- 投稿日:2020-08-06T23:31:08+09:00
AWS CLIのスニペットを公開
aws-cliは便利ですが、ちゃんと使うには些か慣れが入ります。これからaws-cliをばりばり使っていこうと思っている方向けに(&備忘録用に)普段自分が使っているaws-cilのスニペットを公開します。
EC2
- 対象のEC2インスタンスの情報を取得
aws ec2 describe-instances --instance-ids ${INSTANCE_ID}
- 最新のAmazon Linux2 AMI
aws ec2 describe-images --owners amazon --filters 'Name=name,Values=amzn2-ami-hvm-2.0.????????.?-x86_64-gp2' 'Name=state,Values=available' --query 'reverse(sort_by(Images, &CreationDate))[:1].ImageId' --output text
- インスタンスタイプを一覧表示
aws ec2 describe-instance-types --query 'sort_by(InstanceTypes[].{InstanceType:InstanceType, Hypervisor:Hypervisor, Memory:MemoryInfo.SizeInMiB},&Memory)' --output table
- インスタンスを一覧表示
aws ec2 describe-instances --query 'Reservations[].Instances[].{Name: Tags[?Key==`Name`].Value|[0], InstanceId: InstanceId, Status: State.Name, InstanceType:InstanceType}' --output tableSecurity Group
- SecurityGroupを一覧表示
aws ec2 describe-security-groups --query 'SecurityGroups[].{Name:GroupName, GroupId:GroupId, VpcId: VpcId}' --output tableCloudformation
- スタックを一覧表示
aws cloudformation list-stacks --query 'StackSummaries[].StackName'
- [スタックを指定]スタックのステータスを確認
aws cloudformation describe-stacks --stack-name ${STACK_NAME} --query 'Stacks[].{StackName: StackName, StackStatus: StackStatus}' --output tableVPC
- VPCを一覧表示
aws ec2 describe-vpcs --query 'Vpcs[].{Name: Tags[?Key==`Name`].Value|[0], VpcId:VpcId}' --output table
- Subnetを一覧表示
aws ec2 describe-subnets --query 'Subnets[].{Name:Tags[?Key==`Name`].Value|[0], SubnetId:SubnetId}|sort_by(@,&Name)' --output tableIAM
- インスタンスプロファイルを一覧表示
aws iam list-instance-profiles --query 'InstanceProfiles[].{Name: InstanceProfileName, Arn:Arn}' --output tableSSM
- SSM接続可なインスタンスを一覧表示
aws ec2 describe-instances --query 'Reservations[].Instances[?State.Name==`running`][].{Name: Tags[?Key==`Name`].Value|[0], InstanceId: InstanceId}' --output textALB
- ALB名とDNS名を一覧表示
aws elbv2 describe-load-balancers --query "LoadBalancers[].{Name: LoadBalancerName, DNSName:DNSName}" --output table
- 投稿日:2020-08-06T22:51:32+09:00
[AWS] Cloud9でモブプログラミングの環境を作ってみる
Cloud9とは
AWSが提供するクラウドベースのIDEです。
操作はすべてブラウザで完結させることができ、AWS上で実行するサービスの開発や、各種サービスとの親和性も、当然ながら非常に高いのが特徴です。料金
Cloud9そのものに関しては特別な料金はかかりませんが、Cloud9が接続するEC2と、EC2のストレージであるEBSに対して課金が発生します。
当然、インスタンスタイプが高性能なものほど、料金は高くなります。
しかし、一定の時間が経つとEC2インスタンスを停止させるオプションなどもあるので、使い方を工夫することで料金を抑えることはできそうです。モブプログラミングとは
モブプログラミングは、簡単に書くと、複数人で同じ画面をみながらコーディングを進める開発手法です。
役割として、ドライバー(コードを書く人)と、ナビゲーター(指示者)にわかれ、ナビゲーターの指示や意見を元に、ドライバーがコードを書いていきます。
また、役割は10分や15分といった、時間を決めて持ち回るため、タイムキーパーや、モブプログラミング向けのツール(時間計測)を用いることがあります。モブプログラミング、つまりコードをシェアしながら編集するIDEは、MicrosoftのVisual Studio Live Shareが有名ですが、今回は、AWSのCloud9でも出来るんだよ、というこをお伝えしたいと思います。
環境設定
モブプログラミングに参加するアカウントの作成
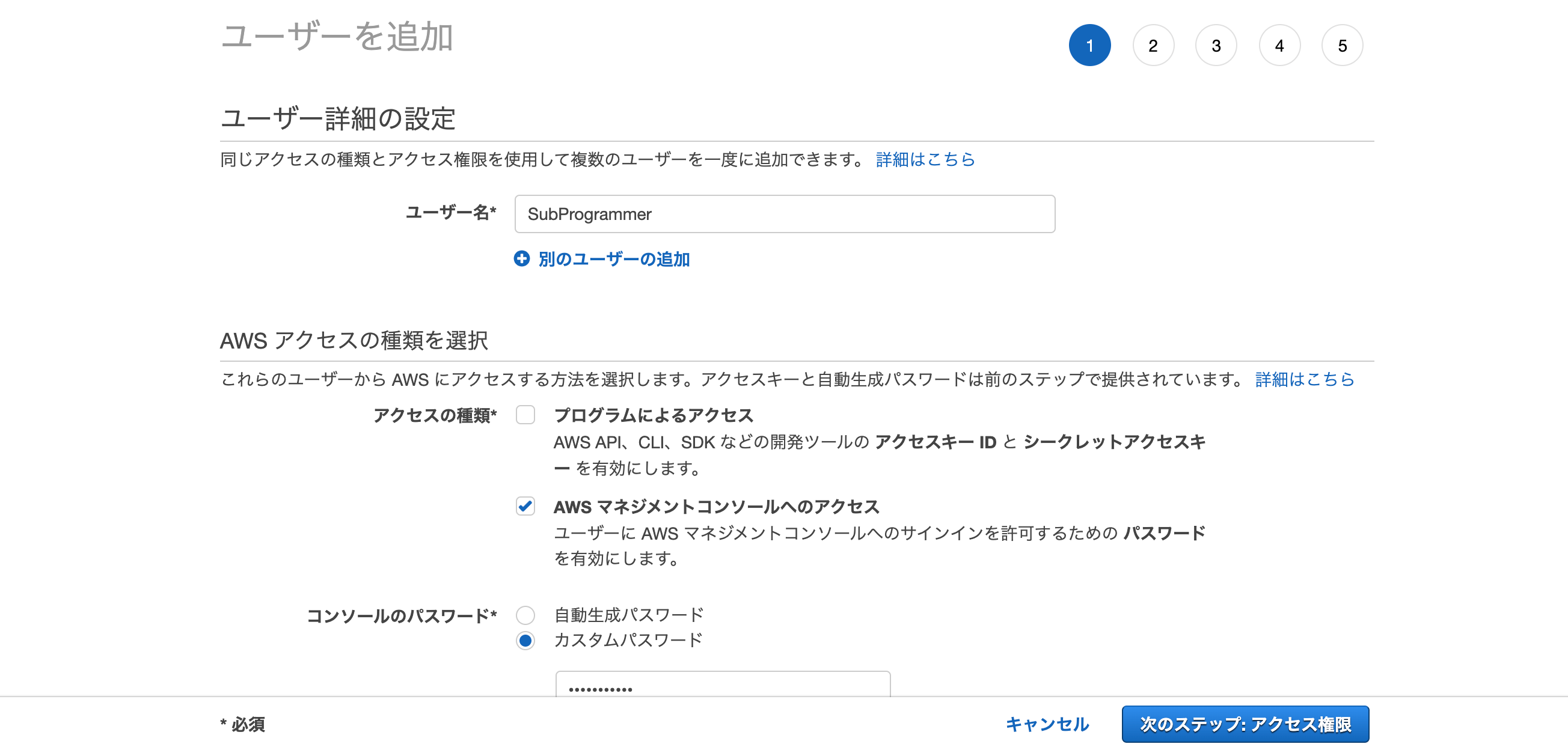
まず、IAMユーザで作成する必要があります。
今回は、わかりやすく「SubProgrammer」という名前のIAMユーザを作成してみます。
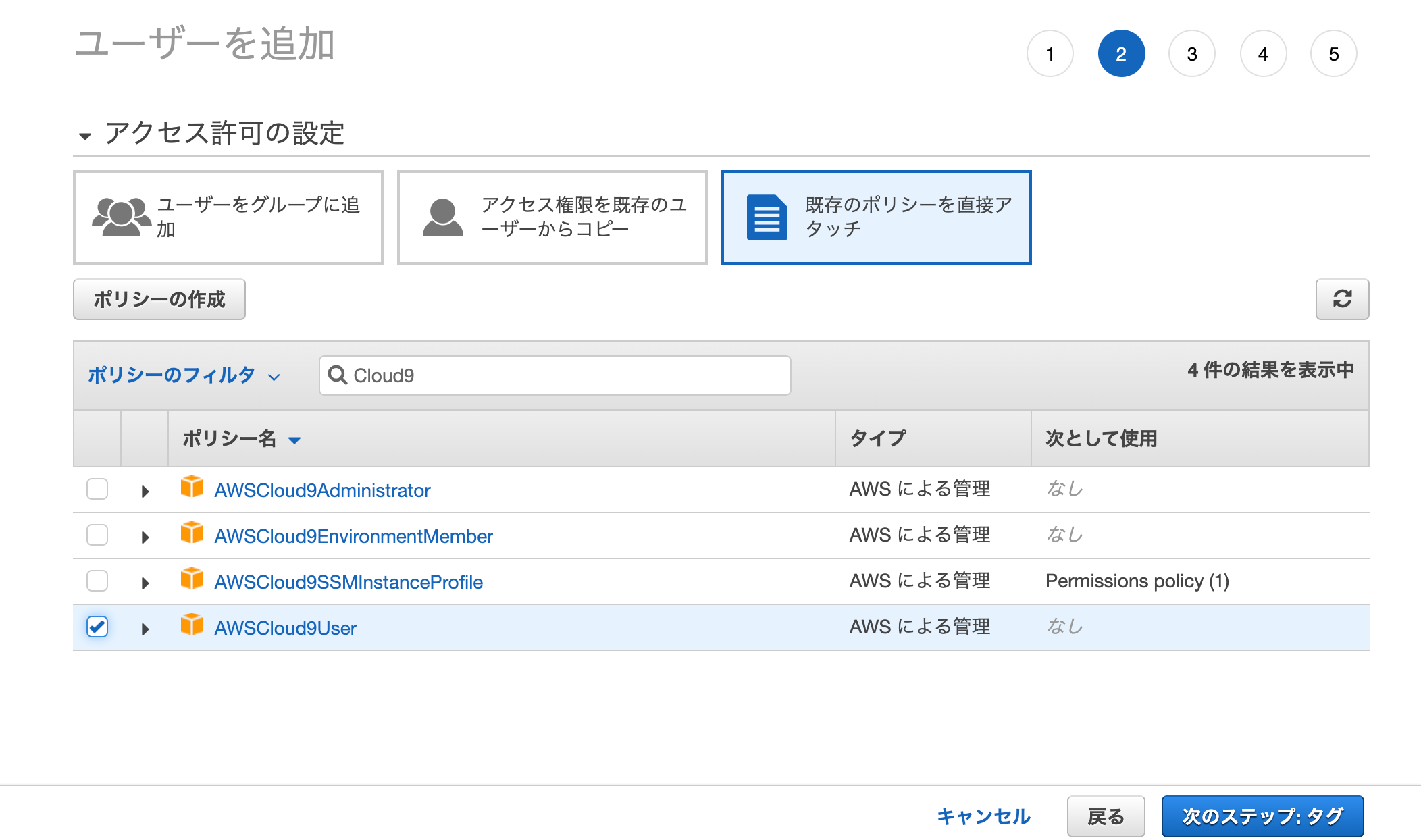
そしてポリシーには既存の「AWSCloud9User」をセットしてください。
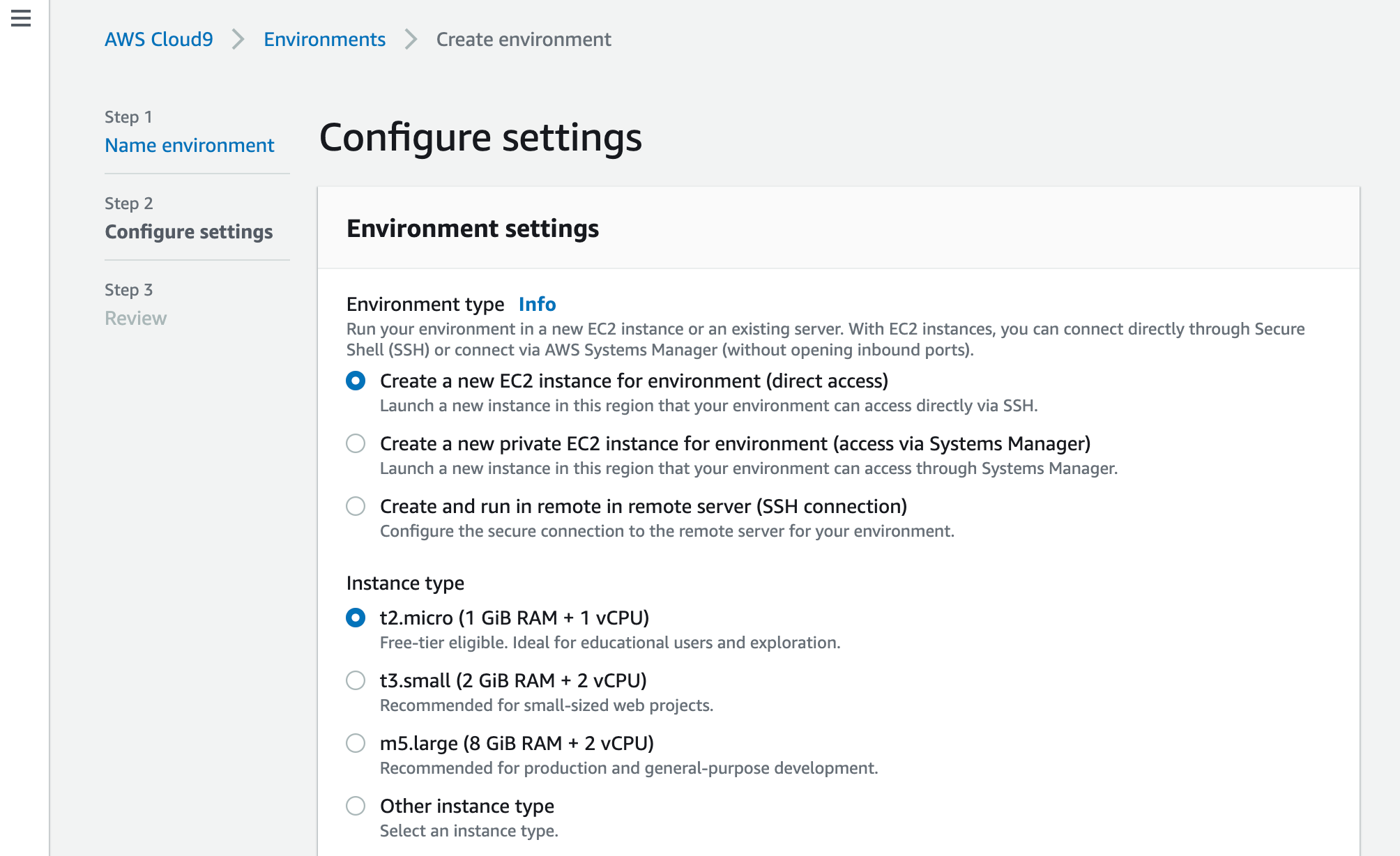
Cloud9の環境作成
続いてメインアカウント側で、Cloud9の環境を作成します。
まずは、サービス一覧より「Cloud9」を選択します。
そして「Create environment」ボタンを押します。
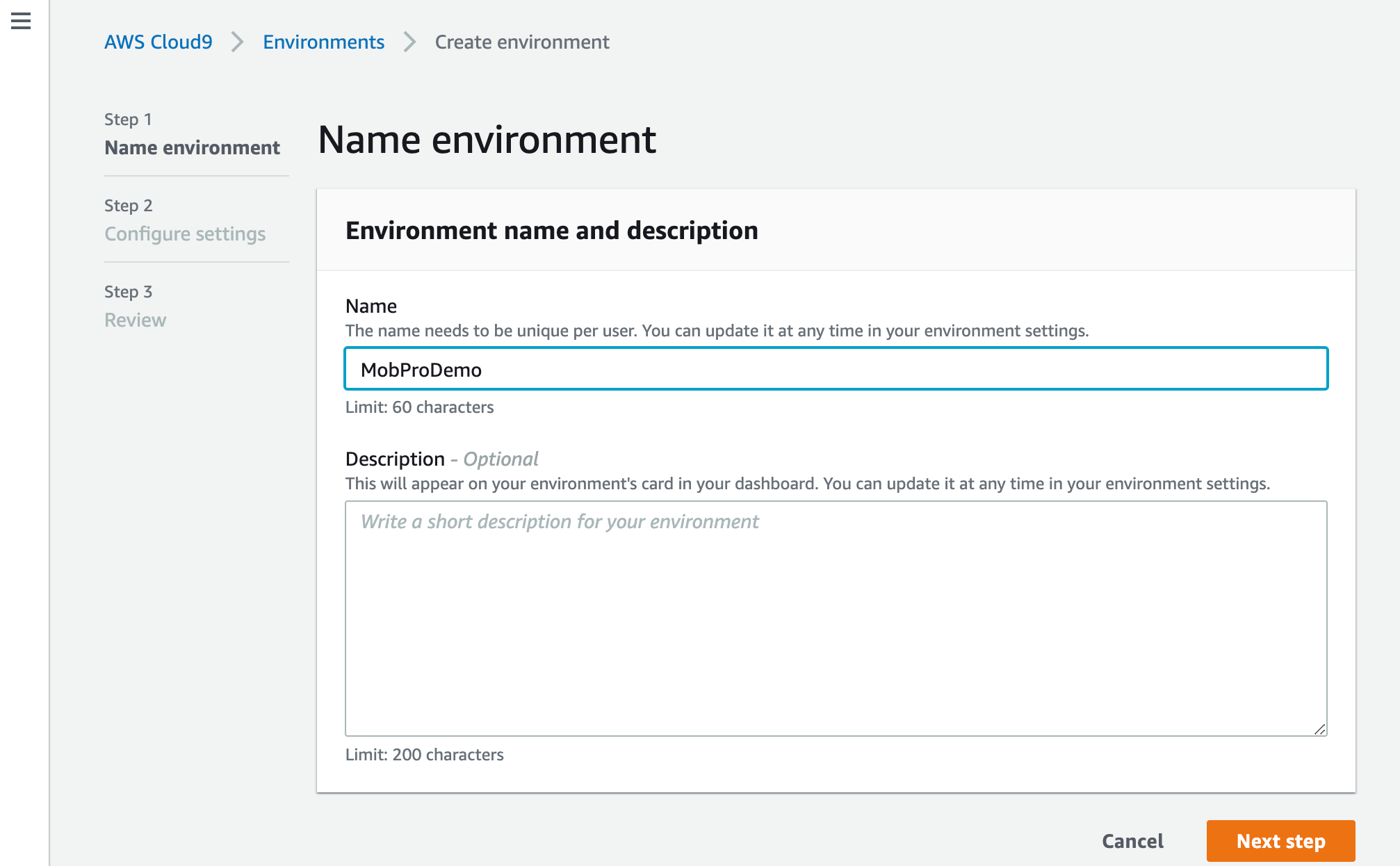
環境名を設定します。
続いて、接続・動作確認のためのEC2インスタンスの情報を入力します。
ここはいったん、デフォルトのままで進めます。
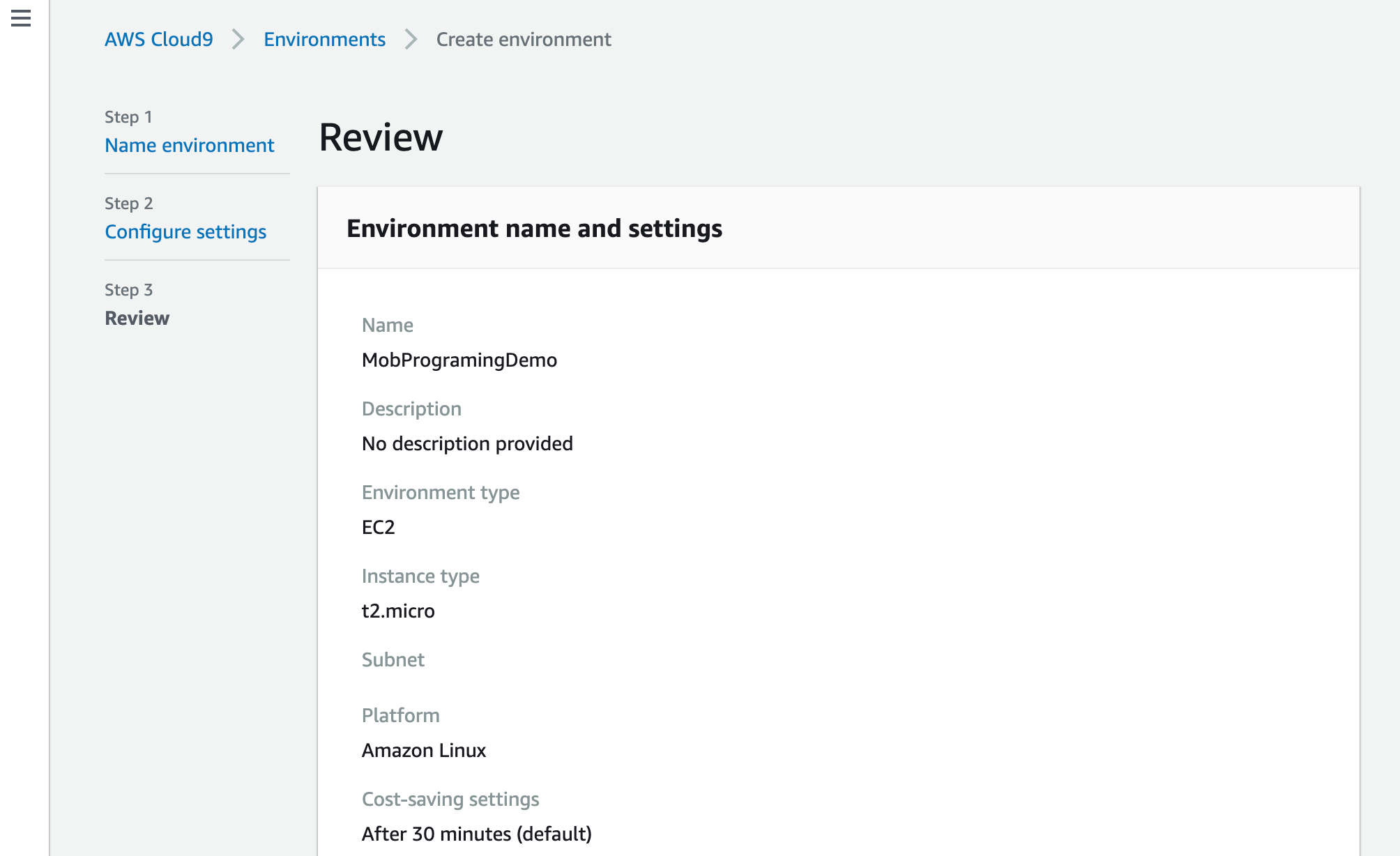
確認画面で確認して、環境を作成します。
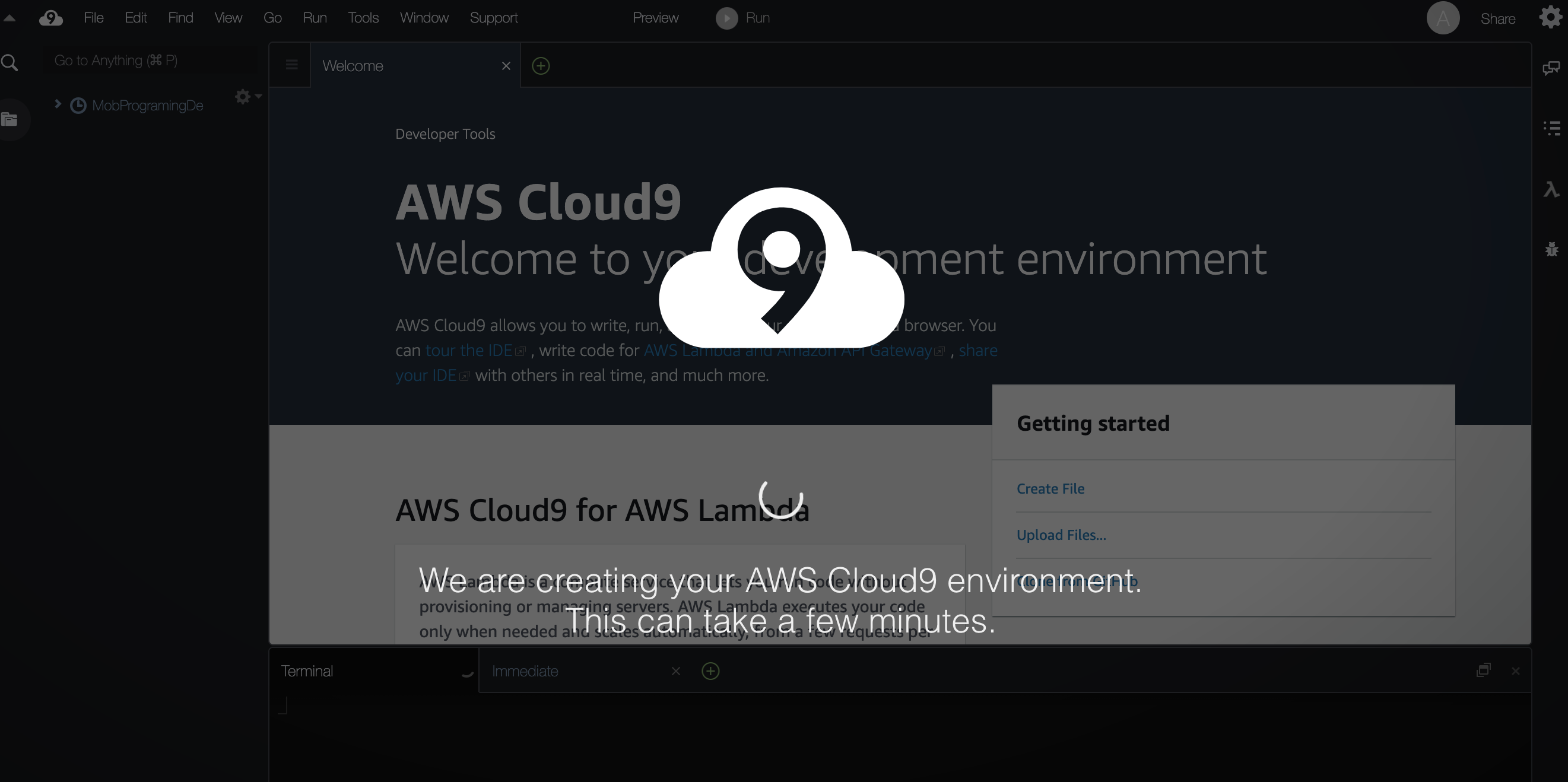
ECインスタンスを生成するので、少し時間がかかります。
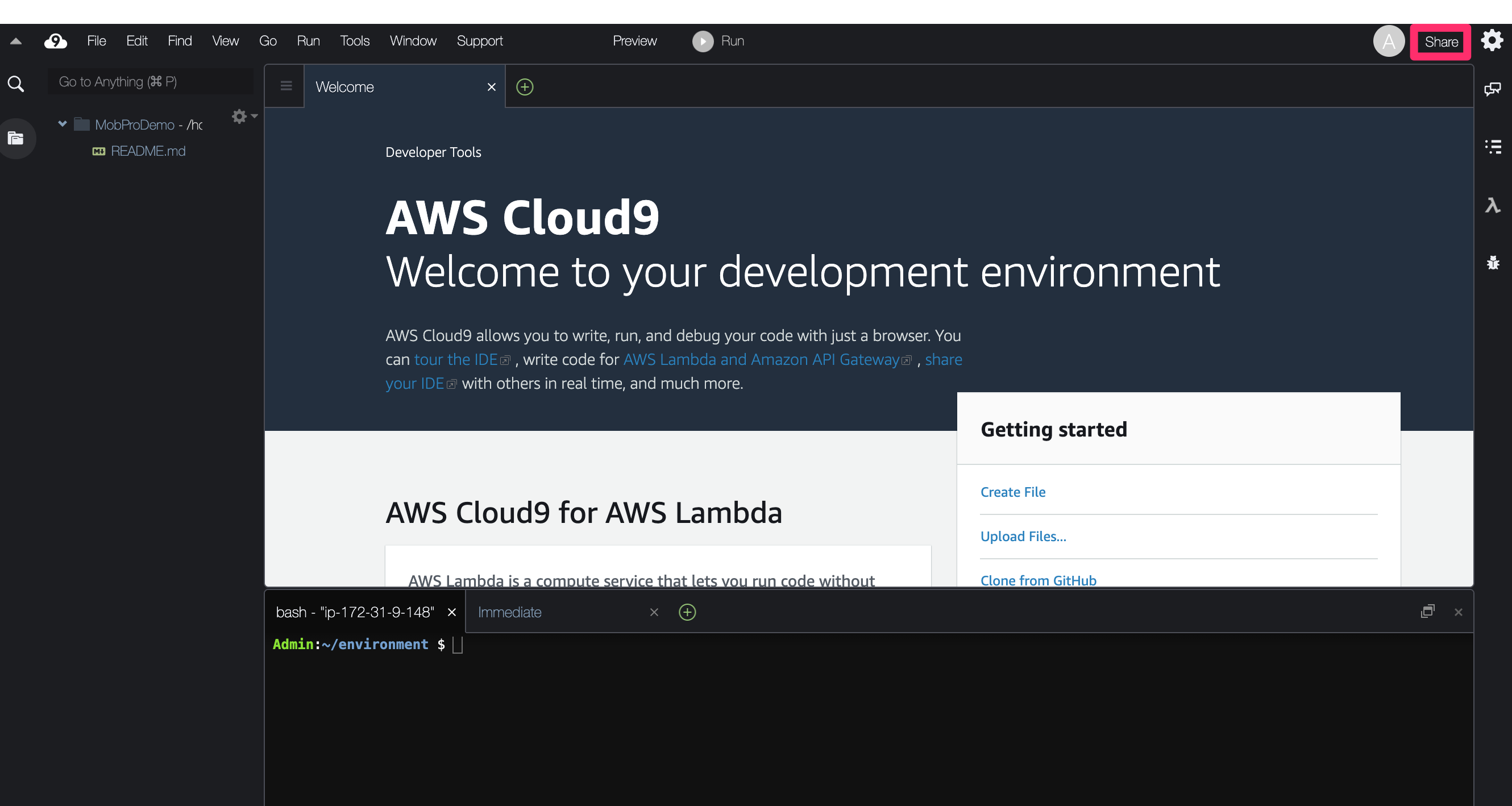
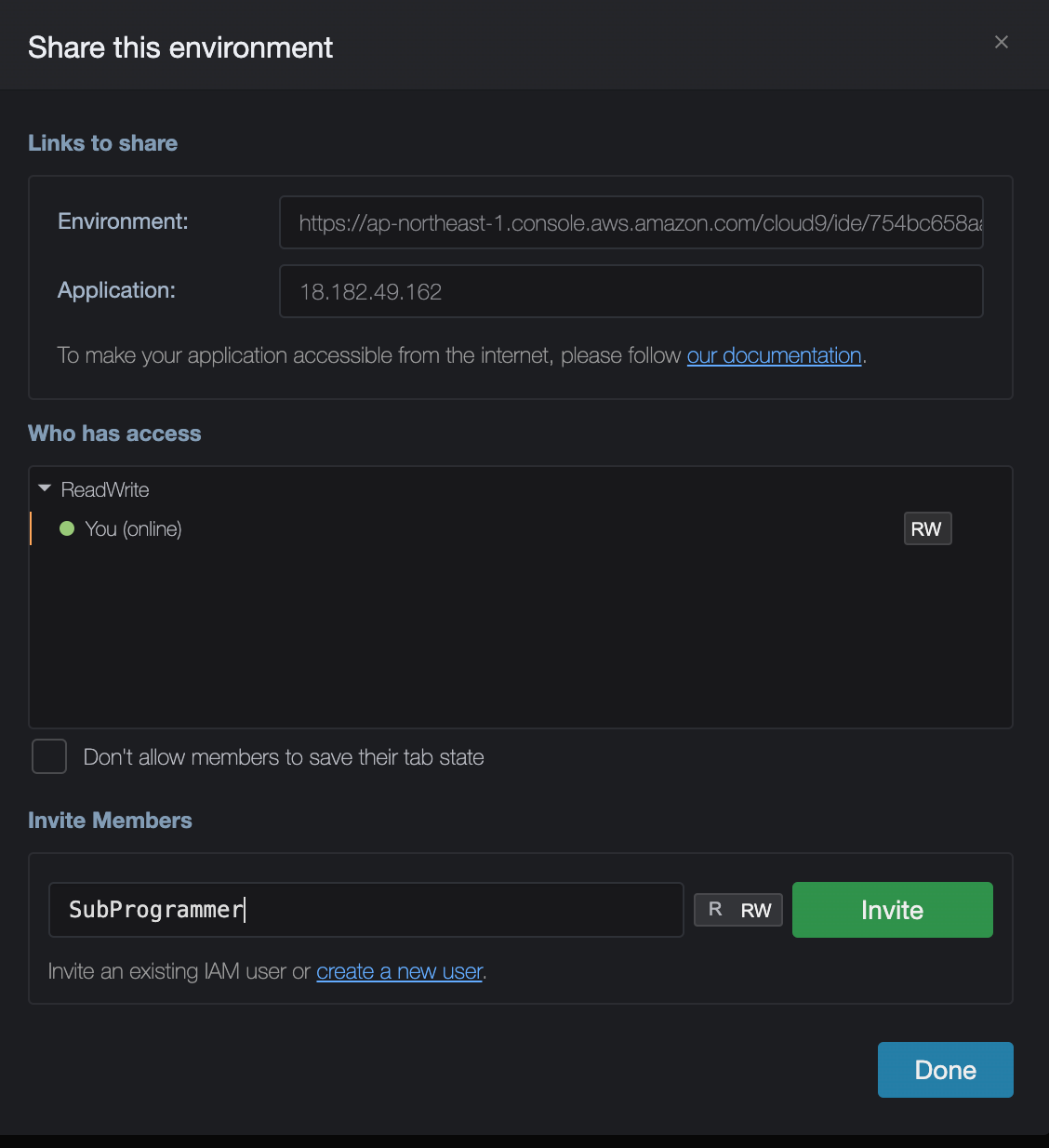
プロジェクトに参加するユーザを追加する
画面右上にある「Share」リンクをクリックします。
ここで、モブプログラミングに参加させたいアカウントを追加します。
実際にコードを書かせないユーザには、権限を「R」のみにして書き込み権限を与えないようにしましょう。
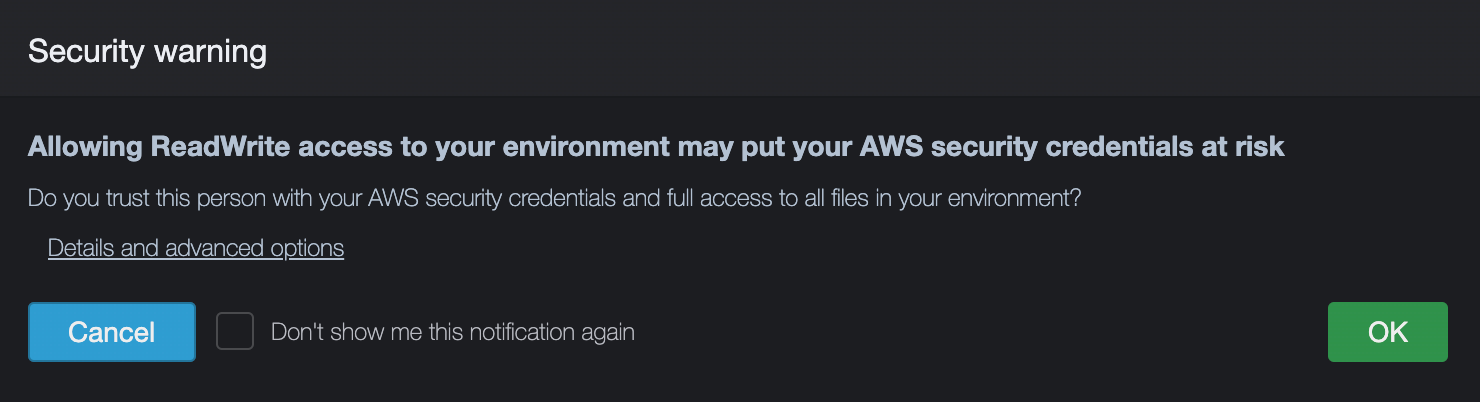
確認画面が表示されるので、そのまま「OK」を押すと、ユーザが自身のCloud9環境に参加できるようになります。
プロジェクトの初期化
このCloud9に接続されるEC2は、Amazon Linuxで、開発に必要なコマンドが予めインストールされています。
Admin:~/environment $ aws --version aws-cli/1.18.104 Python/3.6.10 Linux/4.14.186-110.268.amzn1.x86_64 botocore/1.17.27 Admin:~/environment $ sam --version SAM CLI, version 0.38.0 Admin:~/environment $ cdk --version 1.54.0 (build c01b9b9) Admin:~/environment $さらにはgitも。
Admin:~/environment $ git --version git version 2.14.5で、今回は、SAMでHello Worldな環境を作成しようと思います。
Admin:~/environment $ sam init : ----------------------- Name: sam-app Runtime: python3.7 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./sam-app/README.mdこれで、SAMの環境ができました。
参加アカウント側の操作
続いて、参加するアカウント(SubProgrammer)ですが、まずは普通にマネジメントコンソールにログインします。
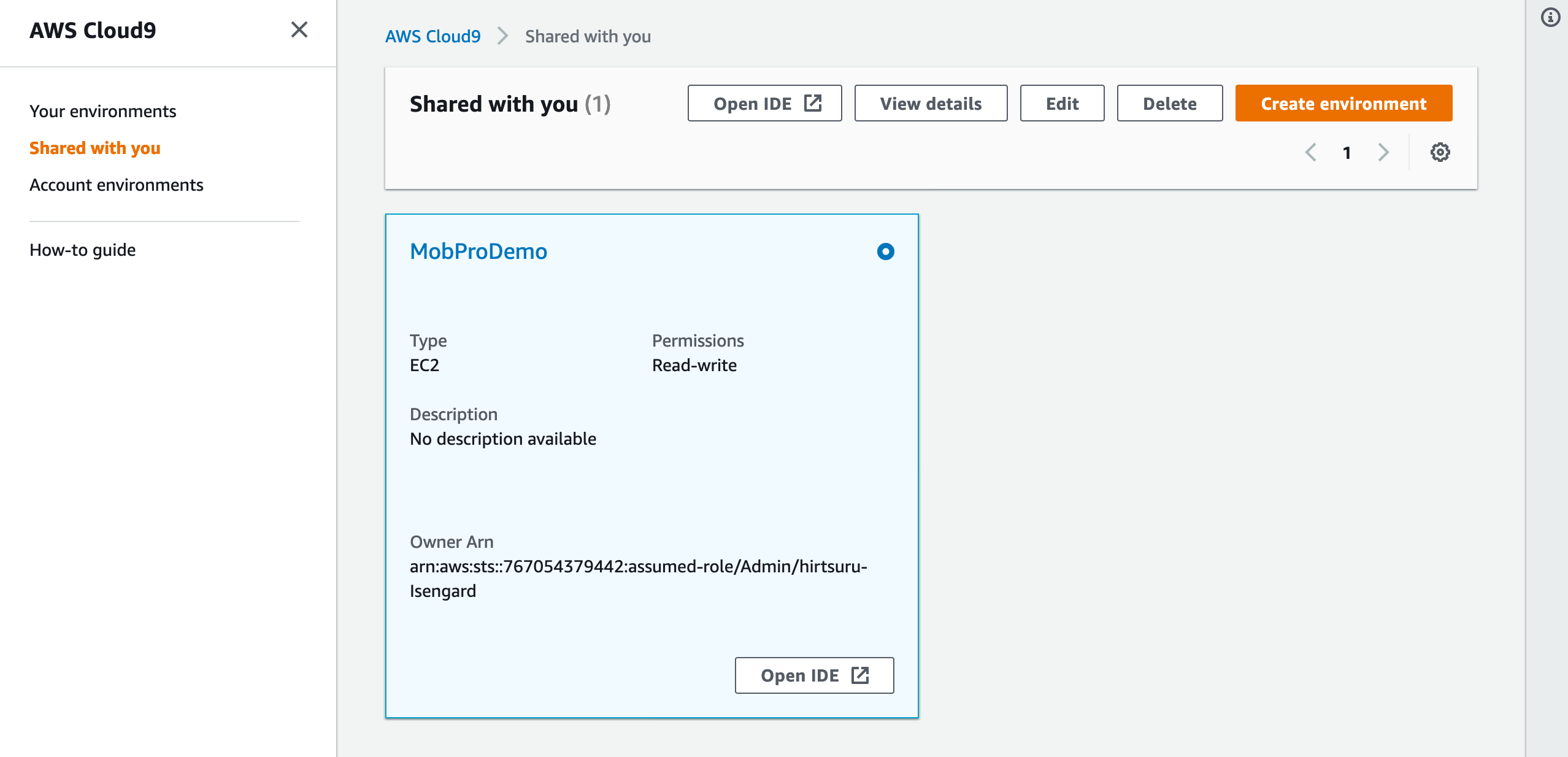
そして、サービスより「CLoud9」を選択します。ここで、左側のメニューより「Shared with you」を選択します。
メインアカウントより追加された環境が表示されるので、その環境の「Open IDE」ボタンを押します。
すると、メインアカウントで先ほど追加したSAMのプロジェクトファイルが追加された状態の画面が表示されます。
画面の同期
通常のままだと、個々に画面が表示されているだけの状態になります。
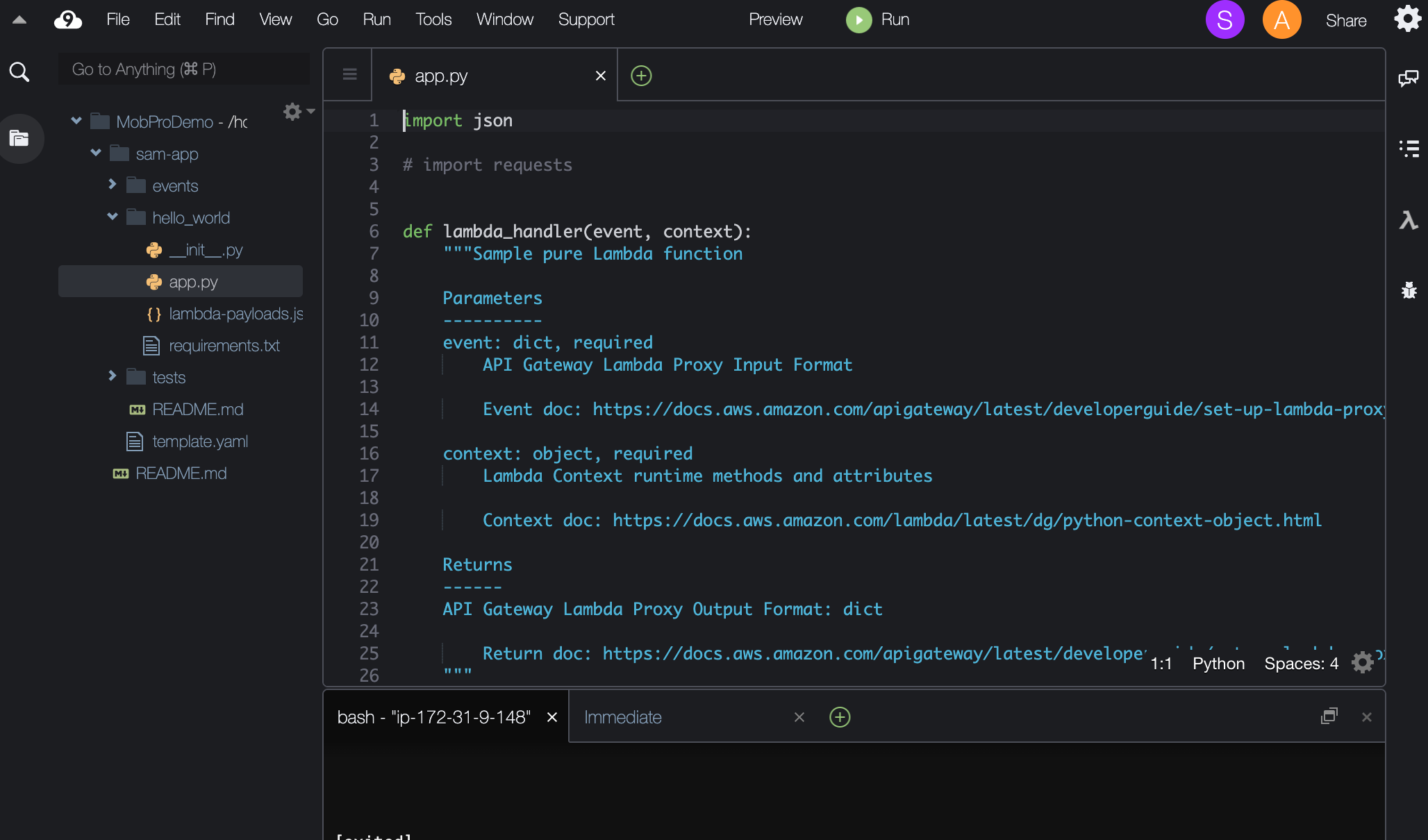
そこで、まずメインアカウント側でMobProDemo / sam-app / hello_world / app.pyを開いてみましょう。
実は、このままの状態だと、サブアカウント側で同じファイルが画面に表示されません。
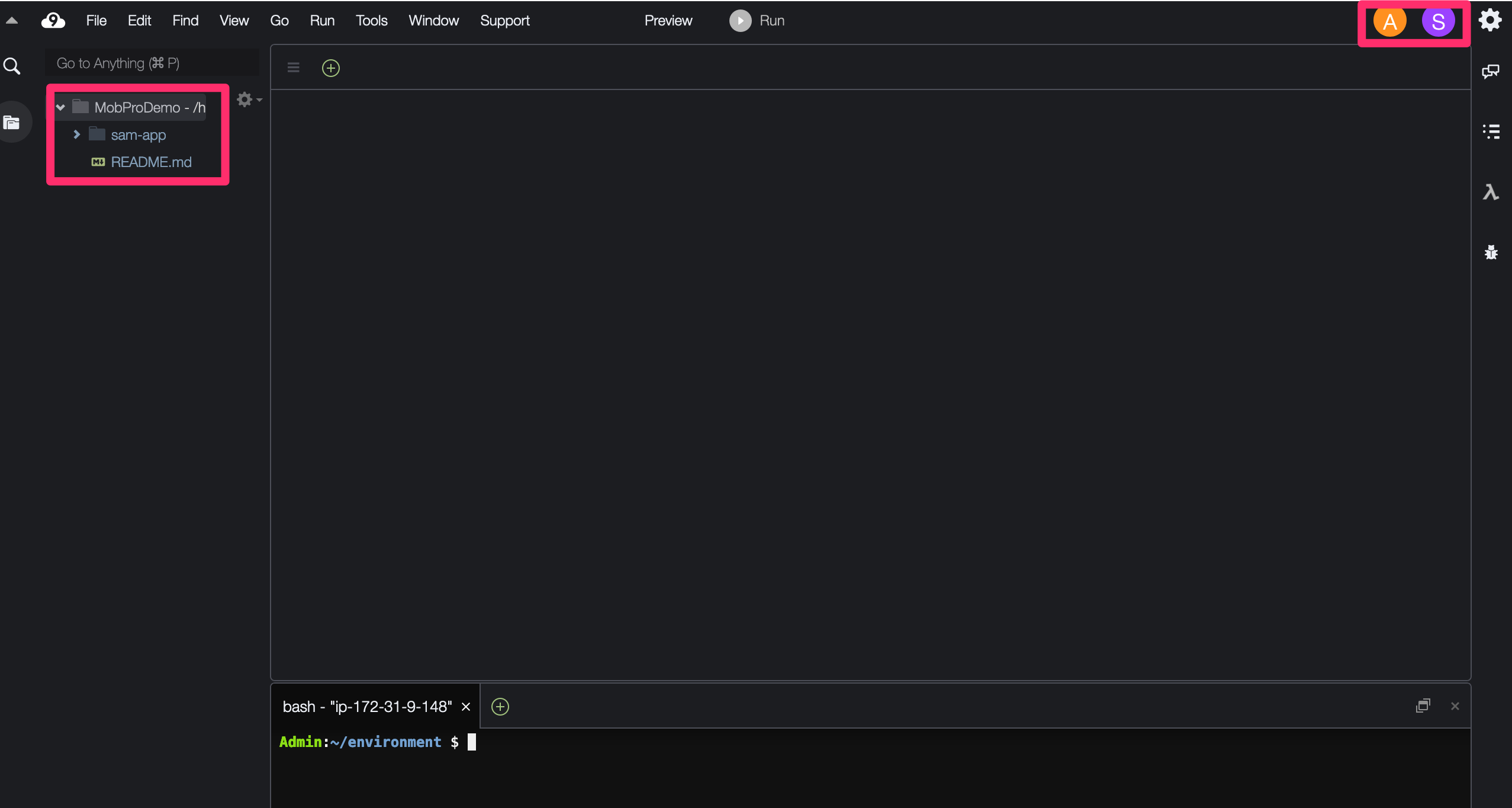
サブアカウント側では、画面丈夫にある「A」(これはユーザの頭文字を表すもので「A」は「Admin = 管理者」、「S」は「SubProgrammer = 自分」を意味します。
この「A」をクリックして、「Open Active File」を選択します。
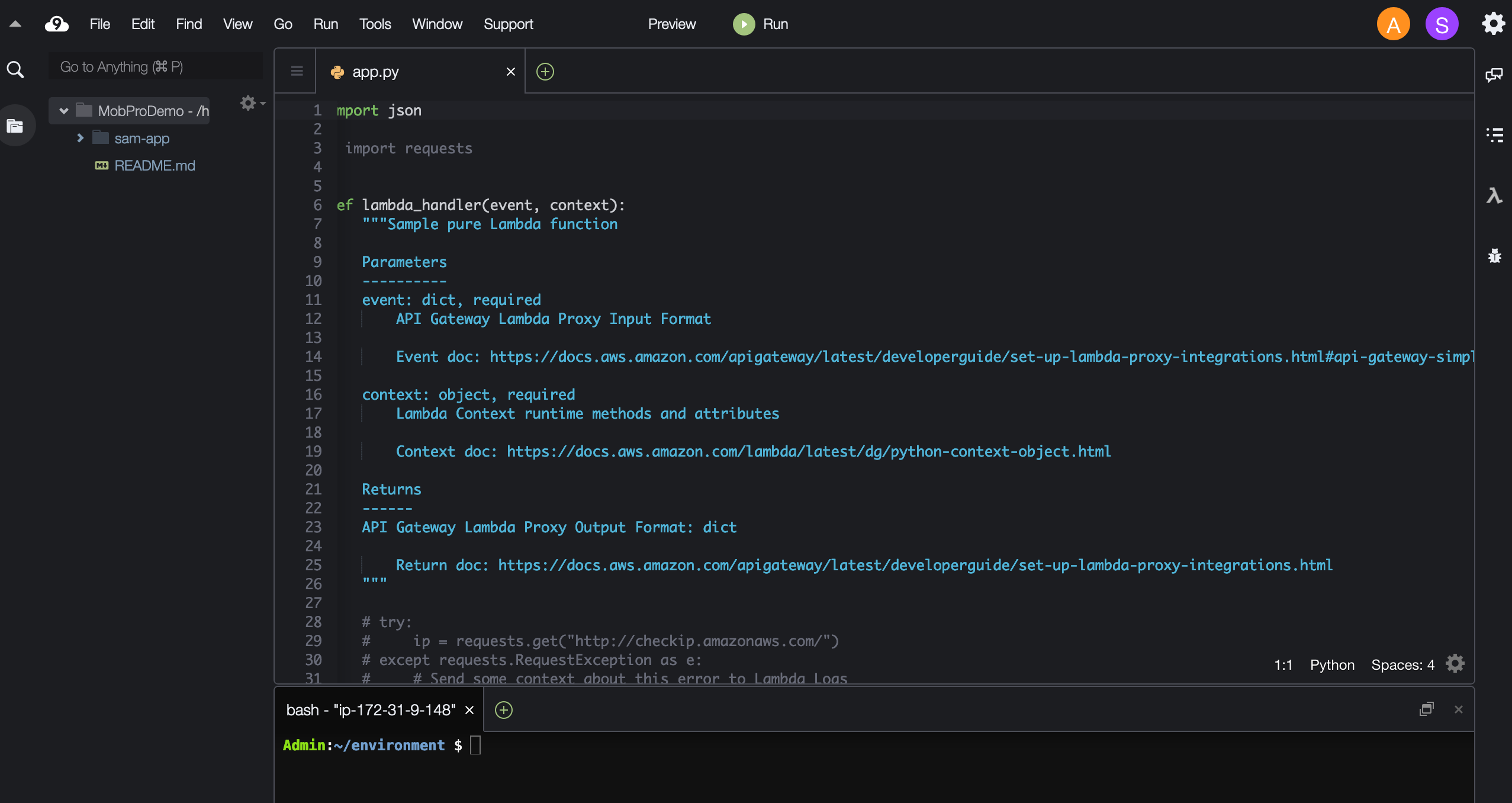
すると、メインアカウントで開いていた操作中のファイルが表示されます。
今回は、SubProgrammerにも書き込み権限を与えているので、SubProgrammerの画面でファイルを修正すると、リアルタイムに、メインアカウントの画面上で入力内容が反映されるようになります。
その逆もしかりです。まとめ
SAMや、CDKのコードをモブプログラミングで開発して、そのままCodeCommitにpushして、パイプライン経由でデプロイやプロビジョニングを走らせて、などといった一気通貫なAWS開発環境を作れるのは、なかなか魅力的だと思います。
それが、さらに画面を共有できることや、各種開発ツールのバージョンも、開発者全員で同期がとれるため、統一性のある開発環境を簡単に構築するためにも活用できるのではないかと思います。ブラウザのみで動作することが前提であるため、クライアント環境に依存しにくい一方で、インターネット回線が必要であったり、ブラウザによって動作が異なったり、あるいはネイティブアプリでないがゆえの高度な機能への対応が若干不足している感は否めません。
が、まだまだ延びしろの大きいIDEであると思いますので、今後の同行に注目してみましょう。

- 投稿日:2020-08-06T22:49:17+09:00
【CodePipeline×Elastic Beanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする、のエラーとその対応方法まとめ
JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする
で発生しうるエラーとその対応方法まとめです。環境
- OS:Windows10
- IDE:Eclipse 2020-03
- JDK:Amazon Correto 8
- フレームワーク:Spring Boot
- AWS
- CodePipeline
- CodeCommit
- CodeBuild
- CodeDeploy
- Elastic Beantalk
- Java SE(Java 8 バージョン 2.10.8)
→ ※2020年6月3日公開の最新版ではないです。ご了承を。- RDS:MySQL Community Edition(バージョン8.0.17)
エラーとその対策集
1. Elastic Beanstalk
(1) アクセス時に、502(Bad Gateway)エラーになる
設定内容を今一度確認しましょう。
【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その2
の「3. Elastic Beanstalk環境の作成」の「[2] 追加設定」を見直して、設定に漏れがないか確認してください。2. RDS
(1) データベースにアクセスできない
アクセス許可の設定を今一度確認しましょう。
【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その2
の「4. データベースの設定」の「[1] RDSにおける接続設定」の(4)~(9)辺りを見直して、漏れがないか確認してください。3. CodePipeline
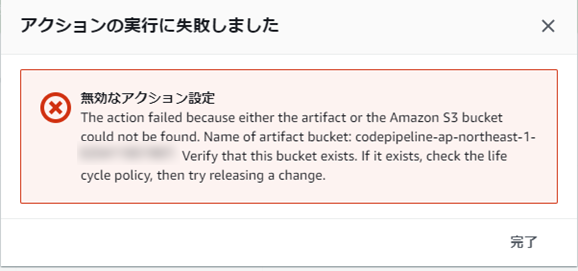
(1) デプロイ時に「The action failed because either the artifact or the Amazon S3 bucket could not be found. ・・・」エラーが出る
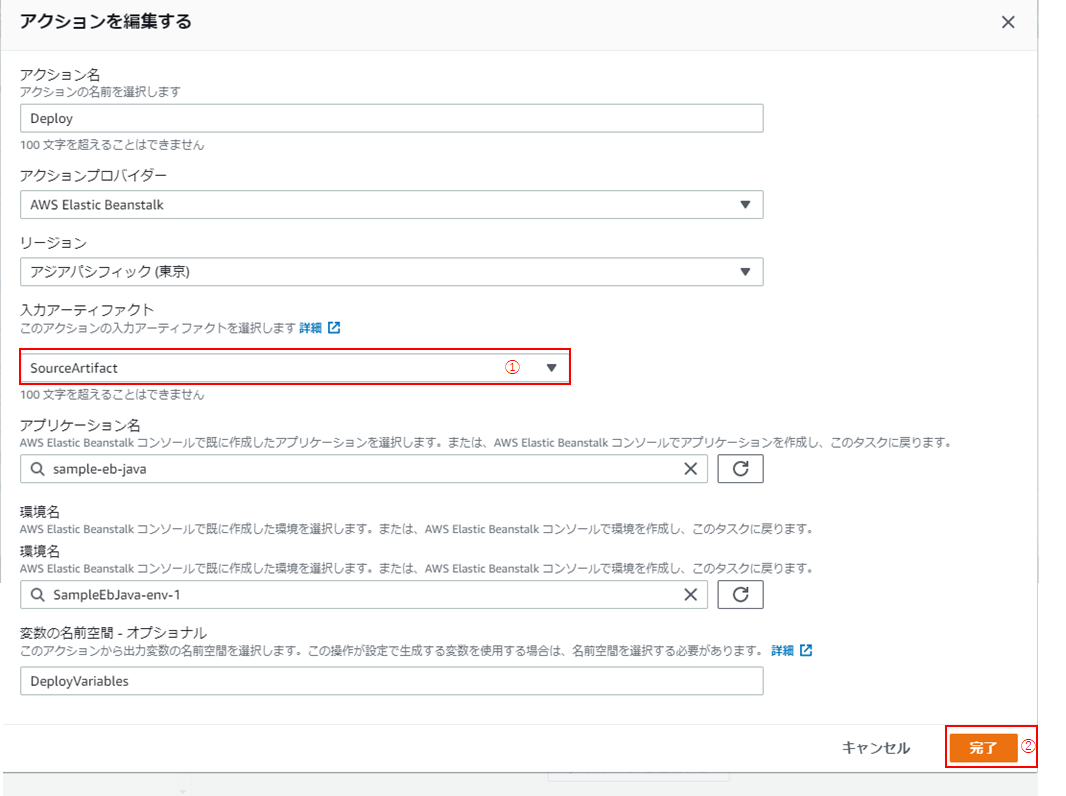
入力アーティファクトをBuildArtifact → SourceArtifactへ変更すると解消します。
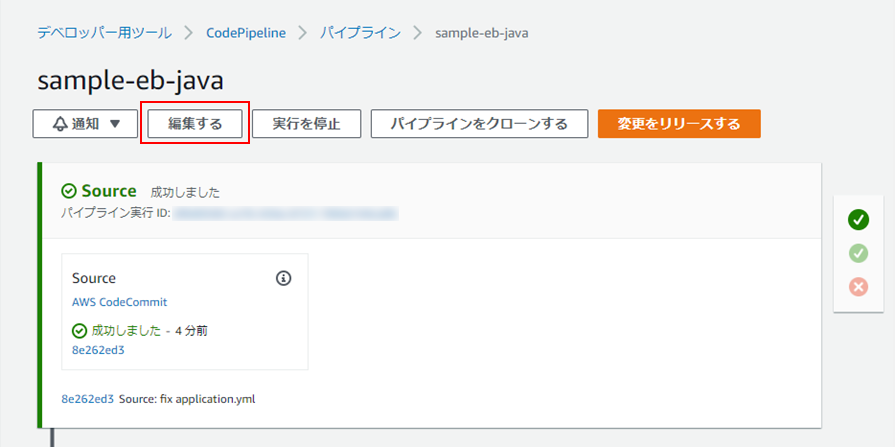
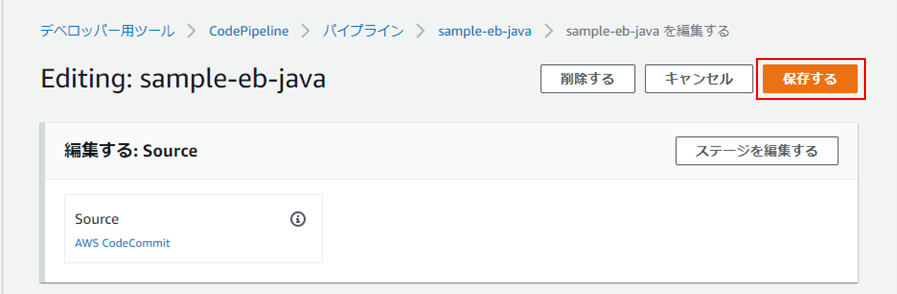
以下の手順で変更してください。①パイプラインにて、「編集する」をクリック。
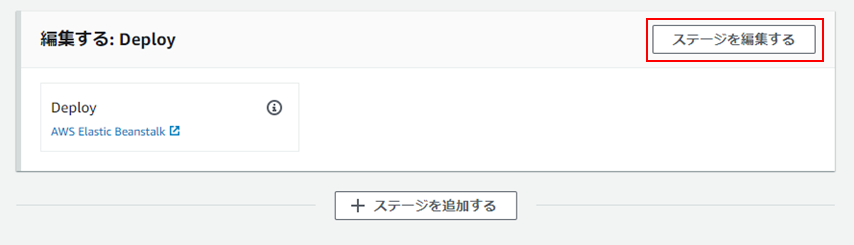
②「Deploy」欄にて、「ステージを編集する」をクリック。
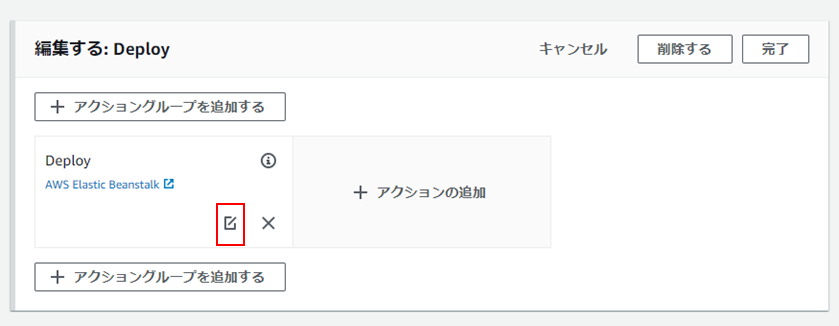
③編集マーク(?)をクリック。
④「入力アーティファクト」を「SourceArtifact」に変更し(①)、「完了」をクリック(②)。
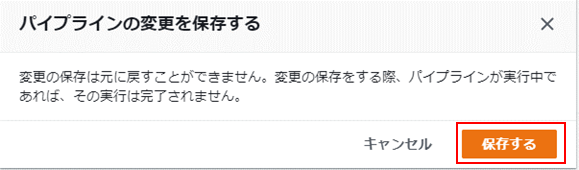
⑤「保存する」をクリック。
⑥「保存する」をクリック。
(2) 「Deployment failed. The provided role does not have sufficient permissions: Failed to deploy application. Service:AWSLogs・・・」が出る
CloudWatchLogsへのアクセス権がないために起こるエラーです。
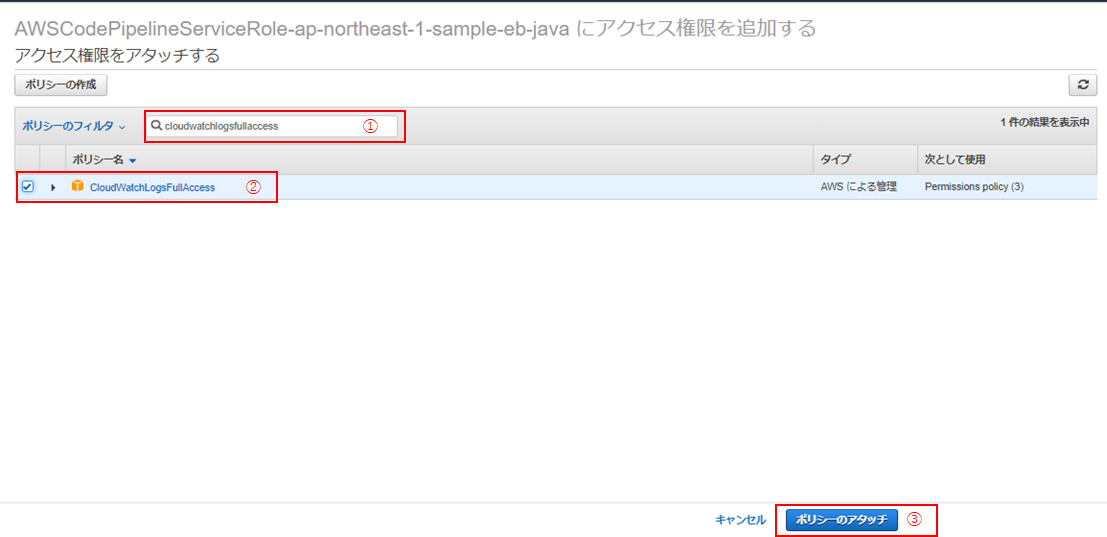
CodePipeline用に作成されたロールに、「CloudWatchLogsFullAccess」ポリシーを付与することで、解決できます。以下、手順です。
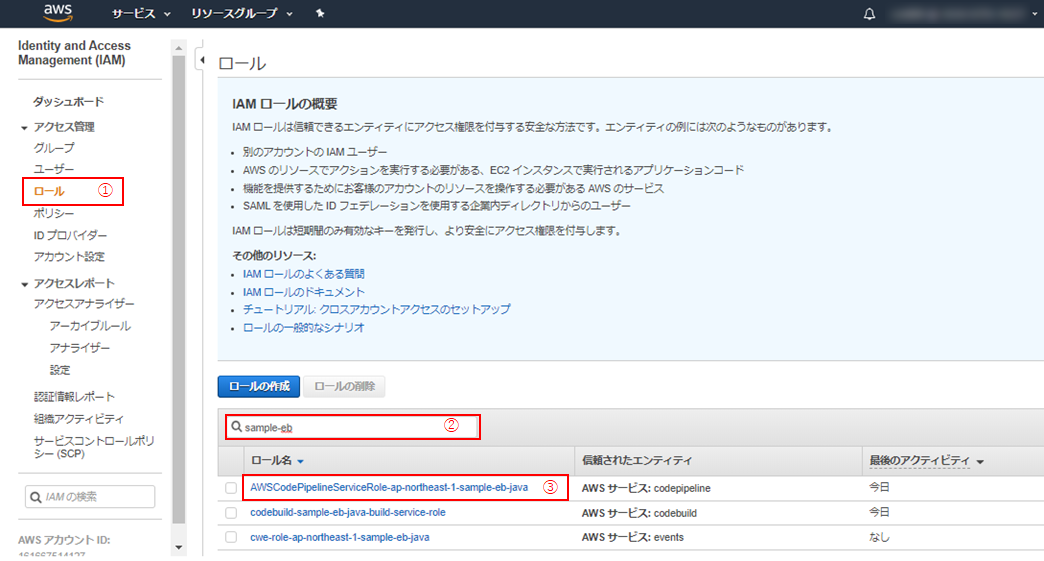
①マネジメントコンソールにて、「IAM」を探してクリック。
②「ロール」(①) > 対象のCodePipelineのロールを検索し(②)、ロール名をクリック(③)。
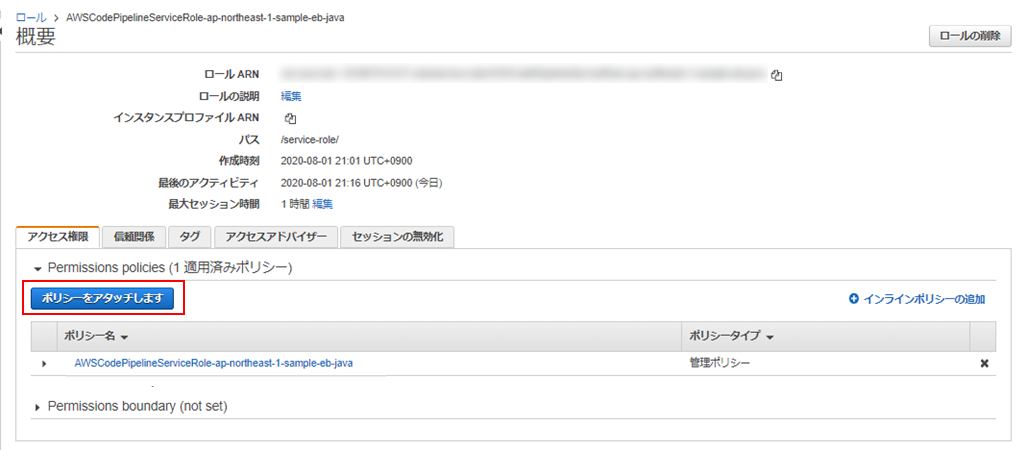
③「ポリシーをアタッチします」をクリック
④「CloudWatchLogsFullAccess」を検索して(①)、チェックを入れ(②)、「ポリシーのアタッチ」(③)をクリック。
終わりに
本編にも書きましたが、自分は、本編の1-[3]-(5)のgradlewの権限変更で3日、そして、5-[1]-(10)のデプロイの段階で3回エラーで躓いて何度も心が折れそうになりました。
エラーが発生しても、めげずに、むしろ、どうやって解決しよっかなーって感じで、楽しんでいきましょう!

- 投稿日:2020-08-06T22:19:06+09:00
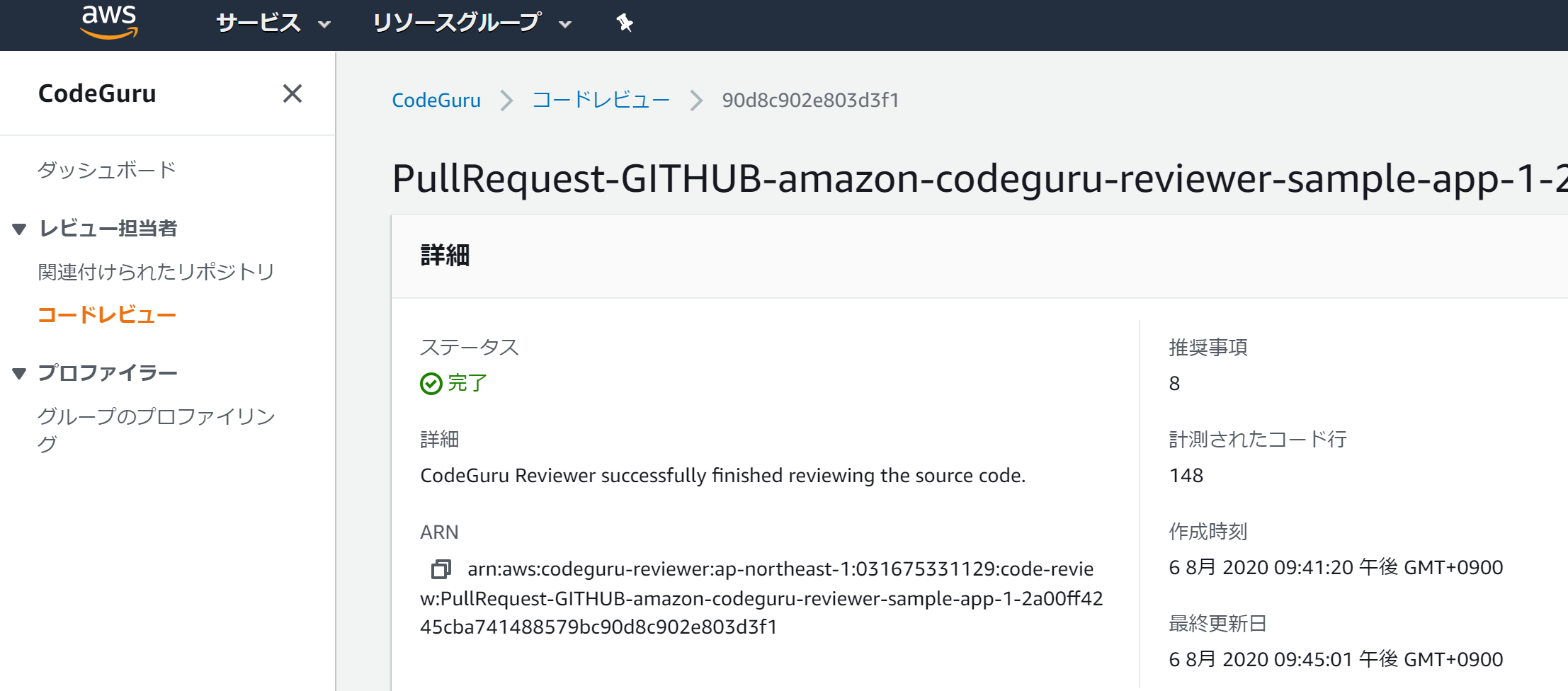
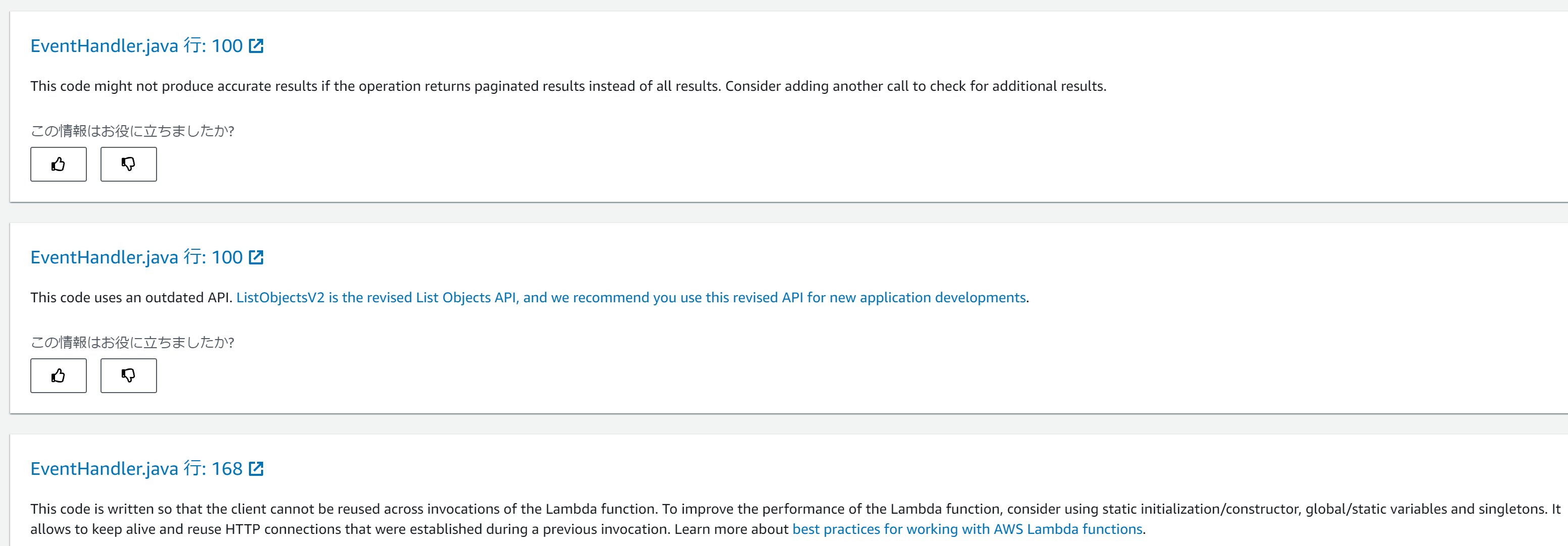
Amazon CodeGuru Reviewer
- POCメモ
【参照情報】
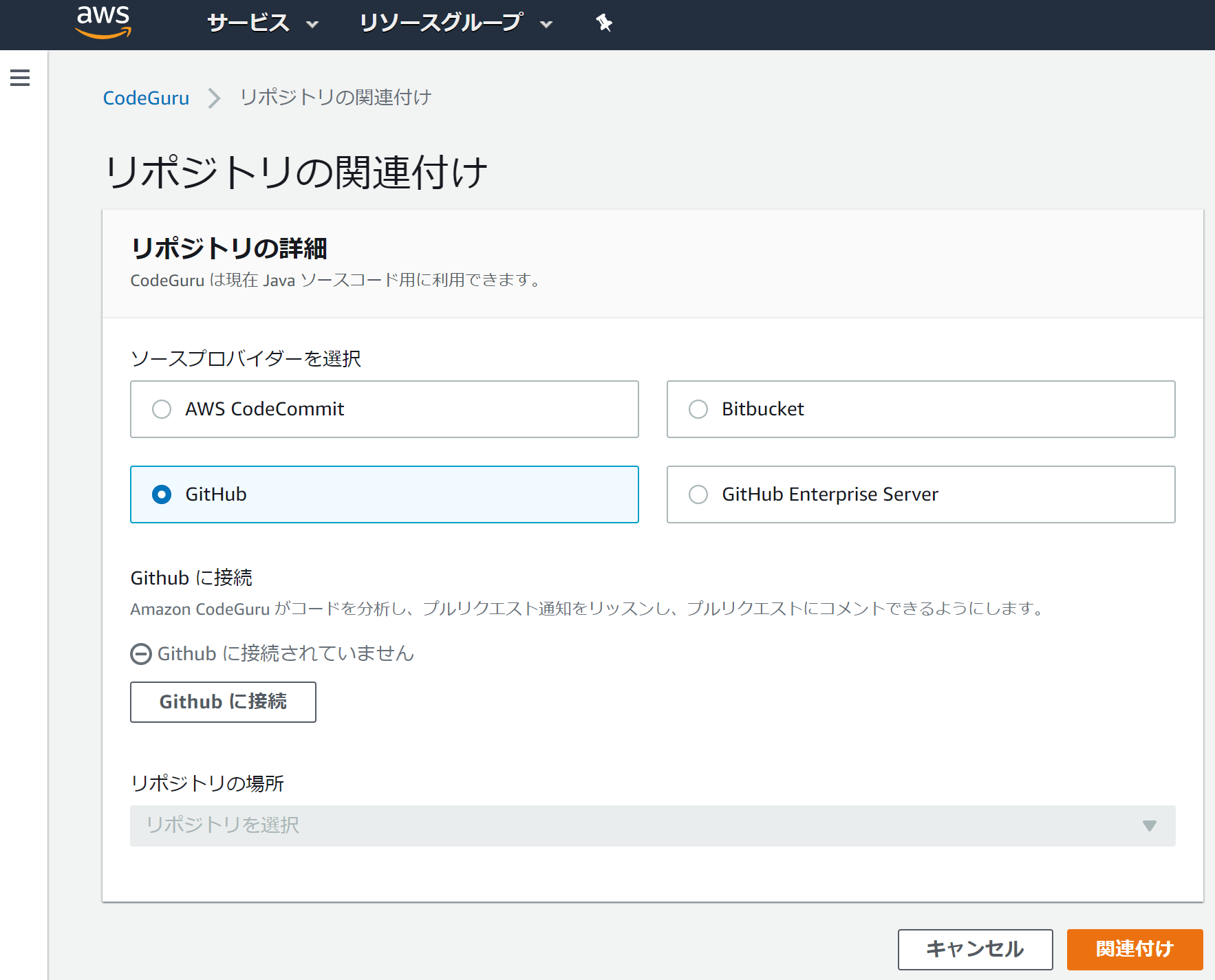
https://docs.aws.amazon.com/codeguru/latest/reviewer-ug/tutorial-github-reviewer.htmlデモ用のリポジトリを自分のリポジトリへフォークする。
マネジメントコンソールにログインしてリポジトリの関連付けの設定。
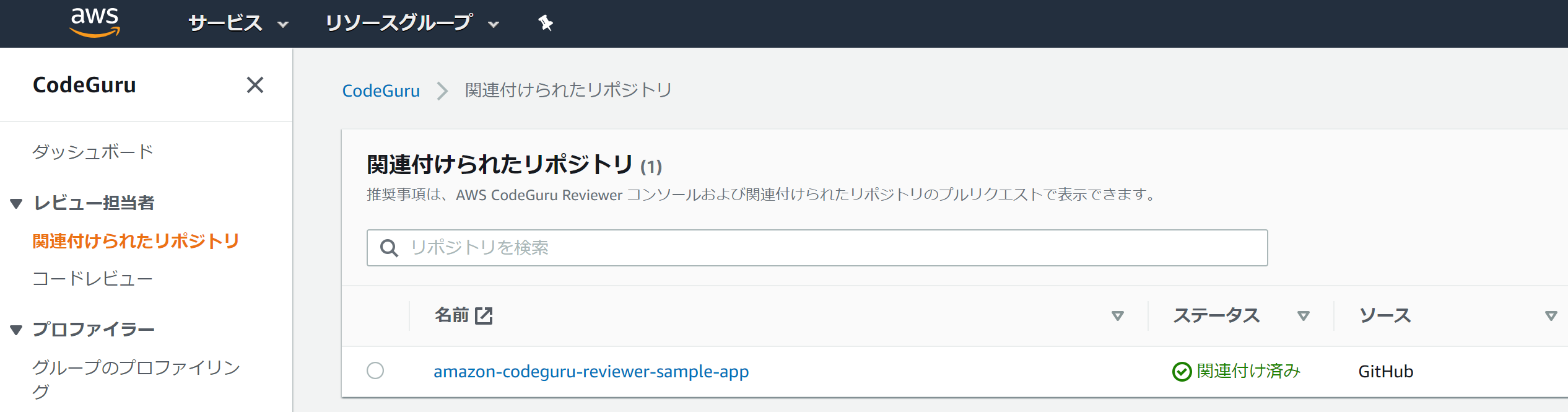
関連付けされたリポジトリの確認。
ローカルにソースコードをクローンし、ブランチ作成してテスト用のソースコードをコミットしてpushする。
C:\Users\gtoru>git clone https://github.com/t-hashi/amazon-codeguru-reviewer-sample-app.git Cloning into 'amazon-codeguru-reviewer-sample-app'... remote: Enumerating objects: 48, done. remote: Counting objects: 100% (48/48), done. remote: Compressing objects: 100% (35/35), done. remote: Total 48 (delta 8), reused 38 (delta 5), pack-reused 0 Unpacking objects: 100% (48/48), 333.27 KiB | 233.00 KiB/s, done. C:\Users\gtoru>cd amazon-codeguru-reviewer-sample-app C:\Users\gtoru\amazon-codeguru-reviewer-sample-app>git switch -c develop Switched to a new branch 'develop' C:\Users\gtoru\amazon-codeguru-reviewer-sample-app>git add --allエクスプローラでファイルコピー
コピーファイル: src/main/java/com/shipmentEvents/handlers/EventHandler.java
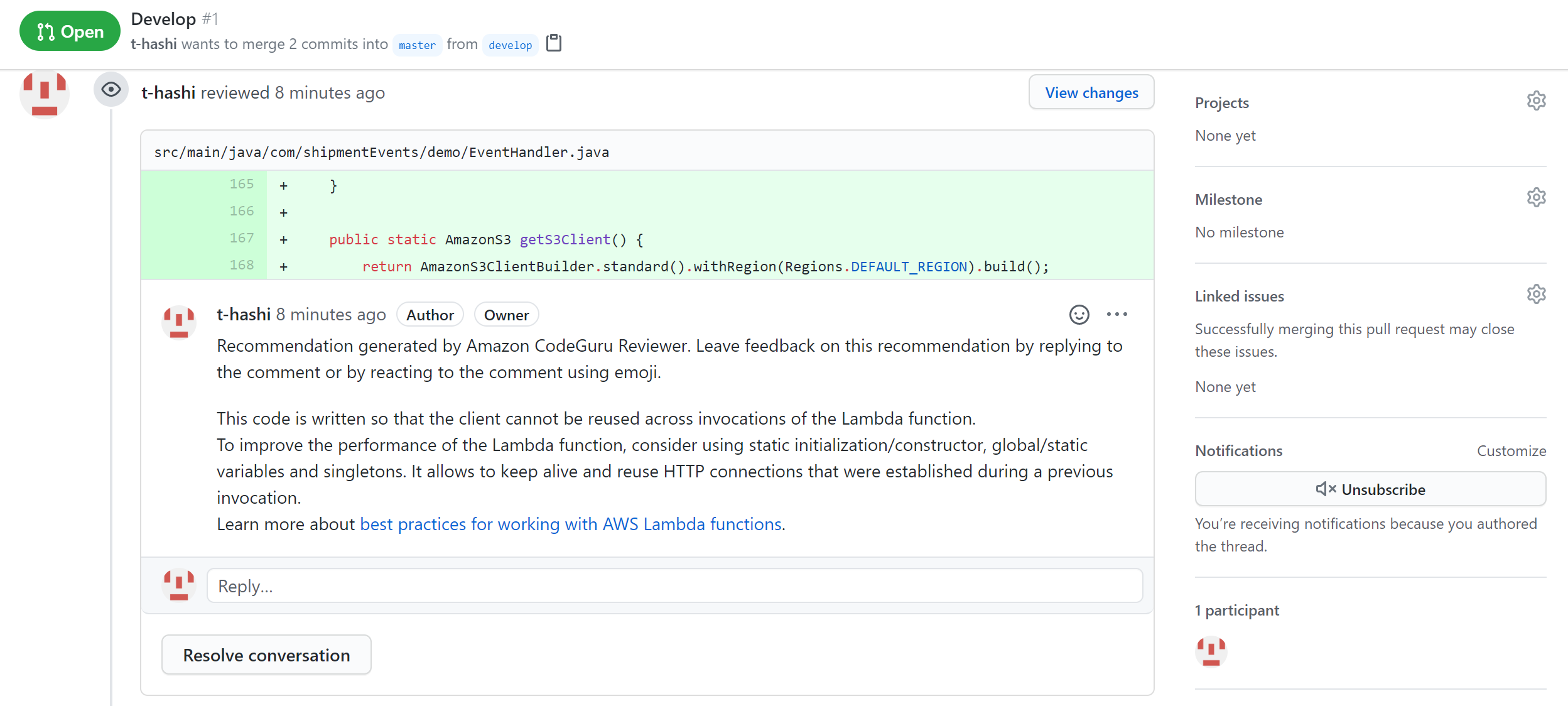
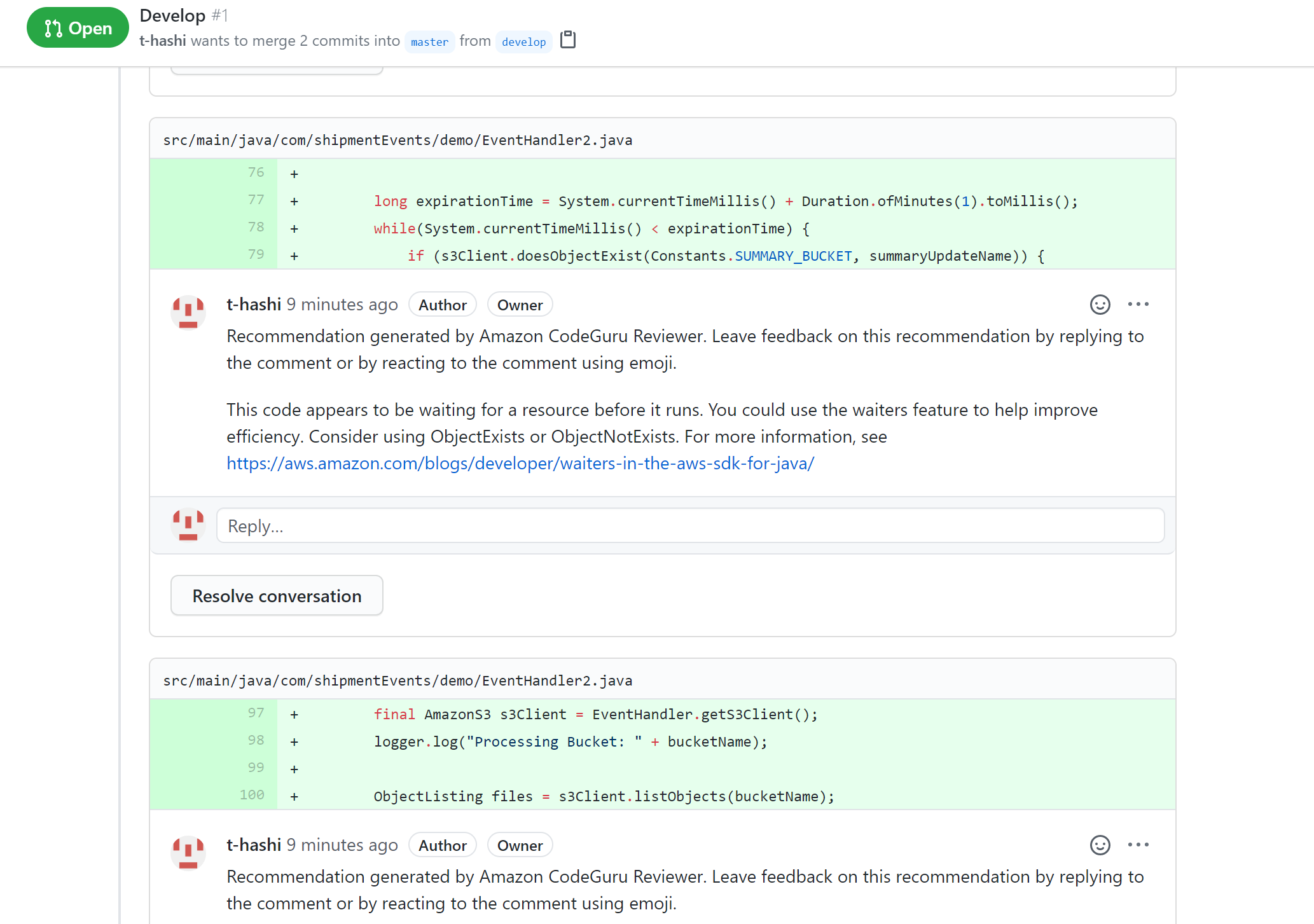
コピー先:src/main/java/com/shipmentEvents/demo/C:\Users\gtoru\amazon-codeguru-reviewer-sample-app>git commit -m "new demo file" [develop 5172a56] new demo file 1 file changed, 174 insertions(+) create mode 100644 src/main/java/com/shipmentEvents/demo/EventHandler.java C:\Users\gtoru\amazon-codeguru-reviewer-sample-app>git push --set-upstream origin develop Enumerating objects: 16, done. Counting objects: 100% (16/16), done. Delta compression using up to 8 threads Compressing objects: 100% (6/6), done. Writing objects: 100% (9/9), 2.95 KiB | 1006.00 KiB/s, done. Total 9 (delta 1), reused 0 (delta 0), pack-reused 0 remote: Resolving deltas: 100% (1/1), completed with 1 local object. remote: remote: Create a pull request for 'develop' on GitHub by visiting: remote: https://github.com/t-hashi/amazon-codeguru-reviewer-sample-app/pull/new/develop remote: To https://github.com/t-hashi/amazon-codeguru-reviewer-sample-app.git * [new branch] develop -> develop Branch 'develop' set up to track remote branch 'develop' from 'origin'.gitでpullリクエストしてしばらくするとレビューが完了する。
しばらくすると
Git上の表示例
- 投稿日:2020-08-06T21:44:31+09:00
sam cli の [SSL: CERTIFICATE_VERIFY_FAILED] エラー回避
sam deploy時の[SSL: CERTIFICATE_VERIFY_FAILED]回避策(暫定)
samのバージョン 0.53.0
会社のイントラネットでsam deployコマンド実行すると以下のようなエラーが出て困ってました。
(Windows, Linux)[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1076)StackOverflowを見ても困っている人が沢山いそうなので記事にしてみます。
おそらくはGit Hubのこのissueが該当するんじゃないかと。
まだOpen issueなんですよね。
GitHub awslabs/aws-sam-cliSSL => proxy causing issues with deployawc cli configファイルのca_certにルート証明書を設定する。他
色々試しましたが、全然ダメです。諦めて禁忌に手を出します(笑)
回避策
自己責任でお願いいたします。
仕方がないので、sam cliに内包しているPythonのコードにパッチを当てます。
- パッチをあてるファイルの場所
例はWindows
sam cliのインストールフォルダ\Amazon\AWSSAMCLI\runtime\Lib\site-packages\botocore\httpsession.pyhttpsession.pydef __init__(self, verify=True, proxies=None, timeout=None, max_pool_connections=MAX_POOL_CONNECTIONS, socket_options=None, client_cert=None, ): self._verify = False #ここをFalseに書き換え self._proxy_config = ProxyConfiguration(proxies=proxies) self._pool_classes_by_scheme = { 'http': botocore.awsrequest.AWSHTTPConnectionPool,sam deploy時にSSLの検証エラーメッセージ(warning)は表示されるものの無事、sam deployできました。
冒頭のissueがcloseされるまで、これで対応しておこうと思います。
余談
開発PCはWindowsですが、AWS CLI関係は公式のDockerコンテナを使わせてもらってます。
コンテナをPullすればすぐに使えるメリットはもちろんのこと
上に書いたパッチコードもvolumeとしてマウントしているので、いつでも元に戻せて便利です。
- 投稿日:2020-08-06T21:00:30+09:00
【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その3
Javaアプリケーション(データベースから値を取得し、JSON形式で結果を返す)をCodePipelineでElasticBeanstalkにCI/CDするハンズオンです。
【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その2
の続きです。環境
- OS:Windows10
- IDE:Eclipse 2020-03
- JDK:Amazon Correto 8
- フレームワーク:Spring Boot
- AWS
- CodePipeline
- CodeCommit
- CodeBuild
- CodeDeploy
- Elastic Beantalk
- Java SE(Java 8 バージョン 2.10.8)
→ ※2020年6月3日公開の最新版ではないです。ご了承を。- RDS:MySQL Community Edition(バージョン8.0.17)
手順
5. パイプラインの作成
いよいよ最終段階。
CodePipelineを作成して、Elastic Beanstalk環境にデプロイします。[1] CodePipelineの作成
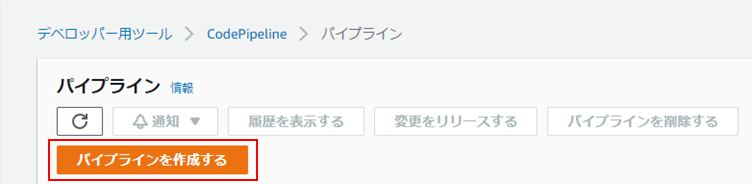
(1)マネジメントコンソールにて、CodePipelineを探し、クリック。
(2)「パイプラインを作成する」をクリック。
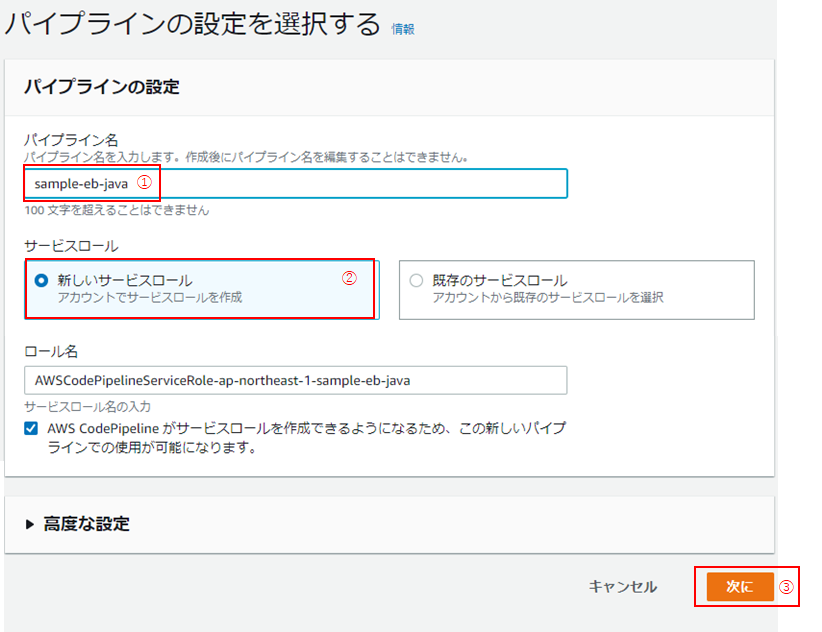
(3)「パイプラインの設定を選択する」画面に遷移したら、「パイプライン名」を入力し(①)、「新しいサービスロール」を選択し(②:デフォルト)、「次に」をクリック(③)。
これにより、パイプライン作成時に「ロール名」に記載のロールが作成されます。
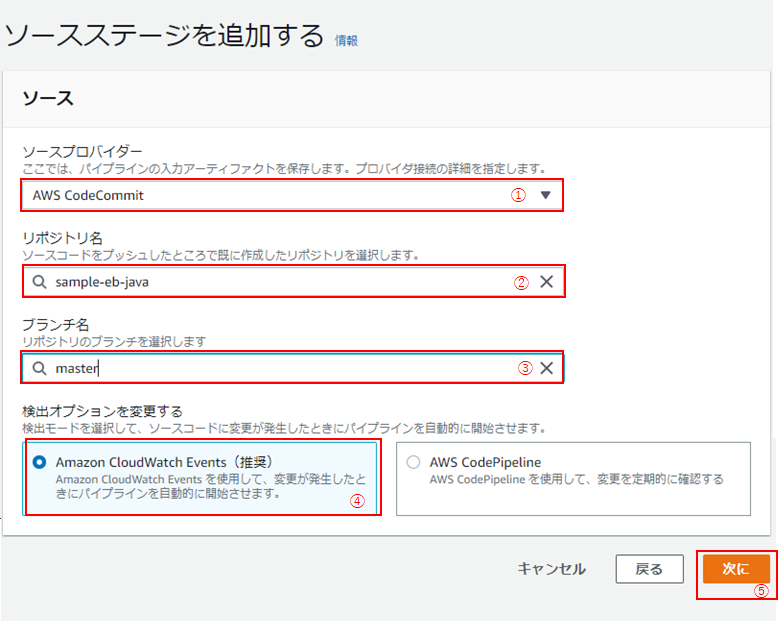
(4)次に、「ソースステージを追加する」画面です。
以下の通り入力・選択し、「次に」をクリック(⑤)
No 名称 設定内容 ① ソースプロバイダー AWS CodeCommit ② リポジトリ名 手順2:Gitリポジトリの作成で作成したリポジトリ名 ③ ブランチ名 master ④ 検出オプションを変更する Amazon CloudWatch Events(推奨)
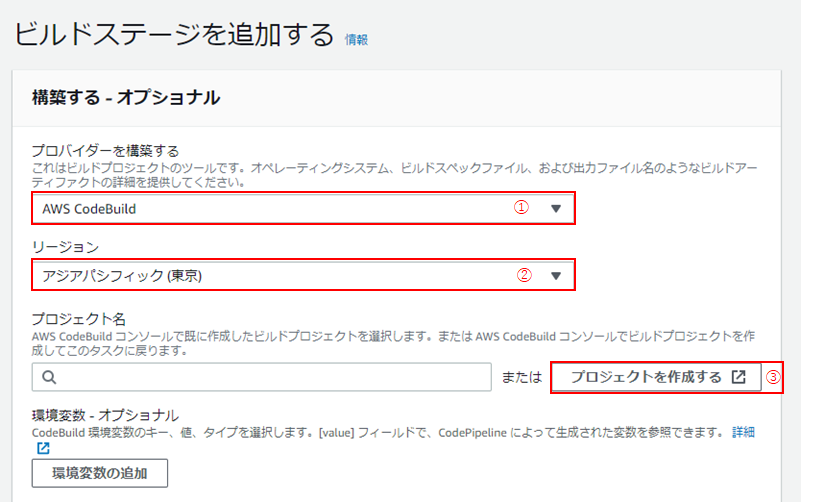
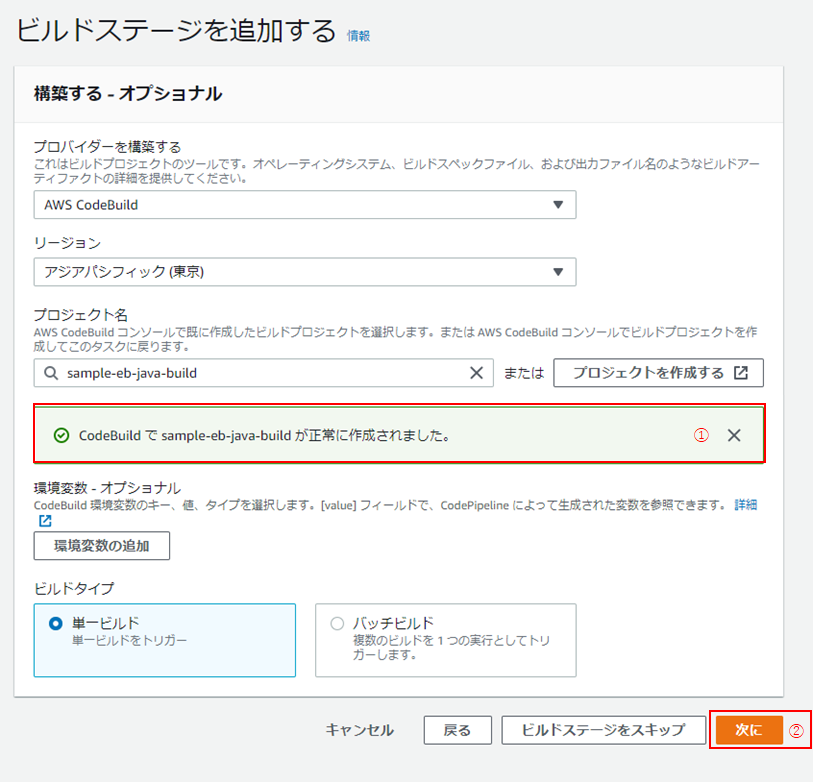
(5) 続いて、「ビルドステージを追加」画面です。
「プロバイダーを構築する」にて、「AWS CodeBuild」を(①)、「リージョン」は「アジアパシフィック(東京)」を選択し(②)、「プロジェクトを作成する」をクリック(③)。
(6)「ビルドを作成する」ウィンドウが立ち上がります。
以下の通り入力・設定し、「CodePipelineに進む」をクリック。
No 名称 設定内容 ① プロジェクト名 任意の名称(今回は「sample-eb-java-build」) ② 環境イメージ マネージド型イメージ ③ オペレーティングシステム AmazonLinux 2 ④ ランタイム Standard ⑤ イメージ aws/codebuild/amazonlinux2-x86_64-standard:3.0 ⑥ イメージのバージョン 最新のものを選択 ⑦ 環境タイプ Linux ⑧ サービスロール 新しいサービスロール ⑨ ロール名 自動で入力される(必要に応じて変更) ⑩ ビルド仕様 ビルドコマンドの挿入 ⑪ ビルドコマンド ※の通り入力 ⑫ 入力モード エディタ(キャプチャは「エディタに切り替える」をクリックしてエディタでの編集モードになっている状態) ※ビルドコマンドの内容version: 0.2 phases: install: runtime-versions: java: corretto8 build: commands: - ./gradlew test
(6) 「ビルドステージを追加する」画面に戻ったら、「CodeBuildで<プロジェクト名>が正常に作成されました。」となっていることを確認し(①)、「次に」をクリック(②)。
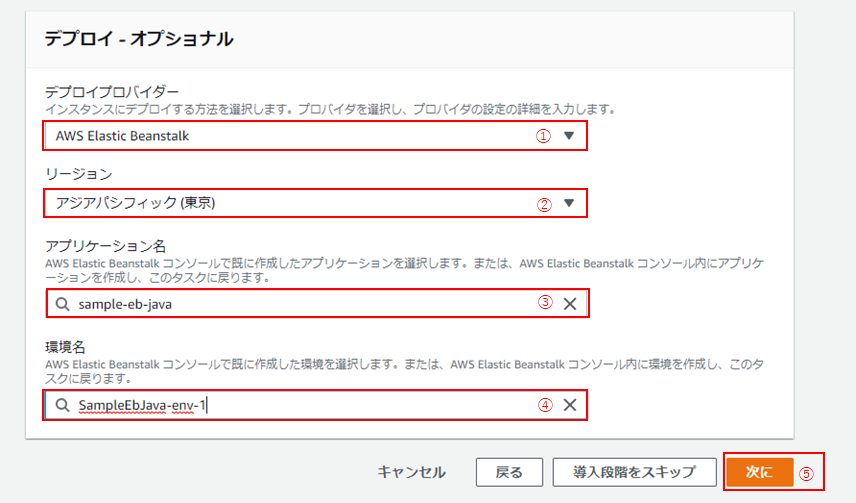
(7) 「デプロイ - オプショナル」画面に遷移したら、以下の通り入力・選択し、「次に」(⑤)をクリック。
No 名称 設定内容 ① デプロイプロバイダー AWS Elastic Beanstalk ② リージョン アジアパシフィック(②) ③ アプリケーション名 「3. Elastic Beanstalk環境の作成」で作成したアプリケーション ④ 環境名 「3. Elastic Beanstalk環境の作成」で作成した環境
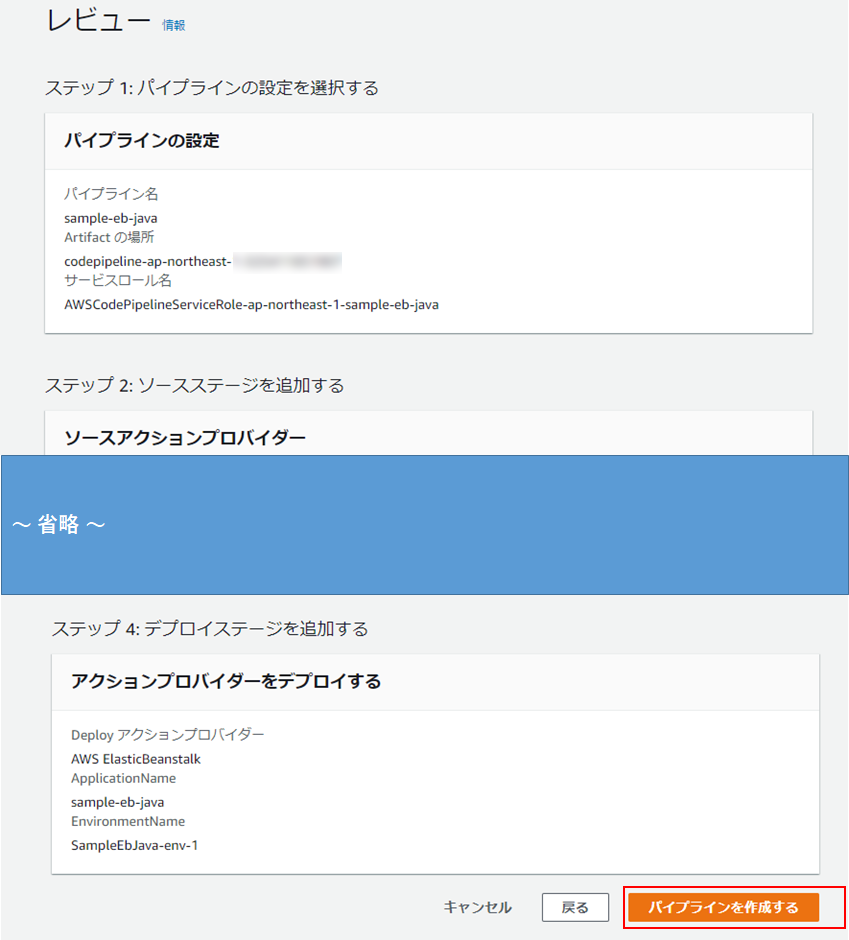
(8) 「レビュー」画面に遷移したら、内容を確認し、「パイプラインを作成する」をクリック。
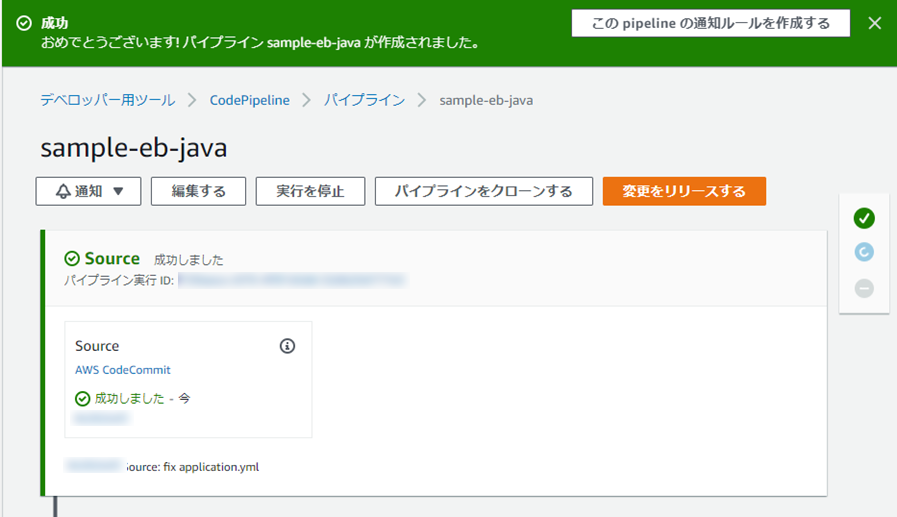
(9) パイプラインが作成され、「2. Gitリポジトリの作成」にて、コミット・プッシュされたコードが順に、ビルド、デプロイされます。
(10) デプロイまで成功(緑色のチェックマークがつく)になったら、OKです。
今後は、CodeCommitのリポジトリのmasterブランチに変更が加わるたびに、このパイプラインが実行されます。
実環境であれば、子ブランチからプルリク → マージされた場合に実行される形になるでしょう。もし、パイプライン実行時にエラーが発生した場合は、
【CodePipeline×Elastic Beanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする、のエラーとその対応方法まとめ
を参考に解決してみてください。(11) Elastic Beanstalkの確認もしましょう。
マネジメントコンソールにて、「サービス」(①) > 「Elastic Beanstalk」の順にクリック。
(12) ナビゲーションペインにて、「環境」をクリック。
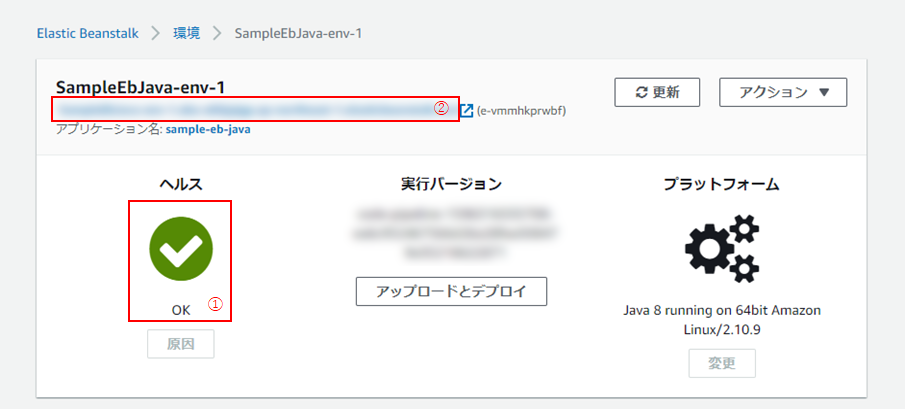
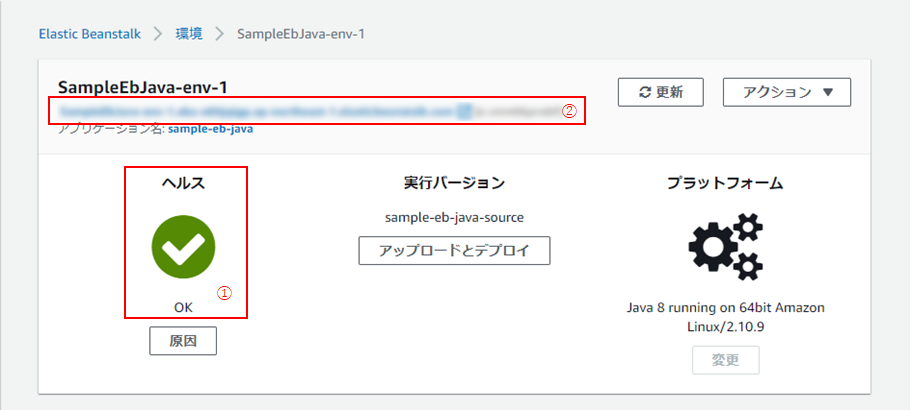
(13) 以下のように、ヘルスが「OK」となっていれば成功です!(①)
[2] 動作確認
(1) 動作確認をしましょう。
ブラウザにて、以下の通り入力&Enterして、以下のような結果が返却されれば成功です!実行URL(2)の②に記載のドメイン/shop-information/1
6. 後片付け
最後に後片付けを行います。
このまま放置しておくと、Elastic Beanstalk環境の作成にて作成された、EC2インスタンス、RDSインスタンスの稼働分だけ、課金されてしまいますので、後片付け(削除)しておきましょう。[1]Elastic Beanstalk
(1) マネジメントコンソールにて、「サービス」(①) > 「Elastic Beanstalk」の順にクリック。
(2) ナビゲーションペインにて、「環境」をクリック。
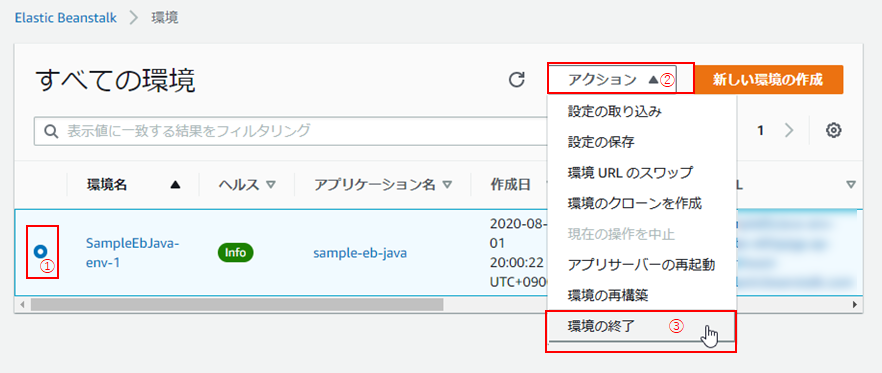
(3) 対象の環境のラジオボタンを選択し(①)、「アクション」 > 「環境の終了」をクリック。
(4) 「環境の削除の確認」画面に遷移するので、環境の名前を入力し(①)、「削除」をクリック(②)。
(5) 続いて、「アプリケーション」の削除。
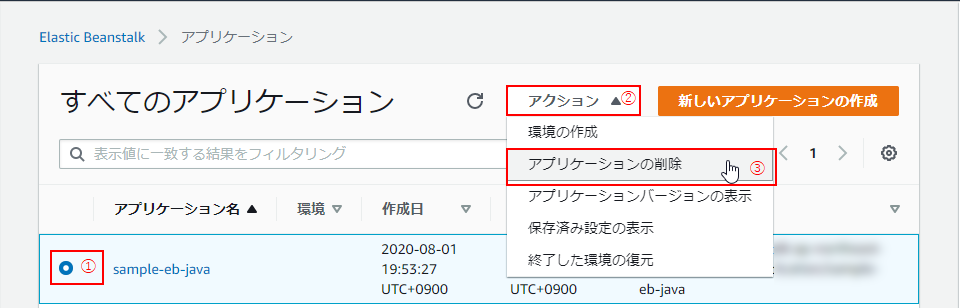
Elastic Beanstalkのナビゲーションペインにて、「アプリケーション」をクリック。
(6) 対象のアプリケーションのラジオボタンを選択し(①)、「アクション」 > 「アプリケーションの削除」をクリック。
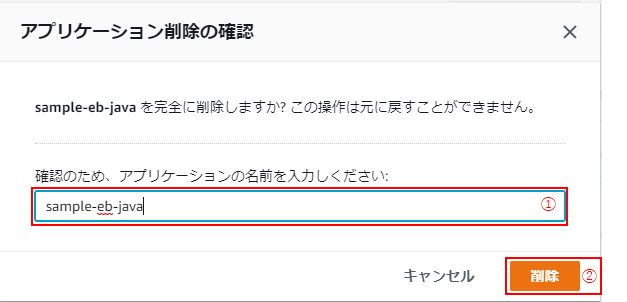
(7)「アプリケーションの削除の確認」のモーダルが立ち上がるので、対象のアプリケーション名を入力し(①)、「削除」をクリック(②)。
[2]CodePipeline
(1) 次に、CodePipeline。
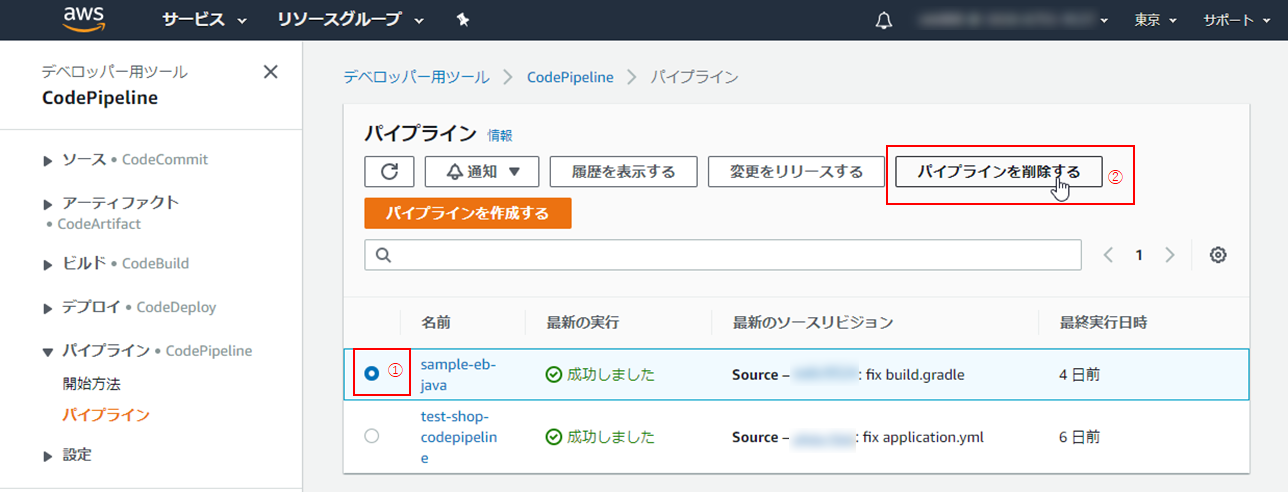
少なくとも、コードに変更を行わなければ料金は発生しないのですが、逆を言えば、なんらかの拍子に変更が加わってしまうと料金が発生してしまうので、こちらも削除しておきましょう。マネジメントコンソールにて、「サービス」(①) > 「Code Pipeline」の順にクリック。
(2) 対象のパイプラインのラジオボタンを選択し(①)、「パイプラインを削除する」をクリック(②)。
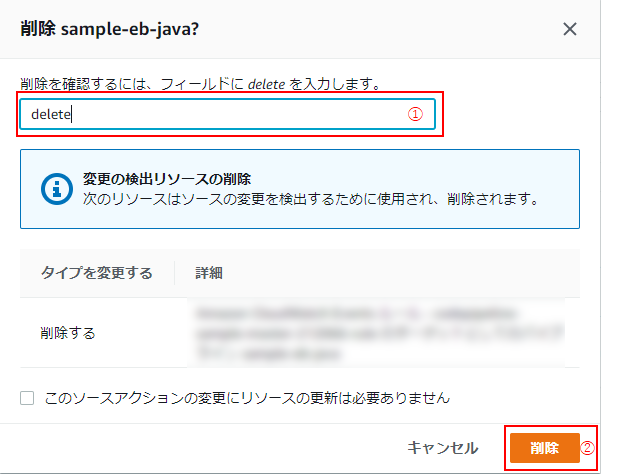
(3) 削除確認のモーダルが立ち上がるので、「delete」と入力し(①)、「削除」をクリック(②)
終わりに
長時間お疲れさまでした。
自分は、1-[3]-(5)のgradlewの権限変更で3日、そして、5-[1]-(10)のデプロイの段階で3回エラーで躓いて何度も心が折れそうになりました。
だけど、できた時の達成感はハンパない!!
少しでも多くの皆さんのお役に立てばと思い、記事にまとめました。もし至らない点、気づいた点などあればコメントいただければ幸いです。
参考
5. パイプラインの作成
6. 後片付け







- 投稿日:2020-08-06T20:58:58+09:00
【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その2
Javaアプリケーション(データベースから値を取得し、JSON形式で結果を返す)をCodePipelineでElasticBeanstalkにCI/CDするハンズオンです。
【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その1
の続きです。環境
- OS:Windows10
- IDE:Eclipse 2020-03
- JDK:Amazon Correto 8
- フレームワーク:Spring Boot
- AWS
- CodePipeline
- CodeCommit
- CodeBuild
- CodeDeploy
- Elastic Beantalk
- Java SE(Java 8 バージョン 2.10.8)
→ ※2020年6月3日公開の最新版ではないです。ご了承を。- RDS:MySQL Community Edition(バージョン8.0.17)
手順
3. Elastic Beanstalk環境の作成
続いて、Elastic Beanstalk環境を作成します。
環境作成 → EC2起動してしまうと、課金の対象になってしまうので、できれば手順5のパイプラインの作成まで一気に駆け抜けるのがベスト!
手順1 ,2でちょっと疲れたな―って方は一度お休みして、気力が回復してから臨んでください。では、いってみましょー!
[1] 環境、アプリケーションの新規作成
(1) AWSマネジメントコンソールにログインし、「サービス」(①) > 「Elastic Beanstalk」を探してクリック。
(2) ナビゲーションペインにて、「環境」をクリック。
(3) 「新しい環境の作成」をクリック。
(4) 「ウェブサーバー環境」を選択し(①)、「選択」をクリック(②)。
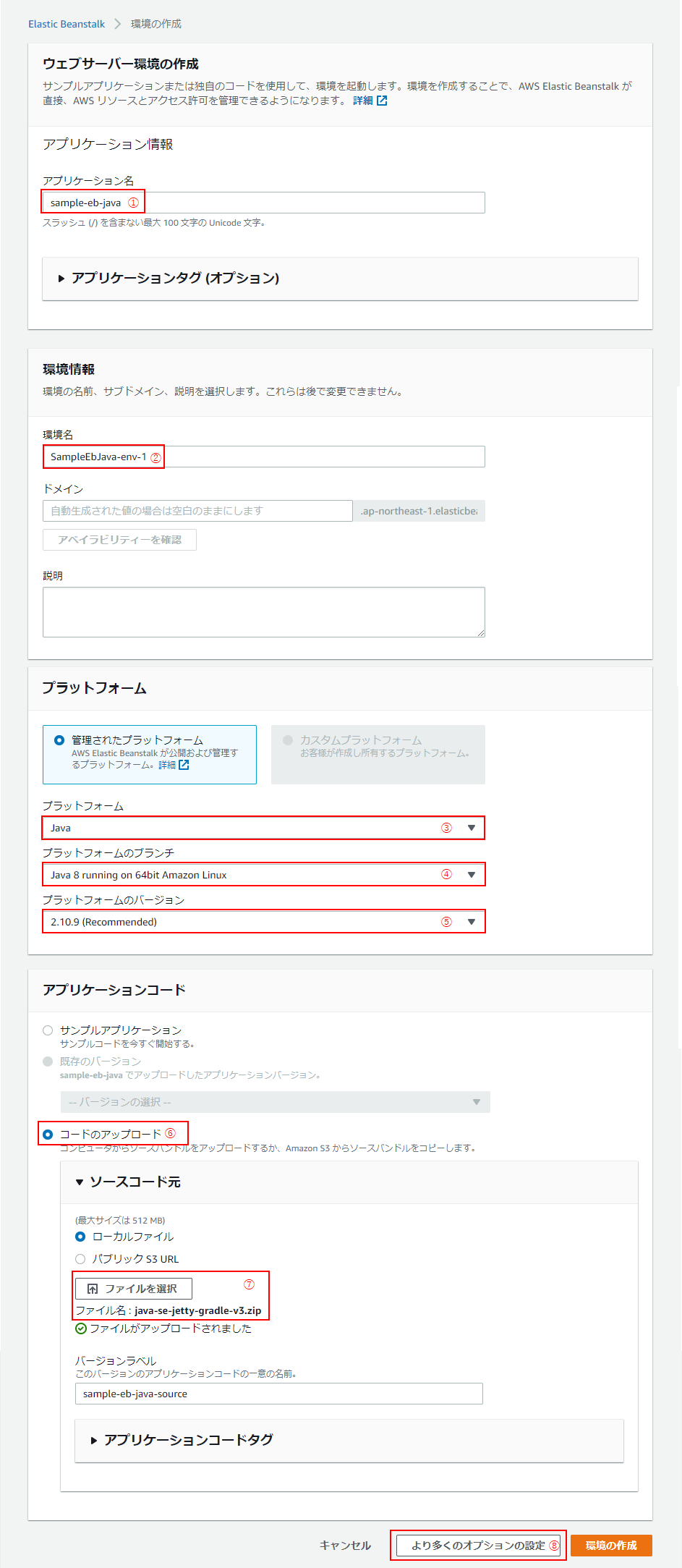
(5)「ウェブサーバー環境の作成」ページに遷移するので、以下の通り入力・設定し、「より多くのオプションの設定」をクリック(⑧)。
No 名称 設定内容 ① アプリケーション名 sample-eb-java ② 環境名 アプリケーション名を入力すると自動で入力される(※1) ③ プラットフォーム Java ④ プラットフォームのブランチ Java 8 running on 64bit Amazon Linux ⑤ プラットフォームのバージョン 2.10.9:Recommendedとなっているもの ⑥ アプリケーションコード 「コードのアップロード」を選択 ⑦ ソースコード元 「ローカルファイル」を選択し、zipファイルをアップロード(※2) ※1:すでに同名の環境が存在する場合は、環境名の後ろに「-n」(nは数字)が入る。
※2:Elastic Beanstalk での Java の開始方法 | awsより、「java-se-jetty-gradle-v3.zip」を取得し、使用。
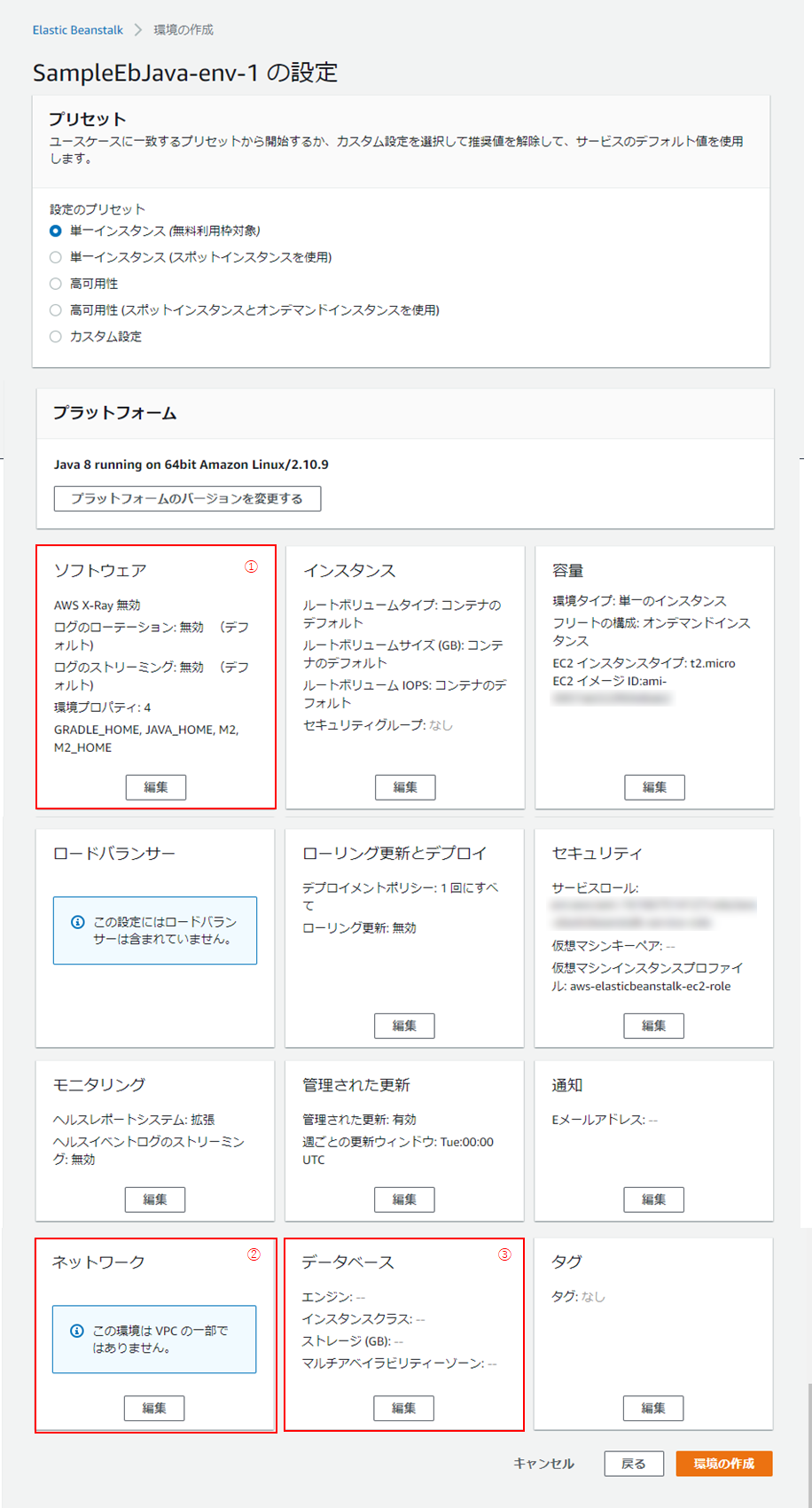
(6) オプションの設定画面に遷移します。全容は以下のキャプチャの通り。
今回は、
- ①:ソフトウェア
- ②:ネットワーク
- ③:データベース
の3つに手を入れます。
(7)まず、①ソフトウェアから。
「ログのストリーミング」の「有効」にチェックを入れ、画面下方の「保存」をクリック。
こうしておくことで、ログが見られるようになるので、環境でのエラーの原因を調べる際に便利です。
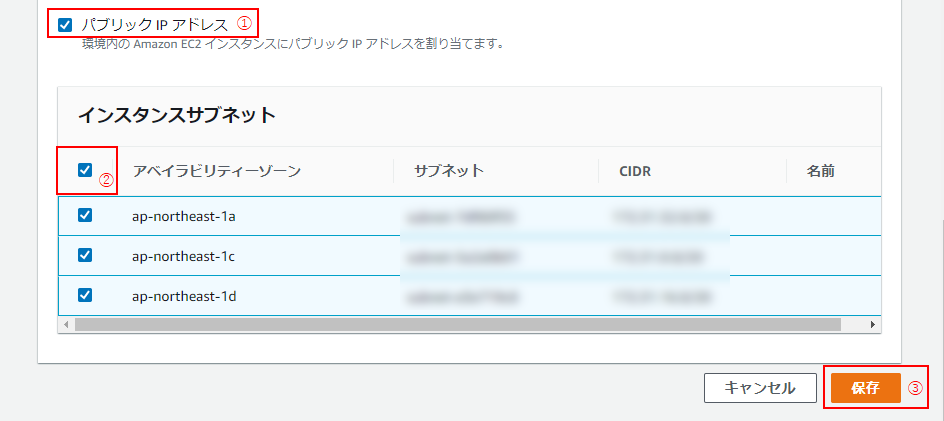
(8) 続いて、②ネットワーク。
パブリックIPアドレス(①)、アベイラビリティーゾーン(②)の左隣のチェックボックスにチェックし、「保存」をクリック(③)。
(9) 最後にデータベース。
ユーザー名(①)、パスワード(②)を設定し、保存をクリック(③)。
(10)「より多くのオプションの設定」画面にて、「環境の作成」をクリック
(11)10分ほどして環境が作成されたら、「ヘルス」が「OK」となっていることを確認し(①)、環境名下のURL(②)をクリック
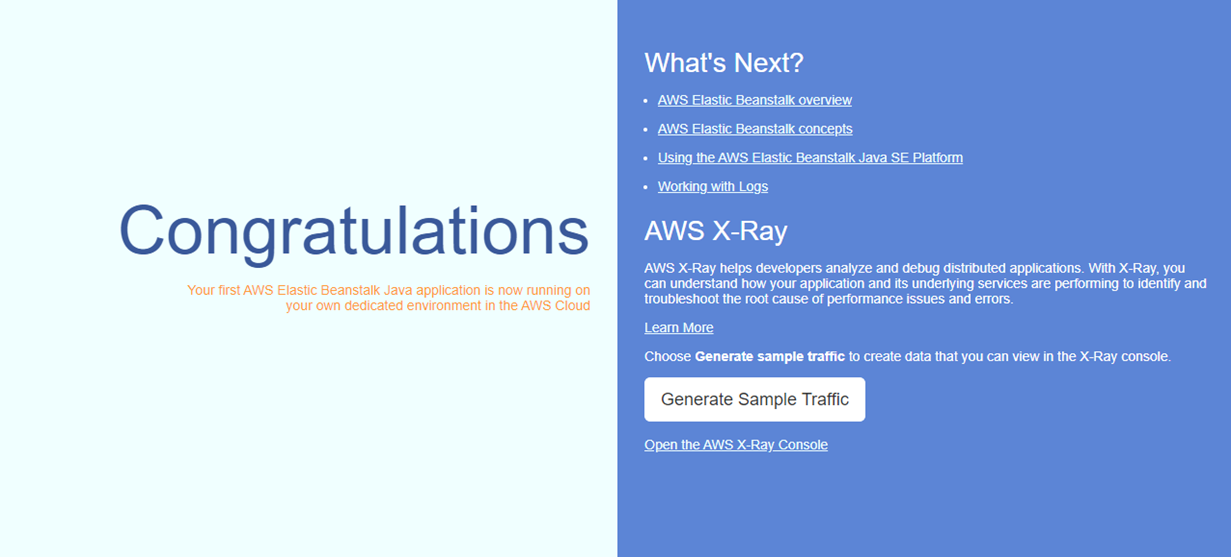
(12) 以下のようなページが表示されれば成功です!
[2] 追加設定
(1) 追加設定もしておきしょう。Elastic Beanstalkのナビゲーションペインの「設定」をクリック。
(2)「インスタンス」の右側の「編集」をクリック。
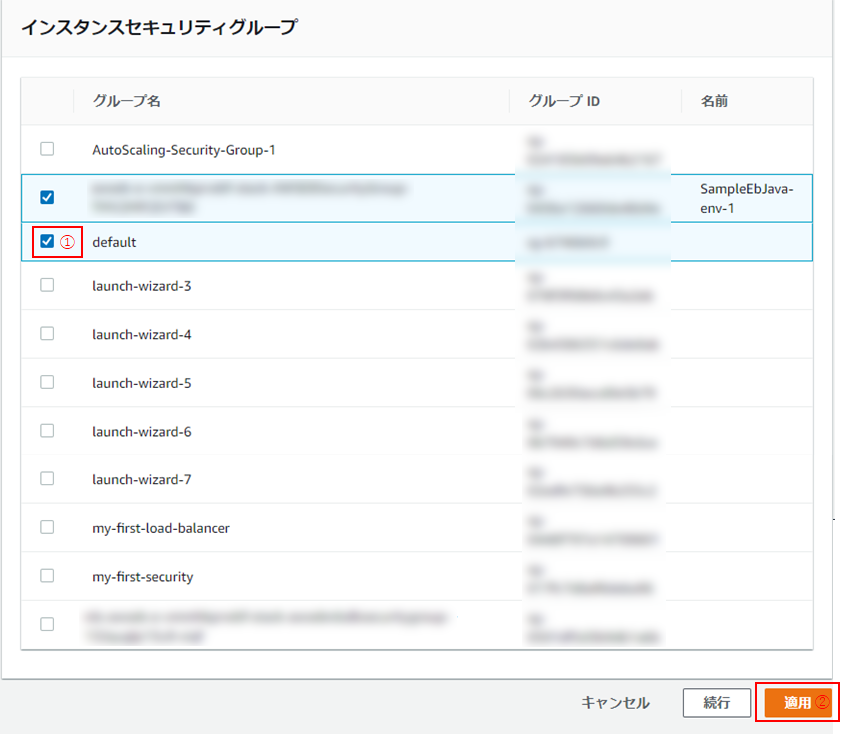
(3)「デフォルト」にチェックを入れ(①)、「適用」をクリック(②)。
【重要】忘れると、通信がうまくいかず、502(Bad Gateway)となりますので、必ず設定してください。
4. データベースの設定
続いて、3. Elastic Beanstalk環境の作成によってできた、データベース(RDS)の設定を行いましょう。
[1] RDSにおける接続設定
(1) マネジメントコンソールにて、RDSを探し、クリック。
(2) ナビゲーションペインにて、「データベース」をクリック。
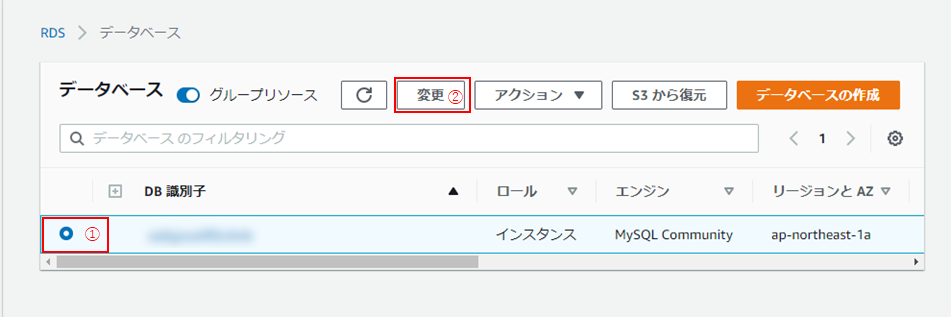
(3) 作成されたデータベースインスタンスのラジオボタンにチェックを入れ(①)、「変更」をクリック(②)。
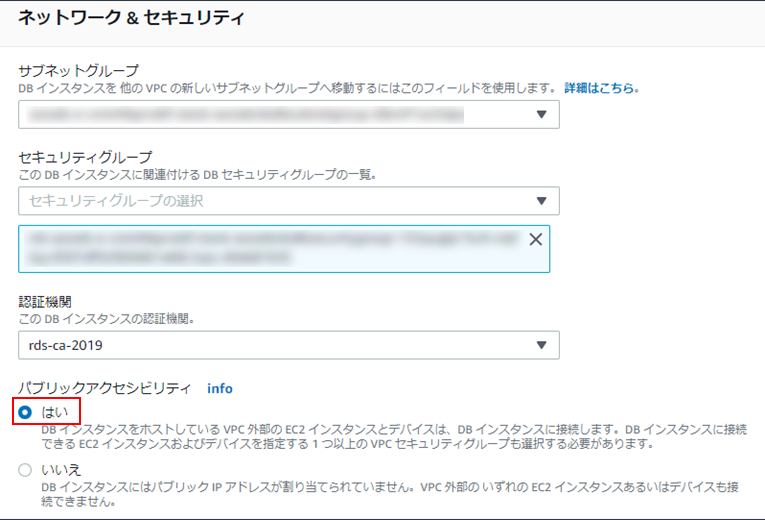
(4) データベースインスタンスの変更画面に遷移するので、「ネットワーク&セキュリティ」欄の「パブリックアクセシビリティ」を「はい」にし、画面下方の「次へ」をクリック。
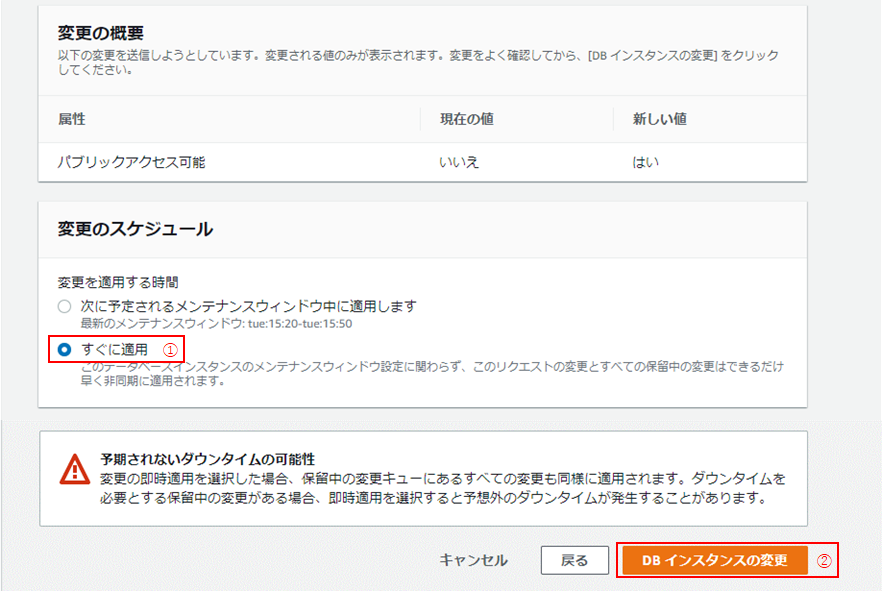
(5)「変更の概要」画面に遷移したら、内容を確認し、「変更のスケジュール」の「すぐに適用」を選択し(①)、「DBインスタンスの変更」をクリック(②)。
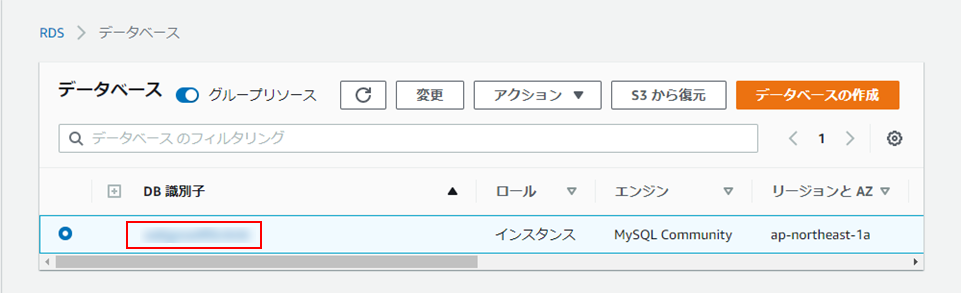
(6)「データベース」画面に戻ったら、データベースインスタンス名の上のリンクをクリック。
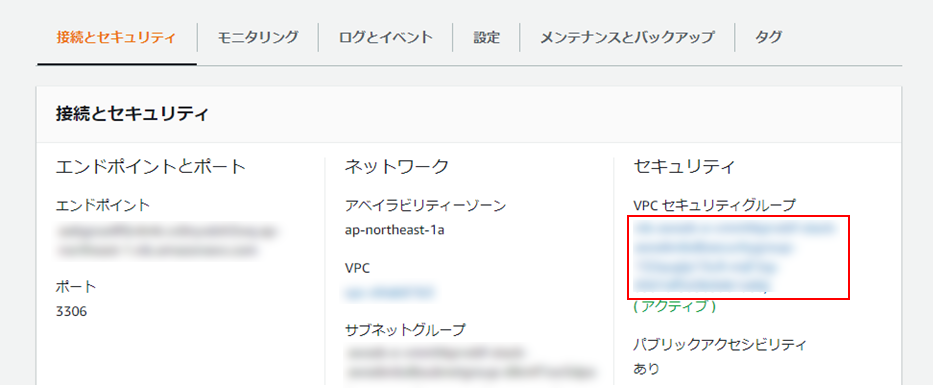
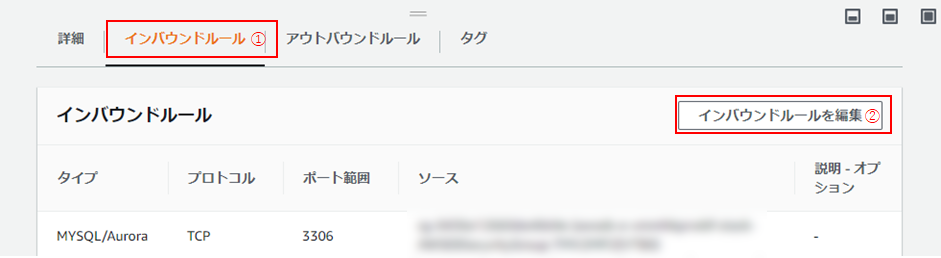
(7) 「接続とセキュリティ」タブにて、「VPCセキュリティグループ」(リンク)をクリック。
(8)「セキュリティグループ」画面に遷移したら、「インバウンドルール」タブをクリックし(①)、「インバウンドルールを編集」をクリック(②)。
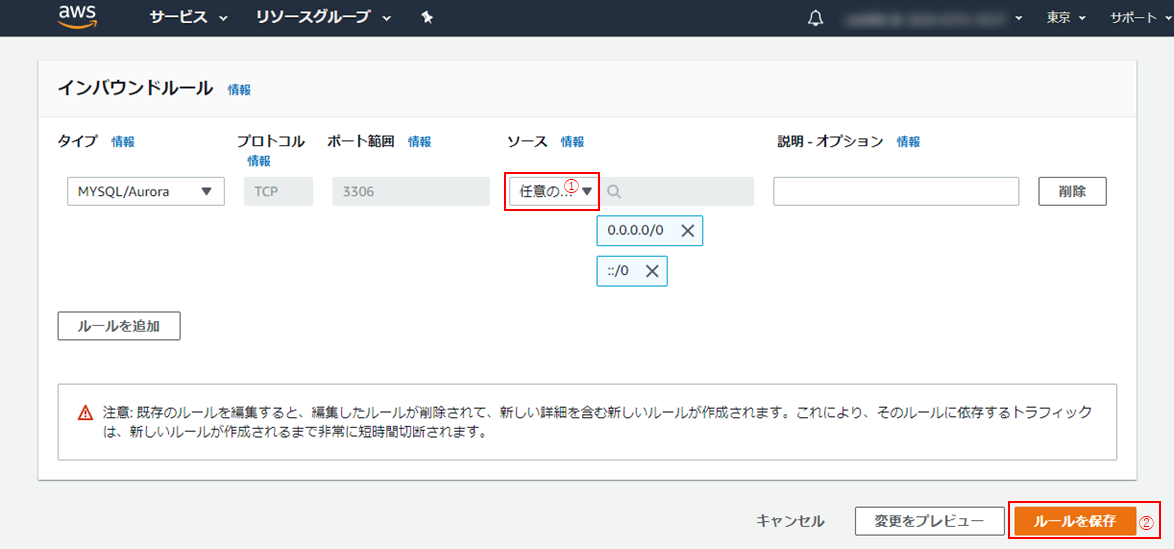
(9)「任意の場所」を選択し(①)、「ルールを保存」をクリック(②)。
【注意】この設定内容は全ての接続元からのアクセスを許可してしまうため、セキュリティ上よくありません。
今回は無線LANを使ってクライアントPCからの接続も行うため、この設定としています。
[2] テーブルの作成
(1) 続いて、接続確認も兼ねて、クライアントPCから、テーブルの作成を行いましょう。
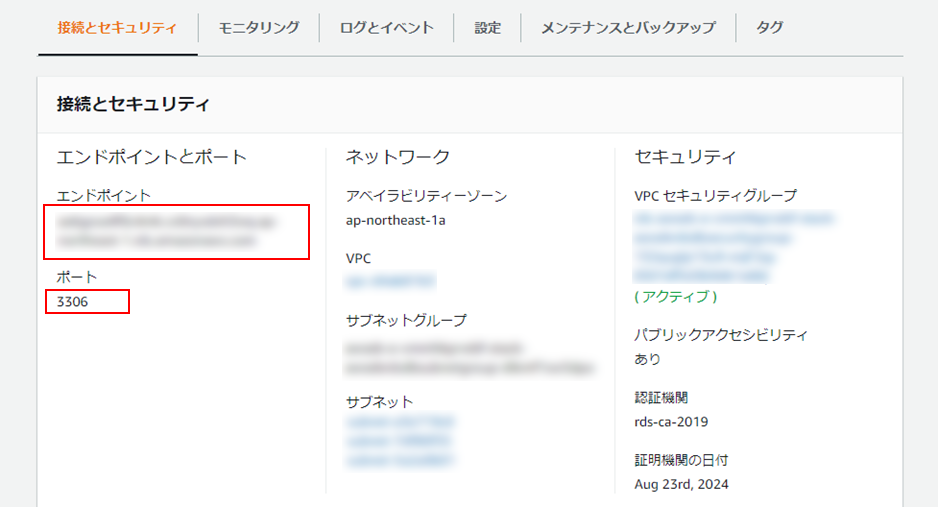
コマンドプロンプトを起動し、以下のコマンドを実行、データベースインスタンスへ接続します。実行コマンド> mysql -h ホスト名-P ポート番号 -u ユーザー名 -pここで、ホスト名は以下のキャプチャの「エンドポイント」(①)、ポート番号はか「ポート」(②:デフォルトは3306)、ユーザー名は3. Elastic Beanstalk環境の作成で設定した「ユーザー名」になります(今回はadmin)。
コマンド実行後、パスワードを聞かれるので、Elastic Beanstalk環境の作成で設定した「パスワード」を入力し、Enter。
ログインできたら、以下のDDL、SQLを実行し、データベース、テーブルの作成、ならびに、データの挿入を行っておきましょう。
データベースとテーブルの作成CREATE DATABASE `sample-db` CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin; USE `sample-db`; CREATE TABLE `shop_informations` ( `shop_id` mediumint(9) NOT NULL AUTO_INCREMENT COMMENT '店舗ID', `shop_name` varchar(100) DEFAULT NULL COMMENT '店舗名', `tel` varchar(15) DEFAULT NULL COMMENT '電話番号', `zip_code` varchar(10) DEFAULT NULL COMMENT '郵便番号', `address` varchar(100) DEFAULT NULL COMMENT '住所', `access` varchar(100) DEFAULT NULL COMMENT 'アクセス', `business_hour` varchar(100) DEFAULT NULL COMMENT '営業時間', `regular_holiday` varchar(100) DEFAULT NULL COMMENT '定休日', PRIMARY KEY (`shop_id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COMMENT='店舗情報';begin; INSERT INTO shop_informations VALUES(1, '春風カフェ', '03-XXXX-XXXX', '100-0005', '東京都千代田区丸の内・・・', '東京駅から徒歩5分', '平日 7:00~21:00/土日祝 10:00~21:00', '不定休'); INSERT INTO shop_informations VALUES(2, '夏海食堂', '050-XXXX-XXXX', '254-0034', '神奈川県宝町・・・', '平塚駅から徒歩10分', '平日 11:00~22:00/土日祝 11:00~20:00', '火曜日'); INSERT INTO shop_informations VALUES(3, '割譲秋山', '049-XXXX-XXXX', '350-0041', '埼玉県川越市六軒町・・・', '川越市駅から徒歩7分/本川越駅から徒歩5分', '昼 11:00~14:00/夜 18:00~23:30', '日曜・祝日'); INSERT INTO shop_informations VALUES(4, '冬空キッチン', '04-XXXX-XXXX', '350-0041', '千葉県我孫子市本町・・・', '我孫子駅から徒歩8分', '昼 11:30~14:00/夜 17:00~23:00', '木曜日'); commit;※上記データは、架空のものになります。実在する店舗ではありません。
[3] Elastic Beanstalkにおける設定
(2) 続いて、Elastic Beanstalkにて、データベース接続用の環境変数を追加します。
マネジメントコンソールにて、Elastic Beanstalkを探してクリック。
(3) 「ソフトウェア」の右端の「編集」をクリック。
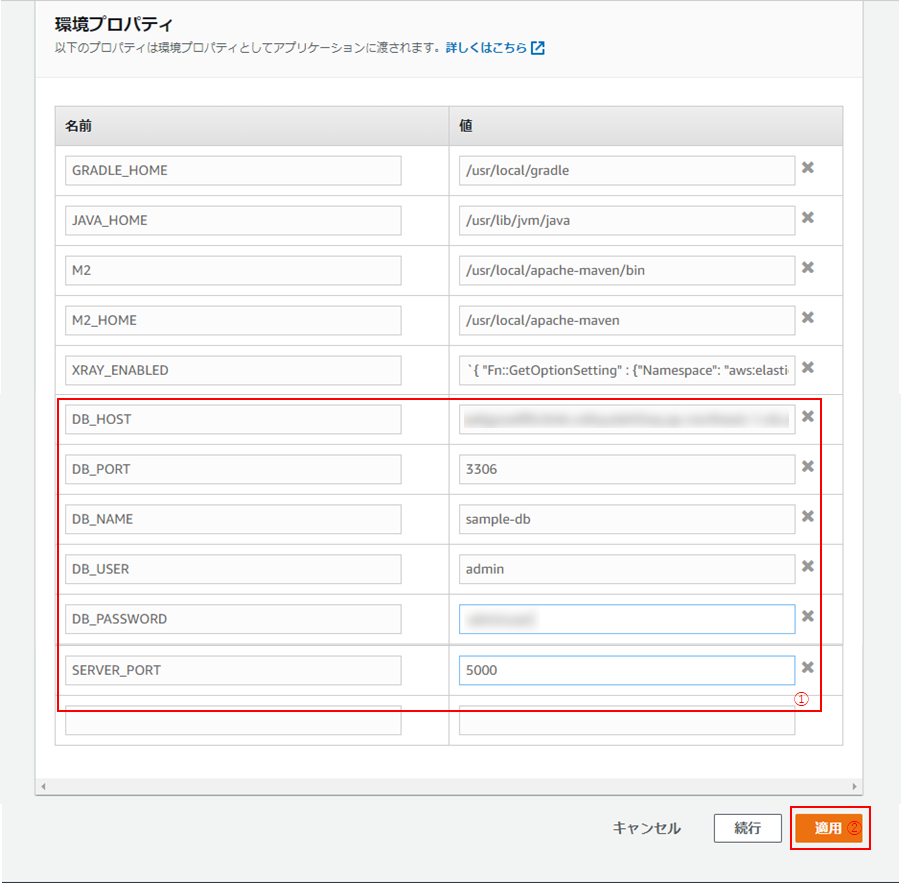
(4) 「環境のプロパティ」欄にて、以下のように設定し(①)、「適用」をクリック(②)。
名前 値 DB_HOST (10)で入力したホスト名 DB_PORT (10)で入力したポート番号 DB_NAME (10)で作成したデータベース名 DB_USER (10)で入力したユーザー名 DB_PASSWORD (10)で入力したパスワード SERVER_PORT 5000
(5) 「1. Java(Spring Boot)アプリケーションの作成」で作成したapplication.ymlの内容を以下のように書き換えます。
application.ymlspring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://${DB_HOST:(10)で入力したホスト名}:${DB_PORT:(10)で入力したポート番号}/${DB_NAME:(10)で作成したデータベース名}?serverTimezone=JST username: ${DB_USERNAME:(10)で入力したユーザー名} password: ${DB_PASSWORD:(10)で入力したパスワード} jpa: database: MYSQL hibernate.ddl-auto: none server: port: ${SERVER_PORT:5000}こうすることで、クライアントPCから、今回作成したデータベースに接続することができるようになります。
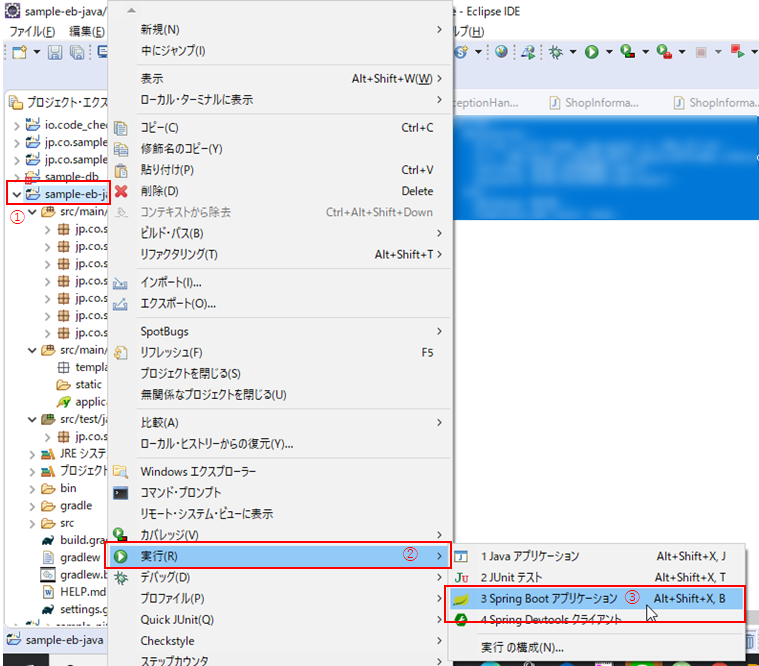
(6) Eclipseにて、作成したプロジェクト上で右クリックし(①)、「実行」(②) > 「Spring Bootアプリケーション」(③)をクリックして、ローカルサーバーを起動しましょう。
(7) ブラウザを立ち上げて、以下のURLを叩き、結果が取得できることを確認します。
実行URLhttp://localhost:5000/shop-information/1(8) application.ymlの変更内容をGitのリモートリポジトリ(CodeCommit)にも反映させます。
コマンドプロンプトを起動して、プロジェクトのルートディレクトリまで移動し、以下の順でコマンドを実行。> git add application.yml > git commit -m "fix application.yml"続編について
続きは、
にて。
5. パイプラインの作成の接続設定と6. 後片付けを行います。参考
手順
3. Elastic Beanstalk環境の作成
4. データベースの接続設定











- 投稿日:2020-08-06T20:57:44+09:00
【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その1
Javaアプリケーション(データベースから値を取得し、JSON形式で結果を返す)をCodePipelineでElasticBeanstalkにCI/CDするハンズオンです。
長いので、
- 【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その1(本記事)
→ 1. Java(Spring Boot)アプリケーションの作成, 2. Gitリポジトリの作成- 【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その2
→ 3. Elastic Beanstalk環境の作成, 4. データベースの設定- 【CodePipeline×ElasticBeanstalk】JavaアプリケーションをCodePipelineでElasticBeanstalkにCI/CDする その3
→ 5. パイプラインの作成, 6. 後片付けにの3記事に内容を分割しています。
作業時間は事前準備を除いて、トータル3時間前後を想定。各記事1時間程度が目安。環境
- OS:Windows10
- IDE:Eclipse 2020-03
- JDK:Amazon Correto 8
- フレームワーク:Spring Boot
- AWS
- CodePipeline
- CodeCommit
- CodeBuild
- CodeDeploy
- Elastic Beantalk
- Java SE(Java 8 バージョン 2.10.8)
→ ※2020年6月3日公開の最新版ではないです。ご了承を。- RDS:MySQL Community Edition(バージョン8.0.17)
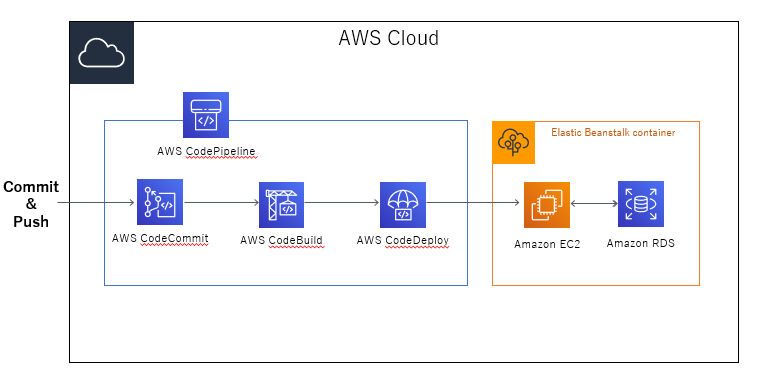
イメージ図
本手順でできる内容のざっくりとしたイメージ図です。
ローカルで編集したコードをコミット → CodeCommitにプッシュすると、CodePipelineにより、アプリケーション実行環境であるElastic Beanstalkまで自動でビルド、デプロイを行ってくれるCI/CDの仕組みを構築します。
事前準備
①Eclipseが未インストールの場合は、
Pleiades All in One Eclipse ダウンロード(リリース 2020-06) | MergeDoc Project
より最新版(2020年8月3日時点)をダウンロードしてください。STS と Lombok が設定済みのため、Spring Bootによる開発にすぐ着手できます。②JDKはAmazon Correto 8を想定しています。
Amazon Corretto 8 のダウンロード | aws
より、ダウンロード→インストールし、Eclipseへの設定を済ませておいてください。③CodeCommitが使えるよう、
AWSのCodeCommit使い方。アクセスキー作るところからなど。| Qiita
を参考に、事前準備を行っておいてください。手順
1. Java(Spring Boot)アプリケーションの作成
まず、EclipseでJava(Spring Boot)アプリケーションを作成します。
店舗IDをもとに、店舗詳細情報を取得する至ってシンプルな内容になっています。
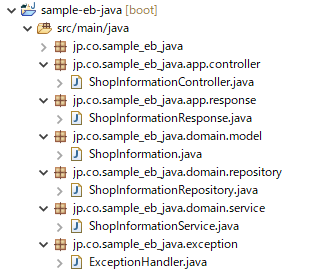
パッケージの構成は以下の通り。sample-eb-java | src/main/java |----jp.co.sample_eb_java | |---- app | | |---- controller | | |---- response | | | |---- domain | | |---- service | | |---- repository | | |---- model | | | |---- exception | | src/main/resources |----application.yml | Buildfile Procfile build.gradle .ebextensions ・・・以下、省略[1] プロジェクトの作成
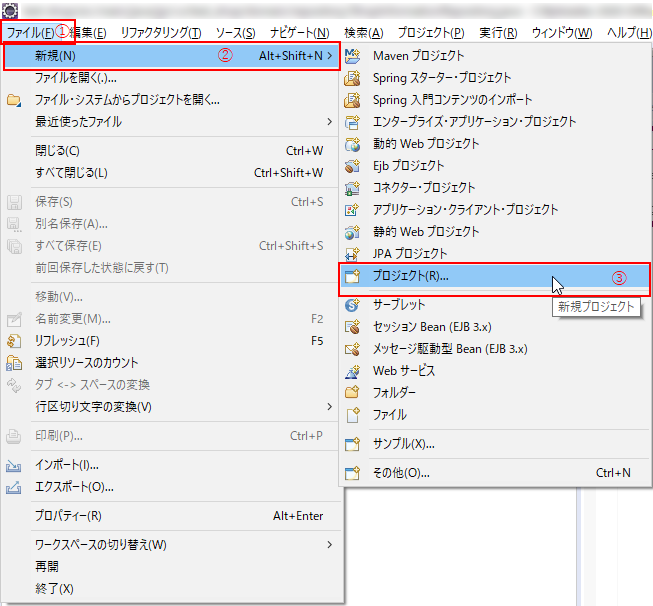
(1) Eclipseを開いたら、「ファイル」(①)> 「新規」(②) > 「プロジェクト」(③)の順でクリック。
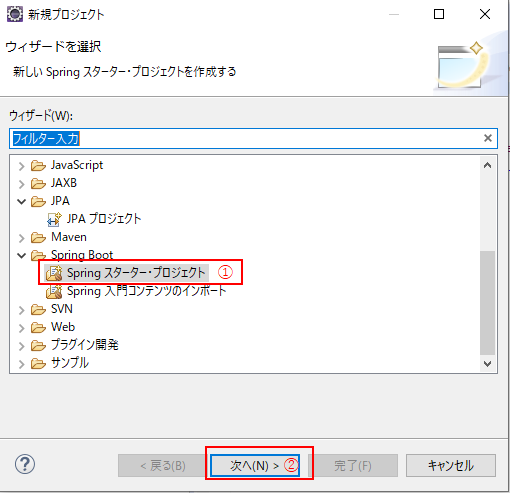
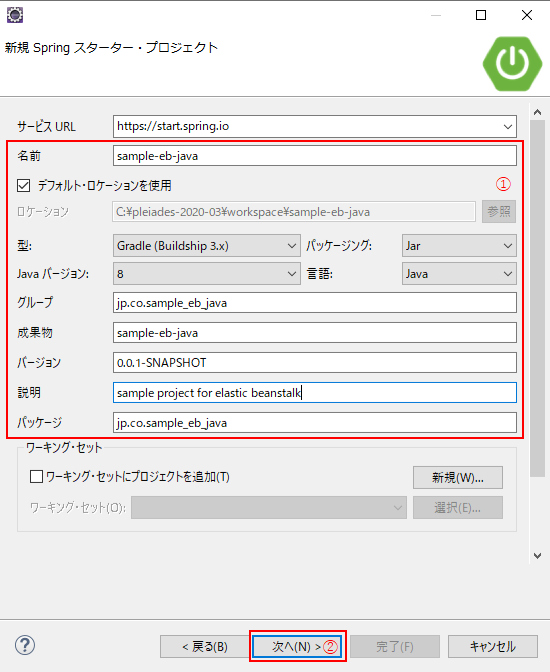
(2) ウィザードが立ち上がったら、「Springスターター・プロジェクト」を選択し(①)、「次へ」(②)をクリック。
(3) 以下のキャプチャのように設定し(①)、「次へ」(②)をクリック。
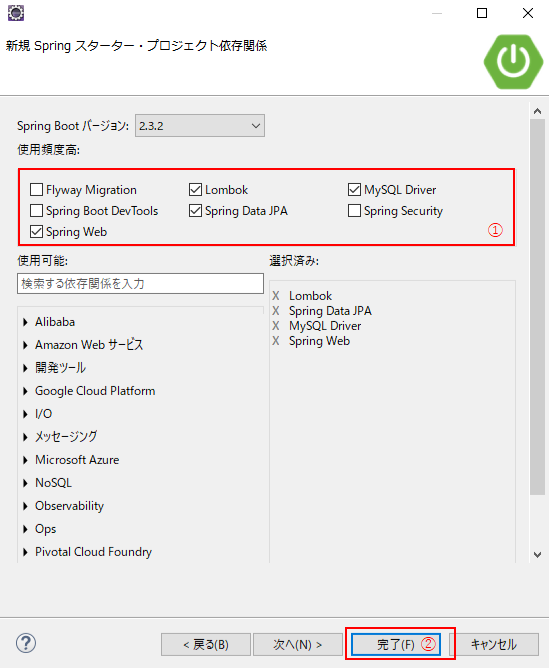
(4)Lombok, MySQL Driver, Spring Data JPA, Spring Webにチェックを入れ(候補に出ていない場合は検索ボックスより検索してください)、「次へ」(②)を押下
[2] 設定ファイルの変更・作成
次に、設定ファイルの変更と作成を行います。
(1)application.propertiesをapplication.ymlに名前変更し、以下のように記述します。
※application.propertiesのままでもいいのですが、最近の潮流(?)を踏まえてそうしました。
application.ymlspring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://${DB_HOST:ホスト名}:${DB_PORT:ポート番号}/${DB_NAME:データベース名}?serverTimezone=JST username: ${DB_USERNAME:ユーザー名} password: ${DB_PASSWORD:パスワード} jpa: database: MYSQL hibernate.ddl-auto: none server: port: ${SERVER_PORT:サーバーポート番号}日本語の箇所は後で変更するので、いったんこのままで。
(2)ルートディレクトリにBuildfileを作成し、以下の通り記述。
Buildfilebuild: ./gradlew assemble(3)ルートディレクトリにProcfileを作成し、以下の通り記述。
Procfileweb: java -jar build/libs/sample-eb-java.jar(4) build.gradleに追記します。追記前の箇所を探し、「bootJar.archiveName = "sample-eb-java.jar"」を追記してください。
build.gradle(追記前)configurations { compileOnly { extendsFrom annotationProcessor } }build.gradle(追記後)configurations { compileOnly { extendsFrom annotationProcessor } bootJar.archiveName = "sample-eb-java.jar" }[3]ソースコードの作成
続いて、ソースコードの作成です。
パッケージ構成はこの章(1. Java(Spring Boot)アプリケーションの作成)の冒頭の通りですが、上まで戻るのも面倒かと思うので、キャプチャを貼っておきます。
(1)まずはEntityクラス。
後から出てきますが、データベースに作成するshop_informationsテーブルに対応する内容となっています。ShopInformation.javapackage jp.co.sample_eb_java.domain.model; import java.io.Serializable; import javax.persistence.*; import lombok.Getter; import lombok.Setter; /** * 店舗情報テーブルに紐づくEntityクラス * * @author CHI-3 * */ @Entity @Getter @Setter @Table(name="shop_informations") @NamedQuery(name="ShopInformation.findAll", query="SELECT s FROM ShopInformation s") public class ShopInformation implements Serializable { private static final long serialVersionUID = 1L; @Id @GeneratedValue(strategy=GenerationType.IDENTITY) @Column(name="shop_id") private Integer shopId; private String access; private String address; @Column(name="business_hour") private String businessHour; @Column(name="regular_holiday") private String regularHoliday; @Column(name="shop_name") private String shopName; private String tel; @Column(name="zip_code") private String zipCode; public ShopInformation() { } }(2)続いて、Repositoryインターフェース。テーブル操作に使用するインターフェースです。
ShopInformationRepository.javapackage jp.co.sample_eb_java.domain.repository; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.stereotype.Repository; import jp.co.sample_eb_java.domain.model.ShopInformation; /** * 店舗情報を扱うリポジトリインターフェース * * @author CHI-3 * */ @Repository public interface ShopInformationRepository extends JpaRepository<ShopInformation, Integer>{ /** * 店舗IDに紐づく店舗情報を取得 * * @param shopId 店舗ID * @return 店舗情報 */ public ShopInformation findByShopId(Integer shopId); }(3)続いて、Serviceクラス。ロジックを提供します。
ShopInformationService.javapackage jp.co.sample_eb_java.domain.service; import java.util.Optional; import org.springframework.stereotype.Service; import jp.co.sample_eb_java.domain.model.ShopInformation; import jp.co.sample_eb_java.domain.repository.ShopInformationRepository; import lombok.RequiredArgsConstructor; /** * 店舗情報を取得するサービスクラス * * @author CHI-3 * */ @Service @RequiredArgsConstructor public class ShopInformationService { private final ShopInformationRepository shopInformationRepository; /** * 店舗情報を取得 * * @param shopId 店舗ID * @return 店舗情報 * @throws Exception */ public ShopInformation getShopInformation(Integer shopId) throws Exception{ // 店舗情報を取得:対象店舗が存在しなければ例外をThrow ShopInformation shopInformation = Optional.ofNullable(shopInformationRepository.findByShopId(shopId)).orElseThrow(Exception::new); return shopInformation; } }(4)次に、Responseクラス。返却する値の成形を行います。
ShopInformationResponse.javapackage jp.co.sample_eb_java.app.response; import jp.co.sample_eb_java.domain.model.ShopInformation; import lombok.Builder; import lombok.Getter; /** * 店舗情報取得用レスポンスクラス * @author CHI-3 * */ @Getter @Builder public class ShopInformationResponse { /** 店舗情報 */ private ShopInformation shopInformation; }(5)お次は、Controllerクラス。JSON形式で値を返却するため、@RestControllerを使っています。
ShopInformationController.javapackage jp.co.sample_eb_java.app.controller; import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RestController; import jp.co.sample_eb_java.app.response.ShopInformationResponse; import jp.co.sample_eb_java.domain.model.ShopInformation; import jp.co.sample_eb_java.domain.service.ShopInformationService; import lombok.RequiredArgsConstructor; /** * 店舗情報を取得するAPI * * @author CHI-3 * */ @RestController @RequiredArgsConstructor public class ShopInformationController { private final ShopInformationService shopInformationService; /** * 店舗情報を取得 * * @param shopId 店舗ID * @return レスポンスエンティティ(店舗情報) * @throws Exception */ @GetMapping("/shop-information/{shopId}") public ResponseEntity<ShopInformationResponse> getShopInformation(@PathVariable("shopId") Integer shopId) throws Exception{ ShopInformation shopInformation = shopInformationService.getShopInformation(shopId); ShopInformationResponse shopInformationResponse = ShopInformationResponse.builder().shopInformation(shopInformation).build(); return new ResponseEntity<>(shopInformationResponse, HttpStatus.OK); } }(6) 最後に、ExceptionHandler。エラーハンドリングしてくれるクラスです。
今回は、存在しない店舗IDをリクエストした際などに、400エラー(Bad Request)を返却する内容になっています。ExceptionHandler.javapackage jp.co.sample_eb_java.exception; import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.ControllerAdvice; import org.springframework.web.bind.annotation.ResponseBody; import org.springframework.web.bind.annotation.ResponseStatus; import lombok.extern.slf4j.Slf4j; /** * 例外ハンドラー * * @author CHI-3 * */ @ControllerAdvice @Slf4j public class ExceptionHandler { @ResponseStatus(HttpStatus.BAD_REQUEST) @org.springframework.web.bind.annotation.ExceptionHandler({Exception.class}) public @ResponseBody ResponseEntity<Object> handleError(final Exception e) { log.info("call ExceptionHandler", e); return new ResponseEntity<>(HttpStatus.BAD_REQUEST); } }2. Gitリポジトリの作成
手順1で作成したプロジェクトをGit管理できるようにします。
手順1で作成したプロジェクト上でローカルリポジトリを作成し、リモートリポジトリと同期する流れで行います。[1] ローカルリポジトリの作成
(1) コマンドプロンプト、またはGitBashを開き、1で作成したプロジェクトのルートディレクトリに移動(cd)した後、リポジトリの初期化を行います(以下のコマンドを実行)。
> git initプロジェクトのルートディレクトリに.gitフォルダができればOK。
(2)コミットする前に、 .gitignoreの書き換えを行います。
デフォルトの記述では、STSなど、必要な機能がコミット対象外となってしまい、後々動作しないなど、不具合の原因になりかねません。
以下の通り記述を変更します。
classファイルやlockファイルなど、コミットの必要のないものが対象外となります。.gitignorebin/* .lock(3)編集内容をコミットします。
以下のコマンドを順に実行すればOK。> git add . > git commit -m "first commit"「first commit」の部分(コミットメッセージ)は任意の内容でOKですが、編集内容がわかるメッセージにしましょう(以降同様。)
(4)再度、.gitignoreを編集します。
機能としては必要だけれども、ローカルからのコミット対象外となるものを記述。.gitignore# Created by https://www.toptal.com/developers/gitignore/api/java,gradle,eclipse # Edit at https://www.toptal.com/developers/gitignore?templates=java,gradle,eclipse ### Eclipse ### .metadata bin/ tmp/ *.tmp *.bak *.swp *~.nib local.properties .settings/ .loadpath .recommenders # External tool builders .externalToolBuilders/ # Locally stored "Eclipse launch configurations" *.launch # PyDev specific (Python IDE for Eclipse) *.pydevproject # CDT-specific (C/C++ Development Tooling) .cproject # CDT- autotools .autotools # Java annotation processor (APT) .factorypath # PDT-specific (PHP Development Tools) .buildpath # sbteclipse plugin .target # Tern plugin .tern-project # TeXlipse plugin .texlipse # STS (Spring Tool Suite) .springBeans # Code Recommenders .recommenders/ # Annotation Processing .apt_generated/ .apt_generated_test/ # Scala IDE specific (Scala & Java development for Eclipse) .cache-main .scala_dependencies .worksheet # Uncomment this line if you wish to ignore the project description file. # Typically, this file would be tracked if it contains build/dependency configurations: #.project ### Eclipse Patch ### # Spring Boot Tooling .sts4-cache/ ### Java ### # Compiled class file *.class # Log file *.log # BlueJ files *.ctxt # Mobile Tools for Java (J2ME) .mtj.tmp/ # Package Files # *.jar *.war *.nar *.ear *.zip *.tar.gz *.rar # virtual machine crash logs, see http://www.java.com/en/download/help/error_hotspot.xml hs_err_pid* ### Gradle ### .gradle build/ # Ignore Gradle GUI config gradle-app.setting # Avoid ignoring Gradle wrapper jar file (.jar files are usually ignored) !gradle-wrapper.jar # Cache of project .gradletasknamecache # # Work around https://youtrack.jetbrains.com/issue/IDEA-116898 # gradle/wrapper/gradle-wrapper.properties ### Gradle Patch ### **/build/ # End of https://www.toptal.com/developers/gitignore/api/java,gradle,eclipse※上記はgitignore.ioで、
- Java
- Gradle
- Eclipse
を条件として作成しました。
変更が完了したら、コミットしておきましょう。
> git add .gitignore > git commit -m "fix .gitignore"(5) gradlewの権限変更を行います。
【重要】この手順を飛ばしてしまうと、ビルド、デプロイ時にエラーになるので、忘れず実施してください。まず、gradlewの権限を確認します。
> git ls -files -s gradlew 100644 fbd7c515832dab7b01092e80db76e5e03fe32d29 0 gradlew上記のままだと、読み取り権限しかないので、以下のコマンドを実行して、実行権限を与えます。
> git update-index --add --chmod=+x gradlew実行が完了したら、再度権限確認を行いましょう。
以下の通り、最初の6桁の数字の下3桁が755になっていればOK。> git ls-files -s gradlew 100755 fbd7c515832dab7b01092e80db76e5e03fe32d29 0 gradlew変更内容をコミットします。
> git add gradlew > git commit -m "fix permission of gradlew"[2] リモートリポジトリの作成
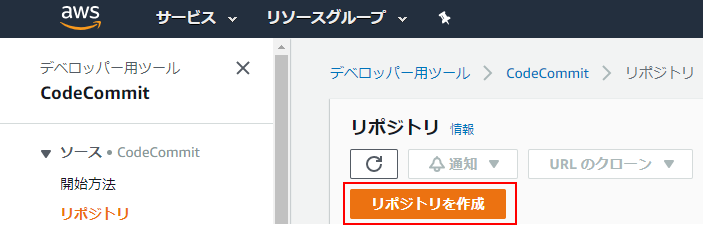
(1) AWSマネジメントコンソールにログインし、「サービス」(①)からCodeCommitを探してクリック(②)。
(2) CodeCommitのページに遷移したら、「リポジトリを作成」をクリック。
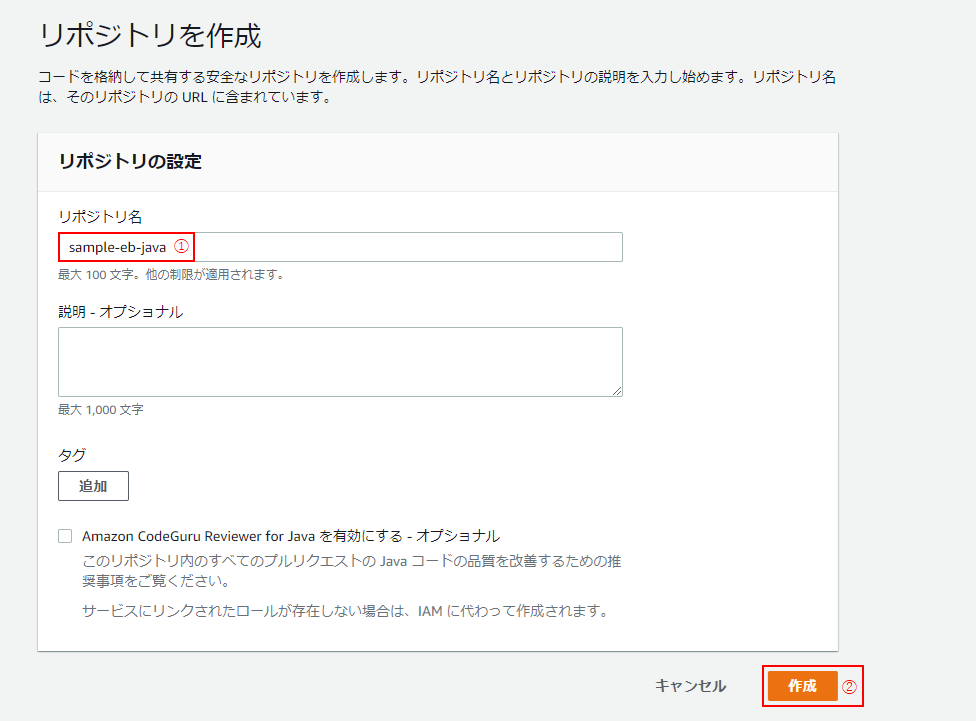
(3)手順1で作成したプロジェクトと同名のリポジトリ名をつけ(①)、「作成」をクリック。
[3] ローカルリポジトリとリモートリポジトリを同期
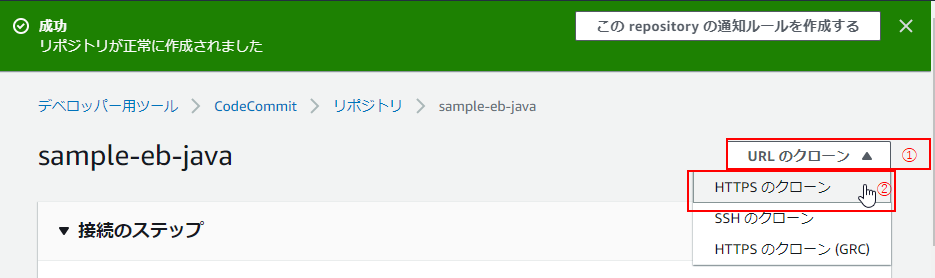
(1)リモートリポジトリの作成が完了すると、以下のようなページに遷移するので、「URLのクローン」(①) > 「HTTPSのクローン」(②)をクリック。
(2)コマンドプロンプト or GitBashを開き、プロジェクトのルートディレクトリにて、以下のコマンドを実行。
> git remote add origin (1)の「HTTPSのクローン」でコピーされたURI(3) 内容をリモートリポジトリのmasterにプッシュ。
> git push -u origin master(4)コンソールにて、リモートリポジトリにローカルリポジトリの内容が反映されていることを確認しましょう。
続編について
続きは、
にて。
3. Elastic Beanstalk環境の作成, 4. データベースの接続設定を行います。参考
環境
手順
1. Java(Spring Boot)アプリケーションの作成
2. Gitリポジトリの作成


- 投稿日:2020-08-06T19:48:07+09:00
AWS firelens(Fluent Bit)でログを分割する方法と複数の場所に転送する方法
aws firelensを使って、ECSのログ収集をする時に以下のような複雑なことをやろうとする場合は自前でfluent bitの設定を変更する必要があって、具体的にはfluent bitの設定を自分で定義してそれを読み込んだコンテナを用意する必要があります。
- 複数の場所にログを転送する
- ログを分割する
やり方
extra.confを用意して、用意したファイルを読み込んだコンテナを作成する。
コンテナの作成の仕方はこちらを参照してください。
この記事ではextra.confの書き方だけを残しています。# cw logs [OUTPUT] Name cloudwatch Match * region us-east-1 log_group_name fluent-bit-cloudwatch log_stream_prefix from-fluent-bit- auto_create_group true # kinesis [OUTPUT] Name firehose Match * region us-west-2 delivery_stream stream-one [OUTPUT] Name firehose Match * region us-west-2 delivery_stream stream-two
Matchの正規表現を作り込むことで例えば、ログレベルごとにログを収集することができます。
また[OUTPUT]を複数定義することで複数の場所にログを転送することができます。
- 投稿日:2020-08-06T19:46:43+09:00
ECSでFirelensを使ってsidecar方式で複雑なログ収集を実現する方法
aws firelensを使って、ECSのログ収集をする時に以下のような複雑なことをやろうとする場合は自前でfluent bitの設定を変更する必要があって、具体的にはfluent bitの設定を自分で定義してそれを読み込んだコンテナを用意する必要があります。
- 複数の場所にログを転送する
- ログを分割する
やり方
1. docker imageを作成する
以下の様に設定ファイルを作ってそれを取り組んだdocker imageを作成してECSで使うパターン。
例えば、docker/fluent-bitディレクトリを作って以下の様にファイルを配置する
Dockerfile fluent-bit.conf parser.conf stream_processing.confDocker file内で設定ファイルをADDしていってます。
FROM amazon/aws-for-fluent-bit:latest ADD fluent-bit.conf / ADD parser.conf / ADD stream_processing.conf /このDockerfileで作ったimageをECS task definitionで起動する。
参考
2. task defで設定ファイルを読み込むパターン
task definitionに設定ファイルを読み込ませるオプションを渡して、その設定ファイルを読み込ませたECS taskを起動させるパターン
task definitnionの中のoptionでextra.confを渡してあげる事で、その設定でfluent bitを起動してくれる。
imageを自分で作って管理する必要がない。
"options": { "config-file-type": "s3", "config-file-value": "arn:aws:s3:::yourbucket/yourdirectory/extra.conf" }参考
- 投稿日:2020-08-06T18:25:05+09:00
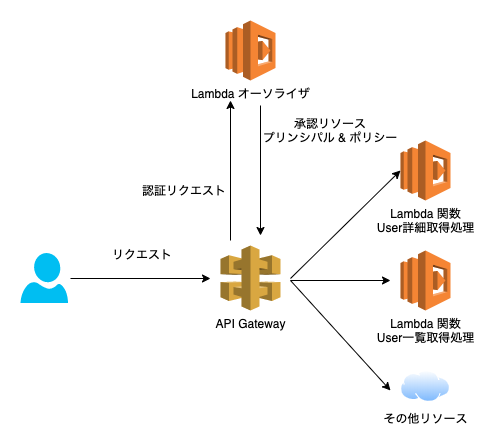
【AWS】API Gateway Lambdaオーソライザー「User is not authorized to access this resource」エラーの原因と対応
上記のようなAPIGatewayで構築したAPIにLambdaオーソライザーを適用した際に、正しい認証情報、正しいAWSリソースへのアクセス権限を設定しているにも関わらず「User is not authorized to access this resource」エラーが発生することがあります。
本記事ではその原因と対応を記載します。原因
Lambdaオーソライザーから返却される認可情報のキャッシングが原因です。
以下のようなアクセスポリシーを返却するコードを記述した際に発生します。
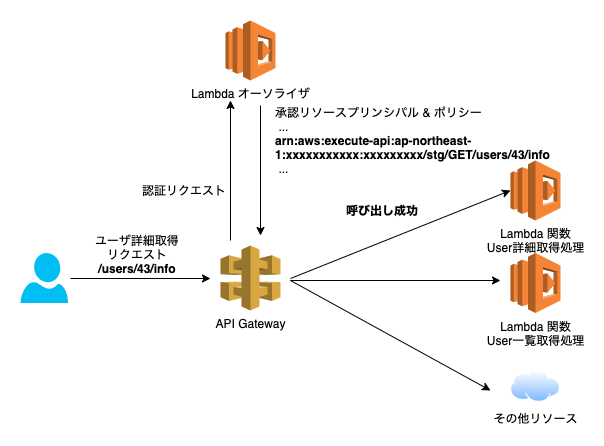
node.js... statementOne.Action = 'execute-api:Invoke'; statementOne.Effect = 'Allow'; // ↓ 以下のアクセス承認するリソースを指定するコードが原因 statementOne.Resource = event.methodArn; ...ポイントは
event.methodArnです。
ここでは呼び出しされたAPIのみのArnが含まれています。
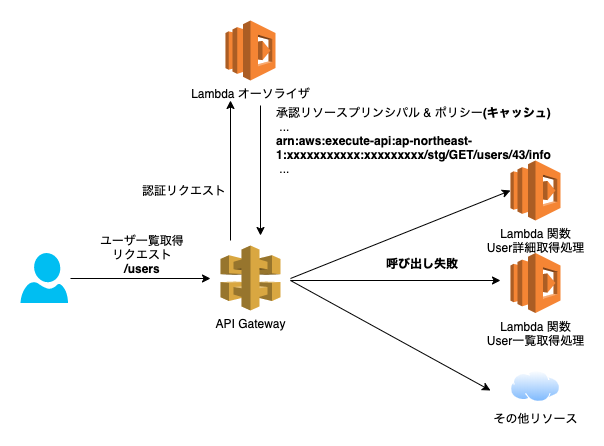
例: arn:aws:execute-api:ap-northeast-1:xxxxxxxxxxx:xxxxxxxxx/stg/GET/users/43/infoこのArnへのアクセス権限を許可したポリシーを返却すると、初回のアクセスはうまくいきます。
しかし同じLambdaオーソライザーが適用されている他のAPIを呼び出した際に、上記のArnが含まれたポリシーがキャッシュとして返却されてしまい、初回アクセスとは別の認可されていないリソースにアクセスすると「User is not authorized to access this resource」エラーが発生します。
対応
2パターンの対応方法があります。
パターン1Lambdaオーソライザーの認可のキャッシュのTTL値を0に設定
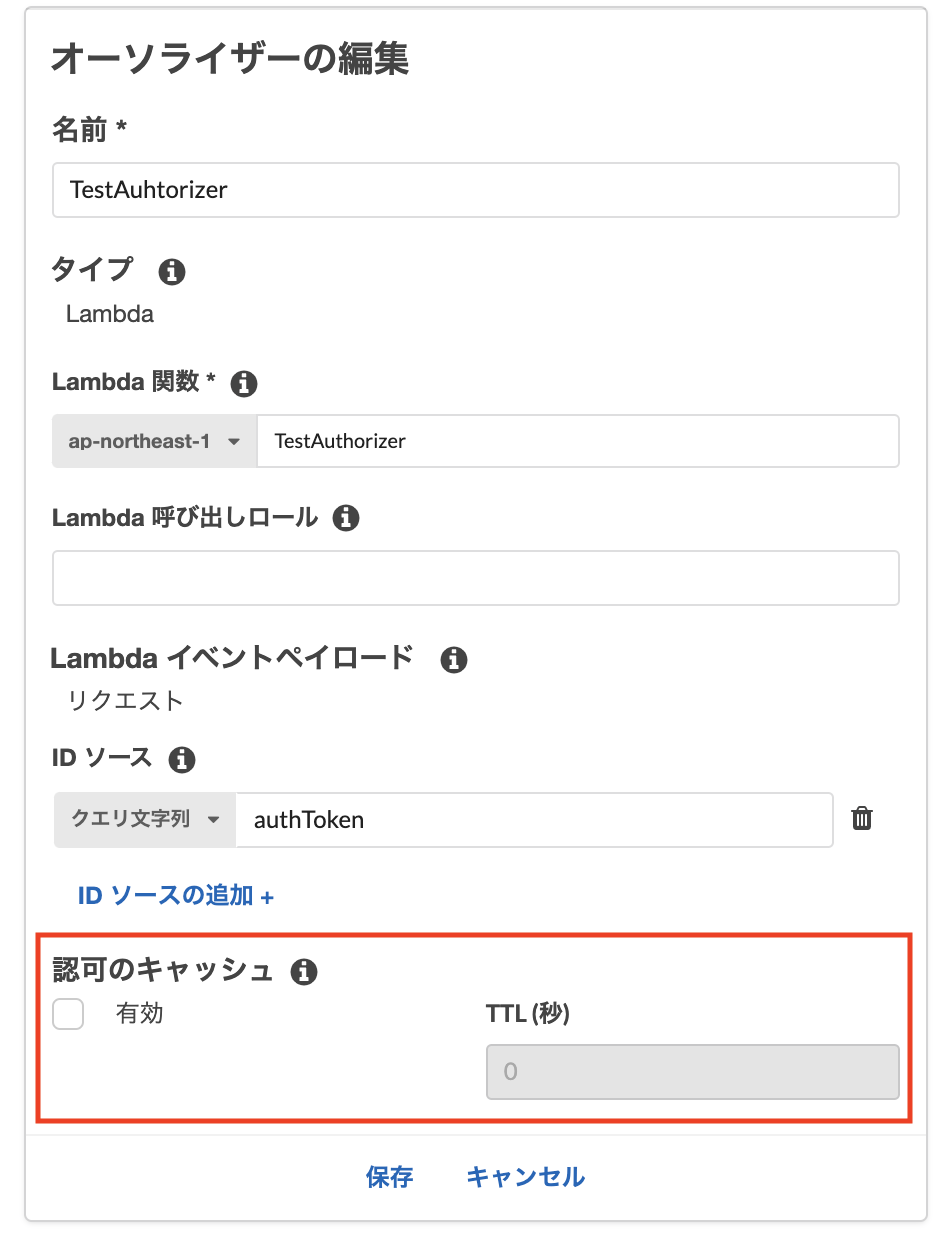
API Gatewayのオーソライザーから対象のオーソライザーを選択して、
TTLを0に変更すると、毎回認証を実行するためevent.methodArnをアクセス承認リソースとして返却しても、問題なく認可が通ります。
ただ毎回認証処理が走るため、パフォーマンス的には優れません。
その点が気になる場合は、後述のパターン2を利用することを推奨します。※ AWS CloudFormation, AWS SAMを利用する場合の注意点
CloudFormation、SAMを利用してLambdaオーソライザーを設定した場合、デフォルトでは認可のキャッシュのTTL値は300秒です。
認可キャッシュのTTL値を変更せずにデプロイしたオーソライザーの設定値をマネジメントコンソールから確認すると...
こんな感じで
undefinedとなっており、キャッシュが無効になっているように見えます。
しかし実際には300秒のキャッシュ設定が有効になっています。
(これに1時間くらいハメられました...)TTLを0に設定する際には、
ReauthorizeEveryを0に設定しましょう。template.yamlTestApi: Type: AWS::Serverless::Api Properties: StageName: Prd Auth: AddDefaultAuthorizerToCorsPreflight: false DefaultAuthorizer: MyLambdaCustomAuthorizer Authorizers: MyLambdaCustomAuthorizer: FunctionPayloadType: REQUEST FunctionArn: Fn::GetAtt: - RestApiAuthFunction - Arn Identity: QueryStrings: - authToken ReauthorizeEvery: 0パターン2 Lambdaオーソライザー側で返却するリソースポリシーを変更
Lambdaオーソライザー側で
event.methodArnを指定するのではなく、ワイルドカードを指定して対応する方法です。node.js... statementOne.Action = 'execute-api:Invoke'; statementOne.Effect = 'Allow'; // ↓ ワイルドカード指定に変更 statementOne.Resource = 'arn:aws:execute-api:*'; ...上記例では、全Lambdaの実行権限を返却しています。
こうすることでポリシーのキャッシュが行われていても、ワイルドカードで許可されたリソースは問題なくコールすることが可能です。
どこまでをワイルドカード指定にするかは、自身のセキュリティポリシーと相談してみてください。キャッシュと併用することができるため、パターン1よりもパフォーマンス的に優れていますが、ワイルドカード指定になる分、セキュリティとトレードオフです。
まとめ
- 1つのオーソライザーを複数のリソースで共有した際に、オーソライザーの認可キャッシュが有効になっていると「User is not authorized to access this resource」が発生する。
- オーソライザーの認可情報のキャッシュが原因であるため、TTLを0にするか認可リソースを拡大することで対応可能
記載情報に誤りがあったらご指摘いただけると助かります。
参考リンク

- 投稿日:2020-08-06T18:20:43+09:00
SageMakerからGoogleCloudVisionに投げてみる
簡単に
AWSのSageMakerを使用している際に、GoogleのCloud Visionに投げてみようと思いたち、OCRを実行した際のメモ書きです。
環境
- SageMakerのconda_python3カーネルを使用
- google-cloud-vision: 1.0.0(初期で入っている(?))
内容
認証
認証に関しては、クリアしている前提とします。
OCR
チュートリアルをそのまま持ってきます。テスト用画像としてテキトーな画像を用意しておきます。
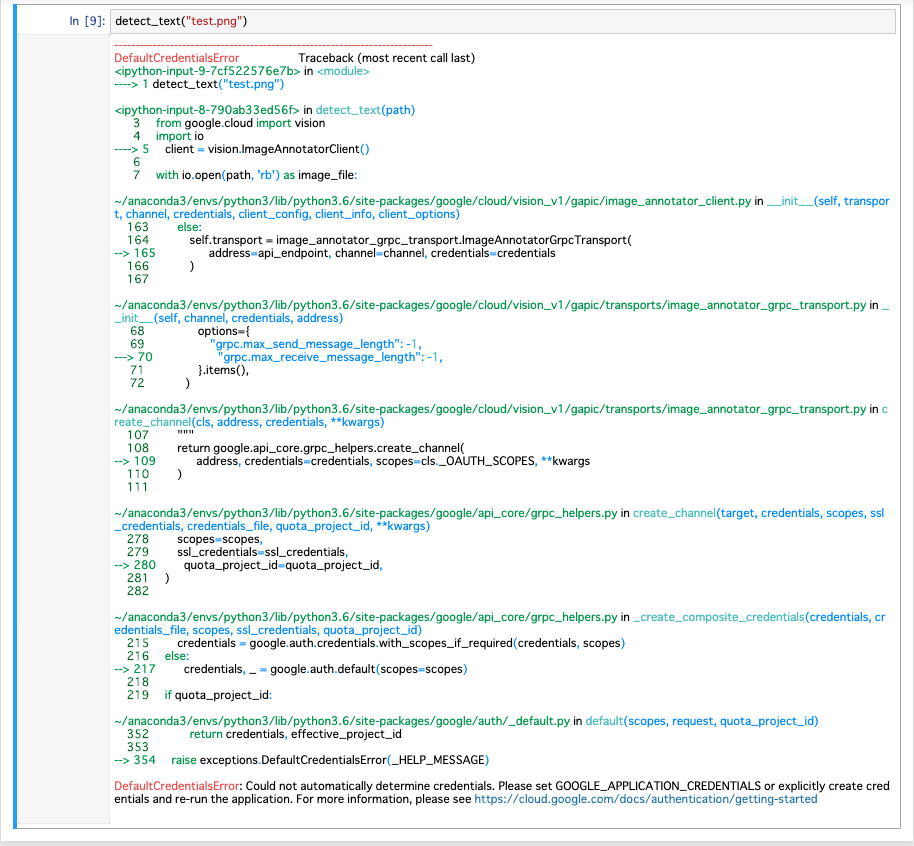
画像からの文字読み取り用のfunctionとして以下のような関数が例として出されています。def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.types.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('\n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message))SageMakerのNotebook上で実行してみましょう。そうすると以下のように認証情報がセットされてませんよというエラーになります。
DefaultCredentialsError: Could not automatically determine credentials. Please set GOOGLE_APPLICATION_CREDENTIALS or explicitly create credentials and re-run the application. For more information, please see https://cloud.google.com/docs/authentication/getting-startedなので、落としてきた認証用のJSONを渡してあげます。
- client = vision.ImageAnnotatorClient() + from google.oauth2 import service_account + credentials = service_account.Credentials.from_service_account_file('credentials.json') + client = vision.ImageAnnotatorClient(credentials=credentials)
無事に「夏」が読み取られたようです。最近暑いですね。。S3から
これだけだとなんなので、S3にある画像をCloud Vision APIに投げつけてみましょう。S3へのアクセス権限の付与は別途必要になります。
def detect_text_from_s3(bucket, key): """Detects text in the file.""" from google.cloud import vision import io import boto3 from google.oauth2 import service_account credentials = service_account.Credentials.from_service_account_file('credentials.json') client = vision.ImageAnnotatorClient(credentials=credentials) s3 = boto3.client('s3') content = s3.get_object(Bucket=bucket, Key=key)['Body'].read() image = vision.types.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('\n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message))- with io.open(path, 'rb') as image_file: - content = image_file.read() + boto3 + s3 = boto3.client('s3') + content = s3.get_object(Bucket=bucket, Key=key)['Body'].read()
無事に読み取れました。
まとめ
今回はSageMakerからGoogleのCloud Vision APIにリクエストを投げて、OCRを実行してみました。AWSのサービスを使いなよ、という気もしますが色々使い分けられても良いかなと思います。



- 投稿日:2020-08-06T18:08:56+09:00
DynamoDB@boto3のクエリの書き方メモ
DynamoDBのクエリの書き方@boto3メモ
DynamoDBのテーブルの項目定義
パーティションキー:primary_id
ソートキー :sort_id
属性1 :timestampコード
a = client.query( TableName='table-name', # Limit=500, KeyConditionExpression='primary_id = :id and begins_with(sort_id, :sort_id)', # 主キー向けのクエリ # FilterExpression='#tstamp > :st and #tstamp <= :ed', # 属性向けのクエリ # ExpressionAttributeNames={ # '#tstamp': 'timestamp' # timestampが予約語になっていて使えなので代替する # }, ExpressionAttributeValues={ ':id':{'S':'primary_001'}, ':sort_id':{'S':f'sort_2020080101'}, # ':st':{'N':'202008010000'}, # ':ed':{'N':'202008010010'}, }, # ExclusiveStartKey={'primary_id': {'S': 'xxxx'}, 'sort_id': {'S': 'yyyy'}}, )
- 投稿日:2020-08-06T16:16:32+09:00
AWS SageMakerでpickleを使ってmodelのsave/loadをするときの注意点
概要
AWS SageMakerで学習インスタンスで学習したモデルをpickleをsave、notebook側でloadをしようとしたら、エラーが出たので対処方法を紹介する。
cloudpickleをつかう
pickleでは、シリアライズする側で
グローバル変数またはその変数を参照しているオブジェクトが
名前空間内に存在しない環境でシリアライズできない。cloudpickle.dump(predictor, open('%s/model'% model_dir, 'wb'))cloudpickleのバージョンは1.3.0
学習インスタンスではデフォルトが1.5.0になっている。
notebook側は1.3.0である。notebookを1.5.0にあげてもエラーがでたため、学習インスタンス側をバージョンダウンさせる必要がある。このため、デプロイする際も学習インスタンス同様cloudpickleのバージョンを1.3.0に指定する。
まとめ
簡単なメモ書きになってしまったが、cloudpickleでエラーになった場合は
バージョンを確認すると良い。
- 投稿日:2020-08-06T14:42:21+09:00
ecsデプロイまで [コマンドまとめ自分用]
リージョンをセット(東京)AWS_REGION=ap-northeast-1ECR中身を確認aws ecr describe-repositories --region ${AWS_REGION}ECRログインaws ecr get-login --region ${AWS_REGION} --no-include-email ==>>docker login -u以下すべてをコピーする. ===>>>login successed!ECRの該当リポジトリ内のpush commandを表示通り
ECSクラスターで起動しているEC2インスタンスへ入るssh -i ~/.ssh/aws-and-infra-ssh-key.pem ec2-user@[EC2インスタンスのpublicIPかElasticIP]EC2内で起動しているdockerコンテナを確認docker ps docker ps -a
text:docker ps -a を削除
docker ps -aq | xargs docker rm
起動コンテナに入るdocker exec -it [起動コンテナID] /bin/bashデータベース生成rails db:create rails db:migrate rails db:migrate:reset rails db:seedデータベース作成中のエラーに対してDATABASE_ENVIRONMENT_CHECK=1 これが出たら RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop
- 投稿日:2020-08-06T14:21:38+09:00
Laravel+AWS-SDK-PHPによるDynamoDBのデータ取得
背景
LaravelでDynamoDB使うにあたり、ORMのlaravel-dynamodbなどもあるが、DynamoDBでORM利用するのが少し違和感あった為にSDK使ってやってみた際のメモ(そもそもPHPのWEBフレームワークでやるなという話ではあるが、せっかくSDKが提供されているので一度使ってみようという感じ)
環境
・Windows 10
・HomeStead 9.5
・PHP 7.4
・Laravel 6.01.準備
AWS-SDK-PHPのインストール
composer require aws/aws-sdk-phpDynamoDBの環境作成
AWS提供のローカルDynamoDBを利用。Vagrantを使っていたので、Dockerと共存が面倒なことになるのでローカルに直接インストールしました。
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/DynamoDBLocal.html※GUIツール(結構便利)
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/workbench.settingup.htmlDynamoDB起動
java -Djava.library.path=C:\localsandbox\DynamoDB\DynamoDBLocal_lib -jar C:\localsandbox\DynamoDB\DynamoDBLocal.jar -port 8001 -sharedDb※HomesteadのVirtualBoxと初期ポート8000が被るので、8001で起動させる
テスト用テーブルの作成
テーブル名:SensorLog
パーティションキー:device_id
ソートキー:receive_dtaws dynamodb create-table --table-name SensorLog --attribute-definitions AttributeName=device_id,AttributeType=S AttributeName=receive_dt,AttributeType=N --key-schema AttributeName=device_id,KeyType=HASH AttributeName=receive_dt,KeyType=RANGE --provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1 --endpoint-url http://localhost:8001※キーのない項目はテーブル作成時に指定できないので、テストデータ作成時に適当に作る。
※テストデータはGUIで適当に作成.envに情報設定
DYNAMODB_REGION=ap-northeast-1 #↓vagrantのlocalhost:xxxxだとつながらないのでローカルIPを設定 DYNAMODB_LOCAL_ENDPOINT=http://192.168.11.99:8001 DYNAMODB_DEBUG=true2.データ取得
・パーティションキーで絞ってデータ検索した結果の最新を取得する。
・パーティションキー+ソートキー(範囲指定)による複合条件検索の結果リストを取得するuse Aws\DynamoDb\Exception\DynamoDbException; use Aws\DynamoDb\Marshaler; use Aws\Sdk as AwsSdk; class SensorLog { /** * @var DynamoDbClient */ private $client; /** * @var Marshaler */ private $marshaler; /** * DynamoModel constructor. */ public function __construct() { // ローカルDBであっても"credentials"定義しないとエラーが吐かれるので注意 $sdk = new AwsSdk([ 'credentials' => [ 'key' => env('DYNAMODB_KEY'), 'secret' => env('DYNAMODB_SECRET'), ], 'endpoint' => env("DYNAMODB_LOCAL_ENDPOINT"), 'region' => env("DYNAMODB_REGION"), 'version' => 'latest' ]); $this->client = $sdk->createDynamoDb(); $this->marshaler = new Marshaler(); } /** * パーティションキー指定による最新データを取得する */ public function getFirst($id) { $tableName = 'SensorLog'; // 検索条件設定:device_idを検索条件にする $key_value = $id; $jsonStr = '{'.'":device_id":'.'"'.$key_value.'"'.'}'; $eav = $this->marshaler->marshalJson($jsonStr); // Limit:1 取得件数を1件に制限 // ScanIndexForward:false ソートキー(receive_dt)を降順指定 $params = [ 'TableName' => $tableName, 'KeyConditionExpression' => '#id = :device_id', 'ExpressionAttributeNames'=> [ '#id' => 'device_id' ], 'Limit' => 1, 'ScanIndexForward' => false, 'ExpressionAttributeValues'=> $eav, ]; try { $result = $this->client->query($params); $data = array(); foreach ($result['Items'] as $recdData) { $data[] = $this->marshaler->unmarshalItem($recdData); } return $data; } catch (DynamoDbException $e) { throw $e; } } /** * パーティションキー+対象日付のデータリストを取得する */ public function getDataByDateTime(int $id, string $dt) { $tableName = 'SensorLog'; // 対象日付の最小時間と最大時間を設定する // receive_dt:YYYYMMDDHHMMSSの値は数値型で格納されている $from_dt = $dt."000000"; $to_dt = $dt."235959"; // バインド変数を設定(device_id,from_dt,to_dt) $key_value = $id; $jsonStr = '{' . '":device_id":' . '"' .$key_value.'",":from_dt":'.$from_dt.',":to_dt":'.$to_dt.'}'; $eav = $this->marshaler->marshalJson($jsonStr); // device_idとreceive_dtによる範囲検索を行う // ScanIndexForward:false ソートキー(receive_dt)を降順指定 $params = [ 'TableName' => $tableName, 'KeyConditionExpression' => '#id = :device_id and receive_dt between :from_dt and :to_dt', 'ExpressionAttributeNames'=> [ '#id' => 'device_id' ], 'ScanIndexForward' => false, 'ExpressionAttributeValues'=> $eav, ]; try { $result = $this->client->query($params); $data = array(); foreach ($result['Items'] as $recdData) { $data[] = $this->marshaler->unmarshalItem($recdData); } return $data; } catch (DynamoDbException $e) { throw $e; } } }呼び出し
・コントローラーで呼び出し
//1.指定IDの最新データを1件取得 $sensorLog = $sensor->getFirst($id); //2.2020-08-06のデータを検索して結果リストを取得 $sensorLogList = $sensor->getDataByDateTime($id, "20200806"); dump($sensorLogList);・結果
参考
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/GettingStarted.PHP.04.html

- 投稿日:2020-08-06T14:18:32+09:00
AWS-SAA試験勉強メモ2
クラスタープレイスメントグループ
単一AZ内のEC2インスタンスを論理的にグループ化したもの。
メリット
- 10Gbpsのフロー制限
- 非ブロッキング
- 非オーバーサブスクライブ
=プレイスメントグループ内のすべてのノードは、すべてのプレイスメントグループ内の他のノードと対話可能
Polocy Validator
自動でIAMアクセスコントロールポリシーを調べてIAMポリシーの文法に準拠していることをチェックする。
確立されたポリシー構文に準拠しないポリシーを保存することは不可。EC2インスタンスの誤削除防止
- 有効化方法(コンソール)
状態 方法 起動時 Enable termination protection 実行中or停止中 Change termination protection
- 有効化方法(コマンド)
サービス コマンド AWS CLI modify-instance-attrinute AWS Tools for Windows PowerShell Edit-EC2InstanceAttribute ネットワークACLのルール番号評価
ルールは低い番号から評価される
EBSのステータスチェック
ステータス 意味 ok 想定通りのパフォーマンス warning 想定よりパフォーマンスが低下 impaired パフォーマンスが致命的に低下 or I/Oが無効 insufficient-data ステータスチェック中 オンプレの仮想マシンイメージのEC2への移行
VM Import/Exportという機能を使用する
ただし、LinuxのImportでは、Importがサポートされるインスタンスタイプ制限がある
※Windowsでは任意のインスタンスのインポートに対応EC2未対応LinuxOS
- 32bit版全般
- RHEL6.0
VMインポート時注意事項
- 事前にNET Framework3.5 SP1の事前インストールが必須
- NTPサーバーとの時刻同期
- DHCPの有効化)VMImportで固定IPの取得は不可
- 投稿日:2020-08-06T14:16:03+09:00
nginx sockets通信 ecsデプロイ 「簡単ログインなど挙動がおかしい」
sshでサインイン
ec2に入る
docker ps
起動しているappコンテナに入る
docker exec -it [] /bin/bash
ls log/production.logを拝見
HTTP Origin header (https://hoge.com) didn’t match request.base_url(http://hoge.com)
エラーを発見2017だけど、aws elb使用時のacm発行したssl(HTTPS化)についての的確な解説
結局nginx.confを設定して、port80をlistenする記述をしないと
X-Forwarded-Protoについて
転送されたプロトコル (http または https).を含める# プロキシ先の指定 # Nginxが受け取ったリクエストをバックエンドのpumaに送信 upstream app { # ソケット通信したいのでpuma.sockを指定 server unix:///app/tmp/sockets/puma.sock; } # httpでのアクセスはhttpsにリダイレクトさせる # serverからhttpに変更 server{ listen 80; # ドメインを指定 server_name sss.red-miso.work; access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; # ドキュメントルートの指定 root /app/public; client_max_body_size 100m; error_page 404 /404.html; error_page 505 502 503 504 /500.html; try_files $uri/index.html $uri @app; keepalive_timeout 5; location @app { proxy_read_timeout 300; proxy_connect_timeout 300; proxy_redirect off; proxy_set_header Host $host; #$http_x_forwarded_protoに変更する。 proxy_set_header X-Forwarded-Proto $http_x_forwarded_proto; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 上記server_name で設定した名前で指定 proxy_pass http://app; } }
- 投稿日:2020-08-06T11:56:56+09:00
AWS DynamoDB/DocumentDBをローカルで確認する手順(自分用メモ)
概要
AWS DynamoDB/DocumentDBをローカルで確認する手順
環境
Microsoft Windows [Version 10.0.19041.388]
Docker version 19.03.8, build afacb8bSAM CLI, version 0.53.0
aws-sdk@2.727.1DynamoDB Local
DynamoDB ローカル セットアップ
DynamoDB ローカル (ダウンロード可能バージョン) のセットアップ
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/DynamoDBLocal.htmlに手順がある
DynamoDB Docker イメージをインストールする
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/DynamoDBLocal.Docker.html
を実施version: '3.7' services: dynamodb-local: image: amazon/dynamodb-local:latest container_name: dynamodb-local ports: - "8000:8000"コンソール出力
>docker-compose up Creating network "sample-sam-node_default" with the default driver Pulling dynamodb-local (amazon/dynamodb-local:latest)... latest: Pulling from amazon/dynamodb-local 638b75f800bf: Pull complete a455ee0c5c58: Pull complete c7e215ba3460: Pull complete Digest: sha256:c8aeb014edfff8b93d7f14054cb9d2a1be214d62b7c5b61eb7fb40893a8404bb Status: Downloaded newer image for amazon/dynamodb-local:latest Creating dynamodb-local ... done Attaching to dynamodb-local dynamodb-local | Initializing DynamoDB Local with the following configuration: dynamodb-local | Port: 8000 dynamodb-local | InMemory: true dynamodb-local | DbPath: null dynamodb-local | SharedDb: false dynamodb-local | shouldDelayTransientStatuses: false dynamodb-local | CorsParams: *GUIツールからの操作
dynamodb-admin
https://github.com/aaronshaf/dynamodb-adminnpm install -g dynamodb-admin set DYNAMO_ENDPOINT=http://localhost:8000 dynamodb-adminコンソール
>dynamodb-admin database endpoint: http://localhost:8000 region: ap-northeast-1 accessKey: xxx dynamodb-admin listening on http://localhost:8001 (alternatively http://0.0.0.0:8001)以下読み替え
ハッシュキー(Hash Attribute Name) → パーティションキー
レンジキー(Range Attribute Name (Optional)) → ソートキーVSCodeからのデバッグ
- VS CodeにAWS Toolkitをインストール
- Code Lensから「Add Debug Configuration」をクリック
"launch": { "configurations": [ { "type": "aws-sam", "request": "direct-invoke", "name": "sample-sam-node:app.lambdaHandler (nodejs10.x)", "invokeTarget": { "target": "code", "projectRoot": "hello-world", "lambdaHandler": "app.lambdaHandler" }, "lambda": { "runtime": "nodejs10.x", "payload": {}, "environmentVariables": {} } } ] }コード編集後、VSCodeのDebugボタンを押すとsam build/invokeを呼び出してくれる
以下でdynamodb localへのアクセスを確認let response; var dynamoOpt = { apiVersion: '2012-08-10', endpoint: "http://192.168.1.X:8000" }; var documentClient = new AWS.DynamoDB.DocumentClient(dynamoOpt); exports.lambdaHandler = async (event, context) => { try { scanItems = await documentClient.scan({TableName: "sample_table"}).promise(); response = { "statusCode": 200, "body": JSON.stringify(scanItems) }; } catch (err) { console.log(err); return err; } return response };Mongo DB (Document DB)
Document DBがMongo DB互換なのでMongo DBを設置すればよい
Node.jsからの接続はMongoDB NodeJS Driverを利用し、接続先はローカルのIPアドレスdocker pull mongo docker run --it --name sample-mongo mongo参考
- 投稿日:2020-08-06T07:41:26+09:00
AWSアカウントのルートユーザを通常運用で使ってはいけません
はじめに
本記事はAWS Well-Architected Labs - Security - 100 - AWS ACCOUNT AND ROOT USER
のハンズオン内容を元にポイントをまとめたものになります。AWS Well-Architected Labsについて知りたい方はこちらをご覧ください。AWSアカウントのルートユーザとは
AWSアカウント作成時に自動的に生成されるユーザです。メールアドレスとパスワードでサインインすることができます。AWSアカウントに関する全ての操作を実行できる唯一のユーザです。そのため、ルートユーザの認証情報は厳重に管理し、通常運用では利用しないようにしましょう。代わりに通常運用で利用するためのIAMユーザ、グループ、ロールをルートユーザで初めに作成しましょう。
ルートユーザの保護
ルートユーザを保護するための施策を紹介します。
MFAの有効化
MFAを有効化することでサインイン時の認証情報にメールアドレスとパスワードに加えてワンタイムパスワードを含めることができます。MFAの種類としては以下があります。
- 仮想 MFA デバイス
- 電話やその他のデバイスで動作し、物理デバイスをエミュレートするソフトウェアアプリケーション
- U2F セキュリティキー
- コンピュータの USB ポートに接続するデバイス
- ハードウェア MFA デバイス
スマートフォンを所有していればすぐに使える仮想MFAデバイスがおすすめです。スマートフォンを紛失しても大丈夫なようにバックアップ機能が付いているアプリケーションを選択しましょう。個人的にはAuthyがおすすめです。また、MFAの有効化はルートユーザだけでなく、IAMユーザも基本は設定すべきと個人的に思います。
秘密の質問
電話での問い合わせやMFA紛失時に本人確認のための質問を用意することができます。ハンズオンでも紹介されてましたが、あまりおすすめされないようです。質問の回答を忘れてしまうとかなり大変そうです。。
代理連絡先の設定
ルートユーザのメールアドレス以外にAWSからの連絡を受け取りたい場合に設定することができます。普段利用しないメールアドレスをルートユーザに設定している場合はいつも確認しているメールアドレスを代理連絡先に登録すると良いと思います。
ルートユーザアクセスキーは発行しない
アクセスキー(アクセスキーIDとシークレットアクセスキー)を使用して、AWSにプログラムによるリクエストを行うことができます。このアクセスキーはルートユーザも作成することはできますが、絶対に発行しないでください。
アクセスキーはプログラムで利用するため、うっかりGitHub等で公開されてしまうリスクがあります。ルートユーザのアクセスキーはパスワードやMFAによる保護をすることができないので、これが漏れてしまうとやられたい放題になってしまうからです。アクセスキーを利用する場合はIAMユーザのものを利用するようにし、アクセスキーを発行するIAMユーザの権限もなるべく制限するようにしましょう。パスワードの定期的変更
ハンズオンではパスワードを定期的に変更することが紹介されていました。しかし、2017年に米国国立標準技術研究所(NIST)からガイドラインとしてサービス提供者がパスワードの定期的な変更を要求すべきではない旨が示されていることもあり、定期変更は必須では無いと思います。定期変更する代わりに複雑なパスワードを設定した方が良いと思われます。
ルートユーザを使った作業
通常運用はルートユーザを使わないようにと説明しましたが、ではどういった作業の場合にルートユーザを使うのかを代表的なものを紹介します。
- AWSアカウントの解約
- アカウント名、ルートユーザー パスワード、および E メールアドレス等のアカウント情報の変更
- AWSサポートプランの変更
- 初期IAMユーザの作成
詳細は公式ドキュメントを参照ください。
おわりに
所属している企業でAWSを利用する場合はAWSアカウントを管理している組織でルートユーザも管理していると思うので、作業者としてはあまりルートユーザを意識することは無いと思います。ただし、AWSアカウントを個人で利用する場合はルートユーザの管理もちゃんとする必要があります。万が一があると痛い目を見るのは自分なので、しっかりと保護対策をしておきましょう。
- 投稿日:2020-08-06T00:30:06+09:00
【AWSSAA(SAA-C02)】受験のために必要な最低限の知識とは?
はじめに
AWS未経験の僕が、以前(7/23)にAWSSAA(SAA-C02)の試験を受験して合格しました。
今回は、AWSSAAの受験のために必要な最低限の知識についてまとめていきたいと思います。※合格体験記については、私のブログに記事がありますのでご覧頂ければと思います。
AWS未経験の僕がSAA-C02をどのように勉強したのか?僕の合格点について
添付の結果の通り、かなりギリギリで合格しています。
(点数:725/合格点:720)AWSSAA(SAA-C02)受験の前に必要な最低限の知識とは?
こちらの知識になります。
- 基本的なネットワーク知識
- TCP/IPの知識
- ストレージプロトコルの知識
では、掘り下げていきたいと思います。
基本的なネットワーク知識
AWSにてインフラを構築するためには、基本的なネットワーク知識が必要です。
なぜなら、VPC(Virtual Private Cloud)の構築に必要になる知識だからです。
例えば、こちらの知識になります。
- CIDR(Classless Inter-Domain Routing)
- サブネットマスク
- IPアドレスの割り振り方
- デフォルトゲートウェイ
こちらの知識は、オンプレミスでのインフラ構築の際にも使用します。
CCNAを勉強して頂くと、この辺の知識は自然と身に付けられるでしょう。
TCP/IPの知識
TCP/IP(Transmission Control Protocol/Internet Protocol)とは、「インターネットなどで一般的に使われるプロトコル」です。
こちらのTCP/IPの知識を事前に覚えておいた方が問題が解きやすいです。
なぜなら、
- セキュリティグループ
- ACL
- Route53
等でTCP/IPの知識が必要とされるからです。
例えば、
- HTTP
- HTTPS
- SSH
- DNS
- SNMP
などは覚えておかないと、そもそもAWSにてインフラ環境の構築ができないです。
これらもまた、CCNAやLPIC level1等を勉強して頂くと身に着けることができます。
こちらのサイトに解説がありますので、ご参考下さい。
TCP/IPをはじめから - ネットワークエンジニアとして
TCP/IPとはストレージプロトコルの知識
ストレージプロトコルについての知識も試験問題を解くためには必要だと感じました。
なぜなら、下記のようなサービスでストレージプロトコルの知識が必要だからです。
- Amazon EFS
- Amazon FSx
- AWS Storage Gateway
上記のサービスを使うためには、こちらのストレージプロトコルの知識を抑えておく必要があります。
- iSCSI
- NFS
- SMB(CIFS)
オンプレミスにてストレージの構築やストレージマウント作業に携わったことのある人であれば、わかりやすいと思います。
ストレージ作業未経験者は、AWSにて実際に手を動かして学んで頂くのが早いです。
まとめ
○AWSSAAに挑戦するためには、これらの知識は最低限レベルで必要
- 基本的なネットワーク知識
- TCP/IPの知識
- ストレージプロトコルの知識
○最低限知識を習得するためには、こちらの資格を勉強すると良い
- LPIC level1
- CCNA
