- 投稿日:2020-07-11T23:51:07+09:00
AtCoder AISing2020 - クソ雑魚注意 - 追記中
エイシング プログラミング コンテスト 2020
2020-07-11T21:00:00+09:00【エイシング2020】本日午後9時からの開催です。ABCと同程度の難易度となっております。
— AtCoder (@atcoder) July 11, 2020
エイシング プログラミング コンテスト 2020 - AtCoder https://t.co/X2Go4UdDJy【エイシング2020】コンテストご参加ありがとうございました。
— AtCoder (@atcoder) July 11, 2020
解説PDF: https://t.co/ucCXKkIZJe
解説放送は後日となります。関連リンク
- コンテストページ
- 問題文 (印刷用一覧)
- 公式解説 PDF
- Twitter で当該コンテストの情報を収集
- https://twitter.com/search...
- 検索クエリ:
-成績 -トレンド #atcoder min_faves:1 since:2020-07-11
- ブログ等
- https://www.google.com/search...
- 検索クエリ:
atcoder (aising OR エイシング) (プログラミング OR コンテスト) 2020 (site:qiita.com OR site:note.com OR site:hatenablog.com)A
初回: AC (PyPy3 (7.3.0))
単純全探索で、剰余がゼロか否か。追記:
「倍数の個数」は簡単に求めることができるようだ。# d の倍数は d*1, d*2, d*3, ... # 正整数 R 以下に含まれる d の倍数の個数は R // d # L 以上 R 以下なら (R // d) - ((L - 1) // d)今更だけど、Python の
//は「切り捨て除算演算子」と呼ぶらしい。B
初回: AC (PyPy3 (7.3.0))
1つ飛ばしで奇数番のみの単純全探索で、値の奇数判定。追記:
code golf奇数番のみ
# range(start, stop, step) range(1,N+1,2) # スライスで L[::2]コード長最短の方のコードがつよい
- 提出 #15187099 - エイシング プログラミング コンテスト 2020
- 奇数判定からの
len()ではなくsum()- 奇数判定
i % 2は
- 奇数なら
True = 1- 偶数なら
False = 0- 標準入力のねじ込み方がヤバイ
[*open(0)][1]でN部分を捨てA部分のみ確保C
初回: TLE (PyPy3 (7.3.0))
解法が分からず。愚直に、重複組み合わせを求めてからの探索。追記:
単純全探索で十分間に合うようだ。そもそも解答手順がなっていないな。条件を満たす n の個数を数学的に判定するのではなく、全探索してしまうことを考えてみましょう。
からの、計算量の見積もり方。
追記:
引き続き TLE。詰めが甘かった。探索範囲の終端を適当に考えていた。まず、$N \leq 10^4$
次に $(x, y, z)$ を条件から判断するが、$n = x^2 + y^2 + ...$ のような式の場合「指数が大きい部分に注目し、とりあえず他は無視」みないな解説をどこかで聞いた気がする。
仮に $x \leq 10^2$ とする。# よってこんな感じであっさり通った ans = [0 for _ in range(1,10_001)] for x in range(1,101): ...D
初回: 未解答
解法が分からず。E
初回: 未解答
何となく記憶にあるが、解法は分からず。F
初回: 未確認
- 投稿日:2020-07-11T23:01:55+09:00
Pythonの高階関数(デコレータ)のサンプル
自前のマシンではSchemeで各種ツールやWebスクリプトを作ってきたが,昨今の安価・高機能・高性能なPaaS,SaaSでSchemeに対応しているはずもなく,代替言語としてのPythonで,Schemeの特徴のひとつである高階関数を扱うためのサンプルを作成・整理した.
なお,高階関数(Higher-order Function)とは,簡単に言えば『関数自体を値として引数にとったり戻り値としたりする関数』である.詳細は,『Structure and Interpretation of Computer Programs』"1.3 Formulating Abstractions with Higher-Order Procedures"を参照.
高階関数の定義と利用
Pythonでもlambdaが使えるが単一の式としてしか扱えないため,defでローカル定義した関数を返す書き方が一般的らしい.
higherorder.pydef threetimes(f): def retfunc(x, y): print(f(f(f(x, y), y), y)) return (retfunc) def f(x, y): return (2 * x + y) threetimes(f)(10, 5) # => f(f(f(x, y), y), y) # => (2 * (2 * (2 * 10 + 5) + 5) + 5) => "115" def threetimes_message(mes = ""): def _threetimes(f): def retfunc(x, y): print(mes, end="") print(f(f(f(x, y), y), y)) return (retfunc) return (_threetimes) threetimes_message("Result = ")(f)(10, 5) # => "Result = 115" threetimes_message()(f)(10, 5) # => "115"なお,対応するSchemeコードの例は次の通り.実行はGaucheで確認.
higherorder.scm(define threetimes (lambda (f) (lambda (x y) (print (f (f (f x y) y) y))))) (define f (lambda (x y) (+ (* 2 x) y))) ((threetimes f) 10 5) ; => (f (f (f 10 5) 5) 5) ; => (+ (* 2 (+ (* 2 (+ (* 2 10) 5)) 5)) 5) => "115" (define threetimes_message (lambda (f . mes) (lambda (x y) (if (not (null? mes)) (display (car mes))) (print (f (f (f x y) y) y))))) ((threetimes_message f "Result = ") 10 5) ; => "Result = 115" ((threetimes_message f) 10 5) ; => "115"デコレータ
高階関数を使用する際のsyntax sugar.語源は,デザインパターンの一種.Flaskなどのフレームワークを高階関数群として定義し,本来の処理を行うユーザ定義関数に機能追加するようにしたい場合に便利な書き方.
decorators.py# threetimes,threetimes_message は higherorder.py の定義を使用 @threetimes def f(x, y): return(2 * x + y) f(10, 5) # => "115" @threetimes_message(mes = "Result = ") def f(x, y): return(2 * x + y) f(10, 5) # => "Result = 115" @threetimes_message() def f(x, y): return (2 * x + y) f(10, 5) # => "115"lambda等を使ったその他サンプル
Wikipediaの記事(高階関数)にある例をいくつか抜粋.
others.pydef args_10_5(f): def _args_10_5(): f(10, 5) return (_args_10_5) def f(x, y): print("x = ", x, ", y = ", y) args_10_5(f)() # => "x = 10 , y = 5" def f(x, y, z, w): return (4 * x + 3 * y + 2 * z + w) f(2, 3, 4, 5) # => 30 def f(x): return (lambda y: lambda z: lambda w: 4 * x + 3 * y + 2 * z + w) f(2)(3)(4)(5) # => 30 def unfold(pred, f, update, seed): if pred(seed): return ([]) else: r = unfold(pred, f, update, update(seed)) r.insert(0, f(seed)) return (r) unfold(lambda x: x > 10, lambda x: x * x, lambda x: x + 1, 1) # => [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
- 投稿日:2020-07-11T22:52:59+09:00
AtCoder エイシング プログラミング コンテスト 2020 参戦記
AtCoder エイシング プログラミング コンテスト 2020 参戦記
むちゃくちゃ眠かったので、直前に20分仮眠して頑張った.
aising2020A - Number of Multiples
1分半で突破. 問題の条件の通り書くだけ. 時間がかかるので、O(1) で解こうとかそういう事は考えない.
L, R, d = map(int, input().split()) result = 0 for i in range(L, R + 1): if i % d == 0: result += 1 print(result)aising2020B - An Odd Problem
2分で突破. 問題の条件の通り書くだけ.
N = int(input()) a = list(map(int, input().split())) result = 0 for i in range(N): if (i + 1) % 2 == 1 and a[i] % 2 == 1: result += 1 print(result)追記: 偶数番目なんてスライスで飛ばせばよかったんや…….
N, *a = map(int, open(0).read().split()) print(sum(1 for e in a[::2] if e % 2 == 1))aising2020C - XYZ Triplets
6分半で突破. N≤104 だから3重ループでも通ると思った. 実際、通った.
N = int(input()) result = [0] * (N + 1) for x in range(1, 101): for y in range(1, 101): for z in range(1, 101): n = x * x + y * y + z * z + x * y + y * z + z * x if n > N: break result[n] += 1 print(*result[1:], sep='\n')aising2020D - Anything Goes to Zero
突破できず. A = B * C のとき A % m = (B % m) * (C % m) % m を使って大きな数の余りは出せるなあと思って、それを使って組んだけど、TLE は出るし、RE も出るしでよく分からないことに. 最初の1回目の処理は事前計算で O(1) に出来るけど、2回目以降はどうするんだろ.
- 投稿日:2020-07-11T21:53:05+09:00
まずodooの概要について(odoo13)
はじめに
pythonに慣れている方ですと、Flask、Djangoなどのフレームワークには触れたことがあるかと思いますが、Odooというpython世界にあるフレームワークにふれる機会はなかなかないのではないでしょうか。実はこのOdooという企業系のソリューションのフレームワークというか、ソフトとうか、っていうのが非常に強力なツールなのです。pythonに慣れていてしかも企業系ソリューションを探しているのであれば、このフレームワークに触れないのはもったいないのではないかなと思います。
私の場合、Odooはdjangoに触ってから初めて触るフレームワークなので、色々勉強がてらアウトプットとして記事を書いていきたいと思い、記事を書きます。
このフレームワークは最初はわけが分からず戸惑うかもしれません。というのも資料がほんとになくて、困り果てるかと思います。自分の場合、英語や中国語の資料を読み漁って、やっとというところでした。日本語ですとほんとに資料がないんです。そこはどうしようも有りません。英語の記事を頑張って読むしかないかなと思います。odooとは
まずはオフィシャルな内容について書くと、OdooとはオープンソースのビジネスシーンのAll in oneみたいなソリューションです。ソリューションパッケージは企業のすべてのニーズに対応できます。企業の販売、CRM、HR、経費、購入、品質管理、採用、休暇、昼食管理、内部フォーラム、内部チャット、顧客クレーム管理、VOIP、EC、企業ウェブサイト、財務、銀行帳簿管理、HR給料管理、WMS倉庫管理、POS、コミュニティショップ、PLMなどなど色々あります。
ざっくりいうと、OdooはERPアプリケーションの一種のソリューションです。同時に、非常に多くのモジュールと呼ばれる補足機能が使用でき、二次開発にも用いられる。Odooの最も大きな特徴はオープンソースとモジュール化です。
オープンソースの意味合い
オープンソースの意味は言うまでもなく、ソースコードはGithubにて公開しております。即ち、誰もがソースコードにアクセスができ、無料でOdooコミュニティ版(企業版もありますが、有料です)を利用できます。
モジュール化とは
Odooにおけるモジュール化とは、Odooの最も特筆すべき特徴です。この特徴はその他のEPRソリューションと大きく違う点だと思います。開発者はかんたんに既存のモジュールを継承し、あるいは拡張し、様々なニーズに対応することができます。
最後に
私はこれまでプログラミングについて一年間程度独学でやってきました。が、その結論としてやはり実践なしでは勉強にならないことがわかりました。何かを勉強しましたじゃ話にもなりません。
以下にその勉強したらどれくらい知識が身につけたかについて感覚的に纏めてみます。勉強しました 20%(2割り程度身につけた)
言語化しました 30%
なにかを作りました 50%
人に教えました 60%という感じではないでしょうか。ということで、結局は何をアウトプットしないと意味がないんじゃないかなと思います。閉じこもってやってられないし、人と共有しない限り、インターアクティブが生まれません。そうするとやる気も続かないのです。とことん自分のわかってる勉強できた知識を言語化して人の役に立つことを発信していくことの大切さを改めて痛感したところです。
さてさてまたね。
- 投稿日:2020-07-11T21:51:43+09:00
実装で学ぶ深層学習(segmentation編) ~SegNet の実装~
環境
tensorflow == 2.2.0
keras == 2.3.1
(202.6.10現在のGoogleColabのdefaultのversion)コード
githubに全コードがのっています。
https://github.com/milky1210/Segnet
記事内のコードは抜粋なので実際に動かしたい方はコードのダウンロードをお願いします。SegNetの論文の内容を要約
要旨
SEMANTIC segmentation と呼ばれる画像の各ピクセルに対して何が映ったピクセルなのかというラベルをDeep learning によって推論を行う問題においてPooling などによって低解像度になった特徴マップを元の次元に復元する上で正確な境界線にマッピングを行うモデルを提案する。
他の研究との差分
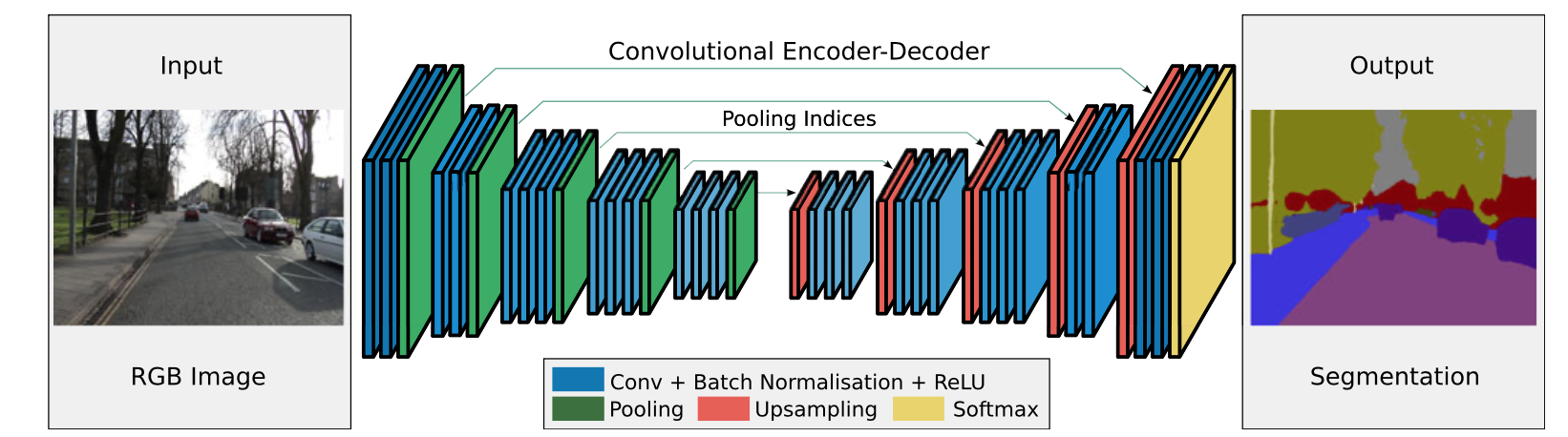
SegNet は通常のFCNのように画像を畳み込み層とpooling層で解像度を小さくしたのちにUpSampling を行っているが解像度をあげるときにpooling indiceと呼ばれる手法を用いて境界が不鮮明になることを防いでいる。
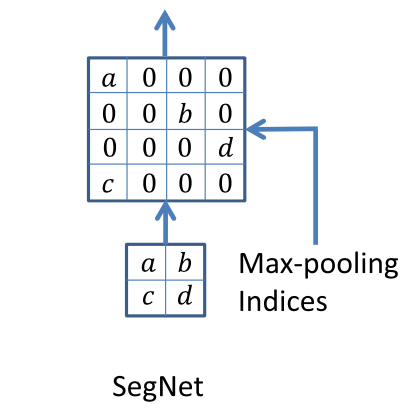
ここでEncodeやDecodeにはVGG16のモデル(画像分類で有名なモデル)の形を継承している。Pooling indices
この図のようにMax Poolingを行ったときにMaxがどこにあったかを覚えておき、UpSamplingの時にその位置に各特徴マップをうつすというものである。性能をVOC12を用いて比較
VOC12とは
SegNetの論文内でも性能の検証のために用いられている画像認識や画像検知、セグメンテーションなどの問題をサポートしているデータセットである。
ここからダウンロードできる。ダウンロードするとVOCdevkit/VOC2012/の中にJPEGImages/とSegmentationObject/が入っておりJPEGImageを入力画像、SegmentationObjectを出力画像として訓練、検証を行う。
それぞれのディレクトリでJPEGImages/~.jpgと SegmentationObject/~.pngが対応している。背景、境界を含めて22クラス分類を行う。
実装
記事内ではモデルの定義と損失関数の定義、訓練のみ取り上げる。
また、訓練、検証は64x64の解像度で行う。モデル定義
まず比較対象としてpooling indice のないSegNet(Encoder-decoder)をVGG16の形を模すと以下のようになる。
def build_FCN(): ffc = 32 inputs = layers.Input(shape=(64,64,3)) for i in range(2): x = layers.Conv2D(ffc,kernel_size=3,padding="same")(inputs) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.MaxPooling2D((2,2))(x) for i in range(2): x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.MaxPooling2D((2,2))(x) for i in range(3): x = layers.Conv2D(ffc*4,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.MaxPooling2D((2,2))(x) for i in range(3): x = layers.Conv2D(ffc*8,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.MaxPooling2D((2,2))(x) for i in range(3): x = layers.Conv2D(ffc*8,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.UpSampling2D((2,2))(x) for i in range(3): x = layers.Conv2D(ffc*4,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.UpSampling2D((2,2))(x) for i in range(3): x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.UpSampling2D((2,2))(x) for i in range(2): x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.UpSampling2D((2,2))(x) for i in range(2): x = layers.Conv2D(ffc,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.Conv2D(22,kernel_size=3,padding="same",activation="softmax")(x) return models.Model(inputs,x)vgg16を模した形にするとこのような構造となり、24層の畳み込み層を持つネットワークとなる。ここで、MaxPooling2Dによって画像を小さくし、UpSampling2Dを用いて画像を大きくしていることに注意する。
次にSegnetとこのモデルの差分をみていく。
まずSegnetはMaxPooling2Dを行う前に以下のようにしてその層でのArgMaxPooling2Dに相当する情報を保持しておく。
この関数はKerasにはなくtensorflowのものを利用する。
よって、オリジナルのKeras Layerを作成する必要がある。
以下のように関数を定義するとKeras上で動くlayerとなる。class MaxPoolingWithArgmax2D(Layer): def __init__(self): super(MaxPoolingWithArgmax2D,self).__init__() def call(self,inputs): output,argmax = tf.nn.max_pool_with_argmax(inputs,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') argmax = K.cast(argmax,K.floatx()) return [output,argmax] def compute_output_shape(self,input_shape): ratio = (1,2,2,1) output_shape = [dim//ratio[idx] if dim is not None else None for idx, dim in enumerate(input_shape)] output_shape = tuple(output_shape) return [output_shape,output_shape]次にUpSamplingを行う時にargmaxであった場所に戻すLayerを定義する(こちらはかなり長め)
class MaxUnpooling2D(Layer): def __init__(self): super(MaxUnpooling2D,self).__init__() def call(self,inputs,output_shape = None): updates, mask = inputs[0],inputs[1] with tf.variable_scope(self.name): mask = K.cast(mask, 'int32') input_shape = tf.shape(updates, out_type='int32') # calculation new shape if output_shape is None: output_shape = (input_shape[0],input_shape[1]*2,input_shape[2]*2,input_shape[3]) self.output_shape1 = output_shape # calculation indices for batch, height, width and feature maps one_like_mask = K.ones_like(mask, dtype='int32') batch_shape = K.concatenate([[input_shape[0]], [1 ], [1], [1]],axis=0) batch_range = K.reshape(tf.range(output_shape[0], dtype='int32'),shape=batch_shape) b = one_like_mask * batch_range y = mask // (output_shape[2] * output_shape[3]) x = (mask // output_shape[3]) % output_shape[2] feature_range = tf.range(output_shape[3], dtype='int32') f = one_like_mask * feature_range # transpose indices & reshape update values to one dimension updates_size = tf.size(updates) indices = K.transpose(K.reshape( K.stack([b, y, x, f]), [4, updates_size])) values = K.reshape(updates, [updates_size]) ret = tf.scatter_nd(indices, values, output_shape) return ret def compute_output_shape(self,input_shape): shape = input_shape[1] return (shape[0],shape[1]*2,shape[2]*2,shape[3])これらによって定義されたLayerを用いてSegnetを定義すると以下のようになる。
def build_Segnet(): ffc = 32 inputs = layers.Input(shape=(64,64,3)) for i in range(2): x = layers.Conv2D(ffc,kernel_size=3,padding="same")(inputs) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x,x1 = MaxPoolingWithArgmax2D()(x) for i in range(2): x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x,x2 = MaxPoolingWithArgmax2D()(x) for i in range(3): x = layers.Conv2D(ffc*4,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x,x3 = MaxPoolingWithArgmax2D()(x) for i in range(3): x = layers.Conv2D(ffc*8,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x,x4 = MaxPoolingWithArgmax2D()(x) for i in range(3): x = layers.Conv2D(ffc*8,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.Dropout(rate = 0.5)(x) x = MaxUnpooling2D()([x,x4]) for i in range(3): x = layers.Conv2D(ffc*4,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = MaxUnpooling2D()([x,x3]) for i in range(3): x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = MaxUnpooling2D()([x,x2]) for i in range(2): x = layers.Conv2D(ffc,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = MaxUnpooling2D()([x,x1]) for i in range(2): x = layers.Conv2D(ffc,kernel_size=3,padding="same")(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) x = layers.Conv2D(22,kernel_size=3,padding="same",activation="softmax")(x) return models.Model(inputs,x)損失関数と最適化
今回損失関数は各ピクセルのクロスエントロピーを利用した。
また、最適化はAdam(lr=0.001, beta_1=0.9, beta_2=0.999)を用いた。結果
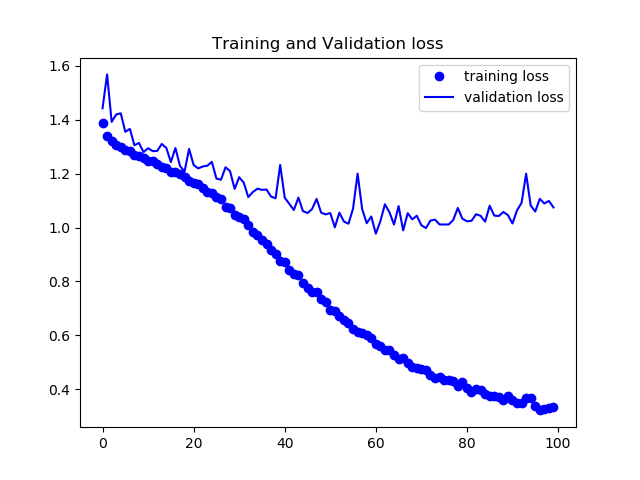
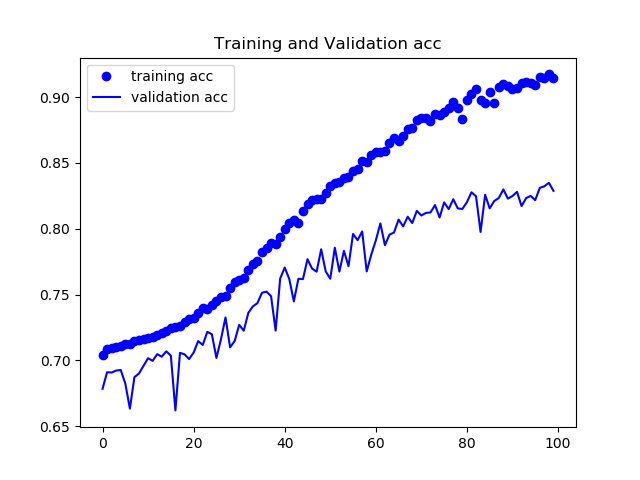
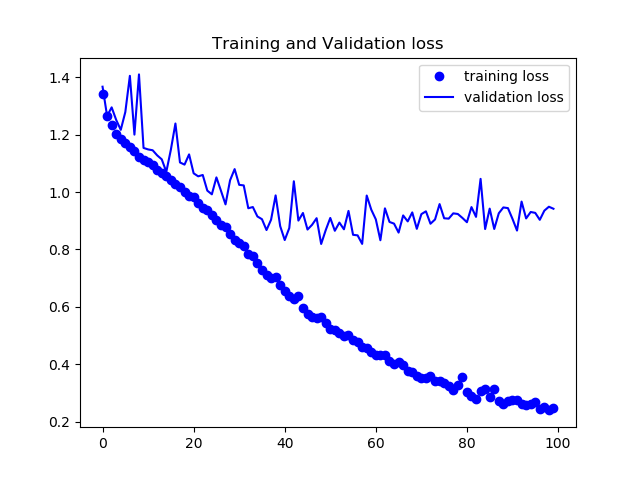
pooling indiceの有無によってどの程度結果に変化が出るかを確認した。
トレーニング内でのloss,各ピクセルでの正答率の平均をグラフにした。
まずPooling Indice の無いモデルの結果
検証データは78%程度の正答率となった。
次にSegNetの結果を載せる。
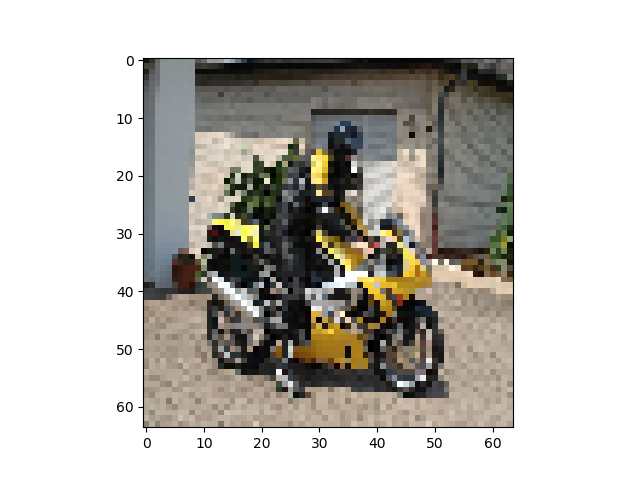
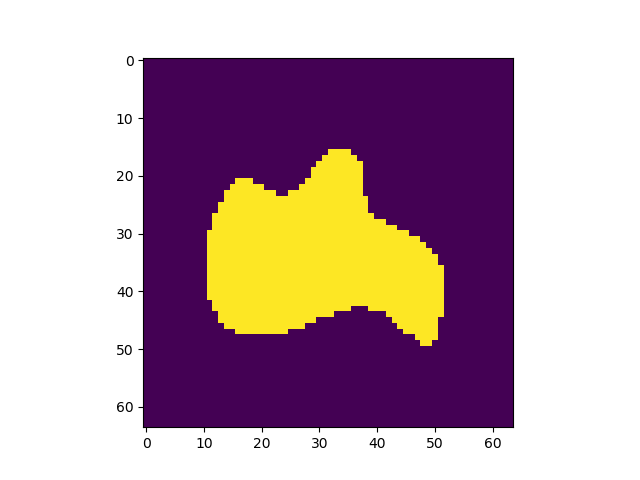
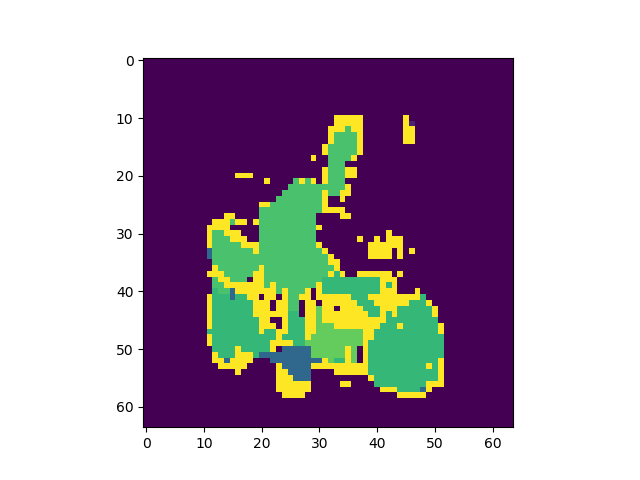
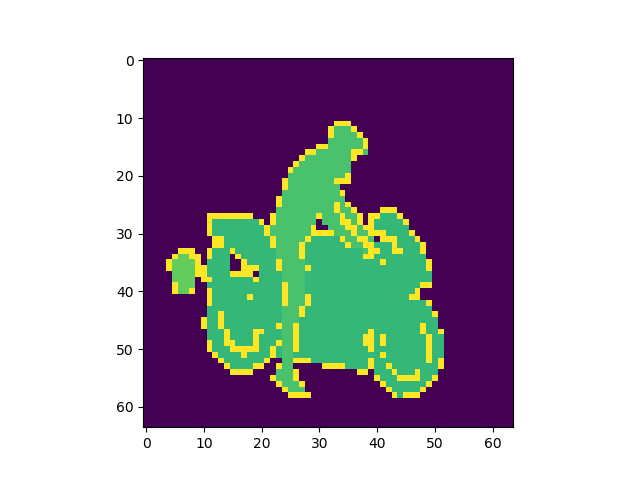
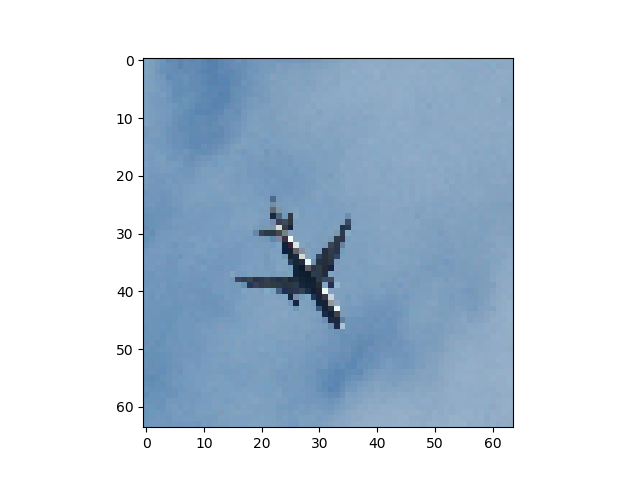
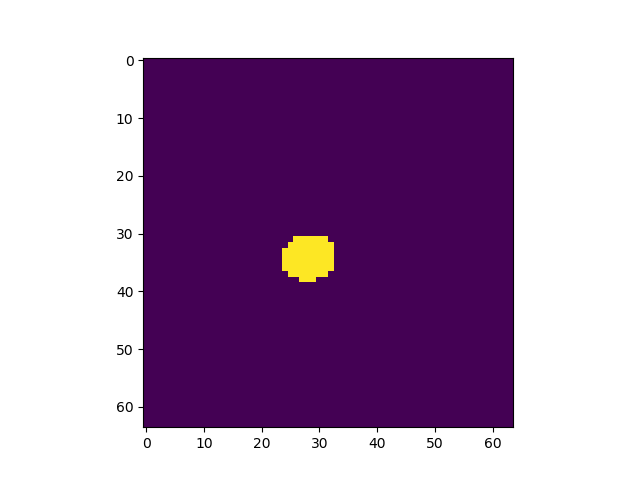
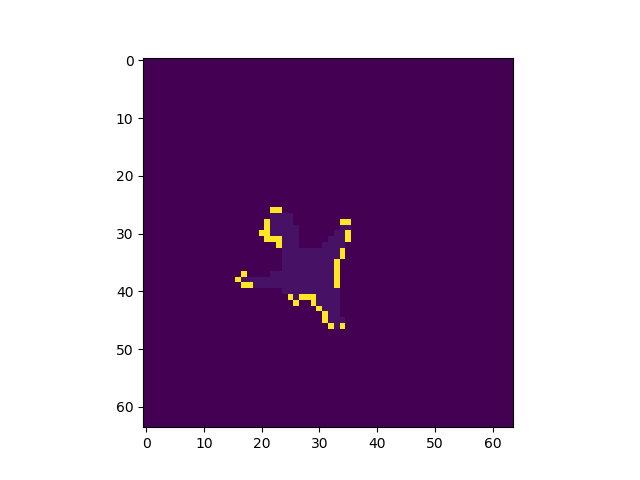
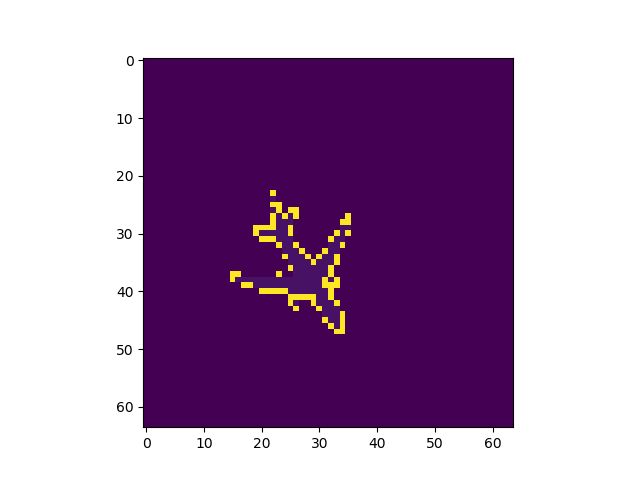
正答率82%程度で安定し、論文通りの挙動を見ることができた。出力画像例
左から入力、Pooling Indice なし、SegNet、GTで全てテストデータ
Pooling Indiceを保持することでかなり精度の向上を見込めることがわかった。



- 投稿日:2020-07-11T20:58:43+09:00
openCVの顔認識で自分の顔をTwitterアイコンに置き換えてZOOMをする
久しぶりの投稿になりますkimo_0takです。
facerigなどで簡単にバ美肉はできますが、自分の顔だけを他の画像に置き換える方法がググっても見つからなかったのでササっと作りました。
100%顔を置き換える保証はないので内輪ネタとしてお使いください。表示される画像はこんな感じ。
使用環境はWindows10、Python3.6.5です。
このプログラムと置き換えたい画像と顔認識モデルのxmlファイルは同じファイルに入れてください。参考にさせていただいたサイトはこちらです。
Haar Cascadesを使った顔検出
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html
OpenCVで画像上に別の画像を描画する
https://note.com/npaka/n/nddb33be1b782
Python+OpenCVでWebカメラの画像を取り込んで処理して表示する話
https://ensekitt.hatenablog.com/entry/2017/12/19/200000では作っていきましょう。
完成したコードは一番下に載せてあるので、それだけ見たい方は下までスクロール。
必要なライブラリのインポート
# OpenCVのインポート import cv2 import numpy as np from PIL import Imageもしインストールしていないライブラリがあれば各自インストールしてください。
コマンドプロンプトを開き、pip install opencv-python pip install numpy pip install Pillowと入力すれば入れられるはず。
諸々の設定
# カメラの解像度設定 WIDTH = 1920 HEIGHT = 1080 # 読み込みする画像の指定 img = "vtuber_may.jpg" cv2_img = cv2.imread(img, cv2.IMREAD_UNCHANGED) #顔認識モデルの指定 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml') # 引数でカメラを選べれる。 cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FRAME_WIDTH, WIDTH) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, HEIGHT)顔認識のカスケード型分類器は自分で作成してもいいですが、面倒だったのでOpencv提供の分類器を使いました。pip install opencvでopencvをインストールした際に付属されてます。
僕の環境では C:\Users{ユーザ名}\AppData\Local\Programs\Python\Python36-32\Lib\site-packages\cv2\data フォルダ内にありました。
画像を合成する関数
def overlayImage(src, overlay, location, size): overlay_height, overlay_width = overlay.shape[:2] # webカメラの画像をPIL形式に変換 src = cv2.cvtColor(src, cv2.COLOR_BGR2RGB) pil_src = Image.fromarray(src) pil_src = pil_src.convert('RGBA') # 合成したい画像をPIL形式に変換 overlay = cv2.cvtColor(overlay, cv2.COLOR_BGRA2RGBA) pil_overlay = Image.fromarray(overlay) pil_overlay = pil_overlay.convert('RGBA') #顏の大きさに合わせてリサイズ pil_overlay = pil_overlay.resize(size) # 画像を合成 pil_tmp = Image.new('RGBA', pil_src.size, (255, 255, 255, 0)) pil_tmp.paste(pil_overlay, location, pil_overlay) result_image = Image.alpha_composite(pil_src, pil_tmp) # OpenCV形式に変換 return cv2.cvtColor(np.asarray(result_image), cv2.COLOR_RGBA2BGRA)Opencvでは画像を合成できないので、PIL形式に変換してから画像を合成する関数を作ります。
ついでに顔の高さと幅にあわせてリサイズもします。
メイン関数
def main(): # 顔認識の左上角の座標を格納する変数 x = 0 y = 0 # 顔の幅と高さを格納する変数 w = 0 h = 0 while True: # VideoCaptureから1フレーム読み込む ret, frame = cap.read() #フレームをグレー形式に変換し、顔認識 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) face = face_cascade.detectMultiScale(gray, 1.3, 5) # 顔が認識されていればx, y, w, hを更新 if face != (): (x, y, w, h) = face[0] # 変数が初期値以外ならフレームに画像を合成 if w != 0: frame = overlayImage(frame, cv2_img, (x, y), (w, h)) # 加工したフレームを表示する cv2.imshow('Frame', frame) # キー入力を1ms待って、ESCを押されたらBreakする k = cv2.waitKey(1) if k == 27: break # キャプチャをリリースして、ウィンドウを閉じる cap.release() cv2.destroyAllWindows()webカメラから1フレーム読み込み、その画像に対して処理を行います。
フレームによっては顔を認識しないこともあるので、認識しなかった場合は以前認識した位置に合成するようにしています。
もし画面内に二人以上の顔が認識された場合はどちらかの顔にしか画像は合成されないので注意。
改良しようかとも思いましたが、そもそも二人同時にZOOMに映ることなんでまずないのでその改良はしませんでした。
メイン関数を実行する処理
if __name__ == '__main__': main()
まとめるとこんな感じ
# OpenCVのインポート import cv2 import numpy as np from PIL import Image # カメラの解像度設定 WIDTH = 1920 HEIGHT = 1080 # 読み込みする画像の指定 img = "vtuber_may.jpg" cv2_img = cv2.imread(img, cv2.IMREAD_UNCHANGED) #顔認識モデルの指定 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml') # 引数でカメラを選べれる。 cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FRAME_WIDTH, WIDTH) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, HEIGHT) def overlayImage(src, overlay, location, size): overlay_height, overlay_width = overlay.shape[:2] # webカメラの画像をPIL形式に変換 src = cv2.cvtColor(src, cv2.COLOR_BGR2RGB) pil_src = Image.fromarray(src) pil_src = pil_src.convert('RGBA') # 合成したい画像をPIL形式に変換 overlay = cv2.cvtColor(overlay, cv2.COLOR_BGRA2RGBA) pil_overlay = Image.fromarray(overlay) pil_overlay = pil_overlay.convert('RGBA') #顏の大きさに合わせてリサイズ pil_overlay = pil_overlay.resize(size) # 画像を合成 pil_tmp = Image.new('RGBA', pil_src.size, (255, 255, 255, 0)) pil_tmp.paste(pil_overlay, location, pil_overlay) result_image = Image.alpha_composite(pil_src, pil_tmp) # OpenCV形式に変換 return cv2.cvtColor(np.asarray(result_image), cv2.COLOR_RGBA2BGRA) def main(): # 顔認識の左上角の座標を格納する変数 x = 0 y = 0 # 顔の幅と高さを格納する変数 w = 0 h = 0 while True: # VideoCaptureから1フレーム読み込む ret, frame = cap.read() #フレームをグレー形式に変換し、顔認識 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) face = face_cascade.detectMultiScale(gray, 1.3, 5) # 顔が認識されていればx, y, w, hを更新 if face != (): (x, y, w, h) = face[0] # 変数が初期値以外ならフレームに画像を合成 if w != 0: frame = overlayImage(frame, cv2_img, (x, y), (w, h)) # 加工したフレームを表示する cv2.imshow('Frame', frame) # キー入力を1ms待って、ESCを押されたらBreakする k = cv2.waitKey(1) if k == 27: break # キャプチャをリリースして、ウィンドウを閉じる cap.release() cv2.destroyAllWindows() if __name__ == '__main__': main()あとはこのプログラムで表示されたwebカメラの画像をOBS Studioで読み込み、virtualcamで仮想カメラとして出力させればいいだけです。
ここでは解説しませんが、こちらのサイトなどを見て設定をしてください。OBS を仮想カメラとして認識させる VirtualCam を利用する方法
https://loumo.jp/archives/24912
Zoomで使用するとこんな感じ。オタク顔をTwitterのアイコンで隠してミーティングができますね。
さいごに
もっとコードの解説をするつもりで少しづつ分けてコード載せたんですが、解説はコメントでほとんど書いてあるしコメント以外のことはopencvのカスケード型分類器の場所くらいしか書くことありませんでした。
あと最近ホロライブのvtuberの紫咲シオンちゃんにハマっているのでよかったら見てください。


- 投稿日:2020-07-11T20:45:06+09:00
「君がデータサイエンティスト?百年速い」といったあいつを見返すまで ~Win 10 Home上にDocker作って「データサイエンス100本ノック(構造化データ加工編)」のSQL版を起動するまで、編~
すべてのはじまり
奴:「君がデータサイエンティスト?百年速いんじゃない?」
・・・いいだろう。やってやろうじゃないか。(その日の深夜)下調べは十分だ。どうやらPython(パイソン),R,SQLが使える必要があるらしい。ふふふ、勝ったな。SQLなら昔、かじったことがある。そのためには、この「データサイエンス100本ノック(構造化データ加工編)」が一番の近道だということも分かった。よ~し、さっそくこの愛機、無銘(:中華ノートPC)へインストールするぜ!
ふむふむ、まずはDockerが必要、と。
よし、ダウンロードOK!実行!っと。ん?なんだこのエラー?
Docker Desktop requires Windows 10 Pro/Enterprise (15063+) or Windows 10 Home (19018+).
Windows 10 Homeのかたは、Ver.19018以上にしなさいってことか。そういや、しばらく、Windows Updateしていなかったかもな。・・あれ?Windows Updateを最新化したのに、まだ、同じメッセージだ。
そういえば、DockerってWin10Proじゃないとだめって聞いたことがあるような。データサイエンス100本ノックではDockerToolboxが必要って書いてあったな。あれ?そんなのDockerにないな。
ヤバイ。詰んだ。。。
くっ、このままでは、あいつにまた馬鹿にされる。底辺ネット民のGGR力を舐めてもらっては困るな。・・・ふむふむ。
Windows 10 Home で WSL 2 + Docker を使うなら、そもそも、Powershellでコマンド実行が必要やったのね。
お、もっとわかりやすいのがここに。あれ?そしたら、データサイエンス100本ノックのInstall手順↓からはずれるぞ。
$ git clone [Repository URL]
$ cd 100knocks-preprocess
$ docker-compose up -d --build
どうやったらいいんだ?
そだそだ、こういう時こそ、おちついて公式ドキュメントだ。ふむふむ。わかったぞ。以下が公式pdfに書かれている手順だ。
1. Gitをインストールする。
2. Dockerをインストールする。
3. 100本ノックリポジトリをクローンする。
4. ターミナル等でdocker-composeファイルのあるディレクトリまで移動
5. ターミナル等でコンテナ作成コマンドを実行する。だけど、 Win 10 Home の場合は、
1. WSLをインストールする。
2. Dockerをインストールする。
3. 100本ノックリポジトリをZIPダウンロードして自分のホームディレクトリ配下に展開する。
4. ターミナル等でdocker-composeファイルのあるディレクトリまで移動(cd 100knocks-preprocess)
5. ターミナル等でコンテナ作成コマンドを実行する。(docker-compose up -d --build)
ということだと理解。早速試してみよう...おや?5の段階でエラーがでたぞ。
そういや、そういった場合は、Dockerのコンテナを再起動して再実行として書いてあったな。
Docker Desktopにいって、(Stop)停止っと。そして起動(Start)。
そんで、
docker-compose up -d --buildの再実行!と、おお!エラーがきえた!ふふふ、よっしゃー!きたこれ!
http://localhost:8888(ここ からもいけるようにしておくよ)
おう、!なんか開いた!このworkの下やな。
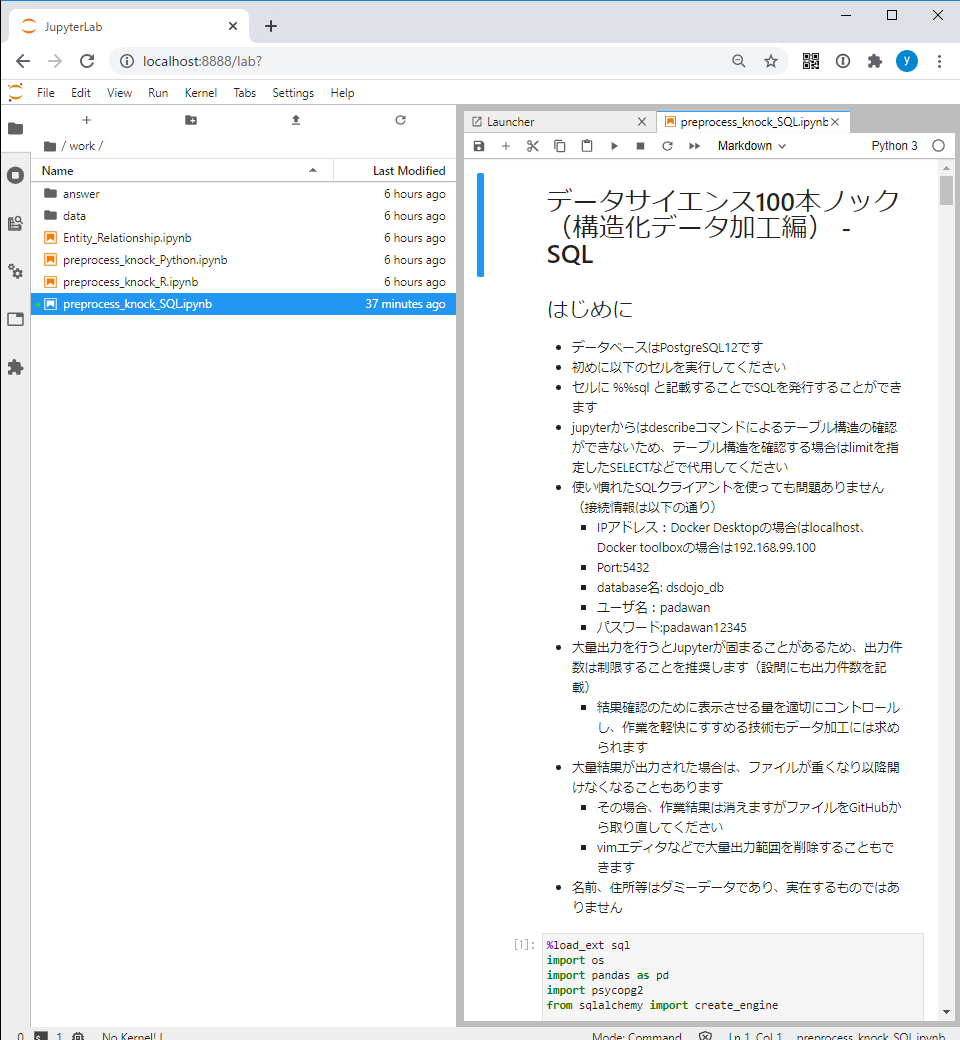
たぶん、このpreprocess_knock_SQL.ipynbてやつをダブルクリックやな!
きたきた!これで、あとはSQLをつかいこなすだけだぜ~。
- 投稿日:2020-07-11T20:13:42+09:00
GCP Cloud Logging で構造化ログを扱う
構造化ログとは
下記のように JSON 等のデータ形式で出力されたログのこと。
GCP では JSON 形式のログは自動的にパースされ、検索クエリで利用できるようになり便利。
(Cloud Run では確認済み)
改行も JSON としてエスケープされるので、副次的に複数行のログも扱いやすくなる。{"level": "INFO", "message": "hello\nworld", "timestamp": "2020-07-01 00:00:00"}Python でログを JSON で出力するサンプル
Pythonでは logger に独自のフォーマッターを設定することでログを JSON 形式で出力することができる。
$ python -V Python 3.8.0logger.pyimport sys import logging import json import traceback class JsonFormatter(logging.Formatter): def format(self, log): return json.dumps({ "level": log.levelname, "message": log.msg, "timestamp": self.formatTime(log, self.datefmt), "traceback": traceback.format_exc() if log.exc_info else [] }) formatter = JsonFormatter(datefmt="%Y-%m-%d %H:%M:%S") stream = logging.StreamHandler(stream=sys.stdout) stream.setFormatter(formatter) logger = logging.getLogger('your-logger-name') logger.setLevel(logging.INFO) logger.addHandler(stream)設定した logger を読み込んで利用する。
sample.pyfrom logger import logger logger.info("hello\nworld") logger.info({"foo": "foo", "boo": "boo"})下記のようなログが出力される。
{"level": "INFO", "message": "hello\nworld", "timestamp": "2020-07-01 00:00:00", "traceback": []} {"level": "INFO", "message": {"foo": "foo", "boo": "boo"}, "timestamp": "2020-07-01 00:00:00", "traceback": []}Cloud Logging
GCP Cloud Logging -> ログビューア画面から検索することができる。
下記のようにログとして出力したデータはjsonPayloadに格納されており、クエリ上でキーを指定できる。resource.type="cloud_run_revision" jsonPayload.level="INFO" jsonPayload.message.foo="foo"下記のようにログが検索結果としてでてくる
{ "insertId": "xxxxxxxxxxxxxxxxxxxxxxxx", "jsonPayload": { "message": {"foo": "foo", "boo": "boo"}, "traceback": [], "timestamp": "2020-07-07 15:33:28", "level": "INFO" }, ... }
- 投稿日:2020-07-11T19:48:08+09:00
原油の製油の最適化
これなに
「OR-Toolsで学ぶ最適化 【線形計画:製油しようぜ】」をpandasを使ったモデルで解き直した記事です。
定式化
変数:原油種類ごと、製品種類ごとの作成量 目的関数:購入費用合計 ー 販売額合計 → 最大化 制約条件 ・原油の購入上限 ・製品ごと需要の上下限 ・製品のオクタン価Pythonで解く
データ設定
原油と製品の表を作成
from io import StringIO from ortoolpy import pd, model_max, lpDot, lpSum dfoil = pd.read_csv(StringIO("""\ 原油,原油_オクタン価,所有量,費用_バレル R0,99,782,55.34 R1,94,894,54.12 R2,84,631,53.68 R3,92,648,57.03 R4,87,956,54.81 R5,97,647,56.25 R6,81,689,57.55 R7,96,609,58.21""")) dfprd = pd.read_csv(StringIO("""\ 製品,製品_オクタン価,需要下限,需要上限,売価 F0,88,415,11707,61.97 F1,94,199,7761,62.04 F2,90,479,12596,61.99"""))変数表作成
変数表は、原油と製品の直積で作成
df = pd.DataFrame( [ [*row1, *row2] for row1 in dfoil.itertuples(False) for row2 in dfprd.itertuples(False) ], columns=dfoil.columns.tolist() + dfprd.columns.tolist(), ) df[:2] # 先頭2行
原油 原油_オクタン価 所有量 費用_バレル 製品 製品_オクタン価 需要下限 需要上限 売価 0 R0 99 782 55.34 F0 88 415 11707 61.97 1 R0 99 782 55.34 F1 94 199 7761 62.04 モデル化&結果表示
m = model_max(df=df) for _, dfs in df.groupby("原油"): m += lpSum(dfs.Var) <= dfs.所有量.iloc[0] for _, dfs in df.groupby("製品"): m += lpSum(dfs.Var) >= dfs.需要下限.iloc[0] m += lpSum(dfs.Var) <= dfs.需要上限.iloc[0] m += (lpDot(dfs.原油_オクタン価, dfs.Var) == lpDot(dfs.製品_オクタン価, dfs.Var)) m.solve(objs=["-費用_バレル", "売価"]) dfr = df.pivot_table("Val", "原油", "製品").round(2) dfr = pd.concat([dfr, dfr.sum().to_frame("計").T]) dfr["計"] = dfr.sum(1) dfr
F0 F1 F2 計 R0 0 782 0 782 R1 894 0 0 894 R2 465.29 30.08 135.63 631 R3 330.04 0 317.96 648 R4 0 956 0 956 R5 0 621.59 25.41 647 R6 689 0 0 689 R7 0 609 0 609 計 2378.33 2998.67 479 5856 (何故かOR-Tools の元記事とは違いますね)
モデル化のポイント
- ortoolpyの0.2.36以降で可能です。
- 最大化モデルは
model_max、最小化モデルはmodel_minで作成します。
- モデル作成時に、下記の引数にDataFrameを指定すると変数としてVar列を作成します。
- df:非負連続変数
- dfb:0-1変数
- dfi:非負整数変数
solve時にobjsで列名のリストを指定すると、その列を目的関数の係数として使用します。
- 列名に「
-」がついていると、-1倍します。- モデルにDataFrameが結びついていると、solve後に結果を
Val列として追加します。以上
- 投稿日:2020-07-11T17:59:51+09:00
[Python] Amazon PA-API 5.0への移行
はじめに
今回はAmazon PA-API5(Product Advertising API 5.0)を叩いて商品情報を引っ張ってくるコードを組んだのでメモしたものです.もともとAmazon PA-APIは頻繁に利用していたのですが2019年12月1日からバージョン4.0かから5.0のPA-APIへと移行したためコードも組み直す必要があったためです.
事前に準備するもの
Amazon出品者アカウントを作成後,こちらから
- Access Key
- Secret Key
- Partner Tag
を取得してください.
pipで以下のようにモジュールをインストールしてください.
$ pip3 install amazon-paapi5Scratchpad
PA-API5.0の仕様はこちらで確認できます.またScratchpadを使えばGUIで簡単にAPIを叩くことができそのリクエストとそれに対するレスポンスがどのようになっているか確認できます.返ってきたJSONレスポンスをみて自分が欲しいデータがどこにあってそれをどうやって取り出すかの参考になります.PythonやPHPなどのサンプルリクエストコードも提示してくれるので非常に便利です.取得した3つのKEYがあればリクエストできるのでコード組む前に試してみるとよいでしょう.
サンプルコード
サンプル1
入力 出力 キーワード(検索クエリ) ASIN
商品価格
商品URL
商品タイトル検索キーワードとしてJANコードを指定することも可能です!
from amazon.paapi import AmazonAPI KEY = "<INPUT YOUR KEY>" SECRET = "<INPUT YOUR SECRET KEY>" TAG = "<INPUT YOUR PARTNER TAG>" COUNTRY = "JP" keyword = "任天堂Switch" amazon = AmazonAPI(KEY, SECRET, TAG, COUNTRY) products = amazon.search_items(keywords=keyword) asin = products["data"][0].asin price = products["data"][0].offers.listings[0].price.amount url = products["data"][0].detail_page_url title = products["data"][0].item_info.title.display_value print(asin, price, url, title)サンプル2
入力 出力 ASIN ASIN
商品価格
JANコード
商品URL
商品タイトルASINはリスト型で定義し,一度のリクエストで最大10のASINを入力にAPIレスポンスを得られます.
#coding:utf-8 from amazon.paapi import AmazonAPI KEY = "<INPUT YOUR KEY>" SECRET = "<INPUT YOUR SECRET KEY>" TAG = "<INPUT YOUR PARTNER TAG>" COUNTRY = "JP" asin_list = ["B087QZ1FWZ","B087QW57NZ","B081T9VJS4","B087QZGN24"]#一度に叩けるのは最大10個 amazon = AmazonAPI(KEY, SECRET, TAG, COUNTRY) products = amazon.get_items(item_id_type="ASIN", item_ids=asin_list) #各ASINに紐付く情報を取りだす for asin in asin_list: try: asin = products["data"][asin].asin price = int(products["data"][asin].offers.listings[0].price.amount) jan = products["data"][asin].item_info.external_ids.ea_ns.display_values[0] url = products["data"][asin].detail_page_url title = products["data"][asin].item_info.title.display_value print(asin, price, jan, url, title) except: None以下のような
asin.txtを入力としたバージョンがこちらasin.txtB087QZ1FWZ B087QW57NZ B081T9VJS4 B087QZGN24 B081T9Z4KG B084XH5NW1 B07YNPWP5M B086ZGFKPR B086ZFTHY2 B084DF682G B07QWR3KDW B07MR6YMXC B081T9MCG7 B084HPJWK9 B087D2NW77#coding:utf-8 from amazon.paapi import AmazonAPI from time import sleep KEY = "<INPUT YOUR KEY>" SECRET = "<INPUT YOUR SECRET KEY>" TAG = "<INPUT YOUR PARTNER TAG>" COUNTRY = "JP" amazon = AmazonAPI(KEY, SECRET, TAG, COUNTRY) def send_request(asin,b): products = amazon.get_items(item_id_type="ASIN", item_ids=asin_list) num = 0 for asin in asin_list: try: num += 1 asin = products["data"][asin].asin price = products["data"][asin].offers.listings[0].price.amount jan = products["data"][asin].item_info.external_ids.ea_ns.display_values[0] url = products["data"][asin].detail_page_url monourl = "https://mnrate.com/item/aid/"+asin title = products["data"][asin].item_info.title.display_value print (asin, jan, price) b.write(asin+","+jan+","+title+","+price+","+url+","+monourl+"\n") sleep(0.1) except: None #何回のAPIリクエストが必要になるかの計算 pages = sum([1 for _ in open('asin.txt')])/10 + 1 a = open("asin.txt","r")#入力ファイル b = open("jan.csv","w")#出力ファイル asin_list = [] num = 0 for i in a: num += 1 asin = i.rstrip() asin_list.append(asin) #ASINリストの長さが10になったらAPIを叩く if len(asin_list) == 10: send_request(asin_list,b) asin_list = [] #一番最後のリクエスト elif num == pages: send_request(asin_list,b) a.close() b.close()
monourlはモノレートページのURLで商品の売れ筋具合の確認が可能です.ちなみにこのコードはせどり用に作ったモノです.
- 投稿日:2020-07-11T17:52:15+09:00
DEAPを使った遺伝的アルゴリズムで初期集団を固定する方法
PythonのライブラリDEAPを使えば、簡単に遺伝的アルゴリズム(GA)によるシミュレーションを行うことが出来る。その際に、最適解に関してある程度事前知識があり計算時間を短縮したいなどの事情により初期集団を固定したい場合がある。
例えばこちらの例のように機械学習の特徴量選択に応用する際、これまで試行したベストモデルからスタートしたいというケースが考えられる。100~数百であれば初期値設定は不要だが、後先考えずに10万程度の特徴量を機械的に作ってしまった人間には需要がある。
その様な場合の対応方法は公式ドキュメントにも案内があるが、実際にテストした情報がウェブ上にあまりないのでここに記載しておく。
公式ドキュメントのOne-Maxモデルによる実験
0or1からなる配列の合計値を評価関数とし、最大化するGAの実装
最適解は全て1の配列、評価関数の最大値が配列の長さとなる
http://deap.gel.ulaval.ca/doc/default/examples/ga_onemax.html
http://deap.gel.ulaval.ca/doc/default/examples/ga_onemax_short.html1. 公式ドキュメント通りのランダムな初期集団からのGA
# ライブラリインポート import numpy as np import random from deap import algorithms from deap import base from deap import creator from deap import tools1-1. 評価関数作成
0or1からなる100要素の配列の合計値
def evalOneMax(individual): return sum(individual), #返り値が一つでもコンマを付ける1-2. Creatorの作成
createでcreatorにFitnessMax、Individualメソッドを追加。
weights=(1.0,)とすることで評価関数の最大化を評価する。creator.create("FitnessMax", base.Fitness, weights=(1.0,)) #引数が一つでもコンマを付ける creator.create("Individual", list, fitness=creator.FitnessMax)1-3. toolboxの作成
resisterでtoolboxに第一変数の名前のメソッドを追加する。
toolbox.attr_bool: random.randint(0,1)
toolbox.individual: toolbox.attr_boolを使って01乱数 > tools.initRepeatによって100回繰り返し100要素のリストを作成(=個体生成)
toolbox.polulation: toolbox.individualによる個体生成を繰り返し、個体集団作成del toolbox toolbox = base.Toolbox() # Attribute generator toolbox.register("attr_bool", random.randint, 0.0, 1.0) # Structure initializers toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_bool, 100) toolbox.register("population", tools.initRepeat, list, toolbox.individual)続いて
algorithms.eaMuPlusLambdaによるGA実行に必要なメソッド
toolbox.evaluate(評価),toolbox.mate(交叉),toolbox.mutate(変異),toolbox.select(選別)を定義する。
deap.toolsを使って下のように書ける。toolbox.register("evaluate", evalOneMax) toolbox.register("mate", tools.cxTwoPoint) toolbox.register("mutate", tools.mutFlipBit, indpb=0.05) toolbox.register("select", tools.selNSGA2)1-4. statsおよび初期集団作成
pop: 初期集団
hof: ベスト個体の保存
stats: 集団の評価関数の統計値の保存"""遺伝的アルゴリズム設定 NGEN 世代まで 1世代の個体数 LAMBDA 次世代に引き継ぐ個体数 MU 交叉確率 CXPB 突然変異確率 MUTPB """ random.seed(4) NGEN = 10 MU = 50 LAMBDA = 100 CXPB = 0.7 MUTPB = 0.3 #個体集団作成 pop = toolbox.population(n=MU) hof = tools.HallOfFame(1) stats = tools.Statistics(lambda ind: ind.fitness.values) stats.register("avg", np.mean, axis=0) stats.register("std", np.std, axis=0) stats.register("min", np.min, axis=0) stats.register("max", np.max, axis=0)1-5.
algorithms.eaMuPlusLambdaによるGA実行pop, log = algorithms.eaMuPlusLambda(pop, toolbox, mu=MU, lambda_=LAMBDA, cxpb=CXPB, mutpb=MUTPB, ngen=NGEN, stats=stats, halloffame=hof)gen nevals avg std min max 0 50 [50.32] [4.71355492] [41.] [63.] 1 100 [56.] [2.02977831] [53.] [63.] 2 100 [59.3] [2.3] [57.] [68.] 3 100 [62.56] [2.03135423] [60.] [69.] 4 100 [65.58] [1.96051014] [63.] [72.] 5 100 [68.46] [1.52590956] [66.] [73.] 6 100 [70.4] [1.34164079] [69.] [74.] 7 100 [72.36] [1.10923397] [71.] [76.] 8 100 [74.06] [1.06602064] [73.] [77.] 9 100 [75.38] [0.79724526] [74.] [77.] 10 100 [76.36] [0.62481997] [76.] [78.]乱数でスタートしたので、初期個体の評価値は41~63におさまっている。
10世代では収束していないが、収束させるのが目的ではないので別にOK。2. 自分で初期集団を定義する方法
初期集団をある特定の値に固定して始めたい場合、公式ドキュメントの該当箇所を以下のように書き換える。
2-1. 自作初期集団の用意
自作初期集団=個体のリストを作成する。
例えば全て0で構成される個体のクローン集団L00から遺伝的アルゴリズムを始めたい場合は以下の様になる。MU = 50 # individual L0 = [0] * 100 # list of individuals L00 = [L0] * MU2-2. creatorの作成
1-2と同じ。
2-3. toolboxの作成
toolbox.populationに代わるメソッドtoolbox.population_guessを定義する。toolbox = base.Toolbox() # population_guessで使う関数 def initPopulation(pcls, ind_init, file): return pcls(ind_init(c) for c in file) # population_guessメソッドの作成 # creator.Individualによって各個体にFitnessを追加する toolbox.register("population_guess", initPopulation, list, creator.Individual, L00)# ここは一緒 toolbox.register("evaluate", evalOneMax) toolbox.register("mate", tools.cxTwoPoint) toolbox.register("mutate", tools.mutFlipBit, indpb=0.05) toolbox.register("select", tools.selNSGA2)2-4. 初期集団作成
hofやstatは同じなので省略
#初期個体生成をpopulation_guessに変える #pop = toolbox.population(n=MU) pop = toolbox.population_guess()2-5.
algorithms.eaMuPlusLambdaによるGA実行pop, log = algorithms.eaMuPlusLambda(pop, toolbox, mu=MU, lambda_=LAMBDA, cxpb=CXPB, mutpb=MUTPB, ngen=NGEN, stats=stats, halloffame=hof)gen nevals avg std min max 0 50 [0.] [0.] [0.] [0.] 1 100 [3.54] [3.04111822] [0.] [9.] 2 100 [8.3] [2.0808652] [6.] [15.] 3 100 [12.4] [2.45764115] [10.] [21.] 4 100 [16.38] [1.92758917] [14.] [22.] 5 100 [20.36] [2.10485154] [18.] [29.] 6 100 [24.52] [1.5651198] [22.] [29.] 7 100 [28.02] [1.74917123] [26.] [33.] 8 100 [31.3] [2.21133444] [29.] [39.] 9 100 [35.] [1.69705627] [33.] [40.] 10 100 [38.16] [1.71300905] [36.] [43.]評価値の最小値0、最大値0の集団 = 自作の初期集団からGAを始めることができた。
- 投稿日:2020-07-11T17:38:45+09:00
[Python]virtualenvの使い方
概要
Pythonのパッケージであるvirtualenvの使用方法を示す。
virtualenvとは
特定ディレクトリ以下をPythonの仮想環境としてセットアップするために用いられる。
これにより、プロジェクトごとにPythonのインタプリタ、パッケージ等のバージョンを個別に管理することができる。※「とあるプロジェクト開発時に特定パッケージのバージョンを上げたら、同パッケージを使用しているもう一方のプロジェクトでエラーを吐くようになった」みたいなことを防げる
基本的な使い方
virtualenvを入手
$ sudo pip install virtualenv
バージョン確認
$ virtualenv --version
ディレクトリ配下に仮想環境を構築
$ virtualenv <dir_name>
仮想環境を有効化
$ . <dir_name>/bin/activate
仮想環境を無効化
(dir_name)$ deactivate
仮想環境を抹消するときはディレクトリごと全消去でOK
$ rm -rf <dir_name>
- 投稿日:2020-07-11T15:56:38+09:00
【OpenCV】【Python】warpPolar()を使用して画像の極座標変換を行う
はじめに
画像を極座標変換したい時(アナログメータを解析したい時とか)のメモです。
下の例は時計ですが、、、?
どうやら、OpenCV3系にあったlinearPolar()やlogPolar()は非推奨となったようなので、warpPolar()を使用しています。
ソースコード
ソースコード全文は以下リポジトリを参照ください。
本投稿には抜粋したものを記載しています。
Kazuhito00/cv-warpPolar-example
cv-warpPolar-exampleは、OpenCVでの極座標変換/逆変換の実行例です。極座標への線形変換
# キュービック補間 + 外れ値塗りつぶし + 極座標へリニアマッピング flags = cv2.INTER_CUBIC + cv2.WARP_FILL_OUTLIERS + cv2.WARP_POLAR_LINEAR # 引き数:画像, 変換後サイズ(幅、高さ)、中心座標(X座標、Y座標)、半径、変換フラグ linear_polar_image = cv2.warpPolar(image, (300, 1000), (480, 270), 220, flags)
極座標からの逆変換
# 逆変換(リニア) flags = cv2.INTER_CUBIC + cv2.WARP_FILL_OUTLIERS + cv2.WARP_POLAR_LINEAR + cv2.WARP_INVERSE_MAP linear_polar_inverse_image = cv2.warpPolar(linear_polar_image, (960, 540), (480, 270), 220, flags)
対数極座標への線形変換
# キュービック補間 + 外れ値塗りつぶし + 対数極座標へリニアマッピング flags = cv2.INTER_CUBIC + cv2.WARP_FILL_OUTLIERS + cv2.WARP_POLAR_LOG # 引き数:画像, 変換後サイズ(幅、高さ)、中心座標(X座標、Y座標)、半径、変換フラグ log_polar_image = cv2.warpPolar(image, (300, 1000), (480, 270), 220, flags)
極座標からの逆変換
# 逆変換(対数) flags = cv2.INTER_CUBIC + cv2.WARP_FILL_OUTLIERS + cv2.WARP_POLAR_LOG + cv2.WARP_INVERSE_MAP log_polar_inverse_image = cv2.warpPolar(log_polar_image, (960, 540), (480, 270), 220, flags)
参考
OpenCV Geometric Image Transformations
以上。










- 投稿日:2020-07-11T15:10:01+09:00
ゼロから始めるLeetCode Day83 「102. Binary Tree Level Order Traversal」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day82「392. Is Subsequence」Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
102. Binary Tree Level Order Traversal
難易度はMedium。
前回と同じく問題集からの抜粋です。問題としては、バイナリツリーが与えられた場合、そのノードの値の階層順の横の同値をまとめたリストを返すアルゴリズムを設計してください。(すなわち、左から右へ、レベルごとに)というものです。
For example: Given binary tree [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 return its level order traversal as: [ [3], [9,20], [15,7] ]例はこんな感じ。
言いたいことは理解してもらえたと思います。解法
DFSで解きました。
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: def levelOrder(self, root: TreeNode) -> List[List[int]]: ans,level = [],0 self.dfs(root,level,ans) return ans def dfs(self,root,level,ans): if not root: return if len(ans) < level+1: ans.append([]) ans[level].append(root.val) self.dfs(root.left,level+1,ans) self.dfs(root.right,level+1,ans) # Runtime: 32 ms, faster than 86.02% of Python3 online submissions for Binary Tree Level Order Traversal. # Memory Usage: 14.2 MB, less than 43.09% of Python3 online submissions for Binary Tree Level Order Traversal.シンプルなDFSですね。
リストとして返すということが決まっているので、リストの長さをとって上げると階層の要素を上手く網羅できます。今回は慣れている深さ優先探索で解いてしまいましたが、discussにはBFSで解いた例や、キューを使って解いた解答もあったりと、個人の好きな解き方が現れそうな感じの問題ですね。
では今回はここまで。お疲れ様でした。
- 投稿日:2020-07-11T15:03:52+09:00
馬の過去成績データを機械学習の特徴量に加える具体的な実装方法
目的
機械学習で競馬予想して、回収率100%を目指す。
今回やること
前回はLightGBMで3着以内に入る馬を予測する機械学習モデルを作った。今回はそこに特徴量として「馬の過去成績」を加えたいのだが、実際にやろうとするとスクレイピングやデータ加工がなかなか大変。そこで、具体的にどういうコードを書いて実装すれば良いのかまとめたいと思う。
ソースコード
まずはnetkeiba.comから2019年に走る全馬の過去成績結果をスクレイピングする。netkeiba.comでは馬ごとにhorse_idが与えられていて、過去成績結果のページURLは、
「https://db.netkeiba.com/horse/(horse_id)」
という構造になっているので、前の記事で作ったscrape_race_results関数を加工して必要なhorse_idを(ついでに騎手idも)スクレイピングする。import time from tqdm.notebook import tqdm import requests from bs4 import BeautifulSoup import re import pandas as pd def scrape_race_results(race_id_list, pre_race_results={}): race_results = pre_race_results for race_id in tqdm(race_id_list): if race_id in race_results.keys(): continue try: url = "https://db.netkeiba.com/race/" + race_id df = pd.read_html(url)[0] # horse_idとjockey_idをスクレイピング html = requests.get(url) html.encoding = "EUC-JP" soup = BeautifulSoup(html.text, "html.parser") # horse_id horse_id_list = [] horse_a_list = soup.find("table", attrs={"summary": "レース結果"}).find_all( "a", attrs={"href": re.compile("^/horse")} ) for a in horse_a_list: horse_id = re.findall(r"\d+", a["href"]) #qiitaでバックスラッシュを使うとバグるので大文字にしてあります。 horse_id_list.append(horse_id[0]) # jockey_id jockey_id_list = [] jockey_a_list = soup.find("table", attrs={"summary": "レース結果"}).find_all( "a", attrs={"href": re.compile("^/jockey")} ) for a in jockey_a_list: jockey_id = re.findall(r"\d+", a["href"]) jockey_id_list.append(jockey_id[0]) df["horse_id"] = horse_id_list df["jockey_id"] = jockey_id_list race_results[race_id] = df time.sleep(1) except IndexError: continue except Exception as e: print(e) break return race_results前の記事を参考にしてDataFrame型に変換する。これで、必要なhorse_idのリストが得られる。
results = scrape_race_results(race_id_list) results = pd.concat([results[key] for key in results]) horse_id_list = results['horse_id'].unique()これを用いて、過去成績データをスクレイピングする。
def scrape_horse_results(horse_id_list, pre_horse_id=[]): horse_results = {} for horse_id in tqdm(horse_id_list): if horse_id in pre_horse_id: continue try: url = 'https://db.netkeiba.com/horse/' + horse_id df = pd.read_html(url)[3] if df.columns[0]=='受賞歴': df = pd.read_html(url)[4] horse_results[horse_id] = df time.sleep(1) except IndexError: continue except Exception as e: import traceback traceback.print_exc() print(e) break except: break return horse_results結構時間はかかるが、スクレイピングしたらまたDataFrame型にしてpickleファイルに保存する。
horse_results = scrape_horse_results(horse_id_list) for key in horse_results: horse_results[key].index = [key] * len(horse_results[key]) df = pd.concat([horse_results[key] for key in horse_results]) df.to_pickle('horse_results.pickle')次に、HorseResultsというクラスを作って、着順と賞金の平均をマージする関数を実装する。
class HorseResults: def __init__(self, horse_results): self.horse_results = horse_results[['日付', '着順', '賞金']] self.preprocessing() def preprocessing(self): df = self.horse_results.copy() # 着順に数字以外の文字列が含まれているものを取り除く df['着順'] = pd.to_numeric(df['着順'], errors='coerce') df.dropna(subset=['着順'], inplace=True) df['着順'] = df['着順'].astype(int) df["date"] = pd.to_datetime(df["日付"]) df.drop(['日付'], axis=1, inplace=True) #賞金のNaNを0で埋める df['賞金'].fillna(0, inplace=True) self.horse_results = df def average(self, horse_id_list, date, n_samples='all'): target_df = self.horse_results.loc[horse_id_list] #過去何走分取り出すか指定 if n_samples == 'all': filtered_df = target_df[target_df['date'] < date] elif n_samples > 0: filtered_df = target_df[target_df['date'] < date].\ sort_values('date', ascending=False).groupby(level=0).head(n_samples) else: raise Exception('n_samples must be >0') average = filtered_df.groupby(level=0)[['着順', '賞金']].mean() return average.rename(columns={'着順':'着順_{}R'.format(n_samples), '賞金':'賞金_{}R'.format(n_samples)}) def merge(self, results, date, n_samples='all'): df = results[results['date']==date] horse_id_list = df['horse_id'] merged_df = df.merge(self.average(horse_id_list, date, n_samples), left_on='horse_id', right_index=True, how='left') return merged_df def merge_all(self, results, n_samples='all'): date_list = results['date'].unique() merged_df = pd.concat([self.merge(results, date, n_samples) for date in tqdm(date_list)]) return merged_dfこれで、例えば過去5レースの成績を特徴量に加えたい場合次のように実装できる。
hr = HorseResults(horse_results) results_5R = hr.merge_all(results_p, n_samples=5)これで、一番右の2列に着順と賞金の直近5レースの平均が追加されているのがわかる。
詳しくは動画で解説しています↓
競馬予想で始めるデータ分析・機械学習



- 投稿日:2020-07-11T14:57:29+09:00
Python手遊び(AtCoder始めてみようかな?)
この記事、何?
AtCoderに興味を持ってブラウザでコード直接タイプしてみた。
で、当然、ローカルで動かして確認してからアップしたくなった。
だったら、半年後とかで自分に対し、「なんだ、こんなのも知らなかったんだ~」とかやりたくなるだろうからソースを保持しておきたいな、と。
(まあ、ローカルで、ね。)
だったらついでに、サンプル問題をコードの一部に持っておいて、テストしてOKになってからにしようか、と。
なので、動作モードを付けて、評価しやすいフレームワーク(?)チックな関数を作った。いきさつ
何やら面白そうなパズルがあると聞きまして・・・
いや、存在自体は知っていたんだけど、内容があまりにもマニアックな印象で、まあ、そういうのはちょっとね、と思っていたので見送ってました。
けど、ScratchでAtCoderに参加できると聞いて、「えっ?専門家御用達じゃないの?」と。。。じゃ、あたしでも参加できるかな、ということではじめてみた。
ちがう。始めてみようと思った。仕様概要?要件?
普通に単体起動できる1つの.pyファイルにする
引数なしで通常動作(提出用)とする
引数で1,2等を入力し、問題文で提示されたテストパタンの実施結果とOK/NGを出力するコード
例1: A - Welcome to AtCoder
■A - Welcome to AtCoder
https://atcoder.jp/contests/practice/tasks/practice_1# practice_1.py # 解答 def practice_1(lines): a = int(lines[0]) b, c = map(int, lines[1].split(' ')) s = lines[2] return [str(a+b+c) + ' ' + s] # 引数を取得 def get_input_lines(lines_count): lines = list() for _ in range(lines_count): lines.append(input()) return lines # テストデータ def get_testdata(pattern): if pattern == 1: lines_input = ['1', '2 3', 'test'] lines_export = ['6 test'] elif pattern == 2: lines_input = ['72', '128 256', 'myonmyon'] lines_export = ['456 myonmyon'] return lines_input, lines_export # 動作モード判別 def get_mode(): import sys args = sys.argv if len(args) == 1: mode = 0 else: mode = int(args[1]) return mode # 主処理 def main(): mode = get_mode() if mode == 0: lines_input = get_input_lines(3) else: lines_input, lines_export = get_testdata(mode) lines_result = practice_1(lines_input) for line_result in lines_result: print(line_result) if mode > 0: print(f'lines_input=[{lines_input}]') print(f'lines_export=[{lines_export}]') print(f'lines_result=[{lines_result}]') if lines_result == lines_export: print('OK') else: print('NG') # 起動処理 if __name__ == '__main__': main()(出力結果)
(base) ...>python practice_1.py 1 6 test lines_input=[['1', '2 3', 'test']] lines_export=[['6 test']] lines_result=[['6 test']] OK (base) ...>python practice_1.py 2 456 myonmyon lines_input=[['72', '128 256', 'myonmyon']] lines_export=[['456 myonmyon']] lines_result=[['456 myonmyon']] OK (base) ...>python practice_1.py 3 5 7 abc 15 abc例2: ABC173 : A - Payment
https://atcoder.jp/contests/abc173/tasks/abc173_a
# abc173_a.py # 解答 def abc173_a(lines): N = int(lines[0]) amari = N % 1000 if amari == 0: answer = 0 else: answer = 1000 - amari return [answer] # 引数を取得 def get_input_lines(lines_count): lines = list() for _ in range(lines_count): lines.append(input()) return lines # テストデータ def get_testdata(pattern): if pattern == 1: lines_input = ['1900'] lines_export = [100] elif pattern == 2: lines_input = ['3000'] lines_export = [0] return lines_input, lines_export # 動作モード判別 def get_mode(): import sys args = sys.argv if len(args) == 1: mode = 0 else: mode = int(args[1]) return mode # 主処理 def main(): mode = get_mode() if mode == 0: lines_input = get_input_lines(1) else: lines_input, lines_export = get_testdata(mode) lines_result = abc173_a(lines_input) for line_result in lines_result: print(line_result) if mode > 0: print(f'lines_input=[{lines_input}]') print(f'lines_export=[{lines_export}]') print(f'lines_result=[{lines_result}]') if lines_result == lines_export: print('OK') else: print('NG') # 起動処理 if __name__ == '__main__': main()(出力結果)
(base) >python abc173_a.py 1 100 lines_input=[['1900']] lines_export=[[100]] lines_result=[[100]] OK (base) >python abc173_a.py 2 0 lines_input=[['3000']] lines_export=[[0]] lines_result=[[0]] OK (base) >python abc173_a.py 2380 620 (例3: ABC173 : B - Judge Status Summary
https://atcoder.jp/contests/abc173/tasks/abc173_b
# abc173_b.py # 解答 def abc173_b(lines): labels = ['AC', 'WA', 'TLE', 'RE'] ns = [0, 0, 0, 0] for line in range(1, len(lines)): for i, label in enumerate(labels): if label == lines[line]: ns[i] += 1 answers = list() for i, label in enumerate(labels): answers.append(label + ' x ' + str(ns[i])) return answers # 引数を取得 def get_input_lines_1stline_as_n_lines(): lines = list() lines.append(input()) for _ in range(int(lines[0])): lines.append(input()) return lines # テストデータ def get_testdata(pattern): if pattern == 1: lines_input = ['6', 'AC', 'TLE', 'AC', 'AC', 'WA', 'TLE'] lines_export = ['AC x 3', 'WA x 1', 'TLE x 2', 'RE x 0'] elif pattern == 2: lines_input = ['10', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC'] lines_export = ['AC x 10', 'WA x 0', 'TLE x 0', 'RE x 0'] return lines_input, lines_export # 動作モード判別 def get_mode(): import sys args = sys.argv if len(args) == 1: mode = 0 else: mode = int(args[1]) return mode # 主処理 def main(): mode = get_mode() if mode == 0: lines_input = get_input_lines_1stline_as_n_lines() else: lines_input, lines_export = get_testdata(mode) lines_result = abc173_b(lines_input) for line_result in lines_result: print(line_result) if mode > 0: print(f'lines_input=[{lines_input}]') print(f'lines_export=[{lines_export}]') print(f'lines_result=[{lines_result}]') if lines_result == lines_export: print('OK') else: print('NG') # 起動処理 if __name__ == '__main__': main()(出力結果)
(base) >python abc173_b.py 1 AC x 3 WA x 1 TLE x 2 RE x 0 lines_input=[['6', 'AC', 'TLE', 'AC', 'AC', 'WA', 'TLE']] lines_export=[['AC x 3', 'WA x 1', 'TLE x 2', 'RE x 0']] lines_result=[['AC x 3', 'WA x 1', 'TLE x 2', 'RE x 0']] OK (base) >python abc173_b.py 2 AC x 10 WA x 0 TLE x 0 RE x 0 lines_input=[['10', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC', 'AC']] lines_export=[['AC x 10', 'WA x 0', 'TLE x 0', 'RE x 0']] lines_result=[['AC x 10', 'WA x 0', 'TLE x 0', 'RE x 0']] OK (base) >python abc173_b.py 5 AC AC WA TLE TLE AC x 2 WA x 1 TLE x 2 RE x 0感想
ま、とりあえずこれで。Bestにするより始めてみよう、という姿勢で。
多分、続けてるといろいろと手を加えると思うけど。とりあえず、WelcomeはそのままペタッとやってACになったので今日からこれを張りまくろう。
と、ABC173はA~Fまで目を通したけど、Dはいまいちピンとこなかった。Fはややこしくて読む気がしなかった。Eはコード書いてみたら地味にめんどくなって中断しちゃった。
まあ、D以降はなれてからでいいかな。Cもだいぶてこずったしね。論理的な組み立てや思考整理で我流がBetterにならないかと思っているところなので、課題に取り組んで、解説動画を見る流れを少しとってみますか、という感じですかね・・・続けば。。。
- 投稿日:2020-07-11T14:10:41+09:00
Pythonで画像を読み込み⇒別名再保存するツールを作った件
概要
友人「大量の画像ファイルが入ったフォルダから、適当な画像ファイルをピックアップして、フォルダと同じ階層にコピーしたうえで、画像ファイルの名前をフォルダ名に変更するツール作って」
私「おかのした」仕様
1.こんなフォルダがあったとします
「KizunaAI」「MiraiAkari」等の各フォルダには大量の画像が入っており、001~のようなファイル名が付いています
対象フォルダimages ├ KizunaAI │ ├ 001.jpg │ └ ....ipg │ ├ MiraiAkari │ ├ 001.jpg │ └ ....ipg └ ....2.それをこうします
各画像フォルダから適当な画像ファイルをコピーし、フォルダと同じ階層に置いたうえで、ファイル名を所属していたフォルダの名前にリネームします。
対象フォルダimages ├ KizunaAI │ ├ 001.jpg │ └ ....ipg ├ KizunaAI.jpg ├ MiraiAkari │ ├ 001.jpg │ └ ....ipg ├ MiraiAkari.jpg └ ....以上!!!!
実装
ひとまず手持ちのAnaconda環境で実装しました。
私「ずいぶん改まって頼んで来たからどんな深刻な内容かと思いきや」
main.pyfrom PIL import Image import os, glob rootpath = "./images" files = os.listdir(rootpath) #rootpath配下の全ディレクトリを取得 dirs = [f for f in files if os.path.isdir(os.path.join(rootpath, f))] #せっかくなのでコンソールに表示 print(dirs) # ['dir1', 'dir2'] #全ディレクトリに対して実行 for dir in dirs : #全ファイルをスキャン files = glob.glob(rootpath +"/"+ dir + "/*.*") #拡張子を引っこ抜く targetFile = files[0] root, ext = os.path.splitext(targetFile) #画像オープン img = Image.open(targetFile) #リネームしてルートパス直下に保存 img.save(rootpath + '/' + dir + ext)EXEにする
Anacondaでプログラムを実行するのはなかなか面倒くさいので、EXE化してワンクリックで動くようします
1.Pyinstallerのインストール
Anaconda の仮想環境ごとEXEにしてくれる凄いツールです。つまりこいつがあればPython環境がない人でも動かせるらしいです。
1KBもないコードに対して300MB越えのEXEを吐き出す困ったちゃんですが、便利なので許します。AnacondaPronptconda install -c conda-forge pyinstaller余談ですが私はcondaでインストールするほうが好きです。
2.EXEにする
あくしろよ
AnacondaPronptpyinstaller main.py --onefile私「できた(バグ無しとは言ってない)」
友人「やりますねぇ!」その他
友人「フォルダ名に"[]"あると対応してくれないんですがそれは」
私「ファ!?」
友人「まあちょっとしかないからここは手動でやるわ」
私「ぐう聖」暇があったらこの不具合対応版も記事にします

- 投稿日:2020-07-11T14:10:41+09:00
Pythonで画像を読み込み⇒別名再保存するツールを作った話
概要
友人「大量の画像ファイルが入ったフォルダから、適当な画像ファイルをピックアップして、フォルダと同じ階層にコピーしたうえで、画像ファイルの名前をフォルダ名に変更するツール作って」
私「おかのした」仕様
1.こんなフォルダがあったとします
「KizunaAI」「MiraiAkari」等の各フォルダには大量の画像が入っており、001~のようなファイル名が付いています
対象フォルダimages ├ KizunaAI │ ├ 001.jpg │ └ ....ipg │ ├ MiraiAkari │ ├ 001.jpg │ └ ....ipg └ ....2.それをこうします
各画像フォルダから適当な画像ファイルをコピーし、フォルダと同じ階層に置いたうえで、ファイル名を所属していたフォルダの名前にリネームします。
対象フォルダimages ├ KizunaAI │ ├ 001.jpg │ └ ....ipg ├ KizunaAI.jpg ├ MiraiAkari │ ├ 001.jpg │ └ ....ipg ├ MiraiAkari.jpg └ ....以上!!!!
実装
ひとまず手持ちのAnaconda環境で実装しました。
私「ずいぶん改まって頼んで来たからどんな深刻な内容かと思いきや」
main.pyfrom PIL import Image import os, glob rootpath = "./images" files = os.listdir(rootpath) #rootpath配下の全ディレクトリを取得 dirs = [f for f in files if os.path.isdir(os.path.join(rootpath, f))] #せっかくなのでコンソールに表示 print(dirs) # ['dir1', 'dir2'] #全ディレクトリに対して実行 for dir in dirs : #全ファイルをスキャン files = glob.glob(rootpath +"/"+ dir + "/*.*") #拡張子を引っこ抜く targetFile = files[0] root, ext = os.path.splitext(targetFile) #画像オープン img = Image.open(targetFile) #リネームしてルートパス直下に保存 img.save(rootpath + '/' + dir + ext)EXEにする
Anacondaは少々面倒くさいので、EXE化してワンクリックで動くようします
1.Pyinstallerのインストール
Anaconda の仮想環境ごとEXEにしてくれる凄いツールです。つまりこいつがあればPython環境がない人でも動かせるらしいです。
1KBもないコードに対して300MB越えのEXEを吐き出す困ったちゃんですが、便利なので許します。AnacondaPronptconda install -c conda-forge pyinstaller余談ですが私はcondaでインストールするほうが好きです。
2.EXEにする
あくしろよ
AnacondaPronptpyinstaller main.py --onefile私「できた(バグ無しとは言ってない)」
友人「やりますねぇ!」その他
友人「フォルダ名に"[]"あると対応してくれないんですがそれは」
私「ファ!?」
友人「まあちょっとしかないからここは手動でやるわ」
私「ぐう聖」暇があったらこの不具合対応版も記事にします
- 投稿日:2020-07-11T14:02:32+09:00
Pythonで1から10までの数字の配列のいろいろな作成方法。
Pythonで1から10までの数字の配列を作成する方法を書いていきます。
よろしくおねがします。まず、基本的な配列の方法。
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]つぎに、for文を使った方法。
a = [] for i in range(1, 11): a.append(i)a = [0]*10 for i in range(10): a[i] = i+1whileを使った方法。
a = [] i = 1 while len(a) < 10: a.append(i) i += 1a = [0]*10 i = 0 while not all(a): a[i] = i+1 i += 1最後に、内包表記の方法。
a = [i for i in range(1, 11)]以上です。
ありがとうございました。
- 投稿日:2020-07-11T13:56:34+09:00
【Pyrhon/Selenium】 XPathとか
Seleniumでスクレイピングする際に押さえておいたら役立った知識を整理しておきます。
XPath
Element を取得する際に必要になります。
イメージは下記の図がわかりやすいです。XPath Helper
XPATHを特定するのに非常に便利な拡張機能があるので、記載しておきます。
XPath HelperShiftキーを押しながら、カーソルを持っていくことで
XPathを取得することができます。
Chrome拡張!XPath Helperのインストールと使い方 | WATLAB -Python, 信号処理, AI-省略する
XPathは下記のように省略することもできます。driver.find_elements(By.XPATH,'//div[@class="products"]')Webdriver メソッド
下記の記事をみておけば問題ないと思います。
Selenium webdriverよく使う操作メソッドまとめ - Qiita自分がよく使うメソッドを下記に整理しておきます。
driver.get
# 使用するURLの指定 driver.get('url')driver.back
# 一つ前のページに戻る driver.back()driver.quit
ウィンドウを閉じることが可能です。
driver.quit()driver.execute_script
これも結構使用します。
driver.execute_script('javascript:smarty.product.pager(2);')PythonでSeleniumを扱ってhtmlに埋め込まれたJavaScriptを実行 - Qiita
driver.find_elements
上記でも紹介した通り、下記のように使用することができます。
driver.find_elements(By.XPATH,'//div[@class="p-products"]')


- 投稿日:2020-07-11T13:40:34+09:00
剛体球衝突アルゴリズムが少し分かるようになる記事
LS-DYNAのCorpuscular Particle Method (CPM)を使用しているのですが、複数種ガスの混合時の粒子数の比の影響(書いていいのか迷うので内容省略します)を考察をしたいと思い、かなり目標から手前の内容ですが、剛体球衝突について勉強しました。
何番煎じかわかりませんが(Qiitaでも@yotapoonさん、@NatsukiLabさんがそれぞれ記事を書かれています)、自分なりに理解したことをまとめたいと思い書いています。1. 剛体球/円盤衝突アルゴリズムとは
下図のようなシミュレーションを行う手法です。(図はWikipediaのKinetic theory of gasesより引用) 調べてみるとゲームプログラミング等でも使用されているようです。
気体分子運動論の解析でも使用されており、wikipediaのBaltzmann distributionの記事では粒子の衝突の結果、粒子の速度分布がMaxwell-Boltzmann分布に収束してゆくことが確認できます。
自分のモチベーションとしては、気体分子の速度分布を算出し、ガスの混合時に各ガスの運動エネルギーがどう変化してゆくか理解したいということがあります。
2. 前提と数学的理解
まず、下記の2つが前提となります。特に大きさを持つというのがランダムな運動を実現するキモとなります。
1) 球/円盤は直径・速度・質量を持つ
2) 球/円盤は等速度直線運動をする=衝突以外で速度は変化しないまた、本記事はthermosimというgithubにアップされていたソースを対象に解説します。
このソースは、いわゆるTime-Step型のシミュレーションを採用しています。(こちらが詳しいです。https://qiita.com/NatsukiLab/items/476e00fea40b86ece31f)
なお、参考文献で示した記事でも同様/類似の手法が記載されていたため、一般的な手法と言えそうです。2.1.衝突判定
粒子i. jの時間$t$での座標を$r(t)$, 速度を$v(t)$,質量を$m$、直径を$d$とします。
まず、下記の式で、現時点で既に衝突している粒子の一覧を取得します。|r_i(t) - r_j(t)|\leq\frac{1}{2}(d_i+d_j)既に衝突しているというのがキモで、現在のステップ(時間$t$)で接触した粒子を接触前まで"巻き戻し"、巻き戻された時点での速度と座標から、速度ベクトルを更新します。(前ステップでは接触していないことは保証されています)
衝突している粒子がわかったら、次はいつ衝突したのかを計算します。
まず、相対速度、相対位置ベクトルを下記のように定義します。なお、時間$t=0$を前回のステップの時間とします。v_{ij}=v_i-v_j\\ r_{ij}=r_i(0)-r_j(0)\\粒子は等速直線運動をするので、前ステップから衝突までの時間を$t_c$として、衝突時の座標は下記のように示されます。
r_i(t_c)=r_i(0)+v_i(t)・t_c\\ r_j(t_c)=r_j(0)+v_j(t)・t_c\\以上から、$|r_i(t) - r_j(t)|=\frac{1}{2}(d_i+d_j)$となるときの時間$t_c$は下記のように示されます。(実際、前ステップの時間を0としているので、$tc$は前ステップから衝突までの時間差分と同じ意味です。)
t_c=\frac{-r_{ij}・v_{ij}-\sqrt{(r_{ij}・v_{ij})^2-v_{ij}^2(r_{ij}^2-0.25(d_i+d_j)^2)}}{v_{ij}^2}単純に上記は$|r_i(t) - r_j(t)|=\frac{1}{2}(d_i+d_j)$の両辺を2乗すると、$t_c$についての2次方程式となるので、解の方程式から導かれます。なお、解は2つあるのですが、+の方の解(大きい方の解)は粒子が貫通後に接触するまでの時間です。
2.2衝突後の速度の更新
衝突前後でも物体の重心は等速直線運動をする性質を利用して、重心系の速度とi,jの相対速度を利用して、衝突後の速度を算出します。
(ここではプログラムに合わせて説明していますが、参考文献の記事の方が直感的な理解がしやすいです)衝突前後で運動量が保存されるので、
m_iv_i+m_jv_j=m_iv_i'+m_jv_j'となります。反発係数を$e$とすると、
e=-\frac{v_i'-v_j'}{v_i-v_j}となるので、これらより、
v_i'=V-e\frac{m_j}{m_i+m_j}v_{ij}\\ v_j'=V+e\frac{m_i}{m_i+m_j}v_{ij}\\ここで、
V=\frac{m_iv_i+m_jv_j}{m_i+m_j}で、重心の速度を意味します。
なお、完全弾性衝突時($e=1$)の関係の図は下記のようになります。
*
dvfとdvは3章でのソースコード中の変数です。コードだとわかりにくい。。3. 実装 (thermosimのthermosim.py/def collideより)
3.1. 衝突判定
thermosim.pyfrom scipy.spatial.distance import squareform,pdist # Find colliding particles D = squareform(pdist(self.r)) ind1, ind2 = np.where(D < .5*np.add.outer(self.d, self.d)) unique = (ind1 < ind2) ind1 = ind1[unique] ind2 = ind2[unique]self.rとself.dにはそれぞれ座標と直径を収めたnp.arrayで、
squareform(pdist(self.r))で現時点での粒子間の距離を、.5*np.add.outer(self.d, self.d)で粒子が接するときの距離を算出します。それぞれ、粒子の数をnとするとnxnのarrayを返します。
unique = (ind1 < ind2)としているのは、上三角の成分(対角は除く)のみが必要な情報なためです。3.2. 衝突時の座標の算出
thermosim.pyru = np.dot(dv, dr)/ndv ds = ru + sqrt(ru**2 + .25*(d1+d2)**2 - np.dot(dr, dr)) if np.isnan(ds): 1/0 # Time since collision dtc = ds/ndv # New collision parameter drc = dr - dv*dtc
dtcは2.1の$-t_c$と同じ意味かつ、同じ算出方法です。drcが衝突時の相対位置ベクトルのはず。速度の更新
thermosim.py# Center of mass velocity vcm = (m1*v1 + m2*v2)/(m1+m2) # Velocities after collision dvf = dv - 2.*drc * np.dot(dv, drc)/np.dot(drc, drc) v1f = vcm - dvf * m2/(m1+m2) v2f = vcm + dvf * m1/(m1+m2)
dvfが何を意味するかは2章の衝突時の図を参照。座標の更新
thermosim.py# Backtracked positions r1f = r1 + (v1f-v1)*dtc r2f = r2 + (v2f-v2)*dtcこれ、
dtcでいいのか?ちょっと考え中です。参考文献
- https://github.com/pierrethibault/thermosim
- 剛体球の大規模数値計算をしたい人生だった, @NatsukiLab
- 大規模剛体球系の高速シミュレーション, @yotapoon
- 剛体円盤分子動力学シミュレーションにおける大規模計算と高速化の手法, 礒部 雅晴, 物性研究, 72(1), pp.21-41,1999-04
- 運動量保存の法則が成り立つ場合の重心の運動
- 2つのボールの衝突


- 投稿日:2020-07-11T13:11:13+09:00
Amazon Rekognitionによる同一人物検出
前回に引き続き、Amazon Rekognitonを使って同一人物の検出を行ってみました。
概要
Amazon Rekognitionのcompare_facesというAPIを使って同一人物の検出を行います。compare_facesに2つの画像を入力するのですが、1つ目が検出したい人物の映った画像、2つ目が検出対象の画像となります。
実行環境
OS:Windows10
言語:Python3.7事前準備
AWS CLI(aws configure)にて、以下の認証情報をセットしておきます。
AWS Access Key ID
AWS Secret Access Key
Default region name
Default output formatソースコード(face_compare.py)
face_compare.pyimport boto3 import sys from PIL import Image,ImageDraw # 引数のチェック if len(sys.argv) != 3: print('2つの画像ファイルを引数に指定してください。') exit() # Rekognitionのクライアントを作成 client = boto3.client('rekognition') # 画像ファイル2つを引数としてcompare_facesを実行 with open(sys.argv[1],'rb') as source: with open(sys.argv[2],'rb') as target: response = client.compare_faces(SourceImage={'Bytes':source.read()},TargetImage={'Bytes':target.read()}) # 同一人物が検出されない場合は処理終了 if len(response['FaceMatches'])==0: print('同一人物は検出されませんでした。') else: # 2つ目の画像ファイルを元に、矩形セット用の画像ファイルを作成 img = Image.open(sys.argv[2]) imgWidth,imgHeight = img.size draw = ImageDraw.Draw(img) # 検出された顔の数分、矩形セット処理を行う for faceMatch in response['FaceMatches']: # BoundingBoxから顔の位置・サイズ情報を取得 box = faceMatch['Face']['BoundingBox'] left = imgWidth * box['Left'] top = imgHeight * box['Top'] width = imgWidth * box['Width'] height = imgHeight * box['Height'] # 矩形の位置・サイズ情報をセット points = ( (left,top), (left + width,top + height) ) # 顔を矩形で囲む draw.rectangle(points,outline='lime') # 画像ファイルを保存 img.save('detected_' + sys.argv[2]) # 画像ファイルを表示 img.show()簡単な解説
概略としては以下のような処理を行っています。
①プログラム実行時の引数からRekognitionに入力する2つの画像ファイルを取得する。
②上記①の画像ファイルを引数としてRekognitionのcompare_facesを実行する。
③Rekognitionから返却されるJsonのFaceMatches・BoundingBoxから、認識された顔の位置・サイズ情報を取得する。
④上記③から矩形付きの画像ファイルを作成し、表示する。実行結果
コマンド
python face_compare.py ichiro1.jpg ichiro2.jpg入力画像1(ichiro1.jpg)
入力画像2(ichiro2.jpg)
出力画像(detected_ichiro2.jpg)
イチロー選手を検出してくれました。
まとめ
前回のdetect_facesと同様に、APIを使って簡単に画像認識を行うことができます。compare_facesを使うことで、大量の画像から探したい人物が映っているものを簡単に抽出することができると思います。AWSのサイトによると、日本では新聞社や写真サービスの会社などで使われているようです。



- 投稿日:2020-07-11T12:49:40+09:00
カラーイラストから線画っぽいものを生成するwebサービスを公開しました
Django + Herokuの勉強です
カメラアプリのフィルタでもいい気がしてきましたファイル選択していいかんじに押せばなんかでます
http://senga-generator.herokuapp.comopencvで、読み込んだ画像のグレースケールとdilationさせたやつとの差分を取ります
あと不具合がだいぶ起きます
以下サンプルです
サンプルとして借用したイラスト
https://seiga.nicovideo.jp/seiga/im8043526
https://seiga.nicovideo.jp/seiga/im8106524
https://seiga.nicovideo.jp/seiga/im6232152
@nocopyrightgirl



- 投稿日:2020-07-11T12:39:22+09:00
簡単な学習 Python 3
初心者がPythonをより速く、より速く学ぶために一歩一歩
https://www.amazon.co.jp/dp/B08CMHMZVS
Pythonは強力なプログラミング言語です。 習得が簡単で楽しいPython。 この本はPythonを生き生きとさせ、風変わりでフルカラーのイラストが物事をより明るい面に保ちます。 オブジェクト指向プログラミングを整理し、クラスとメソッドでコードを再利用する方法、ループや条件ステートメントなどの制御構造を使用する方法、Pythonでシェイプとパターンを描画する方法、キャンバスでゲーム、アニメーション、グラフィックを作成する方法を学びます。
ほんの少しの時間で、Pythonを使用して設計および開発する方法を学ぶことができます。 この本の各レッスンは、わかりやすいステップバイステップのアプローチを使用して、前のレッスンに基づいており、基本を基礎から学ぶことができます。 明確な指示と実践的で実践的な例は、Pythonと対話する方法を示しています。
この本は、Pythonの主なスキルとコーディングを理解するための段階的なガイダンスを教えています。 本の終わりまでに、独自のアプリケーションとゲームを作成できます。 あなたはそれを簡単かつ迅速に学びます。

- 投稿日:2020-07-11T12:35:24+09:00
【備忘】AI・機械学習・python関連のWebサイト【随時更新】
初めに
- pythonやら機械学習の勉強を開始して8カ月程度が経って、素人に毛が生えた程度の私が過去勉強の際に参考になったウェブサイトをご紹介します。
- 網羅性は皆無ですが、自身のブックマークの整理も兼ねて記事にしたいと思います。
Blogs
人工知能ブログ
DeepAgeが運営しているWebサイト。
基礎的な情報から、Tensorflowの使い方まで色々と載ってます。Let'sプログラミング
Buzzword Inc.が運営しているブログ。様々な言語の基本的な内容がきれいに纏まっていて初心者の方(含む自分)にはわかりやすいサイトだと思います。米国データサイエンティストのブログ
Twitterでも広く情報発信をしてくださっている、かめ@米国データサイエンティストさんのブログ。データサイエンティストになりたい人や、米国で働きたい人にとっては参考になる情報ばかりです。note.nkmk.me
pythonの勉強をしていてわからないときにググると、必ずと言っていいほど上位に出てくる素晴らしいサイト。基本的なコードの書き方や、「あの操作、どうするんだっけ?」的な状況の時に非常に役に立ちます。
(このBlogに書いてあることを写経するだけでも結構な勉強になるかと思います。)予備校のノリで学ぶ「大学の数学・物理」
いわずと知れた人気教育系YouTuber:たくみさんのHP。機械学習やDeep Learningを勉強する時に必須な線形代数や統計を勉強する際に非常に役に立ちます。まだまだ、素晴らしいサイトは多くありますが、気が向いたときに随時更新していきたいと思います。
- 投稿日:2020-07-11T12:20:02+09:00
atcoder-cliでpypy3の提出を楽にする
はじめに
みなさんこんにちは.
少し前に茶色になったばかりのatcoder初心者のjacky です.
僕はatcoderでpypy3を使用しているのですが,atcoder-cliを使って提出の簡易化を試した時に少しだけ迷ったので情報共有します.
atcoder-cliとは?
atcoder-cliとは,atcoderに参加する時に,
- テストケースのダウンロード
- テンプレートの作成
- テストの実行
- 提出
あたりをブラウザではなくcli(コマンドライン)でやってしまおうというツールです.
いちいちブラウザ上でテストケースをコピペして,コードテストのタブを開いて...とかやってると無駄に時間を食ってしまうので,
それらの処理を楽にしてくる便利なツールです.
このツール自体の説明やインストール方法は,すでにたくさん良い記事があるのでそちらをご覧ください.参考
- コマンドラインツールatcoder-cliを公開しました(作者様のブログ)
- atcoder-cli チュートリアル(作者様のブログ)
- atcoder初心者こそ環境構築しよう!(atcoder-cli,online-judge-toolsのインストール、使い方)(Qiita)
- AtCoder のディレクトリ作成・サンプルケースのテスト・提出を自動化する。atcoder-cli と online-judge-tools(Qiita)
atcoder-cliを使ってpypy3の提出を行う上記の記事を一通り読んだ人であれば,提出は以下のコマンドで行うことが分かると思います(pypyでの提出を想定)
acc sすると,このような出力になると思います.
[x] PyPy is available for Python interpreter [*] chosen language: 4006 (Python (3.8.2)) [!] the problem "https://atcoder.jp/contests/abc170/tasks/abc170_d" is specified to submit, but no samples were downloaded in this directory. this may be mis-operation [x] sleep(3.00) Are you sure? Please type "abcd"これは要するに,
- pypyが使えるで(使わんけど)
- Python (3.8.2) で提出するで
- このディレクトリにサンプルケースがダウンロードされてないし,操作ミスちゃうか?
- 3秒待ったるわ
- 提出するなら
abcdと入力してやというメッセージです.(3個めのメッセージ(操作ミスちゃうか)は,ほんとに操作ミスではないかぎり無視して構いません.)
ここに書いてあるとおり,普通に提出コマンドを実行すると,
pythonでの解答として提出されてしまいます.
これをPyPyで提出するには,以下のようなコマンドにします.acc s main.py -- --guess-python-interpreter pypyこのときの出力は,
[x] PyPy is available for Python interpreter [x] both Python2 and Python3 are available for version of Python [x] use: 3 [*] chosen language: 4047 (PyPy3 (7.3.0)) [!] the problem "https://atcoder.jp/contests/abc170/tasks/abc170_d" is specified to submit, but no samples were downloaded in this directory. this may be mis-operation [x] sleep(3.00) Are you sure? Please type "abcd"となり,4行目を見るときちんと
PyPy3が選択されていることがわかります.
これで提出を実行すると,きちんとPyPy3での提出になります.詳細は,以下のissueに情報があります.
How can I use PyPy as default language?コマンド打つのめんどくさくない?
一応これで提出自体は出来るようになりましたが,このコマンド打つのめんどくさいし,もっと楽に提出したいです.
僕は楽にするために,VScodeのタスクランナー機能を使っています.
タスクランナー機能についてはあたりを見て下さい.
簡単に言うと,プロジェクトディレクトリ直下に,.vscode/tasks.jsonとしてタスクを記述しておくと,楽に実行できる機能です.僕は以下のような
tasks.jsonを作っています.{ // See https://go.microsoft.com/fwlink/?LinkId=733558 // for the documentation about the tasks.json format "version": "2.0.0", "tasks": [ { "label": "test", "type": "shell", "command": "oj", "args": ["t","-c","'pypy3 main.py'"], "options": {"cwd": "${fileDirname}"} }, { "label": "submit", "type": "shell", "command": "acc", "args": ["s","main.py","--","--guess-python-interpreter","pypy"], "options": {"cwd": "${fileDirname}"} }, ] }
tasksの中の,1個めがテスト実行用のタスクで,2個めが提出用のタスクです.
両方に共通している,"options": {"cwd": "${fileDirname}"}の部分の意味は,これらのコマンドを実行する場所として,今開いているファイルのあるディレクトリを指定する,ということです.
こうしておくことで,コマンドパレットを開いてから楽にタスクを実行できます.
(Command Palette (⇧⌘P))最後に
これで
atcoderライフが快適になり,レートも爆上がりです!!!!!
- 投稿日:2020-07-11T12:20:02+09:00
atcoder-cliでpypyの提出を楽にする(python)
はじめに
みなさんこんにちは.
少し前に茶色になったばかりのatcoder初心者のjacky です.
僕はatcoderでpypy3を使用しているのですが,atcoder-cliを使って提出の簡易化を試した時に少しだけ迷ったので情報共有します.
atcoder-cliとは?
atcoder-cliとは,atcoderに参加する時に,
- テストケースのダウンロード
- テンプレートの作成
- テストの実行
- 提出
あたりをブラウザではなくcli(コマンドライン)でやってしまおうというツールです.
いちいちブラウザ上でテストケースをコピペして,コードテストのタブを開いて...とかやってると無駄に時間を食ってしまうので,
それらの処理を楽にしてくる便利なツールです.
このツール自体の説明やインストール方法は,すでにたくさん良い記事があるのでそちらをご覧ください.参考
- コマンドラインツールatcoder-cliを公開しました(作者様のブログ)
- atcoder-cli チュートリアル(作者様のブログ)
- atcoder初心者こそ環境構築しよう!(atcoder-cli,online-judge-toolsのインストール、使い方)(Qiita)
- AtCoder のディレクトリ作成・サンプルケースのテスト・提出を自動化する。atcoder-cli と online-judge-tools(Qiita)
atcoder-cliを使ってpypy3の提出を行う上記の記事を一通り読んだ人であれば,提出は以下のコマンドで行うことが分かると思います(pypyでの提出を想定)
acc sすると,このような出力になると思います.
[x] PyPy is available for Python interpreter [*] chosen language: 4006 (Python (3.8.2)) [!] the problem "https://atcoder.jp/contests/abc170/tasks/abc170_d" is specified to submit, but no samples were downloaded in this directory. this may be mis-operation [x] sleep(3.00) Are you sure? Please type "abcd"これは要するに,
- pypyが使えるで(使わんけど)
- Python (3.8.2) で提出するで
- このディレクトリにサンプルケースがダウンロードされてないし,操作ミスちゃうか?
- 3秒待ったるわ
- 提出するなら
abcdと入力してやというメッセージです.(3個めのメッセージ(操作ミスちゃうか)は,ほんとに操作ミスではないかぎり無視して構いません.)
ここに書いてあるとおり,普通に提出コマンドを実行すると,
pythonでの解答として提出されてしまいます.
これをPyPyで提出するには,以下のようなコマンドにします.acc s main.py -- --guess-python-interpreter pypyこのときの出力は,
[x] PyPy is available for Python interpreter [x] both Python2 and Python3 are available for version of Python [x] use: 3 [*] chosen language: 4047 (PyPy3 (7.3.0)) [!] the problem "https://atcoder.jp/contests/abc170/tasks/abc170_d" is specified to submit, but no samples were downloaded in this directory. this may be mis-operation [x] sleep(3.00) Are you sure? Please type "abcd"となり,4行目を見るときちんと
PyPy3が選択されていることがわかります.
これで提出を実行すると,きちんとPyPy3での提出になります.詳細は,以下のissueに情報があります.
How can I use PyPy as default language?コマンド打つのめんどくさくない?
一応これで提出自体は出来るようになりましたが,このコマンド打つのめんどくさいし,もっと楽に提出したいです.
僕は楽にするために,VScodeのタスクランナー機能を使っています.
タスクランナー機能についてはあたりを見て下さい.
簡単に言うと,プロジェクトディレクトリ直下に,.vscode/tasks.jsonとしてタスクを記述しておくと,楽に実行できる機能です.僕は以下のような
tasks.jsonを作っています.{ // See https://go.microsoft.com/fwlink/?LinkId=733558 // for the documentation about the tasks.json format "version": "2.0.0", "tasks": [ { "label": "test", "type": "shell", "command": "oj", "args": ["t","-c","'pypy3 main.py'"], "options": {"cwd": "${fileDirname}"} }, { "label": "submit", "type": "shell", "command": "acc", "args": ["s","main.py","--","--guess-python-interpreter","pypy"], "options": {"cwd": "${fileDirname}"} }, ] }
tasksの中の,1個めがテスト実行用のタスクで,2個めが提出用のタスクです.
両方に共通している,"options": {"cwd": "${fileDirname}"}の部分の意味は,これらのコマンドを実行する場所として,今開いているファイルのあるディレクトリを指定する,ということです.
こうしておくことで,コマンドパレットを開いてから楽にタスクを実行できます.
(Command Palette (⇧⌘P))最後に
これで
atcoderライフが快適になり,レートも爆上がりです!!!!!
- 投稿日:2020-07-11T12:04:29+09:00
Python の仮想環境からの脱出 〜自分の作った仮想環境に閉じ込められかけた話〜
前枠
久しぶりに開発しようとMac開いたら,結構前に作った仮想環境に勝手に入ってからしばらく出られなかった.
調べてみると,コマンドが違った模様.環境
- macOS Catalina 10.15.4
- conda 4.6.11
どう解決したのか
入ったとき
(base)$仮想環境から出たい
(base)$ deactivate bash: deactivate: command not found (base)$ source deactivate bash: deactiate: No such file or directoryダメらしい.
調べてみると同じような症状の人がいた.
(base)$ conda deactivate $脱出完了
後枠
仮想環境はまだ慣れない….
使っていくしかないかな.
- 投稿日:2020-07-11T11:14:29+09:00
Cython チュートリアル: shared_ptr の使い方
概要
cythonでC++のコードをラップしてpythonから呼べるようにする、というような内容でいろいろ書きましたが、
今回はcythonでのshared_ptrの書き方を少し解説します。少しだけ癖がありますが、慣れてしまえば大丈夫です。
コードの構成
いつものように、
C++ で書かれたクラスC++ で書かれた関数を
cythonでラップすることで、pythonから呼べるような構成にします。ここでは例として、
C++がTest_CPPというクラスを持っている。C++のTest_CPPがtest_function というメソッドを持っているということにします。
実際のコード
おそらく解説されるよりコードをみた方がわかりやすいと思います。
Py_Test_CPPが、Test_CPPをラップしているクラスになります。test.pyxfrom cython.operator cimport dereference as deref from libcpp.memory cimport shared_ptr, make_shared cdef class Py_Test_CPP: cdef shared_ptr[Test_CPP] ptr def __cinit__(self, int arg1): self.ptr = make_shared[Test_CPP](arg1) def test_function(self): return deref(self.ptr).test_function()必要なもののインポート
まず、
dereference、shared_ptr, make_sharedを使うのでインポートしています。C++側のオブジェクトの参照のしかた
この際、プロパティとして
C++側のクラスオブジェクトのポインタを保持している必要がありましたが、
今回はそれをcdef shared_ptr[Test_CPP] ptrと書いてshared_ptrとして保持しています。コンストラクタ
cython側のコンストラクタである__cinit__では、
make_sharedをself.ptr = make_shared[Test_CPP](arg1)
のように使うことで、cython側のself.ptrをシェアドポインタにしています。関数を呼ぶ
def test_function(self)のところで、C++側の関数test_functionをラップしていますが、
その時はderef(self.ptr)として、実体にアクセスし、そこからC++側の関数を呼ぶことでうまくいきます。まとめ
cythonでshared_ptrを使う時の書き方について備忘録的にまとめた。今回はこの辺で。
おわり。
- 投稿日:2020-07-11T11:14:12+09:00
setuptools でサクッと自作モジュールを作る(python)
概要
自身で何か開発をしていて、クラスや関数をモジュール化することがあるかもしれません。
setuptoolsを使ってsetup.pyを書いてビルドすることによって、test.pyimport mylibみたいなことができるようになりますが、モジュール化するところで
最低限必要なことを備忘録的にまとめたいと思います。
これを準備すればほんとにすぐにモジュール化できます。必要最低限なことだけ書くので、細かいところは公式ドキュメント
を参照お願いします。解説
解説は以下の通りです。
フォルダとファイルを用意する。ライブラリの中身を少し書く。__init__.pyを少し書く。setup.pyを少し書く。python setup.pyのコマンド実行- オプション(ライブラリが他のライブラリに依存している時)
用意するもの
必要なものはこれだけです。
- ライブラリの中身を入れるフォルダ
- 何か関数とかクラスとかを定義したコード(
.py)setup.py__init__.py(アンダースコアは前と後ろ2つずつです)今回は
mylibというモジュールを作るとして、以下のように準備しました。tree .setup.py mylib |-- __init__.py |-- mylib.pyライブラリにしたい関数を書く。
そして、ライブラリの中身になる
mylib.pyに以下のように適当に関数を書きました。mylib.pyclass Test(): def __init__(self): pass def pt(): print("from class Test") def test(): print('hello world')
__init__.pyを準備する。
- なんのファイルをインポートするのか
- どの関数をインポートするのか
について数行書くだけです。
__init__.pyfrom .mylib import ( test, Test, ) __version__ = '0.0.0'この場合、
mylib.pyというファイルから、testという関数と
Testというクラスをこのライブラリに入れる、というふうに書いているだけです。
setup.pyを少し書く。setup.pyfrom setuptools import setup, Extension,find_packages setup( name = 'mylib', packages=find_packages(where='mylib'), package_dir={'': 'mylib'}, )これで大丈夫です。
setup.pyを走らせる。
pythonのライブラリはシェアドオブジェクトファイル(soファイル)として
python の環境フォルダに格納されます。場所はhttps://qiita.com/kenmaro/items/d589d32115154dcd26b2この記事を
参照してください。このフォルダに入れておけば、どこで
pythonを実行しても
import mylibとすることができます。そのようにしたい時は、
python setup.py installと実行してください。
このフォルダに格納するのではなく、
setup.pyがある階層にsoファイルのフォルダを作りたい時
(このときはこの階層でだけimport mylibできます。)
は、python setup.py build_ext --inplaceとすることができます。
オプション(他のライブラリに依存している時)
例えば、自作ライブラリが
tensorflowを内部で呼んでいるなど、
他のライブラリを使っていることがほとんどだと思います。
その時は、以下の作業がプラスで必要です。
requirements.txtを作る。setup.pyを少しだけ変更する。requirements.txt
requirements.txtにrequirements.txttensorflow==2.2というように、必要なライブラリを書いときます。
setup.py に追加
setup.pyfrom setuptools import setup, Extension,find_packages def _requires_from_file(filename): return open(filename).read().splitlines() setup( name = 'mylib', packages=find_packages(where='mylib'), package_dir={'': 'mylib'}, install_requires=_requires_from_file('requirements.txt'), )このように書きます。
これであとは先ほどと同じようにpython setup.py installなどをやってみてください。まとめ
今回はできるだけ最低限の手順だけで
pythonの自作モジュールをsetuptoolsを使うことで実装すること
を解説してみました。今回はこの辺で。
おわり。