- 投稿日:2020-05-22T23:43:36+09:00
Pythonのスライス記法で大混乱した時用の例集
- 投稿日:2020-05-22T23:11:45+09:00
Azure AppServiceにSSHでログインてvenvを有効にする方法
これが最適なやり方かわかりませんが、うまくいきました。
# PYTHON_VERSION=$(python -c "import sys; print(str(sys.version_info.major) + '.'+ str(sys.version_info.minor))") # export PYTHONPATH=$PYTHONPATH:"/antenv/lib/python$PYTHON_VERSION/site-packages"これではうまくいかなかった。
# source /antenv/bin/activate
- 投稿日:2020-05-22T23:11:28+09:00
AutoML (自動機械学習) による時系列データ予測
Azure Machine Learning の AutoML (自動機械学習) を使用して、時系列予測回帰モデルを学習する手順を紹介します。
AutoML (Automated ML) は、データや基本的な設定をインプットするだけで、Azure Machine Learning 側で特徴量エンジニアリンング、モデル選択、ハイパーパラメータ選択などのプロセスを全自動で行ってくれる機能です。詳しくは以下を参照ください。
自動機械学習 (AutoML) とは以下、本記事で使用するサンプルのコードとデータです。
サンプルコード (github)
サンプルデータ (トレーニング用) - 1992年~2016年のビール製造時系列データ
以下のトレーニングデータ (1992~2016年) をもとに、2017年以降のビールの需要予測をします。日付と数値データ (売上など) の2つのカラムを持つ CSV データがあれば同様の手順で試すことが可能です。
Azure Machine Learning の作成
- Azure Portal へのアクセス
- 以下の順にメニューを押下
- [+ リソースの作成]
- [AI + Machine Learning]
- [Machine Learning]

- 以下の項目を適宜設定
- ワークスペース名: 任意
- リソースグループ: 任意
- 場所: 東日本
- ワークスペースのエディション: Enterprise(Auto ML を使用するため、Basic でなく Enterprise を選択します)
上記設定後、[確認および作成]ボタンによりデプロイを開始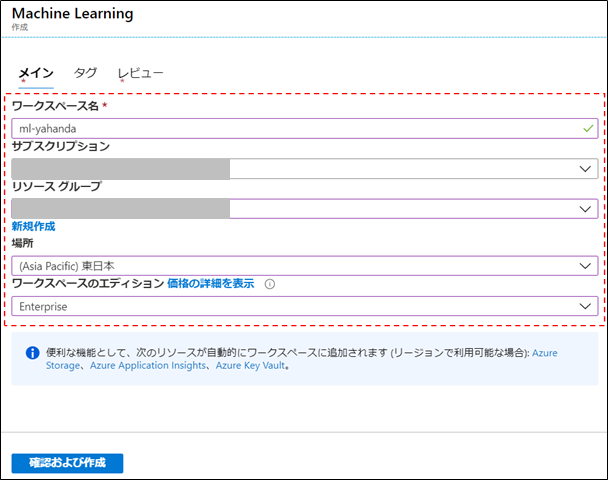
Azure Machine Learning Studio の起動
MLの画面から、Azure Machine Learning Studio の [今すぐ起動する] をクリック
(あるいは、https://ml.azure.com にアクセスして、Azure Machine Learning studio の画面を直接開きます)
コンピューティング インスタンスの作成
- 統合開発画面 Azure Machine Learning studio の [コンピューティング] を開く
- [コンピューティング インスタンス] のタブを選択し、[+新規] をクリック
- 以下の項目を適宜設定
- コンピューティング名: 任意
- Virtual machine type: CPU (Central Processing Unit)
- 仮想マシンのサイズ: デフォルト (Standard_DS3_v2) ※4 vCPUコアあれば十分です
上記設定後、[作成] ボタンによりデプロイを開始
トレーニング クラスターの作成
- 統合開発画面 Azure Machine Learning studio の [コンピューティング] を開く [Compute clusters] のタブを選択し、[+新規] をクリック
- 以下の項目を適宜設定
- コンピューティング名: 任意
- Virtual machine type: CPU (Central Processing Unit)
- 仮想マシンのサイズ: デフォルト (Standard_DS3_v2) ※4 vCPUコアあれば十分です
- 最小ノード数: 0
- 最大ノード数: 1
上記設定後、[作成] ボタンによりデプロイを開始
サンプルコード&データのアップロード
- ml.azure.com から、統合開発画面 Azure Machine Learning studio にアクセスします。
- [ノートブック] をクリックし、[フォルダーのアップロード] をクリックして、github からダウンロードした zip 解凍後のフォルダーをアップロードします。

ノードブックの実行
- [beer-forcasting-automated-ml.ipynb] をクリックし、[Jupyter] > [Jupyter で編集] をクリック
- Kernel の設定
- Jupyter で利用する Python 環境を指定
- [Python 3.6 – AzureML] を選択
- セルの実行(セルの実行方法は以下 3 通り)
- ショートカット:Ctrl + Enter キー (推奨)
- Cell バーから [Run Cells] を選択
- [> Run] を選択
実行している内容の詳細は ノートブック 内の説明を参照ください。
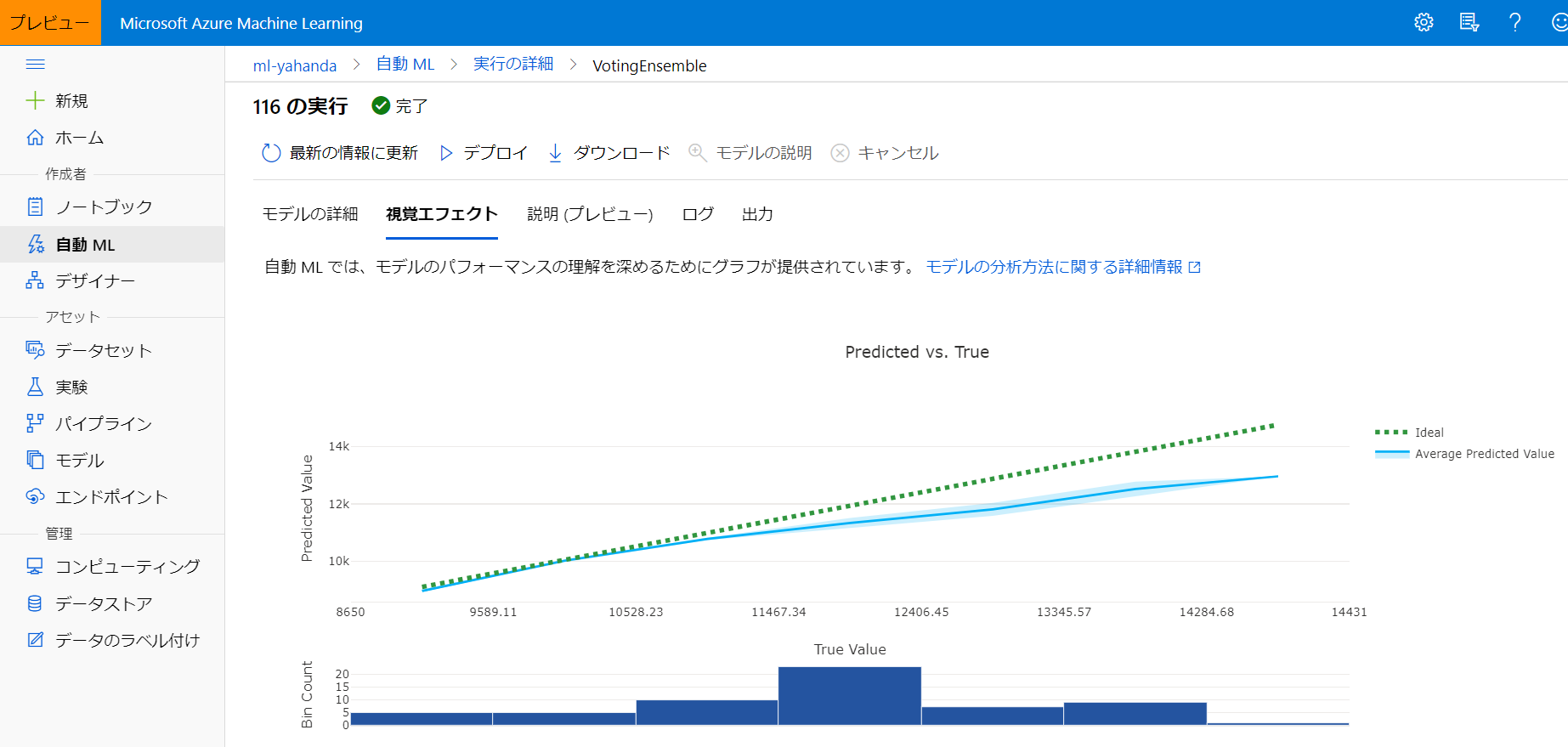
最後まで実行すると、ベストなモデルは平均絶対誤差率 (MAPE) が 6.3% と、非常に高い精度が得られます。
Model MAPE: 0.06370896673493383 Model Accuracy: 0.9362910332650661予測値と実際の値をプロットしたものです。
(モデルの精度確認)
Azure Machine Learning studio の [自動 ML] のメニューからも、AutoML が試行した各種モデルの情報が GUI 経由で確認可能です。
最適なモデルの概要
AutoML が試行したモデルの一覧
モデルの精度
説明変数の重要度
参考








- 投稿日:2020-05-22T23:11:02+09:00
SeleniumでWEBページ全体のキャプチャを取得する Python VBA
Seleniumで WEBページ全体のキャプチャを取得する Python VBA
ポイント
①クロームを使う
②ヘッドレスにする
③1ページごとに縦と横の長さをjavascriptで取得し、セットし、キャプチャを取得する
④急にタイムアウトするような思いサイトは再起動すればクロームを再起動すればOKキャプチャ取得の依頼はいきなり来るので迅速かつ、キャプチャ漏れがないように気を付ける必要があります。
そのために、所定のフォルダにキャプチャができているか最後に確認します。
タイムアウトした場合はクロームを再起動したら、続けてキャプチャ取得できます。
迅速にプログラムを書くために一番簡単な方法にしてます。でもこれでなんとかなりますよ。■環境
・Windodws10
・Python 3.8.3python selenium でWEBページ全体のキャプチャを取得する
WEBページ全体のキャプチャを取得するfrom selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC options = Options() options.add_argument('--hide-scrollbars') #スクロールバーを消す options.add_argument('--incognito') #シークレットモード options.add_argument('--headless') #ヘッドレス(ブラウザが見えなくなります。テスト終了後にこのオプションを追加するのがよい) driver = webdriver.Chrome(options=options) #パスが通っているときの記述 try: WebDriverWait(self.driver, 15).until(EC.presence_of_all_elements_located) driver.get("https://testtesttest.com") #↑キャプチャ対象のURLに移動する 画像や宣伝の多いサイトは突如タイムアウトエラーが頻発することがあるので except Exception: #ここにドライバーの再起動の記述を書く #縦と横のサイズを取得してキャプチャを取得する page_width = driver.execute_script('return document.body.scrollWidth') page_height = driver.execute_script('return document.body.scrollHeight') driver.set_window_size(page_width, page_height) #ファイル名用に現在時刻の取得 now = datetime.datetime.now() zikan = now.strftime('%Y%m%d_%H%M%S') filename = "ファイル名"+ "_"+ zikan + ".jpg" #拡張子はpingでもOK #キャプチャの取得 driver.save_screenshot("./フォルダ名/" + filename) #キャプチャファイルができているか最大5秒探す start=time.time() while time.time()-start<=5: if os.path.exists(./フォルダ名/+filename): break #ファイルが見つかったら抜ける time.sleep(1) else: #キャプチャがみつからなかったときの処理を書く driver.quit()vba seleniumBasicでWebページ全体のキャプチャを取得する
vbaで運用の場合、
多数のエクセルファイルが起動していることが多いのでキャプチャ保存先は
相対パスではなくフルパスで記述してます。
経験上、画像や宣伝の多いサイトは突如タイムアウトエラーが頻発します。
その場合も自作関数OnceMoreGetで再起動処理を入れたら、止まらずに進みました。WEBページ全体のキャプチャを取得するDim deiver as New ChromeDriver Dim tate As Long Dim yoko As Long Dim Target as String driver.AddArgument "headless" 'ヘッドレス driver.AddArgument "disable-gpu" '暫定的に必要なオプション。不必要かもしれませんが念のため driver.AddArgument "incognito" 'シークレットモード driver.AddArgument "hide-scrollbars" 'スクロールバーを消す '読込やタイムアウトの待ち時間を設定する 30秒 driver.Timeouts.PageLoad = 30000 driver.Timeouts.Server = 30000 driver.Timeouts.ImplicitWait = 30000 driver.Timeouts.Script = 30000 driver.Start 'タイムアウトしない軽いサイトならシンプルに 'driver.get("サイトのURL") でOK '↓は画面遷移後タイムアウトしたら再起動する関数 If Not OnceMoreGet(driver, "サイトのURL") Then 'タイムアウト後再起動も失敗した場合はここに何らかの処理を書く End If 'キャプチャ取得処理 tate = driver.ExecuteScript("return document.body.scrollHeight") yoko = driver.ExecuteScript("return document.body.scrollWidth") driver.Window.SetSize yoko, tate Target = "ここにはフルパスでファイル名を入れる" 'スクリーンショット ここでエラーの時もあるのでエラー回避の処理あったほうがいいです。 driver.TakeScreenshot.SaveAs (Target) 'キャプチャができているか Dir関数で確認しましす。 Dim timeout As Date timeout = DateAdd("s", 5, Now) Dim str As String Do str = Dir(Target) If Now > timeout Then 'キャプチャファイルのみつからなかったときの処理を書く End If Loop Until str <> "" driver.quit 'タイムアウトエラーが発生した場合に再起動する関数 Function OnceMoreGet(driver As ChromeDriver, url As String) As Boolean On Error GoTo ErrorHandler diver.Get (url) OnceMoreGet = True Exit Function ErrorHandler: '例外発生した場合再起動 driver.Quit Call WaitFor(3) driver.Start driver.Get (url) OnceMoreGet = True End Function一人で素人が書いてます。
アドバイスとかコメントいただけたら嬉しいです。
- 投稿日:2020-05-22T23:05:49+09:00
日経先物のSQ日を取得(毎月の第二金曜日)
今回は完全にメモ用である。過去から第二金曜日の一覧を取得したいと思う。
こちらのサイトを参考にさせていただいた。import calendar import datetime def get_day_of_nth_dow(year, month, nth, dow): '''dow: Monday(0) - Sunday(6)''' if nth < 1 or dow < 0 or dow > 6: return None first_dow, n = calendar.monthrange(year, month) day = 7 * (nth - 1) + (dow - first_dow) % 7 + 1 return day if day <= n else None #実行 dates = [] for year in range(2000, 2021): for month in range(1, 13): day = get_day_of_nth_dow(year, month, 2, 4) dates.append(["{}-{}-{}".format(year, month, day)]) dates = pd.DataFrame(dates, columns=["date"]) dates["date"] = pd.to_datetime(dates["date"]) dates出力
date 242 2020-03-13 243 2020-04-10 244 2020-05-08 245 2020-06-12 246 2020-07-10 247 2020-08-14 248 2020-09-11 249 2020-10-09 250 2020-11-13 251 2020-12-11 結論
過去の日経先物のSQ日が一瞬で計算できる。(祝日の例外は無視しているが、、、
- 投稿日:2020-05-22T23:01:52+09:00
vimでPython書きたい人へ
対象者
vimを使ってPython書きたい/書いてる人と、カラースキームの編集について知りたい人
ぼくが使っている.vimrcと、Python用のシンタックススクリプト、最後にカラースキームをご紹介します。目次
vimrc
vimは高機能エディターですが、例えばVisual Studioやjupyter notebookなどと違って、UIやらが(プラグインを用いないと)全く充実してないためなんとなく敷居が高いですよね。
かくいうぼくも大して使いこなせていないので練習あるのみな感じですが...
でもデフォルトのキーバインドでも慣れるとサクサク書けたり、色々自由にカスタマイズできるのがvimのいいところかなぁと最近思ったり思わなかったりしています。
いろんなプラグインがgithubに公開されていますしね。
そう言うことで、今日はぼくが今使っている.vimrcを紹介します。ここで紹介されている
.vimrcをコピペして、少しだけカスタマイズしたりしています。
全部コピペで.vimrcを作りたい!という時はここまでやってからコピペして調整してください。
.vimrc
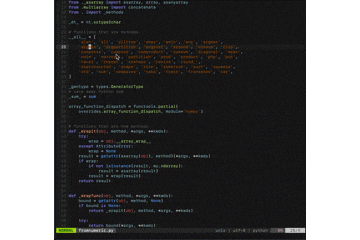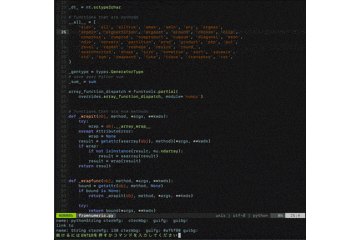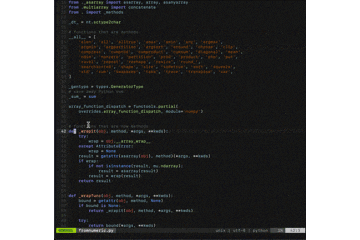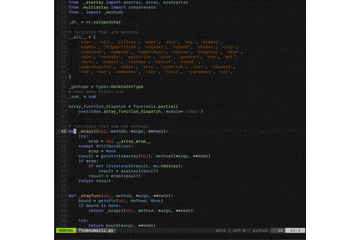
.vimrcset encoding=utf-8 scriptencoding utf-8 " ↑1行目は読み込み時の文字コードの設定 " ↑2行目はVim Script内でマルチバイトを使う場合の設定 " Vim scritptにvimrcも含まれるので、日本語でコメントを書く場合は先頭にこの設定が必要になる "---------------------------------------------------------- " NeoBundle "---------------------------------------------------------- if has('vim_starting') " 初回起動時のみruntimepathにNeoBundleのパスを指定する set runtimepath+=~/.vim/bundle/neobundle.vim/ " NeoBundleが未インストールであればgit cloneする if !isdirectory(expand("~/.vim/bundle/neobundle.vim/")) echo "install NeoBundle..." :call system("git clone git://github.com/Shougo/neobundle.vim ~/.vim/bundle/neobundle.vim") endif endif call neobundle#begin(expand('~/.vim/bundle/')) " インストールするVimプラグインを以下に記述 " NeoBundle自身を管理 NeoBundleFetch 'Shougo/neobundle.vim' " カラースキーム "NeoBundle 'tomasr/molokai' "NeoBundle 'flrnd/plastic.vim' "NeoBundle 'sainnhe/edge' NeoBundle 'cocopon/iceberg.vim' " 花文字 "NeoBundle 'sainnhe/icursive-nerd-font' " カラースキームを調べる NeoBundle 'guns/xterm-color-table.vim' " ステータスラインの表示内容強化 NeoBundle 'itchyny/lightline.vim' " インデントの可視化 NeoBundle 'Yggdroot/indentLine' " 末尾の全角半角空白文字を赤くハイライト NeoBundle 'bronson/vim-trailing-whitespace' " 構文エラーチェック NeoBundle 'scrooloose/syntastic' " 多機能セレクタ NeoBundle 'ctrlpvim/ctrlp.vim' " CtrlPの拡張プラグイン. 関数検索 NeoBundle 'tacahiroy/ctrlp-funky' " CtrlPの拡張プラグイン. コマンド履歴検索 NeoBundle 'suy/vim-ctrlp-commandline' " CtrlPの検索にagを使う NeoBundle 'rking/ag.vim' " プロジェクトに入ってるESLintを読み込む NeoBundle 'pmsorhaindo/syntastic-local-eslint.vim' " pythonコード補完 NeoBundle 'davidhalter/jedi-vim' NeoBundle 'ervandew/supertab' autocmd FileType python setlocal completeopt-=preview let g:SuperTabContextDefaultCompletionType = "context" let g:SuperTabDefaultCompletionType = "<c-n>" "let g:jedi#rename_command = "<c-r>" let g:jedi#force_py_version="3" " vimのlua機能が使える時だけ以下のVimプラグインをインストールする if has('lua') " コードの自動補完 NeoBundle 'Shougo/neocomplete.vim' " スニペットの補完機能 NeoBundle "Shougo/neosnippet" " スニペット集 NeoBundle 'Shougo/neosnippet-snippets' endif call neobundle#end() " ファイルタイプ別のVimプラグイン/インデントを有効にする filetype plugin indent on " 未インストールのVimプラグインがある場合、インストールするかどうかを尋ねてくれるようにする設定 NeoBundleCheck "---------------------------------------------------------- " カラースキーム "---------------------------------------------------------- " カラースキームにmolokaiを設定する "if neobundle#is_installed('molokai') " colorscheme molokai "endif "colorscheme murphy " plasticに設定 "if neobundle#is_installed('plastic') " colorscheme plastic "endif " neonに設定 "if neobundle#is_installed('edge') " set termguicolors " set background=dark " let g:edge_style = 'neon' " let g:edge_disable_italic_comment = 1 " let g:edge_enable_italic = 0 " colorscheme edge "endif " icebergに設定 if neobundle#is_installed('iceberg.vim') colorscheme iceberg endif set t_Co=256 " iTerm2など既に256色環境なら無くても良い syntax enable " 構文に色を付ける "---------------------------------------------------------- " 文字 "---------------------------------------------------------- set fileencoding=utf-8 " 保存時の文字コード set fileencodings=ucs-boms,utf-8,euc-jp,cp932 " 読み込み時の文字コードの自動判別. 左側が優先される set fileformats=unix,dos,mac " 改行コードの自動判別. 左側が優先される set ambiwidth=double " □や○文字が崩れる問題を解決 "---------------------------------------------------------- " ステータスライン "---------------------------------------------------------- set laststatus=2 " ステータスラインを常に表示 set showmode " 現在のモードを表示 set showcmd " 打ったコマンドをステータスラインの下に表示 set ruler " ステータスラインの右側にカーソルの位置を表示する "---------------------------------------------------------- " コマンドモード "---------------------------------------------------------- set wildmenu " コマンドモードの補完 set history=5000 " 保存するコマンド履歴の数 "---------------------------------------------------------- " タブ・インデント "---------------------------------------------------------- set expandtab " タブ入力を複数の空白入力に置き換える set tabstop=2 " 画面上でタブ文字が占める幅 set softtabstop=2 " 連続した空白に対してタブキーやバックスペースキーでカーソルが動く幅 set autoindent " 改行時に前の行のインデントを継続する set smartindent " 改行時に前の行の構文をチェックし次の行のインデントを増減する set shiftwidth=2 " smartindentで増減する幅 "---------------------------------------------------------- " 文字列検索 "---------------------------------------------------------- set incsearch " インクリメンタルサーチ. 1文字入力毎に検索を行う set ignorecase " 検索パターンに大文字小文字を区別しない set smartcase " 検索パターンに大文字を含んでいたら大文字小文字を区別する set hlsearch " 検索結果をハイライト " ESCキー2度押しでハイライトの切り替え nnoremap <silent><Esc><Esc> :<C-u>set nohlsearch!<CR> "---------------------------------------------------------- " カーソル "---------------------------------------------------------- set whichwrap=b,s,h,l,<,>,[,],~ " カーソルの左右移動で行末から次の行の行頭への移動が可能になる set number " 行番号を表示 set cursorline " カーソルラインをハイライト " 行が折り返し表示されていた場合、行単位ではなく表示行単位でカーソルを移動する nnoremap j gj nnoremap k gk nnoremap <down> gj nnoremap <up> gk " バックスペースキーの有効化 set backspace=indent,eol,start "---------------------------------------------------------- " カッコ・タグの対応 "---------------------------------------------------------- set showmatch " 括弧の対応関係を一瞬表示する set matchtime=3 set matchpairs& matchpairs+=<:> source $VIMRUNTIME/macros/matchit.vim " Vimの「%」を拡張する "---------------------------------------------------------- " マウスでカーソル移動とスクロール "---------------------------------------------------------- if has('mouse') set mouse=a if has('mouse_sgr') set ttymouse=sgr elseif v:version > 703 || v:version is 703 && has('patch632') set ttymouse=sgr else set ttymouse=xterm2 endif endif "---------------------------------------------------------- " クリップボードからのペースト "---------------------------------------------------------- " 挿入モードでクリップボードからペーストする時に自動でインデントさせないようにする if &term =~ "xterm" let &t_SI .= "\e[?2004h" let &t_EI .= "\e[?2004l" let &pastetoggle = "\e[201~" function XTermPasteBegin(ret) set paste return a:ret endfunction inoremap <special> <expr> <Esc>[200~ XTermPasteBegin("") endif "---------------------------------------------------------- " ファイル管理 "---------------------------------------------------------- " バックアップファイルやスワップファイルを作成しない set nowritebackup set nobackup set noswapfile "---------------------------------------------------------- " 表示関係 "---------------------------------------------------------- set list " 不可視文字の可視化 set wrap " 長いテキストの折り返し set colorcolumn=100 "100文字目にラインを入れる " スクリーンベルの無効化 set t_vb= set novisualbell " 不可視文字をUnicodeで綺麗に set listchars=tab:»-,trail:-,extends:»,precedes:«,nbsp:%,eol:↲ "---------------------------------------------------------- " マクロおよびキー設定 "---------------------------------------------------------- inoremap jj <Esc> " 入力モード中に素早くjjと入力した場合はESCとみなす " 検索語にジャンプした検索単語を画面中央に持ってくる nnoremap n nzz nnoremap N Nzz nnoremap * *zz nnoremap # #zz nnoremap g* g*zz nnoremap g# g#zz vnoremap v $h " vを二回で行末まで選択 " TABで対応ペアにジャンプ nnoremap <Tab> % vnoremap <Tab> % " Shift + 矢印でウィンドウサイズを変更 "nnoremap <S-Left> <C-w><<CR> "nnoremap <S-Right> <C-w>><CR> "nnoremap <S-Up> <C-w>-<CR> "nnoremap <S-Down> <C-w>+<CR> " 矢印2回押しで行頭・行末へ移動 inoremap <S-Left><S-Left> <Esc>_i inoremap <S-Right><S-Right> <Esc>$i<Right> "---------------------------------------------------------- " neocomplete・neosnippetの設定 "---------------------------------------------------------- if neobundle#is_installed('neocomplete.vim') " Vim起動時にneocompleteを有効にする let g:neocomplete#enable_at_startup = 1 " smartcase有効化. 大文字が入力されるまで大文字小文字の区別を無視する let g:neocomplete#enable_smart_case = 1 " 3文字以上の単語に対して補完を有効にする let g:neocomplete#min_keyword_length = 3 " 区切り文字まで補完する let g:neocomplete#enable_auto_delimiter = 1 " 1文字目の入力から補完のポップアップを表示 let g:neocomplete#auto_completion_start_length = 1 " バックスペースで補完のポップアップを閉じる inoremap <expr><BS> neocomplete#smart_close_popup()."<C-h>" " エンターキーで補完候補の確定. スニペットの展開もエンターキーで確定 imap <expr><CR> neosnippet#expandable() ? "<Plug>(neosnippet_expand_or_jump)" : pumvisible() ? "<C-y>" : "<CR>" " タブキーで補完候補の選択. スニペット内のジャンプもタブキーでジャンプ imap <expr><TAB> pumvisible() ? "<C-n>" : neosnippet#jumpable() ? "<Plug>(neosnippet_expand_or_jump)" : "<TAB>" endif "---------------------------------------------------------- " Syntastic "---------------------------------------------------------- " 構文エラー行に「>>」を表示 let g:syntastic_enable_signs = 1 " 他のVimプラグインと競合するのを防ぐ let g:syntastic_always_populate_loc_list = 1 " 構文エラーリストを非表示 let g:syntastic_auto_loc_list = 0 " ファイルを開いた時に構文エラーチェックを実行する let g:syntastic_check_on_open = 1 " 「:wq」で終了する時も構文エラーチェックする let g:syntastic_check_on_wq = 1 " Javascript用. 構文エラーチェックにESLintを使用 let g:syntastic_javascript_checkers=['eslint'] " Python用. 構文エラーチェックにpep8とpyflakesを使用 let g:syntastic_python_checkers=['pep8', 'pyflakes'] " Javascript, python以外は構文エラーチェックをしない let g:syntastic_mode_map = { 'mode': 'passive', \ 'active_filetypes': ['javascript', 'python'], \ 'passive_filetypes': [] } "---------------------------------------------------------- " CtrlP "---------------------------------------------------------- let g:ctrlp_match_window = 'order:ttb,min:20,max:20,results:100' " マッチウインドウの設定. 「下部に表示, 大きさ20行で固定, 検索結果100件」 let g:ctrlp_show_hidden = 1 " .(ドット)から始まるファイルも検索対象にする let g:ctrlp_types = ['fil'] "ファイル検索のみ使用 let g:ctrlp_extensions = ['funky', 'commandline'] " CtrlPの拡張として「funky」と「commandline」を使用 " CtrlPCommandLineの有効化 command! CtrlPCommandLine call ctrlp#init(ctrlp#commandline#id()) " CtrlPFunkyの絞り込み検索設定 let g:ctrlp_funky_matchtype = 'path' if executable('ag') let g:ctrlp_use_caching=0 " CtrlPのキャッシュを使わない let g:ctrlp_user_command='ag %s -i --hidden -g ""' " 「ag」の検索設定 endif "---------------------------------------------------------- " カラースキーム編集用 "---------------------------------------------------------- " ハイライトグループを知るコマンド:SyntaxInfoを実装 function! s:get_syn_id(transparent) let synid = synID(line("."), col("."), 1) if a:transparent return synIDtrans(synid) else return synid endif endfunction function! s:get_syn_attr(synid) let name = synIDattr(a:synid, "name") let ctermfg = synIDattr(a:synid, "fg", "cterm") let ctermbg = synIDattr(a:synid, "bg", "cterm") let guifg = synIDattr(a:synid, "fg", "gui") let guibg = synIDattr(a:synid, "bg", "gui") return { \ "name": name, \ "ctermfg": ctermfg, \ "ctermbg": ctermbg, \ "guifg": guifg, \ "guibg": guibg} endfunction function! s:get_syn_info() let baseSyn = s:get_syn_attr(s:get_syn_id(0)) echo "name: " . baseSyn.name . \ " ctermfg: " . baseSyn.ctermfg . \ " ctermbg: " . baseSyn.ctermbg . \ " guifg: " . baseSyn.guifg . \ " guibg: " . baseSyn.guibg let linkedSyn = s:get_syn_attr(s:get_syn_id(1)) echo "link to" echo "name: " . linkedSyn.name . \ " ctermfg: " . linkedSyn.ctermfg . \ " ctermbg: " . linkedSyn.ctermbg . \ " guifg: " . linkedSyn.guifg . \ " guibg: " . linkedSyn.guibg endfunction command! SyntaxInfo call s:get_syn_info()初めての方へ
初めてじゃない方はこちらまでスキップしてください。
とりあえず
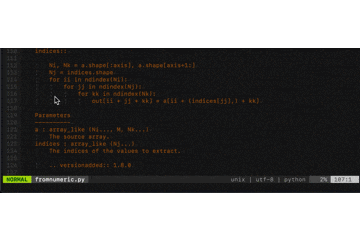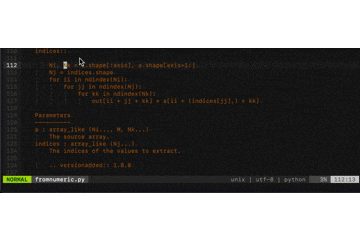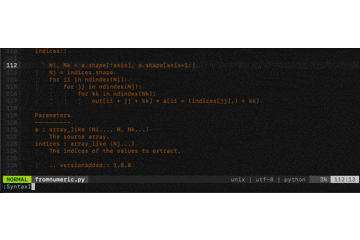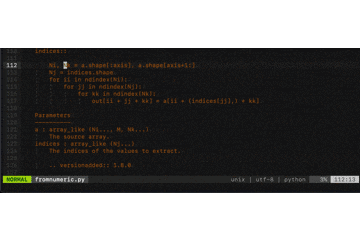
.vimrcを作りましょう。$ cd $ vi .vimrc「え、vimの起動コマンドって
vimじゃなくてviなの?」と思うかもしれませんが、少なくとも現在ではどちらも同じコマンドと見なしていいでしょう。とりあえずこれでvimで
.vimrcを開いた状態になってると思います。
vimは慣れないとなかなか難しいと思うので、とりあえず初歩中の初歩な基礎理解とコマンドだけ紹介します。基礎理解
vimにはいくつかモードがあります。
- ノーマルモード(コマンド入力)
- インサートモード(テキスト編集)
- ビジュアルモード(範囲選択)
ノーマルモードはvimでコマンドを入力したりするモードです。
vimでファイルを開いた時はこのモードになります。
他のモードの時はEscを押すとこのモードになります。
インサートモードは文章やコード自体を書き換えるためのモードです。
ノーマルモードでiやoなどと入力するとこのモードになりテキストを編集できるようになります。
ビジュアルモードは範囲選択をするモードです。
ノーマルモードでvなどと入力するとこのモードになります。
最初はあまり使わないかもしれません。コマンド
とりあえず本記事では次のコマンドだけ頭に入れていればOKだと思います。
足りなければ随時ググってください。ノーマルモードでのコマンド
1 2 i インサートモードに変更 :w 保存 :q vimを終了する :wq 保存してvimを終了する dd 1行削除 yy 1行コピー p 貼り付け(vim内からvim内へのみ) その他のモードでのコマンド
1 2 Esc ノーマルモードに戻る 最初の設定
.vimrcの先頭には次のスクリプトを書きましょう。
日本語を有効化するためのスクリプトです。.vimrcset encoding=utf-8 scriptencoding utf-8
.vimrcを初めて書く場合はとりあえずここまで書いてEscを押してノーマルモードにし、:wqで保存して閉じましょう。
改めて開き直せば日本語が有効になります。クリップボード経由のコピペ有効化
コピペで全部済ませたい人はここまでは手動でやってからにしましょう。
普通にコピペするとめんどくさいことになるはずです。
やっちゃった場合、修正が面倒ならノーマルモードで:q!と入力して保存せず閉じましょう。
コピペ有効化
.vimrc"---------------------------------------------------------- " クリップボードからのペースト "---------------------------------------------------------- " 挿入モードでクリップボードからペーストする時に自動でインデントさせないようにする if &term =~ "xterm" let &t_SI .= "\e[?2004h" let &t_EI .= "\e[?2004l" let &pastetoggle = "\e[201~" function XTermPasteBegin(ret) set paste return a:ret endfunction inoremap <special> <expr> <Esc>[200~ XTermPasteBegin("") endifこれでクリップボードからコピペできるようになります。
つまりインターネットのサイトとかから文章などをコピーしてvimで開いてるファイルにペーストできるようになります。便利!プラグイン管理の
NeoBundle
NeoBundleはもうずいぶん前に開発終了が宣言されてるみたいですね。
開発者はdeinをオススメしているようです。
希望者はここなどを参考に書き換えてください。
ぼくもそのうち気が向いたら移行するかもしれないのでその時はまた記事を書くかも...
NeoBundle
.vimrc"---------------------------------------------------------- " NeoBundle "---------------------------------------------------------- if has('vim_starting') " 初回起動時のみruntimepathにNeoBundleのパスを指定する set runtimepath+=~/.vim/bundle/neobundle.vim/ " NeoBundleが未インストールであればgit cloneする if !isdirectory(expand("~/.vim/bundle/neobundle.vim/")) echo "install NeoBundle..." :call system("git clone git://github.com/Shougo/neobundle.vim ~/.vim/bundle/neobundle.vim") endif endif call neobundle#begin(expand('~/.vim/bundle/')) " インストールするVimプラグインを以下に記述 " NeoBundle自身を管理 NeoBundleFetch 'Shougo/neobundle.vim' " カラースキーム "NeoBundle 'tomasr/molokai' "NeoBundle 'flrnd/plastic.vim' "NeoBundle 'sainnhe/edge' NeoBundle 'cocopon/iceberg.vim' " 花文字 "NeoBundle 'sainnhe/icursive-nerd-font' " カラースキームを調べる NeoBundle 'guns/xterm-color-table.vim' " ステータスラインの表示内容強化 NeoBundle 'itchyny/lightline.vim' " インデントの可視化 NeoBundle 'Yggdroot/indentLine' " 末尾の全角半角空白文字を赤くハイライト NeoBundle 'bronson/vim-trailing-whitespace' " 構文エラーチェック NeoBundle 'scrooloose/syntastic' " 多機能セレクタ NeoBundle 'ctrlpvim/ctrlp.vim' " プロジェクトに入ってるESLintを読み込む NeoBundle 'pmsorhaindo/syntastic-local-eslint.vim' " CtrlPの拡張プラグイン. 関数検索 NeoBundle 'tacahiroy/ctrlp-funky' " CtrlPの拡張プラグイン. コマンド履歴検索 NeoBundle 'suy/vim-ctrlp-commandline' " CtrlPの検索にagを使う NeoBundle 'rking/ag.vim' " pythonコード補完 NeoBundle 'davidhalter/jedi-vim' NeoBundle 'ervandew/supertab' autocmd FileType python setlocal completeopt-=preview let g:SuperTabContextDefaultCompletionType = "context" let g:SuperTabDefaultCompletionType = "<c-n>" "let g:jedi#rename_command = "<c-r>" let g:jedi#force_py_version="3" " vimのlua機能が使える時だけ以下のVimプラグインをインストールする if has('lua') " コードの自動補完 NeoBundle 'Shougo/neocomplete.vim' " スニペットの補完機能 NeoBundle "Shougo/neosnippet" " スニペット集 NeoBundle 'Shougo/neosnippet-snippets' endif call neobundle#end() " ファイルタイプ別のVimプラグイン/インデントを有効にする filetype plugin indent on " 未インストールのVimプラグインがある場合、インストールするかどうかを尋ねてくれるようにする設定 NeoBundleCheck各プラグインの説明は大体ここにウルトラ丁寧な説明が乗っていますので省略しながら説明します。
NeoBundle本体関係NeoBundle本体に関係するところを抜き出します。
それぞれの動作はコメントにある通りですね。
本体関係
.vimrcif has('vim_starting') " 初回起動時のみruntimepathにNeoBundleのパスを指定する set runtimepath+=~/.vim/bundle/neobundle.vim/ " NeoBundleが未インストールであればgit cloneする if !isdirectory(expand("~/.vim/bundle/neobundle.vim/")) echo "install NeoBundle..." :call system("git clone git://github.com/Shougo/neobundle.vim ~/.vim/bundle/neobundle.vim") endif endif call neobundle#begin(expand('~/.vim/bundle/')) " インストールするVimプラグインを以下に記述 " NeoBundle自身を管理 NeoBundleFetch 'Shougo/neobundle.vim' ... call neobundle#end() " ファイルタイプ別のVimプラグイン/インデントを有効にする filetype plugin indent on " 未インストールのVimプラグインがある場合、インストールするかどうかを尋ねてくれるようにする設定 NeoBundleCheckカラースキーム
カラースキームは個人的に試したものの残骸がコメントアウトされています...
molokaiは有名ですね。
ただ、個人的にはicebergが気に入りました。
また、これをぼくにとって見やすいように少しだけカスタマイズしたpycebergも後ほど紹介させていただきます(ダイマ)。.vimrc" カラースキーム "NeoBundle 'tomasr/molokai' "NeoBundle 'flrnd/plastic.vim' "NeoBundle 'sainnhe/edge' NeoBundle 'cocopon/iceberg.vim'有効化の方法はまた後ほど紹介します。
花文字
花文字はなぜか使えませんでした。
かっこいいから使いたかった。
色々調べたのですが、文字列の背景がハイライトされるだけでした...
どなたか情報あれば教えてください泣.vimrc" 花文字 "NeoBundle 'sainnhe/icursive-nerd-font'カラースキームを調べる
詳しくはこちら
使用できるカラーとかが一覧として表示できるコマンド:XtermColorTableが使えるようになります。
カラースキームの色調整に大いに役立ちます。.vimrc" カラースキームを調べる NeoBundle 'guns/xterm-color-table.vim'ステータスラインの表示内容強化
詳しくはこちら
まあ要するに表示される情報が増えるのでありがたいってことです。.vimrc" ステータスラインの表示内容強化 NeoBundle 'itchyny/lightline.vim'ステータスラインを有効にする必要がありますのでここを参考にしてください。
インデント可視化
そのままです。インデントが見えるようになります。
どんな言語でもインデントラインは重要ですよね〜。.vimrc" インデントの可視化 NeoBundle 'Yggdroot/indentLine'不要なスペースをハイライト
コードに紛れる空白文字を赤のハイライトで見えるようにします。
スペースあるせいでコンパイルできない!なんてこともあるので大変ありがたいですね。
さらにさらに、なんと:FixWhitespaceというコマンドでハイライトされた不要なスペースを一括削除できたりもします!
まあこれに頼りすぎず、普段から丁寧なコーディングをしましょう。.vimrc" 末尾の全角半角空白文字を赤くハイライト NeoBundle 'bronson/vim-trailing-whitespace'構文エラーチェック
動作はこちらを見たらわかります。
文法の間違いがあれば教えてくれる感じですね。.vimrc" 構文エラーチェック NeoBundle 'scrooloose/syntastic' " プロジェクトに入ってるESLintを読み込む NeoBundle 'pmsorhaindo/syntastic-local-eslint.vim'単体ではPythonの構文チェックしてくれないのでここを見てください。
多機能セレクタ
ファイルの検索とかバッファの検索とかしてくれるプラグインですね。特に使ってない気がする...
まだまだ修行が足りないということなんでしょうか....vimrc" 多機能セレクタ NeoBundle 'ctrlpvim/ctrlp.vim' " CtrlPの拡張プラグイン. 関数検索 NeoBundle 'tacahiroy/ctrlp-funky' " CtrlPの拡張プラグイン. コマンド履歴検索 NeoBundle 'suy/vim-ctrlp-commandline' " CtrlPの検索にagを使う NeoBundle 'rking/ag.vim'これに関連するCtrlPの設定はこちら
コード補完
コーディングの味方、コード補完ですね。
そういえばneocompleteとか別になくてもjedi-vim使ってるしいいのではないかと思ったけど、別にあっても困ってないから置いています。
そのうち整理するかも。
コード補完
.vimrc" pythonコード補完 NeoBundle 'davidhalter/jedi-vim' NeoBundle 'ervandew/supertab' autocmd FileType python setlocal completeopt-=preview let g:SuperTabContextDefaultCompletionType = "context" let g:SuperTabDefaultCompletionType = "<c-n>" "let g:jedi#rename_command = "<c-r>" let g:jedi#force_py_version="3" " vimのlua機能が使える時だけ以下のVimプラグインをインストールする if has('lua') " コードの自動補完 NeoBundle 'Shougo/neocomplete.vim' " スニペットの補完機能 NeoBundle "Shougo/neosnippet" " スニペット集 NeoBundle 'Shougo/neosnippet-snippets' endif
neocompleteの設定はここカラースキームの有効化
カラースキームの有効化です。
例の如くコメントアウトしてる部分は残骸です。
好きなやつを使ってください。
カラースキーム設定集
.vimrc"---------------------------------------------------------- " カラースキーム "---------------------------------------------------------- " カラースキームにmolokaiを設定する "if neobundle#is_installed('molokai') " colorscheme molokai "endif "colorscheme murphy " plasticに設定 "if neobundle#is_installed('plastic') " colorscheme plastic "endif " neonに設定 "if neobundle#is_installed('edge') " set termguicolors " set background=dark " let g:edge_style = 'neon' " let g:edge_disable_italic_comment = 1 " let g:edge_enable_italic = 0 " colorscheme edge "endif " icebergに設定 if neobundle#is_installed('iceberg.vim') colorscheme iceberg endif set t_Co=256 " iTerm2など既に256色環境なら無くても良い syntax enable " 構文に色を付けるpycebergもぜひ見てみてください!!
(ダイマ2回目)
導入などの紹介はこちら文字コードの設定
文字コードに関する設定集です。
.vimrc"---------------------------------------------------------- " 文字 "---------------------------------------------------------- set fileencoding=utf-8 " 保存時の文字コード set fileencodings=ucs-boms,utf-8,euc-jp,cp932 " 読み込み時の文字コードの自動判別. 左側が優先される set fileformats=unix,dos,mac " 改行コードの自動判別. 左側が優先される set ambiwidth=double " □や○文字が崩れる問題を解決ステータスラインの有効化
ステータスライン(vimエディタの下部)を有効にします。
"---------------------------------------------------------- " ステータスライン "---------------------------------------------------------- set laststatus=2 " ステータスラインを常に表示 set showmode " 現在のモードを表示 set showcmd " 打ったコマンドをステータスラインの下に表示 set ruler " ステータスラインの右側にカーソルの位置を表示するコマンドモードの設定
ノーマルモードでコマンドを色々打ちますが、それをアシストしてくれる機能です。
コマンド履歴はもっと少なくても多分何も困らないでしょう。.vimrc"---------------------------------------------------------- " コマンドモード "---------------------------------------------------------- set wildmenu " コマンドモードの補完 set history=5000 " 保存するコマンド履歴の数タブやインデントの設定
タブやインデント、読みやすいコードを書く上では超重要ですね。
個人的にインデント幅が大きすぎると見にくいと感じるので2にしていますが、なぜかPythonコードを書いてる時は勝手に4になってしまいます。
まあPythonは暗黙の了解でインデント幅は4みたいな風潮があるのでいいですが。
インデントとか可視化されますしね。.vimrc"---------------------------------------------------------- " タブ・インデント "---------------------------------------------------------- set expandtab " タブ入力を複数の空白入力に置き換える set tabstop=2 " 画面上でタブ文字が占める幅 set softtabstop=2 " 連続した空白に対してタブキーやバックスペースキーでカーソルが動く幅 set autoindent " 改行時に前の行のインデントを継続する set smartindent " 改行時に前の行の構文をチェックし次の行のインデントを増減する set shiftwidth=2 " smartindentで増減する幅文字列検索
こちらも重要設定ですね。
文字列検索が便利になります。.vimrc"---------------------------------------------------------- " 文字列検索 "---------------------------------------------------------- set incsearch " インクリメンタルサーチ. 1文字入力毎に検索を行う set ignorecase " 検索パターンに大文字小文字を区別しない set smartcase " 検索パターンに大文字を含んでいたら大文字小文字を区別する set hlsearch " 検索結果をハイライト " ESCキー2度押しでハイライトの切り替え nnoremap <silent><Esc><Esc> :<C-u>set nohlsearch!<CR>ちなみに文字列検索は
/(検索したい文字列)
文字列置換は:%s/(置換対象の文字列)/(置換後の文字列)が基本です。カーソル移動など
vimではノーマルモードなら
h, j, k, lでそれぞれ左 下 上 右と移動できますが、こういったコマンドでの移動の際、長いコードを書いたために1行が折り返して表示されていると、例えばjで移動すると見た目での1行下ではなく、次の行にカーソルが移動してしまったりします。
ここではそれを解消したり、カーソルラインをハイライトしたりの設定をしています。
カーソル関連
/.vimrc"---------------------------------------------------------- " カーソル "---------------------------------------------------------- set whichwrap=b,s,h,l,<,>,[,],~ " カーソルの左右移動で行末から次の行の行頭への移動が可能になる set number " 行番号を表示 set cursorline " カーソルラインをハイライト " 行が折り返し表示されていた場合、行単位ではなく表示行単位でカーソルを移動する nnoremap j gj nnoremap k gk nnoremap <down> gj nnoremap <up> gk " バックスペースキーの有効化 set backspace=indent,eol,start括弧やタグの対応
コーディング中に対応する括弧が一瞬光ります。
括弧をたくさん書くときに便利です。.vimrc"---------------------------------------------------------- " カッコ・タグの対応 "---------------------------------------------------------- set showmatch " 括弧の対応関係を一瞬表示する set matchtime=3 set matchpairs& matchpairs+=<:> source $VIMRUNTIME/macros/matchit.vim " Vimの「%」を拡張するマウス有効化
なんと初期設定のvimではマウスが使えません。
トラックパッドも使えません。
ということで設定しましょう。
マウス有効化
.vimrc"---------------------------------------------------------- " マウスでカーソル移動とスクロール "---------------------------------------------------------- if has('mouse') set mouse=a if has('mouse_sgr') set ttymouse=sgr elseif v:version > 703 || v:version is 703 && has('patch632') set ttymouse=sgr else set ttymouse=xterm2 endif endifファイル管理
vimでファイルを編集すると自動でバックアップファイルやスワップファイルを作成するのですが、別に不要なのでオフにしておきます。
(ファイルのバックアップとかが必要ならそもそもgitとか使った方がいいと思ってます).vimrc"---------------------------------------------------------- " ファイル管理 "---------------------------------------------------------- " バックアップファイルやスワップファイルを作成しない set nowritebackup set nobackup set noswapfile表示関係
空白とか改行とかタブとかを可視化します。
あと一文が長くなったら折り返します。
表示関係設定
.vimrc"---------------------------------------------------------- " 表示関係 "---------------------------------------------------------- set list " 不可視文字の可視化 set wrap " 長いテキストの折り返し set colorcolumn=100 "100文字目にラインを入れる " スクリーンベルの無効化 set t_vb= set novisualbell " 不可視文字をUnicodeで綺麗に set listchars=tab:»-,trail:-,extends:»,precedes:«,nbsp:%,eol:↲マクロとキー設定
ここではデフォルトのキーバインドを直感的に使えるようにオーバーライドしたり新しく設定したりしています。
お好みで追加したり削除したりしてくださいね。
nnoremapはノーマルモードでのキー設定inoremapはインサートモードでのキー設定vnoremapはビジュアルモードでのキー設定<S>はShiftキー<C>はCtrlキー
マクロとキー設定集
.vimrc"---------------------------------------------------------- " マクロおよびキー設定 "---------------------------------------------------------- inoremap jj <Esc> " 入力モード中に素早くjjと入力した場合はESCとみなす " 検索語にジャンプした検索単語を画面中央に持ってくる nnoremap n nzz nnoremap N Nzz nnoremap * *zz nnoremap # #zz nnoremap g* g*zz nnoremap g# g#zz vnoremap v $h " vを二回で行末まで選択 " TABで対応ペアにジャンプ nnoremap <Tab> % vnoremap <Tab> % " Shift + 矢印でウィンドウサイズを変更 "nnoremap <S-Left> <C-w><<CR> "nnoremap <S-Right> <C-w>><CR> "nnoremap <S-Up> <C-w>-<CR> "nnoremap <S-Down> <C-w>+<CR> " 矢印2回押しで行頭・行末へ移動 inoremap <S-Left><S-Left> <Esc>_i inoremap <S-Right><S-Right> <Esc>$i<Right>
neocompleteの設定
neocompleteの設定と、neosnippetの設定です。
他にも色々オプションあるみたいですが、大体下記で事足りるのではないでしょうか。
詳しくはをご覧ください。
コード補完設定
.vimrc"---------------------------------------------------------- " neocomplete・neosnippetの設定 "---------------------------------------------------------- if neobundle#is_installed('neocomplete.vim') " Vim起動時にneocompleteを有効にする let g:neocomplete#enable_at_startup = 1 " smartcase有効化. 大文字が入力されるまで大文字小文字の区別を無視する let g:neocomplete#enable_smart_case = 1 " 3文字以上の単語に対して補完を有効にする let g:neocomplete#min_keyword_length = 3 " 区切り文字まで補完する let g:neocomplete#enable_auto_delimiter = 1 " 1文字目の入力から補完のポップアップを表示 let g:neocomplete#auto_completion_start_length = 1 " バックスペースで補完のポップアップを閉じる inoremap <expr><BS> neocomplete#smart_close_popup()."<C-h>" " エンターキーで補完候補の確定. スニペットの展開もエンターキーで確定 imap <expr><CR> neosnippet#expandable() ? "<Plug>(neosnippet_expand_or_jump)" : pumvisible() ? "<C-y>" : "<CR>" " タブキーで補完候補の選択. スニペット内のジャンプもタブキーでジャンプ imap <expr><TAB> pumvisible() ? "<C-n>" : neosnippet#jumpable() ? "<Plug>(neosnippet_expand_or_jump)" : "<TAB>" endif
Syntasticの設定構文チェック機能の設定集ですね。
ただ、なぜかぼくの環境では動いていないっぽい...?
どこか間違ってそうです...
Syntasticの設定
.vimrc"---------------------------------------------------------- " Syntastic "---------------------------------------------------------- " 構文エラー行に「>>」を表示 let g:syntastic_enable_signs = 1 " 他のVimプラグインと競合するのを防ぐ let g:syntastic_always_populate_loc_list = 1 " 構文エラーリストを非表示 let g:syntastic_auto_loc_list = 0 " ファイルを開いた時に構文エラーチェックを実行する let g:syntastic_check_on_open = 1 " 「:wq」で終了する時も構文エラーチェックする let g:syntastic_check_on_wq = 1 " Javascript用. 構文エラーチェックにESLintを使用 let g:syntastic_javascript_checkers=['eslint'] " Python用. 構文エラーチェックにpep8とpyflakesを使用 let g:syntastic_python_checkers=['pep8', 'pyflakes'] " Javascript, python以外は構文エラーチェックをしない let g:syntastic_mode_map = { 'mode': 'passive', \ 'active_filetypes': ['javascript', 'python'], \ 'passive_filetypes': [] }ちなみに
pep8とpyflakesは$ pip install pep8 pyflakesでインストールできます。
詳しくはこちらCtrlPの設定
多機能セレクタプラグインの設定です。
ファイル検出の設定とかをしています。
CtrlPの設定
.vimrc"---------------------------------------------------------- " CtrlP "---------------------------------------------------------- let g:ctrlp_match_window = 'order:ttb,min:20,max:20,results:100' " マッチウインドウの設定. 「下部に表示, 大きさ20行で固定, 検索結果100件」 let g:ctrlp_show_hidden = 1 " .(ドット)から始まるファイルも検索対象にする let g:ctrlp_types = ['fil'] "ファイル検索のみ使用 let g:ctrlp_extensions = ['funky', 'commandline'] " CtrlPの拡張として「funky」と「commandline」を使用 " CtrlPCommandLineの有効化 command! CtrlPCommandLine call ctrlp#init(ctrlp#commandline#id()) " CtrlPFunkyの絞り込み検索設定 let g:ctrlp_funky_matchtype = 'path' if executable('ag') let g:ctrlp_use_caching=0 " CtrlPのキャッシュを使わない let g:ctrlp_user_command='ag %s -i --hidden -g ""' " 「ag」の検索設定 endifカラースキーム編集用
カラースキーム編集時に、今カーソルを合わせているコードのシンタックスグループなどを教えてくれる便利コマンドです。
:SyntaxInfoコマンドを使えるようにする
.vimrc"---------------------------------------------------------- " カラースキーム編集用 "---------------------------------------------------------- " ハイライトグループを知るコマンド:SyntaxInfoを実装 function! s:get_syn_id(transparent) let synid = synID(line("."), col("."), 1) if a:transparent return synIDtrans(synid) else return synid endif endfunction function! s:get_syn_attr(synid) let name = synIDattr(a:synid, "name") let ctermfg = synIDattr(a:synid, "fg", "cterm") let ctermbg = synIDattr(a:synid, "bg", "cterm") let guifg = synIDattr(a:synid, "fg", "gui") let guibg = synIDattr(a:synid, "bg", "gui") return { \ "name": name, \ "ctermfg": ctermfg, \ "ctermbg": ctermbg, \ "guifg": guifg, \ "guibg": guibg} endfunction function! s:get_syn_info() let baseSyn = s:get_syn_attr(s:get_syn_id(0)) echo "name: " . baseSyn.name . \ " ctermfg: " . baseSyn.ctermfg . \ " ctermbg: " . baseSyn.ctermbg . \ " guifg: " . baseSyn.guifg . \ " guibg: " . baseSyn.guibg let linkedSyn = s:get_syn_attr(s:get_syn_id(1)) echo "link to" echo "name: " . linkedSyn.name . \ " ctermfg: " . linkedSyn.ctermfg . \ " ctermbg: " . linkedSyn.ctermbg . \ " guifg: " . linkedSyn.guifg . \ " guibg: " . linkedSyn.guibg endfunction command! SyntaxInfo call s:get_syn_info()
カラースキームの編集
ぼくはここなどを参考にしました。
vimでコーディングする上でカラースキームって意外と大切だったりします。
明るい色ばかり使っていたら目が疲れますし、全部同じ色だとスペルミスに気づけなかったり、とにかくコーディング効率が悪くなります。
いろんなサイトで「カラースキームといえばこれ!」とか紹介されているのを見たり、既存のカラースキームを探せるサイトとかで自分なりに良さげなのを探してきたりしても、どうにも微妙に納得がいかなかったりしませんか?
ということで、すごく簡単にですがカラースキームの編集方法について説明します。まずは元となるカラースキームを見つけよう
一から自分専用のカラースキームを作るのは心が折れると思いますのでやめときましょう。
今自分の中で一番気に入っているカラースキームを少しずつ編集するだけで十分なものに仕上げることができます。
ぼくはicebergが気に入ったのでこれをもとに少しだけ編集しました。どの部分が気に入らない?
元となるカラースキームを決めたら、どの部分の色が気に入らないか調べましょう。
先に紹介した:SyntaxInfoでハイライトグループを知ることができますので、それを元に編集します。
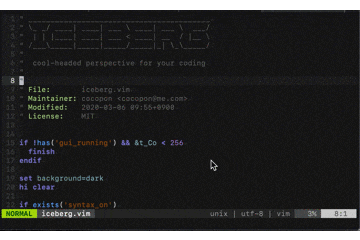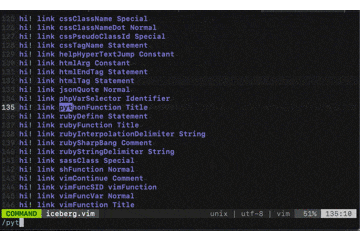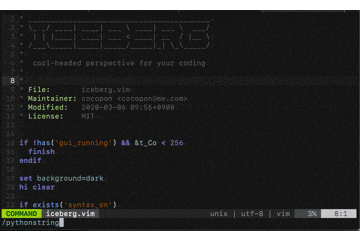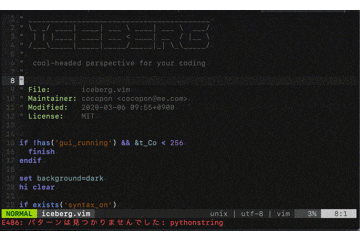
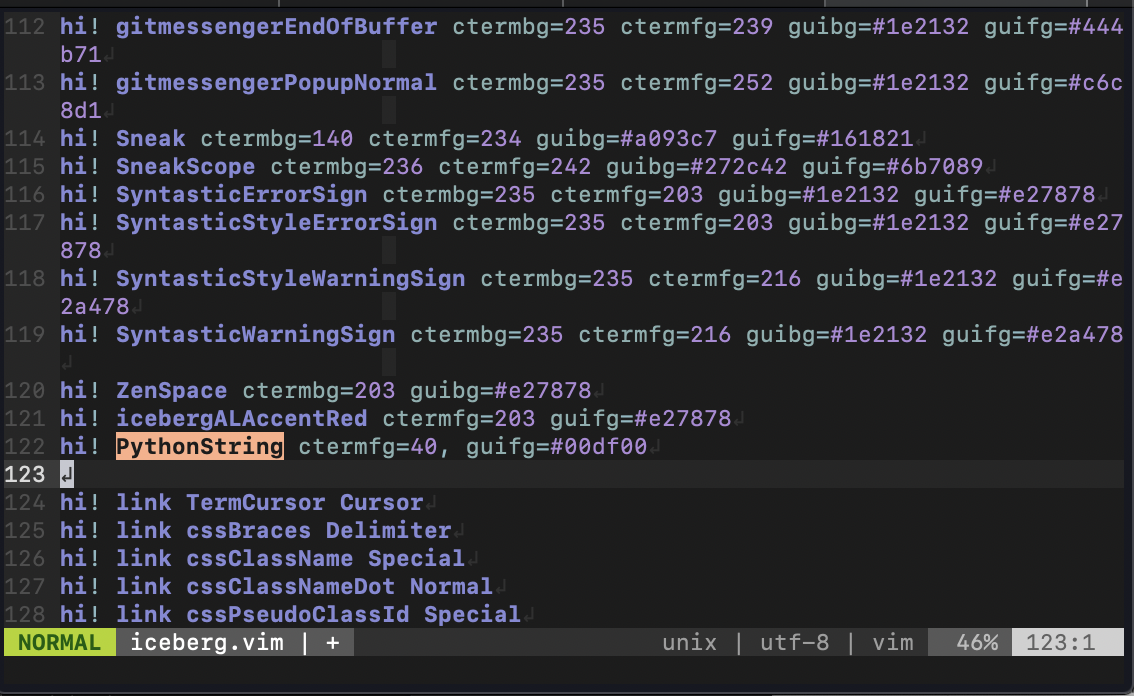
以下では例としてPythonStringグループの色を変更します。
このPythonコードは開きっぱなしで!
カラースキームを開く
カラースキームは
NeoBundleで管理していれば~/.vim/bundle/の中にあると思います。
今回はicebergを編集するので$ vi ~/.vim/bundle/iceberg.vim/colors/iceberg.vimでカラースキームを開きます。
対象のシンタックスグループを検索
vimの文字列検索
/pythonstringとして定義を見てみましょう。
ないですね、はい。
ということは自分で書くしかないわけですね。
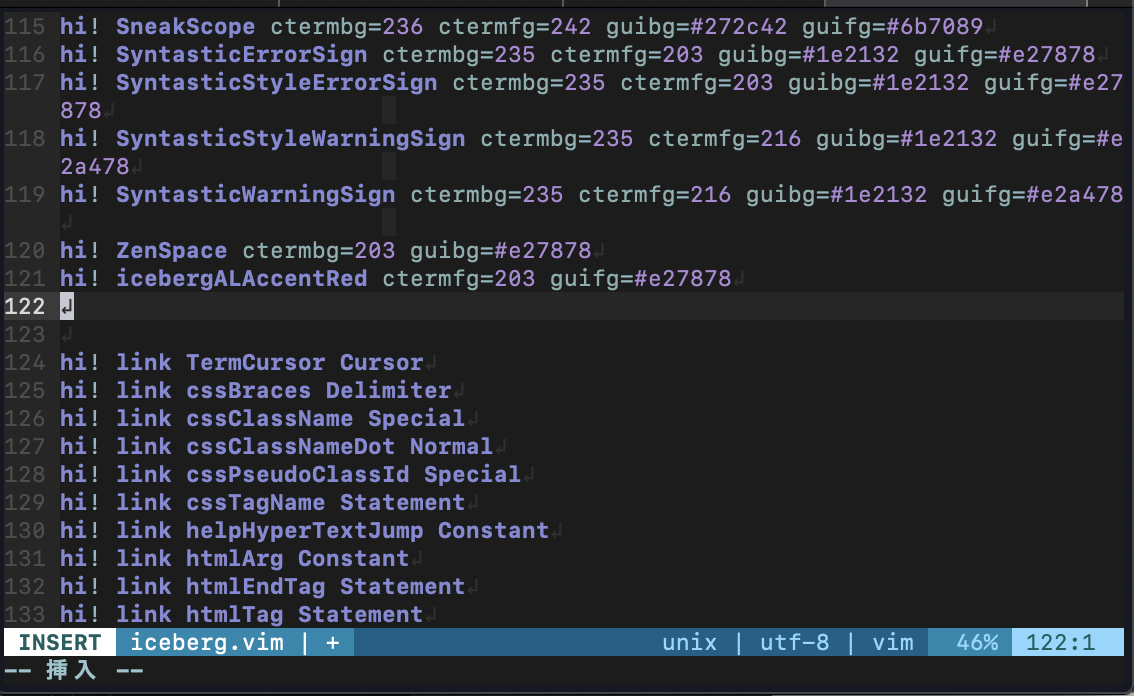
どこに書き足してもいいですが、わかりやすいところにしましょう。
今回はカラースキームの色を直接定義している部分の一番最後にします。
書いてみる
書き方は真似すればOK。
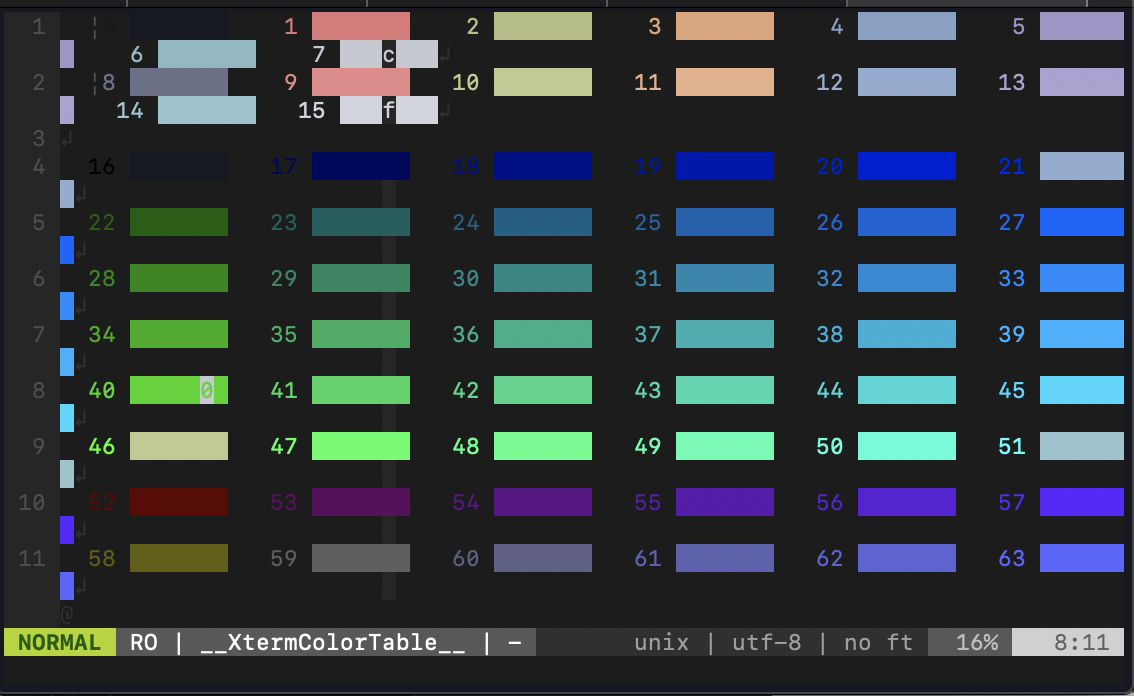
何色がある?っていうのはここで紹介した:XtermColorTableを参考にしましょう。
今回はctermfg=40,guifg=#00df00を使います。
guifgの16進数はビジュアルモードで範囲選択すれば見えますよ〜
書けたらとりあえず:wで保存するだけ保存しましょう。
まだ閉じないように!確認する
ではPythonのコード画面に移りましょう。
:syntax onと入力すれば新しいカラーが反映されるはずです。
派手すぎますね〜やっぱりやめときましょうこの色、とかなったり、微妙に思った色と違ったりするかもしれないので、また書いてみるに戻って編集し直して確認して〜の繰り返しです。以上でカラースキームの編集方法の説明は終了です!
シンタックスファイル
さて、カラースキーム編集したしバッチリ!と思ってるそこのあなた、もう一つ大事な要素を忘れてますよ!
それはシンタックスファイルの存在です。
シンタックスファイルとは、そのまま文法をまとめたファイルのことです。
vimでPython書くならこれを入れておくべきでしょう。
ここにPythonのシンタックスファイルがありますが、これでは(なぜか)クラスのメソッドなどのアトリビュート(hoge.fooのfoo)の色を変えられなかったりします。
ということでぼくがちょっぴり修正したここのpython.vimをREADME.mdに従って~/.vim/syntax/に入れましょう。
そうすればアトリビュートも色を変えられるはずです!pyceberg
最後に、本記事を通してダイマしまくったpycebergを宣伝させてもらいます笑
基本はicebergで、少しぼく好みに色を変更したりしたくらいです。
もしよかったら使ってやってください。導入方法は
README.mdに書いてあります。
1番簡単なのは.vimrcに.vimrcNeoBundle ‘kuroitu/pyceberg’ colorscheme pycebergとやるやり方ですかね〜
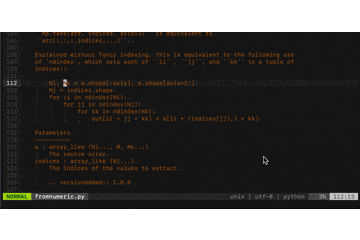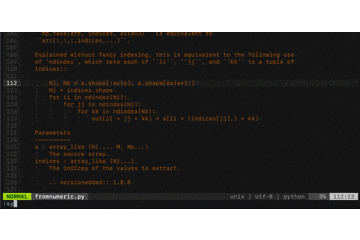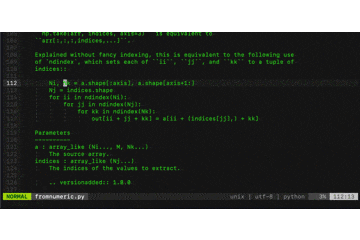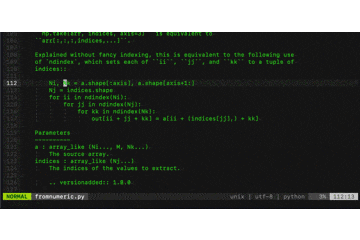
こんな感じになります↓ (画像はnumpyのコードより)
おわりに
すごく長い記事になりました...
まあ何かの参考にでもなれば幸いです。参考
- 投稿日:2020-05-22T22:48:00+09:00
[Python]04章-03 いろいろなデータ構造(多次元リスト)
[Python]04章-03 多次元リスト
前回まではリストを作成して、そこから操作する方法を学びました。
今まで作成したリストは、1次元のリストでした。今回は2次元以上のリストの作成についてみていきます。多次元リストの作成
今まで学んだリストは1次元のリストでした。このリスト内には、文字列や数値を入れられ、任意のデータ型を入れることができました。
実は、リスト内にはさらにリストも入れることができます。これを多次元リストと言います。
具体的に見ていきましょう。
Python Consoleに以下のコードを入力してください。>>>lsls = [[23, 24], [37, 38], [41, 42]] >>>lsls [[23, 24], [37, 38], [41, 42]]リストの各要素がリストとなっている形です。これを表で表すと以下のようになります。
番号 0 1 2 要素 [23, 24] [37, 38] [41, 42] 上の表を参考にしながら、lslsに要素番号を指定すると各要素を確認できます。
>>>lsls[2] [41, 42]では、[41, 42]の42を取り出すにはどうしたらよいでしょうか?
[41, 42]の42は、2番目の要素の中の1番目の要素となりますので、以下のように指定します。>>>lsls [[23, 24], [37, 38], [41, 42]] >>>lsls[2][1] 42なお、紹介程度としてとらえてほしいのですが、以下のように3次元リストも作成が可能です。
>>>lslsls = [[[1, 2],[5, 6]], [[10, 11],[15, 16]], [[26, 27],[28, 29]]] >>>lslsls [[[1, 2], [5, 6]], [[10, 11], [15, 16]], [[26, 27], [28, 29]]] >>>lslsls[2] [[26, 27], [28, 29]] >>>lslsls[2][0] [26, 27] >>>lslsls[2][0][1] 27表で表記すると以下のようになります。リストの要素の中に、2次元リストが格納されている様子がわかります。
番号 0 1 2 要素 [[1, 2],[5, 6]] [[10, 11],[15, 16]] [[26, 27],[28, 29]] 最後に
最後の3次元のリストは複雑なので、2次元リストまでで問題ありません。
実際のデータを表形式で表すことはよくあります。そういったデータを2次元リストに保管して処理することも可能なので、こういうこともできるということを知っておいてください。【目次リンク】へ戻る
- 投稿日:2020-05-22T22:21:02+09:00
[Python]関数
- 投稿日:2020-05-22T22:19:56+09:00
StarGANの実装をしてみた(1)
StarGANの実装をしてみた ~Linux上での実装~
今回は、StarGANの実装をしてみました。
基本的に、githubで公開されているコードをもとに実装を行っていきます。
本ページでは、軽い論文の説明と実装をしていきます。
自分のデータセットを用いて適用する回は、次回やっていきたいと思います。
- StarGANについて超簡単に
- Linux上での実装
簡単ではありますが、上の2項目に従って説明します。
StarGANについて超簡単に
StarGANとは、異なるドメイン間への変換を可能とするGenerative Adversarial Netwok (GAN)の一種であるCycleGANと、GANに多クラス分類の学習を加えたAC-GANを組み合わせたものです。
CycleGANは、2つのドメイン間でのドメイン変換しか行えません。
2つ以上のk個のドメイン間でのドメイン変換を実現するためには、k(k-1)個のGeneratorを学習しなければなりません。
これは、事実上可能ではありますが、面倒くさいです。
この画像は、論文内のものですが、k=4だとすると、4*3=12個のGeneratorが必要だということを表しています。そんな問題を解決するために、StarGANでは、1つのGeneratorで複数のドメインの変換を行うアルゴリズムを導入しています。
5つのドメインがある場合、上の画像のようにあらわされます。
星形をしていますね。だからStarGANなんでしょう。なんか厨二心をくすぐられます。丁寧な説明が他の記事ありましたので、共有いたします。(これ以上の解説は自分のはできない)
Linux上での実装
公開コード
https://github.com/yunjey/StarGAN実装環境
- Ubuntu 18.04 LTS
- Python 3.6
- PyTorch 0.4.0
- Tensorflow 1.4.0公開データセットで実装
まずは、任意のディレクトリにgitをクローンします。
続いて、StarGAN/のディレクトリに移動します。
今回は、論文でも使用されていたCelebA datasetとRaFDいうデータセットをダウンロードしていきます。$ git clone https://github.com/yunjey/StarGAN.git $ cd StarGAN/ $ bash download.sh celebaダウンロード完了です。
. . . inflating: ./data/celeba/images/072137.jpg inflating: ./data/celeba/images/027742.jpg inflating: ./data/celeba/images/188764.jpg inflating: ./data/celeba/list_attr_celeba.txtこちらのCelebA datasetというデータセットは、こちらで公開されております。
このデータセットには、有名人のカラー顔画像が178×218ピクセルで202,599枚含まれています。
これに加えて、それぞれの画像に対して、40種類のattribute (属性) が付与されています。
例えば、Black_Hair、Blond_Hair、Brown_Hair、Male、Youngなどなどです。
もっと知りたい人はこちらを参照ください。
ダウンロードディレクトリには、上のような画像と
list_attr_celeba.txtという各画像に対する属性が記されているtxtファイルが保存されます。
こちらの中身は、[画像フォルダ名] 1 1 -1 1 -1 1 1 ... 1 -1となっています。1 or -1は属性の数の分(40個)あります。
1のとき、その属性であり、-1のとき、その属性ではないことを表します。
こちらは、自分のデータセットで学習させる際に生成する必要があるので覚えておいてください。
学習
まずは、CelebA datasetを使ってStarGANを学習していきます。
$ python main.py --mode train --dataset CelebA --image_size 128 --c_dim 5 \ --sample_dir stargan_celeba/samples --log_dir stargan_celeba/logs \ --model_save_dir stargan_celeba/models --result_dir stargan_celeba/results \ --selected_attrs Black_Hair Blond_Hair Brown_Hair Male Youngコマンドについて説明します。
--mode: モード
--dataset: 用いるデータセット
--image_size: 画像サイズ
--c_dim: attribute (属性) のクラスの数
--sample_dir: サンプルが保存してあるフォルダ
--log_dir: ログを保存するフォルダ
--model_save_dir: モデルを保存するフォルダ
--result_dir: 結果を保存するフォルダ
--selected_attrs: 学習したいattribute (属性)
という感じです。テスト
続いて、テストをしていきます。
$ python main.py --mode test --dataset CelebA --image_size 128 --c_dim 5 \ --sample_dir stargan_celeba/samples --log_dir stargan_celeba/logs \ --model_save_dir stargan_celeba/models --result_dir stargan_celeba/results \ --selected_attrs Black_Hair Blond_Hair Brown_Hair Male Young簡単にできてしまいます。
続いて、RaFDのデータもダウンロードしたい、、、と思ったのですが、申請が必要でした。
おそらく、申請できても、こちらのページにも掲載することはできないと思います。学習するのが面倒くさいという方のためにも、学習済みネットワークをダウンロードしていきます。
$ bash download.sh pretrained-celeba-128x128ダウンロードされたモデルは、
./stargan_celeba_128/modelsに保存されます。
つづいて、以下のコマンドで学習済みネットワークを使って画像変換をしていきます。$ python main.py --mode test --dataset CelebA --image_size 128 --c_dim 5 \ --selected_attrs Black_Hair Blond_Hair Brown_Hair Male Young \ --model_save_dir='stargan_celeba_128/models' \ --result_dir='stargan_celeba_128/results'という感じに超簡単です。
./stargan_celeba_128/resultsに変換画像が保存されます。
これで、公開データセットでの簡単な実装は終了。
次回は、自分で用意したデータセットに適用していきます。



- 投稿日:2020-05-22T22:10:26+09:00
[Python]04章-02 いろいろなデータ構造(リストの操作)
[Python]04章-02 リストの操作
ここでは作成したリストについて、要素を追加したり、削除したりするといった操作について学んでいきたいと思います。
操作をするということですので、基本的にはメソッドを利用していきます。まずは、前回のリストを作成します。今回もPython Consoleを用いて作成していきます。
>>>ls = ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France'] >>>print(ls) ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France']リストへの要素追加
要素の追加には2つの方法があります。それぞれ見ていきましょう。
(1)appendメソッドの利用
作成したlsというリストに、要素を追加することを考えます。要素を追加するにはappendメソッドを利用します。つまり、lsという変数に対して、appendというメソッドで捜査していきます。
lsに'America'という要素を追加してみましょう。以下のコードを入力してください。
最初にlsで中身を確認してから、追加してみます。>>>ls ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France'] >>>ls.append('America') >>>ls ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France', 'America']最後にlsと入力して、lsの中身を確認すると、appendメソッドによって追加された'America'という要素がリストに追加されます。
(2)extendメソッドの利用
appendメソッドではリストに要素を追加できることを確認しました。では、一度に2つ以上を追加するにはどうすればよいでしょうか?
複数の要素を追加するにはextendメソッドを利用します。
具体的には以下のようにコードを打って確認していきたいと思います。先ほどと一緒でlsの中身を確認してから実行します。>>>ls ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France', 'America'] >>>ls.extend(['India','Spain']) >>>ls ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France', 'America', 'India', 'Spain']extendメソッドは、()内を['India','Spain']のようにリストで指定します。
なお、appendメソッドとextendメソッドは、1つの要素を追加するか、2つ以上の要素を追加するかの違いとなります。
これを誤るとエラーとなります。リストからの要素削除
リストから要素を削除する方法についてみていきます。方法は3つあります。
(1)removeメソッドの利用
removeメソッドはリストの中にある要素を直接指定して削除します。
Python Consoleに以下の内容を入力してください。先ほどと一緒でlsの中身を確認してから実行します。
>>>ls ['Japan', 'Canada', 'Australia', 'England', 'German', 'Italy', 'France', 'America', 'India', 'Spain'] >>>ls.remove('Canada') >>>ls ['Japan', 'Australia', 'England', 'German', 'Italy', 'France', 'America', 'India', 'Spain']上記のように、'Canada'が削除されていることを確認できました。
removeメソッドの場合、要素番号でなく、要素の中身を直接指定して削除をします。なお、もしリスト内に同じ値のものがあった場合、その値を削除すると最初に現れたものが削除されます。
>>>numL = [5, 7, 4, 5, 9] >>>numL.remove(5) >>>numL [7, 4, 5, 9](2)del文の利用
これはメソッドを利用するわけではないのですが、同じリスト要素の削除方法としてdel文を紹介します。
Python Consoleに以下の内容を入力してください。先ほどと一緒でlsの中身を確認してから実行します。
>>>ls ['Japan', 'Australia', 'England', 'German', 'Italy', 'France', 'America', 'India', 'Spain'] >>>del ls[3] >>>ls ['Japan', 'Australia', 'England', 'Italy', 'France', 'America', 'India', 'Spain']del文の場合、要素を指定しての削除ではなく、要素番号を指定しての削除となります。
今回、del ls[3]を指定したので、3番目の'German'が削除されました。(もちろん、今回も要素番号は0から始まります)(3)clearメソッドの利用
clearメソッドを利用する際、気をつけなければならないのが、リストの要素をすべて削除することです。ただし、リスト自体は消えずに、空リストとなります。
Python Consoleに以下の内容を入力してください。先ほどと一緒でlsの中身を確認してから実行します。
>>>ls ['Japan', 'Australia', 'England', 'Italy', 'France', 'America', 'India', 'Spain'] >>>ls.clear() >>>ls []リストの探索
リストに指定した要素があるかどうかを探索する方法を見ていきます。
説明の前に、新しくリストを作ります。今度は数値のリストを作成して、説明していきましょう。>>>numL = [60, 80, 70, 90, 50] >>>numL [60, 80, 70, 90, 50](1)indexメソッドの利用
indexメソッドを利用すると、指定した要素の位置を返します。
Python Consoleに以下の内容を入力してください。先ほどと一緒でnumLの中身を確認してから実行します。>>>numL [60, 80, 70, 90, 50] >>>numL.index(70) 2今回、メソッドをindex(70)と指定しているので、リスト中で70の位置を探索します。すると2番目にあることがわかるので、2を返します。
もちろん、存在しない要素を指定すると以下のようにエラーになります。
>>>numL.index(100) Traceback (most recent call last): File "<input>", line 1, in <module> ValueError: 100 is not in list(2)in, not inによる有無の確認方法
これはメソッドを利用する方法でなく、リスト内に指定した要素があるかどうかをinを用いて確認する方法を紹介します。
Python Consoleに以下の内容を入力してください。先ほどと一緒でnumLの中身を確認してから実行します。
>>>numL [60, 80, 70, 90, 50] >>>70 in numL True >>>100 in numL False70 in numLは「numLというリスト内に70という値は存在するか?」という質問をしており、結果は真(True)となります。
また、100 in numLは「numLというリスト内に100という値は存在するか?」という質問をしており、結果は偽(False)となります。また逆に、not inを用いて、存在しないかどうか?も確認できます。
Python Consoleに以下の内容を入力してください。先ほどと一緒でnumLの中身を確認してから実行します。
>>>numL [60, 80, 70, 90, 50] >>>70 not in numL False >>>100 not in numL True70 not in numLは「numLというリスト内に70という値は存在しないか?」という質問をしており、結果は偽(False)となります。
また、100 not in numLは「numLというリスト内に100という値は存在しないか?」という質問をしており、結果は真(True)となります。なお、今回出てきたTrueやFalseはブール型という、整数型や文字列型といった分類の1つになります。
今後説明する、if文やwhile文などの制御構文で登場します。リストの要素のソート
リスト内の要素を並び替える(ソート)方法を説明します。方法は関数を使い方法とメソッドを使う方法です。
(1)sorted関数の利用
sorted関数により、リストの要素を昇順(もしくは降順)に並べ替えすることができます。
Python Consoleに以下の内容を入力してください。先ほどと一緒でnumLの中身を確認してから実行します。
>>>numL [60, 80, 70, 90, 50] >>>sorted(numL) [50, 60, 70, 80, 90] sorted(numL, reverse=True) [90, 80, 70, 60, 50]まず、sorted関数の()内は引数(ひきすう)といい、この引数にリストを入れると、並べ替えができます。
また、引数の後ろにreverse=Trueを指定すると、降順に並べ替えられます。なお、上記の状態で、再度numLの中身を表示させてみたいと思います。
>>>numL [60, 80, 70, 90, 50]この結果から言えるのが、関数を通しても、numL自体は変わらないということ確認できたと思います。
(1)sortメソッドの利用
sortメソッドを指定することで、sorted関数と同じくリストの中身を並べ替えが可能です。
Python Consoleに以下の内容を入力してください。先ほどと一緒でnumLの中身を確認してから実行します。>>>numL [60, 80, 70, 90, 50] >>>numL.sort() >>>numL [50, 60, 70, 80, 90]sortメソッドで、値を並べ替えられることは分かったのですが、そのままでは出力はされません。それを確認するには、numLの中身を確認する必要があります。
なお、sorted関数の時には、並べ替えをしてもnumL自体はソートされなかったですが、sortメソッドの場合はnumL自体ソートされていることを確認できます。
最後に
今日はリストに対する多くのメソッド等が登場しました。
基本的なメソッドは覚えておいて損はないですが、細かな引数の指定など、調べてみるのもよいでしょう。【目次リンク】へ戻る
- 投稿日:2020-05-22T22:00:58+09:00
ラズパイ パイカメラの使い方 Python
皆さんどうもこんにちは。
今回はラズベリーパイでパイカメラを使う方法を紹介していきます。
パイカメラとラズパイ
1.ラズパイの専用スロットにパイカメラを青い線を右側(スロットの向きに合わせて)にして差し込む。スロットに差し込むときは白いカバーを上に引いてから差し込み、終わったら押して戻す。なお、ラズパイにはスロットが2つあるがどちらでも可。
写真のとうりに差し込めば使えます。どのスロットにつけたにしてもカバーの方を青い線が向いていたら大丈夫です。
2ちなみにカメラも同様に取り付けます。
青い線がカバーの方に向いていたら大丈夫です。
3ラズパイの設定でカメラを有効にしてプログラムを書く。
これ以降は僕のYoutubeチャンネルで解説しているのでそちらをご参照ください。



- 投稿日:2020-05-22T21:58:23+09:00
pipreqsがUnicodeDecodeErrorになるときの対処法
pipreqsとは
pythonの外部モジュールを使用した際のrequirements.txtを自動で書きだしてくれる奴。
プロジェクトフォルダ/hoge.pyとなっているときに、cd プロジェクトフォルダ pipreqs .でhoge.pyのrequirements.txtがプロジェクトフォルダ以下に出るはずだったのが、
UnicodeDecodeError: 'cp932' codec can't decode byte 0x81 in position 239: illegal multibyte sequence日本語わかんねーぞでよく出るエラーが出た。
リファレンスを読む。
https://pypi.org/project/pipreqs/
--encodeingオプションがあるらしい。解決コマンド
pipreqs --encoding UTF8 .これで解決。
requirements.txtnetworkx==2.3 plotly==4.4.1 pandas==1.0.3 streamlit==0.60.0無事に出てきました、おしまい。
- 投稿日:2020-05-22T21:53:51+09:00
(小ネタ)pandas.DataFrameでワンライナーで列名順に列をソートする
pandasのDataFrameで、列を「列名」でソートしたいときに、さくっとワンライナーで実行する方法です。
次のようなDataFrameがあったときに
df = pd.DataFrame({4:[1,2,3], 2: [1,2,3], 1:[1,2,3], 3: [1,2,3]})
下のコードで実行できます。
df.T.sort_index().T
アルファベットの列名でも同様に実行可能です。
df = pd.DataFrame({'d':[1,2,3], 'b': [1,2,3], 'a':[1,2,3], 'c': [1,2,3]}) df.T.sort_index().T
ひらがなも上手くいきました。
df = pd.DataFrame({'え':[1,2,3], 'い': [1,2,3], 'あ':[1,2,3], 'う': [1,2,3]}) df.T.sort_index().T
漢字はダメでした。(なんか惜しいけど。)
df = pd.DataFrame({'四':[1,2,3], '二': [1,2,3], '一':[1,2,3], '三': [1,2,3]}) df.T.sort_index().T
以上、どこかで使えるかもしれない小ネタでした。





- 投稿日:2020-05-22T20:55:26+09:00
AWS CLI インストールエラー対処法まとめ
参考文献
- OSのPython古くて困ってる場合はpyenv入れたら便利だよ
- Python2 で get-pip.py で SyntaxError
- Amazon Linux 2でpipをインストール
- AWS CLIのインストール
- pyenv と pyenv-virtualenv をインストールする
エラー内容
$ pip install awscli DEPRECATION: Python 2.6 is no longer supported by the Python core team, please upgrade your Python. A future version of pip will drop support for Python 2.6 The directory '/home/uorat/.cache/pip/http' or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. The directory '/home/uorat/.cache/pip' or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. Requirement already satisfied (use --upgrade to upgrade): awscli in /usr/lib/python2.6/site-packages Requirement already satisfied (use --upgrade to upgrade): botocore==1.0.0b1 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): bcdoc<0.16.0,>=0.15.0 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): colorama<=0.3.3,>=0.2.5 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): docutils>=0.10 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): rsa<=3.1.4,>=3.1.2 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): argparse>=1.1 in /usr/lib/python2.6/site-packages (from awscli) Requirement already satisfied (use --upgrade to upgrade): jmespath==0.7.1 in /usr/lib/python2.6/site-packages (from botocore==1.0.0b1->awscli) Requirement already satisfied (use --upgrade to upgrade): python-dateutil<3.0.0,>=2.1 in /usr/lib/python2.6/site-packages (from botocore==1.0.0b1->awscli) Requirement already satisfied (use --upgrade to upgrade): ordereddict==1.1 in /usr/lib/python2.6/site-packages (from botocore==1.0.0b1->awscli) Requirement already satisfied (use --upgrade to upgrade): simplejson==3.3.0 in /usr/lib64/python2.6/site-packages (from botocore==1.0.0b1->awscli) Requirement already satisfied (use --upgrade to upgrade): six<2.0.0,>=1.8.0 in /usr/lib/python2.6/site-packages (from bcdoc<0.16.0,>=0.15.0->awscli) Requirement already satisfied (use --upgrade to upgrade): pyasn1>=0.1.3 in /usr/lib/python2.6/site-packages (from rsa<=3.1.4,>=3.1.2->awscli) /usr/lib/python2.6/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:315: SNIMissingWarning: An HTTPS request has been made, but the SNI (Subject Name Indication) extension to TLS is not available on this platform. This may cause the server to present an in correct TLS certificate, which can cause validation failures. For more information, see https://urllib3.readthedocs.org/en/latest/security.html#snimissingwarning. SNIMissingWarning /usr/lib/python2.6/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:120: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. For more in formation, see https://urllib3.readthedocs.org/en/latest/security.html#insecureplatformwarning. InsecurePlatformWarning対処法
◆ pyenv git clone
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv◆ bash_profileに追加
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile◆ pyenv バージョン指定/インストール
$ pyenv install -l $ pyenv install 2.7.11◆ Pythonの切り替え
$ pyenv version $ pyenv global 2.7.11 $ python --versionaws-cli インストール
$ pip install awscliaws-cli 番外編①
◆ python-pipを一括インストール
$ yum -y install python-pip◆ インストール確認
$ pip -V pip 9.0.3 from /usr/lib/python2.7/site-packages (python 2.7)◆ aws-cli インストール
$ pip install awscliaws-cli 番外編②
◆ get-pip.pyでインストール
$ curl "https://bootstrap.pypa.io/get-pip.py" -o "get-pip.py" $ sudo python get-pip.py◆ aws-cli インストール
$ pip install awscli
- 投稿日:2020-05-22T20:35:44+09:00
【自然言語処理100本ノック 2020】第3章: 正規表現
はじめに
自然言語処理の問題集として有名な自然言語処理100本ノックの2020年版が4/6に公開されました。
この記事では、以下の第1章から第10章のうち、第3章: 正規表現を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNN, CNN
- 第10章: 機械翻訳
事前準備
回答にはGoogle Colaboratoryを利用しています。
Google Colaboratoryのセットアップ方法や基本的な使い方は、こちらの記事が詳しいです。
なお、以降の回答の実行結果を含むノートブックはgithubにて公開しています。第3章: 正規表現
Wikipediaの記事を以下のフォーマットで書き出したファイルjawiki-country.json.gzがある.
・1行に1記事の情報がJSON形式で格納される
・各行には記事名が”title”キーに,記事本文が”text”キーの辞書オブジェクトに格納され,そのオブジェクトがJSON形式で書き出される
・ファイル全体はgzipで圧縮される
以下の処理を行うプログラムを作成せよ.まずは指定のデータをダウンロードします。
Google Colaboratoryのセル上で下記のコマンドを実行すると、カレントディレクトリに対象の圧縮ファイルがダウンロードされます。!wget https://nlp100.github.io/data/jawiki-country.json.gz【 wget 】コマンド――URLを指定してファイルをダウンロードする
20. JSONデータの読み込み
Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
pandasのread_jsonを用いることで、圧縮ファイルも直接読み込むことができます。
import pandas as pd df = pd.read_json('./jawiki-country.json.gz', lines=True) text_uk = df.loc[df['title'] == 'イギリス', 'text'].values[0] print(text_uk)pandasでJSON文字列・ファイルを読み込み
pandasで任意の位置の値を取得・変更する
pandas.DataFrameの構造とその作成方法21. カテゴリ名を含む行を抽出
記事中でカテゴリ名を宣言している行を抽出せよ.
^はデフォルトでは文字列全体の先頭にのみマッチします。
今回はすべての行をチェックしたいため、MULTILINEオプションを利用して、^を各行の先頭にマッチさせています。import re pattern = r'^(.*\[\[Category:.*\]\].*)$' result = '\n'.join(re.findall(pattern, text_uk, re.MULTILINE)) print(result)Pythonの正規表現モジュールreの使い方
Pythonで文字列を連結・結合22. カテゴリ名の抽出
記事のカテゴリ名を(行単位ではなく名前で)抽出せよ.
一部のカテゴリ名に含まれる「カテゴリ名|記号」の|以降を拾わないようにするために、カッコ内の正規表現にマッチはするが拾ってはこない(?:...)を利用しています。
pattern = r'^.*\[\[Category:(.*?)(?:\|.*)?\]\].*$' result = '\n'.join(re.findall(pattern, text_uk, re.MULTILINE)) print(result)23. セクション構造
記事中に含まれるセクション名とそのレベル(例えば”== セクション名 ==”なら1)を表示せよ.
('=='), ('セクション名'), ('==')のグループを抽出し、=の長さをもとにレベルも併せて表示しています。
pattern = r'^(\={2,})\s*(.+?)\s*(\={2,}).*$' result = '\n'.join(i[1] + ':' + str(len(i[0]) - 1) for i in re.findall(pattern, text_uk, re.MULTILINE)) print(result)24. ファイル参照の抽出
記事から参照されているメディアファイルをすべて抜き出せ.
各行の先頭以外にも登場しているため、MULTILINEオプションを外しています。
pattern = r'\[\[ファイル:(.+?)\|' result = '\n'.join(re.findall(pattern, text_uk)) print(result)25. テンプレートの抽出
記事中に含まれる「基礎情報」テンプレートのフィールド名と値を抽出し,辞書オブジェクトとして格納せよ.
# テンプレートの抽出 pattern = r'^\{\{基礎情報.*?$(.*?)^\}\}' template = re.findall(pattern, text_uk, re.MULTILINE + re.DOTALL) print(template) # フィールド名と値を辞書オブジェクトに格納 pattern = r'^\|(.+?)\s*=\s*(.+?)(?:(?=\n\|)|(?=\n$))' result = dict(re.findall(pattern, template[0], re.MULTILINE + re.DOTALL)) for k, v in result.items(): print(k + ': ' + v)Pythonで辞書を作成するdict()と波括弧、辞書内包表記
26. 強調マークアップの除去
25の処理時に,テンプレートの値からMediaWikiの強調マークアップ(弱い強調,強調,強い強調のすべて)を除去してテキストに変換せよ.
def remove_markup(text): # 強調マークアップの除去 pattern = r'\'{2,5}' text = re.sub(pattern, '', text) return text result_rm = {k: remove_markup(v) for k, v in result.items()} for k, v in result_rm.items(): print(k + ': ' + v)27. 内部リンクの除去
26の処理に加えて,テンプレートの値からMediaWikiの内部リンクマークアップを除去し,テキストに変換せよ.
def remove_markup(text): # 強調マークアップの除去 pattern = r'\'{2,5}' text = re.sub(pattern, '', text) # 内部リンクマークアップの除去 pattern = r'\[\[(?:[^|]*?\|)??([^|]*?)\]\]' text = re.sub(pattern, r'\1', text) return text result_rm = {k: remove_markup(v) for k, v in result.items()} for k, v in result_rm.items(): print(k + ': ' + v)28. MediaWikiマークアップの除去
27の処理に加えて,テンプレートの値からMediaWikiマークアップを可能な限り除去し,国の基本情報を整形せよ.
def remove_markup(text): # 強調マークアップの除去 pattern = r'\'{2,5}' text = re.sub(pattern, '', text) # 内部リンクマークアップの除去 pattern = r'\[\[(?:[^|]*?\|)??([^|]*?)\]\]' text = re.sub(pattern, r'\1', text) # 外部リンクマークアップの除去 pattern = r'https?://[\w!?/\+\-_~=;\.,*&@#$%\(\)\'\[\]]+' text = re.sub(pattern, r'', text) # htmlタグの除去 pattern = r'<.+?>' text = re.sub(pattern, r'', text) # テンプレートの除去 pattern = r'\{\{(?:lang|仮リンク)(?:[^|]*?\|)*?([^|]*?)\}\}' text = re.sub(pattern, r'\1', text) return text result_rm = {k: remove_markup(v) for k, v in result.items()} for k, v in result_rm.items(): print(k + ': ' + v)29. 国旗画像のURLを取得する
テンプレートの内容を利用し,国旗画像のURLを取得せよ.(ヒント: MediaWiki APIのimageinfoを呼び出して,ファイル参照をURLに変換すればよい)
import requests def get_url(text): url_file = text['国旗画像'].replace(' ', '_') url = 'https://commons.wikimedia.org/w/api.php?action=query&titles=File:' + url_file + '&prop=imageinfo&iiprop=url&format=json' data = requests.get(url) return re.search(r'"url":"(.+?)"', data.text).group(1) print(get_url(result))Pythonで文字列を置換
Python, Requestsの使い方おわりに
自然言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。
オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。
- 投稿日:2020-05-22T20:05:13+09:00
線形計画法を用いた生産計画の最適化 (Python + PuLP)
はじめに
数理計画法 (mathematical programming) とは、目的関数と呼ばれる目標値を、ある制約の下で最大化(最小化)する手法です。その中でも、線形計画法 (linear programming; LP) は、目的関数と制約式が変数に関する一次式($\sum_ia_ix_i + b$ という形の式)で表せるものを言います。線形計画法は、数理計画法の中でも単純なものの 1 つですが、それゆえにソルバーやモデリング用のライブラリが充実しており、利用しやすい環境が整っています。特に、企業においては、利益やコストといった金銭的な指標を目的関数として、生産量や輸送量といった制御可能な変数を最適化することが多いかと思います。
本記事では、数理最適化のモデリング技法についてまとめられた以下の書籍から、演習問題を 1 つ取り出して実際に定式化し、Python のモデリング言語である PuLP で実装して最適解を求めるところまでやっていきたいと思います。
Model Building in Mathematical Programming
https://www.amazon.co.jp/dp/1118443330/なお、この演習問題は TFUG の数理最適化グループで行っている輪読の宿題の一つです。TFUG のグループは誰でも参加可能ですので、興味がある方は Slack を覗いてみると良いかもしれません!
本記事は、以下のような構成になっています。始めにモデリングの仕方について簡単に説明した後、例題の問題設定を紹介し、モデリング、実装、検証を行っていきます。
- モデリングの流れ
- 問題設定
- モデリング
- コラム 1:モデリングの恣意性
- モデルの実装
- モデルの検証
- コラム 2:数理最適化モデルのテスト
- おわりに
途中でコラム的な節が挟まっており、読み飛ばしても問題ありませんが、個人的に面白いと感じているトピックについて書いているので、ぜひ読んでみてください。
モデリングの流れ
一般論として、何らかの計画を数理的にモデル化するには、以下の 2 つを定義する必要があります。
- 目的関数
- 制約式
工場の生産計画を例に考えてみましょう。まず、目的関数は、最適化したいコストや利益を表します。例えば、工場 A と工場 B で生産を行うとき、生産コストは次のように表すことができると仮定します。
$$
\text{生産コスト} = \sum_{i \in \{A, B\}} \text{生産単価}_i \times \text{生産量}_i.
$$
この場合、生産単価の高い工場の生産量を減らし、生産単価の低い工場の生産量を増やすことで、生産コストを低く抑えることができそうです。しかし、この式だけでは、実は本当に求めたい最適解を求めることはできません。なぜなら、「○○以上の量を生産しなければいけない」という制約がないため、純粋に生産コストを最小化しようとすると、全く生産を行わないのが最適解になってしまうからです。そこで、次に制約式として、このような事態を避けるために変数に条件を課します。例えば、先ほど触れた「○○以上の量を生産しなければいけない」という制約は、次のように表せます。
$$
\sum_{i \in \{A, B\}} \text{生産量}_i \geq \text{需要量}.
$$他にも、生産計画であれば、工場の生産能力に限度があり、生産量の上限が決まっていることが多いでしょう。こういった業務上の制約や決まりを、数式として表現したものが制約式です。
また、目的関数と制約式を定義するには、以下の情報が必要になります。
- 集合
- 最適化の対象となる要素の集まり。
- 例:工場、対象期間(月や日にち)等。
- パラメータ
- 目的関数や制約式の計算に使用する数値。
- 例:生産単価、生産量上限、需要量等。
- 変数
- 実際に最適化を行いたい数値。
- 例:生産量、輸送量等。
実際に自分で一からモデリングする場合は、個人的には、まず目的関数を定義するのを目指すのがよいと思います。目的関数を定義しようとすると、その過程で必要な情報を整理する必要があるので、集合やパラメータ、変数を決めることにも繋がります。その後、各変数に関して、必要な制約を洗い出し、1 つ 1 つ式として表現していけば完成です。
以降では、例題の問題設定を紹介し、実際にモデリングしていきます。
問題設定:Food manufacture 1
今回扱うのは、食品の生産計画です。具体的には、1 月から 6 月に渡り、毎月原料となる油を購入し、精製・混合することで、食品を作るそうです(マーガリンか何か……?)。この生産計画の中で、各月の各原料油の購入量や消費量を調整することで、最終的に利益を最大化することを目指します。
今回の問題で、目的関数や制約式を考えるには、以下の要素に関係するコストや制約を考える必要があります。
- 在庫
- 購入
- 精製
- 混合
- 販売
それぞれの状況について、詳しく説明していきます。
在庫
原料油の在庫は、新たに購入すると増加し、食品の生産に消費すると減少します。
各原料油は、それぞれ $1000 [t]$ まで在庫として保持しておくことができます。ただし、1 か月あたり $5 [£/t]$ の保管コストがかかります。
また、どの原料油に関しても、在庫は $500 [t]$ で始まり、最終的に $500[t]$ 以上は残すものとします。
購入
上記の油を、1 月から 6 月にかけて、以下の単価で購入します。
月 VEG 1 VEG 2 OIL 1 OIL 2 OIL 3 Jan 110 120 130 110 115 Feb 130 130 110 90 115 Mar 110 140 130 100 95 Apr 120 110 120 120 125 May 100 120 150 110 105 Jun 90 100 140 80 135 購入できる量には、特に制約はありません。
精製
購入した量と元々在庫にあった量のうち、ある量を精製プロセスにかけます。精製する過程では、特にロス等はないものとし、精製にかかるコストも無視できるものとします。
原料油には、植物性と非植物性という 2 つの種類があり、精製プロセスは、油の種類ごとに異なる精製ラインで行われるそうです。精製量の上限は以下のように設定されています。
種類 精製量上限[t/月] 植物性 200 非植物性 250 また、原料油の種類は以下のようになっています。
名前 種類 VEG 1 植物性 VEG 2 植物性 OIL 1 非植物性 OIL 2 非植物性 OIL 3 非植物性 混合
精製した油をすべて混合することで、その月に出荷する食品が完成します。ここでも特にロスは発生しないため、混ぜ合わせた原料油の重量の総和が食品の生産量になります。
また、それぞれの原料油は、下表に示す硬度を持っています。生産される食品の硬度は、原料油の消費量に応じた平均になり、食品の硬度は $3$ から $6$ の間に納まらないといけないそうです。
名前 硬度 VEG1 8.8 VEG2 6.1 OIL1 2.0 OIL2 4.2 OIL3 5.0 販売
生産した食品は、その月のうちに必ず売り切ることが可能だそうです。つまり、生産量がそのまま販売量になります。販売単価は、月によらず $150 [£/t]$ で一定とします。
モデリング:Food manufacture 1
これから、先ほど説明した問題設定を、実際にモデル化していきます。なお、先ほど「目的関数を定義する中で集合やパラメータを決めていくのがよい」と書きましたが、説明には集合、パラメータ、変数を先に書いた方が楽なので、そうしています。
集合
数理最適化モデルにおいて、パラメータや変数の添字になるのが集合です。
今回の問題では、以下の 4 つの集合を考えることにします。原料油
$$
\text{OILS} = \{\text{VEG1}, \text{VEG2}, \text{OIL1}, \text{OIL2}, \text{OIL3}\}.
$$対象期間(月)
$$
\text{TIME_IDX} = \{1, \ldots, 6 \}.
$$精製ライン
$$
\text{REF_LINES} = \{\text{VEG}, \text{NONVEG} \}.
$$(各精製ラインの)精製対象
ラインごとに定義するので、全体としては集合の集合(集合族)になります。
$$
\text{USED_OILS} = \{\text{USED_OILS}_{VEG}, \text{USED_OILS}_{NONVEG}\}.
$$
各精製ラインの中身の集合は、
$$
\begin{aligned}
\text{USED_OILS}_{VEG} &= \{\text{VEG1}, \text{VEG2}, \text{VEG3}\}, \\
\text{USED_OILS}_{NONVEG} &= \{\text{OIL1}, \text{OIL2}\}.
\end{aligned}
$$ここでは天下り的に与えていますが、集合の定義の仕方は一意ではないことに注意してください。集合の定義の仕方によっては、モデルの汎用性が下がってしまうこともあります。これについては、制約式の節で詳しく触れます。
パラメータ
次に、目的関数や制約式の計算に使用するパラメータを定義していきます。
名前 添字 値域 説明 $\text{buy_uc}$ $\text{OILS}$
$\text{TIME_IDX}$$[0, +\infty)$ 原料油の購入単価。 $\text{stock_uc}$ - $[0, +\infty)$ 原料油の保管単価。 $\text{sell_uc}$ - $[0, +\infty)$ 食品の販売単価。 $\text{stock_init}$ $\text{OILS}$ $[0, +\infty)$ 原料油の初期在庫。 $\text{stock_final_lb}$ $\text{OILS}$ $[0, +\infty)$ 原料油の最終的な在庫量の下限。 $\text{stock_ub}$ - $[0, +\infty)$ 原料油の在庫量上限。 $\text{hardness}$ $\text{OILS}$ $[0, +\infty)$ 原料油の硬度。 $\text{ref_ub}$ $\text{REF_LINES}$ $[0, +\infty)$ 精製量の上限。 uc は単価を意味する unit cost の略、lb/ub はそれぞれ lower/upper bound の略で、上下限という意味です。
変数
同様に、最適化の対象となる変数を定義します。変数名には名詞を使うのが望ましいですが、長すぎると式が見づらいので、一部動詞にしています。
名前 添字 値域 説明 $\text{buy}$ $\text{OILS}$
$\text{TIME_IDX}$$[0, +\infty)$ 原料油の購入量。 $\text{use}$ $\text{OILS}$
$\text{TIME_IDX}$$[0, +\infty)$ 原料油の使用量。 $\text{produce}$ $\text{TIME_IDX}$ $[0, +\infty)$ 食品の生産量。 $\text{opening_stock}$ $\text{OILS}$
$\text{TIME_IDX}$$[0, \text{stock_ub}]$ 原料油の月初在庫。 $\text{closing_stock}$ $\text{OILS}$
$\text{TIME_IDX}$$[0, \text{stock_ub}]$ 原料油の月末在庫。 在庫については、$\text{opening_stock}$ と $\text{closing_stock}$ のうち片方だけ宣言すれば十分な場合も多いです。この辺りは個人の好みもあります。
目的関数
必要な情報が出揃ったので、目的関数を定義していきます。今回は、期間全体の利益を最大化したいのでした。
$$
\text{maximize} ~~\text{total_profit}.
$$
ここで、利益は売上と各種コストを用いて、次のように計算できます(なお、会計用語としての「利益」とは厳密には一致しません。設備投資などの固定費は最適化の対象外なので今回無視しています)。
$$
\text{total_profit} = \text{total_sales} - \text{total_buy_cost} - \text{total_stock_cost}
$$
売上と各種コストは、関係する食品や原料油の量と単価をかけ合わせることで計算できます。
$$
\begin{align}
\text{total_sales} &= \text{sell_uc} \times \sum_{t\in \text{TIME_IDX}} \text{produce}_t, \\
\text{total_buy_cost} &= \sum_{oil\in \text{OILS}, t\in \text{TIME_IDX}} \text{buy_uc}_{oil, t} \times \text{buy}_{oil, t}, \\
\text{total_stock_cost} &= \text{stock_uc} \times \sum_{oil\in \text{OILS}, t\in \text{TIME_IDX}} \text{closing_stock}_{oil, t}.
\end{align}
$$制約条件
次に、制約式を書き下していきます。
変数の単純な上下限については、「変数」の節で値域として書いています。初期在庫、最終在庫
1 月の月初在庫は、初期在庫に一致します。
$$
{}^\forall oil\in \text{OILS}, ~~\text{opening_stock}_{oil, 1} = \text{stock_init}_{oil}.
$$6 月の月末在庫は、最終在庫下限以上になるものとします。
$$
{}^\forall oil\in \text{OILS}, ~~\text{closing_stock}_{oil, 6} \geq \text{stock_final_lb}_{oil}.
$$在庫バランス
2 月以降の月初在庫は、前の月の月末在庫に一致します。
$$
{}^\forall t\in {2,\ldots,6}, ~~{}^\forall oil\in \text{OILS}, ~~\text{opening_stock}_{oil, t} = \text{closing_stock}_{oil, t - 1}.
$$月末在庫は、その月の月初在庫に購入量を加え、消費量を引いた量になります。
$$
{}^\forall t\in \text{TIME_IDX}, ~~{}^\forall oil\in \text{OILS}, ~~\text{closing_stock}_{oil, t} = \text{opening_stock}_{oil, t} + \text{buy}_{oil, t} - \text{use}_{oil, t}.
$$生産量バランス
各月の生産量は、原料油の消費量の総和に一致します。
$$
{}^\forall t\in \text{TIME_IDX}, ~~\text{produce}_t = \sum_{oil \in \text{OILS}} \text{use}_{oil, t}.
$$硬度
「生産される食品の硬度は、原料油の消費量に応じた平均になり、食品の硬度は $3$ から $6$ の間に納まらないといけない」という部分ですが、少し複雑です。問題文を素朴に式で表すと、次のようになりますが、変数に関する一次式になっていません。
$$
3 \leq \frac{\sum_{oil\in \text{OILS}} \text{hardness}_{oil} \times \text{use}_{oil, t}}{\text{produce}_t} \leq 6.
$$
しかし、分母を払うことで、一次式に変換することができます。
$$
3 \times \text{produce}_t \leq \sum_{oil\in \text{OILS}} \text{hardness}_{oil} \times \text{use}_{oil, t} \leq 6 \times \text{produce}_t.
$$さらに、元々の式では生産量が $0$ の場合の挙動が怪しいですが、変換後の式であれば、消費量・生産量共に $0$ になるため、制約を満たすことが分かります。今回の問題設定では、生産を行わないということも考えられるので、問題ありません。
精製量上限
今回の生産計画では、精製ラインごとに精製量の上限がありました。式で表現すると、次のように書けます。
$$
{}^\forall line\in \text{REF_LINES}, ~~{}^\forall t\in \text{TIME_IDX}, \sum_{oil\in \text{USED_OILS}_{line}} \text{use}_{oil, t} \leq \text{ref_ub}_{line}.
$$
少し分かりづらいかもしれませんが、各精製ラインに関して、対象となる原料油の消費量の和が、ある上限以下となるような制約をかけています。コラム 1:モデリングの恣意性
なお、精製ラインに関する情報は、別の表現をすることもできます。例えば、$\text{USED_OILS}$ の代わりに、各原料油の精製ラインを意味するパラメータ $\text{ref_line}$ を次のように定義してみます。
添字 値 VEG1 VEG VEG1 VEG OIL1 NONVEG OIL2 NONVEG OIL3 NONVEG これは、問題文に出てきた原料油の種類の表ほぼそのままですから、こちらを使う方が自然かもしれません。このパラメータを使えば、精製量上限の制約は、次のように表現できます。
$$
{}^\forall line\in \text{REF_LINES}, ~~{}^\forall t\in \text{TIME_IDX}, \sum_{\substack{oil\in \text{OILS} ~\text{s.t.} \\ \text{ref_line}_{oil} = line}} \text{use}_{oil, t} \leq \text{ref_ub}_{line}.
$$やっていることは先ほどと同じで、精製対象となる原料油の消費量を足し合わせ、上限で抑えているだけです。こちらのモデルでも、今回のデータであれば、同一の結果を得ることができます。
しかし、どちらの方が望ましいかは、一考の余地があります。
試しに、$\text{VEG1}$ と $\text{VEG2}$ の精製を行う $\text{VEGNEW}$ というラインが追加されるケースを考えてみましょう。既存の原料油の一部しか精製できないラインが作られるというのは、まぁありそうなことです。元のモデルであれば、次のように表現できます。
$$
\begin{aligned}
\text{USED_OILS} &= \{\text{USED_OILS}_{VEG}, \text{USED_OILS}_{VEGNEW}, \text{USED_OILS}_{NONVEG}\},\\
\text{USED_OILS}_{VEG} &= \{\text{VEG1}, \text{VEG2}, \text{VEG3}\}, \\
\text{USED_OILS}_{VEGNEW} &= \{\text{VEG1}, \text{VEG2}\}, \\
\text{USED_OILS}_{NONVEG} &= \{\text{OIL1}, \text{OIL2}\}.
\end{aligned}
$$しかし、$\text{ref_line}$ を使う定式化をしていたら、どうでしょうか? 先ほどの表を見てわかるように、このパラメータは 1 つの原料油について、精製ラインが必ず 1 つに定まることを前提としています。したがって、$\text{VEG1}$ が $\text{VEG}$ にも $\text{VEGNEW}$ にも属する状況は、モデルで表すことができません。
このように、集合とパラメータの定義の仕方 1 つとっても、汎用性の持たせ方には幅があります。問題についての理解が浅いと、間違った方向に汎用性を持たせてしまい(あるいは持たせ損ない)、後でモデルを修正するのが大変になる、なんてこともあります(cf. 早すぎる抽象化 (premature abstraction))。
あらかじめ全ての変更を予見できるわけではありませんし、法改正などで仮定そのものが変わってしまうこともありますが、こういった何気ない集合の定義の仕方に、恣意的な仮定が紛れ込んでいることを自覚するのが重要だと思います。また、実際にモデリングするときには、ユーザー(ドメインエキスパート)の力を借りて、業務への理解を深めることも欠かせません。
モデルの実装:Food manufacture 1
上記のモデルを Python + PuLP で実装していきます。PuLP では、集合やパラメータは Python の任意のデータ構造を使用できるため、使いやすいものを使えば十分です。以降では、変数の宣言、目的関数の定義、および制約式の定義について紹介します。
変数の宣言
PuLP の変数は、次のように宣言します。
# 名前 添字 下限 上限 種類(連続 or 整数) buy = LpVariable.dicts("buy", (OILS, TIME_IDX), lowBound=0, upBound=None, cat='Continuous')ちなみに、ドキュメントには載っていないのですが、行列のような形で宣言することもできるようです。
buy = LpVariable.matrix("buy", (OILS, TIME_IDX), lowBound=0, upBound=None, cat='Continuous')目的関数の設定
まず、定義した変数やパラメータを用いて、目的関数を表現します。
# 目的関数の計算 total_sales = lpSum(produce[t] * sell_uc for t in TIME_IDX) total_buy_cost = lpSum(buy[oil][t] * buy_uc[oil][t] for t in TIME_IDX for oil in OILS) total_stock_cost = lpSum(closing_stock[oil][t] * stock_uc for t in TIME_IDX for oil in OILS) total_cost = total_buy_cost + total_stock_cost total_profit = total_sales - total_cost # 目的関数次に、線形計画問題
LpProblemを定義し、目的関数を足し込むことで設定できます。# モデルの定義と目的関数の設定 model = LpProblem("Food manufacture 1", LpMaximize) model += total_profit次のように、メソッドを使って目的関数を設定することもできます。
model.setObjective(total_profit)目的関数を複数宣言した場合、最後のものだけが使われます。
制約式の設定
制約式も、目的関数と同じように、
modelに足し込むことで宣言可能です。# 生産量バランス for t in TIME_IDX: model += produce[t] == lpSum(use[oil][t] for oil in OILS)目的関数と書き方が同じですが、クラス名からうまく判別しているようです。メソッドで定義することも可能です。
model.addConstraint(produce[t] == lpSum(use[oil][t] for oil in OILS))なお、これまで省略していましたが、目的関数にも制約式にも、個別に名前を付けることができます。
model += produce[t] == lpSum(use[oil][t] for oil in OILS), "Production balance"コード全体
今回実装したモデルのコード全体は以下にまとめます。
import numpy as np import pandas as pd from pulp import LpProblem, LpMaximize, LpVariable, lpSum # 集合の定義 TIME_IDX = [1, 2, 3, 4, 5, 6] OILS = ['VEG1', 'VEG2', 'OIL1', 'OIL2', 'OIL3'] REF_LINES = ['VEG', 'NONVEG'] USED_OILS = { 'VEG': ['VEG1', 'VEG2'], 'NONVEG': ['OIL1', 'OIL2', 'OIL3'] } # パラメータの設定 sell_uc = 150 stock_uc = 5 stock_ub = 1000 stock_init = 500 stock_final_lb = 500 prod_ub = {'VEG': 200, 'NONVEG': 250} hardness_lb = 3 hardness_ub = 6 hardness = {'VEG1': 8.8, 'VEG2': 6.1, 'OIL1': 2.0, 'OIL2': 4.2, 'OIL3': 5.0} buy_uc = { 'VEG1': {1: 110, 2: 130, 3: 110, 4: 120, 5: 100, 6: 90}, 'VEG2': {1: 120, 2: 130, 3: 140, 4: 110, 5: 120, 6: 100}, 'OIL1': {1: 130, 2: 110, 3: 130, 4: 120, 5: 150, 6: 140}, 'OIL2': {1: 110, 2: 90, 3: 100, 4: 120, 5: 110, 6: 80}, 'OIL3': {1: 115, 2: 115, 3: 95, 4: 125, 5: 105, 6: 135} } # 変数の定義 buy = LpVariable.dicts("buy", (OILS, TIME_IDX), lowBound=0) use = LpVariable.dicts("use", (OILS, TIME_IDX), lowBound=0) produce = LpVariable.dicts("produce", TIME_IDX, lowBound=0) opening_stock = LpVariable.dicts("opening_stock", (OILS, TIME_IDX), lowBound=0, upBound=stock_ub) closing_stock = LpVariable.dicts("closing_stock", (OILS, TIME_IDX), lowBound=0, upBound=stock_ub) # 目的関数の計算 total_sales = lpSum(produce[t] * sell_uc for t in TIME_IDX) total_buy_cost = lpSum(buy[oil][t] * buy_uc[oil][t] for t in TIME_IDX for oil in OILS) total_stock_cost = lpSum(closing_stock[oil][t] * stock_uc for t in TIME_IDX for oil in OILS) total_cost = total_buy_cost + total_stock_cost total_profit = total_sales - total_cost # モデルの定義と目的関数の設定 model = LpProblem("Food manufacture 1", LpMaximize) model += total_profit # 制約式 # 初期在庫、最終在庫 for oil in OILS: model += opening_stock[oil][TIME_IDX[0]] == stock_init model += closing_stock[oil][TIME_IDX[-1]] >= stock_final_lb # 各月に関して for t in TIME_IDX: # 在庫バランス for oil in OILS: if t != TIME_IDX[0]: model += opening_stock[oil][t] == closing_stock[oil][t - 1] model += closing_stock[oil][t] == opening_stock[oil][t] + buy[oil][t] - use[oil][t] # 販売量バランス model += produce[t] == lpSum(use[oil][t] for oil in OILS) # 硬度 total_hardness = lpSum(hardness[oil] * use[oil][t] for oil in OILS) model += total_hardness <= hardness_ub * produce[t] model += total_hardness >= hardness_lb * produce[t] # 精製量上限 for line in REF_LINES: total_prod_amount = lpSum(use[oil][t] for oil in USED_OILS[line]) model += total_prod_amount <= prod_ub[line] model.solve() print(model.objective.value()) # 結果: 107842.59264500001上記のコードを実行すると、目的関数の値として
107842.59264500001という値が得られます。これは元々のテキストに書いてあるのと同じため、最適解が求まっていると考えて良さそうです。モデルの検証:Food manufacture 1
前節で、テキストと同じ最適値が求まりました。しかし、実際に数理最適化を仕事で使うときは、最適値も最適解も分からないことが多く、今回のように「答え合わせ」できることは稀です。そこで、モデルを定性的に分析することで、結果の妥当性を検証します。
ここでの定性的な分析とは、モデルの定義から、最適解の取るべき値について予想を立て、実際の計算結果と比較することです。例えば、今回は最初と最後の在庫(の下限)が固定されており、毎月在庫量に応じたコストがかかるため、「まずは在庫を消費していき、途中から在庫を回復させていく方が利益が高くなるだろう」という予想が立てられます。
では、実際に最適解を表示して、この仮説を確かめてみましょう。
期末在庫の最適解は、次のように取得することができます。closing_stock_value = {oil: {t: closing_stock[oil][t].value() for t in TIME_IDX} for oil in OILS}以下のコードで、プロットしてみます。
df = pd.DataFrame(closing_stock_value, index=TIME_IDX, columns=OILS) df.plot()
全く使用していない OIL1 以外、全て初期在庫から 1 度落ちてから回復しており、最適化結果がそれなりに妥当そうだということが確認できました。
ここでは 1 つの仮説だけを検証しましたが、実際にはこのような reasonable な仮定をできるだけ多く立て、最適化結果を検証します。そして、もし最適解が全ての仮説通りの結果になっていたら、どうやら正しく実装できていそうだ、ということが分かります。逆に、最適解が仮説を満たしていなかったら、モデルの実装か、仮説のどちらかが間違っていることになります。これはこれで、モデルそのものを修正したり、モデルへの理解を深めるきっかけになり、非常に有用です。
コラム 2:数理最適化モデルのテスト
ところで、先ほど書いた検証の仕方に違和感を覚えた方もいるのではないでしょうか。ソフトウェアエンジニアなら、「制約が一つ一つ与えられているなら、それぞれについて単体テストを書けばよいのでは?」と思うかもしれません。それはその通りで、書ける状況なら書くべきです。
しかし、数理最適化モデルは、密結合な制約の巨大な集合であり、制約レベルの単体テストは多くの場合困難です。先ほどの制約式も、一見別々に見えて、実はモデルの中でお互いに依存しあっています。例えば、精製量上限の値を小さくしたら、硬度制約を満たせなくなる、ということが平気で起こります。もちろん、モデル自体を 1 つの巨大な関数と見立ててテストすることは可能ですが、同値クラスや境界値などを知ることは難しく、結局「発見的に仮説を立てて検証する」というところに戻ってきます(自動化はできますが)。
実際、オープンソースの数理最適化ソルバーのテストコードを見ても、挙動がわかりやすい toy problem をいくつか解くだけで済ましており、あまり厳密なテストはできていないように見えます(モデルのテストとソルバーのテストでは勝手が違うかもしれませんが)。
数理最適化のテストに関する研究や文献も探しましたが、私が調べた限りでは、それらしきものは見つかりませんでした。見逃しているだけの可能性もありますので、もし「こうすると良いよ」等の意見がありましたら、コメントいただけると幸いです。
一応、このあたりのテストの難しさは、MLSE のコミュニティが取り組んでいる、機械学習モデルのテストの問題にも近い気がするので、こちらのコミュニティの動向を追った方が良いかもしれません。
Challenges for machine learning systems toward continuous improvement
https://www.slideshare.net/chezou/challenges-for-machine-learning-systems-toward-continuous-improvementところで、どうでもいい話題ですが、以前、数理最適化を使っているっぽい以下の記事がプチ炎上して、「テストしろよ」みたいなコメントをされているのをみて、なんとも言えない気分になりました(関係者ではありませんが……)。
「AIで数秒」のはずが…保育所選考、連休返上で作業 さいたま市 - 毎日新聞
https://mainichi.jp/articles/20200204/k00/00m/040/176000cここまで書いたような方法で頑張って検証しても、予期していないデータでモデルが unbounded になったり infeasible になったりすることがあるので、頭が痛いです。世知辛い
おわりに
ということで、生産計画を線形計画法としてモデル化し、PuLP で実際に解いて、結果を検証するところまでやってみました。単純にモデリングの説明だけなら、"Model Building ..." の原書を読むだけで良いと思ったので、少ないなりの実務経験を踏まえた、モデリングに対する自分なりの考えも書くようにしました。
これからモデリングの練習を始めるのであれば、このモデルを自分なりにいろいろ変えてみると良いかもしれません。例えば、購入量に月・油の種類ごとの上下限を設けたり、精製プロセスで 1% ロスするように設定してみたり、色々考えられると思います。
本当はシリーズものにして、演習問題全部解きたかったんですが、力尽きました
解くだけならまだしも、記事にするとなると大変ですね。というわけで、もしこの記事が良いなと思ったら、チャンネル登録といいねお願いします!(YouTuber 風)。


- 投稿日:2020-05-22T19:59:35+09:00
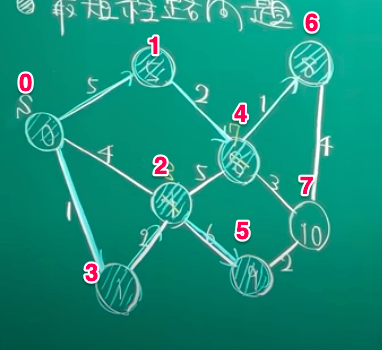
【Python3】14行でダイクストラ法
昨日は14行で素因数分解を実装したのですが、本日はヒープを用いて14行でダイクストラ法を実装しました。上から14行で。
dijkstra.pyfrom heapq import heappush, heappop def dijkstra(vertices_num, edges, src): dist = [float('inf')] * vertices_num heap = [(0, src)] while len(heap): d, from_ = heappop(heap) if d < dist[from_]: dist[from_] = d for _, to, cost in filter(lambda e: e[0]==from_, edges): heappush(heap, (min(dist[to], dist[from_] + cost), to)) return dist if __name__ == '__main__': answer = dijkstra( 8, [ (0, 1, 5), (0, 2, 4), (0, 3, 1), (1, 4, 2), (1, 0, 5), (2, 0, 4), (2, 3, 2), (2, 4, 5), (2, 5, 6), (3, 0, 1), (3, 2, 2), (4, 1, 2), (4, 2, 5), (4, 6, 1), (4, 7, 3), (5, 2, 6), (5, 7, 2), (6, 4, 1), (6, 7, 4), (7, 4, 3), (7, 5, 2), (7, 6, 4) ], 0 ) print(answer) # [0, 5, 3, 1, 7, 9, 8, 10]第1引数は頂点数、第2引数は(from_, to, cost)のリスト、第3引数は開始地点のインデックスになります。返り値は開始地点から各頂点への最短距離を返します。
参考
https://www.youtube.com/watch?v=X1AsMlJdiok
ダイクストラ法に関しては、こちらの動画の説明が非常にわかりやすかったので、そこで扱われている問題を参考にテストケースを作らせて頂きました。赤字は各頂点のインデックスです。
(引用元:上記Youtubeページより)
- 投稿日:2020-05-22T19:50:13+09:00
ゼロから始めるLeetCode Day33「1. Two Sum」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day32「437. Path Sum III」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
LeetCodeに登録した際に一番最初に解くであろう問題について書いてなかったので、今更ながら書きます。
難易度はEasy。
Top 100 Liked Questionsからの抜粋です。問題としては、整数の入った配列と特定の値が格納された変数
targetが与えられます。配列の中から二つの整数を選び、targetと一致する組み合わせを見つけ、配列のインデックスを返すような関数を実装してください。
なお、その組み合わせは一つしか存在せず、かつ同じ値を二度使うことは許されません。Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1].解法
例えば全探索で書いてみるとこうなります。
全探索とはいわゆるしらみつぶしに調べるようにする書き方で、全てのパターンを調べようとする代わりに致命的なパフォーマンスとなってしまうことがほとんどです。
class Solution: def twoSum(self, nums: List[int], target: int) -> List[int]: for i in range(len(nums)): for j in range(i+1,len(nums)): ans = nums[i] + nums[j] if target == ans: return [i,j] # Runtime: 6848 ms, faster than 5.01% of Python3 online submissions for Two Sum. # Memory Usage: 14.6 MB, less than 18.14% of Python3 online submissions for Two Sum.遅いですね。
では代わりにハッシュマップを使って書いてみましょう。class Solution: def twoSum(self, nums: List[int], target: int) -> List[int]: hashmap = {} for i in range(len(nums)): num = nums[i] complement = target - num if num in hashmap: return [hashmap[num],i] else: hashmap[complement] = i # Runtime: 52 ms, faster than 60.15% of Python3 online submissions for Two Sum. # Memory Usage: 15.3 MB, less than 5.11% of Python3 online submissions for Two Sum.かなり速度が改善されましたね。
言語の書き方について学んで短く書いたりするのも大切ですが、それだけではなく、書き方一つで速度を大幅に変えることができるというのがデータ構造とアルゴリズムを学ぶ大きな理由の一つと言えるでしょう。
自分への戒めのためにもここで書いておきます。
こっちの書き方の方が良いよ!とかこの言語で書いてみたよ!とかがあれば是非コメントしてみてください。
- 投稿日:2020-05-22T19:39:32+09:00
Python: 日本語テキスト:単語の連続性から発話の特徴
単語の連続性を知る
発話テキストの分かち書き
前投稿では単語の類似性に焦点を当て、データを加工し分析する方法を学びました。
こちらでは、単語の連続性に焦点を当てたデータ分析について学びます。まず復習として、正規表現を用いた文字列の処理とJanomeによる分かち書きのコードを書きます。
import os import json import pandas as pd import re from janome.tokenizer import Tokenizer # 破綻ではない発話データセットの作成 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] t = Tokenizer() # 分かち書きした単語を格納する空のリストを作成 wakatiO = [] tmp1 = [] tmp2 = '' # 1行ずつ読み込み for row in df_label_text_O.values.tolist(): # 正規表現で不要な文字列を除去 reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') # Janomeで分かち書きして単語をリストへ格納 tmp1 = t.tokenize(reg_row, wakati=True) wakatiO.append(tmp1) tmp1 = [] # 分かち書きした単語を表示 print(wakatiO)単語辞書の作成
この後の分析で扱いやすくするために、単語を数値化します。
数値化するために、単語にIDを付与するための変換リスト(辞書)を作成します。
ここでは、単語の出現数が多い順に連番を付与することにします。データセットを分かち書きし、次に、単語の出現数をカウントして降順に並べ替えます
使用例はこちら
import os import json import pandas as pd import re from janome.tokenizer import Tokenizer from collections import Counter import itertools # 破綻ではない発話データセットの作成 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # 分かち書きし、正規表現で不要な文字列を除去 t = Tokenizer() wakatiO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') tmp1 = t.tokenize(reg_row, wakati=True) wakatiO.append(tmp1) tmp1 = [] # ①単語の出現数をカウント word_freq = Counter(itertools.chain(*wakatiO)) # ②単語を出現数順に並べ替え、dicに追加 dic = [] for word_uniq in word_freq.most_common(): dic.append(word_uniq[0]) # ③単語にIDを付与し辞書を作成 # enumerate(dic) は、for文を使用して`dic`からインデックスを`i`、要素を`word_uniq`に取得します dic_inv = {} for i, word_uniq in enumerate(dic, start=1): dic_inv.update({word_uniq: i}) # 辞書の表示 print(dic_inv)単語の出現数のカウント
単語の出現数をカウントするには
Python標準ライブラリのCounterクラスと itertools.chain()を用います。①Counter 要素の個数をカウントします。 collections.Counter()にリストやタプルを渡すと キーに要素、値に出現回数を持つCounterオブジェクトが生成されます。 また、辞書型のメソッドを使用することができ キーのリスト keys()、値のリスト values()、キーと 値のペアのタプルのリスト items() を取得できます。import collections # リスト`list_`を生成 list_ = ['a', 'c', 'a', 'c', 'b', 'b', 'c', 'c', 'a'] # `list_`の要素をカウント C = collections.Counter(list_) # カウント結果 print(C) Counter({'c': 4, 'a': 3, 'b': 2}) # 要素を指定するとそのカウント結果を返す print(C['c']) 4 # 含まれない要素を指定すると`0`を返す print(C['d']) 0 # 出現回数順に(要素, 出現回数)の形式でタプルを返す print(C.most_common()) [('c', 4), ('a', 3), ('b', 2)] # タプルの2番目の要素を取得 most_common = C.most_common() print(most_common[1]) ('a', 3)多次元のリストを一次元に平坦化
②itertools.chain 多次元のリストを一次元に平坦化します。 リストが [1,2,3,],[4,5,6] のようになっていても それぞれのリストの要素にアクセスすることができます。 多重リストはエラーになるので、*をつけて1重リストとして渡します。import itertools from collections import Counter b = [['A', 'B', 'C',],['D', 'E', 'F']] print(list(itertools.chain(*b))) ['A', 'B', 'C', 'D', 'E', 'F'] a = Counter(itertools.chain(*b)) print(a) Counter({'A': 1, 'B': 1, 'C': 1, 'D': 1, 'E': 1, 'F': 1})単語の並び替え
単語を並び替えるには
③most_common(n)を用います。個数が多い順から少ない順に並べたリストをタプルで返します。
nを指定すると個数が多い方からn個のタプルを返します。nを省略するとすべての要素を返します。from collections import Counter list_ = ['a', 'c', 'a', 'c', 'b', 'b', 'c', 'c', 'a'] C = Counter(list_) print(C) Counter({'c': 4, 'a': 3, 'b': 2}) # 出現回数順に(要素, 出現回数)の形式でタプルを返す print(C.most_common()) [('c', 4), ('a', 3), ('b', 2)] print(C.most_common(2)) [('c', 4), ('a', 3)] # タプルの2番目以降の要素を取得 mc = C.most_common() print(mc[1:]) [('a', 3), ('b', 2)]単語を数値へ変換
破綻ではない発話データセットに対し
作成した辞書を用いて単語をIDへ変換し
新たな配列に格納します。wakatiO には分かち書きされた単語がリストで格納されています。
print(wakatiO[0:1]) [['おはよう', '。'], ['すみません', '、', 'あなた', 'は', '誰', 'です', 'か', '?']]dic_inv にはIDが振られている単語が格納されています。
print(dic_inv['おはよう']) 218 print(dic_inv['。']) 2or文と辞書型のデータ参照(前節で説明した内容)の手法を用い
wakatiOの単語のリストをdic_invのIDに変換します。wakatiO_n = [[dic_inv[word] for word in waka] for waka in wakatiO] [218, 2]後半のfor waka in wakatiOは、 wakatiOの単語リストを1つずつwakaに渡します。 中間のfor word in wakaは、 wakaの単語リストを1単語ずつwordに渡します。 前半のdic_inv[word]は、 wordに対応するIDを辞書dic_invから取得します。使用例はこちら
import os import json import pandas as pd import re from janome.tokenizer import Tokenizer from collections import Counter import itertools # 破綻ではない発話データセットの作成 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # 分かち書きし、正規表現で不要な文字列を除去 t = Tokenizer() wakatiO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') tmp1 = t.tokenize(reg_row, wakati=True) wakatiO.append(tmp1) tmp1 = [] # 単語の出現数をカウント、並べ替え、dicに追加 word_freq = Counter(itertools.chain(*wakatiO)) dic = [] for word_uniq in word_freq.most_common(): dic.append(word_uniq[0]) # 単語にIDを付与し辞書を作成 # enumerate(dic) は、for文を使用して`dic`からインデックスを`i`、要素を`word_uniq`に取得します dic_inv = {} for i, word_uniq in enumerate(dic, start=1): dic_inv.update({word_uniq: i}) # ①単語をIDへ変換 wakatiO_n = [[dic_inv[word] for word in waka] for waka in wakatiO] print(wakatiO_n)辞書からIDを取得
dic_inv[分かち書きされた単語]を用います。同じ内容ですが、再度書くと
wakatiOの単語のリストをdic_invのIDに変換します。wakatiO_n = [[dic_inv[word] for word in waka] for waka in wakatiO] [218, 2]後半のfor waka in wakatiOは、 wakatiOの単語リストを1つずつwakaに渡します。 中間のfor word in wakaは、 wakaの単語リストを1単語ずつwordに渡します。 前半のdic_inv[word]は、 wordに対応するIDを辞書dic_invから取得します。wakatiOの単語のリストをdic_invのIDに変換します。
wakatiO_n = [[dic_inv[word] for word in waka] for waka in wakatiO] [218, 2]後半のfor waka in wakatiOは、 wakatiOの単語リストを1つずつwakaに渡します。 中間のfor word in wakaは、 wakaの単語リストを1単語ずつwordに渡します。 前半のdic_inv[word]は、 wordに対応するIDを辞書dic_invから取得します。単語の連続性からテキストの特徴を知る
N-gramとは
自然言語データを解析するとき、目的がテキストを分類することであれば
単語データから 単語文書行列 を作成します。また、目的がテキストからトピックを抽出することであれば N-gramモデルを作成します。N-gram とは、テキストを連続したN個の文字で分割する方法です。
身近な例では、検索システムのインデックスとして使用されています。
N=1のときは 1-gram(ユニグラム)、N=2のときは2-gram(バイグラム)
N=3のときは3-gram(トリグラム)と呼びます。【テキスト】あいうえお 【 1-gram 】あ | い | う | え | お 【 2-gram 】あい | いう | うえ | えお 【 3-gram 】あいう | いうえ | うえおテキストを連続したN個の単語で分割することもできます。
【テキスト】今日は晴れです。 【 1-gram 】今日 | は | 晴れ | です | 。 【 2-gram 】今日-は | は-晴れ | 晴れ-です | です-。 【 3-gram 】今日-は-晴れ | は-晴れ-です | 晴れ-です-。単語文書行列が同じテキストに含まれる単語の共起性(同じ文中に出現するか)を表すことに対し
N-gramは単語の連続性(どの順番で出現するか)を表します。ここでは単語からトピックを抽出し分析を行いたいため
後者のN-gramモデル、特に2-gramモデルを作成していきます。まずは、簡単な例で2-gramモデルを作成してみます。
word = ['今日', 'は', '晴れ', 'です', '。'] bigram = [] for i in range(len(word)-1): bigram.append([word[i], word[i+1]]) print(bigram) >>> 出力結果 [['今日', 'は'], ['は', '晴れ'], ['晴れ', 'です'], ['です', '。']]2-gramリストの作成
単語を数値へ変換 で作成した単語をIDに変換したデータセットから2-gramリストを作成します。
2-gramリストの作成には DataFrameに対してグループ化を行うgroupby()と 合計値を算出するsum()を用います。まずはgroupby()とsum()の使い方を確認します。
from pandas import DataFrame # DataFrameを用意 df=DataFrame([['AA','Camela',150000,20000], ['BB','Camera',70000,10000], ['AA','earphone',2000,200], ['AA','Video',3000,150], ['BB','earphone',200000,8000], ['BB','Camera',50000,5000], ['AA','Video',1000,200]], columns=['CUSTOMER','PRODUCT','PRICE','DISCOUNT']) df >>> 出力結果 CUSTOMER PRODUCT PRICE DISCOUNT 0 AA Camela 150000 20000 1 BB Camera 70000 10000 2 AA earphone 2000 200 3 AA Video 3000 150 4 BB earphone 200000 8000 5 BB Camera 50000 5000 6 AA Video 1000 200 # 1つの条件でgroupbyし、sumを算出 grouped = df.groupby('CUSTOMER').sum() grouped >>> 出力結果 PRICE DISCOUNT CUSTOMER AA 156000 20550 BB 320000 23000 # 複数の条件でgroupbyし、sumを算出 grouped = df.groupby(['CUSTOMER','PRODUCT']).sum() grouped >>> 出力結果 PRICE DISCOUNT CUSTOMER PRODUCT AA Camela 150000 20000 Video 4000 350 earphone 2000 200 BB Camera 120000 15000 earphone 200000 80002-gramリストの作成において
重複する2-gramは複数回出現していると言うことなので
重要な組み合わせであると考えます。groupby()でグループ化し、合わせてsum()で出現回数(=重み)を計算します。
使用例はこちら
import os import json import pandas as pd import re from janome.tokenizer import Tokenizer from collections import Counter import itertools # 破綻ではない発話データセットの作成 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # 分かち書きし、正規表現で不要な文字列を除去 t = Tokenizer() wakatiO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') tmp1 = t.tokenize(reg_row, wakati=True) wakatiO.append(tmp1) tmp1 = [] # 単語の出現数をカウント、並べ替え、dicに追加 word_freq = Counter(itertools.chain(*wakatiO)) dic = [] for word_uniq in word_freq.most_common(): dic.append(word_uniq[0]) # 単語にIDを付与し辞書を作成 dic_inv = {} for i, word_uniq in enumerate(dic, start=1): dic_inv.update({word_uniq: i}) # 単語をIDへ変換 wakatiO_n = [[dic_inv[word] for word in waka] for waka in wakatiO] # 2-gramリストを作成 tmp = [] bigramO = [] for i in range(0, len(wakatiO_n)): row = wakatiO_n[i] # 2-gramの作成 for j in range(len(row)-1): tmp.append([row[j], row[j+1]]) bigramO.extend(tmp) tmp = [] # 重複する2-gramの個数をカウントし、DataFrame形式で表現します # 配列`bigramO`をDataFrameに変換しcolumnを設定 df_bigramO = pd.DataFrame(bigramO) df_bigramO = df_bigramO.rename(columns={0: 'node1', 1: 'node2'}) # `weight`列を追加し、値を1で統一 df_bigramO['weight'] = 1 # 2-gram個数をカウント df_bigramO = df_bigramO.groupby(['node1', 'node2'], as_index=False).sum() # 出現数が1を超えるリストを抽出します # 出現数=`weight`のsum値 df_bigramO = df_bigramO[df_bigramO['weight'] > 1] # 2-gramの表示 df_bigramO.head(10)2-gramネットワークの作成
単語の類似性では
単語をノード 単語間の類似度をエッジとその重みとして 無向グラフを作成しました。ここでは
単語をノード 単語ペアの出現回数をエッジとその重みとして 有向グラフ(有向ネットワーク)を作成します。有向グラフは、出現順 に意味があると考えます。
例として、単語の出現順や、組織内のコミュニケーションのやり取りが挙げられます。
まず、2-gramリストの作成 で作成した2-gramリストを用いて、有向グラフを作成し可視化してみます。使用例はこちら
import os import json import pandas as pd import re from janome.tokenizer import Tokenizer from collections import Counter import itertools import networkx as nx import matplotlib.pyplot as plt # 破綻ではない発話データセットの作成 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # 分かち書きし、正規表現で不要な文字列を除去 t = Tokenizer() wakatiO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') tmp1 = t.tokenize(reg_row, wakati=True) wakatiO.append(tmp1) tmp1 = [] # 単語の出現数をカウント、並べ替え、dicに追加 word_freq = Counter(itertools.chain(*wakatiO)) dic = [] for word_uniq in word_freq.most_common(): dic.append(word_uniq[0]) # 単語にIDを付与し辞書を作成 dic_inv = {} for i, word_uniq in enumerate(dic, start=1): dic_inv.update({word_uniq: i}) # 単語をIDへ変換 wakatiO_n = [[dic_inv[word] for word in waka] for waka in wakatiO] # 2-gramリストを作成 tmp = [] bigramO = [] for i in range(0, len(wakatiO_n)): row = wakatiO_n[i] # 2-gramの作成 for j in range(len(row)-1): tmp.append([row[j], row[j+1]]) bigramO.extend(tmp) tmp = [] # 配列`bigramO`をDataFrameに変換しcolumnを設定 df_bigramO = pd.DataFrame(bigramO) df_bigramO = df_bigramO.rename(columns={0: 'node1', 1: 'node2'}) # `weight`列を追加し、値を1で統一する df_bigramO['weight'] = 1 # 2-gram個数をカウント df_bigramO = df_bigramO.groupby(['node1', 'node2'], as_index=False).sum() # 出現数が1を超えるリストを抽出 df_bigramO = df_bigramO[df_bigramO['weight'] > 1] # 有向グラフを作成 G_bigramO = nx.from_pandas_edgelist(df_bigramO, 'node1', 'node2', ['weight'], nx.DiGraph) # 作成したグラフを可視化 # レイアウトの設定 pos = nx.spring_layout(G_bigramO) nx.draw_networkx(G_bigramO, pos) plt.show()有向グラフ(有向ネットワーク)の作成
無向グラフの作成に用いた、nx.from_pandas_edgelist()の引数にnx.DiGraphを追加して指定します。
その他の引数の詳細については、2.2.2 類似度ネットワークの作成 を参照してください。G_corlistO = nx.from_pandas_edgelist(df_corlistO, 'node1', 'node2', ['weight'], nx.DiGraph)グラフ(ネットワーク)の可視化
無向グラフの可視化とまったく同様です。
# ライブラリ`Matplotlib`から`pyplot`をimport from matplotlib import pyplot # 各ノードの最適な表示位置を計算 pos = nx.spring_layout(graph) # グラフを描画 nx.draw_networkx(graph, pos) # Matplolibを用いてグラフを表示 plt.show()2-gramネットワークの特徴
有向グラフであっても考え方は無向グラフと同様です。
2-gramネットワークの作成で可視化したグラフを一見しても特徴を把握することは困難なので
指標を用いて定量的に特徴を把握します。ここでもクラスタ係数と媒介中心性を計算してみます。
使用例はこちら
import os import json import pandas as pd import re from janome.tokenizer import Tokenizer from collections import Counter import itertools import networkx as nx import matplotlib.pyplot as plt # 破綻ではない発話データセットの作成 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) label_text = [] for file in file_dir[:10]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # 分かち書きし、正規表現で不要な文字列を除去 t = Tokenizer() wakatiO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') tmp1 = t.tokenize(reg_row, wakati=True) wakatiO.append(tmp1) tmp1 = [] # 単語の出現数をカウント、並べ替え、dicに追加 word_freq = Counter(itertools.chain(*wakatiO)) dic = [] for word_uniq in word_freq.most_common(): dic.append(word_uniq[0]) # 単語にIDを付与し辞書を作成 dic_inv = {} for i, word_uniq in enumerate(dic, start=1): dic_inv.update({word_uniq: i}) # 単語をIDへ変換 wakatiO_n = [[dic_inv[word] for word in waka] for waka in wakatiO] # 2-gramリストを作成 tmp = [] bigramO = [] for i in range(0, len(wakatiO_n)): row = wakatiO_n[i] # 2-gramの作成 for j in range(len(row)-1): tmp.append([row[j], row[j+1]]) bigramO.extend(tmp) tmp = [] # 配列`bigramO`をDataFrameに変換しcolumnを設定 df_bigramO = pd.DataFrame(bigramO) df_bigramO = df_bigramO.rename(columns={0: 'node1', 1: 'node2'}) # `weight`列を追加し、値を1で統一する df_bigramO['weight'] = 1 # 2-gram個数をカウント df_bigramO = df_bigramO.groupby(['node1', 'node2'], as_index=False).sum() # 出現数が1を超えるリストを抽出 df_bigramO = df_bigramO[df_bigramO['weight'] > 1] # 有向グラフの作成 G_bigramO = nx.from_pandas_edgelist( df_bigramO, 'node1', 'node2', ['weight'], nx.DiGraph) # 破綻ではない発話ネットワーク # ①平均クラスタ係数の計算 print('平均クラスタ係数') print(nx.average_clustering(G_bigramO, weight='weight')) print() # ②媒介中心性の計算 bc = nx.betweenness_centrality(G_bigramO, weight='weight') print('媒介中心性') for k, v in sorted(bc.items(), key=lambda x: -x[1]): print(str(k) + ': ' + str(v))
平均クラスタ係数の計算
すべてのノードのクラスタ係数の平均が高いほど、そのネットワークは密であると言えます。
クラスタ係数の平均はnx.average_clustering()を用いて算出します。nx.average_clustering(G, weight=None)G graphを指定します。 (前前節で作成した有向グラフG_bigramOのこと) weight 重みとして使用する数値を持つエッジを指定します。Noneの場合、各エッジの重みは1になります。媒介中心性の計算
あるノードがすべてのノード間の最短経路中にいくつ含まれているかによって求められます。
つまり、情報を効率的に伝える際に最も利用されるノードほど媒介性が高く、中心的であると言えます。nx.betweenness_centrality(G, weight=None)G graphを指定します。 (前前節で作成した有向グラフG_bigramOのこと) weight 重みとして使用する数値を持つエッジを指定します。Noneの場合、すべてのエッジの重みは等しいとみなされます。2-gramネットワークの影響関係
ネットワークの特徴を定量的に把握する指標をいくつか実装しました。さらに
次数分布 を用いて各単語がどう影響し合っているかを見てみます。有向ネットワークでは単語ノードが向きを持つため
入次数: ある単語が他の単語から影響を受ける 出次数: ある単語が他の単語へ影響を与える に分けて考えます。使用例はこちら
import os import json import pandas as pd import re from janome.tokenizer import Tokenizer from collections import Counter import itertools import networkx as nx import matplotlib.pyplot as plt # 破綻ではない発話データセットの作成 file_path = './6110_nlp_preprocessing_data/init100/' file_dir = os.listdir(file_path) label_text = [] for file in file_dir[:100]: r = open(file_path + file, 'r', encoding='utf-8') json_data = json.load(r) for turn in json_data['turns']: turn_index = turn['turn-index'] speaker = turn['speaker'] utterance = turn['utterance'] if turn_index != 0: if speaker == 'U': u_text = '' u_text = utterance else: a = '' for annotate in turn['annotations']: a = annotate['breakdown'] tmp1 = str(a) + '\t' + u_text tmp2 = tmp1.split('\t') label_text.append(tmp2) df_label_text = pd.DataFrame(label_text) df_label_text = df_label_text.drop_duplicates() df_label_text_O = df_label_text[df_label_text[0] == 'O'] # 分かち書きし、正規表現で不要な文字列を除去 t = Tokenizer() wakatiO = [] tmp1 = [] tmp2 = '' for row in df_label_text_O.values.tolist(): reg_row = re.sub('[0-9a-zA-Z]+', '', row[1]) reg_row = reg_row.replace('\n', '') tmp1 = t.tokenize(reg_row, wakati=True) wakatiO.append(tmp1) tmp1 = [] # 単語の出現数をカウント、並べ替え、dicに追加 word_freq = Counter(itertools.chain(*wakatiO)) dic = [] for word_uniq in word_freq.most_common(): dic.append(word_uniq[0]) # 単語にIDを付与し辞書を作成 dic_inv = {} for i, word_uniq in enumerate(dic, start=1): dic_inv.update({word_uniq: i}) # 単語をIDへ変換 wakatiO_n = [[dic_inv[word] for word in waka] for waka in wakatiO] # 2-gramリストを作成 tmp = [] bigramO = [] for i in range(0, len(wakatiO_n)): row = wakatiO_n[i] # 2-gramの作成 for j in range(len(row)-1): tmp.append([row[j], row[j+1]]) bigramO.extend(tmp) tmp = [] # 配列`bigramO`をDataFrameに変換しcolumnを設定 df_bigramO = pd.DataFrame(bigramO) df_bigramO = df_bigramO.rename(columns={0: 'node1', 1: 'node2'}) # `weight`列を追加し、値を1で統一する df_bigramO['weight'] = 1 # 2-gram個数をカウント df_bigramO = df_bigramO.groupby(['node1', 'node2'], as_index=False).sum() # 出現数が1を超えるリストを抽出 df_bigramO = df_bigramO[df_bigramO['weight'] > 1] # 有向グラフの作成 G_bigramO = nx.from_pandas_edgelist( df_bigramO, 'node1', 'node2', ['weight'], nx.DiGraph) # 破綻ではない発話ネットワーク # 入次数の度数を求めてください indegree = sorted([d for n, d in G_bigramO.in_degree(weight='weight')], reverse=True) indegreeCount = Counter(indegree) indeg, cnt = zip(*indegreeCount.items()) # 出次数の度数を求めてください outdegree = sorted([d for n, d in G_bigramO.out_degree(weight='weight')], reverse=True) outdegreeCount = Counter(outdegree) outdeg, cnt = zip(*outdegreeCount.items()) # 次数分布の作成 plt.subplot(1, 2, 1) plt.bar(indeg, cnt, color='r') plt.title('in_degree') plt.subplot(1, 2, 2) plt.bar(outdeg, cnt, color='b') plt.title('out_degree') plt.show()
入次数(indegree)
入次数(indegree)とは
有向グラフでは頂点に入ってくる辺数を言い
無向グラフでは、接続辺の数を言います。ネットワークの入次数を調べるには
in_degree()メソッドを用います。
結果は (node番号, 入次数) の形式で返ってきます。# G_bigramOの入次数を調べる print(G_bigramO.in_degree(weight='weight')) >>> 出力結果 [(1, 208), (2, 155), (4, 148), (5, 126), (7, 47)・・・]出次数(outdegree)
出次数(outdegree)とは
有向グラフでは、頂点から出て行く辺数を言い
無向グラフでは、接続辺の数を言います。出次数を調べるには、out_degree()メソッドを用います。
結果は (node番号, 出次数) の形式で返ってきます。# G_bigramOの出次数を調べる print(G_bigramO.out_degree(weight='weight')) >>> 出力結果 [(1, 248), (2, 12), (4, 83), (5, 65), (7, 57)・・・]


- 投稿日:2020-05-22T19:14:10+09:00
TensorFlow v2 でattribute 'app'が無いと怒られるときの解決方法
0.概要
Tensor Flow v2のサンプルコードを実行した際に,以下のError文が出たときの解決方法についてまとめます.
(Tensor Flow v1へのバックデートは行いません.)1.背景
Tensor Flowの勉強をするにあたり,以下のURL先よりサンプルコード(classify_image.py)をダウンロードしました.
https://github.com/atong01/Imagenet-Tensorflow/blob/master/classify_image.py2.環境
OS:Windows10 Enterprise 1809 64bit
Python:3.7.6
TensorFlow_gpu:v2.1.03.困ったこと
サンプルコードなので,問題なく実行できるかと思いきや,なぜか以下のErrorが出てきてしまいます.
Error文Traceback (most recent call last): File "classify_image.py", line 49, in <module> FLAGS = tf.app.flags.FLAGS AttributeError: module 'tensorflow' has no attribute 'app'なんでやねーん.
で,調べてみたところ
「TensorFlow v2ではtf.appがすでに削除されているので,
『TensorFlow v1にバックデートする』か
『TensorFlow v2のAPI用にコードを書き換える』
のどちらかで対応してね」とのこと.なんやねーん.せっかく苦労して環境構築したんやから,こっから環境をいじりたくないわー.
4.解決方法
で,さらに調べたところ,以下のimport文をコードに書き込んだら問題解決可能との情報を発見.
解決方法import tensorflow.compat.v1 as tf実際,サンプルコードに追記して実行してみたら,問題なく動きました.
よかったー!
参考URLhttps://stackoverflow.com/questions/58258003/attributeerror-module-tensorflow-has-no-attribute-app
- 投稿日:2020-05-22T19:13:20+09:00
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
昨日までのはこちら
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
確率について
辞書で引くと
現象全てに対する割合の事のようです。プログラミングではこの確率の計算も良く出てきます。
また、確率とともに統計というのも扱う分野の一つであるので
プログラマーとしてやっていくなら用語や計算方法については
抑えておいた方が良いかなと思います。確率の用語
抑えておきたい確率の用語をピックアップしました。
用語 英語 意味 確率 Probability 事象が起こる割合 順列 Permutation 異なるn個からr個を取り出した順に1列に並べること 組み合わせ Combination 異なるn個のものからr個を取り出すこと 階乗 Factorial ある正の整数から1までの整数の積 独立 お互いの結果が影響しあうことがないこと 試行 確率を求めるために試しにやってみる行為のこと 反復試行 条件を変えずに、同じ行為を繰り返すような試行 期待値 Expected value 1回の試行で得られる値の平均値 事象 Event 起こること 積事象 2つの事象AとBのうちAとBが同時に起こる事象 全事象 起こる結果全てをまとめたもの 根元事象 Atomic event それ以上細かく分けることが出来ない事象のこと 余事象 ある場合以外の事象 排反事象 同時に起こらない」事象のこと 空事象 存在しない事象のこと ベン図 複数の集合の関係や、集合の範囲を視覚的に図式化したもの オッズ odds 確率論で確率を示す数値 確率分布 probability distribution 確率変数に対して、各々の値をとる確率を表した 確率変数 random variable 起こりうることがらに割り当てている値 離散型(確率変数) Discrete とびとびの数になる確率変数 連続型(確率変数) Continuous 幾らでも細かく刻むことができる確率変数 確率の計算
Pythonでは確率計算をするのに役立つライブラリがあり
比較的楽に確率の計算をすることができます。階乗(factorial)
階乗はmathライブラリなどのfactorialメソッドで計算ができます。計算方法はある正の整数から1までの整数の積になるので
4の階乗であれば4*3*2*1 (4!)となり24になります。import math print(math.factorial(4)) print(math.factorial(10))24
3628800順列
順列とは異なるn個のものからr個選んで一列に並べる場合の数です。リスト(配列)などから順列を生成して列挙することができます。
itertoolsライブラリのpermutationsで求められます。
itertools.permutations(リスト値,選ぶ個数)この場合返却される値そのものはリストではないので
値を見たければリストに変換が必要です。以下は3個の中から2つを選んで並べた際の順列です。
import itertools l = ['A', 'B', 'C'] p = itertools.permutations(l, 2) print(list(p))[('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')]
順列の総数
数が少ない場合は列挙する事ができますが、順列の個数が多すぎると表示はできないので
総数だけを求めるのであればmath.factorialを使って計算できます。計算式は
n! / (n - r)!となるので7個から5個を選ぶ順列の総数はn , r = 7 , 5 math.factorial(n) // math.factorial(n - r)2520
これで求める事ができます。
組み合わせ
組み合わせは異なるn個のものからr個選ぶ場合の数で順列のように順番を考慮しません。リスト(配列)などから順列を生成して列挙することができます。
itertoolsライブラリのcombinationsで求められます。
itertools.combinations(リスト値,選ぶ個数)5個の中から2個を選ぶ組み合わせの列挙は以下のようになります。
l = ['a', 'b', 'c', 'd','e'] c = itertools.combinations(l, 2) print(list(c))[('a', 'b'), ('a', 'c'), ('a', 'd'), ('a', 'e'), ('b', 'c'), ('b', 'd'), ('b', 'e'), ('c', 'd'), ('c', 'e'), ('d', 'e')]
この場合は要素同士の重複はありません。
要素同士の重複も加味して組み合わせを作るには
combinations_with_replacementを用います。
itertools.combinations_with_replacement(リスト値,選ぶ個数)l = ['a', 'b', 'c'] c = itertools.combinations_with_replacement(l, 2) print(list(c))[('a', 'a'), ('a', 'b'), ('a', 'c'), ('b', 'b'), ('b', 'c'), ('c', 'c')]
組み合わせの総数
総数だけを求めるのであれば
math.factorialを使って計算できます。計算式は
n! / (r! * (n - r)!)となるので7個から3個を選ぶ組み合わせの総数は
次のようになります。n , r = 7 , 3 math.factorial(n) // (math.factorial(n - r) * math.factorial(r))35
デカルト積(複数のリストの直積)
複数のリストの直積を作成するにはitertoolsライブラリのproductを用います。
itertools.product(リスト値,リスト値)l1 = ['a', 'b', 'c'] l2 = ['X', 'Y'] p = itertools.product(l1, l2) print(list(p))[('a', 'X'), ('a', 'Y'), ('b', 'X'), ('b', 'Y'), ('c', 'X'), ('c', 'Y')]
引数
repeatに繰り返しの回数を指定すると、イテラブルオブジェクトを繰り返し使用して
直積を生成できます。
itertools.product(リスト値,repeat=回数)l1 = ['a', 'b', 'c'] p = itertools.product(l1, repeat=2) print(list(p))('a', 'a'), ('a', 'b'), ('a', 'c'), ('b', 'a'), ('b', 'b'), ('b', 'c'), ('c', 'a'), ('c', 'b'), ('c', 'c')]
まとめ
確率について触れていきますが、まずは用語とかを覚えてみましょう。
明日は期待値の計算についてです。君がエンジニアになるまであと37日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-22T18:50:13+09:00
Pythonでファッション画像とテキスト文を【スクレイピング】してみた。
はじめに
Qiita初投稿なのでお手柔らかに。
現在修士1年で、研究でディープラーニングとファッションをテーマに何かやろうと考えています。
そこでまず、勉強がてら画像を分類してみようと思い、自分でデータを集めようと今に至るわけです。(既存のデータセット使って分類すればええやん。。。)
実行環境
- Python3.7.4
- MacOS Mojave10.14.6
画像と商品紹介文をセットでスクレイピングしてみた。
今回はPythonのlxmlライブラリを使って画像とテキスト文をスクレイピングしました。スクレイピングどころかプログラミング自体初心者だったので、技術評論社が出版している「Python クローリング&スクレイピング」を参考にしながら自分でコードを組みました。この時からQiitaの存在を知っていれば、Qiitaで解決したはず、、、。コードは以下になります。
補足
今回はメンズのTシャツのみをスクレイピングしたかったためカテゴリーと性別を指定しました。ZOZOTOWNのECサイトは各ページに135の商品があり、それぞれの商品をクリックするとその商品の詳細ページにリンクが移ります。
今回は移った先のページのテキストとトップ画像を一枚スクレイピングするコードを書いています。scraping_zozo_img_text.pyfrom typing import Iterator from typing import List import requests import lxml.html import time import csv import os以下がメインの実行になります。
csvlist = [['no', 'URL', 'item_text']] i = 0 u = 0 j = 0 URL = "https://zozo.jp/men-category/tops/tshirt-cutsew/?pno=" for page in range(1, 100): time.sleep(1) pageUrl = "https://zozo.jp/men-category/tops/tshirt-cutsew/?pno=" + str(page) response = requests.get(pageUrl) #一覧ページにある各アイテムの詳細ページのURLを取得↓↓↓↓ urls = scrape_item_page(response) #各アイテム(一覧ページの画像と対応)の詳細ページへのURLが取得される。 for url in urls: j = j + 1 time.sleep(1) #画像を拾ってフォルダに保存↓↓↓↓↓↓↓ img_url = get_image(url) w_img = requests.get(img_url) with open(str('picture_zozo/')+str(j)+str('.jpg'),'wb') as file: file.write(w_img.content) info = scrape_item_infomation(url) print(info) csvlist.append([j, url, info]) f = open("item_text.csv", 'w') writecsv = csv.writer(f) writecsv.writerows(csvlist) f.close()10行目のresponseにはURLのページ内のさまざまな情報が格納されているイメージを持ってください。
定義した関数の詳細
各ページのアイテムごとのURLを取得する関数
def scrape_item_page(response: requests.Response) -> Iterator[str]: html = lxml.html.fromstring(response.text) html.make_links_absolute(response.url) url=[] for a in html.cssselect('#searchResultList > li > div[class="catalog-item-container"] > a'): url.append(a.get('href')) return urlメインの実行の12行目。
response.textはhtmlのコード全文になります。fromstring関数を使うことで、直接HtmlElementが得られます。
make_links_absoluteで相対リンクから絶対リンクに書き換えます。
6行目でcssselectを使ってhtmlのタグを辿り各商品の詳細ページのURLが含まれるタグの情報を取得します。
7行目で取得したタグの中のhrefに続くURLを取得できます。
(各ページ内で135個ずつURLを取得します。)各アイテムの詳細ページ中のテキスト文を取得する関数
#各アイテムのURLにアクセスして、商品紹介文を取得する関数を定義 def scrape_item_infomation(url): response = requests.get(url) response.encoding = response.apparent_encoding html = lxml.html.fromstring(response.text) infomation = html.cssselect('#tabItemInfo > div[class="innerBox"] > div[class="contbox"]') info = infomation[0].text_content() return infoメインの15行目で135個から1つずつURLを選択し、画像とテキストを獲得します。
5行目のencodingで文字化けを防ぎます。
以下は先ほどと同じで、最後にinfoにテキスト文を代入して、返します。各アイテムの画像情報(画像URL)を取得する関数
#画像の情報をさらってくる関数を定義 def get_image(url): #一覧ページのURL response = requests.get(url) html = lxml.html.fromstring(response.text) html.make_links_absolute(response.url) image = html.cssselect('#photoMain > img') for img in image: img_url = img.get('src') print(img_url) return img_urlテキストを取得する流れとほとんど変わりません。
ここで、画像の情報が手に入ります。メインの21行目でフォルダに画像を保存するコードを書いています。
この時、スクリプトとフォルダが同じ階層にある必要があります。
空のフォルダは事前に作成しておかないと、エラーが出るので注意してください。ちなみに僕は'picture_zozo'というフォルダを作りました。
最後にCSVファイルに「何個めのアイテムであるか(ナンバー)」、「そのアイテムのURL」、「テキスト文」を保存します。取得した画像とURLをクリックした時のページにある画像が同一商品であるかどうかの確認に使えます。
ちなみに画像はこんな感じに保存されます。
ちなみにCSVファイルはこんな感じです。
No URL text 1 https://〜 〇〇 2 https://〜 △△ 3 https://〜 □□ Noの値と○.jpgの値が同じになるようになってます。
メインの実行のfor文以下で、同じURLを用いているのでテキストと画像の組み合わせは同一の商品のものになっています。
まとめ
初めてQiitaの投稿を試みましたが、文章で伝えるのはなかなか難しいですね。僕自身も完璧に説明できるほど習得している訳ではないので説明がわかりずらい部分もあると思いますが、ご容赦ください。イメージが湧きにくい場合は、実際にコードを参考にして、print()を用いて確認してみるといいと思います。
- 投稿日:2020-05-22T18:26:41+09:00
サッカーチームの監督名のリストをpythonでスクレイピングする
概要
Jリーグの監督一覧のページから監督の名前一覧を取得する方法を説明します。
上記のページでは読みに関してはアルファベットの表記しか載っていませんが、名前の読み方や姓、名も同時に取得したかったので、それらについては後で目視で修正することを前提に、自動で変換します。
その方法についても合わせて説明します。注意
スクレイピングは法律的な問題に抵触する可能性がある行為ですので、利用については各自の判断/責任でお願いします。(参考:スクレイピングは違法?3つの法律問題と対応策を弁護士が5分で解説)
環境
Google Colaboratory (2020年4月3日)
コード
Pythonの
requestsで取得したソースファイルをBeatifulSoupで解析して取得します。
インデックスページから各頭文字の監督リストページのURLを一括取得し、各URLのアクセス先から、具体的な名前とアルファベット表記を抽出しています。!pip install romkan#GoogleColaboratoryで動かすときは必要 from bs4 import BeautifulSoup import requests import time import romkan #Jリーグページのurl base_url = "https://data.j-league.or.jp/" index_page_id = "SFIX06/" #htmlソースの取得とパース html_text = requests.get(base_url+index_page_id).text soup = BeautifulSoup(html_text,"lxml") #ソースコードを見ながら情報を抽出するコードを考えて書く #id=player-indexの要素内のthタグ要素をリストで取得する link_elems = soup.find(id='player-index').find_all('th') #名前、アルファベット表記を格納するリストを宣言 directors = [] for link_elem in link_elems: atag = link_elem.find('a') if atag != None: #特定の頭文字で始まる監督一覧ページへのリンク link = atag.get('href') html_text2 = requests.get(base_url+link).text soup2 = BeautifulSoup(html_text2,"lxml") #id=eventViewのtr要素に選手名が入っている footballers = soup2.find(id='eventView').find_all('tr') for footballer in footballers: atag2 = footballer.find('a') if atag2 == None: continue name = atag2.string #名前を表示している要素の次の兄弟要素がアルファベット表記 alpha = atag2.find_parent().find_next_sibling().string #リストに追加 directors.append([name,alpha]) #進捗確認のための出力 print(name,alpha) #サーバに負荷を与えないように1秒待機する time.sleep(1) katakana = "・ ーァアィイゥウェエォオカガキギクグケゲコゴサザシジスズセゼソゾタダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤュユョヨラリルレロヮワヰヱヲンヴ" def is_kata(text): return all([v in katakana for v in text.replace(' ','')])#スペースはあってもよい directors_yomi = [] for v in directors: name, alpha = v[0], v[1] name_f = name.replace('\u3000',' ').replace(' ',' ').replace('・',' ') if is_kata(name_f): fullname = name_f if '\u3000' in name: first = name.split('\u3000')[0] last = name.split('\u3000')[1] #elif ' ' in name else: first = '' last = fullname else: fullname = romkan.to_katakana(alpha) if ' ' in fullname: first = fullname.split(' ')[0] last = fullname.split(' ')[1] fullname = last+' '+ first else: first = '' last = fullname if is_kata(fullname) == False: name = "#####"+name directors_yomi.append([name,alpha,fullname,last,first]) print('\n'.join(['\t'.join(v) for v in directors_yomi]))
- 投稿日:2020-05-22T17:50:49+09:00
Python で環境変数を取得するときは os.getenv を使おう
今まで Python で環境変数を取得するときと言えば、こうしていた。
import os dsn = os.environ.get('DATABASE_URL')しかし最近になって、
os.getenvという方法があることを知った。参考: Pythonのos.getenvとos.environ.getの違い - Qiita
os.getenvはos.environ.getと等価なので、上のコードは以下のように書き換えられる。from os import getenv dsn = getenv('DATABASE_URL')公式としてはどちらかが推奨というわけではないらしいが、個人的には
os.getenvの方が「なんのために os を import するのかが明確」という理由で良いと思う。os モジュールは用途がいくつかあるため
import osとだけ書いてあっても「これ何のためにいるんだっけ」というのがパッとわかりづらいが、from os import getenvであれば「環境変数のために import しているのだな」とすぐわかって良い。※
from os import environしてもいいが、 callable じゃないオブジェクトを import するのは気持ち悪い (気持ちの問題なのでこのあたりは気にしなければ別に良いのかもしれない)
- 投稿日:2020-05-22T17:47:49+09:00
Visual Studio Code & WSLでpython環境作ってみる
動機
今まで直でWSLからpythonコードを実行してきたけど、window上でコード書く、ubuntuで実行っていうのがめんどくさくなってきたので(あと、vimが使えない人なので、、、)、vscodeで一本化してみた。
前提環境
- windows 10 home
- WSLはubuntu18.04.4 LTS (Bionic Beaver)
- ubuntu上にはanacondaインストール済み
拡張機能
とりあえず、pythonの拡張機能を入れてみる。
インストールしたら再起動ボタンも押しておく。
こんな警告が。
anacondaの中のpythonを選択しておくと、警告が消えて実行できた。Jupyter Notebokも試してみる
特に設定せずに、コマンドパレットで、
Python: Create Blank New Jupyter Notebookで簡単にできた。
補足
WSL2がすでに出ているけど、まだ様子見。
参考
VS CodeでPythonするために必要なこと
Visual Studio CodeでJupyter Notebookを動かしてみた



- 投稿日:2020-05-22T17:34:16+09:00
【Python】レシピサイトから「本当に求めているレシピ」を紹介するシステムを作ってみた!
はじめに
こんにちは,HanBeiです。
前回の記事 は機械学習用のデータ収集についてでしたが,今回も続きをやっていきます。
引き続き,Google Colaboratoryを使います。
興味を持たれたら,コメントやLGTMをお願いいたします!
1-1. 目的
レシピサイトを使うけど「量多いな」,「ホントにオススメの料理は美味しいのか?(失礼極まりない)」と思ったので,自分が求めるレシピを探そうと思います。
1-2. ターゲット(この記事を読む理由)
Web上にあるデータを用いて,機械学習用のデータを手に入れたい人 の役に立てれば幸いです。
1-3. 注意
スクレイピングは用法・用量を守って正しく守らないと犯罪になります。
「スクレイピングやりたいから,気にせずやっちゃえー!」
と楽観的な人や,心配な人は少なくとも下の2つの記事は目を通すことをオススメします。miyabisun 様: 「スクレイピングのやり方をQ&Aサイトで質問するな」
nezuq 様: 「Webスクレイピングの注意事項一覧」1-4. 確認事項
この記事はスクレイピングの方法を教えておりますが,一切の責任を負いかねます。
自分で考え,正しい倫理観をもって使ってください。
2. 準備
2-1. レシピサイトの検討
クックパッド,Nadia,白ごはん.comなどオススメのレシピサイトはありますが,今回は楽天レシピを使用していきます。
理由は,
・「リピートしたい」,「簡単だったよ」,「節約できた」などの定量的なデータがある。
・レシピの件数が多いです。
2-2. Google Colaboratoryを使えるようにする
Google Colaboratoryを使うにあたってGoogleアカウントを作っていない人は,作成しましょう。
ノートブックを新規作成する方法は...
1. Google Colaboratoryをクリックして作業を始める
2. Googleドライブから新規作成する
参考: shoji9x9 様 「Google Colabの使い方まとめ」3. 実践
ここからは実装の内容を書いていきます。
3-1. はじめに
まず,ライブラリをインポートします。
from bs4 import BeautifulSoup from google.colab import drive from google.colab import files import urllib import urllib.parse import urllib.request as req import csv import random import pandas as pd import numpy as np import time import datetime調べたい料理名を決めましょう!
# 調べたい料理名 food_name = 'カレー'3-2. レシピのURLを取得
レシピのURLを取得する関数を作ります。
# 各レシピのurlを格納する recipe_url_lists = [] def GetRecipeURL(url): res = req.urlopen(url) soup = BeautifulSoup(res, 'html.parser') # レシピ一覧の範囲を選択 recipe_text = str(soup.find_all('li', class_= 'clearfix')) # 取得したテキストを1行ずつ分割してリストに収納 recipe_text_list = recipe_text.split('\n') # リストを1行ずづ読み込んで料理名が一致する行だけ抽出 for text in recipe_text_list: # 各レシピのurl取得 if 'a href="/recipe/' in text: #特定箇所を指定してurlにいれる recipe_url_id = text[16:27] # urlの結合 recipe_url_list = 'https://recipe.rakuten.co.jp/recipe/' + recipe_url_id + '/?l-id=recipe_list_detail_recipe' # urlを格納 recipe_url_lists.append(recipe_url_list) # 各レシピのタイトル取得 if 'h3' in text: print(text + ", " + recipe_url_list)人気順のレシピを確認する
# 調べたいページの量 page_count = 2 # 料理名をurlに入れるためエンコード name_quote = urllib.parse.quote(food_name) # urlを結合する(1ページのみurl) # 人気順 base_url = 'https://recipe.rakuten.co.jp/search/' + name_quote # 新着順 # base_url = 'https://recipe.rakuten.co.jp/search/' + name_quote + '/?s=0&v=0&t=2' for num in range(page_count): #特定のページ以降を取得する場合 # num = num + 50 if num == 1: # urlを結合する(1ページのみurl) GetRecipeURL(base_url) if num > 1: # urlを結合する(2ページ以降のurl) # 人気順 base_url_other = 'https://recipe.rakuten.co.jp/search/' + name_quote + '/' + str(num) + '/?s=4&v=0&t=2' # 新着順 # base_url_other = 'https://recipe.rakuten.co.jp/search/' + name_quote + '/' + str(num) + '/?s=0&v=0&t=2' GetRecipeURL(base_url_other) # スクレイピングの1秒ルールを適用 time.sleep(1)ここまでを実行すると,タイトルとレシピのURLが表示されます。
ここで取得したレシピ数を確認してみましょう!
# 取得したレシピ数 len(recipe_url_lists)実行すると,17件と表示されます。
次に,各レシピから必要なデータを取得していきます。
data_count = [] recipe_data_set = [] def SearchRecipeInfo(url, tag, id_name): res = req.urlopen(url) soup = BeautifulSoup(res, 'html.parser') for all_text in soup.find_all(tag, id= id_name): # ID for text in all_text.find_all('p', class_= 'rcpId'): recipe_id = text.get_text()[7:17] # 公開日 for text in all_text.find_all('p', class_= 'openDate'): recipe_date = text.get_text()[4:14] # おいしかった, 簡単だった, 節約できたよの3種類のスタンプ数 for text in all_text.find_all('div', class_= 'stampHead'): for tag in text.find_all('span', class_= 'stampCount'): data_count.append(tag.get_text()) # つくったよレポート数 for text in all_text.find_all('div', class_= 'recipeRepoBox'): for tag in text.find_all('h2'): # レポート数が0のとき if tag.find('span') == None: report = str(0) else: for el in tag.find('span'): report = el.replace('\n ', '').replace('件', '') print("ID: " + recipe_id + ", DATE: " + recipe_date + ", 作られた数: " + report + ", リピートしたい: " + data_count[0] + ", 簡単だった: " + data_count[1] + ", 節約できたよ: " + data_count[2]+ ", url: " + url) # csvファイルに書き込むために格納 recipe_data_set.append([recipe_id, recipe_date, data_count[0], data_count[1], data_count[2], report, url]) # スタンプ数を入れていた配列を空にする data_count.clear() # スクレイピングの制限 time.sleep(1)ここで,取得したデータを確認します。
for num in range(len(recipe_url_lists)): SearchRecipeInfo(recipe_url_lists[num], 'div', 'detailContents')実行すると,ちゃんと取得できていることだわかります。
3-3. Google Driveにcsvファイルを出力
Google Driveにスプレットシートを作成し,データを出力していきます
#使用したいディレクトリをマウントする drive.mount('/content/drive')Google Driveの任意のフォルダを選択,ファイル名を指定
「〇〇〇」は指定してください。# google drive上にフォルダ作成し保存先を指定 save_dir = "./drive/My Drive/Colab Notebooks/〇〇〇/" # ファイル名を選択 data_name = '〇〇〇.csv' # フォルダにcsvファイルを保存 data_dir = save_dir + data_name # csvファイルに項目を追加 with open(data_dir, 'w', newline='') as file: writer = csv.writer(file, lineterminator='\n') writer.writerow(['ID','Release Date','Repeat','Easy','Economy','Report','URL']) for num in range(len(recipe_url_lists)): writer.writerow(recipe_data_set[num]) # 作製したファイルを保存 with open(data_dir, 'r') as file: sheet_info = file.read()実行すると,指定のディレクトリに〇〇〇.csvが出力されます。
ここまでの内容を,簡単にスライドに纏めたのでご参考ください。
※今回は,新着順ではなく人気順で出力しています。
3-4. レシピデータの重み付け
Pandasで出力されたcsvファイルを確認します。
# csvを読み込み rakuten_recipes = pd.read_csv(data_dir, encoding="UTF-8") # 列に追加する準備 df = pd.DataFrame(rakuten_recipes) df出力のイメージは省略します。
次にレシピの公開日から今日までの経過日数を算出します。
# rakuten_recipes.csvからRelease Dateを抜き出す date = np.array(rakuten_recipes['Release Date']) # 現在の日にちを取得 today = datetime.date.today() # 型を合わせる df['Release Date'] = pd.to_datetime(df['Release Date'], format='%Y-%m-%d') today = pd.to_datetime(today, format='%Y-%m-%d') df['Elapsed Days'] = today - df['Release Date'] # 経過日数の値のみ取出してあげる for num in range(len(df['Elapsed Days'])): df['Elapsed Days'][num] = df['Elapsed Days'][num].days # 上から5行だけ確認 df.head()すると,URLの列の隣に経過日数が出てきます。
次は,経過日数を重みとし,Repeat,Easy,Economyの3種類のスタンプに重み付けします。
その重み付けされたデータを,既存のレシピの列に追加していきます。
# あまりにも小さい値にならないように修正 weighting = 1000000 # 3種類のスタンプとレポートの値を抜き出す repeat_stamp = np.array(rakuten_recipes['Repeat']) easy_stamp = np.array(rakuten_recipes['Easy']) economy_stamp = np.array(rakuten_recipes['Economy']) report_stamp = np.array(rakuten_recipes['Report']) # 各スタンプとレポートの合計 repeat_stamp_sum = sum(repeat_stamp) easy_stamp_sum = sum(easy_stamp) economy_stamp_sum = sum(economy_stamp) report_stamp_sum = sum(report_stamp) # 重み付けした値の列を追加 ''' リピート重み付け = (リピートのスタンプ数 ÷ リピート合計) × (修正値 ÷ 公開日からの経過日数) ''' df['Repeat WT'] = (df['Repeat'] / repeat_stamp_sum) * (weighting / df['Elapsed Days']) df['Easy WT'] = (df['Easy'] / easy_stamp_sum) * (weighting / df['Elapsed Days']) df['Economy WT'] = (df['Economy'] / economy_stamp_sum) * (weighting / df['Elapsed Days']) # レポートの重要度(0~1の範囲) proportions_rate = 0.5 # 重み付けした値の列を追加 ''' リピート重み付け = (リピート重み付け × (1 - 重要度)) × ((レポート数 ÷ レポート数の合計) × 重要度[%]) ''' df['Repeat WT'] = (df['Repeat WT'] * (1 - proportions_rate)) * ((df['Report'] / report_stamp_sum) * proportions_rate) df['Easy WT'] = (df['Easy WT'] * (1 - proportions_rate)) * ((df['Easy WT'] / report_stamp_sum) * proportions_rate) df['Economy WT'] = (df['Economy WT'] * (1 - proportions_rate)) * ((df['Economy WT'] / report_stamp_sum) * proportions_rate)重み付けについて...
経過日数については,1ヵ月前と1年前の記事があるとして同じ100個のスタンプがついてるとします。
どちらが,レシピのオススメ度が高いかというと1か月前の方です。
なので,経過日数がある記事ほどスコアは低くなるようにしています。重み付けした値の最大値,最小値の範囲を0~1に変えます。
参考にさせていただいたページを載せておきます。QUANON様:「ある範囲における数値を別な範囲における数値に変換する」
df['Repeat WT'] = (df['Repeat WT'] - np.min(df['Repeat WT'])) / (np.max(df['Repeat WT']) - np.min(df['Repeat WT'])) df['Easy WT'] = (df['Easy WT'] - np.min(df['Easy WT'])) / (np.max(df['Easy WT']) - np.min(df['Easy WT'])) df['Economy WT'] = (df['Economy WT'] - np.min(df['Economy WT'])) / (np.max(df['Economy WT']) - np.min(df['Economy WT'])) df.head()実行結果です。
df.head()とやることでトップ5行だけ表示されます。
3-5. オススメのレシピを表示
ユーザから飛んできた点数を5段階評価にして検索を行う。
# 範囲指定に使用(1: 0-0.2, 2: 0.2-0.4, 3: 0.4-0.6, 4: 0.6-0.8, 5: 0.8-1) condition_num = 0.2 def PlugInScore(repeat, easy, economy): # 引数を指定の範囲内に if 1 >= repeat: repeat = 1 if 5 <=repeat: repeat = 5 if 1 >= easy: easy = 1 if 5 <= easy: easy = 5 if 1 >= economy: economy = 1 if 5 <= economy: economy = 5 # 3種類の得点から,レシピを絞り込む df_result = df[((repeat*condition_num) - condition_num <= df['Repeat WT']) & (repeat*condition_num >= df['Repeat WT']) & ((easy*condition_num) - condition_num <= df['Easy WT']) & (easy*condition_num >= df['Easy WT']) & ((economy*condition_num) - condition_num <= df['Economy WT']) & (economy*condition_num >= df['Economy WT'])] # print(df_result) CsvOutput(df_result)検索した結果をcsvファイルに出力する。
〇〇〇は任意の名前を入れてください!# ファイル名を選択 data_name = '〇〇〇_result.csv' # フォルダにcsvファイルを保存 data_dir_result = save_dir + data_name # csvを出力 def CsvOutput(df_result): # 絞り込んだ結果をcsvファイルに出力 with open(data_dir_result, 'w', newline='') as file: writer = csv.writer(file, lineterminator='\n') # タイトル writer.writerow(df_result) # 各値 for num in range(len(df_result)): writer.writerow(df_result.values[num]) # 作製したファイルを保存 with open(data_dir, 'r') as file: sheet_info = file.read() AdviceRecipe()結果を表示する関数を宣言しています。
def AdviceRecipe(): # csvを読み込み rakuten_recipes_result = pd.read_csv(data_dir_result, encoding="UTF-8") # 列に追加する準備 df_recipes_res = pd.DataFrame(rakuten_recipes_result) print(df_recipes_res) print("あなたにおススメの 「 " + food_name + " 」") print("Entry No.1: " + df_recipes_res['URL'][random.randint(0, len(df_recipes_res))]) print("Entry No.2: " + df_recipes_res['URL'][random.randint(0, len(df_recipes_res))]) print("Entry No.3: " + df_recipes_res['URL'][random.randint(0, len(df_recipes_res))])最後に,作りたいレシピに得点をつけてオススメを表示します。
''' plug_in_score(repeat, easy, economy)を代入 repeat : もう一度作りたくなるか? easy : 作るのが簡単かどうか? economy: 節約して作れるか? 主観を1~5の5段評価し,整数を代入する。 1がネガティブ,5がポジション ''' PlugInScore(1,1,1)3種類の得点を
1: もう一度作りたくなるか?
1: 作るのが簡単かどうか?
1: 節約して作れるか?としたときの実行結果は...
4. 課題・問題点
・評価手法の検討
3種類の重み付けされた値が,最高値のレシピに引っ張られ極端な結果になってしまう。
そのため,1か5のみのどちらかに偏る。・スタンプが押された記事が少ない
レシピにスタンプやレポートがついているのが約10%,オール0が約90%
そのため,レシピを点数で評価するのはナンセンスかも。オール0の中にも,素晴らしいレシピがあるはずなので。5. 考察
私はこのシステムを使い「豚キムチ」を検索して,作ってみました。
オススメのレシピだったので美味しかったです^^埋もれていたレシピを発掘できるので,面白かったです。
ここまで読んでいただいた方,誠にありがとうございます。
ぜひ,コメントやアドバイスをいただけると嬉しいです^^



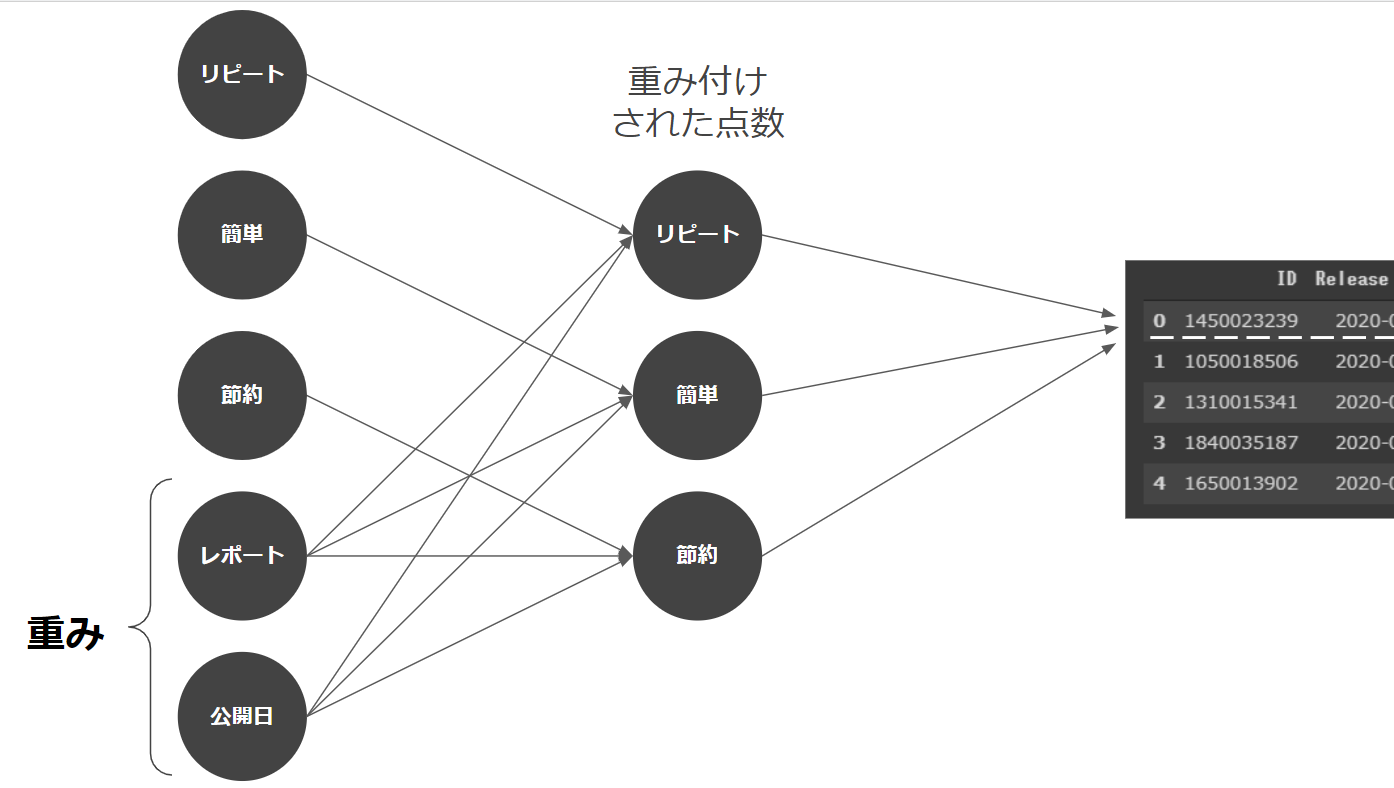

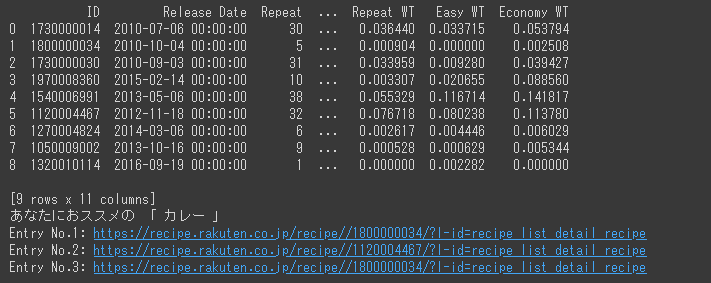
- 投稿日:2020-05-22T16:51:04+09:00
Pythonで線形代数をやってみた(3)
線形代数
理系大学で絶対に習う線形代数をわかりやすく、かつ論理的にまとめる。ちなみにそれをPythonで実装。たまに、Juliaで実装するかも。。。
・Pythonで動かして学ぶ!あたらしい数学の教科書 -機械学習・深層学習に必要な基礎知識-
・世界基準MIT教科書 ストラング線形代数イントロダクション
を基に線形代数を理解し、pythonで実装。環境
・JupyterNotebook
・言語:Python3, Julia1.4.0行列
行列について、少し深く触れてみる。基本的に、
A x = bという、形にするのがスタンダード
行列について、
行列には、行と列が存在する。
・横に並ぶのが、行
・盾に並ぶのが、列
いままで、
u = (1, 2, 3)のようにあらわしてきたのは、列ベクトルのことである。
行ベクトル : u = [1, 2, 3]
列ベクトル : u = (1, 2, 3)とする。
本来であれば、以下のように表記しなければならない。u = \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix}ただし、この記事はマークダウン方式により、めんどくさいので今まで通りに記述する。
線形方程式とベクトル
ex)連立方程式について
\begin{matrix} x - 2y = 1 \\ 3x + 2y = 11 \end{matrix}を列ベクトルで考える。(= 線形的思考)
線形方程式のメリットは負数の指揮を一つの式で表すことができること。
以下のように変形できる、x \begin{bmatrix} 1 \\ 3 \end{bmatrix} + y \begin{bmatrix} -2 \\ 2 \end{bmatrix} = \begin{bmatrix} 1 \\ 11 \end{bmatrix}この時、
u = \begin{bmatrix} 1 \\ 3 \end{bmatrix} , v = \begin{bmatrix} -2 \\ 2 \end{bmatrix} , b = \begin{bmatrix} 1 \\ 11 \end{bmatrix}とおける。これは、u, vについてまとめてAとするとき、以下のようにAx=bの形で書くことができる。
Ax = \begin{bmatrix} 1 & -2\\ 3 & 2 \end{bmatrix} \begin{bmatrix} x\\ y \end{bmatrix} = \begin{bmatrix} 1 \\ 11 \end{bmatrix} = bとなる。この線形方程式で、あてはまるx, yを考える必要がある。
ちなみ解析学的に考えると、直線同士の交点を示す。行列の計算(プログラム)
a = \begin{bmatrix} 0 & 1 & 2 \\ 1 & 2 & 3 \end{bmatrix} , b = \begin{bmatrix} 2 & 1 \\ 2 & 1\\ 2 & 1 \end{bmatrix}とする。行列の計算を行う。
Pythonのコード
import numpy as np a = ([[0, 1 ,2], [1, 2, 3]]) b = ([[2, 1], [2, 1], [2, 1]]) print(np.dot(a, b)) #=>[[ 6 3] # [12 6]]Juliaのコード
using LinearAlgebra a = [0 1 2; 1 2 3] b = [2 1; 2 1; 2 1] a*b #=>2×2 Array{Int64,2}: # 6 3 # 12 6前回のコメントで、
LinearAlgebraモジュールに関することがあったので今回はそれを使って簡単にしてみた。中身の仕組みを理化したい方はモジュールなしでぜひやってほしい。計算合わせにはモジュール使用いいかもね。
- 投稿日:2020-05-22T16:35:11+09:00
pythonで書くガチャ-期間設定機能の追加-
内容
実際にガチャのサービスが運用されると、定期的に新しいアイテムを追加していく必要があります。
前回までのデータ構成では、アイテムを追加したい時間になったら、ガチャアイテム情報を書き換えるという作業が必要でした。そこで、以下の機能要望に対応するデータ構成を考えてみます。
- ガチャの実施期間を設定したい
- ガチャの実施期間が切り替わったら抽選対象アイテムを自動的に追加したい
設定情報の改修
ガチャ情報
gacha
id start_time end_time gacha_group gacha_lottery_id 1 2020-05-01 00:00:00 2020-05-31 23:59:59 A normal_1 2 2020-05-01 00:00:00 2020-05-31 23:59:59 A normal_11 3 2020-05-25 00:00:00 2020-05-31 23:59:59 B fighter_2 4 2020-06-01 00:00:00 2020-06-04 23:59:59 C omake_2_11 5 2020-05-20 00:00:00 2020-05-31 23:59:59 A omake_fighter_6 6 2020-06-01 00:00:00 2020-06-30 23:59:59 C normal_1 7 2020-06-01 00:00:00 2020-06-30 23:59:59 C normal_11 青字(1と2)と赤字(6と7)のIDは、それぞれ同じgacha_lottery_idを使っていますが、使用する抽選グループ対象が、以下のように異なります。
- 2020年5月31日までの抽選対象グループ:
A- 2020年6月1日 からの抽選対象グループ:
Cこのように期間毎の設定を行っておけば、その時間にガチャアイテム情報を更新せずに、切り替えが行なえます。
設定内容をまとめると以下のようになります
- ガチャの実施期間の開始と終了(start_time,end_time)
- 期間内における抽選対象グループ(gacha_group)
- 対応するガチャ方式定義ID(gacha_lottery_id)
ガチャ方式定義情報
gacha_lottery
id item_type times rarity omake_times omake_rarity cost normal_1 0 1 0 0 0 10 normal_11 0 10 0 1 3 100 fighter_2 0 2 0 0 0 30 omake_2_11 0 9 2 2 3 150 omake_fighter_6 2 5 0 1 3 100 抽選対象グループ(gacha_group)の管理は、
ガチャ情報に移管し、gacha_lottery_idによって互いの情報の紐付けを行います。
抽出対照グループ(gacha_group)の項目を持たなくなったために、IDからグループの接頭語(AとかB)を除去しました実装
gacha.pyimport random from datetime import datetime def gacha(lots, times: int=1) -> list: return random.choices(tuple(lots), weights=lots.values(), k=times) def get_rarity_name(rarity: int) -> str: rarity_names = {5: "UR", 4: "SSR", 3: "SR", 2: "R", 1: "N"} return rarity_names[rarity] # ガチャ情報の辞書 def get_gacha_info(now_time: int) -> dict: gachas = { 1: {"start_time": "2020-05-01 00:00:00", "end_time": "2020-05-31 23:59:59", "gacha_group": "A", "gacha_lottery_id": "normal_1"}, 2: {"start_time": "2020-05-01 00:00:00", "end_time": "2020-05-31 23:59:59", "gacha_group": "A", "gacha_lottery_id": "normal_11"}, 3: {"start_time": "2020-05-25 00:00:00", "end_time": "2020-05-31 23:59:59", "gacha_group": "B", "gacha_lottery_id": "fighter_2"}, 4: {"start_time": "2020-06-01 00:00:00", "end_time": "2020-06-04 23:59:59", "gacha_group": "C", "gacha_lottery_id": "omake_2_11"}, 5: {"start_time": "2020-05-20 00:00:00", "end_time": "2020-05-31 23:59:59", "gacha_group": "A", "gacha_lottery_id": "omake_fighter_6"}, 6: {"start_time": "2020-06-01 00:00:00", "end_time": "2020-06-30 23:59:59", "gacha_group": "C", "gacha_lottery_id": "normal_1"}, 7: {"start_time": "2020-06-01 00:00:00", "end_time": "2020-06-30 23:59:59", "gacha_group": "C", "gacha_lottery_id": "normal_11"} } results = {} for gacha_id, info in gachas.items(): start_time = int(datetime.strptime(info["start_time"], '%Y-%m-%d %H:%M:%S').timestamp()) end_time = int(datetime.strptime(info["end_time"], '%Y-%m-%d %H:%M:%S').timestamp()) # 日時の範囲で対象ガチャ情報を絞り込みます if start_time <= now_time <= end_time: results[gacha_id] = info return results # ガチャ方式定義情報の辞書 def get_gacha_lottery_info(gacha_lottery_id: str) -> dict: # gacha_groupを移管しました gacha_lottery = { "normal_1": {"item_type": 0, "times": 1, "rarity": 0, "omake_times": 0, "omake_rarity": 0, "cost":10}, "normal_11": {"item_type": 0, "times": 10, "rarity": 0, "omake_times": 1, "omake_rarity": 3, "cost":100}, "fighter_2": {"item_type": 0, "times": 2, "rarity": 0, "omake_times": 0, "omake_rarity": 0, "cost":30}, "omake_2_11": {"item_type": 0, "times": 9, "rarity": 2, "omake_times": 2, "omake_rarity": 3, "cost":150}, "omake_fighter_6": {"item_type": 2, "times": 5, "rarity": 0, "omake_times": 1, "omake_rarity": 3, "cost":100} } return gacha_lottery[gacha_lottery_id] def set_gacha(items: dict, gacha_items: dict): # ガチャの設定に必要なアイテム情報をガチャアイテム情報に含める dic_gacha_items = {} for gacha_item_id, info in gacha_items.items(): info["item_info"] = items[info["item_id"]] dic_gacha_items[gacha_item_id] = info # 抽選対象リストを抽出 def get_lots(lottery_info: dict): lots = {} omake_lots = {} for id, info in dic_gacha_items.items(): if lottery_info["gacha_group"] != info["gacha_group"]: continue if lottery_info["item_type"] and lottery_info["item_type"] != info["item_info"]["item_type"]: continue if not(lottery_info["rarity"]) or lottery_info["rarity"] <= info["item_info"]["rarity"]: lots[id] = info["weight"] if lottery_info["omake_times"]: if not(lottery_info["omake_rarity"]) or lottery_info["omake_rarity"] <= info["item_info"]["rarity"]: omake_lots[id] = info["weight"] return lots, omake_lots # ガチャ実行 def exec(gacha_lottery_id: str, now_time: int=0) -> list: if not now_time: now_time = int(datetime.now().timestamp()) # 実行可能なガチャ情報を取得 gachas = get_gacha_info(now_time) lottery_info = get_gacha_lottery_info(gacha_lottery_id) ids = [] for gacha_id, gacha_info in gachas.items(): if gacha_lottery_id == gacha_info["gacha_lottery_id"]: lottery_info["gacha_group"] = gacha_info["gacha_group"] print("==%s==:gacha_group:%s" % (gacha_lottery_id, lottery_info["gacha_group"])) lots, omake_lots =get_lots(lottery_info) ids = gacha(lots, lottery_info["times"]) if len(omake_lots) > 0: ids.extend(gacha(omake_lots, lottery_info["omake_times"])) return ids return exec def main(): # アイテム情報 items = { 5101: {"rarity": 5, "item_name": "UR_勇者", "item_type": 1, "hp": 1200}, 4201: {"rarity": 4, "item_name": "SSR_戦士", "item_type": 2, "hp": 1000}, 4301: {"rarity": 4, "item_name": "SSR_魔法使い", "item_type": 3, "hp": 800}, 4401: {"rarity": 4, "item_name": "SSR_神官", "item_type": 4, "hp": 800}, 3201: {"rarity": 3, "item_name": "SR_戦士", "item_type": 2, "hp": 600}, 3301: {"rarity": 3, "item_name": "SR_魔法使い", "item_type": 3, "hp": 500}, 3401: {"rarity": 3, "item_name": "SR_神官", "item_type": 4, "hp": 500}, 2201: {"rarity": 2, "item_name": "R_戦士", "item_type": 2, "hp": 400}, 2301: {"rarity": 2, "item_name": "R_魔法使い", "item_type": 3, "hp": 300}, 2401: {"rarity": 2, "item_name": "R_神官", "item_type": 4, "hp": 300}, 3199: {"rarity": 3, "item_name": "SR_勇者", "item_type": 1, "hp": 600}, # 以下、追加 4101: {"rarity": 4, "item_name": "SSR_勇者", "item_type": 1, "hp": 1000}, 5201: {"rarity": 5, "item_name": "UR_戦士", "item_type": 2, "hp": 1300}, 5301: {"rarity": 5, "item_name": "UR_魔法使い", "item_type": 3, "hp": 1000}, } # ガチャアイテム情報 gacha_items = { 1: {"gacha_group": "A", "weight": 3, "item_id": 5101}, 2: {"gacha_group": "A", "weight": 9, "item_id": 4201}, 3: {"gacha_group": "A", "weight": 9, "item_id": 4301}, 4: {"gacha_group": "A", "weight": 9, "item_id": 4401}, 5: {"gacha_group": "A", "weight": 20, "item_id": 3201}, 6: {"gacha_group": "A", "weight": 20, "item_id": 3301}, 7: {"gacha_group": "A", "weight": 20, "item_id": 3401}, 8: {"gacha_group": "A", "weight": 40, "item_id": 2201}, 9: {"gacha_group": "A", "weight": 40, "item_id": 2301}, 10: {"gacha_group": "A", "weight": 40, "item_id": 2401}, 11: {"gacha_group": "B", "weight": 15, "item_id": 4201}, 12: {"gacha_group": "B", "weight": 30, "item_id": 3201}, 13: {"gacha_group": "B", "weight": 55, "item_id": 2201}, # 以下、追加 14: {"gacha_group": "C", "weight": 1, "item_id": 5101}, 15: {"gacha_group": "C", "weight": 1, "item_id": 5201}, 16: {"gacha_group": "C", "weight": 1, "item_id": 5301}, 17: {"gacha_group": "C", "weight": 9, "item_id": 4101}, 18: {"gacha_group": "C", "weight": 6, "item_id": 4201}, 19: {"gacha_group": "C", "weight": 6, "item_id": 4301}, 20: {"gacha_group": "C", "weight": 6, "item_id": 4401}, 21: {"gacha_group": "C", "weight": 20, "item_id": 3201}, 22: {"gacha_group": "C", "weight": 20, "item_id": 3301}, 23: {"gacha_group": "C", "weight": 20, "item_id": 3401}, 24: {"gacha_group": "C", "weight": 40, "item_id": 2201}, 25: {"gacha_group": "C", "weight": 40, "item_id": 2301}, 26: {"gacha_group": "C", "weight": 40, "item_id": 2401}, } # 実施するガチャのタプル gacha_lottery_ids = ( "normal_1","normal_11","fighter_2","omake_2_11","omake_fighter_6" ) # 動作確認のため、ガチャ実行日時を指定 now_time = int(datetime.strptime("2020-06-01 00:00:00", '%Y-%m-%d %H:%M:%S').timestamp()) #アイテム等をセット func_gacha = set_gacha(items, gacha_items) # gacha_lottery_idの設定にてガチャを実行 for gacha_lottery_id in gacha_lottery_ids: ids = func_gacha(gacha_lottery_id,now_time) if not ids: continue for id in ids: item_info = items[gacha_items[id]["item_id"]] print("ID:%d, %s, %s" % (id, get_rarity_name(item_info["rarity"]), item_info["item_name"])) if __name__ == '__main__': main()補足
実行日時によって対象となるガチャグループが切り替わることを分かりやすいように、
gacha_lottery_idを指定してガチャを実行するようにプログラムを記述しています。実行結果
==normal_1==:gacha_group:C ID:26, R, R_神官 ==normal_11==:gacha_group:C ID:25, R, R_魔法使い ID:22, SR, SR_魔法使い ID:26, R, R_神官 ID:24, R, R_戦士 ID:25, R, R_魔法使い ID:21, SR, SR_戦士 ID:15, UR, UR_戦士 ID:24, R, R_戦士 ID:23, SR, SR_神官 ID:24, R, R_戦士 ID:21, SR, SR_戦士 ==omake_2_11==:gacha_group:C ID:21, SR, SR_戦士 ID:25, R, R_魔法使い ID:24, R, R_戦士 ID:21, SR, SR_戦士 ID:23, SR, SR_神官 ID:25, R, R_魔法使い ID:23, SR, SR_神官 ID:18, SSR, SSR_戦士 ID:25, R, R_魔法使い ID:23, SR, SR_神官 ID:17, SSR, SSR_勇者追記
実際のゲームにおいては以下のフローのように、
gacha_idを指定して、ガチャを実行することになりますので、少々プログラムの構成が違ってきます。
- ゲーム画面(アプリ)側からgacha_idを指定してガチャの実行依頼
- 指定されたgacha_idが有効期限内であることを判定
- ガチャ情報(gacha_idにて取得した情報)を用いて、ガチャを実行
- 投稿日:2020-05-22T15:51:07+09:00
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (2)
前回からの続き
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (1)
https://github.com/legacyworld/sklearn-basic課題 3.1 多項式単回帰の二乗誤差
これは$y = \sin(x)$に$N(0,1)\times0.1$の誤差を載せた訓練データを作り、それを多項式で回帰させる問題。
解説は第3回(1) 56分40秒あたりHomework_3.1.pyimport pandas as pd import numpy as np import matplotlib.pyplot as plt import copy from sklearn.preprocessing import PolynomialFeatures as PF from sklearn import linear_model from sklearn.metrics import mean_squared_error # 訓練用データの数 NUM_TR = 6 np.random.seed(0) rng = np.random.RandomState(0) # 描画用のx軸データ x_plot = np.linspace(0,10,100) # 訓練データ tmp = copy.deepcopy(x_plot) rng.shuffle(tmp) x_tr = np.sort(tmp[:NUM_TR]) y_tr = np.sin(x_tr) + 0.1*np.random.randn(NUM_TR) # Matrixへ変換 X_tr = x_tr.reshape(-1,1) X_plot = x_plot.reshape(-1,1) # 多項式用のデータ # 次数決め打ち degree = 1 pf = PF(degree=degree) X_poly = pf.fit_transform(X_tr) X_plot_poly = pf.fit_transform(X_plot) model = linear_model.LinearRegression() model.fit(X_poly,y_tr) fig = plt.figure() plt.scatter(x_tr,y_tr,label="training Samples") plt.plot(x_plot,model.predict(X_plot_poly),label=f"degree = {degree}") plt.legend() plt.ylim(-2,2) fig.savefig(f"{degree}.png") # 多項式用のデータ # 全ての次数 fig = plt.figure() plt.scatter(x_tr,y_tr,label="Training Samples") for degree in range(1,NUM_TR): pf = PF(degree=degree) X_poly = pf.fit_transform(X_tr) X_plot_poly = pf.fit_transform(X_plot) model = linear_model.LinearRegression() model.fit(X_poly,y_tr) plt.plot(x_plot,model.predict(X_plot_poly),label=f"degree {degree}") plt.legend() mse = mean_squared_error(y_tr,model.predict(X_poly)) print(f"degree = {degree} mse = {mse}") plt.xlim(0,10) plt.ylim(-2,2) fig.savefig('all_degree.png')回帰の計算をさせるためのデータ(
x_tr)とグラフ描画用(x_plot)で2つ用意している。
単にx_tr = x_plotとやると実データがコピーされない。
そのままやるとx_tr = np.sort(tmp[:NUM_TR])の部分で描画用データの数もNUM_TRになってしまい、グラフ描画がおかしくなる。
なのでdeepcopyを利用している。元データとして0-10の間を100等分したものを用意している。
訓練用データはそのうちNUM_TRだけランダムに選ぶ(講座では6つ)
誤差として0-1の間で発生させた乱数に1/10をかけたものをsin(x_tr)に足している。
最初にseedを固定しているため、どの環境で何回実行しても同じ結果が出る。
用意されたデータはこれ
次に1次(直線)で回帰させてみる。結果はこれ。
最後に次数を1-5で変化させてそれぞれグラフに描画してみる。
誤差はこれ。degree = 5だけ数字が合わなかった。
degree = 1 mse = 0.33075005001856256 degree = 2 mse = 0.3252271169458752 degree = 3 mse = 0.30290034474812344 degree = 4 mse = 0.010086018410257538 degree = 5 mse = 3.1604543144050787e-22


