- 投稿日:2020-07-10T23:56:18+09:00
MacOS Cataline で psutil のインストールに失敗
環境
- macOS Cataline 10.15.1
- psutil==5.7.0
psutilは、実行中のプロセスやシステムの利用状況をPythonで取得するためのクロスプラットフォームライブラリ。
状況
psutilを poetryでインストールしようとしたところ、大量のエラーメッセージと共に失敗。$ poetry install --no-root Installing dependencies from lock file Package operations: 35 installs, 0 updates, 0 removals - Installing psutil (5.7.0) clang -Wno-unused-result -Wsign-compare -Wunreachable-code -DNDEBUG -g -fwrapv -O3 -Wall -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include -DPSUTIL_POSIX=1 -DPSUTIL_SIZEOF_PID_T=4 -DPSUTIL_VERSION=570 -DPSUTIL_OSX=1 -I/Users/hinata/.ghq/github.com/Nikkei/b2b-api-article/.venv/include -I/Users/hinata/.pyenv/versions/3.8.2/include/python3.8 -c psutil/_psutil_common.c -o build/temp.macosx-10.14-x86_64-3.8/psutil/_psutil_common.o In file included from psutil/_psutil_common.c:9: In file included from /Users/hinata/.pyenv/versions/3.8.2/include/python3.8/Python.h:25: In file included from /Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/stdio.h:64: /Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/_stdio.h:93:16: warning: pointer is missing a nullability type specifier (_Nonnull, _Nullable, or _Null_unspecified) [-Wnullability-completeness] unsigned char *_base; ^ /Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/_stdio.h:93:16: note: insert '_Nullable' if the pointer may be null unsigned char *_base; ^ _Nullable /Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/_stdio.h:93:16: note: insert '_Nonnull' if the pointer should never be null unsigned char *_base; ^ _Nonnull /Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/_stdio.h:138:32: warning: pointer is missing a nullability type specifier (_Nonnull, _Nullable, or _Null_unspecified) [-Wnullability-completeness] int (* _Nullable _read) (void *, char *, int); ^ /Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/_stdio.h:138:32: note: insert '_Nullable' if the pointer may be null int (* _Nullable _read) (void *, char *, int); ^ _Nullable /Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/_stdio.h:138:32: note: insert '_Nonnull' if the pointer should never be null int (* _Nullable _read) (void *, char *, int); ^ _Nonnull /Library/Developer/CommandLineTools/SDKs/MacOSX10.14.sdk/usr/include/_stdio.h:138:40: warning: pointer is missing a nullability type specifier (_Nonnull, _Nullable, or _Null_unspecified) [-Wnullability-completeness] int (* _Nullable _read) (void *, char *, int); ^MacOSX10.14.sdk周りでたくさん怒られるている。
原因
自分のCatalineのバージョンは10.15なので、変だなと思い潜ってるとsdkが2つ存在していてた。
$ cd /Library/Developer/CommandLineTools/SDKs $ ls MacOSX.sdk MacOSX10.14.sdk MacOSX10.15.sdk10.14を消したら無事インストールできた。古いものが残っていて干渉を起こしていたようだ。
$ ls sudo rm -rf MacOSX10.14.sdk Password: $ ls MacOSX.sdk MacOSX10.15.sdk
- 投稿日:2020-07-10T23:45:01+09:00
yukicoder contest 256 参戦記
yukicoder contest 256 参戦記
前回0完なのに今回は5完. 振れ幅激しい!
A 1107 三善アクセント
1-indexed を 0-indexed に読み替える必要はあるが、問題文の通りに判定するだけ.
A = list(map(int, input().split())) if A[0] < A[1] and A[2] > A[3]: print('YES') else: print('NO')B 1108 移調
H ずらした値を出力するだけ.
N, H, *T = map(int, open(0).read().split()) print(*[t + H for t in T])C 1109 調の判定
12の調全てについて、各調に含まれる音しか使われていないか、全部試せばいい.
N, *T = map(int, open(0).read().split()) x = [0, 2, 4, 5, 7, 9, 11] result = -1 for i in range(12): t = set((i + e) % 12 for e in x) for e in T: if e not in t: break else: if result == -1: result = i else: print(-1) exit() print(result)D 1110 好きな歌
尺取り法でも解けるよなあと思いつつにぶたんで解いた.
from bisect import bisect_left N, D, *A = map(int, open(0).read().split()) t = sorted(A) for a in A: print(bisect_left(t, a - D))E 1111 コード進行
実装重たいなあと思いつつ、DP で解いた. 最初、複雑度の合計がKを超えても計算してて TLE を食らった, PyPy じゃないと TLE になります.
N, M, K = map(int, input().split()) m = 1000000007 pqc = [[] * 301 for _ in range(301)] for _ in range(M): P, Q, C = map(int, input().split()) pqc[P].append((Q, C)) t = [{0: 1} for _ in range(301)] for i in range(N - 1): nt = [{} for _ in range(301)] for j in range(1, 301): for k in t[j]: for q, c in pqc[j]: v = k + c if v <= K: nt[q].setdefault(v, 0) nt[q][v] += t[j][k] nt[q][v] %= m t = nt result = 0 for i in range(1, 301): t[i].setdefault(K, 0) result += t[i][K] result %= m print(result)
- 投稿日:2020-07-10T23:07:09+09:00
[VSCode] Python の print f-string 用のユーザー スニペットを作ってみた
Python 3.8 で採用された、print の f-string debugging(
print(f"{○○○ = }")という書き方)が気に入っています。
ただ、VSCodeだとIntellisenseを使っても結構タイプ量が多くなるので、自分でスニペット作ってみました。・ユーザースニペットの作り方
メニュー>「Code」 >「基本設定」>「ユーザー スニペット」を選択>「検索ボックス」で「Python」を検索>「python.json」ファイルが開く以下の記述を追加します;
python.json{ "Print f-string debugging": { "prefix": "print", "body": [ "print(f\"{$1 = }\")", ], "description": "print(f\"{ = }\")" }, "Print with quote": { "prefix": "print", "body": [ "print(\"$1\")", ], "description": "print(\"\")" }, }以下、簡単な解説です;
"Print f-string debugging" の名前は、あまり関係ありません。
"prefix" が、スニペットを出すトリガーとなる文字です。
"body" が、実際に入力される文字です。
"は\でエスケープする必要があります。また、$1がカーソルの位置になり、$2、$3、、はTabキーを押した時に次に移動する位置になります。"description" が、スニペットが表示された時の説明になります。
"Print with quote" は、ついでに作った
print("")のスニペットです。
このスニペット、自分的にはかなり愛用しています。
- 投稿日:2020-07-10T20:50:43+09:00
pythonで家賃情報を地図上にマッピングする
前回の記事でsuumoから家賃情報を取得しました。
その取得した情報を地図上にマッピングし、位置と家賃の相関を見れるようにしようと思います。実行結果
先に実行した結果を示します。
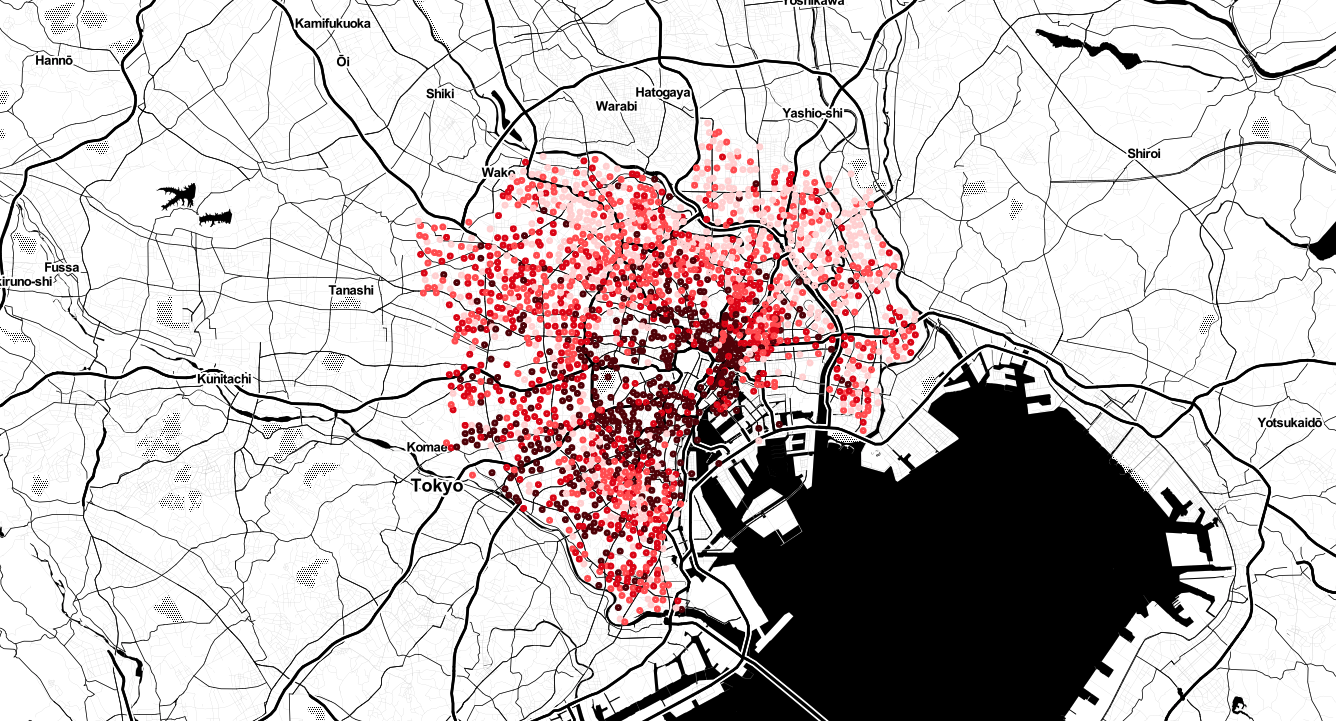
以下のような出力を得られます。
この図は東京都23区のアパートの位置を値段別に色分けしてマッピングしたものです。
色が薄ければ薄いほど安く、濃いほど高いです。
色は4段階で分かれており、それぞれ以下の範囲で記載されています。
25% : 〜 8.59万円
50% : 8.59 〜 10.62万円
75% : 10.62 〜 13.63万円
100% : 13.63 〜 190万円
それぞれ、第一四分位数、第二四分位数、第三四分位数、第四四分位数を計算しています。
色は4段階だけでなく最大12段階まで色分けすることができます。全体的に見ると都心から南西にかけて家賃が安くなっていることが分かります。
また、東や北の方は他の場所と比べて比較的安くなっています。
東京住みの方からすれば当たり前なことかもしれませんが、自分は東京のこと全く知らないので意外な発見でした。
このようにマッピングを行うことで、位置と家賃の情報が視覚的にわかるようになります。
情報取得の範囲を広げるとさらに広い範囲で相関を見ることができるようになります。実行環境
マッピングのために住所を経度・緯度に変換する必要があります。
マッピングの結果をすぐに描画して見たいため、座標変換とマッピングをそれぞれ別の環境で行いました。座標変換
- python3(3.7.0)
- requests(2.24.0)
- beautifulsoup4(4.9.1)
- lxml(4.5.1)
マッピング
- python3(3.7.4)(anaconda3-2019.10)
- folium(0.11.0)
- pandas(0.25.1)
正直全部同じ環境でまとめて行ってもあまり問題ないと思います。
座標変換
マッピングを行うために、まず、取得した住所を座標(経度・緯度)に変化する必要があります。
このように住所や名称からその場所の座標を取得することを「ジオコーディング」というそうです。
ジオコーディングはGoogleやyahooなどのAPIを使用しても行うことができるそうなのですが登録がめんどそうなのでやめました。
色々探していると無料でジオコーディングできるAPIがあるそうなのでそれを利用しました。
利用したAPIはgeocoding.jpです。
調べてみたら色々実装例があったのでそれを参考にコードを作成しました。実装コード
作成したコードは以下です。
get_zahyo.pyimport requests from bs4 import BeautifulSoup import time import csv def get_lat_lon_from_address(address): url = 'http://www.geocoding.jp/api/' latlons = [] payload = {'q': address} r = requests.get(url, params=payload) ret = BeautifulSoup(r.content,'lxml') if ret.find('error'): raise ValueError("Invalid address submitted. {address}") else: x = ret.find('lat').string y = ret.find('lng').string time.sleep(10) return x, y input_path = 'input.csv' output_path = 'output.csv' f1 = open(input_path) reader = csv.reader(f1) f2 = open(output_path, 'a') writer = csv.writer(f2) zahyo_d = {} for row in reader: address = row[1] if address in zahyo_d: print('skip') x = zahyo_d[address][0] y = zahyo_d[address][1] else: print('get zahyo...') x, y = get_lat_lon_from_address(address) zahyo_d[address] = [x, y] row.append(x) row.append(y) writer.writerow(row)input_pathには前回の記事で取得したcsvファイル名を入力し、output_pathには好きなファイル名を入力します。
アクセス数を減らすために、一度取得した住所と座標は辞書で保存しており、以前調べた住所と同じ住所がきた場合は保存してある辞書から引っ張って来るようにしています。
それでも、アクセス数が多くなってしまうので先方サーバに負担をかけないようにtime.sleep(10)でアクセス時間の間隔を開けることが必要です。下記にあるのはinput.csvとoutput.csvの例です。
input.csv(一部)ラ・トゥール神楽坂,東京都新宿区西五軒町,築18年,地下2地上24階建,43万円,2LDK,79.7m2,16階 ラ・トゥール神楽坂,東京都新宿区西五軒町,築18年,地下2地上24階建,57.8万円,3LDK,103.4m2,16階 パール白山,東京都文京区白山4,築36年,8階建,8.3万円,3K,42m2,8階 リバーシティ21イーストタワーズII,東京都中央区佃2,築20年,地下2地上43階建,13.9万円,1LDK,44.2m2,9階output.csv(一部)ラ・トゥール神楽坂,東京都新宿区西五軒町,築18年,地下2地上24階建,43万円,2LDK,79.7m2,16階,35.706903,139.737421 ラ・トゥール神楽坂,東京都新宿区西五軒町,築18年,地下2地上24階建,57.8万円,3LDK,103.4m2,16階,35.706903,139.737421 パール白山,東京都文京区白山4,築36年,8階建,8.3万円,3K,42m2,8階,35.721231,139.746682 リバーシティ21イーストタワーズII,東京都中央区佃2,築20年,地下2地上43階建,13.9万円,1LDK,44.2m2,9階,35.668253,139.786297経度と緯度が追加されていればokです。
注意
住所から座標を検索しても座標が取得できずエラーが起こる住所があります。
エラーが発生した住所をメモしているのでこれらの住所のある行を抜いて実行することをお勧めします。
エラーが発生した時のため、住所と座標の辞書を保存しておくといいかもしれません、先方サーバに負担がかからないし、実行時間も短くなります。エラーが発生した住所 都心部 東京都千代田区神田須田町1 東京都千代田区岩本町2 東京都千代田区神田小川町1 東京都千代田区神田駿河台3 23区東部 東京都葛飾区亀有3 東京都葛飾区お花茶屋2 23区西部 東京都中野区沼袋3 東京都中野区野方3マッピング
住所を座標に変換することができたのでその座標情報を元に地図上にマッピングします。
マッピングのライブラリとしてfoliumを使用しました。ディレクトリ構造
実装コードの説明の前に座標変換が終わった時のディレクトリ構造について説明しておきます。
自分は範囲別に分けるために以下のように東京23区の部分毎にファイルを分けています。
実装コードでの「#データ取得」の部分ではこのディレクトリ構造であることを前提として実装しています。
「#データ取得」の部分は自分のファイル構造に合うようによしなに変更してください。%ls mapping.ipynb output_center.csv output_east.csv output_north.csv output_south.csv output_west.csv実装コード
作成したコードは以下です。
mapping.pyimport folium import pandas as pd #山手線上の駅をマッピング def mapping_stations(_map): locations_station = [[35.681382, 139.76608399999998], [35.675069, 139.763328], [35.665498, 139.75964], [35.655646, 139.756749], [35.645736, 139.74757499999998], [35.630152, 139.74044000000004], [35.6197, 139.72855300000003], [35.626446, 139.72344399999997], [35.633998, 139.715828], [35.64669, 139.710106], [35.658517, 139.70133399999997], [35.670168, 139.70268699999997], [35.683061, 139.702042], [35.690921, 139.70025799999996], [35.701306, 139.70004399999993], [35.712285, 139.70378200000005], [35.721204, 139.706587], [35.728926, 139.71038], [35.731401, 139.72866199999999], [35.733492, 139.73934499999996], [35.736489, 139.74687500000005], [35.738062, 139.76085999999998], [35.732135, 139.76678700000002], [35.727772, 139.770987], [35.720495, 139.77883700000007], [35.713768, 139.77725399999997], [35.707438, 139.774632], [35.698683, 139.77421900000002], [35.69169, 139.77088300000003]] for l in locations_station: folium.Circle(radius=10, location=l, color='blue').add_to(_map) return _map #データを取得 names = ['center', 'east', 'south', 'west', 'north'] df_list = [] for n in names: path = 'output_{}.csv'.format(n) df_list.append(pd.read_csv(path, names=['name', 'address', 'age', 'height', 'rent', 'kinds', 'area', 'floor', 'x', 'y'])) df = pd.concat(df_list) #家賃を数値に変換 df['rent'] = df['rent'].str.strip('万円').astype(float) #同じaddressの処理 address = df['address'].unique() new_df = [] for adr in address: df_adr = df.loc[df['address']==adr] value = df_adr['rent'].mean() new_df.append([value, df_adr.iloc[0, 8], df_adr.iloc[0, 9]]) df = pd.DataFrame(new_df, columns=['rent', 'x', 'y']) #color決定 #colors = ['#fff4f4', '#ffeaea', '#ffd5d5', '#ffaaaa', '#ff8080', '#ff5555', '#ff2b2b', '#ff0000', '#d50000', '#aa0000', '#800000', '#550000'] #colors = ['#fff4f4', '#ffd5d5', '#ff8080', '#ff2b2b', '#d50000', '#800000'] colors = ['#ffd5d5', '#ff5555', '#d50000', '#550000'] num_color = len(colors) df.loc[df['rent']<df['rent'].quantile(1/num_color), 'color'] = colors[0] for i in range(1, num_color-1): df.loc[(df['rent'].quantile(i/num_color) <= df['rent']) & (df['rent'] < df['rent'].quantile((i+1)/num_color)), 'color'] = colors[i] df.loc[df['rent']>=df['rent'].quantile((num_color-1)/num_color), 'color'] = colors[-1] #マッピング location = [df['x'].mean(), df['y'].mean()] _map = folium.Map(location=location, zoom_start=12, tiles="Stamen Toner") for i in range(len(df)): folium.Circle(radius=150, location=[df.loc[i, 'x'], df.loc[i, 'y']], color=df.loc[i, 'color'], fill_color=df.loc[i, 'color'], fill=True,).add_to(_map) #_map = mapping_stations(_map) #値範囲をprint print('{}% : - {:.2f}'.format(int((1)/num_color*100), df['rent'].quantile((1)/num_color))) for i in range(1, num_color): print('{}% : {:.2f} - {:.2f}'.format(int((i+1)/num_color*100), df['rent'].quantile((i)/num_color), df['rent'].quantile((i+1)/num_color))) #anacondaの場合 _map #普通のpythonの場合 #_map.save('map.html')「ディレクトリ構造」の部分で記載したように、「#データ取得」の部分は上記のディレクトリ構造であることを前提としているのでよしなに変更してください。
出力ファイルが一つだけの場合は、#データ取得 path = [path to file] df = pd.read_csv(path, names=['name', 'address', 'age', 'height', 'rent', 'kinds', 'area', 'floor', 'x', 'y'])でいいと思います。
colorsは好きなものを選択することで色の数を変更できます。
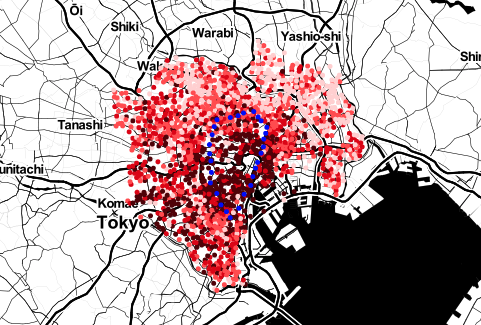
_map = mapping_stations(_map)は東京の山手線の駅の情報をマッピングする関数です。
コメントアウトを削除することで出力することができます。(以下出力例)
anacondaの場合はインライン表示できるので_mapで出力することができます。
普通にpythonで実行する場合はインライン表示できないので _map.save('map.html')で一度saveすることで表示することができます。まとめ
アパートの情報を地図上にマッピングしてみました。
マッピングは情報を視覚的に捉えることができるので非常に便利です。
もっとスクレイピングし、マッピングの範囲を広げることでより全体的な相関を見ることができます。
他にも部屋の広さや、階層など様々な情報をスクレイピングで取得しているので、pandasでデータ分析の方も行ってみようと思います。
- 投稿日:2020-07-10T18:51:56+09:00
Scrapyの環境導入手順
1.Scrapyを導入
画面のnewボタンを押下(uploadボタンの横)
以下のように表示されますのでPython3をクリック
こんな画面が表示される
表示されたら以下文章を入力
!pip install scrapy以下のように pip でインストールするのみです。
インストールが完了すると scrapy コマンドが使えるようになります上記入力後、▶︎I Runボタンを押下
scrapy version
Scrapy 1.5.1終わりに
これでクローリングをするための導入手順は終わりです。
クローリングはクラウドワークスなどの副業サイトなどでもたくさんの募集があったりなど
これからの日本の働き方に適したスキルだと思うので是非、学習してみてはいかがでしょうか。
- 投稿日:2020-07-10T18:44:32+09:00
Watson IoT Platform Data Store Connectorをもう少し使い込んでみる
Watson IoT Platformの提供するData Store Connector (以下DSC)はIoTデバイスから収集した情報を外部データベースに自動的に集積できるという優れものです。
IBMが提供しているApplication SDKとサンプルコードを使用すると簡単に設定できますが、実践的な運用にはやや情報不足な感もあり自分なりに調べた結果をまとめておきます。
1 環境
Python 3.7
wiotp-sdk 0.11.0 (pip3で導入可能)2 準備とサンプルコードの実行
2.1 前提
今回はDSCの接続先としてCloudantを使用し、以下の作業は前提として終了しているものとします。
- IBM Cloudのアカウントを作成する
- Watson IoT Platformのサービスを作成し実行する
- Cloudantのサービスを作成実行する作業方法について詳しい書き物はたくさんありますので、ここでは割愛します。
Qiitaにもたくさんありますので検索してみましょう。2.2 Watson IoT Platformの認証キーとトークンを生成
次にWatson IoT Platformの認証キーとトークンを生成します。
これはこれから実行するコードがwiotp-sdkを使用してWatson IoT Platformの提供するAPIを呼び出す際の認証に使用されるものです。詳細については以下を参照してください。
https://developer.ibm.com/jp/tutorials/iot-generate-apikey-apitoken/特にトークンについては生成時にしか表示されないので、画面に印字された文字列を忘れないようにメモしておきましょう。
2.3 Cloudantサービス資格情報
以下の手順でCloudantのサービス資格情報のうちusernameとpasswordを確認しておきます。
https://cloud.ibm.com/docs/Cloudant?topic=Cloudant-creating-an-ibm-cloudant-instance-on-ibm-cloud&locale=ja#locating-your-service-credentials注)最近のCloudantな二種類の認証方式を提供しているようですが、サービスのプロビジョニンング(作成)のときに「Use both legacy credentials and IAM」を選択しておかないと本稿で扱うコードの実行はうまくいかないです。
ここで確認されたusernameとpasswordはApplication SDKのService Bindingを通してWatson IoT Platformに渡され、Watson IoT PlatformがCloudantにデータを書き込む際の認証に使用されます。
2.4 サンプルコードの実行
以下のリンク先にCloudantへ接続するためのDSCをセットアップするサンプルコードが記載されています。
https://www.ibm.com/support/knowledgecenter/SSQP8H/iot/platform/reference/dsc/cloudant.html
serviceBinding内のusernameとpasswordを2.3で確認したものに書き換えて実行します。
# export WIOTP_AUTH_KEY='kkkkkkkkkkk' # export WIOTP_AUTH_TOKEN='tttttttttttttttt' # python sample.py上記実行例では2.2で生成した認証キーとトークンを使用してサンプルコード(sample.py)を実行しています。
サンプルコード実行前に認証キーとトークンをそれぞれWIOTP_AUTH_KEYとWIOTP_AUTH_TOKENにセットします。3 もう少し使い込む
2.4のようにサンプルコードを実行することで、Watson IoT Platformに報告されたイベントは全てCloudant内のDBに保存されるようになります。
ここでサンプルコードの内容をもう少しよく読んでみると、
- Service Bindingを生成する
- Service Bindingに紐つけてConnectorを生成する
- ConnectorのプロパティとしてDestionationとRuleを生成する
のように何もない状態からいくつかのDSCに必要なオブジェクトを生成していることが分かります。
スクラッチに状態から一応動作するところまで持っていってくれますが、実運用を前提に使いこなしていくためには現在の構成を確認したり変更したりする手順が必要になりそうです。
以下、取り敢えずDSCを使いこなしていくために最低限必要そうな手順をいくつか試していきます。
3.1 諸々のオブジェクトの一覧表示
現状どのような設定になっているのか把握するのは運用上必須です。
Service BindingsとDSCの一覧を表示させるプログラムを書いてみました。ApplicationClient.ServiceBindingsやApplicationClient.dscなどはiteratorでループしていますが、通常のlistとは使い勝手が違うので注意が必要です。例えばlen()を使用していくつ格納されているのか確認しようとしても0が返されてしまいます。
ls_dsc.pyimport wiotp.sdk.application options = wiotp.sdk.application.parseEnvVars() appClient = wiotp.sdk.application.ApplicationClient(options) print("Service Bindings") for s in appClient.serviceBindings: print("ID: " + s.id) print("") print("DSC") for c in appClient.dsc: print("ID: " + c.id) print("serviceId: " + c.serviceId) for d in c.destinations: print("Destination.name: " + d.name) for r in c.rules: print("Rules.id: " + r.id) print("Rules.name: " + r.name) print("Rules.destinatioName: " + r.destinationName) print("Rules.typeId: " + r.typeId) print("Rules.eventId: " + r.eventId)以下、私の環境で実行した結果です。
# export WIOTP_AUTH_KEY='kkkkkkkkkkkkkkkkkkk' # export WIOTP_AUTH_TOKEN='tttttttttttttttttt' # python ls_dsc.py Service Bindings ID: d2b141eb-2390-4fa0-b253-24b14c465298 ID: 5aa553e6-692c-45fd-ba2c-a717a635d5bb ID: 85cb36b6-eda7-48b0-bc5a-6eb2c2f03619 ID: ae5a431d-98f6-4c9b-9ffc-a3ba9206770e ID: 4f905b29-70ce-4f01-a2c6-9feb1c2d3e4a ID: 137becb6-502a-4919-83da-079a434a7175 DSC ID: 5db2d160f7e0960025221b51 serviceId: 4f905b29-70ce-4f01-a2c6-9feb1c2d3e4a Destination.name: events ID: 5db2d1b8f7e0960025221b52 serviceId: 137becb6-502a-4919-83da-079a434a7175 Destination.name: events Rules.id: 5db2d1bbf7e0960025221b53 Rules.name: allevents Rules.destinatioName: events Rules.typeId: * Rules.eventId: *2.4のサンプルコードを修正してイベント通知のみをCloudantに流すようにしたのですが、途中に試行錯誤を挟んだ結果不要なService BindingやDSCが残っています。
DSCは二つありますが、一番目にリストされているもの(ID=5db2d160f7e0960025221b51)はRulesが空のようで機能しないものです。Ruleを作成する前にサンプルコードが異常終了してしまったために不完全な状態で残ったものです。
もう一つの方(ID=5db2d1b8f7e0960025221b52)はDestination/Rulesともに作成済みで機能するものです。Service Bindingsは6個の作成されていますが、有効なDSCが使用しているのはdsc.serviceIdでポイントされているもの(ID=137becb6-502a-4919-83da-079a434a7175)で、残りの5個はやはり不要なものです。
このls_dsc.pyを使えばDSCの設定状況の把握が可能になると思います。現状は最低限のプロパティのみ表示させていますが、必要に応じて表示するプロパティを追加させていけば良いと思います。
表示が可能になったので、次に不要なオブジェクトの削除をしていきます。
3.2 不要なオブジェクトの削除
Python SDKを使って不要なオブジェクトの削除ができる方法を探したのですが見つかりませんでした。
REST APIでdeleteすればOKなので直接curlを使用して削除していくことにします。DSCで使用しているService Bindingは削除できないようなので、先に不要なDSCを削除してから次に不要なService Bindingを削除します。
REST APIの詳細については以下のリンクを参照してください。
https://docs.internetofthings.ibmcloud.com/apis/swagger/v0002/historian-connector.html#/Services認証に使用しているusername/passwordは2.2で作成した認証キーとトークンを指定します。REST APIで指定しているURL内のooooooはWatson IoT Platformのorgnization idに置き換えます。
# curl -X DELETE --user 'kkkkkkkkkkkkkkkkkkk:tttttttttttttttttt' https://oooooo.internetofthings.ibmcloud.com/api/v0002/historianconnectors/5db2d160f7e0960025221b51 # curl -X DELETE --user 'kkkkkkkkkkkkkkkkkkk:tttttttttttttttttt' https://oooooo.internetofthings.ibmcloud.com/api/v0002/s2s/services/5aa553e6-692c-45fd-ba2c-a717a635d5bb # curl -X DELETE --user 'kkkkkkkkkkkkkkkkkkk:tttttttttttttttttt' https://oooooo.internetofthings.ibmcloud.com/api/v0002/s2s/services/d2b141eb-2390-4fa0-b253-24b14c4652 # curl -X DELETE --user 'kkkkkkkkkkkkkkkkkkk:tttttttttttttttttt' https://oooooo.internetofthings.ibmcloud.com/api/v0002/s2s/services/85cb36b6-eda7-48b0-bc5a-6eb2c2f03619 # curl -X DELETE --user 'kkkkkkkkkkkkkkkkkkk:tttttttttttttttttt' https://oooooo.internetofthings.ibmcloud.com/api/v0002/s2s/services/ae5a431d-98f6-4c9b-9ffc-a3ba9206770e # curl -X DELETE --user 'kkkkkkkkkkkkkkkkkkk:tttttttttttttttttt' https://oooooo.internetofthings.ibmcloud.com/api/v0002/s2s/services/4f905b29-70ce-4f01-a2c6-9feb1c2d3e4a # export WIOTP_AUTH_KEY='kkkkkkkkkkkkkkkkkkk' # export WIOTP_AUTH_TOKEN='tttttttttttttttttt' # python ls_dsc.py Service Bindings ID: 137becb6-502a-4919-83da-079a434a7175 DSC ID: 5db2d1b8f7e0960025221b52 serviceId: 137becb6-502a-4919-83da-079a434a7175 Destination.name: events Rules.id: 5db2d1bbf7e0960025221b53 Rules.name: allevents Rules.destinatioName: events Rules.typeId: * Rules.eventId: *削除後に再度ls_dsc.pyを実行して結果を確認しました。
不要なService BindingやDSCが削除されスッキリしました。Service BindingやDSCの削除が可能なことが分かりましたので、諸設定の変更も”削除”して”新規作成”すれば可能です。DSCの導入・設定に必要最低限な機能は確認できましたが、毎回”削除”して”新規作成”も大変そうなので構成のアップデートの方法も確認していきます。
3.3 構成のアップデート
実装初期の試行錯誤や仕様変更などによって一旦生成したDSCの構成を変更したくなることは多いと思われます。
Service BindingやDSC、DSCに内包されるDestinationsやRulesを生成したときに指定された各種プロパティはupdate()メソッドを使用することで変更できるようになっていそうです。現時点では仕様が記述された文書は見つけられていません。あくまでソースコードを読んでみて分かったことです。
以下に一例としてRuleを変更するコードを記載しますが、今後のPython SDKの変更で動作しなくなる可能性もありますのでご注意ください。update_rule.pyimport wiotp.sdk.application options = wiotp.sdk.application.parseEnvVars() appClient = wiotp.sdk.application.ApplicationClient(options) # Get connector instance with its ID (=5db2d1b8f7e0960025221b52) as a key c = appClient.dsc['5db2d1b8f7e0960025221b52'] # Update rule (ID=5db2d1bbf7e0960025221b53) s = { 'deviceType' : '*', 'eventId' : 'bar' } c.rules.update(ruleId='5db2d1bbf7e0960025221b53', ruleType='event', name="allevents", destinationName="events", description="A sample rule", enabled=True, selector=s)上記の例ではeventIdのみを'*'から'bar'に変更しています。
appClient.dscに対してDSCのID(今回の例では5db2d1b8f7e0960025221b52)をキーに指定してIDに対応するDSCのインスタンスを取得します。このインスタンスのrulesに対してupdate()を呼び出すことでRuleの更新が可能です。
このupdate()メソッドの第一引数に更新したいRuleのIDを指定して、残りに更新したいRuleのプロパティをセットします。更新しないプロパティも現状の値をセットして呼び出す仕様のようです。
selector引数の指定がやや難しいですが、ソースコードやPython SDKが呼び出しているREST APIの仕様を読むとどうもこのようにセットするようです。以下、実行結果です。
# export WIOTP_AUTH_KEY='kkkkkkkkkkkkkkkkkkk' # export WIOTP_AUTH_TOKEN='tttttttttttttttttt' # python ls_dsc.py Service Bindings ID: 137becb6-502a-4919-83da-079a434a7175 DSC ID: 5db2d1b8f7e0960025221b52 <- !!!DSCのID serviceId: 137becb6-502a-4919-83da-079a434a7175 Destination.name: events Rules.id: 5db2d1bbf7e0960025221b53 <- !!!RuleのID Rules.name: allevents Rules.destinatioName: events Rules.typeId: * Rules.eventId: * <- !!!変更前 # python update_rule.py <- !!!変更 # python ls_dsc.py Service Bindings ID: 137becb6-502a-4919-83da-079a434a7175 DSC ID: 5db2d1b8f7e0960025221b52 serviceId: 137becb6-502a-4919-83da-079a434a7175 Destination.name: events Rules.id: 5db2d1bbf7e0960025221b53 Rules.name: allevents Rules.destinatioName: events Rules.typeId: * Rules.eventId: bar <- !!!変更後4 まとめ
Python SDKを使用してDSCの設定を確認・削除・変更する方法を紹介しました。
繰り返しになりますがIBMが明確にガイドしていない方法も含まれており、本稿で例示したコードの使用は全て自己責任ということでお願いします。また今後のPython SDKの実装の変更によってこれらのコードが動かなくなる可能性もありますのでご注意ください。
確実なのはREST APIを使用して実装することなのでしょうけれども、Python SDKを使用する方がコードもシンプルですし簡単です。今後Python SDKがより使いやすい形へと進化していってくれることを期待しています。
なおREST APIを使用して設定する方法については以下のQiitaの記事が参考になると思われますので、興味のある方は参照してみてください。
https://qiita.com/Motonaga/items/6304f5f66f63cb566943
- 投稿日:2020-07-10T18:29:07+09:00
venv(Python)
venv とは何か
プロジェクト毎に Python の実行環境を変えたい、あるいはローカル環境を汚したくないなど Python の実行環境を分離する時に使われるのが
venv。Python のバイナリやライブラリの依存関係を任意のディレクトリ配下にまとめ、PATHを上書きするなどして、プロジェクト個別の仮想環境を容易に作成できる。## インストール (Ubuntu20.04) $ sudo apt install python3-venv $ python3.7 -m venv PJ001 $ ls PJ001/ bin include lib lib64 pyvenv.cfg share ## 仮想環境作成 $ source PJ001/bin/activate (PJ001) $ ## 抜けるとき (PJ001) $ deactivate
binには仮想環境の Python 実行ファイルや他パッケージの実行ファイルが配置される。libとincludeには仮想環境で使うライブラリファイルが配置される(activate後に追加した新しいパッケージはlib/pythonX.Y/site-packages/配下にインストールされる)仮想環境を抜けるときはdeactivateを実行。virtualenv と venv の違い
昔からある同様のツールに
virtualenvがある。Python 3.4 以降であればvenvを使うことを推奨とのこと。
- 投稿日:2020-07-10T17:56:23+09:00
Django インラインフォームセットにフォームの追加ボタンを実装する Part2
はじめに
先日「Django インラインフォームセットにフォームの追加ボタンを実装する」という記事を投稿させていただきました。受注入力フォームを題材に、明細行が足りなくなったとき「行を追加」ボタンで行数を増やせるというものでした。
肝心の部分はjQueryでの実装でしたが、記事を書いている途中でもあまりうまい書き方ではないなと感じていました。(それでも、そう書けるようになるまで随分苦労しているのですが、、、)
今回、もう少しマシに書けたので共有させていただきます。環境
- python 3.6.11、 Django 3.0.8
- Bootstrap 4.5.0、 jQuery 3.5.1 slim
コード
前回のコードと共通の部分が多いのですが、改めてこちらに置きました。
記事には必要な部分だけ掲載させていただきます。何が不満だったか
問題の部分は、テンプレートファイル jutyu_form.html内のjQueryで書かれた部分です(後半の
<script> ~ </script>の部分)。
- フォームの要素数分だけidとname属性の同じような設定が繰り返されて冗長。
- そうなっているのは、要素をidで直接指定しているためで、
- 要素数が多いと書くのが面倒。
- 並び順が変わったときやフォームの要素が増減したとき、jQueryの変更も都度必要になる。
Djangoでは、フォームの要素の並び順を指定するのにforms.pyやテンプレートファイルでしていると思います。前回のコードだとjQuery部分でも要素を書く順番が関係してきます。並び順はforms.py等で指定、jQuery部分は行を追加する処理に専念して、並び順は他で指定されたとおりにすべきですね。あっちでもこっちでも似たようなことをされては困ります。
改良点
改良点は、
- 変更の必要な要素をidで直接指定しないで、プログラム的に選択する。
- そうしやすくするために、テンプレートファイルでフォームセットを表示するときに
{{ formset }}などとしてDjangoにレンダリングを任せないで、自分で書きます。方法
フォームセットの行を追加するときに必要な管理情報についてなどは、前回の記事を参照してください。
追加する行は、HTMLのテーブルで1行に書かれている、つまり<tr> ~ </tr>にあるので、
- インラインフォームセットに含まれるフォームの数を取得。
- フォームセットの最初の行(0番目)をコピーして、テーブルの最後に追加。
- 1でコピーした行は入力済みの場合もあるので、入力内容をクリア。
- 追加した行の id, name を書き換える。
- TOTAL_FORMSを1増やす。
となります。コード中 注釈の番号は、上の番号に対応しています。
jutyu/jyutu_form.html(抜粋)jQuery(function ($) { $("button#addForm").on("click", function () { // 1.インラインフォームセットに含まれるフォームの数を取得(=TOTAL_FORMSのvalueを取得) const totalManageElement = $("input#id_jutyudetail_set-TOTAL_FORMS"); const currentJutyuDetailCount = parseInt(totalManageElement.val()); // 2.フォームセットの最初の行(0番目)をコピーして、テーブルの最後に追加。 $("table#detail-table tbody tr:first-child").clone().appendTo("table#detail-table tbody"); // 3.入力内容をクリアする $("table#detail-table tbody tr:last-child").find("select, input").each(function () { // selectなのかinputなのか区別せずとにかくクリア(手抜き) $(this).val(""); $(this).prop("selected", false); // なくても選択解除されるが。。。 $(this).prop("checked", false); // 4.追加した行の id, name を書き換える。 ex. id_jutyudetail_set-0-part → id_jutyudetail_set-1-part var thisName = $(this).attr("name"); thisName = thisName.replace("-0-", "-" + currentJutyuDetailCount + "-"); $(this).attr("name", thisName); $(this).attr("id", "id_" + thisName); }); // 5.TOTAL_FORMSを1増やす $("input#id_jutyudetail_set-TOTAL_FORMS").val(currentJutyuDetailCount + 1); }); });DjangoというよりほとんどjQueryでテーブルの行をコピーする話ですね。
すみません。jQueryについては、こうやればできるんだ!と調べながらやっとできた程度なので解説は勘弁してください。ただ1点だけ、コピーした行で属性をいじらないといけないのは、(今回の例だと)
selectとinput要素です。どう選択するか悩んだのですが、対象として行ごと$("table#detail-table tbody tr:last-child")ごそっと選択し、それをselectとinputについてfindすると簡単そうだったのでそうしてみました。
あとは選択されたものについて、入力内容のクリア、name, idの書き換えを.eachで回しています。本当は対象の要素がどんな属性を持っているかによってクリアの内容を変えたほうが良いのかもしれませんが害はなさそうだったので同じやり方をしています。
Djangoに関わる部分について補足すると、2.の手順でコピーする行は1行目にしています。1行目ーつまりフォームセットの0(ゼロ)番目ーは必ず存在しているだろうことと、id, name属性に含まれている数字はやはり0(ゼロ)なので、4.の手順で数字を書き換える(replace)ときに目印にしています。
replaceする際の対象文字列の指定は、正規表現を使ったほうが良いのかもしれませんが、その部分は特徴的な文字列になる(
"-0-")のでどういう正規表現になるのか悩むよりベタ書きを選びました。4.の手順では、id属性の値はname属性の値の頭に
id_を付け足したものなので、先にnameの値を作ってからidを設定しています。最後に
今は足りない知識が山ほどあるので、無理にカッコイイ書き方よりも分かるやり方で早く動かすほうが先かなと思っています。カッコイイ書き方をしたくてもできないのですが(T_T)
間違っている点、もっと良い書き方等ございましたらご教示いただけると幸いです。また、同じことで悩んでいる方のヒントになれば幸いです。この部分、よく必要になりそうな割に慣れないうちはいろいろな知識が必要で難しくありませんか?
- 投稿日:2020-07-10T17:17:28+09:00
Pythonで統計学②
はじめに
この記事は自己学習のまとめノートとして書かれています。できるだけ間違えのないよう心がけますが、間違えがあればご指摘ください。できるだけ数式で説明するよりコードで説明します。筆者は統計の素人です。
言葉の説明
まずは「母集団」
母集団は言葉の問題です。例を出して考えるとわかりやすいです。仮にあなたが世の中の人のタイピングの平均速度を知りたいとします。その場合母集団は世の中すべての人間のタイピング速度が母集団に当たります。分数でいう分母の母と母集団は近いような意味があるかもないかもしれません。次は「サンプリング」
母集団は大抵多すぎます。なのでそこからデータを抽出することを行います。このことをサンプリングといいます。次は「標本」
サンプリングされたデータそのものです。次は「無作為抽出」
無作為という言葉は馴染みがないかもしれませんが無作為抽出はランダムに標本を抽出することです。次は「記述統計」
分析するデータ全てを持っている統計。次は「推測統計」
一部のデータから全体を推測する統計。不偏分散
不偏分散は分散の分母から1を引いたものです。なぜそのような面倒な概念を登場させるのかというと、標本の分散と母集団の分散は同じ値にならないからです。その誤差を埋めるために1を引くと理解すればいいでしょう。Pythonで実装します。
sigma2 = sum((data-avg_data)**2)/(len(data)-1) print(sigma2) # 9.2区間推定と信頼区間
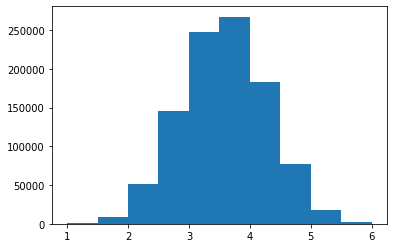
その話を始める前に正規分布について考えます。正規分布は自然界の分布です。形は山なりというかなんというか。自然界の多くの物事は正規分布に従っています。その例として中心極限定理などがあげられます。中心極限定理の詳しい説明は省略しますが、サイコロプログラムを作ってその目を平均が正規分布に従うみたいな理解でいいかと思います。
実際に試してみましょう。from random import randint import matplotlib.pyplot as plt data = [] for _ in range(1000000): dice = [0]*6 # 出た目を保存する配列 for i in range(6): dice[i] = randint(1, 6) # さいころを振る data.append(sum(dice)/len(dice)) # 平均を計算する plt.hist(data)
これが少し不格好ではありますが正規分布です。
区間推定は母集団が正規分布であると仮定して、標本から得られたデータから母平均などを推定する方法です。
信頼区間はn%の確率で母集団の母平均などが含まれる範囲のことです。
通常nは95や99を用いります。平均で例に挙げると母平均が99%の確率で含まれるような範囲であるといえます。
- 投稿日:2020-07-10T17:03:00+09:00
Graphcal lassoを用いた多変数間の相関分析を爆速で試す
モチベーション
データを分析していると、たまに以下のような状況に遭遇します。
- 種類の多いデータの関係性を知りたい
- 割とノイズが激しいけど、他のデータと比較したい
- 見せかけの相関は除外したい
- 本当に関係があるものは僅かしかない、という前提をおきたい
- とりあえず何かしらの手法を試したい
こんな時はとりあえず Graphical lasso を使ってみよう、というお話です。
Graphical lasso とは
ざっくりいえば、変数間の関係をグラフ化する手法です。
多変量ガウス分布を前提とした手法ですので、結構色々なところで使える気がします。
詳しくはこの本が非常にわかりやすく解説してくれます。理論に興味がある方は是非お手に。実装
今回実装したものは、推定された精度行列を相関行列に変換して、グラフで出力するプログラムになります。
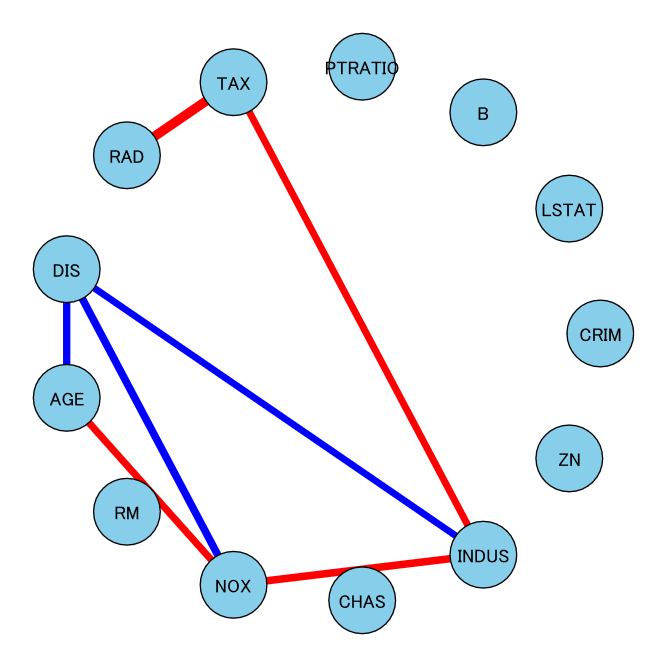
まだまだ改良の余地はありますが、データ分析を進める上での一つの指標にはなると思います。テストデータ用意# テストデータを用意する。 from sklearn.datasets import load_boston boston = load_boston() X = boston.data feature_names = boston.feature_namesメイン処理import pandas as pd import numpy as np import scipy as sp from sklearn.covariance import GraphicalLassoCV import igraph as ig # 同じ特徴量の中で標準化する。 X = sp.stats.zscore(X, axis=0) # GraphicalLassoCV を実行する。 model = GraphicalLassoCV(alphas=4, cv=5) model.fit(X) # グラフデータ生成する。 grahp_data = glasso_graph_make(model, feature_names, threshold=0.2) # グラフを表示する。 grahp_dataグラフ生成関数def glasso_graph_make(model, feature_names, threshold): # 分散共分散行列を取得する。 # -> 参考URL:https://scikit-learn.org/stable/modules/generated/sklearn.covariance.GraphicalLassoCV.html covariance_matrix = model.covariance_ # 分散共分散行列を相関行列に変換する。 diagonal = np.sqrt(covariance_matrix.diagonal()) correlation_matrix = ((covariance_matrix.T / diagonal).T) / diagonal # グラフ表示のために対角成分が0の行列を生成する。 correlation_matrix_diag_zero = correlation_matrix - np.diag( np.diag(correlation_matrix) ) df_grahp_data = pd.DataFrame( index=feature_names, columns=feature_names, data=correlation_matrix_diag_zero.tolist() ) # グラフ生成準備 grahp_data = ig.Graph() grahp_data.add_vertices(len(feature_names)) grahp_data.vs["feature_names"] = feature_names grahp_data.vs["label"] = grahp_data.vs["feature_names"] visual_style = {} edge_width_list = [] edge_color_list = [] # グラフ生成 for target_index in range(len(df_grahp_data.index)): for target_column in range(len(df_grahp_data.columns)): if target_column >= target_index: grahp_data_abs_element = df_grahp_data.iloc[target_index, target_column] if abs(grahp_data_abs_element) >= threshold: edge = [(target_index, target_column)] grahp_data.add_edges(edge) edge_width_list.append(abs(grahp_data_abs_element)*10) if grahp_data_abs_element > 0: edge_color_list.append("red") else: edge_color_list.append("blue") visual_style["edge_width"] = edge_width_list visual_style["edge_color"] = edge_color_list return ig.plot(grahp_data, **visual_style, vertex_size=50, bbox=(500, 500), vertex_color="skyblue", layout = "circle", margin = 50)結果
しきい値をかなり低めに設定しているせいか、直接相関がそれなりに見つかっていますね。
試しに相関が一番強そうな変数同士を見てみます。
相関係数が最も高いのは、RAD(高速道路へのアクセスしやすさ)とTAX($10,000あたりの不動産税率の総計)です。すなわち、高速道路にアクセスしやすいと税金が高いということですね。
正直、このデータだけではなんとも言えないのですが、まるで見当違いな結果でもなさそうです。最後に
とりあえず試せる環境は最高ですね。
結果については、もう少しデータ数が多く、ノイジーなデータであった方がわかりやすかったかもしれません。どこかにないですかね。今回は Graphical lasso を用いて変数間の関係性をグラフ化するところまで行いましたが、その先にはグラフ構造に着目した変化検知手法などもあり、まだまだ勉強のし甲斐がある分野だと感じています。
注意および免責事項
本記事の内容はあくまで私個人の見解であり、所属する組織の公式見解ではありません。
本記事の内容を実施し、利用者および第三者にトラブルが発生しても、筆者および所属組織は一切の責任を負いかねます。
- 投稿日:2020-07-10T17:03:00+09:00
Graphical lassoを用いた多変数間の相関分析を爆速で試す
モチベーション
データを分析していると、たまに以下のような状況に遭遇します。
- 種類の多いデータの関係性を知りたい
- 割とノイズが激しいけど、他のデータと比較したい
- 見せかけの相関は除外したい
- 本当に関係があるものは僅かしかない、という前提をおきたい
- とりあえず何かしらの手法を試したい
こんな時はとりあえず Graphical lasso を使ってみよう、というお話です。
Graphical lasso とは
ざっくりいえば、変数間の関係をグラフ化する手法です。
多変量ガウス分布を前提とした手法ですので、結構色々なところで使える気がします。
詳しくはこの本が非常にわかりやすく解説してくれます。理論に興味がある方は是非お手に。実装
今回実装したものは、推定された精度行列を相関行列に変換して、グラフで出力するプログラムになります。
まだまだ改良の余地はありますが、データ分析を進める上での一つの指標にはなると思います。テストデータ用意# テストデータを用意する。 from sklearn.datasets import load_boston boston = load_boston() X = boston.data feature_names = boston.feature_namesメイン処理import pandas as pd import numpy as np import scipy as sp from sklearn.covariance import GraphicalLassoCV import igraph as ig # 同じ特徴量の中で標準化する。 X = sp.stats.zscore(X, axis=0) # GraphicalLassoCV を実行する。 model = GraphicalLassoCV(alphas=4, cv=5) model.fit(X) # グラフデータ生成する。 grahp_data = glasso_graph_make(model, feature_names, threshold=0.2) # グラフを表示する。 grahp_dataグラフ生成関数def glasso_graph_make(model, feature_names, threshold): # 分散共分散行列を取得する。 # -> 参考URL:https://scikit-learn.org/stable/modules/generated/sklearn.covariance.GraphicalLassoCV.html covariance_matrix = model.covariance_ # 分散共分散行列を相関行列に変換する。 diagonal = np.sqrt(covariance_matrix.diagonal()) correlation_matrix = ((covariance_matrix.T / diagonal).T) / diagonal # グラフ表示のために対角成分が0の行列を生成する。 correlation_matrix_diag_zero = correlation_matrix - np.diag( np.diag(correlation_matrix) ) df_grahp_data = pd.DataFrame( index=feature_names, columns=feature_names, data=correlation_matrix_diag_zero.tolist() ) # グラフ生成準備 grahp_data = ig.Graph() grahp_data.add_vertices(len(feature_names)) grahp_data.vs["feature_names"] = feature_names grahp_data.vs["label"] = grahp_data.vs["feature_names"] visual_style = {} edge_width_list = [] edge_color_list = [] # グラフ生成 for target_index in range(len(df_grahp_data.index)): for target_column in range(len(df_grahp_data.columns)): if target_column >= target_index: grahp_data_abs_element = df_grahp_data.iloc[target_index, target_column] if abs(grahp_data_abs_element) >= threshold: edge = [(target_index, target_column)] grahp_data.add_edges(edge) edge_width_list.append(abs(grahp_data_abs_element)*10) if grahp_data_abs_element > 0: edge_color_list.append("red") else: edge_color_list.append("blue") visual_style["edge_width"] = edge_width_list visual_style["edge_color"] = edge_color_list return ig.plot(grahp_data, **visual_style, vertex_size=50, bbox=(500, 500), vertex_color="skyblue", layout = "circle", margin = 50)結果
しきい値をかなり低めに設定しているせいか、直接相関がそれなりに見つかっていますね。
試しに相関が一番強そうな変数同士を見てみます。
相関係数が最も高いのは、RAD(高速道路へのアクセスしやすさ)とTAX($10,000あたりの不動産税率の総計)です。すなわち、高速道路にアクセスしやすいと税金が高いということですね。
正直、このデータだけではなんとも言えないのですが、まるで見当違いな結果でもなさそうです。最後に
とりあえず試せる環境は最高ですね。
結果については、もう少しデータ数が多く、ノイジーなデータであった方がわかりやすかったかもしれません。どこかにないですかね。今回は Graphical lasso を用いて変数間の関係性をグラフ化するところまで行いましたが、その先にはグラフ構造に着目した変化検知手法などもあり、まだまだ勉強のし甲斐がある分野だと感じています。
注意および免責事項
本記事の内容はあくまで私個人の見解であり、所属する組織の公式見解ではありません。
本記事の内容を実施し、利用者および第三者にトラブルが発生しても、筆者および所属組織は一切の責任を負いかねます。
- 投稿日:2020-07-10T16:52:08+09:00
[python] 機械学習でよく使うテクニック
データフレームを連結する
a = [1,2,3] b = [1,2,3] c = [1,2,3] cols = { "a":a, "b":b, "c":c } da = pd.DataFrame(cols) # 横方向に連結 print(pd.concat([da,da], axis=1, ignore_index=True)) print() # 縦方向に連結 # ignore_indexをTrueに指定しなければ012012となってしまう print(pd.concat([da,da], axis=0, ignore_index=True))出力結果0 1 2 3 4 5 0 1 1 1 1 1 1 1 2 2 2 2 2 2 2 3 3 3 3 3 3 a b c 0 1 1 1 1 2 2 2 2 3 3 3 3 1 1 1 4 2 2 2 5 3 3 3
- 投稿日:2020-07-10T16:32:38+09:00
jupyter notebookを別のhostから接続して使う
jupyter notebookをローカルエリアのマシンから利用する。
違う環境で動作確認とかする為に以下のjupterを別のマシンから使えるようにしたメモ
- macOS 15.5
- ubuntu 20.4やり方は同様です
Anacondaで導入した物でも。pipでjupterを導入しても同じですホームの.jupyterディレクトリに、jupyter_notebook_config.pyを置いて設定を書くだけです。
~/.jupyter/jupyter_notebook_config.py作らせる:
jupyter notebook --generate-config手動で書いても良い
パスワード shaの作成
$ ipython In [1]: from IPython.lib import passwd In [2]: passwd() Enter password: Verify password: Out[2]: 'sha1:abc345fgyy...........................'このsha1:の値を使うのでメモっておく
jupyter_notebook_config.py
c = get_config() c.IPKernelApp.pylab = 'inline' c.NotebookApp.ip = '0.0.0.0' c.NotebookApp.open_browser = False c.NotebookApp.port = 8888 c.NotebookApp.password = u'sha1:abc345fgyy........................'説明:
c.NotebookApp.ip は、サブネットマスク指定です
0.0.0.0 は全てです。
255.255.255.0 では256のNetworkです 192.168.x.xのnetwork等に使うc.NotebookApp.open_browserは、serverを上げたときにbrowserを起動するかです
c.NotebookApp.portは、接続ポートです。8080とか、8880とかご自由にあとは、他のhostのブラウザーから
server_address:8888
で接続すると、パスワードを聞かれます、
- 投稿日:2020-07-10T16:27:24+09:00
Pythonで統計学①
はじめに
この記事は自己学習のまとめノートとして書かれています。できるだけ間違えのないよう心がけますが、間違えがあればご指摘ください。できるだけ数式で説明するよりコードで説明します。筆者は統計の素人です。
平均
平均は単純な概念です。データの合計値をデータの個数で割ったものです。Pythonで計算させてみましょう。
data = np.array([2, 5, 6, 8, 10]) avg_data = sum(data)/len(data) print(avg_data) # 6.2分散
分散も比較的単純な概念です。どの程度データが散らばっているか(分散しているか)を表します。Pythonコードでは次のように書きます。
sigma2 = np.sum((data-avg_data)**2)/len(data) print(sigma2) # 7.359999999999999これはNumpyの配列を使っているのですっきり書くことができます。くわしくはおそらく「Numpy キャスト」みたいな感じでググればよいでしょう。散らばっているという概念は平均からどれくらい離れているのかということを考えれば自ずとPythonコードから見えてくるでしょう。つまり離れている具合は距離なので引き算で計算しており、引き算では負の値をとってしまうので2乗してプラスの値に無理やり直してる程度の理解でいいと思います(^^♪
標準偏差
標準偏差は分散を理解していれば99%わかったようなものです。下のPythonコードで確認しましょう。
from math import sqrt sigma = sqrt(sigma2) print(sigma) # 2.7129319932501073定義は分散にルートをとったものです。
sqrt()は平方根を計算する関数です。なぜ分散に平方根をとる必要があるのか?それは単位をきちんと強制するためです。長さcmのばらつきを考えているのにcm^2 が出てきたら心地よくないというモチベです。
- 投稿日:2020-07-10T16:09:49+09:00
Python Socket通信サンプル/簡易データ投げ込みツール
Socket通信サンプル
PythonのSocket通信サンプル。
データの送信自体は最小2行で書ける。with socket.socket(socket.AF_INET, args.p) as nsocket: # TCPの場合のみconnect if args.p is socket.SOCK_STREAM: nsocket.connect((host, port)) # データ送信 nsocket.send(data)簡易データ投げ込みツール
パラメータを加えたncコマンド風、簡易データ投げ込みツール。
拡張予定。import argparse import socket # パラメータ処理 parser = argparse.ArgumentParser() parser.add_argument("-p", default=socket.SOCK_STREAM, help="Potocol TCP or UDP") parser.add_argument("host", help="Hostname or IP Address") parser.add_argument("port", help="Port number") parser.add_argument("-m", default='0123456789abcdef' , help="Send data") parser.add_argument("-f", type=argparse.FileType('rb'), help="Send data from a file") args = parser.parse_args() send_data = '0123456789abcdef' if args.m: send_data = args.m.encode() if args.f: send_data = args.f.read() # 実際の通信 with socket.socket(socket.AF_INET, args.p) as nsocket: # TCPの場合のみconnect if args.p is socket.SOCK_STREAM: nsocket.connect((args.host, int(args.port))) # データ送信 nsocket.send(send_data) """ # 応答受信 nsocket.settimeout(3) data = nsocket.recv(1024) print(repr(data)) """
- 投稿日:2020-07-10T16:03:32+09:00
OpenCV 特徴量検出をGoogleColaboratoryで
OpenCVのチュートリアルは、仕様が古いものもあるので、とりあえず動かしたいという人向けにコードを載せておきます。
import numpy as np import cv2 from google.colab.patches import cv2_imshow img1 = cv2.imread('box.png', 0) img2 = cv2.imread('box_in_scene.png', 0) akaze = cv2.AKAZE_create() kp1, des1 = akaze.detectAndCompute(img1, None) kp2, des2 = akaze.detectAndCompute(img2, None) # create BFMatcher object bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=False) #bf = cv2.BFMatcher() matches = bf.knnMatch(des1, des2, k=2) # Need to draw only good matches, so create a mask matchesMask = [[0,0] for i in range(len(matches))] # Apply ratio test good = [] good2 = [] for m,n in matches: if m.distance < 0.75*n.distance: good.append([m]) good2.append(m) # cv2.drawMatchesKnn expects list of lists as matches. img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2) cv2_imshow(img3) MIN_MATCH_COUNT =10 if len(good)>MIN_MATCH_COUNT: src_pts = np.float32([ kp1[m.queryIdx].pt for m in good2 ]).reshape(-1,1,2) dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good2 ]).reshape(-1,1,2) M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0) matchesMask = mask.ravel().tolist() h,w = img1.shape pts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2) dst = cv2.perspectiveTransform(pts,M) img3 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA) cv2_imshow(img3) img4 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2) cv2_imshow(img4)
- 投稿日:2020-07-10T15:55:57+09:00
DockerでDjangoアプリケーションをデプロイする
Dockerは、コンテナを利用してアプリケーションの作成、デプロイ、実行を容易にする技術です。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Dockerとは?
Dockerは、コンテナを利用してアプリケーションの作成、デプロイ、実行を容易にする技術です。コンテナを使うことで、開発者はアプリケーションに必要なすべてのコンポーネントをパッケージ化し、後からパッケージとして出荷することができます。また、同じサーバー上でより多くのアプリケーションを稼働させることも可能になります。
Dockerを使えば、コンテナ上で動作しているアプリケーションは互いに隔離されているため、より高いレベルのセキュリティを確保することができます。さらに、Dockerは各コンテナが独自のリソースを持っていることを保証するので、アプリケーションは割り当てられたリソースのみを使用することになります。
前提条件
このガイドを開始する前に、以下のものが必要です。
- Alibaba Cloud ECS Linuxインスタンス。まだLinuxインスタンスをセットアップしていない場合は、この記事で様々なセットアップ方法を紹介します。
- Docker
- Python 2.7
Dockerのインストール
ssh コマンドを使ってサーバにログインします。
$ ssh root@47.88.220.88Ubuntuのパッケージを更新します。
$ sudo apt-get update以下のコマンドで最新版のDockerをインストールします。
$ sudo apt-get install dockerDockerが正しくインストールされていることを確認するには、以下のコマンドを実行します。
$ sudo docker run hello-world正しく実行すれば、上記のコマンドでインスタンスがテストイメージをダウンロードしてコンテナ内で実行できるようになるはずです。
Dockerでのコンテナとイメージ
Alibaba Cloud ECSインスタンスでは、イメージを使用して同じ構成のECSクラスタを作成することができます。同様に、Dockerコンテナにもイメージがあります。概念的には、両者は非常に似ています。Dockerの公式ドキュメントに基づいています。
コンテナイメージは、軽量でスタンドアロンの実行可能なソフトウェアのパッケージであり、それを実行するために必要なすべてのものが含まれています: コード、ランタイム、システムツール、システムライブラリ、設定。
実行中のコンテナは、
$ sudo docker psを実行することで見ることができます。一方、イメージとは、コンテナのスナップショットのような不活性で不変なファイルのことです。イメージは build コマンドで作成され、run コマンドで起動するとコンテナを生成します。
イメージは
$ sudo docker imagesを実行することで見ることができます。Djangoアプリケーションを構築する
まずはDjangoをインストールしてDjangoアプリケーションを作成してみましょう。
$ sudo pip install django==1.9 $ django-admin startproject djangoapp要件ファイル
djangoapp ディレクトリ内に要件ファイルを作成し、アプリケーションが必要とする依存関係を定義します。
$ cd djangoapp $ nano requirements.txt以下の依存関係を追加します。
#requirements.txt Django==1.9 gunicorn==19.6.0Dockerファイルの作成
Dockerには、Dockerファイルから命令を読み込んで自動的にイメージを構築する機能があります。Dockerファイルには、Dockerがイメージを構築するために使用するすべてのコマンドと命令が含まれています。
Dockerfileで使用される基本的なコマンドをいくつか定義してみましょう。
- FROM - 新しいビルドステージを初期化し、その後の命令のためのベースイメージを設定します。そのため、有効なDockerfileはFROM命令で始まらなければなりません。
- RUN - 指定されたコマンドを実行します。
- ADD - コンテナにファイルをコピーします。
- EXPOSE - 実行時にコンテナが指定されたネットワークポートをリッスンしていることをDockerに通知します。
- CMD - 実行中のコンテナにデフォルトを提供します。 では、Dockerfileというファイルを作成してみましょう。
$ nano DockerfileまずはDockerfileに必要なプロパティをすべて定義してみましょう。ベースイメージとメンテナ名を定義します。
# base image FROM python:2.7 # File Author / Maintainer MAINTAINER Esther次に、コンテナ内のアプリケーションフォルダをコピーし、CMDが実行されるディレクトリを定義します。
# Copy the application folder inside the container ADD . /usr/src/app # set the default directory where CMD will execute WORKDIR /usr/src/app最後にデフォルトのコマンドを設定して実行します。
CMD exec gunicorn djangoapp.wsgi:application --bind 0.0.0.0:8000 --workers 3最終的なDockerfileは以下のようになるはずです。
# set the base image FROM python:2.7 # File Author / Maintainer MAINTAINER Esther #add project files to the usr/src/app folder ADD . /usr/src/app #set directoty where CMD will execute WORKDIR /usr/src/app COPY requirements.txt ./ # Get pip to download and install requirements: RUN pip install --no-cache-dir -r requirements.txt # Expose ports EXPOSE 8000 # default command to execute CMD exec gunicorn djangoapp.wsgi:application --bind 0.0.0.0:8000 --workers 3Dockerイメージの構築
以下のコマンドを実行して、dockerイメージを構築します。
$ sudo docker build -t django_application_image . Sending build context to Docker daemon 12.8kB Step 1/7 : FROM python:2.7 ---> 2863c80c418c Step 2/7 : ADD . /usr/src/app ---> 09b03ff8466e Step 3/7 : WORKDIR /usr/src/app Removing intermediate container a71a3bf6af90 ---> 3186c92adc85 Step 4/7 : COPY requirements.txt ./ ---> 701c0be5e039 Step 5/7 : RUN pip install --no-cache-dir -r requirements.txt ---> Running in ed034f98db74 Collecting Django==1.9 (from -r requirements.txt (line 1)) Downloading Django-1.9-py2.py3-none-any.whl (6.6MB) Collecting gunicorn==19.6.0 (from -r requirements.txt (line 2)) Downloading gunicorn-19.6.0-py2.py3-none-any.whl (114kB) Installing collected packages: Django, gunicorn Successfully installed Django-1.9 gunicorn-19.6.0 Removing intermediate container ed034f98db74 ---> 1ffd08204a07 Step 6/7 : EXPOSE 8000 ---> Running in 987b48e1a4ef Removing intermediate container 987b48e1a4ef ---> ef889d6e8fcb Step 7/7 : CMD exec gunicorn djangoapp.wsgi:application --bind 0.0.0.0:8000 --workers 3 ---> Running in 4d929e361d0f Removing intermediate container 4d929e361d0f ---> c6baca437c64 Successfully built c6baca437c64 Successfully tagged django_application_image:latest構築されたイメージは、マシンのローカルのDockerイメージレジストリにあります。イメージを確認するには、
$ sudo docker imagesを実行します。REPOSITORY TAG IMAGE ID CREATED SIZE django_application_image latest c6baca437c64 34 minutes ago 702MBアプリを実行する
$ sudo docker run -p 8000:8000 -i -t django_application_image [2018-03-25 12:29:08 +0000] [1] [INFO] Starting gunicorn 19.6.0 [2018-03-25 12:29:08 +0000] [1] [INFO] Listening at: http://0.0.0.0:8000 [2018-03-25 12:29:08 +0000] [1] [INFO] Using worker: sync [2018-03-25 12:29:08 +0000] [8] [INFO] Booting worker with pid: 8 [2018-03-25 12:29:08 +0000] [9] [INFO] Booting worker with pid: 9 [2018-03-25 12:29:08 +0000] [10] [INFO] Booting worker with pid: 10gunicorn がアプリにサービスを提供しているというメッセージがhttp://0.0.0.0:8000に表示されます。 サーバーの IP (ip_address:8000) に移動し、Django のウェルカムページが表示されるはずです。
実行中のコンテナを見るには
$ sudo docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 100695b41a0a django_application_image "/bin/sh -c 'exec gu…" 13 seconds ago Exited (0) 4 seconds ago hopeful_easley結論
Dockerを使っていると、時としていくつかの問題に直面することがあります。エラーが発生したときに最初にすべきことは、Dockerのログファイルをチェックすることです。
Dockerやその他のコンテナは、アプリケーション開発のための従来の仮想マシンの強力な代替手段です。Alibaba Cloud上でコンテナを実行する方法の詳細については、コンテナサービスのページをご覧ください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-07-10T15:17:02+09:00
ゼロから始めるLeetCode Day82「392. Is Subsequence」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day81 「347. Top K Frequent Elements」Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
392. Is Subsequence
難易度はEasy。前回と同様問題集からの抜粋です。
問題としては、文字列sと文字列tが与えられたとき,sがtの部分連続であるかどうかを調べよ、というものです。
なお、ここでの文字列の部分連続とは、元の文字列から、残りの文字の相対的な位置を崩さずに、文字の一部を削除することによって形成される新しい文字列のことです(何もなくてもよい)。(例えば、"ace "は "abcde "の部分文字列ですが、"aec "はそうではありません)。
Example 1:
Input: s = "abc", t = "ahbgdc"
Output: trueExample 2:
Input: s = "axc", t = "ahbgdc"
Output: false解法
class Solution: def isSubsequence(self, s: str, t: str) -> bool: pre = cur = 0 while pre < len(s) and cur < len(t): if s[pre] == t[cur]: pre +=1 cur +=1 return pre == len(s) # Runtime: 36 ms, faster than 60.46% of Python3 online submissions for Is Subsequence. # Memory Usage: 14.1 MB, less than 35.95% of Python3 online submissions for Is Subsequence.pointerを二つ使って考える形式を取りました。
仮に
sのpreインデックスがtのcurインデックス、すなわち部分文字列が見つかった時にpreの値を増加させ、それ以外の時はcur側の値を増加させることで、tのインデックスをずらすことができます。これをpreとcurそれぞれがsとtの長さ未満の間続けることで、仮にpreの値がsの長さと一致しない場合はFalseを、それ以外の場合はTrueを返すようにしています。何のアルゴリズムというわけではありませんが、総合的に考える問題とあった通り、いろんなやり方があると思いますが、今回はこんな感じになりました。
では今回はここまで。お疲れ様でした。
- 投稿日:2020-07-10T14:35:03+09:00
pythonで最も美しいおっぱいを描いた人が優勝
お酒飲みながら描いた、後悔はしてない
数学って美しいよねって話。
結果
数学でおっぱいを書きます
色をつけます
乳輪をつけて完成
コード
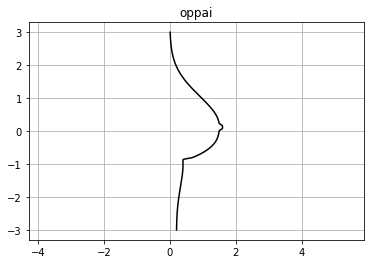
数学でおっぱいを書きます
py.pyimport numpy as np import matplotlib.pyplot as plt def oppai(y): x_1 = (1.5*np.exp(-0.62*(y-0.16)**2))/(1+np.exp(-20*(5*y-1))) x_2 = (1.5+0.8*(y-0.2)**3)*(1+np.exp(20*(5*y-1)))**-1 x_3 = (1+np.exp(-(100*(y+1)-16))) x_4 = (0.2*(np.exp(-(y+1)**2)+1))/(1+np.exp(100*(y+1)-16)) x_5 = (0.1/np.exp(2*(10*y-1.2)**4)) x = x_1+(x_2/x_3)+x_4+x_5 return x def plot_oppai(x, y): plt.title('oppai') plt.axes().set_aspect('equal', 'datalim') plt.grid() plt.plot(x, y, 'black') plt.show() def main(): y = np.arange(-3, 3 + 0.01, 0.01) x = oppai(y) plot_oppai(x, y) if __name__ == '__main__': main()良さげな画像からカラーコードを取得します
ここに良さげな画像をアップロード(例:kirara.png)
https://www.peko-step.com/tool/getcolor.html
カラーコードを取得
肌色:#F5D1B7
乳首:#C87B6D
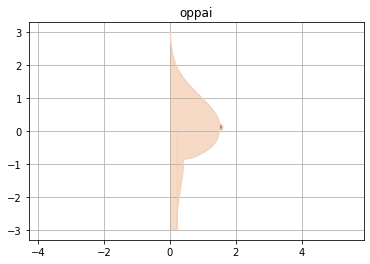
乳輪:#E29577色をつけます
oppaiを弄るだけです。
py.pydef plot_oppai(x, y): plt.title('oppai') plt.axes().set_aspect('equal', 'datalim') plt.grid() plt.plot(x, y, '#F5D1B7') plt.fill_between(x, y, facecolor='#F5D1B7', alpha=0.8)#肌 plt.axvspan(1.52, 1.59, 0.51, 0.53, color = '#C87B6D')#乳首 plt.axvspan(0, 0.18, 0.05, 0.5, color = '#F5D1B7')#下乳補正 plt.show()乳輪を描いて完成
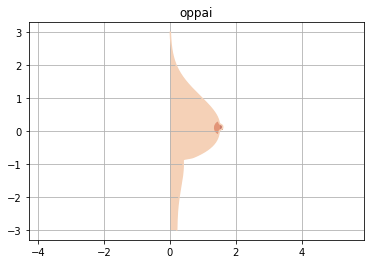
こいつもoppaiを弄るだけです。
py.pyimport matplotlib.patches as patches def plot_oppai(x, y): plt.title('oppai') plt.axes().set_aspect('equal', 'datalim') plt.grid() plt.plot(x, y, '#F5D1B7') plt.fill_between(x, y, facecolor='#F5D1B7', alpha=0.8)#肌 w=patches.Wedge(center=(1.55, 0.1),r=0.2,theta1=120,theta2=240,color='#E29577')#乳輪 ax = plt.axes() ax.add_patch(w) plt.axvspan(1.52, 1.59, 0.51, 0.53, color = '#C87B6D')#乳首 plt.axvspan(0, 0.18, 0.05, 0.5, color = '#F5D1B7')#下乳補正 plt.show()最終的なコード
py.pyimport numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patches def oppai(y): x_1 = (1.5*np.exp(-0.62*(y-0.16)**2))/(1+np.exp(-20*(5*y-1))) x_2 = (1.5+0.8*(y-0.2)**3)*(1+np.exp(20*(5*y-1)))**-1 x_3 = (1+np.exp(-(100*(y+1)-16))) x_4 = (0.2*(np.exp(-(y+1)**2)+1))/(1+np.exp(100*(y+1)-16)) x_5 = (0.1/np.exp(2*(10*y-1.2)**4)) x = x_1+(x_2/x_3)+x_4+x_5 return x def plot_oppai(x, y): plt.title('oppai') plt.axes().set_aspect('equal', 'datalim') plt.grid() plt.plot(x, y, '#F5D1B7') plt.fill_between(x, y, facecolor='#F5D1B7', alpha=0.8)#肌色 w=patches.Wedge(center=(1.55,0.1),r=0.2,theta1=120,theta2=240,color='#E29577')#乳輪 ax = plt.axes() ax.add_patch(w) plt.axvspan(1.52, 1.59, 0.51, 0.53, color = '#C87B6D')#乳首当て plt.axvspan(0, 0.18, 0.05, 0.5, color = '#F5D1B7')#下乳補正 plt.show() def main(): y = np.arange(-3, 3 + 0.01, 0.01) x = oppai(y) plot_oppai(x, y) if __name__ == '__main__': main()まとめ
数学って美しい
乳首も乳輪も、好きな色に変えて遊んでくだせぇ
ピンクの乳首が好きって人はLGTMを、いやいや、黒い乳首の方が興奮するやろって人はフォローお願いします参考
・これのKindle版
Matplotlib&Seaborn実装ハンドブック (Pythonライブラリ定番セレクション)

- 投稿日:2020-07-10T13:37:43+09:00
Pythonで文字列を入力し、そのまま出力、または逆向きに出力する方法。
Pythonでの文字列入力、出力、文字列を逆向きにして出力する方法を書いています。
よろしくおねがいします。まず、Pythonで文字列を入力する方法。
s = input()そのまま、出力したい場合。
print(s)文字列を逆向きにして、出力したい場合。
print(s[::-1])以上です。
ありがとうございました。
- 投稿日:2020-07-10T13:22:07+09:00
【python】pandas で○○が最大となる△△を取り出す
あるい指標について最大であるときの別の指標の値を取り出す
例えば、「信号強度(intensity)が最大になる角度(elevation)」をDataFrame から取り出すことを考えます。import pandas as pd df = pd.DataFrame({'elevation': [45.0, 60.0, 75.0, 90.0], \ 'intensity': [10.0, 11.1, 12.3, 10.0]}) print(df.loc[df.idxmax()["intensity"]]["elevation"])結果は 75.0 とでるはずです。
- idxmax(), idxmin() で最大、最小になる各列のindex を取得できる
- このプログラムでは、DataFrame の index が文字列でも動きます。
df = pd.DataFrame({'elevation': [45.0, 60.0, 75.0, 90.0],\ 'intensity': [10.0, 11.1, 12.3, 10.0]},\ index=['a', 'b', 'c', 'd'])何度も同じことをググっているのでメモしました。(2020/07/10)
- 投稿日:2020-07-10T12:03:27+09:00
pillowを使って綺麗な描画がしたいときはaggdrawを使え
pillowを使って図形を描画する機会があったのだが、デフォルトのまま描画するとバキバキの画像になってしまった。きれいにしたければ倍の大きさで書き出し、リサイズするときにアンチエイリアスを指定すればいいらしいが、ちょっとめんどくさい。
最初からきれいに描けるモジュールを見つけたので書いておく。参考 https://stackoverrun.com/ja/q/3880127
参考 https://aggdraw.readthedocs.io/en/latest/pillowで普通に描く
pollowをつかって普通に描くとこんな感じ。角の処理もされず、ジャギも出ているのがわかるだろうか。
from PIL import Image, ImageDraw image = Image.new('RGB', (300, 300), (255, 255, 255)) draw = ImageDraw.Draw(image) draw.line((150, 50, 250, 250, 50, 250, 150, 50), fill=(0, 0, 0), width=20) draw.line((10, 140, 290, 160), fill=(0, 0, 0), width=20) image.save('test1.png', quality=100)
pillowで普通に描いて角を丸める
一応、角の丸めに関してはバージョンの新しめのpillowなら実装されている。
joint="curve" を引数に追加してやればいい。from PIL import Image, ImageDraw image = Image.new('RGB', (300, 300), (255, 255, 255)) draw = ImageDraw.Draw(image) draw.line((150, 50, 250, 250, 50, 250, 150, 50), fill=(0, 0, 0), width=20, joint="curve") draw.line((10, 140, 290, 160), fill=(0, 0, 0), width=20) image.save('test2.png', quality=100)
これで角は丸められる。書き始めと書き終わりの部分が処理されないので、気になるなら最初の一辺をもう一度なぞるといい。
from PIL import Image, ImageDraw image = Image.new('RGB', (300, 300), (255, 255, 255)) draw = ImageDraw.Draw(image) draw.line((150, 50, 250, 250, 50, 250, 150, 50, 250, 250), fill=(0, 0, 0), width=20, joint="curve") draw.line((10, 140, 290, 160), fill=(0, 0, 0), width=20) image.save('test3.png', quality=100)
aggdrawで描く
インストールは普通にpipでいけた
pip install aggdrawaggdrawでは、pillowで作ったImageにそのまま描画できる。penを定義して、それで書いていく感じ。アンチエイリアスやアルファ合成も勝手にやってくれるので、ジャギが消えているのがわかるだろうか?
from PIL import Image import aggdraw image = Image.new('RGB', (300, 300), (255, 255, 255)) draw = aggdraw.Draw(image) pen = aggdraw.Pen((0, 0, 0), 20) draw.line((150, 50, 250, 250, 50, 250, 150, 50, 250, 250), pen) draw.line((10, 140, 290, 160), pen) draw.flush() image.save('test4.png', quality=100)
おまけ
ブラシ(塗りつぶし)もあるよ
from PIL import Image import aggdraw image = Image.new('RGBA', (300, 300), (255, 255, 255, 255)) draw = aggdraw.Draw(image) brush = aggdraw.Brush((0, 0, 0), 255) draw.line((150, 50, 250, 250, 50, 250, 150, 50, 250, 250), brush) draw.flush() image.save('test5.png', quality=100)





- 投稿日:2020-07-10T09:43:59+09:00
だから僕はpandasを辞めた【データサイエンス100本ノック(構造化データ加工編)篇 #6】
だから僕はpandasを辞めた【データサイエンス100本ノック(構造化データ加工編)篇 #6】
データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。この問題群は、模範解答ではpandasを使ってデータ加工を行っていますが、私達は勉強がてらにNumPyを用いて処理していきます。
はじめに
NumPyの勉強として、データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。
Pythonでデータサイエンス的なことをする人の多くはpandas大好き人間かもしれませんが、実はpandasを使わなくても、NumPyで同じことができます。そしてNumPyの方がたいてい高速です。
pandas大好き人間だった僕もNumPyの操作には依然として慣れていないので、今回この『データサイエンス100本ノック』をNumPyで操作することでpandasからの卒業を試みて行きたいと思います。今回は52~62問目をやっていきます。データのカテゴリ化というテーマのようです。
初期データは以下のようにして読み込みました。import numpy as np import pandas as pd from numpy.lib import recfunctions as rfn # 模範解答用 df_customer = pd.read_csv('data/customer.csv') df_receipt = pd.read_csv('data/receipt.csv') # 僕たちが扱うデータ arr_customer = np.genfromtxt( 'data/customer.csv', delimiter=',', encoding='utf-8', names=True, dtype=None) arr_receipt = np.genfromtxt( 'data/receipt.csv', delimiter=',', encoding='utf-8', names=True, dtype=None)最後に計算結果を構造化配列にして出力するための関数def make_array(size, **kwargs): arr = np.empty(size, dtype=[(colname, subarr.dtype) for colname, subarr in kwargs.items()]) for colname, subarr in kwargs.items(): arr[colname] = subarr return arrP_052
P-052: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計の上、売上金額合計に対して2000円以下を0、2000円超を1に2値化し、顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
顧客別売上はいつもの
np.unique()+np.bincount()で算出します。「2000円以下は0・超えると1」は、2000と比較した真偽値配列を数値に直すだけです(Falseは0、Trueは1と等価です)。In[052]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' unq_id, inv_id = np.unique(arr_receipt['customer_id'][is_member], return_inverse=True) amount_arr = np.bincount(inv_id, arr_receipt['amount'][is_member]) make_array(unq_id.size, customer_id=unq_id, amount=amount_arr, sales_flg=(amount_arr > 2000).view(np.int8))[:10]Out[052]array([('CS001113000004', 1298., 0), ('CS001114000005', 626., 0), ('CS001115000010', 3044., 1), ('CS001205000004', 1988., 0), ('CS001205000006', 3337., 1), ('CS001211000025', 456., 0), ('CS001212000027', 448., 0), ('CS001212000031', 296., 0), ('CS001212000046', 228., 0), ('CS001212000070', 456., 0)], dtype=[('customer_id', '<U14'), ('amount', '<f8'), ('sales_flg', 'i1')])Time[052]# 模範解答 %%timeit df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python') df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() df_sales_amount['sales_flg'] = df_sales_amount['amount'].apply(lambda x: 1 if x > 2000 else 0) df_sales_amount.head(10) # 72.9 ms ± 1.67 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) # 改良 %%timeit df_sales_amount = df_receipt.loc[~df_receipt['customer_id'].str.startswith('Z'), ['customer_id', 'amount']].groupby('customer_id', as_index=False).sum() df_sales_amount['sales_flg'] = (df_sales_amount['amount'] > 2000).astype(int) df_sales_amount.head(10) # 63.5 ms ± 226 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) # NumPy(コード上記参照) # 33.8 ms ± 252 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)P_053
P-053: 顧客データフレーム(df_customer)の郵便番号(postal_cd)に対し、東京(先頭3桁が100〜209のもの)を1、それ以外のものを0に2値化せよ。さらにレシート明細データフレーム(df_receipt)と結合し、全期間において買い物実績のある顧客数を、作成した2値ごとにカウントせよ。
まず、
np.in1d()を用いて購入履歴のある顧客だけを抜き出します。つづいて、郵便番号の前3桁を数値に変換します。.astype('<U3').astype(int)としてもよいですが、ここではnp.frombuffer()を用いて.astype()を介さずに変換しています(P_011参照)。In[053]isin_rec = np.in1d(arr_customer['customer_id'], arr_receipt['customer_id']) post_int_arr = ((np.frombuffer( arr_customer['postal_cd'][isin_rec].tobytes(), dtype=np.int32) - 48).reshape(-1, 8)[:, :3]*np.array([100, 10, 1])).sum(1) postal_flg = ((101 <= post_int_arr) & (post_int_arr <= 209)) make_array(2, postal_flg=np.arange(2), count=np.bincount(postal_flg))Out[053]array([(0, 3906), (1, 4400)], dtype=[('postal_flg', '<i4'), ('count', '<i8')])Time[053]# 模範解答 %%timeit df_tmp = df_customer[['customer_id', 'postal_cd']].copy() df_tmp['postal_flg'] = df_tmp['postal_cd'].apply(lambda x: 1 if 100 <= int(x[0:3]) <= 209 else 0) pd.merge(df_tmp, df_receipt, how='inner', on='customer_id').groupby('postal_flg').agg({'customer_id':'nunique'}) # 109 ms ± 4.89 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) # NumPy(コード上記参照) # 50.2 ms ± 349 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)P_054
P-054: 顧客データデータフレーム(df_customer)の住所(address)は、埼玉県、千葉県、東京都、神奈川県のいずれかとなっている。都道府県毎にコード値を作成し、顧客ID、住所とともに抽出せよ。値は埼玉県を11、千葉県を12、東京都を13、神奈川県を14とすること。結果は10件表示させれば良い。
住所列の先頭の文字を見て、任意の数字に置換します(P_036参照)。
In[054]caps = np.array(['埼', '千', '東', '神'], dtype='<U1') sorter_index = caps.argsort() idx = np.searchsorted(caps, arr_customer['address'].astype('<U1'), sorter=sorter_index) address_code = np.array([11, 12, 13, 14])[sorter_index[idx]] make_array(arr_customer.size, customer_id=arr_customer['customer_id'], address=arr_customer['address'], address_code=address_code)[:10]Out[054]array([('CS021313000114', '神奈川県伊勢原市粟窪**********', 14), ('CS037613000071', '東京都江東区南砂**********', 13), ('CS031415000172', '東京都渋谷区代々木**********', 13), ('CS028811000001', '神奈川県横浜市泉区和泉町**********', 14), ('CS001215000145', '東京都大田区仲六郷**********', 13), ('CS020401000016', '東京都板橋区若木**********', 13), ('CS015414000103', '東京都江東区北砂**********', 13), ('CS029403000008', '千葉県浦安市海楽**********', 12), ('CS015804000004', '東京都江東区北砂**********', 13), ('CS033513000180', '神奈川県横浜市旭区善部町**********', 14)], dtype=[('customer_id', '<U14'), ('address', '<U26'), ('address_code', '<i4')])Time[054]# 模範解答 pd.concat([df_customer[['customer_id', 'address']], df_customer['address'].str[0:3].map({'埼玉県': '11', '千葉県': '12', '東京都': '13', '神奈川': '14'})], axis=1).head(10) # 16.2 ms ± 963 µs per loop (mean ± std. dev. of 7 runs, 1 loop each) # NumPy(コード上記参照) # 4.52 ms ± 176 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)P_055
P-055: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、その合計金額の四分位点を求めよ。その上で、顧客ごとの売上金額合計に対して以下の基準でカテゴリ値を作成し、顧客ID、売上金額と合計ともに表示せよ。カテゴリ値は上から順に1〜4とする。結果は10件表示させれば良い。
- 最小値以上第一四分位未満
- 第一四分位以上第二四分位未満
- 第二四分位以上第三四分位未満
- 第三四分位以上
顧客別売上はいつもの
np.unique()+np.bincount()で算出します。つづいて、np.quantile()を用いて四分位点を求めます。最後に、顧客別売上と四分位点の値を比較して、どのグループに属しているかを求めます(np.searchsorted()を使って求めることも可能)。In[055]unq_id, inv_id = np.unique(arr_receipt['customer_id'], return_inverse=True) amount_arr = np.bincount(inv_id, arr_receipt['amount']) quantiles = np.quantile(amount_arr, np.arange(1, 4)/4) pct_group = (quantiles[:, None] <= amount_arr).sum(0) + 1 make_array(unq_id.size, customer_id=unq_id, amount=amount_arr, pct_group=pct_group)[:10]Out[055]array([('CS001113000004', 1298., 2), ('CS001114000005', 626., 2), ('CS001115000010', 3044., 3), ('CS001205000004', 1988., 3), ('CS001205000006', 3337., 3), ('CS001211000025', 456., 1), ('CS001212000027', 448., 1), ('CS001212000031', 296., 1), ('CS001212000046', 228., 1), ('CS001212000070', 456., 1)], dtype=[('customer_id', '<U14'), ('amount', '<f8'), ('pct_group', '<i8')])P_056
P-056: 顧客データフレーム(df_customer)の年齢(age)をもとに10歳刻みで年代を算出し、顧客ID(customer_id)、生年月日(birth_day)とともに抽出せよ。ただし、60歳以上は全て60歳代とすること。年代を表すカテゴリ名は任意とする。先頭10件を表示させればよい。
In[056]age = arr_customer['age']//10*10 age[age > 60] = 60 arr_customer_era = make_array(arr_customer.size, customer_id=arr_customer['customer_id'], birth_day=arr_customer['birth_day'], age=age) arr_customer_era[:10]
np.clip()やnp.where()を用いてもよいでしょう。Out[056]array([('CS021313000114', '1981-04-29', 30), ('CS037613000071', '1952-04-01', 60), ('CS031415000172', '1976-10-04', 40), ('CS028811000001', '1933-03-27', 60), ('CS001215000145', '1995-03-29', 20), ('CS020401000016', '1974-09-15', 40), ('CS015414000103', '1977-08-09', 40), ('CS029403000008', '1973-08-17', 40), ('CS015804000004', '1931-05-02', 60), ('CS033513000180', '1962-07-11', 50)], dtype=[('customer_id', '<U14'), ('birth_day', '<U10'), ('age', '<i4')])P_057
P-057: 前問題の抽出結果と性別(gender)を組み合わせ、新たに性別×年代の組み合わせを表すカテゴリデータを作成せよ。組み合わせを表すカテゴリの値は任意とする。先頭10件を表示させればよい。
In[057]arr_customer_era = make_array(arr_customer.size, customer_id=arr_customer['customer_id'], birth_day=arr_customer['birth_day'], age=age, era_gender=arr_customer['gender_cd']*100+age) arr_customer_era[:10]Out[057]array([('CS021313000114', '1981-04-29', 30, 130), ('CS037613000071', '1952-04-01', 60, 960), ('CS031415000172', '1976-10-04', 40, 140), ('CS028811000001', '1933-03-27', 60, 160), ('CS001215000145', '1995-03-29', 20, 120), ('CS020401000016', '1974-09-15', 40, 40), ('CS015414000103', '1977-08-09', 40, 140), ('CS029403000008', '1973-08-17', 40, 40), ('CS015804000004', '1931-05-02', 60, 60), ('CS033513000180', '1962-07-11', 50, 150)], dtype=[('customer_id', '<U14'), ('birth_day', '<U10'), ('age', '<i4'), ('era_gender', '<i4')])P_058
P-058: 顧客データフレーム(df_customer)の性別コード(gender_cd)をダミー変数化し、顧客ID(customer_id)とともに抽出せよ。結果は10件表示させれば良い。
ブロキャ。
In[058]dummies = (arr_customer['gender_cd'] == np.array([[0], [1], [9]])).view(np.int8) make_array(arr_customer.size, customer_id=arr_customer['customer_id'], gender_cd_0=dummies[0], gender_cd_1=dummies[1], gender_cd_9=dummies[2])[:10]Out[058]gender_cd = np.ascontiguousarray(arr_customer['gender_cd'])... array([('CS021313000114', 0, 1, 0), ('CS037613000071', 0, 0, 1), ('CS031415000172', 0, 1, 0), ('CS028811000001', 0, 1, 0), ('CS001215000145', 0, 1, 0), ('CS020401000016', 1, 0, 0), ('CS015414000103', 0, 1, 0), ('CS029403000008', 1, 0, 0), ('CS015804000004', 1, 0, 0), ('CS033513000180', 0, 1, 0)], dtype=[('customer_id', '<U14'), ('gender_cd_0', 'i1'), ('gender_cd_1', 'i1'), ('gender_cd_9', 'i1')])P_059
P-059: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を平均0、標準偏差1に標準化して顧客ID、売上金額合計とともに表示せよ。標準化に使用する標準偏差は、不偏標準偏差と標本標準偏差のどちらでも良いものとする。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
式にあてはめるだけ。
scipy.stats.zscore()だと楽。In[059]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' unq_id, inv_id = np.unique(arr_receipt['customer_id'][is_member], return_inverse=True) amount_arr = np.bincount(inv_id, arr_receipt['amount'][is_member]) amount_mean = amount_arr.mean() amount_std = np.sqrt(((amount_arr-amount_mean)**2).mean()) amount_ss = (amount_arr - amount_mean) / amount_std # amount_ss = scipy.stats.zscore(amount_mean) でもOK make_array(unq_id.size, customer_id=unq_id, amount=amount_arr, amount_ss=amount_ss)[:10]Out[059]array([('CS001113000004', 1298., -0.45937788), ('CS001114000005', 626., -0.70639037), ('CS001115000010', 3044., 0.18241349), ('CS001205000004', 1988., -0.20574899), ('CS001205000006', 3337., 0.29011387), ('CS001211000025', 456., -0.76887864), ('CS001212000027', 448., -0.77181927), ('CS001212000031', 296., -0.82769114), ('CS001212000046', 228., -0.85268645), ('CS001212000070', 456., -0.76887864)], dtype=[('customer_id', '<U14'), ('amount', '<f8'), ('amount_ss', '<f8')])P_060
P-060: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を最小値0、最大値1に正規化して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
式にあてはめるだけ。
In[060]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' unq_id, inv_id = np.unique(arr_receipt['customer_id'][is_member], return_inverse=True) amount_arr = np.bincount(inv_id, arr_receipt['amount'][is_member]) amount_min, amount_max = amount_arr.min(), amount_arr.max() amount_mm = (amount_arr - amount_min) / (amount_max - amount_min) make_array(unq_id.size, customer_id=unq_id, amount=amount_arr, amount_mm=amount_mm)[:10]Out[060]array([('CS001113000004', 1298., 0.05335419), ('CS001114000005', 626., 0.02415711), ('CS001115000010', 3044., 0.12921446), ('CS001205000004', 1988., 0.08333333), ('CS001205000006', 3337., 0.14194473), ('CS001211000025', 456., 0.01677094), ('CS001212000027', 448., 0.01642336), ('CS001212000031', 296., 0.00981926), ('CS001212000046', 228., 0.00686479), ('CS001212000070', 456., 0.01677094)], dtype=[('customer_id', '<U14'), ('amount', '<f8'), ('amount_mm', '<f8')])P_061
P-061: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を常用対数化(底=10)して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
In[061]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' unq_id, inv_id = np.unique(arr_receipt['customer_id'][is_member], return_inverse=True) amount_arr = np.bincount(inv_id, arr_receipt['amount'][is_member]) make_array(unq_id.size, customer_id=unq_id, amount=amount_arr, amount_log10=np.log10(amount_arr + 1))[:10]Out[061]array([('CS001113000004', 1298., 3.11360915), ('CS001114000005', 626., 2.79726754), ('CS001115000010', 3044., 3.4835873 ), ('CS001205000004', 1988., 3.29863478), ('CS001205000006', 3337., 3.52348633), ('CS001211000025', 456., 2.6599162 ), ('CS001212000027', 448., 2.65224634), ('CS001212000031', 296., 2.47275645), ('CS001212000046', 228., 2.35983548), ('CS001212000070', 456., 2.6599162 )], dtype=[('customer_id', '<U14'), ('amount', '<f8'), ('amount_log10', '<f8')])P_062
P-062: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を自然対数化(底=e)して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
In[062]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' unq_id, inv_id = np.unique(arr_receipt['customer_id'][is_member], return_inverse=True) amount_arr = np.bincount(inv_id, arr_receipt['amount'][is_member]) make_array(unq_id.size, customer_id=unq_id, amount=amount_arr, amount_log10=np.log1p(amount_arr))[:10]Out[062]array([('CS001113000004', 1298., 7.16935002), ('CS001114000005', 626., 6.44094654), ('CS001115000010', 3044., 8.02125618), ('CS001205000004', 1988., 7.59538728), ('CS001205000006', 3337., 8.1131271 ), ('CS001211000025', 456., 6.12468339), ('CS001212000027', 448., 6.10702289), ('CS001212000031', 296., 5.69373214), ('CS001212000046', 228., 5.433722 ), ('CS001212000070', 456., 6.12468339)], dtype=[('customer_id', '<U14'), ('amount', '<f8'), ('amount_log10', '<f8')])
- 投稿日:2020-07-10T09:37:37+09:00
collections.deque
import collections import queue collections.deque q = queue.Queue() lq = queue.LifoQueue() l = [] d = collections.deque() for i in range(3): q.put(i) lq.put(i) l.append(i) d.append(i) for _ in range(3): print('FIFO queue = {}'.format(q.get())) print('LIFO queue = {}'.format(lq.get())) print('list = {}'.format(l.pop())) #pop(0)でFIFO print('deque = {}'.format(d.pop())) #d.popleft()でFIFO print()実行結果:
FIFO queue = 0 LIFO queue = 2 list = 2 deque = 2 FIFO queue = 1 LIFO queue = 1 list = 1 deque = 1 FIFO queue = 2 LIFO queue = 0 list = 0 deque = 0import collections import queue collections.deque d = collections.deque() for i in range(3): d.append(i) print(d) d.extendleft('x') d.extend('y') print(d) d.rotate() print(d) d.clear() print(d)実行結果:
deque([0, 1, 2]) deque(['x', 0, 1, 2, 'y']) deque(['y', 'x', 0, 1, 2]) deque([])
- 投稿日:2020-07-10T08:26:12+09:00
【PyTorchチュートリアル⑤】Learning PyTorch with Examples (後編)
はじめに
前回に引き続き、PyTorch 公式チュートリアル の第5弾です。
今回は Learning PyTorch with Examples の後編です。
前編はこちらです。3. nn module
3.1. PyTorch: nn
autograd だけでは、ニューラルネットワークのモデルを作成することはできません。
モデルの構築は、nnパッケージを利用します。
nnパッケージには、入力層、隠れ層、出力層を定義する Sequential クラスや、損失関数も含まれています。
下の例では、nnパッケージを使用して2層ネットワークを実装します。import torch # N : バッチサイズ # D_in : 入力次元数 # H : 隠れ層の次元数 # D_out : 出力次元数 N, D_in, H, D_out = 64, 1000, 100, 10 # ランダムな入力データと教師データを作成します x = torch.randn(N, D_in) y = torch.randn(N, D_out) # Use the nn package to define our model as a sequence of layers. nn.Sequential # is a Module which contains other Modules, and applies them in sequence to # produce its output. Each Linear Module computes output from input using a # linear function, and holds internal Tensors for its weight and bias. # nnパッケージを使用して、モデルを一連のレイヤーとして定義します。 # nn.Sequentialは、他のモジュールを順番に適用してモデルを生成します。 # Linear は、線形関数を使用して入力から出力を計算し、重みとバイアスを # 内部テンソルで保持します。 model = torch.nn.Sequential( torch.nn.Linear(D_in, H), torch.nn.ReLU(), torch.nn.Linear(H, D_out), ) # nnパッケージには、損失関数も含まれています。 # 今回は、損失関数として平均二乗誤差(MSE)を使用します。 loss_fn = torch.nn.MSELoss(reduction='sum') learning_rate = 1e-4 for t in range(500): # 順伝播:モデルにxを渡すことにより、予測値 y を計算します。 # 基底クラスである Module は__call__演算子をオーバーライドするため、 # 関数のように呼び出すことができます。 # その場合、入力データのテンソルをモジュールに渡し、出力データのテンソルを生成します。 y_pred = model(x) # ロス(損失)を計算し出力します。 # 損失関数に y の予測値と教師データのテンソルを渡すと # 損失を含むテンソルを返します。 loss = loss_fn(y_pred, y) if t % 100 == 99: print(t, loss.item()) # 逆伝播を計算する前に、勾配をゼロにします。 model.zero_grad() # 逆伝播:損失の勾配を計算します。 # 内部的には、モジュールのパラメーターはrequire_grad = True で保持されているため # すべてのパラメーターの勾配を計算します。 loss.backward() # 確率的勾配降下法を使用して重みを更新します。 with torch.no_grad(): for param in model.parameters(): param -= learning_rate * param.grad3.2. PyTorch: optim
ここまでは、モデルの重みを以下のように自分で計算して更新していました。
param -= learning_rate * param.gradこの計算方法は確率的勾配降下法と呼ばれます。
モデルの重みの計算方法( optimizer / 最適化アルゴリズム)は他にもあり、AdaGrad、RMSProp、Adam など、より高度なアルゴリズムを使用したいケースもでてきます。
PyTorchのoptimパッケージには、いろいろな最適化アルゴリズムがあります。
以下の例では、上の例のように nn パッケージでモデルを定義しますが、重みの更新に optimパッケージのAdamアルゴリズムを使用します。import torch # N : バッチサイズ # D_in : 入力次元数 # H : 隠れ層の次元数 # D_out : 出力次元数 N, D_in, H, D_out = 64, 1000, 100, 10 # ランダムな入力データと教師データを作成します x = torch.randn(N, D_in) y = torch.randn(N, D_out) # nnパッケージを使用して、モデルと損失関数を定義します。 model = torch.nn.Sequential( torch.nn.Linear(D_in, H), torch.nn.ReLU(), torch.nn.Linear(H, D_out), ) loss_fn = torch.nn.MSELoss(reduction='sum') # optimパッケージを使用して、モデルの重みを更新する最適化アルゴリズム(オプティマイザ)を定義します。 # ここでは Adam を使用します。 # optim パッケージには、他にもいろいろな最適化アルゴリズムが含まれています。 # Adam コンストラクタへの最初の引数は、どの Tensor を更新するかを指定します。 learning_rate = 1e-4 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) for t in range(500): # 順伝播:モデルにxを渡すことにより、予測値 y を計算します。 y_pred = model(x) # ロス(損失)を計算し出力します。 loss = loss_fn(y_pred, y) if t % 100 == 99: print(t, loss.item()) # 逆伝播の計算前に、更新する変数(重み)のすべての勾配をゼロにします。 # これは、backward が呼び出されるたびに、勾配が累積される(上書きされない)ためです。 optimizer.zero_grad() # 逆伝播:損失の勾配を計算します。 loss.backward() # オプティマイザのステップ関数を呼び出すと、パラメーターが更新されます。 optimizer.step()3.3. PyTorch: Custom nn Modules
複雑なモデルを構築したい場合、nn.Moduleをサブクラス化して実現できます。
サブクラスで forward 関数をオーバーライドし、入力 Tensor から出力 Tensor を返却する処理を記述することで独自のモジュールを定義できます。
この例では、2層ネットワークをカスタムモジュールサブクラスとして実装します。import torch class TwoLayerNet(torch.nn.Module): def __init__(self, D_in, H, D_out): """ コンストラクタで、2つの nn.Linear モジュールをインスタンス化し、 それらをメンバー変数として割り当てます。 """ super(TwoLayerNet, self).__init__() self.linear1 = torch.nn.Linear(D_in, H) self.linear2 = torch.nn.Linear(H, D_out) def forward(self, x): """ forward 関数では、入力 Tensor を元に、出力 Tensor を返す必要があります。 コンストラクタで定義されたモジュールを使用できます。 """ h_relu = self.linear1(x).clamp(min=0) y_pred = self.linear2(h_relu) return y_pred # N : バッチサイズ # D_in : 入力次元数 # H : 隠れ層の次元数 # D_out : 出力次元数 N, D_in, H, D_out = 64, 1000, 100, 10 # ランダムな入力データと教師データを作成します x = torch.randn(N, D_in) y = torch.randn(N, D_out) # 上で定義したニューラルネットワークモジュールをインスタンス化してモデルを構築します model = TwoLayerNet(D_in, H, D_out) # 損失関数と最適化アルゴリズム(オプティマイザ)を定義します。 # SGD の引数 model.parameters() には、定義したクラスのメンバーである # 2つの nn.Linear モジュールのパラメーターも含まれます。 criterion = torch.nn.MSELoss(reduction='sum') optimizer = torch.optim.SGD(model.parameters(), lr=1e-4) for t in range(500): # 順伝播:モデルに x を渡すことにより、予測値 y を計算します。 y_pred = model(x) # ロス(損失)を計算し出力します。 loss = criterion(y_pred, y) if t % 100 == 99: print(t, loss.item()) # 勾配をゼロにし、逆伝播を計算して、重みを更新します。 optimizer.zero_grad() loss.backward() optimizer.step()3.4. PyTorch: Control Flow + Weight Sharing
動的グラフと重み共有(Weight Sharing)の例として、特殊なモデルを実装します。以下のReLUネットワークは、forward 関数で0から3の乱数を選択し、複数の隠れ層で同じ重みを共有して計算します。
このモデルをModuleサブクラスとして実装します。import random import torch class DynamicNet(torch.nn.Module): def __init__(self, D_in, H, D_out): """ コンストラクターでは、forward 関数で使用する3つの nn.Linear インスタンス(入力層、隠れ層、出力層)を作成します。 """ super(DynamicNet, self).__init__() self.input_linear = torch.nn.Linear(D_in, H) self.middle_linear = torch.nn.Linear(H, H) self.output_linear = torch.nn.Linear(H, D_out) def forward(self, x): """ forward 関数では、0回 から 3回 の値をランダムに選択し、 middle_linearモジュールを複数回再利用して、隠れ層の処理を計算します。 autograd は動的計算グラフのため、順伝播時に構築されます。 そのため、forward 関数内では、ループや条件ステートメントなど、通常のPythonの処理を記述できます。 計算グラフを定義するときに同じモジュールを何度も利用することができます。 これはLua Torchからの改善点で、Lua Torch では各モジュールは1回しか使用できませんでした。 """ h_relu = self.input_linear(x).clamp(min=0) for _ in range(random.randint(0, 3)): h_relu = self.middle_linear(h_relu).clamp(min=0) print(str(_)) print(h_relu.size()) y_pred = self.output_linear(h_relu) return y_pred # N : バッチサイズ # D_in : 入力次元数 # H : 隠れ層の次元数 # D_out : 出力次元数 N, D_in, H, D_out = 64, 1000, 100, 10 # ランダムな入力データと教師データを作成します x = torch.randn(N, D_in) y = torch.randn(N, D_out) # 上で定義したニューラルネットワークモジュールをインスタンス化してモデルを構築します model = DynamicNet(D_in, H, D_out) # 損失関数とオプティマイザーを作成します。 # このモデルは、通常の確率勾配降下法で学習させる(収束させる)のは難しいので、momentumを指定します。 criterion = torch.nn.MSELoss(reduction='sum') optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9) for t in range(500): # 順伝播:モデルにxを渡すことにより、予測値 y を計算します。 y_pred = model(x) # ロス(損失)を計算し出力します。 loss = criterion(y_pred, y) if t % 100 == 99: print(t, loss.item()) # 勾配をゼロにし、逆伝播を計算して、重みを更新します。 optimizer.zero_grad() loss.backward() optimizer.step()終わりに
以上が、PyTorch の5つ目のチュートリアル「Learning PyTorch with Examples」の内容です。
autograd、torch.nn パッケージ、torch.optim パッケージの理解を深めることができました。次回は6つ目のチュートリアル「What is torch.nn really?」を進めてみたいと思います。
履歴
2020/07/10 初版公開
- 投稿日:2020-07-10T06:57:20+09:00
Numeraiトーナメント -伝統的クオンツと機械学習の融合-
はじめに
本記事は、MediumのTowards Data Scienceに寄稿した「Numerai Tournament: Blending Traditional Quantitative Approach & Modern Machine Learning」を和訳したものである。
Numeraiトーナメントについて
Numeraiはクラウドソーシング型ファンドと呼ばれる、不特定多数の人間による株価の予測結果をもとに運用するヘッジファンドである。Numeraiでは予測性能を競うトーナメントが開催される。トーナメント参加者はNumeraiから提供されるデータセットを元に予測モデルを構築し提出を行う。参加者はその予測性能に応じてランキングされ、報酬が支払われる(徴収されることもある)。
Numeraiへの出資者には、ルネッサンス・テクノロジーズの共同創業者であるハワード・モーガン、チューダー・インベストメンツの創業者であるポール・チューダー・ジョーンズ、米国老舗のVCであるユニオン・スクエア・ベンチャーズ、その他の著名なVCやヘッジファンド経験者が含まれており、データセットはファイナンスM/L専門のアドバイザーに監修されている。これまでに参加者に支払われた賞金総額は3400万ドルを超えており、プロジェクトの進捗は良好だと推察される。
(イメージ:Numerai提供)筆者について
筆者はマーケットニュートラルと呼ばれる手法を用いて日本株で資産運用を行っている。マーケットニュートラルとは、ユニバース内(投資対象となる銘柄群)における株価の相対的な騰落を予測し、買いと売りを組み合わせて市場の値動きに依存しない絶対的リターンを狙うものである。筆者は伝統的なクオンツ手法と統計学をベースとし、機械学習を使ってこの株価予測モデルを構築している。運用結果は良好でありその利回りはおよそ40%となっている。
本記事の目的
本記事では、筆者の運用モデル構築の過程において得た知見を共有する。まず伝統的なクオンツ運用の考え方を説明し、それを機械学習とブレンドして最新の予測モデルを構築するための方法を論じる。
注記
Numeraiのデータセットは難読化されており、筆者はこれに対して何らインサイダー的な情報を持ち合わせていない。本記事の内容は筆者の投資およびモデリングの経験による独自の視点によるものである。
伝統的なクオンツ手法
株式リターンの予測に関する研究は古くから行われている。まずは伝統的なクオンツ手法とはどのようなものか、その生い立ちから説明していこう。
BARRAのリスクモデル
現在のクオンツの原型となったのはバー・ローゼンバーグが提唱したリスクモデルだろう[1]。これには諸説あるが、このあたりのウォールストリートの歴史を知るためにはピーター・バーンスタインの著書Capital Ideas(邦訳版タイトル「証券投資の思想革命」)を是非とも読むべきだろう[2]。
1960年代、ローゼンバーグはマーコヴィッツの共分散モデルを元に、個々の企業のリスクを様々な要因を用いて説明する手法を考案した。そしてこれらのリスク要因が、株価の超過リターンに結びついていることを発見した(リスク・プレミアム)。1975年、ローゼンバーグはコンサルティング会社であるバー・ローゼンバーグ・アソシエイツを設立する。この会社はBARRAとして世界中の運用会社に知られることになった。
現在では、BARRAモデルは最も有名なリスクモデルであり、MSCIがベンダーとしてこれを提供している。他のリスクモデルにはAxiomaなどがある。BARRAモデルには様々な種類のモデルがあるが、BARRA Global Equity Model(GEM)は世界中の主要な株式市場の株式を対象としたリスクモデルである[3]。このモデルでは、株式のリターンを以下のようにカントリー要因、産業要因、リスク要因、個別要因に分解している。
これを重回帰モデルで記述すると以下のようになる。Rnは銘柄nの(リスクフリー金利に対する)超過リターン、xは銘柄nの各ファクター(k、j、i)へのファクターエクスポージャー、fはファクターリターン、enはスペシフィックリターンである。ここで重要なのがファクターリターンの考え方である。
ファクターリターン
簡単のため、マルチファクターモデルではなくシングルファクターモデルで説明する。また、具体例としてNumeraiのデータセット構造で説明を進める。ファクターリターンとは、以下のクロスセクション回帰における、回帰係数fを示す。rはeraXにおけるターゲットベクトル、xはeraXにおけるfeatureAのベクトルである。
ファクターリターンとは、そのユニバースにおいてそのリスクファクターにベットするとどれくらいのリターンが見込めるか、という指標である。またファクターエクスポージャーとは、その銘柄がそのリスクファクターに対してどれだけ曝されているか(exposeされているか)を示し、これが大きいほどファクターリターンから得られる恩恵が大きくなる。上の式を見ると分かるように、この回帰モデルは特定の期間(eraX)におけるクロスセクションなモデルであり、実際の検証ではこれを期間毎(例えばマンスリー)に時系列に積み上げてその特徴を観察することになる。
以下にBARRA GEMの資料からファクターリターンを一部抜粋した。ファクターリターンが顕著に右肩上がりで推移するものは、そのファクターにベットしてさえおけば安定してリターンを得ることができる、ということである。逆に顕著に右肩下がりになるのであればそのファクターに逆にベットすればよい(ロングとショートを入れかえる)。現在の2020年においてファクターリターンが一方向に顕著に推移するものは少ない。従って各銘柄のファクターエクスポージャーを念頭に置いて様々なファクターに分散してベットできるようポートフォリオを組むのである。
(図:文献[3]より筆者作成)ファクターリターンとCorrelationの関係
ファクターリターンは回帰係数であるので、目的変数および説明変数のボラティリティを用いてCorrelationに変換することができる。下の式で、bは目的変数yに対する説明変数xの回帰係数、σxyはxとyの共分散、σxとσyはそれぞれxとyの標準偏差である。Correlationとは、ファクターリターンである回帰係数をボラティリティで補正して-1~1の間に規格化したものなのだ。
Correlationはリスクモデル、ひいてはアクティブ運用理論で非常に重要な指標である。アクティブ運用理論ではCorrelationはInformation Coefficientと呼ばれ、投資家のスキルを示す指標となっている。このあたりの詳細説明は割愛する。興味のある方は、アクティブ運用理論で最も有名な書籍を参照してみるとよい[4]。
ここではNumeraiの各featureのファクターリターン(Correlationで計算)を記載した。マルチファクターではなく単純にシングルファクターで計算している。この図から、どのFeatureがどのような特徴を持ち、それ自体でどれだけ説明力を持っているのか一目で判別できる。
なお、これらのファクターリターンはランダムネスによるバラツキを含んでいることに注意が必要である。以下はCorrelation=0.0の場合とCorrelation=0.005の場合のモンテカルロシミュレーションである(100回試行)。ランダムネスでこの程度のバラツキが発生することは、常に頭に入れておくべきである。サンプル期間120程度で統計的な有意性を判断することは非常に難しい問題なのである。なお、ファクターリターンが最も顕著に推移しているのは、当然ながらdexterity4と7である。
Correlationによる評価について
このように考えると、NumeraiがなぜCorrelationで評価を行うか分かるだろう。我々トーナメント参加者1人1人が提出したpredictionは、それ自体がNumeraiにとって既存の特徴量よりも情報を含んだ1つ1つのファクターなのである。Numeraiは参加者が独自に生み出した優秀なファクターリターンを募っているのだ。ファクターリターンが優秀であれば、Numeraiは単純にそれを組み合わせるだけで運用しても良いし、場合によっては性能を高めるために集まった個々のファクターをさらに学習に掛けてもよいのである。
Featureとしてのリスクファクター
本章では、機械学習のために従来のリスクファクターをfeatureとして取り込むのであればどのようになるか考察する。まず重要なのはCountry featureとIndustry featureである。
Country Feature
Numeraiでは世界中の主要市場における株式をユニバースとしていると考えられる。Numeraiトーナメントのデータでは個別銘柄のidは暗号化されており、これを知る術はない。しかしNumerai Signalsにおいて対象銘柄リストが公開されていたのでそれを集計してみた。銘柄数からして現在のNumeraiトーナメントと同じではないかと睨んでいる。Numerai Signalsの銘柄は41ヵ国であり、最も多い国はUS、その後日本、韓国、英国と続く。これらは単純にCountryとして取り込むのではなく、Regionとしてfeatureに取り込む可能性も考えられる(North America、South America、Pacific、etc)。
通常のリスクモデルでは、Country featureは0/1のカテゴリ変数として導入される。ところがNumeraiのデータセットは基本的に5分位であり、且つそれぞれの分位の銘柄数は揃っていることが多い。従ってこのようにfeature化するのであれば、もしも自分であれば各Country(もしくは各Region)のインデックスに対する重回帰を行い、そのベータを特徴量として分位分けする。
例えばこのような所作を行うと、日本の銘柄は東証のインデックスに対してベータが大きくなり、そのfeatureにおける大きな分位に集まることになる(もしくは分類の符号によっては小さな分位に集まる)。そうするともしCountry featureが存在しているのであれば、重要なのは一番端の分位であって、それ以外は情報として不要な分位となるわけだ。Numeraiのanalysis_and_tipsには特徴量の数値が0もしくは1で極端に特徴が現れるという報告があったが、これはこういう可能性があると考えている。
参考までに2010年以降の各国のレラティブリターン推移を示す。
Industry Feature
次に重要なのがIndustry featureである。マーケットの魔術師において、スティーブ・コーエンは株価の動きを形成するのは40%がマーケット、30%が業種、残りの30%が個別要因だと述べている。このfeatureが取り入れられていないはずがないのである。業種の定義は様々であるが、BARRA GEMでは38の業種が定義されている。その他にも、GICSでは60セクターが、FactSetの提供しているRBICSでは12のEconomy、31のSector、89のSubsectorが定義されている。参考までにUS市場におけるEconomy別の銘柄数を示しておく。
IndustryもCountryと同様に業種インデックスに対する重回帰ベータを特徴量として分位分けされている可能性がある。この場合も重要なのは一番端の分位であって、それ以外は情報として不要な分位となる。
参考までに2010年以降のUS市場の各業種のレラティブリターン推移を示す。
Risk Index Feature
Risk Indexには、BARRAで使われているものは取り込まれている可能性が高い。サイズ、バリュー、サクセス(モメンタム)、ボラティリティである。これらは単純に取り込むこともできるが、CountryやIndustryなどの区分によるバイアスを考慮して正規化する場合が多い。
サイズであれば、時価総額だけでなく、売上高、総資産、従業員数などのファクターも考えられる。バリューであれば、PBR、PER、PCFRなどが考えられる。
その他のRisk Indexとして、流動性、グロース、配当、財務レバレッジ等がある。またこのような伝統的なRisk Indexだけでなく、アナリスト情報やニュースから抽出したセンチメント指数などの代替変数も取り込むことができる。参考までに2010年以降のUS市場の各Risk Indexのレラティブリターン推移を示す。
伝統的なクオンツと機械学習の融合
本章では、伝統的なクオンツに対して機械学習を用いることでどのようにパフォーマンスが改善できるか、その方法論を述べる。
ツリーモデル
Barraモデルは単純に個々のリスクファクターの加重平均である。これをもう少し発展させる単純で簡便な方法が存在する。それが交互作用を取ることだ。簡単な例を挙げると、バリューが効きやすい業種とそうでない業種がある。また業種ではなく銘柄の規模を例に取ると、大型株で効きやすいファクター、小型株で効きやすいファクターがある。さらに国によって異なる業種がアウトパフォームする。このような交互作用を考慮するためには、線形モデルは不適当である。線形モデルでは交互作用の項を人間が指定してfeatureとして設定する必要があるからだ。ツリー系の手法であれば特に意図しなくともモデルが独自に交互作用を学習することができる。一方で、ツリー系の手法は格子状の分割となるため線形の分類が苦手であり、もともとのBARRAモデルのリスクプレミアム自体を理解することは不得意である。
これを解決するのが、線形モデルとツリーモデルのアンサンブルやスタッキングである。実際にKaggleで行われたツーシグマのコンペティションでは、線形モデルであるRidge回帰とツリーモデルであるExtraTreesのアンサンブルが上位入賞している[5]。
(図:文献[5]より)Deep Factorモデル
一方でモデルにディープラーニングを用いる事例もある。これはDeep Factorモデルと呼ばれる手法である[6]。従来のクオンツ運用では、ファクターの作成から選定までを運用者であるファンドマネージャーが経験に基づいて行っていたが、Deep Factorモデルではこれをディープラーニングに置き換えることで人間の判断を排除して個々のファクターの持つ非線形性を捉えることを目的とする。
この手法では80個のファクターを用いて月次リターンを予測しており、線形モデルや他の機械学習手法(SVRやランダムフォレスト)による予測をアウトパフォームできることが確認されている。
(図:文献[6]より)このように機械学習を用いることで、伝統的なクオンツモデルを凌ぐことは比較的たやすいものと考えている。ただし、一方でモデルが複雑になることによる可読性の低下や、過学習やスヌーピングバイアスなどの落とし穴もあるため、モデルの構築にはFinance分野特有の知識や勘所が要求される。このあたりの技術的なテクニックについては、NumeraiのアドバイザーであるPrado氏の著書であるファイナンス機械学習を参考とすべきである[7]。
おわりに
本記事では、伝統的なクオンツ運用の考え方を説明し、従来のリスクファクターをfeatureとして取り込む手法を述べ、従来のクオンツと機械学習がどのようにブレンドされるのか説明した。伝統的なクオンツは最新の機械学習とブレンドされることで、より一層と実運用におけるパフォーマンスを改善できる可能性があることがご理解いただけただろう。
また読者の方には、従来のクオンツの考え方に基づく市場の観察方法を知っていただくことで、より実際の市場に興味を持っていただければNumeraiでの分析がさらに楽しいものとなるはずだ。本記事が読者の方の好奇心を刺激し、モデルにインスピレーションを与えることを願っている。最後まで読んで頂き、感謝する。
謝辞
本記事の執筆にあたり、Numerai運営様に画像の提供、文章の校正にご協力頂きました。この場を借りて御礼申し上げます。
参考文献
[1]Barr Rosenberg, Marathe Vinay, "The prediction of investment risk: Systematic and residual risk", 1975
[2]Peter Bernstein, "Capital ideas: The improbable origins of modern Wall Street", 1992
[3]Barra global equity model handbook
[4]Richard Grinold, Ronald Kahn, "Active portfolio management", 1995
[5]Team Best Fitting, "Two Sigma Financial Modeling Code Competition, 5th Place Winners’ Interview", 2017
[6]Kei Nakagawa, Takumi Uchida, "Deep Factor Model: Explaining deep learning decisions for forecasting stock returns with LRP", 2018
[7]Marcos Lopez de Prado, "Advances in financial machine learning", 2018



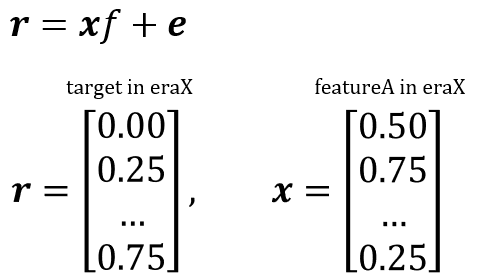
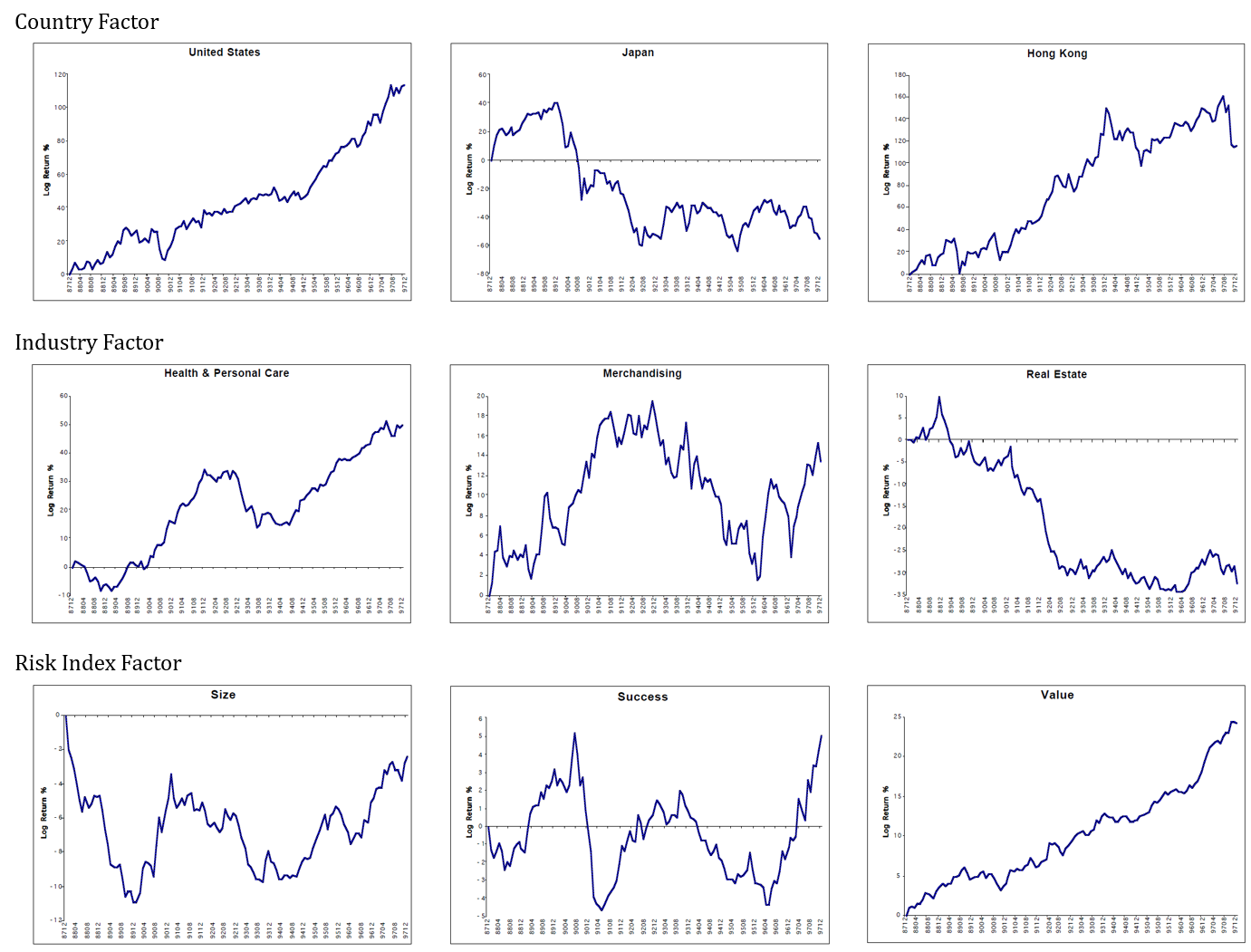
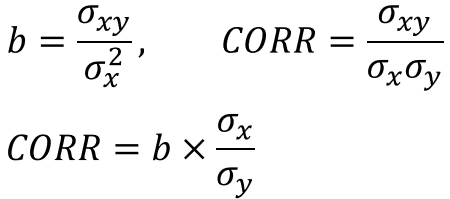
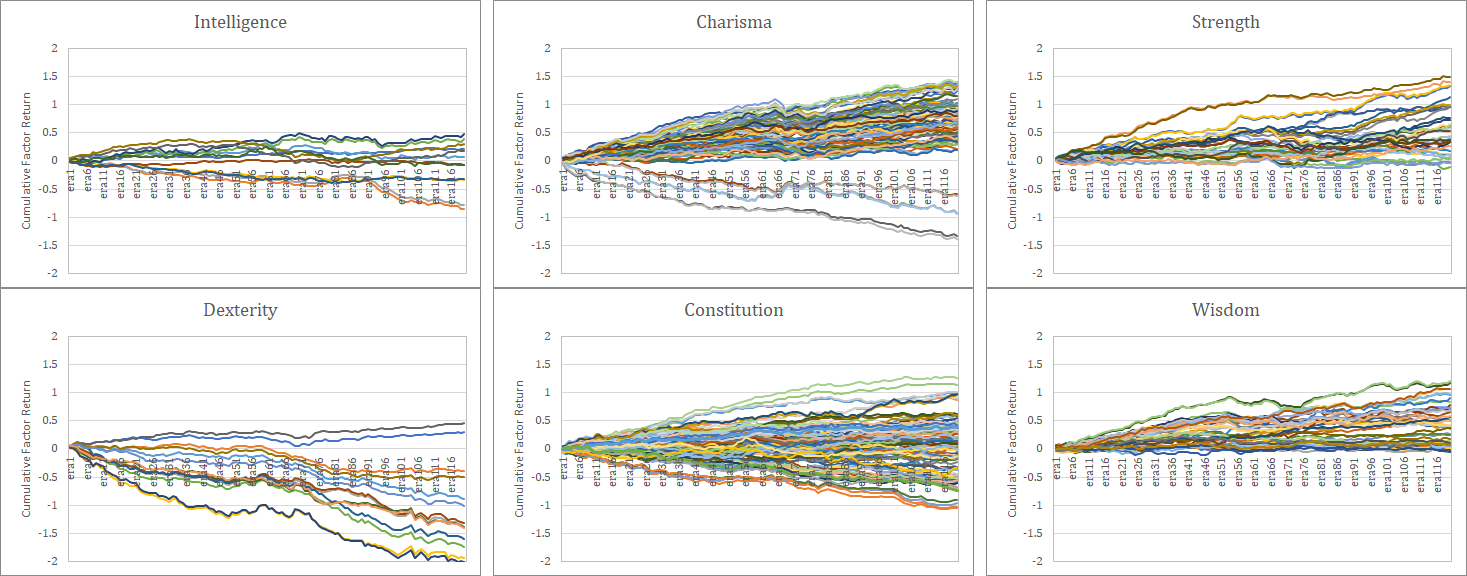
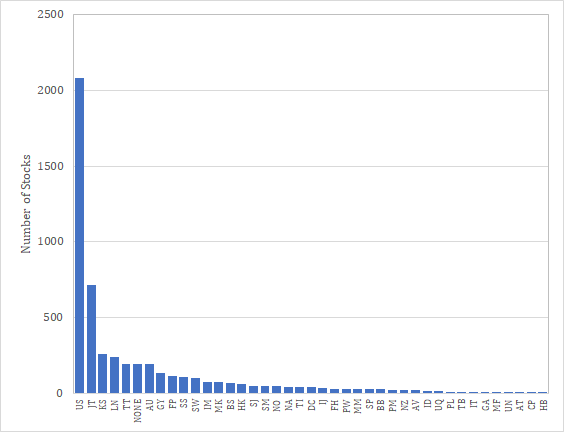
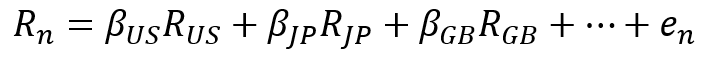
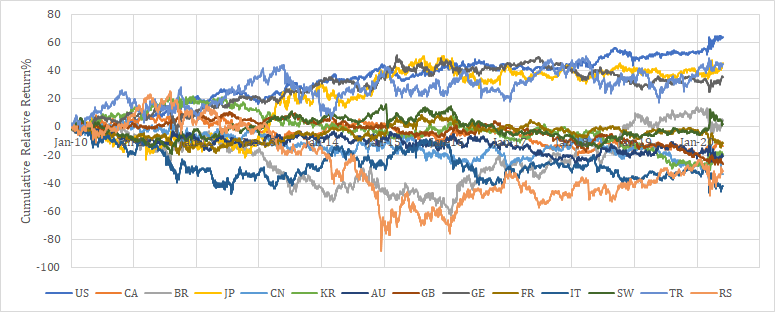
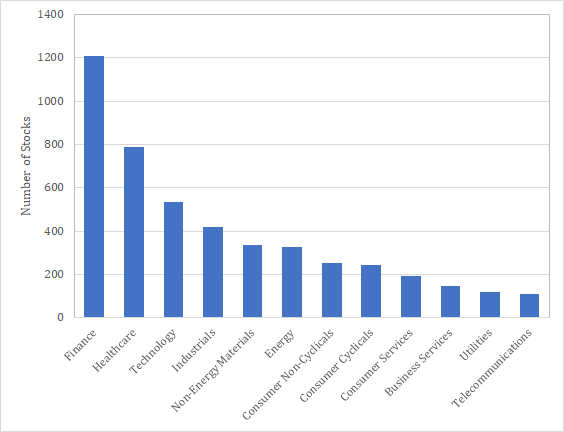
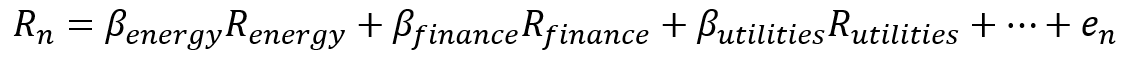
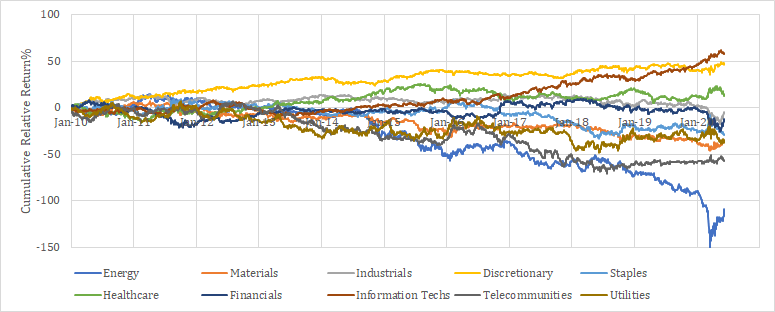
- 投稿日:2020-07-10T05:47:53+09:00
Python 再帰関数から非再帰関数への変換を考える
はじめに
再帰関数は便利な反面、欠点も抱えています。
そのため以前から再帰関数を非再帰関数に変換することがありました。
変換自体は出来ていたのですが、行き当たりばったりで何故そう変換出来るのか理論的に考えていませんでした。
一度しっかりと変換の過程を理論的に考えみたいと思いながらも機会が取れずにいました。
そんな中で、再帰関数の記事がトレンドに上がっていた事があり記事を書き始めました。
(ほったらかしにしていたので大分時間がたってしまいましたが)
別のプログラムを書いていて今更ながらスタックの重要性に気がついたのも要因です。もっとも、再帰関数の有用性を否定するものではありません。
筆者は、再帰関数が大好きです。想定読者
プログラム言語は、何でも良いので Python を使うことにします。
再帰プログラムを作るのに使用したアルゴリズム自体の説明はしません。
そのため、Python が分かりアルゴリズムも分かる(調べられる)方を対象と考えています。コールスタックとスタック
プログラムの実行を制御する方のスタックを、コールスタック(Call Statck)と呼びます。
実行スタック(Execution Stack)、制御スタック(Control Stack)、関数スタック(Function Stack)などと呼ばれる事もあります。
この記事では、コールスタックで統一します。
また、データ構造としてのスタックを単にスタック(Stack)と呼ぶ事にします。なぜ再帰関数が避けられるのか
再帰関数は、関数呼び出しによりコールスタックを使用します。
コールスタックに格納できる容量には上限があります。
コンパイラ等の設定を変更することで容量を変更できますが有限なのは変わりません。
(最近、触っていなのでどの程度融通が利くのか分かりませんが。)
コールスタックの容量を超えると、スタックオーバーフロー(stack overflow)を起こしプログラムの実行が停止します。
再帰関数は、その原理上コールスタックを大量に消費しやすくスタックオーバーフローの原因となりがちです。
設定次第ではありますが、それほど多くない筆者の経験上、コールスタックを使いつぶしてスタックオーバーフローを起こすのは簡単です。
(おまえの糞プログラムのせいだと突っ込まれるかもしれませんが)
そのため、避けられる傾向があります。一方、スタックが使うヒープ領域は、コールスタックよりも比較的融通が利くものです。
(これも設定次第でなおかつ作るプログラム次第ではあると思いますが)
そのため、スタックの使用へと切り替えていこうという訳です。最近は、末尾再帰最適化といって末尾再帰をループ構造に変換してくれる機能をもったコンパイラ等があります。
それほど気にしなくても良くなってきてはいます。
便利になってきたものです。変換方針
この記事では、典型的な変換方法と思いますが、再帰関数をスタックを使って非再帰関数にするのを考えていきたいと思います。
コールスタックの使用をスタックの使用に切り替えるイメージです。階乗
まずは、単純な階乗を例に考えてみます。
階乗 再帰版
階乗を再帰を使って実装すると以下のようなものになります。
def factorialR(n) : if n == 0 : return 1 return n * factorialR(n-1)階乗 再帰版 コールスタックの動き
n=5 としてこの関数を実行した場合のコールスタックの様子を図示してみます。
厳密な動作ではなくイメージとしての動きです。
関数が実行されるとまずその呼び出し自身factorialR(5)をコールスタックに Push します。
factorialR(5)は、実行されると5 * factorialR(4)に変換されます。
Bottom Top f(5)
Bottom Top 5 * f(4) そして、
factorialR(4)を呼び出しコールスタックに Push します。
factorialR(4)は、実行されると4 * factorialR(3)に変換されます。
Bottom Top 5 * f(4) f(4)
Bottom Top 5 * f(4) 4 * f(3) 以下、同じように動作します。
Bottom Top 5 * f(4) 4 * f(3) f(3)
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2)
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2) f(2)
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2) 2 * f(1)
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2) 2 * f(1) f(1)
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2) 2 * f(1) 1 * f(0) 再帰呼び出しが続き、n=0 まで来ました。
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2) 2 * f(1) 1 * f(0) f(0) n=0 の場合は、1 が返されます。
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2) 2 * f(1) 1 * f(0) 1
factorialR(0)が実行され 1 が返されることにより、コールスタックが 1 つ下がります。
そして、n=1 の呼び出し時点に戻り1 * factorialR(0)が解決されて1 * 1 = 1が返されます。
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2) 2 * f(1) 1 同じように前の実行結果が返されたことにより、コールスタックが 1 つ下がります。
n=2 の呼び出し時点に戻り2 * factorialR(1)が解決されて2 * 1 = 2が返されます。
以下、同じように動作します。
Bottom Top 5 * f(4) 4 * f(3) 3 * f(2) 2
Bottom Top 5 * f(4) 4 * f(3) 6
Bottom Top 5 * f(4) 24
Bottom Top 120 最終的に
5 * factorialR(4) = 5 * 24 = 120となり 120 が返されます。再帰版の階乗は、関数の呼び出しを再帰的に行っているので呼び出しがコールスタックに積まれてしまいます。
関数の構造をそのままにコールスタックを使用しないようにしたいです。
上記の関数は、階乗を計算するに途中の計算結果と次の関数呼び出しに使っていた引数が必要でした。
そこで途中の計算結果を 1 つの変数に、次の関数呼び出しに使われていた値をスタックに積むようにしてみます。
5 * f(4)の場合は、5 を変数へ、4 をスタックに積むことになります。
この考えを元に、非再帰版を作ってみたいと思います。階乗 非再帰版
こちらも、n=5 の場合のスタックの動きを図示してみます。
関数が始まると最初に 5 をスタックに Push します。
また、途中の計算結果を保存する変数 Result を 1 にしておきます。
Bottom Top Result 5 1 次の段階では、スタックを pop させて値 5 を取り出します。
そして、取り出した値を Result に掛けます。
最後に、5-1=4の値 4 をスタックに push します。
Bottom Top Result 4 5 次の段階では、スタックを pop させて値 4 を取り出します。
そして、取り出した値を Result に掛けます。
最後に、5-1=3の値 3 をスタックに push します。
Bottom Top Result 3 20 以下、同じように動作します。
Bottom Top Result 2 60
Bottom Top Result 1 120
Bottom Top Result 0 120 値 0 を pop させたら、1 を Result に掛けます。
0 の場合は、次にスタックに push する値はありません。
Bottom Top Result 120 スタックがなくなったので Result の値 120 が n=5 の階乗の答えとして求められます。
階乗が単純なためにスタックを使う意味が見い出せないかと思います。
しかし、変換の一般化のためにこのようにしています。
これを元に関数にしてみます。
愚直に表すならば以下のようになるでしょうか。def factorialL(n): stack = [n] result = 1 current = 0 while len(stack) > 0: current = stack.pop() if current <= 0: current = 1 else : stack.append(current - 1) result *= current return result階乗 非再帰版 その 2
再帰版のコールスタックの動きをスタックで再現してみる実装も考えてみます。
スタックの動きを以下のようにしてみます。
Bottom Top 5 4
Bottom Top 5 4 3
Bottom Top 5 4 3 2
Bottom Top 5 4 3 2 1 n=0 まで来ると
0!=1なので 1 が確定します。
Bottom Top 5 4 3 2 1 1 そして確定した 1 を pop させ、スタックを 1 つ崩します。
この pop させた 1 は、Result として保存しておきます。
Bottom Top Result 5 4 3 2 1 1 次に Top の値 1 を pop させ、スタックを 1 つ崩します。
先ほど保存した 1 と今 pop させた 1 を使い1 * 1を計算し、1を Result として保存します。
これにより n=1 の値が確定しました。
以下、同じように実行させていきます。
Bottom Top Result 5 4 3 2 1 Top の値 2 を pop させて Result の値 1 と掛けて結果 2 を Result に入れる。
Bottom Top Result 5 4 3 2 Top の値 3 を pop させて Result の値 2 と掛けて結果 6 を Result に入れる。
Bottom Top Result 5 4 6 Top の値 4 を pop させて Result の値 6 と掛けて結果 24 を Result に入れる。
Bottom Result 5 24 Top の値 5 を pop させて Result の値 24 と掛けて結果 120 を Result に入れる。
Result 120 スタックがなくなったので Result の値 120 が n=5 の階乗の答えとして求められます。
こちらの場合は、以下のようになるでしょうか。
def factorialL(n): stack = [] for i in range(n, 0, -1) : stack.append(i) result = 1 for i in range(len(stack)) : top = stack.pop() result *= top return result階乗 非再帰版 単純化
もう少しすっきりした実装は以下のようになります。
def factorial1(n): result = 1 for i in range(1, n + 1) : result *= i return resultfrom functools import reduce def factorial2(n): return reduce(lambda a, b: a * b, range(1, n + 1), 1)フィボナッチ数列
次は、フィボナッチ数列を例に取ってみたいと思ます。
フィボナッチ数列 再帰版
フィボナッチ数列の再帰を使った典型的な実装は、以下のようになると思います。
階乗との大きな違いは、1 度の実行で自分自身を 2 回呼び出していることです。def fibonacciR(n) : if n == 0 or n == 1 : return n return fibonacciR(n - 2) + fibonacciR(n - 1)フィボナッチ数列 再帰版 コールスタックの動き
階乗と同じように n=5 の場合のコールスタックの様子を図示してみます。
関数が実行されるとまずfibonacciR(5)がコールスタックに Push されます。
そしてfibonacciR(3) + fibonacciR(4)に変換されます。
Bottom Top f(5)
Bottom Top f(3) + f(4) 次に、
fibonacciR(3)が呼び出されコールスタックに Push されます。
実行されるとfibonacciR(1) + fibonacciR(2)に変換されます。
Bottom Top f(3) + f(4) f(3)
Bottom Top f(3) + f(4) f(1) + f(2) 次に、
fibonacciR(1)が呼び出されコールスタックに Push されます。
fibonacciR(1)は、実行されると 1 が返されます。
これにより、fibonacciR(3)呼び出し時のfibonacciR(1) + fibonacciR(2)が一部解決されて1 + fibonacciR(2)となります。
Bottom Top f(3) + f(4) f(1) + f(2) f(1)
Bottom Top f(3) + f(4) f(1) + f(2) 1
Bottom Top f(3) + f(4) 1 + f(2)
fibonacciR(2)を解決するために、それが呼び出されコールスタックに Push されます。
実行されるとfibonacciR(0) + fibonacciR(1)に変換されます。
Bottom Top f(3) + f(4) 1 + f(2) f(2)
Bottom Top f(3) + f(4) 1 + f(2) f(0) + f(1)
fibonacciR(0)が呼び出されコールスタックに Push されます。
fibonacciR(0)は、実行されると 0 が返されます。
これにより、fibonacciR(2)呼び出し時のfibonacciR(0) + fibonacciR(1)が一部解決されて0 + fibonacciR(1)となります。
Bottom Top f(3) + f(4) 1 + f(2) f(0) + f(1) f(0)
Bottom Top f(3) + f(4) 1 + f(2) f(0) + f(1) 0
Bottom Top f(3) + f(4) 1 + f(2) 0 + f(1) 同じように、
fibonacciR(1)が呼び出されコールスタックに Push されます。
fibonacciR(1)は、実行されると 1 が返されます。
これにより、fibonacciR(2)呼び出し時の0 + fibonacciR(1)が解決されて0 + 1 = 1となります。
Bottom Top f(3) + f(4) 1 + f(2) 0 + f(1) f(1)
Bottom Top f(3) + f(4) 1 + f(2) 0 + f(1) 1
Bottom Top f(3) + f(4) 1 + f(2) 0 + 1
fibonacciR(3)呼び出し時の1 + fibonacciR(1)が解決されて1 + 1 = 2となります。
Bottom Top f(3) + f(4) 1 + 1
fibonacciR(5)呼び出し時のfibonacciR(3) + fibonacciR(4)の一部が解決されて2 + fibonacciR(4)となります。
Bottom Top 2 + f(4) 以下同じように動作します。
Bottom Top 2 + f(4) f(4)
Bottom Top 2 + f(4) f(2) + f(3)
Bottom Top 2 + f(4) f(2) + f(3) f(2)
Bottom Top 2 + f(4) f(2) + f(3) f(1) + f(0)
Bottom Top 2 + f(4) f(2) + f(3) f(1) + f(0) f(1)
Bottom Top 2 + f(4) f(2) + f(3) f(1) + f(0) 1
Bottom Top 2 + f(4) f(2) + f(3) 1 + f(0) f(0)
Bottom Top 2 + f(4) f(2) + f(3) 1 + f(0) 0
Bottom Top 2 + f(4) f(2) + f(3) 1
Bottom Top 2 + f(4) 1 + f(3)
Bottom Top 2 + f(4) 1 + f(3) f(3)
Bottom Top 2 + f(4) 1 + f(3) f(1) + f(2)
Bottom Top 2 + f(4) 1 + f(3) f(1) + f(2) f(1)
Bottom Top 2 + f(4) 1 + f(3) f(1) + f(2) 1
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2)
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2) f(2)
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2) f(0) + f(1)
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2) f(0) + f(1) f(0)
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2) f(0) + f(1) 0
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2) 0 + f(1)
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2) 0 + f(1) f(1)
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2) 0 + f(1) 1
Bottom Top 2 + f(4) 1 + f(3) 1 + f(2) 0 + 1
Bottom Top 2 + f(4) 1 + f(3) 1 + 1
Bottom Top 2 + f(4) 1 + 2
Bottom Top 2 + 3
Bottom Top 5 以上のように動作し、n=5 の時の値 5 が返されます。
長々と記述しましたが、コールスタックの動きとしてはこのようになります。
これだけでは分かりづらいので、このコールスタックの動きを 2 分木を使って表したいと思います。フィボナッチ数列再帰版の 2 分木
2 分木で表してみると、以下のようになります。
graph TB; 0[5]---1[3] 0---2[4] 1---3[1] 1---4[2] 4---5[0] 4---6[1] 2---7[2] 2---8[3] 7---9[0] 7---10[1] 8---11[1] 8---12[2] 12---13[0] 12---14[1]丁度コールスタックの深さが 2 分木の深さに対応しているのが分かります。
また、値が解決する順番が 2 分木の深さ優先探索の探索順に対応しているのが分かります。
2 分木の深さ優先探索は、スタックを使って実装されるとよく説明されます。
ここでは、コールスタックを使って実装した形になりました。さて次に非再帰版を作ってみたいと思います。
フィボナッチ数列 非再帰版
フィボナッチ数列の再帰版も簡素な関数で途中の計算結果と言えるものがありません。
そこで何をスタックに積んでいくかと言うと関数に渡される引数をスタックに積んでいくことにします。今までと同じように n=5 の場合のスタックの様子を図示してみます。
実行を開始すると最初に与えられた引数 5 をスタックに Push します。
Bottom Top 5 次の段階では、スタックを Pop して 5 を取り出します。
5 は、フィボナッチ数列の漸化式から値を確定できないです。
代わりに、n-2とn-1を求める事にします。
つまり、5-2=3と5-1=4をそれぞれスタックに Push していきます。
大きい数から先に Push していく事にします。
Bottom Top 4 3 次の段階では、スタックを Pop して 3 を取り出します。
3 は、値を確定できないので、代わりに 1, 2 をそれぞれ Push します。
Bottom Top 4 2 1 次の段階では、スタックを Pop して 1 を取り出します。
1 は、値として確定できるので Result として保存します。
Bottom Top Result 4 2 1 次の段階では、スタックを Pop して 2 を取り出します。
2 は、値を確定できないので、代わりに 0, 1 をそれぞれ Push します。
Bottom Top Result 4 1 0 1 次の段階では、スタックを Pop して 0 を取り出します。
0 は、値として確定できるので、Result に足し合わせて保存します。
Bottom Top Result 4 1 1 次の段階では、スタックを Pop して 1 を取り出します。
1 は、値として確定できるので、Result に足し合わせて保存します。
Bottom Top Result 4 2 以下、同じように動作します。
Bottom Top Result 3 2 2
Bottom Top Result 3 1 0 2
Bottom Top Result 3 1 2
Bottom Top Result 3 3
Bottom Top Result 2 1 3
Bottom Top Result 2 4
Bottom Top Result 1 0 4
Bottom Top Result 1 4
Result 5 以上のように動作し、こちらも n=5 の時の値 5 が返されます。
これを再び愚直に実装してみたいと思います。def fibonacciL(n) : result = 0 current = 0 stack = [n] while len(stack) > 0 : current = stack.pop() if current == 1 or current == 0 : result += current else : stack.append(current-1) stack.append(current-2) return result階乗と似たような実装に落ち着きました。
(似たような実装にしようとしてはいますが)フィボナッチ数列 非再帰版 単純化
スタックを意識せずに答えだけを求めるならば以下のようにも出来ます。
スタックの場合は、n -> n-1 -> n-2-> ... -> 0のように漸化式の係数が大きい方から求めていました。
こちらは、0 -> 1 -> ... -> nのように係数の小さい方から求めています。def fibonacciL2(n): if n == 0: return 0 x, y = 0, 1 for _ in range(n - 1): x, y = y, x + y return yクイックソート
次にクイックソートも考えてみます。
クイックソート 再帰版
クイックソートを、以下のように再帰で実装してみました。
重複した値も取れるようにしています。
典型的な実装とは多少の差異があるかとは思いますが、クイックソートになっていると思います。
ソートの過程を表示するためにprint()を入れています。
また、そのための補助的な関数を定義して使っています。
isSorted()は、ソートされているか判定するものです。def isSorted(lt): b = lt[0] for x in lt: if b > x: return False b = x return True def getListIndeces(lt, s=0): if len(lt) == 0: return "><" maxLen = len(str(max(lt))) text = reduce(lambda x, y: x + y, [f"{i+s:{maxLen}}, " for i, x in enumerate(lt)], ">") return f"{text[:-2]}<" def listToFormatedString(lt): if len(lt) == 0: return "[]" maxLen = len(str(max(lt))) text = reduce(lambda x, y: x + y, [f"{x:{maxLen}}, " for x in lt], "[") return f"{text[:-2]}]" def getPivot(lt, l, r): return lt[l + int((r - l) / 2)] def quickSort(lt): _quickSort(lt, 0, len(lt) - 1) def _quickSort(lt, l, r): if l >= r: print(f" {getListIndeces(lt[l:r+1], s=l)}, l: {l}, r: {r}\nr: {listToFormatedString(lt[l:r+1])}") return i = l j = r p = getPivot(lt, l, r) print(f" {getListIndeces(lt[l:r+1], s=l)}, l: {l}, r: {r}, p: {p}\ns: {listToFormatedString(lt[l:r+1])}") while i < j: while lt[i] < p: i += 1 while lt[j] > p: j -= 1 if i < j: if lt[i] == lt[j]: j -= 1 else: lt[i], lt[j] = lt[j], lt[i] print(f"p: {listToFormatedString(lt[l:r+1])}, {i}: {lt[j]}, {j}: {lt[i]}") _quickSort(lt, l, i - 1) _quickSort(lt, j + 1, r)引数に
[7, 2, 1, 4, 6, 0, 8, 5, 9, 3]を与えて実行してみます。lt = [7, 2, 1, 4, 6, 0, 8, 5, 9, 3] quickSort(lt) print(lt, isSorted(lt))そうすると以下のような実行結果が表示されます。
>0, 1, 2, 3, 4, 5, 6, 7, 8, 9<, l: 0, r: 9, p: 6 s: [7, 2, 1, 4, 6, 0, 8, 5, 9, 3] p: [3, 2, 1, 4, 6, 0, 8, 5, 9, 7], 0: 7, 9: 3 p: [3, 2, 1, 4, 5, 0, 8, 6, 9, 7], 4: 6, 7: 5 p: [3, 2, 1, 4, 5, 0, 6, 8, 9, 7], 6: 8, 7: 6 p: [3, 2, 1, 4, 5, 0, 6, 8, 9, 7], 6: 6, 6: 6 >0, 1, 2, 3, 4, 5<, l: 0, r: 5, p: 1 s: [3, 2, 1, 4, 5, 0] p: [0, 2, 1, 4, 5, 3], 0: 3, 5: 0 p: [0, 1, 2, 4, 5, 3], 1: 2, 2: 1 p: [0, 1, 2, 4, 5, 3], 1: 1, 1: 1 r: >0<, l: 0, r: 0 r: [0] >2, 3, 4, 5<, l: 2, r: 5, p: 4 s: [2, 4, 5, 3] p: [2, 3, 5, 4], 3: 4, 5: 3 p: [2, 3, 4, 5], 4: 5, 5: 4 p: [2, 3, 4, 5], 4: 4, 4: 4 >2, 3<, l: 2, r: 3, p: 2 s: [2, 3] p: [2, 3], 2: 2, 2: 2 r: ><, l: 2, r: 1 r: [] r: >3<, l: 3, r: 3 r: [3] r: >5<, l: 5, r: 5 r: [5] >7, 8, 9<, l: 7, r: 9, p: 9 s: [8, 9, 7] p: [8, 7, 9], 8: 9, 9: 7 p: [8, 7, 9], 9: 9, 9: 9 >7, 8<, l: 7, r: 8, p: 8 s: [8, 7] p: [7, 8], 7: 8, 8: 7 p: [7, 8], 8: 8, 8: 8 r: >7<, l: 7, r: 7 r: [7] r: ><, l: 9, r: 8 r: [] r: ><, l: 10, r: 9 r: [] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] Trueクイックソート 再帰版 コールスタックの動き
クイックソートもコールスタックの動きを図示して行きます。
まずはf(lt)としてコールスタックに Push されます。
Bottom Top f(lt)初めにピボットとして 6 が選択され、6 未満の値がリストの前へ、6 より大きい値がリストの後へ移動されます。
選り分けた結果、境目のインデックスが 6 なのでlt[0:6]と、lt[7:10]でそれぞれquickSort()が実行されます。
境目のインデックスの値は、ピボットになります。
重複した値がある場合、ピボットとして選択された値が選り分けられたリストに存在する可能性があります。
境目のインデックスは、ソート済みとなり位置が確定されます。
位置が確定した要素は、Resultと表示することにします。
Bottom Top Result f(lt[7:10]),f(lt[0:6])lt[6]次に実行のためにコールスタックに
f(lt[0:6])が Push されます。
Bottom Top Result f(lt[7:10])f(lt[0:6])lt[6]ここでは、ピボットとして 1 が選ばれ、1 未満が前へ、 1 より大きい値が後ろへ分けられます。
区切りのインデックスが 1 となり、lt[0:1]と、lt[2:6]でそれぞれquickSort()が実行されます。
Bottom Top Result f(lt[7:10])f(lt[2:6]),f(lt[0:1])lt[1]+lt[6]コールスタックに
f(lt[0:1])が Push されます。
Bottom Top Result f(lt[7:10])f(lt[2:6])f(lt[0:1])lt[1]+lt[6]
lt[0:1]は、長さが 1 なので位置を確定し、コールスタックから Pop されます。
Bottom Top Result f(lt[7:10])f(lt[2:6])lt[0:2]+lt[6]コールスタックが戻って、次に
lt[2:6]の範囲がソートされます。
ここでは、ピボットとして 4 が選ばれ、4 未満の値と 4 より大きい値の範囲に分けられます。
区切りのインデックスが 4 となり、lt[2:4]と、lt[5:6]でそれぞれquickSort()が実行されます。
lt[4]の位置を確定させます。
Bottom Top Result f(lt[7:10])f(lt[5:6]),f(lt[2:4]),lt[0:2]+lt[4]+lt[6]コールスタックに
f(lt[2:4])が Push されます。
Bottom Top Result f(lt[7:10])f(lt[5:6])f(lt[2:4])lt[0:2]+lt[4]+lt[6]ピボットとして 2 が選ばれ、2 未満と 2 より大きい範囲に分けられます。
区切りのインデックス 2 で分けられlt[2:2]とlt[3:4]でそれぞれquickSort()が実行されます。
lt[2]を確定されます。
Bottom Top Result f(lt[7:10])f(lt[5:6])f(lt[3:4]),f(lt[2:2])lt[0:3]+lt[4]+lt[6]
lt[2:2]もlt[3:4]も実行されますが範囲の長さが 1 以下 なので位置が確定します。
f(lt[2:2])が Push され、長さが 0 なので Pop される。
f(lt[3:4])が 実行され、lt[3]の位置が確定し、 Pop される。
Bottom Top Result f(lt[7:10])f(lt[5:6])lt[0:3]+lt[4]+lt[6]コールスタックが戻って、次に
lt[5:6]の範囲がソートされます。
lt[5:6]も範囲が 1 なので位置が確定し、Pop されます。
これでリストの前半部分がソートされ確定されました。
後半部分も同じように処理されます。
Bottom Top Result f(lt[7:10])lt[0:7]ピボットとして 9 が選ばれ、
lt[7:9]とlt[9:9]に分けられる。
lt[9]が確定する。
Bottom Top Result f(lt[9:9]),f(lt[7:9])lt[0:7]+lt[9]
f(lt[7:9])が Push される。
Bottom Top Result f(lt[9:9])f(lt[7:9])lt[0:7]+lt[9]ピボットとして 8 が選ばれ、
lt[7:8]とlt[8:8]に分けられる。
lt[8]が確定する。
Bottom Top Result f(lt[9:9])f(lt[8:8]),f(lt[7:8])lt[0:7]+lt[8:10]
f(lt[7:8])が Push される。
Bottom Top Result f(lt[9:9])f(lt[8:8])f(lt[7:8])lt[0:7]+lt[8:10]
lt[7]の位置が確定する。
Bottom Top Result f(lt[9:9])f(lt[8:8])lt
lt[8:8]もlt[9:9]も長さが 0 なので何もせずに終了して処理が終わる。
Result ltフィボナッチ数列のコールスタックの動きと同じようになったのが分かります。
クイックソート 非再帰版
クイックソートも非再帰に変換していきます。
今までの考え方と同じようにコールスタックに積まれていく途中経過をスタックに積んでいく形になります。
クイックソートの場合は、次にソートしなければならない範囲をスタックに積んでいく事になります。
実装は、以下のようになりました。
苦労するかと思っていましたが、再帰版とほとんど変わらない形になりました。def quickSortL(lt): length = len(lt) stack = [(0, length - 1)] while len(stack) > 0: l, r = stack.pop() if l >= r: continue i = l j = r p = getPivot(lt, l, r) while i < j: while lt[i] < p: i += 1 while lt[j] > p: j -= 1 if i < j: if lt[i] == lt[j]: j -= 1 else: lt[i], lt[j] = lt[j], lt[i] stack.append((j + 1, r)) stack.append((l, i - 1))2 分探索
ここまで来ると蛇足ですが、2 分探索も考えてみたいと思います。
2 分探索 再帰版
まずは、再帰版ですが、以下のように実装しました。
これは、値が重複しないソートされたリストが渡されるのを前提としています。
uniqueSorted()を使えば条件を満たすリストに出来ます。
これも説明のためにprint()を入れています。def uniqueSorted(lt): return sorted(list(set(lt))) def binarySearchR(lt, n): return _binarySearchR(lt, n, 0, len(lt) - 1) def _binarySearchR(lt, n, l, r): if l > r: return -1 middleIndex = int(l + (r - l) / 2) middleValue = lt[middleIndex] print(getListIndeces(lt[l:r + 1], l)) print(listToFormatedString(lt[l:r + 1]), middleIndex, middleValue) if middleValue > n: return _binarySearchR(lt, n, l, middleIndex - 1) elif middleValue < n: return _binarySearchR(lt, n, middleIndex + 1, r) else: return middleIndex以下のように、実行しました。
lt = [3, 6, 12, 13, 14, 16, 17, 22, 51, 56, 58, 62, 66, 70, 74, 75, 80, 92, 94, 95] n = 70 print(binarySearchR(lt, n))そうすると、以下の実行結果が得られます。
> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19< [ 3, 6, 12, 13, 14, 16, 17, 22, 51, 56, 58, 62, 66, 70, 74, 75, 80, 92, 94, 95] 9 56 >10, 11, 12, 13, 14, 15, 16, 17, 18, 19< [58, 62, 66, 70, 74, 75, 80, 92, 94, 95] 14 74 >10, 11, 12, 13< [58, 62, 66, 70] 11 62 >12, 13< [66, 70] 12 66 >13< [70] 13 70 132 分探索 再帰版 コールスタックの動き
コールスタックを図示します。
まずは、リストとしてlt、探したい数nを 70 としてコールスタックに Push されます。
中央値のインデックスとして 9 が選ばれます。
lt[9]の値は、56 なので求めたい数 70 より小さいです。
そのためリストの後半部分の探索を進める事になります。
Bottom Top f(lt)リストの後半部分の探索の為に、
lt[10:20]としてbinarySearch()が実行されます。
f(lt[10:20])が Push されます。
中央値のインデックスとして 14 が選ばれます。
lt[14]の値は、74 なので求めたい数 70 より大きいです。
そのためリストの前半部分の探索を進める事になります。
Bottom Top f(lt)f(lt[10:20])探索を進める為に、
lt[10:14]としてbinarySearch()が実行されます。
f(lt[10:14])が Push されます。
インデックス 11 が選ばれます。
lt[11]の値は、62 なので求めたい数 70 より小さいです。
そのためリストの後半部分の探索を進める事になります。
Bottom Top f(lt)f(lt[10:20])f(lt[10:14])探索を進める為に、
lt[12:14]としてbinarySearch()が実行されます。
f(lt[12:14])が Push されます。
インデックス 12 が選ばれます。
lt[12]の値は、66 なので求めたい数 70 より小さいです。
そのためリストの後半部分の探索を進める事になります。
Bottom Top f(lt)f(lt[10:20])f(lt[10:14])f(lt[12:14])探索を進める為に、
lt[13:14]としてbinarySearch()が実行されます。
f(lt[13:14])が Push されます。
インデックス 13 が選ばれます。
lt[13]の値は、70 なので求めたい数 70 と等しいです。
等しい数が見つかったので、インデックスの値 13 を返します。
Bottom Top f(lt)f(lt[10:20])f(lt[10:14])f(lt[12:14])f(lt[13:14])以下、値を返すつつ、コールスタックから Pop されます。
Bottom Top f(lt)f(lt[10:20])f(lt[10:14])f(lt[12:14])13
Bottom Top f(lt)f(lt[10:20])f(lt[10:14])13
Bottom Top f(lt)f(lt[10:20])13
Bottom Top f(lt)13
Bottom Top 13 コールスタックの動きが階乗と同じになりました。
条件分岐の違いや返された値で処理を行うかどうか以外は、ほとんど同じ構造をしていると言えると思います。2 分探索 非再帰版
非再帰版は、以下のようになりました。
こちらもクイックソートと同じで、再帰版とほとんど同じ構造に出来ました。def binarySearchL(lt, n): stack = [(0, len(lt) - 1)] while len(stack) > 0: l, r = stack.pop() if l > r: return -1 middleIndex = int(l + (r - l) / 2) middleValue = lt[middleIndex] if middleValue > n: stack.append((l, middleIndex - 1)) elif middleValue < n: stack.append((middleIndex + 1, r)) else: return middleIndex2 分探索の場合は、コールスタックが増減を繰り返さない単純な動きでしたのでスタックを使わなくて簡単に変換出来ます。
多少シンプルにしたものが以下になります。def binarySearchL2(lt, n): l, r = 0, len(lt) - 1 while l <= r: middleIndex = int(l + (r - l) / 2) middleValue = lt[middleIndex] if middleValue > n: l, r = l, middleIndex - 1 elif middleValue < n: l, r = middleIndex + 1, r else: return middleIndex return -1最後に
単純なアルゴリズムしか挙げていないのもありますが、どの再帰関数もコールスタックの動きは、同じようなものになります。
つまり同じような構造で実装できると言えると思います。
結局、再帰関数の構造をしっかり理解できていないから非再帰関数への変換に苦労していたのだと思いました。
大きな違いは、コールスタックを利用するのかスタックを利用するのかぐらいのものです。
そして、学校などで習う基本的なデータ構造とアルゴリズムの大切さが身に染みて分かりました。
基本は大事ですね。
不真面目だった学生時代のツケが回ってきたという事でしょうか(´・ω・`)
付録
コールスタックの深さを確認/変更する。
pythonのコールスタックの深さは、sys.getrecursionlimit()で確認できます。
環境依存ですが、sys.setrecursionlimit(limit)で深さを変更できます。2 分木の mermaid
graph TB; 0[5]---1[3] 0---2[4] 1---3[1] 1---4[2] 4---5[0] 4---6[1] 2---7[2] 2---8[3] 7---9[0] 7---10[1] 8---11[1] 8---12[2] 12---13[0] 12---14[1]
- 投稿日:2020-07-10T04:49:40+09:00
お絵かきソフト
はじめに
ある教授のお絵描きアプリに憧れ自分でも何かできないかと思いました。
完成系
作り方
キャンバスメソッド
import tkinter
class Scribble:
- 左クリックで点を描く
- sx.syを現在位置
def on_pressed(self, event): self.sx = event.x self.sy = event.y self.canvas.create_oval(self.sx, self.sy, event.x, event.y, outline = self.color.get(), width = self.width.get())
- ドラッグ時直前の座標との間に線を描く
def on_dragged(self, event): self.canvas.create_line(self.sx, self.sy, event.x, event.y, fill = self.color.get(), width = self.width.get()) self.sx = event.x self.sy = event.y
- 真ん中クリックで円、右クリックで楕円
def click1(self,event): self.canvas.create_oval(self.sx-20,self.sy-20,self.sx+20,self.sy+20, fill = self.color.get(), width = self.width.get()) def click2(self,event): self.canvas.create_oval(self.sx-40,self.sy-30,self.sx+40,self.sy+30, fill = self.color.get(), width = self.width.get())
ウィンドウを作る
- ボタンオブジェクトでプログラム終了
def create_window(self): window = tkinter.Tk() window.title("お絵かきソフト") self.canvas = tkinter.Canvas(window, bg = "black", width = 600, height = 400) self.canvas.pack() quit_button = tkinter.Button(window, text = "終了", command = window.quit) quit_button.pack(side = tkinter.RIGHT) self.canvas.bind("<ButtonPress-1>", self.on_pressed) self.canvas.bind("<B1-Motion>", self.on_dragged) self.canvas.bind("<ButtonPress-2>",self.click1) self.canvas.bind("<ButtonPress-3>",self.click2)
色の変更
- オプションメニューオブジェクトをウィンドウに配置
COLORS = ["red", "white", "blue", "pink", "green","black"] self.color = tkinter.StringVar() self.color.set(COLORS[1]) b = tkinter.OptionMenu(window, self.color, *COLORS) b.pack(side = tkinter.LEFT)
線の太さ変更
- スケールオブジェクトをウィンドウに配置
self.width = tkinter.Scale(window, from_ = 1, to = 10, orient = tkinter.HORIZONTAL) self.width.set(5) self.width.pack(side = tkinter.LEFT) return window; def __init__(self): self.window = self.create_window(); def run(self): self.window.mainloop() Scribble().run()
完成系のプログラム
import tkinter class Scribble: def on_pressed(self, event): self.sx = event.x self.sy = event.y self.canvas.create_oval(self.sx, self.sy, event.x, event.y, outline = self.color.get(), width = self.width.get()) def on_dragged(self, event): self.canvas.create_line(self.sx, self.sy, event.x, event.y, fill = self.color.get(), width = self.width.get()) self.sx = event.x self.sy = event.y def click1(self,event): self.canvas.create_oval(self.sx-20,self.sy-20,self.sx+20,self.sy+20, fill = self.color.get(), width = self.width.get()) def click2(self,event): self.canvas.create_oval(self.sx-40,self.sy-30,self.sx+40,self.sy+30, fill = self.color.get(), width = self.width.get()) def create_window(self): window = tkinter.Tk() window.title("お絵かきソフト") self.canvas = tkinter.Canvas(window, bg = "black", width = 600, height = 400) self.canvas.pack() quit_button = tkinter.Button(window, text = "終了", command = window.quit) quit_button.pack(side = tkinter.RIGHT) self.canvas.bind("<ButtonPress-1>", self.on_pressed) self.canvas.bind("<B1-Motion>", self.on_dragged) self.canvas.bind("<ButtonPress-2>",self.click1) self.canvas.bind("<ButtonPress-3>",self.click2) COLORS = ["red", "white", "blue", "pink", "green","black"] self.color = tkinter.StringVar() self.color.set(COLORS[1]) b = tkinter.OptionMenu(window, self.color, *COLORS) b.pack(side = tkinter.LEFT) self.width = tkinter.Scale(window, from_ = 1, to = 10, orient = tkinter.HORIZONTAL) self.width.set(5) self.width.pack(side = tkinter.LEFT) return window; def __init__(self): self.window = self.create_window(); def run(self): self.window.mainloop() Scribble().run()https://www.nslabs.jp/monkey-python-02b.rhtml
を参考にさせていただきました。マウス三つのボタンで描くようにしました。
最後に
ひとつ前に戻るボタンやフリーハンドの補正機能など付けてみたかったがコードを理解するのが精一杯でコードの追記があまりできなかった。
夏休みの期間でPythonに力を入れ自分でできる楽しさを味わいたいです。
参考文献
- 投稿日:2020-07-10T03:44:38+09:00
ストップウォッチです
はじめに
カップラーメンが好きで、3分間測るために
ストップウォッチを作ろうと思いました。
これが完成形です。
作り方
2つのライブラリをインポートする
import tkinter as tk import time
ウィンドウを作る
import tkinter as tk class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() master.geometry("300x150") master.title("STOP WATCH") master.config(bg="black") def main(): win = tk.Tk() #win.resizable(width=False, height=False) #ウィンドウを固定サイズに app = Application(master=win) app.mainloop() if __name__ == "__main__": main()タイトル:stop watch
サイズ:300*150
背景色:黒
ボタンを作る
tk.Button(master,text="start",command=self.resetButtonClick,width=10).place(x=10, y=110) tk.Button(master,text="stop",command=self.startButtonClick,width=10).place(x=110, y=110) tk.Button(master,text="reset",command=self.stopButtonClick,width=10).place(x=210, y=110)ボタンの名前や大きさを指定する
完成形のプログラム
import tkinter as tk import time class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() master.geometry("300x150") master.title("STOP WATCH") master.config(bg="black") self.startTime=time.time() self.stopTime=0.00 self.elapsedTime=0.00 self.playTime=False self.canvas = tk.Canvas(master,width=290,height=80,bg="silver") self.canvas.place(x=3,y=10) tk.Button(master,text="start",command=self.resetButtonClick,width=10).place(x=10, y=110) tk.Button(master,text="stop",command=self.startButtonClick,width=10).place(x=110, y=110) tk.Button(master,text="reset",command=self.stopButtonClick,width=10).place(x=210, y=110) master.after(50,self.update) def startButtonClick(self): if self.playTime: self.stopTime=time.time()-self.startTime self.playTime=False def stopButtonClick(self): self.startTime=time.time() self.stopTime=0.00 self.elapsedTime=0.00 self.playTime=False def resetButtonClick(self): if not self.playTime: self.startTime=time.time()-self.elapsedTime self.playTime=True def update(self): self.canvas.delete("Time") if self.playTime: self.elapsedTime=time.time()-self.startTime self.canvas.create_text(280,40,text=round(self.elapsedTime,1),font=("Helvetica",40,"bold"),fill="black",tag="Time",anchor="e") else: self.canvas.create_text(280,40,text=round(self.stopTime,1),font=("Helvetica",40,"bold"),fill="black",tag="Time",anchor="e") self.master.after(50,self.update) def main(): win = tk.Tk() #win.resizable(width=False, height=False) #ウィンドウを固定サイズに app = Application(master=win) app.mainloop() if __name__ == "__main__": main()このソースコードは
https://qiita.com/michimichix521/items/76234e7a991ab92e6fb3
これを参考させてもらいました。
ストップウォッチの色を自分の好きなものにしたり
ボタンの配置を自分が押しやすいように並び替えました。
最後に
このストップウォッチは秒単位でしか測れなくて分での表示ができません。
また1/100秒のくらいまで表示してみたいと思っていましたが、
いろいろ検索してもやり方が分かりませんでした。
Pythonをもっと勉強して次何かを作るときは、自分が思っているようにコーディングできるようになりたいと思いました。参考文献
https://qiita.com/michimichix521/items/76234e7a991ab92e6fb3
- 投稿日:2020-07-10T03:41:21+09:00
お絵描きボード
Tkinterを用いてお絵描きボードを作る!
授業の中で扱った教科書の中のLesson7-3をプログラミングした際に、この描画を連続で行えば線を描けるのではないかと思っていたのを、調べながら形にしました。
Lesson7-3との違い
- 教科書では、クリックという動作で円を描くことをプログラミングしていたが、今回はマウスボタンが押されている間ずっと描画されていること。
- 線を描くには描画される円が大きいと不自然になるので、なるべく小さい円を描画することでより自然な線を描けるようにしたこと。
コード紹介
実際にプログラミングしたコードを紹介します。
import tkinter def mouse_click_func(event): global press press = Trueまず、ここでマウスボタンをクリックすることを定義します。
def mouse_release_func(event): global press press = False次に、マウスボタンを離すことを定義します。
def mouse_move_func(event): global canvas x = event.x y = event.y if press: canvas.create_oval(x - 2, y - 2, x + 2, y + 2, fill = "white", width=0)そして最後に、マウスを動かしている場合で、かつボタンを押し続けているときに円を描画することを定義します。
コードを製作するにあたって
連続的に円を描画するにはボタンのON OFF だけではなくONかつマウスが移動しているという3パターンの場合分けが必要なのです。
私は初め、ボタンを押しながらマウスを動かす・ボタンを離すの2種類で考えていたのですが、どうしたらいいのかわかりませんでした。
そこで、サイトを参照するとボタンのON OFFでまずpress の true false を決めているのを見て、「なるほど」と感動しました。
実行結果
黒板風にしてみた!
改善点1
素早くマウスを動かすときれいな線でなくなってしまう
これはパソコンの処理の問題なのであろうと思われる。点を連続で絵がぐ方法ではない方法なら改善できるかもしれない。
改善点2
一度間違うと消すことが出来ない。マウスボタンを押すか押さないかで点を描くかどうかが決まっているので、点を消すという動作を行うための定義が足りなくなってしまう。
マウスボタンを押す前に何かで場合分け出来たら消しゴムも可能になるのかもしれない。
感想
プログラミングに触れるのは初めてだったので難しい部分もあったが、楽しく取り組めた。興味がわいたので、自主的に取り組んでみようと思う。
- 参考
pythonでTkinterを使ってGUIアプリを作る
[https://daeudaeu.com/programming/python/tkinter/python_tkinter/]いちばんやさしいPython入門教室 著 大澤 文孝