- 投稿日:2020-08-01T23:36:59+09:00
テストアプリを作って理解するUbuntu18.04+Nginx+Flask+Let's lencriptでHTTPSさせるまでの流れ
環境
さくらのVPS
お名前ドットコム
ubuntu18.04
ubuntuのユーザー名:ubuntu(自分のユーザー名に合わせてください)
SSH接続ソフト:Teraterm(コピペ使える、えらい)
python3.6.9
nginx/1.14.0とりあえず最初の呪文。とりあえずインストールするgit
sudo apt update sudo apt upgrade sudo apt install gitpython環境を整える
pythonのインストール
sudo apt install python3-pip python3-dev build-essential libssl-dev libffi-dev python3-setuptools #確認 python3.6 -Vpythonの仮想環境を作成
sudo apt install python3-venv #環境ディレクトリ作成 mkdir ~/myproject cd ~/myproject #仮想環境作成と起動 python3.6 -m venv myprojectenv source myprojectenv/bin/activate #解除方法する方法は、【deactivate】Flaskとuwsgiのインストール
pip install wheel pip install uwsgi flaskサンプル用アプリを作成する
sudo nano ~/myproject/myproject.pyfrom flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "<h1 style='color:#ff0000'>Hello Flask!</h1>" if __name__ == "__main__": app.run(host='0.0.0.0')さくらVPSのネットワーク情報からカスタムポート5000を開ける。
python myproject.pyhttp://"your_ipadress":5000にアクセス
sudo nano ~/myproject/wsgi.pywsgi.pyfrom myproject import app if __name__ == "__main__": app.run()uwsgiのテスト
uwsgi --socket 0.0.0.0:5000 --protocol=http -w wsgi:apphttp://"your_ipadress":5000へアクセスして確認
uWSGIの構成ファイルの作成
deactivate sudo nano ~/myproject/myproject.inimyproject.ini[uwsgi] module = wsgi:app master = true processes = 5 socket = myproject.sock chmod-socket = 660 vacuum = true die-on-term = truesystemdを作成
sudo nano /etc/systemd/system/myproject.service/etc/systemd/system/myproject.service[Unit] Description=uWSGI instance to serve myproject After=network.target [Service] User=ubuntu Group=www-data WorkingDirectory=/home/ubuntu/myproject Environment="PATH=/home/ubuntu/myproject/myprojectenv/bin" ExecStart=/home/ubuntu/myproject/myprojectenv/bin/uwsgi --ini myproject.inisystemdの起動・自動起動・ステータスの確認
sudo systemctl start myproject sudo systemctl enable myproject sudo systemctl status myprojectactivate (running)と出てればOK
※【停止】sudo systemctl stop myproject
※【自動起動停止】sudo systemctl disable myprojectNginxの起動と設定
sudo apt install -y nginx 確認 ls /etc/nginx/sites-available/ >>default とでてればインストールファイルできてるのでOK sudo nano /etc/nginx/sites-available/myproject/etc/nginx/sites-available/myprojectserver { listen 80; server_name <your_ipadress> www.<your_ipadress>; location / { include uwsgi_params; uwsgi_pass unix:/home/ubuntu/myproject/myproject.sock; } }作成したNginxサーバーブロック構成を有効にするには、ファイルをsites-enabledディレクトリにリンクします。
sudo ln -s /etc/nginx/sites-available/myproject /etc/nginx/sites-enabledテスト:
sudo nginx -t
最後にtest is successfulとでてればおknginxの再起動
sudo systemctl restart nginxサイトの確認
http://"your_ipadress"LOG系の確認
sudo less /var/log/nginx/error.log:Nginxエラーログを確認します。 sudo less /var/log/nginx/access.log:Nginxアクセスログを確認します。 sudo journalctl -u nginx:Nginxプロセスのログを確認します。 sudo journalctl -u myproject:FlaskアプリのuWSGIログを確認します。ドメインの設定
お名前ドットコムの利用
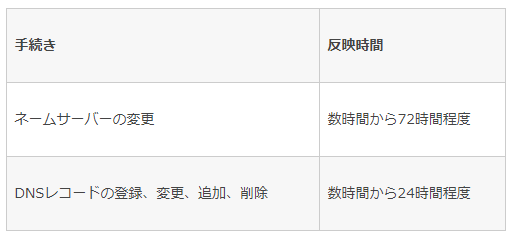
【ドメインの取得・ネームサーバーの設定】
お名前ドットコムにログイン
ドメイン取得
ドメインの詳細からネームサーバーの登録
その他から、
ネームサーバー1:ns1.dns.ne.jp
ネームサーバー2:ns2.dns.ne.jp
を設定する。
完了。
1日後?とかに反映する??たぶん
情報あった
【ドメインの設定】
ドメインNaviにアクセス
「ドメイン設定」→「DNS関連機能の設定」
対象ドメインを選択して次へ
「DNSレコード設定を利用する」
必要項目を入力して「追加」をクリックすると下部に追加。サーバー側の設定
sudo nano /etc/nginx/sites-available/myprojectyour_ipadressをyour_domainに。
要は、設定した独自ドメインに書き換える。/etc/nginx/sites-available/myprojectserver { listen 80; server_name <your_DOMAIN> www.<your_DOMAIN>; location / { include uwsgi_params; uwsgi_pass unix:/home/ubuntu/myproject/myproject.sock; } }HTTPS化する(LetsEncript)
sudo add-apt-repository ppa:certbot/certbot sudo apt install python-certbot-nginx sudo certbot --nginx -d your_domain -d www.your_domain >>outputは以下の分outputPlease choose whether or not to redirect HTTP traffic to HTTPS, removing HTTP access. ------------------------------------------------------------------------------- 1: No redirect - Make no further changes to the webserver configuration. 2: Redirect - Make all requests redirect to secure HTTPS access. Choose this for new sites, or if you're confident your site works on HTTPS. You can undo this change by editing your web server's configuration. ------------------------------------------------------------------------------- Select the appropriate number [1-2] then [enter] (press 'c' to cancel):ENTERを選択。
構成が更新され、Nginxがリロードして新しい設定を取得します。
certbotプロセスが成功し、証明書が保存されている場所を通知するメッセージが表示されます。outputIMPORTANT NOTES: - Congratulations! Your certificate and chain have been saved at: /etc/letsencrypt/live/your_domain/fullchain.pem Your key file has been saved at: /etc/letsencrypt/live/your_domain/privkey.pem Your cert will expire on 2018-07-23. To obtain a new or tweaked version of this certificate in the future, simply run certbot again with the "certonly" option. To non-interactively renew *all* of your certificates, run "certbot renew" - Your account credentials have been saved in your Certbot configuration directory at /etc/letsencrypt. You should make a secure backup of this folder now. This configuration directory will also contain certificates and private keys obtained by Certbot so making regular backups of this folder is ideal. - If you like Certbot, please consider supporting our work by: Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate Donating to EFF: https://eff.org/donate-leNGINXのHTTPを停止
sudo ufw delete allow 'Nginx HTTP'確認
https://"your-domain"結論
意外と簡単。
LINEBOT等はHttps化が必須なので、これで作れますね。
管理用のコマンドとかもまとめておくといいかもです。
- 投稿日:2020-08-01T23:27:55+09:00
【Python】データサイエンス100本ノック(構造化データ加工編) 018 解説
Youtube
動画解説もしています。
問題
P-018: 顧客データフレーム(df_customer)を生年月日(birth_day)で若い順にソートし、先頭10件を全項目表示せよ。
解答
コードdf_customer.sort_values('birth_day', ascending=False).head(10)出力customer_id customer_name gender_cd gender birth_day age postal_cd address application_store_cd application_date status_cd 15639 CS035114000004 大村 美里 1 女性 2007-11-25 11 156-0053 東京都世田谷区桜********** S13035 20150619 6-20091205-6 7468 CS022103000002 福山 はじめ 9 不明 2007-10-02 11 249-0006 神奈川県逗子市逗子********** S14022 20160909 0-00000000-0 10745 CS002113000009 柴田 真悠子 1 女性 2007-09-17 11 184-0014 東京都小金井市貫井南町********** S13002 20160304 0-00000000-0 19811 CS004115000014 松井 京子 1 女性 2007-08-09 11 165-0031 東京都中野区上鷺宮********** S13004 20161120 1-20081231-1 7039 CS002114000010 山内 遥 1 女性 2007-06-03 11 184-0015 東京都小金井市貫井北町********** S13002 20160920 6-20100510-1 3670 CS025115000002 小柳 夏希 1 女性 2007-04-18 11 245-0018 神奈川県横浜市泉区上飯田町********** S14025 20160116 D-20100913-D 12493 CS002113000025 広末 まなみ 1 女性 2007-03-30 12 184-0015 東京都小金井市貫井北町********** S13002 20171030 0-00000000-0 15977 CS033112000003 長野 美紀 1 女性 2007-03-22 12 245-0051 神奈川県横浜市戸塚区名瀬町********** S14033 20150606 0-00000000-0 5716 CS007115000006 福岡 瞬 1 女性 2007-03-10 12 285-0845 千葉県佐倉市西志津********** S12007 20151118 F-20101016-F 15097 CS014113000008 矢口 莉緒 1 女性 2007-03-05 12 260-0041 千葉県千葉市中央区東千葉********** S12014 20150622 3-20091108-6解説
・PandasのDataFrame/Seriesにて、データをソートする方法です。
・情報を昇順あるいは降順に並べ替えて見たい時に使用します。
・'sort_values(<文字列>)'は、指定した文字列を昇順あるいは降順に並べ替える関数です。
・今回の場合、birth_day を降順に並べ替える(=若い順に並べ替える)ため、'sort_values('birth_day',ascending=False)'と記載しています。※参考記事
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.sort_values.html
- 投稿日:2020-08-01T23:12:28+09:00
Google Spread Sheets に Pythonを用いてアクセスしてみた
はじめに
人は生まれながらにGoogle Spread Sheetsにpythonでアクセスしてみたいはず。
そんな欲望を簡単に満たせる記事です。目次
- 1. Google Spread SheetsにPythonを用いてアクセスするための下準備
- 1-1. 新規プロジェクトを作成する
- 1-2. Google Drive APIを有効にする
- 1-3. Google Spread Sheets APIを有効にする
- 1-4. 認証情報を設定する
- 1-5. 秘密鍵を生成する
- 2. Google Spread SheetsにPythonを用いてアクセスする
- 2-1. Google Spread Sheetの共有設定をする
- 2-2. Google Spread Sheetのkeyを取得
- 2-3. プログラム実行!
1. Google Spread SheetsにPythonからアクセスするための下準備
これが一番めんどくさい。
Google Spread Sheetsに外部からアクセスするためには、
Google Cloud Platformを利用するのが一番よさそう。
- Google Cloud Platformでの初期設定の手順は以下の5ステップ
- 1-1. 新規プロジェクトを作成する
- 1-2. Google Drive APIを有効にする
- 1-3. Google Spread Sheets APIを有効にする
- 1-4. 認証情報を設定する
- 1-5. 秘密鍵を生成する
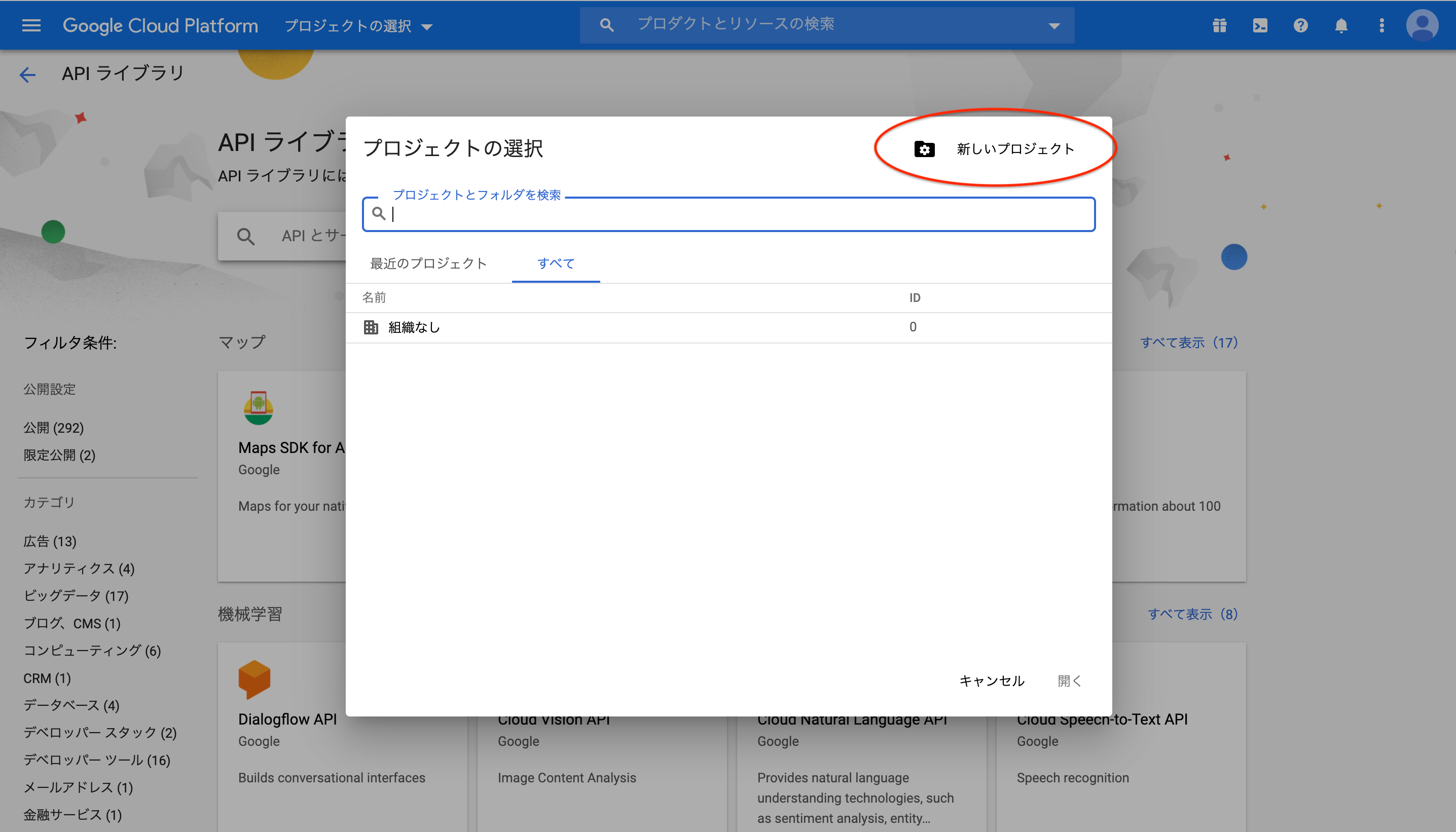
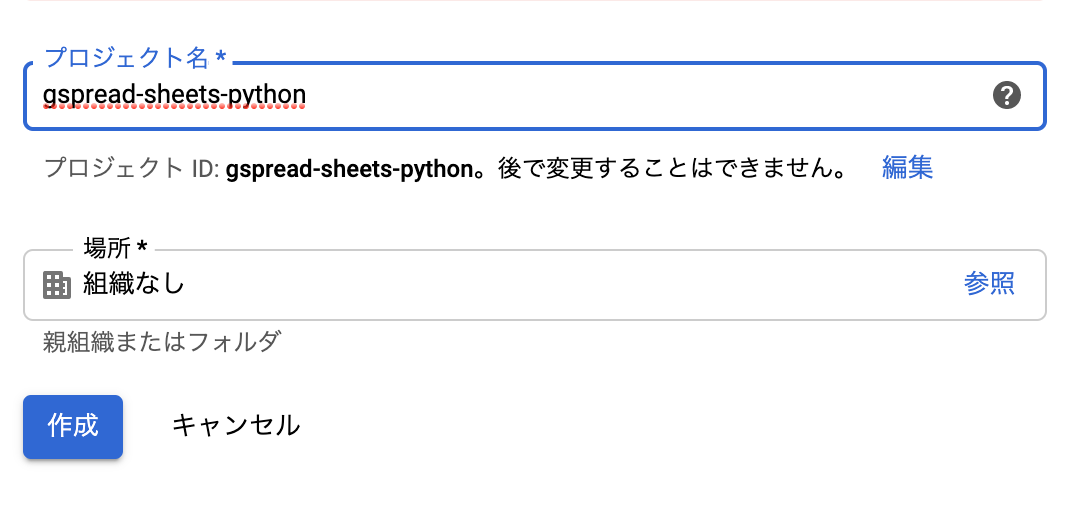
1-1. 新規プロジェクトを作成する
- まずはAPIを取得するための、プロジェクトを用意する必要がある。
- Google Cloud PlatformのAPIライブラリにアクセス
プロジェクトの選択をクリック
新しいプロジェクトをクリック
適当なプロジェクト名を入力してを作成
おしまい
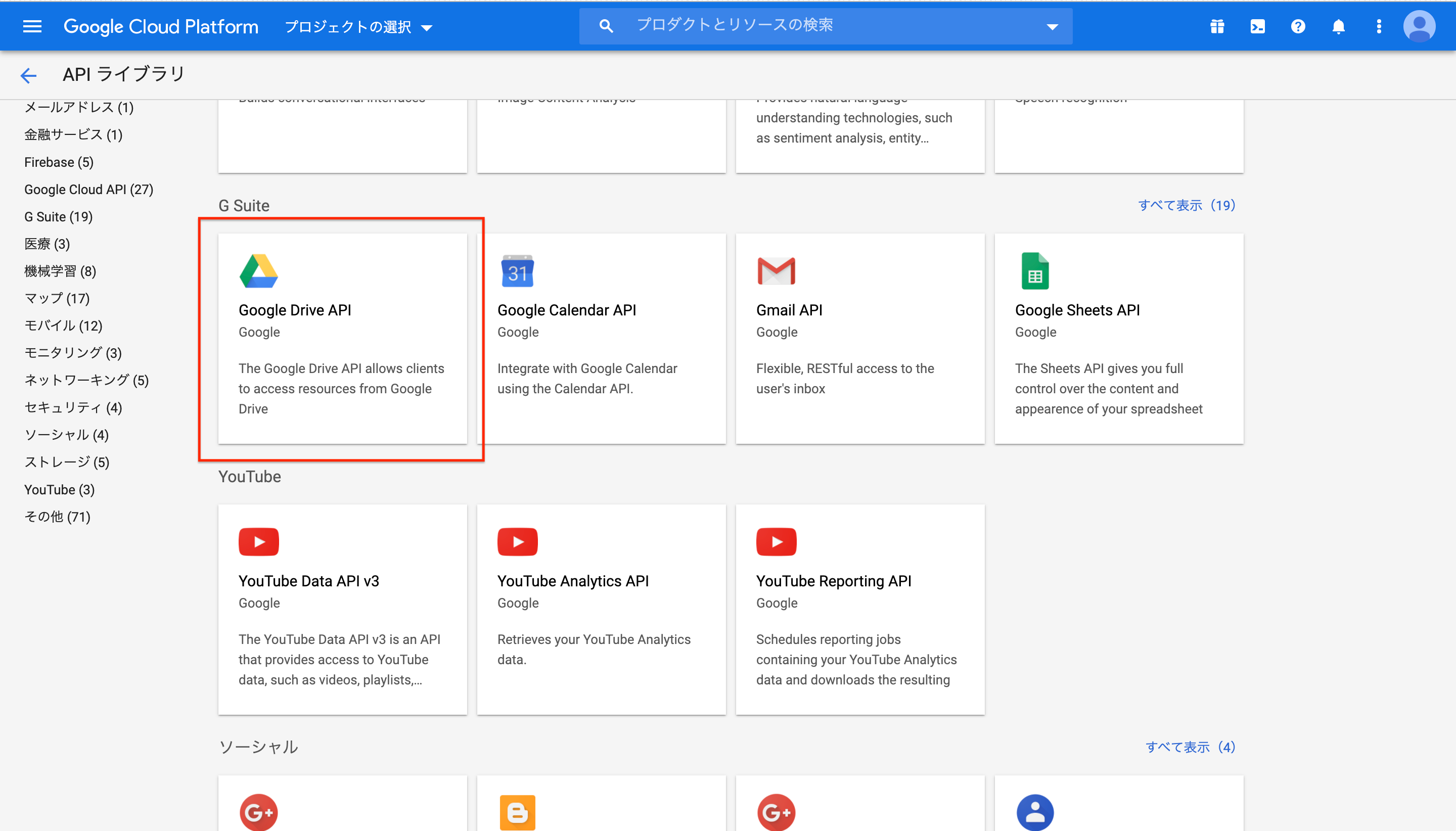
1-2. Google Drive APIを有効にする
- Google DriveのAPIを有効にしないと、Google Spread SheetsにPythonなど、外部からアクセスするのは不可能とのこと。
- 仕方がないので、ぽちぽちしながら有効にします。
Google Drive APIを探してクリック
有効をクリック
1-1で作成ししたプロジェクトを選択
おしまい
1-3. Google Spread Sheets APIを有効にする
- 1-2と同様にGoogle Spread SheetsのAPIを有効にします。
1-4. 認証情報を設定する
- あと少しで下準備はおしまい。
- ここでは外部(Python)からアクセスする際に、認証に用いられる情報を取得します。
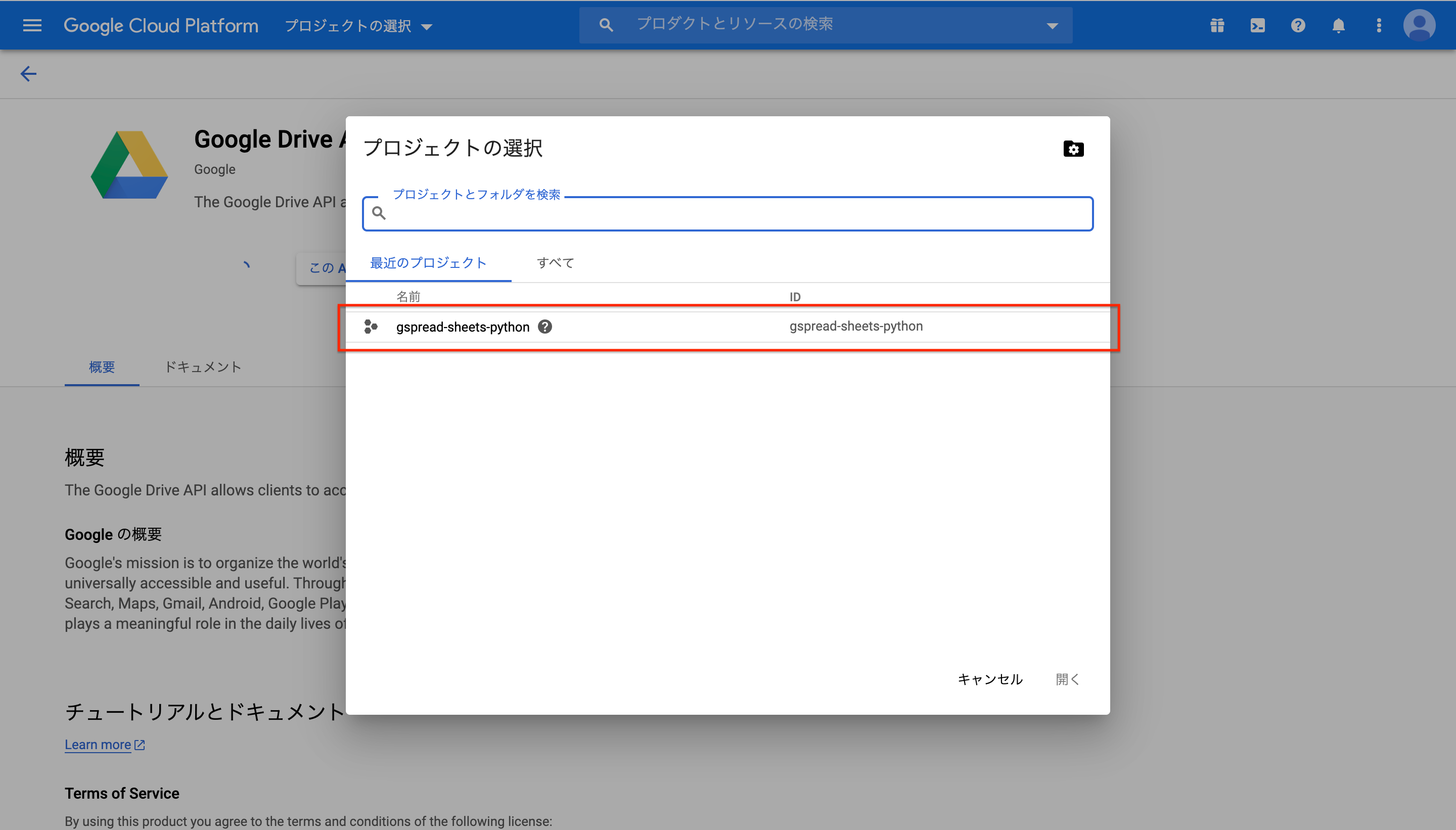
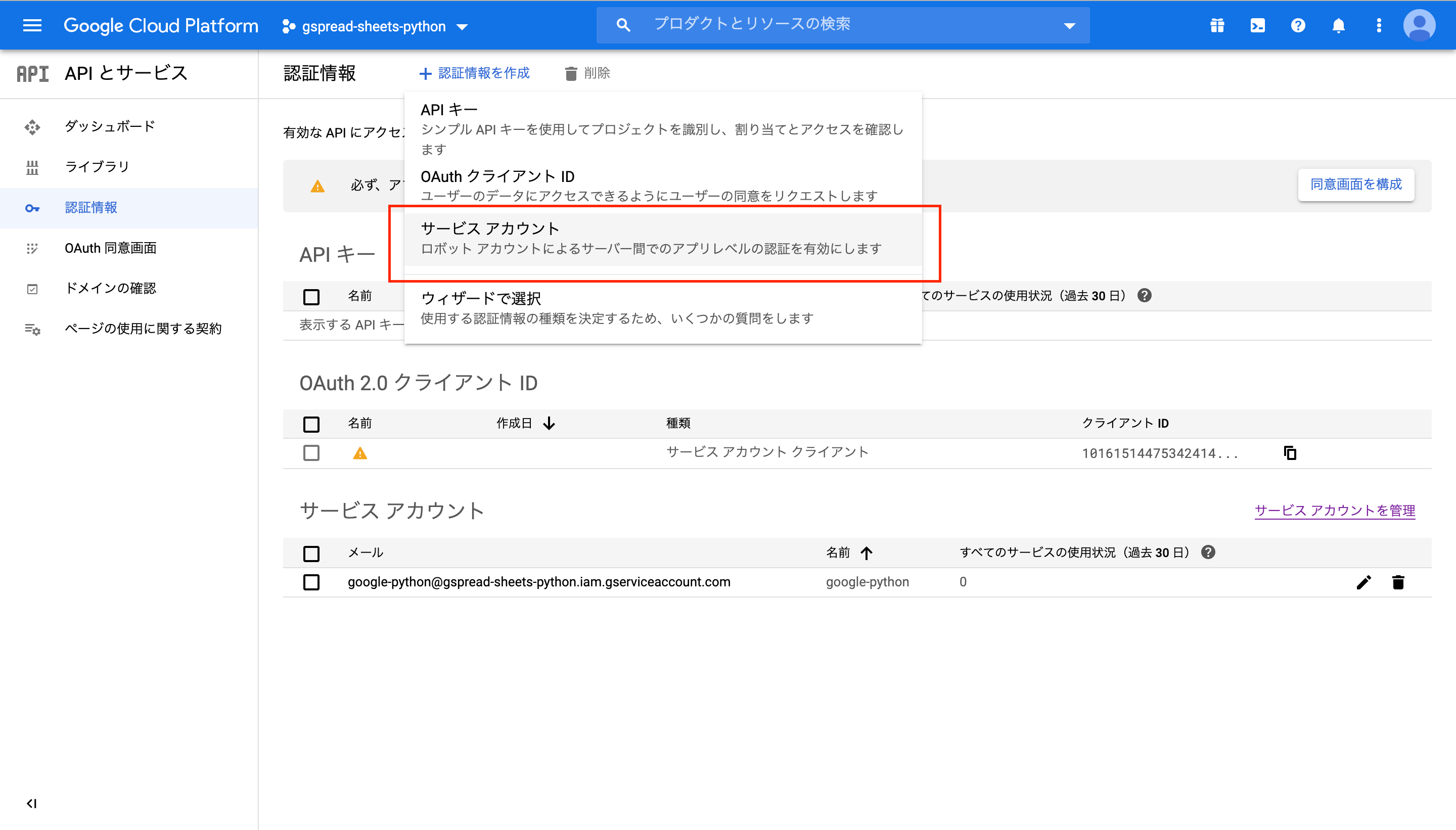
認証情報へ移動し、認証情報を作成をクリックし、サービスアカウントを選択。
サービスアカウント名を適当に記入し、作成をクリック。
- サービスアカウント名はどういったことをするのかを書くといいらしい
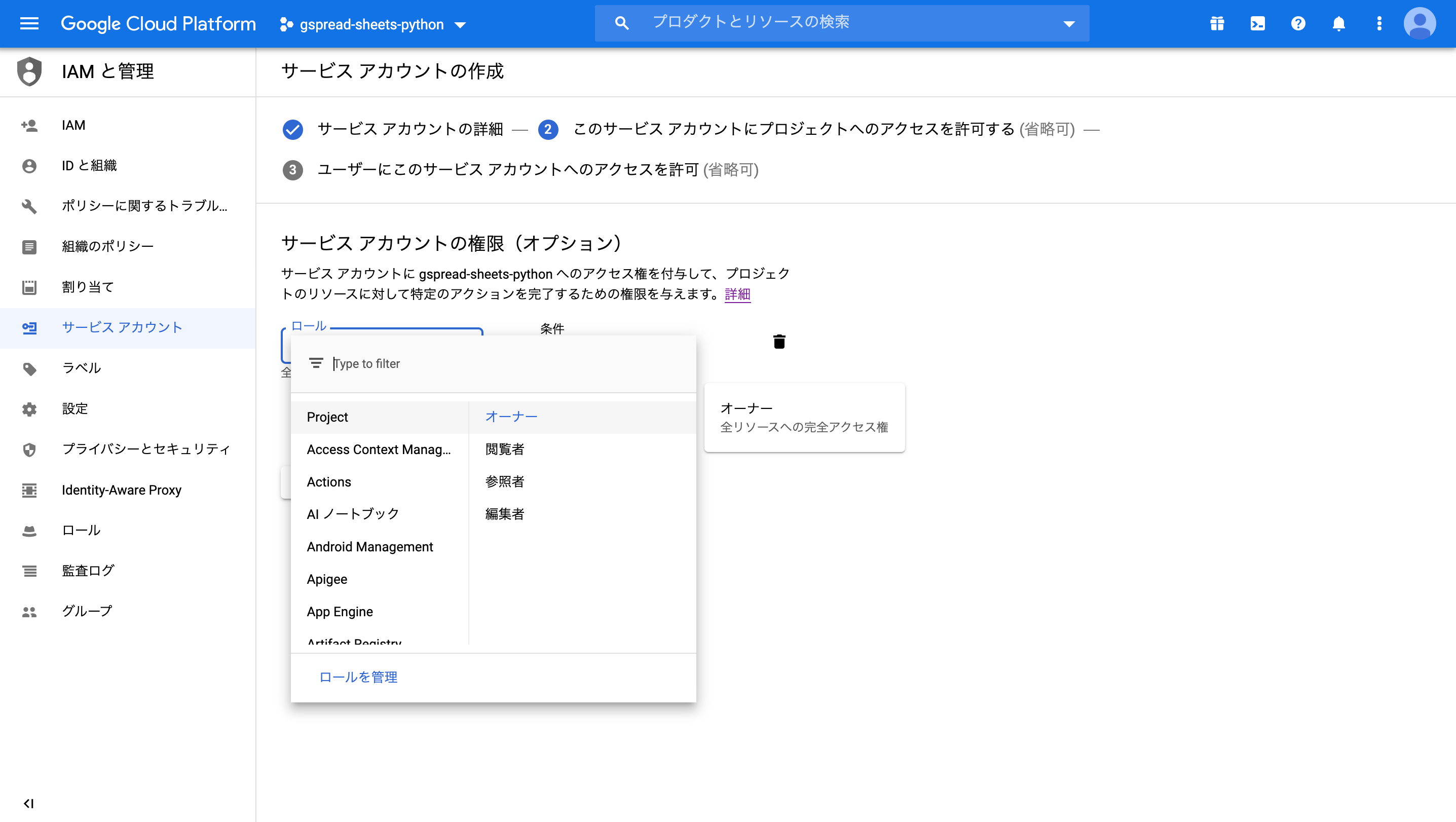
ロール(役割)では、プロジェクト→オーナーを選択。
完了をクリックして終了。
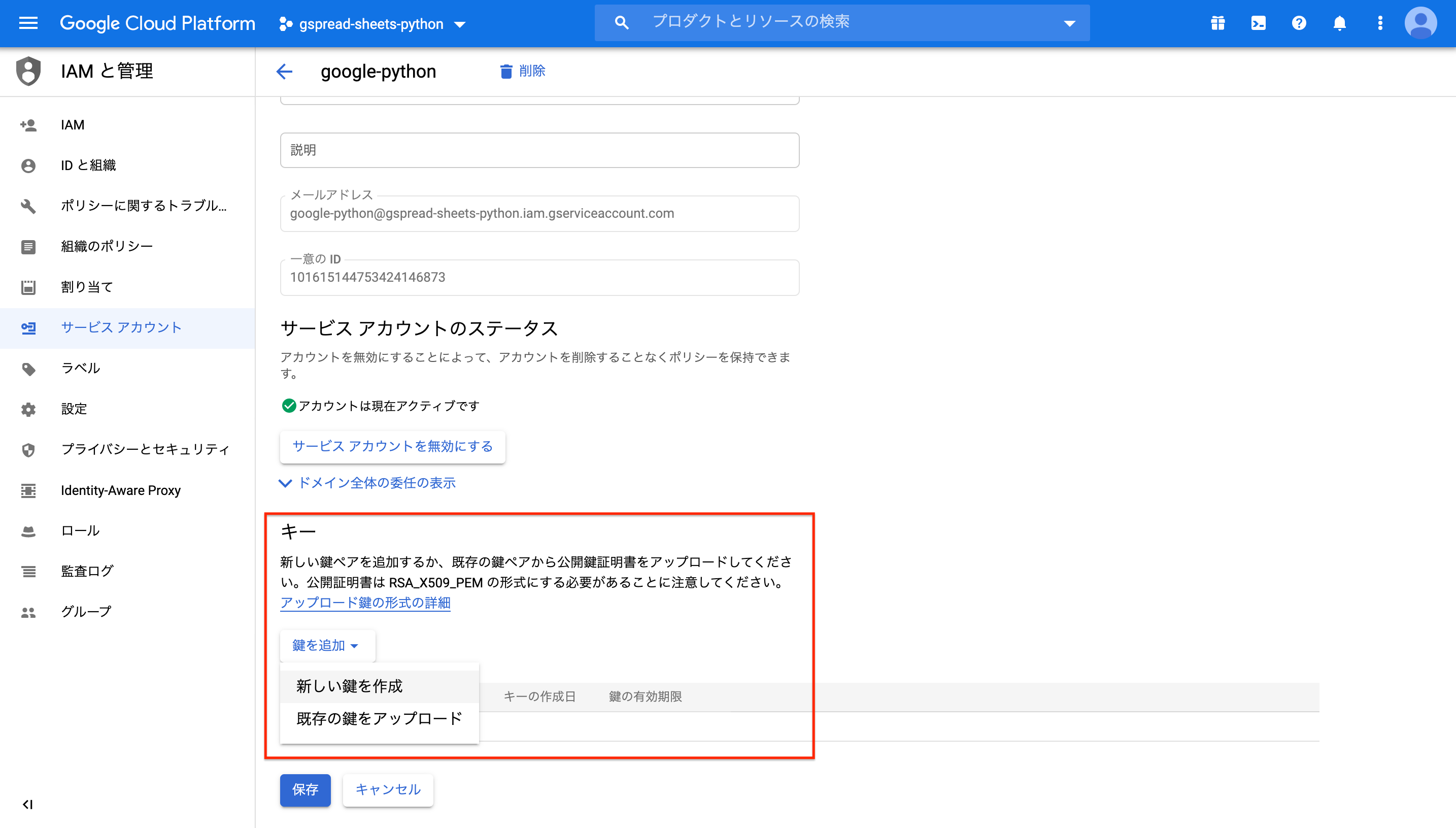
1-5. 秘密鍵を生成する
1-4で作成した認証情報から、秘密鍵を生成します。
- 秘密鍵とは?
- つまり、ここで作成した秘密鍵は誰にも渡さず大切に保管しておきましょう
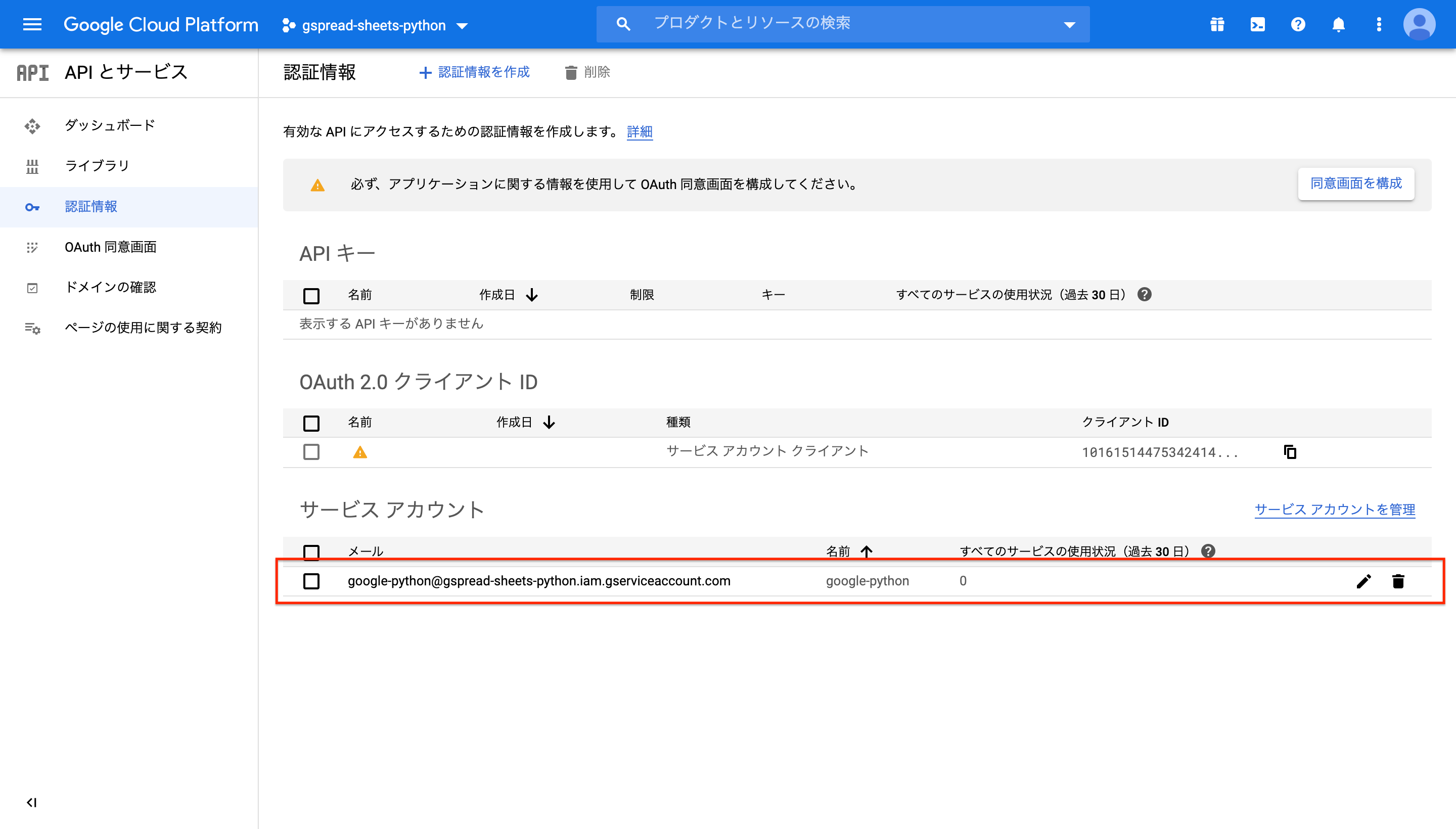
1-4で作成したサービスアカウントをクリック
キーの新しい鍵をクリック
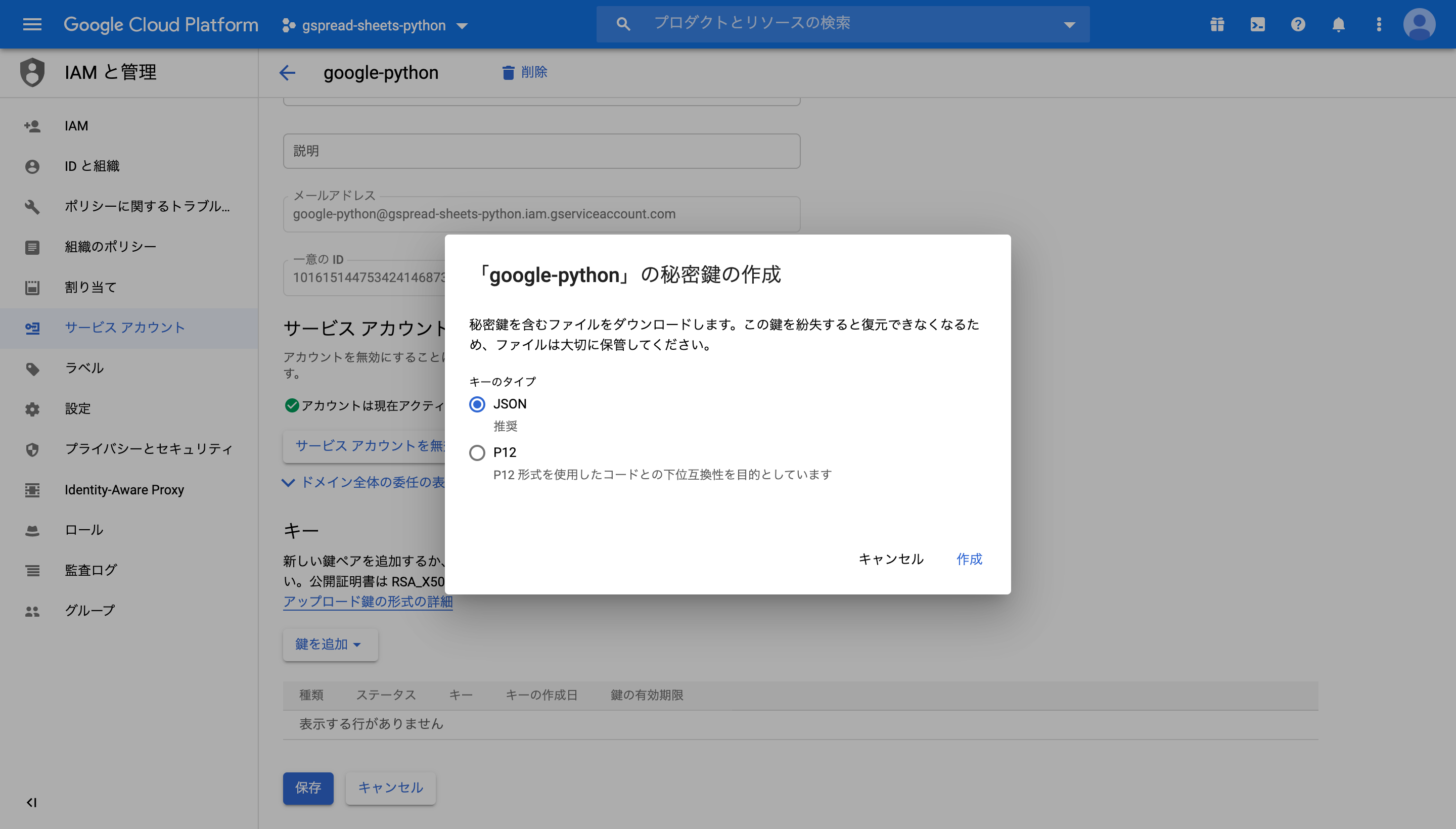
キータイプはjsonを選択し、作成をクリック。
これでjsonファイルが保存される。
2. Google Spread SheetsにPythonを用いてアクセスする
Google Spread SheetsにPythonからアクセスする方法はいくつかあるらしい。
今回は、一番簡単そうだった、gspreadを用いた方法を紹介。手順は以下の3ステップ
2-1. Google Spread Sheetの共有設定をする
2-2. Google Spread Sheetのkeyを取得
2-3. プログラム実行!2-1. Google Spread Sheetの共有設定をする
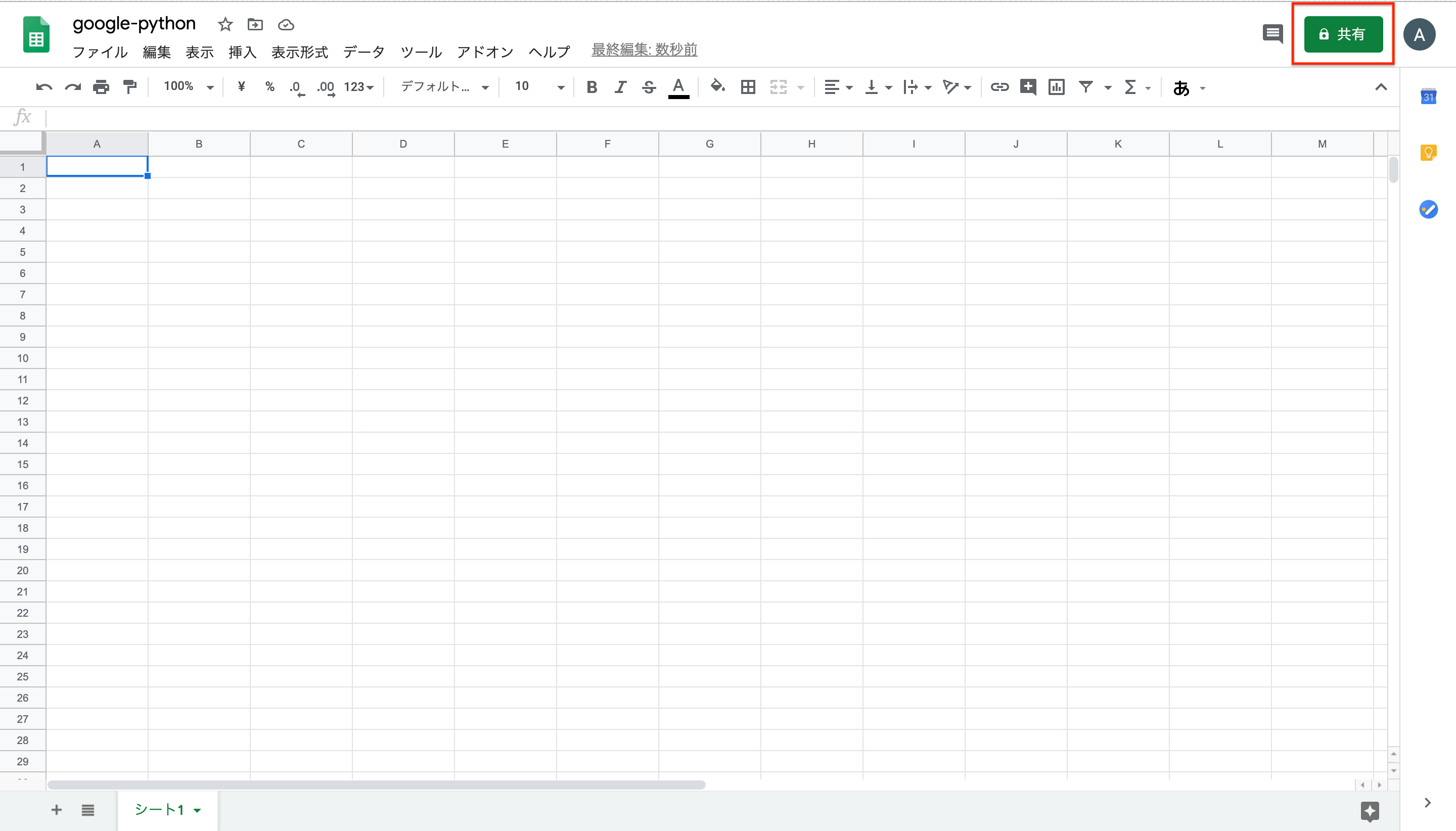
まずはGoogle Spread Sheetsを作成し、共有設定を行います。
1-5でdownloadしたjsonを開き、"client_email"の横に書かれているアドレスをコピーする。
- XXXXXX[at]gspread-sheets-python.YY.gserviceaccount.com みたいなアドレスになってるはず。
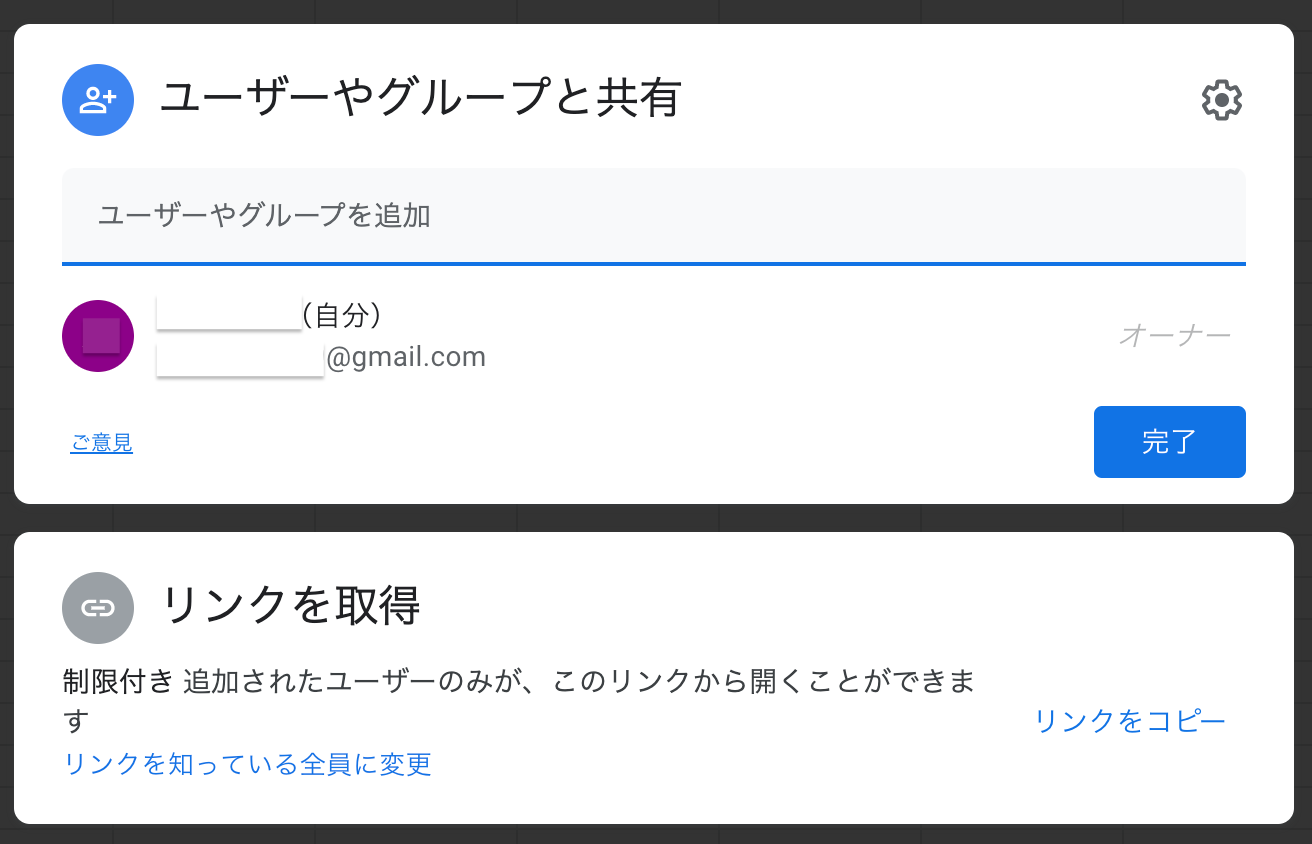
右上の「共有」をクリック
コピーしたアドレスをユーザーやグループに追加に記入。
これで、Google Spread Sheetsの共有設定はおしまい。
2-2. Google Spread Sheetsのkeyを取得
- 2-1で用意したGoogle Spread Sheetsのリンクからkeyを取得できます。
https://docs.google.com/spreadsheets/d/aaaaaaaaaaaaaa/edit#gid=0のaaaaaaaaaaaaaaがkeyになります。
2-3で必要になるので、控えておきましょう。2-3. プログラム実行!
- する前に環境を整えます。
Pythonの環境が自分のPCの環境にない方はこちらを参考にしてください(投稿準備中)
必要なモジュールは以下の3つ
- json
- gspread
- oauth2client
jsonはPython標準のモジュールなので、その他2つをpipで取得します。
pip install gspreadpip install oauth2client
- いよいよプログラムを実行。
- 実行するとこんな感じで値が書き込まれます。

参考コード
gspread_simple.pyimport gspread import json from oauth2client.service_account import ServiceAccountCredentials # (1) Google Spread Sheetsにアクセス def connect_gspread(jsonf,key): scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name(jsonf, scope) gc = gspread.authorize(credentials) SPREADSHEET_KEY = key worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1 return worksheet # ここでjsonfile名と2-2で用意したkeyを入力 jsonf = "~~~~~~~.json" spread_sheet_key = "aaaaaaaaaaaaaa" ws = connect_gspread(jsonf,spread_sheet_key) #(2) Google Spread Sheets上の値を更新 #(2−1)あるセルの値を更新(行と列を指定) ws.update_cell(1,1,"test1") ws.update_cell(2,1,1) ws.update_cell(3,1,2) #(2−2)あるセルの値を更新(ラベルを指定) ws.update_acell('C1','test2') ws.update_acell('C2',1) ws.update_acell('C3',2) #(2-3)ある範囲のセルの値を更新 ds= ws.range('E1:G3') ds[0].value = 1 ds[1].value = 2 ds[2].value = 3 ds[3].value = 4 ds[4].value = 5 ds[5].value = 6 ds[6].value = 7 ds[7].value = 8 ds[8].value = 9 ws.update_cells(ds)参考コード解説
(1) Google Spread Sheetsにアクセス
def connect_gspread(jsonf,key): #spreadsheetsとdriveの2つのAPIを指定する scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] #認証情報を設定する credentials = ServiceAccountCredentials.from_json_keyfile_name(jsonf, scope) gc = gspread.authorize(credentials) #スプレッドシートキーを用いて、sheet1にアクセスする SPREADSHEET_KEY = key worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1 return worksheet # jsonfile名を指定 jsonf = "~~~~~~~.json" # 共有設定したスプレットシートキーを指定 spread_sheet_key = "aaaaaaaaaaaaaa" ws = connect_gspread(jsonf,spread_sheet_key)(2−1) あるセルの値を更新(行と列を指定)
ws.update_cell(行,列,値)となっている。つまり、
ws.update_cell(2,4,100)とすれば、2行目の4列目(D列)に100が書き込まれます。
(2−2) あるセルの値を更新(ラベルを指定)
ws.update_acell(ラベル,値)となっている。つまり、
ws.update_acell("E4",200)とすれば、4行目の5列目(E列)に200が書き込まれます。
(2−3) ある範囲のセルの値を更新
多数のセルに書き込みたい場合はこちらがおすすめ。
ちなみに、Google Spread Sheetsへのアクセスは100秒に100回までと制限されておtり、これを超えてアクセスするとエラーが出てしまいます。
この方法を使えば、アクセス数は2回で済みます。
#セルの範囲を指定して、一次元配列に格納。 ds = ws.range('A1:C3') #アクセス発生 #各セルの値を指定 ds[0].value = 1 ds[1].value = 2 ds[2].value = 3 ds[3].value = 4 ds[4].value = 5 ds[5].value = 6 ds[6].value = 7 ds[7].value = 8 ds[8].value = 9 #値を更新 ws.update_cells(ds) #アクセス発生
- A1:C3と指定した場合、一次元配列に格納される順番は以下の通りです。
A B C 1 ① ② ③ 2 ④ ⑤ ⑥ 3 ⑦ ⑧ ⑨ 参考サイト

- 投稿日:2020-08-01T22:53:55+09:00
CadQueryを使って、3Dプリンタデータ(STLファイル)を作成する
はじめに
本記事は、CadQueryを使って、3Dプリンタデータ(STLファイル)を作成する方法について紹介します。
CadQueryとは、3Dモデルを作れるpythonのライブラリです。
きっかけ
電子工作の幅を広げるために、3Dプリンタを購入しました。
3D CADツール自体は使ったことはなかったので、いろいろと調べたところ、
自分にはCadQueryとFreeCadが使いやすかったです。
(今回は、CadQueryのみ)CadQueryについて
以下が公式の情報となります。
日本語の記事が極端に少ないです。情報
- CadQuery / cadquery
- CadQuery 2.0 Documentation
- CQ-editor
インストール・起動
インストール方法は複数ありますが、今回は一番簡単な
CQ-editorをダウンロードする方法で実施します。※windows10 64bit Homeの場合
CQ-editorより、
"Installation" - "RC1 Windows"よりダウンロードします。"CQ-editor-0.1RC1-win64.zip"を解凍し、"CQ-editor.exe"を実行し起動します。
立方体を作成する
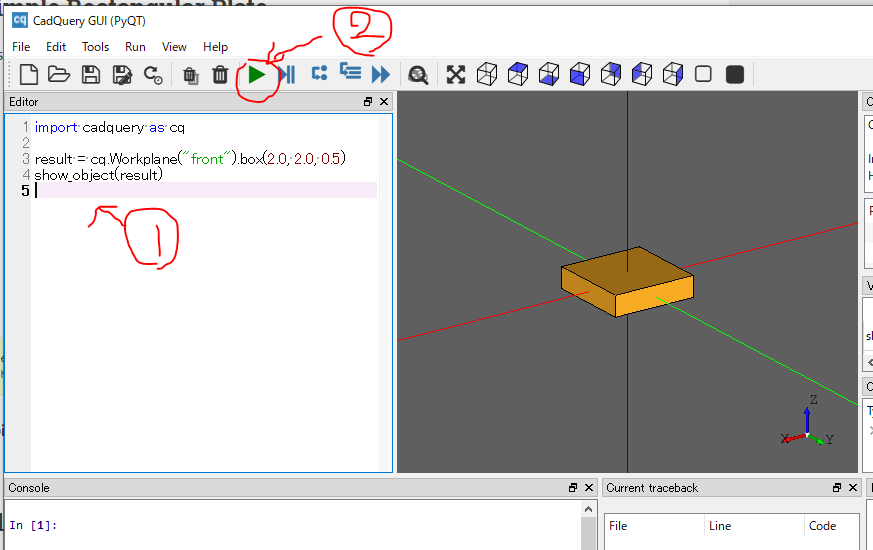
①コードの作成
エディタ部①に、下記のコードを貼り付けます。
test.pyimport cadquery as cq result = cq.Workplane("front").box(2.0, 2.0, 0.5) show_object(result)②コードの実行
再生ボタンを押して、コードを実行します。
立方体が作成されます。
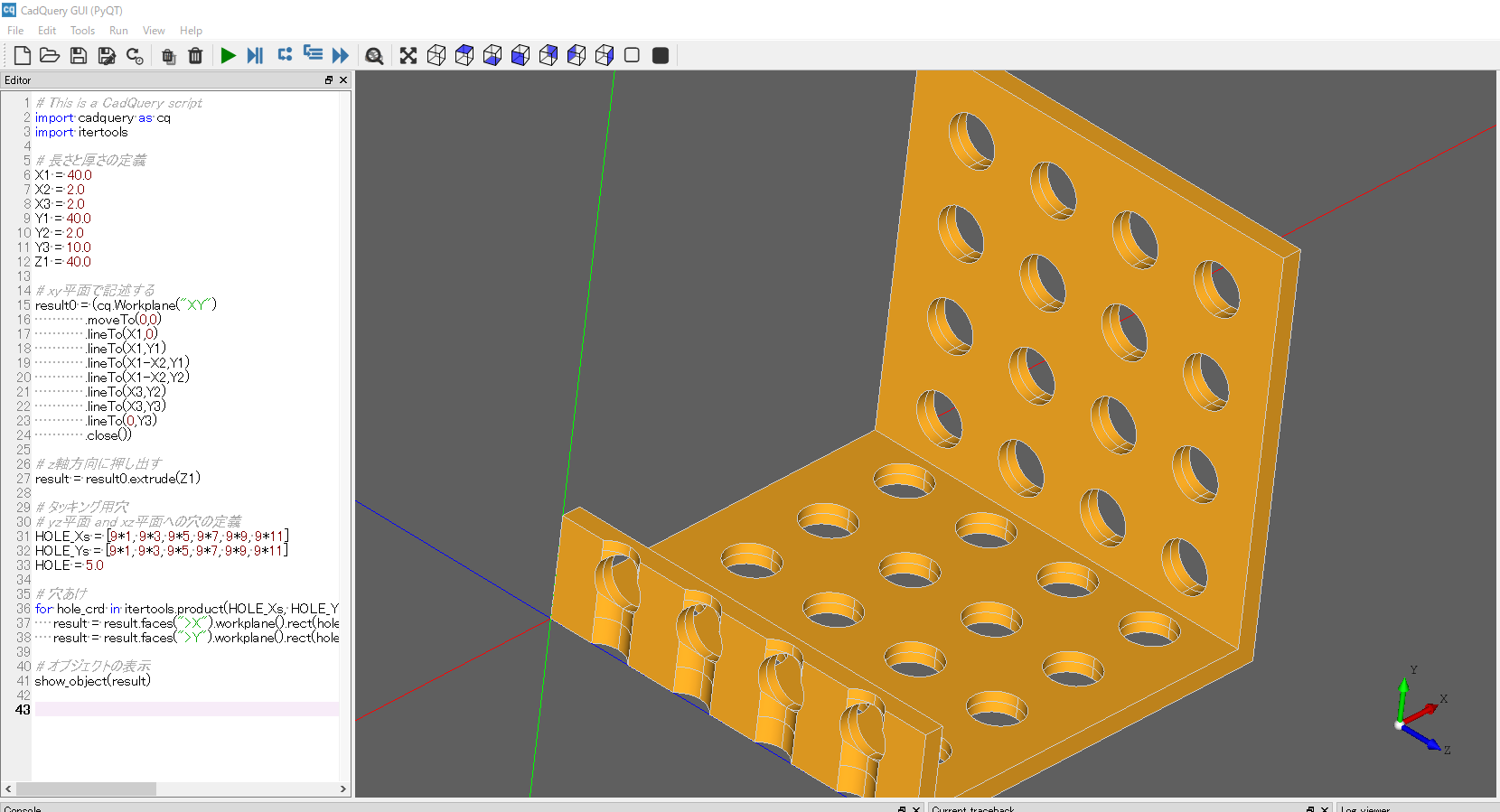
タッキング穴付きフックをつくる
ページの先頭に記載した写真のフックを作成します。
コードの作成
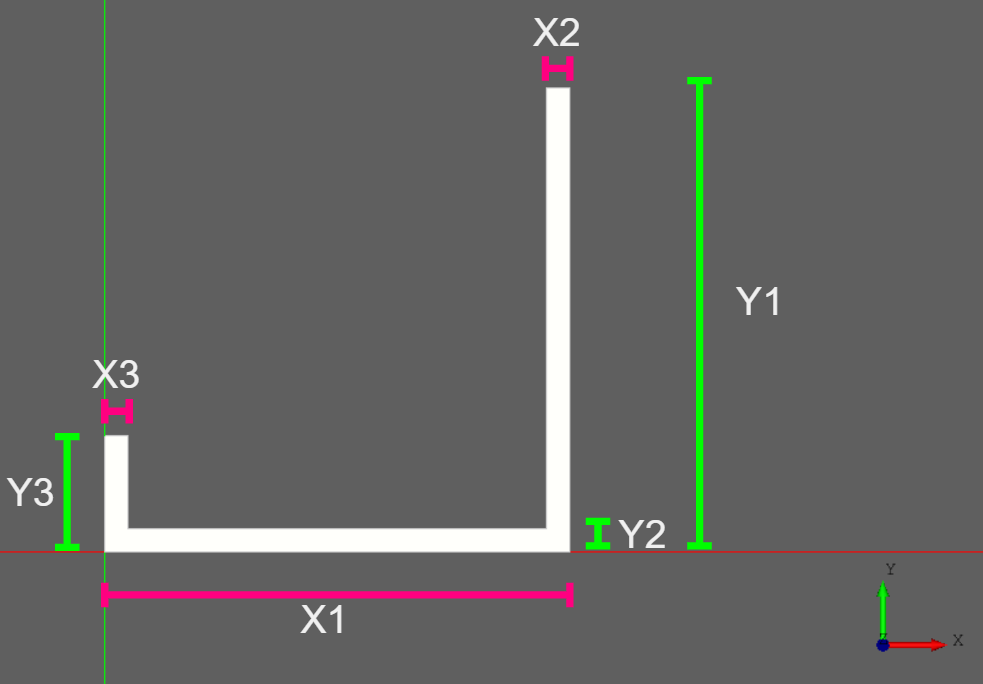
test.py# This is a CadQuery script import cadquery as cq import itertools # 長さと厚さの定義 X1 = 40.0 X2 = 2.0 X3 = 2.0 Y1 = 40.0 Y2 = 2.0 Y3 = 10.0 Z1 = 40.0 # xy平面で記述する result0 = (cq.Workplane("XY") .moveTo(0,0) .lineTo(X1,0) .lineTo(X1,Y1) .lineTo(X1-X2,Y1) .lineTo(X1-X2,Y2) .lineTo(X3,Y2) .lineTo(X3,Y3) .lineTo(0,Y3) .close()) # z軸方向に押し出す result = result0.extrude(Z1) # タッキング用穴 # yz平面 and xz平面への穴の定義 HOLE_Xs = [9*1, 9*3, 9*5, 9*7, 9*9, 9*11] HOLE_Ys = [9*1, 9*3, 9*5, 9*7, 9*9, 9*11] HOLE = 5.0 # 穴あけ for hole_crd in itertools.product(HOLE_Xs, HOLE_Ys): result = result.faces(">X").workplane().rect(hole_crd[0], hole_crd[1], forConstruction=True).vertices().hole(HOLE) result = result.faces(">Y").workplane().rect(hole_crd[0], hole_crd[1], forConstruction=True).vertices().hole(HOLE) # オブジェクトの表示 show_object(result)xy平面のコードとの紐づけ
長さと厚さの定義との座標の関係は以下となります。
コードの実行
コードを実行すると、フック付きのモデルが作成できます。
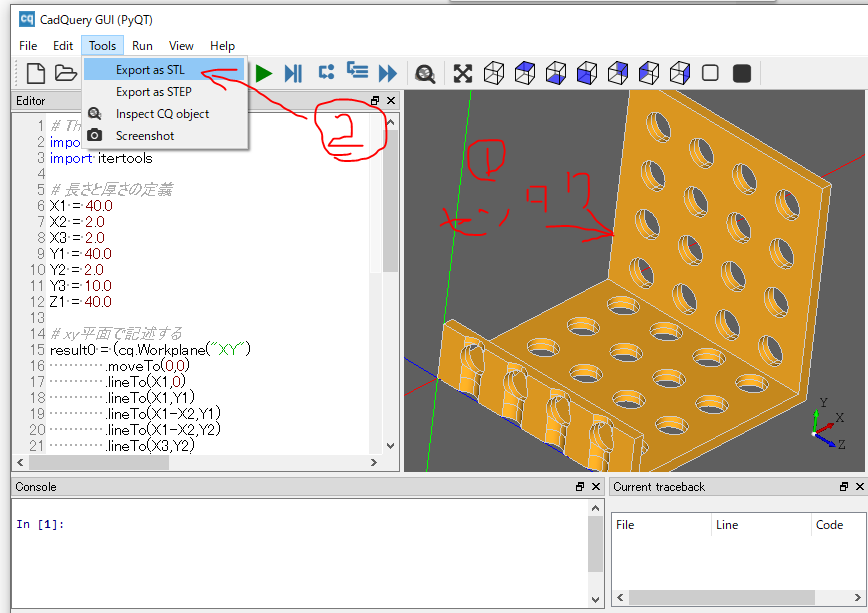
STLファイルを出力する
オブジェクトを選択した後、"Tools" - "Export as STL"を選択します。
ファイル名を指定し、保存します。
あとは、3Dプリンタで印刷します。
さいごに
3Dモデルをコードでかけるのは非常に助かります。

- 投稿日:2020-08-01T21:56:38+09:00
【機械学習】カーネル密度推定を使った教師あり学習 その2
カーネル密度推定を使った教師あり学習
この記事は機械学習の初心者が書いています。
予めご了承ください。カーネル密度推定と教師あり学習の関連性
私が勝手に関連付けました。
詳しいことは(あまり詳しくありませんが)前回の記事をご参照ください。
簡単にまとめると「カーネル密度推定を教師あり学習の分類器に使ってみた!」です。オブジェクト指向
前回の記事でまとめたスクリプトを改造して、オブジェクト指向にしてみました。
名前は「Gaussian kernel-density estimate classifier(ガウスカーネル密度推定分類器)」、略して「GKDEClassifier」です。いま勝手に名付けました。↓スクリプト↓
import numpy as np class GKDEClassifier(object): def __init__(self, bw_method="scotts_factor", weights="None"): # カーネルのバンド幅 self.bw_method = bw_method # カーネルのウェイト self.weights = weights def fit(self, X, y): # yのラベル数 self.y_num = len(np.unique(y)) # 推定した確率密度関数を格納するリスト self.kernel_ = [] # 確率密度関数を格納 for i in range(self.y_num): kernel = gaussian_kde(X[y==i].T) self.kernel_.append(kernel) return self def predict(self, X): # 予測ラベルを格納するリスト pred = [] # テストデータのラベル別確率を格納するリスト self.p_ = [] # ラベル別確率を格納 for i in range(self.y_num): self.p_.append(self.kernel_[i].evaluate(X.T).tolist()) # ndarray化 self.p_ = np.array(self.p_) # 予測ラベルの割り振り for j in range(self.p_.shape[1]): pred.append(np.argmax(self.p_.T[j])) return predラベルは0, 1, 2...(非負整数の小さい順)に割り振ってください。
もしかして:LabelEncoder__init__メソッド
オブジェクトの初期化を行います。
ここではカーネル密度推定で必要なパラメータ、つまりSciPyのgaussian_kdeの初期化に必要な引数を指定します。
今回はgaussian_kdeのデフォルト値と同じ値を設定しました。fitメソッド
教師データを用いて学習を行います。
gaussian_kdeでカーネル密度推定を行ったあと、ラベル0の推定密度関数、ラベル1の推定密度関数……を順に格納していきます。predictメソッド
テストデータの予測を行います。
for i in range(self.y_num): self.p_.append(self.kernel_[i].evaluate(X.T).tolist())ここでは、kernel_から推定密度関数を一つずつ取り出し、テストデータの確率密度を計算しています。
その後のスクリプトが何やらごちゃごちゃしています。もっと簡潔に書きたかったのですが、なかなか思い通りの挙動をしなくて……
コーディング初心者あるある。動けばよい。動くだけマシ。というわけでオブジェクト指向のガウスカーネル密度推定分類器、完成です。
wineデータセット編
PCAとの組み合わせ
wineデータセットには特徴量が13個ありますが、標準化したあと4次元まで次元削減します。
次元削減後のデータで学習と分類を行ってみましょう。from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA # データセットの読み込み wine = datasets.load_wine() X = wine.data y = wine.target # データの分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1, stratify=y) # 標準化 sc = StandardScaler() sc = sc.fit(X_train) X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) # 次元削減 pca = PCA(n_components=4) X_train_pca = pca.fit_transform(X_train_std) X_test_pca = pca.transform(X_test_std) # 学習と予測 f = GKDEClassifier() f.fit(X_train_pca, y_train) y_pred = f.predict(X_test_pca)結果は……?
from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_pred)) # 0.9722222222222222わーい。
テストデータは36個ですから、正解率は35/36。なかなかです。次元削減なし
どうなるでしょうか。
# 学習と予測 f = GKDEClassifier() f.fit(X_train_std, y_train) y_pred = f.predict(X_test_std) print(accuracy_score(y_test, y_pred)) # 0.9722222222222222結果:同じ。
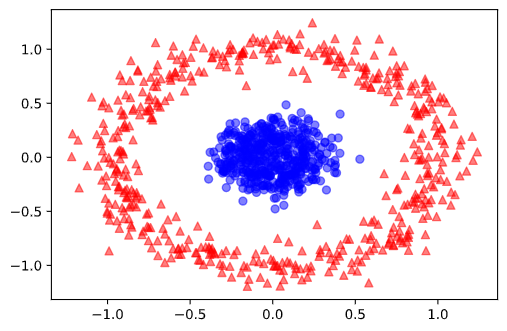
円型データセット編
円型のデータセットを作ってみました。
from sklearn.datasets import make_circles from matplotlib import pyplot as plt X, y = make_circles(n_samples=1000, random_state=1, noise=0.1, factor=0.2) plt.scatter(X[y==0, 0], X[y==0, 1], c="red", marker="^", alpha=0.5) plt.scatter(X[y==1, 0], X[y==1, 1], c="blue", marker="o", alpha=0.5) plt.show()
中心部と外縁部でラベルが異なります。
正しく分類できるかな?X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y) f = GKDEClassifier() f.fit(X_train, y_train) y_pred = f.predict(X_test) print(accuracy_score(y_test, y_pred)) # 0.9933333333333333結論:大勝利。
最後に
ここまでいい感じに分類できていますが、実は大事なことを忘れています。
それは、この分類方法の学術的な正しさです。次回はその議論をしようと思います。つづく?
- 投稿日:2020-08-01T21:48:41+09:00
[PyTorch]セグメンテーションのためのDataAugmentation
0.この記事の対象者
- PyTorchを使って画像セグメンテーションを実装する方
- DataAugmentationでデータの水増しをしたい方
- 対応するオリジナル画像とマスク画像に全く同じ処理を施したい方
- 特に自前のデータセット (
torchvision.datasetsにないデータ)を使用する方1 概要
主に, 教師ありまたは半教師ありでのセグメンテーション用データセットを想定
- 自作データセットクラスの中にDataAugmentation処理を記述
- 対応するオリジナル画像とマスク画像の両方に全く同じ処理を実行
- 「クロップする位置」, 「角度」, 「反転するか否か」を一致させる
- 画像ペア(=オリジナル画像+マスク画像)毎にランダム性のある処理を実行
- ただし, 上述の通り画像ペア内の処理は一致
2 問題点
問題のケースをみる前に, まずは問題ないケースを考えてみます
2.1 問題ないケース(物体クラス認識など)
PyTorchでDataAugmentationする際には, 通常以下のように変換を定義して
transform = torchvision.transforms.Compose([ # 角度degreesだけ回転 transforms.RandomRotation(degrees), # 水平方向に反転 transforms.RandomHorizontalFlip(), # 垂直方向に反転 transforms.RandomVerticalFlip() ])んでデータセットの引数に入れてやります
dataset = HogeDataset.HogeDataset( train=True, transform=transform )おそらく物体クラス認識などではこれで問題ないでしょう
理由は教師データが画像じゃないので, オリジナル画像さえ加工してやればいいため2.2 問題のケース(セグメンテーションなど)
お次に問題となるケース
先ほどのケースとの違いは教師データが画像として与えられている点ですtransform = torchvision.transforms.Compose([ # 角度degreesだけ回転 transforms.RandomRotation(degrees), # 水平方向に反転 transforms.RandomHorizontalFlip(), # 垂直方向に反転 transforms.RandomVerticalFlip() ])んでデータセットの引数に入れてやります
dataset = HogeDataset.HogeDataset( train=True, transform=transform, target_transform=transform )ただし, これだと
HogeDatasetからデータを取得する際, オリジナル画像とマスク画像になされる変換が対応づいたものとはなりません
例) オリジナル画像 : 90度回転, マスク画像 : 270度回転
これでは, データを水増ししても教師データとしては機能しません.
引数target_transformよ, お前はなぜ存在するんだ?ってなりますが, こいつの存在意義はおそらくマスク画像に対してもtorchvision.transforms.Resize()やtorchvision.transforms.ToTensor()のような(ランダム性がない)加工を施すためにあるんじゃないかと思います3 解決策
ということで, オリジナル画像と同じ加工をマスク画像に施すにはどうすればいいのか
解決策としては, 以下のような自作のDatasetクラスを作る方法が考えられるHogeDataset.pyimport os import glob import torch from torchvision import transforms from torchvision.transforms import functional as tvf import random from PIL import Image DATA_PATH = '[オリジナル画像のディレクトリパス]' MASK_PATH = '[マスク画像のディレクトリパス]' TRAIN_NUM = [訓練データ数] class HogeDataset(torch.utils.data.Dataset): def __init__(self, transform = None, target_transform = None, train = True): # transform と target_transform はテンソル化などのランダム性のない変換 self.transform = transform self.target_transform = target_transform data_files = glob.glob(DATA_PATH + '/*.[ファイル拡張子]') mask_files = glob.glob(MASK_PATH + '/*.[ファイル拡張子]') self.dataset = [] self.maskset = [] # オリジナル画像読み込み for data_file in data_files: self.dataset.append(Image.open( DATA_PATH + os.path.basename(data_file) )) # マスク画像読み込み for mask_file in mask_files: self.maskset.append(Image.open( MASK_PATH + os.path.basename(mask_file) )) # 訓練データとテストデータに分割 if train: self.dataset = self.dataset[:TRAIN_NUM] self.maskset = self.maskset[:TRAIN_NUM] else: self.dataset = self.dataset[TRAIN_NUM+1:] self.maskset = self.maskset[TRAIN_NUM+1:] # Data Augmentation # ランダム性のある変換はここで行う self.augmented_dataset = [] self.augmented_maskset = [] for num in range(len(self.dataset)): data = self.dataset[num] mask = self.maskset[num] # ランダムクロップ for crop_num in range(16): # クロップ位置を乱数で決定 i, j, h, w = transforms.RandomCrop.get_params(data, output_size=(250,250)) cropped_data = tvf.crop(data, i, j, h, w) cropped_mask = tvf.crop(mask, i, j, h, w) # 回転(0, 90, 180, 270度) for rotation_num in range(4): rotated_data = tvf.rotate(cropped_data, angle=90*rotation_num) rotated_mask = tvf.rotate(cropped_mask, angle=90*rotation_num) # 水平反転と垂直反転のどちらか # 反転(水平方向) for h_flip_num in range(2): h_flipped_data = transforms.RandomHorizontalFlip(p=h_flip_num)(rotated_data) h_flipped_mask = transforms.RandomHorizontalFlip(p=h_flip_num)(rotated_mask) """ # 反転(垂直方向) for v_flip_num in range(2): v_flipped_data = transforms.RandomVerticalFlip(p=v_flip_num)(h_flipped_data) v_flipped_mask = transforms.RandomVerticalFlip(p=v_flip_num)(h_flipped_mask) """ # DataAugmentation済みのデータを追加 self.augmented_dataset.append(h_flipped_data) self.augmented_maskset.append(h_flipped_mask) self.datanum = len(self.augmented_dataset) # データサイズ取得メソッド def __len__(self): return self.datanum # データ取得メソッド # ランダム性の無い変換はここで行う def __getitem__(self, idx): out_data = self.augmented_dataset[idx] out_mask = self.augmented_maskset[idx] if self.transform: out_data = self.transform(out_data) if self.target_transform: out_mask = self.target_transform(out_mask) return out_data, out_maskやっていることは単純で,
__init__()の内部でDataAugmentationしてやります
その際に各画像ペアについて
- ランダムクロップの位置を固定する
- 固定の角度で回転操作を行う(×4)
- 水平反転する場合, しない場合
- (垂直反転する場合, しない場合)
の全ての場合の加工処理を網羅的に行います
一応, こんな感じでオリジナル画像と全く同じ処理をマスク画像に施してDataAugmetationできます
[補足]回転と反転を組み合わせると重複が生じることがあるので, 反転処理は水平か垂直のどちらかだけ使用することをお勧めします!!4 使い方
3の自作Datasetクラスを使ってみる
import torch import torchvision import HogeDataset BATCH_SIZE = [バッチサイズ] # 前処理 transform = torchvision.transforms.Compose([ torchvision.transforms.Resize((224, 224)), torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) target_transform = torchvision.transforms.Compose([ torchvision.transforms.Resize((224, 224), interpolation=0), torchvision.transforms.ToTensor() ]) # 訓練データとテストデータの用意 trainset = HogeDataset.HogeDataset( train=True, transform=transform, target_transform=target_transform ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=BATCH_SIZE, shuffle=True ) testset = EpiDatasets.EpiDatasets( train=False, transform=transform, target_transform=target_transform ) testloader = torch.utils.data.DataLoader( testset, batch_size=BATCH_SIZE, shuffle=True )
- 投稿日:2020-08-01T20:58:54+09:00
初めてのPython スクスタのMVを連続再生させる
初めてのPython
これまでPCの自動化作業には専らUWSCを使ってたため、興味はあれど中々学習の機会がなかったPythonですが、UWSCの現状もありどこかで始めないとと思っていたところ、先日始めたスクスタ(ラブライブの音ソシャゲー)のおかげで同ゲームのMVを自動再生したいという動機が生まれたのでこの機会にPythonを始めてみました。
内容の都合上、ほぼNoxやBluestacksといったAndroidエミュを使ったソシャゲの自動化マクロの話になります。
環境
Windows10 64bit
Python3.8 64bit
Bluestacks4AndroidエミュはNoxと迷ったのですが、Noxはリップシンクが10フレほどズレるのでBluestacksを利用しました。
pyautoguiのインストール
pip install pyautoguiPythonでの自動化には外せないらしい。
設計
動作はシンプルに下の画面でMVボタンを押し、
画面が遷移した先で再生ボタンを押す。
あとは曲が終わり、また画像1のMVボタンが表示されるまでループさせる。コード
定数宣言部
pydef.pyMAIN_PATH=".\\MVPlay\\" FILE_TYPE="*.png" X:int=0 Y:int=1メインコード
main.py# coding:utf-8 import pyautogui import glob import time from pydef import* def counterModeSerial(i:int,maxcount:int): if i>=maxcount: return 0 else: return i+1 def main(files:list,loopmode:int,waittime:int): i:int=0 while True: loc=pyautogui.locateCenterOnScreen(files[i]) if not(loc==None): time.sleep(waittime) pyautogui.click(loc[X],loc[Y]) i=counterModeSerial(i,len(files)-1) time.sleep(waittime) flist=glob.glob(MAIN_PATH+FILE_TYPE) main(flist,0,0.5)タップさせたいコンポーネントの画像をトリミングしてフォルダに突っ込めばシーケンシャルに実行されるように。
今回のケースではMVとか再生のボタンの画像になります。
MVPlayフォルダを作って中にpngファイルを置けばファイル名でソートされる順番で「認識→タップ→次のファイル→認識...最後の画像を認識したら最初に戻る」を繰り返します。
終了処理を入れてないのでデバッガで起動した場合以外はタスクマネージャーからプロセスをkillする必要があります。フォルダに画像を突っ込めば画像認識とクリックそして次の状態への遷移をやってくれるので、このままでも2Dソシャゲの周回程度なら十分対応できそうですね。
雑感
参照や変数宣言を除けばほぼ10行ほどのコードで動くのは流石だと思いました、簡易でパワフルだと言われるだけのことはあると思います。
locateOnScreen関数がマルチディスプレイに対応しておらず、プライマリディスプレイしかチェックしてくれない(作業モニタをセカンダリに入れ替えてなんとかしましたが)画像認識が遅い等の不満点もちらほら見られましたが、総じて使いやすかったです。
ただインデントで入れ子を表現するのだけは少し怖いと思うのはおっさんだからですかね、きれいなインデントが強制されるので可読性が上がると言う利点もあるのでしょうか。最後に
取り敢えずの目標は達成されましたが、これだと一曲のみのループしかできない上、ボタン押下時にマウスカーソルとアクティブウィンドウが持って行かれるので、ADB経由でコマンドを送信する等そこら辺も改良していきたいと思います。
- 投稿日:2020-08-01T20:56:01+09:00
❤️ブロガーの皆さん❤️"愛されBI"❤️はじめましょ❤️(Pythonで図表作れる人向け)
ブロガーの皆様、「ブログのアクセス情報をGoogle Analyticsよりもいい感じに、自分のブログページでウォッチしたい!」、「自分だけのダッシュボードが欲しい!」と思ったことはないでしょうか?
実はレンタルサーバーを使って簡単に実現できます。
→トップ画像の実物はこちら(https://napinavi.com/?page_id=821)この記事は、
- データ分析に興味を持っていて、
- レンタルサーバーでブログ運営されている方、
- レンタルサーバーでブログ運営しようか迷っている方
に向けて、レンタルサーバーでダッシュボードを作る方法をお届けするべく書いております。
該当しない方、ごめんなさいm(_ _)mなお、私のブログ環境は、以下の通りです。
- ブログソフト:wordpress
- サーバー:ConoHa Wing
レンタルサーバーは以下の2種類ありますが、私の環境は後者(カスタマイズ性低いやつ)にあたります。
- 自由にカスタマイズできる専用サーバー、VPS(Virtual Private Server)
- 自由なソフトウェアインストールが禁止されている共用サーバー(←僕の環境)
でもご安心を。私のようにカスタマイズの自由度が低い共有サーバーでも、下記条件をクリアしていれば大丈夫です!
- 既にPythonがインストールされている
- ジョブスケジューラーが使える
これからレンタルサーバーでブログ開設しようと考えている方へ。
私の環境を立ち上げにかかった時間と、コストも紹介しておきます。
詳細は、私のブログにまとめております。
- 時間:
- 作業環境を決めるまでに3日くらい
- 実際にサーバー契約してブログっぽいものが出来上がるまでに2-3日
- 今後のブログ更新/メンテナンスに数時間/週(見込み)
- 費用:
- ブログ立上げにかかった費用は1万1296円(サーバーレンタル費用1年分のみ、ドメイン代込)
- 今後のブログ運営にかかる費用は1万1296円/年(来年度のサーバーレンタル費用)
前置きが長くなりましたが、この記事ではこんな内容をお届けできればと思います。
- 「愛されBI」って何ぞや?
- 「愛されBI」の作り方
- 躓いたこと・対処法
- 「愛されBI」を作ることの素晴らしさ
- てか、あんた誰よ?
「愛されBI」って何ぞや?
タイトルにある「愛されBI」とは、自分や読者が確認したくなるようなブログ関連の統計情報がリアルタイムに更新されるページのことです。私が作った造語ですが、元ネタは、メルカリOBで現在「株式会社 Growth Camp(グロースキャンプ)」でご活躍されている樫田さんの「愛されダッシュボード」に感銘を受け、命名させていただきました。
この記事ではなく、「愛されダッシュボード」にご興味が沸いた方は、樫田さんの記事をご覧ください。ここまで読んでいただきありがとうございました。
私の「愛されBI」では冒頭に示したような画像が5分置きに更新される仕様となっています。こちらのページからアクセスできますので、イメージが沸かない方はぜひご覧ください。
「愛されBI」の作り方
ここでは、Pythonを使って、簡単な図表が作れることは前提として、Pythonを使って
- どのように統計データを収集するのか
- どのようにリアルタイムに図表を更新するのか
に焦点を絞りたいと思います。1. に関しては、Google Analytics APIとTwitter APIを使っているだけです。
次に、2. に関して作ったものは以下のようなものです。
実は、私のエンジニアレベルが雑魚すぎて、あんまり難しい技術は使っていないので、勘の良い方はこれだけで再現できてしまうと思います。
具体的なタスクはこれだけです。めちゃくちゃ簡単ですね。。。
- Twitter/Google Analytics APIの利用申請をする(1-2時間で終わる!)
- Twitter/Google Analytics APIを叩くPythonプログラムを作る(人のを丸パクリ・・・)
- 取得データから図表を作り保存するPythonプログラムを作る(精一杯愛を注ぐ!)
- 「愛されBI」のページに、画像へのリンクを埋め込む(秒で終わる)
一応ですが、それぞれの概要も説明しておきます。
1. Twitter API/Google Analytics APIの利用申請をする
Twitterに関しては、僕のブログに使える機能や参考にしたリンクを掲載しています。
Googleに関しては、以下の記事を参考にさせていただきました。なお、Google Analyticsのコンテンツについては掲載不可との噂を聞いていたのですが、下記の記事によると公開可能っぽいです。
2. Twitter API/Google Analytics APIを叩くPythonプログラムを作る
Twitterに関しては、1. と同じく、僕のブログにまとめています。
Googleに関して、下記の記事のプログラムがカスタマイズに優れていて秀逸だと思ったので、そのまま拝借しました。3. 取得データから図表を作り保存するPythonプログラムを作る
「愛せるかどうか」を左右する最も大事なところです。
技術的な問題はさておき、自分が把握すべき数字、読者が興味を持つ数字が何なのかを考えることからはじめましょう。
上記が考えられていれば、最終形は、それぞれのブログで違っていいと思います。
ご参考までに、「愛され図表」を設計するにあたり、私が考えたポイントを記載させていただきます。
- そもそも自分のブログのKGI(Key Goal Indicator)は何だろう?
- KGIを達成するために日単位、週単位、月単位に確認すべきことはなんだろう?
- Google AnalyticsやTwitter Analyticsだと届かない痒いところはどこ?
4. 「愛されBI」のページに、画像へのリンクを埋め込む
こんな感じで、画像のリンクを貼るだけです。簡単ですね。
躓いたこと・対処法
躓いたことは以下の通りです。
- ジョブスケジューラーで実行するとコードが動かんやん
- Matplotlibで日本語が文字化けするけどフォントインストールできんやん
- レンタルサーバー上でコーディングするの大変やん
対処法を紹介します。ご参考になれば幸いです。
ジョブスケジューラーで実行するとコードが動かんやん
python [働きもの].pyって実行していた時は動いて画像を吐き出してくれたのに、ジョブスケジューラーにコマンドを登録すると、画像更新が止まってしまう。
このような状況になった場合、pythonコマンド名、実行対象のpythonファイル名、pythonファイルに含まれるディレクトリ名(特に画像の出力先)が相対パスになっていないか、を確認してください。全て絶対パスでなければ動きません。
pythonコマンドの絶対パスは、レンタルサーバーの提供元の情報を確認するのが良いと思います。私が使っているConoHa Wingについてはこちらをご覧ください。
Matplotlibで日本語が文字化けするけどフォントインストールできんやん
共用サーバーでは、sudo権限が伴うような操作が禁止されているはずです(少なくとも、私の環境はNGでした)。なので、Matplotlibで日本語が文字化けする現象への対処が厄介でした。
こちらは、japanize_matplotlibのインポートで対処できました。
japanize_matplotlibの使い方は、下記の記事を参考にしました。もう1点、留意事項です。pip installコマンドは使えるのですが、ユーザー権限で実行する必要があります。ですので、
pip install 【インストールしたいモジュール名】 --user
と、--userをつけましょう。レンタルサーバー上でコーディングするの大変やん
レンタルサーバー上なので、いい感じのエディターを入れられず、
- ローカルで作成したコードを、レンタルサーバーにアップして、細かい調整はサーバー上で使い慣れないviでやる
- 新しく機能追加したい時は、レンタルサーバーからコードをダウンロードして、ローカルで編集して、1. に戻る
と、すごく非効率な作業をしていました。
ある程度動くことが確認できたら、git使いましょう。。。
これまで本番環境にアップする経験が多くなく、gitのありがたみが分かりませんでしたが、本日から心を改めます。「愛されBI」を作ることの素晴らしさ
- Google AnalyticsやTwitter Analyticsでは手が届かない自分仕様のレポートが出てくる。結果、ブログ愛が深まる
- データ加工や分析のいい練習になる
いいことずくめですね。デメリットと言えば、「愛されBI」が気になって、仕事が手に付かないことくらいでしょうか。。
2.に関しては言わずもがなだと思うので、1.に関してだけ補足します。
1.について、私が思う具体的なメリットはこうです。
- 頁別に正確な集計ができる
- 頁タイトル別の集計だと、途中で頁タイトルを変更している場合に、別頁だと見做されてしまいます。一方、頁のurl別だと、同一頁なのに別頁だと見做されることがあります(関連リンクを踏んでる場合に発生します)
- Google Analytics APIから情報を取得し、自分で名寄せすることでこの問題を解決できました。
- 自分がウォッチしたいKGIに基づきレポートを構成できる
- Google AnalyticsのデフォルトレポートはPV(頁ビュー)、ユーザー数、セッション数起点で構成されていますが、私はKGIをブログ閲覧時間としていたので、見たい情報が確認しにくい状況でした。
- Google Analytics APIで閲覧時間を含む様々な情報を提供してくれており、必要な情報を取得し集計することでこの問題を解決できました。Google Analytics APIで取得できる情報の詳細は下記が参考になりました。まずは適当にググって概要を掴んだ上で参照されるのが良いと思います。
- Twitter、Google Analyticsなどの複数ソースを関連付けて分析できる
- 私のブログの集客はTwitterに依存しているので、Twitterでの告知がどのように影響しているかは非常に重要です
- Twitter APIのデータと、Google Analyticsのデータを紐付けることで、該当頁のリンクを含むTweetがブログ集客に与える影響をウォッチできるようになるはずです(現在、開発中)
- ABテストの結果をリアルタイムにモニタリングできる
- 時にはTwitterを使ってABテストをしたい、なんてこともあるでしょう。Twitter Analyticsは、そのようなカスタマイズには対応しておらず、「愛されBI」を作らないにせよ、自分で分析する必要があります。
- 「愛されBI」上にABテストの速報値が掲載されたらどうでしょうか。愛が深まりますよね(現在、開発中)
はい、すばらしいですね。
てか、あんた誰よ?
簡潔にまとめるはずが、思ったよりも長文になってしまいました。。
ここまで読んで下さった方は、多少記事に興味を持っていただいた方だと思うので、簡単に自己紹介をさせていただきます。私、日系のレガシー企業でデータサイエンティスト見習いをしている者です(分析歴1.5年くらい)。
自社の案件だけだと、成長しなさそうだなあ、と危機感を覚え、ブログやTwitterを題材に分析をはじめました。最後に、自己紹介になりそうな投稿を紹介させていただき、この記事を締めくくりたいと思います。
長文にも関わらず、最後までご覧いただきありがとうございました。ふう。需要がなさそうな記事を書いてしまった気がする。。




- 投稿日:2020-08-01T20:49:02+09:00
discord.pyいろんなメモ
初めに
記事を書くのは初めてなので、分かりにくい点などがあるかもしれませんがコメントなどで指摘していただけるとありがたいです。
本記事はdiscord.pyのメモ書きとなっています。
本記事に書いてあることで分からない所があれば質問してください。答えられる範囲で回答します。python 3.8.3
discord.py 1.3.3本記事の基本
import discord client = discord.Client() # ここに記述 client.run("token")役職付与/剥奪
@client.event async def on_message(message): if message.content == "/add": role = discord.utils.get(message.guild.roles, name="ロール名") # サーバー内の「ロール名」というロールを取得 await message.author.add_roles(role) # 上記で取得したロールを付与 if message.content == "/remove": role = discord.utils.get(message.guild.roles, name="ロール名") await message.author.remove_roles(role) # 上記で取得したロールを剥奪ファイルを送信
@client.event async def on_message(message): if message.content == "/send": await message.channel.send(file=discord.file("ファイルのパス"))送信場所がDMかサーバーか判定
@client.event async def on_message(message): if message.content == "/send": if message.guild: # 送信場所がDMだったら await message.author.send("DM") # メッセージ送信者に送信 if not message.guild: # 送信場所がサーバーだったら await message.channel.send("サーバー") # 送信したチャンネルに送信embed(埋め込みメッセージ)の書き方
@client.event async def on_message(message): if message.content == "/embed": embed = discord.Embed(title="タイトル", description="説明", colour=0xff0000) embed.add_field(name="フィールド名", value="フィールド値", inline=False) embed.set_thumbnail(url=message.author.avatar_url) embed.set_image(url="https://vignette.wikia.nocookie.net/hitlerparody/images/a/af/Discord_Logo.png/revision/latest?cb=20181215111027&path-prefix=es") embed.set_author(name="著者名", icon_url="https://image.winudf.com/v2/image1/Y29tLmRpc2NvcmRfaWNvbl8xNTU0MDY5NjU3XzAyMQ/icon.png?w=170&fakeurl=1") embed.set_footer(text="フッター", icon_url=client.user.avatar_url) await message.channel.send(embed=embed)上記のコードの場合こんな感じに表示されます。
基本構造はこんな感じですが、embedを簡単に生成できるサイトもあるので紹介しておきます。
Discord Embed Generatorいろんな変更
だいたいリファレンスに書いてあるのでその情報をこちらに記述します。
チャンネル編集
https://discordpy.readthedocs.io/en/latest/api.html#textchannel
@client.event async def on_message(message): if message.content == "/edit": await message.channel.edit(name="テキストチャンネル") # チャンネル名を変更 await message.channel.edit(topic="トピック") # チャンネルトピックを変更 await message.channel.edit(nsfw=True) # NSFWチャンネルに変更(Falseで無効)ユーザー編集
https://discordpy.readthedocs.io/en/latest/api.html#member
@client.event async def on_message(message): if message.content == "/edit": await message.author.edit(nick="ニックネーム") # ニックネームを変更 await message.author.edit(mute=True) # ボイスチャンネルでミュートに変更(Falseで解除) await message.author.edit(voice_channel=None) # ボイスチャンネルから切断サーバー編集
https://discordpy.readthedocs.io/en/latest/api.html#guild
@client.event async def on_message(message): if message.content == "/edit": await message.guild.edit(name="サーバー") # サーバー名を変更 await message.guild.edit(description="説明") # サーバーの説明を変更 await message.guild.edit(region="europe") # サーバー地域を変更指定できる地域一覧
https://discordpy.readthedocs.io/en/latest/api.html#discord.VoiceRegionチャンネルを作成
@client.event async def on_message(message): if message.content == "/create": ch = await message.channel.category.create_text_channel(name="ch") # 名前「ch」のテキストチャンネルを作成 await message.channel.send(ch.mention + " を作成しました。")いろんな数を取得
@client.event async def on_message(message): if message.content == "/servers": await message.channel.send(len(client.guilds)) # BOTが参加しているサーバー数 await message.channel.send(len(message.guild.members)) # サーバー内のメンバー数を取得こちらのサイトにその他のものが載っています
その他情報
メッセージは文の途中で \n を入れると改行することができます。
最後に
BOTの開発者が集まるサーバーでDiscord Bot Portal JPというサーバーがあります。
こちらのサーバーは質問もすることができるので調べても分からないことがあれば利用すると解決できるかもしれません。
※質問の際は最低限調べてから質問してください
- 投稿日:2020-08-01T20:26:29+09:00
ベランダの写真から植物が写っている部分を抽出するために深層学習を使ってみようと思ったらうまくいかなったので、試行錯誤してみた内容をまとめてみる。後編
前回のあらすじ
ちょっとした出来心で始めた株。しかし、新型コロナウイルス感染症が流行するなんて想像もしておらず、ご多分から漏れることなく投資に失敗し、マイホーム購入のためにこれまで一生懸命貯めた貯金がすっからかんになり、自暴自棄になって宍道湖大橋をトボトボと歩いていたら、後ろから「久しぶり。元気か?!」と声をかけられ...
...というのは冗談で、写真から対象を抽出するというテーマの取り組みについて記事の続きを書きます!
ベランダの写真から植物が写っている部分を抽出するために深層学習を使ってみようと思ったらうまくいかなったので、試行錯誤してみた内容をまとめてみる。前編
検討
前編の後、パラメータをいくつか変えてみるも全く効果なく、虚しい時間が流れるばかり...
そんな中、ふと思いついたのが「転移学習」。
学習済モデルの出力を使って、少ないデータから高精度の識別を実現する手法とのこと...やり方は全然わかんないけど、とりあえずにわか知識で試してみることに!
学習
前編と同じデータを読み込んで、学習済モデルに識別させて、その結果を入力としてニューラルネットワークに学習させてみる。
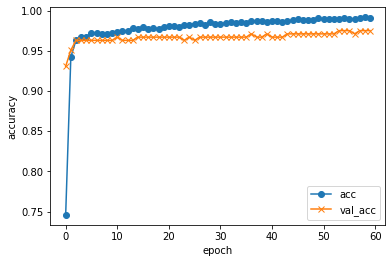
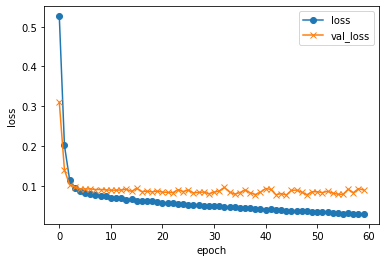
from glob import glob import random X = [] y = [] dirs = ["9*/*.jpg", "0*/*.jpg"] i = 0 min = 1500 for d in dirs: files = glob(d) files = random.sample(files, min if len(files) > min else len(files)) for f in files: X.append(f) y.append(i) i += 1 import pandas as pd df = pd.DataFrame({"X" : X, "y" : y}) from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions # VGG16の学習済モデルを取得 model_VGG16 = VGG16() import cv2 import numpy as np from keras.preprocessing import image X = [] y = [] cnt = 0 for idx in df.index: f = df.loc[idx, "X"] l = df.loc[idx, "y"] print("\r{:05} : [{}] {}".format(cnt, l, f), end="") i += 1 # 画像の読込 img = image.load_img(f, target_size=model_VGG16.input_shape[1:3]) X.append(image.img_to_array(img)) y.append(l) cnt += 1 print() # 前処理 X = np.array(X) X = preprocess_input(X) # VGG16による識別 preds = model_VGG16.predict(X) print('preds.shape: {}'.format(preds.shape)) # preds.shape: (1, 1000) # 識別結果を入力に設定 X = preds from sklearn import model_selection test_size = 0.2 # 学習、検証、テスト用に分割 X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=test_size, random_state=42) X_valid, X_test, y_valid, y_test = model_selection.train_test_split(X_test, y_test, test_size=.5, random_state=42) from keras.utils.np_utils import to_categorical y_train = to_categorical(y_train) y_valid = to_categorical(y_valid) y_test = to_categorical(y_test) from keras.layers import Dense from keras.models import Sequential # 学習モデルの作成 model = Sequential() model.add(Dense(64, input_dim=len(X_train[0]), activation='relu')) model.add(Dense(64, activation='sigmoid')) model.add(Dense(len(y_train[0]), activation='softmax')) # コンパイル model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # 学習 history = model.fit( X_train, y_train, batch_size=25, epochs=60, verbose=1, shuffle=True, validation_data=(X_valid, y_valid)) import matplotlib.pyplot as plt # 汎化制度の評価・表示 score = model.evaluate(X_test, y_test, batch_size=32, verbose=0) print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) #acc, val_accのプロット plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o") plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x") plt.ylabel("accuracy") plt.xlabel("epoch") plt.legend(loc="best") plt.show() #loss, val_lossのプロット plt.plot(history.history["loss"], label="loss", ls="-", marker="o") plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x") plt.ylabel("loss") plt.xlabel("epoch") plt.legend(loc="best") plt.show()実行!!
validation loss:0.0818712607031756 validation accuracy:0.9797570705413818
おぉっ!
なんだこれ?!識別とマーキング
import cv2 import numpy as np div = 10 cl = (0, 0, 255) i = 0 # テスト画像一覧の取得 testFiles = glob("test/*.JPG") testFiles.sort() for f in testFiles: print(f.split("/")[-1]) # ファイルの読込 img = cv2.imread(f) img_output = cv2.imread(f) #print(img.shape) h, w, c = img.shape print(f, h, w, c) # 短辺の取得と分割サイズの設定 size = h if h < w else w size = int(size / 10) print(size) i = 0 k = 0 while size * (i + 1) < h: j = 0 while size * (j + 1) < w: # 分割画像の取得 img_x = img[size*i:size*(i+1), size*j:size*(j+1)] # VGG16による識別 img_test = cv2.resize(img_x, model_VGG16.input_shape[1:3]) img_test = cv2.cvtColor(img_test, cv2.COLOR_BGR2RGB) X = np.array([img_test]) X = preprocess_input(X) preds = model_VGG16.predict(X) # 識別 pred = model.predict(preds, batch_size=32) m = np.argmax(pred[0]) # 精度が85%以上で植物と識別された場合 if pred[0][m] > 0.85 and m == 1: # 植物と識別された場所に赤い四角を描画 cv2.rectangle(img_output, (size*j + 5, size*i + 5), (size*(j+1) - 5, size*(i+1) - 5), cl, thickness=2) j += 1 k += 1 i += 1 img_output = img_output[0:size*i, 0:size*j] f_new = "predicted/{}".format(f.split("/")[-1]) cv2.imwrite(f_new, img_output) print()実行!!
完璧!!
転移学習ってすごい!...って本来の意味での転移学習とは違ってるかもしれないけど。汗
ちなみに手作業でマーキングしたりしてないですからね〜。笑
さて、次は何をするかな〜。



- 投稿日:2020-08-01T19:30:24+09:00
Ren'Pyで2D RPGを作る(3)―アイテムと道具屋
概要
こんにちは、最近ゲーム制作にかまけてエロゲができていないエロゲーマー蟹丸です。Ren'Pyを使った2D RPG制作第三回です。
今回はアイテムと道具屋を作っていきます。前回:Ren'Pyで2D RPGを作る(2)―パーティーとステータス
本記事の範囲
アイテムを実装し、メニュー画面からの使用、道具屋での売買を可能にする背景
RPGにどうしてアイテムが必要なんだ!という思いを抱く人はいないと思います。
バトルを作る前にアイテムを作っておけば戦闘中も回復できるようになるので、先にアイテムを作ってしまいます。1. アイテムを作る
まずはアイテムを作る~メニュー画面から使用する部分を実装していきます。
システム実装
前回と同様こちらはRen'PyではなくただのPythonなので、Pythonがわかる人は自分の好きなようにやってしまえると思います。
※この部分はitem.rpyというファイルのinit pythonステートメント内に書いているものとして読んでください。
まずは
inventoryをdict型で作ります。keyをアイテムのインスタンス、valueを所持アイテム数として使います。ユーザ定義型のインスタンスはhashableなのでdict型のkeyとして使えるんですね。便利です。
普通にPythonコードを書くときはあんまりグローバル変数は使いたくないですが、Ren'Pyはグローバル変数を使ってなんぼなところがあるので容赦なく使います。inventory = {}次にアイテムの基本となる
Itemクラスを作ります。
インスタンス変数として値段、使用可能フラグなどを定義しておきます。
メソッドは使用時のメッセージを返すgetter、取得・売却時の処理などを定義しています。class Item(): def __init__(self, name, desc, price): self.name = name self.desc = desc self.price = price self.sell_price = int(price / 2.0) self.marketable_flag = True # Falseの場合売ることができない self.usable_flag = True # Falseの場合通常時使うことができない self.battle_flag = True # Falseの場合戦闘中に使うことができない self.icon_image = "images/icons/medical_item.png" ### 中略:基本のgetter ### def get_confirm_msg(self): return self.name + "を使いますか?" def get_result_msg(self): return self.name + "を使いました" # お店での購入 def buy_item(self, buy_amount = 1): party_money.add_value(-self.price * buy_amount) inventory[self] += buy_amount # お店での売却 def sell_item(self, sell_amount = 1): party_money.add_value(self.sell_price * sell_amount) inventory[self] -= sell_amount # 拾ったりもらったりしたとき def find_item(self, find_amount = 1): inventory[self] += find_amountアイテム種別ごとに
Itemクラスを継承したクラスを作ります。回復アイテム、ステータスアップアイテム、素材アイテム、レシピアイテムなどなど。自分のゲームで必要になるものを実装します。
以下には例として回復アイテムのクラスのコードを載せます。
- 回復アイテムの対象ステータス
- 回復量
- アイテム使用時のメソッド
を新たに定義しています。
アイテム使用時は対象ステータスのインスタンスのadd_current_value(diff)メソッドを呼び出して回復し、先ほど定義したinventoryからそのアイテムのvalueを一つ減らします。# 回復アイテム class MedicalItem(Item): def __init__(self, name, desc, price, target_stat, amount): super(MedicalItem, self).__init__(name, desc, price) self.target_stat = target_stat self.amount = amount def get_target_stat(self): return self.target_stat def get_amount(self): return self.amount def get_usable_flag(self): if self.target_stat.get_current_value() == self.target_stat.get_max_value(): return False else: return True # 現在値を上げる def use_item(self): self.target_stat.add_current_value(self.amount) inventory[self] -= 1ここまでできたら、以下のようにして
inventoryに所持アイテムを追加します。medical_hp_small = MedicalItem(name = "すこし苦い薬", desc = "体力を小回復する。", price = 50, target_stat = stat_hp, amount = 40) inventory[medical_hp_small] = 3これで所持アイテムを管理できるようになりました。
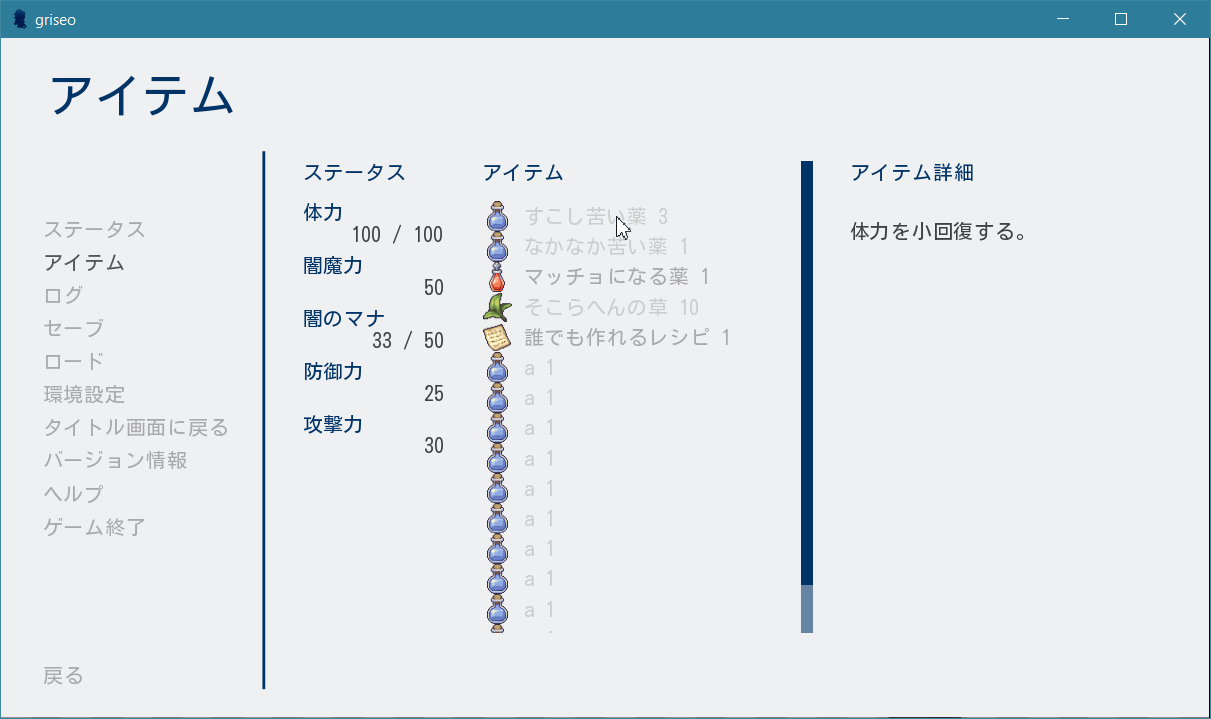
UI実装
こちらがRen'Py独自のもの。今回実装した結果を先に図で示しておきます。
主だった機能と利用した変数などは以下のようになります。
- メニュー画面にアイテム一覧を表示(
inventoryからvalueが0より大きいkeyを表示)- 現在使用可能なアイテムと使用不可能なアイテムで色分け(
usable_flagを利用)- アイテム名にhoverすると右にアイテム説明が表示される(Ren'Pyのtooltipを利用)
- 使用可能なアイテムをクリックすると道具を使用する(
use_item()を使用)それではコードを載せていきます。
screens.rpy# アイテム画面の設定 screen inventory(): tag menu use game_menu(_("アイテム"), scroll="None"): style_prefix "inventory" hbox: # ステータス、アイテム、アイテム一覧を横に並べる spacing 40 vbox: ### 中略:ステータススクリーン(前回参照) ### viewport: # アイテムが多いときにスクロールできるようviewportを使用する scrollbars "vertical" mousewheel True draggable True pagekeys True xsize 350 ysize 500 vbox: label _("アイテム") null height (2 * gui.pref_spacing) for item, amount in inventory.items(): if amount > 0: hbox: $item_name = item.get_name() $usable_flag = item.get_usable_flag() $confirm_msg = item.get_confirm_msg() $desc = item.get_desc() $icon_image = item.get_icon_image() add icon_image if usable_flag and amount > 0: # アイテムが使用可能なとき textbutton _(item_name + " " + str(amount)): tooltip desc action Confirm(confirm_msg, UseItem(item)) else: # 使用不可能なとき。insensitiveにするとtooltipが使えないので注意 textbutton _(item_name + " " + str(amount)): tooltip desc action NullAction() text_style "unusable_text" # 色を変える null height (gui.pref_spacing) vbox: xsize 350 label _("アイテム詳細") $ tooltip = GetTooltip() if tooltip: null height (4 * gui.pref_spacing) text "[tooltip]" ### style省略 ### style unusable_text: color gui.insensitive_colorこのコードでは使用可能なアイテムがクリックされたとき、
confirm_msgを出すConfirmスクリーンを表示し、「はい」が選択された場合UseItemアクションを呼びます。UseItemは独自に実装したActionです。screens.rpyinit: python: class UseItem(Action): def __init__(self, item): self.item = item def predict(self): renpy.predict_screen("notify") def __call__(self): renpy.notify(self.item.get_result_msg()) self.item.use_item()Ren'Pyでは
Actionクラスを継承したクラスはActionとして呼ぶことができ、呼ばれたとき__call__()内の処理が行われます。
ここではUseItem(item)が呼ばれたとき、itemのresult_msgを取得してそれをnotifyに表示したのち、itemのuse_item()メソッドを呼ぶようにしています。最後にここで作った
inventory()スクリーンをゲームメニューに表示します。ステータスの場合と同様ですね。screens.rpyscreen navigation(): ### 中略 ### if main_menu: ### 中略 ### else: textbutton _("ステータス") action ShowMenu("stats") textbutton _("アイテム") action ShowMenu("inventory") # この行を追加これでゲームメニューからアイテムを使えるようになりました。
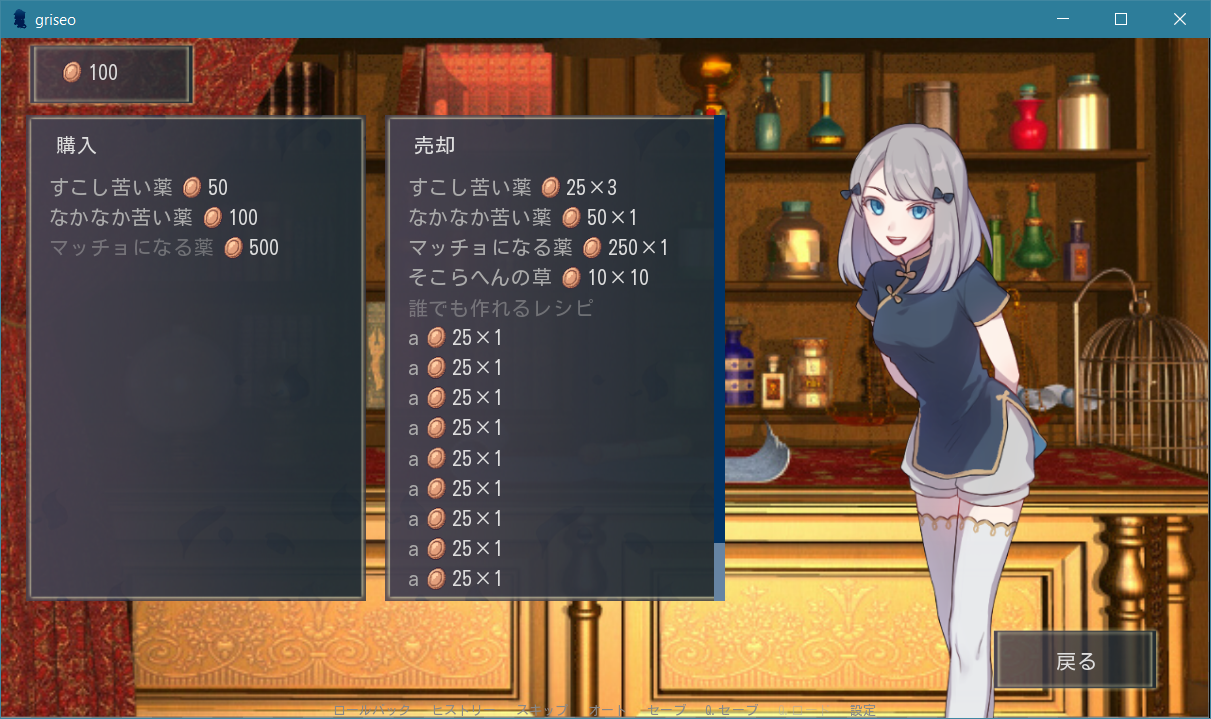
2. 道具屋での売買
アイテムを使えるようになったので、道具屋で売買できるようにしましょう。
Itemクラスで定義していたpriceやbuy_item()メソッドの出番です。システム実装
こちらはあまりやることがなく、道具屋さんにおいてあるアイテムを定義するくらいです。今回はlistにしましたが、在庫の概念がある場合はdictで作れば対応できます。
store.rpy# 道具屋においてあるアイテムを登録する init python: store = [medical_hp_small, medical_hp_medium, enhancing_hp]UI実装
こちらも実装の結果を載せておきます。
いったんありものの画像で作っているので若干不自然ですが(スクロールバーなど特に)、機能的には完全に道具屋さんです。しかも画像では伝わりませんが購入・売却時にチャリーンと音が鳴ります。ゲームっぽいですね!
※使用した素材は記事の最後に載せています。以下コードです。クラス定義も一気に載せます。
store.rpyinit 1 python: # 購入imagemapのtextbuttonが押されたとき class BuyItem(Action): def __init__(self, item): self.item = item def __call__(self): self.item.buy_item() renpy.restart_interaction() renpy.play("audio/sounds/coins.mp3") # 売却imagemapのtextbuttonが押されたとき class SellItem(Action): def __init__(self, item): self.item = item def __call__(self): self.item.sell_item() renpy.restart_interaction() renpy.play("audio/sounds/coins.mp3") screen store_screen(store_instance): style_prefix "store" $current_money = party_money.get_value() # グローバル変数party_money(適当に作ったmoney用クラスのインスタンスから現在値を取得) frame: background "gui/store/blank.png" style_group "mm" xalign 0 yalign 0 hbox: xalign 0.05 yalign 0.03 add "images/icons/money.png" text str(current_money) null height (4 * gui.pref_spacing) hbox: # 購入imagemapと売却imagemapを横に並べる xalign 0.05 yalign 0.4 imagemap: ground "gui/store/background.png" label _("購入") viewport: #yinitial yinitial scrollbars "vertical" mousewheel True draggable True pagekeys True side_yfill True vbox: for item in store_instance: # 道具屋の在庫を金額とともに表示 $item_name = item.get_name() $item_price = item.get_price() hbox: if item_price > current_money: # 所持金よりも高いアイテム textbutton item_name sensitive False add "images/icons/money.png" yalign 1.0 text str(item_price) else: # 買えるアイテム textbutton item_name action BuyItem(item) add "images/icons/money.png" yalign 1.0 text str(item_price) null width (2 * gui.pref_spacing) imagemap: ground "gui/store/background.png" label _("売却") viewport: #yinitial yinitial scrollbars "vertical" mousewheel True draggable True pagekeys True side_yfill True vbox: for item, amount in inventory.items(): # inventoryのアイテムを売値と数量とともに表示 if amount > 0: $item_name = item.get_name() $item_sell_price = item.get_sell_price() $marketable_flag = item.get_marketable_flag() hbox: if marketable_flag: # 売れるアイテム textbutton item_name action SellItem(item) add "images/icons/money.png" yalign 1.0 text str(item_sell_price) text "×" + str(amount) else: # 売れないアイテム textbutton item_name sensitive False button: # 戻るボタン xalign 0.9 yalign 1.0 xsize 145 ysize 100 text "戻る" yalign 0.35 background "gui/store/blank.png" action Return(True) # 呼び出し元のlabelに戻る ### style省略 ###これだけのコードで道具屋さんが作れるのはとても嬉しいですね!
結論と今後
今回はアイテムを実装し、メニュー画面からの使用と道具屋での購入・売却ができるようになりました。
そろそろバトルができそうなので、次回は戦闘システムを作っていこうと思います。参考にしたコードや素材(敬称略)
コード参照&GUIを拝借:
Dragonaqua on Lemmasoft(https://lemmasoft.renai.us/forums/viewtopic.php?f=51&t=57105)
背景:
成瀬直瑚
立ち絵:
わたおきば(https://wataokiba.net/)
アイコン:
素材屋Rosa(http://sozairosa.blog.fc2.com/)
- 投稿日:2020-08-01T19:13:11+09:00
状態とふるまいを持つモデルを実装する (3) - デコレータによる実装例
前回 (状態とふるまいを持つモデルを実装する (2))は、3つの状態を持つ
StopWatchを、二つの方法で実装した。今回はStopWatchを decorator を利用して実装する。まずは、状態遷移を decorator で記述する。状態遷移するメソッドかわかりやすくなる。
from enum import auto def transit(state): def decorator(func): def inner(self, *args, **kwargs): self.start_stop, self.reset = self._TRANSIT[state] func(self, *args, **kwargs) return inner return decorator class StopWatch: WAIT, PAUSE, MEASURE = auto(), auto(), auto() def __init__(self): self._TRANSIT = {StopWatch.WAIT: (self.start, lambda *args: None), StopWatch.PAUSE: (self.start, self.reset_time), StopWatch.MEASURE: (self.pause, lambda *args: None)} self._TRANSIT_REVERSED = {v: k for k, v in self._TRANSIT.items()} self.start_stop, self.reset = self._TRANSIT[StopWatch.WAIT] @property def state(self): return self._TRANSIT_REVERSED[self.start_stop, self.reset] @transit(MEASURE) def start(self): pass @transit(PAUSE) def pause(self): pass @transit(WAIT) def reset_time(self): passさらに状態遷移表をデコレータで切り出してみる。
behaviorデコレータはある状態のときのふるまいを表す。from enum import auto from state_machine import behavior, transit class StopWatch: WAIT, MEASURE, PAUSE = auto(), auto(), auto() def __init__(self): self.state = StopWatch.WAIT @behavior(WAIT, "start") @behavior(MEASURE, "pause") @behavior(PAUSE, "start") def start_stop(self): pass @behavior(PAUSE, "reset_time") def reset(self): pass @transit(MEASURE) def start(self): pass @transit(PAUSE) def pause(self): pass @transit(WAIT) def reset_time(self): passstate_machine.pyfrom functools import wraps def transit(state): def decorator(func): @wraps(func) def inner(self, *args, **kwargs): self.state = state func(self, *args, **kwargs) return inner return decorator def behavior(state, function): def decorator(func): @wraps(func) def inner(self, *args, **kwargs): if self.state == state: getattr(self, function)(*args, **kwargs) else: func(self, *args, **kwargs) return inner return decorator状態を self.state に保持する前提ではあるが、他のモデルでも同じ decorator が使用できるため、モジュール
state_machineとして切り出した。デコレータを処理するタイミングでは、まだ関数がアンバウンドなので、ふるまいを文字列で与えている。関数の
__name__を利用して実行時にバウンドメソッドを呼ぶこともできる。(該当箇所のみ以下に示す。)
なお、functools.wrap()を使用しない decorator があると想定とおり動作しない。(functools.wrap()を使用すると decorator が関数の__name__を書き換えない。)state_machine.pydef behavior(state, function): ... if self.state == state: getattr(self, function.__name__)(*args, **kwargs) ...... @behavior(PAUSE, reset_time) def reset(self): pass ...
- 投稿日:2020-08-01T18:47:57+09:00
【Pytorch】Dataset/DataLoaderについてメモ
概要
Pytorchでデータセット作成時に使用するDataset/DataLoaderあたりをメモ
参考:
データの前処理
データの前処理については
torchvision.transformsまたはalbumentationsあたりのライブラリがある。
どちらも基本的な動作は同じ。
前処理のクラスインスタンスをリストに詰め込んで、Compose()の引数にしてインスタンス作成。
Composeは、__call__(self, img)メソッドを持つので、作成したインスタンスの引数に画像を入れれば前処理される。import alubmentations as alb def get_augmentation(phase): transform_list = [] if phase == 'train': transform_list.extend([albu.HorizonFlip(p=0.5), albu.VerticalFlip(p=0.5)]) transform_list.extend([albu.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), p=1), albu.ToTensor() ]) return albu.Compose(transform_list)Dataset
入力データとそれに対応するラベルを1組ずつ取ってくるモジュール。データの前処理をする場合は、transformsを用いて前処理をかけたデータを返すようにする。
<必要条件>
Datsetの継承__getitem__、__len__の実装以上を満たしていれば基本的にはOK!
Dataset継承クラスのインスタンスがDataLoderの第1引数となる。(DataLodaerについては後で)例えばデータセットが以下のようなディレクトリ構成だとする。
datasets/ ____ train_images/ |__ test_images/ |__ train.csv今回はデータセットに対して、.csvファイルがデータパスとラベルの情報を持っていることを想定してる。
import os.path as osp import cv2 import pandas as pd from torch.utils.data import Dataset import torchvision.transforms as transforms class MyDataManager(Dataset): """My Dataset Args: root(str): root path of dataset directory df(DataFrame): DataFrame object from csv file phase(str): train or test """ def __init__(self, root, df, phase): super(MyDataManager, self).__init__() self.root = root self.df = df self.phase = phase self.transfoms = get_augmentation() def __getitem__(self, idx): img_path = osp.join(self.root, self.df.iloc[idx].name) img = cv2.imread(img_path) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = self.transform(image=img) label = osp.join(eslf.root, self.df.iloc[idx].value) ret = {'image': img, 'label': label} return ret def __len__(self): return len(self.df)今回は、戻り値をdict型にしているが、
return image, labelとしても問題ない。
Segmentationを行う場合などは、ラベルをマスク画像として与える必要があるので、その場合はマスク画像もtransfomする。DataLoader
Datsetで取ってきたデータをDataLoaderの引数とすればいい。
DataLoaderの引数構造は以下、DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)したがって、以下のような関数を作成する。
def dataloader(dir_path,phase,batch_size, num_workers, shuffle=False): df_path = osp.join(dir_path, 'train.csv') df = pd.read_csv(df_path) dataset = MyDataManager(dir_path, df, phase) dl = DataLoader(dataset, batch_size=batch_size, num_workers=num_workers, pin_memory=True, shuffle=shuffle) return dl※まだまだ知識不足な点があるかもしれないのでコメントで教えていただけると幸いです。
- 投稿日:2020-08-01T18:28:27+09:00
Python手遊び(二次元リスト)
この記事、何?
また一言メモっておこうかと。
3x3の二次元リストを作った。# こんなの print(tmp) # [[0, 0, 0], [0, 0, 0], [0, 0, 0]]で、真ん中に「5」って入れようと思ったら、こうなった。なんで?って話。
# こんなの tmp[1][1] = 5 print(tmp) # [[0, 5, 0], [0, 5, 0], [0, 5, 0]]何それ・・・
傾向と対策
作るときには深く考えていなかったのが原因だった。
# ダメな例 tmp_ng =[[0] * 3] * 3 print(tmp_ng) # [[0, 0, 0], [0, 0, 0], [0, 0, 0]]よし、OK! (※OKじゃないです。。。)
# 改善例 tmp_ok = [[0] * 3 for _ in range(3)] print(tmp_ok) # [[0, 0, 0], [0, 0, 0], [0, 0, 0]]この時点では変わらないけど・・・
こうなる。tmp_ng[1][1] = 5 print(tmp_ng) # [[0, 5, 0], [0, 5, 0], [0, 5, 0]] tmp_ok[1][1] = 5 print(tmp_ok) # [[0, 0, 0], [0, 5, 0], [0, 0, 0]]種明かし(?)
>>> tmp_ok[0] == tmp_ok[2] True >>> tmp_ng[0] == tmp_ng[2] True >>> tmp_ok[0] is tmp_ok[2] False >>> tmp_ng[0] is tmp_ng[2] Trueダメな例だと、(C#とかでいうところの) new して作られた[0] * 3 というオブジェクト(?)が3か所に設定される。
言い換えると、1回変数定義され、メモリ確保された場所を3回参照するという配列が作られる。
だから、1種類の値が3か所に現れる。
ただ、改善例だと、for _ in range(3) で3回回る都度、[0] * 3が(C#でいうところの) new される。3回メモリが確保されるのでそれぞれ異なる値が持てる。なるほど。。。
1文字1文字のリテラル、特に制御命令の意味を自然と認識しておけるようにならないと、Python書けますとは言えないなぁ・・・
- 投稿日:2020-08-01T17:59:57+09:00
zsh環境でpoetryのインストール(エラー対処)方法
前提
MacOSがCatalinaからターミナルのデフォルトがzshになり、poetryを追加するだけではエラーになってしまいます。
~/.zshrcにパス追記することで対応できましたので参考にしてください。poetryのインストール
curl -sSL https://raw.githubusercontent.com/sdispater/poetry/master/get-poetry.py | pythonzsh環境ではこの状態でpoetryコマンドを実行するとエラーになります
poetry --version > zsh: command not found: poetry.zshrcにパスを追記
vim ~/.zshrcexport PATH="$HOME/.poetry/bin:$PATH"ターミナルを再起動
poetry --version > Poetry version 1.0.10 poetry self update > You are using the latest versionお疲れさまでした。
- 投稿日:2020-08-01T17:45:10+09:00
Pythonでテキストをクラスタリング
from janome.tokenizer import Tokenizer from sklearn.feature_extraction.text import TfidfVectorizer from scipy.cluster.hierarchy import linkage, fclusterデータ読込み
input.txtには1行に1文書が記載されている前提。
with open('input.txt') as f: org_sentences = f.readlines()形態素解析
各文書を単語ごとに半角スペースで区切る。
t = Tokenizer() sentences = [] for s in org_sentences: tmp = ' '.join(t.tokenize(s, wakati=True)) sentences.append(tmp)ベクトル化
今回はTf-Idfで文書をベクトル化する。
他には、BoW/LSI/LDA/Word2Vecの平均/Doc2Vec/FastTextの平均/BERT等の手段がある。vectorizer = TfidfVectorizer(use_idf=True, token_pattern=u'(?u)\\b\\w+\\b') vecs = vectorizer.fit_transform(sentences) v = vecs.toarray()距離算出
自然言語処理タスクで一般的な、コサイン距離で各ベクトル間の距離を定義する。
その距離をもとに、階層的クラスタリング(単リンク法)で文書をクラスタに束ねていく。z = linkage(v, metric='cosine')クラスタリング
距離0.2を閾値として最終的なクラスタを決定した例。
文書数が膨大になると距離算出に相当時間がかかるため、この閾値を複数試したい場合は上記の距離算出結果を一旦pickleに保存するなどして検証すべき。なお、クラスタ数を閾値とすることも可能。
各文書のクラスタ番号がgroupに格納される。group = fcluster(z, 0.2, criterion='distance') print(group)
- 投稿日:2020-08-01T17:34:49+09:00
プログラミング上達講座4:ピクセルロジック
プログラミング上達講座の3回目です。
ピクセルロジックを題材にして
プログラムを考えてみましょう。解説動画はこちら
ピクセルロジックとは
ピクセルロジックご存知でしょうか?
結構昔からあるゲームで
やったことがある人も多いんじゃないかと。一応のルールは
縦横の数値の数だけマスを黒く塗るゲーム。数値の分だけ連続して塗られ
数値が分かれているところは
最低でも1マス以上白マスが有る。全てのマスを正しく塗ることができたら
絵が完成する。例えば 5 x 5マスの問題で1つの行の数値が
2 2であれば■■□■■という風になる。数値の通りにマスを塗っていけば
良いわけです。初級編:塗りつぶされたマスのチェック関数を作る
一行に塗りつぶされたマスが何マスあるか数えて
数値を出力する関数check_rowを作成してみましょう。イラストロジックのように白マスが間に来たら数値を分けること。
出力は数値のリスト型
check_row(行のデータ): return 数値のリスト例:
check_row('□■□■□■□')1 1 1
中級編:
画像からイラストロジックの問題を作成するプログラムを考えてみよう。
画像の入力データは白黒マスを文字列要素としたリスト型とする。
なお入力データは Nマス x Nマスの正方形とする。下記のような画像データの場合
data = [ '□□■■■■□□', '□■■□□■■□', '■■□□□□■■', '■■■■■■■■', '■■□□□□□□', '■■□□□□■■', '□■■□□■■□', '□□■■■■□□'] N = 8出力例は
解答編
初級編の解答
1個ずつ最初から黒マスの個数を数えていく。
黒マスが続く場合は+1
白マスが来た時に、前が黒マスなら数値を記録し
最後のマスが黒マスなら数値を記録。
□■■■■□□□ 4
□■■■■□□■ 4 1# 黒マスが何個あるかをチェックする def check_row(row): res,checked,count = [],0,0 while True: if row[checked]=='■': count+=1 elif count!=0: res.append(count) count=0 checked+=1 if checked==len(row): if count!=0: res.append(count) break return res check_row('□□□■□■■■□□■■■■■■■□□□')[1, 3, 7]
中級編の解答
行方向と列方向で分けて黒マスの数え上げの結果を出しておく。
出力するものを考える場合は
先に列方向の数値を書き出し、後で行方向の数値を書き出す。繋げたものを文字列として出力する(タブ区切り)
data = [ '□□■■■■□□', '□■■□□■■□', '■■□□□□■■', '■■■■■■■■', '■■□□□□□□', '■■□□□□■■', '□■■□□■■□', '□□■■■■□□'] N = len(data) # 黒マスが何個あるかをチェックする def check_row(row): res,checked,count = [],0,0 while True: if row[checked]=='■': count+=1 elif count!=0: res.append(count) count=0 checked+=1 if checked==len(row): if count!=0: res.append(count) break return res # 行列の結果を格納する result1,result2 = [],[] # row方向 for row in data: tmp = check_row(row) result1.append(tmp) # 列方向 for x in range(N): col = [] for y in range(N): col.append(data[y][x]) tmp = check_row(col) result2.append(tmp) # 出力用の関数を作る def make_num_data(res1,res2,num): row_len = max([len(r) for r in res1]) col_len = max([len(c) for c in res2]) row_num = row_len + num res_data = [] # 先に列方向の出力データを作る for c in range(col_len): tmp = [' '] * row_len for x in range(num): if len(res2[x])-1>=c: tmp+=[str(res2[x][c])] else: tmp+= [' '] res_data.append(tmp) # 行方向のデータをつなげる for n in range(num): tmp = [] for r in range(row_num): if len(res1[n])-1>=r: tmp+=[str(res1[n][r])] else: tmp+= [' '] res_data.append(tmp) return res_data # 出力用のデータを作成する d = make_num_data(result1,result2,N) # 出力 for y in d: print('\t'.join(y))
上級編
イラストロジックを解くプログラムを作ってください。
自分は時間がないので、お手上げでしたwww。
暇な方はぜひチャレンジしてみてください。
まとめ
イラストロジックは問題を作るところと
問題を解くところ、両方の醍醐味があります。問題を解くには効率の良い探索プログラムを書かないと
マス目が大きくなった時に解けなくなってきてしまうので
実装には時間がかかるんじゃないかなーと思いました。時間ができたらチャレンジしたいですね。
それでは。
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython

- 投稿日:2020-08-01T16:41:13+09:00
VS Code の Remote Container で複数のコンテナを起動して作業を切り替える
はじめに
VSCode の Remote Container って便利ですよね。
ローカルPCの環境を汚さずにいろいろな言語を試すことのできるのが最高。ただ、サクッと試したいだけなのに、いちいち言語別に設定するのが面倒だったりしますよね。
この投稿では、1回起動するだけで複数のコンテナに接続できる設定を紹介します。
公式ドキュメントにも書かれているので、詳しく知りたい方はこちらを。
https://code.visualstudio.com/docs/remote/containers-advanced#_connecting-to-multiple-containers-at-onceデモコードの概要
ここでは、golang と python のコンテナを扱うこととします。
.
├── golang
│ ├── .devcontainer.json
│ └── Dockerfile
├── python
│ ├── .devcontainer.json
│ └── Dockerfile
└── docker-compose.yml
設定ファイルの詳細
1. docker-compose.yml
remote-containerで管理するコードの親元を docker-compose.yml に記載します。
build.context でディレクトリを指定し、そこから Dockerfile までの相対パスを dockerfile に書いておけば大丈夫です。
ディレクトリ構成が気に入らなければ、自由に変えることもできます。
docker-compose.ymlversion: "3" services: golang-container: build: context: golang dockerfile: Dockerfile volumes: - .:/workspace:cached environment: TZ: "Asia/Tokyo" command: sleep infinity python-container: build: context: python dockerfile: Dockerfile volumes: - .:/workspace:cached environment: TZ: "Asia/Tokyo" command: sleep infinity2. .devcontainer.json
コンテナごとの設定を .devcontainer.json に記載します。
親子関係をつなぐために、 dockerComposeFile と service の名前は docker-compose.yml で定義したものと一致させています。
workspaceFolder で言語ごとに区分けたディレクトリを指定してやることにより、VS Code のウィンドウ上に他言語が表示されないようにできます。(表示していると警告が出てきたりしてうるさい)
extensions は調べたらいろいろあるので、好きにカスタマイズしたらいいです。
.devcontainer.json{ "name": "Dev Container Golang Env", "dockerComposeFile": "../docker-compose.yml", "service": "golang-container", "workspaceFolder": "/workspace/golang", "extensions": [ "golang.go", "donjayamanne.githistory", "eamodio.gitlens", "codezombiech.gitignore", "mhutchie.git-graph", "esbenp.prettier-vscode", "coenraads.bracket-pair-colorizer", "ionutvmi.path-autocomplete" ], "terminal.integrated.shellArgs.linux": [ "-l" ], "shutdownAction": "stopCompose" }3. Dockerfile
コンテナごとに使いたい設定を記載します。
普通のDockerfileと同じようにかけるので、ライブラリのインストールもしておくと便利です。
ここでは、みんな大好き git の補完ツールをインストールさせています。
DockerfileFROM golang:buster WORKDIR / RUN apt-get update \ && apt-get install -y --no-install-recommends \ git \ openssh-client \ procps \ ca-certificates \ curl \ unzip \ gnupg \ vim \ wget \ && rm -rf /var/lib/apt/lists/* # git RUN wget https://raw.githubusercontent.com/git/git/master/contrib/completion/git-completion.bash -O ~/.git-completion.bash RUN chmod a+x ~/.git-completion.bash RUN echo "source ~/.git-completion.bash" >> ~/.bashrc RUN wget https://raw.githubusercontent.com/git/git/master/contrib/completion/git-prompt.sh -O ~/.git-prompt.sh RUN chmod a+x ~/.git-prompt.sh RUN echo "source ~/.git-prompt.sh" >> ~/.bashrc複数コンテナの起動方法
- VS Code のコマンドパレットを開いて、
Remote-Containers: Open Folder in Container...を選択する- 開きたいディレクトリを選択する(今回は golang か python のディレクトリ)
上記のように普通にRemoteContainerを起動する要領で操作したら、選択したコンテナだけでなく、設定に記載されている他のコンテナも作成してくれます。
切り替えるには、1. 2. の手順と同様に、開きたいディレクトリを選択するだけです。
1回目の起動時にコンテナは立ち上がっているので、ウィンドウが切り替えられてすぐに操作できます。もし別ウィンドウにしたければ、VS Code で新規ウィンドウを作成して、そこから 1. 2. の手順を実行したらいいです。
まとめ
VS Code の Remote Container で複数のコンテナを起動する方法を紹介しました。
ここでは golang と python の2つのコンテナでしたが、自由に追加できます。複数言語を git のプライベートレポジトリで管理するときなんかに役立つのではないでしょうか。
言語のバージョン違いの動作検証なんかにも使えそうですね。ソースコードは github で公開しています。
https://github.com/fumiyakk/demo-multiple-remote-containerspython は poetry を使うために手のこんだ作りになってます。
そのうち poetry と black を組み合わせた python の開発環境について紹介します。
- 投稿日:2020-08-01T16:16:31+09:00
Python初心者によるPython3エンジニア認定基礎試験の勉強方法(2020年8月合格)
今回は「Python3エンジニア認定基礎試験」に合格したため、その学習方法を記載します。
■筆者情報(2020年7月時点)
・インフラエンジニア
・AWS資格はプロフェッショナルまで取得済み
・G検定には合格済み(2020年7月4日受験)
※詳細は「★G検定合格者による受験時の心構えについて(2020年7月合格)」参照。
・プログラミング経験は新人研修程度。
・もちろんPythonは触ったことが無い。■受験動機
私が受験を決めたのは2020年7月にG検定を合格した後の事です。元々G検定を受験した大きな理由は「AWS認定 機械学習-専門知識」を受験するためでした。AWSの専門試験は複数あり、どれを受けようかと思案していたのですが、G検定受験の機会があり、これが合格した暁には「AWS認定 機械学習-専門知識」試験を受験しようと思っていました。
しかし、G検定を合格したことでAI関連の知識領域を広げたいとの欲求が強くなり、上司と相談して「E資格」の受験をすることにしたのです。「E資格」は3つの事前講座を受講する必要があり、最初の講座を2020年9月から受講することになりました。「E資格」ではPythonが使えないと苦労するとのことで、まずは事前学習することにしました。
教材名 区分 勉強方法 ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 書籍 E資格取得の勉強方法を調べると、ほとんどと言ってよいほど登場するバイブル的な書籍。E資格を取得する為には、必須級のアイテム。
ゼロから作るDeep Learningで素人がつまずいたことメモ: まとめ WEB(無料) 上記の書籍を基に実際に勉強を実施され、つまずいた部分を画面ハードコピーまで添付して解説してくださっている@segavvyさんのサイトです。この書籍で学習するにあたっては非常に参考になります。
Anadonda アプリ(無料) 「データサイエンス」や「機械学習関連アプリケーション」のためのPythonおよびR言語用のディストリビューションとのことです。書籍の中でインストールするように記載があります。Numpiを含む機械学習必須のライブラリが一緒にダウンロードされる為、機械学習する人は、これをインストールした方がよいと思います。
spyder アプリ(無料) 「Anadonda」をインストールすると同時に勝手にインストールされる統合開発環境です。途中から使用するようになってから学習効率が飛躍的にアップました。早いうちから使い始めた方がよいと思います。詳細は「【Python機械学習】初心者向けSpyder活用のすすめ(2020年8月時点)」という記事に纏めました。
G検定の受験後にこの本を購入して学習を始めました。
正直、G検定を受験する前にこの本を実施しておきたかった!と思うくらい解りやすい内容で、あれだけ苦戦した関数系の考え方がとてもよく解りました。ただ、やはり実務でのプログラミング経験のない私は、Pythonのコマンドを調べることもしばしば。それが、だんだん効率が悪く感じてきました。いっそのこと、先にPythonの基礎的知識を習得した方が、効率的なんじゃないか?そう考えた結果「Python3エンジニア認定基礎試験」を受験することにしました。■試験内容
試験内容は以下の通りです。
受験費用:一般:10,000円(税抜)
教材名 区分 情報 Python3エンジニア認定基礎試験(公式) Web(無料) まずは公式サイトで試験内容を確認しました。この試験の特徴はテスト範囲が「Pythonチュートリアル」から出題されることが明確になっている点です。どの章から何問出題されるか、まで明確になっています。
■勉強方法と活用した教材
以下の教材を実施しました。
教材名 区分 勉強方法 【公式テキスト】
Python チュートリアル(公式)
(0.5日学習)Web(無料) すべての出題がここからされる前提となっているチュートリアルです。チュートリアルと記載されていますが、説明は全然易しくないので、ついて行くにはググりまくる必要があります。そして、英語の和訳がいまいちなので、とにかく日本語の意味が解りにくく、読んでいると睡魔に襲われることもしばしば。Pythonを理解していないのに、このチュートリアルから読みだしたのが失敗でした。
Python3エンジニア認定基礎試験の効率的な勉強方法! Web(無料) 勉強方法の失敗に気付いた私は、再度勉強方法について調べました。その際に行きついたのがこのサイトです。正直、勉強方法は、このサイトの方針に従って実施しました。非常に有益な情報でした。
プログラミング超初心者が初心者になるためのPython入門 (全3巻)
(1.5週間学習)kindle この3冊でPythonの基礎を勉強しました。Python2を前提に記載されているので、Python3では一部利用できないメソッドもありましたが、私がPythonの基礎を身に付けるのに非常に役に立ちました。3冊ですが1冊が短いので、1日2~3時間勉強していれば、1週間程度で読み終わります。
【模擬試験】Python チュートリアル(公式)
(0.5日学習)Web(無料) 再度、チュートリアル読破に挑戦しました。3冊読んだおかげで大分内容が理解できるようになり、相変わらず睡魔との戦いでしたが、休日1日(12時間くらい)で読み終わりました。正直、その後もチラチラは見ましたが、通して読んだのは1回だけです。
【模擬試験①】
DIVE INTO EXAM
(①②合わせて1週間学習)Web(無料) これまで受験した資格試験の中でも、最上級にイケている模擬問題。問題が毎回ランラムに変更される上、実施した履歴が残るという優れものでした。初回は525点という散々な結果でしたが、5回目で1,000点に到達しました。
とにかく、この模擬試験に出てきた問題で解らないものは徹底的に調べて理解しました。
【模擬試験②】
PRIME STUDY
(①②合わせて1週間学習)Web(無料) 次に実施したのはこちらの模擬試験です。第1回~3回まで無料で実施できます。正直、「DIVE INTO EXAM」より難易度が高く、第1回の初回は65/100点で不合格でした。複雑な問題が多く、時間的にも60分の時間枠ギリギリでの回答となりました。「結果の詳細」メールに関しては、全部の問題の自分の回答と正解が併記されており、何を間違えたかは確認できるようになっています。
こんなキーワードは「チュートリアルに記載がなかった!」と思って調べてみたら、ほとんど「チュートリアル」にしっかり記載されていました。正直「チュートリアル」を2周読むのは辛かったので、私はこの模擬問題集に出てきたキーワードを徹底的に調べて理解する方針としました。例えば、「この5つの文の中で正しい記載はどれか」と言う問題があれっば、間違いの4つの文のどこが間違っているかを徹底的に調べました。その結果、2周目はほとんどが90点以上を超える結果となりました。
■私の模擬問題集実施結果(参考)
これくらいの点数が取れていたら合格できる、という情報です。
DIVE INTO EXAM
以下のような結果となります。問題は40問以上あり毎回入れ替わるのですが、4回くらいやった段階で、さすがに答えが分かるようになってきます。
PRIME STUDY
「DIVE INTO EXAM」で900点以上取れているのに不合格になるレベルの問題です。ただし、しっかり内容を理解することで2回目は90点以上取れるようにはしています。
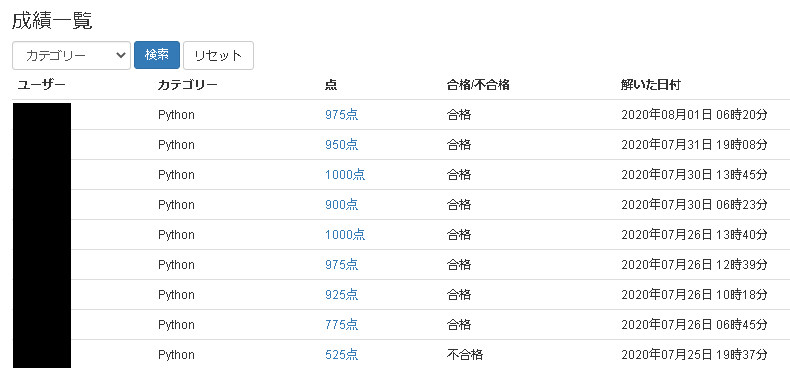
模擬試験名 点数 合否 実施日 第1回 Python 3 基礎 模擬試験 65点 不合格 2020年7月26日 第1回 Python 3 基礎 模擬試験 95点 合格 2020年7月26日 第2回 Python 3 基礎 模擬試験 67.5点 不合格 2020年7月27日 第3回 Python 3 基礎 模擬試験 70点 合格 2020年7月29日 第2回 Python 3 基礎 模擬試験 100点 合格 2020年7月31日 第3回 Python 3 基礎 模擬試験 95点 合格 2020年7月31日 ■試験(8月1日受験:合格)
ポイント 内容 試験会場 「OddesseyID&パスワード」と「指定の身分証明書」だけは忘れてはいけません。[OddesseyID&パスワード]を覚えれないなら、係員に言うと記載する付箋の持ち込みを許可してくれます。私以外の他の受験者も付箋を貰っていました。
他の試験の際には途中でトイレに行くことも許されたのですが、この試験は体調が悪かろうが外に出たら終了、の前提でした。テストが始まる前にも何度も事前にトイレに行くように促され、逆にそれがプレッシャーになりました。途中で腹が痛くなったら、と緊張しながら受験しました。
また、今回はPayPalで事前に受験料を支払いしたのですが、私の試験会場では当日に会社宛ての領収書を発行してもらえました。これがないと会社の事務処理が面倒くさいので助かりました。
所感 問題の内容は規約によって記載できません。ただし、40問の問題を解くのに30分くらいで終わりました。見直しをしても40分弱で終わった形です。40問中30問は自信満々で回答できました。10問くらいは曖昧な状態でしたが、合格ラインは700点であり、さすがに13問は間違っていないだろう、という感覚でした。
また、紙やペンの持ち込みができない為、計算式はすべて暗算する必要があるのですが、困ることはありませんでした。
結果 テストが終了した後はアンケート画面に遷移します。アンケートの回答が完了すると合否が表示されます。
帰りに「試験結果レポート」の印刷物を渡してくれます。他にレポートが発行される訳ではないので、失くしたら困るレポートです。後日に認定証が郵送されてくるので、一緒に保管しておく必要があります。
■合格のポイント
こちらに私が合格のポイントだったと思うことを記載します。
私と同じPython初心者を前提としたポイントになります。「Pythonチュートリアル 第3版」は買わなくてよい
オライリー・ジャパン「Pythonチュートリアル 第3版」という書籍が主教材となっていますが、同じ内容のWeb版があるため買う必要はありません。そのお金があるなら、他の教材に費やしましょう。
公式のチュートリアル(Web)を読むのは後回しにしよう
残念ながら、Python初心者に解るようには記載されていません。急がば回れで他の解りやすい書籍でPythonの基本を理解しましょう。プログラミング超初心者が初心者になるためのPython入門 (全3巻)はおススメです。
とにかくPython環境で実践しよう
とにかく色々な構文を実際に実行してみて、動きを見るのが一番理解が早いです。私は「Spyder」というツールを使って色々なパターンを試すことで構文に関しては相当理解が深まりました。Spyderの詳細は「【Python機械学習】初心者向けSpyder活用のすすめ(2020年8月時点)」に記載しています。学習環境としては最適だと思います。
模擬試験の問題の内容を完全に理解しよう
最後の1週間は模擬試験の問題内容を徹底的に調べることに費やしました。例えば、「この5つの文の中で正しい記載はどれか」と言う問題があれっば、間違いの4つの文のどこが間違っているかを徹底的に調べました。これにより2つの問題集で常に9割以上の正解率になる状態としました。
もし1000点満点を取りたいなら…
私の学習法だとプログラミング超初心者が初心者になるためのPython入門 (全3巻)でPythonプログラムの基礎を学び、模擬試験で試験問題の傾向を学ぶ、とのことで、全く「チュートリアル」を重視していません。1度は読む必要はありますが、2度は読まなくても合格できます。
ただし、1,000点は絶対に取れません。1,000点満点が取りたければチュートリアルを必死に読み込んでください。
■感想
機械学習の為にPythonの勉強を始めて、ある程度体系的に勉強できたことは非常に良かったと思います。自分の知識を資格の形で評価していくことは重要だと思っており、段階的にも必要なステップだったと思っています。
■次回に向けて
次回は「Pythonデータ分析試験]の合格を目指したいと思います。その先に「E資格」と「AWS認定 機械学習-専門知識」の資格取得を視野に入れ、今年度中にすべての資格を取得したいと思います。
この記事がこれから「Python3エンジニア認定基礎試験」を受験される方の参考に少しでもなれば嬉しいです。
以 上
- 投稿日:2020-08-01T16:16:31+09:00
Python初心者によるPython3エンジニア認定基礎試験の勉強方法(2020年8月合格)
今回は「Python3エンジニア認定基礎試験」に合格したため、その学習方法を記載します。
■筆者情報(2020年7月時点)
・インフラエンジニア
・AWS資格はプロフェッショナルまで取得済み
・G検定には合格済み(2020年7月4日受験)
※詳細は「★G検定合格者による受験時の心構えについて(2020年7月合格)」参照。
・プログラミング経験は新人研修程度。
・もちろんPythonは触ったことが無い。■受験動機
私が受験を決めたのは2020年7月にG検定を合格した後の事です。元々G検定を受験した大きな理由は「AWS認定 機械学習-専門知識」を受験するためでした。AWSの専門試験は複数あり、どれを受けようかと思案していたのですが、G検定受験の機会があり、これが合格した暁には「AWS認定 機械学習-専門知識」試験を受験しようと思っていました。
しかし、G検定を合格したことでAI関連の知識領域を広げたいとの欲求が強くなり、上司と相談して「E資格」の受験をすることにしたのです。「E資格」は3つの事前講座を受講する必要があり、最初の講座を2020年9月から受講することになりました。「E資格」ではPythonが使えないと苦労するとのことで、まずは事前学習することにしました。
教材名 区分 勉強方法 ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 書籍 E資格取得の勉強方法を調べると、ほとんどと言ってよいほど登場するバイブル的な書籍。E資格を取得する為には、必須級のアイテム。
ゼロから作るDeep Learningで素人がつまずいたことメモ: まとめ WEB(無料) 上記の書籍を基に実際に勉強を実施され、つまずいた部分を画面ハードコピーまで添付して解説してくださっている@segavvyさんのサイトです。この書籍で学習するにあたっては非常に参考になります。
Anadonda アプリ(無料) 「データサイエンス」や「機械学習関連アプリケーション」のためのPythonおよびR言語用のディストリビューションとのことです。書籍の中でインストールするように記載があります。Numpiを含む機械学習必須のライブラリが一緒にダウンロードされる為、機械学習する人は、これをインストールした方がよいと思います。
spyder アプリ(無料) 「Anadonda」をインストールすると同時に勝手にインストールされる統合開発環境です。途中から使用するようになってから学習効率が飛躍的にアップました。早いうちから使い始めた方がよいと思います。詳細は「【Python機械学習】初心者向けSpyder活用のすすめ(2020年8月時点)」という記事に纏めました。
G検定の受験後にこの本を購入して学習を始めました。
正直、G検定を受験する前にこの本を実施しておきたかった!と思うくらい解りやすい内容で、あれだけ苦戦した関数系の考え方がとてもよく解りました。ただ、やはり実務でのプログラミング経験のない私は、Pythonのコマンドを調べることもしばしば。それが、だんだん効率が悪く感じてきました。いっそのこと、先にPythonの基礎的知識を習得した方が、効率的なんじゃないか?そう考えた結果「Python3エンジニア認定基礎試験」を受験することにしました。■試験内容
試験内容は以下の通りです。
受験費用:一般:10,000円(税抜)
教材名 区分 情報 Python3エンジニア認定基礎試験(公式) Web(無料) まずは公式サイトで試験内容を確認しました。この試験の特徴はテスト範囲が「Pythonチュートリアル」から出題されることが明確になっている点です。どの章から何問出題されるか、まで明確になっています。
■勉強方法と活用した教材
以下の教材を実施しました。
教材名 区分 勉強方法 【公式テキスト】
Python チュートリアル(公式)
(0.5日学習)Web(無料) すべての出題がここからされる前提となっているチュートリアルです。チュートリアルと記載されていますが、説明は全然易しくないので、ついて行くにはググりまくる必要があります。そして、英語の和訳がいまいちなので、とにかく日本語の意味が解りにくく、読んでいると睡魔に襲われることもしばしば。Pythonを理解していないのに、このチュートリアルから読みだしたのが失敗でした。
Python3エンジニア認定基礎試験の効率的な勉強方法! Web(無料) 勉強方法の失敗に気付いた私は、再度勉強方法について調べました。その際に行きついたのがこのサイトです。正直、勉強方法は、このサイトの方針に従って実施しました。非常に有益な情報でした。
プログラミング超初心者が初心者になるためのPython入門 (全3巻)
(1.5週間学習)kindle この3冊でPythonの基礎を勉強しました。Python2を前提に記載されているので、Python3では一部利用できないメソッドもありましたが、私がPythonの基礎を身に付けるのに非常に役に立ちました。3冊ですが1冊が短いので、1日2~3時間勉強していれば、1週間程度で読み終わります。
【模擬試験】Python チュートリアル(公式)
(0.5日学習)Web(無料) 再度、チュートリアル読破に挑戦しました。3冊読んだおかげで大分内容が理解できるようになり、相変わらず睡魔との戦いでしたが、休日1日(12時間くらい)で読み終わりました。正直、その後もチラチラは見ましたが、通して読んだのは1回だけです。
【模擬試験①】
DIVE INTO EXAM
(①②合わせて1週間学習)Web(無料) これまで受験した資格試験の中でも、最上級にイケている模擬問題。問題が毎回ランラムに変更される上、実施した履歴が残るという優れものでした。初回は525点という散々な結果でしたが、5回目で1,000点に到達しました。
とにかく、この模擬試験に出てきた問題で解らないものは徹底的に調べて理解しました。
【模擬試験②】
PRIME STUDY
(①②合わせて1週間学習)Web(無料) 次に実施したのはこちらの模擬試験です。第1回~3回まで無料で実施できます。正直、「DIVE INTO EXAM」より難易度が高く、第1回の初回は65/100点で不合格でした。複雑な問題が多く、時間的にも60分の時間枠ギリギリでの回答となりました。「結果の詳細」メールに関しては、全部の問題の自分の回答と正解が併記されており、何を間違えたかは確認できるようになっています。
こんなキーワードは「チュートリアルに記載がなかった!」と思って調べてみたら、ほとんど「チュートリアル」にしっかり記載されていました。正直「チュートリアル」を2周読むのは辛かったので、私はこの模擬問題集に出てきたキーワードを徹底的に調べて理解する方針としました。例えば、「この5つの文の中で正しい記載はどれか」と言う問題があれっば、間違いの4つの文のどこが間違っているかを徹底的に調べました。その結果、2周目はほとんどが90点以上を超える結果となりました。
■私の模擬問題集実施結果(参考)
これくらいの点数が取れていたら合格できる、という情報です。
DIVE INTO EXAM
以下のような結果となります。問題は40問以上あり毎回入れ替わるのですが、4回くらいやった段階で、さすがに答えが分かるようになってきます。
PRIME STUDY
「DIVE INTO EXAM」で900点以上取れているのに不合格になるレベルの問題です。ただし、しっかり内容を理解することで2回目は90点以上取れるようにはしています。
模擬試験名 点数 合否 実施日 第1回 Python 3 基礎 模擬試験 65点 不合格 2020年7月26日 第1回 Python 3 基礎 模擬試験 95点 合格 2020年7月26日 第2回 Python 3 基礎 模擬試験 67.5点 不合格 2020年7月27日 第3回 Python 3 基礎 模擬試験 70点 合格 2020年7月29日 第2回 Python 3 基礎 模擬試験 100点 合格 2020年7月31日 第3回 Python 3 基礎 模擬試験 95点 合格 2020年7月31日 ■試験(8月1日受験:合格)
ポイント 内容 試験会場 「OddesseyID&パスワード」と「指定の身分証明書」だけは忘れてはいけません。[OddesseyID&パスワード]を覚えれないなら、係員に言うと記載する付箋の持ち込みを許可してくれます。私以外の他の受験者も付箋を貰っていました。
他の試験の際には途中でトイレに行くことも許されたのですが、この試験は体調が悪かろうが外に出たら終了、の前提でした。テストが始まる前にも何度も事前にトイレに行くように促され、逆にそれがプレッシャーになりました。途中で腹が痛くなったら、と緊張しながら受験しました。
また、今回はPayPalで事前に受験料を支払いしたのですが、私の試験会場では当日に会社宛ての領収書を発行してもらえました。これがないと会社の事務処理が面倒くさいので助かりました。
所感 問題の内容は規約によって記載できません。ただし、40問の問題を解くのに30分くらいで終わりました。見直しをしても40分弱で終わった形です。40問中30問は自信満々で回答できました。10問くらいは曖昧な状態でしたが、合格ラインは700点であり、さすがに13問は間違っていないだろう、という感覚でした。
また、紙やペンの持ち込みができない為、計算式はすべて暗算する必要があるのですが、困ることはありませんでした。
結果 テストが終了した後はアンケート画面に遷移します。アンケートの回答が完了すると合否が表示されます。私は「合格」で、正解率は8割以上でした。
帰りに「試験結果レポート」の印刷物を渡してくれます。他にレポートが発行される訳ではないので、失くしたら困るレポートです。後日に認定証が郵送されてくるので、一緒に保管しておく必要があります。
■合格のポイント
こちらに私が合格のポイントだったと思うことを記載します。
私と同じPython初心者を前提としたポイントになります。「Pythonチュートリアル 第3版」は買わなくてよい
オライリー・ジャパン「Pythonチュートリアル 第3版」という書籍が主教材となっていますが、同じ内容のWeb版があるため買う必要はありません。そのお金があるなら、他の教材に費やしましょう。
公式のチュートリアル(Web)を読むのは後回しにしよう
残念ながら、Python初心者に解るようには記載されていません。急がば回れで他の解りやすい書籍でPythonの基本を理解しましょう。プログラミング超初心者が初心者になるためのPython入門 (全3巻)はおススメです。
とにかくPython環境で実践しよう
とにかく色々な構文を実際に実行してみて、動きを見るのが一番理解が早いです。私は「Spyder」というツールを使って色々なパターンを試すことで構文に関しては相当理解が深まりました。Spyderの詳細は「【Python機械学習】初心者向けSpyder活用のすすめ(2020年8月時点)」に記載しています。学習環境としては最適だと思います。
模擬試験の問題の内容を完全に理解しよう
最後の1週間は模擬試験の問題内容を徹底的に調べることに費やしました。例えば、「この5つの文の中で正しい記載はどれか」と言う問題があれっば、間違いの4つの文のどこが間違っているかを徹底的に調べました。これにより2つの問題集で常に9割以上の正解率になる状態としました。
もし1000点満点を取りたいなら…
私の学習法だとプログラミング超初心者が初心者になるためのPython入門 (全3巻)でPythonプログラムの基礎を学び、模擬試験で試験問題の傾向を学ぶ、とのことで、全く「チュートリアル」を重視していません。1度は読む必要はありますが、2度は読まなくても合格できます。
ただし、1,000点は絶対に取れません。1,000点満点が取りたければチュートリアルを必死に読み込んでください。
■感想
機械学習の為にPythonの勉強を始めて、ある程度体系的に勉強できたことは非常に良かったと思います。自分の知識を資格の形で評価していくことは重要だと思っており、段階的にも必要なステップだったと思っています。
■次回に向けて
次回は「Pythonデータ分析試験]の合格を目指したいと思います。その先に「E資格」と「AWS認定 機械学習-専門知識」の資格取得を視野に入れ、今年度中にすべての資格を取得したいと思います。
この記事がこれから「Python3エンジニア認定基礎試験」を受験される方の参考に少しでもなれば嬉しいです。
以 上
- 投稿日:2020-08-01T15:59:40+09:00
Python, pandasによるデータ分析の実践 (東京都COVID-19データ編)
はじめに
新型コロナウイルス新規感染者数の報道を見るたびに「年齢層の内訳をもっと詳しく教えてほしいなあ」と思っていたら、東京都が陽性患者のデータを公開していることを今更ながら知りました。
ここでは、Pythonおよびpandas, seaborn, Matplotlibを使って東京都が公開しているデータを分析・可視化する方法を紹介します。
本記事の主旨は「今後はこうなる」「こういう対策をすべし」という予測や提言ではなく、「こうすると簡単にデータを可視化できるからみんなもやってみてね」ということです。自分で試してみると理解が深まるので、みなさんも是非やってみてください。
なお、グラフのレイアウトや軸の書式などの細部にこだわるとMatplotlibの面倒な処理が必要なので、ここでは深追いしません(最後に少し触れる程度)。広く公開するための見栄えの良いグラフを作るというよりも、自分自身でデータを確認して傾向をつかむための可視化をゴールとします。
サンプルコードはGitHubにもおいてあります。Jupyter Notebook(
.ipynb)のほうが見やすい部分もあるので、あわせてご参照ください。データの概要
東京都
東京都の陽性患者データは以下で公開されている。
東京都の新型コロナウイルス感染症対策サイトの
オープンデータを入手のリンクから辿り着ける。履歴を見ると、平日の10〜15時くらいに更新されている模様。
その他の都道府県
東京都の対策サイトをフォークしたサイトの一覧が以下にまとめられている。
東京都のようにオープンデータへのリンクがあるサイトもある。以下は北海道と神奈川県の例。
サイト上にリンクがない場合も、データ自体はどこかで公開されているはずなので探せば見つかるかもしれない。
以降のサンプルコードでは東京都のデータを使う。他の都道府県のデータは項目などが異なる場合があるが、基本的な扱いは同じ。
その他のデータ
そのほか、新型コロナウイルス関連のデータとしては厚生労働省が発表している国内のPCR検査実施人数や陽性者数、入院者数、死者数などの集計データがある。
ライブラリのバージョン
以降のサンプルコードでの各ライブラリおよびPython本体のバージョンは以下の通り。バージョンが異なると挙動が異なる可能性があるので注意。
import math import sys import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns print(pd.__version__) # 1.0.5 print(mpl.__version__) # 3.3.0 print(sns.__version__) # 0.10.1 print(sys.version) # 3.8.5 (default, Jul 21 2020, 10:48:26) # [Clang 11.0.3 (clang-1103.0.32.62)]データの確認と前処理
pd.read_csv()にダウンロードしたCSVファイルへのパスを指定してDataFrameとして読み込む。2020年7月31日までのデータを例として使う。df = pd.read_csv('data/130001_tokyo_covid19_patients_20200731.csv')
pd.read_csv()の引数にはURLを直接指定することもできるが、試行錯誤する段階では何度も無駄にアクセスすることになってしまうのでローカルにダウンロードするほうが無難。# df = pd.read_csv('https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv')行数・列数および先頭・末尾のデータは以下の通り。
print(df.shape) # (12691, 16) print(df.head()) # No 全国地方公共団体コード 都道府県名 市区町村名 公表_年月日 曜日 発症_年月日 患者_居住地 患者_年代 患者_性別 \ # 0 1 130001 東京都 NaN 2020-01-24 金 NaN 湖北省武漢市 40代 男性 # 1 2 130001 東京都 NaN 2020-01-25 土 NaN 湖北省武漢市 30代 女性 # 2 3 130001 東京都 NaN 2020-01-30 木 NaN 湖南省長沙市 30代 女性 # 3 4 130001 東京都 NaN 2020-02-13 木 NaN 都内 70代 男性 # 4 5 130001 東京都 NaN 2020-02-14 金 NaN 都内 50代 女性 # # 患者_属性 患者_状態 患者_症状 患者_渡航歴の有無フラグ 備考 退院済フラグ # 0 NaN NaN NaN NaN NaN 1.0 # 1 NaN NaN NaN NaN NaN 1.0 # 2 NaN NaN NaN NaN NaN 1.0 # 3 NaN NaN NaN NaN NaN 1.0 # 4 NaN NaN NaN NaN NaN 1.0 print(df.tail()) # No 全国地方公共団体コード 都道府県名 市区町村名 公表_年月日 曜日 発症_年月日 患者_居住地 患者_年代 \ # 12686 12532 130001 東京都 NaN 2020-07-31 金 NaN NaN 70代 # 12687 12558 130001 東京都 NaN 2020-07-31 金 NaN NaN 70代 # 12688 12563 130001 東京都 NaN 2020-07-31 金 NaN NaN 70代 # 12689 12144 130001 東京都 NaN 2020-07-31 金 NaN NaN 80代 # 12690 12517 130001 東京都 NaN 2020-07-31 金 NaN NaN 80代 # # 患者_性別 患者_属性 患者_状態 患者_症状 患者_渡航歴の有無フラグ 備考 退院済フラグ # 12686 男性 NaN NaN NaN NaN NaN NaN # 12687 男性 NaN NaN NaN NaN NaN NaN # 12688 男性 NaN NaN NaN NaN NaN NaN # 12689 女性 NaN NaN NaN NaN NaN NaN # 12690 男性 NaN NaN NaN NaN NaN NaN本データのようなカテゴリカル・データが主である場合、
count()やnunique(),unique(),value_counts()などのメソッドを使うと概要がつかみやすい。
- pandas.DataFrame.count — pandas 1.1.0 documentation
- pandas.DataFrame.nunique — pandas 1.1.0 documentation
- pandas.Series.unique — pandas 1.1.0 documentation
- pandas.Series.value_counts — pandas 1.1.0 documentation
- pandasでユニークな要素の個数、頻度(出現回数)をカウント
count()は欠損値NaNではない要素の数を返す。プライバシー保護のためか、市区町村名や症状、属性などの細かい情報は公開されていない(データがない)ことが分かる。print(df.count()) # No 12691 # 全国地方公共団体コード 12691 # 都道府県名 12691 # 市区町村名 0 # 公表_年月日 12691 # 曜日 12691 # 発症_年月日 0 # 患者_居住地 12228 # 患者_年代 12691 # 患者_性別 12691 # 患者_属性 0 # 患者_状態 0 # 患者_症状 0 # 患者_渡航歴の有無フラグ 0 # 備考 0 # 退院済フラグ 7186 # dtype: int64
nunique()はデータの種類の数を返す。東京都のデータなので全国地方公共団体コードや都道府県名はすべて同じ。print(df.nunique()) # No 12691 # 全国地方公共団体コード 1 # 都道府県名 1 # 市区町村名 0 # 公表_年月日 164 # 曜日 7 # 発症_年月日 0 # 患者_居住地 8 # 患者_年代 13 # 患者_性別 5 # 患者_属性 0 # 患者_状態 0 # 患者_症状 0 # 患者_渡航歴の有無フラグ 0 # 備考 0 # 退院済フラグ 1 # dtype: int64それぞれの列(=
Series)に対してはunique(),value_counts()でユニークな要素およびその個数(出現頻度)が確認できる。print(df['患者_居住地'].unique()) # ['湖北省武漢市' '湖南省長沙市' '都内' '都外' '―' '調査中' '-' "'-" nan] print(df['患者_居住地'].value_counts(dropna=False)) # 都内 11271 # 都外 531 # NaN 463 # ― 336 # 調査中 85 # 湖北省武漢市 2 # 湖南省長沙市 1 # '- 1 # - 1 # Name: 患者_居住地, dtype: int64 print(df['患者_性別'].unique()) # ['男性' '女性' "'-" '―' '不明'] print(df['患者_性別'].value_counts()) # 男性 7550 # 女性 5132 # '- 7 # 不明 1 # ― 1 # Name: 患者_性別, dtype: int64今回は分析対象を公表年月日、患者の年代、退院済フラグに絞る。便宜上、
rename()で列名を変更しておく。df = df[['公表_年月日', '患者_年代', '退院済フラグ']].copy() df.rename(columns={'公表_年月日': 'date_str', '患者_年代': 'age_org', '退院済フラグ': 'discharged'}, inplace=True) print(df) # date_str age_org discharged # 0 2020-01-24 40代 1.0 # 1 2020-01-25 30代 1.0 # 2 2020-01-30 30代 1.0 # 3 2020-02-13 70代 1.0 # 4 2020-02-14 50代 1.0 # ... ... ... ... # 12686 2020-07-31 70代 NaN # 12687 2020-07-31 70代 NaN # 12688 2020-07-31 70代 NaN # 12689 2020-07-31 80代 NaN # 12690 2020-07-31 80代 NaN # # [12691 rows x 3 columns]ここで
copy()を使っているのはSettingWithCopyWarningを防ぐため。今回の場合、データを更新するわけではないので放っておいても問題はない。年代の列を見てみると、
不明や'-といったデータが含まれている。print(df['age_org'].unique()) # ['40代' '30代' '70代' '50代' '60代' '80代' '20代' '10歳未満' '90代' '10代' '100歳以上' # '不明' "'-"] print(df['age_org'].value_counts()) # 20代 4166 # 30代 2714 # 40代 1741 # 50代 1362 # 60代 832 # 70代 713 # 80代 455 # 10代 281 # 90代 214 # 10歳未満 200 # 不明 6 # 100歳以上 5 # '- 2 # Name: age_org, dtype: int64数が少ないので、ここでは除外してしまうことにする。
df = df[~df['age_org'].isin(['不明', "'-"])] print(df) # date_str age_org discharged # 0 2020-01-24 40代 1.0 # 1 2020-01-25 30代 1.0 # 2 2020-01-30 30代 1.0 # 3 2020-02-13 70代 1.0 # 4 2020-02-14 50代 1.0 # ... ... ... ... # 12686 2020-07-31 70代 NaN # 12687 2020-07-31 70代 NaN # 12688 2020-07-31 70代 NaN # 12689 2020-07-31 80代 NaN # 12690 2020-07-31 80代 NaN # # [12683 rows x 3 columns] print(df['age_org'].unique()) # ['40代' '30代' '70代' '50代' '60代' '80代' '20代' '10歳未満' '90代' '10代' '100歳以上']年代の区分が細かいので、もう少し粗くする。右辺全体を括弧
()で囲んでいるのは途中で改行するため。df['age'] = ( df['age_org'].replace(['10歳未満', '10代'], '0-19') .replace(['20代', '30代'], '20-39') .replace(['40代', '50代'], '40-59') .replace(['60代', '70代', '80代', '90代', '100歳以上'], '60-') ) print(df['age'].unique()) # ['40-59' '20-39' '60-' '0-19'] print(df['age'].value_counts()) # 20-39 6880 # 40-59 3103 # 60- 2219 # 0-19 481 # Name: age, dtype: int64日時(公表年月日)の列
date_strは文字列。今後の処理のため、datetime64[ns]型に変換した列dateを追加しておく。df['date'] = pd.to_datetime(df['date_str']) print(df.dtypes) # date_str object # age_org object # discharged float64 # age object # date datetime64[ns] # dtype: object前処理はここまで。ここからは実際にデータを分析・可視化する例を示す。
年代別の新規陽性患者数の推移
ここでは年代別の新規陽性患者数の推移を見る。新規陽性患者数の総数についてはMatplotlibで処理する例として最後に述べる。
積み上げ棒グラフ
pd.crosstab()で日時(公表年月日)と年代のクロス集計を行う。df_ct = pd.crosstab(df['date'], df['age']) print(df_ct) # age 0-19 20-39 40-59 60- # date # 2020-01-24 0 0 1 0 # 2020-01-25 0 1 0 0 # 2020-01-30 0 1 0 0 # 2020-02-13 0 0 0 1 # 2020-02-14 0 0 1 1 # ... ... ... ... ... # 2020-07-27 5 79 34 13 # 2020-07-28 13 168 65 20 # 2020-07-29 9 160 56 25 # 2020-07-30 11 236 83 37 # 2020-07-31 10 332 82 39 # # [164 rows x 4 columns] print(type(df_ct.index)) # <class 'pandas.core.indexes.datetimes.DatetimeIndex'>
datetime64[ns]型に変換した列が新たにインデックスとなり、DatetimeIndexとして扱われる。出力が同じでも文字列型の日時を指定した場合はDatetimeIndexにならないので注意。
resample()で週ごとに集計する。resample()はDatetimeIndexでないと実行できない。df_ct_week = df_ct.resample('W', label='left').sum() print(df_ct_week) # age 0-19 20-39 40-59 60- # date # 2020-01-19 0 1 1 0 # 2020-01-26 0 1 0 0 # 2020-02-02 0 0 0 0 # 2020-02-09 0 2 5 9 # 2020-02-16 0 1 3 6 # 2020-02-23 0 2 3 5 # 2020-03-01 2 5 9 9 # 2020-03-08 0 5 10 11 # 2020-03-15 0 10 27 12 # 2020-03-22 7 100 88 102 # 2020-03-29 16 244 198 148 # 2020-04-05 21 421 369 271 # 2020-04-12 30 350 375 280 # 2020-04-19 32 286 267 264 # 2020-04-26 29 216 165 260 # 2020-05-03 7 105 69 120 # 2020-05-10 2 46 16 46 # 2020-05-17 3 22 10 15 # 2020-05-24 4 43 16 21 # 2020-05-31 2 89 34 22 # 2020-06-07 5 113 17 26 # 2020-06-14 6 177 29 28 # 2020-06-21 10 236 65 23 # 2020-06-28 34 460 107 51 # 2020-07-05 79 824 191 68 # 2020-07-12 66 1006 295 117 # 2020-07-19 78 1140 414 171 # 2020-07-26 48 975 320 134
plot()で可視化。簡単に積み上げ棒グラフが作成できる。df_ct_week[:-1].plot.bar(stacked=True)
[:-1]で最終行(最終週)のデータを除外している。今回のデータでは最終週は土曜日(2020年8月1日)の分が含まれておらず他の週と比較するのは適切でないため除外した。Jupyter Notebookではグラフが出力セルに表示される。画像ファイルとして保存したい場合は
plt.savefig()を使う。Jupyter Notebookの出力を右クリックで保存することもできる。plt.figure() df_ct_week[:-1].plot.bar(stacked=True) plt.savefig('image/bar_chart.png', bbox_inches='tight') plt.close('all')発生条件が不明だが、保存時にX軸ラベルが切れてしまうという不具合があった。以下を参考に
bbox_inches='tight'としたら解消した。上の例のように、そのまま棒グラフを作成すると、X軸ラベルに時刻が表示されてしまう。最も簡単な解決策はインデックスを任意のフォーマットの文字列に変換してしまうこと。
df_ct_week_str = df_ct_week.copy() df_ct_week_str.index = df_ct_week_str.index.strftime('%Y-%m-%d') df_ct_week_str[:-1].plot.bar(stacked=True, figsize=(8, 4))
全体を規格化して年代の比率の推移を見る。
Tは転置(行と列の入れ替え)。転置して合計値で割り算、再度転置してもとに戻すことで規格化できる。6月以降は若年者(20〜30代)が大部分を締めているが、直近は中高齢者(40代以降)の割合も増えつつある。
df_ct_week_str_norm = (df_ct_week_str.T / df_ct_week_str.sum(axis=1)).T
若年者(20〜30代)と高齢者(60代以降)の推移は以下の通り。高齢者の絶対数も3月末のレベル程度まで増えている。
df_ct_week_str[:-1][['20-39', '60-']].plot.bar(figsize=(8, 4))
折れ線グラフ(前週比)
感染拡大の勢いを見るため、前週比を算出する。
shift()でデータをずらして割ればよい。df_week_ratio = df_ct_week / df_ct_week.shift() print(df_week_ratio) # age 0-19 20-39 40-59 60- # date # 2020-01-19 NaN NaN NaN NaN # 2020-01-26 NaN 1.000000 0.000000 NaN # 2020-02-02 NaN 0.000000 NaN NaN # 2020-02-09 NaN inf inf inf # 2020-02-16 NaN 0.500000 0.600000 0.666667 # 2020-02-23 NaN 2.000000 1.000000 0.833333 # 2020-03-01 inf 2.500000 3.000000 1.800000 # 2020-03-08 0.000000 1.000000 1.111111 1.222222 # 2020-03-15 NaN 2.000000 2.700000 1.090909 # 2020-03-22 inf 10.000000 3.259259 8.500000 # 2020-03-29 2.285714 2.440000 2.250000 1.450980 # 2020-04-05 1.312500 1.725410 1.863636 1.831081 # 2020-04-12 1.428571 0.831354 1.016260 1.033210 # 2020-04-19 1.066667 0.817143 0.712000 0.942857 # 2020-04-26 0.906250 0.755245 0.617978 0.984848 # 2020-05-03 0.241379 0.486111 0.418182 0.461538 # 2020-05-10 0.285714 0.438095 0.231884 0.383333 # 2020-05-17 1.500000 0.478261 0.625000 0.326087 # 2020-05-24 1.333333 1.954545 1.600000 1.400000 # 2020-05-31 0.500000 2.069767 2.125000 1.047619 # 2020-06-07 2.500000 1.269663 0.500000 1.181818 # 2020-06-14 1.200000 1.566372 1.705882 1.076923 # 2020-06-21 1.666667 1.333333 2.241379 0.821429 # 2020-06-28 3.400000 1.949153 1.646154 2.217391 # 2020-07-05 2.323529 1.791304 1.785047 1.333333 # 2020-07-12 0.835443 1.220874 1.544503 1.720588 # 2020-07-19 1.181818 1.133201 1.403390 1.461538 # 2020-07-26 0.615385 0.855263 0.772947 0.783626 df_week_ratio['2020-05-03':'2020-07-25'].plot(grid=True)
7月に入って前週比は各年代とも減少傾向にある。
なお、棒グラフとは異なり、
plot()(またはplot.line())で折れ線グラフを作成する場合は上の例のようにX軸の日時データが適当にフォーマットされる。後述のように日時データの内容によってはフォーマットされない場合もあるので注意。ヒートマップ
年代別の新規陽性患者数の推移を把握するための別のアプローチとして、ヒートマップを作成する。
ここでは細かい年代区分をそのまま使う。積み上げ棒グラフの例と同じく
pd.crosstab()でクロス集計。resample()を使わないので文字列型の日時date_strを指定している。横軸を日時にするためTで転置し、縦軸の下側を若くするため[::-1]で転置後の行の並びを反転している。df['age_detail'] = df['age_org'].replace( {'10歳未満': '0-9', '10代': '10-19', '20代': '20-29', '30代': '30-39', '40代': '40-49', '50代': '50-59', '60代': '60-69', '70代': '70-79', '80代': '80-89', '90代': '90-', '100歳以上': '90-'} ) df_ct_hm = pd.crosstab(df['date_str'], df['age_detail']).T[::-1]ヒートマップを作成するにはseabornの関数
heatmap()が便利。plt.figure(figsize=(15, 5)) sns.heatmap(df_ct_hm, cmap='hot')
6月以降、徐々に高齢者に感染が広がっているのが確認できる。
ログスケールのヒートマップは以下を参照。Warningが出たがとりあえず動いた。
データに
0があるとエラーになるため0を0.1に置き換えるという大雑把な処理をしているので要注意。df_ct_hm_re = df_ct_hm.replace({0: 0.1}) min_value = df_ct_hm_re.values.min() max_value = df_ct_hm_re.values.max() log_norm = mpl.colors.LogNorm(vmin=min_value, vmax=max_value) cbar_ticks = [math.pow(10, i) for i in range(math.floor(math.log10(min_value)), 1 + math.ceil(math.log10(max_value)))] plt.figure(figsize=(15, 5)) sns.heatmap(df_ct_hm_re, norm=log_norm, cbar_kws={"ticks": cbar_ticks})
ちなみに、ヒートマップで可視化するというアイデアは以下の記事のフロリダの例を見て知った。
フロリダのグラフを作成した@zorinaqさんが、ヒートマップ以外にも今後の予測など様々なグラフを作成するコードを公開されている。ある程度Pythonの知識がないと難しそうだが、興味があれば見てみるといいかもしれない。
退院済フラグ
注意点
上で示した
count()の結果の通り、公開データで退院済フラグが1になっているのは7186件だが、東京都の新型コロナウイルス感染症対策サイトの「退院等(療養期間経過を含む)」は9615人となっている(2020年7月31日 20:30 更新時点)。
データの反映が遅れているだけなのか、なにか理由があるのかわからないが、公開データの退院済フラグは現状とズレがある可能性があることは留意されたい。
積み上げ棒グラフ
年代別陽性者数の推移の例と同様に、退院済フラグの推移を積み上げ棒グラフで見る。前処理として欠損値
NaNを0に置き換えている。print(df['discharged'].unique()) # [ 1. nan] df['discharged'] = df['discharged'].fillna(0).astype('int') print(df['discharged'].unique()) # [1 0] print(pd.crosstab(df['date'], df['discharged']).resample('W', label='left').sum()[:-1].plot.bar(stacked=True))
X軸に時刻が表示されるのが気になる場合は、年代別陽性者数の推移の例のように、インデックスの日時を文字列に変換すればよい。ここではそのままにしている。以降の例も同じ。
このグラフは公表年月日別の退院済フラグの割合を表している。当然ながら、陽性と確認されてから時間が経っている(= 公表年月日が古い)人の多くは退院している(= 退院済フラグが
1になっている)。年代別で確認する。
pd.crosstab()ではリストで複数の列を指定するとマルチインデックスとして結果が得られる。df_dc = pd.crosstab(df['date'], [df['age'], df['discharged']]).resample('W', label='left').sum() print(df_dc) # age 0-19 20-39 40-59 60- # discharged 0 1 0 1 0 1 0 1 # date # 2020-01-19 0 0 0 1 0 1 0 0 # 2020-01-26 0 0 0 1 0 0 0 0 # 2020-02-02 0 0 0 0 0 0 0 0 # 2020-02-09 0 0 0 2 0 5 0 9 # 2020-02-16 0 0 0 1 0 3 0 6 # 2020-02-23 0 0 0 2 0 3 0 5 # 2020-03-01 0 2 0 5 0 9 0 9 # 2020-03-08 0 0 0 5 0 10 1 10 # 2020-03-15 0 0 0 10 0 27 0 12 # 2020-03-22 0 7 0 100 0 88 2 100 # 2020-03-29 0 16 1 243 4 194 9 139 # 2020-04-05 0 21 5 416 1 368 11 260 # 2020-04-12 1 29 0 350 6 369 10 270 # 2020-04-19 2 30 3 283 6 261 17 247 # 2020-04-26 1 28 8 208 4 161 33 227 # 2020-05-03 1 6 6 99 5 64 23 97 # 2020-05-10 0 2 7 39 3 13 8 38 # 2020-05-17 2 1 10 12 2 8 9 6 # 2020-05-24 3 1 18 25 8 8 5 16 # 2020-05-31 0 2 13 76 8 26 9 13 # 2020-06-07 1 4 17 96 7 10 12 14 # 2020-06-14 3 3 84 93 13 16 17 11 # 2020-06-21 4 6 75 161 18 47 8 15 # 2020-06-28 4 30 37 423 19 88 20 31 # 2020-07-05 44 35 211 613 92 99 46 22 # 2020-07-12 62 4 803 203 250 45 113 4 # 2020-07-19 78 0 1140 0 414 0 171 0 # 2020-07-26 48 0 975 0 320 0 134 0若年者と高齢者をそれぞれグラフにすると以下の通り。
df_dc[:-1]['20-39'].plot.bar(stacked=True)
df_dc[:-1]['60-'].plot.bar(stacked=True)
これも想像通りだが、高齢者のほうが公表年月日が古い人でも退院済フラグが
1になっていない割合が大きく、入院が長引きやすいようである。割合を見やすくするために規格化する。
x_young = df_dc[9:-1]['20-39'] x_young_norm = (x_young.T / x_young.sum(axis=1)).T print(x_young_norm) # discharged 0 1 # date # 2020-03-22 0.000000 1.000000 # 2020-03-29 0.004098 0.995902 # 2020-04-05 0.011876 0.988124 # 2020-04-12 0.000000 1.000000 # 2020-04-19 0.010490 0.989510 # 2020-04-26 0.037037 0.962963 # 2020-05-03 0.057143 0.942857 # 2020-05-10 0.152174 0.847826 # 2020-05-17 0.454545 0.545455 # 2020-05-24 0.418605 0.581395 # 2020-05-31 0.146067 0.853933 # 2020-06-07 0.150442 0.849558 # 2020-06-14 0.474576 0.525424 # 2020-06-21 0.317797 0.682203 # 2020-06-28 0.080435 0.919565 # 2020-07-05 0.256068 0.743932 # 2020-07-12 0.798211 0.201789 # 2020-07-19 1.000000 0.000000 x_young_norm.plot.bar(stacked=True)
x_old = df_dc[9:-1]['60-'] x_old_norm = (x_old.T / x_old.sum(axis=1)).T print(x_old_norm) # discharged 0 1 # date # 2020-03-22 0.019608 0.980392 # 2020-03-29 0.060811 0.939189 # 2020-04-05 0.040590 0.959410 # 2020-04-12 0.035714 0.964286 # 2020-04-19 0.064394 0.935606 # 2020-04-26 0.126923 0.873077 # 2020-05-03 0.191667 0.808333 # 2020-05-10 0.173913 0.826087 # 2020-05-17 0.600000 0.400000 # 2020-05-24 0.238095 0.761905 # 2020-05-31 0.409091 0.590909 # 2020-06-07 0.461538 0.538462 # 2020-06-14 0.607143 0.392857 # 2020-06-21 0.347826 0.652174 # 2020-06-28 0.392157 0.607843 # 2020-07-05 0.676471 0.323529 # 2020-07-12 0.965812 0.034188 # 2020-07-19 1.000000 0.000000 x_old_norm.plot.bar(stacked=True)
若年者と高齢者の退院済フラグが
1になっていない割合を並べて示すと以下の通り。やはり高齢者のほうが入院が長引いている傾向を示している。pd.DataFrame({'20-39': x_young_norm[0], '60-': x_old_norm[0]}).plot.bar()
Matplotlibで処理
これまでの例は
DataFrameのplot()やseabornの関数を使って比較的簡単に処理できたが、場合によってはMatplotlibで処理する必要がある。新規陽性者の総数の推移を例とする。
ここでは
value_counts()で日時の列をカウントして公表年月日ごとの新規陽性者の総数を算出する。sort_index()でソートしないと多い順に並ぶので注意。
- pandas.DataFrame.sort_index — pandas 1.1.0 documentation
- pandas.DataFrame, Seriesをソートするsort_values, sort_index
s_total = df['date'].value_counts().sort_index() print(s_total) # 2020-01-24 1 # 2020-01-25 1 # 2020-01-30 1 # 2020-02-13 1 # 2020-02-14 2 # ... # 2020-07-27 131 # 2020-07-28 266 # 2020-07-29 250 # 2020-07-30 367 # 2020-07-31 463 # Name: date, Length: 164, dtype: int64 print(type(s_total)) # <class 'pandas.core.series.Series'> print(type(s_total.index)) # <class 'pandas.core.indexes.datetimes.DatetimeIndex'>これまでの例とは異なり、
DataFrameではなくSeriesだが考え方はどちらでも同じ。
plot.bar()で棒グラフを生成すると、以下のようにX軸が重なってしまう。s_total.plot.bar()
前週比の例で
plot()で折れ線グラフを生成する場合は日時を適当にフォーマットしてくれると書いたが、この場合はうまくいかない。s_total.plot()
plot()でもうまくいかないのは、インデックスに設定された日時データが周期的ではないからだと思われる(詳しく調べていないので違ってたらすみません)。前週比の例では週ごとのデータが抜けなく存在していたが、この例では
2020-01-26や2020-01-27などの陽性者数が0の日時はデータが存在していない。
reindex()とpd.date_range()を利用して、陽性者数が0の日時にも値を0としてデータを追加する。
- pandas.DataFrame.reindex — pandas 1.1.0 documentation
- pandas.date_range — pandas 1.1.0 documentation
- pandas.DataFrameの行・列を任意の順に並べ替えるreindex
s_total_re = s_total.reindex( index=pd.date_range(s_total.index[0], s_total.index[-1]), fill_value=0 ) print(s_total_re) # 2020-01-24 1 # 2020-01-25 1 # 2020-01-26 0 # 2020-01-27 0 # 2020-01-28 0 # ... # 2020-07-27 131 # 2020-07-28 266 # 2020-07-29 250 # 2020-07-30 367 # 2020-07-31 463 # Freq: D, Name: date, Length: 190, dtype: int64こうすると、
plot()で日時が適当にフォーマットされる。ついでに書いておくとログスケールにしたい場合はlogy=True。s_total_re.plot()
s_total_re.plot(logy=True)
この場合でも
plot.bar()はダメ。s_total_re.plot.bar()
折れ線グラフ以外の種類の場合は、Matplotlibで処理する必要がある。
Formatter, Locatorを設定し、Matplotlibの
bar()でグラフを生成する。
- matplotlib.axis - Formatters and Locators — Matplotlib 3.3.0 documentation
- matplotlib.dates — Matplotlib 3.3.0 documentation
- matplotlib.axes.Axes.bar — Matplotlib 3.3.0 documentation
fig, ax = plt.subplots(figsize=(12, 4)) ax.xaxis.set_major_locator(mpl.dates.AutoDateLocator()) ax.xaxis.set_major_formatter(mpl.dates.DateFormatter('%Y-%m-%d')) ax.xaxis.set_tick_params(rotation=90) ax.bar(s_total.index, s_total)
ログスケールにしたい場合は
set_yscale('log')。fig, ax = plt.subplots(figsize=(12, 4)) ax.xaxis.set_major_locator(mpl.dates.AutoDateLocator()) ax.xaxis.set_major_formatter(mpl.dates.DateFormatter('%Y-%m-%d')) ax.xaxis.set_tick_params(rotation=90) ax.set_yscale('log') ax.bar(s_total.index, s_total)
移動平均線を追加したい場合は、
rolling()を用いる。print(s_total.rolling(7).mean()) # 2020-01-24 NaN # 2020-01-25 NaN # 2020-01-30 NaN # 2020-02-13 NaN # 2020-02-14 NaN # ... # 2020-07-27 252.285714 # 2020-07-28 256.428571 # 2020-07-29 258.142857 # 2020-07-30 258.285714 # 2020-07-31 287.285714 # Name: date, Length: 164, dtype: float64 fig, ax = plt.subplots(figsize=(12, 4)) ax.xaxis.set_major_locator(mpl.dates.AutoDateLocator()) ax.xaxis.set_minor_locator(mpl.dates.DayLocator()) ax.xaxis.set_major_formatter(mpl.dates.DateFormatter('%Y-%m-%d')) ax.xaxis.set_tick_params(labelsize=12) ax.yaxis.set_tick_params(labelsize=12) ax.grid(linestyle='--') ax.margins(x=0) ax.bar(s_total.index, s_total, width=1, color='#c0e0c0', edgecolor='black') ax.plot(s_total.index, s_total.rolling(7).mean(), color='red')
上の例では参考までに設定をいくつか加えた。
margins(x=0)は左右の余白の切り詰め。色の指定は名称でもカラーコードでも可能。さいごに
公開されているデータは限られていますが、それでも自分であれこれ弄って試してみると理解が深まると思います。みなさんも是非やってみてください。
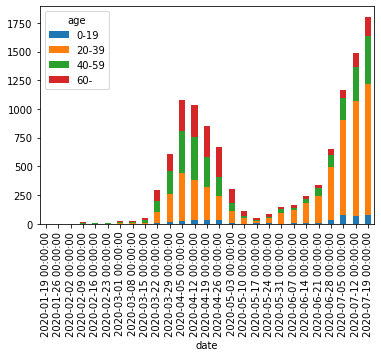
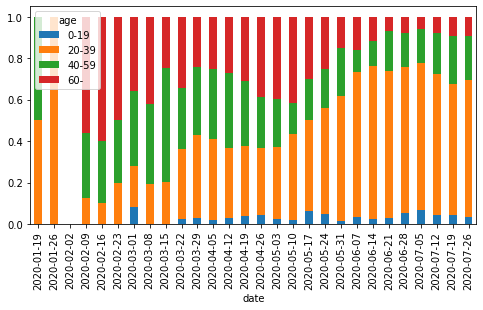
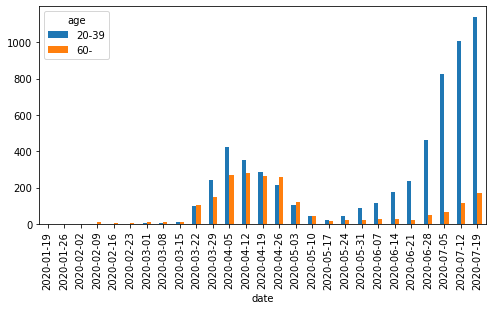

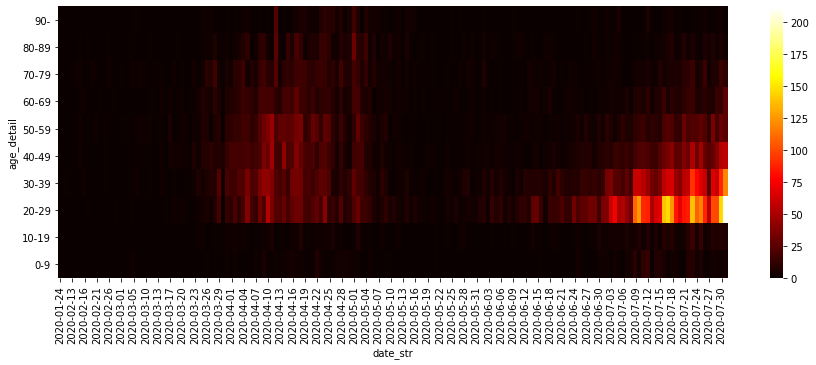
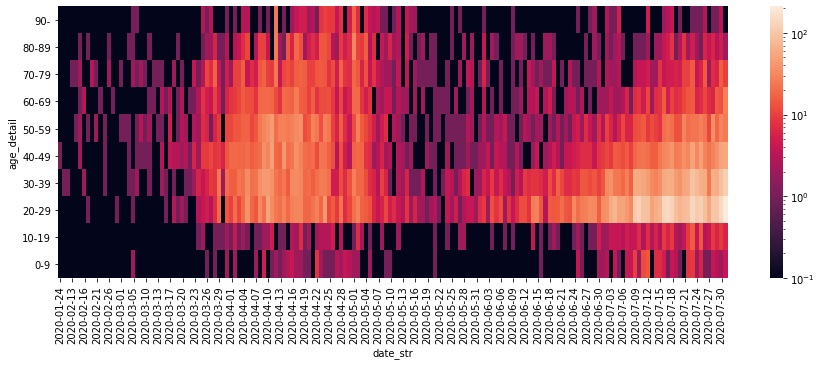


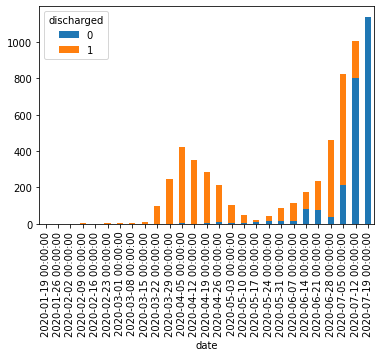
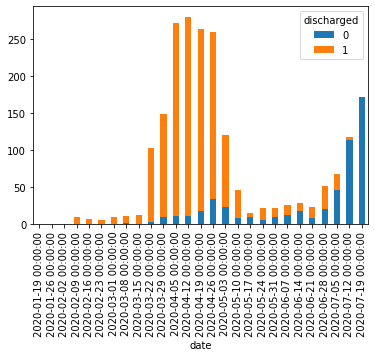

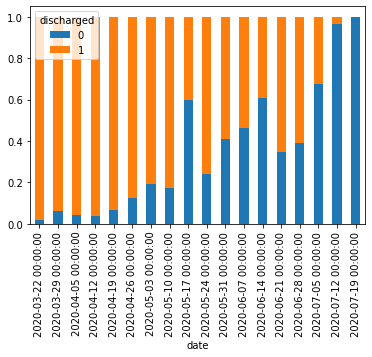
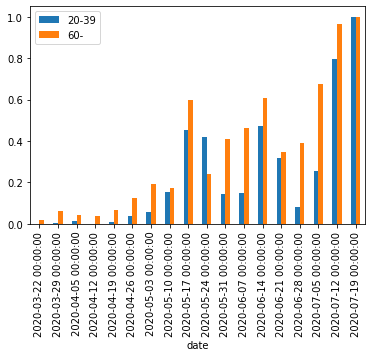
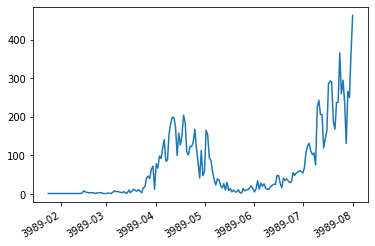
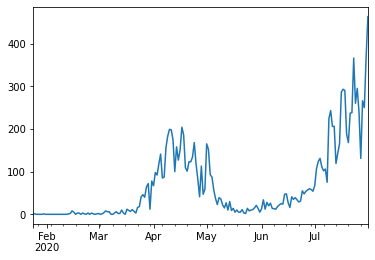
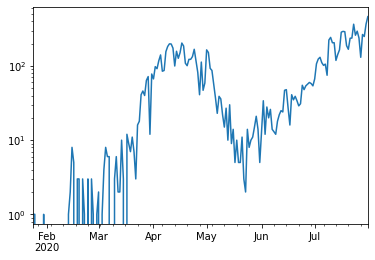
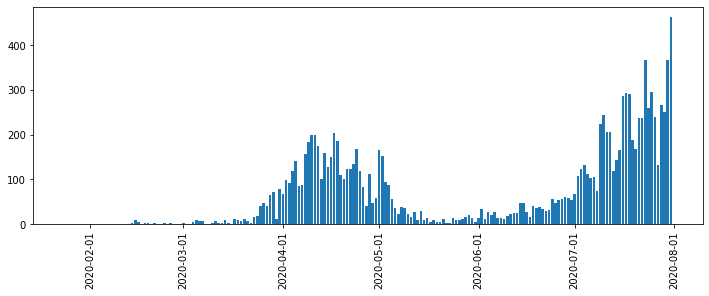
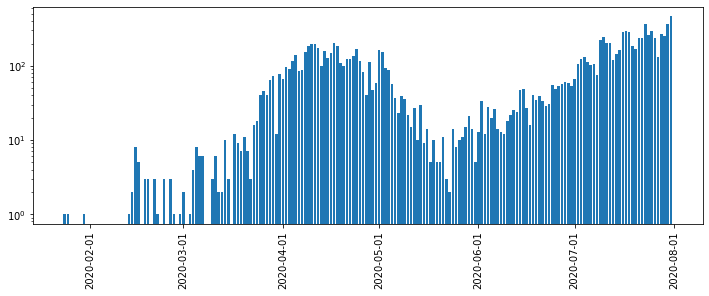
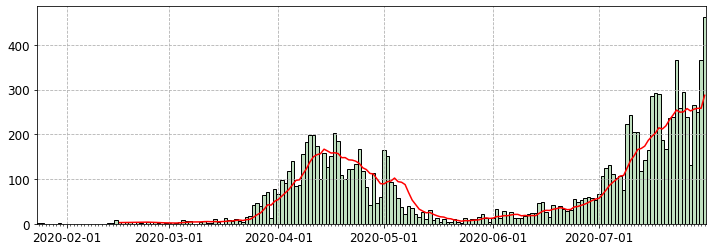
- 投稿日:2020-08-01T15:42:32+09:00
Ubuntu20.04にdropboxをインストールして実行
※ この記事は個人で実行してみた際にうまく行った方法を記しただけで、検証・考察して得た方法ではありません。
※ ほとんど以下の公式サイトに書いてあるとおりです。
https://www.dropbox.com/install-linux手順
1. インストール
以下のコマンドを実行してインストール
cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86_64" | tar xzf -2. ログイン、登録
以下のコマンドを実行してDropboxデーモンを起動
~/.dropbox-dist/dropboxdサーバーで初めて Dropbox を実行する場合、使用中のブラウザでリンクをコピーして貼り付けて新規アカウントを作成するか、既存のアカウントとサーバーを連携させるように指示が表示されます。その後、Dropbox フォルダがホーム ディレクトリに作成されます。(上記公式HPより)
作成された~/Dropboxにファイルを入れると同期されるようになる。
上記プログラムを終了してしまうと、自動同期されないので以下のプログラムの実行などが必要3. 同期させるためのプログラムの実行
公式サイト(以下URL)の下部から"Pythonスクリプト"をダウンロードする
https://www.dropbox.com/install-linuxダウンロードしたpythonプログラムを実行
python3 dropbox.py startこれで自動で同期されるようになる。
python2だとそのままでは実行できない点に注意。
- 投稿日:2020-08-01T15:26:19+09:00
ベランダの写真から植物が写っている部分を抽出するために深層学習を使ってみようと思ったらうまくいかなったので、試行錯誤してみた内容をまとめてみる。前編
はじめに
特定の地点にて、固定されていないカメラで撮影した写真の中から特定のものが写っている箇所を抽出したいという相談があり、「簡単にできますよ〜」って言ったのに、意外と手こずったし、時間もかかりそうだということがわかり「どうしよう?」と思って試行錯誤していたら、それなりの時間でそれなりの結果を得ることができたので、手順をまとめてみます。
概要
抽出する内容がそれほどシビアな条件でなかったことから、以下のような手順を想定していました。
写真
今回使用したのは以下のような写真。
これに以下のようなマーキングを自動で施す。
画像の裁断と分類
以下のコードを用いて、一つの写真を裁断して部品にします。
from glob import glob import cv2 dir_imgs = "imgs" dir_sliced = "sliced" files = glob(dir_imgs + "/*") files.sort() for file in files: img = cv2.imread(file) h, w, c = img.shape # ファイル名、高さ、幅、色 print(file, h, w) size = h if h < w else w size = int(size / 10) print(size) i = 0 k = 0 while size * (i +1) < h: j = 0 while size * (j + 1) < w: img_x = img[size*i:size*(i+1), size*j:size*(j+1)] f_new = "{}/{}-{:02}-{:02}.jpg".format(dir_sliced, file.split("/")[-1].split(".")[0], i, j) cv2.imwrite(f_new, img_x) j += 1 k += 1 i += 1実行するとslicedというフォルダに分割された部品が保存され、一枚あたり120個程度の以下のような部品が作成されます。




これを「01_植物」「99_その他」というフォルダに仕分けをします。
学習
以下のコードを実行してファイルを読み込み、学習させます。
from glob import glob import random X = [] y = [] dirs = ["9*/*.jpg", "0*/*.jpg"] i = 0 min = 1500 for d in dirs: files = glob(d) files = random.sample(files, min if len(files) > min else len(files)) for f in files: X.append(f) y.append(i) i += 1 import pandas as pd import cv2 import numpy as np df = pd.DataFrame({"X" : X, "y" : y}) X = [] y = [] cnt = 0 for idx in df.index: f = df.loc[idx, "X"] l = df.loc[idx, "y"] print("\r{:05} : [{}] {}".format(cnt, l, f), end="") i += 1 img_org = cv2.imread(f) img = cv2.resize(img_org, (100, 100)) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) X.append(img) y.append(l) cnt += 1 print() X = np.array(X) X = X / 255 from sklearn import model_selection test_size = 0.2 X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=test_size, random_state=42) X_valid, X_test, y_valid, y_test = model_selection.train_test_split(X_test, y_test, test_size=.5, random_state=42) from keras.utils.np_utils import to_categorical y_train = to_categorical(y_train) y_valid = to_categorical(y_valid) y_test = to_categorical(y_test) from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D, Dropout from keras.models import Sequential input_shape = X[0].shape model = Sequential() model.add(Conv2D( input_shape=input_shape, filters=64, kernel_size=(5, 5), strides=(1, 1), padding="same", activation='relu')) model.add(MaxPooling2D(pool_size=(4, 4))) model.add(Conv2D( filters=32, kernel_size=(5, 5), strides=(1, 1), padding="same", activation='relu')) model.add(Conv2D( filters=32, kernel_size=(5, 5), strides=(1, 1), padding="same", activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D( filters=16, kernel_size=(5, 5), strides=(1, 1), padding="same", activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(1024, activation='sigmoid')) model.add(Dense(2048, activation='sigmoid')) model.add(Dense(len(y_train[0]), activation='softmax')) # コンパイル model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit( X_train, y_train, batch_size=25, epochs=60, verbose=1, shuffle=True, validation_data=(X_valid, y_valid)) import matplotlib.pyplot as plt # 汎化制度の評価・表示 score = model.evaluate(X_test, y_test, batch_size=32, verbose=0) print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) #acc, val_accのプロット plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o") plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x") plt.ylabel("accuracy") plt.xlabel("epoch") plt.legend(loc="best") plt.show() #acc, val_accのプロット plt.plot(history.history["loss"], label="loss", ls="-", marker="o") plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x") plt.ylabel("loss") plt.xlabel("epoch") plt.legend(loc="best") plt.show()実行結果...
validation loss:0.6690251344611288 validation accuracy:0.6153846383094788
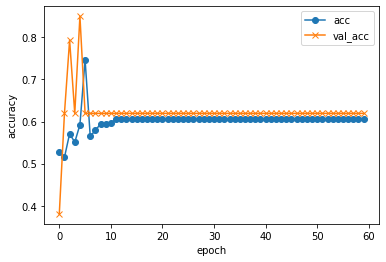
...たぶん全然学習できてない気がする。
はい、失敗!
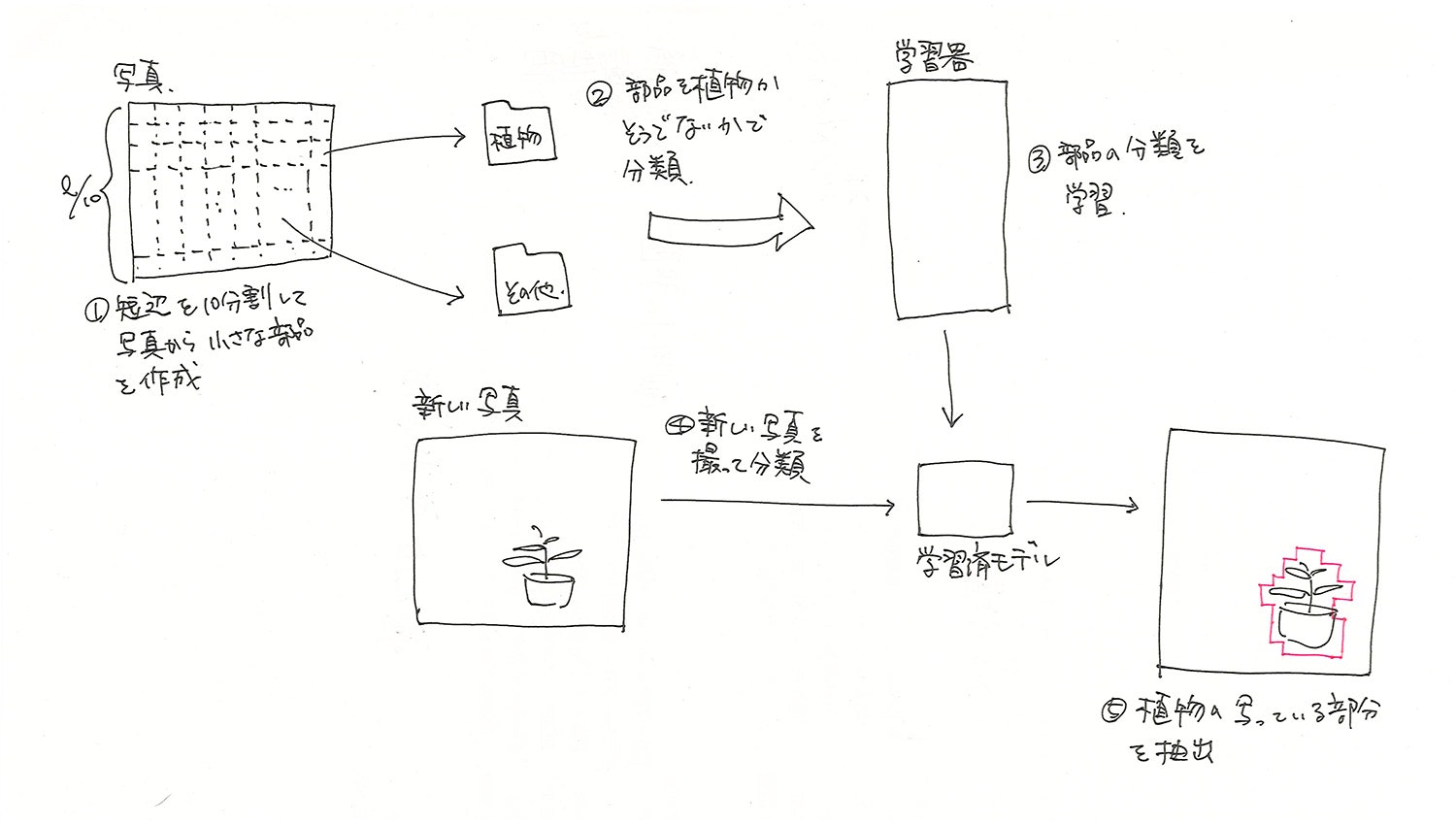



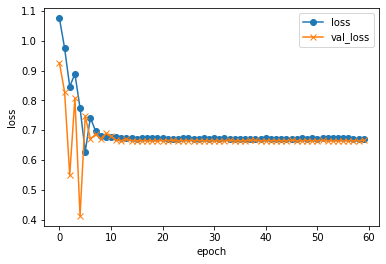
- 投稿日:2020-08-01T14:48:24+09:00
【Python機械学習】初心者向けSpyder活用のすすめ(2020年8月時点)
私は最近になって機械学習に興味を持ちPythonの勉強を始めました。機械学習が前提なのでライブラリが揃った「Anadonda」をインストールして学習環境を構築し、学習を進めていたのですが、途中で「Spyder」を使いだしてから学習効率が大幅にアップしました。
なので、Pythonで機械学習をはじめたばかりの初心者の方向けにこの記事をアップします。■■ Anacondaとは ■■
Anacondaは、科学計算(データサイエンス、機械学習アプリケーション、大規模データ処理、予測分析など)のためのPythonおよびR言語の無料のオープンソースディストリビューションであり、パッケージ管理とデプロイメントを簡略化することを狙ったものである。パッケージのバージョンは、パッケージ管理システム conda によって管理される。Anacondaディストリビューションは1500万人以上のユーザーによって使用されており、Windows、Linux、macOSに対応している1500を超える人気のあるデータサイエンスパッケージが含まれている。
(Wikipediaより引用)機械学習に必要なライブラリ等が揃ったPython環境が提供されるので、機械学習を目的にPythonを使うなら、これ一択といってよい無料パッケージとなります。
■■ Spyderとは(この記事の主役) ■■
Spyder(以前はPydee)はオープンソースでクロスプラットフォームな統合開発環境であり、Pythonで科学用途のプログラミングをすることを意図して作られている。SpyderにはNumPy・SciPy・Matplotlib・IPythonなどが統合されている。
(Wikipediaより引用)記載の通り統合開発環境です。この記事の主役です。「Spyder」は「Anaconda」をインストールした際に、一緒に勝手にインストールされます。
■■ インストール方法 ■■
「Anadonda」のインストール手順は以下に紹介されています。
インストールが完了するとWindowsのスタートアップに「Spyder」が勝手にインストールされています。
「Spyder」を起動すると以下の画面が表示されます。インストール当初に一度起動したのですが使い方が解らず、この子の凄さに気付いていませんでした。途中で行き詰って「Spyder」を使い始めてから、私の学習効率は飛躍的に向上しました。
■■ Spyder操作方法 ■■
①Spyderを起動すると以下の画面が開きます。
②画面左側の「temp.py」の画面に構文を記載します。
③実行ボタンを押します。
④画面右下のコンソールに結果が表示されます。
⑤もちろんプログラムファイルも簡単に保存できます。自分の作ったプログラムは保存していきましょう。
■■ Spyderの良いところ(本題) ■■
ここからが本題です。
如何に「Spyder」が学習環境として優れているかを紹介します。構文を簡単に入力できる
私は当初「Anadonda Powershell Prompt」を起動してターミナルからプログラム入力する形で学習を始めました。教材に記載していた手順であり、最初は何の苦痛もありませんでした。しかし、def文やClass文、for文など長い構文になってくると、いちいち入力するのが非常に手間に感じてきました。
しかし「Spyder」なら構文を画面上でまとめて入力し編集も簡単です。変数を変更しての再実行なども簡単なので、色々と変更して動きを試すことができます。Pythonの勉強中の際は、非常に助かりました。
また関数等が色分けされる為、一目瞭然となって解りやすいです。構文が間違っていたら教えてくれる
そして動かしてみてエラーが出た場合、調査するのに時間を要していました。例えば下の例は「x > 0」の後ろの「:」を抜いた場合に出力されるエラーです。なんだか複数行メッセージが出てきています。なかなか分かりにくいですね。
しかし「Spyder」なら構文が間違っていると列欄に「×」が表示されて、その場で教えてくれます。「×」にカーソルを合わせるとエラーの内容を教えてくれます。些細な構文ミスで悩む必要がなくなります。
変数エクスプローラが使える
例えば以下のような構文を実行します。
a = 20 b = 30 c = (a+b)/3 d = (a+b)%3 e = "kamera" f = "taiko" g = e + f h = ("neko","inu","saru") i = [("aka","ao"),("kiiro","siro")] j = {0 : "test",1 :"tst2",2 : "test3"}変数に何が設定されているか、変数型が知りたい場合は、変数名やtypeコマンドを実行して確認していました。エラーが発生した時などは、これらの作業で非常に時間を取られることになります。
しかし「Spyder」なら画面右上に「変数エクスプローラ」が表示されます。そこに利用した変数が表示されます。変数型とかコマンドを打たなくても確認出来て手間が省けます。
デバックモードが使える
デバックモードと言う機能があります。
これを利用すると、構文が1行ずつ処理されるので、どのように処理されるかが把握できます。
特にdefやif文、for文などを使用しているときには、目に見えて動きが追えて助かります。
特に「変数エクスプローラ」と組み合わせると、どのタイミングで書き換わったか一目瞭然となります。例えば、以下の構文をデバックモードで実行してみます。
test = [] for x in [0,1,2]: for y in [1,2]: if x != y: test.append((x, y))途中までの処理になりますが、以下のようになります。構文画面では現状処理している行に矢印が付きます。変数エクスプローラには、その時点での処理が表示されます。1ステップずつ進めることができるので、処理の内容が手に取るように分かるようになります。どういう処理になるのか理解できなかった構文もこれで簡単に理解できます。
構文画面 変数エクスプローラ画面 過去に作成したスクリプトもすぐに利用可能
作成したプログラムはスクリプトとして簡単に保存できます。
そして、ファイル画面から何時でも引っ張りだせます。
■■ まとめ ■■
上記のようにPythonを身に着けたいと思う初心者には至れり尽くせりの機能が揃っています。実際の業務等で使う際には評価が異なるのかもしれませんが、学習するためのツールとしては非常に優秀なのではないでしょうか。
Pythonの学習をはじめたばかりの初心者の方は、是非活用ください。以 上
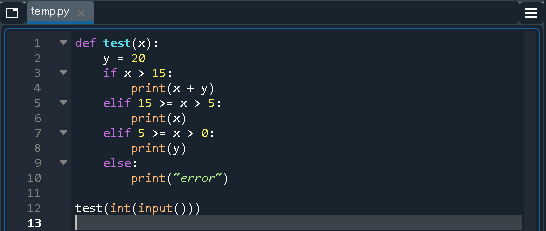
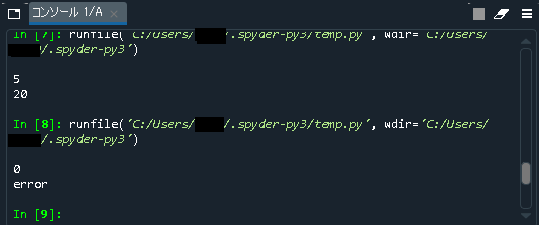
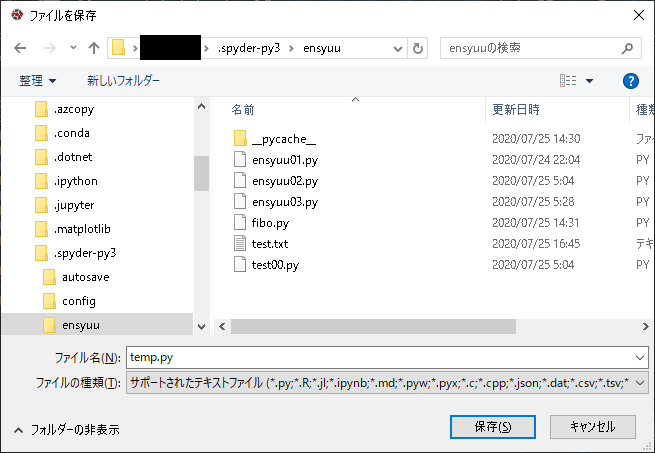
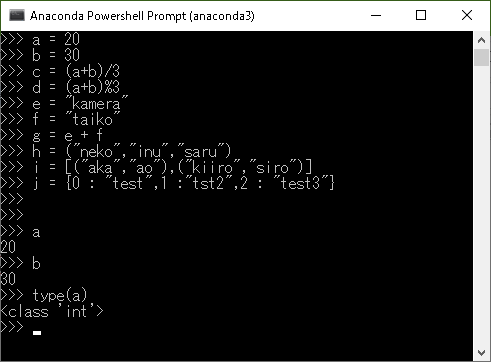
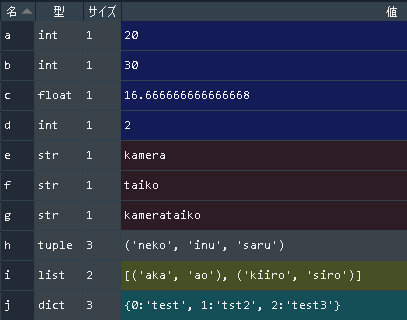
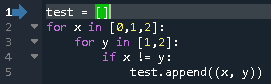

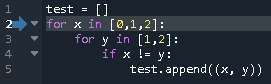

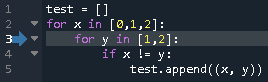

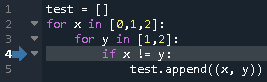

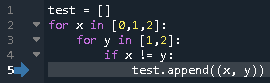

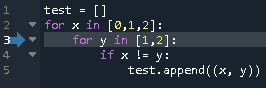
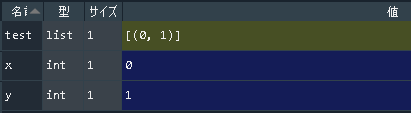
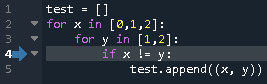
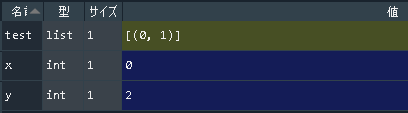
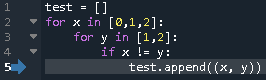
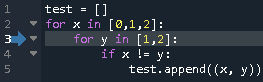
- 投稿日:2020-08-01T14:46:08+09:00
ジャックベラ検定
1 この記事は
ジャックベラ検定をPythonで行う方法を説明します。
2 内容
2-1 ジャックベラ検定とは
ジャックベラ検定とは、標本が正規分布に従うかどうかを判定する手法です。
検定統計量JBは、下記式のとおりになります。by Wikipedia
検定統計量JBはχ二乗分布に従います。検定統計量JBで下記に記載された仮設の検定を行う。(有意水準 p%)
H0(帰無仮説) : 標本は正規分布に従う。
H1(対立仮設) : 標本は正規分布に従わない。
Pythonでは、 stats.jarque_bera(x)で標本xの検定統計量JBを計算できます。stats.jarque_beraの返却値は、[JB計算値, p値]です。
有意水準p=0.05に設定した場合、stats.jarque_beraの返却値p値>0.05であれば、帰無仮説が採択されるため標本は正規分布に従うと判断できます。逆に算出されたp値<=0.05の場合は、標本は正規分布に従わないと判断されます。
2-2 Pythonでのジャックベラ検定の実行例
例1
平均0,分散1の正規分布に従う乱数を10000個発生させ、標本を作製します。その標本に対してジャックベラ検定を行い、標本が正規分布に従うかを検定します。
sample.pyimport numpy as np import matplotlib.pyplot as plt from scipy import stats #正規分布に従う乱数を発生させる。 x = np.random.normal(0, 1, 10000) #標本のヒストグラムを描写する。 fig = plt.figure() ax = fig.add_subplot(1,1,1) ax.hist(x, bins=50) ax.set_title('first histogram') ax.set_xlabel('x') ax.set_ylabel('freq') fig.show() #ジャックベラ検定を行う。 jarque_bera_test = stats.jarque_bera(x) print('Jack Bera:', '\t', jarque_bera_test)(実行結果)ジャックベラ検定の結果、p-value>0.05と算出されているので標本は正規分布に従っているという帰無仮説を採択できます。
test.txtJack Bera: (JB=0.3352314362400006, p-value=0.8456787512712962)
例2
自由度1のχ二乗分布に従う乱数を10000個発生させ、標本を作製します。その標本に対してジャックベラ検定を行い、標本が正規分布に従うかを検定します。
sample.pyimport numpy as np import matplotlib.pyplot as plt from scipy import stats #正規分布に従う乱数を発生させる。 x = np.random.normal(0, 1, 10000) kai=x*x #kaiはχ二乗分布に従う #標本のヒストグラムを描写する。 fig = plt.figure() ax = fig.add_subplot(1,1,1) ax.hist(kai, bins=50) ax.set_title('first histogram') ax.set_xlabel('kai') ax.set_ylabel('freq') fig.show() #ジャックベラ検定を行う。 jarque_bera_test = stats.jarque_bera(kai) print('Jack Bera:', '\t', jarque_bera_test)(実行結果)ジャックベラ検定の結果、p-value<0.05と算出されているので、帰無仮説は棄却され標本は正規分布には従っていないという対立仮設が採用されます。
test.txtJack Bera: (JB=89946.17232671285, p-value=0.0)

- 投稿日:2020-08-01T14:33:57+09:00
python datetimeで「現在の日付のみ」と「現在の日時」を取り出す。
- 投稿日:2020-08-01T14:23:30+09:00
BERTによる文章のネガポジ判定と根拠の可視化
1.はじめに
「PyTorchによる発展的ディープラーニング」を読んでいます。今回は、8章のBERTを勉強したので自分なりのまとめをアウトプットしたいと思います。
2.BERTとは?
Transformer が発表された翌年の2018年に、とうとう自然言語処理分野でも人間を超える精度を持ったBERTが発表されました。
BERTは、あらゆる自然言語処理タスクにファインチューニングで対応でき、なんと11種類のタスクにおいて圧倒的なSoTAを達成したのです。
これが論文に載っているBERTのモデル図です。単語の長さ方向に展開してあるので複雑に見えますが、簡単に言えばTransformerのEncoder部分のみを取り出したものです。では、BERTとTransformerの違いは何処にあるのでしょうか。それは、2種類のタスクによる事前学習と目的のタスクに合わせたファインチューニングの2段階学習を行うことです。
1) 2種類のタスクによる事前学習
センテンスの15%の単語にマスクをしてその単語を当てるタスク(Masked Language Model)と2つの文の文脈が繋がっているのかどうかを判定するタスク(Next Sentence Prediction)を同時に学習します。
入力するセンテンスの先頭には[CLS]を入れ、2つの文には1つ目か2つ目を表す埋め込み表現を加算すると共に間に[SEP]を入れます。
この2つのタスクを学習することによって、単語を文脈に応じて特徴ベクトルに変換できる能力や文が意味的に繋がってるかどうか判定できる能力(おおまかに文の意味を理解する能力)を獲得します。
この地頭を鍛えるような事前学習にはかなり計算コストがかかり、TPUを4つ使っても4日間くらい掛かるらしいですが、誰かが1回やれば後はファインチューニングで様々なタスクが解けるネットワークに変身できるわけです。
2) ファインチューニング
事前学習の重みを初期値として、ラベルありデータでファインチューニングを行います。
事前学習によって地頭が相当鍛えられているので、少ない文章データから性能の良いモデルが作成可能です。論文では、様々なタスクのファインチューニングの計算コストは、TPU1つで1時間以内で終わったということです。以下は、BERTがSoTAを記録した11個のNLPタスクです。
データセット タイプ 概要 MNLI 推論 前提文と仮説文が含意/矛盾/中立のいずれか判定 QQP 類似判定 前提文と仮説文が含意/矛盾/中立のいずれか判定 QNLI 推論 文と質問のペアが渡され、文に答えが含まれるか否かを判定 SST-2 1文分類 文のポジ/ネガの感情分析 CoLA 1文分類 文が文法的に正しいか否かを判別 STS-B 類似判定 2文が意味的にどれだけ類似しているかをスコア1~5で判別 MRPC 類似判定 2文が意味的に同じか否かを判別 RTE 推論 2文が含意しているか否かを判定 SQuAD v1.1 推論 質問文と答えを含む文章で、答えがどこにあるか予測 SQuAD v2.0 推論 v1.1に答えが存在しないという選択肢を加えたもの SWAG 推論 与えられた文に続く文を4択から選ぶ 3) その他の違い
・Transformerでは単語の位置情報をPositonal Encoderではsin,cosからなる値を与えていましたが、BERTでは学習させます。
・活性化関数の一部にReLUではなく、GELU(入力0のあたりの出力がカクっとせず、滑らかになっている)を使っています。3.今回実装するモデル
今回は、BERTの事前学習済みモデルを使って、文章のネガポジ判定をするタスクのファインチューンニングを行います。BERTモデルにはモデルサイズの異なる2つのタイプがあり、今回使うのはBaseと呼ばれる小さい方のモデルです。
BERTの出力は識別用とトークンレベル用の2つあり、今回は識別用に全結合層を接続しネガポジ判定を行います。使用するデータセットは、映画のレビュー(英文)の内容がポジティブなのかネガティブなのかをまとめたIMDb(Internet Movie Dataset)です。
モデルを学習させることによって、ある映画のレビューを入力したら、そのレビューがポジティブなのかネガティブなのかを判定し、レビューの単語の相互Attentionから判定の根拠にした単語を明示させるようにします。
4. モデルのコード
from bert import get_config, BertModel, set_learned_params # モデル設定のJOSNファイルをオブジェクト変数として読み込みます config = get_config(file_path="./data/bert_config.json") # BERTモデルを作成します net_bert = BertModel(config) # BERTモデルに学習済みパラメータセットします net_bert = set_learned_params( net_bert, weights_path="./data/pytorch_model.bin")BERTモデルを作成し、事前学習済みの重みパラメータをセットします。
class BertForIMDb(nn.Module): '''BERTモデルにIMDbのポジ・ネガを判定する部分をつなげたモデル''' def __init__(self, net_bert): super(BertForIMDb, self).__init__() # BERTモジュール self.bert = net_bert # BERTモデル # headにポジネガ予測を追加 # 入力はBERTの出力特徴量の次元、出力はポジ・ネガの2つ self.cls = nn.Linear(in_features=768, out_features=2) # 重み初期化処理 nn.init.normal_(self.cls.weight, std=0.02) nn.init.normal_(self.cls.bias, 0) def forward(self, input_ids, token_type_ids=None, attention_mask=None, output_all_encoded_layers=False, attention_show_flg=False): ''' input_ids: [batch_size, sequence_length]の文章の単語IDの羅列 token_type_ids: [batch_size, sequence_length]の、各単語が1文目なのか、2文目なのかを示すid attention_mask:Transformerのマスクと同じ働きのマスキングです output_all_encoded_layers:最終出力に12段のTransformerの全部をリストで返すか、最後だけかを指定 attention_show_flg:Self-Attentionの重みを返すかのフラグ ''' # BERTの基本モデル部分の順伝搬 # 順伝搬させる if attention_show_flg == True: '''attention_showのときは、attention_probsもリターンする''' encoded_layers, pooled_output, attention_probs = self.bert( input_ids, token_type_ids, attention_mask, output_all_encoded_layers, attention_show_flg) elif attention_show_flg == False: encoded_layers, pooled_output = self.bert( input_ids, token_type_ids, attention_mask, output_all_encoded_layers, attention_show_flg) # 入力文章の1単語目[CLS]の特徴量を使用して、ポジ・ネガを分類します vec_0 = encoded_layers[:, 0, :] vec_0 = vec_0.view(-1, 768) # sizeを[batch_size, hidden_sizeに変換 out = self.cls(vec_0) # attention_showのときは、attention_probs(1番最後の)もリターンする if attention_show_flg == True: return out, attention_probs elif attention_show_flg == False: return outBERTモデルにIMDbのネガ・ポジを判定するLinearをつなげたモデルです。重みパラメータの更新は、BertLayerの全部の層で行うとヘビーなので、BertLayerの最終層(12層目)と追加したLinearのみで行います。
5.コード全体と実行
コード全体は Google Colab で作成し Github に上げてありますので、自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
コードを実行するとたった2epochの学習ですが、テストデータの正解率は約90%でした。前回、Transfomerでも同じタスクをやったのですが、その時の正解率が約85%でしたので、+5ポイントの改善になっています。
さて、判定根拠の明示ですが、
こんな感じで、どの単語を判定根拠にしたかを明示します。(参考)
・つくりながら学ぶ! PyTorchによる発展ディープラーニング
・自然言語処理の王様「BERT」の論文を徹底解説
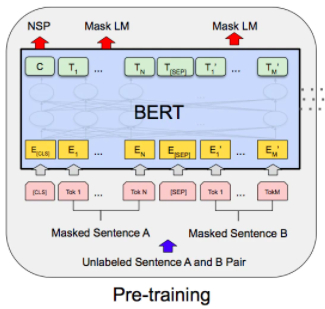
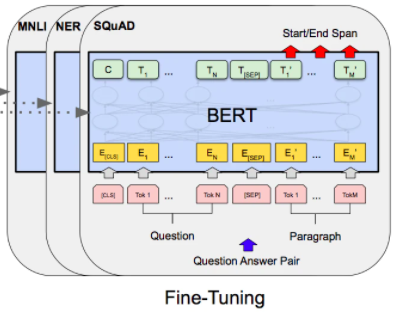
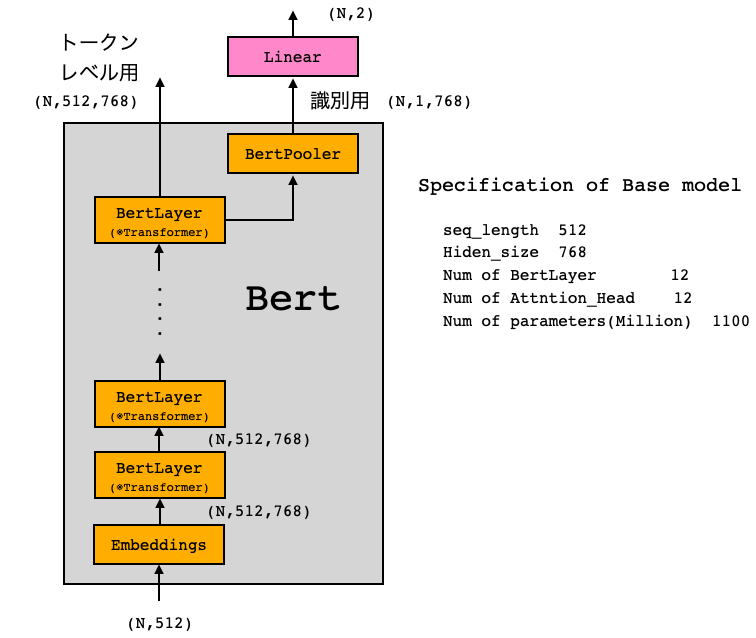

- 投稿日:2020-08-01T12:32:54+09:00
Python手遊び(割り算)
この記事、何?
一言だけ投稿しようかと思って書いてみた。
一言でいうと、割り算の整数解が欲しければ「//」か「divmod」を使おうという話。事例
数を100で割って整数を得る。
修正前のコード
result = int(value / 100)まあ、たいていの場合はこれで動く。
ただ、おっきい数でNG。NGの事例
>>> 38030123828366199/100 380301238283662.0ね?わかりやすい。
修正後のコード
result = value // 100OKの事例
>>> 38030123828366199 // 100 380301238283661で、境目が見てみたくなった。
>>> 38030123828366199/100 380301238283662.0 >>> 38030123828366198/100 380301238283662.0 >>> 38030123828366197/100 380301238283662.0 >>> 38030123828366196/100 380301238283661.94 >>> 38030123828366195/100 380301238283661.94 >>> 38030123828366194/100 380301238283661.94 >>> 38030123828366193/100 380301238283661.94 >>> 38030123828366192/100 380301238283661.94 >>> 38030123828366191/100 380301238283661.94 >>> 38030123828366190/100 380301238283661.9 >>> 38030123828366189/100 380301238283661.9なるほど、わかりやすい。
末尾のビットの気分次第でとびとびの値をとってる。そりゃそうだ。浮動小数の保持できる限界間際の数が偶数ばかりになるというのと同じですね。
計算精度をちゃんと意識しましょう。。。
- 投稿日:2020-08-01T12:01:51+09:00
Pythonでスクレイピング(準備)
スクレイピングを触ってみようと思いPythonのBeautifulSoupを使ってみる。
とりあえず今回は準備から使用するもの
・Python3.6
・BeautifulSoup4
・Anaconda仮想環境の構築
仮想環境の構築から
conda create --name [環境名] python=[version]実際に構築
色々ダウンロードされて終了
BeautifulSoupのインストール
pip install beutifulsoup4上記のコマンドでインストールする
先ほど作成した仮想環境に入り、インストール
インストールされたか下記コマンドで確認pip list
インストールされたことが確認できたので今回はここまで
次は実際に簡単にですが使ってみます!



- 投稿日:2020-08-01T11:44:29+09:00
conda Numpyのようにscikit-learnも高速化する方法
最近、condaで入れるNumpyの方が、pipで入れるNumpyより動作が早いことが少し話題になっています(元記事は最近ではないのですが)。本記事では、scikit-learnもインストールを工夫すれば、より高速に動作することを解説します。
はじめに
記事、「Anaconda の NumPy が高速みたいなので試してみた」
https://tech.morikatron.ai/entry/2020/03/27/100000を最近Twitterのタイムラインで何度も見かけました(元記事は20年3月に記載されたものですが)。
condaでインストールするNumpyの方が、pipでインストールするNumpyより早い、というお話です。
なぜ早いの?
上記の記事では、CPUで「Intel Core i7-9750H」を使用しています。
このCPUの仕様は以下です。
https://www.intel.co.jp/content/www/jp/ja/products/processors/core/i7-processors/i7-9750h.htmlこの仕様の「命令セット拡張」に「Intel® SSE4.1, Intel® SSE4.2, Intel® AVX2」と記載さているのがミソです。
命令セット拡張にAVX2が搭載されています。
その他、割と新しい高性能のIntel CPUではAVX-512も搭載されています。
AVXについては、以下ページが詳しいですが、ストリーミングSIMD拡張命令の後継です。
「要は、1命令で複数の演算を実行できる機能です」
このAVXのAVX2以上を使用して、数学演算を高速化するインテルのCPUの機能がIntel MKL(Math Kernel Library)です。
https://www.xlsoft.com/jp/products/intel/perflib/mkl/index.html種々計算をAVX2やAVX-512で実施することで、高速化してくれます。
condaでインストールするNumpyはCPUがAVX対応であれば、このIntel MKLを使用して計算するので、処理が早くなります。
Intelの頑張り
GPU時代のなか、Intelも頑張っていて、2017年あたり、
Intel MKL はじめ、Intel CPUでの高速化に対応した、Numpyやsckit-learnのライブラリを公開しました。pip install intel-scikit-learn
https://pypi.org/project/intel-scikit-learn/pip install intel-numpy
https://pypi.org/project/intel-numpy/これらであれば、pipでインストールしても、はじめから高速バージョンを使えます。
こういうバージョンも昔Intelから出されたのですが、
本家のNumpyやsklearnにバージョンが追いついていない、保守されていないので、
これらの使用はおすすめはしないです。scikit-learnの高速化
最初に紹介した記事、「Anaconda の NumPy が高速みたいなので試してみた」
https://tech.morikatron.ai/entry/2020/03/27/100000の文中でも、
他にも色々なモジュールが Intel MKL を採用してました。素晴らしい!
NumPy
NumExpr
SciPy
Scikit-Learn
Tensorflow … Windows だと tensorflow-mkl という別パッケージになっている
PyTorch … こちらは pip 経由でも Intel MKL を採用しているそうですとあるように、condaでインストールすると、Intel MKLを使用する高速なバージョンが勝手にインストールされます。
ただ、一番早く動作させたい場合は、scikit-learnのインストールのページの案内に沿いましょう。
https://scikit-learn.org/stable/install.htmlこちらページの
「Third party distributions of scikit-learn」
に書かれている、
「Intel conda channel」
Intel conda channel
Intel maintains a dedicated conda channel that ships scikit-learn:$ conda install -c intel scikit-learn
This version of scikit-learn comes with alternative solvers for some common estimators. Those solvers come from the DAAL C++ library and are optimized for multi-core Intel CPUs.Note that those solvers are not enabled by default, please refer to the daal4py documentation for more details.
Compatibility with the standard scikit-learn solvers is checked by running the full scikit-learn test suite via automated continuous integration as reported on https://github.com/IntelPython/daal4py.
の、Intel conda channelでsckit-learnを入れれば、Intel MKLだけでなく、
scikit-learnのいくつかの処理が、Intel multi-coreに最適化された関数処理に置き換わります。ですので、最速バージョンでのscikit-learnを使用したい場合は、
$ conda install scikit-learn
ではなく、
$ conda install -c intel scikit-learn
でのインストールをおすすめします(Intel AVX2以上対応CPU環境で)。
さいごに
AWSもDeepLearningイメージも、AzureのDSVM(Data Science Virtual Machines)もcondaをベースに管理されています。
そして、condaでscikit-learnがインストールされています。
それらがIntel最適化版かは私は知りません(誰かご存知であれば教えていただきたいです)。
自分で仮想環境をcondaで作り直した場合には、上記の高速版を入れれば良いのですが・・・
(IaaSのマシンのCPUを調べ、AVX2に対応しているかは調べる必要があります。やすいマシンだとAVXにしか対応していない場合がある)以上、Conda Numpyのようにscikit-learnも高速化する方法でした。
(私はあまりCPU周り強くないので、勘違いしている点があればぜひコメントください)備考
【情報発信】
最近私は、自分が面白いと思った記事やサイト、読んだ本の感想などのAIやビジネス、経営系の情報をTwitterで発信しています。小川雄太郎@ISID_AI_team
https://twitter.com/ISID_AI_team私が見ている情報、面白い、重要だ!と思った内容を共有しています。
【その他】私がリードする、AIテクノロジー部開発チームではメンバを募集中です。興味がある方はこちらからお願い致します
【免責】本記事の内容そのものは著者の意見/発信であり、著者が属する企業等の公式見解ではございません