- 投稿日:2020-05-29T22:25:04+09:00
[エラー文]Permanently added the RSA host key for IP address '13.114.40.48' to the list of known hosts.
Githubに鍵を登録できたら、SSH接続できるかコマンドで確認していたら、
表題のエラーが発生した。サーバー[ec2-user@ip-172-31-23-189 ~]$ ssh -T git@github.com Hi <Githubユーザー名>! You've successfully authenticated, but GitHub does not provide shell access.また、同時成功の表示も出ていた。
下記リンクの対応で、無事にエラー文は消せました!
- 投稿日:2020-05-29T21:19:04+09:00
terraformでstateを入れ替える
ステートを消す
terraform state rm aws_vpc_peering_connection.connection-agrepしてリソースが管理されているかまずチェック
terraform state list | grep xxxステートをインポート
terraform import aws_vpc_peering_connection.connection-a pcx-xxxxxxxxxxxxxインポートする際には、リソースを定義しておく
resource "aws_vpc_peering_connection" "connection-a" { peer_vpc_id = data.aws_vpc.vpc.*.id[0] vpc_id = aws_vpc.vamdemic-vpc.id tags = { Name = "vamdemic-and-xxx" } }インポートするだけなら、リソースの中身はいらない
resource "aws_vpc_peering_connection" "connection-a" { }
- 投稿日:2020-05-29T21:14:33+09:00
TerraformでvpcをDataSourceで取得するとき
VPCをDataSourceで取得する
- filterでタグ名を指定している
- 複数のリソースが取得されないように、フィルター条件は多い方が良いかも
data "aws_vpc" "vpc" { filter { name = "tag:Name" values = ["vamdemic-vpc"] } }DataSourceを利用する場合
- リスト型で取得されるので、1つ目の要素を取り出します
data "aws_route_table" "route" { vpc_id = data.aws_vpc.vpc.*.id[0] filter { name = "tag:Name" values = ["vamdemic-route"] } }
- 投稿日:2020-05-29T20:49:09+09:00
CodePipelineの実行結果をAWS ChatBotでSlackに通知するCloudformation
AWS ChatBotで簡単にSlackに通知が出来るようになったということで、やはりCodePipelineの実行結果をSlackに通知したいですよね。
ということで、CodePipelineの実行結果を通知するChatBotを出来る限りCloudFormationで構成していきたいと思います。
ワークスペースの設定
出来る限りCloudFormationで。と書いたのは、最初に行うワークスペースのクライアント設定についてはCloudFormationに対応していないためです。
Slackへのアクセス権の許可ステップなどがあるのでここは仕方がないですね。
ChatBotのクライアント設定はコンソールから実施しておきます。参考: AWS Chatbot を利用して AWS 開発者用ツールの通知を Slack で受け取る方法
上記ドキュメント内の手順2にあるSlackのパーミッション要求を許可してクライアントを設定する箇所だけ完了しておけば残りの作業はCloudFormationで記述可能です。
ChatBotチャネルの設定
ChatBotのクライアントはSlackのワークスペースと1対1の関係にあります。
チャネルはその中で通知を投稿するSlackチャンネルと1対1に対応します。SlackのチャンネルIDとChatBotのワークスペースIDを引数に取る以下のCFnでChatBotチャネルを構成します。
chatbot-channel.ymlParameters: NotifySlackChannel: Type: String Description: Slack Channel ID NotifyChatbotWorkspaceId: Type: String Description: Chatbot Workspace ID Resources: PipelineNotificationChatbotRole: Type: AWS::IAM::Role Properties: RoleName: !Sub service-role-for-pipeline-notification-chatbot AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - chatbot.amazonaws.com Action: - sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/CloudWatchReadOnlyAccess PipelineNotificationChatbot: Type: AWS::Chatbot::SlackChannelConfiguration Properties: ConfigurationName: pipeline-notification-chatbot IamRoleArn: !GetAtt PipelineNotificationChatbotRole.Arn LoggingLevel: ERROR SlackChannelId: !Ref NotifySlackChannel SlackWorkspaceId: !Ref NotifyChatbotWorkspaceIdSlackのチャンネルID
チャンネルリストで該当のチャンネルを右クリックし、[その他のオプション]→[リンクをコピー]して、エディタなどに貼り付けたURLの末尾にある文字列です。
https://example.slack.com/archives/${SlackChannelID} #<-ここワークスペースID
ChatBotのワークスペースは、コンソールからChatBotの設定済みクライアントを開いて該当のワークスペースを開くことで確認出来ます。
CodePipelineの通知を作成
DeveloperTools関係のサービスの通知を作成するには CodeStartNotificationsのNotificationRuleを用いて構築します。
参考:CloudFormation - AWS::CodeStarNotifications::NotificationRule
構築するテンプレートは以下のようになります。
pipeline-notification-rule.ymlParameters: PipelineName: Type: String Description: Target Pipeline Name ChatBotArn: Type: String Description: AWS ChatBot ARN Resources: PipelineNotificationRule: Type: AWS::CodeStarNotifications::NotificationRule Properties: Name: pipeline-notification-rule DetailType: FULL Resource: !Join [ '', [ 'arn:aws:codepipeline:', !Ref 'AWS::Region', ':', !Ref 'AWS::AccountId', ':', !Ref PipelineName ] ] EventTypeIds: - codepipeline-pipeline-pipeline-execution-succeeded - codepipeline-pipeline-pipeline-execution-failed - codepipeline-pipeline-pipeline-execution-canceled Targets: - TargetType: AWSChatbotSlack TargetAddress: !Ref ChatBotArnEventTypeIds
通知するイベントタイプのIDをリストで指定します。
サポートしているIDのリストは、ドキュメントとしては見つけられませんでしたが、AWS CLIから取得できます。aws codestar-notifications list-event-types --filters Name=SERVICE_NAME,Value=CodePipeline上記のコマンドを実行すると、CodePipelineでサポートするイベントタイプのリストが取得できます。
{ "EventTypes": [ { "EventTypeId": "codepipeline-pipeline-action-execution-succeeded", "ServiceName": "CodePipeline", "EventTypeName": "Action execution: Succeeded", "ResourceType": "Pipeline" }, { "EventTypeId": "codepipeline-pipeline-action-execution-failed", "ServiceName": "CodePipeline", "EventTypeName": "Action execution: Failed", "ResourceType": "Pipeline" }, { "EventTypeId": "codepipeline-pipeline-stage-execution-started", "ServiceName": "CodePipeline", "EventTypeName": "Stage execution: Started", "ResourceType": "Pipeline" }, ... ] }この中から、通知を受け取りたいイベントを選択してEventTypeIdsに指定します。
TargetType
TargetTypeで指定可能な値は今のところ次の2つのようです。
ターゲット Value Amazon SNS topic SNS AWS Chatbot client AWSChatbotSlack 指定可能な値のリストは見つけられませんでした。
現時点では以下のURLのサンプルでのみ確認しています。
参考: AWS User Guide - View Notification Rule Targets実行
ここまでのCloudFormationをデプロイすると、CodePipelineの実行後に通知がSlackに届くようになります。
通知のLambdaコード等を書かずにPipeline結果がSlackに通知されるのは捗りますね!



- 投稿日:2020-05-29T18:13:14+09:00
AWS LambdaからSlackのIncoming Webhooksでメッセージを送る際のソースコードと複数メッセージを送る際の注意点
実装する機会があり、少々躓いた箇所があったので備忘録として残しておきます。
Lambda関数やIncoming Webhooksは準備できている想定として、これらの作成手順は省略します。環境
- macOS
- AWS Cloud9
- Node.js 12
実行コード
Lambda関数を1度実行する度に、Slackメッセージを1件だけ送るような場合は、以下のコードで動くと思います。
1度のLambdaで複数のメッセージを送る場合は、注意点があるので後ほど説明します。const env = process.env const request = require('request'); exports.handler = function(event, context) { // リクエスト設定 const options = { url: env.WEB_HOOK_URL, headers: { 'Content-type': 'application/json' }, body: { "username": "jinto", "text": "Hello !!" }, json: true }; //メッセージ送信 request.post(options); return "success !!"; }1度のLambdaで大量のメッセージを送る場合
2〜3件程度のメッセージであれば上記のコードをそのままfor文等で繰り返しても問題ないと思いますが、数十件〜数百件のメッセージを1度のLambdaで処理したい場合は注意が必要です。
仮に上記のコードを、for(let i = 0; i < 100; i++) { //メッセージ送信 request.post(options); }このように100回繰り返した場合、Slackにはメッセージが数件〜数十件しか届かないと思います。自分もここで躓きました。
どうやら、requestメソッドは非同期的に処理されるので、requestを100回実行し終わる前に、Lambda関数の実行そのものが終了してしまうようです。
大量のメッセージを送信したい場合には、requestをpromise化し、async〜awaitで1件ずつ止めてあげると上手く動きます。
Node.jsには、request-promiseという便利なモジュールがあったので、こちらを使用しました。コードを以下に示します。const env = process.env const requestPromise = require('request-promise'); exports.handler = async(event, context) => { // リクエスト設定 const options = { url: env.WEB_HOOK_URL, headers: { 'Content-type': 'application/json' }, body: { "username": "jinto", "text": "Hello !!" }, json: true }; for(let i = 0; i < 100; i++) { await requestPromise.post(options); // 通常のrequestだと非同期的に処理されるので、処理が終わる前にLambda関数が閉じてしまう } return "success !!"; }ご参考までに。
- 投稿日:2020-05-29T18:13:14+09:00
LambdaからSlackにメッセージを送る際のソースコードと複数回メッセージを送る際の注意点
AWSのLambda関数から、SlackのIncoming Webhooksでメッセージを送信する機会があり、少々躓いた箇所があったので備忘録として残しておきます。
Lambda関数やIncoming Webhooksは準備できている想定として、これらの作成手順は省略します。環境
- macOS
- AWS Cloud9
- Node.js 12
実行コード
Lambda関数を1度実行する度に、Slackメッセージを1件だけ送るような場合は、以下のコードで動くと思います。
1度のLambdaで複数回メッセージを送る場合は、注意点があるので後ほど説明します。const env = process.env const request = require('request'); exports.handler = function(event, context) { // リクエスト設定 const options = { url: env.WEB_HOOK_URL, headers: { 'Content-type': 'application/json' }, body: { "username": "jinto", "text": "Hello !!" }, json: true }; //メッセージ送信 request.post(options); return "success !!"; }1度のLambdaで大量のメッセージを送る場合
2〜3件程度のメッセージであれば上記のコードをそのままfor文等で繰り返しても問題ないと思いますが、数十件〜数百件のメッセージを1度のLambdaで処理したい場合は注意が必要です。
仮に上記のコードを、for(let i = 0; i < 100; i++) { //メッセージ送信 request.post(options); }このように100回繰り返した場合、Slackにはメッセージが数件〜数十件しか届かないと思います。自分もここで躓きました。
どうやら、requestメソッドは非同期的に処理されるので、requestを100回実行し終わる前に、Lambda関数の実行そのものが終了してしまうようです。
大量のメッセージを送信したい場合には、requestをpromise化し、async〜awaitで1件ずつ止めてあげると上手く動きます。
Node.jsには、request-promiseという便利なモジュールがあったので、こちらを使用しました。コードを以下に示します。const env = process.env const requestPromise = require('request-promise'); exports.handler = async(event, context) => { // リクエスト設定 const options = { url: env.WEB_HOOK_URL, headers: { 'Content-type': 'application/json' }, body: { "username": "jinto", "text": "Hello !!" }, json: true }; for(let i = 0; i < 100; i++) { await requestPromise.post(options); // 通常のrequestだと非同期的に処理されるので、処理が終わる前にLambda関数が閉じてしまう } return "success !!"; }ご参考までに。
- 投稿日:2020-05-29T17:57:14+09:00
SSMまとめ
概要
AWS Systems Manager(通称SSM)にふれる機会があったので、
知ったことをまとめておくSSMとは
AWSの構成管理ツールのサービスである。
SSMを利用するためには、「SSMエージェント」を操作対象のEC2インスタンスへインストールする必要がある。
SSMには、EC2に対して構成変更を加えるときに使う設定ファイルを保存できる「パラメータストア」という機能があり、EC2に対してエージェントのインストールやパラメータストア内に保存した設定ファイルを選択してのエージェントの起動ができる。、
エージェントとしては例えばCloudWatchエージェントをSSHログインして直接作業せずとも、SSMコンソール経由でインストール、起動できる。例えば冗長構成のEC2インスタンスがあり、各インスタンスへCloudWatchエージェントをインストール、設定を適用して起動・・・とやりたい場合、パラメータストアに保存した設定ファイルを使いまわしつつSSMコンソール経由で作業できるため、楽にミスなく作業できるというメリットがある。
SSMエージェントのセットアップ
1. インストール
参考記事:https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-manual-agent-install.html
例. EC2インスタンスのディストリビューションがUbuntu14.04の場合
# EC2インスタンスへSSHログイン # 一時ディレクトリを作成 mkdir /tmp/ssm # 一時ディレクトリへ移動 cd /tmp/ssm # SSMエージェントのパッケージをDL wget https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/debian_amd64/amazon-ssm-agent.deb # SSMエージェントをインストール(インストールとともにデーモンとして起動する) sudo dpkg -i amazon-ssm-agent.deb # SSMエージェントのステータスを確認 sudo status amazon-ssm-agent =>amazon-ssm-agent start/runningと表示されればOK ※なお、以降はEC2インスタンスを再起動した場合も自動的に立ち上がるようになる以上
2. SSMコンソールでの疎通確認
SSMコンソールページへアクセス > インスタンスとノード-マネージドインスタンス
→SSM管理対象のEC2インスタンスが一覧表示される
一覧にSSMエージェントをインストールしたインスタンスがあればOK
以上
SSMコンソールからEC2へ任意のエージェントをセットアップ
※例. CloudWatchエージェントの場合 (&Ubuntu 14.04の場合)
1. インストール
SSMコンソールへアクセス > 「インスタンスとノード」 > 「マネージドインスタンス」ページで対象のインスタンスにチェックを入れて、「アクション」 > 「コマンドを実行」 と押下
→「コマンドの実行」ページが表示される
「コマンドの実行」ページの「コマンドドキュメント」セクションで「AWS-ConfigureAWSPackage」にチェックを入れる > 「コマンドのパラメータ」セクションの「Action」で「install」を選択 > 「Name」で「AmazonCloudWatchAgent」を入力 > 「Version」で「latest」を選択 > 「ターゲット」セクションで「インスタンスを手動で選択する」を選択し、「Instances」でCloudWatchエージェントをインストールするEC2インスタンスにチェックを入れる > 「実行」を押下
→コマンドID: XXXXXXXのページが表示される。(しばらく待ってF5で更新してステータスが成功になればOK)
これにより、内部的にはaptでのインストールが走る模様。2. インストール確認
対象のEC2インスタンスへSSHログインして以下のコマンドでCloudWatchエージェントがインストールされていることを確認(ubuntu14.04の場合)
# EC2へSSHログイン # 目的のエージェントのインストール確認 apt list --installed | grep cloudwatch =>amazon-cloudwatch-agent XXXXXX [installed,local] と表示されていればOKパラメータストア
設定ファイルの編集
SSMコンソールへアクセス > アプリケーション管理-パラメータストア > 編集したい設定ファイルを選択して「編集ボタンを押下」
→「パラメータの詳細」ページへ遷移
「パラメータの詳細」ページの「値」フィールドを編集して、「変更の保存」を押下
以上
なお、無料利用枠の場合は設定ファイルの文字数は4096文字までとなっている。
半角スペースもカウントされるので注意。節約したいならときには可読性を犠牲にする必要も。SSMコンソールからEC2の任意のエージェントを起動
例. CloudWatchエージェントの場合 (&Ubuntu 14.04の場合)
SSMコンソールへアクセス > インスタンスとノード-Run Command > 「Run Command」ボタンを押下
!
→「コマンドの実行」ページが表示される。
AmazonCloudWatch-ManageAgentにチェック > 以下の通り設定して「実行」を押下
- コマンドのパラメータセクション
- Action:configure
- Mode:ec2
- Optional Configuration Source:ssm
- Optional Configuration Location : 適用するパラメータストア上の設定ファイル名
- Optional Restart:yes
- ターゲットセクション
- ターゲット:監視対象のインスタンス
以上






- 投稿日:2020-05-29T17:07:32+09:00
Minecraft サーバを AWS で作る
Minecraft のサーバを作る。いろんな方が既に記事を書いているので目新しさはない。この組み合わせで動作したという確認。
Minecraft サーバとは
Minecraft はネットワークで通信してマルチプレイができる。マルチプレイをするにはネットワーク内でMinecraftをプレイしているマシンを1台公開してそこに他のプレーヤがつなげるやりかたと、ネットワーク内でサーバ専用サービスを実行するホストを作りサーバにするやりかたの2つがある。
Minecraft でマルチプレイをするには Minecraft の系統と、バージョンを合わせる必要がある。
Minecraft の系統
マルチプレイをするときには、系統を合わせないといけない。今の主な系統は2つ
- Java 版
- 統合版 (Bedrock Edition)
系統は、プレイする全員、および、サーバその系統に合わせる必要がある。
なお、現在公開されているサーバのソフトウェアは Java 版系統。
統合版のサーバも公開されている( https://help.minecraft.net/hc/en-us/articles/360035131651-Dedicated-Servers-for-Minecraft-on-Bedrock- ) が、アルファ版。ちなみに、上記以外の系統も存在する。サーバソフトウェアは公開されていないが、ピア2ピア的にマルチプレイができる。その場合はそれぞれの系統同士でしかマルチプレイできない。
- ブラウザ版
- Raspberry Pi edition
- Earth edition
- Education edition
- Legacy console editon (現在、PS4,Nintendo Switch等は統合版にアップデート、それ以外の旧いプラットフォームではLegacy conosole edition 同士でも異機種だとマルチプレイできないぽい)
New Nintendo 3DS Edition
他に Minecraft China というのがあるがナンダ? https://minecraft-ja.gamepedia.com/Minecraft_China
バージョン
サーバのバージョンと、マルチプレイの参加者の Minecraft のバージョンを合わせる必要がある。
バージョンはJava版において、2020/5/29現在最新のものは以下の2つ。
- 1.15.2 (正式版)
- 20w21a (開発版1.16のスナップショット)
であるが、こちらからダウンロード
https://www.minecraft.net/ja-jp/download/server/
できるサーバのバージョンは正式版の最新のものである 1.15.2。
それ以外の old バージョンや、開発版はこちらから。
サーバの動作環境
java で動作するので Windows / Mac / Linux で動作する。もちろん、Raspsberry Piも!
サーバを動かすのは難しい?
https://minecraft.gamepedia.com/Tutorials/Setting_up_a_server
によると、Setting up a server takes some time, and some technical knowledge. Don't try to set up a server unless you have some basic computer and networking abilities.
とあるけれども、試してみたらあっさり動いた。
AWS サーバを起動
まずは TOKYOリージョン、t2.midium を利用して、Ubuntu 20.04を起動する。
ログイン後、
$ sudo apt update $ sudo apt upgradeをしたあと、Java だけインストール。
とりあえずUbuntu20.04で最新のJREを入れてみた。$ sudo apt install openjdk-14-jrehttps://www.minecraft.net/ja-jp/download/server/
からサーバをダウンロード。
リンクをマウスで右クリックしてアドレスを取得、ssh で以下に貼り付けた。
$ wget https://launcher.mojang.com/v1/objects/bb2b6b1aefcd70dfd1892149ac3a215f6c636b07/server.jar起動してみる
$ java -Xmx1024M -Xms1024M -jar server.jar nogui [08:18:47] [main/ERROR]: Failed to load properties from file: server.properties [08:18:47] [main/WARN]: Failed to load eula.txt [08:18:47] [main/INFO]: You need to agree to the EULA in order to run the server. Go to eula.txt for more info.という結果になった。
$ ls -alhとしてみたら、
total 35M drwxr-xr-x 5 ubuntu ubuntu 4.0K May 28 08:18 . drwxr-xr-x 3 root root 4.0K May 28 07:51 .. -rw-r--r-- 1 ubuntu ubuntu 220 Feb 25 12:03 .bash_logout -rw-r--r-- 1 ubuntu ubuntu 3.7K Feb 25 12:03 .bashrc drwx------ 2 ubuntu ubuntu 4.0K May 28 07:56 .cache -rw-r--r-- 1 ubuntu ubuntu 807 Feb 25 12:03 .profile drwx------ 2 ubuntu ubuntu 4.0K May 28 07:51 .ssh -rw-r--r-- 1 ubuntu ubuntu 0 May 28 08:01 .sudo_as_admin_successful -rw-rw-r-- 1 ubuntu ubuntu 181 May 28 08:18 eula.txt drwxrwxr-x 2 ubuntu ubuntu 4.0K May 28 08:18 logs -rw-rw-r-- 1 ubuntu ubuntu 35M Jan 17 10:06 server.jar -rw-rw-r-- 1 ubuntu ubuntu 940 May 28 08:18 server.propertiesとあって、eula.txt ができているようだ。
$ vim eula.txtとして、中身の
#By changing the setting below to TRUE you are indicating your agreement to our EULA (https://account.mojang.com/documents/minecraft_eula). #Fri May 29 19:21:06 JST 2020 eula=falsefalse を true に書き換えて保存。
もう一度起動
$ java -Xmx1024M -Xms1024M -jar server.jar nogui [08:20:14] [main/WARN]: Ambiguity between arguments [teleport, destination] and [teleport, targets] with inputs: [Player, 0123, @e, dd12be42-52a9-4a91-a8a1-11c01849e498] [08:20:14] [main/WARN]: Ambiguity between arguments [teleport, location] and [teleport, destination] with inputs: [0.1 -0.5 .9, 0 0 0] [08:20:14] [main/WARN]: Ambiguity between arguments [teleport, location] and [teleport, targets] with inputs: [0.1 -0.5 .9, 0 0 0] [08:20:14] [main/WARN]: Ambiguity between arguments [teleport, targets] and [teleport, destination] with inputs: [Player, 0123, dd12be42-52a9-4a91-a8a1-11c01849e498] [08:20:14] [main/WARN]: Ambiguity between arguments [teleport, targets, location] and [teleport, targets, destination] with inputs: [0.1 -0.5 .9, 0 0 0] [08:20:14] [Server thread/INFO]: Starting minecraft server version 1.15.2 [08:20:14] [Server thread/INFO]: Loading properties [08:20:14] [Server thread/INFO]: Default game type: SURVIVAL [08:20:14] [Server thread/INFO]: Generating keypair [08:20:15] [Server thread/INFO]: Starting Minecraft server on *:25565 [08:20:15] [Server thread/INFO]: Using epoll channel type [08:20:15] [Server thread/INFO]: Preparing level "world" [08:20:15] [Server thread/INFO]: Found new data pack vanilla, loading it automatically [08:20:15] [Server thread/INFO]: Reloading ResourceManager: Default [08:20:47] [Server thread/INFO]: Loaded 6 recipes [08:20:47] [Server thread/INFO]: Loaded 825 advancements [08:20:53] [Server thread/INFO]: Preparing start region for dimension minecraft:overworld [08:20:53] [Server-Worker-1/INFO]: Preparing spawn area: 0% [08:20:53] [Server-Worker-1/INFO]: Preparing spawn area: 0% [08:20:54] [Server-Worker-1/INFO]: Preparing spawn area: 0% [08:20:54] [Server-Worker-1/INFO]: Preparing spawn area: 0% [08:20:55] [Server-Worker-1/INFO]: Preparing spawn area: 1% [08:20:55] [Server-Worker-1/INFO]: Preparing spawn area: 2% [08:20:56] [Server-Worker-1/INFO]: Preparing spawn area: 4% [08:20:56] [Server-Worker-1/INFO]: Preparing spawn area: 5% [08:20:57] [Server-Worker-1/INFO]: Preparing spawn area: 7% [08:20:57] [Server-Worker-1/INFO]: Preparing spawn area: 10% [08:20:58] [Server-Worker-1/INFO]: Preparing spawn area: 12% [08:20:58] [Server-Worker-1/INFO]: Preparing spawn area: 14% [08:20:59] [Server-Worker-1/INFO]: Preparing spawn area: 17% [08:20:59] [Server-Worker-1/INFO]: Preparing spawn area: 19% [08:21:00] [Server-Worker-1/INFO]: Preparing spawn area: 22% [08:21:00] [Server-Worker-1/INFO]: Preparing spawn area: 24% [08:21:01] [Server-Worker-1/INFO]: Preparing spawn area: 26% [08:21:01] [Server-Worker-1/INFO]: Preparing spawn area: 29% [08:21:02] [Server-Worker-1/INFO]: Preparing spawn area: 32% [08:21:02] [Server-Worker-1/INFO]: Preparing spawn area: 33% [08:21:03] [Server-Worker-1/INFO]: Preparing spawn area: 36% [08:21:03] [Server-Worker-1/INFO]: Preparing spawn area: 38% [08:21:04] [Server-Worker-1/INFO]: Preparing spawn area: 41% . . .起動したようだ。
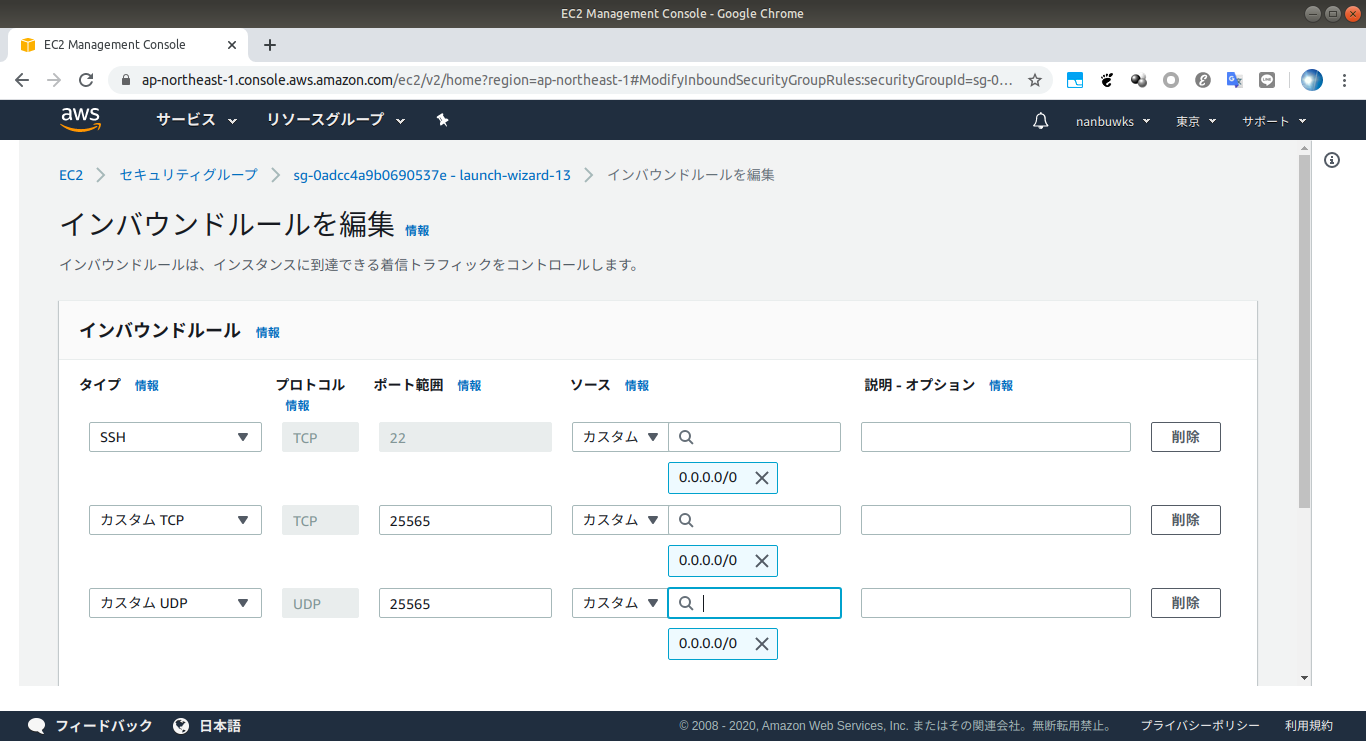
ポート公開
TCP25565 と UDP25565 を開放したら、外部から接続し、プレイできた。
- 投稿日:2020-05-29T16:46:26+09:00
オンプレPC WindowsのイベントログをCloudWatch Logsに送る
概要
今回やることの概要
- オンプレPC(に見立てたEC2)にCloudWatch Agent入れて、WindowsログをCloudWatchログに送る
構成図
こんな構成
- 補足
- EC2はIAMロールをアタッチできる
- オンプレPCはIAMロールをアタッチできない
WindowsのイベントログをCloudWatchログに送るために必要なもの
CloudWatch Agent Winイベントログなどログ取得に必要 IAMポリシー CloudWatchAgentServerPolicyCloudWatchにログを送る権限 IAMユーザー IAMポリシーをオンプレPCに設定するため必要 AWS CLI 必須じゃない。credentialsファイル作成に使用 本記事の概要(目次)
- 概要
- 構成図
- 〇-- 手順紹介 --〇
- 1.オンプレPCを用意(今回はEC2を使う)
- 2.IAMユーザーを作成
- 3.作成したIAMユーザーにIAMポリシー
CloudWatchAgentServerPolicy適用- 4.アクセスキーを作成する
- 5.オンプレPCのWindowsで設定
- 5-1.AWS CLIインストール
- 5-2.credentialsファイル作成
- 5-3.CloudWatch Agentインストール
- 5-4.CloudWatch Agent設定
- 5-5.CloudWatch Agent設定反映
- 5-6.CloudWatch Agent再起動
- 6.動作確認
- 〇-- おまけ --〇
- おまけ(1):credentialsファイルパスを指定する
- おまけ(2):5-4.CloudWatch Agent設定の全て
- おまけ(3):CloudWatch Agentのファイル構造
では、やっていく
手順紹介
1.オンプレPCを用意(今回はEC2を使う)
- WindowsOSの環境を用意する。今回はEC2インスタンスを代用して用意。
- EC2作成手順は省略
2.IAMユーザーを作成
- CloudWatch AgentがCloudWatch Logsにログを書き込む権限を設定するため、IAMユーザーを作成
- IAMユーザーの作成手順は省略
3.作成したIAMユーザーにIAMポリシー
CloudWatchAgentServerPolicy適用
- 手順『2.IAMユーザーを作成』で作成したIAMユーザに必要な権限を設定する
- 必要な権限とは、CloudWatch Logsへの書き込み権限
- CloudWatch Logsへの書き込み権限は、IAMポリシー
CloudWatchAgentServerPolicyこんな感じでポリシーを適用する
4.アクセスキーを作成する
- CloudWatch Logsへの書き込み権限を持つIAMユーザのアクセスキーを作成
- 作成したアクセスキーは、あとでオンプレPC上のWindowsのcredentialsファイル作成に使用
- アクセスキーのcsvファイル
credentials.csvをAWSコンソールからダウンロード
5.オンプレPCのWindowsで設定
- オンプレPC(手順『1.オンプレPCを用意』で作成したEC2)Windowsを設定していく
5-1.AWS CLIインストール
- AWS CLI(AWS Command Line Interface)があるとcredentilsファイルの作成が楽
- credentialsファイルは、手動でも作成できるのでAWS CLIのインストールは必須ではない
- 今回は、AWS CLI v2 をインストール
- 以下サイトでインストーラ(.msi)を取得してインストール
5-2.credentialsファイル作成
- 手順『4.アクセスキーを作成する』で作成したアクセスキー必要
- 手順『4-1.AWS CLIインストール』でインストールしたAWS CLIを使いcredentialsファイルを作成する
- フルパス
C:\Users{ユーザー名}.aws\credentials
- Windowsの設定によっては異なるパスになるかも
- powershellを起動し、
aws configureコマンドを実行し以下を設定する
- アクセスキー
- シークレットアクセスキー
- 標準のリージョン (東京リージョンなら ap-northeast-1)
- 標準の形式 (こだわり無いなら json が無難かも)
設定例PS C:\> aws configure AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY Default region name [None]: ap-northeast-1 Default output format [None]: json※注意※ アクセスキーの情報は公開しないように!
credentialsファイルの中身はこんな感じ
5-3.CloudWatch Agentインストール
- CloudWatch Agentは、WindowsのイベントログをCloudWatch Logsに送る機能がある
- CloudWatch Agentは、Windowsのイベントログ以外のログにも対応してる
- インストーラ
amazon-cloudwatch-agent.msiを入手してインストールするだけ- インストーラはここで入手 ↓
5-4.CloudWatch Agent設定
- "何をCloudWatch Logsに送るか"などの設定をする
- 設定は質問形式で行う
- 質問多い&英語 のダブルパンチで、心が折れる
- でも、落ち着いて確認すれば何とか理解できる(気がする)
- 設定が完了すると
config.jsonファイルが作成されるPowerShellを管理者権限で起動し、
以下コマンドを実行し、質問形式でCloudWatch Agentの設定を行うPS C:\> cd "C:\Program Files\Amazon\AmazonCloudWatchAgent" PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-config-wizard.exe※今回行った全ての設定は、『おまけ:5-4.CloudWatch Agent設定の全て』参照
質問事項を一部抜粋
Do you want to monitor any Windows event log? 1. yes 2. no default choice: [1]: # → Windowsログをモニターしたいので 1 を選択Windows event log name: default choice: [System] # → Systemログを選択する場合は System を選択5-5.CloudWatch Agent設定反映
- 設定をしただけでは反映されない
- 設定を更新した後は、必ず反映する
- 「設定通りに動かん!」なときは、設定の反映を忘れている可能性あり
- 設定を反映すると、
config.jsonの情報がcommon-config.tomlに反映される
- フルパス
C:\ProgramData\Amazon\AmazonCloudWatchAgent\common-config.tomlcommon-config.tomlはテキストエディタで開けるので、反映されたか目視確認もできる設定(config.json)反映PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a fetch-config -m ec2 -c file:config.json -s Successfully fetched the config and saved in C:\ProgramData\Amazon\AmazonCloudWatchAgent\Configs\file_config.json.tmp Start configuration validation... 2020/05/12 22:55:57 Reading json config file path: C:\ProgramData\Amazon\AmazonCloudWatchAgent\Configs\file_config.json.tmp ... Valid Json input schema. No csm configuration found. Configuration validation first phase succeeded Configuration validation second phase succeeded Configuration validation succeeded PS C:\Program Files\Amazon\AmazonCloudWatchAgent>5-6.CloudWatch Agent再起動
- 設定を反映したら、CloudWatch Agentを再起動する
CloudWatchAgent再起動PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a stop PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a status { "status": "stopped", "starttime": "", "version": "1.237768.0" } PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a start PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a status { "status": "running", "starttime": "2020-05-12T23:03:41", "version": "1.237768.0" }これで全ての作業が完了した!
6.動作確認
- Windowsイベントログが、CloudWatch Logs にログとして記録されたことを確認する
CloudWatch Logsにロググループ
testsuoworkgroupsystemが追加された!(期待通り)
開くとホスト名の名称でログストリームがあった(期待通り)
更にログストリームの中にWindows Systemログが記録されてた→成功!(期待通り)
※ログの時刻はグリニッジ標準時なので注意、+9時間で日本時間になります
上手く動いた、ふぅ
おまけ
おまけ(1):credentialsファイルパスを指定する
- aws configure でアクセスキーを設定すると、
C:\Users\{ユーザー名}\.aws\credentialsにcredentialsファイルが作成される
- ↑が標準パス
- CloudWatch Agentはcredentialsファイルを読み込みアクセス権を得る
- 標準パスと異なるパスにcredentialsファイルがあると、CloudWatch Agentがcredentialsを読み込めない
- また、
credentialsに複数のプロファイルがあり、特定のプロファイルを指定したい場合がある- そんなときは、CloudWatch Agentの設定ファイルにcredentialのパスを設定する
- CloudWatch Agentのcredentialsパスの設定は
common-config.toml
- フルパス
C:\ProgramData\Amazon\AmazonCloudWatchAgent\common-config.tomlcommon-config.tomlを編集し、credentialファイルのパスとプロファイル名を設定する- 参考
[credentials] shared_credential_profile = "{profile_name}" shared_credential_file= "{file_name}"例えば、プロファイル名が
defaultで、パスがC:\Users\Administrator\test001\credentialsの場合はこのように設定する[credentials] shared_credential_profile = "default" shared_credential_file = "C:\\Users\\Administrator\\test001\\credentials"
common-config.tomlを編集したら、設定反映を忘れないよう注意設定を反映するPS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a fetch-config -m ec2 -c file:config.json -sおまけ(2):5-4.CloudWatch Agent設定の全て
実施した全ての設定
config.json作成PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-config-wizard.exe ============================================================= = Welcome to the AWS CloudWatch Agent Configuration Manager = ============================================================= On which OS are you planning to use the agent? 1. linux 2. windows default choice: [2]: 2 Trying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? 1. EC2 2. On-Premises default choice: [1]: 2 Please make sure the credentials and region set correctly on your hosts. Refer to http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]: Which port do you want StatsD daemon to listen to? default choice: [8125] What is the collect interval for StatsD daemon? 1. 10s 2. 30s 3. 60s default choice: [1]: What is the aggregation interval for metrics collected by StatsD daemon? 1. Do not aggregate 2. 10s 3. 30s 4. 60s default choice: [4]: Do you have any existing CloudWatch Log Agent configuration file to import for migration? 1. yes 2. no default choice: [2]: Do you want to monitor any host metrics? e.g. CPU, memory, etc. 1. yes 2. no default choice: [1]: Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]: Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. 1. 1s 2. 10s 3. 30s 4. 60s default choice: [4]: Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]: Current config as follows: { "metrics": { "metrics_collected": { "LogicalDisk": { "measurement": [ "% Free Space" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Memory": { "measurement": [ "% Committed Bytes In Use" ], "metrics_collection_interval": 60 }, "Network Interface": { "measurement": [ "Bytes Sent/sec", "Bytes Received/sec", "Packets Sent/sec", "Packets Received/sec" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Paging File": { "measurement": [ "% Usage" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "PhysicalDisk": { "measurement": [ "Disk Write Bytes/sec", "Disk Read Bytes/sec", "Disk Writes/sec", "Disk Reads/sec" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Processor": { "measurement": [ "% Processor Time" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" } } } } Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. 1. yes 2. no default choice: [1]: Do you want to monitor any customized log files? 1. yes 2. no default choice: [1]: 2 Do you want to monitor any Windows event log? 1. yes 2. no default choice: [1]: 1 Windows event log name: default choice: [System] Do you want to monitor VERBOSE level events for Windows event log System ? 1. yes 2. no default choice: [1]: 1 Do you want to monitor INFORMATION level events for Windows event log System ? 1. yes 2. no default choice: [1]: 1 Do you want to monitor WARNING level events for Windows event log System ? 1. yes 2. no default choice: [1]: 1 Do you want to monitor ERROR level events for Windows event log System ? 1. yes 2. no default choice: [1]: 1 Do you want to monitor CRITICAL level events for Windows event log System ? 1. yes 2. no default choice: [1]: 1 Log group name: default choice: [System] testsuoworkgroupssystem Log stream name: default choice: [{hostname}] In which format do you want to store windows event to CloudWatch Logs? 1. XML: XML format in Windows Event Viewer 2. Plain Text: Legacy CloudWatch Windows Agent (SSM Plugin) Format default choice: [1]: Do you want to specify any additional Windows event log to monitor? 1. yes 2. no default choice: [1]: 2 Saved config file to config.json successfully. Current config as follows: { "logs": { "logs_collected": { "windows_events": { "collect_list": [ { "event_format": "xml", "event_levels": [ "VERBOSE", "INFORMATION", "WARNING", "ERROR", "CRITICAL" ], "event_name": "System", "log_group_name": "testsuoworkgroupssystem", "log_stream_name": "{hostname}" } ] } } }, "metrics": { "metrics_collected": { "LogicalDisk": { "measurement": [ "% Free Space" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Memory": { "measurement": [ "% Committed Bytes In Use" ], "metrics_collection_interval": 60 }, "Network Interface": { "measurement": [ "Bytes Sent/sec", "Bytes Received/sec", "Packets Sent/sec", "Packets Received/sec" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Paging File": { "measurement": [ "% Usage" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "PhysicalDisk": { "measurement": [ "Disk Write Bytes/sec", "Disk Read Bytes/sec", "Disk Writes/sec", "Disk Reads/sec" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Processor": { "measurement": [ "% Processor Time" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" } } } } Please check the above content of the config. The config file is also located at config.json. Edit it manually if needed. Do you want to store the config in the SSM parameter store? 1. yes 2. no default choice: [1]: 2 Please press Enter to exit... Program exits now. PS C:\Program Files\Amazon\AmazonCloudWatchAgent> PS C:\Program Files\Amazon\AmazonCloudWatchAgent> PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a status { "status": "running", "starttime": "2020-05-12T22:13:06", "version": "1.237768.0" } PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a stop PS C:\Program Files\Amazon\AmazonCloudWatchAgent> .\amazon-cloudwatch-agent-ctl.ps1 -a status { "status": "stopped", "starttime": "", "version": "1.237768.0" } PS C:\Program Files\Amazon\AmazonCloudWatchAgent>おまけ(3):CloudWatch Agentのファイル構造
Windows環境のCloudWatch Agentは、以下2つのパスに関連データがある
C:\Program Files\Amazon\AmazonCloudWatchAgentコマンド群 C:\ProgramData\Amazon\AmazonCloudWatchAgentログ・設定ファイル群 ■ コマンド群
PS C:\Program Files\Amazon\AmazonCloudWatchAgent> dir Directory: C:\Program Files\Amazon\AmazonCloudWatchAgent Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 1/22/2020 5:23 PM 15840008 amazon-cloudwatch-agent-config-wizard.exe -a---- 1/22/2020 5:24 PM 12058 amazon-cloudwatch-agent-ctl.ps1 -a---- 1/22/2020 5:24 PM 23071 amazon-cloudwatch-agent-schema.json -a---- 1/22/2020 5:24 PM 13621000 amazon-cloudwatch-agent-windows-migration.exe -a---- 1/22/2020 5:24 PM 59071240 amazon-cloudwatch-agent.exe -a---- 1/22/2020 5:24 PM 13782792 config-downloader.exe -a---- 1/22/2020 5:24 PM 29992712 config-translator.exe -a---- 5/12/2020 10:44 PM 1587 config.json -a---- 1/22/2020 5:24 PM 11 CWAGENT_VERSION -a---- 1/22/2020 5:24 PM 4705 LICENSE -a---- 1/22/2020 5:24 PM 96 NOTICE -a---- 1/22/2020 5:23 PM 4759 RELEASE_NOTES -a---- 1/22/2020 5:24 PM 2820872 start-amazon-cloudwatch-agent.exe -a---- 1/22/2020 5:24 PM 99931 THIRD-PARTY-LICENSES■ ログ・設定ファイル群
PS C:\ProgramData\Amazon\AmazonCloudWatchAgent> dir Directory: C:\ProgramData\Amazon\AmazonCloudWatchAgent Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 5/12/2020 10:56 PM Configs d----- 5/12/2020 11:20 PM Logs -a---- 5/12/2020 11:03 PM 3056 amazon-cloudwatch-agent.toml -a---- 1/22/2020 5:24 PM 925 common-config.toml -a---- 5/12/2020 8:50 AM 139 log-config.json
C:\ProgramData\Amazon\AmazonCloudWatchAgent\LogsにCloudWatch Agentのログがある。- CloudWatch Agentが意図した挙動にならないときは、このログを確認すると原因追及に役立つかも
例えば、CloudWatch Agentが
credentilsファイルを読み込めないとこんなエラーが記録される。amazon-cloudwatch-agent.log2020-05-16T01:16:38Z E! cloudwatchlogs: code: SharedCredsLoad, message: failed to load shared credentials file, original error: &awserr.baseError{code:"FailedRead", message:"unable to open file", errs:[]error{(*os.PathError)(0xc000627320)}}, &awserr.baseError{code:"SharedCredsLoad", message:"failed to load shared credentials file", errs:[]error{(*awserr.baseError)(0xc0003e7f00)}}



















- 投稿日:2020-05-29T16:07:40+09:00
CloudWatchまとめ
概要
CloudWatchについて調べる機会があったのでまとめた
CloudWatchの基本機能
監視ツールとしての以下の基本的な機能が備わっているらしい。
基本機能
- 内部リソース(CPUとか)データの収集
- ログの収集(※)
- 収集データに対して閾値を設定してのアラート通知の発砲・インスタンスの停止・再起動
- 収集したデータの視覚化
※EC2のログ監視には別途「CloudWatchエージェント」というツールを監視対象インスタンスへインストールする必要あり(※)。
- また、標準でないメトリクス(=カスタムメトリクス。メトリクスとは監視項目・測定基準データの意味)の収集にも別途「CloudWatchエージェント」というツールを監視対象インスタンスへインストールする必要あり(※)。
- 標準メトリクスは下記
- CPU使用率
- ディスク読み取り(数、サイズ)
- ディスク書き込み(数、サイズ)|
- ネットワーク受信量
- ネットワーク送信量
- ステータスチェック(インスタンスステータスチェック/システムステータスチェックのどちらかが失敗した場合に失敗となる)(※)
- インスタンスステータスチェック(※)
- システムステータスチェック(※)※CloudWatchエージェントのインストール
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/CWL_GettingStarted.html※ステータスチェック
以下2つがあり、全項目OKならば「ステータスチェック」がOKとなる。
- システムステータスチェック
- インスタンスステータスチェック
なお、ステータスチェックについてはCloudWatchじゃなくてEC2のコンソールでもOK/NGは確認できる。
システムステータスチェック
- 対象のインスタンスに対して物理的な問題が発生していないか?のチェック。
- AWSが関与しないと解決できない、自身ではどうにもならない問題の部分である。
- 以下が原因となる例らしい。
- ネットワーク接続の喪失
- システム電源の喪失
- 物理ホスト上のソフトウェアの問題
- ネットワークの到達可能性に影響を与える物理ホスト上のハードウェアの問題
- 物理歴な問題が発生した時のリスクを低減するには以下のようにするらしい
- RDSならマルチAZ構成(マスターで障害が発生したらスレーブに自動で切り替えてくれる)
- EC2ならマルチリージョン、マルチAZ構成(EC2インスタンスを各箇所にちりばめ、ELBを通してアクセスさせることでどこかで障害が発生しても生きているインスタンスで応答するようにする)
インスタンスステータスチェック
- インスタンス内のステータスチェック。以下がNGとなる原因の例らしい。
- システムステータスチェックの失敗
- 不正なネットワークまたはスタートアップ構成
- メモリ不足
- 破損したファイルシステム
- 互換性のないカーネル
- インスタンスステータスチェックについてはなかなか疑問あり。
- 実際にメモリがめちゃくちゃ使われていて、実際にサーバーが死んでいた状態だったときにも引っかかることはなかったし、そもそも全項目が公開されているわけではなく、その判定基準もブラックボックスなので今回の要件には不確定要素が多すぎて使えない。「なんかインスタンス内でなんかおきてまっせ!」というのを検知できるんだなー程度にとどめておき、過度な期待はしない方がよいだろう。
CloudWatchを導入するメリット、デメリット
CloudWatchには以下のメリット、デメリットがあるらしい。
メリット デメリット ・標準メトリクスの収集については自身での設定すら不要
・監視対象であるAWSサービスがアップデートされても自動で追従してくれる
・メトリクスの保管期間が短い(※)(=長期的に保管したいなら自身でCloudWatchから収集済みのメトリクスを抜き出して保管する必要あり(※))
・CloudWatch単体でアラートの発砲や自動再起動をしない期間の設定ができない(やるなら他のサービスも併用しての設定が必要(※))※メトリクスの保管期間
監視間隔 保管期間 1分 15日間 5分 63日間 1時間 455日間 ※メトリクスの長期保管
参考:https://qiita.com/Kept1994/items/aa76ae065d8d16c557a8※アラートを一時的に止める
参考:https://qiita.com/kapioz/items/f2de33075d7f88f00ffeCloudWatchエージェントのセットアップ
- SSM経由でCloudWatchエージェントをインストール
- EC2上で設定ファイルの雛形を作ってSSMのパラメータストアに保存
- パラメータストア上の設定ファイルを編集
- SSMから起動
1. SSMエージェントのセットアップ
SSMまとめ-SSMエージェントのセットアップに従って実施。
2. Cloudwatchエージェントのインストール
SSMまとめ-SSMコンソールからEC2へ任意のエージェントをセットアップに従って実施。
3. CloudWatchエージェントの設定
3.1. CloudWatchエージェントの設定ファイルの雛形作成とパラメータストアへの保存
設定ウィザードに従って実施する。
# メトリクスデータ取得対象のEC2インスタンスへSSHログイン # 設定ウィザードを開始 sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard # 以降、ウィザードに従って回答 ## CloudWatchウィザードの設問について解説 On which OS are you planning to use the agent? =>CloudWatchエージェント動作させるOSを選択 Trying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? =>CloudWatchエージェントを動作させるのはEC2かオンプレミスのサーバーかを選択 Which user are you planning to run the agent? =>CloudWatchエージェントを起動するマシン内のユーザー名を設定 Do you want to turn on StatsD daemon? =>StatsDデーモンを起動するか?(StatsDについては後述) Do you want to monitor metrics from CollectD? =>CollectDでカスタムメトリクスを採取したいか Do you want to monitor any host metrics? e.g. CPU, memory, etc. =>CPU、メモリといったシステム全体に対するカスタムメトリクスを採取したいか Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. =>コアごとのCPUのカスタムメトリクスを採取したいか(これをYesにしても設定ファイル上はONになっていなかったのでバグかもしれない) Do you want to add ec2 dimensions (ImageId, InstanceId, InstanceType, AutoScalingGroupName) into all of your metrics if the info is available? =>利用できるならばImage ID、Instance ID、Instance Type、Auto Scaling Group Nameというディメンジョンを全カスタムメトリクス内に追加したいか ※必要でない限りやらない方がよい。CloudWatch上でのデータ表示時も冗長になるし、APIでデータを取得するときにも全ディメンジョンを指定しないと取れないため面倒になる。 Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. =>カスタムメトリクスを高解像度で取得したいか?全メトリクスに対して高解像度の設定になるが、個々に設定しあにのであれば、このウィザードを終えて出力される設定ファイルをカスタマイズすれば可能。 ※高解像度にするとCloudWatch上に残る期間は短くなる。基本1分でいいのでは。 Which default metrics config do you want? 採取対象のカスタムメトリクスのデフォルト項目。 Basic、Standard、Advancedから選択できる(具体的に各選択肢がどの項目を採取することになるのかは 「https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/create-cloudwatch-agent-configuration-file-wizard.html」を参照)。 選択すると、・・・にあるカスタムメトリクスが採取対象として設定ファイルに載ってくる。 Current config as follows: { .... } Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. =>ウィザードを経て設定ファイルは上記の内容で作成されることになるが問題ないか? 注記:ウィザードの後、手動で設定ファイルをいじることは可能。 ※ウィザードではざっくり設定しかできないので、結局手動で設定ファイルをいじることになるが、いじる前の状態が最終形に近い方が後の設定作業が楽になるので、ここまで真面目に答えておいた方がいい。 Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration? =>移行のためにインポートする既存のCloudWatch Log エージェント設定ファイルを持っているか? ※CloudWatchエージェントでCloudWatch Logsのための設定もできるようになったが、移行するか?ってことみたい。 Do you want to monitor any log files? =>CloudWatch LogsへEC2内のログを送信したいか? Current config as follows: { ... } Please check the above content of the config. The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json. Edit it manually if needed. =>設定ファイルは/opt/aws/amazon-cloudwatch-agent/bin/config.json に保存されている。必要あれば手動で編集せい。 ※SSMでパラメータストアから設定ファイルを指定してCloudWatchを起動する際にはこの場所には配置されない。 SSMから設定ファイルを適用してエージェントを起動した場合、その設定ファイルはEC2内の/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.d/ssm_<設定ファイル名>に保存される。 Do you want to store the config in the SSM parameter store? =>SSMのパラメータストアに設定を保存するか? ここは「yes」を選択する What parameter store name do you want to use to store your config? (Use 'AmazonCloudWatch-' prefix if you use our managed AWS policy) default choice: [AmazonCloudWatch-linux] =>設定をパラメータストアへどんな名前で保存するか?AWSポリシーに従うのであれば「AmazonCloudWatch-」から始めろ。 Which region do you want to store the config in the parameter store? =>どのリージョンのパラメータストアに設定を保存するか? Which AWS credential should be used to send json config to parameter store? =>パラメータストアに設定ファイルを送信するにあたってどのAWSクレデンシャルを使うか? なんかよくわからんかった。 (デフォルトのクレデンシャルの番号に憶えがなかった)。 デフォルトの選択肢で一応動いたので新しく作られる?っぽい3.2. CloudWatchエージェントの設定ファイルの手動編集
SSMまとめ-パラメータストア-設定ファイルの編集に従ってSSMコンソールのパラメータストア上で実施する。
3.3. collectdのセットアップ
EC2内の「ディスク使用状況」やシステム全体としての「メモリ使用状況」のメトリクスを取得するにはcollectdというソフトウェアをEC2へ導入する必要がある。
CloudWatchエージェントの設定ファイルにcollectd使いますと書いておきながら未インストールの状態でcloudwatchエージェントを起動すると、以下のようなエラーが出力される。``` 2020/05/22 08:33:21 E! Error parsing /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml, open /usr/share/collectd/types.db: no such file or directory ```例. Ubuntu 14.04の場合の手順
# EC2へSSHログイン # collectdのインストール sudo apt-get install collectd # collectdの設定 curl -s -S -O "https://raw.githubusercontent.com/awslabs/collectd-cloudwatch/master/src/setup.py" chmod u+x setup.py sudo ./setup.py # 以下、質問に答えてセットアップ Choose AWS region for published metrics: 1. Automatic [ap-northeast-1] 2. Custom Enter choice [1]: 1 DEBUG:urllib3.util.retry:Converted retries value: 1 -> Retry(total=1, connect=None, read=None, redirect=None, status=None) DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): 169.254.169.254:80 DEBUG:urllib3.connectionpool:http://169.254.169.254:80 "GET /latest/meta-data/instance-id/ HTTP/1.1" 200 19 Choose hostname for published metrics: 1. EC2 instance id [XXXXXXXX] 2. Custom Enter choice [1]: 1 DEBUG:urllib3.util.retry:Converted retries value: 1 -> Retry(total=1, connect=None, read=None, redirect=None, status=None) DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): 169.254.169.254:80 DEBUG:urllib3.connectionpool:http://169.254.169.254:80 "GET /latest/meta-data/iam/security-credentials/ HTTP/1.1" 200 37 Choose authentication method: 1. IAM Role [<EC2へアタッチしたIAMロール>] 2. IAM User Enter choice [1]: 1 Enter proxy server name: 1. None 2. Custom Enter choice [1]: 1 Enter proxy server port: 1. None 2. Custom Enter choice [1]: 1 Include the Auto-Scaling Group name as a metric dimension: 1. No 2. Yes Enter choice [1]: 1 Include the FixedDimension as a metric dimension: 1. No 2. Yes Enter choice [1]: 1 Enable high resolution: 1. Yes 2. No Enter choice [2]: 2 Enter flush internal: 1. Default 60s 2. Custom Enter choice [1]: 1 Choose how to install CloudWatch plugin in collectd: 1. Do not modify existing collectd configuration 2. Add plugin to the existing configuration Enter choice [2]: 2 Plugin configuration written successfully. Stopping collectd process ... OK Starting collectd process ... OKなお、CloudWatch の Endpoint(monitoring.{{region}}.amazonaws.com) へ送信しているため、Outbound制限を掛けている場合は 443 ポートの許可が必要らしい。
補足:collectd, procstat, StatsDの違い
CloudWatchエージェントを使ってカスタムメトリクスを採取するにあたって、
状況に応じてcollectd, StatsD, procstatを使いわける必要がある模様。
色々調べた結果、役割上の違いは以下の通りと解釈した。
方法 概要 collectd システム全体としてのディスク使用率、メモリ使用率などの内部リソースが取得できる。別途ソフトウェアのインストールが必要。 procstat プロセス単位のCPU使用率、メモリ使用量などの内部リソースが取得できる。別途ソフトウェアのインストールは不要。 statsD 上記では叶えられないメトリクスデータを収集、送信する(自前でプログラムを用意する必要あり)
- 投稿日:2020-05-29T15:35:47+09:00
[rails]AWS 課金にならないように各機能を削除する方法
下記、AWS公式ページのリンクです。
Elastic IPアドレスを解放する方法
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/elastic-ip-addresses-eip.html#using-instance-addressing-eips-releasingS3バケットを削除する方法
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/user-guide/delete-bucket.htmlインスタンスの停止と起動
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/Stop_Start.html
- 投稿日:2020-05-29T15:24:40+09:00
SESルールの設定方法
やりたいこと
受け取ったファイルを自動でどこかに保管し、管理したい(後続の処理で使いたい)!
- ファイルの受け取り方法: メール
- ファイルの保管場所: どこでも考えた案
保管場所をAmazon S3にして、Amazon SESの Rule Setsを使用する
指定のメールアドレスにメールが送られたら、メールの内容(MIME)をS3にアップロードするよう設定する前提条件
指定のメールアドレスには、Amazon Route53で用意したドメインのメールアドレスを用いる
事前準備(SESへ権限追加)
SESからS3にアップロードする際は、S3 バケットに書き込むためのアクセス権限をSES に付与する必要がある。
方法は、 公式の記事 参照。※ この事前準備(S3 バケットにSESに権限の付与)をせずにSESの設定を進めると
後述するStep4 で下記のエラーが出ます。先に設定しましょう。
Could not write to bucket: XXXXX (Request ID: XXXXXXXXXXXXXXX)
SES Rule の設定を行う
メールが届いたらS3にアップロードするよう、設定を行う場合は
SESのルールと呼ばれるものを設定します。
リージョンはオレゴンに設定(社内の他のプロダクトに合わせたため)
Rule Setsという部分を押下すると、Create a Receipt Ruleというボタンが出てくるので
そのボタンをクリックでルールの設定を進められます。Step 1 : Recipients(受取人)の設定
ここで設定したアドレスにメールが届くと、このルールが適用されます。
Add Recipients押下で、メールアドレスがセットされます。
セットされたアドレスはドメインの検証が必要となるため、Verify domainを押下します。
ドメインの検証が終わったら、Next Stepを押下し、次のステップに進んでください。ドメインの検証
ドメインのDNS設定にレコードを追加
↑の画像にある、Verify domainを押下すると、モーダル出現します。
SESがドメインを認証するためのTXTレコードが表示されるので、表示されたレコードをDNSへ登録してください。
前提条件で述べたとおり、今回はドメインにRoute 53を使用しているので、Use Route 53をクリック
※ Use Route 53ボタンが無く押下出来ない場合や、ドメインの管理を他のサービスで行なっている場合は
値をメモっておき、Route53やその他サービスのドメインにレコード追加すればOKです。もし、下記のWARNINGが出た場合
「このオプションは、既存のすべてのmxレコードを置き換えますが、問題ないですか?」という確認なので
問題ければ、そのままEmail Rceiving Recordのチェックボックスにチェックを入れCreate Records Setsを押下で
ドメインの検証が完了します・・!
ドメイン検証完了の確認
Route53で、Step1で設定したアドレスのドメイン確認します。
MXレコードとTXTレコードが追加されていればOK!
補足
ドメインの検証をせずに、ルールの設定を完了してしまった場合・・・
ドメインの検証は、ルールの設定の最中ではなく後からでも可能です。
SESの「Domains」にてVerify a New Domain押下で設定するか、
Domain Identiesの一覧にある、ドメインから検証完了していないドメインを選択すると
検証をする画面に遷移するので、ドメイン検証可能です。
Step 2 : Actionsの設定
ドメインの検証が終わりモーダルを閉じたら、引き続きルールの設定が可能。
今回は、S3のバケットにアップロードしたいのでS3を選択!
選択したら、Next Step押下します。
us-west-2.console.aws.amazon.com_ses_home_region=us-west-2 (4).png次にアップロードするS3バケットと、バケット内のどのに格納するかのkey(ディレクトリ)名を設定します。
Step 3 : Rule Detailsの設定
ルールの詳細を設定できます。
今回は、ルールの名前だけ設定します。
あとはデフォルトのままにしました。(デフォルトのままの部分は、TLS対応やSPAM、ウィルスのスキャンを設定できるそうです。)
Step 4 : ルールの確認
ルールを確認し、問題なければ
Create Ruleを押下。
これで、SESのRule設定完了です。動作確認方法
Step1で設定したメールアドレス(Recipients)にメールを送信すると
MIMEデータが指定のS3バケット内にアップロードされることが確認できます。Step2で指定したS3バケットを見に行きましょう。











- 投稿日:2020-05-29T14:33:52+09:00
aws-cdkでとりあえずすべてのアクセスをLambdaへ送るように設定
SAMやserverless frameworkではやったことあったけどcdkでは初めてなのでメモ
const regionalUserApiLambda = new lambda.Function(this, 'RegionalUserApi', { functionName: resources.userApi.lambdaName, runtime: lambda.Runtime.GO_1_X, handler: 'main', memorySize: 128, timeout : Duration.seconds(10), code: lambda.Code.fromBucket(resourceBucketRef , resources.userApi.lambdaS3Key) }); const api = new apigateway.RestApi(this, "RegionalUserApiGateway", { restApiName: "RegionalUserApiGateway", description: "regional user api" }); api.root.addMethod(`ANY` , new apigateway.LambdaIntegration(regionalUserApiLambda)) const anyProxy = api.root.addResource("{proxy+}"); anyProxy.addMethod(`ANY` , new apigateway.LambdaIntegration(regionalUserApiLambda))
- 投稿日:2020-05-29T14:30:11+09:00
AWS 利用方法メモ(VPC)
書いてあること
- VPCの利用方法メモ
概要
関連サービス
ルートテーブル:サブネットやゲートウェイからのネットワーク経路情報
セキュリティグループ:各インスタンスへのトラフィックを制御
NATゲートウェイ:プライベートサブネットからインターネットへのアクセスを許可、インターネットからプライベートサブネットへのアクセスを禁止する
ネットワークACL:セキュリティグループを利用してネットワーク単位のアクセス制御を行う
エンドポイント:AWSサービス、インスタンスをプライベート接続するVPC
- VPC
- VPC
- VPCの作成
- 必要事項を入力
- 作成
- 閉じる
サブネット
- VPC
- サブネット
- サブネットの作成
- 必要事項を入力
- 作成
- 閉じる
インターネットゲートウェイ
作成したVPCをインターネット接続できるようにする
- VPC
- インターネットゲートウェイ
- インターネットゲートウェイの作成
- 必要事項を入力
- 作成
- 作成したインターネットゲートウェイを選択
- アクション
- VPCにアタッチ
- アタッチするVPCを選択
- アタッチ
ルートテーブル
パブリックサブネットからインターネット接続できるようにする
- VPC
- ルートテーブル
- ルートテーブルの作成
- 必要事項を入力
- 対象のVPCを選択
- 作成
- 閉じる
- 対象のルートテーブルを選択
- ルートタブ
- ルートの編集
- 送信先:
0.0.0.0/0、ターゲット:作成したインターネットゲートウェイを選択- ルートの保存
- 閉じる
- サブネットの関連付け
- サブネットの関連付けの編集
- パブリックサブネットを選択
- 保存
パブリックサブネットにパブリックIPアドレスを設定
- VPC
- サブネット
- パブリックサブネットを選択
- アクション
- 自動割り当てIP設定の変更
- IPv4の自動割り当てをチェック
- 保存
インターネット接続するサーバーを起動
- EC2
- インスタンスを起動
- 作成したVPC、パブリックサブネットを選択
- 以降、インスタンスを作成・起動する
- インスタンス一覧画面でIPv4パブリックIPが設定されていることを確認
インターネット接続しないサーバーを起動
- EC2
- インスタンスを起動
- 作成したVPC、プライベートサブネットを選択
- 以降、インスタンスを作成・起動する
- インスタンス一覧画面でIPv4パブリックIPが設定されていないことを確認
セキュリティグループ設定
セキュリティグループの設定により2つインスタンス間の通信を許可する。
- VPC
- セキュリティグループ
- セキュリティグループを作成
- 必要事項を入力
- 作成したVPCを選択
- インバウンドルールに
SSH、HTTP、HTTPS、MYSQL/Aurora、すべてのICMP IPv4を選択、ソースをパブリックサブネットのIPアドレスのみ(例えば10.0.1.0/24)とする- セキュリティグループを作成
- EC2
- インスタンス
- プライベートサブネットのインスタンスを選択
- アクション
- ネットワーキング
- セキュリティグループの変更
- 作成したセキュリティグループのみチェック
- セキュリティグループの割り当て
パブリックインスタンスからプライベートインスタンスへSSH接続
- 下記コマンドでSSH接続
bash# pemファイルを作成 $ vi ●●●.pem # pemファイルの中身をコピー&ペースト # パーミッション設定 $ chmod 600 ●●●.pem # SSH接続 $ ssh -i ~/.ssh/●●●.pem ec2-user@プライベートIPNATゲートウェイ
プライベートインスタンスがインターネット通信できるように設定を行う。
※NATゲートウェイは有料のため必要ない場合は削除する
- VPC
- NATゲートウェイ
- NATゲートウェイの作成
- パブリックサブネットを選択
- 新しいEIPの作成
- NATゲートウェイの作成
- サブネット
- プライベートサブネットのルートテーブルを選択
- ルート
- ルートの編集
- 送信先:
0.0.0.0/0、ターゲット:作成したNATゲートウェイを選択- ルートの保存
- 閉じる
ネットワークACL
- VPC
- ネットワークACL
- ネットワークACLの作成
- 必要事項を入力
- 作成したVPCを選択
- 作成
- 作成したネットワークACLを選択
- インバウンドのルール
- インバウンドのルールの編集
- ルールの追加
ルール:10 タイプ:SSH、ルール:20 タイプ:HTTP、ルール:30 タイプ:HTTPSを設定- 保存
- アウトバウンドのルール
- アウトバウンドのルールの編集
- ルールの追加
ルール:10 タイプ:HTTP、ルール:20 タイプ:HTTPS、ルール:30 タイプ:カスタムTCPルール ポート範囲:1024-65535を設定- 保存
- サブネットの関連付け
- サブネットの関連付けの編集
- パブリックサブネット、プライベートサブネット両方をチェック
- 編集
エンドポイント
プライベートインスタンスからNATゲートウェイでインターネット接続させている場合は、NATゲートウェイの設定を解除すること。
- IAM
- ロール
- ロールの作成
- EC2
- 次のステップ
AMAZONS#FULLACCESSをチェック- 次のステップ
- 次のステップ
- ロールの作成
- EC2
- インスタンス
- プライベートインスタンスを選択
- アクション
- インスタンスの設定
- IAMロールの割り当て/置換
- 作成したロールを選択
- 適用
- 閉じる
- S3
- バケットを作成する
- 必要事項を入力
- 次へ
バージョニング、サーバーアクセスのログ記録、オブジェクトレベルのログ記録、デフォルト暗号化をチェック- 次へ
- 次へ
- バケットを作成
- プライベートインスタンスへSSH接続、バケットが参照できるか確認
- 参照できる場合はルートテーブルからNATゲートウェイを削除
- エンドポイント
- エンドポイントの作成
com.amazonaws.ap-northeast-1.s3を選択- 作成したVPCを選択
- プライベートサブネットのルートテーブルを選択
- エンドポイントを作成
- 閉じる
- プライベートサブネットのルートテーブルにエンドポイントは関連付けられる
bash# バケット一覧を確認 $ aws s3 ls # バケット一覧を確認(リージョン指定) $ aws s3 ls --region ap-northeast-1Flow Logs
CloudWatchと連携してVPCのログを取得
- CloudWatch
- ログ
- ロググループ名を入力
- ロググループを作成
- VPC
- 作成したVPCを選択
- アクション
- フローログの作成
- フィルタを
すべて、送信先ロググループを作成したロググループ名を選択- 権限の設定
- 許可
- 再度フローログ作成画面を開き直す
- 作成
- 閉じる
- CloudWatchでログが確認できるようになる
- 投稿日:2020-05-29T08:24:32+09:00
AWS SAMがStep Functionsをサポートしたのでやってみる
はじめに
AWS::Serverless::StateMachine リソースを使用して、SAM テンプレート内で AWS Step Functions の
ステートマシンを定義できるようになりました。
AWS SAM adds support for AWS Step Functions
https://aws.amazon.com/jp/about-aws/whats-new/2020/05/aws-sam-adds-support-for-aws-step-functions/AWS SAM CLI も v0.52.0 で Step Functions Resource をサポートしています。
https://github.com/awslabs/aws-sam-cli/releases/v0.52.0
やってみる
前述のとおり、AWS SAM CLI は v0.52.0 以上である必要があります。
$ sam --version SAM CLI, version 0.52.0ステートマシンの定義ファイルとSAM テンプレートを以下のように作成していきます。
sam-app ├── statemachine │ └── putitem.asl.json └── template.yamlステートマシンの定義
ここでは簡単な例を示すために AWS Step Functions のサービス統合を使用して
Input で受け取った内容をDynamoDB に保存するだけのステートマシンを作成します。
以下のようなシンプルな定義です。Lambda 関数すらありません。
Resource と TableName をプレースホルダ変数としているところに着目してください。statemachie/putitem.asl.json{ "StartAt": "PutDynamoDB", "States": { "PutDynamoDB": { "Type": "Task", "Resource": "${DDBPutItem}", "Parameters": { "TableName": "${DDBTable}", "Item": { "id": {"S.$": "$.id"}, "message": {"S.$": "$.message"} } }, "End": true } } }余談ですが、AWS Toolkit for Visual Studio を使用するとローカルでステートマシンの
グラフを描写できるので便利です。(今回は描写するまでもないんですが。。。)
参考: AWS Toolkit for Visual Studio Code が AWS Step Functions のサポートを開始
https://aws.amazon.com/jp/about-aws/whats-new/2020/03/aws-toolkit-for-visual-studio-code-supports-aws-step-functions/SAM テンプレート
AWS::Serverless::StateMachine リソースを使用しています。
ステートマシンは Definition プロパティでテンプレート内に直接インラインで定義するか
以下のように DefinitionUri プロパティで定義ファイルを指定することができます。
更に DefinitionSubstitutions プロパティを使用することで、デプロイ時に取得した値を
先ほどのステートマシン定義に注入することができます。
また受け取ったデータを保存するための DynamoDB テーブルも定義しています。template.yamlAWSTemplateFormatVersion: "2010-09-09" Transform: AWS::Serverless-2016-10-31 Description: > sam-app Sample SAM Template for Step Functions Resources: PutDynamoDBStateMachine: Type: AWS::Serverless::StateMachine Properties: DefinitionUri: statemachine/putitem.asl.json DefinitionSubstitutions: DDBPutItem: !Sub arn:${AWS::Partition}:states:::dynamodb:putItem DDBTable: !Ref Table Policies: - DynamoDBWritePolicy: TableName: !Ref Table Table: Type: AWS::Serverless::SimpleTable Properties: PrimaryKey: Name: id Type: String ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1その他のプロパティについては以下のドキュメントを参照ください。
AWS::Serverless::StateMachine
https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/sam-resource-statemachine.htmlデプロイ & 結果確認
準備は以上で、あとはいつもどおりに sam deploy するだけです!
$ cd sap-app $ sam deploy --guided変更セットを確認して実行します。
Dynamo DB テーブルおよび ステートマシン、ステートマシン用のロールが作成されます。CloudFormation stack changeset ----------------------------------------------------------------------------------------- Operation LogicalResourceId ResourceType ----------------------------------------------------------------------------------------- + Add PutDynamoDBStateMachineRole AWS::IAM::Role + Add PutDynamoDBStateMachine AWS::StepFunctions::StateMachine + Add Table AWS::DynamoDB::Table -----------------------------------------------------------------------------------------デプロイされたステートマシンを確認すると、SAM によって作成された DynamoDB テーブル名が
定義に反映されていることがわかります。
以下のような入力でステートマシンを実行します。{ "id": "1", "message": "Hello World" }
成功しました。
テーブルにデータも保存されています。
API Gateway を追加する
Amazon API Gateway から 先ほどのステートマシンを実行できるように変更してみます。
SAM テンプレートの編集
AWS::Serverless::StateMachine のプロパティに以下を追加するだけです。SAM の本領発揮ですね。
Events: HttpRequest: Type: Api Properties: Method: POST Path: /request以下のようになります。
template.yamlAWSTemplateFormatVersion: "2010-09-09" Transform: AWS::Serverless-2016-10-31 Description: > sam-app Sample SAM Template for Step Functions Resources: PutDynamoDBStateMachine: Type: AWS::Serverless::StateMachine Properties: DefinitionUri: statemachine/putitem.asl.json DefinitionSubstitutions: DDBPutItem: !Sub arn:${AWS::Partition}:states:::dynamodb:putItem DDBTable: !Ref Table Events: HttpRequest: Type: Api Properties: Method: POST Path: /request Policies: - DynamoDBWritePolicy: TableName: !Ref Table Table: Type: AWS::Serverless::SimpleTable Properties: PrimaryKey: Name: id Type: String ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1再度デプロイします。
$ sam deploy変更セットを確認して実行します。API Gateway が追加されます。
CloudFormation stack changeset ----------------------------------------------------------------------------------------- Operation LogicalResourceId ResourceType ----------------------------------------------------------------------------------------- + Add PutDynamoDBStateMachineHttpRequestRole AWS::IAM::Role + Add ServerlessRestApiDeploymenta4c0d5c32b AWS::ApiGateway::Deployment + Add ServerlessRestApiProdStage AWS::ApiGateway::Stage + Add ServerlessRestApi AWS::ApiGateway::RestApi -----------------------------------------------------------------------------------------デプロイされた API の設定を確認すると、AWS Service Proxy で直接ステートマシンを実行するよう
構成されていることがわかります。
API に対して以下のような Post リクエストを送ります。
$ curl -X POST -d '{"input": "{\"id\": \"2\",\"message\": \"Work From Home\"}","name": "FromAPI","stateMachineArn": "arn:aws:states:ap-northeast-1:123456789012:stateMachine:PutDynamoDBStateMachine-xxxxxxxxxxxx"}' https://yyyyyyyyyy.execute-api.ap-northeast-1.amazonaws.com/Prod/request {"executionArn":"arn:aws:states:ap-northeast-1:123456789012:execution:PutDynamoDBStateMachine-xxxxxxxxxxxx:FromAPI","startDate":1.590690379952E9}API 経由の実行が成功しました。
データも保存されていることが確認できました!
以上です。
参考になれば幸いです。








- 投稿日:2020-05-29T02:10:06+09:00
github actions上で使って aws + terraform + ansible でCI/CD環境を構築してみた
概要
最近github actionsが楽しいのでaws環境でteraform + ansible実行してみた。
EC2を構築し、httpdをインストールする所まで実施。目次
・事前準備
・ディレクトリ構成
・バケット作成
・IAMユーザ作成
・terraformコード作成
・ansible コード作成
・github actions 作成
・githu actions 実行結果事前準備
- EC2のIPの自動取得にdyanamic inventoryが使用できること
ディレクトリ構成
├── README.md ├── ansible │ ├── ansible.cfg │ ├── ec2.ini │ ├── ec2.py │ ├── roles │ │ ├── common │ │ │ ├── files │ │ │ │ └── main.yml │ │ │ └── tasks │ │ └── nginx │ │ ├── files │ │ └── tasks │ │ └── main.yml │ ├── sandbox.yml └── terraform ├── backend.tf ├── data.tf ├── main.tf ├── output ├── output.tf ├── provider.tf └── variables.tfS3バケット作成
tfstate保存用のバケットを作成する。
バケット作成% aws s3 mb s3://tf-sandbox-masa3521 make_bucket: tf-sandbox-masa3521IAMユーザ作成
terraform,ansibleの実行用のIAMユーザを作成する。
EC2とS3、key系はパラメータストアから取得するので必要な権限を付与する。IAMユーザ作成% aws iam create-user --user-name cicd_user { "User": { "Path": "/", "UserName": "cicd_user", "UserId": "***************", "Arn": "arn:aws:iam::***************:user/cicd_user", "CreateDate": "2020-05-21T15:05:18Z" } }アクセスキー付与% aws iam create-access-key --user-name cicd_user { "AccessKey": { "UserName": "cicd_user", "AccessKeyId": "***************", "Status": "Active", "SecretAccessKey": "***************", "CreateDate": "2020-05-22T00:42:37Z" } }権限付与〜policy確認% aws iam attach-user-policy --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess --user-name cicd_user % aws iam attach-user-policy --policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess --user-name cicd_user % aws iam attach-user-policy --policy-arn arn:aws:iam::aws:policy/AmazonSSMReadOnlyAccess --user-name cicd_user % aws iam list-attached-user-policies --user-name cicd_user { "AttachedPolicies": [ { "PolicyName": "AmazonEC2FullAccess", "PolicyArn": "arn:aws:iam::aws:policy/AmazonEC2FullAccess" }, { "PolicyName": "AmazonS3FullAccess", "PolicyArn": "arn:aws:iam::aws:policy/AmazonS3FullAccess" }, { "PolicyName": "AmazonSSMReadOnlyAccess", "PolicyArn": "arn:aws:iam::aws:policy/AmazonSSMReadOnlyAccess" } ] }key作成
EC2に設定する公開鍵/秘密鍵を作成し、作成したものをパラメータストアに登録する。
key作成% ssh-keygen -t rsa -b 4096parameter_storeに登録% aws ssm put-parameter --name "publickey" \ --type SecureString \ --value "$(cat id_rsa.pub)" { "Version": 1, "Tier": "Standard" } % aws ssm put-parameter --name "pravatekey" \ --type SecureString \ --value "$(cat id_rsa)" { "Version": 1, "Tier": "Standard" }terraformコード作成
- data.tfで公開鍵をパラメータストアから取得
- backend.tfでtfstateをリモートで管理
- output.tfでセキュリティーグループのgroupidをファイルに出力 ※後のgithub-actionsで使用
provider.tfprovider "aws" { profile = "default" version = "= 2.61" region = "ap-northeast-1" }backend.tfterraform { backend "s3" { bucket = "tf-sandbox-masa3521" region = "ap-northeast-1" key = "terraform.tfstate" encrypt = true } }data.tfdata "aws_ssm_parameter" "publickey" { name = "publickey" with_decryption = true }variables.tfvariable "region" { default = "ap-northeast-1" } variable "system" { default = "sandbox" }output.tfresource "local_file" "sgroupid" { filename = "./group_id" content = aws_security_group.sandboxSG.id }main.tfresource "aws_vpc" "sandboxVPC" { cidr_block = "10.1.0.0/16" instance_tenancy = "default" enable_dns_support = "true" enable_dns_hostnames = "false" tags = { Name = var.system Env = terraform.workspace } } resource "aws_route_table" "sanbboxRT" { vpc_id = aws_vpc.sandboxVPC.id route { cidr_block = "0.0.0.0/0" gateway_id = aws_internet_gateway.sandboxGW.id } tags = { Name = var.system Env = terraform.workspace } } resource "aws_subnet" "sandboxSUBNET" { vpc_id = aws_vpc.sandboxVPC.id cidr_block = "10.1.0.0/24" tags = { Name = var.system Env = terraform.workspace } } resource "aws_internet_gateway" "sandboxGW" { vpc_id = aws_vpc.sandboxVPC.id tags = { Name = var.system Env = terraform.workspace } } resource "aws_route_table_association" "sandboxRTA" { subnet_id = aws_subnet.sandboxSUBNET.id route_table_id = aws_route_table.sanbboxRT.id } resource "aws_security_group" "sandboxSG" { name = "sandboxSG" description = "Allow SSH inbound traffic" vpc_id = aws_vpc.sandboxVPC.id ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = var.system Env = terraform.workspace } } resource "aws_key_pair" "publickey" { key_name = "key" public_key = data.aws_ssm_parameter.publickey.value tags = { Name = var.system Env = terraform.workspace } } resource "aws_instance" "sandboxinstance" { key_name = aws_key_pair.publickey.id ami = "ami-0f310fced6141e627" instance_type = "t2.nano" vpc_security_group_ids = [ aws_security_group.sandboxSG.id ] subnet_id = aws_subnet.sandboxSUBNET.id associate_public_ip_address = "true" tags = { Name = var.system Env = terraform.workspace } }ansible 作成
ansile.cfg[defaults] deprecation_warnings = False remote_user = ec2-user private_key_file = ./privatekey host_key_checking = Falsesandbox.yml- hosts: tag_Name_sandbox roles: - httedroles/tasks/main.yml--- - name: install apache yum: name: httpd state: present become: true - name: Start httpd service: name: httpd state: started enabled: yes become: truegithub-actions作成
- 実行の為にsecretsの登録が必要
- IPを自動で取得するためDynamic Inventoryで取得する。
- ansble実行の為秘密鍵のダウンロード
- ansible実行前にセキュリティーグループに自分のIPを登録、実行後に自分のIPを削除
secrets登録
terraform-ansible.ymlname: Terraform deploy to Azure on: push: branches: - master jobs: terraform-ansible: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Configure AWS Credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: Setup Terraform uses: hashicorp/setup-terraform@v1 with: terraform_version: 0.12.9 - name: Terraform Init run: terraform init working-directory: ${{ github.workspace }}/terraform - name: Terraform select run: terraform workspace select dev working-directory: ${{ github.workspace }}/terraform - name: Terraform Format run: terraform fmt -check working-directory: ${{ github.workspace }}/terraform - name: Terraform Plan run: terraform plan working-directory: ${{ github.workspace }}/terraform - name: Terraform Apply if: github.ref == 'refs/heads/master' && github.event_name == 'push' run: terraform apply -auto-approve working-directory: ${{ github.workspace }}/terraform - name: Set up Python 3.7 uses: actions/setup-python@v2 with: python-version: 3.7 - name: Install dependencies run: | python -m pip install --upgrade pip pip install boto ansible==2.9.2 - name: Download privatekey run: aws ssm get-parameter --name "privatekey" --with-decryption | jq -r .Parameter.Value > ./privatekey working-directory: ${{ github.workspace }}/ansible - name: modify permission privatekey run: chmod 400 ./privatekey working-directory: ${{ github.workspace }}/ansible - name: open sg run: aws ec2 authorize-security-group-ingress --group-id "$(cat ../terraform/group_id)" --protocol tcp --port 22 --cidr `curl inet-ip.info`/32 working-directory: ${{ github.workspace }}/ansible - name: exec ansible run: ansible-playbook -i ec2.py sandbox.yml working-directory: ${{ github.workspace }}/ansible - name: close sg run: aws ec2 revoke-security-group-ingress --group-id "$(cat ../terraform/group_id)" --protocol tcp --port 22 --cidr `curl inet-ip.info`/32 working-directory: ${{ github.workspace }}/ansiblegithub-actions 結果
[参考]
https://www.terraform.io/docs/github-actions/setup-terraform.html
https://github.com/aws-actions/configure-aws-credentials
https://docs.ansible.com/ansible/latest/user_guide/intro_dynamic_inventory.html


- 投稿日:2020-05-29T02:10:06+09:00
github actionsを使って aws + terraform + ansible でCI/CD環境を構築してみた
概要
最近github actionsが楽しいのでaws環境でteraform + ansible実行してみた。
EC2を構築し、httpdをインストールする所まで実施。目次
・事前準備
・ディレクトリ構成
・バケット作成
・IAMユーザ作成
・terraformコード作成
・ansible コード作成
・github actions 作成
・githu actions 実行結果事前準備
- EC2のIPの自動取得にdyanamic inventoryが使用できること
ディレクトリ構成
├── README.md ├── ansible │ ├── ansible.cfg │ ├── ec2.ini │ ├── ec2.py │ ├── roles │ │ ├── common │ │ │ ├── files │ │ │ │ └── main.yml │ │ │ └── tasks │ │ └── nginx │ │ ├── files │ │ └── tasks │ │ └── main.yml │ ├── sandbox.yml └── terraform ├── backend.tf ├── data.tf ├── main.tf ├── output ├── output.tf ├── provider.tf └── variables.tfS3バケット作成
tfstate保存用のバケットを作成する。
バケット作成% aws s3 mb s3://tf-sandbox-masa3521 make_bucket: tf-sandbox-masa3521IAMユーザ作成
terraform,ansibleの実行用のIAMユーザを作成する。
EC2とS3、key系はパラメータストアから取得するので必要な権限を付与する。IAMユーザ作成% aws iam create-user --user-name cicd_user { "User": { "Path": "/", "UserName": "cicd_user", "UserId": "***************", "Arn": "arn:aws:iam::***************:user/cicd_user", "CreateDate": "2020-05-21T15:05:18Z" } }アクセスキー付与% aws iam create-access-key --user-name cicd_user { "AccessKey": { "UserName": "cicd_user", "AccessKeyId": "***************", "Status": "Active", "SecretAccessKey": "***************", "CreateDate": "2020-05-22T00:42:37Z" } }権限付与〜policy確認% aws iam attach-user-policy --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess --user-name cicd_user % aws iam attach-user-policy --policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess --user-name cicd_user % aws iam attach-user-policy --policy-arn arn:aws:iam::aws:policy/AmazonSSMReadOnlyAccess --user-name cicd_user % aws iam list-attached-user-policies --user-name cicd_user { "AttachedPolicies": [ { "PolicyName": "AmazonEC2FullAccess", "PolicyArn": "arn:aws:iam::aws:policy/AmazonEC2FullAccess" }, { "PolicyName": "AmazonS3FullAccess", "PolicyArn": "arn:aws:iam::aws:policy/AmazonS3FullAccess" }, { "PolicyName": "AmazonSSMReadOnlyAccess", "PolicyArn": "arn:aws:iam::aws:policy/AmazonSSMReadOnlyAccess" } ] }key作成
EC2に設定する公開鍵/秘密鍵を作成し、作成したものをパラメータストアに登録する。
key作成% ssh-keygen -t rsa -b 4096parameter_storeに登録% aws ssm put-parameter --name "publickey" \ --type SecureString \ --value "$(cat id_rsa.pub)" { "Version": 1, "Tier": "Standard" } % aws ssm put-parameter --name "pravatekey" \ --type SecureString \ --value "$(cat id_rsa)" { "Version": 1, "Tier": "Standard" }terraformコード作成
- data.tfで公開鍵をパラメータストアから取得
- backend.tfでtfstateをリモートで管理
- output.tfでセキュリティーグループのgroupidをファイルに出力 ※後のgithub-actionsで使用
provider.tfprovider "aws" { profile = "default" version = "= 2.61" region = "ap-northeast-1" }backend.tfterraform { backend "s3" { bucket = "tf-sandbox-masa3521" region = "ap-northeast-1" key = "terraform.tfstate" encrypt = true } }data.tfdata "aws_ssm_parameter" "publickey" { name = "publickey" with_decryption = true }variables.tfvariable "region" { default = "ap-northeast-1" } variable "system" { default = "sandbox" }output.tfresource "local_file" "sgroupid" { filename = "./group_id" content = aws_security_group.sandboxSG.id }main.tfresource "aws_vpc" "sandboxVPC" { cidr_block = "10.1.0.0/16" instance_tenancy = "default" enable_dns_support = "true" enable_dns_hostnames = "false" tags = { Name = var.system Env = terraform.workspace } } resource "aws_route_table" "sanbboxRT" { vpc_id = aws_vpc.sandboxVPC.id route { cidr_block = "0.0.0.0/0" gateway_id = aws_internet_gateway.sandboxGW.id } tags = { Name = var.system Env = terraform.workspace } } resource "aws_subnet" "sandboxSUBNET" { vpc_id = aws_vpc.sandboxVPC.id cidr_block = "10.1.0.0/24" tags = { Name = var.system Env = terraform.workspace } } resource "aws_internet_gateway" "sandboxGW" { vpc_id = aws_vpc.sandboxVPC.id tags = { Name = var.system Env = terraform.workspace } } resource "aws_route_table_association" "sandboxRTA" { subnet_id = aws_subnet.sandboxSUBNET.id route_table_id = aws_route_table.sanbboxRT.id } resource "aws_security_group" "sandboxSG" { name = "sandboxSG" description = "Allow SSH inbound traffic" vpc_id = aws_vpc.sandboxVPC.id ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = var.system Env = terraform.workspace } } resource "aws_key_pair" "publickey" { key_name = "key" public_key = data.aws_ssm_parameter.publickey.value tags = { Name = var.system Env = terraform.workspace } } resource "aws_instance" "sandboxinstance" { key_name = aws_key_pair.publickey.id ami = "ami-0f310fced6141e627" instance_type = "t2.nano" vpc_security_group_ids = [ aws_security_group.sandboxSG.id ] subnet_id = aws_subnet.sandboxSUBNET.id associate_public_ip_address = "true" tags = { Name = var.system Env = terraform.workspace } }ansible 作成
ansile.cfg[defaults] deprecation_warnings = False remote_user = ec2-user private_key_file = ./privatekey host_key_checking = Falsesandbox.yml- hosts: tag_Name_sandbox roles: - httedroles/tasks/main.yml--- - name: install apache yum: name: httpd state: present become: true - name: Start httpd service: name: httpd state: started enabled: yes become: truegithub-actions作成
- 実行の為にsecretsの登録が必要
- IPを自動で取得するためDynamic Inventoryで取得する。
- ansble実行の為秘密鍵のダウンロード
- ansible実行前にセキュリティーグループに自分のIPを登録、実行後に自分のIPを削除
secrets登録
terraform-ansible.ymlname: Terraform deploy to Azure on: push: branches: - master jobs: terraform-ansible: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Configure AWS Credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: Setup Terraform uses: hashicorp/setup-terraform@v1 with: terraform_version: 0.12.9 - name: Terraform Init run: terraform init working-directory: ${{ github.workspace }}/terraform - name: Terraform select run: terraform workspace select dev working-directory: ${{ github.workspace }}/terraform - name: Terraform Format run: terraform fmt -check working-directory: ${{ github.workspace }}/terraform - name: Terraform Plan run: terraform plan working-directory: ${{ github.workspace }}/terraform - name: Terraform Apply if: github.ref == 'refs/heads/master' && github.event_name == 'push' run: terraform apply -auto-approve working-directory: ${{ github.workspace }}/terraform - name: Set up Python 3.7 uses: actions/setup-python@v2 with: python-version: 3.7 - name: Install dependencies run: | python -m pip install --upgrade pip pip install boto ansible==2.9.2 - name: Download privatekey run: aws ssm get-parameter --name "privatekey" --with-decryption | jq -r .Parameter.Value > ./privatekey working-directory: ${{ github.workspace }}/ansible - name: modify permission privatekey run: chmod 400 ./privatekey working-directory: ${{ github.workspace }}/ansible - name: open sg run: aws ec2 authorize-security-group-ingress --group-id "$(cat ../terraform/group_id)" --protocol tcp --port 22 --cidr `curl inet-ip.info`/32 working-directory: ${{ github.workspace }}/ansible - name: exec ansible run: ansible-playbook -i ec2.py sandbox.yml working-directory: ${{ github.workspace }}/ansible - name: close sg run: aws ec2 revoke-security-group-ingress --group-id "$(cat ../terraform/group_id)" --protocol tcp --port 22 --cidr `curl inet-ip.info`/32 working-directory: ${{ github.workspace }}/ansiblegithub-actions 結果
[参考]
https://www.terraform.io/docs/github-actions/setup-terraform.html
https://github.com/aws-actions/configure-aws-credentials
https://docs.ansible.com/ansible/latest/user_guide/intro_dynamic_inventory.html
- 投稿日:2020-05-29T00:12:34+09:00
AWS IoT Events は IoT デバイスの「ステートマシン」
AWS IoT Hero になったので、やっぱ AWS IoT 関連のアウトプットは必要でしょう、ということでお送りしております。
AWS IoT Events は「ステートマシン」
AWS では目的に応じた IoT 向けサービスが数多く存在しています。
その中でも今回取り上げる AWS IoT Events は説明で損をしている12素晴らしいサービスですので、皆さんに知ってもらいたいと思い、紹介しています。以下は AWS IoT Events の実装画面です。見たことありませんか?そうです、「ステートマシン」です。
ステートマシンって?
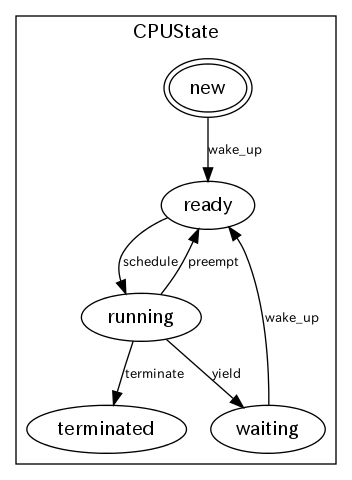
いわゆる「状態遷移(図)」です。
例として挙げられるのが、 OS 内のプロセス遷移です。3 プロセスが New されてから Terminated されるまでの流れが描かれています。
たとえば "Ready" からは決して "Waiting" や "Terminated" に遷移しないとなっているわけです。(もちろん、そうやってコードの実装をする必要があります)
IoT では「状態」が常に発生している
現在はステートレス、システム内部に「状態」を持たずにシステムを作る考え方が、特にサーバレス界隈では常識(要出典)となっています。理由は「スケールしやすい」からです。
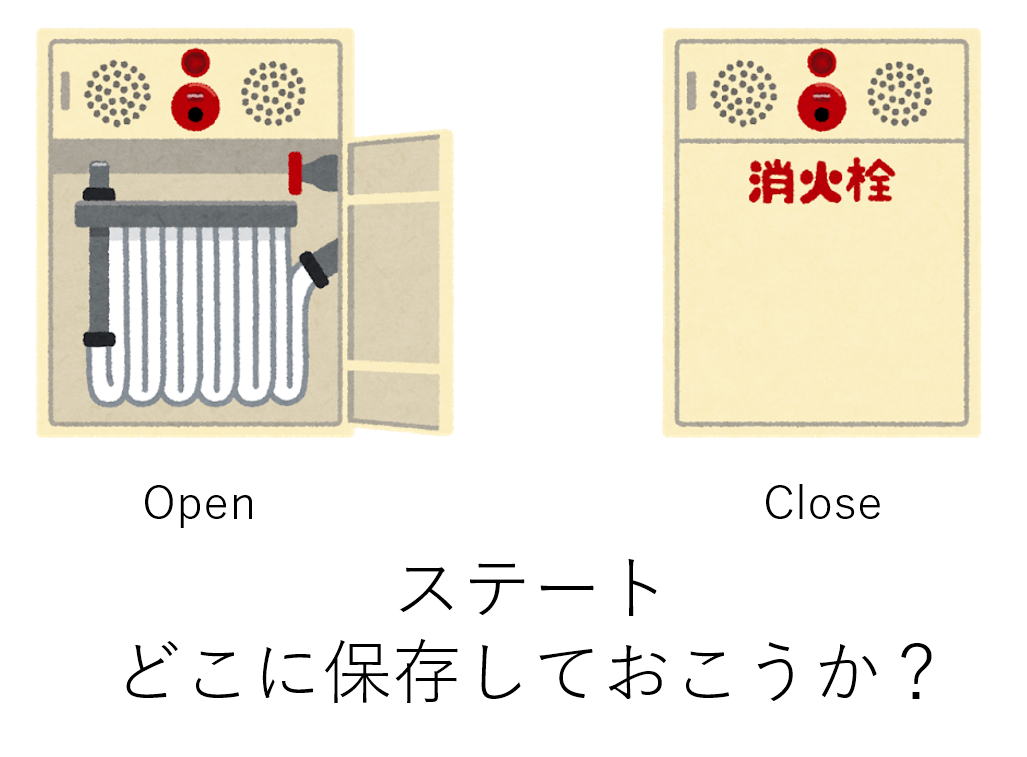
ステートレスとステートフルの解説や、ステートレスだとなぜスケールしやすいのかは ステートレスとは何か がわかりやすいのでご覧ください。話を戻すと、IoT は必ず物理世界に「モノ」があり、モノは常に「状態」を持っています。例えば扉は「開いてる(Open)」と「閉まっている(Close)」のステートがあります。
ここで困るのが、ステートってどこに保存しておこうか? という問題です。
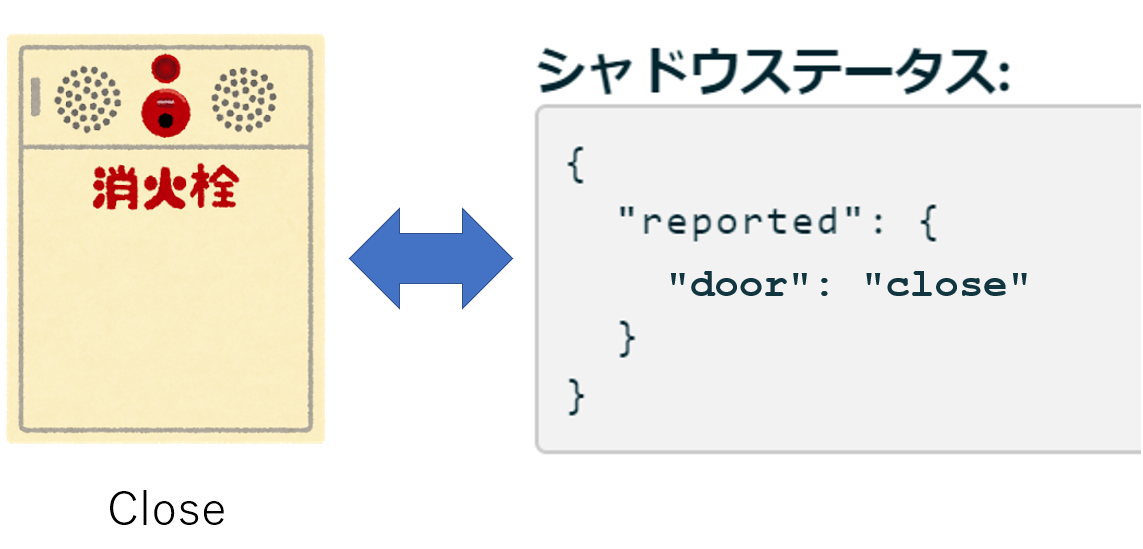
AWS IoT Core の「デバイスシャドウ」をにステートを保存するアプローチ
AWS IoT Core にはデバイスシャドウという、デジタルツイン2の実装ができる機能があり、これをステートの保存先として利用するアプローチが考えられます。
シャドウステータスを更新する方法はクラウド側、デバイス側、それぞれあります。
- クラウド上から
- AWS Lambda (Python なら
update_thing_shadow(**kwargs)です)- デバイス上から
- AWS Greengrass (の中の AWS Lambda)
結局 AWS Lambda ってことですね。
「状態」の実装で面倒な事
「状態」をコードで実現しようとすると、面倒なことが 3つ出てきます。
- コード側
- どのようなステートが存在するのか?
- ステートの遷移条件は?
- ストレージ側
- ステートをどこにどうやって保存するのか?
このうち、「コード」については、実は GoF の State パターンがあるのですが、ダンプカーでコンビニに行く感覚くらいの実装量になります。
かといって、たとえば "open" から "close" へは遷移できるけど "open" から "open" は遷移できない(無視する)という実装を考えると、必殺if文の登場となりますが、ステートが増えた時や遷移条件が変更された時の保守が「うっ」ってなるのは、ちょっと考えれば想像できる話です。前回どこまで遷移したか(=次回はどの「状態」からスタートするか)を保存しておく「ストレージ」もコードが必要となります。
デバイスシャドウであればupdate_thing_shadow()を使いますし、Amazon DynamoDB や Amazon ElastiCache ... まあ色々と考えられますけど、結局コード内に「読みだして、保存する」実装しなければいけませんし、「キーをどうする」とか「データ構造どうしよう」とか、、、もう面倒!!要するに、面倒なんです。
そこで AWS IoT Events
以下のように「状態 (ステート)」と「遷移条件」を指定することができます。
また、「今回はどの状態まで進んだか = 次回はどこからスタートするか」を保存してくれるうえ、次回のスタート場所を自動的に設定してくれます。どの様に動作するかは、アニメーションをご覧ください。
遷移時に「アクション」を呼び出すことができる
状態と遷移条件の実装だけでなく、遷移時の「アクション」も指定できます。例えば "open から close に遷移したときに Amazon SNS 経由で通知を送る" といった事もできます。
イベントは onEnter , onInput , onExit の3つです。(ドキュメントはここ)
- onEnter : その状態になった時に発火
- onExit : その状態じゃなくなった時に発火
- onInput : データ入力を受け取ったら発火
基本的には「データを受け取って(onInput)」→「その状態じゃなくなった(onExit)」→「次の状態になった(次の状態の onEnter)」という形で発火していきます。(たぶん)
ますは onEnter を使えばわかりやすく実装できるでしょう。指定できるアクションは ドキュメント を見てください。
結局 AWS Lambda じゃねぇか!!
そ、そうですね。
とはいえ、Lambda 関数には状態の移行条件のif/switch文を排除できるので、Lambda 関数自体をステートレスに実装できます。まさに「Lambda が Lambda であるために!」
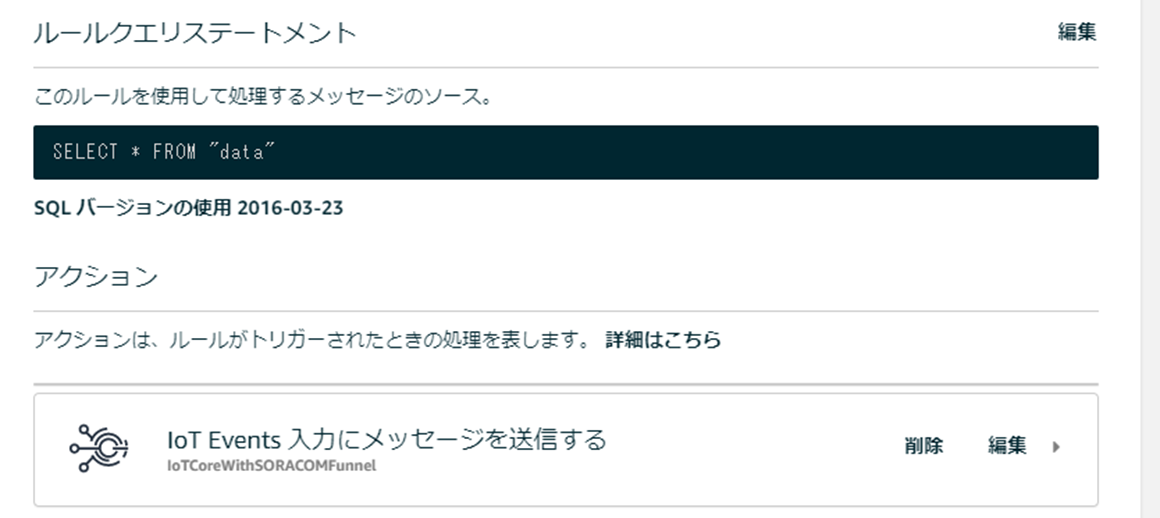
AWS IoT Core と AWS IoT Events はどうやって連携する?
AWS IoT Core のルールに "IoT Events 入力にメッセージを送信する" で OK。
ほかにはどんな使い方が?
AWS IoT Events は内部でタイマーを持っており、これをイベントとして発火させることもできるので AWS IoT Events入門 一定期間通信途絶時にイベント発火してみた こんな使い方もできます。
これも状態管理ですね。
検知器(= 要するにステートマシン) のバックアップは CLI が使える
GUI 特有の「バックアップとかどうするんじゃい」問題は AWS CLI を使うことで解決はできます。
$ aws iotevents list-detector-models { "detectorModelSummaries": [ { "detectorModelName": "DoorState", "creationTime": 1568089449.837 } ] } $ aws iotevents describe-detector-model --detector-model-name "DoorState" > model.jsonあとは
aws iotevents create-detector-modelでmodel.jsonから復元する形となります。(ごめん、ここは未検証)まとめ
AWS IoT Events はステートマシーンです。
ステート管理は AWS IoT Events に任せ、その他のロジックは別で(っていうか、実質 AWS Lambda)と役割を分離しよう。
AWS IoT Events は検知器(要するにステートマシン)の実行回数で課金される、完全従量課金モデルなので、いつデータが発生するかわからないような IoT デバイスと相性が抜群に良いかと思います。
あとがき
じつはこれ、JAWS-UG 広島 14回目@酒まつりの時に、ピンチヒッターとして登壇したときのネタなんです。。。使いまわしでスマセンスマセン。
今回あらたにアニメーション作ったから許してください。当時のスライドはこちらです。悪天候で本当に大変でしたよね。。。でも楽しかった!!
Speaker Desk / AWS IoT Events はステートマシンですから。これからも AWS IoT Hero の名に恥じぬような情報(使いまわしはいいのか?)を皆さんにお届けできたらいいなと思いますし、また、いろいろ教えていただきたく思いますので、お気軽に絡んでいただければと思います!
IoT 芸人として "Still Day One" をいつも心に、 Max 松下でしたー。
バックアップのくだりは
さすが。あざます!EoT