- 投稿日:2020-08-07T23:05:24+09:00
Python で HTTP リダイレクト先の URL を取得する
概要
- Python 3 で HTTP リダイレクト先の URL を取得する
- 動作確認環境: Python 3.8.5 + macOS Catalina
ソースコード
get_redirect.py というファイル名で以下の内容を保存する。
get_redirect.pyimport sys import urllib.request # リダイレクトしないハンドラークラス class NoRedirectHandler(urllib.request.HTTPRedirectHandler): # HTTPRedirectHandler.redirect_request をオーバーライド def redirect_request(self, req, fp, code, msg, hdrs, newurl): self.newurl = newurl # リダイレクト先URLを保持 return None # リダイレクト先 URL を取得する関数 def get_redirect_url(src_url): # リダイレクトしないハンドラーをセット no_redirect_handler = NoRedirectHandler() opener = urllib.request.build_opener(no_redirect_handler) try: with opener.open(src_url) as res: return None # リダイレクトしない URL だった except urllib.error.HTTPError as e: if hasattr(no_redirect_handler, "newurl"): return no_redirect_handler.newurl # リダイレクト先 URL を返す else: raise e # リダイレクト以外で発生した例外なので投げ直す # コマンドライン引数を取得 src_url = sys.argv[1] # リダイレクト先URLを取得 redirect_url = get_redirect_url(src_url) # リダイレクト先URLを出力 if redirect_url is not None: print(redirect_url)実行例。
$ python get_redirect.py https://bit.ly/3kmTOkc https://t.co/yITSBp4ino$ python get_redirect.py https://t.co/yITSBp4ino https://qiita.com/niwasawa$ python get_redirect.py https://qiita.com/niwasawa簡略版
get_redirect.py というファイル名で以下の内容を保存する。
get_redirect.pyimport sys import urllib.request # リダイレクト先URLを取得する関数 def get_redirect_url(src_url): with urllib.request.urlopen(src_url) as res: url = res.geturl() # 最終的な URL を取得 if src_url == url: return None # 指定された URL と同じなのでリダイレクトしていない else: return url # 指定された URL と異なるのでリダイレクトしている # コマンドライン引数を取得 src_url = sys.argv[1] # リダイレクト先URLを取得 redirect_url = get_redirect_url(src_url) # リダイレクト先URLを出力 if redirect_url is not None: print(redirect_url)実行例。
簡易版では、リダイレクト先の URL にリクエストを投げてしまったり、多段リダイレクトの場合は最終的な URL を出力する。$ python get_redirect.py https://bit.ly/3kmTOkc https://qiita.com/niwasawa$ python get_redirect.py https://t.co/yITSBp4ino https://qiita.com/niwasawa$ python get_redirect.py https://qiita.com/niwasawa参考資料
- 投稿日:2020-08-07T22:29:26+09:00
【subprocess】Pythonで別のPythonプログラムを実行したいとき
はじめに
Pythonで書いたコードが複数あり、それらの開始をとある一つのプログラムに制御させたい――
そんなときありますよね。
今回はプログラムの中から他の起動させたいプログラムを非同期で実行させる方法を紹介します。今回のメインコード
import subprocess command = [python (ファイル).py (引数)] proc = subprocess.Popen(command) #->コマンドが実行される(処理の終了は待たない) result = proc.communicate() #->終了を待つコード例
何の捻りもないコードですが、とりあえず動くかのお試しで2つのファイルを作成しました。
call.pyでは与えた引数を出力するようにできています。
コマンドはスペース区切りで””で囲んでリストにします。call.pyimport sys from time import sleep sleep(1) #一秒寝てもらう(非同期になっているか確認のため) args = sys.argv[1] print(args)main.pyimport subprocess command = ["python","call.py,"呼ばれた!"] proc = subprocess.Popen(command) print("呼び出し中") proc.communicate()実行結果
先にmainの「呼び出し中」がprintされていることから、
subprocess.Popen()で実行した処理を待っていないことがわかります。処理時間について
subprocess.Popen()で呼び出すと処理時間が気になります。
1280×800の画像に対して、下記の処理を行うcall_2.pyを呼び出してみます。call_2.pyfrom time import time import numpy as np import cv2 start = time() img = cv2.imread("sample.png") resize = cv2.resize(img,dsize=None,fx=0.5,fy=0.5) #resize kernel = np.ones((5,5),np.uint8) erosion = cv2.erode(resize,kernel) #erode cv2.imwrite("resize.png",erosion) end = time() - start print(end)これでpython main.pyで実行した場合と、python call_2.pyで実行した場合の
printされるendの時間を比べてみました。
何度かコンソールを出入りして試しましたが、
キャッシュに入っても入ってなくても処理時間はほぼ同じでした。
(実際の数字は実行環境に因るかと思いますので割愛)おわりに
subprocess.Popen()で別のpyファイルを実行する方法を紹介しました。
Windows環境では処理速度に差は出ませんでした。
速度面でのネックがないのは嬉しいですね。
ただ、環境がLinuxとかだともしかしたらかわるかもしれません。以上、ご参考になれば幸いです。
参考資料
下記サイトも是非ご参考にしてください
公式ドキュメント(Python3.8.5)
実行したいファイルが別のディレクトリに存在する場合
Pythonからシェルコマンドを実行!subprocessでサブプロセスを実行する方法まとめ
subprocessでPythonからLinuxコマンド実行参考になりそうな本(単に自分が読んでみたい…)
エキスパートPythonプログラミング改訂2版

- 投稿日:2020-08-07T22:29:26+09:00
【subprocess】Pythonのコードの中で別のPythonプログラムを実行したいとき
はじめに
Pythonで書いたコードが複数あり、それらの開始をとある一つのプログラムに制御させたい――
そんなときありますよね。
今回はプログラムの中から他の起動させたいプログラムを非同期で実行させる方法を紹介します。環境
Windows10
python 3.7.6
anaconda 20.02今回のメインコード
import subprocess command = [python (ファイル).py (引数)] proc = subprocess.Popen(command) #->コマンドが実行される(処理の終了は待たない) result = proc.communicate() #->終了を待つコード例
何の捻りもないコードですが、とりあえず動くかのお試しで2つのファイルを作成しました。
call.pyでは与えた引数を出力するようにできています。
コマンドはスペース区切りで””で囲んでリストにします。call.pyimport sys from time import sleep sleep(1) #一秒寝てもらう(非同期になっているか確認のため) args = sys.argv[1] print(args)main.pyimport subprocess command = ["python","call.py,"呼ばれた!"] proc = subprocess.Popen(command) print("呼び出し中") proc.communicate()実行結果
先にmainの「呼び出し中」がprintされていることから、
subprocess.Popen()で実行した処理を待っていないことがわかります。処理時間について
subprocess.Popen()で呼び出すと処理時間が気になります。
1280×800の画像に対して、下記の処理を行うcall_2.pyを呼び出してみます。call_2.pyfrom time import time import numpy as np import cv2 start = time() img = cv2.imread("sample.png") resize = cv2.resize(img,dsize=None,fx=0.5,fy=0.5) #resize kernel = np.ones((5,5),np.uint8) erosion = cv2.erode(resize,kernel) #erode cv2.imwrite("resize.png",erosion) end = time() - start print(end)これでpython main.pyで実行した場合と、python call_2.pyで実行した場合の
printされるendの時間を比べてみました。
何度かコンソールを出入りして試しましたが、
キャッシュに入っても入ってなくても処理時間はほぼ同じでした。
(実際の数字は実行環境に因るかと思いますので割愛)おわりに
subprocess.Popen()で別のpyファイルを実行する方法を紹介しました。
Windows環境では処理速度に差は出ませんでした。
速度面でのネックがないのは嬉しいですね。
ただ、環境がLinuxとかだともしかしたらかわるかもしれません。以上、ご参考になれば幸いです。
参考資料
下記サイトも是非ご参考にしてください
公式ドキュメント(Python3.8.5)
実行したいファイルが別のディレクトリに存在する場合
Pythonからシェルコマンドを実行!subprocessでサブプロセスを実行する方法まとめ
subprocessでPythonからLinuxコマンド実行参考になりそうな本(単に自分が読んでみたい…)
エキスパートPythonプログラミング改訂2版
- 投稿日:2020-08-07T22:27:59+09:00
継続渡しスタイル(CPS)チートシート
例によって,少なくとも約1名(自分自身)には役立ちそうだったので,各言語の継続渡しスタイル(Continuation-passing style,CPS)のサンプル記述を記事としてまとめた.
Python(Python 3):解説付き
対話モードで,
xに10を代入してから,x + 20を評価させてみる.>>> x = 10 >>> x + 20 30このプログラム記述をファイルにしてPythonインタプリタに実行させても,何も表示されない.対話モード(REPL)では,式として評価されたものはその結果を表示するのに対し,ファイル実行(スクリプト)では,そのような表示は行わないためである.
C:\Users\hoge>type sample.py x = 10 x + 20 C:\Users\hoge>python sample.py C:\Users\hoge>もし,ファイル実行で評価結果を表示させたい場合は,評価結果を得た後に,たとえば
C:\Users\hoge>type sample.py x = 10 print(x + 20) C:\Users\hoge>python sample.py 30 C:\Users\hoge>ここで,式として記述する場合は,評価結果を処理する関数を必ず指定しなければならない仕組みを考える.次は,
x + 20を評価したら,その評価結果を関数fに引数として渡して呼び出す関数cadd20を定義し,fにC:\Users\hoge>type sample.py def cadd20(x, f): f(x + 20) x = 10 cadd20(x, print) C:\Users\hoge>python sample.py 30 C:\Users\hoge\python>このように,結果を処理する手続きをあらかじめ指定する仕組みを想定したプログラミング手法を『継続渡しスタイル』(continuation-passing style,CPS)と呼ぶ.このスタイルは,そうとは意識されない形を含め,様々な実装に応用されている.
- コールバック関数(指定する手続き)とハンドラー(呼び出す関数)
- 例外処理の
try(呼び出す手続き)とexcept(指定する手続き)- CPSに自動変換して明確となった値受け渡しからの中間言語記述生成
なお,関数のCPSへの変換は容易であるが,変換した関数を使用するには工夫が必要である.ここでは,既存関数のCPSへの変換と利用例を示す(このチートシートの本体).
from operator import add, sub, mul # func(x, y) = (x + y) * (x - y) def func(x, y): return mul(add(x, y), sub(x, y)) print(func(10, 20)) # => -300 def cps(f): def cps(x, y, c): return c(f(x, y)) return cps cps(add)(10, 20, print) # => 30 def cfunc(x, y, c): return cps(add)(x, y, lambda c1: # x + y -> c1 cps(sub)(x, y, lambda c2: # x - y -> c2 cps(mul)(c1, c2, c))) # c1 * c2 -> c cfunc(10, 20, print) # => -300Scheme(Gauche):『継続』利用例付き
; func(x, y) = (x + y) * (x - y) (define (func x y) (* (+ x y) (- x y))) (display (func 10 20)) ; => -300 (define (cps f) (lambda (x y c) (c (f x y)))) ((cps +) 10 20 display) ; => 30 (define (cfunc x y c) ((cps +) x y (lambda (c1) ; x + y -> c1 ((cps -) x y (lambda (c2) ; x - y -> c2 ((cps *) c1 c2 c)))))) ; c1 * c2 -> c (cfunc 10 20 display) ; => -300せっかくの本家本元なので(?),その時点の『継続』を引数として取り出すことができる
call-with-current-continuation(call/cc)の利用例を併せて示す.(define (func x y) (* (+ x y) (- x y))) (display (func 10 20)) ; => -300 (display (func 20 10)) ; => 300 (define cc) (define (func x y) (* (call/cc (lambda (c) (set! cc c) (+ x y))) (- x y))) (display (func 10 20)) ; => -300 ※ccに(lambda (n) (* n (- 10 20)))相当が格納される (display (cc 3)) ; => -30 (display (func 20 10)) ; => 300 ※ccに(lambda (n) (* n (- 20 10)))相当が格納される (display (cc 3)) ; => 30 (define (func x y) (* (+ x y) (- x (call/cc (lambda (c) (set! cc c) y))))) (display (func 10 20)) ; => -300 ※ccに(lambda (n) (* (+ 10 20) (- 10 n)))相当が格納される (display (cc 3)) ; => 210 (display (func 20 10)) ; => 300 ※ccに(lambda (n) (* (+ 20 10) (- 20 n)))相当が格納される (display (cc 3)) ; => 510Ruby(CRuby)
# func(x, y) = (x + y) * (x - y) def func1(x,y) (x+y)*(x-y) end p func1(10,20) # => -300 add = -> x,y { x+y } sub = -> x,y { x-y } mul = -> x,y { x*y } prn = -> x { p x } cps = -> f { -> x,y,c { c.(f.(x,y)) } } cps[add][10,20,prn] # => 30 cfunc = -> x,y,c { cps.(add).(x, y, -> c1 { # x + y -> c1 cps.(sub).(x, y, -> c2 { # x - y -> c2 cps.(mul).(c1,c2,c) }) }) # c1 * c2 -> c } cfunc[10,20,prn] # => -300JavaScript(Node.js)
// func(x, y) = (x + y) * (x - y) function func1(x,y) { return (x+y)*(x-y) } console.log(func1(10,20)) // => -300 add = (x,y) => x+y sub = (x,y) => x-y mul = (x,y) => x*y cps = f => (x,y,c) => c(f(x,y)) cps(add)(10,20,console.log) // => 30 cfunc = function(x,y,c) { return cps(add)(x, y, c1 => // x + y -> c1 cps(sub)(x, y, c2 => // x - y -> c2 cps(mul)(c1,c2,c))) // x * y -> c } cfunc(10,20,console.log) // => -300備考
記事に関する補足
- そのうち『Iコンビネータ』に関する説明を追加するかもしれない(謎).
参考文献
- お気楽 OCaml プログラミング入門:継続渡しスタイル
変更履歴
- 2020-08-07:参考文献欄を追加
- 2020-08-07:JavaScriptの例を追加
- 2020-08-07:初版公開(Python,Scheme,Ruby)
- 投稿日:2020-08-07T21:52:11+09:00
アルゴリズム 体操24 Subsets
Subsets
個別の要素を持つセットを指定して、その個別のサブセットをすべて見つけます。
例
Input: [1, 3]
Output: [], [1], [3], [1,3]Input: [1, 5, 3]
Output: [], [1], [5], [3], [1,5], [1,3], [5,3], [1,5,3]Solution
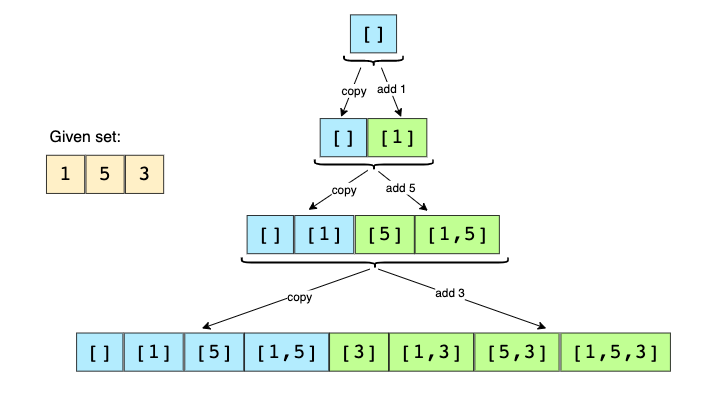
指定されたセットのすべてのサブセットを生成するには、幅優先探索(BFS)アプローチを使用できます。空のセットから始め、すべての数値を1つずつ繰り返し、それらを既存のセットに追加して新しいサブセットを作成できます。
例題として、[1, 5, 3]を考えてみます。
- 空のセットから始めます:[[]]
- 既存のすべてのサブセットに最初の番号(1)を追加して、新しいサブセットを作成します。[[],[1]]
- 既存のすべてのサブセットに2番目の数値(5)を追加します:[[],[1],[5],[1,5]]
- 3番目の数値(3)を既存のすべてのサブセットに追加します:[[],[1],[5],[1,5],[3],[1,3],[5,3],[1,5,3]]
イメージ図
実装
# Time Complexity: O(2^N) where N is the total number of elements in the input set # Space Complexity: O(2^N) def find_subsets(nums): subsets = [] # start by adding the empty subset subsets.append([]) for currentNumber in nums: # we will take all existing subsets and insert the current number in them to create new subsets n = len(subsets) for i in range(n): # create a new subset from the existing subset and insert the current element to it subset = list(subsets[i]) subset.append(currentNumber) subsets.append(subset) return subsets def main(): print("Here is the list of subsets: " + str(find_subsets([1, 3]))) print("Here is the list of subsets: " + str(find_subsets([1, 5, 3]))) main()
- 投稿日:2020-08-07T21:34:01+09:00
アルゴリズム 体操24 Reverse a LinkedList
Reverse a LinkedList
単一LinkedListの先頭を指定すると、LinkedListを逆順にします。反転したLinkedListの新しいヘッドを返す関数を記述します。
例
Solution
三つのポインターである、previous, current, next を利用して、一回のイテレーションでLinkedListを逆にすることができます。
実装
from __future__ import print_function class Node: def __init__(self, value, next=None): self.value = value self.next = next def print_list(self): temp = self while temp is not None: print(temp.value, end=" ") temp = temp.next print() def reverse(head): previous, current, next = None, head, None while current is not None: next = current.next # temporarily store the next node current.next = previous # reverse the current node previous = current # before we move to the next node, point previous to the current node current = next # move on the next node return previous def main(): head = Node(2) head.next = Node(4) head.next.next = Node(6) head.next.next.next = Node(8) head.next.next.next.next = Node(10) print("Nodes of original LinkedList are: ", end='') head.print_list() result = reverse(head) print("Nodes of reversed LinkedList are: ", end='') result.print_list() main()

- 投稿日:2020-08-07T21:25:43+09:00
アルゴリズム 体操24 Middle of the LinkedList
Middle of the LinkedList
単一リンクリストの先頭を指定して、LinkedListの中間ノードを返すメソッドを記述します。
LinkedListのノードの総数が偶数の場合は、2番目の中間ノードを返します。例
Input: 1 -> 2 -> 3 -> 4 -> 5 -> null
Output: 3Input: 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> null
Output: 4Input: 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> null
Output: 4Solution
力ずく戦略の1つは、最初にLinkedListのノード数を数え、次に2番目の反復で中央のノードを見つけることです。 これを1回の反復で実行できるようにするのが肝です。
fastポインターとslowポインターのメソッドを使用して、fastポインターが常にslowポインターよりもノードの2倍先になるようにします。このように、fastポインターがLinkedListの最後に到達すると、slowポインターは中央のノードを指します。
実装
class Node: def __init__(self, value, next=None): self.value = value self.next = next def find_middle_of_linked_list(head): # Time Complexity O(N) # Space Complexity O(1) slow = head fast = head while (fast is not None and fast.next is not None): slow = slow.next fast = fast.next.next return slow def main(): head = Node(1) head.next = Node(2) head.next.next = Node(3) head.next.next.next = Node(4) head.next.next.next.next = Node(5) print("Middle Node: " + str(find_middle_of_linked_list(head).value)) head.next.next.next.next.next = Node(6) print("Middle Node: " + str(find_middle_of_linked_list(head).value)) head.next.next.next.next.next.next = Node(7) print("Middle Node: " + str(find_middle_of_linked_list(head).value)) main()
- 投稿日:2020-08-07T20:59:44+09:00
アルゴリズム 体操24 Cyclic Sort
Cyclic Sort
n個のオブジェクトを含むリストが与えられます。各オブジェクトは、作成時に、作成順序に基づいて1からnまでの一意の番号が割り当てられました。
O(n)の連続な番号に基づいてオブジェクトをin-placeで並べ替える関数を作成します。余分なデータ構造は必要ありません。簡単にするために、連続する番号のみを含む整数のリストが渡されたとします。ただし、各番号は実際にはオブジェクトです。
例
Input: [3, 1, 5, 4, 2]
Output: [1, 2, 3, 4, 5]Input: [2, 6, 4, 3, 1, 5]
Output: [1, 2, 3, 4, 5, 6]Input: [1, 5, 6, 4, 3, 2]
Output: [1, 2, 3, 4, 5, 6]Solution
ご存じのとおり、リストには1からnの範囲の数値が含まれています。 この事実を利用して、数値を並べ替える効率的な方法を考えます。すべての数値は一意であるため、各数値を正しい位置に配置することができます。つまり、1をインデックス0に配置し、2をインデックス1に配置する、などのようにできます。
数値(または一般にオブジェクト)を正しいインデックスに配置するには、まずその数値を見つける必要があります。 最初に数値を見つけて正しい場所に配置すると、O(N^2)、これは受け入れられません。
代わりに、リストを一度に1つの数値で繰り返し、現在の数値が正しいインデックスにない場合は、正しいインデックスの数値と入れ替えます。このようにして、すべての数値を調べ、それらを正しいインデックスに配置し、リスト全体を並べ替えます。
def cyclic_sort(nums): i = 0 while i < len(nums): j = nums[i] - 1 if nums[i] != nums[j]: nums[i], nums[j] = nums[j], nums[i] # swap else: i += 1 return nums def main(): print(cyclic_sort([3, 1, 5, 4, 2])) print(cyclic_sort([2, 6, 4, 3, 1, 5])) print(cyclic_sort([1, 5, 6, 4, 3, 2])) main()
- 投稿日:2020-08-07T20:57:31+09:00
【Python】データサイエンス100本ノック(構造化データ加工編) 010-020 所感+解説リンクまとめ
所感
- データサイエンス100本ノック(構造化データ加工編)の20問目までを解説してあらためて感じました。
- 粛々とデータサイエンス100本ノックを解いていくのは、モチベーション的にも結構きついです。笑
- なので、データサイエンス100本ノックをしている方々でコミュニティを作りたく、データサイエンス100本ノックをやりきる会を作りました?
- こちらのSlack招待URLからご参加ください!!
- ぜひ一緒に励まし合いながら、データサイエンス100本ノックをやり切りたいと思っています!
解説まとめ
- ここからはリンクを貼ります。
- データサイエンス100本ノック初心者の方は、001から順番に解いていくことをおすすめします。
- 001から010までの解説は、こちらをご覧ください。
011
012
013
014
015
016
017
018
019
020
- 投稿日:2020-08-07T20:36:39+09:00
アルゴリズム 体操23 Merge Intervals
Merge Intervals
インターバルリストを引数として、重複するすべてのインターバルをマージして、相互に排他的なインターバルのみを持つリストを作成します。
例
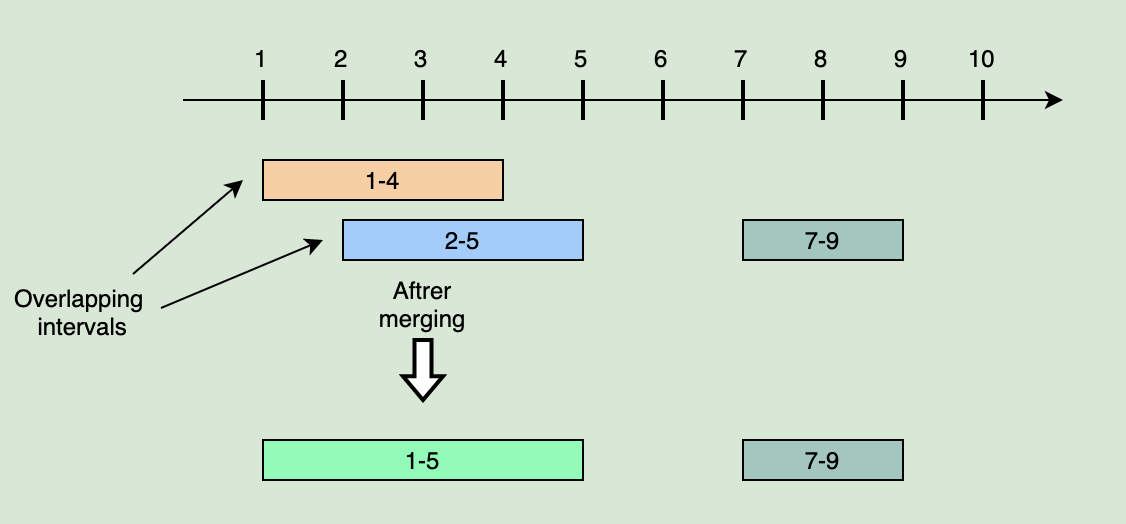
Intervals: [[1,4], [2,5], [7,9]]
Output: [[1,5], [7,9]]
理由: 最初の2つの区間[1,4]と[2,5]は重複しているので、それらを[1,5]
Intervals: [[6,7], [2,4], [5,9]]
Output: [[2,4], [5,9]]Intervals: [[1,4], [2,6], [3,5]]
Output: [[1,6]]Solution
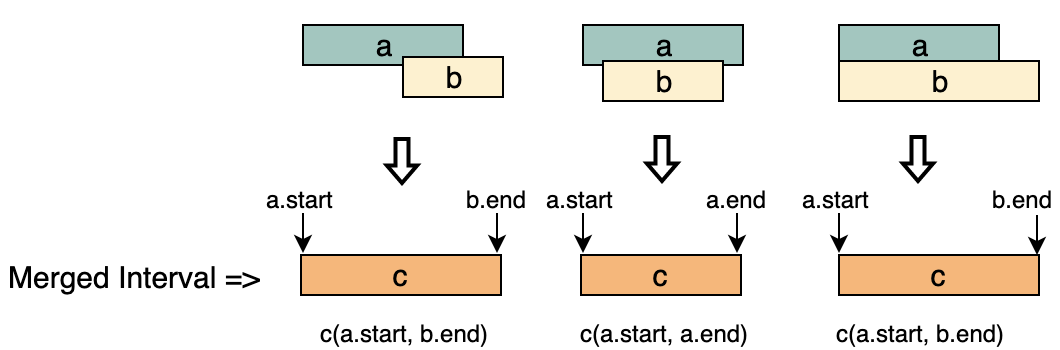
a.start <= b.startである、2つのインターバル("a" と "b")の例を見てみましょう。次の4つのシナリオが考えられます。
- a と b が重ならない。
- b の一部が a に重なる
- b が a に完全に重なる
- a が b と完全に重なり、二つのスタートポイントが同じ。
例えば、こんな感じです。
- 開始時刻の間隔を並べ替えて、a.start <= b.start
- a が b と重なっている場合 (つまり、b.start <= a.end)は、次のような新しいインターバル c にマージする必要があります。
- 上記の2つのステップを繰り返して、c が 次のインターバルと重複する場合は c を次のインターバルにマージします。
実装
class Interval: def __init__(self, start, end): self.start = start self.end = end def print_interval(self): print("[" + str(self.start) + ", " + str(self.end) + "]", end='') def merge(intervals): if len(intervals) < 2: return intervals # sort the intervals on the start time intervals.sort(key=lambda x: x.start) mergedIntervals = [] start = intervals[0].start end = intervals[0].end for i in range(1, len(intervals)): interval = intervals[i] if interval.start <= end: # overlapping intervals, adjust the 'end' end = max(interval.end, end) else: # non-overlapping interval, add the previous internval and reset mergedIntervals.append(Interval(start, end)) start = interval.start end = interval.end # add the last interval mergedIntervals.append(Interval(start, end)) return mergedIntervals def main(): print("Merged intervals: ", end='') for i in merge([Interval(1, 4), Interval(2, 5), Interval(7, 9)]): i.print_interval() print() print("Merged intervals: ", end='') for i in merge([Interval(6, 7), Interval(2, 4), Interval(5, 9)]): i.print_interval() print() print("Merged intervals: ", end='') for i in merge([Interval(1, 4), Interval(2, 6), Interval(3, 5)]): i.print_interval() print() main()
- 投稿日:2020-08-07T20:22:18+09:00
【DRF + Vue.js 】API取得時のエラー(凡ミス)
はじめに
Vueのコンポーネント内から、DRFで作成したAPIを以下のようにaxiosなどで取得する際にエラーが発生した。
.../source/views/Mypage.vueexport default { ... ... mounted() { this.axios.get("/users/" + this.user_id).then(response => { this.Person = response.data }) } };発生したエラー
Access to XMLHttpRequest at 'http://127.0.0.1:8000/XXX/XXX/XXX' from origin 'http://127.0.0.1:8080' has been blocked by CORS policy: Response to preflight request doesn't pass access control check: Redirect is not allowed for a preflight request.VueからのXMLHttpRequestのアクセスがDRF側でブロックされているという感じの内容である。
CORSの設定を確認すると、以下の様にしっかり設定できている。.../settings.pyCORS_ORIGIN_ALLOW_ALL = False CORS_ORIGIN_WHITELIST = ( 'http://localhost:8080', 'http://127.0.0.1:8080', )解決
リクエスト先のURLで最後に '/' をつけるのを忘れていた。
したがって、Vueのコンポーネントファイルを以下の様に修正すればよい。.../source/views/Mypage.vueexport default { ... ... mounted() { // 最後に'/'を追加する api.get("/users/" + this.user_id + '/').then(response => { this.Person = response.data }) } };
- 投稿日:2020-08-07T19:50:39+09:00
Pythonで体験するベイズ推論
「Pythonで体験するベイズ推論」を始めるときにはまったところ。
「Pythonで体験するベイズ推論」を読み始めました。
動かすまでに少しはまったところをメモしておきます。
pymcを入れるのですが、今はpymc4になっています。
書籍のgithubを確認すると、
https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
pymc2とpymc3のスクリプトが載っているので、本を読むときはpymc3をインストールして、gitの中にあるpymc3用のスクリプトを見るようにする。必要なライブラリーは、
pymc3とバックエンドのtheanoになります。
pip install pymc3
基本的に、このpymc3をインストールすると、必要なtheanoがインストールされます。
thenoはpymc3の後ろで動くバックエンドになります。後、必要な
jupyternotebookを入れます。
pip install jupyter一応これで、第一章は動きます。warningを吐きまくりますが、一応動くので大丈夫です。
次に、僕は、好きな
spyderも入れました。
spyderで動かすときは、ここがはまります。
jupyterのCh1_Introduction_PyMC3.ipynbの中のセルのin10で、このままspyderで動かすと、ここでエラーが起きます。#これで動かすと、エラーが出ました。 with model: step = pm.Metropolis() trace = pm.sample(10000, tune=5000,step=step)エラーの理由は、マルチコアの設定がなんかうまく動かないようです。
ここは、このように直します。with model: step = pm.Metropolis() trace = pm.sample(10000, tune=5000,step=step , cores = 1)とりあえずcores=1で、シングルコアで動かせば動きます。ここを2とか4とか入れるとエラーが出ますが、なんか動いて、強制終了すると結果が出ます。普通に動かすときは1を設定しましょう。
jupyternotebookで動くけど、spyderでエラーが出る理由はわかりません。今後は、
pymc4でtensorflowがバックエンドになるそうですが、この書籍の場合はpymc3を入れた方が良いです。
- 投稿日:2020-08-07T19:44:51+09:00
pandasとmatplotlibを使ってPythonで時系列データをグラフに描く
pandasとmatplotlibを使ってPythonでグラフを描く
初めてPythonを使ってグラフを描くため勉強しながら記載しました。
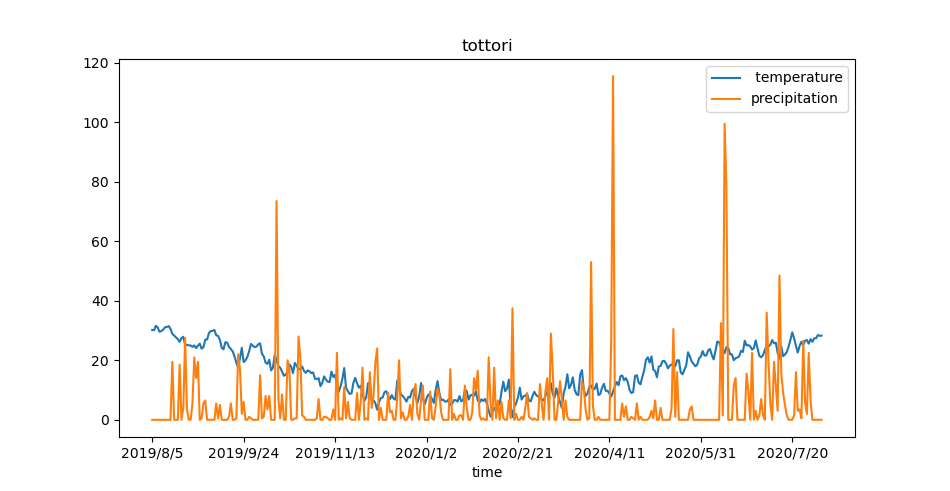
今回は、鳥取市の日平均気温と降水量の日合計のデータをグラフで表示します。
気象庁|過去の気象データ・ダウンロードからデータを取得して
以下のようなcsvファイルを解析します。time, temperature,precipitation 2019/8/5,30.2,0 2019/8/6,30.1,0 2019/8/7,31.6,0 2019/8/8,31,0 2019/8/9,29.6,0 2019/8/10,29.8,0 2019/8/11,30.3,0 …下記のファイルは、Python3.7で動かしました。
from matplotlib import pyplot as plt import pandas as pd # CSVファイルをpandas.DataFrameとして読み込む # index(見出し列)としてtimeの列を指定 # デフォルトでheader=0が指定されており1行目はヘッダーとして無視 data = pd.read_csv(r'data.csv', index_col='time') # 行と列の抽出 # :は全部の行、'[0,1]'はindexとして指定した列を除き2列を抽出 df = data.iloc[:, [0,1]] # データをプロット df.plot() # グラフのタイトル plt.title("tottori") # グラフを表示 plt.show()
参考
Python/pandas/matplotlibを使ってcsvファイルを読み込んで素敵なグラフを描く方法(Mac/Raspberry Pi) - karaage. [からあげ]
pandasでcsv/tsvファイル読み込み(read_csv, read_table) | note.nkmk.me
- 投稿日:2020-08-07T19:29:24+09:00
Anaconda仮想環境をプロジェクトフォルダ内に作成する
Anaconda仮想環境をプロジェクトフォルダ内に作成する
仮想環境を
envフォルダとしてproject_folderの中に作成する。project_folderを渡すだけで簡単に共有先が再現できるようにするため。1. (Anaconda Promptで)
project_folder内に移動cd project_folder2. 仮想環境を作成
conda create --prefix ./env <使用したいライブラリをここに書く>例えば
numpy,matplotlibをインストールした環境を作成する場合はconda create --prefix ./env numpy matplotlib実行すると
project_folder内にenvフォルダが作成される。このenvフォルダ内に仮想環境が入っている。
project_folderごと共有すれば共有先でも同じ環境を有効にできるのが利点。3. 仮想環境を有効にする
conda env listで作成した環境リストを確認し、
conda activate <有効したい仮想環境へのパス>例えばリストの確認結果が以下の場合
# conda environments: # C:\codes\Python\conda_tutorials\project_folder\env <- 作成した環境環境を有効するには
conda activate C:\codes\Python\conda_tutorials\project_folder\env
- 投稿日:2020-08-07T19:03:56+09:00
毎朝5時にGoogle Formに自動回答したい
みなさんこんにちは。夏ですね。
僕もついに部活動が再開し、ワクワクドキドキな訳ですが、一昨日の夜顧問からこんな連絡がきました。- 毎朝5時20分までに検温を行い、結果をGoogleFormから報告してください - 報告がなかった部員は朝練の参加を認めませんそもそも朝練が6時半から始まる時点でイッているので5時20分に連絡しろと言われてもさほど驚かなかったのですが、ここで一つ問題が発生しました。
というのも僕は普段朝5時に起き、そのままパンをかじりながら自転車で駅に向かうので、検温をする時間がないのです。もう少し早起きすれば済む話なのですが、4時起きは流石にきついし体がもたないのでやりたくない。かといって5時に起きて検温なんかしていたら朝練そのものに遅れてしまう。というわけで、朝5時くらいに、心配されない程度の体温をよしなに指定のFormに入力して送信してくれるプログラムを作りたいと思います。
Seleniumでフォームを送信する
本物のフォームを使ってやると僕の身元がバレてしまうので、今回はテスト用に僕が作成した本物と同じ内容のフォームで実装したいと思います。
初期値入力つきURLを用意する
Google Formは、パラメータをつけることで各質問の値を入力した状態でURLを開くことができます。
普通にフォームを開く際のURLは
https://docs.google.com/forms/d/e/1FAIpQLScGgZ8dsBkcSVutvW3JgDLqy3pIEKk12ucjiA8mNQrKopILog/viewform?usp=sf_link
こんな感じでviewformの後に「usp=sf_link」というパラメータがついています。このパラメータは事前入力のない、ピュアな回答フォームであることを示しているので、まずここを「usp=pp_url」に変えて、事前入力があることを知らせてあげます。
そしたら次に各質問の回答をパラメータに入力していきます。フォームの各質問を識別する番号があるので、Chromeの検証画面で質問のdivを探し、2階層目で以下のような番号を探します。
番号を見つけたらentry.番号=回答内容の形でパラメータを加えます。今回は名前と体温をテキストで入力するので以下のようなURLになります。
https://docs.google.com/forms/d/e/1FAIpQLScGgZ8dsBkcSVutvW3JgDLqy3pIEKk12ucjiA8mNQrKopILog/viewform?usp=pp_url&entry.1534939278=荒川智則&entry.511939456=36.5
しかしこのままだと毎日36.5度を報告することになり、流石に怪しまれるので、乱数で良い感じに値を振ります。# 36.1~36.7の間でランダムに値を生成して文字列変換 body_temp = str(36 + random.randint(1,7)/10) # URLの最後に加える url = 'https://docs.google.com/forms/d/e/1FAIpQLScGgZ8dsBkcSVutvW3JgDLqy3pIEKk12ucjiA8mNQrKopILog/viewform?usp=pp_url&entry.1534939278=荒川智則&entry.511939456='+body_tempSeleniumで自動提出
URLが完成したら、あとはSeleniumでURLを開き、ポチッと提出ボタンを押してもらうだけです。
# SeleniumとChromedriverをpipでインストールしておく from selenium import webdriver import chromedriver_binary import time import random body_temp = str(36 + random.randint(1,7)/10) url = 'https://docs.google.com/forms/d/e/1FAIpQLScGgZ8dsBkcSVutvW3JgDLqy3pIEKk12ucjiA8mNQrKopILog/viewform?usp=pp_url&entry.1534939278=荒川智則&entry.511939456='+body_temp # クリックの関数 def click(xpath): driver.find_element_by_xpath(xpath).click() # パスワード入力の関数 def insert_pw(xpath, str): driver.find_element_by_xpath(xpath).send_keys(str) driver = webdriver.Chrome() driver.implicitly_wait(1) driver.get(url) moving_login_button = '/html/body/div[2]/div/div[2]/div[3]/div[2]' time.sleep(1) # Googleアカウントでのログインが必要な場合はログインする if(driver.find_elements_by_xpath(moving_login_button) != []): click(moving_login_button) login_id = "{Googleアカウントのメアド}" login_id_xpath = '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div/div[1]/div/div[1]/input' login_id_button = '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div/div' insert_pw(login_id_xpath, login_id) click(login_id_button) time.sleep(1) login_pw = "{Googleアカウントのパスワード}" login_pw_xpath = '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div[1]/div/div/div/div/div[1]/div/div[1]/input' login_pw_button = '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div/div' insert_pw(login_pw_xpath, login_pw) time.sleep(1) click(login_pw_button) time.sleep(1) submit_button = '//*[@id="mG61Hd"]/div[2]/div/div[3]/div[1]/div/div' click(submit_button) print("Done!") driver.close # メモリーを食うのでちゃんと終了しましょう driver.quit
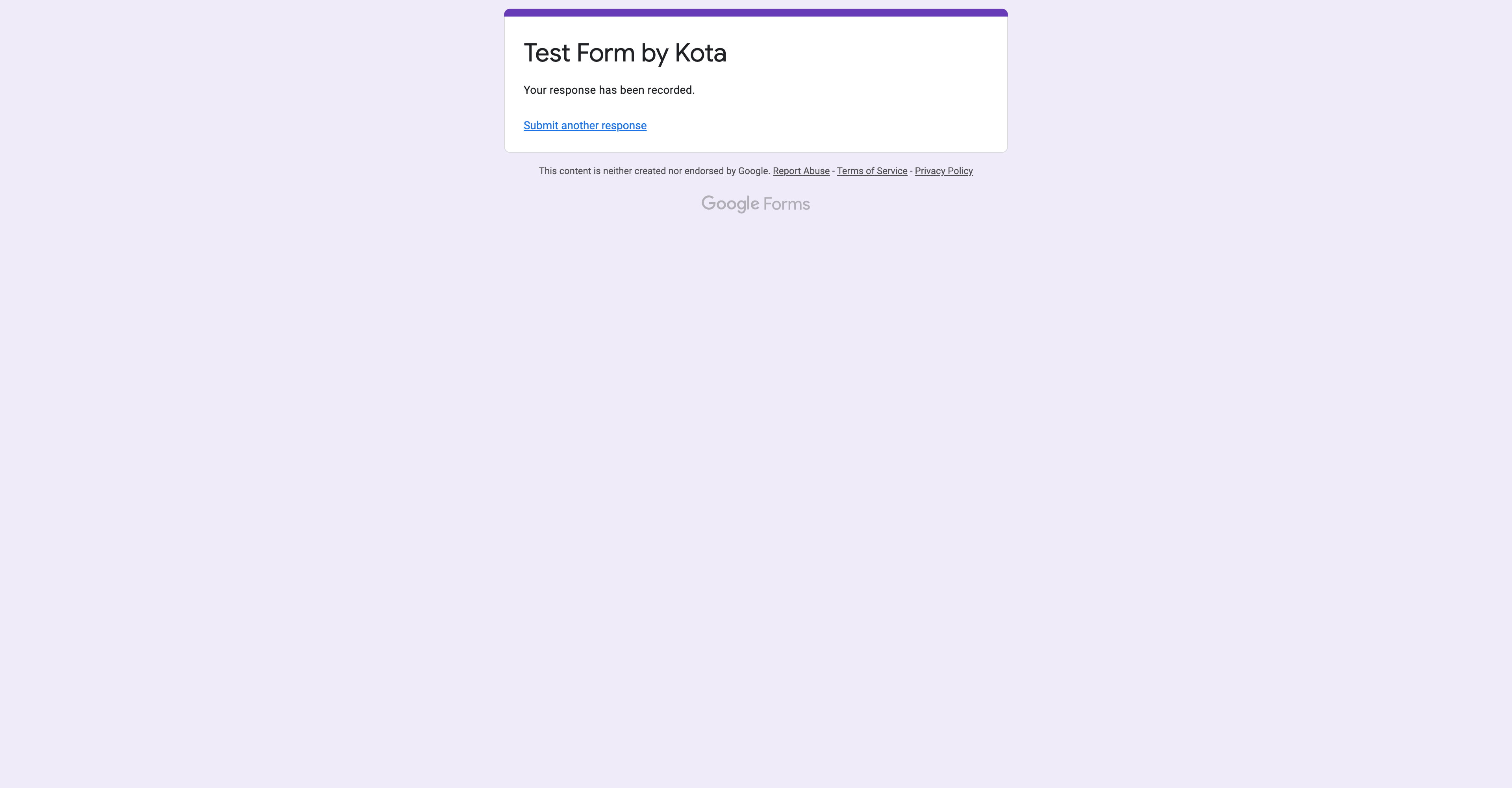
しっかり送信できました。
定期イベントにする
コードが書けたらあとは定期イベント化するだけなのですが、ここで少しつまづいたのでやり方を説明しておきます。
当初予定していた方法としてはAutomatorでアプリ化し、カレンダーに入れて毎日実行する方法(参考)。これなら報告しなくて良い日はカレンダーから外せば良いし、完璧なはず。と思ったのですが、PCをシャットダウンしていると動作しないためボツ。crontabに設定して定期イベント化する方法も同様の理由でボツ。
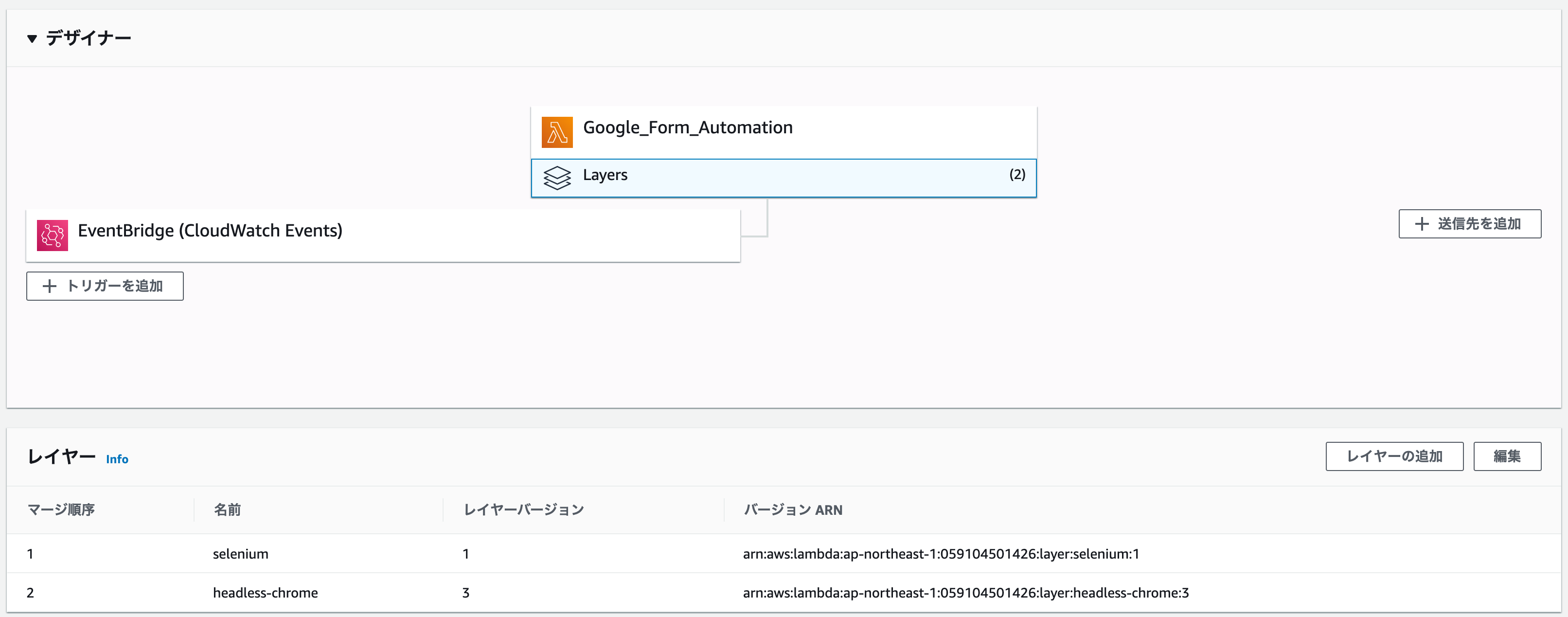
結局臨機応変にイベントの変更はできないものの、PCの状態にかかわらず実行してくれるAWSのLambdaを使用することに決めました。(Lambdaの使い方はこのサイトとかが参考になりました)LambdaのレイヤーにSeleniumとChromedriver、headless-chromiumを上げる
Lambdaでライブラリを使うには各フォルダをzipに圧縮してレイヤーにアップロードする必要があります。今回はSeleniumとChromeのWebdriverであるChromedriver、それからChromeを開かずにスクレイピングを行うためのheadless-chromiumを使用するので、それぞれzipに圧縮してレイヤーに上げていきます。
1. Selenium
mkdir selenium cd selenium mkdir python cd python pip install selenium -t . cd ../ zip -r selenium.zip ./pythonできたzipファイルをそのままレイヤーにアップロードします。
2. Chromedriverとheadless-chromium
curl https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-55/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip curl https://chromedriver.storage.googleapis.com/2.43/chromedriver_linux64.zip > chromedriver.zipできた二つのzipファイルを解凍し、headless-chromeフォルダにまとめます。その後そのheadless-chromeをzipに圧縮してレイヤーにアップロードします。
作業がめんどい方はこちらにselenium.zipもheadless-chrome.zipもまとめて置いてあるので使っていただけると幸いです3. レイヤーを関数に適用
関数の下にある「Layers」を押し、下の「レイヤーの追加」ボタンから二つのレイヤを追加します
※注意※
- Lambda関数のランタイムをPython3.8にするとChromedriverが動いてくれなかった(原因不明)ので、ランタイムはPython3.6か3.7に設定することをお勧めします。
- headless-chromiumとChromedriverの間に互換性がないと動作しないのでこちらから最新版を入手しても動作しない可能性があります。
Lambda用にコードを少し変える
筆者は今までCloud9以外のAWSツールを使ったことがないへっぽこコーダーなので、色んなサイトの見様見真似でなんとかLambdaで動くコードにしました。先人に感謝。
import json from selenium import webdriver import time import random def lambda_handler(event, context): body_temp = str(36 + random.randint(1,7)/10) url = 'https://docs.google.com/forms/d/e/1FAIpQLScGgZ8dsBkcSVutvW3JgDLqy3pIEKk12ucjiA8mNQrKopILog/viewform?usp=pp_url&entry.1534939278=荒川智則&entry.511939456='+body_temp options = webdriver.ChromeOptions() options.binary_location = '/opt/headless-chrome/headless-chromium' # このオプション4つを付けないとChromeは起動せずエラーになります options.add_argument('--headless') # サーバーレスでChromeを起動 options.add_argument('--no-sandbox') # sandbox外でChromeを起動 options.add_argument('--single-process') # タブ/サイトごとのマルチプロセスではなく、シングルプロセスへ切り替える options.add_argument('--disable-dev-shm-usage') # メモリファイルの出力場所を変える driver = webdriver.Chrome('/opt/headless-chrome/chromedriver',options = options) driver.implicitly_wait(1) driver.get(url) def click(xpath): driver.find_element_by_xpath(xpath).click() def insert_pw(xpath, str): driver.find_element_by_xpath(xpath).send_keys(str) moving_login_button = '/html/body/div[2]/div/div[2]/div[3]/div[2]' time.sleep(2) if(driver.find_elements_by_xpath(moving_login_button) != []): click(moving_login_button) # 環境変数でMY_GMAILにGoogleアカウントのメアドを設定してください login_id = MY_GMAIL login_id_xpath = '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div/div[1]/div/div[1]/input' login_id_button = '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div/div' insert_pw(login_id_xpath, login_id) click(login_id_button) time.sleep(1) # 環境変数でMY_PASSWORDにGoogleアカウントのパスワードを設定してください login_pw = MY_PASSWORD login_pw_xpath = '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div[1]/div/div/div/div/div[1]/div/div[1]/input' login_pw_button = '/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div/div' insert_pw(login_pw_xpath, login_pw) time.sleep(1) click(login_pw_button) time.sleep(1) submit_button = '//*[@id="mG61Hd"]/div[2]/div/div[3]/div[1]/div/div' click(submit_button) driver.close driver.quit return { 'statusCode': 200, 'body': json.dumps('Form submission success!!') }注意点
- Chromeの起動オプション
--headless,--no-sandbox,single-process,--disable-dev-shm-usageを付けないとLambda上で正常に起動せず、エラーが出ます。各オプションについての詳細はこちらをご覧ください- レイヤーにアップロードしたファイルはoptディレクトリの配下に置かれます。パスを指定する際はopt/ディレクトリ名/...の形で表記しましょう
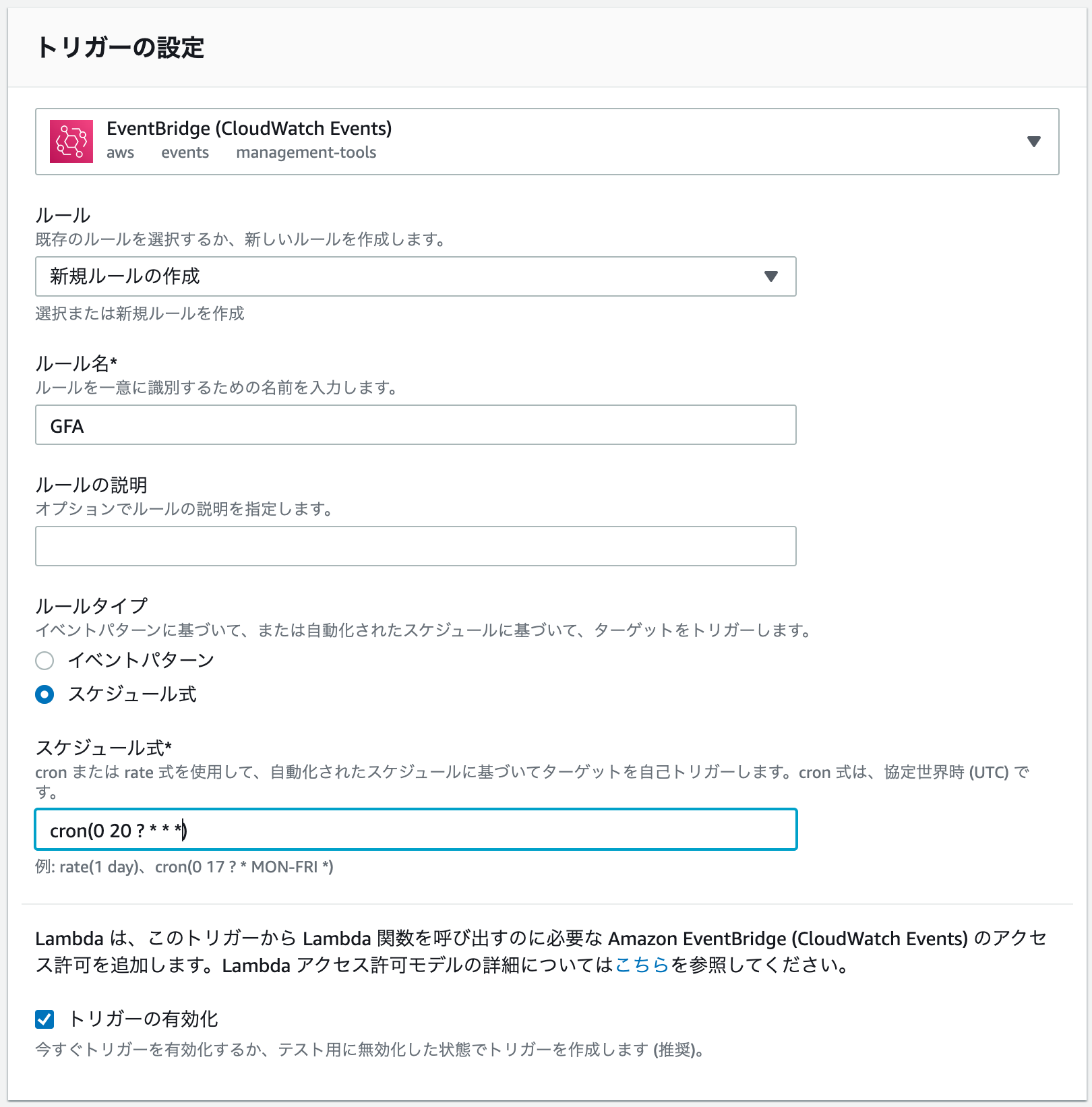
CloudWatch Eventsでトリガーを設定
- 関数の「Layers」をクリックして「トリガーを追加をクリック」し、ドロップダウンから「EventBridge (CloudWatch Events)」を選択します。
- ルールは「新規ルールの作成」で任意のルール名を入力。ルールタイプをスケジュール式にし、今回は毎日朝5時なので
corn(0 20 ? * * *)と入力(LambdaはUTCでトリガーされるので9時間前をセットすることに留意)。トリガーを有効にして「追加」をクリックします。(cronの書き方はこちらをご覧ください)
テスト
最後にしっかり動くかテストしましょう。Lambda関数画面の「テスト」をクリックします。
大丈夫そうですね。おわりに
朝の検温はサボっていますが、寝る前にちゃんと測っているので安心してください。
参考文献
https://masakimisawa.com/selenium_headless-chrome_python_on_lambda/
https://github.com/heroku/heroku-buildpack-google-chrome/issues/56
https://qiita.com/mishimay/items/afd7f247f101fbe25f30


- 投稿日:2020-08-07T18:41:27+09:00
"IFTTT"と"なろう小説API"を使って「小説家になろう」の更新通知を作ってみた
はじめに
小説家になろうにかなりお世話になっていたのですが、更新を画面の前で待ち続けて無駄な時間を過ごすことがしばしば...
無駄だと分かっていても期待してリロードしてしまう自分にあきれて更新を確認してくれるアプリを作ろうと決意しました(したのですが自動化ができていない)。何をするもの?
なろうAPIを用いて、小説の最新話の情報を取得。その後、ローカルにおいてある前回取得した情報と照らし合わせて、更新されているものがあればLINENotifyから通知を送ります。
環境
- Python 3.7.4
- Windows10 64bit
準備…の前にAPIとスクレイピングの違いに関する確認・注意
今回は公式のAPIを用いるのでスクレイピングをしていません。ですが、心配な方は法律の話を確認しておきましょう。
準備(IFTTTでAppletを作成)
IFTTTとは異なるサービスを連携してくれるサービスです。今回はWebhooksとLINENotifyをつなぎ、自分のLINEに通知を送ってもらいます。
手順
1. IFTTTに登録
2. 画面右上にあるCreateをクリック。「if +This Then That」と書かれた画面に遷移します。下図参照。
3. +Thisをクリック。Webhooksを検索バーに打ち込んで選択しましょう。
4. 「Receive a web request」と書かれた欄をクリック。下のような画面に来たら、「Event Name」に好きな名前を入れてください。あとで使います。
5. +Thatをクリック。LINEを選択し、「Send message」の欄をクリック。
6. LINEにログインし、メッセージの内容を「Value1:Value1<br>」にして(しなくても問題ないですが)「Create Action」をクリック。
7. 内容を確認して、Finishをクリック。
8. Exploreをクリックして、検索窓にWebhooksと打ち込んでServicesタブを選択。Webhooksをクリック。もしかしたらこのリンクからいけるかも...?
9. Documentationをクリックすると「Your key is: ~~~~~」と出ているはずなので、それをメモしておきましょう。後で使います。IFTTTはこれで終わりです。ソースコードの説明
GitHubにあげました(ここ)。各関数の説明を簡単に書いて締めます。
importimport requests import yaml import gzip import json import csvget_new_data()
なろうAPIをつかって指定した小説の['ncode', 'title', 'general_lastup', 'general_all_no']を取得します。なろうAPIの使い方は公式サイトや下の記事などを参考にしてください。def get_new_data(): """ payload : json params e.g.) payload = {'out': 'json', 'ncode':'n5455cx-n3125cg-n2267be-n4029bs', 'of':'t-gl', 'gzip':5} reference) https://dev.syosetu.com/man/api/ """ payload = {'out': 'json', 'ncode':'n5455cx-n3125cg-n2267be-n4029bs', 'of':'t-gl-n-ga', 'gzip':5} url = "https://api.syosetu.com/novelapi/api/" r_gzip = requests.get(url, params=payload) r = r_gzip.content r_gzip.encoding = 'gzip' res_content = gzip.decompress(r).decode("utf-8") res = json.loads(res_content)[1:] new_data = [['ncode', 'title', 'general_lastup', 'general_all_no']] for r in res: new_data.append([r['ncode'], r['title'], r['general_lastup'], str(r['general_all_no'])]) return new_dataread_data()
update.csvというファイルから前回取得した小説の総話数、更新日などの情報を読み取ります。初めてこのコード動かすときはupdate.csvは空白なはずなのでそのまま使おうとすると当然エラーになります。その前にget_new_data()と後述のstore_data()を使ってupdate.csvを作っておいてください。def read_data(): f_data = "update.csv" with open(f_data, encoding="utf-8") as f: reader = csv.reader(f) data = [row for row in reader] #data: list(['ncode', 'title', 'general_lastup', 'general_all_no']) return datastore_data(res)
update.csvにリストresに格納された小説の情報を書き込みます。def store_data(res): # res: list(['ncode', 'title', 'general_lastup', 'general_all_no']) output = "update.csv" with open(output, mode='w', newline="", encoding="utf-8") as f: writer = csv.writer(f) for d in res: writer.writerow([d[0], d[1], d[2], d[3]])post_ifttt(json)
先ほどメモしたAppletの名前とWebhooksのkeyをここで使います。コメントアウトしてある場所に代入しましょう。この関数が呼び出されると、LINEに通知が行きます。def post_ifttt(json): # json: {value1: " content "} url = ( "https://maker.ifttt.com/trigger/" + # Appletの名前 + "/with/key/" + # WebhooksのKey ) requests.post(url, json)check(prev_data, new_data)
更新されているかを確認します。更新されている小説に関しては先ほどのpost_ifttt()を呼び出して通知します。def check(prev_data, new_data): # prev_data: [[previous information of bookmark1], [previous information of bookmark2], ...] # new_data: [[new information of bookmark1], [new information of bookmark2], ...] isUpdated = 0 for i in range(len(prev_data)): if(i==0): continue if(prev_data[i][0]==new_data[i][0] and prev_data[i][2]!=new_data[i][2]): message = '\"' + new_data[i][1] + '\"' + 'が更新されました!\n' + 'https://ncode.syosetu.com/' + new_data[i][0] + '/' + new_data[i][3] + '/' print(message) json = {'value1': message) post_ifttt(json) store_data(new_data)実行時にデータを入れるための変数
prev_data = read_data() new_data = get_new_data() check(prev_data, new_data)未解決のやつ
自動化です。Windowsのタスクスケジューラは電源入ってる時しか動かないのが残念ですが、策としてはそれくらいでしょうか...?
参考文献




- 投稿日:2020-08-07T18:41:27+09:00
"IFTTT"と"なろう小説API"を使って「小説家になろう」の更新通知をさせてみた
はじめに
小説家になろうにかなりお世話になっていたのですが、更新を画面の前で待ち続けて無駄な時間を過ごすことがしばしば...
無駄だと分かっていても期待してリロードしてしまう自分にあきれて更新を確認してくれるアプリを作ろうと決意しました(したのですが自動化ができていない)。何をするもの?
なろうAPIを用いて、小説の最新話の情報を取得。その後、ローカルにおいてある前回取得した情報と照らし合わせて、更新されているものがあればLINENotifyから通知を送ります。
環境
- Python 3.7.4
- Windows10 64bit
準備…の前にAPIとスクレイピングの違いに関する確認・注意
今回は公式のAPIを用いるのでスクレイピングをしていません。ですが、心配な方は法律の話を確認しておきましょう。
準備(IFTTTでAppletを作成)
IFTTTとは異なるサービスを連携してくれるサービスです。今回はWebhooksとLINENotifyをつなぎ、自分のLINEに通知を送ってもらいます。
手順
1. IFTTTに登録
2. 画面右上にあるCreateをクリック。「if +This Then That」と書かれた画面に遷移します。下図参照。
3. +Thisをクリック。Webhooksを検索バーに打ち込んで選択しましょう。
4. 「Receive a web request」と書かれた欄をクリック。下のような画面に来たら、「Event Name」に好きな名前を入れてください。あとで使います。
5. +Thatをクリック。LINEを選択し、「Send message」の欄をクリック。
6. LINEにログインし、メッセージの内容を「Value1:Value1<br>」にして(しなくても問題ないですが)「Create Action」をクリック。
7. 内容を確認して、Finishをクリック。
8. Exploreをクリックして、検索窓にWebhooksと打ち込んでServicesタブを選択。Webhooksをクリック。もしかしたらこのリンクからいけるかも...?
9. Documentationをクリックすると「Your key is: ~~~~~」と出ているはずなので、それをメモしておきましょう。後で使います。IFTTTはこれで終わりです。ソースコードの説明
GitHubにあげました(ここ)。各関数の説明を簡単に書いて締めます。
importimport requests import yaml import gzip import json import csvget_new_data()
なろうAPIをつかって指定した小説の['ncode', 'title', 'general_lastup', 'general_all_no']を取得します。なろうAPIの使い方は公式サイトや下の記事などを参考にしてください。def get_new_data(): """ payload : json params e.g.) payload = {'out': 'json', 'ncode':'n5455cx-n3125cg-n2267be-n4029bs', 'of':'t-gl', 'gzip':5} reference) https://dev.syosetu.com/man/api/ """ payload = {'out': 'json', 'ncode':'n5455cx-n3125cg-n2267be-n4029bs', 'of':'t-gl-n-ga', 'gzip':5} url = "https://api.syosetu.com/novelapi/api/" r_gzip = requests.get(url, params=payload) r = r_gzip.content r_gzip.encoding = 'gzip' res_content = gzip.decompress(r).decode("utf-8") res = json.loads(res_content)[1:] new_data = [['ncode', 'title', 'general_lastup', 'general_all_no']] for r in res: new_data.append([r['ncode'], r['title'], r['general_lastup'], str(r['general_all_no'])]) return new_dataread_data()
update.csvというファイルから前回取得した小説の総話数、更新日などの情報を読み取ります。初めてこのコード動かすときはupdate.csvは空白なはずなのでそのまま使おうとすると当然エラーになります。その前にget_new_data()と後述のstore_data()を使ってupdate.csvを作っておいてください。def read_data(): f_data = "update.csv" with open(f_data, encoding="utf-8") as f: reader = csv.reader(f) data = [row for row in reader] #data: list(['ncode', 'title', 'general_lastup', 'general_all_no']) return datastore_data(res)
update.csvにリストresに格納された小説の情報を書き込みます。def store_data(res): # res: list(['ncode', 'title', 'general_lastup', 'general_all_no']) output = "update.csv" with open(output, mode='w', newline="", encoding="utf-8") as f: writer = csv.writer(f) for d in res: writer.writerow([d[0], d[1], d[2], d[3]])post_ifttt(json)
先ほどメモしたAppletの名前とWebhooksのkeyをここで使います。コメントアウトしてある場所に代入しましょう。この関数が呼び出されると、LINEに通知が行きます。def post_ifttt(json): # json: {value1: " content "} url = ( "https://maker.ifttt.com/trigger/" + # Appletの名前 + "/with/key/" + # WebhooksのKey ) requests.post(url, json)check(prev_data, new_data)
更新されているかを確認します。更新されている小説に関しては先ほどのpost_ifttt()を呼び出して通知します。def check(prev_data, new_data): # prev_data: [[previous information of bookmark1], [previous information of bookmark2], ...] # new_data: [[new information of bookmark1], [new information of bookmark2], ...] isUpdated = 0 for i in range(len(prev_data)): if(i==0): continue if(prev_data[i][0]==new_data[i][0] and prev_data[i][2]!=new_data[i][2]): message = '\"' + new_data[i][1] + '\"' + 'が更新されました!\n' + 'https://ncode.syosetu.com/' + new_data[i][0] + '/' + new_data[i][3] + '/' print(message) json = {'value1': message) post_ifttt(json) store_data(new_data)実行時にデータを入れるための変数
prev_data = read_data() new_data = get_new_data() check(prev_data, new_data)未解決のやつ
自動化です。Windowsのタスクスケジューラは電源入ってる時しか動かないのが残念ですが、策としてはそれくらいでしょうか...?
参考文献
- 投稿日:2020-08-07T18:41:27+09:00
"IFTTT"と"なろう小説API"を使って「小説家になろう」の更新を通知をさせてみた
はじめに
小説家になろうにかなりお世話になっていたのですが、更新を画面の前で待ち続けて無駄な時間を過ごすことがしばしば...
無駄だと分かっていても期待してリロードしてしまう自分にあきれて更新を確認してくれるアプリを作ろうと決意しました(したのですが自動化ができていない)。何をするもの?
なろうAPIを用いて、小説の最新話の情報を取得。その後、ローカルにおいてある前回取得した情報と照らし合わせて、更新されているものがあればLINENotifyから通知を送ります。
環境
- Python 3.7.4
- Windows10 64bit
準備…の前にAPIとスクレイピングの違いに関する確認・注意
今回は公式のAPIを用いるのでスクレイピングをしていません。ですが、心配な方は法律の話を確認しておきましょう。
準備(IFTTTでAppletを作成)
IFTTTとは異なるサービスを連携してくれるサービスです。今回はWebhooksとLINENotifyをつなぎ、自分のLINEに通知を送ってもらいます。
手順
1. IFTTTに登録
2. 画面右上にあるCreateをクリック。「if +This Then That」と書かれた画面に遷移します。下図参照。
3. +Thisをクリック。Webhooksを検索バーに打ち込んで選択しましょう。
4. 「Receive a web request」と書かれた欄をクリック。下のような画面に来たら、「Event Name」に好きな名前を入れてください。あとで使います。
5. +Thatをクリック。LINEを選択し、「Send message」の欄をクリック。
6. LINEにログインし、メッセージの内容を「Value1:Value1<br>」にして(しなくても問題ないですが)「Create Action」をクリック。
7. 内容を確認して、Finishをクリック。
8. Exploreをクリックして、検索窓にWebhooksと打ち込んでServicesタブを選択。Webhooksをクリック。もしかしたらこのリンクからいけるかも...?
9. Documentationをクリックすると「Your key is: ~~~~~」と出ているはずなので、それをメモしておきましょう。後で使います。IFTTTはこれで終わりです。ソースコードの説明
GitHubにあげました(ここ)。各関数の説明を簡単に書いて締めます。
importimport requests import yaml import gzip import json import csvget_new_data()
なろうAPIをつかって指定した小説の['ncode', 'title', 'general_lastup', 'general_all_no']を取得します。なろうAPIの使い方は公式サイトや下の記事などを参考にしてください。def get_new_data(): """ payload : json params e.g.) payload = {'out': 'json', 'ncode':読んでいる小説のncodeを入れてください, 'of':'t-gl', 'gzip':5} reference) https://dev.syosetu.com/man/api/ """ payload = {'out': 'json', 'ncode': """ncodeを入れてください""", 'of':'t-gl-n-ga', 'gzip':5} url = "https://api.syosetu.com/novelapi/api/" r_gzip = requests.get(url, params=payload) r = r_gzip.content r_gzip.encoding = 'gzip' res_content = gzip.decompress(r).decode("utf-8") res = json.loads(res_content)[1:] new_data = [['ncode', 'title', 'general_lastup', 'general_all_no']] for r in res: new_data.append([r['ncode'], r['title'], r['general_lastup'], str(r['general_all_no'])]) return new_dataread_data()
update.csvというファイルから前回取得した小説の総話数、更新日などの情報を読み取ります。初めてこのコード動かすときはupdate.csvは空白なはずなのでそのまま使おうとすると当然エラーになります。その前にget_new_data()と後述のstore_data()を使ってupdate.csvを作っておいてください。def read_data(): f_data = "update.csv" with open(f_data, encoding="utf-8") as f: reader = csv.reader(f) data = [row for row in reader] #data: list(['ncode', 'title', 'general_lastup', 'general_all_no']) return datastore_data(res)
update.csvにリストresに格納された小説の情報を書き込みます。def store_data(res): # res: list(['ncode', 'title', 'general_lastup', 'general_all_no']) output = "update.csv" with open(output, mode='w', newline="", encoding="utf-8") as f: writer = csv.writer(f) for d in res: writer.writerow([d[0], d[1], d[2], d[3]])post_ifttt(json)
先ほどメモしたAppletの名前とWebhooksのkeyをここで使います。コメントアウトしてある場所に代入しましょう。この関数が呼び出されると、LINEに通知が行きます。def post_ifttt(json): # json: {value1: " content "} url = ( "https://maker.ifttt.com/trigger/" + # Appletの名前 + "/with/key/" + # WebhooksのKey ) requests.post(url, json)check(prev_data, new_data)
更新されているかを確認します。更新されている小説に関しては先ほどのpost_ifttt()を呼び出して通知します。def check(prev_data, new_data): # prev_data: [[previous information of bookmark1], [previous information of bookmark2], ...] # new_data: [[new information of bookmark1], [new information of bookmark2], ...] isUpdated = 0 for i in range(len(prev_data)): if(i==0): continue if(prev_data[i][0]==new_data[i][0] and prev_data[i][2]!=new_data[i][2]): message = '\"' + new_data[i][1] + '\"' + 'が更新されました!\n' + 'https://ncode.syosetu.com/' + new_data[i][0] + '/' + new_data[i][3] + '/' print(message) json = {'value1': message) post_ifttt(json) store_data(new_data)実行時にデータを入れるための変数
prev_data = read_data() new_data = get_new_data() check(prev_data, new_data)未解決のやつ
自動化です。Windowsのタスクスケジューラは電源入ってる時しか動かないのが残念ですが、策としてはそれくらいでしょうか...?
参考文献
- 投稿日:2020-08-07T18:19:09+09:00
とにかく最速でSerial通信のログをファイルに残す
とにかく今すぐに、USBでつないだ機器からのSerial通信のログを残したい。
そんなときに使えます。環境はMac想定です。
やること
言語はPythonを使用します。
pySerialも使うので、$pip install pyserialでインストールしておきましょう。ソースは以下
logger.pyimport serial com = serial.Serial('/dev/....') while True: line = com.readline().strip().decode('utf-8') print(line) f = open('data.txt', 'a+') f.writelines(line) f.close() com.close()※COMポートは各自確認してください。
COMポートがわからない時
Macであれば、以下のコマンドで一覧を確認できます。
$ ls -l /dev/tty.usb*※参考:https://qiita.com/k-yamada-github/items/c12bafc64f9868f8c85c
ここまでご覧いただきありがとうございました!
改善点、不明点等あればコメントいただけますと幸いです。
- 投稿日:2020-08-07T18:14:56+09:00
HerokuでLINEオウム返しbot ハマった時のチェックポイント
散々こすられてるネタではありますが、ネット上の古い情報に惑わされてオウム返しbotで半日つぶれたので、
恨み反省を込めてメモしておきます。環境
- Mac OS Catalina 10.15.5
- Python 3.7.7
- Heroku
アカウント作成〜Herokuへデプロイ
まず、以下の工程を行いました。
- LINE Developersアカウントの作成
- botアプリの実装(Python)
- Herokuのセットアップ、デプロイ
具体的な手順やコード等に関しては、以下のブログ記事を参照しました。概ねわかりやすくまとまっていますので、ここでは詳しい手順の紹介は割愛します。
が、後述するとおり、最新の仕様では「Fixie」の設定が不要ですので、注意してください。
- LINE Messaging API + Python + Heroku でLINE Botを作る
https://cppx.hatenablog.com/entry/2017/10/31/165128……さて、このとおり実装してbotに話しかけてみたものの、オウム返ししてくれません。
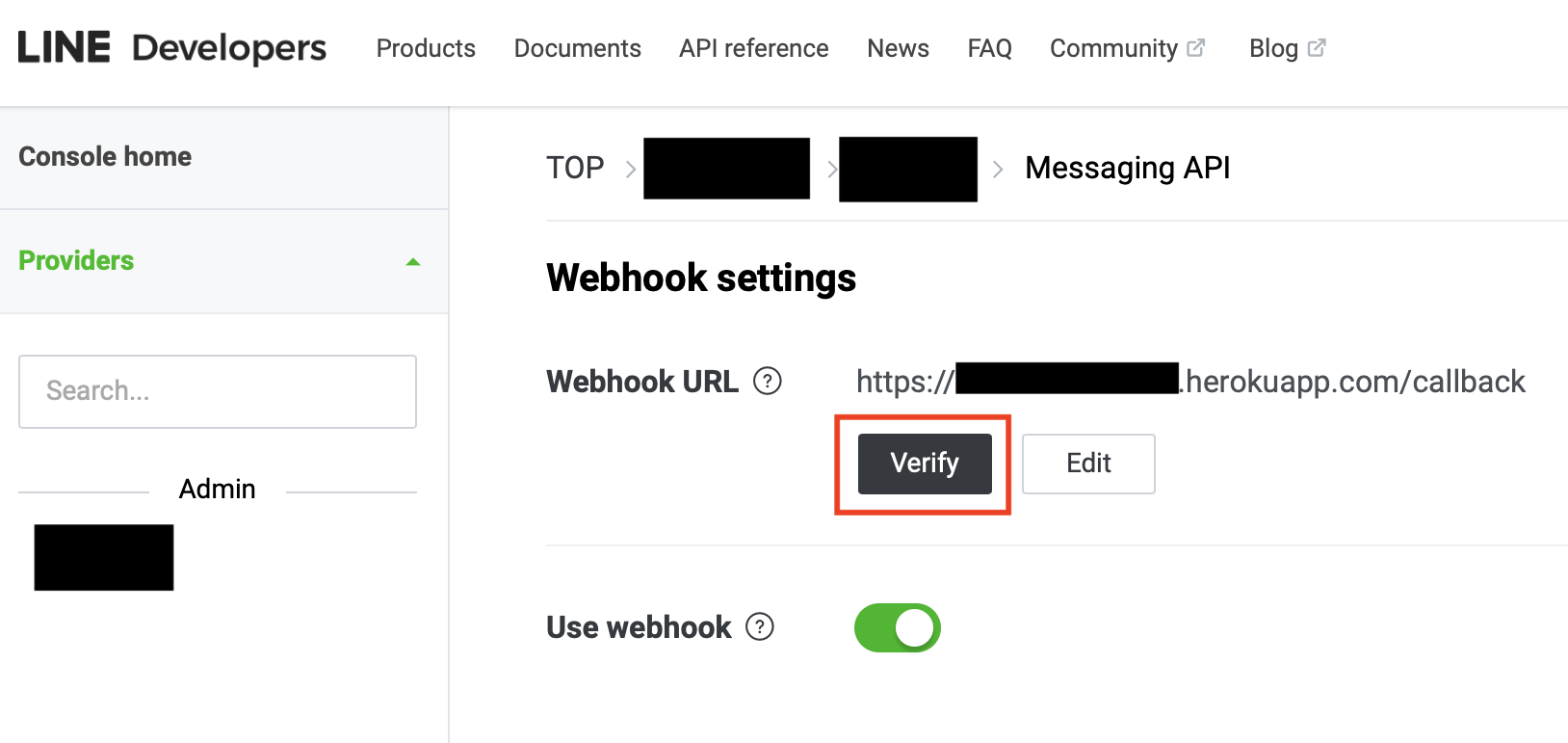
チェックポイント1:WebhookのVerifyボタンで出る500エラー対策
LINE Developers管理画面でWebhookURLのVerifyボタンを押して確認したところ、"The webhook returned an HTTP status code other than 200" というエラー表示が出てきました。
heroku logs -tでログを確認。main.py(botアプリ)は動いており、500エラーが返ってきているようでした。これはVerifyボタンで送られるreplyTokenを有効なreplyTokenではないと判断しているようです。参考記事は以下。
- LINE DevelopersのWebhook URLの接続確認でエラーが出る件について
https://qiita.com/q_masa/items/c9db3e8396fb62cc64edこの記事を参考にコードを追記したところ、Verifyボタンからのリクエストは通るようになりました。
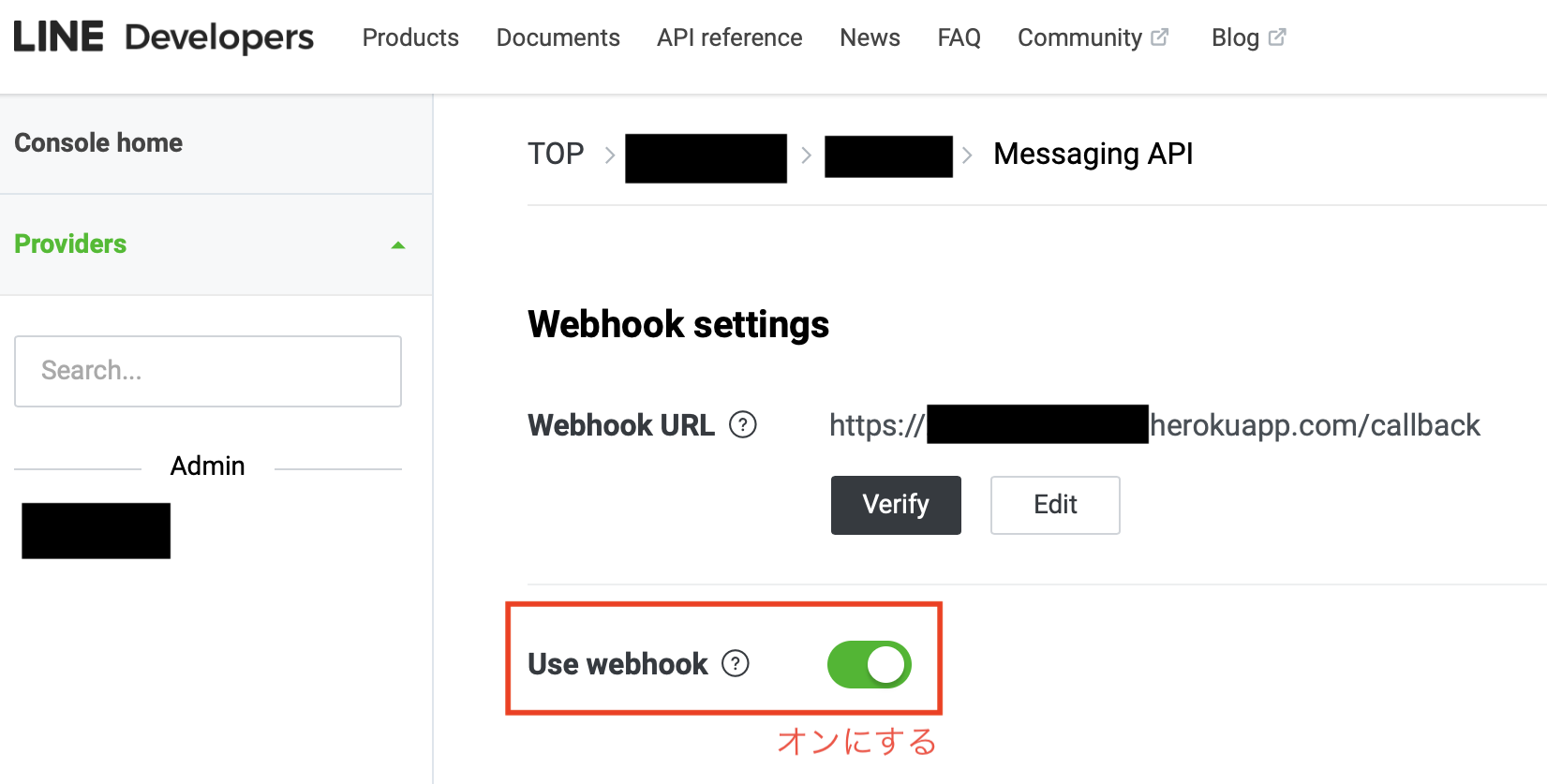
チェックポイント2:Use Webhookをオンにしよう
しかし、スマホで「あ」とか「テスト」とか送っても一向にログが動きません。
……いや凡ミスすぎない?という感じなんですが、Use Webhookがオフになっていました。
オンにしたところ、リクエストは送られるようになりました。
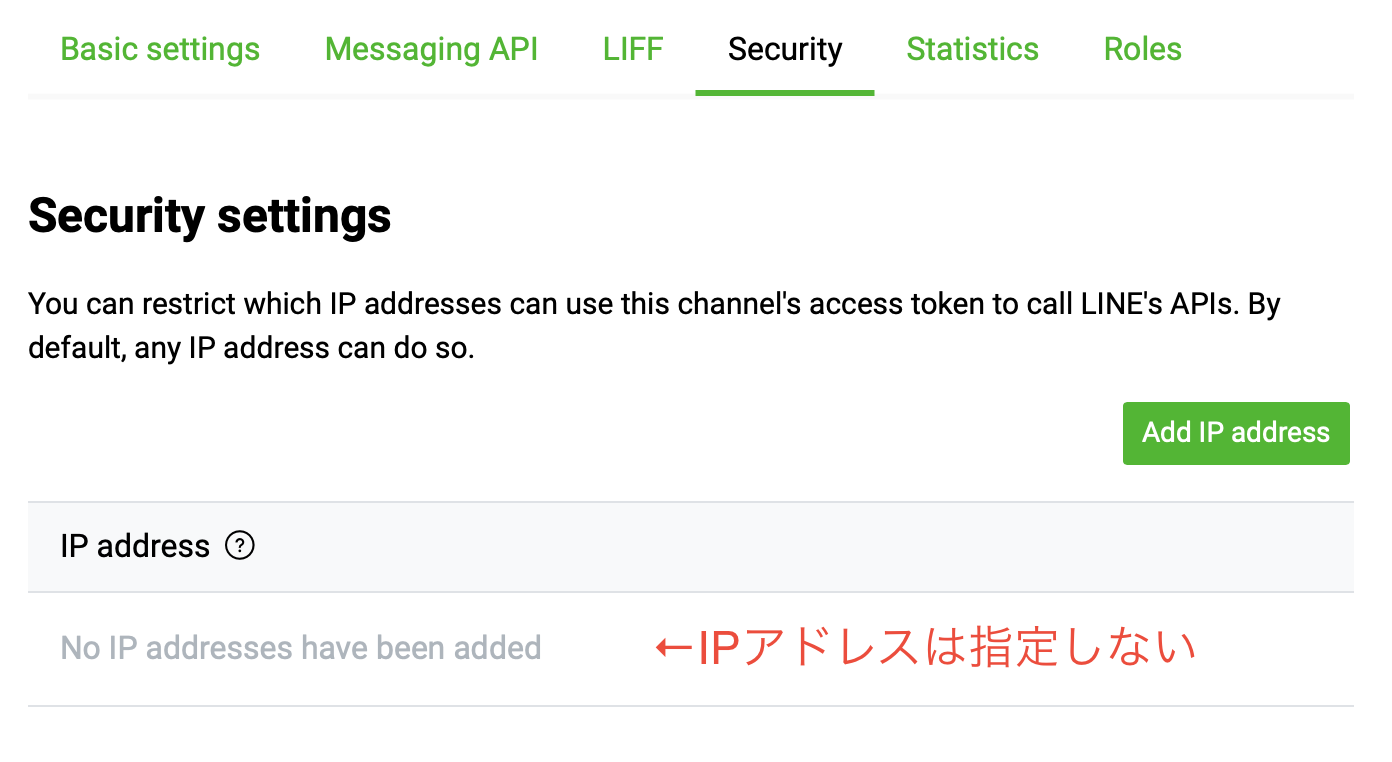
チェックポイント3:最新の仕様ではIPアドレスの指定は不要
しかし、このIPアドレスでは接続できないよ!というエラーが出てしまいます。詳しくは後述の「補足」で書きますが、Fixieの設定に失敗していたため、エラーが起きていました。
HerokuでLINEbotを作るときには何はともあれFixieを設定!と書いてある記事が山のように出てきますが、以下の公式FAQにもあるように、最新の仕様ではIPアドレスの指定は不要です。なので、そもそもFixieを使う必要はありません。
- LINE BOT & Beacon 開発者向けFAQ(随時更新)
https://engineering.linecorp.com/ja/blog/line-bot-beacon-developer-faqs/#4_1Server IP Whitelist は登録しないといけないの?
登録する必要はありません。
制限をかけたい場合は、登録すれば良いです。
逆に指定するとそのIPだけしかアクセスできなくなりますので、エラーが出ている場合には、間違ったIPアドレスがこのリストに入っていないか確認しましょう。
チェックポイント3について補足
FixieのアウトバウンドIPをリストに入れていても、そこから正しく接続できていれば当然問題ないです。
私の場合、Fixieの設定をしたにも関わらず、固定IPからリクエストを送信できておらず、エラーログを見ると"message": "Access to this API denied due to the following reason: Your ip address [*.**.***.***] is not allowed to access this API. Please add your IP to the IP whitelist in the developer center."のエラーが出ていました([...*]部分はアプリを再起動するたびに変わってしまう)。
おそらく、botのアプリ本体のコードにプロキシを使うための記述を入れていなかったためかと思います。以下、PHPの場合ですが参考記事です。Pythonでも恐らくこれに相当する記述の仕方があるのだと思いますが、今回は深入りしません。。。
- 【50:LINE BOT API】PHP+HerokuでオウムBOT
http://onesway.hatenablog.com/entry/line_botPHP側でproxyを経由するという記述が抜けていました。
Fixieで作られたproxyのURLをcurl_setoptで設定したら正常に動作しました。余談
デフォルトで出てくる「メッセージありがとうございます!申し訳ありませんが、このアカウントでは個別のお問い合わせを受け付けておりません。次の配信までお待ちください」メッセージは、LINE Official Account Manager の応答設定>詳細設定>応答メッセージ で適宜オフにするなりしておく必要がある(最初エラーのせいで出てきてるのかと思ってた。。。)。
- 投稿日:2020-08-07T17:44:24+09:00
機械学習講座メモ
イントロダクション【P01】
機械学習とは
データから機械自身に振る舞いを学習させる技術研究領域
- 教師あり学習 原因系Xと結果yの関係性を学習
教師なし学習
データのパターン化や新しい表現形式を獲得する
データパターンの見える化
いずれにも該当しない場合に以上と判断(異常検知)強化学習
報酬を最大化する行動ルールの獲得を目指す深層学習と伝統的機械学習の違い
特徴量エンジニアリングがアルゴリズム側に九州された
民主化の波
- DataRobot
https://www.datarobot.com/jp/- Amazon SageMaker
https://aws.amazon.com/jp/sagemaker/Featuretools | An open source framework for automated feature engineering Quick Start
https://www.featuretools.com/pandasで使うもの
- dataframe, series
- join, merge
- iloc,loc
- map, apply, applymap
(2)
フリーランチ定理
データによって最適なアルゴリズムは変わるペナルティ項=害
PCA:主成分??
アルゴリズムの中
正則化:holdout
アルゴリズムの前
次元削減(特徴抽出、特徴選択)
アルゴリズムの後
交叉検証:kfoldStandardScaler()
平均値を引いて標準偏差で割るfrom sklearn.model_selection import cross_val_score, KFold # build models kf = KFold(n_splits=3, shuffle=True, random_state=0) for pipe_name, est in pipelines.items(): cv_results = cross_val_score(est, X, y, cv=kf, scoring='r2') print('----------') print('algorithm:', pipe_name) print('cv_results:', cv_results) print('avg +- std_dev', cv_results.mean(),'+-', cv_results.std())教師あり学習(回帰)【P02】
- 回帰:正解データが連続量
- 分類:正解データが2値
フェーズ
- モデリングフェーズ
- スコアリングフェーズ
汎化能力を高めるには
* データ量
* 業務知識を反映した特徴量設計
* データの前処理とアルゴリズム評価回帰アルゴリズム
- 最小2乗回帰
- リッジ回帰:L2正則化項を入れる
過学習への対処
- 正則化
- 次元削減(特徴量抽出)
- 次元削減(特徴選択)
- ホールドアウト・交叉検証
- ホールドアウト法
- k-fold(Cross validation)
アルゴリズム
- 決定木
- ランダムフォレスト
- 勾配ブースティング
回帰モデルの評価
- 絶対平均誤差(MAE):実測値と予測値の差の絶対値の平均
- 平均2乗誤差(MSE):実測値と予測値の差の2乗値の平均
- 中央絶対誤差:実測値と予測値の差の絶対値の中央値 外れ値の影響を受けにくい
- R2値:誤差0で1.0平均値予測同等で0.0。悪いとマイナス
教師あり学習(分類)【P03】
分類のアルゴリズム
- K近傍法(K-Nearest Neighbors)
- ロジスティック回帰
- 最尤法
- ニューラルネットワーク
- 形式ニューロン
- 単純パーセプトロン:重み学習を追加
→ 線形分離不可能な問題は解けない- 多層パーセプトロン:入力層と出力層の間に中間層を挿入
誤差逆伝搬法による重み学習- サポートベクターマシン(SVM)
分類モデル評価方法
- 混同行列(Confusion Matrix)
- 偽陰性(FN):PをNと誤判定
- 偽陽性(FP):NをPと誤判定
- 正解率(Accuracy):全体のうち正解の割合(TP+TN/ALL)
- 適合率(Precision):正の中での正解率(TP/TP+FP)
- 再現率(Recall):正と判定した中での正解率((TP/TP+FN)
- F値(F-measure):適合率と再現率の調和平均
データ前処理と次元削減【P04】
データ前処理
- One-hotエンコーディング
- 欠損値補完
- 標準化
- 日時は経過時間に置き換え
次元削減
- 次元の呪い:次元数が大きくなると汎化誤差が大きくなる
- 特徴選択:重要な変数を選択する
- ルールによる選択:欠損、分散
- 基礎統計量に応じた選択:分類、回帰に応じた選択
- モデルによる選択(RFE):
python from sklearn.feature_selection import RFE selector = RFE(RandomForestRegressor(n_estimators=100, random_state=42), n_features_to_select=5)
- 投稿日:2020-08-07T17:42:53+09:00
Flask-RESTX (Flask-RESTPlus) で, サーバ起動せずに swagger.json を取得する
Flask-RESTX でサーバ起動せずにAPIドキュメントである swagger.json を取得したい場面がありました.
はじめに, Flaskアプリケーションのサンプルコードを示します.
from flask import Flask from flask_restx import Api, Resource, fields def create_app(): app = Flask(__name__) api = Api(app) @api.route("/sample") class SampleResource(Resource): @api.marshal_with(api.model("sample model", { "name": fields.String, "age": fields.Integer, })) def get(self): raise NotImplementedError() return app
flask runで起動すると, http://127.0.0.1:5000/swagger.json へのアクセスで, swagger.json を取得できます.しかし, この方法では swagger.json を得るために, デバッグサーバを起動する手間がかかってしまいます. CIなどを使って, 自動で swagger.json を取得して共有するなどしたいケースでやや難があります.
そこで次のようなスクリプトを用意して実行すると, Flaskサーバを立ち上げることなく, swagger.json を取り出すことができます.
import json import sys from app import create_app app = create_app() json.dump( app.test_client().get("/swagger.json").get_json(), sys.stdout, )Flaskに同梱されているテスト用クライアントを使っています.
このスクリプトでは標準出力にだしてますが, ファイルにリダイレクトするなりで, JSONファイルを取得できます.
- 投稿日:2020-08-07T17:37:26+09:00
Streamlitで特許マップ作成
はじめに
- 特許文書をサクッと2次元plotして、グリグリ動かせるやつがほしいなあと思いつつ、ウェブアプリケーション作成を含むので、今まで遠巻きに眺めていたところ、pythonのみでデータ分析のアプリケーションを作れるStreamlitを発見。早速試してみることに。
- プロットに利用した特許データのembeddingデータはこれ
説明↓
(Version 1) Machine-learned vector embedding based on document contents and metadata, where two documents that have similar technical content have a high dot product score of their embedding vectors.
- 一時は、GAE+flaskで作ろうとしていたけど、こっちの方が間単に作れた。
注意:ずっと動かすとGCPのお金かかるので、予告なしに止まります.
ロードバランシングも何もしてないので、出力に時間かかることがあります。1 AI PlatformのNotebooksでipynbファイルなど作成
まずGCP上のAI Notebookでpythonアプリケーション側を作る。
下図のように、.ipynbファイル1個と、.pyファイル2個。
pyファイルのうち、
2 ポート開放など
ウェブ上で参照可能にすべく
StreamlitのTutorialを進めたあと、Run Streamlit remotelyを
参照しつつ、AINotebookが動いてるGCEの外部IPアドレスのポート開放を行う。VPC Network⇒Firewallで、
TCPでport=85801を指定(streamlit指定)。
SourdeIPRange指定を 0.0.0.0/0(全部から受付と提供)※これはセキュリティとしては、解放する対象のアドレスを絞ったほうがいいと思われる。検討中
2 streamlitの中身
3つファイルあり。
* 一つ目は単にstreamlitをインストールして走らせるだけのもの!streamlit run claimgen.py
- 二つ目:フロントのようなもの
plot.py
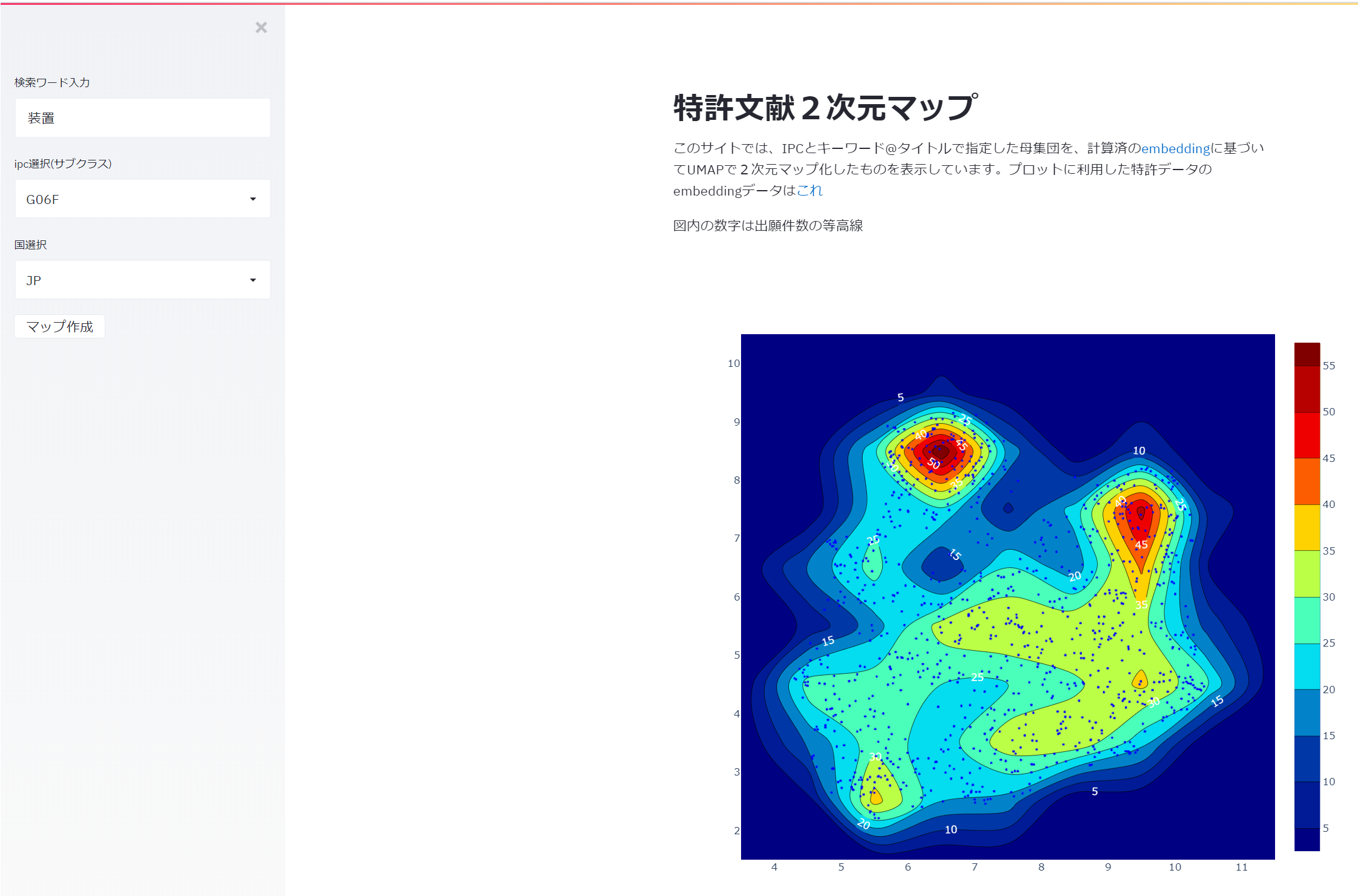
import streamlit as st import pandas as pd import plotly.graph_objects as go #3つ目の作成したpyファイル import um def drawfig(dataframe,cc): x = dataframe['xpos'].values y = dataframe['ypos'].values fig = go.Figure(go.Histogram2dContour( x = x, y = y, #xbins={'end':200, 'size':1, 'start': 0}, zmin = 0, #zmax = 500, #ncontours=50, colorscale = 'Jet', contours = dict( showlabels = True, labelfont = dict( family = 'Raleway', color = 'white' ) ), hoverlabel = dict( bgcolor = 'white', bordercolor = 'black', font = dict( family = 'Raleway', color = 'black' ) ), )) fig.add_scattergl(x=dataframe["xpos"], y=dataframe["ypos"], mode="markers", marker=dict(size=3.5, color="blue"), text= "<a href='" + dataframe["url"]+ "' style='color: rgb(255,255,255)'>" + dataframe["index"] + "<br>" +dataframe["applicant"].str[0:15]+"…<br>"+dataframe["title"].str[0:15]+"…</a>", name="全体" ) #x_disp_range =[-8,10] #y_disp_range =[-7,7] #fig.update_xaxes(range=x_disp_range) #fig.update_yaxes(range=y_disp_range) fig.update_layout( #title=dataframe['appday'].iloc[0], height = 800, width = 800, bargap = 0, hovermode = 'closest', showlegend = False ) fig.write_html(cc+"_heatmap.html") #f2 = go.FigureWidget(fig) #fig.show() return fig st.title('特許文献2次元マップ') st.markdown('このサイトでは、IPCとキーワード@タイトルで指定した母集団を、計算済の[embedding](https://console.cloud.google.com/marketplace/product/google_patents_public_datasets/google-patents-research-data?filter=solution-type:dataset)に基づいてUMAPdで2次元マップ化したものを表示しています。プロットに利用した特許データのembeddingデータは[これ](https://console.cloud.google.com/marketplace/product/google_patents_public_datasets/google-patents-research-data)') if st.button('検索条件指定'): text = st.text_input('検索ワード入力', '装置') ipc = st.selectbox( 'ipc選択', ( 'G06F','A61K','H01L','G01N','H04L','A61B','H04N','C07D','H04W','C12N','G02B','B01D','B65D','H01M','G06Q','B29C','G01R','H04B','A61M','C07C','A61F','H01R','C08L','B01J','B41J','B65G','G11B','H05K','G06K','C02F','G02F','E21B','B23K','H02J','B32B','H02K','B60R','A23L','G03G','C07K','H04M','H05B','C04B','G01B','C08G','A01G','F16H','A01N','C08F','G06T','H01H','F24F','B62D','A01K','C12Q','F16L','A63F','C23C','F16K','B65H','G05B','A47J','E04B','G09G','H01J','B21D','C09D','G11C','F21S','C09K','B65B','A61L','C01B','H02M','G01M','C22C','H04R','G01S','G03B','A63B','C08J','H01F','B23Q','E02D','B60K','H01Q','G01C','B24B','H01B','F16D','E06B','G03F','F04D','A47L','A47B','F21V','F02M','A61N','H02G','F16C','F04B','G09B','G08B','B08B','G09F','F02D','E04H','A47G','B22D','D06F','F16B','B01F','E05B','H03K','A47C','B66B','F25B','E04F','B25J','F25D','G01F','B23B','B05B','B02C','F01N','B25B','E04G','C12P','B23P','H02P','G05D','B60N','H04J','C09J','B60T','B60C','A61H','G10L','G01L','B66C','G01D','F01D','G01V','H01S','G08G','C11D','A61G','A61C','F16F','H03M','C08K','F02B','A01D','H02B','B63B','H02H','F26B','A47K','C12M','B41F','B60W','C07F','B05D','B60L','A41D','C03C','F24C','H01G','F15B','C03B','G01J','F03D','A01H','C10G','F24H','B64C','E02F','B21B','C21D','G07F','B26D','A01C','F04C','B22F','E02B','E21D','A43B','A45D','C22B','C07H','E01C','H04Q','B60J','C25D','B28B','A61J','B41M','B05C','A23K','F16J' )) cc = st.selectbox( '国選択', ('JP', 'MX', 'US','AU','EP','CN')) df = um.get_xypos_df(ipc,text,cc) plotly_fig = drawfig(df.reset_index(),cc) st.write(plotly_fig) st.write(get_apprank(df)) st.write("データ") st.write(df)
- 三つ目はbigqueryとumap関連 SQLinjectionとか大丈夫でしょうか(ドキドキ)
um.py
import umap import pandas as pd from google.cloud import bigquery #bigquery部分 def get_df(s_ipc,s_text,cc): client = bigquery.Client() sql = """ WITH gpat AS ( SELECT publication_number as pubnum, top_terms, url, embedding_v1 as emb FROM patents-public-data.google_patents_research.publications ), pat AS ( SELECT publication_number as pubnum, filing_date as appday, STRING_AGG(DISTINCT title.text) as title, #STRING_AGG(DISTINCT abstract.text) as abst, STRING_AGG(DISTINCT appls.name,'|') as applicants FROM `patents-public-data.patents.publications`,UNNEST(title_localized) as title,UNNEST(assignee_harmonized) as appls,UNNEST(ipc) as ipcs WHERE SUBSTR(publication_number,0,2) = @cc AND title.text LIKE @s_text AND ipcs.code LIKE @s_ipc #AND filing_date > 20000101 GROUP BY pubnum,filing_date ) SELECT gpat.pubnum, gpat.url, gpat.top_terms, pat.title, #pat.abst, pat.applicants, pat.appday, gpat.emb FROM gpat INNER JOIN pat ON gpat.pubnum = pat.pubnum LIMIT 1000 """ ~~長いので省略3 ちょっと分析
この題材:Sonos v.s. googleを使って作成中。
4.苦労した点
- bigqueryの実行結果を、pandasで受け取る部分。 ネット上では、普通に
# Download query results. query_string = """ ~~なんやかんや """ dataframe = ( bqclient.query(query_string) .result() .to_dataframe(bqstorage_client=bqstorageclient) )とto_dataframe()で出来ると書いてあるけど、エラーが出てしまい、治らない。
しょうがないので、tupleのtupleで帰ってくるのを、原始的に列ごと取り出して
pandasに入れた。他にいい方法を見つけたい。
- streamlitは縦にしか追加できない。 画面分割できそうな話だったけど、標準APIでは実現できず。ここはもう少し勉強しないと。 ⇒sidebar入れるだけなら、sidebarに入れたい要素をst.sidebae.~とすればいいだった!
 '
'
- 投稿日:2020-08-07T17:33:46+09:00
自然言語処理とそのデータ前処理の概要
はじめに
機械学習のシステム化に際して、データの前処理に要する時間やリソースを考慮し、設計に活かすノウハウが求められています。
今回は、自然言語を対象としたデータ前処理の概要と、感情極性分析の実装例であるchABSA-datasetにおけるデータ前処理を題材とした性能検証結果を紹介します。投稿一覧
1. 自然言語処理とそのデータ前処理の概要 ... 本投稿
2. 自然言語処理におけるデータ前処理の性能検証本投稿の目次は以下です。
1. 自然言語処理とそのデータ前処理
1.1 自然言語処理とは
人間が意思疎通を行うために日常的に利用している日本語や英語のような、自然に発展してきた言語を自然言語と言います。プログラミング言語のような人工的な言語とは異なり、自然言語は文の意味や解釈が一意に決まらないような曖昧性があります。
自然言語処理とは、自然言語を使って書かれた膨大なテキストデータを、言葉の曖昧性を踏まえてコンピュータが実用的に扱うことを可能にすること、もしくはそのための技術を指します。
自然言語処理の応用例には、スマートスピーカー、Web検索エンジン、機械翻訳、日本語入力システム、感情極性分析などが挙げられます。1.2 機械学習システムにおける自然言語処理のデータ前処理とは
画像データ(ピクセル値の集合)や、各種センサーから取得できる時系列データは数値として表現できるデータです。一方で自然言語とは単語の集合であり、そのままでは数値として扱うことはできません。
データから法則性を抽出する統計的手法である機械学習で自然言語を扱うためには、何らかの形で自然言語を数値データに変換する必要があります。この変換のことをベクトル化、ベクトル化によって得られた数値データとしての表現のことを特徴量と呼びます。
自然言語処理における前処理とは、テキストデータである自然言語から数値データである特徴量への変換(ベクトル化)、およびその前に実施されるノイズの除去や単語列への分解などの処理を指します。自然言語処理分野の前処理の流れを表1に示します。
表1 自然言語処理分野の前処理とデータ状態の遷移
データの状態 処理分類 説明 生データ - ↓ クリーニング 分析対象としたいテキストデータに付随する HTML タグなどのテキスト以外の不要データを除去 文章 - ↓ 分かち書き 文章を品詞ごとに分解し、単語の配列とし(単語分割) て分割 単語列 - ↓ 正規化、ストップワード除去 表記ゆれの統一、分析をする上で無意味な単語の除去 分析に必要な単語列 - ↓ ベクトル化 単語列から数値データへ変換 特徴量ベクトル - 2. 感情極性分析の前処理を題材とした前処理の例
2.1 自然言語処理のユースケース選定
自然言語処理のユースケースの一つに、あるテキストが示す内容の良し悪しを判定し、意思決定支援として活用する感情極性分析があります。例えば、B2C ビジネスにおける SNS 上での自社製品の評判分析や、金融ビジネス向けにおける企業の業績情報を元にした融資・投資の妥当性分析など幅広い分野において活用が見込まれます。
本投稿では、広い業種において採用可能性のある感情極性分析に注目し、インターネット上に公開されている感情極性分析の Python 実装例である chABSA-dataset を題材として以降の説明を実施します。
2.2 取り扱う前処理の概要
chABSA-dataset では、EDINET にて公開されている 2016 年度の有価証券報告書データ (XBRL形式 1 /2,260 企業/約 7.9GB) を生データとして扱います。このデータ中の業績等を説明する文章からポジティブ/ネガティブという感情極性情報を抽出するために、サポートベクタマシン(SVM)を用いた教師あり学習モデルを作成します。chABSA-dataset の処理は大きく 3 つに分けられます。
(1) ポジティブ/ネガティブの判定を実施するモデルをつくるための訓練データを作成するためのアノテーション処理
(2) (1)で作成したデータに基づいたモデル作成(学習)処理
(3) (2)で作成したモデルを利用した感情極性分析処理自然言語処理分野のデータ前処理は、(1)の処理および(2)の処理の前半(モデル作成の手前まで)に含まれています。(1)の処理および(2)の処理に含まれるデータ前処理を、表2 に示します。
表2 chABSA-datasetにおけるデータ前処理
データの状態 処理分類 説明 生データ(XBRL形式) - ↓ クリーニング XML の一種である Xbrl 形式の生データ から、有価証券報告書の業績を表す セクションの HTML データを抽出する 文章(HTML形式) - ↓ クリーニング HTML タグの除去 文章 - ↓ 分かち書き 文章を単語列に分解 単語列 - ↓ 正規化、ストップワード除去 ・数値を 0 に置換 ・空白文字を除去 分析に必要な単語列 - ↓ ベクトル化 単語列から数値データへ変換 特徴量ベクトル - 2.3 データ量見積もり
機械学習においては処理対象のデータ量が多いほど、処理および学習処理の処理時間や必要となるリソース量は多くなります。そのため、入力する生データ量を事前に見積もることが必要となります。
chABSA-dataset における生データである有価証券報告書(2016 年度)の内容・文量は企業毎に異なります。EDINET にて公開されている XBRL形式の有価証券報告書は企業毎にデータファイルが分けられており、1 企業のデータファイルは 10MB 以内でした。chABSA-dataset では全 2,260 企業データ、合計すると約 7.9GB のデータを扱います。
ここで、表2 に示した処理の内容を参照すると、次の 2つのことがわかります。
まず、企業データファイル毎に処理を個別に逐次実施することが可能であり、全企業のデータを一度に処理できる必要はありません。次に、ある企業のデータファイルの前処理結果が他の企業データファイルの処理結果に影響を与えることがありません。そのため、処理順序を考慮することなくバラバラに処理することが可能です。
これらのことから、全データを一度にメモリ上にロードできるような大容量メモリのサーバは必要ではないこと、リソースが許す範囲で並列処理/分散処理の仕組みを適用すれば高速化が可能であることがわかります。
2.4 前処理のための OSS 選定
自然言語処理の前処理において、特徴的なステップは分かち書き(扱う言語が日本語の場合)とベクトル化です。これらの処理に関して個別に OSS 選定の例を挙げます。
2.4.1 分かち書き(単語分割)について
代表的な分かち書き用ライブラリ(形態素解析器)を表3 に示します。それぞれのライブラリによって内部実装や開発言語に違いがありますが、できることは大きく変わりません。
表3 主要な分かち書き用ライブラリ(形態素解析器)
# ライブラリ名 説明 1 MeCab 日本語形態素解析器の主流。IPA コーパスに基づいた日本語辞書が同時公開されている。C++での実装により高速に動作する 2 Janome Python のみで実装された辞書内包型形態素解析器。Python プログラマが使いやすいことを目指して設計されている 3 CaboCha SVM を利用した形態素解析器。日本語辞書は自前で用意する必要があり、データの権利を考慮しながらの開発を必要とする chABSA-dataset において Janome が利用されているように、データサイエンティストがモデル開発の前処理時点で、開発環境への導入の簡易性などの理由から Janome や他の分かち書きライブラリを利用することもあります。
モデルと合わせて前処理のプログラムもデータサイエンティストから受け取るような場合には、辞書データのライセンスや性能に注意しながらライブラリを変更する必要があるかもしれません。
後日アップする「自然言語処理におけるデータ前処理の性能検証」では、 Janome によって書かれた分かち書き処理を、MeCab を使って置換した場合の変更点のポイントと、性能の差を示します。
2.4.2 ベクトル化について
特徴量ベクトルの表現方法はモデルの作り方に大きく依存しています。したがって、基本的にはデータサイエンティストによるベクトル化手法をコードで再現することになるので、推奨するライブラリ等は特にありません。
近年のベクトル化は「単語の意味は周囲の単語によって形成される」という分布仮説に基づくものがほとんどです。その中で、出現頻度でベクトルを作成する「カウントベースな手法」や、単語の並び情報から当てはまる単語を推論するための重みベクトルを活用する「推論ベースの手法」が存在します。
chABSA-dataset では前者の手法が採用されています。後者の手法で代表的なものが Word2vec です。2.4.3 それ以外のステップについて
分かち書きとベクトル化のステップ以外の処理、例えばクリーニング処理や正規化処理は、XML などのデータ形式依存の解析もしくは文字列の置換によって実施されるものがほとんどです。
このとき必要となる機能は、データ形式依存の解析機能やプログラミング言語に標準的に備わっている正規表現処理機能です。したがって、これらのステップにおいても、推奨するライブラリは特にありません。
まとめ
- 本投稿では自然言語処理とはなにか、どのような前処理があるのかを概説しました。
- 自然言語処理の中の感情極性分析に焦点をあて、実装例のchABSA-datasetを題材に前処理の実例を説明しました。
XBRL形式のデータは、企業が公表する有価証券報告書のHTML形式データの外側にメタデータを付与するようにXMLの入れ子構造になっている。 ↩
- 投稿日:2020-08-07T17:09:39+09:00
[GAN] ポケモンの最終進化をさらに進化させようとして闇を見た
ポケモン生成モデル
過去の記事にまとめたStyleGAN2を用いたポケモン生成モデルを使って,ポケモンの最終進化系をさらに進化させてしまおうという悪いことを考えています.最近実装したものがうまくいくことが多くて,神になったつもりになっていたところで思いついたネタです.
今回は利用する技術を少し詳細に解説しつつ,応用例としてポケモンの進化に挑戦した話を紹介したいと思います.
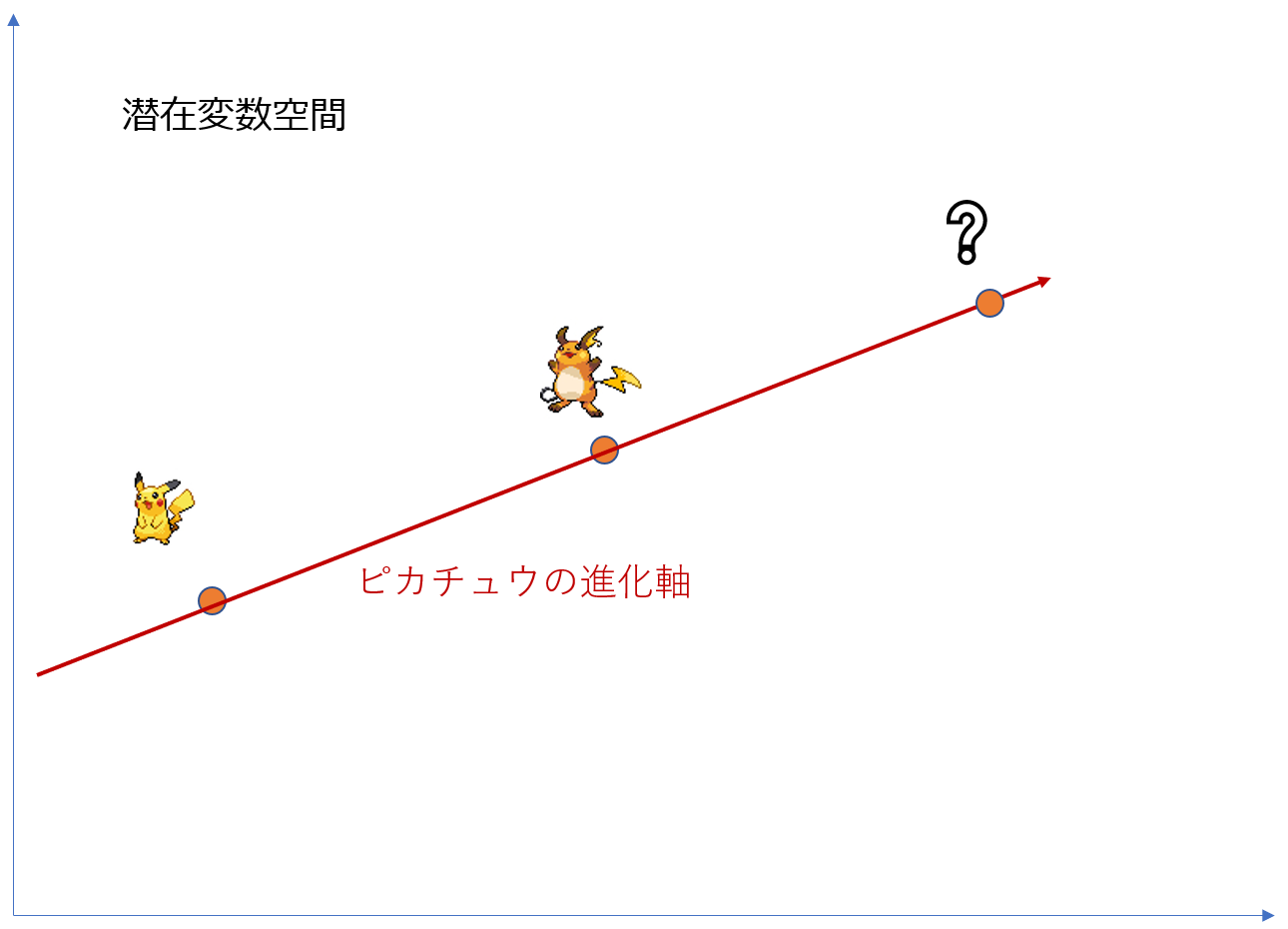
具体的な手法としては,以下の流れです.今回は直線上に進化するポケモンが並んでいると仮説を立てました.ピカチュウ→ライチュウ→?という最終進化の更新を想定して説明します.
- 学習済StyleGAN2のモデルを読み込む
- ピカチュウとライチュウを生成するような潜在変数を推定する
- ピカチュウとライチュウの二点を通るような次元方向のベクトルを計算する
- そのベクトル方向に移動させていけばピカチュウ派生のポケモンが出てくる(はず)
関連研究の紹介
Image2StylyGAN
PGGAN・StyleGANなど,十分に学習された表現力の高い生成モデルはデータセットには存在しない新しい顔を生み出すことが知られています.その性質を利用して,広い潜在変数空間上で任意の画像を生み出すような潜在変数を推定してやろうというのがImage2StyleGANのコンセプトです.
※Image2StyleGANの論文より引用与えられた画像に対応する潜在変数を推定する方法は以下の二つが考えられます.
- 生成モデル(Decoder)に対応するEncoderを学習させる
- 生成画像と所望の画像の類似度を損失関数として,それを最小化するように潜在変数空間上を探索する
前者は経験的にうまくいかないことが知られているらしく,Image2StyleGANでは後者の最適化手法を採用しています.
損失関数には知覚損失(Perceptual Loss)を用いていて,ImageNetで学習済みのVGG16モデルに画像を入力して得られる特徴量を比較することで画像間の類似度を損失として計算しています.知覚損失をAdamで最適化することでVGG16が見ている知覚的な特徴が一致した生成画像を探し出すことができるわけです.Perceptual Modelとしてはzhang, 2018が有名なようで,今回もこれを使うことにします.
画像間の類似度を計算するだけだったら,その目的で学習されているFaceNetなんかを再学習させて独自のモデルを作ってもいいかもしれないですね.
再現実験として,モデルをStyleGAN2(config-f)の学習済モデルに入れ替えて安倍首相を再構成してみたらこうなりました.
InterFaceGAN
こちらの研究も十分に学習された生成モデルにおける潜在変数空間上の画像のふるまいについての研究です.ある属性に関して,潜在変数空間上に分離超平面が存在することを示唆した研究です.分離超平面が推定できればその法線ベクトル方向に潜在変数を移動させればその属性を変化させられるわけです.
※InterFaceGANの論文から引用分離超平面の推定手法はシンプルで結構泥臭い感じになっています.以下のステップを踏みます.例として眼鏡の超平面を推定することを考えます.
- 眼鏡の有無を0-1のスコアで推定するモデルを学習
- 生成モデルからランダムに数万件サンプル画像を生成
- 全サンプル画像に対して眼鏡のスコアを計算して,潜在変数座標とスコアの対応をつける
- SVMで眼鏡あり画像と眼鏡なし画像を最も分離するような超平面を計算する
- 推定された分離超平面の法線ベクトル方向に潜在変数を移動させることで属性値を変化させる
ちなみにこれも再現実験でStyleGAN2のモデルに差し替えて属性を変化させてみたらこんな感じになりました.
性別
年齢
長くなりましたが,この研究のおかげで潜在変数空間上では属性の分離超平面が学習の中で形成されていることがわかります.つまり,ポケモンの進化もある次元方向で表現されているのではないかと考えられます.ただし,さすがに人間の顔の属性とは違ってポケモンは多種多様すぎるので一つの種族の進化系統に限ってそれが成り立つと今回は考えます.
やってみる
今回使うモデルはStyleGAN2(config-f)をMosnterGANのデータセットで学習したモデルです.画像サイズは64x64で,約15000枚の画像を1120kimg分学習しています.
生成画像はこんな感じ
正直品質はよくないんですが,データセットに含まれる画像を扱う分にはこんなもんでも行けるかなと思って使っています.(FIDスコア50くらいで停滞しているのでここで止めてます)
Image2StyleGANでImage Embedding
ピカチュウとライチュウを再現できるような潜在変数が存在するかどうかまずは確かめます.
ピカチュウ
ライチュウ
完全にパチモンですね...この時点でモデルの表現力の低さに絶望してますが,最後までやってみます.
進化前後の二点間を通る次元方向へ移動させる
ピカチュウから進化方向へ少しずつ線形補完してみました.
悪・電気タイプあたりに進化しそうな結果が得られました.だんだん形が崩れていってしまうので,潜在変数空間の表現できる範囲を超えてしまっているんだと思います.表現力不足ですね.
悔しいですがここまできたのでせっかくなのでいろいろ試してみました.
だいたい精神汚染度の高い感じになっていっちゃいますね...
まとめ
自前で学習したStyleGAN2のポケモン生成モデルを使って,ポケモンを進化させようとしてみましたが微妙な感じで終わってしまいました.
解決策としては,学習モデルの改善を検討すべきですね.
表現力不足ということで,多様なポケモンをとらえるために必要なデータ量に達していないことが考えられるので今後はデータ拡張を行ってデータセットの重増しを行おうかと思っています.色違いのデータを入れているのですが,色違いが許されるなら画像全体の色調変換を行った画像を大量に入れても問題ないんじゃないかと.画像枚数をデータ拡張で50000枚くらいに増やして学習してみて再挑戦してみたいテーマでした!
詳しい方など,アドバイスを頂けると泣いて喜びます!







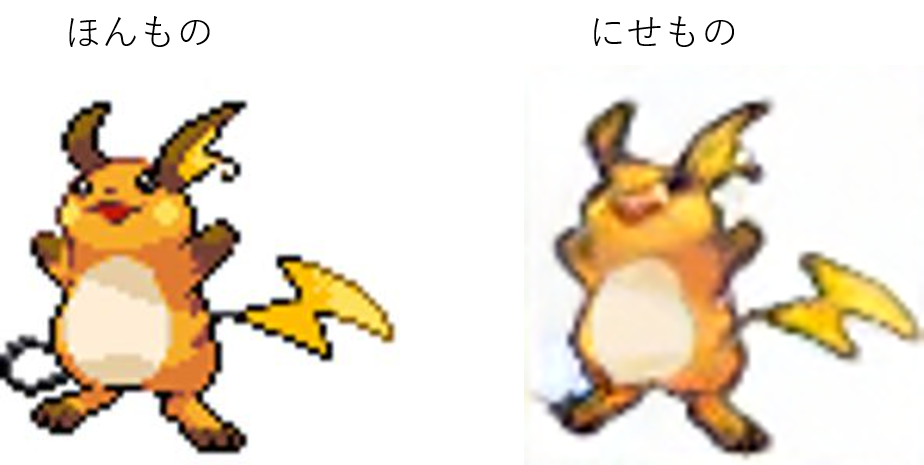



- 投稿日:2020-08-07T17:07:55+09:00
BERTに続いてXLNetを0分ぐらいでちょっと経験してみようとして挫折。
目的
BERTに続いてXLNetを、ちょっと、動かしてみたいと思い、
ぐぐって、一瞬で動きそうな例を試してみた。選んだ例
あまり良いサイトに出会えなく、
以下のgithubのコードを動かしてみた。
https://github.com/zihangdai/xlnetRACE(Reading Comprehension Dataset)という問題を解くための以下のコードを実行した。
run_race.py
RACEの説明
以下は、RACEの一つの問題です。文章を理解して質問に答える(選択肢あり)。
{"answers": ["C", "D", "A", "A"], "options": [["take care of the whole group", "make sure that everybody finishes homework", "make sure that nobody chats in class", "collect all the homework and hand it in to teachers"], ["chat with each other", "listen to the teacher", "make friends", "communicate"], ["get benefits from", "are tired of", "cannot get used to", "hate"], ["Three.", "Four.", "Two.", "Five or six."]], "questions": ["A discipline leader is supposed to _ .", "The new way of learning is said to give students more chances to _ .", "We can see from the story that some students _ this new way of learning.", "How many leaders are there in one group?"], "article": "Take a class at Dulangkou School, and you'll see lots of things different from other schools, You can see the desks are not in rows and students sit in groups. They put their desks together so they're facing each other. How can they see the blackboard? There are three blackboards on the three walls of the classroom!\nThe school calls the new way of learning \"Tuantuanzuo\", meaning sitting in groups. Wei Liying, a Junior 3 teacher, said it was to give students more chances to communicate.\nEach group has five or six students, according to Wei, and they play different roles .There is a team leader who takes care of the whole group. There is a \"study leader\"who makes sure that everyone finishes their homework. And there is a discipline leader who makes sure that nobody chats in class.\nWang Lin is a team leader. The 15-year-old said that having to deal with so many things was tiring.\n\"I just looked after my own business before,\"said Wang. \"But now I have to think about my five group members.\"\nBut Wang has got used to it and can see the benefits now.\n\"I used to speak too little. But being a team leader means you have to talk a lot. You could even call me an excellent speaker today.\"\nZhang Qi, 16, was weak in English. She used to get about 70 in English tests. But in a recent test, Zhang got a grade of more than 80.\n\"I rarely asked others when I had problems with my English tests. But now I can ask the team leader or study leader. They are really helpful.\"", "id": "middle1.txt"}
RACEは、
https://www.cs.cmu.edu/~glai1/data/race/
などからデータをダウンロードできると思います。run_race.py を実行させるためには
- RACEのダウンロード
- xlnet_cased_L-12_H-768_A-12のダウンロード
usageがないので、適当に、以下のオプションで実行しました。
内容、全く理解していません。エラーが出ないように適当にオプションを足したり
減らしたりしました。python run_race.py --do_eval=True --model_dir="./xlnet_cased_L-12_H-768_A-12" --spiece_model_file="./xlnet_cased_L-12_H-768_A-12/spiece.model" --data_dir="./data" --model_config_path="./xlnet_cased_L-12_H-768_A-12/xlnet_config.json" --output_dir="./output" --eval_batch_size=1 --train_eval=False --uncased=False役立つかもしれない情報は以下。
(1)
メモリが足らないというようなエラーが出ましたので、
バッチサイズを最小にして逃げました。--eval_batch_size=1(2)
tensorflowのバージョンは、以下です。2.0.0以降はエラーになるのではないでしょうか。tensorflow 1.15.3
実行結果
以下の結果になりました。4択なので、出鱈目でも0.25なので、全く、正しく動作していないです!!!(問題数は、大半の問題を消して、数問にしました。。。)
⇒ 失敗eval_accuracy = 0.22I0806 18:16:47.620249 10828 evaluation.py:167] Evaluation [45/50] INFO:tensorflow:Evaluation [50/50] I0806 18:17:51.467021 10828 evaluation.py:167] Evaluation [50/50] INFO:tensorflow:Finished evaluation at 2020-08-06-18:17:52 I0806 18:17:52.105508 10828 evaluation.py:275] Finished evaluation at 2020-08-06-18:17:52 INFO:tensorflow:Saving dict for global step 0: eval_accuracy = 0.22, eval_loss = 1.3860148, global_step = 0, loss = 1.3860148 I0806 18:17:52.121129 10828 estimator.py:2049] Saving dict for global step 0: eval_accuracy = 0.22, eval_loss = 1.3860148, global_step = 0, loss = 1.3860148 INFO:tensorflow:================================================================================ I0806 18:17:53.214434 10828 run_race.py:546] ================================================================================ INFO:tensorflow:Eval | eval_accuracy 0.2199999988079071 | eval_loss 1.3860148191452026 | loss 1.3860148191452026 | global_step 0 | I0806 18:17:53.229773 10828 run_race.py:550] Eval | eval_accuracy 0.2199999988079071 | eval_loss 1.3860148191452026 | loss 1.3860148191452026 | global_step 0 | INFO:tensorflow:================================================================================ I0806 18:17:53.229773 10828 run_race.py:551] ================================================================================ C:\_qiita\___xlnet\xlnet-master>まとめ
とりあえず、XLNetを動かしてみようとトライしましたが、提示したサイトのrun_race.pyで
まともな結果は出ませんでした。
多くの方が参照しているサイトなので、使い方が間違えていることは自明です。
役立つ情報としては、
(0)
XLNet、簡単に動かせないかも。(1)
メモリ不足は、
--eval_batch_size=1
で回避できる。(2)
提示のサイト(github)の場合、
tensorflowのバージョンは、2.0.0以降はエラーになる(?)。ぐらいでしょうか。
コメントなどあれば、お願いします。
- 投稿日:2020-08-07T17:07:55+09:00
BERTに続いてXLNetを30分ぐらいでちょっと経験してみようとして挫折。
目的
BERTに続いてXLNetを、ちょっと、動かしてみたいと思い、
ぐぐって、一瞬で動きそうな例を試してみた。選んだ例
あまり良いサイトに出会えなく、
以下のgithubのコードを動かしてみた。
https://github.com/zihangdai/xlnetRACE(Reading Comprehension Dataset)という問題を解くための以下のコードを実行した。
run_race.py
RACEの説明
以下は、RACEの一つの問題です。文章を理解して質問に答える(選択肢あり)。
{"answers": ["C", "D", "A", "A"], "options": [["take care of the whole group", "make sure that everybody finishes homework", "make sure that nobody chats in class", "collect all the homework and hand it in to teachers"], ["chat with each other", "listen to the teacher", "make friends", "communicate"], ["get benefits from", "are tired of", "cannot get used to", "hate"], ["Three.", "Four.", "Two.", "Five or six."]], "questions": ["A discipline leader is supposed to _ .", "The new way of learning is said to give students more chances to _ .", "We can see from the story that some students _ this new way of learning.", "How many leaders are there in one group?"], "article": "Take a class at Dulangkou School, and you'll see lots of things different from other schools, You can see the desks are not in rows and students sit in groups. They put their desks together so they're facing each other. How can they see the blackboard? There are three blackboards on the three walls of the classroom!\nThe school calls the new way of learning \"Tuantuanzuo\", meaning sitting in groups. Wei Liying, a Junior 3 teacher, said it was to give students more chances to communicate.\nEach group has five or six students, according to Wei, and they play different roles .There is a team leader who takes care of the whole group. There is a \"study leader\"who makes sure that everyone finishes their homework. And there is a discipline leader who makes sure that nobody chats in class.\nWang Lin is a team leader. The 15-year-old said that having to deal with so many things was tiring.\n\"I just looked after my own business before,\"said Wang. \"But now I have to think about my five group members.\"\nBut Wang has got used to it and can see the benefits now.\n\"I used to speak too little. But being a team leader means you have to talk a lot. You could even call me an excellent speaker today.\"\nZhang Qi, 16, was weak in English. She used to get about 70 in English tests. But in a recent test, Zhang got a grade of more than 80.\n\"I rarely asked others when I had problems with my English tests. But now I can ask the team leader or study leader. They are really helpful.\"", "id": "middle1.txt"}
RACEは、
https://www.cs.cmu.edu/~glai1/data/race/
などからデータをダウンロードできると思います。run_race.py を実行させるためには
- RACEのダウンロード
- xlnet_cased_L-12_H-768_A-12のダウンロード
usageがないので、適当に、以下のオプションで実行しました。
内容、全く理解していません。エラーが出ないように適当にオプションを足したり
減らしたりしました。python run_race.py --do_eval=True --model_dir="./xlnet_cased_L-12_H-768_A-12" --spiece_model_file="./xlnet_cased_L-12_H-768_A-12/spiece.model" --data_dir="./data" --model_config_path="./xlnet_cased_L-12_H-768_A-12/xlnet_config.json" --output_dir="./output" --eval_batch_size=1 --train_eval=False --uncased=False役立つかもしれない情報は以下。
(1)
メモリが足らないというようなエラーが出ましたので、
バッチサイズを最小にして逃げました。--eval_batch_size=1(2)
tensorflowのバージョンは、以下です。2.0.0以降はエラーになるのではないでしょうか。tensorflow 1.15.3
実行結果
以下の結果になりました。4択なので、出鱈目でも0.25なので、全く、正しく動作していないです!!!(問題数は、大半の問題を消して、数問にしました。。。)
⇒ 失敗eval_accuracy = 0.22I0806 18:16:47.620249 10828 evaluation.py:167] Evaluation [45/50] INFO:tensorflow:Evaluation [50/50] I0806 18:17:51.467021 10828 evaluation.py:167] Evaluation [50/50] INFO:tensorflow:Finished evaluation at 2020-08-06-18:17:52 I0806 18:17:52.105508 10828 evaluation.py:275] Finished evaluation at 2020-08-06-18:17:52 INFO:tensorflow:Saving dict for global step 0: eval_accuracy = 0.22, eval_loss = 1.3860148, global_step = 0, loss = 1.3860148 I0806 18:17:52.121129 10828 estimator.py:2049] Saving dict for global step 0: eval_accuracy = 0.22, eval_loss = 1.3860148, global_step = 0, loss = 1.3860148 INFO:tensorflow:================================================================================ I0806 18:17:53.214434 10828 run_race.py:546] ================================================================================ INFO:tensorflow:Eval | eval_accuracy 0.2199999988079071 | eval_loss 1.3860148191452026 | loss 1.3860148191452026 | global_step 0 | I0806 18:17:53.229773 10828 run_race.py:550] Eval | eval_accuracy 0.2199999988079071 | eval_loss 1.3860148191452026 | loss 1.3860148191452026 | global_step 0 | INFO:tensorflow:================================================================================ I0806 18:17:53.229773 10828 run_race.py:551] ================================================================================ C:\_qiita\___xlnet\xlnet-master>まとめ
とりあえず、XLNetを動かしてみようとトライしましたが、提示したサイトのrun_race.pyで
まともな結果は出ませんでした。
多くの方が参照しているサイトなので、使い方が間違えていることは自明です。
役立つ情報としては、
(0)
XLNet、簡単に動かせないかも。(1)
メモリ不足は、
--eval_batch_size=1
で回避できる。(2)
提示のサイト(github)の場合、
tensorflowのバージョンは、2.0.0以降はエラーになる(?)。ぐらいでしょうか。
コメントなどあれば、お願いします。
- 投稿日:2020-08-07T16:49:57+09:00
OR-Toolsで学ぶ最適化 【線形計画:多段階モデル】
このブログis何
Googleが開発したOR-Toolsを使って数理最適化を学んでいきます。
内容は殆どがこの本を参考にしたものです。
Practical Python AI Projects: Mathematical Models of Optimization Problems with Google OR-Tools (English Edition)著者によるコード一覧はこちら
本ブログに記載するコードは著者オリジナルの物と殆ど変わらず、一部日本語に直したりしている程度です。数学的な厳密さや、理論の解説は優先度低めになってます。ご勘弁を。今回は : 線形計画~多段階モデル編~
意思決定に「いつ」を取り入れます。倉庫を例にとると、今月末に在庫がいくつあるかによって来月の発注量が変わりますよね。同様に、来月の発注量によって再来月の発注量が変わります。このように、ある段階での意思決定がそれ以降の段階での意思決定に影響を及ぼすような状況下での最適な意思決定を考えます。
場面設定
たかし君は石鹸工場を運営しています。工場の業績がたかし君のお小遣いに影響するため、効率の良い運営方法を模索することにしました。
石鹸は様々なオイルを精練・混合することで製造されます。オイルにはアプリコットやアボカドなど色んな香りがあり、それぞれのオイルは種々の脂肪酸を含んでいます(ラウリン、リノール、オレイン酸など)。以下に、オイル$i$に含まれる脂肪酸$A_j$の表を示します。
また、石鹸の性質(洗浄力、泡立ち、肌の乾燥感など)を考慮して、最終的な脂肪酸の含有量がある範囲に収まるように適切に混合します。ここでは、以下の表の範囲に収まるようにするものとします。
ここでは、数か月にわたる意思決定を考えます。各オイルは、すぐに使う用に購入しても良いし、次の月のために購入することもできます。以下の表に、各月の各オイルの価格(ドル/t)を示します。
後で使うために合計1,000tまでならオイルを保管できます。ただし1tあたり月に5ドルの保管費用がかかります。
さらに、たかし君の工場は毎月5,000tの石鹸の需要を満たさねばなりません。現時点で、たかし君の工場には以下の表に示すオイルの在庫があります。
ようやく本題です。費用を最小化するには、どの月にどれくらいのオイルを精練・混合すれば良いのでしょうか?あ~長かった。
定式化:決定変数
各月に各オイルをどれくらい混合するのかという決定変数になりそうですが、これだけでは不十分です。オイルを使う際は買ったものを使っても良いし、在庫として持っていたものを使っても良いため、これらは区別します。また、合計1,000tまでという縛りがある中で、どれくらい在庫用に買えるかも知る必要があります。
したがって、オイルの集合$O$と月の集合$M$に関して、最低でも3つの決定変数が要ります。
x_{i,j} \geq 0 \quad \forall i \in O, \forall j \in M \quad 購入\\ y_{i,j} \geq 0 \quad \forall i \in O, \forall j \in M \quad 混合\\ z_{i,j} \geq 0 \quad \forall i \in O, \forall j \in M \quad 在庫\\$x_{i,j}$は月$j$に購入したオイル$i$が何tか、$y_{i,j}$は石鹸を作るために月$j$に混合したオイル$i$が何tか、$z_{i,j}$は月$j$の初めに所持しているオイル$i$が何tか。を表しています。
また、厳密には必要ありませんが、各月に石鹸が何t作られたかという変数も用意します。これがあったほうが制約などの記述が楽になります。月$j$の石鹸の生産量をt_j \quad \forall j \in Mとします。
定式化:制約
各月に各オイルの在庫がどう変動するのかを指定する必要があります。したがって
z_{i,j} + x_{i,j} - y_{i,j}= z_{i,j+1} \quad \forall i \in O, \forall j \in M \{最終月}という式を用意します。これは月初の在庫に当月の購入分を足して、当月の使用分を差し引いたものが次月の在庫になることを意味します。
各月の倉庫の容量について下限と上限があるので、
C_{min} \leq \sum_{i} z_{i,j} \leq C_{max} \quad \forall j \in M次は混合の制約です。完成品の脂肪酸の範囲について規定がありましたね。先ほどの月あたり生産量$t_j = \sum_{i} y_{i,j} \quad \forall j \in M$を使います。
脂肪酸の集合$A$があり、各脂肪酸$k \in A$について規定範囲$[l_k,u_k]$と、オイル$i$に含まれる脂肪酸$k$の割合$p_{i,k}$を考えます。そうすると脂肪酸の含有量の範囲について、下限と上限の2式が生まれます。\sum_i y_{i,j} p_{i,k} \geq l_k t_j \quad \forall k \in A, \forall j \in M \\ \sum_i y_{i,j} p_{i,k} \leq u_k t_j \quad \forall k \in A, \forall j \in M最後に、各月の需要を満たさねばなりません(今回は5,000tで一定ですが)。月$j$の需要$D_j$を考えて、
t_j \geq D_j \quad \forall j \in M定式化:目的関数
今回の目的は費用最小化でした。すなわち、オイルの購入費用と保管費用の総和を最小にすることです。購入単価はオイルと月によって違いますが、1tあたり保管費用は固定です。してがって目的関数は
\sum_i \sum_j x_{i,j} P_{i,j} + \sum_i \sum_j z_{i,j}p$P_{i,j}$はオイル$i$の月$j$の単価、$p$は1tあたり保管費用(今回は5ドル)を表しています。
実装
今回の例題を解くためのコードを記載します。
my_or_tools.pyやtableutils.py
の中身に関しては著者GitHubをご覧ください。blend_multi.pyfrom my_or_tools import SolVal, ObjVal, newSolver def solve_model(Part,Target,Cost,Inventory,D,SC,SL): #Part:オイルと脂肪酸の表,Target:脂肪酸の含有量の規定,Cost:オイルの購入費用,Inventory:初期在庫, #D:石鹸の需要量,SC:オイルの保管費用,SL:在庫として持てるオイルの範囲 s = newSolver('Multi-period soap blending problem') #ソルバーを宣言 Oils= range(len(Part)) #オイルの種類数 Periods, Acids = range(len(Cost[0])), range(len(Part[0])) #期間数,脂肪酸の種類 Buy = [[s.NumVar(0,D,'') for _ in Periods] for _ in Oils] #決定変数x。オイルiを月jにいくつ買うか Blnd = [[s.NumVar(0,D,'') for _ in Periods] for _ in Oils] #決定変数y。オイルiを月jにいくつ使うか Hold = [[s.NumVar(0,D,'') for _ in Periods] for _ in Oils] #決定変数z。オイルiを月jにいくつ在庫として持っているか Prod = [s.NumVar(0,D,'') for _ in Periods] #補助的な変数。月jに生産した石鹸 CostP= [s.NumVar(0,D*1000,'') for _ in Periods] #補助的な変数。月jの購入費用 CostS= [s.NumVar(0,D*1000,'') for _ in Periods] #補助的な変数。月jの保管費用 Acid = [[s.NumVar(0,D*D,'') for _ in Periods] for _ in Acids] #補助的な変数。月jに生み出した脂肪酸kの量 for i in Oils: s.Add(Hold[i][0] == Inventory[i][0]) #制約。意思決定時点での在庫は与えられている for j in Periods: s.Add(Prod[j] == sum(Blnd[i][j] for i in Oils)) #制約。月jの生産量は使用したオイル量の総和である s.Add(Prod[j] >= D) #制約。月jの生産量はその月の需要量を超えている必要がある if j < Periods[-1]: #最後の月は除く for i in Oils: s.Add(Hold[i][j]+Buy[i][j]-Blnd[i][j] == Hold[i][j+1]) #制約。(その月の始めの在庫)+(購入量)-(使用量)=(次月の初めの在庫) s.Add(sum(Hold[i][j] for i in Oils) >= SL[0]) #制約。保管できるオイルの下限 s.Add(sum(Hold[i][j] for i in Oils) <= SL[1]) #制約。保管できるオイルの上限 for k in Acids: s.Add(Acid[k][j]==sum(Blnd[i][j]*Part[i][k] for i in Oils)) #制約。月jの脂肪酸kの生成量は、オイルの使用量のそのオイルにおける脂肪酸kの含有率の積の総和である s.Add(Acid[k][j] >= Target[0][k] * Prod[j]) #制約。脂肪酸kの生成量の下限 s.Add(Acid[k][j] <= Target[1][k] * Prod[j]) #制約。脂肪酸kの生成量の上限 s.Add(CostP[j] == sum(Buy[i][j] * Cost[i][j] for i in Oils)) #制約。月jの購入費用は購入量と価格の積の総和 s.Add(CostS[j] == sum(Hold[i][j] * SC for i in Oils)) #制約。月jの保管費用は在庫量と保管費用の積の総和 Cost_product = s.Sum(CostP[j] for j in Periods) #目的関数。総購入費用 Cost_storage = s.Sum(CostS[j] for j in Periods) #目的関数。総保管費用 s.Minimize(Cost_product+Cost_storage) #総購入費用と総保管費用の和を最小化する rc = s.Solve() B,L,H,A = SolVal(Buy),SolVal(Blnd),SolVal(Hold),SolVal(Acid) CP,CS,P = SolVal(CostP),SolVal(CostS),SolVal(Prod) return rc,ObjVal(s),B,L,H,P,A,CP,CSmy_blend_multi.pyfrom blend_multi import solve_model Content = [#オイルと含有する脂肪酸 [36,20,33,6,4,0,1], [0,68,13,0,0,8,11], [0,6,0,66,16,5,7], [0,32,0,0,0,14,54], [0,0,49,3,39,7,2], [45,0,40,0,15,0,0,0], [0,0,0,0,0,28,72], [36,55,0,0,0,0,9], [12,48,34,0,4,2,0] ] Target = [#脂肪酸の含有量の規定 [13.3,23.2,17.8,3.7,4.6,8.8,23.6], [14.6,25.7,19.7,4.1,5.0,9.7,26.1] ] Price = [#月ごとのオイルの価格 [118,128,182,182,192], [161,152,149,156,174], [129,191,118,198,147], [103,110,167,191,108], [102,133,179,119,140], [127,100,110,135,163], [171,166,191,159,164], [171,131,200,113,191], [147,123,135,156,116] ] Inventory = [#初期保有在庫 [15],[52],[193],[152],[70],[141],[43],[25],[89] ] def main(): import sys import tableutils m=len(Content) n=len(Content[0]) k=len(Price[0]) if len(sys.argv)<=1: print('Usage is main [content|target|cost|inventory|run] [seed]') return """ elif len(sys.argv)>2: random.seed(int(sys.argv[2])) """ C = Content T = Target K = Price I = Inventory if sys.argv[1]=='content': #オイルと含有する脂肪酸の表を出力 for j in range(m): C[j].insert(0,'O'+str(j)) C.insert(0,['']+['A'+str(i) for i in range(n)]) tableutils.printmat(C,False,1) elif sys.argv[1]=='target': #脂肪酸の含有量の規定を出力 T.insert(0,['']+['A'+str(i) for i in range(n)]) T[1].insert(0,'Min') T[2].insert(0,'Max') tableutils.printmat(T,True,1) elif sys.argv[1]=='cost': #月ごとのオイルの価格を出力 for j in range(m): K[j].insert(0,'O'+str(j)) K.insert(0,['']+['Month '+str(i) for i in range(k)]) tableutils.printmat(K) elif sys.argv[1]=='inventory': #意思決定時点で保有している在庫を出力 for j in range(m): I[j].insert(0,'O'+str(j)) I.insert(0,['Oil','Held']) tableutils.printmat(I) elif sys.argv[1]=='run': #ソルバーを実行 Demand=5000 #毎月の石鹸の需要量 Limits=[0,1000] #在庫として持てる下限と上限 Cost=5 rc,Value,B,L,H,P,A,CP,CS=solve_model(C,T,K,I,Demand,Cost,Limits) if len(B): A.append([0 for l in range(len(A[0]))]) for j in range(len(A)-1): for l in range(len(A[0])): A[j][l] = A[j][l]/P[l] A[-1][l] += A[j][l] for j in range(m): B[j].insert(0,'O'+str(j)) L[j].insert(0,'O'+str(j)) H[j].insert(0,'O'+str(j)) for l in range(n): A[l].insert(0,'A'+str(l)) A[-1].insert(0,'Total') B.insert(0,['Buy qty']+['Month '+str(i) for i in range(k)]) L.insert(0,['Blend qty']+['Month '+str(i) for i in range(k)]) H.insert(0,['Hold qty']+['Month '+str(i) for i in range(k)]) A.insert(0,['Acid %']+['Month '+str(i) for i in range(k)]) P=[P] P[0].insert(0,'Prod qty') CP=[CP] CP[0].insert(0,'P. Cost') CS=[CS] CS[0].insert(0,'S. Cost') tableutils.printmat(B,True,1) tableutils.printmat(L,True,1) tableutils.printmat(H,True,1) tableutils.printmat(P,True,1) tableutils.printmat(CP,True,2) tableutils.printmat(CS,True,2) tableutils.printmat(A,True,1) main()結果
上記のコードを実行すると以下の結果が得られます。
たかし君は無事石鹸工場を良い感じに運営することが出来ました。
発展
今回の例題の発展例としてどんなことが考えられそうか一部紹介します。
・毎月の需要量が変動する
・需要を満たすのではなく、利益を最大化することを優先する。この場合は製品の販売価格が必要になります。
・在庫水準は総計ではなくオイルごとに管理する
・特定のオイルの含有脂肪酸量に不確実性がある場合がある
などです。まとめ
今回はめっちゃ疲れました
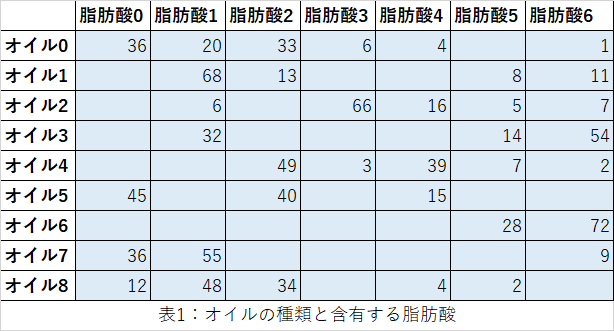
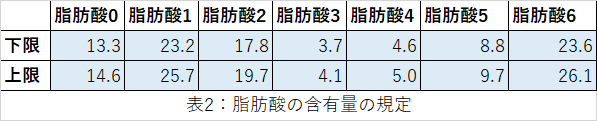
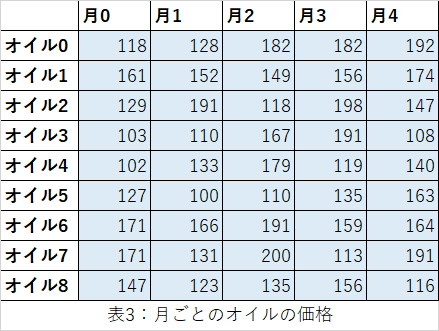
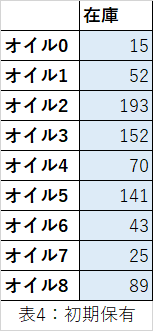
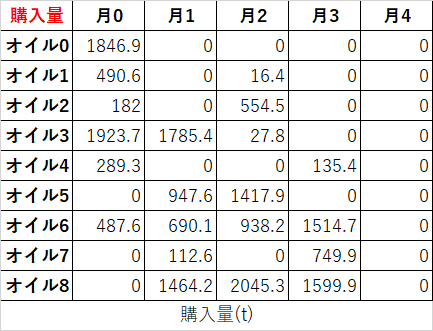
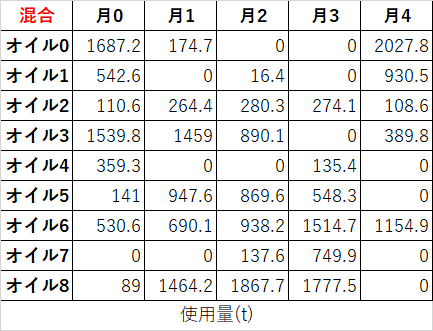
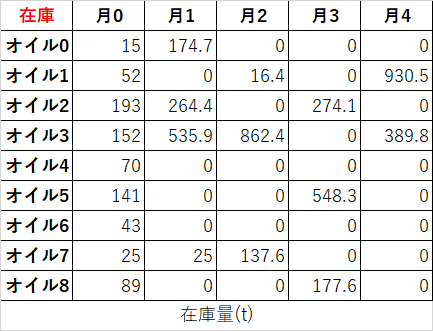


- 投稿日:2020-08-07T15:39:03+09:00
djangoアプリでフロント作るときにmixinの読み込み方がわからなかった話【初学者が参考書片手にpython学習】
はじめに
大高隆・著「動かして学ぶ!Python Django開発入門」を使用して
python・Djangoの学習を始めた初学者です。ruby・railsを使用して4ヶ月ほどプログラミングの勉強をしていましたが、
エンジニア転職にあたり、pythonを使用することになったのでこの本を片手に勉強を始めました。ド級の素人なので、補足・ご指摘等コメントいただけると大変助かります。
概要
一旦バックエンドが落ち着いたので、試しにフロントエンド工作。
そういえば、'rails'だと'application.scss'に記入しておけば
勝手にmixinとか全部読みこんでくれるけど、djangoはどうすれば良いのだろうか??結果
mixinを利用したい.SCSSファイルの最初に
@import "mixin.scss";と、書いておいてあげればいいのでした。そのまんまですね。
参考文献
- 投稿日:2020-08-07T15:06:55+09:00
ロジスティック関数を描いてみる
Overview
けっこう前に sympy でテイラー展開を描いてみたんですけど、
https://qiita.com/arc279/items/dda101b39b96c4aa94d0視覚化するとイメージがわきやすいので、
今回はロジスティック回帰に出てくるロジスティック関数を描いてみます。ロジスティック回帰の詳しい説明はこの辺が詳しいので、以下のサイトの解説と合わせてグラフを眺めてみてください。
http://darden.hatenablog.com/entry/2016/08/22/212522ここでは数式のちゃんとした説明はしません、というかできないw
前準備
$ pip install matplotlib sympy以下、jupyterのセルだと思ってくださいfrom sympy import Symbol from sympy.plotting import plot p = Symbol('p') x = Symbol('x')登場する計算式
\begin{align*} & {\rm オッズ比 }: \frac{p}{1-p} \\ & {\rm ロジット関数 }: f(p) = \log \frac{p}{1-p} \\ & {\rm ロジスティック関数 }: g(x) = \frac{1}{1+e^{-x}} \end{align*}
オッズ比(p) = p/(1-p)jupyterplot(p/(1-p), (p, -2, 2), ylim=(-100, 100), legend=True)
p = 1 で -inf と +inf が繋がっちゃてるのはご愛嬌なんですが、
これの 0 <= p <= 1 を切り取ると、jupyterplot(p/(1-p), (p, 0, 1), ylim=(-100, 100), legend=True)
定義域 0 <= p <= 1 に対して 値域が 0 <= オッズ比(p) < +inf まで拡張されます。
ロジット関数
f(p) = log(p/(1-p))オッズ比の対数を取ることで、
jupyterfrom sympy import log plot(log(p/(1-p)), legend=True)
オッズ比と同じ定義域に対して、値域が -inf < f(p) < +inf まで拡張されてますね。
ロジスティック関数
g(x) = 1/(1+exp(-x))ロジット関数の逆関数なので、
jupyterfrom sympy import exp plot(1/(1+exp(-x)), legend=True)
ロジット関数の値域と定義域が入れ替わって、
- 定義域: -inf < z < +inf
- 値域 : 0 <= g(z) <= 1
つまり、確率 0 <= g(z) <= 1 とみなせる値を出力する関数、と見なせるってことですね。
みたいな解釈で合ってる?