- 投稿日:2020-07-29T22:59:02+09:00
Amazon FSx for Windows の構築と仕様(2020年6月アップデート)
Amazon FSx for Windows の構築と仕様
今回はAWSでWindowsファイルサーバを構築する際のベストプラクティス(?)のFSx for Windows を構築していきます。FSx for Windows自体は2019年から東京リージョンでも利用可能なのですが今年6月のアップデートで更に便利になりましたので、クラウドにファイルサーバを移管したいという場合はご検討を!
AWSの回し者っぽくなりましたが、上手く活用できればお安く運用できますので(笑)Amazon FSx for Windows (以下FSx)とは
Amazon FSx for Windows ファイルサーバーは、業界標準のサーバーメッセージブロック (SMB) プロトコルを介してアクセスできる、信頼性が高くスケーラブルな完全マネージド型のファイルストレージを提供します。Windows Server 上に構築され、ユーザークォータ、エンドユーザーファイルの復元、Microsoft Active Directory (AD) 統合などの幅広い管理機能を提供します。
ざっくりどんなサービスなのかというとWindows Server のファイル共有機能をそのまま使えるフルマネージドのファイルサーバをサービスとして提供しているということになります。
シャドウコピー機能やフォルダアクセス権の設定などWindows Serverっぽく利用できます。「Windows OS のEC2+EBSでいいじゃん」と思うかもしれませんが、FSxならフルマネージドでOSのVerUpなど運用がユーザ側で不要になることに加え、容量によってはEC2+EBS構成よりコストを抑えることができます。
代わりにAD連携が必須という制限があります。
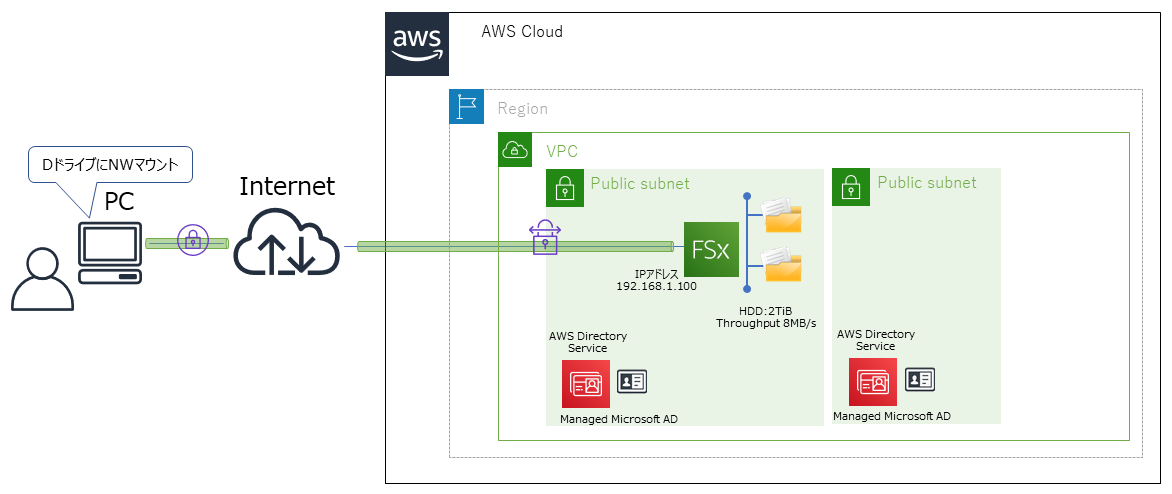
ストレージタイプはSSDとHDDがあり、AWS内のファイル読み書きのスループットキャパシティーもユーザで設定できます。イメージ図
2020年6月のバージョンアップ内容
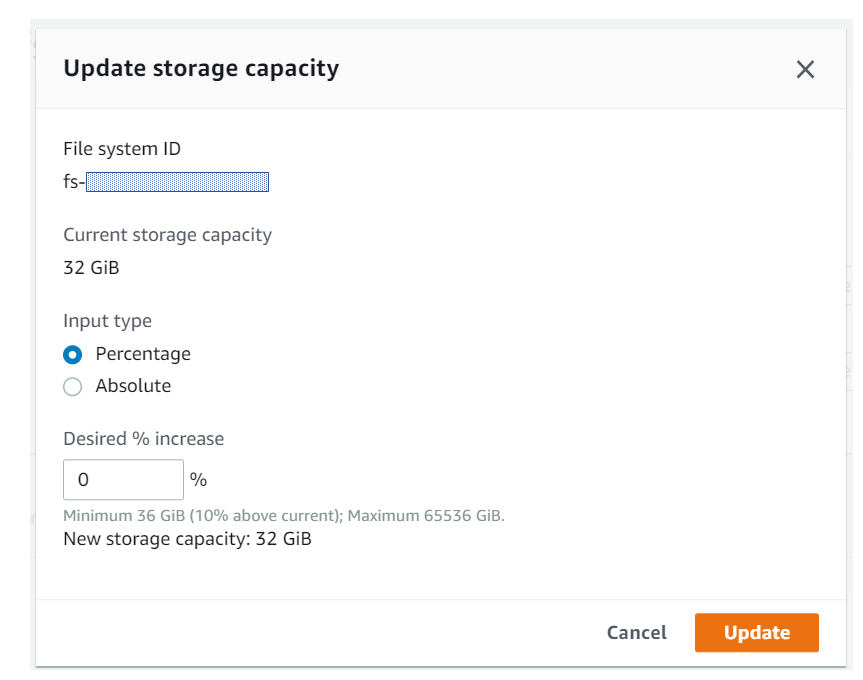
ストレージ容量が変更できるようになりました
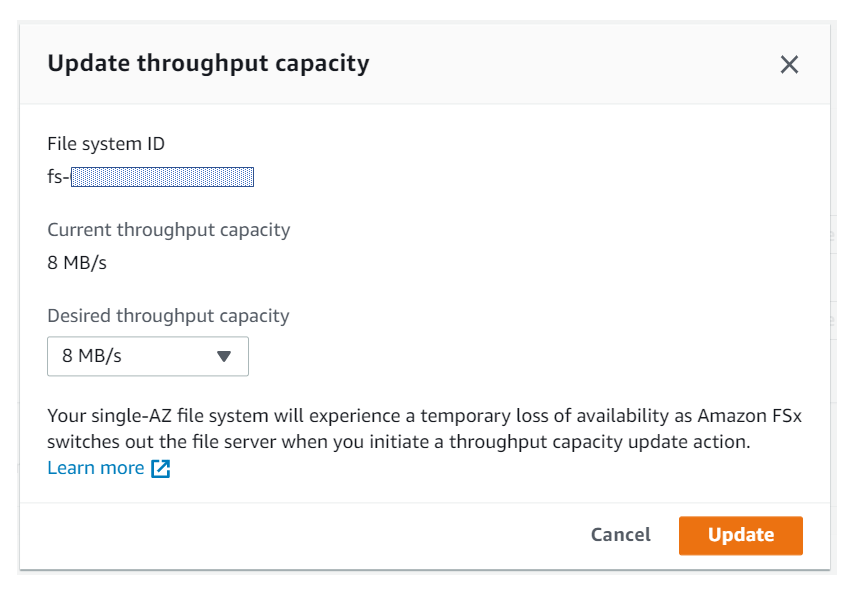
スループットキャパシティーが変更できるようになりました
今までは構築時に設定した上記パラメータは変更できませんでしたが、今回のバージョンアップで変更できるようになりました。
正直、容量とかスループットキャパシティーが変更できないのは「クラウドっぽくないし、微妙なサービスだな…」と思ってましたが、今回の変更でだいぶ印象が変わりましたd(`・ω・’)仕様上の制限
- Managed Microsoft ADもしくはユーザが構築したAD(EC2/オンプレAD)との連携が必須 ※Simple ADはNG
- HDDタイプのストレージ容量は2TB以上必須
- スループットキャパシティーは最低8MB/s
- AWS VPC内からしか利用できない(クライアントPCから利用する場合はVPN接続かDirectconnect接続必須)
今回のゴール
クライアントPCと見立てたAWS WorkSpaces にFSxをネットワークマウントして、ファイル共有ができるようにする。
前提条件
- ADはAWS Managed Microsoft AD を利用
- ストレージタイプはSSD×32GiBで設定
- Single-AZ構成
- AWS WorkSpaces にネットワークマウントする
構築手順
- Managed Microsoft ADを構築し、ドメイン管理者のユーザ、PWを設定
- VPCのDHCPオプションセットを作成し、DNSのIPアドレスをManaged Microsoft ADに設定
- FSxを構築
- FSxをネットワークマウントするWorkSpacesを構築
実際にやってみた
1.と2.ですが本記事のメインではないため、割愛しますが以前に投稿した以下記事を参考にManaged Microsoft ADを構築してください。
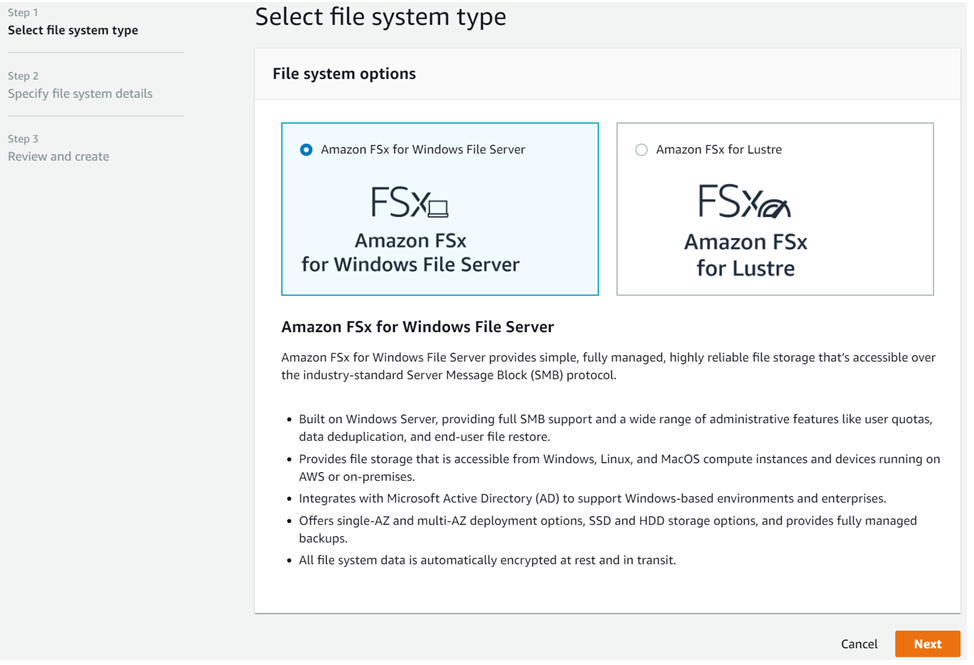
参考記事:AWS Directory Service の構築と仕様次に2. ですが、AWS コンソール画面のサービス検索で[FSx for Windows」と検索して、「Create file system」をクリックして、以下画面まで進めます。
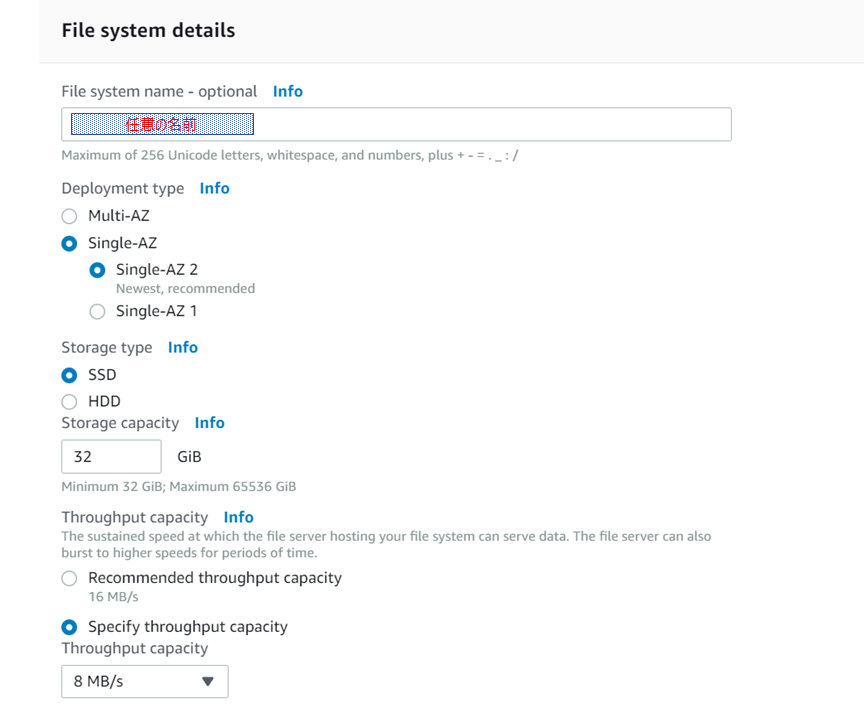
続いて、名前やストレージ容量、スループットキャパシティーを入力します。
最小限のシステムを構築しますので、以下で登録します。
・Single-AZ
・Storage Type = SSD
・Storage capacity = 32GiB
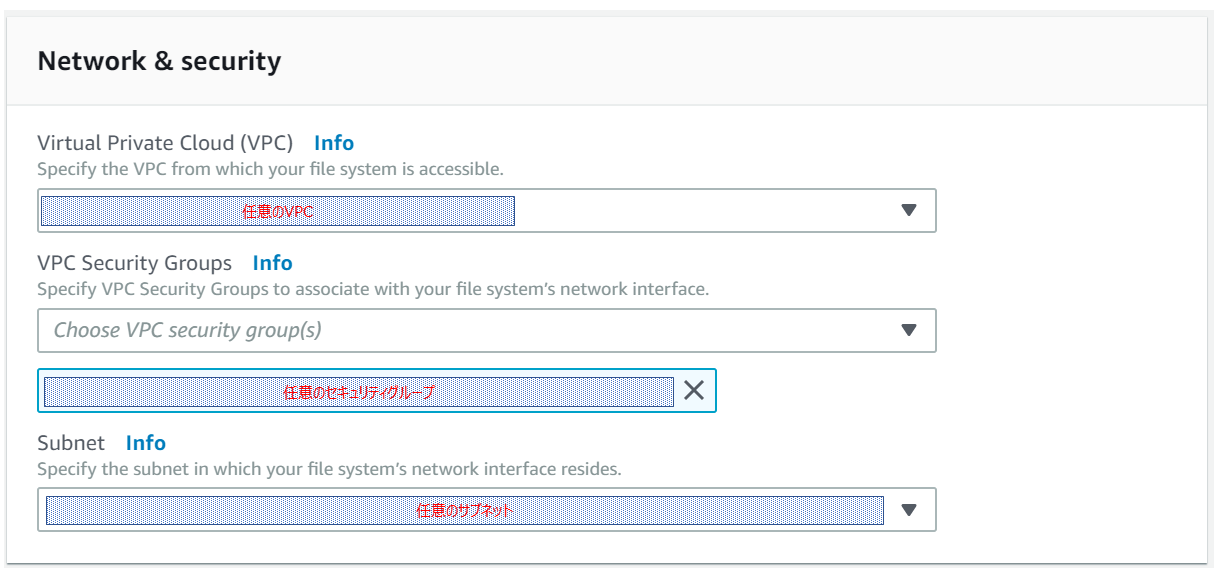
・Throughput capacity = 8MB/s次にデプロイするVPC、セキュリティグループ、サブネットを選択していきます。
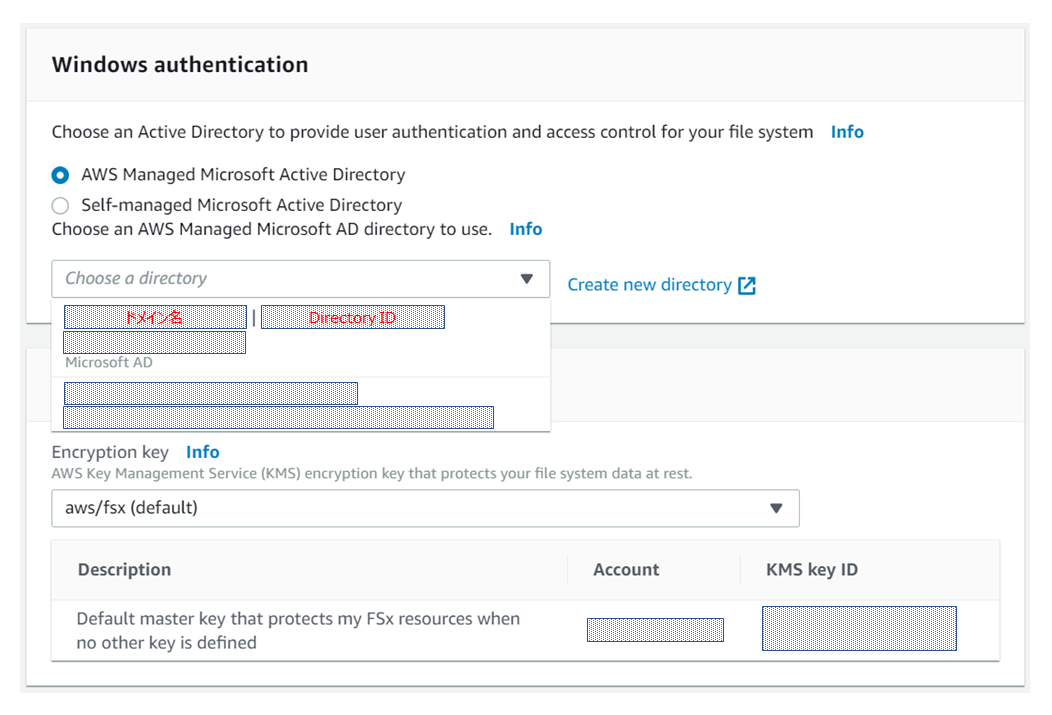
次に利用するDirectoryを選択します。今回は作成したManaged Microsoft ADを利用しますので、「AWS Managed Microsoft AD」を選択し、該当するドメイン名のDirectoryを選択します。
EncryptionはデフォルトのままでOKです。
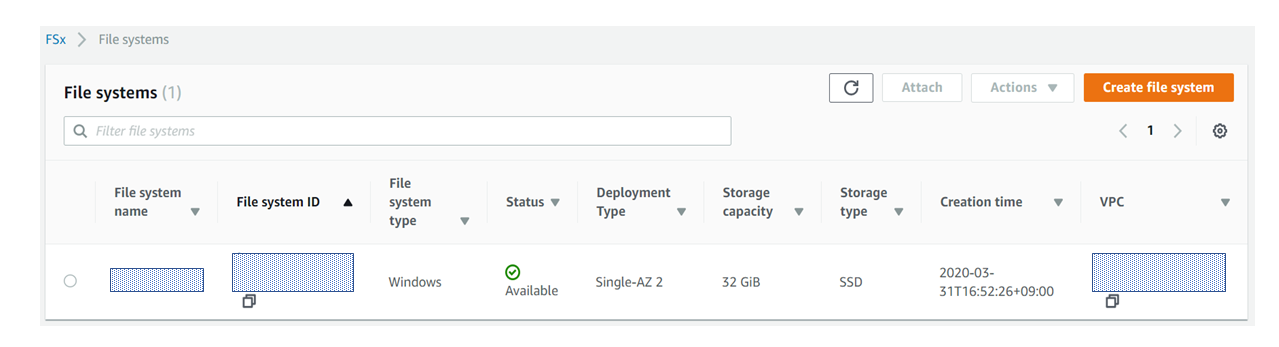
file System作成後、ステータスがActiveになると以下のようになります。
Activeになるまでに30分ほどでかかるので、しばらく休憩です。
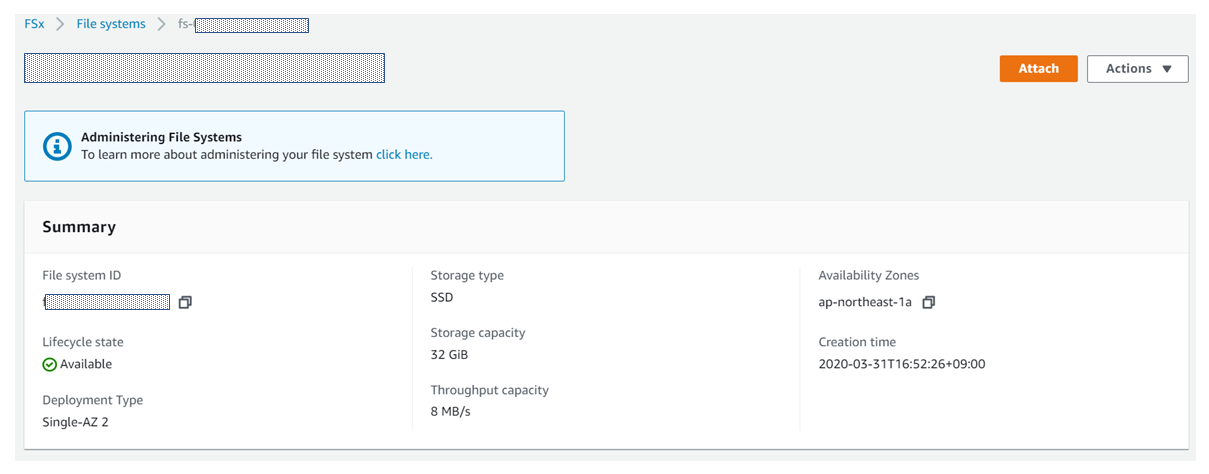
file system IDをクリックすると、該当システムのダッシュボードのような画面にアクセスできます。
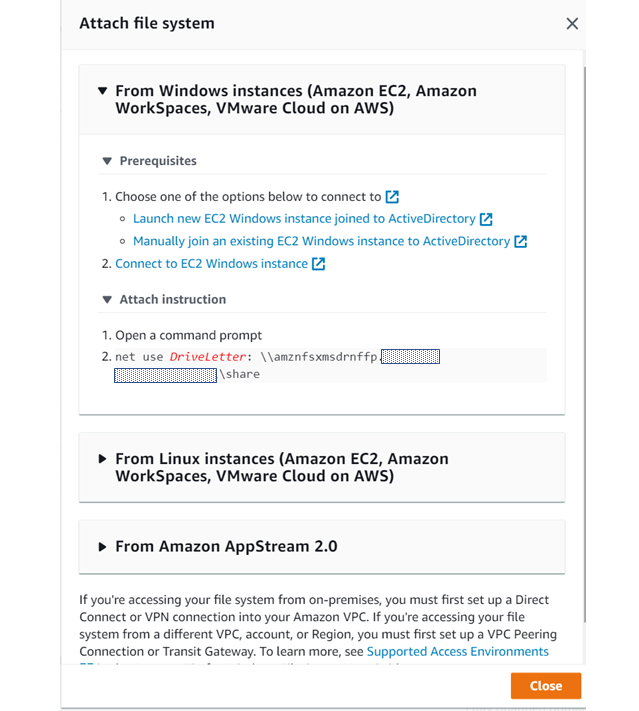
この画面で、設定した容量やスループットキャパシティー、どこのAZにデプロイされているかなどの情報が確認できます。右上の「Attach」をクリックすると以下画面が表示されます。
「▼ Attach instruction」 のコマンドを、FSxをマウントしたいクライアントPCで実行することで、FSxがマウントされます。
これでFSxの設定は完了しました!あとはクライアントPC(※今回はWorkSpacesですが)にマウントするだけです。
4.のWorkSpaces の構築も本記事のメインではないため、割愛します。WorkSpacesは各所記事がありますので、参照しながら構築してください。ただDirectory は同じAWS Managed Microsoft ADを利用してデプロイしてください。
それではWorkspacesにFSxをマウントしていきます。
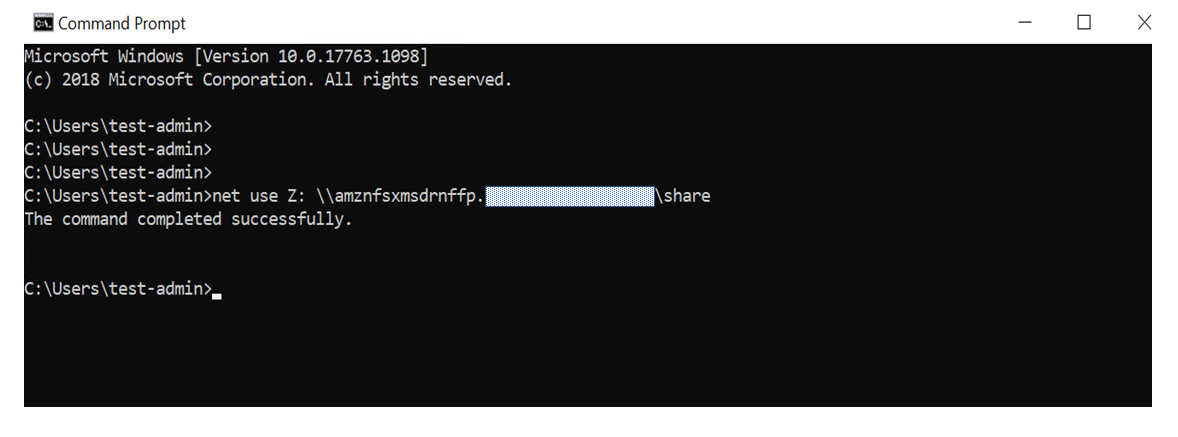
まずWorkSpcesへログインします。ログインするユーザにはネットワークドライブをにマウンドできる権限を付与しておいてください。今回はドメイン管理者でログインします。ログイン後、cmdを管理者権限で起動して、Zドライブにマウントします。
net use :Z \\amznfsxmsdrnffp."ドメイン"\shareコマンド実行すると以下画面のように"completed successfully"と表示されます。
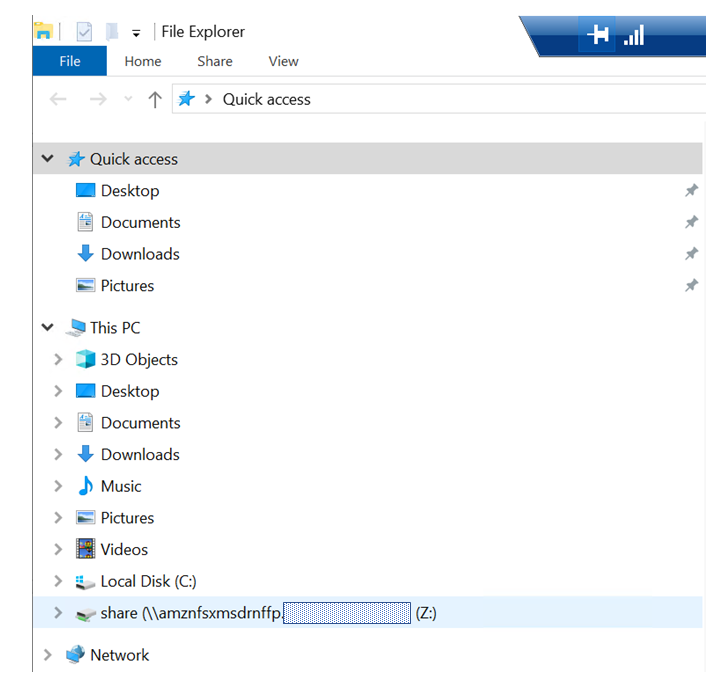
エクスプローラーでマウントされているか確認してみると
無事Zドライブにマウントされていますね!他サービス構成(StorageGW/EC2+EBS)との比較
StorageGWとの違い・・・FSxはGW動作基盤としてのEC2は不要だが、ADが必要
グローバルIPでアクセスし、マウントできない
容量の制限ありEC2+EBSとの違い・・・FSxはサーバOSの管理、メンテナンスが不要
利用容量によっては費用が抑えられる
料金サンプル
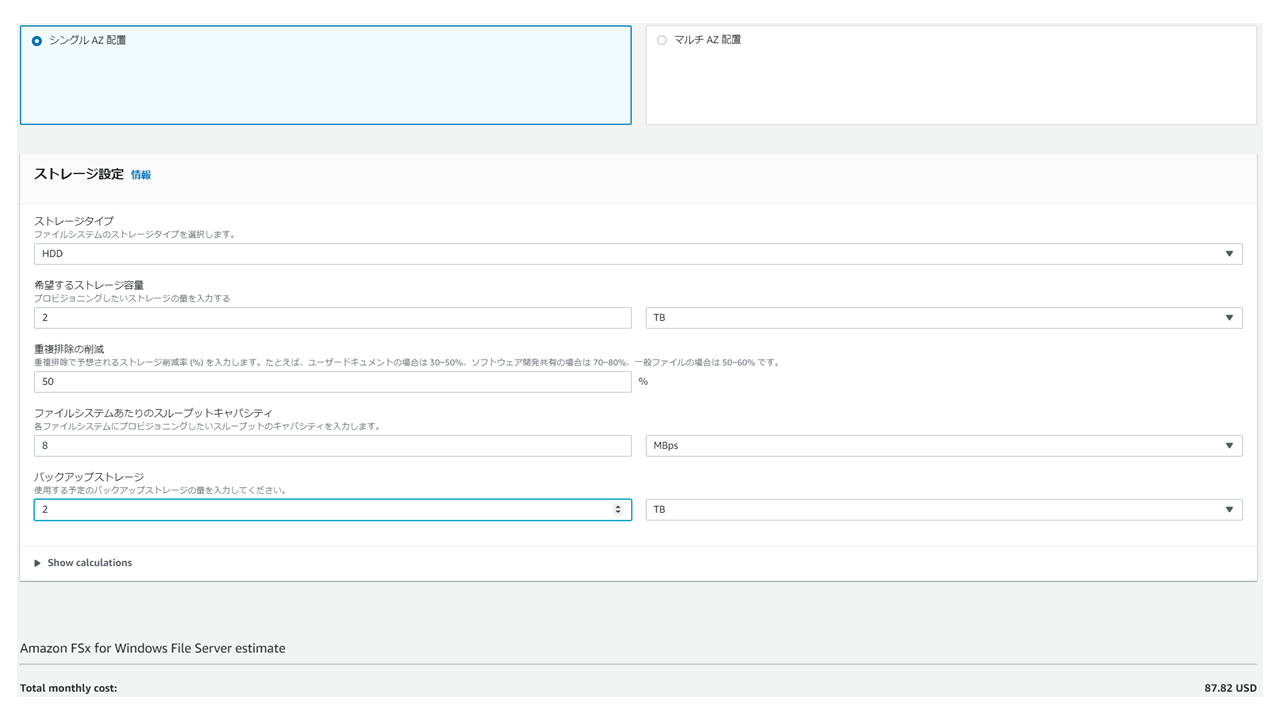
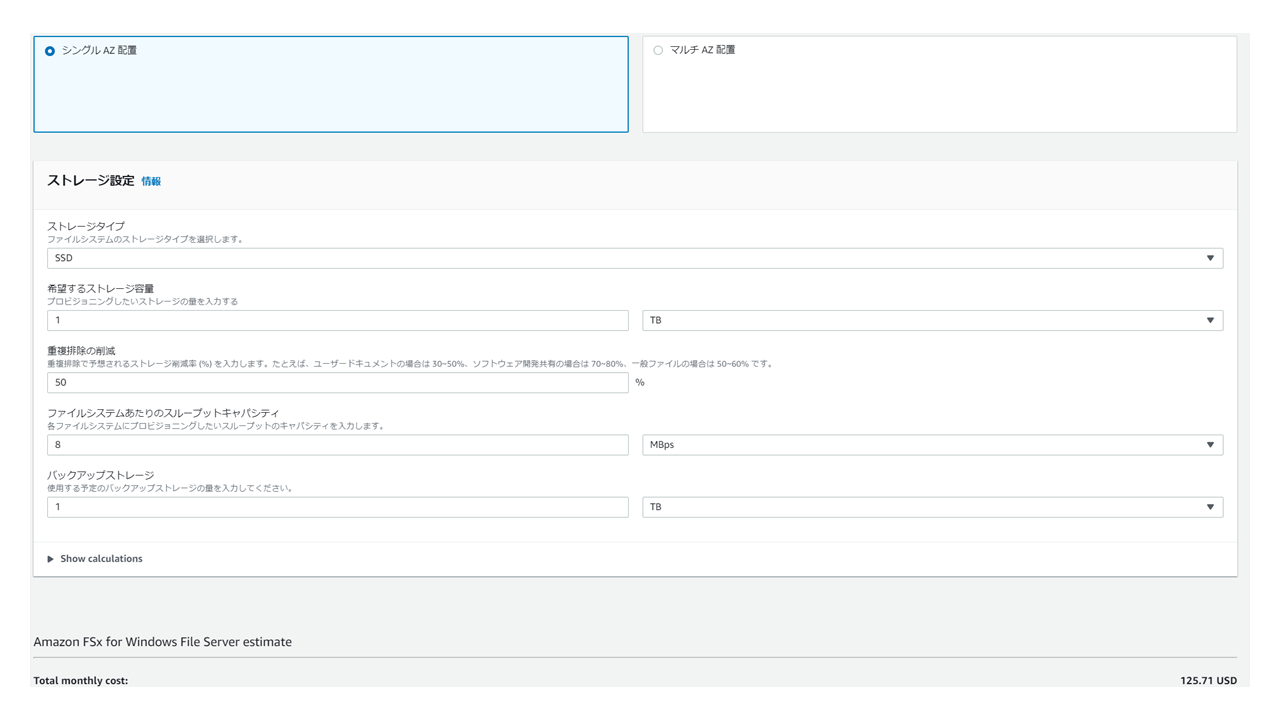
ストレージタイプはSSDとHDDがありますが、HDDがかなりお安いです。ただHDDタイプは2TB以上からの利用なのでご注意ください。
AWS Pricing Calculatorでコスト計算してみました。以下はHDD×2TB の費用です。
1ヵ月 = $87.82次にSSD×1TB の費用です。
1ヵ月 = $125.71HDD×2TBの方がSSD×1TBより$50近く安いです
オンプレからの移行の際には現状1TB未満のファイルサーバでも2TBのHDDタイプで設計したがコストは抑えられそうですね。HDDタイプにした場合のファイルアクセススピードがどんなもんなのかというもの気になるところです。
おまけ
せっかくなので、FSxでシャドウコピーも設定してみましょう。
まず、EC2(Windows インスタンス)をデプロイして、ドメイン参加させます。
参加できたら、ドメイン管理者でEC2へRDPして、ログインします。
ログインできたら、Powershellを管理者モードで起動して、以下コマンドを実行します。
ちなみのFsxのシャドウコピー設定はGUIでは設定できません。#日本語版AMIのEC2からだとコマンドを受付けないため、セッションの言語を英語指定にします PS C:\Windows\system32>$usSession = New-PSSessionOption -Culture en-US -UICulture en-US #ビルトインのセキュリティグループ FSxRemoteAdminのユーザ権限でセッション開始します PS C:\Windows\system32>enter-pssession -ComputerName "Windows Remote PowerShell Endpoint" -SessionOption $usSession -ConfigurationName FsxRemoteAdmin Windows Remote PowerShell Endpoint はFSxのコンソール画面に記載されているのでメモしておいてください。 #シャドウコピー設定をデフォルトの設定(シャドウコピーで使える容量は全体の10%)で有効化します ["Windows Remote PowerShell Endpoint"]: PS>Set-FsxShadowStorage -Default 以下のように表示されればOKです。 FSx Shadow Storage Configuration AllocatedSpace UsedSpace MaxSpace -------------- --------- -------- 0 0 3435973837 #手動でシャドウコピーを取得してみます ["Windows Remote PowerShell Endpoint"]: PS>New-FsxShadowCopy 以下のように表示されればOKです Shadow Copy {DEEBE366-F342-43B4-AD97-F366F1BEFC15} taken successfully. #シャドウコピーの容量を全体の50%に変更してみます ["Windows Remote PowerShell Endpoint"]: PS>Set-FsxShadowStorage -Maxsize "50%" AllocatedSpace UsedSpace MaxSpace -------------- --------- -------- 335544320 425984 17179869184 MaxSpaceがたしかに増えてますね! #デフォルト設定のコピー取得のスケジュールを確認します ["Windows Remote PowerShell Endpoint"]: PS>Set-FsxShadowCopySchedule -Default 以下のように質問されるので、とりあえず「y」で Confirm Are you sure you want to perform this action? Performing the operation "Confirm-Change" on target "Set-FSxShadowCopySchedule". [Y] Yes [A] Yes to All [N] No [L] No to All [?] ヘルプ (既定値は "Y"): y FSx Shadow Copy Schedule スケジュールが表示されました! Start Time Days of Week WeeksInterval ---------- ------------ ------------- 2020-07-27T07:00:00+00:00 Monday,Tuesday,Wednesday,Thursday,Friday 1 2020-07-27T12:00:00+00:00 Monday,Tuesday,Wednesday,Thursday,Friday 1参考にしたページ
- 投稿日:2020-07-29T22:31:30+09:00
【Amazon CloudWatch】アラームの設定





- 投稿日:2020-07-29T22:31:30+09:00
【Amazon CloudWatch】アラームの設定(※作成中)
- 投稿日:2020-07-29T20:37:56+09:00
【サーバーレス初心者向け】Serverless Framework + SwaggerでWeb APIを作る!第1回(全3回)
はじめに
こんにちは!
最近、仕事で初めてサーバーレスアプリを作る機会がありました。その際Serverless Frameworkを使ったのですが、結構お手軽にアプリを作ることができたので、初めてサーバーレスをする方にお勧めだと思いました。今回は自分の整理も兼ねてその手順を記事として残したいと思います。
今回はSwaggerをAPI Gatewayのテンプレートの一部として組み込む方法もご紹介したいと思います。
全部で記事が三つと長いですが、サーバーレスが初めての方でもAPIを構築できるように書きましたので、最後までご覧いただけたら嬉しいです。今回作るもの
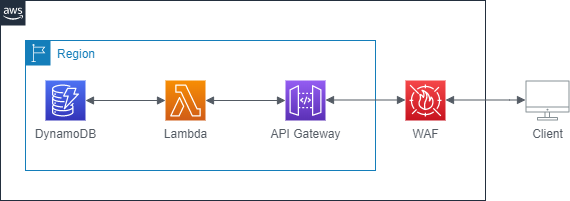
今回は以下のアーキテクト図のようなWeb APIバックエンドを作っていきます。
API GatewayでクライアントからのAPIリクエストを受信し、該当するLambda関数を呼び出し、必要に応じてDynamoDBからのデータ読み出しおよび書き込みを行います。さらに、WAFを適用することでセキュアにします。
APIとしては、ID・名前・身長・体重・年齢の情報を持つPersonモデルを登録・取得・更新・削除するAPIを作りたいと思います。
- GET dev/slsTestApp/v1/api/person/{id}
- POST dev/slsTestApp/v1/api/person
- PUT dev/slsTestApp/v1/api/person/{id}
- DELETE dev/slsTestApp/v1/api/person/{id}
第1回目の本記事では、具体的なAPIロジックは実装せず、簡単なメッセージを返すだけのLambda関数をバックエンドとするAPI Gatewayを作ります。WAFは第2回、DynamoDBを交えたロジック実装は第3回を予定しています。
Serverless FrameworkとSwagger
Serverless Frameworkとはサーバーレスアプリケーションの構成管理およびデプロイをするためのツールです。コマンド一つでデプロイできるため、とても使いやすいです。
SwaggerとはWeb APIの仕様を記述しドキュメント化するツールです。
本記事はSwaggerでAPI仕様を記載し、それをそのままAPI Gatewayのテンプレートとして取り込み、さらにそれをServerless Frameworkを使ってデプロイする一連の流れを解説したものです。Swaggerを使うことでAPIドキュメントがそのままインフラコードとして流用できるため、作業を効率化できます。
事前準備
今回はAWSにデプロイしますので、IAMユーザーの作成をお願いします。アカウントIDを後ほど使います。
環境構築
それではまずはクライアント側の環境構築を行っていきます。
使用する環境・ツールは以下の通りです。
環境
- Windows10
ツール
- Visual Studio Code v1.47.0
- Node.js v12.18.2
- AWS CLI v2
- Serverless framework v1.74.1
- Swagger Viewer v3.0.1
VSCode(Visual Studio Code)のインストール
今回はエディターとしてVisual Studio Codeを使用します。以下のリンクからインストールします。
Visual Studio CodeダウンロードNode.jsのインストール
Serverless Frameworkはnpmパッケージとして公開されていますので、インストールするためにはNode.jsが必要となります。以下のリンク先から皆さんの環境にあうインストーラーをダウンロードし実行してください。
AWS CLIのインストール
以下からインストールします。
インストール後、どこでもよいので適当な場所でコマンドプロンプトを起動し、以下のコマンドを実行して皆さんがお持ちのIAMユーザーの情報を登録してください。
> aws configure AWS Access Key ID [None]: [自身のアクセスキーID] AWS Secret Access Key [None]: [自身のアクセスキー] Default region name [None]: ap-northeast-1 Default output format [None]:Serverless Frameworkのインストール
どこでもよいので適当な場所でコマンドプロンプトを開き、以下のコマンドを実行してインストールします。
ちなみに、以下のコマンドの中で -g オプションを指定しているのは、グローバルに(どこでも使えるように)インストールするためです。> npm install -g serverlessインストールが完了したら、以下のコマンドを実行します。
> serverlessすると、アプリを作る言語を何にするか聞かれます。今回はNode.jsを選択します。
> Serverless: What do you want to make? AWS Node.jsそのあと、作成するプロジェクトフォルダ名を何にするか聞かれますので、お好きな名前を設定してください。
> What do you want to call this project? test最後に「serverless frameworkのアカウントを作るか?」と聞かれます。今回はアカウントを作らないのでNoを選択します。
You can monitor, troubleshoot, and test your new service with a free Serverless account. Serverless: Would you like to enable this? NoこれでServerless frameworkのインストールは完了です。
Swagger Viewerのインストール
最後に、Swagger Viewerをインストールします。こちらはVSCodeのプラグインとして用意されています。
まず、VSCodeを起動し、Ctrl+Shift+Xでプラグインの検索窓を起動します。「Swagger Viewwer」と入力するとSwagger Viewerが見つかると思いますので、インストールボタンをクリックします。
これで、必要な環境は準備できました!
Serverless Frameworkの仕組み
本題に入る前にServerless Frameworkのデプロイの仕組みを簡単に説明します。
Serverless Frameworkはyml形式のテンプレートファイルに記載した内容をCloudFormationテンプレートに変換し、CloudFormationを実行することでAWSへサービスをデプロイします。
デプロイコマンドを実行すると、ローカルにある必要なファイルをCloudFormationテンプレートに変換後、zip化しS3のバケットに配置します。それをソースとしてCloudFormationを実行します。この時、AWS CLIに設定されたシークレット情報を参照しデプロイを行います。これがあるため、事前準備でAWS CLIをインストールしました。Lambda関数をデプロイしてみる
では早速本題に入っていきます!
まずはHTTPリクエストなどは考えない簡単なLambda関数を実装しデプロイするところまでやってみます。
Serverlessアプリインストール時に指定したディレクトリに移動してみると、以下のファイルが作成されていると思います。
- .gitignore → Gitの管理対象としないディレクトリ・ファイルを指定
- handler.js → Lambda関数の記述したファイル
- serverless.yml → Serverless Frameworkの定義ファイル
.gitignoreは今はそのままで結構です。ここではhandler.jsとserverless.ymlを修正していきます。
handler.js
今は以下のようになっていると思います。
handler.js(変更前)'use strict'; module.exports.hello = async event => { return { statusCode: 200, body: JSON.stringify( { message: 'Go Serverless v1.0! Your function executed successfully!', input: event, }, null, 2 ), }; // Use this code if you don't use the http event with the LAMBDA-PROXY integration // return { message: 'Go Serverless v1.0! Your function executed successfully!', event }; };上記はHttpリクエストを受け取ることを前提したコードになっています。しかし前述の通りまずはHTTPリクエストなどは考えないため、既存の部分はコメントアウトして以下のように受け取ったeventとともにシンプルにメッセージをリターンするだけの実装に変えます。
handler.js(変更後)"use strict"; module.exports.hello = async (event) => { return { message: "Go Serverless v1.0! Your function executed successfully!", event, }; /* return { statusCode: 200, body: JSON.stringify( { message: 'Go Serverless v1.0! Your function executed successfully!', input: event, }, null, 2 ), };*/ // Use this code if you don't use the http event with the LAMBDA-PROXY integration // return { message: 'Go Serverless v1.0! Your function executed successfully!', event }; };serverless.yml
今は以下のようになっていると思います。
serverless.yml(変更前)# Welcome to Serverless! # # 中略 # Happy Coding! service: slsTestApp # 中略 provider: name: aws runtime: nodejs12.x # you can overwrite defaults here # stage: dev # region: us-east-1 # 中略 functions: hello: handler: handler.hello # The following are a few example events you can configure # NOTE: Please make sure to change your handler code to work with those events #中略主要な個所について説明していきます。
まず
service:の部分ですが、ここにデプロイするスタック名を定義します。今はserverlessコマンドを実行したときに指定したプロジェクト名がそのまま入っていると思います。serverless(抜粋)service: slsTestApp最終的なスタック名は
servie:にデプロイ対象のstageがハイフンで連結されたものになります。なので上記の例だとdev stageにデプロイした場合はスタック名はslsTestApp-devとなります。次に
provider:ですが、こちらはデプロイする対象のクラウドプラットフォーム名とLambda関数を実装する言語の設定が記載されています。今回の場合はAWSとnode.jsなので、そのようになっていますね。serverless.yml(抜粋)provider: name: aws runtime: nodejs12.x # you can overwrite defaults here # stage: dev # region: ap-northeast-1最後に
functions:の部分です。ここで実装したLambda関数の定義を記載しています。
一つインデントを下げて任意の属性名を記載し、handler:にはLambda関数名を記載します。今回はhander.js内のhello関数を呼び出すので、hander.helloと記載さています。serverless.yml(抜粋)functions: hello: handler: handler.helloでは、serverless.ymlを少し修正していきます。
初めに、Serverless Frameworkでデプロイするstage名とリージョンのデフォルト値を設定します。provider:下の# you can overwrite defaults here直下二行のコメントアウトを外し、以下のように記載します。これで、デフォルトでap-northeast-1リージョンにdevステージとしてデプロイされるようになります。serverless.yml(抜粋、修正後)provider: name: aws runtime: nodejs12.x # you can overwrite defaults here stage: dev region: ap-northeast-1次にhello関数の定義に少し追加します。
name:とdescription:を追加し、hello関数の名前と説明を記載してみてください。serverless.yml(抜粋、修正後)functions: hello: handler: handler.hello name: "slsTestApp-hello-${self:provider.stage}" description: "This function is test app."ここで、
name:に${self:provider.stage}という文字列がありますが、これは変数指定の書き方です。先ほどのprovider:のstage:に指定した値を変数として使用する書き方になります。こうすることで、stageごとにLambda関数を出しわけることができます。では、試しにデプロイしてみます。serverless.ymlと同じ階層で以下のコマンドを実行してみてください。
-vオプションをつけることで途中経過がコンソールに表示されるようになります。sls deploy -v以下のように
Stack Outputsが最後に表示されればデプロイ成功です!functions: hello: slsTestApp-hello-dev layers: None Stack Outputs HelloLambdaFunctionQualifiedArn: … ServerlessDeploymentBucketName: …では、デプロイされたLambda関数を見てみましょう。
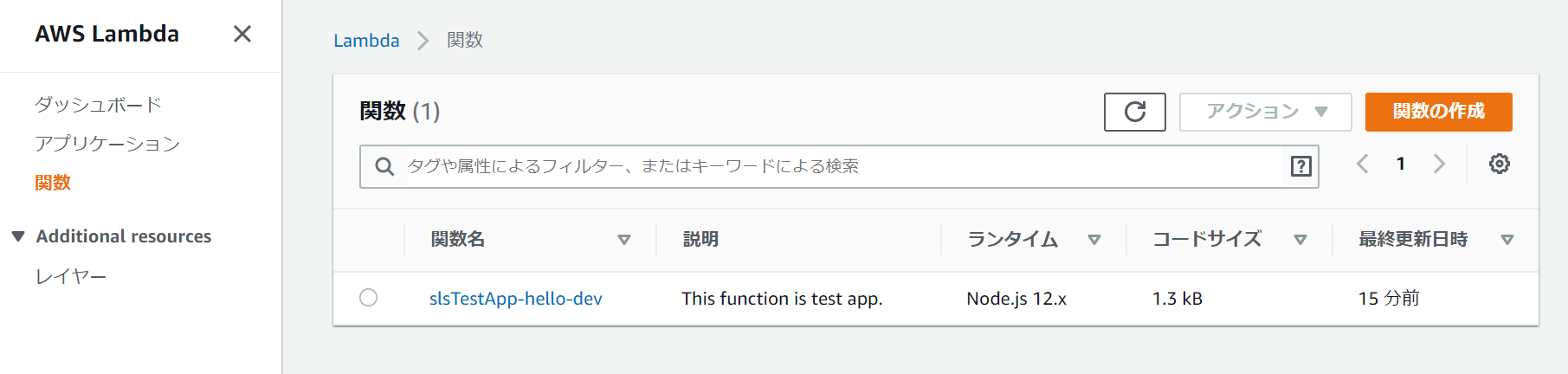
AWSマネージメントコンソールにログインし、Lambdaのページの「関数」メニューを選択します。すると、serverless.ymlで設定したLambda関数が表示されていると思います。
関数をクリックし、Lambda関数の詳細画面を表示します。この画面でLambda関数のテストをすることができますので、やってみます。
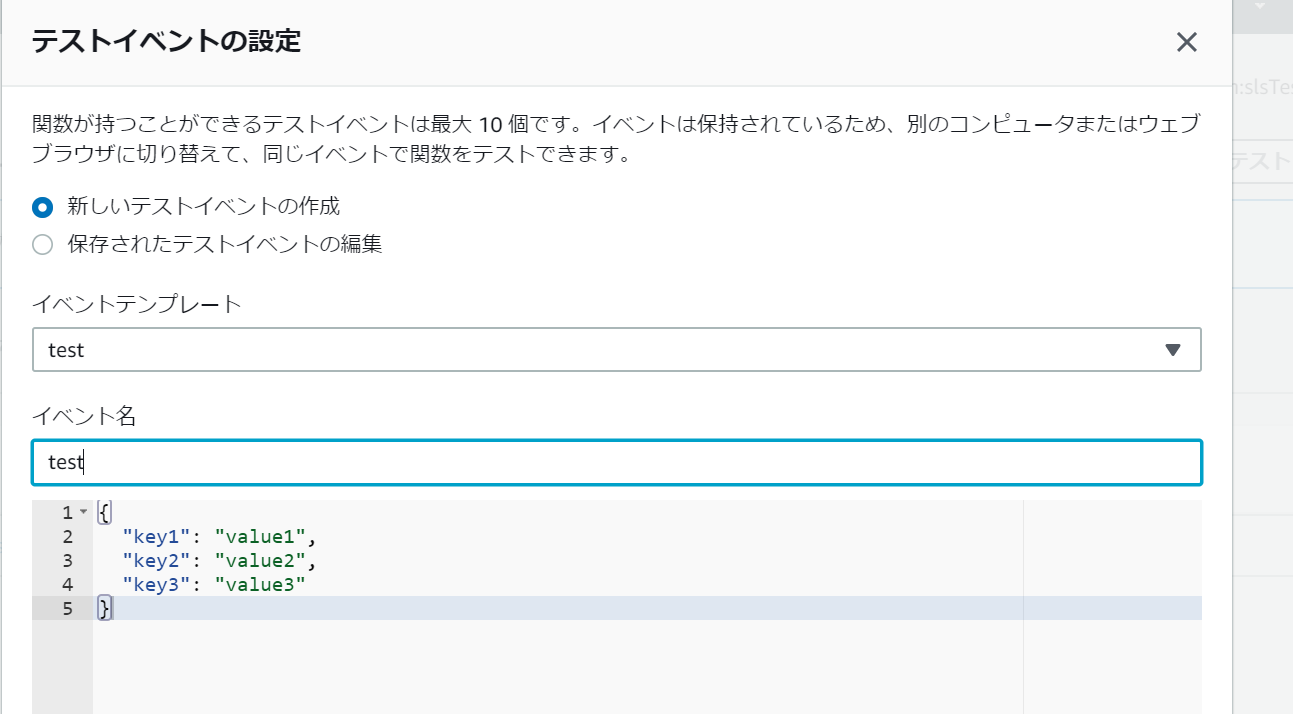
右上の「テストイベントの選択」をクリックし、「テストイベントの設定」をクリックします。
すると、テストで流し込むテストデータの設定画面が表示されます。
任意のイベント名を入力し、それ以外はデフォルトで保存します。
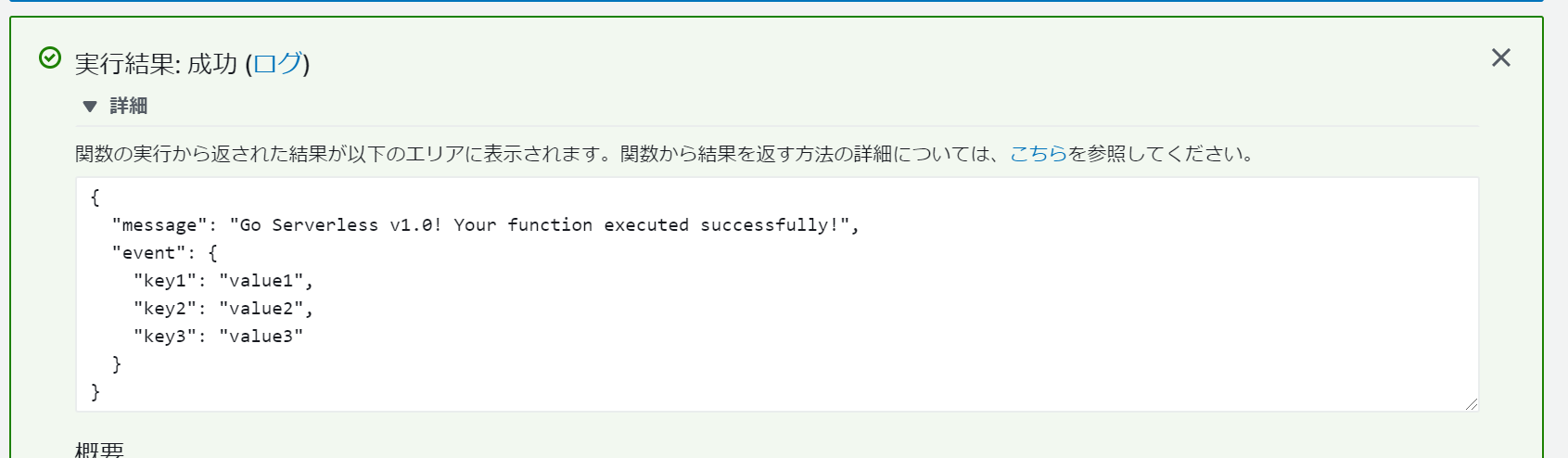
保存したら、「テスト」ボタンをクリックし実行します。
以下のような結果になれば成功です!
Swaggerテンプレートを作る
Lambda関数をServerless Frameworkを使ってデプロイするところまでできました。
次はAPIの実装を行っていくのですが、まずはSwaggerでAPIの仕様を書いてみましょう。
まずは、名前はなんでもよいのでAPI定義を記載するyamlファイルを作成してください。
私はtemplatesというフォルダを作りその下に「swagger.yaml」として作りました。こちらに定義を書いていきます。
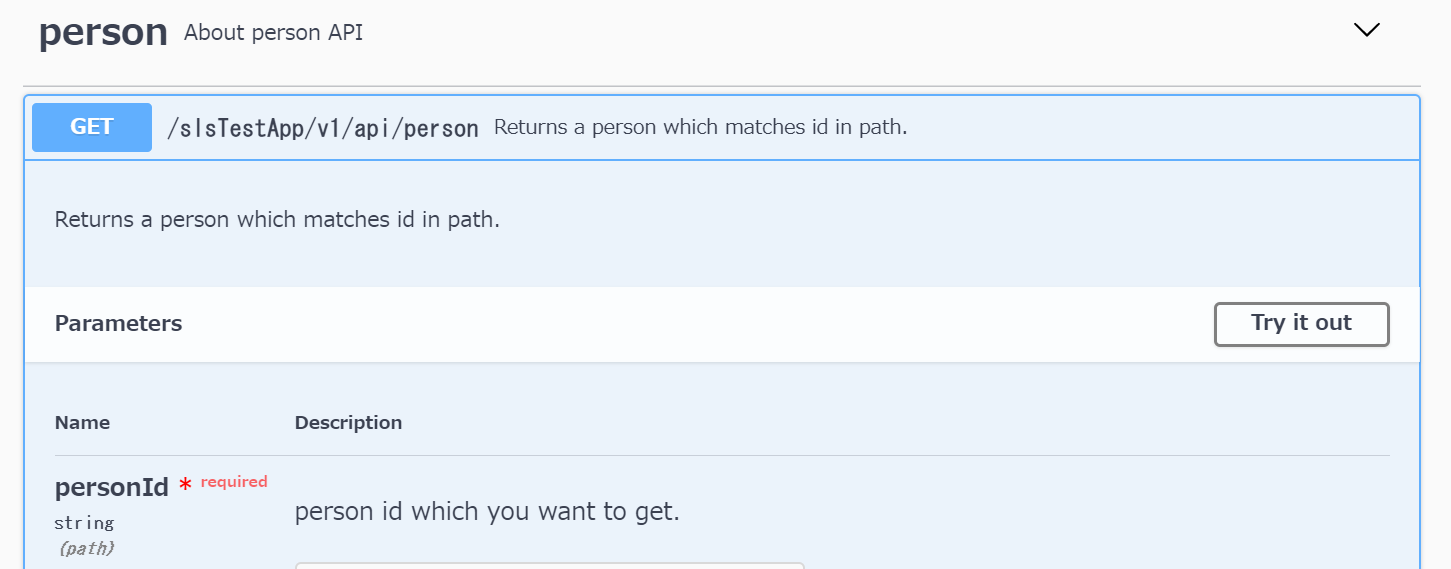
swaggerの書き方を解説しようと思いましたが、すでにわかりやすい記事がありましたので、こちらをご参照ください。今回つくるもので記載したAPIのうち、GET APIの定義を書いたものが以下になります。
swagger.yamlswagger: "2.0" info: title: slsTestApp API description: API description of slsTestApp. version: 1.0.0 host: api.example.com basePath: /dev schemes: - https tags: - name: person description: About person API produces: - application/json consumes: - application/json paths: /slsTestApp/v1/api/person: get: summary: Returns a person which matches id in path. description: Returns a person which matches id in path. tags: - person parameters: - name: personId in: path description: person id which you want to get. required: true type: "string" responses: 200: description: OK schema: $ref: "#/definitions/producePersonModel" 404: description: Not Found schema: $ref: "#/definitions/error" definitions: consumePersonModel: type: object properties: name: type: "string" weight: type: "string" age: type: "string" producePersonModel: type: object properties: personId: type: "string" name: type: "string" weight: type: "string" age: type: "string" error: type: object properties: errorCode: type: "string" errorMessage: type: "string"これをプレビューするには、VSCode上でF1キーを押し、
Preview Swaggerと入力しEnterを押します。以下のような画面が表示されると思います。
Swagger定義を取り込んだAPI Gatewayのデプロイ
先ほど作ったSwaggerをAPI Gatewayのテンプレートとして取り込みデプロイするかを解説していきます。
やることは大きく以下の四つです。
- hello関数の修正
- swagger.yamlにAPI Gateway統合の設定を追記する
- API Gatewayのテンプレートファイルを作成する(Bodyにswaggerファイルを指定)
- serverless.ymlにテンプレートファイルへのパスを記載する
hello関数の修正
先ほどデプロイしたhello関数をHttpリクエストを受け付けられるように変更していきます。
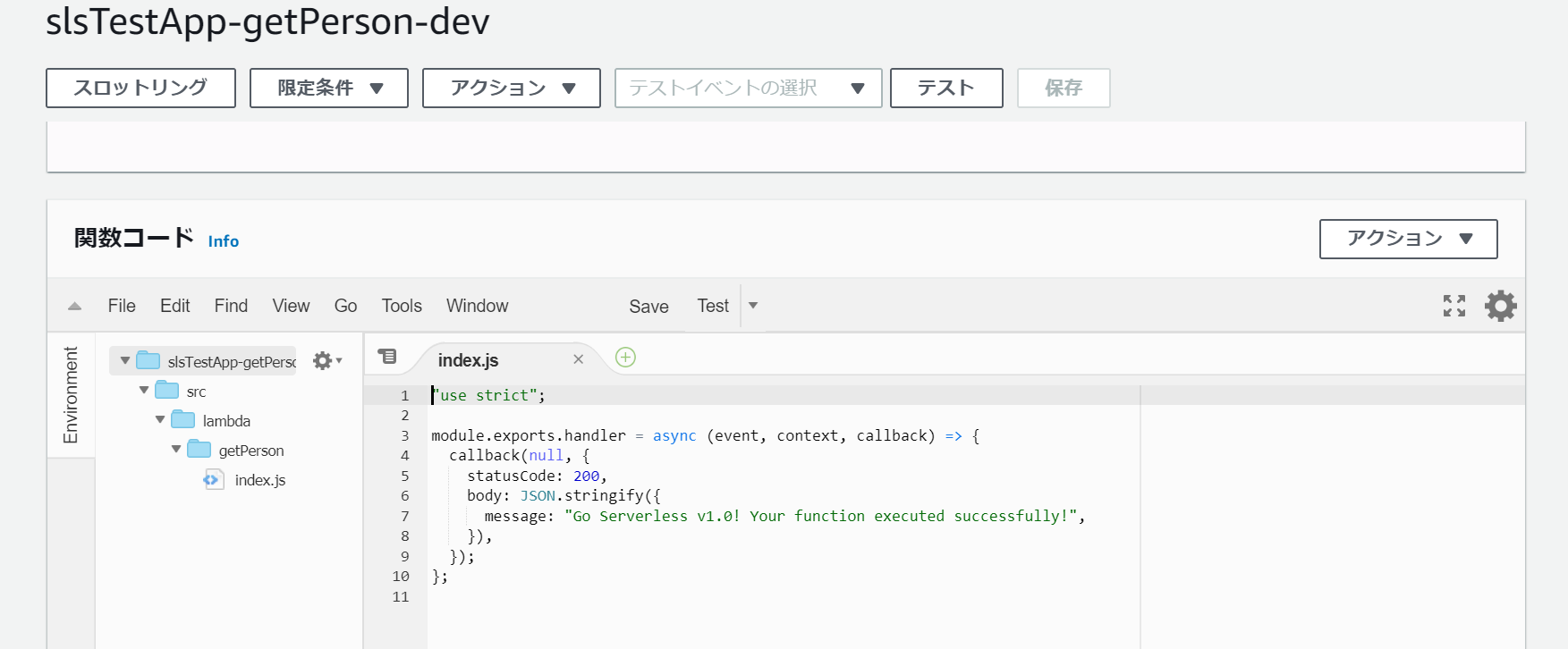
まずはsrc/lamda/getPersonフォルダを作成し、そこにhandler.jsを移動します。さらに、handler.jsからindex.jsに変更し、関数名もhelloからhandlerに変えます。個人的にわかりやすい構成に変えているだけですので、必ずしもこれに倣う必要はありません。
さらに実装を以下のように変更します。これでindex関数が呼ばれるとcallback内のstatusCodeとbodyが返却されるようになります。src/lambda/getPerson/index.js"use strict"; module.exports.handler = async (event, context, callback) => { callback(null, { statusCode: 200, body: JSON.stringify({ message: "Go Serverless v1.0! Your function executed successfully!", }), }); };ファイルパスと関数名を変更したので、serverless.ymlも修正していきましょう。私と同じファイルパス、関数名にした場合は以下のようになります。違う名前にした場合はそちらに変更してください。
serverless.yml(抜粋)functions: getPerson: handler: src/lambda/getPerson/index.handler name: "slsTestApp-getPerson-${self:provider.stage}" description: "This function is test app."ここまでできたら、一度デプロイしておきましょう。
sls deploy -vswagger.yamlにAPI Gateway統合の設定を追記する
swagger.yamlにAPI Gateway統合の設定を記載していきます。今回は最低限の設定のみ記載することとします。
以下のようにメソッド定義の下に
x-amazon-apigateway-integration:を記載し、必要なプロパティを設定していきます。swagger.yaml(抜粋)/slsTestApp/v1/api/person: get: summary: Returns a person which matches id in path. #中略 x-amazon-apigateway-integration: type: aws_proxy responses: default: statusCode: "200" uri: "arn:aws:apigateway:ap-northeast-1:lambda:path/2015-03-31/functions/arn:aws:lambda:ap-northeast-1:{Your Account ID}:function:{Lambda function name}/invocations" passthroughBehavior: "when_no_match" httpMethod: "POST" contentHandling: "CONVERT_TO_TEXT"簡単に解説します。
属性名 説明 type API Gatewayとの統合タイプを指定します。今回はAPI Gatewayのリクエスト処理をするのがLambda関数なので、 aws_proxyを設定しますresponse APIレスポンスのオブジェクトを指定します。今回は細かく設定しないので、上記のコード例のようにしています uri APIのバックエンドのエンドポイントを指定します。今回はLambda関数のuriを指定しています。上記のコード例にAWS Account IDとLambda関数名を入れてください。 httpMethod 呼び出されるHttpメソッドを指定しますが、Lambda関数をバックエンドとして使う場合は常に POSTを指定しますcontentHandling リクエストのペイロードのエンコードタイプを指定します。今回はテキストとして扱いたいので CONVERT_TO_TEXTを指定しますこれでswagger.yamlの修正は完了です。
uri:のAWS Account IDと関数名はみなさんが設定したものを入力してくださいね。API Gatewayのテンプレートファイルを作成する
API GatewayのCloudFormationのテンプレートファイルを作っていきます。
API Gatewayのデプロイには二段階あります。一つはリソース(API定義)のデプロイ、もう一つはデプロイしたリソースをステージにデプロイすることです。ステージにデプロイすることでAPIがweb経由で利用できるようになります。
今回のテンプレートではリソースのデプロイとdev ステージへのリソースデプロイを同時に行うテンプレートを作成します。
templates/に以下のテンプレートファイルを作成します。api-gateway.ymlResources: ApiGatewayRestApi: Type: "AWS::ApiGateway::RestApi" Properties: Body: ${file(./templates/swagger.yaml)} GetPersonApiPermission: Type: "AWS::Lambda::Permission" Properties: FunctionName: "slsTestApp-getPerson-${self:provider.stage}" Action: "lambda:InvokeFunction" Principal: "apigateway.amazonaws.com" ApiGatewayDeployment: Type: AWS::ApiGateway::Deployment Properties: RestApiId: Ref: ApiGatewayRestApi StageName: ${self:provider.stage}
リソース名 説明 ApiGatewayRestApi API Gateway自体のリソース定義です。Bodyには先ほどのswagger.yamlへのパスを記載します GetPersonApiPermission API GatewayからLambda関数を実行するための権限です。 FunctionNameをserverless.ymlの関数名と一致させますApiGatewayDeployment API GatewayのAPI定義をステージへデプロイするための設定です これでAPI Gatewayのテンプレート作成が完了しました。swagger定義を取り込んだAPI Gatewayが作成されるようになります。
serverless.ymlにテンプレートファイルへのパスを記載する
serverless.ymlに先ほど作成したAPI Gatewayのテンプレートファイルへのパスを記載していきます。
以下のようにresourcesに配列形式でテンプレートファイルへのパスを記載します。serverless.yml(抜粋)# you can add CloudFormation resource templates here resources: - ${file(./templates/api-gateway.yml)}これで準備は整いました!ではデプロイしてみましょう。
sls deploy -v動作確認
これでGET APIが実装されているはずですので、実際にAPIを実行してみたいと思います。
まずは、API GatewayのURLをAWSマネージメントコンソールから調べます。
API Gatewayのメニューを開くと先ほどデプロイしたAPI Gatewayがあると思いますので、そちらをクリックします。
左のメニューから「ステージ」を選択し、中央に表示される「dev」をクリックすると、右にURLが表示されます。これにswaggerで定義したURIを連結したものが、最終的なAPIのURIとなります。
このURLをコピーしておきます。
では、動作確認をしてみましょう。今回はcurlコマンドを使います(別途インストールが必要です)。
以下のコマンドを実行します。
curl GET https://{Your Api gateway Id}.execute-api.ap-northeast-1.amazonaws.com/dev/slsTestApp/v1/api/person以下のようなレスポンスが返ってくれば成功です。
{"message":"Go Serverless v1.0! Your function executed successfully!"}Lambdaのデプロイパッケージを削減する
AWSマネージメントコンソールでLambda関数を見てみると、関数の欄が以下のようになっていると思います。
これはLambda関数の実行には本来不要なほかのコードも含まれてしまっているからです。
これを防ぐには、serverless.ymlにexclude設定を追加し、不要なファイルがパッケージされないようにします。
serverless.yml(抜粋)# you can add packaging information here package: exclude: - docs/** - node_modules/** - templates/** - .eslintrc.json - LICENSE - README.md - package-lock.jsonもう一回デプロイしてみると、以下のように必要なものだけパッケージされてるのが分かります。
デプロイしたリソースの削除
デプロイしたAPI GatewayにはまだWAFを適用していないので、だれでもAPIにアクセスできる状態です。使っていないときはデプロイしたリソースを削除しておきましょう。
削除するときは以下のコマンドを実行します。
sls remove再デプロイ時の注意点
再デプロイすると、デプロイに失敗すると思います。
これは、Lambda関数がデプロイされる前にAPI Gatewayがデプロイされるため、API Gatewayで参照されているLambda関数がないためエラーになっています。
ちゃんとした解決策はあると思いますが、ひとまず今は最初にserverless.yml内でapi-gateway.ymlを読み込んでいる箇所をコメントアウトして一度デプロイし、そのあとにコメントアウトを外してデプロイしてみてください。おわりに
今回はごく簡単なメッセージを返すだけのLambda関数を実行するAPIを作りました。
バックエンドの大枠はできつつあるので、次回はWAFを適用し、特定のIPからしかAPIにアクセスできないようにします。

- 投稿日:2020-07-29T18:29:10+09:00
Red Hat OKD4 on AWS を使って見た
OKD4 が 2020年7月にGAとなった。ドキュメントを読むかぎり、Minishiftとは大きく異なり、ハイブリッドクラウドを意識した内容となっているので、実際に動かしてみることにした。
OKD4 は、The Origin Community Distribution of Kubernetes の略とされる(なんか順番違うけど)。OpenShift v4 の大部分の上流となっているオープンソースプロジェクト Origin から配布される。これは Apache License, Version 2.0. で配布されるオープンソースである。
ダウンロード
パソコンに、ocコマンドがインストールされていれば、以下のコマンドでダウンロードすることができる。
$ oc adm release extract --tools quay.io/openshift/okd:4.5.0-0.okd-2020-07-14-153706-gaバイナリをブラウザでダウンロードする場合は、https://github.com/openshift/okd/releases から入手できる。
インストールの実行
OKD4のインストールは、自身のパソコンにインストールするのではなく、Terraform を利用して、AWS, Azure, GCP, RHV, vSphere, OpenStack、そして、ベアメタルなどにインストールする。 今回はAWSを利用して検証した。
先にダウンロードしたファイルを展開すると、
openshift-installコマンドが出てくるので、/usr/local/binなど配置して、シェルから利用できるようにする。AWSの事前準備
以下の条件を満たす必要がある。特にドメイン名を取得する必要がるので、最安レベルでも $9.00 程度の費用が発生する。
- AWSにアカウントを持っておりログイン可能であること。
- Route 53 パブリックでアクセス可能なドメインを持っていること。
- AWSのCLIコマンド aws がセットアップされていること。
- VPC設定があり、インターネットGW、サブネットなど、必要な内容が設定されていること。
インストールコマンドの実行
上記の条件が整っていないと、次のコマンドが動作しない。それから、インストールを開始してから完了するまでに、およそ40分を要したことから、時間的に余裕がある時に実施した方が良い。対話式で必要な項目を要求するので、順番に従ってインストールする。 質問の中で
Pull Secretの入力を要求するところには、{"auths":{"fake":{"auth": "bar"}}}をインプットすれば良い。これで待っているだけで、マスターノードx3、ワーカーノード x3 のクラスタが出来上がる。$ openshift-install create cluster ? Platform aws INFO Credentials loaded from the "default" profile in file "/Users/maho/.aws/credentials" ? Region ap-northeast-1 ? Base Domain takara-teck.uk ? Cluster Name okd4-1 ? Pull Secret [? for help] ********************************** INFO Creating infrastructure resources... INFO API v1.18.3 up INFO Waiting up to 40m0s for bootstrapping to complete... INFO Destroying the bootstrap resources... INFO Waiting up to 30m0s for the cluster at https://api.okd4-1.takara-teck.uk:6443 to initialize... INFO Waiting up to 10m0s for the openshift-console route to be created... INFO Install complete! INFO To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/Users/maho/openshift/auth/kubeconfig' INFO Access the OpenShift web-console here: https://console-openshift-console.apps.okd4-1.takara-teck.uk INFO Login to the console with user: "kubeadmin", and password: "****-****-*****-*****" INFO Time elapsed: 38m2s完了時のAWSコンソール画面は次のようになっている。 m4.xlargeだと月額2万くらいなので、全部で10万円/月くらいの料金となる。
OKD4 クラスタへのアクセス
インストールコマンドを実行したディレクトリに、認証情報がダウンロードされるので、環境変数 KUBECONFIG にパスを設定することで、ocコマンド、または、kubectl コマンドからクラスタへアクセスすることができる。 OCPではバージョンが少し遅れるが、OKDではかなり新しい。
$ export KUBECONFIG=`pwd`/auth/kubeconfig $ oc get node NAME STATUS ROLES AGE VERSION ip-10-0-138-142.ap-northeast-1.compute.internal Ready worker 17m v1.18.3 ip-10-0-145-133.ap-northeast-1.compute.internal Ready master 32m v1.18.3 ip-10-0-161-71.ap-northeast-1.compute.internal Ready master 32m v1.18.3 ip-10-0-170-100.ap-northeast-1.compute.internal Ready worker 18m v1.18.3 ip-10-0-193-251.ap-northeast-1.compute.internal Ready worker 18m v1.18.3 ip-10-0-194-197.ap-northeast-1.compute.internal Ready master 32m v1.18.3ウェブコンソールへのアクセス
ウェブ画面へのアクセスも、インストールコマンドのアウトプットにURLとパスワードが表示されているので、その表示に従ってアクセスすれば良い。
ログイン後は、OCPv4と同じと思って良い。
AWSとの連動程度を確認
高良執筆の本で利用しているサンプルのマニフェストを実行することで、AWSのロードバランサーと連携しているか確認してみる。
$ git clone https://github.com/takara9/codes_for_lessons $ cd codes_for_lessons/step09 $ ls -al total 72 drwxr-xr-x 11 maho staff 352 7 29 17:13 . drwxr-xr-x 17 maho staff 544 7 29 17:13 .. -rw-r--r-- 1 maho staff 2593 7 29 17:13 README.md -rw-r--r-- 1 maho staff 423 7 29 17:13 deploy.yml -rw-r--r-- 1 maho staff 112 7 29 17:13 svc-ext-dns.yml -rw-r--r-- 1 maho staff 120 7 29 17:13 svc-ext.yml -rw-r--r-- 1 maho staff 196 7 29 17:13 svc-headless.yml -rw-r--r-- 1 maho staff 175 7 29 17:13 svc-lb.yml -rw-r--r-- 1 maho staff 150 7 29 17:13 svc-np.yml -rw-r--r-- 1 maho staff 158 7 29 17:13 svc-sa.yml -rw-r--r-- 1 maho staff 244 7 29 17:13 svc.ymlNginxのポッドをデプロイしたあと、type=LoadBalancer のサービスをデプロイする。このLoadBalancerはクラウドサービスのロードバランサーのデプロイをリクエストする。
以下の通り、結果は、ELBがデプロイされ、DNS名でアクセスできるようになった。
maho:step09 maho$ oc apply -f deploy.yml deployment.apps/web-deploy created maho:step09 maho$ oc apply -f svc-lb.yml service/web-service-lb created maho:step09 maho$ oc get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 172.30.0.1 <none> 443/TCP 66m openshift ExternalName <none> kubernetes.default.svc.cluster.local <none> 51m web-service-lb LoadBalancer 172.30.243.5 a97b7ba2627d64bfcaca4880ed09b3e9-1916899538.ap-northeast-1.elb.amazonaws.com 80:30941/TCP 6sDNSへ追加されたロードバランサーの情報が安定したところで、curlコマンドでアクセスを試みる。問題なくアクセスできた。
maho:step09 maho$ curl http://a97b7ba2627d64bfcaca4880ed09b3e9-1916899538.ap-northeast-1.elb.amazonaws.com <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <以下省略>永続ボリュームの利用
PVCをデプロイしてみたが、権限が不足しているためか、Pending状態から先へ進むことがなかった。 ストレージクラスにはAWS EBS用のプロビジョナーが組み込まれているが、問題解決は料金がかかるので見送る。
$ oc get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-pvc-1 Pending gp2 78m $ oc get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE gp2 (default) kubernetes.io/aws-ebs Delete WaitForFirstConsumer true 118mクリーンナップ
次のコマンドで、EC2インスタンスを消去できる。
$ openshift-install destroy cluster INFO Credentials loaded from the "default" profile in file "/Users/maho/.aws/credentials" INFO Disassociated instance=i-0c17651e19a37ab61 name=okd4-1-k446v-worker-profile role=okd4-1-k446v-worker-role INFO Deleted InstanceProfileName=okd4-1-k446v-worker-profile arn="arn:aws:iam::102321567306:instance-profile/okd4-1-k446v-worker-profile" instance=i-0c17651e19a37ab61 INFO Disassociated instance=i-0926f0a10b0442c39 name=okd4-1-k446v-master-profile role=okd4-1-k446v-master-role INFO Deleted InstanceProfileName=okd4-1-k446v-master-profile arn="arn:aws:iam::102321567306:instance-profile/okd4-1-k446v-master-profile" instance=i-0926f0a10b0442c39 <以下省略>まとめ
OKD4 は Minishitの流れを組み、個人がパソコンを使って自己研鑽で利用できる環境と考えていたが、クラウドやオンプレミスの仮想環境で利用するものであり、デフォルト設定では月額10万程度必要な、本格的な構成が出来上がってしまう。
これは凄い! ユーザー企業で OCPv4 の予算を確保するための効果測定の検証であれば、OKD4を利用しても良いのではと思ってしまう。もちろん、OCP4とOKD4は全く同じソフトウェアではないので、あくまでも代用品である。
FAQには、シングルノードのクラスタを構築できるとあるので、次回に試してみたい。
参考資料
[1] OKD Latest Documentation, https://docs.okd.io/latest/installing/installing_aws/installing-aws-default.html
[2] https://github.com/openshift/okd/releases
[3] https://github.com/openshift/okd#getting-started

- 投稿日:2020-07-29T18:11:35+09:00
DjangoをEC2にデプロイしてわかった事
はじめに
今までクラウドプラットフォームはHerokuを使っていたのですがEC2に移行する機会があったので移行作業中に躓いたところの解決策と、EC2にwebアプリをデプロイする上での注意点等についてまとめました。
今回は以下のディレクトリ構造を想定しています
root ├── etc │ └── systemd │ └── system │ └── sampled.service └── home └── ubuntu └── sample └── sample.pyまた1分おきに"OK"を出力するPythonプログラムです
sample.py#!/usr/bin/env python3 import syslog from apscheduler.schedulers.blocking import BlockingScheduler sched = BlockingScheduler() @sched.scheduled_job("interval", minutes=1) def sample(): syslog.syslog("OK") sched.start()余談: AWSアカウントがすぐに作れなかった
自分の場合は電話認証でエラーが出て先に進めなかった為サポートケースを作って対応してもらいました。
結局コールセンターから電話で手動手続きになってアカウントが使用可能になるまで1週間近くかかったのでエラーが出たら直ぐにサポートケースを作って対応してもらいましょう!
EC2インスタンス作るときの注意点
まずEC2インスタンスを作るときの注意点について書いていきます。
EC2インスタンスを作る時、使用するAMIを選択するのですが基本的にはAmazon Linux系を選ぶのがベターですがこれによって後に紹介するデーモンプロセスの作り方が変わってきます。
なので何かしらのサイトを参照しながらデプロイする際はまずどのAMIを使用しているか確認した上で作業を進めましょう!
デーモン化行う際の注意点
次にプログラムのデーモン化で注意すべき点です。
先ほど書いたように使用するAMIによって作り方が変わる部分になります。
今回はUbuntu20.04を使用したためプログラムをデーモン化するためのサービス設定ファイルは以下の場所になっていました。
使用するAMIによって異なる Ubuntu: /etc/systemd/system/sampled.serviceデーモンの環境変数
次にデーモンで環境変数を扱う際の注意点です。
デーモンの環境変数設定が作業を進める際1番躓いた点です。
基本的にターミナルからプログラムを動作させる分には以下のコマンドを打ち込めば問題ないです。
$ SAMPLE=123456789 $ export SAMPLE $ echo $SAMPLE >>> 123456789また環境変数を永続化させたい場合は
sudo vi /etc/profileで設定したい環境変数を以下のように列挙していけば次回起動時から適用されます。
/etc/profileSAMPLE=123456789 export SAMPLEしかし!!
デーモンではこれらの環境変数は読み込まれません <<< ここ重要!!
なのでデーモン専用の環境変数設定を以下のように作りましょう
/etc/sysconfig/sampled_envSAMPLE=123456789また指定した環境変数をデーモンで読み込ませるためにサービス設定に追記します。
/etc/systemd/system/sampled.service''' 省略 ''' [Service] #追記 EnvironmentFile=/etc/sysconfig/sampled_env ''' 省略 '''その後以下のコマンドを打ち込みサービス設定の再読み込みとデーモンの再起動を行います。
$ sudo systemctl daemon-reload $ sudo systemctl restart sampledその後以下のコマンドを打ち込みActiveの項目がactive (running)になっていたら成功です。
$ sudo systemctl status sampled >>> sampled.service - sampled daemon >>> Loaded: loaded (/lib/systemd/system/sampled.service; enabled; vendor preset: enabled) >>> Active: active (running) >>> ''' >>> 省略 >>> '''またプログラムのログを確認したい場合は以下のコマンドで確認できます!
$ sudo journalctl -u sampled >>> Jul 29 17:50:24 ip-省略 sampled.py[省略]: OK >>> Jul 29 17:51:24 ip-省略 sampled.py[省略]: OKファイルのパーミッション設定
次にファイルのパーミッション関連の注意点です。
私はプログラムをデーモン化する時にファイルのパーミッション設定を適切に行えてなかったために躓きました。
先ほど同様以下のコマンドを打ち込みActiveの項目がfailed (Result: exit-code)になっていた場合はパーミッションエラーを疑いましょう。
$ sudo systemctl status sampled >>> sampled.service - sampled daemon >>> Loaded: loaded (/lib/systemd/system/sampled.service; enabled; vendor preset: enabled) >>> Active: failed (Result: exit-code) >>> ''' >>> 省略 >>> '''まずPermission deniedエラーが出現したらデーモン化したいファイルのあるディレクトリに移動して以下のコマンドを打ち込んでください。
~/sampled$ ls -l >>> -rw-r--r-- 1 root root 1052 Jul 29 17:16 sample.pyコマンドで表示されたファイルのアクセス権限を確認してデーモンのサービス設定ファイルに記述したUser、Groupと違う場合は以下のコマンドを打ち込む。
/etc/systemd/system/sampled.service''' 省略 ''' [Service] User=sample Group=sample-group ''' 省略 '''上記の設定である場合
# ファイル権限を変更 $ sudo chown sample:sample-group /home/ubuntu/sample/sample.py $ sudo chmod 755 /home/ubuntu/sample/sample.py #ファイル権限変更の確認 $ ls -l >>> -rwxr-xr-x 1 sample sample-group 1052 Jul 29 17:16 sample.py # デーモンの再起動 $ sudo systemctl restart sampled # デーモンの稼働状況表示 $ systemctl status sampled >>> sampled.service - sampled daemon >>> Loaded: loaded (/lib/systemd/system/sampled.service; enabled; vendor preset: enabled) >>> Active: active (running) >>> ''' >>> 省略 >>> '''これでActiveの項目がactivr (running)になってれば完了です!!
おわりに
普段Linuxを使わない分いろいろなれるまで大変でしたが使いこなせるようになると非常に便利なのでこれからも学習していこうと思います!
やっぱりAWSはすごいわ
ご覧いただきありがとうございました。
- 投稿日:2020-07-29T17:51:20+09:00
TerraformでCloudFrontにACL(AWS WAF)を定義するときのエラー対処方法
エラー内容
TerraformでCloudFrontにWeb ACLを付与しようとした際にプロビジョニングエラーが発生しました。
resource "aws_cloudfront_distribution" "sample" { web_acl_id = ${var.waf_web_acl_id} # ex) bbbbbbbb-xxxx-yyyy-zzzz-aaaaaaaaaaa }Error: error creating CloudFront Distribution: InvalidWebACLId: Web ACL is not accessible by the requester. status code: 400, request id: 1815419a-666c-4b68-8bbe-10a5b77対応策
AWS WAF v2を使用している場合
AWS WAF v2を使用している場合、
web_acl_idにACL IDを指定するとエラーとなります。
そこで、V2ではACLのarnを指定します。resource "aws_cloudfront_distribution" "sample" { web_acl_id = ${var.waf_web_acl_arn} #ex) arn:aws:wafv2:us-east-1:xxxxxxxxx:global/webacl/xxxxxxxxxx/xxxxxxxxxxx", }AWS WAF v1を使用している場合
AWS WAF v1を使用している場合にエラーが出る場合はTerraformを実行するIAMユーザーの権限不足が考えられます。
waf:GetWebACL権限を付与します。【参考】AWS SDKからWAF付きのCloudFrontを作成する時に、’Web ACL is not accessible by the requester.’が出た時の対応覚書
参考
- 投稿日:2020-07-29T17:47:22+09:00
AWS Free Tier limit alert が来て焦った件
AWS Free Tier limit alert
こんな内容のメールが来てびっくりしました。
AWS Free Tier usage limit alerting via AWS Budgets
Dear AWS Customer,Your AWS account 8*********** has exceeded 85% of the usage limit for one or more AWS Free Tier-eligible services for the month of July.
AWS Free Tier Usage as of 07/27/2020 AWS Free Tier Usage Limit 641.0 Hrs 750 hours of Amazon EC2 Linux t2.micro instance usage 今月750時間の上限のうち、641時間使用してますよ〜
注意してくださいね〜という内容で、まずは一安心。
ただちょっと心配だったのでEC2を一旦停止しました。
その覚書としてElastic IP の関連付けを解除
AWS マネジメントコンソールの画面から
サービス > コンピューティング > EC2 を選択左側のタブから
ネットワーク&セキュリティ > Elastic IP を選択該当するElaxtic IP のチェックボックスにチェックが入っていることを確認して
アクション > アドレスの関連付けの解除 > アドレスの関連付けの解除
で関連付けを解除出来ます。
これをやらないとEC2を停止できません。EC2インスタンスの停止
左側のタブから
インスタンス > インスタンス を選択該当するインスタンスID のチェックボックスにチェックが入っていることを確認して
アクション > インスタンスの状態 > 停止
インスタンスの状態がstoppingからstoppedになればOKです。
これでインスタンスは停止できたので請求はされないかと思います^^
安心安心♪
- 投稿日:2020-07-29T17:42:24+09:00
Rust用AWS SDKのRusotoでdefault以外の名前付きプロファイルを使用する
はじめに
RusotoはRustのためのAWK SDKです。
↓はDynamoDBの全てのテーブルを表示するサンプルコードです。use rusoto_core::Region; use rusoto_dynamodb::{DynamoDb, DynamoDbClient, ListTablesInput}; #[tokio::main] async fn main() { let client = DynamoDbClient::new(Region::UsEast1); let list_tables_input: ListTablesInput = Default::default(); match client.list_tables(list_tables_input).await { Ok(output) => match output.table_names { Some(table_name_list) => { println!("Tables in database:"); for table_name in table_name_list { println!("{}", table_name); } } None => println!("No tables in database!"), }, Err(error) => { println!("Error: {:?}", error); } } }出典: rusoto/rusoto: AWS SDK for Rust
サポートしているAWSサービスの一覧はこちらでみれます。
一部のサービスにはサンプルコードが用意されていないので、その場合はCrateのドキュメントを読みましょう。default以外の名前付きプロファイルを使用する
上のサンプルコードではDynamoDBのクライアントを作成するのに
newを使いました。pub fn new(region: Region) -> DynamoDbClient名前付きプロファイルを使ってクライアントを作成するときは
new_withを使います。pub fn new_with<P, D>( request_dispatcher: D, credentials_provider: P, region: region::Region, ) -> DynamoDbClient where P: ProvideAwsCredentials + Send + Sync + 'static, D: DispatchSignedRequest + Send + Sync + 'static,例えば、
~/.aws/credentialsのstagingという名前のプロファイルを使うときは、
上のサンプルコードはこのように書けます。use rusoto_core::{HttpClient, Region}; use rusoto_core::credential::ProfileProvider; use rusoto_dynamodb::{DynamoDb, DynamoDbClient, ListTablesInput}; #[tokio::main] async fn main() { let mut provider = ProfileProvider::new().unwrap(); provider.set_profile("staging"); let client = DynamoDbClient::new_with( HttpClient::new().unwrap(), provider, Region::ApNortheast1 ); let list_tables_input: ListTablesInput = Default::default(); match client.list_tables(list_tables_input).await { Ok(output) => match output.table_names { Some(table_name_list) => { println!("Tables in database:"); for table_name in table_name_list { println!("{}", table_name); } } None => println!("No tables in databases!"), }, Err(error) => { println!("Error: {:?}", error); } } }AWS CLIみたいに--profileオプションでプロファイルを切り替える
コマンドライン引数を扱いたいときは
clap1が便利です。
お洒落なヘルプドキュメントも自動生成してくれます。sample.rsuse clap::{App, Arg}; use rusoto_core::{HttpClient, Region}; use rusoto_core::credential::ProfileProvider; use rusoto_dynamodb::{DynamoDb, DynamoDbClient, ListTablesInput}; #[tokio::main] async fn main() { let matches = App::new("DynamoDB ListTables") .version("1.0") .about("Sample CLI Tool") .arg( Arg::with_name("profile") .short("p") .long("profile") .value_name("PROFILE") .help("Use a specific profile from your credential file.") .takes_value(true), ) .get_matches(); let client = match matches.value_of("profile") { Some(p) => { let mut provider = ProfileProvider::new().unwrap(); provider.set_profile(p); DynamoDbClient::new_with( HttpClient::new().unwrap(), provider, Region::ApNortheast1 ) }, None => DynamoDbClient::new(Region::ApNortheast1) }; let list_tables_input: ListTablesInput = Default::default(); match client.list_tables(list_tables_input).await { Ok(output) => match output.table_names { Some(table_name_list) => { println!("Tables in database:"); for table_name in table_name_list { println!("{}", table_name); } } None => println!("No tables in databases!"), }, Err(error) => { println!("Error: {:?}", error); } } }コンパイルして実行してみます。
実行ファイル名はsampleとしました。$ ./sample Tables in database: default_table_a default_table_b $ ./sample --profile staging Tables in database: staging_table_a staging_table_b
-hを渡してあげれば、ヘルプドキュメントが表示されます。$ ./sample -h DynamoDB ListTables 1.0 Sample CLI Tool USAGE: sample [OPTIONS] FLAGS: -h, --help Prints help information -V, --version Prints version information OPTIONS: -p, --profile <PROFILE> Use a specific profile from your credential file.参考資料
rusoto/rusoto: AWS SDK for Rust
rusoto_dynamodb::DynamoDbClient - Rust
clap-rs/clap: A full featured, fast Command Line Argument Parser for Rust
clapのバージョンに気をつけてください。
sample.rsは2.33.1でビルドしました。この記事を執筆している時点で3.0のベータ版がプレリリースされています。 ↩
- 投稿日:2020-07-29T17:16:34+09:00
【AWS-SAA】VPC関連用語の備忘録
はじめに
AWS-SAAにおいてVPCの理解をきちんとしなければ、合格することは難しいだろう。その一方でVPC関連用語が多く、似たような機能が多いので覚えづらく感じる。本稿では特に覚えづらいVPC関連用語の理解を深めるため、備忘録としてまとめていきたい。
VPC関連用語
VPC
VPCとは?
・ユーザーが定義した仮想ネットワーク環境。概要
・ネットワーク、サブネットの範囲、ルートテーブル、ネットワークゲートウェイなどの設定ができる。VPCエンドポイント
VPCエンドポイントとは?
・VPC内からVPC外へ接続するための、接続点を作るためのサービス。概要
・VPCに対応しているサービスと対応していないサービス、どちらも連携するために接続。Private Link
Private Linkとは?
・Amazonのネットワーク内で、VPC、AWSのサービス、オンプレミスアプリケーション間のプライベート接続が可能になるサービス。概要
・Private Linkを使うことでインターネットに出る必要がなくなる。これによりファイアウォール、インターネットゲートウェイやVPCピア接続などのネットワークの設定が不要になる。またインターネットを経由しないため、ブルートフォース攻撃や DDoS攻撃などの脅威に晒される危険を軽減し、セキュリティ面でも効果がある。VPCピアリング
VPCピアリングとは?
・VPC同士を接続する方法。
概要
・自分のVPC間、別のAWSアカウントのVPCとの間、または別のAWSリージョンのVPCとの間に作成可能。参考
AWS 仕組みと技術がしっかりわかる教科書
VPC
VPC エンドポイント
Private Link1
Private Link2
VPC ピアリング
- 投稿日:2020-07-29T16:08:09+09:00
CDKでサクッとCodeCommit+CodePipeline
はじめに
本投稿は、AWS CDKの勉強を兼ねて試作してみたCodeCommit+CodePipelineでS3にファイルをアップロードする機構について紹介しています。
エンジニアチーム内で「触ってみたいですよね」という声があり興味があった所に、別部署のエンジニアの方からも「CDKいいっすよ〜」という評判を聞いたので触ってみました。AWS CDKとは?
AWS CDKとは、
AWS クラウド開発キット (AWS CDK) は、使い慣れたプログラミング言語を使用してクラウドアプリケーションリソースをモデル化およびプロビジョニングするためのオープンソースのソフトウェア開発フレームワークだそうです。PythonやTypeScriptなんかでインフラの定義がかけて便利です。背景
最初期
過去、制作用の環境としてCloud9が使用されていたのですが、その時の選定要件は、
- 同時編集できる
- 成果物をプレビューできる
- プレビューにBasic認証入れられる
- バージョン管理できる
だったので、Cloud9+Codecommit+Lambda+CloudFront+Lambda@edge+S3でCloud9からCodeCommit経由でS3にhtmlファイル・画像ファイルがアップロードされ、CloudFront経由でプレビューできるというものを作っていました。最初はうまく回っているように見えていました。
問題点
最初はうまく回っているように見えていたCloud9も徐々に問題点が出てきました。
- 一部ファイルがS3に上がっていない。(これはCodeCommit→S3をLambdaでやっている所が怪しいと睨んでいます)
- 案件が増えてきてCloud9の容量が圧迫されている(画像もりもりの制作物なので…)
- そもそも同時編集機能が活用されてない気配がある…
ということで、Cloud9である必要性がなくなっていました。であればローカルで作ってS3に上がればいいよねってことで作り直しの機運が高まりました。(実際にコーディングするメンバーはAWSを触る人たちではないので極力AWSと直接相対しない形を提供してあげたいという思いもありました。)
本題
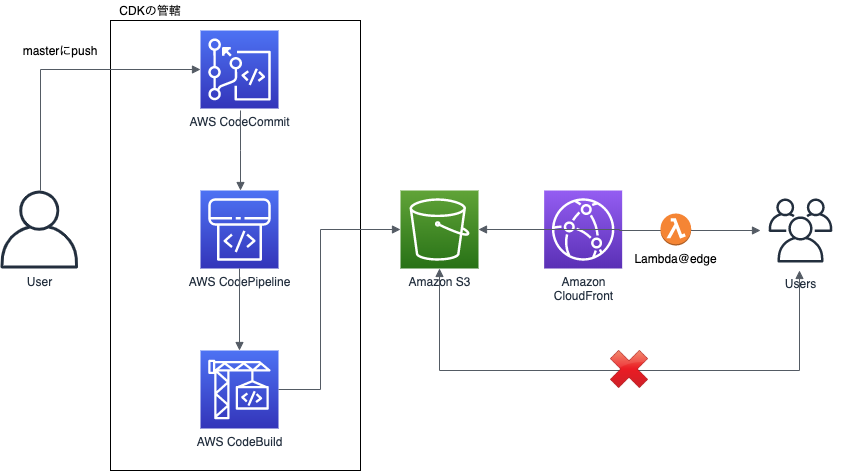
作り直しにあたり、社内で噂を聞いたCDKを採用しました。下図の左側CodeCommit・CodePipeline・CodeBuildのリソース作成をCDKが担当します。(S3+CloudFront+Lambda@edgeは以前のものを流用しました。)
Cloud9時代には、
1Cloud9(1EC2インスタンス)=複数案件=1リポジトリだったものを、1案件=1リポジトリにしました。案件着手時にcdk deployすることで、CodeCommit上にリポジトリの作成とCodePipelineが整備されて、masterにpushするごとに、CodeBuildでS3にファイルがアップロードされるという状態です。実装
ドキュメントに従って、
$ npm install -g aws-cdk $ mkdir test $ cd test $ cdk init test --language python $ source .env/bin/activate $ pip install -r requirements.txtとしてスタートします。
app.py#!/usr/bin/env python3 import os from os.path import join, dirname from dotenv import load_dotenv from aws_cdk import core from test.test_stack import TestStack dotenv_path = join(dirname(__file__), '.env_file') load_dotenv(dotenv_path) app = core.App() TestStack(app, "test", repo_name=os.environ["REPOSITORY_NAME"], env={"account": "xxxxxxxxxxxx", "region": "ap-northeast-1"}) app.synth()test_stack.pyfrom aws_cdk import core from aws_cdk import aws_codecommit as codecommit from aws_cdk import aws_codebuild as codebuild from aws_cdk import aws_codepipeline as codepipeline from aws_cdk import aws_codepipeline_actions as codepipeline_actions from aws_cdk import aws_iam as iam class TestStack(core.Stack): def __init__(self, scope: core.Construct, id: str, repo_name: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) # output先のバケット名 s3_bucket_name = "test-bucket" # CodeCommitのRepository作成 repo = codecommit.Repository(self, "Repository", repository_name=repo_name, description="test.") repository = codecommit.Repository.from_repository_arn(self, repo_name, repo.repository_arn) # CodePipelineの定義 pipeline = codepipeline.Pipeline(self, id=f"test-pipeline-{repo_name}", pipeline_name=f"test-pipeline-{repo_name}") source_output = codepipeline.Artifact('source_output') # CodeCommitの追加 source_action = codepipeline_actions.CodeCommitSourceAction(repository=repository, branch='master', action_name='source_collect_action_from_codecommit', output=source_output, trigger=codepipeline_actions.CodeCommitTrigger.EVENTS) pipeline.add_stage(stage_name='Source', actions=[source_action]) # CodeBuildの追加 cdk_build = codebuild.PipelineProject(self, "CdkBuild", build_spec=codebuild.BuildSpec.from_object(dict( version="0.2", phases=dict( build=dict( commands=[f"aws s3 sync ./ s3://{s3_bucket_name}/"] ) ) ))) cdk_build.add_to_role_policy( iam.PolicyStatement( resources=[f'arn:aws:s3:::{s3_bucket_name}', f'arn:aws:s3:::{s3_bucket_name}/*'], actions=['s3:*'] ) ) build_output = codepipeline.Artifact("CdkBuildOutput") build_action = codepipeline_actions.CodeBuildAction( action_name="CDK_Build", project=cdk_build, input=source_output, outputs=[build_output]) pipeline.add_stage( stage_name="Build", actions=[build_action] )CodeBuild
今にして思うと、
s3 syncしてるだけのCodeBuildってCodeDeployで良かったのでは感があります。
s3 syncする時にs3バケット側の階層を一段深くしたくてこうしていますが、良い解決策はないものでしょうか…codebuildの部分# CodeBuildの追加 cdk_build = codebuild.PipelineProject(self, "CdkBuild", build_spec=codebuild.BuildSpec.from_object(dict( version="0.2", phases=dict( build=dict(commands=[f"aws s3 sync ./ s3://{s3_bucket_name}/"]) ))))デプロイ
あとは
$ cdk deployとしてやればデプロイできますが、使う人向けに以下のようにスクリプトにしておきました。
make.sh#!/bin/bash if [ $# -ne 1 ]; then echo "実行するには1個の引数が必要です。" 1>&2 echo "引数にはプロジェクトコードを指定してください。(プレビュー時のURLに一部使用されます)" exit 1 fi echo REPOSITORY_NAME=$1 > .env_file cdk deploy test --profile xxxxxxx # commitぶっこむ git clone ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/$1 ../$1 mkdir ../$1/$1 touch ../$1/$1/.gitkeep cd ../$1 git checkout -b master git add -A git commit -m "initial commit" git push origin masterこれで、作成するリポジトリ名を引数として
$ ./make.sh test_repositoryとすればOKです。
懸念点
- 今はCDKの中でCodeCommitのリポジトリを作成しているため、スタックを消してしまうとリポジトリごと消えてしまうというリスクがあります。
- 実は初回のdeploy時にはCodeCommit側でmasterブランチが作成されていない(?)ためBuild時に失敗してしまいます。git pushしてあげると正しく動作するので現在のところは放置しています。(が少し気持ち悪い。)
最後に
今回はCDKを使ってCodeCommitからCodeBuild経由でS3にファイルをアップロードする機構を作成しました。
Cloud9時代に比べて評判がいいようなので、このまま何事もなく使ってもらえるといいなと思いつつフィードバックを待ちます。
CDK自体はCloudFormationと直に戦わなくていいので良いものだと思います。
- 投稿日:2020-07-29T15:44:59+09:00
Amazon Linux 2でGoをインストールする
- 投稿日:2020-07-29T14:14:30+09:00
[AWS] Cognitoの基本まとめ
Cognitoとは
一言で説明すると、ウェブアプリケーションやモバイルアプリケーションに、さくっと認証・認可、ユーザ管理の仕組みを構築できるためのサービス、ということになります。
その中で、
- ユーザープール
- IDプール
- Cognito Sync
などの代表的な機能について、まとめました。
ユーザープール
公式のドキュメントには「何億人」とまで記載されていますが、それくらい巨大なユーザ数を、セキュアに管理できる、フルマネージドサービスのユーザディレクトリで、認証の機能を提供します。
ユーザは、
- Amazon
- Apple
などのソーシャルIDプロバイダーやSAMLベースのIDプロバイダ経由でサインインすることもできます。
プロバイダ経由でサインインする場合でも、ユーザープールのディレクトリプロファイルにアクセスすることができます。
ディレクトリプロファイルには、
- ユーザ名
- 電話番号
- 住所
- タイムゾーン
等、標準的なOpenID Connectベースのプロファイルがサポートされています。
その他の主な機能としては、
- ユーザーがサインインするための組み込みのカスタマイズ可能なウェブUI
- 多要素認証(MFA)などのセキュリティ機能
- 漏洩した認証情報のチェック
- アカウントの乗っ取り保護
- 電話とEメールによる検証
- カスタマイズされたワークフローとLambdaトリガーによるユーザー移行
- Eメールアドレスや電話番号によるサインイン認証
- パスワードポリシーの設定
- 利用デバイスの記憶
などがあります。
IDプール
ユーザの一意のIDを作成し、IDプロバイダーで連携させることができるようになります。
IDプールでは、一時的なAWS認証情報を取得することで、各種AWSサービスにアクセスすることが可能となります。
IDプールでは、以下のようなIDプロバイダがサポートされています。
- Login width Amazon
- Apple
- Digits
- Cognito(ユーザープール)
- Open ID Connect
- SAML ID
- 開発者が認証したID
Cognito Sync
アプリケーション関連のユーザデータのデバイス間の同期を有効にする機能です。
クライアントアプリは、データをローカルにキャッシュするため、デバイスがオフラインの状態でもデータへの読み書きが可能になります。
データは、デバイスがオンラインになっている時に同期が行われます。
この時、ユーザが保持できるデータの最大サイズは20MBで、ユーザ情報ストア内のデータセットには、最大1MBのデータを保存できます。
データセット内に保存できるキーの数は1024個までです。なお、現在はより高機能なAppSyncが提供されているため、今後使用を検討する場合は、AppSyncの使用を推奨されています。
対応言語
Cognitoは、AWS Mobile SDKに対応しています。AWS Mobile SDKでは、
- iOS
- Android
- Unity
- Kindle Fire
がサポートされています。
また、ユーザープールに関しては、JavaScriptによる、JavaScript AWS SDK for CognitoによるJavaScriptでの開発も可能です。
コントロールAPI、データAPIがそれぞれ用意されているため、各種言語からの呼び出しも可能です。料金
リージョンごとで料金が異なりますが、ここでは東京リージョンを例にしたいと思います(2020年7月現在)。
ユーザープール
ユーザープールの認証情報、または、ソーシャルIDプロバイダーで直接サインインするユーザ数によって決まります。
ユーザ数 1ユーザあたりの料金 〜50000 無料 50001〜10万 0.0055$(US) 次の90万 0.0046$(US) 次の900万 0.00325$(US) 1000万超 0.0025$(US) SAMLまたはOpenID Connectionフェデレーションを使用してサインインする場合も、ユーザ数によって決まります。
ユーザ数 1ユーザあたりの料金 〜50 無料 50超 0.015$(US) さらに、監査モードを含む高度なセキュリティ機能を使用すると、上記に加えて、下記料金が加算されます。
ユーザ数 1ユーザあたりの料金 〜50000 0.050$(US) 次の5万 0.035$(US) 次の90万 0.020$(US) 次の900万 0.015$(US) 1000万超 0.010$(US) Cognito Sync
こちらもリージョンにより料金が異なりますので、東京リージョンを例にしたいと思います(2020年7月現在)。
無料利用枠
- 最初の12ヶ月間
- 1ヶ月あたり10GBの同期容量
- 1ヶ月あたり100万回の同期オペレーション
無料利用枠外になる場合は、
- 1ヶ月1GBの同期容量あたり 0.19$(US)
- 1ヶ月に1万回の同期オペレーションごと 0.19$(US)また、プッシュ同期を有効にしているとSNSによる通知が行われるため、別途SNSの料金が加算されます。
リージョン
Cognitoは、以下のリージョンでサポートされています(2020年7月現在)。
- バージニア北部(us-east-1)
- オハイオ(us-east-2)
- オレゴン(us-west-2)
- ムンバイ(ap-south-1)
- ソウル(ap-northeast-2)
- シンガポール(ap-southeast-1)
- シドニー(ap-southeast-2)
- 東京(ap-northeast-1)
- カナダ(ca-central-1)
- フランクフルト(eu-central-1)
- アイルランド(eu-west-1)
- ロンドン(eu-west-2)
まとめ
Cognitoは、モバイルアプリケーションだけでなく、ウェブアプリケーションにも使用できるので、一般的なウェブアプリケーションにも、非常に簡単に認証・認可の仕組みを導入することができます。
また、既存のアプリケーションへの導入も比較的簡単に行えます。
次回は、実際にコードを使ったサンプルアプリケーションを作成してみたいと思います。
- 投稿日:2020-07-29T13:04:33+09:00
Lambda(node.js)とJavaScriptのタイムゾーン
Lambda(node.js)で日付の計算をしたら思ったより面倒だったのでまとめる。
やりたかったこと
日本標準時(JST)で先週/先月の範囲を、世界標準時(UTC)で取得したい。
例えば、今日が 2020-07-29 とすると先週の範囲は日曜日始まりでこんな感じ。
タイムゾーン 開始 終了 JST 2020-07-19T00:00:00+0900 2020-07-26T00:00:00+0900 UTC 2020-07-18T15:00:00Z 2020-07-25T15:00:00Z やりたくなかったこと
大した処理じゃないので余計なライブラリは使いたくない。
結論
- タイムゾーンの設定はそのままにプログラム内で対応する
- タイムゾーンオフセット値からJSTを自力で設定する
- UTCへの変換も自力でやる
それぞれのタイムゾーン
Lambdaのタイムゾーン
UTCに固定されている模様。
ググるとTZ環境変数を設定すればいいという記事が大量にヒットする。
ただ、TZ環境変数はAWSに予約されているので、それを変更するのはよろしくなさそう。
Lambda のタイムゾーンを環境変数TZで指定してはいけないっていう話 | Serverworks ENGINEER BLOG他の利用しているAWSサービスでUTCで動作するものもあったので、プログラム内で対応することにした。
JavaScriptのタイムゾーン
JavaScriptのDateクラスにはタイムゾーンを設定する方法はないようだった。
ただgetTimezoneOffsetで分単位の時差は取得できた。JSTは+9時間なので、なぜか-540分が返ってくる。取得した値を+しとけばUTCに変更できそう。
toLocaleStringでタイムゾーン指定の日付文字列を取得して、新しくDateオブジェクトを作る方法もあるようだが、Lambdaでは動作しないのとDateクラスのコンストラクタに日付文字列を渡すのは非推奨だったのでやめた。最終的にJavaScriptのタイムゾーンは無視して
getTimezoneOffsetを使って自力で日時を計算することにした。オレのMacのタイムゾーン
JSTだった。
AWS SAMを使ってローカルで開発していると、ローカルではJSTでLambda上ではUTCになる。
タイムゾーンを変更してテストしたい場合は、TZ環境変数を設定することで変更できる。実装
日本標準時で現在日時を取得
考慮するタイムゾーンはJSTかUTCの2つという前提で、タイムゾーン設定を無視して日本標準時での現在日時を取得することにした。
const jstOffset = 9 * 60; const now = new Date(); const offset = now.getTimezoneOffset() + jstOffset; now.setTime(date.getTime() + offset * 60 * 1000);先週の開始/終了日時を取得
日本標準時で先週の日曜日を取得。
const start = new Date(now.getFullYear(), now.getMonth(), now.getDate()); start.setDate(start.getDate() - 7 - start.getDay());同様に今週の日曜日を取得。
const end = new Date(now.getFullYear(), now.getMonth(), now.getDate()); end.setDate(end.getDate() - end.getDay());先月の開始/終了日時を取得
先月1日を取得。
const start = new Date(now.getFullYear(), now.getMonth() - 1, 1);今月1日を取得。
const end = new Date(now.getFullYear(), now.getMonth(), 1);JST→UTCの変換
それぞれの日付をUTCに変換。
実際はタイムゾーンを変換してないのでgetUTCFULLYearなどは使えない。const jstOffset = 9 * 60; date.setTime(date.getTime() - jstOffset * 60 * 1000); date.getFullYear(); date.getMonth() + 1; date.getDate(); date.getHours();
- 投稿日:2020-07-29T12:49:02+09:00
AWS EventBridgeでCronで設定した時間に起動しない原因と対処法
AWS EventBridge のcron設定でつまづいたので、
その内容を共有します。もし同じ現象の方がいましたらぜひ参考にしてください。現象
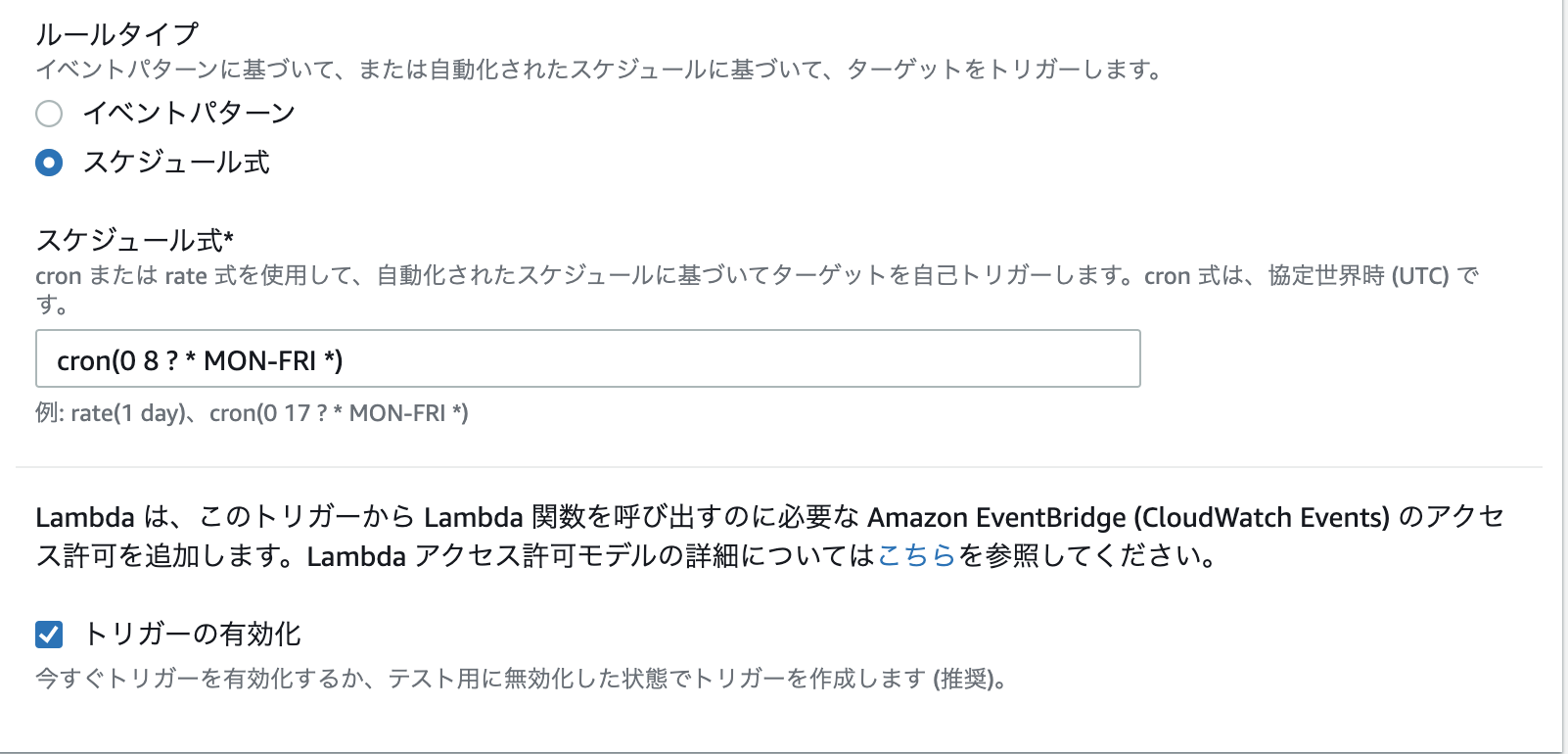
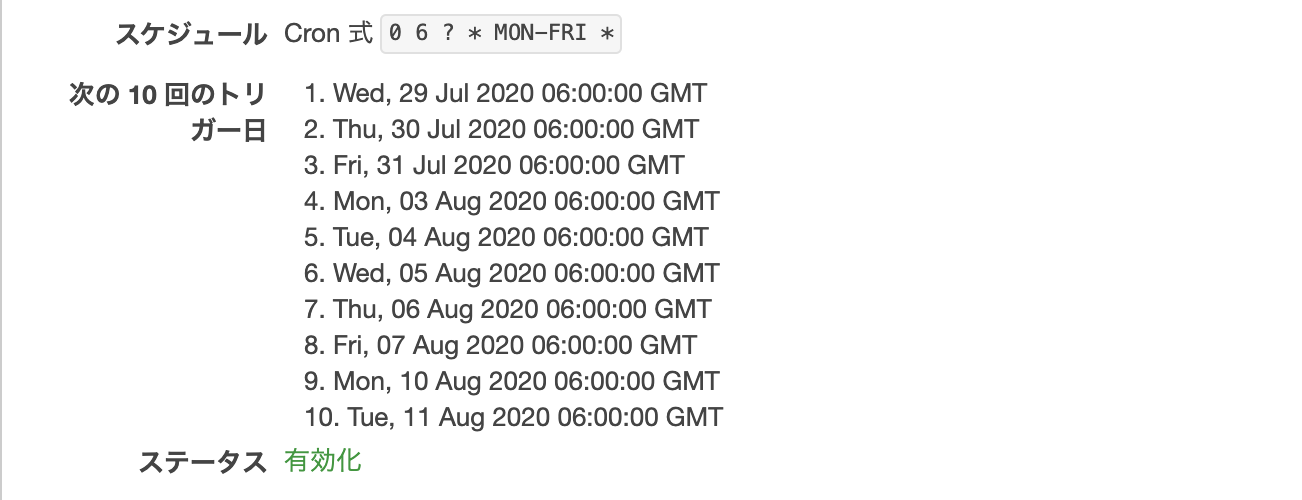
cronの設定を下記の画像のように設定した。
上記の画像のように設定したが
平日の月曜日〜金曜日の8時に起動する認識だったが指定した時間に起動しなかった。
原因
Cronの設定を見直してみると下記のように設定されていた。
確かに平日の月曜日〜金曜日の6時に設定されているが、
GMT基準で設定されているから。GMTと日本の時差は9時間あるので、このCronの設定だと、
月曜日〜金曜日の15時に起動することになります
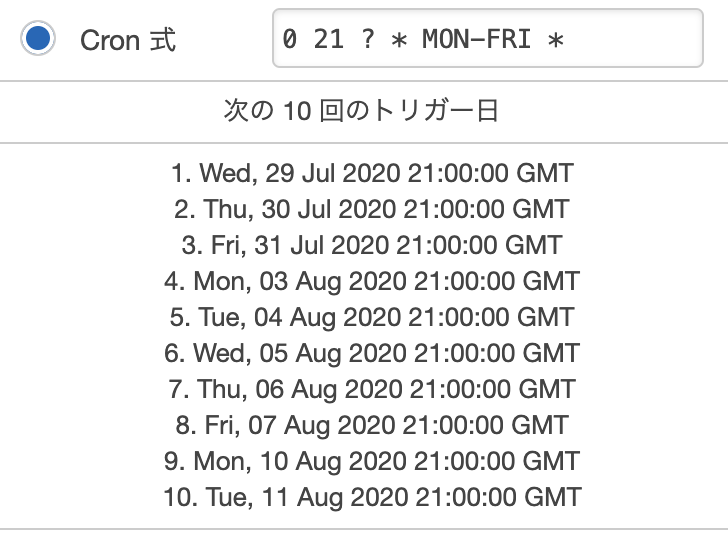
(ちなみにGMTより日本の方が9時間早いです。)対処法
簡単に言うと、日本時間をGMTに変換すればいいだけです。
ちなみに以下のサイトで日本時間をGMTに変換できます。
https://www.jisakeisan.com/
今回は、平日の6時に設定したいので
Cron側で月曜日〜金曜日の21時と設定すれば良いです。

- 投稿日:2020-07-29T11:23:33+09:00
ACMとELBを使いEC2サーバの証明書を一つにまとめる
概要
これまでEC2サーバ毎(コーポレートサイト、Redmine、GitLab等)にサーバ証明書を発行しており、証明書の更新作業が煩雑になっていました。
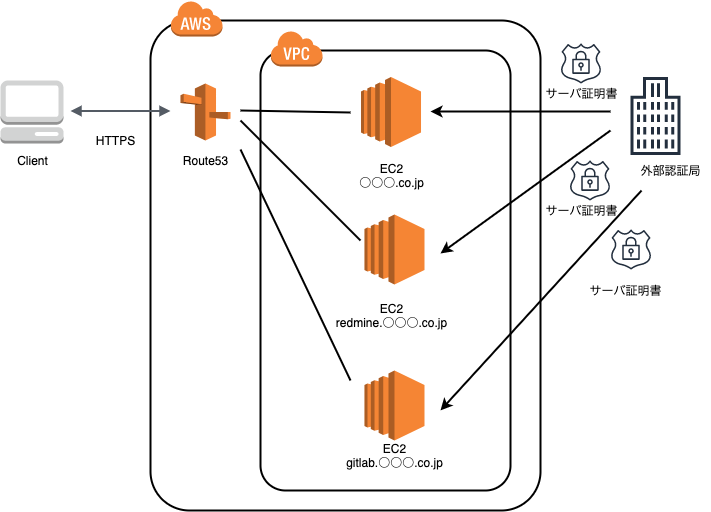
今回、EC2サーバにロードバランサーを挟むことでサーバ証明書を一つにまとめる作業を実施しました。以前のサーバ構成
下記図のようにEC2サーバそれぞれが独立し、サーバ証明書を別々に使用している状態となっていました。
- https://○○○(ドメイン名).co.jp
- https://redmine.○○○(ドメイン名).co.jp
- https://gitLab.○○○(ドメイン名).co.jp etc...
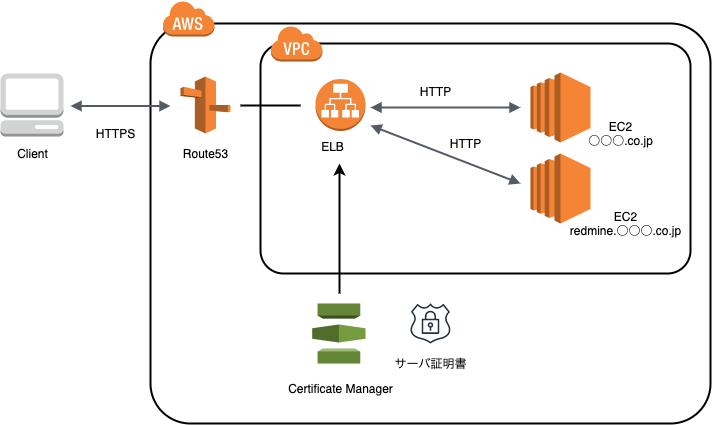
今回の作業後のサーバ構成
下記図のようにELBを挟み、ACMから発行されるサーバ証明書一つに設定しました。
Gitlabについては、以前のサーバ構成のままとしました。
理由については後述(補足②)します。
今回の作業で使用しているAWSサービス
- EC2
- ELB
- Route53
- ACM
前提知識
ACMとは?
AWSのサーバ証明書サービスです。
ELB、CroudFront、APIGatewayのAPIなどACMに統合されたAWSリソースでデプロイできます。ELBとは?
ELBとはALB、NLB、CLBの総称です。
- ALB(Application Load Balancer)
- アプリケーションレイヤー(HTTP/HTTPS)でルーティング
- L7リバースプロキシ
- NLB(Network Load Balancer)
- トランスポートレイヤー(TCP/SSL)でルーティング
- L4 NAT ロードバランサ
- TCPに対応
- CLB(Classic Load Balancer)
- トランスポートレイヤー(TCP/SSL)または(HTTP/HTTPS)のいずれかでルーティング
- L4/L7 リバースプロキシ
- TCP, SSL, HTTP, HTTPSに対応
手順
前提条件
- ホストゾーン、レコード設定は既にされているものとします
(以前のサーバ構成に記載の図の状態にて既に作成されているため)- 記載の手順に関して
- 今回は、各AWSサービスの詳細な手順(画面毎の設定)までは記載しません
- VPC、セキュリティグループ等は、それぞれ適切なものを設定してください
※実作業ではすでに作成されているALBが存在していたので、そちらを使用しましたが、
手順ではLoadBalancerの作成から記載しています。1. ACMのサーバ証明書発行
- Certificate Managerからパブリック証明書のリクエストを実施
- ドメイン名は「○○○(ドメイン名).co.jp」と「*.○○○(ドメイン名).co.jp」を登録
(ワイルドカードを使い「www.○○○(ドメイン名).co.jp」や「redmine.○○○(ドメイン名).co.jp」にも適用できるようにします)- 検証の実施(今回はDNSの検証にて実施)
2. Load Balancerの作成
- ロードバランサーの種類の選択
- 「Application Load Balancer」を選択
- 名前(今回は「○○○(ドメイン名)-elb」としました)
- ロードバランサーのプロトコルはHTTP(ポート80)
3. ターゲットのグループの作成
- ターゲットグループ名:「○○○(ドメイン名)TG」、Redmineの場合は「RedmineTG」etc...としてそれぞれ登録
- ターゲットの種類:インスタンス
- プロトコル:HTTP
- パス: /
- ポート:80
4. Load Balancerのリスナーを追加し、ターゲットと紐付ける
- ロードバランサーのリスナータブからhttps(ポート443)を追加
- 追加したリスナーに「証明書の表示/編集」を押下し、手順1にて発行したACMと紐付ける
- 「ルールの表示/編集」を押下し、手順3で作成したターゲットグループを紐付ける
- ○○○(ドメイン名).co.jpの場合
- IF:ホストが○○○(ドメイン名).co.jp
- THEN 転送先:○○○(ドメイン名)TG
- redmine.○○○(ドメイン名).co.jpの場合
- IF:ホストがRedmineTG
- THEN 転送先:RedmineTG
※ここでは、一番上にあるものから順に処理されます。
5. Route53のエイリアスをLoadBalancerに変更する
- ○○○(ドメイン名).co.jpのタイプAを選択し、下記設定を行います
- エイリアス:はい
- エイリアス先:作成したロードバランサー(○○○(ドメイン名)-elb)
- redmine.○○○(ドメイン名).co.jp等も同様に設定する
補足① メンテナンス画面の作成
アプリケーションロードバランサーは、簡単にメンテナンス画面を表示させることもできます。
- ロードバランサーの設定画面に遷移し、上記手順にて作成したロードバランサーを選択
- リスナーのルールの表示/編集をクリック
- 新規で下記2点を作成
- 社内からのみメンテナンスする環境にアクセス可能にする
- IF: ホストが○○○(メンテナンスする環境のドメイン).co.jp、送信元IPが○○○.○○○.○○○.○○○/32(作業する環境のGIP)
- THEN: ○○○(メンテナンスする環境のドメイン)TG
- メンテナンス画面の作成
- IF: ホストが○○○(メンテナンスする環境ドメイン).co.jp
- THEN:固定レスポンスを返す→メンテナンス画面のhtmlを作成
- 手順3にて作成したルールを一番上に持っていく。 (一番上のものから優先的に処理されるので、こちらを利用します)
※ メンテナンス中のhtml例
- レスポンスコード: 503
- Content-Type: text/html
- レスポンス本文
<pre> <html> <head> <meta charset="utf-8"> <title>Maintenance</title> </head> <body> <p style="text-align: center;"> <span style="font-size: large;">ただいま緊急メンテナンス中です。</span><br /> <span style="font-size: large;">メンテナンス終了予定時刻 : </span><br /> <span style="font-size: xx-large;">2020/07/16 12:00 </span><br /> </p> </body> </html> </pre>補足② GitLabに関して
GitLabもELBにまとめる予定でしたが、現在のELBはALBを使っており、GitLabのSSH接続ができません。
CLB環境を構築することも考えましたが、コスト面から、今回はGitLabのみ以前の構成のままとしました。参考記事
https://aws.amazon.com/jp/elasticloadbalancing/
https://aws.amazon.com/jp/elasticloadbalancing/pricing/
https://qiita.com/wakky_404/items/e082b7545801cf25905c
- 投稿日:2020-07-29T11:04:53+09:00
AWS: lambdaを使わないでEC2の定期起動・定期停止するCloudFormationを作る
はじめに
EventBridgeを使ってEC2の定期起動・停止するCFnを作る時たくさん悩んだので、未来の私がCFn見直した時に思い出せるようにするためのメモ。
※投稿してしまったのですが確認したら今CFnが思うとおりに動いていないので修正中です‼
CloudFormation
1. このCFnでつくられるもの。
■ CloudWatch Event Rule
- 起動させるイベントルール
- 停止させるイベントルール
■ IAM Role
- 自動化用のAutomationAssumeRole
- AWSマネージドポリシー
- 起動イベント用のロール
- カスタムポリシー
- 停止イベント用のロール
- カスタムポリシー
2. つくったテンプレート。
AWSTemplateFormatVersion: 2010-09-09 Description: EC2_Start_Stop Parameters: EC2InstanceID1: Type: String Description: EC2InstanceID1 Default: "i-xxxxxxxxxxxxxxx" EC2InstanceID2: Type: String Description: EC2InstanceID2 Default: "i-yyyyyyyyyyyyyy" StartTime: Type: String Description: start time of Ec2 Default: 00 00 ? * MON-FRI * StopTime: Type: String Description: stop time of Ec2 Default: 00 09 ? * MON-FRI * Resources: # ------------------------------------------------------------# # Event # ------------------------------------------------------------# EventRuleEc2Start: Type: AWS::Events::Rule Properties: Name: Ec2StartRule Description: !Sub ${StartTime} Start ScheduleExpression: !Sub 'cron(${StartTime})' State: ENABLED Targets: - Arn: arn:aws:ssm:ap-northeast-1::automation-definition/AWS-StartEC2Instance:$DEFAULT Id: TargetStartEC2Instance1 RoleArn: !Sub ${StartEc2Role.Arn} Input: !Sub "{\"InstanceId\":[\"${EC2InstanceID1}\"],\"AutomationAssumeRole\":[\"${EC2AmazonSSMAutomationRole.Arn}\"]}" - Arn: arn:aws:ssm:ap-northeast-1::automation-definition/AWS-StartEC2Instance:$DEFAULT Id: TargetStartEC2Instance2 RoleArn: !Sub ${StartEc2Role.Arn} Input: !Sub "{\"InstanceId\":[\"${EC2InstanceID2}\"],\"AutomationAssumeRole\":[\"${EC2AmazonSSMAutomationRole.Arn}\"]}" EventRuleEc2Stop: Type: AWS::Events::Rule Properties: Name: Ec2StopRule Description: !Sub ${StopTime} Stop ScheduleExpression: !Sub 'cron(${StopTime})' State: ENABLED Targets: - Arn: arn:aws:ssm:ap-northeast-1::automation-definition/AWS-StopEC2Instance:$DEFAULT Id: TargetStopEC2Instance1 RoleArn: !Sub ${StopEc2Role.Arn} Input: !Sub "{\"InstanceId\":[\"${EC2InstanceID1}\"],\"AutomationAssumeRole\":[\"${EC2AmazonSSMAutomationRole.Arn}\"]}" - Arn: arn:aws:ssm:ap-northeast-1::automation-definition/AWS-StopEC2Instance:$DEFAULT Id: TargetStopEC2Instance2 RoleArn: !Sub ${StopEc2Role.Arn} Input: !Sub "{\"InstanceId\":[\"${EC2InstanceID2}\"],\"AutomationAssumeRole\":[\"${EC2AmazonSSMAutomationRole.Arn}\"]}" # ------------------------------------------------------------# # AutomationAssumeRole # ------------------------------------------------------------# EC2AmazonSSMAutomationRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - ssm.amazonaws.com - ec2.amazonaws.com Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AmazonSSMAutomationRole Path: "/" #------------------------------------------------------------# # StartEc2 # ------------------------------------------------------------# StartEc2Role: Type: AWS::IAM::Role Properties: RoleName: "StartEC2Role" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - "events.amazonaws.com" Action: sts:AssumeRole Path: / Policies: - PolicyName: StartEc2Role_policy PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: ssm:StartAutomationExecution Resource: !Sub arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:automation-definition/AWS-StartEC2Instance:$DEFAULT - Effect: Allow Action: "iam:PassRole" Resource: !GetAtt EC2AmazonSSMAutomationRole.Arn Condition: StringLikeIfExists: iam:PassedToService: ssm.amazonaws.com # ------------------------------------------------------------# # StopEc2 # ------------------------------------------------------------# StopEc2Role: Type: AWS::IAM::Role Properties: RoleName: "StopEC2Role" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - "events.amazonaws.com" Action: sts:AssumeRole Path: / Policies: - PolicyName: StopEc2Role_policy PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: ssm:StartAutomationExecution Resource: !Sub arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:automation-definition/AWS-StopEC2Instance:$DEFAULT - Effect: Allow Action: "iam:PassRole" Resource: !GetAtt EC2AmazonSSMAutomationRole.Arn Condition: StringLikeIfExists: iam:PassedToService: ssm.amazonaws.com
3. テンプレートのなかみ。
■ parameter
Parameters: EC2InstanceID1: Type: String Description: EC2InstanceID1 Default: "i-xxxxxxxxxxxxxxx" EC2InstanceID2: Type: String Description: EC2InstanceID2 Default: "i-yyyyyyyyyyyyyy" StartTime: Type: String Description: start time of Ec2 Default: 00 00 ? * MON-FRI * StopTime: Type: String Description: stop time of Ec2 Default: 00 09 ? * MON-FRI *定期起動・停止したいインスタンスのインスタンスIDと、実行する時間をparameterで出してます。
同じ時間で起動・停止させるEC2インスタンス2つに対して設定したかったのでIDを入力するところは2つ。
時間はcron式で指定します。このテンプレートはデフォルトで日本時間の平日9:00に起動、18:00に停止するようになってます。■ イベント
EventRuleEc2Start: Type: AWS::Events::Rule Properties: Name: Ec2StartRule Description: !Sub ${StartTime} Start ScheduleExpression: !Sub 'cron(${StartTime})' State: ENABLED Targets: - Arn: arn:aws:ssm:ap-northeast-1::automation-definition/AWS-StartEC2Instance:$DEFAULT Id: TargetStartEC2Instance1 RoleArn: !Sub ${StartEc2Role.Arn} Input: !Sub "{\"InstanceId\":[\"${EC2InstanceID1}\"],\"AutomationAssumeRole\":[\"${EC2AmazonSSMAutomationRole.Arn}\"]}" - Arn: arn:aws:ssm:ap-northeast-1::automation-definition/AWS-StartEC2Instance:$DEFAULT Id: TargetStartEC2Instance2 RoleArn: !Sub ${StartEc2Role.Arn} Input: !Sub "{\"InstanceId\":[\"${EC2InstanceID2}\"],\"AutomationAssumeRole\":[\"${EC2AmazonSSMAutomationRole.Arn}\"]}"AWS::Events::Rule - AWS CloudFormation
トリガーとなるイベントの作成。
Targetsにルールがトリガーされたときに呼び出されるリソースをリスト型で書いていきます。EventRuleEc2Startでは起動させるロールを割り当てたいので、
ArnにStartEC2Instanceを参照させて、RoleArnにはルールがトリガーされた時にこのターゲットに使用されるIAMロールの ARNを書きます。ここには、同じCFn内のStartEc2Roleを使いたいので、!Sub ${StartEc2Role.Arn}でStartEc2RoleのARNを参照しています。(!Subと.ArnでARN取ってこれるの知らなかった。)同様にEventRuleEc2Stopでは停止させるイベントを作成します。Startの部分がStopになるくらいなので割愛。
■ 自動化用ロール
EC2AmazonSSMAutomationRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - ssm.amazonaws.com - ec2.amazonaws.com Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AmazonSSMAutomationRole Path: "/"マネージドポリシーのAmazonSSMAutomationRoleを作成します。
AssumeRolePolicyDocumentにこのロールに関連付けられている信頼ポリシーを書くのですが、ssm.amazonaws.comとec2.amazonaws.comをこのロールを引き受けることができるエンティティに指定したいのでServiceにリスト型で書いておきます。■ 起動・停止用ロール
StartEc2Role: Type: AWS::IAM::Role Properties: RoleName: "StartEC2Role" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - "events.amazonaws.com" Action: sts:AssumeRole Path: / Policies: - PolicyName: StartEc2Role_policy PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: ssm:StartAutomationExecution Resource: !Sub arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:automation-definition/AWS-StartEC2Instance:$DEFAULT - Effect: Allow Action: "iam:PassRole" Resource: !GetAtt EC2AmazonSSMAutomationRole.Arn Condition: StringLikeIfExists: iam:PassedToService: ssm.amazonaws.comAWS::IAM::Role - AWS CloudFormation
起動・停止用のカスタムロールを作成します。
イベントをトリガーにしているので信頼されるエンティティは
events.amazonaws.com。そして、ロールにStartEc2Role_policyというインラインポリシーを追加させるために
Policies以下に定義していきます。AWSサービスにロールを渡すにはPassRoleのアクセス許可が必要なので、ここでEC2AmazonSSMAutomationRoleにアクセス許可を付与しています。イベントと同じくStopの方は割愛。
4. テンプレート展開してみる。
指定した時間通り動いた!わーい!
参考
公式ドキュメントと先人と先輩に感謝。
- AWS サービスにロールを渡すアクセス許可をユーザーに許可する - AWS Identity and Access Management
- AWS-StartEC2Instance - AWS Systems Manager
- AWS Systems Manager AutomationでEC2の自動停止 | ヤマムギ
- EC2インスタンスのスケジュール起動がお手軽に実現できるようになっていた!-Qiita
おわりに
CloudFormationでリソースを作成できても一向にEC2が起きてこなかったり、1つは起動するのにもう1つが起動しなかったりとたくさんはまりました。
間違いや修正点等あったら教えてください!
早くCloudFormationと仲良くなりたい、、
- 投稿日:2020-07-29T08:40:23+09:00
Boto3 に追加されたリトライ処理モードを利用する
はじめに
AWS SDK は Exponential Backoff による自動再試行ロジックが実装されていますが、
Boto3 では 3 つのリトライ処理モードを選択できます。
- legacy (デフォルト)
- standard
- adaptive
botocore の GitHub リポジトリを確認すると、2020年2月ごろに standard および adaptive が
追加され、それ以前の実装は legacy という名称になっています。Add support for new retry modes #1972
互換性のため、デフォルトが legacy となっており、standard/adaptive で追加された機能を
利用するにはリトライ処理モードを明示的に変更する必要があります。リトライ処理モードの変更方法
botocore の config オブジェクトをインスタンス化し、設定情報をクライアントに
渡すことができます。利用可能なオプションはmax_attemptsとmodeです。
リトライ処理モードによってデフォルトの最大試行回数は異なりますが、
max_attempts によってカスタマイズできます。import boto3 from botocore.config import Config config = Config( retries = { 'max_attempts': 10, 'mode': 'standard' } ) ec2 = boto3.client('ec2', config=config)各リトライ処理モードの概要
Legacy retry mode
Boto3 クライアントでデフォルトで使用されるモードです。
バックオフ時間の計算に使用される係数は 2 です。
v1 リトライハンドラー が使用されます。
再試行に対応する errors/exceptions の数が限られています。Standard retry mode
多言語の AWS SDK と一貫性のあるロジックにより、再試行ルールが標準化されています。
legacy モードよりも多くの throttling/limit エラーや例外に対応しています。
バックオフ時間の計算に使用される係数は legacy モード同様 2 ですが、最大値は 20 秒です。
v2 リトライハンドラー が使用されます。
legacy standard デフォルトの最大試行回数 5 3 一時的な接続エラーへの対応 ConnectionError
ConnectionClosedError
ReadTimeoutError
EndpointConnectionErrorRequestTimeout
RequestTimeoutException
PriorRequestNotComplete
ConnectionError
HTTPClientErrorthrottling/limitエラーおよび例外への対応外 Throttling
ThrottlingException
ThrottledException
RequestThrottledException
ProvisionedThroughputExceededExceptionThrottling
ThrottlingException
ThrottledException
RequestThrottledException
TooManyRequestsException
ProvisionedThroughputExceededException
TransactionInProgressException
RequestLimitExceeded
BandwidthLimitExceeded
LimitExceededException
RequestThrottled
SlowDown
EC2ThrottledExceptionステータスコードによる再試行 429/500/502/503/504/509 など 500/502/503/504 遅延時間の計算式 rand(0, 1) * (2 ^ (attempts - 1)) min(rand(0, 1) * 2 ^ attempt, 20) Adaptive retry mode
Standard モードの機能に加えて、トークンバケットアルゴリズムによるクライアント側の
自動レート制限機能や、再試行の毎に AWSサービス側のエラー/例外/HTTPステータスコード
に基づいてレート制限変数を変更する機能が追加されています。
クライアント側でエラー内容に応じて柔軟な再実行を行なうことができますが、
実験的なモードであるため、将来的に機能と動作が変わる可能性があります。参考
Retries - Boto3 Docs
https://boto3.amazonaws.com/v1/documentation/api/latest/guide/retries.html以上です。
参考になれば幸いです。
- 投稿日:2020-07-29T02:32:45+09:00
ECS Fargate(Version 1.4.0)にてffmpegなpipe芸をしようとしたら見事に動かなかったので証跡を書いておく
概要
2020年7月29日現在、Fargateのver 1.4.0にてpipe周りにおかしな挙動があるっぽい。
おかげでffmpegのpipe芸に詰まってそれなりに時間を溶かしたのでメモっておく。
何をしたかったか?
ECSをTask RunするとRTMPを落としてMP4にパッケージングしつつS3に投げ込むっていう超絶シンプルな行いをしたかった。
原本では無いけど、Dockerfileとか起動時用コマンドはこんな感じ。
Dockerfile
FROM ubuntu:18.04 ENV DEBIAN_FRONTEND=noninteractive RUN set -x \ && apt-get update \ && apt-get install -y \ curl \ wget \ tar \ xz-utils \ liblzma-dev \ ca-certificates \ openssl \ musl-dev \ tzdata \ zlib1g-dev \ libssl-dev \ libreadline-dev \ libsqlite3-dev \ libbz2-dev \ libncurses5-dev \ libgdbm-dev \ liblzma-dev \ tk-dev zlibc \ libffi-dev \ zip \ unzip RUN set -x \ && cd /tmp/ \ && wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-4.3-amd64-static.tar.xz \ && tar xvf ffmpeg-4.3-amd64-static.tar.xz \ && cd ffmpeg-4.3-amd64-static \ && mv ffmpeg /usr/bin/ \ && mv ffprobe /usr/bin/ \ && mv model /usr/bin/ \ && mv qt-faststart /usr/bin/ RUN set -x \ && apt-get update \ && apt-get install -y python \ && apt-get install -y python3-pip \ && pip3 install awscli --upgrade --user COPY cmd_in_docker.sh /usr/local/bin CMD ["/usr/local/bin/cmd_in_docker.sh"]cmd_in_docker.sh
#!/bin/bash set -e set -x \ && export PATH=~/.local/bin:$PATH \ && ffmpeg -y -i "rtmp://..." -c copy -f mp4 -movflags frag_keyframe+empty_moov - | aws s3 cp - "s3://バケット名/ファイル名.mp4"ECS Task Runなコマンド
こんなノリ
aws ecs run-task \ --cluster $CLUSTER_ARN \ --task-definition $ECS_TASK_ARN \ --region "ap-northeast-1" \ --network-configuration "awsvpcConfiguration={subnets=$SUBNETS,securityGroups=$SGS,assignPublicIp=ENABLED}" \ --launch-type "FARGATE" \ --platform-version "1.4.0"もともとファイルをEFSに書き出そうとしていたので、その遺産として
--platform-version "1.4.0"としていたのがミスでした。何が起きたのか?
あんまりちゃんとデバックしていないのでなんとも言えませんが、数分経つとffmpegが全く仕事をしなくなります。
そこで落ちてくれればいいのにそれすらしない。厄介ですね。デバッグ準備
仕方がなく、SSMを仕込みました。余談ですがFargate + TerraformでSSMをやるには下記記事が参考になりました。
SSMで接続してffmpegを手動実行
ffmpeg -y -i "rtmp://..." -c copy -f mp4 -movflags frag_keyframe+empty_moov - | aws s3 cp - "s3://バケット名/ファイル名.mp4"を手作業で実行した所、まぁ元気に動くんだなぁーssmで同様のコマンドを動かしてもちゃんと機嫌よく動いてそうなので、いよいよFargateのバージョンを疑う時か…EFSなんて使わずに素直に1.3で動かすか…
— yanoshi (@yanoshi) July 28, 2020もしやということで
1.3.0にしてみたaws ecs run-task \ --cluster $CLUSTER_ARN \ --task-definition $ECS_TASK_ARN \ --region "ap-northeast-1" \ --network-configuration "awsvpcConfiguration={subnets=$SUBNETS,securityGroups=$SGS,assignPublicIp=ENABLED}" \ --launch-type "FARGATE" \ --platform-version "1.3.0"元気に動いたんだなぁ…
あーーーーーやっぱりFargate 1.4が原因だったああああああああああああああああああ
— yanoshi (@yanoshi) July 28, 2020ECS Fargate 1.4.0ではffmpegが現在まともに動かないというどうでもいいナレッジがたまりました…(pipe周りがおかしいっぽい)
— yanoshi (@yanoshi) July 28, 2020余談
その昔、WSLでのffmpegのpipe芸で詰まったことがあったのですが、それと同じような挙動な気がしています…
Windows10で作るMirakurun + Chinachu Gammaな録画サーバー ~VagrantとPT3(BonDriver)を添えて~ - さわっても熱くない花火
所感
あまりにも悲しい気持ちになったので、すごい勢いで証跡を残してしまいました。悲しいなぁ。
各所で1.4.0の悪い噂を聞いていましたが、自分が被ることになるとは…
- 投稿日:2020-07-29T00:21:20+09:00
スタックの有無で待つ状態を切り替える
スタックの有無で wait するコマンドを切り替える。
#!/bin/bash set -eu STACK_NAME="foobar" IS_UPDATE=0 set +e aws cloudformation describe-stacks --stack-name ${STACK_NAME} > /dev/null 2>&1 if [ $? -eq 0 ]; then IS_UPDATE=1 fi set -e aws cloudformation deploy --stack-name ${STACK_NAME} --template-file /path/to/template.yml if [ $IS_UPDATE -eq 1 ]; then aws cloudformation wait stack-update-complete --stack-name ${STACK_NAME} else aws cloudformation wait stack-create-complete --stack-name ${STACK_NAME} fi echo waited参考
- 投稿日:2020-07-29T00:19:22+09:00
「WARNING: psql version 9.2, server version 11.0. Some psql features might not work.」エラー対処(AWSLinux(EC2)からpsql11のインストール)
EC2でpostgresqlを使えるようにするぞー!とやっている最中で「WARNING: psql version 9.2, server version 11.0. Some psql features might not work.」が出てきてふぁ!?ってなっていろいろ調べたので記録します。
Warningの内容
「サーバー側のバージョンは11.0だけどあなたが使っているpsqlバージョンは9.2よ!一部動かないかもしれないわ!」
と忠告してくれているようです。対処
バージョン11のpostgresqlをインストールします。
sudo yum install postgresqlでpostgresqlをインストールしようとすると、なにやらいろいろでてきた後に
--> Finished Dependency Resolution Dependencies Resolved ======================================================================================================================== Package Arch Version Repository Size ======================================================================================================================== Installing: postgresql x86_64 9.2.24-1.amzn2.0.1 amzn2-core 3.0 M Installing for dependencies: postgresql-libs x86_64 9.2.24-1.amzn2.0.1 amzn2-core 235 k Transaction Summary ======================================================================================================================== Install 1 Package (+1 Dependent package) Total download size: 3.3 M Installed size: 17 M Is this ok [y/d/N]:と出てきます。===の中を見ると、9.2のバージョンのpostgresqlをインストールしようとしているようです。
9.2はインストールしたくないので「N」と入力します。
すると
======================================================================================================================== Package Arch Version Repository Size ======================================================================================================================== Installing: postgresql x86_64 9.2.24-1.amzn2.0.1 amzn2-core 3.0 M Installing for dependencies: postgresql-libs x86_64 9.2.24-1.amzn2.0.1 amzn2-core 235 k Transaction Summary ======================================================================================================================== (略) //ここでNを入力 Is this ok [y/d/N]: n Exiting on user command Your transaction was saved, rerun it with: yum load-transaction /tmp/yum_save_tx.2020-07-07.07-38.AfbT_W.yumtx postgresql is available in Amazon Linux Extra topics "postgresql9.6" and "postgresql10" and "postgresql11" To use, run # sudo amazon-linux-extras install :topic: Learn more at https://aws.amazon.com/amazon-linux-2/faqs/#Amazon_Linux_Extras「
postgresql is available in Amazon Linux Extra topics "postgresql9.6" and "postgresql10" and "postgresql11"
To use, run
sudo amazon-linux-extras install :topic:
」
と書いてあります。太字のコマンドを実行するといいよ!って親切に教えてくれました。ありがとう~(^^*)
トピックが三種類(赤字)示されているので、そのうち「postgresql11」を指定します。
sudo amazon-linux-extras install postgresql11インストールが終わったら、バージョンを確認してみます。
psql --version「psql (PostgreSQL) 11.5」とでてきました!
無事インストールできました。つまずいたポイント
以下のコマンドが実行できませんでした。
npn install postgresql11VSCodeでローカル環境で開発していた時のコマンドはダメでした。(なにもわかっていない)
sudo yum install postgres11yumできませんでした。他のインストールはできたのでなぜかこれだけできない状況で?でした。
yumのところをamazom-linux-extras にしたらできたのはどうしてですか?どなたかおしえてください。
- 投稿日:2020-07-29T00:00:13+09:00
Nuxt × Go × AWS で比較コミュニケーション的な掲示板サービス作ってみた
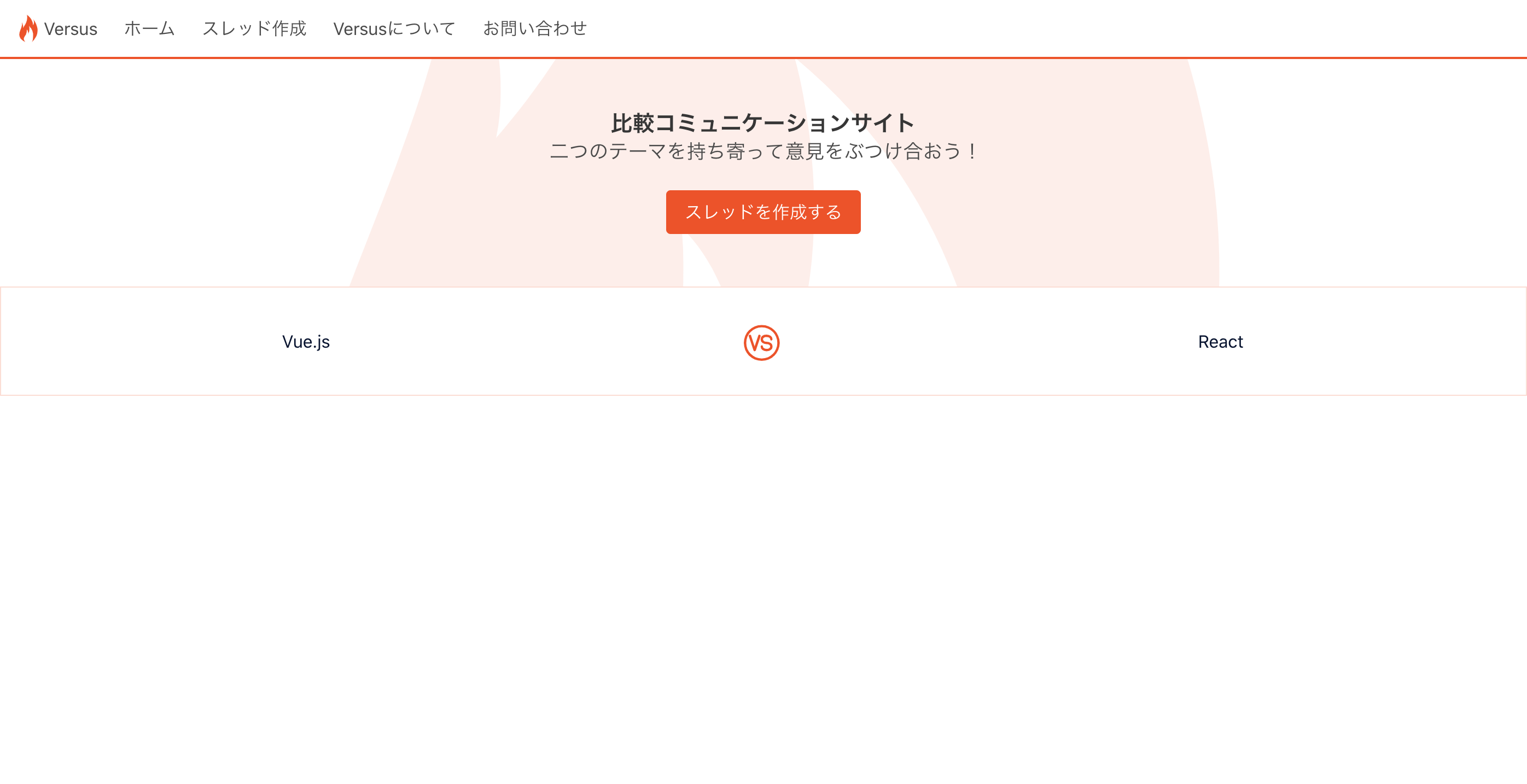
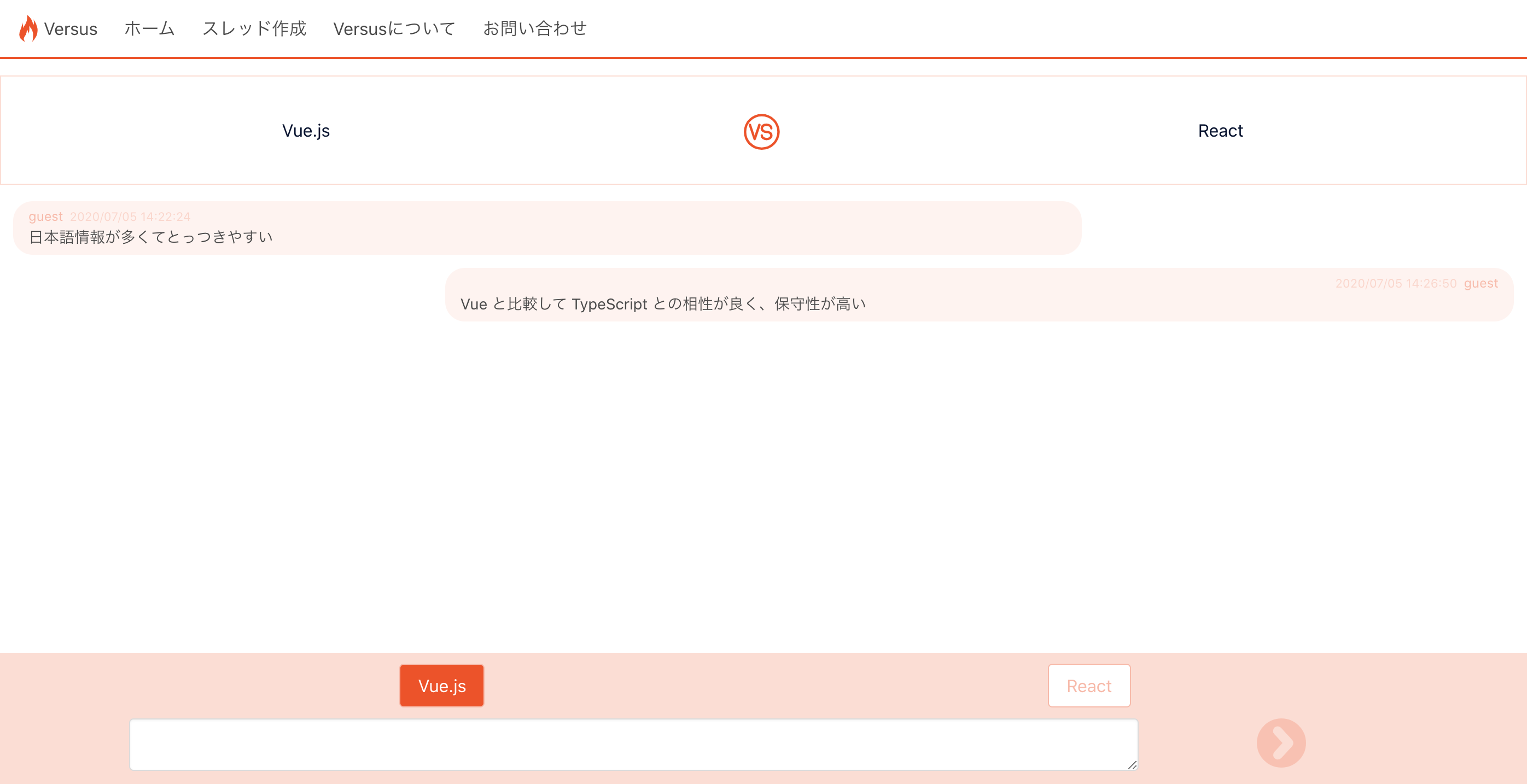
比較コミュニケーションサイト Versus
https://versus-web.net
Twitter で技術マウント合戦している人たちが面白かったので
AWS と Go の勉強がてら、テーマを持ち寄ってコミュニケーションできる簡単な掲示板サイトを作ってみたので作業工程など記録してみる。構成
インフラ
- ECS
- Lambda
- DynamoDB
- API Gateway
- Route 53
バックエンド
- Go
フロントエンド
- Nuxt (SSR)
Go と Fargate 辺りを使ってみたかったのでこんな構成になりました。
作業工程
タスク管理
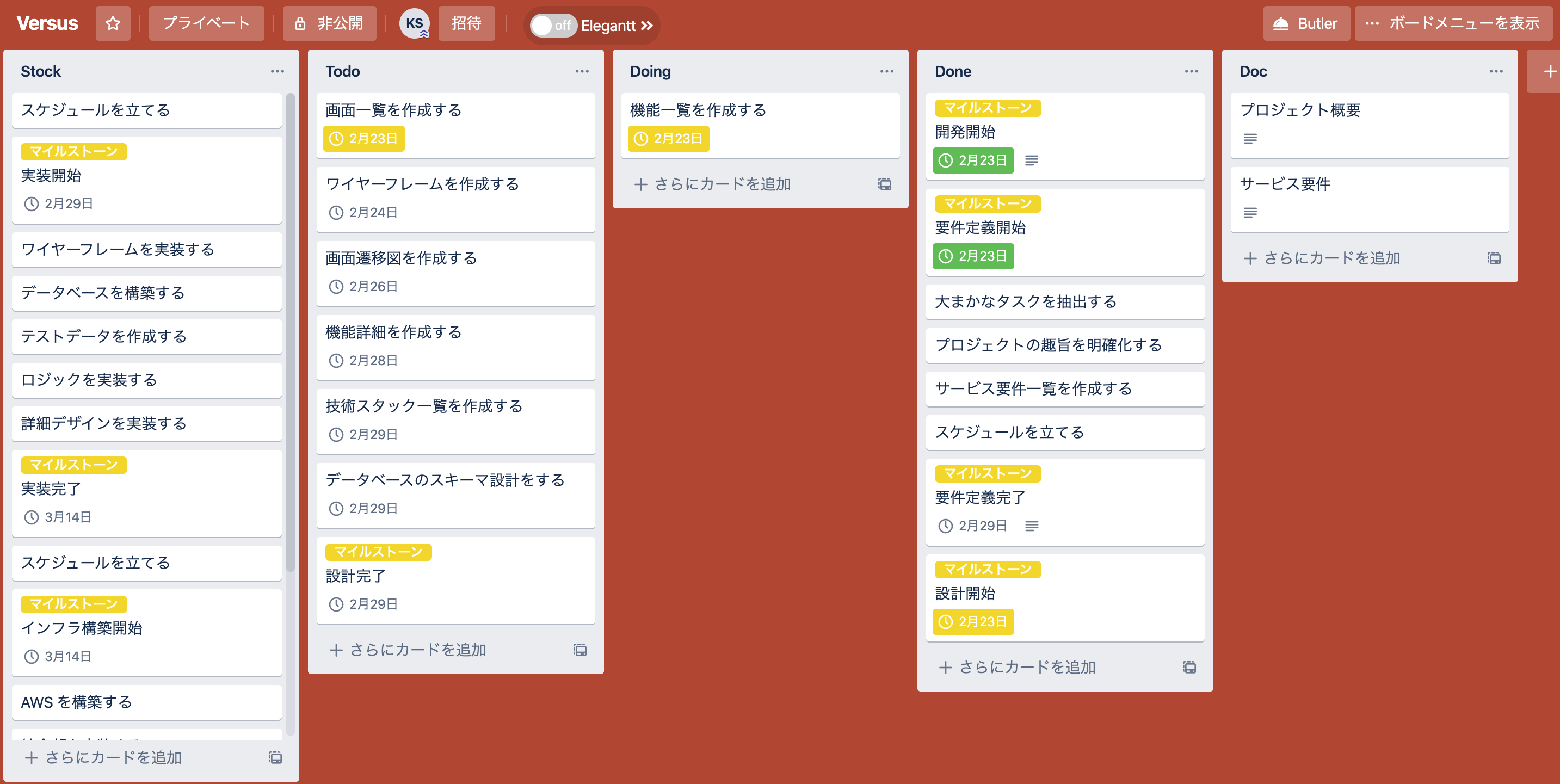
タスク管理ツールとして Trello を使用した。
こんな感じに5カラムで管理してみた。
Doc としてドキュメント管理にも使用してみたが、シンプルでサクサク動くし、個人開発規模ならすごく使いやすいと思った。デザイン
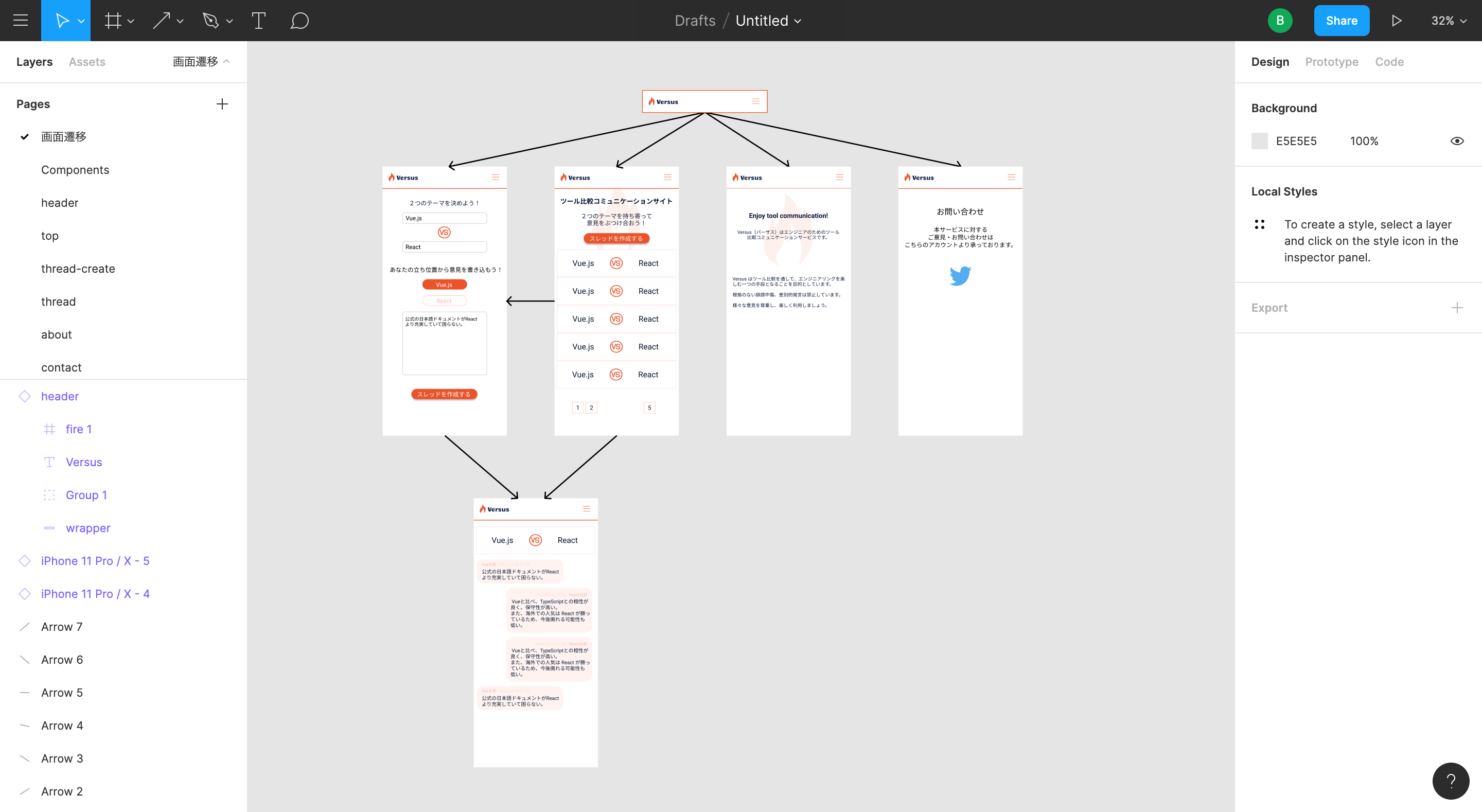
Figma を使用。
こんな感じに遷移図作ったり
色管理もしつつ、わりとしっかりめに使ってみたつもり(デザイナーの方からするとまだまだだろう)
このくらいやっておくと開発時だいぶ楽。開発
Go
Lambda で採用。ディレクトリ構成は以下の通り。
. ├── posts-function │ └── posts │ ├── bin │ ├── cmd │ └── internal │ ├── actions │ ├── handler │ ├── models │ └── repositories └── threads-function └── threads ├── bin ├── cmd └── internal ├── actions ├── handler ├── models └── repositories └── mockAWS SAM を使用することで、コマンドで Go の Lambda 関数を作成することができる。
ディレクトリ構成は golang-standards を参考にした。
どの粒度で Lambda 関数を作成するか迷ったが、リソース単位で分割することにし、以下のようにハンドリングしてみた。handler.gopackage handler import ( "context" "posts/internal/actions" "github.com/aws/aws-lambda-go/events" ) var routes = map[string]actions.ActionFactory{ "GET": actions.NewPostsGetter, "POST": actions.NewPostsPoster, } // CORS compatible var headers = map[string]string{ "Content-Type": "application/json", "Access-Control-Allow-Origin": "*", } func Handler(ctx context.Context, request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { factory := routes[request.HTTPMethod] action := factory() jsonData, err := action.Run(request) if err != nil { return events.APIGatewayProxyResponse{}, err } return events.APIGatewayProxyResponse{ Body: string(jsonData), StatusCode: 200, Headers: headers, }, nil }HTTP メソッドで振り分けるだけなのでルーティングは楽。関数を分ければ当然デプロイも分けられるので、この辺の粒度は規模を見つつといった感じになりそう。(ちなみに他プロジェクトではマイクロサービス粒度で分けていた)
Nuxt
フロントエンドで採用。
基本的に初期表示速度的な意味で SSR をすべきと思っているので今回も SSR を採用。
難しいことをしていないのであまり特筆する点がないのだが
バリデーションに vuelidate を使用してみてとても使いやすかったのでおすすめしたい。
人気の VeeValidate と比較すると、vuelidate はテンプレートとアプリケーションロジックが分離しているので、バリデーション時の処理を細く設定したい要件があるときに使いやすい。所感
AWS と Go がほぼ初見だったためだいぶ苦労した。
Node なら Lambda 上のコードを AWS コンソールから見れるため、とっつきやすさもあるが、Go の場合それができず、デプロイ周りを整えるまで一苦労だった。
新しく何かを作るときは未知の技術は1種類にすべき、みたいな話をどっかで聞いたけどその通りだと思った。
しかし今回の技術スタックはだいぶ耳にすることも多くなってきたので、試してみるのは一興だと思う。