- 投稿日:2020-07-26T23:52:34+09:00
Pythonのエラー 'shift_jis' codec can't encode character '\u6c2e' の解決方法
はじめに
備忘録のために書くので、余計なことは書きません。Pythonでテキストファイルにある文字を別のテキストファイルに移す処理を書いていたら
'shift_jis' codec can't encode character '\u6c2e'というエラーが返されました。どうやら文字のエンコードのエラーらしいです(勉強不足です)
特定の文字だけをreplaceして消す方法もあるようなのですが、種類が多すぎて面倒です。解決法
対象のPythonコードの初めにこれを記述してください。
import codecs codecs.register_error('none', lambda e: ('?hoge?', e.end))そして、ファイルを開く処理のopen関数を以下の様に変更してください。
f = open('file.txt', 'w', encoding='cp932', errors='none')そうすれば、エンコードできない文字だけ?hoge?と置き換わります。消したい場合は'?hoge?'を''にすればOKです。
参考サイト
まじで助かりました。ベストアンサーのkatsukoさん、ありがとうございます。
・(python3でshift_jisのテキストファイル保存でUnicodeEncodeError)[https://teratail.com/questions/38949]
- 投稿日:2020-07-26T23:15:34+09:00
Python Elasticsearch 基本的な使い方まとめ
はじめに
PythonでElasticsearchを使う機会があったため情報を収集していましたが、サイトで使われているElasticsearchのバージョンが古かったり、そもそも、情報が少なかったりしたので、今回、メモとして簡単な例と共に基本的な使い方をまとめました。
この記事を読むことで、低レベルクライアント(elasticsearch-py)を使ったインデックスおよびドキュメントのCRUD操作ができるようになります。
環境
前提として、Elasticsearchはすでに立ち上がっていることとします。
また、実行環境は以下の通りです。特殊なライブラリを使っていないので、どの環境でも基本的には問題ないと思います。
- 利用環境
UbuntuバージョンUbuntu 20.04 LTS
- Elasticsearch環境
Elasticserchバージョン7.7.0
- Python環境
Pythonバージョン$ python -V Python 3.8.4準備
- pipでElasticsearchクライアントのインストール
$ python -m pip install elasticsearch基本操作
ここでは、基本的なPythonからElasticsearchを操作する方法を紹介します。
接続
インストールしたelasticsearchパッケージを利用してElasticsearchが起動しているホスト(localhost)へ接続する方法は以下の通りです。
基本的な接続方法
特にElasticsearch側で認証を設定していなければ、この方法で接続できます。
サンプルfrom elasticsearch import Elasticsearch # Elasticsearchクライアント作成 es = Elasticsearch("http://localhost:9200")ポートや、httpまたはhttpsを指定することもできます。
サンプル# Elasticsearchインスタンスを作成 es = Elasticsearch( ["localhost", "otherhost"], scheme="http", port=9200 )HTTP認証を利用した接続
ElasticsearchにIDやパスワードを設定している場合は、この方法で接続できます。
サンプルes = Elasticsearch( "http://localhost:9200", http_auth=("user_id", "password") )user_idやpasswordは設定されたID、パスワードを表しています。
接続の解除
上記で確立した内部接続をclose()で閉じることができます。
サンプル# Elasticsearchインスタンスを作成 es = Elasticsearch("http://localhost:9200") # 内部接続を閉じる es.close()余談ですが、close()しないと、インスタンスがガーベージコレクションされた際に、例外が発生します。これを防ぐためにも、明示的に書いたほうが良いでしょう。
This warning is created by aiohttp when an open HTTP connection is garbage collected. You’ll typically run into this when closing your application. To resolve the issue ensure that close() is called before the AsyncElasticsearch instance is garbage collected.
https://elasticsearch-py.readthedocs.io/en/master/async.html?highlight=close#receiving-unclosed-client-session-connector-warningインデックスの基本操作
インデックスを扱うための基本的な操作について紹介します。
インデックスの操作には、indicesという属性を使います。
インデックスの作成
studentsというインデックスを作成します。
タイプやドキュメントが入っていない空のインデックスです。サンプルes.indices.create(index='students')マッピングを使った方法
データタイプやインデックスの構造を指定して作成できます。
サンプルmapping = { "mappings": { "properties": { "name": {"type": "text"}, "age": {"type": "long"}, "email": {"type": "text"} } } } es.indices.create(index="students", body=mapping)インデックス情報の収集
ここでは、インデックスの情報を取得する方法を紹介します。
インデックス一覧の取得
接続しているElasticsearchでは、どのようなインデックスがあるのか確認したい場合は、cat属性のindices(index="*", h="index")を利用します。
indicesはインデックス情報を返すメソッドです。
今回は、全インデックスを一覧で取得したいので、引数のindexにはワイルドカードを指定します。また、引数hには、列名を指定することで列情報が改行区切りで返ってきます。
サンプル# インデックス一覧の取得 indices = es.cat.indices(index='*', h='index').splitlines() # インデックスの表示 for index in indices: print(index)実行結果は、以下の通りです。
実行結果.apm-custom-link .kibana_task_manager_1 .apm-agent-configuration students .kibana_1作成したstudentsだけではなく、デフォルトで入っているインデックスも表示されました。
インデックスのマッピングの確認
特定のインデックスのマッピングを確認する場合は、get_mapping(index="インデックス名")を利用します。
サンプルprint(es.indices.get_mapping(index="students"))実行結果は以下の通りです。
実行結果{'students': {'mappings': {'properties': {'age': {'type': 'long'}, 'email': {'type': 'text', 'fields': {'keyword': {'type': 'keyword', 'ignore_above': 256}}}, 'name': {'type': 'text', 'fields': {'keyword': {'type': 'keyword', 'ignore_above': 256}}}}}}}また、引数にindexを指定しない場合、全インデックスのマッピングを取得することができます。
サンプルprint(es.indices.get_mapping())実行結果は割愛します。
インデックスの更新
マッピングを変更してインデックスの構造を更新する場合は、put_mapping(index="インデックス名", body="変更分のマッピング")を利用します。
例えば、studentsに新たに学籍番号を追加する場合は以下のようになります。
サンプルmapping = { "properties": { "student_number": {"type": "long"} } } es.indices.put_mapping(index="students", body=mapping)指定するマッピングは全て渡す必要はなくて、差分だけで良いです。
また、インデックス作成の際にはmappings配下にネストしましたが、更新の場合は、そうではないことに注意しましょう。
現在のマッピングは、以下のようになっています。
現在のマッピング{ "students": { "mappings": { "properties": { "age": { "type": "long" }, "email": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "student_number": { "type": "long" } } } } }見ずらいですが、最後に新たに追加したstudent_numberが表示されています
インデックスの削除
特定のインデックスを削除したい場合は、delete(index="インデックス名")を利用します。
今回は、今まで操作してきたstudentsを消してみます。
サンプルes.indices.delete(index="students")インデックスの存在確認
エラーハンドリングを追加するにあたって、インデックスが存在するか確認したい。
そのような場合は、exists(index="インデックス名")を利用します。
サンプルprint(es.indices.exists(index="students"))実行結果は、以下のようになります
実行結果False先程、インデックスを消したのでFalseが返ってきました。
存在する場合は、Trueが返ってきます。ドキュメントの基本操作
次は、ドキュメントを扱うための基本的な操作について紹介します。
ドキュメントの作成
ドキュメントを新しく登録するには、create(index="インデックス名", id="ドキュメントID", body="新規ドキュメント")を利用します。
※ インデックスが無い場合は、登録するドキュメントから自動的に型を判断して作成されます。
サンプル# 登録したいドキュメント student = { "name": "Taro", "age": 36, "email": "taro@example.com" } # ドキュメントの登録 es.create(index='students', id=1, body=student)登録に成功すると、以下のような結果が出力されます。
実行結果{'took': 1, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 0, 'relation': 'eq'}, 'max_score': None, 'hits': []}}バルクインサート
createを複数回呼び出すことで、複数ドキュメントを登録できますが、bulk(インスタンス, データ)を使うことで、一度に登録できます。
引数で渡すデータの構造は、以下の通りで、少々複雑です。
{ "_op_type": "createやdelete、updateといったアクションを指定" "_index": "インデックス名" "_id": "ドキュメントのIDを指定(createの場合はなくても良い)" "_source": "登録したいドキュメント" }上記のデータを配列に格納して、bulkに渡すことで複数ドキュメントを操作することができます。
今回は、配列ではなく
yieldを使った方法をサンプルとして紹介します。サンプルfrom elasticsearch import Elasticsearch, helpers # bulkを使うために追加 # Elasticsearchインスタンスを作成 es = Elasticsearch("http://localhost:9200") def gendata(): # 登録したいドキュメント students = [ { "name": "Jiro", "age": 25, "email": "jiro@example.com" }, { "name": "Saburo", "age": 20, "email": "saburo@example.com" } ] # bulkで扱えるデータ構造に変換します for student in students: yield { "_op_type": "create", "_index": "students", "_source": student } # 複数ドキュメント登録 helpers.bulk(es, gendata())※ 100MBを超える大量のドキュメントをバルクインサートを実行する場合、エラーが発生します。このようなときは、記事下部に記載した非同期で大量のドキュメントをバルクインサートを参照ください。
ドキュメントの検索
ドキュメントを検索する方法を2つ紹介します。
クエリを使って検索
登録したドキュメントを検索するには、search(index="インデックス名", body="検索クエリ", size=検索数)を利用します。
bodyやsizeは指定しない場合は、全件表示されます。
サンプル# ageの値が20より大きいドキュメントを検索するためのクエリ query = { "query": { "range": { "age": { "gt": 20 } } } } # ドキュメントを検索 result = es.search(index="students", body=query, size=3) # 検索結果からドキュメントの内容のみ表示 for document in result["hits"]["hits"]: print(document["_source"])実行結果は以下のようになります。
実行結果{'name': 'Taro', 'age': 36, 'email': 'taro@example.com'} {'name': 'Jiro', 'age': 25, 'email': 'jiro@example.com'}Saburoの歳は20歳なので、検索から外れ表示されていません。
IDを使って検索
ドキュメントIDを指定して直接検索する場合は、get_source(index="インデックス名", id="ドキュメントID")を利用します。
サンプルでは、idが1のドキュメントを検索しています。
サンプルprint(es.get_source(index="students", id=1))実行結果は以下の通りです。
実行結果{'name': 'Taro', 'age': 36, 'email': 'taro@example.com'}idが1の
Taroが表示されました。ドキュメント数の取得
インデックスの中にドキュメント数がいくつあるのか確認したい場合は、count(index="インデックス名")を利用します。
サンプルprint(es.count(index="students"))実行結果は以下の通りです。
実行結果{'count': 3, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}}countの値が3となっていいるので、インデックスstudentsには現在3つのドキュメントが存在していることがわかります。
ドキュメントの更新
ドキュメント更新にはupdate(index="インデックス名", id="ドキュメントID", body="変更内容")を利用します。
サンプル# doc配下に変更したいパラメータを記述 student = { "doc": { "age": 40 } } # ドキュメントIDを指定して更新 es.update(index="students", id=1, body=student) # 更新されているか確認 print(es.get_source(index="students", id=1))
get_sourceを使って更新されているか確認しました。実行結果{'name': 'Taro', 'age': 40, 'email': 'taro@example.com'}ageが40に変更されています。
ドキュメントの削除
特定のドキュメントを削除する場合は、delete(index="インデックス名", id="ドキュメントID")を利用します。
サンプルでは、idが1のドキュメントを削除します。
サンプルes.delete(index="students", id=1)このドキュメントが本当に削除されているかの確認は次で行います。
ドキュメントの存在確認
ドキュメントの存在を確認するためには、exists(index="インデックス名", id="ドキュメントID")を利用します。
サンプルprint(es.exists(index="students", id=1))実行結果False先程、deleteでidが1のドキュメントを消しているので、Falseが返却され存在しないと表示されました。
存在する場合は、Trueなので、存在と表示されるはずです。※ 余談ですが、インデックスには存在しているものの、
_sourceがあるのか調べるにはexists_sourceを利用します。アドバンス
ここでは、通常あまり使わないようなメソッドや小ネタの紹介をします。
非同期で検索
ドキュメント数が何万とある場合、検索に時間がかかってしまいます。
このような場合、v7.8.0からサポートされたAsyncElasticsearchを使うことで非同期でリソースを効率的に検索することが出来ます。準備
機能を使うためにはasyncioをインストールする必要がありあす。
インストール$ python -m pip install elasticsearch [ async ] > = 7 .8.0非同期の検索サンプル
非同期で検索するためのサンプルを用意しました。
asyncやawaitを付け加えただけで、基本的にはsearchとやることは変わりません。サンプルimport asyncio from elasticsearch import AsyncElasticsearch # 非同期対応したElasticsearchインスタンスを作成 es = AsyncElasticsearch("http://localhost:9200") async def main(): # 非同期検索 result = await es.search( index="students", body={"query": {"match_all": {}}}, size=20 ) # 検索結果の表示 for student in result['hits']['hits']: print(student['_source']) # セッションをクローズ await es.close() # イベントループを取得 loop = asyncio.get_event_loop() # 並列に実行して終るまで待つ loop.run_until_complete(main())動きとしては、
asyncio.get_event_loop()でイベントループを取得- 並列で動かしたい関数
main()にasyncをつけて定義- 時間がかかる処理
searchはawaitをつけて宣言- イベントループの
run_until_completeで並列的に実行しつつ終るまで待つこのような感じです。
非同期でバルクインサート
次は、非同期でバルクインサートを実行する方法を紹介します。
コードはbulkとほとんど変わらず、asyncやawaitおよび非同期に対応したasync_bulkを利用するだけです。サンプルimport asyncio from elasticsearch import AsyncElasticsearch from elasticsearch.helpers import async_bulk # 非同期対応したElasticsearchインスタンスを作成 es = AsyncElasticsearch("http://localhost:9200") async def gendata(): # 登録したいドキュメント students = [ { "name": "Siro", "age": 19, "email": "siro@example.com" }, { "name": "Goro", "age": 13, "email": "goro@example.com" } ] # bulkで扱えるデータ構造に変換します for student in students: yield { "_op_type": "create", "_index": "students", "_source": student } async def main(): # 非同期でバルクインサートを実行 await async_bulk(es, gendata()) # セッションをクローズ await es.close() # イベントループを取得 loop = asyncio.get_event_loop() # 並列に実行して終るまで待つ loop.run_until_complete(main())実行後、登録されたドキュメントを確認すると
ドキュメント一覧{'name': 'Jiro', 'age': 25, 'email': 'jiro@example.com'} {'name': 'Saburo', 'age': 20, 'email': 'saburo@example.com'} {'name': 'Siro', 'age': 19, 'email': 'siro@example.com'} {'name': 'Goro', 'age': 13, 'email': 'goro@example.com'}SaburoとGoroが追加されていることがわかります。
非同期で大量のドキュメントをバルクインサート
100MBを超えるドキュメントを一度にバルクインサートすることは出来ません。
これは、Elasticsearch側で上限が設定されているためです。http.max_content_length
The max content of an HTTP request. Defaults to 100MB.
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-http.htmlこのような大量のデータを扱う場合、async_streaming_bulk(client, actions, その他パラメータ)を利用して、非同期でドキュメントを複数(チャンク)に分割して登録を行います。
パラメータ
指定できるパラメータについて紹介します。
- chunk_size
- 型:整数
- Elasticsearchへ一度に送信するドキュメント数(デフォルト:500)
- max_chunk_bytes
- 型:整数
- リクエストの最大バイトサイズ(デフォルト:100MB)
- raise_on_error
- 型:Bool
- exceptで
BulkIndexError発生時に、エラーリストを取得できるようになる(デフォルト: True)- raise_on_exception
- 型:Bool
Falseにすると、bulk失敗時に例外を発生させず、最後に失敗したアイテムの報告のみ行う(デフォルト:True)- max_retries
- 型:整数
- ステータスエラー
429発生時に再試行を行う回数(デフォルト:0)- initial_backoff
- 型:整数
- 再試行まで待機する秒数、2回以降は
待機秒数 x 2となる(デフォルト:2)- max_backoff
- 型:整数
- 再試行が待機する最大秒数(デフォルト:600)
- yield_ok
- 型:Bool
Falseにすると、出力結果からbulkに成功したドキュメントが表示されなくなる(デフォルト:True)サンプル
以下に簡単なサンプルを紹介します。
サンプルimport asyncio from elasticsearch import AsyncElasticsearch from elasticsearch.helpers import async_streaming_bulk, BulkIndexError # 非同期対応したElasticsearchインスタンスを作成 es = AsyncElasticsearch("http://localhost:9200") async def gendata(): # 登録したいドキュメント students = [ { "name": "Siro", "age": 19, "email": "siro@example.com" }, { "name": "Goro", "age": 13, "email": "goro@example.com" } ] # bulkで扱えるデータ構造に変換します for student in students: yield { "_op_type": "create", "_index": "students", "_source": student } async def main(): try: # ドキュメントを複数(チャンク)に分けてバルクインサート async for ok, result in async_streaming_bulk(client=es, actions=gendata(), chunk_size=50, # 一度に扱うドキュメント数 max_chunk_bytes=52428800 # 一度に扱うバイト数 ): # 各チャンクごとの実行結果を取得 action, result = result.popitem() # バルクインサートに失敗した場合 if not ok: print(f"failed to {result} document {action}") # 例外処理 except BulkIndexError as bulk_error: # エラーはリスト形式 print(bulk_error.errors) # セッションのクローズ await es.close() # イベントループを取得 loop = asyncio.get_event_loop() # 並列に実行して終るまで待つ loop.run_until_complete(main())今回指定した、チャンクに関するパラメータは、
- チャンク数:50
- チャンクの最大バイト数:50MB
こんな感じです。
これらは、登録したいデータに応じてチューニングすると良いと思います。
特定のステータスによるエラーを無視
引数ignoreに無視したい特定のステータスコードを指定することでエラーを無視することができます。
例えば、存在しないインデックスを削除しようとした場合、404エラーが発生します。
404エラーelasticsearch.exceptions.NotFoundError: NotFoundError(404, 'index_not_found_exception', 'no such index [test-index]', test-index, index_or_alias)サンプルではこれを無視してみます。
サンプル# 404と400で発生するエラーを無視 es.indices.delete(index='test-index', ignore=[400, 404])タイムアウト
es側ではデフォルトでタイムアウトが設定されていますが、自分で設定することも出来ます。
方法は簡単で、引数にrequest_timeout=秒数(浮動小数点)を渡すだけです。
あえて短い秒数を指定して、タイムアウトさせるサンプルを用意しました。サンプルprint(es.cluster.health(wait_for_status='yellow', request_timeout=0.001))実行すると、指定した0.001秒以内に処理が終了しなかったため、以下のようなタイムアウトのエラーが表示されました。
タイムアウトエラーelasticsearch.exceptions.ConnectionError: ConnectionError((<urllib3.connection.HTTPConnection object at 0x7f11297c5520>, 'Connection to localhost timed out. (connect timeout=0.001)')) caused by: ConnectTimeoutError((<urllib3.connection.HTTPConnection object at 0x7f11297c5520>, 'Connection to localhost timed out. (connect timeout=0.001)'))レスポンスの整形
Elasticsearchからのレスポンスをそのまま表示すると
レスポンス{'students': {'mappings': {'properties': {'age': {'type': 'long'}, 'email': {'type': 'text', 'fields': {'keyword': {'type': 'keyword', 'ignore_above': 256}}}, 'name': {'type': 'text', 'fields': {'keyword': {'type': 'keyword', 'ignore_above': 256}}}}}}}このようにとても見づらくなってしまいます。
そこで、jsonパッケージを使って整形することで見やすく表示できます。
サンプルimport json from elasticsearch import Elasticsearch # Elasticsearchインスタンスを作成 es = Elasticsearch("http://locahost:9200") # マッピング情報の取得 response = es.indices.get_mapping(index="students") # レスポンスの整形 print(json.dumps(response, indent=2))動きとしては、
json.dumpsに整形したいデータと、インデントのスペース数を指定するだけです。今回はレスポンスのネストが深くなることが予想されたためインデントは2を指定しました。
実行結果{ "students": { "mappings": { "properties": { "age": { "type": "long" }, "email": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } } }見やすく整形されました。
おわりに
Python Elasticserachのクライアントの基本的な使い方を紹介しました。
直接APIを叩くよりも、用意された便利なメソッドを使うことで、直感的に操作できるのでとても便利に感じました。使い方が間違っていたり、その他便利な方法があればコメントお願いします!
参考サイト
- Python Elasticsearch公式
https://elasticsearch-py.readthedocs.io/en/master/api.html- PythonでElasticsearchの操作
https://blog.imind.jp/entry/2019/03/08/185935- 【Python】asyncio(非同期I/O)のイベントループをこねくり回す
https://qiita.com/ynakaDream/items/b63fab24bb30dea6ddb1
- 投稿日:2020-07-26T23:04:14+09:00
MBTiles のデータを Python から参照する
概要
- MBTiles ファイルは GeoJSON から tippecanoe で作成
- 本記事の GeoJSON は国土数値情報から入手したデータを利用
- 国土数値情報 | 駅別乗降客数データ(平成 29 年)
tippecanoe
MBTiles ファイルを作成します。
tippecanoeLAYER_NAME_S=station MIN_ZOOM_LEVEL_S=10 MAX_ZOOM_LEVEL_S=15 IN_S=./geojsons/N05-19_Station2.geojson MBTILES_FILE_S=./mbtiles/N05_19_Station2.mbtiles tippecanoe \ -z${MAX_ZOOM_LEVEL_S} \ -Z${MIN_ZOOM_LEVEL_S} \ -o ${MBTILES_FILE_S} \ -l ${LAYER_NAME_S} \ --force \ ${IN_S}MBTiles のデータを Python で参照
MBTiles や MVT (Mapbox Vector Tile) について、ドキュメントが整備されています。
ざっくりと、
- MBTiles ファイルは SQLite3 データベース
- データは Google Protocol Buffers で符号化されている
- Mapbox 社が提供している mapbox-vector-tile というライブラリを利用
pip install mapbox-vector-tileimport sqlite3 import zlib import mapbox_vector_tile as mvt MBTILES_FILE_PATH = './N05_19_Station2.mbtiles' con = sqlite3.connect(MBTILES_FILE_PATH) cur = con.cursor() cur.execute('select tile_data from tiles where zoom_level = ? and tile_column = ? and tile_row = ?', (10, 908, 624)) row = cur.fetchone() b = zlib.decompress(row[0], zlib.MAX_WBITS | 32) tile_date = mvt.decode(b) print(tile_data) # {'station': {'extent': 4096, 'version': 2, 'features': [{'geometry': {'type': 'Point', ...
- 投稿日:2020-07-26T22:15:08+09:00
Django-allauthでユーザー認証を使う
はじめに
高校一年生のプログラミング初心者です。Qiitaで記事を書くのは初めてなので多少の間違いがあるかもしれません。
django-allauthとは何か
django-allauthとはDjangoを使用したUser周りの処理を簡単に実装できるようにしたモジュールです。Eメールを使用した認証方法などが実装でき、またソーシャルログインなどの実装もこのモジュールを使用することによって比較的簡単に実装できるようになっています。
インストール/設定
pipでdjango-allauthのインストールをする。
pip install django-allauthsettings.pyのINSTALLED_APPS内において必要なソーシャルログインの数だけコードを書き加える。
main_project/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', #ここから追加 'django.contrib.sites', 'allauth', 'allauth.account', 'allauth.socialaccount', # 必要に応じたソーシャルログイン用の記述を書く 'allauth.socialaccount.providers.github', 'allauth.socialaccount.providers.facebook', ]main_project/settings.py#allauthのバックエンドを使用していることを示す AUTHENTICATION_BACKENDS = ( "django.contrib.auth.backends.ModelBackend", "allauth.account.auth_backends.AuthenticationBackend", ) #allauthが使用するためSITE_IDを指定する SITE_ID = 1Djangoがallauth純正のテンプレートを探し出す前にtemplates内のファイルを参照するようにsettings.py内の記述を書き換える。これはall-authの純正テンプレートには必要最低限の機能しか表示されず、多くの場合では見た目を変えるからである。下記の記述により自分で作成したテンプレートが純正のものよりも先に探される。
main_project/settings.pyTEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [ os.path.normpath(os.path.join(BASE_DIR, 'templates')), ], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', 'django.template.context_processors.request', ], }, }, ]settings.pyにプロジェクトの認証方法や認証用に送ったEメールの期限が切れるまでの時間を設定する。このコード内に記載されている物の他に公式ドキュメントにとても詳しく例がおいてある。
main_project/settings.py#emailによって認証する ACCOUNT_AUTHENTICATION_METHOD = "email" ACCOUNT_EMAIL_CONFIRMATION_EXPIRE_DAYS = 2 ACCOUNT_EMAIL_REQUIRED = True #アカウント認証用のEmailを"optional"、"mandatory"、"none"から選ぶ。 ACCOUNT_EMAIL_VERIFICATION = "optional"最後にmakemigrationsまたはmigrateをしておく。
python manage.py makemigrations
urls.py/テンプレートの記載
先ほどsetting.py内のTEMPLATESにおいて純正より先にBASE_DIRにあるtemplatesを参照するように設定したのでtemplatesと名付けたフォルダーをmanage.pyと同じディレクトリに配置する。
プロジェクト内のurls.pyにおいてaccountsをincludeする。
main_project/urls.pyfrom django.contrib import admin from django.urls import path from django.conf.urls import url, include #includeを追加 urlpatterns = [ path('admin/', admin.site.urls), path('accounts/', include('allauth.urls')), ]allauthによって用意されているurls.pyのパスを確認するには仮想環境内の
site-packages/allauth/account/urls.py、もしくはここ(Github)を参照する。HTMLファイル内でallauthのパスを使ってテンプレートへのリンクを明記したいときは
<a href="{% url "account_login" %}"></a>のように通常と同じ表記で対応する。
まとめ
Django-allauthは日本語の記事が少ないと感じたので改めて記事を書いてみました。間違い等があるようでしたら是非ご指摘ください。
追記
元タイトルの「Django-allauthでUserモデルを作る」は誤解を生む可能性があるためタイトルを変更しました。
参照記事
The complete django-allauth guide
Django-allauth tutorial
Django allauthにおけるログイン画面の作成
django-allauth : テンプレートのカスタマイズ
公式ドキュメント
- 投稿日:2020-07-26T22:15:08+09:00
Django-allauthでUserモデルを作る
はじめに
高校一年生のプログラミング初心者です。Qiitaで記事を書くのは初めてなので多少の間違いがあるかもしれません。
django-allauthとは何か
django-allauthとはDjangoを使用したUser周りの処理を簡単に実装できるようにしたモジュールです。Eメールを使用した認証方法などが実装でき、またソーシャルログインなどの実装もこのモジュールを使用することによって比較的簡単に実装できるようになっています。
インストール/設定
pipでdjango-allauthのインストールをする。
pip install django-allauthsettings.pyのINSTALLED_APPS内において必要なソーシャルログインの数だけコードを書き加える。
main_project/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', #ここから追加 'django.contrib.sites', 'allauth', 'allauth.account', 'allauth.socialaccount', # 必要に応じたソーシャルログイン用の記述を書く 'allauth.socialaccount.providers.github', 'allauth.socialaccount.providers.facebook', ]main_project/settings.py#allauthのバックエンドを使用していることを示す AUTHENTICATION_BACKENDS = ( "django.contrib.auth.backends.ModelBackend", "allauth.account.auth_backends.AuthenticationBackend", ) #allauthが使用するためSITE_IDを指定する SITE_ID = 1Djangoがallauth純正のテンプレートを探し出す前にtemplates内のファイルを参照するようにsettings.py内の記述を書き換える。これはall-authの純正テンプレートには必要最低限の機能しか表示されず、多くの場合では見た目を変えるからである。下記の記述により自分で作成したテンプレートが純正のものよりも先に探される。
main_project/settings.pyTEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [ os.path.normpath(os.path.join(BASE_DIR, 'templates')), ], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', 'django.template.context_processors.request', ], }, }, ]settings.pyにプロジェクトの認証方法や認証用に送ったEメールの期限が切れるまでの時間を設定する。このコード内に記載されている物の他に公式ドキュメントにとても詳しく例がおいてある。
main_project/settings.py#emailによって認証する ACCOUNT_AUTHENTICATION_METHOD = "email" ACCOUNT_EMAIL_CONFIRMATION_EXPIRE_DAYS = 2 ACCOUNT_EMAIL_REQUIRED = True #アカウント認証用のEmailを"optional"、"mandatory"、"none"から選ぶ。 ACCOUNT_EMAIL_VERIFICATION = "optional"最後にmakemigrationsまたはmigrateをしておく。
python manage.py makemigrations
urls.py/テンプレートの記載
先ほどsetting.py内のTEMPLATESにおいて純正より先にBASE_DIRにあるtemplatesを参照するように設定したのでtemplatesと名付けたフォルダーをmanage.pyと同じディレクトリに配置する。
プロジェクト内のurls.pyにおいてaccountsをincludeする。
main_project/urls.pyfrom django.contrib import admin from django.urls import path from django.conf.urls import url, include #includeを追加 urlpatterns = [ path('admin/', admin.site.urls), path('accounts/', include('allauth.urls')), ]allauthによって用意されているurls.pyのパスを確認するには仮想環境内の
site-packages/allauth/account/urls.py、もしくはここ(Github)を参照する。HTMLファイル内でallauthのパスを使ってテンプレートへのリンクを明記したいときは
<a href="{% url "account_login" %}"></a>のように通常と同じ表記で対応する。
まとめ
Django-allauthは日本語の記事が少ないと感じたので改めて記事を書いてみました。間違い等があるようでしたら是非ご指摘ください。
参照記事
The complete django-allauth guide
Django-allauth tutorial
Django allauthにおけるログイン画面の作成
django-allauth : テンプレートのカスタマイズ
公式ドキュメント
- 投稿日:2020-07-26T22:11:41+09:00
「データサイエンス100本ノック(構造化データ加工編)」 Python-014 解説
Youtube
動画解説もしています。
問題
P-014: 顧客データフレーム(df_customer)から、ステータスコード(status_cd)の末尾が数字の1〜9で終わるデータを全項目抽出し、10件だけ表示せよ。
解答
コードdf_customer.query("status_cd.str.contains('1$|2$|3$|4$|5$|6$|7$|8$|9$')", engine='python').head(10)出力customer_id customer_name gender_cd gender birth_day age postal_cd address application_store_cd application_date status_cd 4 CS001215000145 田崎 美紀 1 女性 1995-03-29 24 144-0055 東京都大田区仲六郷********** S13001 20170605 6-20090929-2 9 CS033513000180 安斎 遥 1 女性 1962-07-11 56 241-0823 神奈川県横浜市旭区善部町********** S14033 20150728 6-20080506-5 12 CS011215000048 芦田 沙耶 1 女性 1992-02-01 27 223-0062 神奈川県横浜市港北区日吉本町********** S14011 20150228 C-20100421-9 14 CS040412000191 川井 郁恵 1 女性 1977-01-05 42 226-0021 神奈川県横浜市緑区北八朔町********** S14040 20151101 1-20091025-4 16 CS009315000023 皆川 文世 1 女性 1980-04-15 38 154-0012 東京都世田谷区駒沢********** S13009 20150319 5-20080322-1 22 CS015315000033 福士 璃奈子 1 女性 1983-03-17 36 135-0043 東京都江東区塩浜********** S13015 20141024 4-20080219-3 23 CS023513000066 神戸 そら 1 女性 1961-12-17 57 210-0005 神奈川県川崎市川崎区東田町********** S14023 20150915 5-20100524-9 24 CS035513000134 市川 美帆 1 女性 1960-03-27 59 156-0053 東京都世田谷区桜********** S13035 20150227 8-20100711-9 27 CS001515000263 高松 夏空 1 女性 1962-11-09 56 144-0051 東京都大田区西蒲田********** S13001 20160812 1-20100804-1 28 CS040314000027 鶴田 きみまろ 9 不明 1986-03-26 33 226-0027 神奈川県横浜市緑区長津田********** S14040 20150122 2-20080426-4解説
・PandasのDataFrame/Seriesにて、条件に当てはまる先頭データを確認する方法です。
・条件に当てはまる情報を確認したい時に使用します。
・'contains(<文字列>)'は、指定した文字列が含まれているどうかを判定する関数であり、含まれる場合はTrue、含まれない場合はFalseを返します。
・ただし、'.query('---.str.contains(<文字列>))'は、指定した文字列が含まれることを条件として指定します。
・今回の場合、status_cd を文字列に置換するために'status_cd.str'とし、'.contains('[1-9]$')'を続けることで、「1-9」が末尾にある status_cd を指定しています。
・'$'は末尾文字であることを表す正規表現です。正規表現とは、「複数の文字列を1つの記号で表す方法」のことを指します。
・'engine = 'python''について、query の引数である engine には'python'か、'numexpr'かを選択することができますが、strを用いる場合は、'python'を指定してあげないとエラーが発生してしまいます。※正解を見ると、以下のようなコードになっています。確かに'[1-9]$'については、
末尾を表す正規表現'$'と、範囲を表す'[1-9]'で表した方が、より簡単に表現することができます。
・'regex=True'は、正規表現を扱う際に必要とされていました。以下の解答例では'$''-'が正規表現として扱われています。現在は、書かなくても正規表現として扱われるようになっているので、なくても問題ないです。コードdf_customer.query("status_cd.str.contains('[1-9]$', regex=True)", engine='python').head(10)※末尾文字なんだから'str.endswith'を使うんじゃないか、と思われた方もいるかもしれませんが、以下のコードを実行しても何も抽出できません。なぜなら、'str.endswith'は正規表現を処理することができず、'|'を読み取ることができないためです。
コードdf_customer.query("status_cd.str.endswith('1$|2$|3$|4$|5$|6$|7$|8$|9$')", engine='python').head(10)※正規表現については、こちらの記事が参考になります。
https://qiita.com/hiroyuki_mrp/items/29e87bf5fe46de62983c
- 投稿日:2020-07-26T22:10:29+09:00
OpenCVでマウスイベントを取得する ~GUIな集中線ツールを作る~
はじめに
漫画のように集中線の加工がされている画像を見かけた。
ググるとスマホアプリやWebアプリが公開されており特段珍しいものではなかったのだが、私もこれを作ってみたくなった。集中線を描く関数
最初はアレもコレも定数だったが、自然に見えるようあちこちに乱数を付与していった。
また、画像が指示されていないときに単色画像を用意したり注目範囲の指定がないときでも自動でそれっぽく集中線を描くようにした。このようにいろいろ肉付けしていくのは楽しいものだ。
ただし勉強不足につき半透明は実装できていません。ソース1import sys import numpy as np import cv2 import random import math def speed_line(img, center=False, radius=False, color=(255,255,255)): random.seed() h, w = img.shape[:2] # 中心と半径が未設定の場合、自動で設定 xc = w//2 if center == False else center[0] yc = h//2 if center == False else center[1] rx = w//8 if center == False else radius[0] ry = h//8 if center == False else radius[1] r2 = w+h # 外径 max_num = 128 # 線の数 num = int(max_num*random.uniform(0.9,1.3)) # 線の数バラツキ a = 2 * math.pi / num # 角度 b0 = math.pi / max_num # 線(三角形)の先端角度 p = 0.7 # 線(三角形)が出現する確率 for i in range(num): if random.random() < p: b = b0*random.uniform(0.1,1) # 線(三角形)の先端角度バラツキ r = random.uniform(0.9,1.2) # 内径のバラツキ倍率 x1 = xc + int(r*rx*math.cos(i*a)) y1 = yc + int(r*ry*math.sin(i*a)) x2 = xc + int(r2*math.cos(i*a)) y2 = yc + int(r2*math.sin(i*a)) x3 = xc + int(r2*math.cos(i*a+b)) y3 = yc + int(r2*math.sin(i*a+b)) pts = np.array(((x1,y1), (x2,y2), (x3,y3))) cv2.fillConvexPoly(img, pts, color) return img def main(): args = sys.argv if len(args) == 1: img_origin = np.full((240,320,3), (120,120,120), np.uint8) else: img_origin = cv2.imread(args[1]) cv2.imshow("speed line", speed_line(img_origin.copy())) cv2.waitKey(0) cv2.destroyAllWindows() if __name__ == "__main__": main()結果はこんな感じ。
GUI的なことをする
OpenCVにはcv2.setMouseCallback()という関数があり、マウスイベントを管理することができる。
チュートリアルとしてはここ、またQiitaの先人の記事としては以下の記事がわかりやすい。OpenCVを使ってマウスイベント(手動)でテニスコート領域を選択できるようにする
これらを参考に、任意の場所に任意の大きさの楕円を描くプログラムを書いてみる。
メインルーチンからコールバック関数(このあたり正しい呼称は不明)を呼び出すプログラムはウェブ上に多数あるが、
main()という関数からコールバック関数を呼び出そうとしたらグローバル変数の扱いに難儀して何とも小汚いソースになってしまった。もっとエレガントな方法があったら教えて下さい。ソース2import sys import numpy as np import cv2 import random def draw_ellipse(event, x, y, flags, param): global cnt, xc, yc, rx, ry color = (random.randint(0,255), random.randint(0,255), random.randint(0,255)) if event == cv2.EVENT_MOUSEMOVE: img_tmp = img.copy() if cnt == 0: h, w = img.shape[:2] cv2.line(img_tmp, (x,0), (x,h), color) cv2.line(img_tmp, (0,y), (w,y), color) cv2.imshow(winname, img_tmp) elif cnt == 1: rx, ry = abs(x-xc), abs(y-yc) cv2.line(img_tmp, (xc,yc-ry), (xc,yc+ry), color) cv2.line(img_tmp, (xc-rx,yc), (xc+rx,yc), color) cv2.ellipse(img_tmp, (xc,yc), (rx, ry), 0, 0, 360, color) cv2.imshow(winname, img_tmp) if event == cv2.EVENT_LBUTTONDOWN: cnt = cnt + 1 if cnt == 1: xc, yc = x, y elif cnt == 2: rx, ry = abs(x-xc), abs(y-yc) cv2.ellipse(img, (xc,yc), (rx, ry), 0, 0, 360, (0,0,255), 3) cv2.imshow(winname, img) def main(): global img, img_tmp, cnt,winname, xc, yc, rx, ry args = sys.argv if len(args) == 1: img_origin = np.full((240,320,3), (120,120,120), np.uint8) else: img_origin = cv2.imread(args[1]) img = img_origin.copy() cnt = 0 winname = "GUI tool" cv2.namedWindow(winname) cv2.setMouseCallback(winname, draw_ellipse) cv2.imshow(winname, img) while cnt<2: key = cv2.waitKey(1) & 0xFF cv2.waitKey(0) cv2.destroyAllWindows() if __name__ == "__main__": main()結果はこんな感じ。アニメーションPNGはPythonプログラムで作ったのではなく、他のフリーソフトを使った。
両者を合体する
合体するだけでも大変だった。関数の戻り値などを使いこなしたかったのだが、これまたグローバル変数頼みとなってしまった。
多重ループから抜ける処理というのもはじめて書いのだが…変数名が気に入らないな。ソース3import sys import numpy as np import cv2 import random import math def speed_line(img, center=False, radius=False, color=(255,255,255)): # ソース1にあるやつ def draw_ellipse(event, x, y, flags, param): # ソース2にあるやつ def main(): global img, img_tmp, cnt,winname, xc, yc, rx, ry args = sys.argv if len(args) == 1: img_origin = np.full((240,320,3), (120,120,120), np.uint8) else: img_origin = cv2.imread(args[1]) img = img_origin.copy() img_tmp = img.copy() cnt = 0 winname = "speed line" cv2.namedWindow(winname) cv2.setMouseCallback(winname, draw_ellipse) cv2.imshow(winname, img_tmp) # 左クリックを2回するまでループ while cnt<2: cv2.waitKey(1) # グローバル変数によりいつの間にか得ていた楕円情報を使って集中線画像を複数回描く frames = 4 imgs = [] for i in range(frames): imgs.append(speed_line(img_origin.copy(), center=(xc,yc), radius=(rx,ry))) # ピカピカアニメーション isBreak = False while True: for i in range(frames): cv2.imshow(winname, imgs[i]) if cv2.waitKey(1) & 0xFF == ord("q"): isBreak = True if isBreak: break cv2.destroyAllWindows() if __name__ == "__main__": main()結果はこんな感じ。モデルが古いって? ナウなヤングにバカウケなフィギュアなどは持っていないので仕方がない。
終わりに
顔検出と組み合わせればもっと面白いことができる。と思いついたが、すでにそれも動画になっていた。それも8年前にだ。
たとえ周回遅れであっても、自分自身の経験を積むために成果物を発表するのを怠るわけにはいかない。


- 投稿日:2020-07-26T21:12:29+09:00
pythonでJIS X 2028をShift-JISやUTF-16に変換する
あることでJISコードを日本語変換したくなったときのやり方が分からなかったのでメモ。
方法
公開されているJIS X 2028コードの変換表を用いて連想配列を作成する
下は対応表http://unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/JIS0208.TXT
http://ash.jp/code/unitbl21.htmプログラム
jis.phpimport os ar = [] with open('JIS2028.TXT') as f: for t_line in f: # 先頭がコメントの部分は除く if t_line[0] != "#": sjis, jis, utf16 = os.path.basename(t_line).split('\t')[0:3] ar.append([jis, utf16]) # 例) ar['0x3B3D'] -> '0x8695' # JIS -> UTF-16 ar = dict(ar)実行するとき
JISコードの3B3Dから"蚕"を出力する
jis.pyprint(chr(int(ar['0x'+'3B3D'], 16)))terminal$ python jis.py 蚕
- 投稿日:2020-07-26T21:12:29+09:00
pythonでJIS X 0208をShift-JISやUTF-16に変換する
あることでJISコードを日本語変換したくなったときのやり方が分からなかったのでメモ。
方法
公開されているJIS X 0208コードの変換表を用いて連想配列を作成する
下は対応表http://unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/JIS0208.TXT
http://ash.jp/code/unitbl21.htmプログラム
jis.pyimport os ar = [] with open('./JIS0208.TXT') as f: for t_line in f: # 先頭がコメントの部分は除く if t_line[0] != "#": sjis, jis, utf16 = os.path.basename(t_line).split('\t')[0:3] ar.append([jis, utf16]) # 例) ar['0x3B3D'] -> '0x8695' # JIS -> UTF-16 ar = dict(ar)実行するとき
JISコードの3B3Dから"蚕"を出力する
0x3b3dだとエラーが出るので、0x3B3Dにするため文字を大文字に変換する。jis.pyprint(chr(int(ar['0x'+'3b3d'.upper()], 16)))terminal$ python jis.py 蚕
- 投稿日:2020-07-26T21:08:07+09:00
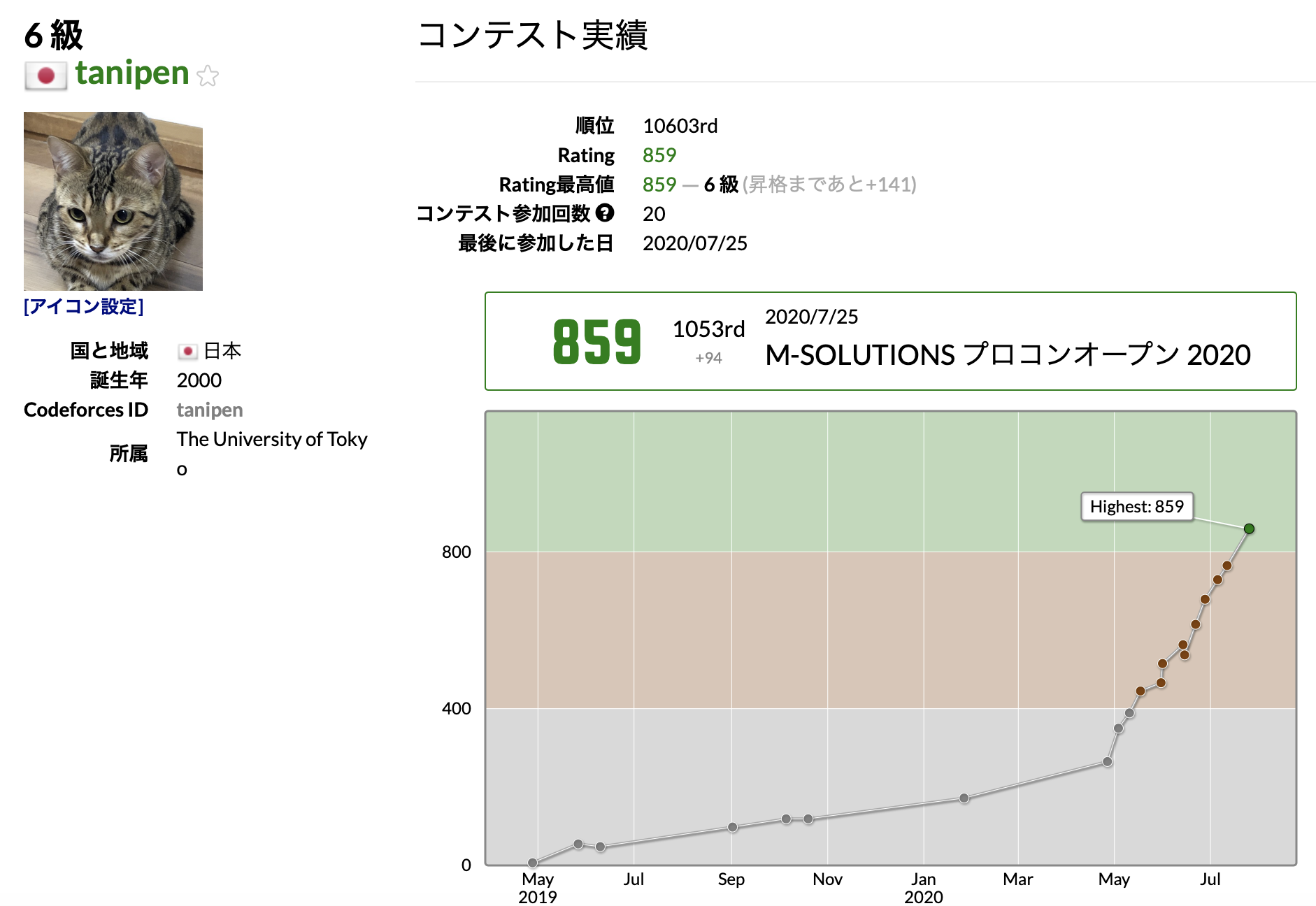
Atcoderで緑になった話
こんにちは。tanipenと申します。
この度Atcoderにてレートが800を超え、名前が緑色になったので、自己紹介がてらこの記事を書かせていただきたいと思います。これから競技プログラミングをやる方の一助となれば幸いです。
Atcoderをはじめるまで
プログラミングにはじめて触れたのは中学生の時でしたが、周りにプログラミングを本気でやっている人がいなかったこと、当時は情報獲得手段に乏しかったことから、細々とひとりで簡単なプログラムを組むにとどまり、AtcoderのAの字もみることなく月日が流れました。
大学に入学したのち、TwitterのFFの方々が盛んにAtcoderの結果を載せるのを見てはじめてAtcoderなるものがあるのを知りました。しばらくはスルーしていたのですが、あまりに
みんながAtcoderをやっている、やってないのはお前だけなTLになることがしばしばであったので、昨年5月、物は試しとやってみることを決意しました。が。
Atcoderに登録した2019年当時は、多忙なアルバイトが毎週土日に入る日々が続き、
全然コンテストに出られない!!!!!
2ヶ月に1回出ては消化不良のまま、十分な勉強・復習もできずにこれまた月日が流れていきました。
その後、今年の5月ごろからアルバイトを変えたことで環境が改善。Pythonを使ったバイトになったこと、例のウイルスのおかげで時間が余ったことも相まって、心機一転、本腰を入れて再開することを決意し、ようやくグラフの傾きが上を向き始めたわけです。
Atcoder遍歴 ~緑になるまでやったこと~
私は上述の通り簡単なプログラムを組んだ経験があり、いわゆるプログラミングの基本や共通のご作法を理解していたことから、「プログラミングを理解する」という(初心者が詰まりがちな)フェーズをすっ飛ばすことができ、以下の2点に重きを置いて勉強することにしました。
- 計算量を考えて解く
- 初歩的なアルゴリズムを理解し使いこなせるようにする
また、私は基本的に文章を読むよりも手を動かして理解する
脳筋タイプですので、ひたすら問題を解こうと決めていました。アルゴリズムを知る
まず、私に足りないものを埋める作業、すなわち使えるアルゴリズムの引き出しを増やす作業をしました。そこで使ったのが競技プログラミングでの典型アルゴリズムとデータ構造というサイトでした。いわゆる競技プログラミングで使うアルゴリズムを、Atcoderなど公開された問題を使いながら紹介してくれ、とても良い教材でした。なかには数学的な理解を必要とするもの(ex. 二項係数の前計算の話など)もあり苦戦しましたが、計算量を意識しながらアルゴリズムを選ぶ、という思考を身に付けることができたと思います。
もっとも、緑に到達するのにある程度解けなくてはいけない灰〜緑前半diffの問題で必要になるのは中級編数学系くらいまでで、それ以降の内容は青〜黄diffで出るようなものも混ざっているので必須ではないと感じました。ただ、緑になるには水〜青diffの問題にもある程度手を出せなくてはならないので、DP、DFS、BFSは練習しておいて良かったと思います。
過去問を解く
ある程度アルゴリズムを理解できたら、あとはAtcoder Problemsさんでひたすら過去問を漁っていました。基本的な方針は
- A,B,Cは絶対解く
- D,Eはとりあえず考えてみて、解けるものは出す。厳しいものは解説を見る
私はあんまり時間をかけて悩むのが苦手なタイプなので、ちょっと考えて理解できなければすぐに解説PDFを読んでACする(してないやつもある)、というステップを踏みました。また、全部をローラーするとなると(緑diffであっても)解けないもので詰まって継続するモチベが落ちてしまうと思ったので、1個1個の完璧を追求するのではなく、とにかく場数を踏むことでトータルの「書く量を増やす」ことを意識しました1。
結果が以下のグラフ。
——あれ、場数を踏むって言ったよね?解いてる量が足りてなくてごめんなさいになっています。夏休みなので頑張ります。
モチベを維持する
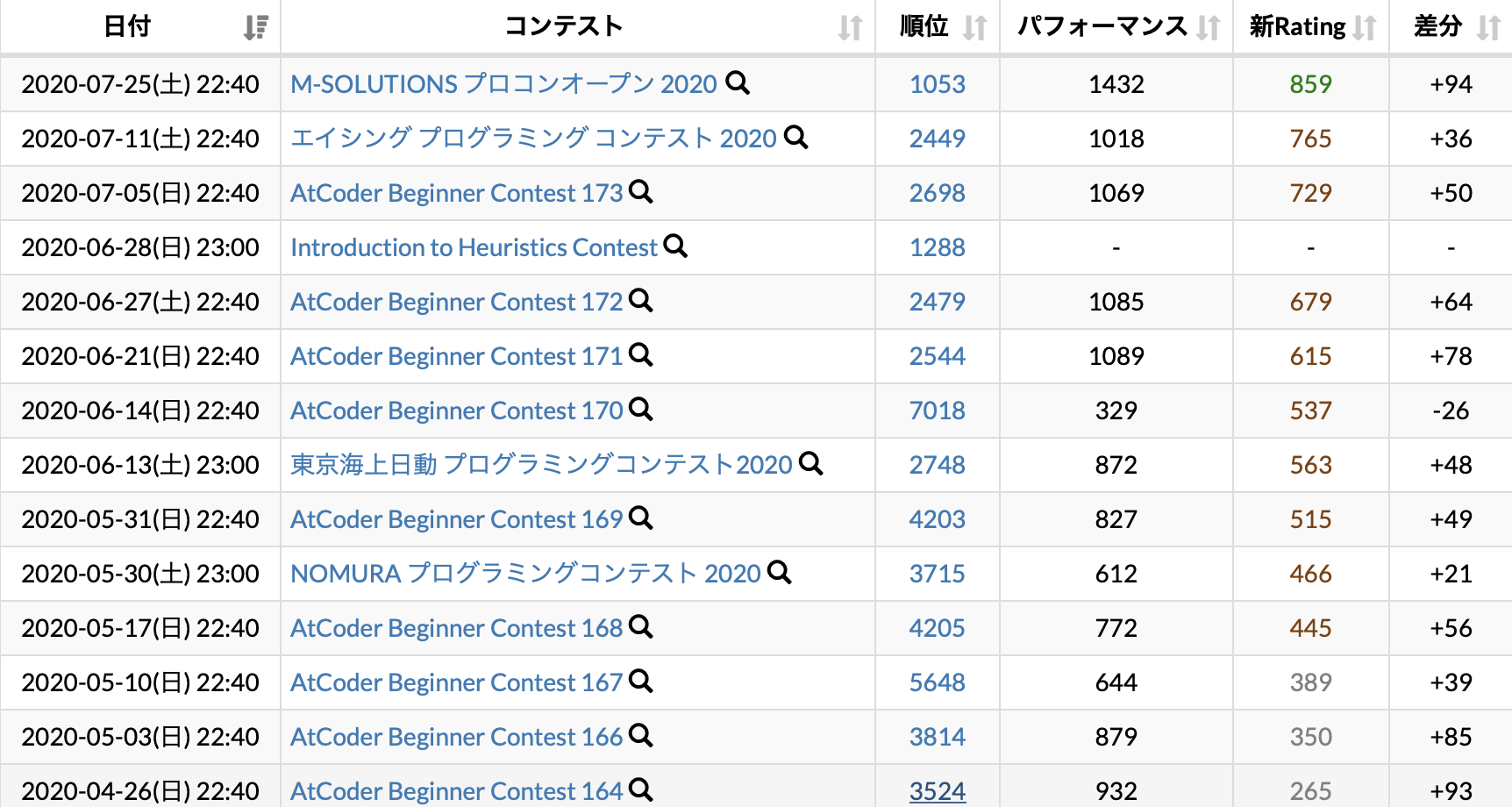
私は幸いに大学の知り合い(TwitterのFFを含む)にAtcoderユーザーが多いので、こっそりお気に入り登録しておいて、コンテストの度にお気に入り内順位表を眺めながら解いています。リアルタイムで競っている感覚になるので、自分以外も頑張っていると思うと、負けられないなと気が引き締まります。
下の画像は本格再開後のコンテスト履歴です。安定してパフォーマンスを出せてはいるものの、中身を見ると脳死でペナを食らっていたり、変なところで詰まって時間を溶かしたりと、まだまだ未熟なのが明白です。
私個人の感覚としては、自分はようやく緑にはなったものの、まだまだアルゴリズムへの理解も浅く、ボロも多い未熟者、という認識です(まさに森に迷い込んでる最中といった具合)。ようやくスタートラインに立てたと思って、次の目標である入水を目指していきたいと思います。
今後の予定
- ABC-E,Fあたりで要求されるようなアルゴリズム(Union-Find, 貪欲法、高度なDP)に対する理解がまだまだ足りていないので、その練習を積んでいくこと
- 灰〜緑色は当たり前のように1発ACできるようにすること
この辺りを頑張っていきたいなと思います。夏休みが終わる頃には(精進グラフだけでも)入水できると嬉しいな。
というわけで駄文を最後まで読みいただき、ありがとうございました。
この辺は個人の価値観にもよるし、宗教戦争の火種にもなりがちですので、自分にあった方法をとるのが吉です。 ↩
- 投稿日:2020-07-26T20:44:10+09:00
Google ColabにMeCabとipadic-NEologdをインストールする
1.はじめに
Google Colab に MeCab と ipadic-NEologd をインストールしようと思ったら意外に手間取ったので備忘録として残します。
2.コード
色々なWeb情報を漁った結果、インストールには下記のコードがベストではないかと思います。
# 形態素分析ライブラリーMeCab と 辞書(mecab-ipadic-NEologd)のインストール !apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1 !pip install mecab-python3 > /dev/null # シンボリックリンクによるエラー回避 !ln -s /etc/mecabrc /usr/local/etc/mecabrc辞書のパスの確認
!echo `mecab-config --dicdir`"/mecab-ipadic-neologd"動作確認
import MeCab m = MeCab.Tagger() sample_txt = "彼女はペンパイナッポーアッポーペンと恋ダンスを踊った。" print("Mecab:\n", m.parse(sample_txt)) path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd" m = MeCab.Tagger(path) print("Mecab ipadic NEologd:\n",m.parse(sample_txt))(参考)
google colab で mecab-ipadic-NEologd を使おうとしたら mecabrc がないと error が出る場合の対処法
hurutoriya/colab-mecab-ipadic-NEologd.ipynb
- 投稿日:2020-07-26T20:42:27+09:00
discord.pyを1.3.4にしなきゃ動かなくなったってお話
経緯
先日discord APIのアップデートが入り、バージョン1.3.4以前のdiscord.pyでは、以下のようなエラーが発生して動作しなくなってします。
TypeError:__new__() got an unexpected keyword argument 'deny_new'(なんか1.2.5の時も似たようなのありましたね。
KeyErrorでしたっけ?)解決法
discord.pyのバージョンを1.3.4以上にしてあげてください(記事掲載時点での最新は1.3.4)。
ちなみに現在のバージョンを確認するには、コンソール上でPythonのインタプリタ(対話モード)を開き、以下のコマンドを実行してください。>>> import discord >>> print(discord.__version__) 1.3.4この場合は記事執筆時点で最新の、1.3.4がインストールされています。
今この記事を見ている人の大半は1.3.4以前のものを使っていると思いますので、1.3.3など違う出力になっていると思います。
バージョンを上げることができれば何でも大丈夫ですが、以下にいくつか方法を提示しておきます。Herokuの場合
Herokuの場合は
requirements.txtというファイルでライブラリを管理しているため、このファイルを編集して上げる必要があります。
以下が例です。requirements.txtdiscord.py>=1.3.4requirements.txtの書き方については、我らが味方note.nkmk.meが解説していますので、興味がある方は是非。
https://note.nkmk.me/python-pip-install-requirements/また、Herokuの場合、requirements.txtに記述したライブラリが自動でアップデートされるわけではないため、1.3.4のリリース後にデプロイをしていない場合、gitでコミットを行いデプロイして上げる必要があります。
「何いってんのかよくわかんねぇよ!」って人は上の通りにrequirements.txtを更新するだけでも大丈夫ですWindowsの場合
Windowsの場合は、以下のコマンドをコマンドプロントで実行すればdiscord.pyを更新することが出来ます。
1.3.4が入らない場合はdiscord.pyの部分をdiscord.py==1.3.4に変更するなどしてみてください。py -3 -m pip install -U discord.py # voice関係のものを使っている場合 py -3 -m pip install -U discord.py[voice]Linux or Macの場合
以下のコマンドをターミナルで実行してみてください。なお筆者はMacを持っていないためMacの仕様はよくわかってません。
python3 -m pip install -U discord.py # Windowsの場合と同様にvoice関係の物を使っている場合 python3 -m pip install -U discord.py[voice]終わりに
いかがでしたでしょうか。
「久しぶりにbotを起動したけど動かない!」みたいな方の手助けになったなら幸いです。
執筆が初めてなので、拙い箇所が多々あるかもしれませんがご容赦ください。最後に、私がよく出没しているdiscordサーバのリンクを貼っておきます。
Discord Bot Portal JP
disocrd botについての質問などができるサーバですので、bot制作で躓いていたら参加してみると良いかもしれません。Happy coding!
- 投稿日:2020-07-26T20:17:44+09:00
【スクレイピングまとめ】| Python Node.js PHP Ruby Go VBA | 6種類の言語でヤフートップをスクレイピング
Python
動画
リポジトリ
https://github.com/yuzuru-program/scraping-python-yahoo
ソース
index.pyimport urllib.request as request from bs4 import BeautifulSoup req = request.Request( "https://www.yahoo.co.jp", None, {} ) instance = request.urlopen(req) soup = BeautifulSoup(instance, "html.parser") li = soup.select('main article section ul')[0].select('li') for m in li: print(m.text) print(m.select("a")[0].get("href")) print()Node.js
動画
リポジトリ
https://github.com/yuzuru-program/scraping-node-yahoo
ソース
package.json{ "dependencies": { "cheerio": "^1.0.0-rc.3", "node-fetch": "^2.6.0" } }index.jsconst fetch = require('node-fetch'); const cheerio = require('cheerio'); const main = async () => { // https://www.yahoo.co.jp/にリクエスト投げる const _ret = await fetch('https://www.yahoo.co.jp/', { method: 'get', headers: { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', }, referrer: '', }).catch((err) => { console.log(err); }); if (_ret.status !== 200) { console.log(`error status:${_ret.status}`); return; } // jqueryチックに使えるように変換 const $ = cheerio.load(await _ret.text()); const _li = $('main article section ul').eq(0).find('li'); // ヤフートップニュースを表示 _li.map(function (i) { console.log(_li.eq(i).text()); console.log(_li.eq(i).find('a').attr()['href']); console.log(); }); }; main();PHP
動画
リポジトリ
https://github.com/yuzuru-program/scraping-php-yahoo
ソース
index.php<?php require_once './phpQuery-onefile.php'; function my_curl($url) { $cp = curl_init(); /*オプション:リダイレクトされたらリダイレクト先のページを取得する*/ curl_setopt($cp, CURLOPT_RETURNTRANSFER, 1); /*オプション:URLを指定する*/ curl_setopt($cp, CURLOPT_URL, $url); /*オプション:タイムアウト時間を指定する*/ curl_setopt($cp, CURLOPT_TIMEOUT, 30); /*オプション:ユーザーエージェントを指定する*/ curl_setopt($cp, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'); $data = curl_exec($cp); curl_close($cp); return $data; } $url = 'https://www.yahoo.co.jp'; $doc = phpQuery::newDocument(my_curl($url)); $ul = $doc->find('main article section')->find("ul:eq(0)"); for ($i = 0; $i < count($ul->find("li")); ++$i) { $li = $ul->find("li:eq($i)"); echo $li[0]->text(); echo "\n"; echo $li[0]->find("a")->attr('href').PHP_EOL; echo "\n"; } ?>phpQuery-onefile.php
https://github.com/yuzuru-program/scraping-php-yahoo/blob/master/phpQuery-onefile.php
Ruby
動画
リポジトリ
https://github.com/yuzuru-program/scraping-ruby-yahoo
ソース
index.rbrequire "nokogiri" require "open-uri" doc = Nokogiri::HTML(open("https://www.yahoo.co.jp")) test = doc.css("main article section ul")[0].css("li") test.each do |li| puts li.content puts li.css("a")[0][:href] puts endGo
動画
リポジトリ
https://github.com/yuzuru-program/scraping-go-yahoo
ソース
index.gopackage main import ( "fmt" "log" "net/http" "github.com/PuerkitoBio/goquery" ) func main() { req, _ := http.NewRequest("GET", "http://yahoo.co.jp", nil) req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36") res, _ := new(http.Client).Do(req) if res.StatusCode != 200 { log.Fatalf("status code error: %d %s\n", res.StatusCode, res.Status) } doc, err := goquery.NewDocumentFromReader(res.Body) if err != nil { log.Println(err) } li := doc.Find("main article section ul").Eq(0).Find("li") li.Each(func(index int, s *goquery.Selection) { fmt.Println(s.Text()) tmp, err := s.Find("a").Attr("href") if err != true { log.Fatal(err) } fmt.Println(tmp + "\n") }) }VBA
動画
ソース
'Microsoft HTML Object Library 'Microsoft Internet Controls ' IEのプロセスを削除する関数 Function IeProcessKill() CreateObject("WScript.Shell").Exec ("taskkill.exe /F /IM iexplore.exe") Application.Wait Now + TimeValue("0:00:2") End Function 'ヤフートップスクレイピング Sub main() Dim ie As InternetExplorer ' IEプロセスを削除' Call IeProcessKill 'IE起動 Set ie = New InternetExplorer 'サイトを非表示 ie.Visible = False Debug.Print "読み込み中..." Debug.Print 'ヤフー ie.Navigate "https://www.yahoo.co.jp/" Do While ie.Busy = True Or ie.readyState < READYSTATE_COMPLETE Loop For Each tmp In ie.document.querySelector("main article section ul").getElementsByTagName("li") Debug.Print Trim(tmp.textContent) Debug.Print tmp.getElementsByTagName("a")(0).href Debug.Print Next tmp ' ブラウザ閉じる ie.Quit Set ie = Nothing End Sub






- 投稿日:2020-07-26T19:53:17+09:00
Pythonでファイルの文字列をデコードする。(Quated-pritableを読めるようにする)
最近会社で文字列でコード処理を書く必要があったので軽くメモとして残しておきます。
よくあるシチュエーションですが、保守対応でエンコード後のファイイルだけが資料として存在しているためデコードして読めるようにする必要があるという物です。
以下のコードでquoted-pritableを可読なものに変更します。
import sys import quopri args=sys.argv inputfile = args[1] outputfile = args[2] # ファイル読み込み with open(inputfile, 'r', encoding='utf-8') as f: #with open(inputfile, 'b') as f: data = f.read() # 変換 pre_decoded = quopri.decodestring(data,header=False) decoded = pre_decoded.decode("utf-8", "ignore") # 出力 with open(outputfile, 'w', encoding='utf-8') as fo: fo.write(decoded)
- 投稿日:2020-07-26T19:49:54+09:00
Google ColabでGoogle driveの公開ファイルを直接ダウンロードする方法
1.はじめに
Google Colab で Google drive の公開ファイル (例えば、fastText日本語版の学習済みモデルとか) を使う場合は、PCに一旦ダウンロードしてから Google drive経由で使うのが一般的だと思います。
普通はこの方法で問題ないわけですが、場合によっては わざわざ別途手動でダウンロードせずに、Google Colab を先頭からポチポチするだけで動くコードにしたいと思ったりするわけです。
今回は、そのための良い方法をWebで見つけましたので、備忘録として残します。
2.サンプルコード
サンプル例は、fastText日本語版学習済みモデル です。URLをクリックすると、まずこの画面が現れます。
この画面で、赤枠のボタンを押すと、ダウンロード画面になります。
そうしたら、このダウンロード画面のURLを控えておきます。後は、以下のコードで、直接ダウンロード出来ます。
# Google drive からfastText日本語モデル(vector_neologd.zip)をダウンロードする import requests def download_file_from_google_drive(id, destination): # ダウンロード画面のURL URL = "https://drive.google.com/uc?id=0ByFQ96A4DgSPUm9wVWRLdm5qbmc&export=download" session = requests.Session() response = session.get(URL, params = { 'id' : id }, stream = True) token = get_confirm_token(response) if token: params = { 'id' : id, 'confirm' : token } response = session.get(URL, params = params, stream = True) save_response_content(response, destination) def get_confirm_token(response): for key, value in response.cookies.items(): if key.startswith('download_warning'): return value return None def save_response_content(response, destination): CHUNK_SIZE = 32768 with open(destination, "wb") as f: for chunk in response.iter_content(CHUNK_SIZE): if chunk: # filter out keep-alive new chunks f.write(chunk) if __name__ == "__main__": file_id = 'TAKE ID FROM SHAREABLE LINK' destination = './data/vector_neologd.zip' # 保存先パスの指定 download_file_from_google_drive(file_id, destination)enjoy !


- 投稿日:2020-07-26T19:49:54+09:00
Google ColabからGoogle driveにある一般公開ファイルを直接ダウンロードする方法
1.はじめに
Google Colab で Google drive にある一般公開ファイル (例えば、fastText日本語版の学習済みモデルとか) を使う場合は、PCに一旦ダウンロードしてからGoogle drive経由で使うのが一般的だと思います。
普通はこの方法で問題ないわけですが、場合によっては わざわざ別途手動でダウンロードせずに、Google Colab を先頭からポチポチするだけで動くコードにしたいと思ったりするわけです。
今回は、そのための良い方法をWebで見つけましたので、備忘録として残します。
2.サンプルコード
サンプル例は、fastText日本語版学習済みモデル です。URLをクリックすると、まずこの画面が現れます。
この画面で、赤枠のボタンを押すと、ダウンロード画面になります。
そうしたら、このダウンロード画面のURLを控えておきます。後は、以下のコードで、直接ダウンロード出来ます。
# Google drive からfastText日本語モデル(vector_neologd.zip)をダウンロードする import requests def download_file_from_google_drive(id, destination): # ダウンロード画面のURL URL = "https://drive.google.com/uc?id=0ByFQ96A4DgSPUm9wVWRLdm5qbmc&export=download" session = requests.Session() response = session.get(URL, params = { 'id' : id }, stream = True) token = get_confirm_token(response) if token: params = { 'id' : id, 'confirm' : token } response = session.get(URL, params = params, stream = True) save_response_content(response, destination) def get_confirm_token(response): for key, value in response.cookies.items(): if key.startswith('download_warning'): return value return None def save_response_content(response, destination): CHUNK_SIZE = 32768 with open(destination, "wb") as f: for chunk in response.iter_content(CHUNK_SIZE): if chunk: # filter out keep-alive new chunks f.write(chunk) if __name__ == "__main__": file_id = 'TAKE ID FROM SHAREABLE LINK' destination = './data/vector_neologd.zip' # 保存先パスの指定 download_file_from_google_drive(file_id, destination)enjoy !
- 投稿日:2020-07-26T19:10:00+09:00
プログラミング上達講座3:メガテンのコードブレイカー
プログラミング上達講座の3回目です。
メガテンのコードブレイカーを題材にして
プログラムを考えてみましょう。解説動画はこちら
コードブレイカーとは
RPG「女神転生」シリーズのミニゲーム
コードブレーカー正式名称は「Hit&Blow」という数当てゲームです。
その昔
ヌメロンという名前でテレビ番組やっていましたね。
ヌメロンだとアイテムが使えたりがありましたが
今回はアイテムとか無しです。ルール
各桁の数字(0-9までの数字)が全て違う、3桁の数字を当てるゲーム
予想の数字を入力して、桁ごとに下記を判定
正解と場所と数字が一致する(ヒット)
場所が違うがその数字が含まれる(ブロー)
1回答ごとにHitとBlowの数を言い、全て当たる(3H)まで行う。例:
正解の数 957
1回目の予想「915」→ 「1H1B」
2回目の予想「234」→ 「0H0B」
3回目の予想「795」→ 「0H3B」
4回目の予想「957」→ 「3H0B」→当たり初級編:コードブレイカーのチェック関数を作る
予想の数値と正解の数字を入力して
HitとBlowの数を返す関数check_callを作ってみよう# 引数:call=予想数字 , solve=正解数字 # 戻り値:(hit , blow)のタプル型(両方数値) def check_call(call , solve): 処理 return (hit , blow)例:
check_call('564','987') →(0,0)
check_call('564','687') →(0,1)
check_call('564','546') →(1,2)
check_call('564','564') →(3,0)中級編:コードブレイカーのゲームを作ってみよう
3桁の数値をランダムで生成して正解数として
正解数を当てに行くミニゲームを作ってみよう。inputで数値入力を受け付け
数値とhit , blowを出力し続ける。3Hになるか、10回当てられなければゲーム終了。
ヒント:
まず正解の数字を1つ作る。
チェックする部分は 初級編の関数を利用する。正解の数字と入力数字が合うまで
各回の予想とhit&blowの出力するimport random import itertools # 数字をチェックする def check_call(call , solve): # 処理を書く return hit , blow # ゲームの開始 # 処理を書く上級編:正解の数字を導き出すアルゴリズム
正解の数字をあらかじめ決めておき、チェック関数の結果を用いて
正解の数字を予想するプログラムを作成してみよう。ヒント:
チェック関数をうまく使うと、正解の候補を考える事が出来るよ!!# 処理を書く解答編
初級編の解答
# 予想と正解をチェックする関数 def check_call(call , solve): hit , blow = 0,0 for i,n in enumerate(call): if solve[i]==n: hit+=1 elif n in solve: blow +=1 return hit , blow print(check_call('564','987')) print(check_call('564','687')) print(check_call('564','546')) print(check_call('564','564'))(0, 0)
(0, 1)
(1, 2)
(3, 0)中級編の解答
まず最初に正解の数字を作る
(10個の数字を使った3桁でダブりのない数字)10個の数字を用いた順列を作るには
itertools.permutations(seq, 3)順列の中から1つ選ぶには
random.choice(リストなど)繰り返しはWhile文かfor文を使い
hit==3か10回当てられない場合に抜ける。import random import itertools # 数字をチェックする def check_call(call , solve): hit , blow = 0,0 for i,n in enumerate(call): if solve[i]==n: hit+=1 elif n in solve: blow +=1 return hit , blow # ゲームの開始 # 正解数値の生成 seq = (0,1,2,3,4,5,6,7,8,9) nums = [str(a)+str(b)+str(c) for a,b,c in itertools.permutations(seq, 3)] solve = random.choice(nums) # 10回繰り返すか、正解で終了 count = 0 while True: count+=1 call = input() hit , blow = check_call(call , solve) print(count , call , '{0}H{1}B'.format(hit , blow)) if hit==3: print('You Win , Solve = {0}'.format(solve)) break if count==10: print('You Lose , Solve = {0}'.format(solve)) break123
1 123 0H1B
789
2 789 0H1B
567
3 567 0H1B
712
4 712 0H1B
254
5 254 0H0B
710
6 710 1H1B
910
7 910 1H0B
817
8 817 0H1B
709
9 709 0H2B
098
10 098 0H1B
You Lose , Solve = 370上級編の解答
チェック関数を使って予想数字から
正解候補の判定結果を全通り求めておく。集合をうまく使うと正解候補を絞り込む事が出来る。
Pythonではsetが集合のデータ型。積集合(intersection)を使うと
候補同士の重なる部分を抽出できる。候補の重なりの中から次の予想を行い
繰り返すと、候補が絞られてゆくサンプルコードはこちら
# 数字をチェックする def check_call(call , solve): hit , blow = 0,0 for i,n in enumerate(call): if solve[i]==n: hit+=1 elif n in solve: blow +=1 return hit , blow # 候補を絞り込むための組み合わせの辞書を作る def all_combination_calc(call): result_dict = {} for i in list(itertools.permutations((0,1,2,3,4,5,6,7,8,9), 3)): num = str(i[0])+str(i[1])+str(i[2]) hit , blow = check_call(call,num) key = '{0}H{1}B'.format(hit , blow) if key in result_dict: tmp = result_dict[key] tmp.append(num) else: tmp = [num] result_dict[key] = tmp return result_dict # 正解の数字を解く def solve_code_break(solve): sets = set([]) call = random.choice([str(a)+str(b)+str(c) for a,b,c in itertools.permutations(seq, 3)]) hit , blow = check_call(call , solve) key = '{0}H{1}B'.format(hit , blow) print(call,key) if call==solve: print('End') else: while True: conbination_dict = all_combination_calc(call) s_choice = conbination_dict[key] sets = set(s_choice) if len(sets) ==0 else sets.intersection(set(s_choice)) call = random.choice(list(sets)) s_hit , s_blow = check_call(call , solve) key = '{0}H{1}B'.format(s_hit , s_blow) print(call,key) if call==solve: break print('End') # 数字当てをする seq = (0,1,2,3,4,5,6,7,8,9) s_nums = [str(a)+str(b)+str(c) for a,b,c in itertools.permutations(seq, 3)] solve = random.choice(s_nums) print('Solve = ', solve) solve_code_break(solve)Solve = 736
936 2H0B
931 1H0B
906 1H0B
836 2H0B
236 2H0B
736 3H0B
Endせっかくなのでシミュレーションしてみる
1000回ほど試行して何回で解けるかシミュレーションしてみる
上級編のコードを改変して集計プログラムに直して試行する。
# 数字をチェックする def check_call(call , solve): hit , blow = 0,0 for i,n in enumerate(call): if solve[i]==n: hit+=1 elif n in solve: blow +=1 return hit , blow # 候補を絞り込むための組み合わせの辞書を作る def all_combination_calc(call): result_dict = {} for i in list(itertools.permutations((0,1,2,3,4,5,6,7,8,9), 3)): num = str(i[0])+str(i[1])+str(i[2]) hit , blow = check_call(call,num) key = '{0}H{1}B'.format(hit , blow) if key in result_dict: tmp = result_dict[key] tmp.append(num) else: tmp = [num] result_dict[key] = tmp return result_dict # 正解の数字を解くシミュレーションをする def code_break_sim(): seq = (0,1,2,3,4,5,6,7,8,9) s_nums = [str(a)+str(b)+str(c) for a,b,c in itertools.permutations(seq, 3)] solve = random.choice(s_nums) term,sets = 1,set([]) call = random.choice([str(a)+str(b)+str(c) for a,b,c in itertools.permutations(seq, 3)]) hit , blow = check_call(call , solve) key = '{0}H{1}B'.format(hit , blow) if call==solve: return term else: while True: conbination_dict = all_combination_calc(call) second_choice = conbination_dict[key] sets = set(second_choice) if len(sets) ==0 else sets.intersection(set(second_choice)) call = random.choice(list(sets)) s_hit , s_blow = check_call(call , solve) key = '{0}H{1}B'.format(s_hit , s_blow) term+=1 if call==solve: return term calc_dict = {} for i in range(1000): key = code_break_sim() if key in calc_dict: calc_dict[key]+=1 else: calc_dict[key]=1 for k,v in sorted(calc_dict.items()): print(k,v)1 2
2 10
3 63
4 196
5 335
6 277
7 86
8 28
9 3だいたい5回くらいで解くことができそうです。
7回もあればほぼほぼ解き終わっていますね。まとめ
コードブレイカー自体は女神転生のミニゲームなので
だいぶ前のゲームでしたが
プログラム的な考え方ができる
いい題材でした。ヌメロン懐かしいですよね。
今なら無双できる気がします。再放送するなら
呼んでくれないかなwwwそれでは。
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython

- 投稿日:2020-07-26T18:55:00+09:00
djangoのデータベースをバックアップする方法
バックアップの方法
formatを指定しない場合(--format jsonなどを書かない場合)はjson形式で出力されます。
全アプリの全テーブルデータを出力
python manage.py dumpdata > filename.json特定のアプリの全テーブルデータを出力
python manage.py dumpdata app_name > filename.json特定のアプリのあるテーブルデータを出力
python manage.py dumpdata app_name.table_name > filename.jsonリストアの方法
python manage.py loaddata filename.json参考
- 投稿日:2020-07-26T18:42:23+09:00
Python3のノート
はじめに
- OS
- Windows10 Pro
- Version
- Python 3.7.3
更新日時
更新日 内容 名前 2020.07.26 Sun 新規作成 Yamada
参考資料
Pythonエンジニア育成推進協会監修 Python 3スキルアップ教科書
最初のプログラム
print('Hello,World')
基本ルール
変数の宣言
- ハッシュ記号は変数名に利用できない
- ドルマークは変数名に利用できない
- 数字で始まる変数名は宣言できない
- Pythonのキーワードに使われている文字列は変数に利用できない
- 文字列リテラルはシングルクォーテーションを扱う
- 文字列リテラルはダブルクォーテーションを扱う
データ型
- 文字列型
- 数値型
- 組み込み型
HelloStr = 'Hello,World' print(HelloStr) # Hello,World
型変換
- 暗黙的型変換
- 変数初期化時に代入演算された値に基づいてデータ型を変換すること(一般的な解釈)
- Pythonでは厳密には型変換ではない
- 各データ型のインスタンスオブジェクトを生成して名前を付ける感じ
name = 'Yamada' print(type(name)) # <class 'str'> age = 18 print(type(age)) # <class 'int'>
文字のエスケープ
表示文字 エスケープ文字 改行 \n タブ \t " \" バックスラッシュ \\
文字列リテラル
- 複数行にまたがる文字列
- 3回のシングルクォートで括る
- 複数行にわたるコメント
- 3回のシングルクォートで括る
使い方
sentence = ''' これは文章です。 入力したとおりに 改行も認識されます。 ''' print(sentence) # ここからコメント ''' 出力内容 これは文章です。 入力したとおりに 改行も認識されます。 ''' # ここまでコメント
文字列の連結
- 文字列の連結には「+」を使います。
- 数値を結合する場合
- str関数を使って文字列に変換すること
使い方
age = 999 firstName = 'Yamada' message = 'Hello ' + firstName + str(age) print(message) # Hello Yamada999中間に変数を挟まない方法
age = 999 firstName = 'Yamada' greeting = 'Hello ' print(greeting + ' ' + firstName + str(age)) # Hello Yamada999
文字列補間
- 文字列内で変数の中身を展開する方法
firstName = 'Yamada' greeting = 'Hello {}'.format(firstName) message = 'Your name is {} '.format(firstName) print(message) print(greeting) ''' Your name is Yamada Hello Yamada '''
組み込み関数
iter関数
文字列やリストなどの順番に並んだデータをイテレータとして返す関数
nextを使うと先頭から順番にデータを取り出します。
firstName = 'Yamada' firstName_iter = iter(firstName) print(next(firstName_iter)) print(next(firstName_iter)) print(next(firstName_iter)) print(next(firstName_iter)) print(next(firstName_iter)) print(next(firstName_iter)) # Y # a # m # a # d # a # 7文字目はないのでStop Iteration # print(next(firstName_iter)) ''' Traceback (most recent call last): File "<stdin>", line 2, in <module> StopIteration '''
今後できるようになること
- 関数とメソッドの違いを説明できるようになる
- 組み込み関数とそうでない関数の違いを説明できるようになること
おわり
print('to be continued !!')
- 投稿日:2020-07-26T18:27:23+09:00
Atcoder M-SOLUTIONS プロコンオープン 2020 Python
総括
AとBしか解けず。
C,Dは次の日考えたら解けましたが、コンテスト中は一度詰まってしまうと発想を切り替えて解くことがなかなか難しいです。問題
https://atcoder.jp/contests/m-solutions2020/tasks
A. Kyu in AtCoder
回答
X = int(input()) if 400 <= X and X <= 599: print(8) elif 600 <= X and X <= 799: print(7) elif 800 <= X and X <= 999: print(6) elif 1000 <= X and X <= 1199: print(5) elif 1200 <= X and X <= 1399: print(4) elif 1400 <= X and X <= 1599: print(3) elif 1600 <= X and X <= 1799: print(2) elif 1800 <= X and X <= 1999: print(1) else: passちょっと考えて解法が思いつかなかったので、愚直にif文を書きました。
200ずつの階層になっているので、200で割ってうまいこと書けば短いコードで書けそうです。
解説PDFでも1行で書かれていました。B. Magic 2
回答
import itertools def check(targets): if targets[1] > targets[0] and targets[2] > targets[1]: return True else: return False if __name__ == "__main__": A, B, C = map(int, input().split()) K = int(input()) targets = [A, B, C] answer = 'No' cases = itertools.product([0, 1, 2], repeat=K) for case in cases: copy_targets = targets.copy() for i in case: copy_targets[i] = copy_targets[i] * 2 if check(copy_targets): answer = 'Yes' break print(answer)制約条件が緩いので愚直に全探索で行けそうです。
A, B, Cをリストの
targetsに格納し、それぞれに対応する添え字(0, 1, 2)とします。
また、魔術の成功条件をチェックする関数をcheck(targets)で作成します。これにより問題文を下記のように言い換えます。
「添え字(0, 1, 2)から1つ選び2倍するという処理をK回行い、check(targets)がTrueとなった場合に'Yes'を表示する」「添え字(0, 1, 2)から1つ選び2倍するという処理をK回行う」は
itertools.productで生成できるので、あとは言い換えた処理をコードに落とすだけです。C. Marks
コンテスト時には解けませんでした。
コンテスト時の回答
import numpy as np N, K = map(int, input().split()) A = list(map(int, input().split())) A = np.array(A) scores = [] for i in range(0, N - K + 1): scores.append(A[i:i+K].prod()) for i in range(0, len(scores)-1): if scores[i] < scores[i+1]: print('Yes') else: print('No')これでは通りません。
とりあえず問題文通りのコードを書きましたが、案の定TLEです。
毎回掛け算をしていると間に合いません。翌日の回答
import numpy as np N, K = map(int, input().split()) A = list(map(int, input().split())) for i in range(K, N): if A[i-K] < A[i]: print('Yes') else: print('No')掛け算を毎回行うと間に合わないので、掛け算をしないで題意を満たす方法を考えます。
問題文を読み返すと、「直近K回の点数を掛け算し、i学期の評点がi-1学期の評点より高いか否かを判定する」とありますので、
i学期とi-1学期の大小を比べるためには掛け算は必要なく、i-K学期のテストの点とi学期のテストの点を比べればそれで終わりです。これに気づければコードを書くのは簡単です。
D. Road to Millionaire
こちらもコンテスト時には解けませんでした。
考え方はわかったものの、一部抜け漏れがありました。
また、そもそも問題を解くという点だけを考えると、下記に記載しているコードは助長で、より簡潔に解く方法があるようです。
コンテスト時回答
import numpy as np N = int(input()) A = list(map(int, input().split())) A = np.array(A) have_money = 1000 have_stock = 0 have_stock_valuation = 0 call_status = True def buy_stock(have_money, have_stock, have_stock_valuation, stock_price): stock_num = have_money // stock_price have_money -= stock_num * stock_price have_stock += stock_num have_stock_valuation += stock_num * stock_price return have_money, have_stock, have_stock_valuation def sell_stock(have_money, have_stock, have_stock_valuation, stock_price): have_money += have_stock * stock_price have_stock = 0 have_stock_valuation = 0 return have_money, have_stock, have_stock_valuation for i in range(N): if call_status: if A[i] < np.max(A[i:]): if A[i] > np.min(A[i:]) and np.argmin(A[i:]) < np.argmax(A[i:]): continue else: have_money, have_stock, have_stock_valuation = buy_stock(have_money, have_stock, have_stock_valuation, A[i]) call_status = False else: if have_stock_valuation / have_stock < A[i]: if i == N -1: have_money, have_stock, have_stock_valuation = sell_stock(have_money, have_stock, have_stock_valuation, A[i]) break if A[i] < A[i+1]: continue else: have_money, have_stock, have_stock_valuation = sell_stock(have_money, have_stock, have_stock_valuation, A[i]) call_status = True print(have_money)これでは通りません。
「同日に売却と購入する」場合を反映しきれていないのでWAとなります。翌日の回答
import numpy as np def buy_stock(have_money, have_stock, have_stock_valuation, stock_price): stock_num = have_money // stock_price have_money -= stock_num * stock_price have_stock += stock_num have_stock_valuation += stock_num * stock_price return have_money, have_stock, have_stock_valuation def sell_stock(have_money, have_stock, have_stock_valuation, stock_price): have_money += have_stock * stock_price have_stock = 0 have_stock_valuation = 0 return have_money, have_stock, have_stock_valuation if __name__ == "__main__": N = int(input()) A = list(map(int, input().split())) A = np.array(A) have_money = 1000 have_stock = 0 have_stock_valuation = 0 call_status = True for i in range(N): if call_status: if i == N - 1: continue if A[i] < A[i+1]: have_money, have_stock, have_stock_valuation = buy_stock(have_money, have_stock, have_stock_valuation, A[i]) call_status = False if not call_status: if have_stock_valuation / have_stock < A[i]: have_money, have_stock, have_stock_valuation = sell_stock(have_money, have_stock, have_stock_valuation, A[i]) call_status = True else: if have_stock_valuation / have_stock < A[i]: have_money, have_stock, have_stock_valuation = sell_stock(have_money, have_stock, have_stock_valuation, A[i]) call_status = True if call_status: if i == N - 1: continue if A[i] < A[i+1] and call_status: have_money, have_stock, have_stock_valuation = buy_stock(have_money, have_stock, have_stock_valuation, A[i]) call_status = False print(have_money)これで通ります。
最適な売買方法は「適切なタイミング」で「買えるだけ買って全部売る」ことである、ということは考えてみるとわかります。
まずは「買えるだけ買って全部売る」を実装するために、
buy_stockとsell_stockという関数を作成しました。次に「適切なタイミング」を考えます。
何通りか実験をしてみると、適切なタイミングは下記であることが推測されます。
- 「買い」のタイミングは、「翌日に値上がりするタイミング」
- 「売り」のタイミングは、「保有株が値上がりしているタイミング」
これで準備はできたので、あとはコードに落としていきます。
注意点としては、買える状態(お金がある状態)と売れる状態(株を保有している状態)をcall_statusで保持しておき、上記に記載した「適切なタイミング」で、buy_stockとsell_stockを実行します。




- 投稿日:2020-07-26T17:53:19+09:00
英英辞書使おうとして読めなくて何度も挫折したので、LINEボットに辞書と翻訳機能とテスト機能を組み込んでみた
はじめに
「英語力を高めたいなら英英辞書を使うといい」と聞いたのですが、
「単語を調べる」→「その単語の解説文に出てくる単語がわからない」→「解説文をコピペして別ウィンドウでGoogle翻訳に突っ込む」→「調べたことを忘れる」→「単語を調べる」→...
の無限ループでGoogle翻訳を毎回開くのが面倒になってきました。なので、
・英英辞書での検索
・(必要な場合は)Google翻訳
・自動で単語帳に追加
・好きな時に単語テスト
がまとめてできるサービスを自作することにしました。
(英和辞書?知らない子ですね...)作ったもの紹介
「辞書 × 単語帳」WordNote
*)Oxford Dictionariesの規約に従ってPowered by OXFORDのロゴを使用しています。サイトはこちら
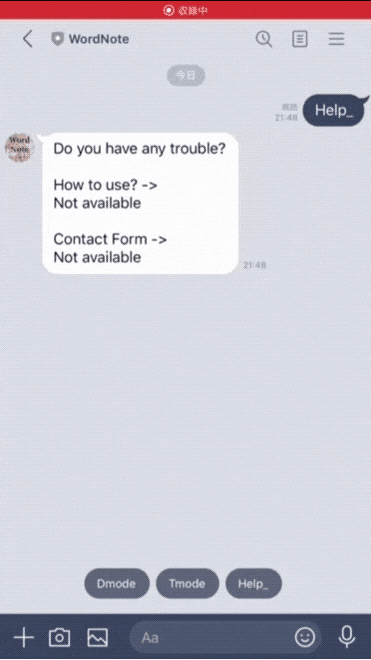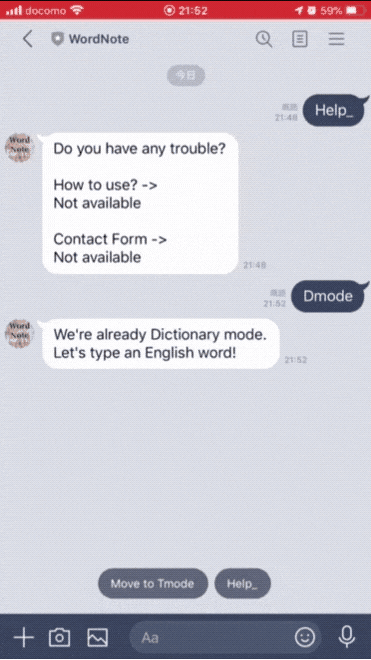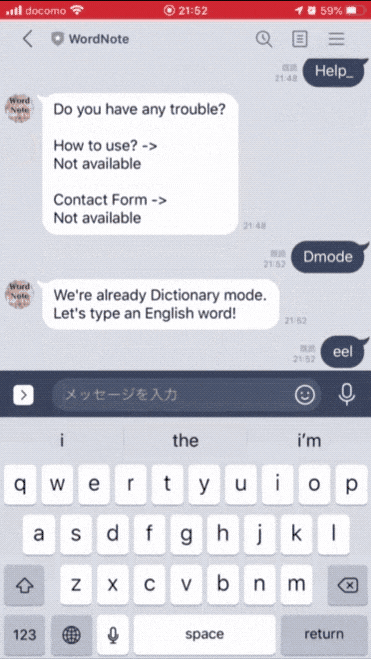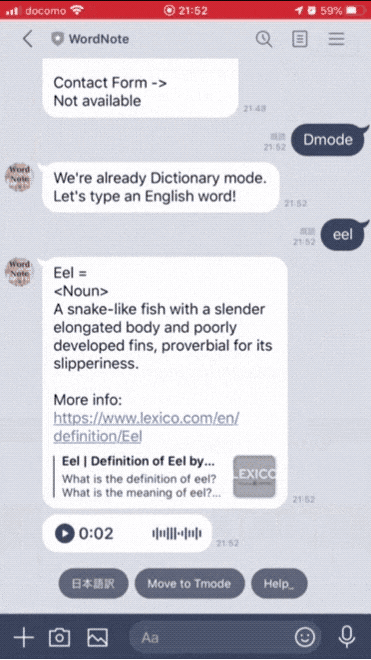
辞書モード
・Oxford Dictionaries APIから単語データを取得し、適当に成形して表示しています。
・日本語訳はGoogle翻訳APIを無料で作る方法を参考に自分のアカウントで作成したAPIを使っています。テストモード
・テスト方法はスペルテスト(スペルを入力)、単語テスト(意味から単語を推測、OX回答)、意味テスト(単語から意味を推測、OX回答)の3種類を用意しています。
・各単語は出題間隔はSuperMemo2をベースにしたアルゴリズムで決定しています。技術的なあれこれ
言語
・Python
・MySQL
・GAS環境&APIs
・Google Cloud Functions
・Cloud SQL
・LINE Messaging API
・Oxford Dictionaries API運用コスト
Cloud SQLが毎月1000円ちょい(一番安いIowa US-centralを使っています)かかりますが、初年度は$300分のクレジットが使えるため実質無料です。
(最初は何も調べずに東京リージョンでやって7000円ほど吹っ飛びました...)技術習得
・Python
note.nkmk.meには超絶お世話になっています。
Pythonで困ったらまずここを見るようにしていました。・GCP
公式ドキュメント(日・英)を中心に時々QiitaやStack Overflowを見ていました。
公式ドキュメントの日本語版は情報が遅いとのことで英語版主に見ていたのですが、出てくる単語がわからないことが多く、だからこそこのボット開発のモチベーションを維持できていた気がします。・LINE Messaging API
こちらも公式ドキュメントがかなり充実していたので、それほど困ることはなかったです。・Oxford Dictionaries API
先々月くらいのアップデートでサンプルコードにPythonが追加されたので、そこを見れば十分扱えると思います。
またこのAPIに関する日本語の情報があまりなかったので、Oxford Dictionaries APIの使い方を書きました。最後に
コード解説は別記事で書く予定です。

- 投稿日:2020-07-26T17:50:21+09:00
CycleGANの再現実装してみた
CycleGANとは
ICCV 2017のUnpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networksで提案されたGANを用いた、画像スタイルを変換する手法です。著者の公開しているソースコードは参考にせずに、自分で論文を参考にして再現実装をしました。
著者のコードと論文のTraining detailsは見ずに再現実装をしたので、著者の実装とはやや異なるので、ご了承ください。
再現実装において、重要な部分はこの記事で述べますが、細かいところの説明は省きます。
実装したコードはgithubにあげたので、細かいところが気になる方はそちらを見てください。画像変換とは
上図のように、画像のドメインを変換することを指します。具体的には、絵の画風(スタイル)を変換したり、馬をシマウマに変換することがあります。
CycleGANの強み
CycleGANが提案される以前にも、多くの画像変換の研究がなされてきました。
そのひとつにPix2Pixがあります。
Pix2PixはConditional GANを用いた画像変換の手法で高い精度を誇りましたが、
学習時に変換する画像のセットを上図のようにpaired(1対1)で用意しなければならない欠点がありました。
このような学習データを探すのはとても難しく、データセットの数が少ないことやそもそもデータセットが存在しないこともあります。
このような問題を解決するために、CycleGANは、上図のようにunpaired(不対)な学習データの画像のセットを用いて画像変換をすることを可能にして学習データを集めるコストを大幅に削減しました。
CycleGANの仕組み
CycleGANは3つのステージに分けることができます。2つ目まではよくあるGANのアルゴリズムです。
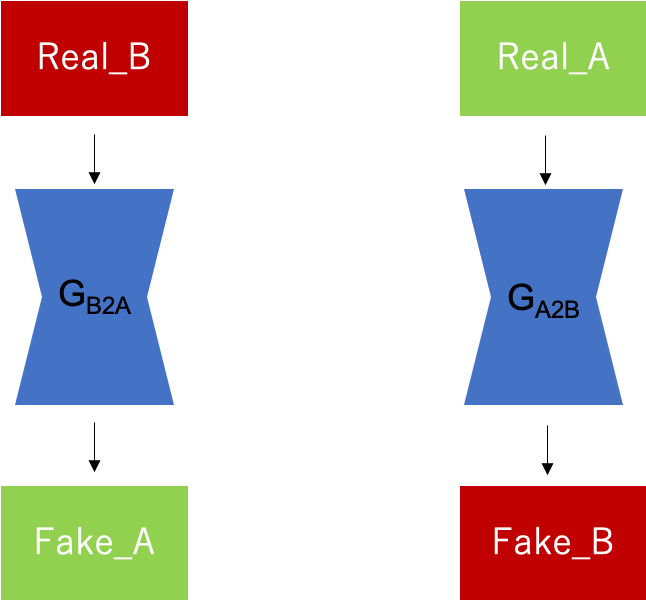
3つ目のCycle ConsistencyがCycleGANの一番の特徴です。Fake画像の生成
まずは上図のように、Generatorを用いて本物の画像B(Real_B)から偽物の画像A(Fake_A)、本物の画像A(Real_A)から偽物の画像B(Fake_B)を生成します。Generatorは共有せずに、それぞれGB2A,GA2Bの2つを用意します。
RealかFakeの判定
次に、元々あるReal画像と生成したFake画像に対してDiscriminatorがRealかFakeどうかを判定します。
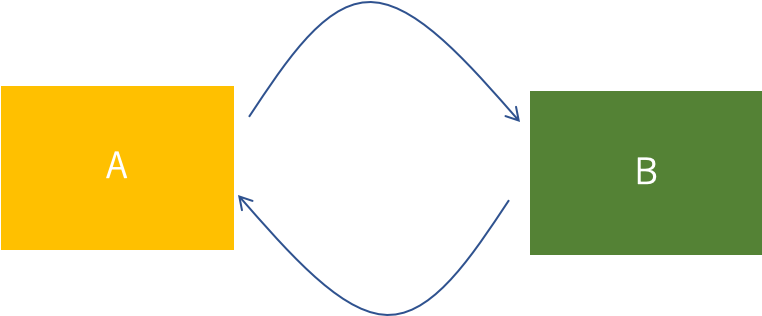
ここでも同様にして、Discriminatorは共有せずに、それぞれDA, DBの2つを用意します。Cycle Consistency
Cycle Consistencyは、上図のような感じで、AからBに変換して、そのBを変換したらもとのAに戻ってきてほしいということを意味します。自分自身が教師になっているイメージです。
具体的には、ウマをシマウマに変換して、そのシマウマをウマに変換すれば、元のウマになって欲しいということです。
クルクルと行き来しているからCycle(循環)、元に戻ってほしいからConsistency(一貫性)。
そのため、2つ合わせてCycle Consistencyと呼ばれていると思います。CycleGANでは、以下のようなアルゴリズムでCycle Consistencyを導入しています。
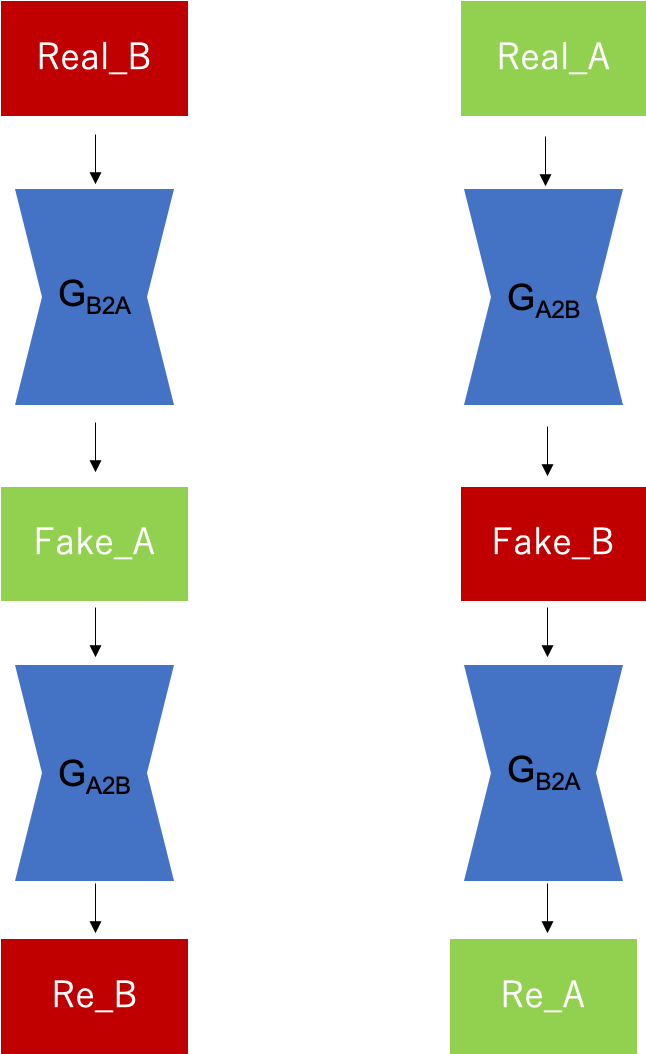
上図のように、Real_BからGeneratorで生成したFake_Aに対して逆のGeneratorを用いてRe_Bを生成します。
Re_BはReal_Bを2回変換したため元のReal_Bに戻って欲しいので、Real_B = Re_BになるようにLossをとります。
Real_Aに対しても、同様な操作をします。
再現実装
GeneratorとDiscriminatorのモデルと学習の仕方の実装について説明します。
Pytorchを用いて実装しました。GeneratorとDiscriminatorのアーキテクチャ
Generatorは上図のようなモデルにしました。特徴量の表現力をあげるために中間層にResNetのblockを用いました。
そのため、ResNetBlockのクラスを定義して、Generatorのクラスにそれを導入しました。model.pyclass ResNetBlock(nn.Module): def __init__(self, dim): super(ResNetBlock, self).__init__() conv_block = [] conv_block += [nn.ReflectionPad2d(1), nn.Conv2d(dim, dim, kernel_size=3), nn.BatchNorm2d(dim), nn.LeakyReLU(0.2), nn.ReflectionPad2d(1), nn.Conv2d(dim, dim, kernel_size=3), nn.BatchNorm2d(dim) ] self.conv_block = nn.Sequential(*conv_block) def forward(self, x): out = x + self.conv_block(x) return out class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.model = nn.Sequential( nn.ReflectionPad2d(3), nn.Conv2d(3, 64, kernel_size=7), nn.BatchNorm2d(64), nn.LeakyReLU(0.2), nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2), nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(256), nn.LeakyReLU(0.2), ResNetBlock(256), ResNetBlock(256), ResNetBlock(256), nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2), nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1), nn.BatchNorm2d(64), nn.LeakyReLU(0.2), nn.ReflectionPad2d(3), nn.Conv2d(64, 3, kernel_size=7, stride=1, padding=0), nn.Tanh() ) self.model.apply(self._init_weights) def forward(self, input): return self.model(input) def _init_weights(self, m): classname = m.__class__.__name__ if classname.find('Conv') != -1: nn.init.normal_(m.weight.data, 0.0, 0.02)
Discriminatorは画像を畳み込んで、最後の層でRealかFakeかどうかの信号を出すように上図のように定義しました。
model.pyclass Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.nf = 64 self.main = nn.Sequential( nn.Conv2d(3, self.nf, 4, 2, 1, bias = False), nn.LeakyReLU(0.2, inplace = True), nn.Dropout(0.1), nn.Conv2d(self.nf, self.nf * 2, 4, 2, 1, bias = False), nn.BatchNorm2d(self.nf * 2), nn.LeakyReLU(0.2, inplace = True), nn.Dropout(0.1), nn.Conv2d(self.nf * 2, self.nf * 4, 4, 2, 1, bias = False), nn.BatchNorm2d(self.nf * 4), nn.LeakyReLU(0.2, inplace = True), nn.Dropout(0.1), nn.Conv2d(self.nf * 4, self.nf * 8, 4, 2, 1, bias = False), nn.BatchNorm2d(self.nf * 8), nn.LeakyReLU(0.2, inplace = True), nn.Dropout(0.1), nn.Conv2d(self.nf * 8, self.nf * 16, 4, 2, 1, bias = False), nn.BatchNorm2d(self.nf * 16), nn.LeakyReLU(0.2, inplace = True), nn.Dropout(0.1), nn.Conv2d(self.nf * 16, self.nf * 32, 4, 2, 1, bias = False), nn.BatchNorm2d(self.nf * 32), nn.LeakyReLU(0.2, inplace = True), nn.Dropout(0.1), nn.Conv2d(self.nf * 32, 1, 4, 1, 0, bias = False), nn.Sigmoid() ) def forward(self, input): output = self.main(input) return output.view(-1, 1).squeeze(1)学習を安定させるために、GeneratorとDiscriminatorの両方にLeakyReLUを使用しました。
同様の理由で、BatchNormを使用しました。学習の仕方
まずは、AとBについてReal画像とFake画像を用意します。
Fake画像はGeneratorを用いてReal画像から生成します。experiment.pyreal_A = data_train[0].to(device) real_B = data_train[1].to(device) fake_A = netG_B2A(real_B) fake_B = netG_A2B(real_A)DiscriminatorAの学習
Discriminatorに関してはGAN Lossのみを考えれば良いです。
Aに関するRealかFakeを判定するDiscriminatorAを学習させます。
criterion_GANはBCELossのことを指しています。
本物を見分けるので、Real_Aに対してlabel=1とします。
次に偽物を見分けます。Fake_Aに対してはlabel=0とします。
それぞれ画像を入力とするDiscriminatorのoutputに対してBCELossをとります。
これで、DiscriminatorのGAN Lossは満たされます。experiment.py#Discriminator Aの学習 optimizerD_A.zero_grad() #本物を見分ける batch_size = real_A.size()[0] label = torch.ones(batch_size).to(device) output = netD_A(real_A) errD_A_real = criterion_GAN(output, label) errD_A_real.backward() #偽物を見分ける label = torch.zeros(batch_size).to(device) output = netD_A(fake_A.detach())#勾配がGに伝わらないようにdetach()して止める errD_A_fake = criterion_GAN(output, label) errD_A_fake.backward() loss_train_D_A_epoch += errD_A_real.item() + errD_A_fake.item() optimizerD_A.step()DiscriminatorBの学習
DiscriminatorBに対しても、DiscriminatorAと同様な学習をさせます。
experiment.py#Discriminator Bの学習 optimizerD_B.zero_grad() #本物を見分ける label = torch.ones(batch_size).to(device) output = netD_B(real_B) errD_B_real = criterion_GAN(output, label) errD_B_real.backward() #偽物を見分ける label = torch.zeros(batch_size).to(device) output = netD_B(fake_B.detach())#勾配がGに伝わらないようにdetach()して止める errD_B_fake = criterion_GAN(output, label) errD_B_fake.backward() loss_train_D_B_epoch += errD_B_real.item() + errD_B_fake.item() optimizerD_B.step()Generatorの学習
Generatorの学習には、GAN LossとCycle Consistency Lossの2つがあります。
GAN Loss
BからAに変換するnetG_B2AとAからBに変換するnetG_A2Bの2つのGeneratorを同時に学習させます。
Generatorは自分が生成したFakeをDiscriminatorにRealと思わせたいので、label=1とします。
先ほどと同様に、それぞれ画像を入力とするDiscriminatorのoutputに対してBCELossをとります。
これで、GeneratorのGAN Lossは満たされます。experiment.py#Generatorの学習 optimizerG.zero_grad() fake_A = netG_B2A(real_B) fake_B = netG_A2B(real_A) #GAN Loss label = torch.ones(batch_size).to(device) output1 = netD_A(fake_A) output2 = netD_B(fake_B) errG_B2A = criterion_GAN(output1, label) errG_A2B = criterion_GAN(output2, label) errG = errG_B2A + errG_A2B loss_train_G_B2A_epoch += errG_B2A.item() loss_train_G_A2B_epoch += errG_A2B.item()Cycle Consistency Loss
netG_A2Bが生成したfake_Bに対して、netG_B2Aを用いてre_Aを生成します。
2回変換を施したので、re_A = Aになって欲しいです。(つまり、元に戻って欲しい)
そのため、real_Aとre_AにL1Lossを取れば良いです。
同じ操作をreal_Bに対しても行います。
(ここでは、criterion_cycleがL1Lossとする)experiment.pyre_A = netG_B2A(fake_B) re_B = netG_A2B(fake_A) #cycle Loss loss_cycle = criterion_cycle(re_A, real_A) + criterion_cycle(re_B, real_B) loss_train_cycle_epoch += loss_cycle.item() errG += loss_cycle errG.backward() optimizerG.step()実験結果
データセット
データセットにはmapsを使用しました。
下図のような航空写真とその地図写真の組み合わせのデータセットです。
trainに1096ペア、testに1098ペアあります。
以下、航空写真をA, 地図写真をBとします。各種パラメータの設定
- 画像のサイズ 256×256
- バッチサイズ 1
- Discriminatorの学習率 両方とも0.000014
- Generatorの学習率 両方とも0.0002
- エポック数 100
- Optimizer Adam
結果
100エポックの学習に丸2日かかりました。
上に示したグラフは、学習時のLossのグラフです。
G_BはAからBに変換するGenerator, G_AはBからAに変換するGenerator, D_AはAがRealかFakeどうかを判別するDiscriminator, D_BはBがRealかFakeどうかを判別するDiscriminator, cycleは2つのCycle Consistency Lossの和を表しています。G_BのLossが高くなっています。2つのGeneratorはどちらともDiscriminatorよりLossが高くなっています。Cycle Consistency Lossは小さいので、うまく機能していることがわかります。
次に、テスト時のLossのグラフです。学習時と同じようなグラフになりました。過学習が起きてないことがわかります。Bに関しては、学習時よりGeneratorとDiscriminatorのグラフが均衡しています。こちらもCycle Consistency Lossは小さいので、うまく機能していることがわかります。100エポック目のテスト時に変換した画像を見てみましょう。
成功例
これが変換する前のペア画像です。
これが変換した後のペア画像です。
もう1組見てみましょう。
これが変換する前のペア画像です。
これが変換した後のペア画像です。
どちらのペアもきれいに変換できていることがわかります。
失敗例
これが変換する前のペア画像です。
これが変換した後のペア画像です。
もう1組見てみましょう。
これが変換する前のペア画像です。
これが変換した後のペア画像です。
どちらのペアも画像がうまく変換されていません。特にBの方は全く変換されていません。
考察
綺麗に生成された画像は住宅街の画像が多く、失敗した画像の多くは木や水を含む画像でした。
このことから、住宅や道路などの変換は学習できていますが、森や山や川や海などの自然の変換の学習に失敗していることがわかりました。また、生成した画像全体にGAN特有のアーティファクトがありました。
失敗した理由1
データセットには、圧倒的に住宅街の画像が多かったので、住宅や道路などの変換を学習するには十分でしたが、自然を含む画像は比較的に少なめでしたので、自然の変換の学習には足りなかったと考えられます。
失敗した理由2
実験で試したデータセットは1種類のみでした。性能を試すには他のデータセットも使用するべきでした。
失敗した理由3
論文のTraining detailsでは、DiscriminatorにPatchGANを使用してました。しかし、自分の再現実装では、普通に画像全てを畳み込んでRealかFakeかどうかの判定をしてしまいました。
失敗した理由4
論文では、Proposed MethodでGANのLossに普通のmin-max optimizationを使っていたので、私も再現実装では、GANのLossに普通のmin-max optimizationを使用していましたが、論文のTraining detailsではLSGANのLossを使用して学習を安定させてました。
失敗した理由5
生成結果を良くするパラメータの調整はやりませんでした。
まとめ
CycleGANの再現実装をしましたが、論文で示されているほどの綺麗な生成画像は生成できませんでした。
DiscriminatorとGeneratorのアーキテクチャが論文と異なることが原因だと考えられます。
しかし、CycleGANの本質であるCycle Consistency Lossを再現実装できて、まあまあな結果が得られたので、自分としてはよかったかなと思います。























- 投稿日:2020-07-26T17:29:24+09:00
#atgm_2020 12匁 特殊な数独をソルバーで解くためにpythonとpulpを勉強する
はじめに
この記事は普段C++とかTypeScriptに慣れ親しんでいる、pythonもソルバーとか使ったことない筆者がpythonとpulpというソルバーライブラリを使ってみる記事です。
「あんたがた」シリーズ第二弾です
前作→#atgt2019 14匁にC++の力で挑んだが甜菜はそんなものをふっとばして答えにたどり着く - Qiitaatgtとは
「あめちゃん」が考案し、2ちゃんねるVIP板にて開催された「VIPPERのあんたがたに挑戦します」
その遊びはTwitterの世界に持ち込まれ、有志によって続いてきました。その正当な流れを組みつつ、新型コロナウィルス対策を施したルールにより、
ステイホームのゴールデンウィークを最高にwktkなものにしてくれたイベント、
それが「ツイッターのあんたがたに挑戦します2020GW」です。
- このイベントは全体戦で、「ツイッターのあんたがたに挑戦します2020GW」のパロディです。 本家GMの皆様におかれましては、本当にごめんなさい。そして心から御礼申し上げます。 パロディの程度や内容については、実戦でお確かめください。
- 本家GM以外のあんたがたも積極的にご参加ください。本家ほどではありませんが、難易度も分量もかなりのレベルです。
- ハッシュタグは #atgm_2020 を使用してください。
- 本イベントに関するツイートにはこのハッシュタグを付けてください。
- GM側からあんたがたに対するサポートは、問題が長時間解けない時のヒント出しです。 ヒントを出す前に、それが必要かどうかの投票を行います。
- このイベントで外出が必要なものはありません。暑い季節ですので、あんたがた各自で水分塩分糖分を補給する、睡眠を十分に確保するなど、健康管理に注意してください。
- 一般の方々には絶対に迷惑をかけない。
- 転んでも泣かない。そして楽しむ心が大事です。
12匁
さて、そうして始まったatgm_2020の12問目、問題を解き進めていくと、16x16の巨大な変則的数独を解く必要が出てきました。
9x9の通常の数独を拡張しただけではなく、
диагональ(対角線)
対角線上も重複してはいけないというルールでした。
ひんと#atgm_2020 pic.twitter.com/BXyALwv0KR
— 2020GW運営のあんたがたに挑戦します (@atgm_2020) July 25, 2020しかし人力で解き進めるにはいささか難しすぎるものでした
こういうのはソルバーに解かせたほうが速いのでは???
解かせ方
数独問題を制約充足問題として定義すれば、最適化の汎用ソルバーで解けますよねという方法です。この方法でも解があれば必ず見つかります。
正直ソルバーの類は扱ったことがないのですが、やってみます。
幸いこの記事には「Pulp使ったConstraint programming」のソースコードが提供されています。
残念なお知らせはpythonで書かれていることです。なぜ残念なお知らせかといえば、どういうわけか私がpythonでなにかしようとするたびに、なにかしらのエラーに遭遇して動かないからですね。まあせめてエラーに遭遇しにくいLinux環境を用意しましょう。
$ sudo apt-get install python3-distutils $ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py $ sudo python3 get-pip.py $ python3 -m pip install pulpとりあえずそこらへんに転がってたUbuntu18.04のVPSにSSHしたところ、pipすらなかったのでそこから導入しました。
python3-distutilsがないとsudo python3 get-pip.pyがコケるとかまじですか・・・。元記事のコードを理解する
内包記法
digits = [str(d + 1) for d in range(n)] boxes = [[(rows[b * i + k], columns[b * j + l]) for k in range(b) for l in range(b)] for j in range(b) for i in range(b)]でたな、内包記法。他の言語ではなかなかお目にかかれない
頭のおかしい特徴的な記法ですね。rangeは[0...n)の整数列をつくるやつですね。
LpVariable.dictschoices = LpVariable.dicts("Choice", (values, rows, columns), 0, 1, LpInteger)PuLP による線型計画問題の解き方ことはじめ - Qiita
によればpulpで変数オブジェクトを作る方法の一つのようですね。多分
Choice_1_1_1,Choice_1_1_2, ...って感じの変数名が作られていくのだと思います。基本的に0が入って、埋まったら1なのかな?目的関数
problem = LpProblem("Solving Sudoku", LpMinimize) # MinimizeでもMaximizeでもOK problem += 0, "Arbitrary Objective Function"目的関数が0ってどういうことなんでしょうね、任意の目的関数とか言われても、ちょっと良くわかりません。
制約
for v in values: for r in rows: problem += lpSum([choices[v][r][c] for c in columns]) == 1, "" for c in columns: problem += lpSum([choices[v][r][c] for r in rows]) == 1, "" for b in boxes: problem += lpSum([choices[v][r][c] for (r, c) in b]) == 1, "" for i in range(n**2): val = inp[i] if val != '0': problem += choices[str(val)][str(i/n + 1)][str(i % n + 1)] == 1, ""
LpVariable.dictsで作った変数は3次元なのでchoices[v][r][c]みたいにアクセスすると個々の変数が取れるようです。
lpSumは名前の通り合計ですね。普通のsumを使うとO(n^2)のオーダーになる、って書いてる記事があるんですが、どういう理屈なんだろうか。上から順に
- 各ますには一つの数字しか入らない
- 各列に同じ数字は1つ
- 各行に同じ数字は1つ
- 3x3 の中に同じ数字は一つ
- もとから入ってる数字
という制約だと思います。
再制約
while True: # cbcソルバー利用 problem.solve() if LpStatus[problem.status] == "Optimal": answers.append(''.join([v for r in rows for c in columns for v in values if value(choices[v][r][c]) == 1])) # 見つけた解を制約として追加 problem += lpSum( [choices[v][r][c] for v in values for r in rows for c in columns if value(choices[v][r][c]) == 1] ) <= 80 else: break何をやってるのかさっぱりです。
80って何???今回の問題に合わせて書き換える
盤面の大きさが違うのをまず直します
- n = 9 - b = 3 + n = 16 + b = 4それから追加の制約が必要です。対角線のことを制約に加えましょう。rangeをサクッとzipできるのいいですね、C++も外部ライブラリじゃなくて標準でできるようになってほしい(C++20ではまだなかったはず)
problem += lpSum([choices[v][i][i] for i in range(n)]) == 1, "" problem += lpSum([choices[v][r][c] for (r, c) in zip(range(n), reversed(range(n)))]) == 1, ""
KeyError: 0Traceback (most recent call last): File "solve.py", line 62, in <module> main(f) File "solve.py", line 35, in main problem += lpSum([choices[v][i][i] for i in range(n)]) == 1, "" File "solve.py", line 35, in <listcomp> problem += lpSum([choices[v][i][i] for i in range(n)]) == 1, "" KeyError: 0だめじゃん。
Python - KeyError pulpを使って特殊な数独を解きたいがエラーが出る|teratail
で質問したところ次のようなことがわかりました。digits = [str(d + 1) for d in range(n)] values = rows = columns = digitsより、keyは
'1'~'16'という文字列なのに、0~15の数値をkeyにしていることが問題だったようです。problem += lpSum([choices[v][str(i + 1)][str(i + 1)] for i in range(n)]) == 1, "" problem += lpSum([choices[v][str(r + 1)][str(c + 1)] for (r, c) in zip(range(n), reversed(range(n)))]) == 1, ""というわけで制約条件を見直しました。
入力の与えかたを変更
元記事では長大な数値列をコマンドライン引数として渡していました。しかしこれは使いにくいし、そもも盤面が大きくなったことで入力を1文字ずつ取り出すわけにはいかなくなりました。
素直にcsvを使いましょう。
当初
pythonでのcsvファイルの読み込み - Qiita
を見てf = csv.reader("input.csv", delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)でリストくれるしいいじゃんと思ってたのですが、
TypeError: '_csv.reader' object is not subscriptableとか言われるらしいですね、ようはイテレータで逐次読み出すような実装だからそのものはリストじゃなくって、だから添字アクセスできません、ということだろうか。teratailでの指摘通り
with open('input.csv') as fp: f = [] lines = fp.read().splitlines() for line in lines: f += line.split(',')にしました。
出力の変更
やっぱり数値列そのまま出てくる元記事のは読めないので整形したいなと思っていたらteratailで回答してくれた人がついでに教えてくれました。
import numpy as np ans = np.array([int(v) for r in rows for c in columns for v in values if value(choices[v][r][c]) == 1]).reshape(16,-1) answers.append(ans) # answers.append(''.join([v for r in rows for c in columns for v in values if value(choices[v][r][c]) == 1]))こんなふうに書き換えました。
最終的なプログラム
# -*- coding: utf-8 -*- import argparse import numpy as np from pulp import LpVariable, LpInteger, LpProblem, LpMinimize, LpStatus, lpSum, value def main(inp): n = 16 b = 4 digits = [str(d + 1) for d in range(n)] values = rows = columns = digits answers = [] choices = LpVariable.dicts("Choice", (values, rows, columns), 0, 1, LpInteger) boxes = [[(rows[b * i + k], columns[b * j + l]) for k in range(b) for l in range(b)] for j in range(b) for i in range(b)] # 問題提議 problem = LpProblem("SolvingSudoku", LpMinimize) # MinimizeでもMaximizeでもOK problem += 0, "Arbitrary Objective Function" # 制約追加 for r in rows: for c in columns: problem += lpSum([choices[v][r][c] for v in values]) == 1, "" for v in values: for r in rows: problem += lpSum([choices[v][r][c] for c in columns]) == 1, "" for c in columns: problem += lpSum([choices[v][r][c] for r in rows]) == 1, "" for b in boxes: problem += lpSum([choices[v][r][c] for (r, c) in b]) == 1, "" problem += lpSum([choices[v][str(i + 1)][str(i + 1)] for i in range(n)]) == 1, "" problem += lpSum([choices[v][str(r + 1)][str(c + 1)] for (r, c) in zip(range(n), reversed(range(n)))]) == 1, "" for i in range(n**2): val = inp[i] if val != '0': problem += choices[str(val)][str(i // n + 1)][str(i % n + 1)] == 1, "" while True: # cbcソルバー利用 problem.solve() if LpStatus[problem.status] == "Optimal": ans = np.array([int(v) for r in rows for c in columns for v in values if value(choices[v][r][c]) == 1]).reshape(16,-1) answers.append(ans) # answers.append(''.join([v for r in rows for c in columns for v in values if value(choices[v][r][c]) == 1])) # 見つけた解を制約として追加 problem += lpSum( [choices[v][r][c] for v in values for r in rows for c in columns if value(choices[v][r][c]) == 1] ) <= 80 else: break if answers: # 最初の解だけ表示 print(answers[0]) if __name__ == '__main__': with open('input.csv') as fp: f = [] lines = fp.read().splitlines() for line in lines: f += line.split(',') main(f)input.csv0,4,6,9,13,14,0,11,0,16,15,8,12,0,0,3 8,0,0,16,0,0,0,0,13,7,0,0,0,0,0,10 11,0,0,0,7,0,3,0,0,0,9,0,0,0,1,0 14,0,0,0,1,0,16,0,0,3,0,6,0,0,0,8 0,0,1,14,0,3,0,0,9,0,0,0,7,0,0,5 16,7,0,0,15,0,0,0,0,5,0,0,0,3,0,6 6,0,4,11,0,2,0,7,0,0,0,16,0,0,10,9 0,13,0,0,16,0,14,0,0,8,6,0,1,0,0,15 0,0,10,0,5,0,8,0,0,11,0,0,9,0,6,0 5,6,0,15,0,13,0,0,14,0,16,9,0,0,0,11 0,0,0,0,0,0,11,0,6,0,0,0,2,0,5,0 9,0,11,0,0,0,0,0,0,0,0,0,0,14,0,0 7,11,0,8,9,1,0,0,16,0,0,0,0,13,0,0 10,0,0,0,0,0,13,16,8,9,7,15,0,0,0,2 13,0,0,0,3,15,0,0,0,12,0,2,8,0,0,7 15,9,2,4,0,7,12,0,5,0,3,0,0,1,0,0outputWelcome to the CBC MILP Solver Version: 2.9.0 Build Date: Feb 12 2015 command line - /home/yumetodo/.local/lib/python3.6/site-packages/pulp/apis/../solverdir/cbc/linux/64/cbc /tmp/86dc532bb7f1470791450da595738a61-pulp.mps branch printingOptions all solution /tmp/86dc532bb7f1470791450da595738a61-pulp.sol (default strategy 1) At line 2 NAME MODEL At line 3 ROWS At line 1167 COLUMNS At line 26363 RHS At line 27526 BOUNDS At line 31624 ENDATA Problem MODEL has 1162 rows, 4097 columns and 17002 elements Coin0008I MODEL read with 0 errors Continuous objective value is 0 - 0.00 seconds Cgl0003I 24 fixed, 0 tightened bounds, 0 strengthened rows, 0 substitutions Cgl0003I 361 fixed, 0 tightened bounds, 0 strengthened rows, 124 substitutions Cgl0003I 111 fixed, 0 tightened bounds, 0 strengthened rows, 8 substitutions Cgl0003I 0 fixed, 0 tightened bounds, 0 strengthened rows, 8 substitutions Cgl0004I processed model has 0 rows, 0 columns (0 integer (0 of which binary)) and 0 elements Cbc3007W No integer variables - nothing to do Cuts at root node changed objective from 0 to -1.79769e+308 Probing was tried 0 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.000 seconds) Gomory was tried 0 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.000 seconds) Knapsack was tried 0 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.000 seconds) Clique was tried 0 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.000 seconds) MixedIntegerRounding2 was tried 0 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.000 seconds) FlowCover was tried 0 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.000 seconds) TwoMirCuts was tried 0 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.000 seconds) Result - Optimal solution found Objective value: 0.00000000 Enumerated nodes: 0 Total iterations: 0 Time (CPU seconds): 0.50 Time (Wallclock seconds): 0.54 Option for printingOptions changed from normal to all Total time (CPU seconds): 0.53 (Wallclock seconds): 0.58 Welcome to the CBC MILP Solver Version: 2.9.0 Build Date: Feb 12 2015 command line - /home/yumetodo/.local/lib/python3.6/site-packages/pulp/apis/../solverdir/cbc/linux/64/cbc /tmp/31c316a84f9740ac877548623e61cbc7-pulp.mps branch printingOptions all solution /tmp/31c316a84f9740ac877548623e61cbc7-pulp.sol (default strategy 1) At line 2 NAME MODEL At line 3 ROWS At line 1168 COLUMNS At line 26620 RHS At line 27784 BOUNDS At line 31882 ENDATA Problem MODEL has 1163 rows, 4097 columns and 17258 elements Coin0008I MODEL read with 0 errors Problem is infeasible - 1.54 seconds Option for printingOptions changed from normal to all Total time (CPU seconds): 1.57 (Wallclock seconds): 1.64 [[ 1 4 6 9 13 14 10 11 2 16 15 8 12 5 7 3] [ 8 3 5 16 2 12 9 15 13 7 14 1 11 6 4 10] [11 2 13 12 7 8 3 6 4 10 9 5 15 16 1 14] [14 10 15 7 1 5 16 4 11 3 12 6 13 2 9 8] [ 2 8 1 14 10 3 6 13 9 15 4 11 7 12 16 5] [16 7 9 10 15 11 1 8 12 5 2 14 4 3 13 6] [ 6 15 4 11 12 2 5 7 3 1 13 16 14 8 10 9] [ 3 13 12 5 16 4 14 9 10 8 6 7 1 11 2 15] [ 4 14 10 2 5 16 8 12 15 11 1 3 9 7 6 13] [ 5 6 8 15 4 13 7 1 14 2 16 9 3 10 12 11] [12 16 7 13 14 9 11 3 6 4 8 10 2 15 5 1] [ 9 1 11 3 6 10 15 2 7 13 5 12 16 14 8 4] [ 7 11 3 8 9 1 2 5 16 14 10 4 6 13 15 12] [10 12 14 1 11 6 13 16 8 9 7 15 5 4 3 2] [13 5 16 6 3 15 4 10 1 12 11 2 8 9 14 7] [15 9 2 4 8 7 12 14 5 6 3 13 10 1 11 16]]というわけで結果が求められました。
余談
私がpythonと格闘している最中に別の人がやっぱりソルバー使ってすでに答えを求めてました。
#atgm_2020
— 古銅@マイクラリソパ民 (@txkodo) July 25, 2020
未検証だがおそらく解答 pic.twitter.com/F5Zj7UPE7d

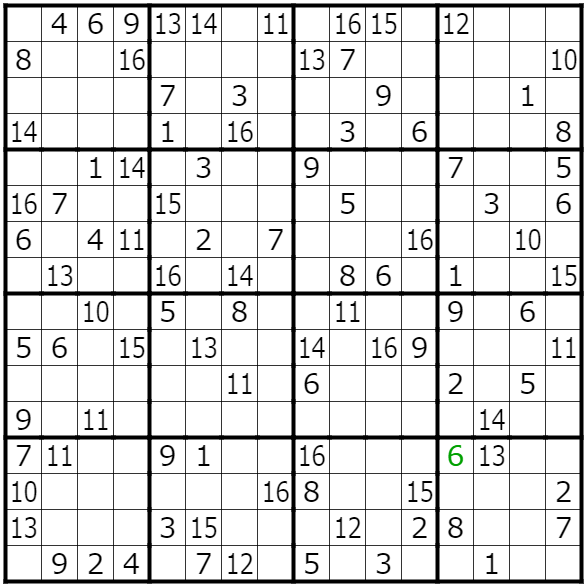

- 投稿日:2020-07-26T17:00:26+09:00
Oxford Dictionaries APIの使い方
Oxford Dictionaries APIとは
一言でいえば、かの有名なOxford Universityが提供する35か国語対応の辞書APIです。
月1000アクセスまでは無償で(商用も含めた)利用が可能です。
詳細はこちら。FAQより抜粋&意訳
Who built the Oxford Dictionaries API?
The Oxford Dictionaries API was built by a team in Oxford Dictionaries which is a part of Oxford University Press. You can find out more about our API here, and more about Oxford Dictionaries here.
Q:誰がOxford Dictionaries APIを作ったの?
A:Oxford University出版局のOxford Dictionaries部門のチームによって構築されました。
詳しくはこちら。What can I do with the Oxford Dictionaries API?
The Oxford Dictionaries API offers an easy way to access powerful lexical data (words, definitions, translations, audio pronunciations, synonyms, antonyms, parts of speech, and more) to use in your apps and websites. Please read our Terms and Conditions before signing up. If you would like to discuss your use of the API then please complete the Enterprise form to contact us.
Q:何ができる?
A:自然言語処理(見出し語変換や定義、翻訳、類義語など)。Which dictionary does the API data come from?
The Oxford Dictionaries API provides access to our current English dictionaries which are available on en.oxforddictionaries.com. This is our most comprehensive current English dictionary dataset and includes enhanced, updated versions of the Oxford Dictionary of English and the New Oxford American Dictionary. It includes more than 350,000 entries and is regularly updated with new words, senses, and definitions.
We also have content in Spanish, German, Portuguese, Romanian, isiZulu, Northern Sotho, Malay, Indonesian...and many more, and we're adding more all the time. Take a look at our supported languages page for the most up-to-date list.Q:データはどこから?
A:こちらのサイトで利用しているものと同じ。Which languages do you support?
In the API, we currently offer content in English, Spanish, German, Portuguese, Romanian, isiZulu, Northern Sotho, Latvian, Malay, Indonesian...and many more, and we're adding more all the time. Take a look at our supported languages page for the most up-to-date list.
If you’re looking for a dictionary dataset for a language which isn’t currently available via the API, we might still be able to help. We have over 35 language datasets, from Afrikaans to Vietnamese, available to license via Oxford Dictionaries Licensing. We are also building content in 100 of the world's languages, many of which are digitally under-represented, as part of our Oxford Global Languages initiative.Q:対応言語は?
A:英語、スペイン語、ドイツ語、ポルトガル語、ルーマニア語、ズールー語、北ソト語、ラトビア語、マレー語、インドネシア語など。アカウントの作り方
こちらからサイトにアクセスし、Get your API keyをクリック
(無料枠で運用したい場合は)左枠のPrototypeのGET STARTEDをクリック
必要事項を記入。なお"Please tell us more about your application"は短くても大丈夫(自分の場合はTo develop English learning bot.としました)。
入力したアドレスにメールが来るので、アカウントアクティベート用のURLをクリック。
アクティベート完了後にトップページに戻り、Sign In
使い方
サインイン後はトップページに(API) CREDENTIALSが追加されるので、そこをクリック
自分で設定したアプリ名をクリック
Application IDとApplication KEYを確認
以下コピペ
app_id = "Your own ID" app_key = "Your own Key" language = "en-gb" word = "Word you want to search" url = "https://od-api.oxforddictionaries.com:443/api/v2/entries/" + language + "/" + word.lower() response = requests.get(url, headers={"app_id":app_id, "app_key":app_key})
response.status_codeが200であれば成功、それ以外であれば失敗
status_code Message 400 Invalid value for filters such as lexicalCategory, registers, domains, etc. Invalid value for fields projections accepted. It is not possible to project a non-existing field. 404 No entry was found matching the selection parameters; OR an invalid filter was specified. 414 URL is too long. 500 Internal error. An error occurred during processing. 試し方
DOCUMENTATIONタブのV2 SWAGGER DOCSをクリック
下の方にあるExpand Operationsをクリック
確認したいプログラミング言語を選択]
例:Pythonを選択
python# for more information on how to install requests # http://docs.python-requests.org/en/master/user/install/#install import requests import json # TODO: replace with your own app_id and app_key app_id = '<my_app_id>' app_key = '<my_app_key>' language = 'en-gb' word_id = 'Ace' fields = 'pronunciations' strictMatch = 'false' url = 'https://od-api.oxforddictionaries.com:443/api/v2/entries/' + language + '/' + word_id.lower() + '?fields=' + fields + '&strictMatch=' + strictMatch; r = requests.get(url, headers = {'app_id': app_id, 'app_key': app_key}) print("code {}\n".format(r.status_code)) print("text \n" + r.text) print("json \n" + json.dumps(r.json()))
word_idに調べたい単語の「原形」を入力
Try it outをクリック
Try it outの下に表示されるAPIの返り値を確認
最後に
月1000回まではちょっと少ない気もしますが、いろいろ使えそうです!




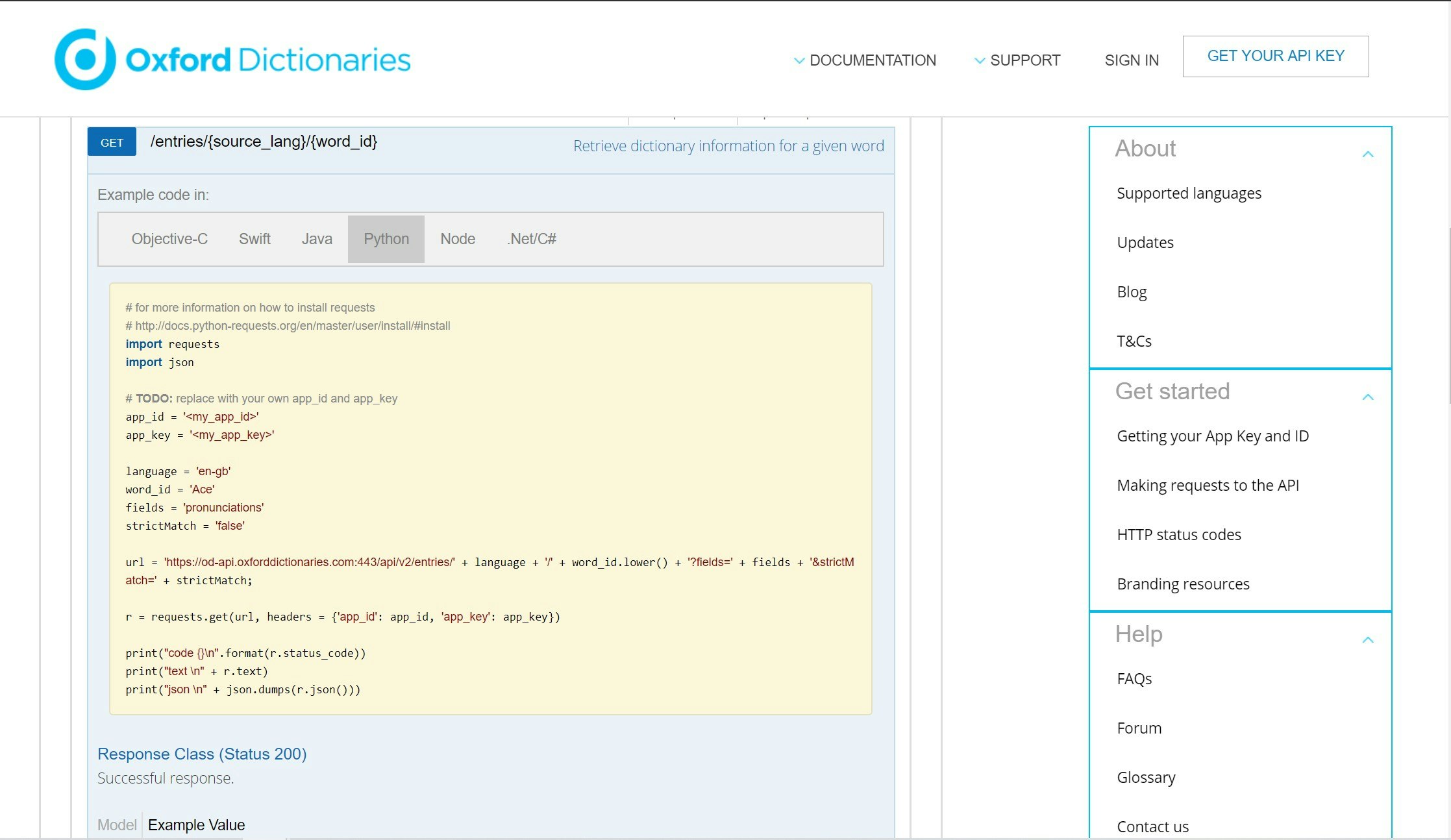
- 投稿日:2020-07-26T16:52:26+09:00
【PySimpleGUI備忘録】Windowの機能とZオーダー・モーダルの設定方法
はじめに
PythonでGUIを作成するとなると最初に考えたのがtkinterを使うことでした。
しかしtkinter、なかなかコードがわかりにくく、管理に自信を無くしていました。そんなときふと下記のサイトを拝見し、PySimpleGUIの存在を知りました。
Tkinterを使うのであればPySimpleGUIを使ってみたらという話この記事ではtkinterとPySimpleGUIで同じ処理をコードで比較しており、
その差が一目瞭然な内容になっています。
PySimpleGUIの長所がわかるので、是非読んでみることをお勧めします。皆さんにお勧めしたいのと同時に、自分も使いこなしたいので、
ドキュメントを読んで今回はウィンドウの機能を把握していきたいと思います。これを読んでわかること
・PySimpleGUIのWindowの引数とその機能
・ポップアップではなく第2画面が表示された場合、
メインウィンドウの操作ができないようにする(Zオーダーを設定する)方法・間接的に第2画面をモーダルにする方法
ドキュメントのURL
PySimpleGUI公式ドキュメント
tkinterに比べてドキュメントがしっかりしている点も高評価です。ちなみにGitにたくさんのサンプルプログラムを置いてくれています。
2018年と比較的最近から開発されているので、ネット上の記事もそこまで多くありません。
自分の求める結果を得る方法がなかなかわからないとき、
下記のサンプルプログラムを漁ればどこかでヒントが得られるはずです。
PySimpleGUI公式サンプルプログラム実行環境
Windows10
anaconda 2020.02
Python 3.7.6
PySimpleGUI 4.15.2以下、備忘録
sg.Windowの引数
デフォルトの設定
Window(title, layout=None, default_element_size=(45, 1), default_button_element_size=(None, None), auto_size_text=None, auto_size_buttons=None, location=(None, None), size=(None, None), element_padding=None, margins=(None, None), button_color=None, font=None, progress_bar_color=(None, None), background_color=None, border_depth=None, auto_close=False, auto_close_duration=3, icon=None, force_toplevel=False, alpha_channel=1, return_keyboard_events=False, use_default_focus=True, text_justification=None, no_titlebar=False, grab_anywhere=False, keep_on_top=False, resizable=False, disable_close=False, disable_minimize=False, right_click_menu=None, transparent_color=None, debugger_enabled=True, finalize=False, element_justification="left", ttk_theme=None, use_ttk_buttons=None, modal=False, metadata=None)'title=[str]
ディスプレイのタイトルバーに表示される文字列layout=[List]
ウィンドウに並ぶウィジェットのリストdefault_element_size=(width,height)[int]
ウィンドウ内のすべての文字の幅と行間のサイズdefault_button_element_size=(width,height)[int]
ウィンドウ内のすべてのボタンの文字幅と行間のサイズauto_size_text=[bool]
Trueの場合ウィンドウ内のウィジェットのサイズが
テキストの長さに合わせられる。auto_size_buttons=[bool]
Trueの場合ウィンドウ内のボタンのサイズがボタンのテキストの長さに合わせられる。location=(x,y)[int]
ピクセル単位で指定するウィンドウの左上隅の座標(位置)
※デフォルトではウィンドウは画面の中央に配置される。size=(width,height)[int]
ピクセル単位で指定するウィンドウのサイズ
※デフォルトではウィンドウは自動サイズ調整され、ユーザーは絶対サイズを設定しない。element_padding=((left,right),(top,bottom))[int]
ウィンドウ内のウィジェットを囲むデフォルトのパディング幅margins=((left,right),(top,bottom))[int]
ウィンドウ内のウィジェットの並ぶ矩形からウィンドウの端までのピクセル数button_color=[str]
ウィンドウ内のすべてのボタンのデフォルトの色font=(font,size)[str,int]
tkinterで使えるフォントを指定できる。フォント一覧はこちらを参考に。progress_bar_color=(bar_color,background_color)[str,str]
ウィンドウ内のすべての進捗バーのデフォルトの色background_color=[str]
背景色border_depth=[int]
ウィンドウ内のすべてのウィジェットのデフォルトのボーダーの幅auto_close=[bool]
Trueの場合ウィンドウは自動的に閉じるauto_close_duration=[int]
ウィンドウが自動で閉じる前の待機時間[秒]icon=[Union][str]
ファイル名またはBase64のいずれか。
※Windowsの場合、ファイル名はICO形式。Linuxの場合、ICOはだめ。force_toplevel=[bool]
Trueの場合、このウィンドウは隠れたマスターウィンドウの操作を受け付けないようにするalpha_channel=[float]
ウィンドウの不透明度(0=非表示,1=完全に表示)。0~1の値は半透明のウィンドウを生成。
※ただしRaspberryPiでは常に1return_keyboard_events=[bool]
Trueの場合キーボードで押した値がreadのeventとして返されるuse_default_focus=[bool]
Trueの場合デフォルトのフォーカスアルゴリズムによってウィジェットにフォーカスする。text_justification=(Union)('left'or'right'or'center')
ウィンドウ内のテキストのデフォルトの揃い位置no_titlebar=[bool]
trueの場合タイトルバーもフレームもウィンドウに表示されない。
(ウィンドウの最小化やクローズができない)grab_anywhere=[bool]
Trueの場合マウスでクリックやドラッグによりウィンドウを移動できる。keep_on_top=[bool]
Trueの場合ウィンドウは画面上の他のすべてのウィンドウの上に作成される。resizable=[bool]
Trueの場合ユーザーはウィンドウのサイズを変更できる。
※すべての要素がサイズ変更にあわせてサイズや位置が変更されるわけではない。disable_close=[bool]
Trueの場合ウィンドウの右上隅にあるXボタンは機能しない。disable_minimize=[bool]
Trueの場合ユーザーはウィンドウを最小化できない。right_click_menu=[List]
右クリックすると現れるメニュー項目の要素のリストtransparent_color=[str]
ウィンドウ内のこの色の部分は完全に透明になる。
この色のスポットをクリックして、このウィンドウの下のウィンドウに移動することもできる。debugger_enabled=[bool]
Trueの場合内部デバッガーが有効になる。
(GUIライブラリなだけあってGUIでエラーを出してくる。)finalize=[bool]
Trueの場合Finalizeメソッドが呼び出される。element_justification=(Union)('left'or'right'or'center')
テキストのみならずウィンドウ内のすべてのウィジェットの揃い位置ttk_theme=[str]
ウィンドウにtkinter ttk "テーマ"を設定する。(デフォルト= DEFAULT_TTK_THEME)
すべてのttkウィジェットのデフォルトをこのテーマに設定する。use_ttk_buttons=[bool]
ウィンドウ内のすべてのボタンにおいて下記適用される。
True = ttkボタンを使用します
False = ttkボタンを使用しない
なし= Macの場合にのみttkボタンを使用modal=[bool]
Trueの場合、このウィンドウはそれが閉じられるまで、ユーザーが操作できる唯一のウィンドウになる。
(このウィンドウが閉じない限りほかのウィンドウの操作はできない)metadata=[any]
ユーザーメタデータ2画面出してZオーダーを設定してみる
第2画面が常に上に来るようにZオーダーを設定してみます。
引数とその機能を参考にして、第2画面のWindow生成時にkeep_on_top=Trueにしてみます。コードは以下
(クラスまで作んなくてもいいんですが、まとまり重視で…)qiita_psg_window.pyimport PySimpleGUI as sg #メイン画面の設定 class MainDisplay: def __init__(self): sg.theme("DarkBlue12") self.layout = [[sg.Text("ボタンを押すとプログラムを終了します")], [sg.Button("Stop",key="-STOP-",size=(10,1))], [sg.Text("ボタンを押すとウィンドウを作成します")], [sg.Button("Make",key="-MAKE-",size=(10,1))]] self.window = sg.Window(title="MainDisplay",layout=self.layout) def make_second_display(self): disp2 = SecondDisplay() disp2.main() del disp2 def main(self): while True: event,value =self.window.read() if event in (None,"-STOP-"): sg.Popup("終了します") break elif event == "-MAKE-": self.make_second_display() self.window.close() #第2画面の設定 class SecondDisplay: def __init__(self): sg.theme("DarkBlue11") self.layout = [[sg.Text("ボタンを押すとこのウィンドウを閉じます")], [sg.Button("Exit",key="-EXIT-",size=(10,1))]] #keep_on_top=Trueにする self.window = sg.Window("SecondDisplay",self.layout,keep_on_top=True) def main(self): while True: event, value = self.window.read() if event == "-EXIT-": sg.Popup("このウィンドウを閉じます") break self.window.close() #メイン画面の表示ループ if __name__ == "__main__": disp1 = MainDisplay() disp1.main()確認の流れですが、起動したメイン画面のMakeボタンを押して第2画面を出します。
この時、メイン画面をクリックしてどうなるかを見ます。・keep_on_top=Falseの場合
メイン画面をクリックすると第2画面が後ろに回ってしまいました。・keep_on_top=Trueの場合
メイン画面をクリックしても第2画面は上に表示されたままです。ここで注意点があります。
このコードのままだとExitボタンを押してもポップアップが表示されません。
それは、第2画面が最上面に表示されるように設定しているからです。
ポップアップも最上面に出したいので、ポップアップの引数も変更します。def main(self): while True: event, value = self.window.read() if event == "-EXIT-": #keep_on_top=Trueにします sg.Popup("このウィンドウを閉じます",keep_on_top=True) break self.window.close()これで、ポップアップも表示されるようになりました。
また、この最上面表示の設定はPySimpleGUIだけでなく
ほかのソフトの画面に対しても有効なので注意が必要です。場合によってはメイン画面もTrueにする必要が出てきますが、
そうなるとのちにお話ししますが第2画面をモーダルにしないと、
第2画面もメイン画面も上位に来れてしまうので、
keep_on_top=Trueにした意味がなくなってしまいます。メイン画面のボタンが押せてしまう問題
Zオーダーは設定できましたが、はみ出ているメインボタンは押せてしまいます。
できればこれも阻止したい。
ということでwindowの引数modal=Trueにしてみました。
エラー…。ドキュメントには引数名は確かにmodalと書いていますが、
もしかしたら間違っているのかもと思い、
modalで検索すると下記のページに行き当たりました。
公式ドキュメント:Making your window modal2種類の方法が書かれていますので、どちらも試しました。
・moodel=Trueにする(引数名が違った)
・Window.make_modal()を追加する
結果…
どちらもダメでした。ちなみにそれっぽいforce_toplevel=Trueもやってみましたが、
別々のクラスですしマスターウィンドウというわけではなさそう?
なので効果なしでした。(簡易説明ではよくわかっていない)先のページ内で、この方法を提示してくれている後に、
なにやらウィンドウをモーダルにするような直接的な方法はサポートしていない
だか何だか書いているような気がします(英語苦手)。
最近はそういう風潮があるそうなので、仕方ないです。少なくともドキュメントからわかる直接的なモーダル化の方法はだめでしたので、
間接的な方法で実現するしかありません。間接的に第2画面をモーダルにする方法
その1 ウィンドウサイズを指定してメインウィンドウよりも大きくする
この場合第2画面が移動できてしまうと意味がないので、
第2画面のタイトルバーをなくすために、no_titlebar=Trueにします。
ついでにメインウィンドウのほうも同様にTrueに設定します。※タイトルバー以外のウィンドウ部分をクリックしながら、
ウィンドウを移動させることが出来るgrab_anywhereは、
デフォルトでFalseなので明記不要です。コードの変更箇所は以下です。少しメインウィンドウが小さくなるようにしています。
class MainDisplay: def __init__(self): sg.theme("DarkBlue12") self.layout = [[sg.Text("ボタンを押すとプログラムを終了します")], [sg.Button("Stop",key="-STOP-",size=(10,1))], [sg.Text("ボタンを押すとウィンドウを作成します")], [sg.Button("Make",key="-MAKE-",size=(10,1))] ] self.window = sg.Window(title="MainDisplay",layout=self.layout, size=(400,200),no_titlebar=True) #変更箇所class SecondDisplay: def __init__(self): sg.theme("DarkBlue11") self.layout = [[sg.Text("ボタンを押すとこのウィンドウを閉じます")], [sg.Button("Exit",key="-EXIT-",size=(10,1))] ] self.window = sg.Window("SecondDisplay",self.layout,keep_on_top=True, size=(420,220),grab_anywhere=True) #変更箇所実行結果
まずはメインウィンドウが開きます
第2画面が完全にメインウィンドウの上に表示されるため、
メインウィンドウをクリックすることが出来ません。
この作戦は成功です。その2 イベントの発生するウィジェットを操作不可にする
たとえばメイン画面ほど大きくすると第2画面の余白が目立つなど、
第2画面のサイズはメインより小さいままでモーダルにしたい場合です。ウィジェットの操作可否はあとからwindow.update()で変更できますので、
第2画面の作成前と終了後にそれらの設定をし直す方法です。
各ウィジェットの操作可否を決めるupdateの引数はdisabledで、
Trueで操作不可に、Falseで操作可能になります。※ただし、この場合メイン画面がクリックできてしまう位置関係なので、
Zオーダーを設定したい場合はメイン画面のkeep_on_topはTrueにできません。
keep_on_topのbool値とウィジェットのenabledは関係ないので、
メイン画面が上面にでてもウィジェットが操作できないようにはできます。コードの変更点は以下です。
def make_second_display(self): #第2画面作成前にボタンを操作不可にする self.window["-MAKE-"].update(disabled=True) self.window["-STOP-"].update(disabled=True) disp2 = SecondDisplay() #第2画面表示 disp2.main() #第2画面が閉じたらボタンを操作可能に戻す self.window["-MAKE-"].update(disabled=False) self.window["-STOP-"].update(disabled=False)コードが増えて直接的な感じがしますが、変更したいウィジェットが少ない場合は簡単です。
使用不可状態になったボタンは下記のように見た目が変わります。
(わかりやすいように第2画面を移動しています)
これで第2画面だけをkeep_on_top=Trueにして、
両画面をno_titlebar=Trueにすれば下記のように、
第2画面が小さいままメインウィンドウが前に出ることなく、
ボタンも押せない実質モーダル化ができます。
変更した部分のコードは以下です。
class MainDisplay: def __init__(self): sg.theme("DarkBlue12") self.layout = [[sg.Text("ボタンを押すとプログラムを終了します")], [sg.Button("Stop",key="-STOP-",size=(10,1))], [sg.Text("ボタンを押すとウィンドウを作成します")], [sg.Button("Make",key="-MAKE-",size=(10,1))]] self.window = sg.Window(title="MainDisplay",layout=self.layout, no_titlebar=True) #←ココclass SecondDisplay: def __init__(self): sg.theme("DarkBlue11") self.layout = [[sg.Text("ボタンを押すとこのウィンドウを閉じます")], [sg.Button("Exit",key="-EXIT-",size=(10,1))]] self.window = sg.Window("SecondDisplay",self.layout, keep_on_top=True,no_titlebar=True) #←ココおわりに
いかがでしたでしょうか。
直接的なモーダルの設定ができないところがまだもやもやしますが、
間接的な方法でも十分目的の実装はできそうな気がしました。他にも方法はあると思うので、これは一例ということで、
同じように困っている方の参考になれば幸いです。

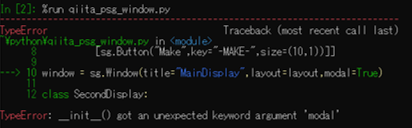




- 投稿日:2020-07-26T14:37:25+09:00
『統計検定準1級対応統計学実践ワークブック』をR, Pythonで解く~第16章重回帰分析~
日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
が統計検定の準備だけでなく統計学の整理に役立つので、R, Pythonでの実装も試みた。問16.1
表でデータが示されているが、ありものデータセットがなく、問16.2と内容が被るので略。
問16.2
R
- c.f. 71. 回帰分析と重回帰分析
data(airquality) head(airquality)A data.frame: 6 × 6 Ozone Solar.R Wind Temp Month Day <int> <int> <dbl> <int> <int> <int> 1 41 190 7.4 67 5 1 2 36 118 8.0 72 5 2 3 12 149 12.6 74 5 3 4 18 313 11.5 62 5 4 5 NA NA 14.3 56 5 5 6 28 NA 14.9 66 5 6
- モデル0
model0 = lm(Ozone ~ 1, data = airquality) summary(model0) sprintf("AIC=%.4f", AIC(model0))Call: lm(formula = Ozone ~ 1, data = airquality) Residuals: Min 1Q Median 3Q Max -41.13 -24.13 -10.63 21.12 125.87 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 42.129 3.063 13.76 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 32.99 on 115 degrees of freedom (37 observations deleted due to missingness) 'AIC=1143.2940'定数項のみのモデル。これでよいはずだがテキストと数字が違う。
- モデル1
model1 = lm(Ozone ~ Solar.R + Wind + Temp + Month, data = airquality) summary(model1) sprintf("AIC=%.4f", AIC(model1))Call: lm(formula = Ozone ~ Solar.R + Wind + Temp + Month, data = airquality) Residuals: Min 1Q Median 3Q Max -35.870 -13.968 -2.671 9.553 97.918 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -58.05384 22.97114 -2.527 0.0130 * Solar.R 0.04960 0.02346 2.114 0.0368 * Wind -3.31651 0.64579 -5.136 1.29e-06 *** Temp 1.87087 0.27363 6.837 5.34e-10 *** Month -2.99163 1.51592 -1.973 0.0510 . --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 20.9 on 106 degrees of freedom (42 observations deleted due to missingness) Multiple R-squared: 0.6199, Adjusted R-squared: 0.6055 F-statistic: 43.21 on 4 and 106 DF, p-value: < 2.2e-16 'AIC=996.7119'テキストと結果が一致。
- モデル2
model2 = lm(Ozone ~ Solar.R + Wind + Temp + Month + Day, data = airquality) summary(model2) sprintf("AIC=%.4f", AIC(model2))Call: lm(formula = Ozone ~ Solar.R + Wind + Temp + Month + Day, data = airquality) Residuals: Min 1Q Median 3Q Max -37.014 -12.284 -3.302 8.454 95.348 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -64.11632 23.48249 -2.730 0.00742 ** Solar.R 0.05027 0.02342 2.147 0.03411 * Wind -3.31844 0.64451 -5.149 1.23e-06 *** Temp 1.89579 0.27389 6.922 3.66e-10 *** Month -3.03996 1.51346 -2.009 0.04714 * Day 0.27388 0.22967 1.192 0.23576 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 20.86 on 105 degrees of freedom (42 observations deleted due to missingness) Multiple R-squared: 0.6249, Adjusted R-squared: 0.6071 F-statistic: 34.99 on 5 and 105 DF, p-value: < 2.2e-16 'AIC=997.2188'テキストと結果が一致。
Python
- RのデータセットをCSV出力したファイルを用いる。
- sklearn.linear_model.LinearRegressionでも重回帰分析が出来るが、各種統計量を直接は出力しないので、各種統計量も出力する statmodels を用いる
- 欠損値を自動処理しないので、事前に取り除く
- c.f. StatsModelsによる重回帰解析
import pandas as pd import statsmodels.api as sm df = pd.read_csv("airquality.csv") df.head()Ozone Solar.R Wind Temp Month Day 0 41.0 190.0 7.4 67 5 1 1 36.0 118.0 8.0 72 5 2 2 12.0 149.0 12.6 74 5 3 3 18.0 313.0 11.5 62 5 4 4 NaN NaN 14.3 56 5 5
- モデル0
- 定数項のみとするため説明変数にダミーでOzoneを入れて定数項を付与後Ozone列を削除している。
df0 = df.drop("Day", axis = 1) df0 = df1[df1.isnull().any(axis = 1) == False] x0 = df0.Ozone x0 = sm.add_constant(x0) x0 = x0.drop("Ozone", axis = 1) y0 = df0.Ozone model0 = sm.OLS(y0, x0) result0 = model0.fit() result0.summary()OLS Regression Results Dep. Variable: Ozone R-squared: -0.000 Model: OLS Adj. R-squared: -0.000 Method: Least Squares F-statistic: -inf Date: Thu, 23 Jul 2020 Prob (F-statistic): nan Time: 05:00:56 Log-Likelihood: -546.04 No. Observations: 111 AIC: 1094. Df Residuals: 110 BIC: 1097. Df Model: 0 Covariance Type: nonrobust coef std err t P>|t| [0.025 0.975] const 42.0991 3.158 13.329 0.000 35.840 48.358 Omnibus: 26.260 Durbin-Watson: 1.108 Prob(Omnibus): 0.000 Jarque-Bera (JB): 35.528 Skew: 1.248 Prob(JB): 1.93e-08 Kurtosis: 4.204 Cond. No. 1.00 Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.テキストと結果が一致。AICが2ずれているがツール(ライブラリ)によりAICの定義が異なるため。ツール内で閉じて比較する分には問題なし。
- モデル1
df1 = df.drop("Day", axis = 1) df1 = df1[df1.isnull().any(axis = 1) == False] x1 = df1.drop("Ozone", 1) x1 = sm.add_constant(x1) y1 = df1.Ozone model1 = sm.OLS(y1, x1) result1 = model1.fit() result1.summary()OLS Regression Results Dep. Variable: Ozone R-squared: 0.620 Model: OLS Adj. R-squared: 0.606 Method: Least Squares F-statistic: 43.21 Date: Thu, 23 Jul 2020 Prob (F-statistic): 1.85e-21 Time: 05:00:29 Log-Likelihood: -492.36 No. Observations: 111 AIC: 994.7 Df Residuals: 106 BIC: 1008. Df Model: 4 Covariance Type: nonrobust coef std err t P>|t| [0.025 0.975] const -58.0538 22.971 -2.527 0.013 -103.596 -12.511 Solar.R 0.0496 0.023 2.114 0.037 0.003 0.096 Wind -3.3165 0.646 -5.136 0.000 -4.597 -2.036 Temp 1.8709 0.274 6.837 0.000 1.328 2.413 Month -2.9916 1.516 -1.973 0.051 -5.997 0.014 Omnibus: 41.274 Durbin-Watson: 2.032 Prob(Omnibus): 0.000 Jarque-Bera (JB): 105.574 Skew: 1.394 Prob(JB): 1.19e-23 Kurtosis: 6.880 Cond. No. 2.53e+03 Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 2.53e+03. This might indicate that there are strong multicollinearity or other numerical problems.テキストと結果が一致。AICが2ずれているがツール(ライブラリ)によりAICの定義が異なるため。ツール内で閉じて比較する分には問題なし。
- モデル2
df2 = df.copy() df2 = df2[df2.isnull().any(axis = 1) == False] x2 = df2.drop("Ozone", 1) x2 = sm.add_constant(x2) y2 = df2.Ozone model2 = sm.OLS(y2, x2) result2 = model2.fit() result2.summary()OLS Regression Results Dep. Variable: Ozone R-squared: 0.625 Model: OLS Adj. R-squared: 0.607 Method: Least Squares F-statistic: 34.99 Date: Thu, 23 Jul 2020 Prob (F-statistic): 6.50e-21 Time: 05:00:24 Log-Likelihood: -491.61 No. Observations: 111 AIC: 995.2 Df Residuals: 105 BIC: 1011. Df Model: 5 Covariance Type: nonrobust coef std err t P>|t| [0.025 0.975] const -64.1163 23.482 -2.730 0.007 -110.678 -17.555 Solar.R 0.0503 0.023 2.147 0.034 0.004 0.097 Wind -3.3184 0.645 -5.149 0.000 -4.596 -2.041 Temp 1.8958 0.274 6.922 0.000 1.353 2.439 Month -3.0400 1.513 -2.009 0.047 -6.041 -0.039 Day 0.2739 0.230 1.192 0.236 -0.182 0.729 Omnibus: 40.425 Durbin-Watson: 2.088 Prob(Omnibus): 0.000 Jarque-Bera (JB): 98.522 Skew: 1.388 Prob(JB): 4.04e-22 Kurtosis: 6.688 Cond. No. 2.60e+03 Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 2.6e+03. This might indicate that there are strong multicollinearity or other numerical problems.テキストと結果が一致。AICが2ずれているがツール(ライブラリ)によりAICの定義が異なるため。ツール内で閉じて比較する分には問題なし。
問16.3
データはこれAquaticToxっすね。
R
スパース推定法による統計モデリング (統計学One Point)
も参考としました。(1)
#install.packages("QSARdata") library(QSARdata) #install.packages("glmnet") library(glmnet) data(AquaticTox)head(AquaticTox_Outcome)A data.frame: 6 × 2 Molecule Activity <fct> <dbl> 1 (d)-limonene 5.29 2 111-trichloro-2-methyl-2-propanolol(chlorobytanol) 3.12 3 111-trichloroethane 3.40 4 1122-tetrachloroethane 3.92 5 112-trichloroethane 3.21 6 11-dichloroethylene(vinylidene 2.84
- 列が長いので5列目までで略
head(AquaticTox_AtomPair[, 1:5])A data.frame: 6 × 5 Molecule AP_FP_522 AP_FP_41 AP_FP_521 AP_FP_402 <fct> <int> <int> <int> <int> 1 (d)-limonene 0 1 1 0 2 111-trichloro-2-methyl-2-propanolol(chlorobytanol) 0 0 0 0 3 111-trichloroethane 0 0 0 0 4 1122-tetrachloroethane 0 0 0 0 5 112-trichloroethane 0 0 0 0 6 11-dichloroethylene(vinylidene 0 0 0 0
- 不要な化合物名列を削除し、値がIntegerなのでNumericにする。
df_x = AquaticTox_AtomPair[, -1] df_x = apply(df_x, 2, as.numeric)
- テキストのResidualの図に該当するはず。
- defaultだとlog(λ)>0しか計算しないのでテキスト通りの範囲とした
model <- glmnet(x = df_x, y = AquaticTox_Outcome$Activity, alpha = 0, lambda = exp(seq(log(exp(-6)), log(exp(6)), length.out = 100))) rmse = apply((predict(model, newx = df_x) - AquaticTox_Outcome$Activity)^2, 2, sum) / nrow(df_x) plot(log(model$lambda), rmse, main = "Residual)
- テキストのcvの図に該当するはず。
- defaultだとlog(λ)>0しか計算しないのでテキスト通りの範囲とした
model.cv <- cv.glmnet(x = df_x, y = AquaticTox_Outcome$Activity, alpha = 0, lambda = exp(seq(log(exp(-6)), log(exp(6)), length.out = 100))) plot(model.cv)
- λの最適値は
model.cv$lambda.min1.19939610203539(2)
- 下記の通り
- model1: λ=0
- model2: λ=e^-2, α=0
- model3: λ=e^-2, α=0.5
- model4: λ=e^-2, α=1
par(mfrow = c(2, 2)) plot(c(model.1$a0, model.1$beta[, 1]), main = "model1", xlab = "variabls", ylab = "coef.") plot(c(model.2$a0, model.2$beta[, 1]), main = "model2", xlab = "variabls", ylab = "coef.") plot(c(model.3$a0, model.3$beta[, 1]), main = "model3", xlab = "variabls", ylab = "coef.") plot(c(model.4$a0, model.4$beta[, 1]), main = "model4", xlab = "variabls", ylab = "coef.") par(mfrow = c(1, 1))
- よって
- (a): model2
- (b): model1
- (c): model4
- (d): model3
(3)
- 下記の通り
- model2.1: α=0
- model2.2: α=0.5
- model2.3: α=1
model2.1 <- glmnet(x = df_x, y = AquaticTox_Outcome$Activity, alpha = 0) model2.2 <- glmnet(x = df_x, y = AquaticTox_Outcome$Activity, alpha = 0.5) model2.3 <- glmnet(x = df_x, y = AquaticTox_Outcome$Activity, alpha = 1) par(mfrow = c(2, 2)) plot(model2.1, xvar = "lambda", main = "model2.1") plot(model2.2, xvar = "lambda", main = "model2.2") plot(model2.3, xvar = "lambda", main = "model2.3") par(mfrow = c(1, 1))
- # of nonzerosの図は(a)だけlog(λ)の範囲が異なっているので再計算して
model2.1 <- glmnet(x = df_x, y = AquaticTox_Outcome$Activity, alpha = 0, lambda = exp(seq(log(exp(-6)), log(exp(6)), length.out = 100))) par(mfrow = c(2, 2)) plot(log(model2.1$lambda), apply(model2.1$beta, 2, function(x) {return(sum(x != 0))}), main = "model2.1", xlab = "log(λ)", ylab = "# of nonzeros") plot(log(model2.2$lambda), apply(model2.2$beta, 2, function(x) {return(sum(x != 0))}), main = "model2.2", xlab = "log(λ)", ylab = "# of nonzeros") plot(log(model2.2$lambda), apply(model2.3$beta, 2, function(x) {return(sum(x != 0))}), main = "model2.3", xlab = "log(λ)", ylab = "# of nonzeros") par(mfrow = c(1, 1))
- つまり
- (a): model2.1
- (b): model2.3
- (c): model2.2
Python
- scikit-learnとstatsmodelsにElastic Netのライブラリがある
下記記事などを参照させていただき実行はできるのだがテキスト、Rの結果と全く合わない、、、すみません勉強します
RのデータセットをCSV出力したファイルを用いる。
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import ElasticNet, enet_path import statsmodels.api as sm y = pd.read_csv("AquaticTox_Outcome.csv") y = y.drop("Molecule", axis = 1) x = pd.read_csv("AquaticTox_AtomPair.csv") x = x.drop("Molecule", axis = 1)(1)
# scikit-learn のみ alpha_range = np.logspace(-6, 6, 30, base=np.e) elout = np.empty((len(alpha_range), 2)) for i, a in enumerate(alpha_range): #l1 = np.log(l1) enet = ElasticNet(l1_ratio = 0, alpha = a) result = enet.fit(x, y) rmse = ((sum((result.predict(x) - y['Activity'])**2))/len(y))**0.5 elout[i] = [a, rmse] plt.plot(np.log(elout[:, 0]), elout[:, 1], color='lightgreen', linewidth=2, label='Elastic net coefficients')
(2)
#scikit-learn enet1 = ElasticNet(alpha = 0) result1 = enet1.fit(x, y) enet2 = ElasticNet(alpha = np.exp(-2), l1_ratio = 0) result2 = enet2.fit(x, y) enet3 = ElasticNet(alpha = np.exp(-2), l1_ratio = 0.5) result3 = enet3.fit(x, y) enet4 = ElasticNet(alpha = np.exp(-2), l1_ratio = 1) result4 = enet4.fit(x, y) fig = plt.figure() fig, axes = plt.subplots(nrows=2, ncols=2, sharex=False) axes[0, 0].scatter(np.arange(0, x.shape[1] + 1), np.append(np.array(result1.intercept_), result1.coef_)) axes[0, 1].scatter(np.arange(0, x.shape[1] + 1), np.append(np.array(result2.intercept_), result2.coef_)) axes[1, 0].scatter(np.arange(0, x.shape[1] + 1), np.append(np.array(result3.intercept_), result3.coef_)) axes[1, 1].scatter(np.arange(0, x.shape[1] + 1), np.append(np.array(result4.intercept_), result4.coef_)) fig.tight_layout() #レイアウトの設定 plt.show()
# statsmodels model1 = sm.OLS(y, sm.add_constant(x)) result1 = model1.fit_regularized(method='elastic_net', alpha = 0) # lambda = 0result2 = model.fit_regularized(alpha = np.exp(-2), L1_wt=0) # lambda = exp(-2), alpha = 0 model2 = sm.OLS(y, sm.add_constant(x)) result2 = model2.fit_regularized(method='elastic_net', alpha = np.exp(-2), L1_wt=0) # lambda = exp(-2), alpha = 0 model3 = sm.OLS(y, sm.add_constant(x)) result3 = model3.fit_regularized(method='elastic_net', alpha = np.exp(-2), L1_wt=0.5) # lambda = exp(-2), alpha = 0.5 model4 = sm.OLS(y, sm.add_constant(x)) result4 = model4.fit_regularized(method='elastic_net', alpha = np.exp(-2), L1_wt=1) # lambda = exp(-2), alpha = 1
- 図は略


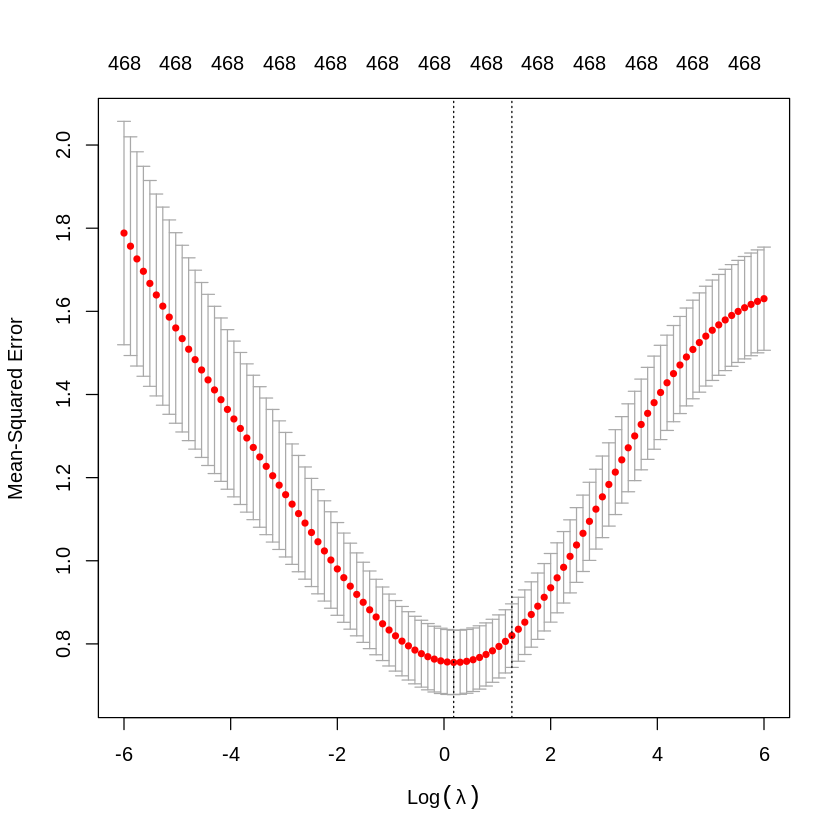

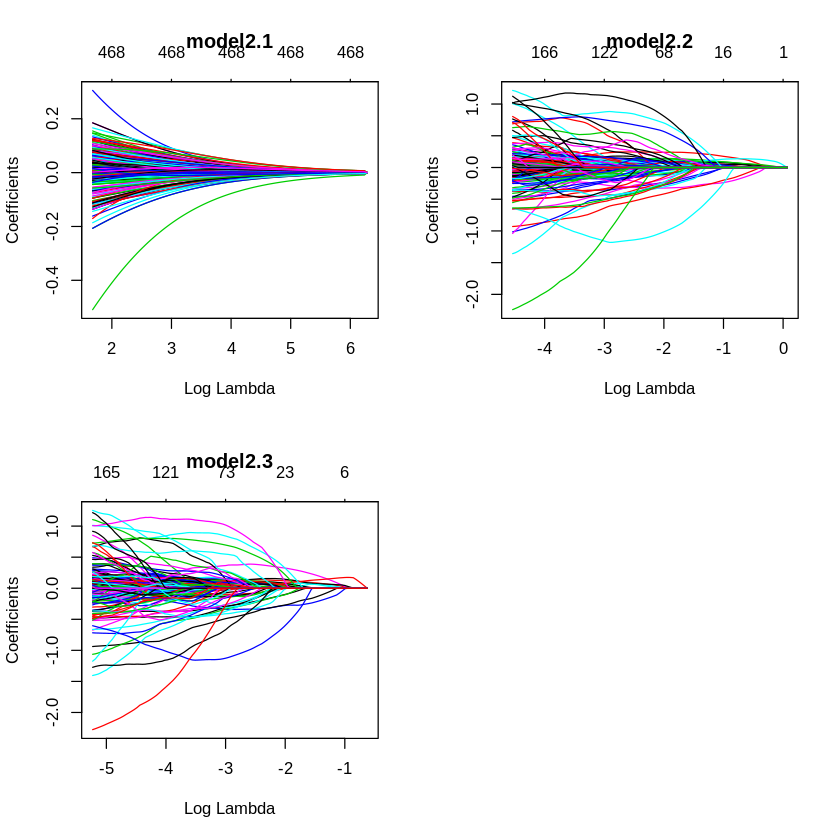
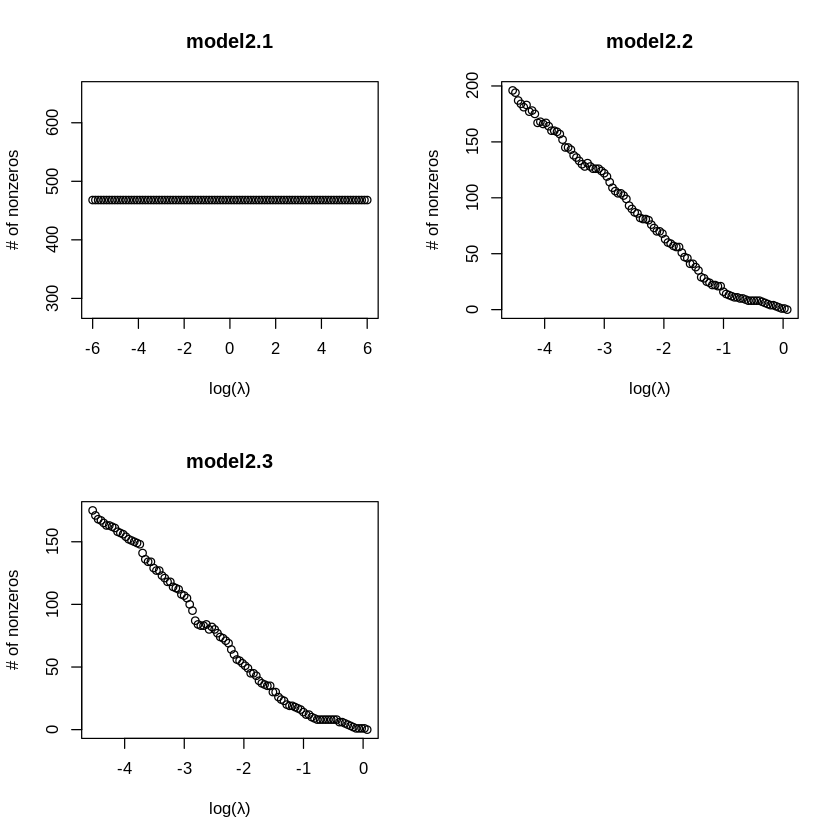

- 投稿日:2020-07-26T14:04:54+09:00
SciPyを使わずに数値積分
はじめに
数値積分を Python で利用する際, SciPy が使用可能なら当然ながら最初から
SciPy を使ったほうが良い. しかし, Pythonista3 のような動作環境下では
仕様上 SciPy を使うことができない. これは不便. ならば, アルゴリズムを
自分で考えて作ってしまえば良いのでは?! そんな流れで NumPy を利用して
数値積分のアルゴリズムを組んでみたというお話.実装する数値積分
$n$ : 数値積分の対象となる独立変数離散データの総数
$x_k$ : 数値積分で用いる独立変数離散データ(不等間隔でも可)
$f(x_k)$ : 従属変数離散データ台形則を用いると定積分は次のように近似できる.
\int_{a}^{b}f(x)\,{\mathrm d}x \approx \sum_{k=0}^{n-1} \frac{1}{2} \bigl\{ f(x_{k}) + f(x_{k+1}) \bigr\} (x_{k+1} - x_{k})Python スクリプト
Python のリストおよび for 文をそれぞれ用いると計算所要時間が延びるので,
NumPy を利用する.import numpy as np def integral_trapez(y, x, initial = None, last_one = True): integ = (y[:-1] + y[1:]) * (x[1:] - x[:-1]) * .5 if initial is not None: integ = np.insert(integ, 0, initial) integ = np.cumsum(integ) return integ if not last_one else integ[-1]計算例 その1
次の定積分を計算してみよう.
\int_{0}^{1} \frac{4}{1+x^2}\,{\mathrm d}x = \pia, b = 0., 1. # 積分下限と積分上限 samples = 10000 # 離散データ数 x = np.linspace(a, b, samples) y = 4. / (1. + x * x) print(f'answer = {integral_trapez(y, x):.10f}')結果
answer = 3.1415926519計算例 その2
アルキメデス曲線
\begin{align*} r &= a\theta \quad (a>0, \, \theta_0 \leq \theta \leq \theta_1) \\ z(\theta) &= re^{i\theta} \\ &= a\theta e^{i\theta} \end{align*}の図心を計算してみる. 図心計算式を以下に記す.
G = \frac{1}{L}\int_{0}^{L} z(s)\, {\mathrm d}s$L$ は曲線の全長である. アルキメデス曲線の曲線に沿った長さ $s$ は次の近似式で表される.
s = s(\theta) \approx \frac{a}{2} \left(\theta^2 - \theta_0^2 \right)${\mathrm d}s = a\theta\,{\mathrm d}\theta$ より置換積分を行うと,
G = \frac{2a}{\left( \theta_1^2 - \theta_0^2 \right)} \int_{\theta_0}^{\theta_1} \theta^2 e^{i\theta}\, {\mathrm d}\thetaPythonスクリプトを書くと次のようになる.
a = 1. theta_0, theta_1 = 8.1 * np.pi, 34.5 * np.pi samples = 10000 theta = np.linspace(theta_0, theta_1, samples) k = 2. * a / (theta_1 ** 2. - theta_0 ** 2.) f = np.power(theta, 2.) * np.exp(1j * theta) G = k * integral_trapez(f, theta) print(f'G = ({G.real:.8f}, {G.imag:.8f})')結果
G = (2.07163963, 0.14684833)参考までに SciPy を利用すると次のようになる.
from scipy.integrate import trapz print(k * trapz(f, theta)) # (2.0716396345278043+0.1468483276532503j)以上.
- 投稿日:2020-07-26T13:22:19+09:00
Restricted Boltzmann Machines理論からnumpyの実装まで
概要
RBMは簡単な生成モデルとして昔からずっと興味が持ってて、今回はその推論を追いながらnumpyで実装してみた。
モデル
Energy-based Models
Energy-based Modelsとは、データセット$\mathbf{V}$の確率分布を学習するために、サンプル$\mathbf{v}$ごとにエネルギー値$E(\mathbf{v})$をつけて、確率を表示するモデルです。
p(\mathbf{v}) = \frac{e^{-E(\mathbf{v})}}{Z}確率の高いサンプルにはエネルギー値は低い、低い確率ならはエネルギー値は高い。
よって、分配関数$Z$は
Z=\sum_\mathbf{v} e^{-E(\mathbf{v})}Restricted Boltzmann Machines(RBM)
RBMはEnergy-based Modelsの一つである同時に、マルコフ確率場(Markov Random Field)の一つでもある。その構造はこの図のように
一つの可視層(Visible Units)と隠れ層(Hidden Units)だけの簡単な構造です。また、Restricted(制限された)っていうのは、接続は可視層と隠れ層の間にだけ限定されて、同じ層のUnitsはお互い独立です。
可視層と隠れ層合わせて、確率はこれになっています
p(\mathbf{v},\mathbf{h}) = \frac{e^{-E(\mathbf{v},\mathbf{h})}}{Z}, \quad Z = \sum_\mathbf{v} \sum_\mathbf{h} e^{-E(\mathbf{v},\mathbf{h})}エネルギー関数$E(\mathbf{v},\mathbf{h})$の定義は
\begin{aligned} E(\mathbf{v},\mathbf{h}) &= -\mathbf{v}^\intercal W\mathbf{h} - \mathbf{b}^\intercal \mathbf{v} - \mathbf{c}^\intercal \mathbf{h} \\ &= -\sum_{i=1}^m\sum_{j=1}^n w_{ij}v_ih_j - \sum_{i=1}^m b_i v_i - \sum_{j=1}^n c_j h_j \end{aligned}多くの場合、隠れ層$\mathbf{h}$をベルヌーイ分布にします、すなわち$\mathbf{h} \in {0,1}^n$。
周辺分布と自由エネルギー
周辺分布$p(\mathbf{v})$を求めるなら
\begin{aligned} p(\mathbf{v}) &= \frac{1}{Z} \sum_{\mathbf{h} \in \{0,1\}^n} \exp(\mathbf{v}^\intercal W \mathbf{h} + \mathbf{b}^\intercal \mathbf{v} + \mathbf{c}^\intercal\mathbf{h}) \\ &= \frac{1}{Z} \exp(\mathbf{b}^\intercal \mathbf{v}) \sum_{\mathbf{h}_1} \cdots \sum_{\mathbf{h}_n} \exp\left(\sum_j^n \mathbf{v}^\intercal W_{\cdot j} h_j + c_j h_j\right) \\ &= \frac{1}{Z} \exp(\mathbf{b}^\intercal \mathbf{v}) \sum_{\mathbf{h}_1} \cdots \sum_{\mathbf{h}_n} \prod_j^n \exp( \mathbf{v}^\intercal W_{\cdot j} h_j + c_j h_j) \\ &= \frac{1}{Z} \exp(\mathbf{b}^\intercal \mathbf{v}) \left(\sum_{h_1}\exp(\mathbf{v}^\intercal W_{\cdot 1} h_1 + c_1 h_1)\right) \cdots \left(\sum_{h_n}\exp(\mathbf{v}^\intercal W_{\cdot n} h_n + c_n h_n)\right) \\ &= \frac{1}{Z} \exp(\mathbf{b}^\intercal \mathbf{v}) \big(1 +\exp(\mathbf{v}^\intercal W_{\cdot 1} + c_1)\big) \cdots \big(1 +\exp(\mathbf{v}^\intercal W_{\cdot n} + c_n)\big) \\ &= \frac{1}{Z} \exp(\mathbf{b}^\intercal \mathbf{v}) \exp\Big(\log\big(1 +\exp(\mathbf{v}^\intercal W_{\cdot 1} + c_1)\big)\Big) \cdots \exp\Big(\log\big(1 +\exp(\mathbf{v}^\intercal W_{\cdot n} + c_n)\big)\Big) \\ &= \frac{1}{Z} \exp\Big(\mathbf{b}^\intercal \mathbf{v}+\sum_j^n \log\big(1 +\exp(\mathbf{v}^\intercal W_{\cdot j} + c_j)\big)\Big) \\ &= \frac{e^{-\mathcal{F}(\mathbf{v})}}{Z} \end{aligned}ここに出った$\mathcal{F}$は自由エネルギー(Free Energy)と呼びます
\mathcal{F}(\mathbf{v}) = -\mathbf{b}^\intercal \mathbf{v}-\sum_j^n \log\big(1 +\exp(\mathbf{v}^\intercal W_{\cdot j} + c_j)\big)numpyで実装ならこうなる
def free_energy(v, W, b, c): first = v @ b.T second = (np.log(1 + np.exp(v @ W + c))).sum(axis=1,keepdims=True) return - first - second条件付き分布
隠れ層$\mathbf{h}$の条件付き分布
\begin{aligned} p(\mathbf{h}\mid \mathbf{v}) &= \frac{p(\mathbf{v},\mathbf{h})}{p(\mathbf{v})} \\ &= \frac{p(\mathbf{v},\mathbf{h})}{\sum\limits_h p(\mathbf{v},\mathbf{h})} \\ &= \frac{\frac{1}{Z}\exp(-E(\mathbf{v},\mathbf{h}))}{\sum\limits_h \frac{1}{Z}\exp(-E(\mathbf{v},\mathbf{h}))} \\ &= \frac{\exp(\mathbf{v}^\intercal W\mathbf{h} + \mathbf{b}^\intercal \mathbf{v} + \mathbf{c}^\intercal \mathbf{h})}{\sum\limits_h \exp(\mathbf{v}^\intercal W\mathbf{h} + \mathbf{b}^\intercal \mathbf{v} + \mathbf{c}^\intercal \mathbf{h})} \\ &= \frac{\exp(\mathbf{v}^\intercal W\mathbf{h})\exp(\mathbf{b}^\intercal \mathbf{v})\exp (\mathbf{c}^\intercal \mathbf{h})}{\sum\limits_h \exp(\mathbf{v}^\intercal W\mathbf{h})\exp(\mathbf{b}^\intercal \mathbf{v})\exp (\mathbf{c}^\intercal \mathbf{h})} \\ &= \frac{\exp(\mathbf{v}^\intercal W\mathbf{h})\exp (\mathbf{c}^\intercal \mathbf{h})}{\sum\limits_h \exp(\mathbf{v}^\intercal W\mathbf{h})\exp (\mathbf{c}^\intercal \mathbf{h})} \\ &= \frac{1}{Z\prime}\exp(\mathbf{v}^\intercal W\mathbf{h})\exp (\mathbf{c}^\intercal \mathbf{h}) \\ &= \frac{1}{Z\prime}\exp\big(\sum_{j=1}^n\mathbf{v}^\intercal W_{\cdot j} h_j + \sum_{j=1}^n c_j h_j\big) \\ &= \frac{1}{Z\prime} \prod_{j=1}^n \exp(\mathbf{v}^\intercal W_{\cdot j} h_j + c_j h_j) \\ &= \frac{1}{Z\prime} \prod_{j=1}^n p\prime(h_j \mid \mathbf{v}) \end{aligned}ここまでわかるのは、同じ層のUnitsはたしかにお互い独立ですよね。そして、$p\prime(h_j \mid \mathbf{v})$はまだ正規化していないの確率分布です。
\begin{aligned} p(h_j =1 \mid \mathbf{v}) &= \frac{p\prime(h_j=1,\mathbf{v})}{p\prime(h_j=0,\mathbf{v}) + p\prime(h_j=1,\mathbf{v})} \\ &= \frac{\exp(\mathbf{v}^\intercal W_{\cdot j} + c_j)}{\exp(0) + \exp(\mathbf{v}^\intercal W_{\cdot j} + c_j)} \\ &= sigmoid(\mathbf{v}^\intercal W_{\cdot j} + c_j) \end{aligned}可視層の$\mathbf{v}$も同じく
p(v_i =1 \mid \mathbf{h}) = sigmoid(W_{i \cdot} \mathbf{h} + b_j)numpyの実装ならば
def sigmoid(x): return 1 / (1 + np.exp(-x)) def h_given_v(v, W, c): return sigmoid(v @ W + c) def v_given_h(h, W, b): return sigmoid(h @ W.T + b)損失関数
学習は最尤推定法で行います。推定したいパラメータ$\theta = {W,\mathbf{b},\mathbf{c}}$、訓練サンプル$\mathbf{v}^{(t)}$に対して、損失関数(loss function)$\mathscr{l}(\theta)$の定義は negative log likelihood です
\begin{aligned} \mathscr{l}(\theta) &= -\log p(\mathbf{v}^{(t)}) \\ &= -\log \sum_{\mathbf{h}} p(\mathbf{v}^{(t)}, \mathbf{h}) \\ &= -\log \frac{1}{Z} \sum_{\mathbf{h}} \exp\big(-E(\mathbf{v}^{(t)},\mathbf{h})\big) \\ &= -\log \sum_{\mathbf{h}} \exp\big(-E(\mathbf{v}^{(t)},\mathbf{h})\big) + \log Z \\ &= -\log \sum_{\mathbf{h}} \exp\big(-E(\mathbf{v}^{(t)},\mathbf{h})\big) + \log \sum_{\mathbf{v},\mathbf{h}} \exp\big(-E(\mathbf{v},\mathbf{h})\big) \end{aligned}微分を取って
\nabla_\theta \mathscr{l}(\theta) = \underbrace{\nabla_\theta -\log \sum_{\mathbf{h}} \exp(-E(\mathbf{v}^{(t)},\mathbf{h}))}_{\text{positive phase}} + \underbrace{\nabla_\theta \log \sum_{\mathbf{v},\mathbf{h}} \exp(-E(\mathbf{v},\mathbf{h}))}_{\text{negative phase}}Positive Phaseには
\begin{aligned} \nabla_\theta -\log \sum_{\mathbf{h}} \exp\big(-E(\mathbf{v}^{(t)},\mathbf{h})\big) &= -\frac{1}{\sum_{\mathbf{h}} \exp(-E(\mathbf{v}^{(t)},\mathbf{h}))} \sum_h \exp(-E(\mathbf{v}^{(t)},\mathbf{h})) \frac{\partial -E(\mathbf{v}^{(t)},\mathbf{h})}{\partial \theta} \\ &= - \sum_h \frac{\exp(-E(\mathbf{v}^{(t)},\mathbf{h}))}{\sum_{\mathbf{h}} \exp(-E(\mathbf{v}^{(t)},\mathbf{h})} \frac{\partial -E(\mathbf{v}^{(t)},\mathbf{h})}{\partial \theta} \\ &= - \sum_h \frac{\frac{\exp(-E(\mathbf{v}^{(t)},\mathbf{h}))}{Z}}{\frac{\sum_{\mathbf{h}} \exp(-E(\mathbf{v}^{(t)},\mathbf{h})}{Z}} \frac{\partial -E(\mathbf{v}^{(t)},\mathbf{h})}{\partial \theta} \\ &= - \sum_h \frac{p(\mathbf{v}^{(t)},\mathbf{h})}{p(\mathbf{v}^{(t)})} \frac{\partial -E(\mathbf{v}^{(t)},\mathbf{h})}{\partial \theta} \\ &= - \sum_h p(\mathbf{h} \mid \mathbf{v}^{(t)}) \frac{\partial -E(\mathbf{v}^{(t)},\mathbf{h})}{\partial \theta} \\ &= \mathbb{E}_\mathbf{h}\left[ \frac{\partial E(\mathbf{v}^{(t)},\mathbf{h})}{\partial \theta} \middle| \mathbf{v}^{(t)} \right] \end{aligned}Negative Phaseには
\begin{aligned} \nabla_\theta \log \sum_{\mathbf{v},\mathbf{h}} \exp\big(-E(\mathbf{v},\mathbf{h})\big) &= \frac{1}{\sum_{\mathbf{v},\mathbf{h}} \exp(-E(\mathbf{v},\mathbf{h}))} \sum_{\mathbf{v},\mathbf{h}}\exp(-E(\mathbf{v},\mathbf{h})) \frac{\partial -E(\mathbf{v},\mathbf{h})}{\partial \theta} \\ &= \sum_{\mathbf{v},\mathbf{h}} \frac{\exp(-E(\mathbf{v},\mathbf{h}))}{\sum_{\mathbf{v},\mathbf{h}} \exp(-E(\mathbf{v},\mathbf{h}))} \frac{\partial -E(\mathbf{v},\mathbf{h})}{\partial \theta} \\ &= \sum_{\mathbf{v},\mathbf{h}} p(\mathbf{v},\mathbf{h}) \frac{\partial -E(\mathbf{v},\mathbf{h})}{\partial \theta} \\ &= - \mathbb{E}_{\mathbf{v},\mathbf{h}}\left[\frac{\partial E(\mathbf{v},\mathbf{h})}{\partial \theta}\right] \end{aligned}よって、勾配は
\nabla_\theta \mathscr{l}(\theta) = \mathbb{E}_{\mathbf{h}}\left[ \frac{\partial E(\mathbf{v}^{(t)},\mathbf{h})}{\partial \theta} \middle| \mathbf{v}^{(t)} \right] - \mathbb{E}_{\mathbf{v},\mathbf{h}}\left[\frac{\partial E(\mathbf{v},\mathbf{h})}{\partial \theta}\right]でも、第二項の$\mathbb{E}_{\mathbf{v},\mathbf{h}}$は intractable なので、近似するしかない。
Contrastive Divergence
Contrastive DivergenceはMCMCの一つである、そのコンセプトは
- $\mathbf{v}^{(t)}$を基で$k$回のギブスサンプリング (Gibbs sampling)を取って、$\tilde{\mathbf{v}}$と$\tilde{\mathbf{h}}$という negative サンプルを取得
- $\mathbb{E}_{\mathbf{v},\mathbf{h}}$を$\tilde{\mathbf{v}}$における点推定に置き換える
\mathbb{E}_{\mathbf{v},\mathbf{h}}[\nabla_\theta E(\mathbf{v},\mathbf{h})] \approx \nabla_\theta E(\mathbf{v},\mathbf{h}) \mid_{\mathbf{v}=\tilde{\mathbf{v}},\mathbf{h}=\tilde{\mathbf{h}}}ギブスサンプリングは二つの層に交代的に行います。
- $\mathbf{h}^{(k)} \sim p(\mathbf{h} \mid \mathbf{v}^{(k)})$
- $\mathbf{v}^{(k+1)} \sim p(\mathbf{v} \mid \mathbf{h}^{(k)})$
そして、それぞれは偏微分を取って
\nabla_W E(\mathbf{v}, \mathbf{h}) = \frac{\partial}{\partial W} - \mathbf{v}^\intercal W \mathbf{h} - \mathbf{b}^\intercal \mathbf{v} - \mathbf{c}^\intercal \mathbf{h} = - \mathbf{h} \mathbf{v}^\intercal\nabla_\mathbf{b} E(\mathbf{v}, \mathbf{h}) = \frac{\partial}{\partial \mathbf{b}} -\mathbf{v}^\intercal W \mathbf{h} - \mathbf{b}^\intercal \mathbf{v} - \mathbf{c}^\intercal \mathbf{h} = - \mathbf{v}\nabla_\mathbf{c} E(\mathbf{v}, \mathbf{h}) = \frac{\partial}{\partial \mathbf{c}} -\mathbf{v}^\intercal W \mathbf{h} - \mathbf{b}^\intercal \mathbf{v} - \mathbf{c}^\intercal \mathbf{h} = - \mathbf{h}よって、各パラメーターの誤差逆伝播(Back Propagation)がわかりました。例えば、$W$の場合
\begin{aligned} W &\Leftarrow W - \eta \big(\nabla_W - \log p(\mathbf{v}^{(t)})\big) \\ &\Leftarrow W - \eta \left(\mathbb{E}_\mathbf{h}\big[ \nabla_W E(\mathbf{v}^{(t)}, \mathbf{h}) \mid \mathbf{v}^{(t)} \big] - \mathbb{E}_{\mathbf{v},\mathbf{h}} [\nabla_W E(\mathbf{v},\mathbf{h})] \right) \\ &\Leftarrow W - \eta \left(\mathbb{E}_\mathbf{h}\big[ \nabla_W E(\mathbf{v}^{(t)}, \mathbf{h}) \mid \mathbf{v}^{(t)} \big] - \mathbb{E}_{\tilde{\mathbf{h}}} [\nabla_W E(\tilde{\mathbf{v}},\tilde{\mathbf{h}}) \mid \tilde{\mathbf{v}}] \right) \\ &\Leftarrow W - \eta \left(\mathbb{E}_\mathbf{h}\big[ -\mathbf{h}{\mathbf{v}^{(t)}}^\intercal \mid \mathbf{v}^{(t)} \big] - \mathbb{E}_\tilde{\mathbf{h}}\big[ -\tilde{\mathbf{h}}\tilde{\mathbf{v}}^\intercal \mid \tilde{\mathbf{v}} \big] \right) \\ &\Leftarrow W + \eta \left(sigmoid({\mathbf{v}^{(t)}}^\intercal W + \mathbf{c}) {\mathbf{v}^{(t)}}^\intercal - sigmoid(\tilde{\mathbf{v}}^\intercal W + \mathbf{c}) \tilde{\mathbf{v}}^\intercal \right) \end{aligned}バイアスの$\mathbf{b}$と$\mathbf{c}$も同じく扱うと
\mathbf{b} \Leftarrow \mathbf{b} + \eta (\mathbf{v}^{(t)} - \tilde{\mathbf{v}})\mathbf{c} \Leftarrow \mathbf{c} + \eta \big(sigmoid({\mathbf{v}^{(t)}}^\intercal W + \mathbf{c}) - sigmoid(\tilde{\mathbf{v}}^\intercal W + \mathbf{c})\big)さて、numpyで実装しましょう
def bernoulli(p): return np.floor(p + np.random.uniform(size=p.shape)) def cd_k(v, W, b, c, k=1): h_p = h_given_v(v, W, c) h = bernoulli(h_p) neg_v_p = v_given_h(h, W, b) neg_v = bernoulli(neg_v_p) neg_h_p = h_given_v(neg_v, W, c) neg_h = bernoulli(neg_h_p) for _ in range(k-1): neg_v_p = v_given_h(neg_h, W, b) neg_v = bernoulli(neg_v_p) neg_h_p = h_given_v(neg_v, W, c) neg_h = bernoulli(neg_h_p) dw = v.T @ h_p - neg_v.T @ neg_h_p db = v - neg_v dc = h - neg_h return dw, db, dcPseudo-likelihood
訓練の前にもう一つの準備が必要です。損失関数は intractable なので、代わりに Pseudo-likelihood というメトリクスを利用します。アイデアは簡単です。訓練サンプル$\mathbf{v}^{(t)}$に対して、ランダムに一つのビットを$1 \to 0$あるいは$0 \to 1$で「破壊」してnegative サンプル$\tilde{\mathbf{v}}$を得られて、そしてこの2つのサンプルの自由エネルギーの差は Pseudo-likelihood です。
\log PL(\mathbf{v}) \approx N \log\Big(sigmoid\big(\mathscr{F}(\tilde{\mathbf{v}}) - \mathscr{F}(\mathbf{v})\big)\Big)numpy の実装
def pseudo_likelihood(v, W, b, c): ind = (np.arange(v.shape[0]), np.random.randint(0, v.shape[1], v.shape[0])) v_ = v.copy() v_[ind] = 1 - v_[ind] fe = free_energy(v, W, b, c) fe_ = free_energy(v_, W, b, c) return (v.shape[0] * np.log(sigmoid(fe_ - fe))).mean(axis=0)訓練
いよいよ訓練がはじめるよ、今回はmnistで試しましょう。
環境とデータ準備
import numpy as np import seaborn as sns import matplotlib.pyplot as plt from sklearn.datasets import fetch_openml from sklearn.preprocessing import minmax_scale data, target = fetch_openml('mnist_784', version=1, return_X_y=True) size, dim = 28, np.array([6,12]) fig, ax = plt.subplots(figsize=(6,4)) img = np.zeros(dim * size, dtype='uint8') for i, d in enumerate(data[:dim.prod()]): ix, iy = divmod(i, dim[1]) img[ix*size:(ix+1)*size, iy*size:(iy+1)*size] = d.reshape(28,28) ax.imshow(img, cmap="gray") ax.set_axis_off() with plt.rc_context({"savefig.pad_inches": 0}): plt.show()
パラメータ設定
train_ds = data.astype(np.float32) / 255.0 def xavier_init(fan_in, fan_out, const=1.0): k = const * np.sqrt(6.0 / (fan_in + fan_out)) return np.random.uniform(-k, k, (fan_in, fan_out)) batch_size = 64 n_batch = (data.shape[0] + batch_size - 1) // batch_size # ceil n_epoch = 10 n_vis, n_hid = 784, 64 lr = 0.1 k = 1 params = { "W": xavier_init(n_vis, n_hid), "b": np.zeros([1, n_vis]), "c": np.zeros([1, n_hid]) }訓練開始
for e in range(n_epoch): cost = [] for v in np.array_split(train_ds, n_batch): dw, db, dc = cd_k(v, params['W'], params['b'], params['c'], k) params['W'] += (lr / v.shape[0]) * dw params['b'] += (lr / v.shape[0]) * db.sum(axis=0) params['c'] += (lr / v.shape[0]) * dc.sum(axis=0) cost.append(pseudo_likelihood(v, params['W'], params['b'], params['c'])) print("Epoch: {} cost: {:.6f}".format(e, np.mean(cost)))出力は
Epoch: 0 cost: -10.212753 Epoch: 1 cost: -8.183398 Epoch: 2 cost: -7.647802 Epoch: 3 cost: -7.483645 Epoch: 4 cost: -7.359071 Epoch: 5 cost: -7.193161 Epoch: 6 cost: -6.994519 Epoch: 7 cost: -6.987463 Epoch: 8 cost: -6.917506 Epoch: 9 cost: -7.007021結果
学習した分布をサンプリングしましょう
def gibbs(v, W, b, c, k=1): h = bernoulli(h_given_v(v, W, c)) for _ in range(k): v = v_given_h(h, W, b) h = bernoulli(h_given_v(bernoulli(v), W, c)) return v images = train_ds[:batch_size] v = gibbs(images, params['W'], params['b'], params['c'], k) size, dim = 28, np.array([8,8]) fig, ax = plt.subplots(1, 2, figsize=(8,5)) img = np.zeros(dim * size, dtype=np.float32) for i in range(dim.prod()): ix, iy = divmod(i, dim[1]) img[ix*size:(ix+1)*size, iy*size:(iy+1)*size] = images[i].reshape((28,28)) ax[0].imshow(img, cmap="gray") ax[0].set_axis_off() ax[0].set(title="original") img = np.zeros(dim * size, dtype=np.float32) for i in range(dim.prod()): ix, iy = divmod(i, dim[1]) img[ix*size:(ix+1)*size, iy*size:(iy+1)*size] = v[i].reshape((28,28)) ax[1].imshow(img, cmap="gray") ax[1].set_axis_off() ax[1].set(title="reconstructed") plt.tight_layout() plt.show()
ちょっとぼけているけど、大体復元しました。
最後に、学習したモデルの中身も見てみましょう
W = minmax_scale(params['W']) dim = np.array([8, 8]) fig, ax = plt.subplots(figsize=(6, 6)) img = np.zeros(dim * size, dtype=np.float32) for i in range(dim.prod()): x, y = divmod(i, dim[1]) img[x*size:(x+1)*size, y*size:(y+1)*size] = W[:,i].reshape(28,28) ax.imshow(img, cmap="gray") ax.set_axis_off() with plt.rc_context({"savefig.pad_inches": 0}): plt.show()
データセットを大体のそれぞれの特徴に分解したことがわかりました。
まとめ
すべての実装コードは Colab に置きました、興味ある方はそっちに参考してください。
https://colab.research.google.com/github/stwind/notebooks/blob/master/rbm-raw.ipynb
参考資料




- 投稿日:2020-07-26T12:24:39+09:00
コマンドライン入力でテキストファイルを読み込んで、整形して吐き出すだけのツール
動機
Elsevierのとある雑誌のこれまで発刊された全論文(オンライン化されてるもの)の書誌情報+アブストラクトのデータベースを作って、その分野の大きな流れをつかみたい。
ってことで、雑誌のページからひたすら書誌情報とアブストラクトをGoogle スプレッドシートに展開して、ついでに翻訳もしてるんだが、翻訳作業はともかく、書誌情報とアブストラクトがシンプルな改行だけで区切られた形になっていて、このままスプレッドシートに張り付けてもDBにならない。
手作業でコピペを繰り返してたが、ええ加減嫌になってきたので、整形してCSV化して吐き出させるプログラムを作る。
調べたこと
コマンドライン入力をどうやるのか
import sys sys.argv[0] # 実行してるファイルのパス sys.argv[1] # 一つ目の入力ファイル読みこみ(1行ずつ)
f=pen(path, mode = r, encoding="UTF-8") for s_line in f: print(s_line) f.close() # あるいは with open(path, mode = r, encoding="UTF-8") as f for s_line in f: print(s_line)ファイル書きこみ
f=pen(path, mode = w, encoding="UTF-8") f.write("文字列") f.close() # あるいは with open(path, mode = r, encoding="UTF-8") as f f.write("文字列")日付時間取得
%Y:年、%m:月、%d:日
%H:時、%M:分、%S:秒import datetme dt_now = datetime.datetime.now() print(dt_now.strftime("%Y_%m_%d_%H_%M_%S"))書いたプログラム
import sys import datetime # ファイルパスをコマンドライン入力から読み取る path = sys.argv[1] # 読み取ったファイルを開く f = open(path, encoding="UTF-8") # 1行ずつ読み取って整形.区切り文字は";" T = "" for s_line in f: print(s_line) if s_line != "\n" : T = T+'"'+s_line.rstrip('\n')+'";' elif s_line == "\n" : T = T + "\n" dt_now = datetime.datetime.now() fname = "MakeDB"+dt_now.strftime("%Y_%m_%d_%H_%M_%S")+".csv" # nf=open()でも良かったが、試しにwwithを使ってみた。 with open(fname,mode='w',encoding="utf-8") as nf: nf.write(T) f.close()
- 投稿日:2020-07-26T11:47:02+09:00
Fusion 360 を Pythonで動かそう その10 理解しづらかったことのおさらい
はじめに
Fusion 360 を Pythonで動かそう その1~9で公式ドキュメントのサンプルをいくつか触ってみました。そのなかから自分が理解しづらかったことのメモ書きとしてまとめた記事です
過去の記事はこちら
その1 スクリプトの新規作成
その2 スケッチに円を描いてみる
その3 スケッチに3つの接線で円を描く
その4 スケッチにいろんな方法で線を描く
その5 最初と最後のおまじないを読んでみる
その6 スケッチポイントを描く
その7 点を通過するスプライン作成
その8 スケッチのフィレットとオフセット
その9 スケッチの交差理解しづらかったこと・・・
Point3D オブジェクト
Fusion 360 API Reference Manual : Point3D Object によると・・・
トランジェント(一時的な) 3D ポイント。トランジェントポイントは、ドキュメントに表示されたり保存されたりしません。トランジェント 3D ポイントは、生の 3D ポイント情報を扱うためのラッパーとして使用されます。Point3D クラスの create メソッドを使用して静的に作成されます。
Point3Dはスケッチで円や線を描くための座標指定に多用されていました。一時的なポイントなのでそのままではFusion360に作図されません。点を作図するにはスケッチポイントやコンストラクションポイントとして配置する必要があります。
例えば SketchPoints.add メソッド:指定した場所に点を作成します。これは、ユーザーインターフェイスの Point コマンドを使用してスケッチポイントを作成するのと同等であり、グラフィックスウィンドウ内に可視ポイントを作成します。
「s 有りオブジェクト」と「s 無しオブジェクト」
同じような名前で「 s 」が有ったり無かったりで結構混乱してしまいました。
スケッチの円を例にして整理すると・・・
- SketchCircles オブジェクト(s 有り) : スケッチ内の円のコレクションです。これは既存の円へのアクセスを提供し、新しい円を作成するためのメソッドをサポートします。 addByCenterRadius メソッドで新しい円を描いたり、item メソッドで既存の円を指定したりできる(指定した結果は 「s 無しオブジェクト」が取得できる)
- SketchCircle オブジェクト(s 無し) : スケッチ内の円。deleteMe メソッドで削除したり、area プロパティで円の面積を取得したりできる
「s 無しオブジェクト」は円そのもの。「s 有りオブジェクト」は「s 無しオブジェクト」のコレクション。「s 無しオブジェクト」を作るときはコレクションに追加する形で作成するということ
「s 有りオブジェクト」と同じ名前の「s 有りプロパティ」
こちらもスケッチの円を例にすると・・・
- SketchCurves.sketchCircles プロパティ :SketchCurves オブジェクトのプロパティのひとつ。このスケッチに関連付けられた「スケッチの円のコレクション = SketchCircles オブジェクト(s 有りオブジェクト)」を返す。
オブジェクトと全く同じ「sketchCircles」という名前なので混乱した?
Input オブジェクトに慣れていこう
例えば押し出しを作成するのであれば・・・
- 想像していた方法 : ExtrudeFeatures.add メソッドにプロファイルや距離などの引数を指定すると押し出しができる
- 実際の方法 : ExtrudeFeatures.add メソッドの引数は ExtrudeFeatureInput オブジェクトひとつだけ。このInput オブジェクトのメソッドやプロパティで押し出しの方法を指定する
分かってしまえばそういうことなんだろうけど想像と違っていたので戸惑った
Fusion 360 API Reference Manual : Getting Started with Fusion 360's API > Input Objects によると入力オブジェクトは、より複雑なオブジェクトを作成するために必要なすべての入力を定義するために使用されます。入力オブジェクトは、APIのコマンドダイアログと同等のものと考えることができます。
とのこと。構築の平面、軸、点の作成も同様にInput オブジェクトが出てくる。UI操作のダイアログでの操作を想像しながら考えればしっくりくるようになりそう?
今後の課題
ObjectCollection を活用できるようになりたい
ObjectCollection オブジェクト :任意のオブジェクト型のリストを扱うために使用される汎用コレクション
Grasshopper のリストやツリーのように活用して複数のオブジェクトを効率よく扱うことができるか?今後の課題です。グローバル座標系とスケッチの座標系とPoint3Dの座標値
グローバル座標系とスケッチの中での座標系とPoint3Dで入力している座標値との関係が理解しきれていないので要調査。
まとめ
Grasshopperのようなビジュアルプログラミングと比べるてしまうと Fusion 360 API にはどうしてもとっつきにくさはあるけどもとても大きな可能性を感じるので引き続き学習を進めていきたい!