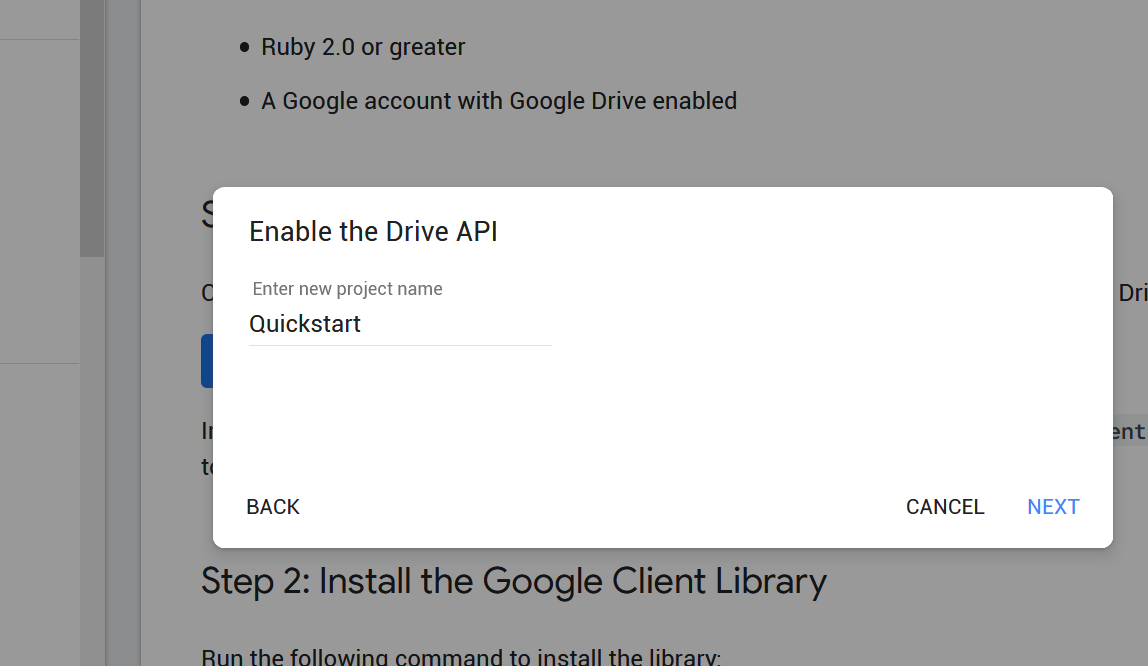
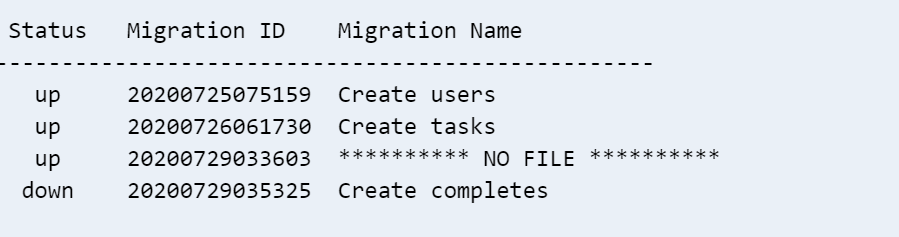
Prefix Verb URI Pattern Controller#Action
games GET /games(.:format) games#index
POST /games(.:format) games#create
new_game GET /games/new(.:format) games#new
edit_game GET /games/:id/edit(.:format) games#edit
game GET /games/:id(.:format) games#show
PATCH /games/:id(.:format) games#update
PUT /games/:id(.:format) games#update
DELETE /games/:id(.:format) games#destroy
Prefix Verb URI Pattern Controller#Action
new_game GET /game/new(.:format) games#new
edit_game GET /game/edit(.:format) games#edit
game GET /game(.:format) games#show
PATCH /game(.:format) games#update
PUT /game(.:format) games#update
DELETE /game(.:format) games#destroy
POST /game(.:format) games#create