- 投稿日:2020-07-30T23:37:32+09:00
pythonでインピーダンス解析(EIS)【impedance.py】
概要
インピーダンス(電気化学インピーダンス)の解析をpythonで行えるライブラリimpedance.pyを紹介します。測定したNyquist plotを、構築した等価回路モデルへフィッティングしてパラメータを得るところまでやります。
有料ソフト等が不要なので気軽に使えます
基本的にimpedance.pyの公式チュートリアルに沿って説明し、ところどころ補足する程度ですのでよっぽど英語を読みたくない人向けです。
説明が要らない人用に一番下にコードをまとめて掲載してます。課題
オープンソースのツールだけを使ってインピーダンス解析をしたい
電気化学インピーダンス解析には測定装置に付随する解析ソフトが必要ですが、測定用PCでいちいち解析するのはめんどくさいですよね。。。
しかしソフトは有料のものが多く、ライセンスの関係で自分のPCに入れることもできない。。。本記事で扱うこと、扱わないこと
扱うこと
impedance.pyについて
扱わないこと
pythonの始め方
"python 使い方"とかで調べてください依存環境
2020/07/22時点
- Python (>=3.7)
- SciPy (>=1.0)
- NumPy (>=1.14)
- Matplotlib (>=3.0)
- Altair (>=3.0)
最新の情報はこちらからDependencyを確認してください→impedance.py(1)インストール
PyPIに登録されているので
pip install impedanceでインストール(2)データのインポート[preprocesing]
測定データはふつうにcsvをread_csvしてpandas.Dataframeとして扱ってもいいが、
preprocessingなるものが用意されているのでせっかくだし使います
サンプルデータが公式から用意されているのでこちらからStep2カラム内のexample.csvをダウンロードfrom impedance import preprocessing frequencies, Z = preprocessing.readCSV('./exampleData.csv') #type(frequencies): <class 'numpy.ndarray'> #type(frequencies[0]): <class 'numpy.float64'> #type(Z): <class 'numpy.ndarray'> #type(Z[0]): <class 'numpy.complex128'>exampleData.csvの中身はこんな感じ
A列が周波数、B列がZの実部、C列がZの虚部でpreprocessing.readCSVのソースコードをみてもただ単にA列をfrequencies、BC列をcomplex型のZにしてreturnしただけでした。実は便利なpreprocessing!!
しょうもない機能かと思ったら、実は使える機能が!
preprocessingはほかにも装置ソフト特有の拡張子にも対応していて(ここ大事)以下のソフトと拡張子に対応しているらしい
ソフト 拡張子 gamry .dta autolab コンマ区切り(.csv?) parstat .txt zplot .z versastudio .par powersuite .txt biologic .mpt chinstruments .txt ソースコードを見ると正規表現などを使ってデータの加工をやってくれてるのでとてもハッピー
(筆者は.mptファイルでうまく使えました)
使い方は以下from impedance import preprocessing frequencies, Z = preprocessing.readFile('ファイルへのpath', instrument='ソフト名') frequencies, Z = preprocessing.ignoreBelowX(frequencies, Z)instrumentオプションに上表のソフト名を渡すとファイルの形式を指定できます。
他には
・第一象限を切り取るpreprocessing.ignoreBelowX(freq, Z)
・周波数でデータを切り取るpreprocessing.cropFrequencies(freq, Z, freqmin=0, freqmax=None)
が用意されています(3)等価回路の作成
今回は以下のような等価回路モデルを例として作成します
from impedance.models.circuits import CustomCircuit circuit = 'R0-p(R1,C1)-p(R2-Wo1,C2)' initial_guess = [.01, .01, 100, .01, .05, 100, 1] circuit = CustomCircuit(circuit, initial_guess=initial_guess)
-で直列、p( , )で並列を表現して文字列としてCustomCircuitクラスに渡すことで等価回路を作成できます。このとき、初期パラメータをinitial_guessオプションにリスト型で渡す必要があります。表現できる回路素子はこちらにまとめられています。
今回はCustomCircuitを用いましたが、ソースコードを見るとRandlesもデフォルトで用意されています。(4)フィッティング
circuit.fit(frequencies, Z) params = circuit.parameters_ #[1.65187261e-02 8.67655045e-03 3.32142565e+00 5.38996281e-03 # 6.30927436e-02 2.32520436e+02 2.19541831e-01] covs = circuit.conf_ #[1.54227642e-04 1.91273738e-04 1.89536697e-01 2.05799010e-04 # 1.93973976e-03 1.62269546e+01 1.75432523e-02]フィッティングを行った後、
circuit.parameters_とcircuit.conf_でそれぞれフィッティング後のパラメータとパラメータの分散を受け取ることができます。
フィッティングアルゴリズムとしてはscipy.optimize.curve_fitが用いられているようです。(5)結果の可視化
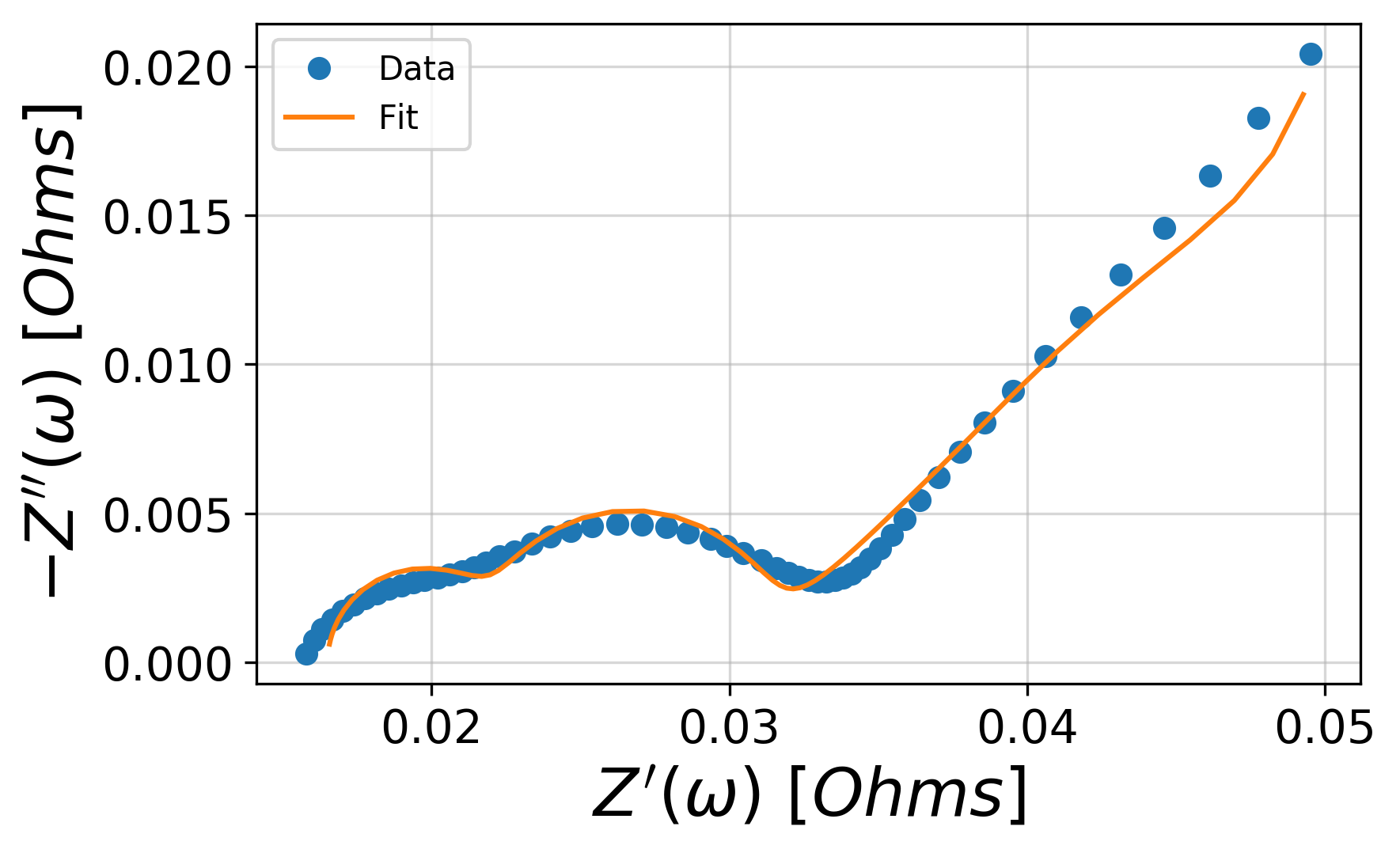
import matplotlib.pyplot as plt from impedance.visualization import plot_nyquist Z_fit = circuit.predict(frequencies) fig, ax = plt.subplots() plot_nyquist(ax, Z, fmt='o') plot_nyquist(ax, Z_fit, fmt='-') plt.legend(['Data', 'Fit']) plt.show()
circuit.predict(frequencies)でフィッティングしたパラメータから計算したシミュレーション結果を取得します。
可視化にはmatplotlibおよびaltairをベースにしたvisualizationが用意されていて、nyquistプロットはplot_nyquistで表示させます。ご丁寧に軸ラベルも書いてくれます。
visualizationにはこのほかにplot_bode(bodeプロット)などいろいろ用意されています。(追記予定)コード
from matplotlib import pyplot as plt from impedance import preprocessing from impedance.models.circuits import CustomCircuit from impedance.visualization import plot_nyquist def main(): frequencies, Z = preprocessing.readCSV('./exampleData.csv') frequencies, Z = preprocessing.ignoreBelowX(frequencies, Z) circuit = 'R0-p(R1,C1)-p(R2-Wo1,C2)' initial_guess = [.01, .01, 100, .01, .05, 100, 1] circuit = CustomCircuit(circuit, initial_guess=initial_guess) circuit.fit(frequencies, Z) print(circuit.parameters_) print(circuit.conf_) Z_fit = circuit.predict(frequencies) fig, ax = plt.subplots() plot_nyquist(ax, Z, fmt='o') plot_nyquist(ax, Z_fit, fmt='-') plt.legend(['Data', 'Fit']) plt.show() if __name__ == '__main__': main()


- 投稿日:2020-07-30T23:34:16+09:00
「データサイエンス100本ノック(構造化データ加工編)」 Python-016 解説
Youtube
動画解説もしています。
問題
P-016: 店舗データフレーム(df_store)から、電話番号(tel_no)が3桁-3桁-4桁のデータを全項目表示せよ。
解答
コードdf_store.query("tel_no.str.contains('[0-9]{3}-[0-9]{3}-[0-9]{4}')", engine='python')出力store_cd store_name prefecture_cd prefecture address address_kana tel_no longitude latitude floor_area 0 S12014 千草台店 12 千葉県 千葉県千葉市稲毛区千草台一丁目 チバケンチバシイナゲクチグサダイイッチョウメ 043-123-4003 140.1180 35.63559 1698.0 1 S13002 国分寺店 13 東京都 東京都国分寺市本多二丁目 トウキョウトコクブンジシホンダニチョウメ 042-123-4008 139.4802 35.70566 1735.0 2 S14010 菊名店 14 神奈川県 神奈川県横浜市港北区菊名一丁目 カナガワケンヨコハマシコウホククキクナイッチョウメ 045-123-4032 139.6326 35.50049 1732.0 3 S14033 阿久和店 14 神奈川県 神奈川県横浜市瀬谷区阿久和西一丁目 カナガワケンヨコハマシセヤクアクワニシイッチョウメ 045-123-4043 139.4961 35.45918 1495.0 4 S14036 相模原中央店 14 神奈川県 神奈川県相模原市中央二丁目 カナガワケンサガミハラシチュウオウニチョウメ 042-123-4045 139.3716 35.57327 1679.0 7 S14040 長津田店 14 神奈川県 神奈川県横浜市緑区長津田みなみ台五丁目 カナガワケンヨコハマシミドリクナガツタミナミダイゴチョウメ 045-123-4046 139.4994 35.52398 1548.0 9 S14050 阿久和西店 14 神奈川県 神奈川県横浜市瀬谷区阿久和西一丁目 カナガワケンヨコハマシセヤクアクワニシイッチョウメ 045-123-4053 139.4961 35.45918 1830.0 11 S13052 森野店 13 東京都 東京都町田市森野三丁目 トウキョウトマチダシモリノサンチョウメ 042-123-4030 139.4383 35.55293 1087.0 12 S14028 二ツ橋店 14 神奈川県 神奈川県横浜市瀬谷区二ツ橋町 カナガワケンヨコハマシセヤクフタツバシチョウ 045-123-4042 139.4963 35.46304 1574.0 16 S14012 本牧和田店 14 神奈川県 神奈川県横浜市中区本牧和田 カナガワケンヨコハマシナカクホンモクワダ 045-123-4034 139.6582 35.42156 1341.0 18 S14046 北山田店 14 神奈川県 神奈川県横浜市都筑区北山田一丁目 カナガワケンヨコハマシツヅキクキタヤマタイッチョウメ 045-123-4049 139.5916 35.56189 831.0 19 S14022 逗子店 14 神奈川県 神奈川県逗子市逗子一丁目 カナガワケンズシシズシイッチョウメ 046-123-4036 139.5789 35.29642 1838.0 20 S14011 日吉本町店 14 神奈川県 神奈川県横浜市港北区日吉本町四丁目 カナガワケンヨコハマシコウホククヒヨシホンチョウヨンチョウメ 045-123-4033 139.6316 35.54655 890.0 21 S13016 小金井店 13 東京都 東京都小金井市本町一丁目 トウキョウトコガネイシホンチョウイッチョウメ 042-123-4015 139.5094 35.70018 1399.0 22 S14034 川崎野川店 14 神奈川県 神奈川県川崎市宮前区野川 カナガワケンカワサキシミヤマエクノガワ 044-123-4044 139.5998 35.57693 1318.0 26 S14048 中川中央店 14 神奈川県 神奈川県横浜市都筑区中川中央二丁目 カナガワケンヨコハマシツヅキクナカガワチュウオウニチョウメ 045-123-4051 139.5758 35.54912 1657.0 27 S12007 佐倉店 12 千葉県 千葉県佐倉市上志津 チバケンサクラシカミシヅ 043-123-4001 140.1452 35.71872 1895.0 28 S14026 辻堂西海岸店 14 神奈川県 神奈川県藤沢市辻堂西海岸二丁目 カナガワケンフジサワシツジドウニシカイガンニチョウメ 046-123-4040 139.4466 35.32464 1732.0 29 S13041 八王子店 13 東京都 東京都八王子市大塚 トウキョウトハチオウジシオオツカ 042-123-4026 139.4235 35.63787 810.0 31 S14049 川崎大師店 14 神奈川県 神奈川県川崎市川崎区中瀬三丁目 カナガワケンカワサキシカワサキクナカゼサンチョウメ 044-123-4052 139.7327 35.53759 962.0 32 S14023 川崎店 14 神奈川県 神奈川県川崎市川崎区本町二丁目 カナガワケンカワサキシカワサキクホンチョウニチョウメ 044-123-4037 139.7028 35.53599 1804.0 33 S13018 清瀬店 13 東京都 東京都清瀬市松山一丁目 トウキョウトキヨセシマツヤマイッチョウメ 042-123-4017 139.5178 35.76885 1220.0 35 S14027 南藤沢店 14 神奈川県 神奈川県藤沢市南藤沢 カナガワケンフジサワシミナミフジサワ 046-123-4041 139.4896 35.33762 1521.0 36 S14021 伊勢原店 14 神奈川県 神奈川県伊勢原市伊勢原四丁目 カナガワケンイセハラシイセハラヨンチョウメ 046-123-4035 139.3129 35.40169 962.0 37 S14047 相模原店 14 神奈川県 神奈川県相模原市千代田六丁目 カナガワケンサガミハラシチヨダロクチョウメ 042-123-4050 139.3748 35.55959 1047.0 38 S12013 習志野店 12 千葉県 千葉県習志野市芝園一丁目 チバケンナラシノシシバゾノイッチョウメ 047-123-4002 140.0220 35.66122 808.0 40 S14042 新山下店 14 神奈川県 神奈川県横浜市中区新山下二丁目 カナガワケンヨコハマシナカクシンヤマシタニチョウメ 045-123-4047 139.6593 35.43894 1044.0 42 S12030 八幡店 12 千葉県 千葉県市川市八幡三丁目 チバケンイチカワシヤワタサンチョウメ 047-123-4005 139.9240 35.72318 1162.0 44 S14025 大和店 14 神奈川県 神奈川県大和市下和田 カナガワケンヤマトシシモワダ 046-123-4039 139.4680 35.43414 1011.0 45 S14045 厚木店 14 神奈川県 神奈川県厚木市中町二丁目 カナガワケンアツギシナカチョウニチョウメ 046-123-4048 139.3651 35.44182 980.0 47 S12029 東野店 12 千葉県 千葉県浦安市東野一丁目 チバケンウラヤスシヒガシノイッチョウメ 047-123-4004 139.8968 35.65086 1101.0 49 S12053 高洲店 12 千葉県 千葉県浦安市高洲五丁目 チバケンウラヤスシタカスゴチョウメ 047-123-4006 139.9176 35.63755 1555.0 51 S14024 三田店 14 神奈川県 神奈川県川崎市多摩区三田四丁目 カナガワケンカワサキシタマクミタヨンチョウメ 044-123-4038 139.5424 35.60770 972.0 52 S14006 葛が谷店 14 神奈川県 神奈川県横浜市都筑区葛が谷 カナガワケンヨコハマシツヅキククズガヤ 045-123-4031 139.5633 35.53573 1886.0解説
・PandasのDataFrame/Seriesにて、条件に当てはまるデータを確認する方法です。
・条件に当てはまる情報を確認したい時に使用します。
・'contains(<文字列>)'は、指定した文字列が含まれているどうかを判定する関数であり、含まれる場合はTrue、含まれない場合はFalseを返します。
・ただし、'.query('列名.str.contains(<文字列>))'は、指定した文字列が含まれることを条件として指定します。
・今回の場合、tel_no を文字列に置換するために'tel_no.str'とし、'.contains('[0-9]{3}-[0-9]{3}-[0-9]{4}')'を続けることで、[0-9]の中から3つ、'-'、[0-9]の中から3つ、'-'、[0-9]の中から4つの数字、といった並びの文字列を指定しています。
・'[]'は範囲を表す正規表現であり、'-'は連続する値の範囲を指定しています。'{}'は繰り返す回数を表す正規表現です。※正規表現については、こちらの記事が参考になります。
https://qiita.com/hiroyuki_mrp/items/29e87bf5fe46de62983c・'engine = 'python''について、query の引数である engine には'python'か、'numexpr'かを選択することができますが、strを用いる場合は、'python'を指定してあげないとエラーが発生してしまいます。
- 投稿日:2020-07-30T23:21:08+09:00
"categorical_crossentropy"と"sparse_categorical_crossentropy"の違い
結論
- 使用するラベルが違います。違いはそれだけです。"categorical_crossentropy"にはonehot(どこか1つが1で他は全て0)のラベルを使用します。"sparse_categorical_crossentropy"のラベルには整数を使用します。
one-hotと整数表現の違い
例)10分類の場合
one-hot表現 整数表現 [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] [9] [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.] [2] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [1] [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [5] 整数ラベルをone-hotラベルに変換
データセットでは整数ラベルのものが多い印象ですが,損失関数の多くは整数ラベルではなく,one-hotラベルを与えてあげないと動きません.そういう場合は変換する必要があります.(というか,むしろ"sparse_categorical_crossentropy"のように整数ラベルのまま学習できる損失関数が少数派だと感じます.)
以下にコードを記します.
import numpy as np n_labels = len(np.unique(train_labels)) train_labels_onehot = np.eye(n_labels)[train_labels] n_labels = len(np.unique(test_labels)) test_labels_onehot = np.eye(n_labels)[test_labels]
- 投稿日:2020-07-30T22:35:05+09:00
【Python初心者】if __name__ == '__main__'を手を動かして理解する。
何をするか
if \_\_name\_\_ == '\_\_main\_\_ ':とすることで、
出力がどう変わるかを4steps+2stepsで体験しました。anaconda>spyderなどツールで間接的に.pyを実行する際の挙動を示しています。
$ python XXX.py と実行する場合は記事下部の参考記事からご覧ください。いざ実践
__name__
1. まず、
print('Hello!')する関数をかき、「hello.py」として保存する。例1_hello.pyを定義する#hello.py def function(): print('Hello!')2. 次の新規.pyで「hello.py」をimportしてみる
例2_hello.pyをimportimport hello hello.function() # Hello!↓
functionが実行されたことがわかる。3. hello.pyを編集して、 __name__ も一緒に出力してみる
例3_nameを追加#hello.py def function(): print('Hello!') print(' __name__とすると、なんと表示されるのか..!? -->' , __name__)4.もう一度importを実行してみると...
例4_hello.pyを実行してみるimport hello hello.function() #Hello! #__name__とすると、なんと表示されるのか..!? --> hello↓
__name__の部分には、「hello.py」の「hello」が表示された!結論( __name__ とは )
__name__ にはimportされたモジュール
'hello.py'のモジュール名'hello'が入っていることが分かった。__main__
次に、hello.pyを編集して、 __main__ を追加してみる。
例1_mainの中に「佐藤」を仕込む。#hello.py def function(name): print('Hello!',name) print('ちなみに__name__の中身は-->',__name__) if __name__ == '__main__': print('mainの中の関数が実行されるのか..?',function('Sato'))hello.pyを実行してみる。
例2_「田中」を表示するimport hello hello.function('Tanaka') #Hello! Tanaka #ちなみに__name__の中身は--> hello↓
__name__はモジュール'hello.py'のモジュール名'hello'のままだった。
そのため、function()内にもかかわらず、if __name__ == '__main__':の中身(仕込んだ「佐藤」)が実行されなかった。結論( __main__ とは )
if __name__ == '__main__':にすることで、__main__以下が実行されないことが分かった。まとめ
importされた時に、実行させない部分を
if __name__ == '__main__':以下に書く。
※ $ python hello.py など直接呼び出すときは実行されます。
- 投稿日:2020-07-30T22:15:18+09:00
【ラビットチャレンジ(E資格)】深層学習(day2)
はじめに
2021/2/19・20に実施される日本ディープラーニング協会(JDLA)E資格合格を目指して、ラビットチャレンジを受講した際の学習記録です。
ラビットチャレンジは「現場で潰しが効くディープラーニング講座」の通学講座録画ビデオを編集した教材を活用したコースです。
質問等のサポートはありませんが、E資格受験のための格安(2020年6月時点での最安値)の講座です。詳細は以下のリンクからご確認ください。
Section1:勾配消失問題
誤差逆伝播法が下位層に進んでいくにつれて、勾配がどんどん緩やかになっていく。
そのため、勾配降下法による更新では下位層のパラメータはほとんど変わらず、訓練は最適値に収束しなくなる。勾配消失の解決方法
活性化関数の選択
- ReLU関数 $$ f(x) = \left\{ \begin{array} \\ x & (x > 0) \\ 0 & (x \leq 0) \\ \end{array} \right. $$ 勾配消失問題の回避とスパース化に貢献することで良い成果をもたらしている。
重みの初期値設定
- Xavier:前の層のノード数がnであるとき、 重みの要素に $\sqrt{\frac{1}{n}}$ を乗算した値。活性化関数はReLu、シグモイド(ロジスティック)関数、双曲線正接関数(tanh)。
- He:前の層のノード数がnであるとき、 重みの要素に $\sqrt{\frac{2}{n}}$ を乗算した値。活性化関数はReLu。
重みの初期値に0を設定すると、どのような問題が発生するか?
→ 全ての値が同じ値で伝わるため。パラメータのチューニングが行われなくなる。
- バッチ正規化 ミニバッチ単位で入力値のデータの偏りを抑制する手法。 中間層出力を正規化する処理を孕んだ層を加えることで、出力が常に平均0、分散1の分布に従うように強制する。 計算の高速化、勾配消失が起きづらくなるというメリットがある。
ミニバッチの平均と分散は
$$\mu_t=\frac{1}{N_t}\sum_{i=1}^{N_t}x_{ni}, \quad \sigma_t^2=\frac{1}{N_t}\sum_{i=1}^{N_t}(x_{ni}-\mu_t)^2$$
と表され、出力を正規化すると
$$\hat x_{ni}=\frac{x_{ni}-\mu_t}{\sqrt{\sigma_t^2-\theta}}$$
となる。
この正規化された出力を学習可能なスケーリングパラメータ $\gamma$ 、シフトパラメータ $\beta$ で線形変換する。
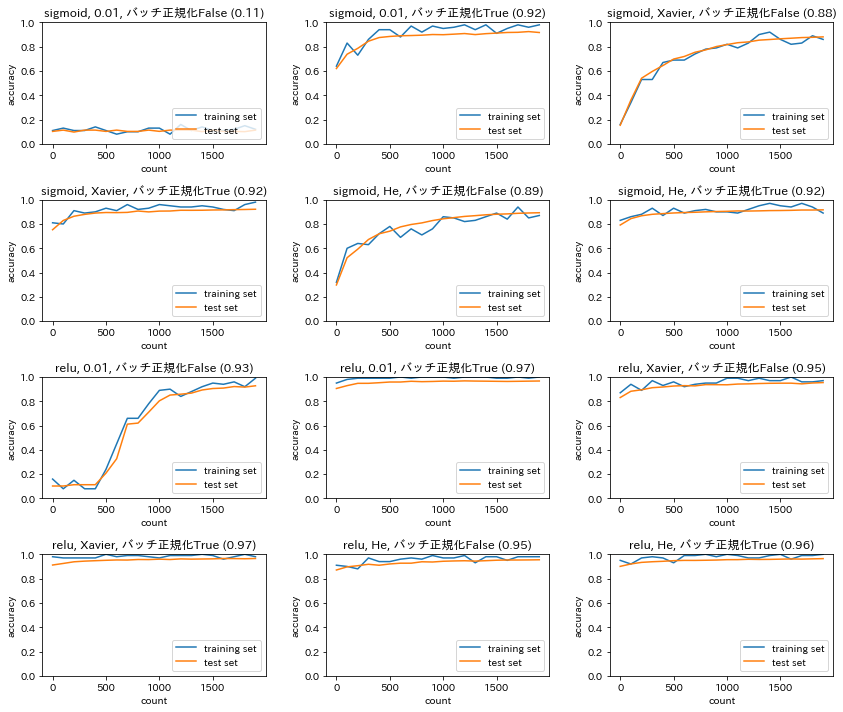
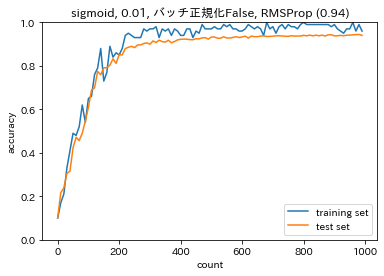
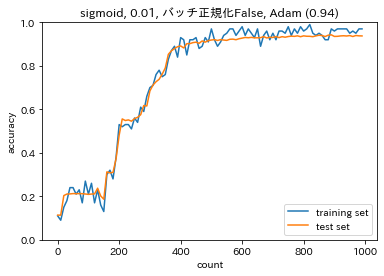
$$y_{ni}=\gamma x_{ni}+\beta$$活性化関数、重みの初期値、バッチ正規化の有無を変更した場合の勾配消失への寄与import sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 import numpy as np from common import layers from collections import OrderedDict from common import functions from data.mnist import load_mnist import matplotlib.pyplot as plt from common import optimizer class MultiLayerNet: ''' input_size: 入力層のノード数 hidden_size_list: 隠れ層のノード数のリスト output_size: 出力層のノード数 activation: 活性化関数 weight_init_std: 重みの初期化方法 weight_decay_lambda: L2正則化の強さ use_dropout: ドロップアウトの有無 dropout_ratio: ドロップアウト率 use_batchnorm: バッチ正規化の有無 ''' def __init__(self, input_size, hidden_size_list, output_size, activation='relu', weight_init_std='relu', weight_decay_lambda=0, use_dropout = False, dropout_ratio = 0.5, use_batchnorm=False): self.input_size = input_size self.output_size = output_size self.hidden_size_list = hidden_size_list self.hidden_layer_num = len(hidden_size_list) self.use_dropout = use_dropout self.weight_decay_lambda = weight_decay_lambda self.use_batchnorm = use_batchnorm self.params = {} # 重みの初期化 self.__init_weight(weight_init_std) # レイヤの生成 activation_layer = {'sigmoid': layers.Sigmoid, 'relu': layers.Relu} self.layers = OrderedDict() for idx in range(1, self.hidden_layer_num+1): self.layers['Affine' + str(idx)] = layers.Affine(self.params['W' + str(idx)], self.params['b' + str(idx)]) if self.use_batchnorm: self.params['gamma' + str(idx)] = np.ones(hidden_size_list[idx-1]) self.params['beta' + str(idx)] = np.zeros(hidden_size_list[idx-1]) self.layers['BatchNorm' + str(idx)] = layers.BatchNormalization(self.params['gamma' + str(idx)], self.params['beta' + str(idx)]) self.layers['Activation_function' + str(idx)] = activation_layer[activation]() if self.use_dropout: self.layers['Dropout' + str(idx)] = layers.Dropout(dropout_ratio) idx = self.hidden_layer_num + 1 self.layers['Affine' + str(idx)] = layers.Affine(self.params['W' + str(idx)], self.params['b' + str(idx)]) self.last_layer = layers.SoftmaxWithLoss() def __init_weight(self, weight_init_std): all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size] for idx in range(1, len(all_size_list)): scale = weight_init_std if str(weight_init_std).lower() in ('relu', 'he'): scale = np.sqrt(2.0 / all_size_list[idx - 1]) # ReLUを使う場合に推奨される初期値 elif str(weight_init_std).lower() in ('sigmoid', 'xavier'): scale = np.sqrt(1.0 / all_size_list[idx - 1]) # sigmoidを使う場合に推奨される初期値 self.params['W' + str(idx)] = scale * np.random.randn(all_size_list[idx-1], all_size_list[idx]) self.params['b' + str(idx)] = np.zeros(all_size_list[idx]) def predict(self, x, train_flg=False): for key, layer in self.layers.items(): if "Dropout" in key or "BatchNorm" in key: x = layer.forward(x, train_flg) else: x = layer.forward(x) return x def loss(self, x, d, train_flg=False): y = self.predict(x, train_flg) weight_decay = 0 for idx in range(1, self.hidden_layer_num + 2): W = self.params['W' + str(idx)] weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W**2) return self.last_layer.forward(y, d) + weight_decay def accuracy(self, X, D): Y = self.predict(X, train_flg=False) Y = np.argmax(Y, axis=1) if D.ndim != 1 : D = np.argmax(D, axis=1) accuracy = np.sum(Y == D) / float(X.shape[0]) return accuracy def gradient(self, x, d): # forward self.loss(x, d, train_flg=True) # backward dout = 1 dout = self.last_layer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # 設定 grads = {} for idx in range(1, self.hidden_layer_num+2): grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.params['W' + str(idx)] grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db if self.use_batchnorm and idx != self.hidden_layer_num+1: grads['gamma' + str(idx)] = self.layers['BatchNorm' + str(idx)].dgamma grads['beta' + str(idx)] = self.layers['BatchNorm' + str(idx)].dbeta return grads # バッチ正則化 layer class BatchNormalization: ''' gamma: スケール係数 beta: オフセット momentum: 慣性 running_mean: テスト時に使用する平均 running_var: テスト時に使用する分散 ''' def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None): self.gamma = gamma self.beta = beta self.momentum = momentum self.input_shape = None self.running_mean = running_mean self.running_var = running_var # backward時に使用する中間データ self.batch_size = None self.xc = None self.std = None self.dgamma = None self.dbeta = None def forward(self, x, train_flg=True): if self.running_mean is None: N, D = x.shape self.running_mean = np.zeros(D) self.running_var = np.zeros(D) if train_flg: mu = x.mean(axis=0) # 平均 xc = x - mu # xをセンタリング var = np.mean(xc**2, axis=0) # 分散 std = np.sqrt(var + 10e-7) # スケーリング xn = xc / std self.batch_size = x.shape[0] self.xc = xc self.xn = xn self.std = std self.running_mean = self.momentum * self.running_mean + (1-self.momentum) * mu # 平均値の加重平均 self.running_var = self.momentum * self.running_var + (1-self.momentum) * var #分散値の加重平均 else: xc = x - self.running_mean xn = xc / ((np.sqrt(self.running_var + 10e-7))) out = self.gamma * xn + self.beta return out def backward(self, dout): dbeta = dout.sum(axis=0) dgamma = np.sum(self.xn * dout, axis=0) dxn = self.gamma * dout dxc = dxn / self.std dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0) dvar = 0.5 * dstd / self.std dxc += (2.0 / self.batch_size) * self.xc * dvar dmu = np.sum(dxc, axis=0) dx = dxc - dmu / self.batch_size self.dgamma = dgamma self.dbeta = dbeta return dx # データの読み込み # (x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True) (x_train, d_train), (x_test, d_test) = load_mnist(normalize=True) print('データ読み込み完了') activations = ['sigmoid', 'relu'] weight_init_stds = [0.01, 'Xavier', 'He'] use_batchnorms = [False, True] iters_num = 2000 train_size = x_train.shape[0] batch_size = 100 learning_rate = 0.1 plot_interval = 100 plot_idx = 0 for k in range(len(activations)): for l in range(len(weight_init_stds)): for m in range(len(use_batchnorms)): network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation=activations[k], weight_init_std=weight_init_stds[l], use_batchnorm=use_batchnorms[m]) train_loss_list = [] accuracies_train = [] accuracies_test = [] lists = [] plot_idx = plot_idx + 1 for i in range(iters_num): batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] d_batch = d_train[batch_mask] # 勾配 grad = network.gradient(x_batch, d_batch) for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'): network.params[key] -= learning_rate * grad[key] loss = network.loss(x_batch, d_batch) train_loss_list.append(loss) if (i + 1) % plot_interval == 0: accr_test = network.accuracy(x_test, d_test) accuracies_test.append(accr_test) accr_train = network.accuracy(x_batch, d_batch) accuracies_train.append(accr_train) print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train)) print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test)) lists = range(0, iters_num, plot_interval) plt.rcParams['figure.figsize'] = (12.0, 10.0) plt.subplot(4,3,plot_idx) plt.plot(lists, accuracies_train, label='training set') plt.plot(lists, accuracies_test, label='test set') plt.legend(loc='lower right') plt.title(activations[k] + ', ' + str(weight_init_stds[l]) + ', バッチ正規化' + str(use_batchnorms[m]) + ' (' + str(np.round(accuracies_test[-1],2)) + ')') plt.xlabel('count') plt.ylabel('accuracy') plt.ylim(0, 1.0) # グラフの表示 plt.tight_layout() # plt.suptitle('活性化関数および重みの初期値を変更した場合の予測精度', fontsize = 16) plt.show()
Section2:学習率最適化手法
学習率の値が大きい場合、最適値にいつまでもたどり着かず発散してしまう。
学習率の値が小さい場合、発散することはないが、小さすぎると収束するまでに時間がかかったり、大域局所最適値に収束しづらくなってしまったりする。
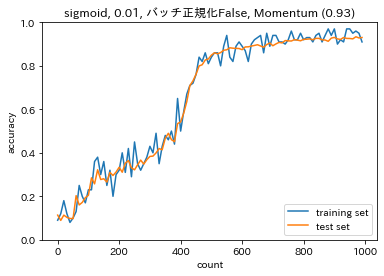
- モメンタム $$ V_t = \mu V_{t-1}-\epsilon\nabla E $$ $$ w^{(t+1)} = w^{(t)}+V_t $$ 誤差をパラメータで微分したものと学習率の積を減算した後、現在の重みに前回の重みを減算した値と慣性の積を加算する。
【モメンタムのメリット】
- 局所最適解にはならず、大域的最適解となる。
- 谷間に着いてから最も低い位置(最適値)に行くまでの時間が早い。モメンタムの勾配# 勾配 grad = network.gradient(x_batch, d_batch) if i == 0: v = {} for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'): if i == 0: v[key] = np.zeros_like(network.params[key]) v[key] = momentum * v[key] - learning_rate * grad[key] network.params[key] += v[key] loss = network.loss(x_batch, d_batch) train_loss_list.append(loss)
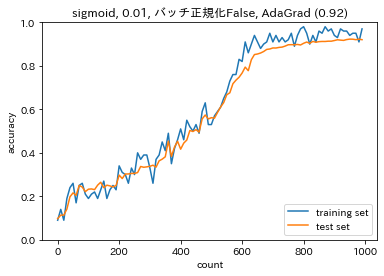
- AdaGrad $$ h_0 = \theta $$ $$ h_t = h_{t-1}+(\nabla E)^2 $$ $$ w^{(t+1)} = w^{(t)}-\epsilon \frac{1}{\sqrt{h_t}+\theta}\nabla E $$ 誤差をパラメータで微分したものと再定義した学習率の積を減算する。
【AdaGradのメリット】
- 勾配の緩やかな斜面に対して、最適値に近づける。AdaGradの勾配# 勾配 grad = network.gradient(x_batch, d_batch) if i == 0: h = {} for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'): if i == 0: h[key] = np.full_like(network.params[key], 1e-4) else: h[key] += np.square(grad[key]) network.params[key] -= learning_rate * grad[key] / (np.sqrt(h[key])) loss = network.loss(x_batch, d_batch) train_loss_list.append(loss)
- RMSProp $$ h_t = \alpha h_{t-1}+(1-\alpha)(\nabla E)^2 $$ $$ w^{(t+1)} = w^{(t)}-\epsilon \frac{1}{\sqrt{h_t}+\theta}\nabla E $$ 誤差をパラメータで微分したものと再定義した学習率の積を減算する。
【RMSPropのメリット】
- 局所的最適解にはならず、大域的最適解となる。
- ハイバーパラメータの調整が必要な場合が少ない。RMSPropの勾配# 勾配 grad = network.gradient(x_batch, d_batch) if i == 0: h = {} for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'): if i == 0: h[key] = np.zeros_like(network.params[key]) h[key] *= decay_rate h[key] += (1 - decay_rate) * np.square(grad[key]) network.params[key] -= learning_rate * grad[key] / (np.sqrt(h[key]) + 1e-7) loss = network.loss(x_batch, d_batch) train_loss_list.appen
- Adam $$ V_t = \mu V_{t-1}-\epsilon\nabla E $$ $$ h_t = \alpha h_{t-1}+(1-\alpha)(\nabla E)^2 $$ $$ w^{(t+1)} = w^{(t)}-\epsilon \frac{V_t}{\sqrt{h_t}+\theta}\nabla E $$
【Adamのメリット】
- モメンタムの過去の勾配の指数関数的減衰平均、RMSPropの過去の勾配の2乗の指数関数的減衰平均というメリットを孕んだアルゴリズムである。Adamの勾配# 勾配 grad = network.gradient(x_batch, d_batch) if i == 0: m = {} v = {} learning_rate_t = learning_rate * np.sqrt(1.0 - beta2 ** (i + 1)) / (1.0 - beta1 ** (i + 1)) for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'): if i == 0: m[key] = np.zeros_like(network.params[key]) v[key] = np.zeros_like(network.params[key]) m[key] += (1 - beta1) * (grad[key] - m[key]) v[key] += (1 - beta2) * (grad[key] ** 2 - v[key]) network.params[key] -= learning_rate_t * m[key] / (np.sqrt(v[key]) + 1e-7) loss = network.loss(x_batch, d_batch) train_loss_list.append(loss)
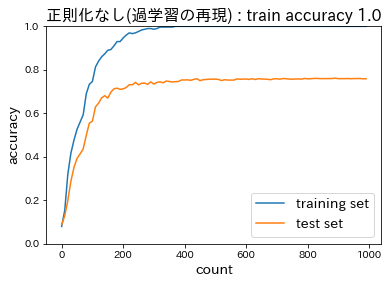
Section3:過学習
テスト誤差と訓練誤差とで学習曲線が乖離し、特定の訓練サンプルに対して特化して学習してしまうこと。
過学習を防ぐには、下記のような方法がある。
L2ノルムを利用:Ridge推定量(縮小推定…パラメータを0に近づけるよう推定)
$$ \sum_{i=1}^n(y_i-\beta_0-\sum_{j=1}^p\beta_jx_{ij})^2 + \lambda\sum_{j=1}^p\beta_j^2 $$
$\lambda$:ハイパーパラメータ
- $\lambda$がゼロであれば最小二乗法と同じ
- $\lambda$を大きくすると$\beta_1,…,\beta_p$は0に近づく($\beta_0$にはペナルティがつかないことに注意)
- 交差検証などによって適切な値に決める
L1ノルムを利用:Lasso(the Least absolute shrinkage and selection operator)推定量(スパース推定…いくつかのパラメータを正確に0に推定)
$$ \sum_{i=1}^n(y_i-\beta_0-\sum_{j=1}^p\beta_jx_{ij})^2 + \lambda\sum_{j=1}^p|\beta_j| $$
- パラメータのL1ノルムに比例するペナルティ
- $\lambda$ を大きくすると多くのパラメータが0になる $\rightarrow$変数選択によるスパースなモデルを生成
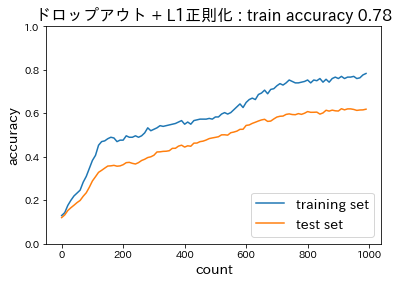
ドロップアウト
ランダムにノードを削除して学習させることにより、データ量を変化させずに異なるモデルを学習させていると解釈できる。<正則化なし(過学習の再現)>
(optimizer.SGD(learning_rate=0.01))
<L2正則化>
(learning_rate=0.01)
<L1正則化>
(learning_rate=0.1)
<ドロップアウト>
(optimizer.SGD(learning_rate=0.01), weight_decay_lambda = 0.01)
(optimizer.Momentum(learning_rate=0.01, momentum=0.9), weight_decay_lambda = 0.01)
(optimizer.AdaGrad(learning_rate=0.01), weight_decay_lambda = 0.01)
(optimizer.Adam(learning_rate=0.01), weight_decay_lambda = 0.01)
<ドロップアウト + L1正則化>
(dropout_ratio = 0.1, weight_decay_lambda=0.005)
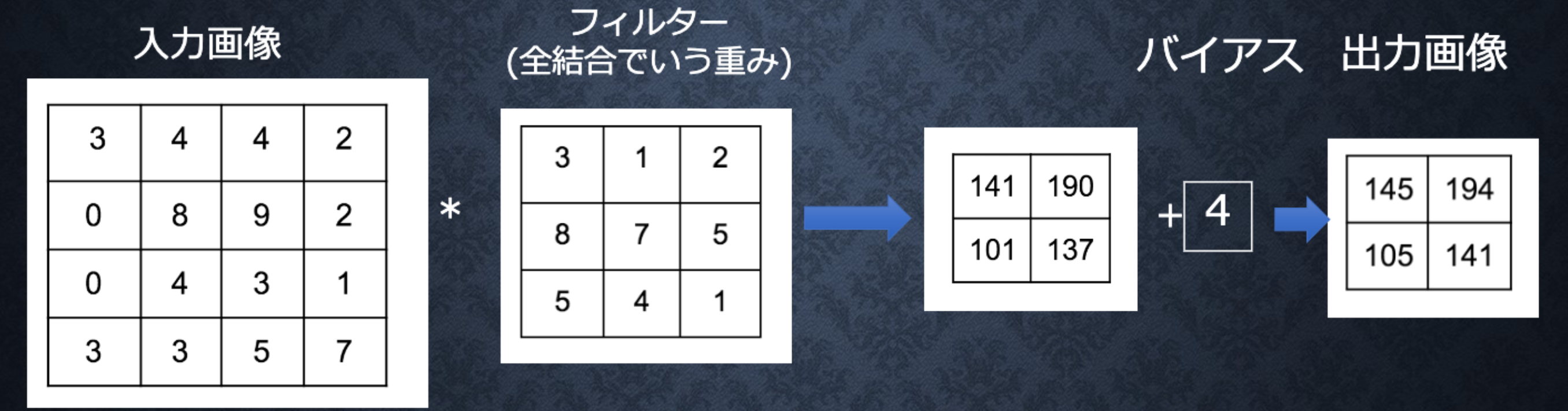
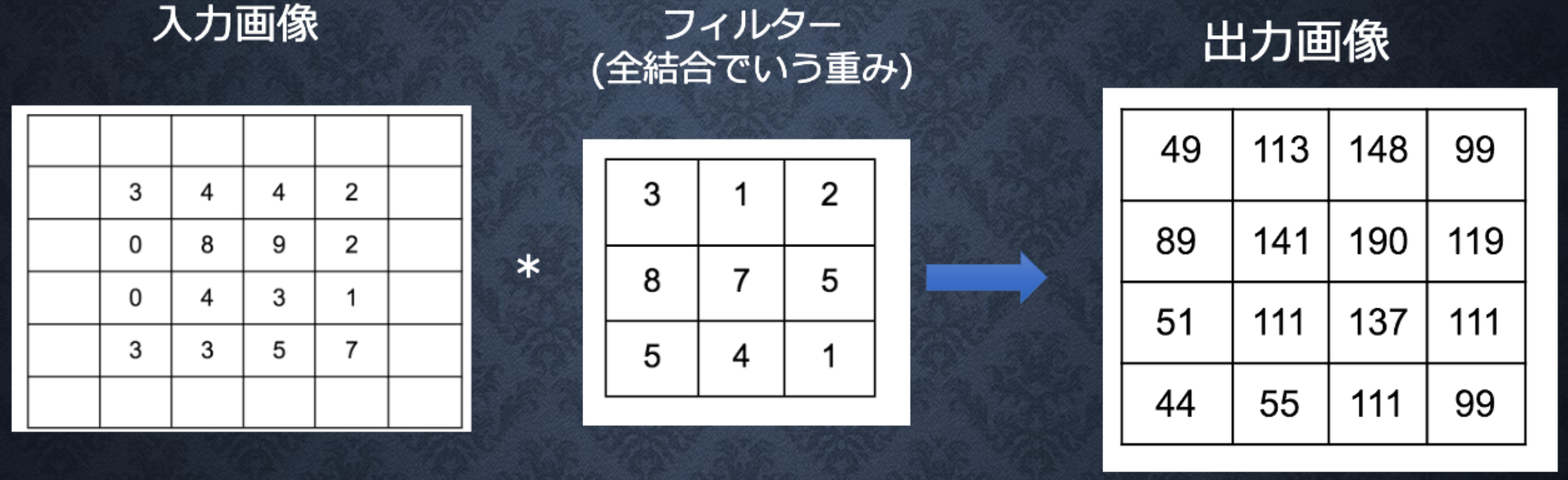
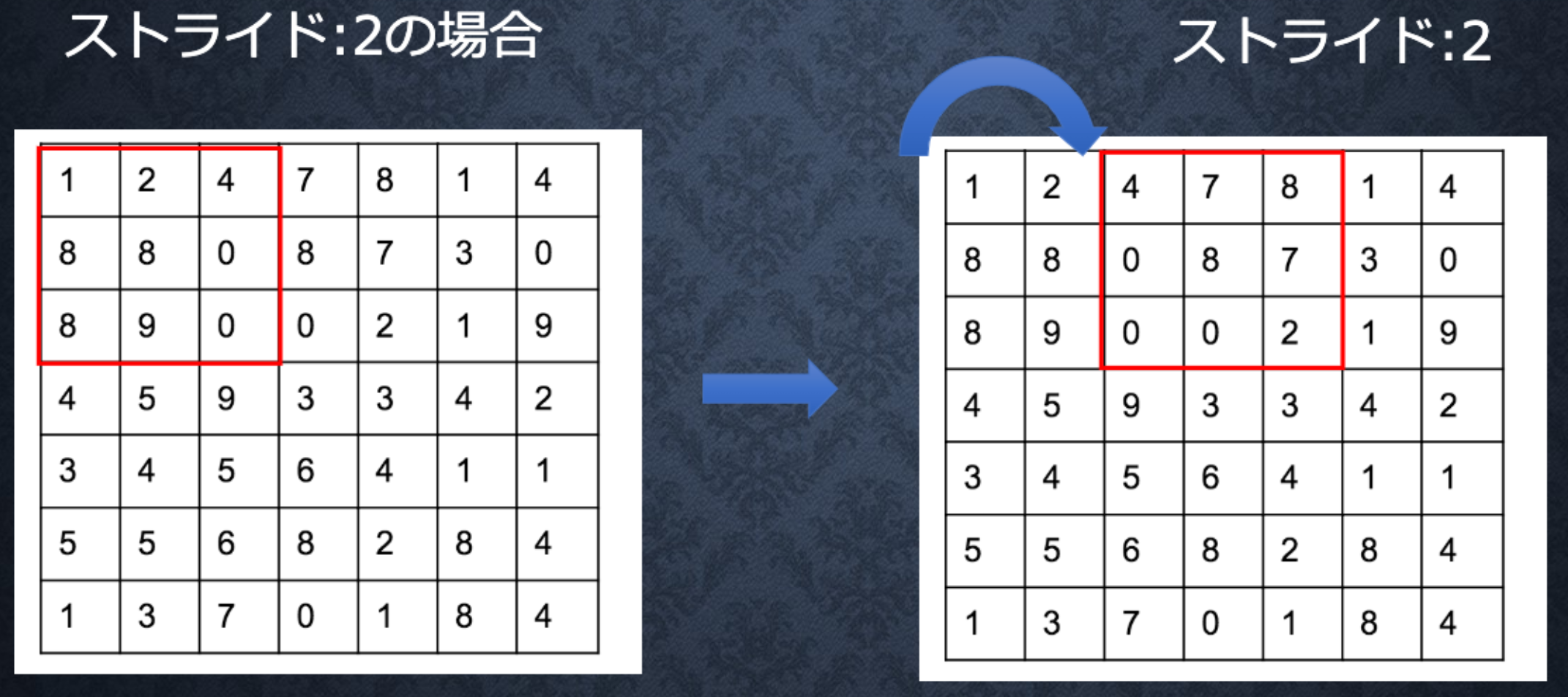
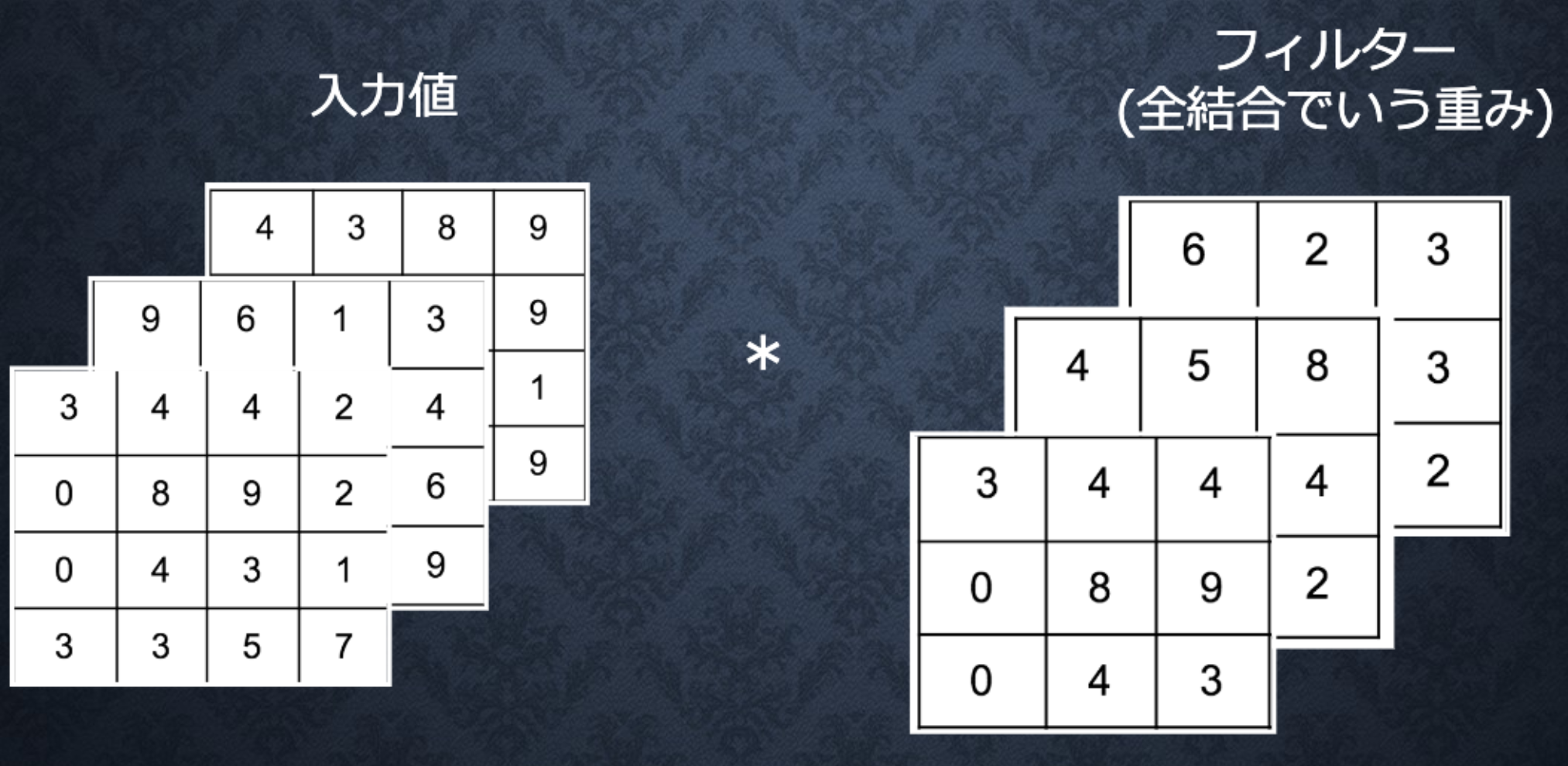
Section4:畳み込みニューラルネットワークの概念
畳み込みの演算概念
バイアス
(ゼロ)パディング
ストライド
チャンネル
なお、入力サイズをW×H、フィルタサイズをFw×Fh、パディングをp、ストライドをsとし、畳み込み層の出力サイズをOW×OHとすると、OWおよびOHは次式により求められる。
$$ OW=\frac{W+2p-Fw}{s}+1, \quad OH=\frac{H+2p-Fh}{s}+1 $$全結合層のデメリット:画像の場合、縦、横、チャンネルの3次元データだが、1次元のデータとして処理される。すなわち、RGBの各チャンネル間の関連性が学習に反映されない。
Section5:最新のCNN(2020年現在は最新とは呼べないが…)
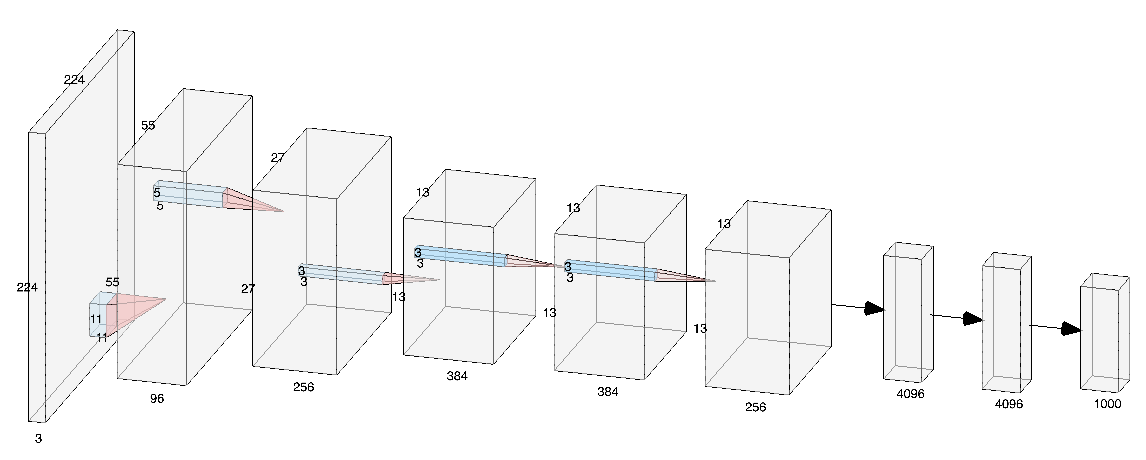
AlexNet
論文の筆頭著者Alex Krizhevskyの名前から、AlexNetと名づけられている。
5層の畳み込み層およびプーリング層など、それに続く3層の全結合層から構成されている。
Yann LeCunらによって1998年に初めて考案されたCNNであるLeNetと比較すると、かなり深い構造になっている。
過学習を防ぐため、サイズ4096の全結合層の出力にドロップアウトを使用している。ChainerのAlexNetは、下記のようなコードになっている。
alex.pyimport chainer import chainer.functions as F import chainer.links as L class Alex(chainer.Chain): """Single-GPU AlexNet without partition toward the channel axis.""" insize = 227 def __init__(self): super(Alex, self).__init__() with self.init_scope(): self.conv1 = L.Convolution2D(None, 96, 11, stride=4) self.conv2 = L.Convolution2D(None, 256, 5, pad=2) self.conv3 = L.Convolution2D(None, 384, 3, pad=1) self.conv4 = L.Convolution2D(None, 384, 3, pad=1) self.conv5 = L.Convolution2D(None, 256, 3, pad=1) self.fc6 = L.Linear(None, 4096) self.fc7 = L.Linear(None, 4096) self.fc8 = L.Linear(None, 1000) def __call__(self, x, t): h = F.max_pooling_2d(F.local_response_normalization( F.relu(self.conv1(x))), 3, stride=2) h = F.max_pooling_2d(F.local_response_normalization( F.relu(self.conv2(h))), 3, stride=2) h = F.relu(self.conv3(h)) h = F.relu(self.conv4(h)) h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2) h = F.dropout(F.relu(self.fc6(h))) h = F.dropout(F.relu(self.fc7(h))) h = self.fc8(h) loss = F.softmax_cross_entropy(h, t) chainer.report({'loss': loss, 'accuracy': F.accuracy(h, t)}, self) return loss







- 投稿日:2020-07-30T22:11:34+09:00
コーディング面接練習サイト「Pramp」を使ってGAFAの面接に挑む
はじめに
コーディング面接というものをご存知でしょうか?
コーディング面接とはGAFAなどをはじめとする海外のTech系企業などで広く行われている面接で,データ構造やアルゴリズム,システムデザイン等の知識を問うものです.
面接 - GoogleGoogleで行われるようなコーディング面接は,
- 45分程度の時間内に
- データ構造やアルゴリズムの基礎に関する問題を
- 面接官と話し合いながら(多くの場合英語で)
- ホワイトボードにコードを書いて解く
といった特徴があります.
データ構造とアルゴリズムの問題自体は,Cracking Coding Interviewのような書籍やLeetcodeのようなサイトを使って練習を積むことができます.
しかしコーディング面接の最大の特徴は「面接官とコミュニケーションを取りながら」問題を解くことです.これは一人で本を読んで問題を解いたり競技プログラミングに取り組むのとはまた違った訓練が必要となります.またGAFAのような海外Tech企業を受ける場合は面接が英語で行われる場合も多いため,「自分の考えを英語で説明する」力も求められます.
それではどのように対策するのか.
もしコーディング面接の経験がある知り合いがいるなら,その人に模擬面接をしてもらうこともできますが,「そんな知り合いいないよ!」という方も多いと思います.しかし世の中は便利なもので,面接の練習ができるサービスがいくつかあります.
そのうちの1つで,かつ日本国内で無料で使えるのがPrampです.
Prampについて日本語で説明した記事があまりなかったので,(私も5回ほど使ってみた程度ですが)簡単に紹介していきたいと思います.
Prampとは
Prampとはコーディング面接練習用のサイトで,無料で登録・利用することができます.面接対策をする世界中の人が使っており,コミュニケーションは基本的に英語で行われます.
最大の特徴は,利用者が面接官と候補者両方の役割を交代して行うことです.
Prampには専門の面接官がいるわけではなく,面接の練習をしている利用者同士が自動的にマッチングされ,半分ずつの時間でお互いに問題を出し合います.
面接官を体験することで学ぶことも多く,面接への理解が深まるというメリットがある一方,面接官をやる分の負担が増えたり,あまり面接官が得意でない候補者とマッチングして面接がうまくいかない可能性があるというデメリットもあります.「わざわざ面接官役なんてやりたくない!」という方もいると思います.気持ちはわかりますが,私が調べた限り無料の面接練習サイトはこれしかなかったので仕方ありません.
Prampを使ってみる
登録
まず,サイトに行ってみます.
「Start Practicing」を押すと,名前とアドレス等を入力する画面になるので,入力するとメールが届きます.メールのリンクをクリックします.
その後進んでいくと,住んでいる地域,現在のスキル,使用する言語などを入力します.これらの情報はあとでプロフィールから変更できるので適当でも構いません.
最後に練習の日程を聞かれます.「もう日程を登録するの?」と驚くかもしれませんが,これをしないと先に進めません.あとで変更,キャンセルができますのでとりあえず適当に選んでください.
これで登録完了です!ダッシュボードに面接の日程が表示されていると思います.
練習日程を決める
続いて練習日程を決めていきます.
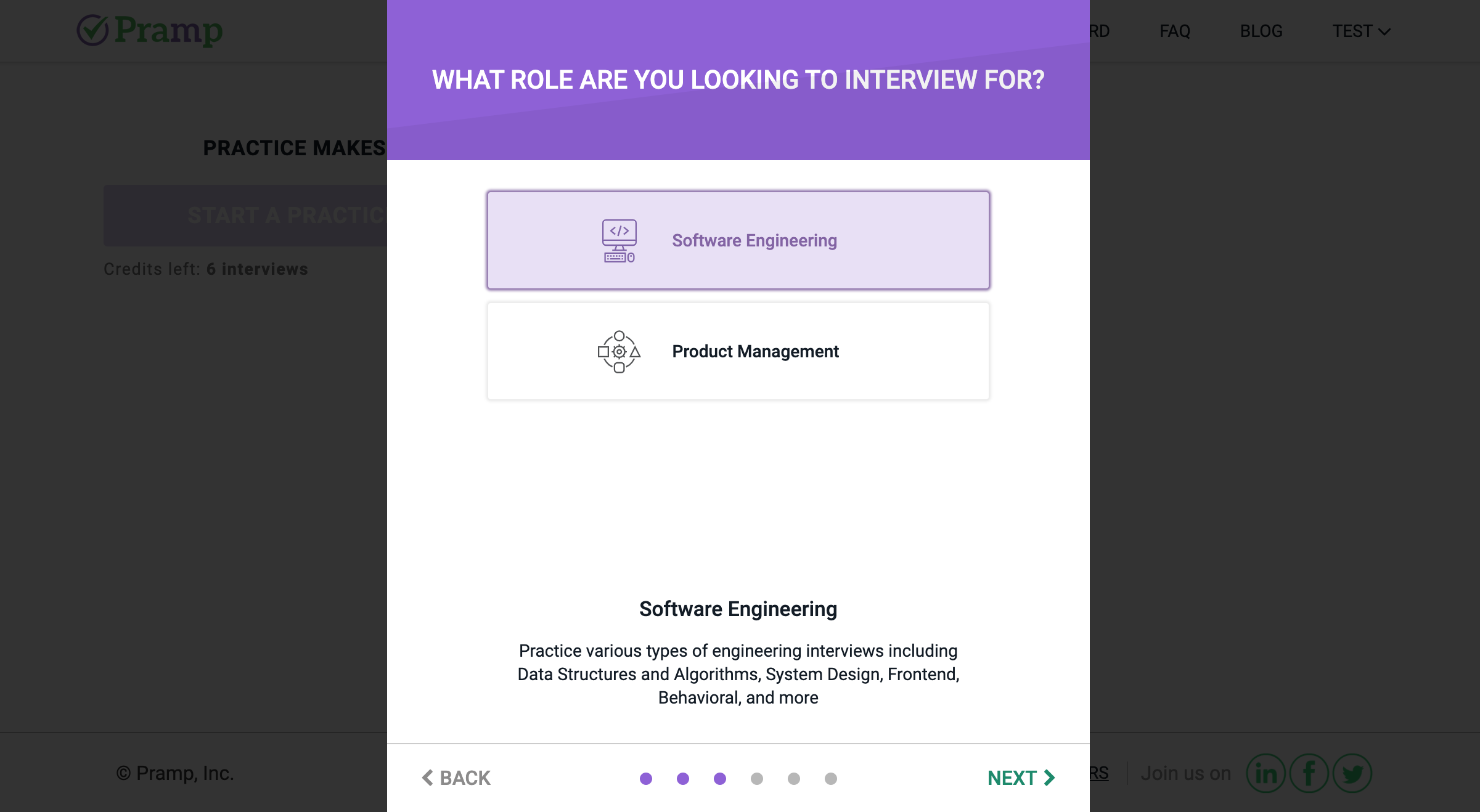
ダッシュボードの「Start a practice session」をクリックすると,まず問題の種類を聞かれます.
一般的なコーディング面接向けの練習であれば「Data structure and algorithms」で良いと思います(私もそれしかやったことがありません).
次に日程を聞かれます.
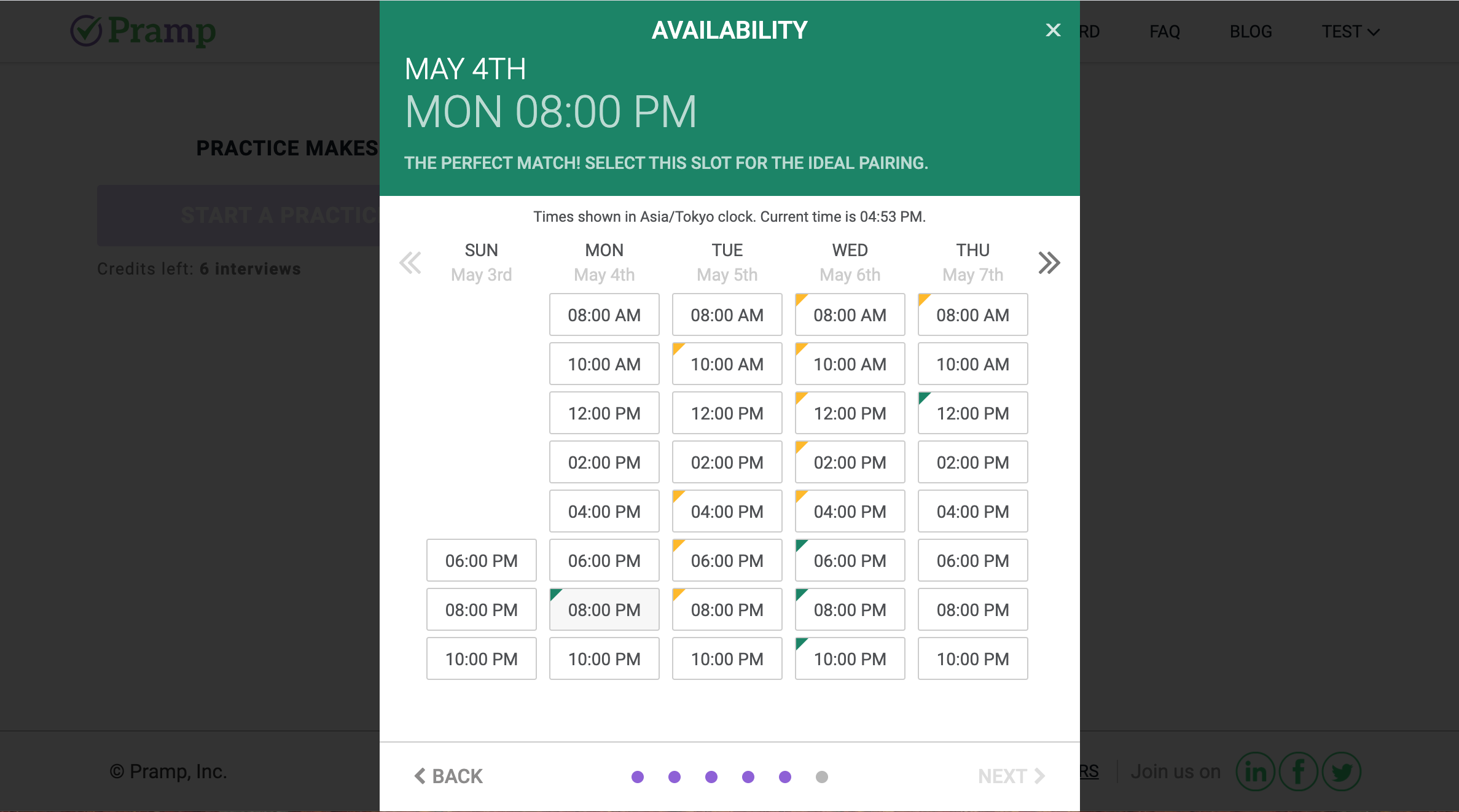
日程カレンダーは2時間おきに時間を選択できます.
カレンダーにはところどころ色が付いている時刻がありますが,どうやら緑色->黄色->無色の順でマッチングしやすい時間帯のようです.ただ私の経験上,無色の時刻を選んでもマッチングできなかったことはないのであまり気にしなくていいかもしれません.予定はダッシュボードで確認できます.変更,キャンセルしたいときは予定の横のボタンで行うことができます.
なお,予定を決めたからといって既に面接相手が決まっているわけではなく,開始時刻になってからマッチングが行われる仕組みのようなので,遠慮なく変更,キャンセルして大丈夫だと思います.面接準備
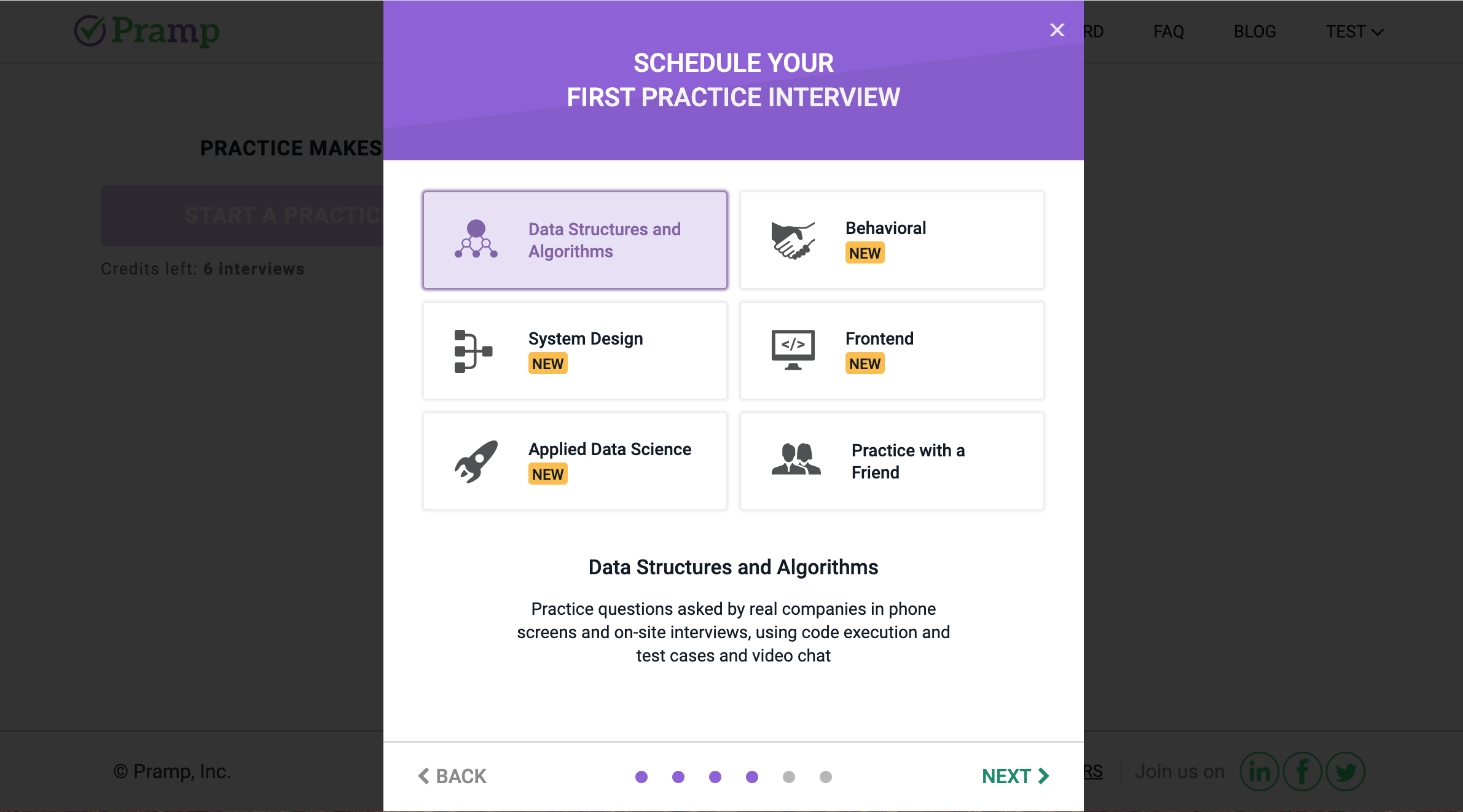
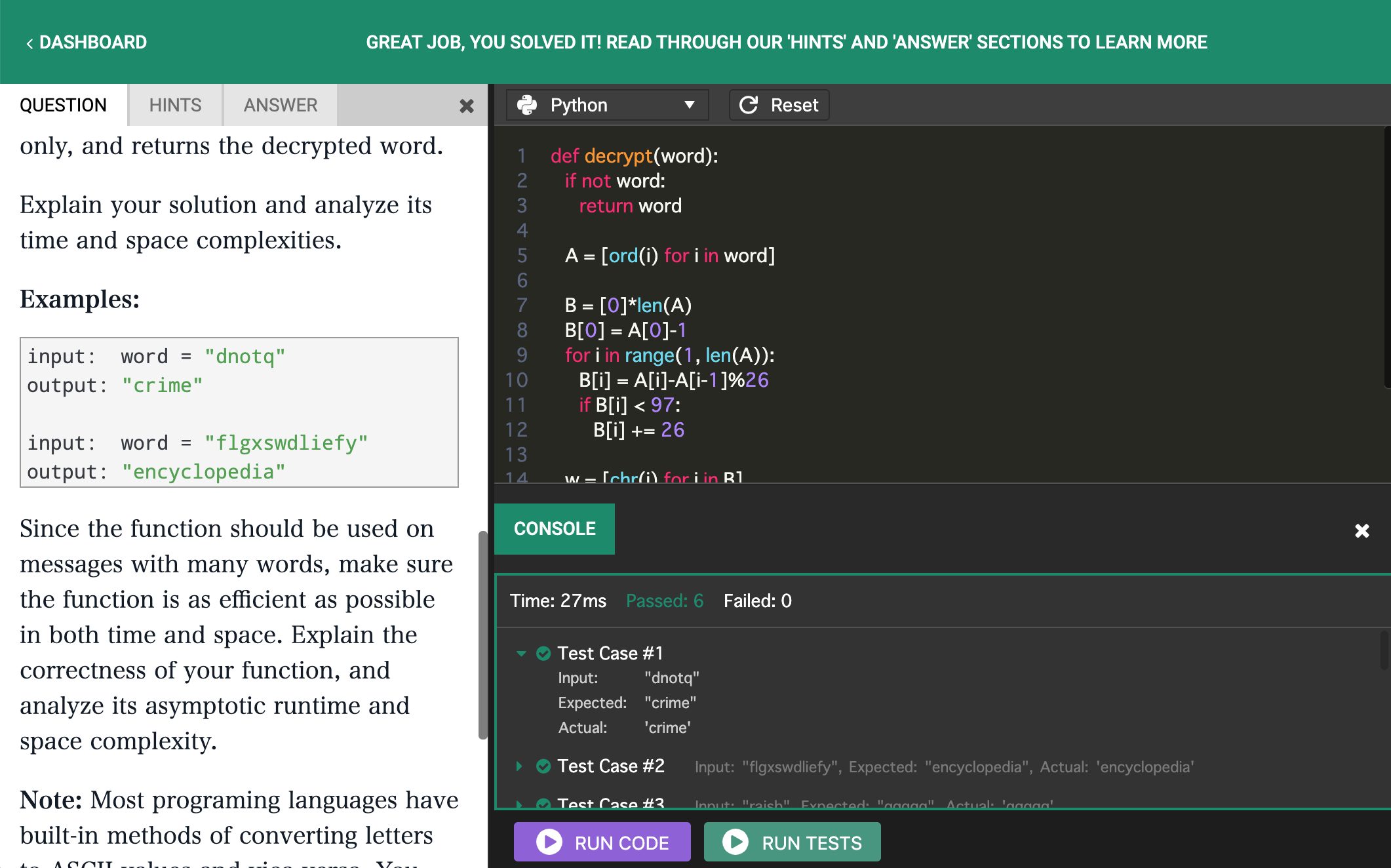
面接のスケジュールを立てると,横に「Question You'll ask」という項目が現れます.これはあなたが面接官役のときに相手に出題する問題です.Prampでは出題する問題があらかじめ決められているので自分で考える必要はありません.面接の前にこの問題を予習しておき,面接官としてうまく振る舞えるように準備しておきます.
なお,初回はこの問題を自分で選ぶことはできません.3回くらい練習をすると,過去に相手から出題された問題の中から次に出す問題がランダムに選択されるようになるので,(キャンセルと再選択を繰り返せば)好きな問題を選べるようになります.問題をクリックすると次のような画面になります.
右側に「Question」「Hints」「Answer」の欄があり,問題文とヒント,答えを見ることができます.解答者からは問題文のみを見ることができ,ヒントと解答は見られません.面接前にこの問題を理解し,必要なら相手にヒントを与えられるようになっておきましょう.
このエディタでは,基本的には指定の入力に対し正しい出力を返す関数を実装すれば良いです(Leetcodeと似ています).
下の「Run Code」は好きな入力で挙動を確認できます.関数を実装したらprint文などを使って出力を確認できます.
一方「Run tests」は用意されたテスト入力に対し正しい答えを返すかジャッジが行われます.全てパスすると緑色に,ミスがあると赤色になります.
面接開始
予定の時刻の5分前になると,ダッシュボードのスケジュールの横に「Join session」というボタンが現れます.そこをクリックすると,マッチング待機画面になります.
経験上遅くとも開始予定時刻から5分以内にはマッチングができ面接に移ります.面接の様子はPramp公式がYoutubeにあげているのでそちらを見た方が雰囲気がつかめると思います.
デフォルトはカメラでお互いの顔が見える状態ですが,カメラをオフにして音声のみにすることもできます(私は基本的に音声のみで練習していました).
自分と相手どちらがはじめに問題を解くかは自動的に割り振られます.問題文は表示されているので,まずはそれを読むところから始め,相手とコミュニケーションを取りながら問題を解いていきます.解き終わったら左上の「Swap roles」のボタンで解答者を交代します.
解答時間の目安はお互い30分ずつです.1時間経っても練習を続けることはできますが,2時間経過すると自動的に終了となるようです.なお,うっかり予定していた練習をすっぽかしてしまった場合も特に罰則などはないので安心してください.
面接後
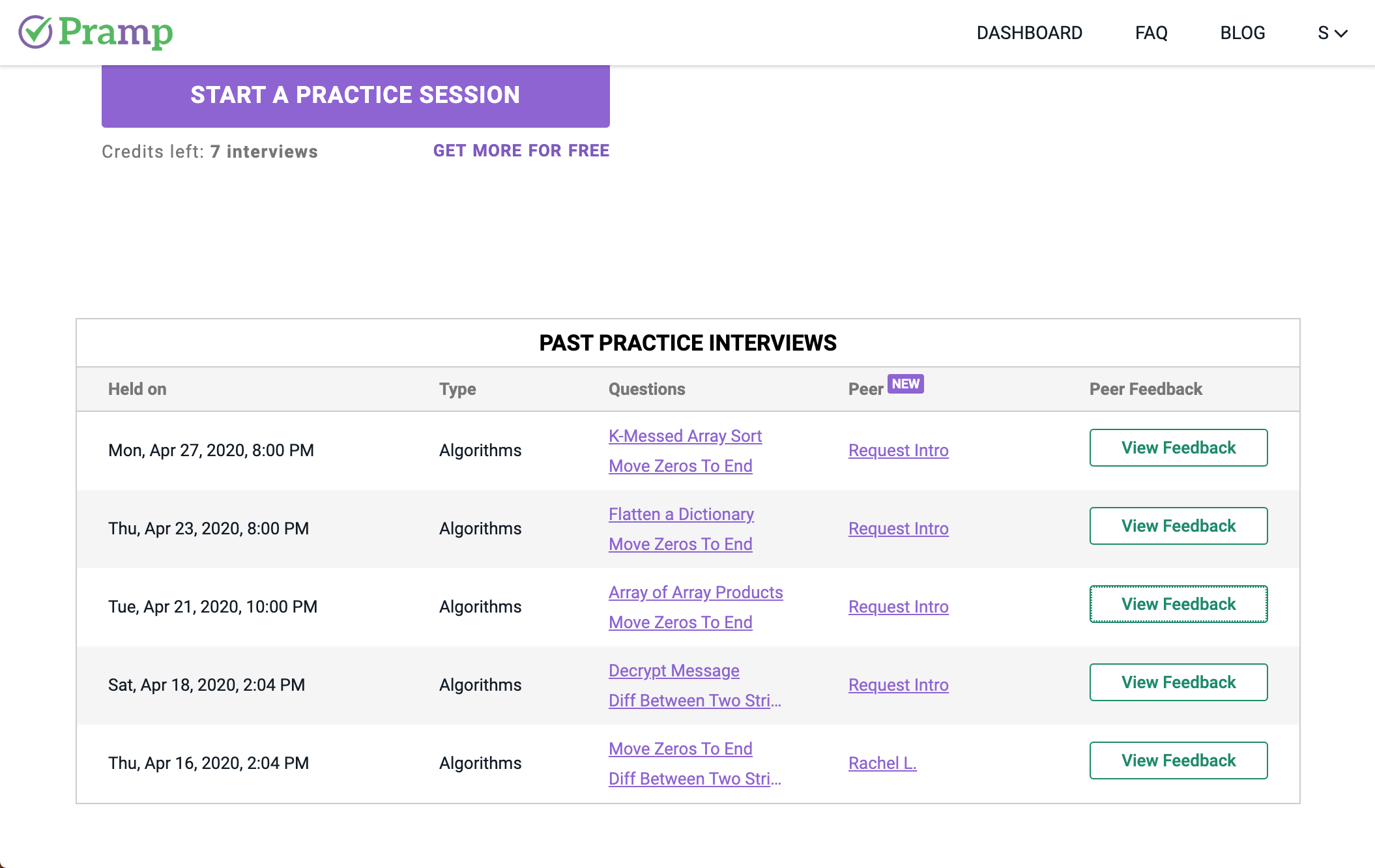
お互いの練習が終了したら面接を終了します.終了後は相手へのフィードバックを記入する画面に移ります.相手のコーディングスキルやコミュニケーションスキルに付いて簡単に評価を書きましょう.
終了後はダッシュボード上で,自分が解いた問題と相手からのフィードバックを確認することができます.
フィードバックはこのような形で見ることができます.大抵皆さん優しいので星3つか4つくれます.
また,「Request Intro」というボタンがあるのですが,双方がこれを押すとマッチングした相手の連絡先を知ることができるようです.素晴らしいスキルを持った相手だったら情報交換してみるのもいいかもしれません.
感想
日本でPrampなどの練習用サービスを使うのは,かなり面接準備を進めてきた人が多いと思いますが,海外では初学者も使っている裾野の広いサービスのように感じました.例えば私がマッチングした人の中には「Dynamic Programmingをほとんど知らない」と言っていた人もいたので,「レベルが高すぎるのではないか」という不安はあまり感じなくて良いと思います.
少なくとも私が解いた問題はそこまで難しいものはありませんでした.感覚的には 「Leeetcodeのmediumの中でも簡単なほうの問題」くらいの難易度が多かったです.
英語でコミュニケーションを取るという点においてはかなり練習になりました.私は英語ペラペラではないため聞き取れない時も多かったですが,具体例で説明してもらったりしながらなんとか理解していました.本番の面接も英語の場合は,こういった練習をやっているかやっていないかで精神的な負担がかなり違うと思います.
大切なのは「まだスキルが十分でないからやめておこう」と思わないことです.スキルが十分でないから練習するのであり,わからないことがあったり詰まったりするのは当たり前なので,とりあえず一度やってみるのはありだと思います.
皆さんもPrampを初めてGAFAの面接突破を目指してみてはいかがでしょうか!








- 投稿日:2020-07-30T20:04:28+09:00
Docker コンテナを構築して altair から png 保存する
私は長い試行錯誤を要したので成果だけでもアップしておく。
chromedriver-binaryの最新版を入れたらgoogle-chrome-stableよりメジャーバージョンが大きくてエラーが出た。Chrome 側でstable以外を使ってもよさそうだが、Chrome にchromedriver-binaryを合わせることにした。DockerfileFROM python # Chrome のインストール RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add && \ echo 'deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main' | tee /etc/apt/sources.list.d/google-chrome.list && \ apt update && apt install -y google-chrome-stable WORKDIR /python COPY requirements.txt . # chromedriver-binary のメジャーバージョンを Chrome に合わせる # google-chrome --version: "Google Chrome 0.0.0.0" のような文字列を返す # grep --only-matching: (各行で) マッチした部分のみを順にすべて返す # head -n 1: メジャーバージョンだけとってくる # sed --in-place: 私は知らなかった RUN sed -e s/chromedriver-binary/chromedriver-binary==`google-chrome --version | grep -o -E "[0-9]*" | head -n 1`.*/ -i requirements.txt RUN pip install --upgrade pip && pip install -r requirements.txtrequirements.txtaltair altair_saver chromedriver-binary jupyter matplotlib numpy pandas scipy==1.5 seleniumタイトルに関係あるのは
altair,altair_saver,chromedriver-binary,seleniumのはず。main.pyimport altair import chromedriver_binary # import によって PATH が通る; モジュールとしては使わない altair.renderers.enable('altair_saver') # 公式ドキュメントにはフォーマットを指定する引数があったが、怒られたので外した altair.Chart(...).....save('plot.png') # 成功した
- 投稿日:2020-07-30T19:47:19+09:00
右クリックと左クリックで画像を指定フォルダに移動させてみた
はじめに
楽に画像を分類できればなーと考えながら作りました。
作ったもの
右クリックと左クリックで画像を指定フォルダに移動させるプログラムを作りました。
画像は神奈川工科大学の標準画像データベースSIDBAからダウンロードしました。
プログラムを実行すると、5枚の画像が表示されます。
地球の画像をクリックしました。ウィンドウが更新されます。
クリックした地球の画像が移動されました。今回は左クリックだったのでLのフォルダに出力されています。
コード
imageMover.pyimport cv2 import glob import shutil import os import numpy as np #画像のサイズは200pxで統一 size = (200, 200) name = [] #ファイル名 data = [] #ファイルのデータ coordinates = [] #クリック時の座標 #移動先のフォルダを作成。LとRがそれぞれ左クリックと右クリックに対応。 os.makedirs('./L', exist_ok=True) os.makedirs('./R', exist_ok=True) #ファイルの読み込み for file in glob.glob('*.bmp'): img = cv2.imread(file) img = cv2.resize(img, size) name.append(file) data.append(img) #マウスクリック時に実行される関数 def click_event(event, x, y, flags, param): if event == cv2.EVENT_LBUTTONDOWN: coordinates[0:3] = [x, y, 'L'] if event == cv2.EVENT_RBUTTONDOWN: coordinates[0:3] = [x, y, 'R'] #画像の枚数 hasWindow = len(data) #画像の残り枚数が1枚以上の場合に実行 while hasWindow > 0: img = cv2.hconcat(data[:5]) while(1): cv2.imshow('img', img) cv2.setMouseCallback("img", click_event) #クリック時 #クリック時の座標を取得し、対応する画像を移動 if len(coordinates) != 0: n = coordinates[0]//200 shutil.move(name[n], coordinates[2]+'/'+name[n]) print(F'フォルダ {coordinates[2]} に {name[n]} を移動しました') data.pop(n) name.pop(n) coordinates = [] hasWindow -= 1 #画像の残り枚数を更新 break #座標を初期化 coordinates = [] #キー入力があるか key = cv2.waitKey(100) & 0xff #キーボードかxが押されたらウィンドウを閉じる if key != 255 or cv2.getWindowProperty('img', cv2.WND_PROP_AUTOSIZE) == -1: cv2.destroyAllWindows() exit()Githubにもアップロードしています。
結論
手動の方が早いのでは?
おわりに
画像の表示数を増やすとかでもっと工夫できそうですね。
最後までご覧いただきありがとうございました。ご指摘・コメントをお待ちしております。




- 投稿日:2020-07-30T18:58:59+09:00
PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた
はじめに
huggingfaceのtransformersのおかけでPyTorchを使って日本語BERTモデルがとても簡単に扱えるようになりました。
既にいろんな方がhuggingface/transformersを使って日本語BERTに関する記事を投稿されておりますが、私も勉強がてら記事を投稿しようと思いました。
参考
つくりながら学ぶ! PyTorchによる発展ディープラーニングの著者の方が投稿されている以下の記事が圧倒的にわかりやすいです。私のようなBERT初学者が詰まりそうなところも含めて丁寧に解説してくれてます。
- 【実装解説】日本語版BERTをGoogle Colaboratoryで使う方法(PyTorch)
- 【実装解説】日本語版BERTでlivedoorニュース分類:Google Colaboratoryで(PyTorch)
上記書籍&Qiita記事を参考に(というかほとんど写経)、私もBERTによる文章分類を実装してみます。
ついでにAttentionによる可視化にも触れていこうと思います。
とりあえずBERTを使って文章分類したい、Attentionの可視化を見てみたいって方向けです。BERTの理論的は話には一切触れておりません。問題設定
いつもどおりlivedoorニュースコーパスを検証データとして扱います。参考記事ではlivedoorニュースの本文を利用されていますが、全く同じでは面白くないので、昔書いた記事と同様にlivedoorニュースコーパスのタイトルのみを使って、文章分類を行ってみようと思います。
実装
参考記事と同様にGoogle Colab上で実装しています。
データ準備
まずはcolabにGoogle Driveをマウント
from google.colab import drive drive.mount('/content/drive')こちらなどを参考にしていただきながら、livedoorニュースコーパスを取得します。Google Driveにlivedoorニュースコーパスのタイトルとカテゴリーを抜き出したデータセットをDataFrameとかにしておいて、Google Driveに格納しておきます。格納後、データの中身を確認した様子は以下のような感じです。
import pickle import pandas as pd # データセット格納先 drive_dir = "drive/My Drive/Colab Notebooks/livedoor_data/" with open(drive_dir + "livedoor_title_category.pickle", 'rb') as f: livedoor_data = pickle.load(f) livedoor_data.head() #title category #0 海外でも快適インターネット!KDDI、「au Wi-Fi SPOT」のサービスを拡充 it-life-hack #1 【特集/JOURNEY】 刺激的で優しいアラブの国へ (4/8) livedoor-homme #2 独女のTwitter、意外な楽しみ方 dokujo-tsushin #3 ピラミッドが20年でつくられたという話は嘘 movie-enter #4 剛力彩芽、“愛情たっぷり”の手作りチョコケーキをプレゼント movie-enterカテゴリーをID化しましょう。
# カテゴリーのリストをデータセットから取得 categories = list(set(livedoor_data['category'])) print(categories) #['topic-news', 'movie-enter', 'livedoor-homme', 'it-life-hack', 'dokujo-tsushin', 'sports-watch', 'kaden-channel', 'peachy', 'smax'] # カテゴリーのID辞書を作成 id2cat = dict(zip(list(range(len(categories))), categories)) cat2id = dict(zip(categories, list(range(len(categories))))) print(id2cat) print(cat2id) #{0: 'topic-news', 1: 'movie-enter', 2: 'livedoor-homme', 3: 'it-life-hack', 4: 'dokujo-tsushin', 5: 'sports-watch', 6: 'kaden-channel', 7: 'peachy', 8: 'smax'} #{'topic-news': 0, 'movie-enter': 1, 'livedoor-homme': 2, 'it-life-hack': 3, 'dokujo-tsushin': 4, 'sports-watch': 5, 'kaden-channel': 6, 'peachy': 7, 'smax': 8} # DataFrameにカテゴリーID列を追加 livedoor_data['category_id'] = livedoor_data['category'].map(cat2id) # 念の為シャッフル livedoor_data = livedoor_data.sample(frac=1).reset_index(drop=True) # データセットをタイトルとカテゴリーID列だけにする livedoor_data = livedoor_data[['title', 'category_id']] livedoor_data.head() #title category_id #0 ナイナイ岡村、AKB特番の出演依頼を拒否 「ああいうところに出るのは……」 0 #1 C-3POが名場面を紹介する『スター・ウォーズinコンサート』日本上陸 1 #2 盗撮現場を配信!? 無料イベント中継のはずが衝撃的瞬間が発覚【話題】 6 #3 「相棒最終回で及川光博へ“非情な仕打ち”」と女性自身 0 #4 長谷部やカズよりも上? 「小学生が好きなスポーツ選手」に意外な選手が 5データの前処理にはtorchtextを使いますので、データセットを学習用、テスト用に分け、tsvファイルに保存します。
# 学習用データとテストデータに分ける from sklearn.model_selection import train_test_split train_df, test_df = train_test_split(livedoor_data, train_size=0.8) print("学習データサイズ", train_df.shape[0]) print("テストデータサイズ", test_df.shape[0]) #学習データサイズ 5900 #テストデータサイズ 1476 # tsvファイルとして保存する train_df.to_csv(drive_dir + 'train.tsv', sep='\t', index=False, header=None) test_df.to_csv(drive_dir + 'test.tsv', sep='\t', index=False, header=None)MeCabとhuggingface/transformersをインストール
こちらに記載させていただいたのですが、MeCabインストールには若干の注意が必要っぽいです。現状は以下のようにpipであれこれインストールすればエラーなく動きました。
# MeCabとtransformersを用意する !apt install aptitude swig !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y # 以下で報告があるようにmecab-python3のバージョンを0.996.5にしないとtokezerで落ちる # https://stackoverflow.com/questions/62860717/huggingface-for-japanese-tokenizer !pip install mecab-python3==0.996.5 !pip install unidic-lite # これないとMeCab実行時にエラーで落ちる !pip install transformerstorchtextでイテレータを作成
tokenizer.encodeで日本語BERTモデルで使える分かち書きが実行でき、tokenizer.convert_ids_to_tokensで分かち書きされたID列を形態素やサブワードに変換できる。めっちゃ便利。import torch import torchtext from transformers.modeling_bert import BertModel from transformers.tokenization_bert_japanese import BertJapaneseTokenizer # 日本語BERTの分かち書き用tokenizerを宣言 tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') # 試しに分かち書きしてみる。 text = list(train_df['title'])[0] wakati_ids = tokenizer.encode(text, return_tensors='pt') print(tokenizer.convert_ids_to_tokens(wakati_ids[0].tolist())) print(wakati_ids) print(wakati_ids.size()) #['[CLS]', '身長', 'が', '低い', '女性', 'は', '結婚', 'に', '不利', '?', '[SEP]'] #tensor([[ 2, 7236, 14, 3458, 969, 9, 1519, 7, 9839, 2935, 3]]) #torch.Size([1, 11])huggingfaceから扱える東北大学の日本語事前学習モデルは文章の形態素数(サブワード数)は512個までです。なのでもし、扱うデータの形態素、サブワード数が512を超える場合は
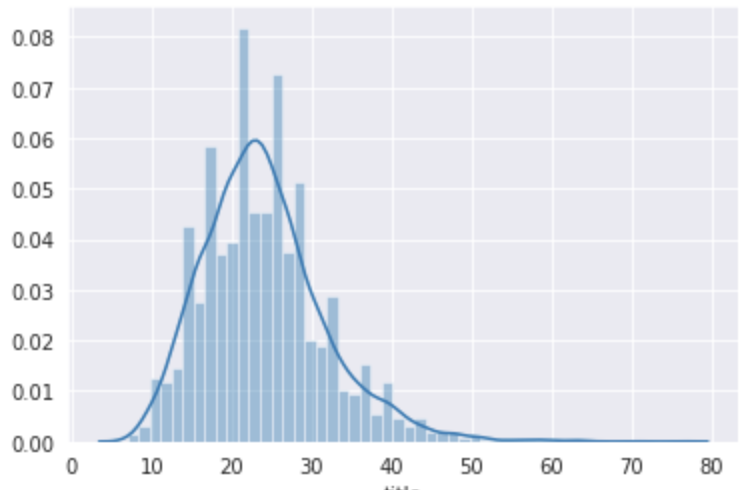
max_lengthを512に指定しましょう。ただし、今回のlivedoorニュースコーパスのタイトルに関しては以下の通り最大でも76個なので、今回はmax_lengthを指定していません。# 日本語BERTで扱える文章の長さは512だけど、livedoorニュースのタイトルの長さは最大でもCLS, SEPトークン入れても76 import seaborn as sns title_length = livedoor_data['title'].map(tokenizer.encode).map(len) print(max(title_length)) # 76 sns.distplot(title_length)
以下のような感じでイテレータを作成する。
tokenizer.encodeのサイズは(1×文章の長さ)なので、[0]を指定する必要がある。# torchtextを使って、学習データとテストデータのイテレータを作成 def bert_tokenizer(text): return tokenizer.encode(text, return_tensors='pt')[0] TEXT = torchtext.data.Field(sequential=True, tokenize=bert_tokenizer, use_vocab=False, lower=False, include_lengths=True, batch_first=True, pad_token=0) LABEL = torchtext.data.Field(sequential=False, use_vocab=False) train_data, test_data = torchtext.data.TabularDataset.splits( path=drive_dir, train='train.tsv', test='test.tsv', format='tsv', fields=[('Text', TEXT), ('Label', LABEL)]) # BERTではミニバッチサイズは16か32を使うようですが、livedoorタイトルは文章の長さが短いので32でもcolab上で動きます。 BATCH_SIZE = 32 train_iter, test_iter = torchtext.data.Iterator.splits((train_data, test_data), batch_sizes=(BATCH_SIZE, BATCH_SIZE), repeat=False, sort=False)分類モデルの宣言
の前に学習済み日本語BERTのインプットとアウトプットの形式を確認しておきましょう。
BERTモデルは以下のように1行で簡単に宣言することができます。便利すぎfrom transformers.modeling_bert import BertModel model = BertModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')モデル自体を
BERTモデルの構造
BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(32000, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( (layer): ModuleList( (0): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (1): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (2): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (3): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (4): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (5): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (6): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (7): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (8): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (9): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (10): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (11): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) (pooler): BertPooler( (dense): Linear(in_features=768, out_features=768, bias=True) (activation): Tanh() ) )この結果を見てわかるように、まずは単語をベクトル変換するEmbeddingの層があって、その次にBertLayerが12個あることがわかります。
更に単語のベクトル次元数や内部の隠れ層の次元数が768次元であることも確認できます。BertModelのインプット、アウトプットの形式をリファレンスで確認しましょう。
BERTモデルのインプットの形式は
(batch_size, sequence_length)と書いてあります。
アウトプットはデフォルトではlast_hidden_stateとpooler_outputが返ってくるようですが、Attention weightはoutput_attentions=Trueを指定することで得られるようです。
Attentionは12層のBertLayerの中にあるそれぞれの12個のMulti head attentionの結果を全て返してくれます。# 上で作ったテストデータのイテレータから batch = next(iter(test_iter)) print(batch.Text[0].size()) # torch.Size([32, 48]) ←(batch_size, sequence_length) # BERTの順伝搬時にoutput_attentions=TrueでAttention weightを取得できる last_hidden_state, pooler_output, attentions = model(batch.Text[0], output_attentions=True) print(last_hidden_state.size()) print(pooler_output.size()) print(len(attentions), attentions[-1].size()) #torch.Size([32, 48, 768]) ← (batch_size, sequence_length×hidden_size) #torch.Size([32, 768]) #12 torch.Size([32, 12, 48, 48]) ← (batch_size, num_heads, sequence_length, sequence_length)BERTで文章ベクトルを取得するときは、last_hidden_stateの各単語ベクトルのうち、先頭のclsトークンのベクトルを文章ベクトルとみなして利用します。
BERTモデルのインプットとアウトプットの形式がなんとなくわかったところで、実際にBERTを使って文章分類を行うモデルを構築します。
私も参考記事の方がそうしているように、huggingfaceが用意しているクラス分類用のライブラリを使うのではなく、自分で実装したほうが勉強になるし、構造がわかりやすいと思うので、クラス分類用ライブラリは使わずに実装します。from torch import nn import torch.nn.functional as F from transformers.modeling_bert import BertModel class BertClassifier(nn.Module): def __init__(self): super(BertClassifier, self).__init__() self.bert = BertModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') # BERTの隠れ層の次元数は768, livedoorニュースのカテゴリ数が9 self.linear = nn.Linear(768, 9) # 重み初期化処理 nn.init.normal_(self.linear.weight, std=0.02) nn.init.normal_(self.linear.bias, 0) def forward(self, input_ids): # last_hidden_stateとattentionsを受け取る vec, _, attentions = self.bert(input_ids, output_attentions=True) # 先頭トークンclsのベクトルだけ取得 vec = vec[:,0,:] vec = vec.view(-1, 768) # 全結合層でクラス分類用に次元を変換 out = self.linear(vec) return F.log_softmax(out), attentions classifier = BertClassifier()ファインチューニングの設定
今までファインチューニングとかしたことなかったのですが、参考記事のように一旦全てのパラメータを計算OFFにしてからパラメータを更新したい箇所だけを更新していくってやり方をするんですね。勉強になりました。
更に学習率もBERTの最後の層は事前学習済なわけで更新は少しだけにして、クラス分類用に差し込んだ最後の全結合層は学習率大きめにするとのこと。なるほどなるほど。# ファインチューニングの設定 # 勾配計算を最後のBertLayerモジュールと追加した分類アダプターのみ実行 # まずは全部OFF for param in classifier.parameters(): param.requires_grad = False # BERTの最後の層だけ更新ON for param in classifier.bert.encoder.layer[-1].parameters(): param.requires_grad = True # クラス分類のところもON for param in classifier.linear.parameters(): param.requires_grad = True import torch.optim as optim # 事前学習済の箇所は学習率小さめ、最後の全結合層は大きめにする。 optimizer = optim.Adam([ {'params': classifier.bert.encoder.layer[-1].parameters(), 'lr': 5e-5}, {'params': classifier.linear.parameters(), 'lr': 1e-4} ]) # 損失関数の設定 loss_function = nn.NLLLoss()学習
参考記事のように本当は訓練モード、検証モードとかで分けて書いたほうが良いところですが、とりあえず動かしたいってことで以下のように学習するのに最低限のコードだけでループを回しております。
エポック数は5でも10でも最終的な精度があまり変化しなかったので、今回はエポック数は5にしておきました。
順調にlossが減っているのでとりあえずよし。# GPUの設定 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # ネットワークをGPUへ送る classifier.to(device) losses = [] # エポック数は5で for epoch in range(5): all_loss = 0 for idx, batch in enumerate(train_iter): batch_loss = 0 classifier.zero_grad() input_ids = batch.Text[0].to(device) label_ids = batch.Label.to(device) out, _ = classifier(input_ids) batch_loss = loss_function(out, label_ids) batch_loss.backward() optimizer.step() all_loss += batch_loss.item() print("epoch", epoch, "\t" , "loss", all_loss) #epoch 0 loss 246.03703904151917 #epoch 1 loss 108.01931090652943 #epoch 2 loss 80.69403756409883 #epoch 3 loss 62.87365382164717 #epoch 4 loss 50.78619819134474精度確認
Fスコアを見てみます。
記事の本文だと90%を超えるようですが、タイトルだけの分類だと85%という結果になりました。
タイトルはたしかに記事の要約的な意味はあるものの、よくこの短いセンテンスで85%も出たなぁと関心しました。from sklearn.metrics import classification_report answer = [] prediction = [] with torch.no_grad(): for batch in test_iter: text_tensor = batch.Text[0].to(device) label_tensor = batch.Label.to(device) score, _ = classifier(text_tensor) _, pred = torch.max(score, 1) prediction += list(pred.cpu().numpy()) answer += list(label_tensor.cpu().numpy()) print(classification_report(prediction, answer, target_names=categories)) # precision recall f1-score support # # topic-news 0.80 0.82 0.81 158 # movie-enter 0.85 0.82 0.83 178 #livedoor-homme 0.68 0.73 0.70 108 # it-life-hack 0.88 0.82 0.85 179 #dokujo-tsushin 0.82 0.85 0.84 144 # sports-watch 0.89 0.87 0.88 180 # kaden-channel 0.91 0.97 0.94 180 # peachy 0.78 0.77 0.78 172 # smax 0.94 0.91 0.92 177 # # accuracy 0.85 1476 # macro avg 0.84 0.84 0.84 1476 # weighted avg 0.85 0.85 0.85 1476Attentionの可視化
最後にAttentionを可視化をすることで文章分類の判断根拠を確認してみます。
可視化するAttention weightはファインチューニングの設定時にBertLayerの最後の層のパラメータを更新させていた、つまり最後の層のAttention weightが今回のタイトル分類用に学習されているので、最後の層のAttention weightが今回のタスクの判断根拠として使えそうです。今回宣言した
BertClassiferモデルはAttention weightを全て返すようにしているので、最後の層だけを以下のようにして取得して、サイズを改めて確認します。batch = next(iter(test_iter)) score, attentions = classifier(batch.Text[0].to(device)) # 最後の層のAttention weightだけ取得して、サイズを確認 print(attentions[-1].size()) # torch.Size([32, 12, 48, 48])今一度リファレンスを確認すると、このサイズの意味は
(batch_size, num_heads, sequence_length, sequence_length)でした。BertEncoderのAttentionはSelf Attentionですので、1つ目のsequence_lengthの各単語に対して、2つ目のsequence_lengthの各単語にどれだけAttentionしているかってことになるのかと。今回は先頭トークンclsを使って文章分類したわけなので、先頭トークンのベクトルがどの単語にAttentionしているかを可視化することで、今回のタスクの判断根拠と見なすことができそうです。
さらにBERTのSelf Attentionは12個のMulti head attentionなので、可視化する際は12個のAttention weightを全て足し合わせて使ってみようと思います。参考書籍を参考に可視化部分を以下のように実装してみました。
def highlight(word, attn): html_color = '#%02X%02X%02X' % (255, int(255*(1 - attn)), int(255*(1 - attn))) return '<span style="background-color: {}">{}</span>'.format(html_color, word) def mk_html(index, batch, preds, attention_weight): sentence = batch.Text[0][index] label =batch.Label[index].item() pred = preds[index].item() label_str = id2cat[label] pred_str = id2cat[pred] html = "正解カテゴリ: {}<br>予測カテゴリ: {}<br>".format(label_str, pred_str) # 文章の長さ分のzero tensorを宣言 seq_len = attention_weight.size()[2] all_attens = torch.zeros(seq_len).to(device) for i in range(12): all_attens += attention_weight[index, i, 0, :] for word, attn in zip(sentence, all_attens): if tokenizer.convert_ids_to_tokens([word.tolist()])[0] == "[SEP]": break html += highlight(tokenizer.convert_ids_to_tokens([word.numpy().tolist()])[0], attn) html += "<br><br>" return html batch = next(iter(test_iter)) score, attentions = classifier(batch.Text[0].to(device)) _, pred = torch.max(score, 1) from IPython.display import display, HTML for i in range(BATCH_SIZE): html_output = mk_html(i, batch, pred, attentions[-1]) display(HTML(html_output))いくつか可視化結果を紹介します。
ヨドバシカメラ梅田店がサブワードで分割されまくりながらも家電に関連するってことで部分的ではあるもののしっかりattentionしてますね。
高橋名人(連打早い人)を根拠にkaden-channelと判定してるの面白い
peachy(女性に関する恋愛とかの記事)。これもいい感じ。
本音トークでpeachyに引きずられてしまったか。
良さげなものを中心に紹介しましたが、正直全体的には微妙なattentionかなって思いました。(実装本当に正しいか不安になってきた...)
とはいえ、サブワードに分割されてもぽい箇所をattentionするのはすごいなぁと関心しました。おわりに
huggingface/transformersと参考記事のおかけでなんとなくではあるものの自分もBERTを動かせるようになりました。
いろんなタスクでBERTを使ってみたいなぁおわり




- 投稿日:2020-07-30T18:33:55+09:00
【Python】リストや文字列から数字のみ抽出する
Pythonでスクレイピングを始めたばかりのスクレイピング初心者です。今回は、スクレイピングで抽出したデータから、数字のみを抽出する方法をメモしておきます。
目的
スクレイピングで抽出したデータから、数字のみを抽出する
実装
正規表現を使って、数字のみ抽出
reモジュールを使用します。ターミナルから以下のコマンドを実行して、regexをインストールしましょう。
$ pip install regexその次に、sample.pyにreモジュールをインポートしましょう。
sample.pyimport reこれでreモジュールを使う準備ができました。
文字列から数字のみ抽出
sample.pyimport re dt = "regnkrnfskrngkaer gksgnkq laergnnktga3r erfkl 登録者数 400人aelrkna erglknnarg" num = re.sub("\\D", "", dt) print(num) # 400リストから数字のみ抽出
sample.pyimport re dt = ['regnkrnfskrngkaer', 'gksgnkq', 'laergnnktgar', 'erfkl', '登録者数 400人', 'aelrkna erglknnarg'] dt_str = ",".join(dt) dt_num = re.sub("\\D", "", dt_str) print(dt_num) # 400文字列と数字が混じったリストから特定の数字のみ抽出
失敗例
sample.pyimport re dt = ['regr111kaer', 'gg443nkq', 'laen56nktgar', 'er39fkl', '登録者数 400人', 'ael09narg'] dt_str = ",".join(dt) dt_num = re.sub("\\D", "", dt_str) print(dt_num) # 111443563940009成功例
sample.pyimport re dt = ['regr111kaer', 'gg443nkq', 'laen56nktgar', 'er39fkl', '登録者数 400人', 'ael09narg'] dt_pop = (dt.pop(4)) dt_num = re.sub("\\D", "", dt_pop) print(dt_num) # 400参考
https://qiita.com/sakamossan/items/161db7418ade037f6f3d
https://qiita.com/ikanamazu/items/ba2a32a1a5924f3bd8e9
- 投稿日:2020-07-30T17:33:16+09:00
pipenvでpytorch@python3.8環境構築
pipenvとは
- プロジェクト毎に、パッケージ管理、仮想環境の構築を行ってくれるツールです。
- 集団で開発する際に、環境を簡単に固定できるので、とても便利ですね。
pytorchとは
- Python向けのオープンソース深層学習ライブラリで、Facebookの人工知能研究グループにより初期開発されました。
- 最近では、日本発祥の深層学習ライブラリのchainerの開発が併合されたことで話題になりましたね。
今回のゴール
- 今回は、python3.8+pytorchの環境をpipenvで構築して、実行確認することを目指します。
- インポートできる程度の確認を行います。runtimeな確認は今回はしません。
実行環境
- OS: windows10 Pro
- python: 3.8
- pipenv: 2020.6.2
pipenvのinstall
$ pip install pipenvpython3.8で初期化
$ pipenv --python 3.8pytorch準備
実行に必要なライブラリは「torch」、「torchvision」。これらをインストールします。
$ pipenv install torch torchvisionこれやると、十中八九エラーになります。多分バージョンの整合が取れないパッケージをインストールしに行くからでしょうか。
パッケージのバージョンを、pythonのバージョン含めて指定する必要があるので、直接パッケージダウンロードサイトから持ってくることにします。以下のリンクを右クリック⇒リンクアドレスをコピー
cu102/torch-1.6.0-cp38-cp38-win_amd64.whl
cu102/torchvision-0.7.0-cp38-cp38-win_amd64.whl再度インストール。今度はURLから直接インストールします。
pipenv isntall https://download.pytorch.org/whl/cu102/torch-1.6.0-cp38-cp38-win_amd64.whl https://download.pytorch.org/whl/cu102/torchvision-0.7.0-cp38-cp38-win_amd64.whlメッサ時間かかるので待ちます。。。エラーなく完了したら、以下を実行します。
$ pipenv run python -c "import torch; import torchvision; print(torch.__version__); print(torchvision.__version__)" 1.6.0 0.7.0上記のようにバージョン出力されているので、インストールできました。
- 投稿日:2020-07-30T16:55:43+09:00
FastAPI 利用方法 ②Advanced - User Guide
書いてあること
- FastAPIを利用した際のメモ(個人用メモのため間違っている可能性あり・・・)
- 公式サイトのドキュメント(Advanced - User Guide)に習って実装
参考
環境
Docker環境を構築して動作確認
起動
bash# main.pyがルートディレクトリにある場合 $ uvicorn main:app --reload --host 0.0.0.0 --port 8000 # main.pyがルートディレクトリにない場合 $ uvicorn app.main:app --reload --host 0.0.0.0 --port 8000Path Operation Advanced Configuration
OpenAPIから除外
include_in_schema=Falseを記載することで、OpenAPIの表示を除外可能。■Source
main.pyimport uvicorn from typing import Optional, Set from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None tags: Set[str] = [] @app.post("/items/", include_in_schema=False, response_model=Item, summary="Create an item") async def create_item(item: Item): """ Create an item with all the information: - **name**: each item must have a name - **description**: a long description - **price**: required - **tax**: if the item doesn't have tax, you can omit this - **tags**: a set of unique tag strings for this item \f :param item: User input. """ return item if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)
Additional Status Codes
返却するステータスコードを変更
JSONResponseにstatus_code、contentを指定して返却することで、ステータスコードを変更することが可能。
コード内でステータスコードを直接変更しているため、OpenAPIドキュメントへは反映されない点に注意。■Source
main.pyimport uvicorn from typing import Optional from fastapi import Body, FastAPI, status from fastapi.responses import JSONResponse app = FastAPI() items = {"foo": {"name": "Fighters", "size": 6}, "bar": {"name": "Tenders", "size": 3}} @app.put("/items/{item_id}") async def upsert_item( item_id: str, name: Optional[str] = Body(None), size: Optional[int] = Body(None) ): if item_id in items: item = items[item_id] item["name"] = name item["size"] = size return item else: item = {"name": name, "size": size} items[item_id] = item return JSONResponse(status_code=status.HTTP_201_CREATED, content=item) if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
http://localhost:8000/items/test
{ "name": "test", "size": 100 }■Response
status_code:201
{ "name": "test", "size": 100 }Return a Response Directly
直接応答を返す
■Source
main.pyimport uvicorn from datetime import datetime from typing import Optional from fastapi import FastAPI from fastapi.encoders import jsonable_encoder from fastapi.responses import JSONResponse from pydantic import BaseModel class Item(BaseModel): title: str timestamp: datetime description: Optional[str] = None app = FastAPI() @app.put("/items/{id}") def update_item(id: str, item: Item): json_compatible_item_data = jsonable_encoder(item) return JSONResponse(content=json_compatible_item_data) if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
{ "title": "string", "timestamp": "2020-07-28T04:58:58.605Z", "description": "string" }■Response
{ "title": "string", "timestamp": "2020-07-28T04:58:58.605000+00:00", "description": "string" }XMLを返却
■Source
main.pyimport uvicorn from fastapi import FastAPI, Response app = FastAPI() @app.get("/legacy/") def get_legacy_data(): data = """<?xml version="1.0"?> <shampoo> <Header> Apply shampoo here. </Header> <Body> You'll have to use soap here. </Body> </shampoo> """ return Response(content=data, media_type="application/xml") if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
■Response
<?xml version="1.0"?> <shampoo> <Header> Apply shampoo here. </Header> <Body> You'll have to use soap here. </Body> </shampoo>Custom Response - HTML, Stream, File, others
デフォルトのJSON以外のファイルタイプを返却することが可能。
パラメータ データ型 content str or bytes status_code int headers dict media_type str パフォーマンス重視のJSON生成
orjsonパッケージを利用する。■Source
main.pyimport uvicorn from fastapi import FastAPI from fastapi.responses import ORJSONResponse app = FastAPI() @app.get("/items/", response_class=ORJSONResponse) async def read_items(): return [{"item_id": "Foo"}] if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
■Response
[ { "item_id": "Foo" } ]HTMLを返却
■Source
main.pyimport uvicorn from fastapi import FastAPI from fastapi.responses import HTMLResponse app = FastAPI() def generate_html_response(): html_content = """ <html> <head> <title>Some HTML in here</title> </head> <body> <h1>Look ma! HTML!</h1> </body> </html> """ return HTMLResponse(content=html_content, status_code=200) @app.get("/items/", response_class=HTMLResponse) async def read_items(): return generate_html_response() if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
■Response
<html> <head> <title>Some HTML in here</title> </head> <body> <h1>Look ma! HTML!</h1> </body> </html>Textを返却
■Source
main.pyimport uvicorn from fastapi import FastAPI from fastapi.responses import PlainTextResponse app = FastAPI() @app.get("/", response_class=PlainTextResponse) async def main(): return "Hello World" if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
■Response
Hello Worldファイル
■Source
main.pyimport uvicorn from fastapi import FastAPI from fastapi.responses import FileResponse some_file_path = "img/test.jpeg" app = FastAPI() @app.get("/") async def main(): return FileResponse(some_file_path) if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)デフォルトの応答クラスを指定
FastAPIインスタンス生成時に
default_response_classを利用することで、デフォルトの応答クラスを指定可能。■Source
main.pyimport uvicorn from fastapi import FastAPI from fastapi.responses import ORJSONResponse app = FastAPI(default_response_class=ORJSONResponse) @app.get("/items/") async def read_items(): return [{"item_id": "Foo"}] if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)Additional Responses in OpenAPI
独自のレスポンスモデルを追加
■Source
main.pyimport uvicorn from fastapi import FastAPI from fastapi.responses import JSONResponse from pydantic import BaseModel class Item(BaseModel): id: str value: str class Message(BaseModel): message: str app = FastAPI() @app.get("/items/{item_id}", response_model=Item, responses={404: {"model": Message}}) async def read_item(item_id: str): if item_id == "foo": return {"id": "foo", "value": "there goes my hero"} else: return JSONResponse(status_code=404, content={"message": "Item not found"}) if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
http://localhost:8000/items/bar
■Response
status_code:404
{ "message": "Item not found" }同じドメインから複数のファイルタイプを返却
■Source
main.pyimport uvicorn from typing import Optional from fastapi import FastAPI from fastapi.responses import FileResponse from pydantic import BaseModel class Item(BaseModel): id: str value: str app = FastAPI() @app.get( "/items/{item_id}", response_model=Item, responses={ 200: { "content": {"image/png": {}}, "description": "Return the JSON item or an image.", } }, ) async def read_item(item_id: str, img: Optional[bool] = None): if img: return FileResponse("img/test.jpeg", media_type="image/png") else: return {"id": "foo", "value": "there goes my hero"} if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
■Response
{ "id": "foo", "value": "there goes my hero" }■Request
http://localhost:8000/items/1?img=true
■Response
指定した画像
独自のレスポンスモデルの事前定義・組み合わせ
302、403:事前に定義しておき、各ドメインで展開
200、404:各ドメインで個別に定義■Source
main.pyfrom fastapi import FastAPI from fastapi.responses import JSONResponse from pydantic import BaseModel class Item(BaseModel): id: str value: str class Message(BaseModel): message: str responses = { 302: {"description": "The item was moved"}, 403: {"description": "Not enough privileges"}, } app = FastAPI() @app.get( "/items/{item_id}", response_model=Item, responses={ **responses, 404: {"model": Message, "description": "The item was not found"}, 200: { "description": "Item requested by ID", "content": { "application/json": { "example": {"id": "bar", "value": "The bar tenders"} } }, }, }, ) async def read_item(item_id: str): if item_id == "foo": return {"id": "foo", "value": "there goes my hero"} else: return JSONResponse(status_code=404, content={"message": "Item not found"}) if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)
Response Cookies
ResponseパラメータでCookieを返却
レスポンスにCookieを含めることが可能。
返却されたCookieはブラウザに保存される■Source
main.pyimport uvicorn from fastapi import FastAPI, Response app = FastAPI() @app.post("/cookie-and-object/") def create_cookie(response: Response): response.set_cookie(key="fakesession", value="fake-cookie-session-value") return {"message": "Come to the dark side, we have cookies"} if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)Response Header
●
■Source
main.pyimport uvicorn from fastapi import FastAPI, Response app = FastAPI() @app.get("/headers-and-object/") def get_headers(response: Response): response.headers["X-Cat-Dog"] = "alone in the world" return {"message": "Hello World"} if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
http://localhost:8000/headers-and-object/
■Response
{ "message": "Hello World" }content-length: 25 content-type: application/json date: Tue28 Jul 2020 07:02:25 GMT server: uvicorn x-cat-dog: alone in the worldResponse - Change Status Code
Responseパラメータでステータスコード変更
■Source
main.pyimport uvicorn from fastapi import FastAPI, Response, status app = FastAPI() tasks = {"foo": "Listen to the Bar Fighters"} @app.put("/get-or-create-task/{task_id}", status_code=200) def get_or_create_task(task_id: str, response: Response): if task_id not in tasks: tasks[task_id] = "This didn't exist before" response.status_code = status.HTTP_201_CREATED return tasks[task_id] if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
http://localhost:8000/get-or-create-task/bar
■Response
"This didn't exist before"Using the Request Directly
Request情報にアクセス
Requestオブジェクトの詳細は下記参照。
https://www.starlette.io/requests/■Source
main.pyimport uvicorn from fastapi import FastAPI, Request app = FastAPI() @app.get("/items/{item_id}") def read_root(item_id: str, request: Request): return { "item_id": item_id, "method": request.method, "url": request.url, "host": request.client.host, "port": request.client.port, } if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
■Response
{ "item_id": "1", "method": "GET", "url": { "_url": "http://localhost:8000/items/1" }, "host": "172.24.0.1", "port": 51072 }Sub Applications - Mounts
Sub FastAPIアプrケーションをマウント
メインのFastAPIアプリケーションとは独立して、特定のURL配下にサブアプリケーションを定義することが可能。
■Source
main.pyimport uvicorn from fastapi import FastAPI app = FastAPI() @app.get("/items") def read_main_item(): return { "item_id": "main", "item_name": "main" } subapp = FastAPI() @subapp.get("/items") def read_sub_item(): return { "item_id": "sub", "item_name": "sub" } app.mount("/subapp", subapp) if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)
http://localhost:8000/subapp/docs
Event: startup - shutdown
FastAPI起動・停止時のイベント
on_eventでFastAPI起動・停止時の処理を設定可能。■Source
main.pyimport uvicorn from fastapi import FastAPI app = FastAPI() items = {} @app.on_event("startup") async def startup_event(): print("*** startup event ***") items["foo"] = {"name": "Fighters"} items["bar"] = {"name": "Tenders"} @app.on_event("shutdown") def shutdown_event(): print("*** shutdown event ***") with open("log.txt", mode="a") as log: log.write("Application shutdown") @app.get("/items") async def read_items(): return {"items": items} if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)Custom Request and APIRoute class
テスト
テストで
startup、shutdownを実行する必要がある場合は、with TestClient・・・を利用する。■Source
main.pyimport uvicorn from fastapi import FastAPI from fastapi.testclient import TestClient app = FastAPI() items = {} @app.on_event("startup") async def startup_event(): items["foo"] = {"name": "Fighters"} items["bar"] = {"name": "Tenders"} @app.get("/items/{item_id}") async def read_items(item_id: str): return items[item_id] def test_read_items(): with TestClient(app) as client: response = client.get("/items/foo") assert response.status_code == 200 assert response.json() == {"name": "Fighters"} if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)Settings and Environment Variables
環境変数の利用
■Source
main.pyimport uvicorn from fastapi import FastAPI import os app = FastAPI() @app.get("/") def get_env(): name = os.getenv("MY_NAME", "default") print(f"Hello {name} from Python") return {"name": f"Hello {name} from Python"} if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
環境変数を設定
bash$ export MY_NAME="test" $ echo $MY_NAME■Response
{ "name": "Hello test from Python" }.envファイルの利用
■Source
.envNAME="AdminApp" EMAIL="admin@example.com"config.pyimport os from os.path import join, dirname from dotenv import load_dotenv env_path = join(dirname(__file__), '.env') load_dotenv(env_path) NAME = os.environ.get("NAME") EMAIL = os.environ.get("EMAIL") # print(NAME) # print(EMAIL)main.pyimport uvicorn from fastapi import FastAPI import config app = FastAPI() @app.get("/info") async def info(): return { "NAME": config.NAME, "EMAIL": config.EMAIL, } if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)■Request
■Response
{ "NAME": "AdminApp", "EMAIL": "admin@example.com" }




- 投稿日:2020-07-30T16:48:15+09:00
transformerに関して
transformerに関して(ざっくりまとめ)
・transformerとは
最近自然言語処理を勉強していて、transformというのを学んだので少しまとめてみました。勉強中ですので間違い等ございましたらご指摘いただけると幸いです。
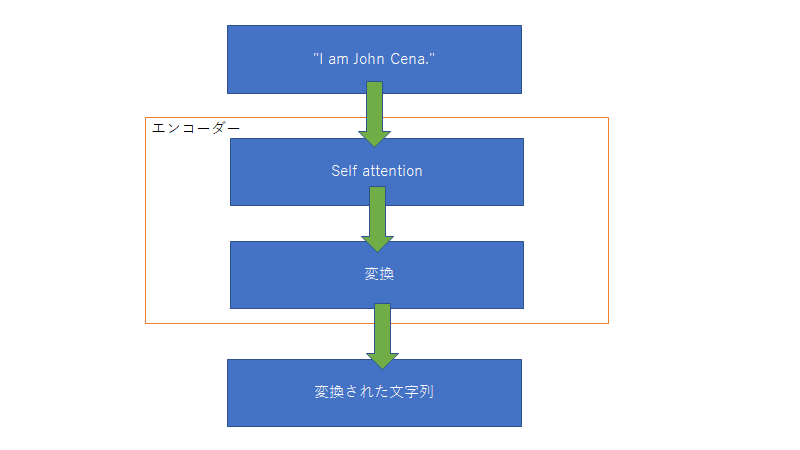
transformerとは、transformerにある文字列を入力するとそれを変換して別の文字列を出力するもの。
例えば、
「"I am John Cena."」 という文字列をtransfornerに入力すると「私はジョンシナです。」とかえすみたいな感じです。形態素解析に関して
文字列はまず単語に分解する必要がある。英語の場合は、"I am John Cena."みたいに文章が単語ごとに分けられているため単語に分割する必要がないが、日本語の場合は「私はジョンシナです。」のように文章が単語で分けられていない。そこで単語単位に分解するために形態素解析を行う。形態素解析とは簡単に言うと、文章を単語単位に分割し、それぞれの形態素の品詞等を判別する作業のことです。具体的例なとして、「私はジョンシナです。」を形態素解析すると「"私","は" , "ジョンシナ","です" , "。"」となります。
単語をどのようにして扱うのか??
文章を単語に分解した後、その単語はどのように扱われるのかというと数値に変換します。例えばthis = [0.2 , 0.4 , 0.5],is = [0.1 , 0.7 , 0.35]のような感じです。これらの特徴が何を表しているのかというとそれぞれの単語の特徴を表している。この[0.2 , 0.4 , 0.5]や[0.1 , 0.7 , 0.35]のことを単語ベクトルという。
単語はどのようにして単語ベクトルへ変換されるのか??
簡単に言うと解析したい自然言語をすべて形態素解析し、出てくる単語を集める。その後ワンホットエンコーディングのような感じで単語をベクトル化する。
例えば今回分析したい文章で出てくる単語が「I am John Cena.」だけだったとすると
I = [ 1 , 0 , 0 , 0 ]
am = [ 0 , 1 , 0 , 0 ]
John Cena = [ 0 , 0 , 1 , 0 ]
. = [ 0 , 0 , 0 , 1 ]
のようにone-hotベクトルに変換することができる。この単語ベクトルをエンコーダーで変更する。そのことにより単語が特徴量に変更することができる。このone-hotベクトルをエンコーダーで変更したベクトルのことをembeddingベクトルと呼ぶ。例としては
I = [ 1 , 0 , 0 , 0 ] ⇒エンコーダー⇒ $x_1$ = [0.3 , -0.3 , 0.6 , 2.2]この$x_1$がembeddingベクトル
こんな感じの考えがここに詳しく(参考にさせていただきました。)
https://ishitonton.hatenablog.com/entry/2018/11/25/200332文字列はどのようにして扱うのか??
これまで単語をベクトルに変換することにはできたがでは文字列はどのようにして変換されるのかというとX = "I am John Cena." ⇒ "I", "am" ,"John Cena","."⇒ $x_1$ , $x_2$ , $x_3$ , $x_4$
(単語をベクトルに変換 $x_n$ はembeddingベクトル)⇒X = [$x_1$ , $x_2$ , $x_3$ , $x_4$]
このように行列に変換される。トランスフォーマーに関して
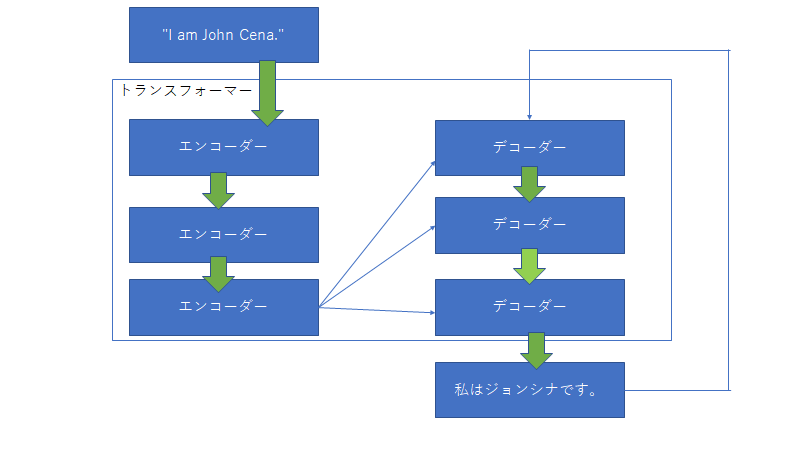
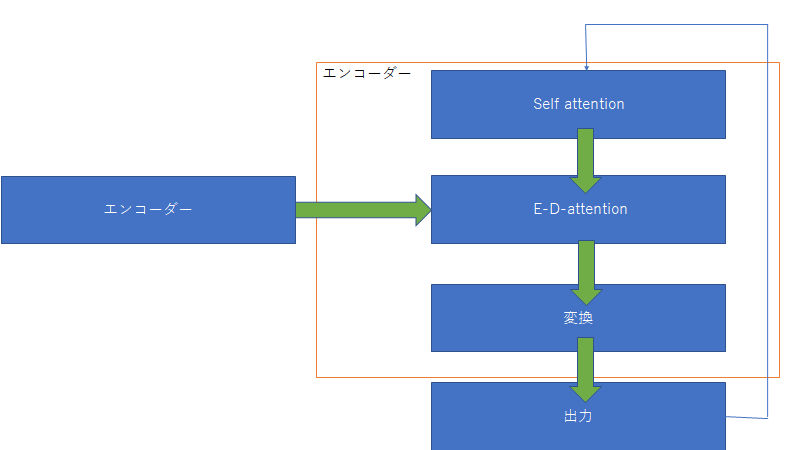
トランスフォーマーは文字列を入力するとある文字列を返すもの。中身に関していうと上図のように多くのエンコーダーとデコーダーからなる。入力された文字列はまず初めにエンコーダーに入る。エンコーダーの中身は下図
このself attentionは入力された文字列の単語同士の関係性についてみている。また単語同士の関係性が強いというのはそれぞれの単語ベクトルの類似性を見ている。そのため、類似性を調べるには行列の内積を調べればいいってことになる。そして変換は一般的なニューラルネットワークを用いて変換される。
そしてデコーダーはエンコーダーからの入力を用いて次の単語を予測する。
このE-D-attentionは入力と出力の関係性を見ている。
ざっくりとしたtransformerはこんな感じです。
ちゃんと知りたい方は
https://qiita.com/omiita/items/07e69aef6c156d23c538ほぼこれを参考にさせていただきました!
めちゃくちゃわかりやすいです!
https://www.youtube.com/watch?v=BcNZRiO0_AE
- 投稿日:2020-07-30T16:41:04+09:00
競技プログラミングにおける正規表現
はじめに
最近、脳トレがてら
AtCoderの過去問を解いています。
AtCoderProblems の 簡単な問題から順に解いてる感じです。やっていて気づきましたが、文字列処理の問題で正規表現を使うと簡単に解ける場合が結構あります。
ソートや貪欲アルゴリズムなど気づけば簡単なパターンがあるのは経験している方も多いと思いますが、そんな感じです。簡単に解けるかどうかは慣れや人にもよると思いますが、コードがキレイに書けるのは間違いありません。特に
C++の場合、一般に文字列処理は複雑になりがちなため、顕著です。
また、標準ライブラリのコードを使用するため、自前の実装に比べてバグを入れてしまう可能性を下げることができることが利点になります。コードを提出して AC した後、もっと他にいい方法や書き方ないかなと、他の方のコードの拝見させてもらうことがあるのですが、あまり正規表現を使っているコードを見かけません。
実際、公式の解説でも正規表現という文字をまあ見かけないです。おそらく正規表現は計算量が表現しづらいことが原因のひとつかなと思います。というのも計算量は処理系が用意する標準ライブラリの実装に依存してしまいます。とはいえ、
AtCoderでは入力される文字列に制約が課されることが多く、文字列の長さが大して長くない場合が多いので実際には大丈夫なケースばかりなイメージです。(というより長すぎる文字列を AtCoder さん側は標準入力させることができるのでしょうか?)というわけで今回は正規表現ではこう解けるみたいなのを紹介していこうと思います。
コードはC++とPythonの実装例を載せておきます。あくまで例なので参考程度に思っていただけたら幸いです。
問題例
ABC 053 B - A to Z String
問題文
すぬけくんは文字列 $s$ の連続した一部分(部分文字列という)を取り出して先頭が $A$ であり末尾が $Z$ であるような文字列を作ることにしました。 すぬけくんが作ることのできる文字列の最大の長さを求めてください。 なお,$s$ には先頭が $A$ であり末尾が $Z$ であるような部分文字列が必ず存在することが保証されます。
制約
- $1 ≦ |s| ≦ 200,000$
- $s$ は英大文字のみからなる
- $s$ には先頭が $A$ であり末尾が $Z$ であるような部分文字列が必ず存在する
入力例
HASFJGHOGAKZZFEGA出力例
12
文字列 $s$ の部分文字列のうち先頭が $A$ ,末尾が $Z$ であるようなものの最大の長さを求めよ という問題になります。
先頭が $A$ ,末尾が $Z$ であるようなものの最大の長さを持つ部分文字列にマッチする正規表現は
A[A-Z]*Zと書けますので、正規表現を使用した実装例は以下のようになります。c++int main() { string s; cin >> s; smatch m; regex_search(s, m, regex("A[A-Z]*Z")); cout << m.str().length() << endl; return 0; }制約から正規表現にマッチする部分文字列は必ず存在するので if 文による分岐を書く必要はありません。
Python での実装例は以下のようになります。pythonimport re S = input() m = re.search(r'A[A-Z]*Z', S) print(len(m.group(0)))ABC 084 B - Postal Code
問題文
Atcoder国では、郵便番号は $A + B + 1$ 文字からなり、$A + 1$ 文字目はハイフン $-$ 、それ以外の全ての文字は $0$ 以上 $9$ 以下の数字です。
文字列 $S$ が与えられるので、Atcoder国の郵便番号の形式を満たすかどうか判定してください。制約
- $1 ≦ A, B ≦ 5$
- $|S| = A + B + 1$
- $S$ は $0$ 以上 $9$ 以下の数字、およびハイフン $-$ からなる
入力例
3 4
269-6650出力例
Yes
正規表現に標準入力で受け取った数字 $A , B$ を組み込めば楽に解けます。
c++int main() { int A, B; cin >> A >> B; string S; cin >> S; const string pat = (boost::format("^\\d{%d}-\\d{%d}$") % A % B).str(); const regex re(pat); cout << (regex_match(S, re) ? "Yes" : "No") << endl; return 0; }上の入力例でいえば、正規表現のパターンは
^\d{3}-\d{4}$のようにフォーマットされています。
C++ の場合、snprintfなどでもフォーマットできますが、std::fmtが来るまではboost::formatを使っててよいと思います。
regex_matchは全体マッチなので、メタ文字^,$は別になくともかまいません。以下は Python での実装例です。
pythonimport re A, B = [int(x) for x in input().split()] S = input() print ('Yes' if re.search(r'\A\d{{{}}}-\d{{{}}}\Z'.format(A, B), S) else 'No')Python で
{}をエスケープするには{{}}とする必要があります。
re.searchとしていますが、re.matchでいいです。そうすれば、メタ文字\A,\Zは必要なくなります。ABC 104 B - AcCepted
問題文
文字列 $S$ が与えられます。$S$ のそれぞれの文字は英大文字または英小文字です。 $S$ が次の条件すべてを満たすか判定してください。
- $S$ の先頭の文字は大文字の $A$ である。
- $S$ の先頭から $3$ 文字目と末尾から $2$ 文字目の間(両端含む)に大文字の $C$ がちょうど $1$ 個含まれる。
- 以上の $A$, $C$ を除く $S$ のすべての文字は小文字である。
制約
- $4 ≤|S|≤10$($|S|$ は文字列 $S$ の長さ)
- $S$ のそれぞれの文字は英大文字または英小文字である。
入力例
AtCoder出力例
AC
$S$ が問題の条件 3つすべて満たすような正規表現を考えます。
1つ目の条件は
^Aと書けます。
2つ目の条件と3つ目の条件から2文字目と末尾は必ず小文字であることがわかるので、^A[a-z](第2条件)[a-z]$のように書くことができます。問題は2つ目の条件をどのように正規表現で書くのか?になります。
(第2条件)内の $C$ の現れる位置について、先頭、末尾、それ以外で場合分けして考えてみると、最終的に[a-z]*C[a-z]*というように書くことができることに気が付きます。以上のことから、正規表現は
^A[a-z]([a-z]*C[a-z]*)[a-z]$のように書けますが、カッコは必要ないので、これは^A[a-z]+C[a-z]+$とできます。以下は C++ と Python の実装例になります。
c++int main() { string S; cin >> S; cout << (regex_match(S, regex("^A[a-z]+C[a-z]+$")) ? "AC" : "WA") << endl; return 0; }pythonimport re print ('AC' if re.match(r'\AA[a-z]+C[a-z]+\Z', input()) else 'WA')例によって全体マッチなので先頭と末尾にマッチするメタ文字は不要です。
ABC 106 C - To Infinity
問題文
Mr. Infinity は, $1$ から $9$ までの数字からなる文字列 $S$ を持っている. この文字列は, 日付が変わるたびに次のように変化する.
- 文字列 $S$ に含まれるそれぞれの $2$ が $22$, $3$ が $333$, $4$ が $4444$, $5$ が $55555$, $6$ が $666666$, $7$ が $7777777$, $8$ が $88888888$, $9$ が $999999999$ に置き換わる. $1$ は $1$ のまま残る.
例えば, $S$ が $1324$ の場合, 翌日には $1333224444$ になり, 翌々日には $133333333322224444444444444444$ になる.
あなたは $5000$ 兆日後に文字列がどのようになっているか知りたい. $5000$ 兆日後の文字列の左から $K$ 文字目は何か?制約
- $S$ は $1$ 文字以上 $100$ 文字以下の文字列.
- $K$ は $1$ 以上 $10^{18}$ 以下の整数.
- $5000$ 兆日後の文字列の長さは $K$ 文字以上である.
入力例
1214
4出力例
2
$5000$ 兆は $5 × 10^{15}$ なので $1$ 文字目ですら $2$ 以上の数が来てしまうとその文字に決定してしまいます。
結局の所、この問題は $1$ が $1$ 文字目から $K$ 回以上連続しているか? という問題に帰着します。
よって出力する文字は
- 文字列 $?$ において、$1$ 文字目から $?$ 文字目まで全て $1$ であれば、$1$
- そうでなければ、答えは $?$ 中に初めて出現する $2$ 以上の文字
と考えられます。
今回は連続する $1$ と その次にくる数字をキャプチャする正規表現
^(1*)([1-9]*)$を使用します。
C++ と Python による実装例は以下のようになります。c++int main() { string S; long long K; cin >> S >> K; smatch m; regex_match(S, m, regex("^(1*)([1-9]*)$")); cout << ((m.length(1) >= K) ? '1' : m.str(2).front()) << endl; return 0; }pythonimport re m = re.match(r'\A(1*)([1-9]*)\Z', input()) print('1' if len(m.group(1)) >= int(input()) else m.group(2)[0])制約から正規表現のグループいずれかにはかならずマッチします。
正規表現の利点は for やら if を書かなくて済むというところでしょうか。
さいごに
もう少し例をあげようと思いましたが、疲れたのでいったんこれまでにします。
調子良ければ更新しようかなと思います。それでは
- 投稿日:2020-07-30T16:34:23+09:00
Pythonで、Rubyのto_sはどう書くのか
Rubyを学習した後に、Pythonの勉強に入った方がいらっしゃると思います。そしてPythonの勉強中、「Rubyのあのメソッドって、Pythonではどう書くんだろう」となることがあると思います。今回は、その
to_s版です。結論
Ruby => 文字列に変換したい値.to_s Python => str(文字列に変換したい値)例
# Rubyの場合 name = SampleUser name.to_s # "SampleUser" # Pythonの場合 name = SampleUser str(name) # "SampleUser"追記
@shiracamus さんコメントより引用(ありがとうございます!!!)
各オブジェクトは strメソッドや reprメソッドを持っています。
str関数(実体はstrクラス)はそれらのメソッドを適切に呼び出して文字列化し、さらに文字コード変換してくれます。
参考: https://docs.python.org/ja/3/library/stdtypes.html#str>>> 123 .__str__() '123' >>> 3.14.__str__() '3.14' >>> None.__str__() 'None'
- 投稿日:2020-07-30T16:10:08+09:00
【Python】ValueError: arrays must all be same length
Python3でスクレイピングをしていたら、ValueError: arrays must all be same lengthのエラーが出た
原因
ValueError: arrays must all be same lengthは、抽出したリストの長さが、違ったらこのエラーが出るらしい例
dt={'key1': [1,2,3], 'key2': [1,2,3,4], 'key3': [1,2]}対策
リストの長さを揃える
例
dt={'key1': [1,2,3], 'key2': [1,2,3], 'key3': [1,2,3]}参考
https://qiita.com/ShoheiKojima/items/30ee0925472b7b3e5d5c
- 投稿日:2020-07-30T16:06:41+09:00
機械学習による株価予測で食っていくことは可能か[実施計画編]
はじめに
本記事は、単なる思い付きで言っています。当方データサイエンティストでも意識高い系エンジニアでもないので、アカデミックな裏付け無しです。
単なるプー太郎の戯言です。株価はランダムウォークということは、重々承知しているものの、過去の株価の機械学習で株価予測ができないかと常々思っている。
例えば、明日の値幅(引値と寄り値の差)がプラスかマイナスかを的中率60%の精度で予測できたとする。サイコロを振って予測した場合の的中率は50%なので、60%の的中率はそんなに無謀ではないように思える。的中率60%ということは、10回予測すると6勝4敗で2回勝ち越しということ。毎回同額を投資したとし、的中して得た利益とはずして失った損失が、長い目で見て打ち消しあったとすれば、10回毎に2回分の利益が積み重なることになる。
個別銘柄だと、空売りでもしなければ、上がると予想した時しか購入チャンスがないので、現物買いだけで成立するようなスキームとする。
すなわち、日経225を予測対象とし、
- 日経225が上がると予測したら、1570 NF日経レバレッジを購入
- 日経225が下がると予測したら、1357 NF日経ダブルインバースを購入
とすれば、現物買いだけで回せるようになる。
手持ち資金が少ないので多少のレバレッジも効かせることができる。日経225の値幅
そこでまず最初に、日経225の値幅がどのくらいあるのかを調べてみる。
日経225の時系列データをcsvに落として、title=NIKKEI225.csvDate,Open,High,Low,Close,Volume 2017-10-31,21896.38,22020.38,21840.07,22011.61,1055801728.0 2017-10-30,22047.95,22086.88,21921.24,22011.67,1397960064.0 2017-10-27,21903.27,22016.5,21815.72,22008.45,1241389952.0 2017-10-26,21698.95,21793.62,21688.56,21739.78,851784320.0 ....以下のようなコードを書いて確認。相場のトレンドによっては、上昇時と下落時の値幅の平均は異なるだろうが、ほぼボックス相場とみなし、値幅の絶対値の平均をとる。
title=n225_statistics.pyimport pandas as pd import numpy as np import matplotlib.pyplot as plt import statistics def calc_histgram(exchange): ''' 値幅分布の標準偏差算出とヒストグラム作成 ''' # 寄値をlistに変換 open_list = exchange['Open'].tolist() # 終値をlistに変換 close_list = exchange['Close'].tolist() diff_list = ((np.array(close_list) - np.array(open_list))/np.array(open_list)).tolist() stdev = statistics.stdev(np.array(diff_list)) # 値幅の平均値を算出する abs_diff_list = np.abs(diff_list) abs_diff_mean = statistics.mean(np.array(abs_diff_list)) print('abs_diff_mean={}'.format(abs_diff_mean)) # 値幅=20のヒストグラムを描画する plt.hist(diff_list, bins=80, rwidth=50) plt.title('n225 price range, sigma={}'.format(stdev)) plt.show() def main(): nikkei_225 = pd.read_csv('NIKKEI225.csv').set_index('Date').sort_index() calc_histgram(nikkei_225) if __name__ == '__main__': main()
2014-10-14~2017-10-31の平均値幅は、0.64%だった。
予測スキーム
今回のスキームでは、NF日経レバレッジ、NF日経ダブルインバースで2倍のレバレッジをかけるので平均値幅ΔはN225の2倍なので、Δ=0.64%×2=1.28%。
1か月に20回相場が開くとし、的中率60%の予測ができれば、月に4回勝ち越すことになり、月間利益は、1日当たりの投資金額×1.28%×4となる。
売買手数料(往復で0.064%)は20回分必要。
このほかに投信の手数料も必要だが、これは微々たる額なので無視。
勝ち越した4日分以外の損益はイーブンだったとする。月間利益 = 1日当たりの投資金額×(1.28%×4-0.064×20)
= 1日当たりの投資金額×3.84%
となる。月利3.84%だと12倍すると年率46%。これはおいしい。本当だろうか?
1日当たりの投資金額を100万円とすれば、月間利益の期待値は38,400円。
いいお小遣いだ。
投資金額を1000万円にすれば、食っていけるやん。どこかが間違っているとすれば、あやしいのは
「日経225の値幅の符号を60%の精度で予測する」というところだが。。。ここを検証していきたいと思う。
まとめ
日経225の値幅の符号を60%の精度で予測することができれば、年率46%の利益が得られるかもしれないという戯言。
つづく。
- 投稿日:2020-07-30T15:44:22+09:00
【Python初心者】書いた記事を集めました
【Python初心者】if __name__ == '__main__'を手を動かして理解する。
https://qiita.com/Rihoritsuko/items/675d19119e311ea339be【Python初心者】住所から都道府県と市区町村を抜き出す(3行)。
https://qiita.com/Rihoritsuko/items/638a90b4461e277600b3【Python初心者】1つのリストを分割する(5行)。
https://qiita.com/Rihoritsuko/items/7c4bae67ad8193365d47【Python初心者】2つのリストを交互に結合する(5行)。
https://qiita.com/Rihoritsuko/items/5ffc004cae89706f9cc3【Python初心者】このフォルダにどんなファイルがあったっけ?」となった時に、1行で検索する。
https://qiita.com/Rihoritsuko/items/16044d8f06e4c155b8a7【Python初心者】pip自体をupdateする
https://qiita.com/Rihoritsuko/items/e093ce01b5782d820997
- 投稿日:2020-07-30T15:41:40+09:00
【Python初心者】住所から都道府県と市区町村を抜き出す(3行)。
結論
都道府県import re #都道府県のみ address = "東京都新宿区西新宿1-1-1" matches = re.match('東京都|北海道|(?:京都|大阪)府|.{2,3}県' , address) print(matches.group()) #--->東京都区import re #区のみ address = "東京都新宿区西新宿1-1-1" ku_number = address.find('区') print(address[:ku_number+1]) #ない場合は空白が返される #--->東京都新宿区市import re #市のみ address = "東京都八王子市横山町1-1" shi_number = address.find('市') print(address[:shi_number+1]) #ない場合は空白が返される #ない場合は空白が返される #--->東京都八王子市町村も同じく.find()で得ることができる。
- 投稿日:2020-07-30T15:13:40+09:00
レンダリング中に登場するwebapiをクロールしてたらCORSで弾かれた
ことの始まり
python3を使って書いたあるページをクローリングするプログラムを動かしていたら
ある日、クローラからこんなエラーが返ってくるようになった。Access to XMLHttpRequest at 'https://target' from origin 'https://xxxxxxxxx' has been blocked by CORS policy: Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource.その時の実装は以下の通り。
import requests res = requests.get("https://target") # webapiのURLクローリングのターゲットとしていたページはbootstrapなんかでデータを読み込んで表示するようなページで、
レンダリング中にbootstrapから呼び出されているwebapiをターゲットにクロールしていた。解決
selenium-wireを使ってクローリングする。
seleniumのwebdriverはレンダリング後のwebページしか取り扱えないがこれはレンダリング中の問い合わせの結果にもアクセスできる。
https://pypi.org/project/selenium-wire/from seleniumwire import webdriver driver = webdriver.Chrome() driver.get("https://target") # TOPページのURL for request in driver.requests: if "xxxxx" in request.url: # 結果が欲しいURLを絞り込む条件(webapiのURL) response_text = request.response.body.decode()小噺
CROSってそもそも何
こちらの記事で勉強させていただきました。
https://qiita.com/att55/items/2154a8aad8bf1409db2b
なるほど、確かに必要。自分みたいなことする人がいるから。CROSの処理をpythonで出来ないのか → 簡単にはできなそう
あまり調べてないけど簡単にはできなそう。だから諦めた。
CORSではプリフライトリクエストというのを先に飛ばしてそれから実際にGETなりPOSTなりしているらしい。
https://developer.mozilla.org/ja/docs/Glossary/Preflight_requestこの記事に
プリフライトリクエストは必要に応じてブラウザが自動的に発行します。通常、フロントエンドの開発者はそのようなリクエストを自分で作成する必要はありません。と書いてあり、
ブラウザが勝手にやってくれる=飛ばし方を隠蔽されてるくさいなと諦めた。
なんかやるにしてもFetchAPIとかXMLHttpRequest使えって記事が出てくるので、javascriptで動かすしかなさそう。NodeJSならできる → できるかも(未検証)
javascriptということで。NodeJSでFetchAPIを使えるらしい。
https://www.npmjs.com/package/node-fetch
- 投稿日:2020-07-30T15:00:32+09:00
【Python】内包表現について簡潔に書いてみる
公開理由
・Qiitaのコメントで内包表現について言及して頂き、今が理解するチャンスだと思った為
(『Pythonチュートリアル』で内包表現自体は聞いたことあるのですが、難しそうで逃げてました。今がチャンス!)内包表現の文法
文法自体は見た目ほど難しくなさそうです。
(難しそうと思って逃げたのが過去の自分・・・汗)[処理内容 for x in リストなど]個人的には次の様に分解すると個人的にしっくりきました。
「for」以降はPythonの普通のfor文と形に変わりはないですしね。
処理内容が前に来たfor文みたいな印象。サンプルコード(内包表現)
各要素を3倍するコード
naiho.pynum_list = [-4, -3, -2, -1, 0, 1, 2, 3, 4] naiho = [x * 3 for x in num_list] print(naiho)または、名前に苗字を入れるコード
kawaii.pygotobun = ["ithika", "nino", "miku", "yotsuba", "itsuki"] hanayome = ["nakano " + z for z in gotobun] print(hanayome)出力結果(内包表現)
計算は普通に出来るし
[-12, -9, -6, -3, 0, 3, 6, 9, 12]文字列を作るのも簡単ですね。工夫すれば使える場面は多そう。
['nakano ithika', 'nakano nino', 'nakano miku', 'nakano yotsuba', 'nakano itsuki']サンプルコード(内包表現無ver)
上記2つのsampleコードをfor文で処理しようとすると次の様になりそうです。
no_naiho.pynum_list = [-4, -3, -2, -1, 0, 1, 2, 3, 4] not_naiho = [] for y in num_list: y *= 3 not_naiho.append(y) print(not_naiho)no_kawaii.pygotobun = ["ithika", "nino", "miku", "yotsuba", "itsuki"] hanayome = [] for a in gotobun: a = "nakano " + a hanayome.append(a) print(hanayome)出力結果(内包表現無ver)
内包有無で変わりはないのですが、一応書いておきます。
[-12, -9, -6, -3, 0, 3, 6, 9, 12]['nakano ithika', 'nakano nino', 'nakano miku', 'nakano yotsuba', 'nakano itsuki']感想
・内包表現を使うことで、for文を思ったより簡略に書くことが出来ると感じた
・内包表現に慣れていないのであれば、まずfor以下を書いてから最後に処理内容を書くようにすると
迷うことが少なくなると思いました。

- 投稿日:2020-07-30T15:00:32+09:00
【Python】内包表記について簡潔に書いてみる
公開理由
・Qiitaのコメントで内包表現について言及して頂き、今が理解するチャンスだと思った為
(『Pythonチュートリアル』で内包表記自体は聞いたことあるのですが、難しそうで逃げてました。今がチャンス!)内包表記の文法
文法自体は見た目ほど難しくなさそうです。
(難しそうと思って逃げたのが過去の自分・・・汗)[処理内容 for x in リストなど]個人的には次の様に分解すると個人的にしっくりきました。
「for」以降はPythonの普通のfor文と形に変わりはないですしね。
処理内容が前に来たfor文みたいな印象。サンプルコード(内包表記)
各要素を3倍するコード
naiho.pynum_list = [-4, -3, -2, -1, 0, 1, 2, 3, 4] naiho = [x * 3 for x in num_list] print(naiho)または、名前に苗字を入れるコード
kawaii.pygotobun = ["ithika", "nino", "miku", "yotsuba", "itsuki"] hanayome = ["nakano " + z for z in gotobun] print(hanayome)出力結果(内包表記)
計算は普通に出来るし
[-12, -9, -6, -3, 0, 3, 6, 9, 12]文字列を作るのも簡単ですね。工夫すれば使える場面は多そう。
['nakano ithika', 'nakano nino', 'nakano miku', 'nakano yotsuba', 'nakano itsuki']サンプルコード(内包表記無ver)
上記2つのsampleコードをfor文で処理しようとすると次の様になりそうです。
no_naiho.pynum_list = [-4, -3, -2, -1, 0, 1, 2, 3, 4] not_naiho = [] for y in num_list: y *= 3 not_naiho.append(y) print(not_naiho)no_kawaii.pygotobun = ["ithika", "nino", "miku", "yotsuba", "itsuki"] hanayome = [] for a in gotobun: a = "nakano " + a hanayome.append(a) print(hanayome)出力結果(内包表記無ver)
内包有無で変わりはないのですが、一応書いておきます。
[-12, -9, -6, -3, 0, 3, 6, 9, 12]['nakano ithika', 'nakano nino', 'nakano miku', 'nakano yotsuba', 'nakano itsuki']感想
・内包表記を使うことで、for文を思ったより簡略に書くことが出来ると感じた
・内包表記に慣れていないのであれば、まずfor以下を書いてから最後に処理内容を書くようにすると
迷うことが少なくなると思いました。
- 投稿日:2020-07-30T14:38:47+09:00
【Python初心者】1つのリストを分割する(5行)。
- 投稿日:2020-07-30T14:31:09+09:00
LINEのトークをデータセットに加工する
LINEのトーク履歴を加工する
Pythonを使ってLINEのトーク履歴を加工します。
初心者向けの記事です。書いている本人がPython初心者なので。そもそもLINEって?
LINE(ライン)は、24時間、いつでも、どこでも、無料で好きなだけ通話やメールが楽しめる新しいコミュニケーションアプリです。
目標
送信した日時、送信した人の名前、送信した内容をPandasのDateFrameにまとめます。
Datetime Name Content 2020/7/30 12:00 わたし こんにちは 2020/7/30 12:01 わたし [スタンプ] ... ... ... CSVに出力すれば、他の分析ソフトで使うこともできます。
トーク履歴のフォーマット
フォーマットを確認
LINEのトーク履歴はPC版のアプリからtxt形式でダウンロード可能。
開くとこんな感じになっているはずです。2019.12.23 月曜日 15:16 --がグループに参加しました。 15:16 --がグループに参加しました。 15:16 -- こんにちは 15:16 -- [スタンプ] 15:16 -- よろしくお願いします 15:16 -- [スタンプ]以下、\nは改行です。
- 日付
yyyy.mm.dd -曜日\n
- 普通のトーク
hh:mm 名前 内容\n
- 改行が含まれるトーク
hh:mm 名前 内容1\n 内容2....\nグループへの参加やメッセージの送信取消など、一部このフォーマットから外れる記述もあります。
これらはデータフレームに追加しません。実装する
txtファイルを読み込む
→改行を含むトーク内容を1つにまとめ直す
→時刻 名前 内容を抽出する
→日付をトークにアペンドする
→DataFrameに加工する
という順で行います。import pandas as pd # txtファイルの読み込み f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close() # 連結を定義 def appending(list, row): row = list[-1] + row del list[-1] list.append(row) data = [] for row in line_data: # 10文字未満の行 if len(row) < 10: row = row[:-1] appending(data, row) # 15文字未満の行 elif len(row) < 15: # 時刻+名前+内容 if row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row) # 改行後のトーク内容 else: row = row[:-1] appending(data, row) # 15文字以上の行 else: # 日付 if row[4] == "." and row[7] == "." and row[-3:-1] == "曜日": row = row[:10] data.append(row) # 時刻+名前+内容 elif row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row) # 改行後のトーク内容 else: row = row[:-1] appending(data, row) data2 = [] for row in data: # 日付を変数dateに代入 if row[4] == ".": date = row # 時刻+名前+内容に日付を連結 else: row = date + "." + row row = row.split(" ") if len(row) == 3: data2.append(row) # リストのデータフレーム化 df = pd.DataFrame(data2, columns=["Datetime", "Name", "Content"]) # 時刻をDatetime型に直す df["Datetime"] = pd.to_datetime(df["Datetime"], format="%Y.%m.%d.%H:%M")txtファイルの読み込み
先頭から1行ずつ読み込みます。
f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close()line_dataの型はリストです。
print(type(line_data)) # <class 'list'>連結を定義
listの一番最後の要素に、現在の行を連結させています。
def appending(list, row): row = list[-1] + row del list[-1] list.append(row)実際に使ってみます。
thanks = ["いつも", "ありがとう"] appending(thanks, "ございます") # thanks = ['いつも', 'ありがとうございます']10行未満の行
hh:mm 名前 内容\nこの形式で表される普通のトークは、名前が1文字、内容が1文字のときに最小の文字数「10」となります。
つまり、10文字を下回る行は「改行を含むトークの、改行後の部分」になります。row = row[:-1] # 最後の一文字は改行\nなので削除 appending(data, row)この処理で、これを↓
01:10 わたし あけましておめでとう!\n ことしもよろしく!\n↓こうします。
01:10 わたし あけましておめでとう!ことしもよろしく!\n15文字未満の行
yyyy.mm.dd -曜日\nこの形式で表される日付の行は、文字数が15となります。
つまり、15文字を下回る行は「普通のトーク」か「改行を含むトークの、改行後の部分」になります。普通のトーク
01:10 わたし あけましておめでとう!\n3文字目が「:」かつ6文字目が「 」になるので、その部分を抽出します。
if row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row)残りはさっきと同じ処理です。
定義したappending関数を使います。15文字以上の行
日付
yyyy.mm.dd -曜日5文字目と8文字目が「.」かつ最後の2文字が「曜日」になるので、その部分を抽出します。
ただし「曜日」の部分は削除します。if row[4] == "." and row[7] == "." and row[-3:-1] == "曜日": row = row[:10] data.append(row)日付以外
さっきと同じです。
ここまでの作業で、リストdata内に「日付」と「時刻 名前 内容」の要素が入りました。
日付をアペンドする
data内の要素のうち、5文字目が「.」なら日付、そうでなければトーク内容です。
日付を変数dateに代入します。if row[4] == ".": date = rowその後「.」で区切りで「時刻 名前 内容」とアペンドすると、
else: row = date + "." + row行(要素)rowは↓のようになります。
yyyy.mm.dd.hh:mm 名前 内容「 」で区切り、「日付と時刻」「名前」「内容」に分けてリストを更新します。
データフレーム化
リストdata2は二重リスト構造になっています。
これをデータフレームに直し、カラム名も新しく付けてあげます。
なんとなく日付と時刻をDatetime型に直しました。これでおしまいです。お疲れさまでした。
Pandasのto_csvを使えば書き出しもできます。最後に
LINEのトーク履歴は自然言語のデータセットとして活用できるのでは?と思ったのがきっかけです。
人間の会話を学習したり、会話から感情を読み取ったり…活用方法はたくさんあると思います。
今回は行の抽出に正規表現を用いませんでした。
このコードでは抽出が上手く行かない場合(抽出したくない行まで取り出してしまう等)、Pythonのreパッケージをお試しください。
自分がやってみた3ヶ月以上前だったのですが、それからこの記事を上げるまでの間にLINEのフォーマットが変わっていました。
以前は環境によってフォーマットが違ったため、もっと複雑なコードが必要でした。
簡単になったとはいえ、少しずつ書いていた記事が全部パーに。コードを新しく書き直しています。
供養のために、以前のコードも書いておきます。import pandas as pd # txtファイルを1行ずつ読み込み f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close() # 改行データを前の行に連結 def appending(list, row): row = list[-1] + row del list[-1] list.append(row) data = [] # 4行目から読み込み for row in line_data[3:]: # 9文字未満の行は連結 if len(row) < 9: row = row[:-1] appending(data, row) # 13文字未満のとき elif len(row) < 13: # 時刻+名前+内容 if row[2] == ":" and row[5] == "\t": row = row[:-1] data.append(row) # 時刻が一桁の場合 elif row[1] == ":" and row[4] == "\t": row = row[:-1] data.append(row) # 連結 else: row = row[:-1] appending(data, row) # 13文字以上のとき else: # 日付 if row[4] == "/" and row[-4] == "(" and row[-2] == ")": row = row[:-4] data.append(row) # 時刻+名前+内容 elif row[2] == ":" and row[5] == "\t": row = row[:-1] data.append(row) # 時刻が一桁の場合 elif row[1] == ":" and row[4] == "\t": row = row[:-1] data.append(row) # 連結 else: row = row[:-1] appending(data, row) data2 = [] for row in data: # 日付をdateに代入 if row[4] == "/": date = row # 時刻+名前+内容に日付を連結 else: row = date + " " + row row = row.split("\t") if len(row) == 3: # 内容に""が付く場合は削除 if row[2][0] == '"' and row[2][-1] == '"': row[2] = row[2][1:-1] data2.append(row) df = pd.DataFrame(data2, columns=["Datetime", "Name", "Content"]) df["Datetime"] = pd.to_datetime(df["Datetime"], format="%Y/%m/%d %H:%M")
- 投稿日:2020-07-30T14:31:09+09:00
LINEのトーク履歴をデータセットに加工する
LINEのトーク履歴を加工する
Pythonを使って、LINEのトーク履歴をいじります。
Python初心者なので、とんでもないミスがあるかもしれません。そもそもLINEって?
LINE(ライン)は、24時間、いつでも、どこでも、無料で好きなだけ通話やメールが楽しめる新しいコミュニケーションアプリです。
この記事を読んでいる方はLINEを知っている前提で、話を進めてもよろしいでしょうか。
今回の目標
送信した日時、送信した人の名前、送信した内容をPandasのDateFrameにまとめます。
理想↓
Datetime Name Content 2020/7/30 12:00 わたし こんにちは 2020/7/30 12:01 わたし [スタンプ] ... ... ... CSVに出力すれば、他の分析ソフトで使うこともできるのでは?
フォーマット
テキストファイルのフォーマット
LINEのトーク履歴はtxt形式でダウンロード可能。
開くとこんな感じになっているはずです。
最近頻繁にアップデートされているので、また形式が変わってるかも。2019.12.23 月曜日 15:16 --がグループに参加しました。 15:16 --がグループに参加しました。 15:16 -- こんにちは 15:16 -- [スタンプ] 15:16 -- よろしくお願いします 15:16 -- [スタンプ]以下、\nは改行です。
- 日付
yyyy.mm.dd -曜日\n
- 普通のトーク
hh:mm 名前 内容\n
- 改行が含まれるトーク
hh:mm 名前 内容1\n 内容2....\nこれ以外は割愛します。
自分で試してみてね。実装する
txtファイルを読み込む
→改行を含むトーク内容を1つにまとめ直す
→時刻 名前 内容を抽出する
→日付をトークにアペンドする
→DataFrameに加工する
という順で行います。import pandas as pd # txtファイルの読み込み f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close() # 連結を定義 def appending(list, row): row = list[-1] + row del list[-1] list.append(row) data = [] for row in line_data: # 10文字未満の行 if len(row) < 10: row = row[:-1] appending(data, row) # 15文字未満の行 elif len(row) < 15: # 時刻+名前+内容 if row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row) # 改行後のトーク内容 else: row = row[:-1] appending(data, row) # 15文字以上の行 else: # 日付 if row[4] == "." and row[7] == "." and row[-3:-1] == "曜日": row = row[:10] data.append(row) # 時刻+名前+内容 elif row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row) # 改行後のトーク内容 else: row = row[:-1] appending(data, row) data2 = [] for row in data: # 日付を変数dateに代入 if row[4] == ".": date = row # 時刻+名前+内容に日付を連結 else: row = date + "." + row row = row.split(" ") if len(row) == 3: data2.append(row) # リストのデータフレーム化 df = pd.DataFrame(data2, columns=["Datetime", "Name", "Content"]) # 時刻をDatetime型に直す df["Datetime"] = pd.to_datetime(df["Datetime"], format="%Y.%m.%d.%H:%M")txtファイルの読み込み
先頭から1行ずつ読み込みます。
f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close()どうやらline_dataはリストのようです。
print(type(line_data)) # <class 'list'>連結を定義
listの一番最後の要素に、現在の行を連結させます。
def appending(list, row): row = list[-1] + row del list[-1] list.append(row)遊んでみましょう。
thanks = ["いつも", "ありがとう"] appending(thanks, "ございます") # thanks = ['いつも', 'ありがとうございます']いつも、ありがとうございます。
10行未満の行
hh:mm 名前 内容\n文字数が最小になるのは、名前が1文字、内容が1文字のときです。
つまり、10文字を下回る行はすべて「改行を含むトークの、改行後の部分」になります。row = row[:-1] # 最後の一文字は改行\nなので削除 appending(data, row)この処理で、これを↓
01:10 わたし あけましておめでとう!\n ことしもよろしく!\n↓こうします。
01:10 わたし あけましておめでとう!ことしもよろしく!\nもっといい例はなかったのか。
15文字未満の行
yyyy.mm.dd -曜日\n日時を表す行は文字数が15です。
15文字を下回る行は「普通のトーク」か「改行を含むトークの、改行後の部分」になります。普通のトーク
01:10 わたし あけましておめでとう!\n3文字目が「:」かつ6文字目が「 」になるので、その部分を抽出します。
if row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row)改行を含むトークに対しては、先ほどと同じ処理を施します。
15文字以上の行
日付
yyyy.mm.dd -曜日5文字目と8文字目が「.」で、最後の2文字が「曜日」です。
上手いこと日付の行をピックアップします。if row[4] == "." and row[7] == "." and row[-3:-1] == "曜日": row = row[:10] data.append(row)「曜日」の部分はなんとなく削除しました。
もちろん残してもいいです。日付以外
さっきと同じです。
ここまでの作業で、リストdata内に「日付」と「時刻 名前 内容」の要素が入りました。
リストdataが空っぽの人、エラーを吐かれている人はLINEのアップデートを恨んでください。日付をアペンドする
data内の要素のうち、5文字目が「.」なら日付、そうでなければトーク内容です。
日付を変数dateに代入します。if row[4] == ".": date = rowその後「.」で区切り、「時刻 名前 内容」とアペンドすると、
else: row = date + "." + row行(要素)rowは↓です。
yyyy.mm.dd.hh:mm 名前 内容「 」で区切り、リストを更新します。
データフレーム化
リストdata2は二重リスト構造です。
Pandasでデータフレームに直し、カラム名をつけてあげます。
せっかくなので、日付と時刻をDatetime型に直しました。これでおしまいです。お疲れさまでした。
Pandasのto_csvを使えば書き出しもできます。最後に
LINEのトーク履歴は自然言語のデータセットとして活用できるのでは?と思ったのがきっかけです。
人間の会話を学習したり、会話から感情を読み取ったり…活用方法はたくさんあると思います。今回は行の抽出に正規表現を用いませんでした。
このコードでは抽出が上手く行かない場合(抽出したくない行まで取り出してしまう等)、Pythonのreパッケージをお試しください。自分がやってみた3ヶ月以上前だったのですが、それからこの記事を上げるまでの間にLINEのフォーマットが変わっていました。
少しずつ書いていた記事が全部パーに。泣きながらコードを新しく書き直しています。
供養のために、以前のコードも書いておきます。import pandas as pd # txtファイルを1行ずつ読み込み f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close() # 改行データを前の行に連結 def appending(list, row): row = list[-1] + row del list[-1] list.append(row) data = [] # 4行目から読み込み for row in line_data[3:]: # 9文字未満の行は連結 if len(row) < 9: row = row[:-1] appending(data, row) # 13文字未満のとき elif len(row) < 13: # 時刻+名前+内容 if row[2] == ":" and row[5] == "\t": row = row[:-1] data.append(row) # 時刻が一桁の場合 elif row[1] == ":" and row[4] == "\t": row = row[:-1] data.append(row) # 連結 else: row = row[:-1] appending(data, row) # 13文字以上のとき else: # 日付 if row[4] == "/" and row[-4] == "(" and row[-2] == ")": row = row[:-4] data.append(row) # 時刻+名前+内容 elif row[2] == ":" and row[5] == "\t": row = row[:-1] data.append(row) # 時刻が一桁の場合 elif row[1] == ":" and row[4] == "\t": row = row[:-1] data.append(row) # 連結 else: row = row[:-1] appending(data, row) data2 = [] for row in data: # 日付をdateに代入 if row[4] == "/": date = row # 時刻+名前+内容に日付を連結 else: row = date + " " + row row = row.split("\t") if len(row) == 3: # 内容に""が付く場合は削除 if row[2][0] == '"' and row[2][-1] == '"': row[2] = row[2][1:-1] data2.append(row) df = pd.DataFrame(data2, columns=["Datetime", "Name", "Content"]) df["Datetime"] = pd.to_datetime(df["Datetime"], format="%Y/%m/%d %H:%M")
- 投稿日:2020-07-30T14:31:09+09:00
【初心者】LINEのトーク履歴をデータセットに加工する
LINEのトーク履歴を加工する
Pythonを使って、LINEのトーク履歴をいじります。
Python初心者なので、とんでもないミスがあるかもしれません。そもそもLINEって?
LINE(ライン)は、24時間、いつでも、どこでも、無料で好きなだけ通話やメールが楽しめる新しいコミュニケーションアプリです。
この記事を読んでいる方はLINEを知っている前提で、話を進めてもよろしいでしょうか。
今回の目標
送信した日時、送信した人の名前、送信した内容をPandasのDateFrameにまとめます。
理想↓
Datetime Name Content 2020/7/30 12:00 わたし こんにちは 2020/7/30 12:01 わたし [スタンプ] ... ... ... CSVに出力すれば、他の分析ソフトで使うこともできるのでは?
フォーマット
テキストファイルのフォーマット
LINEのトーク履歴はtxt形式でダウンロード可能。
開くとこんな感じになっているはずです。
最近頻繁にアップデートされているので、また形式が変わってるかも。2019.12.23 月曜日 15:16 --がグループに参加しました。 15:16 --がグループに参加しました。 15:16 -- こんにちは 15:16 -- [スタンプ] 15:16 -- よろしくお願いします 15:16 -- [スタンプ]以下、\nは改行です。
- 日付
yyyy.mm.dd -曜日\n
- 普通のトーク
hh:mm 名前 内容\n
- 改行が含まれるトーク
hh:mm 名前 内容1\n 内容2....\nこれ以外は割愛します。
自分で試してみてね。実装する
txtファイルを読み込む
→改行を含むトーク内容を1つにまとめ直す
→時刻 名前 内容を抽出する
→日付をトークにアペンドする
→DataFrameに加工する
という順で行います。import pandas as pd # txtファイルの読み込み f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close() # 連結を定義 def appending(list, row): row = list[-1] + row del list[-1] list.append(row) data = [] for row in line_data: # 10文字未満の行 if len(row) < 10: row = row[:-1] appending(data, row) # 15文字未満の行 elif len(row) < 15: # 時刻+名前+内容 if row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row) # 改行後のトーク内容 else: row = row[:-1] appending(data, row) # 15文字以上の行 else: # 日付 if row[4] == "." and row[7] == "." and row[-3:-1] == "曜日": row = row[:10] data.append(row) # 時刻+名前+内容 elif row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row) # 改行後のトーク内容 else: row = row[:-1] appending(data, row) data2 = [] for row in data: # 日付を変数dateに代入 if row[4] == ".": date = row # 時刻+名前+内容に日付を連結 else: row = date + "." + row row = row.split(" ") if len(row) == 3: data2.append(row) # リストのデータフレーム化 df = pd.DataFrame(data2, columns=["Datetime", "Name", "Content"]) # 時刻をDatetime型に直す df["Datetime"] = pd.to_datetime(df["Datetime"], format="%Y.%m.%d.%H:%M")txtファイルの読み込み
先頭から1行ずつ読み込みます。
f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close()どうやらline_dataはリストのようです。
print(type(line_data)) # <class 'list'>連結を定義
listの一番最後の要素に、現在の行を連結させます。
def appending(list, row): row = list[-1] + row del list[-1] list.append(row)遊んでみましょう。
thanks = ["いつも", "ありがとう"] appending(thanks, "ございます") # thanks = ['いつも', 'ありがとうございます']いつも、ありがとうございます。
10行未満の行
hh:mm 名前 内容\n文字数が最小になるのは、名前が1文字、内容が1文字のときです。
つまり、10文字を下回る行はすべて「改行を含むトークの、改行後の部分」になります。row = row[:-1] # 最後の一文字は改行\nなので削除 appending(data, row)この処理で、これを↓
01:10 わたし あけましておめでとう!\n ことしもよろしく!\n↓こうします。
01:10 わたし あけましておめでとう!ことしもよろしく!\nもっといい例はなかったのか。
15文字未満の行
yyyy.mm.dd -曜日\n日時を表す行は文字数が15です。
15文字を下回る行は「普通のトーク」か「改行を含むトークの、改行後の部分」になります。普通のトーク
01:10 わたし あけましておめでとう!\n3文字目が「:」かつ6文字目が「 」になるので、その部分を抽出します。
if row[2] == ":" and row[5] == " ": row = row[:-1] data.append(row)改行を含むトークに対しては、先ほどと同じ処理を施します。
15文字以上の行
日付
yyyy.mm.dd -曜日5文字目と8文字目が「.」で、最後の2文字が「曜日」です。
上手いこと日付の行をピックアップします。if row[4] == "." and row[7] == "." and row[-3:-1] == "曜日": row = row[:10] data.append(row)「曜日」の部分はなんとなく削除しました。
もちろん残してもいいです。日付以外
さっきと同じです。
ここまでの作業で、リストdata内に「日付」と「時刻 名前 内容」の要素が入りました。
リストdataが空っぽの人、エラーを吐かれている人はLINEのアップデートを恨んでください。日付をアペンドする
data内の要素のうち、5文字目が「.」なら日付、そうでなければトーク内容です。
日付を変数dateに代入します。if row[4] == ".": date = rowその後「.」で区切り、「時刻 名前 内容」とアペンドすると、
else: row = date + "." + row行(要素)rowは↓です。
yyyy.mm.dd.hh:mm 名前 内容「 」で区切り、リストを更新します。
データフレーム化
リストdata2は二重リスト構造です。
Pandasでデータフレームに直し、カラム名をつけてあげます。
せっかくなので、日付と時刻をDatetime型に直しました。これでおしまいです。お疲れさまでした。
Pandasのto_csvを使えば書き出しもできます。最後に
LINEのトーク履歴は自然言語のデータセットとして活用できるのでは?と思ったのがきっかけです。
人間の会話を学習したり、会話から感情を読み取ったり…活用方法はたくさんあると思います。今回は行の抽出に正規表現を用いませんでした。
このコードでは抽出が上手く行かない場合(抽出したくない行まで取り出してしまう等)、Pythonのreパッケージをお試しください。自分がやってみた3ヶ月以上前だったのですが、それからこの記事を上げるまでの間にLINEのフォーマットが変わっていました。
少しずつ書いていた記事が全部パーに。泣きながらコードを新しく書き直しています。
供養のために、以前のコードも書いておきます。import pandas as pd # txtファイルを1行ずつ読み込み f = open("line_--.txt", encoding="UTF-8") line_data = f.readlines() f.close() # 改行データを前の行に連結 def appending(list, row): row = list[-1] + row del list[-1] list.append(row) data = [] # 4行目から読み込み for row in line_data[3:]: # 9文字未満の行は連結 if len(row) < 9: row = row[:-1] appending(data, row) # 13文字未満のとき elif len(row) < 13: # 時刻+名前+内容 if row[2] == ":" and row[5] == "\t": row = row[:-1] data.append(row) # 時刻が一桁の場合 elif row[1] == ":" and row[4] == "\t": row = row[:-1] data.append(row) # 連結 else: row = row[:-1] appending(data, row) # 13文字以上のとき else: # 日付 if row[4] == "/" and row[-4] == "(" and row[-2] == ")": row = row[:-4] data.append(row) # 時刻+名前+内容 elif row[2] == ":" and row[5] == "\t": row = row[:-1] data.append(row) # 時刻が一桁の場合 elif row[1] == ":" and row[4] == "\t": row = row[:-1] data.append(row) # 連結 else: row = row[:-1] appending(data, row) data2 = [] for row in data: # 日付をdateに代入 if row[4] == "/": date = row # 時刻+名前+内容に日付を連結 else: row = date + " " + row row = row.split("\t") if len(row) == 3: # 内容に""が付く場合は削除 if row[2][0] == '"' and row[2][-1] == '"': row[2] = row[2][1:-1] data2.append(row) df = pd.DataFrame(data2, columns=["Datetime", "Name", "Content"]) df["Datetime"] = pd.to_datetime(df["Datetime"], format="%Y/%m/%d %H:%M")
- 投稿日:2020-07-30T14:30:18+09:00
【Python初心者】2つのリストを交互に結合する(5行)。

- 投稿日:2020-07-30T13:59:29+09:00
Codeforces Round #658 (Div. 2) バチャ復習(7/29)
今回の成績
今回の感想
前回に引き続き再び誤読していました。詳しくはC問題を見てください。
2時間もかけて3問しか結局解いてないのは効率が悪いので、徐々に解ける問題を増やしていきます。A問題
$a$と$b$の共通部分列で最も短いものが存在すれば長さは1となるので、$a$と$b$で共通する文字のうちの一つを出力すれば良いです。
また、ここでは$a$に含まれる文字で$b$にも含まれるものがあるかを探せば良く、片方をset構造にすれば$O(N)$で調べることが可能です。A.pyt=int(input()) for _ in range(t): n,m=map(int,input().split()) a=list(map(int,input().split())) b=set(map(int,input().split())) for i in a: if i in b: print("YES") print(f"1 {i}") break else: print("NO")B問題
まずはゲームの問題なので最終状態に注目します。最終状態に注目した時に全ての山は0になりますが、直前においては最後の山のみはそのまま残ります。
ここで注目したのが、それぞれの山を残すのか残さないのかという点です(二値化!)。つまり、それぞれの山の石の数が1より多い場合、その山を選ぶプレイヤーは相手に選択権を与えないことができます。これは、その山の石を一つだけ残して相手に渡すことで行うことができます。
しかし、その山の石の数が元々一つの場合、その山を選んだプレイヤーはその一つの石を取り除くしかありません。したがって、石の数が1より大きい山における操作では、次の山の石の数が一つかによって、その山の石を一つ残すか全て除くかを調整すれば良いです。また、石が一つのみの山が1番初めの山から連続する場合はプレイヤーには選択権がないので、初めて石が一つでない山を選ぶことのできるプレイヤーに選択権があり勝利することができると言えます
B.pyt=int(input()) for i in range(t): n=int(input()) a=list(map(int,input().split())) s=["First","Second"] ans=0 for i in range(n): if a[i]!=1: ans=i break else: ans=n-1 print(s[ans%2])C1問題
完全に誤読していました。反転操作は文字列全体だと思ったのですが、自分で選択する接頭辞のみで行うとよく問題文を見たら書いてありました。
Codeforcesでは英語の原文のまま読んでいて見間違いが多発しているので、このような非本質な間違いをなくすことに主眼をおきたいと思います。問題については、初めの方針として$i$番目のbitがどうなるかをまずは考えるべきです(抽象化)。この時、$i$番目のbitだけを反転させる場合を考えますが、ここでは$i$→$1$→$i$の順で選択することで可能です。また、このシミュレーションでは$3n$回程度に収まります。初めの$i$の操作で$i$番目の要素は$1$番目の要素に変わるので、$1$の操作によってその$1$番目にある元々$i$番目の要素だけbit反転させ、最後に$i$で元に戻すと考えれば良いです。わからない場合は図示すると良いと思います。このような問題は発見的に解くしかない気がするので、重要なのは慣れと実験だと思います。
C1.py#誤読… t=int(input()) for _ in range(t): n,a,b=int(input()),input(),input() ans=[] for i in range(n): if a[i]!=b[i]: ans.append(f"{i+1}") ans.append("1") ans.append(f"{i+1}") print(f"{len(ans)}"+" "+" ".join(ans))C2問題以降
今回は飛ばします

- 投稿日:2020-07-30T13:36:00+09:00
ドル円レートを機械学習で予測してみた!
AI株式自動取引アルゴリズム開発してガッポリ稼ぎて〜〜〜
誰しもが持つ夢です。(私だけかもしれません)
今回は、ランダムフォレストでドル円のレートが上がるか、下がるか、そのままかを予測するクラス分類モデルを構築しました。
最初に方針を立てる
回帰モデルor分類モデルの選択→分類モデルにしよう
まず、なぜ回帰モデル(つまりレートをドンピシャで推測するモデル)ではなく、クラス分類モデル(つまりレートが上がるか、下がるか、そのままかの三値分類)を選択したのか。
理由はいくつかあります。・分類モデルの評価は回帰モデルに比べて簡単
・実際にfxで人間が行う動作って(買う、売る、何もしない)の三つだけだしクラス分類でよくない?
・ランダムフォレストちょうど実装したかったんだよねという理由からクラス分類予測を選択しました。
(後から考えると、通過売買において取引量も大事になってきます。取引量を決める際に具体的なレートは大切になってくるので、ピンポイントでレートを予測できる回帰モデルの方がよかったかな〜なんて思ってます。また今度やってみます。)
特徴量どうしよう→テクニカル指標使おう
fxのレート予測モデルを立てる上で特徴量どうしよう、、、ってなりますよね。
じゃあ実際に人間が何を使ってドル円を売買しているのかを考えれば特徴量も浮かんできます。人間はfxで取引する際に行う分析は大きく分けて、テクニカル分析とファンダメンタル分析の二つです。
テクニカル分析っていうのはいわゆるチャートを見て値動きを予想することです。
一方ファンダメンタル分析っていうのはニュースとか世界情勢から値動きを予想することです。今回は機械学習の特徴量として取り込みやすい、テクニカル分析を用います。
なぜ取り込みやすいかというとテクニカル分析は数字だけを扱いプログラム化が簡単だからです。一方ファンダメンタルも取り込もうと思えばできるのですが(テキストマイニングとかすると)、大変でありそもそもファンダメンタルは長期目線での売買に使われることが多いので使用は見送ります。
データセット
方針も決まってきたのでデータセットを探そう。
今回は、investing.com の過去20年分の日足データを使いました。
大体、250日(fx取引は平日のみ)×20年〜5000個のデータを取れます。実装!!!
1. レート情報が入ったcsvファイル読み込み
import pandas as pd df = pd.read_csv("USD_JPY.csv")2. 特徴量(説明変数)の作成
前述の通り、今回は特徴量としてテクニカル分析の数値を用います。
具体的に今回用いたのは、SMA5,SMA20,RSI14,MACD,Bollinger-bands(2σ)の5つです。
各テクニカル指標の詳しい特徴に関してはググってください。
ただし特徴量として用いるテクニカル指標選びの際に気をつけたいのは、いくら統計分析ではなく機械学習だからといってもマルチコ(多重共線性)は極力避けたいので、できるかぎりお互いに相関性のないテクニカル指標を選んでください。テクニカル指標の計算は、超絶便利なtalibというライブラリを使いましょう。一発でテクニカル指標を算出してくれます。
ここで、RSIとMACDに関してはテクニカルの数値そのままを使っているのですが、SMAとボリンジャーバンド の値はそうはいきません。(例えばSMAの値が105だったとしても、そのままだとこの105という数値が高いのか低いのかわからないので特徴量としては適していません。)
そこで、SMAとボリンジャーバンドの値に関してはcloseの値で割ってあげることで、相対的で比較可能な値に変換してから特徴量として用いることにします。この部分に関しては、やり方は他にもたくさんあると思うので各自がいいと思うやり方を試してみてください!
import talib as ta import numpy as np #以降全ての計算でレート終値を使う close = np.array(df["終値"]) #特徴量を入れるための空のdataframeを作成 df_feature = pd.DataFrame(index=range(len(df)),columns=["SMA5/current", "SMA20/current","RSI","MACD","BBANDS+2σ","BBANDS-2σ"]) #以下、talibを用いてテクニカル指標(今回の学習で用いる特徴量)を算出しdf_feature入れる #単純移動平均は、単純移動平均値とその日の終値の比を特徴量として用いる df_feature["SMA5/current"]= ta.SMA(close, timeperiod=5) / close df_feature["SMA20/current"]= ta.SMA(close, timeperiod=20) / close #RSI df_feature["RSI"] = ta.RSI(close, timeperiod=14) #MACD df_feature["MACD"], _ , _= ta.MACD(close, fastperiod=12, slowperiod=26, signalperiod=9) #ボリンジャーバンド upper, middle, lower = ta.BBANDS(close, timeperiod=20, nbdevup=3, nbdevdn=3) df_feature["BBANDS+2σ"] = upper / close df_feature["BBANDS-2σ"] = lower / close3. 教師データ(目的変数)の作成
前述した通り、今回のモデルの教師データは[上がる、下がる、値は(ほぼ)変わらない]の三値です。
そこで、investing.comからダウンロードしたデータの中の前述比率を用いて教師データを作ります。具体的に作成に使用した関数は以下です。
def classify(x): #前日比が-0.2%以下ならグループ0 if x <= -0.2: return 0 #前日比が0.2%<x<0.2%ならグループ1 elif -0.2 < x < 0.2: return 1 #前日比が0.2%以上ならグループ2 elif 0.2 <= x: return 2なぜ前日比を-0.2%と0.2%で区切ったのかと言いますと、
・100 (円/ドル) × 0.002 = 0.2(円/ドル) = 20pipsで、この値はレートが動いたかどうかを判断する値として適切だと考えたから。
・前日比を-0.2%と0.2%で三つのグループに区切ることでデータがほぼほぼ当分されるから。(下の図)
左からグループ0、グループ1、グループ2のデータの数です。ほぼほぼ等分されています。教師データのクラスが等分されていることはランダムフォレストを用いる上でとても大切です。(もちろんクラスが等分されていなくてもできますが、重みづけをする必要があります。詳しくはこちらの方の記事がわかりやすいです。)
以上に注意して教師データを作ります。
df["前日比_float"] = df["前日比%"].apply(lambda x: float(x.replace("%", ""))) #前日比%の分類の仕方。できるだけ各クラスのサンプルが等しいようにわける def classify(x): if x <= -0.2: return 0 elif -0.2 < x < 0.2: return 1 elif 0.2 <= x: return 2 df["前日比_classified"] = df["前日比_float"].apply(lambda x: classify(x)) #教師にしたいデータを一日ずつずらす(意味を考えればわかると思います) df_y = df["前日比_classified"].shift()4. 特徴量と教師データ完成!
少しだけ処理を行います。例えばSMA5を使って特徴量を算出した場合、最初の4日は値がNaNになってしまいます。(5日平均を計算するには最低5日分のデータが要るので)
このように、特徴量データの最初の方にNaNが含まれているので、取り除いてやります。df_xy = pd.concat([df_feature, df_y], axis=1) df_xy = df_xy.dropna(how="any")これで前処理完了です。なお今回はランダムフォレストを用いるので正規化/標準化は必要ありません。
5. モデル学習!
あとは学習するのみです。
ランダムフォレストのパラメータを色々と変えて実験してみると面白いかも...
ランダムフォレストのハイパーパラメータはこちらの記事がわかりやすいです。あと、ハイパーパラメータはoptunaを使って最適化しました。
optunaを使う際、objective関数は最小化したいものをreturnで返すように設定することに注意しましょう。from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import optuna X_train, X_test, Y_train, Y_test = train_test_split(df_xy[["SMA5/current", "SMA20/current","RSI","MACD","BBANDS+2σ","BBANDS-2σ"]],df_xy["前日比_classified"], train_size=0.8) def objective(trial): min_samples_split = trial.suggest_int("min_samples_split", 2,16) max_leaf_nodes = int(trial.suggest_discrete_uniform("max_leaf_nodes", 4,64,4)) criterion = trial.suggest_categorical("criterion", ["gini", "entropy"]) n_estimators = int(trial.suggest_discrete_uniform("n_estimators", 50,500,50)) max_depth = trial.suggest_int("max_depth", 3,10) clf = RandomForestClassifier(random_state=1, n_estimators = n_estimators, max_leaf_nodes = max_leaf_nodes, max_depth=max_depth, max_features=None,criterion=criterion,min_samples_split=min_samples_split) clf.fit(X_train, Y_train) return 1 - accuracy_score(Y_test, clf.predict(X_test)) study = optuna.create_study() study.optimize(objective, n_trials=100) print(1-study.best_value) print(study.best_params)ハイパーパラメータが最適化された時のaccuracyは、
0.6335025380710659
三値分類なのでなかなかの成績だと思います。ランダムに選択した場合の約二倍の成績ですね。
6割の確率で値動きの予想が当たるなら、スプレッド考えても期待値が正になりそう!
多クラス分類の混同行列を考えてみましょう!
Fxで利益を上げるには①と⑨の割合が高いことが望ましいですよね。混同行列を見ると、1+9=48.9%で約半数近くを占めています。また、最も回避したいの は③と⑦のパターンですね(上がると予測したのに実際は下がってしまった、下がると予測したのに実際は上がってしまったというパターン)。これら二つは、③+⑦=7.3%とかなり低い数値になっています。
以上の考察から、今回学習されたモデルは利益を上げることが可能であることがわかります。
また、accuracyが最大となった時のハイパーパラメータは、
{'min_samples_split': 8, 'max_leaf_nodes': 40.0, 'criterion': 'entropy', 'n_estimators': 310.0, 'max_depth': 7}でした。
ハイパーパラメータとaccuracyの関係は以下のようなものとなりました。
(※obejective_value = 1 - accuracyであることに注意!(optunaの仕様))
上の図の色が薄いところがaccuracyが高くなっているところです。
確かに、max_depthは7付近、max_leaf_nodesは30〜40付近、n_estimatorsは300付近で高いパフォーマンスを出せていることが読み取れます。追記:さらなる実験
さてここまでは、3値分類してきましたが、レート上昇or下降の二値分類してみましょう。
変更するのは、3.教師データ作成のclassify関数だけです。
def classify(x): if x <= 0: return 0 else: return 1同じようにモデルを構築し、optunaでハイパーパラメータを最適化してあげると...
accuracy=0.7766497461928934
これで僕も大金持ちですね(白目)!
※投資判断は自己責任です。このように、データの分割方法を変更するだけではなく、用いるテクニカル指標などもいじってみると面白いかもしれませんね!

- 投稿日:2020-07-30T13:36:00+09:00
為替(ドル円レート)を機械学習で予測するモデルの実装
AI為替自動取引アルゴリズム開発してガッポリ稼ぎて〜〜〜
誰しもが持つ夢です。(私だけかもしれません)
今回は、ランダムフォレストでドル円のレートが上がるか、下がるか、そのままかを予測するクラス分類モデルを構築しました。
最初に方針を立てる
回帰モデルor分類モデルの選択→分類モデルにしよう
まず、なぜ回帰モデル(つまりレートをドンピシャで推測するモデル)ではなく、クラス分類モデル(つまりレートが上がるか、下がるか、そのままかの三値分類)を選択したのか。
理由はいくつかあります。・分類モデルの評価は回帰モデルに比べて簡単
・実際にfxで人間が行う動作って(買う、売る、何もしない)の三つだけだしクラス分類でよくない?
・ランダムフォレストちょうど実装したかったんだよねという理由からクラス分類予測を選択しました。
(後から考えると、通過売買において取引量も大事になってきます。取引量を決める際に具体的なレートは大切になってくるので、ピンポイントでレートを予測できる回帰モデルの方がよかったかな〜なんて思ってます。また今度やってみます。)
特徴量どうしよう→テクニカル指標使おう
fxのレート予測モデルを立てる上で特徴量どうしよう、、、ってなりますよね。
じゃあ実際に人間が何を使ってドル円を売買しているのかを考えれば特徴量も浮かんできます。人間はfxで取引する際に行う分析は大きく分けて、テクニカル分析とファンダメンタル分析の二つです。
テクニカル分析っていうのはいわゆるチャートを見て値動きを予想することです。
一方ファンダメンタル分析っていうのはニュースとか世界情勢から値動きを予想することです。今回は機械学習の特徴量として取り込みやすい、テクニカル分析を用います。
なぜ取り込みやすいかというとテクニカル分析は数字だけを扱いプログラム化が簡単だからです。一方ファンダメンタルも取り込もうと思えばできるのですが(テキストマイニングとかすると)、大変でありそもそもファンダメンタルは長期目線での売買に使われることが多いので使用は見送ります。
データセット
方針も決まってきたのでデータセットを探そう。
今回は、investing.com の過去20年分の日足データを使いました。
大体、250日(fx取引は平日のみ)×20年〜5000個のデータを取れます。実装!!!
1. レート情報が入ったcsvファイル読み込み
import pandas as pd df = pd.read_csv("USD_JPY.csv")2. 特徴量(説明変数)の作成
前述の通り、今回は特徴量としてテクニカル分析の数値を用います。
具体的に今回用いたのは、SMA5,SMA20,RSI14,MACD,Bollinger-bands(2σ)の5つです。
各テクニカル指標の詳しい特徴に関してはググってください。
ただし特徴量として用いるテクニカル指標選びの際に気をつけたいのは、いくら統計分析ではなく機械学習だからといってもマルチコ(多重共線性)は極力避けたいので、できるかぎりお互いに相関性のないテクニカル指標を選んでください。テクニカル指標の計算は、超絶便利なtalibというライブラリを使いましょう。一発でテクニカル指標を算出してくれます。
ここで、RSIとMACDに関してはテクニカルの数値そのままを使っているのですが、SMAとボリンジャーバンド の値はそうはいきません。(例えばSMAの値が105だったとしても、そのままだとこの105という数値が高いのか低いのかわからないので特徴量としては適していません。)
そこで、SMAとボリンジャーバンドの値に関してはcloseの値で割ってあげることで、相対的で比較可能な値に変換してから特徴量として用いることにします。この部分に関しては、やり方は他にもたくさんあると思うので各自がいいと思うやり方を試してみてください!
import talib as ta import numpy as np #以降全ての計算でレート終値を使う close = np.array(df["終値"]) #特徴量を入れるための空のdataframeを作成 df_feature = pd.DataFrame(index=range(len(df)),columns=["SMA5/current", "SMA20/current","RSI","MACD","BBANDS+2σ","BBANDS-2σ"]) #以下、talibを用いてテクニカル指標(今回の学習で用いる特徴量)を算出しdf_feature入れる #単純移動平均は、単純移動平均値とその日の終値の比を特徴量として用いる df_feature["SMA5/current"]= ta.SMA(close, timeperiod=5) / close df_feature["SMA20/current"]= ta.SMA(close, timeperiod=20) / close #RSI df_feature["RSI"] = ta.RSI(close, timeperiod=14) #MACD df_feature["MACD"], _ , _= ta.MACD(close, fastperiod=12, slowperiod=26, signalperiod=9) #ボリンジャーバンド upper, middle, lower = ta.BBANDS(close, timeperiod=20, nbdevup=3, nbdevdn=3) df_feature["BBANDS+2σ"] = upper / close df_feature["BBANDS-2σ"] = lower / close3. 教師データ(目的変数)の作成
前述した通り、今回のモデルの教師データは[上がる、下がる、値は(ほぼ)変わらない]の三値です。
そこで、investing.comからダウンロードしたデータの中の前述比率を用いて教師データを作ります。具体的に作成に使用した関数は以下です。
def classify(x): #前日比が-0.2%以下ならグループ0 if x <= -0.2: return 0 #前日比が0.2%<x<0.2%ならグループ1 elif -0.2 < x < 0.2: return 1 #前日比が0.2%以上ならグループ2 elif 0.2 <= x: return 2なぜ前日比を-0.2%と0.2%で区切ったのかと言いますと、
・100 (円/ドル) × 0.002 = 0.2(円/ドル) = 20pipsで、この値はレートが動いたかどうかを判断する値として適切だと考えたから。
・前日比を-0.2%と0.2%で三つのグループに区切ることでデータがほぼほぼ当分されるから。(下の図)
左からグループ0、グループ1、グループ2のデータの数です。ほぼほぼ等分されています。教師データのクラスが等分されていることはランダムフォレストを用いる上でとても大切です。(もちろんクラスが等分されていなくてもできますが、重みづけをする必要があります。詳しくはこちらの方の記事がわかりやすいです。)
以上に注意して教師データを作ります。
df["前日比_float"] = df["前日比%"].apply(lambda x: float(x.replace("%", ""))) #前日比%の分類の仕方。できるだけ各クラスのサンプルが等しいようにわける def classify(x): if x <= -0.2: return 0 elif -0.2 < x < 0.2: return 1 elif 0.2 <= x: return 2 df["前日比_classified"] = df["前日比_float"].apply(lambda x: classify(x)) #教師にしたいデータを一日ずつずらす(意味を考えればわかると思います) df_y = df["前日比_classified"].shift()4. 特徴量と教師データ完成!
少しだけ処理を行います。例えばSMA5を使って特徴量を算出した場合、最初の4日は値がNaNになってしまいます。(5日平均を計算するには最低5日分のデータが要るので)
このように、特徴量データの最初の方にNaNが含まれているので、取り除いてやります。df_xy = pd.concat([df_feature, df_y], axis=1) df_xy = df_xy.dropna(how="any")これで前処理完了です。なお今回はランダムフォレストを用いるので正規化/標準化は必要ありません。
5. モデル学習!
あとは学習するのみです。
ランダムフォレストのパラメータを色々と変えて実験してみると面白いかも...
ランダムフォレストのハイパーパラメータはこちらの記事がわかりやすいです。あと、ハイパーパラメータはoptunaを使って最適化しました。
optunaを使う際、objective関数は最小化したいものをreturnで返すように設定することに注意しましょう。from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import optuna X_train, X_test, Y_train, Y_test = train_test_split(df_xy[["SMA5/current", "SMA20/current","RSI","MACD","BBANDS+2σ","BBANDS-2σ"]],df_xy["前日比_classified"], train_size=0.8) def objective(trial): min_samples_split = trial.suggest_int("min_samples_split", 2,16) max_leaf_nodes = int(trial.suggest_discrete_uniform("max_leaf_nodes", 4,64,4)) criterion = trial.suggest_categorical("criterion", ["gini", "entropy"]) n_estimators = int(trial.suggest_discrete_uniform("n_estimators", 50,500,50)) max_depth = trial.suggest_int("max_depth", 3,10) clf = RandomForestClassifier(random_state=1, n_estimators = n_estimators, max_leaf_nodes = max_leaf_nodes, max_depth=max_depth, max_features=None,criterion=criterion,min_samples_split=min_samples_split) clf.fit(X_train, Y_train) return 1 - accuracy_score(Y_test, clf.predict(X_test)) study = optuna.create_study() study.optimize(objective, n_trials=100) print(1-study.best_value) print(study.best_params)ハイパーパラメータが最適化された時のaccuracyは、
0.6335025380710659
三値分類なのでなかなかの成績だと思います。ランダムに選択した場合の約二倍の成績ですね。
6割の確率で値動きの予想が当たるなら、スプレッド考えても期待値が正になりそう!
多クラス分類の混同行列を考えてみましょう!
Fxで利益を上げるには①と⑨の割合が高いことが望ましいですよね。混同行列を見ると、1+9=48.9%で約半数近くを占めています。また、最も回避したいの は③と⑦のパターンですね(上がると予測したのに実際は下がってしまった、下がると予測したのに実際は上がってしまったというパターン)。これら二つは、③+⑦=7.3%とかなり低い数値になっています。
以上の考察から、今回学習されたモデルは利益を上げることが可能であることがわかります。
また、accuracyが最大となった時のハイパーパラメータは、
{'min_samples_split': 8, 'max_leaf_nodes': 40.0, 'criterion': 'entropy', 'n_estimators': 310.0, 'max_depth': 7}でした。
ハイパーパラメータとaccuracyの関係は以下のようなものとなりました。
(※obejective_value = 1 - accuracyであることに注意!(optunaの仕様))
上の図の色が薄いところがaccuracyが高くなっているところです。
確かに、max_depthは7付近、max_leaf_nodesは30〜40付近、n_estimatorsは300付近で高いパフォーマンスを出せていることが読み取れます。追記:さらなる実験
さてここまでは、3値分類してきましたが、レート上昇or下降の二値分類してみましょう。
変更するのは、3.教師データ作成のclassify関数だけです。
def classify(x): if x <= 0: return 0 else: return 1同じようにモデルを構築し、optunaでハイパーパラメータを最適化してあげると...
accuracy=0.7766497461928934
これで僕も大金持ちですね(白目)!
※投資判断は自己責任です。このように、データの分割方法を変更するだけではなく、用いるテクニカル指標などもいじってみると面白いかもしれませんね!