- 投稿日:2020-08-07T21:55:26+09:00
EC2にCloudWatchエージェントをインストールしてログを確認する
はじめに
Amazon Linux 2にCloudWatchエージェントをインストールして、CloudWatch Logsにログを出力させます。
IAMロールの設定
対象のEC2にCloudWatch LogsリソースへアクセスするためのIAMロールをアタッチします。
今回は以下のポリシーを作成し、EC2にアタッチしていたIAMロールへ追加しました。新規作成ポリシー{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:*:*:*" ] } ] }EC2上での設定
まずは対象のEC2にログインし、以下のコマンドを実行します。
参考:https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/download-cloudwatch-agent-commandline.html#ディレクトリ変更 $ cd /opt/aws #CloudWatchエージェントをダウンロード $ sudo wget https://s3.amazonaws.com/amazoncloudwatch-agent/amazon_linux/amd64/latest/amazon-cloudwatch-agent.rpm #パッケージをインストール $ sudo rpm -U ./amazon-cloudwatch-agent.rpm #CloudWatchエージェントを停止 $ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a stop #CloudWatchエージェントのステータスが"stopped"であることを確認 $ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status { "status": "stopped", "starttime": "", "version": "1.246396.0" } #collectdパッケージをインストール $ sudo yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm $ sudo yum install -y collectd次に、ウィザードを使用してCloudWatch エージェント設定ファイルを作成します。
数字を入力してEnterを押下するか、そのままEnterを押下することで"default choice"が適用されます。
以下に設定例を記載します。$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard ============================================================= = Welcome to the AWS CloudWatch Agent Configuration Manager = ============================================================= On which OS are you planning to use the agent? 1. linux 2. windows default choice: [1]: Trying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? 1. EC2 2. On-Premises default choice: [1]: Which user are you planning to run the agent? 1. root 2. cwagent 3. others default choice: [1]: Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]: Which port do you want StatsD daemon to listen to? default choice: [8125] What is the collect interval for StatsD daemon? 1. 10s 2. 30s 3. 60s default choice: [1]: What is the aggregation interval for metrics collected by StatsD daemon? 1. Do not aggregate 2. 10s 3. 30s 4. 60s default choice: [4]: Do you want to monitor metrics from CollectD? 1. yes 2. no default choice: [1]: Do you want to monitor any host metrics? e.g. CPU, memory, etc. 1. yes 2. no default choice: [1]: Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]: Do you want to add ec2 dimensions (ImageId, InstanceId, InstanceType, AutoScalingGroupName) into all of your metrics if the info is available? 1. yes 2. no default choice: [1]: Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. 1. 1s 2. 10s 3. 30s 4. 60s default choice: [4]: Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]: Current config as follows: { "agent": { "metrics_collection_interval": 60, "run_as_user": "root" }, "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "collectd": { "metrics_aggregation_interval": 60 }, "disk": { "measurement": [ "used_percent" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" } } } } Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. 1. yes 2. no default choice: [1]: Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration? 1. yes 2. no default choice: [2]: Do you want to monitor any log files? 1. yes 2. no default choice: [1]: Log file path: /var/log/messages Log group name: default choice: [messages] /var/log/messages Log stream name: default choice: [{instance_id}] Do you want to specify any additional log files to monitor? 1. yes 2. no default choice: [1]: 2 Saved config file to /opt/aws/amazon-cloudwatch-agent/bin/config.json successfully. Current config as follows: { "agent": { "metrics_collection_interval": 60, "run_as_user": "root" }, "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/var/log/messages", "log_group_name": "/var/log/messages", "log_stream_name": "{instance_id}" } ] } } }, "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "collectd": { "metrics_aggregation_interval": 60 }, "disk": { "measurement": [ "used_percent" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" } } } } Please check the above content of the config. The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json. Edit it manually if needed. Do you want to store the config in the SSM parameter store? 1. yes 2. no default choice: [1]: What parameter store name do you want to use to store your config? (Use 'AmazonCloudWatch-' prefix if you use our managed AWS policy) default choice: [AmazonCloudWatch-linux] Trying to fetch the default region based on ec2 metadata... Which region do you want to store the config in the parameter store? default choice: [ap-northeast-1] Which AWS credential should be used to send json config to parameter store? 1. ASIARKREBPFATTHBNQCS(From SDK) 2. Other default choice: [1]: Successfully put config to parameter store AmazonCloudWatch-linux. Program exits now.ウィザードが終了すると、/opt/aws/amazon-cloudwatch-agent/binにconfig.jsonファイルが作成されています。
次に、設定ファイルを反映します。$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -s -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json続いて、CloudWatch エージェントを開始します。
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a start以上で、EC2上での作業は完了です。
AWSマネジメントコンソールへログインします。
CloudWatch > CloudWatch Logs > Log groupsへアクセスすると、先ほどのウィザードで入力したロググループが追加されています。
ロググループを押下すると、同じくウィザードで設定したログストリームにインスタンスIDが表示されています。
ここからログを確認することができます。


- 投稿日:2020-08-07T21:51:47+09:00
ECSのログをSplunkに送る
はじめに
この記事ではEC2 HostingのECSにデプロイしたアプリケーションのログをSplunkにインデックスする方法についての記事を書きます
Fargateについては別の記事に書きます概要
ECSのログはコンテナごとにLog Driverを選択することでログの出力先を指定できます
Splunkにはre:Invent 2019で発表された FireLens を使ってログを送ります
log_routerはFluentdです(Fluent Bitじゃないよ)Log DriverにSplunkを指定することもできますが、あえてFireLensのfluentdを使います
理由は↓
- fluentdを使うことでSplunkが障害やメンテナンスで落ちてるときに再送してくれる
- JavaのStack Traceのような複数行のログイベントも1イベントとしてまとめてくれる
Splunk log driverはこのようなメリットの裏返しのデメリットがあります
HTTP Event Collectorに直接HTTP POSTするだけなので、再送処理はしてくれません
また、デフォルトでログがJSON形式になってしまいます
Dockerコンテナ内のログをSplunkに入れてみた を参考にログを強引にいい感じの形式にしても、複数行のログをまとめることはできないのです
Splunkでprops.confやtransforms.confでなんとかしようとしても、HTTP POSTで1行ずつ送ってくるっぽいので、どうしようもありません
うーん、過去の自分の記事を否定してるみたいでやだなということで、この ドキュメント(いちおう公式) を参照しながら設定しました
設定方法
以下の手順で設定します
1. SplunkでHTTP Event Collectorを有効化
設定方法は ここらへんの記事 を参考にしてください
2. log_routerコンテナ追加
ログを取りたいサービスが入っているタスク定義に
log_routerコンテナを追加して登録しますkikeyama-services-task.yaml- cpu: 0 environment: [] essential: true firelensConfiguration: type: fluentd options: config-file-type: s3 config-file-value: arn:aws:s3:::mybucket/fluent.conf image: splunk/fluentd-hec:1.2.0 logConfiguration: logDriver: awslogs options: awslogs-group: /ecs/kikeyama-services awslogs-region: us-west-2 awslogs-stream-prefix: ecs memoryReservation: 100 mountPoints: [] name: log_router portMappings: [] user: '0' volumesFrom: []# タスク定義を登録 aws ecs register-task-definition --cli-input-yaml file://./kikeyama-services-task.yamlポイントは↓
- コンテナイメージは
splunk/fluentd-hec:1.2.0を指定firelensConfigurationでS3からfluentdの設定ファイルをとってきているところ(以下抜粋)抜粋firelensConfiguration: type: fluentd options: config-file-type: s3 config-file-value: arn:aws:s3:::mybucket/fluent.confオプションとして、log_routerそのもののログをCloudWatch Logsに送ってます
うまくいかなかったとき用のトラブルシューティングとしてね3. Fluentd設定ファイルを作成してS3に保存
以下のファイルを作成してタスク定義に指定しているS3バケット、パスにアップロードします
fluent.conf<system> log_level info </system> <filter **spring-sfx-demo**> @type concat key log stream_identity_key stream multiline_start_regexp /^\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}\.\d{3}/ flush_interval 5s timeout_label @SPLUNK use_first_timestamp true </filter> <match **> @type relabel @label @SPLUNK </match> <label @SPLUNK> <match **> @type splunk_hec protocol <SPLUNK_HEC_SCHEME (http|https)> hec_host <SPLUNK_HEC_HOST> hec_port <SPLUNK_HEC_PORT> hec_token <SPLUNK_HEC_TOKEN> index <SPLUNK_INDEX> host_key ec2_instance_id source_key ecs_cluster sourcetype_key ecs_task_definition insecure_ssl true <fields> container_id container_name ecs_task_arn source </fields> <format> @type single_value message_key log add_newline false </format> </match> </label> <label @ERROR> <match **> @type relabel @label @SPLUNK </match> </label>ポイントは↓
- ラベル
@SPLUNKでsplunk_hecプラグインを利用<fiter xxxxx>でコンテナごとにconcatを使ってmultiline_start_regexpでログイベントの最初の文字を正規表現で指定して複数行ログも取り込み可能にといったところです
今回はJava Spring Bootで作ったspring-sfx-demoという名前のコンテナのアプリケーションのログを取得します(filterで指定してる名前ね)
@SPLUNKラベル内の<SPLUNK_XXXX>については適宜自分の環境の値を入れてください(<>は要らないよ)では、このファイルをS3にアップロードしましょう
4. サービスを更新
ECSのサービスを更新して上記ステップ2.で登録したタスク定義を指定しましょう
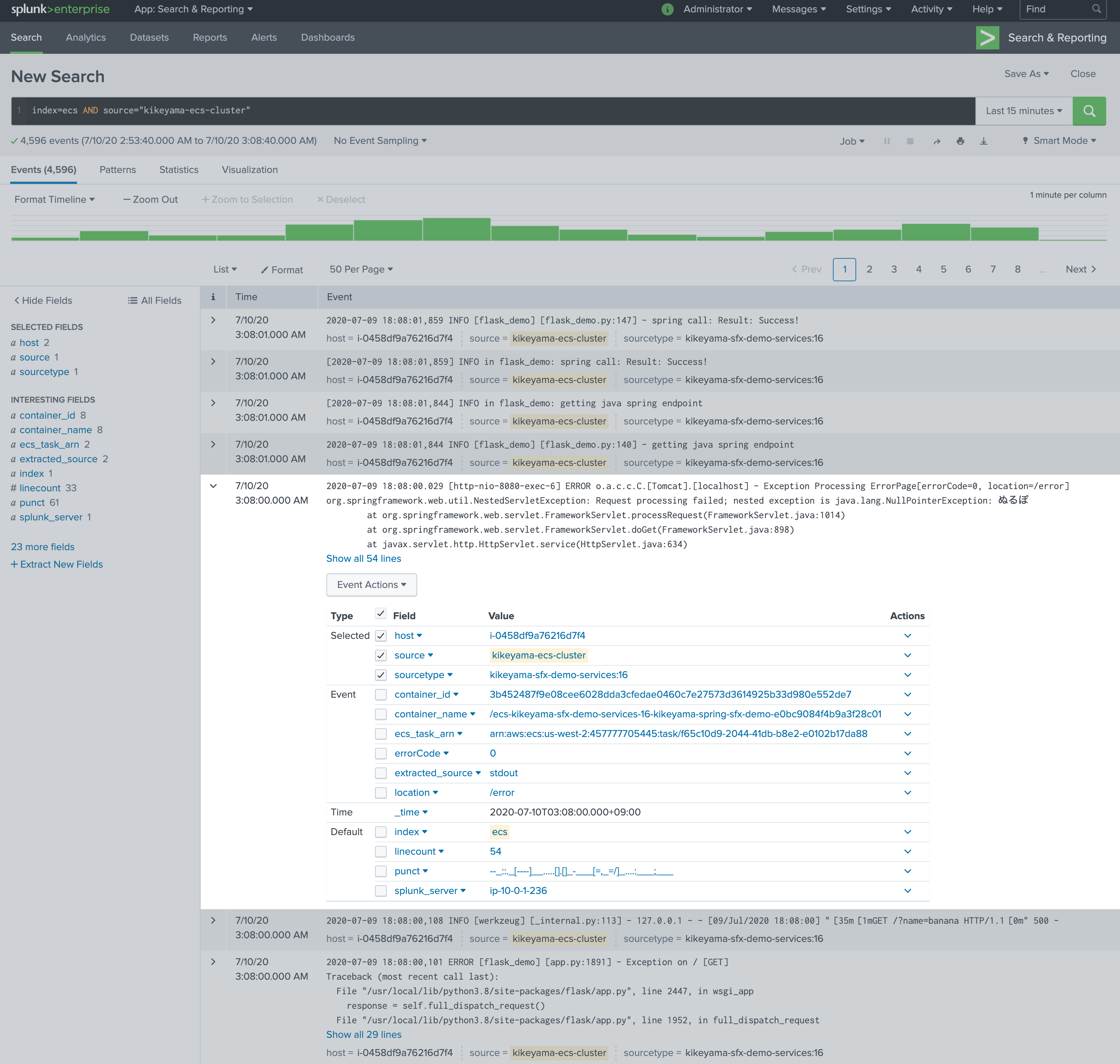
これでログはSplunkに送信されますSplunkでログを確認
ちゃんと複数行のStack Traceも1ログイベントにまとまってますね
今気づいたけどデフォルトでは日付時刻の抽出がちゃんとできてないですね
fluent.conf でちゃんとparseする必要がありますが忘れてましたさいごに
fluentdを使ったのはほぼ初めてなのでけっこう苦戦しました
もう少し設定をちゃんとする余地はあるものの、とりあえずログは取れてるのでヨシとしましょうタイムスタンプのparseについては、気が向いたら対応します
Fargateは若干クセがあったので、ECSと全く同じというわけにはいかなかったです
それについては後日別の記事に書きます乞うご期待
- 投稿日:2020-08-07T21:30:10+09:00
AWSでLAMP環境を構築して、Laravelアプリをデプロイする
今回はAWSのEC2、RDSを用いてLAMP環境を構築して、Laravelアプリをデプロイする手順を紹介します。
今回の流れ
1.RDSを用いてDBサーバー作成
2.EC2を用いてWEBサーバーを作成
3.サーバー間の連携
4.アプリのデプロイ前提条件
・Macを使用
・AWSアカウントを作成済みであること
・GitHubのリモートリポジトリに、開発済みのLaravelアプリが置いてあること1.RDSを用いてDBサーバー作成
コンソールにサインインした後、AmazonRDSに移動します。
続いてオレンジ色のCreate databaseボタンをクリックします。
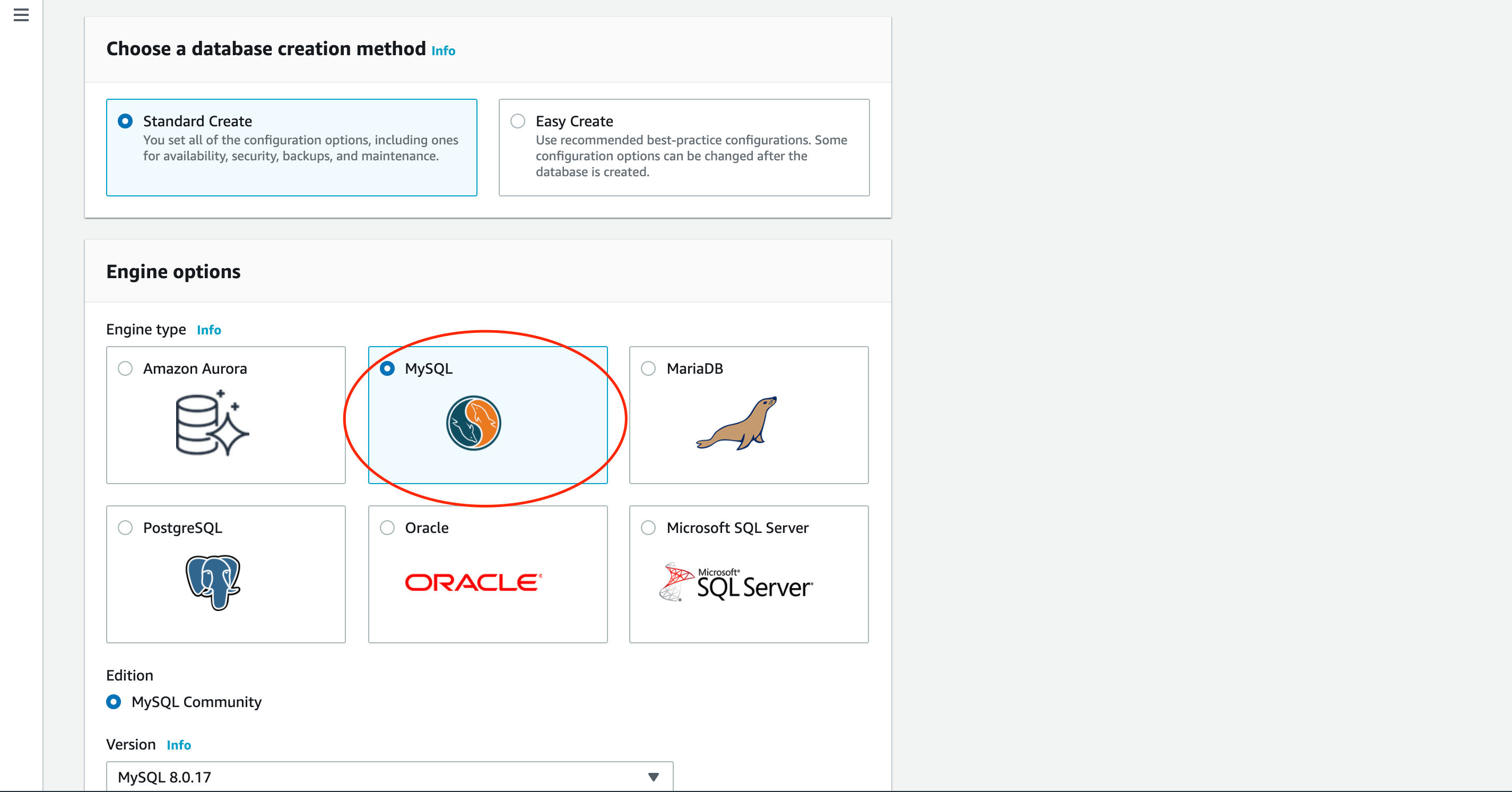
使用するデータベースエンジンを選びます。今回はMySQLを選択します。
バージョンはよしなに選択してください。
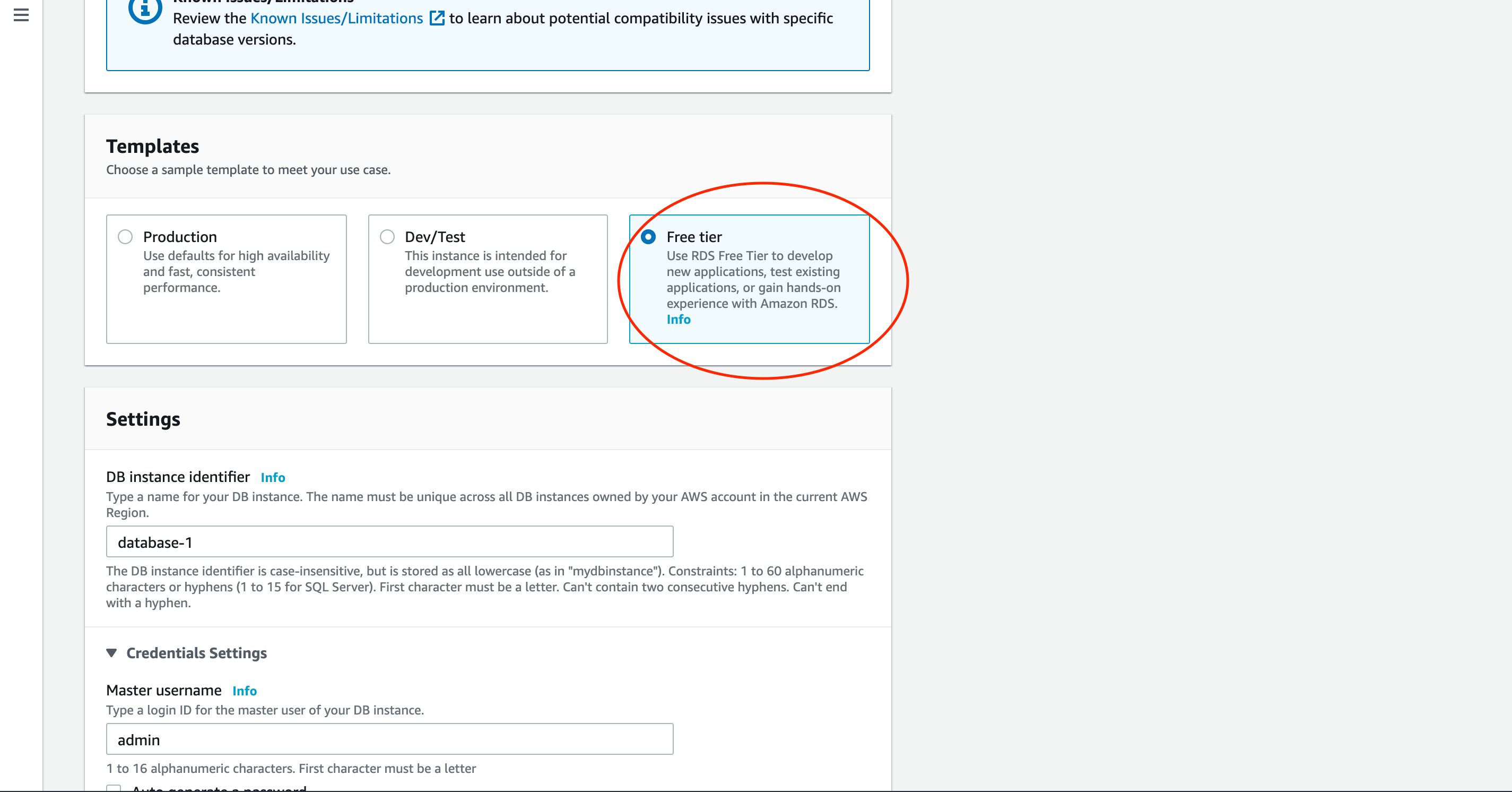
今回は無料利用枠のものを作成します。
本番環境の場合は適したプランを選択してください。
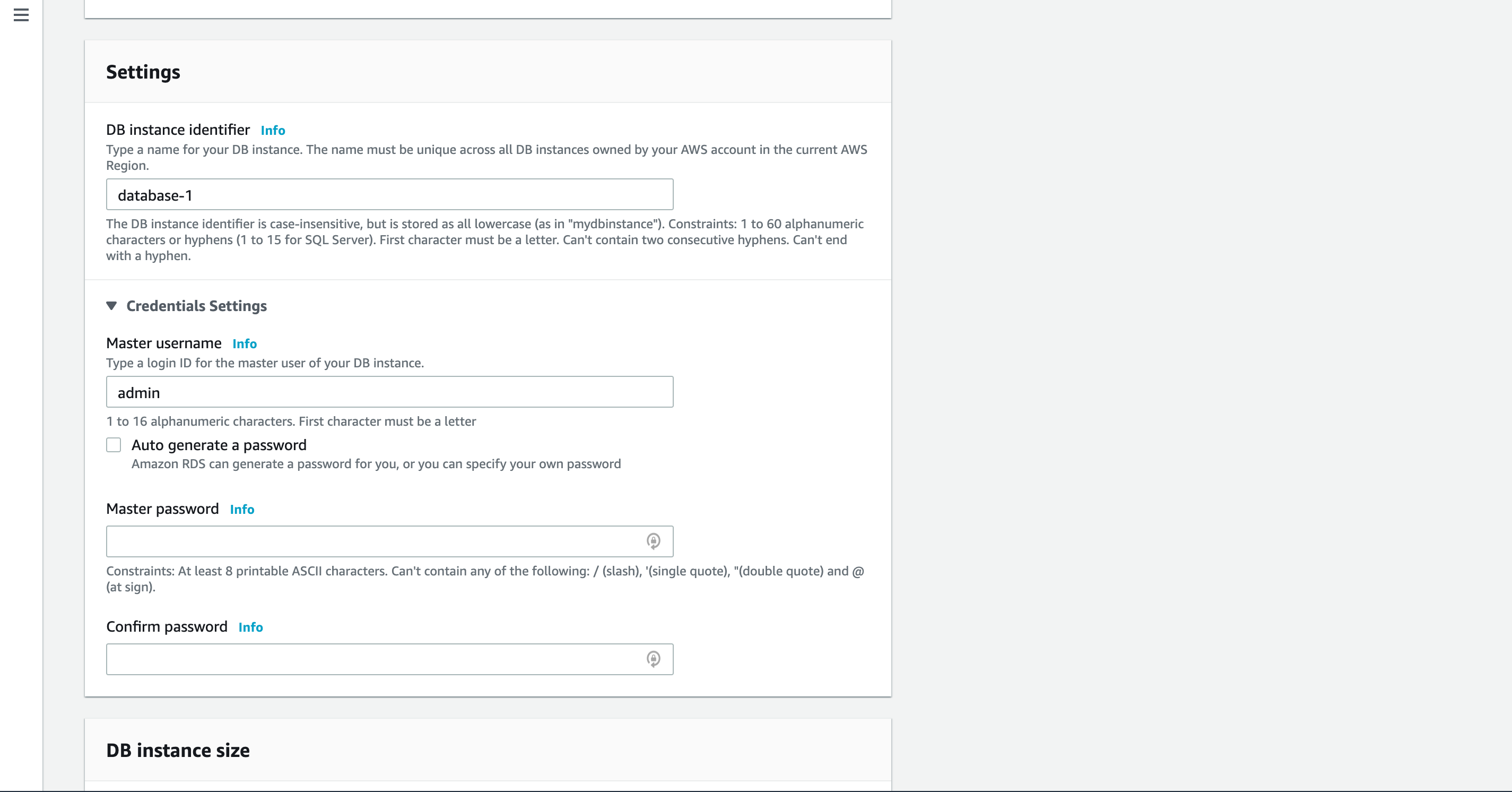
インスタンス名、マスターユーザー名、パスワードを設定します。
後ほど使いますので、安全な場所にメモしておきましょう。
インスタンスのスペック、ストレージの容量等を設定します。
今回はデフォルト設定で進めますが、本番環境の場合はよしなに選択してください。
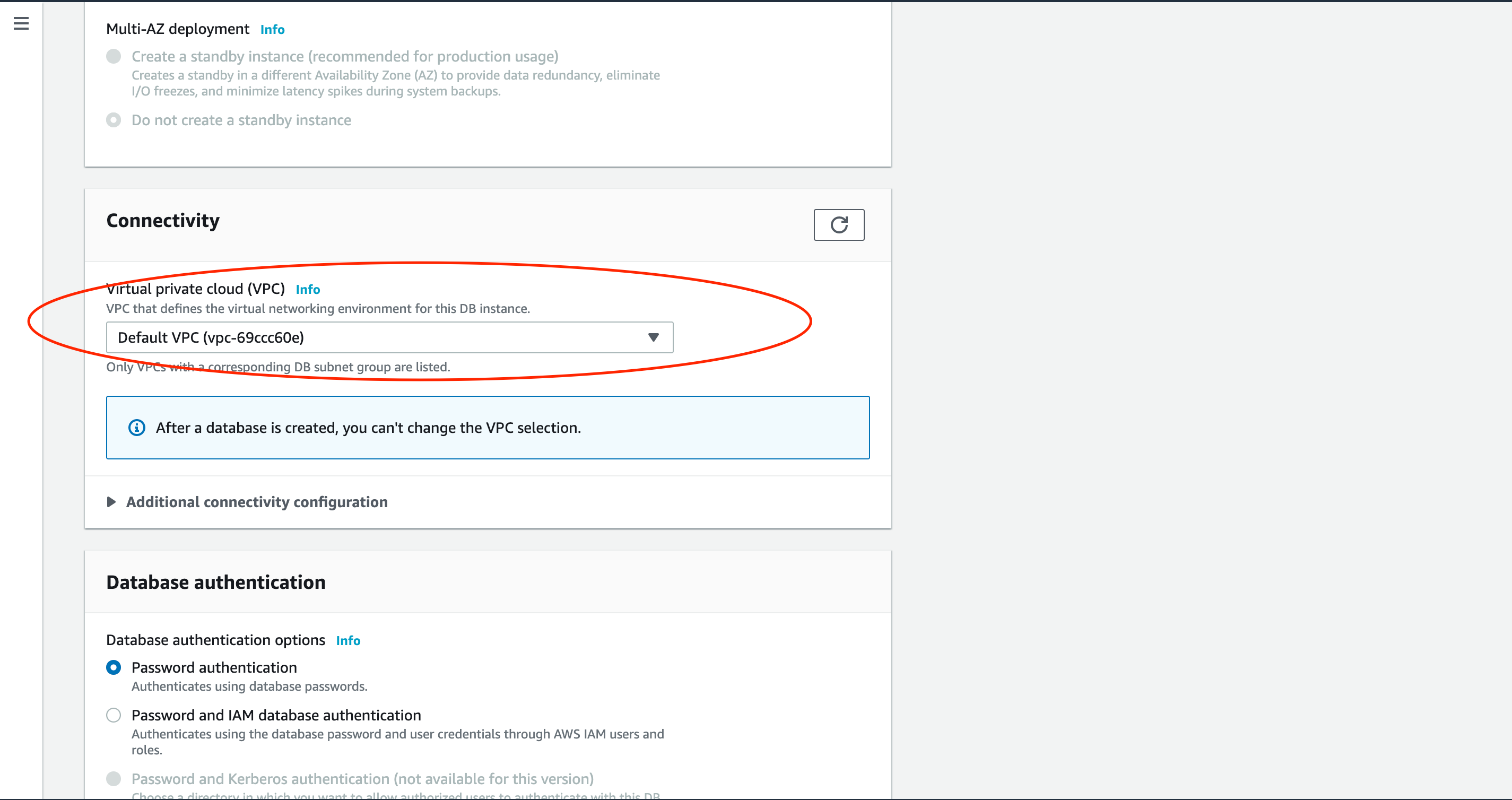
ネットワークの設定を行います。
VPCを作成済みの方は作成したVPCを、そうでない方はデフォルトのVPCを設定しましょう。
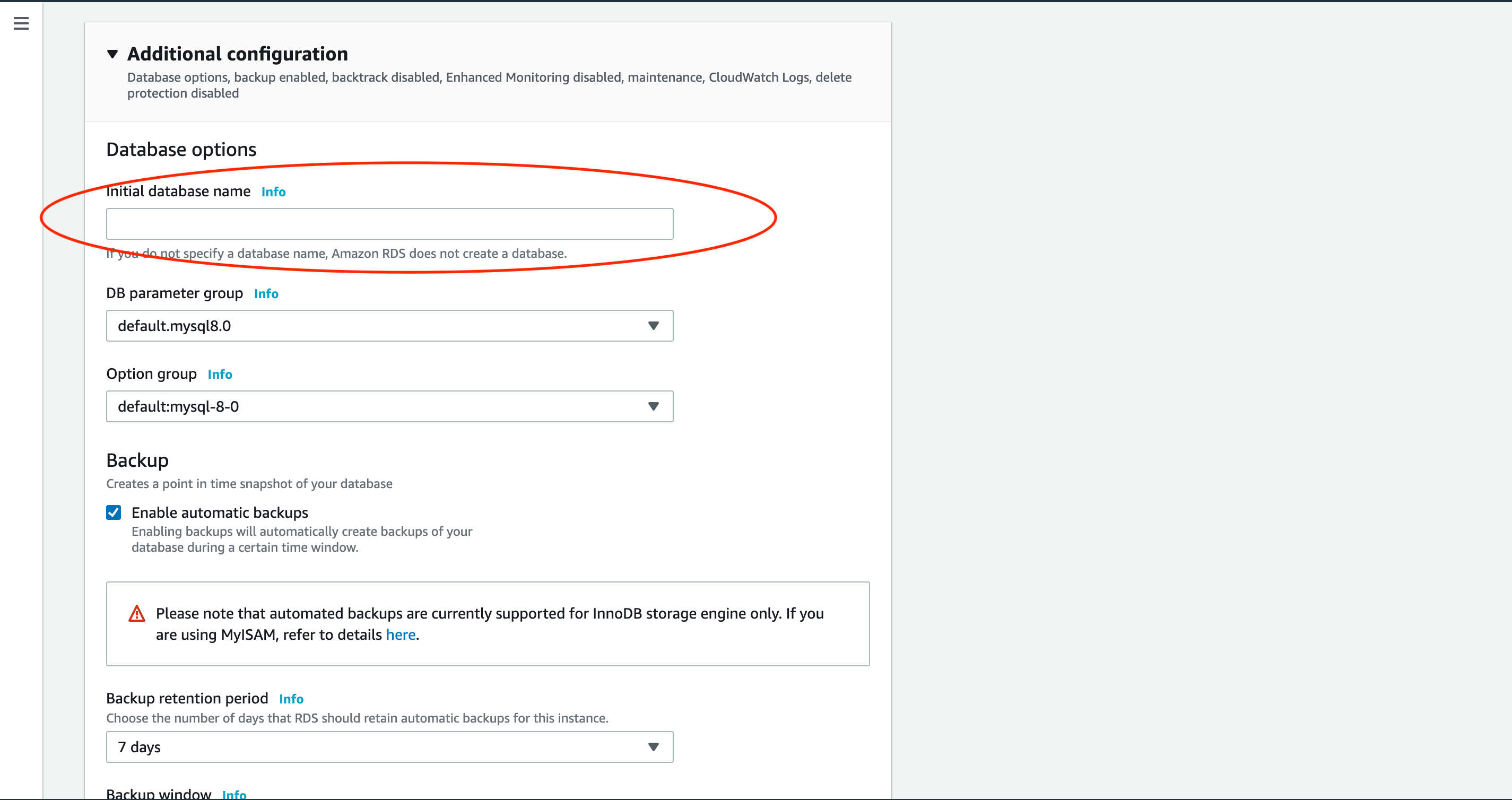
最後にオプションの設定をします。
RDSインスタンス初期化時に自動で作られるデータベースの名前を設定します。
今後データベースに接続する際は、ここで設定したデータベース名を使用します。
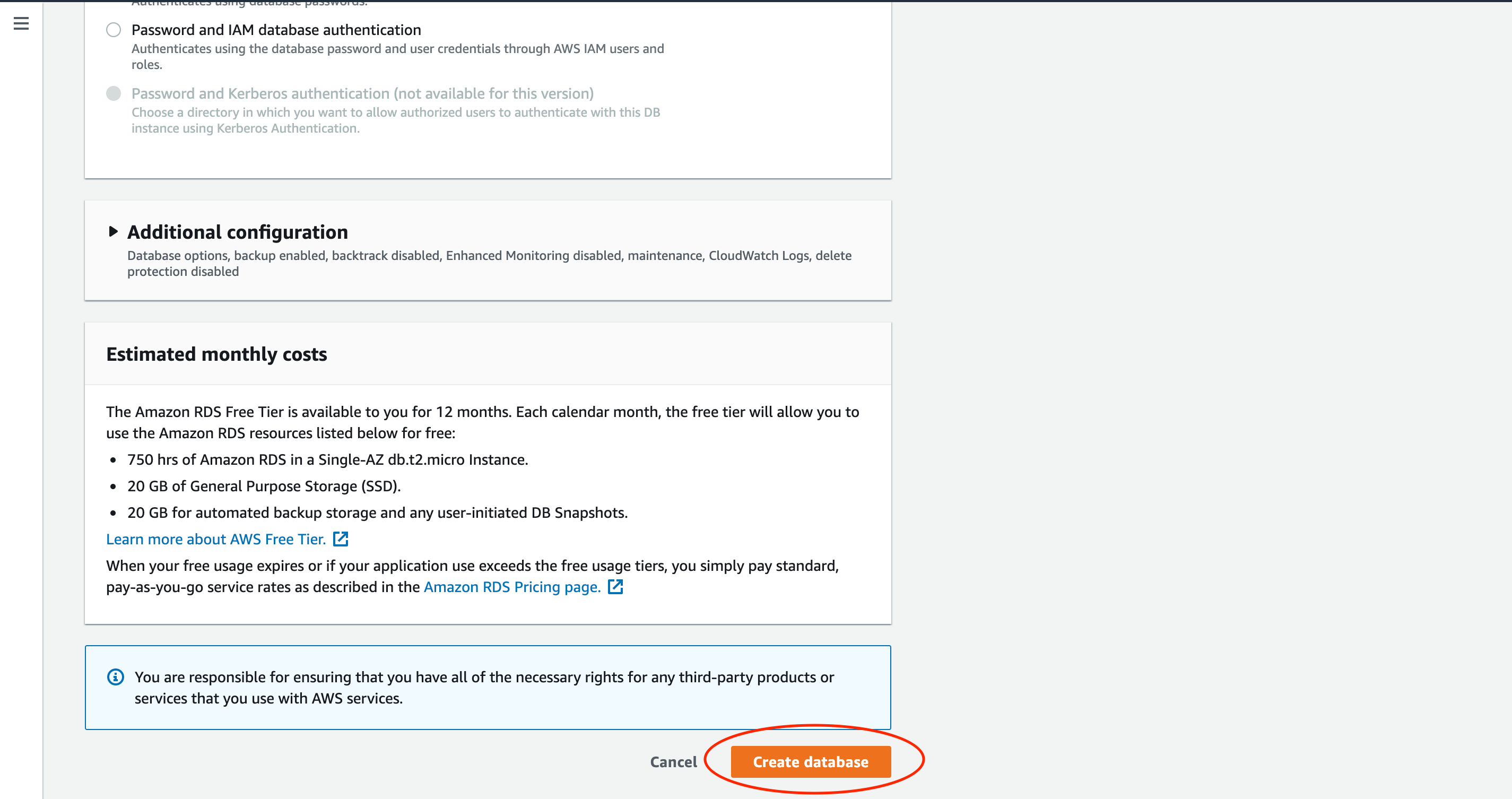
オレンジ色のCreate databaseボタンをクリックして設定したデータベースを作成します。
2.EC2を用いてWEBサーバーを作成
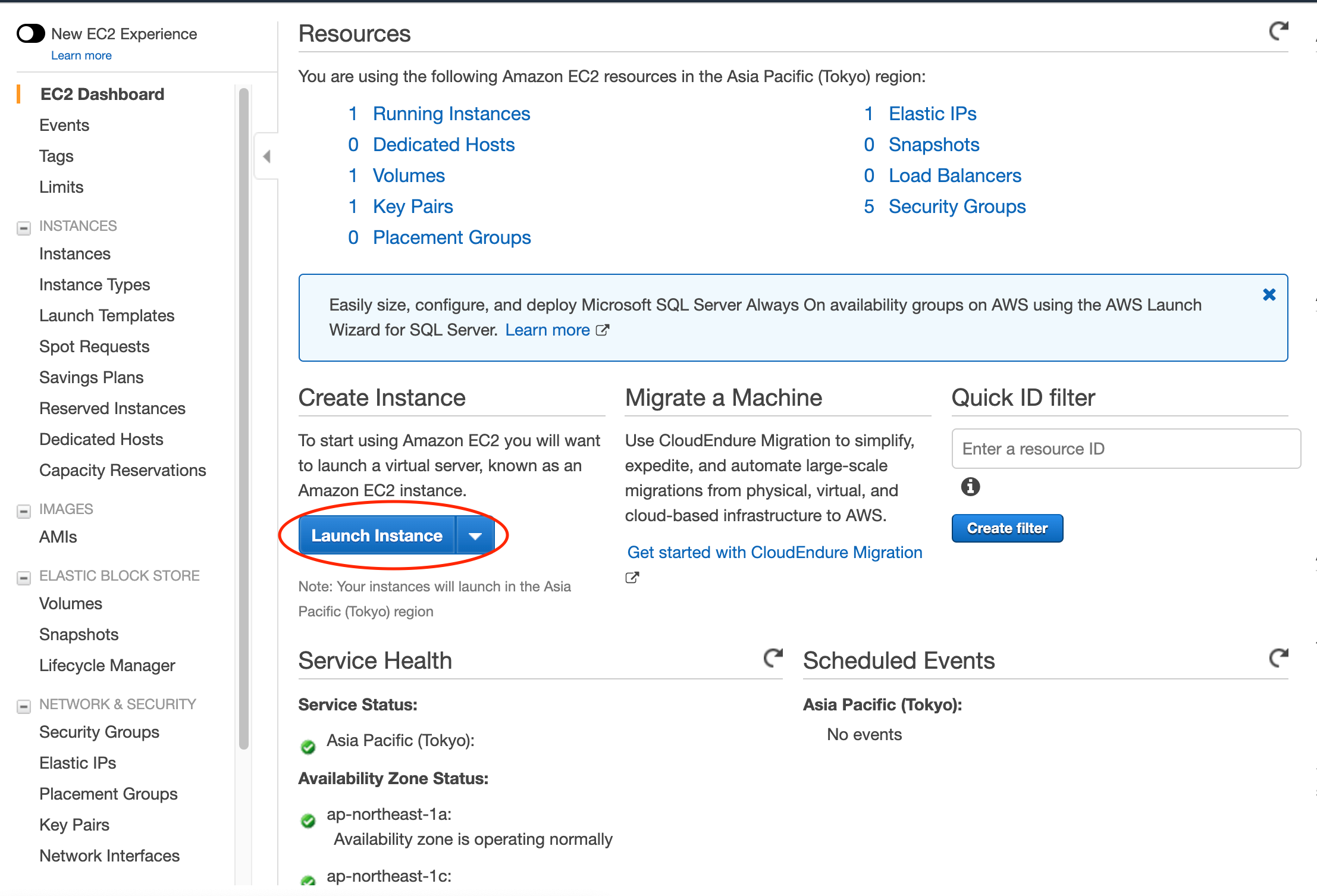
コンソールからAmazon EC2に移動して、青色のLaunch Instanceボタンをクリックします。
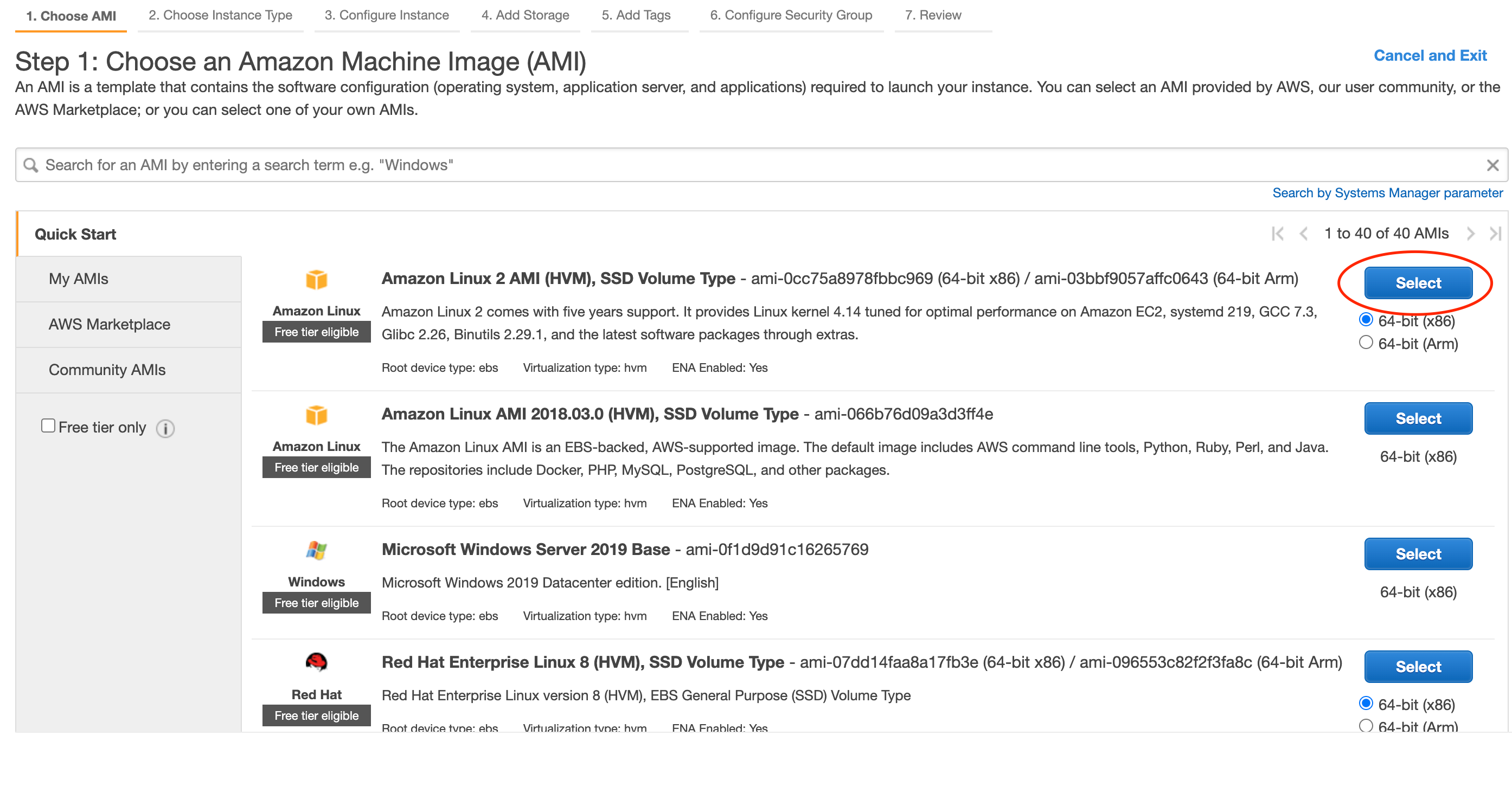
使用するマシンのイメージを選択します。
今回はAmazon Linux 2 AMIを用います。
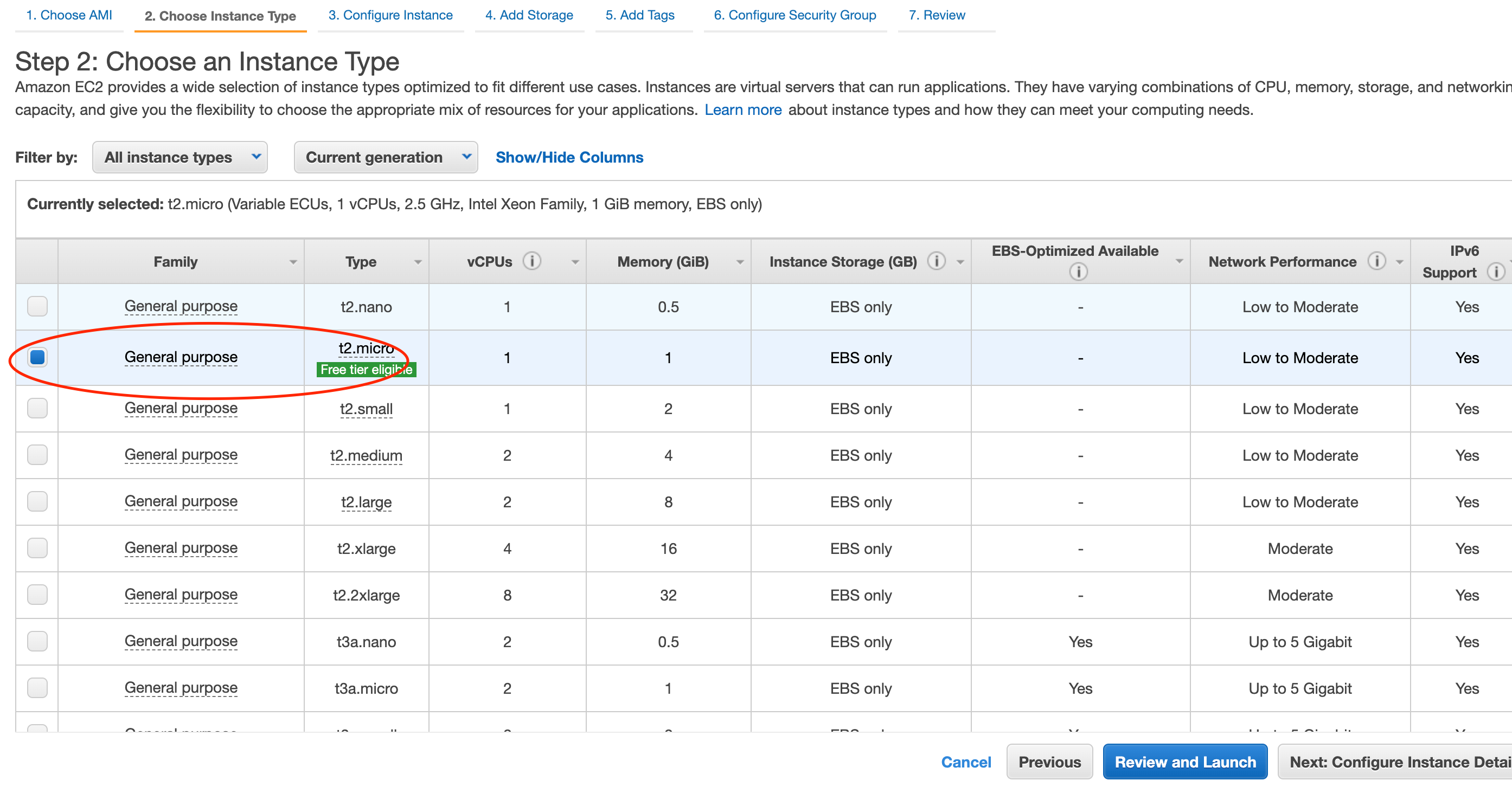
EC2インスタンスタイプを設定します。
CPU、メモリ、ストレージ、ネットワークパフォーマンス等を考慮してよしなに選択します。
今回はt2.microを選択します。(無料利用枠の対象です)
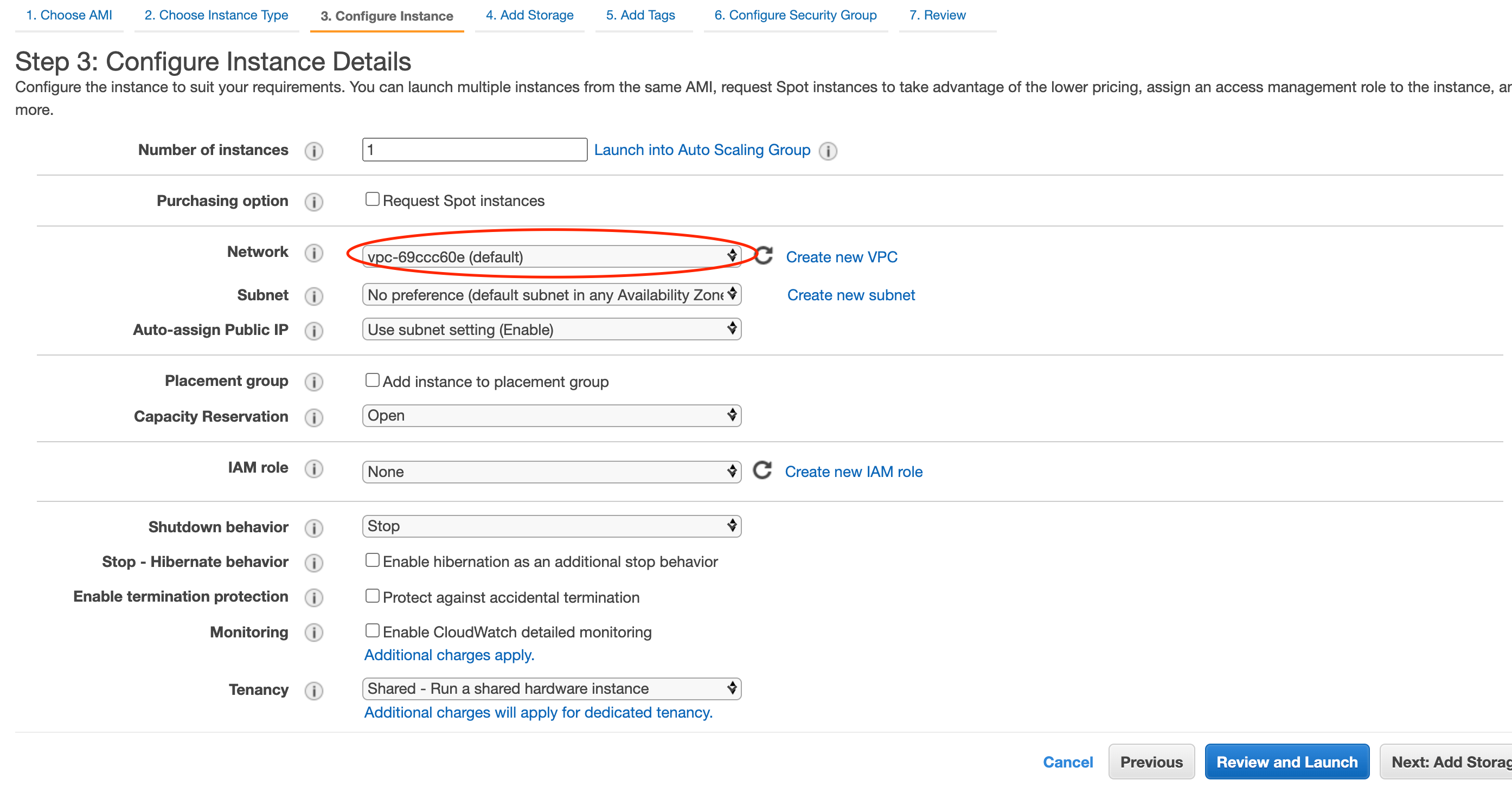
詳細の設定です。
VPCやサブネット等を設定できますが、今回はとりあえずVPCのみ設定しておきます。
RDSで設定したものと同じVPCを選択してください。
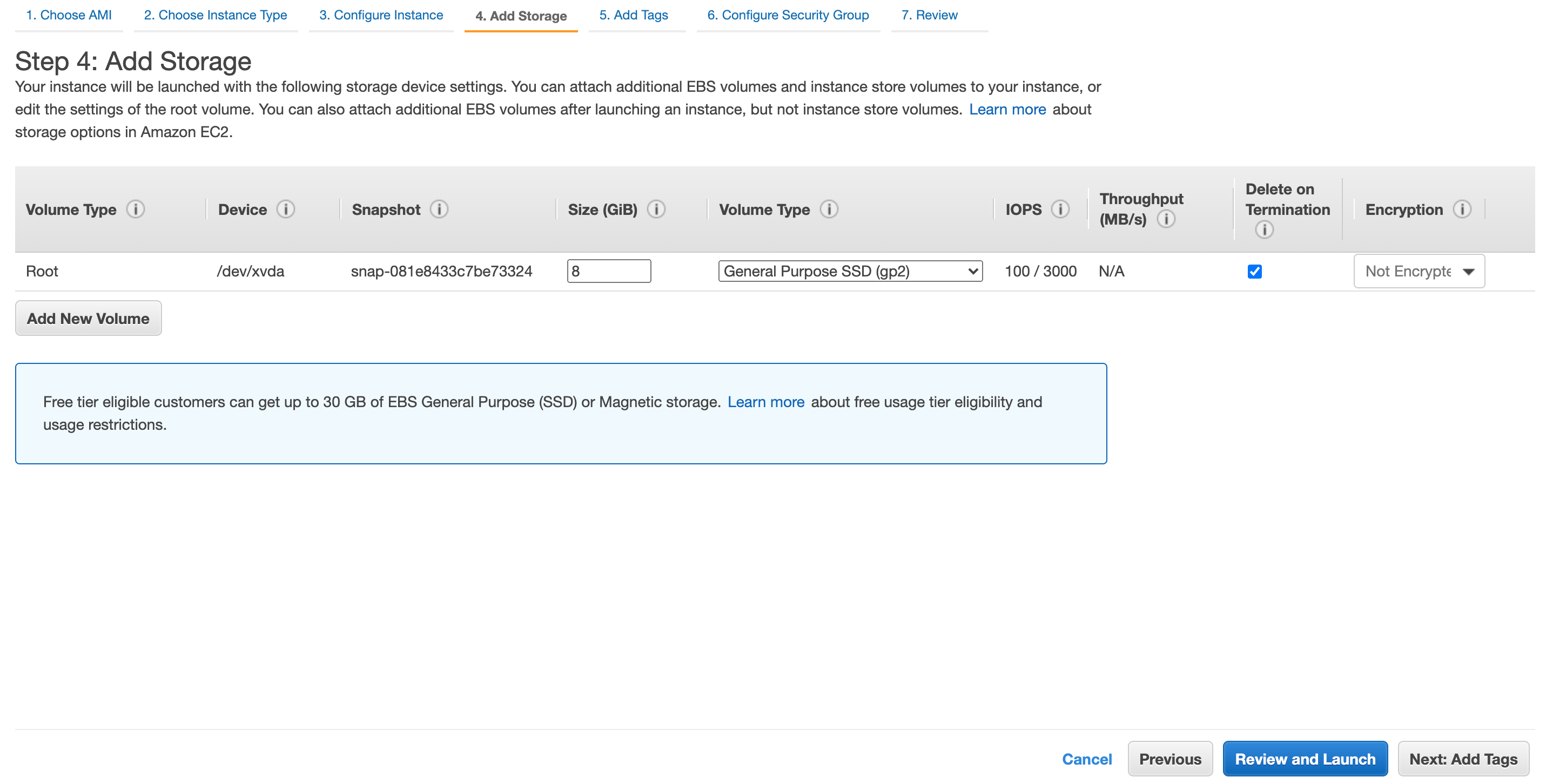
ストレージの設定をします。
他にインスタンスを作成されない場合は30GBまでは無料枠です。
今回はデフォルトの8GBで進めていきます。
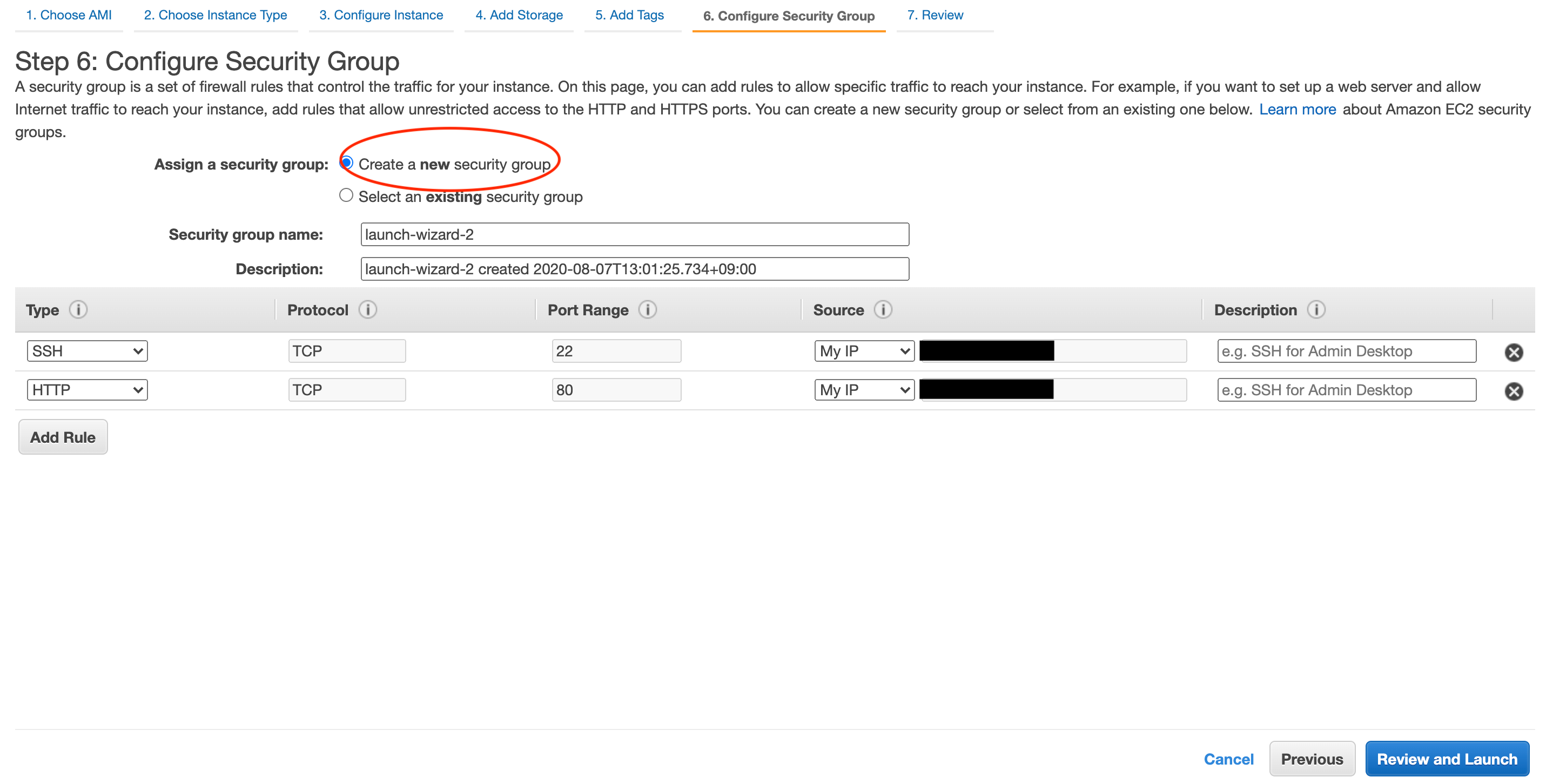
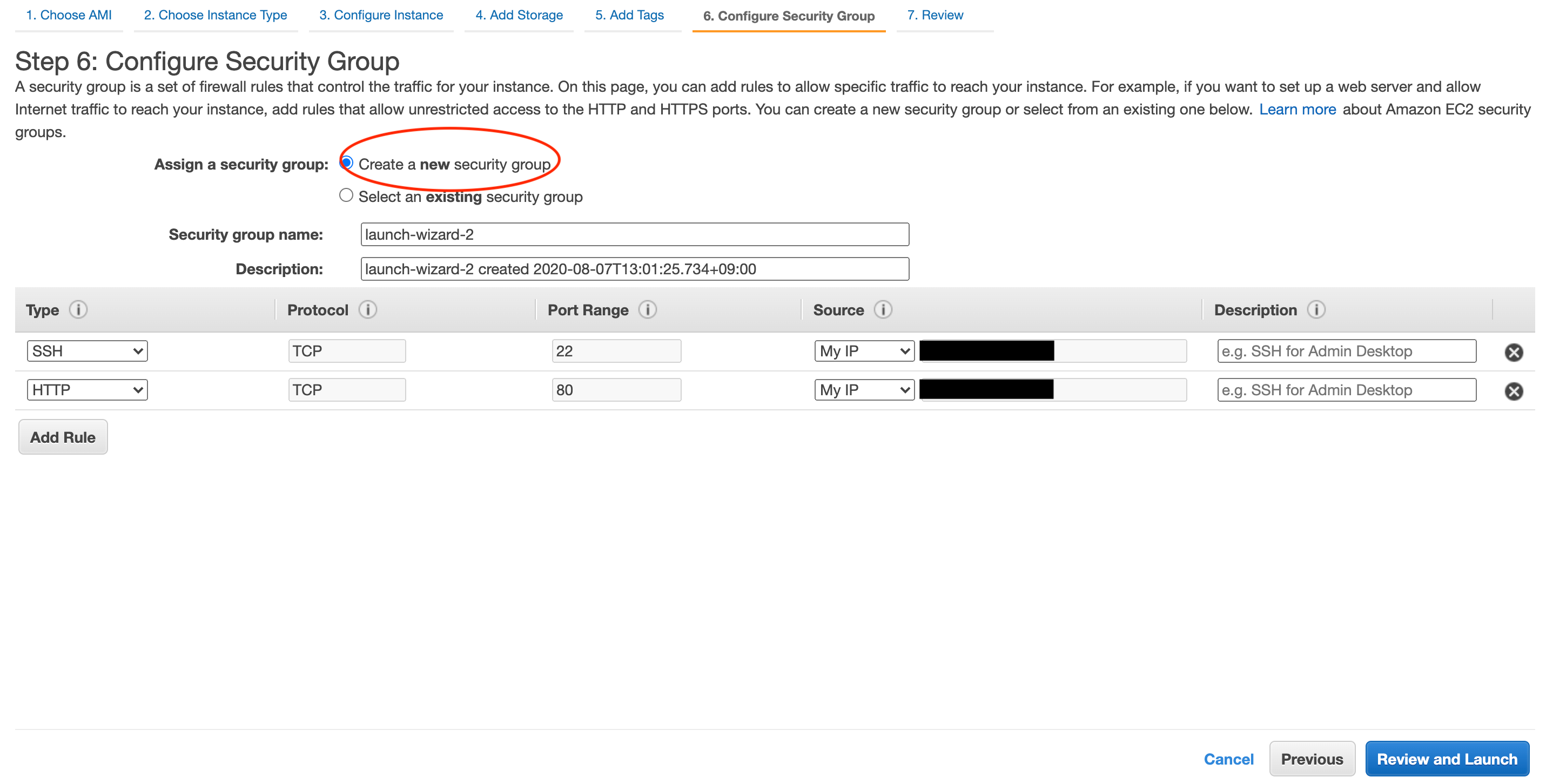
続いてタグの設定ですが今回は未設定のまま進み、セキュリティグループの設定をします。
EC2インスタンスへのアクセス許可、制限を指定します。
まずはSSH接続の設定です。
Create a new security groupを選択し、新しいグループを作成します。
TypeのプルダウンからSSHを選択し、SourceのプルダウンからはMyIPを選択しましょう。
次にHTTP接続です。
Add Ruleをクリックした後、TypeのプルダウンからHTTPを選択し、SourceのプルダウンからはMyIPを選択しましょう。
今回は自分のIPからのみ接続できる設定にします。
本番環境で不特定多数のアクセスを集める場合はHTTPのSourceをAnywhereにしてください。
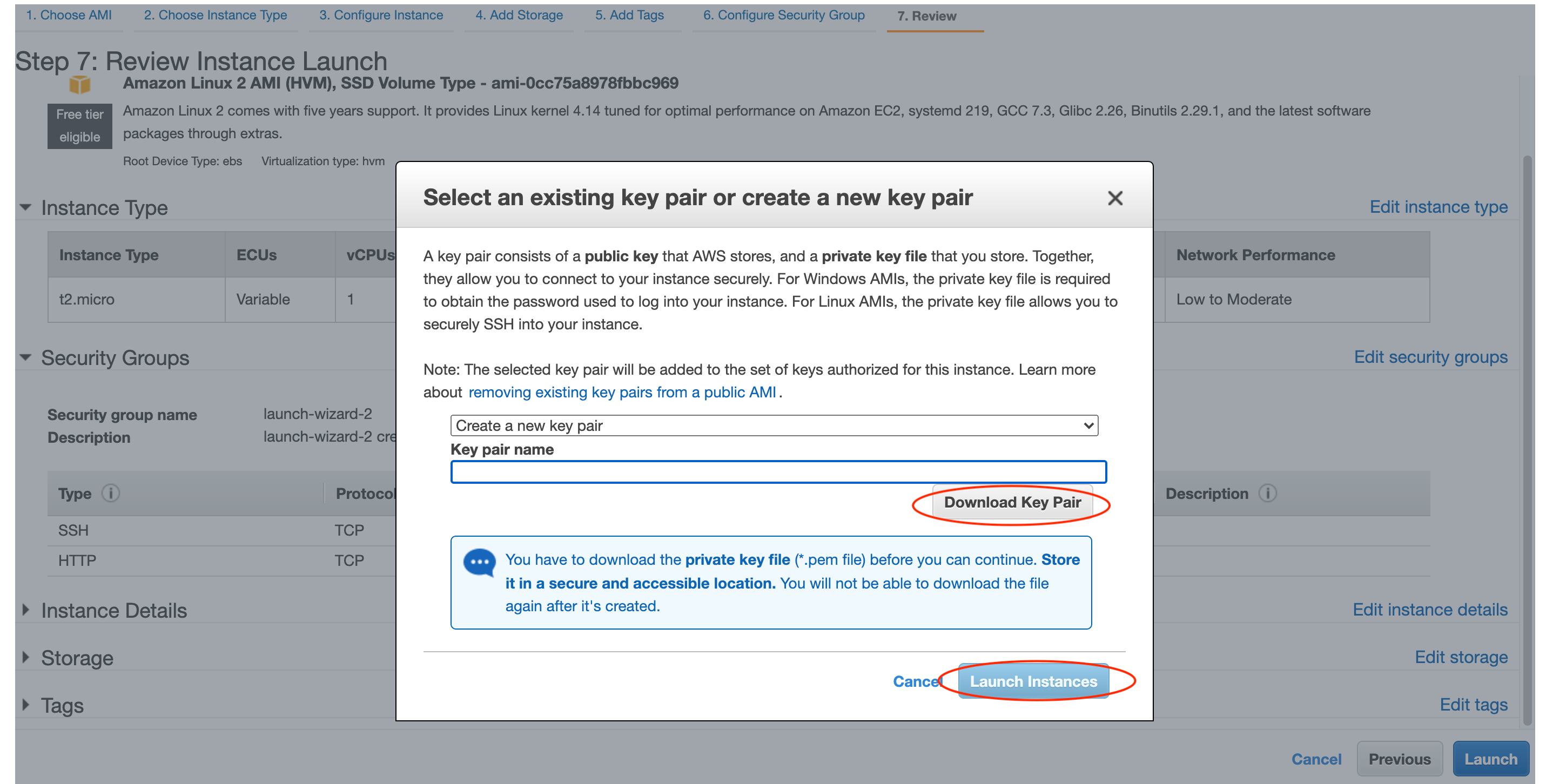
Review and Launchをクリックし確認画面に遷移し、設定内容に問題がなければLaunchをクリックしましょう。
最後に、SSH接続するためのキーペアを作成します。
Create new key pairを選択し、キーペアの名前を設定します。
設定後、Download Key Pairをクリックして.pemファイルをダウンロードします。
このファイルがなければSSH接続できないので、安全な場所で保管してください。
青色のボタンLaunch Instanceをクリックしてインスタンスを起動します。
3.サーバー間の連携
まずは先に作成したRDSの設定を変更し、EC2インスタンスからRDSインスタンスへのアクセスを可能にします。
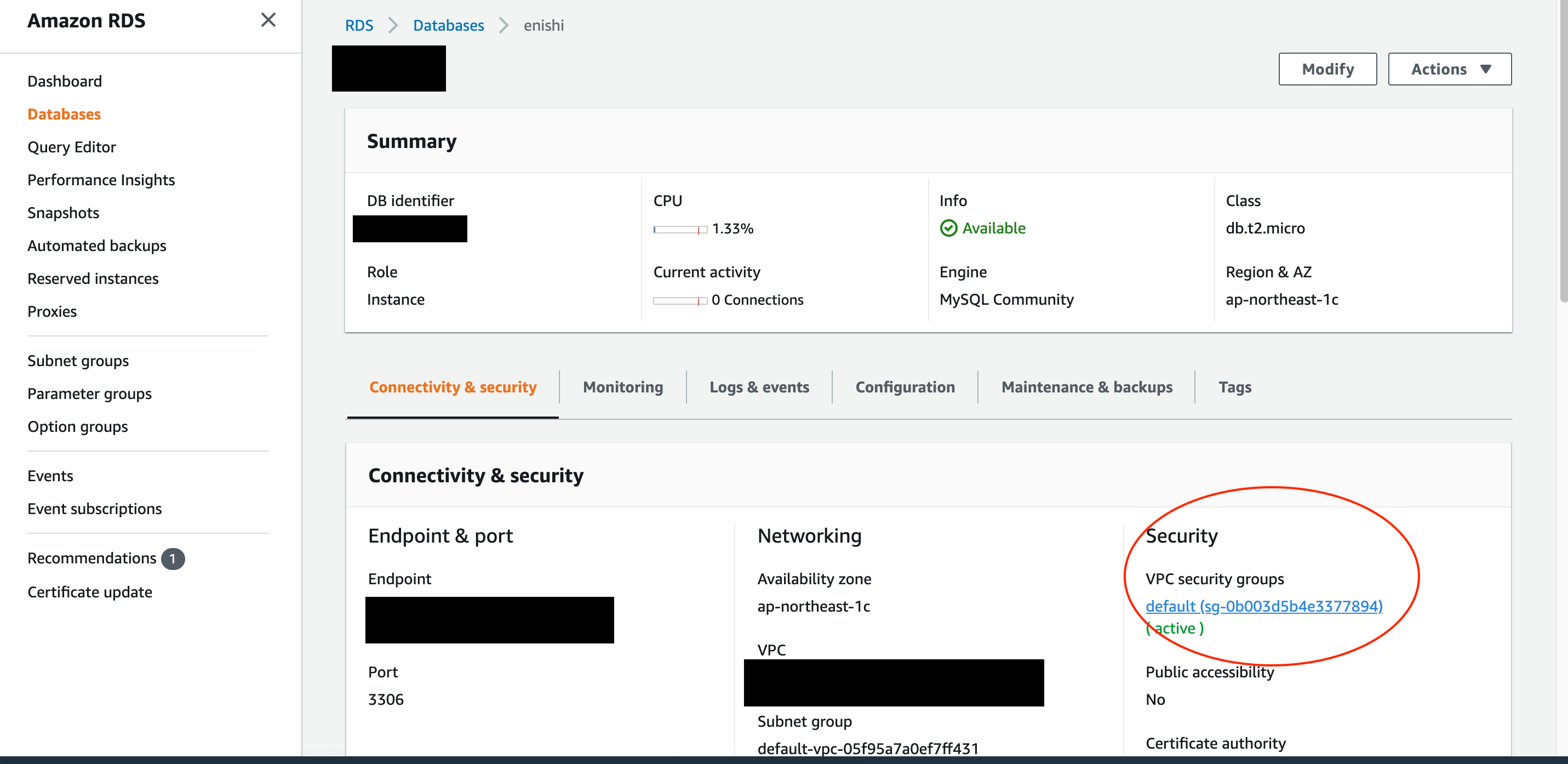
AmazonRDSに移動します。
左側のダッシュボードのDatabasesをクリックして、先に作成したデータベースを選択します。
Connectivity & securityタブのセキュリティグループをクリックします。
デフォルトではEC2インスタンスからRDSインスタンスへのアクセスは許可されていません。
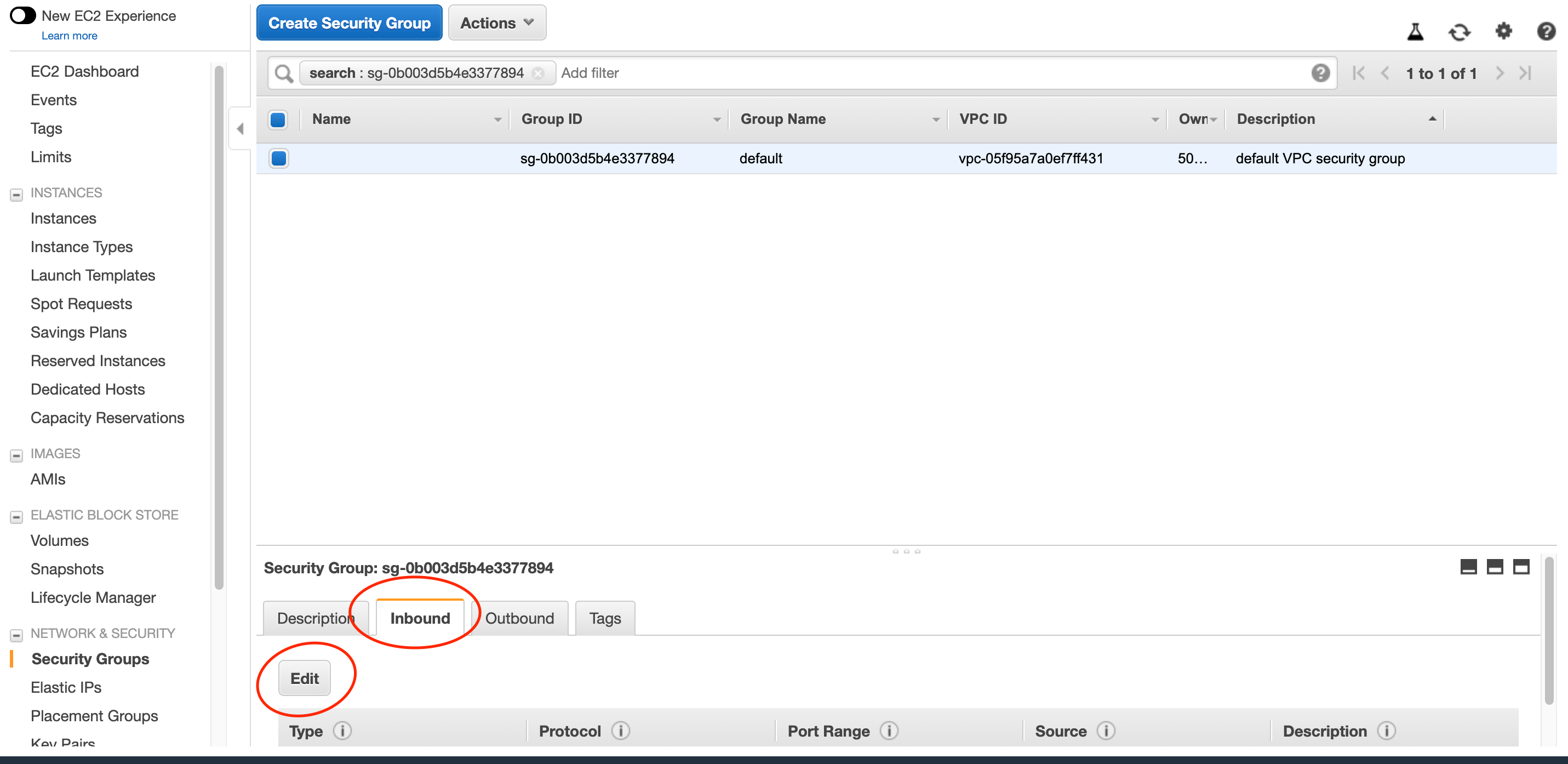
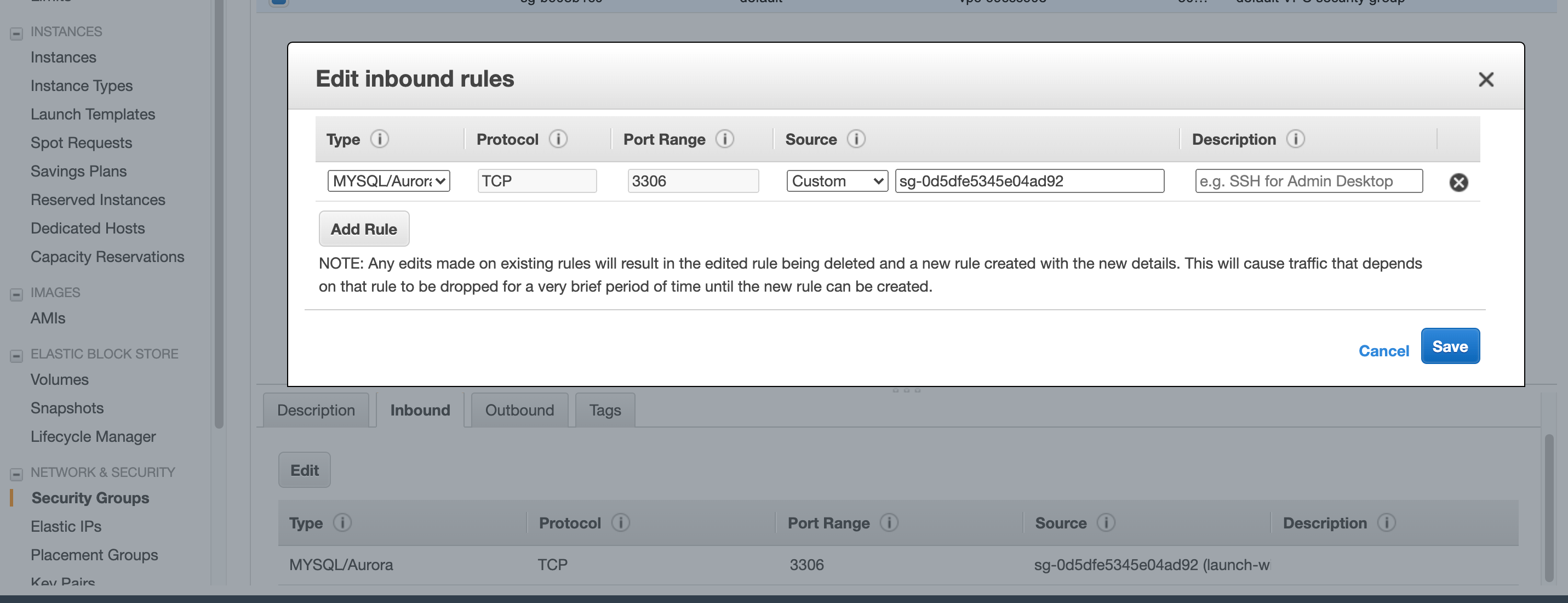
Inboundタブを開きeditをクリックしてセキュリティグループの編集を行います。
TypeをMySQL/Auroraに、SourceをCustomeに設定し先ほど作成したEC2のセキュリティグループの名前を入力します。
利用可能なセキュリティグループが表示されるので、先ほど作成したものを選択します。自動で値が入力されます。
青色のSavaボタンをクリックし設定を反映させます。
続いてEC2インスタンスにSSH接続していきます。
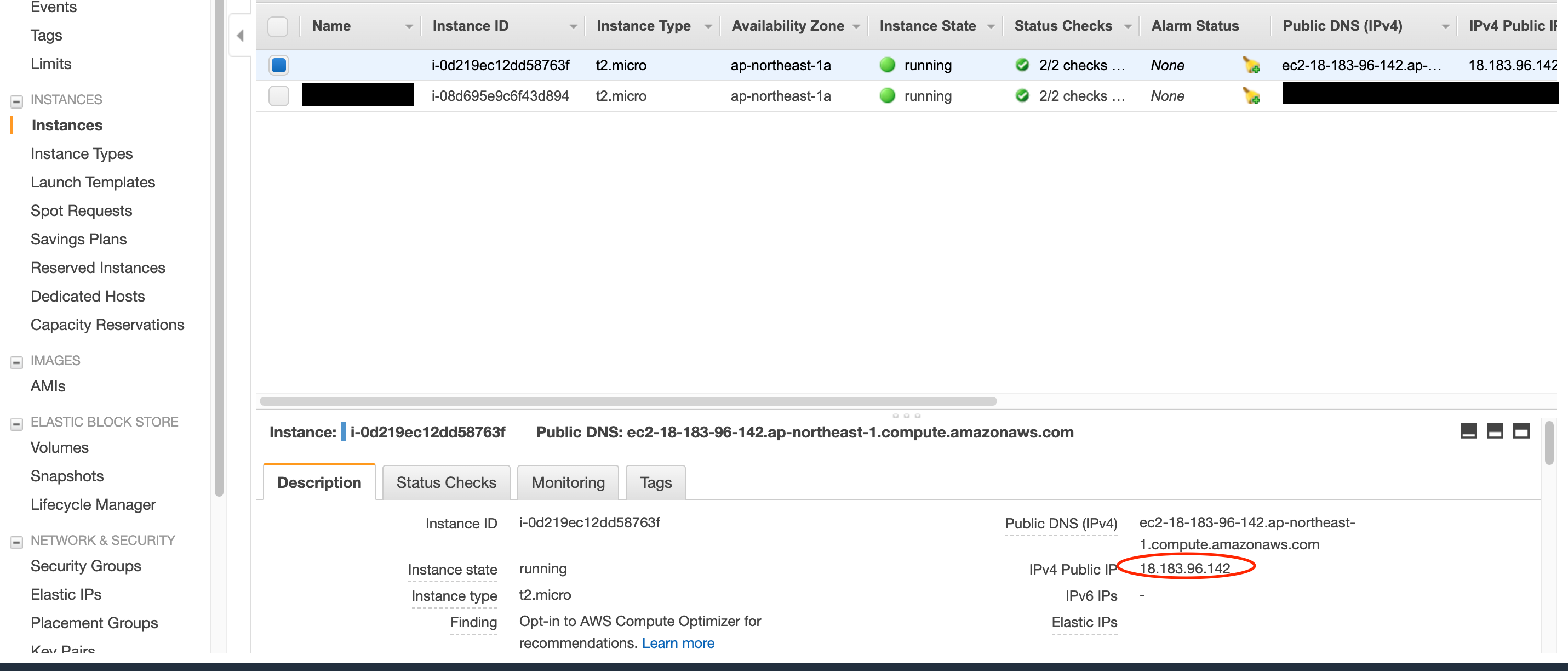
ターミナル上のキーペアがあるディレクトリで以下のコマンドを実行します。ssh -i .pemファイル名 ec2-user@パブリックIPパブリックIPは、接続するインスタンスのこちらをコピーペーストしましょう。
EC2インスタンスにSSH接続できたら、RDSに接続するための準備をしていきます。
MySQLをインストールしたいのですが、MariaDBがデフォルトでインストールされていると競合してしまうので、アンインストールしておきます。$ sudo yum remove mariadb-libsMySQLのリポジトリを追加して、MySQLをインストールします。
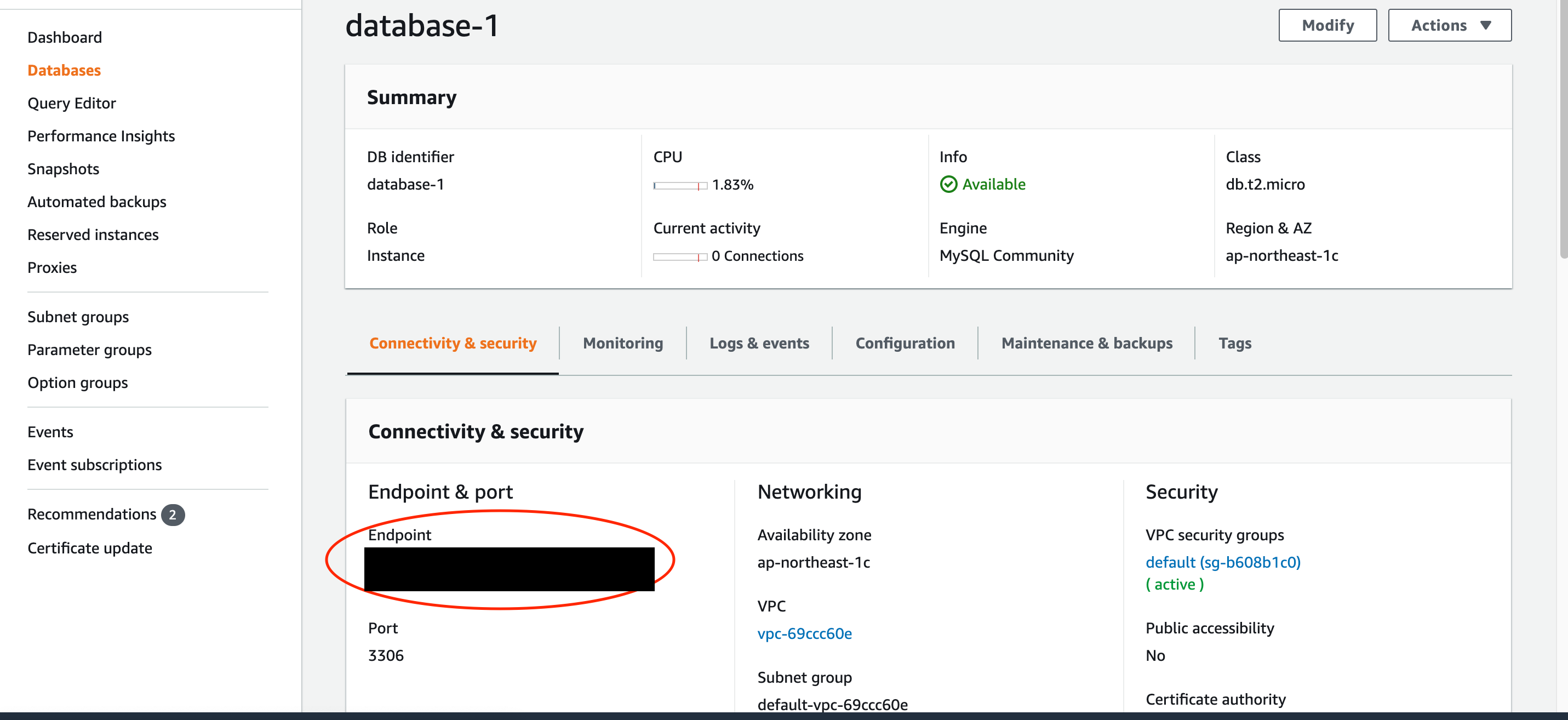
$ sudo yum localinstall https://dev.mysql.com/get/mysql80-community-release-el7-1.noarch.rpm $ sudo yum install mysqlMySQLのホスト名を環境変数に設定して、データベースに接続します。
エンドポイントはRDSインスタンスのホスト名を入力します。
ユーザー名、パスワード、DB名は先に作成したものです。$ export MYSQL_HOST=エンドポイント $ mysql --user=ユーザー名 --password=パスワード DB名
Laravelアプリのためのユーザーを作成し、データベースへのアクセス権限を付与します。mysql> CREATE USER 'ユーザー名' IDENTIFIED BY 'パスワード'; mysql> GRANT ALL PRIVILEGES ON DB名.* TO ユーザー名; mysql> FLUSH PRIVILEGES; mysql> Exit次にEC2インスタンスにApacheとPHPをインストールします。
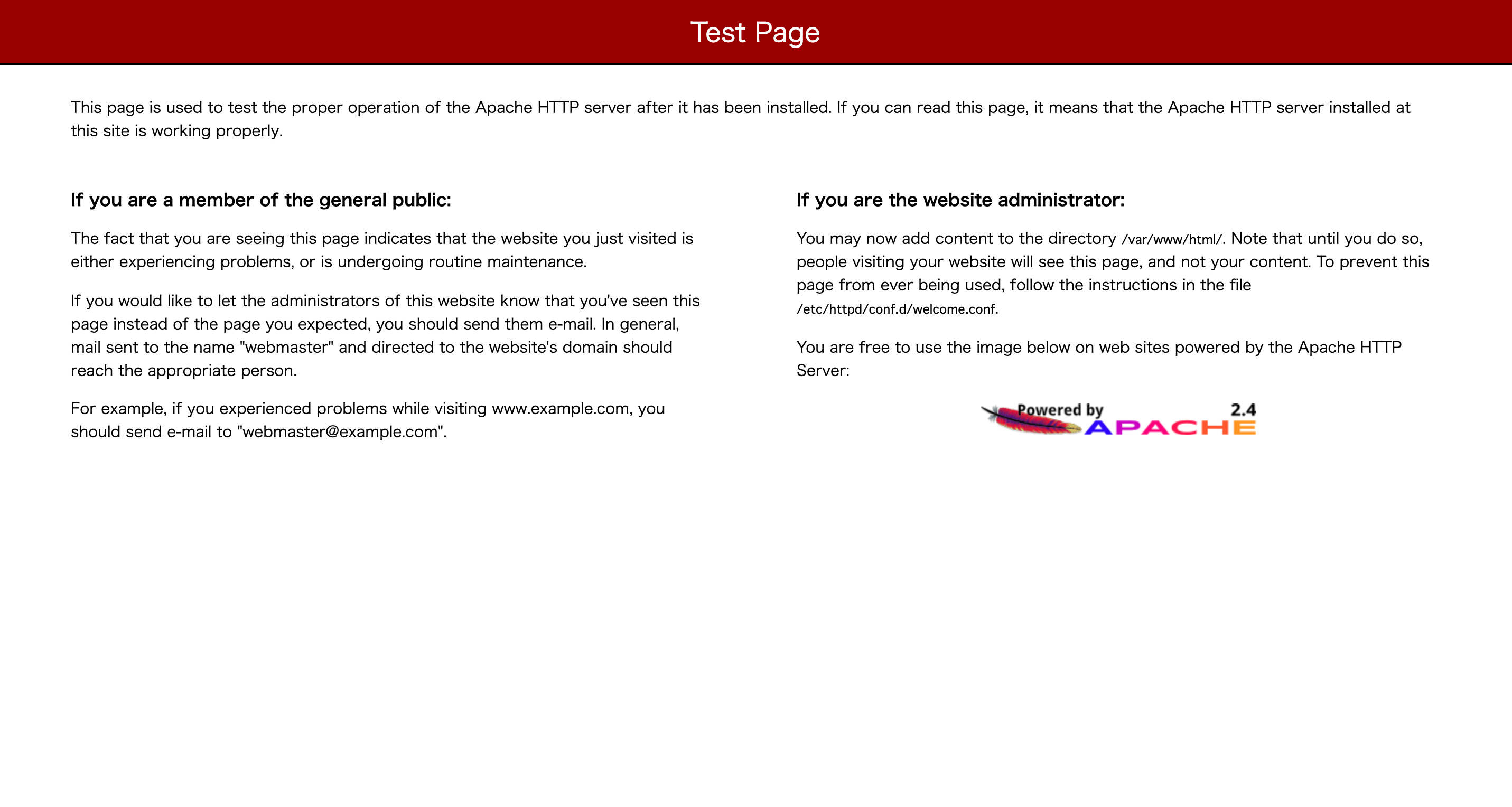
まずはApacheのインストールです。$ sudo yum install -y httpd $ sudo service httpd startパブリックIPアドレスにアクセスして、以下の画面が表示されていればインストール成功です。
PHP並びにLaravelアプリに必要な拡張モジュール等をインストールしていきます。
今回のLaravelのバージョンは5.5なので、対応したPHP拡張モジュールも合わせてインストールしておきます。
また、自分の開発したアプリに必要な拡張モジュールがあれば適宜追加でインストールしてください。$ sudo amazon-linux-extras install -y php7.2 $ sudo yum -y install php-openssl php-pdo php-mbstring php-tokenizer php-xmlこれでLAMP環境を構築することができました。
4.アプリのデプロイ
Laravelアプリのデプロイ、デプロイのための最終準備をしていきます。
まずはEC2インスタンスにGitをインストールします。$ sudo yum -y install git続いて/var/www/htmlに移動して、完成済みのLaravelアプリをgit cloneします。
$ cd /var/www/html $ sudo git clone URLApacheの設定を変更していきます。
/etc/httpd/confに移動して、httpd.confを編集します。$ cd /etc/httpd/conf $ vi httpd.conf以下が編集箇所です。
119行目付近でドキュメントルートを変更し、アクセスがあった際にアプリ直下のpublicディレクトリにファイルを探しにいってくれるようにします。
131行目付近、151行目付近でpublicディレクトリ内での設定の変更を有効にします。
最終行でmod_rewriteを許可することでURLの書き換えを可能にします。#119行目付近 DocumentRoot "/var/www/html/Laravelアプリ/public" #131行目付近 <Directory "/var/www/html/Laravelアプリ/public"> #151行目付近 AllowOverride All #最終行に追加 LoadModule rewrite_module modules/mod_rewrite.so変更後はApacheを再起動させます。
$ sudo systemctl restart httpd続いてComposerをインストールします。
/usr/local/bin/にインストールしてファイル名を変更することで、どこからでもcomposerコマンド一つで呼び出し可能にします。$ cd /usr/local/bin/ $ sudo php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');" $ sudo php -r "if (hash_file('sha384', 'composer-setup.php') === 'e5325b19b381bfd88ce90a5ddb7823406b2a38cff6bb704b0acc289a09c8128d4a8ce2bbafcd1fcbdc38666422fe2806') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;" Installer verified $ sudo php composer-setup.php $ sudo php -r "unlink('composer-setup.php');" $ sudo mv composer.phar composer最後の仕上げです。
アプリの環境変数の設定等を行っていきます。
まずはcomposer.lockファイルを基にパッケージをインストールします。
ディレクトリの権限も変更しておきます。こちらの変更はアプリ起動完了後によしなに変更しても良いかと思います。$ cd /var/www/html $ chmod 777 Laravelアプリ $ cd Laravelアプリ $ chmod 777 bootstrap/cache $ chmod 777 storage/framework/sessions $ chmod 777 storage/framework/views $ chmod 777 storage/logs vendor $ composer install.env.exampleファイルeを基に.envファイルを作成します。
$ cp .env.example .env $ vi .env先に作成したRDCインスタンスを基に、DB接続に関する変数を定義していきます。
ユーザー名、パスワードはRDCインスタンスに接続して登録したものを設定します。DB_CONNECTION=mysql DB_HOST=ホスト名(エンドポイント) DB_PORT=3306 DB_DATABASE=DB名 DB_USERNAME=ユーザー名 DB_PASSWORD=パスワードartisanコマンドを叩いてアプリケーションキーを作成します。
マイグレーションも実行しておきます。(開発済みのアプリなのでマイグレーションファイルがあることが前提です)php artisan key:generate php artisan migrateこれでパブリックIPアドレスにアクセスすれば、アプリケーションが動作しているはずです!
ここまでお疲れ様でした。

- 投稿日:2020-08-07T19:00:24+09:00
AWS IoT Events への入力データを AWS CLI (v2)で作成&送信する
AWS IoT Events を用いた開発の際、テストデータ送信が必要となります。
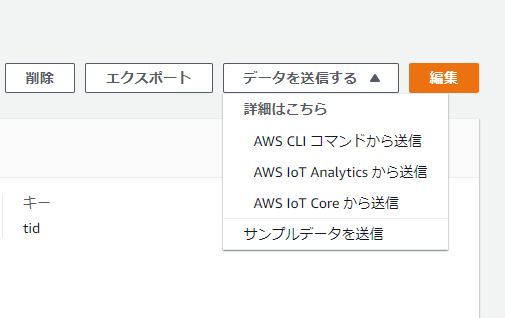
コンソールから [データを送信する] > [サンプルデータを送信] でも、データを送り込むことは可能です。
これを AWS CLI(v2) で実現する方法が本エントリーとなります。
論よりコード (TL;DR)
Input(入力)
IoTData1に対し{"id":"id1","v1":25.0,"v2":"foobar","v3":false}というデータを送りたい場合:bash$ aws iotevents-data batch-put-message \ --messages messageId=${RANDOM},inputName=IoTData1,payload=$(echo '{"id":"id1","v1":25.0,"v2":"foobar","v3":false}' | base64 -w0)※ AWS CLI v2 を使用
※ 要base64コマンド (Ubuntu なら coreutils に入ってます)解説
私の好きな AWS IoT Events は、デバイスのステートマシン(状態遷移)を簡潔に実装できます。
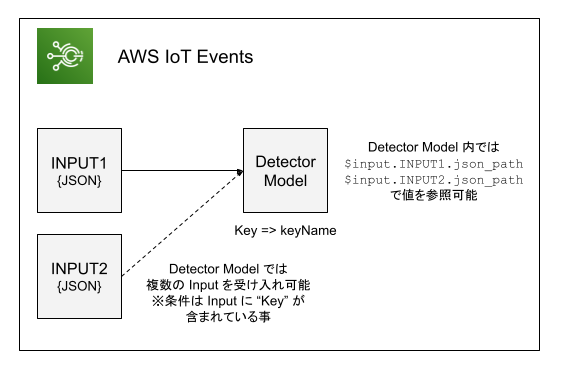
基本的な話は AWS IoT Events は IoT デバイスの「ステートマシン」 をご覧ください。AWS IoT Events の実装は "Input(入力)" と "Detector Model(探知機モデル)" の2つで構成されています。
- Input: スキーマのようなものです。どのような入力がされるのかを Input 内であらかじめ定義しておきます。
- Detector Model: 状態遷移そのものです。 Input からの入力は
$input.INPUT_NAME.json_pathで参照できます。Detector Model を動かすためには Input にデータを送信します。そして、その Input を参照している Detector Model が実行されるため、 Input がエントリーポイントであると言っても良いでしょう。
AWS CLI(v2) で AWS IoT Events にデータを送る
AWS IoT Events の Input へのデータ送信を AWS CLI で行う場合は
iotevents-dataサブコマンドを使います。
--messagesには3つのパラメータを設定します。
messageId: 送信データの ID。ともかく一意になれば何でもよいです。CloudWatch Logs で探すときに使うくらい。例では Bash の ${RANDOM} で生成しています。uuidgen -rでもいいでしょう。InputName: 送信先の Input 名。payload: Detector Model に送信する実データ。bash$ aws iotevents-data batch-put-message \ --messages messageId=${RANDOM},inputName=IoTData1,payload=$(echo '{"id":"id1","v1":25.0,"v2":"foobar","v3":false}' | base64 -w0)もしくは JSON で入力する場合は以下の通り
bash$ aws iotevents-data batch-put-message \ --messages '{"messageId":"1","inputName":"IoTData1","payload":"'$(echo '{"tid":"id1","tmpr":25.0}' | base64 -w0)'"}'payload の base64
payload は blob となっており、base64 encoded textで送ることになるため
base64でエンコードしています。※ AWS CLI v2 では blob は Base64 encoded text がデフォルトとなりました。
※ payload は This can be a JSON string or a Base-64-encoded string representing binary data (in which case you must decode it). となっているのですが、payload="{\"id\":\"id1\",\"v1\":25.0,\"v2\":\"foobar\",\"v3\":false}"は NG でした。なんかいい方法無いのでしょうか?あとがき
もうすぐお盆休みですね!
EoT
- 投稿日:2020-08-07T17:53:16+09:00
AWS SAMとStepFunctionでAthenaの集計処理を自動化する
AWS SAMを見ていたら
AWS::Serverless::StateMachineというStepFunctionのコンポーネントがあったので、それを使ってAthenaの集計処理を実装してみた。
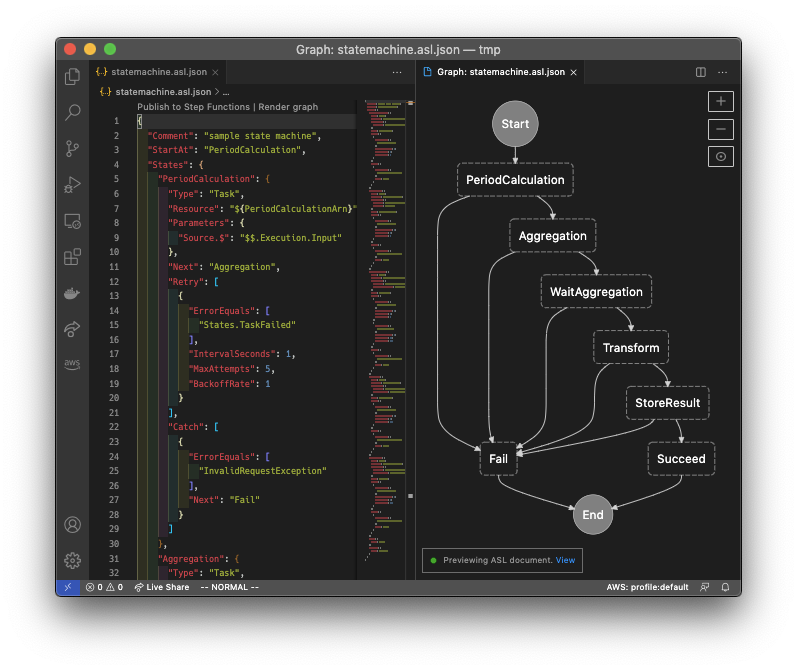
実際は集計期間に応じて処理を分岐してリトライ間隔など調整できるようにしたが、ここではシンプルにした。余談:VSCode + AWS Toolkit
*.asl.jsonファイルを編集するとlintやグラフの描画をリアルタイムに行ってくれるので便利だった。
できればFailタスクはもっと軽く扱って欲しい。
やりたいこと
下記の5タスクをステートマシーンにした。
この処理を週次/月次で実行する。
- 集計期間の計算
- Athenaへのクエリー
- クエリー進捗の確認/待機
- クエリー結果の加工
- S3への保存
StepFunctionでやるメリット
各タスクがシンプルになる
タスクはLambda(node.js)で実装したが、1つのファンクションで1つのことしかしないので各ファンクションがシンプルになる。コードの分岐がなくなる
Choiseなど使うとステートマシーン上で分岐できるので、コード上ではその分岐がなくなる。コードのリトライ処理がなくなる
エラー時のリトライやクエリー完了まで待機するのにエクスポネンシャルバックオフを使ったりできる。こういった処理を自分で実装する必要がなくなる。テストがしやすい
各Lambdaは処理が小さくなるのでローカルでのテストもしやすくなる。
StepFunction自体が入出力の管理をしっかりしないといけないサービスなので、当然各Lambdaの入出力も分かりやすくせざるを得なくなる。
また、AWS上でステートマシーンを実行すると各タスクの入出力と例外が表示されるので、どこでどういう結果になっているのか把握しやすい。初期化
AWS SAMにはStepFunctionを利用したテンプレートが用意されているので、それを元に開発した。
sam initで下記のように選択していく。$ sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore3.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8 13 - dotnetcore2.1 Runtime: 1 Project name [sam-app]: Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git AWS quick start application templates: 1 - Hello World Example 2 - Step Functions Sample App (Stock Trader) 3 - Quick Start: From Scratch 4 - Quick Start: Scheduled Events 5 - Quick Start: S3 6 - Quick Start: SNS 7 - Quick Start: SQS 8 - Quick Start: Web Backend Template selection: 2 ----------------------- Generating application: ----------------------- Name: sam-app Runtime: nodejs12.x Dependency Manager: npm Application Template: step-functions-sample-app Output Directory: . Next steps can be found in the README file at ./sam-app/README.mdこの時点でこのような構成になっている。
functions以下のLambdaを適当に追加・削除し、stock_trader.asl.jsonとtemplate.yamlを編集していく。. └── sam-app/ ├── functions/ │ ├── stock-buyer/ : : : │ │ ├── app.js │ │ └── package.json │ ├── stock-checker/ : : : │ │ ├── app.js │ │ └── package.json │ └── stock-seller/ : : │ ├── app.js │ └── package.json ├── statemachine/ │ └── stock_trader.asl.json : └── template.yaml最終的にはこうなった。
. └── sam-app/ ├── functions/ │ ├── aggregation/ : : : │ │ ├── app.js │ │ └── package.json │ ├── period-calculation/ : : : │ │ ├── app.js │ │ └── package.json │ ├── store-result/ : : : │ │ ├── app.js │ │ └── package.json │ ├── transform/ : : : │ │ ├── app.js │ │ └── package.json │ └── wait-aggregation/ : : │ ├── app.js │ └── package.json ├── statemachine/ │ └── athenaquery.asl.json : ├── samconfig.toml └── template.yamlステートマシーン
全体は省略するが、例えばAthenaのクエリーが完了するのを待つタスクはこのような定義になった。
ParametersのQueryExecutionId.$が対象クエリーを特定するIDで、前工程のタスクの出力を入力値として受け取っている。
RetryのところでInProgressErrorを受け取ってエクスポネンシャルバックオフでリトライするよう定義している。Lambdaのコードではステータスを確認して実行中であればInProgressErrorをスローするだけ。長時間実行してクエリー完了を待つ必要がないのでタイムアウトの心配もない。"WaitAggregation": { "Type": "Task", "Resource": "${WaitAggregationArn}", "Parameters": { "Source.$": "$$.Execution.Input", "QueryExecutionId.$": "$.QueryExecutionId" }, "Next": "Transform", "Retry": [ { "ErrorEquals": [ "States.TaskFailed" ], "IntervalSeconds": 3, "MaxAttempts": 5, "BackoffRate": 1 }, { "ErrorEquals": [ "InProgressError" ], "IntervalSeconds": 5, "MaxAttempts": 10, "BackoffRate": 1.2 } ], "Catch": [ { "ErrorEquals": [ "InvalidRequestException" ], "Next": "Fail" } ] }テンプレート
CloudFormationテンプレートの抜粋。
デフォルトだとStepFunctionのStandardWorkflowで構築される。
DefinitionSubstitutionsに設定した値は、ステートマシーンの定義で${WaitAggregationArn}のようにプレースホルダーとして利用できる。
EventsのところでEventBridgeのスケジュールも同時に定義している。
UTCで毎週土曜日15:05(JSTで毎週日曜00:05)と毎月月末15:05(JSTで毎月1日00:05)。また
Inputのところでステートマシーンの初期入力値を渡している。
さきほどのステートマシーンの定義にある$$.Execution.Inputにこの値が含まれる。AthenaQueryStateMachine: Type: AWS::Serverless::StateMachine Properties: DefinitionUri: statemachine/athenaquery.asl.json DefinitionSubstitutions: PeriodCalculationArn: !GetAtt PeriodCalculation.Arn AggregationArn: !GetAtt Aggregation.Arn WaitAggregationArn: !GetAtt WaitAggregation.Arn TransformArn: !GetAtt Transform.Arn StoreResultArn: !GetAtt StoreResult.Arn Events: Weekly: Type: Schedule Properties: Description: Schedule to run the user ranking state machine every week Enabled: True Input: !Sub '{"IntervalUnit":"Weekly","Env":"${Environment}"}' Schedule: "cron(5 15 ? * SAT *)" Monthly: Type: Schedule Properties: Description: Schedule to run the user ranking state machine every month Enabled: True Input: !Sub '{"IntervalUnit":"Monthly","Env":"${Environment}"}' Schedule: "cron(5 15 L * ? *)" Policies: - LambdaInvokePolicy: FunctionName: !Ref PeriodCalculation - LambdaInvokePolicy: FunctionName: !Ref Aggregation - LambdaInvokePolicy: FunctionName: !Ref WaitAggregation - LambdaInvokePolicy: FunctionName: !Ref Transform - LambdaInvokePolicy: FunctionName: !Ref StoreResultLambda
Athena関連のタスクだけ抜粋。
Aggregation
ここでAthenaのクエリーを実行している。
startQueryExecutionを実行するとQueryExecutionIdが返ってくるので、それを次タスクに渡す。const Athena = require("aws-sdk/clients/athena"); const athena = new Athena(); exports.lambdaHandler = async (event, context) => { const env = event.Source.Env; const query = "select ..."; const params = { QueryString: query, QueryExecutionContext: { Database: `database_${env}`, }, ResultConfiguration: { OutputLocation: `s3://athena-query-result-${env}/`, }, WorkGroup: env, }; const result = await athena.startQueryExecution(params).promise(); const qid = result.QueryExecutionId; const ret = { QueryExecutionId: qid, }; return ret; }WaitAggregation
QueryExecutionIdを受け取りクエリーが完了するまで監視する。
完了したら結果を取得して次のタスクに渡している。
前述の通りInProgressErrorが出ている間は何度も実行されるタスク。今回は結果セットが小さかったので直接次のタスクに渡した。サイズが大きい場合は
QueryExecutionIdだけ渡すなり、別のDBを経由するなりしないといけないかもしれない。
getQueryExecution(QueryExecutionId)で実行情報を取得し、ステータスを見て完了していればgetQueryResults(QueryExecutionId)で結果を取得する。const Athena = require("aws-sdk/clients/athena"); const athena = new Athena(); class InProgressError extends Error { constructor(...params) { super(...params); this.name = this.constructor.name; } } exports.lambdaHandler = async (event, context) => { const qid = event.QueryExecutionId; const params = { QueryExecutionId: qid }; const exec = await athena.getQueryExecution(params).promise(); const list = []; const status = exec.QueryExecution.Status.State; switch (status) { case "QUEUED": case "RUNNING": throw new InProgressError("InProgress"); break; case "FAILED": throw new Error("Failed"); break; case "CANCELLED": throw new Error("Canceled"); break; default: const result = await athena.getQueryResults(params).promise(); const rs = result.ResultSet; const fields = rs.Rows.shift(); for (const row of rs.Rows) { const processed = processRow(fields, row); list.push(processed); } break; } const ret = { QueryResult: list, }; return ret; }デプロイ
初回デプロイは
sam deploy -gで行う。
設定を保存するとsamconfig.tomlが生成され、次回からはsam deployだけでデプロイできる。sam build sam deploy -g
- 投稿日:2020-08-07T12:36:31+09:00
Route 53でのサブドメイン管理パターン
つい先日ひょんなことから、自分のサブドメインの切り方が普通のパターンじゃないことに指摘されて初めて気付きました。
忘れない様にメモとして残します。普通のサブドメイン作成方法
https://docs.aws.amazon.com/ja_jp/Route53/latest/DeveloperGuide/dns-routing-traffic-for-subdomains.html
ここに書かれている通り、通常サブドメインを切るときには、ネイキッドドメインのホストゾーンにレコードを作成しルーティングします。
Https通信を許可したい場合には、ACM等を利用して証明書を発行しますが、こちらもワイルドカード指定で証明書を取得しておけば、追加でサブドメイン用の証明書を逐一取得する必要はありません。
ネイキッドドメインのホストゾーンを選択
サブドメインのレコード作成
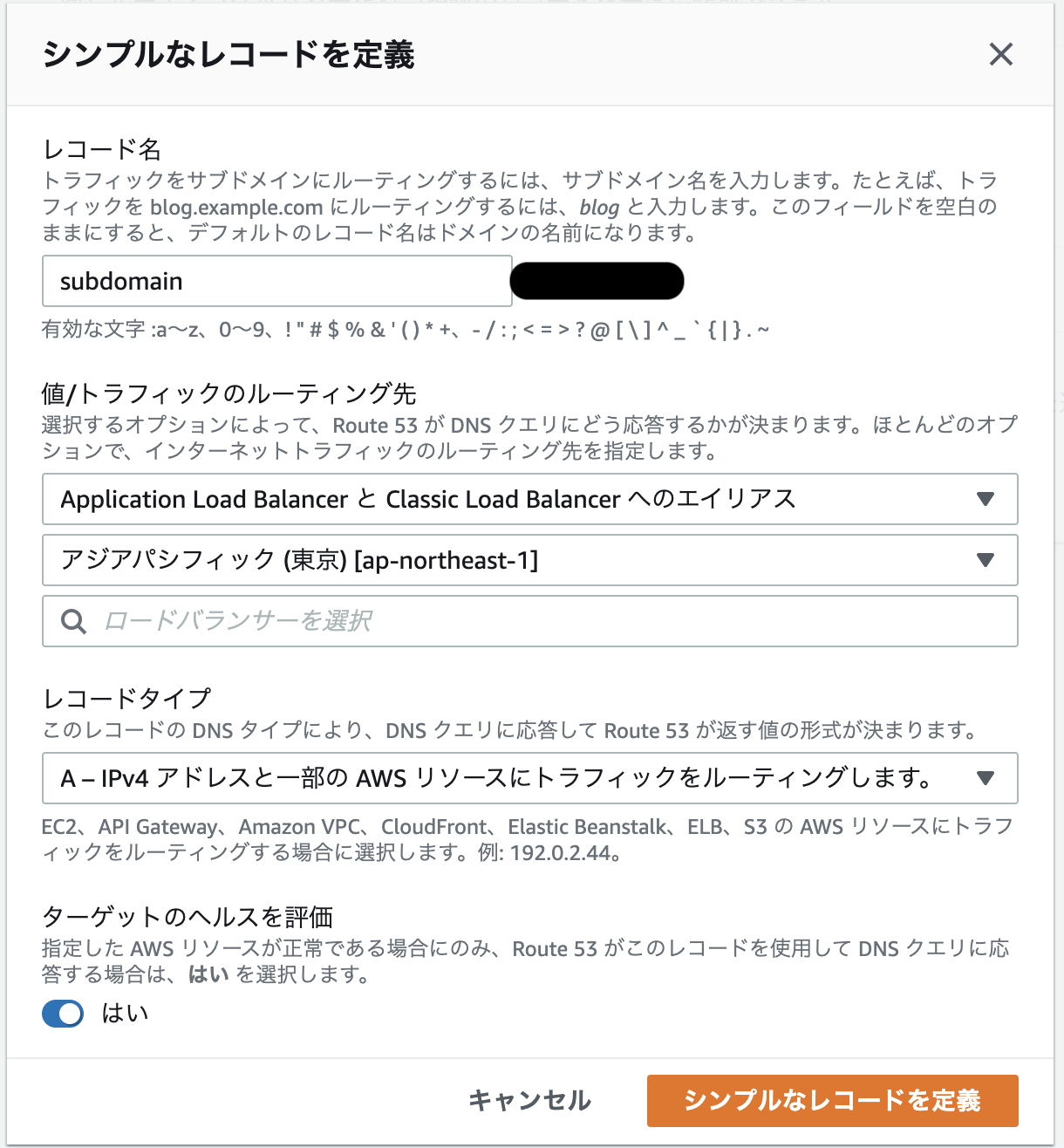
使用したい名前、ルーティングでレコード作成
ALBに繋げたいときは、エイリアスで指定するなど
ネイキッドドメインのホストゾーンにサブドメインレコードを作成していくときに、あらかじめワイルドカード証明書を取得しておくと、新しいレコードに対して追加で証明書が必要なくなる。サブドメインをネイキッドドメインとして作成する方法
僕が特に理由もなく普段やってしまっていた方法はこちらでした。どうしてもこのサブドメインは別個のネイキッドドメインとして扱う必要がある場合などの明確な理由がある場合を除いて通常の作成パターンで作成した方が管理しやすいと思います。
このケースにおいては、新たにサブドメインのホストゾーンを作成します。作成したサブドメインのホストゾーンからNSレコードのバリューを取得し、元のドメイン(example.com)のレコードにサブドメインのNSレコードを追加します。その上で、新たに作成したサブドメインのホストゾーン内部で、ルーティングの設定を行います。
サブドメインのホストゾーン作成
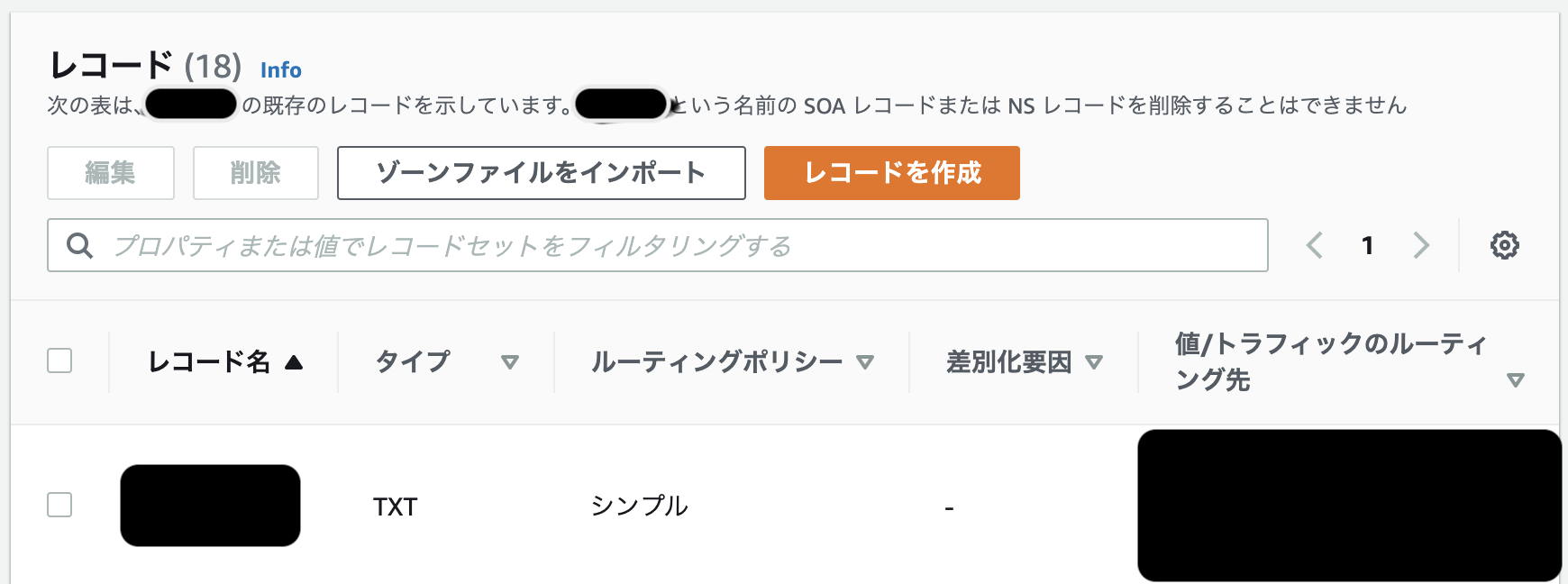
サブドメインのホストゾーン(sub.example.com)のNSレコードの値を取得し、ネイキッドドメイン(example.com)のホストゾーンにサブドメインのNSレコードを作成する
あとは新規に作成したサブドメインのホストゾーンにおいてルーティングの設定をする。以上

- 投稿日:2020-08-07T11:51:29+09:00
Docker SDK & Go言語 を使ってAWS ECRのimageをpull & run する
「AWS ECRにログインして docker imageを pullし、docker runする」
このような作業はあまりプロダクションで手動でやることはありませんが、やるとすれば普通に
aws-cliを使ってECRにLogin, 後はdockerコマンドでの作業となるかと思います。ところで、Go製であるDockerには公式SDKがあります。
今回とある事情があり、github.com/aws/aws-sdk-goとgithub.com/docker/dockerを使って上記の作業をGoのコードのみでやる機会がありました。Develop with Docker Engine SDKs
Examples using the Docker Engine SDKs and Docker APIググっても出てこないくらい触らなそうな作業ではありますが、どこかの誰かのためにサンプルコードを置いておきます。
package main import ( "context" "encoding/base64" "encoding/json" "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/ecr" "github.com/docker/docker/api/types" "github.com/docker/docker/api/types/container" "github.com/docker/docker/api/types/mount" "github.com/docker/docker/client" "github.com/labstack/gommon/log" "io" "os" "strings" "time" ) func main() { auth := getEcrRegistryAuth() pullAndRunContainer(auth) } func getEcrRegistryAuth() string { /* ECR Login */ sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) ecrSdk := ecr.New(sess) authOutput, err := ecrSdk.GetAuthorizationToken(&ecr.GetAuthorizationTokenInput{}) if err != nil { log.Panic(err) } token := authOutput.AuthorizationData[0].AuthorizationToken authStr := aws.StringValue(token) decoded, err := base64.StdEncoding.DecodeString(authStr) // Decode the Base64 encoded token if err != nil { log.Panic(err) } password := strings.ReplaceAll(string(decoded), "AWS:", "") jsonBytes, _ := json.Marshal(map[string]string{ "username": "AWS", "password": password, }) return base64.StdEncoding.EncodeToString(jsonBytes) } func pullAndRunContainer(auth string) { imageUri := `xxxxxxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/my-ecr:latest` containerName := fmt.Sprintf(`test-container-%v`, time.Now().UnixNano()) ctx := context.Background() cli, err := client.NewEnvClient() if err != nil { log.Fatal(err) } reader, err := cli.ImagePull(ctx, imageUri, types.ImagePullOptions{ RegistryAuth: auth, }) if err != nil { log.Panic(err) } io.Copy(os.Stdout, reader) cont, err := cli.ContainerCreate( ctx, &container.Config{ Image: imageUri, Cmd: []string{ `sh`, `-c`, `echo "Run App !!!!!"`, }, Env: []string{ "PASS=xxxxxxxxxxxxxx", // いいのか? }, //Cmd: command, }, &container.HostConfig{ Mounts: []mount.Mount{ { Type: mount.TypeBind, Source: "<HostのMount Dir>", Target: "/mnt", // gyao_yvpub_wrapper内のmount dir }, }, }, nil, containerName) if err := cli.ContainerStart(ctx, cont.ID, types.ContainerStartOptions{}); err != nil { log.Panic(err) } go func() { out, logErr := cli.ContainerLogs(ctx, cont.ID, types.ContainerLogsOptions{ShowStdout: true, ShowStderr: true}) if logErr != nil { log.Error(logErr) } containerLog := streamToString(out) fmt.Println(containerLog) }() exitCode, err := cli.ContainerWait(ctx, cont.ID) if err != nil { log.Fatal(err) } if exitCode != 0 { log.Error(err) out, logErr := cli.ContainerLogs(ctx, cont.ID, types.ContainerLogsOptions{ShowStdout: true, ShowStderr: true}) if logErr != nil { log.Error(err) } containerLog := streamToString(out) fmt.Println(containerLog) } }
- 投稿日:2020-08-07T10:26:13+09:00
Amazon CloudWatchロググループ保持期間をAWS Lambdaで管理しよう
こんにちは、stremapackのrisakoです。
長い梅雨が明けて夏がやってきましたね
コロナに気をつけながら、マスクで熱中症にならないようにもっと注意が必要ですね
今年の夏は体調管理に気をつけて過ごそうと思います。今回したいこと
今回のテーマは「Amazon CloudWatchロググループ保持期間をAWS Lambdaで管理しよう」です!
Amazon ECSやAWS Lambda(以下Lambda)を使っていると、Amazon CloudWatch(以下CoudWatch)にログが溜まり続けてしまいます。
しかも、CloudWatch LogGroupの保持期間はデフォルトで「失効しない」に設定されるため、永遠にログが残り続けてしまい金額も増えてしまいます。今回は、金額を少しでも抑えるために、新規作成されたロググループの保持期間を自動で「1ヶ月」に変更する仕組みをLambdaで入れてみたいと思います!今回のアイテム
- IAM role
- IAM policy
- Amazon CloudWatch LogGroup
- AWS Lambda
- Amazon EventBridge
やってみよう
IAM Role設定
Role名はcloudwatchtest-lambda-roleとしておきます。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }IAM Policy設定
Policy名はcloudwatchtest-lambda-policyです。
CloudWatchを操作できる権限を付与しています。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:DescribeLogGroups", "logs:PutRetentionPolicy", "logs:CreateLogGroup", "logs:PutLogEvents" ], "Resource": "*" } ]Lambda設定
Lamndaの関数は、下記で作成しました。
関数名:change_Retention_for_cloudwatch-logs
ランタイム:Python 3.8関数コード
新規作成されたロググループの保持期間を1ヶ月(30日)に変更したいので、retentionInDays = 30に設定します。
ここは希望の保持期間を指定します。
例:1.3.5.7.60import boto3 logs = boto3.client('logs') def lambda_handler(event, context): loggroupname = event['detail']['requestParameters']['logGroupName'] try: response = logs.put_retention_policy( logGroupName = loggroupname, retentionInDays = 30 ) except Exception as e: print(e)EventBridge設定
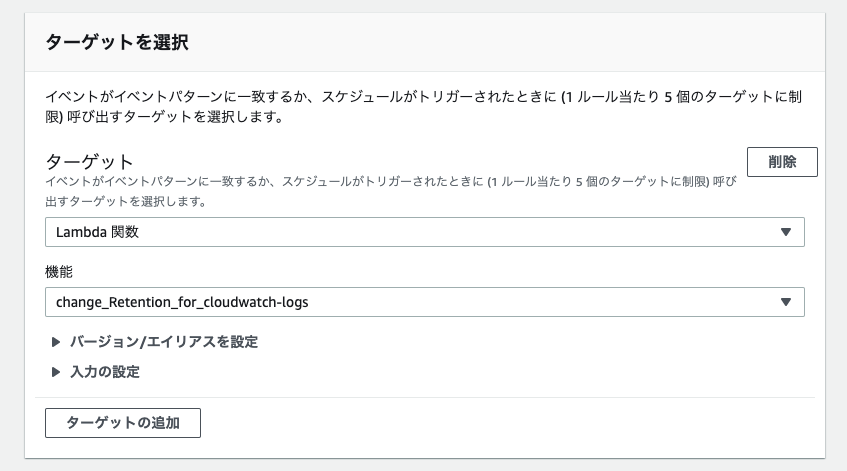
今回は、CloudWatch LogGroupが新規作成されるのをトリガーに上記で作成したLambdaを動かしたいので、EventBridgeのルールで感知してもらうようにします。
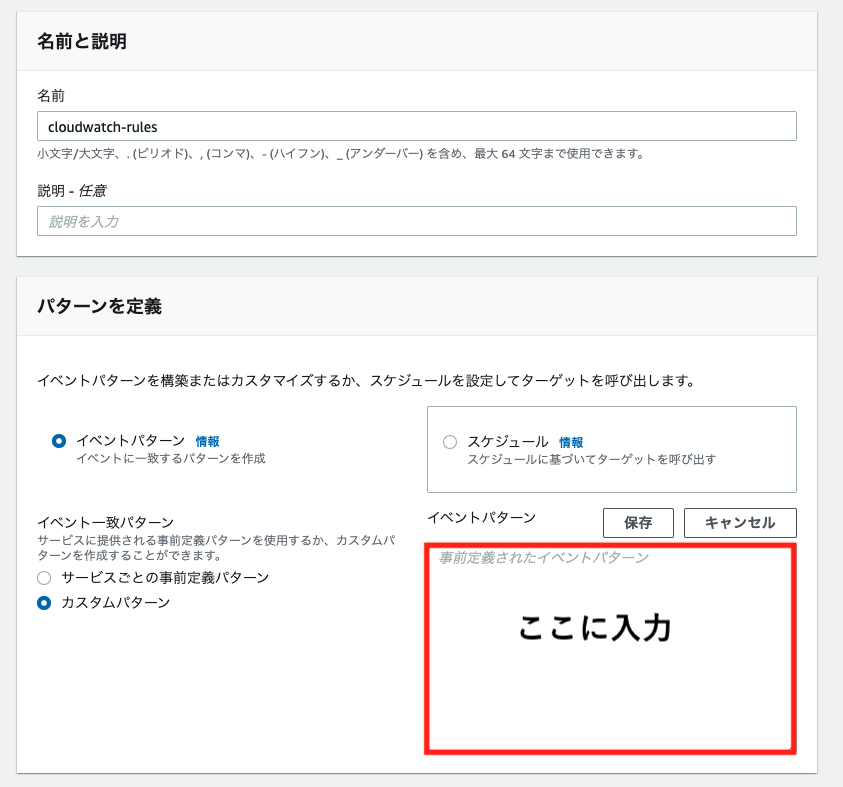
それでは、ルールを作成します。パターンの定義は下記で設定します。
イベントパターン
イベント一致パターン:カスタムパターン定義するコードは、右横に出る四角の中に入れます。
ターゲットは、先ほど作成したLambda関数を指定します。
これで設定は終わり!動かしてみよう
新規作成されたCloudwatch LogGroupの保持期間が1ヶ月になれば、動作確認はOKです!
CloudWatchコンソールの「ロググループを作成」から新規作成します。作成直後
数分後
新規作成してからすぐに保持期間が反映されるわけではないですが、正しく保持期間が設定できていることが確認できます。
これで、ログが溜まり続けて知らぬ間に料金が高くなっているなんてことも防げそうですね参考
・Amazon EventBridge とは
https://docs.aws.amazon.com/ja_jp/eventbridge/latest/userguide/what-is-amazon-eventbridge.html
・Amazon CloudWatch Logs とは
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html
・CloudWatch の使用料金が請求された理由を確認してから、今後の料金を削減するにはどうすればよいですか?
https://aws.amazon.com/jp/premiumsupport/knowledge-center/cloudwatch-understand-and-reduce-charges/?nc1=h_ls


- 投稿日:2020-08-07T09:18:41+09:00
YouTubeでAWSの解説動画(Solution Architect Associate)を作成しました
こんにちは。
YouTubeでAWSの解説動画を作成しました。
レベル的にいうとソリューションアーキテクトのアソシエイト程度を意識しています。1.AWSとは? サービスの概要と認定試験
2.AWSをはじめよう! アカウントの作成方法
3.認証とユーザ管理 (IAM)
4.ストレージサービス (S3, Glacier, EBS, EFS)
5.EC2仮想サーバーとコンテナサービス(ECS)
6.ネットワークサービス (VPC, Route53)
7.データベースサービス (RDS, Redshift, Aurora, DynamoDB, ElasticCache)
8.運用監視サービスおよびIaC (CloudWatch, CloudTrail, ElasticBeanstal, CloudFormation)
9.アプリ間連携サービス (SQS, SNS, SES)
10.開発者ツール (Commit, Build, Deploy, Pipeline)
補足:










- 投稿日:2020-08-07T07:53:55+09:00
自分向けメモ AWS_Route53レコード、ホストゾーン削除
cloud9→Route53→ホストゾーン→
タイプAのレコードを選択して削除
削除と入力して削除※SOAとNSレコードは削除できない。
ホストゾーンでドメインを選択、削除と入力して削除
- 投稿日:2020-08-07T01:07:42+09:00
複数のAWSアカウントの切り替え方法
はじめに
環境ごとに複数のAWSアカウントを利用することがあるのですが毎回アカウントIDを忘れてしまうので対応のメモです。
結論
以下のようにブックマークに保存すれば毎度IDが入力された状態で呼び出されます。
https://{{awsアカウントID}}.signin.aws.amazon.com/console{{awsアカウントID}}の部分にアカウントID(12桁)を入力するようにしてください。
ブックマークでAWSアカウントの環境とか明示してあげるとわかりやすいです!※ アクセスした結果のリダイレクトされたURLをブックマークしないように注意
私はこれをしてて毎回、前回のサインインしていたアカウントのIDが出てきてました。。終わりに
大したことない内容ですが、個人的にハマってたので誰かの役に立てたら嬉しいです!