- 投稿日:2020-07-11T19:49:49+09:00
MySQLのダンプファイルをDockerコンテナで復元する
概要
コンテナを使うことでローカル環境を汚さず
使い終わったらコンテナごと削除されます。ダンプファイルはMySQLが提供しているサンプルを使用しています。
Other MySQL Documentation - Example Databases
使用しているダンプファイル: world database環境
- Docker version 19.03
- MySQL 5.7
MySQLのコンテナを実行する
# コンテナを実行する $ docker container run --rm --name some-mysql -e MYSQL_ROOT_PASSWORD=password -d mysql:5.7 27b05b9a3337d930941c24e6a4ae507d206619de879e7067ef3855f6bc9710b5 # コンテナが実行されていることを確認する $ docker container ls --filter "name=some-mysql" CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 27b05b9a3337 mysql:5.7 "docker-entrypoint.s…" 51 seconds ago Up 49 seconds 3306/tcp, 33060/tcp some-mysqlダンプファイルからデータを復元する
# ホストにあるダンプファイルからコンテナにあるMySQLにデータを流し込む $ docker container exec -i some-mysql /bin/bash -c 'mysql -uroot -p"$MYSQL_ROOT_PASSWORD"' < /file/to/path/world.sqlデータが復元されているか確認する
# コンテナに接続 $ docker container exec -it some-mysql /bin/bash # MySQLに接続 root@container_id /# mysql -uroot -p$MYSQL_ROOT_PASSWORD -Dworld # データーベースの確認 mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | world | +--------------------+ 5 rows in set (0.00 sec) # テーブルの確認 mysql> show tables; +-----------------+ | Tables_in_world | +-----------------+ | city | | country | | countrylanguage | +-----------------+ # レコードの確認 mysql> select * from city; +----+----------+-------------+----------+------------+ | ID | Name | CountryCode | District | Population | +----+----------+-------------+----------+------------+ | 1 | Kabul | AFG | Kabol | 1780000 | | 2 | Qandahar | AFG | Qandahar | 237500 | ... | 4078 | Nablus | PSE | Nablus | 100231 | | 4079 | Rafah | PSE | Rafah | 92020 | +------+--------+-------------+----------+------------+ 4079 rows in set (0.00 sec)実行したコンテナを削除する
# コンテナを停止する $ docker container stop some-mysql some-mysql # コンテナが削除されていることを確認する $ docker container ls --filter "name=some-mysql" CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES参考
- 投稿日:2020-07-11T17:46:36+09:00
dumpをとってリストアしてくれ!と言われた時の手順書
概要
先日MySQLのdumpをとって、別環境に反映しといて!
といわれて、初めてdumpをとって反映という作業をしたので手順等をφ(..)メモメモやりたいこと
環境AのhogeDBのdumpを取得し、環境Bに反映する。
手順
dumpをとる!
今回はtablePlusのGUI操作でdumpを取得したが、コマンドでもできる。
## データベースのダンプをまるっと取得する $ mysqldump -u USER_NAME -p -h HOST_NAME DB_NAME > OUTPUT_FILE_NAME他にもテーブルのみのダンプや、定義のみなど、色々オプションはあるので使うときに調べましょう。
圧縮する!
zip -r hoge.zip hoge.dumpzipコマンドもオプションが色々ある。
例えば、-eでパスワード付き環境Aから環境Bにdumpファイルを転送する!
scpコマンドをつかいます。
### scp [コピー元のパス] [コピー先のパス] # パスの書き方は # ユーザ名@サーバのホスト名(or IPアドレス):コピーしたいファイル、もしくは保存先のパス環境Bでdumpを解凍する!
unzip hoge.zipdumpを環境Bに反映する!
nohup mysql [反映先のDB名] < hoge.dump &
- nohupコマンドについて
- 簡単にいうとコマンドのバックグラウンド実行。
- 実行中に画面を閉じたり、ログアウトするとコマンドが終了してしまうが、それを防ぐことができる
- 参考: https://www.atmarkit.co.jp/ait/articles/1708/24/news022.html
## まとめ
基本的なことだが、今までやる機会がなかったので良い経験になった。
nohupコマンドとかは知っていると知らないのじゃ、作業効率に差が出ると思うので、積極的に使いたい。
- 投稿日:2020-07-11T17:16:22+09:00
MySQL EXPLAINの見方
概要
先日先輩からSQL流す前に、EXPLAINをつけるようにしてね!
と言われてそのとおり実行したのですが、出力結果の内容を理解していなかったので覚え書き...EXPLAINコマンドとは
流したいSQLの前にEXPLAINをつけることで、そのクエリの実行計画をみることができる。
そこで出力された情報をもとにボトルネックを探して、チューニングをしていく。mysql> EXPLAIN select * from users_tbl; +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+ | 1 | SIMPLE | users_tbl | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | NULL | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)出力結果の見方
id
SELECT識別子、実行順序を示してる
select_type
値 詳細 SIMPLE サブクエリやユニオンが含まれていない単純なselect文 SUBQUERY select文のサブクエリに指定されているselect文 PRIMARY UNIONの1つめのselect文 UNION UNIONの2つめ以降のselect文 UNION_RESULT UNIONの無名一時テーブルから結果を取得するselect文 table
出力の行で参照しているテーブルの名前。
partitions
クエリが参照したパーティションテーブル。パーティションされていない場合はNULL
※パーティショニングとは、一つのテーブルを分割する機能type
テーブルの結合方法
- ALL
- フルテーブルスキャン
- インデックスがはられていないため一番遅い
index
- フルインデックススキャン
- インデックスがはられていること以外はALLと同じ、2番目に遅い
rabge
- indexを使用して、範囲検索
const
- PKもしくはuniqueキーを参照して検索、一番速い
possible_keys
テーブルの行検索に使用できるindex。NULLの場合は参照するインデックスがない
key
MySQLが実際に使用してindex
key_ren
MySQLが実際に使用したindexの長さ
ref
行検索の際にindexと比較されるカラムや値。
rows
クエリ実行のためにMySQLが調査する行数。(行数が多い時は推定値)
filtered
テーブル条件によってフィルタ処理される行数の割合。
Extra
MySQL がクエリーを解決する方法に関する追加情報
詳細はhttps://dev.mysql.com/doc/refman/5.6/ja/explain-output.html#explain-extra-informationまとめ
type=null かつ key=null の場合は、インデックスがはられていないテーブルをフルスキャンしているので、要改善。
EXPLAINやチューニングに関する記事を色々調べていると知らないことばかりだった...
今後はSQL流す前にEXPLAINをつけて実行計画をする習慣をつけたい。
- 投稿日:2020-07-11T13:37:07+09:00
30代未経験者の地方(愛知)へのエンジニア転職奮闘記始めます
はじめまして!
33歳のプログラミング未経験者である私が、地元の愛知県に転職活動をしている記録を残していきたいと思います。学んでいる言語はもちろん、転職活動をしていて感じたことを書きたいなと思います。アラサーとなった今、人口が減って経済が縮小していく日本で、どのようなキャリアを造っていくのか悩むことが多くなってきました。そして周りにも同じ悩みをもつ同世代の友人は多いです。
自分の記録が、キャリア形成について悩んでいる方々に少しでもお役に立てばいいなと思います。自己紹介
私は、愛知県生まれ、仕事の関係で静岡県に住み一般企業(安定的企業)で事務職に就いています。
専門学校卒で特段目立ったスキルもなく、凡人サラリーマンです。なぜ転職をしようと考えたのか
私の就いている会社は比較的安定的な企業で、周りの人にも「その会社なら、一生安泰だわ」と言われるような会社です。
ただ内部で仕事をしていると悩むことも多いのです。
例えば
基本的に仕事はルーティーン業務。過去の記録をコピペするような業務です。
言われたことをミスなく黙ってやっていればいいのです。
日々、これは自分がやらなくてもいいんじゃないかな??と感じたり最近ではRPAという自動化システムが導入され始めて、さらに自身の存在価値が疑われるような状況になってきました。なぜエンジニアに転職しようと考えたのか?
基本的に以下の3点です。
・手に職を付けたかったから
・ITがこれからも伸びていく産業だと思うから
・人々の生活を便利にして豊かにすることが出来ると考えたから今回は初投稿なのでここまでとして、次回以降、なぜエンジニアになりたいかさらに掘り下げていきたいと思います!
次回は「凡人サラリーマン転職フェアに行く」をテーマに投稿したいと思います。
よかったら見てください
- 投稿日:2020-07-11T13:37:07+09:00
30代未経験者の地方(愛知)へのエンジニア転職奮闘記
33歳のプログラミング未経験者である私が、地元の愛知県に転職活動をしている記録を残していきたいと思います。学んでいる言語はもちろん、転職活動をしていて感じたことを書きたいなと思います。
20代から現在にかけて、人口が減って経済が縮小していく日本で、どのようなキャリアを造っていくのか悩むことはとても多いです。そして周りにも同じ悩みをもつ同世代の友人は多いです。
自分の記録が、キャリア形成について、少しでもお役に立てばいいなと思います。自己紹介
私は、愛知県生まれ、仕事の関係で静岡県に住み一般企業(安定的企業)で事務職に就いています。
専門学校卒で特段目立ったスキルもなく、凡人サラリーマンです。なぜ転職をしようと考えたのか
私の就いている会社は比較的安定的な企業で、周りの人にも「その会社なら、一生安泰だわ」と言われるような会社です。
ただ内部で仕事をしていると悩むことも多いのです。
例えば
基本的に仕事はルーティーン業務。過去の記録をコピペするような業務です。
言われたことをミスなく黙ってやっていればいいのです。
日々、これは自分がやらなくてもいいんじゃないかな??と感じたり最近ではRPAという自動化システムが導入され始めて、さらに自身の存在価値が疑われるような状況になってきました。なぜエンジニアに転職しようと考えたのか?
基本的に以下の3点です。
・手に職を付けたかったから
・ITがこれからも伸びていく産業だと思うから
・人々の生活を便利にして豊かにすることが出来ると考えたから次回は「凡人サラリーマン転職フェアに行く」をテーマに投稿したいと思います。
- 投稿日:2020-07-11T10:52:52+09:00
[Rails]DBにデータが登録されない場合の対処法
はじめに
フォーム入力内容をDBに保存したいがハマったのでアウトプット
環境
Rails 5.0.7.2
ruby 2.5.1
mysql 14.14問題点
フォーム入力内容を保存しようとすると、パラメータに保存されているがDBに保存されない。
対処方法
保存するメソッドの後ろに!をつけて原因を確認。
すると、validation failed:User must exist(エラー内容は異なる場合がありそう)
原因
アソシエーションが組まれている際に、該当の外部キーが入っておらず、バリデーションで弾かれているのが原因。
optional: trueを記述。
goal.rbclass Goal < ApplicationRecord validates :name, presence: true, uniqueness: true validates :time, presence: true, uniqueness: true validates :days, presence: true, uniqueness: true belongs_to :user, optional: true #ここを編集 endoptional: trueとは、belongs_toの外部キーのnilを許可するというもの。
これでDBに保存できると思います。
参考にしてください!
- 投稿日:2020-07-11T10:50:08+09:00
elasticsearchを使ってみる
Elasticsearchは、分散型でオープンソースの検索・分析エンジンです。by elastic
って、ぶっちゃけ何言ってるかよくわかんない。
全文検索できるっていうから、ちょっと前にクローラーでデータ登録してプチgoogleみたいに使って喜んでいたのだが、kibanaが絡んできたりするとなんかよくわかんねー。
なので、なんかのデータを登録して、よくわからない条件で分析などしてみて、これでおいらもデータサイエンティストさ、ごーごーデータどぶリン、って言ってみたい。
これは、そんな野望の全貌をつづった作業ログである。なんちて。1.elasticsearchを入れてみる
環境はこんな感じにしてみる。
・VirtualBoxによる仮想サーバーを利用
・OSはcentos8
・ホストosはwindows10だけどねcentos8がインストールされたVirtualboxの仮想サーバーは、下ごしらえで各自作っておくように。
ここにjavaとelasticsearchをインストールする。
参考サイト:CentOs8 Elasticsearchをインストールする手順
言われるままにコマンド入れたりすると、javaとelasticsearchがインストールされた。よしよし。
そのあとservice登録、firewall設定と進んで、ホストOSからアクセスしたら、エラーになった。
firewall設定で開けるポートって、9200じゃね?
9200開けてみたら、つながりました。2.データを投入してみる
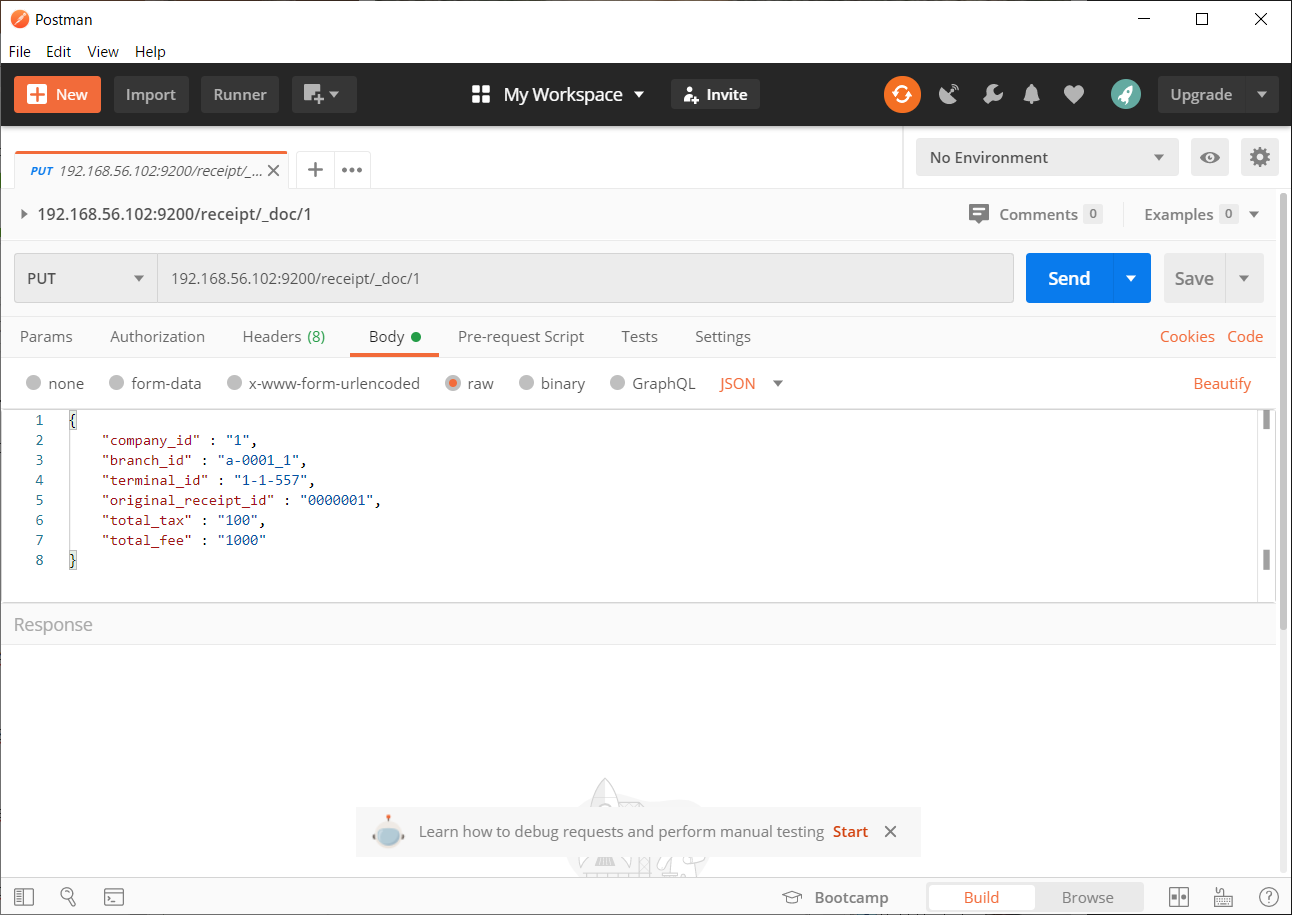
とりあえずPostmanでjsonデータをいきなり入れてみる。
なんか出来たっぽい。
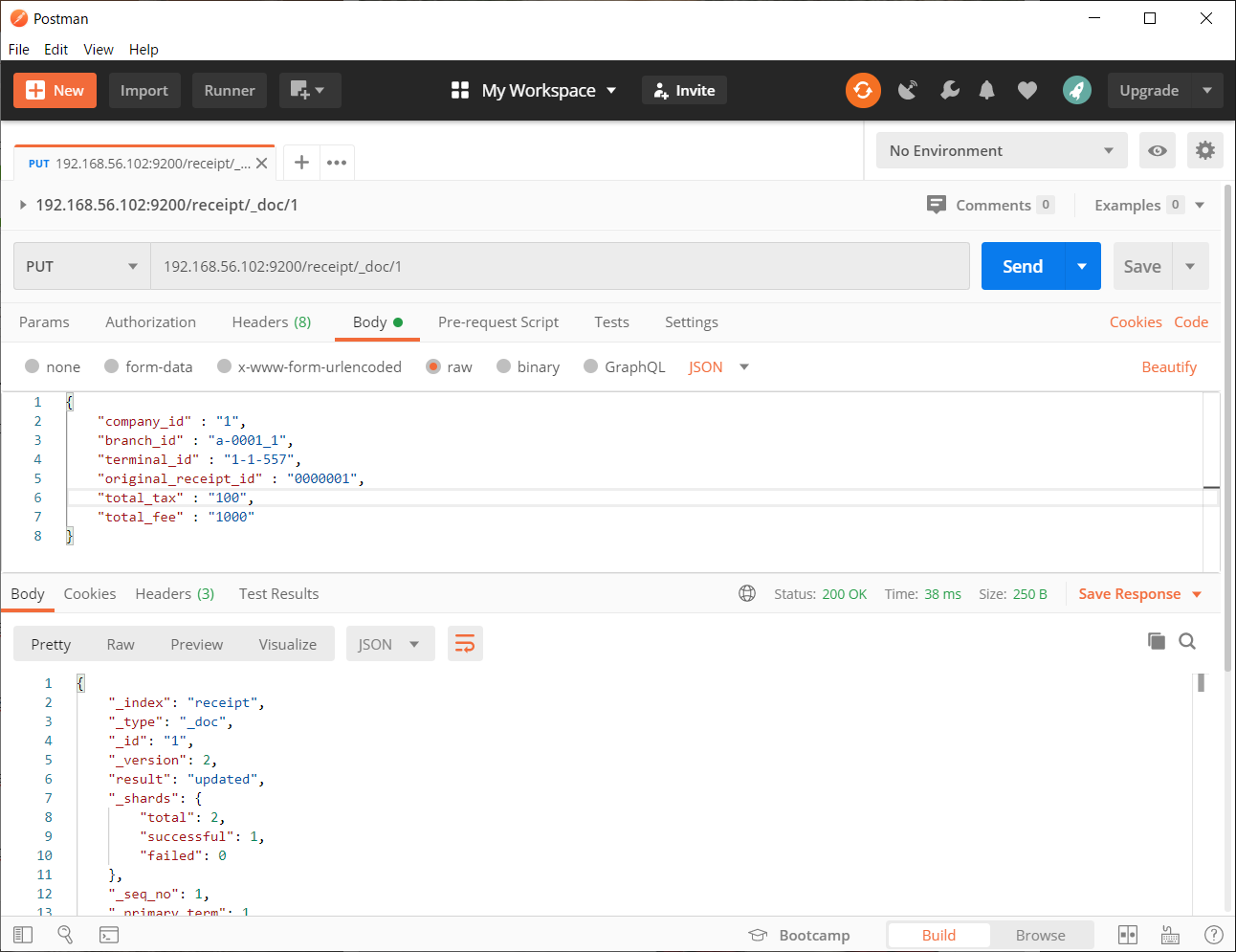
入れたキーを指定してGETしてみる。
さっき入れたデータが_sourceの中に入っている。
これだけ…?何にもしないでデータ登録&呼び出しができてしまった。3.kibanaをインストールしてみる
このサイトを参考にした。さっきの記事とおんなじ人だね。多謝!
なんか設定は正しく出来ているのに、つながったりつながらなかったりする。
サーバー再起動等行って、なんか立ち上がったようだ。
4.kibanaで分析してみる
ここまではいいのだ。大体みんなが言った通りやっていればたどり着くのだ。
ここから俺はどうしたらいいのだ?
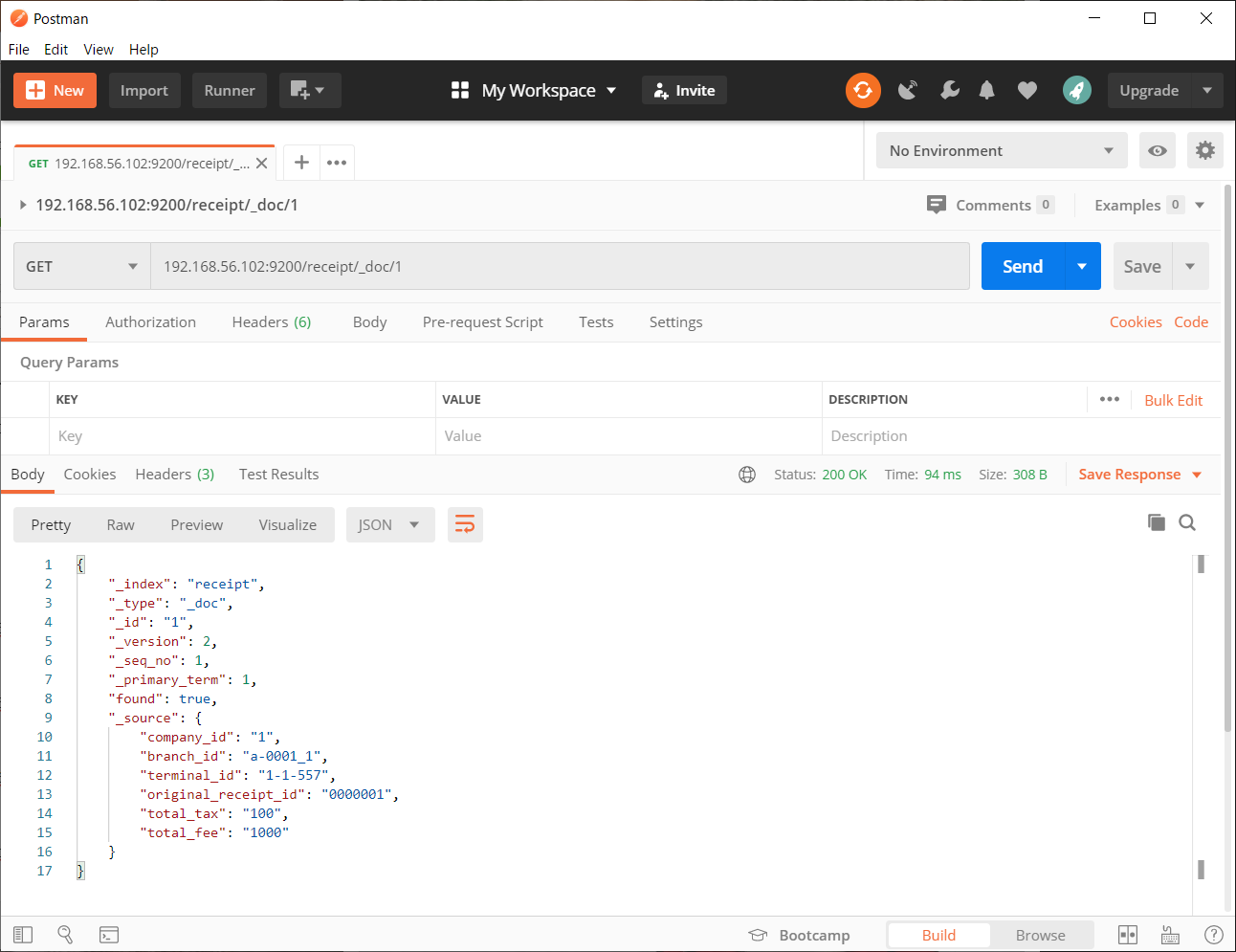
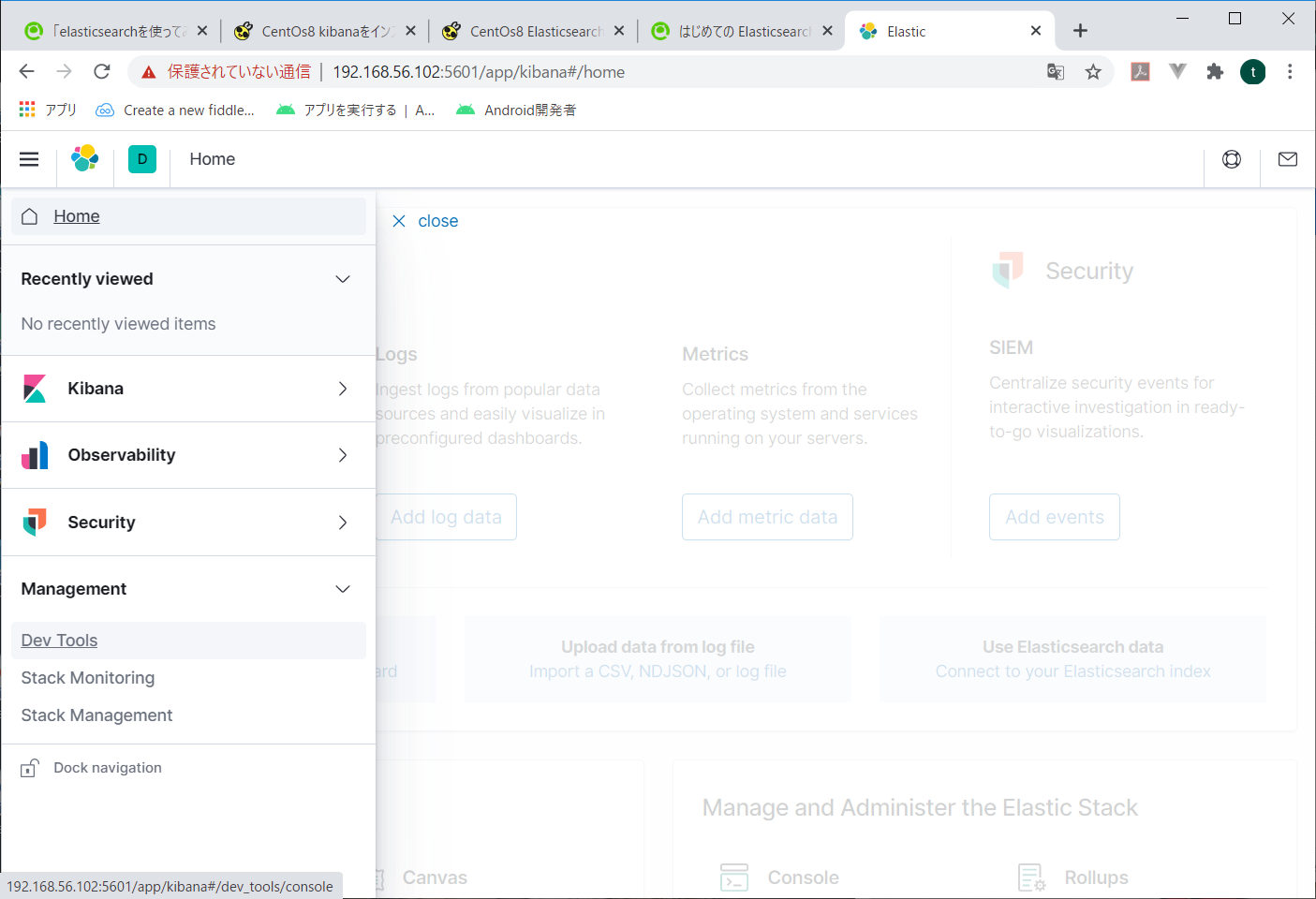
試しにkibanaでさっきPostmanから投入したデータを参照してみる。左メニューのManagementの中の、Dev Toolsを開く
入れるコマンドは基本curlとかと同じようなイメージ。
ただ、elasticsearch前提なので、インデックス名以降を指定すればよいようだ。
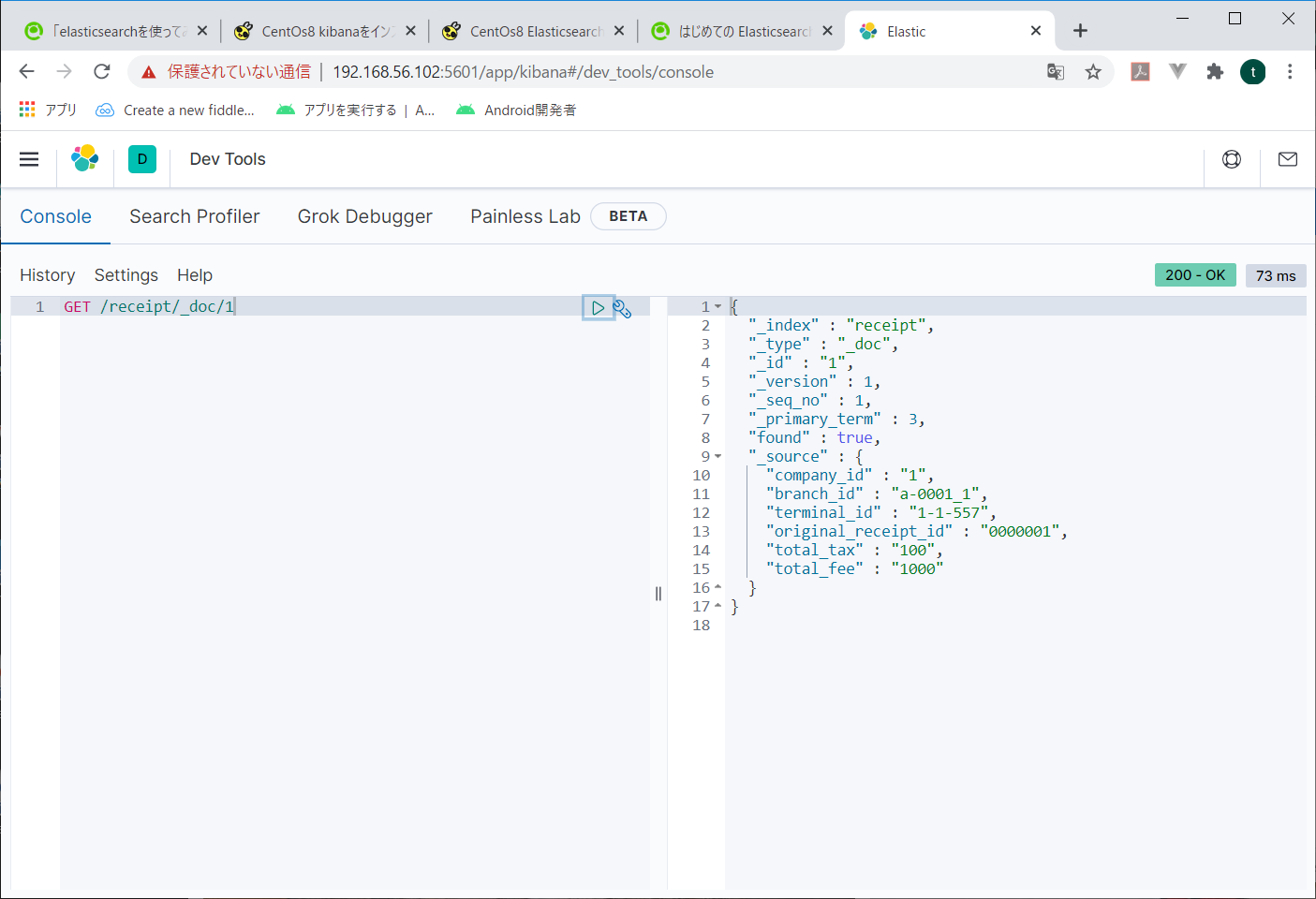
入力したコマンドの右側の緑三角をクリックすると、右側に結果が表示されます。
でも、こうじゃねーんだよ。なんかもっと、データサイエンティストなどぶリンなあれをしたいんだよ。
なので、Discoverを使ってみる。
左メニューからkibanaの中のDiscoverをクリック。
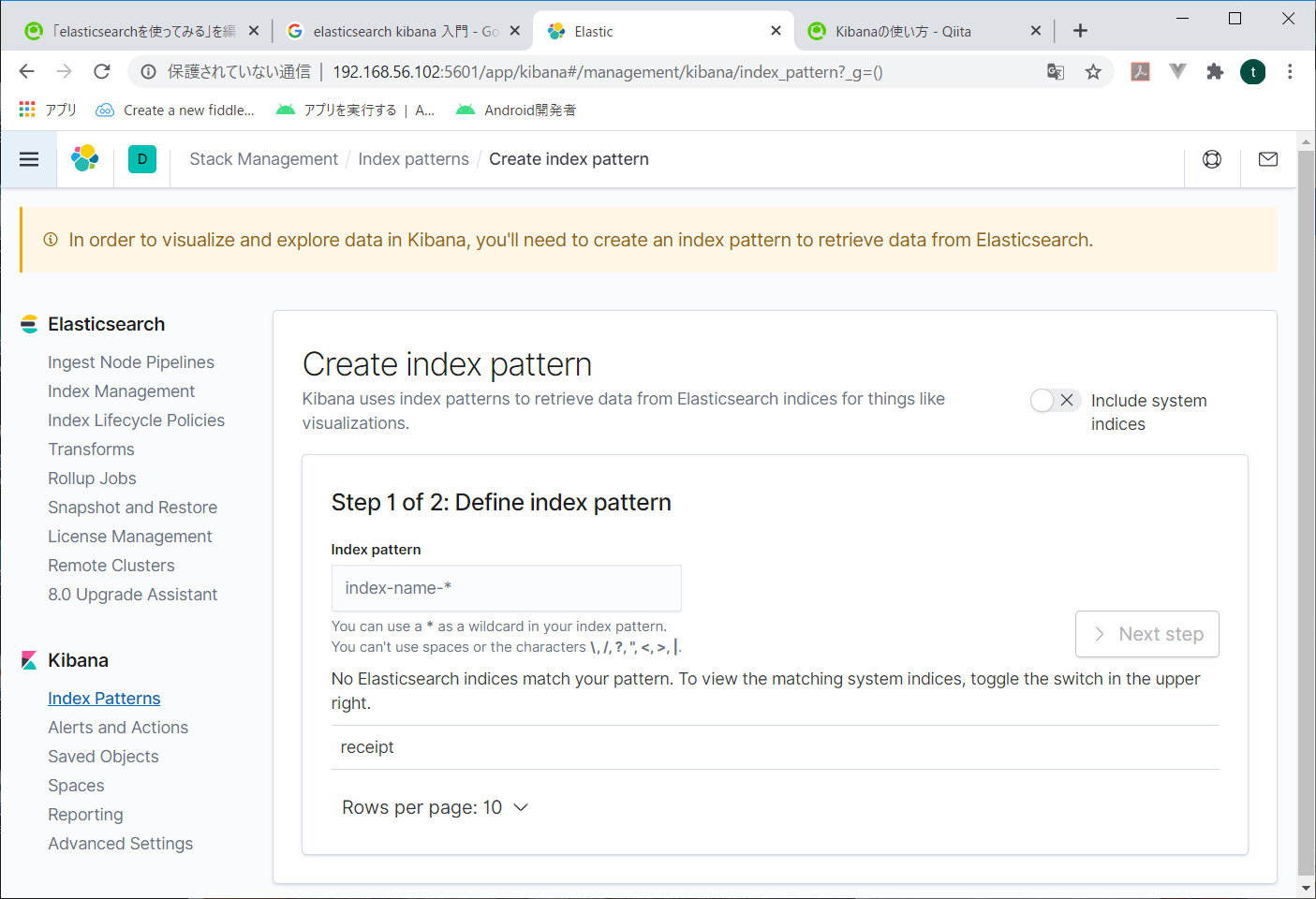
どうやらindex patternというものを作るらしい。
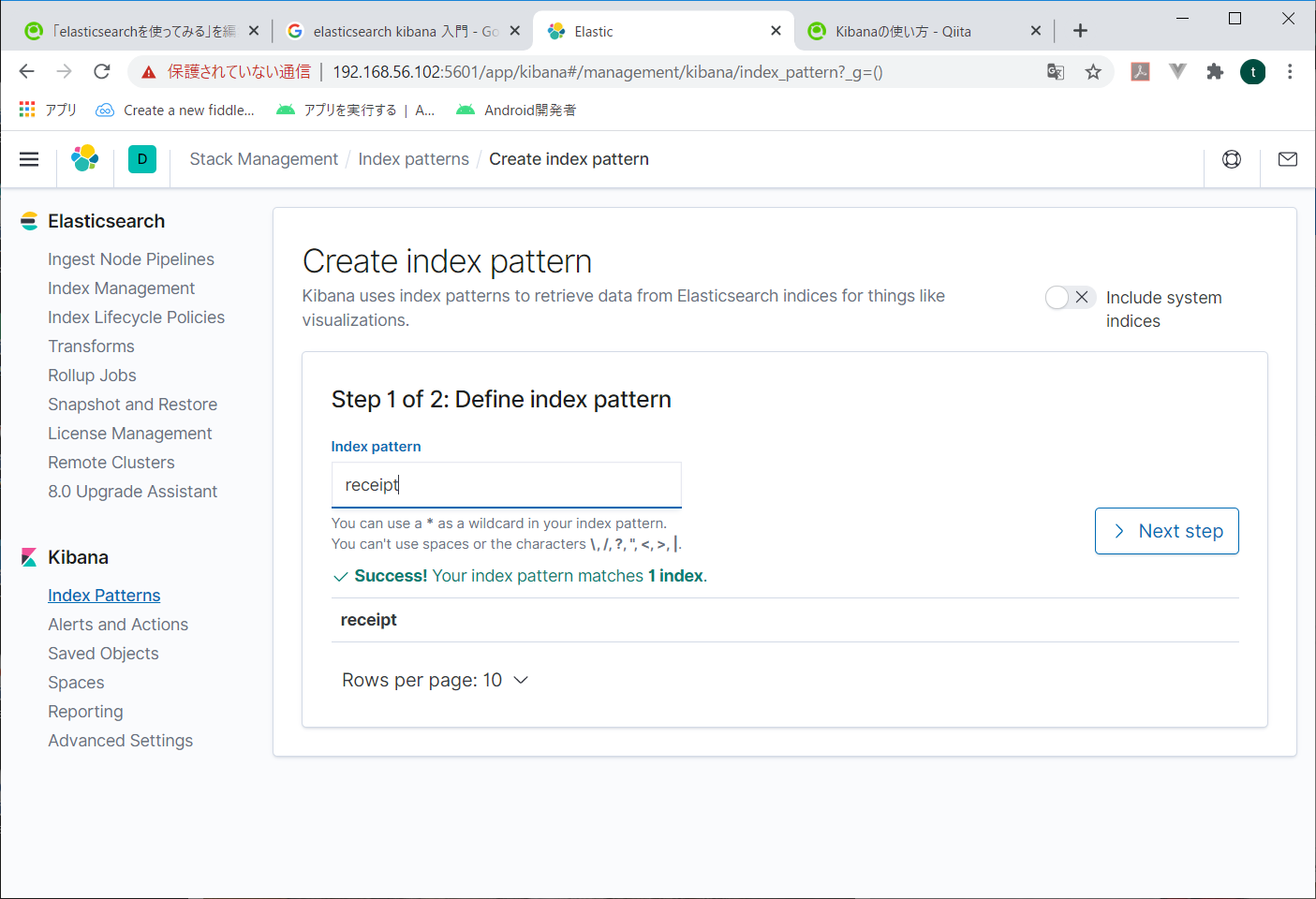
今一つだけ出来ている「receipt」を指定してみる。
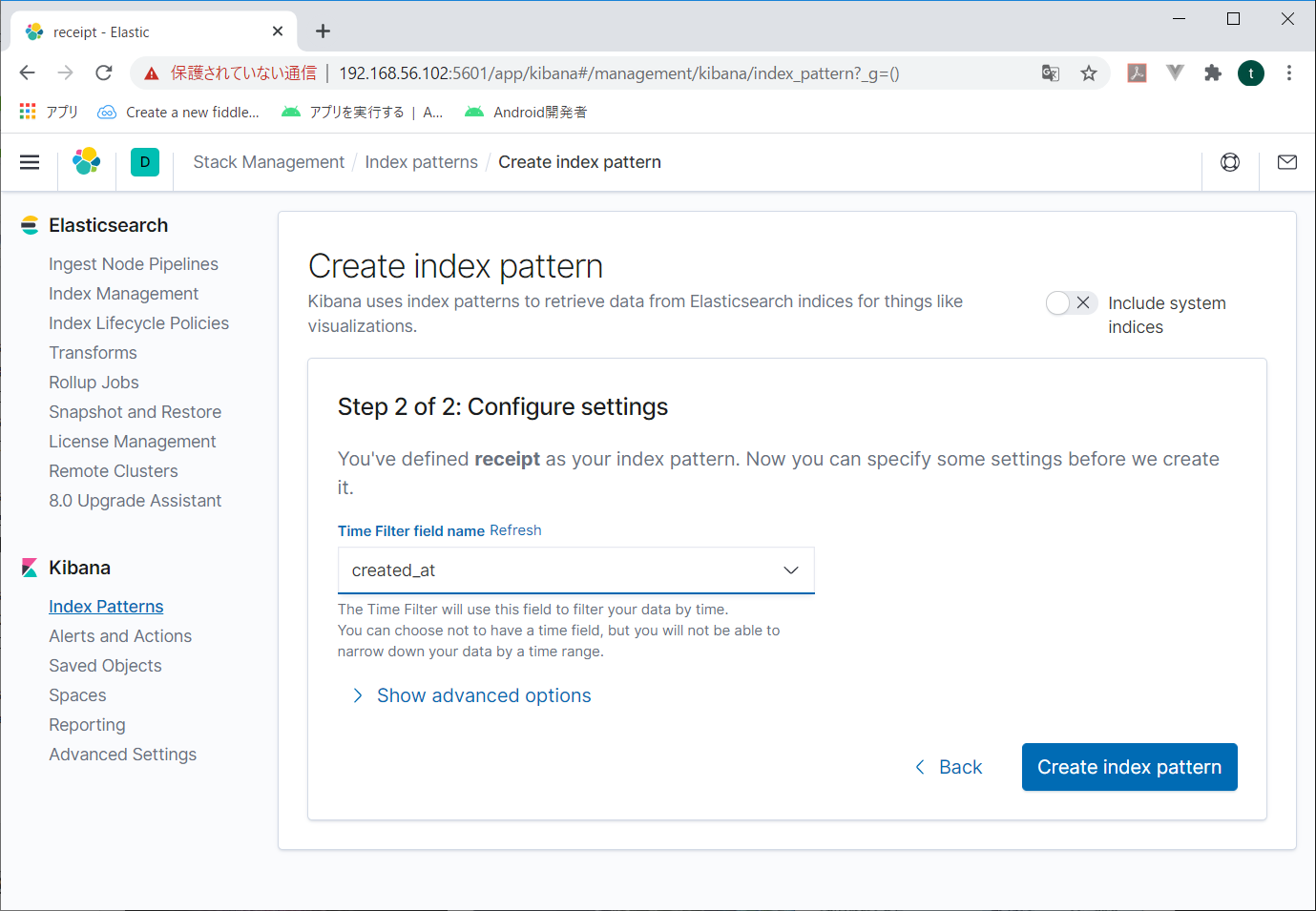
次の画面で検索するときに使用する時間関係の項目を指定する。日付とか時刻とかね。これを指定しないと、後々データが検索できない。
とりあえずcreate_atをしてしておいて、Create index patternをクリック。
何かができたらしい。
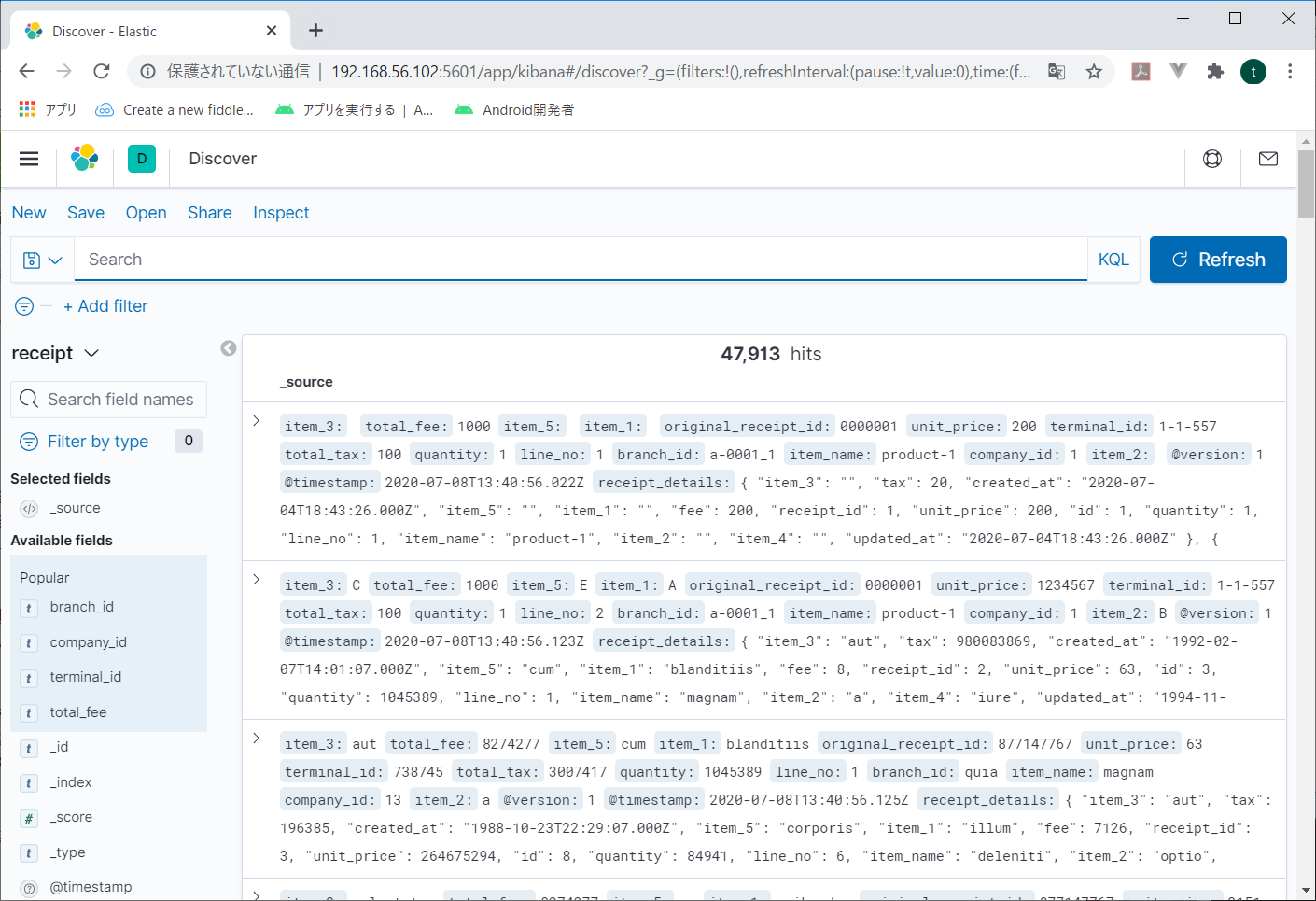
なんとなく環境出来たっぽいから、データをきちんと入れてみるよ。5.logstashでMySQLのデータをelasticsearchに入れる
今回は昔ながらの伝票データを入れてみたいよ。
すなわち、ヘッダレコードに合計金額とか入っていて、明細レコードが複数できている、あれだ。よく知らない若者は、お父さんとか年老いたSEに聞いてみてね。
laravelでseeder使って大量発生させたデータがMySQLに入っているので、これをelasticsearchに入れてみる。
elasticsearchでは非正規データを入れろとか、親子関係はお勧めしない、なんて言われるから、logstashの中で伝票データをひとまとめにしてelasticsearchに入れてみる。
とりあえずlogstashをインストールだ。このサイトを参考にさせていただきました。が、インストールはdnfでしちまったよ。この辺は好みか?
インストール出来たら、MySQLからデータを取ってくるよう、logstash.confを作成する。
と、その前にjdbcを入れとかなくちゃならない。
見よう見まねでインストールしてみる。レポジトリ登録# dnf localinstall https://dev.mysql.com/get/mysql80-community-release-el8-1.noarch.rpmインストール# dnf install mysql-connector-javaどこに入ったかわからないので、探してみる。
# find / mysql-connector* | grep "mysql-connector" /var/cache/dnf/mysql-connectors-community-36a49e3556a965a0 /var/cache/dnf/mysql-connectors-community-36a49e3556a965a0/repodata /var/cache/dnf/mysql-connectors-community-36a49e3556a965a0/repodata/repomd.xml /var/cache/dnf/mysql-connectors-community-36a49e3556a965a0/repodata/4a1e62c80aefb9ae9dcc85524652f5e6f6d01fdb-filelists.xml.gz /var/cache/dnf/mysql-connectors-community-36a49e3556a965a0/repodata/408890bf2054a439cca0f5a2988e8e11c7a08276-primary.xml.gz /var/cache/dnf/mysql-connectors-community-36a49e3556a965a0/packages /var/cache/dnf/mysql-connectors-community.solv /var/cache/dnf/mysql-connectors-community-filenames.solvx /usr/share/doc/mysql-connector-java /usr/share/doc/mysql-connector-java/CHANGES /usr/share/doc/mysql-connector-java/INFO_BIN /usr/share/doc/mysql-connector-java/INFO_SRC /usr/share/doc/mysql-connector-java/LICENSE /usr/share/doc/mysql-connector-java/README /usr/share/java/mysql-connector-java.jar/usr/share/java/に入っていた。
これを指定して、logstash.confを作ってみる。/etc/logstash/conf.d/logstash.confinput { jdbc { jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar" jdbc_driver_class => "com.mysql.cj.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.10.10:3306/receipt" jdbc_user => "receipt" jdbc_password => "p@ssw0rd" statement => "select * from receipt inner join receipt_detail on receipt.id = receipt_detail.receipt_id" } } filter { jdbc_streaming { jdbc_driver_library => "/usr/share/java/mysql-connector-java.jar" jdbc_driver_class => "com.mysql.cj.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.10.10:3306/receipt" jdbc_user => "receipt" jdbc_password => "p@ssw0rd" statement => "select * from receipt_detail where receipt_id = :receipt_id" parameters => {"receipt_id" => "id"} target => "receipt_details" } } output { elasticsearch { index => "receipt" } }conf書いたら保存して、logstashを実行する。
logstashは/usr/share/logstash/binに入っていた。
なので、こんな感じで動かしてみる。# cd /usr/share/logstash # bin/logstash -f "/etc/logstash/conf.d/logstash.conf"kibanaで見てみると、なんか入ってる。
よしゃ。
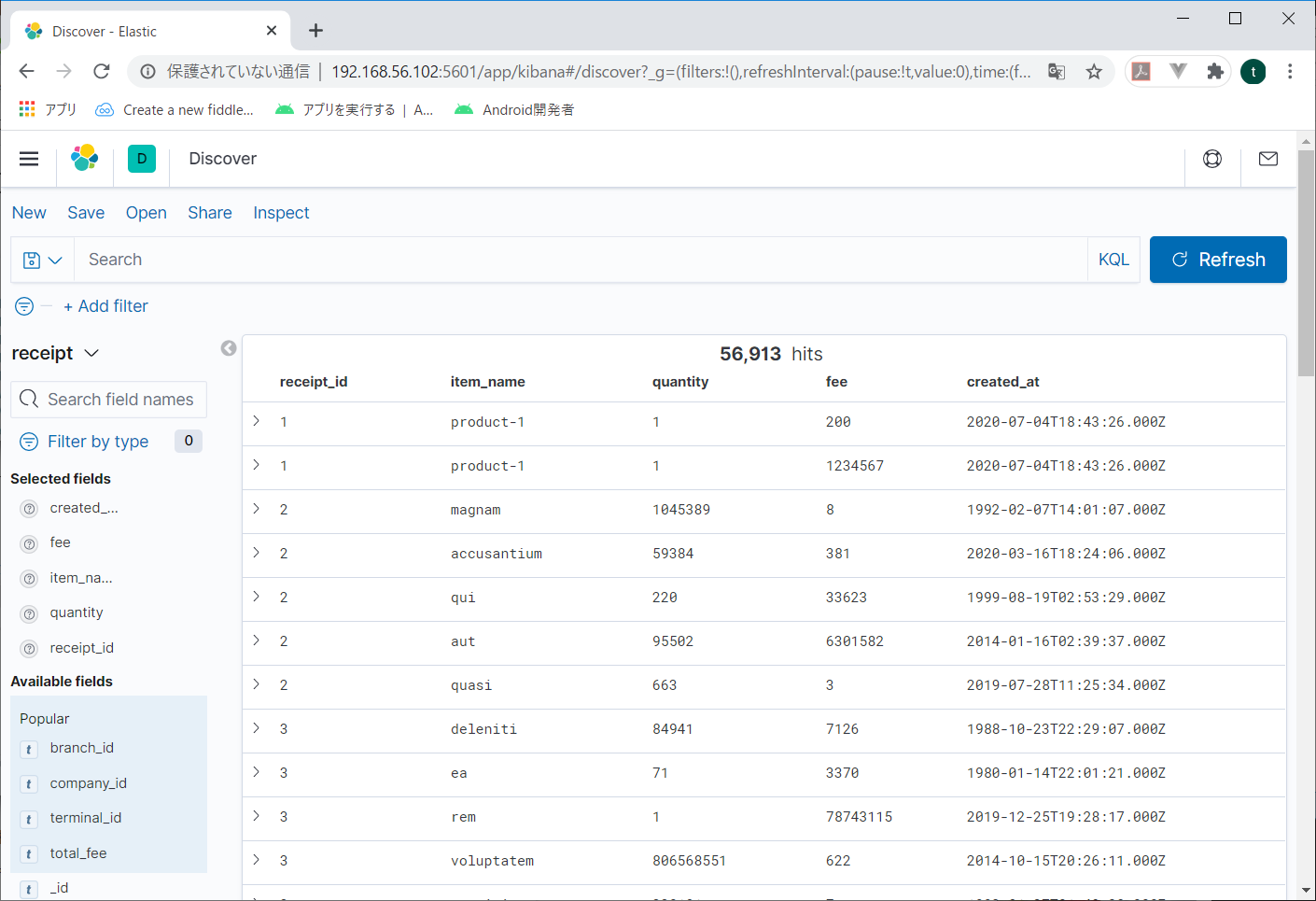
左メニューから項目をポイントして、表示された「ADD」のボタンをクリックすると、その項目だけ表示されるようになる。必要な項目だけ選べるので見やすくなる。
しかし、どうせやるならやっぱりグラフとか地図とかにしたいよね。
とりあえずグラフ作ってみよう。
右メニューからvisualizeをクリックする。
最初に作るときは、真ん中の青ボタンをクリック。
New Visualizationの中からPieをクリック。
作成したreceiptを選択。
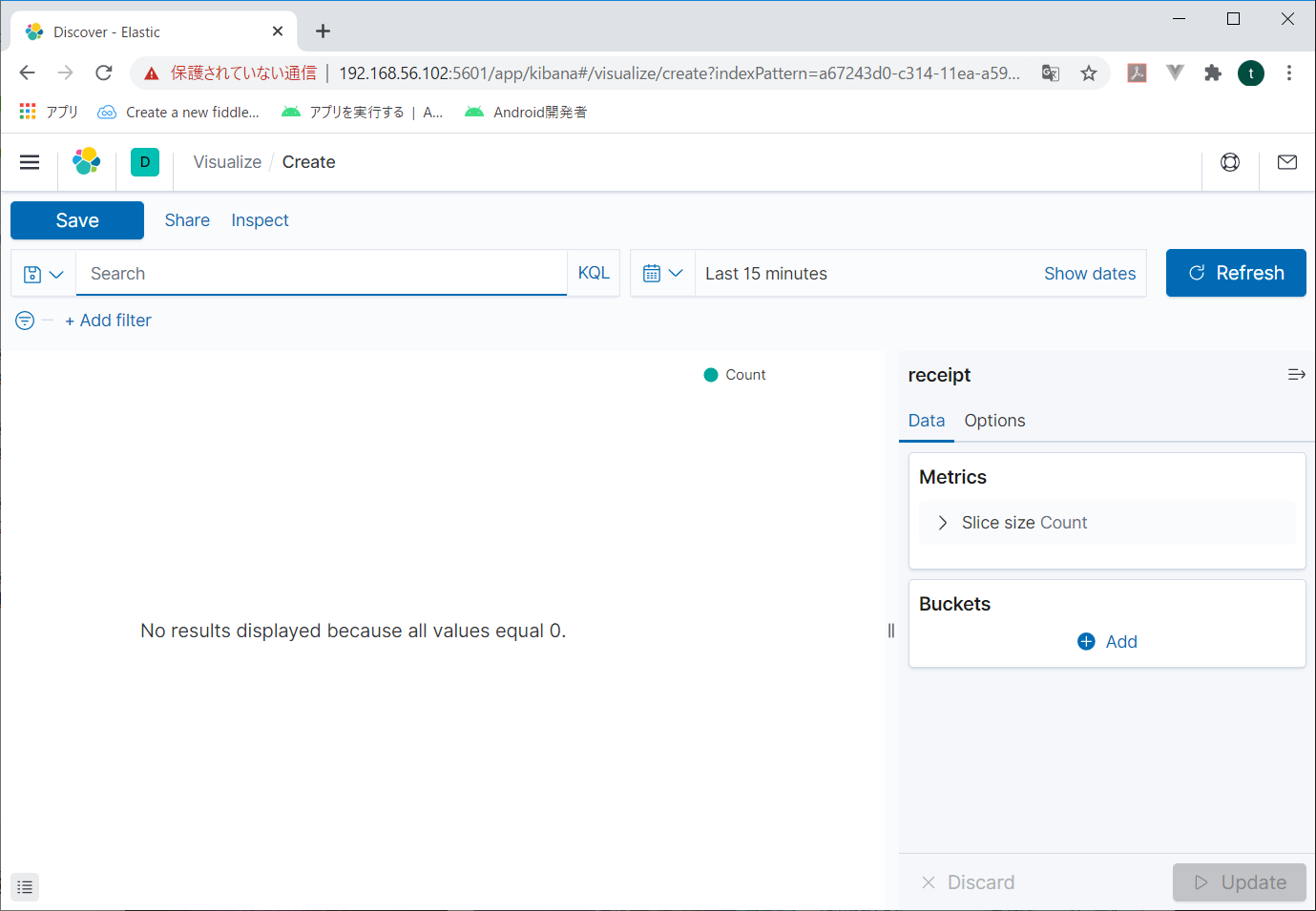
初期画面が表示される。
まずは対象となる時間帯を指定する。右上の、今「Last 15 minutes」の前にあるカレンダーマークをクリック。
時間帯を選択できる画面が表示される。
今回はざっくり「Last 1year」を選択する。と、初期画面が表示される。
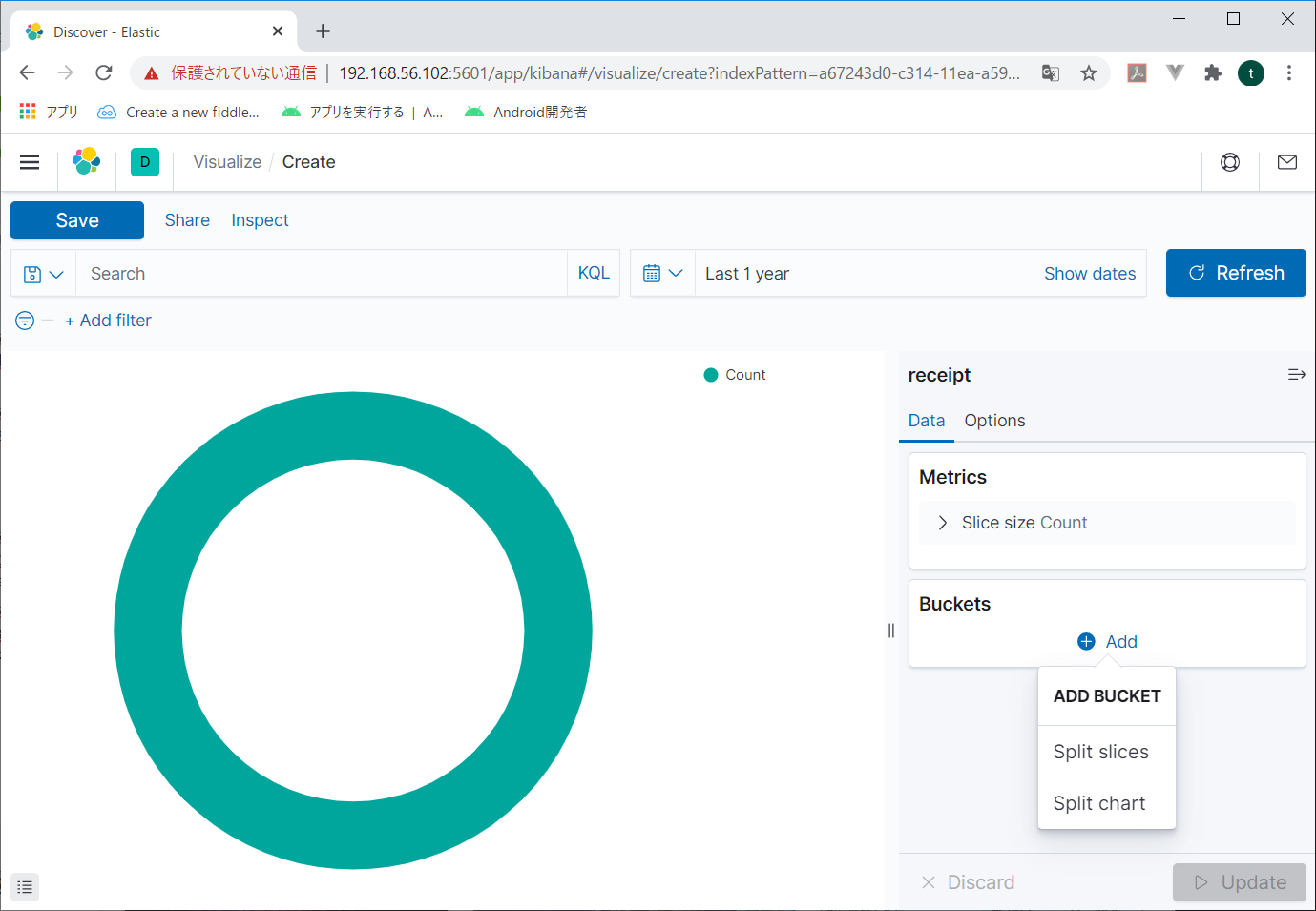
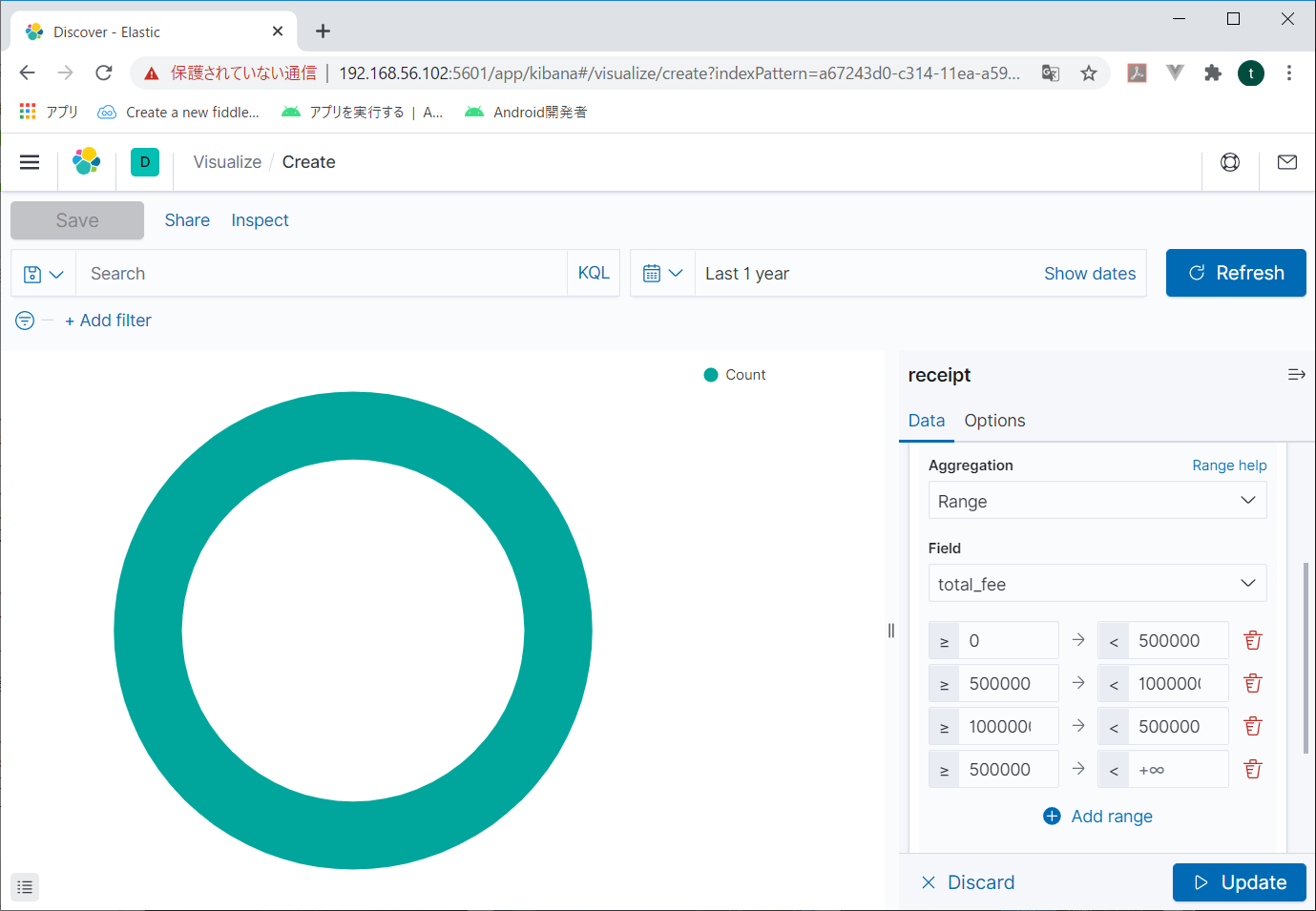
右の「Buckets」の「Add」をクリックすると追加するBucketの選択画面が表示されるので、Split sliceをクリック。
Splitslice
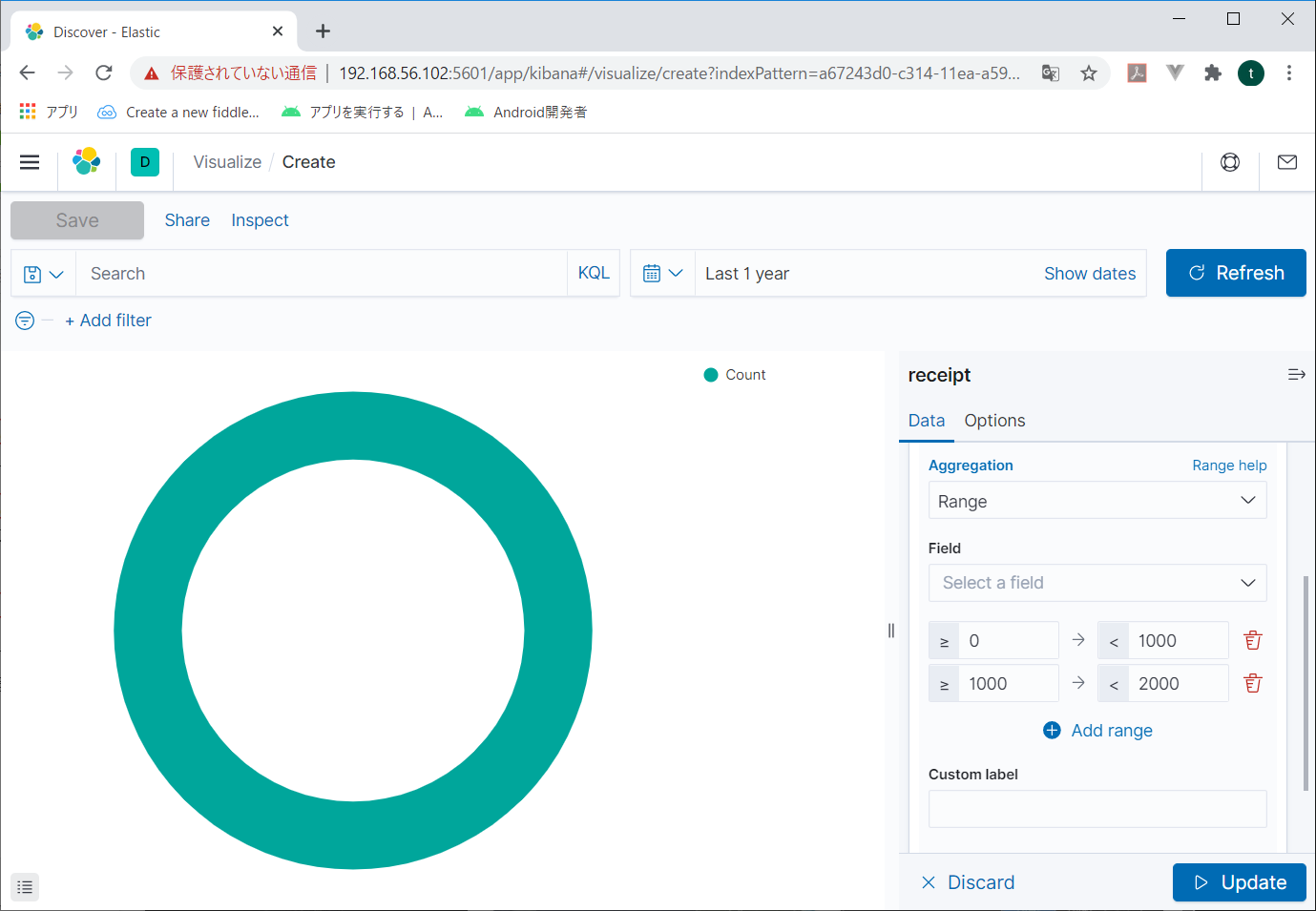
BacketsにSplit sliceが表示され、その下に「Aggregation」という項目が表示される。リストボックスから「RANGE」を指定すると、項目と範囲を指定できる画面が表示される
Fieldにグラフにする項目を指定して、その下に値の範囲を指定する。
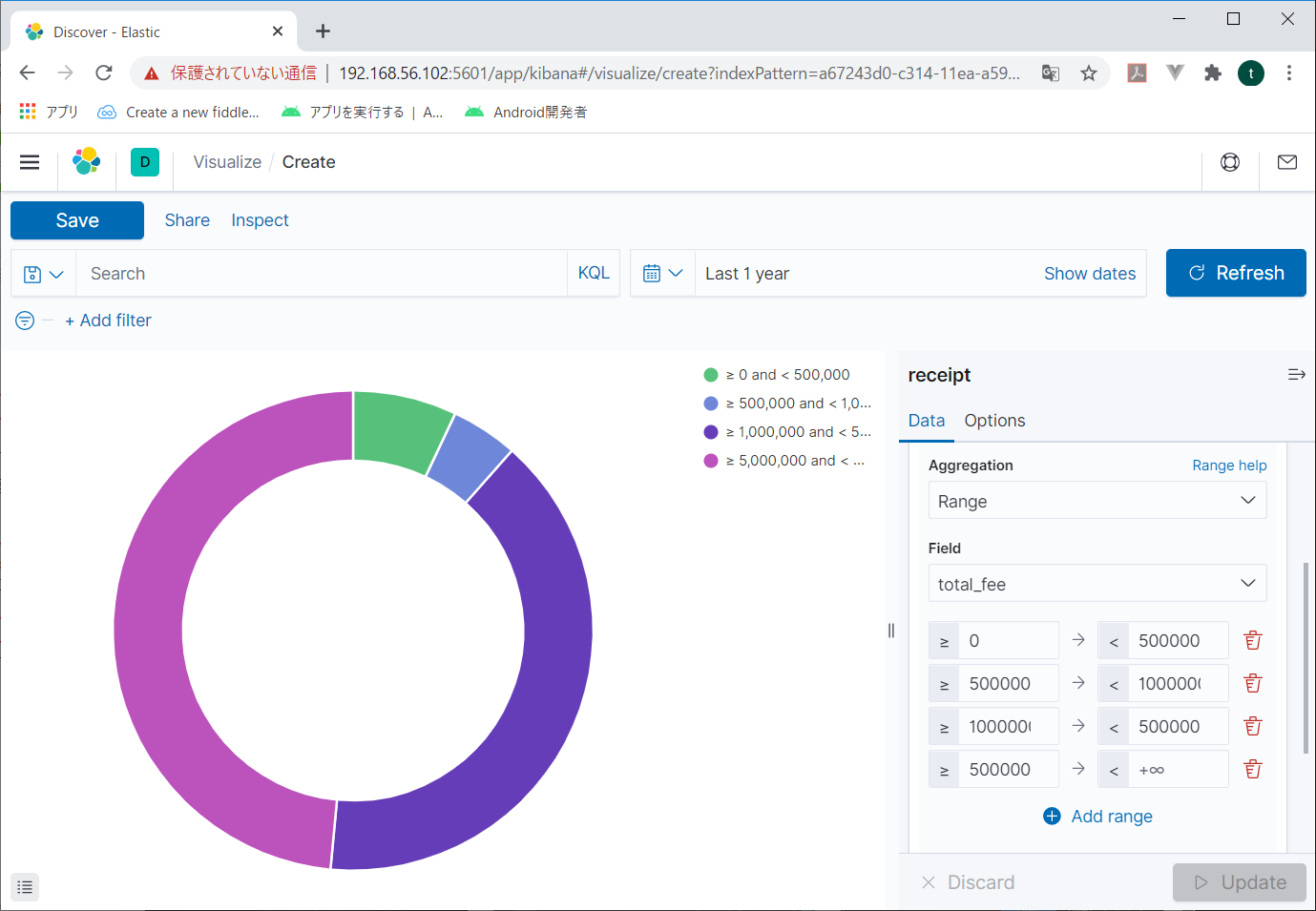
適当に指定したら、右下の「Update」をクリックする。
こんな風にグラフが作成される。
できた!これでelasticsearchにデータを投入して、kibanaで分析する第一歩ができたね。
実際はどう分析するかが肝なんだろうけど。
それはおいおい考えていくよ。そのうち何とかなるだろう。
それじゃーね。ちゃお、あみーち!
- 投稿日:2020-07-11T00:00:05+09:00
【Rails/Docker/mysql】ホストPC直下で開発していたWEBアプリをコンテナで動かしてみたぉ
はじめに
Udemyの動画でDockerを学んだ後、ローカルホストで開発していたアプリケーションをコンテナで動かしてみました。
以下を参考にしながら、まずはdocker-composeを使わずにやってみました。
参考
udemy 米国AI開発者がゼロから教えるDocker講座
https://hub.docker.com/_/rails
https://qiita.com/tatsuya-miyamoto/items/08bd6ea142d02708614f
https://qiita.com/y-suna/items/e52b3af1d80c52b66b31
https://qiita.com/Masato338/items/f162394fbc37fc490dfb実行環境
アプリケーションサーバ(コンテナ直下): puma4.3.3 (rails5.2.4.1 / ruby 2.5.1)
Database(ホスト直下): MySQL 5.6.47
コンテナ(ホスト直下): docker 19.03.8
ホスト: macOS Catalina 10.15.5実施手順
既存アプリケーションを壊さないよう、対象となるアプリケーションのフォルダをコピーして実行しました。
$ cp -r ~/project/memo-space ~/project/memo-space_v2~/project/memo-space -> ~/project/memo-space_v2
Dockerfileを作成する。
DockerfileFROM ruby:2.5.1 RUN apt-get update RUN apt-get install -y mysql-client nodejs vim --no-install-recommends RUN rm -rf /var/lib/apt/lists/* RUN mkdir /myproject WORKDIR /myproject ADD Gemfile /myproject/Gemfile ADD Gemfile.lock /myproject/Gemfile.lock RUN gem install bundler ADD . /myprojectDockerfileに基づきビルド
terminal$ cd ~/projects/memo-space_v2 $ docker build .docker image を確認します。
terminaldocker images REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> df22a2c4c7f7 56 minutes ago 1.07GB ...dockerを実行します。
この時、ホストのrails pumaのポート3000番とmysqlのポート3306番にコンテナのポートを紐づけます。
また、ホストのアプリケーションフォルダ「~/projects/memo-space_v2」にコンテナのフォルダ「/myproject」をマウントします。terminal$ docker run -it -p 3000:3000 -p 3306:3306 -v ~/projects/memo-space_v2:/myproject df22a2c4c7f7 bashファイル「Gemfile.lock」を削除します。
terminal$ rm Gemfile.lockbundle installを実行し、必要なGemをインストールします。
terminal$ bundle installdatabase.ymlに記載された既存のアプリの定義を次の通り修正します。
修正箇所
・mysqlのhost(追記)
・アプリケーション名(修正)config/database.yml# MySQL. Versions 5.0 and up are supported. # # Install the MySQL driver # gem install mysql2 # # Ensure the MySQL gem is defined in your Gemfile # gem 'mysql2' # # And be sure to use new-style password hashing: # http://dev.mysql.com/doc/refman/5.7/en/old-client.html # default: &default adapter: mysql2 encoding: utf8 pool: 5 username: root password: socket: /tmp/mysql.sock development: <<: *default database: memo-space_v2_development #修正 host: docker.for.mac.localhost #追記 # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: <<: *default database: memo-space_v2_test #修正 # As with config/secrets.yml, you never want to store sensitive information, # like your database password, in your source code. If your source code is # ever seen by anyone, they now have access to your database. # # Instead, provide the password as a unix environment variable when you boot # the app. Read http://guides.rubyonrails.org/configuring.html#configuring-a-database # for a full rundown on how to provide these environment variables in a # production deployment. # # On Heroku and other platform providers, you may have a full connection URL # available as an environment variable. For example: # # DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase" # # You can use this database configuration with: # # production: # url: <%= ENV['DATABASE_URL'] %> # production: <<: *default database: memo-space_v2_production #修正 adapter: postgresql # database: postgresql encording: unicorde pool: 5 username: memo-space url: <%= ENV['DATABASE_URL'] %> password: <%= ENV['MEMO-SPACE_DATABASE_PASSWORD'] %>※既存アプリでは、元々production環境として、heroku上のpostgresqlを利用しており上記の記載となっていますが、未修正です。
※コンテナからホストPCへのアクセスは、次の通り指定することで実行できました。
terminalmysql --host=docker.for.mac.localhost -u rootdbをcreateします。
terminalrails db:createdbをmigrateします。
terminalrails db:migrateコンテナの全てのインタフェースにバインディングすることで、ホストPCからアクセスできるようにします。
terminalrails s -p 3000 -b '0.0.0.0'以上により、ホストPCからブラウザでURL「localhost:3000」を指定し、アプリにアクセスできました。