- 投稿日:2020-07-05T23:49:16+09:00
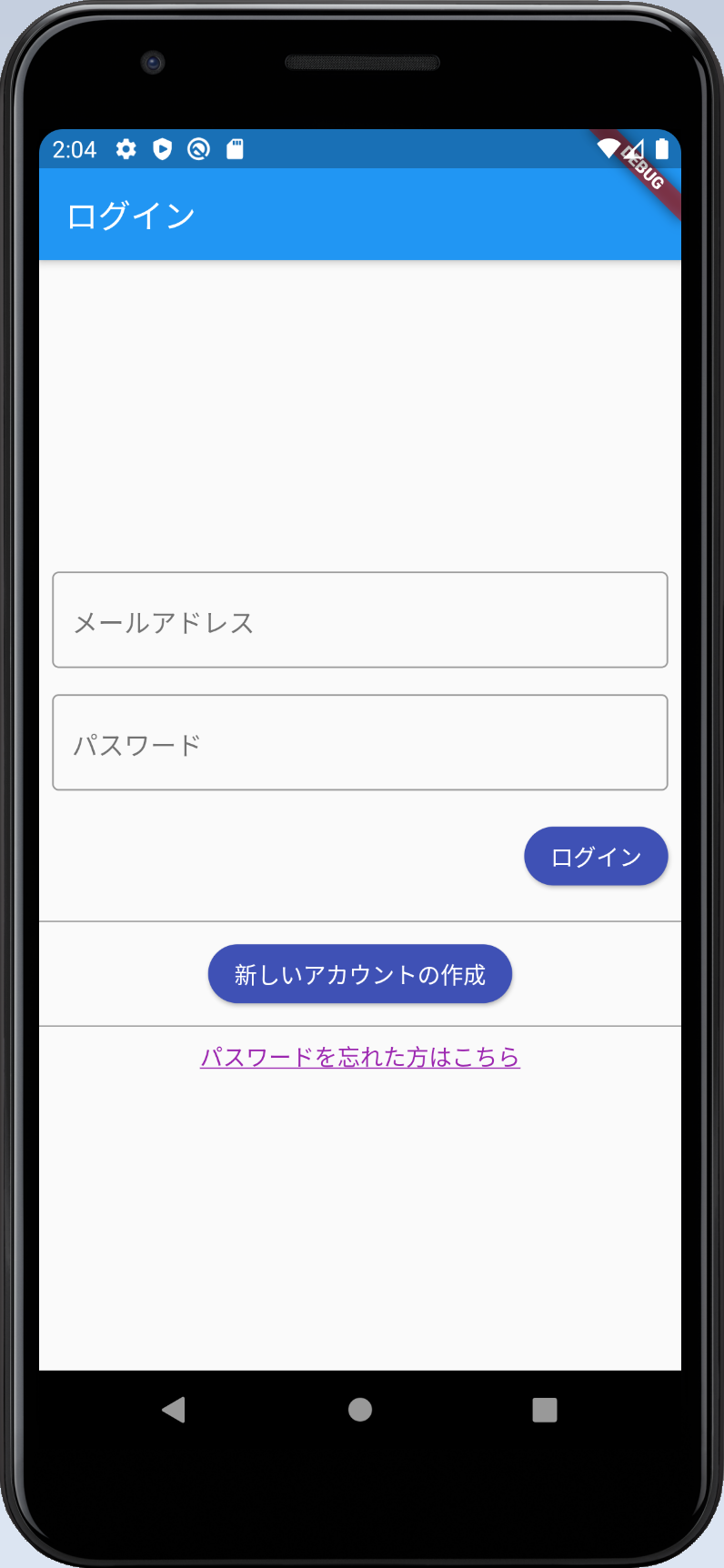
FlutterとAWSで始めるサービス開発 (6)AWS Cognito 「パスワードを忘れた方はこちら」
はじめに
前回の「(5)AWS Cognitoでログイン」では、Cognitoを使ってログイン処理を作成しました。今回は、ユーザーがパスワードを忘れてしまった場合の対処法として一般的な「パスワードを忘れた方はこちら」の処理を作っていきたいと思います。ようするにユーザー自身でのパスワードをリセットする機能になります。
「パスワードを忘れた方はこちら」の処理の流れ
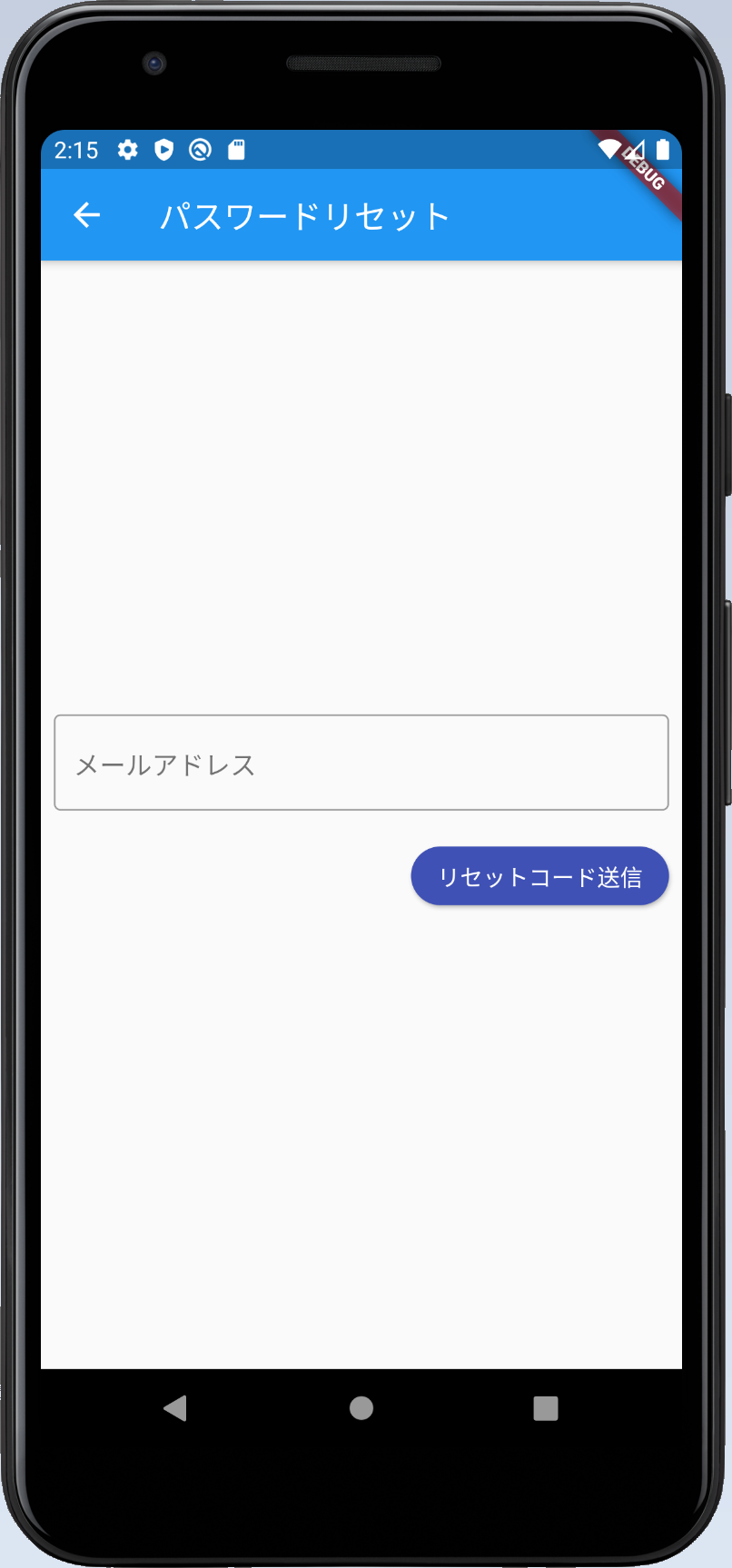
1.ユーザーIDとして登録したメールアドレスを入力してもらいます
2.入力されたメールアドレスにパスワードリセット用のコードを送信します。
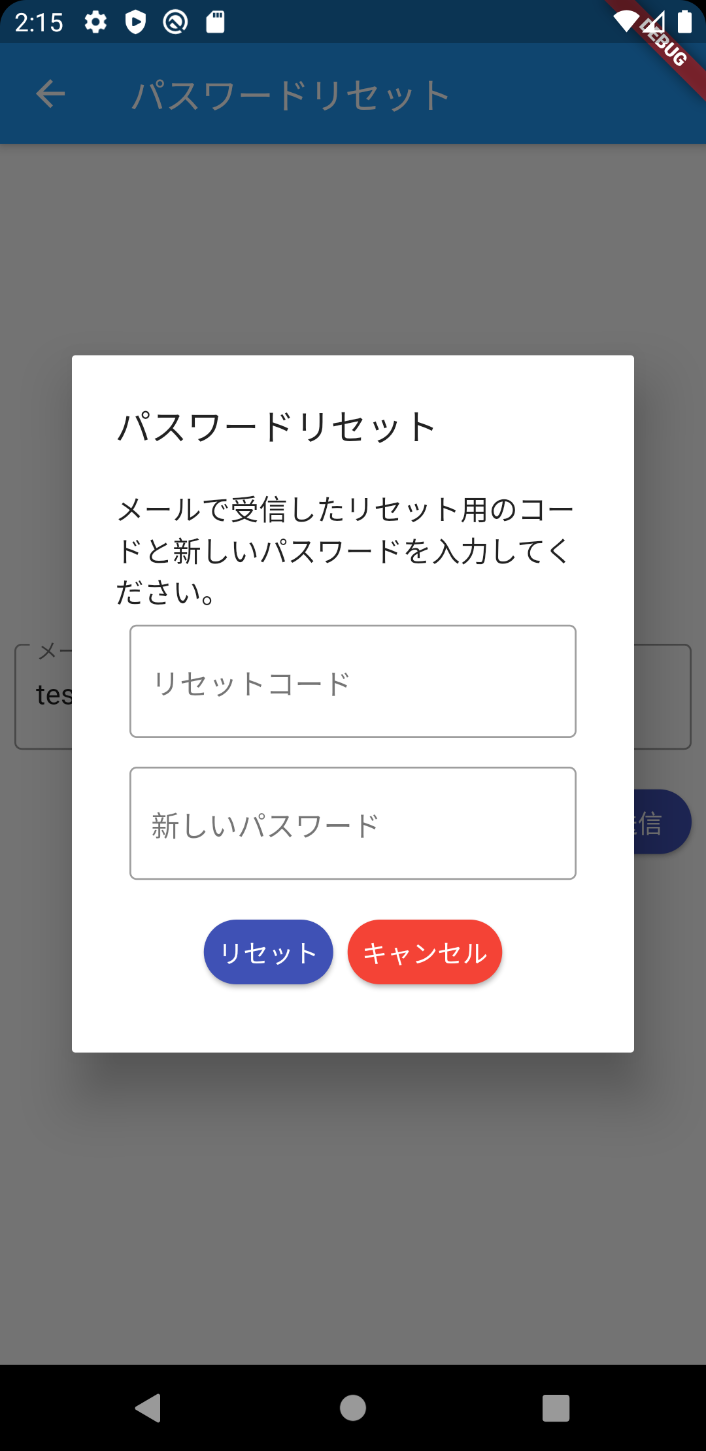
3.ユーザーは受信したコードと新しいパスワードを入力します。前回からの変更点
前回のコードからの変更点を順に説明します。
MaterialAppのroutesにパスワード忘れた方こちら画面用の定義を追加
'/ForgotPassword'という名前で定義を追加しました。
routes: <String, WidgetBuilder>{ '/': (_) => new MyHomePage(), '/TopPage': (_) => new TopPage(), '/RegisterUser': (_) => new RegisterUserPage(), '/ConfirmRegistration': (_) => new ConfirmRegistration(null), '/ForgotPassword': (_) => new ForgotPassword(), },ログイン画面の変更
パスワードリセット画面に飛ぶためのリンクをInkWellで追加しました。デザイン的にもあまり主張しすぎないようにテキストにアンダーラインくらいで抑えめにしてみました。とはいえ全体のバランス悪いですね・・・。タップするとパスワードリセット画面に飛びます。
Divider(color: Colors.black), InkWell( child: Text( 'パスワードを忘れた方はこちら', style: TextStyle( color: Colors.purple, decoration: TextDecoration.underline), ), onTap: () => Navigator.of(context).pushNamed('/ForgotPassword'), ),実装した画面は以下になります。
パスワードリセット画面
パスワードリセットのためにメールアドレスで定義されたユーザーIDを入力する画面、リセット用のコードと新しいパスワードを入力する画面からなります。以下がコード一式です。エラー処理は相変わらず手抜きしています。この連載の目的が達成したら一通りリファクタして、体裁を整えたコードを公開したいなと思いますので、ここでは流れを抑えてください。
class ForgotPassword extends StatelessWidget { final _mailAddressController = TextEditingController(); final _resetCodeController = TextEditingController(); final _passwordController = TextEditingController(); @override Widget build(BuildContext context) { return Scaffold( appBar: AppBar( title: Text('パスワードリセット'), ), body: Center( child: Column( mainAxisAlignment: MainAxisAlignment.center, children: <Widget>[ Padding( padding: const EdgeInsets.all(8.0), child: TextField( decoration: InputDecoration( border: OutlineInputBorder(), hintText: 'test@examle.com', labelText: 'メールアドレス', ), controller: _mailAddressController, ), ), Container( alignment: Alignment.centerRight, padding: const EdgeInsets.all(8.0), child: RaisedButton( child: Text('リセットコード送信'), color: Colors.indigo, shape: StadiumBorder(), textColor: Colors.white, onPressed: () => _forgotPassword(context), ), ), ]), ), ); } void _forgotPassword(BuildContext context) async { final cognitoUser = new CognitoUser(_mailAddressController.text, userPool); try { var response = await cognitoUser.forgotPassword(); print(response); await showDialog( context: context, barrierDismissible: false, builder: (BuildContext context) { return AlertDialog( title: Text('パスワードリセット'), content: SingleChildScrollView( child: Column( mainAxisAlignment: MainAxisAlignment.center, crossAxisAlignment: CrossAxisAlignment.start, children: <Widget>[ Text('メールで受信したリセット用のコードと新しいパスワードを入力してください。'), Padding( padding: const EdgeInsets.all(8.0), child: TextField( decoration: InputDecoration( border: OutlineInputBorder(), hintText: 'リセットコード', labelText: 'リセットコード', ), obscureText: true, controller: _resetCodeController, ), ), Padding( padding: const EdgeInsets.all(8.0), child: TextField( decoration: InputDecoration( border: OutlineInputBorder(), hintText: '新しいパスワード', labelText: '新しいパスワード', ), obscureText: true, controller: _passwordController, ), ), ButtonBar( buttonPadding: const EdgeInsets.all(8), mainAxisSize: MainAxisSize.max, alignment: MainAxisAlignment.center, children: [ RaisedButton( child: Text('リセット'), color: Colors.indigo, shape: StadiumBorder(), textColor: Colors.white, onPressed: () async { try { response = await cognitoUser.confirmPassword( _resetCodeController.text, _passwordController.text); Navigator.of(context) .popUntil(ModalRoute.withName('/')); } catch (e) { print(e); } }, ), RaisedButton( child: Text('キャンセル'), color: Colors.red, shape: StadiumBorder(), textColor: Colors.white, onPressed: () => Navigator.of(context).pop(1), ) ]) ]), )); }); } catch (e) { await showDialog<int>( context: context, barrierDismissible: false, builder: (BuildContext context) { return AlertDialog( title: Text('エラー'), content: Text(e.message), actions: <Widget>[ FlatButton( child: Text('OK'), onPressed: () => Navigator.of(context).pop(1), ), ], ); }, ); } } }以下、リセットコードを送信するための画面です。
ForgotPasswordクラスのbuildメソッドではメールアドレスを入力し、リセットコード送信ボタンを押下したら_forgotPasswordメソッドを実行します。_forgotPasswordメソッドでは、CognitoUserクラスを入力したメールアドレスと、CognitoUserPoolクラスのインスタンスから生成し、CognitoUserクラスのforgotPasswordメソッドを呼び出します。これで入力したメールアドレスにリセット用のコードが飛びます。このメソッド自体はユーザー登録されていないメールアドレスであろうとも成功したようにレスポンスが帰ってきます(ユーザーの存在有無を調べられないようにするためのセキュリティ上の措置だと思います)ので、API呼び出し後、showDialogで、リセットコードと新しいパスワードを入力する画面を表示します。
以下、リセットコードと新しいパスワードの入力画面です。
キャンセルボタンを押下したらひとつ前のリセット画面に戻る、リセットボタンを押下したらCognitoUserクラスのインスタンスのconfirmPasswordメソッドにリセットコードと新しいパスワードをセットして呼び出します。成功したらパスワードがリセットされるので、Navigator.of(context).popUntil(ModalRoute.withName('/'));でログインページに遷移します。
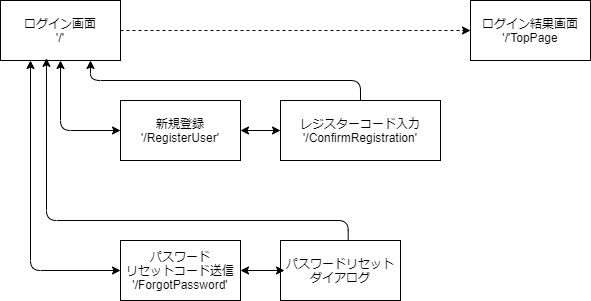
画面遷移
今回の対応で追加した画面遷移も含め下記のようになっています。
まとめ
これで一通りUserPoolsを使った独自のログインIDによるログイン処理が一通り実装できました。次回「(7)AWS Cognito Googleでログイン」とし、GoogleのアカウントでログインしCognitoとフェデレーションする仕組みを見ていきたいと思います。
- 投稿日:2020-07-05T23:42:23+09:00
LambdaをCanaryリリースするSAMテンプレートに自動ロールバックを組み込む
はじめに
LambdaのCanaryリリースは非常に便利。自動でトラフィックコントロールをして様子を見ることができる。
しかし、クラウドネイティブなリリースの完成は、万が一の状況を検知した場合は自動でロールバックすることだ。
今回は、過去に作ったSAMテンプレートに自動ロールバックを組み込んで実際の動作を確認する。前提条件
- SAMテンプレートでCanaryリリースの設定を書いたことがあり、ある程度内容を理解している。特に、
AutoPublishAliasとDeploymentPreferenceの概要と、LambdaPermissionを設定しなければいけない理由が分かっているのが望ましい ⇒ 過去の記事でも紹介してるよ!- CloudWatchアラームをなんとなく分かっている
SAMテンプレートを書く前に
ロールバックの設定は、SAMテンプレートの
AWS::Serverless::Functionリソース内のDeploymentPreferenceのプロパティで設定する。これは標準のCloudFormationにはないSAM独自機能なので、マニュアルには目を通しておく。このドキュメントの
Alarmsの説明にはデプロイによって発生したエラーによってトリガーされる CloudWatch アラームのリスト。
と書かれていて「ごめんちょっとよく分からない」な感じではあるが、要はここで設定したCloudWatchアラームに引っかかるとトリガが引かれてロールバックが走る、ということだった。
なので、ここに指定するCloudWatchアラームを定義してあげればよい。指定するのはARNではなくて名前なので、TerraformとSAMを併用している場合でも、それほど困らずに使えるだろう。
CloudWatchAlarmの定義
デプロイ中に発生する問題を予見するようなアラームなんて千差万別なので「これ」という答えはないが、今回はサンプルとして、「APIGatewayの特定APIの特定ステージで、5XXErrorの合計値が60秒以内に2回以上発生したら挙がるアラーム」を設定する。
あっさり書いたようだが、この辺のプロパティの説明は公式ドキュメントの内容が破滅的に分かりにくいので、ほぼ手探りなのであった。NamespaceとDimensionsについては、API Gateway側のドキュメントに書かれていたので拾えた。Namespaceに設定可能な他のサービスについても、ここでまとめられているので、今後の参考に使えるのではないか。
なお、Dimensionsではリソースとメソッドまで指定できるが、それを拾うメトリクスはカスタムメトリクスの作成が必要そうなので今回は割愛する。実際には、デプロイするアプリケーションの影響範囲に応じて監視範囲を絞るべきだろう。
# ------------------------------------------------------------# # Cloud Watch Alarm # ------------------------------------------------------------# GoApigwTestAlarm: Type: AWS::CloudWatch::Alarm Properties: AlarmName: [好きなアラーム名] AlarmDescription: [適当な説明文] Namespace: AWS/ApiGateway Dimensions: - Name: ApiName Value: [APIGatewayのAPI名] - Name: Stage Value: Prod MetricName: 5XXError Statistic: Sum Period: 60 ComparisonOperator: GreaterThanThreshold Threshold: 1 EvaluationPeriods: 1実際に試してみる
さて、上記のSAMテンプレートをリリースしたとしても、トランザクションを5XXエラーにできなければ意味がない。プロダクトのソースコードに
if id == "99999" { statusCode = 500 }な感じでテキトーに仕込んで、curlでid=99999を流し込もう。
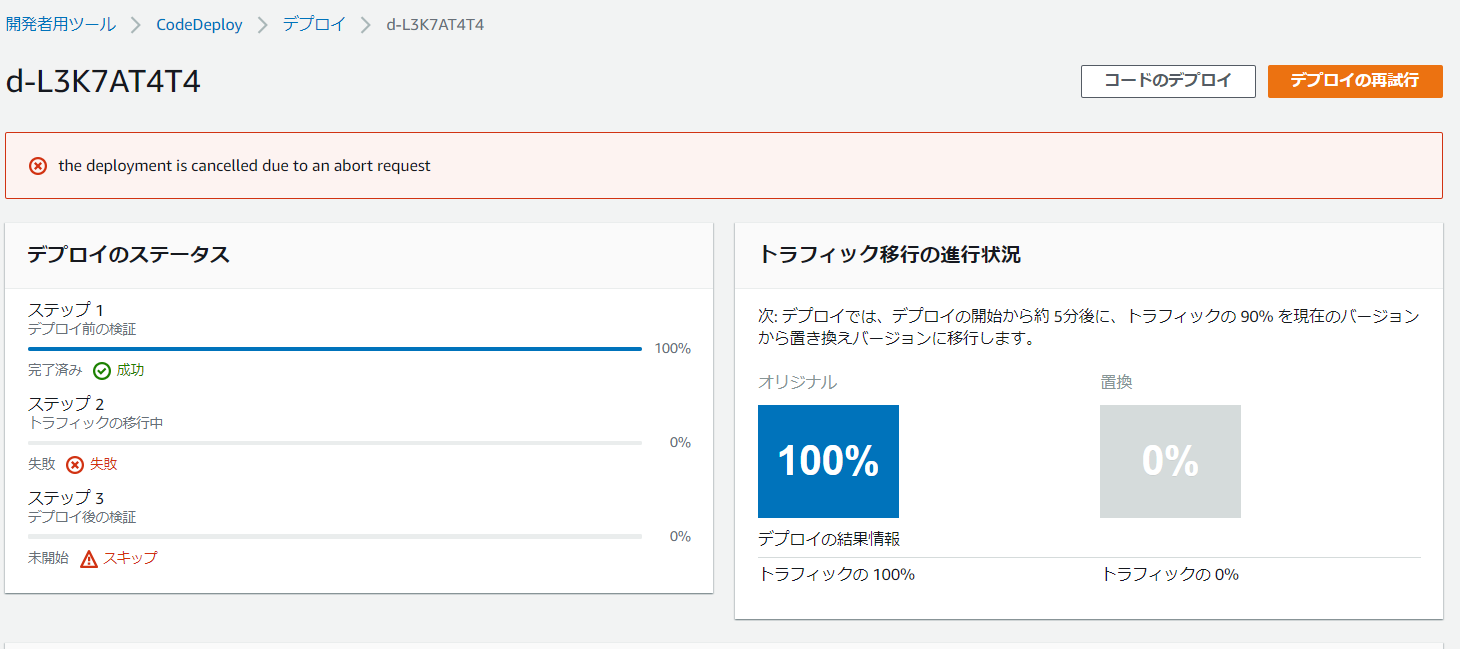
DeploymentPreferenceのTypeの内容次第ではなかなかエラーにならないが、「1分以内に2回5XXエラー」という設定なのでテキトーに叩いていればそのうちにロールバックが発動する。ロールバックが発動すると、
こんな感じでトラフィックがオリジナル側にしか流れなくなり、ロールバックが完了する。
- 投稿日:2020-07-05T23:34:53+09:00
AWS SAA対策メモ(データ分析サービス編)
SAA対策の自分用のメモ。
どんどん更新して加筆修正していく予定。Kinesis
大量のストリーミングの収集処理を行う。IoTなどからのリアルタイムデータを分析。
Kinesis Data Streams
ストリーミングデータをリアルタイムで保存。EMRやLambdaで処理させる。
DBの負荷分散のため、大量のデータをシャードという単位で分割し、複数ノードで並列処理を行う。
シャードは時間あたりの処理数に制限あり。シャード数を増やすことでストリームデータの並列処理ができ、効率よくストリーミングできる。Kinesis Data Firehose
データ蓄積に向けてデータ変換や別サービスへの配信を行う。ストリーミングデータをデータレイクやデータストア、分析ツールにロード。ストリーミングデータをキャプチャして変換し、Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、Splunk にロードして、BIツールでほぼリアルタイムに分析可能Kinesis Data Analytics
ストリーミングデータに対してSQLクエリを投げてリアルタイム分析が可能。DBにデータを移すことなく分析可能。Kinesis Video Streams
ビデオストリームを取り込み、アプリによって動画を解析できるようにする。防犯カメラとか。EMR(Elastic MapReduce)
Hadoopのマネージドサービス。Hadoopとは、大量のデータを処理する分散処理フレームワーク。(非)構造データを変換する。
Data Pipeline
DBからデータの取り出し(Extract)、変換(Transform)、保存(Load)の順次処理を行う。
Glue
ETLとデータカタログのマネージドサービス。
データカタログとは、メタデータを集中管理するもの。
データレイクであるS3に保存されたデータ構造をRedshift用に変換する。Athena
S3データにテーブルを作成し、直接SQLを投げる。
QuickSight
BIツール。
RedshiftやAthena、S3などと接続。
- 投稿日:2020-07-05T23:20:51+09:00
AWS SAA対策メモ(構成管理 & メッセージ編)
SAA対策の自分用のメモ。
どんどん更新して加筆修正していく予定。構成管理系
CloudFormation
インフラリソースを自動でプロビジョニング
テンプレート:プロビジョニングしたいコードを記述(JSON or YAML)
スタック:テンプレートによってプロビジョニングされるリソース
テキストエディタで書くか、CloudFormationデザイナーを使用するElastic Beanstalk
webアプリやサービスをデプロイし、実行環境の管理も簡単にできる。
ブルーグリーンデプロイメント
ブルー(実稼働)からグリーン(準備環境)に切り替えるダウンタイムがないリリース方法。RDSをElastic Beanstalk環境外に指定することで可能。OpsWorks
サーバーの構築の自動化をする
ChefやPuppetが利用可能メッセージ系
SNS
通知サービス
パブリッシャ
メッセージ送信者サブスクライバ
メッセージ送信者トピック
アクセスポイント、通信チャンネルパブリッシャが作成したトピックをサブスクライブすることで、サブスクライバはメッセージを送受信可能。サブスクライバにはHTTP(S), Email, SQS, Lambdaがある。トピックに対して、アプリ側からサブスクライバ宛にメッセージを送るのがパブリッシュ。Lambdaでは、その通知をトリガーに何らかの処理を走らせることができる。
SQS
メッセージキューイングサービス
バッチ処理など非同期で分散処理が可能
想定外の大量のトラフィックを一旦SQSのキューに受け入れ、後から処理していく時によく使われる。バッファリングすることで、DBの負荷を減らせる。また、オートスケールの運用負荷も下げることができる。ロングポーリング
キューが空の場合、メッセージ取得までの待機時間を1~20秒で設定し、メッセージ取得要求の数を減らせる(コストダウン)
逆に、もしキューが空でも取得してしまう(ショートポーリング)と、コストだけかかって意味がない。可視性タイムアウト
メッセージ取得を他の受信者に一定時間見せないようにする。処理の重複やリクエスト数を減らせる。キュー種類
- 標準キュー 最大のスループットだが、配信順序はベストエフォートで配信回数は少なくとも1回
- FIFOキュー(First In, First Out) 送信されている順番に配信され、1回で確実に処理する
SES
メールの送信サービス
Amazon MQ
オンプレから既存のアプリのメッセージング機能を移行するのにおすすめ
FSx For Windows
フルマネージドのWindowsファイルシステム。
WindowsシステムのAWSへの移行を容易にするその他
CodeDeploy
アプリのデプロイの自動化
CodeCommit
コーディングされた内容をGitリポジトリにホスト
CodeBuild
ソースコードをコンパイルし、テストを実行し、デプロイ可能なソフトウェアパッケージを作成できる
CodePipeline
アプリケーションのビルド、テスト、デプロイまでの処理手順を定義・実行
SWF(Simple Workflow Service)
ひとかたまりの処理の状態管理とタスク間の流れの管理サービス。
分散している(非)同期タスクを一連のフローとし、高耐障害性↑↑
- 投稿日:2020-07-05T23:13:31+09:00
EC2インスタンスを起動してからgithub連携できる様になるまでの手順
はじめに
EC2インスタンスを起動してからgithubと連携できる様になるまでの手順を、自分が疑問に思ったことをQ and A形式で掲載します。
至らない点も多々あると思いますがよろしくお願いします!対象者
- 初学者
- AWSを学習中の方
- シェル(ssh)でAWSのEC2インスタンスに接続できた方
この記事で得られること
- AWSでgithubと連携するまでの手順
- パッケージマネジャ(yum)の概要
開発環境
- Amazon Linux AMI 2018.03.0 (HVM), SSD Volume Type
- ngnix
- ruby 2.7.1
- rails 6.3.1
前提
Q.なぜ連携(なぜssh認証する)必要があるのか?
A.githubでは自分のアカウントを使用してサーバーにユーザーとしての認証を行なっています。
同様に、EC2インスタンスという、githubから見て「誰なのか分からない・・・」という状態を「誰なのか分かる!」という状態にします。また、git clone中にセキュリティ観念上、悪意あるデータを通信中に書き込まれる、という可能性がある。通信をssh通信で暗号化することにより、この様なことが防げるメリットがある。
手順(コードのみ)
[ec2-user@ElsticIPアドレス]$ sudo yum -y update
[ec2-user@ElsticIPアドレス]$ sudo yum install git
[ec2-user@ElsticIPアドレス]$ git version # gitがインストールされているか確認
[ec2-user@ElsticIPアドレス .ssh]$ ssh-keygen -t rsa -b 4096
※.sshディレクトリで実行!!
※途中で鍵の名前など設定する入力箇所があるが、全て何も入力しないでenter(3回)を押せばOK。デフォルトの鍵の名前になる。
[ec2-user@ElsticIPアドレス]$ cat ~/.ssh/id_rsa.pub # 表示された文字列を全てコピーする以下のURLにアクセス
https://github.com/settings/keysSSH Keys欄にて、公開鍵のタイトル(自由に入力してOK)と公開鍵の内容(5.でコピーした内容)をペーストする。
[ec2-user@ElsticIPアドレス]$ ssh -T git@github.com
※以下の文言が表示されればOK。yesかno問われたら全てyesHi ! You've successfully authenticated, but GitHub does not provide shell access.
この工程が終わればOKとなります!git cloneができる様になります。
捕捉知識
Q.
sudo yum -y updateって何? 何でupdateするの?A. yumはLinux向けのパッケージマネジャの1つです。
パッケージマネジャとは、様々なアプリケーションやソフトの管理を行うソフトです。
このパッケージマネジャではセキュリティ等に関するソフトも管理されており、抽象的な言い方をすれば「yumにソフト管理を委託している」ということになります。
定期的にupdateすることで、EC2インスタンス(Linux)のメンテナンスができます。Q.
[ec2-user@ElsticIPアドレス .ssh]$ ssh-keygen -t rsa -b 4096で鍵名を設定しないのはなぜ?A. 鍵名が「id_rsa.pub」で作成されるからです。それ以外の名前で鍵を作成すると
[ec2-user@ElsticIPアドレス]$ ssh -T git@github.comを行うために、~/.ssh/configファイルで別途設定を行う必要があります。そのため、初学者向けの手法と言えるかもしれません。Q. 公開鍵と秘密鍵の使い方がよく分からない
A. 私も詳細分からないのですが、ひとまず公開鍵⇨サーバー外でも公開して良い鍵、秘密鍵⇨サーバー外に出してはならない、と覚えておきましょう!
- 投稿日:2020-07-05T22:41:01+09:00
AWS SAA対策メモ(CloudWatch, CloudTrail & Config編)
SAA対策の自分用のメモ。
どんどん更新して加筆修正していく予定。CloudWatch
CloudWatch
システムやリソース情報の収集・監視・可視化を行う
標準メトリクス CPU使用率など
カスタムメトリクス CloudWatchエージェントをサーバーにインストールして設定するプラン
- 基本モニタリング 無料 1分間隔
- 詳細モニタリング 有料 5分間隔
CloudWatch Events
リソース監視を行い、あるイベントをトリガーにアクションを実行する。
例 スポットインスタンスが強制終了されたら、Lambdaを実行して新たなスポットインスタンスを起動
イベント 対象リソースの変化
ターゲット 実行する処理
ルール 定義したイベントのイベントリソースとターゲットのアクションの組み合わせ。CloudWatch Logs
ログの収集と管理。
CloudWatch Logs Metric Filterでフィルタリングが可能。
Elasticsearch Serviceと連携し、Kibanaでビジュアル化可能。CloudTrail
誰がどういった操作をしたかのログを残し、意図しない操作がないかなどを確認できる
アクティビティログは標準で90日間保存
証跡を有効にすると、S3にログが保存される
CloudWatch Logsへの送信を有効にすると、ログをCloudWatch Logsに送れる
グローバルでもリージョンでも使用可能Config
管理されている構成変更の追跡サービス
Configルール
理想の構成 = コンプライアンス準拠として定義し、現在のリソース構成が適合するかを評価する。
例 MFAの有無などConfigアグリゲータ
Configルールの評価結果を複数アカウントやリージョンであっても集約し、一元管理することができる。
- 投稿日:2020-07-05T21:32:06+09:00
Amazon ECSで、サービスが参照するタスク定義のリビジョンのみを更新する
What's?
こういうことがやりたかった、と。
- Amazon ECSで、サービスが参照するタスク定義のリビジョンを更新したい
- タスク定義の中身は特に変えたくなくて、とにかくリビジョンだけ上げたい
参照するコンテナイメージが
latestなどで同じ時に新しいイメージを使いたい場合や、参照しているParameter Storeの値が変わった場合などに。ただ、ここに載せている方法は
deploymentControllerがECSの場合のみです。環境
実行環境は、こちら。
$ aws --version aws-cli/2.0.28 Python/3.7.3 Linux/4.15.0-109-generic botocore/2.0.0dev32コマンド
aws ecs describe-task-definitionコマンドの結果から、不要なものを削ってaws ecs register-task-definitionコマンドに流し込みます。$ aws ecs describe-task-definition --task-definition [タスク定義名] | \ jq '.taskDefinition' | jq -M 'del(.taskDefinitionArn) | del(.revision) | del(.status) | del(.requiresAttributes) | del(.compatibilities)' | \ xargs -0 aws ecs register-task-definition --family [タスク定義名] --cli-input-jsonJSONファイルの実体は、作成したくないですよ、と。
aws ecs register-task-definitionコマンドの--cli-input-jsonオプションで受け取るJSONに、不要な要素が入ったままだとこんな感じになります。$ aws ecs describe-task-definition --task-definition [タスク定義名] | \ jq '.taskDefinition' | \ xargs -0 aws ecs register-task-definition --family [タスク定義名] --cli-input-json Parameter validation failed: Unknown parameter in input: "taskDefinitionArn", must be one of: family, taskRoleArn, executionRoleArn, networkMode, containerDefinitions, volumes, placementConstraints, requiresCompatibilities, cpu, memory, tags, pidMode, ipcMode, proxyConfiguration, inferenceAccelerators Unknown parameter in input: "revision", must be one of: family, taskRoleArn, executionRoleArn, networkMode, containerDefinitions, volumes, placementConstraints, requiresCompatibilities, cpu, memory, tags, pidMode, ipcMode, proxyConfiguration, inferenceAccelerators Unknown parameter in input: "status", must be one of: family, taskRoleArn, executionRoleArn, networkMode, containerDefinitions, volumes, placementConstraints, requiresCompatibilities, cpu, memory, tags, pidMode, ipcMode, proxyConfiguration, inferenceAccelerators Unknown parameter in input: "requiresAttributes", must be one of: family, taskRoleArn, executionRoleArn, networkMode, containerDefinitions, volumes, placementConstraints, requiresCompatibilities, cpu, memory, tags, pidMode, ipcMode, proxyConfiguration, inferenceAccelerators Unknown parameter in input: "compatibilities", must be one of: family, taskRoleArn, executionRoleArn, networkMode, containerDefinitions, volumes, placementConstraints, requiresCompatibilities, cpu, memory, tags, pidMode, ipcMode, proxyConfiguration, inferenceAccelerators
[タスク定義名]の部分を埋めるのが面倒だったら、環境変数の利用でも…。$ TASK_DEFINITION_NAME=[タスク定義名] $ aws ecs describe-task-definition --task-definition ${TASK_DEFINITION_NAME} | \ jq '.taskDefinition' | jq -M 'del(.taskDefinitionArn) | del(.revision) | del(.status) | del(.requiresAttributes) | del(.compatibilities)' | \ xargs -0 aws ecs register-task-definition --family ${TASK_DEFINITION_NAME} --cli-input-json最後に、このタスク定義を使用するサービスを更新して完了です。
$ aws ecs update-service --cluster [クラスタ名] --service [サービス名] --task-definition [タスク定義名]デプロイ方法(
deploymentController)がECSの場合は、ローリング更新が始まります。あとは、サービスの認識しているリビジョンが変わったのを眺めつつ、実際に動作するコンテナが言われ変わるのを待ちましょう。
$ aws ecs describe-services --cluster [クラスタ名] --services [サービス名] | grep taskDefinition "taskDefinition": "arn:aws:ecs:ap-northeast-1:xxxxxxxxxxxx:task-definition/[タスク定義名]:[リビジョン]", "taskDefinition": "arn:aws:ecs:ap-northeast-1:xxxxxxxxxxxx:task:task-definition/[タスク定義名]:[リビジョン]",なお、
deploymentControllerにCODE_DEPLOYを指定している場合は、aws ecs update-service実行時に以下のようなエラーが出て、実行に失敗してしまいます。An error occurred (InvalidParameterException) when calling the UpdateService operation: Unable to update task definition on services with a CODE_DEPLOY deployment controller. Use AWS CodeDeploy to trigger a new deployment.
- 投稿日:2020-07-05T21:09:32+09:00
ポートフォリオを作成するための学習項目
金融の情報システム部門で働いています。
社内SEのポジションですが、事務屋としての仕事の割合が多いです。
会話の中で技術的な話になることはあれど、実際に自分自身で何かを作ることがないため、これからの自分の立ち位置に非常に不安を抱えています。
なので、将来的な転職も選択肢に入れて、ポートフォリオを作成しようと考えています。
これまでに学習してきたこと、これから学習しようとしていることをまとめます。コンピュータサイエンス基礎
「令和02年 イメージ&クレバー方式でよくわかる 栢木先生の基本情報技術者教室 情報処理技術者試験」
大学生の頃に受験して合格しました。
もう何年も前の話なので、応用情報技術者試験をそのうち受けようかと考えています。Linux
「新しいLinuxの教科書」
後述するUdemyのDocker講座でもLinuxをコマンドの学習ができますが、改めて体系的に学ぼうと思います。HTML/CSS
「これから学ぶHTML/CSS 」
1年目の時にお世話になりました。
忘れてしまっていることも多いので、都度読み返すことになりそうです。JavaScript
「確かな力が身につくJavaScript「超」入門 第2版」
JavaScriptは全く未経験なのでこの機に勉強しようかと思います。Python
「独学プログラマー Python言語の基本から仕事のやり方まで」
これは1年目の時に学習しました。「Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる!」
こちらは最近読みました。
非常にわかりやすかったです。
foliumを使って地図上にプロットできたときはちょっと感動しました。Django
「Python Django 超入門」
「独学プログラマー」の本を読んだ後にこちらを学習しました。
Webのチュートリアルなどもやってみたものの、自分自身でアプリを1から作ることはまだできていません。
これも、bootstrapでデザインを整えた時にちょっと感動しました。
チュートリアルではなく、1から再チャレンジします。Docker
米国AI開発者がゼロから教えるDocker講座
https://www.udemy.com/course/aidocker/
Udemyの動画講座です。学習は書籍の方が良いと思っていましたが、動画は画面の動きを見ながら学習できるのでわかりやすいです。
14時間というボリュームのある学習内容も、2倍速で視聴できるので素早く学習できます。
ちょうど今学習中です。入門Docker
https://y-ohgi.com/introduction-docker/
こちらもDockerの勉強ができます。
前述の動画講座は5000円ほどしますが、こちらは無料です。AWS
「Amazon Web Servicesインフラサービス活用大全 システム構築/自動化、データストア、高信頼化 impress top gearシリーズ」
AWSでアプリを動かすことができるまで経験しないと未経験では転職は厳しそうですし、
仮に採用されたとしても労働条件は良いものにならないだろうと思います。CircleCI
「いまさらだけどCircleCIに入門したので分かりやすくまとめてみた」
https://qiita.com/gold-kou/items/4c7e62434af455e977c2
何をするものなのかも正直知りません。
これから勉強していきます。








- 投稿日:2020-07-05T20:17:58+09:00
【AWS DynamoDB】DynamoDB基本構築
目標
AWSのDynamoDBを構築し、簡単なテーブル操作をAWSコンソール及びAWS CLI上で試す
DynamoDBとは
AWSが提供するキーバリュー型のマネージドデータストアサービスです。
データが3つのAZに分散して格納されるため耐久性が高く、格納容量に上限がありません。
また、キーバリュー形式でレイテンシーが低いため、キャッシュやWEBセッションの格納先としても利用されます。より詳しくは以下記事が参考になります。
【AWS】今更ながらDynamoDB入門参考AWSドキュメント
作業の流れ
項番 タイトル 1 DynamoDBを構築する 2 DynamoDBテーブルをAWSコンソール上から操作 3 DynamoDBテーブルをAWS CLIで操作 手順
1.DynamoDBを構築する
①Amazon DynamoDBコンソールへアクセス
②
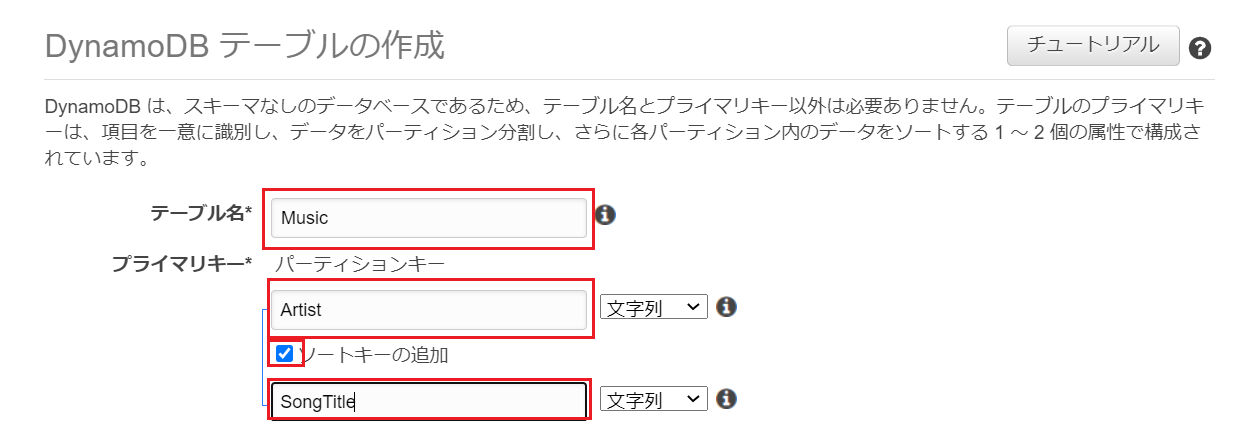
テーブルの作成をクリック③DynamoDB テーブルのテーブル名とプライマリキーの設定
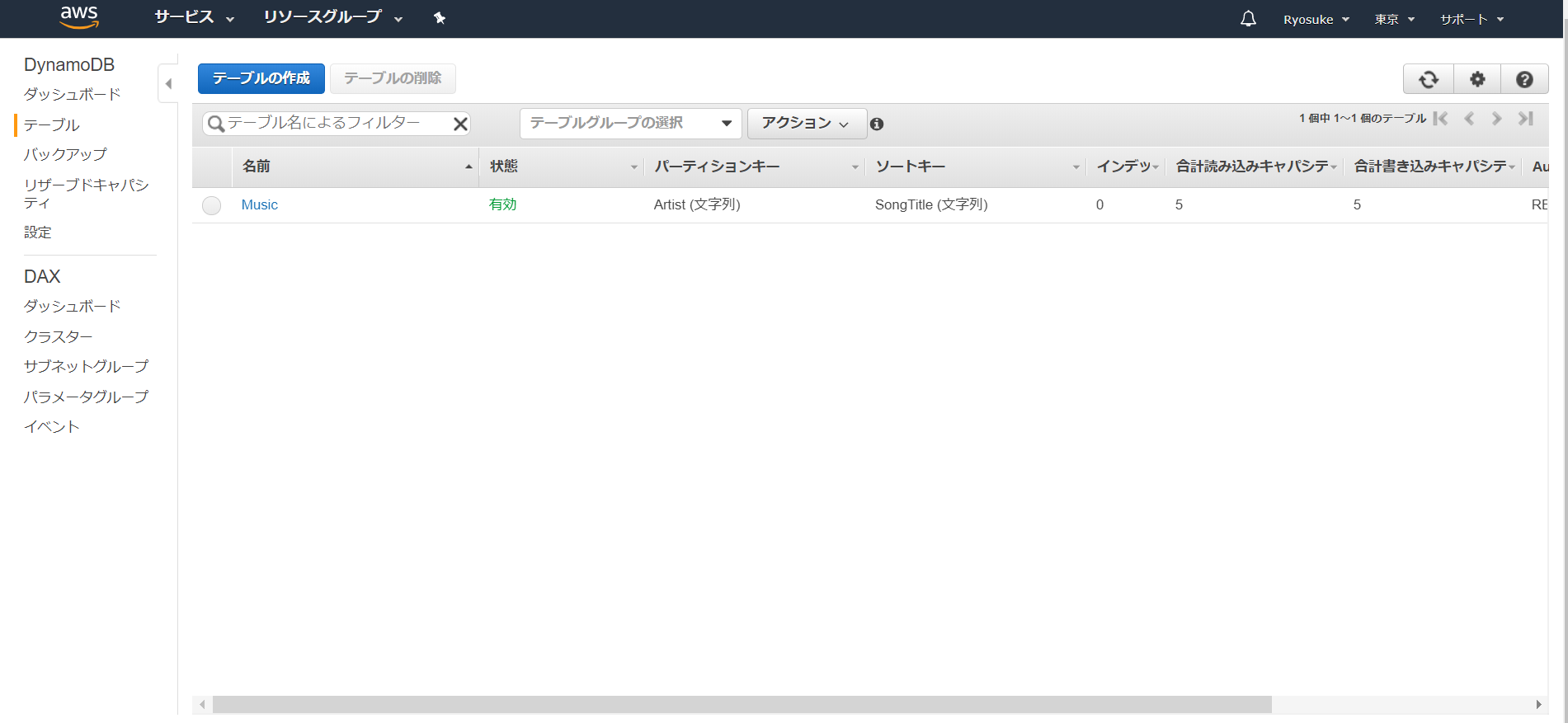
まず、DynamoDBのテーブル名とプライマリキー(※)の設定を行います。
サンプルとして以下のように設定テーブル名:
Music
パーティションキー:Artist
ソートキー(任意設定):SongTitle
※DynamoDBのプライマリキーに関して
プライマリキー
「パーティションキー」または「パーティションキーとソートキーの複合キー」のこと。
プライマリキーによってデータは一意に識別される。パーティションキー(設定必須)
このキーへの格納値に従ってどのパーティションにデータが保存されるかが決まるため、
広範囲の値を持ちうるキーを設定することが推奨のようです(各パーティションへのアクセスが均等に分散され、性能向上につながる)。ソートキー(設定任意)
設定することで、各パーティション内のデータをソートすることが可能となり、
かつAPIではソートキーを指定して取り出すデータの範囲をフィルタできるようです。より詳しくは以下記事参考
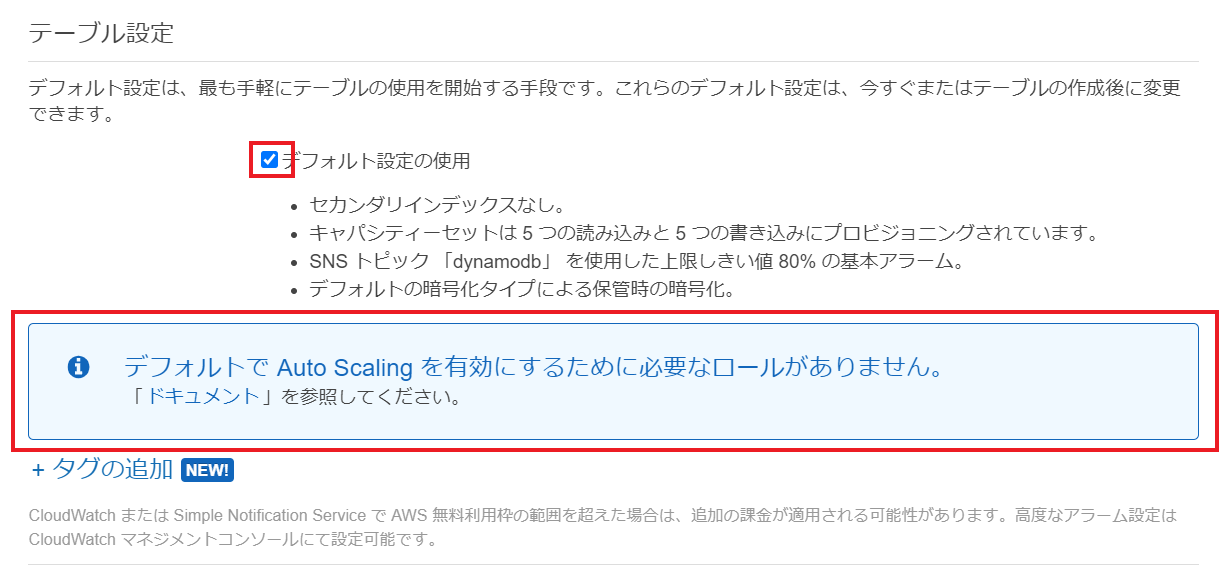
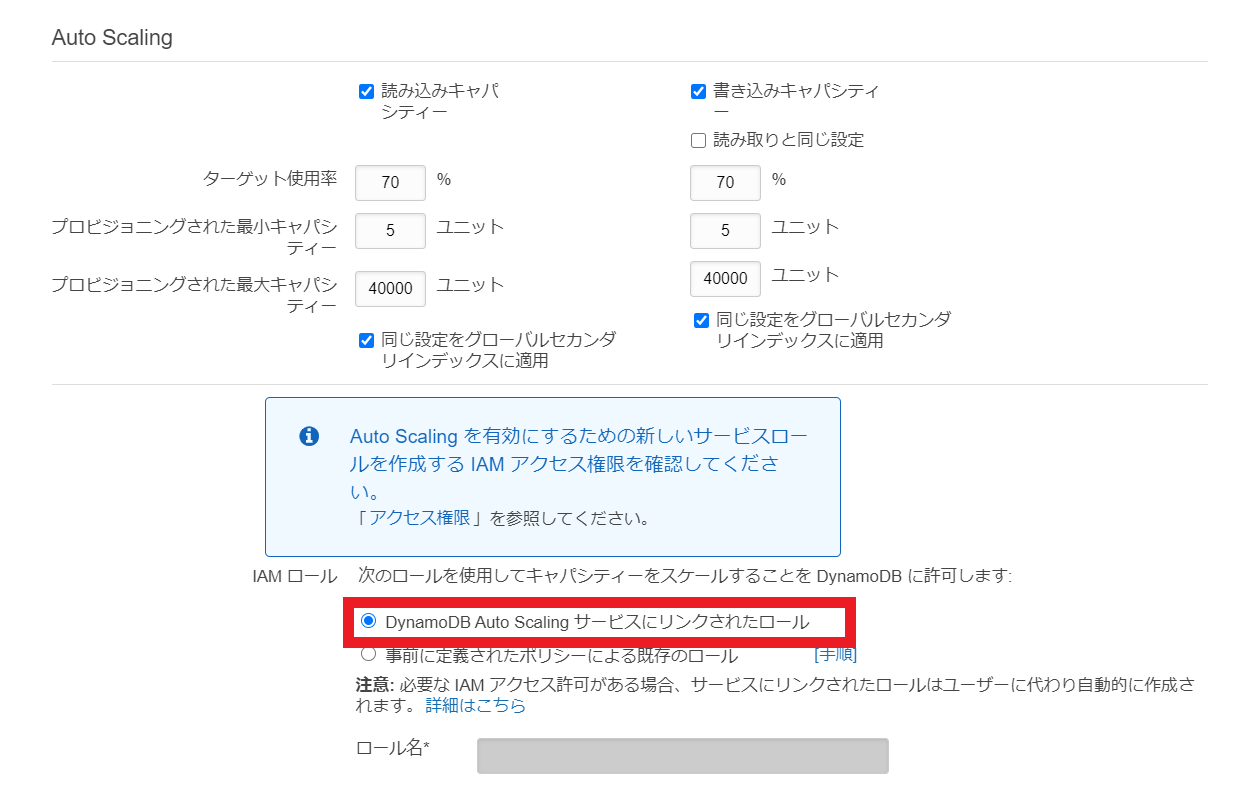
DynamoDBのキー・インデックスについてまとめてみた④スループットキャパシティのAutoScaling用ロール作成(任意設定)
設定は任意です。
DynamoDBではRCU(読み込みスループットキャパシティ)とWCU(書き込みスループットキャパシティ)という指標を利用して、
単位時間あたりの読み込み・書き込み量を決定しています。
そのRCUとWCUのAutoScaling機能(自動拡張・縮小)を利用するためのIAMロールがデフォルトでは存在しないため新規作成します。まずは
デフォルト設定の使用のチェックを外します。
DynamoDB Auto Scaling サービスにリンクされたロールにチェックされていること確認
他項目は今回は設定変更無しとします。
最後に作成をクリック⑤テーブル作成確認
テーブル一覧に追加されたらOKです
2.DynamoDBテーブルをAWSコンソール上から操作
本記事では手順省略致します。
以下AWSドキュメントの「ステップ 2: NoSQL テーブルにデータを追加する」以降を参考に簡単なテーブル操作を試すことができます。
NoSQL テーブルを作成してクエリを実行する3.DynamoDBテーブルをAWS CLIで操作
いくつかサンプルとして実行してみます。
より詳しいコマンドは以下記事参照
aws cli で DynamoDB を使う
AWS CLIでDynamoDB操作(挿入, 取得, 更新, 削除)put-item(データ格納)
$ aws dynamodb put-item --table-name Music --item '{ "Artist": { "S": "Ryosuke" }, "SongTitle": { "S": "FirstSong" }}' $ aws dynamodb put-item --table-name Music --item '{ "Artist": { "S": "Ryosuke" }, "SongTitle": { "S": "SecondSong" }}' $ aws dynamodb put-item --table-name Music --item '{ "Artist": { "S": "Michael" }, "SongTitle": { "S": "FirstSong" }}'scan(データ一覧)
$ aws dynamodb scan --table-name Music { "Count": 3, "Items": [ { "SongTitle": { "S": "FirstSong" }, "Artist": { "S": "Ryosuke" } }, { "SongTitle": { "S": "SecondSong" }, "Artist": { "S": "Ryosuke" } }, { "SongTitle": { "S": "FirstSong" }, "Artist": { "S": "Michael" } } ], "ScannedCount": 3, "ConsumedCapacity": null }get-item( 単一データ取得 )
$ aws dynamodb get-item --table-name Music --key '{ "Artist": { "S": "Ryosuke" }, "SongTitle": { "S": "SecondSong" }}' { "Item": { "SongTitle": { "S": "SecondSong" }, "Artist": { "S": "Ryosuke" } } }query( 条件に一致するItem取得 )
[ec2-user@ip-172-31-34-150 ~]$ aws dynamodb query --table-name Music --key-condition-expression 'Artist = :Artist' --expression-attribute-values '{ ":Artist" : { "S": "Ryosuke" }}' { "Count": 2, "Items": [ { "SongTitle": { "S": "FirstSong" }, "Artist": { "S": "Ryosuke" } }, { "SongTitle": { "S": "SecondSong" }, "Artist": { "S": "Ryosuke" } } ], "ScannedCount": 2, "ConsumedCapacity": null }
- 投稿日:2020-07-05T17:43:13+09:00
データ分析の基礎とデータ分析で使うAWSサービス
データ分析基礎
データレイク
AWSでは、規模にかかわらず、すべての構造化データと非構造データを保存できる一元化されたリボジトリと定義している。
特徴
- 格納できるデータ容量に制限がない
- 格納できるデータの形式に制限がない
- どこにどのようなデータが入っているか管理されているので、必要なデータを探し、取り出すことができる
データウェアハウス
AWSでは、十分な情報に基づく優れた意思決定を行うための、分析可能な情報のセントラルリポジトリと定義している
集約されたリレーションデータとしてデータを保持。
ETL(Extract-Transform-Load)
ETL:データウェアハウスを構築するために必要な前処理。
Extract(抽出)
データベースやデータレイクから、分析に必要なデータを抽出する処理。
分析に使わないデータは抽出しないことが大事。分析に使わないデータを抽出する
- 変換処理やロード処理に不要な性能的、時間的コストがかかる
- データ分析者がデータの要・不要を選択する負担が発生
Transform(変換)
抽出データを変換する処理。
データ変換処理をサボると、分析に専念することができない。
データ単位を小さくすると、高速で分析しやすくなる。Load(ロード)
変換されたデータを、データベースに格納する処理。
このデータベースをターゲットと呼ぶ。
ロード処理は、変換後の大量データを以下に早くターゲットに転送するかがポイントとなる。可視化
BIツールやダッシュボートを使って、可視化。
データ分析で使用するAWSサービス
- Amazon S3
- AWS Glue
- Amazon Athena
- Amazon Redshift
- Amazon QuickSight
Amazon S3
データレイクとして生データをいれる
AWS Glue
データのETL処理を行うAWSのフルマネージドサービス。
機能
- クローラ
- データカタログ
- ジョブ
- トリガー
- ジョブフロー
クローラ
データソースやターゲットとなるS3バゲットやデータベースなどに自動的、定期的にアクセスし、ファイルやテーブルの定義情報を検索するプログラム。
データカタログ
収集したソース及ターゲットのデータ構造は一元管理する場所。
ジョブ
データソースからターゲットに、データをETL処理するための実行処理。
トリガー
丈夫を実行するきっかけとなるイベント定義。
ジョブフロー
複数のジョブやトリガーをチェーン上に繋いだセットを定義。
Amazon Athena
S3以上のファイルに対して標準SQLでアクセスができるようにするマネージドサービス。
Amazon Redshift
データウェアハウスを提供するサービス。
データを格納し、SQLで各種データ操作が行える。Amazon QuickSight
AWSが提供するBIサービス。
各AWSサービスに格納されたデータにアクセスし、分析の画面を作成できる。
独自のメインメモリエンジンを持っている。そのため、高速な分析操作が可能。参考資料
- 投稿日:2020-07-05T17:32:05+09:00
AWS SDK for JavaScriptでS3 のプライベートバケットから画像を取得する
前提
- AWS SDK for JavaScriptがインストールされていること。
処理
aws-sdkを読み込むconst AWS = require('aws-sdk')インスタンス化
const s3 = new AWS.S3({ accessKeyId: 'xxxxxxxxxxxxxxxxx', //アクセスキー secretAccessKey: 'xxxxxxxxxxxxxxxxx', //シークレットアクセスキー region: '' //リージョン })getObjectのパラメーターを用意
const params = { Bucket: "buket", //バケット名 Key: "test.jpg", //キー };
getObjectを実行const s3Promise = s3.getObject(params).promise();処理が成功したらbase64型に変換する
s3Promise.then(function(data) { console.log('data:image/jpg;base64' + data.Body.toString('base64')) }).catch(function(err) { console.log(err); });全体
const AWS = require('aws-sdk') const s3 = new AWS.S3({ accessKeyId: '', //アクセスキー secretAccessKey: '', //シークレットアクセスキー region: '' //リージョン }) const params = { Bucket: "", //バケット名 Key: "", //キー }; const s3Promise = s3.getObject(params).promise(); s3Promise.then(function(data) { console.log('data:image/jpg;base64' + data.Body.toString('base64')) }).catch(function(err) { console.log(err); });
- 投稿日:2020-07-05T17:22:21+09:00
SSM Session Manager で ログ取得ができない時に確認すること
はじめに
AWS Systems Manager のSession Managerを利用してLinuxの操作ログを取得しようと思います。
うまくログが取れない場合に確認するべき点をメモしておきます。利用サービス
以下のサービスを利用します
- AWS Systems Manager(以下SSMと表記)
- Session Manager(以下セッションマネージャーと表記)
- EC2(Linux)
- Windowsは検証していませんが、セッションマネージャーから利用できるPowerShellの結果も同様になることが想定されます
- S3
- ログの保存先に利用します # 本題 ログを保存するにはEC2側でS3にログを書き込むための権限が必要です。
EC2に割り当てる権限
EC2には以下の権限を持つIAMロールを割り当てます
- セッションマネージャーを利用するための権限
- AmazonSSMManagedInstanceCore(AWS 管理ポリシー)
- 権限過剰ですがEC2の管理に必須の権限と認識しているのでこちらを設定しています(権限を限定したい場合)
- 独自で作成した以下のポリシー
- json形式で記述します(今回は put-Session-Manager-log-to-S3.json という名前を使用します)
- <S3バケット名> の部分をログ保存先のバケットに書き換えて使用します
put-Session-Manager-log-to-S3.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": [ "arn:aws:s3:::<S3バケット名>/*", "arn:aws:s3:::<S3バケット名>" ] } ] }今回の内容とは異なるがAWSのドキュメントを参考にすれば解決できそうなケース
以下のケースの場合は参考のリンク先をご確認下さい。
- 「AmazonSSMManagedInstanceCore」ではなくセッションマネージャーだけの権限に限定したい場合
- S3を暗号化している場合
- S3ではなくCloudWatch Logsにログを保存する場合
参考
Session Manager 用のカスタム IAM インスタンスプロファイルを作成する
Session Manager と Amazon S3 および CloudWatch Logs のアクセス許可を持つインスタンスプロファイルを作成する (上記ページ内の関連部分)
- 投稿日:2020-07-05T17:16:17+09:00
EC2にデプロイするも、エラーログに何も表示されない時の可能性
環境
Ruby 2.5.1
Rails 5.2.4.3こちらの記事を参考にAWSにデプロイする過程を終えたのですが、ブラウザからアクセスすると「このサイトに接続できません」となり失敗してしまう…
(注)参考にさせて頂いた記事は大変分かりやすく、記事のせいではありません。
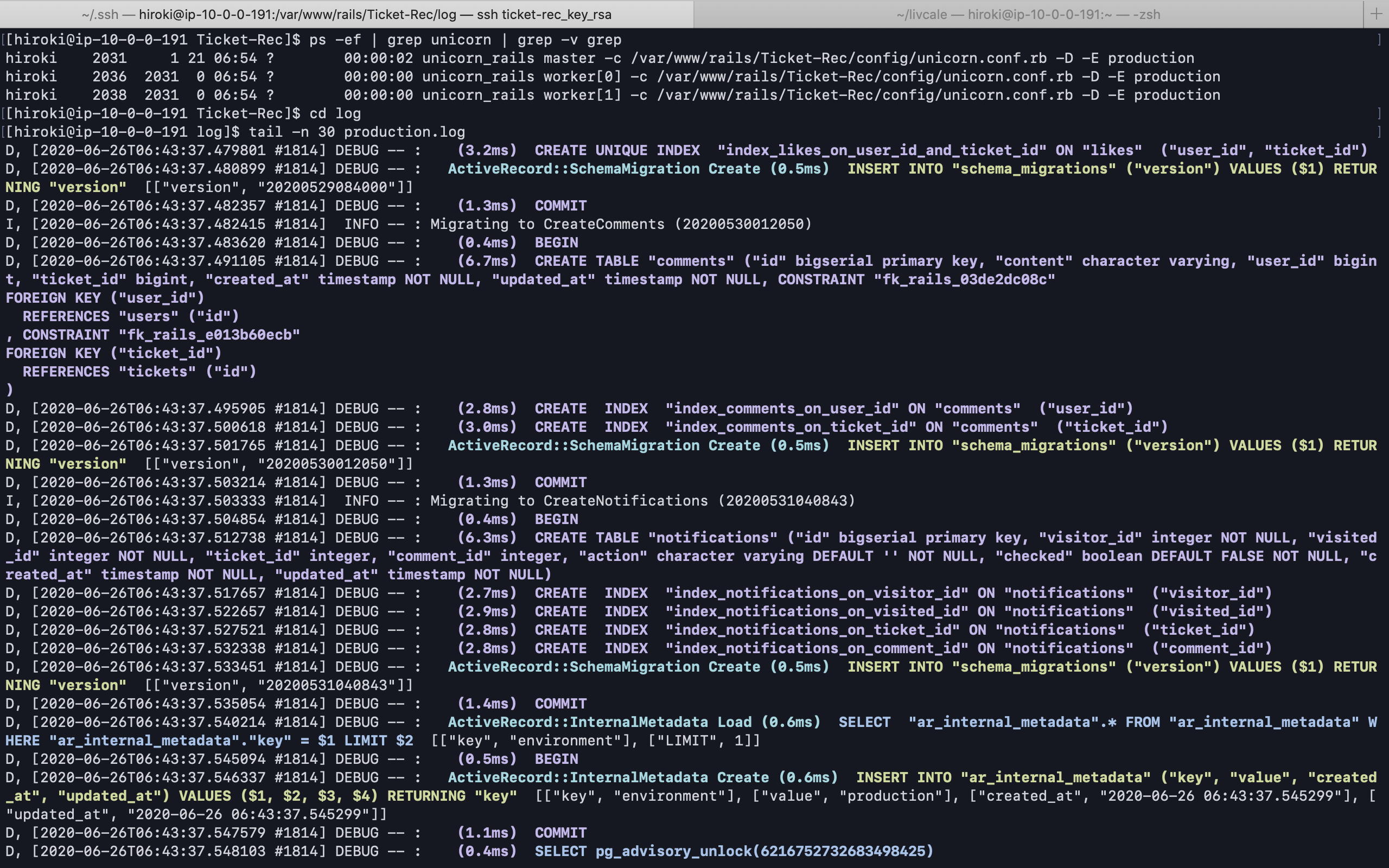
何がダメなのか、記事を参考にログを確認してみます。
サーバー環境(/var/www/rails/アプリ名/)cd log tail -n 30 production.log
何故かログを見てもエラーのようなものが見当たりません。
最初は意味不明でしたが、しばらく悩んだ結果ブラウザからアクセスができてないかもしれないと考えました。そこでcurlを使って直接httpにアクセスしてみます。
$ curl -IXGET http://IPアドレス/ HTTP/1.1 301 Moved Permanently Server: nginx/1.12.2 Date: Sat, 27 Jun 2020 05:09:57 GMT Content-Type: text/html Transfer-Encoding: chunked Connection: keep-alive Location: https://IPアドレス/301が返ってきています。
どうやら、httpへのアクセスがhttpsに勝手にリダイレクトされてしまってるようです。試しにあえてcurlでhttpsにアクセスしてみました。$ curl -IXGET https://IPアドレス/ curl: (7) Failed to connect to IPアドレス port 443: Connection refused433のportが空いてないと怒られました。
確かにセキュリティグループで433の設定はしていないので当然ですね。ということでセキュリティグループのインバウンドルールに433を追加して、ブラウザからhttpでアクセスしてみるとhttpsでページが開きました!(感動)
ただ、今はhttpsではなくてhttpで開くのが本来の目標です…
結果
httpからhttpsにリダイレクトされていた原因は/config/environments/production.rbにある以下の記述でした。
/config/environments/production.rbconfig.force_ssl = trueこちら以前herokuデプロイでssl化した時に記述したものだと思われます…
これがあるとssl化のためにhttpsにリダイレクトするようです。ということでローカルで直してもいいのですがpushしたりcloneしたりするのが面倒なのでとりあえずサーバー内の記述を書き換え、確認だけしてみます。
$ cd /var/www/rails/Ticket-Rec/config/environments/ $ vi production.rb以下のように変更
/config/environments/production.rbconfig.force_ssl = falseunicornを再起動
$ ps -ef | grep unicorn | grep -v grep hiroki 2031 1 0 6月26 ? 00:00:02 unicorn_rails master -c /var/www/rails/Ticket-Rec/config/unicorn.conf.rb -D -E production hiroki 2036 2031 0 6月26 ? 00:00:00 unicorn_rails worker[0] -c /var/www/rails/Ticket-Rec/config/unicorn.conf.rb -D -E production hiroki 2038 2031 0 6月26 ? 00:00:00 unicorn_rails worker[1] -c /var/www/rails/Ticket-Rec/config/unicorn.conf.rb -D -E production $ kill 2031 $ bundle exec unicorn_rails -c /var/www/rails/Ticket-Rec/config/unicorn.conf.rb -D -E productionnginxを再起動
$ sudo service nginx restart再度curlでhttpにアクセスしてみると200が返ってきました!
$ curl -IXGET http://IPアドレス/ HTTP/1.1 200 OK Server: nginx/1.12.2 Date: Sat, 27 Jun 2020 05:27:46 GMT Content-Type: text/html; charset=utf-8 Transfer-Encoding: chunked Connection: keep-alive X-Frame-Options: SAMEORIGIN X-XSS-Protection: 1; mode=block X-Content-Type-Options: nosniff X-Download-Options: noopen X-Permitted-Cross-Domain-Policies: none Referrer-Policy: strict-origin-when-cross-origin ETag: W/"03411acbf679047381b99fd0eda2307c" Cache-Control: max-age=0, private, must-revalidate Set-Cookie: _myapp_session=%2Fj%2FMy4fzeeSRY3imIh%2FCkJg94SzoshjfdaYZhZcEzF4i%2BxXXUZiYY8M%2Flre%2F6TAAvXqfyrr5sJ8ke2aOlhh4o8i6xsMfO7Ubp7LvUQnAxB9gm%2FbQ8Gc%2BLPzZAxcL9OgDLvQaocLN1MTSz6XKaDM%3D--1h9%2FJNHiHiktaWNU--CJuK9RUucx3dkTVkQpjYLg%3D%3D; path=/; HttpOnly X-Request-Id: 9d2ee01e-fa05-40ae-8959-6e9b40f9b3e1 X-Runtime: 0.005877実際にブラウザで開いてみる
ブラウザhttp://IPアドレス/無事アプリにアクセスできました!
めでたしめでたし!と言っても、もしこの後ssl化する時は結局
/config/environments/production.rbconfig.force_ssl = trueに設定すると思われます笑
ただ、繋がらない原因が分かりました。
参考
【画像付きで丁寧に解説】AWS(EC2)にRailsアプリをイチから上げる方法【その1〜ネットワーク,RDS環境設定編〜】
- 投稿日:2020-07-05T17:10:30+09:00
AWS Directory Service について
AWS Directory Service について
今回はAWSがフルマネージドで提供するActiveDirectory(以下AD)について、まとめます。
ユーザの操作制御、データへのアクセス制御などの他にAWSサービスでもAD連携必須というものもあるので、AWSでシステム構築する上で避けては通れないジャンルだと思われます。
私自身AD構築を進める際に色々と調べましたが「初心者向けの情報って全然ないじゃん!」(設定方法をPowershellのコマンドレットで書くんじゃない!)ってどこに向けたらいいか分からない怒りを覚えた記憶があります(笑)。AWS Directory Service とは
AWS公式ページ
公式には以下のように説明されております。AWS Directory Service は、既存の Microsoft AD やライトウェイトディレクトリアクセスプロトコル (LDAP) –対応のアプリケーションをクラウド上で使用するユーザー向けに複数のディレクトリオプションを提供します。また、開発者がディレクトリを通じてユーザー、グループ、デバイス、およびアクセスを管理する場合にも、同じオプションを提供します。
AWS フルマネージドでADを作るとなると「Simple AD」もしくは「AWS Managed Micorosoft AD」(以下MS AD)のどちらかになります。
※EC2にAD機能を持たせるという構成でもAD環境構築は出来ますAWS Directory Serviceの他メニューには「AD Connect」や「AWS Cognito」がありますが若干毛色のちがうサービスになるので、この記事では触れません。以降は主にSimple ADとMS ADについての説明となります。
構成イメージ
Directory ServiceをデプロイするVPCを選択し、さらに2つ以上のAZを選択する形となる。
AWS Directory Serviceの特長および利用メリット
- デフォルトで冗長化設定がされている。
- サーバOSのファームウェアverUpやセキュリティパッチ適用などのメンテナンスをユーザ側で行う必要がない。
- オンプレADとほぼ同じくグループポリシーでユーザ制御やクライアントPCへセキュリティ設定の一斉配布/適用が可能になる。
利用上の留意点
- ADにドメインユーザを作成、グループポリシーの設定、オブジェクトの登録状況確認等をするためには別途Windowsインスタンス(もしくはAD DS機能を持ったサーバ)が必要。
※AWS Directory Service はマネージドサービスのため、ユーザが直接サーバコンソール画面にはアクセスできません。そのため、EC2などユーザがサーバコンソールにアクセスできるリソースから中身の設定を追加してやる必要があります。
- オンプレADのセカンダリ(正確な表現ではないですが)としては利用できない。
※課金がドメインコントローラーの数によって変動するため
※オンプレからのAD移行などので、セカンダリとして構築したい場合はEC2でADを構築しましょう
- 必ずマルチAZでの運用になる(シングルAZでは構成不可)
Simple ADと MS ADの比較
◆Simple AD・・・小規模環境向け簡易AD(単純なAD環境であればこれで問題ない)
・Active Directory管理センター機能や一部のAWSサービスで連携できないなどの機能制限がある。
対応不可AWSサービス:Amazon AppStream 2.0 / AWS FSx for Windows / Amazon chime など
・登録できるオブジェクト数(ユーザ、グループ、コンピュータ)制限がある。◆AWS Managed Microsoft AD・・・一般的なAD(機能的にはWindows Server のものとほぼ同じ)
・Simple ADが対応不可のAWSサービスでも連携できる。
・登録できるオブジェクト数(ユーザ、グループ、コンピュータ)がSimple ADよりも多い。
・Domain Controllers にはAWSで特定のGPOがアタッチ済みで変更できない。
・AWSの作成したユーザ、グループがあり、削除できないなどの制限もある。
(ユーザ名Administrator はAWSで利用制限されており、ユーザが利用できるのはAdmin)MS ADの「ユーザとコンピュータ」、「グループポリシーの管理」はこんな感じです。
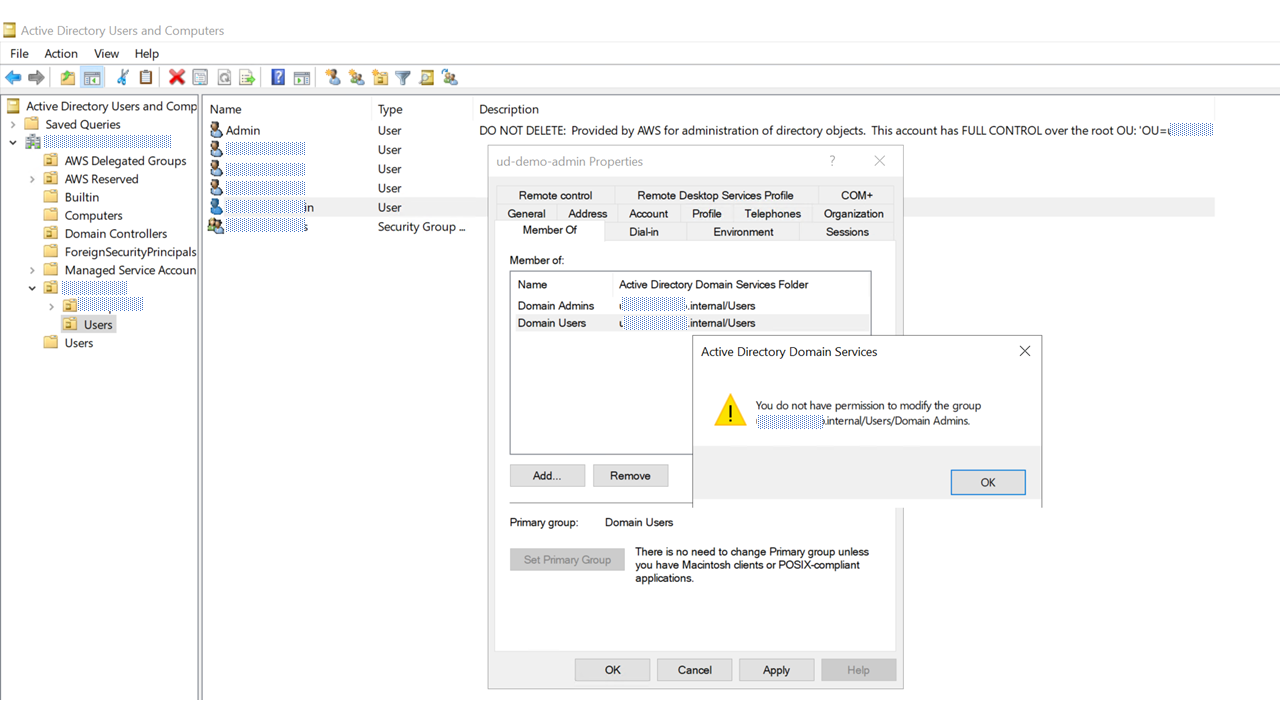
FSxを構築しているのでFsx関係のオブジェクトが出来ています。他サービスもディレクト連携すると自動で追加されるようです。
ちなみにWorkDocus を連携させるとユーザに[GorillaBoyAdministrator]というユーザグループオブジェクトが追加されます。※WorkDocusの管理者権限を持つセキュリティグループのようです。MS ADではユーザ名[Admin]をグループ[Domain Admins]に追加しようとしてもエラーになります。
※他ユーザも同様
管理者権限をユーザに付与したい場合は対象ユーザをグループ[AWS Delegeted administrator]に参加させるようにしてください。
構築手順
Simple ADもMS ADも大体構築手順は同じです。
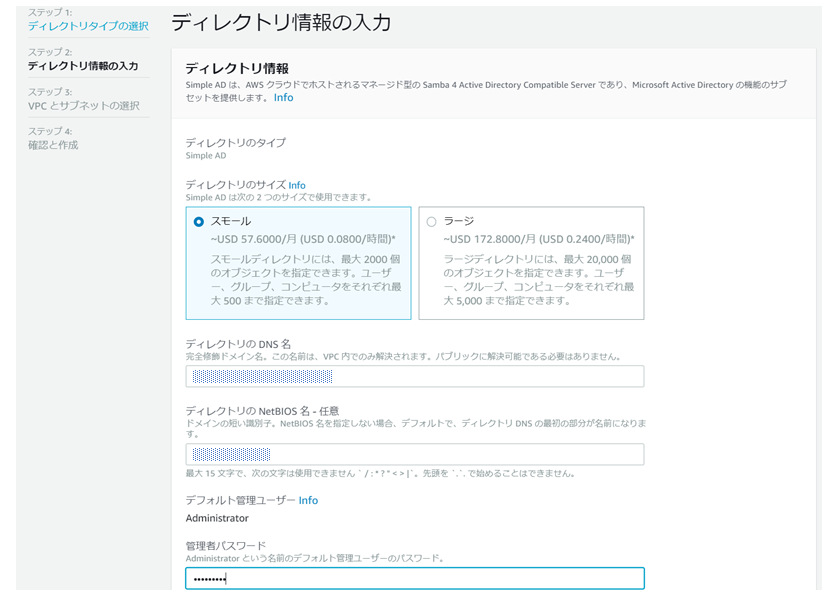
今回はSimple ADを構築するパターンで手順を紹介します。
利用規模に応じて、スモールとラージを選択します。
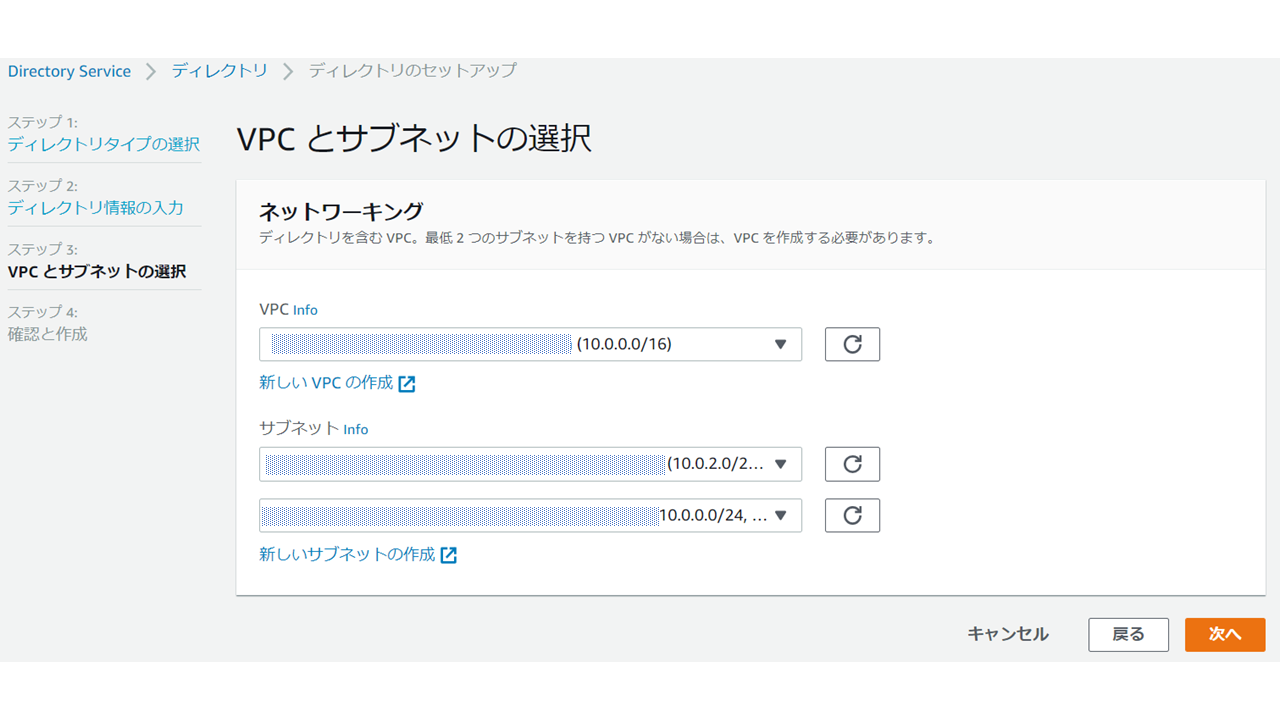
次にデプロイするVPCとサブネットを選択します。
Directory Serviceを作成をすると上記のように設定情報が確認できます。
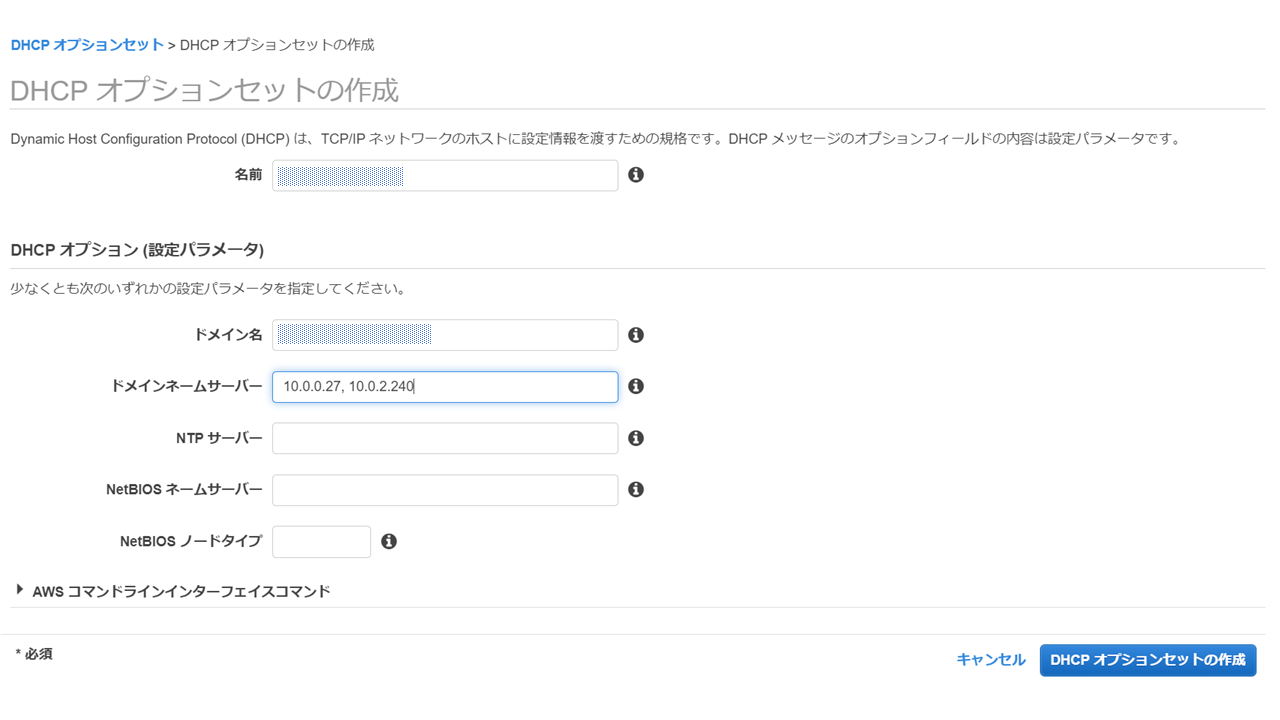
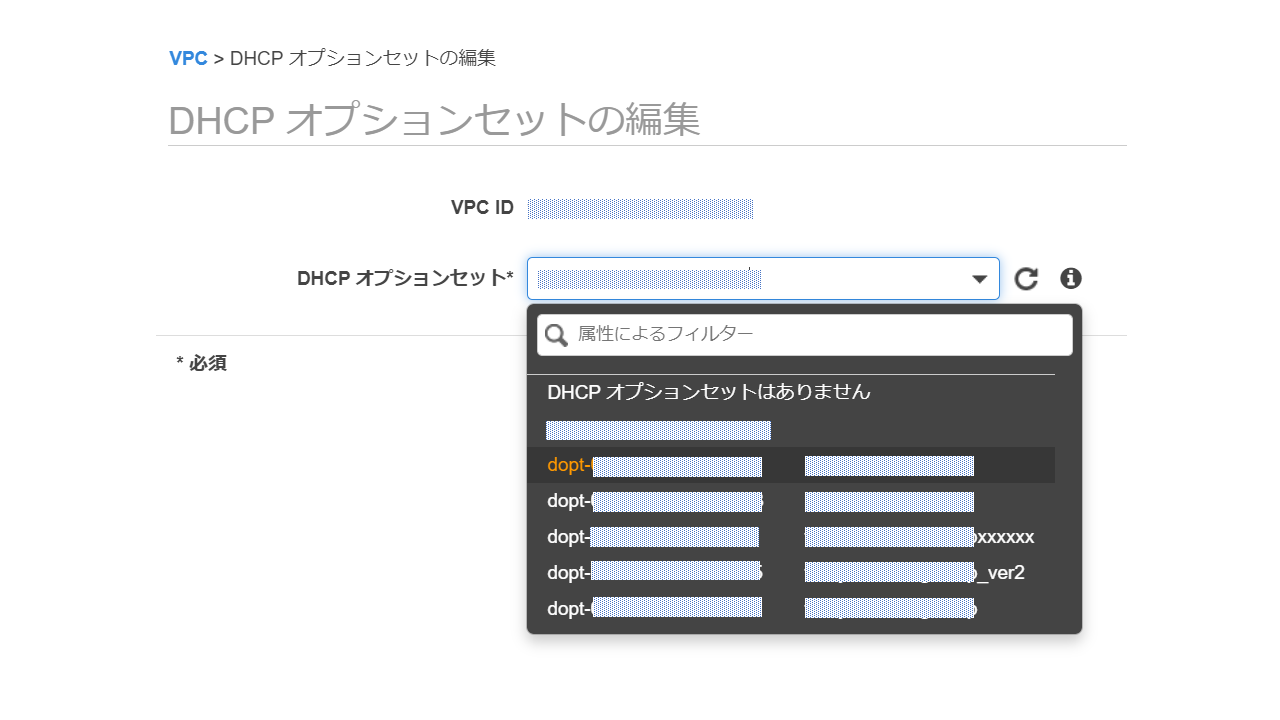
次にVPCのDHCPのオプションセットを作成し、VPC内のDNSがSimple ADに向くように設定します。
DNS情報はSimple ADのディレクト情報で確認できます。
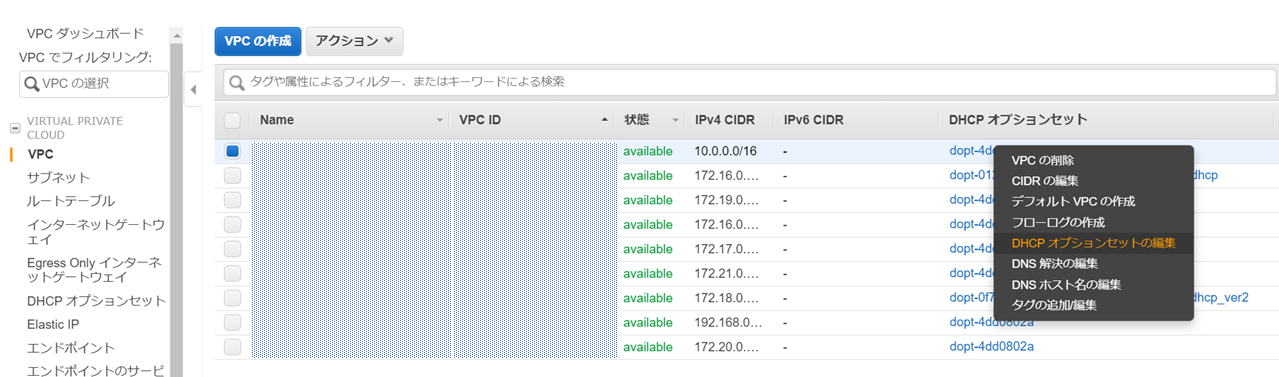
続いて、Simple ADをデプロイしたVPCに先ほど作成したDHCPオプションセットを適用していきます。
AWSサービスをDirectory連携されるときにVPCにDHCPオプションを適用していないと、Directoryを認識できず、連携が失敗します。
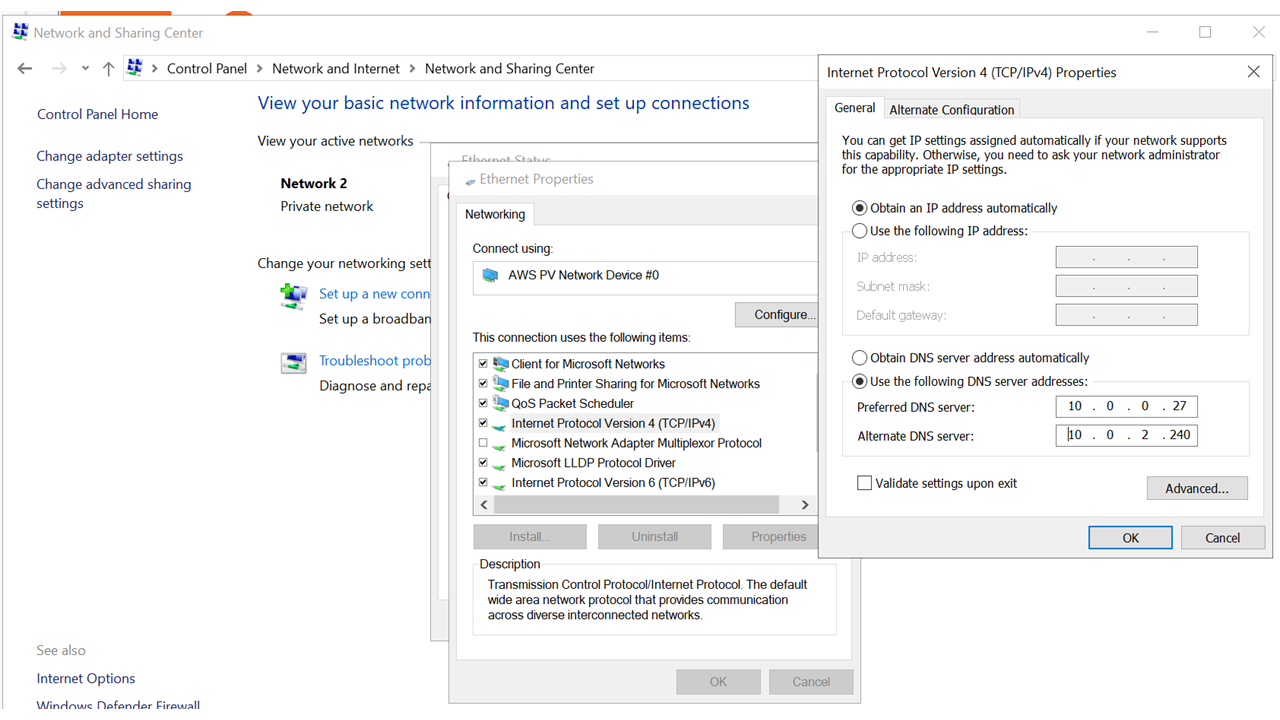
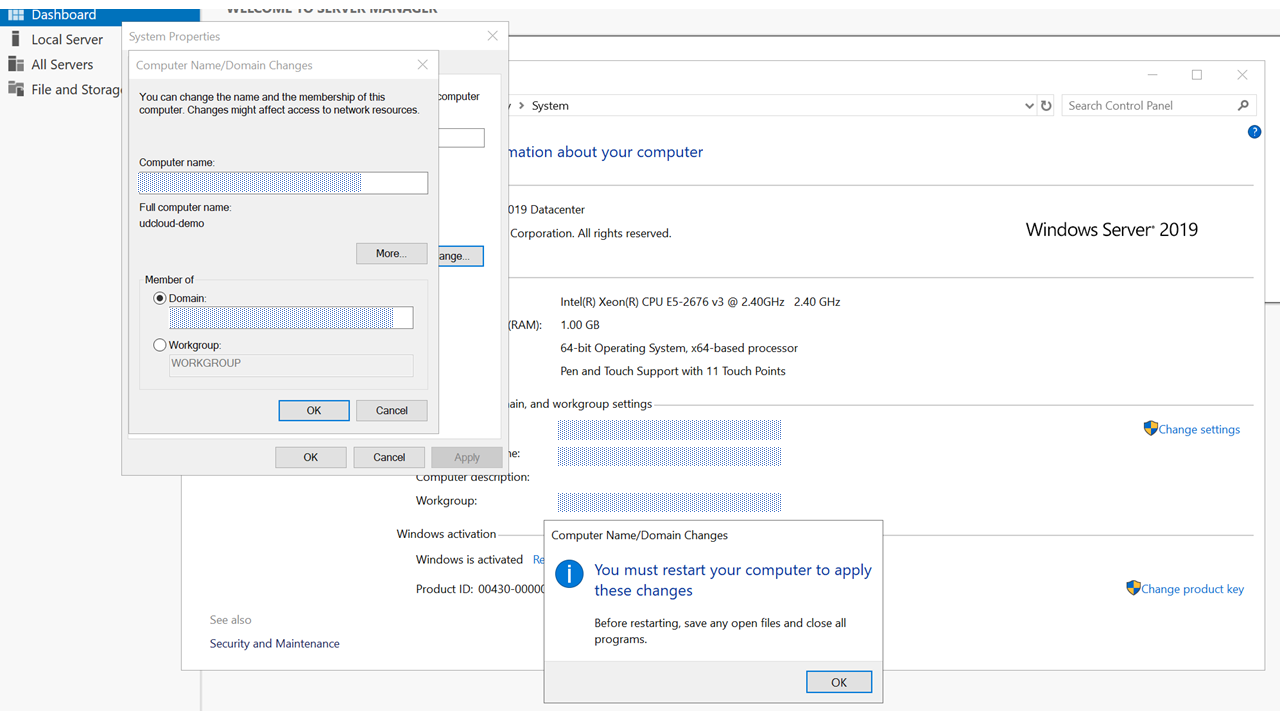
インスタンス側でドメイン参加するにはRDPでインスタンスに接続し、上記のようにNetwork Interface のDNSをSimple ADのアドレスへ変更して、コントロールパネルの[システム]からドメインを変更してください。これでSimple ADの構築およびインスタンスのドメイン参加が完了しました!
料金体系
AWS公式
注意してほしいのは、料金表の価格はドメインコントローラ単位の費用になるということです。
Simple ADでもMS ADでもドメインコントローラは最低2つ必要ですが、何個分必要なのかを意識して試算してください。最後に
AD自体かなり奥が深く、私自身使いこなせるようになるまでには時間がかかると思います。その道のプロからするとおかしな表現も多々あると思いますので、間違いあればご指摘頂ければと思います。



- 投稿日:2020-07-05T16:26:05+09:00
AWS LambdaからRDSへの接続はアンチパターン?Lambdaのコールドスタートとは?対策とは?
VPC LambdaからRDSの呼び出しはアンチパターンだったらしい
Lambdaを起動すると、VPCLambdaで起動する。
VPCLambdaは以下の点で、アンチパターンと言われていた
- 特定の状態において、遅延が発生(ENI作成に伴うコールドスタート)
- Lambdaの同時実行によりVPC内のプライベートIPを消費するため、アドレス管理が必要。
- RDSの最大同時接続数以上に、Lambdaが起動した場合は、接続エラー。だが最近
Hyperplane ENI
RDS Proxy
のアップデートがあり、解消されつつある。Lambdaコールドスタートとは?
Lambdaには、コールドスタートという概念が存在する。
コールドスタートとは、Lambdaの初回実行次に内部的に以下の処理が行われること(=コード実行までに、時間がかかる現象)
- ENIの作成(VPC Lambdaの場合のみ)
- コンテナの作成
- デプロイパッケージのロード
- デプロイパッケージの展開
- ランタイム起動・初期化
Lambdaコールドスタート回避策
- CloudWatch EventsからLambdaを定期実行する(同一Lambda関数の実行コンテナは一定時間再利用される性質を使って)
- Provisioned Concurrency
参考資料
- 投稿日:2020-07-05T15:40:09+09:00
AWS上でPHP7.4が動くEC2を作った
概要
AWS上でPHP7.1が動いているEC2を保有しています。
先日、PHP7.1のサポートがとっくに切れていることを知りまして、バージョンを上げなきゃなと思った次第です。
https://www.php.net/supported-versions.php現在の管理
AWSはterraformで管理されていて、EC2内部はansibleで管理しています。
main.yml- name: Install PHP yum: name={{ item }} state=present enablerepo=epel with_items: - php71 - php71-fpm - php71-mysqlnd - php71-mbstring - php71-gd - php71-bcmath - php71-devel当初の発想
適当にphp71のところをphp74にすれば行けるかなと思ったのですが、そもそもepelにはPHP7.3までしか用意がないようでした。
$ yum list | grep php73.x86_64 php73.x86_64 7.3.17-1.25.amzn1 amzn-updates $ yum list | grep php74.x86_64 $PHP7.3でもいいかなとも思ったんですが、PHP7.3も結局今年中にはActive Supportが切れるようなのでPHP7.4にこだわることにしました。
PHP7.4にする方法を考えた
ぐぐると、remiリポジトリを使う方法が結構出てくるのですが、AmazonはExtra Libraryを使う方法を公式で用意しているみたいです。
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/amazon-linux-ami-basics.html#extras-libraryremiリポジトリにはよくお世話になっていますが、remiリポジトリはRemi Colletさんが管理しているやつなので、今回はAmazon公式で採用している方法を取ることにします。
https://twitter.com/RemiCollet
(remiリポジトリには本当にお世話になっています。ありがとうございます。本人に届くことは無いと思いますが)amazon-linux-extrasを使えるようにする
では早速、公式ドキュメントどおりに
amazon-linux-extras listを打って一覧を確認することにします。$ amazon-linux-extras list -bash: amazon-linux-extras: コマンドが見つかりませんなるほど。
ドキュメントに
(Amazon Linux 2)と書いてあるということは、Amazon Linux 2でしか使えないコマンドであるということですね。(某環境大臣風)$ uname -a Linux ip-10-0-1-144 4.14.171-105.231.amzn1.x86_64 #1 SMP Thu Feb 27 23:49:15 UTC 2020 x86_64 x86_64 x86_64 GNU/Linuxamzn1ってなってますね…
amiを管理しているterraformを書き換えます。
これを
aws_ami.tfdata "aws_ami" "amazon_linux" { ... filter { name = "name" values = ["amzn-ami-hvm-*"] } ... }こんな感じ
aws_ami.tfdata "aws_ami" "amazon_linux" { ... filter { name = "name" values = ["amzn2-ami-hvm-*"] } ... }terraform planを打つと、
forces new resourceと出て、EC2は作り直しになるようでした。
もしかすると私の環境だけかもしれないですが…
EC2なんてansibleとデプロイツールがあれば怖くないということで、バンバン作り直していくことにしました。(なおこの後本番環境に直で置いていた設定ファイルを保存していなかったことで大変後悔することになりますが、それは別の機会で…)作り直した結果、amazon-linux-extrasコマンドが使えるようになりました。
$ amazon-linux-extras list | grep php7.4 42 php7.4=latest enabled [ =stable ]というわけで、ansibleも書き換えていきます。
main.yml- name: Enable PHP7.4 shell: "amazon-linux-extras enable php7.4" changed_when: False - name: Install PHP yum: name={{ item }} state=present enablerepo=amzn2extra-php7.4 with_items: - php - php-fpm - php-mysqlnd - php-mbstring - php-gd - php-bcmath - php-develこんなwarningも出ちゃいましたが、調べたらとりあえず問題はなさそうだったので、先に進みます。次回の記事で解消します。
[DEPRECATION WARNING]: Invoking "yum" only once while using a loop via squash_actions is deprecated. Instead of using a loop to supply multiple items and specifying `name: "{{ item }}"`, please use `name: ['php', 'php-fpm', 'php-mysqlnd', 'php-mbstring', 'php-gd', 'php-bcmath', 'php-devel']` and remove the loop. This feature will be removed in version 2.11. Deprecation warnings can be disabled by setting deprecation_warnings=False in ansible.cfg.PHP7.4になった
こうして無事にPHP7.4になりました。
[ec2-user@ip-172-31-57-63 ~]$ php -v PHP 7.4.5 (cli) (built: Apr 23 2020 00:10:21) ( NTS ) Copyright (c) The PHP Group Zend Engine v3.4.0, Copyright (c) Zend Technologies今後
ここ数年、家庭の事情等であんまりアウトプットする機会もなかったんですが、今後は定期的に学んだことをアウトプットしていきます。
- 投稿日:2020-07-05T15:24:25+09:00
AzureのAWSとの違い(リージョン,NW編)
はじめに
AWSエンジニアですが、諸事情によりAzureも勉強しています。
細かい所を見ると結構違って、理解するのに苦労したのでまとめてみました。私もまだ知識が浅いので、間違いや分りづらい点、また書いて欲しい点などありましたらコメント等頂けると幸いです。
前提知識
リージョンペア
AWSと違い、ペアとして定義されているリージョンが存在します。
ビジネス継続性とディザスター リカバリー (BCDR):Azure のペアになっているリージョン日本の場合、東日本(東京、埼玉)/西日本(大阪)リージョンがペアです。
以下のような利点があります。
- 広域障害時、リージョンの障害復旧はペアの一方を優先するポリシーになっている。
- サービス次第だが、ペアリージョンを利用した冗長機能が備わっている。
注意点もあり、
ペアリージョンの冗長機能を使うと、フェールオーバーさせた時に初めて他方のリージョンで普通に使えるようになります(それまではReadOnlyだったり、読めもしなかったり)。特に読めもしない機能の場合は、災対リージョンで簡単なテストを行う事すらできず、システムが稼働停止した状態でテストする事になるでしょう。
Availability Zones
AzureにもマルチAZ相当の機能があります。(西日本リージョンは対応してないので注意1)
※なお、AWSの場合はAZと呼ぶ事が多いと思いますが、Azureの日本語ドキュメントでは「可用性ゾーン」と記載されています。AWSの場合、サブネットをAZに作成しますが、Azureの場合そのような指定はしません(リージョンにサブネットを作成します)。
※ちなみにGCPも同様です。 >サブネットはリージョン リソースです。サブネットをAZに作成しないという事はマルチAZ構成にする際、サブネット指定によりAZを指定するという方法にはなりません。
どのような使い方をするかはサービスの実装によって異なります。
- Azure VM では、可用性オプションで有効にした上で、ゾーンを選択します。
- SQL Database では、可用性オプションで有効にするのみです。
また、サービスの実装によって異なるので、一見使えそうでも使えないという事もあるので注意が必要です。
例えば、Azure VMは対応してますが、Azure Batchは対応していません。1
※AWS BatchはECS on EC2上で動作する。EC2はマルチAZにできる。すなわちAWS BatchもマルチAZが可能という可用性ゾーンは後からできた機能のようで、発展途上といった所でしょうか。
可用性セット
西日本リージョンは可用性ゾーンに対応していないと記載しましたが、可用性セットという冗長機能は使用できます。
AWSには存在しない概念ですが、DC内での冗長機能2で、更新ドメイン(メンテンスのグループ)と障害ドメイン(基盤のグループ)を分散させる事ができます。Azure VM専用の機能という認識です。
NSG
AWSではサブネットのアクセス制御はネットワークACLを、インターフェースのアクセス制御はSGを使用しますが、AzureではどちらもNSG(Network Security Group)を使用します。
NSGはサブネットにアタッチすることも、インターフェースにアタッチすることもできます。拒否設定もできて、優先度を設定する必要があるので、設定の仕方はACLの方に近いです。
ただ、ステートフルなので戻りのパケットを設定する必要はありません。なお、AWSではSG同士で接続許可ができますが、NSGではIPアドレス指定になってしまいます。
Application Security Groupという拡張機能を合わせて使うことで、グループ毎にアクセス制御が可能です。データベースがグローバルNWに存在する
AzureのマネージドDBサービスはサブネット内にインスタンスが作られるのではなく、グローバルNW上に作られます。(S3のような感じ)
プライベートに制限したい場合は後述のエンドポイントを作成した上で、各DBサービスのファイアウォール機能でパブリックアクセスをブロックします。サービスエンドポイントとプライベートエンドポイント
AWSでグローバルNWを経由せずに各サービスに接続したい場合、VPCエンドポイントを作成しますが、Azureにも同様の機能があります。
サービスエンドポイントとプライベートエンドポイントです。AWSと比較すると、サービスエンドポイントはゲートウェイエンドポイントに、プライベートエンドポイントはインターフェイスエンドポイントに少し近いですが、色々な差異があります。
まずそもそも、サービスエンドポイント、プライベートエンドポイントどちらを使うか選ぶ事ができます。(AWSではサービスで固定)両者を比較すると
サービスエンドポイント
- Vnetとサービスを接続します。
- それ以外の制御は基本的にできません。
- Azure Storageのみ1サービスエンドポイントポリシーで対象リソースの制御が可能です。
- オンプレから直接接続できません。(AWSのゲートウェイエンドポイント同様プロキシサーバーが必要です)
※オンプレからはパブリックで繋ぐというのは可能です。- ゲートウェイエンドポイントと同様、無料です。
プライベートエンドポイント
- リソースに対して作成します。(AWSのインターフェースエンドポイントはサービスに対して作成します)
- NW的に到達可能な範囲全てから接続可能になります。
- オンプレからも直接接続できます。(名前解決は別途必要です)
- エンドポイント側でアクセス制御はできません。(AWSの場合はSGで制御が可能)
- 接続元リソースの送信トラフィックで、インターフェースエンドポイントのIPに対する制御を行う形式になります。
- Application Security Groupに対応してないのでIP指定です。。
- インターフェースエンドポイントと同様、時間とトラフィックに料金が掛かります。
- AWSの場合内部DNSに登録されて見えませんが、Azureの場合プライベートDNSゾーン(Route53のプライベートホストゾーン相当)に登録されますし、レコードを確認できます。
- プライベートDNSゾーンの設定に不備があると接続できないという事になります。
細かな制御は必要ない、料金を掛けたくない場合はサービスエンドポイントを
細かな制御が必要だったり、オンプレから接続したい場合にプライベートエンドポイントを使うというのが選べるのは利点ですね。でもサービスエンドポイントポリシーがストレージのみってのは微妙。
また、インターフェースエンドポイント側は全開放になるのもどうなんでしょうね…
もし組織が分かれていたりしたら、相手を信用するか別の牽制が必須になるかの0か100かみたいな。
(使わない場合、パブリックアクセスになるとはいえサービス側のファイアウォールでIP単位の制御が可能だし)セキュアに使うためのサービスなのに何でガバいの?という気がしてしまいます。。
- 投稿日:2020-07-05T15:13:30+09:00
Golangはじめて物語(APIGateway+Lambdaといっしょ編)
はじめに
Lambda関数を色々触っていると、Javaの限界を感じることが多い(別にJavaをdisるわけではなく、Lambdaとの親和性と言う意味ではイマイチだと主張したい)。
手軽さで言えばPythonは間違いなく最強の一角だと言えるが、importが増えると結局処理が重くなるという話があり、Golangを勧められる機会が増えてきたので、ここらで一丁、覚えてみようと思った。
統合開発環境は何が良いか?
色々と試してみたわけではないが、Eclipseは重いし、Golang拡張はJDKのバージョン縛りがあって面倒だったので、VSCode+Remote Development Extension Pack+EC2にしてみたら非常に快適だった。ローカル環境がWindowsで動かせるモノの制約が面倒だというのもあるので、この構成はオススメ。
Go言語だけ触るなら別に何の環境でも良いのだけど、SAMなりServerless Frameworkなりcurlなりを並行で触ることを考えると、EC2を直接触れるというのは生産性に大きく貢献してくれる。Remote Development Extention Packの導入については、以下の記事が分かりやすかった。
【Qiita】Visual Studio Code Remote Developmentのメモ
VSCodeの日本語対応については以下。
【Qiita】Visual Studio Codeで日本語化する方法[Windows]
どちらもすごい簡単な上にサクッと導入できるのが良い感じだった。VSCodeのインストールからで1時間くらいで済む。
Go言語ランタイムのインストール
デフォルトのEC2にはGo言語のランタイムが入っていないのでインストールする。
$ sudo yum install golangでOK。めちゃくちゃ楽ちん。
export GOPATH=適当なパスをしておくのを忘れないように。
もろもろのモジュール等が散らかってしまう。バージョン1.13以降はGo Modulesが標準搭載されてビルドも楽にできるようになっているぞ!
全体構成
以下のようになる。アプリケーションの仕様は以下の通り。
- id, name を属性に持ったDynamoDBにアクセスするLambda関数を準備する
- DynamoDBはTerraformで準備する
- Lambda関数にはAPI Gateway経由でアクセスする
- Lambda関数、API GatewayのデプロイはSAMを使う(面倒なので、2つのLambdaを1つのAPI Gatewayに統合するのは割愛する)
- DynamoDBへのアクセスは、putUserで書き込みを行い、getUserで参照を行う
- DynamoDBへのアクセスはdynamodbモジュールを介し、putUser, getUser は dynamodb モジュールを呼び出す
. ├── common │ ├── modules │ │ └── dynamodb │ │ ├── dynamodb.go │ │ └── go.mod │ └── terraform │ └── main.tf ├── getUser │ ├── go.mod │ ├── main.go │ ├── main_test.go │ ├── Makefile │ └── template.yml └── putUser ├── go.mod ├── main.go ├── Makefile └── template.yml参考にしたのはGoとSAMで学ぶAWS Lambdaだが、2018年の書籍で2年間の間にGo言語のバージョンが上がってモジュール管理のデファクトがdepからGo Modulesになったりしているので、その辺は吸収する。
事前準備
以下のようにTerraformを書いて、上記仕様の通りのDynamoDBを用意する。
本来はちゃんとリソース分割とかをするが、今回はここが本筋ではないのでテキトーなのはご容赦いただきたい。S3バケットはSAMテンプレートの置き場所なので、これも今回の本筋ではない。
※SAMとTerraformの親和性が悪くて色々残念な感じではあるが、致し方なし……main.tfresource "aws_s3_bucket" "cfn_stack_get" { bucket = "goapigwtest-cfn-stack-get" acl = "private" } resource "aws_s3_bucket" "cfn_stack_put" { bucket = "goapigwtest-cfn-stack-put" acl = "private" } resource "aws_dynamodb_table" "users" { name = "users-table" billing_mode = "PROVISIONED" read_capacity = 1 write_capacity = 1 hash_key = "id" attribute { name = "id" type = "S" } }Go言語のAPI Gatewayの実装。
ご存じの通り、API Gatewayのプロキシ統合におけるリクエストの内容にはクセがあるので、公式のドキュメントを確認しながら作ろう。
※自力で統合リクエストをパースするのは死ねるからやめよう。typeされたAPIGatewayProxyRequesのメンバにアクセスし、APIGatewayProxyResponseのメンバに情報を詰めていくことになる。
putUser/main.gopackage main import ( "context" "log" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-lambda-go/lambdacontext" "local.packages/dynamodb" ) var () const () func init() { } func main() { lambda.Start(handler) } func handler(ctx context.Context, request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { var ( statusCode int id string idIsNotNull bool name string nameIsNotNull bool ) if lc, ok := lambdacontext.FromContext(ctx); ok { log.Printf("AwsRequestID: %s", lc.AwsRequestID) } statusCode = 200 if len(request.QueryStringParameters) == 0 { log.Println("QueryStringParameters is not specified") statusCode = 400 } else { if id, idIsNotNull = request.QueryStringParameters["id"]; !idIsNotNull { log.Println("[QueryStringParameters]id is not specified") statusCode = 400 } if name, nameIsNotNull = request.QueryStringParameters["name"]; !nameIsNotNull { log.Println("[QueryStringParameters]name is not specified") statusCode = 400 } } if statusCode == 200 { err := dynamodb.PutUser(id, name) if err != nil { statusCode = 500 } } response := events.APIGatewayProxyResponse{ StatusCode: statusCode, IsBase64Encoded: false, } return response, nil }最初の方に書いた以下の部分は定数とグローバル変数の定義。
書かなくても良いが、明示的に無いことを示すために書いてみた。こういうのも、モダンプログラミングでは無駄なものとして極力書かないようにするものなのだろうか。var () const ()QueryStringParameters には普通に構造体メンバのようにアクセスできる。
map型なので、キー名から値を取得することも可能だし、map型はlenで要素数を取れる。
C言語っぽくありながら、JavaやPythonのいいとこ取りをしてる感があって好感。if len(request.QueryStringParameters) == 0 { log.Println("QueryStringParameters is not specified") statusCode = 400 } else { if id, idIsNotNull = request.QueryStringParameters["id"]; !idIsNotNull {なお、C言語で言うforの初期化ステートメントのようなことを、if文でもできるようになっている。
最初のステートメントでrequest.QueryStringParameters["id"]の値と中身の有無を取り、その直後に判定するといった感じだ。応答は、以下のように APIGatewayProxyResponse の値を詰めて返してあげれば良い。
response := events.APIGatewayProxyResponse{ StatusCode: statusCode, IsBase64Encoded: false, } return response, nilポイントは、return で2つの値を返していること。
この場合、関数宣言はfunc handler(ctx context.Context, request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error)といった感じで、2つの型を応答に書けばよい。ちなみに、Go言語では関数宣言は
func 関数名(引数名1 型, 引数名2 型……) アウトプットの型が基本形で、アウトプットが複数ある場合は
(アウトプットの型1, アウトプットの型2……)となる。
アウトプットのための構造体を引数で渡す必要がなくなるので、モジュール結合度を低くシンプルに保つことができる。素晴らしい。同じ要領で、getUser側を作る。
getUser/main.gopackage main import ( "context" "encoding/json" "log" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-lambda-go/lambdacontext" "local.packages/dynamodb" ) var () const () func init() { } func main() { lambda.Start(handler) } func handler(ctx context.Context, request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { var ( statusCode int id string idIsNotNull bool record dynamodb.Item returnbody string err error ) if lc, ok := lambdacontext.FromContext(ctx); ok { log.Printf("AwsRequestID: %s", lc.AwsRequestID) } statusCode = 200 if len(request.QueryStringParameters) == 0 { log.Println("QueryStringParameters is not specified.") statusCode = 400 } else { if id, idIsNotNull = request.QueryStringParameters["id"]; !idIsNotNull { log.Println("[QueryStringParameters]id is not specified") statusCode = 400 } } if statusCode == 200 { record, err = dynamodb.GetUser(id) if err != nil { if err.Error() == "Not Found" { statusCode = 404 } else { statusCode = 500 } } else { jsonBytes, _ := json.Marshal(record) returnbody = string(jsonBytes) } } response := events.APIGatewayProxyResponse{ StatusCode: statusCode, IsBase64Encoded: false, Body: returnbody, Headers: map[string]string{ "Content-Type": "application/json", }, } return response, nil }putUser側と比べて大きな差はないが、APIGatewayProxyResponse に Body と Headers を入れているので参考にしていただきたい。Bodyには文字列を設定しなければいけないので、直前で加工している部分がポイントか。
} else { jsonBytes, _ := json.Marshal(record) returnbody = string(jsonBytes) } } response := events.APIGatewayProxyResponse{ StatusCode: statusCode, IsBase64Encoded: false, Body: returnbody, Headers: map[string]string{ "Content-Type": "application/json", }, }DynamoDB接続
接続まわりについては、ある意味定型なので、SDKの利用方法を確認してもらえば良いと思う。
common/modules/dynamodb/dynamodb.gopackage dynamodb import ( "errors" "log" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) type Item struct { Id string `dynamodbav:"id"` Name string `dynamodbav:"name"` } func PutUser(id string, name string) error { sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) svc := dynamodb.New(sess) item := Item{ Id: id, Name: name, } av, err := dynamodbattribute.MarshalMap(item) if err != nil { log.Println("Got error marshalling new item:") log.Println(err.Error()) return err } input := &dynamodb.PutItemInput{ Item: av, TableName: aws.String("users-table"), } _, err = svc.PutItem(input) if err != nil { log.Println("Got error calling PutItem:") log.Println(err.Error()) return err } return nil } func GetUser(id string) (Item, error) { var ( item Item ) sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) svc := dynamodb.New(sess) log.Printf("item: %s", id) result, err := svc.GetItem(&dynamodb.GetItemInput{ TableName: aws.String("users-table"), Key: map[string]*dynamodb.AttributeValue{ "id": { S: aws.String(id), }, }, }) if err != nil { log.Println("Got error calling GetItem:") log.Println(err.Error()) return item, errors.New("Library Error") } err = dynamodbattribute.UnmarshalMap(result.Item, &item) if err != nil { log.Println("Failed to unmarshal Record", err) log.Println(err.Error()) return item, errors.New("Library Error") } if item.Id == "" { log.Printf("Could not find id: %s", id) return item, errors.New("Not Found") } return item, nil }GetUserの途中で、
err = dynamodbattribute.UnmarshalMap(result.Item, &item)としている部分については、DynamoDBから取得した型を普通のJSON型に変換している。
ハマりどころとしては、構造体のメンバ名の先頭が大文字でなければいけないのに対して、テーブル定義上ではカラム名の先頭が小文字になってしまっている場合、以下のようにマッピングしてあげないとエラーになってしまう点。
type Item struct { Id string `dynamodbav:"id"` Name string `dynamodbav:"name"` }パッケージ化
さて、上記のDynamoDBアクセス部品はローカルパッケージ化してアクセスしているようにしている。
体系的に知るには以下をまずは読んだ方が良い。【Qiita】Go Modules でインターネット上のレポジトリにはないローカルパッケージを import する方法
その上で、今回はgetUser, putUserそれぞれのgo.mod内で
replace local.packages/dynamodb => ../common/modules/dynamodbと定義し、main.go内で
import ( "local.packages/dynamodb" )としてアクセスしている。
ハマりどころとして、言語仕様上、funcで定義する関数名の先頭文字が大文字の場合しかパッケージ外からの参照ができないということ。これを知らずに小文字にしていてずっと「Not Found」になって悩んでいたよ…(言語仕様はちゃんと確認しておきましょう)
テストプログラム
goについても、JUnit+Maven/Gradleで
mvn testするような感じで、go testを実行するとテストモジュールが起動される。テストモジュールは以下のような全体像。
getUser/main_test.gopackage main import ( "context" "os" "testing" "github.com/pkg/errors" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambdacontext" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) var ( items = []struct { Id string `dynamodbav:"id"` Name string `dynamodbav:"name"` }{ {"test11111", "Tanaka Ichiro"}, {"test22222", "Sato Jiro"}, } ) const () func setup() error { sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) svc := dynamodb.New(sess) for _, item := range items { av, err := dynamodbattribute.MarshalMap(item) if err != nil { return errors.Wrap(err, "Got error marshalling new item") } _, err = svc.PutItem(&dynamodb.PutItemInput{ Item: av, TableName: aws.String("users-table"), }) if err != nil { return errors.Wrap(err, "Got error calling PutItem") } } return nil } func teardown() error { sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) svc := dynamodb.New(sess) for _, item := range items { _, err := svc.DeleteItem(&dynamodb.DeleteItemInput{ TableName: aws.String("users-table"), Key: map[string]*dynamodb.AttributeValue{ "id": { S: aws.String(item.Id), }, }, }) if err != nil { return errors.Wrap(err, "Got error calling DeleteItem") } } return nil } func TestHandler(t *testing.T) { tests := []struct { queryStringParameters map[string]string expected int }{ {queryStringParameters: map[string]string{"id": "test11111"}, expected: 200}, {queryStringParameters: map[string]string{"id": "test22222"}, expected: 200}, {queryStringParameters: map[string]string{"id": "test33333"}, expected: 404}, } lc := &lambdacontext.LambdaContext{ AwsRequestID: "test request", } ctx := lambdacontext.NewContext(context.Background(), lc) for _, te := range tests { res, _ := handler(ctx, events.APIGatewayProxyRequest{ QueryStringParameters: te.queryStringParameters, }) if res.StatusCode != te.expected { t.Errorf("StatusCode=%d, Expected %d", res.StatusCode, te.expected) } } } func TestMain(m *testing.M) { setup() ret := m.Run() teardown() os.Exit(ret) }基本は以下にメイン処理を書くが、実際の中身はハンドラ側で対応する。
func TestMain(m *testing.M) { setup() ret := m.Run() teardown() os.Exit(ret) }ポイントは、ハンドラを挟んでコールしている
setup()とteardown()で、要は準備と後始末である。今回は、setup()でDynamoDBにレコードを敷き込み、teardown()で削除している。TestHandler()では、実装しているgetUserのメイン処理に従い、queryStringParametersの値を変えたりしつつでループして試験している。
これを
go test ./...でテストモジュールが起動してくる。デプロイ用のSAMテンプレート
以下のような感じで準備する。
これも、今回の本筋ではないので詳細は省く。ここは「とりあえず動けばいい」で作ったのでManagedPolicyArnsとかテキトーすぎるので、そのまま使わないように。getUser/template.ymlAWSTemplateFormatVersion: 2010-09-09 Transform: AWS::Serverless-2016-10-31 Description: APIGateway test for Golang Resources: # ------------------------------------------------------------# # IAM Role # ------------------------------------------------------------# LambdaExecutionRole: Type: AWS::IAM::Role Properties: RoleName: lambdaexecutionrole-get Description: Lambda Execution Role Path: /serivice-role/ AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSLambdaDynamoDBExecutionRole - arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess # ------------------------------------------------------------# # Lambda Function # ------------------------------------------------------------# GoApigwTest: Type: AWS::Serverless::Function Properties: CodeUri: artifact Handler: goapigwtest-get Runtime: go1.x Role: !GetAtt LambdaExecutionRole.Arn Timeout: 180 Events: ApiEvent: Type: Api Properties: Path: testapi Method: get LambdaPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref GoApigwTest Principal: apigateway.amazonaws.com # ------------------------------------------------------------# # Cloud Watch Logs # ------------------------------------------------------------# GoApigwTestLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: !Sub /aws/lambda/${GoApigwTest} RetentionInDays: 1putUser/template.ymlAWSTemplateFormatVersion: 2010-09-09 Transform: AWS::Serverless-2016-10-31 Description: APIGateway test for Golang Resources: # ------------------------------------------------------------# # IAM Role # ------------------------------------------------------------# LambdaExecutionRole: Type: AWS::IAM::Role Properties: RoleName: lambdaexecutionrole-put Description: Lambda Execution Role Path: /serivice-role/ AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSLambdaDynamoDBExecutionRole - arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess # ------------------------------------------------------------# # Lambda Function # ------------------------------------------------------------# GoApigwTest: Type: AWS::Serverless::Function Properties: CodeUri: artifact Handler: goapigwtest Runtime: go1.x Role: !GetAtt LambdaExecutionRole.Arn Timeout: 180 Events: ApiEvent: Type: Api Properties: Path: testapi Method: post LambdaPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref GoApigwTest Principal: apigateway.amazonaws.com # ------------------------------------------------------------# # Cloud Watch Logs # ------------------------------------------------------------# GoApigwTestLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: !Sub /aws/lambda/${GoApigwTest} RetentionInDays: 1今更Makefileかよ!だけど……
サブタイトルの通りの内容ではあるのだけど、使ってみると意外と楽に扱える。
まあ、MavenやらGradleの代わりだと思えば良い。プリミティブに良く出来ているものは、いつになっても使えるものなのだ。getUser/MakefileSTACK_NAME := GoApigwTest-Get STACK_BUCKET := goapigwtest-cfn-stack-get TEMPLATE_FILE := template.yml SAM_FILE := sam.yml build: GOARCH=amd64 GOOS=linux go build -o artifact/goapigwtest-get .PHONY: build deploy: build sam package \ --template-file $(TEMPLATE_FILE) \ --s3-bucket $(STACK_BUCKET) \ --output-template-file $(SAM_FILE) sam deploy \ --template-file $(SAM_FILE) \ --stack-name $(STACK_NAME) \ --capabilities CAPABILITY_NAMED_IAM .PHONY: deploy delete: clean aws cloudformation delete-stack --stack-name $(STACK_NAME) aws s3 rm "s3://$(STACK_BUCKET)" --recursive .PHONY: delete test: go test ./... .PHONY: test clean: rm -rf artifact rm -f sam.yml .PHONY: cleanこれで、
make deployしたら、ばっちりビルドしてAPI Gateway+Lambdaのデプロイまでやってくれる。動かしてみる
やったー動いたー!
$ curl -i -X POST https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/testapi?id=11111\&name=Taro HTTP/2 200 content-type: application/json content-length: 0 date: Sun, 05 Jul 2020 06:00:27 GMT ~ (以下略) ~curl -i -X GET https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/testapi?id=11111 HTTP/2 200 content-type: application/json content-length: 28 date: Sun, 05 Jul 2020 06:06:53 GMT ~ (中略) ~ {"Id":"11111","Name":"Taro"}
- 投稿日:2020-07-05T13:45:39+09:00
AWSにおけるコンテナ関連のサービス
コンテナ関連のサービスには以下のものがある
- Amazon ECR(必須)
- Amazon ECS
- AWS Fargate
- Amazon EKSECRを必須で、どれを使うのかを他の3つから選ぶ。
Amazon Elastic Container Registry(ECR)
AWSが提供する完全マネージド型のDockerコンテナレジストリ。
インフラはすべてAWSが管理。
AWSと完全に統合されているので、従来の方法でアクセス権限の管理が可能と、AWS環境でコンテナワークロードを展開するときにはほぼ必須のサービス。
Docker Hubのようにインターネットへのパブリック公開はない。
脆弱性検査も自動で実施してくれるサービスもあり。残りの3つの説明の前に大事な概念の説明
コントロールプレーンとデータプレーン
コントロールプレーン
コンテナの管理。
コンテナが動作するネットワークやコンテナの死活監視、自動復旧、負荷に応じたスケーリングなどを行う。データプレーン
コンテナが稼働する場所。
コントロールプレーンからの指示にしたがって起動し、コンピューティングリソースをしょうひし、コンテナの状態をコントロールプレーンに通知。Amazon Elastic Container Service(ECS)
AWS完全マネージドのコンテナオーケストレーションサービス。
機能
- オートスケール設定
- ロードバランサー統合
- コンテナのIAM権限管理
- コンテナのセキュリティグループ管理
- Amazon CloudWatchメトリクス統合
- Amazon CloudWatch Logs統合
- スケジュール実行機能統合
特徴
- コンテナオーケストレーションツール
- 他のAWSサービスとの連携が充実
Amazon Elastic Kubernetes Service(EKS)
Kubernetesは、コンテナ運用自動化のためのオープンソースプラットフォーム。
EKSは、AWSマネージドなサービスで、Kubernetesに正式住居したプロダクトとして認定されている。特徴
- Kubernetes用に開発された様々なツールを広く利用できる
AWS Fargate
ホストインスタンスの管理が一切不要なコンテナ実行のためのデータプレーン。
データプレーンとして、EC2も使えるが、EC2と比べると割高。メリット
- ホストインスタンスの管理が省けること
- AmazonEC2の余剰リソースが不要
- プラットフォームのセキュリティはAWS側で常に担保
- オートスケールの設定も不要
デメリット
- ホストインスタンスにSSHログインできないため、dockerコマンドを直接利用できない
- EFSが利用できない
- GPUインスタンスなど仮想マシン最適化されたインスタンスが利用できない
- Windowsコンテナが使えない
参考資料
- 投稿日:2020-07-05T12:50:10+09:00
AWS超基礎: 「Amazon VPC」の構成要素に触れながら、セキュリティグループとNACLの特徴をまとめる
Amazon VPCとは?
Amazon Virtual Private Cloud(VPC)とは、AWSに作成するユーザー専用の仮想的なプライベートネットワーク。
Amazon VPCの構成要素
Amazon VPCは指定したAWSリージョン内に複数のアベイラビリティーゾーンにまたがって定義する。
Amazon VPCを作成するには利用するIPv4アドレスの範囲をCIDRブロックの形式で指定。
指定したCIDRがVPC内部のプライベートアドレスとして利用されるためRFC1918の定められているIPアドレスの利用。
- 10.0.0.0〜10.255.255.255
- 172.16.0.0〜172.31.255.255
- 192.168.0.0〜192.168.255.255
サイズは、/16から/28の範囲。
Amazon VPC作成後の返納には、制限があるため、余裕を持ってアドレス数を確保する。サブネット
Amazon VPC内に作成する最小のネットワークの単位。
EC2などのサーバーリソースはサブネット内で起動。
割り当て済みのCIDRブロックからIPアドレス範囲を切り出し割り当てる。
サブネットは複数アベイラビリティゾーンをまたぐことができないため、リージョン内にアベイラビリティーゾーンを指定して作成。ゲートウェイサービス
インターネットゲートウェイ
パブリックインターネットとの通信を行うゲートウェイ
仮想プライベートゲートウェイ
VPN接続や専用線接続によるオンプレミスとのクローズド通信のためゲートウェイ
VPCピアリング接続
異なるVPCとの接続を提供するゲートウェイ
NAT ゲートウェイ
アウトバウンド通信時にソースアドレス変換を行うマネージドゲートウェイ
ENIとIPアドレス
ENIは、AmazonEC2などのサーバーリソースのネットワークインターフェイス。作成したサブネットのCIDRからプライベートIPアドレスを割り当てられる。
パブリックインターネットへの通信が必要な場合は、パブリックIPアドレスを割り当てる。
パブリックIPアドエスは、デフォルトでAWSが保有するアドレスが自動で割り当てられ、インスタンス停止時には開放されるため動的。
固定のパブリックIPアドレスが必要な場合は、Elastic IPアドレスをリクエストして割り当てられる。ルートテーブル
ルートテーブルでは、宛先となるネットワークアドレスに対して、転送先となるターゲットを指定。
パケットの転送先の制御には、サブネット単位でルートテーブルを設定。セキュリティグループとNACL
項目 セキュリティグループ NACL 適用対象 ENI サブネット 条件 ホワイトリスト飲み ホワイトリスト、ブラックリスト共に可能 条件の評価 すべての条件を評価 記載順に評価し、マッチするものを適用 ステート ステートフル ステートレス Amazon Provided DNS
Amazon VPC内のリソースが名前解決に利用するDNS
参考資料
- 投稿日:2020-07-05T12:45:59+09:00
【AWS】EC2(AmazonLinux)にSSHできない場合に疑うポイント
はじめに
EC2(AmazonLinux)にSSH接続できない場合に確認する点をざっくりまとめてみました。
※僕のわかる範囲になります。不足していたらすいません。概要
- インターネットゲートウェイ確認
- ルートテーブルのサブネット関連付け確認
- 自動割り当てIPアドレス設定
- セキュリティグループ設定確認
- ネットワークACLの設定確認
※全てVPCダッシュボードでの確認になります。
インターネットゲートウェイ確認
インターネットゲートウェイ作成確認
インターネットゲートウェイが作成されているか?
VPCと紐づいているか確認
EC2インスタンスがあるVPCに紐づいているか?
ルートテーブルの設定確認
ルート設定
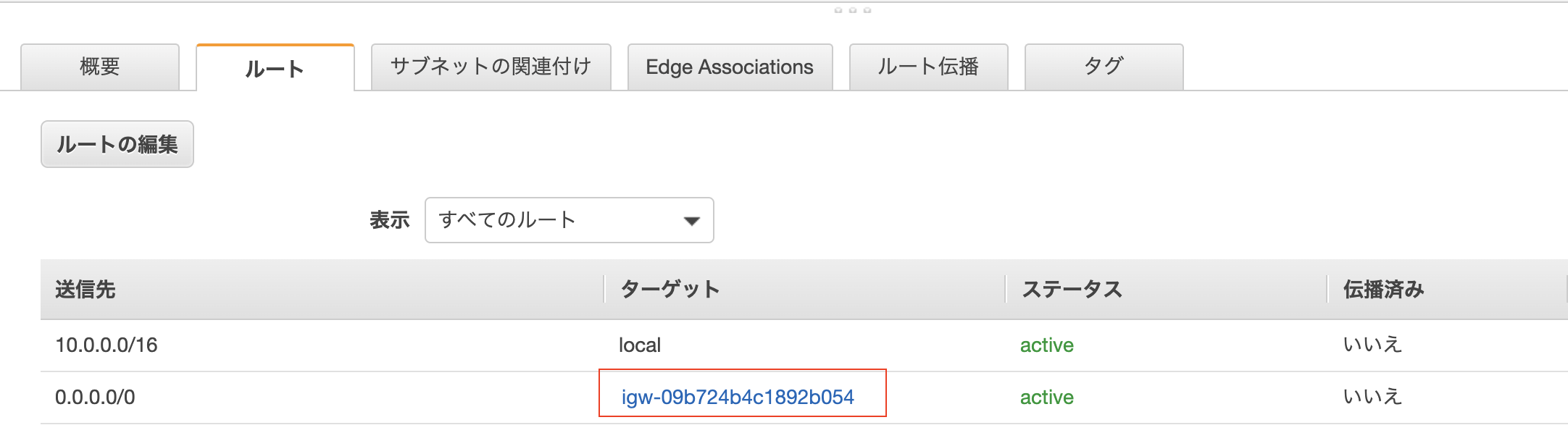
ルートテーブルにインターネットゲートウェイが紐づいているか?
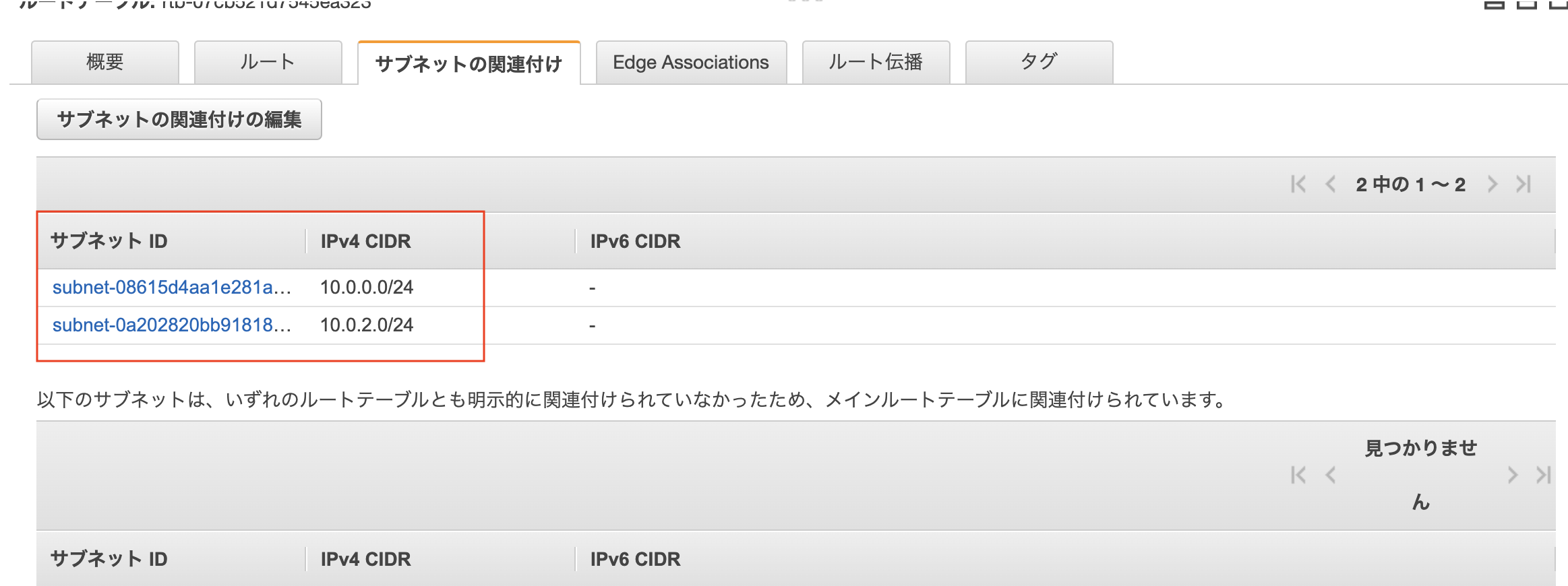
サブネット関連付け設定
EC2インスタンスがあるサブネットがルートテーブルに関連付けされているか確認。
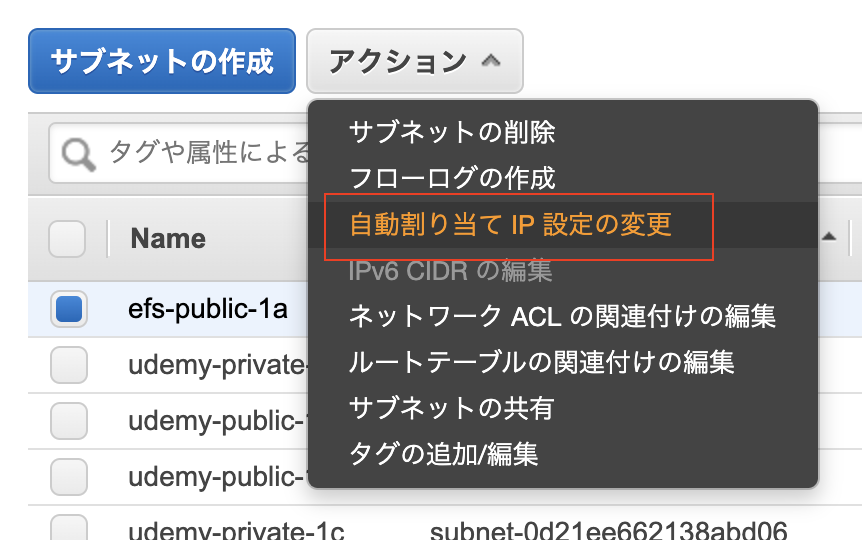
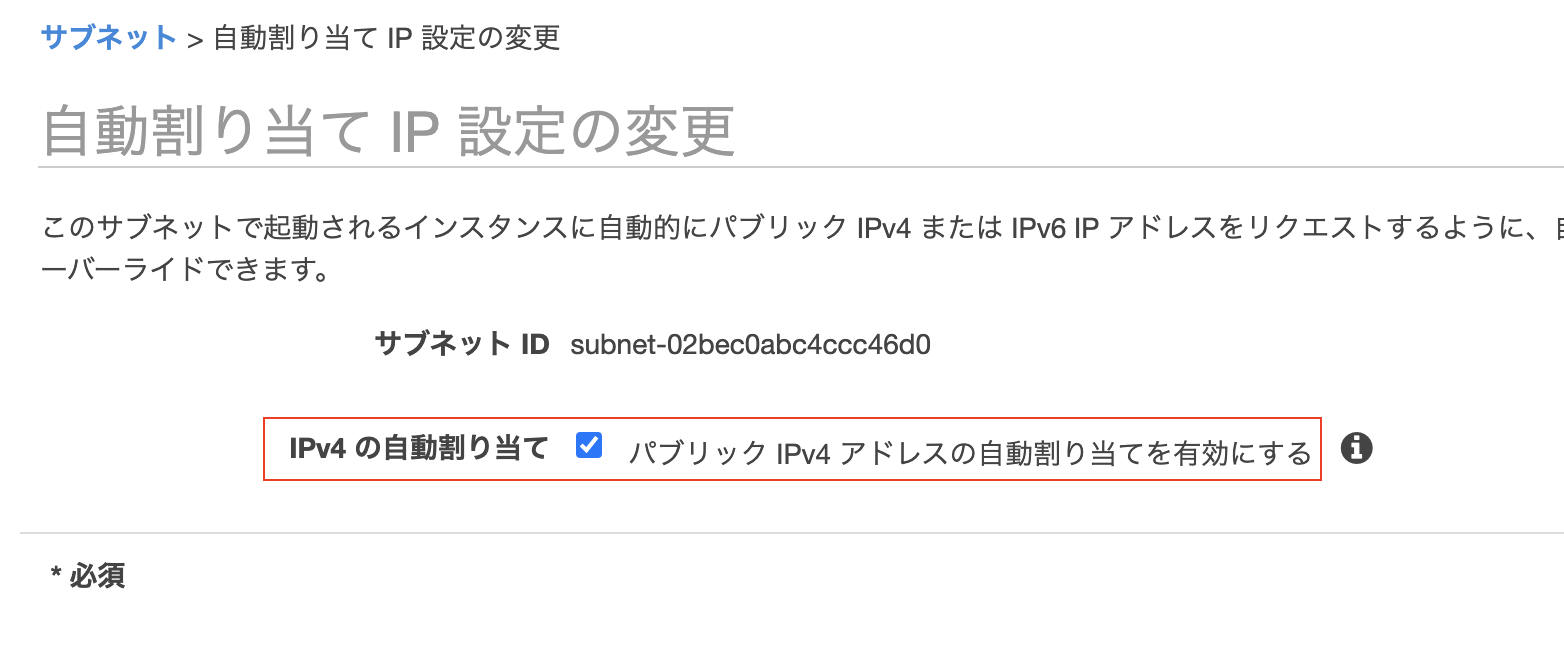
自動割り当てIPアドレス設定確認
①該当のサブネットを右クリックし、自動割り当てIP設定の変更をクリック。
②「IPv4の自動割り当て」に☑️を入れ、保存する。
セキュリティグループ設定確認
SSHのルールを設定しているか?自分のPCからアクセスできるようになっているか?
※下記例の場合は、0.0.0.0/0とフルオープン状態にしております。
ネットワークACL設定確認
サブネットに紐づいているネットワークACLの設定が、SSH接続を拒否する設定になっていないこと
所感
実際にEC2インスタンスに接続するためにVPC設定を実施しましたが、見るべき箇所が多いと感じています。
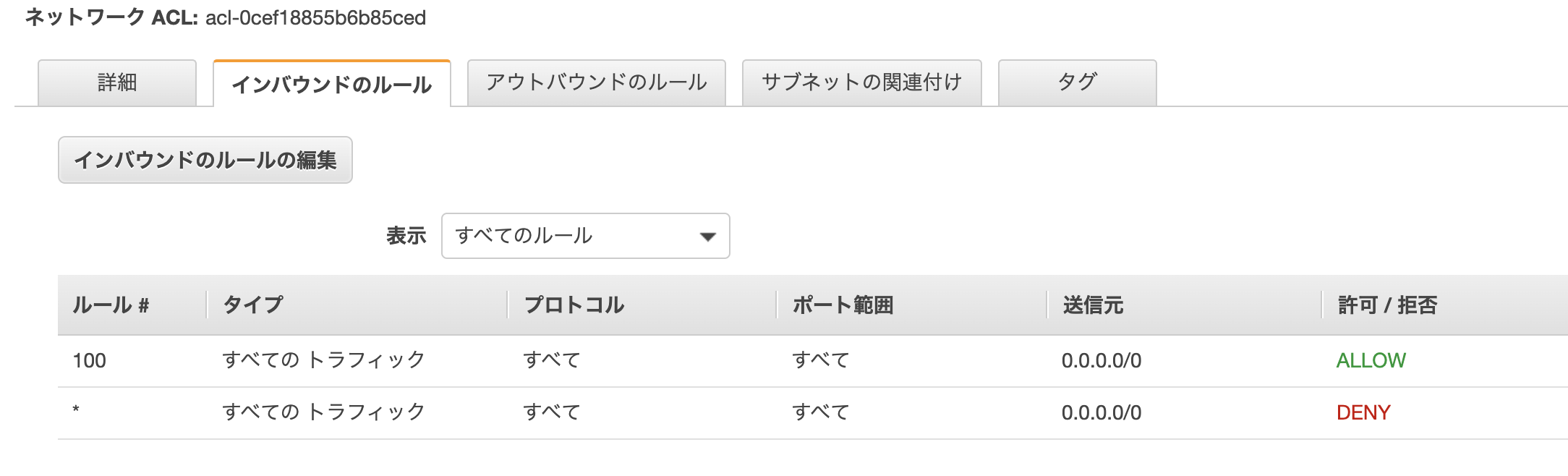
慣れないうちは、わかりづらいのかなと思いました。


- 投稿日:2020-07-05T12:10:04+09:00
AWSアカウント間でRDS Auroraを移行する方法 ~ダウンタイム・データ欠損無し~
RDSの移管って結構難しいですよね。
しかもそれがダウンタイム、データ欠損なし、AWSアカウント超える場合なんかは特に...。
それに対するアプローチを公式ドキュメントを参考に実践しました。
同じ状況に直面した方はぜひ参考にしてください。
■ヘヴィメタルエンジニアリング(はてなブログ)
・AWSアカウント間でRDS Auroraを移行する方法
https://xkenshirou.hatenablog.com/entry/2020/07/05/120526?_ga=2.234389661.2045813696.1593882053-1181011150.1554705110
- 投稿日:2020-07-05T08:51:32+09:00
aws configure profileはenvの前に無力
環境
macOS Catalina 10.15.5
zshtl;dr
AWS CLIの設定切替方法と、AWS_DEFAULT_PROFILEとAWS_PROFILEの違いについて でAWSのPROFILEを切り替えようとして切り替わらなかった原因と対策
切り替わらないよ?
Valueのところが「default」から「personal」に変わっているのに、access_keyとsecret_keyが切り替わらない。
% aws configure list Name Value Type Location ---- ----- ---- -------- profile default manual --profile access_key ****************^-^v env secret_key ****************^-^v env region ap-northeast-1 env AWS_DEFAULT_REGION % export AWS_DEFAULT_PROFILE=personal % aws configure list Name Value Type Location ---- ----- ---- -------- profile personal manual --profile access_key ****************^-^v env secret_key ****************^-^v env region ap-northeast-1 env AWS_DEFAULT_REGION原因
環境変数で指定されている(
~/.zshrcの export で指定している等)と、「Type = env」で切り替わらない対策
①
~/.zshrcのexport部分をコメントアウト
② 既存の値を unsetunset AWS_DEFAULT_REGION unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY解決
% aws configure list Name Value Type Location ---- ----- ---- -------- profile default manual --profile access_key ****************^-^v shared-credentials-file secret_key ****************^-^v shared-credentials-file region ap-northeast-1 config-file ~/.aws/config % export AWS_DEFAULT_PROFILE=personal % aws configure list Name Value Type Location ---- ----- ---- -------- profile personal manual --profile access_key ****************;^-^ shared-credentials-file secret_key ****************;^-^ shared-credentials-file region ap-northeast-1 config-file ~/.aws/config「Type = shared-credentials-file」になっていると、 ~/.aws/credentials や ~/.aws/config から値を取得してくれる。(環境変数に
AWS_ACCESS_KEY_IDやAWS_SECRET_ACCESS_KEYが設定されているうちは、そちらを優先的に参照するらしい)
- 投稿日:2020-07-05T07:29:55+09:00
[AWS]Direct ConnectとTransit Gateway
Direct Connectとは
一言で言うと、オンプレ環境とAWSを繋ぐ専用線、です。
ユースケース
AWSとオンプレ環境を繋ぐには以下の3種類があります。
・Direct Connect
・VPN
・HTTPS・SSHそれぞれで主に以下のような使い方をします。
Direct Connect・・・オンプレとAWS間で大量の通信が発生する場合
VPN・・・コストを抑えたい場合
HTTPS/SSH・・・通信要件がない場合、通信は暗号化して接続する、くらいの感覚回線で括ると、以下のように分けられます。
「インターネット接続」はVPN、HTTPS/SSH
「専用線」はDirect ConnectVPNの場合インターネット回線なので、ベストエフォートとなり速度が安定しない場合があります。
なので業務通信やオンライン処理が必要な場合はDirect Connectを選択した方が良いです。利用料金
Direct Connectは通信キャリアによってサービスとして提供されます。
専用線として1G、10Gを引くことになるので構成にもよりますが月10〜20万くらいはいくのではないでしょうか
(なんかどこのキャリアも明確な金額はあまり載っていないなぁ)ただ、月額でかかるコストには定額の部分と、通信量にかかる金額の両方があるので注意です。
AWS通信量は以下参考
料金-AWS Direct Connectまた、AWSはアウトバウンドの通信量が課金されるのですが、Direct Connectを利用すると割安になる点はメリットと言えます。
専有型とホスト型
また専有型とホスト型でも料金が違うようです。
ホスト型と専有型の違いはクラスメソッドさんの以下サイトがわかりやすいです。
Direct Connect接続タイプとVIF作成パターンをまとめてみた
大雑把に言ってしまうと、回線を占有しているかどうかに違いがあります。専有型
専有型ではDirect ConnectはAWS側のルータと回線事業者のルータ(もしくは自前でもいける??)を直接結線するやり方になります。
これによって1Gbpsや10Gbpsの速度が保証されます。専有VIFとホスト(共有)VIF
VIFとはVirtual Interface、日本語だと仮想インターフェースと呼ばれるものです。
このVIFを作成することでVPCやDirect Connect GateWayと呼ばれる終端装置のようなものに接続します。専有VIFと言うのは一つの専用線から一本VIFを作成して、Direct Connectを所有しているアカウント内のVPCに接続するパターンとなります。
ホスト(共有)VIFはDirect Connectを所有しているアカウントとは別のアカウントにVIFを伸ばすやり方です。
複数アカウント運用をしていて、異なるVPCにもDirect Connect接続したい場合の方法となります。専有型と共有型の違いとして、マネコンから見た時に専有型はDirect Connectの接続が見えることと、Cloud watchメトリクスが使える点です。
ホスト型
パートナーの1Gbpsの回線から仮想的な接続を行う形です。
帯域としては100Mbps〜500Mbpsほどの帯域を専有することが可能。
この場合VIFは一つしか作れません。Transit Gatewayとは
複数のDirect ConnectやVPCを集約するハブのようなサービス
だいぶざっくり書きましたが、以下のような図がイメージしやすいかと思います。Transit Gatewayを利用しない場合
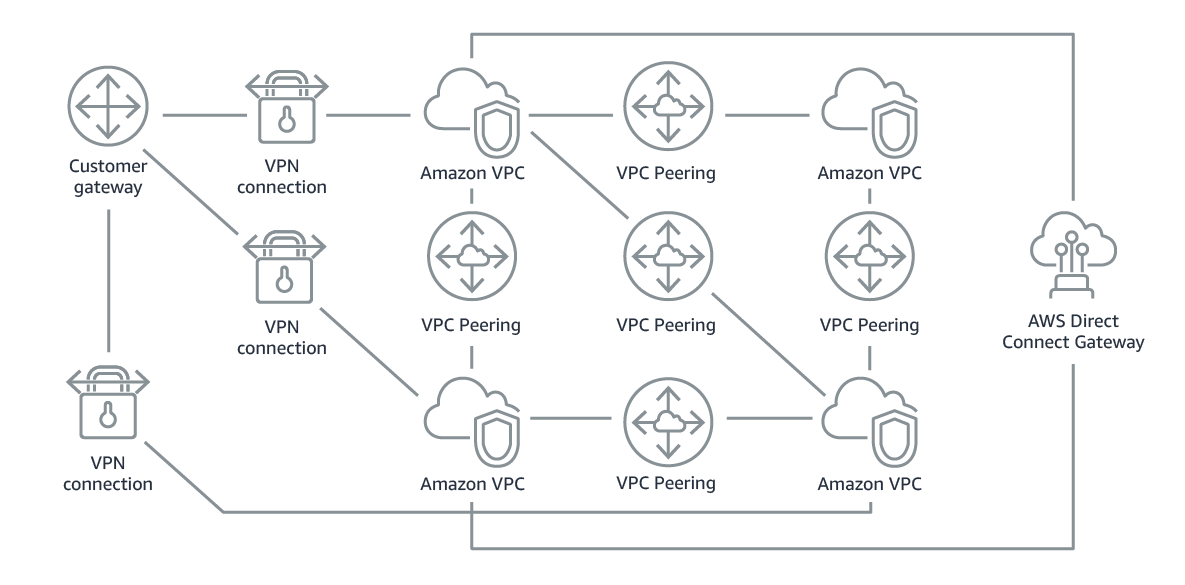
複数VPCがある場合、VPC間はVPCピアリングを設定しないと通信できません。
これは一対一で設定する必要があるので、フルメッシュで設定していく必要があります。
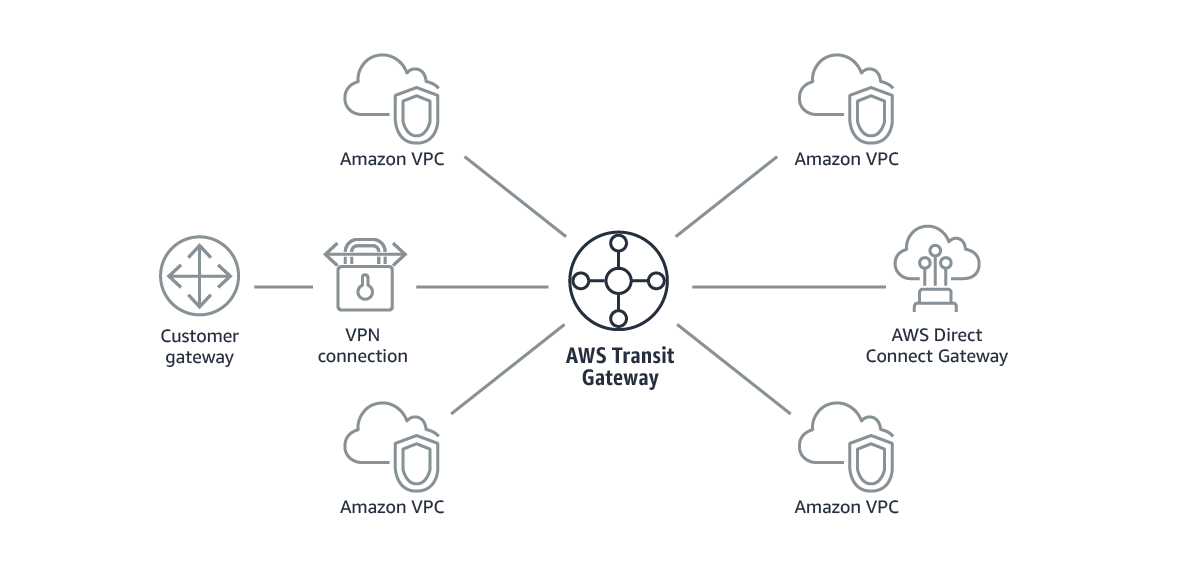
そうなるとVPCが増えれば増えるほど設定は大変です。。。Transit Gatewayを利用した場合
ハブのような形でVPCを繋ぐことができるので、設定も管理も楽です。
何が便利なのか?
・VPCピアリングをいちいち設定する手間が省ける
・今までのDirect Connect Gateway(DXGW)ではVPC〜オンプレ間のみだったが、Transit GatewayではさらにVPC間の接続もできるようになったことと、DXGWでは最大10個までしかVPCを接続できなかったがTransit Gatewayでは数千個ほど接続可能。利用の制約や料金
制約
・他リージョンのVPCは接続できない。
・Transit Gateway同士は接続することができない。
・CIDRが重複しているVPCは繋げない
・DXは1Gbps以上の接続につきTGWのためのトランジット仮想インターフェースは1つだけ
→なのでDXからTransitVIFを2本伸ばしてTGWを二つ作る、という構成はできない。(そんなことする意味もないだろうけど)導入時に気をつける点については以下記事がわかりやすかったです。
Transit Gatewayを導入するときに気をつけたいポイント4選料金
料金体系はわかりやすいです。
固定費
Transit Gatewayの1アタッチ数に月0.07$
例えばVPNとVPCが一つずつ繋がっている場合
0.07✖️2=0.14$/hとなります。変動費
ネットワーク量によっても課金されていきます。
1GBごとの通信量に対して、0.02$課金されていきます。参考資料
AWS Transit Gateway の料金
オンプレとVPCを接続するTransitGatewayとVPNの料金を比較するユースケース
今回はDirect Connectを絡めたユースケースについてのみ書いていきます。
一般的には以下のような構成図となります。
ポイントとしては
・Virtual Private Gateway(VGW)が不要
・VIFの種類はTransit VIFで作成
・DXGWとTGWは別アカウントでもOK
・TGWに接続するVPCも別アカウントでOK終わりに
今回も調べたことをグワーっと書き出しただけなのですが、間違っている部分ありましたらご指摘いただけるとありがたいです!

- 投稿日:2020-07-05T02:28:09+09:00
TerraformでAWS VPCを変更する(outパラメータによる変更プランの変更と適用)
TerraformでAWS VPCを変更するコード(コマンド)
「-out」パラメータでプランを保存した場合、コードとのズレや、環境とのズレが発生していた場合にどのような挙動やメッセージとなるのかを確認する。
下記の4パターンの挙動を確認する。
パターン① 環境も変更したい内容もズレは無し
パターン② 環境にズレがある(変更したい内容と競合する部分)
パターン③ 環境にズレがある(変更したい内容と競合しない部分)
パターン④ main.tfに更新がある実行環境
- Windows 10 Home (1919)
- Git Bash (git version 2.25.1.windows.1)
- AWS CLI (aws-cli/2.0.3 Python/3.7.5 Windows/10 botocore/2.0.0dev7)
- Terraform (v0.12.26)
パターン① 環境も変更したい内容もズレは無し
変更前の状態
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC" } ] } ] }この状態から、Nameタグの内容を変更する変更プランをtfplan1としていったん出力した後に適用してみる。
main.tf
$ cat main.tf provider "aws" { profile = "prj01-profile" region = "us-west-2" } resource "aws_vpc" "prj01VPC" { cidr_block = "10.20.0.0/16" instance_tenancy = "default" tags = { Name = "prj01VPC pattern1" CostGroup = "prj01" } }Nameタグのみ変更するmain.tf
変更対象がNameタグのみであることを確認
$ ../terraform.exe plan Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.prj01VPC: Refreshing state... [id=vpc-06bc5f188ef3b2fe8] ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-place Terraform will perform the following actions: # aws_vpc.prj01VPC will be updated in-place ~ resource "aws_vpc" "prj01VPC" { arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-06bc5f188ef3b2fe8" assign_generated_ipv6_cidr_block = false cidr_block = "10.20.0.0/16" default_network_acl_id = "acl-0ec7d4e945ff1d7f0" default_route_table_id = "rtb-0d64bb221c3f9d1ff" default_security_group_id = "sg-03b425d2c42c1e984" dhcp_options_id = "dopt-0ebee8b328487036e" enable_classiclink = false enable_classiclink_dns_support = false enable_dns_hostnames = false enable_dns_support = true id = "vpc-06bc5f188ef3b2fe8" instance_tenancy = "default" main_route_table_id = "rtb-0d64bb221c3f9d1ff" owner_id = "679788997248" ~ tags = { "CostGroup" = "prj01" ~ "Name" = "prj01VPC" -> "prj01VPC pattern1" } } Plan: 0 to add, 1 to change, 0 to destroy. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.指示通りにoutパラメータを使い変更プランを出力
$ ../terraform.exe plan -out=tfplan1 Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.prj01VPC: Refreshing state... [id=vpc-06bc5f188ef3b2fe8] ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-place Terraform will perform the following actions: # aws_vpc.prj01VPC will be updated in-place ~ resource "aws_vpc" "prj01VPC" { arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-06bc5f188ef3b2fe8" assign_generated_ipv6_cidr_block = false cidr_block = "10.20.0.0/16" default_network_acl_id = "acl-0ec7d4e945ff1d7f0" default_route_table_id = "rtb-0d64bb221c3f9d1ff" default_security_group_id = "sg-03b425d2c42c1e984" dhcp_options_id = "dopt-0ebee8b328487036e" enable_classiclink = false enable_classiclink_dns_support = false enable_dns_hostnames = false enable_dns_support = true id = "vpc-06bc5f188ef3b2fe8" instance_tenancy = "default" main_route_table_id = "rtb-0d64bb221c3f9d1ff" owner_id = "679788997248" ~ tags = { "CostGroup" = "prj01" ~ "Name" = "prj01VPC" -> "prj01VPC pattern1" } } Plan: 0 to add, 1 to change, 0 to destroy. ------------------------------------------------------------------------ This plan was saved to: tfplan1 To perform exactly these actions, run the following command to apply: terraform apply "tfplan1"出力されたファイルの確認
$ ls -al *tfplan1* -rw-r--r-- 1 xxx 197610 1975 7月 5 01:23 tfplan1 $ file tfplan1 tfplan1: Zip archive data, at least v2.0 to extract約2KBのzipファイルですね。
$ unzip tfplan1 Archive: tfplan1 inflating: tfplan inflating: tfstate inflating: tfconfig/m-/main.tf inflating: tfconfig/modules.json $ ls -al -rw-r--r-- 1 xxx 197610 1362 7月 5 01:23 tfplan -rw-r--r-- 1 xxx 197610 1428 7月 5 01:23 tfstate -rw-r--r-- 1 xxx 197610 255 7月 5 01:23 tfconfig/m-/main.tf -rw-r--r-- 1 xxx 197610 41 7月 5 01:23 tfconfig/modules.json $ file tfplan tfplan: data $ file tfstate tfstate: ASCII text $ file tfconfig/m-/main.tf tfconfig/m-/main.tf: ASCII text, with CRLF line terminators $ file tfconfig/modules.json tfconfig/modules.json: JSON data$ cat tfstate { "version": 4, "terraform_version": "0.12.26", "serial": 16, "lineage": "9ea1190d-b435-c622-09c8-310ec94b3088", "outputs": {}, "resources": [ { "mode": "managed", "type": "aws_vpc", "name": "prj01VPC", "provider": "provider.aws", "instances": [ { "schema_version": 1, "attributes": { "arn": "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-06bc5f188ef3b2fe8", "assign_generated_ipv6_cidr_block": false, "cidr_block": "10.20.0.0/16", "default_network_acl_id": "acl-0ec7d4e945ff1d7f0", "default_route_table_id": "rtb-0d64bb221c3f9d1ff", "default_security_group_id": "sg-03b425d2c42c1e984", "dhcp_options_id": "dopt-0ebee8b328487036e", "enable_classiclink": false, "enable_classiclink_dns_support": false, "enable_dns_hostnames": false, "enable_dns_support": true, "id": "vpc-06bc5f188ef3b2fe8", "instance_tenancy": "default", "ipv6_association_id": "", "ipv6_cidr_block": "", "main_route_table_id": "rtb-0d64bb221c3f9d1ff", "owner_id": "679788997248", "tags": { "CostGroup": "prj01", "Name": "prj01VPC" } }, "private": "eyJzY2hlbWFfdmVyc2lvbiI6IjEifQ==" } ] } ] }$ cat tfconfig/m-/main.tf provider "aws" { profile = "prj01-profile" region = "us-west-2" } resource "aws_vpc" "prj01VPC" { cidr_block = "10.20.0.0/16" instance_tenancy = "default" tags = { Name = "prj01VPC pattern1" CostGroup = "prj01" } }$ cat tfconfig/modules.json [ { "Key": "", "Dir": "." } ]プランを適用
$ ../terraform.exe apply tfplan1 aws_vpc.prj01VPC: Modifying... [id=vpc-06bc5f188ef3b2fe8] aws_vpc.prj01VPC: Modifications complete after 7s [id=vpc-06bc5f188ef3b2fe8] Apply complete! Resources: 0 added, 1 changed, 0 destroyed. The state of your infrastructure has been saved to the path below. This state is required to modify and destroy your infrastructure, so keep it safe. To inspect the complete state use the `terraform show` command. State path: terraform.tfstateちゃんと変更されたことを確認
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC pattern1" } ] } ] }ちゃんと該当箇所が変更されていることが確認できた。
マニュアル等では「-input=false」が一緒に使われているけど、これは何だ?パターン② 環境にズレがある(変更したい内容と競合する部分)
main.tf
$ cat main.tf provider "aws" { profile = "prj01-profile" region = "us-west-2" } resource "aws_vpc" "prj01VPC" { cidr_block = "10.20.0.0/16" instance_tenancy = "default" tags = { Name = "prj01VPC pattern2" CostGroup = "prj01" } }Nameタグを「pattern2」に変更する
プランを出力
$ ../terraform.exe plan -out=tfplan2 Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.prj01VPC: Refreshing state... [id=vpc-06bc5f188ef3b2fe8] ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-place Terraform will perform the following actions: # aws_vpc.prj01VPC will be updated in-place ~ resource "aws_vpc" "prj01VPC" { arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-06bc5f188ef3b2fe8" assign_generated_ipv6_cidr_block = false cidr_block = "10.20.0.0/16" default_network_acl_id = "acl-0ec7d4e945ff1d7f0" default_route_table_id = "rtb-0d64bb221c3f9d1ff" default_security_group_id = "sg-03b425d2c42c1e984" dhcp_options_id = "dopt-0ebee8b328487036e" enable_classiclink = false enable_classiclink_dns_support = false enable_dns_hostnames = false enable_dns_support = true id = "vpc-06bc5f188ef3b2fe8" instance_tenancy = "default" main_route_table_id = "rtb-0d64bb221c3f9d1ff" owner_id = "679788997248" ~ tags = { "CostGroup" = "prj01" ~ "Name" = "prj01VPC pattern1" -> "prj01VPC pattern2" } } Plan: 0 to add, 1 to change, 0 to destroy. ------------------------------------------------------------------------ This plan was saved to: tfplan2 To perform exactly these actions, run the following command to apply: terraform apply "tfplan2"この時点ではちゃんとNameタグが「pattern1」から「pattern2」へ変更される内容になっている。
こっそりコンソールからNameタグを変更
変更した結果を出力
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "Name", "Value": "prj01VPC pattern1.2" }, { "Key": "CostGroup", "Value": "prj01" } ] } ] }環境が、裏で変更されている状態をこれで作成。
Nameタグが「pattern1」から「pattern1.2」に変わってしまった。環境が変わってしまった状態でapply
$ ../terraform.exe apply tfplan2 aws_vpc.prj01VPC: Modifying... [id=vpc-06bc5f188ef3b2fe8] aws_vpc.prj01VPC: Modifications complete after 6s [id=vpc-06bc5f188ef3b2fe8] Apply complete! Resources: 0 added, 1 changed, 0 destroyed. The state of your infrastructure has been saved to the path below. This state is required to modify and destroy your infrastructure, so keep it safe. To inspect the complete state use the `terraform show` command. State path: terraform.tfstateコマンドは普通に通ってしまった。
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC pattern2" } ] } ] }状態も変更されている。
なので、この変更前の環境状態はチェックしてくれるわけではなさそう。パターン③ 環境にズレがある(変更したい内容と競合しない部分)
main.tf
$ cat main.tf provider "aws" { profile = "prj01-profile" region = "us-west-2" } resource "aws_vpc" "prj01VPC" { cidr_block = "10.20.0.0/16" instance_tenancy = "default" tags = { Name = "prj01VPC pattern3" CostGroup = "prj01" } }こっそりコンソールからCIDRを追加
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } }, { "AssociationId": "vpc-cidr-assoc-0da88385804f491d2", "CidrBlock": "10.21.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC pattern2" } ] } ] }「10.21.0.0/16」を追加した。
なので、これがどうなるのか?、具体的には警告無しで削除されてしまうのかどうかを確認する。環境が変わってしまった状態でapply
$ ../terraform.exe apply tfplan2 Error: Saved plan is stale The given plan file can no longer be applied because the state was changed by another operation after the plan was created.お! ちゃんとエラーになってくれた。
エラーメッセージもちゃんと「別の操作で状態が変更されたため・・・」となってくれている。パターン④ main.tfに更新がある
まずは環境を元にもどして状態を確認
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } }, { "AssociationId": "vpc-cidr-assoc-0da88385804f491d2", "CidrBlock": "10.21.0.0/16", "CidrBlockState": { "State": "disassociated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC pattern3" } ] } ] }main.tf
$ cat main.tf provider "aws" { profile = "prj01-profile" region = "us-west-2" } resource "aws_vpc" "prj01VPC" { cidr_block = "10.20.0.0/16" instance_tenancy = "default" tags = { Name = "prj01VPC pattern4" CostGroup = "prj01" } }またまたNameタグのみ変更するmain.tfを作成
プランを出力
$ ../terraform.exe plan -out=tfplan4 Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.prj01VPC: Refreshing state... [id=vpc-06bc5f188ef3b2fe8] ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-place Terraform will perform the following actions: # aws_vpc.prj01VPC will be updated in-place ~ resource "aws_vpc" "prj01VPC" { arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-06bc5f188ef3b2fe8" assign_generated_ipv6_cidr_block = false cidr_block = "10.20.0.0/16" default_network_acl_id = "acl-0ec7d4e945ff1d7f0" default_route_table_id = "rtb-0d64bb221c3f9d1ff" default_security_group_id = "sg-03b425d2c42c1e984" dhcp_options_id = "dopt-0ebee8b328487036e" enable_classiclink = false enable_classiclink_dns_support = false enable_dns_hostnames = false enable_dns_support = true id = "vpc-06bc5f188ef3b2fe8" instance_tenancy = "default" main_route_table_id = "rtb-0d64bb221c3f9d1ff" owner_id = "679788997248" ~ tags = { "CostGroup" = "prj01" ~ "Name" = "prj01VPC pattern3" -> "prj01VPC pattern4" } } Plan: 0 to add, 1 to change, 0 to destroy. ------------------------------------------------------------------------ This plan was saved to: tfplan4 To perform exactly these actions, run the following command to apply: terraform apply "tfplan4"この状態でmain.tfを更新
$ cat main.tf provider "aws" { profile = "prj01-profile" region = "us-west-2" } resource "aws_vpc" "prj01VPC" { cidr_block = "10.20.0.0/16" instance_tenancy = "default" tags = { Name = "prj01VPC pattern4.2" CostGroup = "prj01" } }main.tfが変わってしまった状態でapply
$ ../terraform.exe apply tfplan4 aws_vpc.prj01VPC: Modifying... [id=vpc-06bc5f188ef3b2fe8] aws_vpc.prj01VPC: Modifications complete after 7s [id=vpc-06bc5f188ef3b2fe8] Apply complete! Resources: 0 added, 1 changed, 0 destroyed. The state of your infrastructure has been saved to the path below. This state is required to modify and destroy your infrastructure, so keep it safe. To inspect the complete state use the `terraform show` command. State path: terraform.tfstate普通に適用された。
↓環境もちゃんと変更されている。$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-06bc5f188ef3b2fe8", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0373fb92a40bc4aba", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } }, { "AssociationId": "vpc-cidr-assoc-0da88385804f491d2", "CidrBlock": "10.21.0.0/16", "CidrBlockState": { "State": "disassociated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC pattern4" } ] } ] }