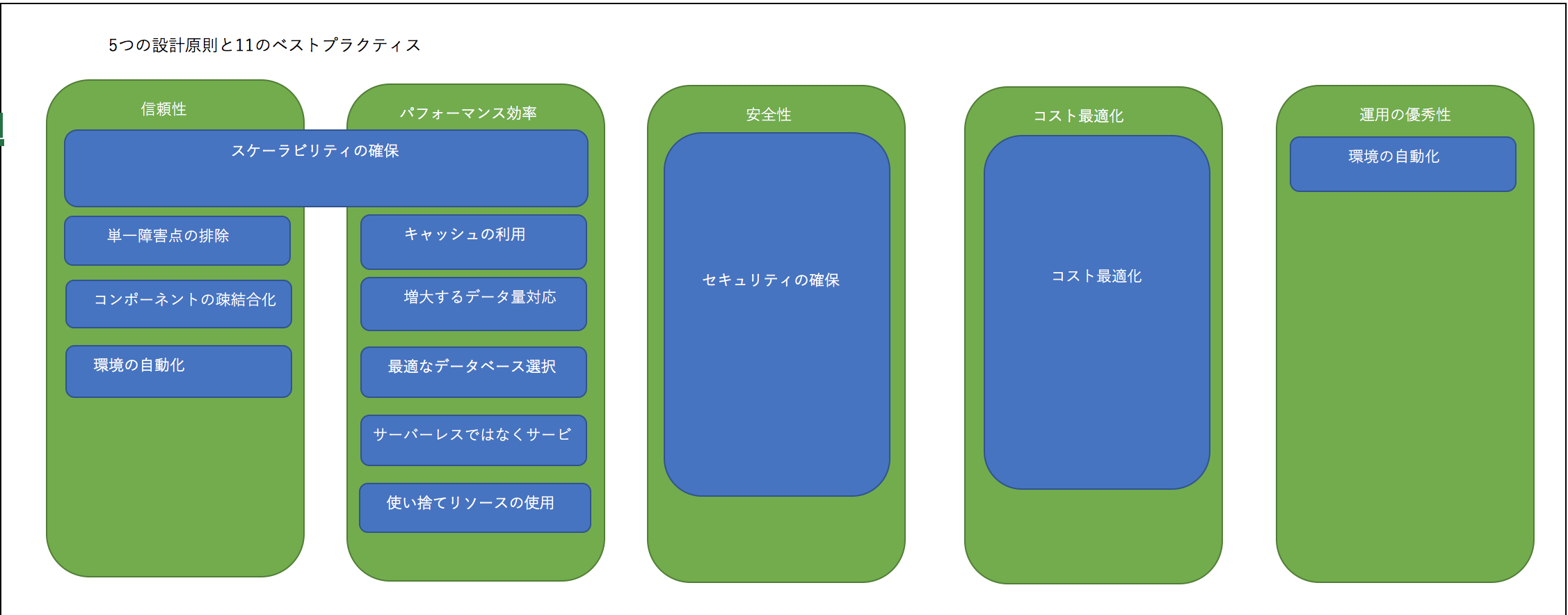
AWSアーキテクチャーの5つの設計原則と11のベストプラクティス 具体的な説明は以下のリンクをご参考ください。 https://qiita.com/Jenny1025/items/ce55c8724daeef626201 AWSのキャッシュの利用は、AWSアーキテクチャーの5つの設計原則と11のベストプラクティスの「キャッシュの利用」と「最適なデータベース選択」、この2つに関わるものです。 キャッシュとは 一度アクセスしたデータを保存して次回アクセス時に高速アクセスできるように仕組みです。 キャッシュの利用 繰り返すとり出すデータやコンテンツについて、キャッシュを利用する構成となります。主なサービスは ①CloudFront ②ElastiCache ③S3 インメモリキャッシュ ElastiCacheはインメモリキャッシュというデータベースです。 CloudFront AWSが提供するCDN(Content Delivery Network)になります。 *CNDはWEBコンテンツ配信処理を高速化するサービスです。
AWSアーキテクチャーの5つの設計原則と11のベストプラクティス 具体的な説明は以下のリンクをご参考ください。 https://qiita.com/Jenny1025/items/ce55c8724daeef626201
AWSのキャッシュの利用は、AWSアーキテクチャーの5つの設計原則と11のベストプラクティスの「キャッシュの利用」と「最適なデータベース選択」、この2つに関わるものです。
一度アクセスしたデータを保存して次回アクセス時に高速アクセスできるように仕組みです。
繰り返すとり出すデータやコンテンツについて、キャッシュを利用する構成となります。主なサービスは ①CloudFront ②ElastiCache ③S3
ElastiCacheはインメモリキャッシュというデータベースです。
AWSが提供するCDN(Content Delivery Network)になります。 *CNDはWEBコンテンツ配信処理を高速化するサービスです。
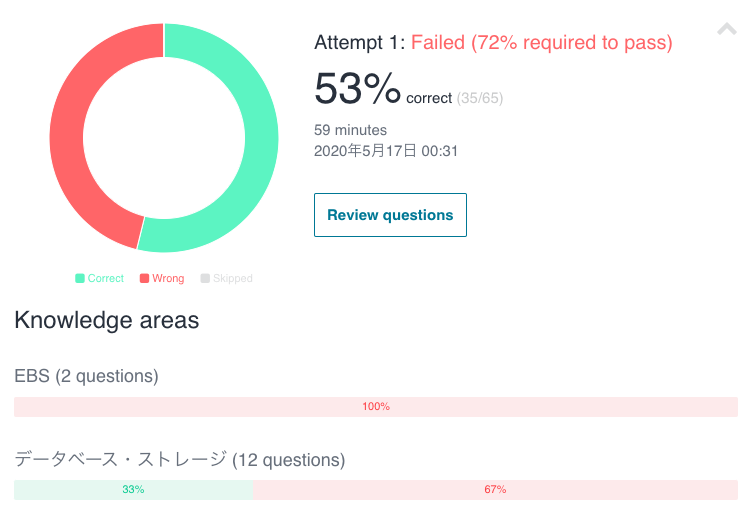
3週間でAWS認定ソリューションアーキテクト-アソシエイト-とったので、勉強法などまとめてみる - Qiitaを読んで、即試験申し込んだ人の12日間に渡る勉強のログです。 ほとんど「動画をみる」しか書いてないので、あまり参考にならないかもしれないですが・・・。 (ハンズオンの動画の際は、手を動かしてました。) 1日目 3週間でAWS認定ソリューションアーキテクト-アソシエイト-とったので、勉強法などまとめてみる - Qiitaを読む。 Udemyで動画購入 試験申込 動画みる(13.IAMの概要まで) 2日目 動画みる(13.IAMの概要まで) 3日目 動画みる(33.VPCの設計まで) 4日目 動画みる(67.Well Architected Frameworkのまとめまで) 5日目 動画みる(81.RDSによるマスタースレーブ構成の構築まで) ↓AutoScaleのハンズオン時、CPUに負荷をかけるプログラム実行例 ストレステストでAutoScalingの検証.txt #stressのインストール wget http://ftp.riken.jp/Linux/dag/redhat/el7/en/x86_64/rpmforge/RPMS/stress-1.0.2-1.el7.rf.x86_64.rpm rpm -ivh stress-1.0.2-1.el7.rf.x86_64.rpm rpm -qa|grep stress stress --version #stressによるCPU負荷がけコマンド stress -c 1 -q & 6日目 動画みる(101.データベースの基礎まで) 7日目 動画みる(109.EFSの構築まで) 8日目 動画みる(122.SNSの構築まで) 9日目 動画見る(終了) 動画についてる模擬試験1をやる 154.おまけ講座:クラウド基礎 155.AWSの位置付け の動画については最初に見たほうがいいかもしれません。 模擬試験の結果 思ったより正解してました。 10日目 模擬試験1の回答確認&復習 模擬試験2をやる 11日目 模擬試験2の回答確認&復習 模擬試験3をやる 12日目 模擬試験3をやる 本番試験 結果 72%以上で合格ですが結果67%で不合格でした。 (模擬試験3を最後までやり切れなかったのが反省) 12日間で受かりたい人はこれより速いペースで進めれば受かる確率が上がると思います。 感想 不合格という結果は悔しいですが、AWSの知識が12日前より圧倒的に身についたのでヨシ! 試験のための勉強は一旦終了とし、プライベートの開発や業務で使って理解が深まったタイミングでまた受けてみようと思います
3週間でAWS認定ソリューションアーキテクト-アソシエイト-とったので、勉強法などまとめてみる - Qiitaを読んで、即試験申し込んだ人の12日間に渡る勉強のログです。
ほとんど「動画をみる」しか書いてないので、あまり参考にならないかもしれないですが・・・。 (ハンズオンの動画の際は、手を動かしてました。)
↓AutoScaleのハンズオン時、CPUに負荷をかけるプログラム実行例
#stressのインストール wget http://ftp.riken.jp/Linux/dag/redhat/el7/en/x86_64/rpmforge/RPMS/stress-1.0.2-1.el7.rf.x86_64.rpm rpm -ivh stress-1.0.2-1.el7.rf.x86_64.rpm rpm -qa|grep stress stress --version #stressによるCPU負荷がけコマンド stress -c 1 -q &
154.おまけ講座:クラウド基礎 155.AWSの位置付け
の動画については最初に見たほうがいいかもしれません。
思ったより正解してました。
72%以上で合格ですが結果67%で不合格でした。 (模擬試験3を最後までやり切れなかったのが反省)
12日間で受かりたい人はこれより速いペースで進めれば受かる確率が上がると思います。
不合格という結果は悔しいですが、AWSの知識が12日前より圧倒的に身についたのでヨシ! 試験のための勉強は一旦終了とし、プライベートの開発や業務で使って理解が深まったタイミングでまた受けてみようと思います
概要 AWSを使っていると新しくインスタンス作ったりとかするときに、表示名つけてあげたり、タグを振ってあげたりしないといけないことがある。 ・・・指針がないとめっちゃ迷うので、ネットで拾ったよさげな記事を参考に定めた。 理由がない場合はこれに従いたい。 参考 https://dev.classmethod.jp/articles/aws-name-rule/ https://qiita.com/hidekatsu-izuno/items/c1c0ce0b56a822c25e5e 自分の命名規則 表示名 <案件名>-<環境名>-<AWSサービス名>-<対象を一意に特定できる補足情報> タグ 以下を絶対に振る キー 値 Name 識別子と同じにする Stack <案件名> Env <環境名>
AWSを使っていると新しくインスタンス作ったりとかするときに、表示名つけてあげたり、タグを振ってあげたりしないといけないことがある。
・・・指針がないとめっちゃ迷うので、ネットで拾ったよさげな記事を参考に定めた。 理由がない場合はこれに従いたい。
参考 https://dev.classmethod.jp/articles/aws-name-rule/ https://qiita.com/hidekatsu-izuno/items/c1c0ce0b56a822c25e5e
<案件名>-<環境名>-<AWSサービス名>-<対象を一意に特定できる補足情報>
以下を絶対に振る
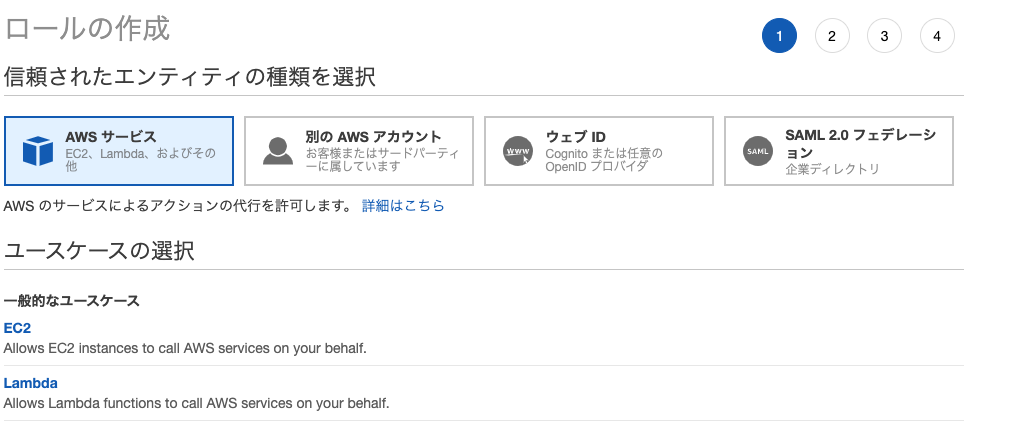
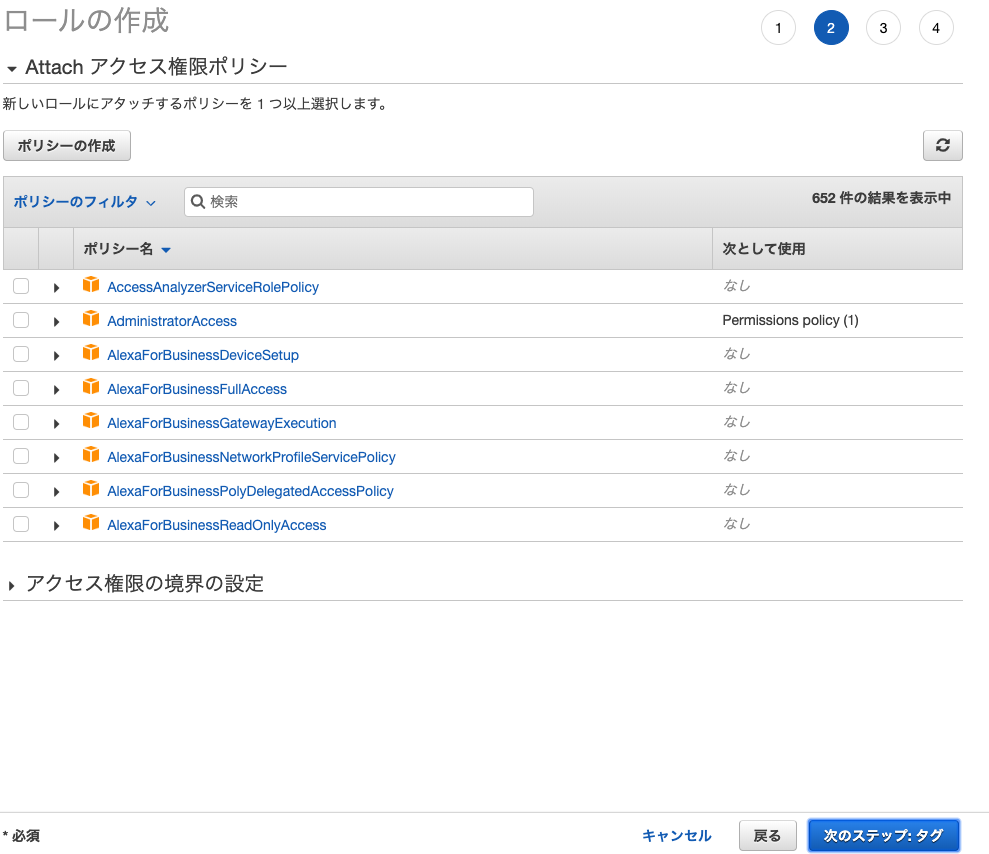
概要 IAMについて調べる機会があったので、 私なりの解釈を交えて以下にまとめた。 IAMとは 「各AWSサービスへのアクセス権限を管理するサービス」である。 以下4つの概念があるが、言葉だけだとわかりづらい。めちゃくちゃわかりやすい概念図を見ればすごく理解できるはず。 概念 概要 IAMポリシー ○○サービスへの読み取り権限あり、書き込み権限ありというアクセス権限設定の雛形である IAMユーザー そのAWSアカウント内の各サービスを利用するユーザーである。「ユーザー名、パスワード、選択してアタッチした複数のIAMポリシー」からなるデータである。各ユーザーのAWSサービスの操作権限はアタッチされたIAMポリシーの通りとなる IAMグループ IAMユーザーの集合体である。IAMユーザーは複数のIAMグループに所属できる。IAMグループは入れ子にすることはできない。IAMグループにもIAMポリシーを複数アタッチでき、IAMグループに所属しているIAMユーザーは、そのIAMグループにアタッチされているIAMポリシーと自身にアタッチされているIAMポリシーで設定されているAWSサービスの操作権限が与えられることになる IAMロール IAMユーザー、グループは人に割り当てられるものであるのに対し、ロールはそれ以外のもの・・・例えばEC2インスタンスなどに割り当てられるものである。IAMロールにも複数のIAMポリシーをアタッチする。指定のインスタンスにIAMロールを割り当てると、そのインスタンスはIAMポリシーで設定されているAWSサービスへの操作権限を有することになり、インスタンス内のプログラムで別AWSサービスを操作することができるようになる。実際にはKMSという仕組みで別AWSサービスを操作するにあたってのアクセスキーとシークレットキーが与えられ、これを使って操作することになる。AWSで用意されているSDKを利用することでこのKMSという仕組みを意識せずとも別サービスを操作することができるため、使ったほうが絶対いい。 ロールの作成 以下、EC2から別のAWSサービスを操作させる場合を例にしたロールの作成手順。 手順 1. IAMのコンソールへアクセス > アクセス管理 - ロール > 「ロールの作成」ボタンを押下 →「ロールの作成」ページへ遷移 2. 「ロールの作成」ページの、「信頼されたエンティティの種類を選択」で「AWSサービス」を選択し、「ユースケースの選択」で「EC2」を選択して「次のステップ:アクセス権限」ボタンを押下 →「Attach アクセス権限ポリシー」ページへ遷移 3. EC2が他のAWSサービスを操作するのに必要なアクセス権限が含まれるポリシーを選択し、「次のステップ:タグ」ボタンを押下 →「タグの追加(オプション)」ページへ遷移 4. 「タグの追加(オプション)」ページで任意の「キー、値」を設定して「次のステップ:確認」を押下 参考:[AWS]表示名、タグの命名規則 →「確認」ページへ遷移 5. 「確認」ページで「ロール名、説明」を入力して「ロールの作成」ボタンを押下 以上 ロールのアタッチ 以下、EC2へのアタッチを例にしたロールのアタッチ手順。 1. EC2のコンソールへアクセス >インスタンス-インスタンス >ロールをアタッチしたいEC2インスタンスにチェックを入れ、アクション >インスタンスの設定 >IAM ロールの割り当て/置換 と押下 →「IAM ロールの割り当て/置換」ページが表示される。 2. 「IAMロール」でEC2インスタンスにアタッチしたいロールを選択して「適用」を押下 以上
IAMについて調べる機会があったので、 私なりの解釈を交えて以下にまとめた。
「各AWSサービスへのアクセス権限を管理するサービス」である。
以下4つの概念があるが、言葉だけだとわかりづらい。めちゃくちゃわかりやすい概念図を見ればすごく理解できるはず。
以下、EC2から別のAWSサービスを操作させる場合を例にしたロールの作成手順。
手順
1. IAMのコンソールへアクセス > アクセス管理 - ロール > 「ロールの作成」ボタンを押下 →「ロールの作成」ページへ遷移
2. 「ロールの作成」ページの、「信頼されたエンティティの種類を選択」で「AWSサービス」を選択し、「ユースケースの選択」で「EC2」を選択して「次のステップ:アクセス権限」ボタンを押下 →「Attach アクセス権限ポリシー」ページへ遷移
3. EC2が他のAWSサービスを操作するのに必要なアクセス権限が含まれるポリシーを選択し、「次のステップ:タグ」ボタンを押下 →「タグの追加(オプション)」ページへ遷移
4. 「タグの追加(オプション)」ページで任意の「キー、値」を設定して「次のステップ:確認」を押下 参考:[AWS]表示名、タグの命名規則 →「確認」ページへ遷移
5. 「確認」ページで「ロール名、説明」を入力して「ロールの作成」ボタンを押下
以上
以下、EC2へのアタッチを例にしたロールのアタッチ手順。
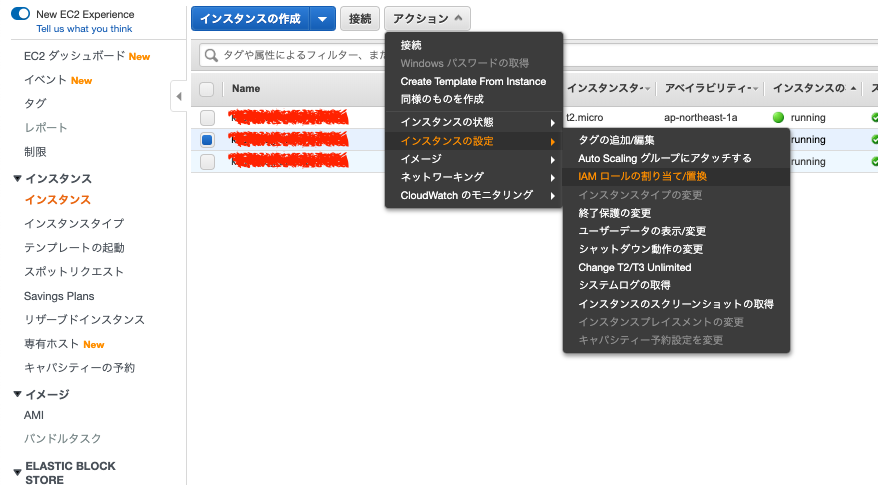
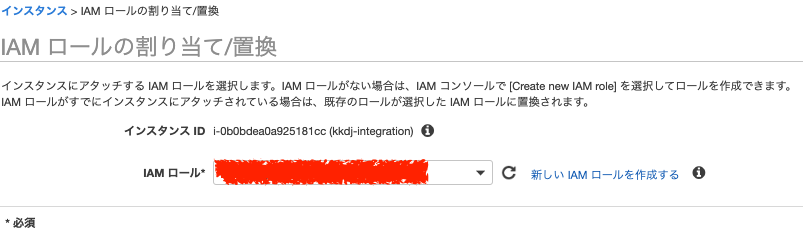
1. EC2のコンソールへアクセス >インスタンス-インスタンス >ロールをアタッチしたいEC2インスタンスにチェックを入れ、アクション >インスタンスの設定 >IAM ロールの割り当て/置換 と押下 →「IAM ロールの割り当て/置換」ページが表示される。
2. 「IAMロール」でEC2インスタンスにアタッチしたいロールを選択して「適用」を押下
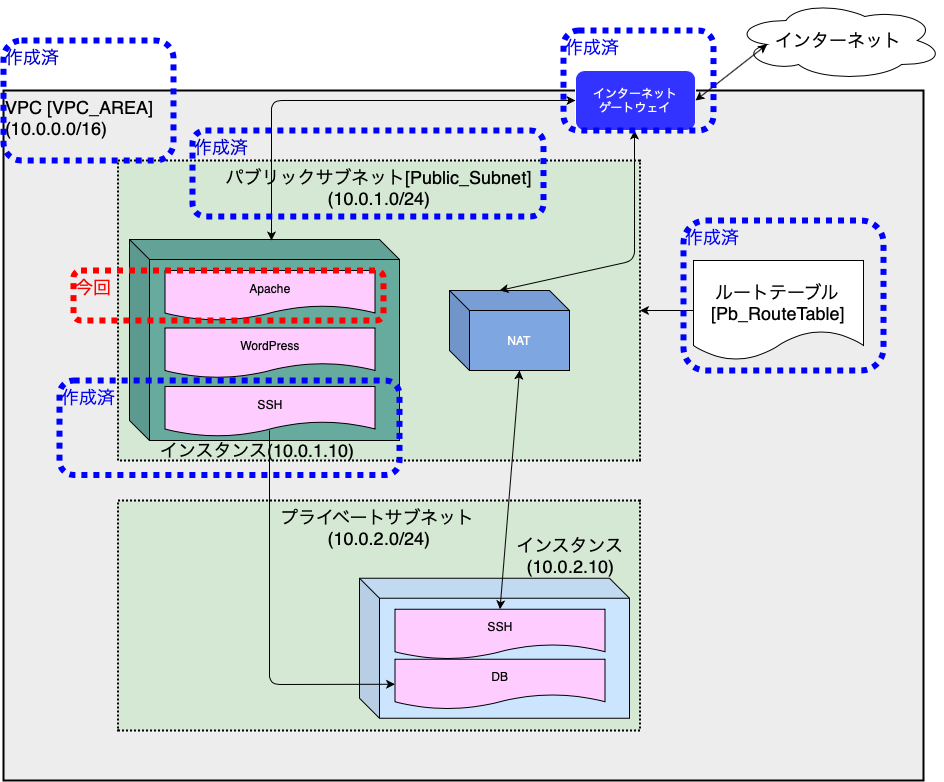
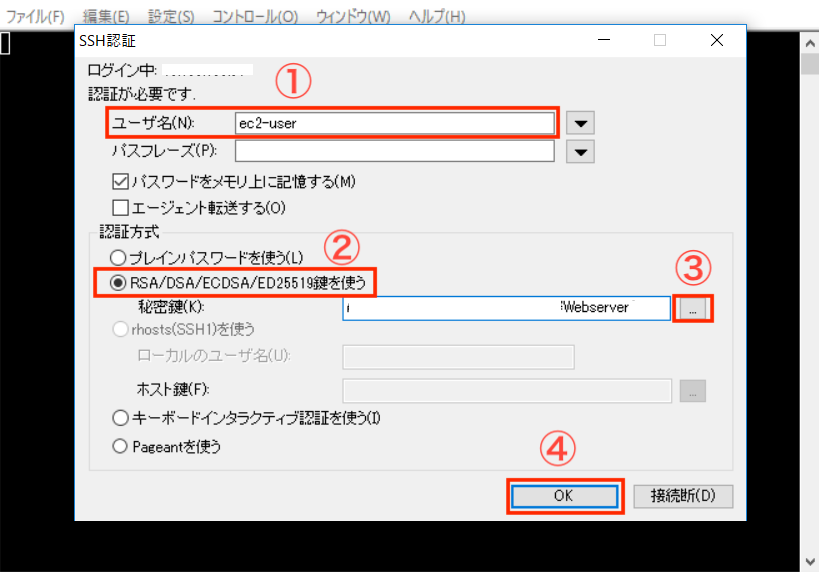
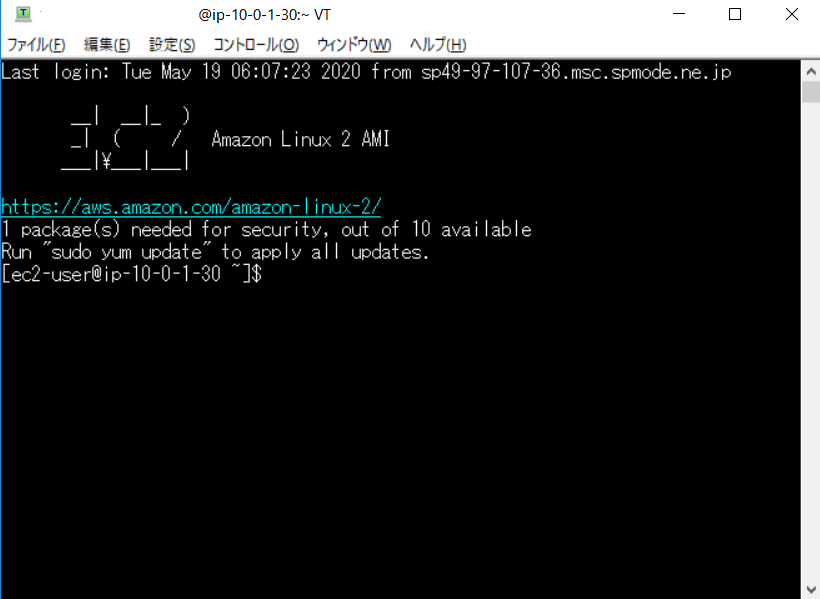
第6回 Apacheのインストール 前回構築したインスタンスに、Apacheをインストールしていきます。 Apacheをインストールすることで、インスタンスにWEBサーバの機能を持たせます。 以下の順で進めていきますのでよろしくお願いします。 TeraTermでインスタンスへログイン Apacheインストール httpd自動起動設定 httpd起動 セキュリティグループの設定 httpd待機ポート確認 セキュリティグループのポート開け 動作確認 TeraTermでインスタンスへログイン インスタンス作成後の確認も踏まえて、自端末からインスタンスへSSH接続を行います。 前回のインスタンス構築後に実施すれば良かったのですが・・・ 今回使用させていただくターミナルソフトは、TeraTermです。 TeraTerm v4.105(窓の杜様に飛びます) 早速TeraTermを起動します。 TeraTermでの入力項目です。 ホスト名 :「パブリックIP」を入力します。 パブリックIPの確認方法 サービス :「SSH」を選択します。(デフォルト) TCPポート: 「22」(デフォルト) 「OK」を選択するとセキュリティ警告が表示されます。 これは当該インスタンスへ初めて接続する場合に表示されるものです。 問題はないので、続けて「OK」ボタンを選択してしまいます。 その後、認証情報を問われますので入力していきます。 ユーザ名:「ec2-user」 最初から登録されているユーザ RSA/DSA/ECDSA/ED25519鍵を使う:「チェック」 秘密鍵:インスタンス起動時に生成したキーファイルを選択(hogehoge .pem ってファイル) 認証に成功すると以下の初期画面が表示されます。 さすがAWS、ログインバーナーもお洒落です。(なんのマーク?) Apacheインストール ログイン後、以下のコマンドを実行しApacheをインストールします。 完了するとcomplete!!と表示されプロンプトが戻ります。 [ec2-user@ip-10-0-1-30 ~]$ sudo yum -y install httpd 本当にインストールされたのか確認をします。 $ yum list installed | grep httpd generic-logos-httpd.noarch 18.0.0-4.amzn2 @amzn2-core httpd.x86_64 2.4.41-1.amzn2.0.1 @amzn2-core httpd-filesystem.noarch 2.4.41-1.amzn2.0.1 @amzn2-core httpd-tools.x86_64 2.4.41-1.amzn2.0.1 @amzn2-core # httpdがインストールされた!! httpd自動起動設定 インストールが終わったらhttpdデーモンの設定を行なっていきます。 Apacheのデーモンがhttpdなので登場するのは、登場するのはほとんどhttpdです。 はじめに、httpdサービスの自動起動を設定します。 この設定で、インスタンス起動時にhttpdも起動します。 # 現状の確認 $ sudo systemctl list-unit-files | grep httpd httpd.service disabled httpd.socket disabled ## 「httpd.service」が「disabled」のため自動起動ではありません!! # 自動起動設定 $ sudo systemctl enable httpd.service Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service. # 自動起動設定確認 $ sudo systemctl list-unit-files | grep httpd httpd.service enabled httpd.socket disabled ## 「httpd.service」が「enable」になったので、自動起動が有効になりました。 httpd起動 インストールした状態だとhttpdは起動していないので起動してあげます。 # httpd起動 $ sudo systemctl start httpd.service ## httpd起動確認 $ sudo systemctl status httpd.service ● httpd.service - The Apache HTTP Server Loaded: loaded (/usr/lib/systemd/system/httpd.service; disabled; vendor preset: disabled) Active: active (running) since Tue 2020-05-19 06:18:46 UTC; 35s ago ### ステータスが「runnning」となっているのでOK Docs: man:httpd.service(8) Main PID: 3913 (httpd) ==============以下略========================== セキュリティグループの設定 ここまででApacheのインストールと起動が完了しました。 しかし、これだけはクライアントからアクセスすることはできません。 Apacheが通信で使用するポートを確認して、インスタンス側でそれを許可する必要があります。 httpd待機ポートの確認 まずはhttpdが使用するポートを確認していきます。 # 以下コマンドで確認 $ sudo lsof -i -n -P | grep apache httpd 3914 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) httpd 3915 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) httpd 3916 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) httpd 3917 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) httpd 3918 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) ## Apacheは「TCP」の「80」で待機していることがわかりました。 セキュリティグループのポート開け httpdが使用するポートが分かったので、セキュリティグループの設定を確認して、必要な設定を行なっていきます。 「EC2 マネジメントコンソール」から、「インバウンドルール」タブの「インバウンドルールの編集」を選択します。 EC2マネジメントコンソールの表示はこちら 初期状態のためTCP22番ポートに対する許可設定しかされていません。 前項で確認したApache用の「TCP」「80」を追加してあげます。 無事に追加できました。 必要な設定が完了したので、Webブラウザからインスタンスに接続してみます。 Webブラウザのアドレスバーにhttp://"パブリックIP"を入力します。すると・・・ インスタンスがApacheのWebサーバとして稼働していることがわかりました。 今回はここまでです、次回はDNS周りの設定をする予定です。 参考文献 完コピにならないよう頑張ります。 Amazon Web Services 基礎からのネットワーク&サーバー構築
前回構築したインスタンスに、Apacheをインストールしていきます。 Apacheをインストールすることで、インスタンスにWEBサーバの機能を持たせます。
以下の順で進めていきますのでよろしくお願いします。
インスタンス作成後の確認も踏まえて、自端末からインスタンスへSSH接続を行います。 前回のインスタンス構築後に実施すれば良かったのですが・・・
今回使用させていただくターミナルソフトは、TeraTermです。 TeraTerm v4.105(窓の杜様に飛びます)
早速TeraTermを起動します。
TeraTermでの入力項目です。
「OK」を選択するとセキュリティ警告が表示されます。 これは当該インスタンスへ初めて接続する場合に表示されるものです。 問題はないので、続けて「OK」ボタンを選択してしまいます。
その後、認証情報を問われますので入力していきます。
認証に成功すると以下の初期画面が表示されます。 さすがAWS、ログインバーナーもお洒落です。(なんのマーク?)
ログイン後、以下のコマンドを実行しApacheをインストールします。 完了するとcomplete!!と表示されプロンプトが戻ります。
[ec2-user@ip-10-0-1-30 ~]$ sudo yum -y install httpd
本当にインストールされたのか確認をします。
$ yum list installed | grep httpd generic-logos-httpd.noarch 18.0.0-4.amzn2 @amzn2-core httpd.x86_64 2.4.41-1.amzn2.0.1 @amzn2-core httpd-filesystem.noarch 2.4.41-1.amzn2.0.1 @amzn2-core httpd-tools.x86_64 2.4.41-1.amzn2.0.1 @amzn2-core # httpdがインストールされた!!
インストールが終わったらhttpdデーモンの設定を行なっていきます。 Apacheのデーモンがhttpdなので登場するのは、登場するのはほとんどhttpdです。
はじめに、httpdサービスの自動起動を設定します。 この設定で、インスタンス起動時にhttpdも起動します。
# 現状の確認 $ sudo systemctl list-unit-files | grep httpd httpd.service disabled httpd.socket disabled ## 「httpd.service」が「disabled」のため自動起動ではありません!! # 自動起動設定 $ sudo systemctl enable httpd.service Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service. # 自動起動設定確認 $ sudo systemctl list-unit-files | grep httpd httpd.service enabled httpd.socket disabled ## 「httpd.service」が「enable」になったので、自動起動が有効になりました。
インストールした状態だとhttpdは起動していないので起動してあげます。
# httpd起動 $ sudo systemctl start httpd.service ## httpd起動確認 $ sudo systemctl status httpd.service ● httpd.service - The Apache HTTP Server Loaded: loaded (/usr/lib/systemd/system/httpd.service; disabled; vendor preset: disabled) Active: active (running) since Tue 2020-05-19 06:18:46 UTC; 35s ago ### ステータスが「runnning」となっているのでOK Docs: man:httpd.service(8) Main PID: 3913 (httpd) ==============以下略==========================
ここまででApacheのインストールと起動が完了しました。 しかし、これだけはクライアントからアクセスすることはできません。
Apacheが通信で使用するポートを確認して、インスタンス側でそれを許可する必要があります。
まずはhttpdが使用するポートを確認していきます。
# 以下コマンドで確認 $ sudo lsof -i -n -P | grep apache httpd 3914 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) httpd 3915 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) httpd 3916 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) httpd 3917 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) httpd 3918 apache 4u IPv6 26636 0t0 TCP *:80 (LISTEN) ## Apacheは「TCP」の「80」で待機していることがわかりました。
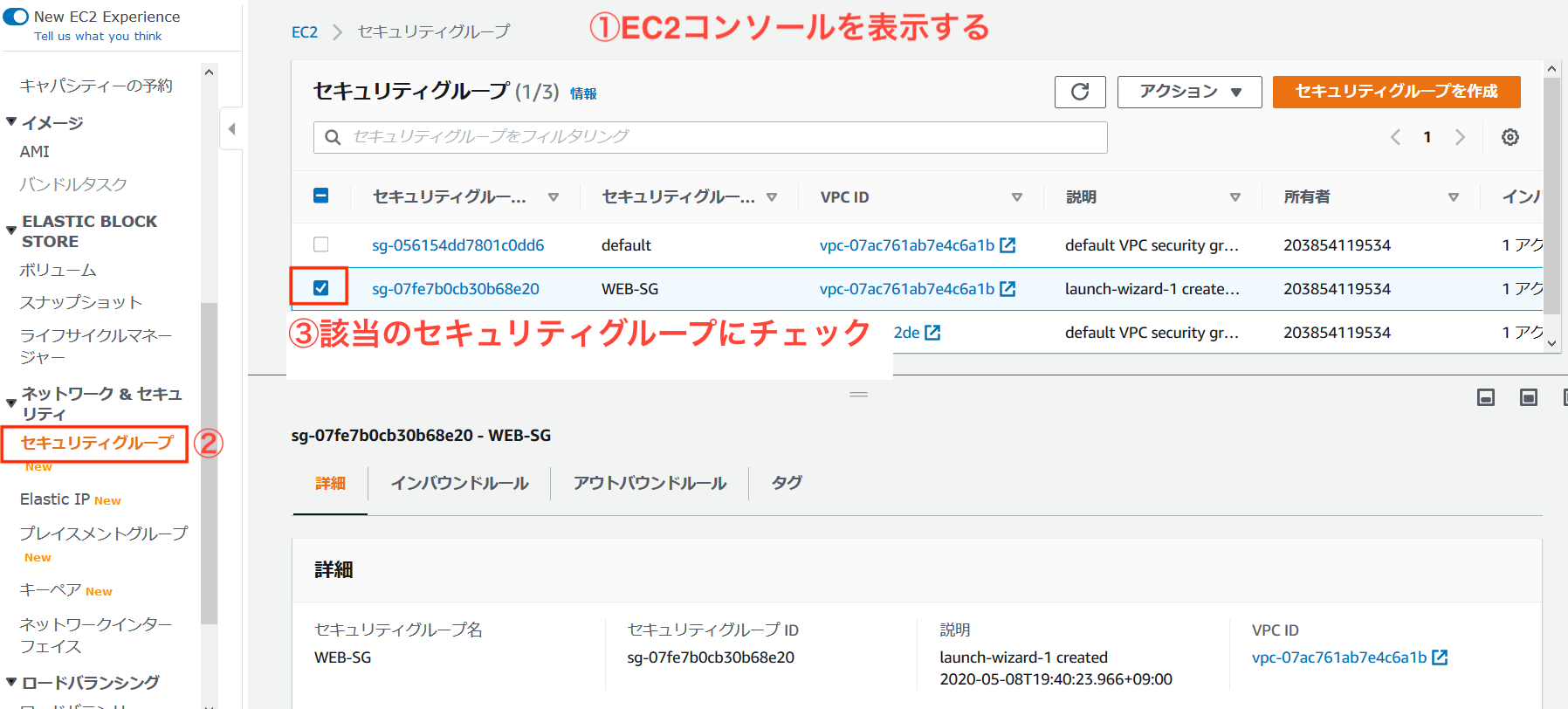
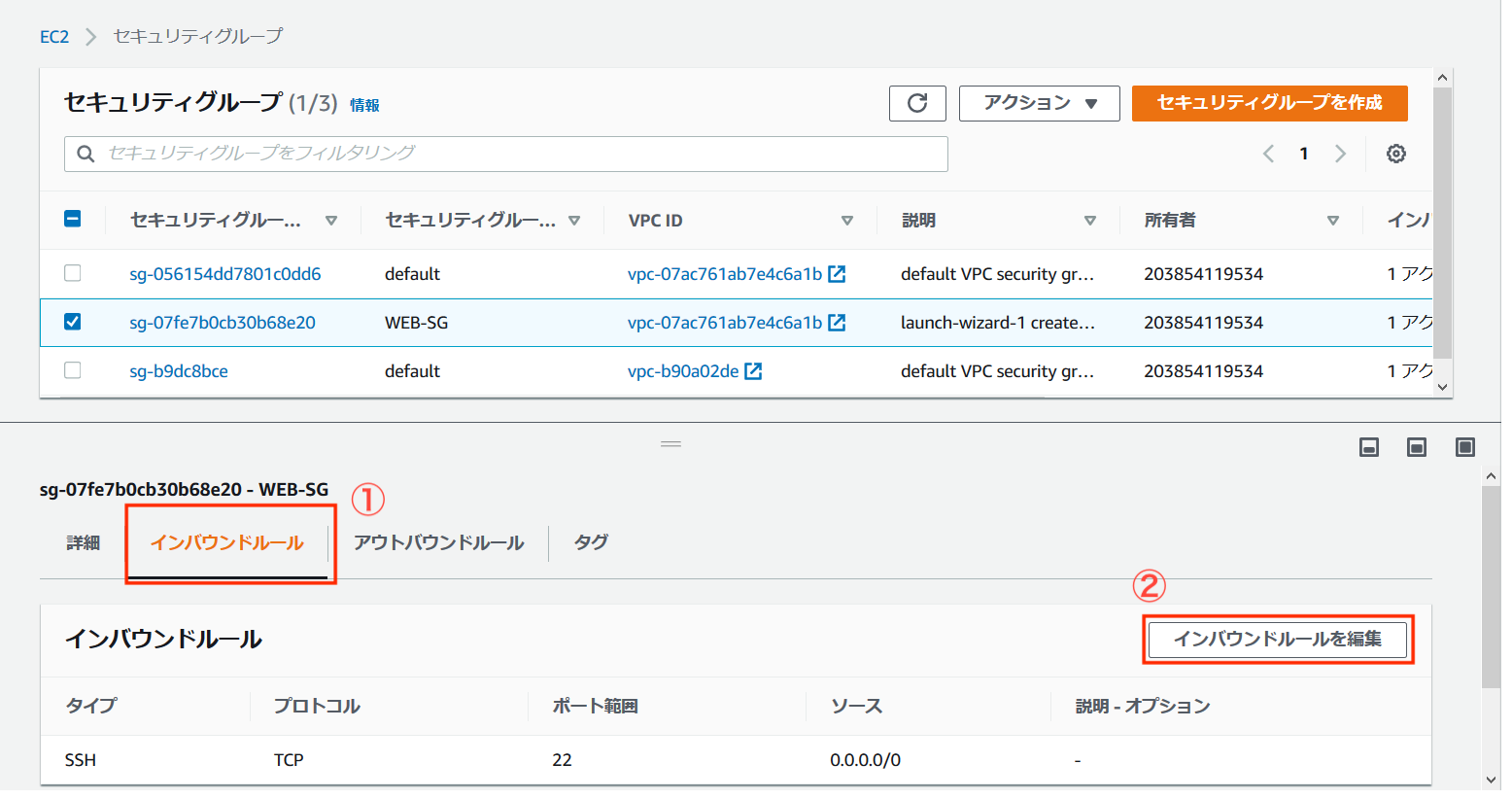
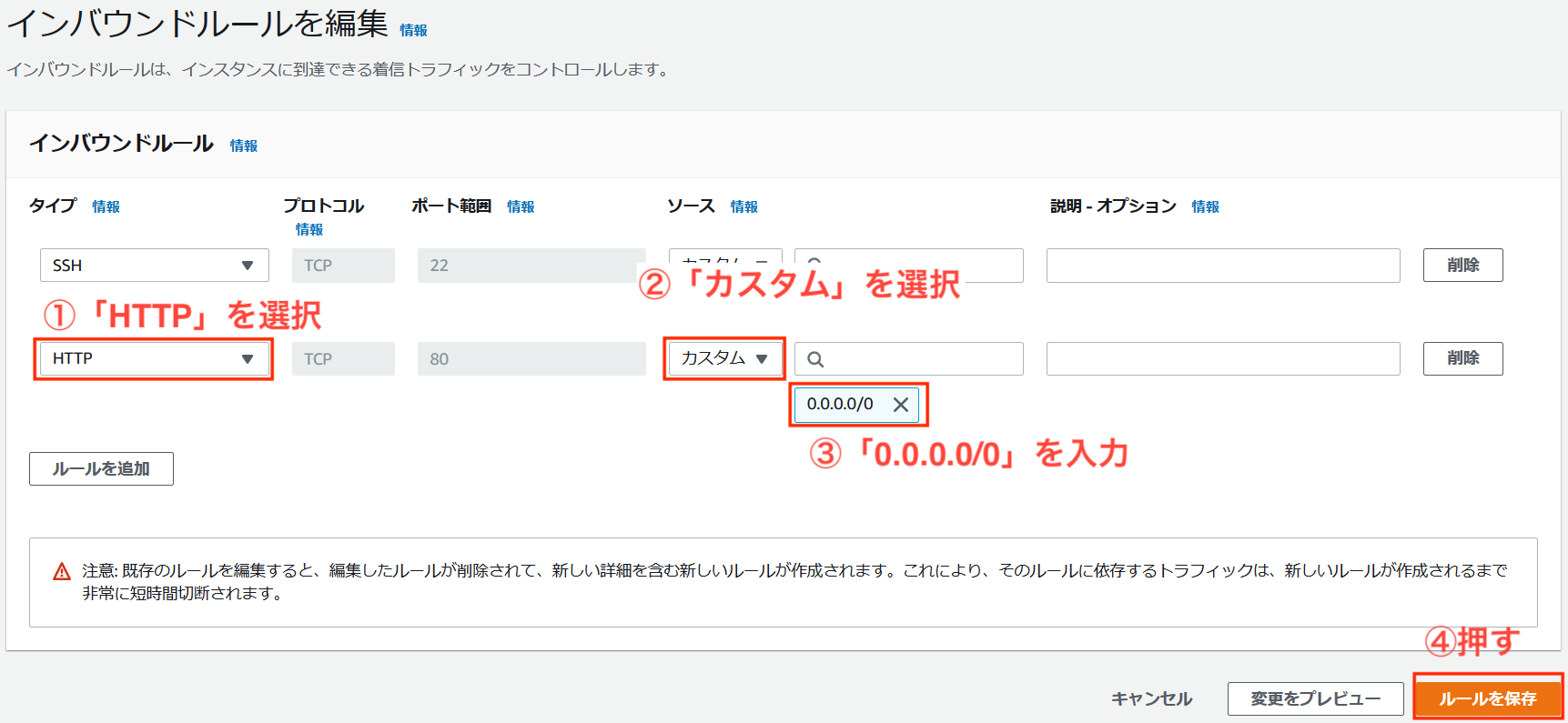
httpdが使用するポートが分かったので、セキュリティグループの設定を確認して、必要な設定を行なっていきます。 「EC2 マネジメントコンソール」から、「インバウンドルール」タブの「インバウンドルールの編集」を選択します。
EC2マネジメントコンソールの表示はこちら
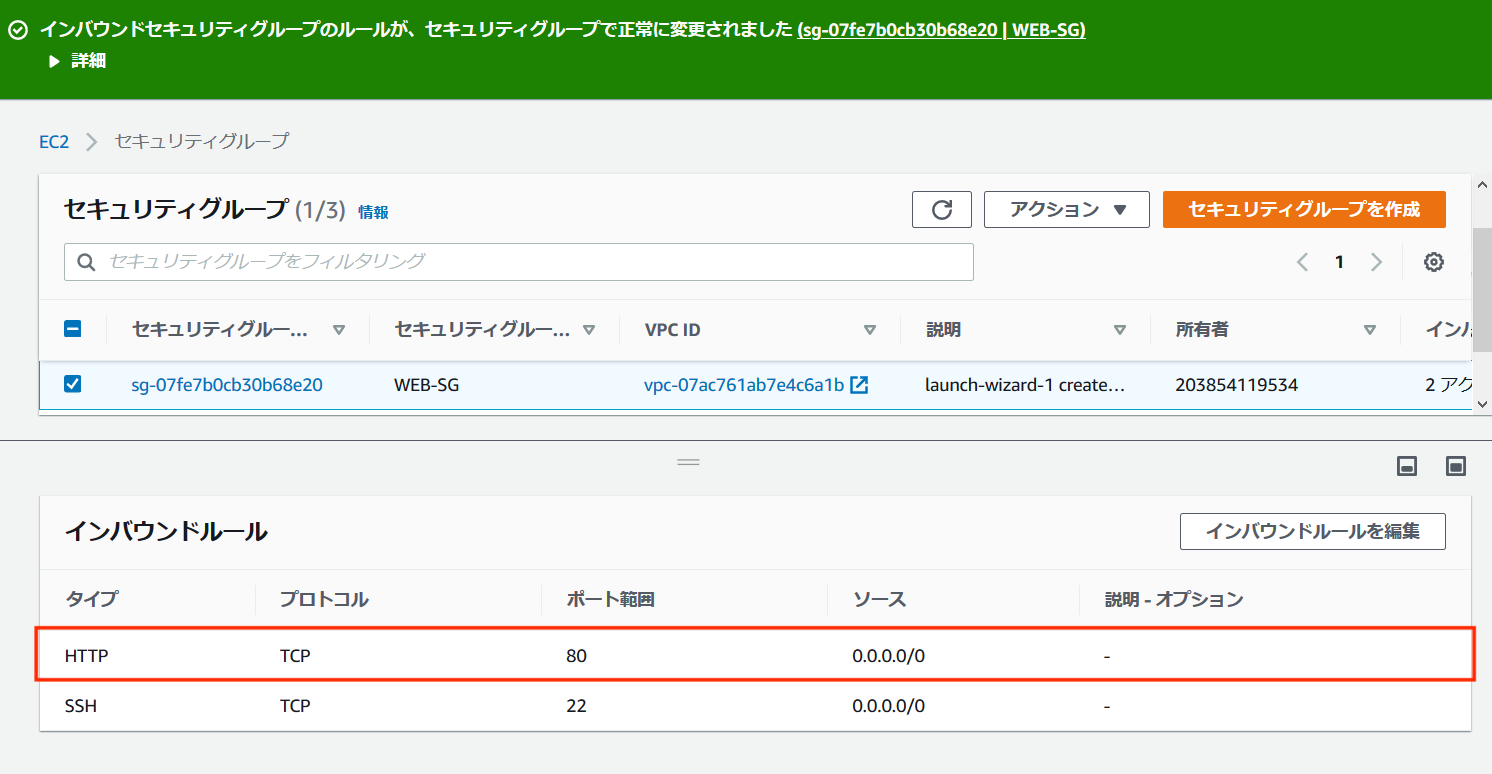
初期状態のためTCP22番ポートに対する許可設定しかされていません。 前項で確認したApache用の「TCP」「80」を追加してあげます。
無事に追加できました。
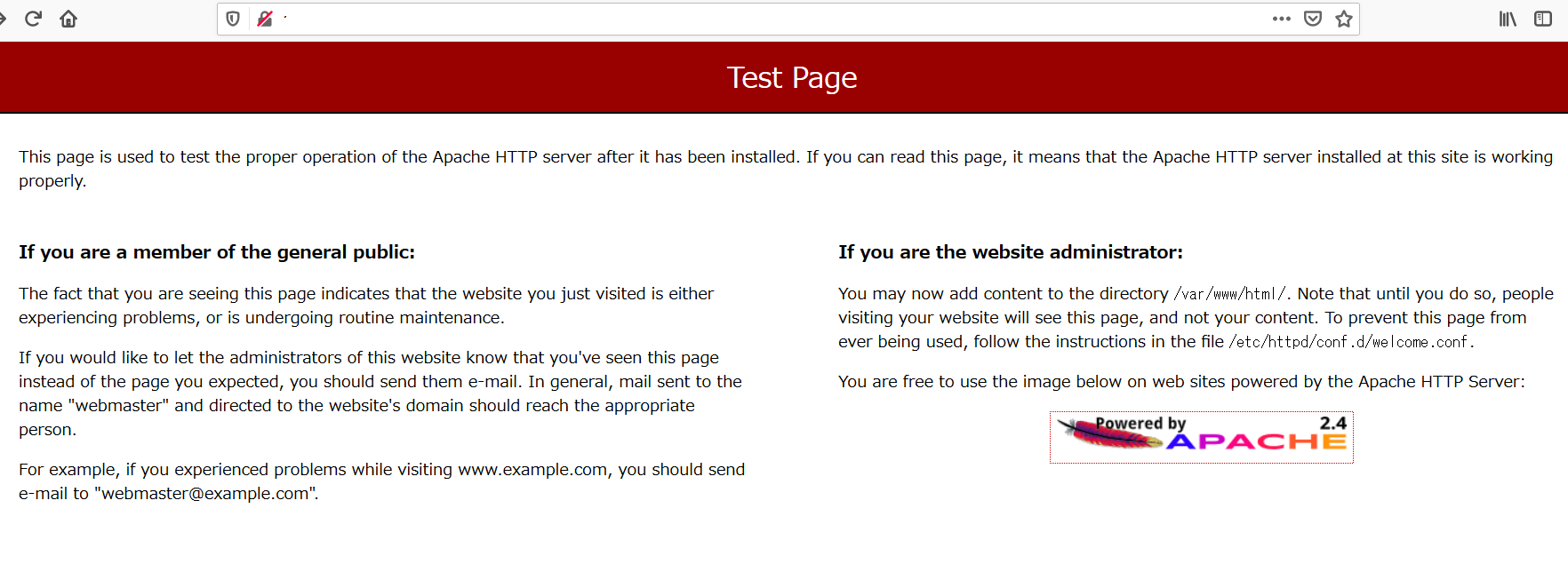
必要な設定が完了したので、Webブラウザからインスタンスに接続してみます。 Webブラウザのアドレスバーにhttp://"パブリックIP"を入力します。すると・・・
http://"パブリックIP"
インスタンスがApacheのWebサーバとして稼働していることがわかりました。 今回はここまでです、次回はDNS周りの設定をする予定です。
完コピにならないよう頑張ります。 Amazon Web Services 基礎からのネットワーク&サーバー構築
EIPとプライベートIPの違いの疑問 この1冊で合格! AWS認定ソリューションアーキテクトでAWS SAAの勉強をしていた。その教材の15Pに「EC2インスタンスに付与できるIPアドレス」が表で書かれていた。 IPの種類 特徴 EIP ・再起動してもIPアドレスが維持される・利用していない場合に課金される パブリックIPアドレス ・ランダムに割り当てられるためにIPアドレスを指定できない・インスタンスを再起動すると別のIPアドレスが割り当て当てられる・IPアドレスを自動で割り当てない子も可能 プライベートIPアドレス ・インスタンス作成時に必ず割り当てられる・インスタンス作成時にIPアドレスを指定できる・再起動しても同じIPアドレスが割り当てられる ここでEIPとプライベートIPアドレスは再起動しても同じIPアドレスを割り当てることができるとのことで、そうすると「EIPは利用していない場合に課金されるし、メリットがあるのか?」という疑問が生じる。 結論 IPの種類 特徴 EIP 再起動してもIPアドレスが維持されるパブリックIP パブリックIPアドレス 再起動するとIPアドレスが変わるパブリックIP プライベートIPアドレス 再起動してもIPアドレスが変わらないプライベートIP つまりEIPはパブリックIPのため、プライベートIPとは用途が異なる。 EIPはパブリックIPのためIPアドレスの数値は任意の数値を指定できず、AWSが保有しているパブリックIPの中からランダムに付与される。
この1冊で合格! AWS認定ソリューションアーキテクトでAWS SAAの勉強をしていた。その教材の15Pに「EC2インスタンスに付与できるIPアドレス」が表で書かれていた。
ここでEIPとプライベートIPアドレスは再起動しても同じIPアドレスを割り当てることができるとのことで、そうすると「EIPは利用していない場合に課金されるし、メリットがあるのか?」という疑問が生じる。
つまりEIPはパブリックIPのため、プライベートIPとは用途が異なる。 EIPはパブリックIPのためIPアドレスの数値は任意の数値を指定できず、AWSが保有しているパブリックIPの中からランダムに付与される。
AWS EC2のユーザーデータをansibleで実行する方法です。もう1回流したいと思うことがあったので、タスクにしました。 - name: run USER_DATA of ec2 instance become: true shell: USER_DATA=$(set -o pipefail; curl http://169.254.169.254/latest/user-data ) && echo $USER_DATA && eval sudo $USER_DATA args: executable: /bin/bash
AWS EC2のユーザーデータをansibleで実行する方法です。もう1回流したいと思うことがあったので、タスクにしました。
- name: run USER_DATA of ec2 instance become: true shell: USER_DATA=$(set -o pipefail; curl http://169.254.169.254/latest/user-data ) && echo $USER_DATA && eval sudo $USER_DATA args: executable: /bin/bash
AWS Lambda とは AWS Lambda はサーバーをプロビジョニングしたり管理する必要なくコードを実行できるコンピューティングサービスです。 関数の AWS Lambda 管理 AWS Lambda API またはコンソールを使用して Lambda 関数の設定を行います。「基本的な関数設定」には、Lambda コンソールで関数を作成するときに指定する説明、ロール、およびランタイムが含まれています。関数の作成後にその他の設定を行ったり、API を使用してハンドラー名、メモリ割り当て、セキュリティグループなどの内容を作成時に設定したりすることができます。 関数コードの外でシークレットを保持するには、関数の設定にシークレットを保存し、初期化時に実行環境から読み取ることができます。環境変数は、保管時に必ず暗号化されます。また、クライアント側でも暗号化できます。外部リソースの接続文字列、パスワード、エンドポイントを削除することにより、環境変数を使用して、関数コードを移植可能にすることができます。 バージョンとエイリアスは、関数のデプロイおよび呼び出しを管理するために作成できるセカンダリリソースです。関数の各種バージョンを発行してそのコードおよび設定を、変更できない別個のリソースとして保存し、特定のバージョンを参照するエイリアスを作成します。その後、関数エイリアスを呼び出すようクライアントを設定し、クライアントを更新するのではなく、クライアントが新しいバージョンをポイントするようにするときにエイリアスを更新します。 ライブラリやその他の依存関係を関数に追加する際、デプロイパッケージを作成してアップロードすると、開発に遅延が生じる可能性があります。レイヤーを使用して関数の依存関係を個別に管理し、デプロイパッケージを小さく保ちます。レイヤーを使用して、独自のライブラリを他の顧客と共有したり、公開されているレイヤーを自分の関数で使用することもできます。 Amazon VPC の AWS リソースで Lambda 関数を使用するには、セキュリティグループとサブネットを使用して設定し、VPC 接続を作成します。関数を VPC に接続すると、リレーショナルデータベースやキャッシュなどのプライベートサブネットのリソースにアクセスできます。MySQL および Aurora DB インスタンスのデータベースプロキシを作成することもできます。データベースプロキシを使用すると、データベース接続を使い果たすことなく、関数の同時実行レベルを上げることができます。 AWS Lambda 関数の呼び出し Lambda 関数を Lambda コンソール、Lambda API、AWS SDK、AWS CLI、AWS ツールキットで直接呼び出すことができます。他の AWS のサービスを設定して関数を呼び出したり、ストリームまたはキューから読み取るように Lambda を設定して関数を呼び出すこともできます。 関数を呼び出す際は、同期的に呼び出すか非同期的に呼び出すかを選択できます。同期呼び出しでは、イベントを処理する関数を待ってレスポンスを返します。非同期呼び出しでは、Lambda は処理のためにイベントをキューに入れ、すぐにレスポンスを返します。非同期呼び出しでは、Lambda によって再試行が行われるため、呼び出しレコードが送信先に送信される場合があります。 関数を使用してデータを自動的に処理するには、1 つ以上のトリガーを追加します。トリガーとは、Lambda リソース、つまりライフサイクルイベント、外部リクエスト、またはスケジュールに応答して関数を呼び出すように設定する別のサービスのリソースのことです。関数は複数のトリガーを持つことができます。各トリガーは、関数を独立して呼び出すクライアントとして機能します。Lambda により関数に渡される各イベントには、1 つのクライアントまたはトリガからのデータしかありません。 ストリームまたはキューから項目を処理するには、イベントソースマッピングを作成することができます。イベントソースマッピングは、Amazon SQS キュー、Amazon Kinesis ストリーム、または Amazon DynamoDB ストリームから項目を読み取り、バッチで関数に送信する Lambda のリソースです。関数が処理する各イベントには、数百または数千の項目を含めることができます。 他の AWS サービスやリソースは、関数を直接呼び出します。たとえば、タイマーで関数を呼び出すように CloudWatch イベント を設定したり、オブジェクトが作成されたときに関数を呼び出すように Amazon S3 を設定したりできます。各サービスにおいて、関数の呼び出しに使用するメソッド、イベントの構造、および構成方法が異なります。詳細については、「他のサービスで AWS Lambda を使用する」を参照してください。 誰が関数を呼び出すか、どのように呼び出されるかによって、スケーリングの動作や発生する可能性のあるエラーの種類が異なります。関数を同期的に呼び出すと、エラーがレスポンスで返され、再試行できます。非同期的に呼び出したり、イベントソースマッピングを使用したり、別のサービスを構成して関数を呼び出す場合、要件を再試行し、多数のイベントを処理するために関数をスケーリングする方法は異なります。詳細については、「AWS Lambda 関数スケーリング」および「エラー処理と AWS Lambda での自動再試行」を参照してください。 同期呼び出し 関数を同期的に呼び出すと、Lambda は関数を実行し、レスポンスを待ちます。関数の実行が終了すると、Lambda は、実行された関数のバージョンなどの追加データとともに、関数のコードからのレスポンスを返します。 非同期呼び出し Amazon Simple Storage Service (Amazon S3) や Amazon Simple Notification Service (Amazon SNS) など、AWS のいくつかのサービスでは、関数を非同期的に呼び出してイベントを処理します。関数を非同期的に呼び出す場合は、関数コードからのレスポンスを待機しません。イベントを Lambda に渡すと、Lambda が残りを処理します。Lambda でエラーを処理する方法を設定し、呼び出しレコードをダウンストリームのリソースに送信して、アプリケーションのコンポーネントを連鎖させることができます。 まずは一読 AWS Lambda関数を非同期で呼ぶ場合の動きを改めて確める https://qiita.com/horit0123/items/295f8dc55d8c07e6512a AWS Lambda イベントソースマッピング イベントソースのマッピングは、イベントソースからを読み取り、Lambda 関数を呼び出す AWS Lambda リソースのことを指します。イベントソースマッピングは、直接 Lambda 関数を呼び出さないサービスのキューまたはストリームから項目を処理するときに使用することができます。 Amazon Kinesis Amazon DynamoDB Amazon Simple Queue Service イベントソースのマッピングは、イベントソースの項目の読み取りや管理のために、関数の実行ロールのアクセス権限を使用します。アクセス権限やイベント構造、設定、ポーリングの動作はイベントソースによって異なります。 AWS LambdaがSQSをイベントソースとしてサポートしました! https://dev.classmethod.jp/articles/aws-lambda-support-sqs-event-source/ 現在はFIFOも対応していました。 AWS Lambda アプリケーション AWS Lambdaのアプリケーション作成を使ってCI/CDパイプラインを一気に構築 https://qiita.com/shonansurvivors/items/b223fbb362aed3c1c536 Lambda 関数のローリングデプロイ ローリングデプロイを使用して、Lambda 関数の新しいバージョンの導入に伴うリスクを制御します。ローリングデプロイでは、システムは関数の新しいバージョンを自動的にデプロイし、徐々に増加するトラフィックを新しいバージョンに送信します。 一般的な Lambda アプリケーションの種類とユースケース 例 1: Amazon S3 プッシュイベントと Lambda 関数の呼び出し 例 2: AWS Lambda での Kinesis ストリームからのイベント取り出しと Lambda 関数呼び出し AWS Lambda 関数を使用する際のベストプラクティス Lambda ハンドラーをコアロジックから分離 実行コンテキストの再利用を活用して関数のパフォーマンスを向上 関数ハンドラー外で SDK クライアントとデータベース接続を初期化し、静的なアセットを /tmp ディレクトリにローカルにキャッシュ 環境変数を使用して、オペレーショナルパラメータを関数に 関数のデプロイパッケージの依存関係を制御 デプロイパッケージのサイズをランタイムに必要な最小限のサイズに Java で記述されたデプロイパッケージを Lambda で解凍する所要時間を短縮 依存関係の複雑さを最小限に抑えます。 Lambda 関数内で、任意の条件が満たされるまでその関数自身を自動的に呼び出すような再帰的なコードを使用しない 参考文献 AWS Lambda とは https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/welcome.html
AWS Lambda はサーバーをプロビジョニングしたり管理する必要なくコードを実行できるコンピューティングサービスです。
AWS Lambda API またはコンソールを使用して Lambda 関数の設定を行います。「基本的な関数設定」には、Lambda コンソールで関数を作成するときに指定する説明、ロール、およびランタイムが含まれています。関数の作成後にその他の設定を行ったり、API を使用してハンドラー名、メモリ割り当て、セキュリティグループなどの内容を作成時に設定したりすることができます。 関数コードの外でシークレットを保持するには、関数の設定にシークレットを保存し、初期化時に実行環境から読み取ることができます。環境変数は、保管時に必ず暗号化されます。また、クライアント側でも暗号化できます。外部リソースの接続文字列、パスワード、エンドポイントを削除することにより、環境変数を使用して、関数コードを移植可能にすることができます。 バージョンとエイリアスは、関数のデプロイおよび呼び出しを管理するために作成できるセカンダリリソースです。関数の各種バージョンを発行してそのコードおよび設定を、変更できない別個のリソースとして保存し、特定のバージョンを参照するエイリアスを作成します。その後、関数エイリアスを呼び出すようクライアントを設定し、クライアントを更新するのではなく、クライアントが新しいバージョンをポイントするようにするときにエイリアスを更新します。 ライブラリやその他の依存関係を関数に追加する際、デプロイパッケージを作成してアップロードすると、開発に遅延が生じる可能性があります。レイヤーを使用して関数の依存関係を個別に管理し、デプロイパッケージを小さく保ちます。レイヤーを使用して、独自のライブラリを他の顧客と共有したり、公開されているレイヤーを自分の関数で使用することもできます。 Amazon VPC の AWS リソースで Lambda 関数を使用するには、セキュリティグループとサブネットを使用して設定し、VPC 接続を作成します。関数を VPC に接続すると、リレーショナルデータベースやキャッシュなどのプライベートサブネットのリソースにアクセスできます。MySQL および Aurora DB インスタンスのデータベースプロキシを作成することもできます。データベースプロキシを使用すると、データベース接続を使い果たすことなく、関数の同時実行レベルを上げることができます。
AWS Lambda API またはコンソールを使用して Lambda 関数の設定を行います。「基本的な関数設定」には、Lambda コンソールで関数を作成するときに指定する説明、ロール、およびランタイムが含まれています。関数の作成後にその他の設定を行ったり、API を使用してハンドラー名、メモリ割り当て、セキュリティグループなどの内容を作成時に設定したりすることができます。
関数コードの外でシークレットを保持するには、関数の設定にシークレットを保存し、初期化時に実行環境から読み取ることができます。環境変数は、保管時に必ず暗号化されます。また、クライアント側でも暗号化できます。外部リソースの接続文字列、パスワード、エンドポイントを削除することにより、環境変数を使用して、関数コードを移植可能にすることができます。
バージョンとエイリアスは、関数のデプロイおよび呼び出しを管理するために作成できるセカンダリリソースです。関数の各種バージョンを発行してそのコードおよび設定を、変更できない別個のリソースとして保存し、特定のバージョンを参照するエイリアスを作成します。その後、関数エイリアスを呼び出すようクライアントを設定し、クライアントを更新するのではなく、クライアントが新しいバージョンをポイントするようにするときにエイリアスを更新します。
ライブラリやその他の依存関係を関数に追加する際、デプロイパッケージを作成してアップロードすると、開発に遅延が生じる可能性があります。レイヤーを使用して関数の依存関係を個別に管理し、デプロイパッケージを小さく保ちます。レイヤーを使用して、独自のライブラリを他の顧客と共有したり、公開されているレイヤーを自分の関数で使用することもできます。
Amazon VPC の AWS リソースで Lambda 関数を使用するには、セキュリティグループとサブネットを使用して設定し、VPC 接続を作成します。関数を VPC に接続すると、リレーショナルデータベースやキャッシュなどのプライベートサブネットのリソースにアクセスできます。MySQL および Aurora DB インスタンスのデータベースプロキシを作成することもできます。データベースプロキシを使用すると、データベース接続を使い果たすことなく、関数の同時実行レベルを上げることができます。
Lambda 関数を Lambda コンソール、Lambda API、AWS SDK、AWS CLI、AWS ツールキットで直接呼び出すことができます。他の AWS のサービスを設定して関数を呼び出したり、ストリームまたはキューから読み取るように Lambda を設定して関数を呼び出すこともできます。 関数を呼び出す際は、同期的に呼び出すか非同期的に呼び出すかを選択できます。同期呼び出しでは、イベントを処理する関数を待ってレスポンスを返します。非同期呼び出しでは、Lambda は処理のためにイベントをキューに入れ、すぐにレスポンスを返します。非同期呼び出しでは、Lambda によって再試行が行われるため、呼び出しレコードが送信先に送信される場合があります。 関数を使用してデータを自動的に処理するには、1 つ以上のトリガーを追加します。トリガーとは、Lambda リソース、つまりライフサイクルイベント、外部リクエスト、またはスケジュールに応答して関数を呼び出すように設定する別のサービスのリソースのことです。関数は複数のトリガーを持つことができます。各トリガーは、関数を独立して呼び出すクライアントとして機能します。Lambda により関数に渡される各イベントには、1 つのクライアントまたはトリガからのデータしかありません。 ストリームまたはキューから項目を処理するには、イベントソースマッピングを作成することができます。イベントソースマッピングは、Amazon SQS キュー、Amazon Kinesis ストリーム、または Amazon DynamoDB ストリームから項目を読み取り、バッチで関数に送信する Lambda のリソースです。関数が処理する各イベントには、数百または数千の項目を含めることができます。 他の AWS サービスやリソースは、関数を直接呼び出します。たとえば、タイマーで関数を呼び出すように CloudWatch イベント を設定したり、オブジェクトが作成されたときに関数を呼び出すように Amazon S3 を設定したりできます。各サービスにおいて、関数の呼び出しに使用するメソッド、イベントの構造、および構成方法が異なります。詳細については、「他のサービスで AWS Lambda を使用する」を参照してください。 誰が関数を呼び出すか、どのように呼び出されるかによって、スケーリングの動作や発生する可能性のあるエラーの種類が異なります。関数を同期的に呼び出すと、エラーがレスポンスで返され、再試行できます。非同期的に呼び出したり、イベントソースマッピングを使用したり、別のサービスを構成して関数を呼び出す場合、要件を再試行し、多数のイベントを処理するために関数をスケーリングする方法は異なります。詳細については、「AWS Lambda 関数スケーリング」および「エラー処理と AWS Lambda での自動再試行」を参照してください。
Lambda 関数を Lambda コンソール、Lambda API、AWS SDK、AWS CLI、AWS ツールキットで直接呼び出すことができます。他の AWS のサービスを設定して関数を呼び出したり、ストリームまたはキューから読み取るように Lambda を設定して関数を呼び出すこともできます。
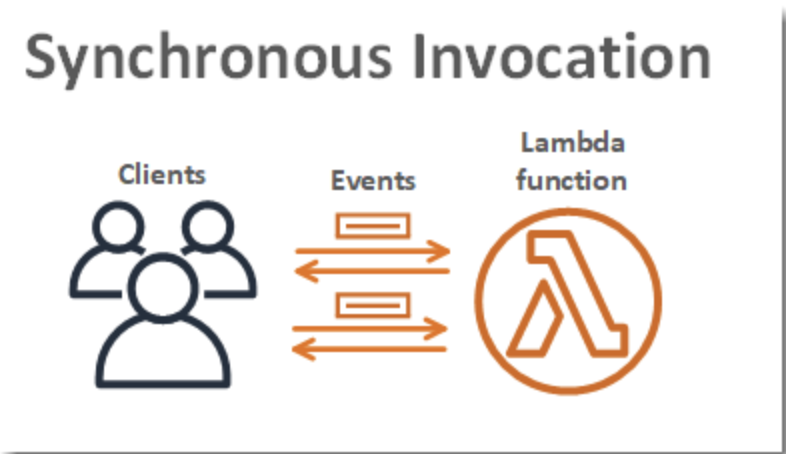
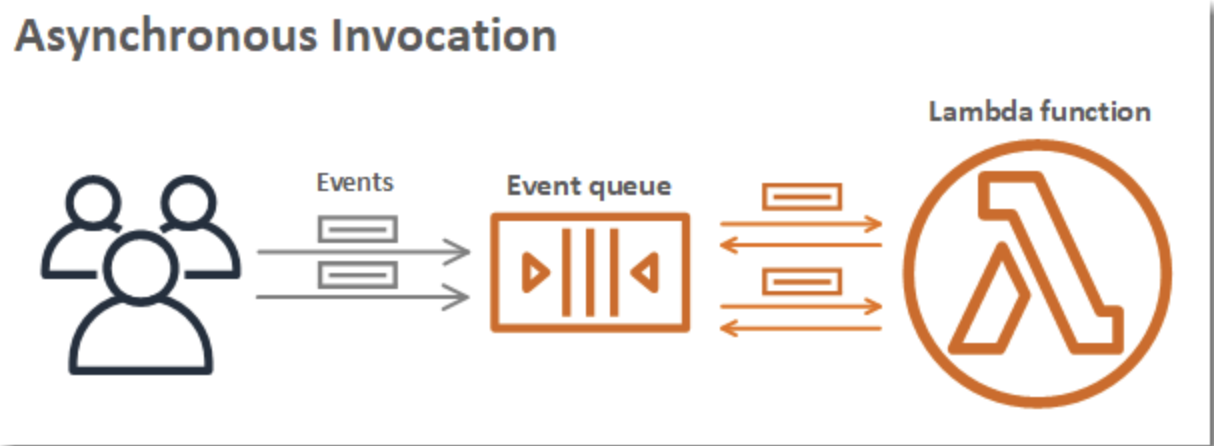
関数を呼び出す際は、同期的に呼び出すか非同期的に呼び出すかを選択できます。同期呼び出しでは、イベントを処理する関数を待ってレスポンスを返します。非同期呼び出しでは、Lambda は処理のためにイベントをキューに入れ、すぐにレスポンスを返します。非同期呼び出しでは、Lambda によって再試行が行われるため、呼び出しレコードが送信先に送信される場合があります。
関数を使用してデータを自動的に処理するには、1 つ以上のトリガーを追加します。トリガーとは、Lambda リソース、つまりライフサイクルイベント、外部リクエスト、またはスケジュールに応答して関数を呼び出すように設定する別のサービスのリソースのことです。関数は複数のトリガーを持つことができます。各トリガーは、関数を独立して呼び出すクライアントとして機能します。Lambda により関数に渡される各イベントには、1 つのクライアントまたはトリガからのデータしかありません。
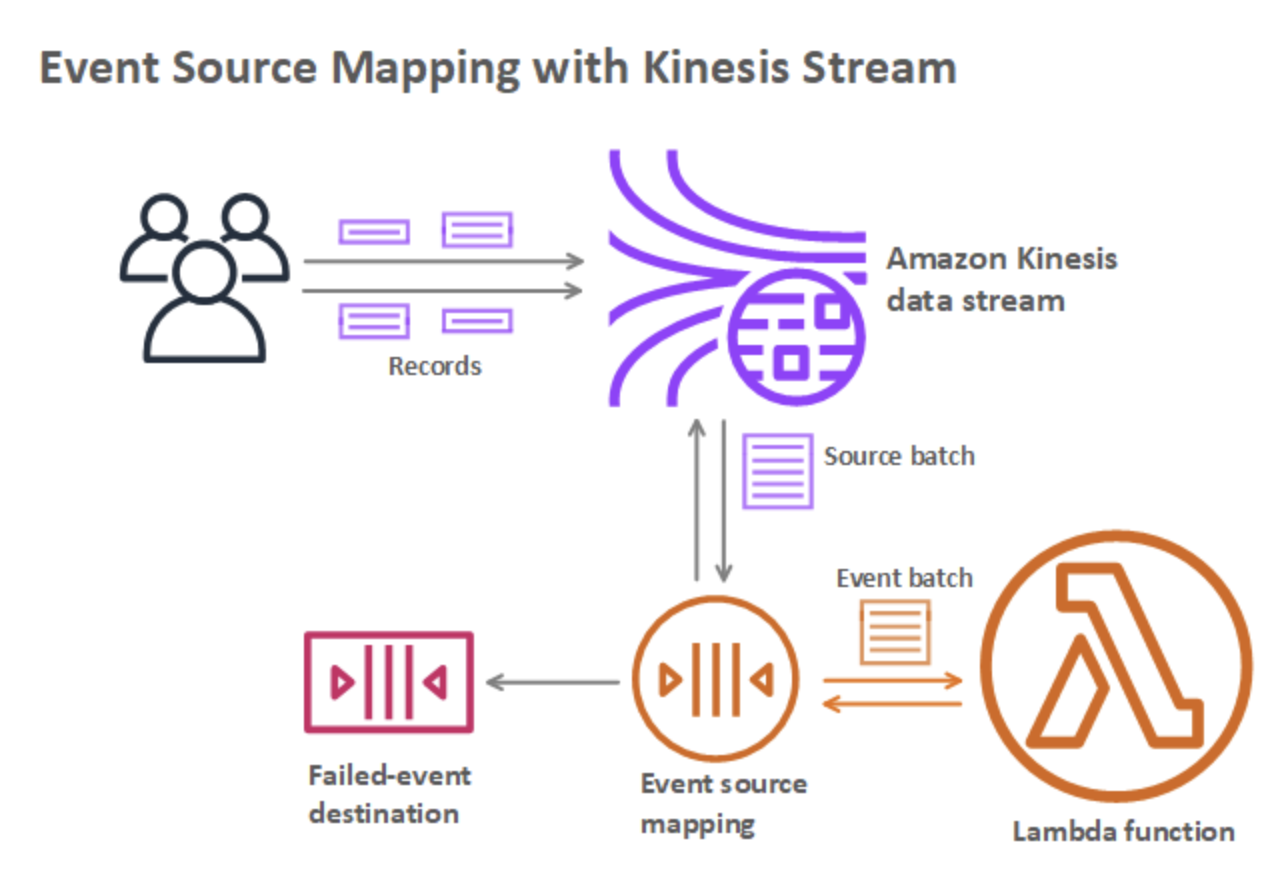
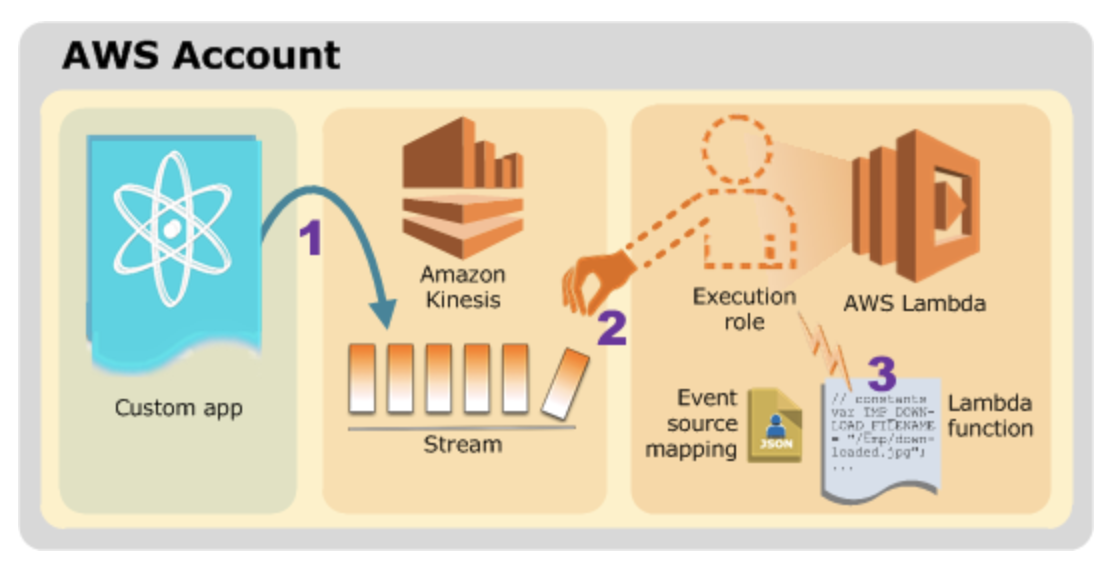
ストリームまたはキューから項目を処理するには、イベントソースマッピングを作成することができます。イベントソースマッピングは、Amazon SQS キュー、Amazon Kinesis ストリーム、または Amazon DynamoDB ストリームから項目を読み取り、バッチで関数に送信する Lambda のリソースです。関数が処理する各イベントには、数百または数千の項目を含めることができます。
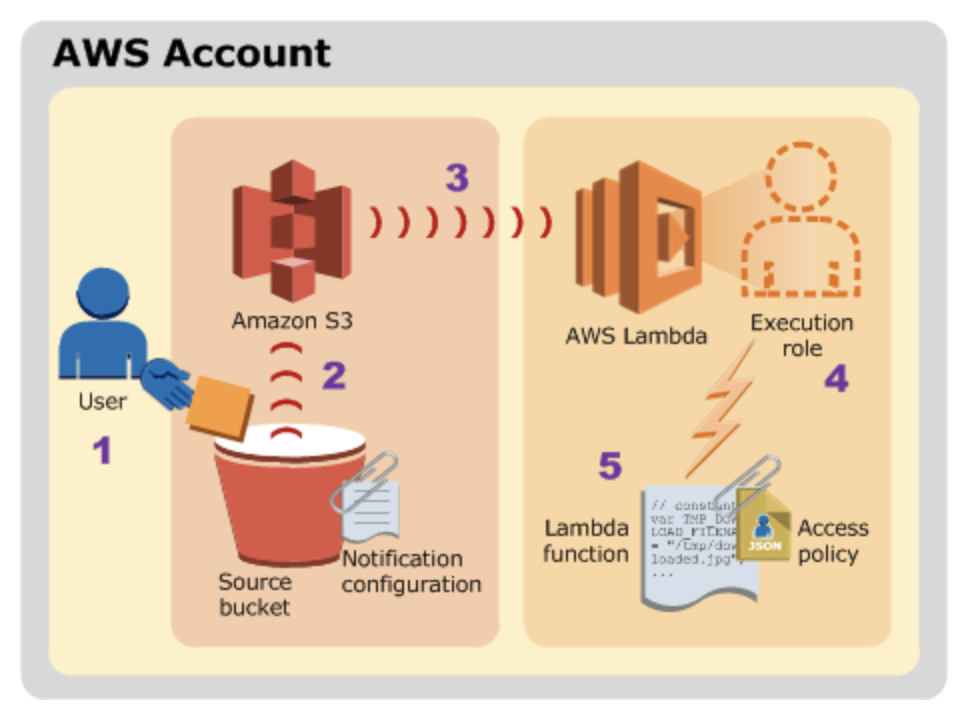
他の AWS サービスやリソースは、関数を直接呼び出します。たとえば、タイマーで関数を呼び出すように CloudWatch イベント を設定したり、オブジェクトが作成されたときに関数を呼び出すように Amazon S3 を設定したりできます。各サービスにおいて、関数の呼び出しに使用するメソッド、イベントの構造、および構成方法が異なります。詳細については、「他のサービスで AWS Lambda を使用する」を参照してください。
誰が関数を呼び出すか、どのように呼び出されるかによって、スケーリングの動作や発生する可能性のあるエラーの種類が異なります。関数を同期的に呼び出すと、エラーがレスポンスで返され、再試行できます。非同期的に呼び出したり、イベントソースマッピングを使用したり、別のサービスを構成して関数を呼び出す場合、要件を再試行し、多数のイベントを処理するために関数をスケーリングする方法は異なります。詳細については、「AWS Lambda 関数スケーリング」および「エラー処理と AWS Lambda での自動再試行」を参照してください。
関数を同期的に呼び出すと、Lambda は関数を実行し、レスポンスを待ちます。関数の実行が終了すると、Lambda は、実行された関数のバージョンなどの追加データとともに、関数のコードからのレスポンスを返します。
Amazon Simple Storage Service (Amazon S3) や Amazon Simple Notification Service (Amazon SNS) など、AWS のいくつかのサービスでは、関数を非同期的に呼び出してイベントを処理します。関数を非同期的に呼び出す場合は、関数コードからのレスポンスを待機しません。イベントを Lambda に渡すと、Lambda が残りを処理します。Lambda でエラーを処理する方法を設定し、呼び出しレコードをダウンストリームのリソースに送信して、アプリケーションのコンポーネントを連鎖させることができます。
まずは一読 AWS Lambda関数を非同期で呼ぶ場合の動きを改めて確める https://qiita.com/horit0123/items/295f8dc55d8c07e6512a
イベントソースのマッピングは、イベントソースからを読み取り、Lambda 関数を呼び出す AWS Lambda リソースのことを指します。イベントソースマッピングは、直接 Lambda 関数を呼び出さないサービスのキューまたはストリームから項目を処理するときに使用することができます。
イベントソースのマッピングは、イベントソースの項目の読み取りや管理のために、関数の実行ロールのアクセス権限を使用します。アクセス権限やイベント構造、設定、ポーリングの動作はイベントソースによって異なります。
AWS Lambdaのアプリケーション作成を使ってCI/CDパイプラインを一気に構築 https://qiita.com/shonansurvivors/items/b223fbb362aed3c1c536
ローリングデプロイを使用して、Lambda 関数の新しいバージョンの導入に伴うリスクを制御します。ローリングデプロイでは、システムは関数の新しいバージョンを自動的にデプロイし、徐々に増加するトラフィックを新しいバージョンに送信します。
関数ハンドラー外で SDK クライアントとデータベース接続を初期化し、静的なアセットを /tmp ディレクトリにローカルにキャッシュ
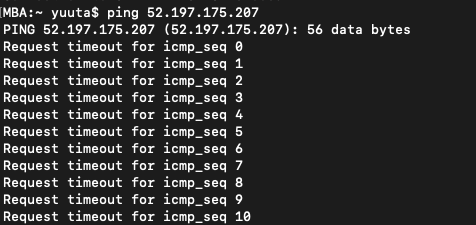
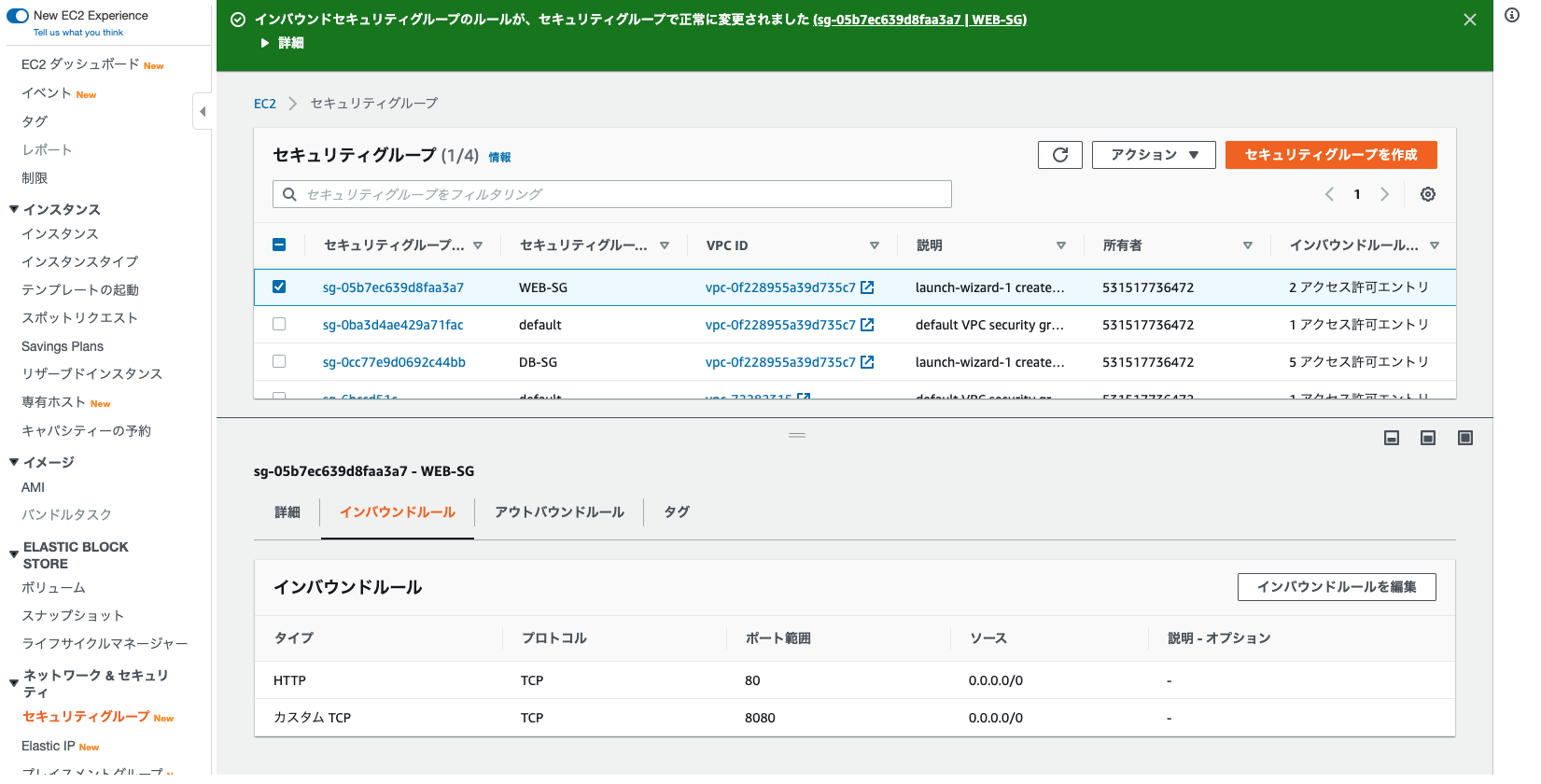
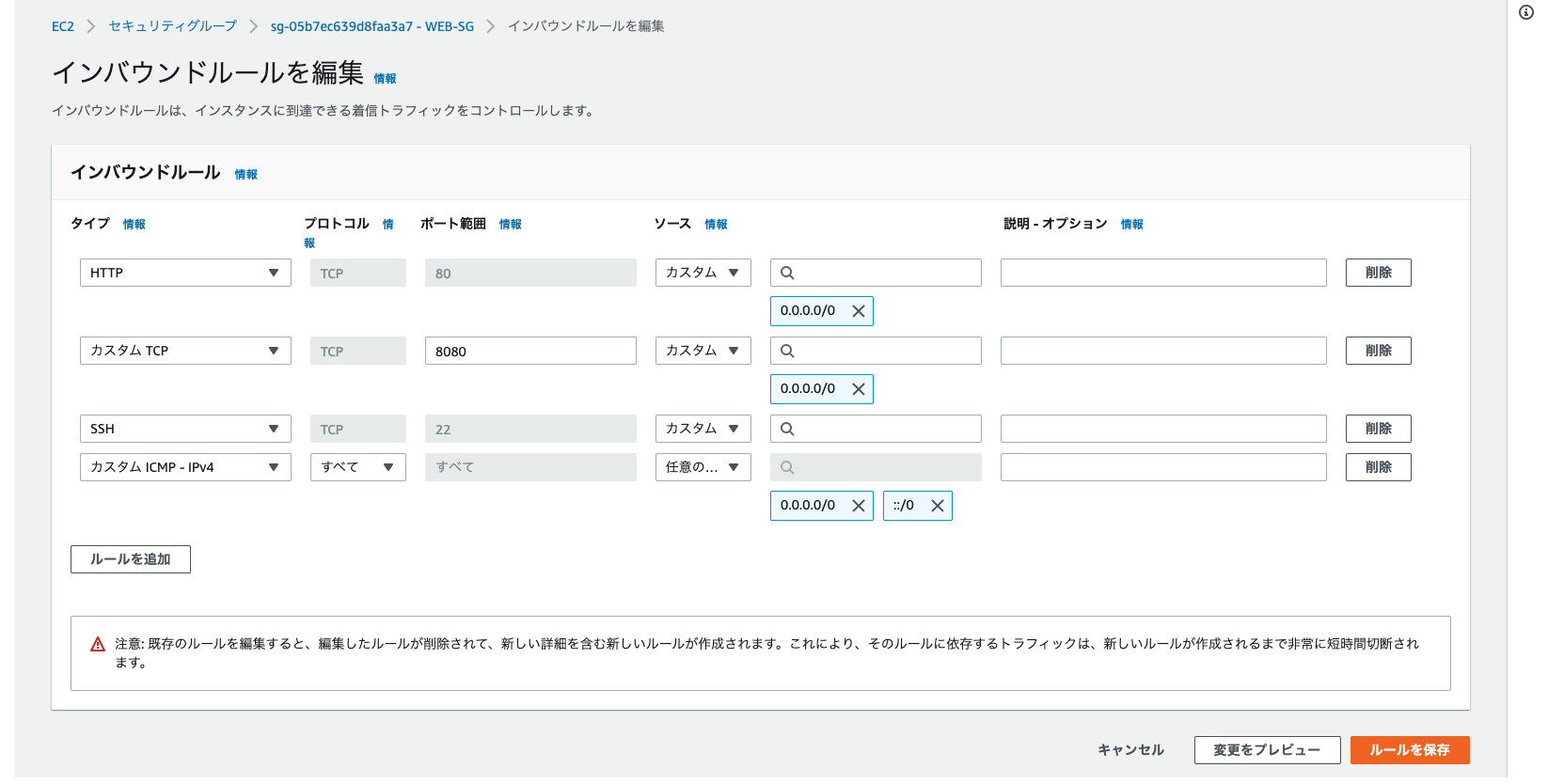
pingコマンドでタイムアウトになる AWSでEC2インスタンスを作成して、pingコマンドで応答確認をしたいのにタイムアウトになる。 ■考えられる理由は大きく2つです。 1. サーバーが停止している 2. ファイアウォールで阻止されている 今回は2.についてです。 ファイアウォールにあたるセキリティグループでICMPを許可する必要があります。 ■手順 1. マネジメントコンソールにログイン 2. 使用しているセキリティグループを選択 3. 「インバウンドルールの編集」をクリック 4. 「カスタム ICMP - IPv4」を選択し、ソースは任意の場所を選択 5. ルールを保存 pingコマンドで応答しない原因がセキリティグループの設定の場合は、以上の設定でpingコマンドが通るはずです。 参考 Amazon Web Services 基礎からのネットワーク&サーバー構築
AWSでEC2インスタンスを作成して、pingコマンドで応答確認をしたいのにタイムアウトになる。
■考えられる理由は大きく2つです。 1. サーバーが停止している 2. ファイアウォールで阻止されている
今回は2.についてです。
ファイアウォールにあたるセキリティグループでICMPを許可する必要があります。
■手順 1. マネジメントコンソールにログイン 2. 使用しているセキリティグループを選択 3. 「インバウンドルールの編集」をクリック 4. 「カスタム ICMP - IPv4」を選択し、ソースは任意の場所を選択 5. ルールを保存
pingコマンドで応答しない原因がセキリティグループの設定の場合は、以上の設定でpingコマンドが通るはずです。
Amazon Web Services 基礎からのネットワーク&サーバー構築
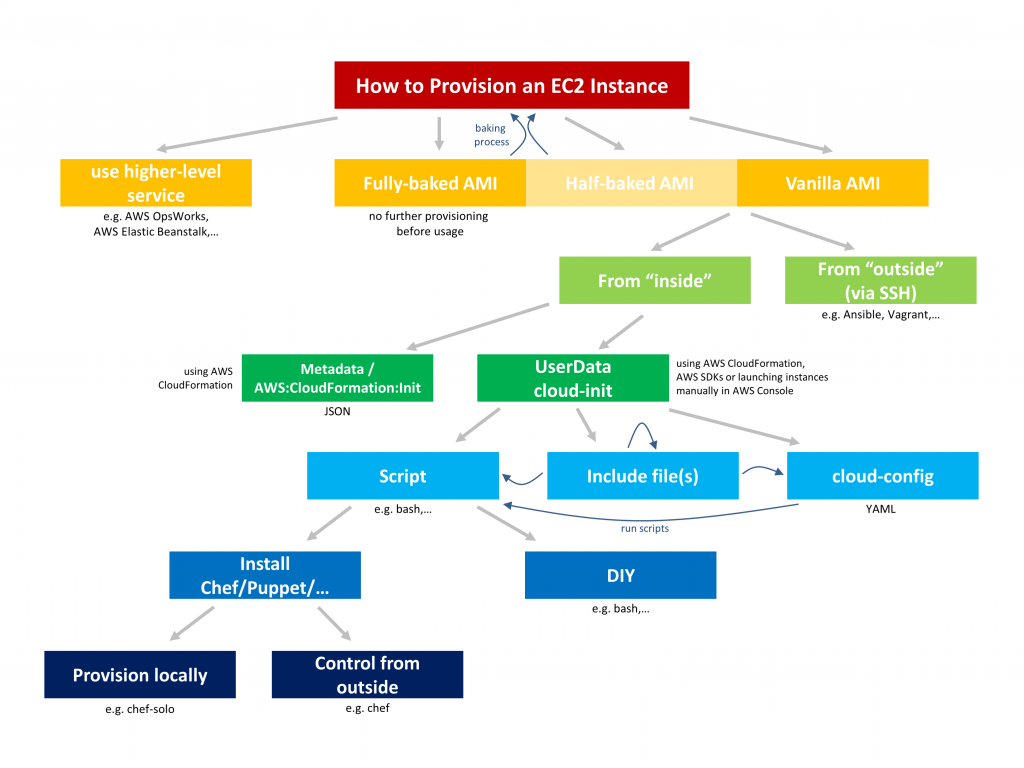
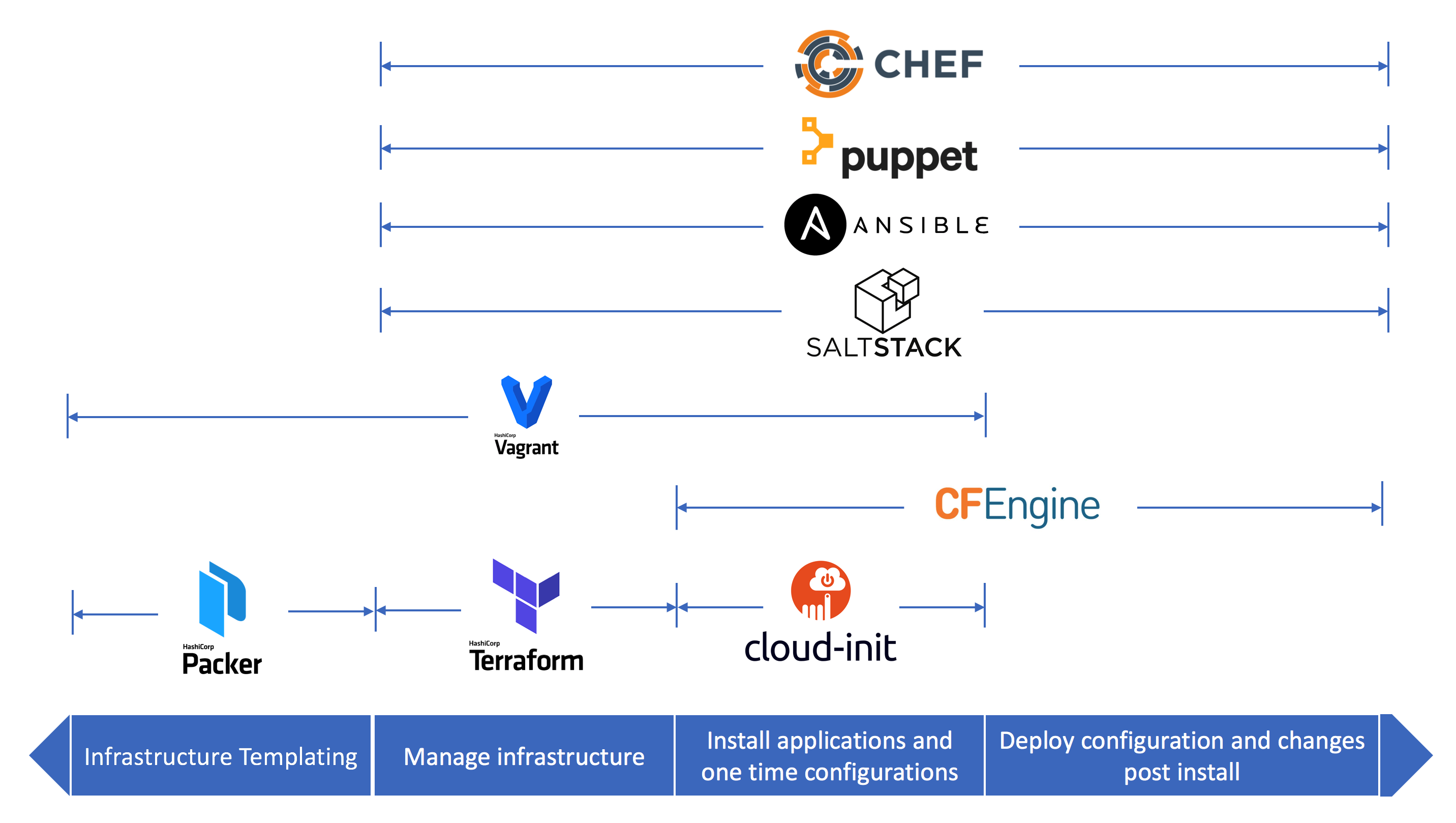
はじめに 本稿は、cloud-init に関して、ふわ っとしたイメージしか持っていなかった私が、自身の記録用にまとめたノートを投稿しているだけですので、エキスパートの方は参考にしないでください。初学者の方にとっては、比較的わかりやすい内容にまとめているつもりです。 cloud-initとは cloud-initは、cloud instanceの初期化メソッドで、様々なクラウドベンダーをサポートしています。 元々、EC2用に作成されたもので、ec2-init というパッケージ名だったそうです。 ドキュメントは、こちらです。 インスタンスの初期設定に必要な、アカウント、リポジトリ設定、パッケージのインストールなど様々な機能もありますし、任意のスクリプトを実行する事も可能です。(CA証明書インストール作業とか、結構楽かも。) cloud-initは #cloud-configで始まる、ユーザーデータ などを受け取り、初期セットアップを行います。 cloud-configは、YAML形式で記述します。 例えば、以下でユーザーを作成します。 #cloud-config users: - default - name: foobar gecos: Foo B. Bar primary_group: foobar groups: users selinux_user: staff_u expiredate: 2012-09-01 ssh_import_id: foobar lock_passwd: false passwd: $6$j212wezy$7H/1LT4f9/N3wpgNunhsIqtMj62OKiS3nyNwuizouQc3u7MbYC 使い分け 構成管理ツールとして、ChefやAnsible、puppetなどがありますが、それらの使い分けに関してまとめてみました。 以下の画像がわかりやすいと思います。 AnsibleやChefなどと被るところがありますが、初期セットアップ という観点で使う場合は、 cloud-init を利用すればいいのではないかと考えています。 terraformで、新たにインスタンスをプロビジョニング、cloud-initで初期セットアップ、Ansibleで構成管理といった連携など考えられます。 Boot Stage cloud-initのboot stageは以下、5つに分かれています。 Generator Local Network Config Final Generator では、cloud-initを実行するか否かの決定をします。実行する場合、Localではメタデータに格納されているネットワーク情報を適用します。Networkではdisk_setupを実行しmodulesをマウントします。Configでは、config_moduleのみをrunします。Finalは一番最後に実行されます。ユーザーログイン後にRunする必要のあるスクリプトはここに記述する必要があります。 それぞれのステージは、以下のコマンドで確認できます。 $ cloud-init status --long status: running time: Fri, 26 Jan 2018 21:39:43 +0000 detail: Running in stage: init-local モジュール郡はそれぞれが上記のStageに紐づいています。例えば、Bootcmd は、cloud_init_modulesに属しており、boot毎に実行されます。 scripts-per-bootでは、cloud_final_modulesに属しており、こちらもboot毎に実行されます。これらは実行のタイミングが異なるので、それを意識した上での記述が必要です。 ドキュメントには、 ブートプロセスの後半で実行できない処理にのみ使用してください。 と書いてあったので、上記でない限りは、 cloud_init_modules 内で処理をした方が良いみたいです。 注意としては、再起動プロセスは runcmd で記述の記述がおすすめ。(runcmdは、config_modulesですが、Final Stageで実行されます。) デバッグ まず、cloud-initのディレクトリ情報は以下の通りになっていました。 $ tree --charset=x /var/lib/cloud/ -L 2 /var/lib/cloud/ |-- data | |-- instance-id | |-- previous-datasource | |-- previous-instance-id | |-- result.json | |-- set-hostname | `-- status.json |-- handlers |-- instance -> /var/lib/cloud/instances/ocid1.instance.oc1.iad.*********** |-- instances | `-- ocid1.instance.oc1.iad.*********** |-- scripts | |-- per-boot | |-- per-instance | |-- per-once | `-- vendor |-- seed `-- sem instanceのcloud-config.txtには、cloud-configの情報が格納されていました。 (これってプロビジョニング後からruncmdなどの記述を変更をしていいのかな。) $ cat cloud-config.txt #cloud-config # from 1 files # part-001 --- cloud_final_modules: - - scripts-user - always locale: ja_JP.utf8 package_upgrade: true packages: - man-pages-ja - multitail - nmap - nc - tmux - tree runcmd: - - sh - -c - echo $(date) >> /tmp/testfile.txt timezone: Asia/Tokyo また実行ログは、/var/log/cloud-init.log に格納されます。基本的に実行確認などは、ここを見ればOKだと思います。 $ cat /var/log/cloud-init.log | grep config-timezone 2020-05-17 16:28:37,630 - handlers.py[DEBUG]: start: modules-config/config-timezone: running config-timezone with frequency once-per-instance 2020-05-17 16:28:37,635 - helpers.py[DEBUG]: Running config-timezone using lock (<FileLock using file '/var/lib/cloud/instances/ocid1.instance.oc1.iad.anuwcljrejk3llyct26xrjijj74qh5i6cgtd33i7575zupmk5g74hk4o7cqa/sem/config_timezone'>) 2020-05-17 16:28:37,636 - handlers.py[DEBUG]: finish: modules-config/config-timezone: SUCCESS: config-timezone ran successfully もしくは以下のような形で、ログ情報を出力する事も可能です。 runcmd: - - sh - -c - echo $(date) >> /tmp/testfile.txt $ cat /tmp/testfile.txt Mon May 18 01:28:38 JST 2020 2020年 5月 18日 月曜日 01:36:08 JST 最後に 初学者としてのcloud-initの私なりの理解をまとめました。 windowsOSをサポートしているcloudbase-initに関してのドキュメントは充実していないようなので、今後そのあたりのまとめ記事など投稿したいなと考えています。 参考情報 Amazon Linuxのcloud-initの実行順番を確認する cloud-initを使ったLinux OSの初期設定 cloud-initをデバッグする Part 1
本稿は、cloud-init に関して、ふわ っとしたイメージしか持っていなかった私が、自身の記録用にまとめたノートを投稿しているだけですので、エキスパートの方は参考にしないでください。初学者の方にとっては、比較的わかりやすい内容にまとめているつもりです。
cloud-init
ふわ
cloud-initは、cloud instanceの初期化メソッドで、様々なクラウドベンダーをサポートしています。 元々、EC2用に作成されたもので、ec2-init というパッケージ名だったそうです。 ドキュメントは、こちらです。
ec2-init
インスタンスの初期設定に必要な、アカウント、リポジトリ設定、パッケージのインストールなど様々な機能もありますし、任意のスクリプトを実行する事も可能です。(CA証明書インストール作業とか、結構楽かも。) cloud-initは #cloud-configで始まる、ユーザーデータ などを受け取り、初期セットアップを行います。
#cloud-config
ユーザーデータ
cloud-configは、YAML形式で記述します。 例えば、以下でユーザーを作成します。
#cloud-config users: - default - name: foobar gecos: Foo B. Bar primary_group: foobar groups: users selinux_user: staff_u expiredate: 2012-09-01 ssh_import_id: foobar lock_passwd: false passwd: $6$j212wezy$7H/1LT4f9/N3wpgNunhsIqtMj62OKiS3nyNwuizouQc3u7MbYC
構成管理ツールとして、ChefやAnsible、puppetなどがありますが、それらの使い分けに関してまとめてみました。 以下の画像がわかりやすいと思います。 AnsibleやChefなどと被るところがありますが、初期セットアップ という観点で使う場合は、 cloud-init を利用すればいいのではないかと考えています。
初期セットアップ
terraformで、新たにインスタンスをプロビジョニング、cloud-initで初期セットアップ、Ansibleで構成管理といった連携など考えられます。
cloud-initのboot stageは以下、5つに分かれています。
Generator では、cloud-initを実行するか否かの決定をします。実行する場合、Localではメタデータに格納されているネットワーク情報を適用します。Networkではdisk_setupを実行しmodulesをマウントします。Configでは、config_moduleのみをrunします。Finalは一番最後に実行されます。ユーザーログイン後にRunする必要のあるスクリプトはここに記述する必要があります。
Generator
Local
Network
Config
Final
それぞれのステージは、以下のコマンドで確認できます。
$ cloud-init status --long status: running time: Fri, 26 Jan 2018 21:39:43 +0000 detail: Running in stage: init-local
モジュール郡はそれぞれが上記のStageに紐づいています。例えば、Bootcmd は、cloud_init_modulesに属しており、boot毎に実行されます。 scripts-per-bootでは、cloud_final_modulesに属しており、こちらもboot毎に実行されます。これらは実行のタイミングが異なるので、それを意識した上での記述が必要です。 ドキュメントには、
Bootcmd
cloud_init_modules
scripts-per-boot
cloud_final_modules
ブートプロセスの後半で実行できない処理にのみ使用してください。
と書いてあったので、上記でない限りは、 cloud_init_modules 内で処理をした方が良いみたいです。
注意としては、再起動プロセスは runcmd で記述の記述がおすすめ。(runcmdは、config_modulesですが、Final Stageで実行されます。)
runcmd
まず、cloud-initのディレクトリ情報は以下の通りになっていました。
$ tree --charset=x /var/lib/cloud/ -L 2 /var/lib/cloud/ |-- data | |-- instance-id | |-- previous-datasource | |-- previous-instance-id | |-- result.json | |-- set-hostname | `-- status.json |-- handlers |-- instance -> /var/lib/cloud/instances/ocid1.instance.oc1.iad.*********** |-- instances | `-- ocid1.instance.oc1.iad.*********** |-- scripts | |-- per-boot | |-- per-instance | |-- per-once | `-- vendor |-- seed `-- sem
instanceのcloud-config.txtには、cloud-configの情報が格納されていました。 (これってプロビジョニング後からruncmdなどの記述を変更をしていいのかな。)
$ cat cloud-config.txt #cloud-config # from 1 files # part-001 --- cloud_final_modules: - - scripts-user - always locale: ja_JP.utf8 package_upgrade: true packages: - man-pages-ja - multitail - nmap - nc - tmux - tree runcmd: - - sh - -c - echo $(date) >> /tmp/testfile.txt timezone: Asia/Tokyo
また実行ログは、/var/log/cloud-init.log に格納されます。基本的に実行確認などは、ここを見ればOKだと思います。
/var/log/cloud-init.log
$ cat /var/log/cloud-init.log | grep config-timezone 2020-05-17 16:28:37,630 - handlers.py[DEBUG]: start: modules-config/config-timezone: running config-timezone with frequency once-per-instance 2020-05-17 16:28:37,635 - helpers.py[DEBUG]: Running config-timezone using lock (<FileLock using file '/var/lib/cloud/instances/ocid1.instance.oc1.iad.anuwcljrejk3llyct26xrjijj74qh5i6cgtd33i7575zupmk5g74hk4o7cqa/sem/config_timezone'>) 2020-05-17 16:28:37,636 - handlers.py[DEBUG]: finish: modules-config/config-timezone: SUCCESS: config-timezone ran successfully
もしくは以下のような形で、ログ情報を出力する事も可能です。
runcmd: - - sh - -c - echo $(date) >> /tmp/testfile.txt
$ cat /tmp/testfile.txt Mon May 18 01:28:38 JST 2020 2020年 5月 18日 月曜日 01:36:08 JST
初学者としてのcloud-initの私なりの理解をまとめました。 windowsOSをサポートしているcloudbase-initに関してのドキュメントは充実していないようなので、今後そのあたりのまとめ記事など投稿したいなと考えています。
Amazon Linuxのcloud-initの実行順番を確認する cloud-initを使ったLinux OSの初期設定 cloud-initをデバッグする Part 1
AWS Lambdaの関数にHTTP APIで値をPOSTする際につまづいたのでメモ。 環境 macOS AWS Cloud9 Node.js 12 問題 Node.jsのfetch()メソッドで、自作したLambda関数にPOSTで値を送信しました。 Lambdaの呼び出しはAPI GatewayのHTTP APIを用いています。 Lambda関数のコード デバックするために、Lambda関数では一旦eventを返すようにしています。 console.logで出力してCloudWacth Logsで確認しても良いと思います。 exports.handler = async(event, context) => { console.log(event) ... return event }; 実行コード require('dotenv').config() const env = process.env var fetch = require("node-fetch") fetch(env.LAMBDA_URL, { // Lambda関数のAPI URL method: 'POST', headers: { 'Content-type': 'application/json' }, body: { "massage": "test massage" }, }) .then(function(res) { return res.json(); }) .then(function(event) { console.log(event); }) eventの中身を確認すると、 { version: '2.0', routeKey: 'XXXXXXXXXX', ... body: '[object Object]', isBase64Encoded: false } bodyの値が'[object Object]'になっています。 解決方法 どうやら、Lambda関数に値を渡すときは、Payloadとして渡す必要があるようで、JSON形式のデータはJSONの文字列に変換した状態で送る必要があるようです。 Payloadに指定した値は文字列に変換されるので、オブジェクトをそのまま指定すると、[object Object]に変換されてしまいます。 ※オブジェクトにtoString()メソッドを適用すると、返り値は[object Object]なる POSTするbodyの値を、JSON.stringify()で文字列に変換して送ることで解決できます。 修正後のコード fetch(env.LAMBDA_URL, { method: 'POST', headers: { 'Content-type': 'application/json' }, body: JSON.stringify({ // JSONを文字列に変換する "massage": "test massage" }), }) .then(function(res) { return res.json(); }) .then(function(event) { console.log(event); }) 出力を見てみると、 { version: '2.0', routeKey: 'XXXXXXXXXX', ... body: '{"massage":"test massage"}', isBase64Encoded: false } POSTしたbodyの値をきちんと確認できました。
AWS Lambdaの関数にHTTP APIで値をPOSTする際につまづいたのでメモ。
Node.jsのfetch()メソッドで、自作したLambda関数にPOSTで値を送信しました。 Lambdaの呼び出しはAPI GatewayのHTTP APIを用いています。
デバックするために、Lambda関数では一旦eventを返すようにしています。 console.logで出力してCloudWacth Logsで確認しても良いと思います。
exports.handler = async(event, context) => { console.log(event) ... return event };
require('dotenv').config() const env = process.env var fetch = require("node-fetch") fetch(env.LAMBDA_URL, { // Lambda関数のAPI URL method: 'POST', headers: { 'Content-type': 'application/json' }, body: { "massage": "test massage" }, }) .then(function(res) { return res.json(); }) .then(function(event) { console.log(event); })
eventの中身を確認すると、
{ version: '2.0', routeKey: 'XXXXXXXXXX', ... body: '[object Object]', isBase64Encoded: false }
bodyの値が'[object Object]'になっています。
'[object Object]'
どうやら、Lambda関数に値を渡すときは、Payloadとして渡す必要があるようで、JSON形式のデータはJSONの文字列に変換した状態で送る必要があるようです。 Payloadに指定した値は文字列に変換されるので、オブジェクトをそのまま指定すると、[object Object]に変換されてしまいます。 ※オブジェクトにtoString()メソッドを適用すると、返り値は[object Object]なる
[object Object]
POSTするbodyの値を、JSON.stringify()で文字列に変換して送ることで解決できます。
fetch(env.LAMBDA_URL, { method: 'POST', headers: { 'Content-type': 'application/json' }, body: JSON.stringify({ // JSONを文字列に変換する "massage": "test massage" }), }) .then(function(res) { return res.json(); }) .then(function(event) { console.log(event); })
出力を見てみると、
{ version: '2.0', routeKey: 'XXXXXXXXXX', ... body: '{"massage":"test massage"}', isBase64Encoded: false }
POSTしたbodyの値をきちんと確認できました。