- 投稿日:2020-08-06T22:38:35+09:00
【Python】macOSでpipを使えるようにする
ラズパイだと
apt-getでpipがインストールできますが、macOSでpipをインストールしたく、そこで詰まってしまったのでその備忘録です。
Homebrewで一発とか思ってたのですが、brew install pipではインストールできません。1公式ページのインストール方法に従う
公式のやり方に従って、以下のcurlコマンドで
get-pipというPythonファイルがダウンロードします。curl https://bootstrap.pypa.io/get-pip.py -o get-pip.pyダウンロードした
get-pip.pyを実行するとpipがインストールされます。$ python3 get-pip.pyインストール完了
whichコマンドを叩いてパスが表示されるので、インストール自体は完了です。
$ which pip /usr/local/bin/pip環境
- macOS 10.15.5 Catalina
- pip 20.2.1
- Python 3.8.5
参考サイト
※筆者はHomeBrewが大好きです。 ↩
- 投稿日:2020-08-06T22:14:12+09:00
PythonでEDINET・TDNETから有価証券報告書・四半期報告書・決算短信のXBRLをダウンロードする
タイトルがクソ長い..
金融界隈で定量的な分析やデータサイエンスをやっている9uantです.
twitterもやってるので,興味ある方はぜひフォローしていただけると!タイトルの通り,決算書類のXBRLを手早くダウンロードするためのコードを共有する.
解説も追々書いていきたい.
以下の2ステップをとる.
- XBRLへのリンクをDataFrame化する
- DataFrameからXBRLのzipファイルをダウンロードする
import os import glob import shutil import re import time from datetime import date, timedelta, datetime from dateutil.relativedelta import relativedelta import requests from bs4 import BeautifulSoup import urllib3 from urllib3.exceptions import InsecureRequestWarning urllib3.disable_warnings(InsecureRequestWarning) from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import Select from selenium.webdriver.common.by import By import zipfile import numpy as np import pandas as pd import jsonXBRLへのリンクをDataFrame化する
EDINET
EDINETにはAPIが存在するため容易.
def edinet_xbrl_link(annual=True, quarter=True, codes=None, year=0,month=0,day=0): ''' 特定の企業の,もしくは全ての有価証券報告書・四半期報告書のXBRLのリンクのDataFrameを作成する Parameters: annual: bool, default True True の場合に有価証券報告書を取得する quarter: bool, default Ture True の場合に四半期報告書を取得する codes: None, int, float, str, or list (codes[code]=int, float,or str), default None None の場合に全ての企業のデータを取得する 銘柄コードを指定すると,それらの企業のデータのみを取得する:point_up_tone4: year, month, day: int, default 0 現在から何日前までのデータを取得するかを指定する(最大5年) Returns: database: pandas.DataFrame database['code']: str 5桁の証券コード database['type']: str 'annual' or 'quarter' database['date']: datetime.date 公開日 database['title']: str 表題 database['URL']: str XBRLのzipファイルをダウンロードするURL ''' edinet_url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json" # codesを文字型の配列に統一する. if codes != None: if type(codes) in (str, int, float): codes = [int(codes)] for code in codes: # 4桁の証券コードを5桁に変換 if len(str(int(code)))==4: code = str(int(code))+'0' # datetime型でfor文を回す def date_range(start, stop, step = timedelta(1)): current = start while current < stop: yield current current += step # 結果を格納するDataFrameを用意 database = pd.DataFrame(index=[], columns=['code','type','date','title','URL']) for d in date_range(date.today()-relativedelta(years=year, months=month, days=day)+relativedelta(days=1), date.today()+relativedelta(days=1)): # EDINET API にアクセス d_str = d.strftime('%Y-%m-%d') params = {'date' : d_str, 'type' : 2} res = requests.get(edinet_url, params=params, verify=False) json_res = json.loads(res.text) time.sleep(5) # 正常にアクセスできない場合 if json_res['metadata']['status']!='200': print(d_str, 'not accessible') continue print(d_str, json_res['metadata']['resultset']['count'])# 日付と件数を表示 # 0件の場合 if len(json_res['results'])==0: continue df = pd.DataFrame(json_res['results'])[['docID', 'secCode', 'ordinanceCode', 'formCode','docDescription']] df.dropna(subset=['docID'], inplace=True) df.dropna(subset=['secCode'], inplace=True) df.rename(columns={'secCode': 'code', 'docDescription': 'title'}, inplace=True) df['date'] = d df['URL'] = df['docID'] df['URL'] = "https://disclosure.edinet-fsa.go.jp/api/v1/documents/" + df['URL'] # 指定された証券コードのみを抽出 if codes != None: df = df[df['code'] in codes] if annual == True: df1 = df[(df['ordinanceCode']=='010') & (df['formCode']=='030000')] df1['type'] = 'annual' database = pd.concat([database, df1[['code', 'type', 'date','title', 'URL']]], axis=0, join='outer').reset_index(drop=True) if quarter == True: df2 = df[(df['ordinanceCode']=='010') & (df['formCode']=='043000')] df2['type'] = 'quarter' database = pd.concat([database, df2[['code', 'type', 'date','title', 'URL']]], axis=0, join='outer').reset_index(drop=True) return databaseTDNET
TDNETからのデータの収集には
seleniumを用いる.
フリーワード検索結果が200件までしか表示されないため,証券コードから検索する関数と,日付から検索する関数を別々に作成した.def tdnet_xbrl_link_by_code(codes): ''' 指定された企業の決算短信をXBRLへのリンクのDataFrameを作成する Parameters: codes: None, int, float, str, or list (codes[code]=int, float,or str), default None None の場合に全ての企業のデータを取得する Returns: database: pandas.DataFrame database['code']: str 5桁の証券コード database['type']: str 'annual' or 'quarter' database['date']: datetime.date 公開日 database['title']: str 表題 database['URL']: str XBRLのzipファイルをダウンロードするURL ''' # codesを文字型の配列に統一する. if type(codes) in (str, int, float): codes = [int(codes)] for i, code in enumerate(codes): # 4桁の証券コードを5桁に変換 if len(str(int(code)))==4: codes[i] = str(int(code))+'0' database = pd.DataFrame(index=[], columns=['code','type','date','title','URL']) for code in codes: # ブラウザを起動する chromeOptions = webdriver.ChromeOptions() chromeOptions.add_argument('--headless') # ブラウザ非表示 driver = webdriver.Chrome(options=chromeOptions) driver.get("https://www.release.tdnet.info/onsf/TDJFSearch/I_head") # 検索ワードを送る duration = driver.find_element_by_name('t0') select = Select(duration) select.options[-1].click() inputElement = driver.find_element_by_id("freewordtxt") inputElement.send_keys(code) inputElement.send_keys(Keys.RETURN) time.sleep(5) # 検索結果が表示されたフレームに移動 iframe = driver.find_element_by_name("mainlist") driver.switch_to.frame(iframe) # 検索結果が0件の場合に処理を終える if driver.find_element_by_id("contentwrapper").text == '該当する適時開示情報が見つかりませんでした。': return database # 検索結果の表の各行からデータを読み取る table = driver.find_element_by_id("maintable") trs = table.find_elements(By.TAG_NAME, "tr") for i in range(len(trs)): title = trs[i].find_elements(By.TAG_NAME, "td")[3].text # 訂正書類でなく,XBRLが存在する,指定された企業の決算短信を選択 if ('決算短信' in title) and ('訂正' not in title) and (len(trs[i].find_elements(By.TAG_NAME, "td")[4].text)!=0) and (code==trs[i].find_elements(By.TAG_NAME, "td")[1].text): date = trs[i].find_elements(By.TAG_NAME, "td")[0].text[:10] date = datetime.strptime(date, '%Y/%m/%d').date() url = trs[i].find_elements(By.TAG_NAME, "td")[4].find_element_by_tag_name("a").get_attribute("href") database = database.append(pd.Series([code,'brief',date,title,url], index=database.columns), ignore_index=True) driver.quit() return databasedef tdnet_xbrl_link_by_date(date=None): ''' 指定された日付,もしくは全ての決算短信をXBRLへのリンクのDataFrameを作成する Parameters: date: None or str ('yyyy/mm/dd'), default None None の場合に全ての日付のデータを取得する Returns: database: pandas.DataFrame database['code']: str 5桁の証券コード database['type']: str 'annual' or 'quarter' database['date']: datetime.date 公開日 database['title']: str 表題 database['URL']: str XBRLのzipファイルをダウンロードするURL ''' database = pd.DataFrame(index=[], columns=['code','type','date','title','URL']) # ブラウザを起動する chromeOptions = webdriver.ChromeOptions() chromeOptions.add_argument('--headless') # ブラウザ非表示 driver = webdriver.Chrome(options=chromeOptions) driver.get("https://www.release.tdnet.info/inbs/I_main_00.html") duration = driver.find_element_by_name('daylist') select = Select(duration) for i in range(1, len(select.options)): driver.get("https://www.release.tdnet.info/inbs/I_main_00.html") duration = driver.find_element_by_name('daylist') select = Select(duration) d = datetime.strptime(select.options[i].text[:10], '%Y/%m/%d').date() print(select.options[i].text) if (date == None) or (date == select.options[i].text[:10]): select.options[i].click() time.sleep(5) # 検索結果が表示されたフレームに移動 iframe = driver.find_element_by_id("main_list") driver.switch_to.frame(iframe) # 検索結果が0件の場合に処理を終える if driver.find_element_by_id("kaiji-text-1").text!='に開示された情報': continue # 最後のページまで処理を続ける while True: # 検索結果の表の各行からデータを読み取る table = driver.find_element_by_id("main-list-table") trs = table.find_elements(By.TAG_NAME, "tr") for i in range(len(trs)): title = trs[i].find_elements(By.TAG_NAME, "td")[3].text # 訂正書類でなく,XBRLが存在する,指定された企業の決算短信を選択 if ('決算短信' in title) and ('訂正' not in title) and (len(trs[i].find_elements(By.TAG_NAME, "td")[4].text)!=0): code = trs[i].find_elements(By.TAG_NAME, "td")[1].text url = trs[i].find_elements(By.TAG_NAME, "td")[4].find_element_by_tag_name("a").get_attribute("href") database = database.append(pd.Series([code, 'brief', d, title,url], index=database.columns), ignore_index=True) if len(driver.find_element_by_class_name("pager-R").text)!=0: driver.find_element_by_class_name("pager-R").click() time.sleep(5) else: # 「次へ」の文字が存在しない場合に処理を終了する break driver.quit() return databaseDataFrameからXBRLをダウンロードする
def dl_xbrl_zip(codes=None, database): ''' XBRLへのリンクをリスト化したDataFrameを参照して,XBRLのzipファイルをダウンロードする Parameters: codes: None, int, float, str, or list (codes[code]=int, float,or str), default None None の場合に全ての企業のXBRLを取得する database: pandas.DataFrame database['code']: str 5桁の証券コード database['type']: str 'annual' or 'quarter' database['date']: datetime.date 公開日 database['title']: str 表題 database['URL']: str XBRLのzipファイルをダウンロードするURL Returns: None ''' database.dropna(subset=['code'], inplace=True) database = database.reset_index(drop=True) # codesを文字型の配列に統一する if codes == None: codes = [None] else: if type(codes) in (str, int, float): codes = [int(codes)] for i, code in enumerate(codes): # 4桁の証券コードを5桁に変換 if len(str(int(code)))==4: codes[i] = str(int(code))+'0' for code in codes: if code == None: df_company = database else: df_company = database[database['code']==code] df_company = df_company.reset_index(drop=True) # 証券コードをディレクトリ名とする dir_path = database.loc[i,'code'] if os.path.exists(dir_path)==False: os.mkdir(dir_path) # 抽出したリストの各行からXBRLへのリンクからzipファイルをダウンロード for i in range(df_company.shape[0]): # EDINETへアクセスする場合 if (df_company.loc[i,'type'] == 'annual') or (df_company.loc[i,'type'] == 'quarter'): params = {"type": 1} res = requests.get(df_company.loc[i,'URL'], params=params, stream=True) if df_company.loc[i,'type'] == 'annual': # 有価証券報告書のファイル名は"yyyy_0.zip" filename = dir_path + r'/' + df_company.loc[i,'date'][:4] + r"_0.zip" elif df_company.loc[i,'type'] == 'quarter': if re.search('期第', df_company.loc[i,'title']) == None: # 第何期か不明の四半期報告書のファイル名は"yyyy_unknown_docID.zip" filename = dir_path + r'/' + df_company.loc[i,'date'][:4] + r'_unknown_' + df_company.loc[i,'URL'][-8:] + r'.zip' else: # 四半期報告書のファイル名は"yyyy_quarter.zip" filename = dir_path + r'/' + df_company.loc[i,'date'][:4] + r'_' + df_company.loc[i,'title'][re.search('期第', df_company.loc[i,'title']).end()] + r'.zip' # TDNETへアクセスする場合 elif df_company.loc[i,'type'] == 'brief': res = requests.get(df_company.loc[i,'URL'], stream=True) # 空白文字を埋める s_list = df_company.loc[i,'title'].split() s = '' for i in s_list: s += i filename = df_company.loc[i,'date'][:4] + r'_' + s[re.search('期第', s).end()] + r'_brief.zip' # 同名のzipファイルが存在する場合,上書きはしない if os.path.exists(filename): print(df_company.loc[i,'code'],df_company.loc[i,'date'],'already exists') continue # 正常にアクセスできた場合のみzipファイルをダウンロード if res.status_code == 200: with open(filename, 'wb') as file: for chunk in res.iter_content(chunk_size=1024): file.write(chunk) print(df_company.loc[i,'code'],df_company.loc[i,'date'],'saved') print('done!') return None
- 投稿日:2020-08-06T21:55:08+09:00
Computer Vision : Semantic Segmentation Part1 - ImageNet pretraining VoVNet
目標
Microsoft Cognitive Toolkit (CNTK) を用いたセマンティックセグメンテーションについてまとめました。
Part1 では、セマンティックセグメンテーションのためのバックボーンに使用する CNN の事前学習を行います。
CNN の事前学習には 1,000カテゴリーの ImageNet の画像を使用します。以下の順で紹介します。
- ImageNet からのダウンロードと準備
- VoVNet : One-Shot Aggregation module
- 訓練における諸設定
導入
ImageNet からのダウンロードと準備
ImageNet [1] は 1.4億枚以上の画像が登録されている大規模な画像データベースです。2017年までは画像認識のコンペティション ILSVCR に使われていました。
今回は ImageNet が管理している画像の URL を使ってダウンロードする方法で 1,000カテゴリーの訓練データを収集しました。ただし、850番目の teddy, teddy bear は一枚もダウンロードできなかったため、Computer Vision : Image Classification Part1 - Understanding COCO dataset で準備した画像で代用しました。
また、ダウンロードした画像には壊れた JPEG ファイルやカテゴリーとは関係のない画像も相当数含まれていたので、自動と手動でクリーニングしました。最終的に収集できた画像は 775,983枚になりました。
今回のディレクトリの構成は以下のようにしました。
COCO
MNIST
NICS
RTSS
|―ImageNet
|―n01440764
|―n01440764_0.jpg
|―…
rtss_imagenet.py
rtss_vovnet57.py
SSMDVoVNet : One-Shot Aggregation module
畳み込みニューラルネットワークのモデルとして、今回は VoVNet [2] (Variety of View Network) を採用しました。VoVNet は DenseNet [3] よりもメモリ使用量と計算コストを削減した CNN モデルです。
One-Shot Aggregation module
VoVNet では、下図の四角で囲まれた One-Shot Aggregation (OSA) モジュールを使用します。
VoVNet57
VoVNet57 のネットワークの構成は以下のようになっています。
Layer Filters Size/Stride Input Output Convolution2D 64 3x3/2 3x224x224 64x112x112 Convolution2D 64 3x3/1 64x112x112 64x112x112 Convolution2D 128 3x3/1 64x112x112 128x112x112 MaxPooling2D 3x3/2 128x112x112 128x56x56 OSA module 128, 256 3x3/1, 1x1/1 128x56x56 256x56x56 MaxPooling2D 3x3/2 256x56x56 256x28x28 OSA module 160, 512 3x3/1, 1x1/1 256x28x28 512x28x28 MaxPooling2D 3x3/2 512x28x28 512x14x14 OSA module 192, 768 3x3/1, 1x1/1 512x14x14 768x14x14 OSA module 192, 768 3x3/1, 1x1/1 768x14x14 768x14x14 OSA module 192, 768 3x3/1, 1x1/1 768x14x14 768x14x14 OSA module 192, 768 3x3/1, 1x1/1 768x14x14 768x14x14 MaxPooling2D 3x3/2 768x14x14 768x7x7 OSA module 224, 1024 3x3/1, 1x1/1 768x7x7 1024x7x7 OSA module 224, 1024 3x3/1, 1x1/1 1024x7x7 1024x7x7 OSA module 224, 1024 3x3/1, 1x1/1 1024x7x7 1024x7x7 GlobalAveragePooling global 1024x7x7 1024x1x1 Dense 1000 1024x1x1 1000x1x1 Softmax 1000 1000 1000 合計 57層の畳み込みと 32倍のダウンサンプリングで構成されます。パラメータの総数は 31,429,159 です。
畳み込み層ではバイアスを使用せずに、Batch Normalization [4] を適用してから活性化関数へ入力します。
最後の全結合層では、Batch Normalization は使用せずにバイアス項を使用します。
活性化関数 Mish
活性化関数には Mish [5] を採用しました。Mish は ReLU を上回る Swish [6] よりも高い性能が報告されている活性化関数です。Mish は以下の式で表されるように、ソフトプラス関数と tanh関数を組み合わせることで簡単に実装できます。
Mish(x) = x \cdot \tanh \left( \log (1 + e^x) \right)Mish は下図のようになります。
Mish は ReLU の deadly neuron を回避し、ReLU が微分すると不連続なのに対して Mish は何度微分しても連続なので、損失関数が滑らかになって最適化しやすくなります。
訓練における諸設定
入力画像は輝度値の最大値 255 で除算します。
各層のパラメータの初期値は He の正規分布 [7] に設定しました。
損失関数は Cross Entropy Error、最適化アルゴリズムは Stochastic Gradient Decent (SGD) with Momentum を採用しました。モーメンタムは 0.9 に固定しました。
学習率には、Cyclical Learning Rate (CLR) [8] を採用し、最大学習率は 0.1、ベース学習率は 1e-4、ステップサイズはエポック数の 10倍、方策は triangular2 に設定しました。
過学習対策として、L2 正則化の値を 0.0005 に設定しました。
モデルの訓練はミニバッチサイズ 64 のミニバッチ学習によって 100 Epoch を実行しました。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-5820K 3.30GHz
・GPU NVIDIA Quadro RTX 5000 16GBソフトウェア
・Windows 10 Pro 1909
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・cntkx 0.1.50
・numpy 1.17.3
・opencv-contrib-python 4.1.1.26
・pandas 0.25.0
・requests 2.22.0実行するプログラム
ImageNet からダウンロードするプログラムと訓練用のプログラムは GitHub で公開しています。
rtss_imagenet.pyrtss_vovnet57.py結果
訓練時の損失関数と誤認識率のログを可視化したものが下図です。左のグラフが損失関数、右のグラフが誤認識率になっており、横軸はエポック数、縦軸はそれぞれ損失関数の値と誤認識率を表しています。
これでバックボーンとなる CNN 事前学習モデルができたので、Part2 ではセマンティックセグメンテーションを実現するための機構を加えて完成させます。
参考
ImageNet
Microsoft COCO Common Objects in ContextComputer Vision : Image Classification Part1 - Understanding COCO dataset
- Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. "ImageNet: A Large-Scale Hierarchical Image Database", IEEE conference on Computer Vision and Pattern Recognition (CVPR). 2009, p. 248-255.
- Youngwan Lee, Joong-won Hwang, Sangrok Lee, Yuseok Bae, and Jongyoul Park. "An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection", the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2019, p. 0-0.
- Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. "Densely Connected Convolutional Networks", the IEEE conference on Computer Vision and Pattern Recognition (CVPR). 2017. p. 4700-4708.
- Ioffe Sergey and Christian Szegedy. "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift", arXiv preprint arXiv:1502.03167 (2015).
- Misra, Diganta. "Mish: A self regularized non-monotonic neural activation function." arXiv preprint arXiv:1908.08681 (2019).
- Ramachandran, Prajit, Barret Zoph, and Quoc V. Le. "Searching for activation functions." arXiv preprint arXiv:1710.05941 (2017).
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification", The IEEE International Conference on Computer Vision (ICCV). 2015, p. 1026-1034.
- Leslie N. Smith. "Cyclical Learning Rates for Training Neural Networks", 2017 IEEE Winter Conference on Applications of Computer Vision. 2017, p. 464-472.



- 投稿日:2020-08-06T21:47:47+09:00
3.PythonによるAIプログライミング
はじめに
いきなりこのページに来られた方は、
親ページから参照をお願いいたします。ここの目的
pycharmを使用して、python言語でAIをコーディングします。コードはコピペでOKです。
ソースコード内の意味が分からなくても実行できます。開発環境の立ち上げ
Pythonプログラムを作成するためにpycharm(PyCharm Community Edition)を起動します。前回作ったPJが表示されるので「
mnist」をクリック
pycharm起動画面 (mnistプロジェクトが起動されました)
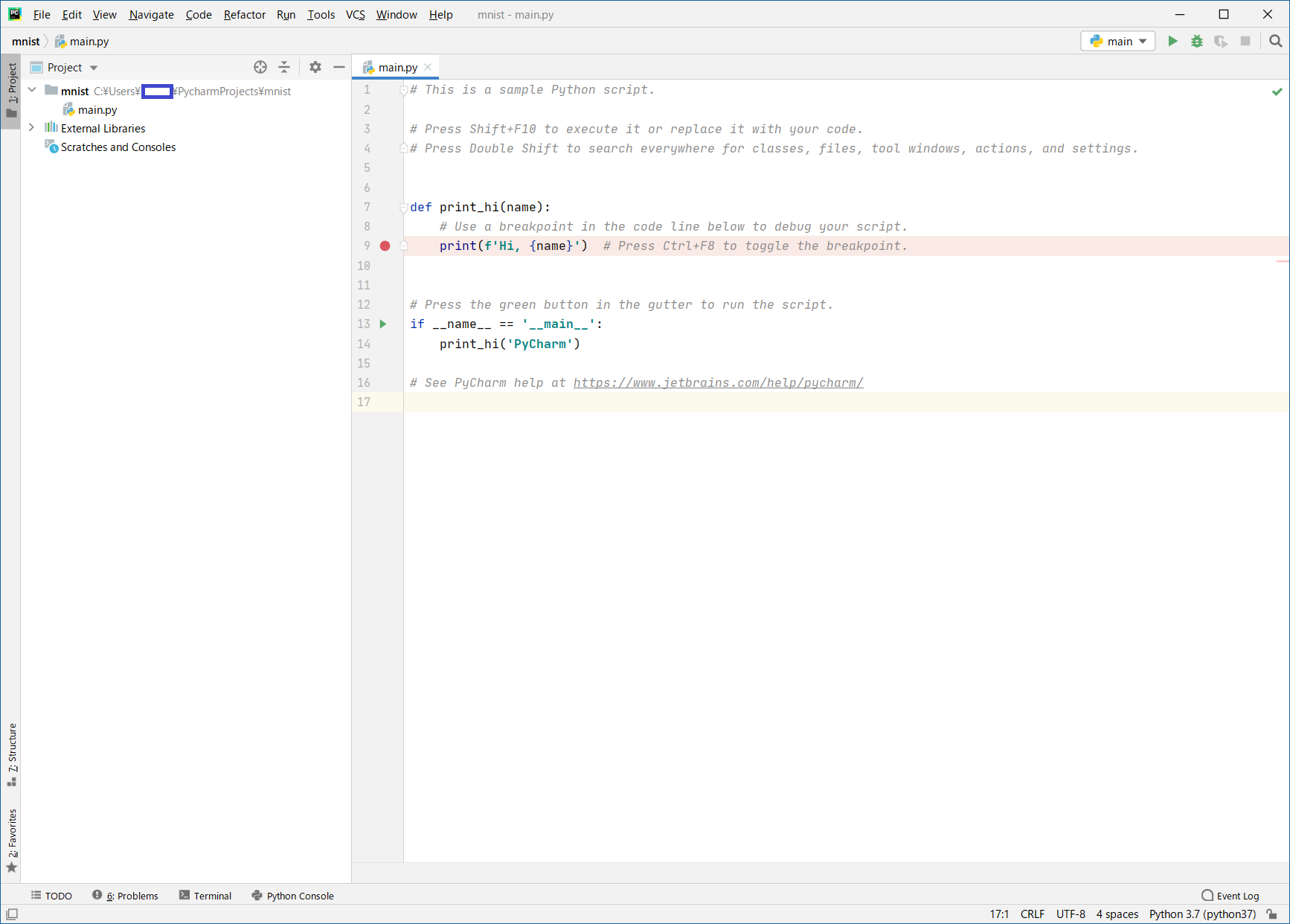
このサンプルのソースコードは、AIとは全く関係がないものなので全部消去します (サンプルのソースコードは、
CTL+AしてDELキーで簡単に消せます)
PythonによるAIプログラミング
- ソースコードは以下です。
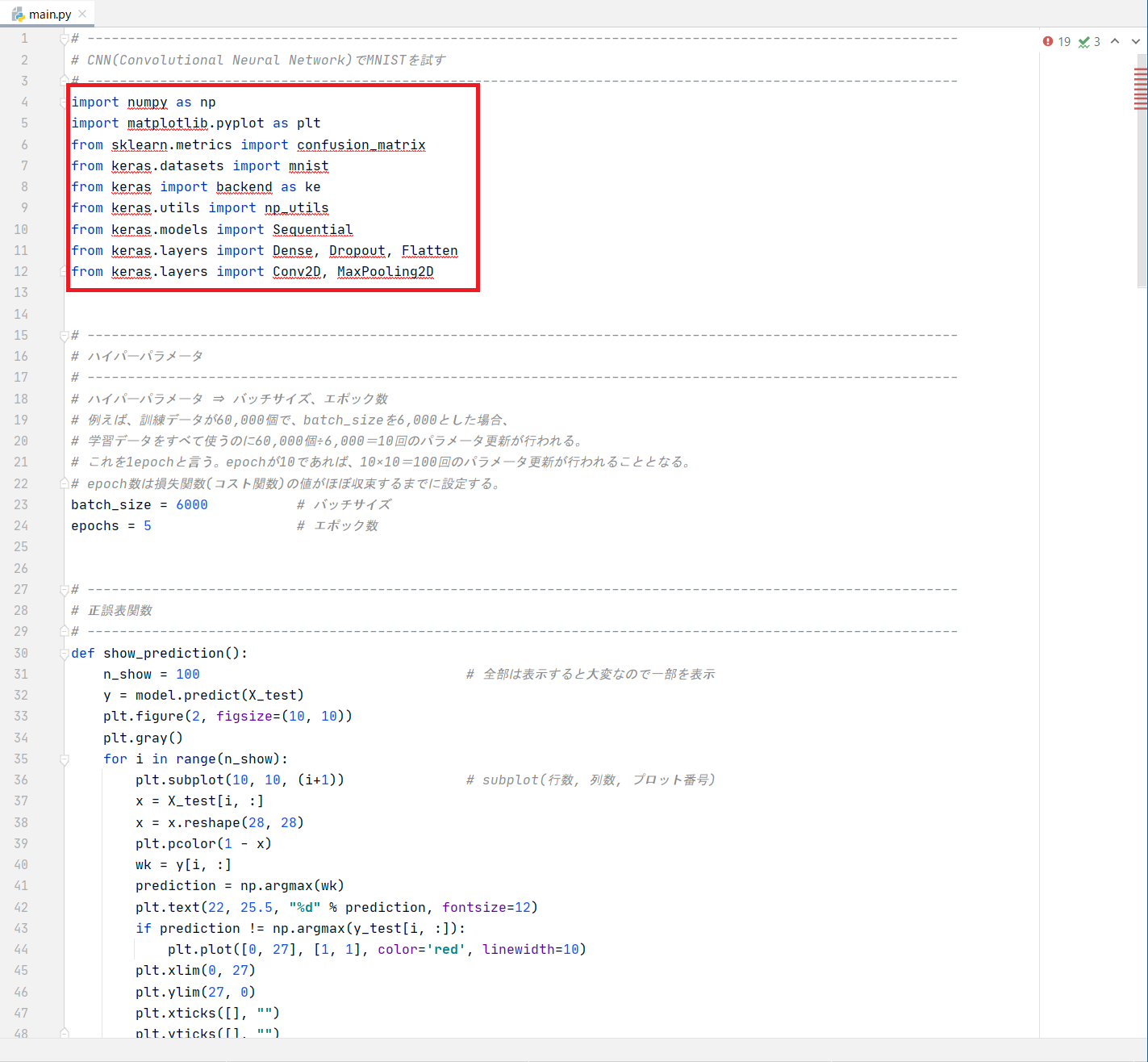
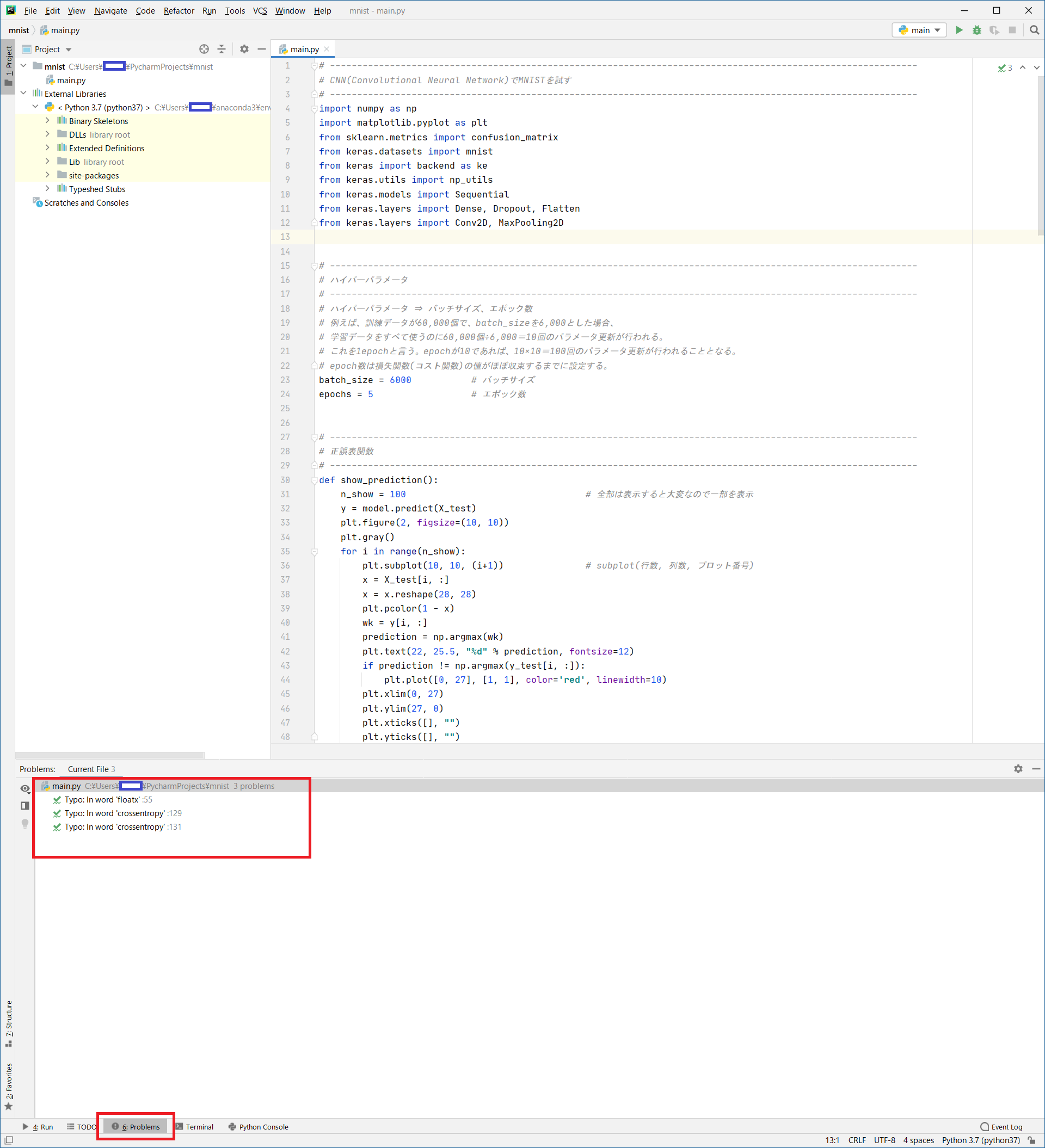
main.py# ------------------------------------------------------------------------------------------------------------ # CNN(Convolutional Neural Network)でMNISTを試す # ------------------------------------------------------------------------------------------------------------ import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import confusion_matrix from keras.datasets import mnist from keras import backend as ke from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D # ------------------------------------------------------------------------------------------------------------ # ハイパーパラメータ # ------------------------------------------------------------------------------------------------------------ # ハイパーパラメータ ⇒ バッチサイズ、エポック数 # 例えば、訓練データが60,000個で、batch_sizeを6,000とした場合、 # 学習データをすべて使うのに60,000個÷6,000=10回のパラメータ更新が行われる。 # これを1epochと言う。epochが10であれば、10×10=100回のパラメータ更新が行われることとなる。 # epoch数は損失関数(コスト関数)の値がほぼ収束するまでに設定する。 batch_size = 6000 # バッチサイズ epochs = 5 # エポック数 # ------------------------------------------------------------------------------------------------------------ # 正誤表関数 # ------------------------------------------------------------------------------------------------------------ def show_prediction(): n_show = 100 # 全部は表示すると大変なので一部を表示 y = model.predict(X_test) plt.figure(2, figsize=(10, 10)) plt.gray() for i in range(n_show): plt.subplot(10, 10, (i+1)) # subplot(行数, 列数, プロット番号) x = X_test[i, :] x = x.reshape(28, 28) plt.pcolor(1 - x) wk = y[i, :] prediction = np.argmax(wk) plt.text(22, 25.5, "%d" % prediction, fontsize=12) if prediction != np.argmax(y_test[i, :]): plt.plot([0, 27], [1, 1], color='red', linewidth=10) plt.xlim(0, 27) plt.ylim(27, 0) plt.xticks([], "") plt.yticks([], "") # ------------------------------------------------------------------------------------------------------------ # keras backendの表示 # ------------------------------------------------------------------------------------------------------------ # print(ke.backend()) # print(ke.floatx()) # ------------------------------------------------------------------------------------------------------------ # MNISTデータの取得 # ------------------------------------------------------------------------------------------------------------ # 初回はダウンロードが発生するため時間がかかる # 60,000枚の28x28ドットで表現される10個の数字の白黒画像と10,000枚のテスト用画像データセット # ダウンロード場所:'~/.keras/datasets/' # ※MNISTのデータダウンロードがNGとなる場合は、PROXYの設定を見直してください # # MNISTデータ # ├ 教師データ (60,000個) # │ ├ 画像データ # │ └ ラベルデータ # │ # └ 検証データ (10,000個) # ├ 画像データ # └ ラベルデータ # ↓教師データ ↓検証データ (X_train, y_train), (X_test, y_test) = mnist.load_data() # ↑画像 ↑ラベル ↑画像 ↑ラベル # ------------------------------------------------------------------------------------------------------------ # 画像データ(教師データ、検証データ)のリシェイプ # ------------------------------------------------------------------------------------------------------------ img_rows, img_cols = 28, 28 if ke.image_data_format() == 'channels_last': X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1) X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) else: X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols) X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) # 配列の整形と、色の範囲を0~255 → 0~1に変換 X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255 X_test /= 255 # ------------------------------------------------------------------------------------------------------------ # ラベルデータ(教師データ、検証データ)のベクトル化 # ------------------------------------------------------------------------------------------------------------ y_train = np_utils.to_categorical(y_train) # 教師ラベルのベクトル化 y_test = np_utils.to_categorical(y_test) # 検証ラベルのベクトル化 # ------------------------------------------------------------------------------------------------------------ # ネットワークの定義 (keras) # ------------------------------------------------------------------------------------------------------------ print("") print("●ネットワーク定義") model = Sequential() # 入力層 28×28×3 model.add(Conv2D(16, kernel_size=(3, 3), activation='relu', input_shape=input_shape, padding='same')) # 01層:畳込み層16枚 model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) # 02層:畳込み層32枚 model.add(MaxPooling2D(pool_size=(2, 2))) # 03層:プーリング層 model.add(Dropout(0.25)) # 04層:ドロップアウト model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) # 05層:畳込み層64枚 model.add(MaxPooling2D(pool_size=(2, 2))) # 06層:プーリング層 model.add(Flatten()) # 08層:次元変換 model.add(Dense(128, activation='relu')) # 09層:全結合出力128 model.add(Dense(10, activation='softmax')) # 10層:全結合出力10 # model表示 model.summary() # コンパイル # 損失関数 :categorical_crossentropy (クロスエントロピー) # 最適化 :Adam model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy']) print("") print("●学習スタート") f_verbose = 1 # 0:表示なし、1:詳細表示、2:表示 hist = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(X_test, y_test), verbose=f_verbose) # ------------------------------------------------------------------------------------------------------------ # 損失値グラフ化 # ------------------------------------------------------------------------------------------------------------ # Accuracy (正解率) plt.plot(range(epochs), hist.history['accuracy'], marker='.') plt.plot(range(epochs), hist.history['val_accuracy'], marker='.') plt.title('Accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='lower right') plt.show() # loss (損失関数) plt.plot(range(epochs), hist.history['loss'], marker='.') plt.plot(range(epochs), hist.history['val_loss'], marker='.') plt.title('loss Function') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper right') plt.show() # ------------------------------------------------------------------------------------------------------------ # テストデータ検証 # ------------------------------------------------------------------------------------------------------------ print("") print("●検証結果") t_verbose = 1 # 0:表示なし、1:詳細表示、2:表示 score = model.evaluate(X_test, y_test, verbose=t_verbose) print("") print("batch_size = ", batch_size) print("epochs = ", epochs) print('Test loss:', score[0]) print('Test accuracy:', score[1]) print("") print("●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ") predict_classes = model.predict_classes(X_test[1:60000, ], batch_size=batch_size) true_classes = np.argmax(y_test[1:60000], 1) print(confusion_matrix(true_classes, predict_classes)) # ------------------------------------------------------------------------------------------------------------ # 正誤表表示 # ------------------------------------------------------------------------------------------------------------ show_prediction() plt.show()
このソースコードを先程のフィールド(赤枠内)に
コピペしてください。
下記の様に赤線枠内に
!赤丸の箇所がある場合は、ライブラリが足りずエラーとなっています。
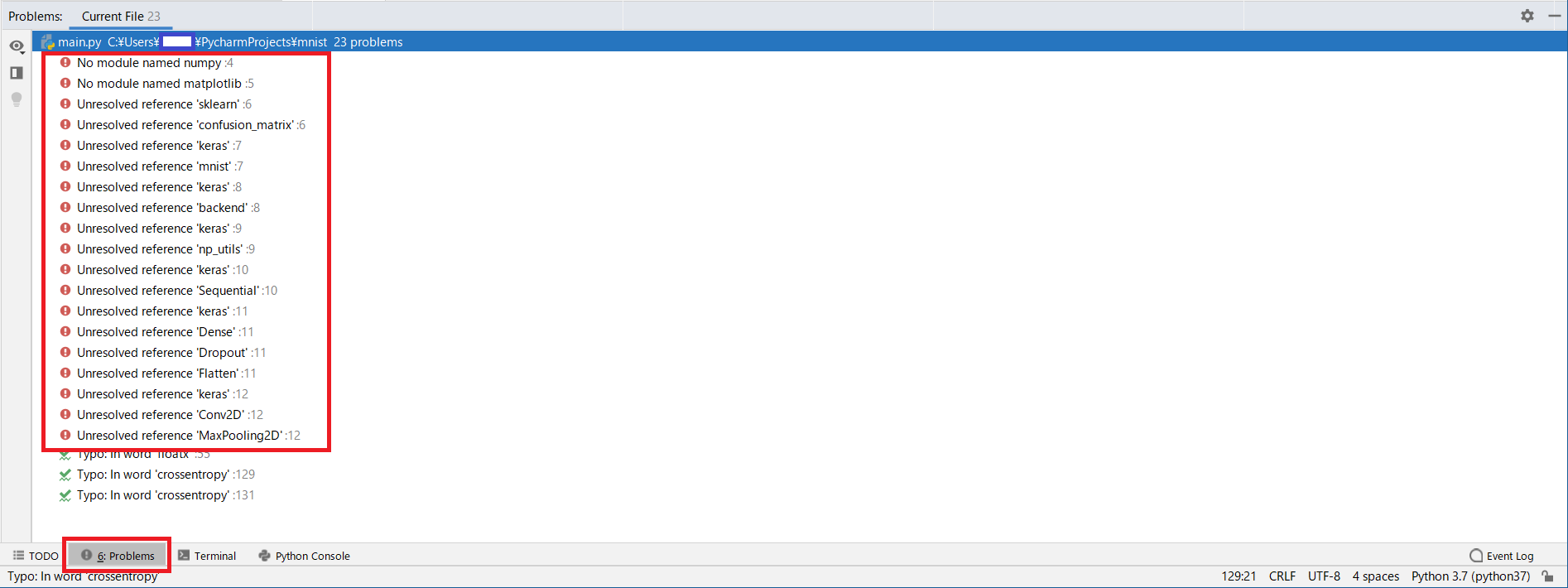
足りていないライブラリは以下で確認できます。
ライブラリが無い箇所に赤色で下線が付いています。
足りないライブラリを以下にまとめます
ライブラリはパッケージに入っています。
sklearnライブラリだけ、scikit-learnというパッケージに入っているので注意。
No. 足りないライブラリ名 必要なパッケージ名称 1 keras keras 2 numpy numpy 3 matplotlib matplotlib 4 sklearn scikit-learn パッケージのインストール
●ライブラリを追加したいので、それに適合したパッケージを追加します
- anacondaを起動し、[
Envionments] -> [python37]をクリック
●kerasパッケージをインストールします
- [
Installed]を[All]に変更- 検索BOXに[
keras]と入力し、kerasパッケージを検索- [
keras]のチェックボックスをONに設定- 右下の[
Apply]をクリックして適応させる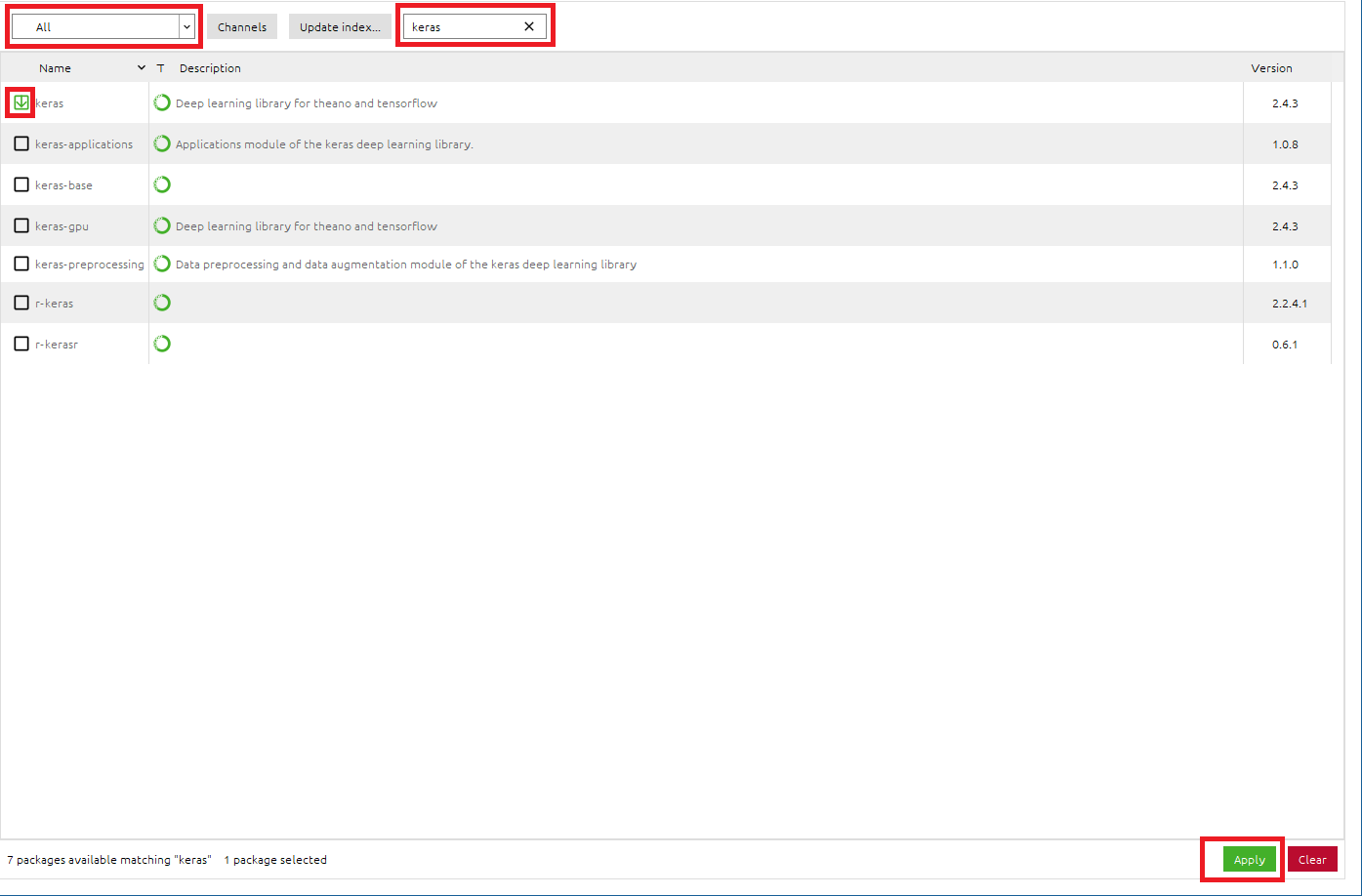
- Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、kerasパッケージをインストール
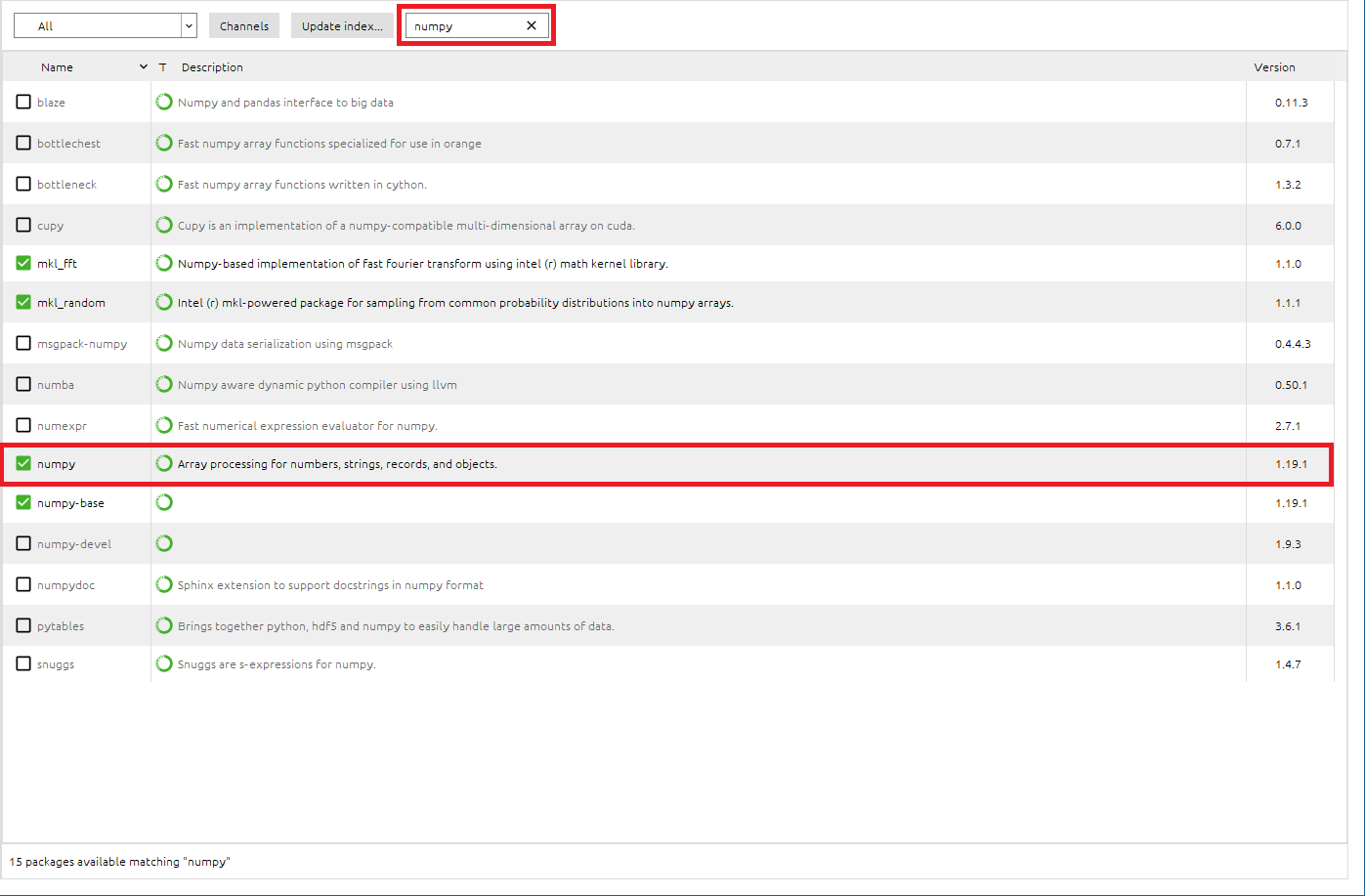
●numpyパッケージをインストールします
- 検索BOXに[
numpy]と入力し、numpyパッケージを検索- numpyパッケージがInstallされていることを確認できました。
kerasはnumpyを使用するため、依存関係からkerasパッケージのインストール時に、numpyも自動的にインストールされていました。ということで、numpyのインストール作業は割愛できました。
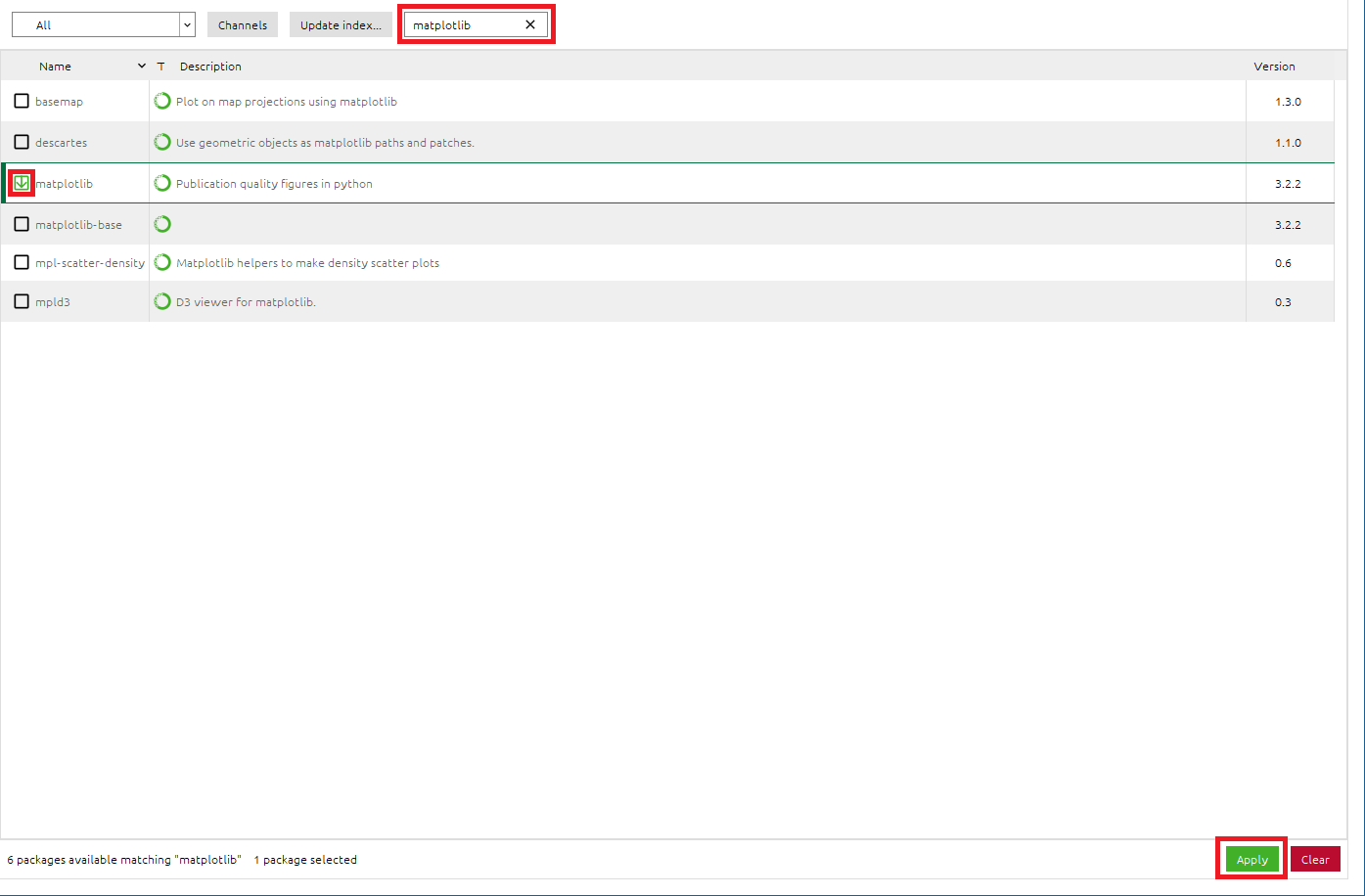
●matplotlibパッケージをインストールします
- 検索BOXに[
matplotlib]と入力し、matplotlibパッケージを検索- [
matplotlib]のチェックボックスをONに設定- 右下の[
Apply]をクリックして適応させる- Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、matplotlibパッケージをインストール
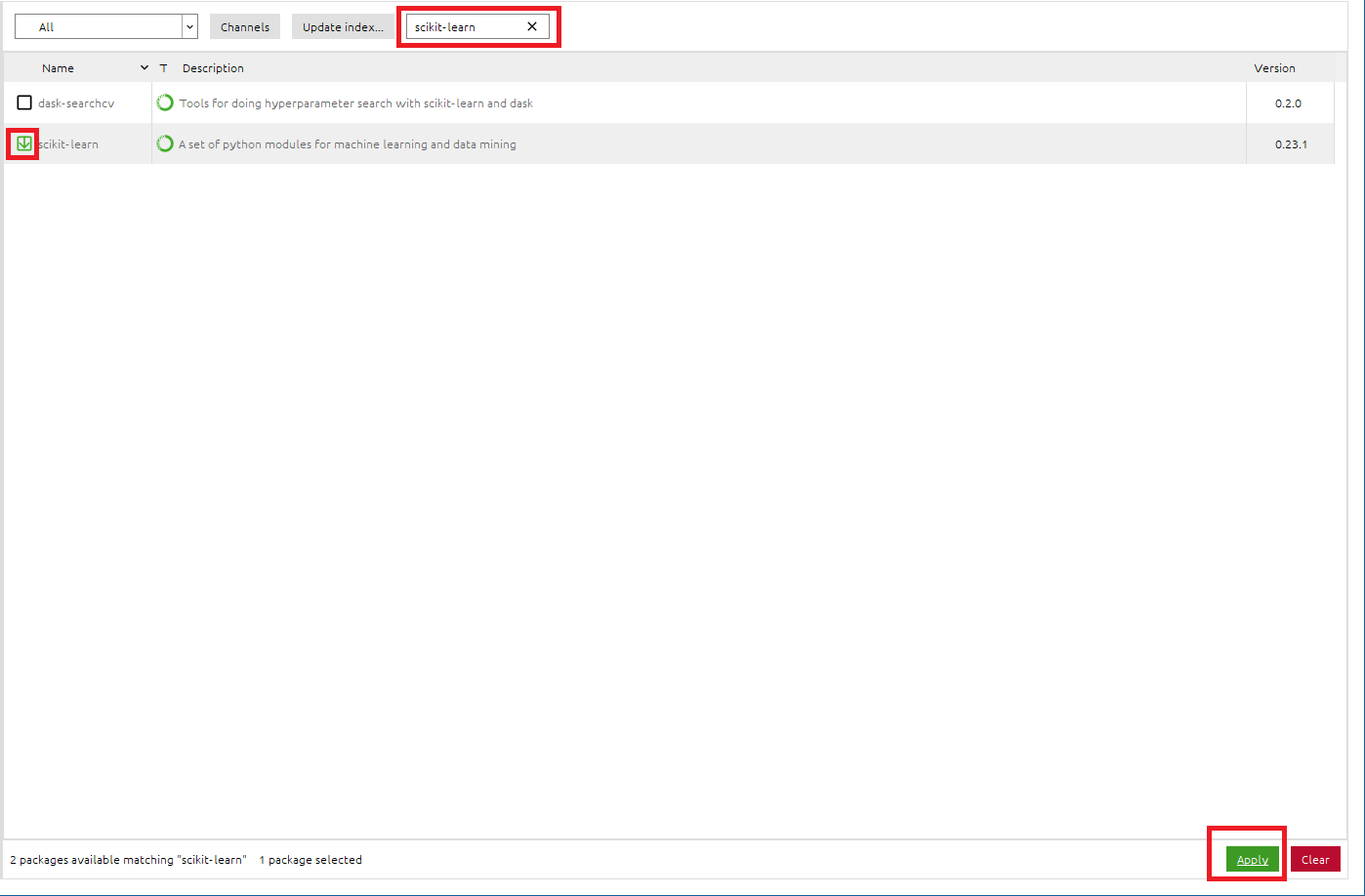
●scikit-learnパッケージをインストールします
- 検索BOXに[
scikit-learn]と入力し、scikit-learnパッケージを検索- [
scikit-learn]のチェックボックスをONに設定- 右下の[
Apply]をクリックして適応させる- Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、scikit-learnパッケージをインストール※sklearnライブラリは、scikit-learnパッケージに入っています。
プログラム実行
- エラーが全てなくなっていることを確認します。
- [
Problems]をクリック- Problemsに
!赤丸が出ていないことを確認
- 右上の「
▶」をクリックしてプログラムを実行してください。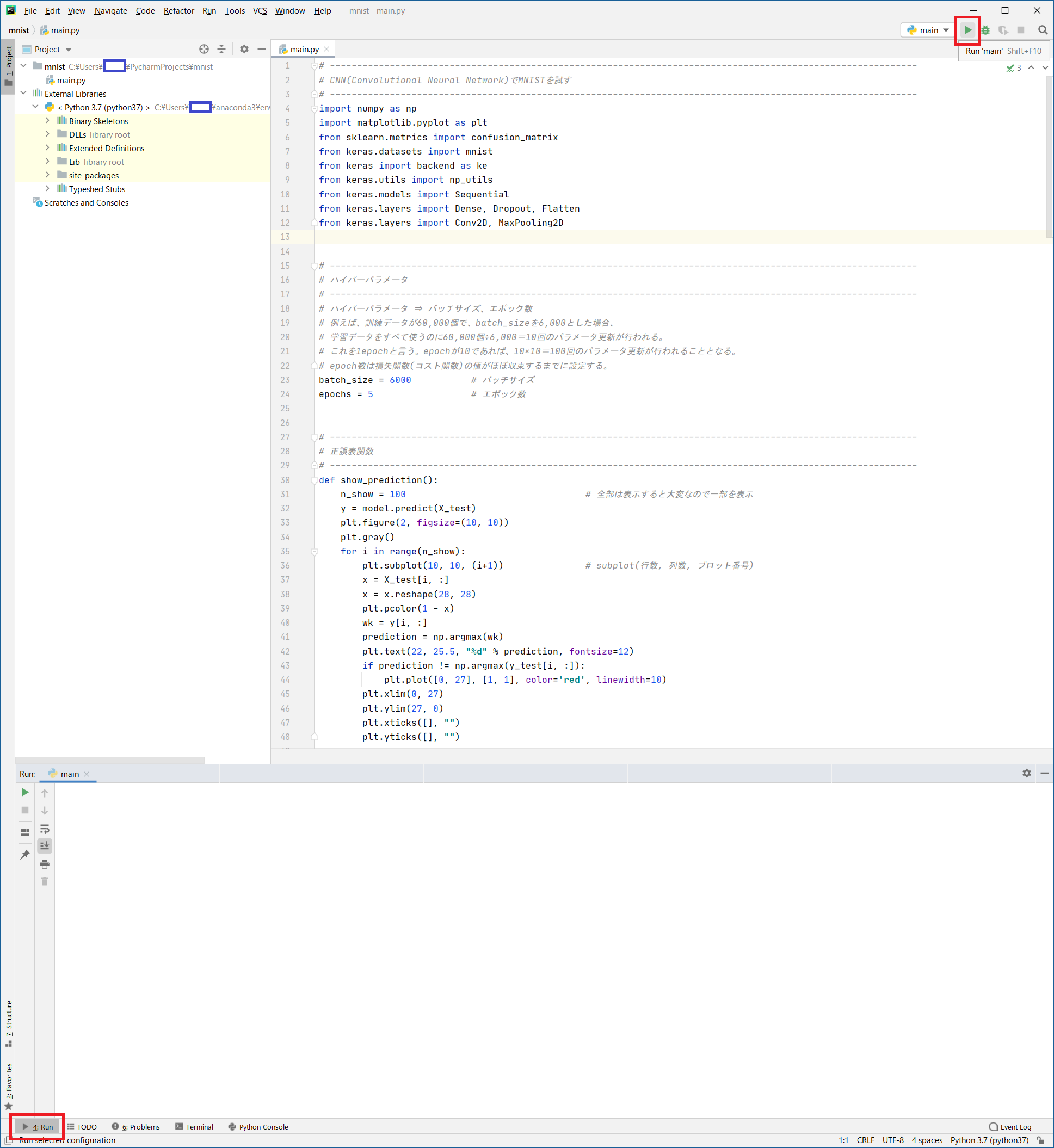
出力結果
- きちんとできると、以下のような結果が得られます。
- 今回は「Test accuracy: 0.9359999895095825」と結果が得られたので、認識率は93.4%でした。
C:\Users\xxxx\anaconda3\envs\python37\python.exe C:/Users/xxxx/PycharmProjects/mnist_sample/qiita.py Using TensorFlow backend. ●ネットワーク定義 2020-08-06 11:36:11.346263: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2 Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 28, 28, 16) 160 _________________________________________________________________ conv2d_2 (Conv2D) (None, 28, 28, 32) 4640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 14, 14, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 14, 14, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 14, 14, 32) 9248 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 7, 7, 32) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 1568) 0 _________________________________________________________________ dense_1 (Dense) (None, 128) 200832 _________________________________________________________________ dense_2 (Dense) (None, 10) 1290 ================================================================= Total params: 216,170 Trainable params: 216,170 Non-trainable params: 0 _________________________________________________________________ ●学習スタート Train on 60000 samples, validate on 10000 samples Epoch 1/5 2020-08-06 11:36:12.480915: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 602112000 exceeds 10% of system memory. 2020-08-06 11:36:14.075159: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 602112000 exceeds 10% of system memory. 6000/60000 [==>...........................] - ETA: 36s - loss: 2.3063 - accuracy: 0.0653 12000/60000 [=====>........................] - ETA: 32s - loss: 2.2858 - accuracy: 0.1563 18000/60000 [========>.....................] - ETA: 29s - loss: 2.2630 - accuracy: 0.2346 24000/60000 [===========>..................] - ETA: 24s - loss: 2.2374 - accuracy: 0.2971 30000/60000 [==============>...............] - ETA: 20s - loss: 2.2083 - accuracy: 0.3415 36000/60000 [=================>............] - ETA: 16s - loss: 2.1742 - accuracy: 0.3779 42000/60000 [====================>.........] - ETA: 12s - loss: 2.1342 - accuracy: 0.4095 48000/60000 [=======================>......] - ETA: 8s - loss: 2.0883 - accuracy: 0.4363 54000/60000 [==========================>...] - ETA: 4s - loss: 2.0373 - accuracy: 0.4610 60000/60000 [==============================] - 44s 733us/step - loss: 1.9787 - accuracy: 0.4864 - val_loss: 1.3384 - val_accuracy: 0.7674 Epoch 2/5 6000/60000 [==>...........................] - ETA: 39s - loss: 1.3002 - accuracy: 0.7305 12000/60000 [=====>........................] - ETA: 37s - loss: 1.2238 - accuracy: 0.7381 18000/60000 [========>.....................] - ETA: 33s - loss: 1.1505 - accuracy: 0.7432 24000/60000 [===========>..................] - ETA: 27s - loss: 1.0788 - accuracy: 0.7513 30000/60000 [==============>...............] - ETA: 23s - loss: 1.0145 - accuracy: 0.7597 36000/60000 [=================>............] - ETA: 18s - loss: 0.9617 - accuracy: 0.7652 42000/60000 [====================>.........] - ETA: 14s - loss: 0.9165 - accuracy: 0.7698 48000/60000 [=======================>......] - ETA: 9s - loss: 0.8742 - accuracy: 0.7754 54000/60000 [==========================>...] - ETA: 4s - loss: 0.8390 - accuracy: 0.7804 60000/60000 [==============================] - 50s 831us/step - loss: 0.8084 - accuracy: 0.7856 - val_loss: 0.4861 - val_accuracy: 0.8541 Epoch 3/5 6000/60000 [==>...........................] - ETA: 41s - loss: 0.4924 - accuracy: 0.8445 12000/60000 [=====>........................] - ETA: 36s - loss: 0.4970 - accuracy: 0.8453 18000/60000 [========>.....................] - ETA: 32s - loss: 0.5020 - accuracy: 0.8486 24000/60000 [===========>..................] - ETA: 28s - loss: 0.5005 - accuracy: 0.8508 30000/60000 [==============>...............] - ETA: 23s - loss: 0.4866 - accuracy: 0.8547 36000/60000 [=================>............] - ETA: 19s - loss: 0.4774 - accuracy: 0.8578 42000/60000 [====================>.........] - ETA: 14s - loss: 0.4730 - accuracy: 0.8603 48000/60000 [=======================>......] - ETA: 9s - loss: 0.4721 - accuracy: 0.8622 54000/60000 [==========================>...] - ETA: 4s - loss: 0.4641 - accuracy: 0.8648 60000/60000 [==============================] - 52s 862us/step - loss: 0.4574 - accuracy: 0.8666 - val_loss: 0.3624 - val_accuracy: 0.9004 Epoch 4/5 6000/60000 [==>...........................] - ETA: 44s - loss: 0.3941 - accuracy: 0.8850 12000/60000 [=====>........................] - ETA: 40s - loss: 0.3863 - accuracy: 0.8882 18000/60000 [========>.....................] - ETA: 34s - loss: 0.3731 - accuracy: 0.8912 24000/60000 [===========>..................] - ETA: 29s - loss: 0.3659 - accuracy: 0.8943 30000/60000 [==============>...............] - ETA: 25s - loss: 0.3545 - accuracy: 0.8971 36000/60000 [=================>............] - ETA: 20s - loss: 0.3461 - accuracy: 0.8987 42000/60000 [====================>.........] - ETA: 15s - loss: 0.3417 - accuracy: 0.9001 48000/60000 [=======================>......] - ETA: 10s - loss: 0.3421 - accuracy: 0.9008 54000/60000 [==========================>...] - ETA: 5s - loss: 0.3367 - accuracy: 0.9023 60000/60000 [==============================] - 52s 874us/step - loss: 0.3332 - accuracy: 0.9033 - val_loss: 0.2740 - val_accuracy: 0.9225 Epoch 5/5 6000/60000 [==>...........................] - ETA: 44s - loss: 0.2830 - accuracy: 0.9168 12000/60000 [=====>........................] - ETA: 39s - loss: 0.2939 - accuracy: 0.9151 18000/60000 [========>.....................] - ETA: 35s - loss: 0.2872 - accuracy: 0.9168 24000/60000 [===========>..................] - ETA: 30s - loss: 0.2782 - accuracy: 0.9193 30000/60000 [==============>...............] - ETA: 25s - loss: 0.2782 - accuracy: 0.9188 36000/60000 [=================>............] - ETA: 20s - loss: 0.2733 - accuracy: 0.9200 42000/60000 [====================>.........] - ETA: 15s - loss: 0.2686 - accuracy: 0.9217 48000/60000 [=======================>......] - ETA: 10s - loss: 0.2684 - accuracy: 0.9222 54000/60000 [==========================>...] - ETA: 4s - loss: 0.2654 - accuracy: 0.9233 60000/60000 [==============================] - 52s 872us/step - loss: 0.2634 - accuracy: 0.9236 - val_loss: 0.2180 - val_accuracy: 0.9360 ●検証結果 32/10000 [..............................] - ETA: 5s 320/10000 [..............................] - ETA: 2s 608/10000 [>.............................] - ETA: 2s 928/10000 [=>............................] - ETA: 1s 1248/10000 [==>...........................] - ETA: 1s 1568/10000 [===>..........................] - ETA: 1s 1920/10000 [====>.........................] - ETA: 1s 2272/10000 [=====>........................] - ETA: 1s 2624/10000 [======>.......................] - ETA: 1s 2976/10000 [=======>......................] - ETA: 1s 3328/10000 [========>.....................] - ETA: 1s 3680/10000 [==========>...................] - ETA: 1s 4032/10000 [===========>..................] - ETA: 1s 4384/10000 [============>.................] - ETA: 1s 4736/10000 [=============>................] - ETA: 0s 5088/10000 [==============>...............] - ETA: 0s 5408/10000 [===============>..............] - ETA: 0s 5728/10000 [================>.............] - ETA: 0s 6048/10000 [=================>............] - ETA: 0s 6368/10000 [==================>...........] - ETA: 0s 6560/10000 [==================>...........] - ETA: 0s 6816/10000 [===================>..........] - ETA: 0s 7104/10000 [====================>.........] - ETA: 0s 7392/10000 [=====================>........] - ETA: 0s 7680/10000 [======================>.......] - ETA: 0s 8000/10000 [=======================>......] - ETA: 0s 8320/10000 [=======================>......] - ETA: 0s 8640/10000 [========================>.....] - ETA: 0s 8960/10000 [=========================>....] - ETA: 0s 9280/10000 [==========================>...] - ETA: 0s 9600/10000 [===========================>..] - ETA: 0s 9920/10000 [============================>.] - ETA: 0s 10000/10000 [==============================] - 2s 196us/step batch_size = 6000 epochs = 5 Test loss: 0.21799209741055967 Test accuracy: 0.9359999895095825 ●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ [[ 966 0 1 1 0 1 6 1 4 0] [ 0 1108 4 2 0 0 3 1 17 0] [ 12 2 954 18 7 0 7 8 21 3] [ 2 2 7 938 0 24 0 11 19 7] [ 1 2 4 1 908 0 10 3 5 48] [ 5 1 3 18 0 834 9 2 14 6] [ 18 4 2 2 6 14 906 2 4 0] [ 1 5 26 7 7 1 0 916 4 60] [ 10 0 5 23 9 18 8 4 878 19] [ 10 5 3 13 8 6 0 7 6 951]] Process finished with exit code 0正解率
- 学習回数を増やす度に、正解率がどんどん上昇しているのが分かると思います。
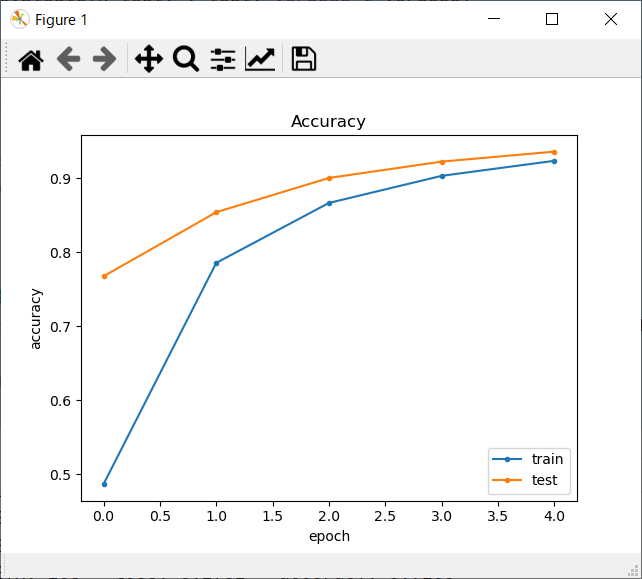
損失関数結果
- 学習回数を増やす度に、損失率がどんどん下降しているのが分かると思います。
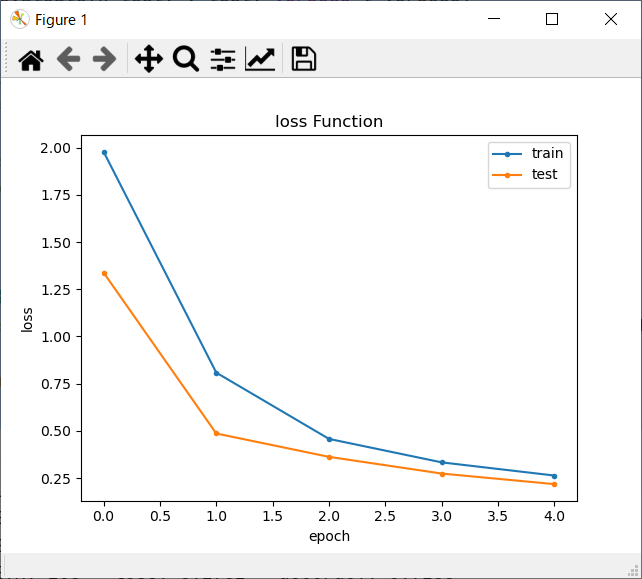
正誤表
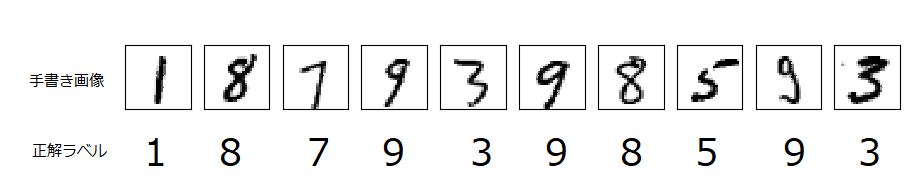
- 検証データは10,000枚ありますが、全部出力させると大変なので、最初の100枚まで結果を出力させています。
- 赤色線で示したものが、AIが認識誤りを起こしたものです。
- 枠内右下にAIが認識した数字を記載しています。

以上
- お疲れ様でした!



- 投稿日:2020-08-06T21:47:47+09:00
3.PythonによるAIプログラミング
はじめに
いきなりこのページに来られた方は、
親ページから参照をお願いいたします。ここの目的
pycharmを使用して、python言語でAIをコーディングします。コードはコピペでOKです。
ソースコード内の意味が分からなくても実行できます。開発環境の立ち上げ
Pythonプログラムを作成するためにpycharm(PyCharm Community Edition)を起動します。前回作ったPJが表示されるので「
mnist」をクリック
pycharm起動画面 (mnistプロジェクトが起動されました)
このサンプルのソースコードは、AIとは全く関係がないものなので全部消去します (サンプルのソースコードは、
CTL+AしてDELキーで簡単に消せます)
PythonによるAIプログラミング
- ソースコードは以下です。
main.py# ------------------------------------------------------------------------------------------------------------ # CNN(Convolutional Neural Network)でMNISTを試す # ------------------------------------------------------------------------------------------------------------ import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import confusion_matrix from keras.datasets import mnist from keras import backend as ke from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D # ------------------------------------------------------------------------------------------------------------ # ハイパーパラメータ # ------------------------------------------------------------------------------------------------------------ # ハイパーパラメータ ⇒ バッチサイズ、エポック数 # 例えば、訓練データが60,000個で、batch_sizeを6,000とした場合、 # 学習データをすべて使うのに60,000個÷6,000=10回のパラメータ更新が行われる。 # これを1epochと言う。epochが10であれば、10×10=100回のパラメータ更新が行われることとなる。 # epoch数は損失関数(コスト関数)の値がほぼ収束するまでに設定する。 batch_size = 6000 # バッチサイズ epochs = 5 # エポック数 # ------------------------------------------------------------------------------------------------------------ # 正誤表関数 # ------------------------------------------------------------------------------------------------------------ def show_prediction(): n_show = 100 # 全部は表示すると大変なので一部を表示 y = model.predict(X_test) plt.figure(2, figsize=(10, 10)) plt.gray() for i in range(n_show): plt.subplot(10, 10, (i+1)) # subplot(行数, 列数, プロット番号) x = X_test[i, :] x = x.reshape(28, 28) plt.pcolor(1 - x) wk = y[i, :] prediction = np.argmax(wk) plt.text(22, 25.5, "%d" % prediction, fontsize=12) if prediction != np.argmax(y_test[i, :]): plt.plot([0, 27], [1, 1], color='red', linewidth=10) plt.xlim(0, 27) plt.ylim(27, 0) plt.xticks([], "") plt.yticks([], "") # ------------------------------------------------------------------------------------------------------------ # keras backendの表示 # ------------------------------------------------------------------------------------------------------------ # print(ke.backend()) # print(ke.floatx()) # ------------------------------------------------------------------------------------------------------------ # MNISTデータの取得 # ------------------------------------------------------------------------------------------------------------ # 初回はダウンロードが発生するため時間がかかる # 60,000枚の28x28ドットで表現される10個の数字の白黒画像と10,000枚のテスト用画像データセット # ダウンロード場所:'~/.keras/datasets/' # ※MNISTのデータダウンロードがNGとなる場合は、PROXYの設定を見直してください # # MNISTデータ # ├ 教師データ (60,000個) # │ ├ 画像データ # │ └ ラベルデータ # │ # └ 検証データ (10,000個) # ├ 画像データ # └ ラベルデータ # ↓教師データ ↓検証データ (X_train, y_train), (X_test, y_test) = mnist.load_data() # ↑画像 ↑ラベル ↑画像 ↑ラベル # ------------------------------------------------------------------------------------------------------------ # 画像データ(教師データ、検証データ)のリシェイプ # ------------------------------------------------------------------------------------------------------------ img_rows, img_cols = 28, 28 if ke.image_data_format() == 'channels_last': X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1) X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) else: X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols) X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) # 配列の整形と、色の範囲を0~255 → 0~1に変換 X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255 X_test /= 255 # ------------------------------------------------------------------------------------------------------------ # ラベルデータ(教師データ、検証データ)のベクトル化 # ------------------------------------------------------------------------------------------------------------ y_train = np_utils.to_categorical(y_train) # 教師ラベルのベクトル化 y_test = np_utils.to_categorical(y_test) # 検証ラベルのベクトル化 # ------------------------------------------------------------------------------------------------------------ # ネットワークの定義 (keras) # ------------------------------------------------------------------------------------------------------------ print("") print("●ネットワーク定義") model = Sequential() # 入力層 28×28×3 model.add(Conv2D(16, kernel_size=(3, 3), activation='relu', input_shape=input_shape, padding='same')) # 01層:畳込み層16枚 model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) # 02層:畳込み層32枚 model.add(MaxPooling2D(pool_size=(2, 2))) # 03層:プーリング層 model.add(Dropout(0.25)) # 04層:ドロップアウト model.add(Conv2D(32, (3, 3), activation='relu', padding='same')) # 05層:畳込み層64枚 model.add(MaxPooling2D(pool_size=(2, 2))) # 06層:プーリング層 model.add(Flatten()) # 08層:次元変換 model.add(Dense(128, activation='relu')) # 09層:全結合出力128 model.add(Dense(10, activation='softmax')) # 10層:全結合出力10 # model表示 model.summary() # コンパイル # 損失関数 :categorical_crossentropy (クロスエントロピー) # 最適化 :Adam model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy']) print("") print("●学習スタート") f_verbose = 1 # 0:表示なし、1:詳細表示、2:表示 hist = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(X_test, y_test), verbose=f_verbose) # ------------------------------------------------------------------------------------------------------------ # 損失値グラフ化 # ------------------------------------------------------------------------------------------------------------ # Accuracy (正解率) plt.plot(range(epochs), hist.history['accuracy'], marker='.') plt.plot(range(epochs), hist.history['val_accuracy'], marker='.') plt.title('Accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='lower right') plt.show() # loss (損失関数) plt.plot(range(epochs), hist.history['loss'], marker='.') plt.plot(range(epochs), hist.history['val_loss'], marker='.') plt.title('loss Function') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['train', 'test'], loc='upper right') plt.show() # ------------------------------------------------------------------------------------------------------------ # テストデータ検証 # ------------------------------------------------------------------------------------------------------------ print("") print("●検証結果") t_verbose = 1 # 0:表示なし、1:詳細表示、2:表示 score = model.evaluate(X_test, y_test, verbose=t_verbose) print("") print("batch_size = ", batch_size) print("epochs = ", epochs) print('Test loss:', score[0]) print('Test accuracy:', score[1]) print("") print("●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ") predict_classes = model.predict_classes(X_test[1:60000, ], batch_size=batch_size) true_classes = np.argmax(y_test[1:60000], 1) print(confusion_matrix(true_classes, predict_classes)) # ------------------------------------------------------------------------------------------------------------ # 正誤表表示 # ------------------------------------------------------------------------------------------------------------ show_prediction() plt.show()
このソースコードを先程のフィールド(赤枠内)に
コピペしてください。
下記の様に赤線枠内に
!赤丸の箇所がある場合は、ライブラリが足りずエラーとなっています。
足りていないライブラリは以下で確認できます。
ライブラリが無い箇所に赤色で下線が付いています。
足りないライブラリを以下にまとめます
ライブラリはパッケージに入っています。
sklearnライブラリだけ、scikit-learnというパッケージに入っているので注意。
No. 足りないライブラリ名 必要なパッケージ名称 1 keras keras 2 numpy numpy 3 matplotlib matplotlib 4 sklearn scikit-learn パッケージのインストール
●ライブラリを追加したいので、それに適合したパッケージを追加します
- anacondaを起動し、[
Envionments] -> [python37]をクリック
●kerasパッケージをインストールします
- [
Installed]を[All]に変更- 検索BOXに[
keras]と入力し、kerasパッケージを検索- [
keras]のチェックボックスをONに設定- 右下の[
Apply]をクリックして適応させる
- Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、kerasパッケージをインストール
●numpyパッケージをインストールします
- 検索BOXに[
numpy]と入力し、numpyパッケージを検索- numpyパッケージがInstallされていることを確認できました。
kerasはnumpyを使用するため、依存関係からkerasパッケージのインストール時に、numpyも自動的にインストールされていました。ということで、numpyのインストール作業は割愛できました。
●matplotlibパッケージをインストールします
- 検索BOXに[
matplotlib]と入力し、matplotlibパッケージを検索- [
matplotlib]のチェックボックスをONに設定- 右下の[
Apply]をクリックして適応させる- Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、matplotlibパッケージをインストール
●scikit-learnパッケージをインストールします
- 検索BOXに[
scikit-learn]と入力し、scikit-learnパッケージを検索- [
scikit-learn]のチェックボックスをONに設定- 右下の[
Apply]をクリックして適応させる- Install PackagesのメッセージBOXが出たら、[
Apply]をクリックして、scikit-learnパッケージをインストール※sklearnライブラリは、scikit-learnパッケージに入っています。
プログラム実行
- エラーが全てなくなっていることを確認します。
- [
Problems]をクリック- Problemsに
!赤丸が出ていないことを確認
- 右上の「
▶」をクリックしてプログラムを実行してください。出力結果
- きちんとできると、以下のような結果が得られます。
- 今回は「Test accuracy: 0.9359999895095825」と結果が得られたので、認識率は93.4%でした。
C:\Users\xxxx\anaconda3\envs\python37\python.exe C:/Users/xxxx/PycharmProjects/mnist_sample/qiita.py Using TensorFlow backend. ●ネットワーク定義 2020-08-06 11:36:11.346263: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2 Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 28, 28, 16) 160 _________________________________________________________________ conv2d_2 (Conv2D) (None, 28, 28, 32) 4640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 14, 14, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 14, 14, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 14, 14, 32) 9248 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 7, 7, 32) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 1568) 0 _________________________________________________________________ dense_1 (Dense) (None, 128) 200832 _________________________________________________________________ dense_2 (Dense) (None, 10) 1290 ================================================================= Total params: 216,170 Trainable params: 216,170 Non-trainable params: 0 _________________________________________________________________ ●学習スタート Train on 60000 samples, validate on 10000 samples Epoch 1/5 2020-08-06 11:36:12.480915: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 602112000 exceeds 10% of system memory. 2020-08-06 11:36:14.075159: W tensorflow/core/framework/cpu_allocator_impl.cc:81] Allocation of 602112000 exceeds 10% of system memory. 6000/60000 [==>...........................] - ETA: 36s - loss: 2.3063 - accuracy: 0.0653 12000/60000 [=====>........................] - ETA: 32s - loss: 2.2858 - accuracy: 0.1563 18000/60000 [========>.....................] - ETA: 29s - loss: 2.2630 - accuracy: 0.2346 24000/60000 [===========>..................] - ETA: 24s - loss: 2.2374 - accuracy: 0.2971 30000/60000 [==============>...............] - ETA: 20s - loss: 2.2083 - accuracy: 0.3415 36000/60000 [=================>............] - ETA: 16s - loss: 2.1742 - accuracy: 0.3779 42000/60000 [====================>.........] - ETA: 12s - loss: 2.1342 - accuracy: 0.4095 48000/60000 [=======================>......] - ETA: 8s - loss: 2.0883 - accuracy: 0.4363 54000/60000 [==========================>...] - ETA: 4s - loss: 2.0373 - accuracy: 0.4610 60000/60000 [==============================] - 44s 733us/step - loss: 1.9787 - accuracy: 0.4864 - val_loss: 1.3384 - val_accuracy: 0.7674 Epoch 2/5 6000/60000 [==>...........................] - ETA: 39s - loss: 1.3002 - accuracy: 0.7305 12000/60000 [=====>........................] - ETA: 37s - loss: 1.2238 - accuracy: 0.7381 18000/60000 [========>.....................] - ETA: 33s - loss: 1.1505 - accuracy: 0.7432 24000/60000 [===========>..................] - ETA: 27s - loss: 1.0788 - accuracy: 0.7513 30000/60000 [==============>...............] - ETA: 23s - loss: 1.0145 - accuracy: 0.7597 36000/60000 [=================>............] - ETA: 18s - loss: 0.9617 - accuracy: 0.7652 42000/60000 [====================>.........] - ETA: 14s - loss: 0.9165 - accuracy: 0.7698 48000/60000 [=======================>......] - ETA: 9s - loss: 0.8742 - accuracy: 0.7754 54000/60000 [==========================>...] - ETA: 4s - loss: 0.8390 - accuracy: 0.7804 60000/60000 [==============================] - 50s 831us/step - loss: 0.8084 - accuracy: 0.7856 - val_loss: 0.4861 - val_accuracy: 0.8541 Epoch 3/5 6000/60000 [==>...........................] - ETA: 41s - loss: 0.4924 - accuracy: 0.8445 12000/60000 [=====>........................] - ETA: 36s - loss: 0.4970 - accuracy: 0.8453 18000/60000 [========>.....................] - ETA: 32s - loss: 0.5020 - accuracy: 0.8486 24000/60000 [===========>..................] - ETA: 28s - loss: 0.5005 - accuracy: 0.8508 30000/60000 [==============>...............] - ETA: 23s - loss: 0.4866 - accuracy: 0.8547 36000/60000 [=================>............] - ETA: 19s - loss: 0.4774 - accuracy: 0.8578 42000/60000 [====================>.........] - ETA: 14s - loss: 0.4730 - accuracy: 0.8603 48000/60000 [=======================>......] - ETA: 9s - loss: 0.4721 - accuracy: 0.8622 54000/60000 [==========================>...] - ETA: 4s - loss: 0.4641 - accuracy: 0.8648 60000/60000 [==============================] - 52s 862us/step - loss: 0.4574 - accuracy: 0.8666 - val_loss: 0.3624 - val_accuracy: 0.9004 Epoch 4/5 6000/60000 [==>...........................] - ETA: 44s - loss: 0.3941 - accuracy: 0.8850 12000/60000 [=====>........................] - ETA: 40s - loss: 0.3863 - accuracy: 0.8882 18000/60000 [========>.....................] - ETA: 34s - loss: 0.3731 - accuracy: 0.8912 24000/60000 [===========>..................] - ETA: 29s - loss: 0.3659 - accuracy: 0.8943 30000/60000 [==============>...............] - ETA: 25s - loss: 0.3545 - accuracy: 0.8971 36000/60000 [=================>............] - ETA: 20s - loss: 0.3461 - accuracy: 0.8987 42000/60000 [====================>.........] - ETA: 15s - loss: 0.3417 - accuracy: 0.9001 48000/60000 [=======================>......] - ETA: 10s - loss: 0.3421 - accuracy: 0.9008 54000/60000 [==========================>...] - ETA: 5s - loss: 0.3367 - accuracy: 0.9023 60000/60000 [==============================] - 52s 874us/step - loss: 0.3332 - accuracy: 0.9033 - val_loss: 0.2740 - val_accuracy: 0.9225 Epoch 5/5 6000/60000 [==>...........................] - ETA: 44s - loss: 0.2830 - accuracy: 0.9168 12000/60000 [=====>........................] - ETA: 39s - loss: 0.2939 - accuracy: 0.9151 18000/60000 [========>.....................] - ETA: 35s - loss: 0.2872 - accuracy: 0.9168 24000/60000 [===========>..................] - ETA: 30s - loss: 0.2782 - accuracy: 0.9193 30000/60000 [==============>...............] - ETA: 25s - loss: 0.2782 - accuracy: 0.9188 36000/60000 [=================>............] - ETA: 20s - loss: 0.2733 - accuracy: 0.9200 42000/60000 [====================>.........] - ETA: 15s - loss: 0.2686 - accuracy: 0.9217 48000/60000 [=======================>......] - ETA: 10s - loss: 0.2684 - accuracy: 0.9222 54000/60000 [==========================>...] - ETA: 4s - loss: 0.2654 - accuracy: 0.9233 60000/60000 [==============================] - 52s 872us/step - loss: 0.2634 - accuracy: 0.9236 - val_loss: 0.2180 - val_accuracy: 0.9360 ●検証結果 32/10000 [..............................] - ETA: 5s 320/10000 [..............................] - ETA: 2s 608/10000 [>.............................] - ETA: 2s 928/10000 [=>............................] - ETA: 1s 1248/10000 [==>...........................] - ETA: 1s 1568/10000 [===>..........................] - ETA: 1s 1920/10000 [====>.........................] - ETA: 1s 2272/10000 [=====>........................] - ETA: 1s 2624/10000 [======>.......................] - ETA: 1s 2976/10000 [=======>......................] - ETA: 1s 3328/10000 [========>.....................] - ETA: 1s 3680/10000 [==========>...................] - ETA: 1s 4032/10000 [===========>..................] - ETA: 1s 4384/10000 [============>.................] - ETA: 1s 4736/10000 [=============>................] - ETA: 0s 5088/10000 [==============>...............] - ETA: 0s 5408/10000 [===============>..............] - ETA: 0s 5728/10000 [================>.............] - ETA: 0s 6048/10000 [=================>............] - ETA: 0s 6368/10000 [==================>...........] - ETA: 0s 6560/10000 [==================>...........] - ETA: 0s 6816/10000 [===================>..........] - ETA: 0s 7104/10000 [====================>.........] - ETA: 0s 7392/10000 [=====================>........] - ETA: 0s 7680/10000 [======================>.......] - ETA: 0s 8000/10000 [=======================>......] - ETA: 0s 8320/10000 [=======================>......] - ETA: 0s 8640/10000 [========================>.....] - ETA: 0s 8960/10000 [=========================>....] - ETA: 0s 9280/10000 [==========================>...] - ETA: 0s 9600/10000 [===========================>..] - ETA: 0s 9920/10000 [============================>.] - ETA: 0s 10000/10000 [==============================] - 2s 196us/step batch_size = 6000 epochs = 5 Test loss: 0.21799209741055967 Test accuracy: 0.9359999895095825 ●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ [[ 966 0 1 1 0 1 6 1 4 0] [ 0 1108 4 2 0 0 3 1 17 0] [ 12 2 954 18 7 0 7 8 21 3] [ 2 2 7 938 0 24 0 11 19 7] [ 1 2 4 1 908 0 10 3 5 48] [ 5 1 3 18 0 834 9 2 14 6] [ 18 4 2 2 6 14 906 2 4 0] [ 1 5 26 7 7 1 0 916 4 60] [ 10 0 5 23 9 18 8 4 878 19] [ 10 5 3 13 8 6 0 7 6 951]] Process finished with exit code 0正解率
- 学習回数を増やす度に、正解率がどんどん上昇しているのが分かると思います。
損失関数結果
- 学習回数を増やす度に、損失率がどんどん下降しているのが分かると思います。
正誤表
- 検証データは10,000枚ありますが、全部出力させると大変なので、最初の100枚まで結果を出力させています。
- 赤色線で示したものが、AIが認識誤りを起こしたものです。
- 枠内右下にAIが認識した数字を記載しています。
以上
- お疲れ様でした!
- 投稿日:2020-08-06T21:45:46+09:00
0からはじめる「Python AIプログラミング」 for windows
はじめに
ここでは、windows10を持っていて、AIプログラミングを「手っ取り早く動かしてイメージをつかみたいと思っている方」向けの手順を説明いたします。
初心者向けのもので、目的は開発環境を整えてプログラム (プログラミングはしません。コピペでOKです^^;) を実行し、「ほぉ、AIプログラミングってこんな感じか~」というところがGOALです。
どんなことをやるか
まず
手書きの数字0~9とその正解ラベル(0~9)がセットになった教師データ60,000枚をAIに学習させます。その後、手書きの数字0~9とその正解ラベル(0~9)がセットになった検証データ10,000枚をAIに検証させて、認識率や検証データの手書き数字がAIによって0~9のどの数字と認識したのかを試してみます。
(1) 教師データ(60,000枚)
手書き画像を正解ラベルに沿って、0~9の数字として覚えさせる。
(2) 検証データ(10,000枚)
手書き画像をAIにより0~9の数字に分類(クラス分類)させ、正解データと比較し当たったかどうかを判定。
※上記データは プログラム実行時に MNISTデータベース から自動的にダウンロードされますので、
画像ファイルの収集や正解ラベリング(画像データと正解ラベルの結びつけ)等の前準備は一切不要となっています。開発環境インストール
まず開発に必要なものをインストールします。
開発環境に必要なソフトウェアは以下の2つです。
No. 開発環境 ソフトウェア 今回使用したバージョン 説明 1 python言語 Anaconda Anaconda Navigator 1.9.12 Anacondaは、Python言語の無料のオープンソースディストリビューションであり、パッケージ管理とデプロイメントの簡略化を狙ったものです。大変便利です。 2 IDE(統合開発環境) pycharm Community 2020.2版 コード解析やグラフィカルなデバッガが可能です。Community Editionは無料です。 ちなみにAIを動かすのに Keras というオープンソースのニューラルネットワークライブラリを使用します。
作業フロー
下記の表のNo.1 → 4 の順で実行していってください。
No. 作業概要 作業内容 説明 1 Anaconda設定 ①Download
②Install
③アプリ設定Kerasというオープンソースのニューラルネットワークライブラリを動かすため、Python言語を使えるようにします。 2 Pycharm設定 ①Download
②Install
③アプリ設定python言語での開発を簡単にし易くするため、統合開発環境を使えるようにします。 3 PythonによるAIプログラミング ①AIプログラミング
②ライブラリ追加
③AIプログラミング実行安心してください。プログラミングはしません。プログラムはコピペでOKです。 4 目的達成 思いにふける お疲れ様でした! 以上
- お疲れ様でした!

- 投稿日:2020-08-06T21:43:33+09:00
・<Slack>Slackに通知する関数を書いて、いつでも引用できるようにする(Python)
- 投稿日:2020-08-06T20:43:21+09:00
続【Python】英文PDF(に限らないけど)をDeepLやGoogle翻訳で自動で翻訳させてテキストファイル、いやHTMLにしてしまおう。
前回の内容と今回やったこと
前回の記事【Python】英文PDF(に限らないけど)をDeepLやGoogle翻訳で自動で翻訳させてテキストファイルにしてしまおう。
では翻訳結果をテキストファイルに出力しましたが、翻訳前の文章と横に並べて見比べられたら便利だと思いませんか。
まだ改善の余地はありますがHTMLで実現しました。
例に使った論文ごちゃごちゃと盛り付けたのでコードが汚いですがご容赦ください(もとからか)。
8/7追記
HTML表示時における
・ 対応する英文or和文への、ハイライト機能・ジャンプ機能
・ ダークモード
を追加しました。また、
非ダークモード時の色合いも優しくしました。逆翻訳(日本語 → 英語)に対応しました。
コード
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys import time import pyperclip as ppc DRIVER_PATH = 'chromedriver.exe' options = Options() options.add_argument('--disable-gpu') options.add_argument('--disable-extensions') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') def parse_merge(text, n=4900, m=1, inv=False): sentences = [] sentence = "" for j, i in enumerate(" ".join( text.split("\r\n")).split(". " if inv == False else "。")): if i in ("", " ", "."): continue if (len(sentence) + len(i) > n) or (j % m == 0): sentences.append(sentence) sentence = "" sentence += i + ("." if inv == False else "。") sentences.append(sentence) return sentences def TranslateFromClipboard(tool, write, filename, isPrint, html, title, sentence_cnt, inv): driver = webdriver.Chrome(executable_path=DRIVER_PATH, chrome_options=options) url = 'https://www.deepl.com/ja/translator' if tool == "DeepL" else f'https://translate.google.co.jp/?hl=ja&tab=TT&authuser=0#view=home&op=translate&sl=auto&tl={"en" if inv else "ja"}' driver.get(url) if tool == "DeepL": textarea = driver.find_element_by_css_selector( '.lmt__textarea.lmt__source_textarea.lmt__textarea_base_style') elif tool == "GT": textarea = driver.find_element_by_id('source') en = parse_merge(ppc.paste(), m=sentence_cnt, inv=inv) ja = [] for sentence in en: if sentence == "": ja.append("") continue cbText = ppc.paste() ppc.copy(sentence) textarea.send_keys(Keys.CONTROL, "v") ppc.copy(cbText) transtext = "" while transtext == "": time.sleep(1) if tool == "DeepL": transtext = driver.find_element_by_css_selector( '.lmt__textarea.lmt__target_textarea.lmt__textarea_base_style' ).get_property("value") elif tool == "GT": try: time.sleep(1) transtext = driver.find_element_by_css_selector( '.tlid-translation.translation').text except: pass if isPrint: print(transtext) ja.append(transtext) textarea.send_keys(Keys.CONTROL, "a") textarea.send_keys(Keys.BACKSPACE) driver.quit() if write: with open(filename + ".txt", "w", encoding='UTF-8') as f: f.write("\n".join(ja)) if html: eng = "" jpn = "" for i, ej in enumerate(zip(en, ja)): eng += f'<br><a id="e{i}" href="#j{i}" onmouseover="over(' + f"'j{i}'" + ')" onmouseout="out(' + f"'j{i}'" + f')">{ej[0]}</a><br>' jpn += f'<br><a id="j{i}" href="#e{i}" onmouseover="over(' + f"'e{i}'" + ')" onmouseout="out(' + f"'e{i}'" + f')">{ej[1]}</a><br>' with open(filename + ".html", "w", encoding='UTF-8') as f: f.write( f'<h1 align="center">{title}</h1>\n<input id="btn-mode" type="checkbox">\n<hr>\n<body>\n<div class="parent">\n<div id="en">\n{eng}\n</div>\n<div id="ja">\n{jpn}\n</div>\n</div>' + '<style>\n:root {\n--main-text: #452b15;\n--main-bg: #f8f1e2;\n--highlight-text: #db8e3c;\n}\n:root[theme="dark"] {\n--main-text: #b0b0b0;\n--main-bg: #121212;\n--highlight-text: #fd8787;\n}\nh1 {\ncolor: var(--main-text);\n}\ninput {\nposition: absolute;\ntop: 1%;\nright: 1%;\n}\n#en {\nwidth: 45%;\nheight: 90%;\npadding: 0 2%;\nfloat: left;\nborder-right:1px solid #ccc;\nmargin: 1%;\noverflow: auto;\n}\n#ja {\nwidth: 45%;\nheight: 90%;\nfloat: right;\nmargin: 1%;\noverflow: auto;\n}\na,\na:hover,\na:visited,\na:link,\na:active {\ncolor: var(--main-text);\ntext-decoration: none;\n}\nbody {\nbackground-color: var(--main-bg);\n}\n</style>\n<script>\nvar a = document.getElementsByTagName("a");\nfunction over(e) {\ndocument.getElementById(e).style.color = getComputedStyle(document.getElementById(e)).getPropertyValue("--highlight-text");\n}\nfunction out(e) {\ndocument.getElementById(e).style.color = getComputedStyle(document.getElementById(e)).getPropertyValue("--main-text");\n}\nconst btn = document.querySelector("#btn-mode");\nbtn.addEventListener("change", () => {\nif (btn.checked == true) {\ndocument.documentElement.setAttribute("theme", "dark");\n} else {\ndocument.documentElement.setAttribute("theme", "light");\n}\nfor (var i = 0; i < a.length; i++) {\na[i].style.color = getComputedStyle(a[i]).getPropertyValue("--main-text");\n}\n});\n</script>\n</body>' ) if __name__ == "__main__": args = [ "DeepL", False, "translated_text.txt", True, False, "EN ↔ JP", 1, False ] if input("1. 英語 → 日本語 2. 日本語 → 英語 ") == "2": args[7] = True if input("1. DeepL 2.GoogleTranslate ") == "2": args[0] = "GT" if input("翻訳結果を書き出しますか? y/n ") == "y": case = input("1. txt 2. HTML 3. both ") if case == "1": args[1] = True format_ = ".txt" elif case == "2": args[4] = True format_ = ".html" elif case == "3": args[1], args[4] = True, True format_ = ".txt/.html" filename = input( f"出力ファイルにつける名前を入力してください(デフォルトは'translated_text{format_}') ") if filename: args[2] = filename if case == "2" or case == "3": title = input("(論文の)タイトルを入力してください ") if title: args[5] = title try: args[6] = int( input("何文ずつ翻訳しますか?(デフォルトは1文ずつ。小さいほど出力がきれいで、大きいほど早くなります。) ")) except: pass if input("翻訳経過をここに表示しますか? y/n ") == "n": args[3] = False input("準備ができたらEnterを押してください") TranslateFromClipboard(*args)読みやすさはかなり上がりましたが、1文ずつ翻訳しているので全文翻訳するのにかなり時間がかかります(実行時の選択でまとめて翻訳することも出来ます)。
まとめ
HTMLやCSSはズブの素人なのでこうしたらもっと良くなる!という点があればご教示いただけると嬉しいです。



- 投稿日:2020-08-06T20:29:04+09:00
Nginx+uWSGI+Flask+Ubuntuで作る本格サーバー(実装編)
インストール編からの続き
各アプリケーションのざっくりとした説明とインストールは
前回の記事を参照Flask
以下の構造になるようなファイルを作っていく
flask_web_application/ ├── application/ │ ├── __init__.py │ └── views.py └── server.pyまずappというFlaskの本体を作成
__init__.pyfrom flask import Flask app = Flask(__name__) import application.viewsルートディレクトリにアクセスしたら
"Hello, World"とだけ返すviews.pyfrom application import app @app.route('/') def show_entries(): return "Hello World"uWSGIが実行するファイル
ようするにここから処理がスタートserver.pyfrom application import app if __name__ == "__main__": app.run(host='0.0.0.0')ちなみに今回は
/home/ubuntu/application/に作ったが
他のディレクトリの場合は
uWSGIを実行するユーザーにchownで権限を渡し
chmodで権限を「775」あたりにしておくこと
後々説明するが今回はuWSGIをグループ名:www-data
ユーザー名:www-dataで実行している
uWSGI
まずuwsgi.iniを作成
uwsgi.iniはuwsgiを起動するときに読み込む設定ファイル起動時に読み込むだけのものなのでどこに置いてもいいが
わかりやすく今回作っているFlaskアプリケーション
の直下にでも置いとくuwsgi.ini[uwsgi] base = /home/ubuntu/application/flask_web_application module = server:app virtualenv = /home/ubuntu/py36_flask_server pythonpath = %(base) callable = app uid = www-data gid = www-data master = true processes = 1 threads = 1 socket = /tmp/uwsgi.sock chmod-socket = 666 vacuum = true die-on-term = true thunder-lock = true主要な部分だけ
変数 説明 base アプリケーションのディレクトリ module app = Flask(__name__)で作ったappのこと virtualenv Pythonの仮想環境のディレクトリ pythonpath baseと同じ callable 呼び出すモジュール(app) uid ユーザー名で実行 gid グループ名で実行 processes 環境とアプリケーションによるがコア数がおすすめ threads Flaskが使うスレッドの数、Flaskをマルチスレッドで実行すること自体おすすめしない(GIL問題) socket UNIXドメインソケット uid、gidで指定するユーザー名・グループ名はあらかじめ作っておく
www-dataなら既に存在しているはず
指定しないとrootで実行することになるのでセキュリティ上あまりよろしくないそのた諸々、参考になる記事
https://uwsgi-docs.readthedocs.io/en/latest/ThingsToKnow.html
https://qiita.com/yasunori/items/64606e63b36b396cf695
https://qiita.com/wapa5pow/items/f4326aed6c0b63617ebd
https://qiita.com/11ohina017/items/da2ae5b039257752e558uWSGIをサービスに追加
$ sudo vi /etc/systemd/system/uwsgi.service #下記を追加 [Unit] Description=uWSGI After=syslog.target [Service] ExecStart=/home/ubuntu/py36_flask_server/bin/uwsgi --ini /home/ubuntu/application/flask_web_application/uwsgi.ini # Requires systemd version 211 or newer RuntimeDirectory=uwsgi Restart=always KillSignal=SIGQUIT Type=notify StandardError=syslog NotifyAccess=all [Install] WantedBy=multi-user.targetExecStartに仮想環境にインストールしたuWSGIを
--iniに先ほど作った設定ファイルを指定しますサービスにuWSGIを追加
$ sudo systemctl enable uwsgiNginx
デフォルトのNginxウェルカムページを消す
conf.d/default.confがあるなら削除
$ sudo rm /etc/nginx/conf.d/default.conf/nginx/sites-enabled/defaultがあるなら削除
$ sudo rm /etc/nginx/sites-enabled/defaultこれでデフォルトサイトは消える
sites-availableとsites-enabledがない場合作成しておく
$ sudo mkdir /etc/nginx/sites-available $ sudo mkdir /etc/nginx/sites-enabledsites-available と sites-enabledは結局なんなのか
基本的には一つのサーバーで複数のドメインを使うためのもので
管理がしやすくなるただ今回は別に複数のドメインを使うわけではないのだが
Ubuntu+Nginx+uWSGIという構造上
conf.dを使うより安定する使い方は
・sites-availableにドメイン別の設定ファイルを作成
・sites-enabledにsites-availableのシンボリックリンクを張るという至って簡単なもの
シンボリックリンクはいわゆるショートカット/etc/nginx/nginx.confのhttpブロック部分の
/etc/nginx/conf.d/*.confを書き換える$ sudo vi /etc/nginx/nginx.conf http{ … include /etc/nginx/conf.d/*.conf; }↓
http{ … include /etc/nginx/sites-enabled/*; }/etc/nginx/sites-available/myapplication.confを追加
$ sudo vi /etc/nginx/sites-available/myapplication.conf # 下記を追加 server { listen 80; root /var/www/html; location / { try_files $uri @yourapplication; } location @yourapplication { include uwsgi_params; uwsgi_pass unix:///tmp/uwsgi.sock; } }ざっくり説明するとtry_filesでURLそのままを
rootから検索、なかったらuWSGIに(URLそのままで)内部リダイレクトするという構造
rootは特になにも入っていない
全部uWSGIに丸投げしてもいいのだけど公式は上記みたいになっているuwsgi_paramsはuWSGIの設定ファイル
unix:///tmp/uwsgi.sockはUNIXドメインソケット
といわれるものでようするにこれでuWSGIとの通信を行う他にTCPで接続したりもできるがポートを占領してしまうので
ドメインソケットを使った方がよいショートカットを作ればnginxの設定は終わり
$ sudo ln -s /etc/nginx/sites-available/myapplication.conf /etc/nginx/sites-enabled/myapplicationアクセス
ここらへんで一旦システムごと再起動することを推薦
できない場合はNginxだけは再起動する$ sudo systemctl restart nginxuwsgiを起動していないなら起動
& sudo systemctl start uwsgiuwsgiのエラーチェック
$ sudo systemctl status uwsginginxのエラーチェック
$ sudo systemctl status nginx一通り読んでエラーがなさそうならアクセスしてみる
$ curl http://127.0.0.1 Hello, Worldまとめ
基本的に静的ファイルはNginxに処理させた方が早い
間違っているこうした方がよいという箇所があったら教えてください
- 投稿日:2020-08-06T20:27:25+09:00
class名をインスタンスを作らずに取得する
概要
クラスオブジェクト自身からclass名を取得する方法が書いてある日本語の記事がなかったので、備忘録として書いておきます。
class名を取得する方法
インスタンスから取得する
ググってもほとんどがこの方法を使って取得していました。
class A: pass a = A() print(a.__class__.__name__) >>> Aクラスオブジェクト自身から取得する
Python3.3から実装された
__qualname__で取得できます。
追記:B.__name__でも取得できるようです。@shiracamusさん、ありがとうございます。
また、__qualname__はクラスオブジェクト内ではB.__qualname__ではなく単純に__qualname__とだけでも書けます。class B: pass print(B.__qualname__) >>> B # 追記 class C: qualname = __qualname__ print(C.__name__) print(C.qualname) >>> C >>> Cおわりに
__qualname__なら、クラスオブジェクト内やクラスオブジェクトを引数に取る関数の中でも取得できますね。
追記:先ほど追記した通り、__name__を使っても取得できるようです。参考文献
- 投稿日:2020-08-06T20:27:08+09:00
[cx_Oracle入門](第16回) LOB型の取り扱い
連載目次
検証環境
- Oracle Cloud利用
- Oracle Linux 7.7 (VM.Standard2.1)
- Python 3.6
- cx_Oracle 8.0
- Oracle Database 19.6 (DBCS HP, 2oCPU)
- Oracle Instant Client 18.5
事前準備
以下のテーブルを作成しておいてください。
SQL> create table sample16(col1 number, col2 blob);LOB型への参照・更新の基本
データが1GBまでであれば、CLOB型であればstr、BLOBであればbyteとして、VARCHAR2型やRAW型のように特段の考慮なく扱えます。1GBを超える場合は一定量ずつ処理するストリーム処理の形式で処理する必要があります。ストリームを介さない方がパフォーマンスには優れますが、1件は1GBに満たないデータであっても、fetchmany()とかするとあっという間にメモリを食いつぶしますので、メモリリソースとフェッチするデータ量(平均サイズ×レコード件数)との兼ね合い次第では、小規模サイズのLOBであってもストリーム処理を検討して下さい。
小規模なデータの更新
全ケースにて、処理対象のデータ(ファイル)は別途ご用意ください。サンプルソースを自環境で動かしてみる場合は、ソース内のファイル名もしくは用意したファイルの名称のどちらかを修正してください。以下、BLOB型へのINSERTのサンプルです。
sample16a.pyimport cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL = """ insert into sample16 values(1, :blobdata) """ with open('screenshot1.png', 'rb') as f: image = f.read() with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: with connection.cursor() as cursor: cursor.execute(SQL, blobdata=image) cursor.execute("commit")小規模なデータの参照
参照は更新ほど簡単ではなく、第9回に解説したoutputtypehandlerを定義する必要があります。以下のサンプルは、先に登録したレコードを参照して、異なる名称のファイルに保存しています。
sample16b.pyimport cx_Oracle def OutputTypeHandler(cursor, name, defaultType, size, precision, scale): if defaultType == cx_Oracle.DB_TYPE_BLOB: return cursor.var(cx_Oracle.DB_TYPE_LONG_RAW, arraysize=cursor.arraysize) USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL = """ select col2 from sample16 where col1 = 1 """ with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: connection.outputtypehandler = OutputTypeHandler with connection.cursor() as cursor: cursor.execute(SQL) lobdata, = cursor.fetchone() with open('screenshot2.png', 'wb') as f: f.write(lobdata)なお、当然ながら、両ファイルの内容は同じです。
$ cmp screenshot1.png screenshot2.png $大規模なデータの更新
BLOBをベースに解説します。おおよそ以下の手順になります。
- LOB列にSQL関数のEMPTY_BLOB()で空のロケータを挿入
- INSERT文のRETURNING句でLOBロケータをバインド
- LOBロケータに対してストリームでデータを流し込む
sample16c.pyimport cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL = """ insert into sample16 values(2, empty_blob()) returning col2 into :blobdata """ # [1.] with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: with connection.cursor() as cursor: blobdata = cursor.var(cx_Oracle.DB_TYPE_BLOB) # [2.] cursor.execute(SQL, [blobdata]) blob, = blobdata.getvalue() offset = 1 bufsize = 65536 # [3.] with open('screenshot1.png', 'rb') as f: # [4.] while True: data = f.read(bufsize) if data: blob.write(data, offset) if len(data) < bufsize: break offset += bufsize connection.commit()以下、コメントの番号に対応しています。
- BLOB列にはSQL関数のEMPTY_BLOB()を使用して空のLOBロケータを挿入しています。そして、RETURNING句を使用して、挿入した空のLOBロケータをバインド変数で受けます。
- バインド変数に対応するPython側の変数を用意します。Cursor.var()を使用してBLOBであることを指定しています。
- バッファのサイズを指定しています。
- オープンしたファイルを3.のサイズ分ずつLOBロケータを介してLOB列に書き込んでいます。
UPDATE文でも、SQL文が変わるだけで流れは同じです。LOB列をEMPTY_BLOB()で更新してください。
大規模なデータの参照
BLOBをベースに解説します。おおよそ以下の手順になります。更新よりは簡単です。
- SELECTリストのLOB列(LOBロケータ)をバインド
- LOBロケータに対してストリームでデータを読み込む
sample16d.pyimport cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL = """ select col2 from sample16 where col1 = 2 """ # [1.] with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: with connection.cursor() as cursor: cursor.execute(SQL) blob, = cursor.fetchone() offset = 1 bufsize = 65536 # [2.] with open('screenshot3.png', 'wb') as f: # [3.] while True: data = blob.read(offset, bufsize) if data: f.write(data) if len(data) < bufsize: break offset += bufsize以下、コメントの番号に対応しています。
- BLOB列をSELECTします。
- バッファのサイズを指定しています。
- オープンしたファイルに、LOBのデータを2.のサイズ分ずつ書き込んでいます。
- 投稿日:2020-08-06T20:26:42+09:00
Nginx+uWSGI+Flask+Ubuntuで作る本格サーバー(インストール編)
複雑になりがちなFlaskを用いたサーバーをインストールから
実装は実装編で
登場人物
Nginx
Webサーバー
基本的にクライアントからの接続はこいつを
通してから処理される
いわば元請けuWSGI
アプリケーションサーバー
今回はWebサーバー(Nginx)とWebアプリケーション(Flask)
とを繋ぐ橋渡し役
いわば中間業者そもそもWSGIとは?
WebServerGatewayInterfaceの略(ウィスキーと読むらしい)
Webアプリケーション(Flask)とWebサーバー(Nginx)間の取り決めのこと
ようするにプロトコル(仕様)これがないと
例えばあるWebサーバー(A)を使った場合
その仕様に乗っ取ったWebアプリケーション(A')
を使わなければいけないことになる(現に昔はそうしてたらしい)
逆もまたしかりその仕様を標準化した形がWSGIということ
当たり前だがこれから使うFlaskもWSGIの仕様に乗っ取ってるFlask
ウェブアプリケーションフレームワーク
実際の処理はこいつが行う
いわば下請けPythonの主要なフレームワークとしてDjangoがあるが
Djangoと比べると必要最低限の機能しか搭載してないので
超軽量かつ簡単に実装できてしまうNetflixやRedditなどが使っている
Virtualenv
Pythonの仮想環境
システムがパッケージで混雑になることを防止
なくても実装はできるがあった方がよい事前準備
リポジトリをアップデート
$ sudo apt updateパッケージの更新
$ sudo apt upgradegcc,gdbなどの開発ツールをインストールしておく(uwsgiのビルドに必要)
$ sudo apt install build-essentialopensslをインストール
$ sudo apt install opensslpip3をインストール
$ sudo apt install python3-pipファイアウォール
ファイアウォールの設定
ubuntu側でもファイアウォールを設定しておく
必要ないと思ったら飛ばしてOKufwをインストール
$ sudo apt install ufwすべてのポートを閉じる
$ sudo ufw default deny必要なポートは開けておく
自分の場合はSSH(22), http(80)$ sudo ufw allow 22 $ sudo ufw allow 80ファイアウォールを有効化
& sudo ufw enableステータスを確認
$ sudo ufw statusちなみにSSHで接続している場合
この順番を守らないと接続できなくなる
可能性があるので注意Nginx
最新版のnginxを入れる方法は
https://nginx.org/en/linux_packages.html
https://xn--o9j8h1c9hb5756dt0ua226amc1a.com/?p=3100
から別に最新版を入れる必要はないならインストールまで
飛ばしてOKPGPキーをダウンロード
$ wget https://nginx.org/keys/nginx_signing.keyキーをインポート
$ sudo apt-key add nginx_signing.keyリポジトリを登録
$ sudo vi /etc/apt/sources.list # 末尾に追加 bionicの部分はubuntuの開発コード deb http://nginx.org/packages/ubuntu/ bionic nginx deb-src http://nginx.org/packages/ubuntu/ bionic nginx~/ubuntu/bionic nginxのbionicの部分は
Ubuntuのバージョンによって書き換える
バージョン 開発コード 16.04 xenial 18.04 bionic 19.10 eoan 20.04 focal ubuntuのversion確認方法は
$ cat /etc/lsb-release DISTRIB_RELEASE=18.04 DISTRIB_CODENAME=bionicリポジトリ情報を更新
sudo apt updateバージョンを確認
$ apt show nginx Package: nginx Version: 1.18.0-1~bionic記事を書いてる時点で1.18.0が安定版らしい
http://nginx.org/en/download.html
で最新版かどうか確認できる---ここまでが最新版を入れる方法---
インストール
$ sudo apt install nginxバージョン確認
$ nginx -v nginx version: nginx/1.18.0あらかじめサービスに登録しておく
$ sudo systemctl enable nginx $ sudo systemctl start nginxアクセスできれば成功
$ curl http://localhost <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> ...80番ポートが開いているなら
許可されてるIPから$ curl http://<パブリックIP>でも確認しておく
Virtualenv
pip3でインストール
$ sudo pip3 install virtualenvバージョン確認
$ virtualenv --version環境を作成
$ virtualenv py36_flask_server --python=python3.6ちなみに指定したバージョンのPythonが入っていない場合
作成に失敗するので事前にインストールしておく下記で環境に入れればOK
$ . <環境名>/bin/activate (py36_flask_server) ubuntu@ip-10-0-0-14:~$uWSGI
virtualenvで作成した環境からpip3でインストール
$pip3 install uwsgiバージョンを確認
$uwsgi --versionちなみにVirtualenvではなくAnacondaを使うという手もあった
ただuWSGIをインストールする段階でエラーが多発するので注意Anacondaを使いたい場合
時間はかかるが解決はするので下記の記事を参考
https://katsuwosashimi.com/archives/300/python-conda-install-uwsgi-failed/Flask
virtualenvで作成した環境からpipでインストール
$pip3 install flask以上
まとめ
インストールの段階でだいぶ長くなってしまった
次は実装編で
- 投稿日:2020-08-06T20:03:36+09:00
【Python, PyPDF2】見開きのPDFを左右に2分割するスクリプト
今回の内容
PyPDF2を使って、見開きでスキャンした資料などのpdfファイルを左右に2分割するスクリプトのメモです。
ソースコード
from PyPDF2 import PdfFileWriter, PdfFileReader import copy def split_pdf(input_pdf, output_filename): pdf_file = PdfFileReader(open(input_pdf, 'rb')) marged = PdfFileWriter() page_num = pdf_file.getNumPages() for i in range(0, page_num): page_L = pdf_file.getPage(i) page_R = copy.copy(page_L) (w, h) = page_L.mediaBox.upperRight page_L.mediaBox.upperRight = (w/2, h) marged.addPage(page_L) page_R.mediaBox.upperLeft = (w/2, h) marged.addPage(page_R) outputStream = open(output_filename, "wb") marged.write(outputStream) outputStream.close() def sample(): input_pdf = "input.pdf" output_filename = "output.pdf" split_pdf(input_pdf, output_filename) if __name__ == "__main__": sample()使い方
split_pdf()に対して、分割するpdfファイルと、出力する際のファイル名を与えることでpdfファイルを2分割します。
簡単な解説
一つのページを左ページ用と右ページ用に2つ用意します。(page_L, page_R)
ページは左下を始点とするので、右上の座標から横幅と高さを取得します。(w, h)
左ページには右側の、右ページには左側の座標を指定することで、それを基準にそれぞれ切り取ります。
今回は、左ページには右上の座標を (w/2, h)、右ページには左上の座標を (w/2, h)として指定し、左右に2分割しています。
蛇足、右ページについては
page_R.mediaBox.lowerLeft = (w/2, 0)とした方が分かりやすいのかもしれません。使い方の例
自分は以下のように使っています。追加、変更分のみ書きます。
import sys, os def main(): argv = [sys.argv[i] for i in range(1,len(sys.argv))] for input_pdf in argv: basename_without_ext = os.path.splitext(os.path.basename(input_pdf))[0] output_filename = "split_{}.pdf".format(basename_without_ext) print("{}を2分割します。".format(os.path.basename(input_pdf))) split_pdf(input_pdf, output_filename) if __name__ == '__main__': main()引数を取得して、for文で回してsplit_pdfに渡します。出力ファイル名は入力ファイル名の先頭にsplit_を付けたものになります。
参考にさせていただいたもの
- 投稿日:2020-08-06T20:00:48+09:00
Windows の Atom で Pylint
本題
C:\Users\<ユーザー名>\AppData\Roaming\Python\Python38\Scripts\pylint.exe
設定(
ctrl+,)> パッケージ > コミュニティパッケージ > linter-pylint > 設定 > Settings > Executable Pathに上記のパスを設定する。Pythonのバージョンとかは適宜変更してください。おまけ
概要
Atomのセットアップするたびに躓くので設定手順を書き残しておこうと思いました。
インストール
Atomのパッケージ(linter-pylint)は、Atom内でインストールすればいいと思う。
setup_pylint_atom.shpip install pylint apm install linter-pylint環境
- Windows Home 10 2004
- Atom 1.49.0
- linter-pylint 2.1.1
- Python 3.8.5
- python.org からダウンロード
- 全ユーザーにインストール
- PATH追加済み
- pylint 20.2.1
さいごに
解決しましたか?
- 投稿日:2020-08-06T19:52:01+09:00
データの水増し(DataAugmentation)をopenCVで
はじめに
8月に入り激アツな日々皆さんいかがお過ごしですか?
私はいまにも溶けそうな勢いでありますが米津玄師の新曲を聞きながら
冷房の効いた昼夜がわからない部屋でコーディングをしてるわけですが皆さん夏と言ったらなんですか?
- 夏祭り?
- 花火?
- かき氷?いや夏と言ったらDataAugmentationの夏ですよ!!!
ということでopenCVでちゃちゃっとDataAugmentationする方法をメモ代わりに書いときます。誰向けなの
- 大量のデータをディレクトリ構造を維持したままDataAugmentationしたい人!
- とりあえず早くデータを作らないと誰かに怒られる人
- プログラム組むのが面倒な人!
- 以下のコマンドで実行
python3 img_change.py input_directory output_directory- 例
python3 img_change.py /data/imageset /data/imagser_changeプログラム
img_change.py# -*- coding: utf-8 -*- import numpy as np import os import cv2 import sys import pathlib import glob from scipy.signal import qspline1d, qspline1d_eval, qspline2d,cspline2d if len(sys.argv) != 3: print("python3 test.py inputdir outputdir") sys.exit() else: input_path = sys.argv[1] file_list = glob.glob(input_path + "/**/**.png", recursive=True) for item in file_list: split_name = item.split('/') output_name = sys.argv[2] + "/" + split_name[-3] + "/" + split_name[-2] + "/" + split_name[-1] output_dir = sys.argv[2] + "/" + split_name[-3] + "/" + split_name[-2] pathlib.Path(output_dir).mkdir(parents=True,exist_ok=True) img = cv2.imread(item, cv2.IMREAD_UNCHANGED) # read image #画像処理部分 ###画像の輝度を上げる chg_img=img*1.2 #輝度が2倍になる ###画像のリサイズ height = img.shape[0] #img.shape[0]*0.5でもとの半分のサイズ width = img.shape[1] chg_img = cv2.resize(img , (int(width), int(height))) ###CLAHE(ヒストグラムができるだけ均等にバラけるように再配分) clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8)) chg_img = clahe.apply(img) ###ノイズ row,col,ch = img.shape # 白 pts_x = np.random.randint(0, col-1 , 1000) #0から(col-1)までの乱数を千個作る pts_y = np.random.randint(0, row-1 , 1000) img[(pts_y,pts_x)] = (255,255,255) #y,xの順番になることに注意 # 黒 pts_x = np.random.randint(0, col-1 , 1000) pts_y = np.random.randint(0, row-1 , 1000) img[(pts_y,pts_x)] = (0,0,0) ###画像を歪める chg_img = cv2.flip(img, 1) #水平方向に反転 chg_img = cv2.flip(img, 0) #垂直方向に反転 cv2.imwrite(output_name,chg_img ) #write image
- 上のプログラムでは以下のディレクトリ構造でプログラムを作成している
$ tree /data └── val ├── A1 │ │ │ ├── 0.png │ ├── 1.png │ ├── 2.png │ └── .... ├── B1 │ │ │ ├── 0.png │ ├── 1.png │ ├── 2.png │ └── .... │ train ├── A1 │ │ │ ├── 0.png │ ├── 1.png │ ├── 2.png │ └── .... ├── B1 │ │ │ ├── 0.png │ ├── 1.png │ ├── 2.png │ └── .... │ test ├── A1 │ │ │ ├── 0.png │ ├── 1.png │ ├── 2.png │ └── .... ├── B1 │ │ │ ├── 0.png │ ├── 1.png │ ├── 2.png │ └── .... │ └──
- よって指定したディレクトリの2つ下のディレクトリの.pngをすべてリストとして取得する感じ
終わりに
- 色々画像の変える方法はあるのでOpenCV画像加工とかで調べて見てね
- 参考サイトPythonで画像処理② Data Augmentation (画像の水増し)
- 投稿日:2020-08-06T19:39:24+09:00
【Discord.py】Cogをついて理解する
僕がDiscord.pyのCogについて勉強したのでそのメモと、「リファレンス読んでもわからな~い!!」という人がいるのでその人たちのために書きました。
注意:これはCogの解説です。Discord.pyをまだマスターしていない人は、先にそちらをマスターしてから見ください。
Cog(コグ)とは??
そもそもCogって何??
Bot開発においてコマンドやリスナー、いくつかの状態を一つのクラスにまとめてしまいたい場合があるでしょう。コグはそれを実現したものです。
Discord.pyのドキュメントに書いてありますが、これを見ても「意味不状態」になる人がいるのではないでしょうか?(僕もそうでしたw)
Cogを応用することでDiscord.pyのファイルを2ファイル以上に分けることができたり、Botを起動中にもファイルを簡単に再読み込みすることができたりします!!
Cogの書き方
コマンド
Cogを使わないときはコマンドを定義するさいに以下のように書きますが、
@bot.command() async def test(ctx): pass #実行内容Cog内でコマンドを定義するときは以下のように書きます。
@commands.command() async def test(self,ctx): pass #実行内容違いは
@bot.~が@commands.~なったのと、引数にselfが追加されたことぐらいですかね(表面的なところは)イベント
Cogを使わないときはイベントを定義するさいに以下のように書きますが、
@bot.event async def on_ready(): pass #実行内容Cog内でイベントを定義するときは以下のように書きます。
@commands.Cog.listener() async def on_ready(self): pass #実行内容違いは
@bot.eventが@commands.Cog.listener()になったことと、さっきと同じように引数にselfが追加されたことですね。変数
Botの使い方Cogを使わないときはBotの名前を表示するさいに以下のように書きますが、
print(bot.user)Cog内で使うときは以下のようになります。
print(self.bot.user)違いは
selfを書かなければいけなくなったってことぐらいですね。Cogの追加
同じファイルのとき
まずは同じファイルのCogを呼び出してみましょう。
main.pyimport discord from discord.ext import commands bot = commands.Bot(command_prefix="!") class Greetings(commands.Cog): def __init__(self, bot): self.bot = bot self._last_member = None @commands.command() async def test(self,ctx): await ctx.send("test!") bot.add_cog(Greetings(bot))こんな感じになります。
つまり、Cogはbot.add_cog(Class名(bot))で読み込みます!!別ファイルのとき
. ┣━main.py ┗━sub.pyもし、ファイルディレクトリが上のようになっていて
sub.pyにあるClassGreetingsを読み込みたいときは以下のようにすることで読み込めます!!main.pyimport discord from discord.ext import commands bot = commands.Bot(command_prefix="!") import sub bot.add_cog(sub.Greetings(bot))まず、
import subでsub.pyを読み込んで、bot.add_cog(sub.Greetings(bot))でsub.py内にあるGreetingsを読み込んでいます!!上以外のディレクトリの場合
上以外のディレクトリの場合も同じように
importを使うことで読み込みできます。
詳しくは、「Python 3でのファイルのimportのしかたまとめ」を見てください。Extensionって何??
Extensionとは上でも言いましたが、Botを起動中にもファイルを簡単に再読み込みすることができるようになる機能のことです。
Extensionを使うことで、
importを使ってファイル指定をせずに済むようになります。例
. ┣━ main.py ┗━ sub.pyファイルディレクトリが上のようになっている場合、以下のようにすることで
sub.pyのGreetingsを読み込むことができます!!main.pyimport discord from discord.ext import commands bot = commands.Bot(command_prefix="!") bot.load_extension("sub")sub.pyimport discord from discord.ext import commands class Greetings(commands.Cog): def __init__(self, bot): self.bot = bot self._last_member = None @commands.command() async def test(self,ctx): pass def setup(bot): return bot.add_cog(Greetings(bot))ファイルの読み込み
bot.load_extension()
Cogファイルを読み込むコード。bot.load_extension("ファイル名")でできます。. ┣━ main.py ┗━ Cog ┗━ sub.pyファイルディレクトリが上のようになっている場合、
bot.load_extension("Cog.sub")で読み込みできます。Extensionを使う上で最も重要な奴
def setup(bot): return bot.add_cog(Greetings(bot))
書き方はdef setup(bot): return bot.add_cog(Class名(bot))です。
最後に
わからないことや追加してほしい情報があれば言ってください。
前の記事の最後に広告Botのことを宣伝していました。
ということで、今回はTakkun's Serverを紹介させていただきます。このサーバーはTakkun#1643が作った雑談サーバー及び、Takkun#1643が作ったBot達のサポートサーバーです。
今後、広告Botのサポートサーバーもこちらに移す予定です![参加する]
https://discord.gg/VX7ceJw
- 投稿日:2020-08-06T19:08:15+09:00
GoogleColabで日本語BERT事前学習済みモデルをお手軽に試してみる
1.はじめに
前回、BERTの事前学習済みモデルをファインチューニングしてネガ・ポジ判定タスクをやってみたわけですが、ファインチューニング無しでも当然ながら動きます。
今回は、GoogleColabで日本語BERT事前学習済みモデルをお手軽に試してみます。
2.セットアップ
セットアップ手順は、以下の様です。コードは、Google Colabで参照下さい(最後にリンクがあります)。
1) モジュールのインストール
必要なモジュール( pyknp, transformers )をインストールします。2) 形態素分析ライブラリーのインストール
京都大学/黒橋・褚・村脇研究室が提供している「日本語形態素解析システムJUMMAN++」を使用しています。3) 日本語BERT事前学習済みモデルダウンロード
京都大学/黒橋・褚・村脇研究室が提供している「BERT日本語Pretrainedモデル」を使用しています。3.BERTはセンター試験問題を解けるか?
今回のモデルは日本語Wikipediaを使って事前学習しています。ということは古今東西の様々な知識を穴埋め問題を解く形で勉強しているわけで、それなら大学入試センター試験の穴埋め問題くらい解けるかもしれないと無茶振りしてみることにしました。題材は平成30年度の世界史Bの問題9です。
正解は①の「貴族」と「カエサル」なわけですが、さてBERTはどう解答するでしょうか。import torch from transformers import BertTokenizer, BertForMaskedLM, BertConfig import numpy as np import textwrap config = BertConfig.from_json_file('./bert/Japanese_L-12_H-768_A-12_E-30_BPE_transformers/config.json') model = BertForMaskedLM.from_pretrained('./bert/Japanese_L-12_H-768_A-12_E-30_BPE_transformers/pytorch_model.bin', config=config) bert_tokenizer = BertTokenizer('./bert/Japanese_L-12_H-768_A-12_E-30_BPE_transformers/vocab.txt', do_lower_case=False, do_basic_tokenize=False) from pyknp import Juman jumanpp = Juman()まず、必要なライブラリーをインポートし、BERTの設定をします。
BERTへの入力は、単語リストの先頭に[CLS]を入れ、文の区切りに[SEP]を入れ、予測したい単語は[MASK]に置き換える仕様になっているので、それを行う関数を定義します。
# 単語リストへ[CLS],[SEP],[MASK]を追加する関数 def preparation(tokenized_text): # [CLS],[SEP]の挿入 tokenized_text.insert(0, '[CLS]') # 単語リストの先頭に[CLS]を付ける tokenized_text.append('[SEP]') # 単語リストの最後に[SEP]を付ける maru = [] for i, word in enumerate(tokenized_text): if word =='。' and i !=len(tokenized_text)-2: # 「。」の位置検出 maru.append(i) for i, loc in enumerate(maru): tokenized_text.insert(loc+1+i, '[SEP]') # 単語リストの「。」の次に[SEP]を挿入する # 「□」を[MASK]に置き換え mask_index = [] for index, word in enumerate(tokenized_text): if word =='□': # 「□」の位置検出 tokenized_text[index] = '[MASK]' mask_index.append(index) return tokenized_text, mask_index関数は、単語リストにの先頭に[CLS]を挿入し、最後に[SEP]を付加し、途中は「。」の後に[SEP]を挿入します。そうやって単語位置を決めてから、予測箇所「□」を[MASK]に置き換え、単語リストと[MASK]位置を返します。
次に、テキストをIDテンソルに変換します。
# テキストをIDテンソルに変換 text = "ギリシア人ポリュビオスは,著書『歴史』の中で,ローマ共和政の国制(政治体制)を優れたものと評価している。彼によれば,その国制には,コンスルという王制的要素,元老院という□制的要素,民衆という民主制的要素が存在しており,これら三者が互いに協調や牽制をしあって均衡しているというのである。ローマ人はこの政治体制を誇りとしており,それは,彼らが自らの国家を指して呼んだ「ローマの元老院と民衆」という名称からも読み取ることができる。共和政期末の内戦を勝ち抜いたかに見えた□でさえも,この体制を壊そうとしているという疑いをかけれ,暗殺されてしまった。" result = jumanpp.analysis(text) # 分かち書き tokenized_text = [mrph.midasi for mrph in result.mrph_list()] # 単語リストに変換 tokenized_text, mask_index = preparation(tokenized_text) # [CLS],[SEP],[MASK]の追加 tokens = bert_tokenizer.convert_tokens_to_ids(tokenized_text) # IDリストに変換 tokens_tensor = torch.tensor([tokens]) # IDテンソルに変換テキストを単語リストにし、先程の関数を使って[CLS],[SEP],[MASK]を追加したら、IDリストに変換し、Pytorchが読めるIDテンソルに変換します。
こんな感じに変換を行います。それでは、[MASK]箇所を推論(上位5つの候補)します。
# [MASK]箇所を推論(TOP5) model.eval() tokens_tensor = tokens_tensor.to('cuda') model.to('cuda') print(textwrap.fill(text, 45)) print() with torch.no_grad(): outputs = model(tokens_tensor) predictions = outputs[0] for i in range(len(mask_index)): _, predicted_indexes = torch.topk(predictions[0, mask_index[i]], k=5) predicted_tokens = bert_tokenizer.convert_ids_to_tokens(predicted_indexes.tolist()) print(i, predicted_tokens)
無茶振りでしたが、1つ目の予測にはちゃんと正解の「貴族」が含まれています! 残念ながら2つ目の「カエサル」は正解できませんでしたが、BERT思ったよりやりますね。
4.BERTは文生成ができるか?
事前学習しかしていないBERTは穴埋め問題と2つの文の繋がりしか学習していないので、そのままでは文生成には向かないです。しかし原理上やれないことはないです。
あるテキストを用意して、先頭の単語に[MASK]を掛け予測をしたら、先頭の単語を予測結果に置き換え、次の単語に[MASK]を掛け予測する、ということを繰り返すとテキストに似た新たな文が生成ができるはずです。
では、やってみましょう。題材は、「ケネディ大統領がアポロ計画の支援を表明した演説(和訳)」です。
# 形態素解析 text = "我々が10年以内に月に行こうなどと決めたのは、それが容易だからではありません。むしろ困難だからです。この目標が、我々のもつ行動力や技術の最善といえるものを集結しそれがどれほどのものかを知るのに役立つこととなるからです。その挑戦こそ、我々が受けて立つことを望み、先延ばしすることを望まないものだからです。そして、これこそが、我々が勝ち取ろうと志すものであり、我々以外にとってもそうだからです。" result = jumanpp.analysis(text) # 分かち書き tokenized_text = [mrph.midasi for mrph in result.mrph_list()] # 単語リストに変換 tokenized_text, mask_index = preparation(tokenized_text) # [CLS],[SEP]の追加 tokens = bert_tokenizer.convert_tokens_to_ids(tokenized_text) # IDリストに変換 tokens_tensor = torch.tensor([tokens]) # IDテンソルに変換先程同様、テキストを単語リストにし、定義した関数を使って[CLS],[SEP]を追加したら、IDリストに変換し、Pytorchが読めるIDテンソルに変換します。
何度も単語予測を行うので、単語を1つ予測する関数を定義します。
# 1単語予測関数 def predict_one(tokens_tensor, mask_index): model.eval() tokens_tensor = tokens_tensor.to('cuda') model.to('cuda') with torch.no_grad(): outputs = model(tokens_tensor) predictions = outputs[0] _, predicted_indexes = torch.topk(predictions[0, mask_index], k=5) predicted_tokens = bert_tokenizer.convert_ids_to_tokens(predicted_indexes.tolist()) return predicted_tokens, predicted_indexes.tolist()[MASK]を掛けた単語を予測し、予測した単語とIDを返す関数です。
そして、文生成をするコードを書きます。
# 文生成 for i in range(1,len(tokens_tensor[0])): tmp = torch.tensor(tokens_tensor) # tokens_tensorをtmpにコピー tmp[0, i]=4 # i番目を[mask]に書き換え predicted_tokens, predicted_indexes =predict_one(tmp, i) # [mask]を予測 if predicted_indexes !=1: # 予測が[UNK]でなければ tokens_tensor[0, i] = predicted_indexes[0] # 予測IDの[0]番目でtokens_tensorのi番目を上書きする target_list = tokens_tensor.tolist()[0] predict_list = bert_tokenizer.convert_ids_to_tokens(target_list) predict_sentence = ''.join(predict_list[1:]) print('------ original_text -------') print(textwrap.fill(text,45)) print('------ predict_text -------') print(textwrap.fill(predict_sentence,45))tokens_tensorを一端tmpにコピーして、tmpに順次[MASK]を掛け予測した結果で、tokens_tensorの該当箇所を上書きする、ということを繰り返します。さて、これを実行すると、
オリジナルが「10年以内に月に行こう」と言っているのに、文生成は「1年以内に海外に行くべきだ」と、やたらこじんまりしてしまいました(笑)。文の中身は、ちょっと意味不明な感じです。事前学習だけだと、文生成はあまり上手く行かないようです。
コード全体は Google Colab で作成し Github に上げてありますので、自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
(参考)
・BERT日本語モデルを使って、クリスマスプレゼントに欲しいものを推測してみた
・ColabでJUMAN++を使う





- 投稿日:2020-08-06T18:07:59+09:00
Azure Speech SDKを用いて、音声からテキストへ変換すーる
はじめに
Azure Speech SDKを用いて、音声からテキストへ変換してみます。
開発環境
- Windows 10
- Python 3.6
- Anaconda
- Azure Speech SDK
マイクから音声を認識する
1.Azureポータルにログインして、音声サービスを作成します。
2.作成したリソースへ移動し、キーと場所をコピーしておいてください。
3.Python 3.6環境を作成します。
conda create -n py36 python=3.6 conda activate py364.ライブラリをインストールします。
pip install azure-cognitiveservices-speech5.プログラムを作成します。
一度だけ音声入力して認識結果を表示するプログラムです。"YourSubscriptionKey"に先ほどコピーしたキーを, "YourServiceRegion"に先ほどコピーした場所を貼り付けてください。日本語を認識したいのでlanguageは"ja-JP"にします。
stt.pyimport azure.cognitiveservices.speech as speechsdk # Creates an instance of a speech config with specified subscription key and service region. # Replace with your own subscription key and service region (e.g., "westus"). speech_key, service_region, language = "YourSubscriptionKey", "YourServiceRegion", "ja-JP" speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) # Creates a recognizer with the given settings speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config) print("Say something...") # Starts speech recognition, and returns after a single utterance is recognized. The end of a # single utterance is determined by listening for silence at the end or until a maximum of 15 # seconds of audio is processed. The task returns the recognition text as result. # Note: Since recognize_once() returns only a single utterance, it is suitable only for single # shot recognition like command or query. # For long-running multi-utterance recognition, use start_continuous_recognition() instead. result = speech_recognizer.recognize_once() # Checks result. if result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(result.text)) elif result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(result.no_match_details)) elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details))こちらは継続的に音声入力して、認識結果を表示するプログラムです。同様にキーと場所、言語の設定をお願いします。
stt.pyimport azure.cognitiveservices.speech as speechsdk import time # Creates an instance of a speech config with specified subscription key and service region. # Replace with your own subscription key and service region (e.g., "westus"). speech_key, service_region, language = "YourSubscriptionKey", "YourServiceRegion", "ja-JP" speech_config = speechsdk.SpeechConfig( subscription=speech_key, region=service_region, speech_recognition_language=language) # Creates a recognizer with the given settings speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config) print("Say something...") def recognized(evt): print('「{}」'.format(evt.result.text)) # do something def start(evt): print('SESSION STARTED: {}'.format(evt)) def stop(evt): print('SESSION STOPPED {}'.format(evt)) speech_recognizer.recognized.connect(recognized) speech_recognizer.session_started.connect(start) speech_recognizer.session_stopped.connect(stop) try: speech_recognizer.start_continuous_recognition() time.sleep(60) except KeyboardInterrupt: print("bye.") speech_recognizer.recognized.disconnect_all() speech_recognizer.session_started.disconnect_all() speech_recognizer.session_stopped.disconnect_all()6.下記コマンドを実行し、話しかけてみてください。
python stt.py認識結果が以下のように表示されます。
音声ファイル(.wav)から音声を認識する
1.導入方法は上と同様にしてください。
2.プログラムを作成します。
.wavファイルを読み込み、音声認識結果を表示するプログラムです。キーと場所を設定してください。
stt_from_file.pyimport azure.cognitiveservices.speech as speechsdk # Creates an instance of a speech config with specified subscription key and service region. # Replace with your own subscription key and region identifier from here: https://aka.ms/speech/sdkregion speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion" speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) # Creates an audio configuration that points to an audio file. # Replace with your own audio filename. audio_filename = "aboutSpeechSdk.wav" audio_input = speechsdk.audio.AudioConfig(filename=audio_filename) # Creates a recognizer with the given settings speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input) print("Recognizing first result...") # Starts speech recognition, and returns after a single utterance is recognized. The end of a # single utterance is determined by listening for silence at the end or until a maximum of 15 # seconds of audio is processed. The task returns the recognition text as result. # Note: Since recognize_once() returns only a single utterance, it is suitable only for single # shot recognition like command or query. # For long-running multi-utterance recognition, use start_continuous_recognition() instead. result = speech_recognizer.recognize_once() # Checks result. if result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(result.text)) elif result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(result.no_match_details)) elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details))音声ファイルはcognitive-services-speech-sdkにあるsampledata\audiofiles\aboutSpeechSdk.wavを用います。
3.下記コマンドを実行し、結果を見てみましょう。
python stt_from_file.pyキーと場所が正しくないと下記のようなエラーが出ます。
(py36) C:\Users\good_\Documents\PythonProjects\AzureSpeech>python stt_from_file.py Recognizing first result... Speech Recognition canceled: CancellationReason.Error Error details: Connection failed (no connection to the remote host). Internal error: 1. Error details: 11001. Please check network connection, firewall setting, and the region name used to create speech factory. SessionId: 77ad7686a9d94b7882398ae8b855d903結果は下記のようになりました。
52秒あるのですが、最初の一行を認識したら、終了してしまうようです。
4.継続的に読み込み、音声認識するためには、下記のようにします。
stt_from_file.pyimport azure.cognitiveservices.speech as speechsdk import time # Creates an instance of a speech config with specified subscription key and service region. # Replace with your own subscription key and region identifier from here: https://aka.ms/speech/sdkregion speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion" speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) # Creates an audio configuration that points to an audio file. # Replace with your own audio filename. audio_filename = "aboutSpeechSdk.wav" audio_input = speechsdk.audio.AudioConfig(filename=audio_filename) # Creates a recognizer with the given settings speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input) print("Recognizing...") def recognized(evt): print('「{}」'.format(evt.result.text)) # do something def start(evt): print('SESSION STARTED: {}'.format(evt)) def stop(evt): print('SESSION STOPPED {}'.format(evt)) speech_recognizer.recognized.connect(recognized) speech_recognizer.session_started.connect(start) speech_recognizer.session_stopped.connect(stop) try: speech_recognizer.start_continuous_recognition() time.sleep(60) except KeyboardInterrupt: print("bye.") speech_recognizer.recognized.disconnect_all() speech_recognizer.session_started.disconnect_all() speech_recognizer.session_stopped.disconnect_all()5.再度実行してみましょう。
下記のように継続的に音声認識できているようです!
お疲れ様でした。
参考


- 投稿日:2020-08-06T17:47:00+09:00
Python BeautifulSoupでImportErrorが出る
Pythonを独学で勉強中です。
詳しいことはまだわかりませんが、自分が躓いた現象をメモしていこうと思います。
ちなみにPython3.8.5ですスクレイピングをする際、BeautifulSoupを使うのですがこれで1度ハマりました。
実行したいコード
titleタグを抽出しようとしました。
コード# html_parser.py import requests from bs4 import BeautifulSoup # 取得したいURL url = "http://example.com" # urlを引数に指定して、HTTPリクエストを送信してHTMLを取得 response = requests.get(url) # 文字コードを自動でエンコーディング response.encoding = response.apparent_encoding # HTML解析 bs = BeautifulSoup(response.text, 'html.parser') title_tag = bs.find('title') # 抽出したタグのテキスト部分を出力 print(title_tag.text)実行結果がこちら
BeautifulSoupのImportErrorが出てしまいました。
結果Traceback (most recent call last): File "c:/python/html.py", line 3, in <module> from bs4 import BeautifulSoup File "C:\Users\*****\AppData\Local\Programs\Python\Python38\lib\site-packages\bs4\__init__.py", line 31, in <module> from .builder import builder_registry, ParserRejectedMarkup File "C:\Users\*****\AppData\Local\Programs\Python\Python38\lib\site-packages\bs4\builder\__init__.py", line 7, in <module> from bs4.element import ( File "C:\Users\*****\AppData\Local\Programs\Python\Python38\lib\site-packages\bs4\element.py", line 19, in <module> from bs4.formatter import ( File "C:\Users\*****\AppData\Local\Programs\Python\Python38\lib\site-packages\bs4\formatter.py", line 1, in <module> from bs4.dammit import EntitySubstitution File "C:\Users\*****\AppData\Local\Programs\Python\Python38\lib\site-packages\bs4\dammit.py", line 13, in <module> from html.entities import codepoint2name File "c:\python\html.py", line 3, in <module> from bs4 import BeautifulSoup ImportError: cannot import name 'BeautifulSoup' from partially initialized module 'bs4' (most likely due to a circular import) (C:\Users\*****\AppData\Local\Programs\Python\Python38\lib\site-packages\bs4\__init__.py)言われなくとも、下記は実行済みです
pip install beautifulsouppip list でも
beautifulsoup4 4.9.1
と確認できます。
ではなぜか....
ファイル名が"html.py"になっていたからです。
Pythonには"html"というパッケージがありそちらを読み込んでしまっていたようです...
- 投稿日:2020-08-06T17:37:48+09:00
【インストール不要⁉︎】インストールする前に知っておきたいPythonの話
はじめに
ご覧いただきありがとうございます。
Pythonをインストールするにあたり調べながらやったところ、失敗しました。
Pythonはインストール方がたくさんあり、どれをどうすればいいのー?と調べれば調べるほど分からなくなります。
これからPythonを始める方にどの方法でインストールするのがおすすめか私なりにまとめてみました。特にプログラミング経験がないがPythonをこれから始めたいと思っている方に有用な記事になるのではないかと思います。
Pythonをインストールする理由
macには標準でPythonがインストールされています。なぜあえてインストールするでしょう。
調べたり、知人に聞いたりして得られた理由が以下の2点です。
- インストールされているPythonのバージョンが古いから
- バージョンの管理ができないから
それぞれについて以下で詳しく解説します。
インストールされているPythonのバージョンが古いから
「macにはPython2が標準で入っているのでPython3をインストールします」といったPython3が標準で入っていないような記述を見かけることがあります。しかし、これは間違いで最近のOSにはPython3も標準で入っています。
入っているものの、バージョンは3.7.3と少し古め(2020年8月6日時点で3.8.5が最新)。
新しい書き方を使用できないなどの不都合が生じる可能性があります。バージョンの管理ができないから
標準でインストールされているPythonを使用している場合、使用するPythonのバージョンを自分で選択することができません。
そのため使用したいライブラリが標準で入っているバージョンをサポートしていない場合、OSの更新の際にPythonのバージョンが更新される、もしくはそのライブラリのサポートの範囲が広がるのを待たなくてはなりません。特にライブラリが古い場合、更新されていない可能性もありますよね。標準のPythonが前のバージョンに戻ることはほとんどないと思われるので使用を諦めなくてはいけなくなります。また、新しいOSでPythonのバージョンが更新されると、自動的に使用するPythonのバージョンが変わることになります。新しいバージョンになると新しい文法が使用できるようになるのと同時に、今までの文法が使用できなくなる可能性もあります。そのため、アプリを開発している途中でPythonのバージョンが変わってしまうとエラーの原因になる可能性があります。
これらがあえてPythonをインストールする理由です。
Pythonをインストールする方法
すでに述べたようにPythonのダウンロード方法はいくつかあります。
- 公式ページから
- Homebrewの使用
- pyenvの使用
それぞれの方法について解説していきます。
公式ページから
Python公式ページのダウンロードページから直接ダウンロードします。そのままですね。
詳しいインストールの方法はこちらの記事を参考にするといいと思います。この方法でのインストールをおすすめする方
- Windows使用者の方
- ターミナルを使用せずにインストールしたい方
インストーラーでインストールすることができるので、視覚的に分かりやすいです。
これ以降に説明する方法はターミナルの操作が必要です。プログラミングをこれから勉強しようと思っている方にとってターミナルの使用は壁が高く感じるのではないでしょうか?そのような方に向いている方法だと思います。
私はWindowsを使用していないので詳しくは分からないのですが、調べているとWindowsの方はこの方法でインストールするのが一般的なようです。Homebrew?
HomebrewとはmacOS・Linux向けのパッケージ管理システムです。
macOS・Linux使用者向けですがWindows使用者の方でも使用できるようです。
ターミナルに以下を打ち込むことで簡単にインストールできます。// Homebrewのインストール /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" // Pythonのインストール brew install python3HomebrewでPythonをインストールし環境構築を行う場合こちらの記事が参考になると思います。
この方法でのインストールをおすすめする方
- 最新のバージョンのPythonを使用したい方
Homebrewではバージョンの指定をせずにインストールすることが可能です。
最新のバージョンを使用したい方にとって上の2行をターミナルにコピペするだけですむこの方法が一番楽だと思います。
またPythonのバージョンのアップグレードも簡単に行えます。
→Pythonのバージョンアップグレードの方法pyenv
pyenvとはPythonのバージョンの切り替えを簡単にしてくれるツールです。
PC全体で使用するPythonのバージョンだけでなく、フォルダごとにバージョンを分けることも可能です。
pyenvを使用してPythonをインストールする方法を以前書きましたので、よろしければこちらをご覧ください。この方法でのインストールをおすすめする方
- チームで開発を行う方
- 複数のアプリの開発を行う方
このインストール法をおすすめする方は、Pythonのバージョンを切り替えたい方です。例えばチームで開発を行っていて開発環境を合わせたい、複数アプリの開発を行っていて切り替える必要があるなどです。新しいバージョンのPythonには新しい文法(新しい書き方)が加わると同時に今までの書き方がサポートされなくなる可能性があります。今まで作成したアプリにサポートされなくなる文法が使用されていると、バージョンの更新と同時にいきなり動かなくなってしまいます。使用するバージョンを切り替えることでそのようなエラーを防ぐことが可能です。
これからPythonをはじめる方におすすめする方法
これはmac使用者の方に限られてしまうのですが、ここまで調べて私が思うおすすめの方法はインストールしない!です。
環境構築は難しいです。環境構築とGoogleにうちこむと難しいと予測変換で出てくるほどです(笑)
よく分からないままインストールしていると、別の方法でインストールされたPythonが複数存在することになってしまいわけがわからなくなります。
標準でインストールされているPythonのバージョンもそこまで古くないので、とりあえずPythonに触れてみるのがいいのではないかと思います。pythonのバージョンを確かめる方法
python3 -V or python3 --version =>Python 3.7.3python -Vとしてしまうと2.o.oのようにPython2のバージョンが出てきてしまうので注意してください。
最後に
これまでpyenvを使用している方が多く、バージョンの管理もしやすいならpyenvを使うのがベストプラクティスなんだと思っていました。
しかし、新しいバージョンで今までの文法がサポートされなくなることは頻繁にあることではないと思います。
また、ライブラリのバージョンアップでサポートするPythonのバージョンが古いほうに伸びるということもあるようです。Python3がmacに入っていないという記述や、bash使用者向けの記事が今でも多いことなどから今までのやり方を続けている方が多いのかもしれません。Pythonを勉強し始めてまだ2週間ほどなので理解できていないところも多々あります。
間違い等ありましたらご指摘おねがいします。最後までご覧いただきありがとうございました。
- 投稿日:2020-08-06T17:29:12+09:00
PythonのSeleniumで秒速でスクレイピングする方法
セレクタをXPATHで取得
Chromeの拡張機能のxPath Finderを使用し素早くページ上のXPATHを指定する。
そしてそこにsend_keysなどで入力項目を送る。
以下はSBI証券のログインのスクリプトの抜粋です。
try: browser.get('https://www.sbisec.co.jp/ETGate') username_field = browser.find_element_by_xpath('/html/body/table/tbody/tr[1]/td[2]/form/div/div/div/dl/dd[1]/div/input') username_field.clear() username_field.send_keys(username) password_field = browser.find_element_by_xpath("/html/body/table/tbody/tr[1]/td[2]/form/div/div/div/dl/dd[2]/div/input") password_field.send_keys(password) login_button = browser.find_element_by_xpath("/html/body/table/tbody/tr[1]/td[2]/form/div/div/div/p[2]/a/input") login_button.click()#click login time.sleep(5)このパターンを使えばSeleniumを使ったプロジェクトが一気に捗ります。
更新履歴
- 2020/06/06 新規作成

- 投稿日:2020-08-06T17:22:17+09:00
anvil-app-serverのデータ管理について
前書き
anvil-app-serverでアプリが動作させられるようになったのはいいのですが、Anvilのサイトで作成したNews Aggregaterアプリを動かそうとしても、すんなりとは動いてくれないようで。。。
ちょっと調査してみました。前提
- AnvilでNews Aggregatorアプリを作成済みであること。
環境
- Ubuntu 20.04 LTS 日本語 Remix
- Hyper-V マネージャー 10.0.18362.1
- anvil-app-server v1.1
News Aggregatorアプリのダウンロードと実行
アプリを作成すると、
View historyからgit cloneコマンドでダウンロードできます。"View history"をクリックし、
"Clone with Git"をクリックし、
"git clone ssh://~"の行をコピーしてコマンドで実行。
git clone ssh://XXXX@anvil.works:2222/324IEWAMVBYU2Y77.git News_Aggregater※
XXXXにはAnvilサイトに登録したアカウントのメールアドレスが入る。
※二要素認証を有効にしているとSSHパブリックキーを使用しないといけない為、使っている場合は一時的に二段階認証を外しておく。Gitにパブリックキー登録してあればすんなりいけると思いますが。
anvil-app-serverでアプリケーションを起動。anvil-app-server --app News_Aggregater
http://localhost:3030にブラウザでアクセス。
でいきなりエラー。
問題点
News Aggrigatorアプリでは記事の
categoryをcategoriesテーブルに予め登録し、そこから選択する方法をとっているのですが、アプリにはテーブルのデータが含まれていないため、「空のデータ」でエラーになる。anvil-app-serverのPostgreSQLへpgadmin4でアクセス
anvil-app-serverは独自のPostgreSQLサーバーを含んでいるので、そちらにアクセスする。
- Username : postgres
- Password : (anvil-app-serverを実行したディレクトリ)/.anvi-data/postgres.password内に記載
- Port : (anvil-app-serverを実行したディレクトリ)/.anvi-data/db/postmaster.opts内に記載
が、見たところ、アプリで必要なはずの
articlesテーブルもcategoriesテーブルもなし。
とりあえず、存在しているテーブルの中身を見ていくと、
app_storage_tablesテーブル内にアプリで作成したテーブルの情報を発見。
また、
create-anvil-appコマンドで作成できるtodoアプリを使ってデータの作成を見ていくと、app_storage_dataテーブルにデータが追加されていることが判明。
つまりどういうことか
ここまでのことから、
- アプリで使用するテーブルの情報は、
app_storage_tablesテーブルにJSON形式で格納される。- アプリからデータにアクセスする場合は、
app_storage_tablesテーブルの情報を元に、app_storage_dataテーブルのJSON形式のデータにアクセスする。どんなアプリを作ってもデータ層とロジック層の整合が取れるという観点では、メタテーブルを使うのは考えられなくもないですが、素人の心を挫く仕組みではあります。
その他
どのようなデータ管理なのか、少し見えてきたところで、データのインポートをしてみようと、Anvilのサイトに戻って、データのダウンロードを行ってみました。
が、ダウンロードしたデータもすんなりインポートできる内容ではありません。
今回のNews Aggrigatorのcategoriesテーブルの場合、
ID name [65114][57547127] entertainment [65114][57547131] business [65114][57547132] travel [65114][57547134] sport の様になっており、このデータをローカルDBのメタテーブルと整合が取れた形でJSON形式データを書き込まなければなりません。
※IDのカラムは「おそらく」Anvilでホストしているサーバーにデータが乗っている際の情報なのでローカルDBではあまり意味がなさそう。直感的にはテーブルIDとrowIDくらいかなという気はします。後書き
有償プランであれば、ある程度融通がきく、とか、適切なアドバイスなりツールの利用なりがある、と想像しますが、無料プランでアプリ作って自前でホストして使うには、少々難易度高いと思います。
まあ、有償プランなら独自ドメインも設定できるようなので、そちらの使い方が本道なのでしょう。





- 投稿日:2020-08-06T17:07:58+09:00
統計学を0から復習【四則演算】
はじめに
統計学を復習しはじめたので、備忘録として自分なりの解釈をまとめていこうと思います。今回は統計のもっとも基礎的な四則演算についてですが、今後は推定・検定・多変量解析・ベイズ統計まで勉強できたらと思います。統計を復習したいと思っている人や自分の統計に対する理解度を確認したい人の参考になるように心掛けます。
統計学とは
そもそも統計学とは何をするための学問でしょうか。統計に関する有名な逸話としてポアンカレとパン屋の話があります。
その逸話とは以下のようなものです。
ポアンカレは馴染みのパン屋で、重量1000gのパンをよく買っていたそうです。ですが、どうも重さをごまかされていると感じたポアンカレは買ったパンの重さを毎回計ることにしました。
1年後にポアンカレはこれまで買ってきたパンの重さが平均950gの正規分布となっていることを確認して、不正を見破ったそうです。さて、ポアンカレのようにパン屋の不正を見破るには、一体どれくらいのパンを買う必要があるのでしょうか?
統計学の区間推定を用いると、以下の図のような定量的な解を与えることができます(Pythonで実装しました)。この場合ですと、おおよそパンを70個くらい買うと99.98%の確信度でパンが1000gとなるように作られていないことが分かります(かなり慎重)。
統計学における四則演算
いきなり統計の区間推定に行く前に、統計学における四則演算の公式を理解する必要があります。公式の導出を行っていますが、面倒であれば結果とコメントだけを確認することである程度理解できると思います。
便宜上、以下のような記号と数式を定義します。また、簡単のためにパンの重量は整数値しか取らない離散値と仮定してしまいますが、連続値(実数)の場合は$\sum_{}$➡$\int$とするだけです。
記号と数式の定義
・$X=(x_1,x_2,x_3・・・x_n):$確率変数(パンの重さが取りえる値、例えば900g,901g,902g・・・1000g,1001g,1002gなど)・$f(x):$確率関数(パンの重さがxとなる確率、例えばf(900g)=0.005, f(1000g)=0.1など)
・$E(X)=\sum_{k}x_{k}f(x_k)=μ_X:$確率変数$X$の期待値($\sum$パンの重さ×その重さのパンの出現確率)
・$V(X)=\sum_{k}(x_k-μ_X)^2f(x_k):$確率変数$X$の分散($\sum$(パンの重さ-全体のパンの重さの平均)$^2$×その重さのパンの出現確率)
確率変数の期待値と分散の四則演算を導出する上で、下記では互いに独立な確率変数$X$と$Y$を仮定することとします。XとYが互いに独立とは$f(x_i,y_j)=f(x_i)×f(y_j)$が成り立ち、$x_i$の発生確率と$y_i$の発生確率に関係性がないということです。例えば、ある日無造作に選んで買うパンの重みは互いに独立と考えることができます。
➀「確率変数$X$+確率変数$Y$」の期待値
確率変数$X$に確率変数$Y$を足した確率変数$X+Y$の期待値を求めていきます。\begin{align} E(X+Y)&=\sum_{j,k}(x_j+y_k)f(x_j,y_k)\\ &=\sum_{j,k}x_jf(x_j,y_k)+\sum_{j,k}y_kf(x_j,y_k)\\ &=\sum_{j}x_jf(x_j)\sum_{k}f(y_k)+\sum_{k}y_kf(y_k)\sum_{j}f(x_j)\\ &=\sum_{j}x_jf(x_j)+\sum_{k}y_kf(y_k)\\ &=E(X)+E(Y) \end{align}3行目の式は$X$と$Y$それぞれの周辺確率(それぞれ$X$と$Y$の影響を排除した確率)と呼ばれるものになっています。最終的に確率変数$X+Y$の期待値は、$X$と$Y$それぞれの期待値を足しただけのものとなりました。引き算では符号が変わるだけです。
➁「確率変数$X$×確率変数$Y$」の期待値
確率変数$X$と確率変数$Y$をかけあわせた確率変数$X×Y$の期待値を求めていきます。$\sum_{j,k}$の意味としては、取りえる全ての$j$と$k$において値を足し合わせる全探索のようなイメージが理解しやすいと思います。\begin{align} E(X×Y)=&\sum_{j,k}\bigl(x_jy_kf(x_j,y_k)\bigr)\\ =&x_1y_1f(x_1,y_1)+x_1y_2f(x_1,y_2)+・・・+x_1y_nf(x_1,y_n)\\ &+x_2y_1f(x_2,y_1)+x_2y_2f(x_2,y_2)・・・+x_2y_nf(x_2,y_n)\\ &・・・\\ &+x_my_1f(x_m,y_1)+x_my_2f(x_m,y_2)・・・+x_my_nf(x_m,y_n)\\ =&x_1f(x_1)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ &+x_2f(x_2)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ &・・・\\ &+x_mf(x_m)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ =&\sum_{j}x_jf(x_j)\sum_{k}y_kf(y_k)\\ =&E(X)E(Y) \end{align}確率変数$X×Y$の期待値は、確率変数$X$と$Y$の期待値をかけあわせただけのものになりました。割り算では$Y$の代わりに$1/Y$という確率変数を使えばよいです。
➂「確率変数$X$×定数$a$」の期待値
確率変数$X$に定数aをかけた確率変数$a×X$の期待値を求めていきます。\begin{align} E(a×X)&=\sum_{j}\bigl(a(x_j)f(x_j)\bigr)\\ &=ax_1f(x_1)+ax_2f(x_2)・・・\\ &=aE(X) \end{align}定数をかけただけの式となりました。割り算は定数$a$を$1/a$とするだけです。
➃「確率変数$X$+確率変数$Y$」の分散
確率変数$X$と確率変数$Y$を足した確率変数$X+Y$の分散を求めていきます。
便宜上、確率変数$X$の期待値は$E(X)=μ_{X}$として表します。\begin{align} V(X+Y)=&\sum_{j,k}\bigl(x_j+y_k-(μ_X+μ_Y)\bigr)^2f(x_j,y_k)\\ =&\sum_{j,k}\bigl(x_j^2+y_k^2+μ_X^2+μ_Y^2+2x_jy_k-2x_jμ_X-2x_jμ_Y-2y_kμ_X-2y_kμ_Y+2μ_Xμ_Y\bigr)f(x_j,y_k)\\ =&\sum_{j,k}\bigl(x_j-μ_X\bigr)^2f(x_j,y_k)+\sum_{j,k}\bigl(y_k-μ_Y\bigr)^2f(x_j,y_k)+2\sum_{j,k}\bigl(x_j-μ_X\bigr)\bigl(y_k-μ_Y\bigr)f(x_j,y_k)\\ =&\sum_{j}\bigl(x_j-μ_X\bigr)^2f(x_j)+\sum_{k}\bigl(y_k-μ_Y\bigr)^2f(y_k)+2\sum_{j}\bigl(x_j-μ_X\bigr)f(x_j)\sum_{k}\bigl(y_k-μ_Y\bigr)f(y_k)\\ =&V(X)+V(Y) \end{align}確率変数$X+Y$の分散は確率変数$X$と$Y$の分散を足し合わせただけの式となりました。ちなみに3行目の第3項目は$X$と$Y$の相関性を表す共分散という統計量で、$X$と$Y$が独立ではない場合は0とはならないので、分散に考慮する必要が出てきます。
➄「確率変数$X$×確率変数$Y$」の分散
確率変数$X$に確率変数$Y$をかけた確率変数$X$×$Y$の分散を求めていきます。\begin{align} V(X×Y)=&\sum_{j,k}\bigl(x_jy_k-μ_Xμ_Y\bigr)^2f(x_j,y_k)\\ =&\sum_{j,k}\bigl((x_jy_k)^2-2x_jy_kμ_Xμ_Y+(μ_Xμ_Y)^2\bigr)f(x_j,y_k)\\ =&\sum_{j,k}(x_jy_k)^2f(x_j,y_k)-μ_Xμ_Y\sum_{j,k}2x_jy_kf(x_j,y_k)+(μ_Xμ_Y)^2\\ =&\sum_{j,k}(x_jy_k)^2f(x_j,y_k)-2(μ_Xμ_Y)^2+(μ_Xμ_Y)^2\\ =&\sum_{j}x_j^2f(x_j)\sum_{k}y_k^2f(y_k)-(μ_Xμ_Y)^2 \\ =&E(X^2)E(Y^2)-(μ_Xμ_Y)^2\\ =&\bigl(V(X)+μ_X^2\bigr)\bigl(V(Y)+μ_Y^2\bigr)-(μ_Xμ_Y)^2 ※V(X)=\sum_{k}(x_k-μ_X)^2f(x_k)=E(X^2)-μ_X^2\\ =&V(X)V(Y)+μ_Y^2V(X)+μ_X^2V(Y) \end{align}確率変数$X×Y$の分散は、確率変数$X$と$Y$の期待値と分散を使って$V(X)V(Y)+μ_Y^2V(X)+μ_X^2V(Y)$となります。期待値のように単純に$V(X×Y)=V(X)V(Y)$とはならないので注意が必要です。
➅「確率変数$X$×定数$a$」の分散
確率変数$X$に定数aをかけた確率変数$a×X$の分散を求めていきます。\begin{align} V(a×X)=&\sum_{j}(ax_j-μ_{ax})^2f(x_j)\\ =&(ax_1-aμ_x)^2+(ax_2-aμ_x)^2+(ax_3-aμ_x)^2+・・・\\ =&a^2\sum_{j}(x_j-μ_{x})^2f(x_j)\\ =&a^2V(X) \end{align}確率変数を$a$倍すると分散は$a^2$倍となるので注意が必要です。
次回
次回は今回導出した統計の四則演算の公式を用いて、冒頭で示した図のように実際にパンの重みの分布を区間推定していくことに取り組みます。
参考
Pythonで理解する統計解析の基礎
Pythonで学ぶ統計検定2級の確率分布①
腑に落ちない人のための不偏性と一致性の解説
[統計学]t-分布、大数の法則、中心極限定理
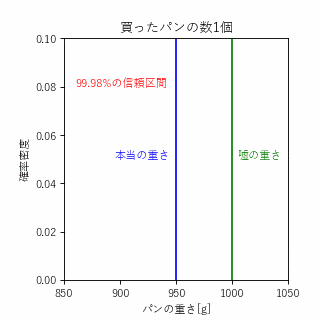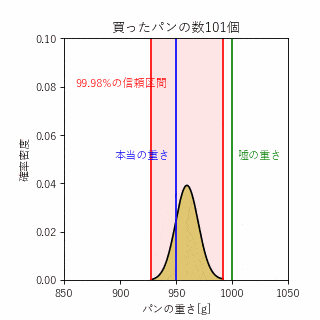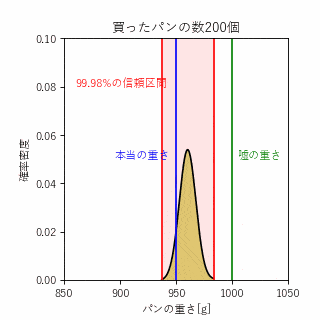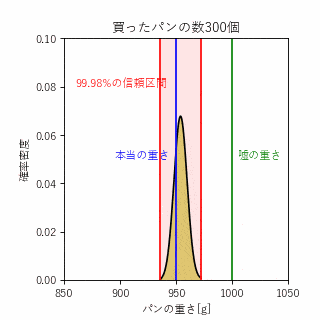
- 投稿日:2020-08-06T17:07:58+09:00
【統計学を0から復習】推定統計学とは?
はじめに
統計学を復習しはじめたので、備忘録として自分なりの解釈をまとめていこうと思います。今回は統計学のもっとも基礎的な確率変数の四則演算についてまとめて、今後は推定・検定・多変量解析・ベイズ統計までまとめていこうと思います。統計を復習したいと思っている人や自分の統計に対する理解度を確認したい人の参考になるように心掛けます。
推定統計学とは
そもそも推定統計学とは何でしょうか。推定統計に関する有名な逸話としてポアンカレとパン屋の話があります。
その逸話とは以下のようなものです。
ポアンカレは馴染みのパン屋で、重量1000gのパンをよく買っていたそうです。ですが、どうも重さをごまかされていると感じたポアンカレは買ったパンの重さを毎回計ることにしました。
1年後にポアンカレはこれまで買ってきたパンの重さが平均950gの正規分布となっていることを確認して、不正を見破ったそうです。さて、実際にポアンカレがパン屋の不正を見破るには、一体どれくらいのパンを買う必要があったのでしょうか?
統計学の区間推定を用いると、以下の図のような定量的な解を与えることができます(Pythonで実装しました)。この場合ですと、おおよそパンを70個くらい買うと99.98%の確信度でパン屋が不正していることが分かります(かなり慎重)。
統計学における四則演算
いきなり統計の区間推定に行く前に、統計学における四則演算の公式を理解する必要があります。公式の導出を行っていますが、面倒であれば結果とコメントだけを確認することである程度理解できると思います。
便宜上、以下のような記号と数式を定義します。また、簡単のためにパンの重量は整数値しか取らない離散値と仮定してしまいますが、連続値(実数)の場合は$\sum_{}$➡$\int$とするだけです。
記号と数式の定義
・$X=(x_1,x_2,x_3・・・x_n):$確率変数(パンの重さが取りえる値、例えば900g,901g,902g・・・1000g,1001g,1002gなど)・$f(x):$確率関数(パンの重さがxとなる確率、例えばf(900g)=0.005, f(1000g)=0.1など)
・$E(X)=\sum_{k}x_{k}f(x_k)=μ_X:$確率変数$X$の期待値($\sum$パンの重さ×その重さのパンの出現確率)
・$V(X)=\sum_{k}(x_k-μ_X)^2f(x_k):$確率変数$X$の分散($\sum$(パンの重さ-全体のパンの重さの平均)$^2$×その重さのパンの出現確率)
確率変数の期待値と分散の四則演算を導出する上で、下記では互いに独立な確率変数$X$と$Y$を仮定することとします。XとYが互いに独立とは$f(x_i,y_j)=f(x_i)×f(y_j)$が成り立ち、$x_i$の発生確率と$y_i$の発生確率に関係性がないということです。例えば、ある日無造作に選んで買うパンの重みは互いに独立と考えることができます。
➀「確率変数$X$+確率変数$Y$」の期待値
確率変数$X$に確率変数$Y$を足した確率変数$X+Y$の期待値を求めていきます。\begin{align} E(X+Y)&=\sum_{j,k}(x_j+y_k)f(x_j,y_k)\\ &=\sum_{j,k}x_jf(x_j,y_k)+\sum_{j,k}y_kf(x_j,y_k)\\ &=\sum_{j}x_jf(x_j)\sum_{k}f(y_k)+\sum_{k}y_kf(y_k)\sum_{j}f(x_j)\\ &=\sum_{j}x_jf(x_j)+\sum_{k}y_kf(y_k)\\ &=E(X)+E(Y) \end{align}3行目の式は$X$と$Y$それぞれの周辺確率(それぞれ$X$と$Y$の影響を排除した確率)と呼ばれるものになっています。最終的に確率変数$X+Y$の期待値は、$X$と$Y$それぞれの期待値を足しただけのものとなりました。引き算では符号が変わるだけです。
➁「確率変数$X$×確率変数$Y$」の期待値
確率変数$X$と確率変数$Y$をかけあわせた確率変数$X×Y$の期待値を求めていきます。$\sum_{j,k}$の意味としては、取りえる全ての$j$と$k$において値を足し合わせる全探索のようなイメージが理解しやすいと思います。\begin{align} E(X×Y)=&\sum_{j,k}\bigl(x_jy_kf(x_j,y_k)\bigr)\\ =&x_1y_1f(x_1,y_1)+x_1y_2f(x_1,y_2)+・・・+x_1y_nf(x_1,y_n)\\ &+x_2y_1f(x_2,y_1)+x_2y_2f(x_2,y_2)・・・+x_2y_nf(x_2,y_n)\\ &・・・\\ &+x_my_1f(x_m,y_1)+x_my_2f(x_m,y_2)・・・+x_my_nf(x_m,y_n)\\ =&x_1f(x_1)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ &+x_2f(x_2)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ &・・・\\ &+x_mf(x_m)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ =&\sum_{j}x_jf(x_j)\sum_{k}y_kf(y_k)\\ =&E(X)E(Y) \end{align}確率変数$X×Y$の期待値は、確率変数$X$と$Y$の期待値をかけあわせただけのものになりました。割り算では$Y$の代わりに$1/Y$という確率変数を使えばよいです。
➂「確率変数$X$×定数$a$」の期待値
確率変数$X$に定数aをかけた確率変数$a×X$の期待値を求めていきます。\begin{align} E(a×X)&=\sum_{j}\bigl(a(x_j)f(x_j)\bigr)\\ &=ax_1f(x_1)+ax_2f(x_2)・・・\\ &=aE(X) \end{align}定数をかけただけの式となりました。割り算は定数$a$を$1/a$とするだけです。
➃「確率変数$X$+確率変数$Y$」の分散
確率変数$X$と確率変数$Y$を足した確率変数$X+Y$の分散を求めていきます。
便宜上、確率変数$X$の期待値は$E(X)=μ_{X}$として表します。\begin{align} V(X+Y)=&\sum_{j,k}\bigl(x_j+y_k-(μ_X+μ_Y)\bigr)^2f(x_j,y_k)\\ =&\sum_{j,k}\bigl(x_j^2+y_k^2+μ_X^2+μ_Y^2+2x_jy_k-2x_jμ_X-2x_jμ_Y-2y_kμ_X-2y_kμ_Y+2μ_Xμ_Y\bigr)f(x_j,y_k)\\ =&\sum_{j,k}\bigl(x_j-μ_X\bigr)^2f(x_j,y_k)+\sum_{j,k}\bigl(y_k-μ_Y\bigr)^2f(x_j,y_k)+2\sum_{j,k}\bigl(x_j-μ_X\bigr)\bigl(y_k-μ_Y\bigr)f(x_j,y_k)\\ =&\sum_{j}\bigl(x_j-μ_X\bigr)^2f(x_j)+\sum_{k}\bigl(y_k-μ_Y\bigr)^2f(y_k)+2\sum_{j}\bigl(x_j-μ_X\bigr)f(x_j)\sum_{k}\bigl(y_k-μ_Y\bigr)f(y_k)\\ =&V(X)+V(Y) \end{align}確率変数$X+Y$の分散は確率変数$X$と$Y$の分散を足し合わせただけの式となりました。ちなみに3行目の第3項目は$X$と$Y$の相関性を表す共分散という統計量で、$X$と$Y$が独立ではない場合は0とはならないので、分散に考慮する必要が出てきます。
➄「確率変数$X$×確率変数$Y$」の分散
確率変数$X$に確率変数$Y$をかけた確率変数$X$×$Y$の分散を求めていきます。\begin{align} V(X×Y)=&\sum_{j,k}\bigl(x_jy_k-μ_Xμ_Y\bigr)^2f(x_j,y_k)\\ =&\sum_{j,k}\bigl((x_jy_k)^2-2x_jy_kμ_Xμ_Y+(μ_Xμ_Y)^2\bigr)f(x_j,y_k)\\ =&\sum_{j,k}(x_jy_k)^2f(x_j,y_k)-μ_Xμ_Y\sum_{j,k}2x_jy_kf(x_j,y_k)+(μ_Xμ_Y)^2\\ =&\sum_{j,k}(x_jy_k)^2f(x_j,y_k)-2(μ_Xμ_Y)^2+(μ_Xμ_Y)^2\\ =&\sum_{j}x_j^2f(x_j)\sum_{k}y_k^2f(y_k)-(μ_Xμ_Y)^2 \\ =&E(X^2)E(Y^2)-(μ_Xμ_Y)^2\\ =&\bigl(V(X)+μ_X^2\bigr)\bigl(V(Y)+μ_Y^2\bigr)-(μ_Xμ_Y)^2 ※V(X)=\sum_{k}(x_k-μ_X)^2f(x_k)=E(X^2)-μ_X^2\\ =&V(X)V(Y)+μ_Y^2V(X)+μ_X^2V(Y) \end{align}確率変数$X×Y$の分散は、確率変数$X$と$Y$の期待値と分散を使って$V(X)V(Y)+μ_Y^2V(X)+μ_X^2V(Y)$となります。期待値のように単純に$V(X×Y)=V(X)V(Y)$とはならないので注意が必要です。
➅「確率変数$X$×定数$a$」の分散
確率変数$X$に定数aをかけた確率変数$a×X$の分散を求めていきます。\begin{align} V(a×X)=&\sum_{j}(ax_j-μ_{ax})^2f(x_j)\\ =&(ax_1-aμ_x)^2+(ax_2-aμ_x)^2+(ax_3-aμ_x)^2+・・・\\ =&a^2\sum_{j}(x_j-μ_{x})^2f(x_j)\\ =&a^2V(X) \end{align}確率変数を$a$倍すると分散は$a^2$倍となるので注意が必要です。
次回
次回は今回導出した統計の四則演算の公式を用いて、冒頭で示した図のように実際にパンの重みの分布を区間推定していくことに取り組みます。
参考
Pythonで理解する統計解析の基礎
Pythonで学ぶ統計検定2級の確率分布①
腑に落ちない人のための不偏性と一致性の解説
[統計学]t-分布、大数の法則、中心極限定理
- 投稿日:2020-08-06T17:07:58+09:00
推定統計学とは?&確率変数の四則演算
はじめに
統計学を復習しはじめたので、備忘録として自分なりの解釈をまとめていこうと思います。今回は統計学のもっとも基礎的な確率変数の四則演算についてまとめて、今後は推定・検定・多変量解析・ベイズ統計までまとめていこうと思います。統計を復習したいと思っている人や自分の統計に対する理解度を確認したい人の参考になるように心掛けます。
推定統計学とは
そもそも推定統計学とは何でしょうか。推定統計に関する有名な逸話としてポアンカレとパン屋の話があります。
その逸話とは以下のようなものです。
ポアンカレは馴染みのパン屋で、重量1000gのパンをよく買っていたそうです。ですが、どうも重さをごまかされていると感じたポアンカレは買ったパンの重さを毎回計ることにしました。
1年後にポアンカレはこれまで買ってきたパンの重さが平均950gの正規分布となっていることを確認して、不正を見破ったそうです。さて、実際にポアンカレがパン屋の不正を見破るには、一体どれくらいのパンを買う必要があったのでしょうか?
統計学の区間推定を用いると、以下の図のような定量的な解を与えることができます(Pythonで実装しました)。この場合ですと、おおよそパンを70個くらい買うと99.98%の確信度でパン屋が不正していることが分かります(かなり慎重)。
統計学における四則演算
いきなり統計の区間推定に行く前に、統計学における四則演算の公式を理解する必要があります。公式の導出を行っていますが、面倒であれば結果とコメントだけを確認することである程度理解できると思います。
便宜上、以下のような記号と数式を定義します。また、簡単のためにパンの重量は整数値しか取らない離散値と仮定してしまいますが、連続値(実数)の場合は$\sum_{}$➡$\int$とするだけです。
記号と数式の定義
・$X=(x_1,x_2,x_3・・・x_n):$確率変数(パンの重さが取りえる値、例えば900g,901g,902g・・・1000g,1001g,1002gなど)・$f(x):$確率関数(パンの重さがxとなる確率、例えばf(900g)=0.005, f(1000g)=0.1など)
・$E(X)=\sum_{k}x_{k}f(x_k)=μ_X:$確率変数$X$の期待値($\sum$パンの重さ×その重さのパンの出現確率)
・$V(X)=\sum_{k}(x_k-μ_X)^2f(x_k):$確率変数$X$の分散($\sum$(パンの重さ-全体のパンの重さの平均)$^2$×その重さのパンの出現確率)
確率変数の期待値と分散の四則演算を導出する上で、下記では互いに独立な確率変数$X$と$Y$を仮定することとします。XとYが互いに独立とは$f(x_i,y_j)=f(x_i)×f(y_j)$が成り立ち、$x_i$の発生確率と$y_i$の発生確率に関係性がないということです。例えば、ある日無造作に選んで買うパンの重みは互いに独立と考えることができます。
➀「確率変数$X$+確率変数$Y$」の期待値
確率変数$X$に確率変数$Y$を足した確率変数$X+Y$の期待値を求めていきます。\begin{align} E(X+Y)&=\sum_{j,k}(x_j+y_k)f(x_j,y_k)\\ &=\sum_{j,k}x_jf(x_j,y_k)+\sum_{j,k}y_kf(x_j,y_k)\\ &=\sum_{j}x_jf(x_j)\sum_{k}f(y_k)+\sum_{k}y_kf(y_k)\sum_{j}f(x_j)\\ &=\sum_{j}x_jf(x_j)+\sum_{k}y_kf(y_k)\\ &=E(X)+E(Y) \end{align}3行目の式は$X$と$Y$それぞれの周辺確率(それぞれ$X$と$Y$の影響を排除した確率)と呼ばれるものになっています。最終的に確率変数$X+Y$の期待値は、$X$と$Y$それぞれの期待値を足しただけのものとなりました。引き算では符号が変わるだけです。
➁「確率変数$X$×確率変数$Y$」の期待値
確率変数$X$と確率変数$Y$をかけあわせた確率変数$X×Y$の期待値を求めていきます。$\sum_{j,k}$の意味としては、取りえる全ての$j$と$k$において値を足し合わせる全探索のようなイメージが理解しやすいと思います。\begin{align} E(X×Y)=&\sum_{j,k}\bigl(x_jy_kf(x_j,y_k)\bigr)\\ =&x_1y_1f(x_1,y_1)+x_1y_2f(x_1,y_2)+・・・+x_1y_nf(x_1,y_n)\\ &+x_2y_1f(x_2,y_1)+x_2y_2f(x_2,y_2)・・・+x_2y_nf(x_2,y_n)\\ &・・・\\ &+x_my_1f(x_m,y_1)+x_my_2f(x_m,y_2)・・・+x_my_nf(x_m,y_n)\\ =&x_1f(x_1)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ &+x_2f(x_2)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ &・・・\\ &+x_mf(x_m)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ =&\sum_{j}x_jf(x_j)\sum_{k}y_kf(y_k)\\ =&E(X)E(Y) \end{align}確率変数$X×Y$の期待値は、確率変数$X$と$Y$の期待値をかけあわせただけのものになりました。割り算では$Y$の代わりに$1/Y$という確率変数を使えばよいです。
➂「確率変数$X$×定数$a$」の期待値
確率変数$X$に定数aをかけた確率変数$a×X$の期待値を求めていきます。\begin{align} E(a×X)&=\sum_{j}\bigl(a(x_j)f(x_j)\bigr)\\ &=ax_1f(x_1)+ax_2f(x_2)・・・\\ &=aE(X) \end{align}定数をかけただけの式となりました。割り算は定数$a$を$1/a$とするだけです。
➃「確率変数$X$+確率変数$Y$」の分散
確率変数$X$と確率変数$Y$を足した確率変数$X+Y$の分散を求めていきます。
便宜上、確率変数$X$の期待値は$E(X)=μ_{X}$として表します。\begin{align} V(X+Y)=&\sum_{j,k}\bigl(x_j+y_k-(μ_X+μ_Y)\bigr)^2f(x_j,y_k)\\ =&\sum_{j,k}\bigl(x_j^2+y_k^2+μ_X^2+μ_Y^2+2x_jy_k-2x_jμ_X-2x_jμ_Y-2y_kμ_X-2y_kμ_Y+2μ_Xμ_Y\bigr)f(x_j,y_k)\\ =&\sum_{j,k}\bigl(x_j-μ_X\bigr)^2f(x_j,y_k)+\sum_{j,k}\bigl(y_k-μ_Y\bigr)^2f(x_j,y_k)+2\sum_{j,k}\bigl(x_j-μ_X\bigr)\bigl(y_k-μ_Y\bigr)f(x_j,y_k)\\ =&\sum_{j}\bigl(x_j-μ_X\bigr)^2f(x_j)+\sum_{k}\bigl(y_k-μ_Y\bigr)^2f(y_k)+2\sum_{j}\bigl(x_j-μ_X\bigr)f(x_j)\sum_{k}\bigl(y_k-μ_Y\bigr)f(y_k)\\ =&V(X)+V(Y) \end{align}確率変数$X+Y$の分散は確率変数$X$と$Y$の分散を足し合わせただけの式となりました。ちなみに3行目の第3項目は$X$と$Y$の相関性を表す共分散という統計量で、$X$と$Y$が独立ではない場合は0とはならないので、分散に考慮する必要が出てきます。
➄「確率変数$X$×確率変数$Y$」の分散
確率変数$X$に確率変数$Y$をかけた確率変数$X$×$Y$の分散を求めていきます。\begin{align} V(X×Y)=&\sum_{j,k}\bigl(x_jy_k-μ_Xμ_Y\bigr)^2f(x_j,y_k)\\ =&\sum_{j,k}\bigl((x_jy_k)^2-2x_jy_kμ_Xμ_Y+(μ_Xμ_Y)^2\bigr)f(x_j,y_k)\\ =&\sum_{j,k}(x_jy_k)^2f(x_j,y_k)-μ_Xμ_Y\sum_{j,k}2x_jy_kf(x_j,y_k)+(μ_Xμ_Y)^2\\ =&\sum_{j,k}(x_jy_k)^2f(x_j,y_k)-2(μ_Xμ_Y)^2+(μ_Xμ_Y)^2\\ =&\sum_{j}x_j^2f(x_j)\sum_{k}y_k^2f(y_k)-(μ_Xμ_Y)^2 \\ =&E(X^2)E(Y^2)-(μ_Xμ_Y)^2\\ =&\bigl(V(X)+μ_X^2\bigr)\bigl(V(Y)+μ_Y^2\bigr)-(μ_Xμ_Y)^2 ※V(X)=\sum_{k}(x_k-μ_X)^2f(x_k)=E(X^2)-μ_X^2\\ =&V(X)V(Y)+μ_Y^2V(X)+μ_X^2V(Y) \end{align}確率変数$X×Y$の分散は、確率変数$X$と$Y$の期待値と分散を使って$V(X)V(Y)+μ_Y^2V(X)+μ_X^2V(Y)$となります。期待値のように単純に$V(X×Y)=V(X)V(Y)$とはならないので注意が必要です。
➅「確率変数$X$×定数$a$」の分散
確率変数$X$に定数aをかけた確率変数$a×X$の分散を求めていきます。\begin{align} V(a×X)=&\sum_{j}(ax_j-μ_{ax})^2f(x_j)\\ =&(ax_1-aμ_x)^2+(ax_2-aμ_x)^2+(ax_3-aμ_x)^2+・・・\\ =&a^2\sum_{j}(x_j-μ_{x})^2f(x_j)\\ =&a^2V(X) \end{align}確率変数を$a$倍すると分散は$a^2$倍となるので注意が必要です。
次回
次回は今回導出した統計の四則演算の公式を用いて、冒頭で示した図のように実際にパンの重みの分布を区間推定していくことに取り組みます。
参考
Pythonで理解する統計解析の基礎
Pythonで学ぶ統計検定2級の確率分布①
腑に落ちない人のための不偏性と一致性の解説
[統計学]t-分布、大数の法則、中心極限定理
- 投稿日:2020-08-06T17:07:58+09:00
【統計学を0から復習】確率変数の四則演算
はじめに
統計学を復習しはじめたので、備忘録として自分なりの解釈をまとめていこうと思います。今回は統計学のもっとも基礎的な確率変数の四則演算についてまとめて、今後は推定・検定・多変量解析・ベイズ統計までまとめていこうと思います。統計を復習したいと思っている人や自分の統計に対する理解度を確認したい人の参考になるように心掛けます。
推定統計学とは
そもそも推定統計学とは何でしょうか。推定統計に関する有名な逸話としてポアンカレとパン屋の話があります。
その逸話とは以下のようなものです。
ポアンカレは馴染みのパン屋で、重量1000gのパンをよく買っていたそうです。ですが、どうも重さをごまかされていると感じたポアンカレは買ったパンの重さを毎回計ることにしました。
1年後にポアンカレはこれまで買ってきたパンの重さが平均950gの正規分布となっていることを確認して、不正を見破ったそうです。さて、実際にポアンカレがパン屋の不正を見破るには、一体どれくらいのパンを買う必要があったのでしょうか?
統計学の区間推定を用いると、以下の図のような定量的な解を得ることができます(Pythonで実装しました)。この場合ですと、おおよそパンを70個くらい買うと99.98%の確信度でパン屋が不正していることが分かります(かなり慎重)。
統計学における四則演算
いきなり統計の区間推定に行く前に、統計学における四則演算の公式を理解する必要があります。公式の導出を行っていますが、面倒であれば結果とコメントだけを確認することである程度理解できると思います。
便宜上、以下のような記号と数式を定義します。また、簡単のためにパンの重量は整数値しか取らない離散値と仮定してしまいますが、連続値(実数)の場合は$\sum_{}$を$\int$とするだけです。
記号と数式の定義
・$X=(x_1,x_2,x_3・・・x_n):$確率変数(パンの重さが取りえる値、例えば900g,901g,902g・・・1000g,1001g,1002gなど)・$f(x):$確率関数(パンの重さがxとなる確率、例えばf(900g)=0.005, f(1000g)=0.1など)
・$E(X)=\sum_{k}x_{k}f(x_k)=μ_X:$確率変数$X$の期待値($\sum$パンの重さ×その重さのパンの出現確率)
・$V(X)=\sum_{k}(x_k-μ_X)^2f(x_k):$確率変数$X$の分散($\sum$(パンの重さ-全体のパンの重さの平均)$^2$×その重さのパンの出現確率)
確率変数の期待値と分散の四則演算を導出する上で、下記では互いに独立な確率変数$X$と$Y$を仮定することとします。XとYが互いに独立とは$f(x_i,y_j)=f(x_i)×f(y_j)$が成り立ち、$x_i$の発生確率と$y_i$の発生確率に関係性がないということです。例えば、ある日無造作に選んで買うパンの重みは互いに独立と考えることができます。
➀「確率変数$X$+確率変数$Y$」の期待値
確率変数$X$に確率変数$Y$を足した確率変数$X+Y$の期待値を求めていきます。\begin{align} E(X+Y)&=\sum_{j,k}(x_j+y_k)f(x_j,y_k)\\ &=\sum_{j,k}x_jf(x_j,y_k)+\sum_{j,k}y_kf(x_j,y_k)\\ &=\sum_{j}x_jf(x_j)\sum_{k}f(y_k)+\sum_{k}y_kf(y_k)\sum_{j}f(x_j)\\ &=\sum_{j}x_jf(x_j)+\sum_{k}y_kf(y_k)\\ &=E(X)+E(Y) \end{align}3行目の式は$X$と$Y$それぞれの周辺確率(それぞれ$X$と$Y$の影響を排除した確率)と呼ばれるものになっています。最終的に確率変数$X+Y$の期待値は、$X$と$Y$それぞれの期待値を足しただけのものとなりました。引き算では符号が変わるだけです。
➁「確率変数$X$×確率変数$Y$」の期待値
確率変数$X$と確率変数$Y$をかけあわせた確率変数$X×Y$の期待値を求めていきます。$\sum_{j,k}$の意味としては、取りえる全ての$j$と$k$において値を足し合わせる全探索のようなイメージが理解しやすいと思います。\begin{align} E(X×Y)=&\sum_{j,k}\bigl(x_jy_kf(x_j,y_k)\bigr)\\ =&x_1y_1f(x_1,y_1)+x_1y_2f(x_1,y_2)+・・・+x_1y_nf(x_1,y_n)\\ &+x_2y_1f(x_2,y_1)+x_2y_2f(x_2,y_2)・・・+x_2y_nf(x_2,y_n)\\ &・・・\\ &+x_my_1f(x_m,y_1)+x_my_2f(x_m,y_2)・・・+x_my_nf(x_m,y_n)\\ =&x_1f(x_1)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ &+x_2f(x_2)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ &・・・\\ &+x_mf(x_m)\bigl(y_1f(y_1)+y_2f(y_2)+・・・y_nf(y_n)\bigr)\\ =&\sum_{j}x_jf(x_j)\sum_{k}y_kf(y_k)\\ =&E(X)E(Y) \end{align}確率変数$X×Y$の期待値は、確率変数$X$と$Y$の期待値をかけあわせただけのものになりました。割り算では$Y$の代わりに$1/Y$という確率変数を使えばよいです。
➂「確率変数$X$×定数$a$」の期待値
確率変数$X$に定数aをかけた確率変数$a×X$の期待値を求めていきます。\begin{align} E(a×X)&=\sum_{j}\bigl(a(x_j)f(x_j)\bigr)\\ &=ax_1f(x_1)+ax_2f(x_2)・・・\\ &=aE(X) \end{align}定数をかけただけの式となりました。割り算は定数$a$を$1/a$とするだけです。
➃「確率変数$X$+確率変数$Y$」の分散
確率変数$X$と確率変数$Y$を足した確率変数$X+Y$の分散を求めていきます。
便宜上、確率変数$X$の期待値は$E(X)=μ_{X}$として表します。\begin{align} V(X+Y)=&\sum_{j,k}\bigl(x_j+y_k-(μ_X+μ_Y)\bigr)^2f(x_j,y_k)\\ =&\sum_{j,k}\bigl(x_j^2+y_k^2+μ_X^2+μ_Y^2+2x_jy_k-2x_jμ_X-2x_jμ_Y-2y_kμ_X-2y_kμ_Y+2μ_Xμ_Y\bigr)f(x_j,y_k)\\ =&\sum_{j,k}\bigl(x_j-μ_X\bigr)^2f(x_j,y_k)+\sum_{j,k}\bigl(y_k-μ_Y\bigr)^2f(x_j,y_k)+2\sum_{j,k}\bigl(x_j-μ_X\bigr)\bigl(y_k-μ_Y\bigr)f(x_j,y_k)\\ =&\sum_{j}\bigl(x_j-μ_X\bigr)^2f(x_j)+\sum_{k}\bigl(y_k-μ_Y\bigr)^2f(y_k)+2\sum_{j}\bigl(x_j-μ_X\bigr)f(x_j)\sum_{k}\bigl(y_k-μ_Y\bigr)f(y_k)\\ =&V(X)+V(Y) \end{align}確率変数$X+Y$の分散は確率変数$X$と$Y$の分散を足し合わせただけの式となりました。ちなみに3行目の第3項目は$X$と$Y$の相関性を表す共分散という統計量で、$X$と$Y$が独立ではない場合は0とはならないので、分散に考慮する必要が出てきます。
➄「確率変数$X$×確率変数$Y$」の分散
確率変数$X$に確率変数$Y$をかけた確率変数$X$×$Y$の分散を求めていきます。\begin{align} V(X×Y)=&\sum_{j,k}\bigl(x_jy_k-μ_Xμ_Y\bigr)^2f(x_j,y_k)\\ =&\sum_{j,k}\bigl((x_jy_k)^2-2x_jy_kμ_Xμ_Y+(μ_Xμ_Y)^2\bigr)f(x_j,y_k)\\ =&\sum_{j,k}(x_jy_k)^2f(x_j,y_k)-μ_Xμ_Y\sum_{j,k}2x_jy_kf(x_j,y_k)+(μ_Xμ_Y)^2\\ =&\sum_{j,k}(x_jy_k)^2f(x_j,y_k)-2(μ_Xμ_Y)^2+(μ_Xμ_Y)^2\\ =&\sum_{j}x_j^2f(x_j)\sum_{k}y_k^2f(y_k)-(μ_Xμ_Y)^2 \\ =&E(X^2)E(Y^2)-(μ_Xμ_Y)^2\\ =&\bigl(V(X)+μ_X^2\bigr)\bigl(V(Y)+μ_Y^2\bigr)-(μ_Xμ_Y)^2 ※V(X)=\sum_{k}(x_k-μ_X)^2f(x_k)=E(X^2)-μ_X^2\\ =&V(X)V(Y)+μ_Y^2V(X)+μ_X^2V(Y) \end{align}確率変数$X×Y$の分散は、確率変数$X$と$Y$の期待値と分散を使って$V(X)V(Y)+μ_Y^2V(X)+μ_X^2V(Y)$となります。期待値のように単純に$V(X×Y)=V(X)V(Y)$とはならないので注意が必要です。
➅「確率変数$X$×定数$a$」の分散
確率変数$X$に定数aをかけた確率変数$a×X$の分散を求めていきます。\begin{align} V(a×X)=&\sum_{j}(ax_j-μ_{ax})^2f(x_j)\\ =&(ax_1-aμ_x)^2+(ax_2-aμ_x)^2+(ax_3-aμ_x)^2+・・・\\ =&a^2\sum_{j}(x_j-μ_{x})^2f(x_j)\\ =&a^2V(X) \end{align}確率変数を$a$倍すると分散は$a^2$倍となるので注意が必要です。
次回
次回は今回導出した統計の四則演算の公式を用いて、冒頭で示した図のように実際にパンの重みの分布を区間推定していくことに取り組みます。
参考
Pythonで理解する統計解析の基礎
Pythonで学ぶ統計検定2級の確率分布①
腑に落ちない人のための不偏性と一致性の解説
[統計学]t-分布、大数の法則、中心極限定理
- 投稿日:2020-08-06T16:04:00+09:00
【python】【scikit-learn】k-最近傍法入門メモ
Scikit-learnの学習メモ
scikit-learnの命名規則
文字 意味 X データ y ラベル train_test_split関数
データ(X, y)をトレーニング用・評価用に分割する関数
分割を行う前に擬似乱数を用いてデータセットをシャッフルする。データポイントはラベルでソートされているので、最後の25%をテストセットにすると,全てのデータポイントがラベル2(1つの値)になってしまうような事態を避けるため。
train_test_split関数でデータ分割
乱数のシードjupyter_notebook.ipynbtrain_test_split( 第一引数: 特徴行列X, 第二引数: 目的変数y, test_size(=0.3): テスト用のデータの大きさの割合, random_state= : データを分割する際の乱数のシード値) random_state=0とすると、出力が決定的になり、常に同じ結果が得られるようになる。(勉強用) from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( iris_dataset['data'], iris_dataset['target'], random_state=0)pandas.DataFrame
pandas.DataFrameimport pandas as pd #リファレンス pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False) #例 iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)出力結果
pandas.plotting.scatter_matrix
pandas.plotting.scatter_matrix
pandas.plotting.scatter_matrix#公式リファレンス pandas.plotting.scatter_matrix(frame, alpha=0.5, figsize=None, ax=None, grid=False, diagonal='hist', marker='.', density_kwds=None, hist_kwds=None, range_padding=0.05, **kwargs) #iris例 iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names) grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(8, 8), marker='o',hist_kwds={'bins' : 20}, s=60, alpha=.8)出力結果
scikit-learnは常に2次元配列
scikit-learnX_new = np.array([[5, 2.9, 1, 0.2]])sklearn.neighbors.KNeighborsClassifier
k-最近傍法によるクラス分類sklearn.neighbors.KNeighborsClassifier
neighbors.KNeighborsClassifier#大切なメソッド .fit(X, y) #Xを学習データ、yを目標値としてモデルを適合させる .predict(X) #提供されたデータのクラスラベルを予測します。 .score(X, y) #与えられたテストデータとラベルの平均精度を返します。
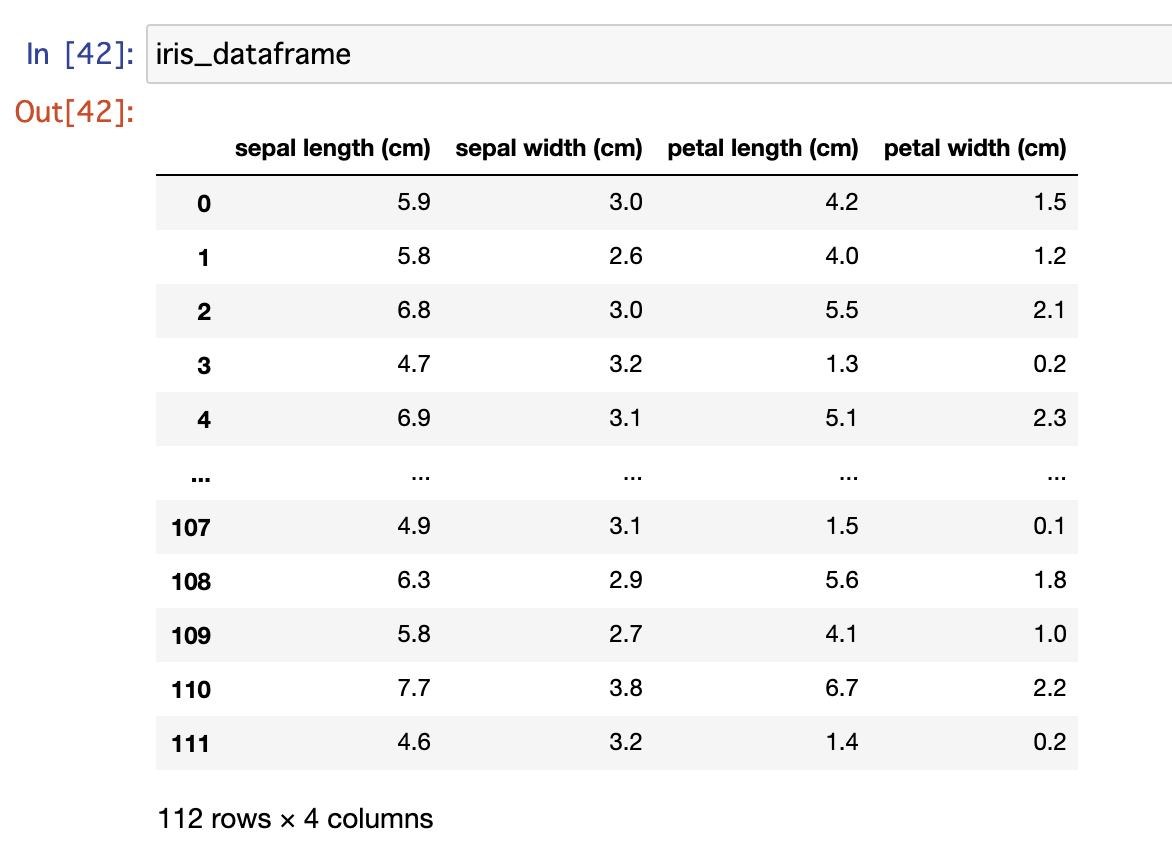
- 投稿日:2020-08-06T14:57:34+09:00
物体検出のYOLOv5やーる
はじめに
物体検出のYOLOv5をやってみます。
開発環境
- Windows10
- Python 3.6
- PyTorch 1.5.1
導入
1.ここからクローンします。
2.YOLOv5環境を作成します。
conda create -n yolov5 python=3.6 conda activate yolov5 cd yolov53.各ライブラリをインストールします。
先にPyTorchをインストールします。
pip install torch===1.5.1 torchvision===0.6.1 -f https://download.pytorch.org/whl/torch_stable.html次にrequirements.txtからライブラリをインストールします。
pip install -U -r requirements.txt実行
下記コマンドを実行し、ウェブカメラの映像を入力します。
python detect.py --source 0SnapCameraなどにウェブカメラを占有される場合は、utils/datasets.pyのLoadStreamsクラス237行目の
cap = cv2.VideoCapture(0 if s == '0' else s)の0のところを1などに変えてみてください。
cap = cv2.VideoCapture(1 if s == '0' else s)Object Detection VOLOv5#Python #OpenCV #AI #DeepLearning #機械学習 #PyTorch pic.twitter.com/iWYxNdnuWi
— 藤本賢志(ガチ本)@pixivFANBOXはじめました (@sotongshi) August 6, 2020ここから他のモデルをダウンロードし、下記の--weightsオプションでパスを指定し実行することも可能です。
python detect.py --source 0 --weights yolov5x.pt各モデルの比較はこちらの記事YOLO V5(V3との比較有)を簡単サクッと試す!が参考になります。
スノボーとスケボー、認識できていてすごい!!
動画ファイル(昔のiPhoneで撮ったmp4)を YOLOv5に。スノボとスキーを認識してる。 #ガチラボ pic.twitter.com/w7QNicwxiJ
— まこらぎ (@makoragi) July 28, 2020YoloV5、環境整えるのにscipyとweightを手動で入れるくらいで、まあまあすぐに動かせれた(といっても初心者な俺は2時間かかった…)。動いてよかった…
— 水たまりの水を飲んだことがある桟よしお (@katapad) July 26, 2020
v3に比べて軽いモデルでも精度が高い。リアルタイムでもいけんことなさそうやけど、他の手法と比べてどういう場面でアドバンテージあるかはわからん pic.twitter.com/pOAPrsM4b6動画ファイル(昔のWHILLハッカソンで撮ったmp4)を YOLOv5に。WHILLが椅子認識してる @sotongshi もしっかり認識してる。
— 組長@圧 (@kumi0708) July 28, 2020
#ガチラボ #WHILL pic.twitter.com/sDJgLt6f32お疲れ様でした。
- 投稿日:2020-08-06T14:17:33+09:00
【RaspberryPi】PythonのデフォルトをPython3に変更
はじめに
検証のため、会社でRaspberryPi zeroを購入し、セットアップしていました。
作成してあったPythonスクリプトを実行すると挙動がおかしい。確認せず実行している私も悪いですが、実行バージョンが2.7じゃないですか。
3.7が入っていることを確認していたので、そいつを実行していると思い込んでいました。備忘録として変更方法を記事にします。
デフォルトをPython3に!
バージョン確認
python --versionここで3系なら終わりです。私は2系なので続けます。
シンボリックリンク確認
ls -l /usr/bin/py*
pythonはpython2.7を使っていることがわかります。
リンクをPython3に変えてあげれば解決!!!シンボリックリンク解除
unlink pythonこれでまずpythonが参照していたpython2へのリンクが解除。
シンボリックリンク設定
ln -s python3 pythonpython3を参照するpythonのシンボリックリンクを作成。
ちゃんとリンクができていることが確認できます。再びPythonのバージョンを確認して変更できていれば成功!!!
(今回の場合、Python3.7.3になっています)最後に
こういう細かいこと(私的に)はすぐに忘れてしまう特性があります。
特に環境設定でどうやるんだっけか?となって、何度も同じことを調べている自分が。。。一人でやっていると疎かになりがちなので、気を付けようと思う今日この頃。。。
- 投稿日:2020-08-06T13:40:12+09:00
インスタンスセグメンテーションのYOLACTやーる(Windows10、Python3.7、CUDA10.0、Pytorch 1.2.0)
はじめに
リアルタイムインスタンスセグメンテーションのYOLACTをやってみます。
開発環境
- Windows 10
- Python 3.7
- CUDA 10.0
- PyTorch 1.2.0
導入
1.ここからクローンします。
2.YOLACT環境を作成します。
conda create -n yolact python=3.7 conda activate yolact cd yolact-master3.各ライブラリをインストールします。
requirements.txtを作成し、インストールします。requirements.txtcython # pytorch::torchvision # pytorch::pytorch >=1.0.1 # cudatoolkit # cudnn # pytorch::cuda100 matplotlib # git # to download COCO dataset # curl # to download COCO dataset # unzip # to download COCO dataset # conda-forge::bash # to download COCO dataset opencv-python pillow<7.0 # bug PILLOW_VERSION in torchvision, must be < 7.0 until torchvision is upgraded # pycocotools PyQt5 # needed on KDE/Qt envs for matplotlibpip install -r requirements.txtpycocotoolsをインストールします。I can't install cocoapi on Windows 10 #185
pip install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI"PyTorchをインストールします。PyTorch v1.2.0 CUDA 10.0
pip install torch==1.2.0 torchvision==0.4.0 -f https://download.pytorch.org/whl/torch_stable.html4.weightsフォルダを作成し、yolact_base_54_800000.pthをダウンロードして、置きます。
実行
下記コマンドを実行してみましょう。input_image.pngを変更して、任意の画像を指定してください。
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --image=input_image.png:output_image.png
input output 下記コマンドを実行し、ウェブカメラの映像を入力します。
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=0SnapCamera等にウェブカメラを占有されている場合は、--video=1などに変更してみてください。
処理速度は8.3fpsくらいでした。Real-Time Instance Segmentation YOLACT#YOLACT #Python #PyTorch #AI #機械学習 #DeepLearning pic.twitter.com/kXKGZ4ZckQ
— 藤本賢志(ガチ本)@pixivFANBOXはじめました (@sotongshi) August 6, 2020YOLACT++
YOLACT++を実行するためには、DCNv2をセットアップする必要がありますが、
cd external/DCNv2 python setup.py build developVisual Studioのエラーが出ました。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\include\crt/host_config.h(133): fatal error C1189: #error: -- unsupported Microsoft Visual Studio version! Only the versions 2012, 2013, 2015 and 2017 are supported! error: command 'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v9.0\\bin\\nvcc.exe' failed with exit status 2エラーの内容を見ると、CUDA9.0のパスが読まれており、しかもVisual Studio 2019には対応していないようです。CUDAのパス(システム環境変数)を10.0にしてみましたが、Visual Studio 2017が入っているのにもかかわらず、参照してくれない模様。Visual Studio 2019はアンインストールしたくないのであきらめることにします。
お疲れ様でした。

