- 投稿日:2020-07-12T23:13:35+09:00
Djangoで期限切れセッションを削除する方法
Djangoで期限切れセッションは削除しちゃおう

Djangoでセッションはdefaultでデータベースに保存されます。
ほっておくと、期限切れセッションが増えてきてしまうので、
削除する方法を紹介したいと思います。試した環境
Django 3.0.5
Python 3.8.2仕様の確認
仕様を確認すると、推奨するやり方が書いてあります。
Clearing the session storeDjango does not provide automatic purging of expired sessions. Therefore, it’s your job to purge expired sessions on a regular basis. Django provides a clean-up management command for this purpose: clearsessions.
自動一掃はしないから、定期的に一掃するのはあなたの仕事ですよ。
でもコマンドは用意してるよって感じですね。どうやら、clearsessions というコマンドあるみたいですね。
削除方法
manage.py があるディレクトリに行き、下記コマンドを打つだけです。
$ python manage.py clearsessionsこれで、期限切れのセッションのみをデータベースから削除してくれるみたいです。
確認
DBのテーブル確認
セッションはdjango_sessionテーブルで確認できます。
現在2件のデータが入ってます。sqlite> select session_key, expire_date from django_session; 3dub24wutcq28y7lhgnfl2rasoy37646|2020-07-11 19:20:40 g7s29wnv45boguo5np33yroq61t4v9c2|2020-07-25 13:50:10expire_date は 2020-07-11 と 2020-07-25 です。
コマンドによる削除
現在の日付を確認して、セッションを削除します。
$ date 2020年 7月 12日 日曜日 23:00:36 $ python manage.py clearsessionsテーブルを確認してみましょう。
sqlite> select session_key, expire_date from django_session; g7s29wnv45boguo5np33yroq61t4v9c2|2020-07-25 13:50:101件のみになりました。
2020-7-12 23:00:36 時点で 2020-07-11 のセッションはexpireしてるので、削除されました。ご参考までに
実際にコマンドのソースコードを確認してみましょう。
clearsessionsのソースclass SessionStore(SessionBase): ... @classmethod def clear_expired(cls): cls.get_model_class().objects.filter(expire_date__lt=timezone.now()).delete()
expire_date < timezone.now()
で現在時刻より前のデータを対象にしているのが、分かると思います。参考にしたサイト
https://stackoverflow.com/questions/7296159/django-session-database-table-cleanup
- 投稿日:2020-07-12T22:56:07+09:00
PaizaスキルチェックD,Cランクでよく使うもの一覧~Python~
はじめに
この記事ではPaizaのスキルチェックで僕がよく使ったものを一覧にしてまとめています。
主にD,Cランクの問題を解くことを想定していますので、参考になれば幸いです。
ちなみに僕はBランクなので、同じレベルかそれ以上の方には参考にならないと思います。
そもそもPaizaを初めて使う人はこの記事を参考にしてください。
Python Paiza-スキルチェックと 標準入力(input)のいろいろ①input()を使った標準入力
Paizaの問題を解く時に一番最初にすることは、入力例から必要となる値を取ってくることです。
そのためにinputを使います。input()の特徴
inputは入力れいにある値を文字列型(str)として取ってきます。
そのため数字にしたい時にはint(input())で数字に直しましょう。また、
input()は1行丸ごと取ってきます。#a b cと入力。 paiza = input() print(paiza) #abc print(type(paiza)) #変数paizaの型を確認 #<class 'str'> (文字列型)input()の一般的な使い方
#入力例'Hello' paiza = input() #paiza変数に値を保管 #ここだけコピーすれば良いです! print(paiza) #Hello
()を忘れないように気をつけましょう。1行に複数の値がある時
先ほどは一つの値を取ってきましたが、複数の値を取ってくるときはどのようにすれば良いでしょうか?
#a b cと入力。 paiza = input().split() #ここだけコピーすれば良いです! print(paiza) #['a', 'b', 'c'] print(type(paiza)) #<class 'list'>このようにリストとして取って来れます。
あとはfor文などを使えばうまく使えそうですね。1行に複数の値がある時に1つ1つの値を取り出す
先ほどは1行に複数の値がある時の取り出し方を紹介しましたが、リストではなく1つ1つ取ってく流場合にはどのようにしたら良いのでしょうか?
#a bと入力 paiza, skill = input().split() #ここだけコピーすれば良いです! print(paiza) #a print(skill) #b print(type(paiza)) #<class 'str'> print(type(skill)) #<class 'str'>このようにすれば値を1つ1つ変数に代入して取って来れます。
ただし、1行の値の個数に対して変数の数が足りていないとエラーが起きるので気をつけましょう。#a b cと入力 paiza, skill = input().split() #値a, b, cの3つに対して、変数がpaiza, skillの二つしかないので足りない #ValueError: too many values to unpack (expected 2)足りないよ!と怒られてしまいました。
数字にする
先ほども述べたように
inputは文字列として値を取ってきます。
では数字にするには?#1を入力 paiza = input() print(paiza) #1 print(type(paiza)) #<class 'str'> paiza_number = int(paiza) #ここだけコピーすれば良いです! #int()を使って数字にする print(type(paiza_number)) #<class 'int'>リスト内包表記
では複数の値を数字にする方法を見ていきましょう。
リスト内包表記をいうものを使います。#1と2を入力 number1, number2= [int(x) for x in input().split()] #ここだけコピーすれば良いです! print(number1) #1 print(number2) #2 print(type(number1)) #<class 'int'> print(type(number2)) #<class 'int'>ちょっと難しいと思うので説明します。
input().split()には1と2がリストとして入っています。
そのリストの要素をfor文で1つずつ取り出して、xに代入します。
そしてそのxをint(x)で数字にして、number1に代入します。
もっと詳しく知りたいかたは是非調べてみてください・map関数
この方法とは別に
mapを使った方法もあります。
こちらの方が短いので使いやすいかもしれないです。#1 2 3と入力 number1, number2, number3 = map(int, input().split()) #ここだけコピーすれば良いです! print(a) #1 print(b) #2 print(c) #3 print(type(number1)) #<class 'int'> print(type(number2)) #<class 'int'> print(type(number3)) #<class 'int'>②リスト
リストはしょっちゅう使います。
ただリストを用意するだけでなく、リストに追加したり削除したりする方法を紹介していきます。空のリストを用意
paiza = []これはリストを空にすることにも使えます。
要素を追加
#リスト名.append(追加したい値) paiza.append('a') print(paiza) #['a']要素を削除
remove
print(paiza) #['a', 'b', 'c'] #リスト名.remove(要素名) paiza.remove('a') print(paiza) #['b', 'c']del
#del リスト名[インデックス番号] print(paiza) #['a', 'b', 'c'] del paiza[1] print(paiza) #['a', 'c']並び替え
この場合下のリストが並び替えられるので注意してください。
小さい方から
paiza = [2,5,3,1,4] paiza.sort() print(paiza) #[1, 2, 3, 4, 5]大きい方から
paiza = [2,5,3,1,4] paiza.sort(reverse=True) print(paiza) #[5, 4, 3, 2, 1]
reverseは逆順にする指定です。リストを出力
#'ここに区切りたいものを入れる'.join(リスト名) paiza = ['a', 'b', 'c', 'd', 'e'] print('?'.join(paiza)) #?で区切る #a?b?c?d?e③ループ
Paizaのスキルチェックで頻繁にループが使われます。
基本的なforループの使われ方は是非調べてみてください。何行もの入力を取り出す時
何行もの入力を取り出す時
inputを何回も書くのはめんどくさいです。
そんな時for文で取り出すようにしましょう。for i in range(繰り返したい回数): #使用例:range(5) paiza = input()このように書くことで
inputをrangeに入力した数字の回数だけ繰り返すことができます。入力されたものを取り出しリストに格納
#a b c d e paiza = [] for i in range(5): a = input() paiza.append(a) print(paiza) #['a', 'b', 'c', 'd', 'e']
input()で1行の入力を取り出し、それをリストに追加するのを5回繰り返します。④小数点の調整
小数点切り捨て
単純な割り算
a = 10 b = 3 paiza = 10//3 print(paiza) #3math.floor
import math a = 10.123 print(math.floor(a)) #10小数点切り上げ
import math a = 10.123 print(math.ceil(a)) #10⑤偶数と奇数
if文を使った偶数と奇数の判定は何回か出てきます。
number = 2 if number%2==0: print('ok') else: print('no') #okあまりを出す計算をして、あまりが0ならば
okを出力し、それ以外ならnoを出力するというもの。最後に
自分が今思いつくものでよく使ったものを一通り上げました。
随時更新していく予定です。
- 投稿日:2020-07-12T22:49:07+09:00
【メモ】ROSで複数トピックからメッセージをSubscribe
はじめに
ROSでは複数のトピックをSubscribeする場合が多いので、そのときのやり方をメモ
以下の記事がとても参考になりました。
ROSで複数のトピックから同期的にメッセージを受け取る方法
複数のメッセージをSubscribeするには、
message_filtersを使う。
例えば、ROSのtutorialsのlistenerを拡張すると、#/usr/bin/env python import message_filters import rospy from std_msgs.msg import Int32 # Define callback def callback(msg1, msg2): print(msg1.data) print(msg2.data) # Initialize Subscriber node rospy.init_node('listener') # Define Subscriber sub1 = message_filters.Subscriber('listener1', Int32) sub2 = message_filters.Subscriber('listener2', Int32) queue_size = 10 fps = 100. delay = 1 / fps * 0.5 mf = message_filters.ApproximateTimeSynchronizer([sub1, sub2], queue_size, delay) mf.registerCallback(callback) rospy.spin()
message_filters.ApproximateTimeSynchronizer()で複数のsubscriberを同期している。尚、python2の場合は、
fps=100.のようにfloat型にしなければdelay=0と計算されてしまうので注意!
- 投稿日:2020-07-12T22:24:28+09:00
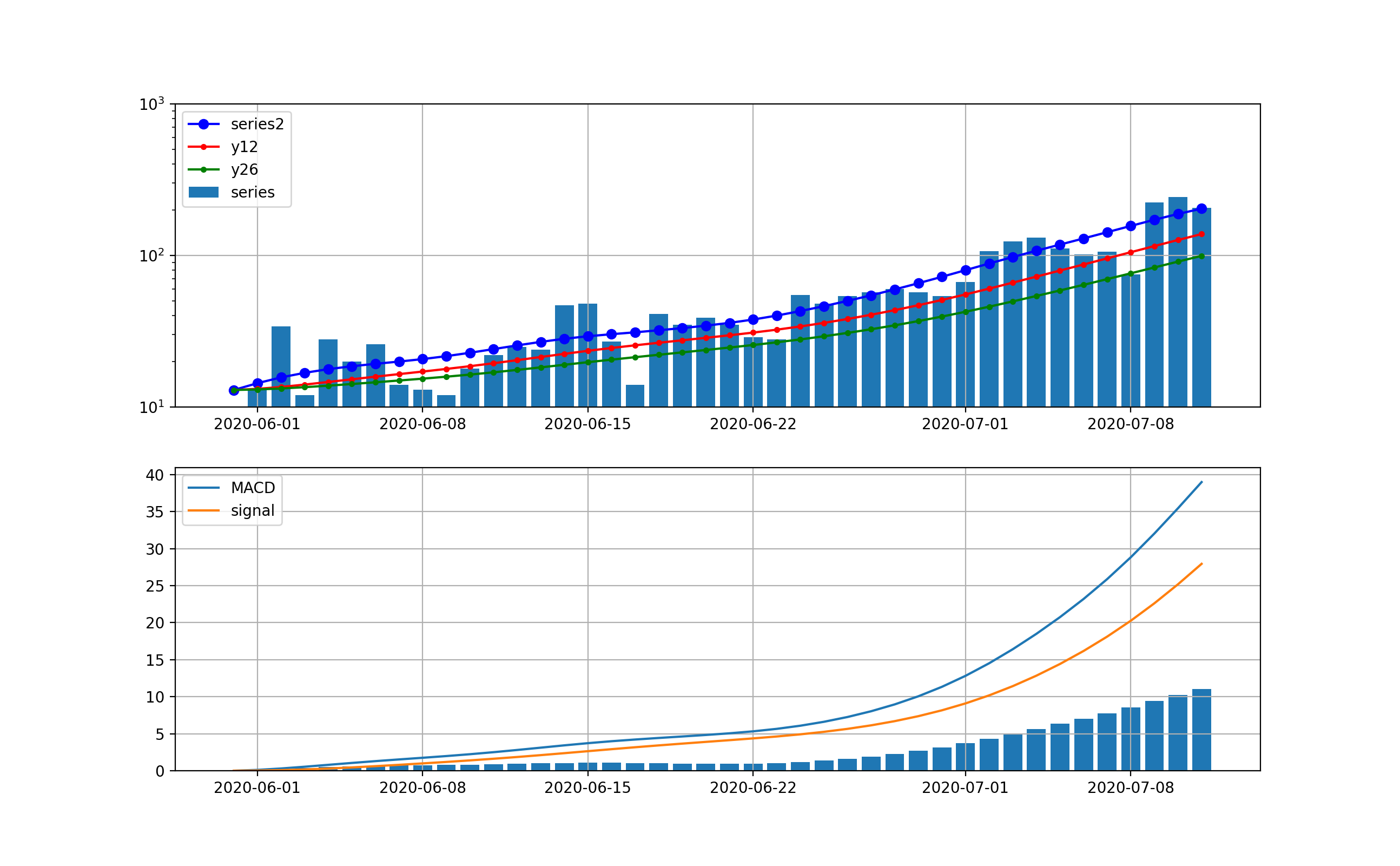
【感染症モデル入門】対数グラフを見てみると。。。「第二波だ」から1週間‼
前回の記事からもう一週間たったが、その後の傾向をまとめようと思う。
今回は、株価予想に使っているMACDを利用して、今後の状況を見たいと思う。
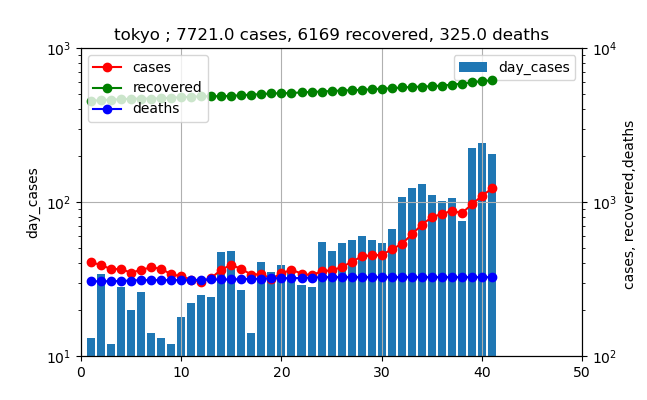
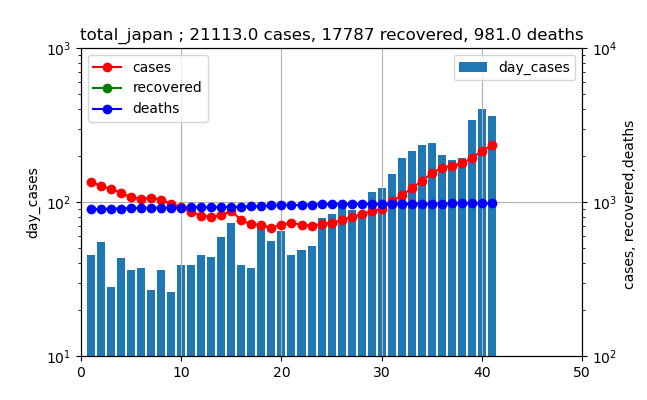
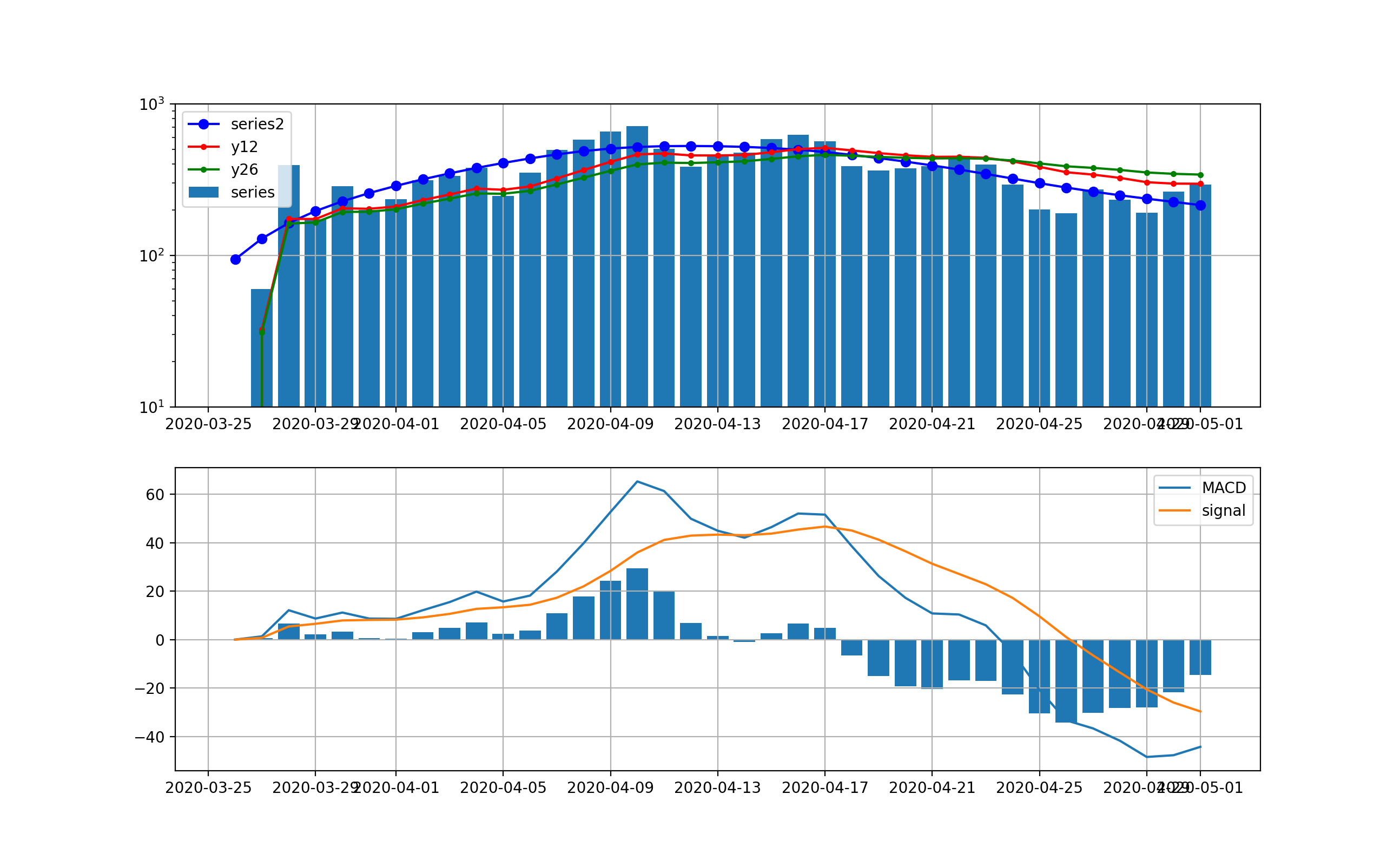
まず、現在の状況を普通の対数グラフで見ると、東京と全国はそれぞれ以下のとおりである。
東京は、既に第一波の最大値を超えて、なお指数関数的に増加中である。ただし、先週の日~水曜日が少し減少傾向を示したが、態勢には影響なしである。また、本日も206人と日曜日であるが、ほぼ同様な感染数となっている。
一方、全国も同様に指数関数的に増加している。全国も日~水曜日に減少が見られた。全国も本日371人とほぼ同様な感染数である。
MACDを適用する
まず、第一波の3月下旬から4月末までの変化に適用する。
ロジックは簡単に記載すると以下のとおりMACD=12日EMA-26日EMA Signal=MACDの9日EMA ヒストグラム=Signal-MACDここで、EMA(Exponential Moving Average)は、以下の漸化式で計算される。
{S_{{t}}=\alpha \times Y_{{t-1}}+(1-\alpha )\times S_{{t-1}} }ここで、$Y_{{t-1}}$はt-1時点の観測値、$S_{{t-1}}$は一個前のEMAである。$\alpha = {2 \over {N+1}}$であり、N=9で0.2程度の値であり、$S_{{t}}$は今の観測点に近いほど大きく評価して平均に取り入れている。
ということで、第一波の時の動きは以下のとおりと計算できる。
東京は以下のとおり、減少傾向は4月17日以降ははっきり読み取れるが、ノイズが大きい。
全国は以下のとおりで、ほぼ東京と同様に4月17日以降減少傾向が見て取れる。
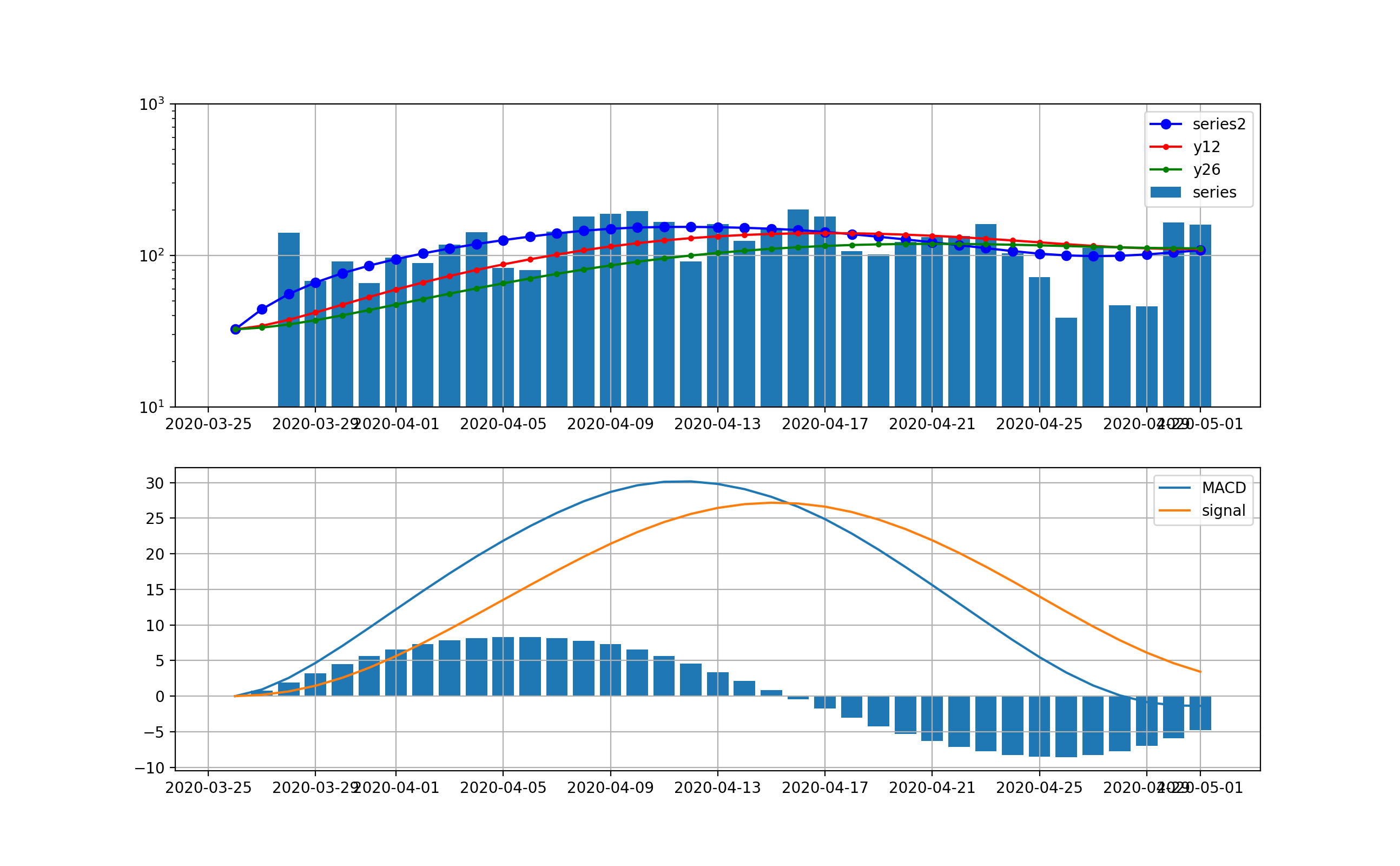
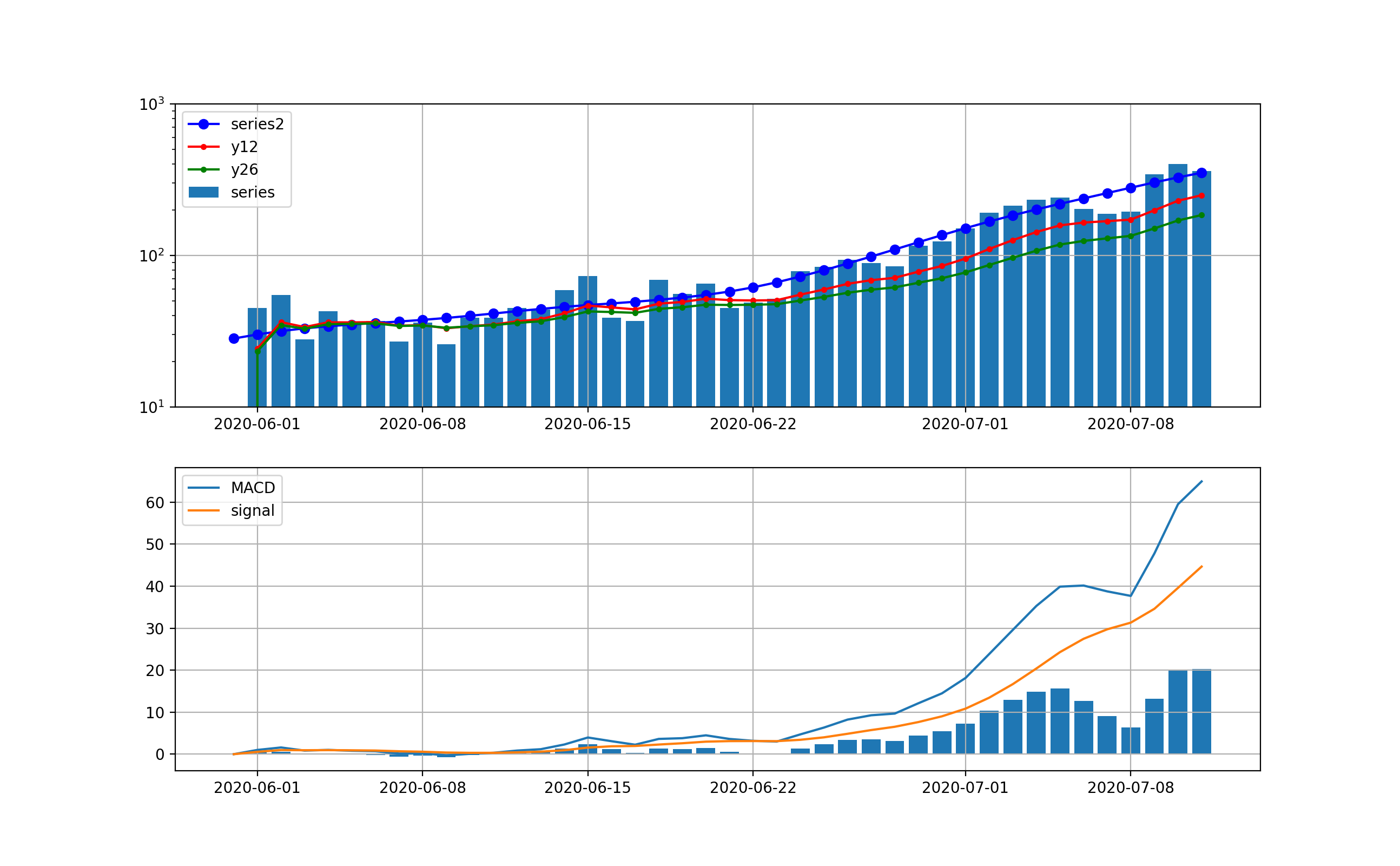
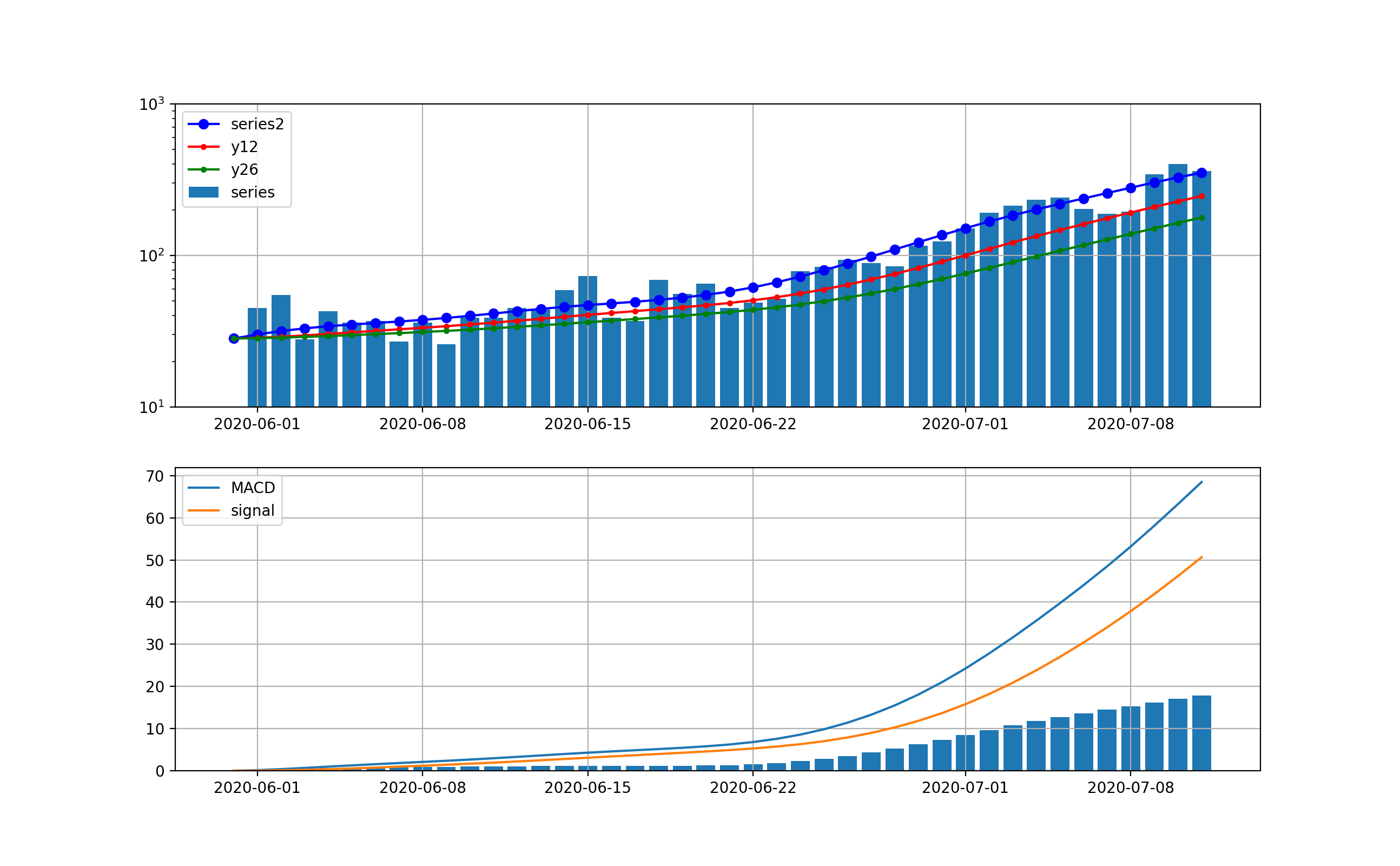
実は上記を見るとやはり毎日の変動が大きいので、シストレの記事と同様に、ここでDecomposeを導入してトレンド曲線を利用して同じ処理をしたものを示す。
東京は以下のとおりとなり、明らかに4月15日をピークとして減少傾向に転じていることが分かる。
全国は以下のとおりとなった。こちらも4月16日をピークに減少傾向に転じている。
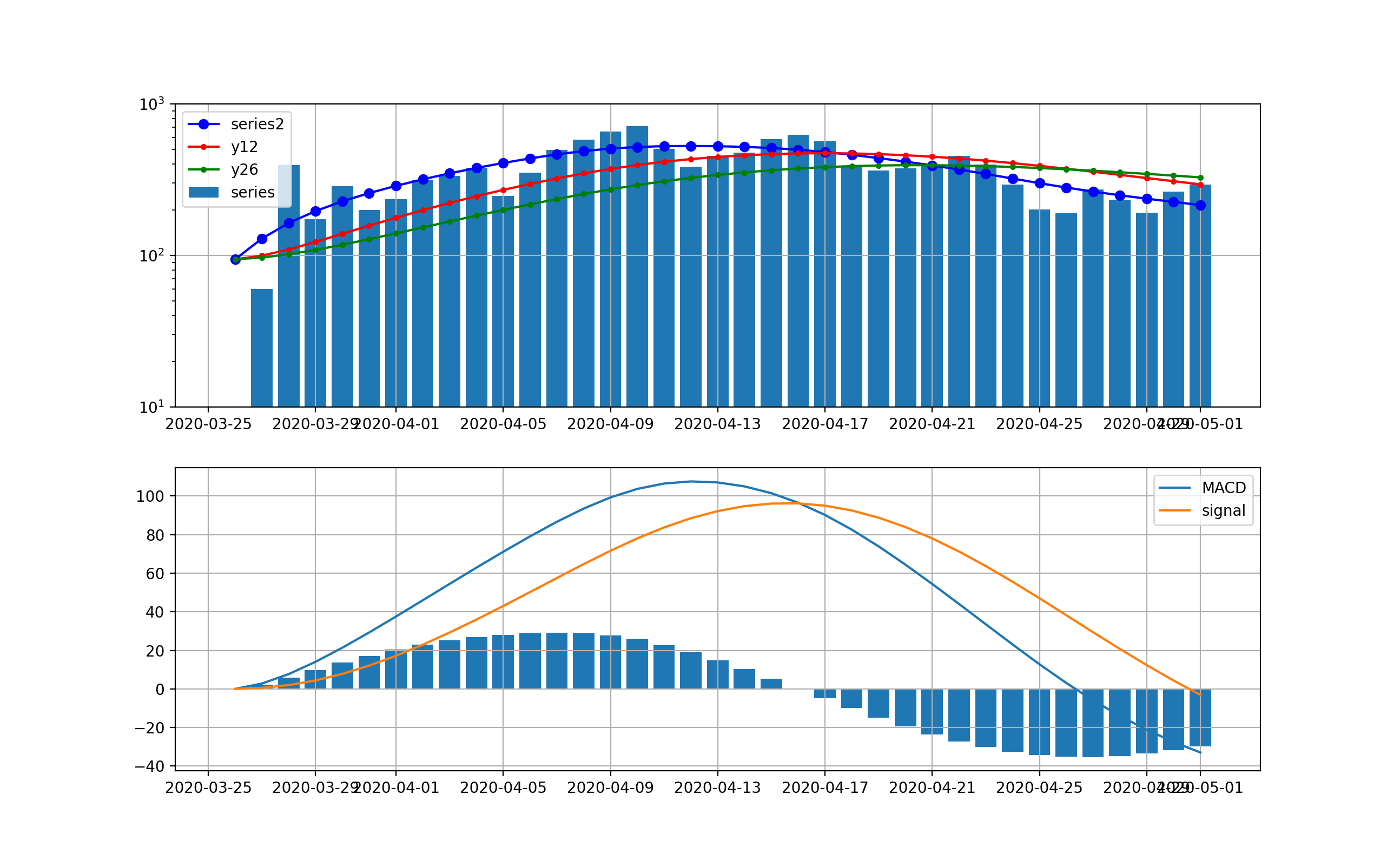
ということで、この解析方式はコロナの感染数の時系列でも感染数ピークを見るためには利用出来そうである。第二波に適用する
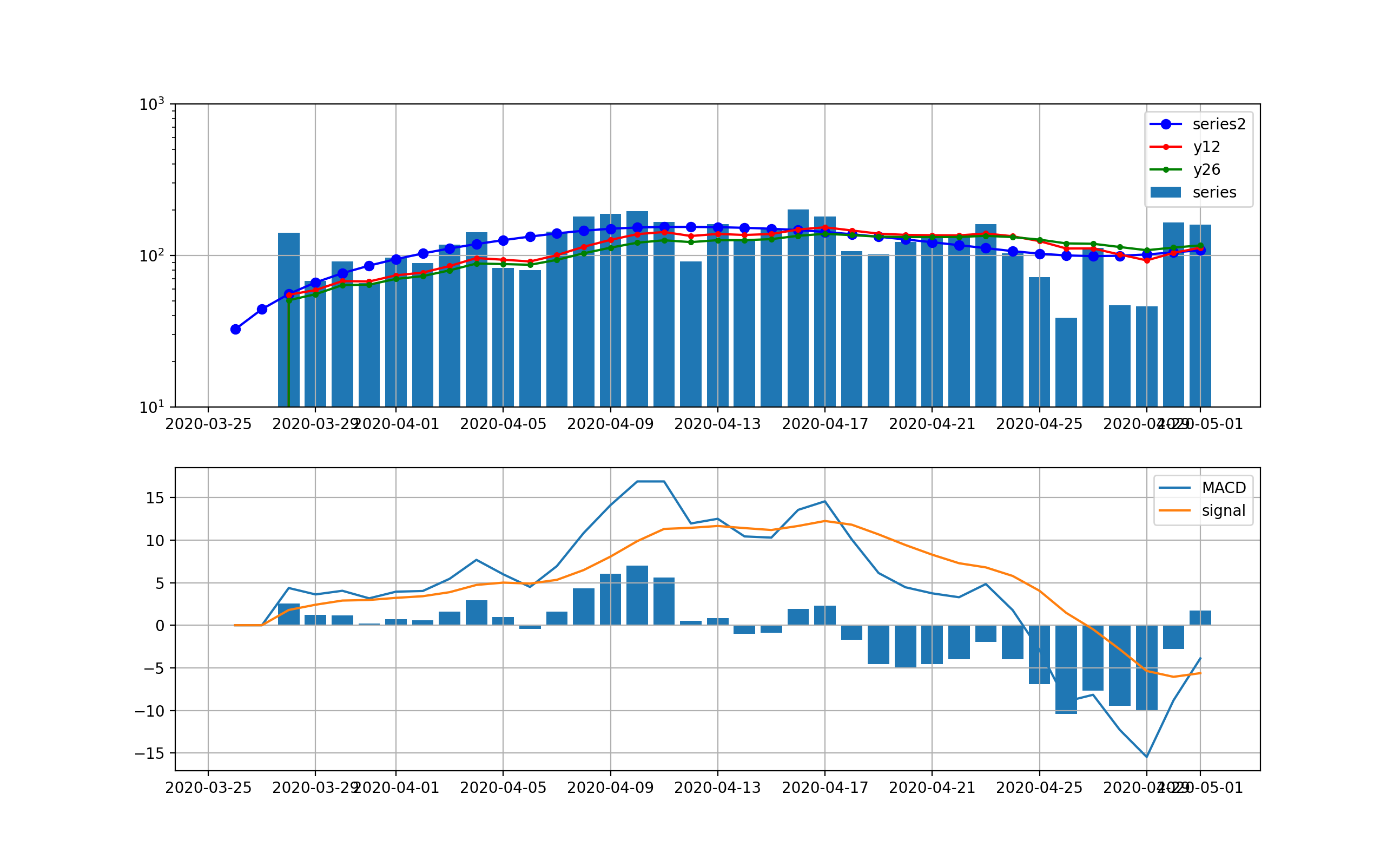
東京の結果は以下のとおりとなった。
まず、処理なしに対する分析;この分析においても指数関数的な増加は明白であり、10日から2週間程度で500人レベルの感染数に到達しそうである。
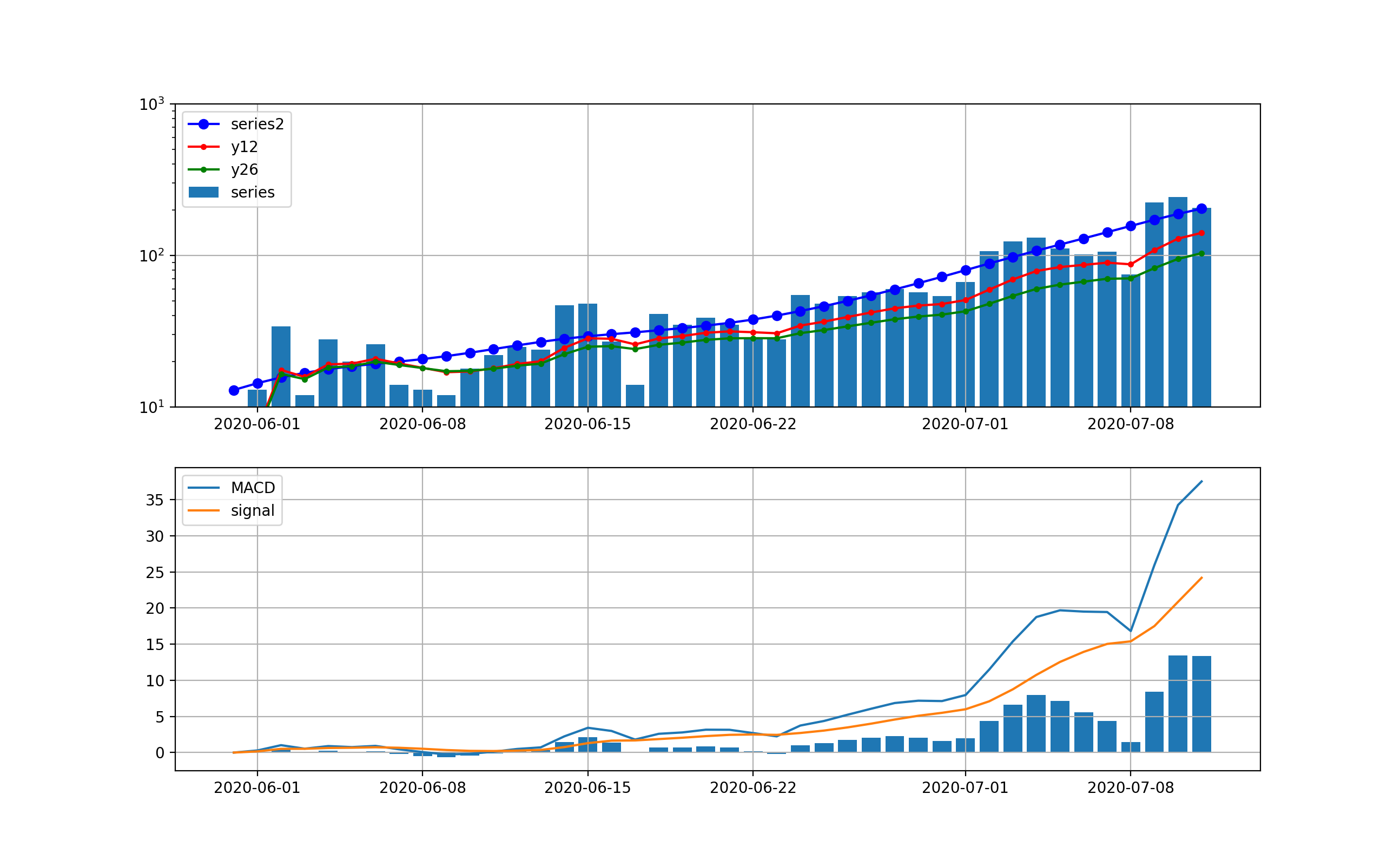
decomposeしてトレンド曲線に対する分析;こちらのグラフではさらに下がる気配は一向になく、当分この傾向が続くことが予想される。つまり、MACD曲線やsignal曲線は下に凸になっており、その差が当面増加することをうかがわせる。株価などはこの差が負へ転換するところが下落のシグナルとみなせるがこの図はその気配がない。
全国の分析も以下のとおり、ほぼ東京と同様な曲線である。
同じく、decomposeしてトレンド曲線に対する分析は以下のとおり
ちょっと背景分析
全国も東京と同様な傾向となっています。
もちろん首都圏の数字が大きいので同じような傾向になるのは当然な気がしますが、今回の第二波の開始は青いプロットの傾きやsignal-MACDの棒グラフの立ち上がりから、6月22日あたりである。
そこで、このトリガーが何に起因しているか、考えてみる。
トリガー候補は、以下の二つである。
① 緊急事態宣言解除が5月25日
② 東京アラート解除が6月11日
これらを比較して、感染から検査で発見されるまで10日程度と考えれていることから、どう見ても、東京アラート解除が増加のトリガーとなっていると考えるのが妥当なようだ。
逆に云うと、東京アラートは一定の効果があったとも言えそうである。今後の感染数増加で危惧されること
まず、最初に見えてくるのは、最初のグラフで示した東京の感染数の赤いプロットを見ると、もはや1200程度まで増加しており、今後同じ指数で増加するように見える。
つまり、10日弱で3000床は埋まりそうな勢いである。
通常の入院日数は10日程度の報道があるので、10日弱で3000床というのはちょっと怖い数字である
そして次には重症患者の増加である。重症患者増加は時間遅れがあり、今は第一波の重傷者が回復しているので、減少に見える。しかし、これは第一波では7日から10日遅れ位で発生し始めており、これから発生することが危惧される。そして、今は若年層が7-8割と聞くのでその効果で重症化が抑えられている。しかし、感染数が多くなると高齢者の絶対数も増え、重症化の絶対数の増加は防げない。
そして最後に、医療がひっ迫し始める入院から40日後には死亡数も増え始める。このままでは、東京ばかりか全国の感染拡大が止まる気配は無く、やはり限定的な非常事態宣言を発令して、東京からの移動制限や特定領域の業務制限などの処置をとって、できるだけ若者感染から高リスク者への感染を防ぐ措置をとる必要があると考える。
できるだけ、東京アラートと同様な強力な推進力を持って実施しないと拡大を抑えることはできないと想定される。まとめ
・MACDを感染数予測に適用してみた
・指数関数的な継続的増加が示唆された
・とにかく初動(もう遅れ気味だが)が大切なので、東京アラート級の感染封じ込め措置を発令すべきである・経済を回しながら、上記アラートをどのような対策セットとすべきかは重要なので早急に提言して実行してほしい
おまけ(とりあえずコード)
import matplotlib.pyplot as plt import numpy as np import pandas as pd import datetime as dt from pandas_datareader import data import statsmodels.api as sm from statsmodels.tsa.seasonal import STL #pandasでCSVデータ読む。C:\Users\user\simulation\COVID-19\csse_covid_19_data\japan\test data = pd.read_csv('data/covid19/test_confirmed.csv',encoding="cp932") data_r = pd.read_csv('data/covid19/test_recovered.csv',encoding="cp932") data_d = pd.read_csv('data/covid19/test_deaths.csv',encoding="cp932") #data = pd.read_csv('data/test_confirmed_.csv',encoding="cp932") #data_r = pd.read_csv('data/test_recovered_.csv',encoding="cp932") #data_d = pd.read_csv('data/test_deaths_.csv',encoding="cp932") confirmed = [0] * (len(data.columns) - 1) day_confirmed = [0] * (len(data.columns) - 1) confirmed_r = [0] * (len(data_r.columns) - 1) day_confirmed_r = [0] * (len(data.columns) - 1) confirmed_d = [0] * (len(data_d.columns) - 1) diff_confirmed = [0] * (len(data.columns) - 1) days_from_1_Jun_20 = np.arange(0, len(data.columns) - 1, 1) beta_ = [0] * (len(data_r.columns) - 1) gamma_ = [0] * (len(data_d.columns) - 1) daystamp = "531" #city,city0 = "東京","tokyo" city,city0 = "合計","total_japan" skd=1 #データを加工する t_cases = 0 t_recover = 0 t_deaths = 0 for i in range(0, len(data_r), 1): if (data_r.iloc[i][0] == city): #for country/region print(str(data_r.iloc[i][0])) for day in range(1, len(data.columns), 1): confirmed_r[day - 1] += data_r.iloc[i][day] if day < 1+skd: day_confirmed_r[day-1] += data_r.iloc[i][day] else: day_confirmed_r[day-1] += (data_r.iloc[i][day] - data_r.iloc[i][day-skd])/(skd) t_recover += data_r.iloc[i][day] for i in range(0, len(data_d), 1): if (data_d.iloc[i][0] == city): #for country/region print(str(data_d.iloc[i][0]) ) for day in range(1, len(data.columns), 1): confirmed_d[day - 1] += float(data_d.iloc[i][day]) #fro drawings t_deaths += float(data_d.iloc[i][day]) for i in range(0, len(data), 1): if (data.iloc[i][0] == city): #for country/region print(str(data.iloc[i][0])) for day in range(1, len(data.columns), 1): confirmed[day - 1] += data.iloc[i][day] - confirmed_r[day - 1] -confirmed_d[day-1] if day == 1: day_confirmed[day-1] += data.iloc[i][day] else: day_confirmed[day-1] += data.iloc[i][day] - data.iloc[i][day-1] def EMA1(x, n): a= 2/(n+1) return pd.Series(x).ewm(alpha=a).mean() day_confirmed[0]=0 df = pd.DataFrame() date = pd.date_range("20200531", periods=len(day_confirmed)) df = pd.DataFrame(df,index = date) df['Close'] = day_confirmed df.to_csv('data/day_comfirmed_new_{}.csv'.format(city0)) date_df=df['Close'].index.tolist() #ここがポイント print(date_df[0:30]) series = df['Close'].values.tolist() stock0 = city0 stock = stock0 start = dt.date(2020,6,1) end = dt.date(2020,7,12) bunseki = "trend" #series" #cycle" #trend cycle, trend = sm.tsa.filters.hpfilter(series, 144) series2 = trend y12 = EMA1(series2, 12) y26 = EMA1(series2, 26) MACD = y12 -y26 signal = EMA1(MACD, 9) hist_=MACD-signal ind3=date_df[:] print(len(series),len(ind3)) fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 8, 4*2),dpi=200) ax1.bar(ind3,series,label="series") ax1.plot(ind3,series2, "o-", color="blue",label="series2") ax1.plot(ind3,y12, ".-", color="red",label="y12") ax1.plot(ind3,y26, ".-", color="green",label="y26") ax2.plot(ind3,MACD,label="MACD") ax2.plot(ind3,signal,label="signal") ax2.bar(ind3,hist_) ax1.legend() ax2.legend() ax1.set_ylim(10,1000) #ax2.set_ylim(10,1000) ax1.set_yscale('log') #ax2.set_yscale('log') ax1.grid() ax2.grid() plt.savefig("./fig/{}/ema_decompose_%5K%25D_{}_{}new{}.png".format(stock0,stock,bunseki,start)) plt.pause(1) plt.close() df['Close']=series #series" #cycle" #trend df['series2']=series2 df['y12'] = EMA1(df['Close'], 12) df['y26'] = EMA1(df['Close'], 26) df['MACD'] = df['y12'] -df['y26'] df['signal'] = EMA1(df['MACD'], 9) df['hist_']=df['MACD']-df['signal'] date_df=df['Close'].index.tolist() print(df[0:30]) fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 8, 4*2),dpi=200) ax1.bar(ind3,series, label="series") ax1.plot(df['series2'],"o-", color="blue",label="series2") ax1.plot(df['y12'],".-", color="red",label="y12") ax1.plot(df['y26'],".-", color="green",label="y26") ax2.plot(df['MACD'],label="MACD") ax2.plot(df['signal'],label="signal") ax2.bar(date_df,df['hist_']) ax1.legend() ax2.legend() ax1.set_ylim(10,1000) ax1.set_yscale('log') ax1.grid() ax2.grid() plt.savefig("./fig/{}/ema_df_decompose_%5K%25D_{}_{}new{}.png".format(stock0,stock,bunseki,start)) plt.pause(1) plt.close()
- 投稿日:2020-07-12T22:16:59+09:00
PatchMatchで画像マッチング&点群の位置合わせ
PatchMatchで遊んでみます。
PatchMatchとは?(ざっくり)
PatchMatchの大雑把な概要としては、
ある画像と別の画像で類似している部分を見つけようぜ!
というアルゴリズムです。Photoshopでは絵から特定の箇所を消したりするときとかに使われています。
ベースの考え方としては、超ざっくり以下の通り。
1.メインの画像とターゲットの画像の全ピクセルの対応関係をランダムにセット。 最終的にはこの対応関係の組が類似したピクセルの組となる。 2.隣接するピクセルは同じパーツの部位である確率が高いだろうという考えのもと、 現在の類似度と隣接するピクセルの類似度を比較し、 現在設定されている類似度よりも大きい(より類似度が高い)場合、その値に更新する。 3.以下繰り返しPatchMatchはテンプレートマッチングのような使い方をされる場合がありますが、
ほかにも、隣接する部分は同じようになるという共通的な発想のもとで、
同じ面はデプス同じやろ!という着眼点でColmapではデプスの推定に利用されたりします。
広く応用できそうな理論です。
2つの画像をマッチングさせてみる。
今回の記事で重要なポイントは、
PatchMatchを利用すればある2つの画像に映っている類似した個所が
ピクセルレベルで判定できる、ということです。
SfMをやっていると特徴点マッチングという言葉がたびたび出てきますが、
特徴点マッチングは特徴点ありきの処理なので、
環境に左右されやすく、特徴点の数がすくないと処理に失敗することも難点です。PatchMatchならマッチング数もっとふやせるんじゃね?
という目的のもと、以下の処理で遊んでみます。1.2つの画像でPatchMatch実行。SADで全ピクセルに類似するピクセルの組を算出 2.マッチングした2つの組をRansac実行。外れ値を除去する。PatchMatchでどれくらい正確に、そして件数多くマッチングできるかみてみます。
ついでに、RGBD画像と内部パラメータの情報も使って点群化・位置合わせも行ってみます。
うまくマッチングできていれば、
ノイズの影響も受けずに上手に位置合わせできるかもしれません。3.抽出したピクセルの組より点群化 4.抽出した点群を位置合わせ 5.4のパラメータを使って大本の点群に対して位置合わせコード
https://github.com/MingtaoGuo/PatchMatch
コアな処理の部分は上記コードをお借りします。
そのまま使うとマリアの顔がアバターになるコードなので、
PatchMatchの実行結果だけを利用するよう修正します。reconstruction.pydef reconstruction(f, A, B,AdepthPath="",BdepthPath=""): A_h = np.size(A, 0) A_w = np.size(A, 1) temp = np.zeros_like(A) srcA=[] dstB=[] colorA=np.zeros_like(A) colorB=np.zeros_like(A) for i in range(A_h): for j in range(A_w): colorA[i, j, :] = A[[i],[j],:] colorB[i, j, :] = B[f[i, j][0], f[i, j][1], :] temp[i, j, :] = B[f[i, j][0], f[i, j][1], :] srcA.append([i,j]) dstB.append([f[i, j][0], f[i, j][1]]) # ついでにPatchMatchで取得した類似ピクセルを当てはめてみる。 # 画像Bのピクセルをつかって画像Aを再構成するイメージ cv2.imwrite('colorB.jpg', colorB) cv2.imwrite('colorA.jpg', colorA) src=np.array(srcA) dst=np.array(dstB) print(src.shape) print(dst.shape) srcA_pts = src.reshape(-1, 1, 2) dstB_pts = dst.reshape(-1, 1, 2) # RANSAC print(srcA_pts.shape) print(dstB_pts.shape) M, mask = cv2.findHomography(srcA_pts, dstB_pts, cv2.RANSAC, 5.0) matchesMask = mask.ravel().tolist() im_h = cv2.hconcat([A,B]) cv2.imwrite('outputMerge.jpg', im_h) outputA = np.zeros_like(A) outputB = np.zeros_like(A) for i in range(srcA_pts.shape[0]): if mask[i] == 0: continue srcIm = [srcA_pts[i][0][0],srcA_pts[i][0][1]] dstIm = [dstB_pts[i][0][0],dstB_pts[i][0][1]] outputA[srcIm[0],srcIm[1],:]=A[srcIm[0],srcIm[1],:] outputB[dstIm[0],dstIm[1],:]=B[dstIm[0],dstIm[1],:] im_h = cv2.hconcat([outputA, outputB]) cv2.imwrite('outputMatch.jpg', im_h)D im_h = cv2.hconcat([A, B]) for i in range(srcA_pts.shape[0]): if mask[i] == 0: continue srcIm = [srcA_pts[i][0][0],srcA_pts[i][0][1]] dstIm = [dstB_pts[i][0][0],dstB_pts[i][0][1]] cv2.line(im_h, (srcIm[0], srcIm[1]), (dstIm[0]+int(1280 * 0.3), dstIm[1]), (0, 255, 0), thickness=1, lineType=cv2.LINE_4) cv2.imwrite('outputMatchAddLine.jpg', im_h) if AdepthPath!="": # 画像のデプスデータ・内部パラメータがある場合は、 # 点群化してマッチング情報で位置合わせもしてみる。 # PatchMatchだけなア以下の処理は不要 import open3d as o3d def CPD_rejister(source, target): from probreg import cpd import copy type = 'rigid' tf_param, _, _ = cpd.registration_cpd(source, target, type) result = copy.deepcopy(source) result.points = tf_param.transform(result.points) return result, tf_param.rot, tf_param.t, tf_param.scale def Register(pclMVS_Main, pclMVS_Target): # CPD : step1 Run CPD for SfM Data result, rot, t, scale = CPD_rejister(pclMVS_Target, pclMVS_Main) # CPD : step2 Apply CPD result for MVS Data lastRow = np.array([[0, 0, 0, 1]]) ret_R = np.array(rot) ret_t = np.array([t]) ret_R = scale * ret_R transformation = np.concatenate((ret_R, ret_t.T), axis=1) transformation = np.concatenate((transformation, lastRow), axis=0) return transformation, rot, t, scale def getPLYfromNumpy_RGB(nplist, colorList): # nplist = np.array(nplist) pcd = o3d.geometry.PointCloud() pcd.points = o3d.utility.Vector3dVector(nplist) pcd.colors = o3d.utility.Vector3dVector(colorList) return pcd def numpy2Dto1D(arr): if type(np.array([])) != type(arr): arr = np.array(arr) if arr.shape == (3, 1): return np.array([arr[0][0], arr[1][0], arr[2][0]]) if arr.shape == (2, 1): return np.array([arr[0][0], arr[1][0]]) else: assert False, "numpy2Dto1D:未対応" def TransformPointI2C(pixel2D, K): X = float(float(pixel2D[0] - K[0][2]) * pixel2D[2] / K[0][0]) Y = float(float(pixel2D[1] - K[1][2]) * pixel2D[2] / K[1][1]) Z = pixel2D[2] CameraPos3D = np.array([[X], [Y], [Z]]) return CameraPos3D def getDepthCSPerView(path): import csv # depthデータ取得 in_csvPath = path with open(in_csvPath) as f: reader = csv.reader(f) csvlist = [row for row in reader] return csvlist # depthデータ(CSV) Adepthlist = getDepthCSPerView(AdepthPath) Bdepthlist = getDepthCSPerView(BdepthPath) pclA=[] pclB=[] colorA=[] colorB=[] ALLpclA=[] ALLpclB=[] ALLcolorA=[] ALLcolorB=[] # デプス値が1.5m範囲を点群に復元 depth_threshold = 1.5 # メートル depth_scale = 0.0002500000118743628 threshold = depth_threshold / depth_scale # RGBカメラの内部パラメータ # width: 1280, height: 720, ppx: 648.721, ppy: 365.417, fx: 918.783, fy: 919.136, retK = np.array([[918.783, 0, 648.721], [0, 919.136, 365.417], [0, 0, 1]]) cnt = 0 for y in range(len(Adepthlist)): for x in range(len(Adepthlist[0])): ADepth = float(Adepthlist[y][x]) BDepth = float(Bdepthlist[y][x]) if (ADepth == 0 or ADepth > threshold) or (BDepth == 0 or BDepth > threshold): continue AXYZ = TransformPointI2C([x,y, ADepth], retK) BXYZ = TransformPointI2C([x,y, BDepth], retK) ALLpclA.append(numpy2Dto1D(AXYZ)) ALLpclB.append(numpy2Dto1D(BXYZ)) color = A[int(srcIm[0])][int(srcIm[1])] ALLcolorA.append([float(color[0] / 255), float(color[1] / 255), float(color[2] / 255)]) color = B[int(dstIm[0])][int(dstIm[1])] ALLcolorB.append([float(color[0] / 255), float(color[1] / 255), float(color[2] / 255)]) ALLpclA = getPLYfromNumpy_RGB(ALLpclA,ALLcolorA) ALLpclB = getPLYfromNumpy_RGB(ALLpclB,ALLcolorB) o3d.io.write_point_cloud("ALL_pclA_Before.ply", ALLpclA) o3d.io.write_point_cloud("ALL_pclB_Before.ply", ALLpclB) for i in range(srcA_pts.shape[0]): if mask[i] == 0: continue srcIm = [srcA_pts[i][0][0], srcA_pts[i][0][1]] dstIm = [dstB_pts[i][0][0], dstB_pts[i][0][1]] ADepth = float(Adepthlist[int(srcIm[0])][int(srcIm[1])]) BDepth = float(Bdepthlist[int(dstIm[0])][int(dstIm[1])]) if (ADepth == 0 or ADepth > threshold) or (BDepth == 0 or BDepth > threshold): continue AXYZ = TransformPointI2C([int(srcIm[1]), int(srcIm[0]), ADepth], retK) BXYZ = TransformPointI2C([int(dstIm[1]), int(dstIm[0]), BDepth], retK) pclA.append(numpy2Dto1D(AXYZ)) pclB.append(numpy2Dto1D(BXYZ)) color = A[int(srcIm[0])][int(srcIm[1])] colorA.append([float(color[0] / 255), float(color[1] / 255), float(color[2] / 255)]) color = B[int(dstIm[0])][int(dstIm[1])] colorB.append([float(color[0] / 255), float(color[1] / 255), float(color[2] / 255)]) pclA = getPLYfromNumpy_RGB(pclA,colorA) pclB = getPLYfromNumpy_RGB(pclB,colorB) o3d.io.write_point_cloud("pclA_Before.ply", pclA) o3d.io.write_point_cloud("pclB_Before.ply", pclB) trans, rot, t, scale = Register(pclA, pclB) pclB.transform(trans) o3d.io.write_point_cloud("pclA_After.ply", pclA) o3d.io.write_point_cloud("pclB_After.ply", pclB) ALLpclB.transform(trans) o3d.io.write_point_cloud("ALL_pclA_After.ply", ALLpclA) o3d.io.write_point_cloud("ALL_pclB_After.ply", ALLpclB)結果:画像マッチング
ということでやってみます。
これが
こう。
いやよくわかんねぇな。
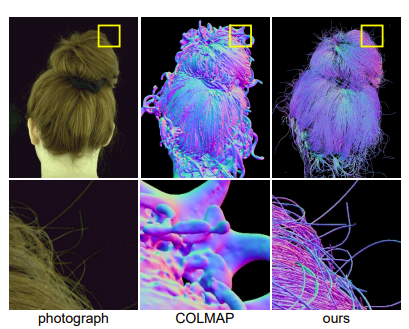
マッチングさせてransacで外れ値除去したピクセルを抽出・表示します。
いやよりわかんねぇな。
でもなんとなく形は一致してそうです。
トラッキング、動体検知などに使えそうな気配を感じます。結果:点群の位置合わせ
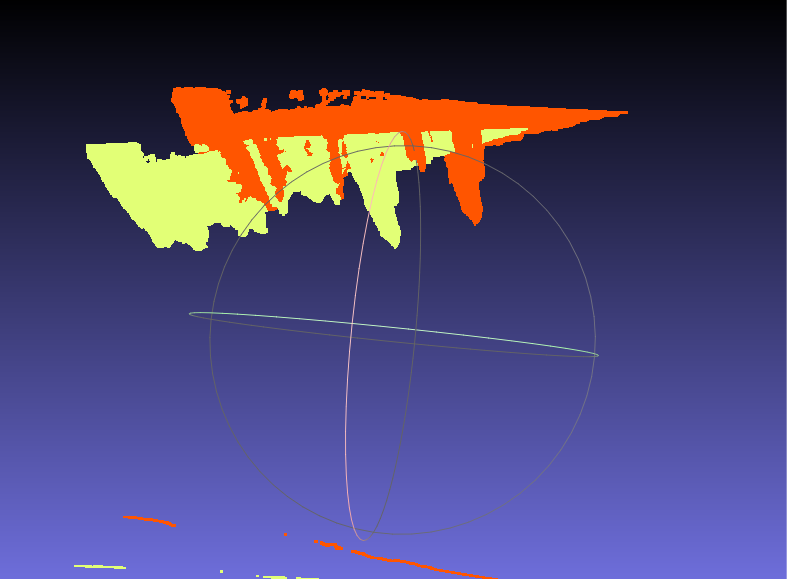
さきほどの結果の答え合わせ・・・になるかどうかはわかりませんが、
抽出した情報をもとに2つの視点の点群の位置合わせを行ってみます。3.抽出したピクセルの組より点群化 4.抽出した点群を位置合わせ 5.4のパラメータを使って大本の点群に対して位置合わせこれが
こう。
うーん!微妙だ!
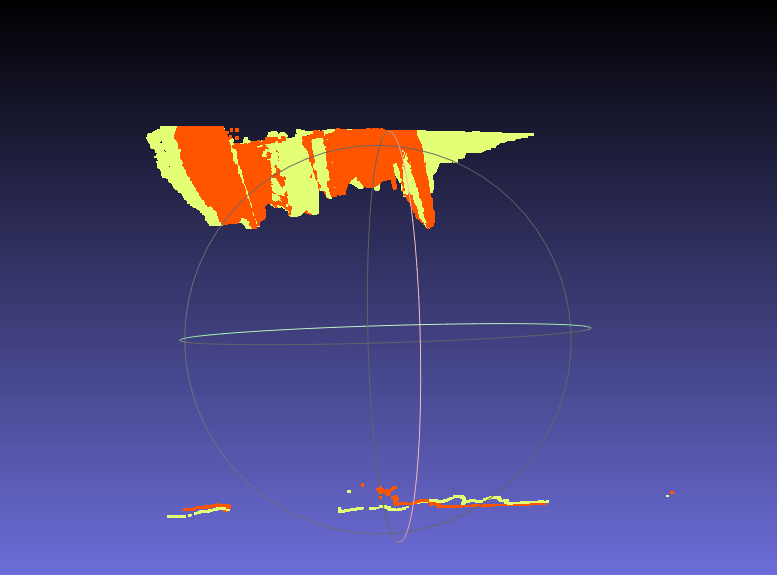
以上です。[追記]
前回の結果はデプスの精度がよくなかったので
別のデータで検証しました。ノイズだらけの点群ですが、
二次元マッチングがうまくいっているおかげか
割と自然にうまくマッチングできました。マッチング時の外れ値の除去にRansacのみを利用しましたが、
せっかく点群にしたので、次回はマッチングしたポイントの距離も考慮して
外れ値を除去してみます。






- 投稿日:2020-07-12T22:03:02+09:00
製薬企業研究者がSeabornについてまとめてみた
はじめに
ここではSeabornの基本的な利用方法について解説します。
Python3系の使用を想定しています。インポート
慣例として、
snsとしてインポートすることが多いです。Seaborn_1.pyimport seaborn as snsSeabornの適用
matplotlibで作成した図に対して、
seaborn.set()メソッドを用いることで、見た目を変えることができます。Seaborn_2.py%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns sns.set() x = [1, 2, 3] y = [3, 1, 2] plt.title('Line-chart') # グラフタイトル plt.xlabel('X-axis') # x軸ラベル plt.ylabel('Y-axis') # y軸ラベル plt.plot(x, y) # グラフを作成 plt.savefig('seaborn_2.png') # グラフを画像ファイルとして保存
まとめ
ここでは、Seabornの基本的な利用方法について解説しました。
Matplotlibで作成した図の見た目を変更したい場合は使ってみると良いでしょう。参考資料・リンク

- 投稿日:2020-07-12T22:02:35+09:00
製薬企業研究者がSciPyについてまとめてみた
はじめに
SciPyは、科学技術計算を行うためのライブラリです。
ここでは、SciPyでよく使うメソッドなどについて解説します。
Python3系の使用を想定しています。インポート
以下のいずれかの方法でライブラリをインポートします。
SciPy_1.pyimport Scipy as sp from SciPy import モジュール名積分
積分には、
scipy.integrate.quadが使えます。SciPy_2.pyfrom scipy.integrate import quad def my_func(x): return x**2 + 2*X + 3 result, error = integrate.quad(my_func, 0, 10)まとめ
ここでは、SciPyでよく使われるメソッドなどについて紹介してきました。
基本的な計算はNumPyでできることが多いですが、少し応用的なことになると、SciPyが必要になります。参考資料・リンク
- 投稿日:2020-07-12T21:49:57+09:00
pythonで一方的に通知するdiscord botをつくる(requests, jsonのみ使用)
内容
pythonを使ったdiscord botをつくるとなると、大きく分けて2つタイプがあるようです。
- 対話的に動作するタイプ
- discord.pyというライブライが便利らしい。この記事では扱いません。
- 一方的に通知するタイプ
- 定期的に通知するにはこちら。以下で説明します。
webhook URL取得
チャンネルごとに取得が必要です。
こちらのページの「Webhook URLを取得」が参考になります。
オプション設定はコードでできるのでパスしてもよし。簡易版
一番シンプルな構成は以下。
import requests, json webhook_url = 'さっき取得したWebhook URL' main_content = {'content': '送るテキスト'} headers = {'Content-Type': 'application/json'} response = requests.post(webhook_url, json.dumps(main_content), headers=headers)送信成功!
botの見た目
botの見た目はコード内で以下のように定義できます。
アイコンの設定には画像のURLが必要のようです。以下ではtwitterアカウントのアイコンのURLを与えています。
ローカルの画像ファイルの場合は、Webhook URL取得時に設定するほかなし?import requests, json webhook_url = 'さっき取得したWebhook URL' main_content = { 'username': 'お名前', 'avatar_url': '画像のURL', 'content': 'テキスト' } headers = {'Content-Type': 'application/json'} response = requests.post(webhook_url, json.dumps(main_content), headers=headers)送信成功!
メッセージの見た目を凝りたい
埋め込み(embeds)を使います。詳しくはこちら。
例を以下にあげます。import requests, json webhook_url = 'さっき取得したWebhook URL' embeds = [ { 'description': 'googleのページ', 'color': 15146762, 'image': { 'url': '画像のURL' } } ] main_content = { 'username': 'お名前', 'avatar_url': '画像のURL', 'content': 'テキスト', 'embeds': embeds } headers = {'Content-Type': 'application/json'} response = requests.post(webhook_url, json.dumps(main_content), headers=headers)こんな見た目になります。
左の縦棒の色は
embedsの中のcolorで設定します。
数字と色の対応はこちら。「Color Mixer」のバーを動かして表示したい色を探し、「Decimal:」の右の数字を与えてください。
関数にして使い回す
例えばこんな感じです。
テキストだけ送るときはchannel,contentだけ引数を与えます。
埋め込みを使いたい時は、必要な情報をembであたえます。emb = { 'description': '埋め込み内テキスト', 'color': '色', 'img_url': '画像URL', 'content': '本文' }def send_discord_msg(channel, content, emb=0): webhook_dic = {'channel 1': 'channel 1のWebhook URL', 'channel 2': 'channel 2のWebhook URL'} webhook_url = webhook_dic[channel] main_content = { 'username': 'botの名前', 'avatar_url': 'アイコンURL', 'content': content } if emb != 0: color_dic = { '色1': 15146762, '色2': 49356, } embeds = [ { 'description': emb['description'], "color": color_dic[emb['color']], "image": { "url": emb['img_url'] }, } ] main_content.update({'embeds': embeds}) main_content['content'] = emb['content'] headers = {'Content-Type': 'application/json'} try: res = requests.post(webhook_url, json.dumps(main_content), headers=headers) except Exception as e: print(e)

- 投稿日:2020-07-12T21:49:49+09:00
【初心者向け】Pythonでパス設定するときに「\」が含まれていると予期せぬ動作になる
はじめに
本記事は、Windows環境でパスの設定をする場合など「\」バックスラッシュを含んだ文字列を扱う際の、注意と対処法をまとめています。
(Macはパスの区切り文字が「/」スラッシュになっていますので、パスの設定の際はとくに気にしなくても大丈夫かと思います。)文字列に「\」バックスラッシュが含まれていると予期せぬ動作になる
例えば、下記のようにWindowsの環境でフォルダパスの指定をした際に、想定した文字列と異なる扱いになるときがあります。
dir_name = 'C:\testDir' print(dir_name) # 想定した文字列 > C:\testDir # 実際に表示される文字列 > C: estDirなぜこのようなことが起こるかというと、windowsのパスの区切り文字である「\」バックスラッシュは、Pythonで「エスケープシーケンス」という処理に使われるからです。
「エスケープシーケンス」がどういう処理かというと、例えば文字列の中で改行をしたいとき
txt = 'ここで改行→←改行' # print(txt)で 以下のように表示させたい # ここで改行→ # ←改行改行を入れたいからといってエンターを押しても、コード上で改行されてしまいエラーになってしまいます。
txt = 'ここで改行→ ←改行' # SyntaxError: EOL while scanning string literalそこで「改行」などの特殊な文字を表すための方法が「エスケープシーケンス」です。
改行を意味する文字は、バックスラッシュ'\'と'n'を組み合わせた'\n'で表します。txt = 'ここで改行→\n←改行' print(txt) # ↓表示される文字列 # ここで改行→ # ←改行最初のパスの設定の例だと
dir_name = 'C:\testDir'の\t部分が「TAB」という文字に扱われ
Pythonで'C:[TAB]estDir'と認識され、不自然にスペースの空いた文字列になっていたのです。対処法
そこで「\」をエスケープシーケンス用の「\」ではなく、そのまま「\」バックスラッシュという文字列として扱う方法があります。
方法1:raw文字列
文字列の最初に「そのまま」という意味の「raw」の頭文字「r」をつけます。
raw文字列と言われ、エスケープシーケンスが行われず、そのままの文字列として扱われるようになります。# rを付けると そのままの文字列として扱われ、エスケープされない r'C:\testDir' # ただし最後に「\」が含まれているものは対応できない r'C:\testDir\' # SyntaxError: EOL while scanning string literal方法2:「\」バックスラッシュをエスケープする
「\」も特殊な文字なので「これはバックスラッシュです」とエスケープシーケンスで表現することができます。
バックスラッシュを2つ「\\」書くとバックスラッシュとして扱われます。# バックスラッシュを2つ「\\」書いてバックスラッシュ自体をエスケープさせる 'C:\\testDir'方法3:「\」バックスラッシュを「/」スラッシュに書き換える
パスに対してならこの方法が一番いいと考えています。
Linux、Macのパスの区切り文字文字は「/」スラッシュになっているため、「/」に統一するよう意識すると、環境を変更したときの不具合を防止することができます。Windowsも区切り文字「/」スラッシュで対応出来るため
「\」バックスラッシュを「/」スラッシュに書き換えて対処します。# 「\」バックスラッシュを「/」スラッシュに書き換える 'C:/testDir'注意点
バックスラッシュをスラッシュに書き換える際の注意として
パスを取得する関数を利用した場合、パスの区切り文字は「\」バックスラッシュになります。以下は、'C:\testDir'で実行しているとします。
import os # カレントディレクトリの取得(作業中のフォルダ) current_dir = os.getcwd() print(current_dir) # C:\testDir 「\」バックスラッシュで取得されるこの取得したパスを利用して、以降のパスを自身で設定する場合、「/」「\」が混在しないように注意が必要です。
import os # カレントディレクトリの取得 current_dir = os.getcwd() # 画像用フォルダを設定 「/」で続きのパスを書く image_dir = f'{current_dir}/image' print(image_dir) # C:\testDir/image 「\」「/」混在pythonの関数では、混在していても動きはしますが、別のシステムにパスを渡すときや、パスを文字列操作するときにエラーになったりします。
例)SeleniumでChromeのダウンロードフォルダを設定するときそこで対処法として、パスを取得する際に「\」を「/」に置き換えてから、取得するようにします。
import os # カレントディレクトリの取得のときに区切り文字を「/」に置き換え current_dir = os.getcwd().replace(os.sep,'/') print(current_dir) # C:/testDirおわりに
ご覧いただきありがとうございました。
「\」バックスラッシュの対応方法はいろんな方法がありますが、現場や自分自身でルールを設けて統一して、不具合のない開発が出来るようにしていきましょう。参考
- 投稿日:2020-07-12T21:46:51+09:00
freeCodeCampでPythonの勉強:その1
freeCodeCampのカリキュラムが追加された!
freeCodeCampにおいて、以下のカリキュラムが追加されました。(こちらの記事参照)
- Scientific Computing with Python(Pythonでの科学的計算)
- Data Analysis with Python(Pythonでのデータ分析)
- Information Security(情報セキュリティ)
- Machine Learning with Python(Pythonでの機械学習)
せっかくなのでこれを機に勉強しようと思い立った次第。
今回の記事ではScientific Computing with Python(Pythonでの科学的計算)で行ったことを紹介します。Scientific Computing with Pythonをやってみた
大きくこの分野は以下の二つに分かれていました。
- Python for Everybody
- Scientific Computing with Python Projects
Python for EverbodyではPythonとはという部分から、基本構文や、ネットワーク、データベースなどを動画+選択式の問題で学ぶことができました。動画は全て英語なので、字幕や翻訳を使いながらどうにか解読しました。
Scientific Computing with Python Projectsでは実際に問題が出され、コードを書いて提出すると言った形式で学ぶことができます。ローカルに実行環境がなくても
repel.itというブラウザ上で動く環境が提供されているので安心です。(私はローカルにソースをコピーして書きました)
また、テストコードも用意されており、全てのテストが通れば提出可能になります。これから数回の記事では、Scientific Computing with Python Projectsで出された問題と、個人的なポイントを紹介していきます。
1問目:Arithmetic Formatter
最終的に欲しいものは
arithmetic_arrangerメソッドで、動きは以下の通りarithmeric_arranger(["32 + 698", "3801 - 2", "45 + 43", "123 + 49"])Output:
32 3801 45 123 + 698 - 2 + 43 + 49 ----- ------ ---- -----また、第2引数にbool型の値を指定することができ、
Trueの時は計算結果も出力させないといけないです。実装方針
上パーツ(
32 3801 45 123)、
中パーツ(+ 698 - 2 + 43 + 49)、
下パーツ(----- ------ ---- -----)に分けて、最後に\nでつなげる。皆さんにもトライしていただきたいので、私の実装は載せません…
個人的ポイント: 文字列の右寄せ、中央寄せ、左寄せ
この問題では以下のように、上、中、下パーツが右に揃っている必要があります。
○○○32 +○698 ----- ○:空白そこで文字列メソッド
rjust()が使いました。(中央寄せ:center()、左寄せ:ljust())
また、数値を右寄せにしたいときには一度str()で文字列に変換したのちに使います。私は以下のように右寄せを行いました。
""" top_num=32, mid_num=698 top_num_len=2, mid_num_len=3 op='+' or '-' """ row_len = max(top_num_len, mid_num_len) + 2 # +と空白1つ分 top = top_num.rjust(row_len) mid = op + mid_num.rjust(row_len - 1)最後に
このように、問題を解くと普段あまり使わない物の発見(今回で言えば文字寄せのメソッド)が多いのでとても楽しいです。
次の問題はTime Calculatorです。
- 投稿日:2020-07-12T21:42:01+09:00
GCPのJupyter LabからGSRにGitするやり方
1.目的
最近、GCP上でcloud shellからGSRへのadd, commit, pushといった基本的な一連の流れはだいぶ慣れてきたものの、実際の開発はjupyter Labとかでやることも多いから、cloud shellからじゃなくてJupyter Labからpushできると便利だなと思い、基本の流れをまとめました。
具体的には、GCPのAI Platformからノートブックを立ち上げます。
2.早速やってみよう
(1)先にリポジトリを作っておく
「Qiita」というリポジトリをGSR上で作り、「test.txt」を事前にcloud shellからpushしておきました。
(下記はGSRのQiitaリポジトリの画面)
(2)Jupyter Labの立ち上げ
GCPのハンバーガーメニュー(左側のメニュー)から「AI Platform」を選択。
※私はピン止めしているので上の方に出てきますが、実際は結構下の方にあります。その後、ノートブックを選択し、インスタンスを作成します。
※私はリージョンはasia-northeastにしています。
(3)ディレクトリの作成
下記のように、新しいフォルダを作っておきます。
今回はQiita_notebookというディレクトリを手動で作っておきました。
※clone_jupyterというディレクトリは別途私が個人的に作っているだけなので、無視してください。
(4)Git用のnotebookを作成→GSRからクローンする
(3)で作成したQiita_notebookディレクトリ内にnotebookを作ります。
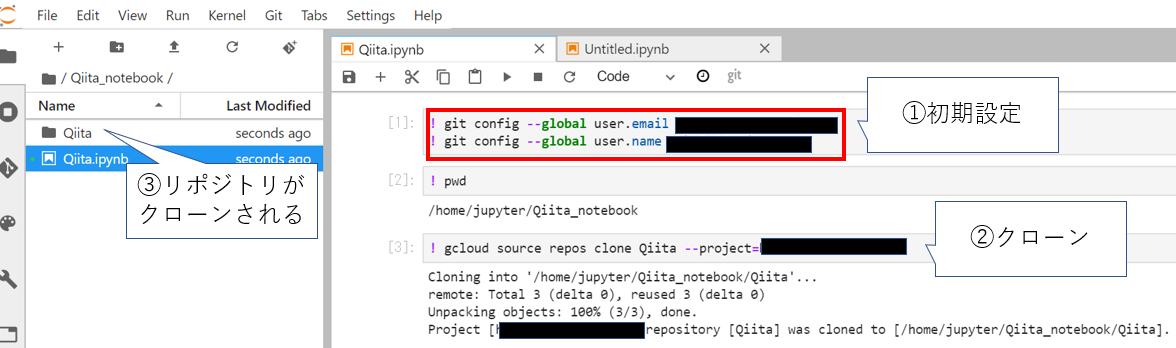
今回は「Qiita.ipynb」です。このnotebook内で、下記のようにコマンドを打っていきます。
①初期設定
ここは通常のGitと同じ流れです。②クローン
GSRのQiitaリポジトリをクローンします→これを実行すると、上のキャプチャの③のように、突如ぽこっと「Qiita」リポジトリがクローンされます
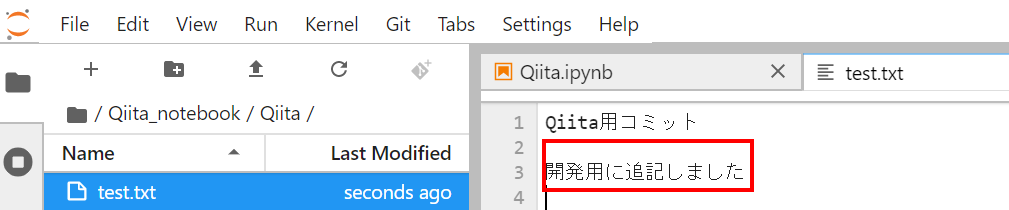
(5)テキストファイルを修正してみる
Qiitaリポジトリに移動し、test.txtを開き、下記のように追記
→保存して閉じておきます。※ここが、実際は開発時にコードを修正しているイメージです。
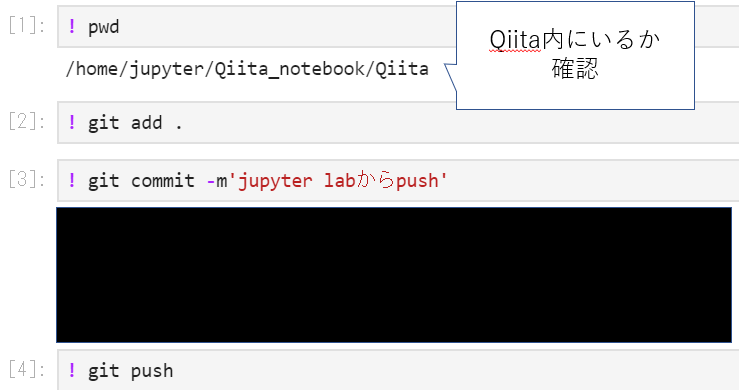
(6)Qiita.ipynbをQiitaリポジトリ内に移動
手動になりますが、今はQiitaリポジトリの外にいるQiita.ipynbをCutして、QiitaリポジトリにPasteしておきます。
※こうしないと、この後pushができませんでした。
(7)いよいよ、pushしていく
下記のようにコマンドを打つと、GSRへpushされます!
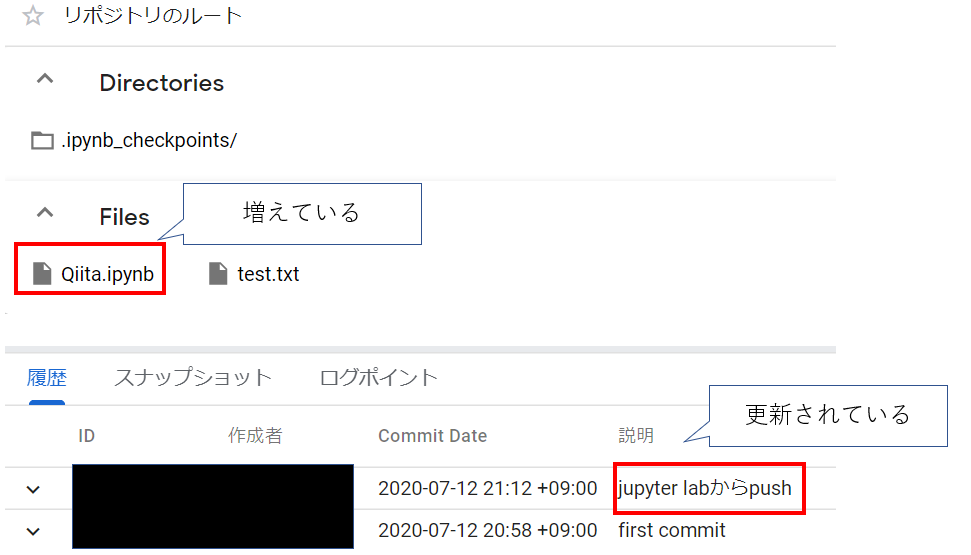
(8)GSRで確認
無事にjupyter Labからpushできていました!
3.結び
いかがでしたでしょうか。
私はGitの学習をし始めたのが最近なので、jupyter lab(notebook)からpushできることを知りませんでした。
この後はブランチやマージ、コンフリクトの解消についても学習し投稿していきたいと思います!

- 投稿日:2020-07-12T20:32:29+09:00
世界一無駄な可視化グランプリがあったら優勝したい・OP関数を進化させて可視化を学ぶ
日頃、何のために可視化を教えているのか!!!!
それはこの為だ
OP関数を進化させたい!!前回作成したOP関数はこちら
Python言語のmatplotlibで綺麗な曲線
OPを描く関数を作成して
可視化を行います。なお、単なる静止画だと面白くないので
ipywidgetsの機能を付けています。数値
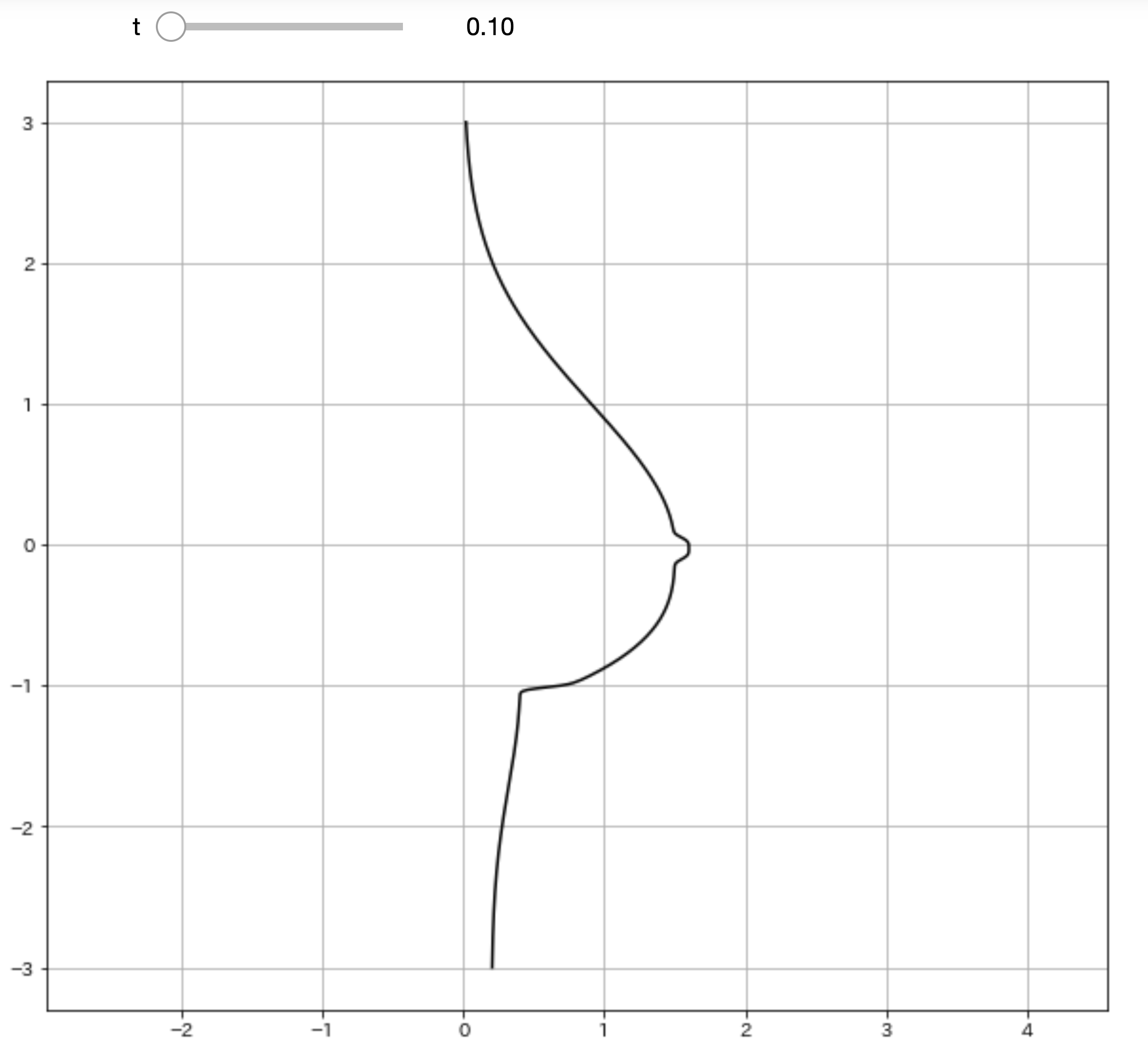
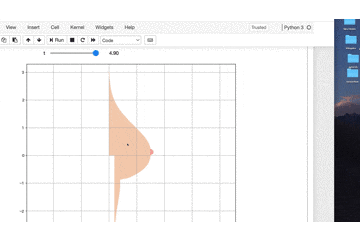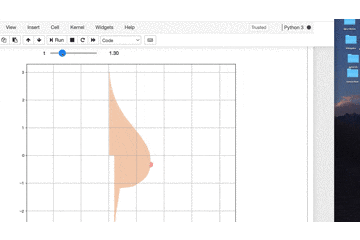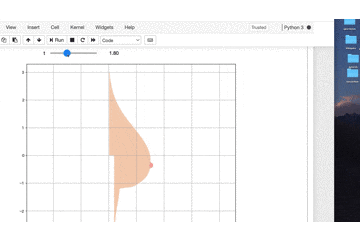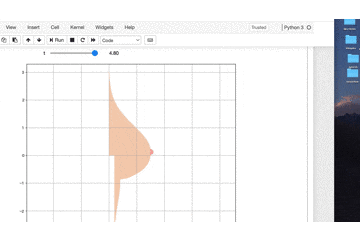
tを変えるとビヨンビヨン動きます。import numpy as np import matplotlib.pyplot as plt from ipywidgets import interact, FloatSlider, IntSlider import warnings warnings.simplefilter('ignore') %matplotlib inline def oppai(y,t): x_1 = (1.5 * np.exp((0.12*np.sin(t)-0.5) * (y + 0.16 *np.sin(t)) ** 2)) / (1 + np.exp(-20 * (5 * y + np.sin(t)))) x_2 = ((1.5 + 0.8 * (y + 0.2*np.sin(t)) ** 3) * (1 + np.exp(20 * (5 * y +np.sin(t)))) ** -1) x_3 = (1+np.exp(-(100*(y+1)+16*np.sin(t)))) x_4 = (0.2 * (np.exp(-(y + 1) ** 2) + 1)) / (1 + np.exp(100 * (y + 1) + 16*np.sin(t))) x_5 = (0.1 / np.exp(2 * (10 * y + 1.2*(2+np.sin(t))*np.sin(t)) ** 4)) x = x_1 + (x_2 / x_3) + x_4 + x_5 return x t = FloatSlider(min=0.1, max=5.0, step=0.1, value=0) y = np.arange(-3, 3.01, 0.01) @interact(t=t) def plot_oppai(t): x = oppai(y,t) plt.figure(figsize=(10,9)) plt.axes().set_aspect('equal', 'datalim') plt.grid() plt.plot(x, y, 'black') plt.show()
ふっ
これだと味気ない黒い曲線で描かれるだけで
芸術の域には達していませんね。理想に近づけるために関数に色を付けていきましょう。
改良したOP関数はこちら
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patches from ipywidgets import interact, FloatSlider, IntSlider import warnings warnings.simplefilter('ignore') %matplotlib inline def oppai(y,t): x_1 = (1.5 * np.exp((0.12*np.sin(t)-0.5) * (y + 0.16 *np.sin(t)) ** 2)) / (1 + np.exp(-20 * (5 * y + np.sin(t)))) x_2 = ((1.5 + 0.8 * (y + 0.2*np.sin(t)) ** 3) * (1 + np.exp(20 * (5 * y +np.sin(t)))) ** -1) x_3 = (1+np.exp(-(100*(y+1)+16*np.sin(t)))) x_4 = (0.2 * (np.exp(-(y + 1) ** 2) + 1)) / (1 + np.exp(100 * (y + 1) + 16*np.sin(t))) x_5 = (0.1 / np.exp(2 * (10 * y + 1.2*(2+np.sin(t))*np.sin(t)) ** 4)) x = x_1 + (x_2 / x_3) + x_4 + x_5 return x t = FloatSlider(min=0.1, max=5.0, step=0.1, value=0) y = np.arange(-3, 3.01, 0.01) @interact(t=t) def plot_oppai(t): x = oppai(y,t) plt.figure(figsize=(10,9)) plt.axes().set_aspect('equal', 'datalim') plt.grid() # 改良ポイント b_chiku = (0.1 / np.exp(2 * (10 * y + 1.2*(2+np.sin(t))*np.sin(t)) ** 4)) b_index = [i for i ,n in enumerate(b_chiku>3.08361524e-003) if n] x_2,y_2 = x[b_index],y[b_index] plt.axes().set_aspect('equal', 'datalim') plt.plot(x, y, '#F5D1B7') plt.fill_between(x, y, facecolor='#F5D1B7', alpha=1) plt.plot(x_2, y_2, '#F8ABA6') plt.fill_between(x_2, y_2, facecolor='#F8ABA6', alpha=1) plt.show()
素晴らしい色艶ですね!!!
可視化の仕組み
matplotlibの仕組み上では
まずどこにプロットするかを決めないといけません。散布図では二つの数値が必要になります。
縦軸の数値と横軸の数値です。全体の描画に用いている縦軸方向の数値は固定です。
y = np.arange(-3, 3.01, 0.01)
yは-3から3までの0.01刻みの数値群です。これに対して横軸方向の値を計算で求めてあげます。
関数oppai(y,t)では数値群yに対して1つ1つ計算して
数値群xを作成します。引数
tは微調整するための数値で
これも0.1から5までの0.1刻みの数値で計算しています。xとyの数値群を用いて散布図にプロットします。
plt.plot(x, y)これでこの滑らかな曲線
OPが描かれています。次に
plt.fill_betweenです
これは色で塗りつぶしを行います。そして最大のポイントが曲線の
B地区
個人的に一番好きなポイントです。これも塗りつぶしポイントの範囲を計算しないといけません。
b_chiku = (0.1 / np.exp(2 * (10 * y + 1.2*(2+np.sin(t))*np.sin(t)) ** 4)) b_index = [i for i ,n in enumerate(b_chiku>3.08361524e-003) if n] x_2,y_2 = x[b_index],y[b_index]ここで縦横方向でちょうど良い範囲に収まるような
数値計算をしています。
enumerate(b_chiku>3.08361524e-003)では
その数値よりも大きいかがTrueorFalseで返ります。
それがB地区のインデックス値となるのでB地区の数値を
全体の曲線OPの数値群からインデックスで数値を取得します。これで
B地区の計算ができたので良い感じの色で塗ってあげて
Finishです。最後に
いやーー
動かすと数値計算大変けれども
静止画では味わえない醍醐味が得られるはずです。Pythonやmatplotlibを使う意義はここにあります。
データサイエンスは詳しくなくても、可視化は勉強する価値があります。ちなみに色合いは
#F8ABA6
この色が好みでした。色は好きな色に変えてくださいね。
それでは作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-07-12T20:11:18+09:00
【GAS/Python】アイコンのダブルクリックだけでメールを自動送信できるようにしてみた
あらすじ
定常的なメールの送信作業が発生しており、面倒なので
自動化することにしました。自動化にあたり、以下要件を満たすものを作ることにしました。
1.送信トリガをタイマーなどではなく、デスクトップアイコンのクリックにしたい
2.特定のファイルを自動的に添付したい
3.メール送信時のみオンラインにし、送信後はすぐにオフラインにしたいそこで、GAS(Google Apps Script)が便利そうかつ使用経験がないので、
上記要件を満たすツールをGASで作ろうと思いました。上記3つの要件が本当に実現化なのか、まず最初に検討しました。
要件1: 送信トリガをタイマーではなく、デスクトップアイコンなどのクリックにしたい
実際にGASを少し使ってみたり調べたりした限りでは、残念ながらGASの実行トリガは
以下しかないようでした。① スプレッドシートから
② 時間主導型
③ カレンダーから※ トリガはGASのエディタより、以下で設定
編集 -> 現在のプロジェクトのトリガー -> トリガーを追加このうち、①スプレッドシートのトリガ設定詳細を調べると
・起動時
・編集時
・変更時
・フォーム送信時とあり、「起動時」をトリガにすればいけるんじゃね?と考え、
スプレッドシートを開くことでトリガを発動させ、メール送信しようと
思い至りました。なので、PythonのSeleniumでGASが紐付いたスプレッドシートを開くことで、
トリガにすることにしました。… なんかもっと簡単な、手軽な方法がありそうな気もしましたが、
スプレッドシート起動をトリガにしても特に害がなさそうなこと、
また未体験のGASを使ってみるという趣旨もあるため、これでいくことに。Selenium実行時に必要になるchromeドライバーのダウンロードは下記ページから行いました。
https://sites.google.com/a/chromium.org/chromedriver/downloads要件2: 特定のファイルを自動的に添付したい
これをGASでやるのは、意外と難しそうであることが判明しました。
というのも、スプレッドシートがサーバー上に存在する以上、GASのスクリプトもサーバーサイドで実行されるようで、クライアンドであるローカルPC上のファイルを操作するのは中々難儀なようです。
そのためか例えばローカルにあるCSVやテキストファイルなどを読み込んだ上でそれらファイルに記載の情報を抽出する方法は分かっても、ローカルのファイルをそのファイル形式のまま添付する方法は分かりませんでした。
※ 以下ページ参照
http://googleappsscript.hatenablog.com/entry/2017/08/30/120000
https://centerwave-callout.com/%E3%83%AD%E3%83%BC%E3%82%AB%E3%83%AB%E3%81%AE%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB%E3%82%92gas%E3%81%A7%E6%89%B1%E3%81%86/一方でサーバーサイド、例えばGoogle Driveに置いてあるファイルの添付などは容易に実施できるようです。
そのため、添付したいローカルファイルは一旦Google Driveにアップロードし、それを添付することにしました。一旦Google Driveを経由するため少しまどろっこしいやり方になりますが、これも運用上問題が発生しなければ、これでOKでしょう。
Google Driveへのアップロードは、PythonのPyDriveが便利そうなので、それで行くことに。
最初にGASを使おうと思ったのに、またPython。。
要件3: メール送信時のみオンラインにし、送信後は即座にオフラインにしたい
GASがサーバーサイドで実行される以上、ローカルのファイルと同様にローカルの環境を操作することも難しいこと、また上記の要件1と2でPythonが絡むことから要件3もPythonで実施しようと思い、Wi-Fiの接続/切断を簡単に操作できるパッケージぐらいあるでしょ…と軽く考えて調べてみましたが、残念ながら見つかりませんでした。
しかし、PowserShellであればWi-Fiの操作が簡単にできること、またPowerShellスクリプトもPython側から容易に呼び出せることが分かったため、Wi-Fi操作はPowerShellで実施することに。
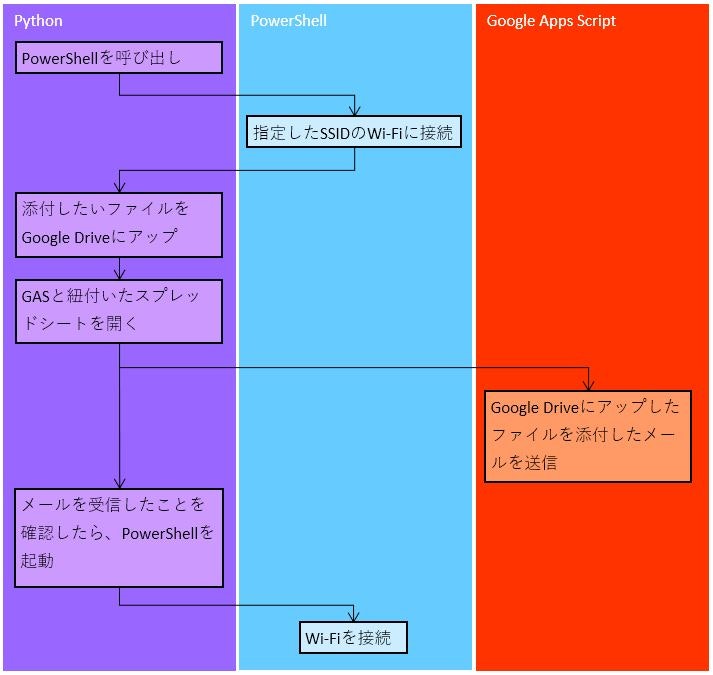
自動化ツールのフロー
要件1 ~ 3は全部実現化だと分かりましたが、実現のための手段が少し複雑になったので、一旦整理することに。
処理の前半~中ごろに関しては既に述べた通りですが、問題は後半。
GASを起動させてメールを送信した場合、アックをローカルで動いているPythonに送り、そのタイミングでWi-Fiを切断するためのPowerShellスクリプトを呼び出してオフラインにし終了…とするのが理想です。しかし、例によってローカル環境との連携が難しいため、以下で対応としました。※ メール送信の宛先は自分を含めることが前提
1.Python側でスプレッドシートのURLを叩いてからGmailの受信ボックスを1秒おきくらいに見に行き、自動送信したメールが届いていないかその度に確認
2.もし届いていた場合、「送信が完了しました」のダイアログをPython側で表示
3.もしスプレッドシートのURLを叩いてから一定時間(30秒くらい?)経過しても自動送信したメールが届かない場合、「送信に失敗しました」のダイアログをPython側で表示上記方策により、メール送信の成功/失敗がユーザー側で把握できるようになります。
こうなるともう全部Pythonでいいじゃん…という迷いがこの辺りで生じてきましたが、本件の趣旨の1つとして「使ったことがないGASを使ってみる」というのがあるので、GASで実現できる部分はGASでいこうと思います。
その他・細かいところの設計
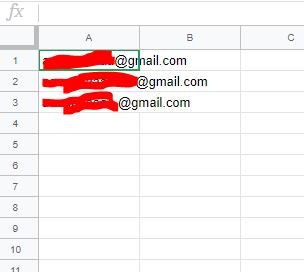
GAS起動のトリガとして開くスプレッドシートが、本当に単なるトリガ以外の役割がないのは寂しいのと、メールの宛先が今後増えたりする場合に送付先アドレスをハードコーディングするのはイケてないと判断したため、送付先アドレスはスプレッドシートに列挙することにしました。
図のように、A1セルから下に向かって順に記載していきます。
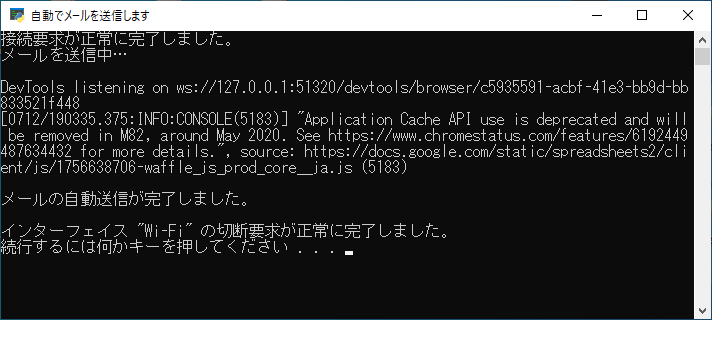
実施結果
作成したPythonスクリプトとPowerShellスクリプトを適切なところに置き、前述のようにGASを書いてトリガを設定し、GoogleDriveAPIを有効にした上で、.pyのショートカットをデスクトップに置き、それを叩けば自動メール送信が実行できます。参考までに、実施結果は以下のようになりました。
ソース
1.Python:メイン部分
auto_mail_tool.pyimport os import time import email import imaplib import datetime import chromedriver_binary from selenium import webdriver from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from selenium.webdriver.chrome.options import Options # Googleアカウントのアドレスとパスワードを設定 address = 'メールアドレス' pw = 'パスワード' # スプレッドシートを開いてgasを起動し、メール送信 def generate_gas_script(): print('メールを送信中…') # ブラウザをヘッドレス起動(バックグラウンド表示)するための設定 option = Options() # オプションを用意 option.add_argument('--headless') # ヘッドレスモードの設定を付与 option.add_argument('--lang=ja-JP') # 操作するブラウザを開く drv = webdriver.Chrome(options=option) time.sleep(3) # 操作するページを開く drv.get("開きたいスプレッドシートのURL") # アドレスバーにアドレスを入力 drv.find_element_by_id('Email').send_keys(address) time.sleep(3) # 「次へ」ボタンをクリック drv.find_element_by_id('next').click() time.sleep(3) # パスワードを入力 drv.find_element_by_id('password').send_keys(pw) time.sleep(3) # 「次へ」ボタンをクリック drv.find_element_by_id('submit').click() time.sleep(5) drv.quit() # スプレッドシートが開けたはずなので、ブラウザを閉じる # wifiへの接続/切断 def wifi(mode): if mode == 'connect': # 指定したSSIDのwifiに接続(SSID自体はPowerShell内で設定) os.system('powershell -Command' + ' ' + \ 'powershell -ExecutionPolicy RemoteSigned .\\wifi_on.ps1') time.sleep(5) elif mode == 'disconnect': # 接続中のwifiから切断 os.system('powershell -Command' + ' ' + \ 'powershell -ExecutionPolicy RemoteSigned .\\wifi_off.ps1') # 送信メールに添付したいファイルをGoogle Driveにアップロード def up_file_on_drive(): # アップロード対象のファイルがあるパス及びファイル名を設定 tgtfolder = '添付したいファイルが置いてあるパス' tgtfile = '添付したいファイルの名前' dlttgt = 'title = ' + '"' + tgtfile + '"' # ファイルIDの取得に使用 # Google Drive APIを使用するための認証処理 gauth = GoogleAuth() drive = GoogleDrive(gauth) # 既に同名のファイルが格納されている場合、削除 file_id = drive.ListFile({'q': dlttgt}).GetList()[0]['id'] f = drive.CreateFile({'id': file_id}) f.Delete() time.sleep(3) # ファイルをアップロード folder_id = 'Google Driveのファイル格納先ID' f = drive.CreateFile({'title': tgtfile, 'mimeType': 'excel/xlsx', 'parents': [{'kind': 'drive#fileLink', 'id':folder_id}]}) f.SetContentFile(tgtfolder + tgtfile) f.Upload() time.sleep(3) # メールが送信されたか確認 def confirm_mail_sent(): tgtac = imaplib.IMAP4_SSL('imap.gmail.com', 993) # gmail受信メールサーバ(IMAP)のホスト名とSSLを用いたメール受信のポート番号 tgtac.login(address, pw) waitsec = 30 # メール送信確認ロジックのタイムアウト時間[sec] tgtmail = 'GAS側で設定した送信「メールの件名 ' + get_today() # 自動送信したメールが受信されているか、1秒おきに最新メールから確認 for i in range(waitsec, 0, -1): title = get_latest_mail_title(tgtac) # 最新メールの件名を取得 time.sleep(1) # 1ループ1秒 if title == tgtmail: # もし最新メールの件名が自動送信したメールのものだったら print('\nメールの自動送信が完了しました。\n') return # 確認のための時間がタイムアウトした場合 print('\nメールの自動送信に失敗しました。\n') # 最新メールの件名を取得 def get_latest_mail_title(mail): mail.select('inbox') # メールボックスの選択 data = mail.search(None, 'ALL')[1] # メールボックス内にあるすべてのデータを取得 tgt = data[0].split()[-1] # 最新メールの順番を取得 x = mail.fetch(tgt, 'RFC822')[1] # メールの情報を取得(Gmailで読取可能な規格を指定) ms = email.message_from_string(x[0][1].decode('iso-2022-jp')) # パースして取得 sb = email.header.decode_header(ms.get('Subject')) ms_code = sb[0][1] # 文字コード取得 # 最新メールの件名のみを取得 if ms_code != None: mtitle = sb[0][0].decode(ms_code) else: mtitle = sb[0][0] return mtitle # 本日の日付を取得 def get_today(): now = datetime.date.today() tdy = str(now.year) + '/' + str(now.month) + '/' + str(now.day) # 年月日で表示 wknum = now.weekday() # 本日の曜日番号を取得(0:月 ... 6:日) wk = get_now_weekday(wknum) # 本日の曜日を取得 return tdy + '(' + wk + ')' # 本日の曜日を取得 def get_now_weekday(key): wkdict = {0: '月', 1: '火', 2: '水', 3: '木', 4: '金', 5: '土', 6: '日'} return(wkdict[key]) if __name__ == '__main__': wifi('connect') # 1. 指定したSSIDのWi-Fiを接続 up_file_on_drive() # 2. 添付したいファイルを一旦GoogleDriveにアップ generate_gas_script() # 3. スプレッドシートを開いてGASを起動 confirm_mail_sent() # 4. GASによって送信されたメールが届いているか確認 wifi('disconnect') # 5. wifiを切断 os.system('PAUSE') # コンソールを止める2.GAS:メール送信部分
sending_email.gsfunction mail_send() { // メール情報を設定 var recip = get_recipient(); // 送信先のメールアドレス(スプレッドシートに記載)を取得 var subject = 'メール件名:' + get_nowdate(); var yourname = '○○各位'; var myname = '○○担当'; var body = yourname + '\n\n' + myname + 'です。\n\n' + '本日分の○○をお送り致します。\n\n以上、宜しくお願い致します。' var filename = '添付したいファイルの名前'; var foldername = 'test' var tgtfile = DriveApp.getFilesByName(filename).next(); const options = {name: '○○担当', attachments:[tgtfile]}; // メール送信 GmailApp.sendEmail(recip, subject, body, options); } // スプレッドシートに記載の送信先メールアドレスを取得 function get_recipient(){ // スプレッドシートの対象シートを設定 var spdsht = SpreadsheetApp.getActiveSpreadsheet(); var sheet = spdsht.getActiveSheet(); // 1行目に記載のアドレスを取得 var tgtcell = sheet.getRange('A1'); var rcps = tgtcell.getValue(); var tgtval = rcps; // 2行目以降に記載のアドレスを取得 for (let i = 2; tgtval != ''; i++) { tgtcell = sheet.getRange('A' + i); tgtval = tgtcell.getValue(); rcps = rcps + ', ' + tgtval; } return rcps; // console.log(rcps) // デバッグ } // 本日の年月日(曜日含む)を取得 function get_nowdate() { var da = new Date(); // 今日の年月日を取得 var y = da.getFullYear(); var m = da.getMonth() + 1; // 月は-1の値で取得するため var d = da.getDate(); // 今日の曜日を取得 var downum = da.getDay(); // 曜日番号を取得 var downow = ['日', '月', '火', '水', '木', '金', '土'][downum]; // 曜日番号に対応する曜日を選択 return y + '/' + m + '/' + d + '(' + downow + ')'; }3.PowerShell:Wi-Fi接続/切断用
3-1.接続時
wifi_on.ps1netsh wlan connect name="接続したいWi-FiのSSID"3-2.切断時
wifi_off.ps1netsh wlan disconnect備考:MATLABから.pyを呼び出したい場合
system関数を用いて.m に以下のように記述します。
system('実行したい.pyのパス')その他・思ったこと
・Seleniumでスプレッドシートを開くためにブラウザを開く処理はヘッドレスにて実施していますが、
何故かヘッドレスで起動する場合はそうでない場合と比較して異なる画面が表示され、若干苦しみました。
(画面が異なることはsave_screenshotによる画面キャプチャで発覚)
結局、もう異なる画面で割り切って進めた結果が上記です。参考:https://teratail.com/questions/276976
・GASにはPythonの対話モード(インタラクティブモード)に相当する機能はないのかなあ。。
あれば非常に便利だと思うんだけども。参考にさせていただいた情報
特に下記サイト様にお世話になりました。ありがとうございます。
最後
ご指摘・改善案・間違い指摘、大歓迎です。どしどし下さい。宝くじ10万円当たったばりに喜びます。
- 投稿日:2020-07-12T20:06:52+09:00
enumの互換性エラーの対処法
Optunaインストール時に起きたエラーの原因と対処法
環境は以下の通り
- Windows 10 Home
- python 3.6.5
- pip 19.3.1
Optunaをインストールしようと以下コードを実行したらエラーが出た
実行文pip install optuna実行結果Collecting optuna Downloading https://files.pythonhosted.org/packages/33/32/266d4afd269e3ecd7fcc595937c1733f65eae6c09c3caea74c0de0b88d78/optuna-1.5.0.tar.gz (200kB) |████████████████████████████████| 204kB 1.7MB/s Collecting alembic Downloading https://files.pythonhosted.org/packages/60/1e/cabc75a189de0fbb2841d0975243e59bde8b7822bacbb95008ac6fe9ad47/alembic-1.4.2.tar.gz (1.1MB) |████████████████████████████████| 1.1MB 6.4MB/s Installing build dependencies ... error ERROR: Command errored out with exit status 1: command: 'D:\Users\(user_name)\Anaconda3\python.exe' 'D:\Users\(user_name)\Anaconda3\lib\site-packages\pip' install --ignore-installed --no-user --prefix 'C:\Users\(user_name)\AppData\Local\Temp\pip-build-env-5wsdb490\overlay' --no-warn-script-location --no-binary :none: --only-binary :none: -i https://pypi.org/simple -- 'setuptools>=40.8.0' wheel cwd: None Complete output (14 lines): Traceback (most recent call last): File "D:\Users\(user_name)\Anaconda3\lib\runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "D:\Users\(user_name)\Anaconda3\lib\runpy.py", line 85, in _run_code exec(code, run_globals) File "D:\Users\(user_name)\Anaconda3\lib\site-packages\pip\__main__.py", line 16, in <module> from pip._internal.main import main as _main # isort:skip # noqa File "D:\Users\(user_name)\Anaconda3\lib\site-packages\pip\_internal\main.py", line 8, in <module> import locale File "D:\Users\(user_name)\Anaconda3\lib\locale.py", line 16, in <module> import re File "D:\Users\(user_name)\Anaconda3\lib\re.py", line 142, in <module> class RegexFlag(enum.IntFlag): AttributeError: module 'enum' has no attribute 'IntFlag' ---------------------------------------- ERROR: Command errored out with exit status 1: 'D:\Users\(user_name)\Anaconda3\python.exe' 'D:\Users\(user_name)\Anaconda3\lib\site-packages\pip' install --ignore-installed --no-user --prefix 'C:\Users\(user_name)\AppData\Local\Temp\pip-build-env-5wsdb490\overlay' --no-warn-script-location --no-binary :none: --only-binary :none: -i https://pypi.org/simple -- 'setuptools>=40.8.0' wheel Check the logs for full command output.エラー内容
エラー文ERROR: Command errored out with exit status 1: 'D:\Users\(user_name)\Anaconda3\python.exe' 'D:\Users\(user_name)\Anaconda3\lib\site-packages\pip' install --ignore-installed --no-user --prefix 'C:\Users\(user_name)\AppData\Local\Temp\pip-build-env-5wsdb490\overlay' --no-warn-script-location --no-binary :none: --only-binary :none: -i https://pypi.org/simple -- 'setuptools>=40.8.0' wheel Check the logs for full command output.原因
標準ライブラリenumモジュールではなく、enum34パッケージのものが使われており、Python 3.6以降、enum34ライブラリは標準ライブラリenumと互換性がなくなったため。
解決策
Python3.6以降を使う場合、enum34ライブラリも不要なので、アンインストールし標準ライブラリのenumモジュールを使う。
enum34をアンインストールpip uninstall enum34enum34をアンインストール後、再度
pip install optunaを実行すると、無事Optunaをインストールすることができました!
- 投稿日:2020-07-12T20:00:20+09:00
Windows10 HomeにDockerをインストールしようと思ったがうまくいかなかった
Windows10 HomeにDockerをインストール
Pythonの勉強を始めようと思ってるんですが、どうせならDockerで
環境を作ろうかなと思ったわけです。ただ、Docker Desktop for Windows は Hyper-V の利用を前提としているので
Windows10 Proが必要みたいなんですよね。
Windows10 HomeでDockerを使うにはDocker Toolboxをインストールすればいいらしい。Docker Toolboxのインストール手順を調べてたんですが、
Docker Desktop for WindowsがWindows10 HomeDのWSL2に対応するという記事を見まして
Windows10 HomeにDockr Desktop for windowsのインストールを試してみました。まずはDockerインストールやってみる
Dockerをインストール。
https://docs.docker.com/docker-for-windows/install/
DockerhubからGet stableボタンをクリック。
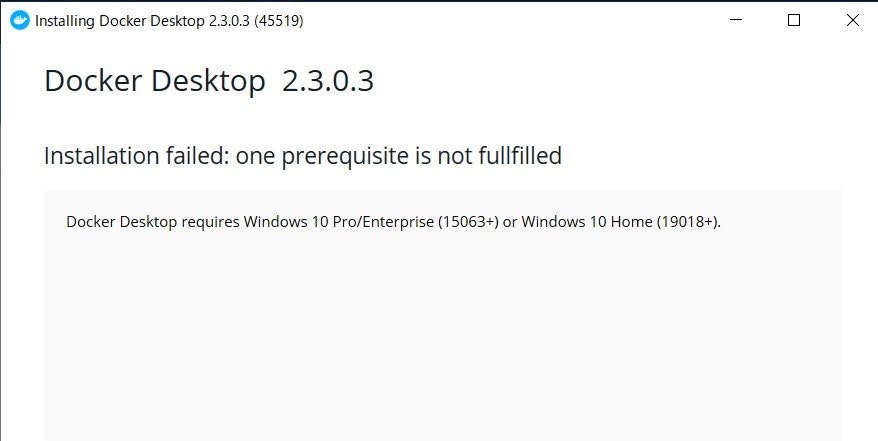
インストールをスタート。
ダメみたいですね。
OSビルドが古い感じ?Windowsアップデートをやってみる
Docker Desktop for windowsに対応しているのは、
Windows10 Home(19018以降)ってことみたいなので、アップデートをしてみる。調べてみるとWindows Insider Programでスローにしてアップデートするってことらしいけど。
スロー設定ってないやん。
https://news.mynavi.jp/article/20200616-1057186/
配信方法が、リンク制からチャネル制にされてるのか。
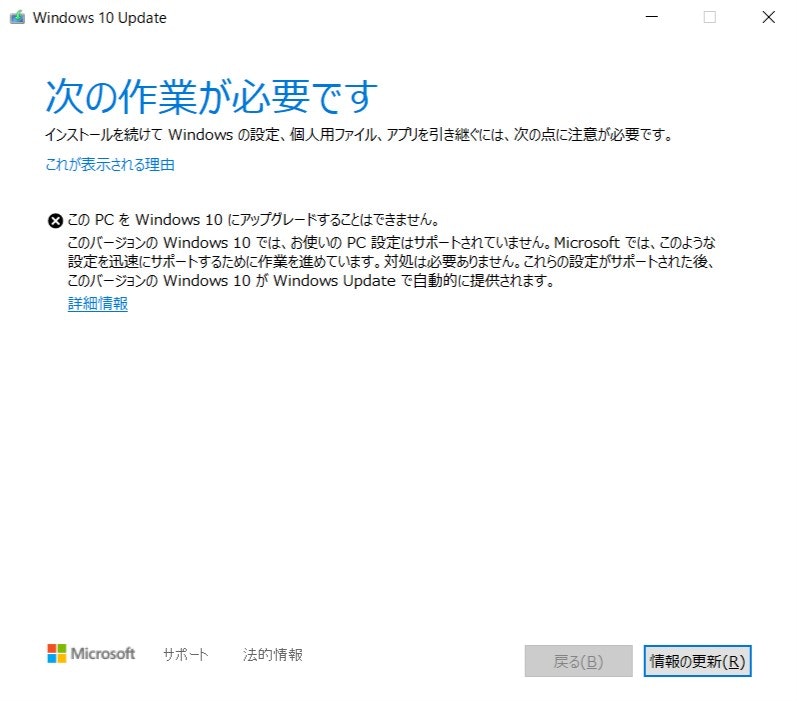
Fastリング→Devチャネル、Slowリング→Betaチャネル、Release Previewリング→Release Previewチャネルってことね。よし、Windows10 updateっと。
あれ、止まっちゃった。
何が引っかかってんだろ。
アップデート先に進まないし。
これが解決するまで保留だな。



- 投稿日:2020-07-12T19:55:39+09:00
FastAPI Tutorialメモ その1
はじめに
FastAPI Souce: https://github.com/tiangolo/fastapi
FastAPI Document: https://fastapi.tiangolo.comIntro & First Step
FastAPIチュートリアルのメモ。
基本的にはFastAPIの公式チュートリアルを参考にしていますが、自身の学習のため一部分を省略したり順番を前後させています。
正しい詳細な情報は公式ドキュメントを参考いただければと思います。Web & Python 初心者かつ翻訳はGoogleとDeepL頼りのため、間違い等ありましたらご指摘いただけますと幸いです。
開発環境
Ubuntu 20.04 LTS
Python 3.8.2
pipenv 2018.11.26目標
FastAPIとは
FastAPIは、Pythonの型ヒントに基づいてAPIを構築するための高速・軽量・モダンなWebフレームワーク。
APIのオープンスタンダードであるOpenAPI(Swagger)とJSONスキーマに準拠しています。
詳しくは公式ドキュメントをご確認ください。手順
FastAPIのインストール
FastAPIを
pipを使用しインストールします。
以下のコマンドでFastAPIで使用するすべての依存関係と機能をインストールできるので、開発環境ではとりあえずこのコマンドでインストールしてみましょう。
サーバとして使用するuvicornも一括でインストールできます。$ pip install fastapi[all] ████████████████████████████████████████ 100%pythonのインタラクティブシェルで確認してみます。
$ python Python 3.8.2 (default, Apr 21 2020, 18:13:10) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> >>> from fastapi import FastAPI >>>エラーが表示されなければインストールは成功です。
また、私の環境ではpipenvを使用しているため、pipenv install fastapi[all]でインストールしましたが、今のところ問題はありません。ここでは割愛しますが
fastapiやuvicornを別々にインストールすることも可能です。サーバの起動
FastAPIをインストールしたところで、さっそくサーバを起動してみましょう。
まず、
main.pyファイルに簡単なFastAPIのコードを書きます。
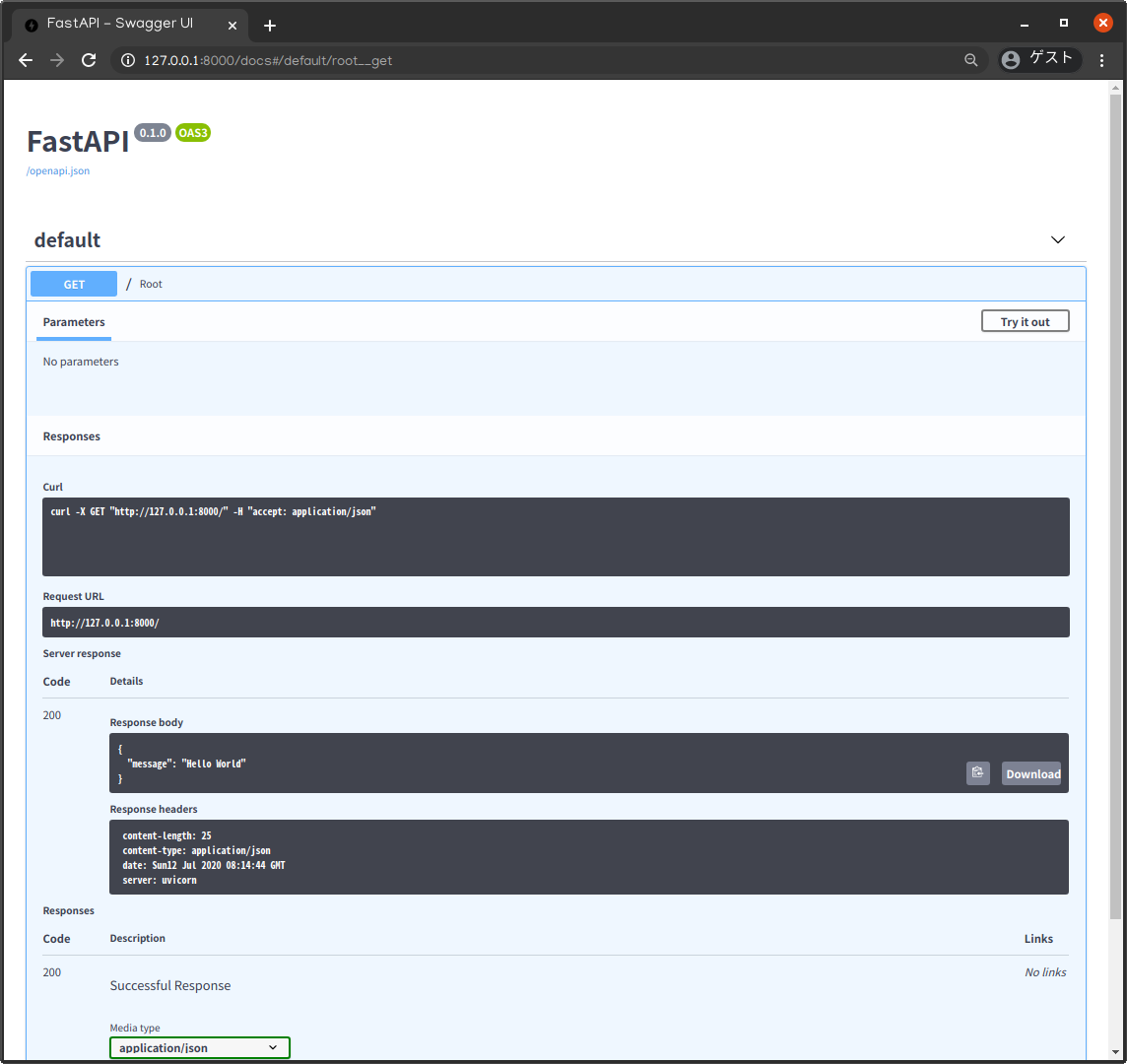
(コードは基本的に公式ドキュメントから引用しています。参考をご確認ください。)main.pyfrom fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}コードを保存したら、サーバを以下のコマンドで起動します。
$ uvicorn main:app --reload以下のような表示が出力されればサーバが起動しています。
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) INFO: Started reloader process [28720] INFO: Started server process [28722] INFO: Waiting for application startup. INFO: Application startup complete.出力に
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)という行があります。
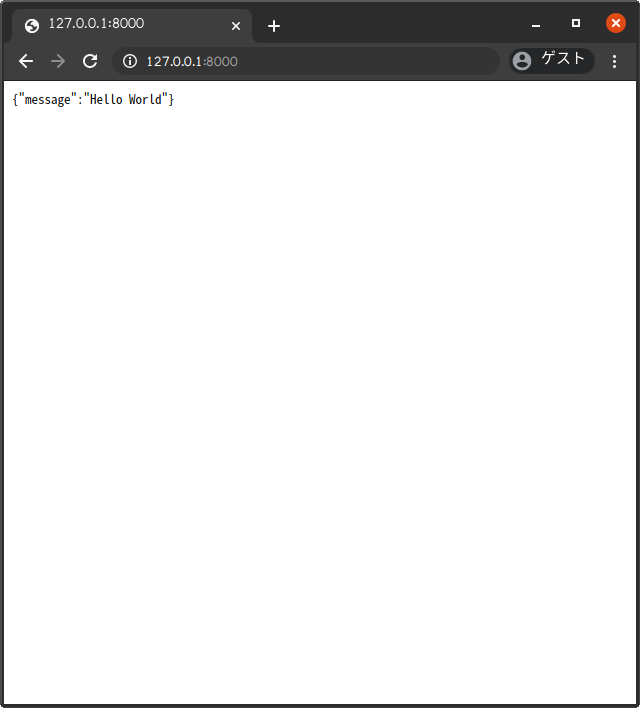
ローカルマシンでアプリが起動しているURL( http://127.0.0.1:8000 )とサーバの停止方法(Controlキー + C)を教えてくれているようです。さっそく http://127.0.0.1:8000 をブラウザで表示してみましょう。
main.pyのroot関数の返り値(return {"message": "Hello World"})が表示されるはずです。
uvicorn main:app --reloadについて
mainはmain.pyファイル(= Pythonモジュール)を参照
- ファイル名は自由に設定することが可能です。
control.pyなどに変更してみましょう。その場合はコマンドも変更する必要があります。appはmain.pyファイル内のapp = FastAPIで生成されたオブジェクトを参照
- これもファイル名同様に自由に設定することが可能です。
--reloadはコードが変更するたびにサーバを再起動するためのオプションです
- このオプションは開発環境でのみ使用することが推奨されています。
Swagger UIの確認
FastAPIはOpenAPIに準拠にしており、Swagger UIによるインタラクティブなAPIドキュメントを自動生成してくれます。
http://127.0.0.1:8000/docs にアクセスして確認してみましょう。
また、その他にもhttp://127.0.0.1:8000/redoc にアクセスすることでReDocによるドキュメントも確認できます。
コードの確認
main.pyの内容を確認してみましょう。このコードは、FastAPIの基本のコードとなっています。FastAPIのインポート
まず、
FastAPIクラスをインポートします。このFastAPIによって作成するAPIのすべての機能が提供されています。from fastapi import FastAPIインスタンスの作成
次に、FastAPIのインスタンスとなる変数を作成します。この変数がFastAPIの実体となります。
from fastapi import FastAPI app = FastAPI()ここで作成したインスタンス変数
appがuvicornコマンドのオプションmain:appに対応しています。
もし、ファイル名をcontrol.py、インスタンス変数をmy_instance = FastAPI()とした場合はuvicornコマンドは以下のようになるでしょう。$ uvicorn control:my_instance --reload INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)Path Operationの作成
ここでのPathとはURLの最後、ドメイン名とポート名以降の
/から始まる部分を指します。
https://example.com/items/fooというURLの場合は/items/fooの箇所がFastAPIにおけるPathに該当します。また、Pathは一般的なendpointやrouteと同じ意味と思っても良いでしょう。
FastAPIでは、Pathの役割は「API構築における"concerns"(関心)と"resource"(リソース)の分離」とされています。
プログラムを関心(目的、何をしたいか)という単位とリソース(資源、何を使用するか)という単位で分割するため、という意味でしょうか。詳しい方がいれば教えてください。また、Path OperationのOperationはHTTPのメソッドと同義です。
主に使用されるメソッドは以下の通りです。
- POST: データの作成
- GET: データの読み込み
- PUT: データの更新
- DELETE: データの削除
HTTPはこれらのメソッドを使うことでWebサーバの各Pathと通信することができます。
APIを構築する際には、特定の処理を実行するためにこれらのHTTPメソッドを使用しています。OpenAPIではHTTPメソッドはoperationと呼ばれており、FastAPIでもそれにならってoperationという用語が使用されています。
インスタンス変数を使用して path operation decoratorを定義しましょう。
from fastapi import FastAPI app = FastAPI() @app.get("/")デコレータ関数
@app.get("/")によって、FastAPIは以下のリクエストをすぐ下の関数を使用して処理することができます。
- pathが
/、かつ- operationに
getメソッドを使用デコレータ関数については他の記事を参照してください。
ここでは、デコレータ関数の直下にある関数がpath/に対応していることをFastAPIに伝えるため使用しています。また、このようなデコレータ関数をpath operation decorator(パス操作デコレータ)と呼びます。以下のように
get以外のoperationも使用することができます。
- @app.post()
- @app.put()
- @app.delete()
path operation function(パス操作関数)の定義
コードの確認の最後に、パス操作関数の定義と戻り値の設定を行います。
path operation decorator(パス操作デコレータ)
@app.get("/")によって処理の起点となるHTTPリクエストを定義することができました。
次に、処理を行う関数をデコレータのすぐ下に定義します。from fastapi import FastAPI app = FastAPI() @app.get("/") async def root():ここで使われるパス操作関数(
async def root():)は通常のPython関数と変わりません。
クライアントがgetoperationでURL/へリクエストを送信し、サーバがそれを受信する度にFastAPIによってこの関数が呼び出されます。
( http://127.0.0.1:8000 にアクセスした際にも、この関数が呼び出されたいました。)また、
async defの代わりに通常の関数を定義することも可能です。from fastapi import FastAPI app = FastAPI() @app.get("/") def root(): return {"message": "Hello World"}
async(非同期処理)についてはコチラの公式ドキュメントを参照してください。後は
returnで返り値を設定すれば、最初のコードの確認は終了します。from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}返り値に関して、複数の値では
dictやlist、単数の値ではstr、intなどの型で返り値を設定できます。
その他にも、Pydanticモデルを返すことも可能です。
以上の他にもJSONに自動変換されるオブジェクトやモデルは(ORMなども含めて)たくさんあるそうです。ぜひ調べてみてください。終わりに OpenAPIについて
今回はFastAPIの公式チュートリアルのうち、IntroとFirst Stepsを取り上げました。
最後、OpenAPIとSchemaについての記述を取り上げます。OpenAPIとは
OpenAPIはREST APIを記述するためのフォーマットのことであり、SwaggerはOpenAPIを記述する際に使用することオープンソースのツールセットのこと。
以下の記事に簡単にまとめられていました。FastAPIでは、APIの定義がOpenAPIに準拠しており、すべてのAPIで"スキーマ"が生成されます。
スキーマとは
"スキーマ"とは何らかの定義や記述のことです。実装されたコードではなく、抽象的な概念を指しています。
APIスキーマ
APIにおける"スキーマ"を考える場合、OpenAPIは作成されたAPIのスキーマ定義の方法を規定する仕様になります。
このスキーマ定義には、APIへのパスやAPIが取得する可能性のあるパラメータなどが含まれます。
データスキーマ
"スキーマ"という言葉は、JSONコンテンツなどのような何らかのデータの形を指す場合もあります。
その場合は、JSONの属性やそれらが持つデータ型などを意味します。
OpenAPIとJSONスキーマの関係
OpenAPIは作成されたAPIの"APIスキーマ"を定義し、そのスキーマではJSONデータスキーマの標準である"JSONスキーマ"を使用してAPIが送受信するデータの定義(あるいは、その他の"スキーマ")が含まれています。
FastAPIでは、2種類のインタラクティブなドキュメントシステム(Swagger UI, ReDoc)を動かすためにOpenAPIスキーマを使用しています。
参考
- 投稿日:2020-07-12T19:26:12+09:00
Pythonチュートリアルを参考にxmlファイル読み込み
data3.xml<data> <country name="Liechtenstein"> <rank>1</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank>4</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank>68</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>findall 同じ子ノードすべてを参照する
findやfindallでほしいタグを指定する
以下ではすべてのcountryタグを取得するfrom xml.etree import ElementTree path = 'data3.xml' tree = ElementTree.parse(path) root = tree.getroot() countries = root.findall('country') for country in countries: gdppc = country.find('gdppc') print(country.attrib) print(gdppc.text){'name': 'Liechtenstein'} 141100 {'name': 'Singapore'} 59900 {'name': 'Panama'} 13600孫ノードまで取得
for文をネストする。
cnt = 1 for child in root: print('---', cnt, '---') print(child.tag, child.attrib, child.text) for gild in child: print(gild.tag, gild.attrib, gild.text) cnt += 1--- 1 --- country {'name': 'Liechtenstein'} rank {} 1 year {} 2008 gdppc {} 141100 neighbor {'name': 'Austria', 'direction': 'E'} None neighbor {'name': 'Switzerland', 'direction': 'W'} None --- 2 --- country {'name': 'Singapore'} rank {} 4 year {} 2011 gdppc {} 59900 neighbor {'name': 'Malaysia', 'direction': 'N'} None --- 3 --- country {'name': 'Panama'} rank {} 68 year {} 2011 gdppc {} 13600 neighbor {'name': 'Costa Rica', 'direction': 'W'} None neighbor {'name': 'Colombia', 'direction': 'E'} None参考URL
https://docs.python.org/ja/3/library/xml.etree.elementtree.html
- 投稿日:2020-07-12T18:53:31+09:00
【Python】7DaysToDieをDiscordから管理したい! 2/3
Discordから管理できるBOTの作成
前回に続き今度はメインとなるDiscordから管理できるプログラムを作成していきます。
sdtd_run.pyの作成
$ cd $ mkdir -p $HOME/python/discord/Sdtd $ cd $HOME/python/discord/ $ vim sdtd_run.py続いてsdtd_run.pyは確認箇所が2つあります。
- API
- ADMIN
#!/bin/env python import discord import threading import os import re import time import subprocess as prc from Sdtd import command API = "ここにディスコードAPIを記入してください。" ADMIN = "ここにディスコードのサーバ管理者の名前を記入します。例:Dream" #SubADMIN ="必要であれば副官の名前" client = discord.Client() @client.event async def on_message(message): #サーバ管理者を指定します。副官がいる場合は以下のようにorで繋げてください。 #if message.author.name == (ADMIN) or message.author.name == ("SubADMIN"): if message.author.name == (ADMIN): cmd = command.SDTD() if message.content.startswith('/help'): cmdhelp = cmd.command_help() await message.channel.send(cmdhelp) elif message.content.startswith('/member'): await message.channel.send(cmd.player_joined_check()) elif message.content.startswith('/server-start'): timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) await message.channel.send(timemsg + "--- サーバを起動します。(起動には5分程掛かかる場合があります。)") thread = threading.Thread(target=cmd.start) thread.start() elif message.content.startswith('/server-stop'): timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) await message.channel.send(timemsg + "--- サーバを停止します。") thread = threading.Thread(target=cmd.stop) thread.start() elif message.content.startswith('/server-restart'): timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) await message.channel.send(timemsg + "--- サーバを再起動します。") thread = threading.Thread(target=cmd.stop) thread.start() time.sleep(15) timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) await message.channel.send(timemsg + "--- サーバを起動します。(起動には5分程掛かかる場合があります。)") thread = threading.Thread(target=cmd.start) thread.start() elif message.content.startswith('/server-status'): timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) await message.channel.send(timemsg + "--- サーバの状況を表示します。") await message.channel.send(cmd.status()) client.run(API)続いてcommand.pyを作成します。
$ cd Sdtd $ vim command.py続いてcommand.pyは確認箇所が3つあります。
- webhooks APIの記入
- ゲームディレクトリの場所の確認。(バニラならデフォでOK)
- Screenの場所の確認(恐らくデフォでOK)
#!/bin/env python import os import re import sys import requests import subprocess as prc import time import glob as g from telnetlib import Telnet class SDTD(object): def __init__(self): #ディスコードのWebhooks APIを埋める。 self.discord = "Discord_Webhooks_API" #screen生成ディレクトリの確認。 self.screendir = "/var/run/screen/S-" + os.environ['USER'] #今回は/sdtdで作成しているので以下で設定。mod鯖にするときは適時変更。 self.gamedir = os.environ['HOME'] + "/steamcmd/sdtd" def port_check(self): p1 = prc.Popen(["lsof"], stdout=prc.PIPE) p2 = prc.Popen(["grep", "7Days"], stdin=p1.stdout, stdout=prc.PIPE) p3 = prc.Popen(["grep","-E","TCP..:"], stdin=p2.stdout, stdout=prc.PIPE) p4 = prc.Popen(["awk", "-F:", "NR==1 {print $2}"], stdin=p3.stdout, stdout=prc.PIPE) p5 = prc.Popen(["awk", "{print $1}"], stdin=p4.stdout, stdout=prc.PIPE) p1.stdout.close() p2.stdout.close() p3.stdout.close() p4.stdout.close() output = p5.communicate()[0].decode('utf-8') return output[:-1] def proc_check(self): p1 = prc.Popen(['ps', 'x'], stdout=prc.PIPE) p2 = prc.Popen(["grep", "-v","grep"], stdin=p1.stdout, stdout=prc.PIPE) p3 = prc.Popen(["grep", "7DaysToDieServer.x86_64"], stdin=p2.stdout, stdout=prc.PIPE) p4 = prc.Popen(["awk","{print $1}"], stdin=p3.stdout,stdout=prc.PIPE) p1.stdout.close() p2.stdout.close() p3.stdout.close() output = p4.communicate()[0].decode('utf-8') return output[:-1] def screen_check(self): p1 = prc.Popen(['ps', 'x'], stdout=prc.PIPE) p2 = prc.Popen(["grep", "-v","grep"], stdin=p1.stdout, stdout=prc.PIPE) p3 = prc.Popen(["grep", "SCREEN"], stdin=p2.stdout, stdout=prc.PIPE) p4 = prc.Popen(["awk","{print $1}"], stdin=p3.stdout, stdout=prc.PIPE) p1.stdout.close() p2.stdout.close() p3.stdout.close() output = p4.communicate()[0].decode('utf-8') return output[:-1] def command_help(self): lists = ( "```/help この内容を表示します。\n" "/server-stop 7Days to Die サーバを停止します。\n" "/server-start 7Days to Die サーバを起動します。\n" "/server-restart 7Days to Die サーバを再起動します。\n" "/server-status 7Days to Die サーバの状態を表示します。\n" "/member 現在接続しているユーザを確認します。\n```" ) return lists def server_status(self): init = 0 port = self.port_check() if port != "": port_status_msg = "ポート [" + port + "] で解放されています。" init += 1 else: port_status_msg = "ポートは解放されていません。" init -= 1 process = self.proc_check() if process != "": proc_status_msg = "GAME PID [" + process[:-1] + "] で稼働しています。" init += 1 else: proc_status_msg = "プロセスは稼働していません。" init -= 1 screen = self.screen_check() if screen != "": screen_status_msg = "SCREEN PID [" + screen[:-1] + "] で稼働しています。" init += 1 else: screen_status_msg = "スクリーンは稼働していません。" init -= 1 message = port_status_msg + "\n" + proc_status_msg + "\n" + screen_status_msg + "\n" return message,init def status(self): message = self.server_status()[0] return message def player_joined_check(self): status = self.server_status()[1] sts_msg = self.server_status()[0] if status <= 0: msg = "サーバが正常に起動していません。\n" + sts_msg return msg login_status = [] member = "" with Telnet('localhost',8081) as tn: tn.write(b'lp\n') time.sleep(1) tn.write(b'exit\n') login_mem = tn.read_all().decode().split("\n")[16:-1] for i in range(len(login_mem)): login_status += [login_mem[i].replace('\r','\n')] member += login_status[i] return member[:-1] def start_check(self): for i in range(420): status = self.server_status()[1] if status == 3: timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) payload = { "content" : timemsg + "--- サーバの起動が完了しました。" } requests.post(self.discord, data=payload) sys.exit() time.sleep(1) else: status = self.server_status()[0] timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) payload = { "content" : timemsg + "--- サーバの起動に失敗しました。状況を確認してください。\n" + status } requests.post(self.discord, data=payload) sys.exit() def stop_check(self): for i in range(30): status = self.server_status()[1] if status == -3: timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) payload = { "content" : timemsg + "--- サーバの停止が完了しました。" } requests.post(self.discord, data=payload) sys.exit() time.sleep(1) else: status = self.server_status()[0] timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) payload = { "content" : timemsg + "--- サーバの停止に失敗しました。状況を確認してください。\n" + status } requests.post(self.discord, data=payload) sys.exit() def start(self): status = self.server_status()[1] if status == 3: timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) payload = { "content" : timemsg + "--- サーバは既に起動しています。" } requests.post(self.discord, data=payload) sys.exit() os.chdir(self.gamedir) com1 = prc.run(["screen", "-dmS", "sdtd"], stdout=prc.PIPE) time.sleep(2) com2 = prc.run(['screen','-S','sdtd','-p','0','-X','exec','/bin/bash','startserver.sh'], stdout=prc.PIPE) sys.stdout.buffer.write(com1.stdout) time.sleep(2) sys.stdout.buffer.write(com2.stdout) self.start_check() def stop(self): prc_chk = self.proc_check() scn_chk = self.screen_check() status = self.server_status()[1] if status == 3: message = "say 10秒後サーバを停止します。\n\n".encode('utf-8') with Telnet('localhost',8081) as tn: tn.write(message) time.sleep(10) tn.write(b'shutdown\n') try: tn.interact() except: pass if status == -3: timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime())) payload = { "content" : timemsg + "--- サーバは既に停止しています。" } requests.post(self.discord, data=payload) sys.exit() if prc_chk != "": prc.Popen(['kill', '-9',prc_chk], stdout=prc.PIPE) if scn_chk != "": prc.Popen(['kill', '-9',scn_chk], stdout=prc.PIPE) os.chdir(self.screendir) for remove in g.glob("*"): os.remove(remove) self.stop_check()※port_checkの以下の部分について(どちらでもOK)
p3 = prc.Popen(["grep","-E","TCP..:"], stdin=p2.stdout, stdout=prc.PIPE)
本来はp3 = prc.Popen(["grep","TCP \*:"], stdin=p2.stdout, stdout=prc.PIPE)
と記述していましたが、掲載する時にPythonの文字色が崩れたので仕方なく変更してます。timemsg = time.strftime("%Y/%m/%d %H:%M:%S ", time.strptime(time.ctime()))
これを何回も書いているのを一つにまとめたいけど、まとめるとディスコードに送られる時刻は更新されない。
command.pyが呼ばれる度に一旦初期化して、時刻を再取得する方法が未だわかりませんね。sdtd_start.shの作成
$ cd $HOME/python/discord $ vim sdtd_start.shsdtd_start.shの内容
次に起動用のシェルスクリプトを書きます。
#!/bin/sh DIR=$(cd $(dirname $0); pwd) PID=$(ps x |grep sdtd_run.py |grep -v grep |awk '{print $1}') case "$1" in "start" ) if [[ $PID == "" ]]; then env python $DIR/sdtd_run.py > /dev/null & sleep 3 PID=$(ps x |grep sdtd_run.py |grep -v grep |awk '{print $1}') date +"%Y-%m-%d %H:%M:%S --- [$PID] start" else echo "pid already exists.[$PID]" fi ;; "restart" ) if [[ $PID != "" ]]; then kill -9 $PID sleep 2 date +"%Y-%m-%d %H:%M:%S --- [$PID] kill ok" fi env python $DIR/sdtd_run.py > /dev/null & sleep 3 PID=$(ps x |grep sdtd_run.py |grep -v grep |awk '{print $1}') date +"%Y-%m-%d %H:%M:%S ---[$PID] start" ;; "stop" ) if [[ $PID != "" ]]; then kill -9 $PID sleep 2 date +"%Y-%m-%d %H:%M:%S --- [$PID] kill ok" else echo "pid does not exist." fi ;; "status" ) if [[ $PID != "" ]]; then echo "running PID:"$PID else echo "not running." fi ;; * ) if [[ $PID != "" ]]; then kill -9 $PID sleep 2 date +"%Y-%m-%d %H:%M:%S --- [$PID] kill ok" fi env python $DIR/sdtd_run.py > /dev/null & sleep 3 PID=$(ps x |grep sdtd_run.py |grep -v grep |awk '{print $1}') date +"%Y-%m-%d %H:%M:%S --- [$PID] start" esacsdtd_start.shの権限変更
$ chmod +x sdtd_start.shお疲れさまでした。では最後に実行して確認してみましょう。
- 投稿日:2020-07-12T17:59:28+09:00
pandasメモ
学びのメモとして、pandas周辺のコードをチートシート代わりに自分の参考用としてまとめています。
1. pandasのインポート
import pandas as pd2. DataFrameの作り方
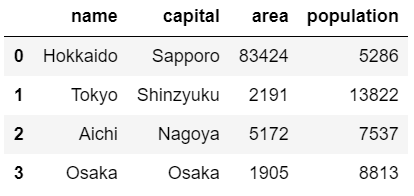
辞書から作成する方法と、CSVファイルから読み込む方法の2つがある。
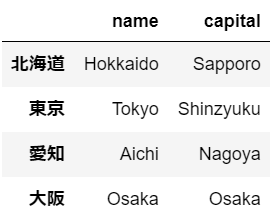
①辞書から作成する方法import pandas as pd dict = {"name":["Hokkaido","Tokyo","Aichi","Osaka"], "capital":["Sapporo","Shinzyuku","Nagoya","Osaka"], "area":[83424,2191,5172,1905], "population":[5286,13822,7537,8813]} prefecture = pd.DataFrame(dict) prefecture
②CSVファイルから読み込む方法
import pandas as pd #read_csv関数を使用 prefecture = pd.read_csv("path/to/prefecture.csv")しかし、このままではcsvファイルの行ラベルが、それ自体が列として認識されてしまうため、最初の列に行インデックスが含まれていることを以下の様に知らせる。
import pandas as pd #index_col=0とすることで、インデックスが0である列が行ラベルであることを知らせる prefecture = pd.read_csv("path/to/prefecture.csv", index_col = 0)3. 行ラベルの設定
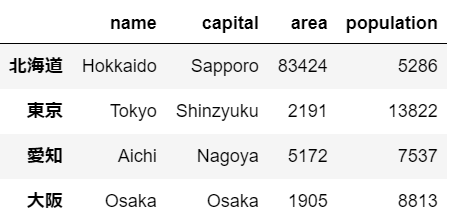
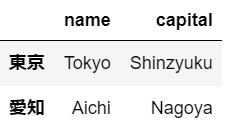
prefecture.index = ["北海道","東京","愛知","大阪"]
4. DataFrameからデータを選択
角括弧("[]")を用いる方法と、locやilocなどのアクセスメソッドを用いる方法の2種類がある。
①[]を用いる方法#nameの列のみを選択 prefecture["name"]
しかし、この方法で取り出したデータ型はpandasSeriesというデータ型であり、DataFrameではない。DataFrameとしてデータを取り出すには以下の様に[]を2重にして記述する。#角括弧を二重にすることでデータ型をDataFrameにしたままデータを抽出 prefecture[["name"]]
また、以下の様にして複数列を取り出すこともできる
#複数の列を選択できる prefecture[["name","capital"]]
横の行を取り出すためにはスライスを使用する。
prefecture[1:3]
②loc、ilocを用いる方法
locはラベルに基づいてデータを選択、ilocは位置に基づいてデータを選択できる。
locは、以下の様にDataframe名.loc["行ラベル"]と記述すると、その行のデータを選択できる。prefecture.loc["東京"]
しかし、このやり方ではまだデータ型がDataFrameではなくなってしまうため、DataFrameとして選択したい場合は角括弧を二重で用いる。prefecture.loc[["東京"]]
以下の様に記述することで、複数の行を選択できる。
prefecture.loc[["東京","愛知"]]
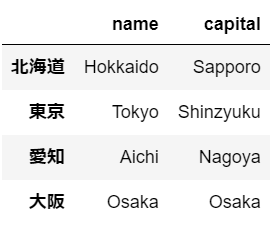
さらに、以下の様に記述すれば、列も指定ができ、指定をした行と列の交差点のみのデータを選択できる。
prefecture.loc[["東京","愛知"],["name","capital"]]
リストと同様、":"だけで全選択を意味する。#":"を用いて、行を全選択 prefecture.loc[:,["name","capital"]]
ilocはlocで行ラベルを使用する代わりに、インデックスを使用。
#下記2つは全く同じ結果を返す。 prefecture.loc[["東京"]] prefecture.iloc[[1]] #下記2つは全く同じ結果を返す。 prefecture.loc[["東京","愛知"]] prefecture.iloc[[1,2]] #下記2つは全く同じ結果を返す。 prefecture.loc[["東京","愛知"],["name","capital"]] prefecture.iloc[[1,2],[0,1]] #下記2つは全く同じ結果を返す。 prefecture.loc[:,["name","capital"]] prefecture.iloc[:,[0,1]]






- 投稿日:2020-07-12T17:45:18+09:00
【Python】7DaysToDieをDiscordから管理したい! 1/3
概要
【Python】7DaysToDieをDiscordから管理したい! 1/3 (環境構築)
【Python】7DaysToDieをDiscordから管理したい! 2/3 (Discordから管理できるBOTの作成)
【Python】7DaysToDieをDiscordから管理したい! 3/3 (動作チェック)経緯について
以前はMinecraftをDiscordから管理できるプログラムを書いていたいのですが、
今回はSteamの7Daysをやることになったので、7Daysでもできないかということで作りました。元々面倒くさがりで、コンソール画面を開いて管理するのも面倒で、
自分以外の副管に操作を任せたい時がある。等々の理由で製作に至りました。本プログラムについて
このプログラムはDiscord BotとDiscord Webhookを使用しています。
また現在も楽しよう楽しようの考えでPythonの学習を続けています。
もっと良いプログラム書き方やブログの改善点等、他意見があれば是非コメント下さると励みになります。前提条件
- 基本的なUnix系の知識、コマンドを使用できること。
- Pythonの基礎知識があること。(なくてもほぼコピペで動くようには書くつもり)
- Discordを導入していること
- DiscordのAPIが利用できること。(Bot導入済みであること)
動作環境
- Python3.6.9 使用(3系なら動く)
- CentOS Linux release 7.8.2003 (Core)
ディレクトリ構造
$HOME/ ┝ python/ ┕ discord/ ┝ sdtd_run.py ┝ sdtd_start.sh ┕ Sdtd/ ┕ command.py ┝ steamcmd ┝ linux32 ┝ linux64 ┝ .... //以下デフォルトのディレクトリ群 ┕ sdtd ← これが今回使用するディレクトリになります。実装に必要なライブラリ等のインストール
//steamcmdで使用 # yum -y install glibc.i686 libstdc++.i686 //discordで使用 # yum -y install libffi-dev libnacl-dev python3-dev //pythonプログラムで使用 # yum -y install screen lsof awk # pip install discord.py requestsFirewalldの設定
使用するポートの穴あけを行ってください。
# firewall-cmd --permanent --add-port=26900/tcp # firewall-cmd --permanent --add-port=26900-2603/udp # firewall-cmd --reloadSteamCMDから7DaysToDieをDL&IN
//以下から一般ユーザーで作業を行います。 $ mkdir steamcmd $ cd steamcmd/ $ curl -sqL "https://steamcdn-a.akamaihd.net/client/installer/steamcmd_linux.tar.gz" | tar zxf - $ ./steamcmd.sh Steam>login anonymous Steam>force_install_dir sdtd Steam>app_update 294420 validate Steam>quit7DaysToDieのstartserver.shの編集
$ cd sdtd $ vim startserver.sh#!/bin/sh SERVERDIR=`dirname "$0"` cd "$SERVERDIR" PARAMS=$@ CONFIGFILE= while test $# -gt 0 do if [ `echo $1 | cut -c 1-12` = "-configfile=" ]; then CONFIGFILE=`echo $1 | cut -c 13-` fi shift done if [ "$CONFIGFILE" = "" ]; then PARAMS="-configfile=serverconfig.xml" else if [ -f "$CONFIGFILE" ]; then echo Using config file: $CONFIGFILE else echo "Specified config file $CONFIGFILE does not exist." exit 1 fi fi export LD_LIBRARY_PATH=. #export MALLOC_CHECK_=0 if [ "$(uname -m)" = "x86_64" ]; then ./7DaysToDieServer.x86_64 -logfile $SERVERDIR/7DaysToDieServer_Data/logs/output_log__`date +%Y-%m-%d__%H-%M-%S`.txt -quit -batchmode -nographics -dedicated $PARAMS else echo "7 Days to Die only supports 64 bit operating systems!" exit 1 fiserverconfig.xmlの編集
vim serverconfig.xmlコンソール操作にTelnetを使用するので記述が必要です。(localhostだからパスなしでOK)
<property name="TelnetEnabled" value="true"/> <!-- Enable/Disable the telnet --> <property name="TelnetPort" value="8081"/> <!-- Port of the telnet server --> <property name="TelnetPassword" value=""/> <!-- Password to gain entry to telnet interface. If no password is set the server will only listen on the local loopback interface -->環境構築は以上です。続いてメインの実装を行っていきましょう!
- 投稿日:2020-07-12T17:11:46+09:00
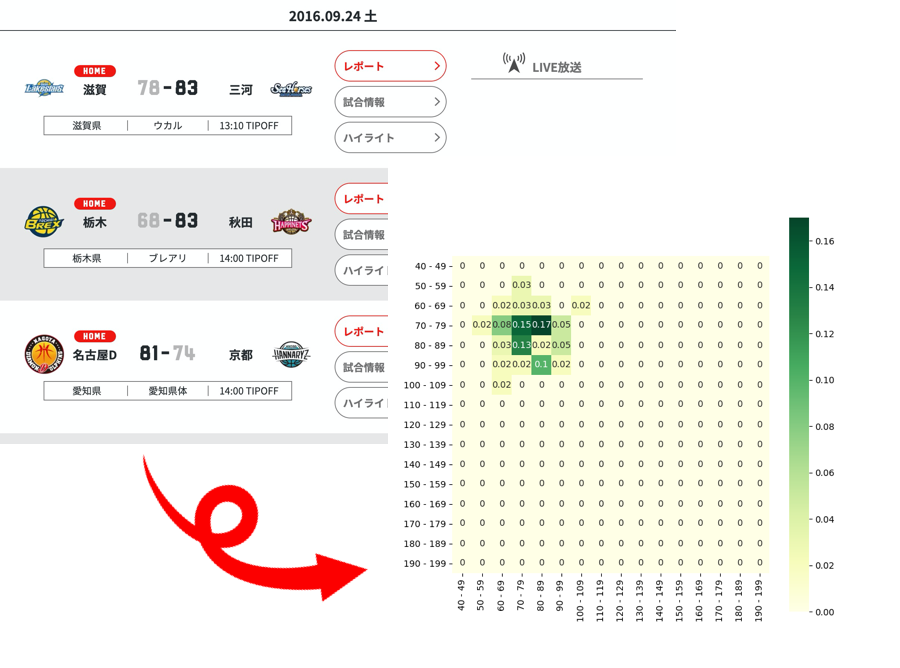
Bリーグの得失点をヒートマップで可視化
目的
Bリーグの試合結果から得失点のヒートマップを作成します
実装
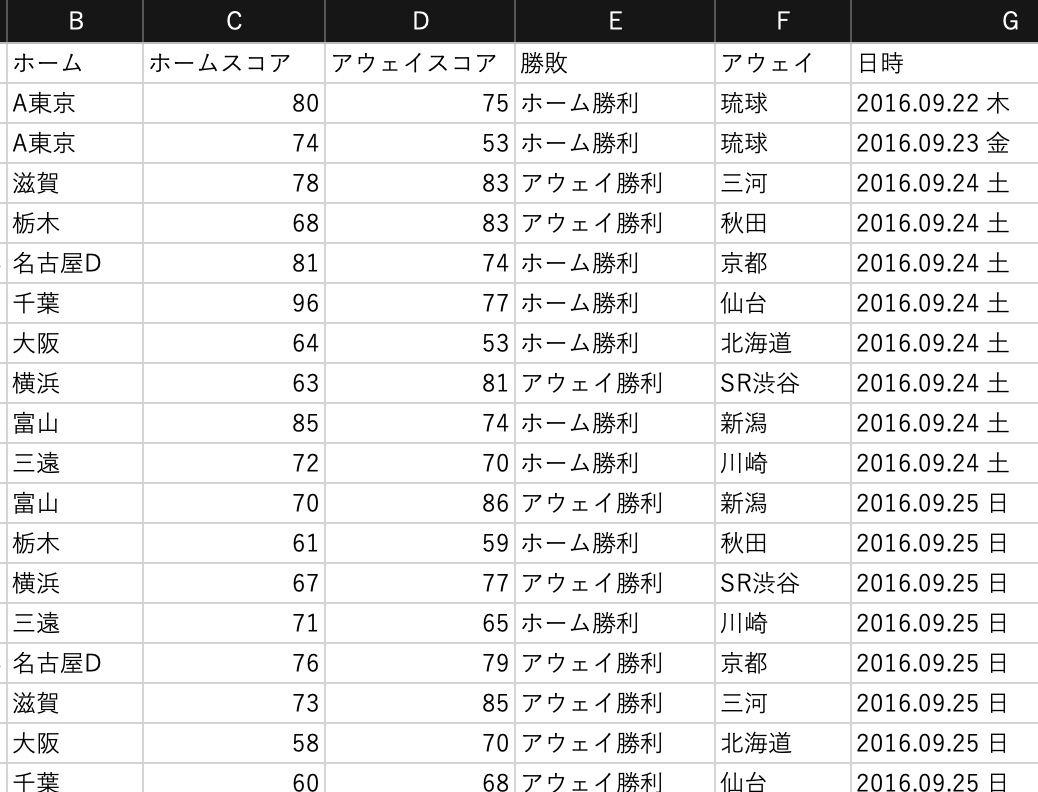
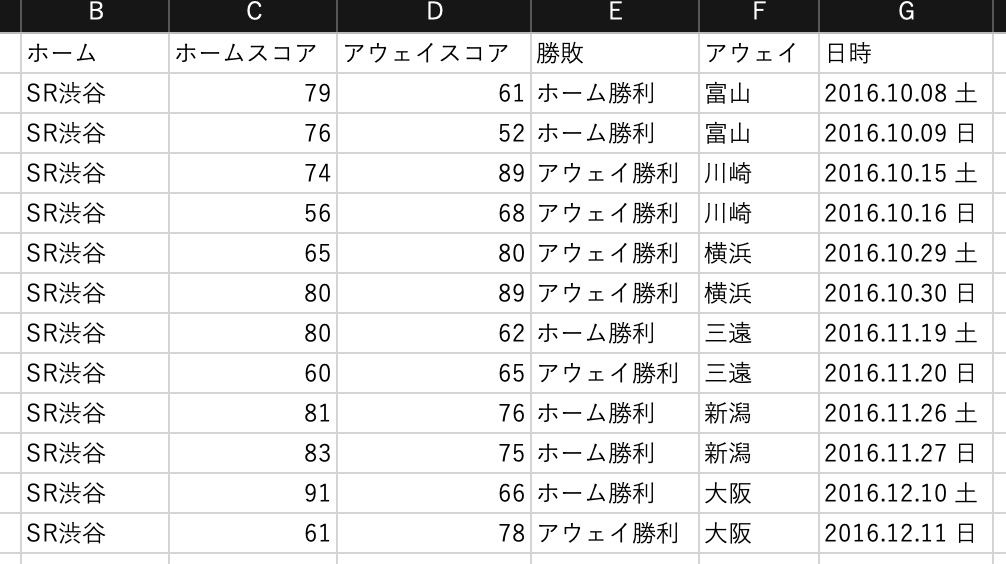
データ取得
こちらのサイトからBリーグの試合結果を取得します
https://www.bleague.jp/schedule/?s=1&tab=1&year=2019&event=2&club=&setuFrom=1取得はPythonのSeleniumを使用します
取得結果はpandas.DataFrameにまとめます結果
整形
得点頒布のラベル付け
バスケはサッカーや野球と比較すると得点の幅が広いため、10点区切りの頒布表を作成します
こちらの記事を参考に得点の階級カラムを追加します
https://qiita.com/kshigeru/items/bfa8c11d1e6487c791d3labels = [ "{0} - {1}".format(i, i + 9) for i in range(40, 200, 10) ] df['ホームスコア頒布'] = pd.cut(df['ホームスコア'], np.arange(40, 201, 10), labels=labels) df['アウェイスコア頒布'] = pd.cut(df['アウェイスコア'], np.arange(40, 201, 10), labels=labels)40〜200点までを10点区切りでラベル付けを行います
範囲外のものにはNaNがセットされます結果
ホーム/アウェイごとにグルーピング
ホームの戦績とアウェイの戦績は差が出ることが予想できるので、
ホーム戦のヒートマップ、アウェイ戦のヒートマップ、全戦のヒートマップを作成しますfor team in teamList: teamHomeDf = df.query('ホーム == @team') teamAweyDf = df.query('アウェイ == @team') teamDf = pd.concat([teamHomeDf, teamAweyDf])teamListには全チームのチーム名が格納されています
結果
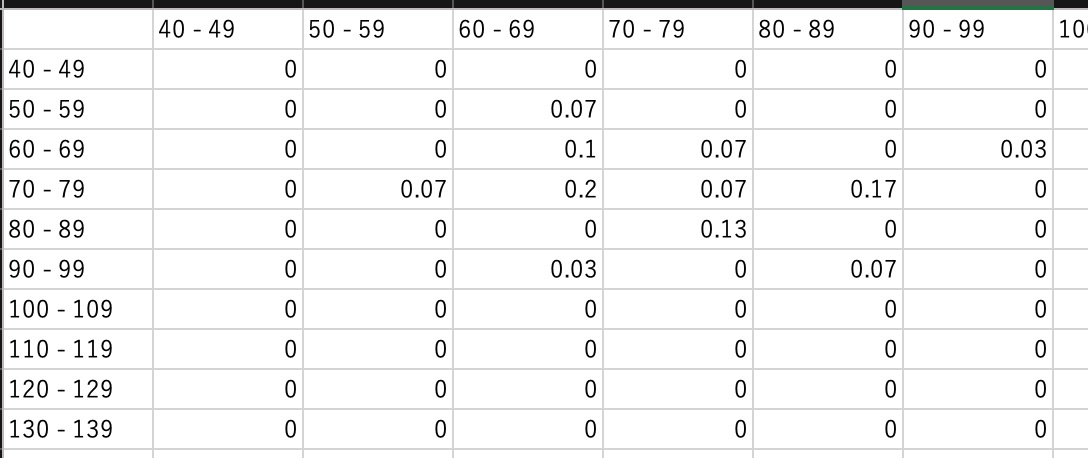
ヒートマップ用のデータ作成
ヒートマップ作成のためにデータを図のように整形します
distributionDf = teamHomeDf.groupby(['ホームスコア頒布', 'アウェイスコア頒布']) distributionDf = distributionDf.size().unstack() distributionDf = distributionDf.fillna(0) cols = distributionDf.columns indexs = distributionDf.index for index in indexs: for col in cols: allDf.at[index, col] = round(distributionDf.at[index, col] / total, 2) plt.figure(figsize=(8, 8)) sns.heatmap(allDf, annot = True, cmap = color, vmin = 0, square = True) if not os.path.exists(path): os.makedirs(path) plt.savefig(path + '/' + fileNm) plt.close('all')allDfには図のようなデータをセットしておきます
出力
整形したデータをもとにヒートマップを出力します
ヒートマップについてはこちら
https://note.nkmk.me/python-seaborn-heatmap/
https://matplotlib.org/tutorials/colors/colormaps.htmlplt.figure(figsize=(8, 8)) sns.heatmap(allDf, annot = True, cmap = 'hot', vmin = 0, square = True) if not os.path.exists(path): os.makedirs(path) plt.savefig(path + '/' + fileNm) plt.close('all')出力されたヒートマップ


- 投稿日:2020-07-12T17:00:50+09:00
Nvidiaから出ているJetPack(NVIDIA SDK Manager)を使ってOpenCvやCudaの簡単なインストールを目指す
Nvidiaから出ているJetPack(NVIDIA SDK Manager)を使ってOpenCvやCudaの簡単なインストールを目指す
NividiaのGPUの乗ったマシンを用意する
NividiaのGPUは搭載したPCを用意する必要があります
$ apt-cache search "^nvidia-[0-9]{3}$"apt-cacheでそのPCにインストールできるNvidiaドライバがわかる。
NVIDIA SDK ManagerはCuda10.0がインストールされる。NVIDIAドライバは410以上がインストールされる。
Cuda10.0に対応したWindows機を利用するまたはJatsonを利用する。
未対応ならNVIDIA SDK Managerをあきらめ、Cudaのバージョンを下げ手動インストールにするhttps://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
古いPCのGpuのドライバは410以下のため、Cuda10.0は動作しない
仮想環境ソフトを利用する
Parallels DesktopやVMWareなど
ここではparallels-desktopを使います
追記 仮想環境だとGeforceドライバが認識しない
MacならディアルブートでLinuxを起動させるか、Windowsを利用するか
外部のJetsonNanoに転送してインストールするか
(#1)ubuntuをインストールする
日本語版Ubuntu配布サイト
カーソルはCtrk+altで開放します
Parallels Tool CDがマウントされるので一緒にインストールするとよいです。#更新する sudo apt-get update sudo apt-get upgradeNVIDIAグラフィックドライバーとCudaのバージョンの関係
NVIDIA SDK ManagerのCudaのバージョンは10.0である。古いPCのGpuと古いNividaドライバーだと動作しない。NVIDIA SDK Managerの自動インストールをあきらめて、Cudaのバージョンを下げて手動インストールに切り替えるか、新しいPCを新調するかになる
GPUがNvidiaかどうか確認する
sudo lshw -C display 仮想環境上だとVirtual Video Adapterとでる 仮想環境ではNivideドライバーはインストールできないので、ホストPC(Linux or Windows)上でNivideドライバをインストールする必要があるUbuntuがGPUを認識しているか調べる
$ sudo ubuntu-drivers devicesNvidiaドライバインストール 方法1
UbuntuがGPUを認識しているか調べる
$ sudo ubuntu-drivers devicesGPUの型番が正しく表示されたら,以下のコマンドを実行してドライバのインストールする
$ sudo ubuntu-drivers autoinstall# マシンにインストール済みのNVIDIAドライバを一覧表示 $ dpkg -l | grep nvidia # apt-getでインストールできるNVIDIAドライバの一覧表示 $ apt-cache search "^nvidia-[0-9]{3}$"nvidia-smiコマンドでドライバのバージョンやGPUの詳細が表示されるか確認する
$ nvidia-smi正しく表示されたたらCudaのインストールへ進む
nvidia-smiを実行したらエラーが出た
$ nvidia-smi NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running. nvidia-smiはnvidiaのドライバを確認することができなかった.最新のドライバが入ってるかどうか確認してね.この場合,Nouveauを無効化することで解決する.まず,/etc/modprobe.d/blacklist-nouveau.confを作成し,以下のように編集する.
$ sudo vim /etc/modprobe.d/blacklist-nouveau.conf以下の内容を記入
blacklist nouveau options nouveau modeset=0次に以下のコマンドを実行し,カーネルモジュールを再読込する.
$ sudo update-initramfs -u $ sudo reboot $ nvidia-smiPCを再起動し,nvidia-smiが実行できればCUDAのインストールに進む
Nvidiaドライバインストール 方法2
Nvidia Driverをダウンロードする
搭載されているGPUのドライバを選択しRun形式のファイルをダウンロードしインストールする
$ chmod +x GPUドライバ名.run $ sudo sh GPUドライバ名.runnvidia-smiコマンドでドライバのバージョンやGPUの詳細が表示されるか確認する
$ nvidia-smi再インスール時の注意
NVIDIA SDK Managerを先にインストールすると最新のNVIDIAグラフィックドライバーをインストールされてしまい、その後マシンにあった古いグラフィックドライバーを入れようとすると、エラーが起きインストールできないことがありました。依存解決のコマンドaptitudeを使って再インストールを試しましたが、デスクトップ画面で硬直して動かなくなった。
マシンがハングアップしたので注意
sudo aptitude install libnvidia-encode-418
参考素直にアンインストールして再インストールしたほうがいいかもしれない
sudo apt-get --purge remove nvidia-* sudo apt-get --purge remove cuda-*CudaとOpenCvのインストール
NVIDIA SDK Managerをインストールする
ネットに繋がっていないとインストールできません
ダウンロードしJetPackアーカイブを解凍しインストールします。
Nvidiaアカウントを作成する必要があります
HostMachienを選択します。
JetPack4.3を選択します。下の方にあるダウンロードの後にインスールするを必ずチェックします
ダウンロード中にインストールするとエラーになることがあるので必ずチェックを入れます
30Gぐらい容量が必要ですインストール完了
自動でOpenCvとCudaがインストールできました。
JetPack 4.3 in jetson components:
L4T R32.3.1 (K4.9) Ubuntu 18.04 LTS aarch64 CUDA 10.0 cuDNN 7.6.3 TensorRT 6.0.1 VisionWorks 1.6 OpenCV 4.1 (4.1.1) Nsight Systems 2019.6 Nsight Graphics 2019.5 Nsight Compute 2019.3 SDK Manager 1.0.0cudaの場所
/usr/local/cuda /usr/local/cuda-10.0opencvの確認方法
$ sudo apt-get install python3-pip $ sudo pip3 install numpy$ python3 >>> import cv2 >>> print(cv2) >>> cv2.__version__ 4.1.1公式cudaのインストール方法
公式cudaの説明
パスの設定を追加する
$ sudo apt install vim# vimをアップデートする sudo apt install vim # xとyにバージョン数字を入れる $ sudo vim ~/.bashrc ## CUDA and cuDNN paths export PATH=/usr/local/cuda-x.y/bin:${PATH} export LD_LIBRARY_PATH=/usr/local/cuda-x.y/lib64:${LD_LIBRARY_PATH} # 環境変数$LD_LIBRARY_PATHにNVIDIAドライバのパスを追加 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia-番号 #保存する $ source ~/.bashrc # 確認する $ nvcc -V # CUDA Toolkitの場所の確認 $ which nvcc #/usr/local/cuda-10.0/bin/nvcccuDNN のRunTimeのインストールと動作確認
cuDNN Runtime Library for Ubuntuh
cuDNN Developer Library for Ubuntuh
cuDNN Code Samples and User Guide for Ubuntu
をダウンロードしダブルクリックでインストールcuDNNの動作確認
cuda-10.0/binにパスが通っているかどうかの確認します
通っていれば、cuda-install-samples-10.0.shを実行できます
ホームディレクトリで実行します。引数にフォルダ名を記入します。cuda-install-samples-10.0.shを実行するとホームディレクトリにサンプルフォルダが生成されます。Makeファイルがあるのでmakeします
binフォルダにサンプルファイルが生成されるので実行し試します。
deviceQueryを実行しcuda deviceが有効か確認します$ cd /usr/local/cuda-10.0/bin # /usr/local/cuda-10.0/bin/cuda-install-samples-10.0.sh # ホームディレクトリにサンプルコードのあるディレクトリをコピー $ cuda-install-samples-10.0.sh フォルダ名 $ cd フォルダ名/NVIDIA_CUDA-10.0_Samples $ make $ cd NVIDIA_CUDA-10.0_Samples/bin/x86_64/linux/release $ ./deviceQuery $ ./bandwidthTest $ ./volumeRendercuDNNのインストール確認
dpkg -lコマンドでインストール済みのパッケージを一覧表示する.
# マシンにインストール済みのcuDNNパッケージを一覧表示 $ dpkg -l | grep cudnncuDNNの保存場所
# debパッケージが保存されているディレクトリを確認(-Lオプション) $ dpkg -L libcudnn7Yoloをインストールする
$ sudo apt install git $ git clone https://github.com/AlexeyAB/darknet.git $ cd darknet darknet$ vim Makefile GPU=1 CUDNN=1 OPENCV=1 darknet$ make-lcudaが見つからない エラーが出る
libcuda.soがどこにあるか検索する
# libcuda.soがどこにあるか検索する $ locate libcuda.so # libcuda.soの場所がヒットする /usr/local/cuda-10.0/targets/x86_64-linux/lib/stubs/libcuda.so /usr/loca/cuda-10.0/targets/aarch64-linux/lib/stubs/libcuda.solibcuda.soファイルを見つけたら、x86_64-linux-gnuフォルダに作る。x86_64-linuxフォルダにlibcuda.so.1のシンボリックリンクを作るとよい記事を見つける
sudo ln -s /usr/local/cuda-10.0/targets/x86_64-linux/lib/stubs/libcuda.so /usr/lib/x86_64-linux-gnu/libcuda.so.1 # libcuda.so.1とlibcuda.so 両方のシンボリックリンクが必要 sudo ln -s /usr/local/cuda-10.0/targets/x86_64-linux/lib/stubs/libcuda.so /usr/lib/x86_64-linux-gnu/libcuda.so#再びmake $ make clean $ makecudnn.hファイルがないとでる。cudnn.hファイルをコピーする
cuDNN Library for Linuxをダウンロードします
#cuDNNパッケージを解凍する。Finderからでも解凍可能 $ tar -xzvf cudnn-x.x-linux-x64-v8.x.x.x.tgz $ sudo cp cuda/include/cudnn*.h /usr/local/cuda/include $ sudo cp cuda/lib/libcudnn* /usr/local/cuda/lib64 $ sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*make時のcudnn.h not foundがエラーが出なくなる
cudnn関連
libcudnn.so.7.0.1以外のlibcudnn.soファイルを削除する /usr/local/cuda/lib64 $ sudo rm -rf libcudnn.so libcudnn.so.7 再生する sudo ln -s libcudnn.so.7.0.1 libcudnn.so.7 sudo ln -s libcudnn.so.7 libcudnn.somake clean makedarknet/objが書き込めない
darknet/obj 権限を変更する
$ sudo chmod 777 ホームパス/darknet/obj ホームパス/darknet/backup再びmake
$ make clean $ makeweightsをダウンロード
AlexeyAB版には含まれていないのでpjreddieからダウンロード
$ wget https://pjreddie.com/media/files/yolov3.weightsYoloを実行してみる
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpgYolo実行時のエラー
Not compiled with OpenCV, saving to predictions.png instead
DarkNetのMakefileのopenCvが1になっていない
$ vim Makefile OPENCV=1CUDA driver version is insufficient for CUDA runtime version
CUDA driver version is insufficient for CUDA runtime version : No Such File or Directory
保留
参考
NVIDIAグラフィックドライバがインストールされていないと出る?調査中cudaを更新もする sudo apt-get install cudaNo CUDA-capable device is detected
CUDA対応デバイスが検出されない
仮想環境上ではNvidiaのGPUを認識しないため。仮想環境を止めてホストPCにOSを入れ直してやるCUDAとNVIDIAドライバ(/usr/lib/nvidia-***)のPATHチェック
出力に"/usr/local/cuda-10.0/lib64"と"/usr/lib/nvidia-番号"が含まれているか?
$ echo $LD_LIBRARY_PATHCUDAとnvccコマンドのPATHチェック
出力が"/usr/local/cuda-10.0/bin/nvcc"になっているか?
$ which nvcc /usr/local/cuda-10.0/bin/nvccnvidia-smiコマンドのPATHチェック
出力が"/usr/bin/nvidia-smi"になっているか?
$ which nvidia-smi /usr/bin/nvidia-smiアンインストール方法
# xにバージョンを入れる sudo apt remove cuda-x-y sudo apt autoremove sudo apt remove libcudnnx libcudnnx-dev libcudnnx-doc rm -rfv ~/NVIDIA_CUDA-x.y_Samples/ # サンプルコードを消す。 # ~/.bashrcに追加されたPATHの設定をテキストエディタなどで消す。 # ログアウトしてPATHの設定の変更を反映ポイント
Nvidia GPUを搭載したマシンを用意する
仮想環境にNvidiaのグラフィックドライバーはインストールはできない
Nividia Sdk ManegerのCudaは10.0なので古いNividiaドライバでは動かない。Cuda10.0を動作できるNvidiaDriverを利用する
cuDNNパッケージを解凍し、指定したファイル(cudnn*.h)などを指定したところへコピーする
locate libcuda.soでlibcuda.soの場所を把握する。シンボリックリンクを/usr/lib/x86_64-linux-gnuに貼る
vimで.bashrcを編集した後、source ~/.bashrcで保存しないと適用されない結論
Jetson nanoを使う時はNividia Sdk Manegerを使ったほうがよい。cuda10とNividiaドライバが対応している
PCにインストールする場合はGPUを調べ、NvidiaDriverが410以上に対応しているならNividia SDKを試しに使ってみる 410未満未対応ならSDKを諦め手動インストールでやる参考サイト
閃き- blog
かなり詳しく書いてありますNVIDIA SDK Manager on Dockerで快適なJetsonライフ
Jetson TX2 への JetPack のセットアップ手順
https://pysource.com/2019/08/29/yolo-v3-install-and-run-yolo-on-nvidia-jetson-nano-with-gpu/
(#1)
CUDA on WSL2
WSL2を使えばWindows上にLinuxを構築しWindowsのGPUドライバを利用できるようです。
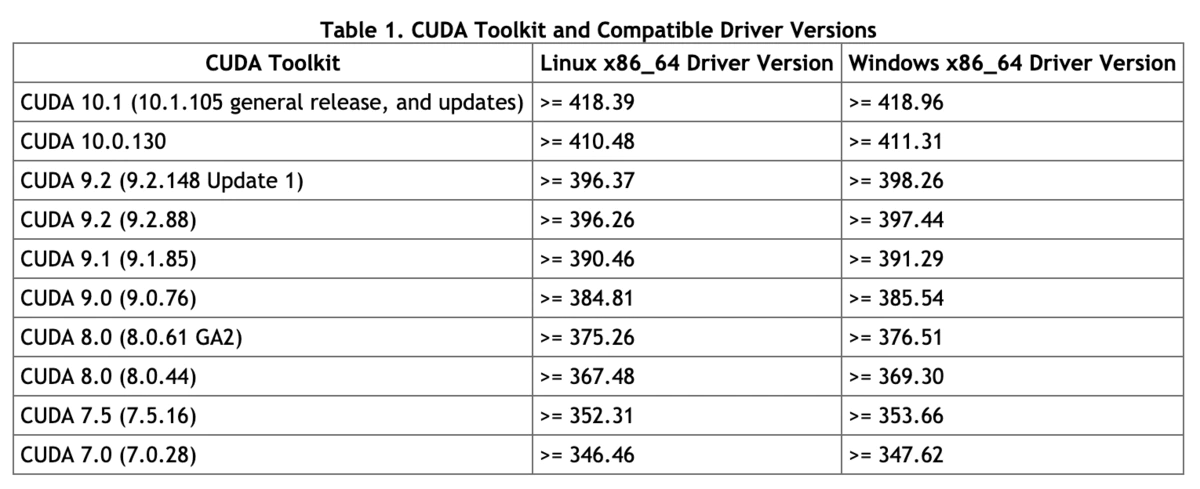
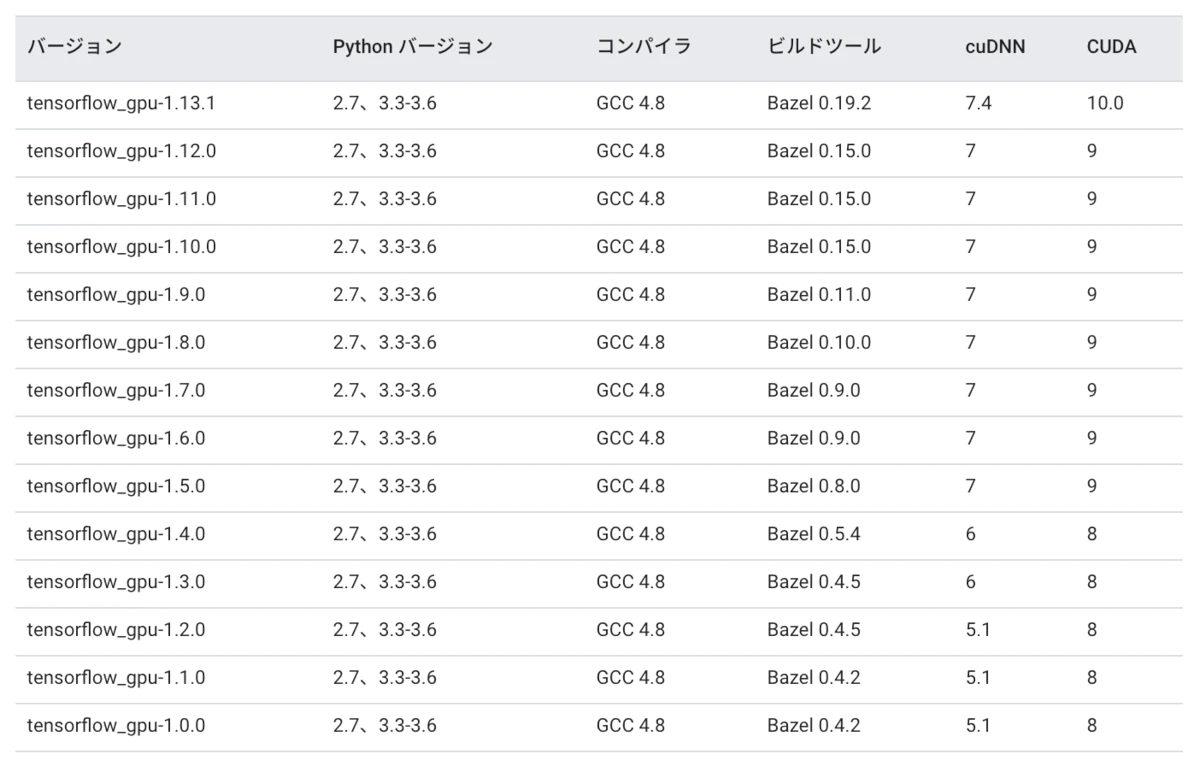

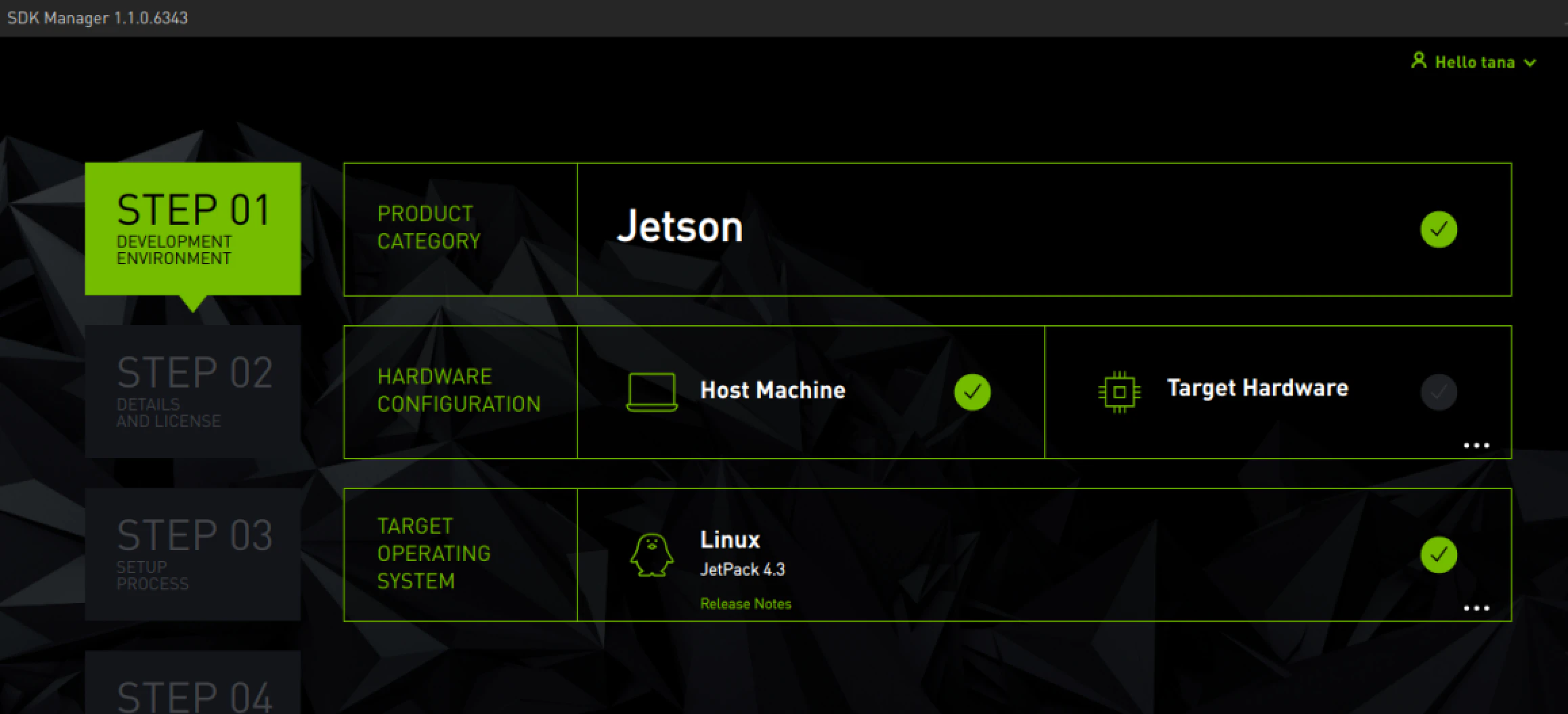
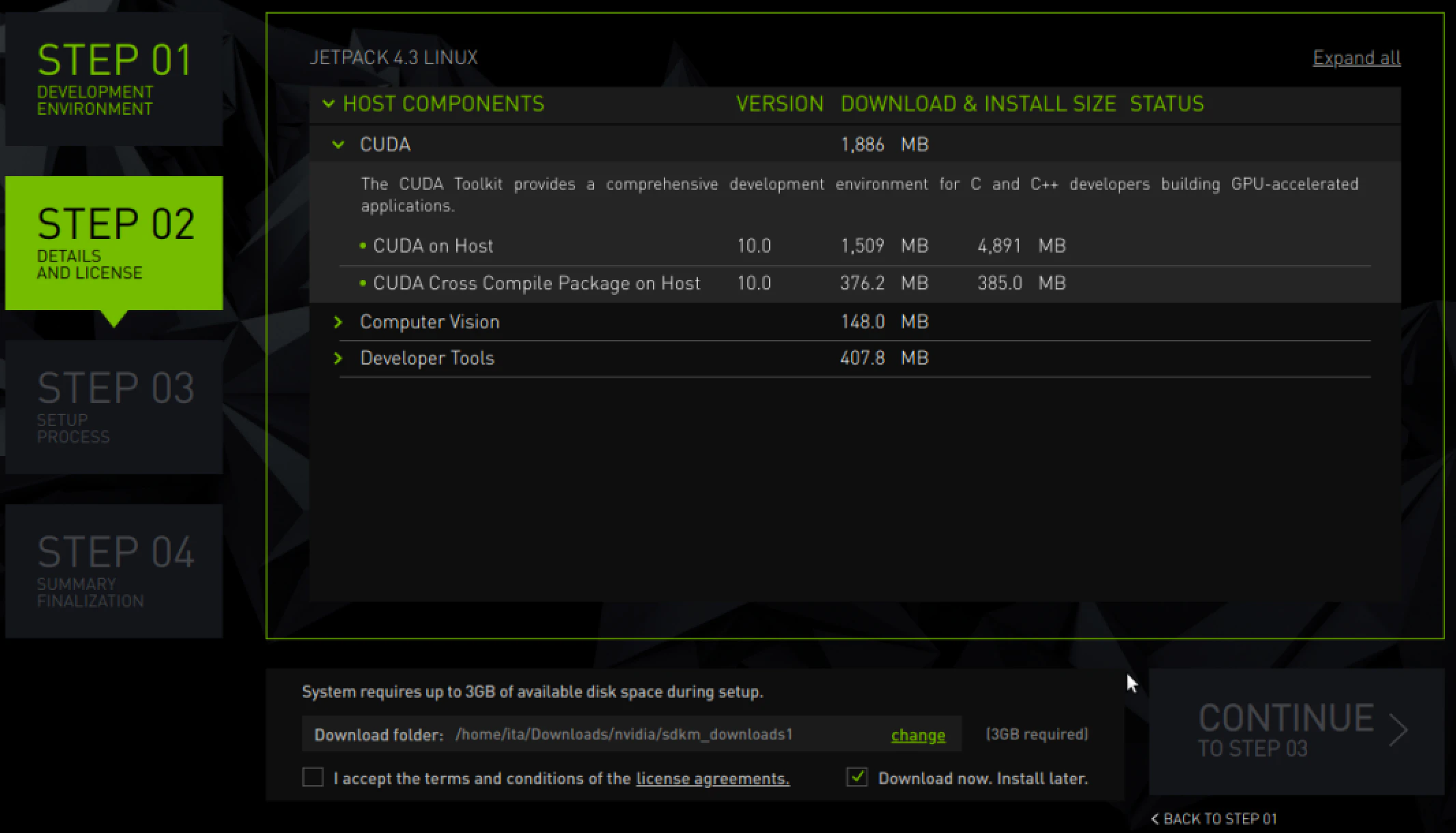
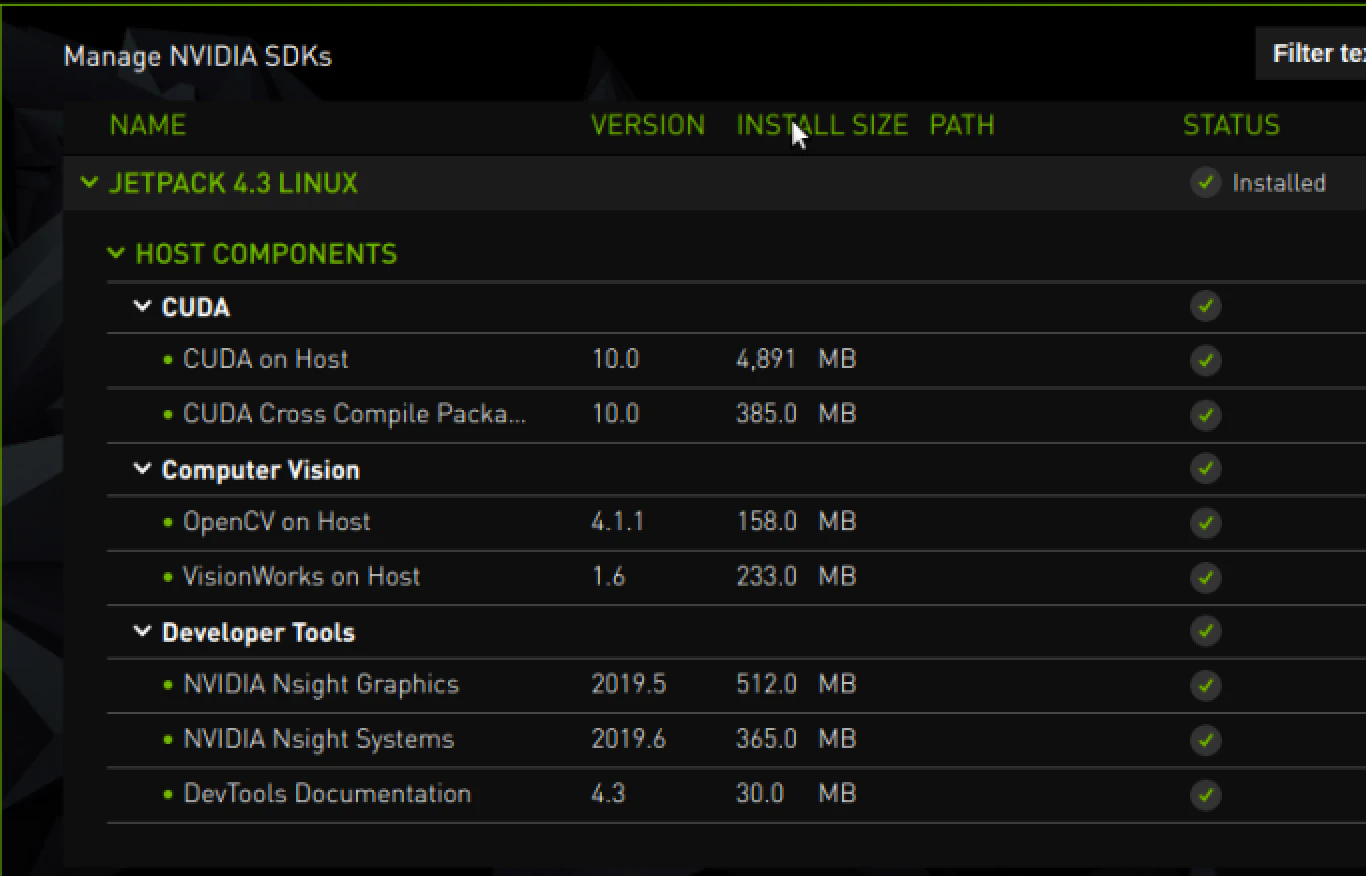

- 投稿日:2020-07-12T16:56:35+09:00
PiotroskiのF-Scoreとは
1 この記事は?
株式投資の銘柄スクリーニングを行うときの有名な指標としてJoel GreenblattのMagic formulaがありますが、この記事では別の銘柄スクリーニング手法であるPiotroskiのF-Scoreを紹介したと思います。
2 PiotroskiのF-Scoreとは
下記の9個の基準のうち、対象銘柄がその基準を満たせば+1点得点を加算していきます。
2-1 Profitability Criteria
基準に合致していれば得点を1点、合致していなければ得点を0点とする。
番号 基準 得点 1 過去1年度のリターンがプラスになっていること 0 or 1 2 過去1年度の営業キャッシュフロー(operating cash flow)がプラスになっていること 0 or 1 3 前年度に対し今年度のROA(総資産利益率)が上昇していること 0 or 1 4 今年度について、 営業キャッシュフロー/総資産 > ROA であること 0 or 1 得点小計1 0 ~ 4 2-2 Leverage, Kiquidity and Source of Funds Criteria
番号 基準 得点 5 前年度に対し今年度の長期借入金が減っていること 0 or 1 6 前年度に対し今年度の流動比率(*1)が上昇していること 0 or 1 7 前年度に新規株式発行を行っていないこと 0 or 1 得点小計2 0 ~ 4 (*1)流動比率(=流動資産/流動負債)は、1年以内に現金化できる資産が、1年以内に返済すべき負債をどれだけ上回っているかを表す指標
2-3 Operating Efficiency Criteria
番号 基準 得点 8 前年度に対し本年度の売上総利益(gross margin)が上昇していること 0 or 1 9 前年度に対し今年度の資本回転率(asset turnover ratio)が上昇していること 0 or 1 得点小計3 0 ~ 2 売上総利益(gross margin) = 売上高 - 売上原価
資本回転率(asset turnover ratio) = 売上高 / 総資本2-4 F-Score
F-Scoreは上記記載の9項目の得点(=得点小計1 + 得点小計2 + 得点小計3)のことです。
F-Scoreが8点以上の銘柄を投資対象とし、半年に1回か1年に1回ほどF-Scoreの再計算を行います。
F-Scoreの考え方は、小型株や中型株の選定に適していると一般的に言われます。3 Coming Soon
日本株を対象にして、F-Score戦略をとるとどの程度Returnを出せるのか? Pythonでcodingを行い検証してみたいです。
- 投稿日:2020-07-12T16:40:14+09:00
【要約】Transformerを用いた物体検出モデル「End-to-End Object Detection with Transformers」
はじめに
「End-to-End Object Detection with Transformers」(DETR) が気になったので、論文を読んで少し動作確認もしてみました。簡潔に記録として残しておきます。
[論文, Github]DETRとは(要約)
・Facebook AI Researchが今年5月に公開したモデル
・自然言語処理分野で有名なTransformerを初めて物体検出に活用
・下図のように、CNN + Transformerのシンプルなネットワーク構成
・NMSやAnchorBoxのデフォルト値等、人手による調整が必要な部分を排除し「End-to-End」な物体検出を実現
・上記を実現するためのポイントとして、"Bipartite Matching Loss"と"Parallel Decoding"の効果を主張
・物体検出だけでなく、セグメンテーションタスクへも適用可能
推論コード例
論文よりコードを引用します。以下のように、モデル定義から推論処理までが40行程度でシンプルに書けます。
import torch from torch import nn from torchvision.models import resnet50 class DETR(nn.Module): def __init__(self, num_classes, hidden_dim, nheads, num_encoder_layers, num_decoder_layers): super().__init__() # We take only convolutional layers from ResNet-50 model self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2]) self.conv = nn.Conv2d(2048, hidden_dim, 1) self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers) self.linear_class = nn.Linear(hidden_dim, num_classes + 1) self.linear_bbox = nn.Linear(hidden_dim, 4) self.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2)) self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2)) def forward(self, inputs): x = self.backbone(inputs) h = self.conv(x) H, W = h.shape[-2:] pos = torch.cat([ self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1), self.row_embed[:H].unsqueeze(1).repeat(1, W, 1), ], dim=-1).flatten(0, 1).unsqueeze(1) h = self.transformer(pos + h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1)) return self.linear_class(h), self.linear_bbox(h).sigmoid() detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6) detr.eval() inputs = torch.randn(1, 3, 800, 1200) logits, bboxes = detr(inputs)※この論文のコードのままだと、公開されている学習済みモデルをloadする事はできません。(model定義の書き方が違うため)
実際に学習済みモデルで検出を行う場合は、本家Githubのdetr_demo.ipynbのようにすると良いです。動作確認
学習済みモデルを使って実際に動作を確認してみました。環境は以下の通りです。
・OS : Ubuntu 18.04.4 LTS
・GPU : GeForce RTX 2060 SUPER(8GB) x1
・PyTorch 1.5.1 / torchvision 0.6.0検出処理の実装は本家のdetr_demo.ipynbを参考にし、OpenCVでwebカメラからキャプチャした画像に対して検出を行いました。使用したモデルはResNet-50ベースのDETRです。
以下は実際の検出結果です。正常に検出が実行されていることが確認できました。(COCOのクラスに含まれない物も撮影対象にしてしまっていますが)
自分の環境では、推論処理自体は45msec(約22FPS)程度で回っているようでした。
※文献値は、V100上で28FPSおわり
DETRの勉強と動作確認を行いました。新しいタイプの手法なので、精度や速度の面でこれからさらに発展していくのかもと思います。
Transformerは自然言語処理専用というようなイメージを持っていましたが、最近では画像を扱うモデルへの導入も進んでいるのですね。今後、もっと勉強していきたいと思います。(Image GPTも動かしてみたいです。)参考
・「DETR」Transformerの物体検出デビュー
https://medium.com/lsc-psd/detr-transformer%E3%81%AE%E7%89%A9%E4%BD%93%E6%A4%9C%E5%87%BA%E3%83%87%E3%83%93%E3%83%A5%E3%83%BC-dc18e582dec1
・End-to-End Object Detection with Transformers (DETR) の解説
https://qiita.com/sasgawy/items/61fb64d848df9f6b53d1
・Transformer を物体検出に採用!話題のDETRを詳細解説!
https://deepsquare.jp/2020/07/detr/


- 投稿日:2020-07-12T16:36:27+09:00
[Python]2進数 エイシング2020D
エイシング2020D
Xは非常に大きな値になるので、単純にシミュレートすることはできません。
ここで、Xのpopcountは高々Nであることから、Xをpopcountで割った値は必ずN未満となります。
また、Xiを反転させたとき、そのような整数のpopcountは(Xのpopcount±1)に等しいです。
したがって、まず1~Nまでのすべての数について、それらをpopcountで割ったあまりに置き換えて0になるまでの操作回数を求めておき、次に、Xi=1であるような各桁について、(Xのpopcount+1)で割ったあまりの総和と(Xのpopcount-1)で割ったあまりの総和を求めておくと、f(Xi)を、Xiが1であれば、(Xのpopcount-1)で割ったあまりの総和-2^iを(Xのpopcount-1)で割ったあまりを求め、これを(Xのpopcount-1)で割ることで、N未満の数を得ることができ、同様に、Xiが0であれば、(Xのpopcount+1)で割ったあまりの総和+2^iを(Xのpopcount+1)で割ったあまりを求め、これを(Xのpopcount+1)で割ることで、N未満の数を得ることができます。
以上より、各Xiについて、0になるまでに必要な操作回数をO(1)で判定できることが分かりました。ここで、1~Nまでのすべての数について操作回数を求めるための計算量について2*10^5以下の数のpopcountは高々18、18以下の数のpopcountは高々4、4以下の数のpopcountは高々2、2以下の数のpopcountは高々1であり、最大でも5回の操作で0に到達することが分かります。
したがって、O(NlogN)により、1~Nまでのすべての数について操作回数を求めることができることがいえ、この問題をO(NlogN)で解けることが分かりました。
ただし、Xのpopcountが0または1のケースに注意してください。サンプルコードn = int(input()) x = input() # 元のpopcount original_pop_count = x.count('1') # 反転して-1count one_pop_count = original_pop_count - 1 # 反転して+1count zero_pop_count = original_pop_count + 1 # ±1それぞれにおける余り if one_pop_count == 0: one_mod = 0 else: one_mod = int(x, 2) % one_pop_count zero_mod = int(x, 2) % zero_pop_count # f の前計算 f = [0] * 220000 pop_count = [0] * 220000 for i in range(1, 220000): pop_count[i] = pop_count[i//2] + i % 2 f[i] = f[i % pop_count[i]] + 1 # pow2 の前計算 one_pow2 = [1] * 220000 zero_pow2 = [1] * 220000 for i in range(1, 220000): if one_pop_count != 0: one_pow2[i] = one_pow2[i-1] * 2 % one_pop_count zero_pow2[i] = zero_pow2[i-1] * 2 % zero_pop_count # n-1, n-2, ,, 0 for i in range(n-1, -1, -1): if x[n-1-i] == '1': if one_pop_count != 0: nxt = one_mod # - 2^i % 2 nxt -= one_pow2[i] nxt %= one_pop_count print(f[nxt] + 1) else: print(0) if x[n-1-i] == '0': nxt = zero_mod nxt += zero_pow2[i] # + 2^i % 2 nxt %= zero_pop_count print(f[nxt] + 1)
- 投稿日:2020-07-12T16:16:41+09:00
Kaggle Titanic データで学ぶ、基本的な可視化手法
はじめに
【随時更新】Kaggle テーブルデータコンペで使う EDA・特徴量エンジニアリングのスニペット集におけるスニペットを主に利用して、 Kaggle の Titanic データ を利用して基本的なデータの可視化を行います。
前提
import numpy as np import pandas as pd import pandas_profiling as pdp import matplotlib.pyplot as plt import seaborn as sns import warnings warnings.filterwarnings('ignore') cmap = plt.get_cmap("tab10") plt.style.use('fivethirtyeight') %matplotlib inline pd.set_option('display.max_rows', None) pd.set_option('display.max_columns', None) pd.set_option("display.max_colwidth", 10000)target_col = "Survived" data_dir = "/kaggle/input/titanic/"フォルダの確認
!ls -GFlash /kaggle/input/titanic/total 100K 4.0K drwxr-xr-x 2 nobody 4.0K Jan 7 2020 ./ 4.0K drwxr-xr-x 5 root 4.0K Jul 12 00:15 ../ 4.0K -rw-r--r-- 1 nobody 3.2K Jan 7 2020 gender_submission.csv 28K -rw-r--r-- 1 nobody 28K Jan 7 2020 test.csv 60K -rw-r--r-- 1 nobody 60K Jan 7 2020 train.csvデータを読みこむ
train = pd.read_csv(data_dir + "train.csv") test = pd.read_csv(data_dir + "test.csv") submit = pd.read_csv(data_dir + "gender_submission.csv")データを確認
train.head()
レコード数、カラム数の確認
print("{} rows and {} features in train set".format(train.shape[0], train.shape[1])) print("{} rows and {} features in test set".format(test.shape[0], test.shape[1])) print("{} rows and {} features in submit set".format(submit.shape[0], submit.shape[1]))891 rows and 12 features in train set 418 rows and 11 features in test set 418 rows and 2 features in submit setカラムごとの欠損数を確認
カラムごとにどのくらい欠損があるか確認する。
train.isnull().sum()PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64欠損値の可視化
欠損に規則性があるか確認する。
plt.figure(figsize=(18,9)) sns.heatmap(train.isnull(), cbar=False)
各カラムの要約統計量の確認
各カラムごとに平均や標準偏差、最大値、最小値、最頻値などの要約統計量を確認してデータをざっと理解する。
train.describe()
データの件数 (頻度) を集計
ターゲットの割合を確認
sns.countplot(x=target_col, data=train)
カテゴリ値の割合を確認
col = "Pclass" sns.countplot(x=col, data=train)
ターゲットの値ごとのあるカラムの割合を確認
col = "Pclass" sns.countplot(x=col, hue=target_col, data=train)
col = "Sex" sns.countplot(x=col, hue=target_col, data=train)
ヒストグラム
縦軸は度数、横軸は階級で、データの分布状況を可視化する。
ビンの大きさが異なれば異なったデータの特徴を示すためいくつか試す。col = "Age" train[col].plot(kind="hist", bins=10, title='Distribution of {}'.format(col))
col = "Fare" train[col].plot(kind="hist", bins=50, title='Distribution of {}'.format(col))
カテゴリごとのヒストグラム
f, ax = plt.subplots(1, 3, figsize=(15, 4)) sns.distplot(train[train['Pclass']==1]["Fare"], ax=ax[0]) ax[0].set_title('Fares in Pclass 1') sns.distplot(train[train['Pclass']==2]["Fare"], ax=ax[1]) ax[1].set_title('Fares in Pclass 2') sns.distplot(train[train['Pclass']==3]["Fare"], ax=ax[2]) ax[2].set_title('Fares in Pclass 3') plt.show()
ターゲットのカテゴリごとのカラムのヒストグラム
col = "Age" fig, ax = plt.subplots(1, 2, figsize=(15, 6)) train[train[target_col]==1][col].plot(kind="hist", bins=50, title='{} - {} 1'.format(col, target_col), color=cmap(0), ax=ax[0]) train[train[target_col]==0][col].plot(kind="hist", bins=50, title='{} - {} 0'.format(col, target_col), color=cmap(1), ax=ax[1]) plt.show()
ターゲットの値ごとのあるカラムのヒストグラム(重ねる場合)
col = "Age" train[train[target_col]==1][col].plot(kind="hist", bins=50, alpha=0.3, color=cmap(0)) train[train[target_col]==0][col].plot(kind="hist", bins=50, alpha=0.3, color=cmap(1)) plt.title("histgram for {}".format(col)) plt.xlabel(col) plt.show()
カーネル密度推定
ざっくりいうとヒストグラムを曲線化したもの。Xに対するYを取得できる。
sns.kdeplot(label="Age", data=train["Age"], shade=True)
クロス集計
カテゴリデータのカテゴリごとの出現回数を算出する。
pd.crosstab(train["Sex"], train["Pclass"])
pd.crosstab([train["Sex"], train["Survived"]], train["Pclass"])
ピボットテーブル
カテゴリごとの量的データの平均
pd.pivot_table(index="Pclass", columns="Sex", data=train[["Age", "Fare", "Survived", "Pclass", "Sex"]])
カテゴリごとの量的データの最小値
pd.pivot_table(index="Pclass", columns="Sex", data=train[["Age", "Fare", "Pclass", "Sex"]], aggfunc=np.min)
散布図
2つのカラムの関係性を確認する。
散布図
sns.scatterplot(x="Age", y="Fare", data=train)
散布図(カテゴリごとに色分け)
sns.scatterplot(x="Age", y="Fare", hue=target_col, data=train)
散布図行列
sns.pairplot(data=train[["Fare", "Survived", "Age", "Pclass"]], hue="Survived", dropna=True)
箱ひげ図
データのばらつきを視覚化する。
カテゴリごとの箱ひげ図
カテゴリごとにデータのばらつきを確認する。
sns.boxplot(x='Pclass', y='Age', data=train)
ストリップチャート
データをドットで表した図。2つのデータに一方がカテゴリカルな場合に利用する。
sns.stripplot(x="Survived", y="Fare", data=train)
sns.stripplot(x='Pclass', y='Age', data=train)
ヒートマップ
カラムごとの相関係数のヒートマップ
sns.heatmap(train.corr(), annot=True)
参考

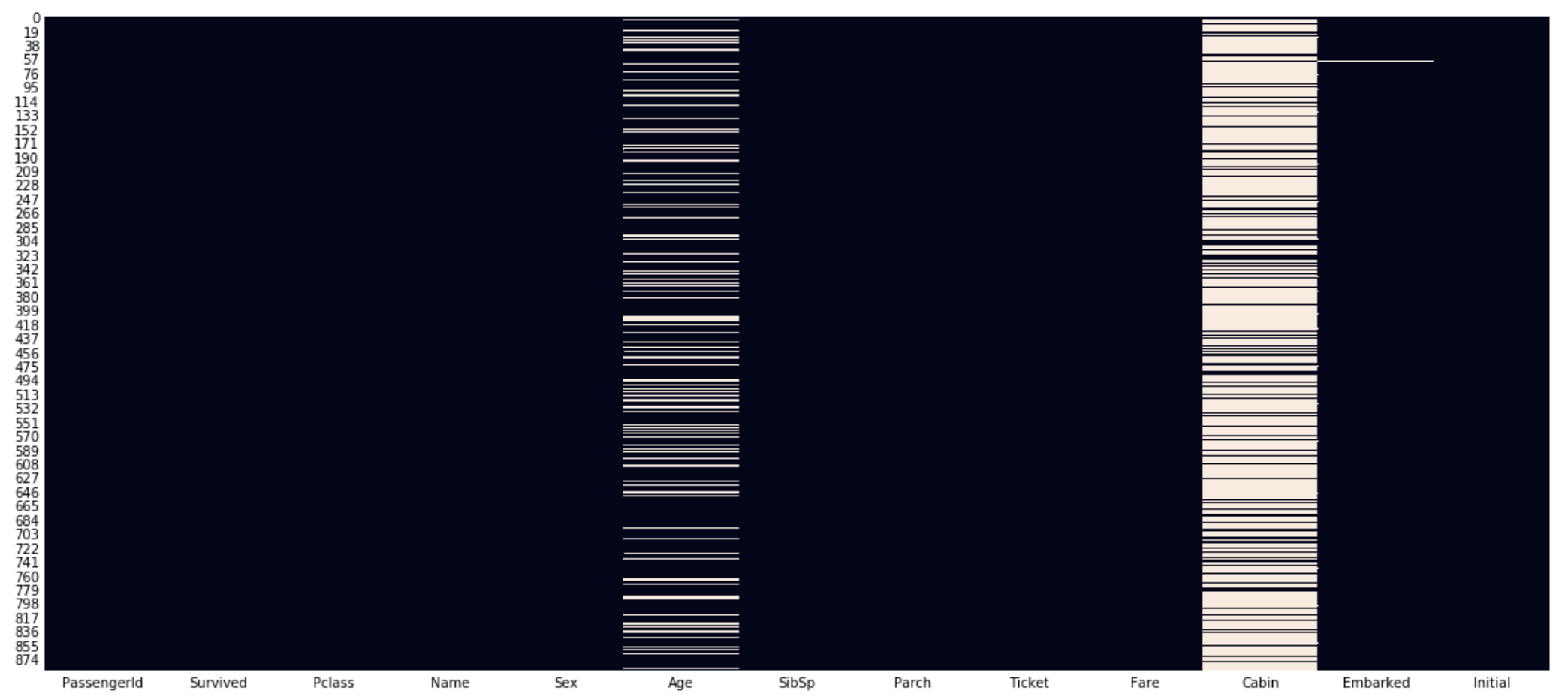
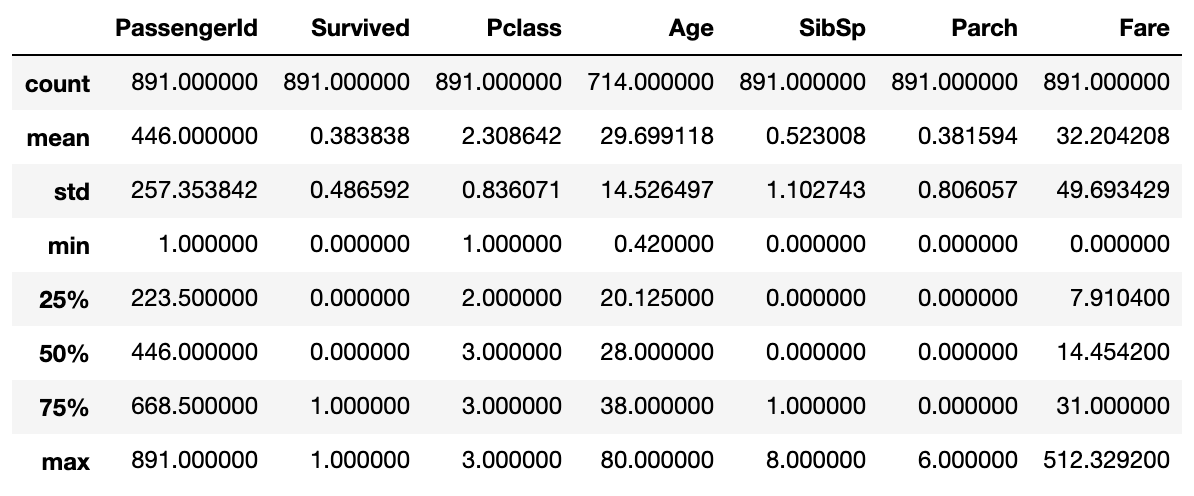
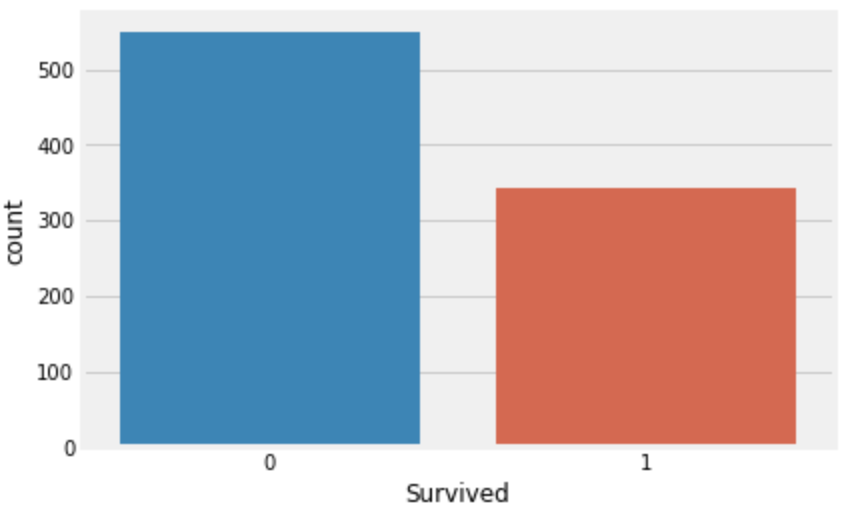
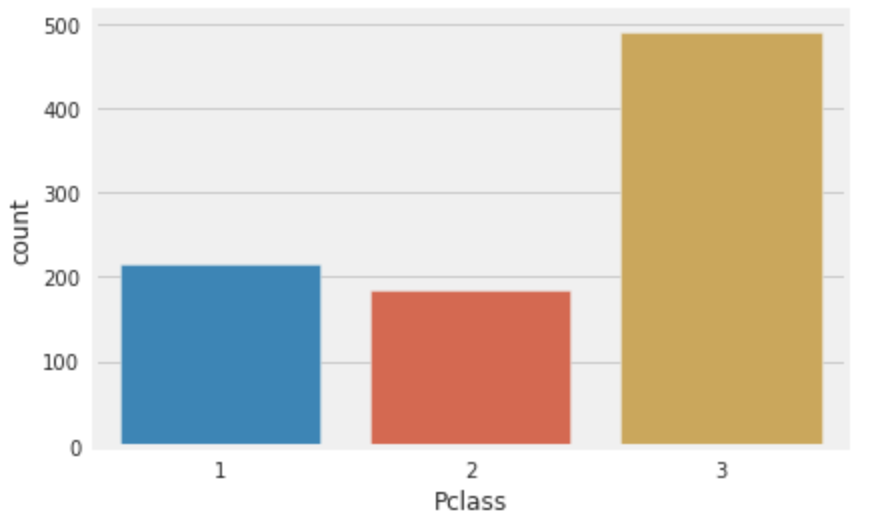
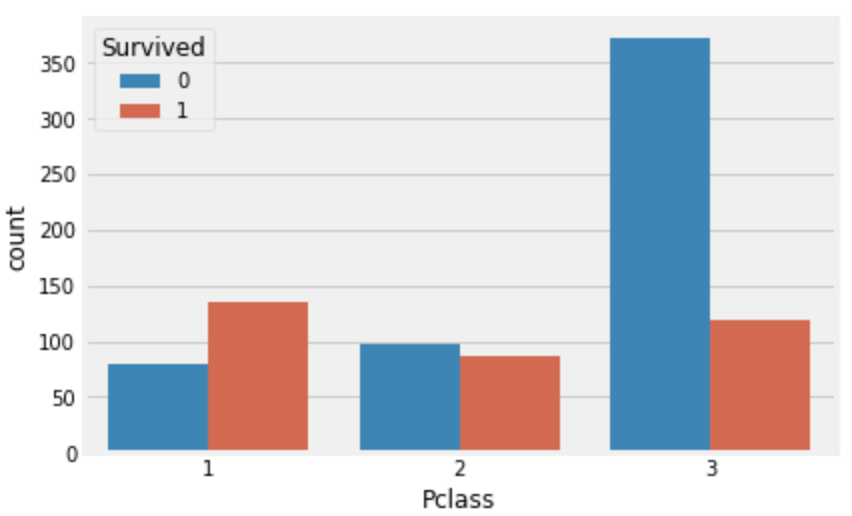
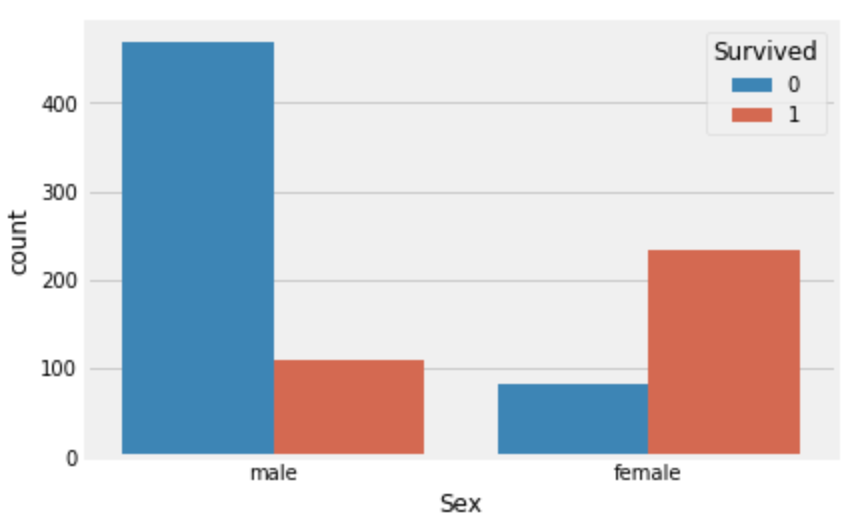
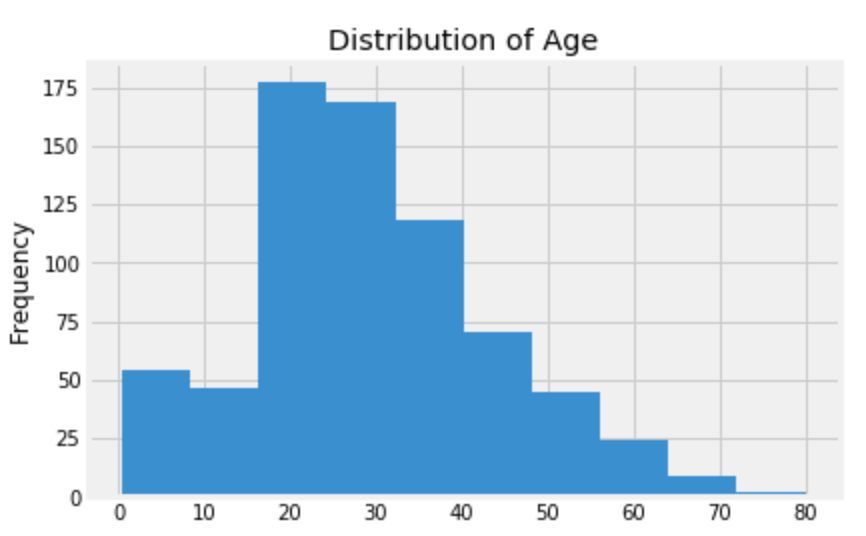
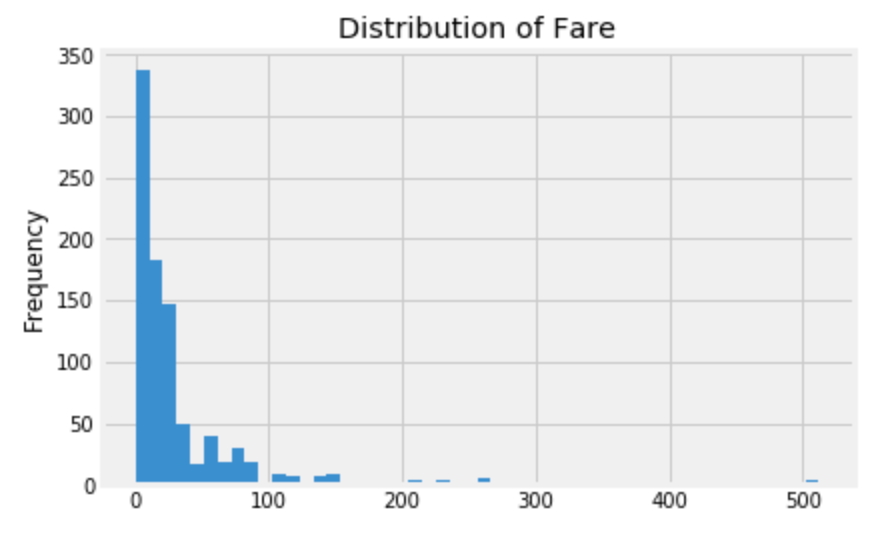
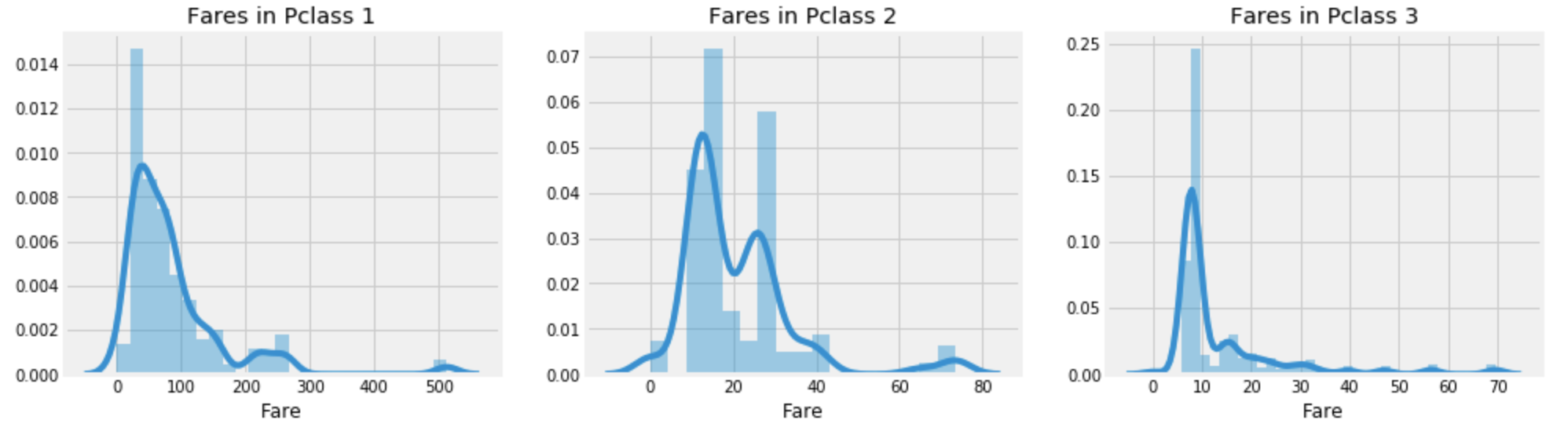
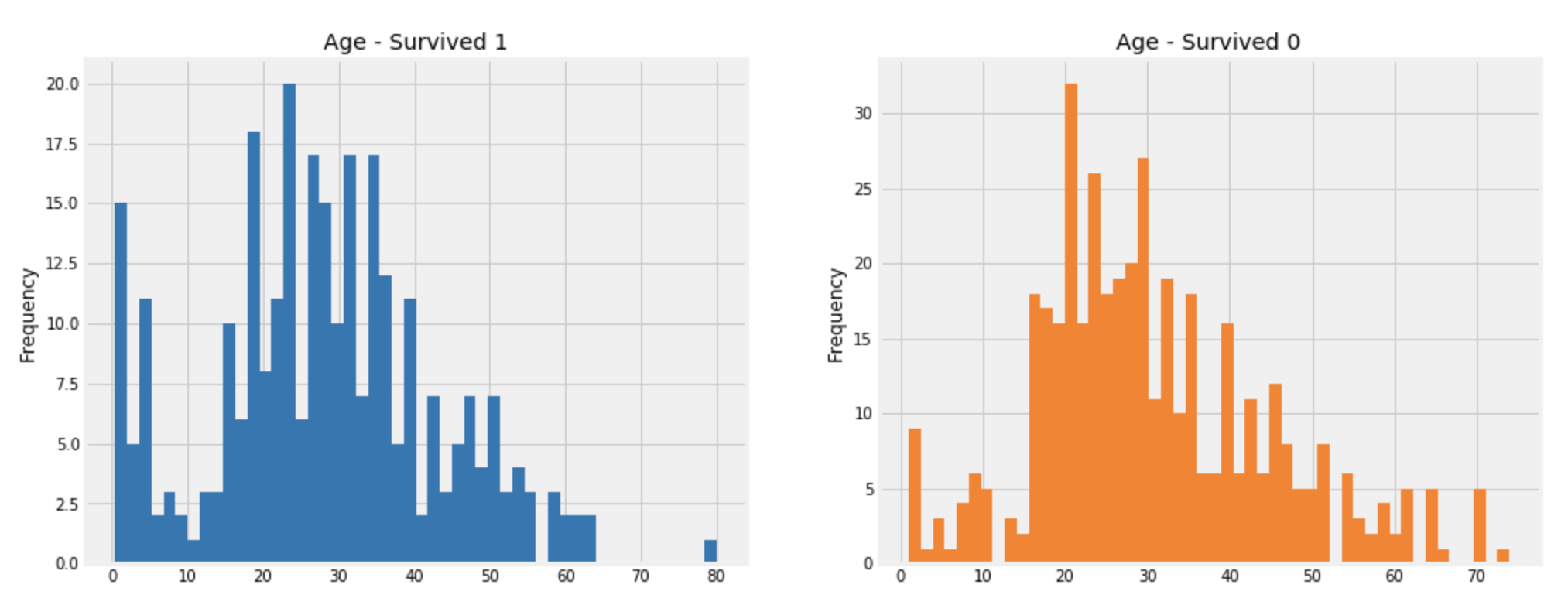
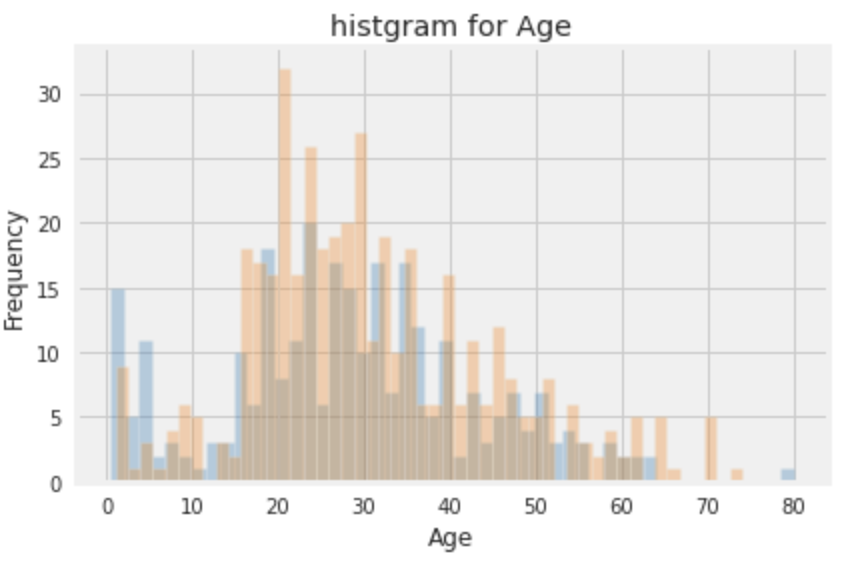
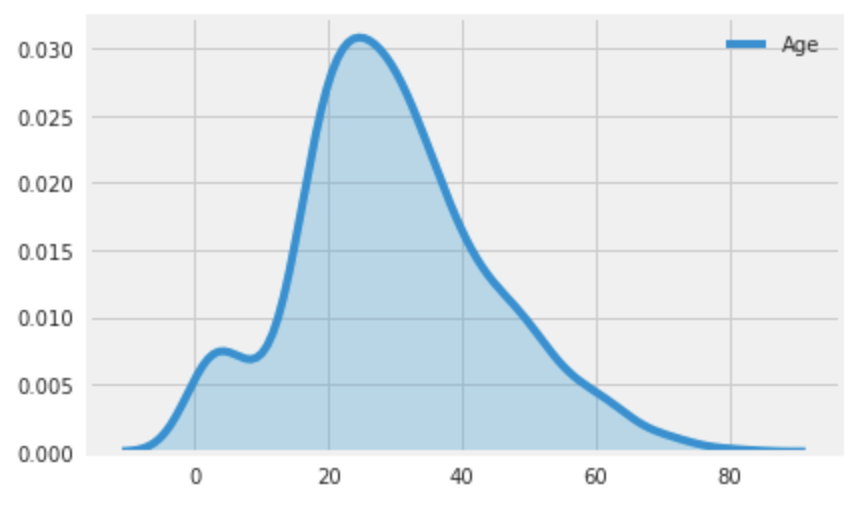

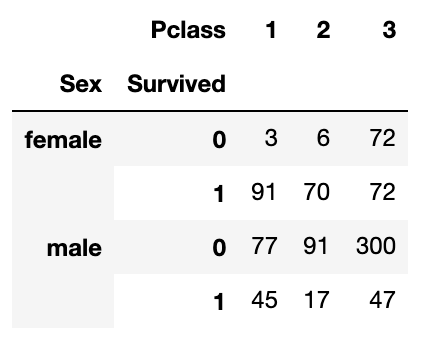
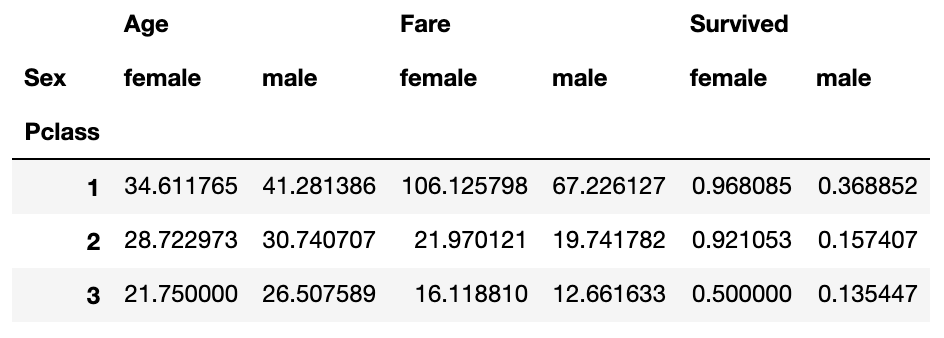
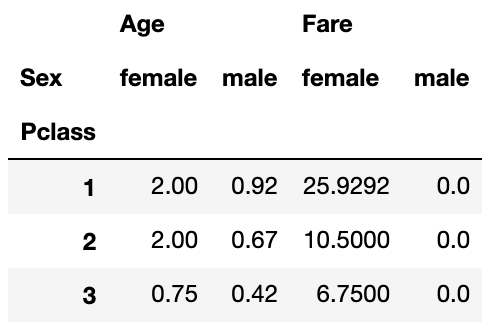
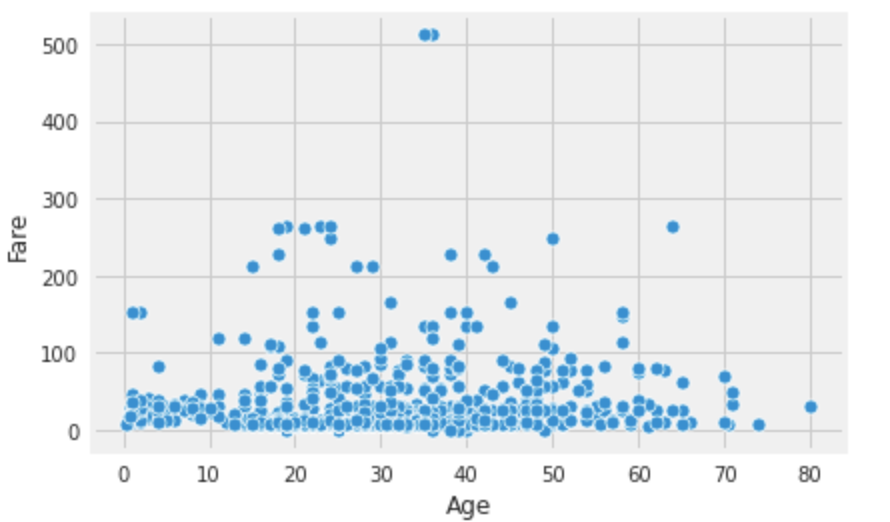
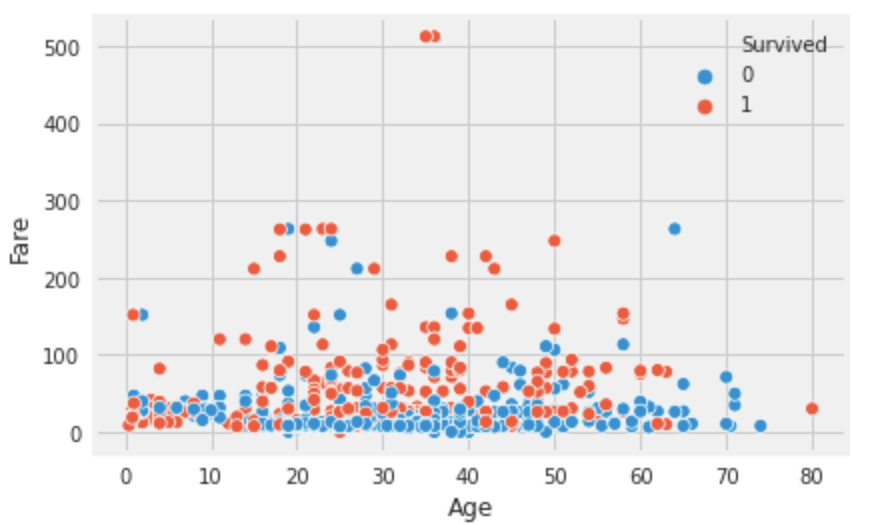
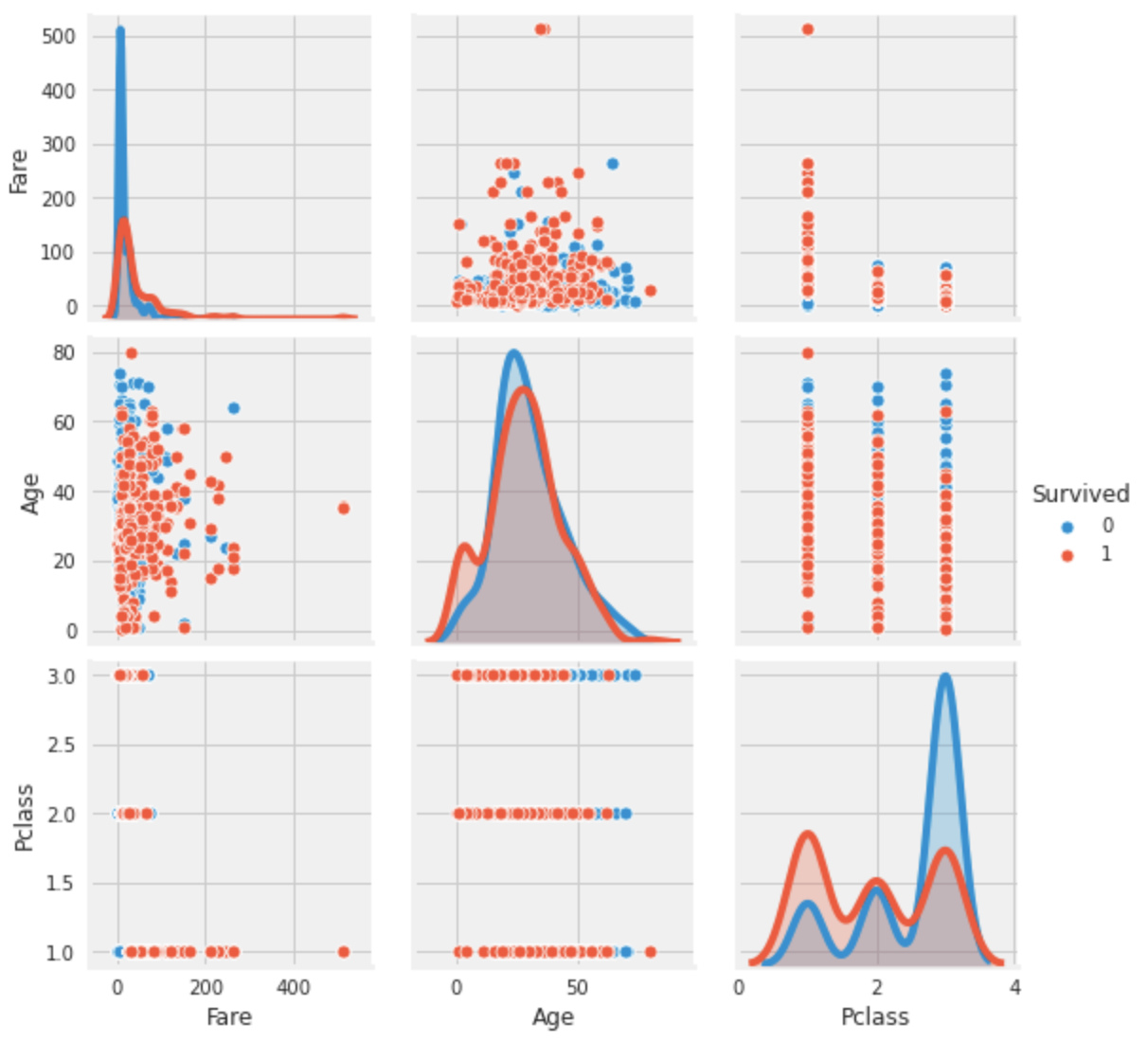
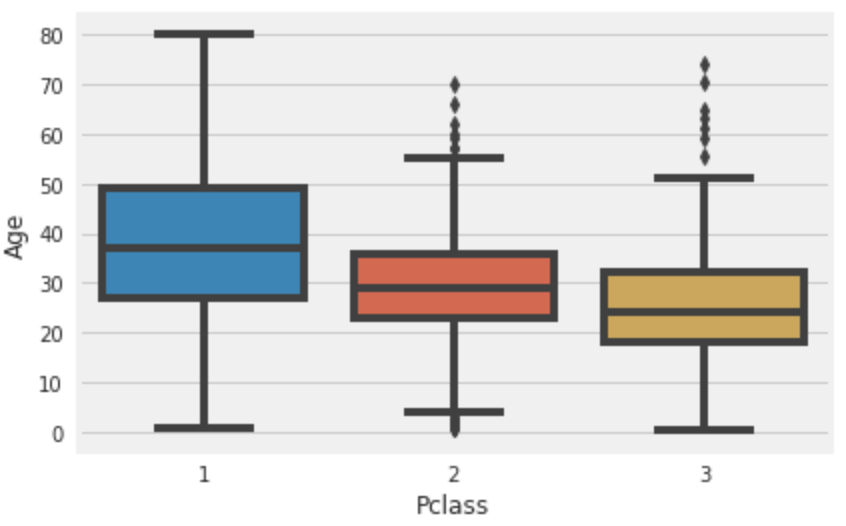
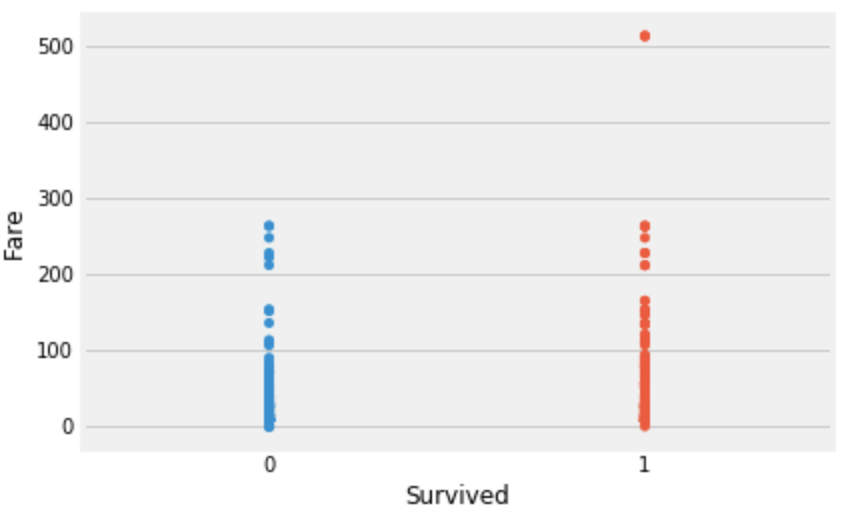
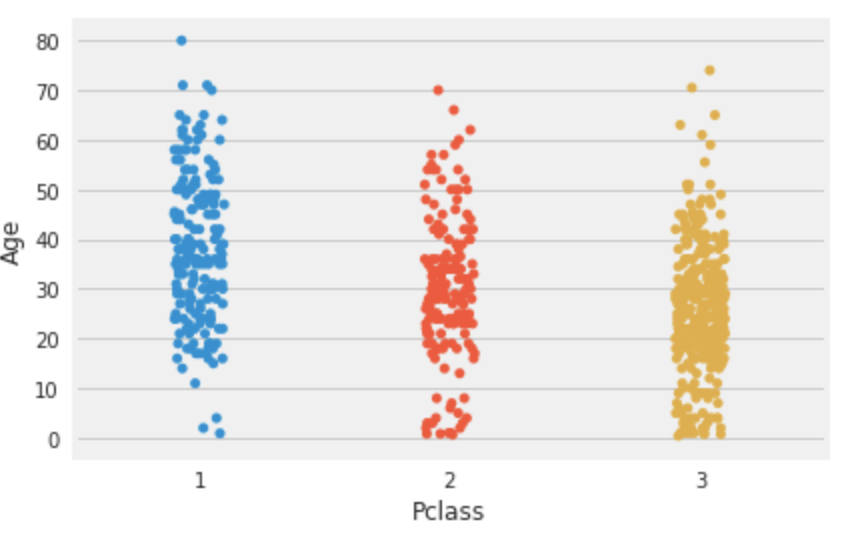
- 投稿日:2020-07-12T15:51:12+09:00
Python csvを読み込んでtxtに書き出し
data2.csvNafn,Sysla,ID,Starfsgrein,Aldur,Kynlíf Dom,Árnessýsla,00027861s,Embættismaður,30,karlkyns Ola,Gullbringusýsla,00033014s,bankastjóri,26,kona Qiv,Vestur-Skaftafellssýsla,00087295j,Sjómaður,47,karlkyns Uba,Suður-Múlasýsla,00043765e,Bóndi,66,kona Yhe,Norður-Múlasýsla ,00021559e,Fréttaritari,35,kona・csvモジュールは標準ライブラリ
・読み込み、書き出しファイルの相対パス、モードを指定
・キーと値を=で結んだものをリスト化し、セミコロンでjoinimport csv def get_data_csv(path, mode): list = [] with open(path, mode) as f: dict_data = csv.DictReader(f) for dict in dict_data: list.append(dict) return list if __name__ == "__main__": read_path = 'data2.csv' read_mode = "r" write_path = 'write_data2.txt' write_mode = "w" list = get_data_csv(read_path, read_mode) with open(write_path, write_mode) as f: for dict in list: str = ";".join([key + '=' + value for key, value in dict.items()]) f.write(str) f.write('\n')write_data2.txtNafn=Dom;Sysla=Árnessýsla;ID=00027861s;Starfsgrein=Embættismaður;Aldur=30;Kynlíf=karlkyns Nafn=Ola;Sysla=Gullbringusýsla;ID=00033014s;Starfsgrein=bankastjóri;Aldur=26;Kynlíf=kona Nafn=Qiv;Sysla=Vestur-Skaftafellssýsla;ID=00087295j;Starfsgrein=Sjómaður;Aldur=47;Kynlíf=karlkyns Nafn=Uba;Sysla=Suður-Múlasýsla;ID=00043765e;Starfsgrein=Bóndi;Aldur=66;Kynlíf=kona Nafn=Yhe;Sysla=Norður-Múlasýsla ;ID=00021559e;Starfsgrein=Fréttaritari;Aldur=35;Kynlíf=kona参考URL
- 投稿日:2020-07-12T15:48:27+09:00
Python csvファイル読み込み
pandasコマンドいろいろ
data2.csvNafn,Sysla,ID,Starfsgrein,Aldur,Kynlíf, Dom,Árnessýsla,00027861s,Embættismaður,30,karlkyns Ola,Gullbringusýsla,00033014s,bankastjóri,26,kona Qiv,Vestur-Skaftafellssýsla,00087295j,Sjómaður,47,karlkyns Uba,Suður-Múlasýsla,00043765e,Bóndi,66,kona Yhe,Norður-Múlasýsla ,00021559e,Fréttaritari,35,kona以下の例でしていること
・read_csvでindexを指定(指定しないと0, 1, 2, ・・・)
・列を指定して出力
・行を取得
・列を取得
・行をスライス
・行・列名を指定して値を取得
・行index、列indexを指定して値を取得import pandas csv_input = pandas.read_csv("data2.csv") print('///csv_input///\n') print(csv_input) print('---------------') print("///csv_input['ID']///\n") print(csv_input['ID']) print('---------------') print('///csv_input.index.values///\n') print(csv_input.index.values) print('---------------') print('///csv_input.columns.values///\n') print(csv_input.columns.values) print('---------------') print('///csv_input.iloc[2, 3]///\n') print(csv_input.iloc[2, 3]) print('---------------') print("///csv_input.loc[2, 'Starfsgrein']///\n") print(csv_input.loc[2, 'Starfsgrein']) print('---------------') print("///csv_input.loc[2:4, 'Starfssgrein']///\n") print(csv_input.loc[2:4, 'Starfsgrein']) print('---------------') print('///csv_input.iloc[2:4, 3]///\n') print(csv_input.iloc[2:4, 3]) print('---------------') print('\n***************\n') csv_input = pandas.read_csv("data2.csv", index_col=0) print('///csv_input///\n') print(csv_input) print('---------------') print("///csv_input['ID']///\n") print(csv_input['ID']) print('---------------') print('///csv_input.index.values///\n') print(csv_input.index.values) print('---------------') print('///csv_input.columns.values///\n') print(csv_input.columns.values) print('---------------') print('///csv_input.iloc[2, 2]///\n') print(csv_input.iloc[2, 2]) print('---------------') print("///csv_input.loc['Qiv', 'Starfsgrein']///\n") print(csv_input.loc['Qiv', 'Starfsgrein']) print('---------------') print("///csv_input.loc['Qiv':'Uba', 'Starfsgrein']///\n") print(csv_input.loc['Qiv':'Uba', 'Starfsgrein']) print('---------------') print('///csv_input.iloc[2:4, 2]///\n') print(csv_input.iloc[2:4, 2])user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ python3 pand_test.py ///csv_input/// Nafn Sysla ID Starfsgrein Aldur Kynlíf 0 Dom Árnessýsla 00027861s Embættismaður 30 karlkyns 1 Ola Gullbringusýsla 00033014s bankastjóri 26 kona 2 Qiv Vestur-Skaftafellssýsla 00087295j Sjómaður 47 karlkyns 3 Uba Suður-Múlasýsla 00043765e Bóndi 66 kona 4 Yhe Norður-Múlasýsla 00021559e Fréttaritari 35 kona --------------- ///csv_input['ID']/// 0 00027861s 1 00033014s 2 00087295j 3 00043765e 4 00021559e Name: ID, dtype: object --------------- ///csv_input.index.values/// [0 1 2 3 4] --------------- ///csv_input.columns.values/// ['Nafn' 'Sysla' 'ID' 'Starfsgrein' 'Aldur' 'Kynlíf'] --------------- ///csv_input.iloc[2, 3]/// Sjómaður --------------- ///csv_input.loc[2, 'Starfsgrein']/// Sjómaður --------------- ///csv_input.loc[2:4, 'Starfssgrein']/// 2 Sjómaður 3 Bóndi 4 Fréttaritari Name: Starfsgrein, dtype: object --------------- ///csv_input.iloc[2:4, 3]/// 2 Sjómaður 3 Bóndi Name: Starfsgrein, dtype: object --------------- *************** ///csv_input/// Sysla ID Starfsgrein Aldur Kynlíf Nafn Dom Árnessýsla 00027861s Embættismaður 30 karlkyns Ola Gullbringusýsla 00033014s bankastjóri 26 kona Qiv Vestur-Skaftafellssýsla 00087295j Sjómaður 47 karlkyns Uba Suður-Múlasýsla 00043765e Bóndi 66 kona Yhe Norður-Múlasýsla 00021559e Fréttaritari 35 kona --------------- ///csv_input['ID']/// Nafn Dom 00027861s Ola 00033014s Qiv 00087295j Uba 00043765e Yhe 00021559e Name: ID, dtype: object --------------- ///csv_input.index.values/// ['Dom' 'Ola' 'Qiv' 'Uba' 'Yhe'] --------------- ///csv_input.columns.values/// ['Sysla' 'ID' 'Starfsgrein' 'Aldur' 'Kynlíf'] --------------- ///csv_input.iloc[2, 2]/// Sjómaður --------------- ///csv_input.loc['Qiv', 'Starfsgrein']/// Sjómaður --------------- ///csv_input.loc['Qiv':'Uba', 'Starfsgrein']/// Nafn Qiv Sjómaður Uba Bóndi Name: Starfsgrein, dtype: object --------------- ///csv_input.iloc[2:4, 2]/// Nafn Qiv Sjómaður Uba Bóndi Name: Starfsgrein, dtype: objectcsvファイルを辞書に変換
DictReader関数を使用。
import csv def get_data_csv(path, mode): list = [] with open(path, mode) as f: dict_data = csv.DictReader(f) for dict in dict_data: list.append(dict) return list if __name__ == "__main__": path = 'data2.csv' mode = "r" list = get_data_csv(path, mode) for dict in list: print(dict)user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ python3 get_csv.py {'Nafn': 'Dom', 'Sysla': 'Árnessýsla', 'ID': '00027861s', 'Starfsgrein': 'Embættismaður', 'Aldur': '30', 'Kynlíf': 'karlkyns'} {'Nafn': 'Ola', 'Sysla': 'Gullbringusýsla', 'ID': '00033014s', 'Starfsgrein': 'bankastjóri', 'Aldur': '26', 'Kynlíf': 'kona'} {'Nafn': 'Qiv', 'Sysla': 'Vestur-Skaftafellssýsla', 'ID': '00087295j', 'Starfsgrein': 'Sjómaður', 'Aldur': '47', 'Kynlíf': 'karlkyns'} {'Nafn': 'Uba', 'Sysla': 'Suður-Múlasýsla', 'ID': '00043765e', 'Starfsgrein': 'Bóndi', 'Aldur': '66', 'Kynlíf': 'kona'} {'Nafn': 'Yhe', 'Sysla': 'Norður-Múlasýsla ', 'ID': '00021559e', 'Starfsgrein': 'Fréttaritari', 'Aldur': '35', 'Kynlíf': 'kona'}csvファイルをリストに変換
reader関数を使用。
import csv def get_data_csv(path, mode): list = [] with open(path, mode) as f: data = csv.reader(f) for row in data: list.append(row) return list if __name__ == "__main__": path = 'data2.csv' mode = "r" list = get_data_csv(path, mode) for element in list: print(element)user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ python3 get_csv.py ['Nafn', 'Sysla', 'ID', 'Starfsgrein', 'Aldur', 'Kynlíf'] ['Dom', 'Árnessýsla', '00027861s', 'Embættismaður', '30', 'karlkyns'] ['Ola', 'Gullbringusýsla', '00033014s', 'bankastjóri', '26', 'kona'] ['Qiv', 'Vestur-Skaftafellssýsla', '00087295j', 'Sjómaður', '47', 'karlkyns'] ['Uba', 'Suður-Múlasýsla', '00043765e', 'Bóndi', '66', 'kona'] ['Yhe', 'Norður-Múlasýsla ', '00021559e', 'Fréttaritari', '35', 'kona']参考URL
- 投稿日:2020-07-12T15:45:44+09:00
UbuntuやVScodeでpip、pandasをインストール
VScodeのターミナルでpip
PS C:\Users\TEST_USER\MyShell> python -m pip install pandasPS C:\Users\TEST_USER\MyShell> pip install scipy Collecting scipy Downloading scipy-1.5.1-cp38-cp38-win_amd64.whl (31.4 MB) |████████████████████████████████| 31.4 MB 152 kB/s Requirement already satisfied: numpy>=1.14.5 in c:\users\test_user\appdata\local\programs\python\python38\lib\site-packages (from scipy) (1.18.2) Installing collected packages: scipy Successfully installed scipy-1.5.1Ubuntuでpip(失敗編)
user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ pip install pandas Command 'pip' not found, but there are 18 similar ones. user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ python3 -m pip freeze /usr/bin/python3: No module named pipuser_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ python3 Python 3.8.2 (default, Mar 13 2020, 10:14:16) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import pandas Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'pandas' >>>Ubuntuでpipコマンドをインストール
参考URL
https://qiita.com/HiroRittsu/items/e58063fb74d799d37cc4
この手順通り実行。user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 1825k 100 1825k 0 0 242k 0 0:00:07 0:00:07 --:--:-- 412kuser_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ sudo python3 get-pip.py Collecting pip Downloading pip-20.1.1-py2.py3-none-any.whl (1.5 MB) |████████████████████████████████| 1.5 MB 1.0 MB/s Collecting wheel Downloading wheel-0.34.2-py2.py3-none-any.whl (26 kB) Installing collected packages: pip, wheel Successfully installed pip-20.1.1 wheel-0.34.2pipインストール確認。
user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ python3 -m pip list | grep pip pip 20.1.1user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ python3 Python 3.8.2 (default, Mar 13 2020, 10:14:16) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import pandas >>>pandasをインストール
user_name@DESKTOP-3128479:/mnt/c/Users/TEST_USER/MyShell$ pip install pandas Defaulting to user installation because normal site-packages is not writeable Collecting pandas Downloading pandas-1.0.5-cp38-cp38-manylinux1_x86_64.whl (10.0 MB) |████████████████████████████████| 10.0 MB 1.4 MB/s Collecting pytz>=2017.2 Downloading pytz-2020.1-py2.py3-none-any.whl (510 kB) |████████████████████████████████| 510 kB 2.5 MB/s Collecting python-dateutil>=2.6.1 Downloading python_dateutil-2.8.1-py2.py3-none-any.whl (227 kB) |████████████████████████████████| 227 kB 1.3 MB/s Collecting numpy>=1.13.3 Downloading numpy-1.19.0-cp38-cp38-manylinux2010_x86_64.whl (14.6 MB) |████████████████████████████████| 14.6 MB 540 kB/s Requirement already satisfied: six>=1.5 in /usr/lib/python3/dist-packages (from python-dateutil>=2.6.1->pandas) (1.14.0)Installing collected packages: pytz, python-dateutil, numpy, pandas WARNING: The scripts f2py, f2py3 and f2py3.8 are installed in '/home/user_name/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. Successfully installed numpy-1.19.0 pandas-1.0.5 python-dateutil-2.8.1 pytz-2020.1参考URL
- 投稿日:2020-07-12T15:40:26+09:00
【強化学習】ついに人間を超えた!?Agent57を解説/実装してみた(Keras-RL)
強化学習の評価でよく使われるAtariのゲームですが、ついに57全てのゲームで人間を超えた手法が現れたようです。
早速実装してみました。※ネット上の情報をかき集めて自分なりに実装しているので正確ではない点はご了承ください
※解釈違いの内容がある可能性もご注意ください(理解が追いついていない部分があります)コード全体
本記事で作成したコードは以下です。
- github
- GoogleColaboratory(実行結果付き)
※GoogleColaboratoryはmultiprocessingの相性が悪いらしく1Actorのみの学習となります)
※MountainCarの学習をのせています目次
構成としては前半が技術解説で後半が実装の説明になります。
- Agent57とは
- NGU(Never Give Up)の解説
- 内部報酬について
- POMDPへの対策(UVFAとRetrace)
- Agent57の解説
- 行動価値関数について
- メタコントローラーについて
- 実装
- 内部報酬の実装
- 探索ポリシーの実装
- 行動価値関数モデルの実装
はじめに
Agent57はいわゆるDQN系列の強化学習手法となります。
DQN系列のAgent57までの技術に関しては以前記事にしているのでよかったらどうぞ
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(準備編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(Q学習編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(DQN編)
- 【強化学習】Keras-rlでRainbowを実装/解説
- 【強化学習】Keras-rlでApe-Xを実装/解説(並列プログラミング)
- 【強化学習】2018年度最強と噂のR2D2を実装/解説してみた
- 【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
- 【強化学習】R2D3を実装/解説してみた(Keras-RL)
Agent57について
強化学習の指標として Atari2600 の57個のゲームがよく使われていますが、ついに57個全てのゲームで人間の性能を超えた強化学習手法が現れました。
既存の手法では Montezuma's Revenge 等、学習が難しいゲームがありましたが Agent57 ではちゃんと学習できるようになったみたいです。以下はDeepMindの記事より引用した各手法の比較です。
F(ApeX)やG(R2D2)もすごいと思いましたが、それを超えて圧倒的な性能ですね。
・参考
Agent57: Outperforming the human Atari benchmark
Atari完全制覇! Atari57ゲーム全てで人間を超えたAgent57とは!?Agent57に至るまで
(図はDeepMindの記事より引用)
本記事では NGU(Never Give Up) と Agent57 について解説します。
図の通りAgent57は既存のDQN手法を改良して実現しています。
過去の手法について気になった内容は私の過去の記事を参考にしてもらえればと思います。NGU/Agent57で大きく変わった部分は、探索(Exploration)と搾取(Exploitation)に焦点を当て、報酬が得られにくい環境に対しても効率的に探索できる仕組みを導入している点です。
それ以外にもいろいろな手法が取り入れられているので1つずつ説明していきたいと思います。NGU(Never Give Up)
強化学習において未知の領域を探索(exploration)する事と報酬を手に入れる事(搾取:exploitation)はトレードオフの関係にあります。
既存の手法では報酬が疎な(報酬を手に入れるまでが長い)ゲームではうまく学習できない問題がありました。
そこでNGUでは報酬に内部報酬(Intrinsic Reward)を追加することで効率的な探索を実現しています。内部報酬は以下の3つの条件を満たすように設定されます。
- 1エピソード内で同じ状態を訪れないようにする(強め)
- トレーニング全体で同じ状態を訪れないようにする(弱め)
- エージェントの行動に関係なく変化する状態を無視する
・参考
(論文)Never Give Up: Learning Directed Exploration Strategies
Never give Up! Atari完全制覇に繋がる、困難な環境でも諦めずに探索を行う強化学習!内部報酬(Intrinsic Reward)
NGUでは外部報酬(Extrinsic Reward:従来の報酬)に対して内部報酬(Intrinsic Reward)を加える形で報酬を定義します。
$$r_{t}=r^e_t + \beta r^i_t$$
ここで $r^e_t$ が外部報酬、$r^i_t$ が内部報酬で、$\beta$ は内部報酬を重みづけする定数です。
そしてこれらを足し合わせた $r_{t}$(拡張報酬)を用いてトレーニングを行います。では内部報酬を見ていきます。(図は論文より引用、以降この図を図Aといいます)
内部報酬は生涯記憶部(life long novelty module:図Aの右側の緑枠)とエピソード記憶部(episodic novelty module:図Aの右側の赤枠)から作成されます。
生涯記憶部からは $\alpha_t$、エピソード記憶部からは $r^{episode}_t$ という値を生成し、以下のように合成します。
$$ r^i_t = r^{episode}_t・min ( max ( \alpha _{t}, 1 ), L ) $$
日本語で書くと、内部報酬 = エピソード記憶部 × 生涯記憶部 です。
※ただし、生涯記憶部は1以下なら1、L以上ならLになる
※ L は最大スケール報酬を表す定数です(論文ではL=5)まずはエピソード記憶部から見ていきます。
エピソード記憶部(episodic novelty module)
エピソード記憶部では1エピソード内で同じ状態を訪れないように報酬を決めます。
全体のフローは以下です。(図Aの赤枠部分に該当)
- 埋め込み関数(embedding network)を用いて現在の状態から制御可能状態(controllable state)を出す
- 制御可能状態とエピソードメモリ(episodic memory M)より、k近傍法(k-nearest neighbors)で現在の状態の訪問回数の近似値を出す
- 訪問回数の近似値より、エピソード記憶部($r^{episode}_t$) を出す
- 制御可能状態をエピソードメモリに追加する
埋め込み関数と訪問回数の近似値に関しては後述します。
エピソードメモリは1エピソードの最初に初期化されます。
これにより1エピソード内での訪問回数を判断しているようです。埋め込み関数(embedding network)
埋め込み関数は制御可能状態を生成するニューラルネットワークの関数です。
現在の状態をp次元に圧縮するだけのシンプルなニューラルネットワークのようですね。
問題は学習で、以下のように Siamese network に見立てて学習します。
(この図は図A左側の詳細な図になります)
入力は1つ前の状態と現在の状態で、出力が各アクションの選ばれる確率です。
要するに、前の状態と今の状態の差分からどのアクションが実行されたかを学習するネットワークとなります。このネットワークで行動に紐づいて変化する状態のみを学習していると思われます。
参考:【深層距離学習】Siamese NetworkとContrastive Lossを徹底解説
k近傍法による訪問回数の近似
エピソード記憶部($r^{episode}_t$)は訪問回数をもとに算出します。
訪問回数はエピソードメモリと現在の状態より、k近傍法を用いて近似することで算出しています。
以下数式による説明です。エピソード記憶部($r^{episode}_t$)は以下です。
$$ r^{episode}_t = \frac{1}{ \sqrt{ n(f(x _{t})) } }$$
$n(f(x_t))$ が訪問回数です。
訪問回数はカーネル関数Kを用いて近似するとの事で、以下になります。$$ \frac{1}{ \sqrt{ n(f(x_t)) } } \approx \frac{1}{ \sqrt{ \sum_(f_i \in N_k)K(f(x_t), f_i) } + c} $$
cは最小の疑似訪問回数を保証する定数です。(c=0.001)
Kは、メモリ内の制御可能状態と今の制御可能状態とのk近傍法により計算されます。$$ K(x,y) = \frac{\epsilon}{ \frac{d^2(x,y)}{d^2_m} + \epsilon} $$
$\epsilon$ は小さな定数です。($\epsilon$=0.001)
d はユークリッド距離を表し、$d^2_m$はユークリッド距離の移動平均を表します。生涯記憶部(life long novelty module)
生涯記憶部はRND(Random Network Distillation)が用いられています。
・参考
Exploration by Random Network Distillation の効果を MountainCar で試した。
(論文) Exploration by Random Network DistillationRNDの説明ですが、普通はある状態において未知の状態かどうかを判断したい場合、訪問回数を数えて訪問回数が多いほど既知の状態と考えるものです。
しかしRNDでは逆転の発想をしています。
参考ブログの方の例えがうまかったので使わせてもらいますが、RNDではまずスクラッチの地図を用意します。
最初は地図は銀紙で覆われていますが、訪れるごとに少しずつ削れて行きます。
この削れ具合を見て、どれだけ未知かを判断する方法がRNDとなります。ではこれをどう実現するかというと、同じ構造の2つのニューラルネットワークを用意します。(A,Bとします)
Aは初期状態のままにし、BはAに近づくように学習します。
このBの学習が銀紙を削る行為に相当します。
これにより、AとBを比べて誤差が大きい=探索されていない場所、誤差が小さい=よく探索された場所になるわけですね。MDPとPOMDP
強化学習の前提の話に戻ります。
Q学習ではMDP(マルコフ決定過程)の確率モデルが前提となっています。
このモデルを簡単に言うと、ある状態でアクションを実行するとランダムな状態に移行し決まった報酬がもらえるというモデルです。
(一般的な強化学習のモデルですね)しかし、NGUでは内部報酬が加えられるので同じ状態に移行しても報酬が変わります。
ですのでNGUはMDPではなく、POMDP(部分観測マルコフ決定過程)のモデルとして考える必要があります。・参考
マルコフ決定過程(Wikipedia)
部分観測マルコフ決定過程(Wikipedia)しかし、POMDPとして考えることはMDPに比べてはるかに難しくなるのでNGUでは次の2つの回避策を導入しています。
- 外部報酬をQネットワークに直接入力する
- エピソード内のすべての入力(状態、アクション、および報酬)の履歴を要約する内部状態表現を維持
また、内部報酬による探索行動は報酬に直接加えれるので、探索行動を簡単にオフにする事が出来ません。
この問題を解決するために、NGUでは外部報酬と探索行動を同時に学習する手法を提案しています。UVFA(Universal Value Function Approximators)
DQNはある状態を入力としてQ値を推定するのが一般的です。
ここで、入力を状態だけではなく目標(goal)も加え一般化した価値関数がUVFAです。NGUはこのUVFAを用いますが、目標の代わりに$\beta$(内部報酬の反映率:探索率)を入力としています。
これにより探索行動も同時に学習することを提案しています。
$\beta = 0$ の場合は探索がオフの場合の結果を取得でき、$\beta > 0$は探索がオンの場合の結果を取得できるようになるわけですね。・参考
(DeepMind社のスライド) Universal Value Function Approximators
(論文) Universal Value Function ApproximatorsRetrace
Q学習はTD学習の中でも Off-Policy という探索方法をとっています。
(逆にTD学習で On-Policy な探索の一つに Sarsa というのがあります)違いは更新するQ値の参照先で、Off-Policyの場合は方策に従いません。
(Q学習ではQ値が最大となるアクションを選んでいます)
On-Policy の場合は方策に従い取得します。
(例えば ε-greedy で探索している場合は、参照先も ε-greedy を使います)Off-Policy で問題となるのが実際に行動した方策(Behavior policy)と学習したい方策(Target policy)が異なる点です。
これが異なるといつまでたっても値が収束しない(安全でない)可能性があります。
Retraceの論文ではこれを解決するために4つの手法(既存手法3つ+Retrace)を比較し、Retrace が優れている事を示しています。Retrace を簡単に言うと過去の結果を元に方策を予測し、その差分で学習をコントロールする方法です。
(学習のコントロールに使う係数を cutting traces coefficients($c_s$) と言っています)NGUでは Retrace を取り入れています。
・参考
今さら聞けない強化学習(10): SarsaとQ学習の違い
強化学習のOn-PolicyとOff-Policy
(Off-policyに関する論文1) Q(λ) with Off-Policy Corrections
(Off-policyに関する論文2) Off-Policy Temporal-Difference Learning with Function Approximation
(DeepMind社のスライド)off-policy deep RL
(Retraceの論文) Safe and efficient off-policy reinforcement learning
(Retrace論文の日本語スライド)safe and efficient off policy reinforcement learning
強化学習理論の基礎2
[Review] UCL_RL Lecture05 Model Free Control割引率
割引率($\gamma$)は$\beta$(内部報酬の反映率)に依存し変化させます。
$\beta=0$ の場合は $\gamma=max$、$\beta=max$ の場合は $\gamma=min$ とします。
(具体的には $\beta=0$ は $\gamma=0.997$、$\beta=max$ は $\gamma=0.99$)探索時は外部報酬の影響が小さくなるのでその調整のための割引率ですね。
Agent57
NGUで効率的な探索を実現できましたが、一部のゲームでは単純なランダム探索と同等のスコアしか出ない場合もありました。
また、NGUの欠点の1つに学習の進捗に関係なく探索してしまう点がありました。Agent57では以下を提案し、これらを改善しました。
- 外部報酬と内部報酬を分離する新しいパラメータを導入し、内部報酬の学習を安定させた
- メタコントローラーを導入し、探索率を優先順位に従って選択できるメカニズムを導入した
(論文) Agent57: Outperforming the Atari Human Benchmark
行動価値関数(Q関数)のアーキテクチャの変更
NGUでは学習が不安定になる場合がありました。
外部報酬と内部報酬のスケール・スパース性が異なる場合や、ある報酬のみが他の報酬に比べて過剰に反応する場合に起こります。Agent57では、外部報酬と内部報酬で報酬の性質が非常に異なる場合に行動価値関数を学習することは難しいと推測し、行動価値関数のアーキテクチャの変更を提案しました。
具体的には外部報酬を学習する $Q(x,a,j;\theta^e)$ と内部報酬を学習する $Q(x,a,j;\theta^i)$ に行動価値関数を分割し、以下の数式でQ値を求めます。
(ベルマン演算子(transformed Bellman operator)に基づいてるそうです)$$ Q(x,a,j;\theta) = h(h^{-1}(Q(x,a,j;\theta^e)) + \beta_j h^{-1}( Q(x,a,j;\theta^i)))$$
$\beta_j$は内部価値関数の反映率(探索率)、hはベルマン演算子関数?です。
hはあまりよく分かっていませんが、R2D2のrescaling関数と同じもので、以下となります。$$ h(z) = sign(z)(\sqrt{|z|+1}-1 ) + \epsilon z $$
$$ h^{-1}(z) = sign(z)(( \frac{ \sqrt{1+4\epsilon (|z|+1+\epsilon} + 4\epsilon }{ 2\epsilon } ) -1)$$
メタコントローラー
NGUとAgent57では内部報酬を用いて探索率($\beta_j$)を設定できるようになりました。
ただNGUでは、探索率は各Actor毎に固定としていました。
例えばActorが4の場合は以下みたいな感じです。(値は仮です)Actor1:$\beta_j$=0(探索なし)
Actor2:$\beta_j$=0.1(なんとなく探索)
Actor3:$\beta_j$=0.2(少し探索)
Actor4:$\beta_j$=0.3(そこそこ探索)探索率はトレーニングの早い段階では高めの値を用いた方がいいですが、トレーニングが進むと低い値を用いた方がいい事が予想されます。
そこで効率のいい探索率を選択する手法を取り入れるためにAgent57ではメタコントローラーを提案しました。メタコントローラーでは、効率のいい探索率の選択を、どの探索ポリシー(NGUでいうActor)を選べば最大の報酬を得られるかという多腕バンディット問題(Multi-armed bandit problem:MAB問題)に見立ててこれを解決しています。
(ここでの報酬は、1エピソード内における割引されていない外部報酬の合計を指します)・参考
私が以前書いた記事:【強化学習】複数の探索ポリシーを実装/解説して比較してみた(多腕バンディット問題)
多腕バンディット問題の理論とアルゴリズム
強化学習入門:多腕バンディット問題多腕バンディット問題(Multi-armed bandit problem:MAB問題)
MAB問題を簡単に言うと、複数のスロット(アーム)から一定回数選んだ場合に報酬を最大にする問題です。
例えばスロットが4つ(A,B,C,D)あったとします。
100回スロットを選んだあとに賞金が最大になる選び方はどういう選び方でしょうか?という問題です。
4つのスロットが賞金を出す確率は分かりません。一般的なMAB問題では賞金が出る確率はスロット毎に一定です。(最初に決めた後は変化しない)
しかし Agent57 では報酬の出る確率(報酬結果)が変化していきます。
そのためメタコントローラーでは少し工夫をしています。sliding-window UCB法
Agent57ではMAB問題に対するアルゴリズムとしてUCB法を用いています。
しかし報酬が変化するのでそのままではUCB法を適用できません。
そこで、直近の数エピソードのみを対象にUCB法を用いることを提案しています。
これを sliding-window UCB法と論文内では言っています。
直近の数エピソードだけを見る点以外はUCB法と変わりません。実装
内部報酬(Intrinsic Reward)
埋め込み関数(embedding network)
学習時のネットワーク構造と使用時のネットワーク構造が違う特殊なニューラルネットワークを作る必要があります。
まずは値取得用の埋め込み関数です。
論文には画像処理層といった記載はなく、この記事内での用語となります。(論文は画像入力が前提のため)
次に学習用の埋め込み関数です。
上記の図を実装したコードは以下となります。
※画像入力の場合のモデルとなります
※重みを共有するために各レイヤーには名前を付けていますinput_sequence = 入力フレーム数 input_shape = 入力形式 nb_actions = アクション数値取得用埋め込み関数c = input_ = Input(shape=(input_sequence,) + input_shape) c = Conv2D(32, (8, 8), strides=(4, 4), padding="same", name="l0")(c) c = Conv2D(64, (4, 4), strides=(2, 2), padding="same", name="l1")(c) c = Conv2D(64, (3, 3), strides=(1, 1), padding="same", name="l2")(c) c = Dense(32, activation="relu", name="l3")(c) emb_model = Model(input_, c)トレーニング用埋め込み関数# 入力を2つ作ります c1 = input1 = Input(shape=(input_sequence,) + input_shape) c2 = input2 = Input(shape=(input_sequence,) + input_shape) # 重みを共有しつつ、ネットワークを作ります l = Conv2D(32, (8, 8), strides=(4, 4), padding="same", name="l0") c1 = l(c1) c2 = l(c2) l = Conv2D(32, (4, 4), strides=(2, 2), padding="same", name="l1") c1 = l(c1) c2 = l(c2) l = Conv2D(64, (3, 3), strides=(1, 1), padding="same", name="l2") c1 = l(c1) c2 = l(c2) l = Dense(32, activation="relu", name="l3") c1 = l(c1) c2 = l(c2) # 結合 c = Concatenate()([c1, c2]) c = Dense(128, activation="relu")(c) c = Dense(nb_actions, activation="softmax")(c) emb_train_model = Model([input1, input2], c) # optimizerは論文より model.compile( loss='mean_squared_error', optimizer=Adam(lr=0.0005, epsilon=0.0001))損失関数ですが、最尤推定法で学習するとしか論文には記載がありませんでした。(多分…)
なのでとりあえず平均二乗誤差にしています。・参考
闇のKerasのTPU術:入力が2つあるモデルと、入力が1つのモデルの係数を相互転移させる方法
多入力多出力モデル(Keras公式)次に emb_train_model から emb_model に重みをコピーするコードです。
def sync_embedding_model(): for i in range(4): # layer数分回す train_layer = emb_train_model.get_layer("l" + str(i)) val_layer = emb_model.get_layer("l" + str(i)) # 重みをコピー val_layer.set_weights(train_layer.get_weights())入力がバラバラでさらに重みも共有するすごいモデルができました。。。
埋め込み関数(embedding network)の学習
論文にほとんど書かれていないような…
一応 Embeddings target の更新間隔が1エピソードに1回と書かれています。
Embeddings targetって何ですかね…。とりあえず学習方法は行動価値関数の学習と同じサンプルを使用して実行し、emb_train_model → emb_model への同期は1エピソードに1回としました。
batch_size = バッチサイズ def forward(observation): # 毎フレームの学習のタイミング # 経験メモリからバッチ用の経験をランダムに取得する batchs = memory.sample(batch_size) # データを整形する state0_batch = [] # 前の状態 state1_batch = [] # 次の状態 emb_act_batch = [] for batch in batchs: state0_batch.append(batchs["前の状態"]) state1_batch.append(batchs["次の状態"]) # アクションは one-hot vector にしてデータを作成 a = np_utils.to_categorical( batchs["アクション"], num_classes=nb_actions ) emb_act_batch.append(a) # トレーニング emb_train_model.train_on_batch( [state0_batch, state1_batch], # 入力は前の状態と次の状態の2つ emb_act_batch # 教師はアクション ) def backward(self, reward, terminal): if terminal: # エピソード終了タイミングで同期 sync_embedding_model() ※numpy化は省略埋め込み関数(embedding network)の値取得
emb_model から値を取り出すだけですね。
state = 現在の状態 cont_state = emb_model.predict([state], batch_size=1)[0] ※numpy化は省略エピソード記憶部の計算
ここの計算ですが幸いなことに論文内に疑似コードが書いてありました。
それをpython風疑似コードで表すと以下です。def calc_int_episode_reward((): state = 現在の状態 k = k近傍法での数(k=10) epsilon = 0.001 c = 0.001 cluster_distance = 0.008 maximum_similarity = 8 # 埋め込み関数から制御可能状態を取得 cont_state = embedding_network.predict(state, batch_size=1)[0] # エピソードメモリ内の全要素とユークリッド距離を求める euclidean_list = [] for mem_cont_state in int_episodic_memory: euclidean = np.linalg.norm(mem_cont_state - cont_state) euclidean_list.append(euclidean) # 上位k個が対象 euclidean_list.sort() euclidean_list = euclidean_list[:k] # ユークリッド距離2乗 euclidean_list = np.asarray(euclidean_list) ** 2 # 平均を出す ave = np.average(euclidean_list) # 訪問回数を近似する(数式のΣの計算) count = 0 for euclidean in euclidean_list: d = euclidean / ave # 論文で説明がないけど疑似コードに書いてある… # ある一定の距離は最短距離にまとめてる? d -= cluster_distance if d < euclidean_list[0]: d = euclidean_list[0] count += epsilon / (d+epsilon) s = np.sqrt(count) + c # ここも論文に説明はないけど、ある程度小さい値は0にまるめてる? if s > maximum_similarity: episode_reward = 0 else: episode_reward = 1/s # 論文の疑似コードにはないが、エピソードメモリに制御可能状態を追加 int_episodic_memory.append(cont_state) if len(int_episodic_memory) >= 30000: int_episodic_memory.pop(0) return episode_reward生涯記憶部(life long novelty module)
RNDモデル
RNDのモデルは以下です。
出力に大きな意味はありません。
画像処理層ありの場合のコードは以下です。def build_rnd_model(): # 入力層 c = input = Input(shape=(input_sequence,) + input_shape) # 画像処理層 c = Conv2D(32, (8, 8), strides=(4, 4), padding="same")(c) c = Conv2D(64, (4, 4), strides=(2, 2), padding="same")(c) c = Conv2D(64, (3, 3), strides=(1, 1), padding="same")(c) # Dense c = Dense(128)(c) model = Model(input, c) # loss、optimizerは論文より model.compile( loss='mean_squared_error', optimizer=Adam(lr=0.0005, epsilon=0.0001)) return model # train_model が target_model に近づくイメージです rnd_target_model = build_rnd_model() rnd_train_model = build_rnd_model()RNDの学習
こちらも論文にほとんど書かれていないと思います…
埋め込み関数と同様に行動価値関数の学習と同じサンプルを使用しています。
(学習に使用した=訪問した、という解釈で学習させています(けどちょっとあやしいかも…))def forward(observation): # 毎フレームの学習のタイミング # 経験メモリからバッチ用の経験をランダムに取得する batchs = memory.sample(batch_size) # データを整形する state0_batch = [] # 前の状態 state1_batch = [] # 次の状態 for batch in batchs: state0_batch.append(batchs["前の状態"]) state1_batch.append(batchs["次の状態"]) # target の値を取得 rnd_target_val = rnd_target_model.predict(state1_batch, batch_size) # トレーニング rnd_train_model.train_on_batch(state1_batch, rnd_target_val) ※numpy化は省略生涯記憶部の計算
生涯記憶部の計算式ですが、まず rnd_target_model と rnd_train_model の2乗誤差を出します。
$$ err(x_t) = || \hat{g}(x_t;\theta) - g(x_t)||^2$$
それを元に以下の計算式で生涯記憶部を出します。
$$ \alpha_t = 1 + \frac{ err(x_t) - \mu_e }{ \sigma_e }$$
ここで $\sigma_e$ は $err(x_t)$ の標準偏差、$\mu_e$ は $err(x_t)$ の平均になります。
標準偏差と平均が出てきましたね…
どうやって計算するかは論文に記載がありませんが…、計算するには過去の結果を保存しないといけないですね。
とりあえず $err(x_t)$ を保存する配列を作りました。
ただ、無限に追加されると困るので上限も作っています。以下コードです。
#--- 計算用の変数 rnd_err_vals = [] rnd_err_capacity = 10_000 #--- 計算部分 def calc_int_lifelong_reward(): state = 現在の状態 # RNDの取得 rnd_target_val = rnd_target_model.predict(state, batch_size=1)[0] rnd_train_val = rnd_train_model.predict(state, batch_size=1)[0] # 2乗誤差を出す mse = np.square(rnd_target_val - rnd_train_val).mean() rnd_err_vals.append(mse) if len(rnd_err_vals) > rnd_err_capacity: rnd_err_vals.pop(0) # 標準偏差 sd = np.std(rnd_err_vals) if sd == 0: return 1 # 平均 ave = np.average(rnd_err_vals) # life long reward lifelong_reward = 1 + (mse - ave)/sd return lifelong_reward内部報酬の計算
内部報酬は以下の数式です。
$$ r^i_t = r^{episode}_t・min ( max ( \alpha _{t}, 1 ), L ) $$
L = 5 episode_reward = エピソード記憶部 lifelong_reward = 生涯記憶部 if lifelong_reward < 1: lifelong_reward = 1 if lifelong_reward > L: lifelong_reward = L intrinsic_reward = episode_reward * lifelong_reward探索率(β)と割引率(γ)
探索ポリシーは探索率(β)と割引率($\gamma$)のペアで表され、以下の式で計算されます。
割引率はNGUとAgent57で計算式が違います。(一応両方かいておきます)まずは探索率の計算式です。
\beta_i = \left\{ \begin{array}{ll} 0 \qquad (i = 0) \\ \beta \qquad (i = N-1) \\ \beta・\sigma(10\frac{2i-(N-2)}{N-2}) \quad (otherwise) \end{array} \right.$\sigma$ はシグモイド関数で、$\beta$ は反映率の最大値です。
def sigmoid(x, a=1): return 1 / (1 + np.exp(-a * x)) def create_beta_list(N, max_beta=0.3): beta_list = [] for i in range(N): if i == 0: b = 0 elif i == N-1: b = max_beta else: b = 10 * (2*i-(N-2)) / (N-2) b = max_beta * sigmoid(b) beta_list.append(b) return beta_listNGUの割引率です。
$$ \gamma_i = 1 - exp \Bigl( \frac{ (N-1-i)log(1-\gamma_max) + (ilog(1-\gamma_min)) }{N-1} \Bigr)$$
def create_gamma_list_ngu(N, gamma_min=0.99, gamma_max=0.997): if N == 1: return [gamma_min] if N == 2: return [gamma_min, gamma_max] gamma_list = [] for i in range(N): g = (N - 1 - i)*np.log(1 - gamma_max) + i*np.log(1 - gamma_min) g /= N - 1 g = 1 - np.exp(g) gamma_list.append(g) return gamma_listAgent57の割引率です。
\gamma_j = \left\{ \begin{array}{ll} \gamma0 \qquad (j=0) \\ \gamma1 + (\gamma0 - \gamma1)\sigma(10 \frac{2i-6}{6} ) \qquad (j \in (1,...,6)) \\ \gamma1 \qquad (j=7) \\ 1-exp(\frac{(N-9)log(1-\gamma1) + (j-8)log(1-\gamma2)}{N-9}) \quad (otherwise) \end{array} \right.def create_gamma_list_agent57(N, gamma0=0.9999, gamma1=0.997, gamma2=0.99): gamma_list = [] for i in range(N): if i == 1: g = gamma0 elif 2 <= i and i <= 6: g = 10*((2*i-6)/6) g = gamma1 + (gamma0 - gamma1)*sigmoid(g) elif i == 7: g = gamma1 else: g = (N-9)*np.log(1-gamma1) + (i-8)*np.log(1-gamma2) g /= N-9 g = 1-np.exp(g) gamma_list.append(g) return gamma_list内部報酬のモデル(UVFA)
ここは理解が怪しいです…。
以下の図はAgent57の行動価値関数のモデルです。
右下に [アクション, 外部報酬, 内部報酬, 探索率] の記載があります。
しかし、これをどう追加するかが書かれていないんですよね…とりあえず以下のように内部報酬の行動価値関数のみに探索率をohe-hotベクトルで追加しています。
(内部報酬や外部報酬をそのまま入力すると学習しなくなったりしたんですよね…)
以下コードです。
内部報酬用の行動価値関数のみの記載です。
((UVFA)とコメントがある部分がUVFAで変更している部分です)from keras.utils import to_categorical # Q関数用のモデルを作成する箇所 def build_actval_int_model(): # 入力層 c1 = input1 = Input(shape=(input_sequence,) + input_shape) c2 = input1 = Input(shape=(policy_num,)) # (UVFA)追加 # 画像処理層 c1 = Conv2D(32, (8, 8), strides=(4, 4), padding="same")(c1) c1 = Conv2D(64, (4, 4), strides=(2, 2), padding="same")(c1) c1 = Conv2D(64, (3, 3), strides=(1, 1), padding="same")(c1) c = Concatenate()([c1, c2]) # (UVFA)追加 # lstm c = LSTM(512)(c) # dueling network c = DuelingNetworkのモデルを作成(c) model = Model([input1, input2], c) # (UVFA)変更 model.compile(loss=clipped_error_loss, optimizer=Adam(lr=0.0001, epsilon=0.0001)) return model # モデルを作成 actval_int_model = build_actval_int_model() actval_int_model_target = build_actval_int_model()内部報酬モデルのトレーニング
# 毎フレーム def forward(observation): # batchデータを取得 batchs = memory.sample() # データを整形 state0_batch = [] state1_batch = [] policy_batch = [] for batch in batchs: state0_batch.append(batchs["前の状態"]) state1_batch.append(batchs["次の状態"]) # 探索ポリシーを one-hot化 t = to_categorical(batchs["探索ポリシー"], num_classes=policy_num) policy_batch.append(t) # 入力は stateと探索ポリシー state0_batch = [state0_batch, policy_batch] state1_batch = [state1_batch, policy_batch] # Q値を出す例 state0_qvals = actval_int_model.predict(state0_batch, batch_size) (更新用の state0_qvals の計算) # 学習 actval_int_model.train_on_batch(state0_batch, state0_qvals)Q値の計算
NGUでのQ値の計算は、Agent57の行動価値関数の分割によりなくなったので省略します。
Agent57でのQ値の計算式は、内部報酬と外部報酬の組み合わせた以下になります。$$ Q(x,a,j;\theta) = h(h^{-1}(Q(x,a,j;\theta^e)) + \beta_j h^{-1}( Q(x,a,j;\theta^i)))$$
def rescaling(x, epsilon=0.001): if x == 0: return 0 n = math.sqrt(abs(x)+1) - 1 return np.sign(x)*n + epsilon*x def rescaling_inverse(x, epsilon=0.001): if x == 0: return 0 n = math.sqrt(1 + 4*epsilon*(abs(x)+1+epsilon)) - 1 return np.sign(x)*( n/(2*epsilon) - 1) def get_qvals(): state = 現在の状態 policy_index = 探索ポリシー # 外部のQ値を出す qvals_ext = avtval_ext_model.predict(state, batch_size=1)[0] # 探索ポリシーone-hot policy_onehot = to_categorical(policy_index, num_classes=policy_num) # 内部のQ値を出す qvals_int = avtval_int_model.predict([state, policy_onehot], batch_size=1)[0] # 探索率 beta = int_beta_list[policy_index] # Q値を計算 qvals = [] for i in range(nb_actions): q_ext = rescaling_inverse(qvals_ext[i]) q_int = rescaling_inverse(qvals_int[i]) qval = rescaling(q_ext + beta * q_int) qvals.append(qvals) return qvalsRetrace
先に言いますが、Retraceの実装は保留にしています(内容理解できず…)
理解できていない内容を記載しておきます。Retrace関数は以下です。
$$ c_s = \lambda min(1, \frac{\pi(A_s|X_s)}{\mu(A_s|X_s)}) $$
$\pi$ が探索ポリシー(Target Policy)で、$\mu$が振る舞いポリシー(Behavior Policy)の各アクションの確率分布になります。
ただ、DQNで探索ポリシーは完全greedy(Q値最大値のみを選ぶ)なので、確率分布はQ値最大値のアクションが1、それ以外が0になる気がします。
そうなると分子が0か1しかとらない形になるので常に0になっちゃう気がするけど…orz振る舞いポリシーの方はたぶん ε-greedy になるので以下になるかと思います(?)
\mu(\alpha|s) = \left\{ \begin{array}{ll} \epsilon/N + 1 - \epsilon \quad (argmax_{\alpha \in A} Q(s, \alpha)) \\ \epsilon/N \quad (otherwise) \end{array} \right.ここで N はアクション数。
あとがき
LSTMまわりとかキューに関してとか並列処理とか細かいところは説明しきれていません。。。
ソースコードは公開しているので細かい部分はそちらで確認してください。これで強化学習のアルゴリズムとして1つの目標に到達した感はありますが、まだまだ改善の余地はあると思います。
一番改善してほしいのはなんといっても要求スペックですね。
R2D2の頃からそうでしたが論文内ではActor数は512となっています。
私のPCでは2、多くても4が限界です…(CPUが1つしかないのもありますが)
次の新しい手法に期待ですね。