- 投稿日:2020-07-30T22:31:05+09:00
AWSのDMS(Data Migration Service)を使ったDB移行のために、新機能の「移行前評価(Premigration assessments)」を試してみた!
前提
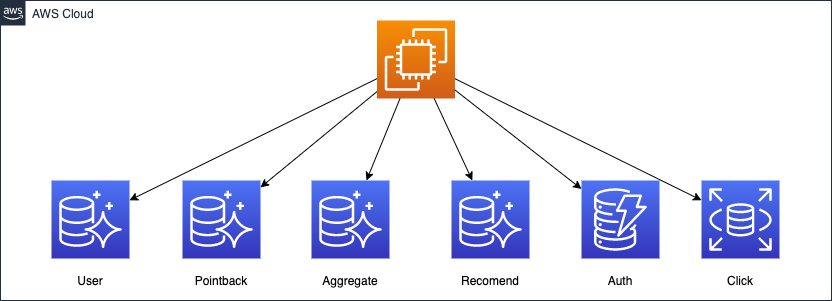
ハピタスにはデータベースインスタンスが複数存在しています。
データベースインスタンスごとに役割がおおよそ決められており、効果的に活用できていれば
メンテナンスも部分的にできたり、負荷分散も適切に行えたり、有用な構成だったと思います。しかしながら、長年様々なエンジニアによって改修が行われ、データベースインスタンス同士の依存関係も大きくなり、
一つのデータベースであれば単純に WEB アプリケーション上で一つのSQLで完結できたはずのものが
php を介して、SQL の問い合わせ結果を使いマージして、複雑な処理を行うため
その処理がボトルネックになってきています。メンテナンスもハピタスのインフラの歴史的な背景の理由などで複雑化しています。そこで DMS を使って、データベースの統合を進めています。
元々
こうする
課題したい課題
課題は色々ありましたが、
本トピックでは 2020年7月29日の昨日にリリースされた DMS の Premigration assessments 「移行前評価」について使ってみて事前検証したので共有します。できたての機能なので、本日 7月30日時点では New とマークがついていますね。
使われる場合は事前に https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.AssessmentReport.html を一読してみてください。
- ソース: RDS for MySQL 5.6
- ターゲット Aurora MySQL
- フルロードおよび CDC を使う
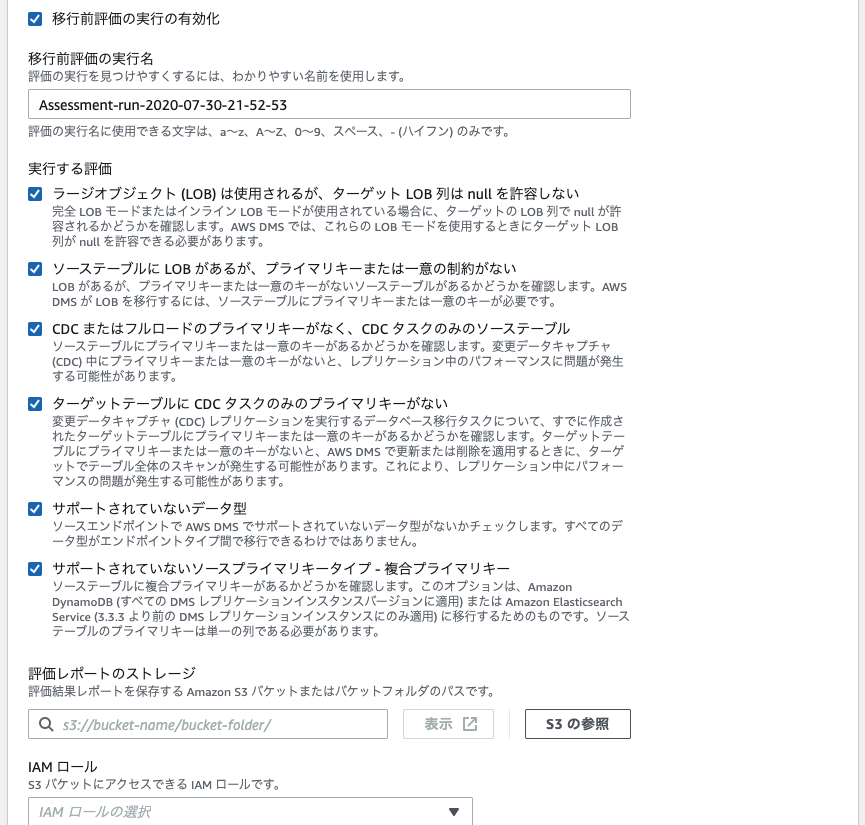
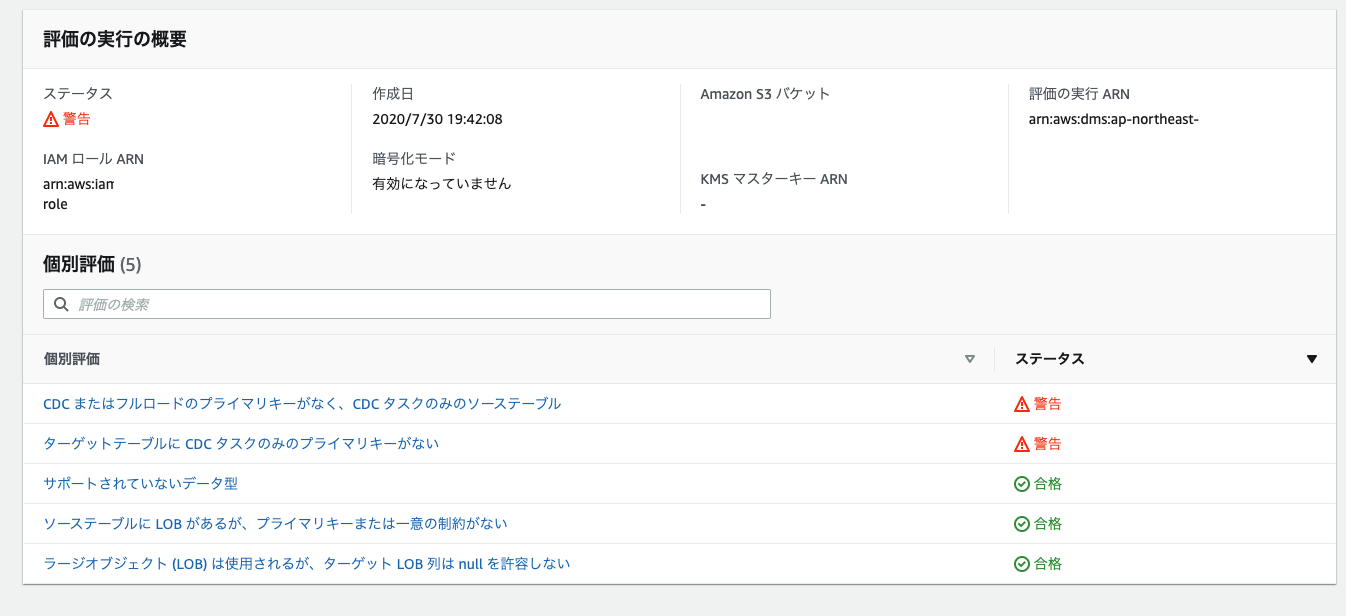
上記の環境の場合、以下の5項目が評価対象となるようです。
- CDC またはフルロードのプライマリキーがなく、CDC タスクのみのソーステーブル
- サポートされていないデータ型
- ソーステーブルに LOB があるが、プライマリキーまたは一意の制約がない
- ターゲットテーブルに CDC タスクのみのプライマリキーがない
- ラージオブジェクト (LOB) は使用されるが、ターゲット LOB 列は null を許容しない
この評価がエラーとなっても 必ずしも問題になるわけではなく、 DMS タスクの開始はできるようです。
表示されたメッセージから扱っている環境がどういった問題が起き得るかが推測できます。
事前に テーブルの定義を一つ一つ調査していたものが自動でチェックできるので、とても便利ですね。設定方法
※ 事前にレプリケーションインスタンス、エンドポイント(ソース/ターゲット)、セキュリティグループなどは作成、設定済みの前提
- DMS 用の IAMロールを作成します
- ロール作成画面 から DMS を選択します
- ポリシー名を AmazonDMSRedshiftS3Role で検索してチェックをつけます
- IAMロールの名前を設定します
- データ移行タスク からデータ移行タスクを作成します。
- 設定をそれぞれ入力します
移行前評価の実行の有効化にチェックをいれます- そうすると以下のような表示がされます。不要な評価がある場合はチェックをはずし (環境が該当しないものはチェックが付いていても評価されないようです)
評価レポートのストレージはレポートを保存する S3 のバケットとパスを指定しますIAM ロールでは 1. で作成したロールを選びます- ちなみに
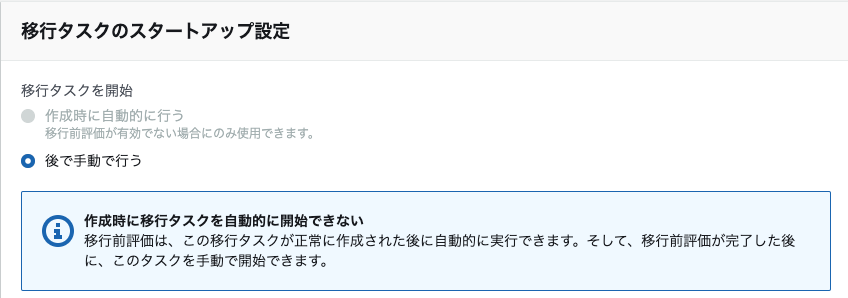
移行前評価を有効にすると移行タスクのスタートアップ設定で作成時に自動的に行うが選べないようになっています。評価を行ってから、問題ないか判断、および問題点を改善して、実行できるようになっていると思われます※ 移行前評価の画面
※
移行前評価を有効にすると移行タスクのスタートアップ設定で作成時に自動的に行うが選べない
以上で作成が完了です
ハピタスのあるDBで検証してみた結果
見事に警告が2つ表示されました。
評価のリンクをクリックすると json ファイルが配置された S3 バケットのパスに遷移します。
具体的にはこんな感じで問題のあるテーブルがわかります
$ jq < table-with-no-primary-key-or-unique-constraint.json { "test-name": "table-with-no-primary-key-or-unique-constraint", "test-result": "warning", "table-results-summary": { "failed": 0, "passed": 0, "warning": 3 }, "table-results": { "failed": [], "passed": [], "warning": [ { "schema-name": "pointback", "table-name": "status", "table-result": "warning", "message": "Table has no primary key or unique constraint", "column-data": [] }, { "schema-name": "pointback", "table-name": "result", "table-result": "warning", "message": "Table has no primary key or unique constraint", "column-data": [] }, { "schema-name": "pointback", "table-name": "special", "table-result": "warning", "message": "Table has no primary key or unique constraint", "column-data": [] } ] } } $ jq < target-table-has-unique-key-or-primary-key-for-cdc.json { "test-name": "target-table-has-unique-key-or-primary-key-for-cdc", "test-result": "warning", "table-results-summary": { "warning": 3, "passed": 0, "failed": 0 }, "table-results": { "warning": [ { "schema-name": "pointback", "table-name": "status", "table-result": "warning", "message": "Table is missing a primary key or unique constraint", "column-data": [] }, { "schema-name": "pointback", "table-name": "result", "table-result": "warning", "message": "Table is missing a primary key or unique constraint", "column-data": [] }, { "schema-name": "pointback", "table-name": "special", "table-result": "warning", "message": "Table is missing a primary key or unique constraint", "column-data": [] } ], "passed": [], "failed": [] } }上記について対応するべく、target の テーブルに対して、AUTOINCREMENT の プライマリーキーを設定しました
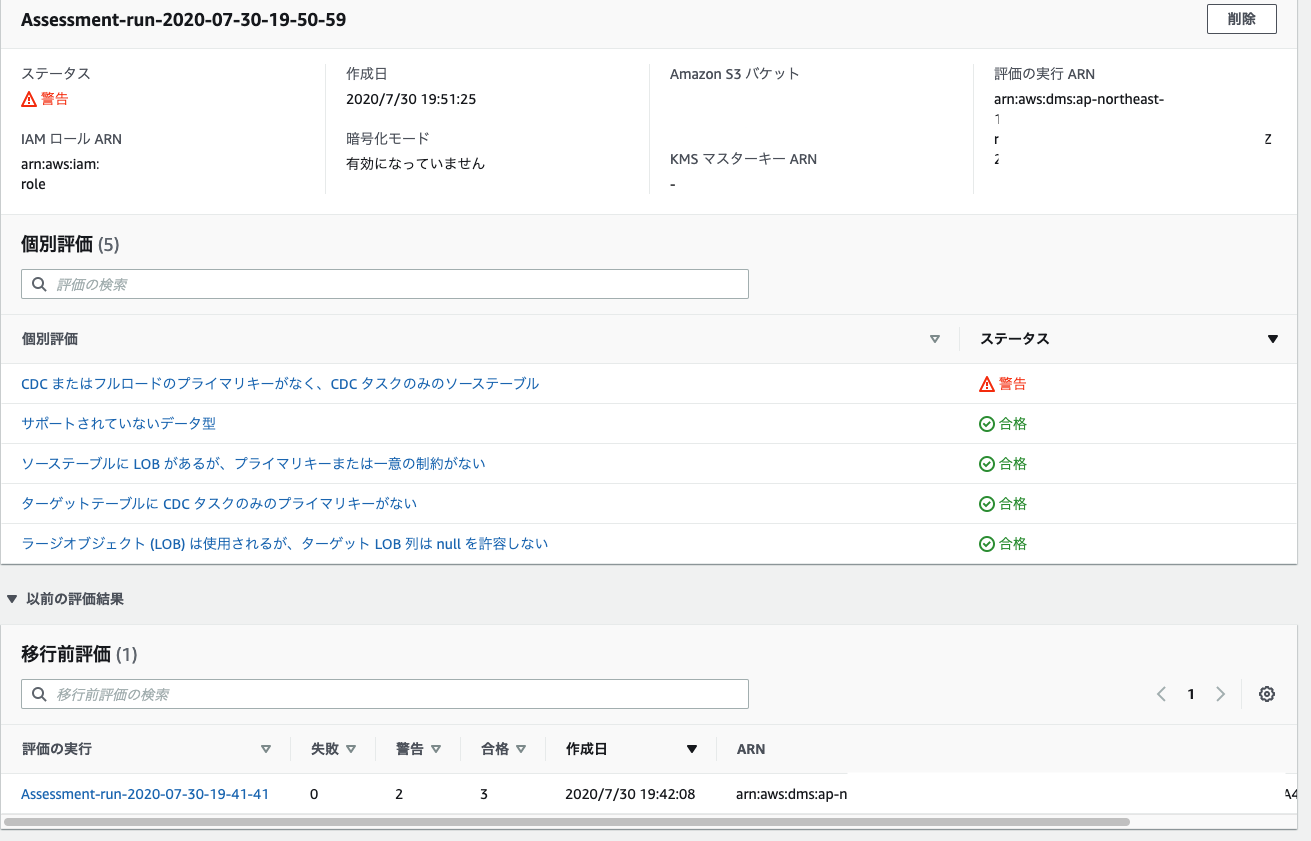
その上で再度、移行前評価を作成すると以下のような結果となりました
CDC またはフルロードのプライマリキーがなく、CDC タスクのみのソーステーブルのみがまだ警告がでています。
ここは対応しなくて問題ないと判断しました。
なぜなら移行元のテーブルのデータは約1万レコードしかないからです。その程度のレコード数では負荷にならないと判断し、DMS を実行しました。結果的には数分で移行は完了し、負荷の上昇はほぼ発生しませんでした。
使ってみた感想
オンプレから AWS の移行でも、 AWS 内のサービス移行でもこういった評価が自動でされることは個別に一つ一つチェックすることで発生する見落としを防ぐのに効果的だと思いました。
もちろん自分でチェックした場合でも、評価が自動でされる場合にも、問題点が見つかった場合にどう対処するかは各々の環境で考えなくてはいけませんが、そこだけに集中できるのはとても有用です。

- 投稿日:2020-07-30T22:22:49+09:00
AWS マーケットプレイスにおける Veritas NetBackup のデプロイメント 前編
はじめに
Veritas NetBackup はエンタープライズクラスのデータ保護を実現するための大変パワフルなツールです。本稿では データ保護の基本となるバックアップサーバーをマーケットプレイスから超簡単に構築する方法を紹介します。
データ保護が必要な理由
まずはこちらの動画をご覧ください!
AWSではそのサービスに対して”責任共有モデル”という概念が適用されています。
https://aws.amazon.com/jp/compliance/shared-responsibility-model/
こちらのURLにあるようにお客様のデータ、データの整合性、設定内容、暗号化、トラフィックの保護については全てお客様で責任を持つように定義されています。AWSが担保するのはAWSのインフラストラクチャであってそのデータではありません。したがって、これらのデータは自己の責任において保護、担保する必要があります。これからVeritas NetBackupを使ってそのデータを保護するための仕組みについてご紹介します。
デプロイの準備
ログインします。
ページ中央部にマーケットプレイスへのリンクが表示さています。
移動して NetBackup を検索しましょう。
マーケットプレイスの NetBackup が表示されます。ここでは一般向けを選びましょう。
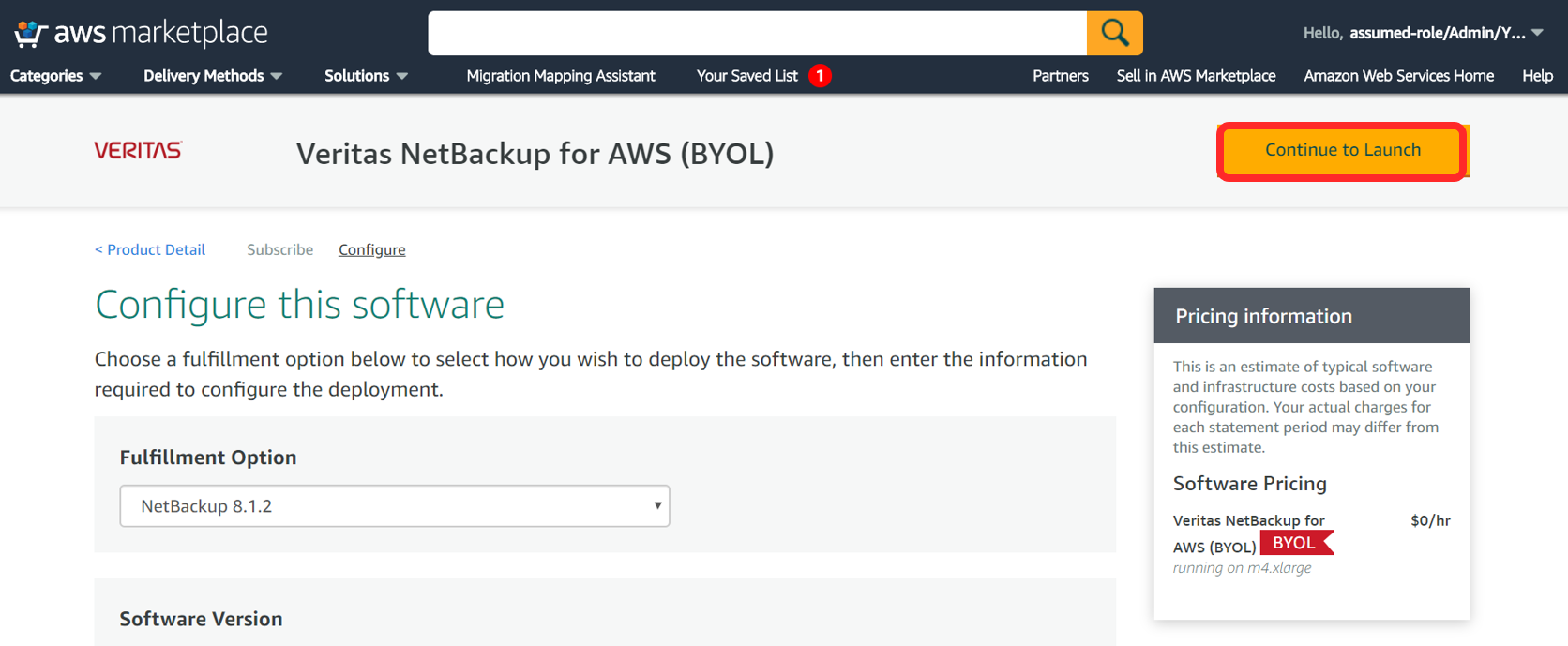
選択して[Continue to Subscribe]します。
[Continue to Configuration]でここから構成開始です!
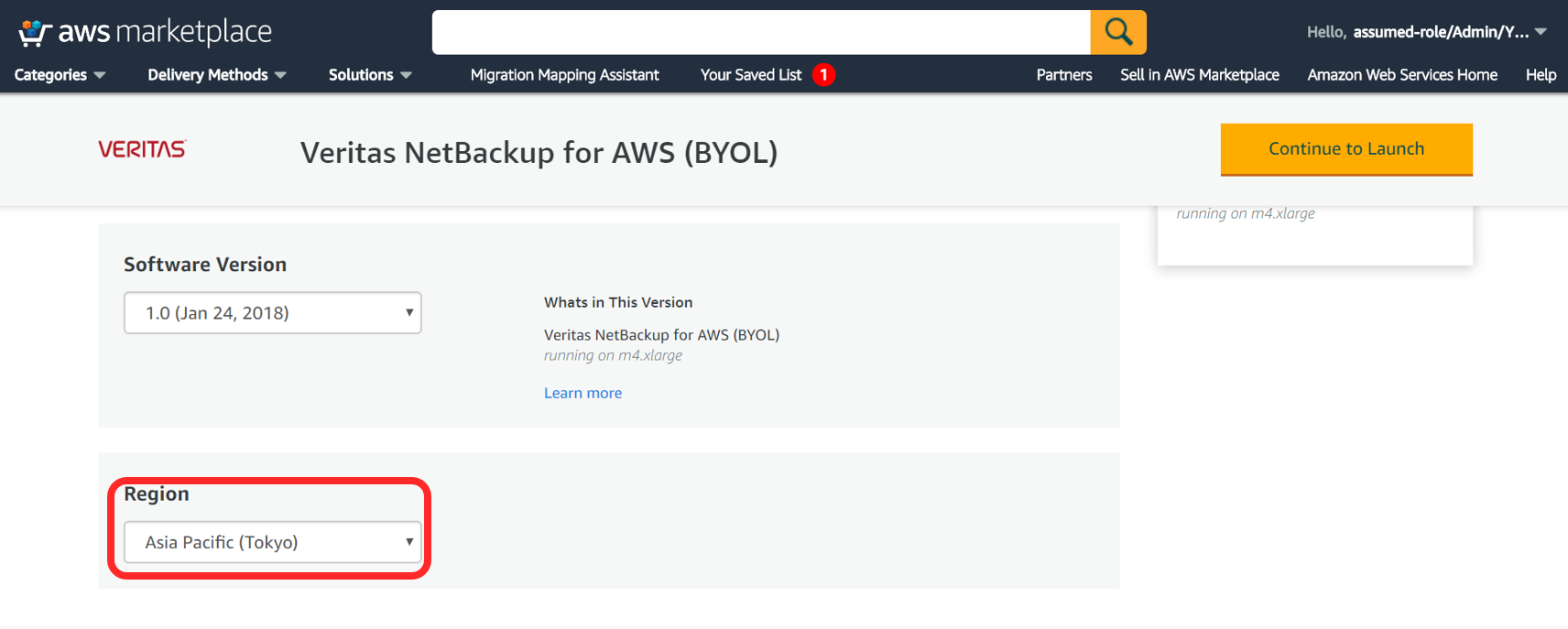
構成するバージョンを選びます。今回はちょっと古いですが 8.1.2 を選びます。
テンプレートのバージョンとデプロイするリージョンを選択します。
選択したら Cloud Formation をロンチします。
ここでロンチを選択すればCF(Cloud Formation) のスタックの作成開始です!
おわりに
ここまでがCFを起動する前の準備です。簡単でしたね!次回の中編では具体的なリソースの準備やパラメーターについて解説します。リソースがいるなら先に言って欲しいですね。。
商談のご相談はこちら
本稿からのお問合せをご記入の際には「お問合せ内容」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願い致します!







- 投稿日:2020-07-30T22:22:49+09:00
AWS マーケットプレイスによる Veritas NetBackup のデプロイメント 前編
はじめに
Veritas NetBackup はエンタープライズクラスのデータ保護を実現するための大変パワフルなツールです。本稿では データ保護の基本となるバックアップサーバーをマーケットプレイスから超簡単に構築する方法を紹介します。
データ保護が必要な理由
まずはこちらの動画をご覧ください!
AWSではそのサービスに対して”責任共有モデル”という概念が適用されています。
https://aws.amazon.com/jp/compliance/shared-responsibility-model/
こちらのURLにあるようにお客様のデータ、データの整合性、設定内容、暗号化、トラフィックの保護については全てお客様で責任を持つように定義されています。AWSが担保するのはAWSのインフラストラクチャであってそのデータではありません。したがって、これらのデータは自己の責任において保護、担保する必要があります。これからVeritas NetBackupを使ってそのデータを保護するための仕組みについてご紹介します。
デプロイの準備
ログインします。
ページ中央部にマーケットプレイスへのリンクが表示さています。
移動して NetBackup を検索しましょう。
マーケットプレイスの NetBackup が表示されます。ここでは一般向けを選びましょう。
選択して[Continue to Subscribe]します。
[Continue to Configuration]でここから構成開始です!
構成するバージョンを選びます。今回はちょっと古いですが 8.1.2 を選びます。
テンプレートのバージョンとデプロイするリージョンを選択します。
選択したら Cloud Formation をロンチします。
ここでロンチを選択すればCF(Cloud Formation) のスタックの作成開始です!
おわりに
ここまでがCFを起動する前の準備です。簡単でしたね!次回の中編では具体的なリソースの準備やパラメーターについて解説します。リソースがいるなら先に言って欲しいですね。。
商談のご相談はこちら
本稿からのお問合せをご記入の際には「お問合せ内容」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願い致します!
- 投稿日:2020-07-30T19:18:38+09:00
5年たったらAWS CLIの薄いラッパーコマンドが出来ていた
AWSを使い始めた頃からAWS CLIのコマンドを打つのが面倒になると作成していたスクリプトがある。自分のMacでしか動かすつもりがなかったが、Macを交換するタイミングでGitHubに上げた。
今どき使わない機能もあるが1年に1,2つくらい追加してきた感じ。出来はよくないが面倒だと思った時に追加してきたので面倒がなくなった。面倒なときにしか追加されないのでほとんどのawsコマンドが網羅されていない。同じようなコマンドが同じ名前で存在したのでネーミングセンスがないっぽい。
左手で完結したかっただけなんだ・・・
https://github.com/ryo0301/saw特徴
- awsコマンドと同じような使い方
- bashで書かれている
- コピペ駆動開発なので作り方を思い出す必要がない
- エラー処理が雑で
Ctrl-Cで止まらないことがある- 自分のことしか考えていないので他人のPCで動かない可能性がある
.docにヘルプが書けるが自作なので見ない- コンプリーターがある(bashのみ)
- aws-cli, jq, pecoに極度の依存。コマンドによってはnode.jsとssh-keygenに依存。
コマンド
この中からいくつか紹介。
ディレクトリとファイルがそのままサービスとコマンドになっている。$ saw Usage: saw <service> <command> dynamodb └── count-table ec2 ├── list-instances └── login-instance iam └── assume-role kinesis ├── list-shards ├── list-streams ├── merge-shards └── split-shard lambda ├── exec-local ├── invoke-function └── update-function s3 ├── get-object-by-version-id └── list-object-versions ssm ├── start-session └── start-ssh-session waf └── list-ip-setss3
get-object-by-version-id
指定したS3オブジェクトのバージョンを
pecoでリストして、選択したバージョンをダウンロードする。
ec2
list-instances
EC2インスタンスのリストを
pecoでリストする。
単体では使わない。他のコマンド内部でよく使う。
kinesis
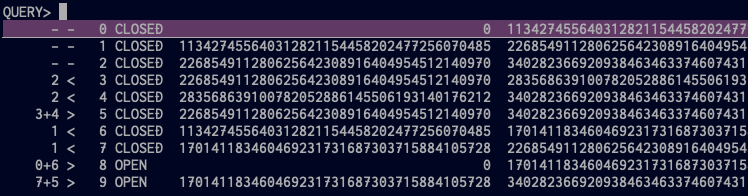
list-shards
Kinesis Streamのシャードを
pecoでリストする。
2 < 3や2 < 4はシャード 2 から 3 と 4 にsplitしたということ。
お察しの通り3+4 > 5はシャード 3 と 4 を 5 としてmergeしたということ。
CLOSEDなシャードは読み込み限定になり、しばらくして削除されたと思う。
うろ覚え・・・
split-shard
pecoで選択したシャードをsplitする。
merge-shards
pecoで選択した2つのシャードをmergeする。
隣接したシャードしかmergeできないのはKinesisの仕様通り。
Ctrl+spaceで複数選択できる(pecoの機能)。
ssm
start-ssh-session
一時キーペアを作成しEC2 Instance Connectで公開鍵を転送した後、Session Manager経由でEC2インスタンスにSSH接続する。キーペアは切断時に破棄される。
--forwardパラメータでポートフォワーディングが出来る。
--forward remoteでリモートポートフォワーディング。
--forward localでローカルポートフォワーディング。
今のところ接続先を経由してRDSに接続したりは出来ない。localhost固定になっているところを動的にすればすぐできるかも。
lambda
exec-local
AWS SAMがなかった頃にローカルでLambdaの開発がしたくて作ったコマンド。
Lambdaの設定をAWSから取得してくるので、コードなしでもファンクションが存在しないと動作しない。設定が取得できたら割り当てられたIAMロールをAssumeRoleして実際のファンクションの権限でコードを実行する。
iam
assume-role
AWS CLIにAssumeRoleしてくれる機能が実装されてなかった頃に作ったコマンド。
↓こちらの記事で書いたやつだったと思う。
MacからAWSにアクセスする時はAssumeRoleすることにしたその他のコマンド
dynamodb count-table
セグメントごとにレコードをカウントして加算しているようだが並列処理になってない気がする。なんのために作ったのか思い出せない。ec2 login-instance
インスタンスをpecoでリストして、選択したインスタンスに指定したキーペアでログインする。もう使う機会がなくなった。ssm start-session
Session Manager単体でEC2インスタンスにアクセスする。最近はstart-ssh-sessionしか使ってない。などなど。





- 投稿日:2020-07-30T18:10:35+09:00
【今日始めたAWS】S3に静的ウェブサイトをホストする
はじめに
30代未経験からエンジニア転職をめざすコーディング初学者のYNと申します。お読みいただきありがとうございます。
20年に入ってコーディングの勉強を始め、この記事を書く2時間ぐらい前にAWSアカウントを作成しました。何から勉強すべきか全くわかりませんので、とりあえず目についたチュートリアルを進めて行きます。今回やったこと
チュートリアルに従い、とりあえず静的なウェブサイトをS3にデプロイしました。
「20分で終わる」と書かれていましたが、しっかり2時間かかりました。
また、今回はCloud9でなく、自前のPC(mac)上で開発を進めていきます。
手順
- ローカルPCにレポジトリをクローン
- aws-cliをインストール
- aws-cliの設定
- S3にバケットを作成
- 静的ウェブページのデプロイ
ローカルPCにレポジトリをクローン
チュートリアルでは
Cloud9を使っていますが、今回はローカルPCにレポジトリをクローンしています。
まずは適当なフォルダを作り、そこへ移動してクローンします。$ cd ~ $ mkdir aws-tutorial $ cd aws-tutorial $ git clone -b python https://github.com/aws-samples/aws-modern-application-workshop.gitaws-cliをインストール
チュートリアルでは、
aws-cliを使うところから始まるのですが、(今回は自前のPCを使うので)そもそもインストールから始めなければなりません。今回はhomebrewを使ってインストールします。$ brew install awscliこちらの記事を参考にさせていただきました。
aws-cliの設定
当然ながら、
aws-cliをインストールしただけでは動かすことはできません。設定が必要です。
公式ドキュメントを見つつ設定していきます。
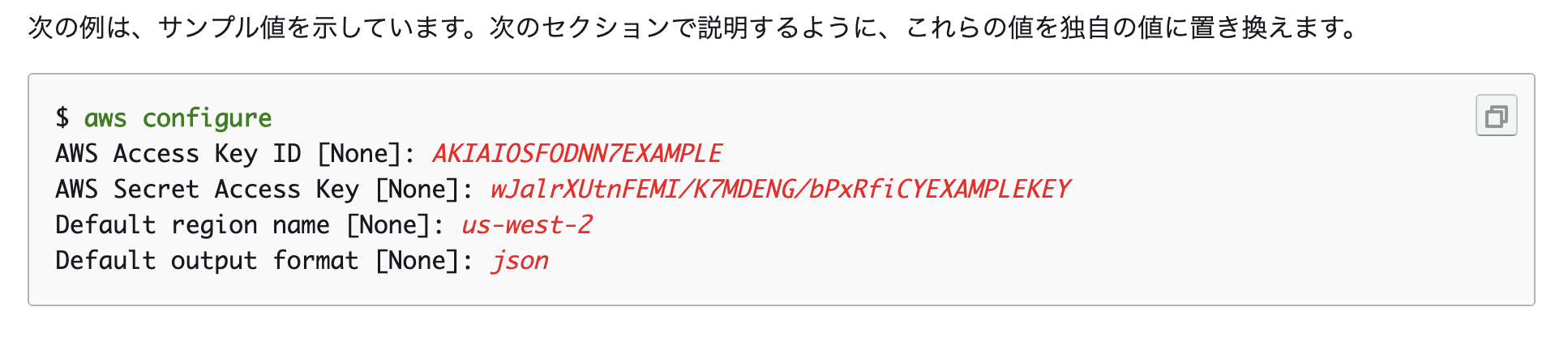
今回はaws configure を使用したクイック設定をします。
下記4つの設定が必要です。
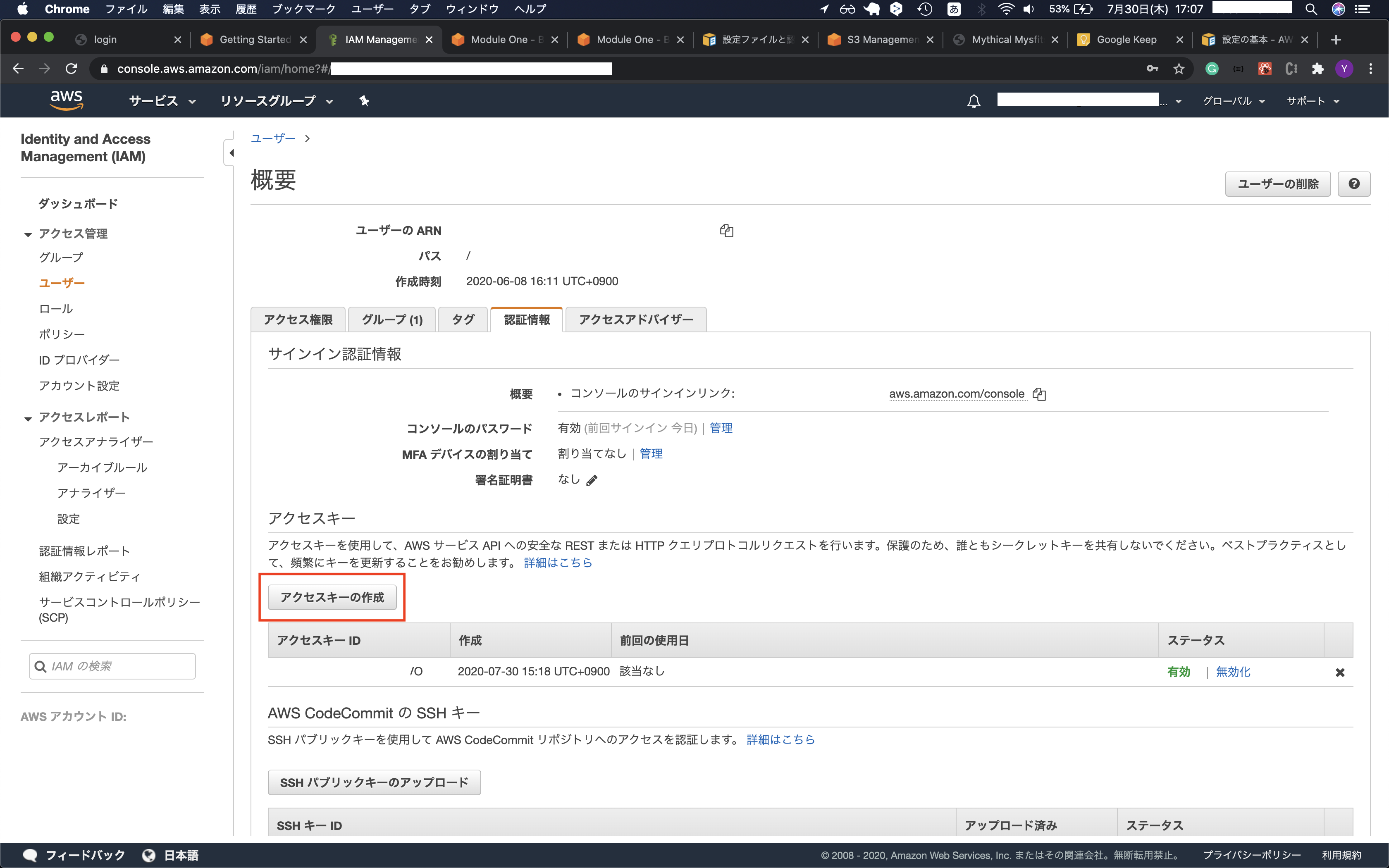
アカウントキー
AWSのサービスを切り替えてIAMへ移り、設定を確認します。下図のアクセスキーを作成ボタンを押すと見れます。
シークレットアクセスキー
上記アカウントキーと一緒に見れます。デフォルトリージョン
AWSのリージョンを設定します。
自分はオハイオを選んだのでus-east-2を入力しました。デフォルトフォーマット
とくに気にしない場合はjsonでOKです。S3にバケットを作成
ここまで終わってようやくチュートリアルのstep3に進むことができます。
しかし、私は最初の
でつまづいてしまいました。InvalidSignatureException: The request signature we calculated does not match the signature you provided.まず、上記エラーはアカウントキーを再設定することで対処しました。
対処に際してはこちらの記事を参考にさせていただきました。An error occurred (InvalidBucketName) when calling the CreateBucket operation: The specified bucket is not valid.次に、S3バケットの命名規則に準じている(と思っていた)にもかかわらず、上記エラーが出てしましました。
対処に際しては、こちらの記事を参考にさせていただきつつ、大文字や小文字などといろいろいじったら解決しました。静的ウェブページのデプロイ
次に、ウェブサイトの初期表示ページを設定します。
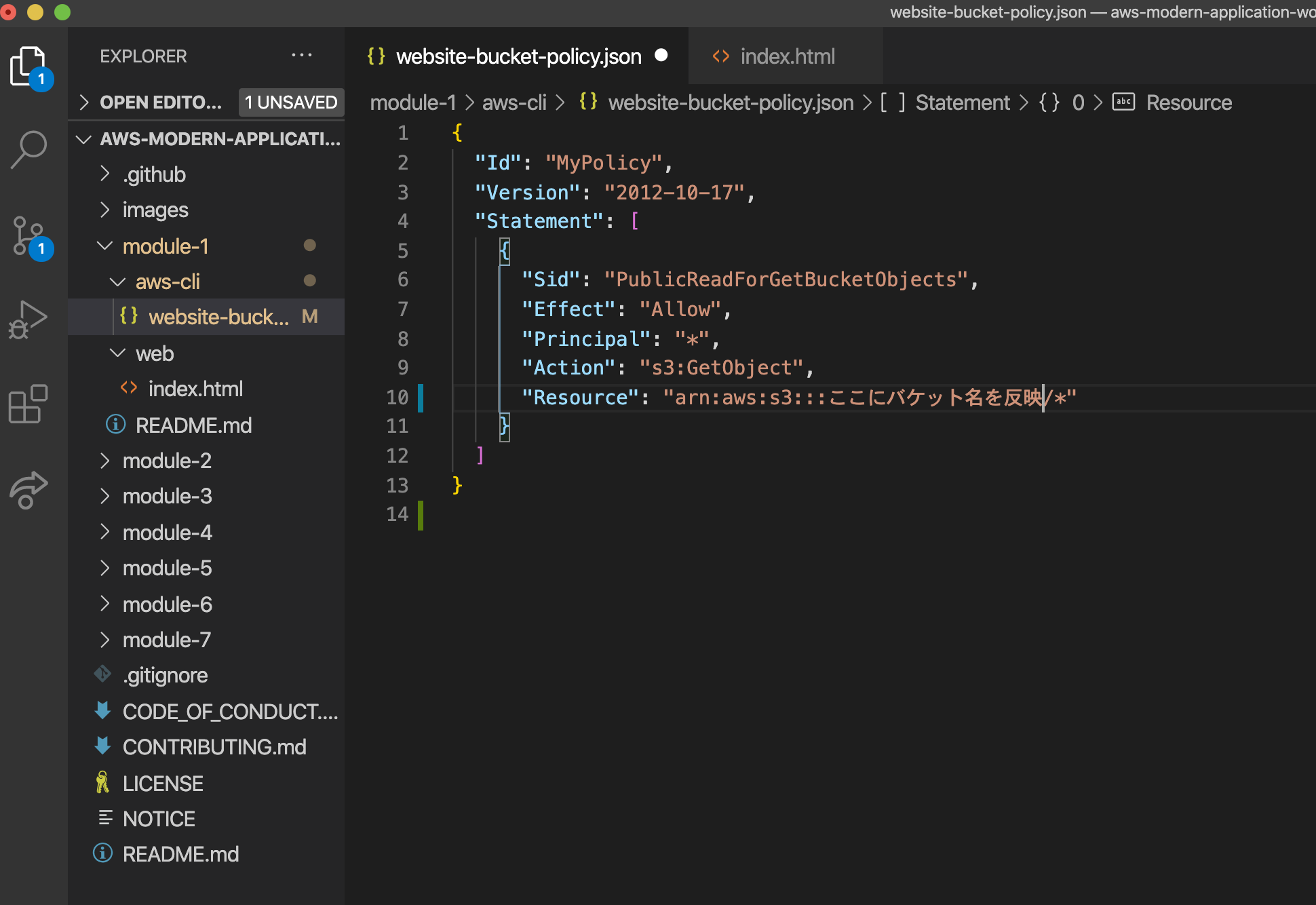
そして、バケットポリシーにバケット名を反映します。
その後、ウェブサイトにバケットポリシーを適用します。
ローカルPCで作業する場合、Cloud9とファイルパスが異なるので少し書き換える必要があります。今、~/aws-tutorialにいるとすると、aws s3api put-bucket-policy --bucket REPLACE_ME_BUCKET_NAME --policy file://~/aws-tutorial/aws-modern-application-workshop/module-1/aws-cli/website-bucket-policy.jsonと書き換えます。
最後に、ウェブサイトをデプロイして完了です。ローカルPCを使う場合、上記同様に書き換える必要があります。
ここまで終わって、初めてウェブページをブラウザで開くことができます。
urlは、選んだAWSリージョンごとに(微妙に)異なるので注意が必要です。
最後に
本当にただ簡単なチュートリアルとこなしただけなのですが、(初心者なこともあり)予想以上に手間取ってしまいました。
何か間違い等あればご指摘いただければ幸いです。
お読みいただきありがとうございました。





- 投稿日:2020-07-30T18:10:35+09:00
【今日から始めるAWS】S3に静的ウェブサイトをホストする
はじめに
30代未経験からエンジニア転職をめざすコーディング初学者のYNと申します。お読みいただきありがとうございます。
20年に入ってコーディングの勉強を始め、この記事を書く2時間ぐらい前にAWSアカウントを作成しました。何から勉強すべきか全くわかりませんので、とりあえず目についたチュートリアルを進めて行きます。今回やったこと
チュートリアルに従い、とりあえず静的なウェブサイトをS3にデプロイしました。
「20分で終わる」と書かれていましたが、しっかり2時間かかりました。
また、今回はCloud9でなく、自前のPC(mac)上で開発を進めていきます。
手順
- ローカルPCにレポジトリをクローン
- aws-cliをインストール
- aws-cliの設定
- S3にバケットを作成
- 静的ウェブページのデプロイ
ローカルPCにレポジトリをクローン
チュートリアルでは
Cloud9を使っていますが、今回はローカルPCにレポジトリをクローンしています。
まずは適当なフォルダを作り、そこへ移動してクローンします。$ cd ~ $ mkdir aws-tutorial $ cd aws-tutorial $ git clone -b python https://github.com/aws-samples/aws-modern-application-workshop.gitaws-cliをインストール
チュートリアルでは、
aws-cliを使うところから始まるのですが、(今回は自前のPCを使うので)そもそもインストールから始めなければなりません。今回はhomebrewを使ってインストールします。$ brew install awscliこちらの記事を参考にさせていただきました。
aws-cliの設定
当然ながら、
aws-cliをインストールしただけでは動かすことはできません。設定が必要です。
公式ドキュメントを見つつ設定していきます。
今回はaws configure を使用したクイック設定をします。
下記4つの設定が必要です。
アクセスキー
AWSのサービスを切り替えてIAMへ移り、設定を確認します。下図のアクセスキーを作成ボタンを押すと見れます。
シークレットアクセスキー
上記アカウントキーと一緒に見れます。デフォルトリージョン
AWSのリージョンを設定します。
自分はオハイオを選んだのでus-east-2を入力しました。デフォルトフォーマット
とくに気にしない場合はjsonでOKです。S3にバケットを作成
ここまで終わってようやくチュートリアルのstep3に進むことができます。
しかし、私は最初の
でつまづいてしまいました。InvalidSignatureException: The request signature we calculated does not match the signature you provided.まず、上記エラーはアカウントキーを再設定することで対処しました。
対処に際してはこちらの記事を参考にさせていただきました。An error occurred (InvalidBucketName) when calling the CreateBucket operation: The specified bucket is not valid.次に、S3バケットの命名規則に準じている(と思っていた)にもかかわらず、上記エラーが出てしましました。
対処に際しては、こちらの記事を参考にさせていただきつつ、大文字や小文字などといろいろいじったら解決しました。静的ウェブページのデプロイ
次に、ウェブサイトの初期表示ページを設定します。
そして、バケットポリシーにバケット名を反映します。
その後、ウェブサイトにバケットポリシーを適用します。
ローカルPCで作業する場合、Cloud9とファイルパスが異なるので少し書き換える必要があります。今、~/aws-tutorialにいるとすると、aws s3api put-bucket-policy --bucket REPLACE_ME_BUCKET_NAME --policy file://~/aws-tutorial/aws-modern-application-workshop/module-1/aws-cli/website-bucket-policy.jsonと書き換えます。
最後に、ウェブサイトをデプロイして完了です。ローカルPCを使う場合、上記同様に書き換える必要があります。
ここまで終わって、初めてウェブページをブラウザで開くことができます。
urlは、選んだAWSリージョンごとに(微妙に)異なるので注意が必要です。
最後に
本当にただ簡単なチュートリアルとこなしただけなのですが、(初心者なこともあり)予想以上に手間取ってしまいました。
何か間違い等あればご指摘いただければ幸いです。
お読みいただきありがとうございました。
- 投稿日:2020-07-30T18:05:21+09:00
awscliでs3バケットの中身を全部ダウンロードする
recursiveで再帰的aws s3 cp s3://aws-bucket . --recursive
- 投稿日:2020-07-30T15:42:47+09:00
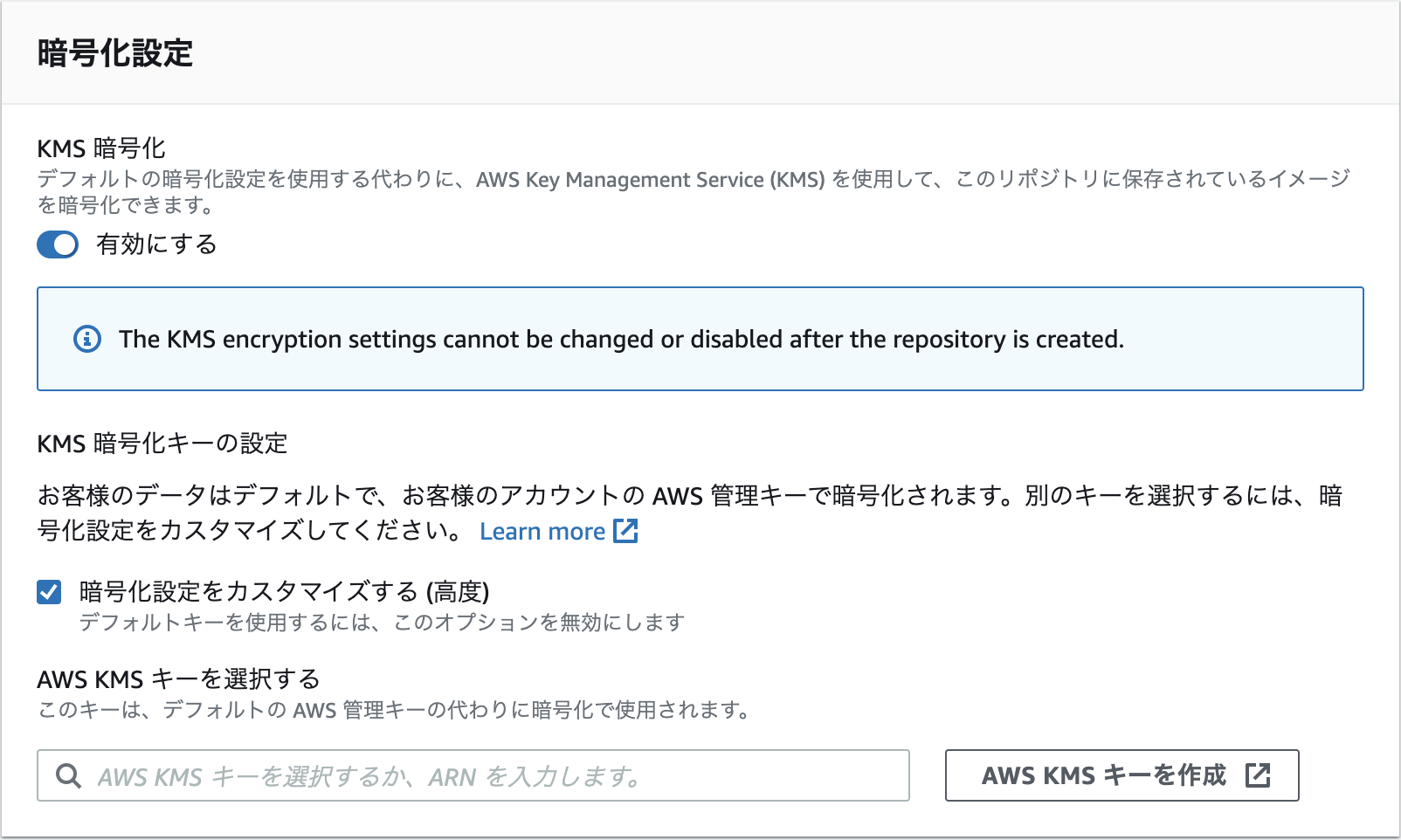
ECRでKMSがサポートされるようになった
アナウンス
仕様
ドキュメント
https://docs.aws.amazon.com/AmazonECR/latest/userguide/encryption-at-rest.html
時間があるときに試してみる。
リポジトリ作成後は有効化出来ないようなので、作成時に有効化する必要がある模様。
- 投稿日:2020-07-30T15:22:09+09:00
AWS EC2にNginxをインストールする
はじめに
環境
- EC2インスタンス作成済み
- Amazon Linux 2 AMI (HVM), SSD Volume Type
- 64 ビット (x86)
- タイプ:t2.micro
やったこと
EC2サーバーでの操作
接続
$ ssh -i xxxx.pem ec2-user@パブリックIP(またはDNS)amazon-linux-extrasの確認
amazon-linux-extrasを使ってインストールできるパッケージの確認をします。
$ which amazon-linux-extras $ amazon-linux-extras 0 ansible2 available [ =2.4.2 =2.4.6 =2.8 =stable ] 2 httpd_modules available [ =1.0 =stable ] 3 memcached1.5 available [ =1.5.1 =1.5.16 =1.5.17 ] 5 postgresql9.6 available [ =9.6.6 =9.6.8 =stable ] 6 postgresql10 available [ =10 =stable ] 8 redis4.0 available [ =4.0.5 =4.0.10 =stable ] ...略 38 nginx1 available [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ] 41 postgresql11 available [ =11 =stable ] ... 略参考:
amazon-linux-extrasについて
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-install-extras-library-software/Nginxのインストール
$ sudo amazon-linux-extras install nginx1 $ nginx -v nginx version: nginx/1.18.0初期設定ファイルのバックアップ
$ sudo cp -a /etc/nginx/nginx.conf /etc/nginx/nginx.conf.back起動設定
Nginx起動
$ sudo systemctl start nginxインスタンス起動時にNginxも自動で起動させる
$ sudo systemctl enable nginx Created symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service.設定確認
$ systemctl status nginx ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; enabled; vendor preset: disabled) Drop-In: /usr/lib/systemd/system/nginx.service.d └─php-fpm.conf Active: active (running) since 木 2020-07-30 14:34:02 JST; 1min 20s agoブラウザで確認
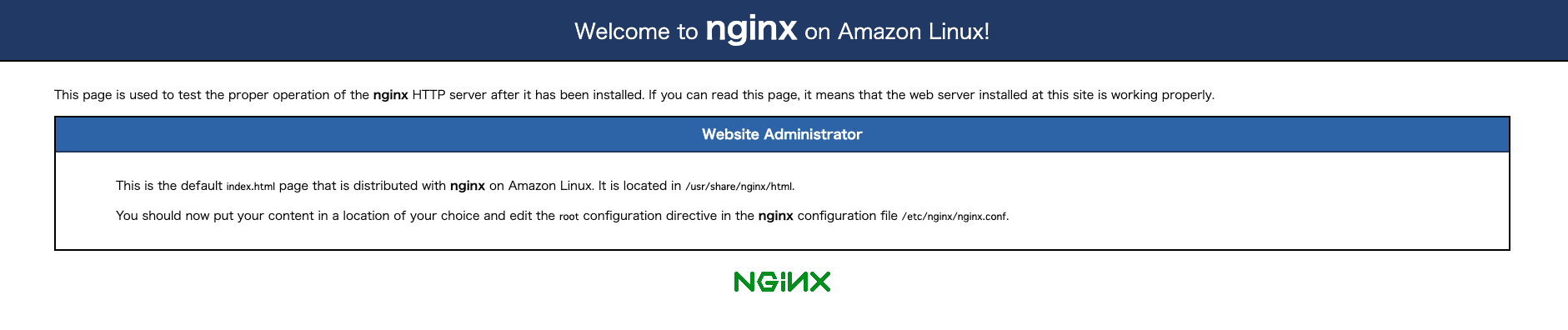
EC2接続時に使用したパブリックIP(またはDNS)をアドレスバーに入力して接続します。
「正しくインストールできています」のページが表示されました
- 投稿日:2020-07-30T12:59:58+09:00
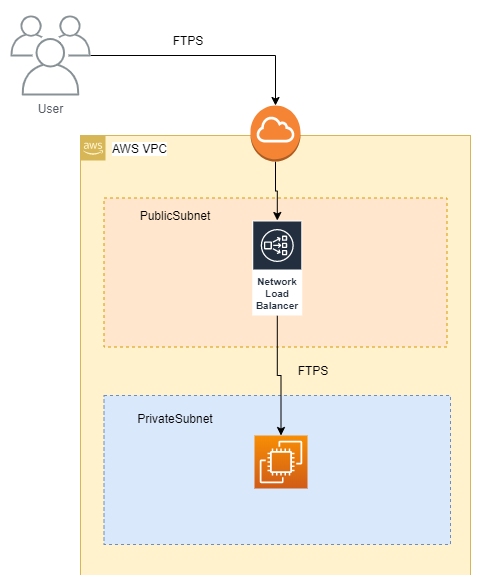
[AWS] NLB経由でFTP接続する際の注意点
内容
- AWSにおいて、ロードバランサー配下のEC2でFTPサーバを稼働させて外部からFTP接続する際の注意点
- FTPはパッシブモード、暗号化方式はexplicit(明示的)モードを使用する
- FTPサーバは、vsftpdを使用する
構成
こうしたかった理由
- EC2はウェブサーバとして使用していて、ACMを使用してサーバ証明書を安価に使用したかった(ACMはEC2には使えない)
- NLBをかますことで、EC2に外部IPアドレスを付与させないようにしたかった
NLBの設定
リスナーの追加
制御ポート:21(TCP)
データ転送用ポート:60001(TCP)
データ転送用ポート:60002(TCP)
データ転送用ポート:60003(TCP)ターゲットグループの追加
1.で設定したリスナーに対して、バックエンドのEC2に繋ぐようにそれぞれターゲットグループを作成するセキュリティグループの設定
セキュリティグループを追加して、EC2インスタンスに設定する。
タイプ プロトコル ポート範囲 ソース カスタムTCP TCP 21 外部から接続してくるユーザのグローバルIPアドレス カスタムTCP TCP 60001-60002 外部から接続してくるユーザのグローバルIPアドレス EC2の設定
- vsftpdをインストールする
sudo yum install vsftpd sudo systemctl enable vsftpd.service sudo systemctl start vsftpd.service
- vsftpdの設定をする
sudo vim /etc/vsftpd/vsftpd.conflisten=YES listen_ipv6=NO ssl_enable=YES rsa_cert_file=/etc/pki/tls/certs/vsftpd.pem ssl_sslv2=NO ssl_sslv3=NO ssl_tlsv1=YES force_local_data_ssl=YES force_local_logins_ssl=YES pasv_enable=YES pasv_min_port=60001 pasv_max_port=60003 pasv_addr_resolve=YES pasv_address=<NLB DNSホスト名 or NLBのAレコードを設定したホスト名> tcp_wrappers=NO
- vsftpdの起動スクリプトを修正する(注意点)
このままでも動作するが、EC2を再起動した際にvsftpdが自動起動に失敗する事象が発生した。
● vsftpd.service - Vsftpd ftp daemon Loaded: loaded (/usr/lib/systemd/system/vsftpd.service; enabled; vendor preset: disabled) Active: failed (Result: exit-code) since Thu 2020-07-30 03:50:54 UTC; 58s ago Process: 787 ExecStart=/usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf (code=exited, status=2) Jul 30 03:50:54 ip-10-221-233-5.ap-northeast-1.compute.internal systemd[1]: Starting Vsftpd ftp daemon... Jul 30 03:50:54 ip-10-221-233-5.ap-northeast-1.compute.internal vsftpd[787]: 500 OOPS: cannot resolve host:corpweb.common.hk-test.net Jul 30 03:50:54 ip-10-221-233-5.ap-northeast-1.compute.internal systemd[1]: vsftpd.service: Control process exited, code=exited status=2 Jul 30 03:50:54 ip-10-221-233-5.ap-northeast-1.compute.internal systemd[1]: vsftpd.service: Failed with result 'exit-code'. Jul 30 03:50:54 ip-10-221-233-5.ap-northeast-1.compute.internal systemd[1]: Failed to start Vsftpd ftp daemon.pasv_address に登録したホスト名の名前解決ができていないのが原因らしい。
サービスの起動順序では、networkサービスの起動後にvsftpdが起動するように設定されているが、それでも名前解決に失敗する。
何かしらのサービスの起動順序に依存しているのだろうと思うが、そのサービスを特定できなかった。
しかたないので、vsftpdの起動スクリプトで一定時間待機(私は30秒にした)させることで、名前解決できるようにした。
もっといい解決策をご存知の方がいれば教えて下さい。sudo vim /etc/systemd/system/multi-user.target.wants/vsftpd.service# ExecStart=/usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf ExecStart=/usr/bin/bash -c "sleep 30; /usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf"以上。
- 投稿日:2020-07-30T12:20:17+09:00
AWS Lambda with EFS で MeCab, NEologd & CaboCha を動かす (2020年7月時点)
はじめに
過去に以下のような記事を書きました。
AWS Lambda で MeCab を動かす (2018年9月時点)この記事で最後に
「Neologdも入れたかったけれども、Lambdaのtemp領域の制限でアウト。
(中略)
そうこう言っている間にLambdaのtemp領域の制限が一気に3GBくらいになってくれないかな。と書いて終わりました。それから約2年。Lambda の temp 領域制限は変わりませんが、代わりに(?)Lambda から EFS にアクセスできるようになりました。これでようやく念願の NEologd を手軽に Lambda 上で動かせるようになりましたので、その方法をまとめます。
まぁ、ホントに EFS に MeCab と NEologd を突っ込むだけなので特別なことはしていません。
NEologdとは
正式には
mecab-ipadic-NEologdという名称で、多数のWeb上の言語資源から得た新語を追加することでカスタマイズした MeCab 用のシステム辞書です。
(詳しい説明は GitHub の README を参照ください。)Lambda で外部のライブラリを利用する場合、そのライブラリを Lambda 関数と一緒に Zip で固めてアップロードするか、もしくは Lambda Layer を利用する必要があります。そして、Lambda 関数、Lambda Layer ともに容量に制限があり、基本的にはサイズの大きいライブラリを使うことは難しい状況でした。特に NEologd は新語辞書なので 1GB 以上の容量があり、到底 Lambda で取り回せるサイズではありませんでした。
このサイズ制限の問題を EFS を利用することによって回避することがこの記事の目的です。
なお、EFS を Lambda から利用する場合、Lambda は VPC 内に置く必要があります。なんとなく VPC が絡む時点で、以前ほど気軽ではなくなってしまう気がしますが、EFS を使う以上避けられないのです。
MeCab&NEologd を動かす
EFS を作成する
パフォーマンスモードやネットワークアクセス、ファイルシステムポリシーなど真面目にやると設定する項目はたくさんありますが、とりあえず MeCab と NEologd を動かすことが目的なので全てデフォルト設定で作成します。VPC もデフォルトのものをそのまま使います。
EFS のアクセスポイントを作成する
Lambda からアクセスするためのアクセスポイントを作ります。
所有者ユーザーID:1001、所有者グループID:1001、アクセス許可:7777、パス:/lambdaで作成します。ここもとりあえず最低限動かすことだけを考えた設定です。ビルド用の EC2 を作成する
MeCab、NEologd をビルドするための EC2 を作成します。
基本的にここも特に特別な設定は不要でデフォルトのままで良いのですが、NEologd のビルドが結構メモリを食うのでインスタンスタイプはやや大きめを指定します。(私は t2.large を使いました。)先ほど作成した EFS をマウントするので VPC はやはりデフォルトのものを利用します。OS は Amazon Linux 2 を使います。Python3.8 のインストール
Amazon Linux 2 に最初から入っているのは、Python2.7 なので、まず Python3.8 をインストールします。インストール方法は以下の記事を参考にしてください。ここで Amazon Linux 2 のアップデートも行います。
EC2(Amazon Linux 2)にPython 3.8, Pip 3.8をインストールするEFS のマウント
先ほど作成した EFS をビルド用の EC2 にマウントします。EFS の IP はコンソールから確認できます。権限は一旦777で。
EFSのマウントsudo mount -t nfs \ -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 \ <EFSのIP アドレス>:/ /mnt sudo chmod 777 /mntMeCab & IPA辞書 インストール
まず、MeCab, IPA辞書 のインストールに必要なプログラムをインストールしておきます。
前準備sudo yum -y install gcc-c++ git patch次に MeCab 本体を Google ドライブからダウンロードしてインストールします。
--prefix=/mnt/lambdaでインストール先に先ほどマウントした EFS を指定します。
なお、URL は古くなる可能性があるので、最新のダウンロード先は作者のサイトを確認してください。MeCabのダウンロードとインストールcd ~ curl -L "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE" -o mecab-0.996.tar.gz tar -zxvf mecab-0.996.tar.gz cd mecab-0.996 sudo ./configure --prefix=/mnt/lambda --with-charset=utf8 sudo make sudo make installそして MeCab 標準で推奨されている IPA 辞書をダウンロードしてインストールします。先ほどと同様に
==prefix=/mnt/lambdaで EFS をインストール先に指定します。NEologd だけ使う場合でも、NEologd のインストール後のテストに利用されるのでインストール必須のようです。
なお、こちらの URL も古くなる可能性があるので、MeCab 本体と同様に確認してください。IPA辞書のダウンロードとインストールcd ~ curl -L "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM" -o mecab-ipadic-2.7.0-20070801.tar.gz tar -zxvf mecab-ipadic-2.7.0-20070801.tar.gz cd mecab-ipadic-2.7.0-20070801 sudo ./configure --prefix=/mnt/lambda --with-charset=utf8 --with-mecab-config=/mnt/lambda/bin/mecab-config sudo make sudo make install後続の NEologd インストール時に MeCab の実行が必要なのであらかじめパスを通しておきます。
パスの設定export PATH=$PATH:/mnt/lambda/binNEologd インストール
ここで本題の NEologd をインストールします。詳細なインストール方法については前述の GitHub を参照して頂きたいですが、ただ単にインストールするだけなら、下記の通りやることはいたって簡単です。
なお、インストール先は、オプション未指定の場合、先にインストールした MeCab のコンフィグファイルmecab-configに従って決まります。今回は未指定でも勝手に MeCab と同じパスにインストールされます。また、インストールオプションがあり、オプションによっては一部の辞書ファイルのインストールをスキップしてサイズを小さくできるようです。が、今回は細かいことは気にせず全部入りでインストールします。なにせインストール先は Elastic File System なので。NEologdのダウンロードとインストールcd ~ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git cd mecab-ipadic-neologd ./bin/install-mecab-ipadic-neologd -n -amecab-python3 インストール
最後に Python から MeCab を呼び出すためのライブラリを同じく
/mnt/lambda配下にインストールします。
(直接/mnt/lambdaにインストールしようとすると、Permission error になってしまうので、一旦ホームディレクトリにインストールしてから/mnt/lambdaにコピーしています。なんかもっとスマートな方法がある気がするのですが…。)mecab-python3のインストールpip3 install mecab-python3 -t ~/temp sudo cp -r ~/temp/* /mnt/lambdaこれで MeCab と NEologd の準備は完了です。
Lambda の作成
MeCab と NEologd がインストールされた EFS を利用する Lambda 関数を作成します。
Lambda の設定
- 環境変数
PYTHONPATHに/mnt/lambdaを指定- ランタイム
- Python3.8
- VPC
- EFS, EC2で利用したデフォルトのVPC
- デフォルトVPCに紐つく各AZのサブネット
- EC2作成時にウィザードから作られたセキュリティグループを指定
- ファイルシステム
- 上記で作成したファイルシステムとアクセスポイントを指定
- ローカルマウントパスには
/mnt/lambdaを指定- ロール
- ポリシー
AmazonElasticFileSystemClientReadWriteAccesを追加なお、MeCab の処理はそこそこ時間とメモリを食うのでデフォルトの値だと足りません。必要量は対象とするテキストの長さによるので動かして調整してみてください。
ソースコード
本当に必要最低限の処理だけ書いて、とりあえず NEologd を参照して分かち書きが出来ていることを確認します。トリガは API Gateway の想定です。
lambda_function.pyimport json import MeCab # IPA辞書を利用 ipadic_tagger = MeCab.Tagger('-O wakati -r /dev/null -d /mnt/lambda/lib/mecab/dic/ipadic') # NEologdを利用 neologd_tagger = MeCab.Tagger('-O wakati -r /dev/null -d /mnt/lambda/lib/mecab/dic/mecab-ipadic-neologd') def lambda_handler(event, context): print(event['body']) text = json.loads(event['body'])['text'] return { "statusCode": 200, "headers": { "Content-Type": "application/json", "Access-Control-Allow-Origin": "*" }, "body": json.dumps({ "ipadic": ipadic_tagger.parse(text), "neologd": neologd_tagger.parse(text) }) }結果確認
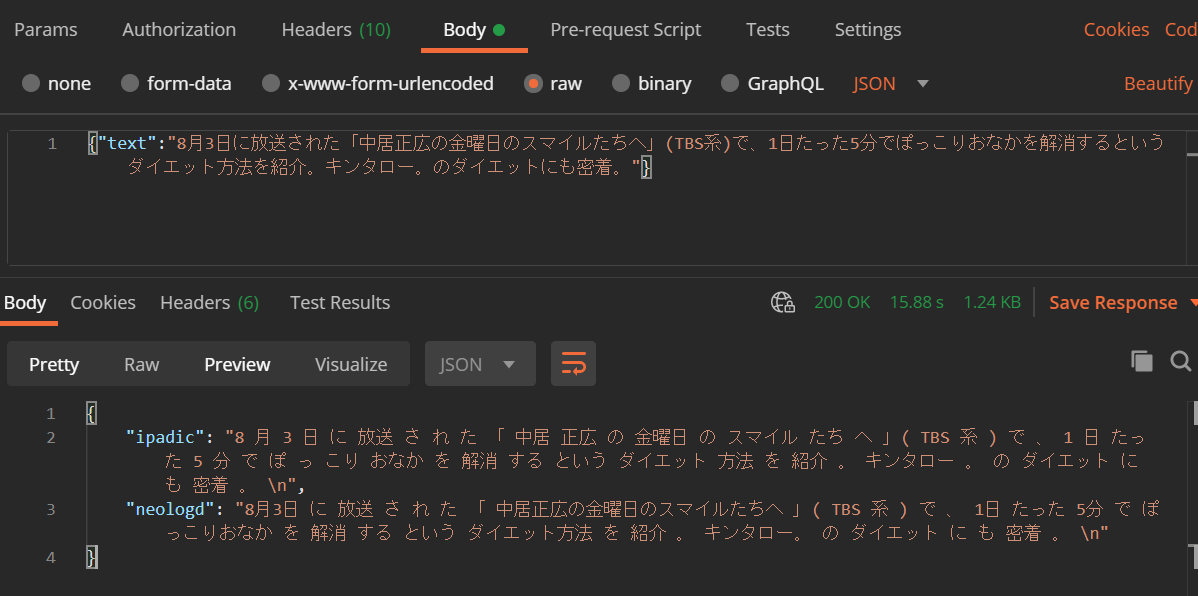
Lambda 関数に API Gateway (HTTP API) のトリガを設定し、Postman からテスト実行します。
分かち書きの対象としたテキストは MeCab 実行結果の例で使われている以下の一文です。8月3日に放送された「中居正広の金曜日のスマイルたちへ」(TBS系)で、1日たった5分でぽっこりおなかを解消するというダイエット方法を紹介。キンタロー。のダイエットにも密着。
文章がスペースで区切られ、分かち書きがされていることがわかります。IPA 辞書を使った場合と NEologd を使った場合とを比較すると、後者ではきちんと
中居正広の金曜日のスマイルたちへが一語と認識されていることがわかります。そのほかにも「ぽっこりおなか」「ダイエット方法」なども NEologd の方では一語になっています。ちなみに MeCab の出力形式は上記だけでなく、例えば品詞、活用形、読みなどをあわせて出力することもできます。詳細は公式サイトを参照してください。
ということで、無事に MeCab と NEologd を Lambda 上で動かすことができました。
Cabocha も動かす
さて、無事に MeCab と NEologd を使って分かち書きができるようになったのはイイのですが、問題はここから先これを使って何をするかです。
私の場合は、とあるアンケートの解答テキストが手元にたくさんあって、これをちょろっと分析してみようと思って、とりあえず分かち書きしてみたのですが、これだけだと結局何にもわかんないんですよね。せいぜいワードクラウドが作れるとかその程度で。なかでも困るのは「XXXは適切だと思うか?」という問いに対して、「YYYYなので適切だと思う」「ZZZのため適切ではない」という2つの解答があった場合、これを単純に分かち書きするとどちらも「適切」という言葉が抽出されてしまうということです。「適切でないとは言い切れない」「適切ではないかと考える」みたいなさらに複雑なパターンもあり、これらを単純な分かち書きで処理するのは難しそうです。
こうした問題に対処できるかも、と考えて今回一緒に導入しようとしたのが日本語係り受け解析器の CaboCha です。
CaboCha/南瓜: Yet Another Japanese Dependency Structure Analyzerこれを使うことにより、文章を形態素に分けた後に単語間の修飾関係を解析することができるそうです。単純に MeCab で分かち書きだけするより、一歩先に進んだ分析ができるような気がします。
ということで MeCab, NEologd と同様に CaboCha も EFS にインストールして Lambda から使えるようにします。
Cabocha のインストール
詳しいインストール方法は前述の公式サイトに載っていますので参照してください。ここでは簡単にインストールする方法を紹介します。
まず前提となる CRF++ のダウンロードとインストールを行います。
CRF++のダウンロードとインストールcd ~ wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" -O CRF++-0.58.tar.gz tar zxfv CRF++-0.58.tar.gz cd CRF++-0.58 ./configure --prefix=/mnt/lambda sudo make sudo make install次に CaboCha をダウンロードします。
(CaboCha のダウンロードだけやたらゴチャゴチャしてますが、色々試した結果これが一番スマートな方法でした。もっとスマートな方法があったら教えてください。)CaboChaのダウンロードcd ~ FILE_ID=0B4y35FiV1wh7SDd1Q1dUQkZQaUU FILE_NAME=cabocha-0.69.tar.bz2 curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=${FILE_ID}" > /dev/null CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=${FILE_ID}" -o ${FILE_NAME}CaboCha インストール時に
crfpp.hとmecab.hが/usr/include配下に必要になるので、これを/mnt/lambda/includeからコピーします。
(なお、詳細は後述しますが、この部分が Lambda 実行時に一工夫必要になってしまう要因なんじゃないかという気がします…。)ヘッダファイルのコピーsudo cp -r /mnt/lambda/include/* /usr/includeCaboCha 本体をインストールします。
CaboChaのインストールcd ~ tar jxvf cabocha-0.69.tar.bz2 cd cabocha-0.69 ./configure --prefix=/mnt/lambda --with-mecab-config=`which mecab-config` --with-charset=UTF8 sudo make sudo make install最後に CaboCha に同梱の Python バインディングをインストールします。mecab-python3 と同様にテンポラリのディレクトリにインストールしてから
/mnt/lambdaにコピーします。CaboChaのPythonバインディングのインストールpip3 install ~/cabocha-0.69/python/ -t ~/temp2 sudo cp -r ~/temp2/* /mnt/lambdaLambda 関数のソースコード更新
EFS に CaboCha のインストールが完了したので、後は Lambda のコードで
import CaboChaしてやれば良いだけ、と思いきやそのままやると以下のエラーで動きません。[ERROR] Runtime.ImportModuleError: Unable to import module 'lambda_function': libcabocha.so.5: cannot open shared object file: No such file or directory
libcabocha.soライブラリが無いと言われています。実際には/mnt/lambda/lib配下にあるのですが。import MeCabしたときは、/mnt/lambda/lib配下のlibmecab.soが認識できている(と思われる)のに、なぜか CaboCha の場合は認識できないようです。
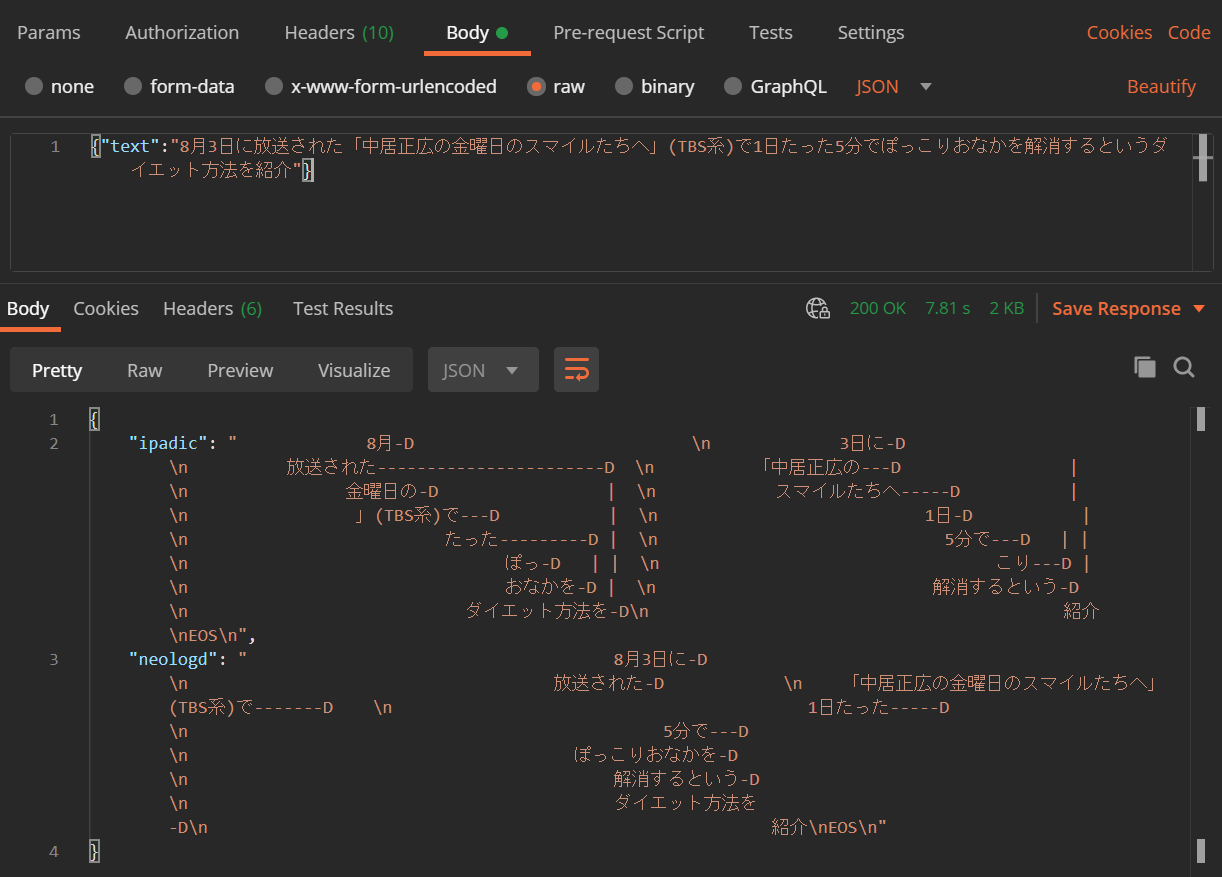
そこで、import CaboChaする前にctypes.cdll.LoadLibraryを使ってlibmecab.soライブラリを直接読み込みます。lambda_function.pyimport json import os import ctypes path, directory, files = next(os.walk('/mnt/lambda/lib')) for file in files: if file.startswith('libcabocha.so'): ctypes.cdll.LoadLibrary(os.path.join(path, file)) import CaboCha # IPA辞書を利用 ipadic_parser = CaboCha.Parser("-d /mnt/lambda/lib/mecab/dic/ipadic") # NEologdを利用 neologd_parser = CaboCha.Parser("-d /mnt/lambda/lib/mecab/dic/mecab-ipadic-neologd") def lambda_handler(event, context): print(event['body']) text = json.loads(event['body'])['text'] return { "statusCode": 200, "headers": { "Content-Type": "application/json", "Access-Control-Allow-Origin": "*" }, "body": json.dumps({ "ipadic": ipadic_parser.parseToString(text), "neologd": neologd_parser.parseToString(text) }) }結果確認
MeCab のときと同様に Postman から実行して結果を確認します。対象となるテキストも MeCab のときと同様のものを使います。(後半の「キンタロー。のダイエットにも密着。」は省略しましたが。)
無事に実行できました。が、このままだとなんのこっちゃかわかりませんので、結果を整形します。IPA辞書利用8月-D 3日に-D 放送された-----------------------D 「中居正広の---D | 金曜日の-D | スマイルたちへ-----D | 」(TBS系)で---D | 1日-D | たった---------D | 5分で---D | | ぽっ-D | | こり---D | おなかを-D | 解消するという-D ダイエット方法を-D 紹介NEologd利用8月3日に-D 放送された-D 「中居正広の金曜日のスマイルたちへ」(TBS系)で-------D 1日たった-----D 5分で---D ぽっこりおなかを-D 解消するという-D ダイエット方法を-D 紹介それぞれ IPA 辞書を使った場合と NEologd を使った場合というように辞書を指定して係り受け解析ができていることがわかります。前者は、形態素の段階で「ぽっこり」が一語として扱われていないので「ぽっ」が「こり」にかかっていることになっています(笑)
ちなみに CaboCha も MeCab 同様に出力モードがあり、係り受けの精度など、細かい分析をするための情報を出力することができます。こちらも詳細は公式サイトを参照してください。
ということで無事に CaboCha も Lambda 上で動かすことができました。
さいごに
Lambda with EFS で MeCab, NEologd & CaboCha を動かす一例でした。前回似たような記事を書いたからという理由だけで、特に深く考えて EFS に NEologd を入れたわけではありませんでした。が、こうした辞書データは頻繁に更新が入るため、EFS で外付けにしておくことで本体の Lambda 関数とは別に更新がかけられて便利かもしれません。Lambda with EFS の有効な使い道の一つのパターンなのかもな、と思いました。
とはいえ、Lambda の temp 領域サイズアップもいまだに期待しています。よろしくお願いします。
参考記事
https://qiita.com/hitomatagi/items/e63dd8c4b879de156628
https://qiita.com/osyou84/items/4e2f686d82bf9e1166e8
https://qiita.com/ayuchiy/items/c3f314889154c4efa71e
- 投稿日:2020-07-30T11:48:54+09:00
[AWS] ReactアプリでCognitoユーザープール認証を行ってみる
Cognitoの基本
「[AWS] Cognitoの基本まとめ」をご覧ください。
前提
今回はReactを使用するので、事前に
- Node.js
- npm
をインストールしておいてください。
あと、AWSアカウントの用意もお忘れなく。準備
ユーザープールの作成
まず、マネジメントコンソールにログインして、サービス「Cognito」の画面を表示します。
まだユーザープール、IDプールともに未作成のはずなので、下記のような画面になると思います。
ここで「ユーザープールの管理」ボタンを押します。
そして「ユーザープールを作成する」ボタンを押します。
すると、プール名の入力を促されるので、適当なプール名を入力してください。
今回は、ここで「デフォルトを確認する」ボタンを押します。
一応内容を確認して、一番下にある「プールの作成」ボタンを押します。
すぐに作成完了の画面が出るので、プールIDを控えておきましょう(控え忘れてもあとで確認はできます)。
アプリクライアントの作成
今回は、外部プロバイダではなくユーザープールで認証を行うので、作成したユーザープールにアプリクライアントを作成します。
画面右側にある「アプリクライアント」を選択してください。
ここで「アプリクライアントの追加」リンクをクリックします。
アプリクライアント名に適当な名称を入力します。
あと、今回は簡単なサンプルにしたいので「クライアントシークレットを生成」のチェックだけ外してください。
それ以外はデフォルトのままとしておきます。
「アプリクライアントの作成」ボタンを押します。
すると、画面が切り替わるので「アプリクライアントID」を控えておきましょう(これも後で確認することはできます)。
IDプールの作成
ユーザープールが作成できたので、今度は、アカウントを管理するIDプールを作成します。
画面上部にある「フェデレーテッドアイデンティティ」のリンクをクリックします。
まずはIDプール名に適当な名称を指定しましょう。
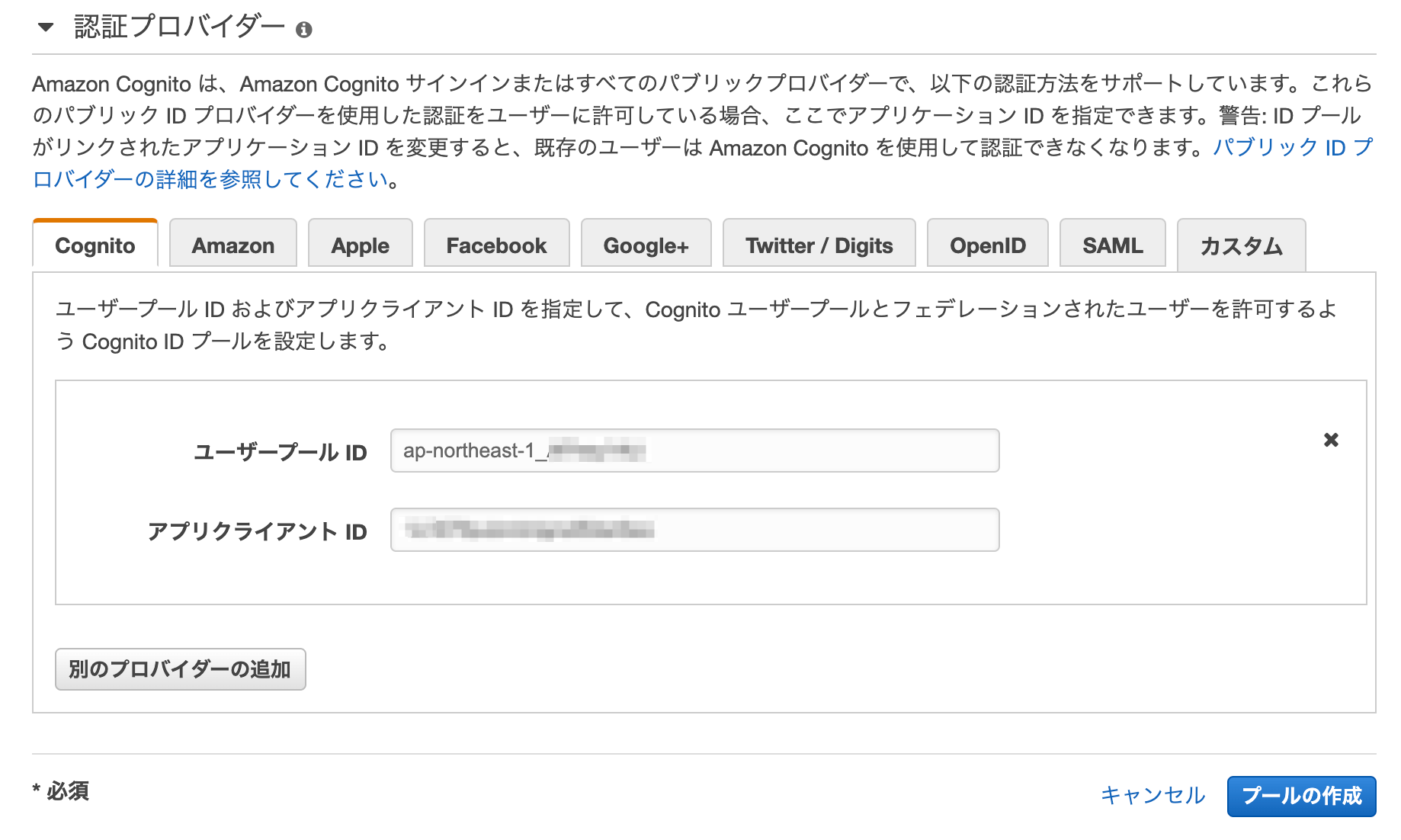
そして、画面の下の方に移動すると「認証プロバイダー」というリンクをがあるので、これをクリックして入力領域を展開します。
ここで、ここまでに控えておいた、ユーザープールID、アプリクライアントIDを入力します。
そして「プールの作成」ボタンを押します。
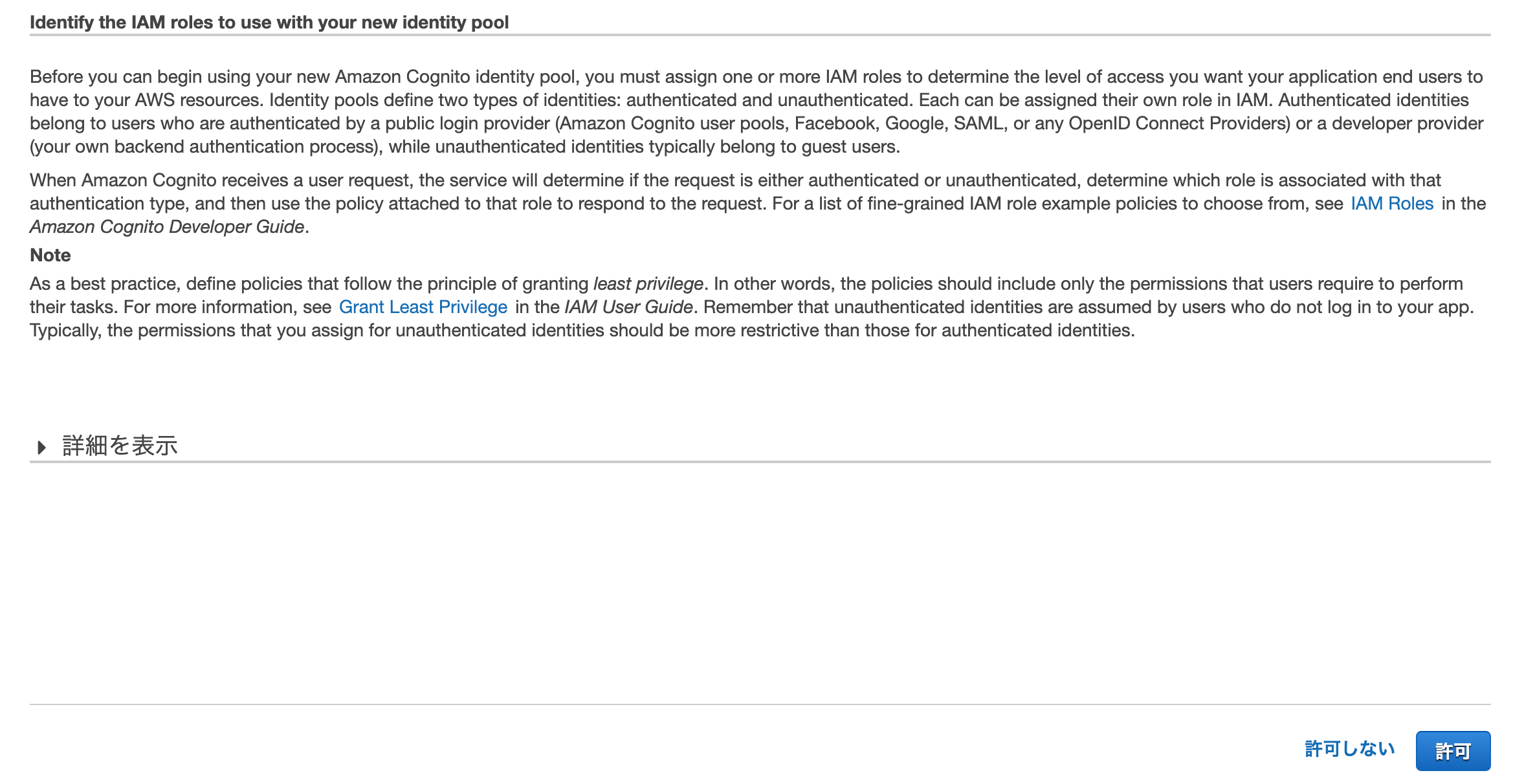
しばらくすると、IAMロールを作成する画面が出てきます。
特に何も変更せず、そのまま「許可」ボタンを押してください。
クライアントアプリの作成
Reactアプリの作成
まず最初に、
create-react-appをインストールします。$ npm install -g create-react-app続いて、下記コマンドでアプリケーションのプロジェクトを作成します。
$ create-react-app cognito-test完了したら、一応正しくセットアップできているか確認してみます。
$ cd cognito-test $ npm start
http://localhost:3000/にアクセスして、下記のような画面が表示されればOKです。
「Ctrl+C」で一度終了させてください。
Apmplifyのインストール
今回はクライアントにJavaScriptを使うため、Amplifyを使用したいと思います。
プロジェクトのディレクトリ配下で、以下のコマンドを実行してください。$ npm install aws-amplify aws-amplify-react @aws-amplify/ui-reactCognitoのコードを書く
package.json
まず、上でインストールしたライブラリが追加されているか確認しましょう。
dependenciesに、以下の2行を追記してください。"aws-amplify": "^3.0.22", "aws-amplify-react": "^4.1.21", "@aws-amplify/ui-react": "^0.2.13"src/index.js
続いて、index.jsを以下のように修正します。
index.jsimport React from 'react'; import ReactDOM from 'react-dom'; import './index.css'; import App from './App'; import * as serviceWorker from './serviceWorker'; import Amplify from 'aws-amplify'; Amplify.configure({ Auth: { identityPoolId: 'IDプールのID', region: 'ap-northeast-1', userPoolId: 'ユーザープールID', userPoolWebClientId: 'アプリクライアントID' } }); ReactDOM.render( <React.StrictMode> <App /> </React.StrictMode>, document.getElementById('root') ); // If you want your app to work offline and load faster, you can change // unregister() to register() below. Note this comes with some pitfalls. // Learn more about service workers: https://bit.ly/CRA-PWA serviceWorker.unregister();とします。
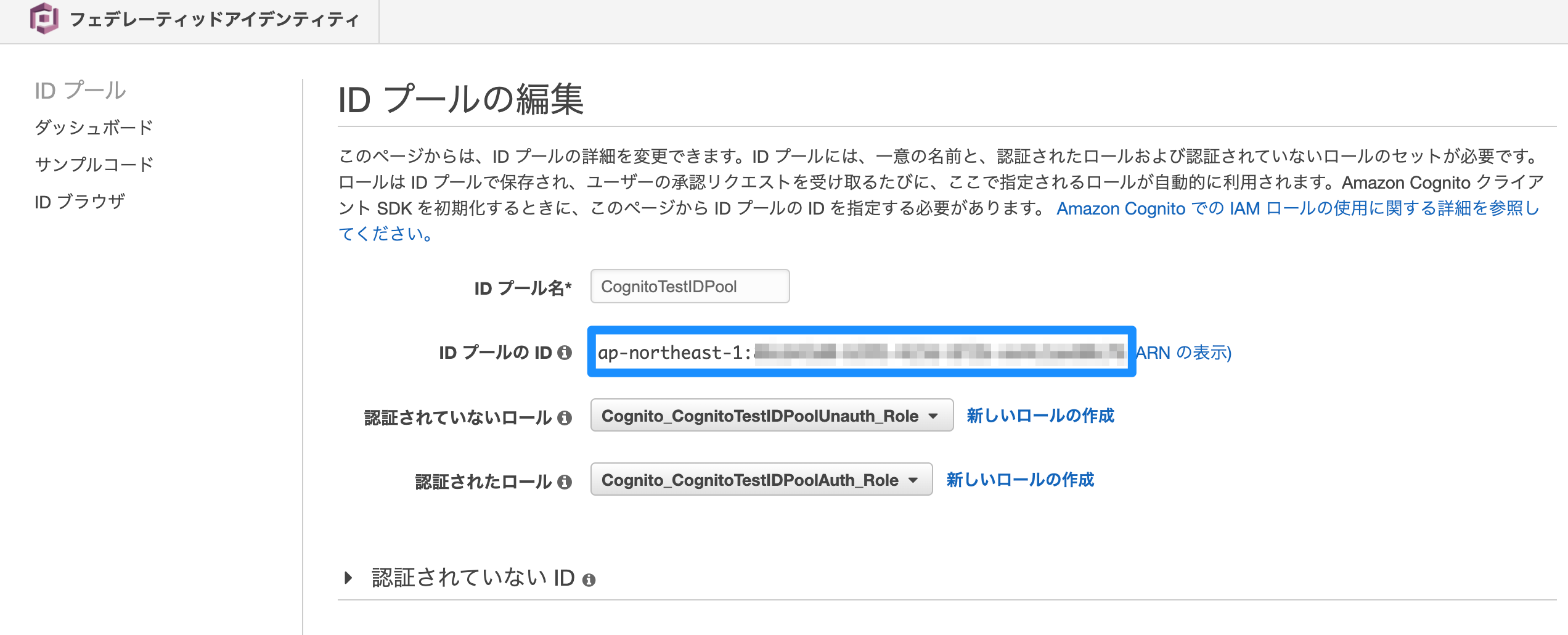
IDプールのIDは、IDプールの画面で「IDプールの編集」から確認できます。
src/App.js
続いて、App.jsも、下記のように書き換えてしまってください。
import React from 'react'; import { withAuthenticator } from '@aws-amplify/ui-react'; function App() { return ( <div className="App"> </div> ); } export default withAuthenticator(App);以上。
これだけです、たったこれだけ。動作確認
いざ起動
まずはアプリケーションを起動します。
$ npm startそして
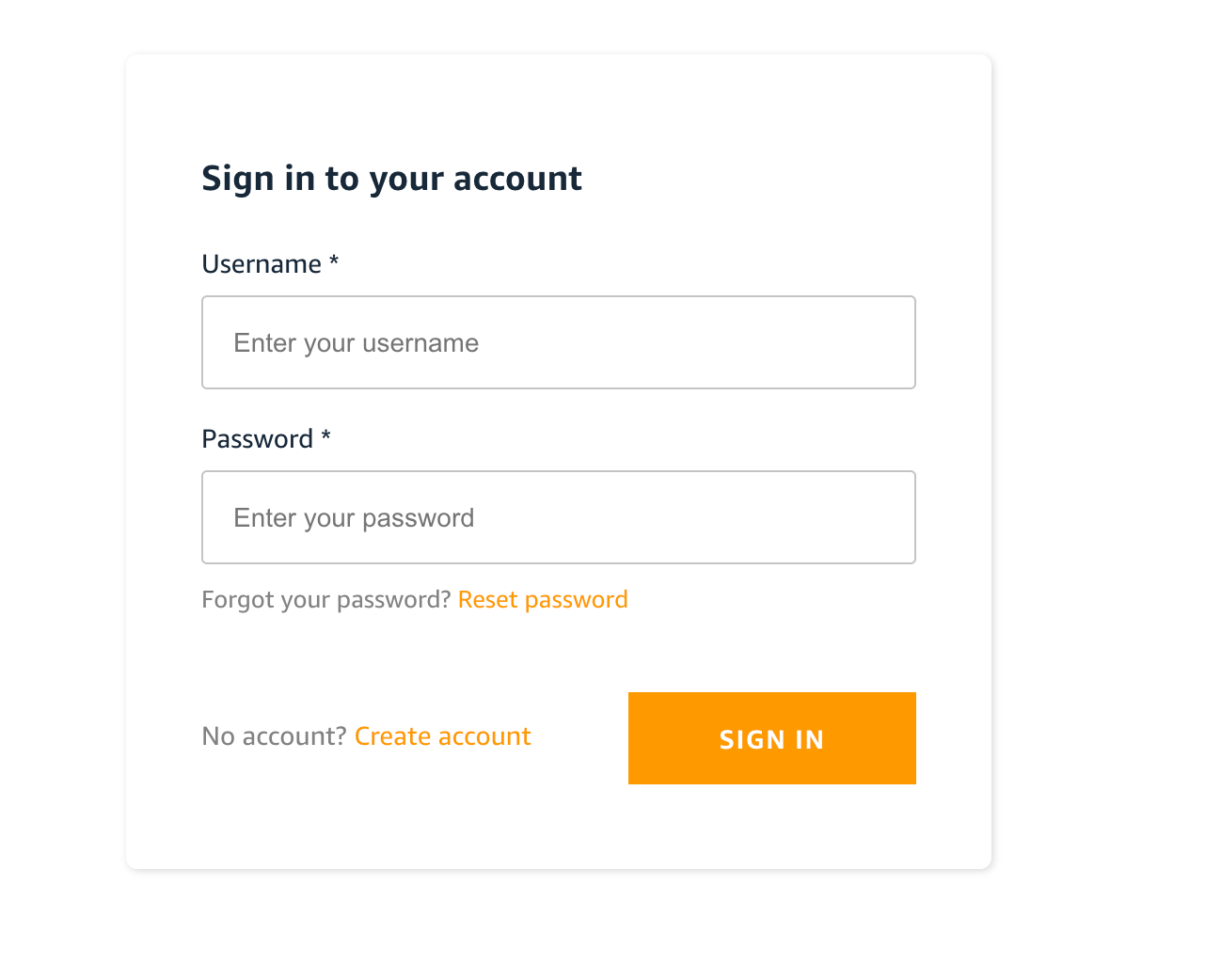
http://localhost:3000/にアクセスすると、画面が先ほどとは違い、以下のような画面が出てきます。
Cognitoのデフォルトの認証画面です。
ユーザ作成
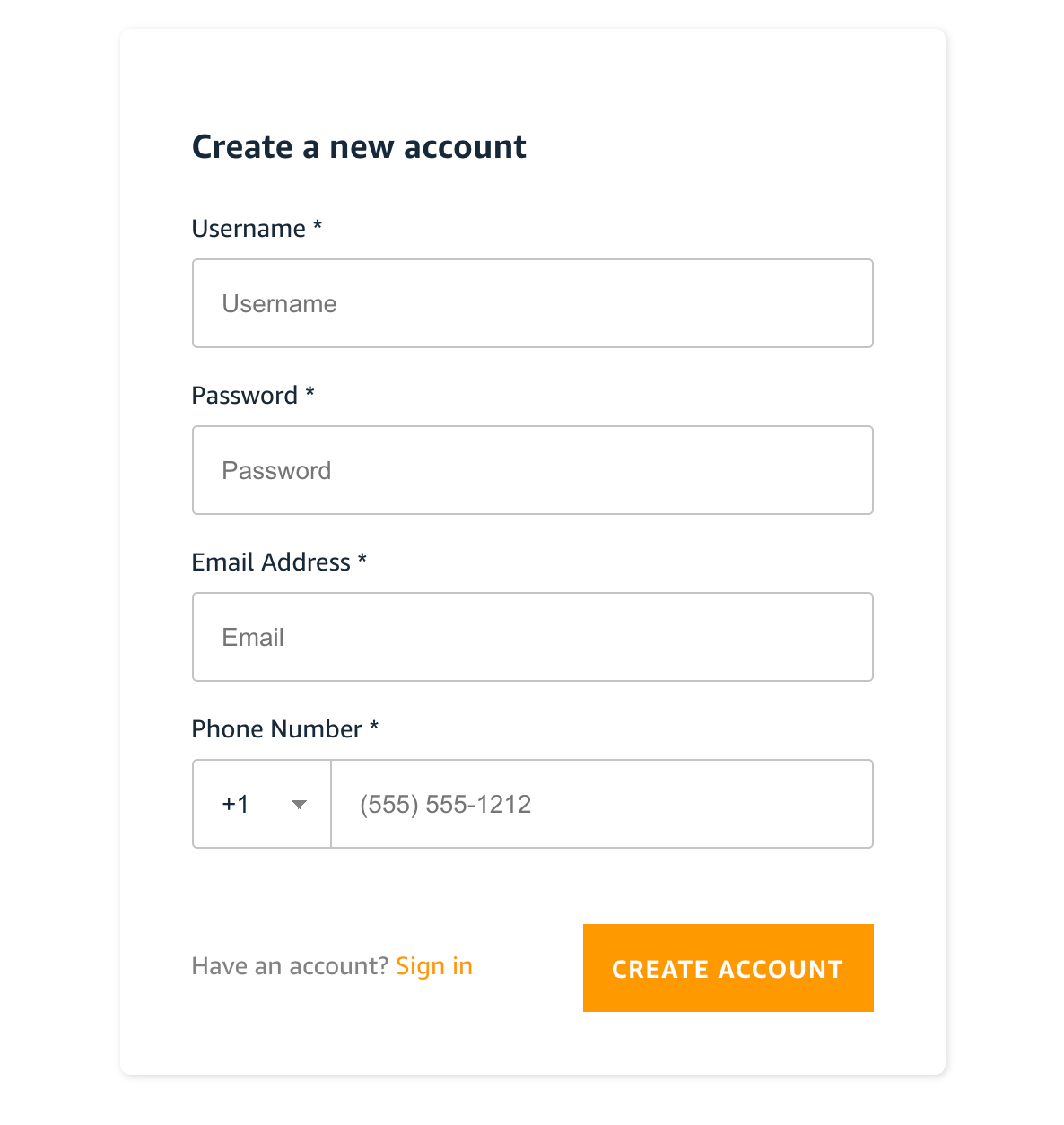
この時点では、まだユーザを1つも登録していないので「Create account」のリンクから、ユーザを登録してみましょう。
この時、標準の設定で、メールアドレス認証を有効にしているので、メールアドレスはメールを受信できる有効なものを指定してください。
「CREATE ACCOUNT」ボタンを押すと、確認画面が表示されます。
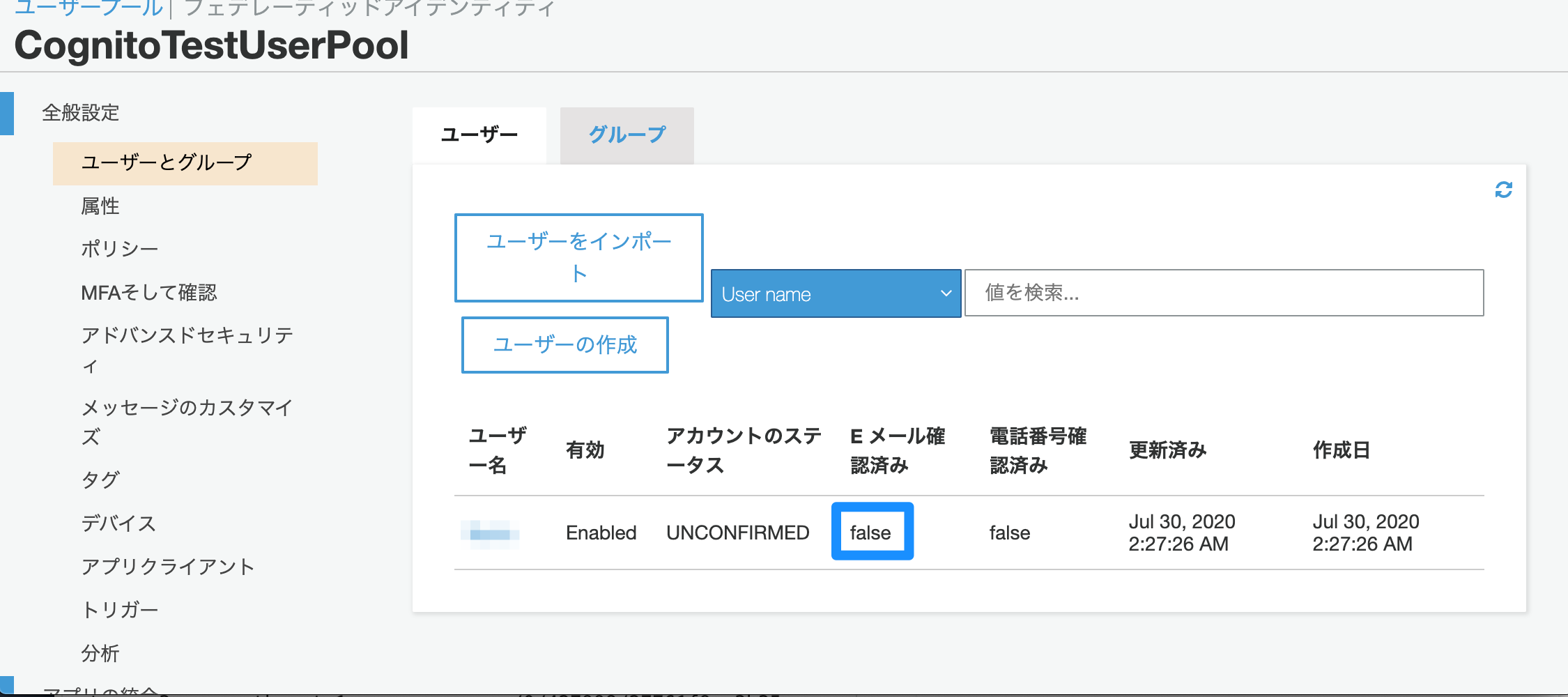
なお、この時点でマネジメントコンソール画面でユーザープールの状態をみてみると、
と、ユーザが作成され、Eメール確認済みが「false」になっていることが確認できます。
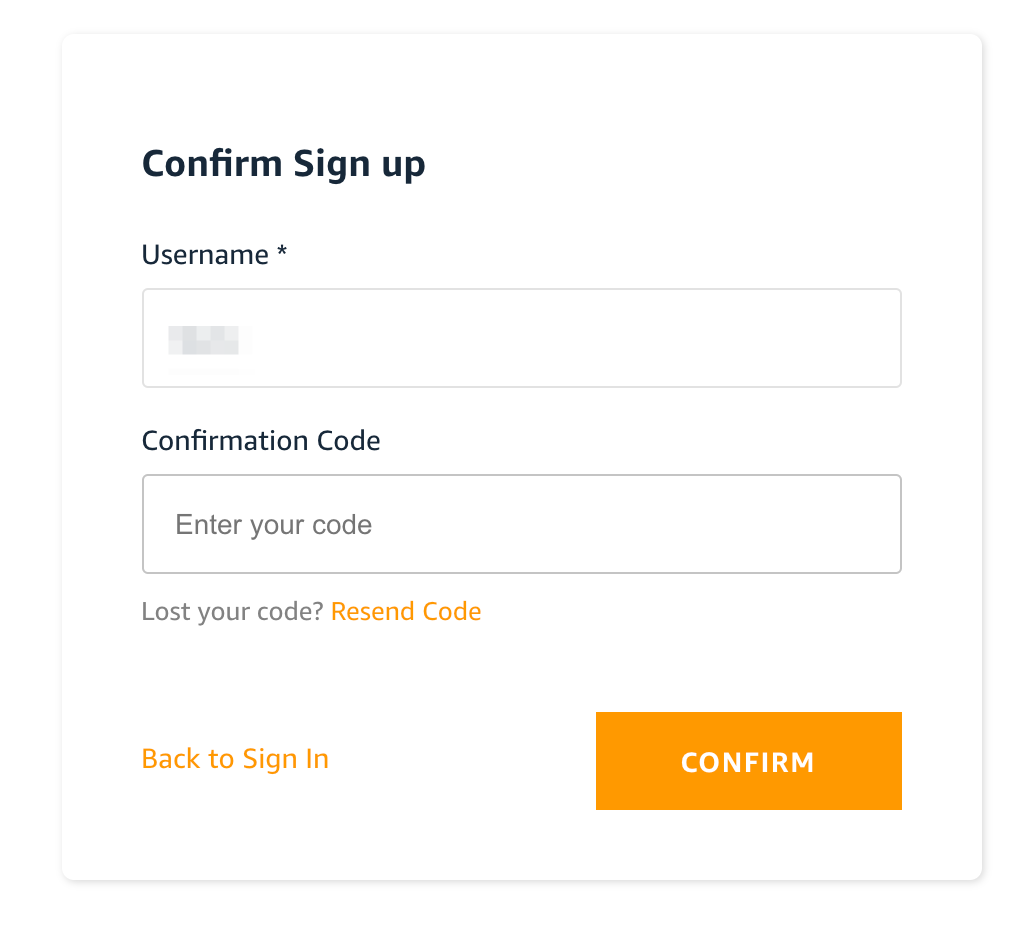
では、話を戻して、Confirmation Codeに、受信したメールに記載されているコードを入力して「CONFIRM」を押してみましょう。
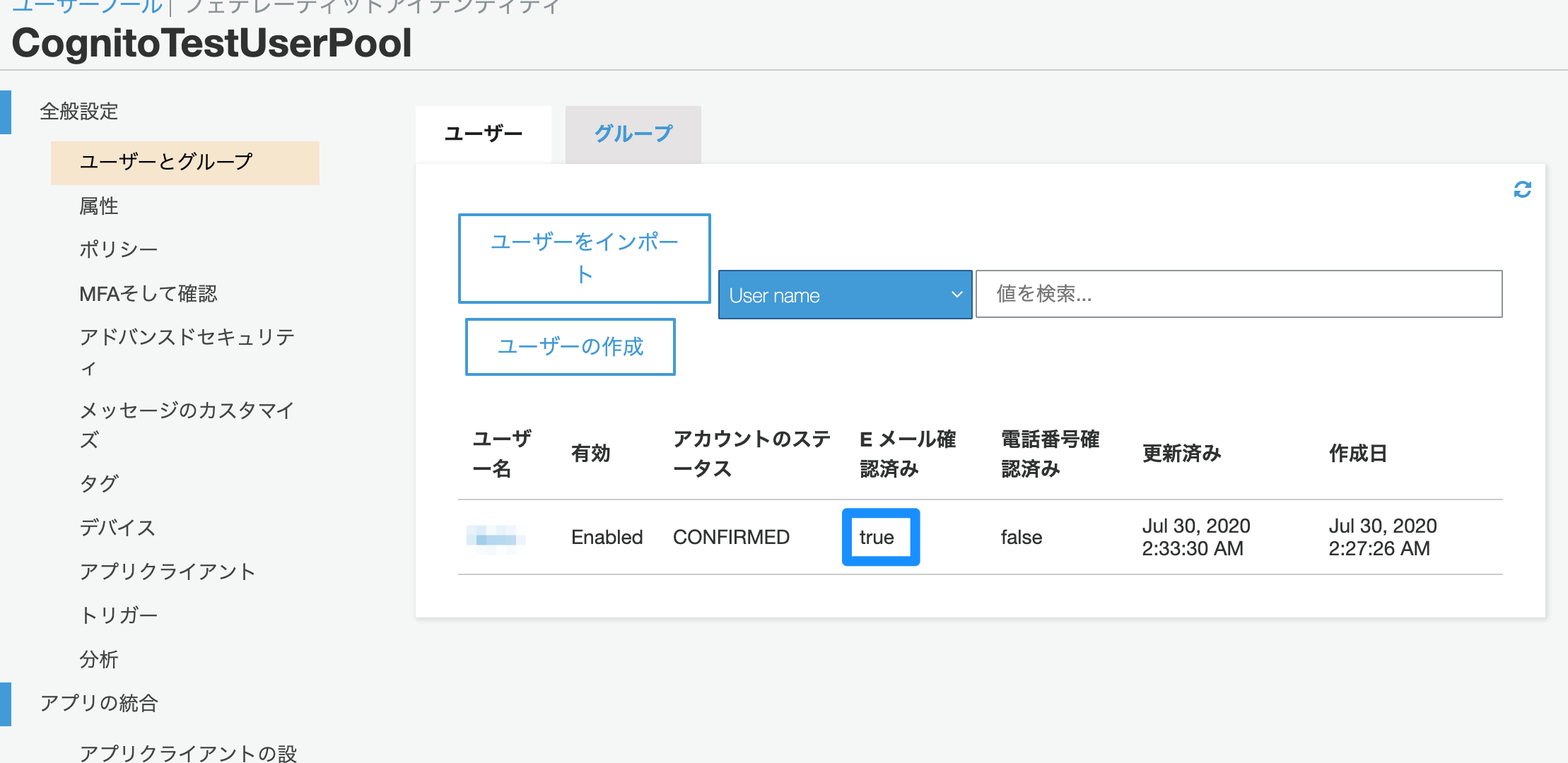
すると、画面が真っ白くなりますが(認証後に表示するページを指定していないため)、マネジメントコンソールの画面で確認してみると、
Eメール確認済みが「true」にかわっているかと思います。
まとめ
認証・認可の機能を追加する、ってなかなか敷居が高いイメージでしたが、さくっとできてしまいました。
次は、FacebookなどからSSOする方法について解説したいと思います。








- 投稿日:2020-07-30T08:35:29+09:00
ドメイン駆動設計のミッション層を設計する手法を紹介
今回の記事では、前回の「エリック・エヴァンスが提唱したアーキテクチャの4層モデルを拡張する」の記事で紹介した
5層アーキテクチャモデルのミッション層を設計する方法について紹介する。前回の記事について以下のURLを参照
https://qiita.com/aLtrh3IpQEnXKN7/items/b7fe2014ccefcbb9e458
ミッション層を理解する鍵は抽象表現主義
抽象表現主義とは人間の心象世界を絵画に表現することを目指した表現技法。
現実の世界に基づい絵画を描写する写実主義とは対極に位置する心象風景をモチーフに絵画を記載する手法。
抽象表現主義はオートマティスムと呼ばれる「何か別の存在に憑依されて肉体を支配されているかのように、自分の意識とは無関係に動作を行ってしまう現象」に基づいて絵画を描写する手法を取り入れている。
そのため、抽象表現主義によって取り入れられた絵画は水のような流体状になった作品が仕上がる。
現実の世界を水のような流体として捉える抽象表現主義の描写がミッション層のロジックを理解することに繋がる。
下記は抽象表現主義によって作成された作品。
ミッション層を巨大なキャンバスとして捉える
ミッション層を設計する場合、巨大なキャンバスとして捉えることが設計を行うポイントになる。
キャンバスの中では、登場人物が役割を演じ、特定のシーンが切り取られ作品として完成する。
キャンバスは以下の要素によって構成されている。
・タイトル
・俳優
・俳優が演じる役割
・俳優が使用する道具ミッション層では、外部から取り込んだエネルギーを変換し、別のオブジェクトに変換して出力するというプロセスがロジックの流れになる。
そのため、ミッション層で実行されるロジックは、映画のワンシーンのように脚本に沿って各俳優が役割を演じるというロジックになる。
ミッション層のロジックは文脈に基づいて作成されるため、DCIアーキテクチャによって実装が行われる。DCIアーキテクチャに関する説明は下記の記事参照
https://qiita.com/aLtrh3IpQEnXKN7/items/355ad12f82ac424abea3ミッション層のロジックはクライアントサーバシステム
ミッション層のロジックは、サービスを受けるクライアントとサービスを提供するサーバーに分割する。
サービスを受けるクライアントは外部情報を保持し、外部情報をサーバに提供してサービスを受ける。
サーバーは受け取った外部情報を基に提供するサービスを決定する。アリストテレスの四原因説を使用してミッション層内で発生する力の種類、方向性、役割について把握する
四原因説とはアリストテレスが自著『自然学』の中で論じた、自然学の現象に関する4種類の原因。以下の4つの因子で構成されている。
目的因・・・物事の終り、すなわち物事がそれのためにでもあるそれ(目的)をも原因と言う。
形相因・・・形相または原型。
作用因・・・新たな結果・成果を産出する意味での作用因。力のスタート地点を表す。
質料因・・・存在するものの物質的な原因。銅像においては青銅が、銀盃においては銀が該当四原因説に基づく力の種類、ロジックはドメイン層のメソッドに依存している。
ミッション層では四原因説に該当するドメイン層のメソッドが相互作用し、ロジックを形成する。
四原因説とドメイン層の繋がりを把握することで、ミッション層の全体の流れを把握することができるようになる。
四原因説とドメイン層の繋がりに関しては下記の記事参照
https://qiita.com/aLtrh3IpQEnXKN7/items/0b7abd4ddbc48a8430d6ミッション層を構成する要素
ミッション層を構成するクラス一覧。
Mission・・・目的を表す。ユースケース層のワンシーンを切り取った名称。
Actor・・・役割を演じるためのクラス。Roleを実装だけのクラスなのでメソッドは何も実装されないが、特定のActorのみ演じられるRoleも存在するため、Roleの生成条件を実装する可能性がある。
Role・・・Actorが演じる役割。四原因説の作用因に該当するドメイン層のメソッドが実装される。
Tool・・・Roleが使用する道具。四原因説の質料因と形相因に該当するドメイン層のメソッドが実装される。


- 投稿日:2020-07-30T04:43:58+09:00
AWS IAM メモ
後で書き直す
IAM:AWS全体の認証認可基盤
IAM user
アカウント作成時のルートユーザーとは異なる作成されたユーザー
権限を制限したIAM userを付与するのが基本
policyやroleをアタッチできる
しかしIAM groupへpolicyやroleをアタッチして使うのがベストプラクティスIAM group
roleやpolicyをアタッチ可能な集合
ここにユーザーを所属させるのがベストプラクティスIAM policy
デフォルトで用意されているAWSへのアクセス権限IAM role
EC2やlamdaにアタッチして権限付与ができる
内部的には使い捨てのキーとパスを発行しているらしい
- 投稿日:2020-07-30T02:49:46+09:00
AWSの監視入門したのでCloudWatchについてざっくりまとめ
ブログからの転載です
https://wally-ngm.hatenablog.com/entry/2020/07/28/180048
最近こちらのハンズオンをちらほら進めております.
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-hands-on/:embed:cite今日は監視編をやってみましたが, CloudWatchって色々機能あって驚いたのでメモしておきます.
全て網羅しているわけではないです.まとめ
サービス 用途 備考 メトリクス ちょい調べたい ときに使える ロググループ インサイトでクエリの対象になる. mysqlでいうテーブル的な. ロググループへログを集める設定が別途必要 インサイト クエリ書いてログをより好きなように見れる.(4xx系のエラーだけにフィルタしたり) アラーム 何か異常起きたら知らせれる. SNS使って知らせると楽ちん ダッシュボード ダッシュボード メトリクス
リソースのメトリクスをぽちぽち選んで見れる.
Redash的なダッシュボードではなく, そのときに見たいものを見るような用途で使いそう.Redashみたいなダッシュボードが欲しい場合は,
ダッシュボードという別の機能を使える.ロググループとインサイト
ロググループに対して各アプリケーションはログを吐き出す.
EC2とかが吐き出したログは勝手にCloudWatchで見れるようになるが, ロググループを指定するのはルールとか, cloudwatch agentが関係してきそうだけどそのへんはまだ分からない.
インサイトではクエリを書いてそのログを好きなように加工して見れる.アラーム
EC2が死んだときとか, CPUの使用量が増えたときなどにアラームを出せる.
アラームの出す先はSNSっていうサービスを使ったり, Lambda使ったりできる.ダッシュボード
今まで見てきたようなメトリクス, インサイトを常にまとめて見たいときに使える.Redash的なやつ.
次はちゃんと稼働してるサービスの監視設定したい.
あともうちょっと何にお金がかかって何にお金がかからないのかを調べて追記したい.
- 投稿日:2020-07-30T00:15:32+09:00
Prisma CloudでAWSリソースの脆弱性管理(Lambda編)
Palo Alto社のセキュリティ製品、Prisma CloudをでAWSリソースの脆弱性管理を行ってみます。
今回は、Lambdaに対して、脆弱性診断をかけてみます。準備
Prisma Cloudアカウントがない方は、以前の投稿をご参照ください。
https://qiita.com/Hiroyama-Yutaka/items/0c5205749bc54e3ec056脆弱性診断
Computeメニューに存在します。
今回は、(AWS Lambda)に対して、実施してみます。準備
適当にLambdaファンクションを作成。今回はSAMでPythonベースのファンクションを作りました。
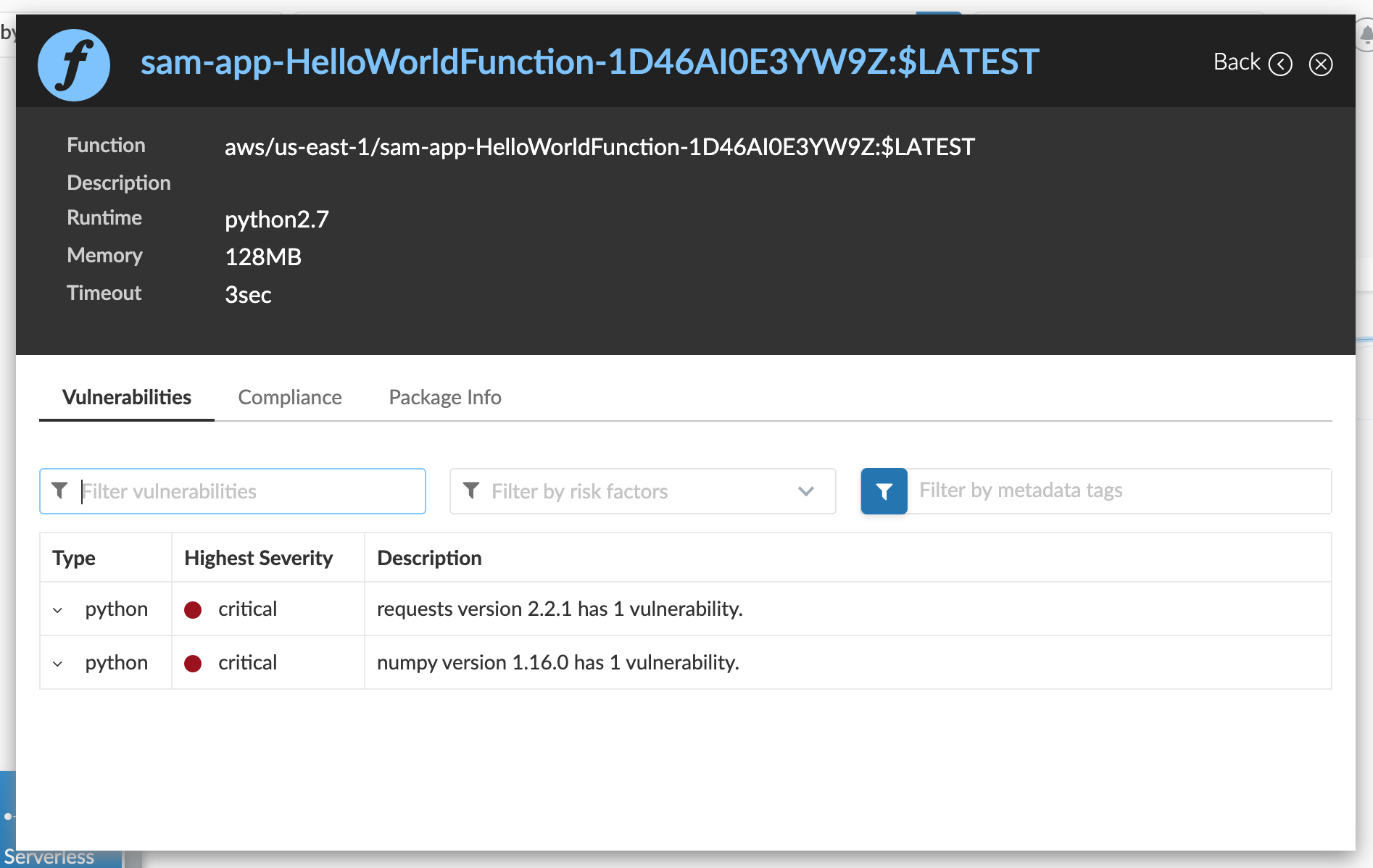
今回は、意図的に脆弱性のあるライブラリバージョン(numpy1.16.0, request2.2.1)を使用しておきました。
https://nvd.nist.gov/vuln/detail/CVE-2019-6446
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2014-1830手順に従って環境変数をセット。Prisma CloudコンソールにLambdaファンクションが表示されます。
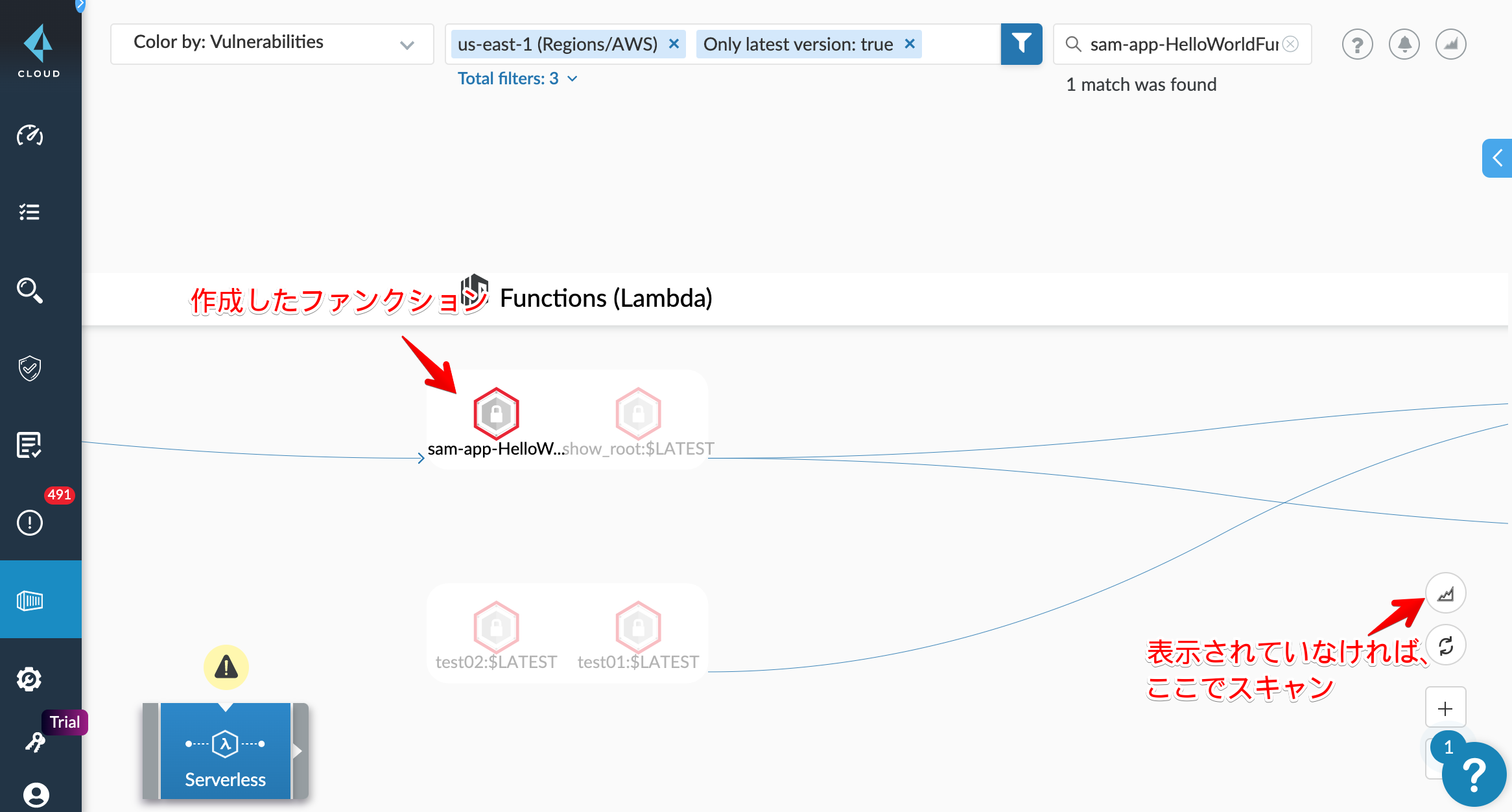
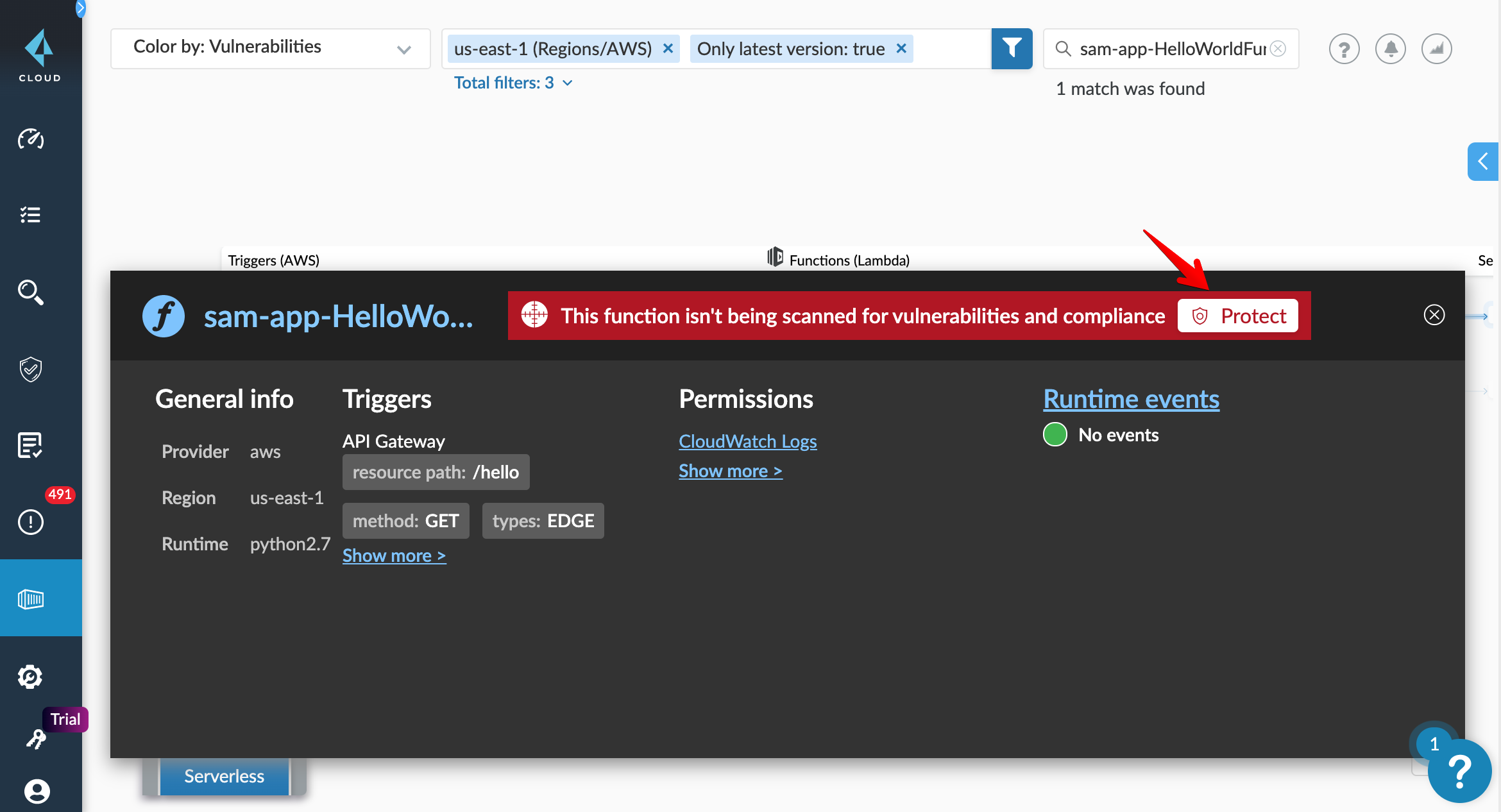
最初は、ファンクションがグレーアウトされていると思います。(↑のキャプションのアイコン)
ClickしてScan対象にしましょう。
成功すると、ファンクションアイコンが赤くなります。
スキャン
初回に自動的にスキャンが走っています。
中を覗くと、しっかり仕込んだ脆弱性を検知してくれています。
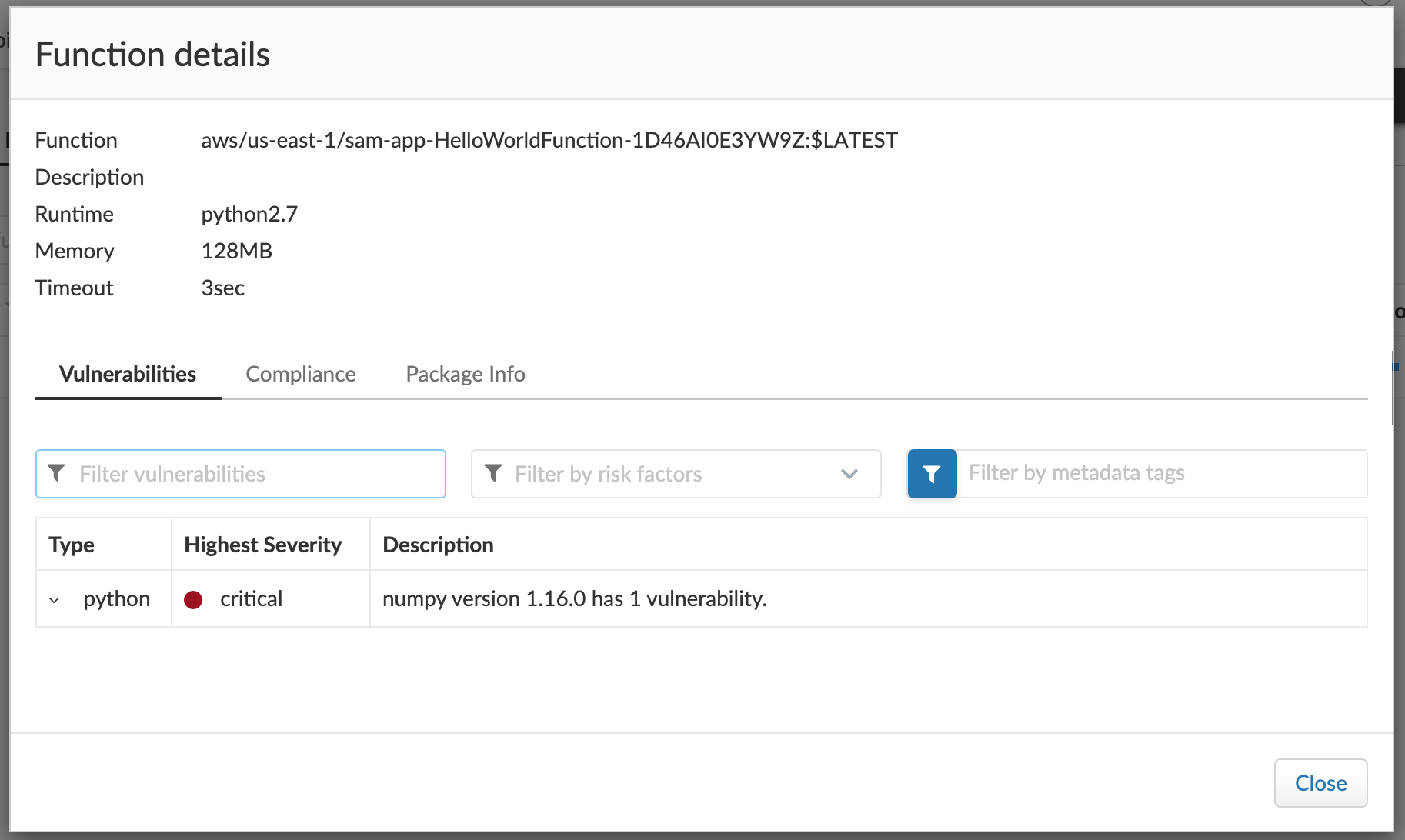
requestsをアップデート。
$ cat hello_world/requirements.txt requests==2.2.1 $ vi hello_world/requirements.txt $ cat hello_world/requirements.txt requests==2.20.0 $ sam build $ sam deploy再スキャンして確認!
無事、requestsの脆弱性が解消が確認できました。
まとめ
Prisma CloudでAWS Lambdaの脆弱性スキャンをしてみました。
Prisma CloudのAWS Lambdaには、脆弱性スキャン以外にも、実行開始をフックして、起動引数に攻撃性のある内容が含まれていないかなどをチェックする機能も備えています。その機能や別のサービスなどは別の機会に試してみます。