- 投稿日:2020-05-29T23:10:03+09:00
DynatraceでPythonアプリケーションのパフォーマンスを監視する♪
Dynatrace で Pythonアプリケーションを監視するための、Oneエージェントエクステンション(下記)がリリースされたので紹介します。
https://github.com/dlopes7/autodynatrace2020年5月末の時点で、これは、Dynatrace社員によって開発された(公式ではない)プライベートなエクステンションになりますが、簡単にPythonアプリケーションのパフォーマンスを可視化できますので、是非お試しください!
対応モジュール
celery
concurrent.futures
confluent_kafka
cx_Oracle
django
flask
grpc
pika (RabbitMQ)
pymongo
pysnmp
redis
ruxit (Dynatrace plugin framework)
sqlalchemy
urllib3
custom annotations手順
1. 監視対象のPythonが動作するホスト上に、Oneエージェントをインストールします。Dynatraceのメニュー”Deploy Dynatrace”から、コマンド3つをコピーして叩くだけですね!(Linuxの場合)
2. 以下のコマンドで、エクステンションモジュールをインストールします
pip install autodynatrace3. 監視対象のPythonのコードに以下を追加して、エクステンションモジュールを組み込みます
import autodynatrace4. 監視対象のPythonを実行します
結果
以下、Flask から SQLAlchemy で SQLite をupdate するシンプルなアプリでの例になります。
1. Dynatraceメニューの”Hosts”から、監視対象のホストを表示します。Pythonプロセスが検出されています。これはエクステンションが使用されていない場合でも同じですね。このPythonプロセスをクリックします
2. ここからがエクステンション導入効果になります。Pythonプロセス上でFlaskがサービスとして検出されています!(嬉しい♪)Flaskをクリックし、サービスとしてのパフォーマンスを見てみます。
3. 中央のInfoGraphicに、前後の通信相手がきっちり捉えられています。サービスとしての応答時間、エラー率、スループットも監視されていますね
(Dynatraceの場合、AIがこれらメトリックの異常を自動で監視します)
FlaskがコールしているSQLiteをクリックしてみると...
Databaseとしてのパフォーマンスが監視されています!下図のように"Anlyze outlier"(外れ値分析)から、特別処理時間が遅かったSQLクエリを簡単に割り出すこともできます
Dynatraceの理念 = Do more with less! (より少ない手間でより多くを行う)
このエクステンションにも宿っているようですね♪
Dynatraceを試してみたい!という方へ!
https://www.dynatrace.com/ja/ から、フリートライアル(2週間)のお申し込みができます。数分後にはDynatraceのテナントをご利用頂けます






- 投稿日:2020-05-29T22:31:36+09:00
Qiskit: 量子ボルツマンマシンの実装
はじめに
今回実装したのは
A quantum algorithm to train neural networks using low-depth circuitsに書かれているQuantum Approximate Boltzmann Machine (QABoM)です.
量子アニーリングマシンを使ったボルツマンマシンは有名だと思いますが,これはゲート式の量子コンピュータを使ったものになっています.
アニーリングを用いたボルツマンマシンに関してはminatoさんが紹介しているのでそちらを参照お願いします.
D-Waveから量子ゲートマシンまでのRBMのボルツマン学習パラメータの最適化に量子古典ハイブリッドアルゴリズムの一つであるQAOAを用いています.これに関しては他に詳しい解説をしている方がいるのでそちらにお任せしようと思います.
なお,この記事の著者は機械学習の専門家ではないため,ボルツマンマシンについて省きます.
アルゴリズム
QABoMのステップは大きく分けて五つあります.それぞれについて軽く説明していきたいと思います.
(参照:Appendix A)
なお,ここではvをvisible層のインデックス,hをhidden層のインデックス,vをvisible+hiddenのインデックスとしています.step 0
full initial Hamiltonian と partial initial Hamiltonianを定義します.
H_I = \sum_{j \in u} Z_j \\ H_{\bar{I}} = \sum_{j \in h} Z_jfull mixer Hamiltonian と partial mixer Hamiltonian を定義します.
H_M = \sum_{j \in u} X_j \\ H_{\bar{M}} = \sum_{j \in h} X_jepoch 0におけるweight$J_{jk}^0$とbias$B_j^0$を定義します.
step 1
epoch nにおいてfull cost Hamiltonian と partial cost Hamiltonianを定義します.
\hat{H_C^n} \equiv \sum_{j,k \in u} J_{jk}^n \hat{Z_j} \hat{Z_k} + \sum_{j \in u} B_j^n \hat{Z_j} \\ H_{\tilde{C}} \equiv \sum_{j,k \in u} J_{jk}^n \hat{Z_j} \hat{Z_k} + \sum_{j \in h} B_j^n \hat{Z_j}step 2
ここからQAOAを用いて最適化を行っていきます.(Unclamped)
step 2-a
QAOAのパラメータを初期化します.
step 2-b
QAOAを実行します.その際期待値の算出に使うHamiltonianは$H_C^n$になります.
step 2-c
QAOAを実行して得られた最適な回路から期待値$$と$$を求めregisterします.
step 3
それぞれのdeta string $x$に対してQAOAを実行していきます.(Clamped)
step 3-a
QAOAのパラメータを初期化します.
step 3-b
deta stringをvisible unitにencodeします.
・$1$のときはX gateを
・$0$のときはなにもしない
これでencodeすることができます.step 3-c
QAOAを実行します.その際期待値の算出に使うHamiltonianは$H_{\tilde{C}}^n$になります.
step 3-d
QAOAを実行して得られた最適な回路から期待値$$と$$を求めregisterします.
step 4
パラメータを更新していきます.
\delta J_{jk}^n = \bar{<Z_j Z_k>}_D - <Z_j Z_k> \\ \delta B_j^n = \bar{<Z_j>}_D - <Z_j> \\ J_j^{n+1} = J_j^n + \delta J_j^n \\ B_i^{n+1} = B_j^n + \delta B_j^nstep 5
$epoch = n+1$して,step1に戻ります.
code
# coding: utf-8 from qiskit.aqua.utils import tensorproduct from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister from qiskit.quantum_info.analysis import average_data import numpy as np from copy import deepcopy from QAOA import QAOA from my_functions import sigmoid class QBM: def __init__(self, num_visible=2, num_hidden=1, steps=3, tmep=1.0, quant_meas_num=None, bias=False, reduced=False): self.visible_units = num_visible # v self.hidden_units = num_hidden # h self.total_units = self.visible_units + self.hidden_units self.quant_meas_num = quant_meas_num self.qaoa_steps = steps self.beta_temp = tmep self.state_prep_angle = np.arctan(np.exp(-1 / self.beta_temp)) * 2.0 self.param_wb = 0.1 * np.sqrt(6. / self.total_units) self.WEIGHTS = np.asarray(np.zeros(shape=[self.visible_units, self.hidden_units])) if bias: self.BIAS = np.asarray(np.zeros(shape=[self.hidden_units])) else: self.BIAS = None self.reduced = reduced self.obs = self.observable() self.obs_tilde = self.observable(tilde=True) self.data_point = None '----------------------------------------------------------------------' def Zi_Zj(self, q1, q2): I_mat = np.array([[1, 0], [0, 1]]) Z_mat = np.array([[1, 0], [0, -1]]) if q1 == 0 or q2 == 0: tensor = Z_mat else: tensor = I_mat for i in range(1, self.total_units): if i == q1 or i == q2: tensor = tensorproduct(tensor, Z_mat) else: tensor = tensorproduct(tensor, I_mat) return tensor def Zi(self, q): I_mat = np.array([[1, 0], [0, 1]]) Z_mat = np.array([[1, 0], [0, -1]]) if q == 0: tensor = Z_mat else: tensor = I_mat for i in range(1, self.total_units): if i == q: tensor = tensorproduct(tensor, Z_mat) else: tensor = tensorproduct(tensor, I_mat) return tensor def observable(self, tilde=False): visible_indices = [i for i in range(self.visible_units)] hidden_indices = [i + self.visible_units for i in range(self.hidden_units)] total_indices = [i for i in range(self.total_units)] obs = np.zeros((2**self.total_units, 2**self.total_units)) for q1 in visible_indices: for q2 in hidden_indices: obs += -1.0 * self.Zi_Zj(q1, q2) if self.BIAS is not None: if tilde: for q in hidden_indices: obs += -1.0 * self.Zi(q) elif not tilde: for q in total_indices: obs += -1.0 * self.Zi(q) return obs '----------------------------------------------------------------------' def U_circuit(self, params, qc): visible_indices = [i for i in range(self.visible_units)] hidden_indices = [i + self.visible_units for i in range(self.hidden_units)] total_indices = [i for i in range(self.total_units)] p = 2 alpha = self.state_prep_angle for i in total_indices: qc.rx(alpha, i) for i in visible_indices: for j in hidden_indices: qc.cx(i, j) beta, gamma = params[:p], params[p:] def add_U_X(qc, beta): for i in total_indices: qc.rx(-2**beta, i) return qc def add_U_C(qc, gamma): for q1 in visible_indices: for q2 in hidden_indices: qc.cx(q1, q2) qc.rz(-2**gamma, q2) qc.cx(q1, q2) return qc for i in range(p): qc = add_U_C(qc, gamma[i]) qc = add_U_X(qc, beta[i]) return qc def unclamped_circuit(self, params): qr = QuantumRegister(self.total_units) cr = ClassicalRegister(self.total_units) qc = QuantumCircuit(qr, cr) qc = self.U_circuit(params, qc) qc.measure(range(self.total_units), range(self.total_units)) return qc def make_unclamped_QAOA(self): qaoa = QAOA(qc=self.unclamped_circuit, observable=self.obs, num_shots=10000, p=2) counts = qaoa.qaoa_run() return counts def clamped_circuit(self, params): qr = QuantumRegister(self.total_units) cr = ClassicalRegister(self.total_units) qc = QuantumCircuit(qr, cr) for i in range(len(self.data_point)): if self.data_point[i] == 1: qc.x(i) qc = self.U_circuit(params, qc) qc.measure(range(self.total_units), range(self.total_units)) return qc def make_clamped_QAOA(self, data_point): self.data_point = data_point qaoa = QAOA(qc=self.clamped_circuit, observable=self.obs_tilde, num_shots=10000, p=2) counts = qaoa.qaoa_run() return counts def train(self, DATA, learning_rate=0.2, n_epochs=100, quantum_percentage=1.0, classical_percentage=0.0): assert (quantum_percentage + classical_percentage == 1.0) DATA = np.asarray(DATA) assert (len(DATA[0]) <= self.visible_units) for epoch in range(n_epochs): print('Epoch: {}'.format(epoch+1)) visible_indices = [i for i in range(self.visible_units)] hidden_indices = [i + self.visible_units for i in range(self.hidden_units)] total_indices = [i for i in range(self.total_units)] new_weights = deepcopy(self.WEIGHTS) if self.BIAS is not None: new_bias = deepcopy(self.BIAS) counts = self.make_unclamped_QAOA() unc_neg_phase_quant = np.zeros_like(self.WEIGHTS) for i in range(self.visible_units): for j in range(self.hidden_units): model_expectation = average_data(counts, self.Zi_Zj(visible_indices[i], hidden_indices[j])) unc_neg_phase_quant[i][j] = model_expectation unc_neg_phase_quant *= (1. / float(len(DATA))) if self.BIAS is not None: unc_neg_phase_quant_bias = np.zeros_like(self.BIAS) for i in range(self.hidden_units): model_expectation = average_data(counts, self.Zi(hidden_indices[i])) unc_neg_phase_quant_bias[i] = model_expectation unc_neg_phase_quant_bias *= (1. / float(len(DATA))) pos_hidden_probs = sigmoid(np.dot(DATA, self.WEIGHTS)) pos_hidden_states = pos_hidden_probs > np.random.rand(len(DATA), self.hidden_units) pos_phase_classical = np.dot(DATA.T, pos_hidden_probs) * 1. / len(DATA) c_pos_phase_quant = np.zeros_like(self.WEIGHTS) if self.BIAS is not None: c_pos_phase_quant_bias = np.zeros_like(self.BIAS) if not self.reduced: iter_dat = len(DATA) pro_size = len(DATA) pro_step = 1 for data in DATA: counts = self.make_clamped_QAOA(data) ct_pos_phase_quant = np.zeros_like(self.WEIGHTS) for i in range(self.visible_units): for j in range(self.hidden_units): model_expectation = average_data(counts, self.Zi_Zj(visible_indices[i], hidden_indices[j])) ct_pos_phase_quant[i][j] = model_expectation c_pos_phase_quant += ct_pos_phase_quant if self.BIAS is not None: ct_pos_phase_quant_bias = np.zeros_like(self.BIAS) for i in range(self.hidden_units): model_expectation = average_data(counts, self.Zi(hidden_indices[i])) ct_pos_phase_quant_bias[i] = model_expectation c_pos_phase_quant_bias *= ct_pos_phase_quant_bias pro_bar = ('==' * pro_step) + ('--' * (pro_size - pro_step)) print('\r[{0}] {1}/{2}'.format(pro_bar, pro_step, pro_size), end='') pro_step += 1 c_pos_phase_quant *= (1. / float(len(DATA))) if self.BIAS is not None: c_pos_phase_quant_bias *= (1. / float(len(DATA))) neg_visible_activations = np.dot(pos_hidden_states, self.WEIGHTS.T) neg_visible_probs = sigmoid(neg_visible_activations) neg_hidden_activations = np.dot(neg_visible_probs, self.WEIGHTS) neg_hidden_probs = sigmoid(neg_hidden_activations) neg_phase_classical = np.dot( neg_visible_probs.T, neg_hidden_probs) * 1. / len(DATA) new_weights += learning_rate * \ (classical_percentage * (pos_phase_classical - neg_phase_classical) + quantum_percentage * (c_pos_phase_quant - unc_neg_phase_quant)) if self.BIAS is not None: new_bias = new_bias + learning_rate * \ (quantum_percentage * (c_pos_phase_quant_bias - unc_neg_phase_quant_bias)) self.WEIGHTS = deepcopy(new_weights) if self.BIAS is not None: self.BIAS = deepcopy(new_bias) with open("RBM_info.txt", "w") as f: np.savetxt(f, self.WEIGHTS) if self.BIAS is not None: np.savetxt(f, self.BIAS) with open("RBM_history.txt", "a") as f: np.savetxt(f, self.WEIGHTS) if self.BIAS is not None: np.savetxt(f, self.BIAS) f.write(str('*' * 72) + '\n') print('') print("Training Done! ") def transform(self, DATA): return sigmoid(np.dot(DATA, self.WEIGHTS)) if __name__ == '__main__': qbm = QBM(num_visible=6, num_hidden=2,bias=True) train_data = [[1, 1, 1, 1, 1, 1], [1, 1, 1, 1, -1, 1], [-1, -1, 1, -1, 1, 1], [-1, -1, -1, 1, 1, 1], [1, 1, -1, -1, 1, 1], [1, -1, -1, -1, 1, 1], [1, 1, 1, 1, -1, -1], [1, 1, 1, -1, -1, -1]] qbm.train(DATA=train_data, n_epochs=100, quantum_percentage=1.0, classical_percentage=0.0) print(qbm.transform(train_data))codeの解説
def Z_i def Z_iZ_j def observavleで$Z_i Z_j$などを作成していくことができます.
また,observable関数のtildeをTrueにすることで$H_{\tilde{C}}^n$を作成します.def U_circuit # QAOAに用いるparameter circuitの作成 def unclamped_circuit # step2 で使用するcircuit def make_unclamped_QAOA # step2 の実行 def clamped_circuit # step3 で使用するcircuit def make_clamped_QAOA # step3 の実行自作ライブラリーQAOAについて
今回自作のQiskitライブラリーQAOAを使用しています.
# coding: utf-8 from qiskit import BasicAer, execute from qiskit.quantum_info.analysis import average_data from scipy.optimize import minimize import numpy as np def classica_minimize(cost_func, initial_params, options, method='powell'): result = minimize(cost_func, initial_params, options=options, method=method) return result.x class QAOA: def __init__(self, qc, observable, num_shots, p=1, initial_params=None): self.QC = qc self.obs = observable self.SHOTS = num_shots self.P = p if initial_params is None: self.initial_params = [0.1 for _ in range(self.P * 2)] else: self.initial_params = initial_params def QAOA_output_layer(self, params): qc = self.QC(params) backend = BasicAer.get_backend('qasm_simulator') results = execute(qc, backend, shots=self.SHOTS).result() counts = results.get_counts(qc) expectation = average_data(counts, self.obs) return expectation def minimize(self): initial_params = np.array(self.initial_params) opt_params = classica_minimize(self.QAOA_output_layer, initial_params, options={'maxiter':500}, method='powell') return opt_params def qaoa_run(self): opt_params = self.minimize() qc = self.QC(opt_params) backend = BasicAer.get_backend('qasm_simulator') results = execute(qc, backend, shots=self.SHOTS).result() counts = results.get_counts(qc) return counts if __name__ == '__main__': passこれは以前紹介したQiskit: Qiskit Aquaを使わないQAOAの実装という記事で紹介したcodeの汎用版です.
#実行結果
簡単な入力データを用いて古典制限ボルツマンマシンとの比較を行いました.
train_data = [[1, 1, 1, 1, 1, 1], [1, 1, 1, 1, -1, 1], [-1, -1, 1, -1, 1, 1], [-1, -1, -1, 1, 1, 1], [1, 1, -1, -1, 1, 1], [1, -1, -1, -1, 1, 1], [1, 1, 1, 1, -1, -1], [1, 1, 1, -1, -1, -1]]なお,古典のボルツマンマシンのcodeはこちらを参考にしています.
pythonで制約ボルツマンマシン実装古典制限ボルツマンマシンの結果
lerning_late = 0.2
n_epoch = 100[[4.54858185e-216 2.33105820e-106] [4.35459577e-305 1.00000000e+000] [1.00000000e+000 3.29488973e-199] [1.00000000e+000 1.56917283e-202] [1.00000000e+000 1.17411435e-196] [1.00000000e+000 5.94251933e-244] [0.00000000e+000 1.00000000e+000] [3.48247512e-141 1.00000000e+000]]QABoMの結果
lerning_late = 0.2
n_epoch = 100[[0.59991237 0.68602485] [0.74497707 0.89553788] [0.26436565 0.113528 ] [0.2682931 0.1131361 ] [0.58273232 0.3268427 ] [0.41413436 0.14647751] [0.74056361 0.94317095] [0.7317069 0.8868639 ]]一応一致していますかね?
個人的には古典よりもはっきりとした結果が得られないのが不満です.改良版を作成した方がいたら私のほうまでお願いします.ちなみに古典は一瞬で解が出ますが,量子はcorei7,CPUmemory16GBで半日かかります.
もう少しゆっくり実験を行いたいのですが,,,(じっくり計算を行ったのをそのうち載せます.)
まとめ
このプログラム自体は以前から作成していたものですが,如何せんcodeが汚かったので載せていませんでした.
他の言語(確かpyquil)で書かれているものも一つ公開されていたので,私はqiskitで実装をしてみました.日本語が不自由なのは許してください.
参考サイト一覧
論文:A quantum algorithm to train neural networks using low-depth circuits
Qiskit: Qiskit textbook
QAOA: Quantum Native Dojo
RBM: pythonで制約ボルツマンマシン実装
- 投稿日:2020-05-29T20:43:48+09:00
ゼロから始めるLeetCode Day40「114. Flatten Binary Tree to Linked List」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day39「494. Target Sum」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
40回目です。そろそろ辞め時が分からなくなってきました。
問題
114. Flatten Binary Tree to Linked List
難易度はMedium。
Top 100 Liked Questionsからの抜粋です。二分木が与えられるので、フラットなリストに変換するようなアルゴリズムを設計してください。
これだけでは分かりづらいので例を見てみましょう。
1 / \ 2 5 / \ \ 3 4 6 The flattened tree should look like: 1 \ 2 \ 3 \ 4 \ 5 \ 6やはり例を見ると分かりやすいですね。
解法
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: def flatten(self, root: TreeNode) -> None: prelevel = None """ Do not return anything, modify root in-place instead. """ def dfs(node): if node: dfs(node.right) dfs(node.left) nonlocal prelevel node.right = prelevel node.left = None prelevel = node dfs(root) # Runtime: 36 ms, faster than 74.14% of Python3 online submissions for Flatten Binary Tree to Linked List. # Memory Usage: 14.6 MB, less than 8.70% of Python3 online submissions for Flatten Binary Tree to Linked List.dfsで解きました。
prelevelで代入する要素を保持し、ひたすらnode.rightに要素を、node.leftにNoneを代入し、prelevelに次の要素を入れる、というものです。良い感じの回答にまとまりました。
今回はこの辺で。お疲れ様でした。
- 投稿日:2020-05-29T19:57:30+09:00
Ansible 自作モジュール作成 ~その2:ただコマンドを実行したい人生~
前回の記事:Ansible 自作モジュール作成 ~その1:引数受け取りたい人生~
振り返り
- モジュールの雛形作った
- 複数の引数受け取れた
ただコマンドを実行してみる
相変わらずの教科書 Ansibleのモジュール開発(Python実装編) 様を参考に、まずは
run_commandを試してみる。makefifo.py#!/usr/bin/python # -*- coding: utf-8 -*- from ansible.module_utils.basic import AnsibleModule # メイン処理 #----------------------------------------------------------- def main(): # AnsibleModuleクラス: moduleを作成 module = AnsibleModule( # 引数受け取り argument_spec=dict( # 引数: path(str型, 必須) path=dict(type='str', required=True), # 引数: owner(str型, 必須) owner=dict(type='str', required=True), # 引数: group(str型, 必須) group=dict(type='str', required=True), # 引数: mode(str型, 必須) mode=dict(type='str', required=True), ), # 引数チェックを有効 supports_check_mode=True ) # 何も考えずに実行するんだぜ rc, stdout, stderr = module.run_command("/bin/touch /tmp/udon.txt") # コマンド結果を返却 module.exit_json( changed=True, rc=rc, stdout=stdout, stderr=stderr ) if __name__ == '__main__': main()実行~
$ ansible -i test_grp 192.168.56.104 -m makefifo -M library -u root -a "path=/tmp/hoge owner=root group=root mode=0644" 192.168.56.104 | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "rc": 0, "stderr": "", "stderr_lines": [], "stdout": "", "stdout_lines": [] } $ ssh root@192.168.56.104 "ls -l /tmp" 合計 0 -rw-r--r--. 1 root root 0 5月 29 10:45 2020 udon.txt -rw-------. 1 root root 0 5月 27 06:34 2020 yum.logよしよし。
引数を利用してコマンド実行
取り急ぎは
pathを利用してmkfifoしてみよう。ownerとかはまたあとで。
ちなみにココで「makefifoじゃなくてmkfifoやん・・・」と気づいて名前変えた。mkfifo.py# pathを利用したい rc, stdout, stderr = module.run_command("/usr/bin/mkfifo ")えーと、、ここに…どうすんだ?じつは
Python使うの初めてなので変数の結合とかわからないんだよな。
そしたらping.pyを調べる時に参考にしていた [python初心者向け]関数の引数のアスタリスク(*)の意味様 に書いてあるぞ!def loop2(before, *args, after): print(before) for arg in args: print(arg + '!') print(after)なるほど、
+で文字列結合できるんやな。mkfifo.py# pathを利用したい rc, stdout, stderr = module.run_command("/usr/bin/mkfifo " + )・・・えーと、、この変数はなんだ?
dict型というperlでいうところのHashみたいなもんだというのはわかるのだが。あ!これもAnsibleのモジュール開発(Python実装編)さんに書いてったな!
print '{"message_key":"%s"}' % (module.params['message'])ということはつまりこうだな!
mkfifo.py#!/usr/bin/python # -*- coding: utf-8 -*- from ansible.module_utils.basic import AnsibleModule # メイン処理 #----------------------------------------------------------- def main(): # AnsibleModuleクラス: moduleを作成 module = AnsibleModule( # 引数受け取り argument_spec=dict( # 引数: path(str型, 必須) path=dict(type='str', required=True), # 引数: owner(str型, 必須) owner=dict(type='str', required=True), # 引数: group(str型, 必須) group=dict(type='str', required=True), # 引数: mode(str型, 必須) mode=dict(type='str', required=True), ), # 引数チェックを有効 supports_check_mode=True ) # pathを利用したい rc, stdout, stderr = module.run_command("/usr/bin/mkfifo " + module.params['path']) # コマンド結果を返却 module.exit_json( changed=True, rc=rc, stdout=stdout, stderr=stderr ) if __name__ == '__main__': main()さぁときは満ちた!実行!!
$ ansible -i test_grp 192.168.56.104 -m mkfifo -M library -u root -a "path=/tmp/udon_pipe owner=root group=root mode=0644" 192.168.56.104 | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "rc": 0, "stderr": "", "stderr_lines": [], "stdout": "", "stdout_lines": [] } $ ssh root@192.168.56.104 "ls -l /tmp" 合計 0 -rw-r--r--. 1 root root 0 5月 29 10:45 2020 udon.txt prw-r--r--. 1 root root 0 5月 29 10:54 2020 udon_pipe -rw-------. 1 root root 0 5月 27 06:34 2020 yum.logよしよし、なんか少しずつ進んでるぞぉ。
今日はココまで。
- 投稿日:2020-05-29T19:55:03+09:00
Flaskを使用し、外部ファイルを実行する
やったこと
Flaskでウェブページを作成。
ボタンをクリックすると外部のスクレイピングファイルを実行させる。Flaskの準備
Flaskのインストール
pip install Flask元となるファイルを作成
root.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def hello(): return 'Hello!' if __name__ == "__main__": app.run(debug=True)実行
python root.pyその後
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)と、出力されるのでhttp://127.0.0.1:5000/ へアクセスします。
Hello!が表示されています。
テンプレートエンジン「Jinja2」を使ってHTMLを書く
import等追加する
root.py# from flask import Flask # 追加↓ from flask import Flask, render_template app = Flask(__name__) @app.route('/') def hello(): #return 'Hello!' # 追加↓ return render_template('layout.html', title='Scraping App') if __name__ == "__main__": app.run(debug=True)templatesフォルダを作成し、その中にlayout.htmlを作ります。
buttonタグをクリックすることでGETメソッドを送信するようにします。layout.html<!doctype html> <html> <head> <!-- ↓ render_templateの中で書いたtitleが入る --> <title>{{ title }}</title> </head> <body> <div class="member"> <img src="/static/img/akimoto.jpg" alt="img1"> <h2>秋元真夏</h2> <form method="GET" action="/scraping"> <button type="submit">Start Scraping</button> </form> </div> </body> </html>staticフォルダを作成し、中にcss、img作成し、見た目を整える。
最終的なファイル中身
root.pyfrom flask import Flask, render_template # ↓ Flaskを通し実行したいファイルをインポート import scraping app = Flask(__name__) @app.route('/') def hello(): return render_template('layout.html', title='Scraping App') # ↓ /scrapingをGETメソッドで受け取った時の処理 @app.route('/scraping') def get(): # ↓ 実行したいファイルの関数 return scraping.scraping() if __name__ == "__main__": app.run(debug=True)layout.html<!doctype html> <html> <head> <title>{{ title }}</title> <link rel="stylesheet" href="/static/css/index.css"> </head> <body> <div class="member"> <img src="/static/img/akimoto.jpg" alt="img1"> <h2>秋元真夏</h2> <form method="GET" action="/scraping"> <button type="submit">Start Scraping</button> </form> </div> </body> </html>↓ 今回実行したスクレイピングファイル
乃木坂46ブログの画像をスクレイピングで取得する最終のフォルダ構成
- /root.py
- /scraping.py
- /templates
- layout.html
- /static
- /css
- /index.css
- /img
- /akimoto.jpg
表示画面
ボタンをクリック後、作成されたフォルダ
これまでコンソールから実行していたPythonファイルをウェブページを通して行えるようになりました!


- 投稿日:2020-05-29T19:52:46+09:00
☆安西先生…!!データ分析がしたいです……その1 データ準備☆ PythonでNBAの選手スタッツ(成績)を分析してみる。バスケ
全国のバスケ好きのみなさん、こんにちは。相田彦一と申します。
普段はとある高校のバスケットボールチームでマネージャー兼データサイエンティストとして様々なデータの分析を仕事としています。今回は本場アメリカのプロバスケットリーグであるNBAの選手スタッツ(成績)を分析したいと思います。
分析といっても簡単なものですが、お付き合いください。第1回目はデータ準備ということでスクレイピング&前処理についてです。
第2回以降がいつになるかはわかりません、ご容赦ください。永遠にないかもしれません。環境
Google Colaboratoryを使いました。
今回紹介する処理はプリインストールされているライブラリだけで動かすことができます。大変便利です。データ収集
スクレイピング
データ収集の部分をどうしようかと検索していると、下記のブログ記事をみつけました。
ほとんどこの記事と内容そのままですが、選手の身長、体重などもスクレイピングするかもしれないと思い、選手個人ページのURLもスクレイピング対象に含めました。
一定間隔でカラム名を表すレコードが挿入されているので、そのレコードはスキップするようにしました。data = pd.DataFrame() years = [i for i in range(2000, 2002)] for year in years: url = "https://www.basketball-reference.com/leagues/NBA_{}_per_game.html".format(year) # this is the HTML from the given URL html = urlopen(url) soup = BeautifulSoup(html) soup.findAll('tr', limit=2) # use getText()to extract the text we need into a list headers = [th.getText() for th in soup.findAll('tr', limit=2)[0].findAll('th')] # exclude the first column as we will not need the ranking order from Basketball Reference for the analysis headers = ['URL'] + headers[1:] + ['Year'] rows = soup.findAll('tr')[1:] player_stats = [[rows[i].a.get('href')] + [td.getText() for td in rows[i].findAll('td')] for i in range(len(rows)) if (rows[i].findAll('td')) and (rows[i].a)] stats = pd.DataFrame(player_stats) stats['Year'] = str(year) stats.columns = headers data = pd.concat([data, stats]) data = data.dropna()スクレイピングする対象のページの一例はこちらです。
そのシーズンに出場した選手のスタッツがすベて1ページのサイトに収まっているので、ドラッグしてエクセルなどの表計算ソフトにコピペしても十分にデータ収集できると思います。
今回は20年間(2000年~2019年)のデータを対象としました。スクレイピング結果はこのようになりました。
URL Player Pos Age Tm G GS MP FG FGA FG% 3P 3PA 3P% 2P 2PA 2P% eFG% FT FTA FT% ORB DRB TRB AST STL BLK TOV PF PTS Year 0 /players/a/abdulta01.html Tariq Abdul-Wahad SG 25 TOT 61 56 25.9 4.5 10.6 .424 0.0 0.4 .130 4.4 10.2 .435 .426 2.4 3.2 .756 1.7 3.1 4.8 1.6 1.0 0.5 1.7 2.4 11.4 2000 1 /players/a/abdulta01.html Tariq Abdul-Wahad SG 25 ORL 46 46 26.2 4.8 11.2 .433 0.0 0.5 .095 4.8 10.7 .447 .435 2.5 3.3 .762 1.7 3.5 5.2 1.6 1.2 0.3 1.9 2.5 12.2 2000 2 /players/a/abdulta01.html Tariq Abdul-Wahad SG 25 DEN 15 10 24.9 3.4 8.7 .389 0.1 0.1 .500 3.3 8.6 .388 .393 2.1 2.8 .738 1.6 1.9 3.5 1.7 0.4 0.8 1.3 2.1 8.9 2000 3 /players/a/abdursh01.html Shareef Abdur-Rahim SF 23 VAN 82 82 39.3 7.2 15.6 .465 0.4 1.2 .302 6.9 14.4 .478 .477 5.4 6.7 .809 2.7 7.4 10.1 3.3 1.1 1.1 3.0 3.0 20.3 2000 4 /players/a/alexaco01.html Cory Alexander PG 26 DEN 29 2 11.3 1.0 3.4 .286 0.3 1.2 .257 0.7 2.2 .302 .332 0.6 0.8 .773 0.3 1.2 1.4 2.0 0.8 0.1 1.0 1.3 2.8 2000 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 703 /players/z/zellety01.html Tyler Zeller C 29 MEM 4 1 20.5 4.0 7.0 .571 0.0 0.0 4.0 7.0 .571 .571 3.5 4.5 .778 2.3 2.3 4.5 0.8 0.3 0.8 1.0 4.0 11.5 2019 704 /players/z/zizican01.html Ante Žižić C 22 CLE 59 25 18.3 3.1 5.6 .553 0.0 0.0 3.1 5.6 .553 .553 1.6 2.2 .705 1.8 3.6 5.4 0.9 0.2 0.4 1.0 1.9 7.8 2019 705 /players/z/zubaciv01.html Ivica Zubac C 21 TOT 59 37 17.6 3.6 6.4 .559 0.0 0.0 3.6 6.4 .559 .559 1.7 2.1 .802 1.9 4.2 6.1 1.1 0.2 0.9 1.2 2.3 8.9 2019 706 /players/z/zubaciv01.html Ivica Zubac C 21 LAL 33 12 15.6 3.4 5.8 .580 0.0 0.0 3.4 5.8 .580 .580 1.7 2.0 .864 1.6 3.3 4.9 0.8 0.1 0.8 1.0 2.2 8.5 2019 707 /players/z/zubaciv01.html Ivica Zubac C 21 LAC 26 25 20.2 3.8 7.2 .538 0.0 0.0 3.8 7.2 .538 .538 1.7 2.3 .733 2.3 5.3 7.7 1.5 0.4 0.9 1.4 2.5 9.4 2019 前処理
欠損値
FG%(フィールドゴール成功率=シュート成功率と思ってください)などの確率を表すスタッツは試投数が0であれば空文字になっているようです。NaNに置換します。
data = data.replace(r'^\s*$', np.NaN, regex=True)データ型変更
データ型が文字列になっています。数字として扱いたいデータをfloatに変換します。整数のみのデータもありますが、面倒なので全部floatにします。
変更前に、パーセントで表される成績が.XXXという表記になっており、そのままでは数字に変換できないので先頭に0をつけます。add_zero_cols = [col for col in data.columns if '%' in col] num_cols = ['Age'] + list(data.columns[5:-1]) for col in add_zero_cols: data[col] = '0' + data[col] for col in num_cols: data[col] = data[col].astype(float)確認してみましょう。平均得点トップ10を表示します。
data.sort_values('PTS', ascending=False)[['Player', 'PTS', 'Year']].head(10)
Player PTS Year 11135 James Harden 36.1 2019 3266 Kobe Bryant* 35.4 2006 3428 Allen Iverson* 33.0 2006 1813 Tracy McGrady* 32.1 2003 7954 Kevin Durant 32.0 2014 3818 Kobe Bryant* 31.6 2007 10167 Russell Westbrook 31.6 2017 1249 Allen Iverson* 31.4 2002 3442 LeBron James 31.4 2006 715 Allen Iverson* 31.1 2001 問題なさそうです。ジェームズ・ハーデン、アレン・アイバーソン、コービー・ブライアントなど日本でも知名度があるスーパースターが勢揃いしています。
名前の後ろの*マークが何を表すかデータソースのページを軽く確認したのですが、よくわかりませんでした
殿堂入りしている選手を表しているかもしれません。追加データ 身長・体重
追加でスクレイピング項目に含めていた個人ページのURLから身長、体重もデータを収集しました。
(冒頭のコードを少し変えるだけで収集できるので追加データに対するコードは省略します)最終的にこのようなデータが準備できました。(右端にWeightとHeightのカラムが追加されました)
Player Pos Age Tm G GS MP FG FGA FG% 3P 3PA 3P% 2P 2PA 2P% eFG% FT FTA FT% ORB DRB TRB AST STL BLK TOV PF PTS Year Weight Height 0 Tariq Abdul-Wahad SG 25.0 TOT 61.0 56.0 25.9 4.5 10.6 0.424 0.0 0.4 0.130 4.4 10.2 0.435 0.426 2.4 3.2 0.756 1.7 3.1 4.8 1.6 1.0 0.5 1.7 2.4 11.4 2000 101.24 1.98 3 Shareef Abdur-Rahim SF 23.0 VAN 82.0 82.0 39.3 7.2 15.6 0.465 0.4 1.2 0.302 6.9 14.4 0.478 0.477 5.4 6.7 0.809 2.7 7.4 10.1 3.3 1.1 1.1 3.0 3.0 20.3 2000 102.15 2.06 5 Ray Allen* SG 24.0 MIL 82.0 82.0 37.4 7.8 17.2 0.455 2.1 5.0 0.423 5.7 12.2 0.468 0.516 4.3 4.9 0.887 1.0 3.4 4.4 3.8 1.3 0.2 2.2 2.3 22.1 2000 93.07 1.96 7 John Amaechi C 29.0 ORL 80.0 53.0 21.1 3.8 8.8 0.437 0.0 0.1 0.167 3.8 8.7 0.439 0.438 2.8 3.6 0.766 0.8 2.6 3.3 1.2 0.4 0.5 1.7 2.0 10.5 2000 122.58 2.08 8 Derek Anderson SG 25.0 LAC 64.0 58.0 34.4 5.9 13.4 0.438 0.9 2.8 0.309 5.0 10.7 0.472 0.470 4.2 4.8 0.877 1.3 2.8 4.0 3.4 1.4 0.2 2.6 2.3 16.9 2000 88.08 1.96 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 11561 Delon Wright PG 26.0 TOT 75.0 13.0 22.7 3.2 7.4 0.434 0.7 2.2 0.298 2.6 5.2 0.492 0.478 1.6 2.0 0.793 0.9 2.6 3.5 3.3 1.2 0.4 1.0 1.4 8.7 2019 83.08 1.96 11566 Thaddeus Young PF 30.0 IND 81.0 81.0 30.7 5.5 10.4 0.527 0.6 1.8 0.349 4.8 8.6 0.564 0.557 1.1 1.7 0.644 2.4 4.1 6.5 2.5 1.5 0.4 1.5 2.4 12.6 2019 99.88 2.03 11567 Trae Young PG 20.0 ATL 81.0 81.0 30.9 6.5 15.5 0.418 1.9 6.0 0.324 4.6 9.6 0.477 0.480 4.2 5.1 0.829 0.8 2.9 3.7 8.1 0.9 0.2 3.8 1.7 19.1 2019 81.72 1.86 11572 Ante Žižić C 22.0 CLE 59.0 25.0 18.3 3.1 5.6 0.553 0.0 0.0 NaN 3.1 5.6 0.553 0.553 1.6 2.2 0.705 1.8 3.6 5.4 0.9 0.2 0.4 1.0 1.9 7.8 2019 115.32 2.08 11573 Ivica Zubac C 21.0 TOT 59.0 37.0 17.6 3.6 6.4 0.559 0.0 0.0 NaN 3.6 6.4 0.559 0.559 1.7 2.1 0.802 1.9 4.2 6.1 1.1 0.2 0.9 1.2 2.3 8.9 2019 108.96 2.13 ちなみに過去20年での身長トップ10は
df.groupby(['Player']).max().reset_index().sort_values('Height', ascending=False)[['Player', 'Year', 'Height', 'Weight']].head(10)
Player Year Height Weight 672 Gheorghe Mureșan 2000 2.31 137.56 1641 Shawn Bradley 2005 2.29 106.69 1890 Yao Ming* 2011 2.29 140.74 1653 Sim Bhullar 2015 2.26 163.44 1442 Pavel Podkolzin 2006 2.26 118.04 1656 Slavko Vraneš 2004 2.26 124.85 1519 Rik Smits 2000 2.24 113.50 172 Boban Marjanović 2019 2.24 131.66 1449 Peter John Ramos 2005 2.21 124.85 583 Edy Tavares 2017 2.21 118.04 単位はm(メートル)です。3位は万里の長城とも呼ばれたあのヤオ・ミンです。身長デカすぎぃ。
おわり
無事にデータが準備できたので、次回は可視化してみたいと思います。
おまけ
平均アシスト トップ10
data.sort_values('AST', ascending=False)[['Player', 'AST', 'Year']].head(10)
Player AST Year 6617 Deron Williams 12.8 2011 7061 Rajon Rondo 11.7 2012 9486 Rajon Rondo 11.7 2016 4085 Steve Nash* 11.6 2007 4686 Chris Paul 11.6 2008 2977 Steve Nash* 11.5 2005 6440 Steve Nash* 11.4 2011 6509 Rajon Rondo 11.2 2011 9819 James Harden 11.2 2017 7641 Rajon Rondo 11.1 2013 平均リバウンド トップ10
data.sort_values('TRB', ascending=False)[['Player', 'TRB', 'Year']].head(10)
Player TRB Year 7236 Earl Barron 18.0 2013 651 Danny Fortson 16.3 2001 10372 Andre Drummond 16.0 2018 11056 Andre Drummond 15.6 2019 1974 Ben Wallace 15.4 2003 6391 Kevin Love 15.2 2011 10537 DeAndre Jordan 15.2 2018 8695 DeAndre Jordan 15.0 2015 9163 Andre Drummond 14.8 2016 6894 Dwight Howard 14.5 2012 規定試合数に達していない選手は除外しないとダメそう。
- 投稿日:2020-05-29T19:48:53+09:00
ゼロから作るDeep Learning2の応用 スパムフィルタ
1.はじめに
ステイホーム期間中に「ゼロから作るDeep learning② 自然言語処理編」を読みました。
何とか最後までたどり着きましたが、このテキストには応用例があまり記載されていません。
そこで、テキストのコードを活用して、スパムフィルタ(文書分類モデル)を作成してみます。
本検討はQiitaの記事ゼロから作るRNNによる文章分類モデルを参考にしました。2.データ
Kaggleにある「SMS Spam Collection Dataset」を利用します。
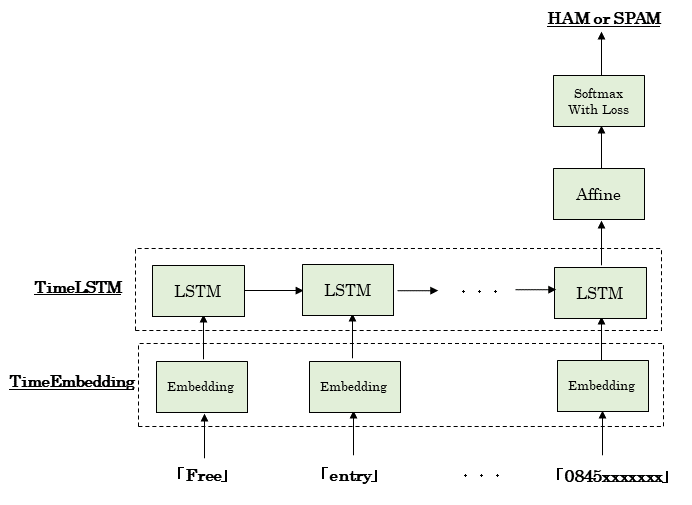
3.モデルの概要
- LSTMによる文書分類
- テキストの6章のコードを活用
- 最後のLSTMから出てきた隠れ状態ベクトルhをAffine変換で2値化し、Softmax関数で正規化する。
4.実装
- Google Colabの準備
# coding: utf-8 from google.colab import drive drive.mount('/content/drive')
- モジュールのインポート
import sys sys.path.append('drive/My Drive/Colab Notebooks/spam_filter') import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn import metrics from keras.preprocessing.text import Tokenizer from keras.preprocessing import sequence %matplotlib inline
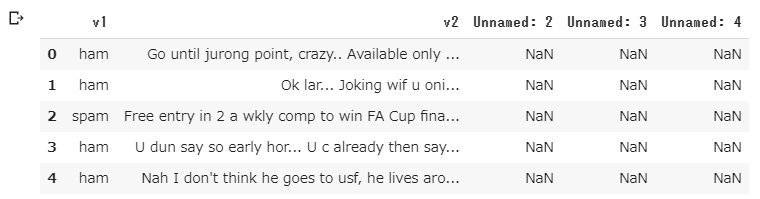
- CSVファイルをpandasで読み込んで最初の5行を表示
1列目はラベル(ham or spam)、2列目がメッセージ、3~5列は空行です。
spamのメッセージは「大当たり! すぐにxxxまで連絡して」的なものが多いようです。df = pd.read_csv('drive/My Drive/Colab Notebooks/spam_filter/dataset/spam.csv',encoding='latin-1') df.head()
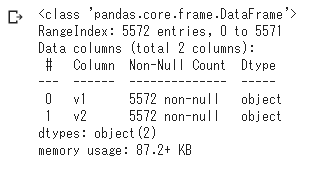
- 空行を削除して情報表示
メッセージの総数は5572df.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'],axis=1,inplace=True) df.info()
- hamとspamの総数
hamがspamの6倍くらい多いsns.countplot(df.v1) plt.xlabel('Label') plt.title('Number of ham and spam messages')
- scikit-learnでラベルエンコーディング
- kerasのTokenizerでメッセージをトークン化
X = df.v2 Y = df.v1 le = LabelEncoder() Y = le.fit_transform(Y) max_words = 1000 max_len = 150 tok = Tokenizer(num_words=max_words) tok.fit_on_texts(X) word_to_id = tok.word_index X_ids = tok.texts_to_sequences(X) X_ids_pad = sequence.pad_sequences(X_ids,maxlen=max_len)
- 各メッセージの語数をヒストグラムで表示
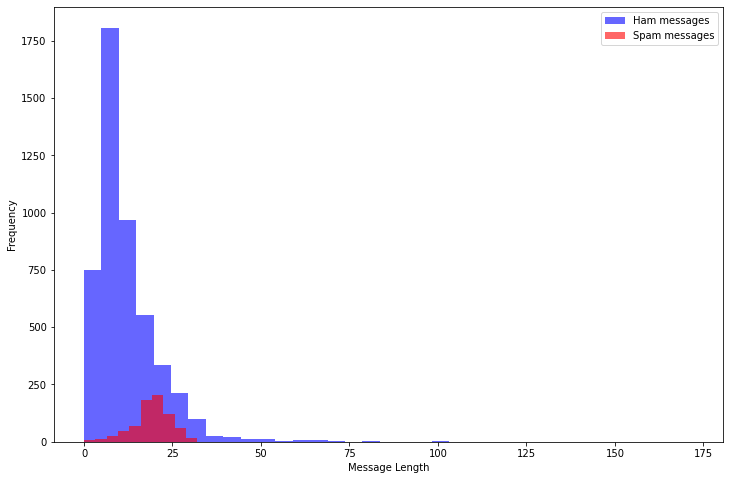
最大でも100語程度で、Spamの方が長いものが多い。message_len = [len(v) for v in X_ids] df['message_len']=message_len plt.figure(figsize=(12, 8)) df[df.v1=='ham'].message_len.plot(bins=35, kind='hist', color='blue', label='Ham messages', alpha=0.6) df[df.v1=='spam'].message_len.plot(kind='hist', color='red', label='Spam messages', alpha=0.6) plt.legend() plt.xlabel("Message Length")
モデルの実装
- sigmoid関数、softmax関数、cross_entropy_error関数の定義
テキストから変更なし。def sigmoid(x): return 1 / (1 + np.exp(-x)) def softmax(x): if x.ndim == 2: x = x - x.max(axis=1, keepdims=True) x = np.exp(x) x /= x.sum(axis=1, keepdims=True) elif x.ndim == 1: x = x - np.max(x) x = np.exp(x) / np.sum(np.exp(x)) return x def cross_entropy_error(y, t): if y.ndim == 1: t = t.reshape(1, t.size) y = y.reshape(1, y.size) # 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換 if t.size == y.size: t = t.argmax(axis=1) batch_size = y.shape[0] return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
- Affine、Softmax、SoftmaxWithLoss、Embeddingの各レイヤーの定義
テキストから変更なし。class Affine: def __init__(self, W, b): self.params = [W, b] self.grads = [np.zeros_like(W), np.zeros_like(b)] self.x = None def forward(self, x): W, b = self.params out = np.dot(x, W) + b self.x = x return out def backward(self, dout): W, b = self.params dx = np.dot(dout, W.T) dW = np.dot(self.x.T, dout) db = np.sum(dout, axis=0) self.grads[0][...] = dW self.grads[1][...] = db return dx class Softmax: def __init__(self): self.params, self.grads = [], [] self.out = None def forward(self, x): self.out = softmax(x) return self.out def backward(self, dout): dx = self.out * dout sumdx = np.sum(dx, axis=1, keepdims=True) dx -= self.out * sumdx return dx class SoftmaxWithLoss: def __init__(self): self.params, self.grads = [], [] self.y = None # softmaxの出力 self.t = None # 教師ラベル def forward(self, x, t): self.t = t self.y = softmax(x) # 教師ラベルがone-hotベクトルの場合、正解のインデックスに変換 if self.t.size == self.y.size: self.t = self.t.argmax(axis=1) loss = cross_entropy_error(self.y, self.t) return loss def backward(self, dout=1): batch_size = self.t.shape[0] dx = self.y.copy() dx[np.arange(batch_size), self.t] -= 1 dx *= dout dx = dx / batch_size return dx class Embedding: def __init__(self, W): self.params = [W] self.grads = [np.zeros_like(W)] self.idx = None def forward(self, idx): W, = self.params self.idx = idx out = W[idx] return out def backward(self, dout): dW, = self.grads dW[...] = 0 np.add.at(dW, self.idx, dout) return None
- TimeEmbedding、LSTM、TimeLSTMの各レイヤーの定義
テキストから変更なし。class TimeEmbedding: def __init__(self, W): self.params = [W] self.grads = [np.zeros_like(W)] self.layers = None self.W = W def forward(self, xs): N, T = xs.shape V, D = self.W.shape out = np.empty((N, T, D), dtype='f') self.layers = [] for t in range(T): layer = Embedding(self.W) out[:, t, :] = layer.forward(xs[:, t]) self.layers.append(layer) return out def backward(self, dout): N, T, D = dout.shape grad = 0 for t in range(T): layer = self.layers[t] layer.backward(dout[:, t, :]) grad += layer.grads[0] self.grads[0][...] = grad return None class LSTM: def __init__(self, Wx, Wh, b): ''' Parameters ---------- Wx: 入力`x`用の重みパラーメタ(4つ分の重みをまとめる) Wh: 隠れ状態`h`用の重みパラメータ(4つ分の重みをまとめる) b: バイアス(4つ分のバイアスをまとめる) ''' self.params = [Wx, Wh, b] self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] self.cache = None def forward(self, x, h_prev, c_prev): Wx, Wh, b = self.params N, H = h_prev.shape A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b f = A[:, :H] g = A[:, H:2*H] i = A[:, 2*H:3*H] o = A[:, 3*H:] f = sigmoid(f) g = np.tanh(g) i = sigmoid(i) o = sigmoid(o) c_next = f * c_prev + g * i h_next = o * np.tanh(c_next) self.cache = (x, h_prev, c_prev, i, f, g, o, c_next) return h_next, c_next def backward(self, dh_next, dc_next): Wx, Wh, b = self.params x, h_prev, c_prev, i, f, g, o, c_next = self.cache tanh_c_next = np.tanh(c_next) ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2) dc_prev = ds * f di = ds * g df = ds * c_prev do = dh_next * tanh_c_next dg = ds * i di *= i * (1 - i) df *= f * (1 - f) do *= o * (1 - o) dg *= (1 - g ** 2) dA = np.hstack((df, dg, di, do)) dWh = np.dot(h_prev.T, dA) dWx = np.dot(x.T, dA) db = dA.sum(axis=0) self.grads[0][...] = dWx self.grads[1][...] = dWh self.grads[2][...] = db dx = np.dot(dA, Wx.T) dh_prev = np.dot(dA, Wh.T) return dx, dh_prev, dc_prev class TimeLSTM: def __init__(self, Wx, Wh, b, stateful=False): self.params = [Wx, Wh, b] self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] self.layers = None self.h, self.c = None, None self.dh = None self.stateful = stateful def forward(self, xs): Wx, Wh, b = self.params N, T, D = xs.shape H = Wh.shape[0] self.layers = [] hs = np.empty((N, T, H), dtype='f') if not self.stateful or self.h is None: self.h = np.zeros((N, H), dtype='f') if not self.stateful or self.c is None: self.c = np.zeros((N, H), dtype='f') for t in range(T): layer = LSTM(*self.params) self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c) hs[:, t, :] = self.h self.layers.append(layer) return hs def backward(self, dhs): Wx, Wh, b = self.params N, T, H = dhs.shape D = Wx.shape[0] dxs = np.empty((N, T, D), dtype='f') dh, dc = 0, 0 grads = [0, 0, 0] for t in reversed(range(T)): layer = self.layers[t] dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc) dxs[:, t, :] = dx for i, grad in enumerate(layer.grads): grads[i] += grad for i, grad in enumerate(grads): self.grads[i][...] = grad self.dh = dh return dxs def set_state(self, h, c=None): self.h, self.c = h, c def reset_state(self): self.h, self.c = None, None
- Rnnlmクラスの定義
最後に出てきた隠れ状態ベクトルhをAffine変換して2値化し、Softmax関数で正規化する。class Rnnlm(): def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100, out_size=2): V, D, H, O = vocab_size, wordvec_size, hidden_size, out_size rn = np.random.randn # 重みの初期化 embed_W = (rn(V, D) / 100).astype('f') lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b = np.zeros(4 * H).astype('f') affine_W = (rn(H, O) / np.sqrt(H)).astype('f') affine_b = np.zeros(O).astype('f') # レイヤの生成 self.embed_layer = TimeEmbedding(embed_W) self.lstm_layer = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True) self.affine_layer = Affine(affine_W, affine_b) self.loss_layer = SoftmaxWithLoss() self.softmax_layer = Softmax() # すべての重みと勾配をリストにまとめる self.params = self.embed_layer.params + self.lstm_layer.params + self.affine_layer.params self.grads = self.embed_layer.grads + self.lstm_layer.grads + self.affine_layer.grads def predict(self, xs): self.reset_state() xs = self.embed_layer.forward(xs) hs = self.lstm_layer.forward(xs) xs = self.affine_layer.forward(hs[:,-1,:]) # 最後の隠し層をAffine変換 score = self.softmax_layer.forward(xs) return score def forward(self, xs, t): xs = self.embed_layer.forward(xs) hs = self.lstm_layer.forward(xs) x = self.affine_layer.forward(hs[:,-1,:]) # 最後の隠し層をAffine変換 loss = self.loss_layer.forward(x, t) self.hs = hs return loss def backward(self, dout=1): dout = self.loss_layer.backward(dout) dhs = np.zeros_like(self.hs) dhs[:,-1,:] = self.affine_layer.backward(dout) # 最後の隠し層にAffine変換の誤差逆伝搬を設定 dout = self.lstm_layer.backward(dhs) dout = self.embed_layer.backward(dout) return dout def reset_state(self): self.lstm_layer.reset_state()
- OptimizerとしてSGDの定義
テキストから変更なしclass SGD: ''' 確率的勾配降下法(Stochastic Gradient Descent) ''' def __init__(self, lr=0.01): self.lr = lr def update(self, params, grads): for i in range(len(params)): params[i] -= self.lr * grads[i]ここから学習
- データを学習データ(85%)と試験データ(15%)に分離
X_train,X_test,Y_train,Y_test = train_test_split(X_ids_pad,Y,test_size=0.15)
- ハイパーパラメータ等の設定
# ハイパーパラメータの設定 vocab_size = len(word_to_id)+1 batch_size = 20 wordvec_size = 100 hidden_size = 100 out_size = 2 # hamとspamの2値問題 lr = 1.0 max_epoch = 10 data_size = len(X_train) # 学習時に使用する変数 max_iters = data_size // batch_size # Numpy配列に変換する必要がある x = np.array(X_train) t = np.array(Y_train)
- 学習
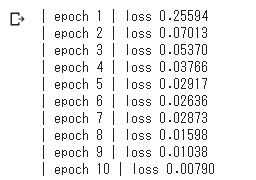
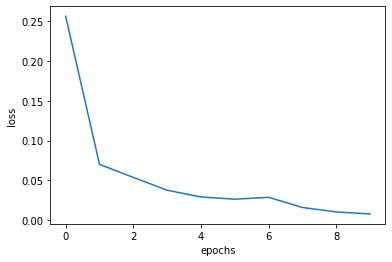
- ミニバッチでメッセージを20ずつ処理
- テキストにあるTruncated BPTTは適用していない。
total_loss = 0 loss_count = 0 loss_list = [] # モデルの生成 model = Rnnlm(vocab_size, wordvec_size, hidden_size, out_size) optimizer = SGD(lr) for epoch in range(max_epoch): for iter in range(max_iters): # ミニバッチの取得 batch_x = x[iter*batch_size:(iter+1)*batch_size] batch_t = t[iter*batch_size:(iter+1)*batch_size] # 勾配を求め、パラメータを更新 loss = model.forward(batch_x, batch_t) model.backward() optimizer.update(model.params, model.grads) total_loss += loss loss_count += 1 avg_loss = total_loss / loss_count print("| epoch %d | loss %.5f" % (epoch+1, avg_loss)) loss_list.append(float(avg_loss)) total_loss, loss_count = 0,0 x = np.arange(len(loss_list)) plt.plot(x, loss_list, label='train') plt.xlabel('epochs') plt.ylabel('loss') plt.show()
- 試験データの推論
result = model.predict(X_test) Y_pred = result.argmax(axis=1)
- 正答率
98%!
Kaggleの他の人のノートブックと比べても悪くない。# calculate accuracy of class predictions print('acc=',metrics.accuracy_score(Y_test, Y_pred))
- 混同行列
# print the confusion matrix print(metrics.confusion_matrix(Y_test, Y_pred))
5.まとめ
今回、このツールの作成のために試行錯誤することで、テキストの理解を深めることができました。
もし同じようにゼロから作るディープラーニング②を読まれた方がいたら、サンプルプログラムを活用して、何らかのアプリを作成してみることをお勧めします。
おまけ
自作smsで判定
一つ目は野球の試合を一緒に見に行こうと誘うもの。
二つ目は、自作Spam(訳さなくてよい)。
意外にも?ちゃんと判定できてる。texts_add = ["I'd like to watch baseball game with you. I'm wating for your answer.", "Do you want to meet new sex partners every night? Feel free to call 09077xx0721." ] X_ids_add = tok.texts_to_sequences(texts_add) X_ids_pad_add = sequence.pad_sequences(X_ids_add,maxlen=max_len) result = model.predict(X_ids_pad_add) Y_pred = result.argmax(axis=1) print(Y_pred)


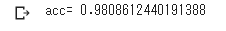


- 投稿日:2020-05-29T19:46:25+09:00
ずぶの素人がPythonを始めたい
世の中のマニュアルは日本語で書かれているとは思えないくらい難しい
まず、世の中には難しい環境構築の話が多すぎる。
- フォルダごとに設定したら良い
- プロジェクトごとに変えられるように
- 設定を保存できる
- のちのちのためにrequirement.txtを作るんだ!
いやいや、僕らみたいな本当の初心者にはそれはいらないから、最短ルートだけ教えて下さい。という話です。
今現在の開発で要らないところでつまづいて、始められないのはもったいないと個人的には思っています。
最低限の設定をして、まがいなりにも動けば良い。適当に準備した環境構築だと、未来的に・・とかマウントとってくる人もいるし、正しい指摘をする人もいるだろうけど、初心者がまず始めたいならとりあえずこれ!ということを書きました。早ければ10分もあればPython始められます。
始めよう、Python
とはいえ、コマンドプロンプトやBashのコマンドは少しは叩いたことがあるよ、というレベルの人向け。cdとlsとpwdくらい知ってるよ、という人ね。コマンドも1行も打ちたくないっていう人は、コードを書くことを諦めて、データロボットとかに頼りましょう。
Windows編, Ubuntu編
Anacondaのダウンロードとインストール
Anacondaがてっとり早い。Anacondaをダウンロードしてきてインストール。
重たいけど、入れちゃえばいい。動けばいい。
こちらの記事がわかりやすい。仮想環境を作る
インストールしたら、AnacondaのGUIは一切使わないのが使いやすい。
結果的に僕もこれで慣れました。コマンドプロンプト(もしくはAnaconda prompt)で仮想環境を作ります。
なんで仮想環境が要るのか?って?そこら中に書いてあるのでググりましょう。例えばpython3.7系の環境を作るなら、下記を叩くだけ。env_nameだけ自分の好みの名前にすると良い。
個人的にはversionがわかるように、py37_projectのような名前がおすすめ。conda create -n env_name python=3.7あとは仮想環境をActivateして、自分で必要なパッケージを追加していく。
下記は一例。conda activate env_name conda install numpy matplotlib conda install scikit-leran詳しく知りたい方は下記の記事が詳しい。
IDEやEditorで仮想環境を指定する
今はVSCODEかPyCharmの2択。個人的にはVSCODEの1択だけど、より設定が簡易なのはPyCharmだと思う。
launch.jsonなんて、ずぶの素人には、なにそれ美味しいの?レベルかなぁって。僕も昔はよくわからなかったよ。。
とりあえずクリックしたら動くのはPyCharmだと思う。
PyCharm
設定からproject interpreterを選択する。
Pythonの開発環境メモが詳しい。VSCODE
Pythonの拡張機能を入れればInterpreterの選択がSuggestされるし、左下のほうにあるアイコンを押しても変更できる。
VSCodeでのPython、Jupyter実行環境の構築方法に書いてあります。Hello, World
あとは、とりあえずmain.pyをいうファイルを作って下記を実行して動けばOK。
main.pyprint('Hello, World')MacOS編
PyenvとPyenv Virtualenvのインストール
MacはAnacondaとの相性が激烈に悪い(という噂)ので、おとなしくPyenvとVirtualenvを入れる。
一時期Pipenvがいいかも!と思ったんだけど、あっという間に更新されなくなってどこかに消えていった(と認識している)
あとPipenvは昔使っていて、いつの間に環境が壊れて、いい思い出がないというのもあります。Pipenv信者の方ごめんなさい。Homebrewさえ入っていればコマンド一発です。
詳しく知りたい人は下記参照。MacOSとHomebrewとpyenvで快適python環境を。
brew install pyenvPyenvの設定
おまじないでお使いのShellの設定に追記します。
まあMacでPython動かしたいとか思うなら、このくらいは編集できたほうが良いと思う。
.zshrcか.bash_profileにこんな3行を追加しましょう。.zshrc,.bash_profileexport PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"設定を終えたら、シェルを再起動するか、下記を実行。
zsh -l or source ~/.bash_profilePyenvによるPythonのインストール
インストールできるバージョンの確認
pyenv install --list所望のVersionをインストール
pyenv install 3.7.7 pyenv install 3.7.6何種類でも入れられます。使いたいバージョンを入れておきましょう。
Virtualenvのインストールと仮想環境の作成
インストール
brew install pyenv-virtualenv仮想環境の作成
これで3.7.7ベースの仮想環境が作れます。
pyenv virtualenv 3.7.7 env_nameあとはanacondaのほうと全く同じようにモジュールを追加できます。
pyenv activate env_name pip install numpy matplotlib pip install scikit-leranフォルダに環境を紐付けるとか、そういうおしゃれで便利なこともできるので、こちらを参照してください。
Mac(Homebrew)でPython(pyenv/virtualenv)開発環境を作る
まとめ
「本当に初めてPython使いたいんです。」という問い合わせが社内でもよくあります。コマンドを叩くのが精一杯です、という人にも最低限、仮想環境を作って開発してほしいという思いがあります。
はじめっからAnacondaいれて、GUIからJupyter立ち上げりゃいいじゃん、という人もいると思うし、それも正解だと思います。
ただ、大抵の場合は、最終的に.pyを作ることにはなると思うので、はじめからそこだけは準備してもいいかなと。ここまで揃えてからjupyterを立ち上げる、というのが個人的には筋が良いと考えています。
おしまい。
- 投稿日:2020-05-29T19:37:01+09:00
Ansible 自作モジュール作成 ~その1:引数受け取りたい人生~
Ansible使おうとしたら名前付きパイプ(
makefifo)相当がなかったので自作モジュールを頑張ることにした。参考サイト
- Ansibleのモジュール開発(Python実装編)
- すっごい分かりやすくて好き!
- ansible コマンドでモジュール引数 ( パラメータ ) を複数渡す方法
ansibleコマンド実行時に複数の引数を与える方法環境
$ cat /etc/redhat-release CentOS Linux release 7.7.1908 (Core) $ ansible --version ansible 2.9.7 config file = /etc/ansible/ansible.cfg configured module search path = [u'/home/ansi/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules'] ansible python module location = /usr/lib/python2.7/site-packages/ansible executable location = /bin/ansible python version = 2.7.5 (default, Aug 7 2019, 00:51:29) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)]雛形を作る
参考サイトを見つつ
makefifo.py#!/usr/bin/python # -*- coding: utf-8 -*- from ansible.module_utils.basic import AnsibleModule module = AnsibleModule( dict=( message=dict() ) ) print '{"message_key":"%s"}' % (module.params['message'])んーとこんな感じでいいのかなぁ~。早速実行してみよう。
$ ansible -i test_grp 192.168.56.104 -m makefifo -M library -u root -a message=test 192.168.56.104 | FAILED! => { "msg": "Unable to import makefifo due to invalid syntax" }OOPS!! あれれ。。いきなり躓いたぞい。
Ansibleのバージョンによって差分があるのかな?ということで既存のモジュールを解体して作ってみようと方向シフト。
$ find /usr/lib/python2.7/site-packages -type f -name ping.py /usr/lib/python2.7/site-packages/ansible/modules/system/ping.pyコイツをコピってきて
pong.pyにリネームしてまずは正常動作確認。$ ansible -i test_grp 192.168.56.104 -m pong -M library -u root -a data=hoge 192.168.56.104 | SUCCESS => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": false, "ping": "hoge" }うん、動いてる。
ココから中身の要らなさそうな部分を削ってみた結果、以下まで削ることができた。
pong.py#!/usr/bin/python # -*- coding: utf-8 -*- from ansible.module_utils.basic import AnsibleModule # メイン処理 #----------------------------------------------------------- def main(): # AnsibleModuleクラス: moduleを作成 module = AnsibleModule( # 引数受け取り argument_spec=dict( # 引数: data(str型,def:pong) data=dict(type='str', default='pong'), ), # 引数チェックを有効 supports_check_mode=True ) # 結果dict: resultを作成 result = dict( # key: ping に引数で与えられたkey: data のvalueを格納 ping=module.params['data'], ) # resultの中身を key=value,の形で出力 module.exit_json(**result) if __name__ == '__main__': main()$ ansible -i test_grp 192.168.56.104 -m pong -M library -u root -a data=hoge 192.168.56.104 | SUCCESS => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": false, "ping": "hoge" }コイツを雛形にしよう。
引数を受け取る
makefifoに必要なパラメータは以下かなと考える。
パラメータ 変数名(key名) 型 必須 ファイルパス path str ○ 所有者(ユーザ) owner str ○ 所有者(グループ) group str ○ パーミッション mode str ○ まずはコイツらを受け取っって結果に返すだけのモジュールを作ってみる。
makefifo.py#!/usr/bin/python # -*- coding: utf-8 -*- from ansible.module_utils.basic import AnsibleModule # メイン処理 #----------------------------------------------------------- def main(): # AnsibleModuleクラス: moduleを作成 module = AnsibleModule( # 引数受け取り argument_spec=dict( # 引数: path(str型, 必須) path=dict(type='str', required=True), # 引数: owner(str型, 必須) owner=dict(type='str', required=True), # 引数: group(str型, 必須) group=dict(type='str', required=True), # 引数: mode(str型, 必須) mode=dict(type='str', required=True), ), # 引数チェックを有効 supports_check_mode=True ) # 結果dict: resultを作成 result = dict( path=module.params['path'], owner=module.params['owner'], group=module.params['group'], mode=module.params['mode'], ) # resultの中身を key=value,の形で出力 module.exit_json(**result) if __name__ == '__main__': main()
requiredとかそのあたりはAnsibleのモジュール開発(Python実装編)さんを参考に。さて動作確認...複数の引数を与えるのはどうするんだ?で調べたら以下が見つかった。
ありがてぇありがてぇ。
$ ansible -i test_grp 192.168.56.104 -m makefifo -M library -u root -a "path=/tmp/hoge owner=root group=root mode=0644" 192.168.56.104 | SUCCESS => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": false, "group": "root", "mode": "0644", "owner": "root", "path": "/tmp/hoge" }できた!よしよし、あとは
Pythonで実装するだけだな。
取り敢えず今日はココまで。
- 投稿日:2020-05-29T19:00:23+09:00
Qiitaのトレンド情報を保存しておくDocker環境を作ろう!
Qiitaのトレンド情報を保存しておく環境をDockerで作成しました。
基本的にコンテナを立ち上げていれば、毎日勝手にスクレイピング処理が走り、JSON化したトレンド情報を保存してくれます。この記事は以下のような方におすすめです。
- Qiitaのトレンドを分析しておきたいな
- Pythonの勉強を少しやってみたいな
- Dockerちょっと触ってみたい
※保存しておくQiitaのJSONフォーマットについて
- author(トレンド入りした著者の一覧
- list(トレンド記事の一覧
- tag(トレンドの記事に付けられたタグ一覧
実際に保存しておくJSONの中身は以下のようになっています。
author: Qiitaにトレンド入りした著者を取得する著者のユーザーネームを一覧化。
[ "uhyo", "suin", "Yz_4230", "atskimura", "pineappledreams", "Amanokawa", "k_shibusawa", "minakawa-daiki", "morry_48", "c60evaporator", "takuya_tsurumi", "TomoEndo", "yhatt", "CEML", "moritalous", "svfreerider", "daisukeoda", "karaage0703", "tommy19970714", "tyru", "galileo15640215", "keitah", "mocapapa", "akeome", "ssssssssok1", "yuno_miyako", "katzueno", "cometscome_phys", "mpyw", "akane_kato" ]
list: Qiitaにトレンド入りした記事の一覧を取得する以下の情報を出力します。
- 記事のUUID(記事のID)
- 記事のタイトル
- 記事のURL
- 記事の著者名
- LGTM数
- 記事に付けたれたタグ, タグURL
[ { "article_id":"e66cbca2f582e81d5b16", "article_title":"Let's Encryptを使用しているウェブページをブロックするプロキシサーバー", "article_url":"https://qiita.com/uhyo/items/e66cbca2f582e81d5b16", "author_name":"uhyo", "likes":66, "tag_list":[ { "tag_link":"/tags/javascript", "tag_name":"JavaScript" }, { "tag_link":"/tags/node.js", "tag_name":"Node.js" }, { "tag_link":"/tags/proxy", "tag_name":"proxy" }, { "tag_link":"/tags/https", "tag_name":"HTTPS" }, { "tag_link":"/tags/letsencrypt", "tag_name":"letsencrypt" } ] }, { "article_id":"83ebaf96caa2c13c8b2f", "article_title":"macOSのスクリーンセーバーをHTML・CSS・JSで作る (Swiftスキル不要)", "article_url":"https://qiita.com/suin/items/83ebaf96caa2c13c8b2f", "author_name":"suin", "likes":60, "tag_list":[ { "tag_link":"/tags/html", "tag_name":"HTML" }, { "tag_link":"/tags/css", "tag_name":"CSS" }, { "tag_link":"/tags/javascript", "tag_name":"JavaScript" }, { "tag_link":"/tags/macos", "tag_name":"macos" } ] } ]Qiitaのトレンドは1日に2回、毎日5時/17時に更新更新されていますが、そこまで記事の入れ替わりはないので1日1回だけの実行にしておこうと思います。
tag: Qiitaにトレンド入りした記事に付けられたタグを取得する[ { "tag_link":"/tags/python", "tag_name":"Python" }, { "tag_link":"/tags/r", "tag_name":"R" }, { "tag_link":"/tags/%e6%a9%9f%e6%a2%b0%e5%ad%a6%e7%bf%92", "tag_name":"機械学習" } ]上記の記事の一覧でもタグは取得していますが、一個の記事に紐付けられたタグなので、異なる記事で同じタグが付いていた場合重複してしまいます。そのため、重複したタグを省いてトレンド入りしたタグだけ一覧で保存しておく処理にしました。
DockerでPythonが実行できる環境を作成しよう
簡易的なDocker環境を作成していきます。
ディレクトリ構成は以下のような感じ。├── batch │ └── py │ └── article.py ├── docker │ └── python │ ├── Dockerfile │ ├── etc │ │ └── cron.d │ │ └── qiita │ └── requirements.txt ├── docker-compose.yml └── mnt └── json ├── author ├── list └── tag
batchdirectory
pythonファイルを置いています。
このファイルがスクレイピングを行う実ファイルです。
dockerdirectory
コンテナの内部で必要なものだったり、実際のcron設定はここで置いています
mntdirectory
host上のディレクトリをマウントしていて、ここにスクレイピングの結果JSONファイルが生成されますQiitaのトレンドをスクレイピングで取得しよう (
batch directory)batchディレクトリの中にある実ファイル
article.pyの中身です。
過去にこんな記事を書いていたので、詳しいやり方とかはそっちで解説しています。
≫ Qiitaのトレンド(ランキング)を取得してSlackに送信する
この記事ではあくまでプログラムだけにします。上記の記事のプログラムとの相違点は以下の2点です。
記事の一覧だけ欲しいねん!って人は上記の記事だけで事足りると思います。
- トレンド入りした記事のタグと著者を取得
- 取得した内容をJSON化して保存しておく
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import json import datetime import os def get_article_tags(detail_url): tag_list = [] res = requests.get(detail_url, headers=headers) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(res.text, "html.parser") tags = soup.find_all(class_="it-Tags_item") for tag in tags: tag_name = tag.get_text() tag_link = tag.get('href') tag_list.append({ 'tag_name' : tag_name, 'tag_link': tag_link }) return tag_list def write_json(json_list, path): with open(path, 'w') as f: f.write(json.dumps(json_list, ensure_ascii=False, indent=4, sort_keys=True, separators=(',', ':'))) def mkdir(path): os.makedirs(path, exist_ok=True) def get_unique_list(seq): seen = [] return [x for x in seq if x not in seen and not seen.append(x)] def get_unique_tag(tag_lists): tags = [] for v in tag_lists: for i in v: tags.append(i) return tags try: # Root URL url = "https://qiita.com/" headers = { "User-Agent" : "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" } today_date = datetime.datetime.now().date() items = [] item_json = [] result = [] res = requests.get(url, headers=headers) # htmlをBeautifulSoupで扱う soup = BeautifulSoup(res.text, "html.parser") try: main_items = soup.find(class_="p-home_main") for main_items in soup.find_all(): if "data-hyperapp-props" in main_items.attrs: item_json.append(main_items["data-hyperapp-props"]) items = json.loads(item_json[1]) except: raise Exception("Not Found Json Dom Info") if 'edges' not in items['trend']: raise Exception("The expected list does not exist") try: item_detail_list = [] tags_list = [] author_list = [] for edges in items['trend']['edges']: uuid = edges['node']['uuid'] title = edges['node']['title'] likes = edges['node']['likesCount'] article_url = url + edges['node']['author']['urlName'] + '/items/' + uuid author_name = edges['node']['author']['urlName'] create_at = datetime.datetime.now().date() tag_list = get_article_tags(article_url) item = { 'article_title' : title, 'article_url' : article_url, 'article_id' : edges['node']['uuid'], 'likes' : likes, 'uuid' : uuid, 'author_name' : author_name, 'tag_list' : tag_list, } item_detail_list.append(item) tags_list.append(tag_list) author_list.append(author_name) mkdir('/mnt/json/list/') mkdir('/mnt/json/tag/') mkdir('/mnt/json/author/') # タグをuniqu化 tags_list = get_unique_tag(tags_list) # jsonファイルを書き出し write_json(item_detail_list, f"/mnt/json/list/{today_date}.json") write_json(tags_list, f"/mnt/json/tag/{today_date}.json") write_json(author_list, f"/mnt/json/author/{today_date}.json") except: raise Exception("Can't Create Json") except Exception as e: # jsonファイル作成失敗 mkdir('/mnt/log/') with open(f'/mnt/log/{today_date}', 'w') as f: f.write(e)次に上記のファイルを実行する環境を作成します。
Pythonを動かすためのDocker部分を作成(
docker directory)docker-compose.ymlの作成
ここは大したことしてない。
volumesでPC上のディレクトリとマウント。version: "3" qiita_batch: container_name: "qiita_batch" build: context: ./docker/python tty: true volumes: - ./batch:/usr/src/app - ./mnt:/mntDockerfileの作成
Dockerfile汚いのは許して...軽く説明だけ↓
- コンテナ内のタイムゾーンの設定(cron設定のため
- cronを反映
- requirement.txtで必要なモジュールをインストール
cronをちゃんと指定した日本時間で実行したいのであれば、タイムゾーンの設定は必須ですね。
なんかごちゃごちゃやって、ようやく日本時間に変えられたんですが、もっとうまいやり方あるはず...。cronの設定はetc/cron.d/qiitaにまとめておいて、後々crontabに書き込むような処理にしてます。管理が楽になるのでこっちの方がいいかなと。間違っても
crontab -rというコマンドは呼び出してはいけない...!!FROM python:3 ARG project_dir=/usr/src/app WORKDIR $project_dir ADD requirements.txt $project_dir/py/ ADD /etc/cron.d/qiita /etc/cron.d/ ENV TZ=Asia/Tokyo RUN apt-get update && \ apt-get install -y cron less vim tzdata && \ rm -rf /var/lib/apt/lists/* && \ echo "${TZ}" > /etc/timezone && \ rm /etc/localtime && \ ln -s /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \ dpkg-reconfigure -f noninteractive tzdata && \ chmod 0744 /etc/cron.d/* && \ touch /var/log/cron.log && \ crontab /etc/cron.d/qiita && \ pip install --upgrade pip && \ pip install -r $project_dir/py/requirements.txt CMD ["cron", "-f"]Pythonの実行に必要なパッケージをまとめたrequirement.txtを作成
requirement.txtは自分のMacbookProで使用していたものを出力しただけなので、かなり適当に色々なものが入っています。いらないものは適宜削ってくださいまし。
beautifulsoup4とrequestsとjsonだけあれば事足ります。なんか足らん!って人は動かしながら足らないやつpip install!!appdirs==1.4.3 beautifulsoup4==4.8.1 bs4==0.0.1 certifi==2019.9.11 chardet==3.0.4 Click==7.0 filelock==3.0.12 get==2019.4.13 gunicorn==20.0.4 idna==2.8 importlib-metadata==1.5.0 importlib-resources==1.0.2 itsdangerous==1.1.0 Jinja2==2.11.1 MarkupSafe==1.1.1 post==2019.4.13 public==2019.4.13 query-string==2019.4.13 request==2019.4.13 requests==2.22.0 six==1.14.0 soupsieve==1.9.5 urllib3==1.25.7 virtualenv==20.0.1 Werkzeug==1.0.0 zipp==2.2.0cron設定
/etc/cron.d/qiitaの中身ですPATH=/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin LANG=ja_JP.UTF-8 # Create Qiita JSON (every day AM:10:00) 0 10 * * * python /usr/src/app/py/article.py >> /var/log/cron.log 2>&1こんな感じ!
あとはdocker-compose up -dでやれば立ち上がるので、放置しておけば勝手にQiitaにスクレイピングしに行ってjsonファイルを作成してくれます。簡易的なDocker環境で出来るのでおすすめ!
- 投稿日:2020-05-29T18:54:55+09:00
LinuxをDiscord Botで操作してみた
初めに
この記事は僕がPythonで作ったDiscord Botを簡単に共有できればと思い書いたものです
あまり詳しくは書きませんが誰かの役に立てれば幸いですこのBotで出来ること
Discord からLinuxを操作できます
「ls」コマンドや 「less」コマンドなど基本的に何でも使えます。
ただvimやsudoなどユーザーが追加で入力するものなどは使えません(コード追加すれば可能だと思われ)
二千文字の制限がDiscordにあるのでそれ以上のものは送信できません。
あとエラー処理してないのでvimなど開こうとするとbotが飛びます。実行環境
Debian 10
Python 3.7.3コード
import subprocess # インストールした discord.py を読み込む import discord # 自分のBotのアクセストークンに置き換えてください TOKEN = 'ボットのトークン' # 接続に必要なオブジェクトを生成 client = discord.Client() # 起動時に動作する処理 @client.event async def on_ready(): # 起動したらターミナルにログイン通知が表示される print('ログインしました') async def job(message): await message.channel.send('そろそろ寝ましょう!') # メッセージ受信時に動作する処理 @client.event async def on_message(message): # メッセージ送信者がBotだった場合は無視する if message.author.bot: return # 「/neko」と発言したら「にゃーん」が返る処理 if message.content == '/neko': await message.channel.send('にゃーん') if message.content == '/konn': await message.channel.send("こん") if message.author.id == DiscordのユーザーID: messStr = str(message.content)#ユーザーのメッセージを取得 messList = messStr.split(" ")#ユーザーのメッセージをスペース区切りで配列にする res = subprocess.check_output(messList)#そのコマンドを実行、出力をresに代入 res = res.decode("utf-8")#resをutf-8ででデコード await message.channel.send(res)#メッセージを送信 else: await message.channel.send("権限がありません") client.run(TOKEN)ユーザーIDについて
途中で出てきたユーザーIDというのはDiscordで確認できます。
そのIDを使ってコマンドを実行してよいユーザーなのかを判定しています。IDを表示する方法
ユーザー設定→テーマ→開発者モード をオンにします
そしてDiscordのユーザーを右クリックしてIDをコピーから参照できます。
- 投稿日:2020-05-29T18:08:20+09:00
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
昨日までのはこちら
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回はスクレイピングについてです。
スクレイピングとは
スクレイピングとは何でしょうか?
スクレイピングはWEBサイトなどからデータを取得する技術のことです。
スクレピング自体は様々な言語で行うことができます。スクレイピングに必要な知識
ざっくりですが、こう言う知識があると役立ちます。
通信の仕組み
WEBから情報を取得するには通信を行わなければなりません。
インターネットの基本となるHTTP通信の仕組みを抑えておく必要があります。HTML、Javascript、CSS
WEBサイトはHTMLとJavascriptとCSSで構成されています。
サイト内の構成要素の仕組みを抑えておく必要があります。全文検索と正規表現マッチ
WEBサイトから情報を取得した際に、必要な情報だけを抜き取ります。その際、必要な情報があるのかどうか、必要な情報と合致するのかどうかを判定する必要があります。
条件の判定をするためには正規表現の知識が必要となります。プログラミング言語
WEBサイトへのアクセスや、構文解析を効率的に行うには
プログラミング全般の知識や、プログラミング言語の特性などの知識が必要となります。ライブラリ
通常はどのプログラミング言語でも、スクレイピング用のツール(ライブラリ)が存在します。
1からプログラムを作成するのは非効率であり、ライブラリの使い方を習得する必要があります。データマイニングアルゴリズム
情報を取得して、必要な部分だけを効率よく出力するにはデータ解析の知識が必要になります。DOM解析
DOM(Document Object model)とは、XML文書を操作するための標準的な仕様のことを言います。
プログラミング言語によるXML文書の要素やテキストの操作を可能にします。
DOMとは、XML文書全体を読み込み、 文書中のあらゆる要素をツリー構造のノードとして解析する方式です。スクレイピングではDOMの知識が必要となります。
HTMLパーサー(パース)
HTMLのテキスト部分だけを抜き出したり、特定タグの内容を抽出することインターネットセキュリティー
WEBサイトにアクセスして情報取得をする都合、どうしてもセキュリティーの問題が付き纏います。
間違えた使い方をすると、サイトに存在を与えたり、逮捕されたりする可能性もあるので
気をつけなければなりません。スクレイピングは便利な技術であるが、以下の点に気を付ける必要があります。
利用規約違反
他者のウェブサイト上の利用規約で「スクレイピング禁止」と記載されている場合に
スクレピングを行うと利用規約違反になり、損害賠償請求などがされる可能性があります。ただし、利用規約がユーザとの間で効力を生じさせるためには、以下の措置が必要になります。
利用規約をユーザに示し取引の開始に当たり、同意クリックをさせる。会員登録の必要がなく、誰でも見られるコンテンツを、スクレイピングする場合には
上記利用規約違反にならないとも考えられますが、日々法律は変わりますので注意が必要です。また、スクレイピング対象のサイトが、クローラのウェブサイトのアクセスを制限するための
措置(robot.txtなど)が取られている場合にクローリングした場合には、民法上の不法行為に該当する可能性があります。著作権
スクレイピングで取得するコンテンツは、膨大になることから、コンテンツ一つ一つに同意を取ることは現実的ではありません。そのため、例外規定として、情報解析のための複製等を著作権者の同意なく行うことを認めているようです(著作権法47条の7)。
スクレイピングによって、収集されたコンテンツを他人に譲渡する(ネット配信なども含む)行為は、著作権法上、違反とされています。
コンテンツにオリジナリティがあれば「著作物」として著作権法上、保護されます。
そのようなコンテンツをコピーしたり、自社側のサーバに保存する行為は、著作権者の同意がない限りは、著作権侵害になる行為です。
偽計業務妨害
一定の間隔で当該ウェブサイトにアクセスすることになりますが、その間隔が短くなると
当該サイトのサーバにかかる負荷が重くなり、正常なサイト運営を妨げることとなる場合があります。このような場合には、当該サイト事業者の業務を妨害したとして
偽計業務妨害罪が成立する可能性があります(刑法233条)。岡崎市立中央図書館事件
2010年3月頃、市民から岡崎市立図書館のウェブサイトの蔵書検索システムに対し 接続が出来ないと苦情があったようで その後もウェブサイトの閲覧が困難になる事態が相次いだ。 同年4月15日、同図書館が迷惑なアクセスを受けていると 愛知県警岡崎署に被害届を提出し、5月25日にアクセスを行っていた男性が 蔵書検索システムに高頻度のリクエストを故意に送りつけたとして 偽計業務妨害容疑で逮捕された。男性の作成したクローラに違法性はなく
図書館の蔵書検索システムに不具合が存在していた。しかし、岡崎市立中央図書館のウェブサイトは、自治体のサイトとしては専門家でも
想像できないほどに脆弱なものであったため
市町村の怠慢と、担当者の不知などいくつもの不運が重なった事件です。本来はお粗末な運営をしていた自治体側が悪いのですが
法律上はそうはならないこともあります。自治体や国関係のインフラは非常に稚拙で、まともな運用がされていないことが多く
スクレピング対象としては好ましくないこともありますので
スクレピングする際は注意しましょう。その他の留意事項
.
Amazonの商品ページをwebスクレイピング・クローリングすることは利用規約違反ですが
法的に問題はないでしょうか?相手のサーバーに負荷をかけるような行為は、偽計業務妨害又は電子計算機損壊等業務妨害に該当する可能性があります。
応答があってから次の処理をするなどの動きにしておくなどの注意が必要です。
また、ページを複製しているので、私的複製の範囲を超える場合は著作権侵害の問題も生じえます。
自分で閲覧する目的やデータ解析の目的の範囲にとどめておく必要があります。.
Amazonの商品ページをwebスクレイピング・クローリングするツールを作成し
配布・販売すること自体は利用規約違反になるでしょうか?また、法的に問題はないでしょうか?
利用規約の書き方次第ですが、ツールの利用のみ禁止されているのであれば
配布を受けてツールを利用した場合の行為が規約違反になるということになるのではないでしょうか。使われ方によっては業務妨害や著作権侵害の幇助犯に該当する可能性もありうると思います。
まとめ
まずはスクレイピングをする前に注意事項を抑えておこう。
いきなりコードを走らせると大変なことになるかも知れないので。君がエンジニアになるまであと30日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-29T17:54:11+09:00
構成図をコード管理できるDiagram as Code(Diagrams)を試してみた
Diagram as Code(Diagrams)を試す
https://diagrams.mingrammer.com/
普段、構成図はCacooなどのオーサリングツールを利用していますが、
Pythonコードで構成図を描画できるというツールを使ってどこまで書けるか試してみました。結論、所感
- シンプルに書けるので謳われてる通り、新しいシステムのプロトタイプ化が素早くできるのがよい
- 学習コストも低く、Pythonに慣れてさえいればすぐ書き始められる
- フォントサイズの変更属性はあったが、注釈とか書く方法がわからなかった
環境について
- macOS Catalina
- Python 3.6.8
動作要件
- Python 3.6 以上
- Graphviz が必要
事前準備
新しく仮想環境を作りその中にパッケージをインストールしていきます。
この手順は任意です。python -m venv ~/envs/diagrams source ~/envs/diagrams/bin/activateInstallation
https://diagrams.mingrammer.com/docs/getting-started/installation
# Homebrewでインストール brew install graphviz # pipでインストール pip install diagrams例題
とりあえず例題を使って出力してみました。
from diagrams import Diagram from diagrams.aws.compute import EC2 from diagrams.aws.database import RDS from diagrams.aws.network import ELB with Diagram("Web Service", show=False): ELB("lb") >> EC2("web") >> RDS("db")python diagram.py 2020-05-29 13:50:05.901 +[__NSCFConstantString length]: unrecognized selector sent to class 0x 2020-05-29 13:50:05.905 *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '+[__NSCFConstantString length]: unrecognized selector sent to class 0x'早速、エラーに遭遇しました。
まったく原因がわからず、issueなど漁りながらとりあえず元々インストール済みだったgraphvizをアップグレードすることにしました。brew upgrade graphvizバージョンを 2.40.1 -> 2.44.0 にアップグレードできました。
python diagram.py無事出力できました。
お試し構成
from diagrams import Cluster, Diagram from diagrams.aws.compute import EC2, ElasticBeanstalk from diagrams.aws.database import RDS from diagrams.aws.network import ELB, Route53 from diagrams.onprem.client import Client graph_attr = { } def draw(): with Diagram("web_service", show=False, graph_attr=graph_attr, direction="TB"): route53 = Route53('route53') client = Client('client') client >> route53 with Cluster("ElasticBeanstalk"): with Cluster("WEB"): with Cluster("Subnet1"): web1 = EC2("web") lb1 = ELB("lb1") lb1 >> web1 with Cluster("Subnet2"): web2 = EC2("web") lb2 = ELB("lb2") lb2 >> web2 route53 - [lb1, lb2] with Cluster("DB"): db_master = RDS("master") with Cluster("Subnet3"): rds1 = RDS("slave1") with Cluster("Subnet4"): rds2 = RDS("slave2") db_master - [rds1, rds2] [web1, web2] >> db_master if __name__ == '__main__': draw()出力イメージ
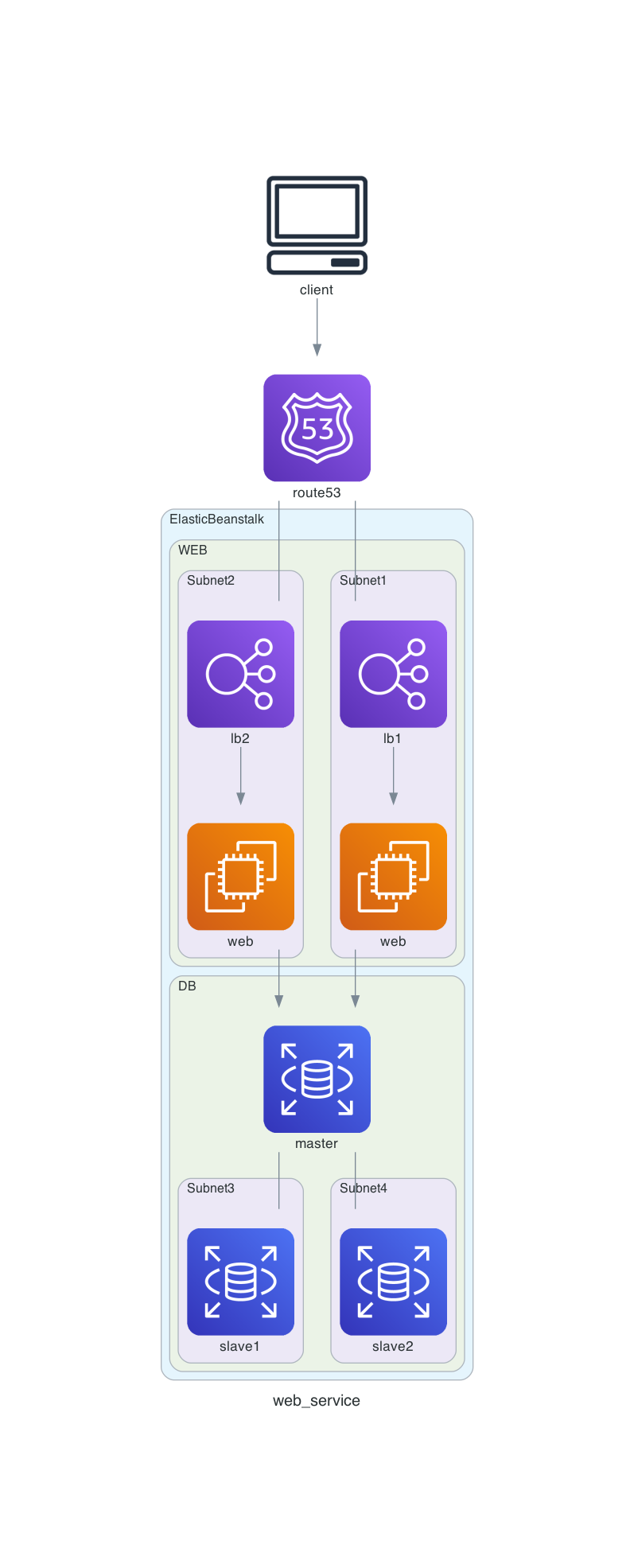
- 投稿日:2020-05-29T17:47:36+09:00
rollbar pythonの404 not foundをフィルタする
メモ
今回はsanicを利用していた。 フィルタしたいクラスをexception_level_filtersでignoredすれば良い ... from sanic.exceptions import NotFound rollbar_token = os.getenv('ROLLBAR_TOKEN', None) opts = { 'exception_level_filters': (NotFound, 'ignored') } if rollbar_token: rollbar.init(rollbar_token, opts)
- 投稿日:2020-05-29T17:34:56+09:00
Pythonで__END__(もどき)を実現する
PerlやRubyの
__END__。それなりに大きいテキストデータをプログラムの末尾に置いておけるので便利である。しかし、Pythonでは使用できない。複数行文字列はあるが、後置することができない。そこで、こういうものを末尾に置くと「データ」が読み込めるモジュールを作ってみた。
''' __END__ データ '''ただし、引用符は
'''と"""の両方に対応しているが、同じものをデータ部内に書くことができない。不完全ではあるが、改善が難しそうなので現時点でのものを公開する。Python2/3両対応です(PyPyでも動くようです)。
enddata.pyimport sys from io import StringIO def getdata(): ret = StringIO() with open(sys._getframe().f_back.f_code.co_filename,'rb') as f: strStart = None while True: line = f.readline() if not line or line.rstrip().decode('utf-8') == '__END__': break strStart = line.rstrip() # read until the str finishes as ret should not contain trailing quote prev = None while True: line = f.readline() if not line or line.rstrip() == strStart.rstrip(): break if prev is not None: ret.write(prev) prev = line.decode('utf-8') if prev is not None: ret.write(prev) ret.seek(0) return rettest.py#!/usr/bin/python from enddata import getdata print(getdata().read().rstrip()) ''' __END__ Hello END World! '''
Hello END World!が出力される。
- 投稿日:2020-05-29T17:25:45+09:00
「14日で作る量子コンピュータ」を読んでみる。1日目
はじめに
今日から「14日で作る量子コンピュータ」という本を買ったので、これを実装しながら量子コンピュータについての理解を深めていきたいと思っています。この本は、14日をかけて最終的に簡易的な量子コンピュータのシミュレータを実装していくというものです。どちらかというと理論重視な感じで、量子力学全くわからない自分ですが、どうにかして読解していきたいと思います。
今回は、量子力学の基礎のところまでを読んでいきます。0 環境構築
ここでは、Pythonの環境構築と数値計算、図形描画を行う。
0.1 Python、モジュールのインストール
Pyhthonのバージョンは3.8.2を想定している。インストールの方法については公式サイト(https://www.python.org/downloads/)からインストーラを
・ダウンロード
・回答
・インストール
の三段階でできる。これに関しては他のサイトを参考にした方が良い。
次にPythonで使う外部モジュールは、numpy: 行列計算などを主に行うモジュール。大事 scipy: 科学計算を行うモジュール。初めて使う。大事 matplotlib: グラフ描画を行うモジュール。大事これらのインストールは以下のコマンドでできる
$ pip install numpy scipy matplotlib0.2 数値計算の基礎
私はScipyを使ったことがないので、それ用のサンプルスクリプトを残しておく。書籍でも適当な関数の積分を行なっている。
sample.pyimport scipy.integrate as integrate import math # 積分区間 x_min = 0 x_max = 1 # 積分する対象のグラフ def func(x): return math.exp(x) # 理論上の積分結果 exact = math.e - 1 # 積分演算 result, err = integrate.quad(func, x_min, x_max) print("積分結果:" + str(result)) print("計算誤差:" + str(result - exact) + " (推定誤差:" + str(err) + ")")これを実行したところこのようになった。
$ python sample.py >積分結果:1.7182818284590453 >計算誤差:2.220446049250313e-16 (推定誤差:1.9076760487502457e-14)1 量子力学の基礎(シュレディンガーの方程式)
1.1 波動関数
量子コンピュータで扱う粒子には、波としての性質と粒子としての性質があるようでこの性質のために量子の状態を扱うためには、波動関数と言われる関数を使用する。波動関数には記号
ψを用いる。\begin{array}{l} \psi(x,y):波動関数\\ x:位置\\ y:時間 \end{array}波動関数の絶対値の二乗がその地点に粒子が存在する確率を表す性質がある。そのため波動関数は以下の規格化条件を満たす必要がある。
\begin{array}{l} \S 1.1(規格化条件)\\ \int_{-\infty}^{\infty}\left|\psi(x,t)\right|^2dx \end{array}1.2 シュレディンガー方程式
シュレディンガー方程式は波動関数の振る舞いを決定する方程式で、以下のように表される。
\begin{array}{l} \S 1.2(シュレディンガー方程式)\\ (1)\quad i\hbar\frac{\partial\psi(x,t)}{\partial t}=\hat{H}(x,t)\psi(x,t)\\ i:虚数単位\\ \hbar:ディラック定数(1.055\times 10^{-34}[Js])\\ \hat{H}(x,t):ハミルトニアン \end{array}虚数単位の説明は省く。ディラック定数は、プランク定数(h)を2πで割った定数です。
ハミルトニアンは古典力学においては、要は系のエネルギーを表すもののようです。これにハットが付くことで量子力学へと転換されていることを意味する。このハットは、内部の運動量pが運動量演算子に、位置xが位置演算子に置き換えることを意味する。\begin{array}{l} \S 1.3 (ハミルトニアン[量子力学])\\ (2)\quad\hat{H}=\hat{T}+\hat{V}\\ (3)\quad\hat{T}=\frac{\hat{p}^2}{2m}\\ (4)\quad\hat{V}=V(\hat{x},t)\\ \hat{p}:運動量演算子\\ \hat{x}:位置演算子 \end{array}ここで定義している波動関数は位置
xと時間tで定義されている。このような表し方を位置表示(座標表示?)という。また、運動量と時間によって波動関数を表す方法を、運動量表示というらしい。
位置表示の場合には運動量演算子と位置演算子は以下のように変換できる。\begin{array}{l} \S 1.4(位置表示の演算子)\\ \hat{p}=\frac{\hbar}{i}\frac{\partial}{\partial x}\\ \hat{x}=x \end{array}ここで位置演算子と運動量演算子は正準交換条件を満たす必要がある。正準交換条件とは、
\begin{array}{l} \S 1.5(正準交換条件)\\ [\hat{x},\hat{p}]=\hat{x}\hat{p}-\hat{p}\hat{x}=i\hbar \end{array}
位置演算子と運動量演算子は↑のような形を満たさないと行けないらしい。これらを踏まえて、シュレディンガー方程式は次のように書き換えることができる。
\begin{array}{l} \S 1.6(シュレディンガー方程式)\\ i\hbar\frac{\partial\psi(x,t)}{\partial t}=\left[-\frac{\hbar^2}{2m}\frac{\partial^2}{\partial x^2}+V(x,t)\right]\psi(x,t) \end{array}1.3 ポテンシャルが時間に依存しない場合
ポテンシャルが時間に依存しない場合、ψを次のように二つの関数に分けて考える。
\psi(x,t)=\phi(x)T(t)ここではこのような形となる解(変数分離解)を求める。これ以外の解の形については考えなくても良いみたい。理由はわからなかった。シュレディンガーの方程式にこれを代入すると、
\begin{align} i\hbar\frac{d(\phi(x)T(t))}{d t} &=& -\frac{\hbar^2}{2m}\frac{d (\phi(x)T(t))}{d x}+V(x)\phi(x)T(t)\\ i\hbar\phi(x)\frac{d T(t)}{d t} &=& -\frac{\hbar^2}{2m}T(x)\frac{d \phi(x)}{d x}+V(x)\phi(x)T(t) \end{align}両辺を
ϕ(x)T(t)で割ると、i\hbar\frac{1}{T(t)}\frac{d T(t)}{d t}=\frac{1}{\phi(x)}\left[-\frac{\hbar^2}{2m}\frac{d^2 \phi(x)}{d x^2}+V(x)\phi(x)\right]式を見ると、左辺にt右辺にxのみ変数がある状態となっている。左辺と右辺が常に等しいので、両辺は定数となる。ここで定数(分離定数)をEとおくと、
\begin{align} E &=& i\hbar\frac{1}{T(t)}\frac{d T(t)}{d t}\\ E &=& \frac{1}{\phi(x)}\left[-\frac{\hbar^2}{2m}\frac{d^2 \phi(x)}{d x^2}+V(x)\phi(x)\right] \end{align}上の式を整理すると、
\frac{d T(t)}{d t}=-\frac{iE}{\hbar}T(x)T(x)の微分がT(x)に定数を欠けたものとなっているので、この微分方程式を解くと指数関数の形になり、定数T0を使って、
T(x)=T_{0}e^{-i\omega t}\quad ただし\omega=\frac{E}{\hbar}ここから波動関数は単振動していることがわかる。またディラック定数はプランク定数を2πで割ったものなので、
\begin{array}{l} \S 1.7 (アインシュタインの関係)\\ E=\hbar\omega=hv\\ v:振動数 \end{array}またxについての式を変形することで時間に依存しないシュレディンガー方程式が得られる。
\begin{array}{l} \S 1.8 (時間に依存しないシュレディンガー方程式)\\ \left[ -\frac{\hbar^2}{2m}\frac{d^2}{d x^2}+V \right]\phi(x)=E\phi(x) \end{array}このような式を固有方程式とよび、Eは固有エネルギー、φは固有エネルギー関数という。
参考
- 投稿日:2020-05-29T16:25:04+09:00
【Windows10】「ゼロから作るDeep Learning」環境構築
はじめに
この資料は、「ゼロから作るDeep Learning」(1)~(3)の各書籍のコードを動かすために必要な準備を記載したものです。
基本的にプログラム書いたことのない方か、経験が浅い方向けです。
Windows上では開発しないという方にも役立つかもしれません。「gitとかvscodeとかそんなもの当たり前に入ってるよ!」
という方にはこの資料は不要なのでご注意ください。Pythonのインストール
公式サイトからインストーラをダウンロードする。
https://www.python.org/ページ上部の'Donwloads'をポイントし、'Download for Windows'の下に表示されるリンクをクリックするとダウンロードできる。
インストール時にパスを通しておくことを忘れずに。
具体的には、インストールウィザードの最初の画面で、「Add Python 3.X to PATH」にチェックを入れる。これを怠るとpipコマンドが使えない。
また、Windowsストアにある未インストールのPythonと誤認してコマンドを受け付けてくれなくなるなどの不具合が出る場合がある(経験談)。gitのインストール
サンプルコードがgithubにあるのでダウンロードはgit cloneで行うことにする。
そのための準備として、gitのインストールが必要となる。gitのインストールは公式サイトへ。
https://git-scm.com/ページ右側にある'Download x.xx.xx for Windows'のリンクをクリックするとインストーラがダウンロードできる。
Pythonモジュール類のインストール
本書のプログラムの実行に必要なライブラリ類をインストールしておく。
必要なライブラリは巻によって異なるが、まず1巻のみを読み進めるならばnumpyとmatplotlabの2つのみインストールしておけば問題ない。
それ以外のライブラリ類は2巻・3巻のコードを実行するために必要となるものである。スタートメニューからgit bashを起動する。
(コマンドプロンプトでも可能)
まず、pip自体をアップデートしておく。
pipは頻繁にアップデートされるので、既にpythonをインストールしている方でもアップデートすることをおすすめする。bash$ pip install --upgrade pipnumpy [1~3巻]
その後、numpyをインストール。
numpyはPythonの数値計算ライブラリである。bash$ pip install numpymatplotlib [1~3巻]
続いて、matplotlibをインストール。
matplotlibは機械学習本体の動作には関わらないが、機械学習の進み具合や性能をグラフで表示して評価するために用いる。bash$ pip install matplotlibsklearn [2巻]
2巻では、上記2つに加えてsklearnが必要になる。
(なくてもコードの実行は可能だが、学習にかかる時間が非常に長くなるためインストールした方がいい)
1巻では必要ない。bash$ pip install sklearnCuPy [2巻・3巻]
2巻・3巻のオプションで、1巻では必要ない。
オプションなのでインストールしなくても構わない(なくても現実的な計算時間で収まる)。
ただし、プログラムを改造するなどして複雑化しようとする場合は導入した方がよい。CuPyはNVIDIAのGPUを搭載したPCでしか使用できない。
インストール方法は下記の別記事を参照。
https://qiita.com/BARANCE_TW/items/30abf85c55070a2bdc9dPillow [3巻]
Pillowは画像処理用のライブラリである。
色空間を変更したり、2値化したりと画像を加工する機能を持つ。bash$ pip install pillowGraphviz [3巻]
graphvizはグラフ描画用のツールである。
ここで言うグラフは、matplotlibで描く一般的なグラフではなく、グラフ理論で用いられるエッジとノードからなるグラフのことを指す。インストール方法は下記の別記事を参照。
https://qiita.com/BARANCE_TW/items/c3f7816d38cc9e746bbdサンプルコードのclone
cloneの前に、適当な作業用のディレクトリ(フォルダ)を作成しておく。
以下では、Cドライブ直下に"ai"というディレクトリを作成した場合を想定。
(つまり、C:\aiがワークスペースディレクトリになる)次にリポジトリURLをブラウザで開き、右側にある緑のボタンを押して表示されるclone用のURLをコピーする。
各巻のリポジトリは下記。
- 「ゼロから作るDeep Learning」のリポジトリ https://github.com/oreilly-japan/deep-learning-from-scratch
- 「ゼロから作るDeep Learning 2」のリポジトリ https://github.com/oreilly-japan/deep-learning-from-scratch-2
- 「ゼロから作るDeep Learning 3」のリポジトリ https://github.com/oreilly-japan/deep-learning-from-scratch-3
clone URLをコピーしたら、git bashを開き、下記の
{clone URL}のところにコピーしたclone用URLを貼り付けて実行する。
少しすると、サンプルコードが該当ディレクトリにcloneされる。bash$ cd /c/ai $ git clone {clone URL}vscodeのインストール
1巻の序盤までは対話式コンソールでも十分なコード量だが、中盤以降は爆発的にコード量とファイル数が増えるので、何かしらの環境を利用することをおすすめする。
ここではvscodeをインストールするが、好きなIDEやエディタがあるのであればそれでも構わないと思う。vscodeは下記からダウンロードする。
ワークスペースを開く
vscodeを起動したら、まずはさきほどcloneしたディレクトリをワークスペースとしてopenする。
「ファイル」メニューをクリックし、「フォルダーを開く」を選択する。
(「ワークスペースを開く」ではないので注意)
その後、cloneしたディレクトリまで移動して「フォルダーの選択」をクリックすると、ワークスペースが開く。
左側の「エクスプローラー」にcloneしたファイルの一覧が表示されていることを確認する。launch.jsonの編集
vscodeでは「Ctrl」+「F5」でコードの実行ができる(または「F5」でデバッグ実行)。
しかし、その際の実行ディレクトリは、デフォルトではワークスペースのルートディレクトリになってしまう。
この状態のままだと、次のような問題が発生する。
- コードが記載されたファイルの場所を起点として記述したfrom・importが想定通りに働かなくなる。
- pickleなどでファイルをread/writeする際のディレクトリが、ワークスペースのルートディレクトリになってしまう。
この問題を解決するために、launch.jsonを編集してファイルのあるディレクトリを実行ディレクトリにする。
まず、左側のアイコンが並んだ場所から「実行」タブを選択し、「launch.jsonファイルを作成します」を選択する。
次に、「Select a debug configuration」という表示が現れるので、「Python File」をクリック。
すると、launch.jsonの編集画面が表示される。
このファイルは、ワークスペースのルートディレクトリ直下にある「.vscode」ディレクトリの中に格納される。
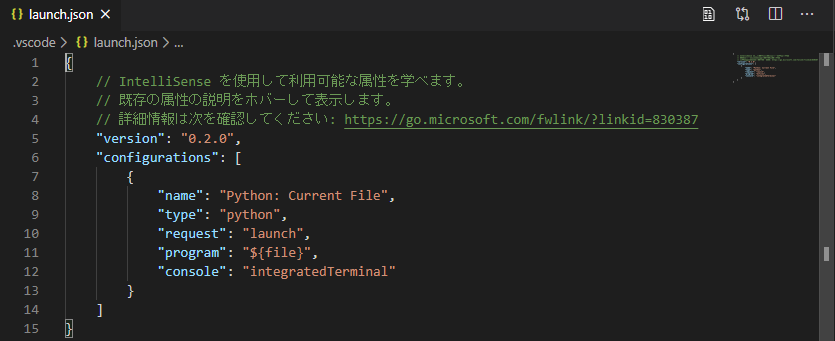
このファイルの「configurations」の値に
"cwd": "${fileDirname}"という表記を付け加える。
付け加えた後のファイルは下記のようになる。launch.json{ // IntelliSense を使用して利用可能な属性を学べます。 // 既存の属性の説明をホバーして表示します。 // 詳細情報は次を確認してください: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Python: Current File", "type": "python", "request": "launch", "program": "${file}", "console": "integratedTerminal", // カンマを末尾に追加 "cwd": "${fileDirname}" // ここに追加!! } ] }これで、「Ctrl」+「F5」で実行時にファイルのあるパスに移ってからプログラムが実行されるようになった。



- 投稿日:2020-05-29T16:19:08+09:00
PythonとC#でLチカ
PythonでLチカ
知識ゼロから作って学ぶIoT入門
Arduinoではありますがブレッドボードの説明やLチカ説明が載っており、1500円セールの時なら元はとれます。gpioのピンの一覧を表示する
基板のGPIOの番号を確認します。
$ gpio readallwiringpiライブラリー古い場合はエラーが出た場合
ライブラリーが古い場合はエラーが出ます
Oops - unable to determine board type... model: 17wiringpiを更新する
cd /tmp $ wget https://project-downloads.drogon.net/wiringpi-latest.deb $ sudo dpkg -i wiringpi-latest.deb再度
gpio readallgpioのPIN番号の表示
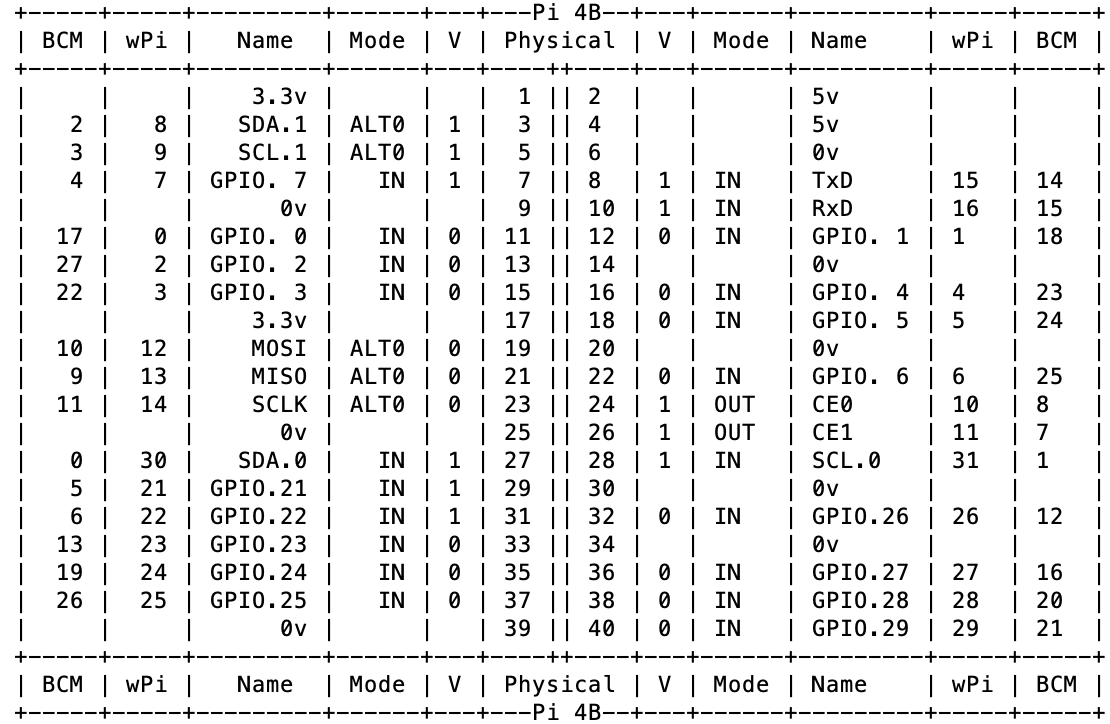
Physical = 連番 PIN
0v = GND
ターミナルに表示されます
左側に3.3Vの電流がそれぞれのPINに流れています
右側に5Vの電流がそれぞれのPINに流れています0vがGNDになります。GNDはマイナス
GNDについてはUmedyの動画で詳しく説明しています。
GPIについてUmedyの動画で体系的に学ぶことをお勧めします。GPIO.BOARD: 物理ピン番号(連番) GPIO.BCM: 役割ピン番号(broadcomが命名しているもの)GPIO番号はモデルごと違うのでPIN連番(BOARD)を使う
GPIO番号はモデルごと違う場合があるので、PIN番号で指定するGPIO.BOARD(連番)を使った方がよいみたいです。
l.py#!/usr/bin/env python # -*- coding: utf-8 -*- import RPi.GPIO as GPIO #RPi.GPIOモジュールをインポート from time import sleep #GPIO.setmode(GPIO.BCM) #GPIO.setmode(GPIO.BOARD) #連番を利用する GPIO.setmode(GPIO.BOARD) GPIO.setup(7, GPIO.OUT) try: while True: GPIO.output(7, GPIO.HIGH) sleep(0.5) GPIO.output(7, GPIO.LOW) sleep(0.5) except KeyboardInterrupt: # GPIO設定クリア GPIO.cleanup()$ python l.pay
全体の流れ
PINのプラス(赤)からブレッドボードを通してPIN マイナス(黒)(GND)につなげる
ダイオードに電流が流れすぎないように抵抗を加えて調整する必要がある
パーツをまとめて購入(サンプルファイルCD付き)
最終的にこれらをC#に変換しマイクロソフトがGPIOライブラリを使って使おうと思います。ポイント
センサーパーツをAmazonでまとめて購入できる
体系的にGPIOを学んだほうがよい。UmedyにRaspberyの動画があった
Amazonの安いテスターを買って電流がちゃんと流れているか確認すると理解が早まる
パーツをまとめて購入セットにはサンプルプロジェクトファイルがあり、自走学習が可能と思われる次回 C#でLチカ
マイクロソフトがGPIOライブラリをリリースしてきたのでそれを使ってlチカをやってみます。




- 投稿日:2020-05-29T16:19:08+09:00
RaspberryPi PythonとC#でLチカ
PythonでLチカ
知識ゼロから作って学ぶIoT入門
Arduinoではありますがブレッドボードの説明やLチカ説明が載っており、1500円セールの時なら元はとれます。gpioのピンの一覧を表示する
基板のGPIOの番号を確認します。
$ gpio readallwiringpiライブラリー古い場合はエラーが出た場合
ライブラリーが古い場合はエラーが出ます
Oops - unable to determine board type... model: 17wiringpiを更新する
cd /tmp $ wget https://project-downloads.drogon.net/wiringpi-latest.deb $ sudo dpkg -i wiringpi-latest.deb再度
gpio readallgpioのPIN番号の表示
Physical = 連番 PIN
0v = GND
ターミナルに表示されます
左側に3.3Vの電流がそれぞれのPINに流れています
右側に5Vの電流がそれぞれのPINに流れています0vがGNDになります。GNDはマイナス
GNDについてはUmedyの動画で詳しく説明しています。
GPIについてUmedyの動画で体系的に学ぶことをお勧めします。GPIO.BOARD: 物理ピン番号(連番) GPIO.BCM: 役割ピン番号(broadcomが命名しているもの)GPIO番号はモデルごと違うのでPIN連番(BOARD)を使う
GPIO番号はモデルごと違う場合があるので、PIN番号で指定するGPIO.BOARD(連番)を使った方がよいみたいです。
l.py#!/usr/bin/env python # -*- coding: utf-8 -*- import RPi.GPIO as GPIO #RPi.GPIOモジュールをインポート from time import sleep #GPIO.setmode(GPIO.BCM) #GPIO.setmode(GPIO.BOARD) #連番を利用する GPIO.setmode(GPIO.BOARD) GPIO.setup(7, GPIO.OUT) try: while True: GPIO.output(7, GPIO.HIGH) sleep(0.5) GPIO.output(7, GPIO.LOW) sleep(0.5) except KeyboardInterrupt: # GPIO設定クリア GPIO.cleanup()$ python l.pay
全体の流れ
PINのプラス(赤)からブレッドボードを通してPIN マイナス(黒)(GND)につなげる
ダイオードに電流が流れすぎないように抵抗を加えて調整する必要がある
パーツをまとめて購入(サンプルファイルCD付き)
最終的にこれらをC#に変換しマイクロソフトのGPIOライブラリを使って使おうと思います。追記
Sample File URL
OSOYOOのサイト サンプルファイルと動画がありましたポイント
センサーパーツをAmazonでまとめて購入できる
体系的にGPIOを学んだほうがよい。UmedyにRaspberyの動画があった
Amazonの安いテスターを買って電流がちゃんと流れているか確認すると理解が早まる
パーツをまとめて購入セットにはサンプルプロジェクトファイルがあり、自走学習が可能と思われる次回 C#でLチカ
マイクロソフトがGPIOライブラリをリリースしてきたのでそれを使ってlチカをやってみます。
- 投稿日:2020-05-29T15:57:11+09:00
ホロジュールをスクレイピングしてCLIで表示する
ホロライブの配信スケジュールであるホロジュールをスクレイピングして内容を簡易的にCLIで表示するプログラムを作りました。
ソースコード
利用上の注意
このツールは外部ライブラリとしてrequestsを使っています。pipをすでにインストールしている場合
pip install requests で対応できますまた、このツールはホロライブ公式と全く関係がありません。必要以上の実行でサーバーに負担をかけないようにしてください。
使い方
リポジトリ内のmain.pyを実行することで以下のような内容を表示できます。
また、実行時にオプションをつけることができ、--helpでその内容を確認することができます。例として、
- --all ホロスターズなどを含む、Bilibili動画以外のすべてのスケジュールを表示
- --eng メンバーの名前を英語で表示
- --tomorrow 明日のスケジュールを表示
などが使えます。これらのオプションは同時に設定して実行することができます。
Notes
製作にあたり、自分が詰まったところをメモします。
まず、スクレイピングで得られたデータの中から、どのようにホロライブメンバーとそれ以外を分けるか悩みました。対応として、
scraping.pydef delete_exception(time_list, stream_members_list, stream_url_list, is_all): EXCEPTION_LIST = {'Yogiri', 'Civia', 'SpadeEcho', 'Doris', 'Artia', 'Rosalyn'} if not is_all: #Slice to get only non-hololive members (e.g. holostars hololive-ID) EXCEPTION_LIST = EXCEPTION_LIST | set(get_member_list()[29:]) for i in range(len(time_list)): if stream_members_list[i] in EXCEPTION_LIST: time_list[i] = None stream_members_list[i] = None stream_url_list[i] = None time_list = [i for i in time_list if not i is None] stream_members_list = [i for i in stream_members_list if not i is None] stream_url_list = [i for i in stream_url_list if not i is None] return time_list, stream_members_list, stream_url_listホロライブのYoutube配信のメンバーと、Bilibili配信のメンバーの集合を予め用意しておき、
オプションなどから、除外するメンバーの集合を作り、それに属するスクレイピングした要素をNoneに置き換え、最後にまとめて内包表記で削除するようにしました。ちなみに、リストでも同じように実装できますが、要素の番号がいらない場合、リストよりも集合を使ったほうが何倍も早いです。
もう一つ困ったこととして、名前が英語のメンバーと日本語のメンバーがいることで、半角全角の違いから列をきれいに揃えて表示できないという問題がありました。これを解決するために、標準ライブラリのunicodedataを使いました。unicodeif unicodedata.east_asian_width(stream_members_list[i][0]) == 'W': m_space = ' ' * ( (-2 * len(stream_members_list[i]) + 18)) else: m_space = ' ' * ( (-1 * len(stream_members_list[i]) ) + 18)unicodedataのeast_asian_widthは引数の文字(Charであるため一文字)が全角日本語の文字の場合Wを返してくれます。これによって、名前の文字数なども考慮しつつ、スペースを用いて揃った行で表示させることができました。
最後に
すでに何人かにクローンされていて嬉しく感じます。今後もこのリポジトリの改善に努めたいと思います。
- 投稿日:2020-05-29T15:57:04+09:00
弓道の採点簿(的中の結果を記録する冊子)を画像解析してみた。(Google Colaboratory)
弓道の採点簿とは
飛ばした矢が的にあったか外したかを記録する冊子です。
記録の仕方は団体によって様々ですが、今回は朱色のインクで○を付けているものについて、解析チャレンジしました。
拙いコードですが、誰かの参考になればと思います。
本プログラムの構成
google collaboratery の利用
google collaboratery を利用する前提でプログラムを作成しました。
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja
google collab は完全にクラウドで実行される Jupyter ノートブック環境です。
設定不要で無料で利用できるので、パソコンがない!というときや、パソコンにpython入れてない!という場合でも簡単に使えます。さらに、自分のパソコンにはライブラリをインストールする手間が必要ですが、google collab には大体のライブラリがインストール済みなので脳死で実行できるのも意外と大きな利点です。
今回は画像を読み書きするので、google Drive と連携させることにしました。
電子データ化計画
本コードの設計は次の通りです。
1. グーグルドライブと連携、フォルダの作成
2. 画像の取得、画像サイズ変更
3. 採点簿のフレームを認識
4. 採点簿の赤色の円を認識
5. 円の位置情報を配列化
6. Excelに書き込む冊子の外枠の認識
ある条件で直線を認識させ、認識された直線の中で最も画像の端にある縦線、横線を戻り値として指定しました。
- ハフ変換による直線検出を用いています。
detect_line.pydef resize_im(self, im): # 画像のサイズを固定 # -------------------------------------------- size = self.x_pixel h, w, c = im.shape width,height = size, round(size * ( h / w )) im_resize = cv2.resize(im,(width, height)) return im_resize def detect_line(self): # フレームを検出する # ----------------------------------------- im = cv2.imread(path_Now_Projects + self.FileName) im_resize = self.resize_im(im) # parameter G = 1 + 2 * self.nomalization(10) T1 = 1 + 2 * self.nomalization(7) T2 = 1 + 2 * self.nomalization(2) # 画像を加工する(ノイズ除去、ぼかし、二値化) im_denoise = cv2.fastNlMeansDenoising(im_resize) im_gray = cv2.cvtColor(im_denoise, cv2.COLOR_BGR2GRAY) im_gau = cv2.GaussianBlur(im_gray,(G,G),0) im_th = cv2.adaptiveThreshold(im_gau, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY,T1,T2) if detail2 == True: cv2.imwrite(self.path_project + self.ImName + "_th.jpg", im_th) # 直線を抽出する。 imgEdge = cv2.Canny(im_th,50,150,apertureSize = 3) # キャニー法によるエッジの検出 minLineLength = self.nomalization(200) # 検出する直線の長さの閾値(画素数依存) maxLineGap = self.nomalization(20) # 直線が連続とみなせる隙間の最長距離(画素数依存) th = self.nomalization(50) lines = cv2.HoughLinesP(imgEdge,2,np.pi/180,th,minLineLength=minLineLength,maxLineGap=maxLineGap) # ハフ近似による直線の検出 # 直線を青で描画しつつ、フレームの直線を選別する。 im_line = im_resize frame_left,frame_under, frame_over, frame_right = [10000]*4,[1]*4, [10000]*4, [1]*4 # 初期値の設定 # 全ての直線を描画 for i in range(len(lines)): for x1,y1,x2,y2 in lines[i]: cv2.line(im_line,(x1,y1),(x2,y2),(255,0,0),2) # フレームの直線の選別 if frame_left[0] > x1 and abs(y1-y2) >3*abs(x1-x2) : # x座標が最も小さい縦線 frame_left = [x1,y1,x2,y2] if frame_under[1] < y1 and 3*abs(y1-y2) < abs(x1-x2) : # y座標が最も大きい横線 frame_under = [x1,y1,x2,y2] if frame_over[1] > y1 and 3*abs(y1-y2) < abs(x1-x2) : # y座標が最も小さい横線 frame_over = [x1,y1,x2,y2] if frame_right[0] < x1 and abs(y1-y2) >3*abs(x1-x2) : # x座標が最も大きい縦線 frame_right = [x1,y1,x2,y2] # フレームを示す直線を緑で描画する。 cv2.line(im_line,(frame_left[0], frame_left[1]),(frame_left[2], frame_left[3]),(0,255,0),2) cv2.line(im_line,(frame_under[0], frame_under[1]),(frame_under[2], frame_under[3]),(0,255,0),2) cv2.line(im_line,(frame_over[0], frame_over[1]),(frame_over[2], frame_over[3]),(0,255,0),2) cv2.line(im_line,(frame_right[0], frame_right[1]),(frame_right[2], frame_right[3]),(0,255,0),2) if detail2 == True: # デバック用の画像を保存する。 cv2.imwrite(self.path_project + self.ImName + "_line.jpg", im_line) return frame_left, frame_under, frame_over, frame_right4つの直線それぞれの交点を求める
get_4point.pydef cross_point(self, p1, p2): # 2点を通る直線2本の交点の導出 # ----------------------------------------------------------- return solve( [ solve(p1,[1,1]), solve(p2,[1,1]) ], [1,1] ) def get_4point(self, f_under, f_left,f_over,f_right):# 2点を通る直線4本の交点4つを取得 # ------------------------------------------------------------------------------------ f_under = np.array([f_under[0:2], f_under[2:4]]) f_left = np.array([f_left[0:2], f_left[2:4]]) f_over = np.array([f_over[0:2], f_over[2:4]]) f_right = np.array([f_right[0:2], f_right[2:4]]) UL = self.cross_point(f_under, f_left) OL = self.cross_point(f_over , f_left) UR = self.cross_point(f_under, f_right) OR = self.cross_point(f_over, f_right) return [OL, OR, UL, UR]任意の4点での四角形のトリミング
transform_by4.pydef transform_by4(self, points):# 任意の4点から長方形にトリミング # -------------------------------------------------------------- im = cv2.imread(path_Now_Projects + self.FileName) im_resize = self.resize_im(im) points = sorted(points, key=lambda x:x[1]) # yが小さいもの順に並び替え。 top = sorted(points[:2], key=lambda x:x[0]) # 前半二つは四角形の上。xで並び替えると左右も分かる。 bottom = sorted(points[2:], key=lambda x:x[0], reverse=True) # 後半二つは四角形の下。同じくxで並び替え。 points = np.array(top + bottom, dtype='float32') # 分離した二つを再結合。 width = max(np.sqrt(((points[0][0]-points[2][0])**2)*2), np.sqrt(((points[1][0]-points[3][0])**2)*2)) height = max(np.sqrt(((points[0][1]-points[2][1])**2)*2), np.sqrt(((points[1][1]-points[3][1])**2)*2)) dst = np.array([ np.array([0, 0]), np.array([width-1, 0]), np.array([width-1, height-1]), np.array([0, height-1]), ], np.float32) trans = cv2.getPerspectiveTransform(points, dst) # 変換前の座標と変換後の座標の対応を渡すと、透視変換行列を作ってくれる。 im_trimming = cv2.warpPerspective(im_resize, trans, (int(width), int(height))) # 透視変換行列を使って切り抜く。 if detail2 == True: cv2.imwrite(self.path_project + self.ImName +'_trimming.jpg', im_trimming) return im_trimming赤い円の抽出
赤い色の抽出の仕方は、hsv色空間のある範囲でmask処理をしたりとめんどくさいことをします。
- マスク処理で参照したサイト
https://note.nkmk.me/python-opencv-numpy-alpha-blend-mask/
def detect_red(self, im_trimming):# 赤色のみを抽出 # ------------------------------------------------ im = im_trimming im_resize = self.resize_im(im) # 赤色 (Hが0~30,150~180の範囲が赤)のマスクを用意 hsv = cv2.cvtColor(im_resize, cv2.COLOR_BGR2HSV) lower1 = np.array([150, 30, 100]) # HSV upper1 = np.array([179, 255, 255]) # HSV img_mask1 = cv2.inRange(hsv, lower1, upper1) lower2 = np.array([0, 30, 100]) # HSV upper2 = np.array([30, 255, 255]) # HSV img_mask2 = cv2.inRange(hsv, lower2, upper2) # 2つの赤用マスクを結合させる mask = cv2.bitwise_or(img_mask1, img_mask2) # マスクをかけ、赤の円のみを残す im_red = cv2.bitwise_and(im_resize, im_resize, mask=mask) if detail2 == True: # デバッグ用の画像を保存 cv2.imwrite(self.path_project + self.ImName + "_red.jpg", im_red) return im_red円検出
赤だけ抽出した画像に対して円検出を行います。条件の設定をミスるとあらゆる模様を円として認識してしまうので、条件だしは必須。
今回も直線検出と同様、ハフ関数を用いています。
- ハフ変換による円検出
detect_circle.pydef detect_circle(self, im_trimming):# 円の位置を取得 # --------------------------------------------------- # parameter minD = self.nomalization(58) p2= self.nomalization(12) minR = self.nomalization(30) maxR = self.nomalization(36) Lx0 = self.nomalization(10) Ly0 = self.nomalization(86) Lx = self.nomalization(90) Ly = self.nomalization(72) # 赤抽出の画像から円を検出する。 im_red = self.detect_red(im_trimming) im_gray = cv2.cvtColor(im_red,cv2.COLOR_BGR2GRAY) # 検出する円の大きさを画素数に基づいた円の大きさ前後に設定 circles = cv2.HoughCircles(im_gray, cv2.HOUGH_GRADIENT, dp=1, minDist = minD, # 検出を許す円ごとの間隔 param1=1, param2=p2, # 検出しきい値 minRadius=minR, # 検出する半径の最小 maxRadius=maxR) # 検出する半径の最大全コード
kaiseki.py# coding: utf-8 # 採点簿の的中の写真を電子化する # ________________________________ # 出力ユーザー設定 "True"or"False" detail1 = True detail2 = True # 1 = 確認用の画像 # 2 = パラメータ調整用の画像 # ________________________________ # import一覧 import numpy as np from numpy.linalg import solve import os import cv2 import sys import pandas as pd import openpyxl as excel from pandas import ExcelWriter import matplotlib.pyplot as plt # google drive と連携する from google.colab import drive drive.mount('/content/drive') # pathリスト path_Now_Projects = 'drive/My Drive/OU_kyudo/Now_Projects/' path_Past_Projects = 'drive/My Drive/OU_kyudo/Past_Projects/' # フォルダ作成する def make_folder(path): if os.path.exists(path)==False: os.mkdir(path) make_folder(path_Now_Projects) make_folder(path_Past_Projects) # 画像名を取得する files = [] for filename in os.listdir(path_Now_Projects): if os.path.isfile(os.path.join(path_Now_Projects, filename)): #ファイルのみ取得 files.append(filename) if len(files)==0: print("画像をNow_Projectsフォルダに入れてください。") sys.exit() #============================= #<<<<<< C l a s s >>>>>>>>>> class Tekichu(object): # 初期化する。 # -------------------------------- def __init__(self): # 画像名(拡張子あり) self.FileName = "" # 画像名(拡張子なし) self.ImName, self.ext = "","" # project名とそのpath名 self.project = "" self.path_project = "" # 画像の横方向の画素数 self.x_pixel = 1800 def set_variable(self, file): # 画像の名前をセットする # ---------------------------------------------------- # project名とそのpath名 self.project = input("画像("+ file +") の project名 を入力 : ") self.path_project = "drive/My Drive/OU_kyudo/Now_Projects/" + self.project +"/" # project名のフォルダを作成 if os.path.exists(self.path_project)==False: os.mkdir(self.path_project) # 画像名(拡張子あり) self.FileName = file # 画像名(拡張子なし) self.ImName, self.ext = os.path.splitext(file) # 画素で変動するパラメータを基準値を用いて正規化 def nomalization(self, val): return int(self.x_pixel *(val / 1200)) def resize_im(self, im): # 画像のサイズを固定 # -------------------------------------------- size = self.x_pixel h, w, c = im.shape width,height = size, round(size * ( h / w )) im_resize = cv2.resize(im,(width, height)) return im_resize def detect_line(self): # フレームを検出する # ----------------------------------------- im = cv2.imread(path_Now_Projects + self.FileName) im_resize = self.resize_im(im) # parameter G = 1 + 2 * self.nomalization(10) T1 = 1 + 2 * self.nomalization(7) T2 = 1 + 2 * self.nomalization(2) # 画像を加工する(ノイズ除去、ぼかし、二値化) im_denoise = cv2.fastNlMeansDenoising(im_resize) im_gray = cv2.cvtColor(im_denoise, cv2.COLOR_BGR2GRAY) im_gau = cv2.GaussianBlur(im_gray,(G,G),0) im_th = cv2.adaptiveThreshold(im_gau, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY,T1,T2) if detail2 == True: cv2.imwrite(self.path_project + self.ImName + "_th.jpg", im_th) # 直線を抽出する。 imgEdge = cv2.Canny(im_th,50,150,apertureSize = 3) # キャニー法によるエッジの検出 minLineLength = self.nomalization(200) # 検出する直線の長さの閾値(画素数依存) maxLineGap = self.nomalization(20) # 直線が連続とみなせる隙間の最長距離(画素数依存) th = self.nomalization(50) lines = cv2.HoughLinesP(imgEdge,2,np.pi/180,th,minLineLength=minLineLength,maxLineGap=maxLineGap) # ハフ近似による直線の検出 # 直線を青で描画しつつ、フレームの直線を選別する。 im_line = im_resize frame_left,frame_under, frame_over, frame_right = [10000]*4,[1]*4, [10000]*4, [1]*4 # 初期値の設定 # 全ての直線を描画 for i in range(len(lines)): for x1,y1,x2,y2 in lines[i]: cv2.line(im_line,(x1,y1),(x2,y2),(255,0,0),2) # フレームの直線の選別 if frame_left[0] > x1 and abs(y1-y2) >3*abs(x1-x2) : # x座標が最も小さい縦線 frame_left = [x1,y1,x2,y2] if frame_under[1] < y1 and 3*abs(y1-y2) < abs(x1-x2) : # y座標が最も大きい横線 frame_under = [x1,y1,x2,y2] if frame_over[1] > y1 and 3*abs(y1-y2) < abs(x1-x2) : # y座標が最も小さい横線 frame_over = [x1,y1,x2,y2] if frame_right[0] < x1 and abs(y1-y2) >3*abs(x1-x2) : # x座標が最も大きい縦線 frame_right = [x1,y1,x2,y2] # フレームを示す直線を緑で描画する。 cv2.line(im_line,(frame_left[0], frame_left[1]),(frame_left[2], frame_left[3]),(0,255,0),2) cv2.line(im_line,(frame_under[0], frame_under[1]),(frame_under[2], frame_under[3]),(0,255,0),2) cv2.line(im_line,(frame_over[0], frame_over[1]),(frame_over[2], frame_over[3]),(0,255,0),2) cv2.line(im_line,(frame_right[0], frame_right[1]),(frame_right[2], frame_right[3]),(0,255,0),2) if detail2 == True: # デバック用の画像を保存する。 cv2.imwrite(self.path_project + self.ImName + "_line.jpg", im_line) return frame_left, frame_under, frame_over, frame_right def cross_point(self, p1, p2): # 2点を通る直線2本の交点の導出 # ----------------------------------------------------------- return solve( [ solve(p1,[1,1]), solve(p2,[1,1]) ], [1,1] ) def get_4point(self, f_under, f_left,f_over,f_right):# 2点を通る直線4本の交点4つを取得 # ------------------------------------------------------------------------------------ f_under = np.array([f_under[0:2], f_under[2:4]]) f_left = np.array([f_left[0:2], f_left[2:4]]) f_over = np.array([f_over[0:2], f_over[2:4]]) f_right = np.array([f_right[0:2], f_right[2:4]]) UL = self.cross_point(f_under, f_left) OL = self.cross_point(f_over , f_left) UR = self.cross_point(f_under, f_right) OR = self.cross_point(f_over, f_right) return [OL, OR, UL, UR] def transform_by4(self, points):# 任意の4点から長方形にトリミング # -------------------------------------------------------------- im = cv2.imread(path_Now_Projects + self.FileName) im_resize = self.resize_im(im) points = sorted(points, key=lambda x:x[1]) # yが小さいもの順に並び替え。 top = sorted(points[:2], key=lambda x:x[0]) # 前半二つは四角形の上。xで並び替えると左右も分かる。 bottom = sorted(points[2:], key=lambda x:x[0], reverse=True) # 後半二つは四角形の下。同じくxで並び替え。 points = np.array(top + bottom, dtype='float32') # 分離した二つを再結合。 width = max(np.sqrt(((points[0][0]-points[2][0])**2)*2), np.sqrt(((points[1][0]-points[3][0])**2)*2)) height = max(np.sqrt(((points[0][1]-points[2][1])**2)*2), np.sqrt(((points[1][1]-points[3][1])**2)*2)) dst = np.array([ np.array([0, 0]), np.array([width-1, 0]), np.array([width-1, height-1]), np.array([0, height-1]), ], np.float32) trans = cv2.getPerspectiveTransform(points, dst) # 変換前の座標と変換後の座標の対応を渡すと、透視変換行列を作ってくれる。 im_trimming = cv2.warpPerspective(im_resize, trans, (int(width), int(height))) # 透視変換行列を使って切り抜く。 if detail2 == True: cv2.imwrite(self.path_project + self.ImName +'_trimming.jpg', im_trimming) return im_trimming def detect_red(self, im_trimming):# 赤色のみを抽出 # ------------------------------------------------ im = im_trimming im_resize = self.resize_im(im) # 赤色 (Hが0~30,150~180の範囲が赤)のマスクを用意 hsv = cv2.cvtColor(im_resize, cv2.COLOR_BGR2HSV) lower1 = np.array([150, 30, 100]) # HSV upper1 = np.array([179, 255, 255]) # HSV img_mask1 = cv2.inRange(hsv, lower1, upper1) lower2 = np.array([0, 30, 100]) # HSV upper2 = np.array([30, 255, 255]) # HSV img_mask2 = cv2.inRange(hsv, lower2, upper2) # 2つの赤用マスクを結合させる mask = cv2.bitwise_or(img_mask1, img_mask2) # マスクをかけ、赤の円のみを残す im_red = cv2.bitwise_and(im_resize, im_resize, mask=mask) if detail2 == True: # デバッグ用の画像を保存 cv2.imwrite(self.path_project + self.ImName + "_red.jpg", im_red) return im_red def detect_circle(self, im_trimming):# 円の位置を取得 # --------------------------------------------------- # parameter minD = self.nomalization(58) p2= self.nomalization(12) minR = self.nomalization(30) maxR = self.nomalization(36) Lx0 = self.nomalization(10) Ly0 = self.nomalization(86) Lx = self.nomalization(90) Ly = self.nomalization(72) # 赤抽出の画像から円を検出する。 im_red = self.detect_red(im_trimming) im_gray = cv2.cvtColor(im_red,cv2.COLOR_BGR2GRAY) # 検出する円の大きさを画素数に基づいた円の大きさ前後に設定 circles = cv2.HoughCircles(im_gray, cv2.HOUGH_GRADIENT, dp=1, minDist = minD, # 検出を許す円ごとの間隔 param1=1, param2=p2, # 検出しきい値 minRadius=minR, # 検出する半径の最小 maxRadius=maxR) # 検出する半径の最大 circle_position = [[0 for i in range(20)] for j in range(13)] total_number = [0 for i in range(13)] warning = False if circles is not None: circles = circles.squeeze(axis=0) # 円の中心を取得 im_circle = self.resize_im(im_trimming) # 採点簿の格子に合わせたパラメータ x_level = [int(Lx0+i*Lx) for i in range(13)] y_level = [int(Ly0+j*Ly) for j in range(21)] # 全ての格子を描画する for i in x_level: cv2.line(im_circle,(i, 0),(i, int(self.x_pixel * 9/16)),(0,0,255),1) for j in y_level: cv2.line(im_circle,(0, j),(self.x_pixel, j),(0,0,255),1) # 円の中心位置を格子と比較し配列化 for cx, cy, r in circles: # 円の円周と中心を描画する。 cv2.circle(im_circle, (cx, cy), r, (0, 255, 0), 2) cv2.circle(im_circle, (cx, cy), 2, (0, 255, 0), 2) horizontal = int((cx-Lx0) // Lx) vertical = int((cy-Ly0)// Ly) # 円が格子をはみ出すと異常を検出して対応する if vertical >= 20: vertical = 19 warning = True # 配列に記録 circle_position[horizontal][vertical] += 1 # 1格子内に2つ以上検出すると異常を記録する if circle_position[horizontal][vertical] >= 2: warning = True if detail1 == True: cv2.imwrite(self.path_project + self.ImName + "_circles.jpg", im_circle) # 合計的中を計算 for i in range(13): total_number[i] = np.sum(circle_position[i]) # 文字化 for i in range(13): for j in range (20): if circle_position[i][j] == 1: circle_position[i][j] = "○" elif circle_position[i][j] == 0: circle_position[i][j] = "・" # 結合 data = np.r_[np.array([total_number]), np.array(circle_position).T] # トータルが0行目、的中が1~20行目になるよう結合 df = pd.DataFrame(data) # 結果を表示 if warning == True : print("【警告】結果に誤りがあります。"+ self.FileName) print(df) return df def tekichu_main(self):# class内のメインプログラム # ------------------------------------------------ f_left, f_under , f_over, f_right = self.detect_line() box_points = self.get_4point(f_left, f_under , f_over, f_right) im_trimming = self.transform_by4(box_points) df = self.detect_circle(im_trimming) wb = excel.Workbook() # 新規ワークブックを作る wb.save(self.path_project + self.project +".xlsx") writer = ExcelWriter(self.path_project + self.project + '.xlsx') df.to_excel(writer, sheet_name = self.ImName) # Excelに書き込み writer.save() return df #================================== #>>> mainプログラム >>>>>>>>>>>>>>> if __name__ == '__main__': for i in range(len(files)): tek1 = Tekichu() tek1.set_variable(files[i]) df = tek1.tekichu_main() print("正常に終了しました")実行手順
本当は適当に撮った写真で解析したかった
でも無理でした。
的中の円がどの位置にあるかを解析するには、採点簿の格子の位置関係を把握する必要があります。
それを認識するために直線検出の関数を用いたのですが、、、
背景が入ると予測不能な検出の仕方をしてしまいます。さすがにこれはどうしようもありません。
⇒ 画像を背景の入らないようにトリミングしてもらう
このことを条件に、安定した解析ができるようにしました。
ドライブの準備
まずは、本プログラムの仕様上、"kyudo" というフォルダ、その中に ”New_Projects” "Past_Projects" という2つのフォルダを作成します。
”New_Projects”にはいている画像を処理する設計なので、そこに先ほどトリミングした画像を入れます。
準備が出来たら実行ボタン!これで回る...
と思いきや、ドライブのマウントを指示されます。Google Collabを開いて最初の実行時は
ドライブのマウントの仕方など、初めての方は一読させると良いかと思います。
知っている方は飛ばしてください。
ここで、自分のアカウントを選択します。
これでマウントは完了です。
続いて、project名を入力してください。project名を入力後に実行すると、解析した結果が表示され、表のデータがドライブに保存されると思います。
GUI画面で一部をユーザーに処理させたほうが良かった
このあと、Google Colabを使わず、Tkinterを用いてGUI(グラフィックユーザーインターフェイス)で処理をさせるコードも書いてみましたが、精度や運用の面でもそちらの方が良かったです。
まあでも、これはこれで勉強になったし楽しかったです。
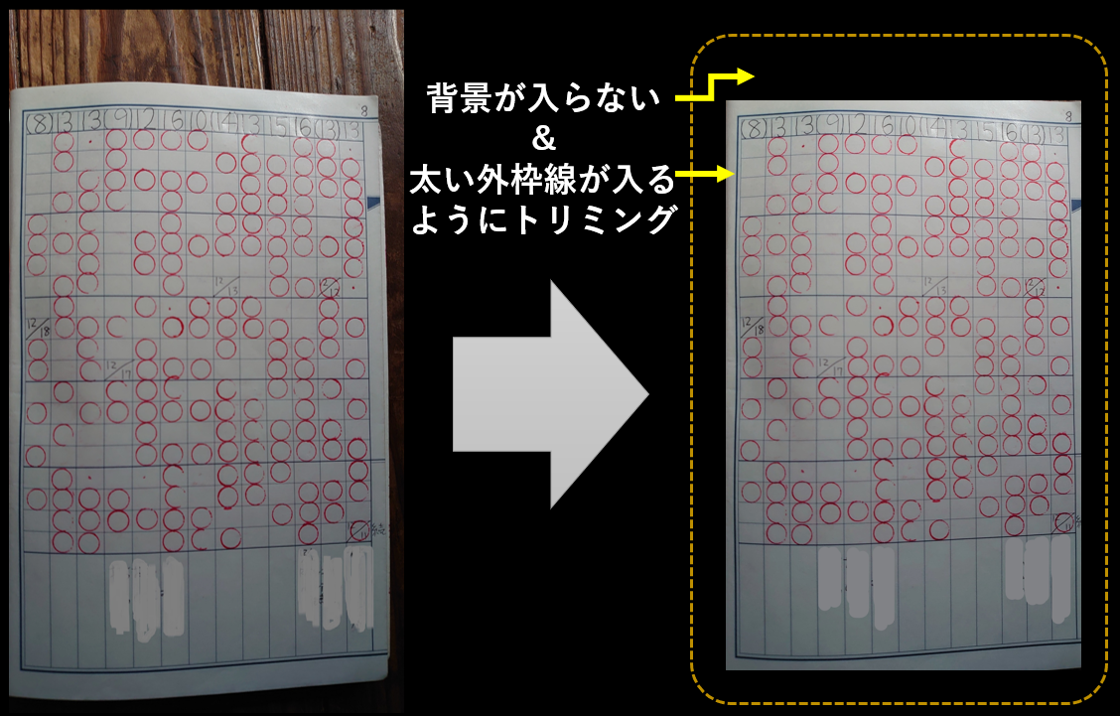
- 投稿日:2020-05-29T15:45:18+09:00
パーセプトロンの基本と実装
パーセプトロンの学習
使用するネットワーク
・入力層,中間層,出力層の3層でできているネットワークです.
・層と層の間はフルで連結します.
・すべてのニューロンは$1$か$0$を出力します.
パーセプトロンの目的は中間層と出力層の間の重み(シナプス荷重)を学習し,入力パターンに対応する出力パターンを生成することです.
入力層
$M$個のニューロンがあるとします.
外部からの入力をそのまま受け取って,出力します.
$i$番目のニューロンの出力は以下の式で表します.
$$output_i = input_i$$中間層
$N$個のニューロンがあるとします.
中間層の$j$番目のニューロンに与える入力は,すべての入力層ニューロンの出力値にシナプス荷重$w_{i,j}$をかけた値の和です.
$$input_j=\sum_{i=1}^{M}{w_{i,j}output_i}$$そして,それぞれの中間層ニューロンに受け取った信号に閾値$\theta_j$を設定し,その分だけ減らします.
$$input_j-\theta_j$$出力は$0$か$1$だけなので,出力関数$f(x)$を設定します.なので,中間層の$j$番目のニューロンの出力値は以下の式で表します.
$$output_j = f(input_j-\theta_j)$$f(u) = \left\{ \begin{array}{ll} 1 & (u \gt 0) \\ 0 & (u \leq 0) \end{array} \right.出力層
出力層の入力も中間層の入力と同じく,前の層のすべてのニューロンの出力値にシナプス荷重をかけたものになります.出力層のニューロン個数を$1$とします.
$$input_o=\sum_{j=1}^{N}{w_{j,o}output_j}$$
そして,出力層の出力は中間層と同じく,入力から閾値を引いた値に$f(x)$を適応した結果です.
$$output_o=f(input_o-\theta_o)$$
f(u) = \left\{ \begin{array}{ll} 1 & (u \gt 0) \\ 0 & (u \leq 0) \end{array} \right.学習
学習時,他のパラメータは変えず,出力層と中間層の間のシナプス荷重$w_{j,o}$だけを更新します.
$$\Delta w_{j,o}=\eta(t_o-output_o)output_j$$
$$w^{t+1}=w^{t}+\Delta w_{j,o}$$
$\eta$は学習率で,小さい正の値を設定するのが一般的です.
$t_o-output_o$は教師データの出力$t_o$と実際の出力データ$output_o$の差分です.なので,計算して出した結果と教師信号が違うときだけ,シナプス荷重が更新されることが分かります.パーセプトロンの収束定理の説明や証明はここで割愛します.興味があったら,調べてみてください.
実装
パラメータ設定
- 入力データ
- $0$以上$15$以下の整数対$(x,y)$に対して,$x \gt y$のとき$1$,$x \leq y$のとき$0$を返す関数を想定します.
- このようなデータを$2000$個を用意しました.
- データの中の半分を学習用で,半分をテスト用にしました.
- ネットワーク構造
- 入力層
- ニューロン数:$8$個
- $16x+y$を$8$桁の二進数で表し,各桁をニューロンに渡します
- 中間層
- ニューロン数:$30$個(適当に設定した,いろいろ実験してみると楽しいです)
- 出力層
- ニューロン数:$1$個
- シナプス荷重
- $[-0.005,0.005)$の一様乱数
- 他のパラメータ
- 実験回数$200$回
- 学習率:$\eta = 10^{-4}$
コード
ライブラリーの導入と入力パスの設定
import numpy as np import matplotlib.pyplot as plt PATH_X = "./../input_x.npy" PATH_Y = "./../input_y.npy"入力データを$(x,y)$の形から,長さ$8$の$0$と$1$の列に変換
def to_input(data): x = data[0] y = data[1] n = x * 16 + y return np.array([int(k) for k in format(n, '08b')])パーセプトロンクラス
注意! プログラム中の荷重計算は上で説明した式をベクトルとして考え,計算しています.class Perceptron: def __init__(self, m, n, o): # decide initial weight [-0.005,0.005) # 1を足したのは閾値を簡単に扱うため self.w_IM = np.random.rand(n,m+1) - 0.5 self.w_IM = self.w_IM / 100 self.w_MO = np.random.rand(o,n+1) - 0.5 self.w_MO = self.w_MO / 100 # calculate accuracy def get_acc(self, x, y): ok = 0 for i in range(len(x)): # 常に1を出力するニューロンを加えています mid_in = np.inner(np.append(x[i],1.), self.w_IM) mid_out = np.array([int(k > 0) for k in mid_in]) # 常に1を出力するニューロンを加えています out_in = np.inner(np.append(mid_out,1.), self.w_MO) ok += int(int(out_in[0] > 0) == y[i]) return ok / len(x) def learn(self, train_x, train_y, eta = 0.00001): # 常に1を出力するニューロンを加えています mid_in = np.inner(np.append(train_x,1.), self.w_IM) mid_out = np.array([int(k > 0) for k in mid_in]) # 常に1を出力するニューロンを加えています out_in = np.inner(np.append(mid_out,1.), self.w_MO) out = int(out_in[0] > 0) # 出力と教師データの値から荷重を更新しています self.w_MO[0,:-1] = self.w_MO[0,:-1] + eta * (train_y - out) * mid_outパラメータの設定と結果グラフの描画
def main(): # read datas x = np.load(PATH_X) y = np.load(PATH_Y) # split datas train_x, test_x = np.split(x, 2) train_y, test_y = np.split(y, 2) # preprocess - transfer data into inputs datas = np.array([to_input(k) for k in train_x]) tests = np.array([to_input(k) for k in test_x]) # number of neurons input layer m = 8 # number of neurons mid layer n = 10 # number of neurons output layer o = 1 # define the perceptron P = Perceptron(m,n,o) # learning time N = 10 cnt = 0 x = np.linspace(0,200,200) acc_train = np.copy(x) acc_test = np.copy(x) while True: acc = P.get_acc(datas, train_y) acc_train[cnt] = acc acc = P.get_acc(tests, test_y) acc_test[cnt] = acc print("Try ", cnt, ": ", acc) cnt += 1 for i in range(len(datas)): P.learn(datas[i], train_y[i]) if cnt >= 200: break plt.plot(x,acc_train,label="train") plt.plot(x,acc_test,label="test") plt.savefig("result.png") if __name__ == "__main__": main()Githubにもアップしています.
https://github.com/xuelei7/NeuralNetwork/tree/master/Perceptron結果
※横軸が試行回数で,縦軸は正解率
中間層ニューロン数$30$の場合:
中間層ニューロン数$100$の場合:
おわりに
何か適切ではない点がありましたら,修正したいと思いますので,ご迷惑をお掛けしますが,作者までご連絡ください.
参考資料
「ニューラルネットワーク」,吉富康成,朝倉書店,
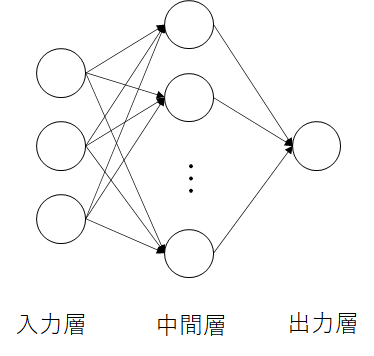
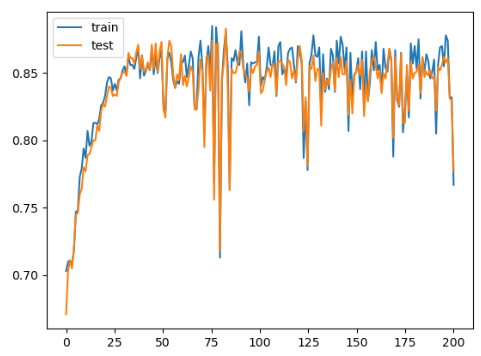
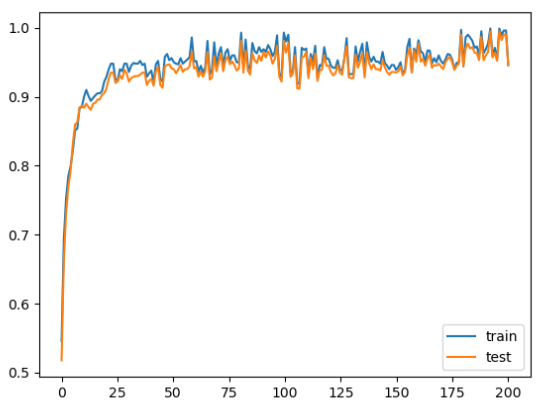
- 投稿日:2020-05-29T15:07:21+09:00
panelやpooled panelのミクロデータを使うときに、各主体の識別子を使って、主体間の関係性を示す重み行列を作る(Python使用)。
背景
突然ですが、タイトルに書いた重み行列を作らなくてはいけなくなりました。
使う言語はpythonです。また、Jupyterで編集しました。
なお、この研究は下準備段階ですので、試行錯誤的な作業の結果として紹介させてください。少し具体的に説明すると、以下に示すデータを使って、データ内の主体間の関係性を示す重み行列を作りたいと思っています。
データ
ある調査の結果を示すデータで、数年間分・四半期の時系列かつ横断面データです。
しかし、1年毎にサンプルに含まれる調査対象が変わるので、完全なパネルデータというわけではなく、1年間は四半期パネルデータですが、次の年はサンプル構成が変わります。だから、そのつなぎ目を見ると、プールドパネルになってるわけですね。
主な変数は、「地域」「家の識別子」「世帯の識別子」「個人の識別子」「調査年」「その他人口統計学的な変数」です。やりたいこと
以上のデータ内に含まれる各主体間の関係性の強さを識別する行列を作りたいと思っています。
ということで、目標は、
「地域」「家の識別子」「世帯の識別子」が同じ主体を識別できる行列の作成です。問題点
このデータは時系列的な性質を持っており、「地域」「家の識別子」「世帯の識別子」「個人の識別子」が同じ一方で、「調査年」が異なる主体をどう扱うかが難しいところです。
仮に、完全なパネルデータなら気にする必要もないのですが、不完全なパネルなので、どのような分析をするか次第でデータの集計やサブサンプルの作成が必要になります。しかし、まあとりあえず、四半期パネルの部分は無視して、このデータセットをプールドパネル(毎年異なる主体がサンプルに含まれるデータ)として扱うことにしました。したがって、集計もサンプルの分割もしません。
また、付加的な仮定として、「調査年」が異なる同じ人物どうしの関係性は無いと考えました。
だから、トイプードル2001年と、トイプードル2002年はデータ上では同じ家・世帯に住む異なる主体となりますが、僕の作る重み行列内では、一切関わりがない(0)主体どうしであるとしました。
「同じ人物 and 異なる年」どうしの関係性を含めてしまうと、時系列的な自己相関が空間的な自己相関と混ざってしまうと考えたためです。用いたデータ
実際に使うデータセットは結構重いので、それに似せた簡単な実験用データを作ってみました。
なお、csvファイルの貼り方が分からないので、表を見せるだけでご了承ください。表1, 2001年のデータ
house hh ind age 21 13 1 21 11 13 1 33 21 13 2 24 10 6 1 43 21 71 1 32 表2, 2002年のデータ
house hh ind age 21 13 1 22 21 13 2 55 21 13 2 24 10 6 1 44 21 71 1 33 house:家の識別子、hh:世帯の識別子、ind:人の識別子、age:年齢(いらない)
流れの説明
1, すべての時期のデータを呼び出して、新たな識別子yearをつける。 2, すべての主体に時期を気にせず新たな識別子id1をふる。加えて、時期が異なるが同じ主体には同じ識別子id2をふる 3, id1名を名前にした列を作る(全ての要素が0)。 4, id1名のリストを作り、iでfor文を回す(ここでは、列名を指定している) 5, id1名のリストについて、jでfor文を回す(ここでは、行名を指定している) 6, jのid2=iのid2のときは 7, スキップor0を入れる 8, jのid2!=iのid2ののときは 9, jの特定の識別子A = iの特定の識別子Aのときは(Aはhouseのみ、houseとhhのときとで2パターン考慮してみたい) 10, 列iのj番目の要素を1にする。 11, 列iの総和を求め、列iの全ての要素を割る 12, id名がついている列以外の列を捨てる。 13, 各idの要素の和を求め、1になっているか確認する。コード
# モジュールのインポート import numpy as np import pandas as pd """1,2, すべてのデータを呼び出して、yearをつけてから結合し、idをふる。""" dfname=["sample2001.csv", "sample2002.csv"] years=[2001, 2002] # すべてのデータを呼び出して、yearをつける。 for i in [z for z in range(len(dfname))]: # データを読み込む際に、i==0、i==1で指定したいから整数のリスト[0,1]にした if i == 0: df = pd.read_csv(dfname[i]) df["year"] = years[i] # iでリストyearsの中の年を位置で指定 df["id1"] = 0 df["id2"] = 0 for j in range(len(df)): house = df.iat[j, 0] # 主体を識別するのに十分な識別子を4つ指定した。 hh = df.iat[j, 1] ind = df.iat[j, 2] year = years[i] ID1 = str(house) + str(hh) + str(ind) + str(year) # 年まで含むことで、時系列・主体の識別子の2点から主体にidをふれる ID2 = str(house) + str(hh) + str(ind) # 年を外すことで、主体の識別子だけから主体にidをふれる df.iat[j, 5] = ID1 # 各要素ごとに情報を置換 df.iat[j, 6] = ID2 # 各要素ごとに情報を置換 else: df_add = pd.read_csv(dfname[i]) df_add["year"] = years[i] df_add["id1"] = 0 df_add["id2"] = 0 for j in range(len(df_add)): house = df_add.iat[j, 0] # 主体を識別するのに十分な識別子を4つ指定した。 hh = df_add.iat[j, 1] ind = df_add.iat[j, 2] year = years[i] ID1 = str(house) + str(hh) + str(ind) + str(year) # 年まで含むことで、時系列・主体の識別子の2点から主体にidをふれる ID2 = str(house) + str(hh) + str(ind) # 年を外すことで、主体の識別子だけから主体にidをふれる df_add.iat[j, 5] = ID1 # 各要素ごとに情報を置換 df_add.iat[j, 6] = ID2 # 各要素ごとに情報を置換 df = pd.merge(df, df_add, how="outer") # dfとdf_addをマージ """3・4, ID名が名前のリストを2つ作り、id1名の列をdfの中に作る""" id1_name = df["id1"].tolist() id2_name = df["id2"].tolist() for i in id1_name: df[str(i)] = 0 """4~11, 他の主体との関連性を指定(識別子はhouseだけ)。そのあと、列iの総和を1に調整する""" for i in range(len(id1_name)): # 列を指定(列は位置で指定する。i+7) for j in range(len(id1_name)): # 行を指定(行も位置で指定する。i ) if df.iat[i, 6] != df.iat[j, 6]: # iは列名(df["i+7"]の列名)だが、行名とみれば、上から順に指定できる。jがズレていく。 if (df.iat[i, 0] == df.iat[j, 0]) and (df.iat[i, 1] == df.iat[j, 1]): # houseとhhがiとjとで同じ場合を指定 df.iat[j, i+7] = 1 iname = id1_name[i] ilist = df[str(iname)].tolist() # i列の中身をリスト化 isum = sum(ilist) # 上で作ったリストの和を計算 if isum != 0: # isum=0のもので割ると問題が生じるようだ df[str(iname)] = df[str(iname)] / isum # 加重値を計算 """12・13, 行列を示す列名だけ残す""" df = df.drop(columns={"house", "hh", "ind", "age", "year", "id2"}) # 要らない列を消去 WeightList = [] # 各列の和を格納する箱 for i in range(len(id1_name)): iname = id1_name[i] ilist = df[str(iname)].tolist() wisum = sum(ilist) WeightList.append(wisum) print(WeightList)注意点として、idを2つ作ったことをあげておきます。
id1は、「家・世帯・人・調査年度」の識別子を左からくっつけたものです。
id2は、「家・世帯・人」の識別子を左からくっつけたものです。
全体としては、id1で行列を作りました。また、コード内では「関係しあう主体」の識別として「家・世帯」の2つの要素を用いました。以下に示す結果では、「家」のみで関連性を識別した結果もお見せします。
結果
以下、できた加重行列と各列の和(和が1になってるか確認用)を載せます。
表3, houseとhhの同じ主体どうしが関係している事を示す重み行列
表4, houseの同じ主体どうしが関係している事を示す重み行列(コードを一部変える必要あり)
各列の和
[1.0, 0, 1.0, 0, 1.0, 1.0, 1.0, 0, 1.0, 0]行列を解釈するうえで注意する点としては、
例えば表4では、列「211312001」を見ると、行「211322001」及び「行「211322002」と関連していることが分かりますが、実はこの2つの行が指定するのは同一人物です。
調査年が異なるから、別の主体として識別されたわけですね。まとめ
実は、この重み行列を使って、空間計量経済的な分析を行おうと思っています。
こういう風に重み行列を作っている人はザックリ見た感じ見当たらないですが、果たして問題ないのかどうか、、、。
以上です。ありがとうございました。
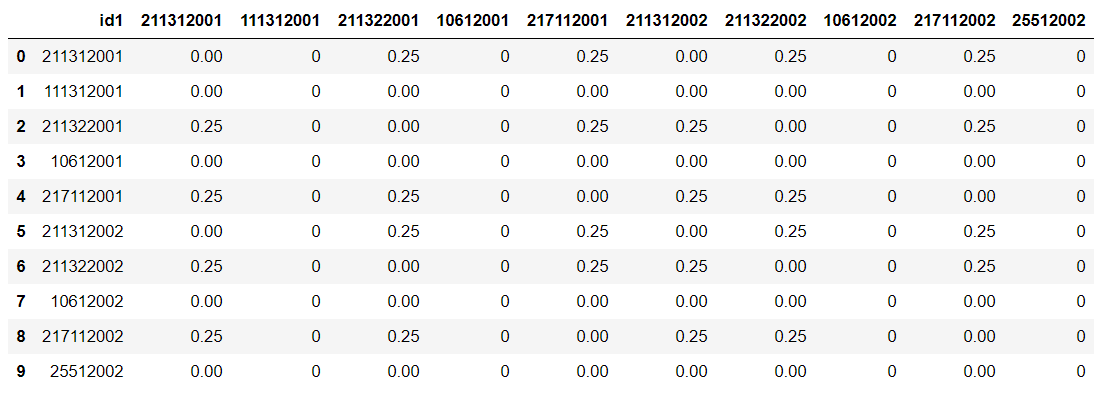
- 投稿日:2020-05-29T14:20:52+09:00
Azure Databricks を使って CSV/JSON ログを加工して Power BI レポートを作成してみた
概要紹介
Azure Databricks を使って、アクセスログを分析してレポートを作る。という小さなプロジェクトがありましたので、手順を共有します。全体概要図はこんな感じです。Defender ATP と Office 365 Admin Center からログを収集して、Azure Blob Storage に格納します。Azure Databricks を使って分析・加工・統合をして Power BI のレポートで閲覧出来るようにしています。
お品書き
以下の 4 Step で進めていきます。Step 1 & 2 では、Pandas と Spark Dataframe の違いを見極めるために、基本的に同じことをローカル PC 上の Pandas DataFrame と Azure Databricks 上の DataFrame をそれぞれ使って実行してみました。CSV/JSON それぞれの読み込みから始めます。
お手軽なサイズのデータで簡単に集計する場合は Pandas で、大容量データを加工する際は Databricks を試してみて下さい。
Step 3 では Dataframe データを Power BI で接続するため、または手元に保管するために色々なフォーマットに書き込んでいます。
最後に Step 4 で Power BI からレポートとして閲覧するまで。を確認します。
- Step1 : Python Pandas/Azure Databricks を使った CSV ファイルの読み込み、加工
- Step2 : Azure Databricks を使った JSON ファイルの加工
- Step3 : 上記加工データを CSV/Parquet/Table に書き込む
- Step4 : Databricks に接続して Power BI から閲覧出来るレポートを作成する
Step 1-1 : Microsoft 365 Audit Log(CSV) を Python で Pandas を使って加工する
まず単体テストをイメージして、ローカル環境で CSV ファイルを取り込んで Python Pandas を使って加工・可視化してみます。Python 開発環境については以下のエントリが参考になると思います。
Pandas で取り込んでみます。
Inputimport pandas as pd df = pd.read_csv('AuditLog_2020-01-11_2020-04-11.csv') print(df)どんな情報を持っているのか列名と型タイプをチェックしてみます。
Inputprint(df.columns) df.dtypesOutputIndex(['CreationDate', 'UserIds', 'Operations', 'AuditData'], dtype='object') CreationDate object UserIds object Operations object AuditData object dtype: object最初の 5 行を表示してみます。
Inputdf.head(5)OutputCreationDate UserIds Operations AuditData 0 2020-04-10T21:24:57.0000000Z abc@contoso.com UserLoggedIn {"CreationTime":"2020-04-10T21:24:57","Id":"ba..." 1 2020-04-10T20:55:58.0000000Z abc@contoso.com FileUploaded {"CreationTime":"2020-04-10T20:55:58","Id":"80..." 2 2020-04-10T20:32:49.0000000Z abc@contoso.com UserLoggedIn {"CreationTime":"2020-04-10T20:32:49","Id":"51..." 3 2020-04-10T20:33:39.0000000Z abc@contoso.com FileAccessed {"CreationTime":"2020-04-10T20:33:39","Id":"c0..." 4 2020-04-10T19:32:36.0000000Z abc@contoso.com UserLoggedIn {"CreationTime":"2020-04-10T19:32:36","Id":"28..."AuditData 列のデータは今回は使わないので、列ごと削除してしまいます。「inplace=True」オプションを付けることで DataFrame に変更を反映することが出来ます。
CreationDate 列には 日付・時刻データが書き込まれているのですが、このままでは使えないので日付・時刻データ型に変換します。
Inputdf['CreationDate'] = pd.to_datetime(df['CreationDate'])Output使用前:2020-04-10T21:24:57.0000000Z 使用後:2020-04-10 21:24:57データ型を確認してみます。「datetime64」に変換されています。
Inputdf.dtypesOutputCreationDate datetime64[ns] UserIds object Operations object dtype: objectPower BI レポート作成の際に必要になりそうなデータを列で持つことにします。Power BI 側でメジャーを作成することも出来ますが、レポート閲覧時のパフォーマンスが良くなるかなと思って列で持たせました。
Inputdf['Hour'] = df['CreationDate'].dt.hour df['Weekday_Name'] = df['CreationDate'].dt.weekday_name df['DayofWeek'] = df['CreationDate'].dt.dayofweek最後に、列名と型タイプを確認してみます。
Inputprint(df.columns) df.dtypesOutputIndex(['CreationDate', 'UserIds', 'Operations', 'Hour', 'Weekday_Name', 'DayofWeek'], dtype='object') CreationDate datetime64[ns] UserIds object Operations object Hour int64 Weekday_Name object DayofWeek int64 dtype: object確認が出来たら結果を CSV ファイルに書き込んでみます。
Inputdf.to_csv('AuditLog_2020-01-11_2020-04-11_edited.csv')Step 1-2: Microsoft 365 Audit Log(CSV) を Azure Databricks で加工する
分析するログファイルが限られている場合は Pandas でも良いのですが、メモリに乗らない大容量のログデータをまとめて分析する場合はどうでしょう。Azure Databricks の DataFrame を使って同じことが出来るか試してみます。
Azure Data Lake Storage Gen2 アカウントを作成して CSV ファイルをアップロードします。
参考:「Azure Data Lake Storage Gen2 アカウントを作成する」を参照してください。CSV ファイルを Azure Databricks に読み込みます。チームメンバーの Qiita エントリが参考になりました。
参考:「Azure DatabricksからData Lake Storage Gen2をマウントする」Databricks でのデータハンドリングはこちらの Qiita エントリが参考になりました。
参考:「pysparkでデータハンドリングする時によく使うやつメモ」ファイルシステムをマウントします。
Inputconfigs = {"fs.azure.account.auth.type": "OAuth", "fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", "fs.azure.account.oauth2.client.id": "<サービスプリンシパルのアプリケーションID>", "fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope = "<scope-name>", key = "<key-name>"), "fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/<AADのファイルシステム名テナントID>/oauth2/token", "fs.azure.createRemoteFileSystemDuringInitialization": "true"} dbutils.fs.mount( source = "abfss://auditlog@<ストレージアカウント名>.dfs.core.windows.net/", mount_point = "/mnt/auditdata", extra_configs = configs)すでにマウントされていてエラーになる場合は、一度アンマウントして下さい。
Optionaldbutils.fs.unmount("/mnt/auditdata")CSV ファイルを読み込みます。ここで「inferschema='true'」を指定していることで型タイプを類推してデータを Dataframe に格納してくれます。
InputSpark_df = spark.read.format('csv').options( header='true', inferschema='true').load("/mnt/auditdata/AuditLog_2020-01-11_2020-04-11.csv")どんな情報を持っているのか列名と型タイプをチェックしてみます。Spark Dataframe は CreationDate を timestamp 型で認識してくれました。
InputSpark_df.printSchema()Outputroot |-- CreationDate: timestamp (nullable = true) |-- UserIds: string (nullable = true) |-- Operations: string (nullable = true) |-- AuditData: string (nullable = true)最初の 5 行を表示してみます。show メソッドに False を指定すると Truncate(切り捨て) オプションが外されて、カラムデータの内容が全て表示されます。
InputSpark_df.show(5, False)Output+-------------------+---------------------+------------+------------------------------------------+ |CreationDate |UserIds |Operations |AuditData | +-------------------+---------------------+------------+------------------------------------------+ |2020-04-10 21:24:57|abc@contoso.com|UserLoggedIn|"{""CreationTime"":""2020-04-10T21:24:57"| |2020-04-10 20:55:58|abc@contoso.com|FileUploaded|"{""CreationTime"":""2020-04-10T20:55:58"| |2020-04-10 20:32:49|abc@contoso.com|UserLoggedIn|"{""CreationTime"":""2020-04-10T20:32:49"| |2020-04-10 20:33:39|abc@contoso.com|FileAccessed|"{""CreationTime"":""2020-04-10T20:33:39"| |2020-04-10 19:32:36|abc@contoso.com|UserLoggedIn|"{""CreationTime"":""2020-04-10T19:32:36"| +-------------------+---------------------+------------+------------------------------------------+ only showing top 5 rows前回同様に、AuditData 列を除外して、Power BI レポート作成の際に必要になりそうなデータを列で持つことにします。
Inputfrom pyspark.sql.functions import concat, date_format, col, lit Spark_df = Spark_df.select('CreationDate', 'UserIds', 'Operations', date_format('CreationDate', 'HH').alias('Hour'),date_format('CreationDate', 'u').alias('DayofWeek'), date_format('CreationDate', 'EE').alias('Weekday_Name')) Spark_df = Spark_df.withColumn("Day_Weekday",concat(col("DayofWeek"),lit('_'),col("Weekday_Name"))) Spark_df.show()Output+-------------------+--------------------+-------------------+----+---------+------------+--------+ | CreationDate| UserIds| Operations|Hour|DayofWeek|Weekday_Name|Day_Weekday| +-------------------+--------------------+-------------------+----+---------+------------+--------+ |2020-04-10 21:24:57|abc@contoso...| UserLoggedIn| 21| 5| Fri| 5_Fri| |2020-04-10 20:55:58|abc@contoso...| FileUploaded| 20| 5| Fri| 5_Fri| |2020-04-10 20:32:49|abc@contoso...| UserLoggedIn| 20| 5| Fri| 5_Fri| |2020-04-10 20:33:39|abc@contoso...| FileAccessed| 20| 5| Fri| 5_Fri| |2020-04-10 19:32:36|abc@contoso...| UserLoggedIn| 19| 5| Fri| 5_Fri|Step 2: Defender ATP から情報を収集して Azure Databricks Spark で加工する
Microsoft Defender Advanced Threat Protection (DATP) というソリューションがあって、エンタープライズ環境を脅かす様々な脅威を回避、検出、調査、対策することが出来るのですが、Advanced Hunting という機能を使うと、Microsoft Defender Security Center に保管された 最大 30 日間のデータを様々な条件で検索して分析に使うことが出来ます。
今回は、Databricks から REST API を使って Security Center の情報を収集して、Step 1 と同様に加工してみましょう。
Advanced Hunting API を Python から呼び出すために、まずアクセストークンを取得します。
Inputimport json import urllib.request import urllib.parse tenantId = '00000000-0000-0000-0000-000000000000' # Paste your own tenant ID here appId = '11111111-1111-1111-1111-111111111111' # Paste your own app ID here appSecret = '22222222-2222-2222-2222-222222222222' # Paste your own app secret here url = "https://login.windows.net/%s/oauth2/token" % (tenantId) resourceAppIdUri = 'https://api.securitycenter.windows.com' body = { 'resource' : resourceAppIdUri, 'client_id' : appId, 'client_secret' : appSecret, 'grant_type' : 'client_credentials' } data = urllib.parse.urlencode(body).encode("utf-8") req = urllib.request.Request(url, data) response = urllib.request.urlopen(req) jsonResponse = json.loads(response.read()) aadToken = jsonResponse["access_token"]Kusto クエリを実行して情報を取得します。今回は特定のプロセスがネットワーク接続を含むイベントを開始した際のログを収集することにします。ユーザプロセスをトラックしてアクティビティを分析することが出来るからです。
Inputquery = 'DeviceNetworkEvents' # Paste your own query here url = "https://api.securitycenter.windows.com/api/advancedqueries/run" headers = { 'Content-Type' : 'application/json', 'Accept' : 'application/json', 'Authorization' : "Bearer " + aadToken } data = json.dumps({ 'Query' : query }).encode("utf-8") req = urllib.request.Request(url, data, headers) response = urllib.request.urlopen(req) jsonResponse = json.loads(response.read()) schema = jsonResponse["Schema"] results = jsonResponse["Results"]Advanced Hunting API から取得した情報を Spark Dataframe に格納します。
InputrddData = sc.parallelize(results) Spark_df2 = spark.read.json(rddData)どんな情報を持っているのか列名と型タイプをチェックしてみます。Timestamp に 日時情報が格納されているのですが、今回は timestamp 型で認識してくれませんでした。
InputSpark_df2.printSchema()Outputroot |-- ActionType: string (nullable = true) |-- AppGuardContainerId: string (nullable = true) |-- DeviceId: string (nullable = true) |-- DeviceName: string (nullable = true) |-- InitiatingProcessAccountDomain: string (nullable = true) |-- InitiatingProcessAccountName: string (nullable = true) |-- InitiatingProcessAccountObjectId: string (nullable = true) |-- InitiatingProcessAccountSid: string (nullable = true) |-- InitiatingProcessAccountUpn: string (nullable = true) |-- InitiatingProcessCommandLine: string (nullable = true) |-- InitiatingProcessCreationTime: string (nullable = true) |-- InitiatingProcessFileName: string (nullable = true) |-- InitiatingProcessFolderPath: string (nullable = true) |-- InitiatingProcessId: long (nullable = true) |-- InitiatingProcessIntegrityLevel: string (nullable = true) |-- InitiatingProcessMD5: string (nullable = true) |-- InitiatingProcessParentCreationTime: string (nullable = true) |-- InitiatingProcessParentFileName: string (nullable = true) |-- InitiatingProcessParentId: long (nullable = true) |-- InitiatingProcessSHA1: string (nullable = true) |-- InitiatingProcessSHA256: string (nullable = true) |-- InitiatingProcessTokenElevation: string (nullable = true) |-- LocalIP: string (nullable = true) |-- LocalIPType: string (nullable = true) |-- LocalPort: long (nullable = true) |-- Protocol: string (nullable = true) |-- RemoteIP: string (nullable = true) |-- RemoteIPType: string (nullable = true) |-- RemotePort: long (nullable = true) |-- RemoteUrl: string (nullable = true) |-- ReportId: long (nullable = true) |-- Timestamp: string (nullable = true) |-- _corrupt_record: string (nullable = true)「InitiatingProcessFileName」を使って、プロセス毎の統計情報を確認してみます。
InputeSpark_df2.groupBy("InitiatingProcessFileName").count().sort("count", ascending=False).show()Output+-------------------------+-----+ |InitiatingProcessFileName|count| +-------------------------+-----+ | svchost.exe|10285| | MsSense.exe| 2179| | chrome.exe| 1693| | OfficeClickToRun.exe| 1118| | OneDrive.exe| 914| | AvastSvc.exe| 764| | backgroundTaskHos...| 525| | MicrosoftEdgeCP.exe| 351|「Timestamp」カラムのデータ型を Timestamp 型に変換して、Step 1 と合わせて「CreationDate」という名前のカラム名で保存します。
Inputfrom pyspark.sql.types import TimestampType Spark_df2 = Spark_df2.withColumn("CreationDate", Spark_df2["Timestamp"].cast(TimestampType())) Spark_df2.printSchema()前回同様に、不要な列を除外して、Power BI レポート作成の際に必要になりそうなデータを列で持つことにします。
Inputfrom pyspark.sql.functions import concat, date_format, col, lit Spark_df2 = Spark_df2.select('CreationDate', 'DeviceId', 'DeviceName', 'InitiatingProcessFileName', 'InitiatingProcessAccountName', 'RemoteUrl', 'RemoteIP', 'LocalIP', date_format('CreationDate', 'HH').alias('Hour'),date_format('CreationDate', 'u').alias('DayofWeek'), date_format('CreationDate', 'EE').alias('Weekday_Name')) Spark_df2 = Spark_df2.withColumn("Day_Weekday",concat(col("DayofWeek"),lit('_'),col("Weekday_Name"))) Spark_df2.show()列名と型タイプを確認してみます。すっきりしましたね。
InputSpark_df2.printSchema()Outputroot |-- CreationDate: timestamp (nullable = true) |-- DeviceId: string (nullable = true) |-- DeviceName: string (nullable = true) |-- InitiatingProcessFileName: string (nullable = true) |-- InitiatingProcessAccountName: string (nullable = true) |-- RemoteUrl: string (nullable = true) |-- RemoteIP: string (nullable = true) |-- LocalIP: string (nullable = true) |-- Hour: string (nullable = true) |-- DayofWeek: string (nullable = true) |-- Weekday_Name: string (nullable = true) |-- Day_Weekday: string (nullable = true)Step 3: 上記加工データを CSV/Parquet/Table に書き込む
いい感じに整いましたので、今度は Step 1 と Step 2 で加工したデータを、色々な形式で書き込んでみます。
1. Databricks での CSV 取り扱い (Databricks Documentation CSV files)
Step 1 のデータを Spark_df、Step 2 のデータを Spark_df2 に作成しているので、CSV ファイルに書き込んでみます。coalesce(1) で出力ファイルを 1 つに出来ます。Header 情報が必要な場合は オプションで「true」に設定しましょう。
InputSpark_df.coalesce(1).write.option("header", "true").csv("/mnt/auditdata/AuditLog_2020-01-11_2020-04-11_edited.csv")Databricks にマウントした Azure Data Lake Storage Gen2 ストレージアカウントに CSV ファイルが作成されているのを確認しましょう。ダウンロードしてみると CSV ファイルは指定したファイル名が付いたフォルダ直下に格納されているようです。
(参考) CSV の読み込みは以下の通り
``` python:Input #Spark Dataframe Spark_df = spark.read.format('csv').options( header='true', inferschema='true').load("/mnt/auditdata/Spark_df.csv") display (Spark_df) #pandas import pandas as pd pd_dataframe = pd.read_csv('/dbfs/mnt/auditdata/Spark_df.csv') ```2. Databricks での Parquet 取り扱い (Databricks Documentation Parquet files)
Parquet 形式でも書き込んでみます。
InputSpark_df.write.mode("append").parquet("/mnt/auditdata/parquet/audit")(参考) Parquet の読み込みは以下の通り
Input#Python data = sqlContext.read.parquet("/mnt/auditdata/parquet/audit") display(data) #Scala %scala val data = sqlContext.read.parquet("/mnt/auditdata/parquet/audit") display(data) #SQL %sql CREATE TEMPORARY TABLE scalaTable USING parquet OPTIONS ( path "/mnt/auditdata/parquet/audit" ) SELECT * FROM scalaTable3. Databricks での Tables 取り扱い (Databricks Documentation Tables)
Databricks Table 形式でも書き込んでみます。
InputSpark_df.write.saveAsTable("worktime") worktime = spark.sql("select * from worktime") display(worktime.select("*"))Step 4 : Databricks に接続して Power BI から閲覧出来るレポートを作成する
最後にこれまでのデータを使って Power BI で閲覧が出来るようにレポートを作成してみます。
Azure Portal から Databricks Workspace を起動して、左側のパネルから「Cluster」を表示して、接続する Table を稼働しているクラスタを選択します。
クラスタ設定パネルで、「Advanced Options」を選択して「JDBC/ODBC」メニューを表示します。
設定画面には以下の情報が含まれています。
- Hostname
- Port
- Protocol
- HTTP Path
- JDBC URL
これらの情報を使って接続先設定文字列を取得します。
https://<Hostname>:<Port>/<HTTP Path>具体的には以下のような文字列になるはずです。
Server : https://xxx-xxx.1.azuredatabricks.net:443/sql/protocolv1/o/687887143797341/xxxx-xxxxxx-xxxxxxxx
Databrick のワークスペース管理画面、右上のユーザプロファイルのアイコンをクリックして「User Settings」をクリックします。
「Access Tokens」のタブをクリックして「Generate New Token」ボタンをクリックします。
「Generate New Token」の画面で「Comment」欄に「Power BI」と書いておきます。オプションなので書かなくても大丈夫です。
「Generate」ボタンをクリックして作成されたトークンをコピーして保管しておきます。
Power BI Desktop を起動して「Get Data」から接続先データソースとして「Spark」を選びます。
Spark 接続設定で「Server」欄に、先程取得した接続先設定文字列をペーストします。プロトコルは「HTTP」、接続モードに「Direct Query」を選んで「OK」ボタンをクリックします。
Spark 接続設定で「User name」欄に、「token」と入力し、先程取得した Password をペーストします。「Connect」ボタンをクリックします。
Step 3 で作成したテーブルのリストが表示されますので、Power BI レポートに必要なテーブルを選んで「Load」ボタンをクリックします。
Step 1 から 3 で準備したデータを使って、 Power BI Desktop で最終的にはこんな感じでレポートを作ってみました。
まとめ
今回、Databricks を使ったログ解析と可視化を進めてみました。Databricks の潜在能力の一部しか活用していない感はあります。実際には大量のデータを蓄積した Data Lake に対する分散処理が必要になるような場面で本来の実力を発揮するに違いありません。
それでも Scala, Python, R, SQL とどんな言語でも使える万能な処理基盤である点、ストリーム処理、機械学習、可視化が出来つつ、Power BI も含めた Azure の様々なサービスとの連携も出来る点が素晴らしいと感じました。
データはあるけど、どう活用すればいいのか悩んでいたり、データ加工に課題を持っていたりする方全員に自信を持って Azure Databricks をおすすめいたします。
おまけ
Azure SQL database や Cosmos DB との連携も気になったので次回やってみようと思います。
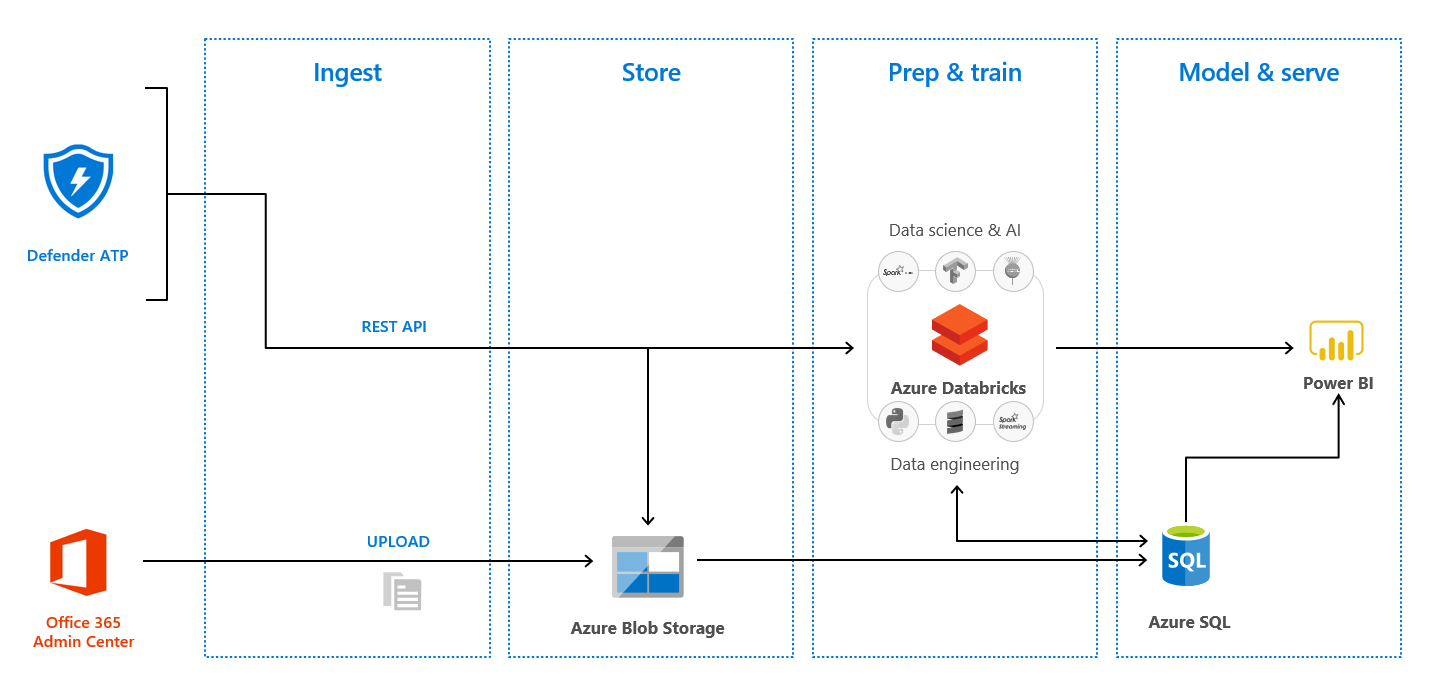

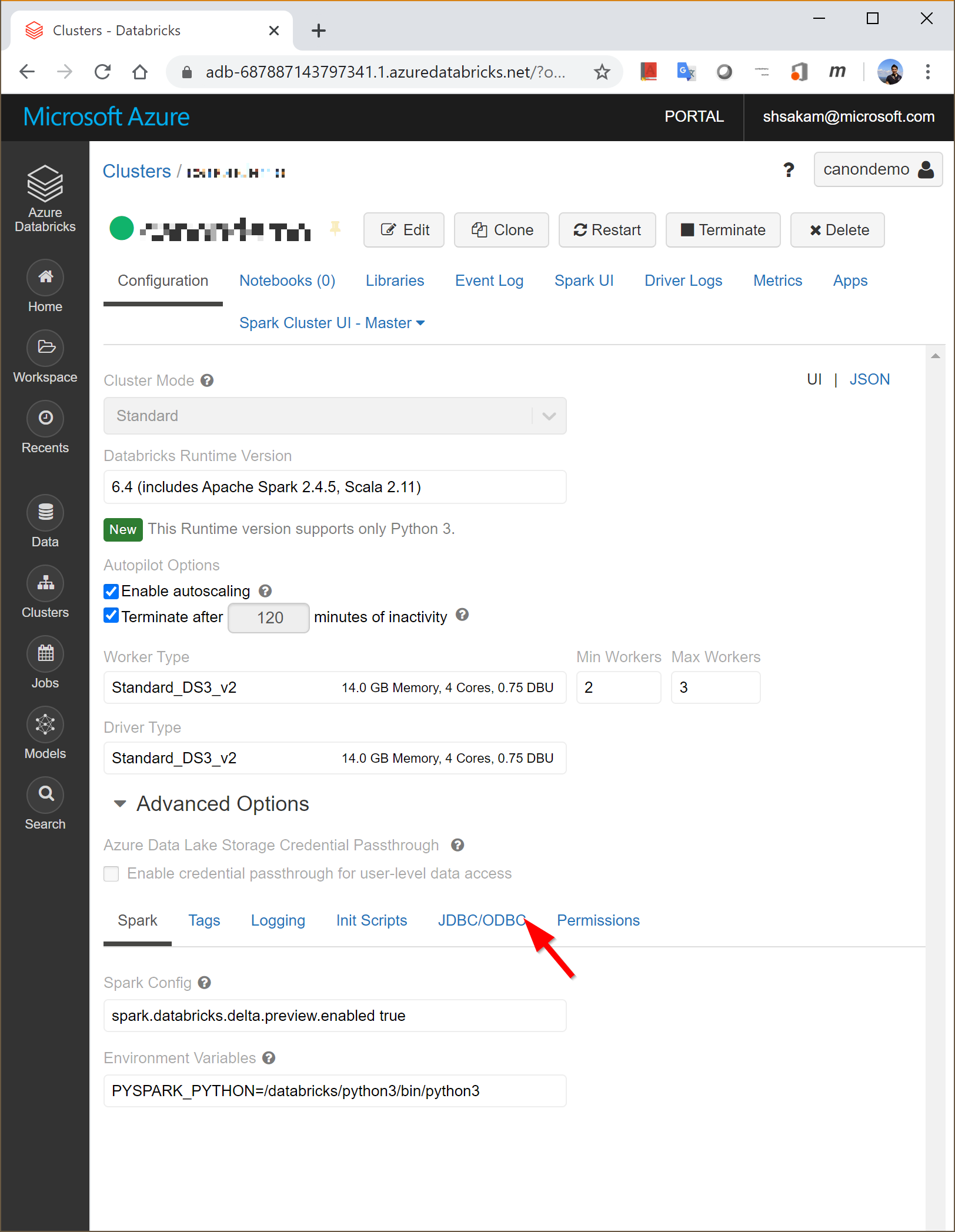


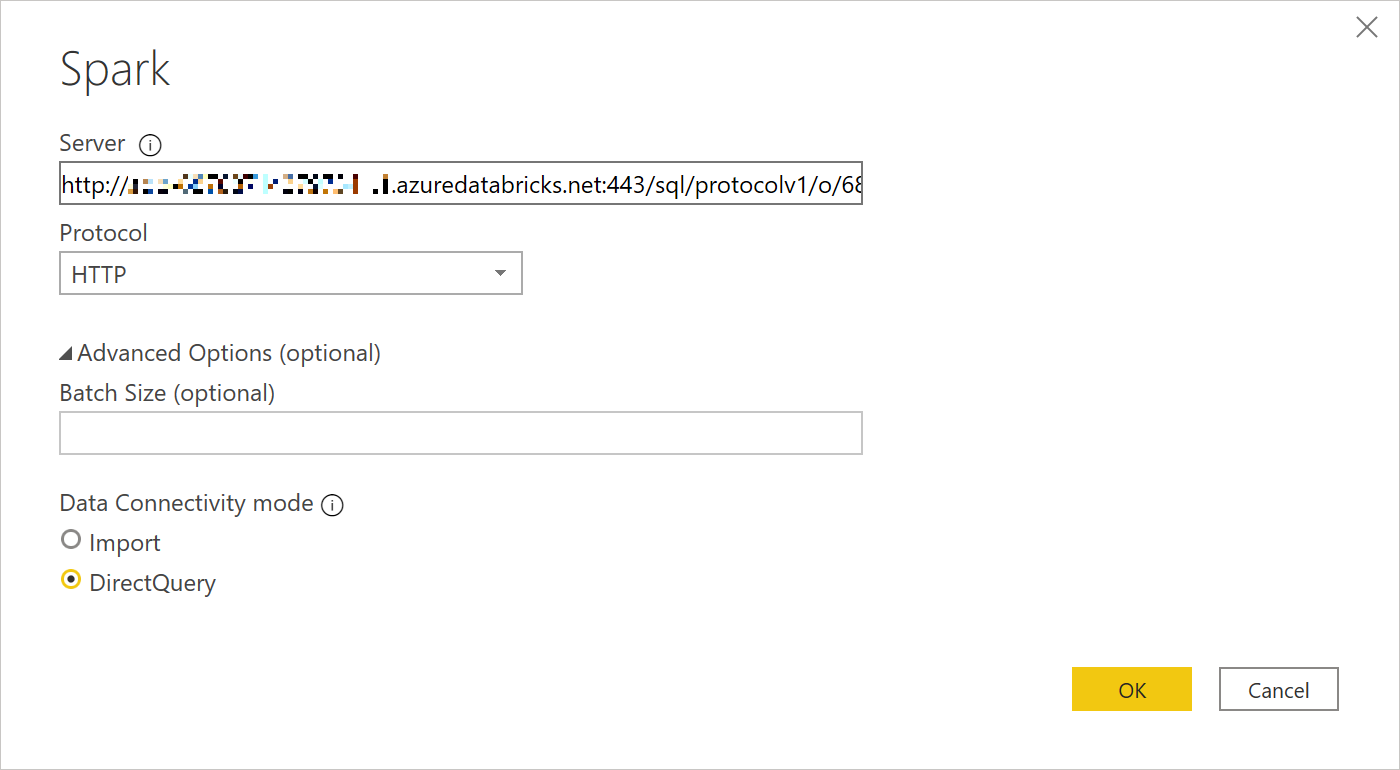
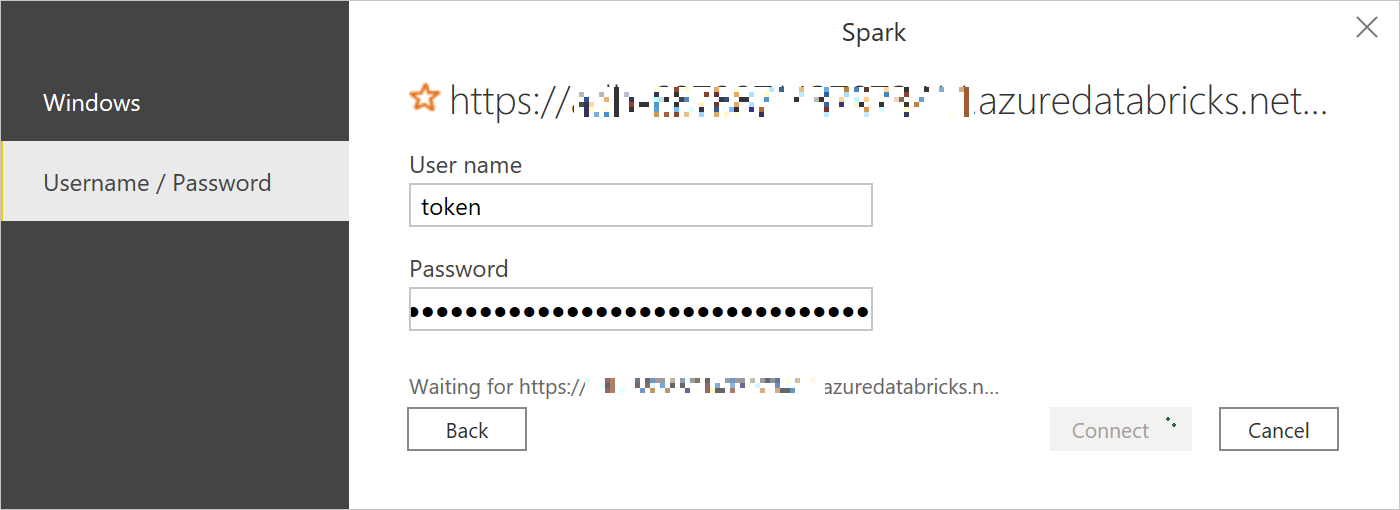
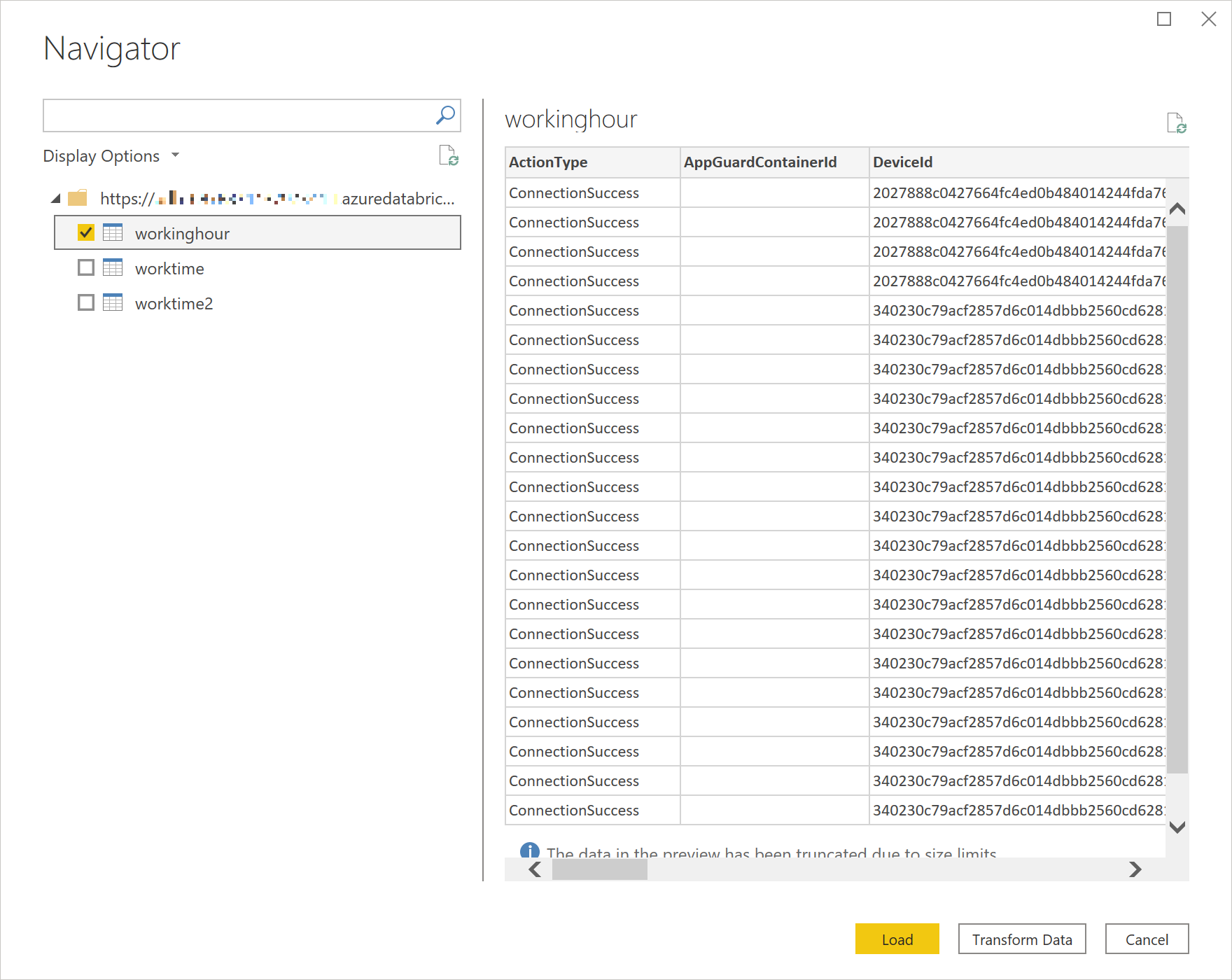
- 投稿日:2020-05-29T13:46:07+09:00
全角スペースによるSyntaxError: invalid syntax
- 投稿日:2020-05-29T12:26:33+09:00
AtCoder Beginner Contest 095 過去問復習
所要時間
感想
以前にD問題が解けなくて悔しい思いをしたのですが、今回は解けたのでほっとしました。
これからはもっと速さが要求されると思うので、典型の発想をしっかり身に付けるようにします。A問題
トッピングの数は○の数に対応するのでcountして出力すれば良いです。
answerA.pys=input() print(700+s.count("o")*100)B問題
B問題ですが少し注意の必要な問題です。
まずは全てのドーナツを先に一つずつ買う必要があります。
また、この時に全てのドーナツを買うことができます。
その後、最も少ないお菓子の素の消費量で作ることのできるドーナツをできるだけ作れば良いです。answerB.pyn,x=map(int,input().split()) m=[int(input()) for i in range(n)] m.sort() x-=sum(m) ans=n print(ans+x//m[0])C問題
この問題でも若干引っかかってしまいました。まだまだ鍛錬がたりません。
ピザはちょうどではなく多めにあっても良いことに気付いてませんでした。
まず、$a+b \leqq c \leftrightarrow$(A,Bのピザを単体で買う方が安い場合)は、単純にA,Bをそれぞれx,y枚ずつ買うのが最適です。
そうでない場合($\leftrightarrow$ABのピザを買う方が安い場合)は、xがyより安い場合とyがxよりも安い場合(x=yはどちらに含んでもOK)で分ける必要があります。
前者の場合を考えます。この時、$2 \times x$枚のABピザを買って、残りの$y-x$枚のBのピザについてもABのピザを$2 \times (y-x)$買って補填するかBのピザを$y$枚買って補填するかで少ない値段のものを選べば良いです。
また、同様にして後者の場合も考えられるので、以下のようになります。
answerC.pya,b,c,x,y=map(int,input().split()) if a+b<=2*c: print(x*a+y*b) else: if x<=y: print(min(2*x*c+(y-x)*b,2*y*c)) else: print(min(2*y*c+(x-y)*a,2*x*c))D問題
少し説明が複雑なのと図をいくつか書く必要があったので手書きで書きました。
見にくいところもあると思いますがご容赦ください。また、$r,l$を求めたうえで累積最大値を求めるのに$O(N)$、$r2,l2$を求めるのに$O(N)$であり、①,②のパターンの最大値を求めるのに$O(1)$、③,④のパターンの最大値を求めるのに$O(N)$なので、余裕を持って制限時間内で通すことができます。
answerD.pyfrom itertools import accumulate n,c=map(int,input().split()) sushi=[list(map(int,input().split())) for i in range(n)] r=[sushi[0][1]-sushi[0][0]] for i in range(1,n): r.append(r[-1]+sushi[i][1]-(sushi[i][0]-sushi[i-1][0])) l=[sushi[n-1][1]-(c-sushi[n-1][0])] for i in range(n-2,-1,-1): l.append(l[-1]+sushi[i][1]-((c-sushi[i][0])-(c-sushi[i+1][0]))) r2=[sushi[0][1]-2*sushi[0][0]] for i in range(1,n): r2.append(r2[-1]+sushi[i][1]-2*(sushi[i][0]-sushi[i-1][0])) l2=[sushi[n-1][1]-2*(c-sushi[n-1][0])] for i in range(n-2,-1,-1): l2.append(l2[-1]+sushi[i][1]-2*((c-sushi[i][0])-(c-sushi[i+1][0]))) r=list(accumulate(r,max)) l=list(accumulate(l,max)) cand=[l[-1],r[-1]] for i in range(n): if 0<=n-i-2<=n-1: cand.append(l2[i]+r[n-i-2]) cand.append(r2[i]+l[n-i-2]) print(max(max(cand),0))answerD_shortest.pyfrom itertools import * n,c,*u=map(int,open(0).read().split());x,a=u[::2]+[c],[0]+list(accumulate(u[1::2]));ans=l=r=0 for b in range(n+1):t,d,l,r=a[n]-a[b],c-x[b],max(l,a[b]-x[b-1]),max(r,a[b]-2*x[b-1]);ans=max(ans,l+t-2*d,r+t-d) print(ans)


- 投稿日:2020-05-29T11:31:53+09:00
秒でHello,Flask!できるけど、その中身を知らない人
はじめに
flaskを始めようとしたときに、一番最初にローカルホストを作って、そこに”hello, flask!”と表示させる。けど、その中身のコードの内容はその時理解できていない人が多いかもしれない。
そこで、一つ一つ意味をしっかりと書いてみた。とりあえず、Hello,Falskまで
環境
Windows PC
Visual Studio Code ver.1.45.1
Python 3.8flaskのインストール
- cmdを開いて、
pip3 install flaskを入力し勝手にインストール。- vscodeを開く。(vscode内の環境構築についてはほかの人の記事を見てください)
- 以下のpythonコードの
app.pyを作成。python : app.py
app.py# coding: utf-8 from flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "Hello, Flask!" if __name__ == "__main__": app.run()
- その後に出てくるローカルホスト(http://~)にブラウザでアクセス。
- そこには、
というような画面が出てくる。(余白邪魔だったかな...)
app.pyについて
app.py# coding: utf-8 from flask import Flask app = Flask(__name__) @app.route("/test") def hello(): return "Hello, Flask!" if __name__ == "__main__": app.run(debug=True)このコードで何をしているのか
from flask import Flaskについては、flaskというモジュールを読み込む。flaskの中身を話すと話がズレそうなので、ここでは省略。
このとき、Flask(__name__)このコードは、name というのは、勝手に定義される変数。ファイルのモジュール名が入る。 ファイルをスクリプトとして直接実行したときは name は main になる。
import Flaskのみでもよいが、その場合、つぎのコードが
flask.Flask(__name__)に指定しなければならなくなるので、最初から書いといたほうが楽。
'''python
@app.route("/test")
``@app.route()`はURLと関数を関連付けるためのもの。これはhtmlなどとの関連つけたときに、関わってくるものになるので、これ単体ではなんともいえない。
あとのコード内容についてはpythonの基礎的なところなので省略。さいごに
僕自身も始めたばかりなので、ミスがあれば教えてください。

- 投稿日:2020-05-29T09:47:50+09:00
Cloud Pak for Data (Watson Studio)でpandasデータをExcel形式でデータ資産に保存する
project_libを使った分析プロジェクトのデータ資産へのファイル保存方法は別の記事に書きましたが、Excel形式で保存するには少しコツが必要でした。
いろいろ調べていたら、stackoverflowのこちらの記事が有効でした。実際にやってみた例を記載します。
使ったpandasデータフレーム# サンプルデータ Iris import pandas as pd from sklearn.datasets import load_iris iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['iris_type'] = iris.target_names[iris.target] df.head()
このデータをExcel形式で保存してみます。
流れは、pandas.to_excelで一旦環境内にExcelファイルとして保存し、# 一度Excelファイルとして環境内に出力する filename = 'iris.xlsx' df.to_excel(filename, index=False) !pwd !ls -l # -output-0 # /home/wsuser/work # total 12 # -rw-r-----. 1 wsuser watsonstudio 8737 May 28 06:53 iris.xlsxioバイトストリームとして読み込んで、project_libで分析プロジェクトに保存します。
from project_lib import Project project = Project.access() import io with open(filename, 'rb') as z: data = io.BytesIO(z.read()) project.save_data(filename, data, set_project_asset=True, overwrite=True)分析プロジェクトに保存されたことを確認します。
念のため、ダウンロードして中身を見てみます。
無事、150行のIrisデータがExcel形式で保存できました。
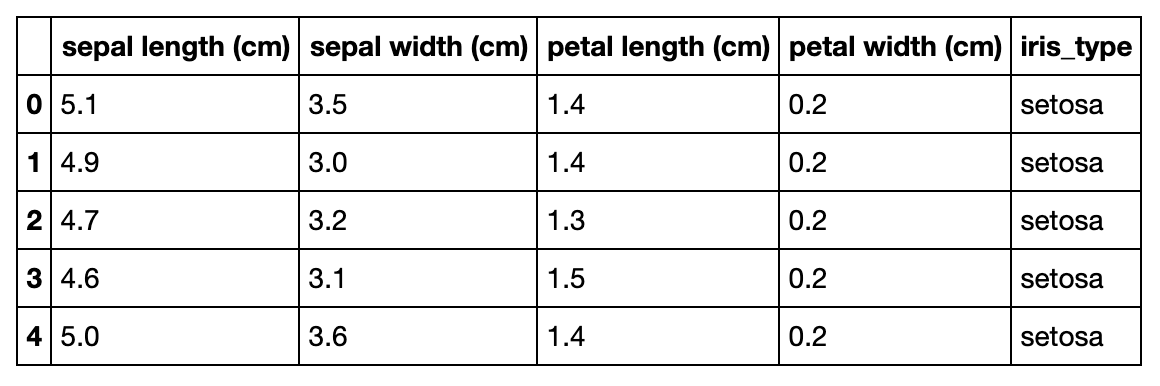

- 投稿日:2020-05-29T08:40:04+09:00
Cloud Pak for Dataで関数をデプロイする
Cloud Pak for Data (以下CP4D)で、Pythonの関数をデプロイすることが可能です。用途は主にモデル実行の前後処理で、try&exceptのエラー処理も組み込めますし、なにより複数のモデルを呼び出す(使い分ける)ことが可能になります。
CP4D v2.5 製品マニュアルより抜粋
https://www.ibm.com/support/knowledgecenter/ja/SSQNUZ_2.5.0/wsj/analyze-data/ml-deploy-functions_local.htmlPython 関数は、モデルのデプロイと同じ方法で Watson Machine Learning にデプロイできます。ご使用のツールとアプリケーションは、Watson Machine Learning Python クライアントまたは REST API を使用して、デプロイ済みのモデルにデータを送信するのと同じ方法で、デプロイ済みの関数にデータを送信できます。関数をデプロイすることで、詳細 (資格情報など) を非表示にしたり、データをモデルに渡す前に前処理したり、エラー処理を実行したり、呼び出しを複数のモデルに組み込んだりできます。これらの機能はすべて、アプリケーションではなくデプロイされた関数内に組み込まれています。
WMLでの関数のデプロイは先行記事がありますが、IBM CloudサービスのWatson Studioでのやり方であり、CP4Dでは少しやり方が異なっていてハマったので、うまく行った例を記事として残します。
シンプルな関数を作ってOnline型でデプロイし、動作を確認してみた結果です。構成イメージ
Notebookで作成したモデルと関数は、デプロイメントスペースへ格納し、各々をOnline型でデプロイします。関数にはモデルのデプロイメントを呼び出すように設定しておくことで、関数のデプロイメントの呼び出し → モデルのデプロイメントの呼び出しという構成にします。Notebookの最後で、関数のデプロイメントをスコアリング実行して動作を確認します。
Notebookで実際に作ってみる
CP4Dにログインし、分析プロジェクトを開き、新規のNotebookを起動します。確認したCP4Dのバージョンはv3.0 LAです。
準備:モデルの作成とデプロイ
先にモデルを作成してデプロイしておきます。このデプロイメントIDを、関数の中で呼び出すために後ほど使用します。
(1) モデルを作成する
Irisデータを使ったランダムフォレストのモデルを作ります。
# Irisサンプルデータをロード import pandas as pd from sklearn.datasets import load_iris iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['iris_type'] = iris.target_names[iris.target] # ランダムフォレストでモデルを作成 from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier X = df.drop('iris_type', axis=1) y = df['iris_type'] X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0) clf = RandomForestClassifier(max_depth=2, random_state=0, n_estimators=10) model = clf.fit(X_train, y_train) # モデルの精度を確認 from sklearn.metrics import confusion_matrix, accuracy_score y_test_predicted = model.predict(X_test) print("confusion_matrix:") print(confusion_matrix(y_test,y_test_predicted)) print("accuracy:", accuracy_score(y_test,y_test_predicted))上記の
modelが学習済モデルです。(2) モデルを保存しデプロイする
モデルをデプロイメントスペースに保存し、Online型のデプロイメントを作成します。
操作はWML clientを使います。(参考記事)# WML clientの初期化と認証 from watson_machine_learning_client import WatsonMachineLearningAPIClient import os token = os.environ['USER_ACCESS_TOKEN'] url = "https://cp4d.host.name.com" wml_credentials = { "token" : token, "instance_id" : "openshift", "url": url, "version": "3.0.0" } client = WatsonMachineLearningAPIClient(wml_credentials) # デプロイメントスペースID一覧の表示 # client.repository.list_spaces() # デプロイメントスペースへ切り替え (IDは上記のlist_spaces()で調べる) space_id = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" client.set.default_space(space_id) # モデルのメタ情報を記述 model_name = "sample_iris_model" meta_props={ client.repository.ModelMetaNames.NAME: model_name, client.repository.ModelMetaNames.RUNTIME_UID: "scikit-learn_0.22-py3.6", client.repository.ModelMetaNames.TYPE: "scikit-learn_0.22", client.repository.ModelMetaNames.INPUT_DATA_SCHEMA:{ "id":"iris model", "fields":[ {'name': 'sepal length (cm)', 'type': 'double'}, {'name': 'sepal width (cm)', 'type': 'double'}, {'name': 'petal length (cm)', 'type': 'double'}, {'name': 'petal width (cm)', 'type': 'double'} ] }, client.repository.ModelMetaNames.OUTPUT_DATA_SCHEMA: { "id":"iris model", "fields": [ {'name': 'iris_type', 'type': 'string','metadata': {'modeling_role': 'prediction'}} ] } } # モデルを保存 model_artifact = client.repository.store_model(model, meta_props=meta_props, training_data=X, training_target=y) model_id = model_artifact['metadata']['guid'] # Online型でデプロイメントを作成 dep_name = "sample_iris_online" meta_props = { client.deployments.ConfigurationMetaNames.NAME: dep_name, client.deployments.ConfigurationMetaNames.ONLINE: {} } deployment_details = client.deployments.create(model_id, meta_props=meta_props) dep_id = deployment_details['metadata']['guid'](3) モデルの動作確認
作ったモデル(デプロイメント)がちゃんと動くか、一応確認しておきます。WML clientを使って動作確認が可能です。
# サンプルデータを生成しJSON化 scoring_x = pd.DataFrame( data = [[5.1,3.5,1.4,0.2]], columns=['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)'] ) values = scoring_x.values.tolist() fields = scoring_x.columns.values.tolist() scoring_payload = {client.deployments.ScoringMetaNames.INPUT_DATA: [{'fields': fields, 'values': values}]} # スコアリング実行 prediction = client.deployments.score(dep_id, scoring_payload) prediction以下の結果が返ってくれば、動作確認は完了です。
output{'predictions': [{'fields': ['prediction', 'probability'], 'values': [[0, [0.8131726303900102, 0.18682736960998966]]]}]}関数の作成
作成する関数に対しては、いろいろとお作法があります。
- 2層にネストした関数とする
- 外側の関数では、ライブラリのインポートなどを行う
- 内側の関数名はscoreとし、入力データpayloadを受け取って処理を行い結果をreturnする
- returnする出力データは、JSONシリアル化可能な辞書またはリスト
こちらが実際に作った関数です。WML clientを使ったデプロイメントの実行の仕方は参考記事を参照してください。
関数の作成# variables for function func_variables = { "url" : url, "space_id" : space_id, "dep_id" : dep_id, "token" : token } # Function for scoring model only def iris_scoring(func_vars=func_variables): from watson_machine_learning_client import WatsonMachineLearningAPIClient # 注意点:wml_credentialsはここに定義する wml_credentials = { "token" : func_vars['token'], "instance_id": "openshift", "url": func_vars['url'], "version" : "3.0.0" } client = WatsonMachineLearningAPIClient(wml_credentials) def score(scoring_payload): try: client.set.default_space(func_vars['space_id']) prediction = client.deployments.score(func_vars['dep_id'], scoring_payload) return prediction except Exception as e: return {'error': repr(e)} return score関数内で使う変数群は、関数の外で定義しておき関数に渡します。urlはCP4DのURL(FQDNまで。最後のスラッシュ無し)、space_idは先ほど作成したモデルをデプロイしたデプロイメントスペースのID、dep_idはそのモデルのデプロイメントIDです。
関数の中身は、シンプルに先ほどのOnlineデプロイメントを呼び出すのみです。なおコメントにも書いていますが、WML clientの初期化を外側関数でやること、またそこでつかうwml_credentialsを外側関数の中で定義することがポイントです。関数外で定義したwml_credentialsを引数で受け取るようにするとうまく動きません。ここがIBM CloudのWatson Studioと違う点のようで、とてもハマりました。
作成した関数の動作確認をしておきます。
Notebookで続けて以下のように実行し、関数からデプロイメントの呼び出しが成功するかどうかを確認します。入力データscoring_payloadは先ほど作成したサンプルデータを使います。関数の動作確認# 関数を実行(内側関数にscoring_payloadを渡す) iris_scoring()(scoring_payload)以下の結果が返ってくればOKです。
output{'predictions': [{'fields': ['prediction', 'probability'], 'values': [['setosa', [0.9939393939393939, 0.006060606060606061, 0.0]]]}]}関数の保存
関数をデプロイメントスペースに保存します。
# メタ情報を作成 meta_props = { client.repository.FunctionMetaNames.NAME: 'iris_scoring_func', client.repository.FunctionMetaNames.RUNTIME_UID: "ai-function_0.1-py3.6", client.repository.FunctionMetaNames.SPACE_UID: space_id } # 関数を保存 function_details = client.repository.store_function(meta_props=meta_props, function=iris_scoring) function_id = function_details['metadata']['guid']デプロイメントスペースでは、資産の下の「機能」というセクションに登録されている事がわかります。
関数のデプロイ
デプロイメントスペースに保存した関数を、Online型でデプロイします。
# メタ情報を作成 meta_props = { client.deployments.ConfigurationMetaNames.NAME: "iris_scoring_online", client.deployments.ConfigurationMetaNames.ONLINE: {} } # デプロイメントを作成 function_deployment_details = client.deployments.create(function_id, meta_props=meta_props) func_dep_id = function_deployment_details['metadata']['guid']これで関数をデプロイできました。実行準備完了です。
関数の動作確認
さっそく動作確認してみます。WML clientを使ってデプロイメントをスコアリング呼び出しします。
prediction = client.deployments.score(func_dep_id, scoring_payload) prediction先ほどと同じ、以下の結果が返ってくれば成功です。
output{'predictions': [{'fields': ['prediction', 'probability'], 'values': [['setosa', [0.9939393939393939, 0.006060606060606061, 0.0]]]}]}これで、関数を使ってモデル呼び出しを行うシンプルな方法が確立できました。
後ほどより応用的な複数モデルの呼び出しパターンを投稿する予定です。
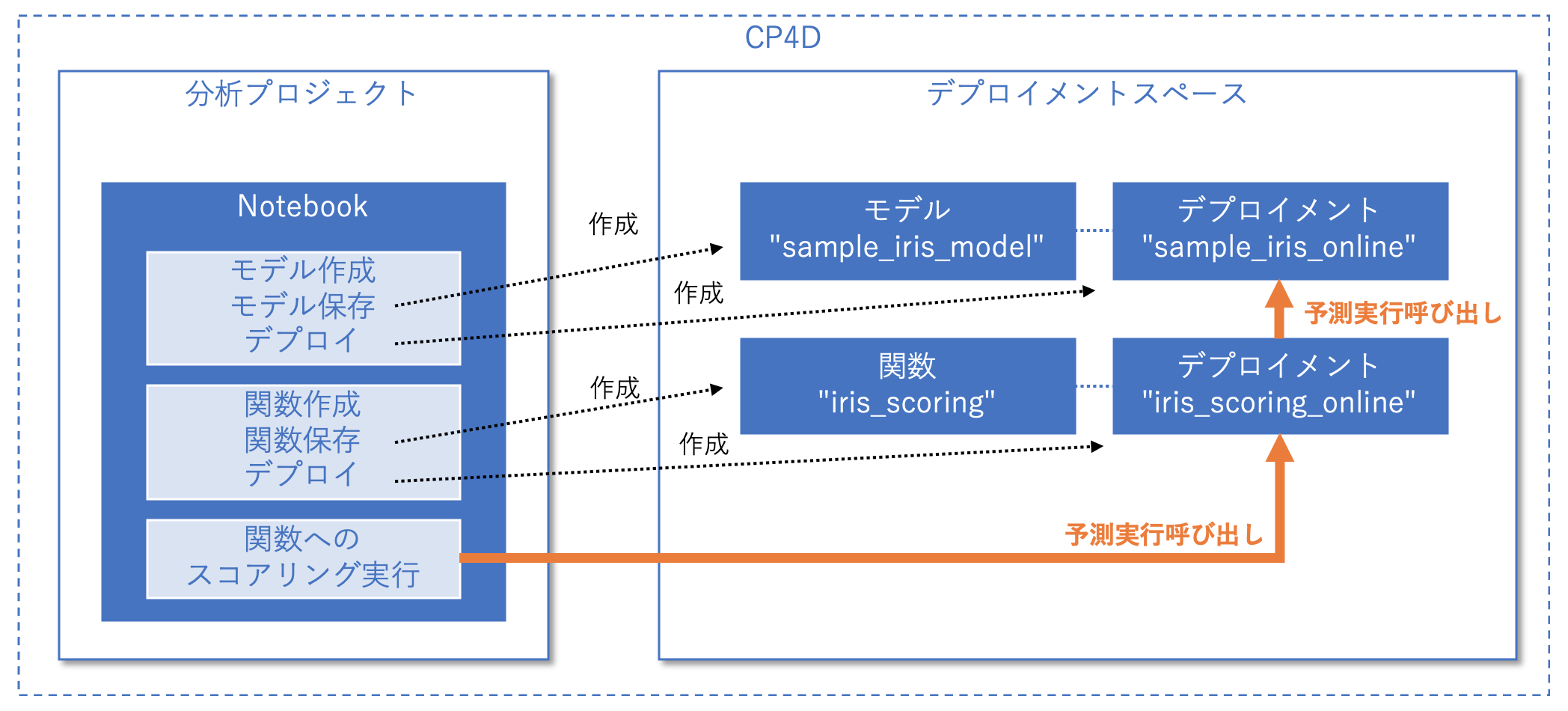

- 投稿日:2020-05-29T03:02:45+09:00
(雑記メモ) PythonによるCSVデータ取得・処理からのExcelへのデータ更新パターン
Excelシートの作成・更新(A)とそのシートに追加するデータ(CSVなど)の取得・処理(B)をどうするか? 個人用の雑記
A. シートの作成・更新
はじめに
以下の処理パターンがある。
- ワークブックの新規オブジェクトにシート/データを追加後、名前を付けて保存=新規作成
- 既存のワークブックを読み込みデータを追加後、新しい名前を付ける=テンプレート利用
- 既存のワークブックを読み込みデータを追加後、同じ名前を付ける=既存シートの更新利用
一般的にopenpyxlライブラリを使っておけばOK(他のライブラリにはもっと処理が速いものがある。ただしその分読み込みにしか対応していない=そのワークブックのオブジェクトへの書き込み(更新)ができないなどの制約がある)。
1. シートの作成
1-1. ワークブックのオブジェクト(wb)の作成
- ①「オブジェクトにデータを追加後、名前を付けて保存=新規作成」 ライブラリのインポート
from openpyxl import Workbook wb = Workbook()
- ②「既存のbookを読み込みデータを追加後、新しい名前を付ける=テンプレート利用」
- ③「既存のbookを読み込みデータを追加後、同じ名前を付ける=既存シートの更新利用」
from openpyxl import Workbook wb = px.load_workbook(self.template_filepath)1-2. ワークシートのオブジェクト(ws)の作成
ws = wb.worksheets[sheetnum] / wb.worksheets[self.sheetname]2. ワークシートに追加するデータの用意と追加(後述)
- 2-1. データの取得
- 2-2. データの加工
- 2-3. ワークシートのオブジェクト(wb/ws/cell)へデータを順次代入する (後でそのオブジェクトにファイル名を指定して実際の保存を行う)。
4. ワークブックの保存
そのワークブックのワークシートのオブジェクトに追加したデータを実際のワークブックに保存する。
- 既存のファイルパスを指定するとパターン③、
- 新しいファイルパスを指定すると①または②になる
wb.save(self.output_filepath)B. ワークシートに追加するデータの用意と追加
はじめに
実装パターンとしては以下が挙げられる
- データをデフォルトの方法で取得した後、データ形式を整えてから順次ワークシートのオブジェクトに追加する
- データを特定ライブラリで取得した後、同ライブラリで一括エクスポートする
- データを特定ライブラリで取得した後、データ形式を整えてから順次ワークシートのオブジェクトに追加する
1. データを取得する
この方法として以下のパターンがある
- ①通常のwith openを使う
- ②大規模なデータ処理に特化したライブラリを使う
そのデータに余分なデータがあったり、集計が必要な場合はこれで前処理をする。このライブラリでは、データフレームと呼ぶ形式でデータをCSVなどから取得してくる。データフレームとして取得されたデータは集計・計算処理がしやすい形になっている。ワークシートを更新したり、既存のファイルをテンプレートとして利用するのでなく、取得したデータを加工してエクスポートしたいだけならばこれだけでもOK。
なおメモリが問題になることも多いので以下を参考にする
https://www.sejuku.net/blog/74447
その他関連
https://qiita.com/gangun/items/f97c40f5540f8011c252①通常のopenを使うケース
順次取得する
wizh open(self.source_filepath, 'r', encoding='utf-8') as file: while True: line = file.readline() row = next(line) #これは次の項目の話と被る ws.append(row) #これは次の項目の話
- 1行目(カラム)をスキップする方法
https://teratail.com/questions/107027
with open(self.source_filepath, 'r', encoding='utf-8') as file: next(file)②データ処理に特化したライブラリを使うケース
この方法で最初に得られるデータのタイプをデータフレームと呼ぶ。普通はpandasを使う。daskでデータを読み込むと早い。multiprossessの並列処理は最高らしい。だが使いクセがなくて躓きにくいのもこの順。集計方法などの詳細は多岐にわたるため基本的には省略する。なお、データのタイプに注意しないで処理するとエラーになる。
(1) ライブラリのインポート
import pandas as pd / import dask as dd(2) データを取得する
下記コードでデータソースからdataframeというタイプのデータが得られる
df = pd.read_csv(self.source_filepath ,encoding=self.source_file_encoding) df = dd.read_excel(self.source_filepath ,encoding=self.source_file_encoding)
- Note: 1行目(カラム)をスキップする方法
We can use the header and skiprows option to tell Pandas not to use the column labels already in our spreadsheet. Note that both header=None and skiprows=1 must be set in this case, as the first row of actual data will be skipped if the header option is missing.
https://wellsr.com/python/python-pandas-read_excel-to-import-excel-file-into-dataframe/read_csv(self.source_filepath ,encoding=self.source_file_encoding, header=None, skiprows=1)
- 順次取得する場合(メモリ利用の削減)
- pandas の chunksizeオプション
- chunksize=*** を指定 → 指定した数値分chunkというタイプのデータの塊が得られる
せっかくなのでPandasのchunksizeもパターンを変えて実験しました。結論から言うと、1000万行に対してchunksize=30000辺りが一番速く処理が終わった。
https://qiita.com/gangun/items/17155a8b59079e37b075read_csv(self.source_filepath ,encoding=self.source_file_encoding, chunksize=30000)
- 並列分散処理をしながら取得する場合(メモリ利用の効率化)
- dask
- multiprossess (installにクセがある)
参考:
https://qiita.com/hoto17296/items/586dc01aee69cd4915cc
https://qiita.com/simonritchie/items/e174f243bc03fb25462e
https://qiita.com/simonritchie/items/1ce3914eb5444d2157ac
- データをワークブックオブジェクトから取得するケース
参考:
https://soudegesu.com/post/python/cell-excel-with-openpyxl/・行/列単位の読み取り
for col in ws.iter_cols(min_row=2): ... for row in ws. iter_rows(min_row=2): ...・セル単位の取得
(略)3. データをワークブックオブジェクトに追加する
「A. シートの作成・更新」と交差する部分になる。なぜならば、取得・加工したデータをOpenPyXlで作成したシート/セルのオブジェクトに追加する必要があるので。
ここでいうデータとは実際のセルの値の他、データ型や書式(レイアウト)も含む。ここでは詳しくはメモしないこととする。なおこれらに関し検索すると、行→セルのように処理していくか、列を指定したとしても最終的にはセル単位での処理を行うような説明が多い。ただしレイアウトに関してはOpenPyXlで既存ワークブック(テンプレート)を読み込んだ時、そのシートで条件付き書式が設定されていれば、元の書式を丸ごと保つことが可能な場合がある。これにより例えば小計の行にのみ色を付けるといったことが可能になる。
- データをchunk型で取得しているが、行単位でデータを追加するケース
for chunk in chunks: rows = chunk.values for row_data in rows_data: row_data = row_data.tolist() ws.append(row_data)
- データをデータフレーム型で取得しており、行単位でデータを追加するケース
for i in dataframe_to_rows(df, index=False, header=True): ws.append(row)
- セル単位で追加するケース
例1
https://gist.github.com/bisco/a65e71c8ba45337f91174e6ae3c139f9例2
セル内改行
https://www.relief.jp/docs/openpyxl-line-feed.htmlws['A1'].value = 'AAA\nBBB' ws['A1'].alignment = openpyxl.styles.Alignment(wrapText=True)例3
rows_data = df.values.tolist() for i, row_data in enumerate(rows_data): for j, cell_data in enumerate(row_data): if type(cell_data) is int: ws.cell(row=i+1, column=j+1).number_format = '#'#currentFormat ws.append(row_data)
- 行列形式
[[...],[...]]でデータを取得しており、それを行ごとに追加する場合for row in matrix: ws.append(row)
- 特定列で追加するケース
ws['B2'] = '=vlookup(A2,C:C,1,false)' 特定列のセルの処理 for row, cellObj in enumerate(list(ws.columns)[col_num]: #col_num:列番号 n= '=vlookup(A%d,C:C,1,false)' %(row+1) cellObj.value = n
- データフレームをそのままファイル出力する場合(新規作成または上書き更新)
df.reset_index().to_csv(self.output_filepath, encoding=self.output_file_encoding, index=False) df.reset_index().to_excel(self.output_filepath, encoding=self.output_file_encoding, index=False) #reset_index()はオプション
参考になった記事などまだあるので暇なときに順次追加予定