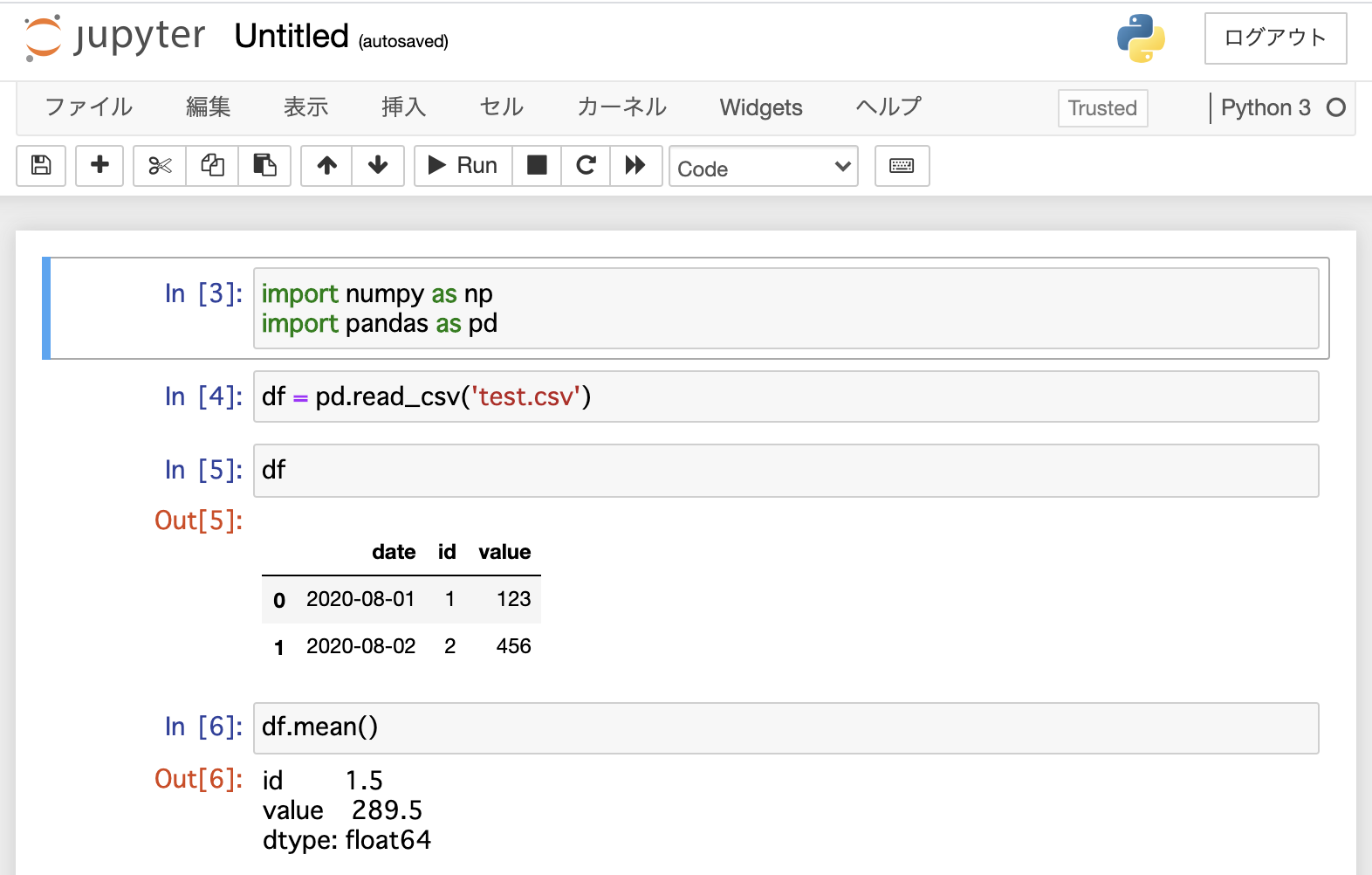
jupter notebookブラウザから notebook にアクセス
test.csv があるところで「新規」から Python3 Console を立ち上げて、以下の画面にあるくらいまで実行してエラーにならなければOK
以上
Enjoy your Python life.
- 投稿日:2020-09-08T18:28:42+09:00
Faster R-CNNをpytorchでサクッと動かしてみた
はじめに
Faster R-CNNをちゃんとしたデータセットで動かしている記事が少なくてかなり苦労したから備忘録
初めての記事投稿なので至らないところもあるとは思いますが何か間違い等ありましたらご指摘をお願いします。
諸注意
※本記事はPSCAL VOCフォーマットのデータセット向けです。
私はBDD100KというデータセットをPascalVOCフォーマットに変換して学習を行ったためclassラベルがBDD100Kのものとなっています。コード
すべてのコードはgithubに上げます。
(一応以下のコードすべてコピペしてclass名をデータセットに合わせれば動くはず)インポート
サクッと
import numpy as np import pandas as pd from PIL import Image from glob import glob import xml.etree.ElementTree as ET import torch import torchvision from torchvision import transforms from torchvision.models.detection.faster_rcnn import FastRCNNPredictordataloader.py#データの場所 xml_paths_train=glob("##########/*.xml") xml_paths_val=glob("###########/*.xml") image_dir_train="#############" image_dir_val="##############"上2行はxmlファイルの場所
した2行は画像の場所データの読み込み
dataloader.pyclass xml2list(object): def __init__(self, classes): self.classes = classes def __call__(self, xml_path): ret = [] xml = ET.parse(xml_path).getroot() for size in xml.iter("size"): width = float(size.find("width").text) height = float(size.find("height").text) for obj in xml.iter("object"): difficult = int(obj.find("difficult").text) if difficult == 1: continue bndbox = [width, height] name = obj.find("name").text.lower().strip() bbox = obj.find("bndbox") pts = ["xmin", "ymin", "xmax", "ymax"] for pt in pts: cur_pixel = float(bbox.find(pt).text) bndbox.append(cur_pixel) label_idx = self.classes.index(name) bndbox.append(label_idx) ret += [bndbox] return np.array(ret) # [width, height, xmin, ymin, xamx, ymax, label_idx]アノテーションの読み込み
classesには使用したデータのクラスを入れてください。
dataloader.py#trainのanotationの読み込み xml_paths=xml_paths_train classes = [###################################] transform_anno = xml2list(classes) df = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"]) for path in xml_paths: #image_id = path.split("/")[-1].split(".")[0] image_id = path.split("\\")[-1].split(".")[0] bboxs = transform_anno(path) for bbox in bboxs: tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"]) tmp["image_id"] = image_id df = df.append(tmp, ignore_index=True) df = df.sort_values(by="image_id", ascending=True) #valのanotationの読み込み xml_paths=xml_paths_val classes = [#######################] transform_anno = xml2list(classes) df_val = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"]) for path in xml_paths: #image_id = path.split("/")[-1].split(".")[0] image_id = path.split("\\")[-1].split(".")[0] bboxs = transform_anno(path) for bbox in bboxs: tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"]) tmp["image_id"] = image_id df_val = df_val.append(tmp, ignore_index=True) df_val = df_val.sort_values(by="image_id", ascending=True)画像の読み込み
dataloader.py#画像の読み込み # 背景のクラス(0)が必要のため、dog, cat のラベルは1スタートにする df["class"] = df["class"] + 1 class MyDataset(torch.utils.data.Dataset): def __init__(self, df, image_dir): super().__init__() self.image_ids = df["image_id"].unique() self.df = df self.image_dir = image_dir def __getitem__(self, index): transform = transforms.Compose([ transforms.ToTensor() ]) # 入力画像の読み込み image_id = self.image_ids[index] image = Image.open(f"{self.image_dir}/{image_id}.jpg") image = transform(image) # アノテーションデータの読み込み records = self.df[self.df["image_id"] == image_id] boxes = torch.tensor(records[["xmin", "ymin", "xmax", "ymax"]].values, dtype=torch.float32) area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0]) area = torch.as_tensor(area, dtype=torch.float32) labels = torch.tensor(records["class"].values, dtype=torch.int64) iscrowd = torch.zeros((records.shape[0], ), dtype=torch.int64) target = {} target["boxes"] = boxes target["labels"]= labels target["image_id"] = torch.tensor([index]) target["area"] = area target["iscrowd"] = iscrowd return image, target, image_id def __len__(self): return self.image_ids.shape[0] image_dir1=image_dir_train dataset = MyDataset(df, image_dir1) image_dir2=image_dir_val dataset_val = MyDataset(df_val, image_dir2)DataLoaderの作成
dataloader.py#データのロード torch.manual_seed(2020) train=dataset val=dataset_val def collate_fn(batch): return tuple(zip(*batch)) train_dataloader = torch.utils.data.DataLoader(train, batch_size=1, shuffle=True, collate_fn=collate_fn) val_dataloader = torch.utils.data.DataLoader(val, batch_size=2, shuffle=False, collate_fn=collate_fn)僕が回したときはすぐGPUのメモリがあふれたからbatch_sizeは小さめ
モデルの定義
少ない学習枚数でも精度出したいんだったらmodel1.pyをおすすめします。
ただ自分である程度モデルもいじりたい!って方はmodel2.pyを使ってください。
(model2の方は解説記事無いに等しく、しかもtorchvisionのチュートリアルのソースコード間違ってるせいで永遠と悩みました。)※注意num_classesは分類したいクラス数+1にしないと動きません。
(+1というのは背景も分類対象だから)model1は普通にresnet50で学習済みモデルをバックボーンにしてる
model1.pymodel = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False)####True ##注意 クラス数+1 num_classes = (len(classes)) + 1 in_features = model.roi_heads.box_predictor.cls_score.in_features model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)model2はこんな感じ(チュートリアルにバグが潜んでるとは、、、)
model2.pyimport torchvision from torchvision.models.detection import FasterRCNN from torchvision.models.detection.rpn import AnchorGenerator backbone = torchvision.models.mobilenet_v2(pretrained=True).features backbone.out_channels = 1280 anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),), aspect_ratios=((0.5, 1.0, 2.0),)) #チュートリアルパクるとここでエラー吐く。([0]を['0']にすれば動く) ''' roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0], output_size=7, sampling_ratio=2) ''' #デフォ roi_pooler =torchvision.ops.MultiScaleRoIAlign( featmap_names=['0','1','2','3'], output_size=7, sampling_ratio=2) # put the pieces together inside a FasterRCNN model model = FasterRCNN(backbone, num_classes=(len(classes)) + 1,###注意 rpn_anchor_generator=anchor_generator) #box_roi_pool=roi_pooler)FasterRCNN関数にはいろんな引数がありかなりモデルをいじれます。
詳しくは こちら学習
自動微分ってすばらしいよね
train.py##学習 params = [p for p in model.parameters() if p.requires_grad] optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005) num_epochs = 5 #GPUのキャッシュクリア import torch torch.cuda.empty_cache() device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') ##model.cuda() model.train()#学習モードに移行 for epoch in range(num_epochs): for i, batch in enumerate(train_dataloader): images, targets, image_ids = batch##### batchはそのミニバッジのimage、tagets,image_idsが入ってる images = list(image.to(device) for image in images) targets = [{k: v.to(device) for k, v in t.items()} for t in targets] ##学習モードでは画像とターゲット(ground-truth)を入力する ##返り値はdict[tensor]でlossが入ってる。(RPNとRCNN両方のloss) loss_dict= model(images, targets) losses = sum(loss for loss in loss_dict.values()) loss_value = losses.item() optimizer.zero_grad() losses.backward() optimizer.step() if (i+1) % 20 == 0: print(f"epoch #{epoch+1} Iteration #{i+1} loss: {loss_value}")結果の表示
注意 ここでのctegoryを記入例に従って使用データのラベルを記入してください。
test.py#結果の表示 def show(val_dataloader): import matplotlib.pyplot as plt from PIL import ImageDraw, ImageFont from PIL import Image #GPUのキャッシュクリア import torch torch.cuda.empty_cache() device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') #device = torch.device('cpu') model.to(device) model.eval()#推論モードへ images, targets, image_ids = next(iter(val_dataloader)) images = list(img.to(device) for img in images) #推論時は予測を返す ''' - boxes (FloatTensor[N, 4]): the predicted boxes in [x1, y1, x2, y2] format, with values of x between 0 and W and values of y between 0 and H - labels (Int64Tensor[N]): the predicted labels for each image - scores (Tensor[N]): the scores or each prediction ''' outputs = model(images) for i, image in enumerate(images): image = image.permute(1, 2, 0).cpu().numpy() image = Image.fromarray((image * 255).astype(np.uint8)) boxes = outputs[i]["boxes"].data.cpu().numpy() scores = outputs[i]["scores"].data.cpu().numpy() labels = outputs[i]["labels"].data.cpu().numpy() category={0: 'background',##################} #categoryの記入例 #category={0: 'background',1:'person', 2:'traffic light',3: 'train',4: 'traffic sign', 5:'rider', 6:'car', 7:'bike',8: 'motor', 9:'truck', 10:'bus'} boxes = boxes[scores >= 0.5].astype(np.int32) scores = scores[scores >= 0.5] image_id = image_ids[i] for i, box in enumerate(boxes): draw = ImageDraw.Draw(image) label = category[labels[i]] draw.rectangle([(box[0], box[1]), (box[2], box[3])], outline="red", width=3) # ラベルの表示 from PIL import Image, ImageDraw, ImageFont #fnt = ImageFont.truetype('/content/mplus-1c-black.ttf', 20) fnt = ImageFont.truetype("arial.ttf", 10)#40 text_w, text_h = fnt.getsize(label) draw.rectangle([box[0], box[1], box[0]+text_w, box[1]+text_h], fill="red") draw.text((box[0], box[1]), label, font=fnt, fill='white') #画像を保存したい時用 #image.save(f"resample_test{str(i)}.png") fig, ax = plt.subplots(1, 1) ax.imshow(np.array(image)) plt.show() show(val_dataloader)
こんな感じで表示されるはず
最後に
- 初めて記事書きました。ただソースコードを貼っただけに近いですが参考にしていただけると幸いです。
- 論文解説とかもやってみたいなぁ
参考文献
torchvisionのチュートリアルはこちら

- 投稿日:2020-09-08T18:26:05+09:00
Google Colaboratoryでdarknetコマンドが使えない!
背景
./darknet detector train 〜でyoloの重みをGoogle Colaboratoryで学習させたかったが(ローカルで動作検証済み)、./darknet: permission deniedと権限エラーが表示される
環境
・mac OS Catalina 10.15.6
・Google Colaboratory
・python 3.6.9
・tensorflow 1.4.2内容
権限エラー
まずは、下記を解決する
./darknet: permission denied
darknetの権限を変更する事で解決したchmod 755 darknet
しかし、再度エラーが
バイナリファイルの実行エラー
次に、下記を解決する./darknet: cannot execute binary file: exec format errorこれは、コンパイルしたファイルが対応しておらず、実行できないとのこと
gccのバージョンがGoogle Colaboratory4.9以降は採用していないという訳だった
実際、Makefileをmakeした際の出力を確認するとgnu version! gcc versions later than 5 are not supported!とgccのバージョンエラーが記載されていた
コンパイラの変更コマンドで確認してみよう!update-alternatives --config gccやはりどうやらgcc 7のためのようだ
解決策
下記コマンドを流し、gcc 4.8をインストールしてデフォルトに設定する
!sudo update-alternatives --remove-all gcc !sudo update-alternatives --remove-all g++ !sudo add-apt-repository ppa:ubuntu-toolchain-r/test -y !sudo apt-get update !sudo apt-get install gcc-4.8 g++-4.8 !sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.8 50 !sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.8 50 !sudo update-alternatives --install /usr/bin/cc cc /usr/bin/gcc 50 !sudo update-alternatives --set cc /usr/bin/gcc !sudo update-alternatives --install /usr/bin/c++ c++ /usr/bin/g++ 50 !sudo update-alternatives --set c++ /usr/bin/g++ !sudo update-alternatives --config gcc !sudo update-alternatives --config g++
コンパイラ変更コマンドで確認した結果、きちんとgcc 4.8をデフォルトとして設定することが出来た$!update-alternatives --config gcc There is only one alternative in link group gcc (providing /usr/bin/gcc): /usr/bin/gcc-4.8 Nothing to configure.
以上
- 投稿日:2020-09-08T18:25:49+09:00
Azure Form Recognizerで帳票をバッチ処理する
Azure Form recognizerというサービスがあります。
https://azure.microsoft.com/ja-jp/services/cognitive-services/form-recognizer/帳票をいい感じに読み取って狙ったデータを抽出してくれる優れものです。APIもあるので複数の帳票をまとめて処理できるPython scriptを書いてみました
https://github.com/yosukearaiMS13/formrecognizerbatch/blob/master/fy.py以下、スクリプトの中身と使い方について説明します
スクリプトの中身
スクリプトは、ドキュメントにあるサンプルを拡張して作っています
https://docs.microsoft.com/ja-jp/azure/cognitive-services/form-recognizer/quickstarts/python-labeled-data?tabs=v2-0スクリプトは4つのsectionから構成されています
https://github.com/yosukearaiMS13/formrecognizerbatch/blob/master/fy.pyfr.py# Configurations: 各種設定パラメータ # Post 分析対象pdf section ## Form recognizerに対し、分析対象データを一旦全部postします # Get analyze results section ## 先ほどpostしたデータの分析結果(抽出されたデータ含む)を取得します。 # 抽出結果のcsv出力 section ## 抽出結果を出力します。余計な空白の除去と、信頼性が低い抽出値の置き換え ##(しきい値以下の場合抽出値は採用せず、代わりに信頼度を[]囲みで出力) ## を行っていますGet analyze resultsと抽出結果のcsv出力sectionでは、Form recognizerから返されたjsonをパースしています。jsonのフォーマットはこちらです
https://github.com/Azure-Samples/cognitive-services-REST-api-samples/blob/master/curl/form-recognizer/Invoice_1.pdf.ocr.json各セクションで利用しているAPIは以下です
- Post 分析対象pdf: Analyze Form
- Get analyze results: Get Analyze Form Result
- CSV出力section: Get Custom Model
- 当該APIにて定義済みの全ラベルを取得し、csvのヘッダの値として使用していますスクリプトの使い方
1. 環境
Win10 Enterprise, Python 3.8.5, IDEは任意
2. データ抽出準備
(※前提作業~データ抽出準備1までは、こちらのQiita記事も参考になります)
前提作業: 以下を先にやっておきます
- Form Recognizer リソースの作成
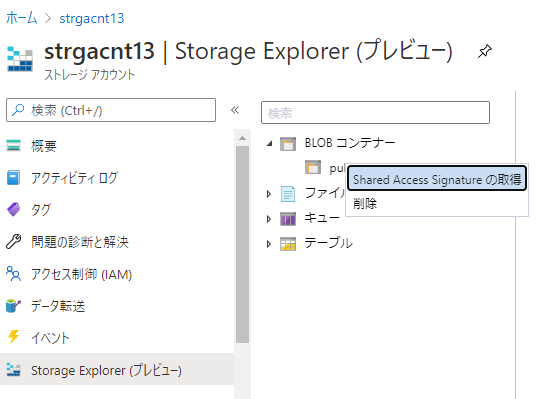
- Azure blobの作成(ストレージアカウントの作成->コンテナの作成まで)
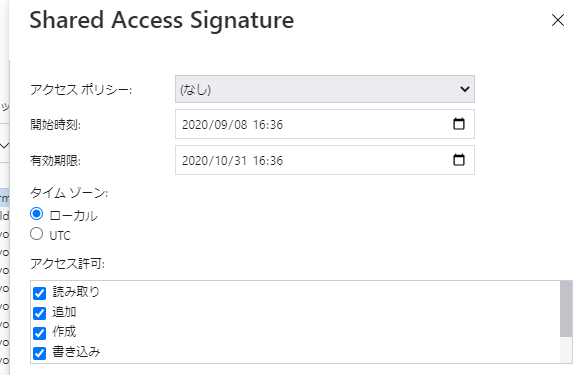
- Azure blobの設定(Shared Access Signatureの作成)(Azure PortalのStorage Explorerメニューを使うと便利です)
- (アクセス許可の欄は全てcheckします)
- (生成されたURL値を後から使いますので、保存しておいてください)

データ抽出準備1(初回のみ実施)
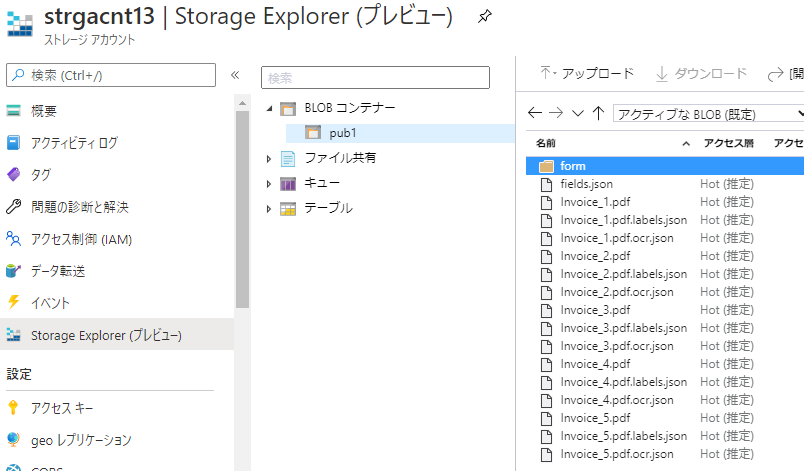
- モデル作成用のトレーニングデータをAzure blobに格納する: 以下の形で最低5ファイル(この場合invoice_1~5.pdf)を配置ください(xx.jsonは後から作られるファイルですのでここでは無視)
- ラベル(タグ)付けツールの設定:
- ラベル付けツールはこちら https://fott.azurewebsites.net/
- ラベル付け手順: 以下ドキュメントの手順に従い、ラベル付けツールへの接続->プロジェクト作成、まで実施
- pythonスクリプトへの設定#1
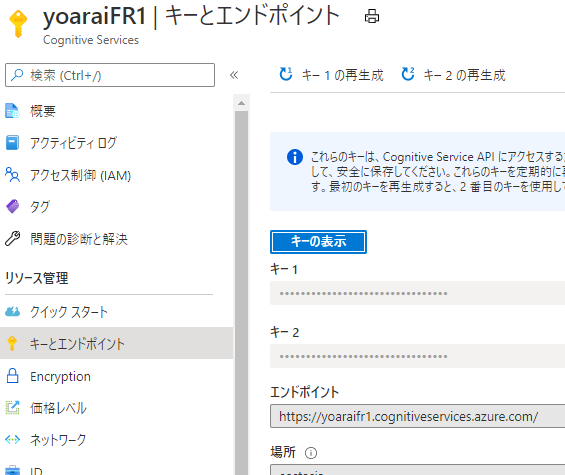
fr.py## Configurations endpoint = r"https://xxxxx.cognitiveservices.azure.com/" apim_key = "xxxxx" model_id = "xxxxx" sourceDir = r"C:\xxxxx\*" confidence_setting = 0.9 # 0~1. 信頼性がこの値以下の場合採用しない- endpoint: Form Recognizerのエンドポイント
- apim_key: Form Recognizerのキー1 or 2
- sourceDir: 分析対象の帳票ファイルの配置場所をフルパスで記述
- confidence_setting: 0~1の値を設定(※スクリプトの仕様として、信頼性がこの値以下の場合抽出された値は採用せず、代わりに信頼性の評価値を[]囲みで出力する仕様にしています)
- データ抽出準備2(ラベルを追加修正する度に実施)
- ラベル(タグ)付けツール(https://fott.azurewebsites.net/)にて、読み込まれたトレーニングデータ(帳票)にラベルをつけていく。つけ終わったらTrainして、モデルを生成する
- 以下ドキュメントの手順: フォームにラベルを付ける-> カスタム モデルをトレーニングする、まで実施
- こちらのQiita記事 の手順も参考になります
- Train後Model IDが生成されます(以下)。この値は後で使います
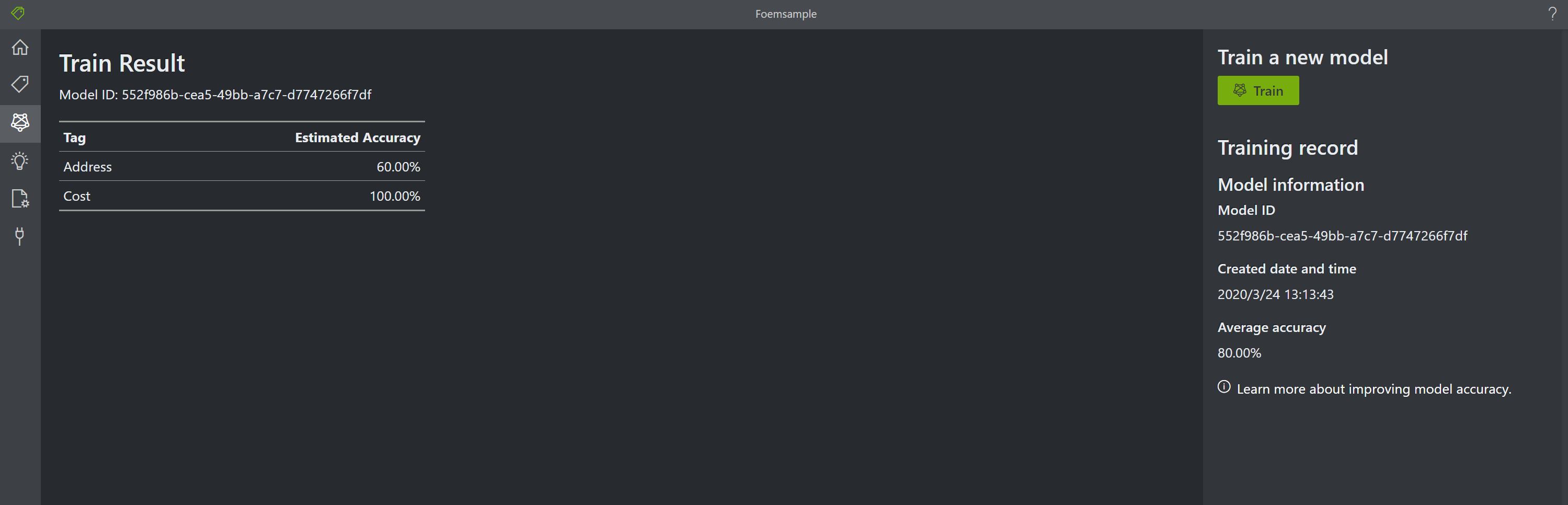
- pythonスクリプトへの設定#2: model_id
fr.py## Configurations endpoint = r"https://xxxxx.cognitiveservices.azure.com/" apim_key = "xxxxx" model_id = "xxxxx" sourceDir = r"C:\xxxxx\*" confidence_setting = 0.9 # 0~1. 信頼性がこの値以下の場合採用しない- Model_id: 上記で取得したModel IDをセットします
3.データ抽出実施
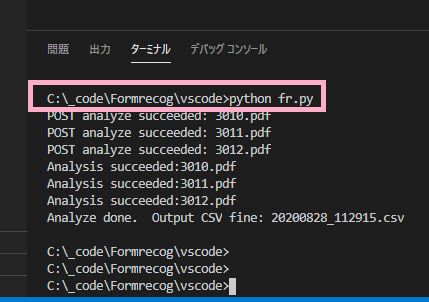
- sourceDirに分析対象の帳票ファイルを配置する
- fr.pyを実行
- スクリプトと同じフォルダにデータ抽出結果csvが出力されます
4. 制約など
- トレーニング及び分析対象帳票のファイル形式ですが、PDFしか試していません
- Form recognizerの現行バージョンv2.0ベースで作っています。他バージョンで使う場合、APIのURLの適宜変更と、Form recognizerが返すjsonフォーマット変更への対応が必要になると思います
- 投稿日:2020-09-08T18:18:01+09:00
pythonでクローリング,スクレイピング,文字取得と画像保存
下準備
import re import requests from pathlib import Path import requests from bs4 import BeautifulSoup作業フォルダを作る
output_folder = Path('作業フォルダ') output_folder.mkdir(exist_ok=True)yahoo天気のデータを取得したい
requestsを使ってhtmlの要素を取得する。
url = 'https://weather.yahoo.co.jp/weather/jp/13/4410.html' html = requests.get(url).textこのままだと読みにくいのでBeautifulSoupで構造を書き直す
soup = BeautifulSoup(html, 'lxml')soupを確認して取得したい情報がどこにあるか確認する。
今回は今日明日の天気を取得したいとする。ctrl + F で該当ワードを検索する。
class="yjMt"が確認できた。
soupで要素を指定して取得
today = soup.select('.yjMt')divが取得したいときは select('div')
classが取得したいときは('.class')
idが取得したいときは('#id')
imgが取りたいときは selectよりsoup.find_all('img') の方が便利かも取得できた内容を確認
today[<h2 class="yjMt">今日明日の天気</h2>, <h2 class="yjMt">週間天気</h2>, <h2 class="yjMt">ピンポイント天気</h2>]三つの要素が取れてしまうので、listの番号を指定して取り出す必要がある。
同じ要領で最高最低気温を取得
high = soup.select('.high') low = soup.select('.low')low[<li class="low"><em>25</em>℃[+2]</li>, <li class="low"><em>28</em>℃[+3]</li>]今日明日の情報が入ってきているのでlistの番号を指定。
不要な文字列を取り除く。today_low= str(low[0]).replace('<li class="high"><em>', '').replace('</em>', '').replace('</li>', '')画像の取得
webサイト上で画像を右クリック
urlをコピーしてctrl + F で該当urlを検索する。classがpictであると分かった
pict = soup.select('.pict') pict[<p class="pict"><img alt="曇時々雨" border="0" src="https://s.yimg.jp/images/weather/general/next/size150/203_day.png"/>曇時々雨</p>, <p class="pict"><img alt="曇のち晴" border="0" src="https://s.yimg.jp/images/weather/general/next/size150/266_day.png"/>曇のち晴</p>, <div class="cmnMod pict"> <ul> <li> <dl> <dt>雨雲レーダー</dt> <dd><a data-ylk="slk:zmradar; pos:1" href="//weather.yahoo.co.jp/weather/zoomradar/?lat=35.6965&lon=139.4472&z=10"><img alt="雨雲の動き" height="150" src="https://weather-pctr.c.yimg.jp/r/iwiz-weather/raincloud/1599021000/202010-0000-pf1300-20200902133000.gif?w=200&h=150" width="200"/> </a></dd> </dl> </li><!-- --><li> <dl> <dt>天気図</dt> <dd><a data-ylk="slk:chart; pos:1" href="/weather/chart/"><img alt="天気図" height="150" src="https://weather-pctr.c.yimg.jp/r/iwiz-weather/chart_v2/1599012878/WM_ChartA_20200902-090000.jpg?w=200&h=150" width="200"/> </a></dd> </dl> </li><!-- --><li> <dl> <dt>気象衛星</dt> <dd><a data-ylk="slk:stlt; pos:1" href="/weather/satellite/"><img alt="気象衛星" height="150" src="https://weather-pctr.c.yimg.jp/r/iwiz-weather/satellite_v2/1599022735/WM_H-JPN-IR_20200902-140000.jpg?w=200&h=150" width="200"/> </a></dd> </dl> </li> </ul> </div>]画像のurlだけが取得したい。
画像urlの前後に「"」があるので、これを指定文字として文字区切りする。
区切った後のリストから該当urlのあるリスト番号を指定する。sp = re.split('"', str(pict)) sp[7]'https://s.yimg.jp/images/weather/general/next/size150/203_day.png'urlから画像を取り出してPILで表示させる
from PIL import Image from io import BytesIO img = requests.get(sp[7]).content today_pict = Image.open(BytesIO(img)) today_pict
保存
today_pict.save("today_pict.png")以上

- 投稿日:2020-09-08T17:53:09+09:00
リスト型、タプル型2
リスト型、タプル型2
アンパック代入
スライスを使った代入に似た機能としてアンパック代入があります。
イコールの左右に複数の要素を記入して、一度に複数の要素に対して代入を行う機能です。
アンパック代入では、イコールの左右で要素数が揃っていないとエラーになるので注意が必要です。
アンパック代入を使うと、次のように一発で変数の入れ替え(Swap)を実行できます。
変数などを使って要素を保存しておく必要がありません。
【アンパック代入を使う】
a = 1
b = 2
b, a = a, b
print(a, b)
↓
2 1※Pythonでは、複数の要素をカンマで区切って列挙すると、タプルとして扱われます。
この記法を使うと、丸括弧を使わずにタプルを作ることができます。
アンパック代入では、タプルの要素として含まれた変数を対象に、代入を行っていることになります。スライスのステップ数
スライスに与えるコロン(:)で区切ったパラメータは、実は、3つ与えることができます。
3つ目の数値はステップとして扱われます。
スライスで「n個とばしながら要素を取り出す」という指定ができます。
【リストからスライスで要素を取り出す】
a = [1, 2,3 ,4, 5]
a
↓
[1, 2, 3, 4, 5]a[1:4]
↓
[2, 3, 4]a[2:100]
↓
[3, 4, 5]a[::2]
↓
[1, 3, 5]
※リストから偶数番目の要素を取り出すスライスを使った要素の代入と削除
スライスと代入を組み合わせると、リストの複数の要素を一括して置き換えることができます。
置き換えを行いたい要素をスライスで指定し、イコールの左に置きます。
置き換えたい要素をイコールの右側に置きます。
右側の要素は、リストやタプルなどのシーケンスである必要があります。
【要素の追加】
a = [1, 2, 3, 4, 5]
a[2:4] = [’Three’, ‘Four’, ‘Five’]
a
↓
[1, 2, ’Three’, ‘Four’, ‘Five’, 5]イコールの左側では、(0から数えて)2番目と3番目の要素をスライスで指定しています。
右側の要素では、3つの文字列を持ったリストを指定しています。
左右で要素の数が異なる場合でも、自動的に整合性を保つように処理をしてくれます。
del文とスライスを組み合わせると、複数の要素をいっぺんに削除することができます。
【要素の削除】
a = [1, 2, 3, 4, 5]
del a[2:]
a
↓
[1, 2]
※2行目の「del a[2:]」で3番目から最後まで削除する
- 投稿日:2020-09-08T16:32:51+09:00
No module named tkinterを解決する
背景
yoloを使用する際に、ラベル付けを行うBBox-Label-Toolを使用した際に(main.pyを実行すると)No module named _tkinterとエラー表示された件の解決を行った
環境
・mac OS Catalina 10.15.6
・python 2.7.16
・tcl-tk 8.6.10手順
試行錯誤
調べたところpyenvでpythonをインストールし直すらしい
brew install tcl-tkは行った
しかし、No module named PIL等うまく行かない
どうやらpythonコマンドを実行するとデフォルトのpythonを使用してしまうらしい#一致しない $pyenv versions system * 2.7.16 (set by /****/****/.pyenv/version) 3.7.3 $python --version python 3.7.3※今回は、pyenvのpythonのバージョンはデフォルトのpythonのバージョンと同じものを使用した
解決策
pyenvのパスを優先させる
以下を実行した$ vim /etc/paths /usr/local/bin /usr/bin /bin /usr/local/sbin /usr/sbin /sbinしかし、うまく行かない
ベストアンサー
以下を行う
pyenv init source ~/.bash_profileまたは
eval "$(pyenv init -)"
以上
追記)
・ターミナルを閉じるとまた、初期状態に戻ってしまうようです。
・BBox-Label-Toolは使用できるようになりますが、対話モードでimport tkinterを行ってもエラーが生じるようです。
- 投稿日:2020-09-08T16:09:20+09:00
[Python] 受け取った関数がユーザーが定義した関数であることを確認する
Pythonでライブラリを作っている時に、「与えられた関数は本当にユーザーが実装した関数か?」をチェックしたい時に使えるTipsです。
まず関数(callable)かどうか判定
これは言うまでもないですね。
import inspect inspect.isfunction(func)ビルトイン関数、frozen関数かどうかを判定
Pythonでは、C言語で記述されたビルトイン関数、またPythonで記述された標準ライブラリのうち、バイトコードの形でPython処理系に組み込まれたfrozen関数が使えます。たとえば
builtins.sorted()はビルトイン関数、zipimport.zipimporter()はfrozen関数です。
sys.modulesを用いる方法これは比較的わかりやすいと思うのですが、
sys.modulesからfuncが定義されたモジュールオブジェクトを探します。これに__file__という属性がなければビルトイン関数またはfrozen関数です。(ビルトインモジュール及びfrozenモジュール以外はPythonでは必ずファイルと1対1に対応します)modname = func.__module__ mod = sys.modules[modname] fname = getattr(mod, '__file__', None) return fname != None
codeオブジェクトを用いる方法他の方法として以下のような方法があります。こちらの方が簡潔だと思います。
co = getattr(func, '__code__', None) return co != Noneユーザーが作成した関数かを判定
いくつか方法はあると思いますが、ここでは関数の定義されたファイルのパスを取得し、それが
__main__モジュールのパス(STDINならワーキングディレクトリ)以下に位置していれば、既存のライブラリではなくユーザーが作成したファイルであると判定します。
なお、この判定はワーキングディレクトリ以下にライブラリのキャッシュを置くパッケージマネージャ(pyflowなど)では機能しないかもしれません。
また、os.chdir等を使ってワーキングディレクトリを変更しつつimportを行っている場合も機能しないかもしれません。(そんなプログラムあるのか知りませんが)filename = path.abspath(co.co_filename) return filename.startswith(path.join(get_maindir(), '')) def get_maindir(): mm = sys.modules['__main__'] fname = getattr(mm, '__file__', None) if fname == None: # STDIN return os.getcwd() else: return path.dirname(path.abspath(mm.__file__))全ソースコード
import sys import os import inspect from os import path def is_userfunc_b(func): if not inspect.isfunction(func): return False modname = func.__module__ mod = sys.modules[modname] fname = getattr(mod, '__file__', None) if fname == None: return false fname = path.abspath(fname) return fname.startswith(path.join(get_maindir(), '')) def is_userfunc(func): if not inspect.isfunction(func): return False co = getattr(func, '__code__', None) if co == None: return False # Check that the file is placed under main module filename = path.abspath(co.co_filename) return filename.startswith(path.join(get_maindir(), '')) def get_maindir(): mm = sys.modules['__main__'] fname = getattr(mm, '__file__', None) if fname == None: # STDIN return os.getcwd() else: return path.dirname(path.abspath(mm.__file__))
- 投稿日:2020-09-08T15:56:56+09:00
TypeError:mul():argument 'other' (position 1) must be Tensor,not listエラーの解決法
以下のプログラムを実行した際に次のようなエラーが出た。
実行文seqlen = torch.tensor(10) mask = [[1] * seqlen]エラー文TypeError:mul():argument 'other' (position 1) must be Tensor,not list原因
Pytorchのバージョン由来のエラー
torch>0.3.1からtorch.tensorとリストの演算が不可能になっているらしい解決法
- pytorchのバージョンを
torch<=0.3.1に下げる- 次のようにプログラムを修正する
変更前mask = [[1] * seqlen]変更後mask = [[1] * int(seqlen)]
- 投稿日:2020-09-08T15:34:00+09:00
windowsで快適なPython 3 (Anaconda)開発環境を作る
はじめに
僕が書いたC/C++版も必要な方は是非ご参考ください
Windowsで開発環境を築きたいという人は多いと思います。
そこで、開発環境を作りたいと思います。
試したバージョンはWindows10です。
Anacondaの説明はいらない。早くインストール方法・始め方を見たいという方はこちらをクリックしてください随時、画像の追加や本文の修正をします。
問題点、誤字、アドバイスなどありましたらコメント欄で教えて下さい。入れるもの
生のPython3ではなくanaconda(Python3)を使います。
anacondaとは?
メリット1
Python3とはプログラミング言語です。1
しかし、読者の中にはディープラーニングや科学計算などに使いたいと思っている人が多数いらっしゃると思います。
それらはPython3だけではできません。2
しかし、anacondaなら行列計算(numpy)、科学計算(scipy)、さらにデータ管理に便利なライブラリ(pandas)、機械学習(scikit-learn)など必要なものが既に入っています。
それは非常に便利な事です。メリット2
Python自体もソフトウェアですから、定期的にバージョンアップをしています。
anacondaなら複数バージョンを用意することができます。3これによって更新したらライブラリが動かなくなった!とか更新が面倒くさい!とかが軽減されるはずです。anacondaのインストール手順
ダウンロード
公式のサイトへアクセスします
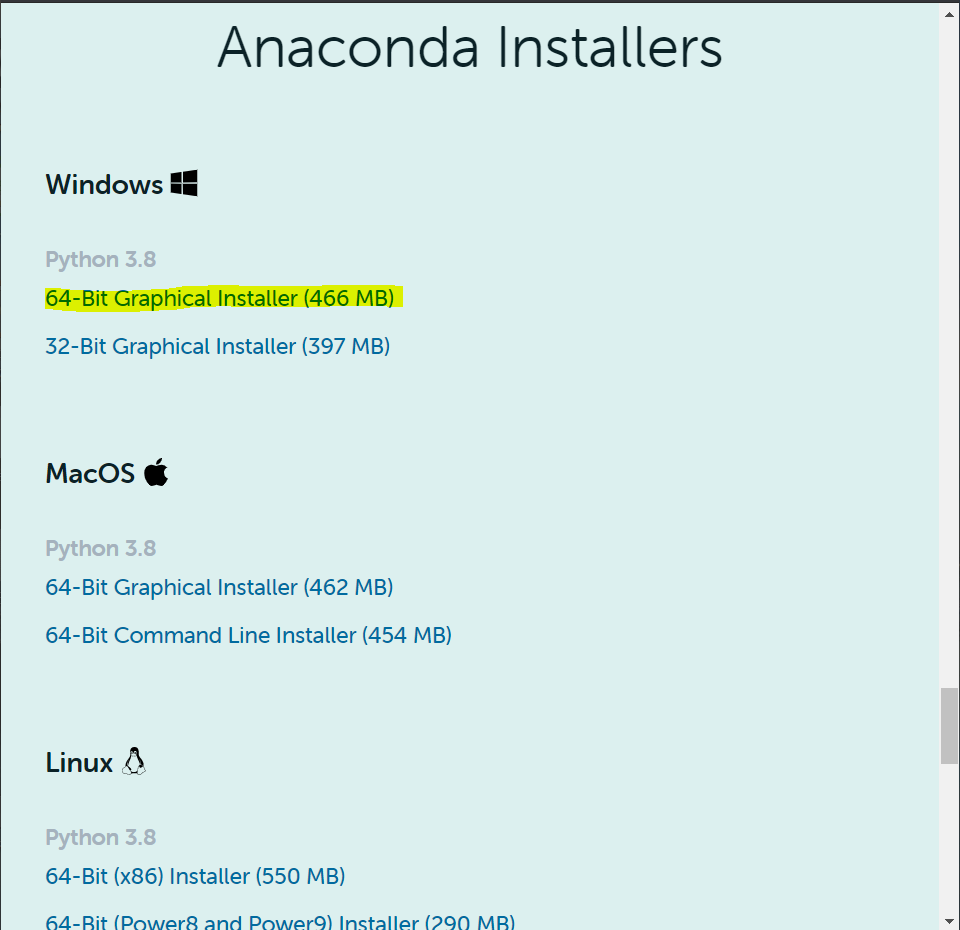
アクセスした後、下の図のところまでスクロールしてください。そのあと、黄色で塗った"64-Bit Graphical Installer "4をクリック5してください。
これでダウンロードは完了です。インストール
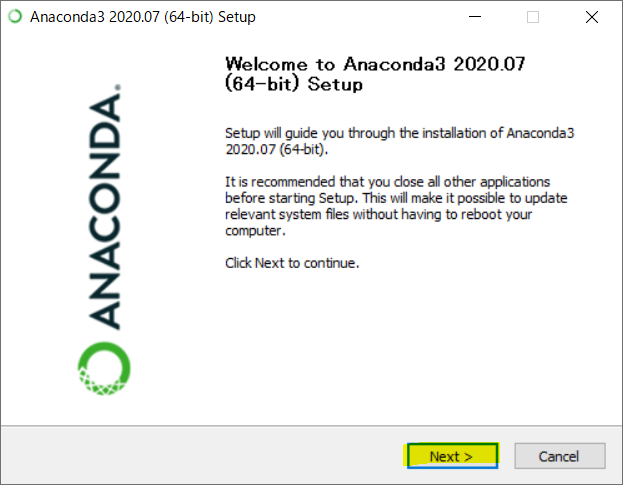
"Anaconda3-ほにゃらら-Windows-x86_64"をクリックしてください。(ほにゃららには日付が入ります。僕の場合は"2020.7"でした。違う場合も気にしないください)
ダブルクリックするとこのような画面が出てきます("2020.7"は違くても気にしない(ry )。"Next >"を押してください。
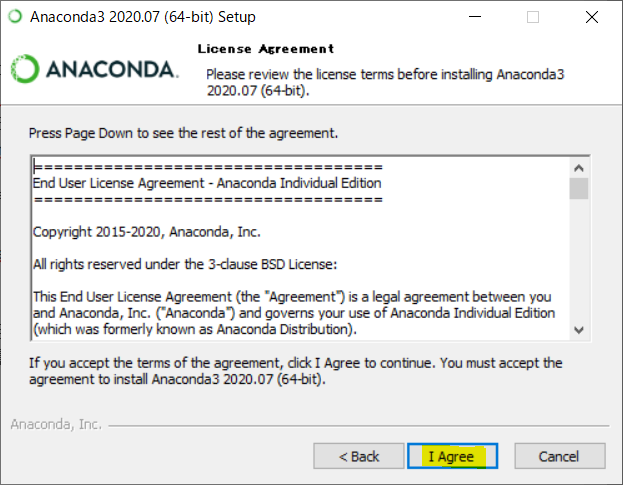
クリックすると、ソフトウェア利用許諾契約6が出てきます。良く読みましょう。
(え?英語難しいって?英語はほかの人に聞いてください、僕も出来ないので(震え声))。7
進む場合は"I Agree"を押してください。
特段何かする場合以外は何も設定を変えずに進んで大丈夫だと思います。
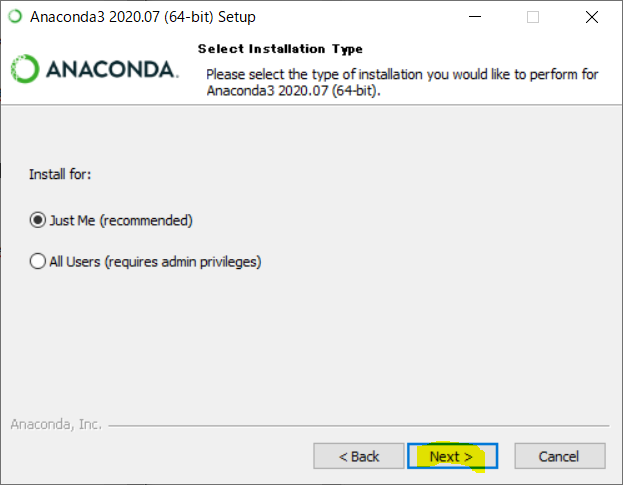
"Next >"を押してください。
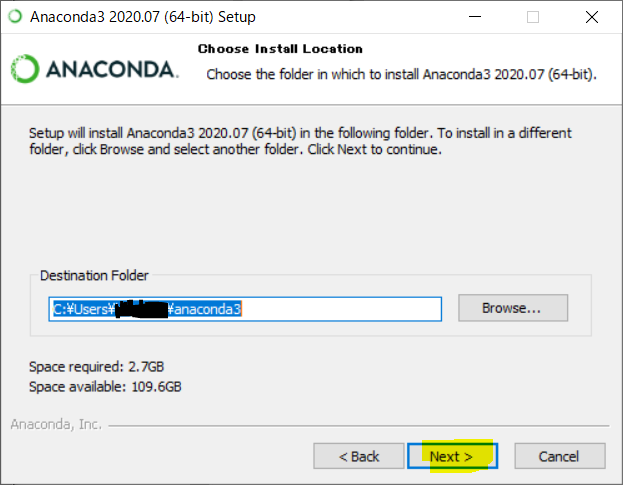
インストール先を選びます。個人的にはネット記事を設定などをするとき、インストール先を変えているとやりずらいので変えない事をお勧めします。(黒塗りの部分にはあなたのWindowsのユーザー名が入ります)
後、容量が結構必要なので注意が必要です。
"Next >"を押してください。
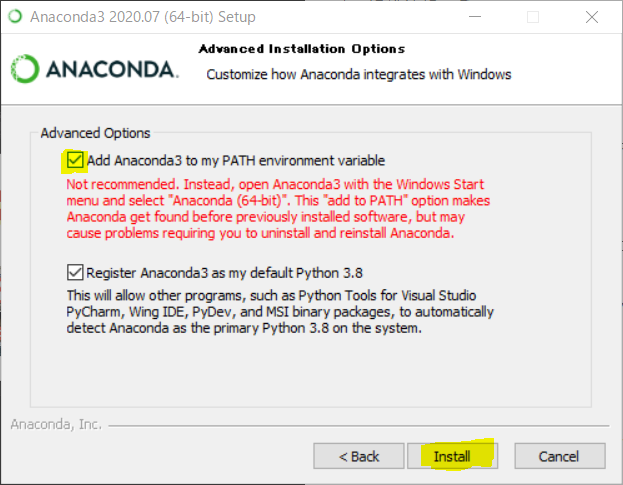
"Add Anaconda3 to my PATH environment variable"は非推奨ですが、初めての人はこちらをチェックすることをおすすめします。8
"Register Anaconda3 as my default Python 3.8"はそのままで大丈夫だと思います。
"Next >"を押してください。
僕の環境ではインストールに5分くらい時間がかかりました。
こちらの画面がでればインストール完了です。
"Next >"を押してください。
二つのものはチェックを入れていると閉じたときブラウザでWEBページが開きます。面倒なら外してもらって構いません。
"Finish"を押してください。
コマンドプロンプトの中心でPythonを叫んだもの
さて、Anacondaのインストールは完了しました。
早速、コマンドプロンプト
を起動させてpython --versionと入力してみます。
上手くいった場合、Python 3.8.3と出力されます。(数値の部分はバージョンなので違う場合がありますが気にしないでください)
失敗した場合、'python' は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。とでるか
Microsoft Storeのページが出てきてPythonのインストールをお勧めされてしまいます。
これの場合PATHが通っていないかインストールに失敗している可能性があります。
"Add Anaconda3 to my PATH environment variable"にチェックを入れたか確認して、アンインストールのち"Add Anaconda3 to my PATH environment variable"にチェックを入れてAnacondaを再インストールしてみてください。終わりに
お疲れ様でした。
これでPython3とAnacondaにインストールされているライブラリを使うことができます。あなたが次にできること
* Pythonの文法を学ぶ * Jupyter Notebookを使ってみる * TensorflowやPytorch、Djangoなど自分に必要なライブラリをインストールする * Anacondaで複数のPythonのバージョンを用意する。
正確には言語処理系と言いますが、とりあえず気にしないください。 ↩
逆に効率的な行列計算や科学計算やニューラルネットワークを自分で実装できる人はこの記事読む必要ありません ↩
同じバージョンでも複数用意できますのでご安心ください ↩
古いパソコンだと32bit版しか動かない場合がありますが、現在のパソコンなら原則大丈夫だと思います。個人的には32bitのパソコンは性能的にPython使うのは厳しいと思いますが、下の"32-Bit Graphical Installer "をクリックすると32bit版をダウンロードできます。 ↩
ファイルサイズはバージョンアップによって変更されている場合がありますが、気にしなくて結構です。テザリング中などの場合は通信量を気をつけてください。 ↩
この名称であっているか不安です。詳しい方是非、コメント欄でお教えください。 ↩
BSD Licenseなようなのでで日本語記事の二次情報を見ても良いかもしれません。ただ、BSD Licenseにもいくつか種類があるのと、二次情報は信憑性が疑わしい場合があります。 ↩
このオプションを選ぶと事前に入れた今回インストールしないAnaconda以外のPythonが壊れてしまったり、今後にインストールするPythonが上手くいかなかったりする可能性があるようです。ですが、チェックを入れないと自力でAnacondaのPATHを追加しなければならず大変だと思います。 ↩


- 投稿日:2020-09-08T15:15:19+09:00
Python組み込み関数〜divmod~ 割り算の商と余りを同時に取得しよう
はじめに
今回の記事では、Pythonの「divmod関数」について取り上げます。
「divmod関数」は、割り算した時の商と余りを一気に取得できる便利なものです。
「divmod」関数を使えるようになって、Pythonの知識を深めていきましょう。通常の割り算での商と余り
Pythonで通常の割り算では、商を求めるときは「/」、余りを求めるときは「%」を使用します。
#商 12 / 4 >>>3.0#商 12 / 5 >>>2.4#小数点を切り捨て 12 // 5 >>>2#余り 12 % 4 >>> 0#余り 12 % 5 >>> 2divmod関数
では早速「divmod関数」を使用していきます。
まずはコードを見て確認していきましょう。quotient, remainder = divmod(12, 5) print(quotient) #2 print(remainder) #2見てわかるように、変数を2つ用意し、1つ目の変数には商が、2つ目の変数には余りが入ります
そしてポイントとなるのが、1つ目の変数には、「小数点を切り捨てにした状態の商」が入ります。
つまり、「//」を使用した時と同じということです。次に変数1つで受け取るとどのようになるのか確認しましょう。
tuple = divmod(12, 5) print(tuple) #(2, 2)このようにタプルとして受け取れます。
取り出したいときは、print(tuple[0], tuple[1]) #2 2とすれば取り出せます。
比較
最後に普通に商と余りを出すときと、「divmod関数」を使った時とを比較してみましょう。
#普通 quotient = 12 / 5 remainder = 12 % 5 print(quotient) #2.4 print(remainder) #2#divmod関数 quotient, remainder = divmod(12 / 5) print(quotient) #2 print(remainder) #2たった1行ですが短くなっているのがわかります。
たった1行でも短くなるなら使わない手はないので、積極的に使っていきましょう。最後に
今回の記事では、Pythonの「divmod関数」について取り上げました。
今後も役立つモジュールや組み込み関数なども記事にしていくので、よかったらみて行ってください。
- 投稿日:2020-09-08T15:15:19+09:00
Pythonモジュール~divmod~ 割り算の商と余りを同時に取得しよう
はじめに
今回の記事では、Pythonの「divmod関数」について取り上げます。
「divmod関数」は、割り算した時の商と余りを一気に取得できる便利なものです。
「divmod」関数を使えるようになって、Pythonの知識を深めていきましょう。通常の割り算での商と余り
Pythonで通常の割り算では、商を求めるときは「/」、余りを求めるときは「%」を使用します。
#商 12 / 4 >>>3.0#商 12 / 5 >>>2.4#小数点を切り捨て 12 // 5 >>>2#余り 12 % 4 >>> 0#余り 12 % 5 >>> 2divmod関数
では早速「divmod関数」を使用していきます。
まずはコードを見て確認していきましょう。quotient, remainder = divmod(12, 5) print(quotient) #2 print(remainder) #2見てわかるように、変数を2つ用意し、1つ目の変数には商が、2つ目の変数には余りが入ります
そしてポイントとなるのが、1つ目の変数には、「小数点を切り捨てにした状態の商」が入ります。
つまり、「//」を使用した時と同じということです。次に変数1つで受け取るとどのようになるのか確認しましょう。
tuple = divmod(12, 5) print(tuple) #(2, 2)このようにタプルとして受け取れます。
取り出したいときは、print(tuple[0], tuple[1]) #2 2とすれば取り出せます。
比較
最後に普通に商と余りを出すときと、「divmod関数」を使った時とを比較してみましょう。
#普通 quotient = 12 / 5 remainder = 12 % 5 print(quotient) #2.4 print(remainder) #2#divmod関数 quotient, remainder = divmod(12 / 5) print(quotient) #2 print(remainder) #2たった1行ですが短くなっているのがわかります。
たった1行でも短くなるなら使わない手はないので、積極的に使っていきましょう。最後に
今回の記事では、Pythonの「divmod関数」について取り上げました。
今後も役立つモジュールなども記事にしていくので、よかったらみて行ってください。
- 投稿日:2020-09-08T15:14:55+09:00
WEBカメラ取り込みVer3
前回作成した物。
WEBカメラ取り込みVer2前回はGPIOを使用したプログラム。
今回は撮影枚数を指定しての撮影プログラム。
基本構成は前回と変わらず。
ライブラリ
cap_save_prg.pyimport cv2 import os,os.path from pathlib import Path import sys from datetime import datetime import time基本構成に
pathlibを追加したくらい。この辺りは色々と調べながらなので、結構適当です。
保存先とファイル名の定義
cap_save_prg.pysave_dir_path = '保存先' filename = 'ファイル名'お好みの場所で構いません。
最近はデスクトップ上にフォルダを作成してその中でプログラム保存や
撮影画像の保存を行う様にしています。ディレクトリの作成
cap_save_prg.pyos.makedirs(save_dir_path,exist_ok=True) base_path = os.path.join(save_dir_path,filename) datename = datetime.now().strftime('%m%d%H%M')いつも通りとなっています。
使用デバイスの定義
cap_save_prg.pydevice_id = 0 width = 640 height = 480 fps = 30 cap = cv2.VideoCapture(device_id) cap.set(cv2.CAP_PROP_FRAME_WIDTH, width) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height) cap.set(cv2.CAP_PROP_FPS, fps)今回は調べている中でOpencvの機能を設定が出来る下りの記述を見つけたので
試しに使ってみようと思い、盛った記述になっています。まぁ撮影するだけなら
cv2.VideoCapture()で問題ないです。画像撮影
cap_save_prg.pyn = 0 while True: ret,frame = cap.read() cv2.imshow(filename,frame) key = cv2.waitKey(1) & 0xFF cv2.imwrite((base_path + datename +'_'+ str(n) + ".png"),frame) pathl,dirsl,filesl = next(os.walk(save_dir_path)) file_count = len(filesl) print(file_count) time.sleep(0.2) cap.release n += 1 if file_count == 100: break今回はプログラムスタートと同時に撮影がスタート
保存先のディレクトリ内ファイル数をカウントする様にしています。設定値に到達でプログラムストップとなります。
本当なら
cv2.imwriteの前にif key == ord('s'):を入れてキーボードを押したら
撮影スタートにしたかったんですが
NameError:name 'file_count' is not definedが発生。色々と調べたけど、解消出来なかったので一旦ヨシとしました。
まとめ
一つのプログラムであれもこれもしようとしてしまうので私の頭脳では対処しきれず知恵熱発生…
作った物を1つずつ改良していくしかないなぁ~と思い
まぁショボい物をアップして悶えながらやってます。以上です。
- 投稿日:2020-09-08T13:55:33+09:00
kabuステーション®APIのWebsocketをPythonで受ける
概要
前回に引き続き、auカブコム証券が個人に提供するkabuステーションAPIをPythonから利用する。
今回は、銘柄のWebsocketによる配信をPythonで受ける。また同時に、銘柄の登録、登録解除、登録全解除のコードも紹介する。環境
- Windows 10
- Python 3.8.5 ( Microsoft Store からインストール )
追加パッケージ
- websockets
- requests
- pyyaml
コード
銘柄登録
import json import requests import yaml # --- def get_token(): with open('auth.yaml', 'r') as yml: auth = yaml.safe_load(yml) url = 'http://localhost:18080/kabusapi/token' headers = {'content-type': 'application/json'} payload = json.dumps( {'APIPassword': auth['PASS'],} ).encode('utf8') response = requests.post(url, data=payload, headers=headers) return json.loads(response.text)['Token'] # --- token = get_token() EXCHANGES = { 1: '東証', 3: '名証', 5: '福証', 6: '札証', } payload = json.dumps({ 'Symbols': [ {'Symbol': 8306 ,'Exchange': 1}, # MUFG {'Symbol': 9433 ,'Exchange': 1}, # KDDI # ... 50件まで登録可 ],}).encode('utf8') url = 'http://localhost:18080/kabusapi/register' headers = {'Content-Type': 'application/json', 'X-API-KEY': token,} response = requests.put(url, payload, headers=headers) regist_list = json.loads(response.text) print('配信登録銘柄') for regist in regist_list['RegistList']: print("{} {}".format( regist['Symbol'], EXCHANGES[regist['Exchange']]))銘柄登録解除
URLの変更のみで対応する。表示部は流用可能である。
url = 'http://localhost:18080/kabusapi/unregister'全登録銘柄解除
payloadが不要となる。url = 'http://localhost:18080/kabusapi/unregister/all' headers = {'Content-Type': 'application/json', 'X-API-KEY': token,} response = requests.put(url, headers=headers)配信表示
登録した銘柄の配信を受け続ける。Ctrl+Cで終了する。
json.loadsするresponseに.textがつかないので注意のこと。import asyncio import json import websockets # --- async def stream(): uri = 'ws://localhost:18080/kabusapi/websocket' async with websockets.connect(uri, ping_timeout=None) as ws: while not ws.closed: response = await ws.recv() board = json.loads(response) print("{} {} {}".format( board['Symbol'], board['SymbolName'], board['CurrentPrice'], )) loop = asyncio.get_event_loop() loop.create_task(stream()) try: loop.run_forever() except KeyboardInterrupt: exit()なお、サーバ側がハートビート未実装のため
websockets.connectにping_timeout=Noneの引数が必要である。【要望】WebSocket のping/pong対応
Issue#8 https://github.com/kabucom/kabusapi/issues/8
- 投稿日:2020-09-08T13:14:30+09:00
オウム返しLINE BOT 作成
はじめに
オウム返しするline chatbot を作ります。
他にも参考になる記事はたくさんありますが、今回は自分がつまずいたところを含めて書いていこうと思います。
*LINEdevelopersに登録している前提で書いてます。登録してない方は「LINEdevelopers 使い方」などで調べると色々出てきます。実行環境
window7 64bit
python 3.6.4
editer Atom(何でも良い)
ライブラリ:
heroku
Flask
line-bot-sdkHerokuの準備
Herokuとは簡単にいうと、自分で作ったwebアプリを簡単に公開できるようです。
line botを作るにあたって必要ですのでインストールしときましょう。
アカウント作成してHerokuをインストールします。
https://jp.heroku.com/インストールとアカウント作成ができたらコマンドプロンプトで
heroku loginと入力すると
このような画面がブラウザで表示されるので「Log in」を押す。
すると
無事ログイン出来た事が確認できます。ファイル作成
必要なのは
runtime.txt
requirements.txt
Procfile
main.py
の4つを作ります。ひとつずつ見ていきましょう
・runtime.txtの中身python-3.6.4・requirements.txtの中身
Flask==1.1.2 line-bot-sdk==1.17.0これはコマンドプロンプトで pip freeze と入力してコピペ
・Procfile (拡張子なし)の中身web: python main.py・main.py
from flask import Flask, request, abort import os from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) app = Flask(__name__) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) @app.route("/") def hello_world(): return "hello world!" @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text)) if __name__ == "__main__": # app.run() port = int(os.getenv("PORT")) app.run(host="0.0.0.0", port=port)main.pyは編集せずそのままコピペで使えます(引用)
これらのファイルを1つのフォルダにまとめましょう。アプリケーションの作成と設定
コマンドプロンプトにて
heroku create ******* heroku config:set YOUR_CHANNEL_ACCESS_TOKEN="**********" --app ********** heroku config:set YOUR_CHANNEL_SECRET="**********" --app ***************の部分を自分の環境に合わせて入力します。
最初の「heroku create *****」にはアプリ名を入れます。
YOUR_CHANNEL_ACCESS_TOKENとYOUR_CHANNEL_SECRETはLINEdevelopersの「チャンネル基本設定」「Messaging API設定」に書いてあります。
その後の「--app *****」にアプリ名を入れます。Herokuをデプロイ
コマンドプロンプトにて
git init git add . git commit -m "test commit" git push masterと順番に入力します。
最後にheroku open入力すると・・・
とブラウザ上に表示できれば成功です。
あとはlineアプリ内でオウム返しbotの動作確認ができると思います。
つまずいたところ
そもそもの入力ミスが非常に多かった。。
「Procfile」ファイルが「Procfile.text」になっていた事が原因でエラー解決するのに時間掛かった。。
意外と簡単なミスって気づかない。
あとどこでエラーが出てるか分からないって人はheroku logと入力するとエラーの原因が分かるかも。
cheer up!!


- 投稿日:2020-09-08T11:56:57+09:00
写真から3Dモデルを作る方法を思いついた その033次元空間への投影
どーもKsukeです。
写真から3Dモデルを作る方法を思いついたその03で、3次元空間への投影をやっていきます。
その2はこちらhttps://qiita.com/Ksuke/items/8a3a2faa90263b439f8b※注意※
この記事は思いついて試した事の末路を載せているだけなので、唐突なネタやBad Endで終わる可能性があります。やってみる
手順
1.画像(2次元データ)を3次元データへ拡張
2.向きの調整
3.重ね合わせところどころにあるコードは、最後にまとめたものを載せてあります。
1.画像(2次元データ)を3次元データへ拡張
画像は2次元のデータのまま3次元空間に投影します。投影という言葉を使っているのは、画像のオブジェクトに光を当て、光が当たらない影の部分を取り出すように値を置いていくからです。イメージとしては、100枚の画像を重ね合わせて空間にしているようなものです。
こうすることで、
・前方から見るとオブジェクトを正面から見たときのシルエットと一致する空間
・前方から見るとオブジェクトを側面から見たときのシルエットと一致する空間
・前方から見るとオブジェクトを上面から見たときのシルエットと一致する空間
が出来上がります。3次元データへ拡張#2次元の画像を、3次元方向に引き延ばして投影する。 def imgProject(img,imgSize): #画像をz軸方向に繰り返し配置することで、画像に厚みを持たせ引き延ばして投影する projectSpace = np.tile(img[:,:,None],(1,1,imgSize)) #投影した空間を返す return projectSpace #背景分離した画像を3次元空間に点群のオブジェクトとして投影する(トレース・オン!) imgProjectSpaces = [imgProject(sepBackImg,imgSize) for sepBackImg in sepBackImgs]2.向きの調整
画像を3次元空間に投影しましたが、各空間のオブジェクトの向きはバラバラです。オブジェクトを正面から撮った画像から作った空間の前方にはオブジェクトの正面が来ているでしょうし、オブジェクトを側面から撮った画像から作った空間の前方にはオブジェクトの側面が来ているはずです。
ここで向きをそろえるために、軸の入れ替えを行います。全ての空間で、空間の前方にオブジェクトの正面が来るようにします。
こうすることで
・前方から見るとオブジェクトを正面から見たときのシルエットと一致する空間
・側方から見るとオブジェクトを側面から見たときのシルエットと一致する空間
・上方から見るとオブジェクトを上面から見たときのシルエットと一致する空間
が出来上がります。向きの調整#元にした画像によって空間の前方に来ている面が、コップの正面、側面、上面とバラバラなので、 #すべての空間において前方にコップの正面が来るように、軸を入れ替え向きをそろえる transposeValues = [(0,1,2),(0,2,1),(2,1,0)] transposedSpaces = [imgProjectSpace.transpose(*transposeValue) for imgProjectSpace,transposeValue in zip(imgProjectSpaces,transposeValues)]3.重ね合わせ
各空間の向きが合わさったら、すべての空間を重ねていきます。重ねることで、前方、側方、上方のいずれから見てもオブジェクトのシルエットと一致する空間が出来上がります。
重ね合わせ#各空間の点群を重ね合わせて、正面、側面、上面のいづれから見ても写真と同じシルエットに見える点群を作成する imgProjectSpace = transposedSpaces[0] for transposedSpace in transposedSpaces[1:]: imgProjectSpace = imgProjectSpace*transposedSpace動作確認
最後にコードが問題なく動くか確認。
1.3次元データへ拡張の確認
下のコードをblenderで実行して
動確用1#投影したばかりの空間から、点群の位置の座標のlistを作る imgCoords = [binary2coords(imgProjectSpace) for imgProjectSpace in imgProjectSpaces] #各画像の頂点のずらし幅 offsets = [[-50,-150,-50],[-50,-50,-50],[-50,50,-50]] #各画像の頂点をオブジェクトとして登録するときの名前 names = ['frontSpace','sideSpace','topSpace'] #頂点を描画 [addObj(coords=imgCoord,name = name,offset=offset) for imgCoord,name,offset in zip(imgCoords,names,offsets)]こんな感じのオブジェクト(という名の点群)が表示されれば成功。
2.向きの調整の確認
下のコードをblenderで実行して
動確用2#軸を調整した空間から、点群の位置の座標のlistを作る imgCoords = [binary2coords(transposedSpace) for transposedSpace in transposedSpaces] #各画像の頂点のずらし幅 offsets = [[-150,-150,-50],[-150,-50,-50],[-150,50,-50]] #各画像の頂点をオブジェクトとして登録するときの名前 names = ['frontTransposedSpace','sideTransposedSpace','topTransposedSpace'] #頂点を描画 [addObj(coords=imgCoord,name = name,offset=offset) for imgCoord,name,offset in zip(imgCoords,names,offsets)]こんな感じのオブジェクト(という名の点群)が表示されれば成功。
3.重ね合わせの確認
下のコードをblenderで実行して
動確用3addObj(coords=binary2coords(imgProjectSpace),name = "objectSpace",offset=[-250,-50,-50])こんな感じのオブジェクト(という名の点群)が表示されれば成功。
ちなみに上の確認用3つを同時に実行するとこんな感じ
次は?
やっと点群でのオブジェクトの3次元表示ができたので、次は点群からポリゴンやその頂点を生成していきたいと思います。
コードまとめ
前回のコードの後ろに追加すれば動くはずです。
関数編
コードまとめ(関数編)#2次元の画像を、3次元方向に引き延ばして投影する。 def imgProject(img,imgSize): #画像をz軸方向に繰り返し配置することで、画像に厚みを持たせ引き延ばして投影する projectSpace = np.tile(img[:,:,None],(1,1,imgSize)) #投影した空間を返す return projectSpace実行コード編
コードまとめ(実行コード編)#背景分離した画像を3次元空間に点群のオブジェクトとして投影する(トレース・オン!) imgProjectSpaces = [imgProject(sepBackImg,imgSize) for sepBackImg in sepBackImgs] #元にした画像によって空間の前面に来ている面が、コップの正面、側面、上面とバラバラなので、 #すべての空間において前面にコップの正面が来るように、軸を入れ替え向きをそろえる transposeValues = [(0,1,2),(0,2,1),(2,1,0)] transposedSpaces = [imgProjectSpace.transpose(*transposeValue) for imgProjectSpace,transposeValue in zip(imgProjectSpaces,transposeValues)] #各空間の点群を重ね合わせて、正面、側面、上面のいづれから見ても写真と同じシルエットに見える点群を作成する imgProjectSpace = transposedSpaces[0] for transposedSpace in transposedSpaces[1:]: imgProjectSpace = imgProjectSpace*transposedSpace print("step03:projection of image in 3D space is success\n") #以下確認表示用(メインの流れと関係ないので、次の回では多分消えてる) #投影したばかりの空間から、点群の位置の座標のlistを作る imgCoords = [binary2coords(imgProjectSpace) for imgProjectSpace in imgProjectSpaces] #各画像の頂点のずらし幅 offsets = [[-50,-150,-50],[-50,-50,-50],[-50,50,-50]] #各画像の頂点をオブジェクトとして登録するときの名前 names = ['frontSpace','sideSpace','topSpace'] #頂点を描画 [addObj(coords=imgCoord,name = name,offset=offset) for imgCoord,name,offset in zip(imgCoords,names,offsets)] #軸を調整した空間から、点群の位置の座標のlistを作る imgCoords = [binary2coords(transposedSpace) for transposedSpace in transposedSpaces] #各画像の頂点のずらし幅 offsets = [[-150,-150,-50],[-150,-50,-50],[-150,50,-50]] #各画像の頂点をオブジェクトとして登録するときの名前 names = ['frontTransposedSpace','sideTransposedSpace','topTransposedSpace'] #頂点を描画 [addObj(coords=imgCoord,name = name,offset=offset) for imgCoord,name,offset in zip(imgCoords,names,offsets)] addObj(coords=binary2coords(imgProjectSpace),name = "objectSpace",offset=[-250,-50,-50])
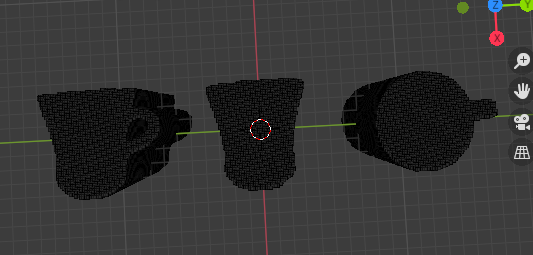
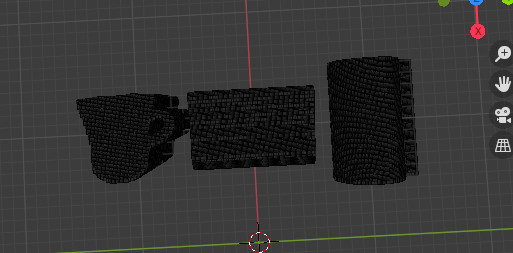

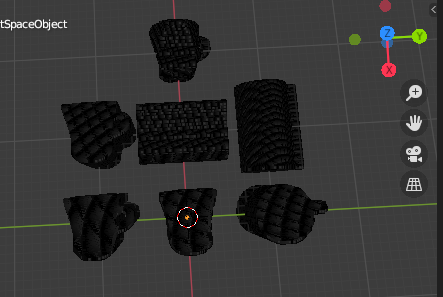
- 投稿日:2020-09-08T11:53:08+09:00
Tensorflowの旧バージョンをインストールする
前置き
今回は強化学習のフレームワークのKeras-RLを使用するために,TensorFlowの1.14.0をインストールしたいと思います.
環境
- OS: Mac OS Mojave 10.14.6
- 言語 : Python 3.7,3.8
インストール
通報のインストールの場合
terminal$ pip install tensorflowバージョン指定する場合
terminal$ pip install tensorflow==1.14.0しかし以下のようなエラーが出る場合があります.
terminal$ pip install tensorflow==1.14.0 Collecting tensorflow Could not find a version that satisfies the requirement tensorflow (from versions: ) No matching distribution found for tensorflowTensorFlow公式サイトをみながら対処しましたが,自分の場合は解決に至らず...
(イメージの配布もTensorFLow 2.Xしかなさそう...?)
TensorFlowのバージョンによってPythonバージョンの制約もあるので確認しましょう.解決法
以下の2つで解決できました.
1. イメージファイルのURLを直打ちする
terminal$ pip3 install --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.14.0-py3-none-any.whl2. pyenv を使用する
pyenvとは
pyenvとはPythonの複数のバージョンを使い分けるコマンドラインツールで、RubyのrbenvやNodeJSのnvmのようなバージョン管理ツールです。これを作ったのは日本の方のようで、すごいですね。これを使えば案件ごとにpythonのバージョンを細かく決められるので、とても便利に使えます。
pyenvのインストールについてはこちらの記事が参考になります.
pyenvを使ってMacにPythonの環境を構築する
pyenvでTensorFlow1.14対応のPython3.7をインストールしてみます.terminal$ pyenv install 3.7.2次にpipでTensorFlowをインストールします.
terminalpip install tensorflow==1.14.0これで無事インストールできました.
- 投稿日:2020-09-08T09:39:47+09:00
E資格取得を目指して ~序文~
E資格とは
ディープラーニングの理論を理解し、適切な手法を選択して実装する能力や知識を有しているかを認定する。
(公式サイトより)きっかけ
pythonを使ったデータ分析周りのノウハウを溜めようと思って始めたところ、本資格の存在を知り、
どうせやるならそこまでできるようになれば、新しい世界が見えるようになるかなと思って始めました。勉強始めました
とりあえず「ゼロから作るDeepLearing」を買って一通りやるところから始めました。
目標は2021年の2月試験合格目指してます
- 投稿日:2020-09-08T08:56:56+09:00
Python(Django REST Framework) + Herokuで入荷チェックLINE Botを作ってみました(デプロイ~LINE連携編)
Python(Django REST Framework) + Herokuで入荷チェックLINE Botを作ってみました(DRF紹介編)の続きです。
こちらではHerokuに作成したアプリをデプロイして、LINEと連携するまでの手順をまとめています。
Django REST Frameworkの概要については前回の記事をご覧ください。■やったこと
コロナの影響で買えなくなってしまった商品の入荷情報を定期+任意のタイミングでチェックして、その内容を通知するLINE Botを作りました。
■Herokuとは
Heroku は、アプリケーションの開発から実行、運用までのすべてをクラウドで完結できるPaaSです。
以下の特徴があります。
- Ruby,Java,PHP,Python,Node,Go,Scala,Clojureに対応
- クレジットカードを登録した場合、1,000時間/月を無料で使用可能
- デプロイが簡単
- アドオンが豊富
Herokuの特徴についてはこちらの記事がわかりやすかったです。
・デプロイについて
DRFで作成したアプリをデプロイする場合に必要な作業はざっくり以下の5つです。
それぞれの作業量は大したことありません。(settings.pyの修正だけ少し面倒かも知れません。)
- デプロイに使用するパッケージを追加でインストール
- 必要なファイルの準備
- gitとの紐づけ(herokuを使用するためにはgitとの連携が不可欠です。)
- settigs.pyの修正
- wsgi.pyの修正
今回は一番オーソドックスな
git push heroku masterでデプロイする方法の紹介です。
デプロイ自体はスムーズにできました。結構エラーは出ましたが調べれば簡単に解決できるものが多かったです。Herokuではデプロイする度にバージョンがカウントアップされていきます。バージョンごとにロールバックなどもできるようです。
詳細なデプロイ手順については後述します。
memo:
githubと連携して自動デプロイすることもできるようですが、今回は一旦省略します。
というか本当に時間が無くてその辺の手順を詳しく見ることができていません…■制作を始める前に
クローリング、スクレイピングをする前にはこちらを一読してからのほうがよいと思います。
今回はseleneを使用した実装内容は載せていませんが、1アクセス毎にtime.sleep(1)していました。
また、robots.txtでクロールが禁止されていないことを確認しました。■ 実装内容
前回の記事でDRFの概要は説明したので、今回はいきなり実装内容を紹介していきます。
・Model
linebot/models.pyfrom django.db import models class Checklog(models.Model): checked_at = models.DateTimeField(auto_now_add=True) checked_url = models.TextField() checked_result = models.TextField(default="sample") product_name = models.CharField(max_length=128)Modelについては特筆すべきことはありません。
Modelを作成したらマイグレートします。・Serializer
linebot/serializers.pyclass LogSerializer(serializers.ModelSerializer): class Meta: model = Checklog fields = ('checked_at', 'checked_url', 'checked_result', 'product_name') def create(self, validated_data): log = Checklog( checked_at = timezone.now(), checked_url = validated_data['checked_url'], checked_result = validated_data['checked_result'], product_name = validated_data['product_name'], ) log.save()Serializerについても特筆すべきことは無いと思います。
checked_at以外はserializer.is_valid()でバリデーションを通過したデータを登録しています。・URL
line_project/urls.pyfrom django.contrib import admin from django.conf.urls import url, include from django.urls import path from lineapi.urls import router as lineapi_router urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^api/', include(linebot_router.urls)), ]linebot/urls.pyfrom rest_framework import routers import linebot.views as view from django.conf.urls import url router = routers.DefaultRouter() router.register('line', view.CallbackView) # urlpatterns = [ # url(r'^callback', view.CallbackView, name='callback'), # ]
http://(ホスト名)/api/line/でlinebot/views.pyのCallbackViewを呼び出すように指定しています。memo:
routerにはModelView以外登録することができません。
他のクラスを継承したViewを呼び出す場合は、urlpatternsで記載する必要があります。
APIViewを使いたかったんですが、発生するエラーが解決できず、泣く泣くModelViewを使用しています。・View
linebot/views.pyimport random import django_filters import requests from rest_framework import viewsets, status, filters from django.utils import timezone from django.core import serializers from rest_framework import authentication, permissions from rest_framework.views import APIView from rest_framework.decorators import action, api_view from rest_framework.response import Response from .models import Checklog from .business import get_information_goods_stock from .serializer import LogSerializer import json REPLY_ENDPOINT = 'https://api.line.me/v2/bot/message/reply' PUSH_ENDPOINT = "https://api.line.me/v2/bot/message/push" ACCESS_TOKEN = '(LINE Businessで発行されるアクセストークン)' HEADER = { "Content-Type": "application/json", "Authorization": "Bearer " + ACCESS_TOKEN } def check_goods_stock(reply_token): # 入荷情報を取得する関数、seleneを使用して実装しました。 # 具体的な実装内容は今回省略します。 resultList = get_information_goods_stock() reply = "" for result in resultList: serializer = LogSerializer(data={'product_name':result.product_name, 'checked_result':result.checked_result, 'checked_url':result.checked_url}) serializer.is_valid() # ここでバリデーションしてシリアライズ serializer.save() # ここでinsert(正確にはSerealizerのcreate関数が呼ばれている) reply += result.productName + ":" + result.checkedResult + "\n" payload = { "replyToken":reply_token, "messages":[ { "type":"text", "text": reply } ] } requests.post(REPLY_ENDPOINT, headers=HEADER, data=json.dumps(payload)) # リプライメッセージを送信 # return json.dumps(payload, ensure_ascii=False) # テスト用 def check_goods_stock_scheduled(user_id): resultList = get_information_goods_stock() message = "" for result in resultList: serializer = LogSerializer(data={'product_name':result.product_name, 'checked_result':result.checked_result, 'checked_url':result.checked_url}) serializer.is_valid(): # ここでバリデーションしてシリアライズ serializer.save() # ここでinsert message += result.productName + ":" + result.checkedResult + "\n" payload = { "to": [user_id], "messages":[ { "type":"text", "text": message } ] } requests.post(PUSH_ENDPOINT, headers=HEADER, data=json.dumps(payload)) # プッシュメッセージを送信 # return json.dumps(payload, ensure_ascii=False) # テスト用 def other_reply(reply_token): payload = { "replyToken":reply_token, "messages":[ { "type":"text", "text": "その単語には対応していません…" } ] } requests.post(REPLY_ENDPOINT, headers=HEADER, data=json.dumps(payload)) class CallbackView(viewsets.ModelViewSet): serializer_class = LogRegistSerializer queryset = Checklog.objects.filter(checked_at__lte=timezone.now()).order_by('-checked_at')[:8] # LINEでメッセージを送った場合に呼ばれる @action(methods=['post'], detail = False) def callback(self, request): reply = "" request_json = json.loads(request.body.decode('utf-8')) # requestの情報をdictionary形式で取得 for e in request_json['events']: reply_token = e['replyToken'] # 返信先トークンの取得 message_type = e['message']['type'] # typeの取得 if message_type == 'text': text = e['message']['text'] # 受信メッセージの取得 if "チェック" in text: reply += check_goods_stock(reply_token) # リプライメッセージを送るメソッド else: reply += other_reply(reply_token) # return Response(reply) # テスト用 return Response("OK", status=status.HTTP_200_OK) # Herokuのschedulerから呼び出す(schedulerについては後述) @action(methods=['post'], detail = False) def schedule(self, request): check_goods_stock_scheduled("(ユーザーID)") # プッシュメッセージを送るメソッド # return Response(reply) # テスト用 return Response("OK", status=status.HTTP_200_OK)◆
CallbackView
/api/line/callback/でcallbackメソッド、/api/line/schedule/でscheduleメソッドが呼ばれます。
いずれもPOSTリクエストのみを受け付けています。今回は入荷チェックを実行する関数の実装内容は省略しますが、seleneを使用して実装しています。
seleneはシンプルで使いやすかったのでおすすめです。テストツールなので本来の使い方とは異なりますが…
クローリング、スクレイピングをする場合は■制作を始める前にをぜひご覧ください。◆
check_goods_stock任意のタイミングで入荷情報をチェックする場合に使用されます。
REPLY_ENDPOINTにリプライメッセージを送ります。◆
check_goods_stock_scheduled入荷情報を定期的にチェックするためのメソッドです。
PUSH_ENDPOINTにプッシュメッセージを送ります。
プッシュメッセージを送る際には、送信先のユーザーIDを確認しておく必要があります。
check_goods_stockとの重複がひどいですね… もう少しなんとかならんもんか…と思います。memo:
Viewでは、ModelViewSetを継承していますが、本来はAPIViewを継承するのが理想的だと思います。
APIViewを継承する場合、getやpostメソッドをオーバーライドして使用します。
HTTPリクエストのメソッドに応じてそれぞれの関数が呼ばれます。
しかし先述の通り、発生するエラーが解決できずAPIViewを継承した形で実装できませんでした…
仕方ないのでModelViewSetを継承して、serializer_classとquerysetを記載してあります。本当に無駄なコードですね…実装内容は以上です!
■Herokuへのデプロイ方法
・事前準備
Herokuの公式サイトからHerokuアカウントを作成します。
アカウントを作成したら、コマンドライン上でherokuコマンドを使用する為にHeroku Toolbeltをインストールします。
インストールできたら以下のコマンドでバージョン情報が表示されるかを確認してください。
表示されればインストールが成功しています。cmdheroku --version
- gitコマンドがコマンドライン上で使用できるような状態にしてください。
また、作成したアプリをリモートリポジトリにpushしておいてください。・パッケージの追加インストール
追加でパッケージをインストールします。
cmdpip install gunicorn pip install django-heroku pip install dj-database-url pip install django-toolbeltgunicorn
gunicornはWSGI(Web Server Gateway Interface)サーバーです。ウィスキーと読みます。
WSGIは、WebサーバーとPython Webアプリケーションフレームワークの間の標準インターフェイスです。django-heroku
django-herokuはDjangoプロジェクトをHerokuにデプロイするために必要なライブラリが集まったパッケージです。
dj-database-url
dj-database-urlはdb接続文字列を環境変数DATABASE_URLから取得する際に必要になるパッケージのようです。
今回はこの書き方はしないので、dj-database-urlをインストールするかどうかはお好みになると思います。django-toolbelt
django-toolbeltは
django、psycopg2、gunicorn、dj-database-url、dj-static、static3が詰まったパッケージみたいですが、参考にしたサイトの多くでdj-database-urlやgunicornを個別にもインストールしていました。
個別のインストールは不要では…?と思いましたが、この辺りは自信が無いので、一応分けてインストールしました。memo:
今回は静的ファイルを扱わないので必要ありませんが、純粋なDjangoアプリでhtml等も扱う場合には別途whitenoiseというパッケージをインストールします。以上で必要なパッケージは揃いました。
・必要なファイル三種の用意
1.requirements.txt
アプリを動かすために必要なパッケージの情報をHerokuに伝えるためのファイルを用意します。
プロジェクトのルートディレクトリで以下のコマンドを実行してください。requirements.txtが作成されます。cmdpip freeze > requirements.txt中身を見てみると、これまでこの仮想環境内にインストールされたパッケージ名とそのバージョンが記載されています。
requirements.txtをHerokuに渡すことで、デプロイ時に必要なパッケージを自動でインストールしてくれます。これでパッケージ関連の準備は終わりです。
2.runtime.txt
Heroku上でアプリを動かすときに、Pythonのどのバージョンを使用するかをHerokuに知らせるためのファイルです。
プロジェクトのルートディレクトリに以下の内容でruntime.txtを作成してください。
runtime.txtpython-3.6.4ここで指定するバージョンは、Herokuで対応しているものにしてください。
3.Procfile
Procfile(拡張子なし)をプロジェクトのルートディレクトリに作成します。
Heroku 上で実行するコマンドを記載します。Procfileweb: gunicorn (プロジェクトのルートディレクトリ名).wsgi --log-file -これは"gunicornを起動してログは標準出力に吐いてね。"と指定しています。
アプリを動かすだけならProcfileは不要説もあるようですが、やはりログ出力はしたいので用意することをお勧めします。新しく用意するファイルは以上です。
・settings.pyの修正
settings.pyimport dj_database_url # staticファイルを扱う場合は追記 STATIC_URL = '/static/' # staticファイルを扱う場合は追記 STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles') # SECRET_KEY = '(記載されている内容は別途利用するので覚えておいて、こちらは消してください)' DEBUG = False # TrueからFalseに変更してください # 修正 MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', # コメントアウトします。ここをコメントアウトしないとPOSTリクエストが弾かれ、LINEとの連携ができません。※1 # 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] # 追記 try: from .local_settings import * except ImportError: pass DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': '(スキーマ名)', 'USER': '(ユーザー名)', 'PASSWORD': '(パスワード)', 'HOST': 'host', 'PORT': '5432', } } # 追記 db_from_env = dj_database_url.config(conn_max_age=600, ssl_require=True) DATABASES['default'].update(db_from_env) # 追記 if not DEBUG: SECRET_KEY = os.environ['SECRET_KEY'] import django_heroku django_heroku.settings(locals()) # 修正 ALLOWED_HOSTS = ['(heroku createで付けたアプリ名).herokuapp.com']※1
CSRF対策のためのミドルウェアなので、本来はコメントアウトすべきものではないはずです。
これ以外の方法で実装する手段が見つけられなかったため、コメントアウトという方法を選択しています。
settings.pyに記載のDATABASESの中身は後ほど確認するHeroku上のPostgreSQLへの接続情報を記載します。・local_settings.pyの作成
local_settings.pyimport os # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) SECRET_KEY = '(settings.pyの修正で控えたSECRET_KEYの値)' # DATABASES = { # 'default': { # 'ENGINE': 'django.db.backends.sqlite3', # 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), # } # } DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': '(スキーマ名)', 'USER': '(ユーザー名)', 'PASSWORD': '(パスワード)', 'HOST': 'localhost', 'PORT': '3306', } } DEBUG = True # ローカル環境ではデバッグ表示を有効化しておきます。 ALLOWED_HOSTS = ['127.0.0.1','localhost']
settings.pyの修正に伴って、local_settings.pyを用意します。
ローカル環境とHeroku上で使用するDBを切り替えたり、SECRET_KEYをsettings.py上に書かなくてよくするための工夫です。・wsgi.pyの修正
wsgi.pyimport os from django.core.wsgi import get_wsgi_application os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'line_project.settings') application = get_wsgi_application()・gitとの紐づけ
今回作成するアプリ用のリポジトリを用意したら、gitのリポジトリとHerokuのリポジトリを結びつけます。
まず、Heroku側にも新しくリポジトリを作成します。
cmdheroku create (任意のアプリ名)以下のようなサクセスメッセージが表示されるはずです。
この時点でhttps://(任意のアプリ名).herokuapp.com/にアクセスするとデモページ(?)が表示されます。cmdCreating app... done, ⬢ (任意のアプリ名) https://(任意のアプリ名).herokuapp.com/ | https://git.heroku.com/(任意のアプリ名).gitここまで来たらいよいよgitとの紐づけです。
以下のコマンドを実行します。cmdheroku git:remote -a (任意のアプリ名)これで、Herokuのリポジトリとgitのリポジトリが紐づきました。
.gitignoreは以下のように修正しておきます。
.gitignore__pycache__ db.sqlite3 .DS_Store local_settings.py・最後!デプロイする前に、Herokuに諸々追加
cmdheroku config:set DISABLE_COLLECTSTATIC=1 ※1 heroku addons:add scheduler:standard ※2 heroku buildpacks:set heroku/python ※3 heroku buildpacks:add wrecodde/chromedriver ※4 heroku buildpacks:add wrecodde/google-chrome ※4 heroku config:set SECRET_KEY=(settings.pyの修正で控えたSECRET_KEYの値) ※5 heroku addons:create heroku-postgresql:hobby-dev ※6 heroku pg:info -a (任意のアプリ名) ※7※1
COLLECTSTATICは静的ファイルを扱う際に必要となる機能です。今回は不要なので'1'を設定して無効化しておきます。
静的ファイルを扱う際には不要な設定です。※2
schedulerというアドオンを追加しています。これで定期的にリクエストを飛ばして、入荷情報を定期チェックします。
また、Herokuは30分使用していないとスリープ状態になります(無料アカウントの場合のみ)。
そのため、schedulerを使用して10分後ごとに適当なGETリクエストをすることでスリープしないようにします。
必須なアドオンではありません。なお、Heroku schedulerの利用にはクレジットカードの登録が必要です。※3
ビルドパックにpythonを指定しています。これによって、デプロイしたアプリはPythonで作成されたアプリとしてビルドされます。※4
chromedriverおよびgoogle-chromeというビルドパックを追加しています。
今回はseleneを使用して入荷情報をwebサイトへ確認しに行く処理があるので追加でインストールしました。
インストールしないとwebドライバーが無いためエラーになります。
これは、必要な場合のみ追加してください。※5
SECRET_KEYを環境変数にセットしています。
先ほどsettings.pyを修正した際に、DEBUGがfalseになっている場合は環境変数からSECRET_KEYを取得するように記載したため必要な設定です。※6
Heroku上にPostgreSQLを用意します。※7
先ほど用意したPostgreSQLへの接続情報を確認します。
こちらに表示された値でsettigs.pyのDATABASESを修正してください。Buildpackとは
Heroku でアプリケーションをコンパイルするために使用するオープンソーススクリプトを集めたもの。
公式より引用・デプロイ!
cmdgit push heroku master ※1 heroku ps:scale web=1 ※2 heroku run python manage.py migrate ※3 heroku logs --tail ※4※1
git管理されている最新のアプリをHerokuのリポジトリにpushします。
デプロイ自体はこれで完了です。※2
herokuを起動します。※3
DBをマイグレートします。※4
起動中のHerokuアプリのログをtailしながら表示します。
必要に応じてお使いください。以上でデプロイ完了です!お疲れさまでした!
■LINEとの連携方法
ここまででDRFを使用してWebAPIを作成し、Herokuを使用して公開する方法を紹介しました。
最後に、LINEとの連携方法を紹介します。1.デベロッパーアカウントの作成
LINEとの連携にはLINE MessagingAPIを使用します。
LINE MessagingAPIを使用するためにはLINEのデベロッパーアカウントが必要になります。
デベロッパーアカウントは、LINE Developers公式サイトから作成します。
LINEアカウントでログインすれば簡単に作成できます。2.LINE Botアカウントの作成
公式のLINE Botの作成手順を参考に、Botのアカウントを作成してみてください。かなりわかりやすいです。
channelを作成し、このような画面が表示されることを確認してください。
3.Webhook URLの設定
webhookURLは、サービスがPOSTリクエストを送る先のURLになります。
指定したURLへ、Webhookイベントオブジェクトを持つPOSTリクエストが送られてきます。先ほどの画面から、MessagingAPIタブをクリックするとWebhook settingsという項目があります。
Webhook URLに、今回作成したアプリのcallbackViewを呼び出すURLをセットしてください。
今回だとhttps://(アプリ名).herokuapp.com/api/line/callback/ですね。4.Channel access tokenの取得
MessagingAPIタブではChannel access tokenという項目も確認できます。
こちらから発行されるトークンをViews.pyの
ACCESS_TOKENにセットしてください。5.疎通確認
改めて
git push heroku masterします。Webhook settingsのverifyをクリックすると、以下のようなポップアップが表示されます。
これで疎通確認が取れました。もし上手くいかない場合は、Herokuのログを見ながら原因を探りましょう。
この間だけDEBUGを有効化するのも一つの手ですね。6.メッセージ送信!
今回は"チェック"という文字列の入った単語を送ると、入荷情報を教えてくれて、それ以外の単語を送ると非対応のメッセージが返ってきます。
以上でテキストメッセージを返す、LINE Bot作成までの手順の紹介は終わりです。本当にお疲れ様でした!
■雑感
LINE公式でFlaskを使用したサンプルがあったのでそれを使えばもっと楽だったな…と思います… 完成間際に存在を知りました…
DRFである必要はなかった…LINE公式のリファレンスは日本語にも対応していてわかりやすいです。
今回はテキストを返すだけの簡単なBotでしたが、よりリッチなものにするために必要な機能のリファレンスもとても充実しています。使えていない機能が山ほどあります。
それらを使ってもう少し凝ったことがしたいなぁと思います。■ Advanced REST Clientの紹介
作成当初から、curlコマンドでリクエストを送って動きを確かめていたんですが、jsonをデコードしようとするとコマンドプロンプトの文字コ―ドの問題で上手くいきませんでした…
そこで代わりにAdvanced REST Clientを使いました。
Chromeの拡張機能で、リクエストの内容を書いてSENDボタンを押せばリクエストを送ることができます。
また、一度書いた設定は保存しておくことができるので、打ち直す必要もありません。
jsonのデコードの問題も解消されました。■ 参考にさせていただいたサイト
Messaging APIリファレンス
Django+HerokuでLINE Messaging APIのおそ松botを作るまで
[Django REST Framework] View の使い方をまとめてみた
herokuで悩んだところ
"初めてのHeroku開発"の前に〜Herokuのクセを理解する〜
Django REST framework カスタマイズ方法 - チュートリアルの補足

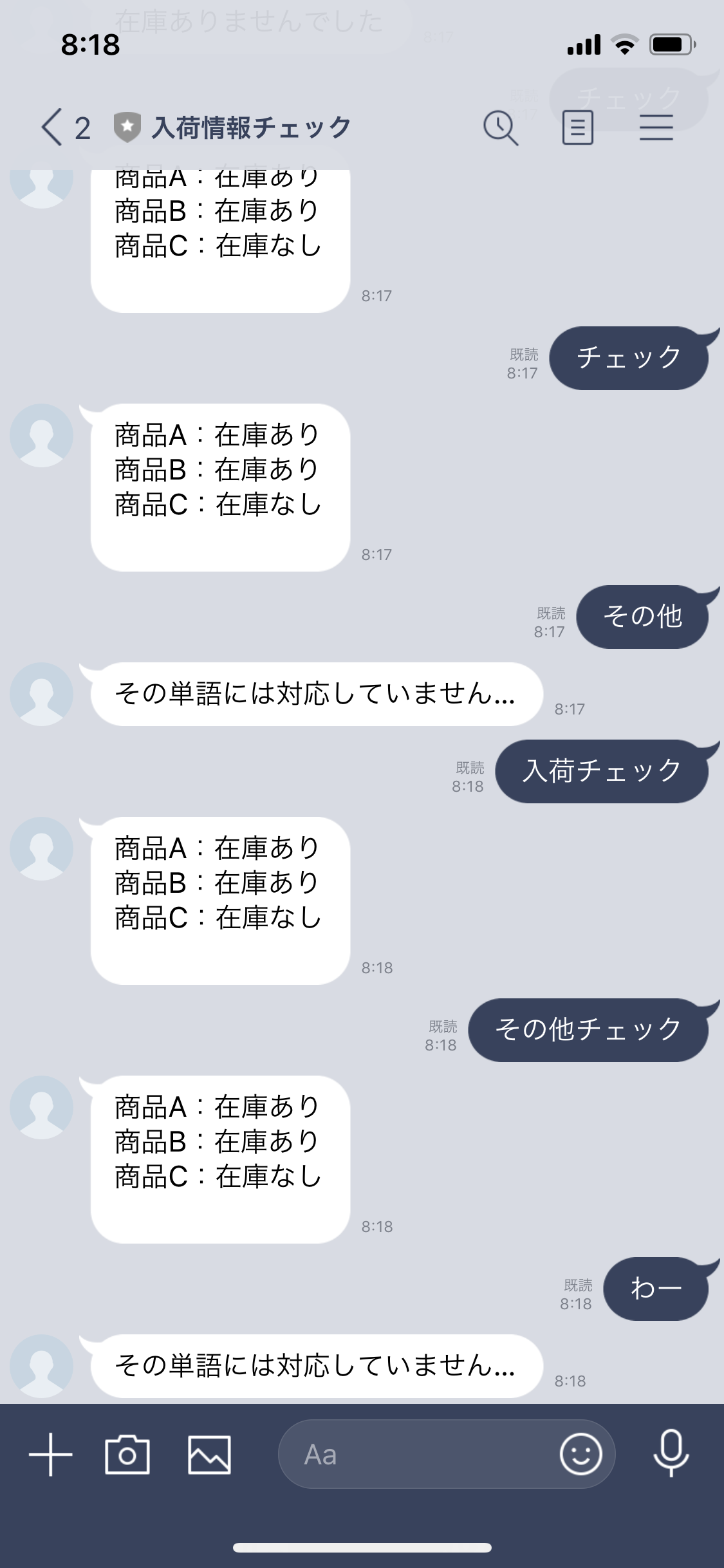
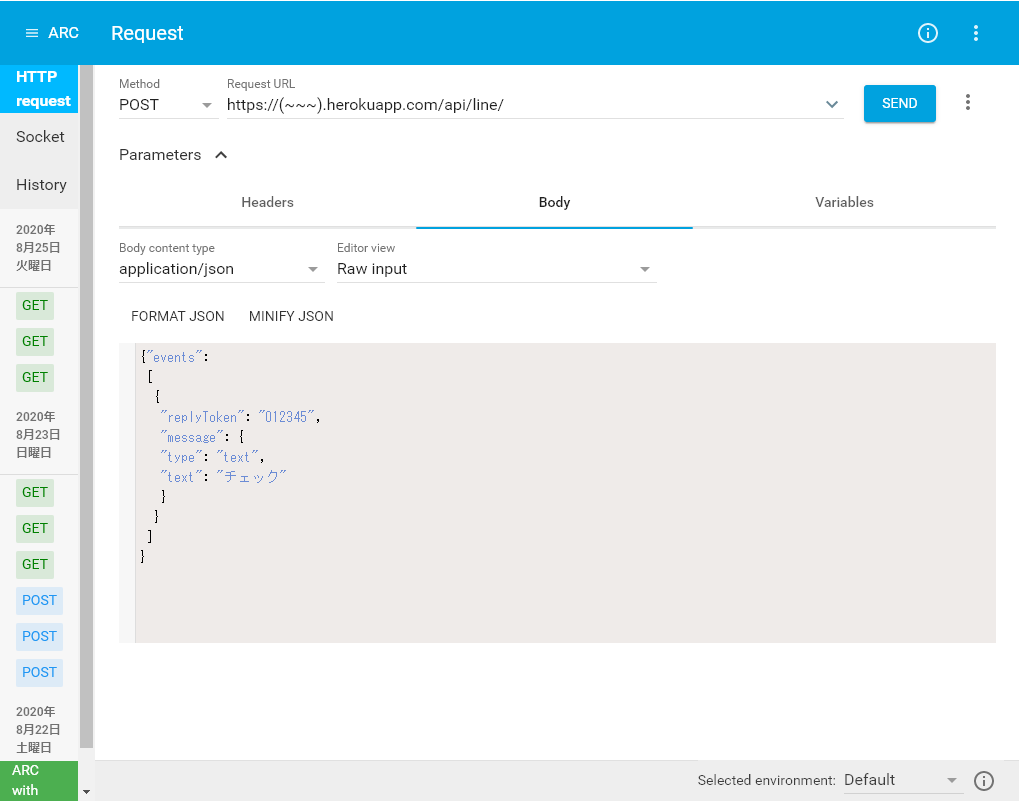
- 投稿日:2020-09-08T08:10:21+09:00
PyTorchでの学習・推論を高速化するコツ集
本記事では、NVIDIAから発表されているPyTorchでのディープラーニングを高速化するコツ集を紹介します。
本記事について
本記事は、NVIDIAのArun Mallyaさんの発表、
「PyTorch Performance Tuning Guide - Szymon Migacz, NVIDIA」
に、説明やプログラムを追加して、解説します。
本記事のポイントは、Andrej KarpathyがTwitterで呟いている通りとなります。
good quick tutorial on optimizing your PyTorch code ⏲️: https://t.co/7CIDWfrI0J
— Andrej Karpathy (@karpathy) August 30, 2020
quick summary: pic.twitter.com/6J1SJcWJslこれを分かりやすく、解説します。
※Andrej Karpathy
ImageNetを整えたフェイフェイ・リー先生のところで博士号を取得
現在はテスラのAI部門のディレクター
ImageNetで人の性能はエラー率5%とあるが、あの結果を出すために、ヒト代表でやったImageNetに挑戦した人本記事の内容
- 内容の注意点
- DataLoaderについて(num_workers、pin_memory)
- torch.backends.cudnn.benchmark = True について
- ミニバッチサイズを大きくしよう()
- Multi-GPUの設定
- テンソルの変換関数はJITに
- その他のTips
0. 内容の注意点
本記事で説明する内容は使用しているGPU環境に依存します。
ご自身の環境でどれが有効かを確かめてみてください。
本記事のプログラムは全て、
https://github.com/YutaroOgawa/Qiita/tree/master/pytorch_performance
で公開しています。Jupyter Notebook形式となっています。
本記事では【性能変化】を、「MNISTの訓練1epoch」の時間で簡単に確認します。
1. DataLoaderについて
PyTorchのDataLoaderには2点、デフォルト設定であまりよくない点があります。
https://pytorch.org/docs/stable/data.html1.1 num_workers
まず、引数がデフォルトでは
num_workers=0となっている点です。
その結果、ミニバッチの取り出しがSingle processになっています。
num_workers=2などに設定することで、multi-process data loadingとなり、処理が高速化されます。CPUのコア数は以下で確認できます。
# CPUのコア数を確認 import os os.cpu_count() # コア数コア数については2あれば1GPUに対しては十分な印象があります。
DataLoaderを以下のように作成します。
# デフォルト設定のDataLoaderの場合 train_loader_default = torch.utils.data.DataLoader(dataset1,batch_size=mini_batch_size) test_loader_default = torch.utils.data.DataLoader(dataset2,batch_size=mini_batch_size) # データローダー:2 train_loader_nworker = torch.utils.data.DataLoader( dataset1, batch_size=mini_batch_size, num_workers=2) test_loader_nworker = torch.utils.data.DataLoader( dataset2, batch_size=mini_batch_size, num_workers=2) # データローダー:フル train_loader_nworker = torch.utils.data.DataLoader( dataset1, batch_size=mini_batch_size, num_workers=os.cpu_count()) test_loader_nworker = torch.utils.data.DataLoader( dataset2, batch_size=mini_batch_size, num_workers=os.cpu_count())【性能変化】
MNISTの訓練1epochで性能変化を確認します。# GPUの確認 !nvidia-smiで使用環境のGPUが確認できます。
今回は、
●ケース1:p3.2xlarge(NVIDIA® VOLTA V100 Tensor Core GPU)
●ケース2:Google Colaboratory(Tesla Turing T4 Tensor Core GPU )となります。Google Colaboratoryは毎回GPUの種類が異なるので注意が必要です。
【defaultの場合】
●ケース1:p3.2xlarge:14.73秒
●ケース2:Google Colaboratory:10.01秒【num_workers=os.cpu_count()の場合】
●ケース1:p3.2xlarge:3.47秒
●ケース2:Google Colaboratory:9.43秒どちらも早くなりましたが、ケース1は1/3程度までと、非常に高速化されました。
なお、p3.2xlargeはCPUコア数が8で、Goole ColaboratoryはCPUコア数が2です。
ただ、コア数は2でnum_workers=2で十分な印象があります。
元の発表でも2以上はそれほど差はないようです。
1.2 pin_memory
PyTorchのDataLoaderは引数
pin_memory=Falseがデフォルトです。
pin_memory=Trueにすることで、automatic memory pinningが使用できます。GPUのメモリ領域がページングされないようになり、高速化が期待されます。
(参考)
https://pytorch.org/docs/stable/data.html#memory-pinning
https://zukaaax.com/archives/301(メモリのページングについて解説)
https://wa3.i-3-i.info/word13352.html実装は以下の通りです。
# デフォルト設定のDataLoaderの場合 train_loader_default = torch.utils.data.DataLoader(dataset1,batch_size=mini_batch_size) test_loader_default = torch.utils.data.DataLoader(dataset2,batch_size=mini_batch_size) # データローダー pin memory train_loader_pin_memory = torch.utils.data.DataLoader( dataset1, batch_size=mini_batch_size, pin_memory=True) test_loader_pin_memory = torch.utils.data.DataLoader( dataset2, batch_size=mini_batch_size, pin_memory=True)先ほどと同じく、MNISTの訓練1epochで性能変化を確認します。
【defaultの場合】
●ケース1:p3.2xlarge:14.73秒
●ケース2:Google Colaboratory:10.01秒【pin_memory=Trueの場合】
●ケース1:p3.2xlarge:13.65秒
●ケース2:Google Colaboratory:9.82秒【num_workers=os.cpu_count()の場合】
●ケース1:p3.2xlarge:3.47秒
●ケース2:Google Colaboratory:9.43秒【num_workers=os.cpu_count() & pin_memory=Trueの場合】
●ケース1:p3.2xlarge:3.50秒
●ケース2:Google Colaboratory:9.35秒デフォルト設定と比較すると、高速化されているのが分かります。
num_workersを設定していると、今回のMNISTでは規模が小さすぎるのか、pin_memoryの効果は見えません。
1.3 DataLoaderの作り方の結論
[1] PyTorchでDataLoaderを作成する場合は、引数num_workersとpin_memoryを変更し、以下のように実装すること。
# デフォルト設定 train_loader_default = torch.utils.data.DataLoader(dataset1,batch_size=mini_batch_size) test_loader_default = torch.utils.data.DataLoader(dataset2,batch_size=mini_batch_size) # データローダー 推奨 train_loader_pin_memory = torch.utils.data.DataLoader( dataset1, batch_size=mini_batch_size, num_workers=os.cpu_count(), pin_memory=True) test_loader_pin_memory = torch.utils.data.DataLoader( dataset2, batch_size=mini_batch_size, num_workers=os.cpu_count(), pin_memory=True) # もしくはデータローダー num_workers=2 train_loader_pin_memory = torch.utils.data.DataLoader( dataset1, batch_size=mini_batch_size, num_workers=2, pin_memory=True) test_loader_pin_memory = torch.utils.data.DataLoader( dataset2, batch_size=mini_batch_size, num_workers=2, pin_memory=True)2. torch.backends.cudnn.benchmark = True について
2.1 解説
訓練を実施する際には、
torch.backends.cudnn.benchmark = Trueを実行しておきましょう。これは、ネットワークの形が固定のとき、GPU側でネットワークの計算を最適化し高速にしてくれます。
通常のCNNのようにデータの入力サイズが最初や途中で変化しない場合はTrueにします。
ただし、計算の再現性がなくなるのでその点は注意が必要です。
(PyTorchの計算再現性について)
https://pytorch.org/docs/stable/notes/randomness.html実装は例えば次の通りとなります。
def MNIST_train_cudnn_benchmark_True(optimizer, model, device, train_loader, test_loader): # デフォルトで訓練 epochs = 1 # 追加 torch.backends.cudnn.benchmark = True # 処理 for epoch in range(1, epochs+1): train(model, device, train_loader, optimizer, epoch) test(model, device, test_loader)なお、ここで関数train()は以下のような形です。
def train(model, device, train_loader, optimizer, epoch): model.train() # 訓練モードに for batch_idx, (data, target) in enumerate(train_loader): # データ取り出し data, target = data.to(device), target.to(device) optimizer.zero_grad() # 伝搬 output = model(data) # 損失計算とバックプロパゲーション loss = F.nll_loss(output, target) loss.backward() optimizer.step()速度を比較します。DataLoaderはデフォルト設定にしておきます。
【defaultの場合】
●ケース1:p3.2xlarge:14.73秒
●ケース2:Google Colaboratory:10.01秒【torch.backends.cudnn.benchmark = Trueの場合】
●ケース1:p3.2xlarge:14.47秒
●ケース2:Google Colaboratory:9.66秒今回はMNISTを解いているだけなので、ネットワークも小さいため、この効果が薄いですが、少し高速化されました。
2.2 結論
プログラム実行時に、
torch.backends.cudnn.benchmark = Trueを入れましょう3. ミニバッチサイズを大きくしよう
ミニバッチサイズが大きい方が学習が安定します。
そのため、ミニバッチサイズは大きくしましょう。PyTorchのAMP(Automatic Mixed Precision)機能により、実際には想定計算以上のミニバッチサイズが可能なケースがあります。
3.1 AMP(Automatic Mixed Precision)機能について
AMP(Automatic Mixed Precision)とは、混合精度を意味します。
通常、FP32(32ビット浮動小数点)で計算されますが、半分のFP16(16ビット浮動小数点)で精度を落とさずにメモリの使用量を節約し、計算速度も向上させる機能です。
さらに、TensorコアがあるGPUであれば、2倍以上の8倍から16倍程度高速化されます。
(訓練で最大12倍、推論で最大6倍程度)
(参考)
https://www.nvidia.com/ja-jp/data-center/tensor-cores/なお、V100のVoltaには、TENSORコア第1世代が搭載されており、
TシリーズにはTURING TENSORコア第2世代が搭載されています。
TURING TENSORコア第2世代は、第1世代よりさらに2倍程度早くなるそうです。
3.2 AMP(Automatic Mixed Precision)を使用する
使用方法などの解説はこちらです。
(参考)
https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/
https://pytorch.org/docs/stable/notes/amp_examples.html上記のexamplesに従って実装します。
先ほどの関数test()を書き換えます。
def train_PyTorchAMP(model, device, train_loader, optimizer, epoch): model.train() # 訓練モードに scaler = torch.cuda.amp.GradScaler() for batch_idx, (data, target) in enumerate(train_loader): # データ取り出し data, target = data.to(device), target.to(device) optimizer.zero_grad() # 伝搬 # Runs the forward pass with autocasting. with torch.cuda.amp.autocast(): output = model(data) loss = F.nll_loss(output, target) # Scales loss. Calls backward() on scaled loss to create scaled gradients. scaler.scale(loss).backward() # scaler.step() first unscales the gradients of the optimizer's assigned params. scaler.step(optimizer) # Updates the scale for next iteration. scaler.update()
scaler = torch.cuda.amp.GradScaler()でscalerを作成し、scalerでforward計算、loss計算、バックプロパゲーション、パラメータ更新をラップします。DataLoaderをデフォルト設定にして、AMPを利用し、速度を比較します。
【defaultの場合】
●ケース1:p3.2xlarge:14.73秒
●ケース2:Google Colaboratory:10.01秒【AMPの場合】
●ケース1:p3.2xlarge:14.21秒
●ケース2:Google Colaboratory:11.97秒今回のMNISTでは1回の計算量なども少ないので、あまり効果は感じられませんでした。
なお、このAMPを利用することで、想定以上にミニバッチサイズを大きくすることが可能になりますが、
ミニバッチサイズを大きくした場合の注意点としては以下を意識します。[1] 学習率の値の調整
[2] weight decay(重み減衰)の調整:optimizerの罰則項の大きさ
[3] 学習にウォームアップ(warmup)を取り入れる:学習の初期は学習率を0から線形に徐々に大きくして一定のところまで上げる
[4] 学習に学習率減衰(learning rate decay)を取り入れる:学習の終盤は学習率を徐々に小さくしていく3.3 LARSやLAMBについて
また、大規模なミニバッチの場合には、OptimizerにLARSやLAMB、NVIDIAのLAMBであるNVLAMBなどの使用も検討します。
大規模なミニバッチの場合、
同じ時間をかけても、ミニバッチサイズが小さいときよりもtotalのepoch数が少なくなります。それを補うために単純に学習率を大きくすると、今度は高すぎる学習率で訓練が安定しづらい
という問題が発生します。
そこで、学習率に“trust ratio”と呼ばれる、勾配に応じた係数をかける手法がLARS(Layerwise Adaptive Rate Scaling)です。
また、LAMB(Layer-wise Adaptive Moments optimizer for Batch training)は、LARSに各ウェイトパラメータの1epochごとの変化の速度も考慮した最適化手法となります。
LAMBを使うことで、通常81時間かかるBERTの学習を、76分と、100倍程度高速化できます。
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
https://arxiv.org/abs/1904.00962
(NVIDIAのA Guide to Optimizer Implementation for BERT at Scaleより)(参考)
https://medium.com/nvidia-ai/a-guide-to-optimizer-implementation-for-bert-at-scale-8338cc7f45fd
https://developer.nvidia.com/blog/pretraining-bert-with-layer-wise-adaptive-learning-rates/
https://postd.cc/optimizing-gradient-descent/
https://towardsdatascience.com/an-intuitive-understanding-of-the-lamb-optimizer-46f8c0ae48663.4 NVIDIAでLAMBなどを使用する方法
まず、以下のNVIDIAのAPEX (A PyTorch Extension)のページを参考にapexをインストールします。
https://github.com/NVIDIA/apex
https://nvidia.github.io/apex/$ git clone https://github.com/NVIDIA/apex $ cd apex $ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./実装は以下の通りです。
まずtrain()を書き換えます。from apex import amp def trainAMP(model, device, train_loader, optimizer, epoch): model.train() # 訓練モードに for batch_idx, (data, target) in enumerate(train_loader): # データ取り出し data, target = data.to(device), target.to(device) optimizer.zero_grad() # 伝搬 output = model(data) # 損失計算とバックプロパゲーション loss = F.nll_loss(output, target) # AMP Train your model with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() optimizer.step()そして、trainAMP()を用いた訓練関数を書きます。
def MNIST_trainAMP(optimizer, model, device, train_loader, test_loader): epochs = 1 start = time.time() torch.backends.cudnn.benchmark = True # 処理 for epoch in range(1, epochs+1): trainAMP(model, device, train_loader, optimizer, epoch) test(model, device, test_loader) # かかった時間 print("=======かかった時間========") print(time.time() - start)optimizerをapex.optimizers.FusedLAMBに設定します。
NVIDIAのLAMBAはNVLAMBと呼ばれます。import apex # モデル、学習率とoptimizerを設定 model = Net().to(device) lr_rate = 0.1 optimizer = apex.optimizers.FusedLAMB(model.parameters(), lr=lr_rate)# Initialization opt_level = 'O1' model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)AMPでモデルとoptimizerを初期化します。
最後に訓練を実施します。
MNIST_trainAMP(optimizer, model, device, train_loader_pin_memory, test_loader_pin_memory)以上が、大規模なミニバッチに対する、NVIDIAのLAMB optimizerの使用方法となります。
4. Multi-GPUの設定
Multi-GPUで訓練する場合は、
DATAPARALLELのtorch.nn.DataParallelではなく、
DISTRIBUTEDDATAPARALLELのtorch.nn.parallel.DistributedDataParallel
を使用します。これは以下の講演スライドのように、
DATAPARALLELだとCPUの1コアしか使用してくれないからです。
DISTRIBUTEDDATAPARALLELであれば、1GPUに対して、1CPUコアが割り当てられます。
また、NVIDIAのAPEXの
apex.parallel.DistributedDataParallelは、torch.nn.parallel.DistributedDataParallelと同じように使用できますが、利点があります。それは、NVIDIAの
apex.parallel.DistributedDataParallelが、Synchronized Batch Normalizationになっている点です。PyTorchのバッチノーマライゼーション層はMulti-GPUの場合、各GPUごとに割り当てられたミニバッチ内でバッチノーマライゼーションを実施し、各GPUごとに平均と標準偏差を求め、それらを平均して、バッチノーマライゼーションの平均、標準偏差を学習させていきます。
これは、各GPUごとにバッチノーマライゼーションを行うので、Asynchronized Batch Normalizationと呼びます。
Multi-GPUに分散された全データでのバッチノーマライゼーションと計算結果が変わってしまいます。
PyTochの場合、
torch.nn.SyncBatchNormを使う作戦もあるのですが、結構実装が面倒です。NVIDIAのAPEXの
apex.parallel.DistributedDataParallelを使用し
sync_bn_model = apex.parallel.convert_syncbn_model(model)
でモデルを変換するだけで、Synchronized Batch Normalization*になります。(参考)
https://nvidia.github.io/apex/parallel.html
https://github.com/NVIDIA/apex/tree/master/apex/parallel
https://github.com/NVIDIA/apex/tree/master/examples/simple/distributed5. テンソルの変換関数はJITに
テンソルへの個別操作の関数には、デコレエータ@torch.jit.scriptをつけて、PyToch JIT(C++実行形式)にしておき、
高速化します。JIT(Just-In-Time Compiler)とは、ソフトウェアの実行時にコードのコンパイルを行い実行速度の向上を図るコンパイラのことです。
TensorflowやKerasはdefine and runで、コンパイルしてから実行します(その分、コード記述が面倒であった)
PyTorchはdefine by runで、データを流しながら計算を構築します。
ただ、決まりきった計算関数については先にコンパイルしておいた方が良いので、JITでC++実行形式(操作上はPythonから実行する)にします。例えば、活性化関数のgeluを定義したいとき、通常の定義と、JITでの定義は以下のようになります。
def gelu(x): return x * 0.5 * (1.0 + torch.erf(x / 1.41421)) @torch.jit.script def fused_gelu(x): return x * 0.5 * (1.0 + torch.erf(x / 1.41421))PyTorch JITにするにはデコレータ
@torch.jit.scriptを関数につけます。これの実行速度を比較すると、
import time x = torch.randn(2000, 3000) start = time.time() for i in range(200): gelu(x) # かかった時間 print("=======かかった時間========") print(time.time() - start)と
import time x = torch.randn(2000, 3000) start = time.time() for i in range(200): fused_gelu(x) # かかった時間 print("=======かかった時間========") print(time.time() - start)では、
●ケース1:p3.2xlarge(NVIDIA® VOLTA V100 Tensor Core GPU)
で、9.8秒→6.6秒
●ケース2:Google Colaboratory(Tesla Turing T4 Tensor Core GPU )
で、13.94秒→13.91秒
でした。
Google Colaboratoryでは変化がほとんどないのですが、AWSのp3.2xlargeでは6割ほどまで時間が短縮されています。
6. その他のTips
6.1 バックプロパゲーションが不要なモデルの設定
GANの計算などで、バックプロパゲーションが不要なモデルを全体の一部に使用する場合、
model.zero_grad()ではなく、
for param in model.parameters(): param.grad = Noneで勾配計算をNoneにします。これは、model.zero_grad()だと実際にはメモリ領域を消費するためです。
6.2 バッチノーマライゼーションの前の層はバイアスパラメータをFalseに
バッチノーマライゼーションで標準化して、平均0にするのであれば、その前の層にバイアスパラメータがあると、それを打ち消すようにバッチノーマライゼーションも定数項を学習することになります。
計算時間も、計算量ももったいないので、バッチノーマライゼーションの前の層はバイアスパラメータはFalseに設定し、バイアス項を使用しないようにしておきます。
まとめ
以上、PyTorchでの学習・推論を高速化するコツを紹介しました。
いくつかの手法は、Google Colaboratoryの場合、
「裏側で何か起こっているのか、機能しない?もしくは自動で機能している?」ような感じを受けました。一方で、普通にクラウドでGPUインスタンスを立ててPyTorchでディープラーニングをする際には、本記事は使える点も多いかと思います。
ぜひご活用いただければ幸いです♪
備考
【執筆者】電通国際情報サービス(ISID)AIトランスフォーメーションセンター 開発Gr
小川 雄太郎(主書「つくりながら学ぶ! PyTorchによる発展ディープラーニング」 、その他「自己紹介詳細」)【Twitter】
IT・AI関連やビジネス・経営系を中心に、私が面白いと思った記事や最近読んだ新刊書籍の感想などを発信しています。これらの分野の情報を収集したい方はぜひフォローしてみてください♪(海外情報が多めです)小川雄太郎@ISID_AI_team
https://twitter.com/ISID_AI_team【その他】
私がリードする、「AIトランスフォーメーションセンター 開発チーム」ではメンバを募集中です。ご興味、ご関心をお持ちの方は、こちらのページから、応募をお待ちしております。【そくめん君】
いきなり応募は・・・という方は、カジュアル面談を「そくめん君」で行わせていただいております。
こちらもぜひご利用ください♪
https://sokumenkun.com/2020/08/17/yutaro-ogawa/【免責】本記事の内容そのものは著者の意見/発信であり、著者が属する企業等の公式見解ではございません


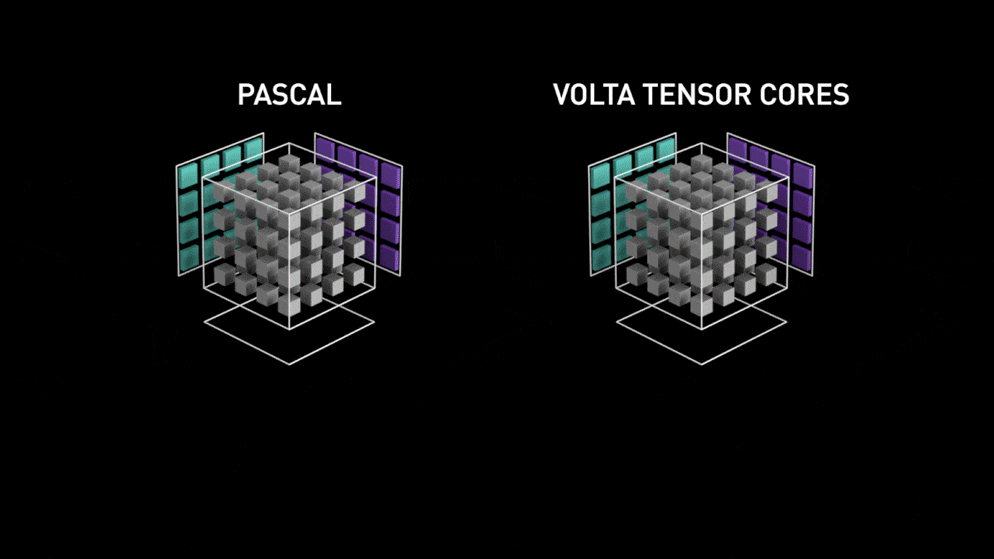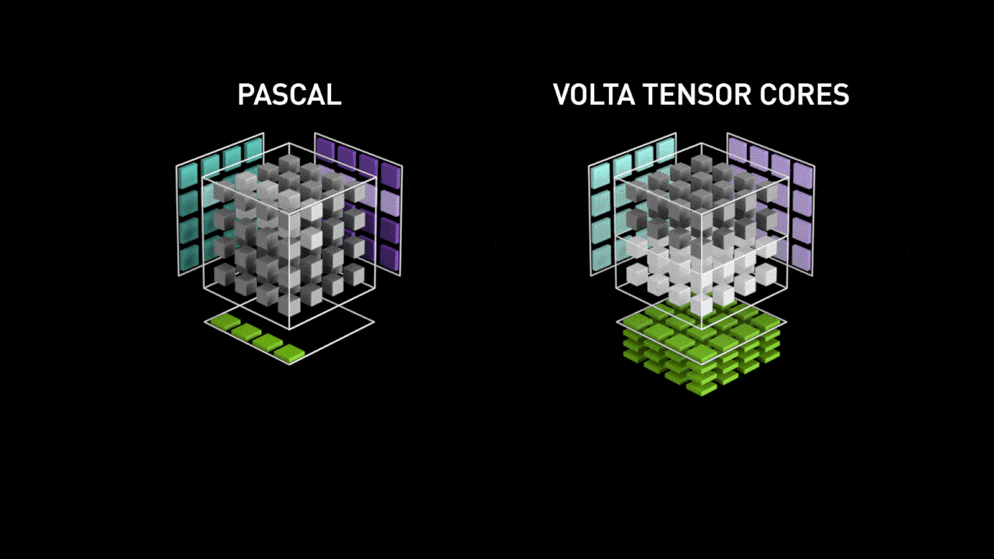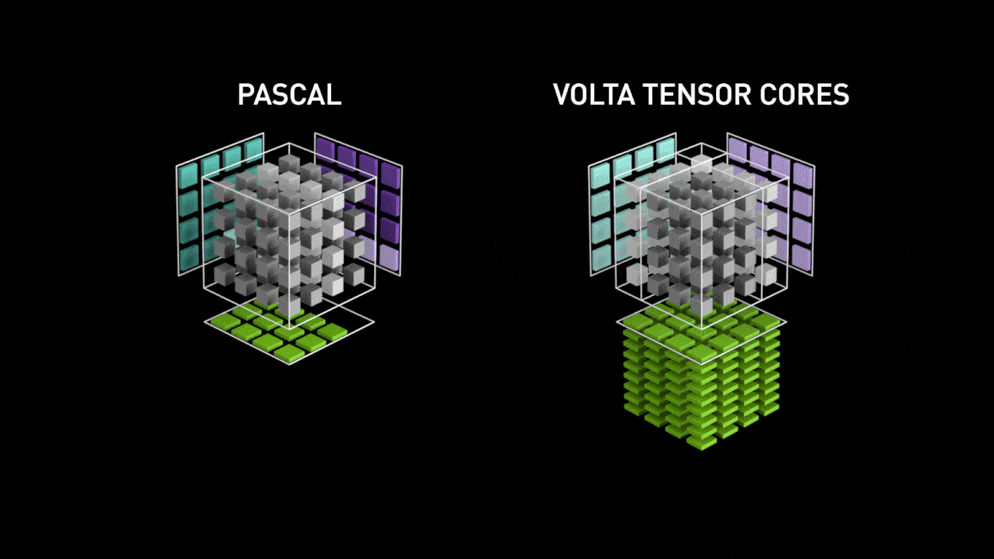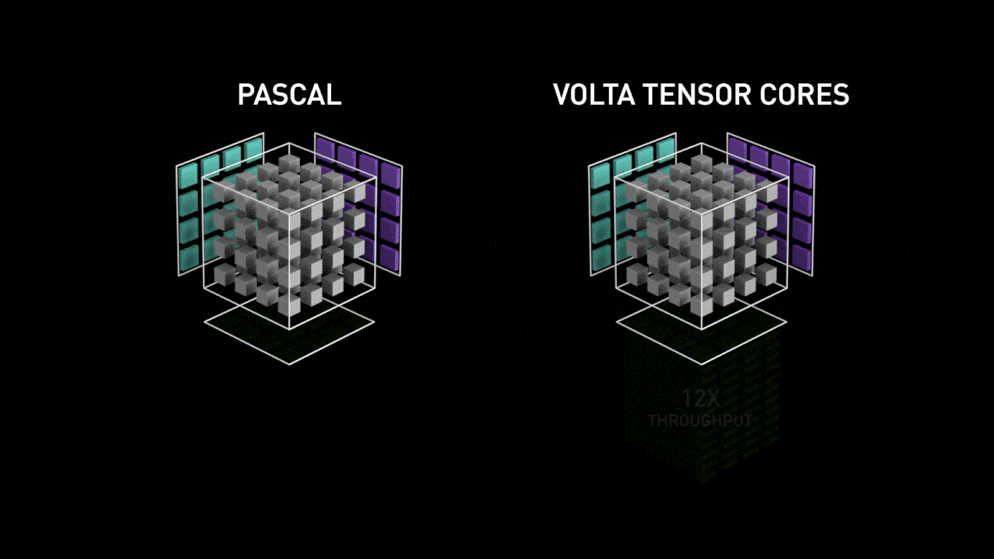
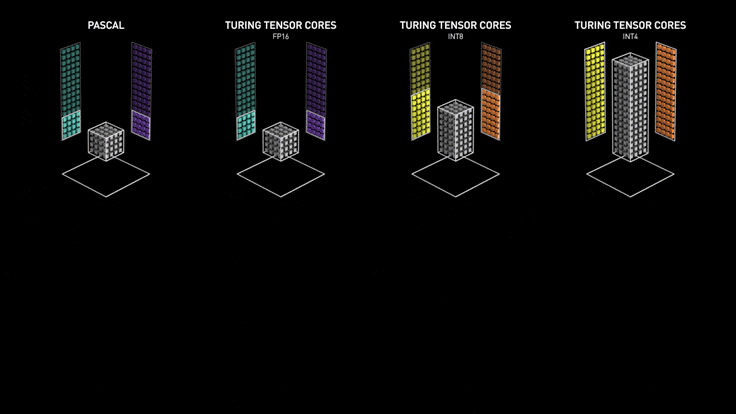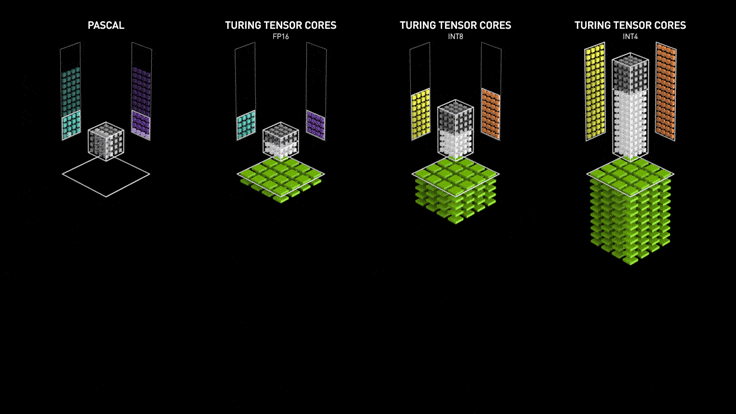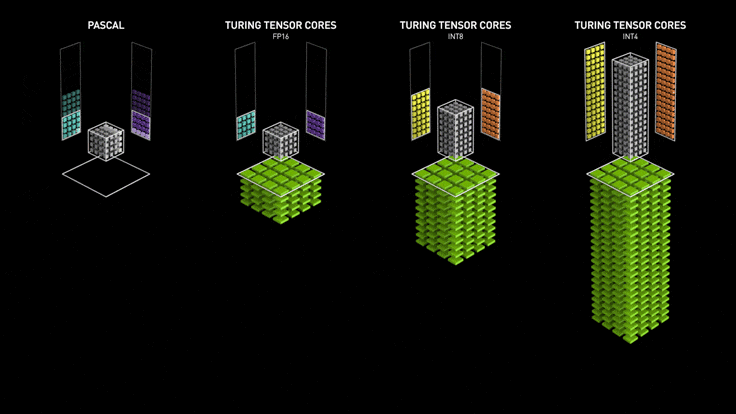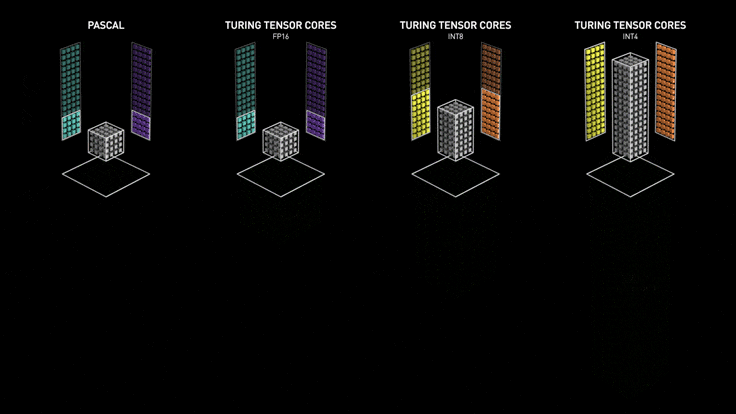

- 投稿日:2020-09-08T05:55:36+09:00
【Python】PDFを元の書式を保ってDeepLで自動翻訳する。【要Windows・Word】
はじめに
以前、PDFの自動翻訳についての記事を書きましたが、
やっぱり画像や数式、段組みなど、元の形を保ちたい!
という心残りがあったため、手段を探したところ、Wordを利用した方法にたどり着いたので紹介したいと思います。
ただし、PDFとWordとの相性によってはあまりきれいに加工できない場合もあります。使用例
PDFはこちらからお借りしました→https://mirela.net.technion.ac.il/publications/
文字幅・文字数の関係で位置がずれています。
$EN→JA$
必要なもの
・Windows PC
・Microsoft Word
・ChromeDriver(下記プログラムをそのまま実行する場合は実行ディレクトリ下に保存してください)流れ
プログラム開始
↓
Wordで対象PDFをdocxとして開く
↓
Paragraphごとに文章を取得
↓
SeleniumでDeepL翻訳
↓
Word経由で書き換え
↓
PDFとして保存
↓
プログラム終了実装
1段落ごとにやってると時間がかかるのでマルチスレッドで実行するようにしました。
何らかの理由で段落の位置を管理している番号がズレてしまうようでしたら、時間はかかりますが1段落ごとに翻訳するバージョンも載せておくのでお試しください。import win32com.client from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys import time import re import pyperclip as ppc from math import ceil from threading import Thread, Lock DRIVER_PATH = 'chromedriver.exe' options = Options() options.add_argument('--disable-gpu') options.add_argument('--disable-extensions') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') def Deeptrans(t, driver): global translated_texts stextarea = driver.find_element_by_css_selector( '.lmt__textarea.lmt__source_textarea.lmt__textarea_base_style') ttextarea = driver.find_element_by_css_selector( '.lmt__textarea.lmt__target_textarea.lmt__textarea_base_style') for i in range(t * unit, min((t + 1) * unit, length)): sourse_text = sourse_texts[i] if re.search(r"[\x00-\x1F\x7F]", sourse_text.strip()) or len(sourse_text.strip()) < 5: continue lock.acquire() ppc.copy(sourse_text) stextarea.send_keys(Keys.CONTROL, "v") lock.release() translated_text = "" while not translated_text: time.sleep(1) translated_text = ttextarea.get_property("value") stextarea.send_keys(Keys.CONTROL, "a") stextarea.send_keys(Keys.BACKSPACE) translated_texts[str(i + 1)] = translated_text def runDriver(t): driver = webdriver.Chrome(DRIVER_PATH) url = 'https://www.deepl.com/ja/translator' driver.get(url) Deeptrans(t, driver) driver.quit() def multiThreadTranslate(file_path, font): global lock, length, unit, sourse_texts, translated_texts app = win32com.client.Dispatch("Word.Application") app.Visible = True #コメントアウトでWord非表示 doc = app.Documents.Open(file_path) try: doc.Paragraphs(1).Range.Font.Name = font except: print('指定されたフォントは存在しません') doc.Close(SaveChanges=0) app.Quit() return length = doc.Paragraphs.Count n = 9 #Chromeを9つ開いて同時実行 unit = ceil(length / n) lock = Lock() clipboard = ppc.paste() sourse_texts = [doc.Paragraphs(i + 1).Range.Text for i in range(length)] translated_texts = {} threads = [] for t in range(n): thread = Thread(target=runDriver, args=(t, )) thread.setDaemon(True) thread.start() threads.append(thread) for thread in threads: thread.join() for k, v in translated_texts.items(): doc.Paragraphs(int(k)).Range.Text = v.replace('\n', '\r') doc.Paragraphs(int(k)).Range.Font.Name = font doc.SaveAs2(FileName=re.sub("(.+)(\.pdf)", r"\1_jp.pdf", file_path), FileFormat=17) doc.Close(SaveChanges=0) app.Quit() print('Process is completed.') ppc.copy(clipboard) if __name__ == '__main__': file_path = input('PDFの絶対パスを入力してください: ') print('フォントを選択してください') fonts = {'1': '游明朝', '2': 'メイリオ', '3': 'BIZ UDP明朝 Medium', '4': 'その他'} font = fonts[input(' '.join( [", ".join(list(fonts.items())[i]) for i in range(len(fonts))]) + ": ")] if font == 'その他': font = input('フォント名を入力してください: ') multiThreadTranslate(file_path, font=font)
1段落ずつver.(プログレスバーのおまけ付き)
import win32com.client from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys import time import re import pyperclip as ppc from tqdm import tqdm DRIVER_PATH = 'chromedriver.exe' options = Options() options.add_argument('--disable-gpu') options.add_argument('--disable-extensions') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') def Deeptrans(file_path, font): clipboard = ppc.paste() app = win32com.client.Dispatch("Word.Application") app.Visible = True doc = app.Documents.Open(file_path) driver = webdriver.Chrome(executable_path=DRIVER_PATH, chrome_options=options) url = 'https://www.deepl.com/ja/translator#en/ja' driver.get(url) stextarea = driver.find_element_by_css_selector( '.lmt__textarea.lmt__source_textarea.lmt__textarea_base_style') ttextarea = driver.find_element_by_css_selector( '.lmt__textarea.lmt__target_textarea.lmt__textarea_base_style') for i in tqdm(range(doc.Paragraphs.Count)): sourse_text = doc.Paragraphs(i + 1).Range.Text if re.search(r"[\x00-\x1F\x7F]", sourse_text.strip()) or len(sourse_text.strip()) < 5: continue ppc.copy(sourse_text) stextarea.send_keys(Keys.CONTROL, "v") translated_text = "" while not translated_text: time.sleep(1) translated_text = ttextarea.get_property("value") stextarea.send_keys(Keys.CONTROL, "a") stextarea.send_keys(Keys.BACKSPACE) doc.Paragraphs(i + 1).Range.Text = translated_text doc.Paragraphs(i + 1).Range.Font.Name = font driver.quit() doc.SaveAs2(FileName=re.sub("(.+)(\.pdf)", r"\1_jp.pdf", file_path), FileFormat=17) doc.Close(SaveChanges=0) app.Quit() print('Process is completed.') ppc.copy(clipboard) if __name__ == '__main__': file_path = input('PDFの絶対パスを入力してください: ') print('フォントを選択してください') fonts = {'1': '游明朝', '2': 'メイリオ', '3': 'BIZ UDP明朝 Medium', '4': 'その他'} font = fonts[input(' '.join( [", ".join(list(fonts.items())[i]) for i in range(len(fonts))]) + ": ")] if font == 'その他': font = input('フォント名を入力してください: ') Deeptrans(file_path, font)
まとめ
Word様様です。
興味がありましたらどうぞお試しください。
