- 投稿日:2020-07-11T23:10:41+09:00
QuarkusがJava Lambdaを救う!?
すごいですQuarkus!!!!!!
JavaのLambdaのコールドスタートがチョッパヤです!!以下の公式サイトを参考に試しました。
https://quarkus.io/guides/amazon-lambda#tracing-with-aws-xray-and-graalvm
テスト対象
前回のAWS LambdaのJavaは遅い?とほぼ同じですが、以下が異なります。いずれもQuarkusの制限?制約?です。
- アノテーションが付いてる
- httpClientがUrlConnectionHttpClient
ソース全体
package example; import javax.inject.Named; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import software.amazon.awssdk.services.s3.S3Client; import software.amazon.awssdk.services.s3.model.PutObjectRequest; import software.amazon.awssdk.services.s3.model.PutObjectResponse; import software.amazon.awssdk.core.sync.RequestBody; import software.amazon.awssdk.regions.Region; @Named("test") public class TestLambda implements RequestHandler<Object, Object> { @Override public Object handleRequest(Object input, Context context) { String ENV_BUCKET = System.getenv("BUCKET"); S3Client s3 = S3Client.builder() .region(Region.AP_NORTHEAST_1) .httpClient(software.amazon.awssdk.http.urlconnection.UrlConnectionHttpClient.builder().build()) .build(); PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("filename.txt").build(), RequestBody.fromString("contents")); System.out.println(result); return ""; } }検証結果
回数 レイテンシ(ms) 処理内容 1 2700 2 250 3 305 4 319 5 187 前回はコールドスタートが6200msだったので、めちゃ早になりました!
検証結果(+Provisioned Concurrency)
こんなチョッパヤなQuarkusさんをProvisionedにしたらどうなるんでしょうね。ワクワクしますね。
回数 レイテンシ(ms) 処理内容 1 417 2 198 3 206 4 270 5 147 期待を裏切らない速さ!すごいよ、Quarkus!
参考
https://quarkus.io/guides/amazon-lambda#tracing-with-aws-xray-and-graalvm
https://aws.amazon.com/jp/blogs/architecture/field-notes-optimize-your-java-application-for-aws-lambda-with-quarkus/
- 投稿日:2020-07-11T23:10:36+09:00
Golangはじめて物語(第2話: Gin+ECS+Fargateといっしょ編)
はじめに
前回の続編。
サーバレスの走り切り処理を書いたのだから、今度は常駐処理を書いてみよう。JavaではWebアプリケーションサーバはSpringがデファクトになりつつあるが、GoのWebアプリケーションフレームワークはGinが良いという話を聞いた。今回は、Ginを試してみつつ、せっかく作ったのだから常駐のサーバレスコンテナで動かしてみよう。
統合開発環境は前回に引き続き、VSCode+Remote Development Extension Pack+EC2を使った。
Cloud9でいいじゃんという話もありつつ、ここはもう好みの問題だということで、こっちを使い続けた。
※Cloud9も使いやすくて好き。Go言語ランタイムのインストールなんかも、前回の記事を参照。
全体構成
以下のようになる。アプリケーションの仕様は以下の通り。
※Ginのサンプルプロジェクトを少しだけ改造。
- /articleのリソースにPOST(BODYにJSONで
{"Title": "hoge", "Description": "hige"}を渡す)と、内部の構造体に該当の情報を格納する- /articleのリソースへのPOSTはバリデーションチェックを行い、JSONの情報に不足がある場合は400応答する
- /articleのリソースにGETすると、
{"Title": "hoge", "Description": "hige"}なJSONを返す。ただし起動直後は何も登録されていなくてnullを返す. ├── docker-compose.yml ├── Dockerfile ├── .gitignore ├── go.mod ├── handlers │ ├── articleFunc.go │ └── go.mod ├── main.go ├── main_test.go ├── Makefile └── modules └── article ├── article.go └── go.modWebアプリケーションサーバの実装
メイン処理
すごい。Ginかなり簡単。main.goは以下だけで済む。
main.gopackage main import ( "local.packages/handlers" "local.packages/modules/article" "github.com/gin-gonic/gin" "github.com/fvbock/endless" ) func initRouter() *gin.Engine { article := article.New() router := gin.Default() router.GET("/article", handler.ArticlesGet(article)) router.POST("/article", handler.ArticlePost(article)) return router } func main() { endless.ListenAndServe(":8080", initRouter()) }initRouter()では
gin.Default()でrouterを定義し、これが各リソース・メソッドの振り分けを、ハンドラ関数を呼び出す形でしてくれる。
もっと簡単に↓こんな感じでも動くのだが、これだとテストコードが上手く組めなさそうだったので少し直した。func main() { article := article.New() r := gin.Default() r.GET("/article", handler.ArticlesGet(article)) r.POST("/article", handler.ArticlePost(article)) r.Run() // listen and serve on 0.0.0.0:8080 }mainの
endless.ListenAndServe()の部分なんかはこのサイトで詳細が紹介されている。
わざわざグレースフルリスタートにしなくても他にやり方あったっぽいな…。ハンドラ
こちらもそんなに特別なことはしていない。Ginのフレームワークが簡単に使える理由として、
-c.Bind()で簡単にコンテキストからBodyを取得できる
-c.Status(http.StatusXXX)で簡単ステータスコードを設定できる
-c.JSON(http.StatusXXX, [文字列])で簡単にレスポンスのBodyの文字列をJSONにして返却できる
といったところか。いやこれメチャクチャ簡単だな!handlers/articleFunc.gopackage handler import ( "net/http" "local.packages/modules/article" "github.com/gin-gonic/gin" ) func ArticlesGet(articles *article.Articles) gin.HandlerFunc { return func(c *gin.Context) { result := articles.GetAll() c.JSON(http.StatusOK, result) } } type ArticlePostRequest struct { Title string `json:"title"` Description string `json:"description"` } func ArticlePost(post *article.Articles) gin.HandlerFunc { return func(c *gin.Context) { requestBody := ArticlePostRequest{} c.Bind(&requestBody) item := article.Item{ Title: requestBody.Title, Description: requestBody.Description, } if err := post.Check(item); err != nil { c.Status(http.StatusBadRequest) } else { post.Add(item) c.Status(http.StatusNoContent) } } }Articleモジュール
これは特別なことはしていない単純なモジュール
modules/article/article.gopackage article import ( "log" "errors" ) type Item struct { Title string `json:"title"` Description string `json:"description"` } type Articles struct { Items []Item } func New() *Articles { return &Articles{} } func (r *Articles) Check(item Item) error { if item.Title == "" { log.Println("Title is not specified") log.Println(item) return errors.New("Request Parameter Error") } if item.Description == "" { log.Println("Description is not specified") log.Println(item) return errors.New("Request Parameter Error") } return nil } func (r *Articles) Add(item Item) { r.Items = append(r.Items, item) } func (r *Articles) GetAll() []Item { return r.Items }パッケージ化
パッケージ化も詳細は前回記載済みなので、細かい話は割愛。
今回は以下のように依存関係を定義した。普通にディレクトリ構造を反映しただけ。go.modmodule go-container-test go 1.13 require ( github.com/fvbock/endless v0.0.0-20170109170031-447134032cb6 github.com/gin-gonic/gin v1.6.3 github.com/stretchr/testify v1.4.0 local.packages/handlers v0.0.0-00010101000000-000000000000 local.packages/modules/article v0.0.0-00010101000000-000000000000 ) replace local.packages/handlers => ./handlers replace local.packages/modules/article => ./modules/articlego.modmodule handler go 1.13 require ( github.com/gin-gonic/gin v1.6.3 local.packages/modules/article v0.0.0-00010101000000-000000000000 ) replace local.packages/modules/article => ../modules/articlemodules/article/go.modmodule article go 1.13テストプログラム
今回は、以下のようにinitRouter関数をテストした。
testingではアサーションが使えないので、github.com/stretchr/testify/assertを使ってみた。ぶっちゃけ、全然使いこなせていない。詳細はこの記事が分かりやすい。返ってきたBodyのJSONなんかは、func JSONEqとかを使うべきなんだろうな。本当は、POSTで登録したものをGETして確認したかったのだが、gin.Default()すると初期化されてしまうようで、うまく動かなかった。まあ、コンテナに状態を持つなよってことだな……。
test_main.gopackage main import ( "os" "io" "strings" "testing" "log" "net/http" "net/http/httptest" "github.com/stretchr/testify/assert" ) var () const () func setup() error { return nil } func teardown() error { return nil } func TestInitRouter(t *testing.T) { tests := []struct { method string url string body io.Reader expectedCode int expectedBody string }{ {method: http.MethodGet, url: "/article", body: nil, expectedCode: 200, expectedBody: "null"}, {method: http.MethodPost, url: "/article", body: strings.NewReader("{\"hoge1\":\"hige1\", \"hoge2\":\"hige2\"}"), expectedCode: 400, expectedBody: ""}, {method: http.MethodPost, url: "/article", body: strings.NewReader("{\"Title\":\"test\", \"hoge2\":\"hige2\""), expectedCode: 400, expectedBody: ""}, {method: http.MethodPost, url: "/article", body: strings.NewReader("{\"hoge1\":\"hige1\", \"Description\":\"test desc.\"}"), expectedCode: 400, expectedBody: ""}, {method: http.MethodPost, url: "/article", body: strings.NewReader("{\"Title\":\"test\", \"Description\":\"test desc.\"}"), expectedCode: 204, expectedBody: ""}, } for _, te := range tests { router := initRouter() w := httptest.NewRecorder() request, _ := http.NewRequest(te.method, te.url, te.body) request.Header.Set("Content-Type", "application/json") router.ServeHTTP(w, request) assert.Equal(t, te.expectedCode, w.Code) assert.Equal(t, te.expectedBody, w.Body.String()) } } func TestMain(m *testing.M) { setup() ret := m.Run() teardown() os.Exit(ret) }ビルド
まずはコンテナ化の前にローカルビルドから。
まあ、何も大したことはやってないけど……。Makefilebuild: GOARCH=amd64 GOOS=linux go build -o artifact/go-container-test .PHONY: build test: go test ./... .PHONY: test clean: rm -rf artifact .PHONY: cleanで、しっかりテストまで動いたら、今度はDockerで固める。
JavaでSpringBootなFatJarをコピーするノリで、上記のmake buildしたものをCOPYしたら動かなかった。そりゃそうだ。バイナリなんだから、しっかり実行環境を合わせてビルドしないとね……。ということで、探してみたところ、泥臭いビルド用コンテナでビルドして
extractしてからビルド用コンテナにCOPYして、ということをせずとも、「Docker multistage build」をやれば一つのDockerfileで書けるらしい。素晴らしい。以下の記事に詳しく書かれている。上記を踏まえて、今回のDockerfileは以下のようにする。
DockerfileFROM golang:1.13-alpine3.12 as build ENV GOPATH /go RUN apk add --update --no-cache git COPY . /go/src WORKDIR /go/src RUN go build -o go-container-test . FROM alpine:3.12 RUN mkdir /app WORKDIR /app COPY --from=build /go/src/go-container-test /app/go-container-test CMD ["/app/go-container-test"]これを
docker buildして、docker runすればバッチリ動作するぞ!ちゃんと-p 8080:8080するのは忘れないように。ちなみに、この方法で作ったDockerコンテナのイメージサイズは以下の通り20MBとめちゃくちゃ小さい。Javaのコンテナサイズに慣れてると、かなり凄いと感じる。
REPOSITORY TAG IMAGE ID CREATED SIZE go-container-test latest XXXXXXXXXXXX About an hour ago 21.1MBECSで動かす
もうここまでやってだいぶ疲れたので、先日急にリリースされたCopilotを使ってみる。
Copilotの詳細は以下のClassMethodの記事で。
- 【Developers.IO】ECSのオペレーションを劇的に簡略化するAWS Copilotが発表されました!
さて、これを参考にしながら、copilotをインストールして
copilot initすると……
えっすごい!本当にあの、画面ポチポチでやってもTerraformでやってもCloudFormationでやってもクソ面倒臭いECSとALBの設定がほんのちょっとの質問に答えて10分待つくらいで動いた!
今回は試していないけど、どうやらCI/CDパイプラインまで作れるとか、凄すぎるぜ……。
※ちなみに、今回のアプリはパスが/だと404応答になってしまい、デフォルトの設定ではALBのヘルスチェックが通らなかったので、少しだけ手直しはした。しかし、あまりに動作がブラックボックスすぎてアンコントローラブルにならないのかこれは…。
動かしてみる
やったー動いたー!
$ curl -i -X POST -H "Content-Type: application/json" -d '{"Title":"Hello", "Description":"Hello Gin!!"}' http://go-co-Publi-XXXXXXXXXX.ap-northeast-1.elb.amazonaws.com/article HTTP/1.1 204 No Content Date: Sat, 11 Jul 2020 13:22:36 GMT Connection: keep-alive $ curl -i http://go-co-Publi-XXXXXXXXXX.ap-northeast-1.elb.amazonaws.com/article HTTP/1.1 200 OK Date: Sat, 11 Jul 2020 13:22:39 GMT Content-Type: application/json; charset=utf-8 Content-Length: 47 Connection: keep-alive [{"title":"Hello","description":"Hello Gin!!"}]

- 投稿日:2020-07-11T21:34:53+09:00
【aws-cli】リージョン一覧を出力するコマンド
検証環境
aws-cli 2.0.30
有効になっているリージョンの一覧を出力する
コマンド
$ aws ec2 describe-regions出力
{ "Regions": [ { "Endpoint": "ec2.eu-north-1.amazonaws.com", "RegionName": "eu-north-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-south-1.amazonaws.com", "RegionName": "ap-south-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.eu-west-3.amazonaws.com", "RegionName": "eu-west-3", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.eu-west-2.amazonaws.com", "RegionName": "eu-west-2", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.eu-west-1.amazonaws.com", "RegionName": "eu-west-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-northeast-2.amazonaws.com", "RegionName": "ap-northeast-2", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-northeast-1.amazonaws.com", "RegionName": "ap-northeast-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.sa-east-1.amazonaws.com", "RegionName": "sa-east-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ca-central-1.amazonaws.com", "RegionName": "ca-central-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-southeast-1.amazonaws.com", "RegionName": "ap-southeast-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-southeast-2.amazonaws.com", "RegionName": "ap-southeast-2", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.eu-central-1.amazonaws.com", "RegionName": "eu-central-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.us-east-1.amazonaws.com", "RegionName": "us-east-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.us-east-2.amazonaws.com", "RegionName": "us-east-2", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.us-west-1.amazonaws.com", "RegionName": "us-west-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.us-west-2.amazonaws.com", "RegionName": "us-west-2", "OptInStatus": "opt-in-not-required" } ] }無効になっているリージョンも含めて出力する
コマンド
--all-regionsオプションをつけることで全てのリージョンを出力する。$ aws ec2 describe-regions --all-regions出力
{ "Regions": [ { "Endpoint": "ec2.af-south-1.amazonaws.com", "RegionName": "af-south-1", "OptInStatus": "not-opted-in" }, { "Endpoint": "ec2.eu-north-1.amazonaws.com", "RegionName": "eu-north-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-south-1.amazonaws.com", "RegionName": "ap-south-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.eu-west-3.amazonaws.com", "RegionName": "eu-west-3", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.eu-west-2.amazonaws.com", "RegionName": "eu-west-2", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.eu-south-1.amazonaws.com", "RegionName": "eu-south-1", "OptInStatus": "not-opted-in" }, { "Endpoint": "ec2.eu-west-1.amazonaws.com", "RegionName": "eu-west-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-northeast-2.amazonaws.com", "RegionName": "ap-northeast-2", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.me-south-1.amazonaws.com", "RegionName": "me-south-1", "OptInStatus": "not-opted-in" }, { "Endpoint": "ec2.ap-northeast-1.amazonaws.com", "RegionName": "ap-northeast-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.sa-east-1.amazonaws.com", "RegionName": "sa-east-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ca-central-1.amazonaws.com", "RegionName": "ca-central-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-east-1.amazonaws.com", "RegionName": "ap-east-1", "OptInStatus": "not-opted-in" }, { "Endpoint": "ec2.ap-southeast-1.amazonaws.com", "RegionName": "ap-southeast-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.ap-southeast-2.amazonaws.com", "RegionName": "ap-southeast-2", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.eu-central-1.amazonaws.com", "RegionName": "eu-central-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.us-east-1.amazonaws.com", "RegionName": "us-east-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.us-east-2.amazonaws.com", "RegionName": "us-east-2", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.us-west-1.amazonaws.com", "RegionName": "us-west-1", "OptInStatus": "opt-in-not-required" }, { "Endpoint": "ec2.us-west-2.amazonaws.com", "RegionName": "us-west-2", "OptInStatus": "opt-in-not-required" } ] }
OptInStatusフィールドについて
値 説明 opt-in-not-required デフォルトで有効になっているリージョン not-opted-in 無効になっているリージョン opted-in 有効になっているリージョン 参考
- 投稿日:2020-07-11T18:58:33+09:00
高卒フリーターから、Web系自社開発企業のエンジニアになるまで
はじめに
一浪して入った大学を中退し、webエンジニアを目指して学習を開始してから約半年間、
晴れてweb系自社開発企業様からサーバーサイドエンジニアとして内定を頂けたので、学習過程や、就職活動で得た知見を共有したいと思います。
就職活動中の方のご参考になれば幸いです!僕のスペックは以下の通りです。
今年23歳/高卒/フリーター/社会人経験なし
謙遜ではなく、どう考えても高スペックではありません。
こんな僕が内定を得るためには、そう選択肢はありません。やるべきことは決まっていました。モダンな技術を使用したポートフォリオを作ること。
以下、学習手順と、就職活動内容を書きます。
目次
- ポートフォリオ紹介
- ProgateにてHello World (2020/1月)
- ドットインストールを貪る (2020/2月)
- モダンな技術にチャレンジ(Docker,AWS) (2020/3月)
- ポートフォリオ作成 (2020/4月~6月)
- いざ、就職活動へ (2020/6月~7月)
- 就活を終えての所感
ポートフォリオ紹介
これが僕が作成したポートフォリオになります。
概要
「美味しい」を共有するをモットーに、お食事招待、レストラン検索や料理に関する記事投稿ができるSNSアプリです。
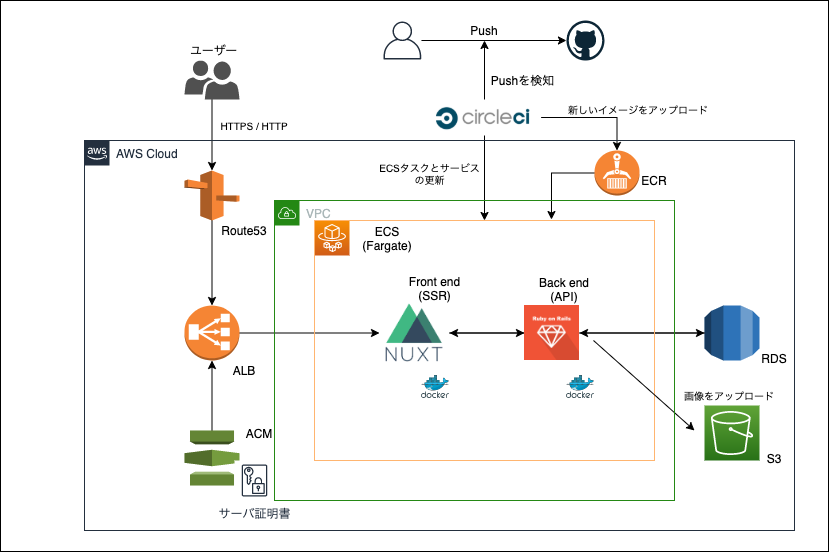
クラウドアーキテクチャ
言語・使用技術
- インフラ
- AWS(ECS-FARGATE/ALB/Route53/VPC/RDS)
- Terraform (本番環境インフラをコードで管理)
- CircleCI (CI/CD)
- Docker/docker-compose
- バックエンド
- Ruby 2.6.3
- Rails(API) 5.2.3
- Mysql 5.7.30
- フロントエンド
- Nuxt.js(SSR) 2.0.0
- element-ui (CSSフレームワーク)
高評価を頂いた点
- トップページ等のデザインが凝ってあり、印象が良い。
- UI/UXが整っている。
- SSR、CI/CD、Terraform等の高度な技術を取り入れている。
補足説明
完成8割段階で就職活動を開始し内定を得られたので、まだまだ改善点が多く、ポートフォリオのレベルとしては高いとは言えないと思います。あくまで必要最低限レベルくらいだったと思います...。
1、ProgateにてHello World (2020/1月)
学習した講座
1 HTML/CSS
2 Javascript
3 Ruby
4 Ruby on rails
5 SQL
6 Command Line
7 Git
「プログラミングを学べば、バイト代くらいは余裕で稼げます」
こんな煽り文句を鵜呑みにした僕は、Progateにて学習を開始します。
各種基本文法をざっくり習得し、「プログラミングってこんな感じなんだな」程度の知見を得ます。
まだ個人でサービスを開発するレベルには程遠い感じでした。2、ドットインストールを貪る (2020/2月)
学習した講座
1 詳解HTML 基礎文法編
2 詳解CSS 基礎文法編
3 詳解JavaScript 基礎文法編
4 詳解JavaScript オブジェクト編
5 詳解JavaScript DOM編
6 ローカル開発環境の構築
7 Ruby on Rails 5 入門
8 Active Record 入門
9 Sinatora 入門
10 Mysql 入門
11 シェルスクリプト 入門
12 その他自分が面白そうと思った講座
ローカル開発環境の構築をハンズオンで行い、自分のローカル上でアプリケーションを開発できるようになりました。
「自分で0からwebアプリを作れる」ということに無限大の可能性を感じ、プログラミングにどっぷりハマります。この段階でプログラミングを小遣い稼ぎではなく、職として学んで行くことを決意しました。
上記の講座以外にも自分で興味を持った講座を貪ってました(寄り道しすぎたのは反省点です...)。
この期間で基礎を徹底的にインプットしまくったおかげで、新しい言語や応用の技術に挑戦するとき、「基礎×基礎」で何でも理解できるという自信がつきました。
まぁ要するに「俺にわからないことはない」という過信ですね。
以降難しい技術の学習が楽しいものと思えるようになったのはこの期間のおかげです。しかし、その過信も次のフェーズで打ち砕かれます。
3、モダンな技術にチャレンジ(Docker,AWS) (2020/3月)
この期間が一番辛かった時期だったと思います。
ローカルで開発したwebアプリを公開したいと思い、AWSの学習を開始しました。
しかし、ここでインフラの壁にぶち当たります。どの入門系書籍や記事を見ても「チョットナニイッテルカワカラナイ」
インフラを理解するにはコンピューターサイエンスの幅広い知識が必要となり、
今までの知見では太刀打ちできません。
吐かれるエラー文も意味がわからず、ググっても解決方法が見つからない...。よって最低限の知識を得るために「キタミ式 基本情報処理技術者試験」を購入し、ざっくり通読しました。
基本ソフトウェア、ネットワーク、セキュリティの知見を得たことで、AWSの各種サービスの役割を理解できるようになりました。世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
次にこの記事をハンズオンでやったおかげで初めてRailsのデプロイに成功しました。さらにDockerを用いた開発手法のメリットも理解できるようになり、「Docker/Kubernetes 実践コンテナ開発入門」を購入し、Dockerにも挑戦しました。
ローカルのRailsアプリをDocker化することに成功したところで、必要な知識はもう十分という実感を得ました。
満を辞してポートフォリオ作成に取り掛かります。4、ポートフォリオ作成 (2020/4月~6月)
参考にした教材や記事
1 Vue,Nuxt超入門
2 Webサイト デザイン集
3 Github 超入門
4 いまさらだけどCircleCIに入門したので分かりやすくまとめてみた
5 初心者でもできる! ECS × ECR × CircleCIでRailsアプリケーションをコンテナデプロイ
6 AWS,FargateとTerraformで最強&簡単なインフラ環境を目指す
この時期は毎日が楽しかったです。
夢中でコード書いて、気づいたら夜が明けていたこともありました(真似しないでください)。
やはりプログラミングが好きなんだなと再実感しました。フロントエンドも何かしらのフレームワークを使い、凝ってみたいと思い、Nuxt.jsを採用し、RailsをAPIサーバーとして連携させる構成にしました。
Nuxtに関しては未学習だったため、教材や公式ドキュメントを見てキャッチアップしながらポートフォリオを作成していきました。あとポートフォリオのトップページやログイン直後の画面はめちゃくちゃ凝っておくことをお勧めします。
採用担当者様からサイトの第一印象でその後の評価も決まるとのアドバイスをいただきました。CI/CDやTerraformの構築に関しては、Qiita等で同様の環境での実装例を調べ、サンプルソースコードで理解できない箇所は公式ドキュメントを参考にしていました。
5、いざ、就職活動へ (2020/6月~7月)
はやく働きたいという焦りから、ポートフォリオ完成の8割の段階でWantedlyへの応募を開始し、就職活動しながらポートフォリオをブラッシュアップしていきました。
実際この選択は失敗だったなと反省しております。
なぜなら応募して返信があった場合、その会社様についての企業研究や面接対策を優先しないといけないため、ポートフォリオに時間を割くことができなかったからです。ある採用担当者様から、「技術力は認めるけど、ちょっと機能が不十分ですね...」とのご指摘を頂く羽目になりました。
「焦り」はこんな簡単なことすら気付けなくしてしまう。恐ろしいですね。
今回希望する企業様から内定を頂けたのは本当に幸いでした。
皆様には100%完成した段階で応募をかけ始めることをお勧めします。結果的に12社応募し、ご返事いただけたのは4社でした。
それと面接対策として僕がやっていたのは
業務未経験のWeb系エンジニア志望者が面接で聞かれる頻出質問とその対策
こちらの動画を参考に、質問における返答のテンプレ集を作成しました。
聞かれる質問の8割ぐらいはこの動画と同様のものでしたので、結果的に大成功でした。そして焦りと後悔の葛藤の中、Twitterへの直営業を考えていた矢先、
第一希望として応募させていただきた企業様から内定の連絡をいただきました。6、就活を終えての所感
「高卒フリーターの業務未経験でもwebエンジニアになれます!」なんて言うのは胡散臭いので気が引けますが、しっかりとしたプロセスを踏めば内定をもらえるというのを証明できたと思います。
学習順序を間違えなかったのが挫折しなかった一番の要因だと思います。
この半年間ここまでの熱量を注げたのはそれくらいプログラミングが好きだったからです。
生半可じゃ確実に無理でした。
今後ともこの熱量を絶やさずWebエンジニアとして成長していきたいと思います。最後までお読みいただきありがとうございました!。
- 投稿日:2020-07-11T18:52:27+09:00
AWS ネットワーク基本概要メモ
リージョン
AWSの各サービスが提供されている地域のこと
日本でサービスを展開する場合は通常tokyoリージョンを使うアベイラビリティゾーン
同一リージョン内のある独立したそれぞれのデータセンターのこと。
1つのリージョンは2つ以上のアベイラビリティーゾーンがある。
離れた距離にデータセンターを持つことで災害に対応できるようにしている。例えばEC2を立ち上げるとき、まずリージョンを選び、アベイラビリティーゾーンを選びます。
そのとき複数のアベイラビリティゾーンにサーバをそれぞれ立ち上げれば、災害などで障害が起こっても、他のサーバは大丈夫なので、障害に強くなる。VPC(バーチャルプライベートクラウド)
AWS上に仮想ネットワークを構築できるサービス。
AWS上にサーバを作るときは、まずVPCを作り、その中をサブネットでわけ、そのサブネットの中にサーバーを設置するという流れになる。リージョンをまたいで作ることはできず、いつのVPCは一つのリージョン内を選択する。
VPC内に複数のサブネットを作れ、それぞれのサブネットの内のアベイラビリティゾーンは違うものが選択できる。サブネット
VPCを作ったら、さらにその中を区切りたい場合はサブネットで区切る。
アベイラビリティゾーンを1つ設定する。
例えばVPC内に2つのサーバ(webサーバ、DBサーバ)を作るとき、webサーバはインターネットからアクセスでき(パブリックサブネット)、DBサーバは隔離(プライベートサブネット)したいとき、それぞれサブネットを分けてアクセスを制御する。IPアドレス 表記法
IPアドレスのネットワーク部とホスト部
例えば
192.168.128.0
このうち前半の192.168.128まではネットワーク部と言い、自分が使用しているネットワークの所までくる所までのネットワークのアドレス。
後半の0の部分はホスト部と言い、自分のネットワークの、どの機器に情報を送るかのアドレスCidr表記
192.168.128.0/24
前半何ビットまでの部分がネットワーク部かを/以下の数値で表した表記法。
この場合は前半24ビットつまり10進数で192.168.128までがネットワーク部でそれ以下がホスト部。ホスト部は、自由はネットワーク内で自由に設定できるよ、任意の数だよ、ということになる。
この場合、192.168.128.0〜192.168.128.255までの256種類のホストを設定できる。サブネットマスク表記
192.168.128.0/255.255.255.0
ネットワーク部を/より後ろの255(つまり2進数で11111111)部分で表し、ホスト部を0(つまり2進数で00000000)部分で表す。VPCとサブネットのIPアドレスの割り当て
VPCやサブネットにはそれぞれアドレスを割り当てる必要がある。
VPCの中にサブネットを構成する場合は、VPCのIPアドレスのホスト部にサブネットを含める。
例として
VPC(IPアドレス 10.0.0.0/16)の中に2つのサブネット(IPアドレス[10.0.10.0/24][10.0.20.0/24])
などのように割り当てる。ルートテーブル
ネットワークは、ルーターがIPアドレスの行き先を管理しているので、ネットワークとネットワークがIPアドレスを通じて接続できる。
AWSではこのルーティングをルートテーブルという形で表現する。
書式としては
宛先IPアドレス 次のルーター(ターゲット) 行き先 10.0.10.0/24 local 自身のネットワーク 10.0.20.0/24 ルーターB 0.0.0.0/0 ルーターC 「デフォルトルート」ルートテーブルのどこにも該当しない場合の経路 外部インターネットにつなげたい場合は0.0.0.0/0のターゲットにインターネットゲートウェイ指定するとインターネットに接続できる
- 投稿日:2020-07-11T18:52:27+09:00
AWS ネットワーク基本概要
リージョン
AWSの各サービスが提供されている地域のこと
日本でサービスを展開する場合は通常tokyoリージョンを使うアベイラビリティゾーン
同一リージョン内のある独立したそれぞれのデータセンターのこと。
1つのリージョンは2つ以上のアベイラビリティーゾーンがある。
離れた距離にデータセンターを持つことで災害に対応できるようにしている。例えばEC2を立ち上げるとき、まずリージョンを選び、アベイラビリティーゾーンを選びます。
そのとき複数のアベイラビリティゾーンにサーバをそれぞれ立ち上げれば、災害などで障害が起こっても、他のサーバは大丈夫なので、障害に強くなる。VPC(バーチャルプライベートクラウド)
AWS上に仮想ネットワークを構築できるサービス。
AWS上にサーバを作るときは、まずVPCを作り、その中をサブネットでわけ、そのサブネットの中にサーバーを設置するという流れになる。リージョンをまたいで作ることはできず、いつのVPCは一つのリージョン内を選択する。
VPC内に複数のサブネットを作れ、それぞれのサブネットの内のアベイラビリティゾーンは違うものが選択できる。サブネット
VPCを作ったら、さらにその中を区切りたい場合はサブネットで区切る。
アベイラビリティゾーンを1つ設定する。
例えばVPC内に2つのサーバ(webサーバ、DBサーバ)を作るとき、webサーバはインターネットからアクセスでき(パブリックサブネット)、DBサーバは隔離(プライベートサブネット)したいとき、それぞれサブネットを分けてアクセスを制御する。
- 投稿日:2020-07-11T18:08:12+09:00
未経験が受託企業に入って1年経ったので、学んだスキル全部書いてみる
はじめに
2019年6月にキャリアをスタートさせました。
Railsエンジニアとして1年でいろいろなことを学んできたので、簡単にまとめていきます。いろいろなキャリアの積み方があるのでどれほど成長できてるのかは不明ですが、ほんの一例としてご参考ください。
※表現のおかしい点等ありましたら、ご指摘頂けますと嬉しいです。前回:未経験が受託企業に入って半年経ったので、学んだスキル全部書いてみる
簡単な経歴
・一般大卒
パソコンスキルはitunesで音楽入れる程度
・某アパレルチェーンで3年勤務
内2年管理職
パソコンスキルはWordで毎週報告書を書く程度
・2018/12〜 Mac購入
某オンラインスクールで勉強開始
・2019/3〜 独学開始、都内もくもく会に週1参加、Menta契約、アプリ作成
・2019/6〜 就職
・2020/7 現在(2年目)半年〜1年で学んだこと
1)技術関連
Ruby/Rails
4ヶ月くらいは毎日触っていました。
入社当初よりだいぶ読むのに抵抗が無くなったなと思ってましたが、初めて別PJに移ると、同じRailsでもすんなり読めない箇所が結構出てきたので、まだまだ甘いんだなと痛感しました。業務フロー的にすごく複雑な機能の設計〜開発を担当し、作りながらお客様と何度も要件を擦り合わせ、完成後も改めてメンバーへ共有するのにはとても苦労した覚えがあります。
また、これまでは機能の追加や改修、0から開発などやってきましたが、次案件では主に
CapybaraSeleniumを使ったスクレイピングをやりました。
Jobの仕組みや各サイトごとの要素取得のコツ、そして今まで以上にbyebugの貴重さを学びました。SQL(ActiveRecord)
実際に使ってもらうお客様の1部署が多忙で、システムを使っての作業まで回らないということがよくあり、最初のうちはこちらで「毎月◯日に叩くコマンド」というのを複数用意して実行していました(もうやりたくない)。
基本的には某テーブルに溜まっている先月分のデータのステータスを、条件に当てはまれば全て「未→承認」に変える、というものでしたが、先方の業務フローがいまいち不明瞭だったり、イレギュラーがあまりにも多く、実際のデータに弾かれて一発で終わるなんてまあありませんでした。
そのため「叩く→止まる(トランザクションで戻る)→要件確認して都度コード修正」が毎回しばらく続きました。こんな書き方があるのか、というところまで色々と試しながら書いていけたかなと思います。
Git
わざわざ書くことではないかもですが、日常的に
git stashgit log --onelineを使うようになりました。
また、コンフリクトが発生しても、焦らずに冷静に対応できるようになりました(経験って怖い)。WordPress
Rails案件と掛け持ちして、20%くらいの時間を割いてやってました。
テーマ選定(Cocoon,OnePress等5テーマで試作)から、実際のお客様の要望に合わせたサイト製作、複数プラグイン導入、
Lightsailでのサーバー利用、Route 53でのドメイン作成、Letsencryptを使用したSSL化、Google Analyticsなどの周辺設定 等、一通り経験できました。直接PHPをいじっての細かいカスタマイズはまだまだできないですが、テーマに乗っかればそこそこのサイトなら作れるようになりました。
0から新規サービス立ち上げ
こちらはとても良い経験になりました。
同PJ内ではありますが、新規サービスの要件定義〜設計〜開発〜テスト〜リリースまで一貫して行いました。
コンセプトは同じでもユーザー層が変わったため、画面が業務用のB向け→C向けに変わったのが印象的でした。タイトなスケジュールの中、Railsはもちろん、Deviseの詳細設定や別サービスとのDB共有、Viewの細かい調整やまで行いました。
Pure CSSに慣れてなく、初めてフロントが嫌になりました(当時)。AWS
実務では主に
CloudFrontAWS WAFElastic Load BalancerACMRoute 53あたりを触りました。
まったく分からない中でなんとか模索しつつ、何日も日を跨ぎながらやった記憶があります。
セキュリティの仕組みと知識が大まかにつきました。
他にもCloudWatchTrusted AdvisorGuardDutyあたりも触りました。
気付いたらコンソール画面への抵抗も無くなっていました。
だいぶ時間を使ってたので、コードが書きたいなあと思うことも多かったです。個人では
AWS SAAという資格に合格しました。
実務で触ったあとにかなりの実力不足を痛感したので、せめて最低ラインまで浅く広く知識を得たいと思い学習し始めました。
結果、半年前の目標を達成できた形になりました。AWS認定ソリューションアーキテクトアソシエイト(AWS SAA)合格記
↑ 詳細はこちらに書いてますので、よかったら読んでみてください。ステージング/本番環境へのデプロイ
新規サービス立ち上げ時も、相変わらず毎週のようにデプロイ作業を行なっていました。
本番が落ちるなんていつものことでした(まだリリース前だったので勘弁)。
焦りながら必死でバグを見つけて修正していたので、デプロイする日は胃がキリキリしていました。開発環境がガラッと変わると、本番へ反映させてもcssがうまく反映されずなんだこりゃと思うことがありましたが、単純に
rails assets:precompileを忘れてただけということがありました。今まで先人の用意したデプロイ一括コマンドにあやかって叩いてたので、甘えてたなと思うと同時に、そういえば自分の独学時代もHerokuにだけcss反映されずによく困ってたなwとか思い出して、懐かしんでました。
2)顧客対応
タスク/スケジュール管理
PLを任されていた関係で、雨のように降り注いでくる要望の全てを、お客様用へは
ガントチャート、社内ではTrelloでまとめて管理していました。
ガントチャートはGoogleスプレッドシートから使用していました。
エクセルができないまま使い始めたので、大学時代にちゃんとやっとけば後悔しました。
Googleスプレッドシートを爆速で活用するための基本&応用の関数10選
Trelloは自分で提案して導入し、時間の限られる中でチームで効率よくタスクが見渡せるように工夫しました。
カスタマイズがしやすかったので、カードごとの工数表示やボードごとの自動工数計算など、必要なものはどんどん取り入れてました。
小規模チームのタスクをTrelloで管理する業務効率化
半年前にもありましたが、対応部署の増加や繁忙期が重なるなどでやりとりに苦戦するようになり、さらなる工夫が求められました。
・毎週のMTGを必要がない限り無くした
・部署ごとのチャットでの問い合わせで、問題に対する情報が足りず何往復もすることが多かったため、必須項目を絞り込みGoogleフォーム問い合わせ+スプレッドシート自動更新+slack通知で大幅な時短化をさせた
・なるべく常にYESで答えていたが、多すぎるタスク量と開発の優先順位を考えてNOも使うようにした(でも相手の気を損ねないようにする)などを行いました。
[補足]次の1年でやりたいこと
今後学びたいスキルを書いていきます。
開発に力を入れたいです。※ アドバイス等頂けると嬉しいです。
Rails
上でも書いてますが案件が代わり改めて基礎力が低いことを通感しました。
原点に戻って、基礎からサッと復習したいなと思います。
Ruby on Rails チュートリアル
プロを目指す人のためのRuby入門 言語仕様からテスト駆動開発・デバッグ技法まで
現場で使える Ruby on Rails 5速習実践ガイドあとは別PJだけでなく、社外で書かれてるコードを読むのも勉強になるので、githubで公開されてるコード等を積極的に読みたいです。
AWSをいじる
資格こそ取ったものの、実際に触るとなると全然できる自信がありません。
いわゆる「頭でっかち」状態だと思います。自分でVPC周りを組み立ててみたり、LambdaやSQSなどよく使われているであろうサービスにも慣れておきたいです。
できればコンテナサービス周りにも手を出してみたいです(先にDockerの勉強も必要ですが…)JavaScript
実務であまりJavaScriptを触っておらず、エンジニアとして結構な弱点だと感じています。
Vue.jsやReactなどに焦点をおかず、まずはじっくり生JavaScriptに慣れていこうと思います。改訂新版JavaScript本格入門 ~モダンスタイルによる基礎から現場での応用まで
JavaScript Primer
まずはこの辺りを参考にする予定です。IT基礎
知識不足を日々感じます。
まずは基本情報でIT基礎を網羅的に頭に叩き込みます。
時期もちょうど良いので、秋の試験まで受けてしまおうかなと。その後
LinuxSQLあたりも、王道めな技術書をざっと読んで早く頭に入れてしまいたいです。チームリーダー
一度経験させて頂きましたが、やや特殊な案件だった(笑)ため、普通の案件で経験してみたいです
相手が強いエンジニアの方でもきちんとコミュニケーションできるように、早くITスキルを高めていきます。突破力
ググり力こそ上がりましたが、基礎知識不足のせいか諦めて社内の人を頼ることも多々ありました。
ベースの力をつけるのはもちろん、その上で分からないことも粘り強く最後まで諦めないようにして、突破できる力をつけたいです。
ただ仕事なので、これ以上無駄だと判断したらタイミングよく見切るクセもつけたいです。なるべく意識してるのですが、この境目がなかなか難しいです。
- 投稿日:2020-07-11T15:52:38+09:00
AWSコスト削減でやってみたこと
はじめに
サービス開始後、時間が経つにつれ肥大化するAWSのコスト。
とうとうその金額に白羽の矢が立った為、AWSのコストを削減する9の方法 を実際に試したので、その実施内容を紹介します。1. 未使用状態のAmazon EC2やAmazon RDS インスタンスへの支払いを止める
効果が最も高かったのがこれです。すぐに着手すべき最強の一手でした。
EC2のスケジューリング
DEV環境やSTG環境は平日夜間・休日は使用しないしない為、平日日勤のみ起動するようにしました。
Auto Scalingで管理していたので、Auto Scaling のスケジュールに基づくスケーリングを利用しました。また、公式にAWS Instance Schedulerというものがあるのでこちらを利用しても良いかもしれません。RDSのスケジューリング
こちらもEC2同様、平日日勤のみ起動するようにしました。
RDSインスタンスの起動停止はboto3によるRDSインスタンスの起動停止を行うLambdaを作成し、cloudwatch eventで定期実行させています。2. Amazon DynamoDB にはオンデマンドのキャパシティーモードを利用する
DynamoDBの課金形態は「オンデマンドキャパシティー」という使った分だけ費用が発生するものと、「プロビジョニング済みキャパシティー」という予め需要予測を行い、指定したキャパシティに応じて費用が発生するものの2種類があります。
今回は、費用対リクエストの観点でクラスメソッドさんのDynamoDBのオンデマンドとプロビジョニングの料金を比較をしてみたを参考にコストを見積もり、
- オンデマンドキャパシティーを利用
- プロビジョニング済みキャパシティーにてキャパシティ容量を最適化
の2種類で対応しました。
3. 十分に活用されていないEC2インスタンス(RDSインスタンス)への支払いを止める
インスタンスタイプが需要に対して過剰に設定されているインスタンスのダウンサイジングを実施しました。
資料中には「CPU使用率が 40% 未満」が一つの目安として挙げられており、こちらを参考にしています。RDSインスタンスも同様にダウンサイジングを行ましたが、EC2に比べこちらの方が効果は大きいように感じています。
理由の一つとして、RDSインスタンスはEC2インスタンスに比べ1インスタンスあたりの料金が高いことがあるのではないかと思います。4. 十分に活用されていないネットワークリソースを削除する
不要なELB、EIP の削除を実施しました。
各AWSコンポーネントはコードで管理していたのですが、EIPはコード管理していなかった為、一時的に取得されたものや不要になったものが存在していました。5. Savings Plans、リザーブドインスタンスを利用する
常時起動前提のインスタンスはスケジューリングによる停止ができない為、Savings Plans及びリザーブドインスタンスの利用によりコストを削減しました。
Savings Plansは昨年発表された新しい割引プランですが、リザーブドインスタンスとの使い分けとして以下の使い分けができそうです。
EC2インスタンス、Fargate、Lambda -> Savings Plans
RDS、Redshift、ElastiCache、Elasticsearch -> リザーブドインスタンスまとめ
AWSコストはEC2インスタンスとRDSインスタンスの占める割合が多いことを改めて感じさせられました。
闇雲に手を付けて工数対削減費用効果が弱くなることを懸念していた中で今回の要点は良かったように思います。
日々のコスト管理もできるようにしたいですね!参考文献
この記事は以下の情報を参考にして執筆しました。
- 投稿日:2020-07-11T14:40:36+09:00
「自分用メモ」AWSのベストプラクティスとなる主な設計原則
■主な設計原則には次のような内容がある。
◎スケーラビリティ
◎デプロイ可能なリソース
◎環境の自動化
◎疎結合化
◎サーバー代わりのマネージドサービス
◎柔軟なデータストレージオプション
- 投稿日:2020-07-11T14:18:12+09:00
【AWS】WordPress「画像を切り抜く際にエラーが発生しました。」の対処方法
現象
Amazon LinuxインスタンスでWordpressをたてた。その際に画像を編集すると「画像を切り抜く際にエラーが発生しました。」とエラーが発生し、画像を切り抜けない。
原因
原因はphp-gdというプログラムがインストールしていないため。
実際にphp-gdがインストールされているか、下記コマンドを入力して確かめたが、やはりインストールされていなかった。yum info php-gd表示結果
$ yum info php-gd 読み込んだプラグイン:xxx 利用可能なパッケージ 名前 : php-gd アーキテクチャー : xxx バージョン : xxx リリース : xxx 容量 : xxx リポジトリー : xxx 要約 : A module for PHP applications for using the gd graphics : library URL : http://www.php.net/ ライセンス : PHP and BSD 説明 : The php-gd package contains a dynamic shared object that : will add support for using the gd graphics library to PHP(一部内容省略)
対処法
1.php-gdを下記コマンドでインストール。
sudo yum -y install php-gd2.下記コマンドで再起動して有効化。
sudo systemctl restart httpd.service3.念のため、再起動できているか確認。
sudo systemctl status httpd.service4.php-gdがインストールされているか確認。
$ yum info php-gd 読み込んだプラグイン:xxx インストール済みパッケージ 名前 : php-gd アーキテクチャー : xxx バージョン : xxx リリース : xxx 容量 : xxx リポジトリー : installed 提供元リポジトリー : xxx 要約 : A module for PHP applications for using the gd graphics : library URL : http://www.php.net/ ライセンス : PHP and BSD 説明 : The php-gd package contains a dynamic shared object that : will add support for using the gd graphics library to PHP.(一部内容省略)
上記作業で、画像を編集する際も「画像を切り抜く際にエラーが発生しました。」というエラーが解消され、画像を切り抜けるようになった。
参考
https://webbibouroku.com/Blog/Article/wordpress-php-gd
https://www.it-swarm-ja.tech/ja/php/amazon-linux-2%e3%81%aegd%e7%94%bb%e5%83%8f%e6%8b%a1%e5%bc%b5%e3%81%ab%e9%96%a2%e3%81%99%e3%82%8b%e5%95%8f%e9%a1%8c/807484822/
- 投稿日:2020-07-11T13:18:51+09:00
【AWS】EC2インスタンスにnode.jsをインストールしてサンプルプログラムを実行
環境
Windows 10 Home
Tera Term 4.105(Macの人はTerminal)前提
・Amazon Linux EC2
-SSH接続可能
-アウトバウンドのHTTP接続が可能node.jsをインストール
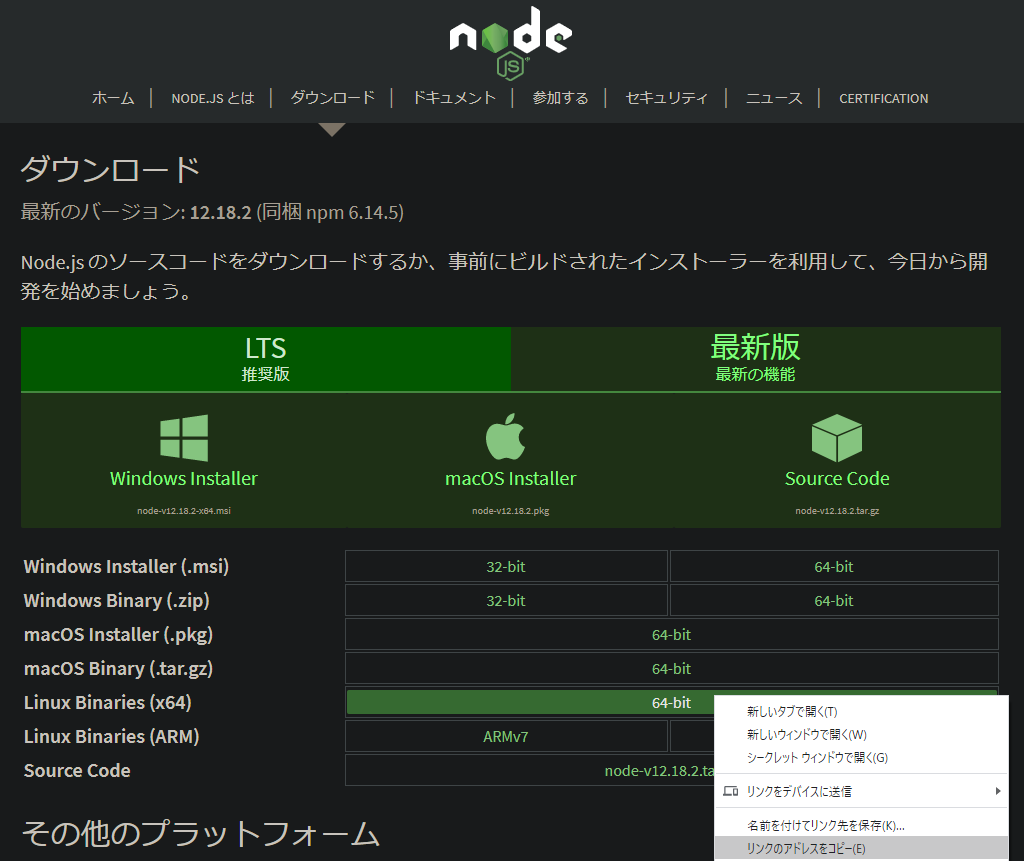
ec2-linux$ cd ~ $ wget https://nodejs.org/dist/v12.18.2/node-v12.18.2-linux-x64.tar.xz公式サイトから最新バージョンのリンクを取得
node-v12.18.2-linux-x64.tar.xz
ec2-linux$ cd ~ $ wget https://nodejs.org/dist/v12.18.2/node-v12.18.2-linux-x64.tar.xztarファイルがあることを確認
ec2-linux$ ls $ node-v12.18.2-linux-x64.tar拡張子がxzになっているのでtarに変換
ec2-linux$ mv node-v12.18.2-linux-x64.tar.xz node-v12.18.2-linux-x64.tar解凍
ec2-linux$ tar xvf node-v12.18.2-linux-x64.tar色々出力されて止まったら解凍完了
実行コマンドがインストールされるnode-v12.18.2-linux-x64/binにパスを設定して移動
ec2-linux$ export PATH=$PATH:~/node-v12.18.2-linux-x64/bin $ cd node-v12.18.2-linux-x64/binapp.jsというサンプルプログラムを用意
app.jsconst http = require('http'); const hostname = 'localhost'; const port = 8080; const server = http.createServer((req, res) => { res.statusCode = 200; res.setHeader('Content-Type', 'text/plain'); res.end('Hello World'); }); server.listen(port, hostname, () => { console.log(`Server running at http://${hostname}:${port}/`); });実行
ec2-linux$ touch app.js $ vim app.js ~~~~~~サンプルプログラムを貼付け(vimコマンドは各自お調べください)~~~~~~ $ node app.js Server running at http://localhost:8080/
- 投稿日:2020-07-11T13:11:13+09:00
Amazon Rekognitionによる同一人物検出
前回に引き続き、Amazon Rekognitonを使って同一人物の検出を行ってみました。
概要
Amazon Rekognitionのcompare_facesというAPIを使って同一人物の検出を行います。compare_facesに2つの画像を入力するのですが、1つ目が検出したい人物の映った画像、2つ目が検出対象の画像となります。
実行環境
OS:Windows10
言語:Python3.7事前準備
AWS CLI(aws configure)にて、以下の認証情報をセットしておきます。
AWS Access Key ID
AWS Secret Access Key
Default region name
Default output formatソースコード(face_compare.py)
face_compare.pyimport boto3 import sys from PIL import Image,ImageDraw # 引数のチェック if len(sys.argv) != 3: print('2つの画像ファイルを引数に指定してください。') exit() # Rekognitionのクライアントを作成 client = boto3.client('rekognition') # 画像ファイル2つを引数としてcompare_facesを実行 with open(sys.argv[1],'rb') as source: with open(sys.argv[2],'rb') as target: response = client.compare_faces(SourceImage={'Bytes':source.read()},TargetImage={'Bytes':target.read()}) # 同一人物が検出されない場合は処理終了 if len(response['FaceMatches'])==0: print('同一人物は検出されませんでした。') else: # 2つ目の画像ファイルを元に、矩形セット用の画像ファイルを作成 img = Image.open(sys.argv[2]) imgWidth,imgHeight = img.size draw = ImageDraw.Draw(img) # 検出された顔の数分、矩形セット処理を行う for faceMatch in response['FaceMatches']: # BoundingBoxから顔の位置・サイズ情報を取得 box = faceMatch['Face']['BoundingBox'] left = imgWidth * box['Left'] top = imgHeight * box['Top'] width = imgWidth * box['Width'] height = imgHeight * box['Height'] # 矩形の位置・サイズ情報をセット points = ( (left,top), (left + width,top + height) ) # 顔を矩形で囲む draw.rectangle(points,outline='lime') # 画像ファイルを保存 img.save('detected_' + sys.argv[2]) # 画像ファイルを表示 img.show()簡単な解説
概略としては以下のような処理を行っています。
①プログラム実行時の引数からRekognitionに入力する2つの画像ファイルを取得する。
②上記①の画像ファイルを引数としてRekognitionのcompare_facesを実行する。
③Rekognitionから返却されるJsonのFaceMatches・BoundingBoxから、認識された顔の位置・サイズ情報を取得する。
④上記③から矩形付きの画像ファイルを作成し、表示する。実行結果
コマンド
python face_compare.py ichiro1.jpg ichiro2.jpg入力画像1(ichiro1.jpg)
入力画像2(ichiro2.jpg)
出力画像(detected_ichiro2.jpg)
イチロー選手を検出してくれました。
まとめ
前回のdetect_facesと同様に、APIを使って簡単に画像認識を行うことができます。compare_facesを使うことで、大量の画像から探したい人物が映っているものを簡単に抽出することができると思います。AWSのサイトによると、日本では新聞社や写真サービスの会社などで使われているようです。



- 投稿日:2020-07-11T12:59:05+09:00
【AWS SDK】EC2自動構築用スクリプト
目標
AWS SDK(AWS SDK for Ruby)を利用してEC2自動構築を行う。
はじめに
AWS SDKの基礎知識をまとめた後、実際の動作をAWS SDK for Rubyを利用したEC2自動構築で試してみます。
AWS SDK
AWSが提供しているAPIの一種で、AWSがサポートする様々なプログラミング言語にライブラリとしてインポートして利用します。
現在以下の言語がサポートされており、各種プログラムからのAWSリソース操作を可能にします。・C++
・Go
・Java
・JavaScript
・.NET
・Node.js
・PHP
・Python
・Ruby(本記事ではこれを利用)AWS CLI、SDK利用時の認証
AWS CLI(OSコマンドライン上やシェルスクリプト、PowerShell上で利用)、AWS SDK(各種プログラミング言語上で利用)を利用する際には認証情報が必要となります。
認証情報の設定方法には以下3つの方法が存在しており、参照優先度が異なります。
項番 優先度 認証情報の設定箇所 1 高 OS環境変数 2 中 認証情報ファイル 3 低 インスタンスプロファイル(IAMロール認証) ①OS環境変数
環境変数のAWS_ACCESS_KEY_ID および AWS_SECRET_ACCESS_KEYという環境変数を利用して認証情報の設定が可能です。
認証設定方法の中で最も優先度が高いです。
例えば以下のように設定を行います。# For LINUX export AWS_ACCESS_KEY_ID=your_access_key_id export AWS_SECRET_ACCESS_KEY=your_secret_access_key # For Windows set AWS_ACCESS_KEY_ID=your_access_key_id set AWS_SECRET_ACCESS_KEY=your_secret_access_key②認証情報ファイル
OSユーザのホームディレクトリ内の「aws」ディレクトリに存在する「credentials」というファイルが認証情報ファイルです。
そのファイル内のaws_access_key_idとaws_secret_access_keyにアクセスキーとシークレットアクセスキーを投入します。# 認証情報ファイル ~/.aws/credentials[default] aws_access_key_id = your_access_key_id aws_secret_access_key = your_secret_access_key③インスタンスプロファイル
インスタンスプロファイルとは、IAMロールを利用した認証で利用される実行環境ことです。
IAMロール作成時に自動作成されます。
IAMロールを納めるための容器であり、EC2にアタッチする時に必要なコネクターの役割をするようです。
IAMロールを利用するこの認証方法はAWS SDK及びAWS CLI利用時のベストプラクティスであり、アクセスキーとシークレットアクセスキーを利用する上記2つの方法より認証情報漏洩のリスクが軽減されるため推奨されております。
ちなみに、認証方法としての優先度が最も低いため、環境変数や認証情報ファイル内の情報に注意を払う必要があります。インスタンスプロファイルの詳細に関しては、以下サイトが参考になりました。
EC2にIAMRole情報を渡すインスタンスプロファイルを知っていますか?作業の流れ
項番 タイトル 1 AWS SDK for Rubyのセットアップ 2 EC2自動構築用スクリプトのセットアップ 3 動作検証 手順
1.AWS SDK for Rubyのセットアップ
①AWS SDK for Rubyインストール
かなり時間かかるので注意…gem install aws-sdk②アクセスキーとシークレットアクセスキーの発行
アクセスキーとシークレットアクセスキーが未発行の場合は新規作成する必要があります。
手順は以下を参考
【AWS CLI】Red Hat Enterprise Linux 8でAWS CLIを使用可能にする(3. アクセスキーIDとシークレットアクセスキーの発行)③認証情報ファイルの編集
今回はAWS SDKの認証情報を認証情報ファイル内に設定する形で保存します。
認証情報ファイル~/.aws/credentials内のaws_access_key_idとaws_secret_access_keyにアクセスキーとシークレットアクセスキーを記載してください。# 認証情報ファイル編集 vi ~/.aws/credentials[default] aws_access_key_id = your_access_key_id aws_secret_access_key = your_secret_access_key2.EC2自動構築用スクリプトのセットアップ
①EC2自動構築用スクリプトをAWS SDKをセットアップした環境に配備
スクリプト内の各種環境依存の変数(<ami_id>、<keypair_name>、<security_group_id>、<instance_type>、<az_name>、<subnet_id>、<userdata_pass>)は環境に従って書き換えをします。また、
<userdata_pass>に指定したファイルの中にはEC2に設定したいユーザデータ処理を書いておきます。ファイル名: ec2_create.rb# ********************************************************************************** # 機能概要: EC2の自動構築 # スクリプト用法: ruby <スクリプトパス> <インスタンス名> # ********************************************************************************** unless ARGV.size() == 1 puts "The number of arguments is incorrect." exit end require 'aws-sdk' require 'base64' # EC2の構成要素定義(以下変数を環境に応じて編集) image_id = '<ami_id>' # AMIID key_name = '<keypair_name>' # キーペア名 security_group_ids = '<security_group_id>' # セキュリティグループID instance_type = '<instance_type>' # インスタンスタイプ availability_zone = '<az_name>' # 利用AZ subnet_id = '<subnet_id>' # 利用サブネットID user_data = '<userdata_pass>' # ユーザデータのファイルパス # ユーザデータ設定 if File.exist?(user_data) file = File.open(user_data) script = file.read file.close else script = '' end encoded_script = Base64.encode64(script) # EC2リソース操作用インスタンス作成 ec2 = Aws::EC2::Resource.new # EC2作成実施 instance = ec2.create_instances({ image_id: image_id, min_count: 1, max_count: 1, key_name: key_name, security_group_ids: [security_group_ids], user_data: encoded_script, instance_type: instance_type, placement: { availability_zone: availability_zone }, subnet_id: subnet_id }) # インスタンスが利用可能になるまで待機 ec2.client.wait_until(:instance_running, {instance_ids: [instance[0].id]}) # インスタンス名(Nameタグ)を付与 instance_name = ARGV[0] instance.batch_create_tags({ tags: [{ key: 'Name', value: instance_name }]}) puts "#{instance_name}(#{instance[0].id})が作成されました!"3.動作検証
<前提>
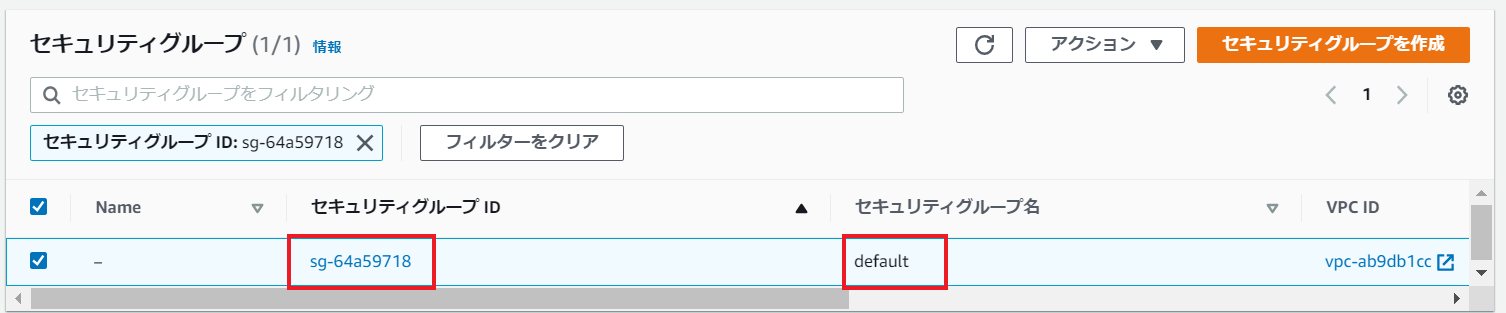
以下のパラメータでEC2を作成します。# EC2の構成要素定義(以下変数を環境に応じて編集) image_id = 'ami-067152a7c26866dcb' # AMIID key_name = 'mykeypair' # キーペア名 security_group_ids = 'sg-64a59718' # セキュリティグループID instance_type = 't2.medium' # インスタンスタイプ availability_zone = 'ap-northeast-1a' # 利用AZ subnet_id = 'subnet-41d23b09' # 利用サブネットID user_data = '/tmp/userdata' # ユーザデータのファイルパスまた、EC2に設定予定のユーザデータは以下の内容
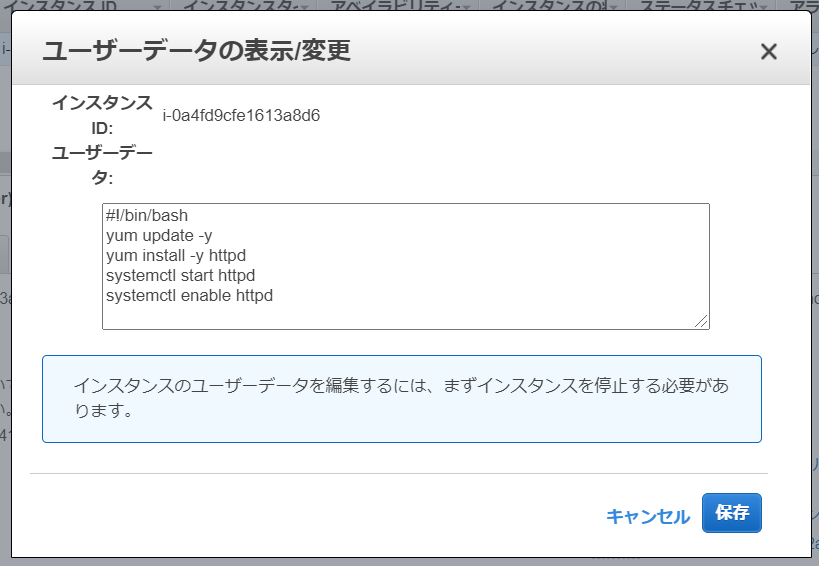
$ cat /tmp/userdata #!/bin/bash yum update -y yum install -y httpd systemctl start httpd systemctl enable httpd①スクリプト実行
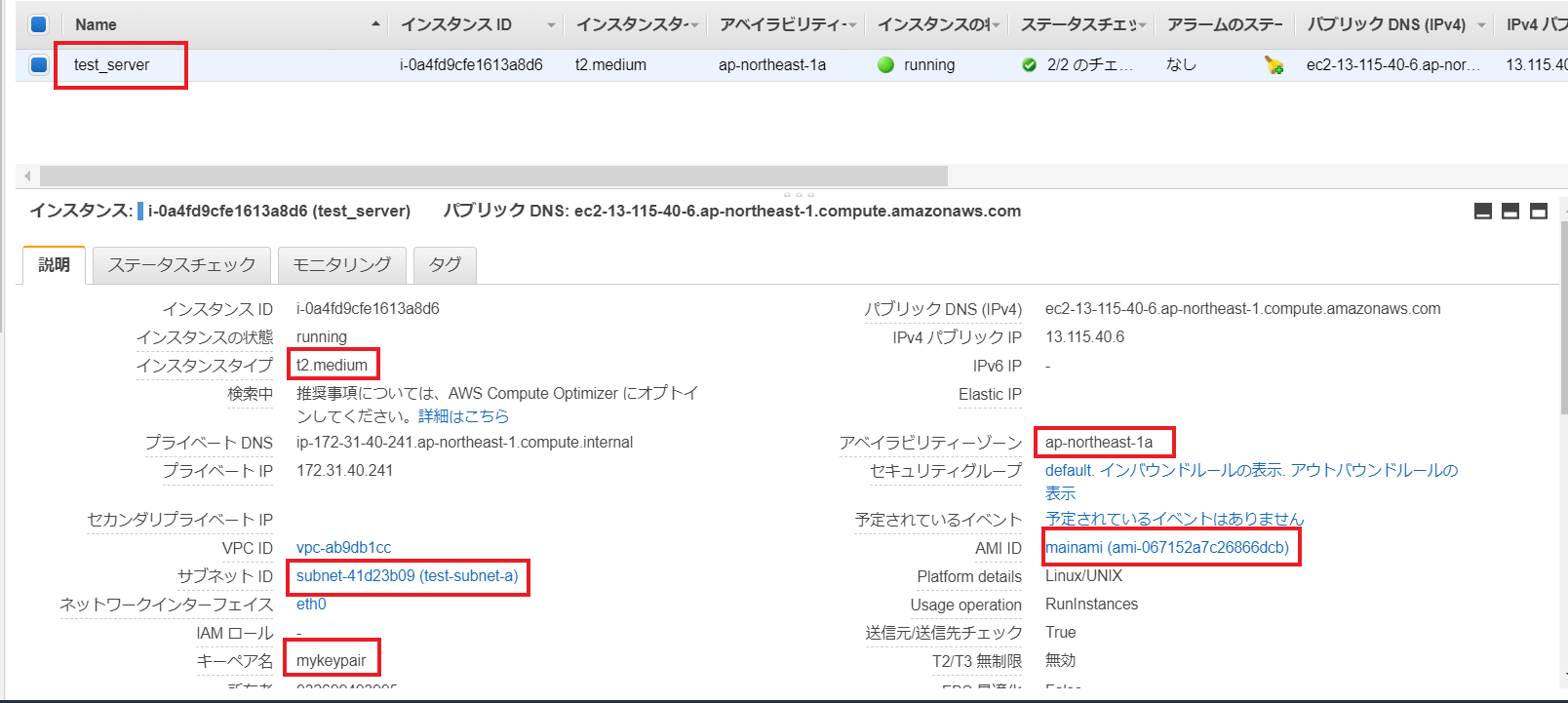
インスタンス名を第一引数に指定してスクリプト実行します。$ ruby ec2_create.rb test_server test_server(i-0a4fd9cfe1613a8d6)が作成されました!②結果確認
インスタンス名、インスタンスタイプ、サブネットID、キーペア名、AZ名、AMIIDがスクリプト内での設定値通り設定されています。
付与されているセキュリティグループもOK
ユーザデータも内容適切でした。
一応OSログイン確認と、ユーザデータが正常に実行されているかも確認してみます。
# httpdがユーザデータ実行により起動している $ systemctl status httpd ● httpd.service - The Apache HTTP Server Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled) Active: active (running) since Sat 2020-07-11 03:03:01 UTC; 12min ago Docs: man:httpd.service(8) Main PID: 21821 (httpd) Status: "Total requests: 0; Idle/Busy workers 100/0;Requests/sec: 0; Bytes served/sec: 0 B/sec" CGroup: /system.slice/httpd.service tq21821 /usr/sbin/httpd -DFOREGROUND tq21831 /usr/sbin/httpd -DFOREGROUND tq21832 /usr/sbin/httpd -DFOREGROUND tq21833 /usr/sbin/httpd -DFOREGROUND tq21834 /usr/sbin/httpd -DFOREGROUND mq21835 /usr/sbin/httpd -DFOREGROUND Jul 11 03:03:01 ip-172-31-40-241.ap-northeast-1.compute.internal systemd[1]: Starting The Apache HTTP Server... Jul 11 03:03:01 ip-172-31-40-241.ap-northeast-1.compute.internal systemd[1]: Started The Apache HTTP Server. # また、enabledにもなっている $ systemctl is-enabled httpd enabled全て設定値通りに作成されているのでOKとします!
参考サイト
各種サービスにおけるAWS SDK For Rubyを利用した実装例が確認できます。
AWS SDK for Ruby コード例所感
AWS CLIは業務でよく使っていたのですが、AWS SDKを使ったのはこれが初でした。
AWS CLIよりコーディングとしての実装はかなり楽に感じます(例えばインスタンスのステータス待ちなどは、AWS CLIだとForループで何秒間隔で状態確認をするみたいな実装をしていたのですが、AWS SDKだとwait_untilメソッドを呼ぶだけの1行コードで済んでしまいました)。
今回は以上です。見て頂きありがとうございました。
- 投稿日:2020-07-11T12:59:05+09:00
【AWS SDK】EC2自動構築用スクリプト開発
目標
AWS SDK(AWS SDK for Ruby)を利用してEC2自動構築を行う。
はじめに
AWS SDKの基礎知識をまとめた後、実際の動作をAWS SDK for Rubyを利用したEC2自動構築で試してみます。
AWS SDK
AWSが提供しているAPIの一種で、AWSがサポートする様々なプログラミング言語にライブラリとしてインポートして利用します。
現在以下の言語がサポートされており、各種プログラムからのAWSリソース操作を可能にします。・C++
・Go
・Java
・JavaScript
・.NET
・Node.js
・PHP
・Python
・Ruby(本記事ではこれを利用)AWS CLI、SDK利用時の認証
AWS CLI(OSコマンドライン上やシェルスクリプト、PowerShell上で利用)、AWS SDK(各種プログラミング言語上で利用)を利用する際には認証情報が必要となります。
認証情報の設定方法には以下3つの方法が存在しており、参照優先度が異なります。
項番 優先度 認証情報の設定箇所 1 高 OS環境変数 2 中 認証情報ファイル 3 低 インスタンスプロファイル(IAMロール認証) ①OS環境変数
環境変数のAWS_ACCESS_KEY_ID および AWS_SECRET_ACCESS_KEYという環境変数を利用して認証情報の設定が可能です。
認証設定方法の中で最も優先度が高いです。
例えば以下のように設定を行います。# For LINUX export AWS_ACCESS_KEY_ID=your_access_key_id export AWS_SECRET_ACCESS_KEY=your_secret_access_key # For Windows set AWS_ACCESS_KEY_ID=your_access_key_id set AWS_SECRET_ACCESS_KEY=your_secret_access_key②認証情報ファイル
OSユーザのホームディレクトリ内の「aws」ディレクトリに存在する「credentials」というファイルが認証情報ファイルです。
そのファイル内のaws_access_key_idとaws_secret_access_keyにアクセスキーとシークレットアクセスキーを投入します。# 認証情報ファイル ~/.aws/credentials[default] aws_access_key_id = your_access_key_id aws_secret_access_key = your_secret_access_key③インスタンスプロファイル
インスタンスプロファイルとは、IAMロールを利用した認証で利用される実行環境ことです。
IAMロール作成時に自動作成されます。
IAMロールを納めるための容器であり、EC2にアタッチする時に必要なコネクターの役割をするようです。
IAMロールを利用するこの認証方法はAWS SDK及びAWS CLI利用時のベストプラクティスであり、アクセスキーとシークレットアクセスキーを利用する上記2つの方法より認証情報漏洩のリスクが軽減されるため推奨されております。
ちなみに、認証方法としての優先度が最も低いため、環境変数や認証情報ファイル内の情報に注意を払う必要があります。インスタンスプロファイルの詳細に関しては、以下サイトが参考になりました。
EC2にIAMRole情報を渡すインスタンスプロファイルを知っていますか?作業の流れ
項番 タイトル 1 AWS SDK for Rubyのセットアップ 2 EC2自動構築用スクリプトのセットアップ 3 動作検証 手順
1.AWS SDK for Rubyのセットアップ
①AWS SDK for Rubyインストール
かなり時間かかるので注意…gem install aws-sdk②アクセスキーとシークレットアクセスキーの発行
アクセスキーとシークレットアクセスキーが未発行の場合は新規作成する必要があります。
手順は以下を参考
【AWS CLI】Red Hat Enterprise Linux 8でAWS CLIを使用可能にする(3. アクセスキーIDとシークレットアクセスキーの発行)③認証情報ファイルの編集
今回はAWS SDKの認証情報を認証情報ファイル内に設定する形で保存します。
認証情報ファイル~/.aws/credentials内のaws_access_key_idとaws_secret_access_keyにアクセスキーとシークレットアクセスキーを記載してください。# 認証情報ファイル編集 vi ~/.aws/credentials[default] aws_access_key_id = your_access_key_id aws_secret_access_key = your_secret_access_key2.EC2自動構築用スクリプトのセットアップ
①EC2自動構築用スクリプトをAWS SDKをセットアップした環境に配備
スクリプト内の各種環境依存の変数(<ami_id>、<keypair_name>、<security_group_id>、<instance_type>、<az_name>、<subnet_id>、<userdata_pass>)は環境に従って書き換えをします。また、
<userdata_pass>に指定したファイルの中にはEC2に設定したいユーザデータ処理を書いておきます。ファイル名: ec2_create.rb# ********************************************************************************** # 機能概要: EC2の自動構築 # スクリプト用法: ruby <スクリプトパス> <インスタンス名> # ********************************************************************************** unless ARGV.size() == 1 puts "The number of arguments is incorrect." exit end require 'aws-sdk' require 'base64' # EC2の構成要素定義(以下変数を環境に応じて編集) image_id = '<ami_id>' # AMIID key_name = '<keypair_name>' # キーペア名 security_group_ids = '<security_group_id>' # セキュリティグループID instance_type = '<instance_type>' # インスタンスタイプ availability_zone = '<az_name>' # 利用AZ subnet_id = '<subnet_id>' # 利用サブネットID user_data = '<userdata_pass>' # ユーザデータのファイルパス # ユーザデータ設定 if File.exist?(user_data) file = File.open(user_data) script = file.read file.close else script = '' end encoded_script = Base64.encode64(script) # EC2リソース操作用インスタンス作成 ec2 = Aws::EC2::Resource.new # EC2作成実施 instance = ec2.create_instances({ image_id: image_id, min_count: 1, max_count: 1, key_name: key_name, security_group_ids: [security_group_ids], user_data: encoded_script, instance_type: instance_type, placement: { availability_zone: availability_zone }, subnet_id: subnet_id }) # インスタンスが利用可能になるまで待機 ec2.client.wait_until(:instance_running, {instance_ids: [instance[0].id]}) # インスタンス名(Nameタグ)を付与 instance_name = ARGV[0] instance.batch_create_tags({ tags: [{ key: 'Name', value: instance_name }]}) puts "#{instance_name}(#{instance[0].id})が作成されました!"3.動作検証
<前提>
以下のパラメータでEC2を作成します。# EC2の構成要素定義(以下変数を環境に応じて編集) image_id = 'ami-067152a7c26866dcb' # AMIID key_name = 'mykeypair' # キーペア名 security_group_ids = 'sg-64a59718' # セキュリティグループID instance_type = 't2.medium' # インスタンスタイプ availability_zone = 'ap-northeast-1a' # 利用AZ subnet_id = 'subnet-41d23b09' # 利用サブネットID user_data = '/tmp/userdata' # ユーザデータのファイルパスまた、EC2に設定予定のユーザデータは以下の内容
$ cat /tmp/userdata #!/bin/bash yum update -y yum install -y httpd systemctl start httpd systemctl enable httpd①スクリプト実行
インスタンス名を第一引数に指定してスクリプト実行します。$ ruby ec2_create.rb test_server test_server(i-0a4fd9cfe1613a8d6)が作成されました!②結果確認
インスタンス名、インスタンスタイプ、サブネットID、キーペア名、AZ名、AMIIDがスクリプト内での設定値通り設定されています。
付与されているセキュリティグループもOK
ユーザデータも内容適切でした。
一応OSログイン確認と、ユーザデータが正常に実行されているかも確認してみます。
# httpdがユーザデータ実行により起動している $ systemctl status httpd ● httpd.service - The Apache HTTP Server Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled) Active: active (running) since Sat 2020-07-11 03:03:01 UTC; 12min ago Docs: man:httpd.service(8) Main PID: 21821 (httpd) Status: "Total requests: 0; Idle/Busy workers 100/0;Requests/sec: 0; Bytes served/sec: 0 B/sec" CGroup: /system.slice/httpd.service tq21821 /usr/sbin/httpd -DFOREGROUND tq21831 /usr/sbin/httpd -DFOREGROUND tq21832 /usr/sbin/httpd -DFOREGROUND tq21833 /usr/sbin/httpd -DFOREGROUND tq21834 /usr/sbin/httpd -DFOREGROUND mq21835 /usr/sbin/httpd -DFOREGROUND Jul 11 03:03:01 ip-172-31-40-241.ap-northeast-1.compute.internal systemd[1]: Starting The Apache HTTP Server... Jul 11 03:03:01 ip-172-31-40-241.ap-northeast-1.compute.internal systemd[1]: Started The Apache HTTP Server. # また、enabledにもなっている $ systemctl is-enabled httpd enabled全て設定値通りに作成されているのでOKとします!
参考サイト
各種サービスにおけるAWS SDK For Rubyを利用した実装例が確認できます。
AWS SDK for Ruby コード例所感
AWS CLIは業務でよく使っていたのですが、AWS SDKを使ったのはこれが初でした。
AWS CLIよりコーディングとしての実装はかなり楽に感じます(例えばインスタンスのステータス待ちなどは、AWS CLIだとForループで何秒間隔で状態確認をするみたいな実装をしていたのですが、AWS SDKだとwait_untilメソッドを呼ぶだけの1行コードで済んでしまいました)。
今回は以上です。見て頂きありがとうございました。
- 投稿日:2020-07-11T09:27:48+09:00
大戦略の設計フレームワークを作成する
DIMEをベースとした大戦略の設計フレームワークを作成する
下記の記事で、進化心理学のマズローの要求階層モデルを利用して大戦略レベルにおける戦略の判断モデルを作成した。
https://qiita.com/aLtrh3IpQEnXKN7/items/e7552ffc1ec31de1b8c5
大戦略において戦略の判断も重要だが、大戦略を設計、運用する設計図も重要である。
2020年のアメリカ、中国、ロシアはDIMEと呼ばれる概念で大戦略を設計、運用している。
DIMEとは・・・国家戦略を考える際に重要となる、外交(Diplomacy)、インテリジェンス(Intelligence)、軍事(Military)、経済(Economy)の4要素を組み合わせた国家の安全保障の基本戦略。
今回の記事ではDIMEをベースとして、大戦略の設計、運用を行うフレームワーク作成する。21世紀の新しい戦争のスタイル、超限戦
超限戦とは
中国人民解放軍の喬良、王湘穂によって提唱された21世紀の新しい戦争の形態。
超限戦の記載されている以下の文言が21世紀の新しい戦争の形態である。
「あらゆるものが手段となり、あらゆるところに情報が伝わり、あらゆるところが戦場になりうる。すべての兵器と技術が組み合わされ、戦争と非戦争、軍事と非軍事という全く別の世界の間に横たわっていたすべての境界が打ち破られるのだ」ゲラシモフドクトリン
ロシアの参謀総長が2013年に提唱した新しい軍事行動の形態。
以下が文言の内容である。
「アラブの春」という出来事は戦争ではない。だから私たち軍人に対する教訓もないというのは、当然、誰にとっても一番簡単なことだろう。しかし、その逆も真かもしれない。つまり、まさにこれらの出来事こそが、21世紀の戦争の典型なのだ。
死傷者と破壊規模、すなわち悲惨な社会、経済、政治的結果について言えば、こうした新しいタイプの戦争は、実際に起きたどの戦争結果にも匹敵する。
まさに「戦争のルール」が変わってしまった。政治や戦略上の目標達成に向けた、非軍事的手段の役割は大きくなり、また多くの場合、その有効性は、軍隊の力を上回るようになってきている。
紛争に適用する手段の重点は、政治、経済、情報、人道、その他の非軍事的手段を幅広く用いる方向へと変化してきた。これらの手段は、住民が抗議する可能性に応じ、適用される。軍事と民間の境界線が消えていく
現在、世界を覆うインターネット回線は軍事と民間の両者で共有して使用している。
インターネット技術は軍事技術の転用から始まったため、民間での使用はむしろ2次的なものだったが
世界のグルーバル化によって民間でのインターネット使用が主流になってしまった。
インターネット技術の発展は人類の社会に利便性よりも脆弱性を提供してしまった。カール・フォン・クラウゼヴィッツの三位一体理論を拡大する
カール・フォン・クラウゼヴィッツは著書である戦争論において、情熱、精神、偶然が重なり合って戦争という現象が発生する戦争の三位一体理論を提唱した。
クラウゼヴィッツの三位一体理論に関する解説は下記の記事を参照
https://qiita.com/aLtrh3IpQEnXKN7/items/83e9ca26ec2817a9bf0b戦争論は、軍人であったフォン・クラウゼヴィッツの立場と当時のナポレオン戦争の状況を考慮して分析される書物である。
なぜなら、クラウゼヴィッツは大戦略レベルにおける外交、ナポレオン戦争が発端にして始まったスペインにおけるゲリラ戦における分析を行っていないからである。
三位一体理論は軍人の視点で戦略レベル、作戦レベル、戦術レベルを分析、統一した理論と考えられる。
クラウゼヴィッツの三位一体理論は拡大する余地がある。
クラウゼヴィッツの三位一体理論に情報レベル、大戦略レベル、ゲリラ戦レベルの要素を追加し、クラウゼヴィッツの三位一体理論を近代戦に適応させる。ポリシー・・・政策レベルの要素。ビジョンを共有するインナーサークルの構築、大戦略の作成 or 再構築など人間の頭脳に該当する
ネットワーク・・・大戦略レベルの上位に存在する情報レベルの要素。人脈の作成、情報の分析 or 統合、ネットワークの構築など人間の血液に該当
信頼・・・大戦略レベルに該当する要素。大戦略は外交、同盟関係の締結などを行う。このレベルでは信頼が最も重要な要素となるため、共通の価値観を共有する必要がある
混沌・・・ゲリラレベルに該当する要素。ゲリラは無形、無秩序、創造性に該当する。ゲリラレベルはコントロールできないアクターレベルに該当する要素であるクラウゼヴィッツの三位一体理論を拡張
ポリシー・・・政策レベル
ネットワーク・・・情報レベル
信頼・・・大戦略レベル
情熱・・・戦略レベル
精神・・・作戦レベル
偶然・・・戦術レベル
混沌・・・ゲリラレベル大戦略を運用する際のインテリジェンスの重要性
インテリジェンスとは
インテリジェンスとは、収集したデータを分析、加工、配布する一連の行動を包括する概念である。
人間は外部からの情報を受信し、フィードバックを発生させ行動パターンを変化させる。
インテリジェンスは大戦略、戦略、作戦、戦術、ゲリラを運用するための血液、潤滑油に該当する。
現在ではインターネットによって情報配信環境が整備され、5Gによって情報の通信スピードは更に加速している。近代は情報過負荷の時代である。
インテリジェンス活動によって収集したデータのフィルタリング、情報の質の向上を行うことが大戦略全体の活動を向上させることに繋がる。ジョンボイドのOODAループを大戦略の運用に適用する
ジョンボイドとはアメリカの航空戦略家である。ジョンボイドは朝鮮戦争の航空戦、ナチスの電撃戦を研究し、人間の意識決定のスピードが勝敗が分けたと結論づけた。
人間の意識決定のプロセスを可視化したのが以下のOODAループである。
OODAループは、観察(Observe)- 情勢への適応(Orient)- 意思決定(Decide)- 行動(Act)の順番で構成されている。
このモデルを大戦略、戦略、作戦、戦術、ゲリラに拡大しインテリジェンス活動と結びつけることによって、インテリジェンスによる巨大なフィードバックバックシステムを構築することできる。大戦略の設計図を作成する
大戦略全体の見取り図を作成する。情報、大戦略、戦略、作戦、戦術、ゲリラの活動内容は以下の通りになっている。
政策・・・インナーサークルの構築、大戦略の作成 or 再構築
情報・・・経済、文化、スポーツ事業による相互交流の構築、全ての情報を統合 AND 分析
大戦略・・・外交、条約の締結、同盟関係の構築、同盟国間の資源、技術の提供
戦略・・・作戦レベルの行動の開発 or 更新、人事活動による新規人材獲得、広報活動による世論の形成、技術の研究 or 開発、作戦レベルのグルーピングし組み合わせ行動計画の作成 or 実行
作戦・・・特定の活動領域で行われる活動の順番を作成、作戦のスケジューリング、戦術レベルの行動を順番通りに実行
戦術・・・作戦で定義された手順に沿って何らかの技術デバイスを使用し活動を実行
ゲリラ・・・コントロールすることができない非コントロールアクター、戦術で実行されるサービス受給者、ゲリラの活動は創造性を生み出すために自主性を尊重する以下に大戦略全体の関連図を配置。
この図に応じて大戦略の設計、運用を実施する。
テクノ地政学(Geo-Technology)
テクノ地政学とは従来の地政学の理論にテクノロジーによるインフラ構築の観点を加えたものである。
地政学の基本的な理論は以下のURLを参照
https://ja.wikipedia.org/wiki/%E5%9C%B0%E6%94%BF%E5%AD%A6#:~:text=%E5%9C%B0%E6%94%BF%E5%AD%A6%EF%BC%88%E3%81%A1%E3%81%9B%E3%81%84%E3%81%8C%E3%81%8F,%E7%A0%94%E7%A9%B6%E3%81%99%E3%82%8B%E3%82%82%E3%81%AE%E3%81%A7%E3%81%82%E3%82%8B%E3%80%8221世紀の戦争は技術レベルが明確な勝敗を分けるようになった。そのため、自由な経済活動とは制限され、軍事、安全面を考慮した新しい経済活動の枠組みが求められている。
現在、インターネットの通信サービスの9割は海底ケーブルを通して実施されている。この海底ケーブルの設置場所も軍事的な安全面を考慮され、同盟国間の枠組みで建設が進められている。
大戦略の設計図にテクノ地政学(Geo-Technology)の地図によるビジュアライズ化という観点を加えることで大戦略の活動内容を明確にイメージできるようになる。AWSのサーバーリージョン
世界の海底ケーブル




- 投稿日:2020-07-11T09:19:10+09:00
rails サーバー途中から立ち上がらない
$cd アプリ名
$rails s
でいつも立ち上げているのですが立ち上がらなくなりました。
どうしたら立ち上がりますか?

- 投稿日:2020-07-11T02:04:30+09:00
(AWS初心者)なんのためにVPC構築するのか?
(結論)EC2(Webサーバー)をつくるためにVPCを構築する
▼EC2を作成するためには?
VPCをつくって、更にそこからネットワーク(サブネット)を分けて、その中にサーバーを設置する。▼じゃあそのVPCを作成するためには?
リージョンを選択してアベイラビリティーゾーンにまたがってVPCをつくる。見返した時、パッと思い出せるよう,一つ一つ調べてみた。
リージョンとは
AWSの各サービスが提供されている地域のこと。日本にあるのは東京リージョンのみ。
日本でサービスを展開する場合は東京リージョンに提供してもらえばよい。アベイラビリティーゾーンとは
独立したデータセンターのこと。
【用語】
・データセンター・・・顧客のサーバー機などを収容し、運用管理している施設。ドラマとかでよくみるやつ。
尚、災害でサーバーがダメになっても替えがきくように東京リージョンにはアベイラビリティーゾーンが3つあるそう。VPCとは
Virtual Private Cloudの略。
AWSアカウント専用の仮想ネットワークを作成できるサービス。Q.仮想のメリットは?
A. ルーターやゲートウェイなどのネットワーク機器がなくても、インターネットを利用できる!【用語】
・ ルーター・・・IPアドレスを見て行き先を振り分けてくれる機器。「あなたはあっち行って」「君はこっち行って」的な。
・ ゲートウェイ・・・ 規格(予め決められた基準)が違うネットワークを中継する機器サブネットとは
VPCを更に細かく分けた仮想ネットワークのこと。
ネットワークによって役割を変えたいときに活躍する。
・WEBサーバーはネットワークで見れるようにしたい!
・データベースサーバーはネットワークから見れないようにしたい!
など。

- 投稿日:2020-07-11T01:05:27+09:00
AWS System Manager Session ManagerでEC2にSSH,SCP接続する
はじめに
Session Managerというものを今更知った。
セキュリティグループでsshを開けたり、踏み台サーバを経由してEC2にアクセスしたり、といったことがより楽に、安全になるようだ。本記事では
- Session Managerの基本的な設定手順
- 監査ログの出力設定手順
- Session Manager + ssh,scpコマンドでEC2にアクセスする手順
- Session Managerでのアクセスを無効にする手順
を示す。
Session Managerとは
Session Manager はフルマネージド型 AWS Systems Manager 機能であり、インタラクティブなワンクリックブラウザベースのシェルや AWS CLI を介して、EC2 インスタンス、オンプレミスインスタンス、仮想マシン (VM) を管理できます。Session Manager を使用すると、インバウンドポートを開いたり、踏み台ホストを維持したり、SSH キーを管理したりすることなく、監査可能なインスタンスを安全に管理できます。また、Session Manager を使用すると、マネージドインスタンスへの簡単なワンクリックのクロスプラットフォームアクセスをエンドユーザーに提供しつつ、インスタンスへの制御されたアクセス、厳格なセキュリティプラクティス、完全に監査可能なログ (インスタンスアクセスの詳細を含む) が要求される企業ポリシーに簡単に準拠できます。
上記をまとめるとSession Managerのメリットは大きく分けると以下の2つである。
- SSH鍵、アクセス制御、踏み台サーバの管理・設定が不要になる
- 監査ログを残すことができる
Session Managerの基本的な設定手順
EC2インスタンス、ロール作成などの基本的な部分は掻い摘んで説明させていただく。
EC2インスタンスの作成
セキュリティグループでSSHを許可する必要はない。
キーペアの作成も不要。
ロール作成
IAMでロールの作成を行う。
ユースケースの選択でEC2を選択する。
AmazonSSMFullAccessを選択する。
適当に名前を入力し、ロールを作成する。
ロールをEC2へアタッチ
EC2インスタンスの作成で作成したインスタンスを選択し、
IAM ロールの割り当て/置換を選択する。
ロール作成で作成したロールを選択し、適用する。
Session Managerを起動し、EC2にログイン
インスタンスをチェックし、
接続ボタンを押下する。
セッションマネージャーを選択し、接続ボタンを押下する。
別タブでターミナルが表示される。
以下のコマンドでec2-userにスイッチすれば、いつものように扱える。sudo su --login ec2-user
監査ログの出力設定手順
CloudWatch Logsの有効化
AWS Systems Managerでナビゲーションペインの
セッションマネージャーを選択する。
設定タブを選択し、編集ボタンを押下する。
CloudWatch Logsをチェック。ログデータを暗号化するは今回はチェックしない。CloudWatchのロググループは、事前に作成したものを指定する。
ログ出力の確認
ログの出力を確認するため、もう一度EC2インスタンスにログインし、コマンドを実行してみる。
Session ManagerのTOP画面からログインする。セッションの開始を押下する。
インスタンスを選択し、
セッションを開始するを押下する。
無事ログインできた。
適当にコマンドを入力した後、右上の終了ボタンを押下し、セッションを終了する。
CloudWatch Logsに移動し、監査ログの出力設定手順で指定したロググループにログストリームが作成されていること、入力したコマンドが出力されていることを確認する。
Session Manager + ssh,scpコマンドでEC2にアクセスする手順
Session ManagerでEC2インスタンスにSSH, SCPで接続するためにはEC2の秘密鍵が必要だ。
これを試す際はEC2インスタンスを再作成して、秘密鍵をダウンロードしておくこと。SSMエージェントのインストール
EC2インスタンスにSSMエージェントのバージョン2.3.672.0以降がインストールされている必要がある。
Amazon Linuxにはデフォルトでインストールされているため、インストール作業は不要。
その他の場合はこちらの目次を参考にインストールしていただきたいSSM許可ポリシーの作成し、接続を有効化
本手順はユーザが管理者権限を持つ場合、実施不要。
Session Managerのセッション開始を許可するIAMポリシーを作成する。
IAMコンソールからポリシーを選択し、ポリシーの作成ボタンを押下する。
JSONタブを選択し、以下のJSONを貼り付け、ポリシーを作成する。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "ssm:StartSession", "Resource": [ "arn:aws:ec2:*:*:instance/instance-id", "arn:aws:ssm:*:*:document/AWS-StartSSHSession" ] } ] }
IAMコンソールに戻り、ユーザを選択し、先ほど作成したポリシーをアタッチする。
AWS CLIのインストール
以下にしたがってAWS CLIをインストールする。
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2.html
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-chap-configure.html
Session Managerプラグインのインストール
以下にしたがってSession Managerプラグインをインストールする。
SSH設定ファイルを更新
~/.ssh/configに以下を追記する。なかったら新規作成。# SSH over Session Manager host i-* mi-* ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"接続
ssh -i /path/my-key-pair.pem username@instance-id
無事接続することができた。
scpコマンドも同様に接続することができる。Session Managerでのアクセスを無効にする手順
Session Managerのセッション開始を拒否するIAMポリシーを作成する。
IAMコンソールからポリシーを選択し、ポリシーの作成ボタンを押下する。
JSONタブを選択し、以下のJSONを貼り付け、ポリシーを作成する。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor1", "Effect": "Deny", "Action": "ssm:StartSession", "Resource": "arn:aws:ssm:*:*:document/AWS-StartSSHSession" } ] }
IAMコンソールに戻り、ユーザを選択し、先ほど作成したポリシーをアタッチする。
SSHコマンドを実行し、EC2への接続が拒否されることを確認する。
おわりに
System Managerについて基本を学んだ。より、手軽に安全にEC2にアクセスできるので積極的に活用したい。
余談だが、SSH接続の際、パーミッション問題などでなかなか接続するのに苦労した。
デバッグログ出力させるとトラブルシューティングしやすかった。ssh -vT 〜参考
https://qiita.com/e__koma/items/009565384efbecb8a46e
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/session-manager-getting-started-enable-ssh-connections.html
https://dev.classmethod.jp/articles/session-manager-launches-tunneling-support-for-ssh-and-scp/
https://www.bioerrorlog.work/entry/session-manager-ec2-user


























- 投稿日:2020-07-11T00:58:02+09:00
AWS EC2インスタンスの終了方法(セキュリティGの削除とキーペアの削除)
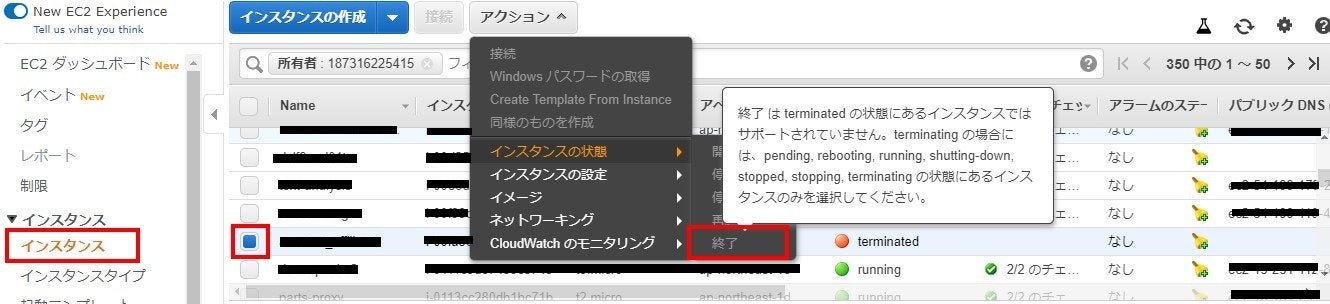
インスタンスの終了
- AWSにログイン
- 「EC2」をクリック
- 左ペインから「インスタンス」をクリック
- 右ペインに表示されたインスタンス一覧から削除したいインスタンスにチェック
- 「アクション」→「インスタンスの状態」→「終了」を選択
セキュリティグループの削除
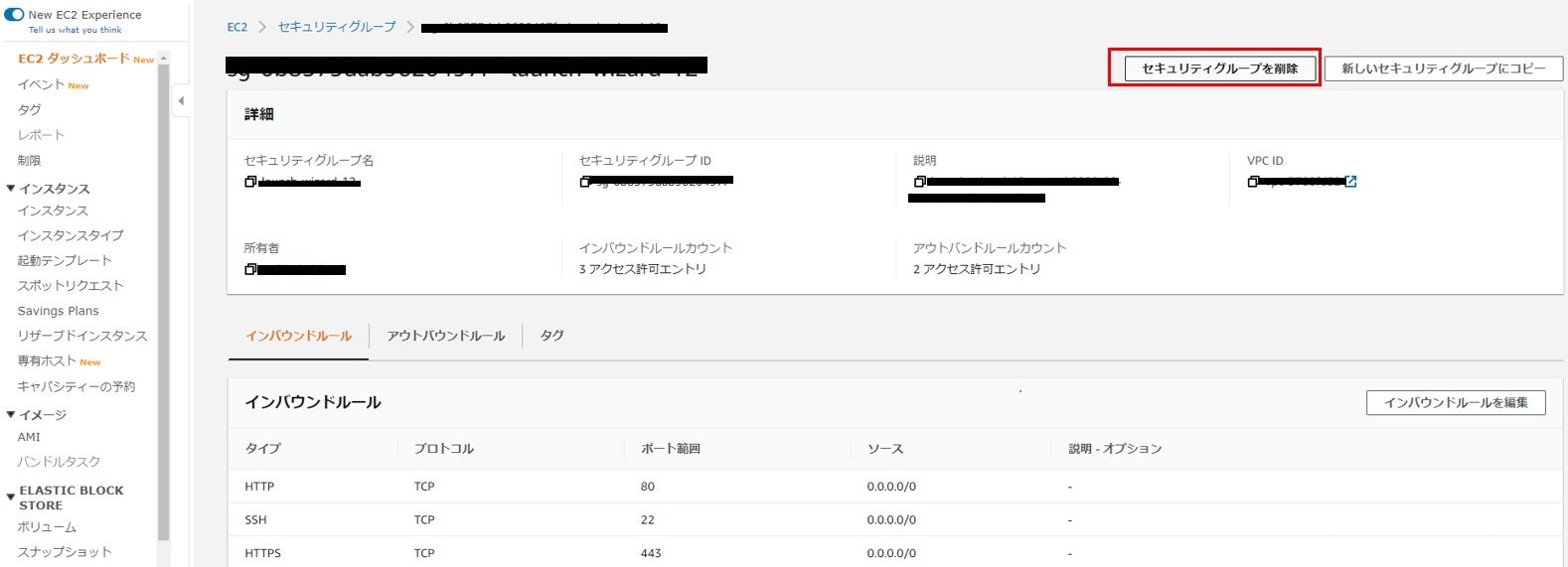
- 左ペインから「セキュリティグループ」をクリック
- 該当のセキュリティグループを選択する
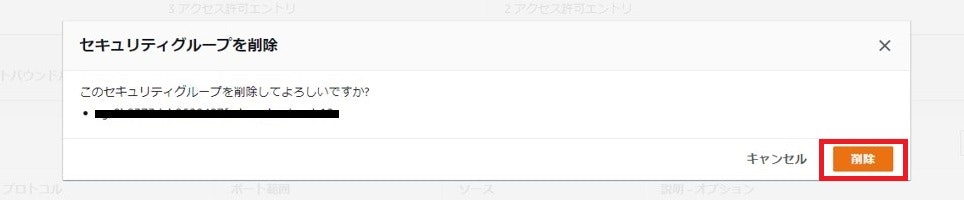
- 右上の「セキュリティグループを削除」をクリック
表示されたポップアップの「削除」をクリック
削除されたことを確認する
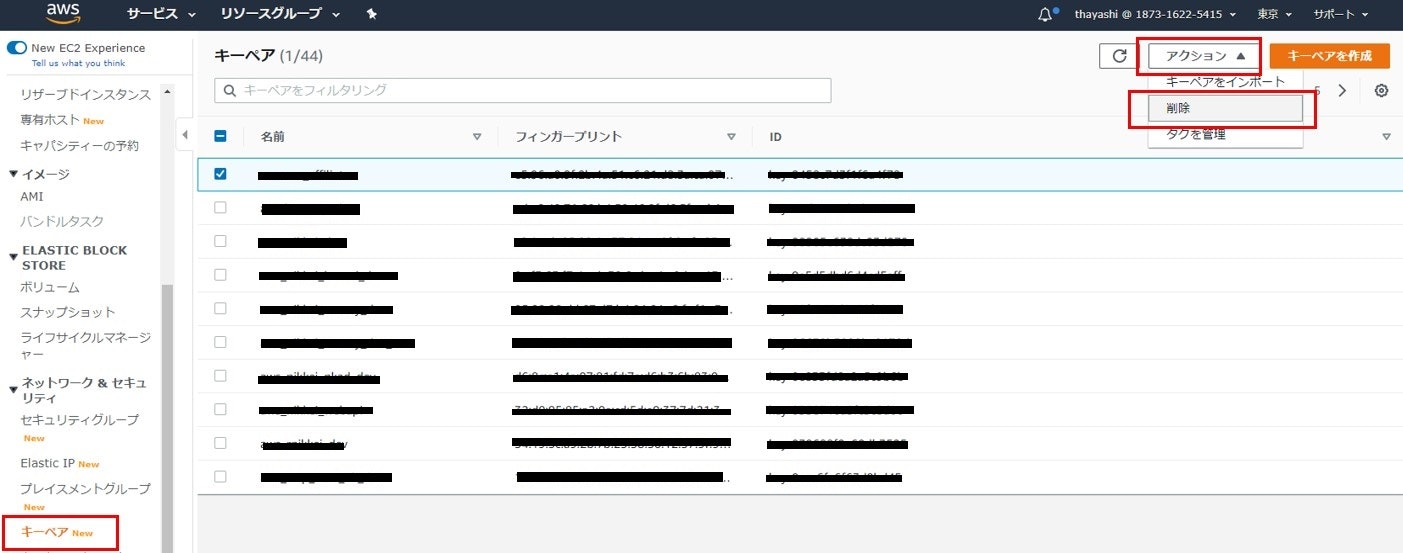
キーペアの削除
- 左ペインから「キーペア」をクリック
- メインカラムに表示されたキーペア一覧から、該当のものを選択する
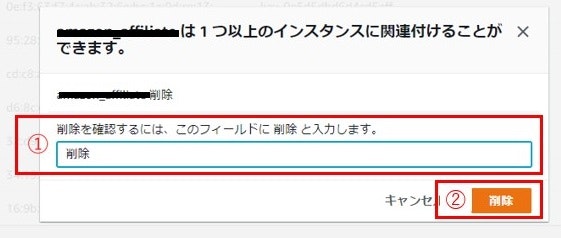
右上の「アクション」→「削除」を選択
フィールドに削除を入力し「削除」ボタンをクリック
「キーペア」一覧から削除されていることを確認して終了
お疲れ様でした!

- 投稿日:2020-07-11T00:32:56+09:00
AWS RDSに接続できないときの対策
AWS RDSに接続できないときの対策
備忘録を兼ねて。
AWSのRDSインスタンスに接続できないときに考えることはいくつかあります。
- セキュリティグループの設定
- ポートの確認
- ユーザーIDが正しいか確認
…
などなどやっても接続できないときは、パブリックアクセシビリティが無効になっているかもしれません。
確認・変更するときは、DBインスタンスの概要画面から変更をクリック:
「ネットワーク & セキュリティ」の「パブリックアクセシビリティ」が「いいえ」になっている場合、セキュリティグループを開放していても接続できません。
「はい」に変更しましょう。
初歩的なところですが、DBインスタンス作成時のデフォルトはパブリックアクセシビリティがオフになっているようなので、少しハマりました。
参照
EC2からRDS(MySQL)に接続できない。セキュリティグループの設定について・・・
Amazon LinuxからPostgreSQL(RDS)へ接続する
- 投稿日:2020-07-11T00:32:56+09:00
AWS RDSにローカルから接続できないときの対策
AWS RDSにローカルから接続できないときの対策
備忘録を兼ねて。
AWSのRDSインスタンスにローカルから接続できないときに考えることはいくつかあります。
- セキュリティグループの設定
- ポートの確認
- ユーザーIDが正しいか確認
…
などなどやっても接続できないときは、パブリックアクセシビリティが無効になっているかもしれません。
確認・変更するときは、DBインスタンスの概要画面から変更をクリック:
「ネットワーク & セキュリティ」の「パブリックアクセシビリティ」が「いいえ」になっている場合、セキュリティグループを開放していても接続できません。
「はい」に変更しましょう。
初歩的なところですが、DBインスタンス作成時のデフォルトはパブリックアクセシビリティがオフになっているようなので、少しハマりました。
参照
EC2からRDS(MySQL)に接続できない。セキュリティグループの設定について・・・
Amazon LinuxからPostgreSQL(RDS)へ接続する
- 投稿日:2020-07-11T00:29:28+09:00
[AWS]CloudwatchエージェントをRunCommandのみでインストールする
概要
CloudWatchエージェントをEC2インスタンスにインストールする時に毎回忘れる(主にコマンドドキュメント名)ので、自分用の備忘録として記事にしておきます。
要するに、SSM(SystemsManager)のRunCommandを用いて設定する内容です。
また、RunCommandの前提となるSSMエージェントのインストールやIAMポリシーの設定は割愛しました。
上記、公式ドキュメントを参照してください。エージェントインストール
まずは、CloudWatchエージェントのインストールです。
マネジメントコンソールのSystems Managerにアクセス
左メニューより[Run Command]を選択
右メイン画面内の[Run Command]を選択
Command documentにて[AWS-ConfigureAWSPackage]を選択
中段のCommand parametersのNameにて[AmazonCloudWatchAgent]と入力
インストール先のEC2インスタンスを好きな手段で選択
「特定のタグが付与されたEC2インスタンスにインストール方法」「手動で選択する方法」「リソースグループから選択する方法」から選択できる。1
ここでは、手動で選択する例を表示している。
以降はオプション
デフォルトでは結果をS3に出力しようとするが、マネジメントコンソールからそのまま確認することもできるため、今回の用途であればオフでも可。
最下部[Run]によって実行
ステータスを確認する
結果がFaildの時は、Instance ID列の対象インスタンスID名をクリックすると、コマンドの詳細が表示されるので、原因究明に役立つ。
エージェントに設定投入
- インストール手順の1~3を実行し、RunCommandの画面を表示
Command documentにて[AmazonCloudWatch-ManageAgent]を選択
インストールするエージェント設定をOptional Configuration Locationに入力2
インストール手順の6~8を実行し、同様にコマンドを実行する
よくある失敗
以下、私が経験したよくある失敗パターンを掲載します。
- 対象のEC2インスタンスに、IAMポリシー(AmazonSSMManagedInstanceCore)が付与されていない。設定方法は公式ドキュメント参照
- 対象のEC2インスタンスに、SSMエージェントがインストールされていない。設定方法は公式ドキュメント参照
- セキュリティグループ等で、HTTPSのアウトバウンド通信が阻害されている
- その他前提条件を満たしていない。
履歴機能
RunCommandには履歴機能があります。以前は完全に同じコマンド(同じ対象先、同じオプション)でしか実行できずあまり意味がなかったのですが、
少し前から[Copy to new]機能が実装されてめちゃめちゃ便利になりました。
[Run Command]画面のここから履歴機能を表示
再利用したい過去のコマンドを選択
右上のメニューより[Copy to New]を選択
2で選択した過去のコマンドの設定が最初から入力された状態でコマンドの詳細画面に遷移する3












