- 投稿日:2020-08-01T23:58:20+09:00
OAuth認証アプリのCloudFront設定でハマった話
はじめに
独自ドメインの小さなWebアプリを、AWSで以下のお安い構成でセットアップしてみました。
- Route53 (独自ドメインを管理)
- AWS Certificate Manager (ACM。SSL証明書を管理)
- CloudFront
- EC2
CloudFrontはキャッシュ用のエッジサーバとしてではなく、ACMと紐付けてSSLを利用したいため配置しています。
しかし、この構成にしたところアプリに実装していたOAuth認証が急に動かなくなりました。。。最終的にCloudFrontの設定を見直して解決できたので、忘れないようにメモとして残しておきます。
同じように悩んだ人の参考になれば幸いです。最終的な設定だけ見たい方は、まとめをどうぞ。
GoogleのOAuth認証が通らなくなった
もともと、静的なWebコンテンツを
CloudFront+S3の構成でSSLでホストしていたため、それに倣ってCloudFront+EC2もセットアップしてみました。
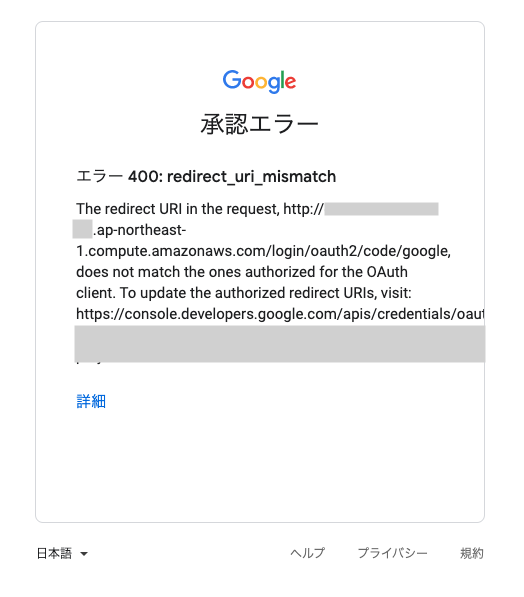
CloudFrontのキャッシュ設定はほぼデフォルトのままです。いざアプリケーションでGoogleのOAuth認証してみると・・・
エラー 400: redirect_uri_mismatch
The redirect URI in the request, http://***.ap-northeast-1.compute.amazonaws.com/login/oauth2/code/google, does not match the ones authorized for the OAuth client.GoogleのOAuthで設定したリダイレクトURIにマッチしないエラーとなりましたorz
上記のエラーメッセージを見ると、認証後のリダイレクト先がEC2のパブリックDNS
http://*****.ap-northeast-1.compute.amazonaws.com/...になってしまっているようです。
確かにGoogleのOAuth設定で、リダイレクト先に独自ドメインのみを許可しているので、 それ以外のURIにリダイレクトできないのは正しい制御ではあるのですが・・・
なぜリダイレクト先がEC2のパブリックDNSになってしまう?
リダイレクト用のURIはアプリ側でホスト名を設定して生成しています。
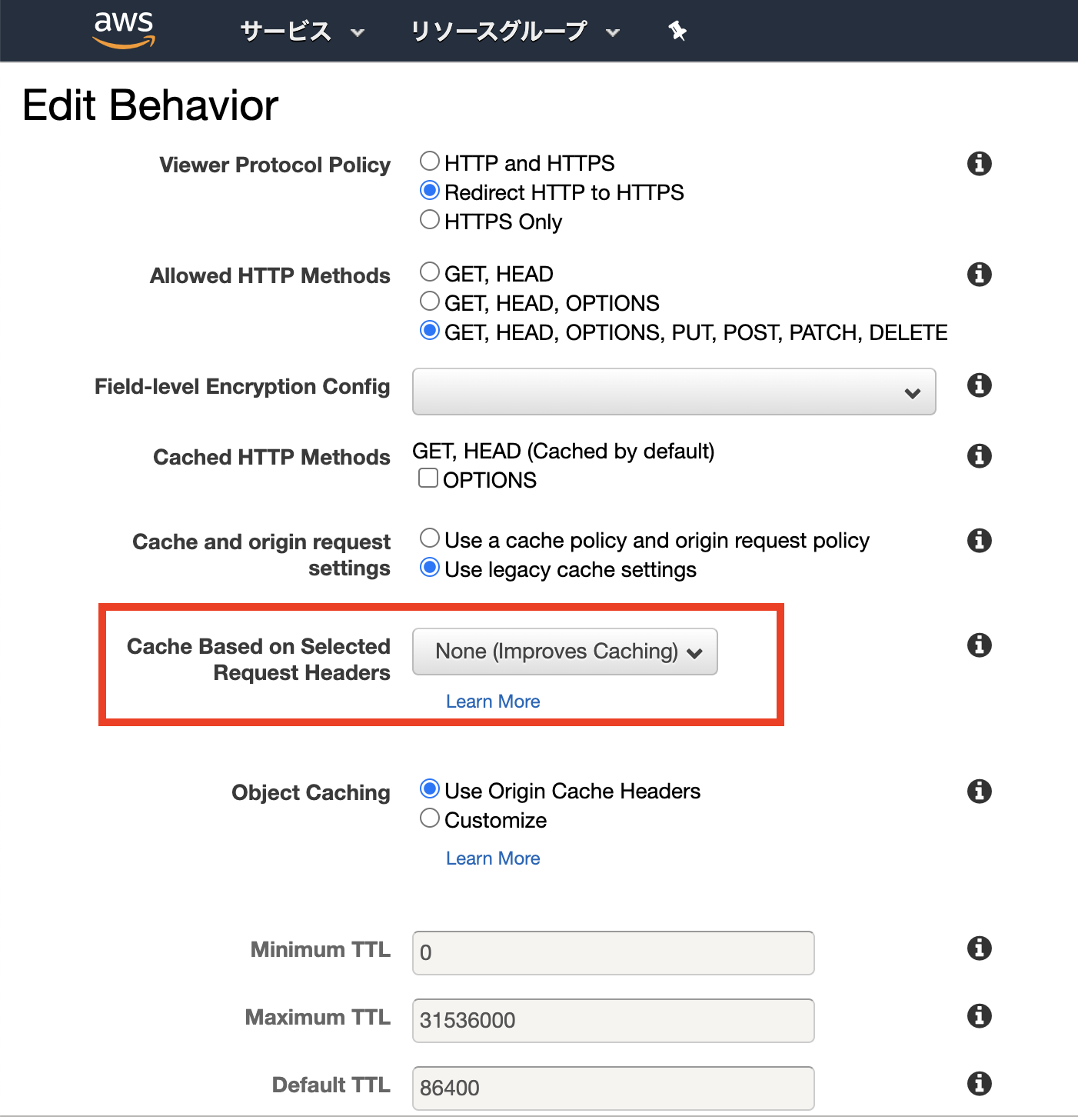
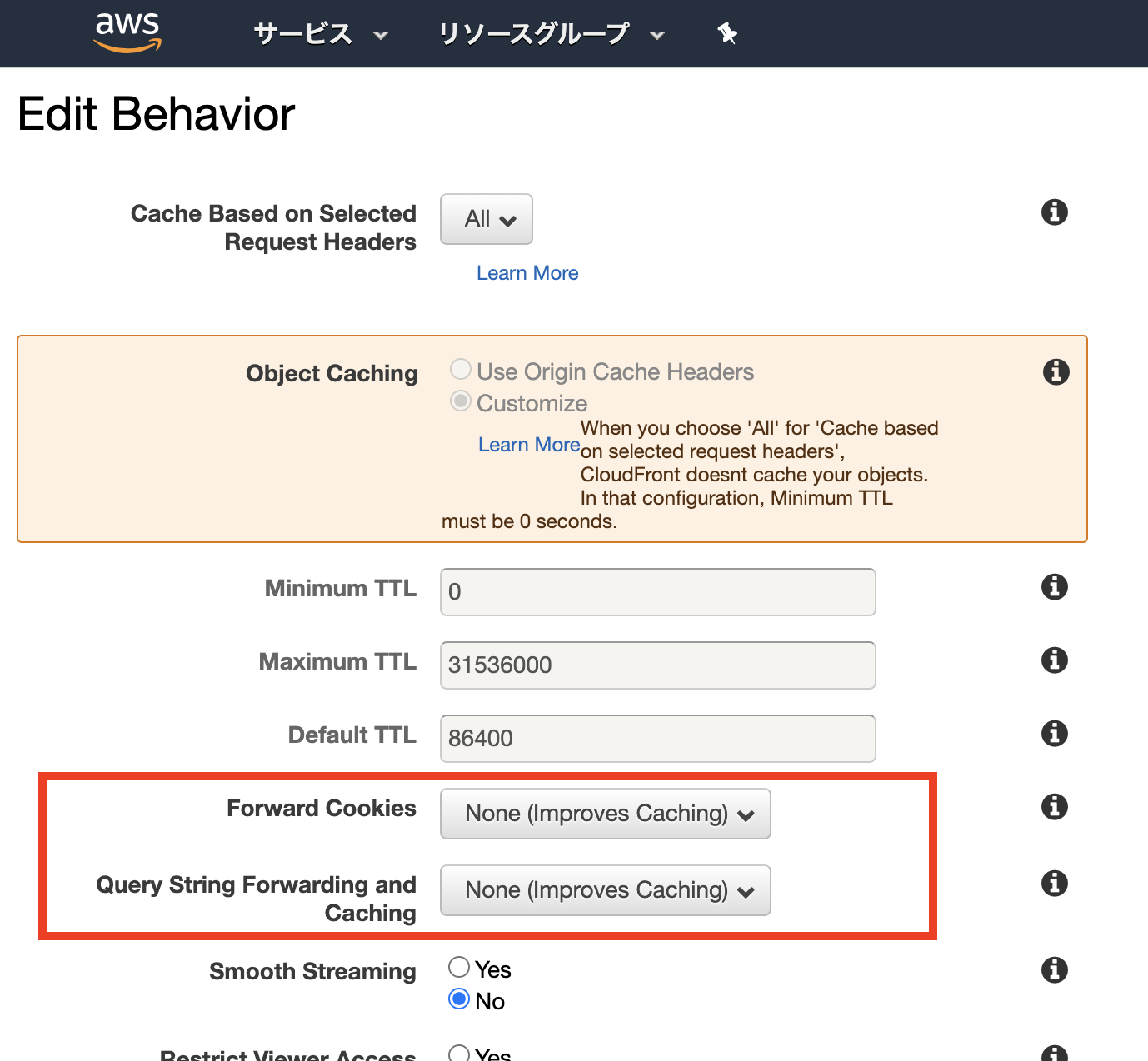
つまり、 EC2に独自ドメインのホスト名が渡ってきていないことが問題のようです。ホスト名はリクエストヘッダで指定するので、改めてCloudFrontの設定をみてみると・・・
怪しい設定がありました。
Cache Based on Selected Request Headers とは
この項目を調べるにあたり、以下の記事がとても参考になりました。
https://michimani.net/post/aws-about-cache-spec-of-cloudfront/#cache-based-on-selected-request-headers-1どうやらCloudFrontはエッジサーバとしてコンテンツをキャッシュするために、デフォルトではリクエストヘッダの値を考慮しないだけでなく、 オリジンにリクエストヘッダを転送しないようです。
公式の説明文 を読むと、
[None(Improves Caching)]の説明には特に記載がないですが、[All(すべて)]には代わりに、CloudFront はすべてのリクエストをオリジンに送信します。
とありました。
なるほど、
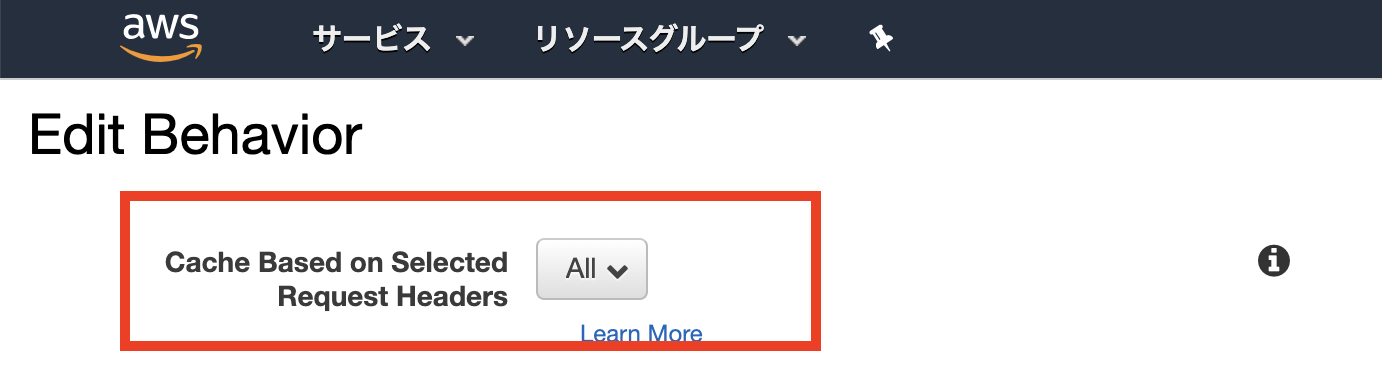
こいつが元凶この設定を見直す必要があったようです。オリジンにリクエストヘッダを転送する設定
今回、オリジンはEC2のためキャッシュは不要、かつリクエストヘッダも転送して欲しいため
[All]に変更しました。
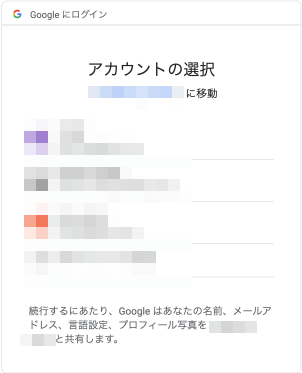
これで無事にEC2にホスト名を含むリクエストヘッダが転送されるはずです。設定変更後にアプリのログインボタンを押下すると・・・
無事にアカウント選択画面まで進みました!
アカウントを選択してみると、、、
まさかのエラーorz
これはアプリ側で用意しているエラーレスポンスですが、つまり
Status Code: 401 Unauthorized
のようです。
GoogleのOAuthからアプリへのリダイレクトは成功していますが、アプリ側の処理で問題があるようです。Forward Cookies と Query String Forwarding and Caching
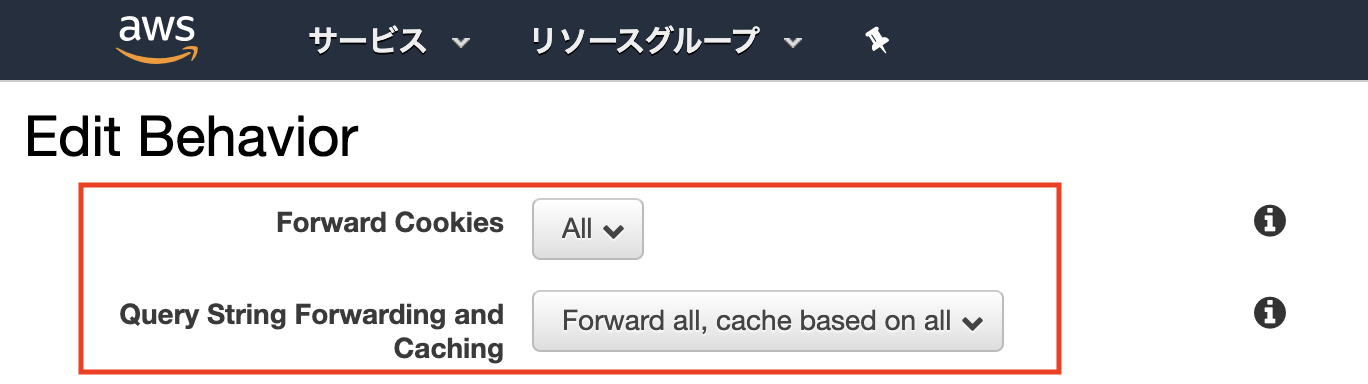
意気消沈しながらも、改めてCloudFrontの設定をみてみると・・・
CookieやURIのクエリパラメータに関する設定がありました。
この項目も以下の記事に詳しく説明されていました。これらの設定も、デフォルトではコンテンツをキャッシュするために値の考慮をしないだけでなく、
Cookieやクエリパラメータがオリジンに転送されないようです。つまりこの設定も
None (Improves Caching)だとオリジンに転送しないんですね。オリジンにCookieとクエリパラメータを転送する設定
すべてのCookie、クエリパラメータをオリジンに転送して欲しいため
[All]に変更しました。
以上の設定で、無事に
CookieおよびURIのクエリパラメータがオリジンに転送されるようになりました。画面ショットは省きますが、これで
CloudFront+EC2の構成で無事にOAuth認証でログインが行えるようになりましたまとめ
CloudFrontをEC2などAppサーバの手前に配置する場合、以下の項目でオリジンへの転送の設定を行う必要があります。
Cache Based on Selected Request Headers
リクエストヘッダをオリジンに転送するため[All]を指定Forward Cookies
Cookieをオリジンに転送するため[All]を指定Query String Forwarding and Caching
クエリパラメータをオリジンに転送するため[Forward all, cache based on all]を指定参考
https://michimani.net/post/aws-about-cache-spec-of-cloudfront/

- 投稿日:2020-08-01T22:32:24+09:00
ec2にdocker環境を構築してみた
railsアプリをec2を利用して本番環境でデプロイした際に、dockerを導入してみました。
ec2にdocker及びdocker-composeをインストールするには以下を参考にしました。
https://qiita.com/y-do/items/e127211b32296d65803aec2にsshログインし、mysqlにマイグレーションするまでは以下が詳しく書いてあります。
https://qiita.com/naoki_mochizuki/items/f795fe3e661a3349a7ceMySQLの設定以降
amazon linuxではデフォルトがmariadbのため以下のエラーが出ます。
$ sudo service mysqld start Redirecting to /bin/systemctl start mysqld.service Failed to start mysqld.service: Unit not found.該当する方は以下を参考にmysqlをインストールしてください。
https://qiita.com/hamham/items/fd77bb0bb167a150dc8e#mysql57%E3%81%AE%E5%B0%8E%E5%85%A5また、ここまで手順どおり進めても以下のコマンドでエラーが出ます。
$ rake db:create RAILS_ENV=production rake db:migrate RAILS_ENV=production rake aborted! Mysql2::Error::ConnectionError: Unknown MySQL server host 'db' (2) Tasks: TOP => db:migrate (See full trace by running task with --trace)こちらはdockerの導入のためにdatabase.ymlの設定を以下のように変更したためです。
host: localhost #変更前 host: db #変更後そのため、データベースの作成にはdockerコマンドで実行する必要があります。
しかし、dockerコマンドを実行しようとすると以下のエラーになります。ERROR: Couldn’t connect to Docker daemon at http+docker://localhost – is it running?権限不足によるエラーのため、以下を参考に権限を変更してください。
https://qiita.com/dnnnn_yu/items/14a31721a2870b735938ここまで進んだらdockerコマンドが使用できると思いますので以下のコマンドを実行して下さい。
$ docker-compose up -d コンテナの作成(バックグラウンドで起動モード) $ docker ps -a 起動しているかの確認データベースを作成しようとするとエラーが出ます。
$ docker-compose run web rails db:create RAILS_ENV=production Mysql2::Error::ConnectionError: Access denied for user 'root'@'172.18.0.5' (using password: NO)これは参考サイトでdatabase.ymlのproduction環境のpasswordが設定されていないからです。
以下のように設定してあげましょう。// database.yml production: <<: *default host: <%= ENV['DB_HOST'] %> database: <%= ENV['DB_DATABASE'] %> username: <%= ENV['DB_USERNAME'] %> password: <%= ENV['DB_PASSWORD'] %>これでデータベースの作成ができると思います。
$ docker-compose run web rails db:create RAILS_ENV=production
- 投稿日:2020-08-01T21:51:04+09:00
AWS LambdaからAWS AppConfigを呼び出してみた
1. 初めに
皆さん、AWS AppConfigを利用されていますか? AWS AppConfig は 2019年12月にリリースされた機能で、こちらのブログが出た際には私は記事を何度も読み直し、一番の売りは何だろう?他のデータストア(例えば、DynamoDBやParameter Store)に設定情報を格納するのと何が違うのだろう?と考えたものです。
その AWS App Configについて簡単にご紹介したいと思います。
2. 要約
- より安全なデプロイをしたい場合に活用すると効果的
- 設定はアプリ側でキャッシュすることでレイテンシーやAWS サービス利用料の削減につながる
- 設定のリリースにカナリア・リニアデプロイを実現
3. AWS App Configとは
冒頭にもリンクを付けましたが、AWS AppConfigは、Amazonの内部で使われていた仕組みをAWSのサービスとして提供したサービスで、AWS Systems Manager の機能の1つとして AWS AppConfig がリリースされました。AWS AppConfig を使用すると、Amazon Elastic Compute Cloud (EC2) インスタンス、コンテナ(ECS/EKS)、およびLambda等で実行されているアプリケーションが、コードやインフラのビルドやデプロイに関係なく、アプリケーション設定の変更を迅速に、より安全に、デプロイすることを支援する仕組みです。
AWSのマネージドなサービスとして提供されているため、利用者による運用の手間が軽減されています。
4. AWS AppConfigを使う最大のメリットは何か?
私は、個人的には、「より安全に」 という部分がポイントだと思っています。
以前から私がアプリケーションを構築する際に、アプリケーションで必要な設定情報は多くのケースで以下のいずれかに配置していました。
- 実行モジュール内に同梱する定義ファイル
- 実行モジュール外に配置し、ランタイムから参照できるファイル
- 環境変数
- データベース
つまり、AWS AppConfigがなくても簡単な手法でコードに設定情報を注入し動作させていました。例えば、以下の二つの目的だけであれば、従来から行われていた方法で十分機能すると思います。
- アプリを動かす
- 設定を外部から反映するもし、皆さんが設定情報の反映に対して以下の運用上の課題をお持ちであれば、AWS AppConfigを利用する価値がでてくると考えます。
・設定情報を直接反映しているために、入力値・フォーマットの検証が不十分でエラーになることがある。
・設定を反映した後でエラーになった場合の影響範囲が大きい
・エラー時の切り戻しが手動で手間がかかる・ミスが発生する。ということで、「設定値の検証」「設定値のデプロイ」「設定値の切り戻し」についてAWS AppConfigがどのような支援をするのか書きたいと思います。
4.1 設定値の検証
設定値を皆さんはどのように入力しているでしょうか?例えばアプリケーションで利用する設定値の値をデータベースに保持していた場合、直接データベースにSQLやCSVのLoad等をしているでしょうか?あるいは、アプリケーションを実装して、入力値のチェックを実装しているでしょうか?
もし、何等か検証方法を実装したうえで、必ず、その検証を実施後に設定値が格納されているのであれば、この機能はそれほど既存の方法と大差はないかもしれません。
検証されていることが保証できない入力方法を採用している場合、
AWS AppConfigでは、設定値をAWS AppConfigにデプロイする際に、二種類のバリデーションをサポートしており、そのバリデーションでエラーが発生するとデプロイされません。
二種類とは、
1. JSONスキーマ(JSON スキーマバージョン 4.X)による検証
2. AWS Lambda関数による検証
です。詳細はこちらを参照してください。複数の設定値の組み合わせによるチェック等、ロジックや他のデータソースへのアクセスをして検証するような場合には、AWS Lambdaを利用したバリデーションを実装いただくとデプロイ前に不適切な値を検知できます。
4.2 設定値のデプロイ
アプリケーションをデプロイする際には、B/Gデプロイメントや、Rollingによるデプロイまた、カナリアデプロイなど、デプロイ戦略を考え、
- 切り戻しの迅速さ
- 影響範囲の最小化
- コスト効率性
等を考慮して決定するかと思います。では、そのデプロイメントを実行するパイプラインについて少し考えたいと思います。パイプラインは、アプリケーションと設定は同一のパイプラインを使っているでしょうか?その場合、アプリケーションの設定のみの変更でビルドやデプロイが不要という場合はないでしょうか?もし、そういう状況があり、迅速に簡単にデプロイをしたいということであれば、まず、「パイプライン」の分割を検討してみましょう。アプリケーションモジュールのデプロイと設定値のデプロイのサイクルが同じである場合、分割する必要はないかもしれませんが、個別でデプロイがあるのであれば、分割することで、軽量な設定値のデプロイが可能になります。ただ、パイプラインを分割しただけでは、「設定を反映した後でエラーが発生した場合の影響範囲」の最小化には何も貢献していません。パイプラインを分けても分けなくても、設定値に問題があった場合のランタイム(実行環境)への影響は同じです。そことで、登場するのがAWS AppConfigです。AWS AppConfigでは、アプリケーションがAWS AppConfigに設定情報を取得するAPIを呼び出す際に”ClientId"というパラーメータを渡して呼び出します。AWS AppConfigでは、設定変更のデプロイが行われれると一定期間、ClientIdを利用して、応答する値を調整します。具体的には、変更前の既存の値として応答するケースと、デプロイ要求された新バージョンの値の応答を、ClientIdをみて指定された割合で応答するようにします。したがって、100種類のClientIdで設定情報の取得が行われ、10%のみ新バージョンを応答する設定を仮にした場合、10個のClientIdは新バージョン、90個は旧バージョンの値を応答される形で試すことができます。この割合も徐々に増やすことをAWS AppConfigはサポートしており、アプリケーションモジュールのデプロイと同様に設定値のデプロイにおいても、徐々に増やし安全なデプロイをすることが可能です。設定方法はこちらのドキュメントを見ていただければと思います。
なお、設定情報を実際にデプロイする際には、設定情報をCode Commitで管理しその変更をトリガーにCodePipelineを起動して設定をAWS AppConfigに反映する方法がサポートされております。
その統合の構成手順はこちらで書かれているので実際に動かす際にご覧いただければと思います。4.3 設定値の切り戻し
さて、設定のデプロイをAWS AppConfigの機能と、アプリケーションのコーディングでClientIdを指定して呼び出すことにより徐々に範囲を拡大していったとしても何等かの不具合が発生し、設定を戻したいというケースがある場合、AWS AppConfigを利用すると、一定時間の間、事前に指定されたCloudWatch Alarmを監視し、Alarm状態になった場合は、次のステップには進まず、設定をもとの値に戻す動きが可能となります。
人の判断ではなく、CloudWatch Alarmを利用した判断であり、迅速に自動で元に戻すことができるため、より安全なデプロイを設定情報に対して実施することが可能になります。
5. AppConfigに反映された設定値の取得の注意事項
アプリケーションが設定値をAppConfigから取得するLambda関数内のコード(Pyhton)の例は以下の通りです。
app.pyclient = boto3.client('appconfig') id=str(uuid.uuid4()) envId=os.environ['EnvId'] def callAppConfig(version): config = client.get_configuration( Application="SampleApp", Environment=envId, Configuration="SampleConfigProfile01", ClientConfigurationVersion=version, ClientId=id )ポイントは2つあります。
1. ClientConfigurationVersionパラメータを指定していること
2. ClientIdを指定していること
です。5.1 AppConfigのAWSサービス利用料とget_configuration時のパラメータ
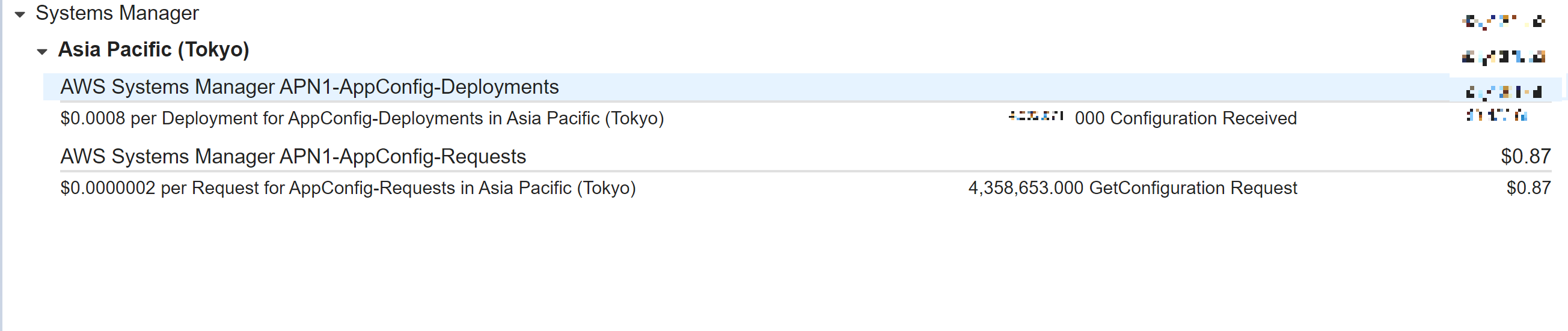
AWS AppConfigの利用料金はこちらです。2020年8月1日時点では、以下の通りです。
100万回、get_configuration APIコール当たり、0.2USD発生します。また、「受信した構成」については、1回につき「0.0008USD」発生します。
受信した構成について注意が必要です。
AWS AppConfigのget_configurationを呼び出す際には、「ClientConfigurationVersion」を指定できます。ただ、これは、事実上、必須パラメータだと誤認識いただいたほうが良いと私は考えます。
なぜなら、これを指定し忘れるとget_configurationを呼び出す都度、「構成情報を受信」、つまり、「受信した構成」の料金が0.0008USDが発生するためです。AWS AppConfigのget_configurationは、Version指定がない場合、現在の設定情報を応答します。その中には以下のような形式で現在のバージョン情報が含まれています。
ConfigurationVersion': 'e5aa23ff-0b57-49cd-bc10-f551cf245cc8'このバージョン情報を指定してget_configurationを呼び出す場合、それが現在のAWS AppConfigのバージョンと一致していればNoneを応答し、「100万回、get_configuration APIコール」の1回には該当しますが、「受信した構成」の対象にはなりません。
ということで、AWS AppConfigのAWSサービス利用料の最適化の観点から2回目以降の呼び出しについては、Version情報を設定することが重要です。
参考まで5.2 受信した構成情報のキャッシュの実装
私は、2020年8月1日時点で東京リージョンでget_configurationを呼び出した結果、応答時間は平均して200ms程度でした。
つまり、毎回get_configurationを呼び出していると処理の遅延が大きくなりますし、前述した通りAWS サービス利用料にも影響がでます。そこで、重要なのがアプリケーション側でのキャッシュです。get_configurationを呼び出し、Noneではなく設定情報を受け取った場合、TTL(Time to Live)を自身で管理・設定し、一定時間経過したら(例えば10秒)AppConfigのget_configurationを呼び出しNoneまたは、新たな設定を受け取る工夫をすることが重要だと考えます。AWS Lambdaの場合ではあれば、Global 変数としてConfigとConfigの有効期限を保持し、有効期限が切れた場合は、get_configrationするような関数を実装しておくことによって(例えばLayerを利用して)効率のよい設定値の取得が可能になると考えます。5.3 設定情報の取得時のClientId指定によるデプロイ戦略の恩恵
既に開設しましたが、設定情報を一括で反映する場合、影響範囲が大きくなる可能性があります。AWS AppConfigでは、一括反映もサポートしていますが、Exponetialなデプロイやリニアなデプロイが可能になっています。仕組みは応答する値をClientIdの値をみて判断するというものです。つまり、全インスタンスが同じClientIdを指定すると意味がありません。Lambdaであれば関数のインスタンスごとに異なるIdを指定することで効果を発揮します。例えば、UUIDをグローバル変数で関数初期化時に生成することで、関数インスタンスごとにユニークなIDとなり、デプロイ戦略の恩恵を受けることができるようになると思います。
設定値の取得の注意事項については以上です。
6. AppConfigの単位
当記事では解説しませんでしたが、設定情報を皆さんはバージョン管理していますか?バージョン管理をすることで、いつの時点でだれが変更したのか、過去の値は何が設定されていたのか確認することもできます。ですので、バージョン管理可能なGitHubやAWS Code Commitをご活用いただければと思います。CodeCommitからCodePipeline、そして、AppConfigの連携はこちらで解説されていますのでご確認ください。
さて、AppConfigをCodeCommitでバージョン管理し、デプロイメントパイプライン(CodePipeline)を利用し、かつ、AppConfigをつかってデプロイすると気になるのが、設定情報の単位です。どの単位で設定情報を構成するとよいのか?ということを悩むことになるかもしれません。「これがベスト!」という回答を私は現時点で持っていませんが、設定情報を利用するアプリケーション側の粒度と設定情報のコンテキストを考慮して決定するのが良いかなと思います。大量の設定を1つのファイルにまとめてデプロイすることももちろん可能ですが、メンテナンス性は関係ない変更を受け取るといった影響もでますので、「設定の管理」や「アプリケーション側の共通性」等を考慮して決めるとよいかと思います。7. まとめ。
AWS AppConfigについて使いどころを解説してみました。サービスの可用性を高めるためには「予防」と「検知」と「対応」が重要になると考えます。設定値を事前に検証してデプロイし予防をしておくこと、設定をリリースする範囲を限定化しておき全停止を予防しておくこと、そして、影響が出ていないかCloudWatch Alarmを利用して検知し迅速に戻す等の対応をすること、これが可用性を高めることにつながると考えます。せひ、運用性の向上の観点からAppConfigをご検討いただければと思います。

- 投稿日:2020-08-01T18:24:14+09:00
クラウドインフラ(AWS)を使う上で重要だと思ったこと
AWSなどのクラウドインフラを初めて使う人に向けて、個人的に重要そうだなと思うコンセプトとかを紹介する。
一般的なアーキテクチャをクラウドインフラで構築すること自体はそんなに難しくない(極論、webコンソールからポチポチすれば作れる)が、思想や背景などを理解していないと運用で困る羽目になるので、その辺りを理解することが重要だと考えていて、その手助けになれば幸いである。
1. マネージド・サービス
クラウドインフラでは基本的に、そのサービス自体の管理は全てクラウドベンダーがやってくれる。
クラウドインフラの利用者は面倒なミドルウェア/セキュリティのアップデートやログの出力やデータのバックアップなどをほとんど気にする必要がない。基本的にはクラウドベンダーが勝手にやってくれるor更新用のボタンをwebコンソールから押せば対応が完了する。
クラウドインフラ利用者にとっての利点としてはざっくり以下
- 煩雑なインフラ管理を任せられる
- インフラ管理の歴史はまた別の機会に紹介...
- 基本的にデフォルトで最適化されたサービスを利用できる
- 自分たちは貴重な時間をアプリケーションのビジネスロジックを組み込むことにより集中できる
注意点としては、サービス単体(例:RDS)のメンテナンスはしてくれるが、サービスの負荷や冗長化などは利用者が設計する必要がある(
クラウドベンダーの責任範囲で後述)。参考
2. マイクロサービス
AWSが出している各サービスはマイクロサービスで構成されている。
要はEC2もRDSもそれぞれ別のサービスであり、それぞれの責任を果たしている。
そのためクラウドインフラの利用者(我々ソフトウェアエンジニア)は、サービス毎の責任を理解した上で、それらをいい感じに組み合わせてサービスを作る必要がある。また、各サービスがマイクロサービス化されていることもあり、基本的にAPI経由でのアクセスが可能である。SDKなどを通してAPIベースでAWSの各リソースにアクセスすることが出来る(webコンソールからポチポチしなくて済む)。
(余談)
マイクロサービスが故、各サービス毎にwebコンソールでのお作法が違う。例えば、リソースの削除の際に
deleteと入力させるものもあれば、リソース名を入力させるものもある。良くも悪くもマイクロサービスなので、各サービスごとにルールなどは別になってる(AWSの中の人も言ってる)。3. クラウドベンダーの責任範囲
3-1. 責任共有モデル
AWSは公式で責任共有モデルというものを公開している(以下、公式から拝借)。要は、AWS側が負うべき責任範囲と、利用者が負うべき責任範囲を提示している。AWSはこの思想のもとにサービスを提供しているため、サービス利用者もこの考えのもと自分たちのアプリケーションを構築していく必要がある。
参考
3-2. SLA
一般的にソフトウェアにはSLA(Service Level Agreement)というものが定められている。
これはソフトウェアベンダーが「年間のサービスのダウンタイム(サービス障害などでサービスが使えない状態)を総稼働時間のN%以内となるように運用します」という感じのものであり、一般的には99.N%で設けられる。
これはAWSも持っていて、AWSのほとんどのサービス(100個以上!)でSLAが設定されてますにいい感じに載っている(殆どのサービスは99.9%を保証している)。
SLAを破ってしまった場合にはサービスクレジット返還がなされる。要は、返金処理で済まされる。
ただしサービスクレジット返還の対象になるには複数AZに対してサービスの配置を行ったり、複数エンドポイントへの接続が失われるなどベストプラクティスに準じている必要がある。
そのため、クラウドインフラは
落ちる前提で設計することが重要になる(冗長化とかの話に繋がる)。ただし、障害に対して入念に備えることは固定費の増加にも繋がるので、そこは組織のお財布や優先度によって調整するべき事項である(組織によって正解は変わる)。
4. 料金体系
AWSの料金体系はサービスによって異なるので一概には言えないが、基本的には
使った分だけ課金される。要は、リソースを起動させていた時間に対して課金されることが多い。リソースのインスタンスサイズ毎に料金が設定されており、使った分だけ加算される(課金は1分単位くらいだった気がする)。基本的には各サービスごとに料金体系が記載されているので、そちらを参考にすること。
例えば以下はEC2の料金表
参考
5. 情報源
基本的にはクラウドベンダーがサービス毎のチュートリアル/デザインパターン/ベストプラクティスなどを公開している。サービスは日々更新されており、最新情報に沿わないとうまく行かないこともあるので、Qiitaとかで調べる前に一度公式のものを覗いてみることをオススメする。
なお、サービスの性質上一般的なデザインパターンやプラクティスが適応できなさそうな場合には、AWSサポートで相談もできる(有料)。
参考


- 投稿日:2020-08-01T18:18:05+09:00
CodeBuildのテストレポート機能でコードカバレッジレポートがサポートされたから、また使ってケチつけてみた
TL; DR
結論から言えば、オススメです。
下記のような画面を見て、問題なさそうだと思った方は、是非とも使ってみてください。
現在では、未実行ラインを表示/確認ができません。
しかし、実装される未来は近い気がします。AWS様ありがとうございます、一生ついていきます!
ですが、あともう一声、お願いします!!!はじめに
2020年5月22日になり、テストレポート機能が一般公開されました。
それから早2ヶ月後の7月30日、ついに欲しかったコードカバレッジレポートのサポートがされました。
AWS CodeBuild がコードカバレッジレポートをサポート
この機能がどのようなものなのか、実際に動かして確かめてみたくありませんか?
ということで、実際に試してみます。なお、本記事は下記の続きとして記載しています。
よろしければ、下記もご覧ください。CodeBuildのテストレポート機能が一般公開されたから使ってケチつけてみた - Qiita
事前準備
コードカバレッジレポートってなんやねん、という方は、ざっと流し読みしてみてください。
コードカバレッジレポート
ここでいうコードカバレッジレポートは、テスト実行時のソースコードカバレッジ(網羅率)を集計したファイルのことです。
カバレッジ(網羅率)分析とは | ソフトウェアの検証の種類 | テクマトリックス株式会社
JaCoCoが有名ですが、それ以外にも多くのフォーマットがあるみたいです。
CodeBuildのレポート機能では、上記コードカバレッジレポートファイルを組込むことで、カバレッジを可視化できます。
似たようなサービスとして、 Codecov や Coveralls が挙げられますね。実際に試してみた
CodeBuildで、テストレポート機能におけるコードカバレッジレポートの表示動作確認をしてみましょう。
なお、CodeCommitとCodeBuildのプロジェクトの新規作成については、 以前の記事で記載 しているため、省略します。
CodeCommitにソースコードをプッシュする
CodeCommitに、CodeBuildでビルドするためのソースコードをプッシュします。
動作確認ができればなんでも良いので、好きな言語で試してみましょう。
つまり僕は、前回同様Perlで試してみるわけです。ディレクトリ構造は、下記の通りです。
CodeCommitリポジトリのディレクトリ構造test-reports-sample/ |- buildspec.yml # CodeBuildの実行ファイル |- lib/ | |- sample.pm # テスト対象コード(モジュール) | |- t/ |- sample.t # テストコードまず、テスト対象コードです。
lib/sample.pmuse strict; use warnings; use utf8; package Sample; sub get_one { my ($self, $is_true) = @_; print "True¥n" if $is_true; return 1; } sub get_two { return 2; } 1;このうち、ブランチカバレッジの表示用に書いている箇所は
print "True¥n" if $is_true;の部分です。
$is_trueは引数に応じて変化します。
引数が真の場合 (Perlなので1などを引数に設定した場合)、print "True¥n"が実行されます。次に、テストコードです。
t/sample.tuse strict; use warnings; use utf8; use Test::More; use lib 'lib'; use sample; subtest 'サンプルテスト' => sub { my $test = "pass"; ok $test; }; subtest 'サンプルテスト2' => sub { my $expected = 1; my $actual = Sample->get_one; is $actual, $expected; }; done_testing;
サンプルテストについては、以前のコードと同じため、説明は省略します。
use lib 'lib';にてlib/ディレクトリにパスを通し、use sampleでlib/sample.pmモジュールをインポートします。
また、サンプルテスト2におけるSample->get_oneにより、lib/sample.pmモジュールにおけるget_one関数を実行します。下記2点がポイントです。
get_two関数を呼出していないif $is_trueは真になり得ず、ブランチカバレッジは100%にならないCodeBuildでは、buildspec.ymlファイルにより動作を定義できるため、こちらも作ります。
buildspec.ymlversion: 0.2 phases: install: commands: - curl -L https://cpanmin.us/ -o cpanm && mv cpanm /usr/bin/cpanm && chmod +x /usr/bin/cpanm - curl -fsSL --compressed https://git.io/cpm > cpm && mv cpm /usr/bin/cpm && chmod +x /usr/bin/cpm build: commands: - cpm install -g TAP::Harness::JUnit - cpm install -g Devel::Cover::Report::Clover # - prove -lv -j5 --harness TAP::Harness::JUnit sample.t # テストレポートだけを出力する場合のコマンド - HARNESS_PERL_SWITCHES="-MDevel::Cover=+ignore,^t" prove -lvr -j5 --harness TAP::Harness::JUnit t - cover -report clover reports: sample-test-report: files: - junit_output.xml sample-coverage-clover-report: file-format: CloverXml files: - cover_db/clover.xml
Devel::Cover::Report::Cloverモジュールをインストールすることで、Clover形式のXMLを出力できます。
HARNESS_PERL_SWITCHES="-MDevel::Cover=+ignore,^t" prove -lvr -j5 --harness TAP::Harness::JUnit tコマンドにて、junit_output.xmlテストレポートファイルを生成し、同時にテストカバレッジを計測するためcover_dbディレクトリを生成します。
その後cover -report cloverコマンドにて、Clover形式のXMLであるcover_db/clover.xmlファイルを生成します。上記
cover_db/clover.xmlファイルを、reportsにおけるsample-coverage-clover-reportにて、CloverXmlフォーマットを指定して設定します。
以降、前回との差分とPerl固有の内容についての詳細です。
前回のCodeBuildイメージは Amazon Linux だったためか、なぜか依存モジュールをインストールしてくれなくて大変な思いをしました。
今回は Ubuntu イメージにしたことで、expat-develのDebian版ライブラリlibexpat1-devをインストールする必要がなくなり、必要なPerlモジュールだけをインストールするだけで依存モジュールのインストールもしてくれました。
また、Devel::Coverモジュールのcoverコマンドには、JSON形式のコードカバレッジレポートファイルを生成してくれます。
しかし、CodeBuildのテストレポート機能で対応しているSimpleCov JSON形式とは異なるため、正常に読み込んでくれません。
Devel::Cover::Report::Clover以外であっても、CodeBuildのテストレポート機能が対応している形式で出力してあげれば、正常に読み込んでくれると思います。
- CodeBuildに関するもの
- Perlに関するもの
- cover - report coverage statistics - metacpan.org
- Devel::Cover - Code coverage metrics for Perl - metacpan.org
- Devel::Cover::Report::Clover - Backend for Clover reporting of coverage statistics - metacpan.org
- 第49回 CPANモジュールの品質を支えるCI技術(3):Perl Hackers Hub|gihyo.jp … 技術評論社
- lib - モジュールの検索パスを追加 - Perlゼミ
- perl - How to install XML::Parser without expat-devel? - Stack Overflow
CodeBuildで自動テストする
上記3ファイルを入れたリポジトリで、CodeCommit経由でCodeBuildを走らせます。
CodeBuildによるビルドは、手動で構いません。CodeBuildでビルド通過後にテストレポートを確認する
CodeBuildでビルドが完了したら、テストレポートを確認しましょう。
CodeBuildにtest-reports-sampleビルドプロジェクトを作成し、ビルド結果のレポートタブを開きます。
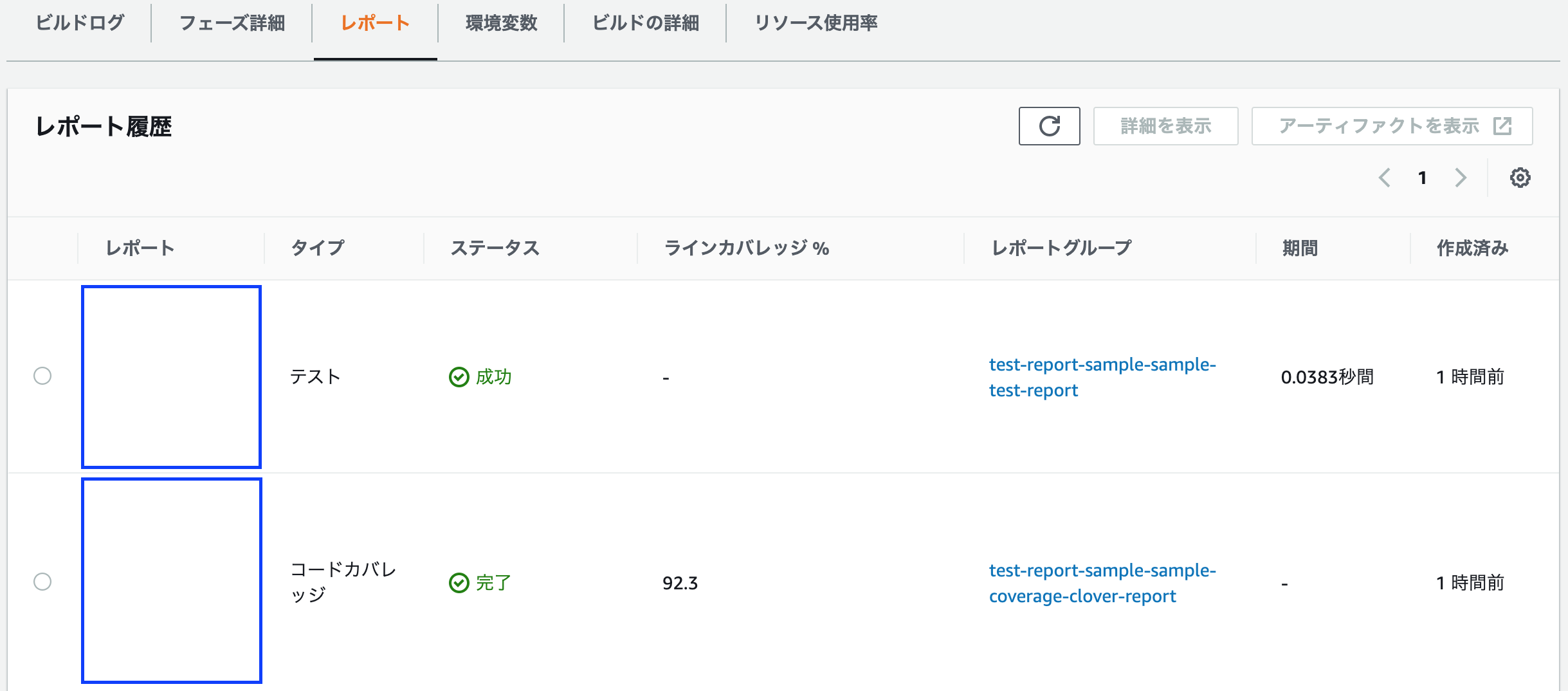
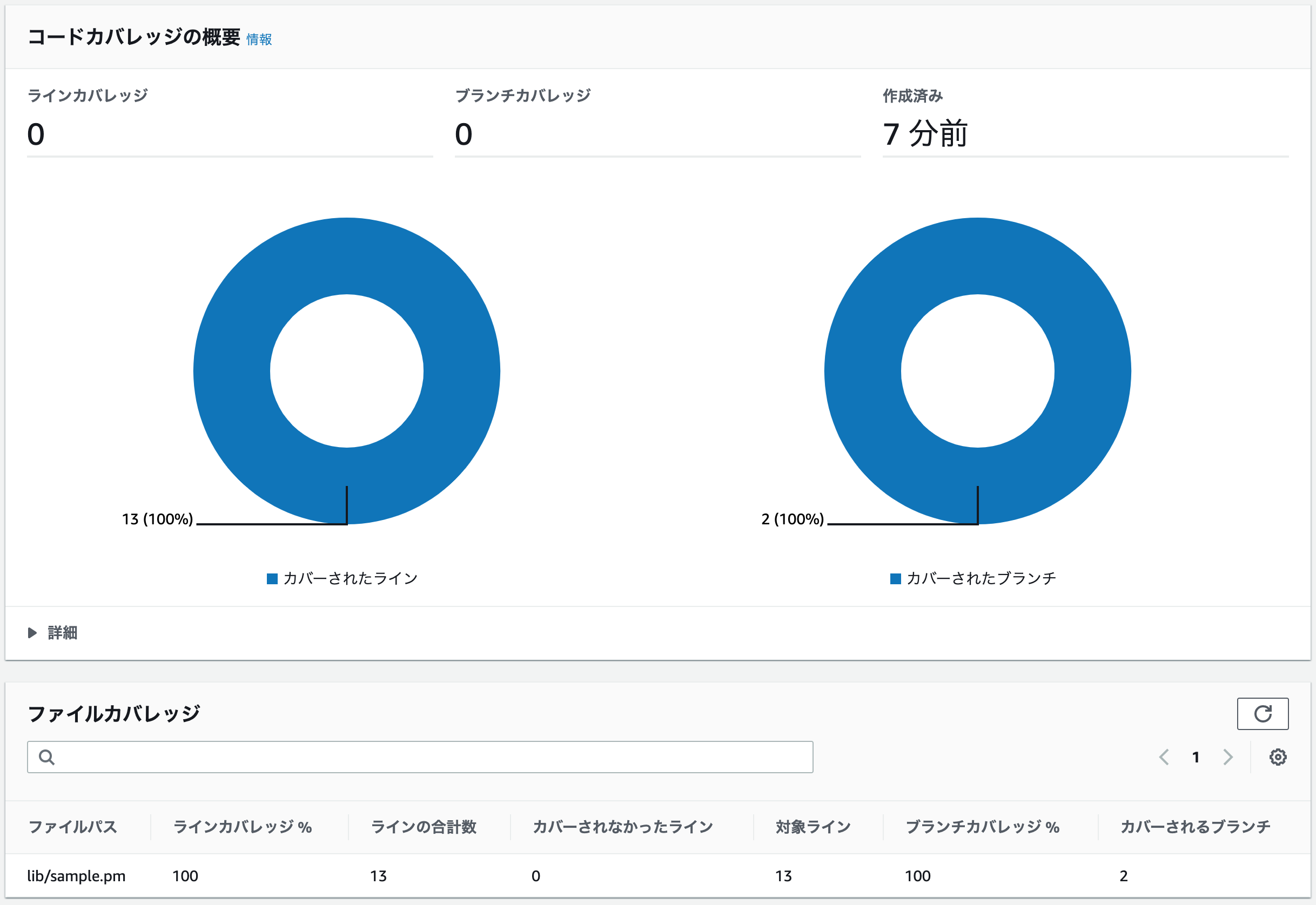
以前までの画面とは異なり、「タイプ」という項目が追加されています。
また、タイプの中身として「テスト」と「コードカバレッジ」の2種類が存在することがわかります。では、コードカバレッジである
test-report-sample-sample-coverage-clover-reportグループのレポートを見てみましょう。
カバレッジ測定結果として、ラインカバレッジとブランチカバレッジの円グラフがデカデカと載っていることがわかります。
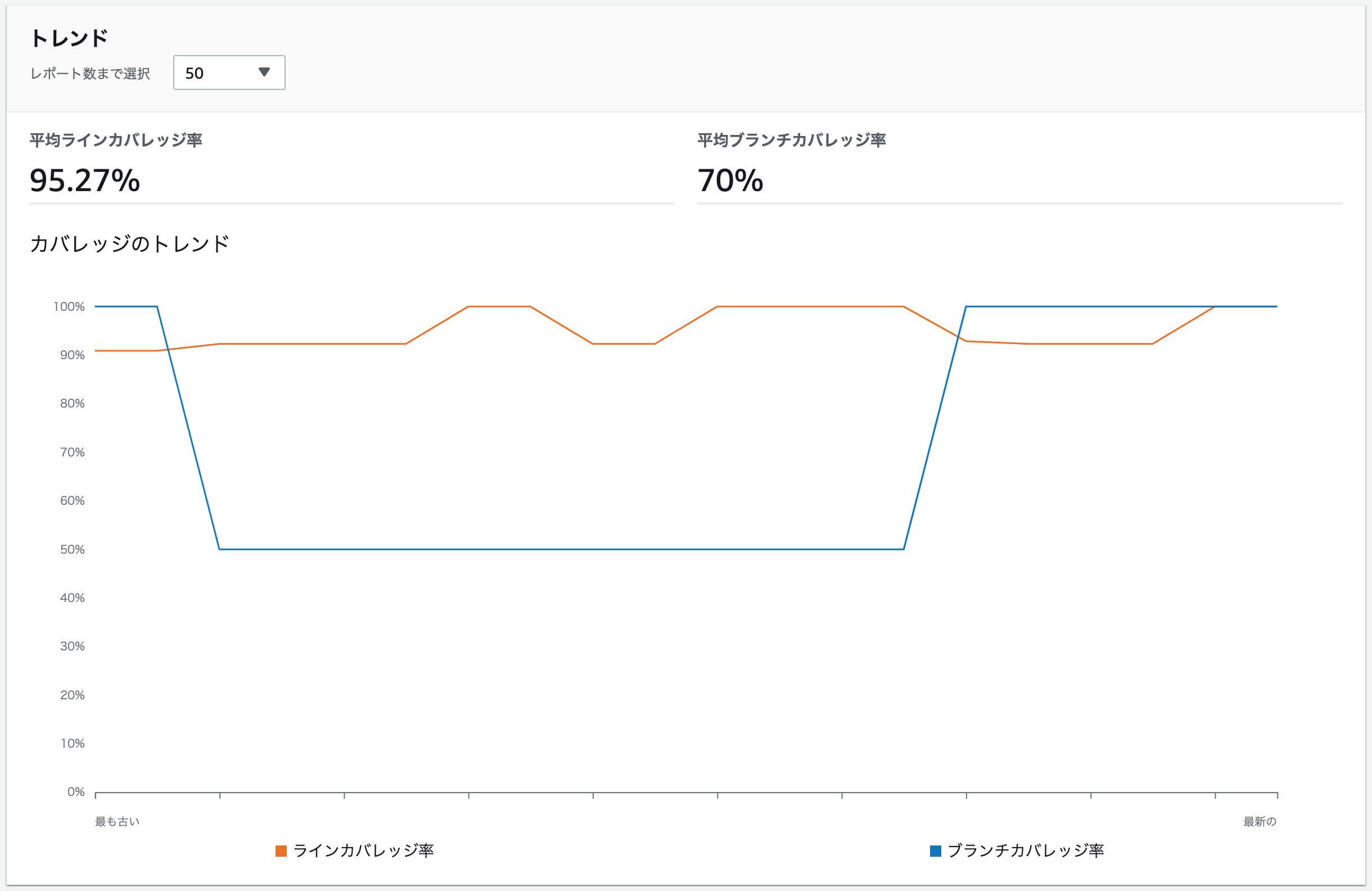
また、lib/sample.pmファイルを計測していることが、一覧で表示されていることがわかります。レポートグループ画面は、下記の通り(再掲)です。
カバレッジの履歴が一眼でわかります。
平均の数値はよくわかりませんが、こっちは便利そうですね。
ただ、ここでわかりづらいのですが、ラインカバレッジとブランチカバレッジは独立している、という点です。
それぞれについて、説明します。ラインカバレッジとブランチカバレッジの解説
以降は、Perlにおける
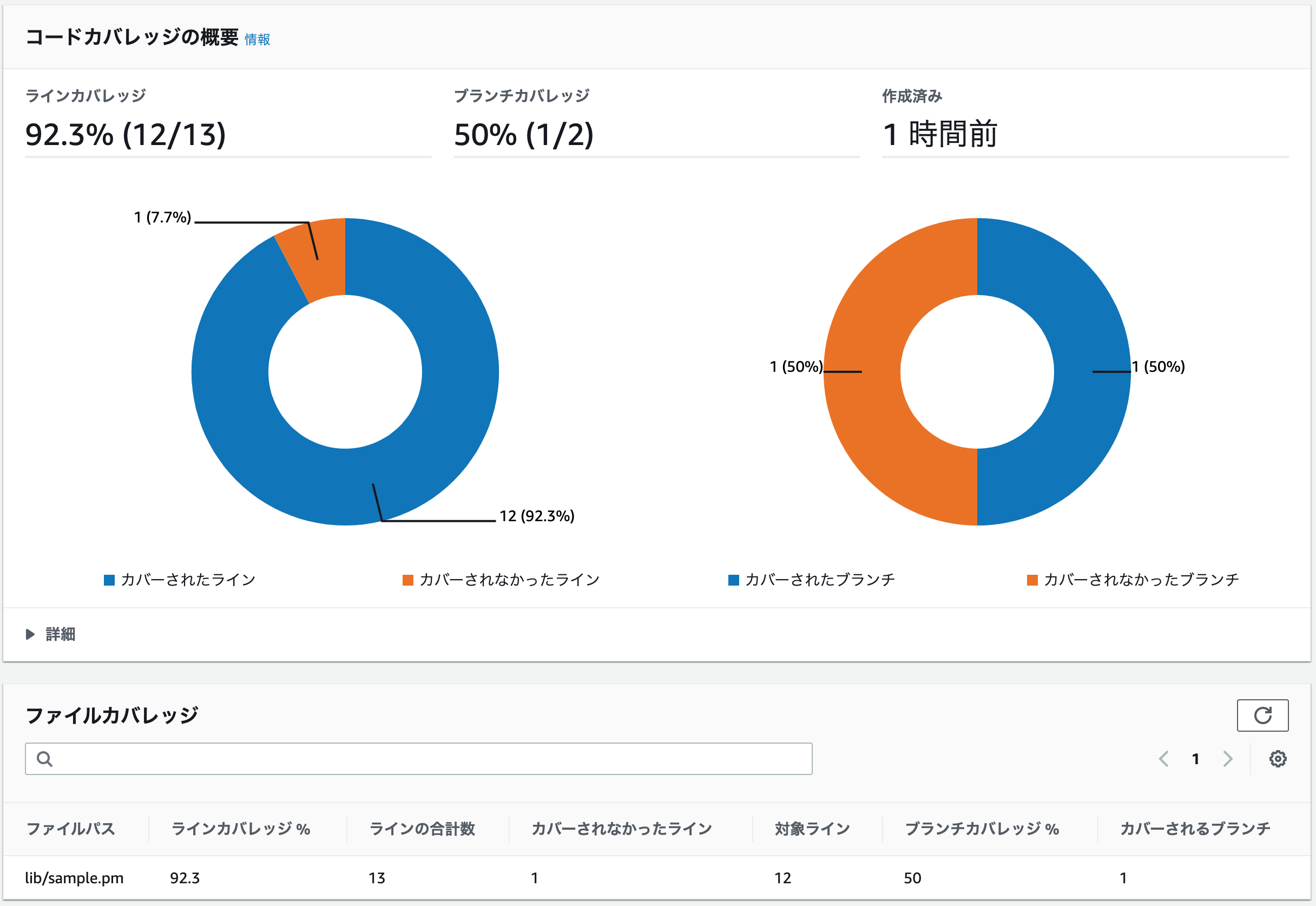
Devel::Coverモジュール固有の問題である可能性もあるので、話半分で聞いてください。ラインカバレッジの項目では、1行だけ実行されなかったことがわかります。
ここでいう未実行の1行とは、get_two関数におけるreturn 2;の行のことを指します。その証拠に、
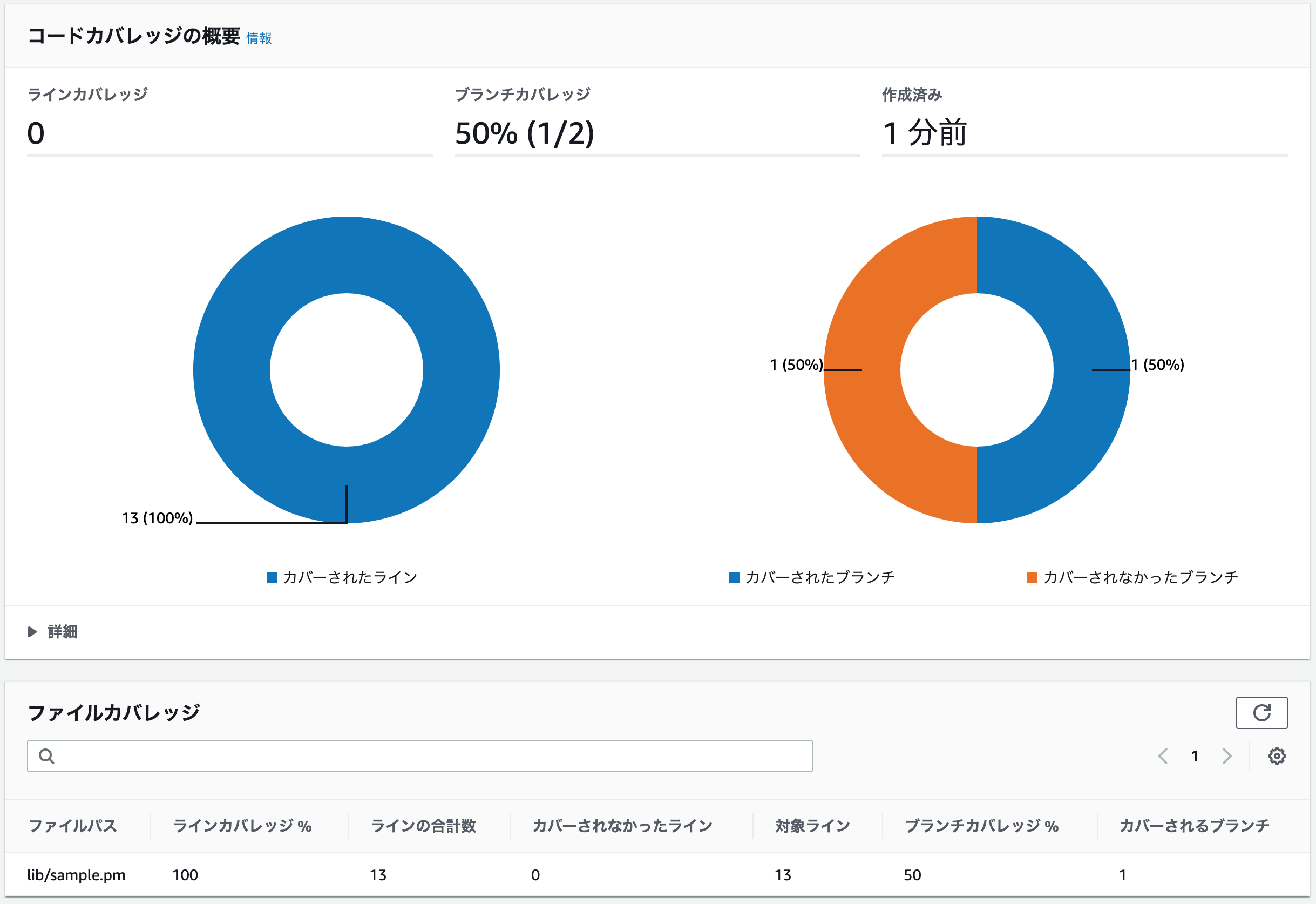
get_two関数を呼出すテストコードを追記した場合、下記のような画面になります。サンプルテスト3を追加したテストコード(抜粋)subtest 'サンプルテスト3' => sub { my $expected = 2; my $actual = Sample->get_two; is $actual, $expected; };
ラインカバレッジ0って何......?
つまり、
print "True¥n" if $is_true;の行におけるprint "True¥n"は実行されていないにも関わらず、行単位では実行しているためにラインカバレッジは100%になった、というわけです1。一方、ブランチカバレッジは2つしかありませんが、そのうち1つは
print "True¥n" if $is_true;の$is_trueが 真である場合の実行分岐を指しています。その証拠に、
$is_trueが真になるget_one関数を呼出すテストコードを追記した場合、下記のような画面になります。
サンプルテスト3は、スキップして実行します。サンプルテスト4を追加したテストコード(抜粋)subtest 'サンプルテスト3' => sub { plan(skip_all => 'ignore test'); # サンプルテスト3はスキップする my $expected = 2; my $actual = Sample->get_two; is $actual, $expected; }; subtest 'サンプルテスト4' => sub { my $expected = 1; my $actual = Sample->get_one(1); is $actual, $expected; };
ブランチカバレッジ0って何......?
ここで注意すべき点としては、ブランチカバレッジはラインカバレッジの上位互換ではない、という点です。
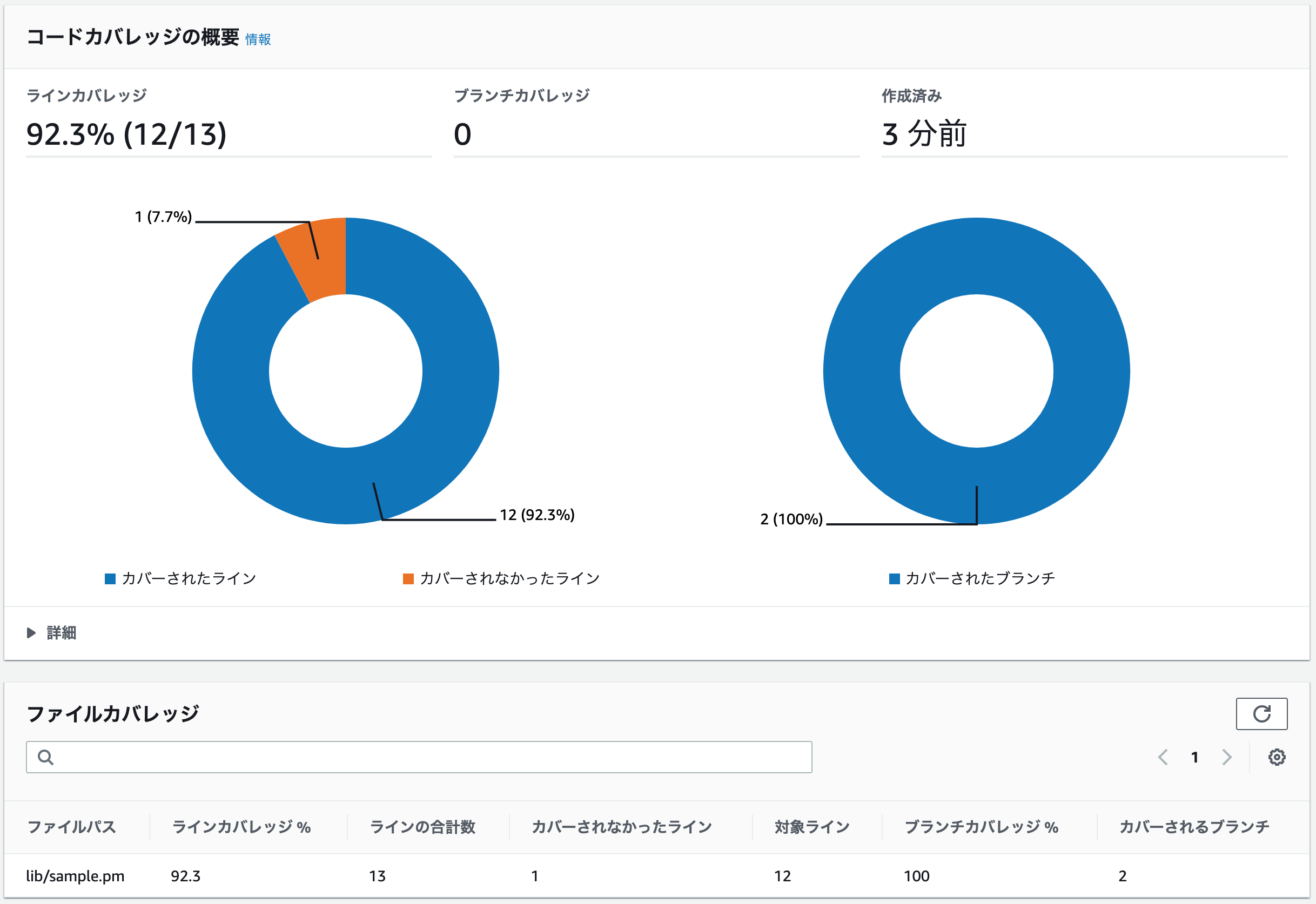
$ C0 \leqq C1 $ という不等式が成立しない点に注意してください。ちなみに、全てのカバレッジを100%にすると、下記のような表示画面になります。
CodeBuildテストレポート機能の利点/欠点
機能自体は理解できたので、CodeBuildテストレポート機能におけるコードカバレッジレポートの利点と欠点を、それぞれ書いていきます。
利点
前回と被る面もありますが、利点を挙げていきます。
グラフィカルなUIでテスト結果が確認できる
以前までは、CodeBuildのテスト結果は全てCloudWatch LogsのCUIライクな表示でしか確認できませんでした。
テストレポートだけでなくコードカバレッジレポートもグラフィカルに表示できることで、テストレポートの必要最低限の機能は満たせたのではないかと考えます。折れ線グラフがわかりやすい
僕の書いた記事を、AWSの中の人が読んでくださったのか定かではありませんが、折れ線グラフが非常にわかりやすいです。
折れ線グラフであれば直近のカバレッジが見えますし、どれだけカバレッジを増やしているかも一目瞭然です。https://qiita.com/Morichan/items/d747f429067c082bc982#平均テスト通過率平均実行数の意味がわからない
別サービスを契約しなくて良い
現在の機能だけでも、CodecovやCoverallsなどの別サービスを契約する必要性は下がります。
CodeCommitを使う際はプライベートリポジトリの場合が多いため、プライベートリポジトリの場合は有料契約になってしまう上記サービスを使わなくても良い点は、利点としてかなり大きいと思います。欠点
いくつか気になる点はあるので、
(また、タイトルでもケチつけると書いちゃったので、)粗探しをします。
ただ、前回よりはずいぶんよくなったと思います。平均ラインカバレッジ率/平均ブランチカバレッジ率の意味がわからない
直前以外の平均ラインカバレッジ/平均ブランチカバレッジも、あまり使わない気がします。
大事なのは、直前のカバレッジだと思うのですが、なぜ平均値を出しているのか、よくわかりません。
しかも、1度でもテストで失敗してしまうと(理論上)100%には二度と戻らないのも、悲しいです。
単純に、最新カバレッジを表示するのではダメなのでしょうか?あと、ちょっとしたことですが、カバレッジ率を日本語に訳すと網羅率率ですか???
平均ラインカバレッジ/平均ブランチカバレッジが100%の時の表示が気になる
せっかく頑張って100%にしたのに、
0は悲しいです。
ここは100%にしてほしいなーと思います。レポートグループタイプが固定
一度レポートグループを作成してしまうと、作成したレポートグループのタイプを変更できません。
レポートグループタイプおよびレポートタイプは、
TESTとCODE_COVERAGEの2種類があります。
レポートタイプは、buildspec.ymlで指定したfile-formatで、下記に依存して自動的に設定されます。The following test report file formats are supported:
- CucumberJson
- JunitXml
- NunitXml
- TestNGXml
- VisualStudioTrx
The following code coverage report formats are supported:
- JaCoCoXml
- SimpleCov
- CloverXml
- CoberturaXml
前者が
TEST、後者がCODE_COVERAGEとして、内部処理で分けているみたいです。また、レポートグループタイプは、最初に
buildspec.ymlでレポートを自動生成する際に設定したfile-formatの値に依存したタイプが、これまた自動的に設定されます。レポートグループタイプは(AWSマネジメントコンソール上でも)変更できないため、レポートグループを削除する or レポートグループ名を変更する、いずれかをしない限り、次のようなエラーが発生し、CodeBuildがエラー終了します。
CLIENT_ERROR: Error in UPLOAD_ARTIFACTS phase:
[CoverageReports: [error creating report: InvalidInputException: Report group type doesn't match expected report type, report group type is TEST, but report type is CODE_COVERAGE]]翻訳結果:
CLIENT_ERROR:UPLOAD_ARTIFACTSフェーズのエラー:
[CoverageReports: [レポートの作成エラー: InvalidInputException: レポートグループタイプが予期されるレポートタイプと一致しません。レポートグループタイプはTESTですが、レポートタイプはCODE_COVERAGEです]]つまり、最初に
file-formatを間違えて設定してしまうと、以降はCodeBuildのフェーズエラーを見ない限りエラー内容に気付けません。
最初に使おうと試行錯誤している利用者には、思わぬ落とし穴になりそうです。すみませんが、この問題の解決策はすぐには思いつきそうにありません。
今後のアップデートに期待します。おわりに
タイトルでは貶しているように見えたらごめんなさい。
中身としては、結構ベタ褒めで書いたつもりです。それだけ、僕はこの機能を求めていました。
AWSの中の人、本当にお疲れ様です!今後もアップデートがあると信じて、期待しましょう!!!
ラインカバレッジの定義としては、別に間違っていません。これに気をつけるために、ブランチカバレッジという物があるわけです。 ↩
- 投稿日:2020-08-01T17:57:17+09:00
VPC内でLambda to Athenaを実現する
はじめに
VPC内で全体的に終わらせる方法がまとまってなくてめちゃくちゃハマったので、ここでまとめておきます。
今回のゴール
VPC内にあるAthenaに対してLabmda上からクエリを正常に投げて結果を取得する。
Security面の細かい話はここでは触れないので、ご了承ください。Athenaを使えるようにする
Ahtenaの前にS3の準備
AthenaはS3上のファイルに対してSQLを投げれる仕組みみたいな感じのサービスになっています。
なので、まずはS3の準備を行います。と言っても普通にバケットを作成するだけです。
ただし、今回はVPC内で全てを完結させたいので、「パブリックアクセスをすべてブロック」で作成するものとします。S3のVPCエンドポイントを作成する
S3にVPCから繋ぐにはエンドポイントが必要なので、VPCサービスからVPCエンドポイントを作成します。
この際のVPCには今回閉じ込めておきたいVPCを指定しておいてください(この後特に言及しませんが、VPC指定する際は全てこのVPCを設定してください)。サブネットは分かるまで全部設定しておけば良いと思います。
Athenaのテーブルを作成する
繋ぐ先ができたので、Athenaの設定をやっていきます。
Athenaの設定は基本的にAthenaの画面上から可能です。Athenaの画面上からテーブルの作成に移りたいのですが、初期はよく分からないのと色んなリンクが足りてないため(一度作ると困らないので、その画面はもう見えませんが)、右上のチュートリアルから作成するのが良いと思います。
テーブルの中身は今回は特に問わないので、適当に作ってください。
ファイル形式もCSVとかTSVとかで大丈夫です。AthenaのPartitionの話
RDBでいうIndex付きのカラムみたいな感じで考えると良いかなと思います。
S3内ではこのPartitionに沿ってフォルダが構成され、ファイルが配置されます。Athenaの料金体系的にスキャンしたサイズによってちゃりんちゃりんするという仕組みになっています。
Partitionをつけなかったり多くのPartitionを検索しまくると多くのお金がかかる形になるため、プロダクションで使うには必須と言える機能となっています。しかし、Partitionに分けすぎるとSELECT時に多くのファイルを読み込むため性能が劣化すると言われていたり、INSERT時に制約に引っかかる可能性(1回のINSERTで100個のPartitionにしかInsertできない)もあるため、ここはしっかり設計する必要があります。
INSERTしてSELECTしてみる
あとはデータ入れて取得してみてください。
普通にINSERTとSELECTが出来るので、少量のデータを入れて取り出せます。ここで失敗するのであればVPCエンドポイントが作られていないくらいしか考えられません。
Lambdaの設定をやっていく
まずは関数を設定してください。
言語はどれでも問題ありませんが、私がいつもPythonで作っているため、コード上の説明はPythonで説明します。
ロールについては新設している前提で書きます。Lambdaの設定(タブ編)
セキュリティタブの設定は下記に書くIAMのロール設定の箇所なので割愛します。
基本情報
ここは実行してからいじっていけば良いと思います。
IAMの説明だけしておきます。Athenaを使うためのIAMロール
既存のポリシーをアタッチする前提とすると
AmazonAthenaFullAccessとAWSLambdaVPCAccessExecutionRoleを追加しておけばOKです。
本当なら(特に)Ahtena周りはLambdaで使用する権限のみを渡した方が良いとは思いますが、とりあえずの設定ということでフルにして話を進めます。VPC
今回使っているVPCを選択してサブネットは全部選択しておいてください。
セキュリティグループの設定は以下に書いておきます。セキュリティグループの設定
ちょっと通信がどのポートなのか微妙にわかってないので、とりあえずフルオープンの設定。
(多分443でやっているとは思っているのですが、まだ試せてません。)本当はポート範囲とかはしっかり設定した方が良いです。
タイプ: すべてのトラフィック プロトコル: 全て ポート範囲: 全て ソース: 自分自身を設定しておいてください。コードをローカルで作成する
実行環境はlambda-dockerのようにDocker上で実行できる環境もありますが、ライブラリ読み込めなかったことがあったり別でlambda-docker用の環境用意したりが面倒という理由であんまり使ってません。
もちろんLambdaをテストでも実行するとちゃりんちゃりんしないといけないので、そこらへんはご自身の状況と照らしわせてください。【参考URL】
https://qiita.com/anfangd/items/bb448e0dd30db3894d92Lambda環境でライブラリを使用する
Lambda環境でpipは使えないため、ローカルでインストールしたものをコードと一緒にアップロードしてあげる必要があります。
今回はよくあるboto3ではなく、lambda-pyathenaというLambda環境でAthenaを簡単に使用するためのライブラリがありそれを使います。
ローカル上では以下のコマンドように-tオプションでソースコードと同じ場所にインストールしておけばOKです。pip install lambda-pyathena -t .【参考URL】
https://pypi.org/project/lambda-pyathena/実コード部分
pythonコード部分はシンプルです。
from pyathena import connect import os def lambda_handler(event, context): cursor = connect(aws_access_key_id="YOUR ACCESS KEY", aws_secret_access_key="YOUR SECRET ACCESS KEY", s3_staging_dir="S3 PATH FOR RESULT", region_name=os.environ['AWS_REGION'], work_group="YOUR WORK GROUP", schema_name="YOUR SCHEMA").cursor() cursor.execute("SELCT * FROM USERS;") print(cursor.description) print(cursor.fetchall()) return {}aws_access_key_idとaws_secret_access_keyについて
Athenaに繋ぐにはLambdaが実行する際に設定される環境変数ではダメでした(なぜかは分からない)。
なので、セキュリティ認証情報メニューからアクセスキーを発行して設定してあげる必要があります。region_nameについては文字列で設定できますが、大抵は同じreasionにあると思うので、環境変数からとるコードにしています。
work_groupとschema_nameについて
これはAthena見ればすぐ分かります。
execute出来るSQL
SELECTとINSERTは可能ですが、他は(多分)出来ません。
SELECTはきちんとPartition設定して設定しないと破産するとかINSERTが遅いとか注意点はありますが、知ってるやつで取得できるのは楽ですね。
CREATE TABLEも出来ますが、あんまりLambdaからはやらないかなと思って省きました。
細かいところはLambdaの仕様書やlambda-pyathenaの仕様書読んでください。コード書き終わったあと
コードを丸ごとZip化してアップロードします。
ただし、アップロードしてもまだ実行できません。
正確にいうと、実行してもAthenaへの接続部分でタイムアウトします。エラーが出てくれないので、ここでマジハマりました。
AthenaとGlueのVPCエンドポイントを設定する
Athenaはデータの管理をGlueでやっています。
Glueで見ると上で作ったデータベースやテーブルがあるかと思います。この2つにVPC内から繋ぐにはVPCエンドポイントを設定する必要があるため作成しておきます。
サービスカテゴリ: AWS サービス名: com.amazonaws.ap-northeast-1.athena, com.amazonaws.ap-northeast-1.glue VPC: 今回使用しているVPC サブネット: 全部チェック プライベート DNS 名を有効にする: チェックする セキュリティグループ: Lambdaと同じセキュリティグループ実行
これで全ての設定が終わったのでLambda上から実行しましょう。
パラメータを渡すことができますが、簡単なのでここでは割愛します。無事思った通りの動作をしたら設定は完了です。
終わりに
VPC内のLambdaの話が全然なくてめちゃくちゃハマりましたが、とりあえず出来た良かった。
- 投稿日:2020-08-01T17:53:47+09:00
[感想]AmazonWebServicesエンタープライズ基盤設計の基本
予備知識レベル
私の知識レベルとしては、このような感じです。
- 2019年よりサーバサイド開発
- 下記のAWS関連の書籍を読んだ
- Amazon Web Services 基礎からのネットワーク&サーバー構築
- AWSをはじめよう
- 業務ではほぼAWSは触らない
- プライベートで開発したシステムをAWSでデプロイしたことはある
上に挙げた2冊のAWS書籍は、いろいろな方がおすすめしているのを見て、amazonでも評価が高かったので購入しました。どちらも予備知識がなくても読み進められるように丁寧に解説されていて、最初の1冊としては大正解だったと思っています。
今度はブログシステムをAWS上で動かすだけでなく、ストレージの使い分け、負荷分散の方法、オートスケーリングの構築方法などを学びたいと思い、掲題の書籍を購入しました。
感想
基板設計のベストプラクティスだけでなく、なぜそれがベストプラクティスなのかが丁寧に解説されていて、理屈がないと覚えられない自分にとっては大変ありがたかったです。
それまでAWSの認定資格には興味をもったことがなかったのですが、この本を通じて基板設計の重要さと面白さを実感して、挑戦してみたい気持ちになりました。ちなみに、2016年のアメリカの調査では、稼げるIT関連資格の1位が「AWS認定アソシエーションアーキテクト-アソシエイト」だったらしいです。
以降は、章ごとに感想を書いていきます。
※ 間違って理解している箇所などありましたら、ご指摘いただけると大変嬉しいです
リージョン選びとネットワークの設計
この本を読むまでは、VPCはインスタンスを起動するために必要な場所、という程度の理解でした。
VPCは仮想ネットワークのことですが、複数のアベイラビリティゾーンを横断することができます。これはオンプレミス環境でいえば、複数のデータセンタを横断するプライベートなネットワークを構築することに相当し、実はすごいことなんじゃないか、と認識が変わりました。
リージョンの選び方
リージョンの選び方については、「ユーザが日本に住んでいたら東京リージョンでしょ」と簡単に考えていましたが、社内規定などでデータ保管場所や方法に制限がないか、使用したいAWSのサービスや機能が東京リージョンにも導入されているかなど、事前に考えなければならないことがあることがわかりました。サービスの価格もリージョンによって異なるので、その点も注意するほうが良さそうです。
メインルートテーブルを直接編集しない理由
VPC内のサブネットからインターネットに接続できるようにするには、ルートテーブルと呼ばれるトラフィック経路の定義にインターゲットゲートウェイのルートを追加する必要があります。
VPCを作成すると、メインルートテーブルが自動で作成されますが、「インターネットゲートウェイのルートを追加する場合は新たにカスタムルートテーブルを作成する」とこれまで読んだ書籍に書かれていました。メインルートテーブルを使わず、なぜ新たにルートテーブルを作る必要があるのか、と疑問に思っていたのですが、これは事故防止のためらしいです。新たにサブネットを作成すると、自動的にメインルートテーブルが関連づけられるので、意図せずパブリックなサブネットになってしまうからです。
セキュリティグループとネットワークACLの違い
VPC内のアクセス制御には、セキュリティグループとネットワークACLの2つの方法があります。
これら2つともファイアウォールだと紹介されていました。ファイアウォールというと、インターネット経由で侵入する不正なアクセスから守るための防火壁、などと別のところで説明されていたのを何度か読みましたが、具体的な働きをようやく理解できたと感じました。
セキュリティグループ
- インスタンスごとのアクセス制御
- ステートフル
- インバウンドはデフォルトで遮断
- アウトバウンドはデフォルトで許可
ネットワークACL
- サブネットごとのアクセス制御
- ステートレス
- デフォルトで許可
ざっくりとですが、上記のような違いがあるらしいです。
ステートレスという言葉は、最初どういう意味かわかりませんでした。Webサーバに対して、ユーザのセッション情報などを保持しない、という意味で使われているのは見たことがありましたが、ステートレスなファイアウォールという表現は初めてでした。
ステートレスというのは、リクエストを受けた際に、ポート情報などの接続に関する情報を保持することを指すようです。これにより、たとえばインスタンスからリクエストを送信した場合、そのリクエストに対するレスポンスは確立済みの接続として扱われるので、インバウンドルールで制限されていたとしてもファイアウォールと通過できるようです。
セキュリティグループとネットワークACLの使い分けについては、正直よくわからなかったので、下記の記事を参考にしました。AWSサポートの方が書かれている記事です。
当該セグメントのインスタンスすべてに共通する通信だけを大きくネットワークACLで許可し、各インスタンスへのアクセスはセキュリティグループで細かく制限する、という方法によって、比較的安全で楽に運用できるかと思います。
セキュリティグループは、APサーバ用、DBサーバ用と用途ごとに作成しておくことが一般的らしいです。
たとえばAPサーバを追加したときは、APサーバ用のセキュリティグループを適用するだけで、特に設定を変更せずにDBサーバに接続できるようになるため便利なようです。
仮想マシンとオブジェクトストレージ
仮想マシンはEC2ですが、オブジェクトストレージという言葉は初耳でした。
この本では、EBSなどのブロックストレージとS3などのオブジェクトストレージについて解説されています。AWSのストレージサービスには、他にEFSなどのファイルストレージがあるのですが、それについては触れられていなかったと記憶しています。
EBSとS3の使い分け
EBSはElastic Block Storeの略なのでブロックストレージ、S3はオブジェクトストレージです。
ブロックストレージでは、データを複数のブロックと呼ばれる単位に分割して保存するため、ファイルの一部を変更する場合は当該ブロックだけを書き換えればよいため、更新が高速で、使用する帯域幅が少なく済むそうです。
オブジェクトストレージは、ファイルとメタデータを合わせたオブジェクトという単位でデータを扱うため、テキストファイルの1文字を変更するだけでも、ファイル全体の更新が必要になるようです。ブロックストレージよりも低速ですが、容量は無制限で従量課金制であるため、拡張に柔軟な点が利点といえそうです。
次のように使い分けると良いらしいです。
- EBS
- 更新頻度が高く、低遅延が求められるデータ
- EC2インスタンスのブートボリュームやDBデータ領域など
- S3
- 更新頻度が低く、増え続けるデータ
- 画像や動画、アプリケーションのログなど
コンテンツをS3に移動するメリット
S3を使用するメリットをまとめてみました。
- VPCから独立しているため、S3を使うことでEC2インスタンスのネットワーク負荷を抑えられる
- ネットワーク負荷を抑えた結果、Eより安価なインスタンスタイプに変更できる可能性がある
- 容量が実質的に無制限であるため、EBSのように上限を気にする必要がない
- 自動的に3つ以上のデータセンターに冗長化されるため、バックアップを取る必要がない
このように、S3を使用するメリットは多いので、使用できる場面があれば積極的に使用していきたいなと思いました。
インスタンスストアって何?
EC2インスタンスを起動すると、インスタンスストアと呼ばれるストレージが割り当てられるようです。これはインスタンスの料金に含まれ、選択したインスタンスタイプにより容量が決まるようです。
注意しなければならないと感じたのは、インスタンスストアに保存したデータは永続化されないという点です。障害などでインスタンスが削除されたりすると、インスタンスストアも同時に削除されます。そのため、永続化する必要のあるデータは、インスタンスの外付けストレージであるEBSに保存したほうが良さそうです。
インスタンスのバックアップの取り方
インスタンスのOSやアプリケーションのデータをどう保持しておくとよいのか、自分なりに整理してみます。
EBSにはスナップショットという機能があり、ある時点でのボリュームのバックアップが作成できます。このスナップショットからAMIを作成することができるため、同じソフトウェア構成のインスタンスを新たに追加することもできるようです。
異常のあるインスタンスの自動再起動
CloudWatchというAWSリソース監視用のサービスに、ヘルスチェックという機能があり、これを利用すればEC2インスタンスが正常に動作しているか1分ごとにチェックすることができるようです。
インスタンスに障害が起きた場合は、EC2 Auto Recoveryというサービスを利用して、問題のあるインスタンスを停止・再起動する処理を自動化することができます。これだけで、インスタンスの物理ホストが移動し、復旧することが可能なようです。
負荷分散とスケーリング
スケーリングという言葉は知っていましたが、スケールアウトとスケールアップが違う意味だということは初めて知りました。
スケールアウト(水平スケーリング)はクラウドと相性が良いスケーリングですが、アプリケーション設計の段階からスケールアウトを想定しておかなければならないため、押さえておきたいと思いました。
また、負荷分散の方法を知りたい、というのが、この本を購入した理由のひとつなので、詳しく解説されていて良かったです。
スケールアウトしやすい設計
個人的には、この本を読んで最も面白いと思った部分です。
高性能なマシンに変更するスケールアップ(垂直スケーリング)に対して、サーバの数を増やすことで負荷の増大に対処することをスケールアウト(水平スケーリング)というようです。
まず、サーバをステートレスにすることが、スケールアウトしやすい設計の基本のようです。セッション情報などはインスタンスに持たせず、Elastic CacheやDynamoDBなど外部で管理することで、サーバを増減させやすくなります。
データベースサーバーの場合は、お互いに同期させなければならないためにスケールアウトが難しいようです。RDSを使用している場合は、読み取り専用のデータベースとしてリードレプリカを別途作成することで、負荷を分散させることができます。負荷が増大したときは、リードレプリカについては台数を増やすことで、マスタDBについてはインスタンスタイプを高性能なものにスケールアップすることで対応するようです。
マルチAZ構成にしてDBインスタンスの可用性を高められる
WebサーバーやAPサーバーは、複数台のインスタンス構成にすることで可用性が高められることがわかりました。では、DBサーバーの可用性を高めるにはどうすればよいのだろう、という疑問の答えも書いてありました。
RDSにはマルチAZデプロイメントというオプションがあり、これを有効にすると、マスターDBの複製が他のアベイラビリティーゾーン(AZ)に作られます。新しく複製されたほうはスタンバイDBと呼ばれ、マスターDBに障害が起きた場合は、自動的にスタンバイDBにフェイルオーバーされます。
フェイルオーバーという言葉も知らなかったのですが、稼働中のシステムに障害が生じて停止した際に、自動的に待機システムに切り替える仕組みだそうです。スタンバイDBは名前の通り待機システムなので、リードレプリカのように読み込み性能を向上させる効果はないようです。
Auto Scalingでインスタンス数を自動で調整する
インスタンス数を増減する機能は、Auto Scalingというサービスによって提供されます。本を読むまえは、ロードバランサあたりにそういう機能があるのかと想像していましたが違いました。
Auto Scalingでは、いつ、どんなインスタンスを、どこに、どれくらい配置するかを事前に定義します。このうちの「いつ」の部分で、監視システムのCloud Watchアラームが使われます。また、何日の何時からキャンペーンを行う、というように事前にわかっている場合は、スケジュールに基づいてインスタンスを増減することも可能なようです。
Auto Scalingは可用性を高めるだけでなく、余分なリソースを持たなくて済むため、コスト削減にも役に立つらしいです。
疎結合
この疎結合という章の中に、SNSやSQSやLambdaの説明が書かれていました。
SNSは、たしかSimple Notification Serviceの略で、アプリケーションからメールを送信するために実際に使用したことがありました。最初に目次を見たときは、なぜこれが疎結合につながるのか、と疑問に思いました。
キューを挟むことで可用性と拡張性が高まる
Web・APサーバーがリクエストを受け取り、自身で処理する、という構成に、何も問題はないように自分には思えましたが、これは密結合となるようです。
これを疎結合にするには、Web・APサーバーがリクエストを受けた後、SNS経由でキューにジョブ実行のメッセージを送るようにします。キューは、これから実行する予定のジョブを蓄積して、非同期でひとつずつ処理できるようにする仕組みです。
ジョブごとにキューを作成し、さらに各キューに対してそれぞれ複数のEC2インスタンスを割り当てます。そうすることで、各キューの負荷に応じて個別にスケーリングすることが可能になります。こうした構成も疎結合と表現するようです。
Lambdaによる疎結合とは?
予備知識として、Lambdaはコードをサーバレスで実行するためのサービス、ということは知っていました。EC2インスタンスを起動して、さらにプログラム実行に必要なOSやソフトウェアをインストールする、という手順をスキップして、Lambdaではコードを用意するだけで実行できます。
自分の知識はその程度でしたので、Lambdaと疎結合がどう関係するのか想像できませんでした。
この本では、仮想マシンの台数が増えて運用保守が大変になる、という疎結合化のデメリットを解消するものとして、Lambdaが紹介されていました。
先述の例では、複数のキューそれぞれに複数のEC2インスタンスを割り当てていました。こうすることで可用性と拡張性は高まるのですが、各インスタンスのOSのアップデートやセキュリティパッチ当て、障害復旧などの手間がかかります。しかし、このEC2インスタンスをLambdaに置き換えれば、こうしたわずらわしさから解放されるという意味です。
Lambdaを使用してコードを実行すれば、実行環境の管理やスケーリングを自動化されます。また、EC2インスタンスはコードを実行したかどうかにかかわらず料金が発生しますが、Lambdaはコード実行に使用した時間に対してだけ料金が発生するため、大幅にコストを削減できるようです。
CDNとDNS
DNSについては、他のAWSの書籍でも説明されていたので、ドメイン名とIPアドレスを対応づけるためのサービス、という程度の理解はありました。デプロイしたアプリケーションに、独自ドメインでアクセスしたいときに利用しました。
CDNは、CSSフレームワークのBootstrapを利用するときに使ったことがありましたが、誰でも利用できるように公開されているファイル、という誤った認識をしていました。
Cloud Frontはコンテンツをキャッシュして高速に配信する仕組み
AWSにはCloud FrontというCDNサービスがあります。
CDNの働きを理解する際、S3バケットに置かれたコンテンツにアクセスする例がわかりやすかったです。CDNでは、世界中に設置されたデータセンターに、コンテンツのキャッシュを保存します。ユーザーのリクエストは、それらのデータセンターのうち最もレイテンシーの短いデータセンターにルーティングされます。
このとき、コンテンツを保持するS3バケットをオリジン、コンテンツのキャッシュを保持するデータセンターをエッジロケーションと呼ぶようです。
Route53はいろいろなルーティングを実現できる
さきほども書きましたが、デプロイしたアプリケーションに独自ドメインでアクセスするときに、AWSのDNSであるRoute53を使いました。ちなみに53は、DNSサーバが53番ポートで動作することに由来します。
Route53には、独自ドメインとIPアドレスを単純に対応づけるだけなく、次のようなルーティングも可能なようです。
- 加重ラウンドロビン:同一のDNSクエリに対し、トラフィックの5%だけを別のWebサーバーに流す、といった重み付けができる
- Latency Based Routing:エンドポイントごとの応答時間を常に把握して、リクエストを最速のエンドポイントにルーティングする
- 位置情報ルーティング:日本国外のユーザーからのリクエストは、英語コンテンツを提供するWebサーバーに流す、といった位置情報に基づくルーティング
こうした処理を、ルーティングのレイヤーで担うことができることを知らなかったので、感心しました。
セキュリティ
この章にはIAMやKMSの説明が書かれていました。
セキュリティのベストプラクティスは、与えるアクセス権限もユーザーの範囲も、必要最小限に絞り込むこと、と書いてありました。これは非常にわかりやすい説明ですが、IAMは自分にとっては多機能すぎて、実際に使うときに適切な設定ができるか不安になりました。
暗号鍵を管理するKMSというサービス
KMSというサービスが紹介されていたのですが、この本を読むまで知りませんでした。
Key Management Serviceの略で、安全に鍵を管理するためのサービスのようです。データを暗号化するためのデータキーと、そのデータキー自体を暗号化するマスターキーという概念があるようです。
ちゃんと理解できた自信がないので、これ以上は説明できません。
基板構築の自動化
この最後の章では、Infrastructure as Codeについて説明されていました。
といっても、ページ数はそれほど割かれておらず、概要がさくっと書かれているような印象を自分は受けました。Infrastructure as Codeと聞いて自分が連想するのはTerraformでしたが、この本ではAWSのサービスであるCloud Formationが紹介されていました。
まとめ
まとめ、という章が本の中にあるわけではなく、私個人の感想のまとめです。
一言でいえば、自分には最高の本でした。各サービスの説明があり、そのあとにベストプラクティスが紹介されている、という構成なのですが、どんな構成にするのがよいか自分で考えながら読むと、まるでミステリーを読んでいるようで本当に楽しかったです。
この本を読んでAWS認定資格に興味が出たので、新たに「AWS認定ソリューションアーキテクト[アソシエイト]」という本を購入して読んでみました。こちらはさらに網羅的に幅広い機能を説明されているような感じで、また試験で問われやすい部分を強調してあるので、試験対策には良いと思いました。
しかし、読んでいて楽しかったのは、圧倒的にこの「AmazonWebServicesエンタープライズ基盤設計の基本」です。「ハンズオンでAWS上にブログシステムを構築してみたけれど、他のリソースのことも知りたい、でも認定試験にはまだそれほど興味はない」という自分と同じような境遇の方がいましたら、この本はおすすめです。
- 投稿日:2020-08-01T17:49:38+09:00
【初学者向け】AWSでSSL化する方法
はじめに
ポートフォリオをAWSを使いSSL化を目的にやっています。既にEC2を用いてデプロイが済んでいてRoute53でドメインを取得している前提で勧めさせていただきますのでご了承下さい。
まだAWSを用いてデプロイをされていない方は世界一丁寧なAWS解説。の下準備からデプロイ2までを済ませて下さい。
ドメインの取得が済んでいない方はこちらの記事を参照下さい。私が書いたものですが、結構手抜きで申し訳ございません、、、SSLサーバー証明書とは
この辺は知らなくても真似して行けば問題なく出来ますが、知らずにやるのと知った上でやるのでは違うと思うので書いておきます。
SSLとは、簡単に言うとWebサイトとそのサイトを閲覧しているユーザとのやり取り(通信)を暗号化するための仕組みです。
この鍵マークがついているのはSSL化されている証拠になります。
もしSSL化されていない場合ですと悪意のあるユーザーによって閲覧しているホームページのアドレスや、掲示板に書き込んだ内容、ショッピングサイトで入力したクレジットカード番号やパスワードなども盗み見ることが出来てしまいます。手順
私の雑な説明より他の方が書いた記事の方が参考になるのでこの記事のRoute53の項目まで進めてください。
ただしCertificate Managerの途中でタグを追加という項目が増えていますが、中身は空でも問題ありません!
ロードバランサーについてはまだ、サブネットが一つしかありませんので先に新たなサブネットを作る必要があります。
世界一丁寧なAWS解説。下準備編でやったサブネット作成と同じ手順で新たなサブネットを作成していきます。
ここで注意して欲しい事を三つ紹介します。
1 新たに作るサブネットのアベイラビリティゾーンは最初のサブネットとは違うものにしましょう。
2 IPv4 CIDR ブロックの値は10.0.1.0/24にしましょう。
3 作ったサブネットのルートテーブルの設定をお忘れなく!
以上の3点が守られていればまた先ほどの記事のロードバランサーのところから進めてもらって大丈夫です!きっとこれで上手く行くはずです!
拙い文でしたが最後まで読んでいただきありがとうございます!
- 投稿日:2020-08-01T16:24:26+09:00
AWS CLIでポリシーのjsonファイルを指定するとMalformedPolicyエラー
常識の範疇かもしれないけど、数時間悩んだ挙句に解決した時には「これ半年ぐらい前にもやった気がする」と思ったので、僕が3回目に悩んだときのためにメモしておく。
AWS CLIでポリシーのjsonファイルを指定するとMalformedPolicyエラー
AWS CLIでS3バケットにポリシーを設定する
put-bucket-policyでは、ポリシードキュメントをJSONファイルとしてあらかじめ用意しており、--policyオプションで指定する。公式ドキュメントのExampleは以下のようになっている。aws s3api put-bucket-policy --bucket MyBucket --policy file://policy.jsonきっとフルパスで指定するのが無難だろう、でもWindowsの場合区切り文字やドライブはどう描くのが正解かなと思いながらいくつかやってみると、次のようなエラーになる。
A client error (MalformedPolicy) occured: policies must be valid JSON and the first byte must be '{'正しいJSON形式ではないというのだから、JSONLintでチェックしたり、文字コードや改行コード疑ったりもしたが、解決しない。
Windowsでは
file://C:\Temp\policy.jsonのように指定答えはStackoverflowに書かれてた。問題はJSONファイルの内容ではなくて、ファイルパスの指定方法だった。
ポリシーファイルパスには
file://プロトコルをつけることが必要
$ aws s3api put-bucket-policy --bucket kryptonite \ --policy file:///home/superman/aws-example/public-bucket-policy.json
もしくは(Windows)
$ aws s3api put-bucket-policy --bucket kryptonite \ --policy file://C:\Temp\public-bucket-policy.json
もしくは(相対パス)
$ aws s3api put-bucket-policy --bucket kryptonite \ --policy file://public-bucket-policy.jsonWindowsでは
file://C:\Temp\policy.jsonのようにフルパスを指定するらしい。file://C:\Tempってまさかと思うけど、これでポリシーの設定ができた。まさかと思うけど、これでいいのだ。参考
- 投稿日:2020-08-01T16:16:03+09:00
【AWS・Python】Slash Commandsを拡張性高くより楽に実装する
1. はじめに
本記事は、拙作【AWS・Python】Slash Commandsを拡張性高くより楽に実装するの実装をより楽に修正した物です。
できる物などは変わらずに、よりコード的にすっきりしたのと、実装の際のコストが減ったような気がするので記事にしました。
2. 実装
2.1 以前の方法(Chain Of Responsibility)
以前、SlashCommandを実装したときは、GoFのデザインパターンの1つである
Chain Of Responsibilityを利用しました。
詳細は、前記事に譲りますが、実装する際は以下の4つの手順を踏む必要がありました。
CommandExecutorクラスを継承するクラスを新規作成する__init__(self)にて、自身が受け付けるslash_command文字列を付与execute()関数を実装する- 新規作成したクラスを、数珠つなぎに呼べるように
CommandExecutorRequestHandlerクラスを作成するこの方法には、追加が楽というメリットはありますが以下に挙げるようなデメリットもありました。
ChainOfResponsibilityの概念を覚える必要がある- SlashCommandsを受け入れるコードを書くまでに4ステップ踏む必要がある
CommandExecutorRequestHandlerに新規作成したクラスを追加しないと動作しないCommandExecutorRequestHandlerに追加したクラスの順序によっては予期せぬ動作をする
AllAcceptなどの全ての処理を行うクラスを一番最初に追加すると、後続の処理は全て動かなくなる、などChainOfResponsibilityの性質上、条件分岐を複数回行うため実行時間が遅くなる2.2 今回の方法(Decorator)
以前に対して、今回は
Decoratorというのを利用します。
こちらも、GoFのデザインパターンで登場する名前と同じなのですが、
実際の処理はデザインパターンで登場するような処理とは異なります。この方法を利用すると、上記のデメリットはほぼ全て解決されます。
2.2.1 コマンドを追加する処理
実際にコーディングが必要なのは以下の通りです。
コメントで、上記の手順と対応する番号を付与します。example.py@SlashCommand.add(command="/hoge") # 1, 2: commandがSlashCommandで受け付ける文字列 def hoge(params: dict): # 3: 処理関数の実装 """ /hogeというコマンドを受け取って処理を行う """ return { "response_type": "in_channel", "text": f"hoge: {str(params)}" } @SlashCommand.add(command="/fuga") # 1, 2: commandがSlashCommandで受け付ける文字列 def fuga(params: dict): # 3: 処理関数の実装 """ /fugaというコマンドを受け取って処理を行う """ return { "response_type": "in_channel", "text": f"fuga: {str(params)}" } # 4: 正確には4と対応しないが、数珠つなぎの部分と対応 SlashCommand.execute(params=<payload_from_slack>)2.2.2 SlashCommand本体の実装
以下は、以前の実装方法でいうところの
CommandExecutorクラスです。
decoratorで受け取った関数を、{command: 関数}というdictで保持しておき、
SlashCommand.execute()が呼ばれた際に辞書の文字列でアクセスしています。slash_command.pyclass SlashCommand: """ Decoratorを利用して、処理の登録と実行を行っている メッセージの読み取りを始め、処理の移譲をおこなう。 """ executor_dict: dict = {} guard = None def __init__(self): pass @staticmethod def _get_command_from(params: dict) -> str: """ paramsに入ったcommand文字列を取得 """ if 'command' not in params: raise Exception if len(params['command']) == 0: raise Exception return params['command'][0] @classmethod def add(cls, command: str, guard=False): """ このdecorator()が受け取るfを登録しておく """ def decorator(f): cls.executor_dict[command] = f if guard: cls.guard = f return f return decorator @classmethod def execute(cls, params: dict): command = cls._get_command_from(params=params) if command in cls.executor_dict: return cls.executor_dict[command](params=params) else: if cls.guard is not None and callable(cls.guard): return cls.guard() else: raise NotImplementedError2.3 Chaliceを利用した実装例
最後に
chaliceを利用した実装例を載せます。
デコレータを利用することで、すっきりとした見通しの良いコードになった気がします。以前の実装方法のソースコードはここにあります。
(実装の都合上、/hogeや/fugaはchalicelibというパッケージの中に含まれています。)app.pyimport urllib.parse from chalice import Chalice app = Chalice(app_name='<your_project_name>') # ================== # このあたりに上記のコード # ================== class SlashCommand: # 行数の関係で省略、上記と同じコードが入ります。 pass @SlashCommand.add(command="/hoge") # 1, 2: commandがSlashCommandで受け付ける文字列 def accept_hoge(params: dict): # 3: 処理関数の実装 """ /hogeというコマンドを受け取って処理を行う """ return { "response_type": "in_channel", "text": f"hoge: {str(params)}" } @SlashCommand.add(command="/fuga") # 1, 2: commandがSlashCommandで受け付ける文字列 def accept_fuga(params: dict): # 3: 処理関数の実装 """ /fugaというコマンドを受け取って処理を行う """ return { "response_type": "in_channel", "text": f"fuga: {str(params)}" } @app.route('/slack/slash_commands', methods=['POST'], content_types=['application/x-www-form-urlencoded']) def receive_slash_command(): request = app.current_request if request.raw_body is None: # 予期しない呼び出し。400 Bad Requestを返す return {'statusCode': 400} payload = urllib.parse.parse_qs(request.raw_body.decode('utf-8')) return SlashCommand.execute(params=payload)3. おわりに
以前までは、
ChainOfResponsibilityってかなり便利だなと思っていたのですが、
実装の手順が煩雑になったりとデメリットの方が最近は目につくようになりました。その点、decoratorは、メタプログラミング、と名のつく通り、かなりいろいろなことができるので便利です。
(あまりに複雑なものは、後々の自分や他の人への可読性という意味では危ないですが・・・)この方法を利用すれば、SlashCommandの処理のみに集中できるので良いかと思います!
- 投稿日:2020-08-01T15:11:52+09:00
[AWS] Lamdba 関数を AWS CLI を使ってデプロイする
はじめに
AWS Lambda を使ってサーバレスな環境での処理を実施出来るのは良いが、毎回 AWS マネジメントコンソール からメンテナンスするのも億劫だし、できれば Lambda 関数のコードは Git 等で管理したい。
というわけで、Lambda 関数のコードはローカルでメンテナンスを行い、AWS CLI を使ってデプロイする方法について見ていく。
前提条件
本記事における前提条件は以下の 4 点。
- デプロイ対象の Lambda 関数がすでに存在していること
- つまり
iam create-roleでロール作成を事前に行うのではなくaws lambda create-functionで Lambda 関数を作成するのでもない- 既存の Lambda 関数に対する 更新 を行うことが目的となる
- AWS CLI がインストールされていること
- AWS CLI を実行するためのユーザがいること
前準備
AWS CLI を使うには、前提条件 でも挙げた次の 2 点が必要なので、そのための確認と前準備を行う。
- AWS CLI がインストールされていること
- AWS CLI を実行するためのユーザがいること
AWS CLI の確認
本記事では AWS CLI の実行と確認を EC2 インスタンス上で行ったので、 AWS CLI のインストールは行っていない。
念の為、インストールされているかの確認とバージョンの確認をしておく。# 所在確認 $ which aws /usr/bin/aws # (一応)バージョン確認 $ aws --version aws-cli/1.14.9 Python/2.7.13 Linux/4.9.81-35.56.amzn1.x86_64 botocore/1.8.13※ AWS CLI のインストールについては こちらのドキュメント を参照。
AWS CLI の設定
AWS CLI ユーザ
「アクセスの権限」に「プログラムによるアクセス」のみを選択してユーザを作成。ユーザ名は
aws-cliとした。
以下のロールを持つグループAws-Cliを作成し、作成したユーザに紐付けた。権限は持たせ過ぎかも。
アカウント グループ ロール aws-cli Aws-Cli EC2FullAccess, S3FullAccess, LambdaFullAccess で、大事なポイント。
作成後に発行されるクレデンシャルは AWS CLI の設定を行う際に必要になる。必ずメモ、もしくは csv でダウンロードしておくこと。
ここで保存しておかないと、もう手に入れる術が無いらしい。AWS CLI の設定
aws configureコマンドで設定を行う。設定項目は多くないので敷居は全然高くない。$ aws configure AWS Access Key ID [None]: ${Access Key} # <- AWS CLI ユーザ作ったときの Access Key AWS Secret Access Key [None]: ${Secret Access Key} # <- AWS CLI ユーザ作ったときの Secret Access Key Default region name [None]: ${Region Name} # <- デプロイ対象のリージョン Default output format [None]: json # <- json/yaml/txt/table を選択できるここで Access Key と Secret Access Key を指定することでデプロイ先が決まる、つまり 指定したキーに紐づくユーザが存在する環境に対してデプロイされる、ということになる。この辺はしっかりと理解しておきたい。
AWS CLI によるデプロイ
前準備が整ったので、実際に AWS CLI を使って Lambda 関数のデプロイを行っていく。
環境変数の設定
環境変数の適用コマンド
もし Lambda 関数に対して環境変数を設定したい場合、以下のコマンドで設定できる。
$ aws lambda update-function-configuration --function-name Hogehoge --environment Variables={KeyName1=string,KeyName2=string}参考: update-function-configuration
デプロイ
デプロイコマンド
デプロイは対象のリソースを
zipで固めてコマンドを実行するだけで良い。$ zip -r lambda.zip . $ aws lambda update-function-code --function-name Hogehoge --zip-file fileb://lambda.zipこのとき
zipで固めるのは Lambda 関数のコードがあるディレクトリ。デプロイの例
ディレクトリ構造が以下の場合( Python で Lamdba 関数を実装 )
git-repository/ + src/ + functions/ + Hogehoge/ | + conf/ | | + Hogehoge.conf | + lambda_function.py + Piyopiyo/ + conf/ | + Piyopiyo.conf + lambda_function.py
Hogehogeをデプロイしたければ
cd git-repository/src/function/HogehogeでHogehoge/まで移動zip -r lambda.zip .でHogehoge以下を固める- で、
aws lambda update-function-code ~を実行してデプロイする流れとなる。
環境変数の適用例
説明が前後するが、
conf/Hogehoge.congの中身に Lambda 関数の環境変数を次のような形で定義していた場合、HOGE=hogeeeeee PIYO=poiyooooo Bar=Barrrrrrrr環境変数の設定 で挙げたコマンドを以下のようにすることで、ファイルの中身を環境変数に反映させることも出来る。
cd git-repository/src/function/Hogehoge # 1. ファイル末尾の空行を削除 # 2. ファイルの改行コードを `,` に置換 # 3. ファイル末尾にできた `,` を `` に置換(トリムする) # 4. 上記工程を `Variables={}` の中で行った後、環境変数を Lambda に適用 aws lambda update-function-configuration --function-name Hogehoge --environment Variables={`cat conf/Hogehoge.conf | tr -s "\n" | tr '\n' ',' | sed s/,$//`}おまけ
Jenkins からのデプロイ
AWS CLI を使って Jenkins ジョブから Lambda 関数のデプロイも簡単にできたので、その手順も備忘録としてあげておく。
なお今回、 Jenkins は EC2 で構築しているので、AWS CLI のインストールは行っていない。
Jenkins ジョブの作成
任意のジョブ名を入力して「フリースタイル・プロジェクトのビルド」を選択する。
ビルドパラメータの設定
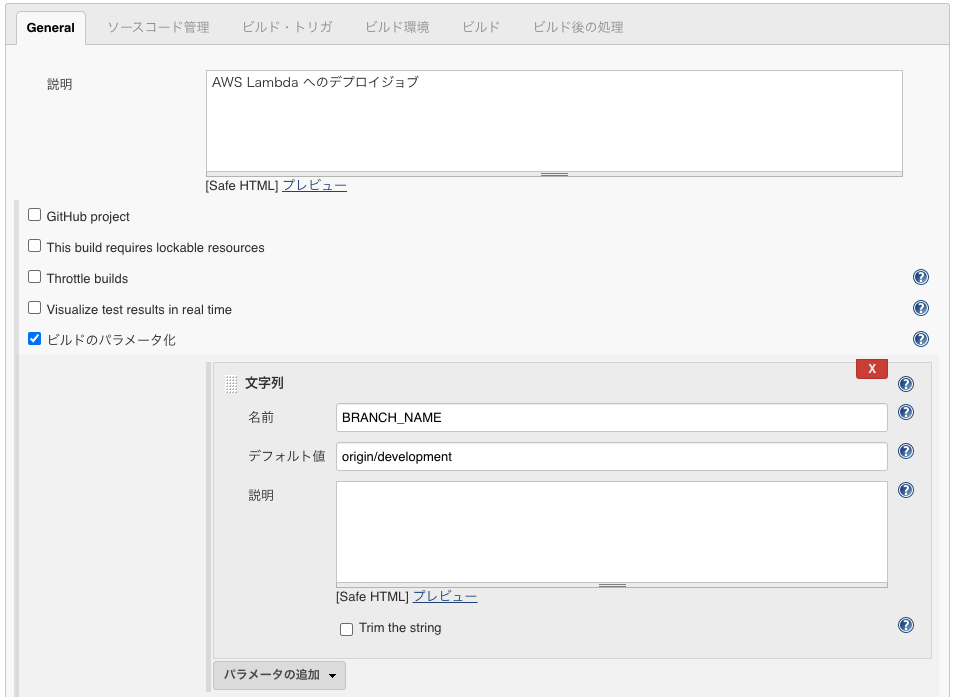
「説明」には本ジョブに関する説明を記入する。
それから、後述の ソースコード管理の選択 で Git を選択するので、入力された文字列をデプロイ対象のブランチとする べく
- 「ビルドのパラメータ化」にチェックを入れ
- 「名前」と「デフォルト値」を入力する
ソースコード管理の選択
ここでは GitHub のリポジトリを扱いたいので
- Git を選択
- リポジトリ URL には GitHub のURL を入力
- 認証情報は、有れば入力
- ブランチ指定子は ビルドパラメータの設定 で入力した文字列を
$を接頭辞につけて指定する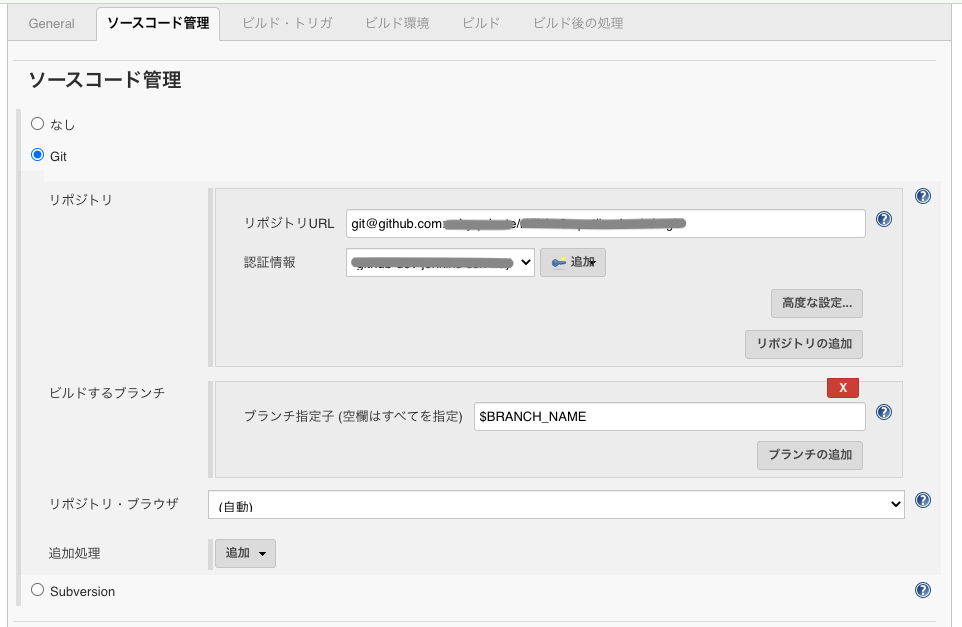
ビルド処理
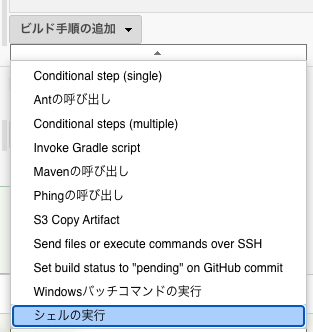
シェルの実行を選択
AWS CLI を使用して Lambda 関数をデプロイしたいので、ビルド処理では「シェルの実行」を選択する。
ビルドシェル
ビルドシェルは以下の通り。
で指定したリポジトリはジョブ実行時に
$WORKSPACE配下にクローンされてくる。
で、$WORKSPACE配下の __デプロイしたい Lambda 関数のソースコードがあるところまで移動 し、AWS CLI によるデプロイ で示したようにaws lamdaコマンドから環境変数の適用とデプロイを行う。#!/bin/bash # # Hogehoge # # ここで Lambda 関数としてデプロイしたいディレクトリまで移動する cd $WORKSPACE/src/function/Hogehoge # 環境変数の適用 ## 1. ファイル末尾の空行を削除 ## 2. ファイルの改行コードを `,` に置換 ## 3. ファイル末尾にできた `,` を `` に置換(トリムする) ## 4. 上記工程を `Variables={}` の中で行った後、環境変数を Lambda に適用 aws lambda update-function-configuration --function-name Hogehoge --environment Variables={`cat conf/Hogehoge.conf | tr -s "\n" | tr '\n' ',' | sed s/,$//`} # デプロイ ## デプロイ対象のリソースを zip で固めたうえで zip -r lambda.zip . ## AWS CLI でデプロイする ### function-nameはlambda上の上書き対象の関数名 aws lambda update-function-code --function-name Hogehoge --zip-file fileb://lambda.zip exitまとめにかえて
所感
AWS CLI からコマンドを実行する際、どこに対してデプロイするのか を CLI を実行するときに指定しないのが気持ち悪かった。
当初、「デプロイ先を指定しないでどこにデプロイするんだ ?」と疑問だったのだが、手順を調べていくなかで
aws configureで CLI の設定を行うことを知った。で、
aws configureを実行した際に AWS CLI ユーザの Access Key と Secret Access Key を設定することでデプロイ先が決まるんだな、ということで腹に落ちた。この辺、なんとなくで使っているとモヤモヤ感が残るので、しっかり理解して使っていきたい。
このあと試したいこと
今回は Lambda 関数が既に AWS 上に存在する前提で、それに対するデプロイを AWS CLI から行えることを確認した。
が、Lambda 関数が存在しない状態でもデプロイが出来るようにしてみたい。に書いたように
aws iam create-roleとaws lambda create-functionを組み合わせることで対応はできるが、以下の記事によると SAM を利用することでも実現できる様子。なので、そのうちこちらも試してみたい。
参考
AWS 本家
- AWS CLI のインストール
- AWS CLI の設定
- AWS Command Line Interface での AWS Lambda の使用
- update-function-configuration
- update-function-code
上記以外
- 投稿日:2020-08-01T15:11:52+09:00
[AWS] Lambda 関数を AWS CLI を使ってデプロイする
はじめに
AWS Lambda を使ってサーバレスな環境での処理を実施出来るのは良いが、毎回 AWS マネジメントコンソール からメンテナンスするのも億劫だし、できれば Lambda 関数のコードは Git 等で管理したい。
というわけで、Lambda 関数のコードはローカルでメンテナンスを行い、AWS CLI を使ってデプロイする方法について見ていく。
前提条件
本記事における前提条件は以下の 4 点。
- デプロイ対象の Lambda 関数がすでに存在していること
- つまり
aws iam create-roleでロール作成を事前に行うのではなくaws lambda create-functionで Lambda 関数を作成するのでもない- 既存の Lambda 関数に対する 更新 を行うことが目的となる
- AWS CLI がインストールされていること
- AWS CLI を実行するためのユーザがいること
前準備
AWS CLI を使うには、前提条件 でも挙げた次の 2 点が必要なので、そのための確認と前準備を行う。
- AWS CLI がインストールされていること
- AWS CLI を実行するためのユーザがいること
AWS CLI の確認
本記事では AWS CLI の実行と確認を EC2 インスタンス上で行ったので、 AWS CLI のインストールは行っていない。
念の為、インストールされているかの確認とバージョンの確認をしておく。# 所在確認 $ which aws /usr/bin/aws # (一応)バージョン確認 $ aws --version aws-cli/1.14.9 Python/2.7.13 Linux/4.9.81-35.56.amzn1.x86_64 botocore/1.8.13※ AWS CLI のインストールについては こちらのドキュメント を参照。
AWS CLI の設定
AWS CLI ユーザ
「アクセスの権限」に「プログラムによるアクセス」のみを選択してユーザを作成。ユーザ名は
aws-cliとした。
以下のロールを持つグループAws-Cliを作成し、作成したユーザに紐付けた。権限は持たせ過ぎかも。
アカウント グループ ロール aws-cli Aws-Cli EC2FullAccess, S3FullAccess, LambdaFullAccess で、大事なポイント。
作成後に発行されるクレデンシャルは AWS CLI の設定を行う際に必要になる。必ずメモ、もしくは csv でダウンロードしておくこと。
ここで保存しておかないと、もう手に入れる術が無いらしい。AWS CLI の設定
aws configureコマンドで設定を行う。設定項目は多くないので敷居は全然高くない。$ aws configure AWS Access Key ID [None]: ${Access Key} # <- AWS CLI ユーザ作ったときの Access Key AWS Secret Access Key [None]: ${Secret Access Key} # <- AWS CLI ユーザ作ったときの Secret Access Key Default region name [None]: ${Region Name} # <- デプロイ対象のリージョン Default output format [None]: json # <- json/yaml/txt/table を選択できるここで Access Key と Secret Access Key を指定することでデプロイ先が決まる、つまり 指定したキーに紐づくユーザが存在する環境に対してデプロイされる、ということになる。この辺はしっかりと理解しておきたい。
AWS CLI によるデプロイ
前準備が整ったので、実際に AWS CLI を使って Lambda 関数のデプロイを行っていく。
環境変数の設定
環境変数の適用コマンド
もし Lambda 関数に対して環境変数を設定したい場合、以下のコマンドで設定できる。
$ aws lambda update-function-configuration --function-name Hogehoge --environment Variables={KeyName1=string,KeyName2=string}参考: update-function-configuration
デプロイ
デプロイコマンド
デプロイは対象のリソースを
zipで固めてコマンドを実行するだけで良い。$ zip -r lambda.zip . $ aws lambda update-function-code --function-name Hogehoge --zip-file fileb://lambda.zipこのとき
zipで固めるのは Lambda 関数のコードがあるディレクトリ。デプロイの例
ディレクトリ構造が以下の場合( Python で Lambda 関数を実装 )
git-repository/ + src/ + functions/ + Hogehoge/ | + conf/ | | + Hogehoge.conf | + lambda_function.py + Piyopiyo/ + conf/ | + Piyopiyo.conf + lambda_function.py
Hogehogeをデプロイしたければ
cd git-repository/src/function/HogehogeでHogehoge/まで移動zip -r lambda.zip .でHogehoge以下を固める- で、
aws lambda update-function-code ~を実行してデプロイする流れとなる。
環境変数の適用例
説明が前後するが、
conf/Hogehoge.congの中身に Lambda 関数の環境変数を次のような形で定義していた場合、HOGE=hogeeeeee PIYO=poiyooooo Bar=Barrrrrrrr環境変数の設定 で挙げたコマンドを以下のようにすることで、ファイルの中身を環境変数に反映させることも出来る。
cd git-repository/src/function/Hogehoge # 1. ファイル末尾の空行を削除 # 2. ファイルの改行コードを `,` に置換 # 3. ファイル末尾にできた `,` を `` に置換(トリムする) # 4. 上記工程を `Variables={}` の中で行った後、環境変数を Lambda に適用 aws lambda update-function-configuration --function-name Hogehoge --environment Variables={`cat conf/Hogehoge.conf | tr -s "\n" | tr '\n' ',' | sed s/,$//`}おまけ
Jenkins からのデプロイ
AWS CLI を使って Jenkins ジョブから Lambda 関数のデプロイも簡単にできたので、その手順も備忘録としてあげておく。
なお今回、 Jenkins は EC2 で構築しているので、AWS CLI のインストールは行っていない。
Jenkins ジョブの作成
任意のジョブ名を入力して「フリースタイル・プロジェクトのビルド」を選択する。
ビルドパラメータの設定
「説明」には本ジョブに関する説明を記入する。
それから、後述の ソースコード管理の選択 で Git を選択するので、入力された文字列をデプロイ対象のブランチとする べく
- 「ビルドのパラメータ化」にチェックを入れ
- 「名前」と「デフォルト値」を入力する
ソースコード管理の選択
ここでは GitHub のリポジトリを扱いたいので
- Git を選択
- リポジトリ URL には GitHub のURL を入力
- 認証情報は、有れば入力
- ブランチ指定子は ビルドパラメータの設定 で入力した文字列を
$を接頭辞につけて指定するビルド処理
シェルの実行を選択
AWS CLI を使用して Lambda 関数をデプロイしたいので、ビルド処理では「シェルの実行」を選択する。
ビルドシェル
ビルドシェルは以下の通り。
で指定したリポジトリはジョブ実行時に
$WORKSPACE配下にクローンされてくる。
で、$WORKSPACE配下の __デプロイしたい Lambda 関数のソースコードがあるところまで移動 し、AWS CLI によるデプロイ で示したようにaws lamdaコマンドから環境変数の適用とデプロイを行う。#!/bin/bash # # Hogehoge # # ここで Lambda 関数としてデプロイしたいディレクトリまで移動する cd $WORKSPACE/src/function/Hogehoge # 環境変数の適用 ## 1. ファイル末尾の空行を削除 ## 2. ファイルの改行コードを `,` に置換 ## 3. ファイル末尾にできた `,` を `` に置換(トリムする) ## 4. 上記工程を `Variables={}` の中で行った後、環境変数を Lambda に適用 aws lambda update-function-configuration --function-name Hogehoge --environment Variables={`cat conf/Hogehoge.conf | tr -s "\n" | tr '\n' ',' | sed s/,$//`} # デプロイ ## デプロイ対象のリソースを zip で固めたうえで zip -r lambda.zip . ## AWS CLI でデプロイする ### function-nameはlambda上の上書き対象の関数名 aws lambda update-function-code --function-name Hogehoge --zip-file fileb://lambda.zip exitまとめにかえて
所感
AWS CLI からコマンドを実行する際、どこに対してデプロイするのか を CLI を実行するときに指定しないのが気持ち悪かった。
当初、「デプロイ先を指定しないでどこにデプロイするんだ ?」と疑問だったのだが、手順を調べていくなかで
aws configureで CLI の設定を行うことを知った。で、
aws configureを実行した際に AWS CLI ユーザの Access Key と Secret Access Key を設定することでデプロイ先が決まるんだな、ということで腹に落ちた。この辺、なんとなくで使っているとモヤモヤ感が残るので、しっかり理解して使っていきたい。
このあと試したいこと
今回は Lambda 関数が既に AWS 上に存在する前提で、それに対するデプロイを AWS CLI から行えることを確認した。
が、Lambda 関数が存在しない状態でもデプロイが出来るようにしてみたい。に書いたように
aws iam create-roleとaws lambda create-functionを組み合わせることで対応はできるが、以下の記事によると SAM を利用することでも実現できる様子。なので、そのうちこちらも試してみたい。
参考
AWS 本家
- AWS CLI のインストール
- AWS CLI の設定
- AWS Command Line Interface での AWS Lambda の使用
- update-function-configuration
- update-function-code
上記以外
- 投稿日:2020-08-01T15:10:57+09:00
AWS Cloud Mapを使って内部通信で扱うEC2の名前解決をする
はじめに
2020/7/29に、AWS Cloud Mapがアップデートされ、EC2のインスタンスをインスタンスIDで登録できるようになったようだ。
え、これってもしかして、これまではEC2単独で済むような低SLAの内部通信のサーバでも、わざわざ前段にNLB立ててRoute53のプライベートホストゾーンを設定しなければいけなかったのが不要になるということ?神アップデートじゃん!ということで、さっそく試してみた。
前提条件
- AWS Cloud Mapって何?が分かっていること
まあ、概要はクラスメソッド先生の記事がたいへん分かりやすいので、これを見ておけば充分かと思う。
API取得編
基本は通常のサービスディスカバリの登録手順と同じである。
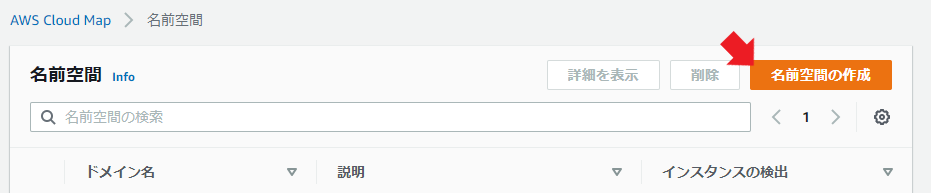
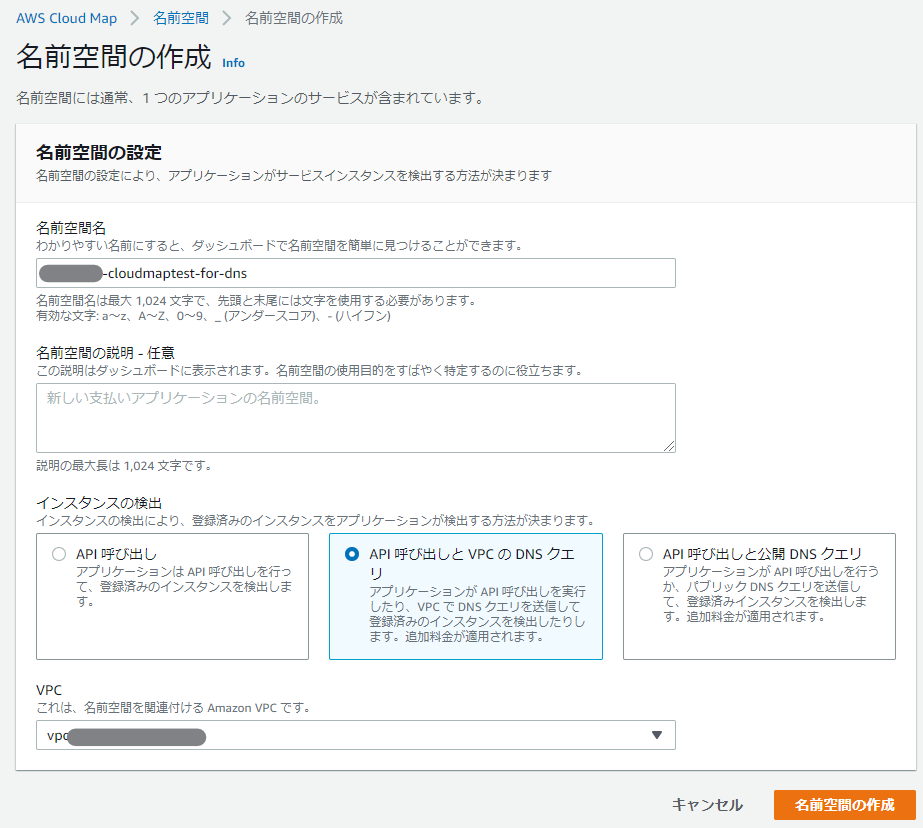
まずは名前空間を作成する。
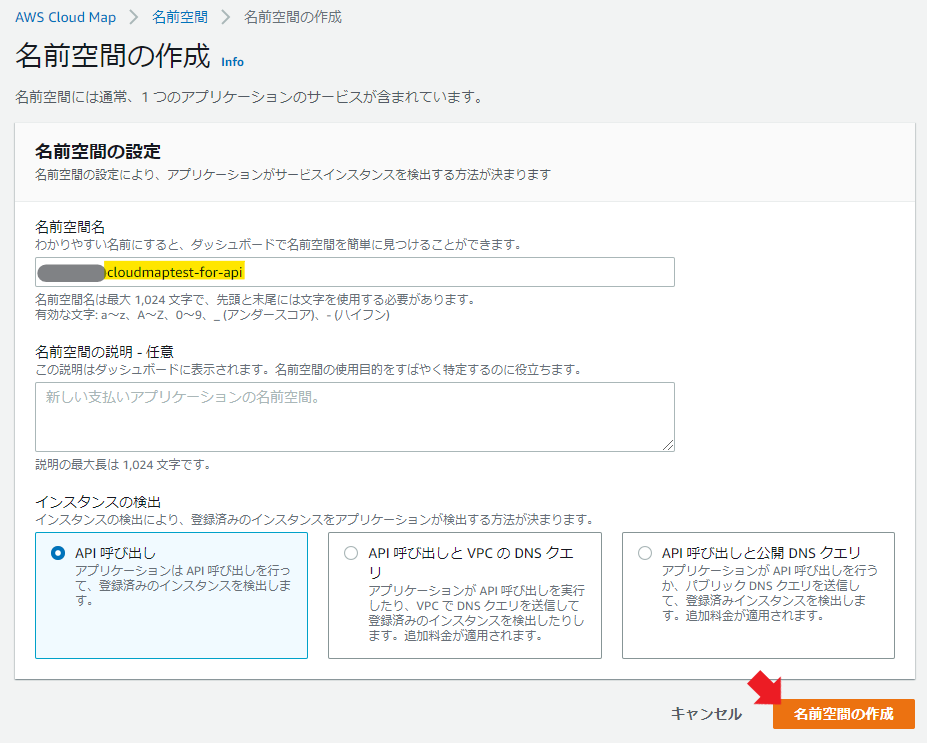
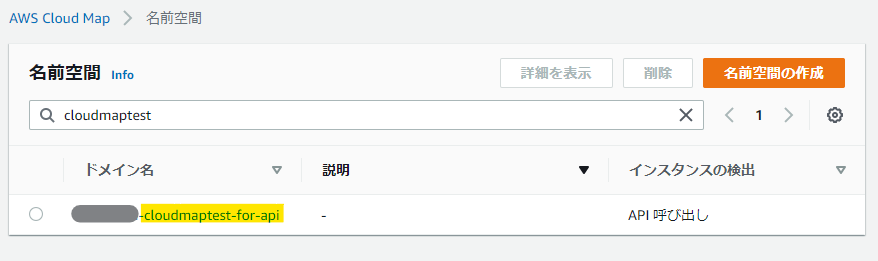
適当な名前空間名と説明を入れて、今回は「API呼び出し」を選択する。
ちょっと待てば名前空間の作成は完了。
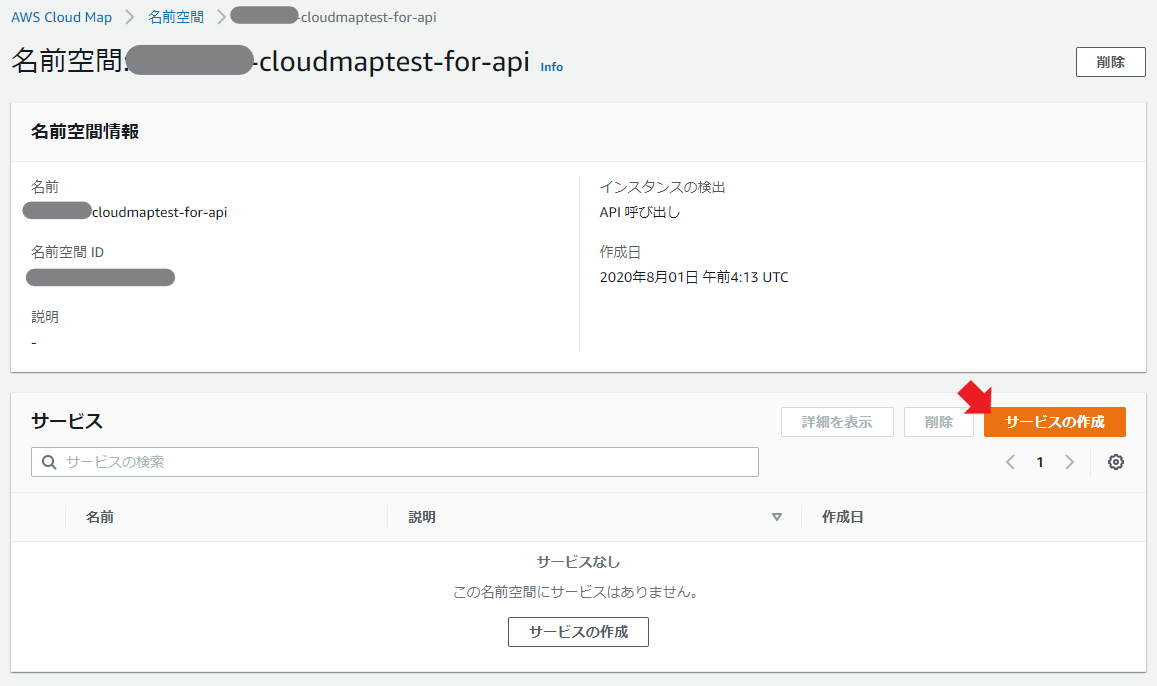
ここで、作ったドメイン名のリンクを踏み、サービスの作成を行う。
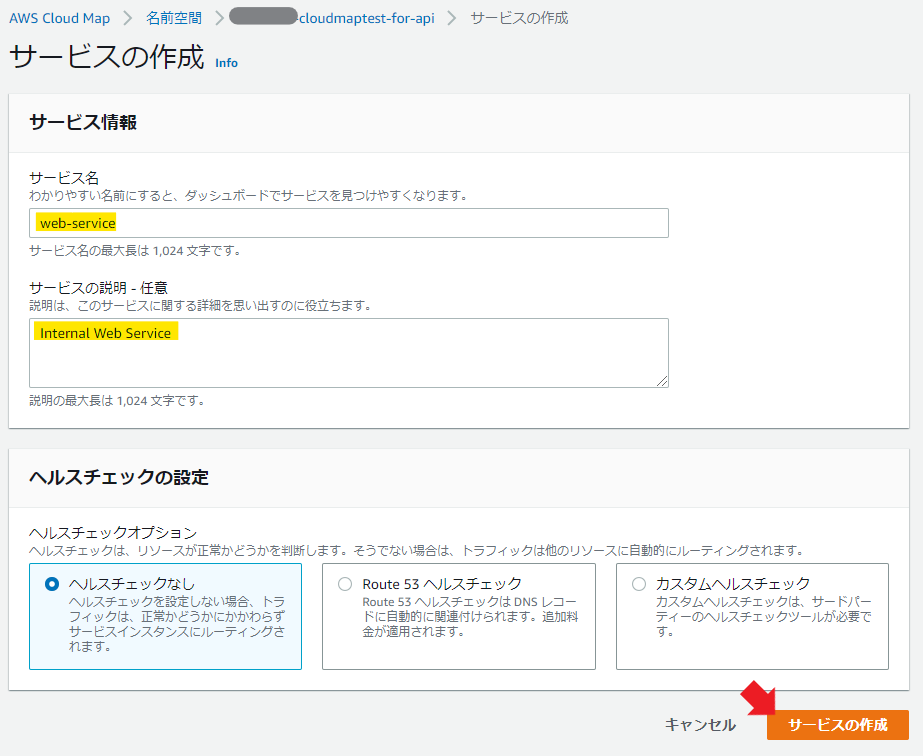
サービス名と説明とヘルスチェックはテキトーに設定する。
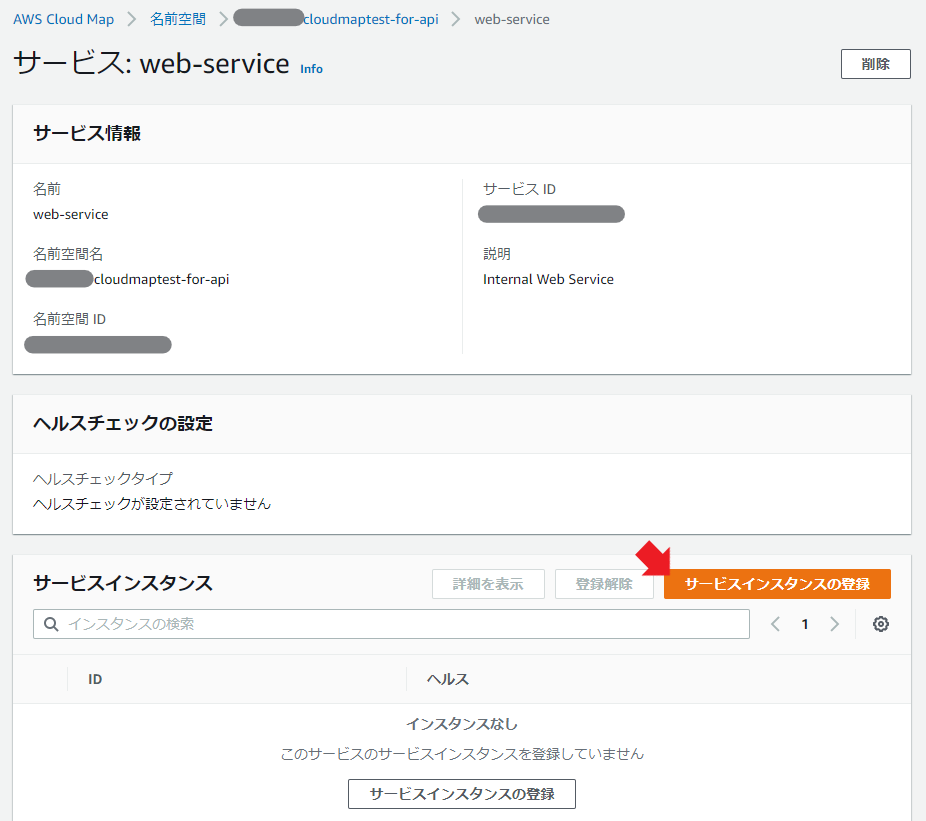
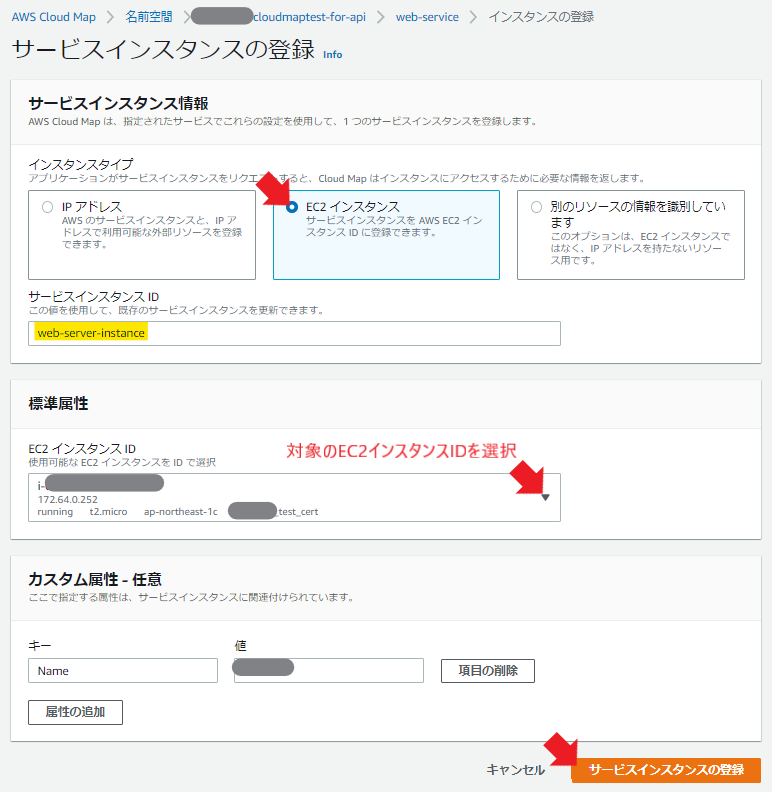
サービスが作れたら、今度はインスタンスを紐づける。
インスタンスタイプで「EC2インスタンス」を選択し、適当なサービスインスタンスIDを設定し、対象のEC2インスタンスIDをプルダウンから選択し、カスタム属性をテキトーに設定する。
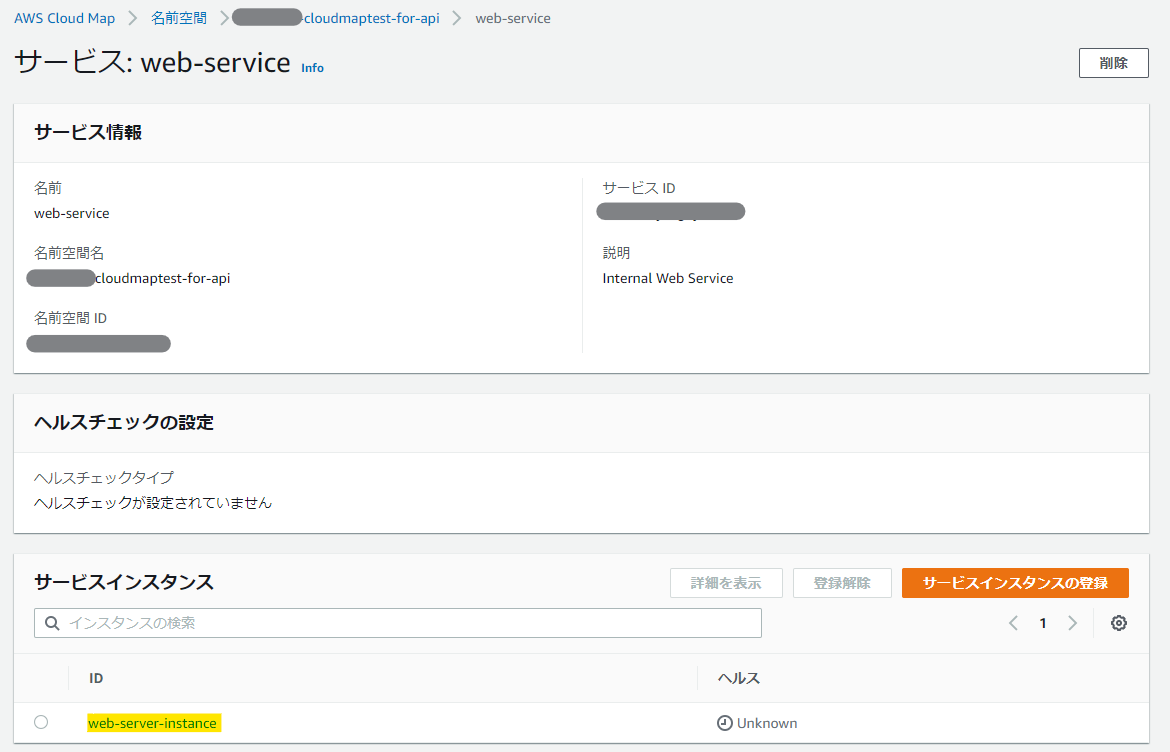
完成!
サービス名からIPアドレスを参照できるかCLIで試してみる。
$ aws servicediscovery discover-instances --namespace-name cloudmaptest-for-api --service-name web-service{ "Instances": [ { "InstanceId": "web-server-instance", "NamespaceName": "cloudmaptest-for-api", "ServiceName": "web-service", "HealthStatus": "UNKNOWN", "Attributes": { "AWS_EC2_INSTANCE_ID": "[インスタンス]", "AWS_INSTANCE_IPV4": "172.64.0.252", "Name": "[設定したタグ]" } } ] }あとはもうお分かりだろう。jqコマンドを使えばIPアドレスを抜き出すことができる。
$ jq -r '.Instances[].Attributes.AWS_INSTANCE_IPV4'DNS参照編
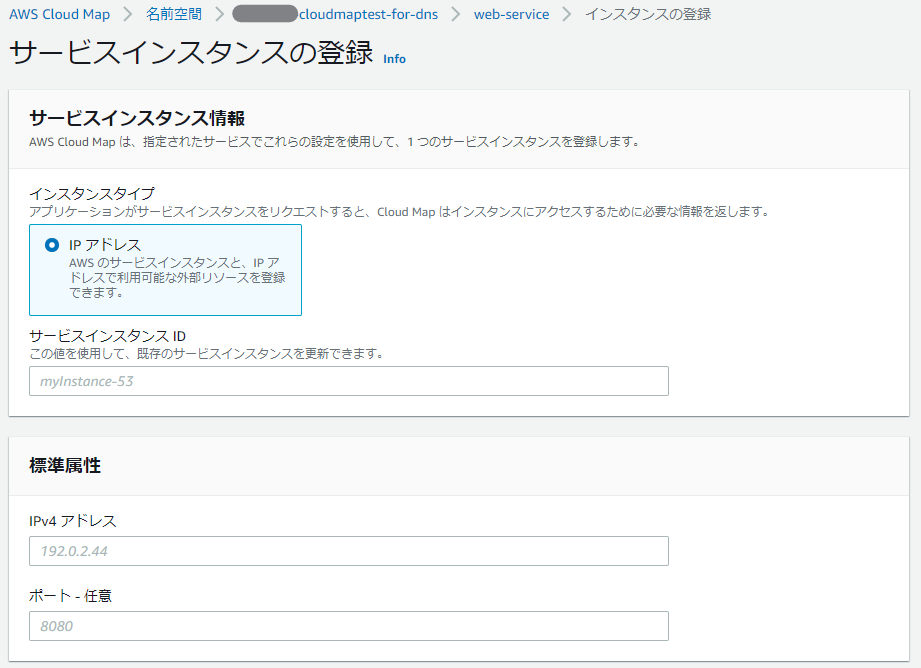
残念ながら、「API 呼び出しと VPC の DNS クエリ」の名前空間では、インスタンスIDでのEC2インスタンス指定はまだできないようであった。
名前空間を「API呼び出しとVPCのDNSクエリ」で作成して進めいくと…
EC2のインスタンスIDを選択することができない!
AWS Cloud MapのAPI仕様書にも、以下のような文章があったので、CLIからなら設定できるとかそういう話でもなさそう。
AWS_EC2_INSTANCE_ID
HTTP namespaces only. The Amazon EC2 instance ID for the instance. If the AWS_EC2_INSTANCE_ID attribute is specified, then the only other attribute that can be specified is AWS_INIT_HEALTH_STATUS. When the AWS_EC2_INSTANCE_ID attribute is specified, then the AWS_INSTANCE_IPV4 attribute will be filled out with the primary private IPv4 address.
本当はこっちをやりたかったのだけど……。
結論
DNSを引くことができれば、現状でELBを経由している部分について、ELBを削除してAWS Cloud Mapを設定してあげさえすればアプリケーションの修正が不要になって最高だったので一歩見劣り。それでも、リソースを減らせるというのは嬉しいのである。
- 投稿日:2020-08-01T14:34:36+09:00
EC2のデプロイに関わるエラーを確認するコマンド一覧
この記事の使い方
EC2、RDS(MySQL)、Rails、nginx、pumaを使用してデプロイする際のお供に。
何を隠そうこれは筆者のためのメモでもあります。笑
Amazon linuxとAmazon linux2でコマンドが違っていたりして混乱するので。使用するAMI
Amazon linux2
Nginx関連
$ sudo systemctl start nginx.service #起動 $ sudo systemctl status nginx.service #ステータス確認 $ tail -f log/nginx.error.log #エラーログ確認 $ sudo nginx -t #設定ファイル内の間違いを教えてくれるpuma関連
$ bundle exec pumactl start #起動MySQL関連
$ sudo systemctl start mysqld.service #起動 $ sudo systemctl status mysqld.service #ステータス確認見てくださりありがとうございました。
この記事がデプロイの助けになれば幸いです。
- 投稿日:2020-08-01T10:19:48+09:00
【AppSync・Amplify】データのIDや作成時刻を自動で設定するリゾルバ
はじめに
AWSのAppSyncやAmplifyを使用することで、GraphQLのAPIを容易に構築することができます。
mutationでデータを作成するときに、IDやcreatedAtの値をAWS側で自動で割り振ることができます。そのためには、リクエストマッピングテンプレートに以下を設定します。
IDやcreatedAtを自動で設定する例{ "version": "2017-02-28", "operation": "PutItem", "key": { "ID": { "S": "$util.autoId()" }, "createdAt": { "S": "$util.time.nowFormatted("yyyy-MM-dd HH:mm:ssZ", "+09:00") " } }, "attributeValues": $util.dynamodb.toMapValuesJson($ctx.args.input), }まとめ
$util.autoId()や$util.time.nowFormatted()を設定することで、DynamoDB側でデータの作成が可能です。
もちろん、クエリに含める必要はなくなります。
- 投稿日:2020-08-01T10:13:42+09:00
【AppSync・Amplify】ページングを実現する[ nextToken ]のリゾルバ設定
はじめに
AWSのAppSyncやAmplifyを使用することで、GraphQLのAPIを容易に構築することができます。
返却されるデータをページ分割し、リクエストに応じて追加のデータを取り出すことができます。
そのためには、nextTokenをAPIから返却させ、次のリクエストに含める必要があります。レスポンスにnextTokenを含める方法
レスポンスにnextTokenを含めるには、以下の項目を設定します。
// 1回のリクエストで帰ってくるデータは最大20件に設定 "limit": $util.defaultIfNull($ctx.args.first, 20), "nextToken": $util.toJson($util.defaultIfNullOrEmpty($ctx.args.nextToken, null)),:リクエストマッピングテンプレートの例 { "version": "2017-02-28", "operation": "Query", "query": { ... }, // 1回のリクエストで帰ってくるデータは最大20件に設定 "limit": $util.defaultIfNull($ctx.args.first, 20), ... "nextToken": $util.toJson($util.defaultIfNullOrEmpty($ctx.args.nextToken, null)), "select": "ALL_ATTRIBUTES", }まとめ
"nextToken": $util.toJson($util.defaultIfNullOrEmpty($ctx.args.nextToken, null)),と設定することで、nextTokenが返却されます。次のリクエストにnextTokenを含めることで、追加のデータをクエリすることができます。
- 投稿日:2020-08-01T10:00:27+09:00
【AppSync・Amplify】GraphQLで新しい順にデータを取得する時のリゾルバ
はじめに
AWSのAppSyncやAmplifyを使用することで、GraphQLのAPIを容易に構築することができます。
返却されるデータの調整はフロント側でも可能ですが、
エンドポイント側で DynamoDB のリゾルバーのマッピングテンプレートを適切に設定しておくことが重要です。新しい順にデータを取得する方法
データを追加された新しい順に取り出すには、以下の項目を設定します。
"scanIndexForward": false,リクエストマッピングテンプレートの例{ "version": "2017-02-28", "operation": "Query", "query": { ... }, ... "scanIndexForward": false, "select": "ALL_ATTRIBUTES", }まとめ
scanIndexForwardをfalseに設定することで、新しいデータから順に返却されます。
- 投稿日:2020-08-01T03:17:15+09:00
yps並走記録 Task3 SQL:テーブル作成(復習)バッチ作成(復習)~php.ini設定~GitHubにファイルをアップロード~WordPress5.4.2セットアップ
早くも3週目になりました、yps
今回はなるべくリアルタイムで課題をやりながらログを取っていきたいと思います。まずはSQL周りの復習
MySQLのエンコード設定を直します
エンコード設定をutf8mb4に戻す(mysql cliから日本語扱えるようにutf8にしてた)
sudo vi /etc/my.cnf最終行に以下を追記
[client] default-character-set=utf8mb4編集を保存し、mysqlを再起動
sudo systemctl restart mysql練習で使うデータをダウンロード
cd /tmp
sudo yum install wget
wget http://tech.pjin.jp/wp-content/uploads/2016/04/worldcup2014.zip
unzip http://worldcup2014.zipデータの確認
ls -la worldcup2014.sqlデータベース作成
MySQLにログインして…
mysql -u root -p (パスワードを入力)データベースを作成
create database worldcup2014db;使うデータベースにDLしたデータを指定
use worldcup2014db;
source ./worldcup2014.sql;テーブルを表示して確認
show tables;確認用バッチ処理とコマンドを作成していきます
参考:バッチ処理とは?
Laravelでモデルを作成(参考:https://blog.codecamp.jp/php_mvc01)
php artisan make:model Models/Player作成したモデルを確認
ls -la app/Models/Player.phpバッチ記述用のファイルを作成
php artisan make:command TestCommand作成したファイルを確認
ls -la app/Console/Commands/TestCommand.phpここからは
1. SSH接続したVS Codeを使って
2. /var/www/html/ypsフォルダ(Laravelのプロジェクトファイル)
で作業していきますapp/console/commandsのCommands.phpファイルに以下を記述
Commands.php<?php namespace App\Console\Commands; use Illuminate\Console\Command; use App\Models\Player; class TestCommand extends Command { /** * The name and signature of the console command. * * @var string */ protected $signature = 'test_command'; /** * The console command description. * * @var string */ protected $description = 'Test Command'; /** * Create a new command instance. * * @return void */ public function __construct() { parent::__construct(); } /** * Execute the console command. * * @return int */ public function handle() { $players = Player::get(); foreach($players as $player) { echo $player->name."\n"; } return 0; } }保存したらターミナルで以下のコマンドを打って確認
キャッシュをクリア
php artisan config:clear上記で作成したバッチコマンドを入力
php artisan test_command | head無事選手名が表示されればOK
MySQL日本語が打てない問題の一先ずの対応 = sqlファイルを作成して読み込ませる
どうしてもコマンドを使って行う場合の対応。
≒基本的にLaravelを使ってSQLは操作するので特に問題はなさそう?一時ファイルに移動
cd /var/tmp
sqlファイルを作成
vi get_players.sql以下を記述
use worldcup2014db; select * from players where name = '酒井';ターミナルで下記を打ってパスワードを入力
mysql -u root -p < ./get_players.sql酒井選手が2桁表示できればOK
(ファイルに出力したい場合はmysql -u root -p < ./get_players.sql > ./out.txt)~MySQLの復習&バッチ作成ここまで~
php.iniファイルを編集
主にPHPをアプリケーションで使用する際に日本語で文字化けしたりしないような設定をしていくようです。
※事前に
sudo yum install colordiff -yで差分を見られるようにしておく参考リンクを見ながらphp.iniの設定を編集
sudo vi /etc/php.iniまずはデフォルトのエンコーディングがUTF-8に…
default_charset = "UTF-8"
しかしこれ、あとで調べたら5.2以降のPHPはデフォルトでUTF-8になってるみたい…ということで設定要らんかったのかorz
気を取り直して、mbstringの探しつつ確認をしていきます。
[mbstring]の設定は一番下の方にありました…
mbstring.language = Japanese//コメントアウトを外す
mbstring.encoding_translation = Off//コメントアウトを外してoffにする
mbstring.detect_order = auto//コメントアウト外す※参考リンクが古いためか、ブログ記事では手動で設定するような記述になっているがautoのままでいいみたいです
(多分PHPのバージョンの関係)
date.timezone = Asia/TokyoPHPのバージョンが表示されてしまわないように変更
expose_php = Offパフォーマンス関連の設定
memory_limit = 128Mこれはデフォルトの設定なので確認だけポストリクエストのマックスサイズを128Mに変更
post_max_size = 128Mファイルをアップロードする際のマックスサイズをPOSTに合わせて128Mに変更
upload_max_filesize = 128Mついでにエラーログの設定もしておきましょう
error_log= "/var/log/php_errors.log"全部できてれば…
colordiff -u /etc/php.ini.org /etc/php.iniって打てば--- /etc/php.ini.org 2020-07-07 18:04:58.000000000 +0900 +++ /etc/php.ini 2020-07-31 23:28:50.392713681 +0900 @@ -373,7 +373,7 @@ ; threat in any way, but it makes it possible to determine whether you use PHP ; on your server or not. ; http://php.net/expose-php -expose_php = On +expose_php = Off ;;;;;;;;;;;;;;;;;;; --- /etc/php.ini.org 2020-07-07 18:04:58.000000000 +0900 +++ /etc/php.ini 2020-08-01 01:02:55.357913512 +0900 @@ -373,7 +373,7 @@ ; threat in any way, but it makes it possible to determine whether you use PHP ; on your server or not. ; http://php.net/expose-php -expose_php = On +expose_php = Off ;;;;;;;;;;;;;;;;;;; ; Resource Limits ; @@ -584,6 +584,7 @@ ; http://php.net/error-log ; Example: ;error_log = php_errors.log +error_log = "/var/log/php_errors.log" ; Log errors to syslog (Event Log on Windows). ;error_log = syslog @@ -690,7 +691,7 @@ ; Its value may be 0 to disable the limit. It is ignored if POST data reading ; is disabled through enable_post_data_reading. ; http://php.net/post-max-size -post_max_size = 8M +post_max_size = 128M ; Automatically add files before PHP document. ; http://php.net/auto-prepend-file @@ -842,7 +843,7 @@ ; Maximum allowed size for uploaded files. ; http://php.net/upload-max-filesize -upload_max_filesize = 2M +upload_max_filesize = 128M ; Maximum number of files that can be uploaded via a single request max_file_uploads = 20 @@ -919,7 +920,7 @@ [Date] ; Defines the default timezone used by the date functions ; http://php.net/date.timezone -;date.timezone = +date.timezone = Asia/Tokyo ; http://php.net/date.default-latitude ;date.default_latitude = 31.7667 @@ -1533,7 +1534,7 @@ ; language for internal character representation. ; This affects mb_send_mail() and mbstring.detect_order. ; http://php.net/mbstring.language -;mbstring.language = Japanese +mbstring.language = Japanese ; Use of this INI entry is deprecated, use global internal_encoding instead. ; internal/script encoding. @@ -1571,7 +1572,7 @@ ; automatic encoding detection order. ; "auto" detect order is changed according to mbstring.language ; http://php.net/mbstring.detect-order -;mbstring.detect_order = auto +mbstring.detect_order = auto ; substitute_character used when character cannot be converted ; one from anotherってなるはず(らしい)
そしてコンソールに戻ってphpのエラーログファイル作成&設定を行います
sudo touch /var/log/php_errors.log
sudo chown nginx:nginx /var/log/php_errors.logここまでできたら設定反映のためにphp-fpmとnginxを再起動
sudo systemctl restart php-fpm
sudo systemctl restart nginx~php.iniの設定ここまで~
Gitインスコ&GitHubとの連携
参考までに予備知識:https://qiita.com/moonbass630/items/383fc8300a83784e4c82
まずはgitをインストール
sudo yum install git -y
ディレクトリをLaravelのプロジェクトに移動して…
cd /var/www/html/yps
gitをinitします(意味が分からない方のための参考リンク:https://26gram.com/git-init)
git initブラウザでGitHubを開いて新規リポジトリ作成
- Newボタンを押して新規作成
- リポジトリをPrivateに
- gitignoreにLaravelを追加
- create Repositoryを押して
- add readme.mdをクリックして完了
- リポジトリの画面の右側のCodeボタンをクリックして
- Clone with SSHと書かれたところに書いてあるgit@github.comから始まるリポジトリのurlをコピー
※GitHubにはすぐ戻ってくるのでブラウザは開いたままが推奨
Gitの設定ファイルを記述
ターミナルでまたLaravelのプロジェクトファイルへ戻ります
cd /var/www/html/yps/Gitの設定ファイルを編集
sudo vi .git/config下記を記述します
[remote "origin"] url = "リポジトリのurl" //作成時にコピーしたもの fetch = +refs/heads/*:refs/remotes/origin/* [branch "master"] remote = origin merge = refs/heads/master [user] name = 自分のgithubユーザー名 email = 自分のメアド [core] repositoryformatversion = 0 filemode = true bare = false接続用の秘密鍵を作成
ssh-keygen -t rsa -b 4096 -C "自分のメアド"
enterを押して
パスワードを2回入力下記コマンドを打って表示される文字列をコピーしておく
cat ~/.ssh/id_rsa.pubGitHubに文字列を登録
- 右上のアイコンを押してアカウントメニューを表示
- Settings ⇒ SSH and GPG keys
- New SSH keyをクリック
- Titleは適当なものをつける
- Keyと書いてあるところに上記(
cat ~/.ssh/id_rsa.pubコマンド)で表示されたキーを張り付け- Add SSH keyを押すと登録完了
GitHubをリモート登録
ターミナルでLaravelプロジェクトフォルダに戻ります
cd /var/www/html/yps/差分ファイルを全てステージングして、マスターブランチにpush
git add .
git commit -am "initial"
git push origin master
yesを入力してパスワードを入力すればソースコードの登録完了。develop / feature ブランチを切る
参考リンク:https://qiita.com/Naoki206/items/e5520453f92dcd4274f1
参考リンクを見ながらdevelopブランチとfeatureブランチを切る
$git branch現在のブランチの確認
$git branch developdevelopブランチ作成
$git checkout developdevelopブランチへ移動
$git push origin developリモートに反映~git導入&GitHub連携ここまで~
Masterから分岐させて開発終了後にmergeを使ってmasterブランチへ取り込むことによってgitではバージョン管理をする…
Gitは一応Progateでいじって、Qiitaでも初心者向けの記事読んだりしてたけど、今回色々いじってようやく仕組みが腑に落ちた感あるな~今回はまとめ作ってたらすんごい時間になってしまったのでこの辺で…
次回はWP導入していじるみたいです。今まで色々やってきたことの解像度が大分上がってきて楽しくなってきたぞ~(夜中のテンション)
- 投稿日:2020-08-01T01:45:28+09:00
Terraformで、AWS Lambda関数を登録して動かしてみる
What's?
- はじめてのAWS Lambdaを試してみたい
- AWS LambdaのデプロイはTerraformで行いたい
というお題で。
やっておきたいこと、動かし方としては
- AWS Lambda関数は、Terraformでzip圧縮してアップロードする
- AWS Lambda関数からログを出力する
- Amazon CloudWatch Logsへ出力するようにロググループを作成する
- AWS Lambda関数から環境変数を読み込む
- 環境変数の暗号化にはAWS KMSのCMKを用いる
- 動作確認はAWS CLIで行う
というところで。
環境
今回の環境は、こちらです。
$ terraform version Terraform v0.12.29 + provider.archive v1.3.0 + provider.aws v2.70.0 $ aws --version aws-cli/2.0.36 Python/3.7.3 Linux/4.15.0-112-generic exe/x86_64.ubuntu.18AWSのクレデンシャルは、環境変数で設定します。
$ export AWS_ACCESS_KEY_ID=... $ export AWS_SECRET_ACCESS_KEY=... $ export AWS_DEFAULT_REGION=ap-northeast-1AWS Lambda関数を作成する
最初に、AWS Lambda関数を作成します。
AWS Lambdaのラインタイムはいろいろ選ぶことができるわけですが、今回はPythonにしました。
Pythonのランタイムは、現時点の最新バージョンである3.8を使うことにします。
ソースコードは、こちら。
app/lambda.py
※appというディレクトリ配下に置いていますimport logging import os logger = logging.getLogger('lambda_logger') logger.setLevel(logging.INFO) def handler(event, context): logger.info('function = %s, version = %s, request_id = %s', context.function_name, context.function_version, context.aws_request_id) logger.info('event = %s', event) base_message = os.environ['BASE_MESSAGE'] last_name = event['last_name'] first_name = event['first_name'] return { 'message': f'{base_message}, {first_name} {last_name}!!' }環境変数とリクエストから値を読みつつ、メッセージにして返す、という簡単な関数です。
base_message = os.environ['BASE_MESSAGE'] last_name = event['last_name'] first_name = event['first_name'] return { 'message': f'{base_message}, {first_name} {last_name}!!' }ログの実装は、こちらを参考に。
動かしてみてハマったのですが、ログレベルを
INFOにしないと、今回のコードではログが出力されませんでした…。logger = logging.getLogger('lambda_logger') logger.setLevel(logging.INFO)Terraformの構成ファイルを書く
それでは、Terraformの構成ファイルを書いていきます。次のファイルに。
main.tfTerraformやProviderのバージョン指定
terraform { required_version = "0.12.29" } provider "aws" { version = "2.70.0" } provider "archive" { version = "1.3.0" }AWS Lambda関数をアップロードする定義
先ほど作成した、Pythonコードをアップロードする定義を書きます。
locals { function_name = "my_lambda_function" } data "archive_file" "function_source" { type = "zip" source_dir = "app" output_path = "archive/my_lambda_function.zip" } resource "aws_lambda_function" "function" { function_name = local.function_name handler = "lambda.handler" role = aws_iam_role.lambda_role.arn runtime = "python3.8" kms_key_arn = aws_kms_key.lambda_key.arn filename = data.archive_file.function_source.output_path source_code_hash = data.archive_file.function_source.output_base64sha256 environment { variables = { BASE_MESSAGE = "Hello" } } depends_on = [aws_iam_role_policy_attachment.lambda_policy, aws_cloudwatch_log_group.lambda_log_group] }こちらで、先ほど作成した
appディレクトリ配下にあるAWS Lambda関数のファイルをzipファイルにします。data "archive_file" "function_source" { type = "zip" source_dir = "app" output_path = "archive/my_lambda_function.zip" }で、こちらを使ってAWS Lambda関数をリソース定義。
resource "aws_lambda_function" "function" { function_name = local.function_name handler = "lambda.handler" role = aws_iam_role.lambda_role.arn runtime = "python3.8" kms_key_arn = aws_kms_key.lambda_key.arn filename = data.archive_file.function_source.output_path source_code_hash = data.archive_file.function_source.output_base64sha256 environment { variables = { BASE_MESSAGE = "Hello" } } depends_on = [aws_iam_role_policy_attachment.lambda_policy, aws_cloudwatch_log_group.lambda_log_group] }
handlerは、[ファイル名(拡張子なし].[関数名]で指定ですね。AWS Lambdaに与えるロール、AWS KMSキーは、あとで定義します。この部分ですね。
role = aws_iam_role.lambda_role.arn kms_key_arn = aws_kms_key.lambda_key.arn環境変数は、こちら。先ほどのPythonコードで、環境変数として読み込んでいた変数名ですね。
environment { variables = { BASE_MESSAGE = "Hello" } }
depends_onには、このあとに作成するIAMロール、Amazon CloudWatch Logsを設定しています。depends_on = [aws_iam_role_policy_attachment.lambda_policy, aws_cloudwatch_log_group.lambda_log_group]この
depends_onについては、Terraformのドキュメントを参考に設定しています。IAMロールを定義する
次に、IAMロールを定義します。今回は、
AWSLambdaBasicExecutionRoleポリシーをベースに、AWS KMSに関する権限を与えることにします。AWS Lambdaに関するポリシーは、こちらに記載があります。
AWS Lambda 実行ロール / Lambda 機能の管理ポリシー
AWS CLIで、定義を見てみましょう。
$ aws iam get-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole { "Policy": { "PolicyName": "AWSLambdaBasicExecutionRole", "PolicyId": "ANPAJNCQGXC42545SKXIK", "Arn": "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole", "Path": "/service-role/", "DefaultVersionId": "v1", "AttachmentCount": 0, "PermissionsBoundaryUsageCount": 0, "IsAttachable": true, "Description": "Provides write permissions to CloudWatch Logs.", "CreateDate": "2015-04-09T15:03:43+00:00", "UpdateDate": "2015-04-09T15:03:43+00:00" } }
AWSLambdaBasicExecutionRoleポリシーに付与されている権限は、こんな感じですね。Amazon CloudWatch Logsに関するものです。$ aws iam get-policy-version --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole --version-id v1 { "PolicyVersion": { "Document": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }, "VersionId": "v1", "IsDefaultVersion": true, "CreateDate": "2015-04-09T15:03:43+00:00" } }Assume Roleしつつ、
AWS Lambda 実行ロール / IAM API によるロールの管理
data "aws_iam_policy_document" "assume_role" { statement { actions = ["sts:AssumeRole"] effect = "Allow" principals { type = "Service" identifiers = ["lambda.amazonaws.com"] } } }
AWSLambdaBasicExecutionRoleを拡張する感じにします。data "aws_iam_policy" "lambda_basic_execution" { arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" } data "aws_iam_policy_document" "lambda_policy" { source_json = data.aws_iam_policy.lambda_basic_execution.policy statement { effect = "Allow" actions = [ "kms:Decrypt" ] resources = ["*"] } } resource "aws_iam_policy" "lambda_policy" { name = "MyLambdaPolicy" policy = data.aws_iam_policy_document.lambda_policy.json } resource "aws_iam_role_policy_attachment" "lambda_policy" { role = aws_iam_role.lambda_role.name policy_arn = aws_iam_policy.lambda_policy.arn } resource "aws_iam_role" "lambda_role" { name = "MyLambdaRole" assume_role_policy = data.aws_iam_policy_document.assume_role.json }具体的には、AWS KMSに関する権限を追加します。
data "aws_iam_policy_document" "lambda_policy" { source_json = data.aws_iam_policy.lambda_basic_execution.policy statement { effect = "Allow" actions = [ "kms:Decrypt" ] resources = ["*"] } }Amazon CloudWatch Logsグループを定義する
AWS Lambda関数のログを格納する、Amazon CloudWatch Logsグループを定義します。
resource "aws_cloudwatch_log_group" "lambda_log_group" { name = "/aws/lambda/${local.function_name}" }ロググループ名は、
/aws/lambda/[AWS Lambda関数名]で作成します。Python の AWS Lambda 関数ログ作成 / AWS マネジメントコンソール でログを表示する
AWS KMSキーを定義する
環境変数の暗号化で使用する、AWS KMSキー(CMK)を作成します。
resource "aws_kms_key" "lambda_key" { description = "My Lambda Function Customer Master Key" enable_key_rotation = true deletion_window_in_days = 7 } resource "aws_kms_alias" "lambda_key_alias" { name = "alias/my-lambda-key" target_key_id = aws_kms_key.lambda_key.id }リソースを作成する
ここまで準備したので、あとはTerraformを実行してリソースを作成します。
$ terraform apply動作確認する
では、動作確認してみます。
Amazon CloudWatch Logsでログをtailしつつ
$ aws logs tail /aws/lambda/my_lambda_function --followこちらを参考にして
AWS Lambda関数を呼び出してみます。
$ aws lambda invoke --function-name my_lambda_function --payload '{"first_name": "Taro", "last_name": "Tanaka"}' --log-type Tail output.txt Invalid base64: "{"first_name": "Taro", "last_name": "Tanaka"}"が、エラーになります…。
今回使っているAWS CLI v2では、与えるパラメーターの扱いが変わっているようです。
AWS CLI バージョン 2 はデフォルトで base64 エンコードされた文字列としてバイナリパラメータを渡すようになりました
というわけで、
--cli-binary-format raw-in-base64-outオプションをつけて実行$ aws lambda invoke --function-name my_lambda_function \ --payload '{"first_name": "Taro", "last_name": "Tanaka"}' \ --cli-binary-format raw-in-base64-out \ --log-type Tail output.txt { "StatusCode": 200, "LogResult": "U1RBUlQgUmVxdWVzdElkOiBlNTZhYTI5Ny1jYTQyLTQ2NWEtOTNiZC1iZTZhMWQxZTQ5ZjAgVmVyc2lvbjogJExBVEVTVApbSU5GT10JMjAyMC0wNy0zMVQxNjozNDowMi41ODJaCWU1NmFhMjk3LWNhNDItNDY1YS05M2JkLWJlNmExZDFlNDlmMAlmdW5jdGlvbiA9IG15X2xhbWJkYV9mdW5jdGlvbiwgdmVyc2lvbiA9ICRMQVRFU1QsIHJlcXVlc3RfaWQgPSBlNTZhYTI5Ny1jYTQyLTQ2NWEtOTNiZC1iZTZhMWQxZTQ5ZjAKW0lORk9dCTIwMjAtMDctMzFUMTY6MzQ6MDIuNTgzWgllNTZhYTI5Ny1jYTQyLTQ2NWEtOTNiZC1iZTZhMWQxZTQ5ZjAJZXZlbnQgPSB7J2ZpcnN0X25hbWUnOiAnVGFybycsICdsYXN0X25hbWUnOiAnVGFuYWthJ30KRU5EIFJlcXVlc3RJZDogZTU2YWEyOTctY2E0Mi00NjVhLTkzYmQtYmU2YTFkMWU0OWYwClJFUE9SVCBSZXF1ZXN0SWQ6IGU1NmFhMjk3LWNhNDItNDY1YS05M2JkLWJlNmExZDFlNDlmMAlEdXJhdGlvbjogMS4zNiBtcwlCaWxsZWQgRHVyYXRpb246IDEwMCBtcwlNZW1vcnkgU2l6ZTogMTI4IE1CCU1heCBNZW1vcnkgVXNlZDogNTEgTUIJSW5pdCBEdXJhdGlvbjogMTEzLjA1IG1zCQo=", "ExecutedVersion": "$LATEST" }今度は、呼び出せたようです。結果を確認。
$ cat output.txt {"message": "Hello, Taro Tanaka!!"}OKです。
Amazon CloudWatch Logsの方は、こんな感じの出力になります。
2020-07-31T16:34:02.582000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd START RequestId: e56aa297-ca42-465a-93bd-be6a1d1e49f0 Version: $LATEST 2020-07-31T16:34:02.583000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd [INFO] 2020-07-31T16:34:02.582Z e56aa297-ca42-465a-93bd-be6a1d1e49f0 function = my_lambda_function, version = $LATEST, request_id = e56aa297-ca42-465a-93bd-be6a1d1e49f0 2020-07-31T16:34:02.583000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd [INFO] 2020-07-31T16:34:02.583Z e56aa297-ca42-465a-93bd-be6a1d1e49f0 event = {'first_name': 'Taro', 'last_name': 'Tanaka'} 2020-07-31T16:34:02.584000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd END RequestId: e56aa297-ca42-465a-93bd-be6a1d1e49f0 2020-07-31T16:34:02.584000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd REPORT RequestId: e56aa297-ca42-465a-93bd-be6a1d1e49f0 Duration: 1.36 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 51 MB Init Duration: 113.05 msうまくいったようですね。
環境変数音暗号化について
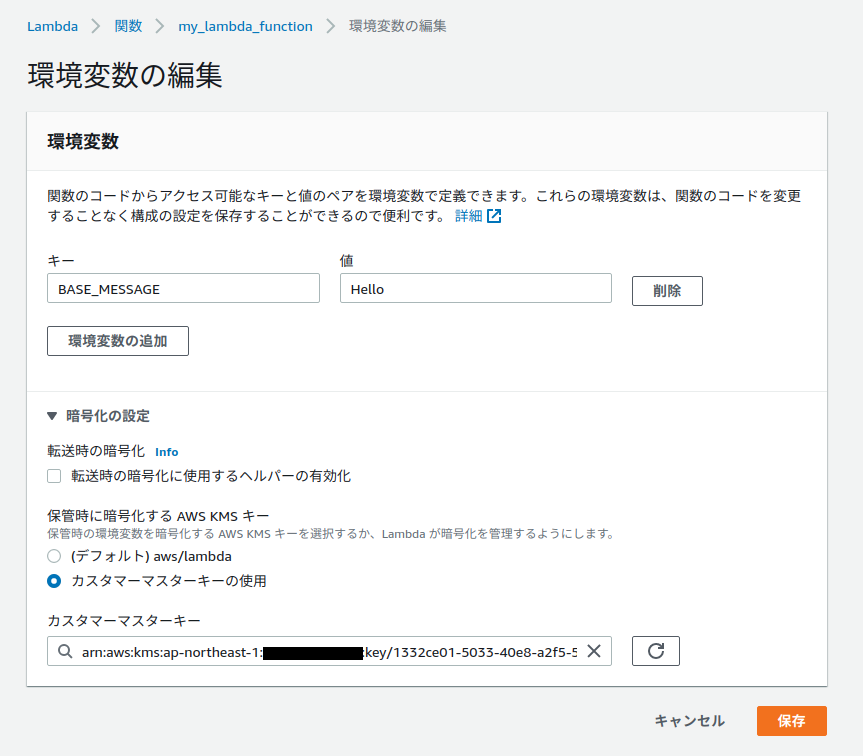
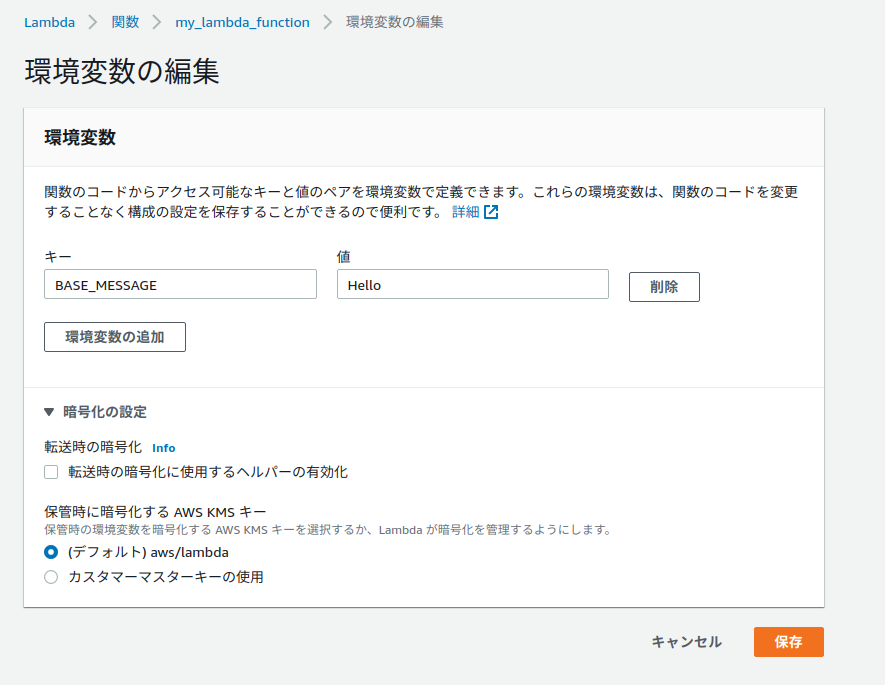
AWS Lambdaの環境変数の暗号化についてですが、Terraformで指定できるのは
kms_key_arnで、こちらは「保存時に暗号化するAWS KMSキー」を指しています。
環境変数の値自体は、ふつうに見えています。
マネージメントコンソール上で暗号化した状態にするには、「転送時の暗号化」を行うことになりますが、これはTerraformではできなさそうです…。
AWS CLIでも、見れますね。
$ aws lambda get-function-configuration --function-name my_lambda_function { "FunctionName": "my_lambda_function", "FunctionArn": "arn:aws:lambda:ap-northeast-1:[AWSアカウントID]:function:my_lambda_function", "Runtime": "python3.8", "Role": "arn:aws:iam::[AWSアカウントID]:role/MyLambdaRole", "Handler": "lambda.handler", "CodeSize": 394, "Description": "", "Timeout": 3, "MemorySize": 128, "LastModified": "2020-07-31T16:48:37.579+0000", "CodeSha256": "R3089h8mTmE2HmcSK1p5w0qUMdpuSBao2kne6aZw8hU=", "Version": "$LATEST", "Environment": { "Variables": { "BASE_MESSAGE": "Hello" } }, "KMSKeyArn": "arn:aws:kms:ap-northeast-1:[AWSアカウントID]:key/bf526778-7e70-4a9f-a28f-f1e4ee911c66", "TracingConfig": { "Mode": "PassThrough" }, "RevisionId": "038d76ab-1769-445f-845d-56df8720ffc0", "State": "Active", "LastUpdateStatus": "Successful" }このあたりは、また時間があったら調べることにしましょう。
ちなみに、
kms_key_arnを指定しない場合は、環境変数の暗号化にはデフォルトの暗号化キー(AWS管理のCMK)が使用されます。

- 投稿日:2020-08-01T01:45:28+09:00
TerraformでAWS Lambda関数を作成してみる
What's?
- はじめてのAWS Lambdaを試してみたい
- AWS LambdaのデプロイはTerraformで行いたい
というお題で。
やっておきたいこと、動かし方としては
- AWS Lambda関数は、Terraformでzip圧縮してアップロードする
- AWS Lambda関数からログを出力する
- Amazon CloudWatch Logsへ出力するようにロググループを作成する
- AWS Lambda関数から環境変数を読み込む
- 環境変数の暗号化にはAWS KMSのCMKを用いる
- 動作確認はAWS CLIで行う
というところで。
環境
今回の環境は、こちらです。
$ terraform version Terraform v0.12.29 + provider.archive v1.3.0 + provider.aws v2.70.0 $ aws --version aws-cli/2.0.36 Python/3.7.3 Linux/4.15.0-112-generic exe/x86_64.ubuntu.18AWSのクレデンシャルは、環境変数で設定します。
$ export AWS_ACCESS_KEY_ID=... $ export AWS_SECRET_ACCESS_KEY=... $ export AWS_DEFAULT_REGION=ap-northeast-1AWS Lambda関数を作成する
最初に、AWS Lambda関数を作成します。
AWS Lambdaのラインタイムはいろいろ選ぶことができるわけですが、今回はPythonにしました。
Pythonのランタイムは、現時点の最新バージョンである3.8を使うことにします。
ソースコードは、こちら。
app/lambda.py
※appというディレクトリ配下に置いていますimport logging import os logger = logging.getLogger('lambda_logger') logger.setLevel(logging.INFO) def handler(event, context): logger.info('function = %s, version = %s, request_id = %s', context.function_name, context.function_version, context.aws_request_id) logger.info('event = %s', event) base_message = os.environ['BASE_MESSAGE'] last_name = event['last_name'] first_name = event['first_name'] return { 'message': f'{base_message}, {first_name} {last_name}!!' }環境変数とリクエストから値を読みつつ、メッセージにして返す、という簡単な関数です。
base_message = os.environ['BASE_MESSAGE'] last_name = event['last_name'] first_name = event['first_name'] return { 'message': f'{base_message}, {first_name} {last_name}!!' }ログの実装は、こちらを参考に。
動かしてみてハマったのですが、ログレベルを
INFOにしないと、今回のコードではログが出力されませんでした…。logger = logging.getLogger('lambda_logger') logger.setLevel(logging.INFO)Terraformの構成ファイルを書く
それでは、Terraformの構成ファイルを書いていきます。次のファイルに。
main.tfTerraformやProviderのバージョン指定
terraform { required_version = "0.12.29" } provider "aws" { version = "2.70.0" } provider "archive" { version = "1.3.0" }AWS Lambda関数をアップロードする定義
先ほど作成した、Pythonコードをアップロードする定義を書きます。
locals { function_name = "my_lambda_function" } data "archive_file" "function_source" { type = "zip" source_dir = "app" output_path = "archive/my_lambda_function.zip" } resource "aws_lambda_function" "function" { function_name = local.function_name handler = "lambda.handler" role = aws_iam_role.lambda_role.arn runtime = "python3.8" kms_key_arn = aws_kms_key.lambda_key.arn filename = data.archive_file.function_source.output_path source_code_hash = data.archive_file.function_source.output_base64sha256 environment { variables = { BASE_MESSAGE = "Hello" } } depends_on = [aws_iam_role_policy_attachment.lambda_policy, aws_cloudwatch_log_group.lambda_log_group, aws_kms_key.lambda_key] }こちらで、先ほど作成した
appディレクトリ配下にあるAWS Lambda関数のファイルをzipファイルにします。data "archive_file" "function_source" { type = "zip" source_dir = "app" output_path = "archive/my_lambda_function.zip" }で、こちらを使ってAWS Lambda関数をリソース定義。
resource "aws_lambda_function" "function" { function_name = local.function_name handler = "lambda.handler" role = aws_iam_role.lambda_role.arn runtime = "python3.8" kms_key_arn = aws_kms_key.lambda_key.arn filename = data.archive_file.function_source.output_path source_code_hash = data.archive_file.function_source.output_base64sha256 environment { variables = { BASE_MESSAGE = "Hello" } } depends_on = [aws_iam_role_policy_attachment.lambda_policy, aws_cloudwatch_log_group.lambda_log_group, aws_kms_key.lambda_key] }
handlerは、[ファイル名(拡張子なし].[関数名]で指定ですね。AWS Lambdaに与えるロール、AWS KMSキーは、あとで定義します。この部分ですね。
role = aws_iam_role.lambda_role.arn kms_key_arn = aws_kms_key.lambda_key.arn環境変数は、こちら。先ほどのPythonコードで、環境変数として読み込んでいた変数名ですね。
environment { variables = { BASE_MESSAGE = "Hello" } }
depends_onには、このあとに作成するIAMロール、Amazon CloudWatch Logs、AWS KMSキーを設定しています。depends_on = [aws_iam_role_policy_attachment.lambda_policy, aws_cloudwatch_log_group.lambda_log_group, aws_kms_key.lambda_key]IAMロールを定義する
次に、IAMロールを定義します。今回は、
AWSLambdaBasicExecutionRoleポリシーをベースに、AWS KMSに関する権限を与えることにします。AWS Lambdaに関するポリシーは、こちらに記載があります。
AWS Lambda 実行ロール / Lambda 機能の管理ポリシー
AWS CLIで、定義を見てみましょう。
$ aws iam get-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole { "Policy": { "PolicyName": "AWSLambdaBasicExecutionRole", "PolicyId": "ANPAJNCQGXC42545SKXIK", "Arn": "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole", "Path": "/service-role/", "DefaultVersionId": "v1", "AttachmentCount": 0, "PermissionsBoundaryUsageCount": 0, "IsAttachable": true, "Description": "Provides write permissions to CloudWatch Logs.", "CreateDate": "2015-04-09T15:03:43+00:00", "UpdateDate": "2015-04-09T15:03:43+00:00" } }
AWSLambdaBasicExecutionRoleポリシーに付与されている権限は、こんな感じですね。Amazon CloudWatch Logsに関するものです。$ aws iam get-policy-version --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole --version-id v1 { "PolicyVersion": { "Document": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }, "VersionId": "v1", "IsDefaultVersion": true, "CreateDate": "2015-04-09T15:03:43+00:00" } }Assume Roleしつつ、
AWS Lambda 実行ロール / IAM API によるロールの管理
data "aws_iam_policy_document" "assume_role" { statement { actions = ["sts:AssumeRole"] effect = "Allow" principals { type = "Service" identifiers = ["lambda.amazonaws.com"] } } }
AWSLambdaBasicExecutionRoleを拡張する感じにします。data "aws_iam_policy" "lambda_basic_execution" { arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" } data "aws_iam_policy_document" "lambda_policy" { source_json = data.aws_iam_policy.lambda_basic_execution.policy statement { effect = "Allow" actions = [ "kms:Decrypt" ] resources = ["*"] } } resource "aws_iam_policy" "lambda_policy" { name = "MyLambdaPolicy" policy = data.aws_iam_policy_document.lambda_policy.json } resource "aws_iam_role_policy_attachment" "lambda_policy" { role = aws_iam_role.lambda_role.name policy_arn = aws_iam_policy.lambda_policy.arn } resource "aws_iam_role" "lambda_role" { name = "MyLambdaRole" assume_role_policy = data.aws_iam_policy_document.assume_role.json }具体的には、AWS KMSに関する権限を追加します。
data "aws_iam_policy_document" "lambda_policy" { source_json = data.aws_iam_policy.lambda_basic_execution.policy statement { effect = "Allow" actions = [ "kms:Decrypt" ] resources = ["*"] } }Amazon CloudWatch Logsグループを定義する
AWS Lambda関数のログを格納する、Amazon CloudWatch Logsグループを定義します。
resource "aws_cloudwatch_log_group" "lambda_log_group" { name = "/aws/lambda/${local.function_name}" }ロググループ名は、
/aws/lambda/[AWS Lambda関数名]で作成します。Python の AWS Lambda 関数ログ作成 / AWS マネジメントコンソール でログを表示する
AWS KMSキーを定義する
環境変数の暗号化で使用する、AWS KMSキー(CMK)を作成します。
resource "aws_kms_key" "lambda_key" { description = "My Lambda Function Customer Master Key" enable_key_rotation = true deletion_window_in_days = 7 } resource "aws_kms_alias" "lambda_key_alias" { name = "alias/my-lambda-key" target_key_id = aws_kms_key.lambda_key.id }リソースを作成する
ここまで準備したので、あとはTerraformを実行してリソースを作成します。
$ terraform apply動作確認する
では、動作確認してみます。
Amazon CloudWatch Logsでログをtailしつつ
$ aws logs tail /aws/lambda/my_lambda_function --followこちらを参考にして
AWS Lambda関数を呼び出してみます。
$ aws lambda invoke --function-name my_lambda_function --payload '{"first_name": "Taro", "last_name": "Tanaka"}' --log-type Tail output.txt Invalid base64: "{"first_name": "Taro", "last_name": "Tanaka"}"が、エラーになります…。
今回使っているAWS CLI v2では、与えるパラメーターの扱いが変わっているようです。
AWS CLI バージョン 2 はデフォルトで base64 エンコードされた文字列としてバイナリパラメータを渡すようになりました
というわけで、
--cli-binary-format raw-in-base64-outオプションをつけて実行$ aws lambda invoke --function-name my_lambda_function \ --payload '{"first_name": "Taro", "last_name": "Tanaka"}' \ --cli-binary-format raw-in-base64-out \ --log-type Tail output.txt { "StatusCode": 200, "LogResult": "U1RBUlQgUmVxdWVzdElkOiBlNTZhYTI5Ny1jYTQyLTQ2NWEtOTNiZC1iZTZhMWQxZTQ5ZjAgVmVyc2lvbjogJExBVEVTVApbSU5GT10JMjAyMC0wNy0zMVQxNjozNDowMi41ODJaCWU1NmFhMjk3LWNhNDItNDY1YS05M2JkLWJlNmExZDFlNDlmMAlmdW5jdGlvbiA9IG15X2xhbWJkYV9mdW5jdGlvbiwgdmVyc2lvbiA9ICRMQVRFU1QsIHJlcXVlc3RfaWQgPSBlNTZhYTI5Ny1jYTQyLTQ2NWEtOTNiZC1iZTZhMWQxZTQ5ZjAKW0lORk9dCTIwMjAtMDctMzFUMTY6MzQ6MDIuNTgzWgllNTZhYTI5Ny1jYTQyLTQ2NWEtOTNiZC1iZTZhMWQxZTQ5ZjAJZXZlbnQgPSB7J2ZpcnN0X25hbWUnOiAnVGFybycsICdsYXN0X25hbWUnOiAnVGFuYWthJ30KRU5EIFJlcXVlc3RJZDogZTU2YWEyOTctY2E0Mi00NjVhLTkzYmQtYmU2YTFkMWU0OWYwClJFUE9SVCBSZXF1ZXN0SWQ6IGU1NmFhMjk3LWNhNDItNDY1YS05M2JkLWJlNmExZDFlNDlmMAlEdXJhdGlvbjogMS4zNiBtcwlCaWxsZWQgRHVyYXRpb246IDEwMCBtcwlNZW1vcnkgU2l6ZTogMTI4IE1CCU1heCBNZW1vcnkgVXNlZDogNTEgTUIJSW5pdCBEdXJhdGlvbjogMTEzLjA1IG1zCQo=", "ExecutedVersion": "$LATEST" }今度は、呼び出せたようです。結果を確認。
$ cat output.txt {"message": "Hello, Taro Tanaka!!"}OKです。
Amazon CloudWatch Logsの方は、こんな感じの出力になります。
2020-07-31T16:34:02.582000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd START RequestId: e56aa297-ca42-465a-93bd-be6a1d1e49f0 Version: $LATEST 2020-07-31T16:34:02.583000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd [INFO] 2020-07-31T16:34:02.582Z e56aa297-ca42-465a-93bd-be6a1d1e49f0 function = my_lambda_function, version = $LATEST, request_id = e56aa297-ca42-465a-93bd-be6a1d1e49f0 2020-07-31T16:34:02.583000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd [INFO] 2020-07-31T16:34:02.583Z e56aa297-ca42-465a-93bd-be6a1d1e49f0 event = {'first_name': 'Taro', 'last_name': 'Tanaka'} 2020-07-31T16:34:02.584000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd END RequestId: e56aa297-ca42-465a-93bd-be6a1d1e49f0 2020-07-31T16:34:02.584000+00:00 2020/07/31/[$LATEST]31685a31fb3045d49d3585154de2b0dd REPORT RequestId: e56aa297-ca42-465a-93bd-be6a1d1e49f0 Duration: 1.36 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 51 MB Init Duration: 113.05 msうまくいったようですね。
環境変数音暗号化について
AWS Lambdaの環境変数の暗号化についてですが、Terraformで指定できるのは
kms_key_arnで、こちらは「保存時に暗号化するAWS KMSキー」を指しています。
環境変数の値自体は、ふつうに見えています。
マネージメントコンソール上で暗号化した状態にするには、「転送時の暗号化」を行うことになりますが、これはTerraformではできなさそうです…。
AWS CLIでも、見れますね。
$ aws lambda get-function-configuration --function-name my_lambda_function { "FunctionName": "my_lambda_function", "FunctionArn": "arn:aws:lambda:ap-northeast-1:[AWSアカウントID]:function:my_lambda_function", "Runtime": "python3.8", "Role": "arn:aws:iam::[AWSアカウントID]:role/MyLambdaRole", "Handler": "lambda.handler", "CodeSize": 394, "Description": "", "Timeout": 3, "MemorySize": 128, "LastModified": "2020-07-31T16:48:37.579+0000", "CodeSha256": "R3089h8mTmE2HmcSK1p5w0qUMdpuSBao2kne6aZw8hU=", "Version": "$LATEST", "Environment": { "Variables": { "BASE_MESSAGE": "Hello" } }, "KMSKeyArn": "arn:aws:kms:ap-northeast-1:[AWSアカウントID]:key/bf526778-7e70-4a9f-a28f-f1e4ee911c66", "TracingConfig": { "Mode": "PassThrough" }, "RevisionId": "038d76ab-1769-445f-845d-56df8720ffc0", "State": "Active", "LastUpdateStatus": "Successful" }このあたりは、また時間があったら調べることにしましょう。
ちなみに、
kms_key_arnを指定しない場合は、環境変数の暗号化にはデフォルトの暗号化キー(AWS管理のCMK)が使用されます。