- 投稿日:2020-07-29T23:49:53+09:00
HuggingFaceのBertJapaneseTokenizerで分かち書きしようとするとMeCabのinitializingで落ちたりencodeでも落ちたりする
同じエラーで躓いた人の調べる時間が少しでも減りますように、メモとして記事に起こしておきます。
以下はGoogle Colab上で実行しています。
こちらを参考にColab上でMeCabとhuggingfaceのtransformersをインストールします。
!apt install aptitude swig !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3 !pip install transformers日本語用BERTのtokenizerで分かち書きを試みます。
from transformers.tokenization_bert_japanese import BertJapaneseTokenizer # 日本語BERT用のtokenizerを宣言 tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') text = "自然言語処理はとても楽しい。" wakati_ids = tokenizer.encode(text, return_tensors='pt') print(tokenizer.convert_ids_to_tokens(wakati_ids[0].tolist())) print(wakati_ids)以下のようなエラーがでてしまいました。
---------------------------------------------------------- Failed initializing MeCab. Please see the README for possible solutions: https://github.com/SamuraiT/mecab-python3#common-issues If you are still having trouble, please file an issue here, and include the ERROR DETAILS below: https://github.com/SamuraiT/mecab-python3/issues issueを英語で書く必要はありません。 ------------------- ERROR DETAILS ------------------------ arguments: error message: [ifs] no such file or directory: /usr/local/etc/mecabrc --------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) <ipython-input-3-f828f6470517> in <module>() 2 3 # 日本語BERT用のtokenizerを宣言 ----> 4 tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') 5 6 text = "自然言語処理はとても楽しい。" 4 frames /usr/local/lib/python3.6/dist-packages/MeCab/__init__.py in __init__(self, rawargs) 122 123 try: --> 124 super(Tagger, self).__init__(args) 125 except RuntimeError: 126 error_info(rawargs) RuntimeError:エラー出力に親切にこちらを見るように言ってくれているので、URL先の指示通りに、mecab-python3をインストールするときに
pip install unidic-liteも実行すればMeCabのinitializingで落ちることはなくなりました。が、今度は
encodeでValueError: too many values to unpack (expected 2)と怒られてしまいました。--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-5-f828f6470517> in <module>() 6 text = "自然言語処理はとても楽しい。" 7 ----> 8 wakati_ids = tokenizer.encode(text, return_tensors='pt') 9 print(tokenizer.convert_ids_to_tokens(wakati_ids[0].tolist())) 10 print(wakati_ids) 8 frames /usr/local/lib/python3.6/dist-packages/transformers/tokenization_bert_japanese.py in tokenize(self, text, never_split, **kwargs) 205 break 206 --> 207 token, _ = line.split("\t") 208 token_start = text.index(token, cursor) 209 token_end = token_start + len(token) ValueError: too many values to unpack (expected 2)このエラーについてはこちらでmecab-python3の開発者?の方が言及されている通り、mecab-python3のバージョンを
0.996.5に指定してやれば解決しました。まとめると、pipであれこれインストールするときは以下のように宣言すればエラーでなくなると思います。
!apt install aptitude swig !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3==0.996.5 !pip install unidic-lite !pip install transformers↑を実行する前に既にpipでmecab-python3の最新版をインストールしてしまっている場合は、一度colabのセッションを再接続するのをお忘れなく。セッションの切断の仕方はcolab画面の右上のRAMとかディスクとか書いてる▼をクリックして、セッションの管理から行えます。
from transformers.tokenization_bert_japanese import BertJapaneseTokenizer # 日本語BERT用のtokenizerを宣言 tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') text = "自然言語処理はとても楽しい。" wakati_ids = tokenizer.encode(text, return_tensors='pt') print(tokenizer.convert_ids_to_tokens(wakati_ids[0].tolist())) print(wakati_ids) #Downloading: 100% #258k/258k [00:00<00:00, 1.58MB/s] # #['[CLS]', '自然', '言語', '処理', 'は', 'とても', '楽しい', '。', '[SEP]'] #tensor([[ 2, 1757, 1882, 2762, 9, 8567, 19835, 8, 3]])無事に
BertJapaneseTokenizerで分かち書きできました。おわり

- 投稿日:2020-07-29T23:21:42+09:00
PythonでDIを勉強するためにサクッとプログラム書いてみた①
背景
会社でDI(Dependency Injection)についての話が出たが、
イマイチちゃんと分かっていなかったのでお勉強することにしたそもそもDIって何よ
・依存性の注入(直訳)
・結合度の低下によるコンポーネント化の促進
・単体テストの効率化
・特定のフレームワークへの依存度低下
・DIコンテナってのがあるらしい(へぇ)個人的には、単体テストがしやすくなるってところに惹かれた。
後、実装時に(見かけ上)コンポーネント化されたとしても、
各々依存しあってたらあまりメリットないもんね。(筋子じゃダメなんだ、いくらでないとダメだ、というイメージは本当に無駄)
早速書いてみる
何はともあれ、書いてみる。
まずは、依存しまくっている例。
no_di.pyclass Country: def getCountry(self): return "Japanese" class Position: def getPosition(self): return 'SuperStar' class HorseName: def getName(self): return 'Caesario' class GreatRealCondition: def __init__(self): self.c = Country() self.p = Position() self.h = HorseName() def getGreatRealCondition(self): return self.c.getCountry() + "\n" + self.p.getPosition() + "\n" + self.h.getName() + "!" if __name__ == '__main__': g = GreatRealCondition() print(g.getGreatRealCondition())実行結果.Japanese SuperStar Caesario!何の文章か分からない方はyoutubeで
「ジャパニーズスーパースターシーザリオ!」で検索。GreatRealConditionクラスは、
・Countryクラス
・Positionクラス
・HorseNameクラスこれらのクラスと密な関係(三密)になっている。
ということは、これらのクラスは、バラバラに見えて、実はほぼ一つのクラスである、と言える。
再利用も出来ないし、そもそもテストも出来ない(値を変えてみたり、なんてことは今のところ出来ない)。
Countryクラスなどにセッターを入れれば値を変えることはできるが、もはやGreatRealConditionクラスのテストではないよね。なので、依存度を下げてみる。
on_di.pyclass Country: def getCountry(self): return "Japanese" class Position: def getPosition(self): return 'SuperStar' class HorseName: def getName(self): return 'Caesario' class GreatRealCondition: def __init__(self, c: Country, p: Position, h: HorseName): self.c = c self.p = p self.h = h def getGreatRealCondition(self): return self.c.getCountry() + "\n" + self.p.getPosition() + "\n" + self.h.getName() + "!" if __name__ == '__main__': c = Country() p = Position() h = HorseName() g = GreatRealCondition(c, p, h) print(g.getGreatRealCondition())実行結果.Japanese SuperStar Caesario!先ほどと同じ結果になった。
ここで大きく変わったことは、
GreatRealConditionクラスが他クラスを持たなくなったこと
に尽きる。
さっきまで、3密クラスに依存していて、他に使い道がなかったGreatRealConditionクラスが、
コンストラクタで3密クラスを持たせるようにすることで、いろんな用途が出来た。
(本当はいろんなパターンで試そうと思ったのだが、長くなりそうなのでまた今度)とまあ、コンストラクタを使って、「依存性を注入」したわけです。
最初はこんな感じ。
今後
今回はコンストラクタを使用して注入したんだけど、
setterで注入だったり、インタフェース定義して注入したりといろいろ方法があるみたいなので是非試してみようと思います。
あと、pythonだと結構DIめんどいかも。
(慣れてないだけか)Thanks!!
参考になった記事はこちらです。
ありがとうございます。
https://qiita.com/mkgask/items/d984f7f4d94cc39d8e3c
- 投稿日:2020-07-29T23:11:42+09:00
不動点コンビネータを用いた無名版再帰関数の実行方法まとめ
諸般の理由で『Pythonのlambda式を用いたラムダ計算の基礎表現』を書いた後にHaskellに触れたところ,無名版再帰関数を実行する不動点コンビネータがとんでもなく簡単に書けたため,同じ方法でSchemeやPythonでもできないか試したところ,これまたあっさりできたので,まとめメモ的に新しく記事にした.
このような内容がQiitaや書籍,ネット上に星の数の更に星の数乗ほどあることは承知しているが,この手の話はYコンビネータ(Zコンビネータ)が大きな割合を占めており(実際,元記事でも取り上げている),関心のある人々の数多ある参考資料のひとつ程度に捉えてもらえると幸いである.ツッコミ,編集リクエスト歓迎.
不動点コンビネータの定義
Haskell,Scheme,Pythonでの考察および実行例を述べる.なお,不動点コンビネータとは,$f(g(f))=g(f)$が成り立つ関数$g$を指す.
Haskell(GHC)
式に従い,不動点コンビネータを定義する.
Prelude> g f = f (g f)階乗計算を行う無名関数を用いた動作確認を行った結果は次の通り.
Prelude> g (\fact -> \n r -> if n == 0 then r else fact (n-1) (n*r)) 5 1 120Scheme(Gauche)
式に従い,不動点コンビネータを定義する.
gosh> (define (g f) (f (g f))) g階乗計算を行う無名関数を用いた動作確認を行った結果は次の通り.※注意:実行環境によっては危険!
gosh> (((g (lambda (fact) (lambda (n) (lambda (r) (if (= n 0) r ((fact (- n 1)) (* n r))))))) 5) 1) ; いつまでも表示されず → 強制終了引数評価を先に行うという仕様上,実際の階乗計算の前に自己適用
(g f)を繰り返して無限ループに陥り,メモリを食い潰していった模様.同様の現象はYコンビネータでも起こるため,実際に稼働するZコンビネータへの変換と同じく,
(g f)を,自由変数yを引数にもつlambda式でくくることで(ラムダ計算で言うη簡約の逆適用,実装上はクロージャの活用),呼び出されるまで実行を据え置くようにする.なお,Haskellの引数は実際に必要となるまで評価されない(遅延評価機能のひとつ)ため,このような問題が起こらない.gosh> (define (g f) (f (lambda (y) ((g f) y)))) g書き直した不動点コンビネータについて,階乗計算を行う無名関数を用いた動作確認を行った結果は次の通り.
gosh> (((g (lambda (fact) (lambda (n) (lambda (r) (if (= n 0) r ((fact (- n 1)) (* n r))))))) 5) 1) 120Python(Python3)
式に従って不動点コンビネータを定義…したいところだが,Schemeと同じく引数評価を先に行うことがわかっているので,書き直したSchemeの定義と同じ内容の定義を行う.なお,lambda式を直接変数に代入するのはPEP8非推奨であり,内部で(クロージャで)定義した関数を返す関数を返す,という記述方法が一般的であるため,それにしたがった定義を行う.
>>> def g(f): ... def ret(y): ... return g(f)(y) ... return f(ret) ... >>>階乗計算を行う無名関数を用いた動作確認を行った結果は次の通り.
>>> g(lambda fact: lambda n: lambda r: r if n == 0 else fact(n-1)(n*r))(5)(1) 120補足説明
無名関数,高階関数
プログラミングにおける『無名関数』とは,関数名を持たずに引数のみを持つ関数定義のことを指す.関数定義構文を用いる必要がないため,関数定義を引数として受け取れる『高階関数』への小さな任意処理の埋め込み追加などによく用いられる.なお,高階関数は,関数定義を戻り値として返すことができるものも含まれる.
再帰関数,無名再帰
無名関数の最大の欠点は,関数名がないために,『再帰関数』を定義するのも実行するのも,特別な方法が必要となることである.その方法としては,自身の引数の名前で自身を呼び出せるようにしてくれる高階関数を別途用意したり,実行環境が無名関数の場所を自動的に覚えて特別な名前で自身を呼び出せるようにしたりといったものがある(Wikipedia『無名再帰』を参照).
不動点コンビネータ
この記事では,無名再帰のための高階関数として『不動点コンビネータ』を定義する方法に焦点を当てている.不動点コンビネータには様々な関数があり,その中でも有名なのが,自身も無名関数として示されることが多いYコンビネータである.この記事では,Yコンビネータを特に意識しなくとも定義できる不動点コンビネータについて述べている.
備考
記事に関する補足
- 概説に留めたいため,この記事では正確な定義や位置付けは述べていない.
- PEP8非推奨は高階関数大好き人間にはやっぱりつらたん.
変更履歴
- 2020-07-29:初版公開
- 投稿日:2020-07-29T23:11:42+09:00
不動点コンビネータを用いた無名再帰関数の実行方法まとめ
諸般の理由で『Pythonのlambda式を用いたラムダ計算の基礎表現』を書いた後にHaskellに触れたところ,無名再帰関数を実行する不動点コンビネータがとんでもなく簡単に書けたため,同じ方法でSchemeやPythonでもできないか試したところ,これまたあっさりできたので,まとめメモ的に新しく記事にした.
このような内容がQiitaや書籍,ネット上に星の数の更に星の数乗ほどあることは承知しているが,この手の話はYコンビネータ(Zコンビネータ)が大きな割合を占めており(実際,元記事でも取り上げている),関心のある人々の数多ある参考資料のひとつ程度に捉えてもらえると幸いである.ツッコミ,編集リクエスト歓迎.
不動点コンビネータの定義
Haskell,Scheme,Pythonでの考察および実行例を述べる.なお,不動点コンビネータとは,$f(g(f))=g(f)$が成り立つ関数$g$を指す.
Haskell(GHC)
式に従い,不動点コンビネータを定義する.
Prelude> g f = f (g f)階乗計算を行う無名関数を用いた動作確認を行った結果は次の通り.
Prelude> g (\fact -> \n r -> if n == 0 then r else fact (n-1) (n*r)) 5 1 120Scheme(Gauche)
式に従い,不動点コンビネータを定義する.
gosh> (define (g f) (f (g f))) g階乗計算を行う無名関数を用いた動作確認を行った結果は次の通り.※注意:実行環境によっては危険!
gosh> (((g (lambda (fact) (lambda (n) (lambda (r) (if (= n 0) r ((fact (- n 1)) (* n r))))))) 5) 1) ; いつまでも表示されず → 強制終了引数評価を先に行うという仕様上,実際の階乗計算の前に自己適用
(g f)を繰り返して無限ループに陥り,メモリを食い潰していった模様.同様の現象はYコンビネータでも起こるため,実際に稼働するZコンビネータへの変換と同じく,
(g f)を,自由変数yを引数にもつlambda式でくくることで(ラムダ計算で言うη簡約の逆適用であるη展開,実装上はクロージャの活用),呼び出されるまで実行を据え置くようにする.なお,Haskellの引数は実際に必要となるまで評価されない(遅延評価機能のひとつ)ため,このような問題が起こらない.gosh> (define (g f) (f (lambda (y) ((g f) y)))) g書き直した不動点コンビネータについて,階乗計算を行う無名関数を用いた動作確認を行った結果は次の通り.
gosh> (((g (lambda (fact) (lambda (n) (lambda (r) (if (= n 0) r ((fact (- n 1)) (* n r))))))) 5) 1) 120Python(Python3)
式に従って不動点コンビネータを定義…したいところだが,Schemeと同じく引数評価を先に行うことがわかっているので,書き直したSchemeの定義と同じ内容の定義を行う.なお,lambda式を直接変数に代入するのはPEP8非推奨であり,内部で(クロージャで)定義した関数を返す関数を返す,という記述方法が一般的であるため,それに従った定義を行う.
>>> def g(f): ... def ret(y): ... return g(f)(y) ... return f(ret) ... >>>階乗計算を行う無名関数を用いた動作確認を行った結果は次の通り.
>>> g(lambda fact: lambda n: lambda r: r if n == 0 else fact(n-1)(n*r))(5)(1) 120補足説明
無名関数,高階関数
プログラミングにおける『無名関数』とは,関数名を持たずに引数のみを持つ関数定義のことを指す.関数定義構文を用いる必要がないため,関数定義を引数として受け取れる『高階関数』への小さな任意処理の埋め込み追加などによく用いられる.なお,高階関数は,関数定義を戻り値として返すことができるものも含まれる.
再帰関数,無名再帰
無名関数の最大の欠点は,関数名がないために,『再帰関数』を定義するのも実行するのも,特別な方法が必要となることである.その方法としては,自身の引数の名前で自身を呼び出せるようにしてくれる高階関数を別途用意したり,実行環境が無名関数の場所を自動的に覚えて特別な名前で自身を呼び出せるようにしたりといったものがある(Wikipedia『無名再帰』を参照).
不動点コンビネータ
この記事では,無名再帰のための高階関数として『不動点コンビネータ』を定義する方法に焦点を当てている.不動点コンビネータには様々な関数があり,その中でも有名なのが,自身も無名関数として示されることが多いYコンビネータである.この記事では,Yコンビネータを特に意識しなくとも定義できる不動点コンビネータについて述べている.
備考
記事に関する補足
- 概説に留めたいため,この記事では正確な定義や位置付けは述べていない.
- PEP8非推奨は高階関数大好き人間にはやっぱりつらたん.
変更履歴
- 2020-07-29:初版公開
- 投稿日:2020-07-29T22:42:01+09:00
Python: 関数の処理時間を綺麗に測りたい
はじめに
scikit-learnに限らず関数の実行時間を計測したいことはたまにあると思いますが、計測後に計算を挟んだりとごちゃごちゃしてしまいます。
コード
関数の処理時間を計測したいのであれば、Pythonのおもしろい機能の一つであるデコレータを使ったほうが個人的には良いと思います。デコレータに汚い計算を任せてしまえということです。
import time def clock(func): def clocked(*args): t0 = time.perf_counter() result = func(*args) elapsed = time.perf_counter() - t0 arg_str = ", ".join(repr(arg) for arg in args) print("[%0.8fs %s(%s) -> %r" % (elapsed,func.__name__,arg_str,result)) return result return clockedデモ
scikit-learnの学習時間を簡単に測定して見ます。先程のコードはclockdeco.pyに保存しています。
from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from clockdeco import clock # load iris datasets iris = datasets.load_iris() X = iris.data[:,[2,3]] y = iris.target X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0) # preprocessing from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(X_train) X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) def modelDemo(model,x_train,y_train,test): model.fit(x_train,y_train) y_pred = model.predict(test) return round(accuracy_score(y_test,y_pred),2) # Perceptron from sklearn.linear_model import Perceptron @clock def PerceptronDemo(): ppn = Perceptron(max_iter=40,eta0=0.1,random_state=0,shuffle=True) result = modelDemo(model=ppn,x_train=X_train_std,y_train=y_train,test=X_test_std) return result # LogisticRegression from sklearn.linear_model import LogisticRegression from sklearn.linear_model import SGDClassifier @clock def LogisticRegressionDemo(): #lr = LogisticRegression(C=1000.0,random_state=0) lr = SGDClassifier(loss="log") result = modelDemo(model=lr,x_train=X_train_std,y_train=y_train,test=X_test_std) return result # SuportVectorMachine from sklearn.svm import SVC @clock def SVMDemo(): svm = SVC(kernel="linear", C=1.0, random_state=0) result = modelDemo(model=svm,x_train=X_train_std,y_train=y_train,test=X_test_std) return result # DecisionTree from sklearn.tree import DecisionTreeClassifier @clock def DecisionTreeDemo(): tree = DecisionTreeClassifier(criterion="entropy",max_depth=3,random_state=0) result = modelDemo(model=tree,x_train=X_train,y_train=y_train,test=X_test) return result # RandomForest from sklearn.ensemble import RandomForestClassifier @clock def RandomForestDemo(): forest = RandomForestClassifier(criterion="entropy",n_estimators=10,random_state=1,n_jobs=2) result = modelDemo(model=forest,x_train=X_train,y_train=y_train,test=X_test) return result # KNN from sklearn.neighbors import KNeighborsClassifier @clock def KNNDemo(): knn = KNeighborsClassifier(n_neighbors=5,p=2,metric="minkowski") result = modelDemo(model=knn,x_train=X_train,y_train=y_train,test=X_test) return result # wbdc dataset # pipeline test from skutils import load_wdbc_dataset df = load_wdbc_dataset() X = df.loc[:,2:].values y = df.loc[:,1].values # クラスを0,1にする from skutils import label_encode le,y = label_encode(y) X_train_w,X_test_w,y_train_w,y_test_w = train_test_split(X,y,test_size=0.20,random_state=1) from sklearn.decomposition import PCA from sklearn.pipeline import Pipeline @clock def wdbc_piplineDemo(): procs = [("scl",StandardScaler()), ("pca",PCA(n_components=2)),("clf",LogisticRegression(random_state=1,solver='lbfgs'))] pipe_lr = Pipeline(procs) pipe_lr.fit(X_train_w,y_train_w) return round(pipe_lr.score(X_test_w,y_test_w),2) demos = [globals()[name] for name in globals() if name.endswith("Demo") and name != "modelDemo"] if __name__ == "__main__": for demo in demos : demo()デコレータのおかげでかなりすっきり書けるようになったのではないでしょうか。ちなみに実行結果は以下のようになります。

- 投稿日:2020-07-29T22:32:56+09:00
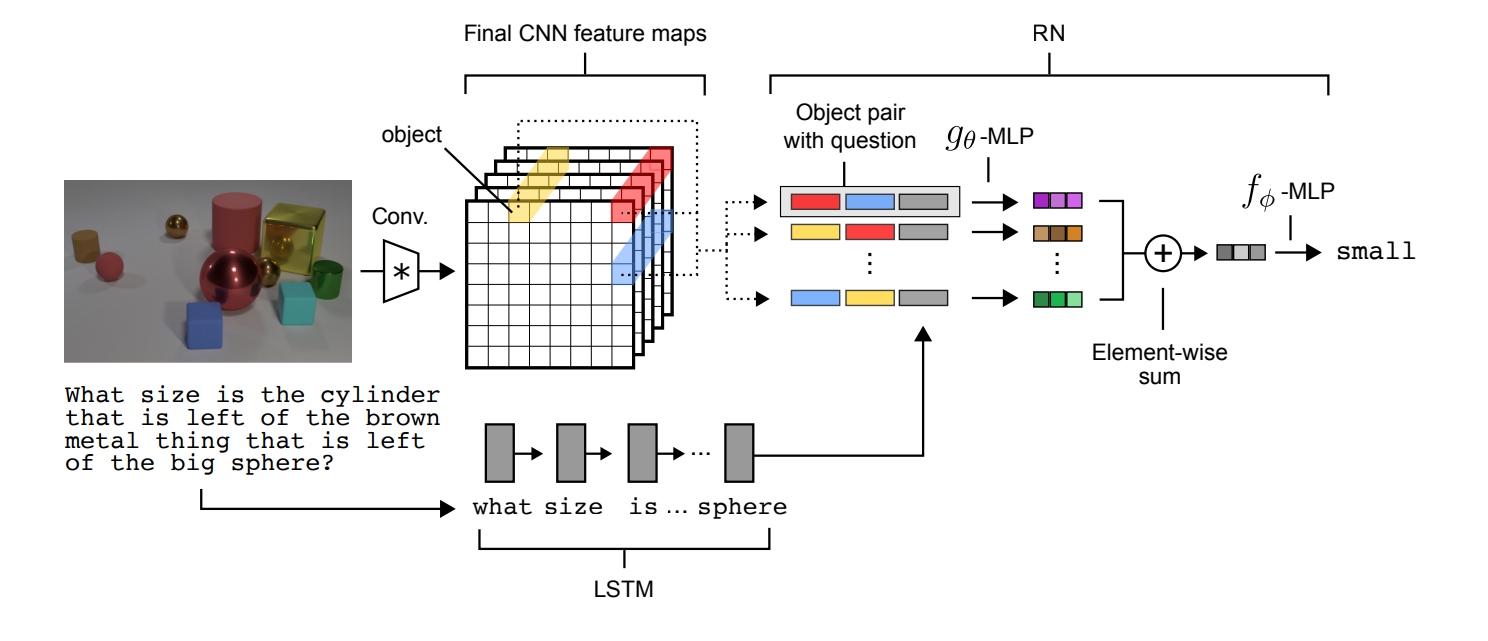
Relational Network
前回の記事の続きで、Relational Networkのできる限りの説明になります。
Relational Networkについて
まずは元論文のリンクを(https://arxiv.org/pdf/1706.01427)
実験結果から見てしまいましょう。
これはCLEVRというオブジェクトの関係から回答を導くデータセットの正解率になります。よくあるニューラルネットワーク(CNN+LSTM、まあ今はあんまり使われてないみたいですが)の正解率は低く、人間(Human)を下回っています。一方、Relational Networkを用いた(CNN+LSTM+RN)は人間を上回る結果が出ています。
この結果から分かりますが、シンプルなニューラルネットワーク(NN)というものは関係というものを認識する能力が低いのです。そこで提案されたのがこのRelational Networkです。後述しますが、関係性を出力に反映するためにシンプルなニューラルネットワークとは違った特殊な構造を持っています。で、この技術をARCで使おうと考えているわけです。Relational Network詳細
Relational Networkは式で表すと次のような構造になっています。
RN(O)=f_\phi (\sum_{i,j}g_\theta(o_i,o_j))ここで$O=\{ o_1,o_2,\dots o_n \},o_i\in \mathbb{R}^m$で$o_i$はオブジェクトを表します。そして、$f_\phi$と$g_\theta$はパラメータつきの関数(Relational NetworkではMLPで実装)を表します。
図で表すと以下のようになります。CNNとLSTMでオブジェクトを認識し、それをRNに入力することで回答を出すという構造です。
このRNの式、正直、私もいまいちよく分かっていないのですが、$g_\theta$で各オブジェクト毎の関係性を出力し、それらを加算して、$f_\phi$で統合し出力を得るみたいです。ただ、よくあるNN(すべてのオブジェクトを一列に並べてしまって、MLPに入力する)と違うのは二つのオブジェクトを表すベクトルと質問ベクトルだけを並べてMLPに入力しているという点です。これはよくあるNNより制限された構造と考えられ、この制限によりネットワークがオブジェクト間の関係性を学習しやすくなるのだと思っています。Sort Of CLEVRデータセット
論文で実際に使用されたデータセットはほかにもあるようですが、Sort OF CLEVRの実験の追試をしてみました。Sort Of CLEVRの例は以下の図になります。
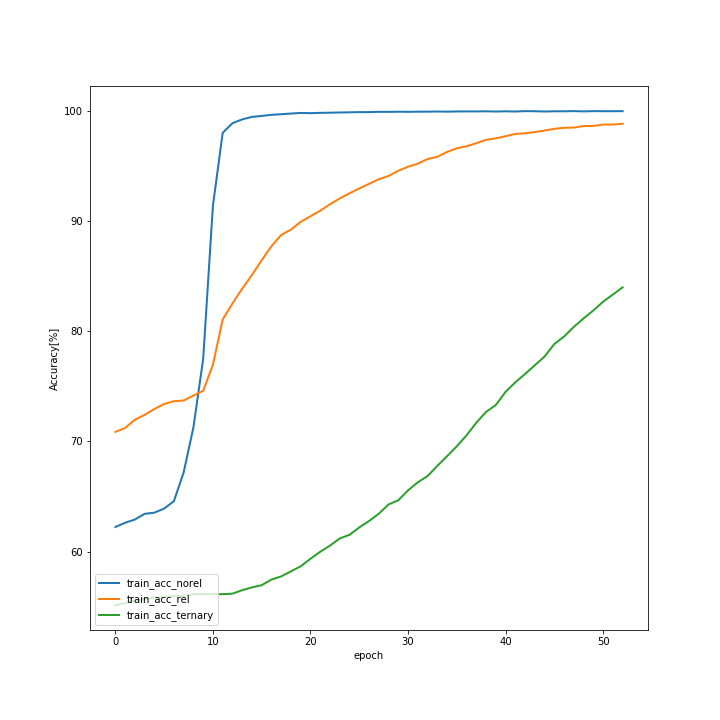
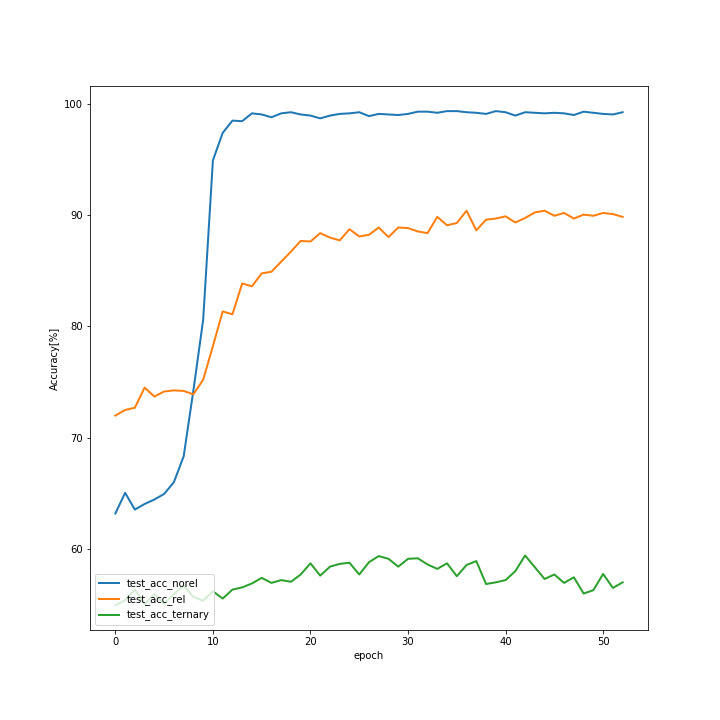
このデータセットは画像と質問文(図では文章が書いてありますが、実際には質問文はエンコードされています。)で構成されています。画像にはいくつかのオブジェクトがあり、質問文はそのオブジェクトに関する質問で成り立っています。質問には2つ種類があり、オブジェクト間の関係を考慮する必要のない質問(Non-relational question)とオブジェクト間の関係を考慮する必要のある質問(Relational question)があります。そして、図右上にもありますが、ここでもCNN+RNはCNN+MLPを上回った正解率を特にRelational questionで出しています。私も追試はしたのですが、正直ほとんどこのリポジトリ(https://github.com/kimhc6028/relational-networks)を参考にしただけなので、コードは特に載せません。追試の結果だけ示します。まず、訓練データの正解率です。
次にテストデータの正解率です。
訓練とテストの差を見る限り、20epochを超えたあたりで、過学習気味ですが、test_acc_relが90%近いのは良いのではないでしょうか。そして一番悪いtest_acc_ternary。これは3つのオブジェクトに関する質問なのですが、完璧に過学習状態であり、test_acc_relと比べても正解率が低いです。一応、60%は出ていますが、三つの関係というのはRNでも難しいようです。3つ以上の関係性は三体問題のような例もあるように、そもそもが難しいものだとは思います。ただ、Sort of Clevrの3つの関係性の問題はそこまで難しいものではない(私が解けば100%に近い数字が出ると思います。)ので、改善の余地があるでしょう。まとめと今後
論文の結果からもわかるように、RNはシンプルなNNと比べて、関係性を処理する能力が高いということが分かります。ただし、3つの関係性には苦戦しているようで、3つ以上の関係性が必要な問題はARCにもあるでしょう。そこで、次はReccurent Relatinal Network(RRN)に挑戦してみようと思います。正直、この記事かなり適当なのですが、ただのRNではARCが解けないと思っていたので、このRRNに早く取り組みたかったからです。RRNを使うと数独も解ける用で、フォーマット的にも数独とARCは近いものがあると思います。まあ、どうなるかやってみましょう。


- 投稿日:2020-07-29T22:15:57+09:00
Pandas : 条件を満たす行を抽出時のエラー ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all(). の原因と対策
結論
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().のエラーの原因として、
複数条件なのにそれぞれを
()で括っていない、& | ^などのbit演算ではなくand or notなどと書いているなどが検索で出てきますが1 2
isinをinにしてしまっていた時も同様のエラーメッセージがおきるので気をつけましょう。原因となったコード
error.pytmp__ = transactions[(transactions["year"] == "2014" ) & (transactions ["month"] in ["06","07","08"]))]訂正したコード
correct.pytmp__ = transactions[(transactions["year"] == "2014" ) & (transactions["month"].isin( ["06","07","08"]))]
nkmkさんのブログ記事にこのエラーが起きるケースとその理由(PandasやNumby ndarrayでは曖昧性解消のため、bitwise(&,|,~)を使うとelement-wiseなoperator(and,or,norなど) にoverride されるようになっている)が書かれています https://note.nkmk.me/python-numpy-pandas-value-error-ambiguous/ ↩
stackoverflowの記事ではどのように曖昧であるかをもう少し詳しく説明してあります。https://stackoverflow.com/questions/36921951/truth-value-of-a-series-is-ambiguous-use-a-empty-a-bool-a-item-a-any-o ↩
- 投稿日:2020-07-29T21:20:01+09:00
「FORTRAN77数値計算プログラミング」のプログラムをCとPythonに移植してみる(その3)
前回の記事
「FORTRAN77数値計算プログラミング」のプログラムをCとPythonに移植してみる(その2)はじめに
その1、その2とFortran77数値計算プログラミングの1章のコードを確認してきました。
本では、1章にこのあと3つプログラムが載っているのですが、これ、全部誤差がどうなるかを確認しているものです。前回@cure_honey さんに教えていただいたとおり、16進数を基数とした浮動小数点数を使った計算結果が今のIEEE754方式の浮動小数点数での結果とは合わず、本での検証とはずれていくばかりなので、このあたりのコードはもう飛ばすことにします。
誤差について飛ばすと次は乱数のお話で、乱数生成ってCにもPythonにも関数があるのでそれも飛ばすと、お次は5章、「連立1次方程式とLU分解」です。LU分解
本の5章、P.52〜の式を引きつつ、LU分解についてまとめます。
連立一次方程式の解き方
$n\times n$行列の行列$A$
A=\begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn} \end{pmatrix}\tag{1}があって、$b$および$x$はそれぞれ次のようなベクトルのとき、
b = \begin{pmatrix} b_1\\ b_2\\ \vdots\\ b_n \end{pmatrix}\tag{2} \\x = \begin{pmatrix} x_1\\ x_2\\ \vdots\\ x_n \end{pmatrix}\tag{3} \\この$A$と$b$に対して
Ax = b\tag{4}となる$x$を求める連立一次方程式を考えます。
LU分解とは
LU分解というのは、与えられた行列$A$を左下三角行列$L$と右上三角行列$U$との積で表すことです。つまり、
A=\begin{pmatrix} ■&0&0&0&0\\ ■&■&0&0&0\\ ■&■&■&0&0\\ ■&■&■&■&0\\ ■&■&■&■&■ \end{pmatrix} \begin{pmatrix} ■&■&■&■&■\\ 0&■&■&■&■\\ 0&0&■&■&■\\ 0&0&0&■&■\\ 0&0&0&0&■ \end{pmatrix} \equiv LUになるように■を定めることです。ただし実際は、
A=\begin{pmatrix} 1&0&0&0&0\\ ■&1&0&0&0\\ ■&■&1&0&0\\ ■&■&■&1&0\\ ■&■&■&■&1 \end{pmatrix} \begin{pmatrix} ■&■&■&■&■\\ 0&■&■&■&■\\ 0&0&■&■&■\\ 0&0&0&■&■\\ 0&0&0&0&■ \end{pmatrix} \equiv LU\tag{5}という形に限定します。
こうすることで、方程式$(4)$がLUx=b\tag{6}となって、これを解くためには、まず
Ly=b\tag{7}の解$y$を求め、つぎにこの解$y$を右辺に持つ方程式
Ux=y\tag{8}を解いて$x$を求めればよくなります。式が2つに増えてしまって、めんどくさそうですが、行列が三角行列になると、ずっと簡単に解くことが出来ます。
Fortranのコード
sdecom.fPROGRAM SDECOM * * * Sample program of DECOMP and SOLVE * * * PARAMETER (NDIM = 20) * REAL A(NDIM,NDIM),B(NDIM),X(NDIM) REAL W(NDIM),V(NDIM) INTEGER IP(NDIM) * DO 10 NN = 1, 2 * N = 10 * NN * CALL LUDATA (NDIM, N, A, B) * CALL ANCOMP (NDIM, N, A, ANORM) * WRITE (*,2000) ANORM 2000 FORMAT (/' ---- DECOMP and SOLVE ----'/ $ ' 1-norm of A = ',1PE13.6) CALL DECOMP (NDIM, N, A, W, IP) CALL SOLVE (NDIM, N, A, B, X, IP) CALL ESTCND (NDIM, N, A, V, IP, W, $ ANORM, COND) * WRITE (*,2001) (X(I), I=1,N) 2001 FORMAT (' solution X(I)'/(1X,5F9.5)) * WRITE (*,2002) COND 2002 FORMAT (' condition number = ',1PE13.6) * 10 CONTINUE * ENDludata.fSUBROUTINE LUDATA (NDIM, N, A, B) * * * Sample data of DECOMP and SOLVE * * * REAL A(NDIM,N),B(N) DO 510 I =1, N DO 520 J = 1, N A(I,J) = 0.0 520 CONTINUE 510 CONTINUE * A(1,1) = 4.0 A(1,2) = 1.0 DO 530 I = 2, N - 1 A(I,I-1) = 1.0 A(I,I) = 4.0 A(I,I+1) = 1.0 530 CONTINUE A(N,N-1) = 1.0 A(N,N) = 4.0 DO 540 I = 1, N B(I) = 0.0 DO 550 J = 1, N B(I) = B(I) + A(I,J) * J 550 CONTINUE 540 CONTINUE * RETURN ENDancomp.fSUBROUTINE ANCOMP (NDIM, N, A, ANORM) * * * Compute 1-norm of A toestimate * * condition number of A * * * REAL A(NDIM,N) * ANORM = 0.0 DO 10 K = 1, N S = 0.0 DO 520 I = 1, N S = S + ABS(A(I,K)) 520 CONTINUE IF (S .GT. ANORM) ANORM = S 10 CONTINUE * RETURN ENDdecomp.fSUBROUTINE DECOMP (NDIM, N, A, W, IP) * * * LU decomposition of N * N matrix A * * * REAL A(NDIM,N),W(N) INTEGER IP(N) * DATA EPS / 1.0E-75 / * DO 510 K = 1, N IP(K) = K 510 CONTINUE * DO 10 K = 1, N L = K AL = ABS(A(IP(L),K)) DO 520 I = K+1, N IF (ABS(A(IP(I),K)) .GT. AL) THEN L = I AL = ABS(A(IP(L),K)) END IF 520 CONTINUE * IF (L .NE. K) THEN * * ---- row exchange ---- * LV = IP(K) IP(K) = IP(L) IP(L) = LV END IF * IF (ABS(A(IP(K),K)) .LE. EPS) GO TO 900 * * ---- Gauss elimination ---- * A(IP(K),K) = 1.0 / A(IP(K),K) DO 30 I = K+1, N A(IP(I),K) = A(IP(I),K) * A(IP(K),K) DO 540 J = K+1, N W(J) = A(IP(I),J) - A(IP(I),K) * A(IP(K),J) 540 CONTINUE DO 550 J = K+1, N A(IP(I),J) = W(J) 550 CONTINUE 30 CONTINUE * 10 CONTINUE * RETURN * * ---- matrix singular ---- * 900 CONTINUE WRITE (*,2001) K 2001 FORMAT (' (DECOMP) matrix singular ( at ',I4, $ '-th pivot)') N = - K RETURN * ENDsolve.fSUBROUTINE SOLVE (NDIM, N, A, B, X, IP) * * * Solve system of linear equations * * A * X = B * * * REAL A(NDIM,N),B(N),X(N) INTEGER IP(N) * REAL*8 T * * ---- forward substitution ---- * DO 10 I = 1,N T = B(IP(I)) DO 520 J = 1, I-1 T = T - A(IP(I),J) * DBLE(X(J)) 520 CONTINUE X(I) = T 10 CONTINUE * * ---- backward substitution ---- * DO 30 I = N, 1, -1 T = X(I) DO 540 J = I+1, N T = T - A(IP(I),J) * DBLE(X(J)) 540 CONTINUE X(I) = T * A(IP(I),I) 30 CONTINUE * RETURN ENDestcnd.fSUBROUTINE ESTCND(NDIM, N, A, V, IP, Y, $ ANORM, COND) * * * Estimate condition number of A * * * REAL A(NDIM,N),V(N),Y(N) INTEGER IP(N) * REAL*8 T * DO 10 K = 1,N T = 0.0 DO 520 I = 1, k-1 T = T - A(IP(I),K) * DBLE(V(I)) 520 CONTINUE S = 1.0 IF (T .LT. 0.0) S = -1.0 V(K) = (S + T) * A(IP(K),K) 10 CONTINUE * DO 30 K = N, 1, -1 T = V(K) DO 530 I = K+1, N T = T - A(IP(I),K) * DBLE(Y(IP(I))) 530 CONTINUE Y(IP(K)) = T 30 CONTINUE * YMAX = 0.0 DO 540 I = 1, N IF (ABS(Y(I)) .GT. YMAX) YMAX = ABS(Y(I)) 540 CONTINUE * COND = ANORM * YMAX * RETURN ENDコードの理解
sdecom
メインプログラム。例題のための配列の大きさを与えるNDIMをPARAMETER文で定義しています。
ludata
ludataというサブルーチンはまず、
N=10のときに
A=\begin{pmatrix} 4.0 & 1.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 \\ 1.0 & 4.0 & 1.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 \\ 0.0 & 1.0 & 4.0 & 1.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 \\ 0.0 & 0.0 & 1.0 & 4.0 & 1.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 \\ 0.0 & 0.0 & 0.0 & 1.0 & 4.0 & 1.0 & 0.0 & 0.0 & 0.0 & 0.0 \\ 0.0 & 0.0 & 0.0 & 0.0 & 1.0 & 4.0 & 1.0 & 0.0 & 0.0 & 0.0 \\ 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 1.0 & 4.0 & 1.0 & 0.0 & 0.0 \\ 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 1.0 & 4.0 & 1.0 & 0.0 \\ 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 4.0 & 1.0 \\ 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 0.0 & 1.0 & 4.0 \\ \end{pmatrix}b=\begin{pmatrix} 6.00000 & 12.00000 & 18.00000 & 24.00000 & 30.00000 & 36.00000 & 42.00000 & 48.00000 & 54.00000 & 49.00000 \end{pmatrix}という行列を作っています。
このとき、行列$b$は、b_i = \sum_{j=1}^na_{ij}jで求められています。
やりたいことは、この$A$と$b$に対してAx = bとなる$x$を求めることでした。
ancomp
次に、ancompというサブルーチンは、
||A||_1 = \max_{1\leq k\leq n} \sum_{i=1}^n|a_{ik}|\tag{9}という行列のノルムに基づいて条件数を設定しています。これが$ANORM$という変数に設定されています。
ここで作業用変数$S$に倍精度実数型の宣言を行っていないのは、このノルム自身はそれほど制度を必要としないからだそう。decomp
decompが、本題のLU分解を行うサブルーチン。
引数は、行列$A$に対応する2次元配列$A$とインデックスベクトル$p$に対応する1次元の整数型配列$IP$、行列の次元$N$です。
まず配列$IP$を、IP(k) = k, \quad k=1,2,\cdots, nで初期化してから、ピボットの部分選択を行いながらガウス消去法によってLU分解を実行します。
solve
LU分解した結果を使って方程式$(4)$を解くサブルーチンがsolveです。
estcnd
行列$A$の条件数の推定値を計算するサブルーチンがestcnd。ただし、行列$A$があらかじめdecompによってLU分解されていることが前提。
Cのコード
sdecom.h#ifndef NDIM #define NDIM 20 #endif void ludata(int n, float a[NDIM][NDIM], float b[NDIM]); float ancomp(int n, float a[NDIM][NDIM]); int decomp(int n, float a[NDIM][NDIM], float w[NDIM], int ip[NDIM]); void solve(int n, float a[NDIM][NDIM], float b[NDIM], float x[NDIM], int ip[NDIM]); float estcnd(int n, float a[NDIM][NDIM], float v[NDIM], int ip[NDIM], float y[NDIM], float anorm);sdecom.c#include <stdio.h> #include<stdlib.h> #include "sdecom.h" int main(void) { float a[NDIM][NDIM], b[NDIM], x[NDIM]; float w[NDIM], v[NDIM]; int ip[NDIM]; int nn; int n; float anorm, cond; int i,j; for(nn = 1; nn < 3; nn++){ n = 10 * nn; ludata(n, a, b); anorm = ancomp(n, a); printf(" ---- DECOMP and SOLVE ----\n 1-norm of A = %13.6E\n" , anorm); n = decomp(n, a, w, ip); solve(n, a, b, x, ip); cond = estcnd(n, a, v, ip, w, anorm); printf(" solution X(I)\n"); for(i=0; i<n; i++){ if(i != 0 && i % 5 == 0) { printf("\n"); } printf(" %.5f", x[i]); } printf("\n condition number = %13.6E\n", cond); } return 0; }ludata.c#include <stdio.h> #include "sdecom.h" void ludata(int n, float a[NDIM][NDIM], float b[NDIM]) { int i, j; for(i=0; i<n; i++){ for(j=0; j<n; j++){ a[i][j] = 0.0f; } } a[0][0] = 4.0f; a[0][1] = 1.0f; for(i=1; i<n-1; i++){ a[i][i-1] = 1.0f; a[i][i] = 4.0f; a[i][i+1] = 1.0f; } a[n-1][n-2] = 1.0f; a[n-1][n-1] = 4.0f; for(i=0; i<n; i++){ b[i] = 0.0f; for(j=0; j<n; j++) { b[i] += (a[i][j] * (j+1)); } } }ancomp.c#include <stdio.h> #include <math.h> #include "sdecom.h" float ancomp(int n, float a[NDIM][NDIM]) { int i,k; float s; float anorm = 0.0f; for(k=0; k<n; k++){ s = 0.0f; for(i=0; i<n; i++) { s = s + fabsf(a[i][k]); } if (s > anorm){ anorm = s; } } return anorm; }decomp.c#include <stdio.h> #include <math.h> #include <float.h> #include "sdecom.h" int decomp(int n, float a[NDIM][NDIM], float w[NDIM], int ip[NDIM]) { //double eps = 1.0e-75; int i,j,k,l; float al; int lv; for(k=0; k<n; k++){ ip[k] = k; } for(k=0; k<n; k++){ l = k; al = fabsf(a[ip[l]][k]); for(i=k+1; i<n; i++){ if(fabsf(a[ip[i]][k]) > al) { l = i; al = fabsf(a[ip[l]][k]); } } if(l != k) { lv = ip[k]; ip[k] = ip[l]; ip[l] = lv; } if((fabsf(a[ip[k]][k]) <= DBL_EPSILON)) { printf(" (DECOMP) matrix singular ( at %4d-th pivot)\n", k); n = -k; break; } else { a[ip[k]][k] = 1.0f / a[ip[k]][k]; for(i=k+1; i<n; i++) { a[ip[i]][k] = a[ip[i]][k] * a[ip[k]][k]; for(j=k+1; j<n; j++) { w[j] = a[ip[i]][j] - a[ip[i]][k] * a[ip[k]][j]; } for(j=k+1; j<n; j++) { a[ip[i]][j] = w[j]; } } } } return n; }solve.c#include <stdio.h> #include "sdecom.h" void solve(int n, float a[NDIM][NDIM], float b[NDIM], float x[NDIM], int ip[NDIM]) { double t; int i,j; for(i=0; i<n; i++){ x[i] = 0.0f; } for(i=0; i<n; i++){ t = b[ip[i]]; for(j=0; j<i; j++){ t = t - a[ip[i]][j] * (double)x[j]; } x[i] = t; } for(i=n-1; i>-1; i--){ t = x[i]; for(j=i+1; j <n; j++){ t = t - a[ip[i]][j] * (double)x[j]; } x[i] = t * a[ip[i]][i]; } }estcnd.c#include <stdio.h> #include <math.h> #include "sdecom.h" float estcnd(int n, float a[NDIM][NDIM], float v[NDIM], int ip[NDIM], float y[NDIM], float anorm) { float cond; double t; int i,k; float s; float ymax; for(k=0; k<n; k++){ t = 0.0; for(i=0; i<k; i++){ t = t - a[ip[i]][k] * (double)v[i]; } s = 1.0f; if( t < 0.0f) { s = -1.0f; } v[k] = (s + t) * a[ip[k]][k]; } for(k=n-1; k>-1; k--){ t = v[k]; for(i=k+1; i<n; i++){ t = t - a[ip[i]][k] * (double)y[ip[i]]; } y[ip[k]] = t; } ymax = 0.0f; for(i=0; i<n; i++){ if(fabsf(y[i]) > ymax){ ymax = fabsf(y[i]); } } cond = anorm * ymax; return cond; }ただ愚直にFortranのコードを置き換え。
変数をいっそのことグローバルで定義しちゃおうかな、とか思ったものの、個人的に無理でやめました。Pythonのコード
import scipy.linalg as linalg import numpy as np def ludata(n): a = [[0.0] * n for i in range(n) ] a[0][0] = 4.0 a[0][1] = 1.0 for i in range(1,n-1): a[i][i-1] = 1.0 a[i][i] = 4.0 a[i][i+1] = 1.0 a[n-1][n-2] = 1.0 a[n-1][n-1] = 4.0 b = [0.0] * n for i in range(n): for j in range(n): b[i] += (a[i][j] * (j+1)) return a,b for nn in range(1,3): n = 10 * nn a,b = ludata(n) LU = linalg.lu_factor(a) x = linalg.lu_solve(LU, b) print(x)Pythonには、SciPyという強力な数値計算ライブラリがあり、当然のようにLU分解の関数もあるわけですね…。
そんなわけでゴリゴリ書くのはデータ作ってるところだけでした。まとめ
探せばC言語にもなんか良さげなライブラリ公開されているんじゃないかなーとか思ったり。
とりあえず、だいぶ寝かせてしまった3回目、数式書くのが結構めんどくさかったです。
- 投稿日:2020-07-29T20:51:48+09:00
初心者がSeleniumでWebDriverを使うときにつまづいた時に参考にしたコードなど
画面内にない要素をクリックすることはできない
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")スクロールして画面内に出すか、
driver.set_window_size(xxxx,yyyy)で最初に画面サイズを変更する。
自分は毎回スクロールするのが面倒なので画面サイズを1980、1280にした。
他にもIDなどの要素までスクロールできるっぽい。
ユーザーエージェントがないとロボット扱いしてくるサイトもあるので
options.add_argument(f'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36')ユーザーエージェントを偽装する。
Javascriptのボタンなどをクリックできない場合
elements = driver.find_element_by_xpath("XPATH") loc = elements.location x, y = loc['x'], loc['y'] actions = ActionChains(driver) actions.move_by_offset(x, y) actions.click() actions.perform()XPATHの座標でクリックする。
テキストが画面内にないと.textなどでは取得できない
text = driver.find_element_by_id("ID").get_attribute("textContent")get_attributeで取得する。
おわり
まだ始めて一ヶ月なのでこれ違うよなどツッコミがあるかもしれませんが、優しく言ってくださると幸いです。
- 投稿日:2020-07-29T20:39:41+09:00
M-SOKUTIONS プロコンオープン 2020
M-SOKUTIONS プロコンオープン 2020にバーチャル参加しました。
ABCDの4問ACでした。
Python3を使用しています。A問題
ifで条件分岐させます。
import sys def input(): return sys.stdin.readline()[:-1] def main(): X = int(input()) if X >= 1800: print(1) elif X >= 1600: print(2) elif X >= 1400: print(3) elif X >= 1200: print(4) elif X >= 1000: print(5) elif X >= 800: print(6) elif X >= 600: print(7) else: print(8) if __name__ == "__main__": main()B問題
条件を満たすまで操作を行い、操作回数がK以下であれば魔術を成功させられたと考えます。
これは入力されるA、B、C、Kが小さいために可能です。
M君は数字を2倍にする操作を行うため、最も小さい数となるべきAに操作を行わないことが分かります。
つまり、Aの値が固定された状態で考えます。
while文で、BがAより大きくなるように操作を行います。
これにより、Bの値が固定されます。
同様にwhile文でBより大きいCを求めることができます。import sys def input(): return sys.stdin.readline()[:-1] def main(): A, B, C = map(int,input().split()) K = int(input()) count = 0 while A >= B: B = B * 2 count += 1 while B >= C: C = C * 2 count += 1 if count <= K: print("Yes") else: print("No") if __name__ == "__main__": main()C問題
この問題は、前学期より評点が高いが低いか判定する必要があるだけで、実際の評点を求める必要はありません。
N学期の評点はA[0]*A[1] ~ *A[N-1]で求められます。
N+1学期の評点はA[1] ~ *A[N-1]*A[N]で求められます。
評点の高低を比較するだけなので、A[0]とA[N]を比較するだけで十分です。
これをfor文で繰り返し、N-K個の結果を表示します。import sys def input(): return sys.stdin.readline()[:-1] def main(): N, K = map(int,input().split()) A = list(map(int,input().split())) for i in range(N - K): if A[i] < A[i + K]: print("Yes") else: print("No") if __name__ == "__main__": main()D問題
株価が低いときに買って、株価が高いときに売りたいというのが基本的な目標です。
まずi番目とi+1番目を比較し、大きくなっていれば1、小さくなっていれば-1というリストを作ります。 (リスト内包表記の利用)
1のときは買えるだけ買います。
1が続くということは株価が上がっていくということなので、一番初めに1になった地点で買えばOKです。
同様に-1になったときは全ての株を売ります。
-1が続くということは株価が下がっていくということなので、一番初めに-1になった地点で売ればOKです。import sys def input(): return sys.stdin.readline()[:-1] def main(): N = int(input()) A = list(map(int,input().split())) zougen = [-1 if A[i] > A[i + 1] else 1 for i in range(N - 1)] money = 1000 kabu = 0 for i in range(N-1): if zougen[i] == 1: kabu += money // A[i] money = money % A[i] else: money += kabu * A[i] kabu = 0 print(A[-1] * kabu + money) if __name__ == "__main__": main()
- 投稿日:2020-07-29T20:39:41+09:00
M-SOLUTIONS プロコンオープン 2020
M-SOLUTIONS プロコンオープン 2020にバーチャル参加しました。
ABCDの4問ACでした。
Python3を使用しています。A問題
ifで条件分岐させます。
import sys def input(): return sys.stdin.readline()[:-1] def main(): X = int(input()) if X >= 1800: print(1) elif X >= 1600: print(2) elif X >= 1400: print(3) elif X >= 1200: print(4) elif X >= 1000: print(5) elif X >= 800: print(6) elif X >= 600: print(7) else: print(8) if __name__ == "__main__": main()B問題
条件を満たすまで操作を行い、操作回数がK以下であれば魔術を成功させられたと考えます。
これは入力されるA、B、C、Kが小さいために可能です。
M君は数字を2倍にする操作を行うため、最も小さい数となるべきAに操作を行わないことが分かります。
つまり、Aの値が固定された状態で考えます。
while文で、BがAより大きくなるように操作を行います。
これにより、Bの値が固定されます。
同様にwhile文でBより大きいCを求めることができます。import sys def input(): return sys.stdin.readline()[:-1] def main(): A, B, C = map(int,input().split()) K = int(input()) count = 0 while A >= B: B = B * 2 count += 1 while B >= C: C = C * 2 count += 1 if count <= K: print("Yes") else: print("No") if __name__ == "__main__": main()C問題
この問題は、前学期より評点が高いが低いか判定する必要があるだけで、実際の評点を求める必要はありません。
N学期の評点はA[0]*A[1] ~ *A[N-1]で求められます。
N+1学期の評点はA[1] ~ *A[N-1]*A[N]で求められます。
評点の高低を比較するだけなので、A[0]とA[N]を比較するだけで十分です。
これをfor文で繰り返し、N-K個の結果を表示します。import sys def input(): return sys.stdin.readline()[:-1] def main(): N, K = map(int,input().split()) A = list(map(int,input().split())) for i in range(N - K): if A[i] < A[i + K]: print("Yes") else: print("No") if __name__ == "__main__": main()D問題
株価が低いときに買って、株価が高いときに売りたいというのが基本的な目標です。
まずi番目とi+1番目を比較し、大きくなっていれば1、小さくなっていれば-1というリストを作ります。 (リスト内包表記の利用)
1のときは買えるだけ買います。
1が続くということは株価が上がっていくということなので、一番初めに1になった地点で買えばOKです。
同様に-1になったときは全ての株を売ります。
-1が続くということは株価が下がっていくということなので、一番初めに-1になった地点で売ればOKです。import sys def input(): return sys.stdin.readline()[:-1] def main(): N = int(input()) A = list(map(int,input().split())) zougen = [-1 if A[i] > A[i + 1] else 1 for i in range(N - 1)] money = 1000 kabu = 0 for i in range(N-1): if zougen[i] == 1: kabu += money // A[i] money = money % A[i] else: money += kabu * A[i] kabu = 0 print(A[-1] * kabu + money) if __name__ == "__main__": main()
- 投稿日:2020-07-29T19:17:05+09:00
Vue.js+Flaskで画像のアップロード機能
概要
今回はフロントエンドにVue.js、バックエンドにFlaskを用いた画像認識アプリを作ります。
ひとまず今回は画像アップロード機能までの実装です。環境
- Docker
- Vue-cli
- flask (pipenv)
上記の環境で環境構築しました。
手順や詳細は以下のリンクを参照してください。要所の説明
Vue
詳細を説明するのは、以下のコード。
Home.vue// 画像をサーバーへアップロード onUploadImage () { var params = new FormData() params.append('image', this.uploadedImage) // Axiosを用いてFormData化したデータをFlaskへPostしています。 axios.post(`${API_URL}/classification`, params).then(function (response) { console.log(response) })
- 取得した画像はBase64化がなされている。「data:image/jpeg:base64,〜」
- FormDataにより、データをHTTPリクエストで「キー:値」の形式へ。
- Axiosを適用し、'127.0.0.1:5000/classification'+ POSTメソッドでデータを送信。
Flask
詳細を説明するのは、以下のコード。
app.py@app.route('/classification', methods=['POST']) def uploadImage(): if request.method == 'POST': base64_png = request.form['image'] code = base64.b64decode(base64_png.split(',')[1]) image_decoded = Image.open(BytesIO(code)) image_decoded.save(Path(app.config['UPLOAD_FOLDER']) / 'image.png') return make_response(jsonify({'result': 'success'})) else: return make_response(jsonify({'result': 'invalid method'}), 400)
- FormDataの内部に「data:image/jpeg:base64,〜」が存在。ファイル名を取得。
- Pillow(PIL)で画像を取得。
- 画像の保存。
全体像
Vue
Home.vue<template> <div> <div class="imgContent"> <div class="imagePreview"> <img :src="uploadedImage" style="width:100%;" /> </div> <input type="file" class="file_input" name="photo" @change="onFileChange" accept="image/*" /> <button @click='onUploadImage'>画像判定してくだちい・・・</button> </div> </div> </template> <script> import axios from 'axios' const API_URL = 'http://127.0.0.1:5000' export default { data () { return { uploadedImage: '' } }, methods: { // 選択した画像を反映 onFileChange (e) { let files = e.target.files || e.dataTransfer.files this.createImage(files[0]) }, // アップロードした画像を表示 createImage (file) { let reader = new FileReader() reader.onload = (e) => { this.uploadedImage = e.target.result } reader.readAsDataURL(file) }, // 画像をサーバーへアップロード onUploadImage () { var params = new FormData() params.append('image', this.uploadedImage) // Axiosを用いてFormData化したデータをFlaskへPostしています。 axios.post(`${API_URL}/classification`, params).then(function (response) { console.log(response) }) } } } </script>Flask
留意点
- CORSにより、異なるオリジン(プロトコルやドメイン、ポート)でもリソースを共有できる。
- CORSは異なるWebアプリケーションを持つ場合、必須。
- app.config['JSON_AS_ASCII'] = False により日本語対応可能。
app.py# render_template:参照するテンプレートを指定 # jsonify:json出力 from flask import Flask, render_template, jsonify, request, make_response # CORS:Ajax通信するためのライブラリ from flask_restful import Api, Resource from flask_cors import CORS from random import * from PIL import Image from pathlib import Path from io import BytesIO import base64 # static_folder:vueでビルドした静的ファイルのパスを指定 # template_folder:vueでビルドしたindex.htmlのパスを指定 app = Flask(__name__, static_folder = "./../frontend/dist/static", template_folder="./../frontend/dist") #日本語 app.config['JSON_AS_ASCII'] = False #CORS=Ajaxで安全に通信するための規約 api = Api(app) CORS(app) UPLOAD_FOLDER = './uploads' app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER # 任意のリクエストを受け取った時、index.htmlを参照 @app.route('/', defaults={'path': ''}) @app.route('/<path:path>') def index(path): return render_template("index.html") @app.route('/classification', methods=['POST']) def uploadImage(): if request.method == 'POST': base64_png = request.form['image'] code = base64.b64decode(base64_png.split(',')[1]) image_decoded = Image.open(BytesIO(code)) image_decoded.save(Path(app.config['UPLOAD_FOLDER']) / 'image.png') return make_response(jsonify({'result': 'success'})) else: return make_response(jsonify({'result': 'invalid method'}), 400) # app.run(host, port):hostとportを指定してflaskサーバを起動 if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)様子
こんな感じ
非常に参考になりました
https://developer.mozilla.org/ja/docs/Web/HTTP/CORS
画像をPOST、顔検出、canvasで顔にお絵かき

- 投稿日:2020-07-29T19:07:10+09:00
pythonでdictを使う時のメモ[競プロ]
計算量がO(1)という嘘んくささ(一応理由は理解しているつもりですが)に拒否感があり、今まで頑なにdictを使ってきていなかったのですが、先週参加したFHCでdictを使うと楽な問題が出たのでメモ
使うタイミング
値をとる範囲が大きく、sparse な時
行える操作
key, value の形で要素を持つ
要素の挿入、削除、更新、検索がO(1)で行える
参考:Wikipedia HashTableよく使う操作
行える操作 コード コメント 宣言 b = {'one': 1, 'two': 2, 'three': 3} a = dict(key1=value1,key2=value2,..) などその他いろいろな書き方 要素数 len(d) 値の参照 d[key] d[key]keyが存在しない時KeyErrorになる 値の参照(存在するか不明) d.setdefault(key,default) key が辞書に存在すれば、その値を返します。そうでなければ、値を default として key を挿入し、 default を返します 要素の追加 d[key] = value 更新も同じ 要素の更新 d[key] = value 追加も同じ 要素の削除 del d[key] なければKeyError 要素の削除(存在するか不明) d.pop(key,default) なければdefaultを返す 要素の検索 key in d 要素の検索(valueを使いたい時) d.get(key,default) key に対応するvalueを返す。key が存在しなければdefaultを返す 辞書の全ての要素の削除 clear() 挿入した順番の逆順に取り出し d.popitem() 順序の反転 reversed(d) リスト化 list(d.items()) タプルのリストとして返る リスト化(key,valueのみ) list(d.keys()) ループ(key,value) d.items() key,valueがタプルで返る ループ(key,value片方のみ) d.keys() or d.values() 例
dict.py>>>dic = dict(a=1,b=2,c=3) # 文字列の場合でも"" などつけずそのまま書く >>> dic {'a': 1, 'b': 2, 'c': 3} # ただし参照する時はつける >>> dic[a] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'dict' >>> dic["a"] 1 >>> dic.pop("a") 1 >>> dic {'b': 2, 'c': 3} # この書き方で定義することも可能 >>> dic.clear() >>> dic {} >>> dic = {1:1,2:1,3:2,4:3,5:5} # key は数値でもOK >>> dic[1] 1 >>> dic[1]=8 >>> dic {1: 8, 2: 1, 3: 2, 4: 3, 5: 5} >>> dic.get(1,-1) 8 >>> list(dic.keys()) [1, 2, 3, 4, 5] >>> list(dic.values()) [8, 1, 2, 3, 5] >>> list(dic.items()) [(1, 8), (2, 1), (3, 2), (4, 3), (5, 5)] # 要素をループしたい場合 >>> for k,v in dic.items(): ... print(k,v) ... 1 8 2 1 3 2 4 3 5 5競プロの問題での利用
せっかくなので、冒頭で紹介したFHCの問題をdictを使って解きます。
問題自体に興味のある方は僕が書いた解説なんかもよかったらみてください今回は宣言、代入の他はgetでの値の参照,items()でのループくらいしか使っていませんが、sparse なdp を簡単に書くことができました。二分探索でidxを持ちつつやったのとは雲泥の違いだったので今後も使っていきたいものです。
timer.pyimport bisect import sys read = sys.stdin.buffer.read input = sys.stdin.buffer.readline readlines = sys.stdin.buffer.readlines # step1:座圧して(ソートした順番で)DPを左端と右端両方から行う # dp_l[i] = max(dp_l[j] + h[i],h[i]) 場所iにつながる木(i=j+h[j]) をdictで探す # dp_r[i] = max(dp_r[j] + h[i],h[i]) # step2:dp_l_dictの全てのkey i に対して、dp_r_dictのkeyにあるかをdictで探す(p[i]+h[i] がp[j]-h[j]となるj i,j を探すのと同値) # step3:step2で一致するi,jに対して、ans = max(ans,dp_l[i]+dp_r[j]) t = int(input()) for case in range(t): n = int(input()) p = [0] * n h = [0] * n for i in range(n): p[i], h[i] = map(int, input().split()) p, h = zip(*sorted(zip(p, h))) # p で昇順にsort 右に倒すものは昇順に、左に倒すものは降順に見る # 左から順番にみていく 左から見たものに # dp はkey がpos,value が長さ で置く dp_r_dict = {} # 右に倒れる木の列のなかでpos が末端(右端)列の中で最長の長さ dp_l_dict = {} for i in range(n): # dict[p[i]]があればそれを返し、なければ0を返す # もしp[i]で終わるものがあればそれをつなげて伸ばすことができるため tmp = dp_l_dict.get(p[i], 0) + h[i] if dp_l_dict.get(p[i] + h[i], 0) < tmp: # 同様 dp_l_dict[p[i] + h[i]] = tmp r_max = 0 for i in range(n - 1, -1, -1): tmp = dp_r_dict.get(p[i], 0) + h[i] if dp_r_dict.get(p[i] - h[i], 0) < tmp: dp_r_dict[p[i] - h[i]] = tmp r_max = max(r_max, dp_r_dict[p[i] - h[i]]) # step3:dp_l_dict に対して、全てのkey でdp_r_dictのkey と一致するのがあるかを調べmaxをとる ans = 0 for pos, l_len in dp_l_dict.items(): tmp = l_len + dp_r_dict.get(pos, 0) # 全て右向きでもOK ans = max(ans, tmp) # 全て左向きを考慮する ans = max(ans, r_max) case_str = "Case #" + str(case + 1) + ": " + str(ans) print(case_str)終わりに
間違いやもっと良い書き方等ありましたらコメントください。
参考
- 投稿日:2020-07-29T18:16:46+09:00
<python >このフォルダにどんなファイルがあったっけ?」となった時に、1行で検索する。
結論
結論os.listdir(path)きっかけ
Downloadsに入っている書類を全部一覧でんみたいなと思ったところが始まりです。
各論
pathを調べる#方法1 option+command+C #Macならファイルを選択しながら「option」「command」「C」を押すと”絶対PATH”が得られる #例:/Users/"ユーザ名"/Downloads/"あるファイル名"' #方法2 #ファイル名検索をする #勉強中listdirでファイル・フォルダを取得する#今回は、Downloadsのデータを取得する import os path = '/Users/username/Downloads' files = os.listdir(path) for file in files: print(file)追加:glob()も便利
拡張子(.pdf)を指定してファイル名を調べたいimport glob path = '/Users/username/Downloads' print(glob.glob(path+'/*.pdf'))現在に限って検索したい場合
現在のファイルのパスを調べたい(絶対パス)
カレントディレクトリimport os print(os.getcwd())例えば、私はspyderでpythonを書いているので、
/Users/username/.spyder-py3
と返ってきます。
現在のファイル内を拡張子(.py)を指定して調べたい(ファイル名)
拡張子を指定import glob glob.glob('*.py')/Users/username/.spyder-py3のファイルの中には
untitled0.py
temp.py
template.py
history_internal.py
history.pyが入っていると返ってきました。
globの便利な使い方はこちら
Pythonで条件を満たすパスの一覧を再帰的に取得するglobの使い方
- 投稿日:2020-07-29T18:11:35+09:00
DjangoをEC2にデプロイしてわかった事
はじめに
今までクラウドプラットフォームはHerokuを使っていたのですがEC2に移行する機会があったので移行作業中に躓いたところの解決策と、EC2にwebアプリをデプロイする上での注意点等についてまとめました。
今回は以下のディレクトリ構造を想定しています
root ├── etc │ └── systemd │ └── system │ └── sampled.service └── home └── ubuntu └── sample └── sample.pyまた1分おきに"OK"を出力するPythonプログラムです
sample.py#!/usr/bin/env python3 import syslog from apscheduler.schedulers.blocking import BlockingScheduler sched = BlockingScheduler() @sched.scheduled_job("interval", minutes=1) def sample(): syslog.syslog("OK") sched.start()余談: AWSアカウントがすぐに作れなかった
自分の場合は電話認証でエラーが出て先に進めなかった為サポートケースを作って対応してもらいました。
結局コールセンターから電話で手動手続きになってアカウントが使用可能になるまで1週間近くかかったのでエラーが出たら直ぐにサポートケースを作って対応してもらいましょう!
EC2インスタンス作るときの注意点
まずEC2インスタンスを作るときの注意点について書いていきます。
EC2インスタンスを作る時、使用するAMIを選択するのですが基本的にはAmazon Linux系を選ぶのがベターですがこれによって後に紹介するデーモンプロセスの作り方が変わってきます。
なので何かしらのサイトを参照しながらデプロイする際はまずどのAMIを使用しているか確認した上で作業を進めましょう!
デーモン化行う際の注意点
次にプログラムのデーモン化で注意すべき点です。
先ほど書いたように使用するAMIによって作り方が変わる部分になります。
今回はUbuntu20.04を使用したためプログラムをデーモン化するためのサービス設定ファイルは以下の場所になっていました。
使用するAMIによって異なる Ubuntu: /etc/systemd/system/sampled.serviceデーモンの環境変数
次にデーモンで環境変数を扱う際の注意点です。
デーモンの環境変数設定が作業を進める際1番躓いた点です。
基本的にターミナルからプログラムを動作させる分には以下のコマンドを打ち込めば問題ないです。
$ SAMPLE=123456789 $ export SAMPLE $ echo $SAMPLE >>> 123456789また環境変数を永続化させたい場合は
sudo vi /etc/profileで設定したい環境変数を以下のように列挙していけば次回起動時から適用されます。
/etc/profileSAMPLE=123456789 export SAMPLEしかし!!
デーモンではこれらの環境変数は読み込まれません <<< ここ重要!!
なのでデーモン専用の環境変数設定を以下のように作りましょう
/etc/sysconfig/sampled_envSAMPLE=123456789また指定した環境変数をデーモンで読み込ませるためにサービス設定に追記します。
/etc/systemd/system/sampled.service''' 省略 ''' [Service] #追記 EnvironmentFile=/etc/sysconfig/sampled_env ''' 省略 '''その後以下のコマンドを打ち込みサービス設定の再読み込みとデーモンの再起動を行います。
$ sudo systemctl daemon-reload $ sudo systemctl restart sampledその後以下のコマンドを打ち込みActiveの項目がactive (running)になっていたら成功です。
$ sudo systemctl status sampled >>> sampled.service - sampled daemon >>> Loaded: loaded (/lib/systemd/system/sampled.service; enabled; vendor preset: enabled) >>> Active: active (running) >>> ''' >>> 省略 >>> '''またプログラムのログを確認したい場合は以下のコマンドで確認できます!
$ sudo journalctl -u sampled >>> Jul 29 17:50:24 ip-省略 sampled.py[省略]: OK >>> Jul 29 17:51:24 ip-省略 sampled.py[省略]: OKファイルのパーミッション設定
次にファイルのパーミッション関連の注意点です。
私はプログラムをデーモン化する時にファイルのパーミッション設定を適切に行えてなかったために躓きました。
先ほど同様以下のコマンドを打ち込みActiveの項目がfailed (Result: exit-code)になっていた場合はパーミッションエラーを疑いましょう。
$ sudo systemctl status sampled >>> sampled.service - sampled daemon >>> Loaded: loaded (/lib/systemd/system/sampled.service; enabled; vendor preset: enabled) >>> Active: failed (Result: exit-code) >>> ''' >>> 省略 >>> '''まずPermission deniedエラーが出現したらデーモン化したいファイルのあるディレクトリに移動して以下のコマンドを打ち込んでください。
~/sampled$ ls -l >>> -rw-r--r-- 1 root root 1052 Jul 29 17:16 sample.pyコマンドで表示されたファイルのアクセス権限を確認してデーモンのサービス設定ファイルに記述したUser、Groupと違う場合は以下のコマンドを打ち込む。
/etc/systemd/system/sampled.service''' 省略 ''' [Service] User=sample Group=sample-group ''' 省略 '''上記の設定である場合
# ファイル権限を変更 $ sudo chown sample:sample-group /home/ubuntu/sample/sample.py $ sudo chmod 755 /home/ubuntu/sample/sample.py #ファイル権限変更の確認 $ ls -l >>> -rwxr-xr-x 1 sample sample-group 1052 Jul 29 17:16 sample.py # デーモンの再起動 $ sudo systemctl restart sampled # デーモンの稼働状況表示 $ systemctl status sampled >>> sampled.service - sampled daemon >>> Loaded: loaded (/lib/systemd/system/sampled.service; enabled; vendor preset: enabled) >>> Active: active (running) >>> ''' >>> 省略 >>> '''これでActiveの項目がactivr (running)になってれば完了です!!
おわりに
普段Linuxを使わない分いろいろなれるまで大変でしたが使いこなせるようになると非常に便利なのでこれからも学習していこうと思います!
やっぱりAWSはすごいわ
ご覧いただきありがとうございました。
- 投稿日:2020-07-29T18:07:10+09:00
情報システム部がなんちゃってデータサイエンスをやるための方法
1章:はじめに
記事の趣旨
世の中では、「デジタルトラスフォーメーション(DX)」、「データドリブン経営」、「AI活用」などのビックワードが飛び交い、競合他社のちょっと盛り目のプレス記事などを目にした会社の偉い人から、うちも取り組めと言われて困っている情報システム部(情シ)の方が多くおられます。そのような方々にコンサルとして、表題のような話をすることがあるので、その内容を簡単にまとめました。もちろん、最初からお金をかけて、ベンダーに発注したり、データサイエンティストを雇う方法もありますが、情シの方がある程度データサイエンスを腹落ちさせて、ためにしやってみて、その後の外部に委託するなどの方向性を決めるほうが個人的にはお勧めです。
基本的には平易に書いているつもりですが、わからない単語や用語は都度調べながら読んで頂ければと思います。
対象とするケース
今回の記事の対象は、全くデータサイエンスやっていないような組織が対象です。(既に自分たちもしくは外部発注してモデルを作成したり、DataRobotのようなAuto MLツールを活用している組織は除きます。)いろいろ勧められて、BIツールを導入して可視化までは出来ている、もしくは買ってやってみたけど上手く出来てないくらいのレベル感の組織をイメージして下さい。
また、対象とするようなデータは、構造化データとします。(文書や写真のような非構造化データは対象としません。)なんちゃっての活動に意味あるの?
と思った方もおられるでしょう。私の感覚では、どの企業様も、綺麗ではないにしろそこそこデータは蓄積されています。データサイエンスのためにはデータの収集が肝なのですが、幸いにも情シの方は自社のシステムデータの扱いは専門分野でであり、上手くできることが多いです。データさえそろえば、何かしらの価値あるユースケースを設定でき結果が得られる場合が多いです。また、結果は駄目でも、データサイエンスへの理解が深まるという価値もあります。
日本企業のデータ活用の現在地
他の会社はどうなの?と思われた方も多いでしょう。
私の主なお客様は、製造・流通が多いのですが、肌感としては、3000億以上のお客様は流石に着手されています。1000億〜3000億は会社に寄りけり、それ以下だと手が回っていないことが多いと思います。業界としては、流通系のほうが浸透しており、製造は遅れをとっている印象があります。また、全体として、すごく力を入れている企業とまったくやっていない企業の温度差が激しいです。
まずはやってみることが大切!2章:必要な知識
まずは必要な知識を身につけることが必要です。
必要な知識は、「データサイエンスの概要とユースケース」、「ドメイン知識」、「IT知識」、「統計知識」の4つに大別して説明します。データサイエンスの概要とユースケース
まずは全体感の把握が必要です。なんとなくAIを使って解決します!では話になりません。まずは何が出来るかを理解することが必要です。できることは多岐に渡るのですが、「わかりやすさ(取っつきやすさ)」と「有用性」を考えると、「分類」と「回帰」の概要とユースケースの把握が必要です。ネット等でこのあたりの知識とユースケースをキャッチアップしましょう。また、時系列で変化するようなデータの分析は、難易度が上がるので後回しでも良いでしょう。
ドメン知識
いわゆるテーマとするお題やその業界特有の業務知識の部分です。この点については、自社の話なので、特に勉強は必要ないと思います。(もちろん、後々に深い分析のために現場へのヒアリング等は必要になると思いますが。)
IT知識
「ハード系」と「ソフト系」に大別します。「ハード系」は、環境を準備する知識です。自分のPCにローカル環境を構築しても良いですし、クラウド上にサーバを立てるのもありですし、SaaSのサービス上で実行するのもありだと思います。(こちらについても一般的な情シの方はキャッチアップ不要かと思います。)
「ソフト系」では、基本はPythonとなります。(お好みでRでも良いです。)また、データの収集加工にSQLの知識は必要になります。実行方法は、Jupter Notebookにてソースコードを書くが基本ですが、最近では、UI上でビジブルに実施するソフト(Sagemaker StudioやWatson Stuioなど)なども無料や安価で使えますので、コードにアレルギーのある方はそちらでも良いと思います。
具体的には「Python実践データ分析100本ノック」の前半と「PythonではじめるKaggleスタートブック」などを読んで、例題をときながらイメージをつけてゆくのが良いと思います。
大量データを扱うと分散処理などの知識も必要になるのですが、まずは数万から数十万くらいの小さなレベルのデータからはじめましょう。統計知識
こちらが一番ハードルが高く、かつここから入ると挫折します。現在はAuto MLが一般化され、「Amazon SageMaker Autopilot」や「IBM Watson Studio Auto AI」など統計の知識無でデータサイエンスをやってみる方法がありますので、今回はその活用を前提します。無料枠があるのでまずはQiitaの記事等を参考に動かしてみましょう。上記の本やAutoMLの実施中に、わからない言葉しらべならがら知識を増やすことが良いと思います。
まとめ
まずは自社のケースを考える前に、上記の知識となんとなく腹落ちするまで、お勉強しましょう。
30時間くらいあれば大丈夫だと思います。
キャリアアップにもつながるので頑張ってお勉強!
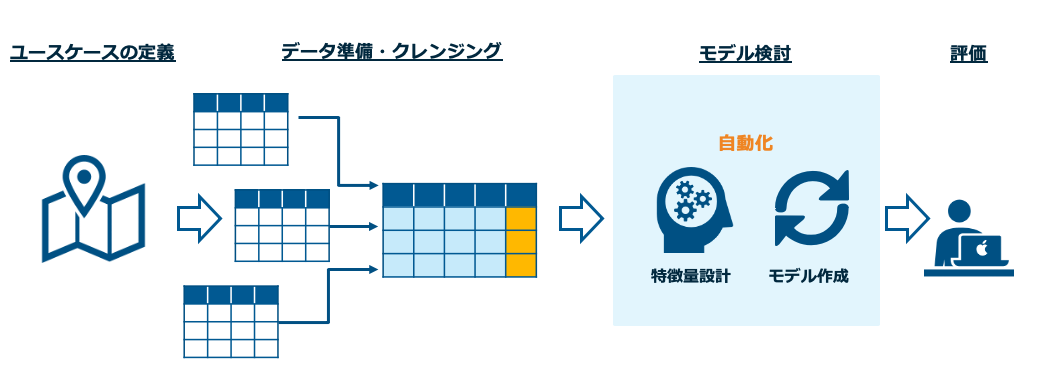
実践
知識も身についているはずなので次は実践です。データサイエンスの一般的な作業ステップは下記になります。
ユースケース定義
まずは、自社のデータに何があるかをざっと書き出して眺めてみます。そして、世間のユースケースの検索や社内の業務部門と話している中で聞いたことのある課題などを思い出してみましょう。そのなかで、これ可能かもというユースケースの仮説を作ります。ここで詰まるとお手上げなのですが、なにかあるはずです。頑張って考えてみて下さい。
データ準備、クレンジング
データ準備は、基本的にはいいろいろなところからデータをかき集めて、1つのテーブルを作るイメージです。2章の勉強を進めて頂ければわかるとおもうのですが、予測したいもの(目的変数)と、その変数に決定に関わっていそうなもの(説明変数)を準備します。
例として、ECサイト促進のEメールをコスト効率よく送ることをお題とするとします。その際の母体となるデータはメールの送信履歴です。目的変数は「1ヶ月以内にECサイトでの購買をしたかどうかのフラグや購買回数」になります。説明変数としては、送信対象者の年齢、性別、過去の累計購買金額などなど有ると思うので、それを想像し、集められるものを集めます。ユースケースの設定さえできれば、こちらの作業のハードルはそこまで高くないと思います。
モデル作成
ここが最もハードルの高い箇所になります。通常ならば、特徴量設計、モデル選定・アンサンブル、ハイパーパラメータチューニングなど専門的な知識が必要となります。ただし、今回ではAuto MLを前提としますので、データを放り込んで待つだけとなります。
!基本はクラウドサービスですので、個人情報や機密情報はサニタイズしてから放り込みましょう!
上記の例にとると、ここでは送信対象の者の属性から、買ってくれるか否かの予測を実施するモデルを作成することになります。評価
ここは少し統計の知識が必要です。Auto MLが返してくれる結果を専門用語を検索しながら理解しましょう。実際によさげな結果だったなら、実データを使い未来の予測を行ってみます。良い感じにまとまったら、上司の方や業務部門に共有してみましょう。ネイティブなことを言う人は少なく、これがデータサイエンスを根付かせる第一歩になると思います。
まとめ
すこし抽象的な内容になってしまいましたが、なんとなくやることのイメージはつかめたかと思います。これからはITが企業の運命を握る時代であり、情シの位置づけも変わってきています。その一方で、システム保守部隊から脱却できず、社会の流れとのGAPをもつ組織もたくさんみております。(コンサルとしての課題感でもあります。)この記事を読んで、一人でも行動を起こしてくれる人がいると幸いです。わからない事があれば、質問への回答も実施します。
最後に
自身の機械学習系のコード知識の整理ために、Qiitaの投稿をはじめましたが、今回はDXコンサルトして話してる事をまとめてみました。評判が良ければ今後も書いていこうと思うので、ためになったなと思ったらLGTMやフォローをお願いします。次はユースケース検討をもう少し深掘りしようと思います。私のまとめ記事は↓
Pythonで機械学習を実施する際の必要な知識まとめ



- 投稿日:2020-07-29T18:07:10+09:00
情報システム部がなんちゃってデータサイエンスをはじめるための方法
1章:はじめに
記事の趣旨
世の中では、「デジタルトラスフォーメーション(DX)」、「データドリブン経営」、「AI活用」などのビックワードが飛び交い、競合他社のちょっと盛り目のプレス記事などを目にした会社の偉い人から、うちも取り組めと言われて困っている情報システム部(情シ)の方が多くおられます。そのような方々にコンサルとして、表題のような話をすることがあるので、その内容を簡単にまとめました。もちろん、最初からお金をかけて、ベンダーに発注したり、データサイエンティストを雇う方法もありますが、情シの方がある程度データサイエンスを腹落ちさせて、ためにしやってみて、その後の外部に委託するなどの方向性を決めるほうが個人的にはお勧めです。
基本的には平易に書いているつもりですが、わからない単語や用語は都度調べながら読んで頂ければと思います。
対象とするケース
今回の記事の対象は、全くデータサイエンスやっていないような組織が対象です。(既に自分たちもしくは外部発注してモデルを作成したり、DataRobotのようなAuto MLツールを活用している組織は除きます。)いろいろ勧められて、BIツールを導入して可視化までは出来ている、もしくは買ってやってみたけど上手く出来てないくらいのレベル感の組織をイメージして下さい。
また、対象とするようなデータは、構造化データとします。(文書や写真のような非構造化データは対象としません。)なんちゃっての活動に意味あるの?
と思った方もおられるでしょう。私の感覚では、どの企業様も、綺麗ではないにしろそこそこデータは蓄積されています。データサイエンスのためにはデータの収集が肝なのですが、幸いにも情シの方は自社のシステムデータの扱いは専門分野でであり、上手くできることが多いです。データさえそろえば、何かしらの価値あるユースケースを設定でき結果が得られる場合が多いです。また、結果は駄目でも、データサイエンスへの理解が深まるという価値もあります。
日本企業のデータ活用の現在地
他の会社はどうなの?と思われた方も多いでしょう。
私の主なお客様は、製造・流通が多いのですが、肌感としては、3000億以上のお客様は流石に着手されています。1000億〜3000億は会社に寄りけり、それ以下だと手が回っていないことが多いと思います。業界としては、流通系のほうが浸透しており、製造は遅れをとっている印象があります。また、全体として、すごく力を入れている企業とまったくやっていない企業の温度差が激しいです。
まずはやってみることが大切!2章:必要な知識
まずは必要な知識を身につけることが必要です。
必要な知識は、「データサイエンスの概要とユースケース」、「ドメイン知識」、「IT知識」、「統計知識」の4つに大別して説明します。データサイエンスの概要とユースケース
まずは全体感の把握が必要です。なんとなくAIを使って解決します!では話になりません。まずは何が出来るかを理解することが必要です。できることは多岐に渡るのですが、「わかりやすさ(取っつきやすさ)」と「有用性」を考えると、「分類」と「回帰」の概要とユースケースの把握が必要です。ネット等でこのあたりの知識とユースケースをキャッチアップしましょう。また、時系列で変化するようなデータの分析は、難易度が上がるので後回しでも良いでしょう。
ドメン知識
いわゆるテーマとするお題やその業界特有の業務知識の部分です。この点については、自社の話なので、特に勉強は必要ないと思います。(もちろん、後々に深い分析のために現場へのヒアリング等は必要になると思いますが。)
IT知識
「ハード系」と「ソフト系」に大別します。「ハード系」は、環境を準備する知識です。自分のPCにローカル環境を構築しても良いですし、クラウド上にサーバを立てるのもありですし、SaaSのサービス上で実行するのもありだと思います。(こちらについても一般的な情シの方はキャッチアップ不要かと思います。)
「ソフト系」では、基本はPythonとなります。(お好みでRでも良いです。)また、データの収集加工にSQLの知識は必要になります。実行方法は、Jupter Notebookにてソースコードを書くが基本ですが、最近では、UI上でビジブルに実施するソフト(Sagemaker StudioやWatson Stuioなど)なども無料や安価で使えますので、コードにアレルギーのある方はそちらでも良いと思います。
具体的には「Python実践データ分析100本ノック」の前半と「PythonではじめるKaggleスタートブック」などを読んで、例題をときながらイメージをつけてゆくのが良いと思います。
大量データを扱うと分散処理などの知識も必要になるのですが、まずは数万から数十万くらいの小さなレベルのデータからはじめましょう。統計知識
こちらが一番ハードルが高く、かつここから入ると挫折します。現在はAuto MLが一般化され、「Amazon SageMaker Autopilot」や「IBM Watson Studio Auto AI」など統計の知識無でデータサイエンスをやってみる方法がありますので、今回はその活用を前提します。無料枠があるのでまずはQiitaの記事等を参考に動かしてみましょう。上記の本やAutoMLの実施中に、わからない言葉しらべならがら知識を増やすことが良いと思います。
まとめ
まずは自社のケースを考える前に、上記の知識となんとなく腹落ちするまで、お勉強しましょう。
30時間くらいあれば大丈夫だと思います。
キャリアアップにもつながるので頑張ってお勉強!
実践
知識も身についているはずなので次は実践です。データサイエンスの一般的な作業ステップは下記になります。
ユースケース定義
まずは、自社のデータに何があるかをざっと書き出して眺めてみます。そして、世間のユースケースの検索や社内の業務部門と話している中で聞いたことのある課題などを思い出してみましょう。そのなかで、これ可能かもというユースケースの仮説を作ります。ここで詰まるとお手上げなのですが、なにかあるはずです。頑張って考えてみて下さい。
データ準備、クレンジング
データ準備は、基本的にはいいろいろなところからデータをかき集めて、1つのテーブルを作るイメージです。2章の勉強を進めて頂ければわかるとおもうのですが、予測したいもの(目的変数)と、その変数に決定に関わっていそうなもの(説明変数)を準備します。
例として、ECサイト促進のEメールをコスト効率よく送ることをお題とするとします。その際の母体となるデータはメールの送信履歴です。目的変数は「1ヶ月以内にECサイトでの購買をしたかどうかのフラグや購買回数」になります。説明変数としては、送信対象者の年齢、性別、過去の累計購買金額などなど有ると思うので、それを想像し、集められるものを集めます。ユースケースの設定さえできれば、こちらの作業のハードルはそこまで高くないと思います。
モデル作成
ここが最もハードルの高い箇所になります。通常ならば、特徴量設計、モデル選定・アンサンブル、ハイパーパラメータチューニングなど専門的な知識が必要となります。ただし、今回ではAuto MLを前提としますので、データを放り込んで待つだけとなります。
!基本はクラウドサービスですので、個人情報や機密情報はサニタイズしてから放り込みましょう!
上記の例にとると、ここでは送信対象の者の属性から、買ってくれるか否かの予測を実施するモデルを作成することになります。評価
ここは少し統計の知識が必要です。Auto MLが返してくれる結果を専門用語を検索しながら理解しましょう。実際によさげな結果だったなら、実データを使い未来の予測を行ってみます。良い感じにまとまったら、上司の方や業務部門に共有してみましょう。ネイティブなことを言う人は少なく、これがデータサイエンスを根付かせる第一歩になると思います。
まとめ
すこし抽象的な内容になってしまいましたが、なんとなくやることのイメージはつかめたかと思います。これからはITが企業の運命を握る時代であり、情シの位置づけも変わってきています。その一方で、システム保守部隊から脱却できず、社会の流れとのGAPをもつ組織もたくさんみております。(コンサルとしての課題感でもあります。)この記事を読んで、一人でも行動を起こしてくれる人がいると幸いです。わからない事があれば、質問への回答も実施します。
最後に
自身の機械学習系のコード知識の整理ために、Qiitaの投稿をはじめましたが、今回はDXコンサルトして話してる事をまとめてみました。評判が良ければ今後も書いていこうと思うので、ためになったなと思ったらLGTMやフォローをお願いします。次はユースケース検討をもう少し深掘りしようと思います。私のまとめ記事は↓
Pythonで機械学習を実施する際の必要な知識まとめ
- 投稿日:2020-07-29T18:07:10+09:00
情報システム部(初心者)がなんちゃってデータサイエンスをはじめるための方法
1章:はじめに
記事の趣旨
世の中では、「デジタルトラスフォーメーション(DX)」、「データドリブン経営」、「AI活用」などのビックワードが飛び交い、競合他社のちょっと盛り目のプレス記事などを目にした会社の偉い人から、うちも取り組めと言われて困っている情報システム部(情シ)の方が多くおられます。そのような方々にコンサルとして、表題のような話をすることがあるので、その内容を簡単にまとめました。もちろん、最初からお金をかけて、ベンダーに発注したり、データサイエンティストを雇う方法もありますが、情シの方がある程度データサイエンスを腹落ちさせて、ためにしやってみて、その後の外部に委託するなどの方向性を決めるほうが個人的にはお勧めです。
基本的には平易に書いているつもりですが、わからない単語や用語は都度調べながら読んで頂ければと思います。
対象とするケース
今回の記事の対象は、全くデータサイエンスやっていないような組織が対象です。(既に自分たちもしくは外部発注してモデルを作成したり、DataRobotのようなAuto MLツールを活用している組織は除きます。)いろいろ勧められて、BIツールを導入して可視化までは出来ている、もしくは買ってやってみたけど上手く出来てないくらいのレベル感の組織をイメージして下さい。
また、対象とするようなデータは、構造化データとします。(文書や写真のような非構造化データは対象としません。)なんちゃっての活動に意味あるの?
と思った方もおられるでしょう。私の感覚では、どの企業様も、綺麗ではないにしろそこそこデータは蓄積されています。データサイエンスのためにはデータの収集が肝なのですが、幸いにも情シの方は自社のシステムデータの扱いは専門分野でであり、上手くできることが多いです。データさえそろえば、何かしらの価値あるユースケースを設定でき結果が得られる場合が多いです。また、結果は駄目でも、データサイエンスへの理解が深まるという価値もあります。
日本企業のデータ活用の現在地
他の会社はどうなの?と思われた方も多いでしょう。
私の主なお客様は、製造・流通が多いのですが、肌感としては、3000億以上のお客様は流石に着手されています。1000億〜3000億は会社に寄りけり、それ以下だと手が回っていないことが多いと思います。業界としては、流通系のほうが浸透しており、製造は遅れをとっている印象があります。また、全体として、すごく力を入れている企業とまったくやっていない企業の温度差が激しいです。
まずはやってみることが大切!2章:必要な知識
まずは必要な知識を身につけることが必要です。
必要な知識は、「データサイエンスの概要とユースケース」、「ドメイン知識」、「IT知識」、「統計知識」の4つに大別して説明します。データサイエンスの概要とユースケース
まずは全体感の把握が必要です。なんとなくAIを使って解決します!では話になりません。まずは何が出来るかを理解することが必要です。できることは多岐に渡るのですが、「わかりやすさ(取っつきやすさ)」と「有用性」を考えると、「分類」と「回帰」の概要とユースケースの把握が必要です。ネット等でこのあたりの知識とユースケースをキャッチアップしましょう。また、時系列で変化するようなデータの分析は、難易度が上がるので後回しでも良いでしょう。
ドメン知識
いわゆるテーマとするお題やその業界特有の業務知識の部分です。この点については、自社の話なので、特に勉強は必要ないと思います。(もちろん、後々に深い分析のために現場へのヒアリング等は必要になると思いますが。)
IT知識
「ハード系」と「ソフト系」に大別します。「ハード系」は、環境を準備する知識です。自分のPCにローカル環境を構築しても良いですし、クラウド上にサーバを立てるのもありですし、SaaSのサービス上で実行するのもありだと思います。(こちらについても一般的な情シの方はキャッチアップ不要かと思います。)
「ソフト系」では、基本はPythonとなります。(お好みでRでも良いです。)また、データの収集加工にSQLの知識は必要になります。実行方法は、Jupter Notebookにてソースコードを書くが基本ですが、最近では、UI上でビジブルに実施するソフト(Sagemaker StudioやWatson Stuioなど)なども無料や安価で使えますので、コードにアレルギーのある方はそちらでも良いと思います。
具体的には「Python実践データ分析100本ノック」の前半と「PythonではじめるKaggleスタートブック」などを読んで、例題をときながらイメージをつけてゆくのが良いと思います。
大量データを扱うと分散処理などの知識も必要になるのですが、まずは数万から数十万くらいの小さなレベルのデータからはじめましょう。統計知識
こちらが一番ハードルが高く、かつここから入ると挫折します。現在はAuto MLが一般化され、「Amazon SageMaker Autopilot」や「IBM Watson Studio Auto AI」など統計の知識無でデータサイエンスをやってみる方法がありますので、今回はその活用を前提します。無料枠があるのでまずはQiitaの記事等を参考に動かしてみましょう。上記の本やAutoMLの実施中に、わからない言葉しらべならがら知識を増やすことが良いと思います。
まとめ
まずは自社のケースを考える前に、上記の知識となんとなく腹落ちするまで、お勉強しましょう。
30時間くらいあれば大丈夫だと思います。
キャリアアップにもつながるので頑張ってお勉強!
実践
知識も身についているはずなので次は実践です。データサイエンスの一般的な作業ステップは下記になります。
ユースケース定義
まずは、自社のデータに何があるかをざっと書き出して眺めてみます。そして、世間のユースケースの検索や社内の業務部門と話している中で聞いたことのある課題などを思い出してみましょう。そのなかで、これ可能かもというユースケースの仮説を作ります。ここで詰まるとお手上げなのですが、なにかあるはずです。頑張って考えてみて下さい。
データ準備、クレンジング
データ準備は、基本的にはいいろいろなところからデータをかき集めて、1つのテーブルを作るイメージです。2章の勉強を進めて頂ければわかるとおもうのですが、予測したいもの(目的変数)と、その変数に決定に関わっていそうなもの(説明変数)を準備します。
例として、ECサイト促進のEメールをコスト効率よく送ることをお題とするとします。その際の母体となるデータはメールの送信履歴です。目的変数は「1ヶ月以内にECサイトでの購買をしたかどうかのフラグや購買回数」になります。説明変数としては、送信対象者の年齢、性別、過去の累計購買金額などなど有ると思うので、それを想像し、集められるものを集めます。ユースケースの設定さえできれば、こちらの作業のハードルはそこまで高くないと思います。
モデル作成
ここが最もハードルの高い箇所になります。通常ならば、特徴量設計、モデル選定・アンサンブル、ハイパーパラメータチューニングなど専門的な知識が必要となります。ただし、今回ではAuto MLを前提としますので、データを放り込んで待つだけとなります。
!基本はクラウドサービスですので、個人情報や機密情報はサニタイズしてから放り込みましょう!
上記の例にとると、ここでは送信対象の者の属性から、買ってくれるか否かの予測を実施するモデルを作成することになります。評価
ここは少し統計の知識が必要です。Auto MLが返してくれる結果を専門用語を検索しながら理解しましょう。実際によさげな結果だったなら、実データを使い未来の予測を行ってみます。良い感じにまとまったら、上司の方や業務部門に共有してみましょう。ネイティブなことを言う人は少なく、これがデータサイエンスを根付かせる第一歩になると思います。
まとめ
すこし抽象的な内容になってしまいましたが、なんとなくやることのイメージはつかめたかと思います。これからはITが企業の運命を握る時代であり、情シの位置づけも変わってきています。その一方で、システム保守部隊から脱却できず、社会の流れとのGAPをもつ組織もたくさんみております。(コンサルとしての課題感でもあります。)この記事を読んで、一人でも行動を起こしてくれる人がいると幸いです。わからない事があれば、質問への回答も実施します。
最後に
自身の機械学習系のコード知識の整理ために、Qiitaの投稿をはじめましたが、今回はDXコンサルトして話してる事をまとめてみました。評判が良ければ今後も書いていこうと思うので、ためになったなと思ったらLGTMやフォローをお願いします。次はユースケース検討をもう少し深掘りしようと思います。私のまとめ記事は↓
Pythonで機械学習を実施する際の必要な知識まとめ
- 投稿日:2020-07-29T16:40:27+09:00
pythonでExcelのデータをJSONに変換する
概要
pythonでexcelのデータをJSONに変換します。
変換するexcelデータは日本食品標準成分表より、
以下の果実類のexcelファイルを使おうと思います。(クリックするとファイルがダウンロードされます。)
https://www.mext.go.jp/component/a_menu/science/detail/__icsFiles/afieldfile/2016/01/15/1365344_1-0207r.xlsx
excel2jsonとopenpyxlの二つの方法でやってみます。
(excel2jsonの方はうまくいってないです。)方法1 excel2jsonを使う
excel2jsonはpythonでexcelのデータをJSONに変換するモジュールなんですが、機能がとても限られています。excelを読み込んでjsonファイルを作成するくらいしかないです。
とりあえずインストールしてみます。末尾の
-3を入れないと別のモジュールがインストールされるので注意。$ pip install excel2json-3インストールできたら使ってみましょう。コードはこれだけ
excel2json.pyfrom excel2json import convert_from_file convert_from_file("変換したいexcelファイルのPATH")実行するとexcelファイルと同じディレクトリにjsonファイルが生成されます。jsonファイルの名前はexcelのsheetの名前(固定っぽい)です。
ダウンロードしてきたexcelファイルをそのまま入れて実行したらうまくjsonファイルが作成できなかったので、表の上の余計な部分を消して再実行してみます。
修正後のexcelファイルはこんな感じ↓
できたjsonファイルを開いて見ると...
{ "\u98df\u54c1\u7fa4": "07", "\u98df\u54c1\u756a\u53f7": "07001", "\u7d22\u5f15\u756a\u53f7": 751.0, ... }このようにunicodeになってしまっています。
試しにvscodeの「encode decode」というextensionsで修正してみるとこんな感じになりました。{ "食品群": "07", "食品番号": "07001", "索引番号": 751.0, ... }コードの量が少なくて、すでに整っているデータならとても楽にできますが、取得するデータを指定できなかったりして少し不便です。
文字コードに関しても、上記以外の方法が見つかなかったので、とりあえず他の方法を試してみようとおもいます。方法2 openpyxlを使う
openpyxlはpythonでexcelの操作をするためのモジュールです。まずはopenpyxlをインストールします
$ pip install openpyxlインストールできたら使ってみます。
excellファイルはダウンロードしてきたものをそのまま使ってるので注意してください。
今回は食品番号、食品名、食物繊維、カリウム、鉄、ビタミンB1、ビタミンCの7項目を取得します。
コードはこちら
import openpyxl import json load_book = openpyxl.load_workbook('excelファイルのPATH') sheet = load_book['07 果実類'] json_path = 'jsonファイルのPATH' fruits_list = [{ "food_id": 0, "name": "" }] for i in range(9, 183): food_id = sheet.cell(row = i, column = 2).value name = sheet.cell(row = i, column = 4).value dietary_fiber = sheet.cell(row = i, column = 21).value potassium = sheet.cell(row = i, column = 24).value iron = sheet.cell(row = i, column = 28).value vitamin_b1 = sheet.cell(row = i, column = 48).value vitamin_c = sheet.cell(row = i, column = 56).value food_id = int(food_id) if dietary_fiber == 'Tr': dietary_fiber = 0 if potassium == 'Tr': potassium = 0 if iron == 'Tr': iron = 0 if vitamin_b1 == 'Tr': vitamin_b1 = 0 if vitamin_c == 'Tr': vitamin_c = 0 if name.split(" ")[0][0] == '(' or name.split(" ")[0][0] == '(': name = name.split(" ")[1] else: name = name.split(" ")[0] if fruits_list[-1]['name'] != name: fruits_list.append({ "food_id": food_id, "name": name, "dietary_fiber": dietary_fiber, "potassium": potassium, "iron": iron, "vitamin_b1": vitamin_b1, "vitamin_c": vitamin_c, }) fruits_list.pop(0) data_dict = { "data": "fruits", "fruits": fruits_list } with open(json_path, mode = 'w', encoding = 'utf-8') as f: f.write(json.dumps(data_dict, ensure_ascii = False, indent = 4))記事に関する部分を説明しておきます。
import openpyxl import json load_book = openpyxl.load_workbook('excelファイルのPATH') sheet = load_book['sheet名'] json_path = 'jsonファイルのPATH'openpyxlと、jsonを操作したいのでjsonモジュールもimportしておきます。
openpyxl.load_workbook()でexcelファイルを読み込んで、load_book['sheet名']でsheetを取得します。food_id = sheet.cell(row = 1, column = 2).valueexcelのセルを行と列で指定してデータを取得します。このコードだと1行2列のデータを取得しています。
fruits_list.append({ "food_id": food_id, "name": name, "dietary_fiber": dietary_fiber, "potassium": potassium, "iron": iron, "vitamin_b1": vitamin_b1, "vitamin_c": vitamin_c, })取得したデータを辞書にまとめて、配列に追加します。
data_dict = { "data": "fruits", "fruits": fruits_list } with open(json_path, mode = 'w', encoding = 'utf-8') as f: f.write(json.dumps(data_dict, ensure_ascii = False, indent = 4))最後にさっきのデータを辞書にしてjsonファイルに書き込みます。
open()のmode='a'はファイルを書き込みモードで開くことを指定しています。ちなみに、modeがrだと読み込みモード、aだと追記モードになります。まとめ
- excel2json
- 短いコードでまとめて変換できるので楽。
- ただ汎用性はそんなに高くない。
- 日本語のデータはできない?(方法あったらぜひ教えてください。)
- openpyxl
- 取得したいデータを指定して取得できるので汎用性高い。
- データが整ってなくてもpythonで何とかできる。
- 取得したいデータが増えてくると少し大変かも?
- 投稿日:2020-07-29T16:27:29+09:00
Transformerによる文章のネガポジ判定と根拠の可視化
1.はじめに
「PyTorchによる発展的ディープラーニング」を読んでいます。今回は、7章のTransformerを勉強したので自分なりのまとめをアウトプットしたいと思います。
2.Transformerとは?
2017年自然言語処理の分野でエポックメイキングな論文「Attention All You Need」が発表されました。そこで提案されたモデルが Transformer で、翻訳タスクにおいて今まで主流であったRNNを一切使わずに、Attention のみでSOTAを達成しました。
以後、自然言語処理分野では BERT、XLNet など、この Transformer をベースにしたモデルが席巻し、自然言語処理なら Transformer と言われるようになりました。
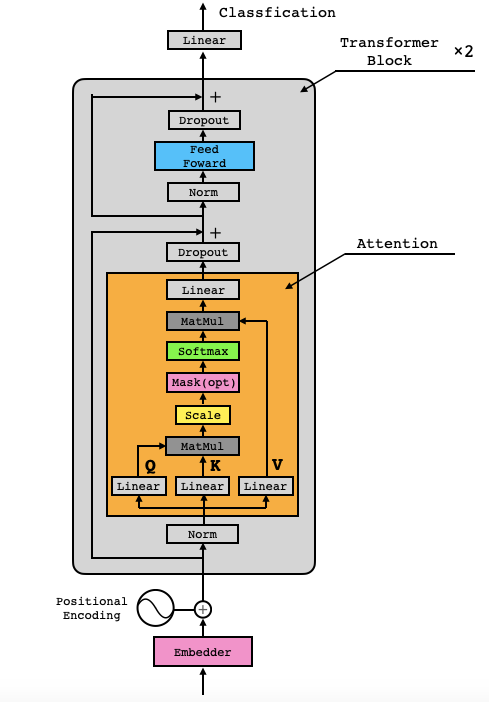
これが、翻訳タスクを行うTransformerのモデル図です。例えば日英翻訳を考えると、左側のEncoderで日文の各単語のAttentionを学習し、その情報を参照しつつ右側のDecoderで英文の各単語のAttentionを学習するわけです。それでは、特徴を5つ説明します。
1) Psitional Encoding
Transformer最大の狙いは、RNNのように単語を1つづつ処理するのではなく、センテンス毎に単語を全て並列処理することで、GPUを活用し処理速度の大幅アップを図ることです。そのために、Positional Encodingで各単語に単語順の情報を付加し、並列処理によって単語順の情報が失われることを防いでいます。2) Scaled dot-product Attention
これが Transfrmer の肝なので、少し丁寧に説明します。Attentionの計算には、Query(Attentionを計算したい単語ベクトル)、Key(関連度の計算に使う単語ベクトルの集まり)、Value(重み付け和計算に使うベクトルの集まり)の3つが登場します。
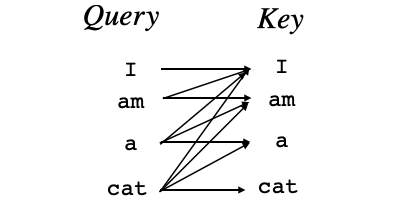
センテンスが「吾輩」、「は」、「猫」、「で」、「ある」と5つの単語で構成されているときに、「吾輩」のAttentionをどう計算するかを説明します。関連度はベクトルの内積で計算できるので、「吾輩」ベクトルQueryと5つの単語ベクトルの転置行列$Key^T$の内積を取ります。そして、${\sqrt{d_k}}$で割ってからSoftmaxを掛けることで、「吾輩」にどの単語がどの程度関連しているかを表す重み(Attention Weight)を求めます。
${\sqrt{d_k}}$で割る理由は、内積計算で大き過ぎる値があるとSoftmaxを掛けたとき、それ以外の値が0になってしまう恐れがあるためです。
次に、Attention Weight と5つの単語ベクトルの行列Valueを内積することで、「吾輩」に関連度の深い単語のベクトル成分が支配的なContext Vectorが計算できます。これが「吾輩」のAttentionの計算です。
さて、Trandformer は並列計算が可能で、全てのQueryに対して一気に計算が出来るので、
このように全てのQueryのAttention計算が一発で完了します。この計算が論文では下記の式で表されています。
Attention(Q, K, V)=softmax(\frac{QK^T}{\sqrt{d_k}})V3) Multi-Head Attention
Scaled dot-product Attentionへの入力 Query, Key, Value は、前段の出力がそれぞれの全結合層を経由して入って来る構造になっています。つまり、前段の出力にそれぞれ重み$W_q,W_k,W_v$を掛けたものです。
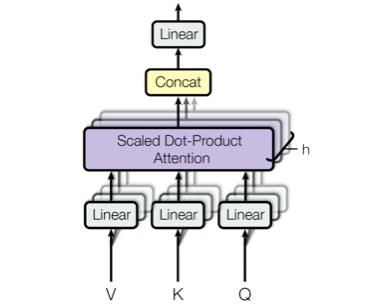
このとき、大きな Query, Key, Valueのセット(ヘッドと言います)を1つ持たせるよりも、小さな Query, Key, Valueのヘッドを複数個持たせ、それぞれのヘッドが潜在表現$W_q,W_k,W_v$を計算し最後に1つにした方がパフォーマンスが上がるというのが Multi-Head Attentionです。4) Musked Multi-Head Attention
Decoder側のAttentionも並列計算するわけですが、「I」のAtentionを計算するとき、「am」、「a」、「cat」を計算対象に入れると、予測すべき単語をカンニングすることになるので、Keyにある先の単語は見えなくするためにマスクを掛けます。この機能を加えた Multi-Head Attention を、Musked Multi-Head Attention と呼びます。
5) Position-wise Feed-Forward Networks
これは、Attention層からの出力を2層の全結合層で特徴量を変換するユニットです。入力が(単語数,単語埋め込み次元数)、これに2つの全結合層の重みとの内積をとったものが出力(単語数,単語埋め込み次元数)となります。各単語毎に独立したニューラルネットワークがある様な形になるので、Position-wise という名前を付けています。3.今回実装するモデル
今回は、Transformer翻訳モデルの左側のEncoderだけを使って、センテンスの各単語のAttentionを学習することで分類タスクを解かせるモデルを実装します。
使用するデータセットは、映画のレビュー(英文)の内容がポジティブなのかネガティブなのかをまとめたIMDb(Internet Movie Dataset)です。
モデルを学習させることによって、ある映画のレビューを入力したら、そのレビューがポジティブなのかネガティブなのかを判定し、レビューの単語の相互Attentionから判定の根拠にした単語を明示させるようにします。
それでは、入力から順番に実装して行きたいと思います。
4.モデルのコード
class Embedder(nn.Module): '''idで示されている単語をベクトルに変換します''' def __init__(self, text_embedding_vectors): super(Embedder, self).__init__() self.embeddings = nn.Embedding.from_pretrained( embeddings=text_embedding_vectors, freeze=True) # freeze=Trueによりバックプロパゲーションで更新されず変化しなくなります def forward(self, x): x_vec = self.embeddings(x) return x_vecPytorchのnn.Embeddingユニットを使って、単語IDを埋め込みベクトルに変換する部分です。
class PositionalEncoder(nn.Module): '''入力された単語の位置を示すベクトル情報を付加する''' def __init__(self, d_model=300, max_seq_len=256): super().__init__() self.d_model = d_model # 単語ベクトルの次元数 # 単語の順番(pos)と埋め込みベクトルの次元の位置(i)によって一意に定まる値の表をpeとして作成 pe = torch.zeros(max_seq_len, d_model) # GPUが使える場合はGPUへ送る device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") pe = pe.to(device) for pos in range(max_seq_len): for i in range(0, d_model, 2): pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model))) pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * i)/d_model))) # 表peの先頭に、ミニバッチ次元となる次元を足す self.pe = pe.unsqueeze(0) # 勾配を計算しないようにする self.pe.requires_grad = False def forward(self, x): # 入力xとPositonal Encodingを足し算する # xがpeよりも小さいので、大きくする ret = math.sqrt(self.d_model)*x + self.pe return retPositional Encoderの部分です。
class Attention(nn.Module): '''Transformerは本当はマルチヘッドAttentionですが、 分かりやすさを優先しシングルAttentionで実装します''' def __init__(self, d_model=300): super().__init__() # SAGANでは1dConvを使用したが、今回は全結合層で特徴量を変換する self.q_linear = nn.Linear(d_model, d_model) self.v_linear = nn.Linear(d_model, d_model) self.k_linear = nn.Linear(d_model, d_model) # 出力時に使用する全結合層 self.out = nn.Linear(d_model, d_model) # Attentionの大きさ調整の変数 self.d_k = d_model def forward(self, q, k, v, mask): # 全結合層で特徴量を変換 k = self.k_linear(k) q = self.q_linear(q) v = self.v_linear(v) # Attentionの値を計算する # 各値を足し算すると大きくなりすぎるので、root(d_k)で割って調整 weights = torch.matmul(q, k.transpose(1, 2)) / math.sqrt(self.d_k) # ここでmaskを計算 mask = mask.unsqueeze(1) weights = weights.masked_fill(mask == 0, -1e9) # softmaxで規格化をする normlized_weights = F.softmax(weights, dim=-1) # AttentionをValueとかけ算 output = torch.matmul(normlized_weights, v) # 全結合層で特徴量を変換 output = self.out(output) return output, normlized_weightsAttentionの部分です。ここでの mask計算は、テキストデータが短く<pad>を入れた箇所は、softmaxを掛けたら0になって欲しいので、該当箇所をマイナス無限大(-1e9)に置き換えています。
class FeedForward(nn.Module): def __init__(self, d_model, d_ff=1024, dropout=0.1): '''Attention層から出力を単純に全結合層2つで特徴量を変換するだけのユニットです''' super().__init__() self.linear_1 = nn.Linear(d_model, d_ff) self.dropout = nn.Dropout(dropout) self.linear_2 = nn.Linear(d_ff, d_model) def forward(self, x): x = self.linear_1(x) x = self.dropout(F.relu(x)) x = self.linear_2(x) return xFeed Forward の部分です。単純な2層の全結合層です。
class TransformerBlock(nn.Module): def __init__(self, d_model, dropout=0.1): super().__init__() # LayerNormalization層 # https://pytorch.org/docs/stable/nn.html?highlight=layernorm self.norm_1 = nn.LayerNorm(d_model) self.norm_2 = nn.LayerNorm(d_model) # Attention層 self.attn = Attention(d_model) # Attentionのあとの全結合層2つ self.ff = FeedForward(d_model) # Dropout self.dropout_1 = nn.Dropout(dropout) self.dropout_2 = nn.Dropout(dropout) def forward(self, x, mask): # 正規化とAttention x_normlized = self.norm_1(x) output, normlized_weights = self.attn( x_normlized, x_normlized, x_normlized, mask) x2 = x + self.dropout_1(output) # 正規化と全結合層 x_normlized2 = self.norm_2(x2) output = x2 + self.dropout_2(self.ff(x_normlized2)) return output, normlized_weightsAttention と Feed Foward を組み合わせて、Transformer Block を作る部分です。両方とも、Layer Normalization と Dropoutを掛けると共に、ResNetと同様な残渣結合を行っています。
class ClassificationHead(nn.Module): '''Transformer_Blockの出力を使用し、最後にクラス分類させる''' def __init__(self, d_model=300, output_dim=2): super().__init__() # 全結合層 self.linear = nn.Linear(d_model, output_dim) # output_dimはポジ・ネガの2つ # 重み初期化処理 nn.init.normal_(self.linear.weight, std=0.02) nn.init.normal_(self.linear.bias, 0) def forward(self, x): x0 = x[:, 0, :] # 各ミニバッチの各文の先頭の単語の特徴量(300次元)を取り出す out = self.linear(x0) return out最後にネガポジ判定をする部分です。各文の先頭単語の特徴量を使用して分類し、その損失をバックプロパゲーションして学習することで、先頭単語の特徴量が自然と文章のネガ・ポジを判定する特徴量になります。
class TransformerClassification(nn.Module): '''Transformerでクラス分類させる''' def __init__(self, text_embedding_vectors, d_model=300, max_seq_len=256, output_dim=2): super().__init__() # モデル構築 self.net1 = Embedder(text_embedding_vectors) self.net2 = PositionalEncoder(d_model=d_model, max_seq_len=max_seq_len) self.net3_1 = TransformerBlock(d_model=d_model) self.net3_2 = TransformerBlock(d_model=d_model) self.net4 = ClassificationHead(output_dim=output_dim, d_model=d_model) def forward(self, x, mask): x1 = self.net1(x) # 単語をベクトルに x2 = self.net2(x1) # Positon情報を足し算 x3_1, normlized_weights_1 = self.net3_1( x2, mask) # Self-Attentionで特徴量を変換 x3_2, normlized_weights_2 = self.net3_2( x3_1, mask) # Self-Attentionで特徴量を変換 x4 = self.net4(x3_2) # 最終出力の0単語目を使用して、分類0-1のスカラーを出力 return x4, normlized_weights_1, normlized_weights_2今まで定義したクラスを使って、最終的にモデル全体を組み上げる部分です。
5.コード全体と実行
コード全体は Google Colab で作成し Github に上げてありますので、自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
実行すると、
こんな形で、判定結果とその根拠を表示します。
6.日本語データセットでもやってみる。
色々Webを見ていると、chABSA-datasetという日本の上場企業の有価証券報告書から文章を取り出しネガポジ判定し判定根拠を表示する例があったので、同様に Google Colab でまとめてみました。自分でやってみたい方は、この 「リンク」 をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
(参考)
・つくりながら学ぶ! PyTorchによる発展ディープラーニング
・ディープラーニングでネガポジ分析アプリを作ってみた(python)【前編】
・論文解説 Attention Is All You Need (Transformer)




- 投稿日:2020-07-29T16:08:09+09:00
CDKでサクッとCodeCommit+CodePipeline
はじめに
本投稿は、AWS CDKの勉強を兼ねて試作してみたCodeCommit+CodePipelineでS3にファイルをアップロードする機構について紹介しています。
エンジニアチーム内で「触ってみたいですよね」という声があり興味があった所に、別部署のエンジニアの方からも「CDKいいっすよ〜」という評判を聞いたので触ってみました。AWS CDKとは?
AWS CDKとは、
AWS クラウド開発キット (AWS CDK) は、使い慣れたプログラミング言語を使用してクラウドアプリケーションリソースをモデル化およびプロビジョニングするためのオープンソースのソフトウェア開発フレームワークだそうです。PythonやTypeScriptなんかでインフラの定義がかけて便利です。背景
最初期
過去、制作用の環境としてCloud9が使用されていたのですが、その時の選定要件は、
- 同時編集できる
- 成果物をプレビューできる
- プレビューにBasic認証入れられる
- バージョン管理できる
だったので、Cloud9+Codecommit+Lambda+CloudFront+Lambda@edge+S3でCloud9からCodeCommit経由でS3にhtmlファイル・画像ファイルがアップロードされ、CloudFront経由でプレビューできるというものを作っていました。最初はうまく回っているように見えていました。
問題点
最初はうまく回っているように見えていたCloud9も徐々に問題点が出てきました。
- 一部ファイルがS3に上がっていない。(これはCodeCommit→S3をLambdaでやっている所が怪しいと睨んでいます)
- 案件が増えてきてCloud9の容量が圧迫されている(画像もりもりの制作物なので…)
- そもそも同時編集機能が活用されてない気配がある…
ということで、Cloud9である必要性がなくなっていました。であればローカルで作ってS3に上がればいいよねってことで作り直しの機運が高まりました。(実際にコーディングするメンバーはAWSを触る人たちではないので極力AWSと直接相対しない形を提供してあげたいという思いもありました。)
本題
作り直しにあたり、社内で噂を聞いたCDKを採用しました。下図の左側CodeCommit・CodePipeline・CodeBuildのリソース作成をCDKが担当します。(S3+CloudFront+Lambda@edgeは以前のものを流用しました。)
Cloud9時代には、
1Cloud9(1EC2インスタンス)=複数案件=1リポジトリだったものを、1案件=1リポジトリにしました。案件着手時にcdk deployすることで、CodeCommit上にリポジトリの作成とCodePipelineが整備されて、masterにpushするごとに、CodeBuildでS3にファイルがアップロードされるという状態です。実装
ドキュメントに従って、
$ npm install -g aws-cdk $ mkdir test $ cd test $ cdk init test --language python $ source .env/bin/activate $ pip install -r requirements.txtとしてスタートします。
app.py#!/usr/bin/env python3 import os from os.path import join, dirname from dotenv import load_dotenv from aws_cdk import core from test.test_stack import TestStack dotenv_path = join(dirname(__file__), '.env_file') load_dotenv(dotenv_path) app = core.App() TestStack(app, "test", repo_name=os.environ["REPOSITORY_NAME"], env={"account": "xxxxxxxxxxxx", "region": "ap-northeast-1"}) app.synth()test_stack.pyfrom aws_cdk import core from aws_cdk import aws_codecommit as codecommit from aws_cdk import aws_codebuild as codebuild from aws_cdk import aws_codepipeline as codepipeline from aws_cdk import aws_codepipeline_actions as codepipeline_actions from aws_cdk import aws_iam as iam class TestStack(core.Stack): def __init__(self, scope: core.Construct, id: str, repo_name: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) # output先のバケット名 s3_bucket_name = "test-bucket" # CodeCommitのRepository作成 repo = codecommit.Repository(self, "Repository", repository_name=repo_name, description="test.") repository = codecommit.Repository.from_repository_arn(self, repo_name, repo.repository_arn) # CodePipelineの定義 pipeline = codepipeline.Pipeline(self, id=f"test-pipeline-{repo_name}", pipeline_name=f"test-pipeline-{repo_name}") source_output = codepipeline.Artifact('source_output') # CodeCommitの追加 source_action = codepipeline_actions.CodeCommitSourceAction(repository=repository, branch='master', action_name='source_collect_action_from_codecommit', output=source_output, trigger=codepipeline_actions.CodeCommitTrigger.EVENTS) pipeline.add_stage(stage_name='Source', actions=[source_action]) # CodeBuildの追加 cdk_build = codebuild.PipelineProject(self, "CdkBuild", build_spec=codebuild.BuildSpec.from_object(dict( version="0.2", phases=dict( build=dict( commands=[f"aws s3 sync ./ s3://{s3_bucket_name}/"] ) ) ))) cdk_build.add_to_role_policy( iam.PolicyStatement( resources=[f'arn:aws:s3:::{s3_bucket_name}', f'arn:aws:s3:::{s3_bucket_name}/*'], actions=['s3:*'] ) ) build_output = codepipeline.Artifact("CdkBuildOutput") build_action = codepipeline_actions.CodeBuildAction( action_name="CDK_Build", project=cdk_build, input=source_output, outputs=[build_output]) pipeline.add_stage( stage_name="Build", actions=[build_action] )CodeBuild
今にして思うと、
s3 syncしてるだけのCodeBuildってCodeDeployで良かったのでは感があります。
s3 syncする時にs3バケット側の階層を一段深くしたくてこうしていますが、良い解決策はないものでしょうか…codebuildの部分# CodeBuildの追加 cdk_build = codebuild.PipelineProject(self, "CdkBuild", build_spec=codebuild.BuildSpec.from_object(dict( version="0.2", phases=dict( build=dict(commands=[f"aws s3 sync ./ s3://{s3_bucket_name}/"]) ))))デプロイ
あとは
$ cdk deployとしてやればデプロイできますが、使う人向けに以下のようにスクリプトにしておきました。
make.sh#!/bin/bash if [ $# -ne 1 ]; then echo "実行するには1個の引数が必要です。" 1>&2 echo "引数にはプロジェクトコードを指定してください。(プレビュー時のURLに一部使用されます)" exit 1 fi echo REPOSITORY_NAME=$1 > .env_file cdk deploy test --profile xxxxxxx # commitぶっこむ git clone ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/$1 ../$1 mkdir ../$1/$1 touch ../$1/$1/.gitkeep cd ../$1 git checkout -b master git add -A git commit -m "initial commit" git push origin masterこれで、作成するリポジトリ名を引数として
$ ./make.sh test_repositoryとすればOKです。
懸念点
- 今はCDKの中でCodeCommitのリポジトリを作成しているため、スタックを消してしまうとリポジトリごと消えてしまうというリスクがあります。
- 実は初回のdeploy時にはCodeCommit側でmasterブランチが作成されていない(?)ためBuild時に失敗してしまいます。git pushしてあげると正しく動作するので現在のところは放置しています。(が少し気持ち悪い。)
最後に
今回はCDKを使ってCodeCommitからCodeBuild経由でS3にファイルをアップロードする機構を作成しました。
Cloud9時代に比べて評判がいいようなので、このまま何事もなく使ってもらえるといいなと思いつつフィードバックを待ちます。
CDK自体はCloudFormationと直に戦わなくていいので良いものだと思います。
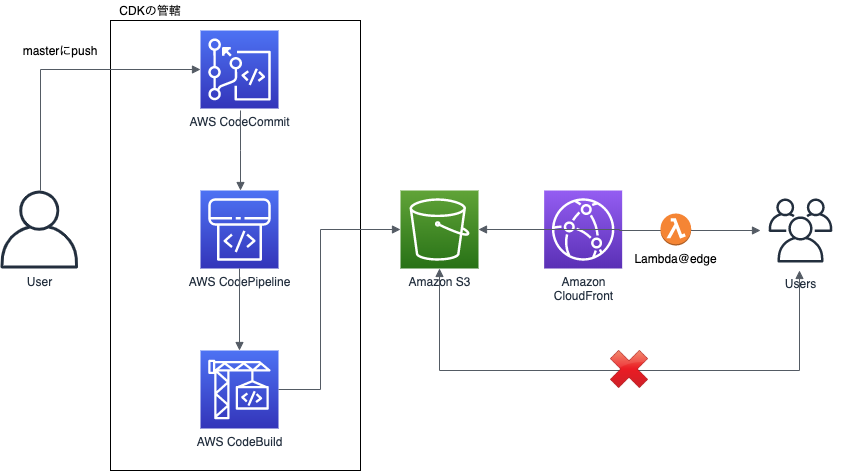
- 投稿日:2020-07-29T16:06:34+09:00
Educational Codeforces Round 91 バチャ復習
結果
感想
昨日から解く量を増やすためにできるだけ毎日コドフォのバチャをすることに決めました。
AtCoderのD~Fで毎回もう少しで解けそうな問題に阻まれているので、レベル帯の近いコドフォのdiv2またはエデュフォを解きます。
ABCでもよかったのですが、7,8割くらいの問題は埋めてしまいレベルにあった問題が少ないと感じたので、コドフォを解くことにします。今回はC問題とD問題で誤読をして長時間使ってしまい、D問題に至ってはコンテスト中に解きおわることができませんでした。どちらも決して難しくないので、わからない場合は問題の読み直しをするようにします。
A問題
この問題でも出力するものを間違えてサンプルが合いませんでした。与えられた数列$p$に対し、増減が反転するもの(極値)が一つでもあれば何番目かを記録してその前後と合わせて出力します。また、極値が一つも存在しない時は数列全体で単調減少or増加なので、題意を満たす$i,j,k$の組はなくNoを出力すれば良いです。
A.py#誤読(出力するものミス) t=int(input()) for _ in range(t): n=int(input()) p=list(map(int,input().split())) for i in range(1,n-1): if p[i-1]<p[i] and p[i]>p[i+1]: print("Yes") print(i,i+1,i+2) break else: print("No")B問題
posによりジャンケンの順番は変わりますが、$c_1c_2…c_n$はそれぞれ$n$回別の手($s_1s_2…s_n$)と対戦することになります(主体と客体の言い換え)。したがって、$c_i$には$s_1s_2…s_n$と対戦して最も勝てる手を選べばよく$s_1s_2…s_n$のなかで"R"が1番多い場合は"P","S"が1番多い場合は"R","P"が1番多い場合は"S"とすれば良いです。また、任意の$i$でこれが言えるので、ジャンケンの回数の長さの文字列を出力すれば良いです。
B.pyt=int(input()) for i in range(t): S=input() l=len(S) r=S.count("R") s=S.count("S") p=S.count("P") m=max(r,s,p) if m==r: print("P"*l) elif m==s: print("R"*l) else: print("S"*l)C問題
誤読して余る人が出てはならないと思っていたのですが、よく見たら余る人が出ても良いと書いてありました。反省です。
この場合は、スキルの高いプログラマから順番に$x$を超えるように組み合わせればよく、最後に組み合わせても$x$を超えないようなプログラマの組み合わせが出る可能性がありますが、そのような組み合わせは無視すれば良いです。
また、この貪欲法であれば最も少ない人数でグループを構成できるので、最もグループ数が多くなると言うことができます。
C.pyt=int(input()) for _ in range(t): n,x=map(int,input().split()) a=sorted(list(map(int,input().split())),reverse=True) now=[100000000000,0] for i in range(n): now=[min(now[0],a[i]),now[1]+1] if now[0]*now[1]>=x: d.append(now) now=[100000000000,0] print(len(d))D問題
こちらも誤読してBerserkで不連続な二人も指定できると思い難しくしていました。実際は連続な二人のみなのでそこまで難しくないです。
連続している人は倒すことができるので、倒す人が連続している部分(以下、連続部分)に注目します。また、連続部分で最後に残った人をBerserkで倒す場合、その部分を挟む倒さない人($L$と$R$)のうちの一方がその人を超えるパワーを持つ必要があるので、挟む人の情報が必要です。
ここで、連続部分の長さを$k$で割って余りが出る場合はその余りをBerserkによって減らす必要があり、この時はその連続部分の中で最大のパワーを持つ人($X$)とその両隣りに位置する人を選択して倒すことが最適となります。
また、$X$が$L$及び$R$よりも高いパワーである場合はその$X$をFireballで倒す必要があり、Fireballが使えない($\leftrightarrow$連続部分の長さが$k$より短い)時及び残った人の順番が異なる時は題意を満たさないので、-1を出力する必要があります。
以上を実装して以下のようになりますが、余り整理して思考できていなかったので、少し乱雑なコードになります。
D.pyn,m=map(int,input().split()) x,k,y=map(int,input().split()) a=list(map(int,input().split())) c=list(map(int,input().split())) b=set(c) d=[] now=[] for i in range(n): if a[i] not in b: now.append(i) if i==n-1: d.append([now[0]-1,a.index(max(a[now[0]:now[-1]+1])),now[-1]+1]) else: if now!=[]: #端とmaxのインデックス(端は-1,nがありうる) d.append([now[0]-1,a.index(max(a[now[0]:now[-1]+1])),now[-1]+1]) now=[] #位置が順番通りでないやつ now=0 lc=len(c) for i in range(n): if a[i]==c[now]: now+=1 if now==lc: break else: exit(print(-1)) l=len(d) ans=0 for i in range(l): e=d[i] f=e[2]-e[0]-1 if e[0]==-1: m=a[e[2]] elif e[2]==n: m=a[e[0]] else: m=max(a[e[0]],a[e[2]]) if m>a[e[1]]: ans+=(f%k*y) ans+=min((f//k)*x,(f//k)*k*y) else: if f<k:exit(print(-1)) ans+=(f%k*y) #一回はまとめてkで倒さないと ans+=x ans+=min((f//k-1)*x,(f//k-1)*k*y) print(ans)E問題以降
今回は解かないです。

- 投稿日:2020-07-29T15:56:29+09:00
【Python】日本経済新聞社様のニュースタイトルとURLを自動取得するWebスクレイピングコードを作った
公開理由
・Webスクレイピングを最近勉強中で、同じく勉強している人の役に立ちたいと思ってますので。
・自分の学習のアウトプットの為。アウトプットの練習。
・Webスクレイピングとか、Seleniumとか触り始めて1か月たたない程度の人間のアウトプットです。逆にこれから
始める人も普通にこれくらいにはなれるよって指針にもお使いくださいませ。
・超詳細な解説を出来るほど理解出来ておりません。ざっくりした理解しか出来ていないので、読まれる方はそのあたりご理解頂ければ幸いです。
・robots.txtを参照し、問題なさそうだと判断し、実施しております。作成したコード
newspaper.pyimport requests from bs4 import BeautifulSoup import pandas as pd #Webスクレイピングに必要なリスト作成 elements_title = [] elements_url = [] #Webスクレイピング処理 def get_nikkei_news(): url = "https://www.nikkei.com/" response = requests.get(url) html = response.text soup = BeautifulSoup(html,"html.parser") #titleについての処理 title_list = soup.select(".k-card__block-link") for title in title_list: elements_title.append(title.text) #urlについての処理 url_list = soup.select(".k-card__block-link") for i in url_list: urls = i.get("href") if "http" not in urls: urls = "https://www.nikkei.com" + urls elements_url.append(urls) else: elements_url.append(urls) #Webスクレイピング処理呼び出し get_nikkei_news() #pandas処理 df = pd.DataFrame({"news_title":elements_title, "news_url":elements_url}) print(df) df.to_csv("nikkei_test_select.csv", index=False, encoding="utf-8")出力結果(コンソールのみ)
news_title news_url 0 20年度成長率、マイナス4%台半ば 政府見通し https://www.nikkei.com/article/DGXMZO62026930Z... 1 米豪2プラス2、中国の強権路線に「深刻な懸念」 https://www.nikkei.com/article/DGXMZO62026150Z... 2 危うい「習近平政治」全否定、米中衝突誘うソ連の呪縛 https://www.nikkei.com/article/DGXMZO61984420Y... 3 原燃の再処理工場、安全審査に合格 稼働は21年度以降 https://www.nikkei.com/article/DGXMZO62026760Z... 4 コロナで留学中断、突如の就活入り 帰国学生に試練 https://www.nikkei.com/article/DGXMZO61953440X... .. ... ... 70 小型ロケット、空中発射めざす 中小など実証試験 https://www.nikkei.com/article/DGXMZO61958380X... 71 マルナカ、技能実習生を母国のイオンで優先採用 https://www.nikkei.com/article/DGXMZO62005790Y... 72 水際対策強化、国際線再開目指す 那覇空港ビル社長 https://www.nikkei.com/article/DGXMZO62017470Y... 73 神奈川銀行の近藤頭取、初の生え抜き 融資審査を改革 https://www.nikkei.com/article/DGXMZO61933170X... 74 とり天 大分のもてなしの味、食べ歩きも楽しみ https://www.nikkei.com/article/DGXMZO56989060Z...概要説明
・日本経済新聞社様(https://www.nikkei.com/)
のトップページに表示されているあらゆるニュースや広告のタイトルとそのURLを
csv形式で吐き出す処理を行うWebスクレイピングコードになります。
BeautifulSoupとrequestsを使ってWebスクレイピングを行うベーシック(だと思われる)なコードだと思っています。・ニュースタイトルとurlを格納する空のリストを用意して、
そのリストに入れるためのデータを抽出するための処理をそれぞれ関数内で行っています。
ニュースタイトルの抽出は、ただ取り出しに行くだけで良かったのですが、URLは「https://」(プロトコル部分)が最初からついているのもあれば
ついていないものもあったので、条件分岐を行い、ついていないものについては「https://www.nikkei.com」
を付け加えております。
(もしかしたらURLの一部でおかしいものが出力されてしまうかもです。目視で確認した感じなさそうでしたが、、、あった際は修正ですね(-_-;))・print()で出力しさらに、csv形式で出力するようにしています。
ただ、utf-8での出力なので、WindowsPC上で開くと文字化けがすごいです。自分はatomとかgoogledrive,Cloud9等で
内容確認してますので、このコードコピペして出力確認する方は、参考までに宜しくお願い致します
コード解説(ざっくり)
Webスクレイピング処理を行う関数の以下の部分は、私はおまじないだと思って割り切ってコーディングしてます。
urlにWebスクレイピングをしたい対象のURLをコピペして、そのURLからHTMLファイルをごっそり持ってきて、
HTMLパースで構造を分析する、みたいな流れだと思ってます。parts.pyurl = "https://www.nikkei.com/" response = requests.get(url) html = response.text soup = BeautifulSoup(html,"html.parser")以下のコードでは、タイトルを取り出しています。
そして、取り出したタイトルをリストに格納してる処理になります。parts.pytitle_list = soup.select(".k-card__block-link") for title in title_list: elements_title.append(title.text)以下のコードで、urlを取り出しています。ただし、取り出すだけでは内容が不足する事が
あったため、if文で条件分岐を行い、不足していた場合はその不足分を補った上で
リストに格納している形になります。parts.pyurl_list = soup.select(".k-card__block-link") for i in url_list: urls = i.get("href") if "http" not in urls: urls = "https://www.nikkei.com" + urls elements_url.append(urls) else: elements_url.append(urls)以下はpandasというモジュールを利用し、csv形式にして吐き出す処理を行っています。
pandasでは辞書型にして、キーに列の名称、ヴァリューにそれぞれの列の要素を設定してあげると
きれいにデータをcsv形式で出力出来ました。
便利ですね。pandas。parts.pydf = pd.DataFrame({"news_title":elements_title, "news_url":elements_url}) print(df) df.to_csv("nikkei_test.csv", index=False, encoding="utf-8")
- 投稿日:2020-07-29T15:14:40+09:00
DeepLabCutを使う
DeepLabCutは環境構築が結構大変なのがネックだと思います。自分も沼にハマりました。
Githubレポジトリの説明はかなり充実していますし、日本語の記事も詳しく説明してあるのが見つかります。
ただ、これらだけだと詰まってしまったので、そのポイントをまとめました。誰向けか
- DeepLabCutを使いたい人
- GPUサーバーを持っている人(持っていない人はColabを使う記事が参考になります)
- GPUサーバーが共有のもので、根幹となるnvidia-driverなどを勝手にアップデートできない人(アップデートできる人はアップデートして本家の説明に従えばすぐ出来ます。)
結論
自分の使えるサーバーの環境と、GUI環境があるかによって最適解が変わります
そもそもCUDAもNVIDIA Driverも入っていない場合はこちらの記事のカバー範囲外なので、別の記事を参照してください。すみません。CUDA
CUDAのバージョンは、nvidia-smiのコマンドで確認できます。
CUDA10, CUDA9→可能です
CUDA8→不可能です。Google Colabを使ったやり方に切り替えましょう。GUI環境
CUDA9,10 × GUI環境 → ラベリングも学習もできます。
CUDA9,10のみ → ラベリングと学習は別の環境で行います。自分の場合
自分が使えるGPU環境は2つあり、1つはGUI環境付きだけどCUDA8.0で、もう1つはCLIだけでCUDA9.0でした。
どちらも共有のサーバーで、nvidia-driverのアップデートは出来ない状況でした。
ラベリングはWindowsで行いました。以下は、CUDA9.0以上であるという前提で話を進めます。
デスクトップ環境がある場合
DeepLabCut公式の説明に従ってAnacondaを使って環境構築すれば直ぐにできます。簡単。
ただし、デフォルトではCUDA10を持っていることが想定されているので、CUDA9の場合は設定ファイルの書き換えを行う必要があります。
こちらを見ながらpython・tensorflow-gpu・cudnnのバージョンをCUDAに合わせて選ぶ必要があります。
tensorflow-gpuとcudnnについては、Anaconda Cloudを見て欲しいバージョンがあるかどうかを確認してください。
Anaconda Cloudで公開されていないパッケージを指定すると、Resolve Package not foundのエラーが出ます。依存関係とかではなく、単純にその指定されたバージョンが見つからないということです。CUDA9の場合は、cudnn=7.3.1などにすれば上手くいくと思います。この場合のtensorflowは1.5から1.12の間のものであれば何でもいい気がしています。
pythonは3.6にする必要があります。
最終的に、dependencies: - python=3.6 - tensorflow-gpu==1.12.0 - cudnn=7としておけば上手く行くはずです。
この編集が終われば後は本家の説明に戻って大丈夫です。記事の続きは無関係です。デスクトップ環境がない場合
他の記事でも使われている手法ですが、ラベリングはGUI環境のあるCPUで行って、学習をGPU環境でやるのが一番楽です。(色々と頑張ればSSH先のDeepLabCutをローカルでGUI操作できるのかもしれませんが、自分では無理でした。やり方分かる方いらっしゃったら是非教えて下さいm(_ _)m)
少しめんどくさいですが、適当なCPUでラベリング環境を作り、GPUサーバーに学習環境を作りましょう。CPUのラベリング環境は、公式の説明に従えば良くて、GPUかCPUかを選ぶ時にCPUをちゃんと選択するだけです。
次に、サーバーの学習環境を作る時は、少し面倒です。
This base container is mainly useful for server deployment for training networks and video analysis (i.e. you can move this to your server, University Cluster, AWS, etc) as it assumes you have no display.
と書いてある通り、Dockerコンテナを使うのが良いです。
ここで、必要になってくるのが
- Docker
- nvidia-docker(dockerのバージョンが19.03以降であれば不要です)
です。こちらが入っているかはそれぞれ
docker versionやnvidia-dockerと打てばわかります。(なかったらcommand not foundになります)
入っていない場合は頑張ってインストールしてください。
これらは絶対に必要になるので、共有サーバーであっても管理者にお願いしていれてもらうしか有りません。
後はレポジトリの説明に従ってコマンドを打っていけばOKです。まとめ
- ラベリングと学習を別環境で行うことも許容する
- CUDAのバージョンが大事 がポイントだと思います。
このセットアップにかなりの時間を溶かしてしまいました、、、
皆さんの時間が救われますように。本家の論文執筆時にはtensorflow-gpu=1.0.0が使われたらしいのですが、Anaconda Cloudの方を見ると公開されていなかったです。
CUDA8が無理な理由
対応するcudnnがないからです。対応表を見ると、cudnnは5.1か6が必要なのですが、Anaconda Cloudを見ると公開されていません。
ただし、CUDA8.0で使えるcudnn7.1.3があったので、もしかしたらこのバージョンを指定すれば上手くいくかもしれません。
また、CUDA8.0の場合も怪しくて、対応表を見る限りtensorflowは1.4.0までしか動きません。linuxであれば、2020/7現在では1.4.1なら公開されているので、こちらは使えるかもしれません。
tensorflow-gpu == 1.4.1に変更した場合、package conflictのエラーが出ました。恐らくAnacondaの設定ファイルを使って一気に全てをインストールするのは無理なので、とりあえず仮想環境だけ作って、バージョンコンフリクトが起きないものを一個ずつ入れていく必要があると思います。
pipenvやPoetryをうまく使えば依存関係を解決してくれそうでしたが、そこまでは確認していません。
ここまでしてローカルで動かしたいか?ってことなので、Colabを使うのが良いと思います。Deeplabcutを使う上で詰まったこと
こちらの記事にあるように、promptを立ち上げる時に管理者権限で行う必要があります。右クリックから選択できます。
そうしないと、Manage ProjectでProjectの作成ができません。
また、DeepLabCutを使っていく上で、deeplabcut.extract_frames(config_path)とする場面が出てきますが、この時に管理者権限で立ち上げていないと、labeled_dataに画像が入っていないという現象が起きます。
おまけ
DeepLabCut周りの環境構築したりする中で、デバッグにはまったポイントです。もしかしたら役に立つかも?
nvidia-dockerの使い方
これまでは、docker run --runtime=nvidiaで指定するものとばかり思っていたが、
今使っているサーバーでは、nvidia-docker runでコマンドを打てばうまくいく。どうしてもjupyter labのトークンが通らない時
jupyter notebook passwordを使って、パスワードを設定する。そのパスワードを入れても通らない場合は、もう何かがバグっている。
- 投稿日:2020-07-29T14:20:58+09:00
PyCharmでUE4 Python
UE4 Python Editor Script Plugin
APIはこちら
https://docs.unrealengine.com/en-US/PythonAPI/index.html
2020/07/29時点でベータです
名前の通りEditor用で、自動処理をさせるのに便利ですPyCharmとの連携
いずれデバッグ環境まで整えたいですが、今回はコード補完まで
UE4からのPython起動方法は
Output Logからファイル名指定の方法前提です
Pythonプラグイン インストール
再起動Python Stub ファイル作成 (unreal.py)
Developer Modeにチェック
私の場合はこの状態で再起動することによって Python Stubファイルが生成されました
Recompile(Ctrl+Alt+Shift+P)でも作成されます
PyCharmでの利用
UE4 PythonはVersion2なので、Interpreterを変更する
先ほど生成された unreal.pyをPythonプロジェクトにコピーする
unreal.py がでかすぎる
https://forums.unrealengine.com/development-discussion/python-scripting/1633549-unreal-module-via-pycharm
こちらにあるように、Pycharmの読み込みサイズ制限を解除しますunreal.py をコピーしない
https://forums.unrealengine.com/development-discussion/python-scripting/1545347-how-do-you-get-auto-completion-and-stuff?p=1571620#post1571620
interpreterの設定を行います
unreal.pyが生成される場所を指定します
Python用関数をC++で作成したときに更新されたファイルを読み込めて便利ですDebug
できるようです
http://guillaumepastor.com/programming/debug-unreal-engine-python-using-pycharm/私の環境でも設定できましたら当ドキュメント更新します


- 投稿日:2020-07-29T14:08:58+09:00
PythonにおけるXSS(クロスサイトスクリプティング)対策
今回は、Webアプリケーション脆弱性の一つであるクロスサイトスクリプティング(XSS)に対して、Pythonではどのように対処すればよいかについて、調べたことを書いていきます。
本ページで表示している結果は、webサイトを自作しそのサイトへ入力を行った結果となります。第三者のwebサイトへのXSS攻撃は行わないでください。
XSSとは
クロスサイトスクリプティングとは、Webサイトへアクセスした際にページ内容が生成されるような「動的なWebサイト」に存在する欠陥を利用して、攻撃者が悪意のあるスクリプトをユーザのもとに送り込み実行させる攻撃手法のことです。
例えば、以下のようにユーザの入力値によってhtml構造が決定するようなWebサイトがあるとします。
<!DOCTYPE html> <html> <body> {"ユーザの入力値"} さんようこそ </body> </html>上記のhtml文中のユーザの入力値が
takeshiである場合<!DOCTYPE html> <html> <body> takeshi さんようこそ </body> </html>となり、結果Webページは以下の画像のように「takesiさんようこそ」という文が出力されます。
しかし、html文中のユーザの入力値が<script>alert("XSS")</script>である場合<!DOCTYPE html> <html> <body> <script>alert("XSS")</script> さんようこそ </body> </html>となり、webページ上に以下の画像のようにポップアップが表示されてしまい、webアプリケーション制作者の意図とは異なる結果が出力されてしまいます。
今回は埋め込まれたスクリプトがalertのみであり特に被害はないですが、もし埋め込まれるスクリプトが不正プログラムの感染や他の不正サイトへの誘導などを行う場合ユーザは甚大な被害を被る可能性があります。
XSS対策
XSSの脆弱性に対処するためには、ユーザの入力に対してエスケープ処理を施します。エスケープ処理とはHTMLとして意味のある文字を別の文字列に置き換える処理のことを言います。HTMLの構文では、「>」や「<」,「"」,「&」などが意味のある文字として扱われるためこれらを、「>」や「<」などに置換します。これにより、入力値が
<script>alert("XSS")</script>などのHTMLとして意味のある文字列であったとしても、ブラウザで表示する際にはただの文字列として認識さるようになります。PythonにおけるXSS対策
Pythonでは以下のように文字列をHTMLの文に埋め込み、動的にWebサイトを作成することができます。
#htmlの基礎 html_body = """ <!DOCTYPE html> <html> <body> {} さんようこそ </body> </html> """ #この入力によって動的にサイトを作成する input_text = "ユーザの入力値" print(html_body.format(input_text))上記のコードではユーザの入力値となる
input_textに対してエスケープ処理がされていないため、悪意ある入力がなされた場合スクリプトが実行されてしまいます。
上記のコードにエスケープ処理を施したものが以下のコードになります。html_body = #略 input_text = "ユーザの入力値" #エスケープ処理を行う候補文字の辞書 escape_table = { "&": "&", '"': """, "'": "'", ">": ">", "<": "<", } #特殊文字のみをエスケープ処理する関数 def escape_function(text): return "".join(escape_table.get(chara,chara) for chara in text) #エスケープ処理 input_text = escape_function(input_text) print(html_body.format(input_text))この時ユーザの入力が
<script>alert("XSS")</script>のようなスクリプト文であっても、エスケープ処理がなされているので、ブラウザは特殊文字ではなく、ただの文字列として認識し以下の画像のような出力となります。
ページのソースを見てみると、エスケープ処理によって特殊文字の変換が行われていることが確認できます。<!DOCTYPE html> <html> <body> <script>alert("XSS")</script> さんようこそ </body> </html>ちなみに、エスケープ処理は自作関数を用いて行いましたが、標準ライブラリである
htmlのescapeを用いることでエスケープ処理を行うことができます。import html html_body = #略 input_text = "ユーザの入力値" #エスケープ処理 input_text = html.escape(input_text) print(html_body.format(input_text))今回はこのくらいにします。
参考文献
1-2. クロスサイトスクリプティング
サニタイジング(エスケープ)とは?XSSに有効な理由や実装方法について徹底解説
Pythonで特殊なHTML文字をエスケープする
html --- HyperText Markup Language のサポート — Python 3.8.5 ドキュメント


- 投稿日:2020-07-29T14:04:17+09:00
JupyterHub でカスタムアクションを定義する(hook 機能)
JupyterHub の
hook機能を使うと、ログイン時にユーザ毎のディレクトリを自動作成できたりする。設定ファイル(
jupyterhub_config.py)に関数として定義する。
hook には以下の種類がある。
c.JupyterHub.user_redirect_hookc.Spawner.auth_state_hookc.Spawner.post_stop_hookc.Spawner.pre_spawn_hookc.Authenticator.post_auth_hook※それぞれの詳細な説明は割愛(未調査)
公式リポジトリにサンプルスクリプトが紹介されている。
jupyterhub/examples/bootstrap-script at master · jupyterhub/jupyterhub
例えばユーザフォルダを自動作成するhookアクションは以下。
# in jupyterhub_config.py import os def create_dir_hook(spawner): username = spawner.user.name # get the username volume_path = os.path.join('/volumes/jupyterhub', username) if not os.path.exists(volume_path): # create a directory with umask 0755 # hub and container user must have the same UID to be writeable # still readable by other users on the system os.mkdir(volume_path, 0o755) # now do whatever you think your user needs # ... pass # attach the hook function to the spawner c.Spawner.pre_spawn_hook = create_dir_hook※起動ユーザの所有権限になるため、合わせて chown / chmod もした方が良さそう。
- 投稿日:2020-07-29T13:10:04+09:00
Seleniumでchromedriverのエラーが出る
Seleniumでクローリング環境を構築するとき、下記のようなエラーが出ました。Mac環境です。
selenium.common.exceptions.WebDriverException: Message: ‘chromedriver’ executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/homeパスが通ってないよ、ということらしい。
chromedriverが保存されている場所を指定してみる。webdriver.Chrome(executable_path='Chromedriverがあるパス')JupyterLab 上では動いた。
.pyにエクスポートしてテストすると、ダメ。chromedriver_binaryをインストールする。
pip install chromedriver_binaryJupyterLab上では接頭に「!」をつけてこのように↓
!pip install chromedriver_binaryで、とりあえずOK。
chromedriver_binaryはchromedriverとバージョンを合わせておいたほうがよいです。
- 投稿日:2020-07-29T12:44:44+09:00
pythonでメールを飛ばすモジュールを作った話
作ったものの概要
smtplibとかMIMETextを使ってメールを飛ばすモジュール作ってみました。
引数に件名、本文、送信元、送信先、Ccを指定することで送信が可能です。
今回利用していた送信元メールが認証不要のものだったので、認証機能はとくに作ってません。
多分server.loginとかやればできると思います。(試してませんが。。。)コード
mail.pyimport smtplib from email.mime.text import MIMEText def send_mail(subject, body, f_email, t_email, c_email): # 送受信先とメール件名、本文の指定 msg = MIMEText(body, "html") msg["Subject"] = subject msg["To"] = t_email msg["From"] = f_email msg["Cc"] = c_email # サーバを指定する。サーバーとポートにメールサーバー名とポート番号を渡しておく server = smtplib.SMTP(サーバー, ポート) # メールを送信する server.send_message(msg) # 閉じる server.quit() return
- 投稿日:2020-07-29T12:32:40+09:00
旧帝国大学理系学部中退がプログラミングを始めて半年でPaizaのスキルチェックでAランクとるまでのぽえむ
~学ぶことへの喜びを取り戻すまでの道程~
意外と自分と同様のタイプの学歴コンプレックスに苦しんでる方が沢山いるかも, と思ったのでPaizaスキルチェックでAランクをとれた喜びを共有, そしてこれからの自分の学習の指針を改めて明示的にしたいと思ったので, 思い切って記事を書いてみようかと思いました.
緩い自己紹介
高校の頃は数学が得意でした. 某旧帝国大学の理学部に入りました. そのあと研究というものへ一切の興味を失い, 勿論プログラムなんかも全く学習せずに文字通り何も学ばずに4年生で中退しました. 以後とあるきっかけでソフトのテスターの職に就くまで完全にサイエンスとは縁のない生活を送っていました.そんな自分がプログラミングを通してサイエンスを生きる喜びと感じ, 一つの実力の指針であるPaizaスキルチェックAランクを"Hello World"から半年で身につけれたお話です.
~1月~きっかけはExcelのマクロでした
テスター業務はExcelでの単純作業が非常に多かったです. 当時の自分にとっては意外だったのですが, 想像以上に半角・全角関連の"バグ"が多く, またリーダーの方がテスターの書いたレポートの半角・全角その他の書式を統一するVBAマクロを使っており, プログラムでの"オートメーション"に興味を強く持ちました.
以後業務で暇な時間はVBAマクロの学習に充てていたのですが, メモ帳へログを毎日出力するマクロ, 簡単なTodoアプリを作った辺りでこの言語必ずしも今のホットな(当時はスクレイピングに強く惹かれていました)技術に適してないことを感じ言語の乗り換えを考えました.~2月~天使(Python)にふれたよ
個人で使っている環境(MacOS)でのVBAの出来の悪さで乗り換えを決意しました. 初めはC#を試したのですが(今は好きな言語の一つです, unity等絡めて創作に用いたい), これも環境設定が当時の自分にとっては難しく, オブジェクト指向でかつ多くの人がオススメしているという理由からpythonの学習を始めました.
~3月~私はRaspberry Piの夢を見る
pythonの初歩はProgateで学びました. とりあえず動く, 綺麗なコードを写経するというのはいい体験でした. また, HTML, JavaScript, SQL等今のエンジニアにとっては避けて通れない技術を体系的に学べたのもよかったです. この頃に実家に置いてあったRaspberry Pi2を親から貰い, Linuxの世界を初めて知りました. CUIでほとんど完結する世界に自分はめんどくさがりやの究極のミニマリスト的美を感じ惹かれていました. Raspberry Piを手にしたからにはLチカにも手を出したのですが,
main.pydef main(): pass if __name__ == '__main__': main()の意味がどうしても理解出来ず, pythonのより細かい仕様を理解したいと思ってからみんなのpythonを買い読み始めました.
またVimの世界には驚きました. こんな効率厨の極みみたいな考えが30年前からあったのには素直に感動を感じました.~4月5月~プログラミングと数学の関係
命題 プログラミング能力と数学の学力は無関係だ. がありますが, これが自分にとって軽い悩みのタネでした. なぜならば自分は受験までの数学ならばできる, より高度な内容となった瞬間わからなくなるというとこもあり, 正常にこの命題を考えることができないみたいなのがあったからです. 緊急事態宣言が出て仕事も自宅待機となってしまい, やや消極的な理由とはいえ今まで以上にプログラミングの学習に時間を割いていました. しかしイライラを一番感じてたのもこの時期です. ウェブフレームFlask等で当たり前のように出てくるデコレータ, 複雑怪奇に感じたクラスの継承, 等は残念ながらProgateでは納得できる理論を学べませんでした. 新鮮だったのは再帰を用いたフィボナッチの導出等. 変数名にそのまま数学の用語を使える算数の問題は当時難解に感じたオブジェクト指向の一筋の光に感じました.
今は自信をもっていいます. プログラミングへの適正と数学のセンスには明白な相関があります.自分の場合の話ですけれども, ここから先学んだ抽象度の高いプログラミングの概念は全て数学の問題に置き換えることで消化していけました. ここから先それについて話していきます.~6月~Paizaデビュー
Progateの次となるEラーニングの題材を求め, Paizaを始めました. 音速でPaizaのPythonコースを終え(Progateより難易度は高いと思う), しかしFlaskコース, AIコースはとても難易度が高くやり応えを感じました.スキルチェックはコースを進めている内に進められたので手を出しました. まさかスキルチェックを等して内包表記, フォーマット, ラムダ式等発展的な内容を学べるようになるとは知らずに.
よくある話ですが, スキルチェックは標準入力の難易度の高さにいきなり壁を感じました. 今は整数値の取得には以下のような関数を用いることが多いです.input.py# input 23 34 43 1 34 def input_line(): line = input().split() return [int(i) for i in line]ラムダ式なんかを使いこなせたらもっと簡潔に書けそうです. しかし幸いにして受験数学とスキルチェックで使われてるアルゴリズム, 必要な抽象思考が似ている部分もあり割と楽しみながらB問題あたりまでは解けるようになりました. この部分は地味に共有したい感覚です. 多くの人が躓いていることを自分にはわかるという体験は自信に繋がりました(ほんとうに東大数学を解いてたころを思い出します).
出てくる問題には行列の考え, 漸化式の考えなんかがいかせる問題が多く楽しいです(どうやらNumPyは使えるみたいです).
下記のような問題を行列計算に置き換える作業はなんか楽しいです.'.'と'#'で作られた長方形のアスキーアートを右に90度回転させることを考える ..##. .##.# ##...matrix.py''' input ..##. .##.# ##... ''' import numpy as np map = [] for n in range(3): map.append(input()) map_array = np.zeros((3, 5), dtype='int32') for x in range(3): for y in range(5): if map[x][y] == '#': map_array[x][y] = 1 map_array = map_array.T print(map_array) ''' output [[0 0 1] [0 1 1] [1 1 0] [1 0 0] [0 1 0]] '''転置行列をこんなに簡単に作れるとは中々に楽しいです. 面積計算, 自己相似問題なんかはNumPyが本当に強力に感じました.
~7月~Aランク取得
オブジェクト指向という概念が楽しくなってきました.pythonという言語の考え方も好きです. 明示的に記述することを?とする考えは自分は好きです.
そして7月23日
Aランクを取得できました. 正直ランクをそこまで意識してたわけでもなかったのですが, 特に苦痛を感じずに半年でAランクをとれたということは素直に嬉しかったですし, モチベーションにもなりました. そしてなによりも厳しくもオープンなプログラミングの世界に感謝しています. 何もかもが不自由なコロナ時代の今, 仮にプログラミングを学んでいなかったらと考えるだけでグロテスクな気もちになります.
終わりに
とにかくQiita, Progate, Paizaへは深く感謝しています. これらがなければモチベーションを維持することは難しかったと思ってます. 現在は機械学習・AIの技術を学び, 音楽の構造の解析なんかをできたらいいなとぼんやりと将来像を描いてます.
この話はみなに共感してもらえる話でないこと, 自分自身まだ何もやり遂げていないこと, それらはわかっているのだが, だからこそありのままの今の心境の記述に価値があるのではと思ったのが当記事を書こうと思った動機です. つまりは受験数学で一度でも成功したものはもしかしたらこれくらいすんなりとプログラミングを学べるのではないのかな, というだけの話です. もちろん受験数学は一例です, しかしアルゴリズムを生み出すには数学の問題を解くのに非常に近い思考が必要だと強く感じました. 一つの可能性についての話として捉えて頂けると幸いです.
