- 投稿日:2020-05-17T23:39:03+09:00
railsでアプリを作る際にdbを指定する方法
railsでアプリを作る際にdbを指定する方法
簡単なことなのですが、よくDB指定を忘れてアプリを作ってしまう私への戒めの備忘録です、、、。
データベースの指定
rails newをする際に、データベースを指定してアプリを作ります。
何も指定しないとデータベースのデフォルトはsqliteになるので、Mysqlなどを使いたい時に行います。例
$ rails new アプリ名 --database=mysql簡略化した書き方でこういうのもあります。
例$ rails new アプリ名 -d mysqlこっちの方が簡単でいいですね、-dはデータベースの意味です。
簡単に備忘録として書かせていただきました。
- 投稿日:2020-05-17T23:18:26+09:00
(ECS,Rails6)ロードバランサー ALB と データベース RDS とECRを使ってコマンドラインから ECSにRails6のアプリをデプロイ
はじめに
ECSの概要とECS CLIを使ってアプリのデプロイの仕方について書いていきます。
ECSやその他のサービスに関して、そこまで理解できてないので間違ってる部分も多いと思います。
とりあえず記事通りに作業したらRails6のアプリケーションをECSにデプロイできる様に記事を書きたいと思います。
もしうまくいかなかったらおそらく権限関係なので権限を見直してみてください。
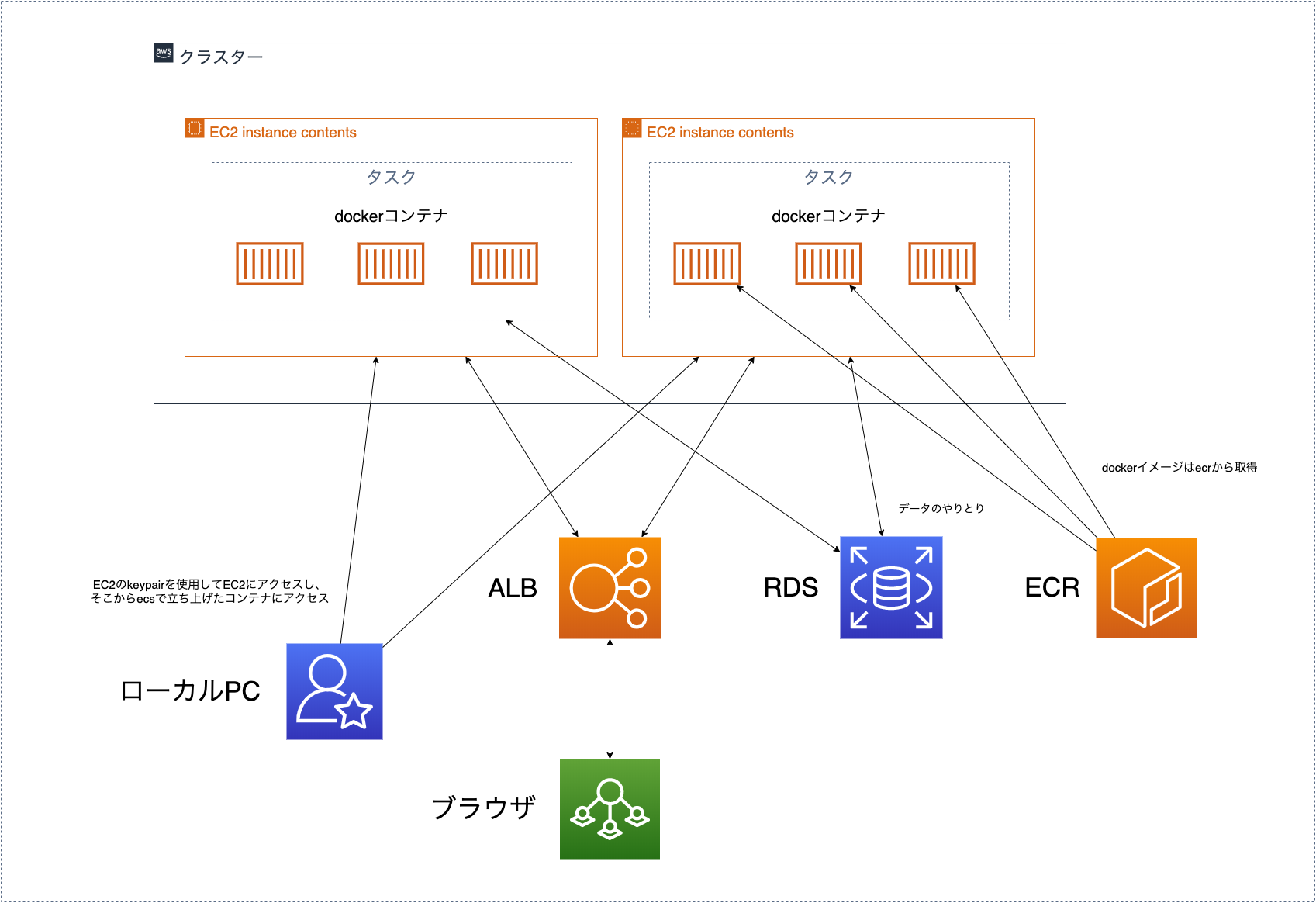
ECSの概要
ECSはdockerのコンテナをそのままaws上にデプロイできるサービスです。
docker-hubやecrなどのdockerイメージのレジストリからイメージを持ってきてコンテナを作成してデプロイできます。
自分がやった場合、下記の様になりました。
ECSはクラスターと言うEC2のインスタンス群みたいなのをまず作ります。
このクラスター内にEC2があり、その中にECSのタスクと言うのを作ります。
このタスク上でdockerのコンテナが起動される形になります。
dockerコンテナの起動に関してはecsにタスク定義を作成してこのタスク定義を元にdockerコンテナを作成していくことになります。
dockerコンテナの起動に必要なdockerイメージに関してはdockerイメージレジストリから取ってきます。
docker hubの場合は誰でも見れてしまうのでecrを使うのが良いと思います。
作成したコンテナはALBを通して公開されます。
ALBを使うことで負荷がかかった時に新しくタスクの作成し負荷を分散できます。
作成したコンテナに関してはec2インスタンスにkeypairを使ってそこからdockerコンテナにアクセスする形になります。
ちなみにFargateを使う場合は確かコンテナにアクセスできなかった気がします。
デプロイ
前提として
- PCはMac
- ローカルPCにdockerとmysqlがインストールされていることRailsアプリの作成
まずRailsアプリの作成をします。
適当なフォルダを作成してそこに Dockerfile docker-compose.yml Gemfile Gemfile.lock を作成します。
内容は下記の様にします。
Dockerfile
FROM node:13.5-alpine as node RUN apk add --no-cache bash curl && \ curl -o- -L https://yarnpkg.com/install.sh | bash -s -- --version 1.21.1 FROM ruby:2.6.5-alpine COPY --from=node /usr/local/bin/node /usr/local/bin/node COPY --from=node /opt/yarn-* /opt/yarn RUN ln -fs /opt/yarn/bin/yarn /usr/local/bin/yarn RUN apk add --no-cache git build-base libxml2-dev libxslt-dev postgresql-dev postgresql-client tzdata bash less && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime RUN apk add --no-cache alpine-sdk \ mysql-client \ mysql-dev ENV APP_ROOT /app RUN mkdir $APP_ROOT WORKDIR $APP_ROOT RUN gem update --system && \ gem install --no-document bundler:2.1.4 ADD ./Gemfile $APP_ROOT/Gemfile ADD ./Gemfile.lock $APP_ROOT/Gemfile.lock RUN bundle install ADD . $APP_ROOTdocker-compose.ymlversion: "3" services: db: image: mysql:5.7 command: mysqld --character-set-server=utf8 --collation-server=utf8_unicode_ci environment: MYSQL_ROOT_PASSWORD: password MYSQL_PASSWORD: password MYSQL_USER: myuser MYSQL_DATABASE: ecs_development ports: - "3306:3306" web: build: . command: bash -c "yarn install && rails db:migrate && rails s -p 3000 -b '0.0.0.0'" ports: - "3000:3000" volumes: - .:/app tty: true links: - dbGemfile
# frozen_string_literal: true source "https://rubygems.org" git_source(:github) {|repo_name| "https://github.com/#{repo_name}" } gem 'rails', '~> 6.0.2', '>= 6.0.2.2'Gemfile.lockは中身は空でOK
ファイルが作成できたら
docker-compose run --rm web rails new . --database=mysql --skip-bundle --skip-testこのコマンドを実行します。
そうするとrailsのファイルがローカルに作成されていると思います。
config/database.ymlのdevelopmentの部分を下記の様に変更します。
database.ymldevelopment: <<: *default host: db username: myuser password: password database: ecs_developmentそしたら
docker-compose up --buildコマンドを実行します。
コンテナが起動したらrails6はwebpackerを使っているので下記コマンドを実行します。
docker-compose exec web rails webpacker:installそうするとlocalhost:3000にアクセスすると見慣れた画面が表示されると思います。
scaffoldでuserのcrudを作ります。
docker-compose exec web rails generate scaffold user name:string age:integer docker-compose exec web rails db:migrateconfig/routes.rbにroutesを追加します。
routes.rbroot to: "users#index"これでlocalhost:3000にアクセスすると
この画面が表示されると思います。
とりあえずこれでアプリのベースの作成は終わりです。
aws-cli ecs-cliのインストール
デプロイに使うツールをインストールします。
brew install awscli brew install amazon-ecs-cliaws configureの設定
aws configureを設定します。
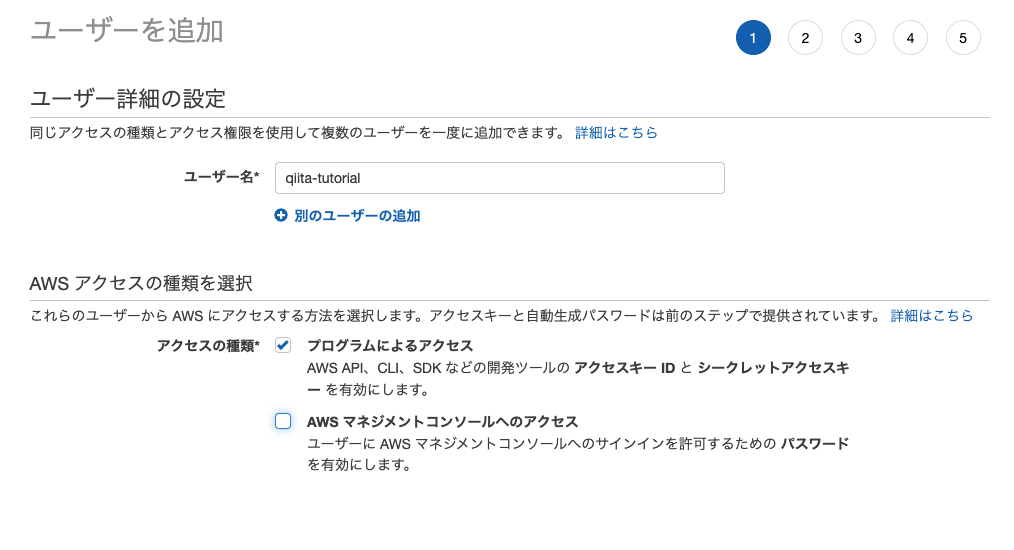
まずIAMユーザーを作る必要があるのでAWSコンソールにアクセスします。
IAMの画面を表示してユーザーの追加ボタンをクリックします。
プログラムによるアクセスにチェックをつけ次へボタンを押します。
ポリシーのアタッチ画面にて
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
を追加します。
そのまま次へボタンを押していくと最後にユーザーのアクセスキーとシークレットキーが表示されるので保存しておきます。
そしたらaws configureの設定をします。
コマンドラインで
aws configureと入力して
access_keyとsecret_keyの入力
regionはap-northeast-1と入力します。
これで aws configureの設定は終わりです。
IAMユーザーの権限は不足しているので後々追加していきます。
クラスターの作成
クラスターの作成時にec2のキーペアを設定するのでまずキーペアの作成を行います。
EC2の画面を表示するとそのサイドメニューにキーペアと言うものがあります。
このキーペアをクリックしてキーペアを作成し、pemファイルをローカルpcにおきます。
自分の場合はホーム直下にaws-keypairフォルダを作成してそこに置いています。
ファイルに関しては権限を変更しておく必要があります。
自分の場合は下記の上になります。
chmod 400 aws-keypair/qiita-tutorial.pemファイルのパスは自分の環境のものに変更してください。
それではECSのクラスターを作成していきます。
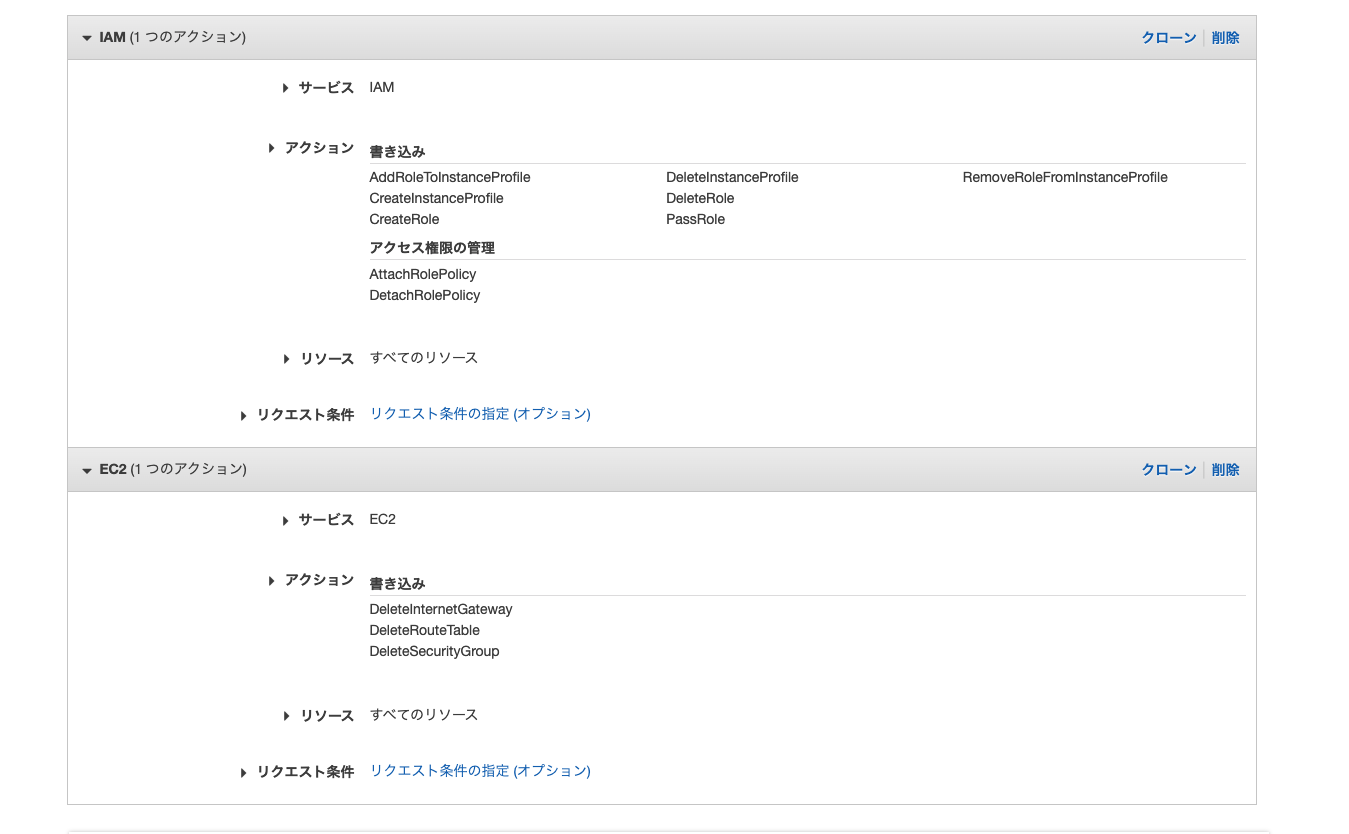
クラスターの作成に関してはECS_FullAccessで付与されないが必要な権限が結構あるので別途追加する必要があります。
IAMのポリシーからポリシー作成をクリックします。
ビジュアルエディタでサービス、アクションを選択していきます。
まずIAMに関しては
- AddRoleToInstanceProfile
- CreateInstanceProfile
- CreateRole
- DeleteInstanceProfile
- DeleteRole
- PassRole
- RemoveRoleFromInstanceProfile
- AttachRolePolicy
- DetachRolePolicy
を追加します。
次にEC2に関して
- DeleteInternetGateway
- DeleteRouteTable
- DeleteSecurityGroup
を追加します。
最終的に下記の画像の様になればOKです。
ポリシーの作成をしたら作成したポリシーをユーザーにアタッチします。
IAMのユーザーから作成したユーザーをクリックしてアクセス権限の追加をクリックします。
そしたら既存のポリシーを追加をクリックして作成したポリシーを追加します。
ポリシーの追加が終わったら
下記のコマンドを実行します。
アクセスキーとシークレットキーに関してはIAMユーザーを作成したときの物を利用してください。
キーペアの名前も自分が作成したキーペアの名前に変更してください。
ecs-cli configure --cluster qiita-tutorial --default-launch-type EC2 --config-name qiita-tutorial --region ap-northeast-1 ecs-cli configure profile --access-key access_key --secret-key secret_key --profile-name qiita-tutorial-profile ecs-cli up --keypair qiita-tutorial --capability-iam --size 1 --instance-type t2.micro --cluster-config qiita-tutorial --ecs-profile qiita-tutorial-profile実行するとクラスターの作成が行われます。
--size 1 と設定しているのでec2インスタンスが一つ立ち上がっているはずです。
これでクラスターの作成は終わりです。
RDSの作成
デプロイの準備は整いましたがデータベースにrdsを使うのでrdsの作成を行なっていきます。
rdsの画面を表示してデータベースの作成をクリックします。
簡単作成、MySQL,無料利用枠を選択します。
DB インスタンス識別子、マスターユーザー名、パスワードを設定して作成します。
作成できたら作成したrdsをクリックすると接続とセキュリティの部分にエンドポイントが記載されています。
ローカルPCからrdsへアクセスができる様にするためにRDSの変更をクリックして
パブリックアクセシビリティ をありにします。
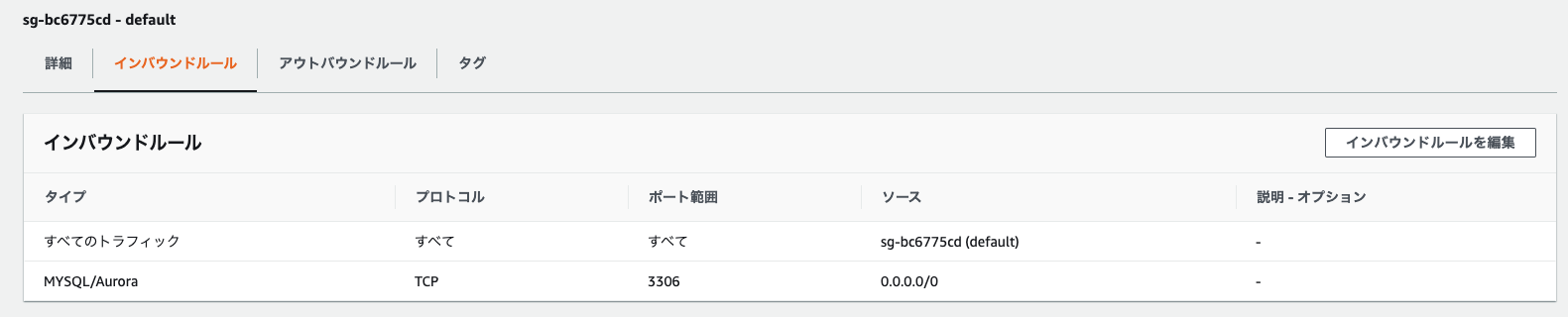
またセキュリティーグループの設定も必要なので行います。
作成したrdsのセキュリティーと接続の部分にVPC セキュリティグループの欄があります。
クリックできる様になっているのでクリックします。
rdsのセキュリティーグループが表示されると思います。
インバウンドルールの部分をクリックします。
タイプはMYSQL/Auroraを選択します。
ソースの設定は下記の画像の様にしましたが細かい設定を行いたい場合は適宜行なってください。
そしたらローカルPCから下記コマンドでrdsに接続します。
mysql -h rdsのエンドポイント -u rdsのユーザー名 -pこれでパスワードを入力するとrdsに接続できるはずです。
そしたらデータベースの作成を行います。
CREATE DATABASE ecs_development default character set utf8;;これでrdsにデータベースの作成ができました。
database.ymlの修正
host,username,passwordを環境変数を見る様に修正します。
config/database.ymldevelopment: <<: *default host: <%= ENV['MYSQL_HOST'] %> username: <%= ENV['MYSQL_USER'] %> password: <%= ENV['MYSQL_PASSWORD'] %> database: ecs_developmentALBの設定
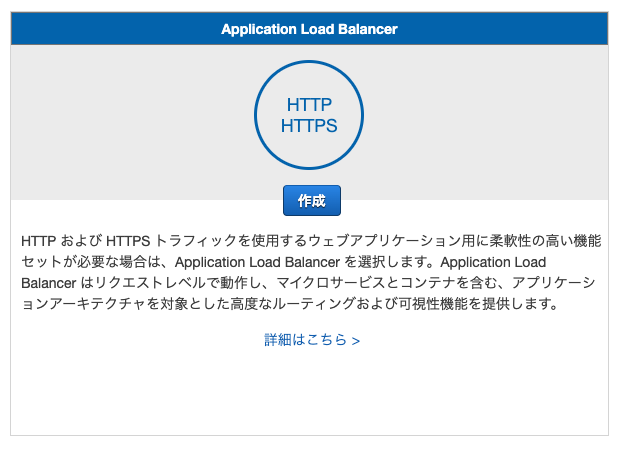
次にALBの設定を行なっていきます。
EC2の画面の再度メニューからロードバランサーをクリックします。
そしたらロードバランサー作成をクリックします。
そしたらApplication Load Balancerの作成をクリックします。
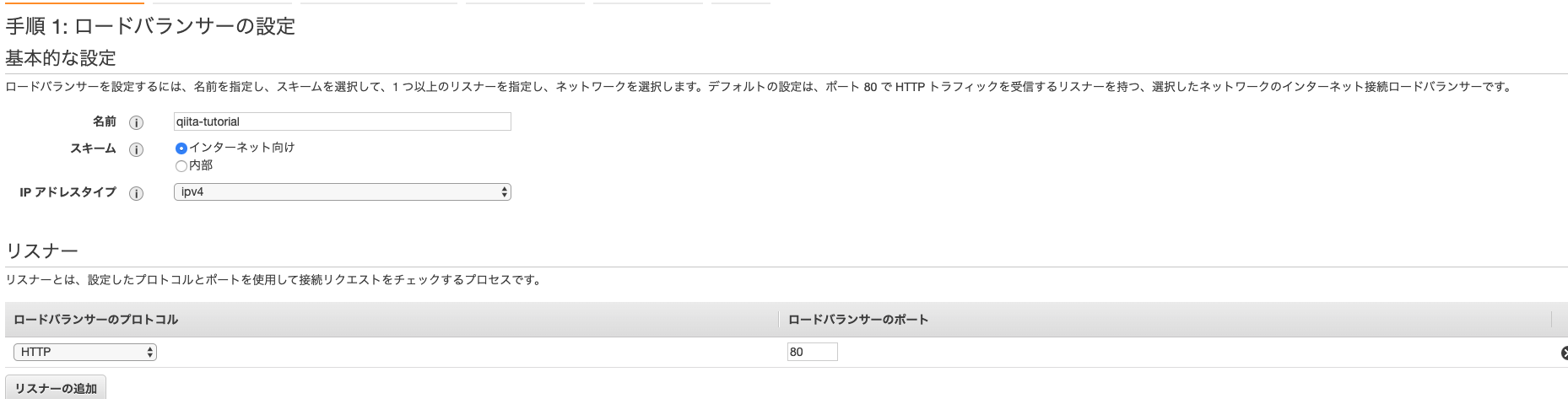
まず名前を入力します。
リスナーはそのままで大丈夫です。
vpcの設定ですがecsのec2インスタンスのvpcを選択しなくてはいけません。
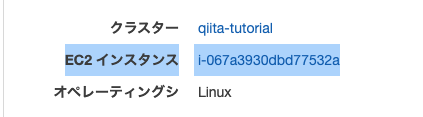
確認の仕方はクラスターのタスクのコンテナインスタンスをクリックします。
ec2インスタンスがあるのでクリックします。
ec2インスタンスが表示されます。
したの説明の部分にvpcのidが記載されています。
確認したらそのvpcをロードバランサーの作成の部分のvpcの選択でそれを選択します。
セキュリティーグループは新しいセキュリティーグループを作成をクリックします。
そして下記の画像の様に設定します。
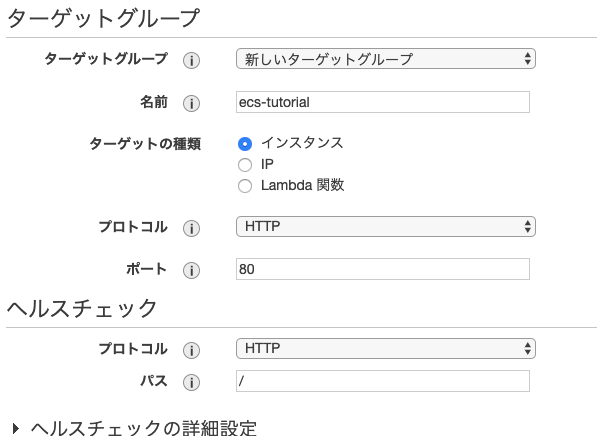
ターゲットグループの設定の部分で新しいターゲットグループを選択して名前を入力します。
ターゲットはインスタンスを選択します。
次へいくとec2インスタンスの選択画面が出るのでecsで使うec2インスタンスを選択して登録済みに追加ボタンをクリックします。
あとは次へを押して作成すればOKです。
config/environment/development.rbの修正
rails6ではhost名を明示的に記載しないと起動しません。
なのでconfig/environment/development.rbに下記を追加します。
development.rbconfig.hosts << ALBのdns名を記載ecrにイメージの登録
ecsで利用するイメージをecrに登録していきます。
ecrの画面を開きレポジトリの作成をクリックします。
適当に名前を入力して作成します。
レポジトリの作成が終わったらローカル環境でdockerイメージをビルドしてpushします。
まず
docker build . -t ecrのURIを実行します。
そしたら次に下記コマンドでecrにpushします。
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin ecrのURI docker push ecrのURIこれでecrへのpushはOKです。
デプロイ
デプロイの準備ができたのでデプロイします。
まずデプロイ用のdocker-compose.ymlを作成します。
名前はdocker-compose-deploy.ymlとします。
docker-compose-deploy.ymlversion: '3' services: web: image: rdsのURI command: bash -c "yarn install && rails db:migrate && rm /app/tmp/pids/server.pid && rails s -p 3000 -b '0.0.0.0'" environment: MYSQL_USER: rdsのuser名 MYSQL_PASSWORD: rdsのpassword MYSQL_HOST: rdsのエンドポイント TZ: "Japan" ports: - "80:3000" logging: driver: awslogs options: awslogs-group: ecs-tutorial awslogs-region: ap-northeast-1 awslogs-stream-prefix: webそしたら
ecs-cli compose -f docker-compose-deploy.yml up --create-log-groups --cluster-config qiita-tutorial --ecs-profile qiita-tutorial-profileこのコマンドを実行します。
そうするとタスクが起動します。
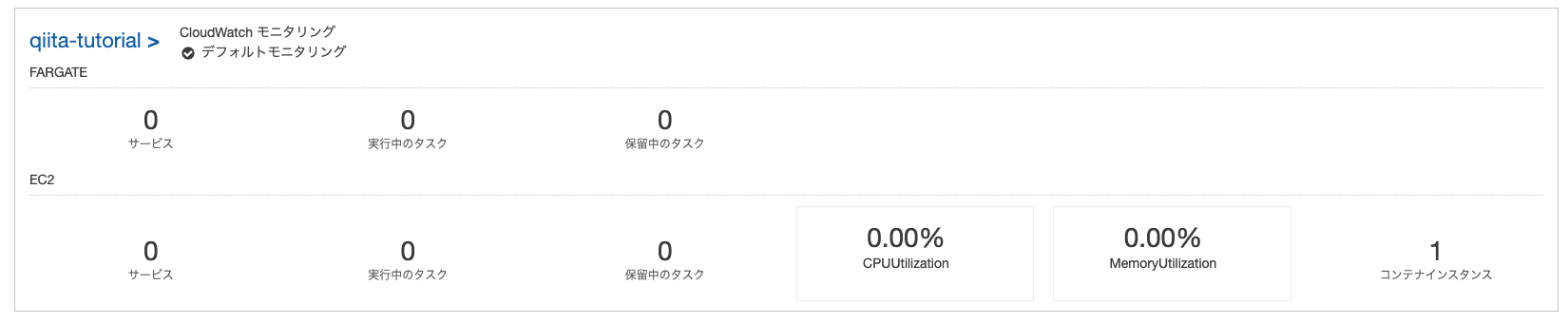
ecsの画面で実行中のタスクに1と書いてあればOKです。
もしうまくいかない場合はcloud watchにログが出されていると思うのでそちらを確認してください。
確認
これでデプロイできているはずなのでALBのdns名をurlに貼り付けます。
そうすると....
無事開けました。
もちろんデータの登録もできます。
コンテナにアクセス
とりあえずこれでデプロイはOKですがecsコンテナにアクセスもしてみます。
まずecsで使われているec2インスタンスのセキュリティーグループを確認してインバウンドルールに関して全てのマイIPからの全てのトラフィックを許可します。
ecsコンテナへのアクセスにはsshを使用します。
まずecsで起動しているec2インスタンスのプライベートipをコピーします。
そして
ssh -i keypairのパス ec2-user@ec2インスタンスのパブリックdnsを実行します。
そうするとec2インスタンスにssh接続できるので
docker psを実行します。
そうするとコンテナが起動しているので
docker exec -i -t コンテナID bashを実行するとbashに入れます。
試しに
rails -vと実行すると
bash-5.0# rails -v Rails 6.0.3こう返ってきました
これでecsで起動したdockerへのアクセスはOKです。
終わり
とりあえずこれで終わりです。
いろいろ問題点あるとは思うのでお気づきの点があれば指摘していただけると助かります。












- 投稿日:2020-05-17T22:54:25+09:00
Webアプリケーション(Rails)のコードレビューをする時に気にしている観点
コードをレビューする時にいつも似たようなところを指摘している気がしたので自分が気にしている観点をまとめてみました。
使用言語に依存しない観点もありますが、私は仕事では主にRailsを使っているので、RubyやRailsに特化した観点もあります。とりあえず現時点で思いつくものをざっと書きましたが、今後も気にしている観点を思い出したら追記していきます。
開発もQiita記事も最初から完璧を目指さずに継続してデリバリー(CD)していくのがよいですね。インデントやコーディングルール
インデントやコーディングルールに従っているかなど、コードの静的な部分のチェックは静的解析ツールを使いましょう。
人が目視で確認するのは時間がもったいないし、漏れやブレが発生します。
また細かいところにばかりに気が取られてしまい本来指摘すべきところを見逃してしまいます。静的解析ツールはRubyではRubocopが有名です。
このような開発をサポートする機能の導入は初期開発では後回しにされがちですが、静的解析ツールは途中で入れるのがとても大変です。
後から追加しようとすると、ルールを緩和したり免除するコードがでてきてしまうので初期開発の段階で入れるようにしましょう。
個人的にはきつめに設定しておいて、必要に応じて緩和していくのが良いと思います。静的コードチェックに縛られすぎないか
1つ前に静的コードチェックを使えと書いたばかりで早速矛盾するテーマなのですが、静的コードチェックの指摘を直すためにわかりづらい修正をするくらいなら静的コードチェックの方を緩和したり例外を設定した方が良いです。
よくあるのがメソッドの行数超過です。
メソッドが一定行を超えると分割しろと言われるのですが、処理が1つのまとまりであるとことが妥当な場合はわかりづらくなってしまうだけなので無理に分ける必要はないと思います。HTTPのステータスコードは適切か
Railsだとステータスコードとメソッドやレスポンスの整合性があっていなくても問題なく動くことが多いので、ステータスコードの使い方が適切かを確認するようにしています。
細かい使い分けは人によって解釈が分かれるところだと思いますが、主要なステータスコードについて私の解釈を書きます。2XX
リクエストを正常に処理した時のステータスコードです。
201 Created
POSTやPUTリクエストでリソースを生成した時に使います。
201を使う場合はレスポンスボディに生成したリソースを返却することがよくあります。
もし返却するものがないのであれば、204 No Contentを使った方が良いと思います。204 No Content
DELETEリクエストでリソースを削除した時に使うことが多いですが、POSTやPUTなどでもレスポンスボディがない場合に使います。
これを使う場合はレスポンスボディに値を入れてはいけません。200 OK
上記以外で正常なレスポンスを返す場合は基本的に200 OKを使えば良いと思います。
3XX系
別のページへリダイレクトさせたい時のステータスコードです。
301 Moved Permanently
恒久的に別のページにリダイレクトさせる場合は301を使います。
例えばWebページを移行した場合などに古いページのURLから新しいページへリダイレクトさせる時に使います。
また、SEO対策としても役立ちます。301を指定すると検索エンジンが新しいURLをインデックスしてくれます。303 See Other
私も最近まで意識していなかったのですが、リソースを登録・更新させた後にそのリソースの詳細ページなどにリダイレクトさせる場合は303を使います。
下記のようなパターンです。
POST /resources でリソースを新規登録して、リソース情報を表示するページ(GET /resources/:id)へリダイレクト302 Found
301とは異なり、一時的に別のページにリダイレクトさせる場合は302を使います。
Railsでredirect_toを使うとデフォルトで302になりますが、リダイレクトさせる目的を考えると302の用途は少なく、301 or 303に振り分ける方が適切なことが多いと思います。4XX系
クライアント起因のエラーが発生した場合のステータスコードです。
404 Not Found
ページが見つからない場合に使われるステータスコードです。
画面に大きく「404」と表示されることも多いので一般の方でも知っている方が多いと思います。人によっては考え方が分かれるところかもしれませんが、私はリソースが見つからないことがクライアントにとって異常なのか正常なのかを考えて404と200を使い分けるようにしています。
イメージしやすいようにいくつか具体例を挙げます。
GET /resources/:idでリソースが見つからない場合
クライアントが存在しないidを指定しているため404を返却TODOリストを取得する
GET /todosでTODOが0件の場合
TODOが0件ということは正常動作なので200を返却お店検索で絞り込み条件を指定したら0件になった
クライアントが指定した条件に合致するお店がなかったの404を返却
SEO観点でも0件のお店検索結果ページを検索エンジンにインデックスさせたくないので404を指定することでインデックスさせない。401 Unauthorized
認証が必要なアクションに対して有効な認証情報が渡されなかった場合に使用します。
403 Forbidden
認証はしているが利用権限が不足している場合に使用します。
例えば、あるリソースに対して読み取り専用のユーザーが更新を行おうとした場合などに使用します。ただし、403を使う時に考慮した方が良い点が1つあります。
あるユーザーにとって非公開のリソースにアクセスした場合です。
この場合、システム的に考えるとアクセス権限がないので403を使いたくなりますが、403を返却するとリソースが存在していることがユーザーに伝わってしまいます。
こういう場合は存在自体を知らせない方が良いので、存在しないという意味を込めて404を返却するのが良いでしょう。400 Bad Request
必須パラメーターが指定されていないなど不正なリクエストが来た場合に使用します。
401, 403, 404に当てはまらない場合には大体400を使うことが多いです。410 Gone
期間限定のキャンペーンページで期間が終了してページを削除した後など、恒久的に削除するURLにアクセスされた時に使います。
蛇足ですが、最近はキャンペーン期間が終わっても放置されているページが多くて検索した時のノイズになってしまい邪魔ですね。
期限が過ぎたら削除するというタスクも積んでおき、きちんと実行してほしいものです。5XX系
サーバー起因のエラーが発生した場合のステータスコードです。
500 Internal Server Error
サーバーで予期せぬエラーが発生した場合に使用します。
プログラムで明示的に500エラーを発生させることはあまりないと思うので、明示的に500エラーを返却している箇所があったら適切なエラーを返却するように修正した方が良いと思います。503 Service Unavailable
定期メンテナンスなどにより、一時的に正常にアクセスできずメンテナンスページを表示する場合などに利用します。
クライアントへのエラーメッセージが適切か
エラーが発生した時にクライアントにエラーメッセージを返却することがあると思いますが、そのメッセージが適切かを確認します。
観点はそのエラーメッセージを受け取ってアクションを起こせるかです。
よくある悪い例は複数入力項目がある画面で1つ入力条件を満たしていない時に「入力項目が不正です」のような項目を特定しないメッセージを返すパターンです。
これだとどの項目が間違っているのか分からず、何をすれば良いか分からなくなります。
「xx項目の値は数値で入力してください」のように項目とエラー原因を伝えてあげましょう。ただ、ユーザーに細かく伝えることがNGの場合もあります。
例えばID/パスワードを入力するログイン画面で存在するIDを指定してパスワードが間違っていた場合に「パスワードが間違っています」と返してしまうとIDが存在していることがユーザーに伝わってしまいます。
この実装をしてしまうと悪意のあるユーザーが適当にIDを入力して存在しているIDのリストを作ることができてしまいます。
ログイン画面はIDが存在しない場合もパスワードだけが違う場合も「ログイン情報が不正です」のように何が間違っているか特定できないメッセージを返すのが良いです。apiのレスポンスは意味のある値を返す
最近のWebアプリケーションはフロントとバックエンドを別で作ることが多いと思います。
そのためバックエンドはAPIとして機能を提供することがよくあります。
APIを作る際、列挙型の項目を返却する時は値を見るだけで意味がわかるように返却すべきです。
例えば下記のようなステータスがあるとします。enum status { todo: 1, in_progress: 2, done: 3 }これをフロントに返却する場合は数値(1, 2, 3)ではなく名称('todo'など)を返却すべきです。
status=1のように数値を返却するとレスポンスを見た時に1ってなんだっけ?となっていしまいますが、status='todo'のように名称を返却するとパッと見ただけで意味を理解することができます。配列の並び順が一意になるか
配列を返却する場合は配列の並び順が一意になるかをチェックします。
下記ではuser_idで絞り込んだreviews配列を返却していますが、orderを指定していないのでどのような並び順で返却されるのか不定です。
呼び出し元が並び順を気にしないことが確定しているのであれば良いですが、並び順が定まるようにorderを指定しましょう。def my_reviews(user_id) Review.where(user_id: user_id) end下記ではcreated_atの降順を指定しています。これであれば新規作成したものから順番に取得できそうです。
def my_reviews(user_id) Review.where(user_id: user_id).order(created_at: :desc) endただこれでもまだ問題があります。created_atが同じreviewがある場合に順番が定まりません。
並び順を確実に定めるには下記のようにorderに指定しているカラムで一意になるようになっているかを考えると良いです。
今回は一意にするために第2ソートにidの降順を指定しました。def my_reviews(user_id) # 1. created_atの降順に並べる。ただしcreated_atはユニーク制約はないので同日がありえる # 2. 同日だった場合、idの降順に並べる。idはユニークなので同じ値はありえない # => 並び順が一意に定まる Review.where(user_id: user_id).order(created_at: :desc, id: :desc) end他人が読んでスムーズに理解できること
コードレビューをしている時に理解するのに時間がかかる実装や勘違いしてしまう実装を見かけることがあります。
このような実装は今後このコードを見る人全員が同じように感じてコードリーディングの工数を上げてしまい、バグを埋め込む確率も上げてしまうので可能な限りシンプルな実装にした方が良いです。
どうしてもシンプルにできない場合はコメントを入れるなどすると良いと思います。
Railsなどフレームワークを使っていると下記のようにフレームワークの枠から離れた使い方をしていると勘違いさせてしまうことがあります。
勘違いさせるコードは高確率で後々バグを生み出すのでなくしていきましょう。class Review belongs_to :user enum status { open: 0, close: 1, } end class User # × デフォルトのアソシエーションなのに条件を指定して絞り込んでいる has_many :reviews, -> { open } # ○ 条件をつける場合はそれがわかる名前にしましょう has_many :open_reviews, -> { open }, class_name: 'Review' end class Hoge def fuga(user_id) user = User.find user_id # ここだけ見るとuserのreviewsを全部取得していると勘違いする可能性が高い user.reviews end endYAGNI
ご存知の方も多いと思いますが、YAGNIという言葉があります。
詳細はwikipediaを参照してください。
https://ja.wikipedia.org/wiki/YAGNI上記に記載されている通り、まだ使わない機能を想像して実装しておいてもそのまま使える可能性はほとんどありません。
未来を想像して書いているコードを見かけたら要注意です。実装されたコードを削除してもらうのは心苦しいですが削除しておく方が良いことが多いです。
残しておくと後々それが邪魔になったり、リファクタリングの時に使っていないのに直さないといけなかったりと生産性が下がる可能性があります。メソッドや定数のscopeは小さくする
外部から呼び出さないメソッドや定数はprivateにしておきましょう。
publicだとそのメソッドや定数に手を入れる時の影響範囲がソース全体になっていしまいますが、privateだと同Class内だけを気にすれば良いのでリファクタリングなどソース修正の影響範囲調査がかなり楽になります。責務は適切か
各クラスはそれぞれ責務を持っています。その責務が守れているかをチェックします。
例えばアカウントをアクティベートするアクションについて考えてみます。
- アクティベーションするにはtokenが必要
- Accountのstatusとアクティベート日時を更新してtokenを削除する
アクティベーションする時に実行される処理はAccountの責務を持っているAccountモデルが知っているべきことなので、下記の○のような方針で実装されている方が良いです。
class AccountController # × アクティベーションの時にすべきことをcontrollerが把握している def activate account = Account.find_by(token: params[:token]) account.status = :activated account.activated_at = Time.now account.token = nil account.save! end # ○ アクティベーションの時にすべきことをcontrollerは知らず、accountモデルに依頼している def activate account = Account.find_by(token: params[:token]) account.activate! end end class Account def activate! status = :activated activated_at = Time.now token = nil save! end endincludes, eager_load, preload
これらの違いが曖昧な方は、Railsを使っている方は必ず1回は見ていると思われる下記のQiita記事をご覧ください。
https://qiita.com/k0kubun/items/80c5a5494f53bb88dc58includesはpreloadとeager_loadを勝手に使い分けてくれる便利な存在です。
Railsを使い始めたことはincludesを使っておけばいいだろうくらいに思っていたのですが今の考えは逆です。
基本preloadかeager_loadを使うようにしています。
というのも実装する時にjoinすべきかどうかはきちんと把握して実装すべきと考えているからです。
実装によってjoinしたりしなかったりするincludesは制御が難しく予期せぬ挙動をしてしまう可能性があるので使わない方が良いです。無駄なjoinはないか
ActiveRecordはとても便利ですが、RailsエンジニアからSQLを遠い存在にしているように感じます。
自分でSQLを書いていると書かないようなSQLも平気で発行してしまいます。
その中でも特に見かけるのは無駄にjoinしているパターンです。
下記に具体例を示します。
organizatoin_idを指定してその組織に所属するuserを取得するメソッドfind_by_organizationです。class User has_many :user_organization def self.find_by_organization(organization_id) # × organizationsテーブルは結合する必要がない # select * from users inner join user_organizations on users.id = user_organizations.user_id inner join organizations on user_organizations.organization_id = organizations.id where organizations.id = #{organization_id} joins(user_organization: :organization).merge(Organization.where(id: organization_id)) # ○ user_organizationsしか結合していない # select * from users inner join user_organizations on users.id = user_organizations.user_id where user_organizations.organization_id = #{organization_id} joins(:user_organization).merge(UserOrganization.where(organization_id: organization_id)) end end class Organization has_many :user_organization end class UserOrganization belongs_to :user belongs_to :organization end
- 投稿日:2020-05-17T22:38:17+09:00
客先常駐エンジニアが5年かけてWeb開発企業に転職するためにした3つのこと
お前誰よ
社会人も6年目に突入しました。東京都在住のエンジニアです。
理系4年制大学を卒業し、新卒でSESをメインサービスとした企業に就職しました。
自身が何のために理系大学を受験し、エンジニアを志望することになったのかを見つめ直した結果、
5年かけてSES→SES→派遣→Web受託と会社を転々としました。ここで「Web開発企業に転職するために5年もいらないだろ・・・」と思われそうですが、
Web開発がしていきたい!と方向性が確定したのは2社目を辞める時です。
なのに3社目も派遣じゃないかって?よくある転職エージェントに洗脳されてしまった結果です・・・。
現在は苦しみ嬉しみながらRuby on RailsをメインとしたWebアプリケーション開発に携わっています。誰に向けているのか
- 現在客先常駐をしていて、Web開発企業に転職を望んでいる方
- 開発志望で入社し、プログラミングをしたいのに何故かインフラをやられている方
あくまでも個人的な知見となりますため、参考程度に閲覧して頂ければ幸いです。
何をしたのか
Web開発におけるトレンドをキャッチアップする
ありがたいことに私が大学生の時よりもインターネットに情報が溢れています。
- 常駐先の業務を爆速で終わらせる。マイルストーンを意識し、修正があっても間に合うギリギリで報告する
- Web開発企業に転職するにはどういった技術が必要なのかを洗い出す
基本的にQiitaやTwitter、Google検索で「Web開発 トレンド」などと検索したり、
Tech系のYouTuberの動画を観ていました。キャッチアップした技術をざっくりと学ぶ
ここで断っておきますが、私はポートフォリオの作成はしておりません。
世間的にはWeb開発企業に転職するならポートフォリオが必要不可欠!と言われていますが、
それは本当にエンジニアの経験がゼロに等しい人が対象だと思います。私の場合、バックボーンとして基本設計/詳細設計/仮想サーバ構築・運用/ネットワーク構築/情報システム部(社内SE)の経験があったため、それを伸ばす方向でWeb開発企業に転職するために必要な技術を学んでいきました。
具体的には以下の通りです。
- AWSやDockerを学び、Web開発のインフラについてのスキルを得る
- バージョン管理としてGit/Githubについて学ぶ。この時issue、PullRequest、GithubFlowについても理解する
- トレンドになっているプログラミング言語としてPythonを学び、Paizaスキルチェックをやってみる
学習教材はUdemyを使用しました。ハンズオン形式で体系的に学べるので自分に合っていたと感じています。
不定期でセールを実施しており、良質な教材が1500円程度で購入できます。
- ゼロからはじめる Dockerによるアプリケーション実行環境構築
- 手を動かしながら2週間で学ぶAWS 基本から応用まで
※こちら現在登録不可となっているため、以下のコースがよろしいかと思います。
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得- Git: もう怖くないGit!チーム開発で必要なGitを完全マスター
- 現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
また、学習目的としては主に以下の2点です。
- Web開発に携わっていきたい想いを裏付ける
- 自ら進んでキャッチアップしていく姿勢をアピールする
転職するために重要視していたことは
- 何のためにその技術を学んだか
- なぜその技術を選んだか
- 学んだ結果何が得られたか
を具体的に説明できるレベルまで学習することでした。
世の中にはつよつよエンジニアが多く、そういった方々ばかり見て比較していると疲れ、挫折してしまう恐れがあります。
あくまでも自分自身のための転職なのでがっつりは学ばずに自分に合った対応をしていきました。Web開発に強いエージェントに登録する
Web開発に携わりたいことを目的とした場合、これまでの2回の転職は失敗していると判断できます。
特に3社目の転職は、Web開発企業に転職を望みながらも自身のスキルセットが不足しているため、
実現不可とエージェントに判断されてしまいました。
その結果、募集対象の企業が狭まり、インフラの知識を深めていくためにIT派遣企業へ転職しました。その後業務の中でこれまでの経歴を含めITインフラの重要性を理解することが出来たため、
3回目の転職に踏み切りました。具体的な転職エージェント名は避けさせて頂きます。申し訳ありません。
しかし、そのエージェントは私自身のレベルだけて募集企業を判断せずに多くの求人を紹介してくれました。
結果として
- 最新の技術を当たり前に使っている
- Ruby on Railsを強みとした受託開発企業
に転職することが出来ました。
さいごに
最後まで閲覧頂きありがとうございました!
この記事はIT業界に数多く存在する客先常駐エンジニアがWeb開発企業へ転職したほんの一例です。
MacbookでVScodeを開いてドヤ顔でコーディングする自分を想像しながら、
目標に向かって努力していきましょう!
皆様の転職活動がより良いものになるよう祈っております。
- 投稿日:2020-05-17T22:38:17+09:00
客先常駐エンジニアがWeb開発企業に転職するためにした3つのこと
お前誰よ
社会人も6年目に突入しました。東京都在住のエンジニアです。
理系4年制大学を卒業し、新卒でSESをメインサービスとした企業に就職しました。
自身が何のために理系大学を受験し、エンジニアを志望することになったのかを見つめ直した結果、
5年かけてSES→SES→派遣→Web受託と会社を転々としました。ここで「Web開発企業に転職するために5年もいらないだろ・・・」と思われそうですが、
Web開発がしていきたい!と方向性が確定したのは2社目を辞める時です。
なのに3社目も派遣じゃないかって?よくある転職エージェントに洗脳されてしまった結果です・・・。
現在は苦しみ嬉しみながらRuby on RailsをメインとしたWebアプリケーション開発に携わっています。誰に向けているのか
- 現在客先常駐をしていて、Web開発企業に転職を望んでいる方
- 開発志望で入社し、プログラミングをしたいのに何故かインフラをやられている方
あくまでも個人的な知見となりますため、参考程度に閲覧して頂ければ幸いです。
何をしたのか
Web開発におけるトレンドをキャッチアップする
ありがたいことに私が大学生の時よりもインターネットに情報が溢れています。
- 常駐先の業務を爆速で終わらせる。マイルストーンを意識し、修正があっても間に合うギリギリで報告する
- Web開発企業に転職するにはどういった技術が必要なのかを洗い出す
基本的にQiitaやTwitter、Google検索で「Web開発 トレンド」などと検索したり、
Tech系のYouTuberの動画を観ていました。キャッチアップした技術をざっくりと学ぶ
ここで断っておきますが、私はポートフォリオの作成はしておりません。
世間的にはWeb開発企業に転職するならポートフォリオが必要不可欠!と言われていますが、
それは本当にエンジニアの経験がゼロに等しい人が対象だと思います。私の場合、バックボーンとして基本設計/詳細設計/仮想サーバ構築・運用/ネットワーク構築/情報システム部(社内SE)の経験があったため、それを伸ばす方向でWeb開発企業に転職するために必要な技術を学んでいきました。
具体的には以下の通りです。
- AWSやDockerを学び、Web開発のインフラについてのスキルを得る
- バージョン管理としてGit/Githubについて学ぶ。この時issue、PullRequest、GithubFlowについても理解する
- トレンドになっているプログラミング言語としてPythonを学び、Paizaスキルチェックをやってみる
学習教材はUdemyを使用しました。ハンズオン形式で体系的に学べるので自分に合っていたと感じています。
不定期でセールを実施しており、良質な教材が1500円程度で購入できます。
- ゼロからはじめる Dockerによるアプリケーション実行環境構築
- 手を動かしながら2週間で学ぶAWS 基本から応用まで
※こちら現在登録不可となっているため、以下のコースがよろしいかと思います。
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得- Git: もう怖くないGit!チーム開発で必要なGitを完全マスター
- 現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
また、学習目的としては主に以下の2点です。
- Web開発に携わっていきたい想いを裏付ける
- 自ら進んでキャッチアップしていく姿勢をアピールする
転職するために重要視していたことは
- 何のためにその技術を学んだか
- なぜその技術を選んだか
- 学んだ結果何が得られたか
を具体的に説明できるレベルまで学習することでした。
世の中にはつよつよエンジニアが多く、そういった方々ばかり見て比較していると疲れ、挫折してしまう恐れがあります。
あくまでも自分自身のための転職なのでがっつりは学ばずに自分に合った対応をしていきました。Web開発に強いエージェントに登録する
Web開発に携わりたいことを目的とした場合、これまでの2回の転職は失敗していると判断できます。
特に3社目の転職は、Web開発企業に転職を望みながらも自身のスキルセットが不足しているため、
実現不可とエージェントに判断されてしまいました。
その結果、募集対象の企業が狭まり、インフラの知識を深めていくためにIT派遣企業へ転職しました。その後業務の中でこれまでの経歴を含めITインフラの重要性を理解することが出来たため、
3回目の転職に踏み切りました。具体的な転職エージェント名は避けさせて頂きます。申し訳ありません。
しかし、そのエージェントは私自身のレベルだけて募集企業を判断せずに多くの求人を紹介してくれました。
結果として
- 最新の技術を当たり前に使っている
- Ruby on Railsを強みとした受託開発企業
に転職することが出来ました。
さいごに
最後まで閲覧頂きありがとうございました!
この記事はIT業界に数多く存在する客先常駐エンジニアがWeb開発企業へ転職したほんの一例です。
MacbookでVScodeを開いてドヤ顔でコーディングする自分を想像しながら、
目標に向かって努力していきましょう!
皆様の転職活動がより良いものになるよう祈っております。
- 投稿日:2020-05-17T22:38:17+09:00
客先常駐エンジニアが5年かけてWeb受託開発に転職するためにした3つのこと
お前誰よ
社会人も6年目に突入しました。東京都在住のエンジニアです。
理系4年制大学を卒業し、新卒でSESをメインサービスとした企業に就職しました。
自身が何のために理系大学を受験し、エンジニアを志望することになったのかを見つめ直した結果、
5年かけてSES→SES→派遣→Web受託と会社を転々としました。ここで「Web開発企業に転職するために5年もいらないだろ・・・」と思われそうですが、
Web開発がしていきたい!と方向性が確定したのは2社目を辞める時です。
なのに3社目も派遣じゃないかって?よくある転職エージェントに洗脳されてしまった結果です・・・。
現在は苦しみ嬉しみながらRuby on RailsをメインとしたWebアプリケーション開発に携わっています。誰に向けているのか
- 現在客先常駐をしていて、Web開発企業に転職を望んでいる方
- 開発志望で入社し、プログラミングをしたいのに何故かインフラをやられている方
あくまでも個人的な知見となりますため、参考程度に閲覧して頂ければ幸いです。
何をしたのか
Web開発におけるトレンドをキャッチアップする
ありがたいことに私が大学生の時よりもインターネットに情報が溢れています。
- 常駐先の業務を爆速で終わらせる。マイルストーンを意識し、修正があっても間に合うギリギリで報告する
- Web開発企業に転職するにはどういった技術が必要なのかを洗い出す
基本的にQiitaやTwitter、Google検索で「Web開発 トレンド」などと検索したり、
Tech系のYouTuberの動画を観ていました。キャッチアップした技術をざっくりと学ぶ
ここで断っておきますが、私はポートフォリオの作成はしておりません。
世間的にはWeb開発企業に転職するならポートフォリオが必要不可欠!と言われていますが、
それは本当にエンジニアの経験がゼロに等しい人が対象だと思います。私の場合、バックボーンとして基本設計/詳細設計/仮想サーバ構築・運用/ネットワーク構築/情報システム部(社内SE)の経験があったため、それを伸ばす方向でWeb開発企業に転職するために必要な技術を学んでいきました。
具体的には以下の通りです。
- AWSやDockerを学び、Web開発のインフラについてのスキルを得る
- バージョン管理としてGit/Githubについて学ぶ。この時issue、PullRequest、GithubFlowについても理解する
- トレンドになっているプログラミング言語としてPythonを学び、Paizaスキルチェックをやってみる
学習教材はUdemyを使用しました。ハンズオン形式で体系的に学べるので自分に合っていたと感じています。
不定期でセールを実施しており、良質な教材が1500円程度で購入できます。
- ゼロからはじめる Dockerによるアプリケーション実行環境構築
- 手を動かしながら2週間で学ぶAWS 基本から応用まで
※こちら現在登録不可となっているため、以下のコースがよろしいかと思います。
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得- Git: もう怖くないGit!チーム開発で必要なGitを完全マスター
- 現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
また、学習目的としては主に以下の2点です。
- Web開発に携わっていきたい想いを裏付ける
- 自ら進んでキャッチアップしていく姿勢をアピールする
転職するために重要視していたことは
- 何のためにその技術を学んだか
- なぜその技術を選んだか
- 学んだ結果何が得られたか
を具体的に説明できるレベルまで学習することでした。
世の中にはつよつよエンジニアが多く、そういった方々ばかり見て比較していると疲れ、挫折してしまう恐れがあります。
あくまでも自分自身のための転職なのでがっつりは学ばずに自分に合った対応をしていきました。Web開発に強いエージェントに登録する
Web開発に携わりたいことを目的とした場合、これまでの2回の転職は失敗していると判断できます。
特に3社目の転職は、Web開発企業に転職を望みながらも自身のスキルセットが不足しているため、
実現不可とエージェントに判断されてしまいました。
その結果、募集対象の企業が狭まり、インフラの知識を深めていくためにIT派遣企業へ転職しました。その後業務の中でこれまでの経歴を含めITインフラの重要性を理解することが出来たため、
3回目の転職に踏み切りました。具体的な転職エージェント名は避けさせて頂きます。申し訳ありません。
しかし、そのエージェントは私自身のレベルだけて募集企業を判断せずに多くの求人を紹介してくれました。
結果として
- 最新の技術を当たり前に使っている
- Ruby on Railsを強みとした受託開発企業
に転職することが出来ました。
さいごに
最後まで閲覧頂きありがとうございました!
この記事はIT業界に数多く存在する客先常駐エンジニアがWeb開発企業へ転職したほんの一例です。
MacbookでVScodeを開いてドヤ顔でコーディングする自分を想像しながら、
目標に向かって努力していきましょう!
皆様の転職活動がより良いものになるよう祈っております。
- 投稿日:2020-05-17T21:53:02+09:00
railsでmysqlでdb:createしたらAccess denied for user 'root'@'localhost'
調べると
Access denied for user 'root'@'localhost' (using password: NO)の対処はたくさん出てくるけど、Access denied for user 'root'@'localhost'で終わっているエラーはすぐに出てこないので自分用に残します。対処法
mysqlにユーザーを指定してログイン。
別のマシンでサーバーが動いていたら、ホスト名も指定する。
パスワード入力を求められるので、パスワードを覚えていたら入力。
間違えて何度もエラーが出るなら頭にsudo付けたら入れる。$ mysql -u root -p任意のユーザー名とパスワードを入力する。
ここではユーザーに全てのDB操作権限を付与している。
*.*にDBの名前を入れる。
大文字小文字区別しないので小文字でもいい。
私の場合は既存のユーザーに権限付与したので、存在しないユーザーを指定したらユーザー作成から始めないといけないかもしれない。mysql> GRANT ALL PRIVILEGES On *.* TO ユーザー名@localhost IDENTIFIED BY ‘パスワード’;このあとに
rails db:createしても同じエラーが出たので,database.ymlを修正。
usernameとpasswordに先程作成した任意のユーザー名とパスワードを入力。config/database.ymldefault: &default adapter: mysql2 encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: ユーザー名 password: パスワード socket: /var/run/mysqld/mysqld.sock development: <<: *default database: hoge_development test: <<: *default database: hoge_test production: <<: *default database: hoge_production username: hgoe password: <%= ENV['HOGE_PASSWORD'] %>$ rails db:create Created database 'hoge_development' Created database 'hoge_test'上手く行きました。
ちなみに表示されるプロンプトの意味
促す 意味 mysql> 新しいクエリの準備ができました -> 複数行クエリの次の行を待機しています '> 一重引用符(')の完了を待つ "> 二重引用符(")の完了を待つ `> バックティック(`)の完了を待つ /*> コメント(/*)の完了を待つ
- 投稿日:2020-05-17T21:34:18+09:00
Cloud Run(マネージド版)でCloud Memorystoreに接続する
本記事で言いたいこと
- Cloud RunのマネージドからMemorystoreへの接続が可能になりさらに素晴らしいサービスへと進化
- Cloud SQLを使用するよりはほんの1手間いるがそれでも接続は容易
本記事で説明しないこと
- VPCのネットワーク設計
事前準備
Cloud Memorystore
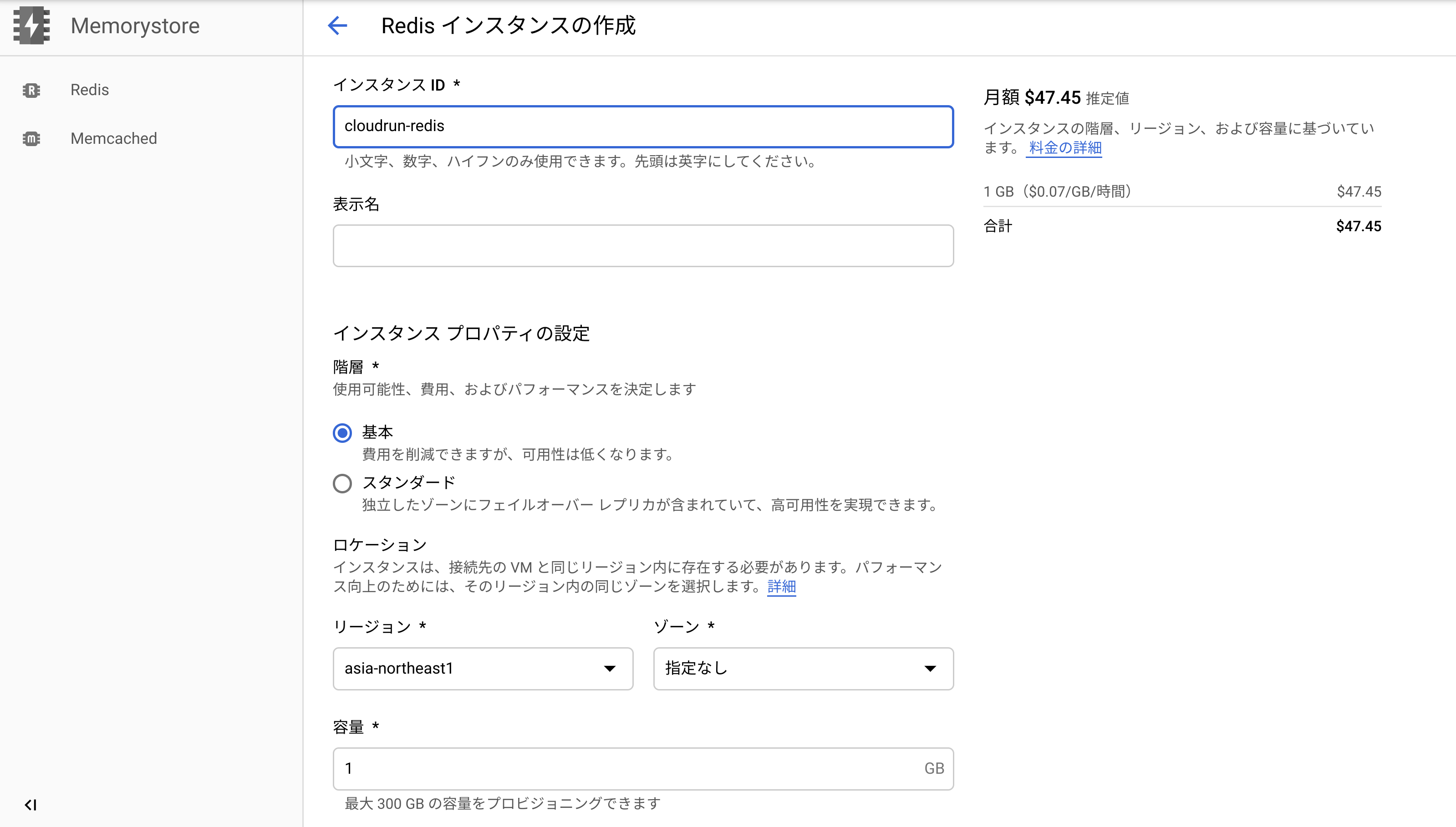
まずは接続するCloud Memorystoreのインスタンスを作成します。
Cloud Runにてデプロイするリージョンに合わせて設定し、他は好みでよいと思いますが、本番環境で使用する場合は可用性を高くするために階層はスタンダードを選択するようにした方がいいです。
また容量により料金も高くなりますが、容量と同時にネットワークスループットも高くなります。
注意するのはネットワークの設定です。初期値はリージョンに基づくVPCネットワークのdefaultという値が使用されています。もし使用するVPCネットワークを変更する際はこちらを編集する必要があります。(本記事通りにdefautlで設定しても動作することは動作します)
Serverless VPC Access
https://cloud.google.com/vpc/docs/configure-serverless-vpc-access
次にCloud Runから作成したMemorystoreに繋ぐためのサーバーレスVPCアクセスコネクタを作成します。
GCPのコンソールからは以下のようなメニューから開くことができます。
初回はAPIを有効にする必要があるので、有効化します。
コンソール画面上部にある「コネクタ作成」からVPCへのアクセスするコネクタを作成します。
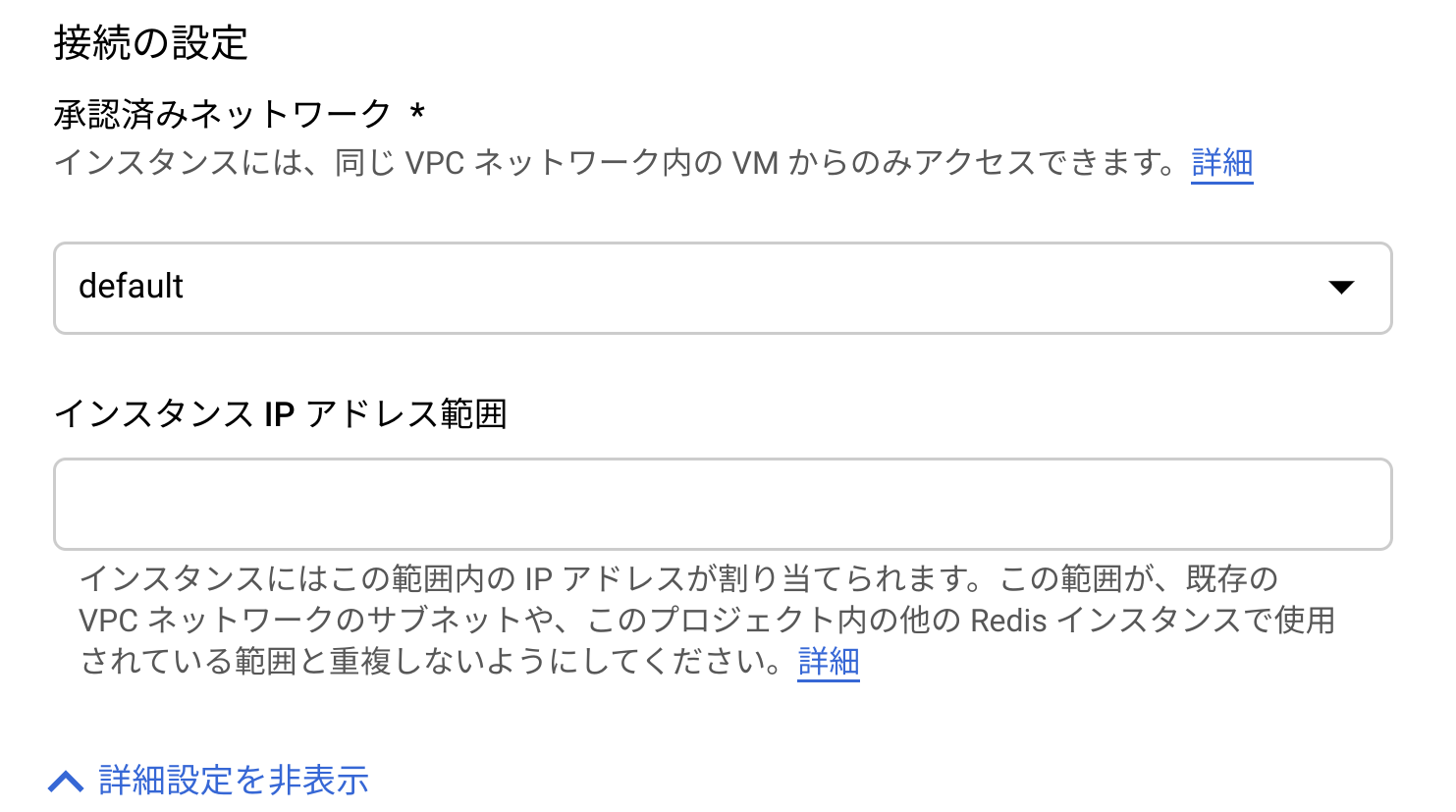
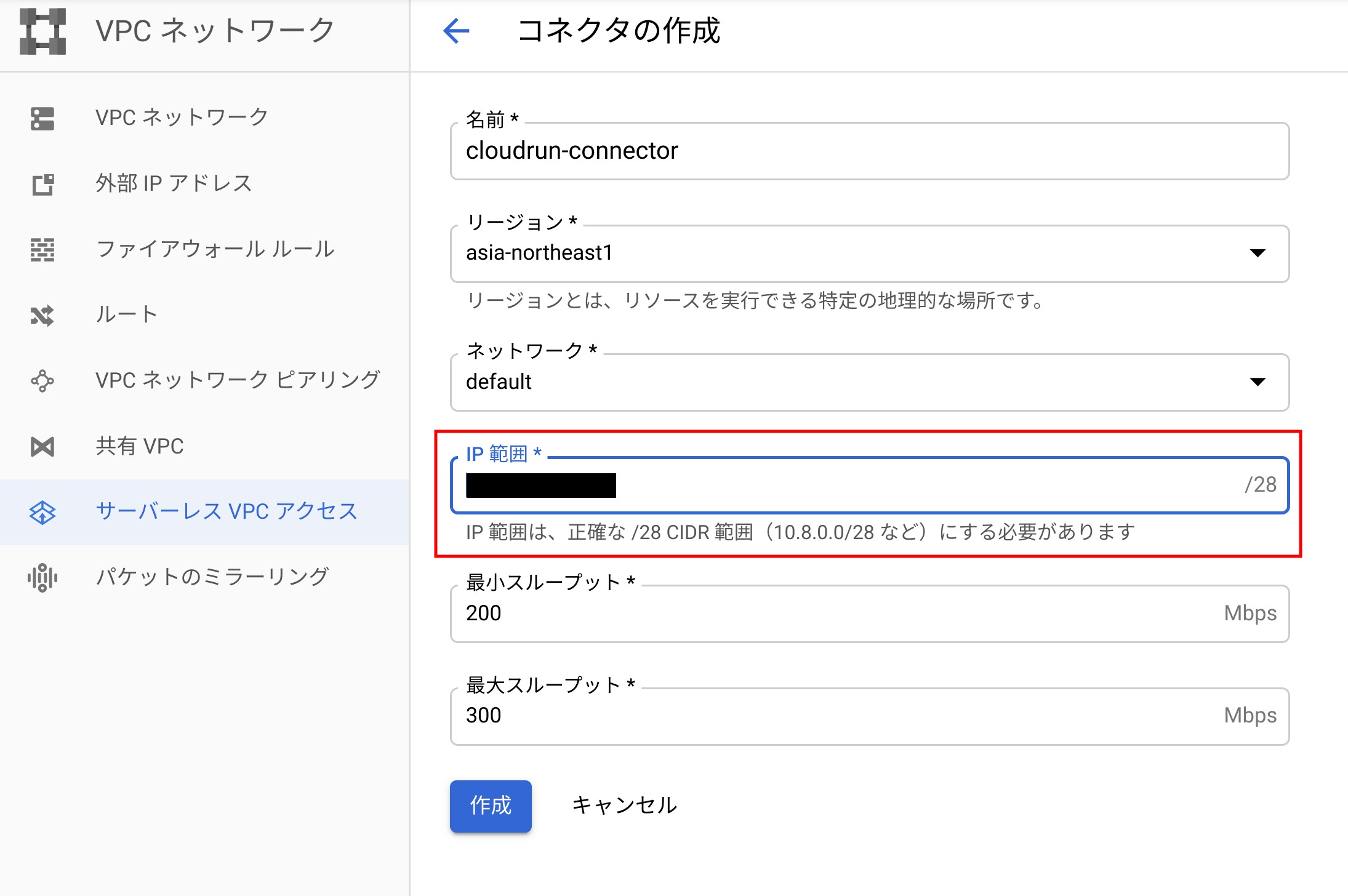
ここで大事なのは指定するIP範囲です。コネクタにて使用するIPの範囲となるので、Cloud Memorystoreで作成したRedisインスタンスのIPもそうですが、 予約されていないIPレンジ を指定する必要があります。
Cloud Run
ここからは実際にCloud RunにデプロイするアプリケーションからMemorystoreまでの接続の設定を説明します。
Railsアプリケーション
まずは使用するアプリケーションの準備をします。今回は例としてRailsを使用するとして以下のアプリケーションを用意しました。
https://github.com/chimame/connection-memorystore-rails-from-cloudrunREADMEに記載はしているのですが、1つ1つ説明していきます。
Cloud Build
まずはRailsを動かすためのコンテナを用意する必要がありますので、その前段階であるコンテナイメージを準備します。
コンテナのビルドは私が以前記載したKanikoを使用する方法でビルドすることができますのでそちらも興味あれば目を通してみて下さい。
https://qiita.com/chimame/items/e959843e86419f51e45aこの記事を書いている2020年5月17日現在はCloud RunからVPCへの接続設定はBeta版であるため使用できるようにBetaのインストールを実施します。
$ gcloud components install --quiet beta次にKanikoを使用するためのオプションを有効にしておきます。
$ gcloud config set builds/use_kaniko True最後にコンテナイメージをビルドするためにCloud Buildのコマンドを実行します。Cloud Buildの設定は
cloudbuild.ymlに固有の設定が必要なので必要に応じて修正して下さい。$ gcloud builds submit --project <Google Cloud Platform Project ID> --config ./cloudbuild.ymlこれでCloud Runにデプロイするためのコンテナイメージのビルドが完了です。簡単ですね。
Cloud RunでMemorystoreを使用する
本記事の1番重要かつ伝えたい内容のコマンドであるCloud RunのデプロイとVPCへの接続です。
$ gcloud beta run deploy <your cloud run service name> \ --image gcr.io/<Google Cloud Platform Project ID>/<Container Image Name>:latest \ --vpc-connector <your serverless vpc access connector name> \ --platform managed \ --region asia-northeast1 \ --allow-unauthenticated \ --set-env-vars RAILS_ENV=production \ --set-env-vars RAILS_MASTER_KEY=<your Rails master key> \ --set-env-vars REDIS_HOST=<your Cloud Memorystore instance host ip> \ --set-env-vars REDIS_PORT=6379一番大事なオプションは
vpc-connectorです。これはBetaをインストールすることで使用することができます。ここの指定するのは作成したVPCアクセスコネクタの名称です。なので本記事内では 「cloudrun-connector」 として作成したのでそれを指定することになります。
更には接続するRedisのホスト名を指定します。これもCloud Memorystoreで作成したインスタンスのIPアドレスを指定すれば接続が可能なはずです。最後に
ついにマネージド版のCloud RunもMemorystoreへの接続が来ました。Cloud SQL同様に接続まで結構楽に行うことができます。これが正式リリースされればCloud Runの死角はかなり少なるでしょう。
ただし、Serverless VPC Accessは使用することでCloud Memorystoreとは別に料金はかかるのでそこは使用に注意して下さい。
https://cloud.google.com/vpc/docs/configure-serverless-vpc-access#pricing個人的に後はCloud Load Balancingからの接続が可能となると完璧なサーバレスになると思って期待しております。



- 投稿日:2020-05-17T21:28:19+09:00
【Rails】directory for stderr_path=log/unicorn_stderr.log not writable (ArgumentError)
定期的に再起動しているDocker上のRailsコンテナが、稀に起動失敗する。
Dockerが原因かと思い色々調べたが、ごく簡単な理由でした。原因
logディレクトリがgitignoreされていた。
unicornの起動にはパスまでのディレクトリが予め存在していないといけないため注意。通常は
rake db:migrateする際にlogディレクトリも生成されるためたまたま起動に成功していたが、
何らかの理由でスキップされるとunicornの実行時にコケる。対処
log/.keepを作ってgitignoreを以下の様ににする。
(デフォルトでこれになっているはずなんだけど、何故か別の設定で上書きされていた).gitignore/log/* !/log/.keep
.dockerignoreもある場合はlogディレクトリが消されていないか確認しておく。ちゃんちゃん
- 投稿日:2020-05-17T21:17:45+09:00
Rails Docker 環境構築
前提
railsでDockerの環境構築をした時の備忘録。
Docker for macインストール済み本題
rails |--Dockerfile |--Gemfile |--Gemfile.lock |--docker-compose.ymlDockerfile.FROM ruby:2.4.5 RUN apt-get update -qq && apt-get install -y build-essential nodejs RUN mkdir /app WORKDIR /app COPY Gemfile /app/Gemfile COPY Gemfile.lock /app/Gemfile.lock RUN bundle install COPY . /appDockerfileをbuildしDocker Image(コンテナ仮想環境の雛形が作成される)
Gemfile.source 'https://rubygems.org' gem 'rails', '5.0.0.1'Gemfile(Installしたいgemを定義)→bundle installコマンド実行→gemがインストールされる→InstallしたgemがGemfile.lockに記載される
docker-compose.ymlversion: '3' services: web: #Railsコンテナの定義 build: . #Dockerfileを元にイメージを作成し使用すること command: bundle exec rails s -p 3000 -b '0.0.0.0' #Rails起動のコマンド volumes: - .:/app ports: - 3000:3000 #<公開するポート番号>:<コンテナ内部の転送先ポート番号> depends_on: - db #Railsが起動する前にMySQLサーバーが先に起動するように設定 tty: true stdin_open: true db: #MySQLサーバーコンテナの定義 image: mysql:5.7 volumes: - db-volume:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: password volumes: db-volume: #この定義によりPC上にdb-volumeという名前でボリューム(データ保持領域)が作成される上記設定が終わったらターミナルにてRailsプロジェクトの作成
terminal.rails$ docker-compose run web rails new . --force --database=mysql
docker-compose run webでwebサービスのコンテナで後ろのコマンドを実行するコマンド
--forceは、既存ファイルを上書きするオプション
--databace=mysqlはMySQLを使用する設定を入れるオプションbuildが完了したら、Railsで使用するデーターベースファイルを編集
config/database.yml#省略 default: &default adapter: mysql2 encoding: utf8 pool: 5 username: root password: password #編集 host: db #編集 #省略設定が完了したら下記のコマンドをターミナルに入力
terminal.rails$ docker-compose up -d上記は、現在のディレクトリにあるdocker-compose.ymlに基づいてコンテナ(仮想環境)を起動するコマンド
続いて、開発環境用のデータベースが作成されていないため、下記コマンドで作成
terminal.rails$ docker-compose run web bundle exec rake db:create
bundle exec rakeの部分は、Rails環境にインストールされているrakeコマンドを実行している
rake db:createでRailsで使用するデータベースをMySQLサーバー上に作成してくれるブラウザでlocalhost:3000と入力しRailsの画面が出てきたら完了!
- 投稿日:2020-05-17T20:36:35+09:00
【AWS】The procedure to deploy on EC2
Introduction
I am on my way to get a Ruby developer.
This article is a note for me, but I would be happy if helpful for someone.Environment
- macOS10
- Rails 5.2.3
- Nginx
- Unicorn
- Postgresql
- Sidekiq
- Redis
Create a EC2 instance
- Select Amazon Linux AMI 2018.03.0(HVM,SSD Volume Type.
- Select t2.micro(for within free tier)
- Create a key pair.
↓
Public DNS generated.
(This article referred:
https://qiita.com/Quikky/items/2897573a42fd71cfc47f)Prepare to install rbenv
$ sudo yum install git $ sudo yum -y install gcc $ sudo yum -y install gcc-c++ $ sudo yum -y install zlib-devel $ sudo yum -y install openssl-devel $ sudo yum -y install readline-develInstall rbenv
$ mkdir ~/.rbenv $ git clone https://github.com/rbenv/rbenv.git ~/.rbenv $ mkdir ~/.rbenv/plugins ~/.rbenv/plugins/ruby-build $ git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build $ cd ~/.rbenv/plugins/ruby-build $ sudo ./install.sh $ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile $ source ~/.bash_profileInstall Ruby
$ rbenv install 2.4.6 $ rbenv rehash $ rbenv global 2.4.6 $ ruby -vInstall Bundler
$ rbenv exec gem install bundler -v 2.0.1 $ rbenv rehashCreate a project on GitHub
Push to GitHub
On Mac $ git remote add origin <URL Address> $ git add . $ git commit -m "1st push" $ git push -u origin masterPull from GitHub to EC2
$ git clone <URL Address> $ cd <The project's directory>Install Rails
$ gem i -v 5.2.3 rails $ gem list rails$ bundle installThe below command executed due to an error occurred.
$ gem install pg -v '1.1.4' --source 'https://rubygems.org/'Install postgreSQL
$ yum install postgresql $ sudo yum install postgresql-develTo avoid the SQLite3's error
$ sudo yum install sqlite-develConfigure instance's security group inbound
- Configure Custom TCP/IP port 3000 0.0.0.0/0 additionally.
Start PostgreSQL on the EC2 instance
$ sudo yum install -y postgresql-server $ sudo /sbin/service postgresql initdb $ sudo /sbin/service postgresql startConfigure PostgreSQL on the EC2 instance
Master username:<the project's name> Master password:<password> postgres=# create role <username> with createdb login password '<password>'; postgres=# create database [database_name] owner [user_name]; $ sudo -u postgres psql postgres=# create role <The project's name> with createdb login password '<password>'; postgres=# create database <the project's name>_production owner <The project's name>; postgres=# create database <the project's name>_development owner <the project's name>; postgres=# create database <the project's name>_test owner <the project's name>; postgres=# \qCreate DB(Postgres)
.bash_profile export POSTGRES_USERNAME="<The project's name>" export POSTGRES_PASSWORD="<Password>" The project's directory $ rails db:create/var/lib/pgsql9/data/pg_hba.conf local all all peer ↓ local all all md5 Modified$ rails db:create $ rails db:migrateConfigure SMTP
Configure the environment variable in .bash_profile.
EMAIL_ADDRESS EMAIL_PASSWORDAfter that, execute the below command to reflect it.
$ source .bash_profile
- Launch Redis server on EC2.
- Select ElasticCache.
- Press 'Create'.
Primary endpoint generated.
Select 'security group' for Redis's inbound configuration on VPC configuration.
- Add it on the inbound edition of sg-694f3715.
- Custom TCP:TCP
- port:6379
- source 0.0.0.0/0
Configure the below files
config/initializers/sidekiq.rb config/redis.ymlRestart the project and start Sidekiq
$ bundle exec sidekiqInstall Nginx
$ sudo yum install nginxCopy /usr/local/etc/nginx/nginx.conf which is on Mac to EC2
$ scp -i ~/.ssh/<The project name名> nginx.conf ec2-user@XXXXXXXXXXXXXXXXXXXXX.amazonaws.com:~/nginx.conf $ sudo cp ~/nginx.conf /etc/nginx/Modify the port number and root directory.
Start Unicorn
$ unicorn -c config/unicorn.rb -E production -DStart Nginx
$ sudo service nginx startAdd port80(HTTP) for VPS configuration.
Modify the permission of the home directory to 744(drwxr--r--)
$ chmod 755 ~/Restart Nginx
$ sudo service nginx restartCreate DB on the production environment
$ rails db:migrate RAILS_ENV=productionRestart Unicorn
$ kill [pid] $ unicorn -c config/unicorn.rb -E production -DAn error occured in the asset pipeline.
Modify config.assets.compile from false to true in config/environments/production.rb↓↓↓↓↓↓↓ My detail
*https://kakuyon.hatenablog.com/entry/2018/07/15/03
3059 referred.
───────
*https://kakuyon.hatenablog.com/entry/2018/07/15/033059 referred.
↑↑↑↑↑↑↑ The detail of the edit request
- 投稿日:2020-05-17T19:54:47+09:00
TECH CAMP 6週目
さて、5月19日の報告会に向けての個人アプリ開発。幼稚園の出席簿アプリを開発中です。機能的には応用カリキュラムの復習も兼ねて、作成したChat-spaceと同様の機能+αといったところです。転職に使用するポートフォリオはこれと、あとは随時開発して増やしていこうと考えています。
また、報告会後に残りの機能実装、テスト、デプロイを実施予定です。ちなみに、個人アプリはメンターへの質問禁止です。【学習内容】
・復習
(データベース設計、Haml、Sassでのマークアップ、deviseを使用したユーザー管理機能、メッセージ送信機能)
・CSV出力機能ちなみに個人で開発しますが、Githubを使用し機能毎にブランチを切り替えながら進めていきました。Git、Githubの使い方に早く慣れよう‥と思った矢先にまたも事件が発生‥。
・復習
進め方はほとんどChat-spaceと同じなので、ほぼほぼスムーズにいきました。しかし、構想や設計の甘さがあり、開発途中でそれをまたゼロから作ることになり、さらに再開発中もデータベースのカラムを追加したりと反省点が多く浮き彫りになりました。
今後は構想の段階から細かい仕様を詰める必要がありますね。〈機能説明〉
お子さんが休みの場合はこちらのフォームに入力し送信。
そしてこちらが一覧表示されます。日付が新しいものが上にきます。
幼稚園の先生はこちらを使用し出席管理。名前は一応あいうえお順ですが、自分はアルファベットなので先頭になっちゃってます(笑)
・CSV出力機能
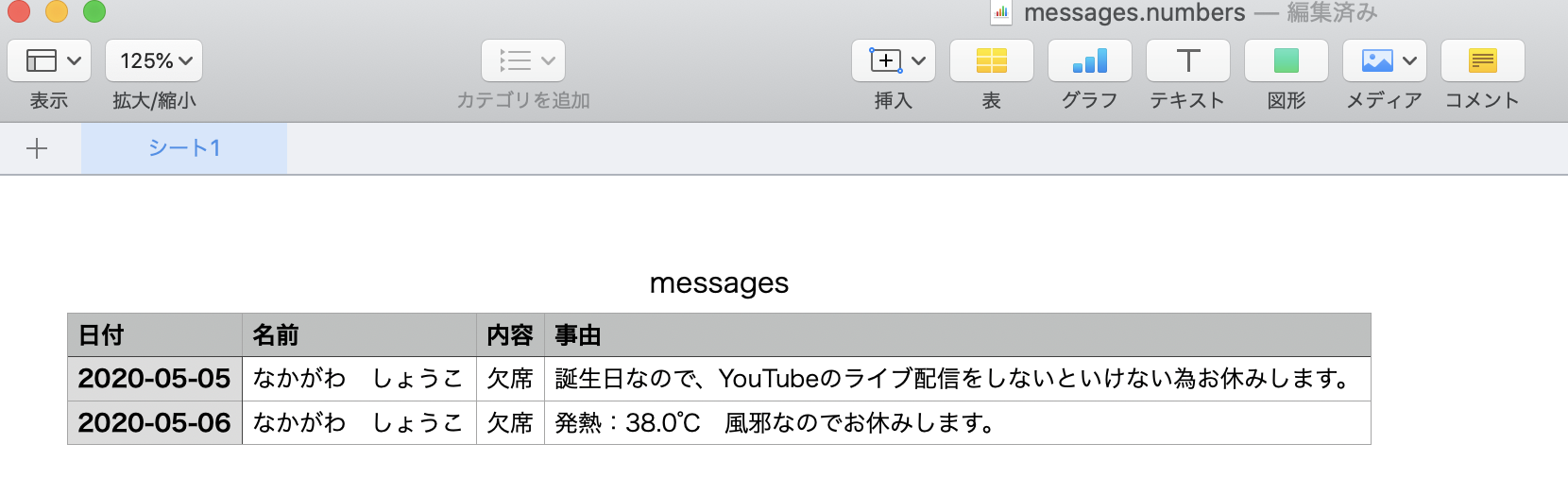
今回新たに学んだのはこれ。データベースの内容をスプレットシートに出力し、パソコン内へ保存します。またその中で、別のテーブルの内容を持ってくる必要がある為、.joins()でテーブルの結合も合わせて実施しました。viewフォルダ内にファイルを作成。
view/messages/index.html.rubyrequire "csv" CSV.generate do |csv| @messages = Message.joins(:user) column_names = ["日付","名前", "内容", "事由"] csv << column_names @messages.each do |message| column_values = [message.dayname, message.user.name, message.absence, message.body] csv << column_values end endアイコンをクリックしたら出力できるようにhamlを編集。
view/messages/index.html.haml=link_to messages_path(format: :csv) do = icon('fas','download')〈機能説明〉
クリックすると‥
スプレットシートに出力され保存が可能!
ちなみに上記欠席内容のデータと、下記のように出席データも可能。
これでペーパーの出席簿はいらないですね!
これ以外にも実装したい内容はありましたが、自分のスキルが足りなくて悔しい思いをしています。
あと事件というのは、Githubでコミットする前に間違えてブランチを切り替えてしまい、その前日に作った分が全て消えた事です。ショックでしたけど、その分CSVをまたやる事になり良い復習になりました!参考




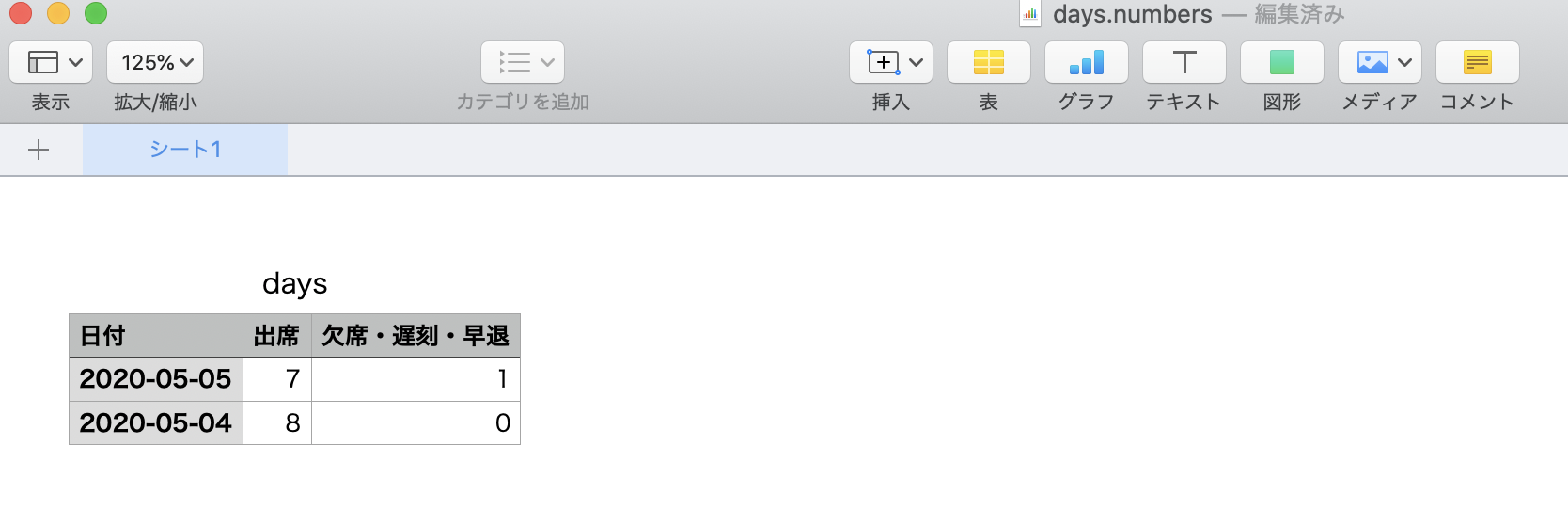
- 投稿日:2020-05-17T19:48:31+09:00
【開発ログ⑮】外部リンクやPDFリンクをつけたい
前提について
はじめまして、 プログラミングスクールに通ういりふねと申します。この記事は、スクールの課題である個人アプリの開発の記録を書くことで、自身のアウトプットに利用しています。もし、読んでいただけた方がいましたら、フィードバックをしていただけたら嬉しいです。
開発するのは「有給休暇管理ツール」です。仕様は過去記事をどうぞ。
アプリはデプロイまで行いますが、サービスとして提供するものではありません。あくまでも自学習の一環ですので、ご理解下さい。では本題へどうぞ。
今回の実施内容
今回は厚生労働省のリンクや有給休暇の届出のPDFのリンクを付けたいと思います。おまけ機能的なものですね。実際には以下の手順で実施します。
- 厚生労働省のリンクを実装
- 新しいタブで開くを実装
- google driveの共有設定
- 有給休暇の届出のリンクを実装
厚生労働省のリンクを実装
ページ左下の関連サイトのボタンに設置します。こちらは、link_toにURLを入力するだけなので、とっても簡単です。
branches/_side.html.haml〜中略〜 .links = link_to '#' do 有給休暇届 = link_to "https://www.mhlw.go.jp/shingi/2004/04/s0428-7b2a.html", class: "link" do 関連サイト新しいタブで開くを実装
実際にリンクをクリックすると、現在開いている有給休暇管理ツールのページから厚生労働省のページに遷移します。これでは、いちいち戻るボタンを押す必要があるので、新しいタブにリンク先が表示されるようにします。
branches/_side.html.haml〜中略〜 .links = link_to '#' do 有給休暇届 = link_to "https://www.mhlw.go.jp/shingi/2004/04/s0428-7b2a.html", target: :_blank, class: "link" do 関連サイト追加したのは、「target: :_blank」の部分です。これで、新しいタブで開くようになりました。
google driveの共有設定
次にPDFの文書「年次有給休暇届」のリンクを実装します。有給休暇の申請を紙ベースで管理している会社の方が多いと思いますので、有給休暇管理ツールに見本があれば、すぐにプリントアウトして社員さんに渡してあげることができます。
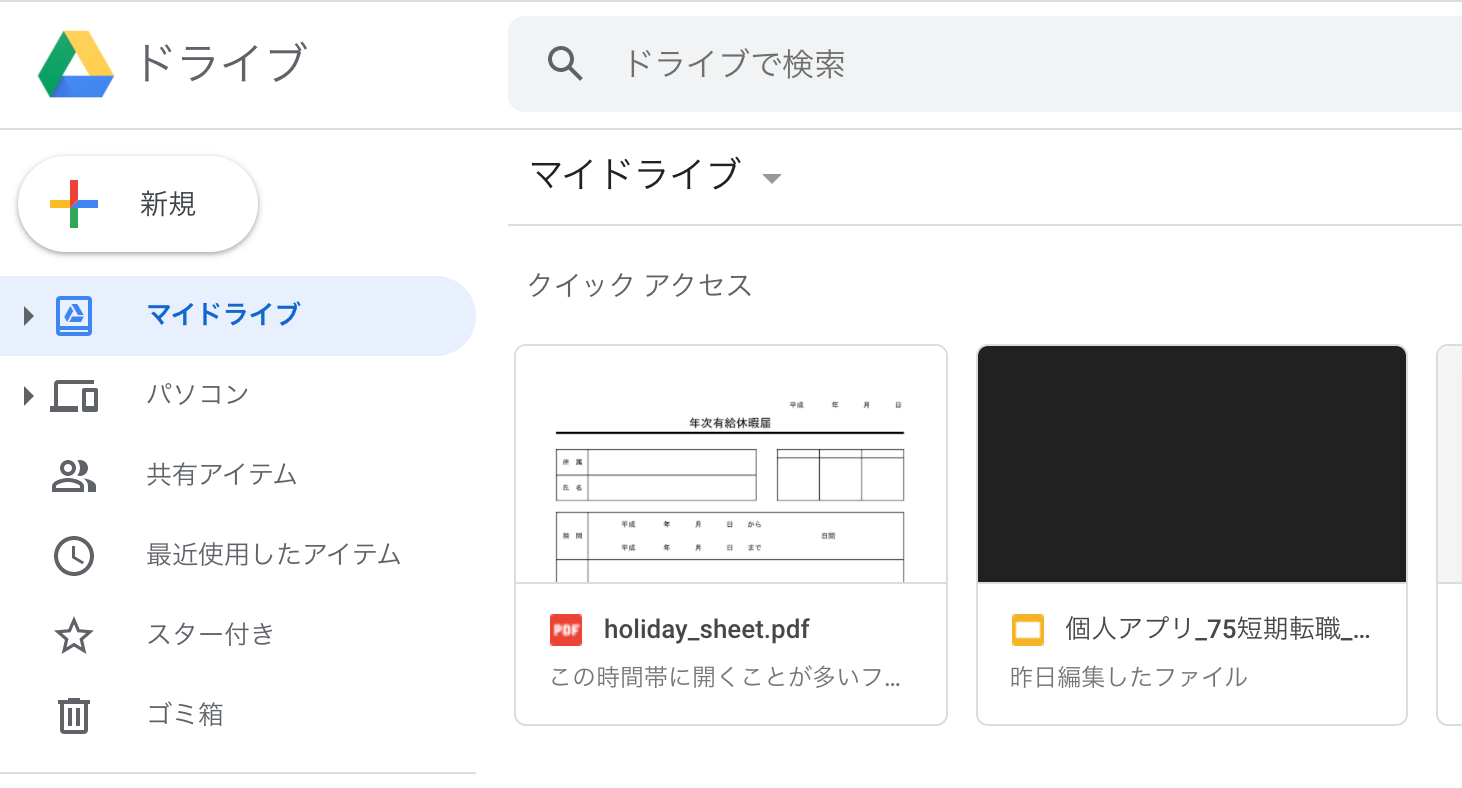
今回は、google driveの共有設定を利用してリンクを取得します。
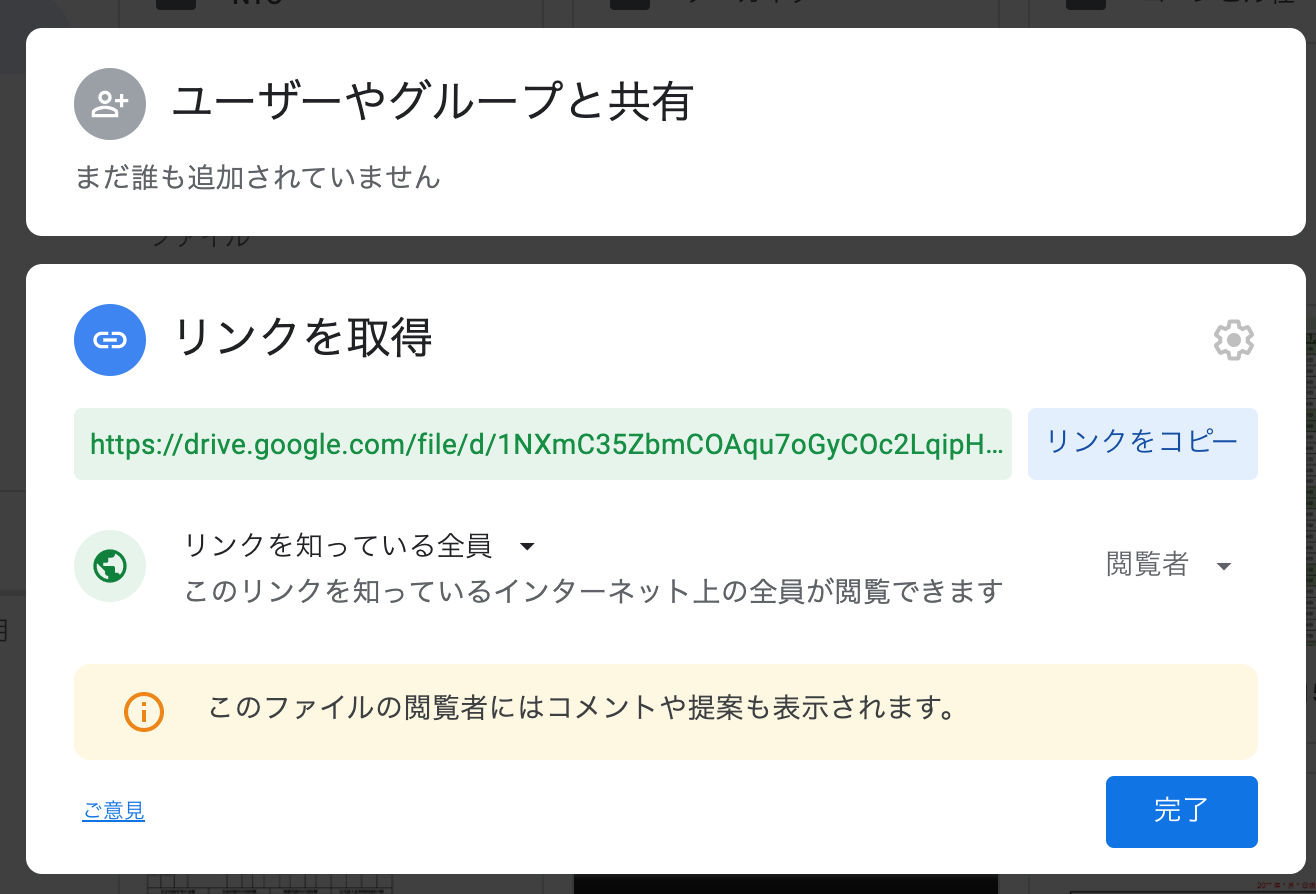
まずは、自身のdriveにPDFファイルを保存します。保存はドラッグ&ドロップでOKです。次に共有したいファイルを右クリックして、「共有」を押します。出てきたメニューの下側にリンクを取得があるので、その中の「リンクを知っている全員に変更」をクリック、「リンクをコピー」をクリックします。
参考にさせていただいた記事「Google ドライブのファイルを共有する」有給休暇の届出のリンクを実装
最後に取得したリンクをrailsのlink_toに反映させます。
branches/_side.html.haml〜中略〜 .links = link_to "https://drive.google.com/file/d/1NXmC35ZbmCOAqu7oGyCOc2LqipHDGDJj/view?usp=sharing", target: :_blank, class: "link" do 有給休暇届 = link_to "https://www.mhlw.go.jp/shingi/2004/04/s0428-7b2a.html", target: :_blank, class: "link" do 関連サイトこちらの方法は、手軽にできますが、開いたリンクにアカウント名やメールアドレスが表示されるので、きちんとサービスとして実施する際には、専用のgoogleアカウントを用意するか、別の方法が良いかも知れません。
今日の振り返り
個人発表会が近くなってきました。有休の付与と消化を手入力で行うという意味ではだいぶ形になってきましたが、大切な付与計算などは省いているので、5月19日以降も継続してアプリケーションを作っていこうと思います。

- 投稿日:2020-05-17T19:26:32+09:00
EC2を再起動するのに必要なコマンド自分用
$ sudo service nginx restart $ sudo systemctl restart postgresql $ ps -ef | grep unicorn | grep -v grep $ bundle exec unicorn_rails -c /var/www/rails/Portfolio/config/unicorn.conf.rb -D -E productionデータベースを再起動する必要があるのは忘れがち。
たとえsudo systemctl status postgresqlで動いていても、データベースの再起動はするべき。
- 投稿日:2020-05-17T18:25:08+09:00
selectタグには疑似要素が指定できない。
結論
selectタグには疑似要素が指定できないのでdivタグでラップしました。
背景
selectタグを使用したときにデフォルトで表示される上下矢印ボタンをモダンな感じにしたかったのですが
デフォルトのボタンを消して、:before疑似要素で何とかしようとしていて詰まってしまいました。解決方法
こちらのサイト「フォームのセレクトボックスとチェックボックス・ラジオボタンをCSSで装飾する」にたどり着き、selectタグには疑似要素が指定できないことがわかりました。
上記サイトでは、divタグで囲んでdivタブの疑似要素で表示させれば良いこともわかりましたので、次のサンプルコードを書きました。sample.scss&__selectWrapper { position: relative; .select-form { -webkit-appearance: none; background-color: #fff; width: 100%; height: 46px; padding: 0 30px 0 15px; border-color: rgb(187, 187, 187); } &::before { content: ''; position: absolute; right: 15px; top: 8px; width: 30px; height: 30px; background-color: red; }これでセレクトボックスの右側に赤い四角を表示させることができるようになりました。
あとは良しなにfontawesomeなり画像ファイルなりに変更しましょう。


- 投稿日:2020-05-17T18:15:24+09:00
描いて理解する Action Cable
はじめに
コロナ騒ぎで時間があるので Rails の Action Cable を触ってみました。
基本的な使い方は Rails ガイドで調べましたが、いまいちピンとこなかったので理解するために図を描きました。特に用語についての章を読んでもそれぞれの用語の関係性がよく分からなかったので、自分なりに整理しています。
用語について
Connection, Consumer
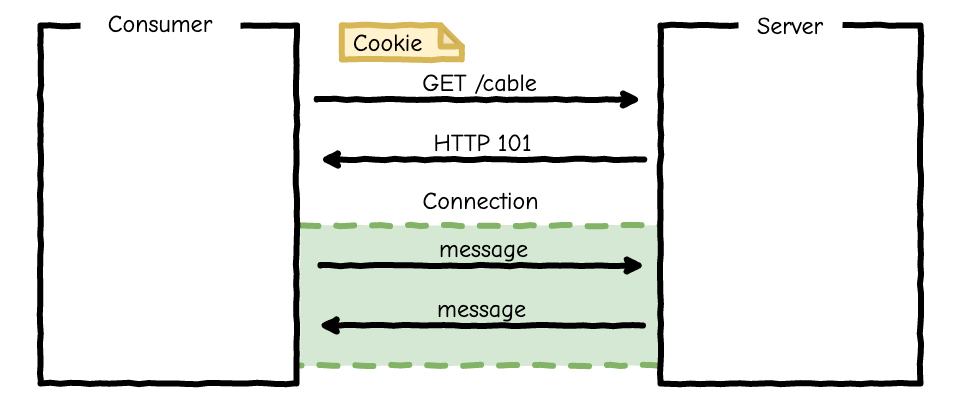
WebSocket の基礎
- Web 上でクライアント、サーバ間の双方向通信を実現するための通信規格
Upgrade: websocketヘッダをつけた HTTP リクエストで開始- レスポンスとして HTTP ステータス 101(Switching Protocols) が返ってきたら TCP コネクションを使いまわして WebSocket として通信ができる
- 送信できるデータはテキストまたはバイナリ
- HTTP とは別のプロトコルなので Cookie などは送られない
- 通信が確立したあとはクライアント、サーバどちらからでもメッセージを送ることが可能
Connection
- WebSocket としてのコネクションを表すクラス
- (おそらく)WebSocket として通信が確立した時点でインスタンスが生成される
- 開始時のリクエストはふつうの HTTP なので Cookie も送られる
- なので
connection.rbではcookiesが使える- 認証処理はこのクラス内に記述
Consumer
- WebSocket コネクションのクライアント(ブラウザなど)
- HTTP とは異なり、同じブラウザの異なるタブは完全に別のクライアントとして扱われる
Consumer を区別する方法
HTTP とは異なり毎回認証情報が送られたりはしないので、コネクション確立時に「このコネクションは誰のものか」をサーバー側で管理する必要がある。
そのためのしくみとして Action Cable では Connection クラスの
identified_byを使う。# app/channels/application_cable/connection.rb module ApplicationCable class Connection < ActionCable::Connection::Base identified_by :current_user def connect self.current_user = User.find_by(id: cookies.encrypted[:user_id]) end end endChannel, Subscription
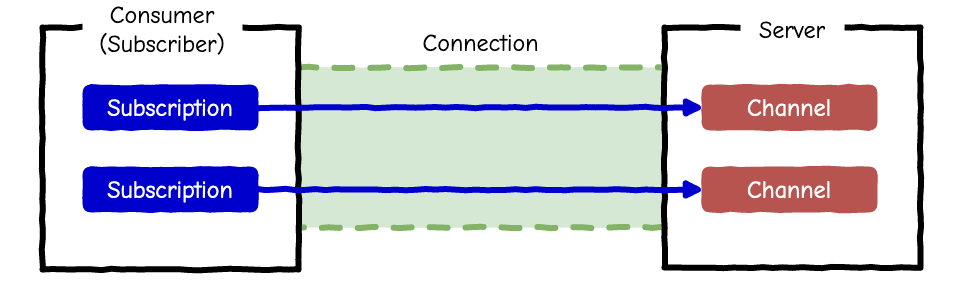
Channel
- 文字通りのチャンネル
- Controller のようなもの
Subscription
- チャネルの購読
- ひとつのコネクション内でいくつでも作成可能
- あるチャネルの購読をしている、という意味ではコンシューマをサブスクライバとも呼ぶ
以下のように
consumer.subscriptions.createで新たなSubscriptionオブジェクトが作成され、consumer.subscriptionsに追加される。chat_channel.jsimport consumer from "./consumer" consumer.subscriptions.create("ChatChannel", { // 略 });Stream
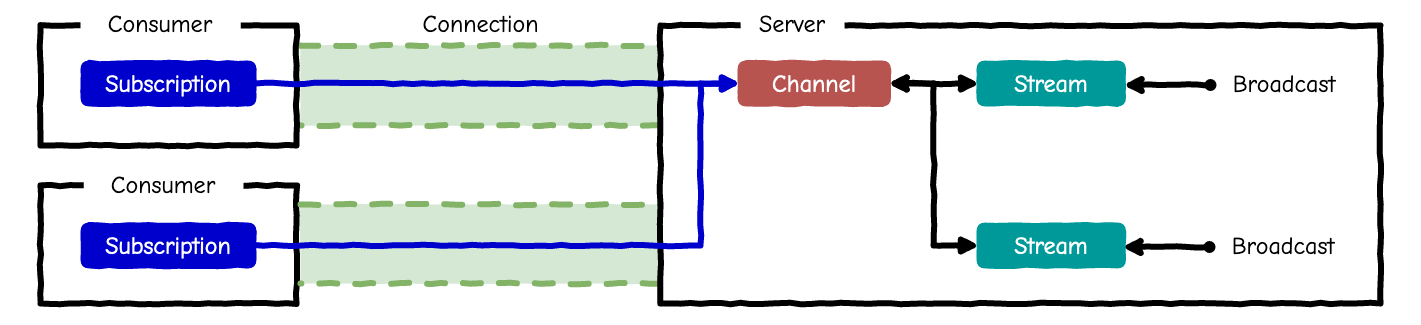
- ブロードキャストを行う場合に使う
- チャネルがサブスクリプションとストリームの紐付けを行う
- あるストリームにブロードキャストした場合、そのストリームに紐づくサブスクリプションにメッセージが送られる
例
たとえば以下のようなチャネルクラスを定義しておくと
ChatChannelをサブスクライブしたときにchat_001というストリームに紐付けられる。chat_channel.rbclass ChatChannel < ApplicationCable::Channel def subscribed stream_from "chat_001" end endこの状態で以下のコードが実行されると、サブスクライバに
{"text": "Hello, World!"}というJSON文字列が送られる。broadcastdata = {text: "Hello, World!"} ActionCable.server.broadcast("chat_001", data)ストリームに対するブロードキャスト自体は、Rails アプリケーションのどこからでも実行可能。
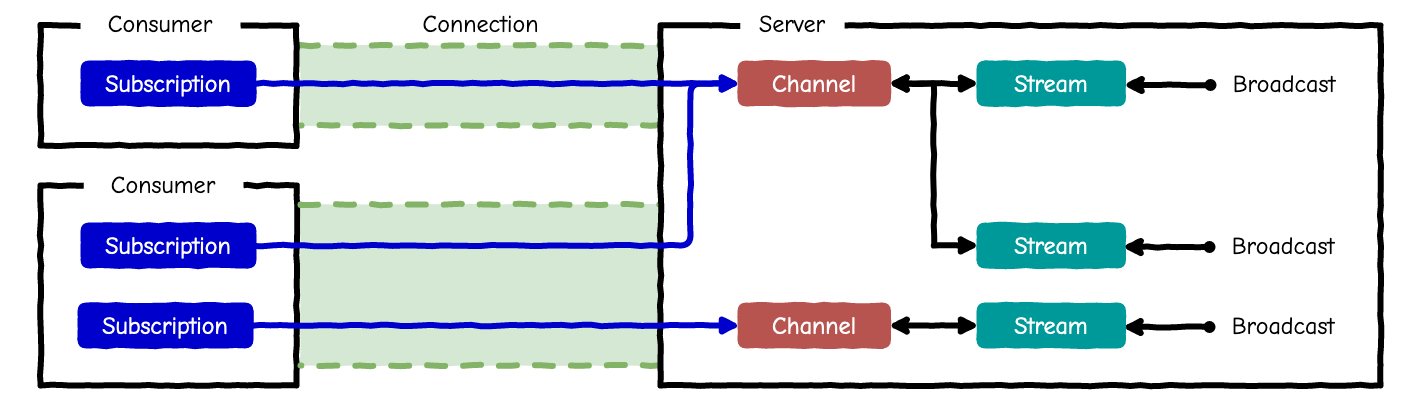
複数のStream
前節の例では固定文字列だったので、どのサブスクリプションも同じストリームに紐付いていました。しかし、チャネルをサブスクライブするときサーバー側にパラメータを渡すことができるので、ユーザーごと、もしくは開いているページごとに異なるストリームに紐付けることが可能です。
まとめ
ストリームとサブスクリプションの関係がよく分からなかったのでそこを中心に図示してみました。この図だとストリームが必須みたいに見えてしまうので、action パラメータによってサーバー側のメソッドを実行する、という観点でも整理して別途記事にしてみようと思います。

- 投稿日:2020-05-17T18:01:19+09:00
正規表現でバリデーション設定した項目を空欄のままでも通過できるようにしたい
はじめに
電話番号やメールアドレス等の入力値のフォーマットチェックに正規表現が使える。
指定した文字列、数列以外の値が入力されたらバリデーションチェックに引っ掛かる仕組みだ。
今回は任意入力とした項目を指定された正規表現、または空欄のままでもバリデーションが通過するようにしたい。
電話番号にバリデーションをかけてみよう
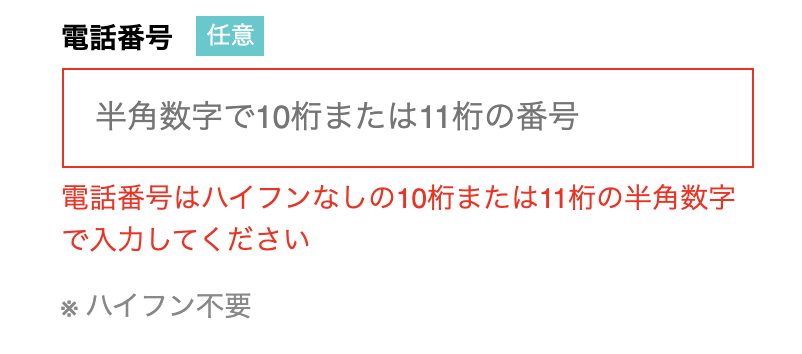
今回は電話番号を例にして、まずは電話番号にバリデーションをかけてみる
validates :phone_number, format: { with: /\A\d{10,11}\z/ }これはハイフンなしの10桁または11桁の半角数字で入力してくださいという意味の正規表現だ。
今回は電話番号は任意入力にしたいのでpresence: trueは書いてないし、このままでいいだろうと思ったが…。
問題発生
指定された正規表現でのバリデーションは突破し、次に入力欄を空白にして進んだらバリデーションに引っかかってしまった!
原因
どうやら正規表現でバリデーションをかけるとその正規表現以外の入力をたとえ空欄(nil)でも受け付けなくなってしまうらしい。
解決法その1
メンターに聞いてみるとカスタムメソッドというのを用いて
「空か、あるいは10桁または11桁の半角数字」といったカスタムメソッドを作るという方法があると言われたが、カスタムメソッドについて調べると非常に面倒臭いし大変そうである。
↓カスタムメソッドの参考記事
https://qiita.com/h1kita/items/772b81a1cc066e67930eなので自分で他の方法がないか考えて試行錯誤した結果、非常に簡単な解決法が見つかった。
解決法その2
以下のようにallow_blank: trueを追加するだけである。
validates :phone_number, format: { with: /\A\d{10,11}\z/ }, allow_blank: trueこれは文字通り空欄のままでもOKという意味。
これで電話番号が未入力でもバリデーションが通るようになりました!
まとめ
入力値を正規表現、または空欄でバリデーションを通過したい場合はallow_blank: trueを追加すれば良い。

- 投稿日:2020-05-17T17:31:21+09:00
【開発ログ⑭】社員を削除したら有休データも削除したい
前提について
はじめまして、 プログラミングスクールに通ういりふねと申します。この記事は、スクールの課題である個人アプリの開発の記録を書くことで、自身のアウトプットに利用しています。もし、読んでいただけた方がいましたら、フィードバックをしていただけたら嬉しいです。
開発するのは「有給休暇管理ツール」です。仕様は過去記事をどうぞ。
アプリはデプロイまで行いますが、サービスとして提供するものではありません。あくまでも自学習の一環ですので、ご理解下さい。では本題へどうぞ。
今回の実施内容
前回までで有休登録の機能が実装できたので、今回は社員と支社の削除機能を実装します。具体的には以下の通りです。
- 社員削除の問題点
- 社員削除の制約の設定
- 支社の削除画面の検討
- ビューで確認
社員削除の問題点
今回のアプリケーションでは、4つのテーブルを用意しています。社員は、employeeテーブルに保存していますが、外部キーとして支社のbranch_idを持っています。社員にとっては親テーブルは支社になるわけです。さらに社員は、有休登録されたデータを複数持ちます。これは、holidayテーブルに保管され、holidayレコードは、外部キーとして社員のemployee_idを持ちます。
親子関係を表すと以下のとおりです。
親:支社のbranchテーブル
子:社員のemployeeテーブル
孫:有休のholidayテーブルここで、親や子(つまり支社や社員)を削除すると、その下のテーブルには外部キーに対応する親レコードがなくなってしまいエラーになってしまいます。
そこで、社員を削除したら、社員の持つ有休データもまとめて消せるように実装していきます。社員削除の制約の設定
実装は非常に簡単で、モデルファイルにdependent制約を記述するだけです。
参考にさせていただいた記事「[Rails] has_manyおよびbelongs_toへのdependent: :destroyの設定について」@after4649様employee.rbclass Employee < ApplicationRecord 〜中略〜 has_many :holidays, dependent: :destroy 〜中略〜 endアソシエーションを記述しているhas_manyの後ろに文章を追記するだけで、コントローラーなどの設定は変更せずにそのまま使用することができました。
ただし、記事にもありますが、belongs_toの方につけると大変なことになるので、注意が必要です。それからこのdependent制約には:destroy以外にも記述方法があるようなので、ご自身にあったものを使用して下さい。支社の削除画面の検討
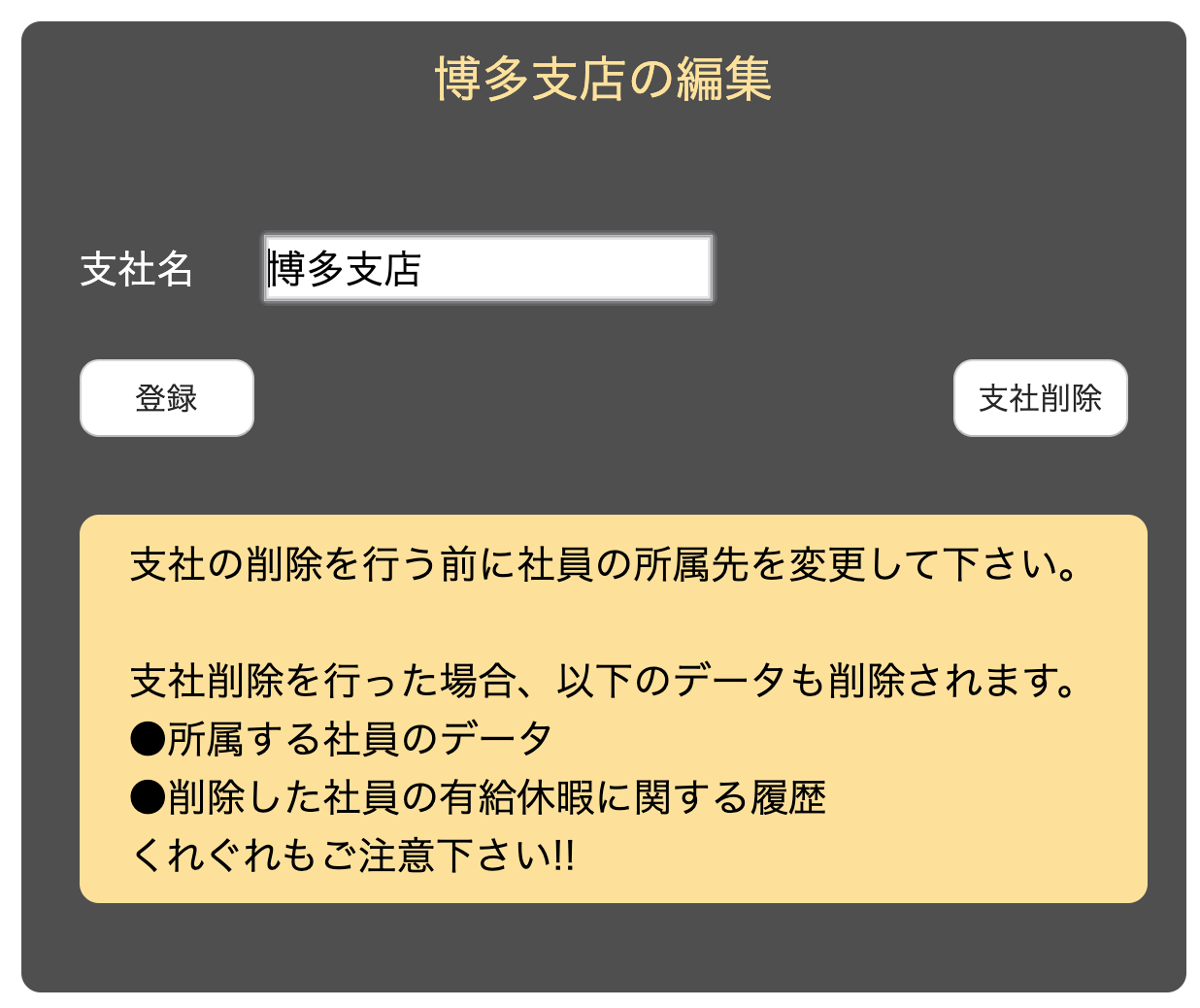
社員の設定は、これで良いとして支社を削除する際に同じように社員とその有休のデータをまとめて削除してよいか悩みましたが、同じようにdependent制約をかけることにしました。
そのかわり、支店削除は簡単に行えないよいうにステップに分けるようにしました。
まず、削除ボタンがindexに表示されないように「編集/削除」のボタンを設定し、編集画面を表示させます。編集画面内に「支社削除」がありますが、大きめの文字で注意を促します。
ここについては、私の技術がさらに向上したときに別の方法を検討しようと思います。今は、これが精一杯汗ビューで確認
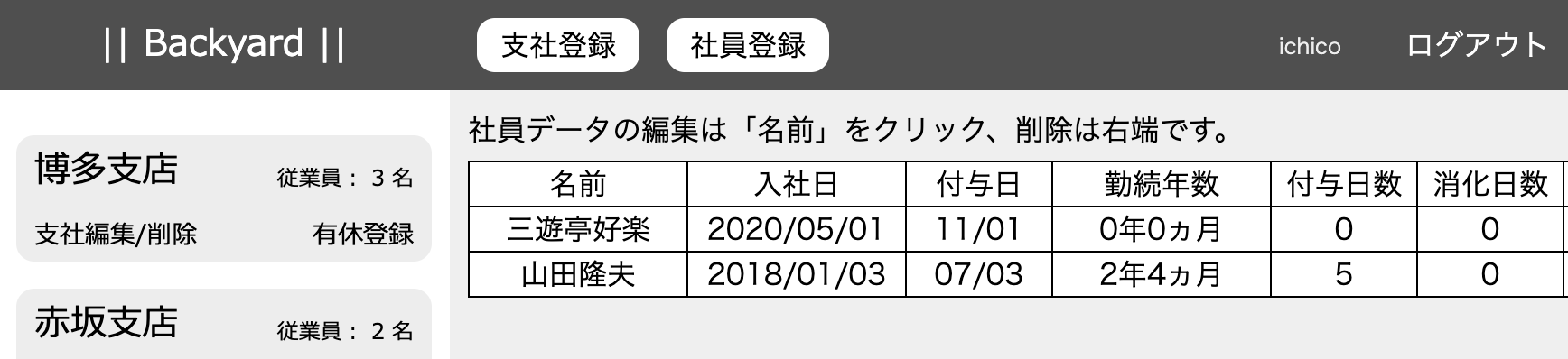
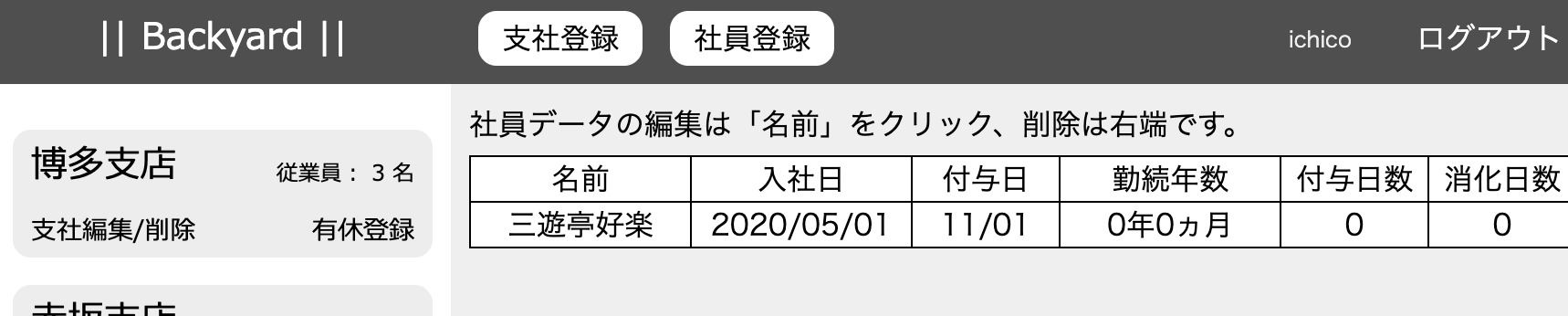
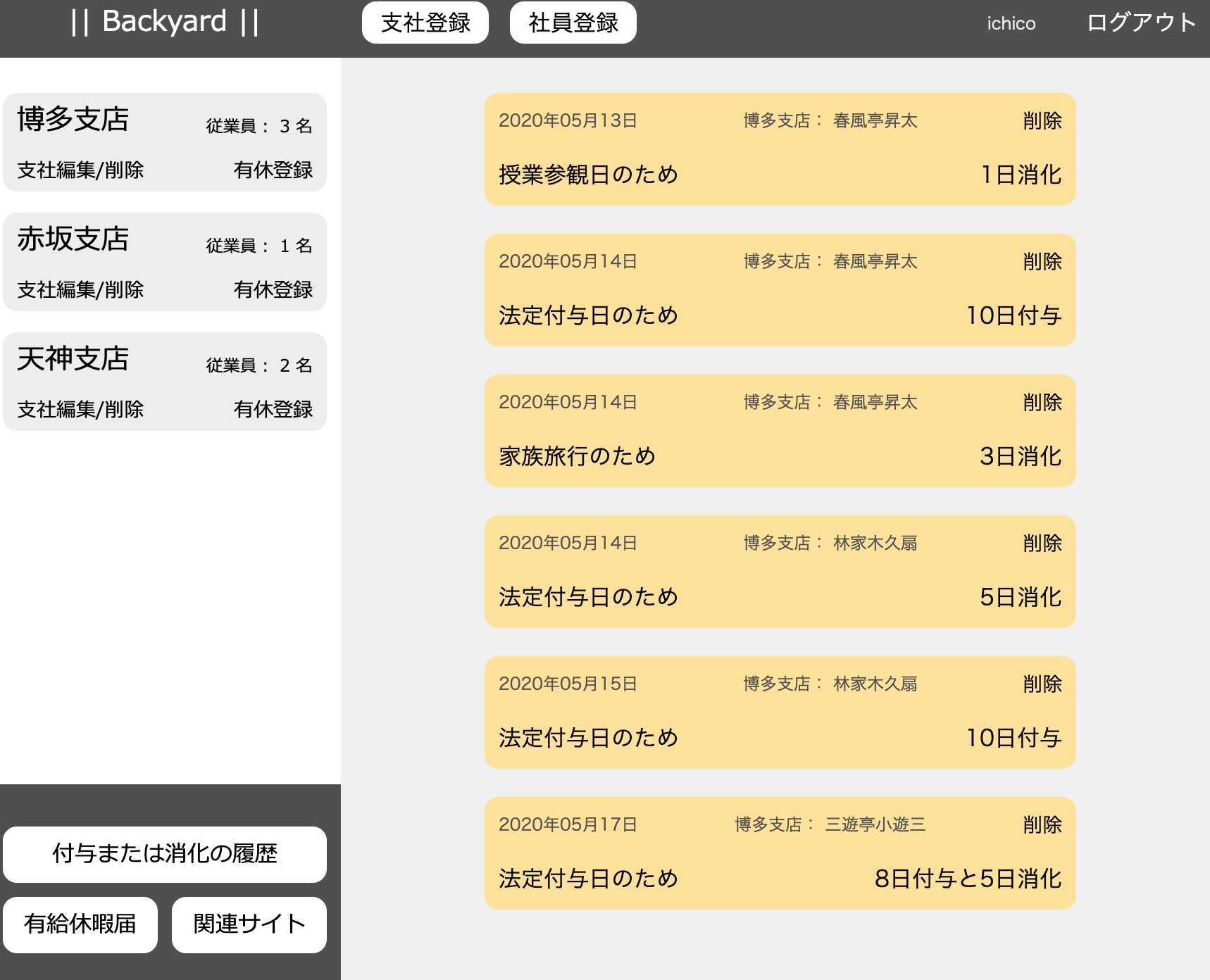
ちょっと回り道をしましたが、ビューで確認します。座布団運びの山田くんは、5日有休を付与されていますが、このたび解雇となります。
社員の削除は表の右端(これも簡単に押せないよう配慮しているつもり)にあります。クリックすると見事に削除されました。
付与及び消化の履歴にも山田くんの履歴は残っていません。無事に成功しました。
ちなみに可愛そうだったので、この後山田くんは再登録してあげることにしました。今日の積み上げ
dependent制約は、実はカリキュラムで触れられていました。まだまだ知識が十分定着していないのかも知れません。今後もどんどんアウトプットをして学んだことを定着させたいです。
- 投稿日:2020-05-17T17:12:55+09:00
YouTube Data APIを使わずにチャンネルの最新ライブ配信IDを取得する方法
バックグランド
最近の個人アプリ開発中に出会った問題です。
YouTubeのライブ配信が日々活発している今、チャンネルIDを持ちながらそのチャンネルの最新ライブ配信の情報を取得したい場合がよくあります。しかし、YouTube Data APIを使って最新ライブ配信情報を取得しようとすると以下二つの問題があります。
- チャンネル情報丸ごと取得する
チャンネル(channels)リソースからチャンネル最新動画取得しようとしてもライブ配信情報(ライブ配信中または公開予定の情報)が含まれない。(現在2020年5月時点)- チャンネルIDを持って
searchリソースを使うと、どうやら書き込み操作と同様に扱われるので他の情報取得操作リスト(list)の何十倍のクォータコスト(https://developers.google.com/youtube/v3/getting-started?hl=ja) が消費されます。ライブ配信情報の有無を頻繁に取得・更新しないと意味ないので、
searchリソースを使うと一日使えるクォータコストの割り当てはすぐなくなります。一方、ライブ配信IDであるvideoIdを取得する手段があれば、videoIdを指定して動画(videos)リソースから低いクォータコストでライブ配信の情報をアクセスできます。
そのため、YouTube Data APIを使わずにチャンネルの最新ライブ配信IDであるvideoIdを取得することが必要とされています。方法(Ruby)
あまり使われていないかもしれませんが、チャンネルにライブ配信情報があれば下記のurlを使ってその最新のライブ配信playerをページに埋め込むことができます。
url = "https://www.youtube.com/embed/live_stream?channel=<チャンネルID>"最新のライブ配信を表示してくれれば話がしやすくなります。次のやることが
そのページを裸にして必要な情報videoIdを取り出すことです。content = Net::HTTP.get_response(URI.parse(url)).entity unless content.match(/watch\?.+/) == nil match = content.match(/watch\?.+/)[0] videoId = match.sub("watch?v=","").sub("\">","") endYouTubeのページやurlには基本的に
watch?v=<videoId>のような形に書かれているので、取得したcontentからmatchとsubメソッド使えばvideoIdを簡単に入手できます。(そこにちゃんと整備したYouTubeさんに感謝)
videoIdを入手した以上、YouTube Data APIの動画(videos)リソースを使えば配信状態やら配信時間やらの取得はもう何ても来い!参考(PHPでのやり方)
https://stackoverflow.com/questions/58040154/how-to-get-live-video-id-from-from-youtube-channel-html
- 投稿日:2020-05-17T16:54:33+09:00
【開発ログ⑬】formに0は入れさせない!!
前提について
はじめまして、 プログラミングスクールに通ういりふねと申します。この記事は、スクールの課題である個人アプリの開発の記録を書くことで、自身のアウトプットに利用しています。もし、読んでいただけた方がいましたら、フィードバックをしていただけたら嬉しいです。
開発するのは「有給休暇管理ツール」です。仕様は過去記事をどうぞ。
アプリはデプロイまで行いますが、サービスとして提供するものではありません。あくまでも自学習の一環ですので、ご理解下さい。では本題へどうぞ。
今回のアプリのフォームについて
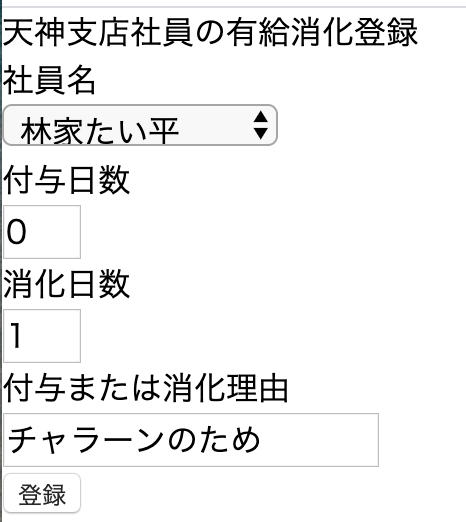
記事にはしていませんが、有休の付与や消化を登録するフォームとそれらを表示するログを作成しました。以下は写真です。
こちらは、フォームです。たい平師匠がよくわからない理由で休もうとしていますが、今回は見逃します。
次に有休の付与や消化の履歴を確認するビューです。社員の消化理由を確認したいとか、有休登録を行ったけど間違って登録していないか確認したいなど、入力する人にとって必要であろうと思い設置しています。有休登録の削除もできます。
この消化の履歴は、右下に「付与か」「消化か」「付与と消化」が表示されるようにメソッドを設定していますが、ここの条件が今回のテーマに関連します。以下はメソッド部分です。
holiday.rbclass Holiday < ApplicationRecord 〜中略〜 def add_or_delete if add_day.nil? "#{delete_day}日消化" elsif delete_day.nil? "#{add_day}日付与" else "#{add_day}日付与と#{delete_day}日消化" end end endadd_day(付与日数)やdelete_day(消化日数)がnil(空)かどうかを条件に設定していますが、そこで問題になるのが、「0」という存在です。
0もデータでnilとは違う
例えば、有休登録時に付与を0、消化を1と登録すると、履歴には「0日付与と1日消化」と表示されてしまって、非常に不格好になりました。これを避けるためにモデルファイルに定義しているメソッドの条件を「nilまたは0ではない」と変更してもよいのですが、この後、実装する機能にいちいちこの条件を設定するのは面倒。ということでフォーム入力時点で「0」が登録されないようにしたいのです。
今回の実施内容
毎度のことながら前置きが長くなりましたが、ここから真の本題です。付与日や消化日のカラムには、nilか1以上の数字しか入らないようにいくつか改良します。具体的には以下のことを行いました。全部必要だったかどうかは、わかりません。
- バリデーション「exclusion」
- フォームの入力制限
- リセットボタンの設置
バリデーション
0を保存させないと思って真っ先に検索したのが、バリデーションでした。調べてみると「exclusion」という、特定の文字を保存させないバリデーションがありました。
参考にさせていただいた記事【Rails】完全解説!Railsのバリデーションの使い方をマスターしよう!
記事を元に付与日と消化日に「0」という文字が入らないようにバリデーションをかけてみました。
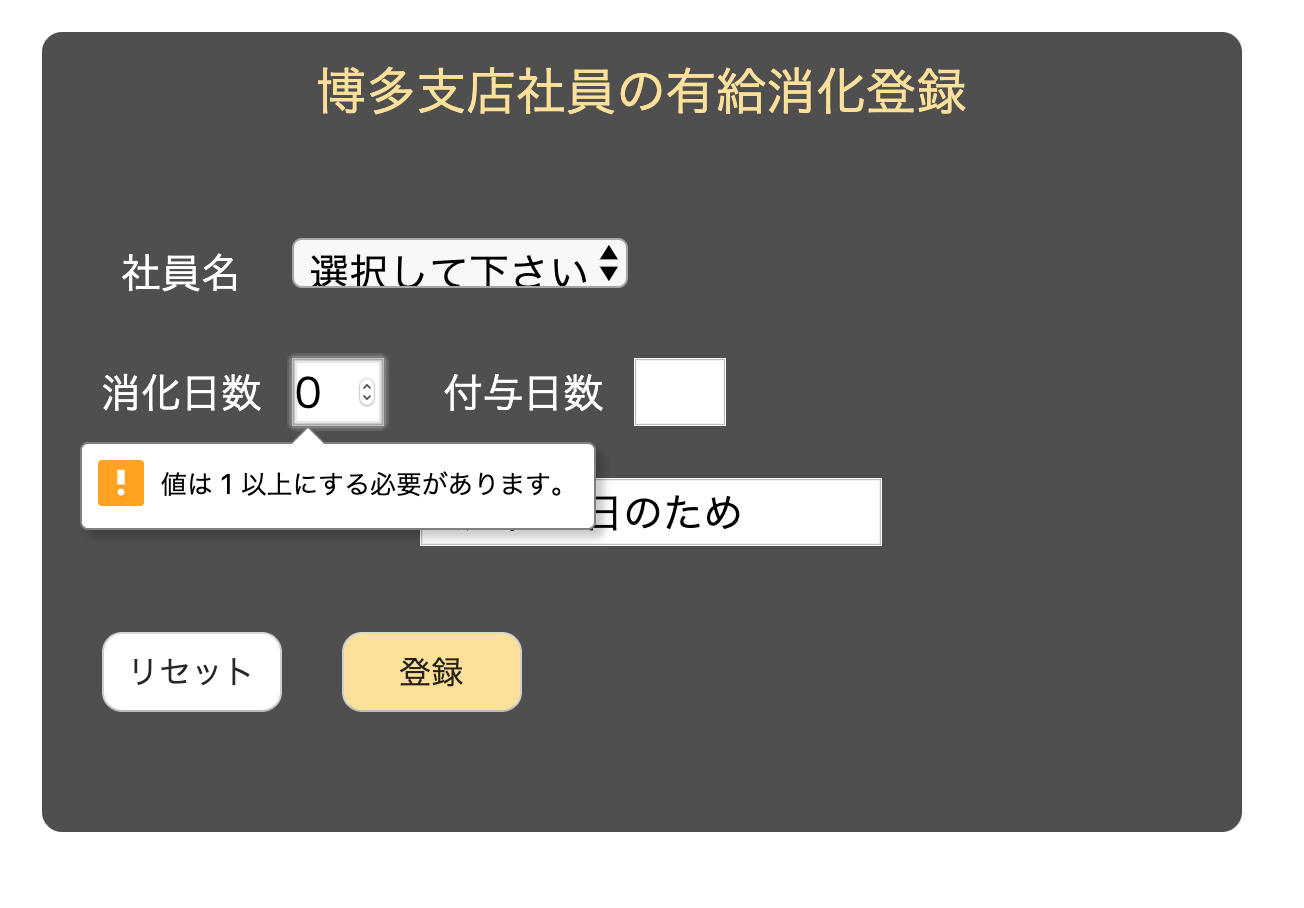
holiday.rbclass Holiday < ApplicationRecord validates :reason, presence: true validates :add_day, exclusion: { in: [0]} validates :delete_day, exclusion: { in: [0]} 〜中略〜 end0と入れて試してみましたが、どうやら保存されていないようです。念のため、10日付与なども行いましたが、こちらはちゃんと保存できました。
フォームの入力制限
しかし、保存されずにindexに戻ってきてしまうため、利用者の方にとっては、なぜ保存されなかったのかが分かりにくくなってしまいます。例えば、付与日を2、消化日を0と打ったが、送信前に間違えに気づき、付与日を0、消化日を2に修正して送信ボタンを押したのに保存されていないなどです。
そこで、フォームそのものにも1以下の数字は入れられないように制限をかけていきます。holidays/new.html.haml〜中略〜 .field .field-label = f.label "消化日数" .field-input = f.number_field :delete_day, max: "50", min: "1" .field .field-label = f.label "付与日数" .field-input = f.number_field :add_day, max: "50", min: "1" 〜以下省略〜number_fieldに最大50、最小1を追記しました。これによりフォームの上下のボタンでは1~50までしか選択できないようになりました。万が一、手入力で、0を入れて送信しようとしたときには、このフォームの制限によりエラー文が出てくるようになります。
リセットボタンの設置
これで、0を保存されず、かつフォーム上でも0が送信できないように設定できましたが、念のためフォームのリセットボタンも設置します。わざわざ手入力で0を入れる方は少ないと思ったので、何かの入力ミスで0になってしまったけれど、フォームについている上下ボタンでは、変更できない!!という事態を防ぐためです。
holidays/new.html.haml〜中略〜 .btns = f.button "リセット", type: :reset, class: 'btn' = f.button "登録", type: :submit, class: 'btn'最初、「f.reset...」とsubmitと同じ要領で記入していたのですが、うまく行かなかったので、再び調べて、下の記事で解決しました。
参考にさせていただいた記事「Railsでリセットボタンの実装方法」ビューの確認
最終的なビューのスクリーンショットを取り忘れていたので、CSSが付与された後の状態になりますが、以下のように完成しました。
今日の積み上げ
今まで、派手な機能にばかり目を向けていたので、こういった機能も大切であると学びました。あからさまなエラーが出ない分、開発者として細やかな気配りが求められるのではないかと思います。
一方で、こういったバリデーションは、必要であれば、どんどん付けられるのかも知れません。必要十分な量にとどめておかないと作業量が増えすぎるとも感じました。


- 投稿日:2020-05-17T14:48:53+09:00
ドリル(自作)
経緯
某プログラミングスクールのドリルはわかってなかったことだらけで勉強になるのですが,「問題は」出すけど,「解釈,解答の背景」は自分で調べろ的なスタンスなので公開記事で記述形式でまとめていきます。
ちなみに前回の記事のようにスクールの問題は限定記事にまとめて復習しています。ちなみに下のを解く場合,自分が示した答えは最適解とは限りませんが,参考程度にして自分で調べていただければと。
railsにおけるコールバックってなんなの?
*
*
*
*
*
*
*
*
*
*
*
*A
・オブジェクトはrailsのアクションで生成されたり削除されたりする。この過程をオブジェクトライフサイクルという。このサイクルのなかでオブジェクトが変化する前後で行われる処理がコールバック。
・乱暴に噛み砕くとはデータベースから抽出する時,登録する時に行われる処理。身近なものだとバリデーションとかもそう。データベースに登録する前になにか処理を行うなら,before_createとか,モデルにメソッド同様に記述。シンボルってなんなの?
*
*
*
*
*
*
*
*
*
*
*
**
A
見た目は文字列だけど処理では数値として扱われるよ。シンボルに対応する数値は1対1だからたくさん定義をしてもメモリを圧迫しないよ
selfってなんなの?
*
*
*
*
*
*
*
*
*
*A
・モデルを通過するオブジェクトそのものだよ
・モデルの中はインスタンスとか定義してないから@postをコントローラーで定義しても認識してくれない。だからselfがその代わりになってくれる。p self.nameってやったらTaroが出力される感じ。selfはわざわざ定義する必要なし。CSRFという攻撃の意味とrails上での対策
*
*
*
*
*
*
*
*
*
*
*
*A
クッキーを不正に利用して他人のアカウントで不正操作(投稿削除)を行うこと。(噛み砕き)
対策ー protect_from_forgery with: :exception
これによってフォームからの投稿ごとに不正に利用されていないかトークンを発行して照合している。countの使い方(引数の有無でどう変わるか)
*
*
*
*
*
*
*
*
*
*
*A
レシーバの要素数を返します。
引数を指定しない場合は、レシーバの要素数を返します。
引数を一つ指定した場合は、レシーバの要素のうち引数に一致するものの個数をカウント
ブロックを指定した場合は、ブロックを評価して真になった要素の個数をカウント
- 投稿日:2020-05-17T14:40:52+09:00
Rubyの基礎~わかりにくいところ復習~
オブジェクト
オブジェクトとは、Rubyで扱うデータのことを指します。
文字列オブジェクトでは文字を扱います。
文字をダブルクォーテションまたはシングルクォーテーションで囲むことによって文字列になります。つまりそれを文字列オブジェクトと言います。
文字列オブジェクトの他にも、時刻オブジェクトや、日付オブジェクト、配列オブジェクト、数値オブジェクトなどもあります。
オブジェクト名 扱うもの 文字列オブジェクト 文字 配列オブジェクト 複数のデータ 数値オブジェクト 数値 時刻オブジェクト 時間 日付オブジェクト 日付 メソッド
メソッドとは、プログラミングにおける何らかの処理をする命令群のことです。
例えば、ターミナルに文字列オブジェクトを出力したい時にはputsメソッドを使います。オブジェクトを別のオブジェクトに形を変えるメソッドもあります。
例えばlengthメソッドです。このメソッドは文字列メソッドに使えるメソッドで文字列メソッドを自身の文字数の値を数値メソッドに変換します。
to_sメソッドは数値メソッドを文字列メソッドに変換してくれます。返り値
返り値とは、オブジェクトや、メソッドが処理されたあとの最終的な値のことです。
Rubyのオブジェクト自体、メソッドを利用した式には必ず返り値があります。つまりlengthメソッドを使ったときは、文字列の文字数の値の数値を返り値として返します。
to_sメソッドは数値オブジェクトを、文字列オブジェクトに変換して、それを返り値として返します。
to_iメソッドは文字列オブジェクトを数値オブジェクトに変換してくれます。
- オブジェクト単体の返り値はそのオブジェクト自体を返します。
- 計算式はその式の答えが返り値として返ります。
- メソッドを利用したときはその処理の実行結果が返り値として返ります。
- しかしputsメソッドは返り値として
nilを返します。空という意味です。出力と返り値は別です。- 代入式は格納した値(代入した値)自体が返り値です。
getsメソッドはユーザーが入力した値の文字列オブジェクトを返り値として返します。
getsメソッドは、末尾に改行がついて返り値として返してしまいます。バックスラッシュ記法の\nがついた状態です。
それを取り除くにはchompメソッドを使います。このメソッドを使うと新たに\nを取り除いた状態の文字列オブジェクトを返してくれます。比較演算子
== は左右の式や値が等しい時にtrueを返り値として返します。等しくないときはfalseを返します。
それとは逆に
!= では左右の値が等しくない時にtrueを返し、等しい時にfalseを返します。変数
変数とはオブジェクトの入れ物のようなもので、その入れ物に名前がついています。
変数にオブジェクトを格納することができるのです。
変数は最代入が可能で値を更新することができます。
それに対して、定数は最代入が原則として禁止で、かつ全て大文字で書くのが慣習です。
つまり、固定した値を格納したい時に定数を使います。ハッシュ
ハッシュは変数の一つで、複数のデータを持つことができるオブジェクトです。
値をキーで管理しています。このペアで保存する形式のことをキーバリューストアと言います。
ハッシュオブジェクトのキーには文字列オブジェクトとシンボルオブジェクトが使えます。
実行速度がシンボルオブジェクトの方が速いので、シンボルオブジェクトが推奨されます。
シンボルオブジェクトは名前を識別するためのラベルのようなものでほぼほぼ文字列オブジェクトと同義で使えます。index.rbhash = {} ##空のハッシュを生成 hash[:name] = "taro" ##値の代入 hash[:age] = 20 ##値の代入 puts hash[:name] ##値の取得自分で定義するメソッド
putsのような処理を自分で定義してメソッド化することができます。
同じコードを何度も書かなくて済みますし、コードの可読性も上がります。また。修正や管理もしやすくなります。定義は defの隣に任意のメソッド名を書いてendまでの間に実行した処理を記述します。
index.rbdef my_name puts "私の名前は太郎です。" end注意しなければならないのはメソッドの定義部分はそのメソッドが呼びだれるまで読み込まれません。
ですのでメソッド名が呼び出される前は定義部分はスルーされます。index.rbdef my_name ##次にここが読まれる。それまではスルー。 puts "私の名前は太郎です。" end my_name ##メソッドの呼び出し 最初にここが読まれるwhile文
同じ処理を繰り返すことができる文法です。
index.rbwhile 条件式 do #処理 end条件式の部分がtrueであるかぎり処理を何回も繰り返します。
つまり
index.rbwhile true do #処理 endだと無限ループでプログラムを終了させなくできます。
処理の中にexitメソッドを使えば特定の時に無限ループを止めることができます。
配列
配列とは配列オブジェクトのことです。ハッシュがキーでオブジェクトを管理していたのに対して、配列は順番で管理します。配列にはハッシュも入れることができます。
順番の管理は0から始まるので、1つ目に入れた要素は0で管理されます。
配列オブジェクトに要素を追加するときは<<メソッドを使います。
配列の数を数えたいときはlengthメソッドを使います。変数のスコープ
変数にはその変数が使える範囲というものが決まっています。
通常はメソッド内では。そのメソッド内で定義された変数しか使用することができません。
メソッド外で定義された変数を使うには引数を使います。引数
メソッドを呼び出す部分に書く引数を本引数と言います。
また、メソッドを定義している部分に書く引数を仮引数と言います。
本引数と呼び出したい変数は同じ名前である必要がありますが、本引数と仮引数は同じでなくて構いません。
仮引数で設定した名前でメソッド内で変数を使えます。index.rbdef age_sister(age) puts "my sister is #{age} years old." return age ##putsメソッドは返り値としてnilを返してしまうのでreturn文で変数の値を返り値として返している end sister = 25 ##age_sisterメソッドのスコープ外に変数sisterが定義されている。 age_sister_and_me(sister) ##age_sisterメソッドを呼び出す部分で本引数に変数sisterを取っている。
return文はそこで返り値が確定するのでそこで処理が終了する。
定義されたメソッドの返り値は最後に記述された式の値が返ります。index.rbdef animal_name(name) puts "この動物は#{name}です。" return "僕は#{name}!" end puts animal_name("犬")上記のような場合、animal_nameメソッドでreturn文が使われているので返り値として"僕は犬!"が返ります。
putsメソッドで 僕は犬! が出力されています。
メソッドの呼び出し側で定義された("犬”)はメソッド内で変数として使うことができます。今回で言うと変数nameとして使えるようになっています。引数は関数を呼び出す際にどんなことを出力させるか決めるために利用される。
メソッドは引数を渡すと何かを返してくれる。
メソッドが引数を受け取るときその名前は何でも良い。
メソッドの最後で、メソッドの呼び出し元に値を返すときはreturnを使います。eachメソッド
eachメソッドとは繰り返しのためのメソッドです。
配列オブジェクトにeachメソッドを使うと、その配列の要素の数だけ繰り返し処理が行われます。
- 投稿日:2020-05-17T13:39:20+09:00
【開発ログ⑫】有休未消化のアラートを実装
前提について
はじめまして、 プログラミングスクールに通ういりふねと申します。この記事は、スクールの課題である個人アプリの開発の記録を書くことで、自身のアウトプットに利用しています。もし、読んでいただけた方がいましたら、フィードバックをしていただけたら嬉しいです。
開発するのは「有給休暇管理ツール」です。仕様は過去記事をどうぞ。
アプリはデプロイまで行いますが、サービスとして提供するものではありません。あくまでも自学習の一環ですので、ご理解下さい。では本題へどうぞ。
今回実施する内容
前回までで、有休に関する簡単な計算までが終了しましたので、今回は有給休暇の未消化アラートを実装したいと思っています。以下の手順で実施します。今回は軽め。
- 未消化アラートとは?
- 未消化アラートの実装
- ビューに表示
未消化アラートとは?
働き方改革法案により、2019年4月1日より有給休暇を消化させることが、義務化されました。条件は有休を10日以上持つ社員に対して、毎年5日以上は時期を指定して計画的に消化させるというものです。毎年の期間については、就業規則により変わると考えられますが、今回は「直近付与日から次回付与日までの間」に5日未満しか消化していない社員については、有給休暇管理表のアラートカラムに「未消化」を表示させることにします。
未消化アラートの実装
今回も、モデルファイルに未消化アラートを表示させるメソッドを記述しておきます。
employee.rbclass Employee < ApplicationRecord 〜中略〜 def delete_days_alert a = total_delete_day b = total_add_day if b >= 10 && a < 5 "未消化" else "-" end end endIF文の前のメソッド、total_delete_dayとtotal_add_dayは、前回の記事で定義済みです。これは、直近の付与日から現在までの日数を計算するメソッドになります。
そして、IF文の条件は、b(付与日数の合計)が10以上、かつ、a(消化日数の合計)が5未満のとき、ということになります。有休の付与日数が10日未満の方やすでに今年5日以上消化している方は対象外となります。
ビューに表示
branches/index.html.haml.main =render 'branches/mainheader' 〜中略〜 %th{id: "short", class: "bgc"} 5日消化 〜中略〜 - @employees.each do |employee| %tr 〜中略〜 %th{id: "short", class: "bgc"} = employee.delete_days_alert 〜中略〜結果は、以下のとおりです。
未消化アラートは、目立ったほうが良いと思ったので、5日消化カラムには、class名bgcを追加し、黄色の背景色を設定しました。今日の積み上げ
本来であれば、「未消化」と表示されている方だけに黄色を表示させたかったのですが、私の能力では調べても実装できませんでした。一応、hamlでclassを定義する際にIF文で条件を定義し、条件に合う時、classを追加するという方法があるようです。まだまだ未熟であると感じましたが、できる限りで頑張りたいと思います。
参考にさせていただいた記事
「【Haml】条件(if)に応じてClassを変更させる方法」@nishina555様
「Hamlで条件に合わせてclassを追加する方法」@day-1様
「Hamlで条件に合う時だけ特定のクラスを加えたい」@aprikip様
- 投稿日:2020-05-17T13:25:31+09:00
【Rails 】画像必須のテストデータの作成方法
Rails5.2を用いてアプリケーションを開発中です。
プロフィール画像の設定が必須であるユーザーのテストデータを
作成した際に行ったことを記載します。行ったこと
プロフィール画像をテストデータに入れる必要があり、
どのフォルダにテストデータ用の画像をいれればいいのか・・と一瞬悩みましたが
行うことはシンプルでした。①dbフォルダの中に、fixturesというフォルダを新規作成
②fixturesというフォルダの中に、テストデータとして登録したい画像を入れる
③db/seeds.rb内に以下を記載。
seeds.rb(1..20).each do |n| Company.create!( email: "email#{n}@example.com", name: "#{n}名前", profile_photo: open("#{Rails.root}/db/fixtures/test.JPG"), profile:"#{n}test", password_digest:"#{n}test", industry:"#{n}test", occupation:"#{n}test", corporation_name:"#{n}test" ) end *Companyモデルのデータを作成したかったので、この部分は任意で変更ください。 *(1..20)で20個のデータを作成するよう指定。 *profile_photoの部分で先ほど用意した画像のパスを指定しています。④ターミナルでrails db:seedを実行
以上でテストデータが作成できているかと思われます。
- 投稿日:2020-05-17T12:49:48+09:00
【開発ログ⑪】有休付与日から現在までの消化日数の合計を計算〜残日数まで
前提について
はじめまして、 プログラミングスクールに通ういりふねと申します。この記事は、スクールの課題である個人アプリの開発の記録を書くことで、自身のアウトプットに利用しています。もし、読んでいただけた方がいましたら、フィードバックをしていただけたら嬉しいです。
開発するのは「有給休暇管理ツール」です。仕様は過去記事をどうぞ。
アプリはデプロイまで行いますが、サービスとして提供するものではありません。あくまでも自学習の一環ですので、ご理解下さい。では本題へどうぞ。
今回の実施内容
前回までで、従業員の入社日をもとに付与日(入社日から6ヶ月後の有休が付与される日)と勤続年数まで計算できました。今日は、消化日数の合計を計算させます。具体的には以下の手順で考えます。
- 消化日数の合計とは?
- 今回扱う消化日数の合計は?
- 合計する対象範囲を検索
- 検索結果を合計させる
- 合計した結果をビューに表示
- ローカルブラウザで確認できればOK
消化日数の合計とは?
まず毎年もらえる有給休暇は、付与されてから2年間有効となります。消化する場合は、古いものから順に消化されるのもポイントです。
例えば、2018年4月1日に入社した方が、有休のうち3日間を2回に分けて消化した場合、以下のような流れになります。
日付 有休の増減 残日数 2018/4/1 入社時は増減なし 0日 2018/10/1 有休10日付与 10日 2019/1/1 有休3日消化★ 7日 2019/10/1 有休11日付与 18日 2020/1/1 有休3日消化★ 15日 2020/5/17 有休の残日数を確認 15日 2020/10/1 有休4日は未使用のまま消滅、有休12日付与 23日 つまり、現在2020/5/17日時点の有休消化日の合計は、以下の2つをレコードをテーブルから検索し、合計すればよいということになります。
- 直近付与日から現在までの合計(2019/10/01~2020/5/17)
- 2つ前の付与日から直近付与日までの合計(2018/10/1~2019/10/1)
ただし、この計算式で行く場合は、別途2020/10/01に未消化のまま消滅する有休も計算させる必要があります。
今回扱う消化日数の合計は?
今回、最終的にアプリケーションでで実装したい日数計算は、以下の通りになります。
① 過去2年間の付与日数の合計
② 直近付与日から現在までの消化日数合計
③ 2つ前の付与日から直近付与日までの消化日数合計
④ ①から②と③を引いた残日数長々書きましたが、私自身の備忘録として書かせていただきました。よって、今後考え方が変わるかも知れません。あくまで記事作成時点のいりふねの脳内の出来事とお考え下さい。
で、今回実装したのは、「②直近付与日から現在までの消化日数合計」なので、これの紹介を以下より行います。合計する対象範囲を検索
前回までは、社員のレコードのみで表を作成していましたが、今回から有給休暇のレコードも計算に入ってきます。社員はemployeeテーブル、有給休暇はholidayテーブルにそれぞれ格納されているので、コントローラーから編集します。
employees_controller.rbclass EmployeesController < ApplicationController def index @employees = Employee.where(branch_id: params[:branch_id]).includes(:holidays) end 〜中略〜 end後半にincludesメソッドでemployee_idをもつholidayのレコードも一緒に取得しています。includesメソッドはカリキュラムで「N+1問題」を学んだときに登場しました。その際は、1対多関係のテーブルのうち、外部キーを持つ多のレコードを取得する際に、主キーを持つレコードを先読みするために使用すると学びました。今回は主キーをもつレコードに紐付く外部キーのレコードを取得しているので、順番が逆になっていますが、無事使えました。
参考にした記事「Railsで1対多のテーブルデータを取得し表示させる」@bitarx様
次にモデルファイルで、「直近付与日から現在まで」検索を行わせるメソッドを定義します。
models/employee.rbclass Employee < ApplicationRecord 〜中略〜 def range_to_add_or_delete grant_day = hire_date >> 6 month = grant_day.month day = grant_day.mday year = Date.today.year grant_date_this_year = Time.local(year, month, day) if grant_date_this_year > Date.today last_year = year - 1 grant_date_this_year = Time.local(last_year, month, day) else grant_date_this_year end holidays.where(created_at: grant_date_this_year..Date.tomorrow) endまず、冒頭のgrant_dayは、法定付与日(入社日から6ヵ月後)を計算しています。これに「.month」や「.mday」のメソッドを使用して、月と日の数字を取り出して変数に格納しています。年については、「Date.today」で今日の日付を用意し、それに「.year」メソッドを実行することで年の数字を取り出しています。最後に「Time.local」で3つの数字を合体させ、一旦直近付与日(grant_date_this_year)を完成させます。
参考にさせていただいた記事「[Ruby入門] 14. 日付と時刻を扱う(全パターン網羅)」@prgseek様
続けて、IF文の箇所ですが、条件に応じて年を加工して、最終的な直近付与日を確定させています。条件は、先程作った直近付与日(grant_date_this_year)が現在の日付より大きいかというものです。これを行う理由は、法定付与日が12月の方などは、直近法定付与日の結果が2020年12月1日と未来の日付になってしまうからです。そこで、一旦完成させた直近付与日が、現在の日付よりも大きくなっている場合は、年からマイナス1を実行して、「last_year」という新しい変数で、直近付与日を作り直しています。else以降は、必要かどうかが、現段階で判断できません。すみません。
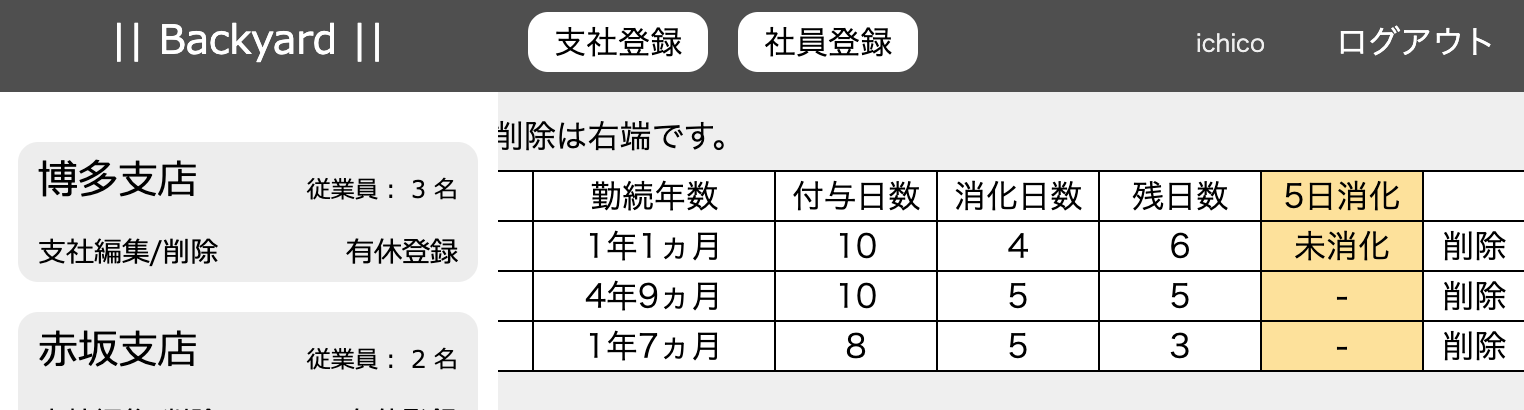
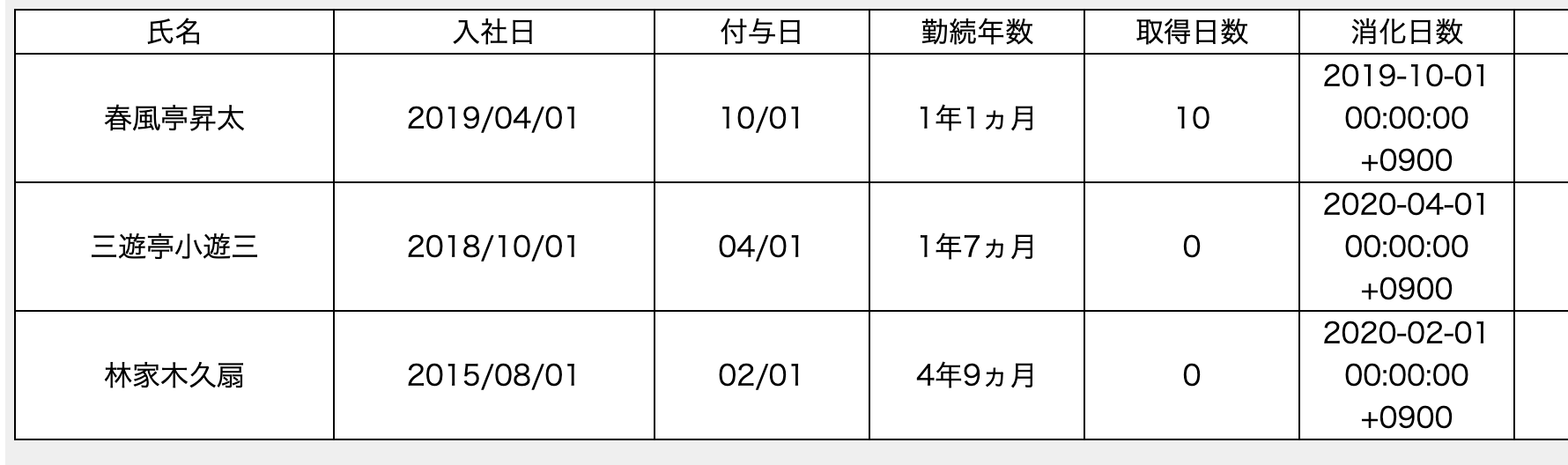
途中結果のビューですが、消化日数のカラムに各社員の直近付与日が表示されました。4月入社の昇太師匠も未来の日付にならずに済んでいます。良かった〜!!
コードの解説に戻ります。
最後の1文で完成した直近付与日から現在までの範囲のcreated_atを検索し、必要なレコードを検索させます。参考にさせていただいた記事「ActiveRecordで日付・時刻の範囲検索をシンプルに書く方法」@hachi8833様
検索結果を合計させる
指定の範囲で検索できたので、これを元に合計を出していきます。モデルファイルに合計を計算させるメソッドを別で書きます。
なお、今回は開発途中ということで付与日の合計日数も同じ方式で計算することにしました。前述した通り付与日の合計の算出方法は別にありますが、付与日の合計には他に実装しなければならないメソッドがあるので、今回はビュー確認用で一旦同じにしておきます。models/employee.rbclass Employee < ApplicationRecord 〜中略〜 def total_delete_day total_delete_day = range_to_add_or_delete.sum(:delete_day) end def total_add_day total_add_day = range_to_add_or_delete.sum(:add_day) end def calculate_remaining_days a = total_delete_day b = total_add_day b - a end end「.sum」メソッドの引数は、合計を出したいカラム名になります。
参考にさせていただいた記事「【Rails】カラムの合計値を求める!」@tomokichi_ruby様ついでにcalculate_remaining_daysを定義し、残日数を計算させています。本来であれば、付与日の合計と消化日の合計を引いた結果が、マイナスであればエラーが出るように条件分岐させるべきですが、同じくビュー確認用でシンプルに引き算だけさせます。
合計した結果をビューに表示
branches/index.html.haml.main =render 'branches/mainheader' .main__body 社員データの編集は「名前」をクリック、削除は右端です。 %table %tr ~中略~ %th{id: "short"} 付与日数 %th{id: "short"} 消化日数 %th{id: "short"} 残日数 - @employees.each do |employee| %tr 〜中略〜 %th{id: "short"} = employee.total_add_day %th{id: "short"} = employee.total_delete_day %th{id: "short"} = employee.calculate_remaining_days 〜中略〜先程、定義したメソッドを「index.html.haml」に反映させました。ビューの結果は以下のとおりです。無事に計算させることができました。
今日の積み上げ
だいぶ、Qiitaの記事投稿に慣れてきました。内容の割に文章が多いと感じますが、自分が調べたことや躓いたこと、同じ初学者の助けになればと思えば、解説がバカ丁寧になるものなのかな?と思うようにしています。とはいえ、参考にさせていただいた記事のように簡潔に書いて初学者の参考になる記事も多いので、簡潔さを意識したいです。以上。

- 投稿日:2020-05-17T12:35:17+09:00
【rails】RSpecを用いた統合テスト
フューチャスペックを利用して、ブラウザ上の操作を再現し、期待する動作が行われることを確認する統合テストを行う。
フューチャスペック
RSpecを使って統合テストを行うためのスペック。
テスト環境の仮装ブラウザを操作し、ボタンを押したときの挙動をテストできる。gem
Capybaraを導入し、フィーチャスペックを書く。capybara
ブラウザの操作を再現するのに必要なgem。
特定の要素をクリックした利、フォームから値を入力したり、表示状態を確認したりできる。準備
capybaraを導入する
Gemfilegroup :test, :development do gem 'capybara' endterminalbundle installspec/rails_helper.rbrequire 'capybara/rspec' #追記テスト対象のビューにIDを付加
app/views/tweets/_form.html.erb<%= form.text_field :image, placeholder: "Image Url", id: "image" %> <%= form.text_area :text, placeholder: "text" , rows: "10", id: "text" %> <%= form.submit "SEND" %>フォルダ
spec/featuresを作成する。
ファイルspec/features/tweet_spec.rbを作成する。テストコード
を書く。
spec/features/tweet_spec.rbrequire 'rails_helper' feature 'tweet', type: :feature do let(:user) { create(:user) } scenario 'ユーザー情報が更新されていること' do #ログイン前には投稿ボタンがない visit root_path # 投稿ボタンがないことを確認 expect(page).to have_no_content('投稿する') # ログイン処理 # ログインフォームのあるページに移動する visit new_user_session_path # emailを入力する fill_in 'user_email', with: user.email # パスワードを入力する fill_in 'user_password', with: user.password # ログインボタンをおす find('input[name="commit"]').click expect(current_path).to eq root_path expect(page).to have_content('投稿する') # ツイートの投稿 expect { click_link('投稿する') expect(current_path).to eq new_tweet_path fill_in 'image', with: 'https://s.eximg.jp/expub/feed/Papimami/2016/Papimami_83279/Papimami_83279_1.png' fill_in 'text', with: 'フューチャースペックのテスト' find('input[type="submit"]').click }.to change(Tweet, :count).by(1) end endvisitメソッド
引数にURLまたはプレフィックスを指定することで、そのページに移動することができる。
example# "/tweets"に移動する visit("/tweets") # tweet_pathに移動する visit tweet_pathclick_onメソッド
HTML要素をクリックすることができる。
引数にHTML要素のvalue属性を指定する。fill_inメソッド
第一引数にHTMLのIDを、第二引数に with:入力値をとることで、指定したフォームに値が入力される。
find('input[name="commit"]').clickでログインボタンのクリックを再現する。example# <input type="submit" name="commit" value="こんにちは">という要素をクリック click_on("こんにちは") # <a href="/users/new">会員登録する</a>という要素をクリック click_on("会員登録する")フィーチャスペックの特製
・記法が単体テストと異なる
フィーチャスペック 単体テスト scenario it background before feature describe given let ・複数のexpectが同一テスト内に記述される。
1つの動作の結果として、期待する複数のexpectがある場合は、その通り書く。テスト
terminal$ bundle exec rspec spec/features/tweet_spec.rb 2020-05-17 12:00:08 WARN Selenium [DEPRECATION] Selenium::WebDriver::Chrome#driver_path= is deprecated. Use Selenium::WebDriver::Chrome::Service#driver_path= instead. tweet ユーザー情報が更新されていること Finished in 0.43572 seconds (files took 1.54 seconds to load) 1 example, 0 failures期待する通り動作することが確認できた。
- 投稿日:2020-05-17T10:56:15+09:00
【Rails Tutorial 機能拡張】REST API を追加してみた
こんにちは。業務でRuby / Rails によるバックエンドエンジニアをしています。
業務経歴が半年立ったので、改めて幅広くRailsについて知りたいと思いRails Tutorial を完遂しました。最後の「14.4.1 サンプルアプリケーションの機能を拡張する」の項のREST API機能の実装に取り組んでみたので、コードを掲載します。
誤っている点や改善点などあれば教えていただけると幸いです。
環境
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.4 BuildVersion: 19E287 $ ruby -v ruby 2.6.5 $ rails -v Rails 6.0.0前提
Usersリソースのみに機能を追加しました。
すなわち、indexアクション、showアクション、createアクション、updateアクションについての実装をしました。アプリケーションコード
respond_toメソッドを使って要求されたHTMLとJSONのフォーマットごとにレスポンスを返せるようにしました。app/controllers/users_controller.rbclass UsersController < ApplicationController before_action :logged_in_user, only: %i[index edit update following followers] before_action :correct_user, only: %i[edit update] before_action :admin_user, only: :destory def index @users = User.where(activated: true).paginate(page: params[:page]) respond_to do |format| format.html format.json { render json: @users, status: 200 } end end def show @user = User.find(params[:id]) redirect_to(root_url) && return unless @user.activated? @microposts = @user.microposts.paginate(page: params[:page]) respond_to do |format| format.html format.json { render json: @user, status: 200 } end end def new @user = User.new end def create @user = User.new(user_params) if @user.save respond_to do |format| format.html do @user.send_activation_email flash[:info] = 'Please check your email to activate your account.' redirect_to root_url end format.json { render json: @user, status: 200 } end else respond_to do |format| format.html { render 'new' } format.json { render json: @user.errors, status: 400 } end end end def edit @user = User.find(params[:id]) end def update @user = User.find(params[:id]) if @user.update(user_params) respond_to do |format| format.html do flash[:success] = 'Profile updates' redirect_to @user end format.json { render json: @user, status: 200 } end else respond_to do |format| format.html { render 'edit' } format.json { render json: @user.errors, status: 400 } end end end def destroy @user = User.find(params[:id]) @user.destroy flash[:success] = 'User deleted' redirect_to users_url end def following @title = 'Following' @user = User.find(params[:id]) @users = @user.following.paginate(page: params[:page]) render 'show_follow' end def followers @title = 'Following' @user = User.find(params[:id]) @users = @user.followers.paginate(page: params[:page]) render 'show_follow' end private def user_params params.require(:user).permit(:name, :email, :password, :password_confirmation) end def correct_user redirect_to root_url unless correct_user?(User.find(params[:id])) end def admin_user redirect_to(root_url) unless current_user.admin? end endテストコード
テスト項目は主に下記としました。
- HTTPステータスコード
- レスポンスの内容
test/integration/users_api_test.rbrequire 'test_helper' class UsersApiTest < ActionDispatch::IntegrationTest def setup @user = users(:michael) end test 'GET /users' do log_in_as(@user) get users_path, as: :json assert_response 200 user_response = JSON.parse(response.body) assert 30, user_response.count end test 'GET /users/:id' do log_in_as(@user) get user_path(@user), as: :json assert_response 200 user_response = JSON.parse(response.body) assert @user.name, user_response['name'] assert @user.email, user_response['email'] end test 'POST /users' do # 新規ユーザー作成失敗 assert_no_difference 'User.count' do post users_path, params: { user: { name: '', email: '' } }, as: :json end assert_response 400 error_response = JSON.parse(response.body) assert_includes error_response['name'], "can't be blank" assert_includes error_response['email'], "can't be blank" # 新規ユーザー作成成功 assert_difference 'User.count', 1 do post users_path, params: { user: { name: 'New User', email: 'new_user@example.com', password: 'password', password_confirmation: 'password' } }, as: :json end assert_response 200 user_response = JSON.parse(response.body) assert_equal 'New User', user_response['name'] assert_equal 'new_user@example.com', user_response['email'] end test 'PUT /users/:id' do log_in_as(@user) # 更新前のユーザー情報の確認 get user_path(@user), as: :json non_updated_user_response = JSON.parse(response.body) assert_not_equal 'Updated User', non_updated_user_response['name'] assert_not_equal 'updated@example.com', non_updated_user_response['email'] # ユーザー情報更新失敗 patch user_path(@user), params: { user: { name: '', email: '' } }, as: :json assert_response 400 error_response = JSON.parse(response.body) assert_includes error_response['name'], "can't be blank" assert_includes error_response['email'], "can't be blank" # ユーザー情報更新成功 patch user_path(@user), params: { user: { name: 'Updated User', email: 'updated@example.com' } }, as: :json assert_response 200 updated_user_response = JSON.parse(response.body) assert_equal 'Updated User', updated_user_response['name'] assert_equal 'updated@example.com', updated_user_response['email'] end end最後に
REST APIの項には、
セキュリティには十分注意してください。認可されたユーザーにのみAPIアクセスを許可する必要があります。
との記載がありましたが、この認可の機能についてはブラウザでログインしたユーザーのみを認可するというやり方をとりました。
とはいえ、APIとしてブラウザ外から利用されることを前提に考えるとこの方法では良くなかったような気がしています。
こうしたAPIの認可はリクエストのクエリパラメーターにuser_idやトークンをついかして、あらかじめ発行したトークンを持つユーザーに各アクションを許可するようなやり方があるようですね。
上記のようなブラウザ外から利用されることを前提にした認可機能についても今後実装してみたいなと思っています。
- 投稿日:2020-05-17T10:27:01+09:00
railsでDM機能を作成する
やあ!こんにちは竹内と申しますぞ✋
action_cableを使ってrailsでDM作成するの難しいですよね。私はちんぷんかんぷんでした?
今回の記事では違う方法でDMを作っていくよ!実務経験ないまんなので誤りがあるかもしれないからコメントくれると嬉しいです?完成目標
ユーザー2人が会話できるチャットルーム(DM)を作成する
実装する
解説は後ほど行うので、コードをコピペしてまずは作ってしまいましょう!
まずは適当なプロジェクトを作成する$ rails new dm_app次に各テーブルを作成していく。
DM機能を実装するためには以下のモデルが必要になる。
Userモデル → ユーザーを管理する
Entrieモデル → どのユーザーがどのルームに属しているかを管理する
Roomモデル → チャットルームに2人のユーザーが入っているかを管理する
Messageモデル → ユーザーがルームに送信するメッセージを管理するまずはdeviseを用いてUserモデルを作成する
Gemfileに以下を追加し、bundle installしてdeviseを導入する。
gem 'devise'$ rails g devise:install deviseに対応したコントローラの作成 $ rails g devise:controllers users Usersモデルを作成 $ rails g devise user deviseに対応したビューの作成 $ rails g devise:views 忘れずにいつものやつ〜 $ rails db:create $ rails db:migrateコントローラーを作成する
$ rails g controller users index show $ rails g controller rooms show $ rails g controller messagesモデルを作成する
Userはdeviseで作成したので残りのRoom, Entry, Messageを作成する
$ rails g model room $ rails g model entry user:references room:references $ rails g model message user:references room:references body:text $ rails db:migrateアソシエーション(関連付け)
models/user.rbclass User < ApplicationRecord # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable, :trackable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :trackable, :validatable has_many :messages, dependent: :destroy has_many :entries, dependent: :destroy endmodels/entry.rbclass Room < ApplicationRecord belongs_to :user belongs_to :room endmodels/room.rbclass Room < ApplicationRecord has_many :messages, dependent: :destroy has_many :entries, dependent: :destroy endmodels/message.rbclass Message < ApplicationRecord belongs_to :user belongs_to :room endコントローラーを編集する
users_controller.rbclass UsersController < ApplicationController before_action :authenticate_user! def index @users=User.all end def show @user=User.find(params[:id]) @currentUserEntry=Entry.where(user_id: current_user.id) @userEntry=Entry.where(user_id: @user.id) if @user.id == current_user.id @msg ="他のユーザーとDMしてみよう!" else @currentUserEntry.each do |cu| @userEntry.each do |u| if cu.room_id == u.room_id then @isRoom = true @roomId = cu.room_id end end end if @isRoom != true @room = Room.new @entry = Entry.new end end end endrooms_controller.rbclass RoomsController < ApplicationController before_action :authenticate_user! def create @room = Room.create Entry.create(room_id: @room.id, user_id: current_user.id) Entry.create(params.require(:entry).permit(:user_id, :room_id).merge(room_id: @room.id)) redirect_to "/rooms/#{@room.id}" end def show @room = Room.find(params[:id]) if Entry.where(user_id: current_user.id, room_id: @room.id).present? @messages = @room.messages.all @message = Message.new @entries = @room.entries else redirect_back(fallback_location: root_path) end end endmessages_controller.rbclass MessagesController < ApplicationController before_action :authenticate_user! def create if Entry.where(user_id: current_user.id, room_id: params[:message][:room_id]).present? @message = Message.new(message_params) if @message.save redirect_to "/rooms/#{@message.room_id}" end else redirect_back(fallback_location: root_path) end end private def message_params params.require(:message).permit(:user_id, :body, :room_id).merge(user_id: current_user.id) end endルーティングを作成する
routes.rbRails.application.routes.draw do devise_for :users root "users#index" resources :users, :only => [:index, :show] resources :messages, :only => [:create] resources :rooms, :only => [:create, :show] # For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html endビューを作成する
users/index.html.erb<h1>DMサンプル</h1> <h2>User一覧ページ</h2> <% if user_signed_in? %> <h2><%= current_user.email %>でログインしています</h2> <%= link_to "SignOut", destroy_user_session_path, :method => :delete, class:"signOutButton" %> <% number = 1%> <div class="flex"> <% @users.each do |u| %> <div class="user-in"> <p>プロフィール No.<%= number %></p> <p><%= u.email %>さん</p> <p><%= link_to 'ユーザーページへ', user_path(u.id) %></p> </div> <% number += 1 %> <% end %> </div> <% else %> <%= link_to "SignUp", new_user_registration_path %> <br> <%= link_to "SignIn", new_user_session_path %> <% end %> <style> .signOutButton{ text-decoration:none; display:inline-block; border:3px solid royalblue; background-color:aliceblue; padding:5px; } .flex{ display:flex; flex-wrap:wrap; } .user-in{ display:block; width:300px; text-align:center; border:1px solid darkgray; background-color:gainsboro; flex-shrink: 0; } </style>users/show.html.erb<h1>ユーザー詳細ページ</h1> <div class="user-in"> <h2><%= @user.email %></h2> <% if @user.id == current_user.id %> <%= @msg %> <% else %> <% if @isRoom == true %> <p><%= link_to 'DMへ', room_path(@roomId) %></p> <% else %> <%= form_for @room do |f| %> <%= fields_for @entry do |e|%> <% e.hidden_field :user_id, value: @user.id %> <% end %> <%= f.submit "DMを開始する"%> <% end %> <% end %> <% end %> </div> <%= link_to "ユーザー一覧に戻る", users_path %> <style> .user-in{ width:300px; padding:10px; margin:10px; text-align:center; border:1px solid darkgray; background-color:gainsboro; } </style>rooms/show.html.erb<div class="user-in"> <% @entries.each do |e| %> <h3><strong><a href="/users/<%= e.user.id %>"><%= e.user.email%></a></strong></h3> <% end %> <p>2人のDM❤️</p> </div> <div class="dmMain"> <% @messages.each do |m| %> <strong><%= m.body %></strong> <small><%= m.user.email %>さん</small><hr> <% end %> <%= form_for @message do |f| %> <%= f.text_field :body, :placeholder => "メッセージを入力して下さい" , :size => 100 %> <%= f.hidden_field :room_id, :value => @room.id %> <br> <%= f.submit "送信する" %> <% end %> </div> <%= link_to "ユーザー一覧に戻る", users_path %> <style> .user-in{ text-align:center; border:1px solid darkgray; background-color:gainsboro; } .dmMain{ padding:30px; border:1px solid darkgray; background-color:gainsboro; } </style>解説
テーブル設計を考える(多対多のアソシエーション)
DM機能を作るためにどんなテーブルが必要でしょうか?
UsersテーブルとRoomsテーブルを用意すればDM機能が完成するのではと考えた人は間違いです。
ユーザーは他のユーザーとDMをするためにルームを作ります。下記の図(汚くてすみません汗)ではuser.id:1がuser.id:2とuser.id:3とuser.id:4と会話するために3つのルームを作っています。つまり1人のユーザーが複数のルームを抱えています。対してルームはというとRoom.id:1にはUser.id:1とUser.id:2の2人のユーザーが入っています。つまりルームも複数(2人)のユーザーを抱えているわけです。この関係を多対多(M:N)の関係と呼びます。
多対多の関係を実現するには中間テーブルを利用します。
多対多ではなぜ中間テーブルを必要とするかはこの記事で理解するようにしてください
今回はUsersテーブルとRoomsテーブルが多対多の関係になっているので中間テーブルEntriesを置き、どのユーザーがどのルームに所属しているかの情報を管理します。またRoomsテーブルでも複数(2人)のユーザーが複数のメッセージを送る多対多の関係であるため同じように中間テーブルMessagesを置き、どのユーザーがどのルームでどんなメッセージを送ったのかを管理します。
上記の表はそれぞれの関係性を図にしたものである。
1人のUserが複数のEntryを持っており、(User has many entries)
Entryは誰か1人のUserに所属している。(Entry belongs to a user)Roomは複数(2人だけのルームなので2つ)のEntryを持っており、(Room has many entries)
Entryはどこか1つのRoomに所属している。(Entry belongs to a Room)1人のUserは複数のMessageをやり取りするので、(User has many messages)
Messageは送信主の1人のUserに所属する。(Message belongs to a User)Roomはそこでやりとりをする複数のMessageを持っており、(Room has many Messages)
Messageは特定(1つだけ)のRoomに所属する(Message belongs to a Room)
モデルを作る際は下記のようになる。(Userはdeviseで!)
$ rails g model room $ rails g model entry user:references room:references $ rails g model message user:references room:references body:textreferences型は外部キーを保存する時に使用します。
今回はentrysとmessagesが中間テーブルになるのでuser_idとroom_idを外部キーとして持つ必要があります。そのため、user:referencesとroom:referencesと入力します。こうすることでmigrateファイルでは下記のように記載してくれます。migrate/_create_entries.rbclass CreateEntries < ActiveRecord::Migration[6.0] def change create_table :entries do |t| t.references :user, null: false, foreign_key: true t.references :room, null: false, foreign_key: true t.timestamps end end endmigrate/_create_messages.rbclass CreateMessages < ActiveRecord::Migration[6.0] def change create_table :messages do |t| t.references :user, null: false, foreign_key: true t.references :room, null: false, foreign_key: true t.text :body t.timestamps end end endアソシエーションを記述する
先ほど図に落としこんだテーブルの関係性を実際にmodelsファイルにアソシエーションの記述をすると下記のようになる。
models/user.rbclass User < ApplicationRecord has_many :messages, dependent: :destroy has_many :entries, dependent: :destroy endmodels/entry.rbclass Room < ApplicationRecord belongs_to :user belongs_to :room endmodels/room.rbclass Room < ApplicationRecord has_many :messages, dependent: :destroy has_many :entries, dependent: :destroy endmodels/message.rbclass Message < ApplicationRecord belongs_to :user belongs_to :room endbelongs_to (モデル名)の後に dependent: :destroyをつけることで親元のデータが消去された時に子のデータも自動で消去されるようになるので付けときましょう!
コントローラーを作成してルーティングを設定する
コントローラーを作成する
①users/indexページでDMをしたいユーザーを探す(ユーザー一覧ページ) →
②users/showページでDMを開始するボタンを押す →
③room/showページでログインしているユーザーとDMボタンを押されたユーザーが会話する(messageのbodyがcreateされる)
このような流れで作りたいので下記のようにコントローラーとページを作成する。$ rails g controller users index show $ rails g controller rooms show $ rails g controller messagesルーティングを作成する
routes.rbRails.application.routes.draw do devise_for :users root "users#index" resources :users, :only => [:index, :show] resources :messages, :only => [:create] resources :rooms, :only => [:create, :show] endresourcesについては https://qiita.com/GeekSalon/private/57a6be49186ef3bce9f3
Usersコントローラー, ビューの設定
users_controller.rbclass UsersController < ApplicationController before_action :authenticate_user! def index @users=User.all end def show @user=User.find(params[:id]) @currentUserEntry=Entry.where(user_id: current_user.id) @userEntry=Entry.where(user_id: @user.id) if @user.id == current_user.id @msg ="他のユーザーとDMしてみよう!" else @currentUserEntry.each do |cu| @userEntry.each do |u| if cu.room_id == u.room_id then @isRoom = true @roomId = cu.room_id end end end if @isRoom != true @room = Room.new @entry = Entry.new end end end end@user=User.find(params[:id]) @currentUserEntry=Entry.where(user_id: current_user.id) @userEntry=Entry.where(user_id: @user.id)上から順番に読み解いていきましょう
まずはユーザーの詳細ページなのでfindメソッドでユーザーの情報を所得しています。
2行目と3行目ではwhereメソッドを使って、中間テーブルEntrysテーブルの中に記録されているcurrent_user(2行目)とfindメソッドで所得した詳細ページのユーザーのuser_idが含まれているレコードを全て所得して、それぞれインスタンス変数currentUserEntryとuserEntryに代入しておきます。
*モデル名.where(カラム名: 条件) とすることで条件に合うレコードを全て取得することができます。次にif文で2パターンの条件分岐をさせています。1つ目はcurrent_userが自分の詳細ページにアクセスした場合(例外)、2つ目がメインとなるcurrent_userが自分以外のユーザーの詳細ページにアクセスした場合です。自分で自分のユーザー詳細ページにアクセスしたユーザーには「他のユーザーとDMしてみよう」というメッセージを渡してあげましょう?
@currentUserEntry.each do |cu| @userEntry.each do |u| if cu.room_id == u.room_id then @isRoom = true @roomId = cu.room_id end end endここで先ほど用意したインスタンス変数のcurrentUserEntryとuserEntryを使います。2つの変数をeach文を用いて1つずつ取り出し、同じroom_idが発見された場合はcurrentUserEntryとuserEntryの2人が既にDMのルームを作っているということになるので、
@isRoom = true
@roomId = cu.room_id
を実行します。@isRoom = true と記述することでtrueではないとき、すなわちDMのルームが未作成の場合の処理を後に実行するので必要になります。@roomID = cu.room_id ではshowページで <%= link_to 'DMへ', room_path(@roomId) %> このようにDMのルームに行くリンクのパスを設定するために記述しています。そのためcu.room_idではなくu.room_idでも問題ありません?if @isRoom != true @room = Room.new @entry = Entry.new endそしてここでは2人のルームが未作成だった場合の処理を実行しています。
rooms_controller.rbclass RoomsController < ApplicationController before_action :authenticate_user! def create @room = Room.create Entry.create(room_id: @room.id, user_id: current_user.id) Entry.create(params.require(:entry).permit(:user_id, :room_id).merge(room_id: @room.id)) redirect_to "/rooms/#{@room.id}" end def show @room = Room.find(params[:id]) if Entry.where(user_id: current_user.id, room_id: @room.id).present? @messages = @room.messages.all @message = Message.new @entries = @room.entries else redirect_back(fallback_location: root_path) end end endmessages_controller.rbclass MessagesController < ApplicationController before_action :authenticate_user! def create if Entry.where(user_id: current_user.id, room_id: params[:message][:room_id]).present? @message = Message.new(message_params) if @message.save redirect_to "/rooms/#{@message.room_id}" end else redirect_back(fallback_location: root_path) end end private def message_params params.require(:message).permit(:user_id, :body, :room_id).merge(user_id: current_user.id) end endRoomsコントローラー, ビューの設定
Messagesコントローラー, ビューの設定
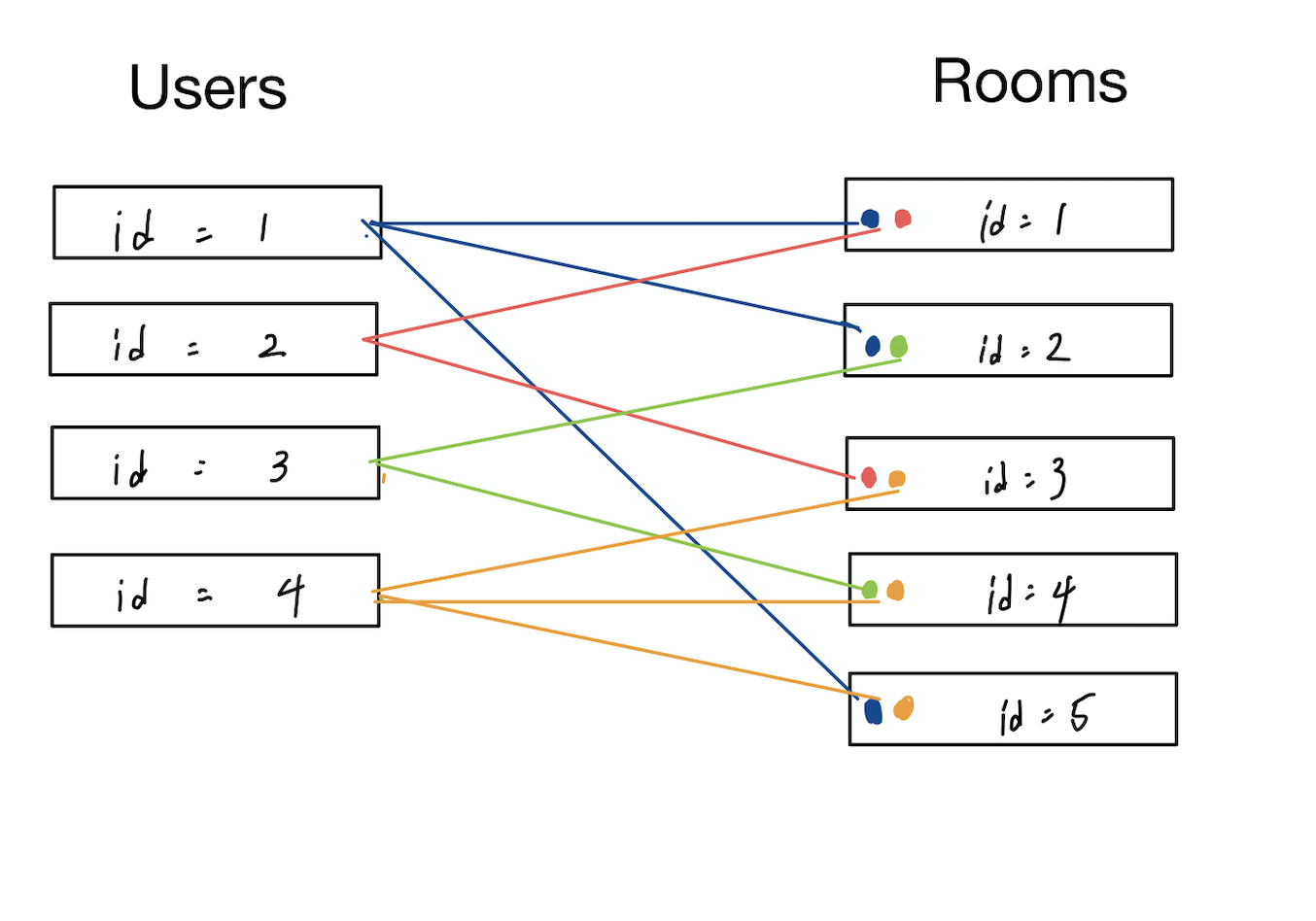
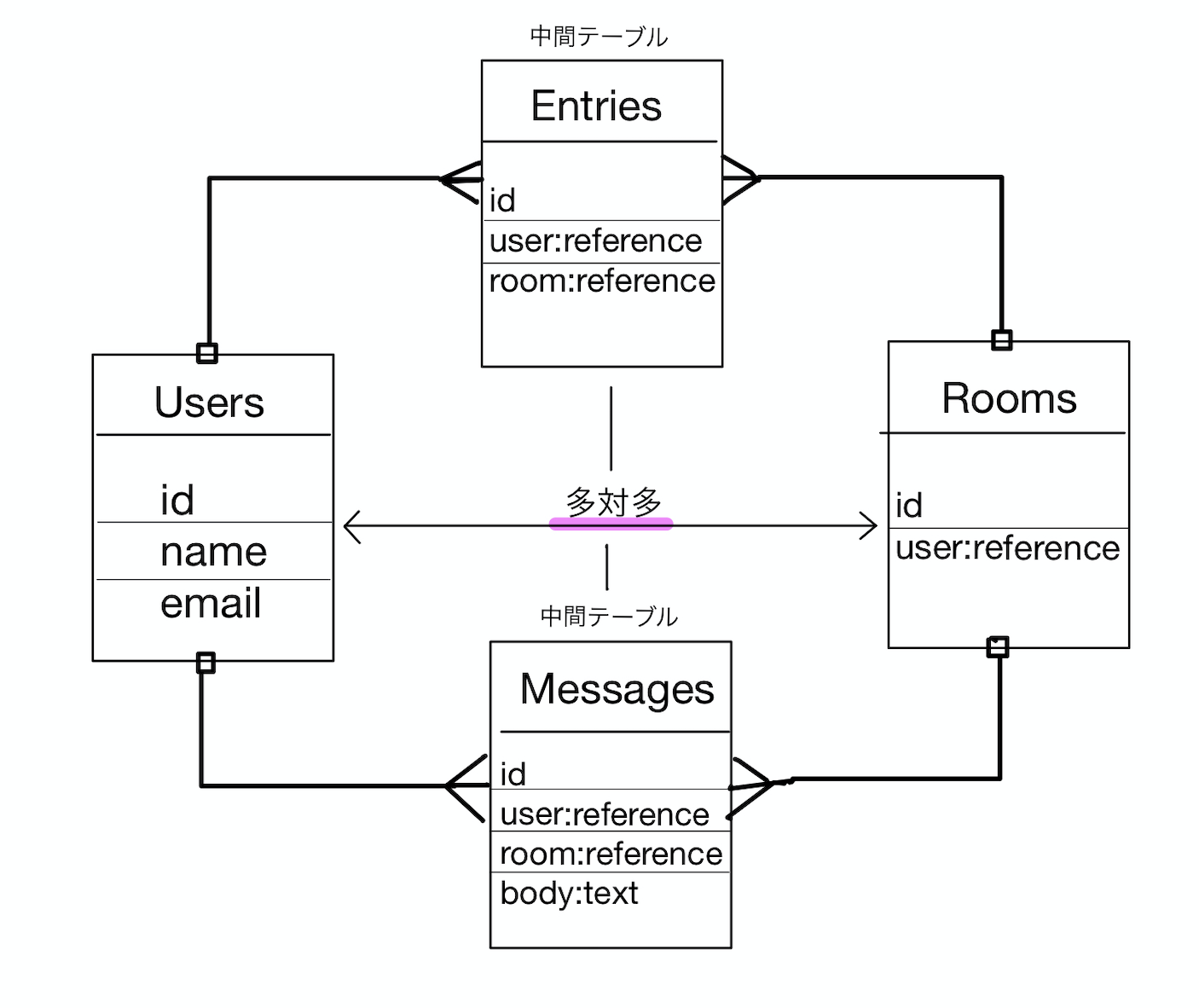
- 投稿日:2020-05-17T10:22:06+09:00
【Rails】deviseの導入 基礎
Railsアプリにて、ユーザー管理機能のためのgemである、
「devise」を導入する基本の手順を
備忘録も兼ねてご紹介。1. Gemfile に devise を追加
最下行に記載。
Gemfilegem 'devise'bundle instrallを実行する。
2. devise を適用させる
ターミナルrails g devise:install3. devise仕様の Userモデルを作成
通常のモデル作成用コマンドとは違って、devise専用のコマンドで、
Userモデルを作成します。ターミナルrails g devise user実行後、ルーティングに「devise_for :users」と追記され、
ログインと新規登録で必要なルーティングが生成されるようです。◉ 続けて実行します。
ターミナルrails db:migrate4. 新規登録・ログインできるようにする
ヘッダー等に「新規登録」「ログイン」できるボタンを作る。
user_signed_in? メソッドにより、未ログイン時はログイン時と違う表示になります。sample.haml.header .header__user-btn - if user_signed_in? = link_to "新規投稿", new_post_path, class: "btn" = link_to "ログアウト", destroy_user_session_path, method: :delete, class: "btn" - else = link_to "ログイン", new_user_session_path, class: "btn" = link_to "新規登録", new_user_registration_path, class: "btn"devise用のビューを作る
実際に登録やログイン情報を入力する画面を表示させます。
rails g devise:viewsここまでで、登録→ログイン→ログアウトまで実装できています。
※メールアドレスは無効な物でも使用できる状態です。
以上で終了です。
ご覧いただきありがとうございました。
- 投稿日:2020-05-17T08:51:01+09:00
VSCode個人的拡張機能(Ruby on Rails開発)
zenkaku
Rainbow End
indent-rainbow
endwise
Code Spell Checker
スペルミスを検出してくれる拡張機能です。
適応されるファイルタイプが以下のタイプのみとなります。defaultでサポートされているfiletypeAsciiDoc C, C++ C# css, less, scss Elixir Go Html Java JavaScript JSON / JSONC LaTex Markdown PHP PowerShell Pug / Jade Python reStructuredText Rust Scala Text TypeScript YAMLしかし、このままだとRubyなどがサポート対象外なので
settings.jsonに以下のように記載する
(WindowsならCtrl+Pでファイル検索できます)settings.json{ . . "上に色々書いてます": false, #以下を挿入します "cSpell": { "enabledLanguageIds": [ "css", "html", "javascript", "json", "less", "markdown", "plaintext", "scss", "text", "ruby", "yaml", "yml" ] #ここまで }(※注意 最終行に挿入する場合(上の例)は上の行の最後尾に ,(カンマ) をつけるのを忘れずに。途中の行に挿入する場合は今回挿入したものの最後尾に ,(カンマ) をつける。)