- 投稿日:2020-05-17T23:48:40+09:00
機械学習モデルを逆解析する
逆解析とは
- 広義には,出力から入力を推定したり,何らかの方程式の解を求めること.
- 狭義には,材料設計や化学などの分野において,欲しい物性を先に定めて,それを実現する素材の条件を求める解析のこと.
一般に,合成元の条件から,合成された物質の物性を求めることを順問題ということから,その逆方向ということで逆問題を解くとか表現することもあります.
この記事の目的
機械学習モデルの逆解析を行うこと.
機械学習によって物性が予測できるようになったなら,そのモデルの出力が所定の値になるような入力値を探索することができるはずです.
しかし,入力次元(説明変数の数)が多いほど探索すべき空間は膨大になり,探索時間や計算機の性能に応じて逆解析ができないケースが発生するはずです.
- そこで,まずは単純なデータに対して予測モデルを作成し,逆解析が可能であることを確認します.
- その後,説明変数の数を増加させながら,逆解析の精度がどのように落ちていくかを調査します.(後日追記予定)
基本設計
複雑なことはせずに,回帰モデルに対して出力が最小になるような入力値を探索することを試みます.
回帰モデルとしては差し当たりランダムフォレストを.
探索アルゴリズムとしてはSMBO(Sequential Model-based Global Optimization)を使用し,そのライブラリとしてhyperoptを使用します.(他にも様々な手法があります).
1. トイモデルに対する逆解析
環境
- Python 3.6.10
- scikit-learn 0.22.0
- hyperopt 0.2.4
設定
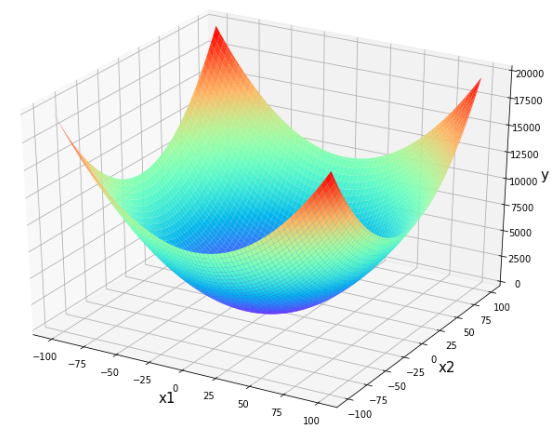
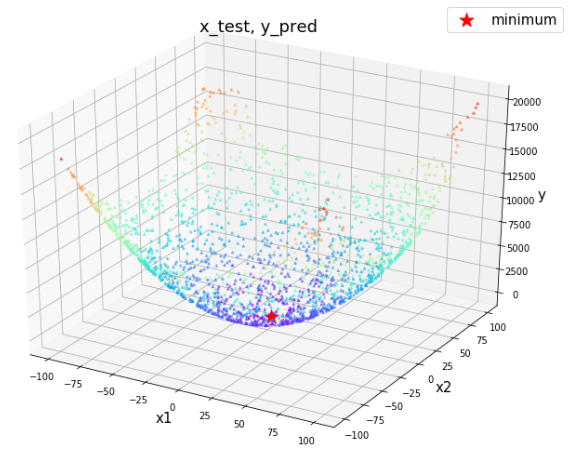
簡単なモデルとして,
y= x_1 {}^2 + x_2 {}^2, \qquad (x_1, x_2) \in \mathbb{R} ^2なる対応を考えます.明らかに最小値は$0$で,これを与える点は$(x_1, x_2) = (0,0)$です.
上のグラフ生成のためのコード
import matplotlib.pyplot as plt import numpy as np from mpl_toolkits.mplot3d import Axes3D def true_function(x, y): """真の関数""" return x ** 2 + y ** 2 X, Y = np.mgrid[-100:100, -100:100] Z = true_function(X, Y) plt.rcParams["font.size"] = 10 # フォントサイズを大きくする fig = plt.figure(figsize = (12, 9)) ax = fig.add_subplot(111, projection="3d", facecolor="w") ax.plot_surface(X, Y, Z, cmap="rainbow", rstride=3, cstride=3) ax.set_xlabel('x1', fontsize=15) ax.set_ylabel('x2', fontsize=15) ax.set_zlabel('y', fontsize=15) plt.show()1.1 トレーニング・テストデータの生成
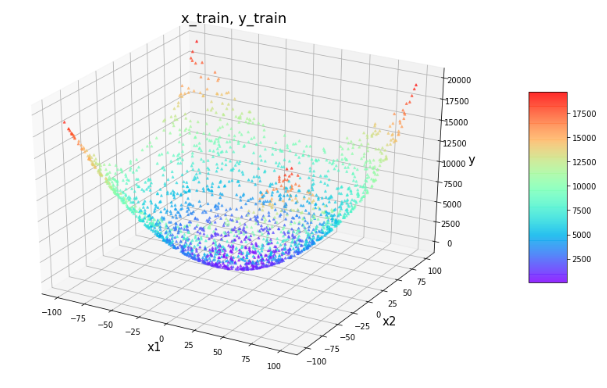
上記の対応に基づき,入出力のサンプル群を生成します.
生成したトレーニングデータを描画します.
上のグラフ生成のためのコード
from sklearn.model_selection import train_test_split def true_model(X): return true_function(X[:,[0]], X[:,[1]]) X = np.random.uniform(low=-100,high=100,size=(3000,2)) Y = true_model(X) test_size = 0.3 # 分割比率 x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=0) fig = plt.figure(figsize = (12, 9)) ax = plt.axes(projection ="3d") sctt = ax.scatter3D(x_train[:,0], x_train[:,1], y_train[:,0], c=y_train[:,0], s=8, alpha = 0.6, cmap = plt.get_cmap('rainbow'), marker ='^') plt.title("x_train, y_train") ax.set_xlabel('x1', fontsize=15) ax.set_ylabel('x2', fontsize=15) ax.set_zlabel('y', fontsize=15) plt.show()1.2 学習・推論
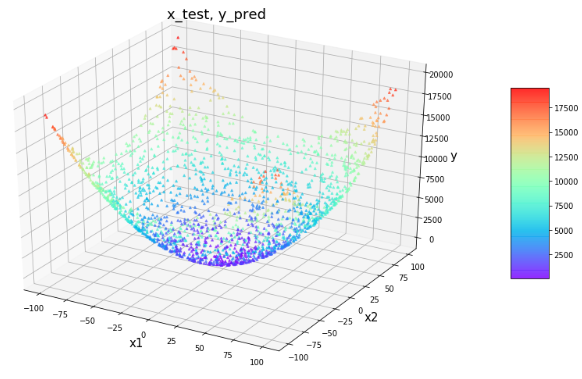
先ほどのトレーニングデータでランダムフォレストを学習させ,テストデータに対して推論させた結果を描画します.
概ね正しい値を推定できているようです.
1.3 回帰モデルに対する最小値の探索
hyperoptによる最小値の探索を試みます.
最小化対象となる関数を定義したのち,最小値を与える点を探索し,得られた点を先ほどの図に重ねて描画します.
上のグラフ生成のためのコード
from hyperopt import hp from hyperopt import fmin from hyperopt import tpe def objective_hyperopt_by_reg(args): """hyperopt用の目的関数""" global reg x, y = args return float(reg.predict([[x,y]])) def hyperopt_exe(): """hyperoptによる最適化の実行""" # 探索空間の設定 space = [ hp.uniform('x', -100, 100), hp.uniform('y', -100, 100) ] # 探索開始 best = fmin(objective_hyperopt_by_reg, space, algo=tpe.suggest, max_evals=500) return best best = hyperopt_exe() print(f"best: {best}") fig = plt.figure(figsize = (12, 9)) ax = plt.axes(projection ="3d") sctt = ax.scatter3D(x_test[:,0], x_test[:,1], y_test[:,0], c=y_test[:,0], s=6, alpha = 0.5, cmap = plt.get_cmap('rainbow'), marker ='^') ax.scatter3D([best["x"]], [best["y"]], [objective_hyperopt_by_reg((best["x"], best["y"]))], c="red", s=250, marker="*", label="minimum") plt.title("x_test, y_pred", fontsize=18) ax.set_xlabel('x1', fontsize=15) ax.set_ylabel('x2', fontsize=15) ax.set_zlabel('y', fontsize=15) plt.legend(fontsize=15) plt.show()output100%|██████████████████████████████████████████████| 500/500 [00:09<00:00, 52.54trial/s, best loss: 27.169204190118908] best: {'x': -0.6924078319870626, 'y': -1.1731945130395605}最小点に近い点が得られました.
まとめと課題
この記事では,回帰モデルの学習 ⇒ 逆解析 の手続きを単純なデータに対して実行しました.
今回は入力次元が小さかったため,偶然にもうまく最小値を探索できましたが,実際のデータに適用にするには様々な課題が生じると予想されます.
- データが少なすぎて学習が足りない.
- 不適切な回帰モデルを選択してしまったために現実にはあり得ない解を導いてしまう.
- 説明変数の次元が高すぎてうまく探索できない・あるいは極所解にトラップされる.
- データの分布に偏りがあり,疎な領域における学習が不十分.
- 過大なノイズを学習してしまう.
また,逆問題は適切に扱わないと極めてナンセンスな解析をしてしまう恐れがあると予想されます.
- そもそも解が存在しない
- 解が唯一ではない
- 真の分布が不連続であり,解が安定でない
このような問題があるにもかかわらず逆問題を設定してしまったが故に,無駄な労力を費やすことは絶対に避けたいところです.
参考

- 投稿日:2020-05-17T23:22:17+09:00
時系列分析やってみた!(ARモデル)
概要
時系列分析のライブラリを実際に使ってみました。
(statsmodels.api.tsa)
本記事は、筆者が時系列分析の理論を勉強してて、
理解を定着させるために書いた自己満の記事です。分析概要
下記の(定常性を持つ)ARモデルでデータを作成し、
それをstatsmodelsライブラリ「ARMA」でパラメータ推定を行いました。
また、定常性を持つかをADF検定で行ってみました。
- 作成データ:下記モデルAR(1)で日単位のデータを作成(2018/1/1〜2019/12/31)
$y_{t}=2+0.8y_{t-1}$- 学習モデル:定数項ありAR(1) ※ARMA(1,0)
- 学習方法:最尤推定
前提
ARモデル(自己回帰モデル Auto-Regression)
下記のように、時点tの値が過去直近時点(t-1)〜(t-p)の値の線型結合で表されるモデル。
$u_{t}$は誤差項であり、ホワイトノイズ(平均0の正規分布)。
(t-p)までで表される場合、AR(p)モデルと表記する。
今回はAR(1)モデルでデータを作成し、AR(1)モデルでパラメータ推定を行う。
$y_{t}=c+a_{1}y_{t-1}+a_{2}y_{t-2}+\ldots +a_{p}y_{t-p}+u_{t}$定常性
「全時点において、平均が一定で、k時点前との共分散がkにのみ依存する」場合、
その時系列は「定常性を持つ」という。
今回の分析対象であるAR(1)モデルの場合、
定常性を持つ条件は下記の通りである。
「$y_{t}のモデル式における、y_{t-1}$の係数$a_{1}$ が $|a_{1}| < 1$を満たす。」DF検定
単位根検定と呼ばれる検定の一つ。
対象の時系列をAR(1)と仮定し、
(帰無仮説を「単位根である」とし)
対立仮説を「定常性である」として行う検定。
検定量は標準正規分布。ADF検定(拡張DF検定)
DF検定がAR(1)のみであるのに対し、
それを拡張させ、AR(p)でも適用できるようにした検定。
DF検定と同様に、
対立仮説は「定常である」であり、
検定量は標準正規分布。分析詳細(コード)
1. ライブラリインポート
import os import pandas as pd import random import matplotlib.pyplot as plt import seaborn as sns from IPython.display import display import statsmodels.api as sm2. データ作成
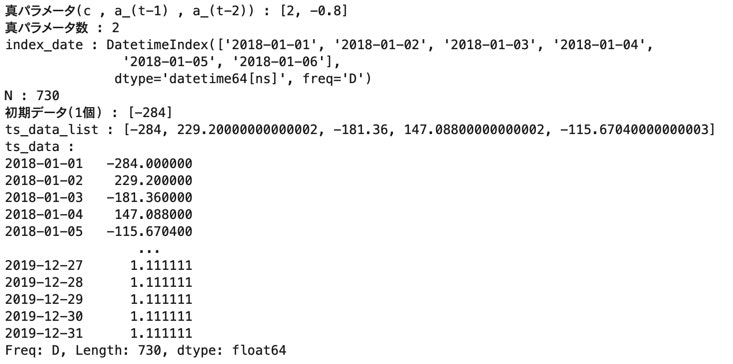
データ;ts_data
# 真パラメータ (定常にするため全て1未満) params_list = [2 , -0.8] params_num = len(params_list) print("真パラメータ(c , a_(t-1) , a_(t-2))" , ":" , params_list) print("真パラメータ数" , ":" , params_num) #時系列データ作成 index_date = pd.date_range('2018-01-01' , '2019-12-31' , freq='D') N = len(index_date) init_y_num = params_num - 1 init_y_list = [random.randint(-1000 , 1000) for _ in range(init_y_num)] print("index_date" , ":" , index_date[:6]) print("N" , ":" , N) print("初期データ({}個)".format(init_y_num) , ":" , init_y_list) ts_data_list = list() for i in range(N): if i < init_y_num: ts_data_list.append(init_y_list[i]) else: y = params_list[0] + sum([params_list[j+1] * ts_data_list[i-(j+1)] for j in range(params_num - 1)]) ts_data_list.append(y) print("ts_data_list" , ":" , ts_data_list[:5]) ts_data = pd.Series(ts_data_list , index=index_date) print("ts_data" , ":") print(ts_data)
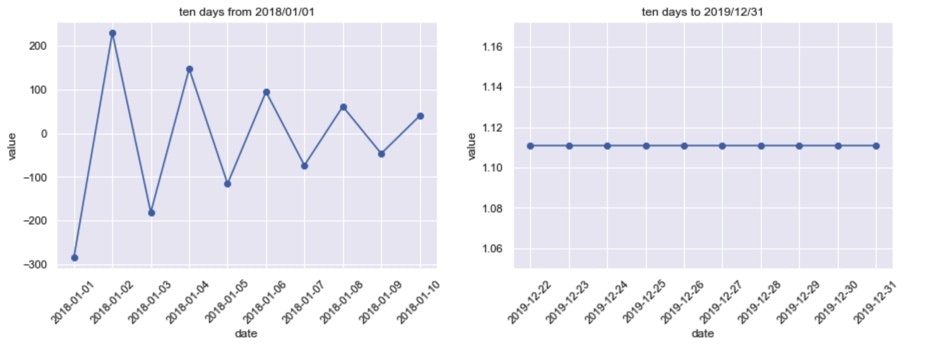
3. グラフ化(折れ線)_データ確認
# グラフ作成 fig = plt.figure(figsize=(15 ,10)) data = ts_data[:10] ax_1 = fig.add_subplot(221) ax_1.plot(data.index , data , marker="o") plt.title("ten days from 2018/01/01") plt.xlabel("date") plt.ylabel("value") plt.xticks(rotation=45) data = ts_data[-10:] ax_2 = fig.add_subplot(222) ax_2.plot(data.index , data , marker="o") plt.title("ten days to 2019/12/31") plt.xlabel("date") plt.ylabel("value") plt.xticks(rotation=45) plt.show()
4. ARモデル学習
下記3種のデータでモデル学習し、結果を確認。
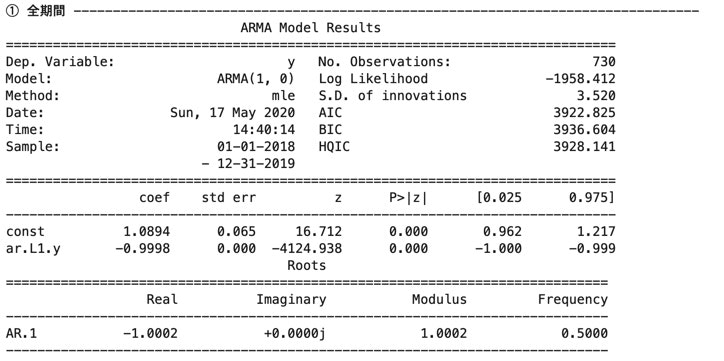
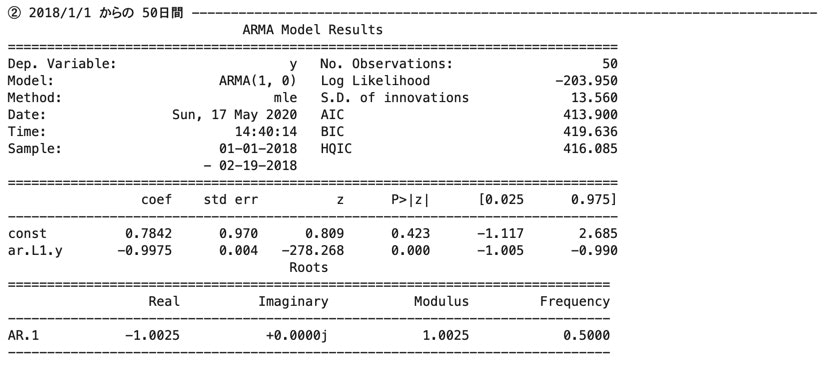
① 全期間(2018/1/1 ~ 2019/12/31)
② 2018/1/1 からの 50日間
③ 2019/12/31 までの 50日間# AR学習結果_学習データ① (全期間) print("① 全期間" , "-" * 80) data = ts_data arma_result = sm.tsa.ARMA(data , order=(1 , 0)).fit(trend='c' , method='mle') print(arma_result.summary()) print() # AR学習結果_学習データ② (2018/1/1 からの 50日間) print("② 2018/1/1 からの 50日間" , "-" * 80) data = ts_data[:50] arma_result = sm.tsa.ARMA(data , order=(1 , 0)).fit(trend='c' , method='mle') print(arma_result.summary()) print() # AR学習結果_学習データ③ (2019/12/31 までの 50日間) print("③ 2019/12/31 までの 50日間" , "-" * 80) data = ts_data[-50:] arma_result = sm.tsa.ARMA(data , order=(1 , 0)).fit(trend='c' , method='mle') print(arma_result.summary()) print()
…
①と②について係数(coef)を比較すると、
定数項(const)と$y_{t-1}$の係数(ar.L1.y)共に、
①の方が真のモデルに近い。
③に関してはログにて「対象時系列は定常性を持たない。定常性の時系列を入力すべき。」と出力された。①〜③の結果より、
始めの時点の方が後の時点に比べ、上手くモデルにフィット出来ている形になった。
何故だろう?5. ADF検定
4.と同様のデータ①〜③について、ADF検定を行う。
P値を確認し、どれ程の有意水準で帰無仮説を棄却する形になるか確認。
※対立仮説:対象時系列は定常性を持つ。# AR学習結果_学習データ① (全期間) print("① 全期間" , "-" * 80) data = ts_data result = sm.tsa.stattools.adfuller(data) print('value = {:.4f}'.format(result[0])) print('p-value = {:.4}'.format(result[1])) print() # AR学習結果_学習データ② (2018/1/1 からの 50日間) print("② 2018/1/1 からの 50日間" , "-" * 80) data = ts_data[:50] result = sm.tsa.stattools.adfuller(data) print('value = {:.4f}'.format(result[0])) print('p-value = {:.4}'.format(result[1])) print() # AR学習結果_学習データ③ (2019/12/31 までの 50日間) print("③ 2019/12/31 までの 50日間" , "-" * 80) data = ts_data[-50:] result = sm.tsa.stattools.adfuller(data) print('value = {:.4f}'.format(result[0])) print('p-value = {:.4}'.format(result[1])) print()
全て検定値(value)が絶対値的にとても大きく、
P値(p-value)が0.0になっている。
有意水準を1%にしたとしても、
①〜③全て、帰無仮説が棄却される形となった。(全てp値が0.0であり、比較的意味の無い比較かもしれないが、)
検定量の絶対値を比較すると、
① > ② > ③
であり、(データが完全にAR(1)なので)
ADF検定の結果としても始めの時点の方がより正しく評価されている感じになった。まとめ
モデル学習結果とADF検定より、
始めの時点の方が正しく評価される形であった。
特に③のモデル学習結果については、全くの想定外であった。
何故そのような結果になったのか、因果関係について筆者はまだ理解出来ていない。
勉強を続けていくうちに分かればいいなと思っている。



- 投稿日:2020-05-17T23:21:51+09:00
Qiitaの自身の記事をエクスポートして、GithubにPushする
はじめに
Qiitaで投稿している記事を1記事1ファイルにエクスポートし、GithubにPushするコードです。
先人の知恵がありましたので参考にさせていただきました。参考にさせてもらった、Qiita API v2 を使って自身の全投稿をエクスポートする Python スクリプトを書いた が実行環境Python2.7でしたので、私が利用している3.7.7でも動くよう少しコードを修正しました。実行環境
OS:macOS
Python:3.7.7処理概要
- ローカル環境でPythonでQiitaAPIを使い、1記事ずつ1ファイルに作成する。
- 作成したファイルをGithubにPushする。
コード
# -*- coding: utf-8 -*- import json import os import sys import requests import subprocess def abort(msg): print('Error!: {0}'.format(msg)) sys.exit(1) def get(url, params, headers): r = requests.get(url, params=params, proxies=proxies, headers=headers) return r def post(url, data_dict, headers_dict): r = requests.post(url, data=json.dumps(data_dict), proxies=proxies, headers=headers_dict) return r def print_response(r, title=''): c = r.status_code h = r.headers print('{0} Response={1}, Detail={2}'.format(title, c, h)) def assert_response(r, title=''): c = r.status_code h = r.headers if c<200 or c>299: abort('{0} Response={1}, Detail={2}'.format(title, c, h)) class Article: def __init__(self, d): self._title = d['title'] self._html_body = d['rendered_body'] self._md_body = d['body'] self._tags = d['tags'] self._created_at = d['created_at'] self._updated_at = d['updated_at'] self._url = d['url'] user = d['user'] self._userid = user['id'] self._username = user['name'] def save_as_markdown(self): title = self._title body = self._md_body.encode('utf8') filename = '{0}.md'.format(title) fullpath = os.path.join(MYDIR, filename) # バイナリモードに変更 # 参考)https://go-journey.club/archives/7113 with open(fullpath, 'wb') as f: f.write(body) # ファイル出力先を指定。出力したいディレクトリを指定してください。 MYDIR = os.path.abspath("/Users/shin/github/Qiita") proxies = { "http": os.getenv('HTTP_PROXY'), "https": os.getenv('HTTPS_PROXY'), } # Qiitaアクセストークン取得 token = os.getenv('QIITA_ACCESS_TOKEN') # 環境変数で指定しない場合は以下のように設定する # token = 'アクセストークン' headers = { 'content-type' : 'application/json', 'charset' : 'utf-8', 'Authorization' : 'Bearer {0}'.format(token) } # 認証ユーザの投稿一覧 url = 'https://qiita.com/api/v2/authenticated_user/items' params = { 'page' : 1, 'per_page' : 100, } r = get(url, params, headers) assert_response(r) # print_response(r) items = r.json() print('{0} entries.'.format(len(items))) for i,item in enumerate(items): print('[{0}/{1}] saving...'.format(i+1, len(items))) article = Article(item) article.save_as_markdown() # GithubにPush # 参考)https://www.atmarkit.co.jp/ait/articles/2003/13/news031.html subprocess.run(["cd", "/Users/shin/github/Qiita"]) # 更新内容をインデックスに追加(ステージングエリアに追加)→コミット対象にしている subprocess.run(["git", "add", "-A"]) # ローカルリポジトリにコミット subprocess.run(["git", "commit", "-a", "-m", "AutomaticUpdate"]) # ローカルリポジトリの内容をリモートリポジトリに反映 subprocess.run(["git", "push", "origin", "master"])参考
- 投稿日:2020-05-17T23:08:39+09:00
AtCoder Beginner Contest 168 参戦記
AtCoder Beginner Contest 168 参戦記
700番切ったの初めてなのでイヤッッホォォォオオォオウ!! 入水!!!
ABC168A - ∴ (Therefore)
2分で突破. 書くだけ.
N = int(input()) if N % 10 in [2, 4, 5, 7, 9]: print('hon') elif N % 10 in [0, 1, 6, 8]: print('pon') elif N % 10 in [3]: print('bon')ABC168B - ... (Triple Dots)
2分で突破. 書くだけ.
K = int(input()) S = input() if len(S) <= K: print(S) else: print(S[:K] + '...')ABC168C - : (Colon)
9分半で突破. 分でも時針が動くことを忘れているアホが発生. 数学は苦手だけど流石にこのレベルならなんとか…….
from math import pi, sin, cos, sqrt A, B, H, M = map(int, input().split()) y1 = A * cos(2 * pi * (H + M / 60) / 12) x1 = A * sin(2 * pi * (H + M / 60) / 12) y2 = B * cos(2 * pi * M / 60) x2 = B * sin(2 * pi * M / 60) print(sqrt((y1 - y2) * (y1 - y2) + (x1 - x2) * (x1 - x2)))ABC168D - .. (Double Dots)
9分半で突破. 問題としては入り口から順に幅優先探索するだけで簡単なのだが、'No' の場合は無いんだと心を強く持って提出するのがきつかった.
from collections import deque N, M = map(int, input().split()) AB = [map(int, input().split()) for _ in range(M)] links = [[] for _ in range(N + 1)] for a, b in AB: links[a].append(b) links[b].append(a) result = [-1] * (N + 1) q = deque([1]) while q: i = q.popleft() for j in links[i]: if result[j] == -1: result[j] = i q.append(j) print('Yes') print('\n'.join(str(i) for i in result[2:]))ABC168E - ∙ (Bullet)
解けそうで解けなかった. 多分 Ai か Bi のどちらかが0の時の場合が詰めきれてない.
追記: (Ai, Bi) = (0, 0) の特別扱いの仕方が間違ってた. (0, 0) はすべての魚と仲が悪いので後から足し込まないと駄目だった.
b/a と -a/b の仲が悪いのは分かるが、残念ながら Python には有理数がないので (a, b) のタプルで代用する. ところで (1, 2) と (-4, 2) は仲が悪いがそれがぱっとわからないので、a, b それぞれを gcd(a, b) で割って通分しておく. こうすると (1, 2) と (-2, 1) になるので、(a, b) と仲が悪いのが (-b, a), (b, -a) だけに絞れる. また (-b, a), (b, -a) は (-a, -b) とも仲が悪いので、(a, b) と (-a, -b) はグループとなる. あとは存在する (a, b) 毎に場合の数は 2^((a, b) の個数 + (-a, -b) の個数) + 2^((-b, a) の個数 + (b, -a) の個数) - 1 (最後の -1 は無いがダブっている分) となるので乗算していき、最後に (0, 0) の個数を足し、一個も選ばなかった分を1つ差っ引けば答えになる.
理屈は簡単だけど、実装はカロリー高くてめんどくさいです…….
from math import gcd N = int(input()) AB = [map(int, input().split()) for _ in range(N)] t = [] d = {} d[0] = {} d[0][0] = 0 for a, b in AB: i = gcd(a, b) if i != 0: a //= i b //= i t.append((a, b)) d.setdefault(a, {}) d[a].setdefault(b, 0) d[a][b] += 1 used = set() result = 1 for a, b in t: if (a, b) in used: continue used.add((a, b)) if a == 0 and b == 0: continue i = d[a][b] j, k, l = 0, 0, 0 if -a in d and -b in d[-a]: j = d[-a][-b] used.add((-a, -b)) if -b in d and a in d[-b]: k = d[-b][a] used.add((-b, a)) if b in d and -a in d[b]: l = d[b][-a] used.add((b, -a)) result *= pow(2, i + j, 1000000007) + pow(2, k + l, 1000000007) - 1 result %= 1000000007 result += d[0][0] - 1 result %= 1000000007 print(result)
- 投稿日:2020-05-17T23:03:10+09:00
RasPiでサーボモーターを動かしてみる(360度ぐるぐる版)
まえおき
サーボモーターSG-90を使うときにも書きましたがずいぶん昔に購入してほったらかしだったPI HATを使ってみたら、どうも思った動きにならなかったので、試行した顛末です。
パーツ
- RasPi3 / RasPi2
- サーボモーター FS90R
- モーター用の電源
- モーターコントローラ Adafruit 16チャンネル PWM/サーボ HAT for Raspberry Pi
環境
- python 3.7.3
- adafruit-circuitpython-servokit 1.2.1
調べたこと、やったこと
ひとまず、最初にすることは、製品のページからサンプルコードを確認しました。
説明を超訳すると、1で正回転、-1で逆回転、0.5で半分のパワーで回転できると。
回転を止めるのは0でいいらしい。ひとまず、全力での回転がどれぐらいかわからないけど、まずは1で回してみる。
kit.continuous_servo[1].throttle = 1逆回転は、
kit.continuous_servo[1].throttle = -1ん?とりあえず、止めよう。
kit.continuous_servo[1].throttle = 0止まらん、、、止まって~~
ひとまず、モーター用の電源を抜こう。で、以下のコードでいけそうな感じ。
# Adafruit 16-Channel PWM/Servo HAT & Bonnet for Raspberry Pi & FS90R sample # # see: # https://learn.adafruit.com/adafruit-16-channel-pwm-servo-hat-for-raspberry-pi # # test system: # python 3.7.3 # adafruit-circuitpython-servokit 1.2.1 import time from adafruit_servokit import ServoKit # Set channels to the number of servo channels on your kit. # 8 for FeatherWing, 16 for Shield/HAT/Bonnet. kit = ServoKit(channels=16) ch = 1 def fs90r_convert(throttle): """ Parameters ---------- throttle : float require -1.0 .. 1.0, but no check Returns : float -0.4(right rotation) <= 0.1(stop) <= 0.6(left rotation) """ return 0.1 + throttle / 2 # left rotation (0.1 .. 1.0(max)) for i in range(1,11): v = fs90r_convert(i/10) print( "i=%f v=%f" % (i/10, v) ) kit.continuous_servo[ch].throttle = v time.sleep(1) # right rotation (-0.1 .. -1.0(max)) for i in range(-1,-11,-1): v = fs90r_convert(i/10) print( "i=%f v=%f" % (i/10, v) ) kit.continuous_servo[ch].throttle = v time.sleep(1) # stop rotation kit.continuous_servo[ch].throttle = fs90r_convert(0) time.sleep(1) # left rotation, max throttle kit.continuous_servo[ch].throttle = fs90r_convert(1) time.sleep(1) # right rotation, half throttle kit.continuous_servo[ch].throttle = fs90r_convert(-0.5) time.sleep(1) # stop rotation kit.continuous_servo[ch].throttle = fs90r_convert(0)ポイントは
def fs90r_convert(throttle): return 0.1 + throttle / 2で、FS90R用の換算を挟みました。どうも、0では停止せず、0.1で停止するようです。
引数は、サンプルプログラムで解説されている1から-1の範囲を与えて、正回転、逆回転、0で停止できます。参考

- 投稿日:2020-05-17T22:50:33+09:00
PythonでABC168のA~Cを解く
はじめに
大事故です。
A問題
考えたこと
やるだけn = input() if n[-1] == '3': print('bon') elif n[-1] == '0' or n[-1] == '1' or n[-1] == '6' or n[-1] == '8': print('pon') else: print('hon')B問題
考えたこと
やるだけk = int(input()) s = input() n = len(s) if n <= k: print(s) else: print(s[:k]+"...")C問題
考えたこと
時針と分針の角度を計算して余弦定理。←cosの対称性を勘違いして6WA()。cosの値は$\frac{\pi}{2}$に対して対称じゃないですよ?なにを考えてるんですか?受験生なのに受験数学できないimport math a, b, h, m = map(int,input().split()) a_s = (30 * h) % 360 + 0.5 * m b_s = (6*m) s = max(a_s,b_s) - min(a_s,b_s) ans = math.sqrt(a**2+b**2-2*a*b*math.cos(math.radians(s))) print(ans)D問題
1から近い順に見ていって、それぞれの親ノード(1に近い方)の番号をつければ解けそう。BFSとか?
まとめ
私は雑魚です。
- 投稿日:2020-05-17T22:40:02+09:00
Python でつくる簡易 Slack API クライアント
Slack API の公式 Python クライアント はよくできていると思うのだけど、諸事情あってこれを使わずに Python から Slack API を利用する必要があり、自前で超簡易的に Slack クライアントを書いてみた。
import urllib.request import json class SlackAPI: def __init__(self, token: str, api_base: str = 'https://slack.com/api/'): self.token = token self.api_base = api_base def __call__(self, name: str, charset: str = 'utf-8', **kwargs) -> dict: req = urllib.request.Request( url = self.api_base + name, data = json.dumps(kwargs).encode(charset), headers = { 'Authorization': f'Bearer {self.token}', 'Content-Type': f'application/json; charset={charset}', }) with urllib.request.urlopen(req) as res: return json.load(res) def __getitem__(self, key: str): return lambda **kwargs: self(key, **kwargs)こんなノリで使える。
token = 'xoxb-000000000000-0000000000000-xxxxxxxxxxxxxxxxxxxxxxxx' slack_api = SlackAPI(token)# ユーザ一覧を取得する slack_api['users.list']()# メッセージを投稿する slack_api['chat.postMessage'](channel='XXXXXXXXX', text='Yo!', as_user=True)もちろん RTM API などは使えないが、Web API であればほとんどこれで実行できるのではないか。(そこまでいろいろ試したわけではないので「この API は実行できない」などあればコメントして欲しい)
追記 (2020.05.18)
コメントにて、JSON のリクエストボディに対応していない API もあるとご指摘いただいたので、これに対応してみた。
import urllib.request import json class SlackAPI: def __init__(self, token: str, api_base: str = 'https://slack.com/api/'): self.token = token self.api_base = api_base def __getitem__(self, key: str): return lambda **kwargs: self.post(key, **kwargs) def get(self, name: str, **kwargs) -> dict: req = urllib.request.Request( url = self.api_base + name + '?' + urllib.parse.urlencode(kwargs), headers = { 'Authorization': f'Bearer {self.token}', }) with urllib.request.urlopen(req) as res: return json.load(res) def post(self, name: str, charset: str = 'utf-8', **kwargs) -> dict: req = urllib.request.Request( url = self.api_base + name, data = json.dumps(kwargs).encode(charset), headers = { 'Authorization': f'Bearer {self.token}', 'Content-Type': f'application/json; charset={charset}', }) with urllib.request.urlopen(req) as res: return json.load(res)明示的に
getメソッドを使った場合はapplication/x-www-form-urlencodedでデータを送信する。slack_api.get('conversations.list', limit=20)
- 投稿日:2020-05-17T22:31:21+09:00
RasPiでサーボモーターを動かしてみる(180度版)
まえおき
ずいぶん昔にサーボモーターを制御できるPI HATを購入して、ハンダ付けまでしていたのですが、それっきりすっかり忘れていました。電子部品の在庫確認をしていたら、見つけてしまったので動作確認してみました。
パーツ
- パーツというか、RasPi3
- サーボモーター SG-90
- モーター用の電源
- モーターコントローラ Adafruit 16チャンネル PWM/サーボ HAT for Raspberry Pi
確認したら、まだ現行の製品でした。
環境
- python 3.7.3
- adafruit-circuitpython-servokit 1.2.1
調べたこと、やったこと
サーボモーターは、180度回転するタイプ(左右90度ともいえる)と、360度ぐるぐる回転するタイプがあるようです。180度回転するタイプも360度回転するタイプも、製品の情報をたどると、サンプルコードに到達できたのですが、ここのコードをコピペしても、思ったように動きませんでした。まず、はんだ付け失敗かとも思ったんですが、サーボモーターを接続する場所(16か所あります)を変更しても、動きは同じ。うーむ、、、、
これは、ハンダ付けでダマができているのが問題ではないと思い(責任転嫁か!)、ちょっとパラメータを変えてみて試行してみました。
で、以下のコードでだいたいいけそうでした。
# Adafruit 16-Channel PWM/Servo HAT & Bonnet for Raspberry Pi & SG90 sample # # see: # https://learn.adafruit.com/adafruit-16-channel-pwm-servo-hat-for-raspberry-pi # # test system: # python 3.7.3 # adafruit-circuitpython-servokit 1.2.1 import time from adafruit_servokit import ServoKit # Set channels to the number of servo channels on your kit. # 8 for FeatherWing, 16 for Shield/HAT/Bonnet. kit = ServoKit(channels=16) ch = 1 kit.servo[ch].set_pulse_width_range(500, 2400) # 0..180 step 30 angle for v in range(0,181,30): print( "value=", v ) kit.servo[ch].angle = v time.sleep(1) # 0, 180 step 90 angle x 3set for i in range(1,3): for v in range(0,181,90): kit.servo[ch].angle = v time.sleep(1) # stop(90 angle) kit.servo[ch].angle = 90ポイントは
kit.servo[ch].set_pulse_width_range(500, 2400)で、サーボモーターSG-90のデータシートを確認して、下が0.5ms pulse、上が2.4ms pulseらしいので設定しました。このパラメータでも、ちょっと180度に足りていない気もしますが、ひとまずよしとしときます。
参考

- 投稿日:2020-05-17T22:28:22+09:00
[Python]03章-01 Turtle グラフィックス(グラフィック入門)
[Python]03章-01 グラフィック入門
本章では、今まで学んだ変数やメソッドなどの知識を用いて、習得した範囲でのグラフィックを作成していきたいと思います。
今後、Pythonで学ぶオブジェクト指向の話やメソッドに関する話が深く問われてきます。それらを学ぶ上で、グラフィックを用いることにより、理解が深まると考えています。
グラフィックでよく用いられるのがTurtle(タートル:亀)グラフィックスです。TurtleはPythonの基本的な文法がわかっていれば、記述が可能です。
小学校・中学校でもプログラミングが必須
2020年よりプログラミングが小学校で必須となりました。そこでよく用いられるのがスクラッチというプログラミングツールです。このプログラミングツールの目指すところはアルゴリズム(※)の能力を養成することにあります。
(※)アルゴリズムとは、プログラム等で行われる処理手順のことです。詳細は割愛しますが、プログラムを書いていくうえで重要な内容となってきます。
もし興味があれば操作ができますのでぜひ試してみてください。(無料)
スクラッチサイトそのスクラッチでもそうですが、スクラッチは前述した通り、小中学校で使うツールです。グラフィックも特に難しくなく操作ができますが、ここではPythonで動かすことを考えていきましょう。
Turtleを作る
いくつか習っていないプログラムコードがありますが、コメントを添えつつ、また詳細は後述しますので、とりあえず今はおまじないと思っていてください。
今回のプログラムはプログラムコードをエディタで作成して実行していきたいと思います。フォルダchap03を作成し、その中にファイル名03-01-01.pyを作成します。
まずは、一番上に以下のコードを入力します。
03-01-01.pyimport turtleこれはturtleプログラムを行う上で、外部から読み込んでいる(インポート)ことを意味します。詳細は後の章で後述します。
とりあえず今は、turtleプログラムを動かすために外部からプログラムを読み込んでいるという認識で構いません。03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle次もまたおまじないのようなものになりますが、肝心のturtle(亀)を作らないといけません。
そこで、以下のようにturtleを作ります。なお、亀に何か名前を付けてみるのもいいかもしれません。(今回自分はtaroという名前にしましたが、ここは自由で構いません)03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle()そして実行してみてください。すると一瞬、白い画面が出たかと思います。
これだと実行結果がすぐ閉じられてしまうので、以下の個所にturtle.done()と記載してください。これにより、turtle.done()の時点でいったんプログラムを止めることができます。これは最後に書きます。
03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #いったんここでプログラムを止める。 turtle.done()実行すると、以下の結果になります。
これだと矢印の形であり、亀の形をしていません。また亀は本来緑色のイメージなので、形と色を変えていきたいと思います。
亀に対する処理命令
では亀の形と色を変えていきたいと思います。
以下のコードを入力してください。03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #形を亀に、色を緑にする taro.shape('turtle') taro.color('green') #いったんここでプログラムを止める。 turtle.done()実行すると、以下のように亀の形と色の変更ができたと思います。
さて、追加したこの2行、どこかで見たことないでしょうか?
2章で文字列のメソッドを扱った時のことを思い出してください。str.count('r') str.lower()といったメソッドがあったと思います。実はこれらはstrに対する処理命令と2章で述べましたが、今回もtaroというturtle(亀)に対して、何かしらの処理命令を行っているのです。
今回は「shape(形)を'turtle'(亀の形)に、color(色)を'green'(緑)にしなさい」という処理命令を行っているのです。
実際に動かすのは次回にしたいと思います。しかし結局動かすのはメソッドとなりますので、turtleを動かすための基本的なメソッドを次回習得していきたいと思います。
最後に
今回はいくつか見慣れないプログラムコードがありますが、これらについては重要であるため必ず後の章で説明します。
今回学んだ、taro.shape()とtaro.color()のメソッドについて、ほかにもいろいろな形や色があります。
以下のサイトに詳細がありますので、形を変えてみたり、色を変えてみたりしてみてください。
shape()メソッド【目次リンク】へ戻る

- 投稿日:2020-05-17T22:28:22+09:00
[Python]03章-01 Turtle グラフィックス(turtleの作成)
[Python]03章-01 turtleの作成
本章では、今まで学んだ変数やメソッドなどの知識を用いて、習得した範囲でのグラフィックを作成していきたいと思います。
今後、Pythonで学ぶオブジェクト指向の話やメソッドに関する話が深く問われてきます。それらを学ぶ上で、グラフィックを用いることにより、理解が深まると考えています。
グラフィックでよく用いられるのがTurtle(タートル:亀)グラフィックスです。TurtleはPythonの基本的な文法がわかっていれば、記述が可能です。
小学校・中学校でもプログラミングが必須
2020年よりプログラミングが小学校・中学校で必須となりました。そこでよく用いられるのがスクラッチというプログラミングツールです。このプログラミングツールの目指すところはアルゴリズム(※)の能力を養成することにあります。
(※)アルゴリズムとは、プログラム等で行われる処理手順のことです。詳細は割愛しますが、プログラムを書いていくうえで重要な内容となってきます。
もし興味があれば操作ができますのでぜひ試してみてください。(無料)
スクラッチサイトそのスクラッチでもそうですが、スクラッチは前述した通り、小中学校で使うツールです。グラフィックも特に難しくなく操作ができますが、ここではPythonで動かすことを考えていきましょう。
Turtleを作る
いくつか習っていないプログラムコードがありますが、コメントを添えつつ、また詳細は後述しますので、とりあえず今はおまじないと思っていてください。
今回のプログラムはプログラムコードをエディタで作成して実行していきたいと思います。フォルダchap03を作成し、その中にファイル名03-01-01.pyを作成します。
まずは、一番上に以下のコードを入力します。
03-01-01.pyimport turtleこれはturtleプログラムを行う上で、外部から読み込んでいる(インポート)ことを意味します。詳細は後の章で後述します。
とりあえず今は、turtleプログラムを動かすために外部からプログラムを読み込んでいるという認識で構いません。03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle次もまたおまじないのようなものになりますが、肝心のturtle(亀)を作らないといけません。
そこで、以下のようにturtleを作ります。なお、亀に何か名前を付けてみるのもいいかもしれません。(今回自分はtaroという名前にしましたが、ここは自由で構いません)03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle()そして実行してみてください。すると一瞬、白い画面が出たかと思います。
これだと実行結果がすぐ閉じられてしまうので、以下の個所にturtle.done()と記載してください。これにより、turtle.done()の時点でいったんプログラムを止めることができます。これは最後に書きます。
03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #いったんここでプログラムを止める。 turtle.done()実行すると、以下の結果になります。
これだと矢印の形であり、亀の形をしていません。また亀は本来緑色のイメージなので、形と色を変えていきたいと思います。
亀に対する処理命令
では亀の形と色を変えていきたいと思います。
以下のコードを入力してください。03-01-01.py#turtleプログラムを動かすために外部からプログラムを読み込んでいる import turtle #taroという名前でturtle(亀)を作る。 taro = turtle.Turtle() #形を亀に、色を緑にする taro.shape('turtle') taro.color('green') #いったんここでプログラムを止める。 turtle.done()実行すると、以下のように亀の形と色の変更ができたと思います。
さて、追加したこの2行、どこかで見たことないでしょうか?
2章で文字列のメソッドを扱った時のことを思い出してください。str.count('r') str.lower()といったメソッドがあったと思います。実はこれらはstrに対する処理命令と2章で述べましたが、今回もtaroというturtle(亀)に対して、何かしらの処理命令を行っているのです。
今回は「shape(形)を'turtle'(亀の形)に、color(色)を'green'(緑)にしなさい」という処理命令を行っているのです。
実際に動かすのは次回にしたいと思います。しかし結局動かすのはメソッドとなりますので、turtleを動かすための基本的なメソッドを次回習得していきたいと思います。
最後に
今回はいくつか見慣れないプログラムコードがありますが、これらについては重要であるため必ず後の章で説明します。
今回学んだ、taro.shape()とtaro.color()のメソッドについて、ほかにもいろいろな形や色があります。
以下のサイトに詳細がありますので、形を変えてみたり、色を変えてみたりしてみてください。
shape()メソッド【目次リンク】へ戻る
- 投稿日:2020-05-17T22:23:30+09:00
(備忘録)Docker ComposeでTensorFlow + Flask + Nginx環境構築時のメモ
はじめに
自分の備忘録用です
Docker ComposeでTensorFlow + Flask + Nginxの環境を作る時のメモです。
ちょうど、TensorFlowを使ったアプリの備忘録
を作っていましたが、切り出して整理しようと思った次第です。。。
この手順を実行すれば、TensorFlow使ったWeb APIが動くはずです
自分用に作った記事なので、分かりにくい点や情報、技術が古いかもしれませんがご了承ください参考資料
この記事を作るにあたって参考にさせて頂きました
- docker-composeでgunicorn+nginx+flaskを動かしてみた話
- DockerでDjangoの開発環境を再構築!!!!
- Docker入門(第六回)〜Docker Compose〜
- 初心者向けdocker-composeコマンド逆引き
- docker-compose コマンドまとめ
- Dockerコマンド よく使うやつ
- Docker一括削除コマンドまとめ
環境 ※以下のVerでなくても動くと思いますが、古いのでご注意下さい
 Ubuntuバージョン$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.4 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.4 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionicDockerバージョン$ docker version Client: Docker Engine - Community Version: 19.03.8 API version: 1.40 Go version: go1.12.17 Git commit: afacb8b7f0 Built: Wed Mar 11 01:25:46 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.8 API version: 1.40 (minimum version 1.12) Go version: go1.12.17 Git commit: afacb8b7f0 Built: Wed Mar 11 01:24:19 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683Docker-Composeバージョン$ docker-compose version docker-compose version 1.25.5, build unknown docker-py version: 4.2.0 CPython version: 3.7.4 OpenSSL version: OpenSSL 1.1.1c 28 May 2019
Ubuntuバージョン$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.4 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.4 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionicDockerバージョン$ docker version Client: Docker Engine - Community Version: 19.03.8 API version: 1.40 Go version: go1.12.17 Git commit: afacb8b7f0 Built: Wed Mar 11 01:25:46 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.8 API version: 1.40 (minimum version 1.12) Go version: go1.12.17 Git commit: afacb8b7f0 Built: Wed Mar 11 01:24:19 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683Docker-Composeバージョン$ docker-compose version docker-compose version 1.25.5, build unknown docker-py version: 4.2.0 CPython version: 3.7.4 OpenSSL version: OpenSSL 1.1.1c 28 May 2019※なぜかbuild unknown。時間掛かりそうだったので諦めました
ディレクトリ構成
適当に作っています$\tiny{※凝視したらダメです}$
ゴミファイルが多いですが、Githubに置いてあります。
ソースディレクトリ構成dk_tensor_fw ├── app_tensor │ ├── Dockerfile │ ├── exeWhatMusic.py │ ├── inputFile │ │ └── ans_studyInput_fork.txt │ ├── mkdbAndStudy.py │ ├── requirements.txt │ ├── studyModel │ │ ├── genre-model.hdf5 │ │ ├── genre-tdidf.dic │ │ ├── genre.pickle │ ├── tfidfWithIni.py │ └── webQueApiRunServer.py ├── docker-compose.yml ├── web_nginx ├── Dockerfile └── nginx.confdocker-composeでローカル環境作るのに必要なファイル
docker-compose.ymlversion: '3' services: ########### Appサーバ設定 ########### app_tensor: container_name: app_tensor # サービス再起動ポリシー restart: always # ビルドするdockerファイルが格納されたディレクトリ build: ./app_tensor volumes: # マウントするディレクトリ - ./app_tensor:/dk_tensor_fw/app_tensor ports: # ホスト側のポート:コンテナ側のポート - 7010:7010 networks: - nginx_network ########### Appサーバ設定 ########### ########### Webサーバ設定 ########### web-nginx: container_name: web-nginx build: ./web_nginx volumes: # マウントするディレクトリ - ./web_nginx:/dk_tensor_fw/web_nginx ports: # ホストPCの7020番をコンテナの7020番にポートフォワーディング - 7020:7020 depends_on: # 依存関係を指定。web-serverの起動より前にapp-serverを起動するようになる - app_tensor networks: - nginx_network ########### Webサーバ設定 ########### networks: nginx_network: driver: bridge※ (参考)上記でポート番号を指定していますが、以下のコマンドで確認してます。
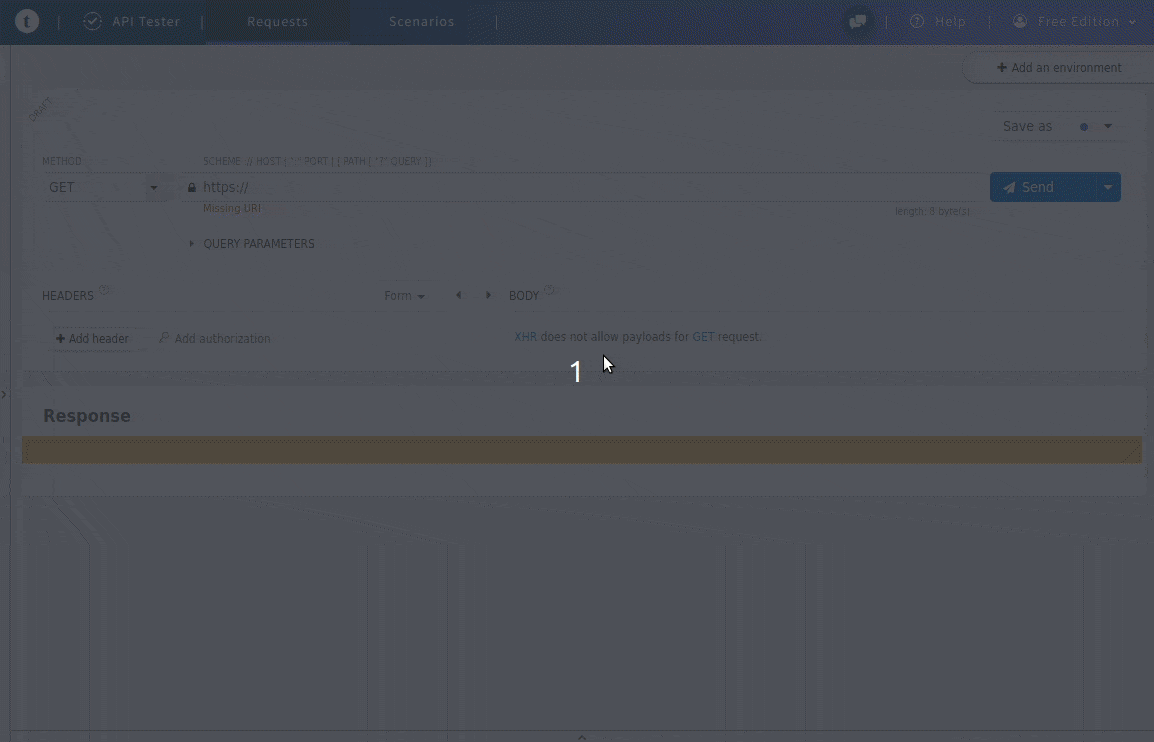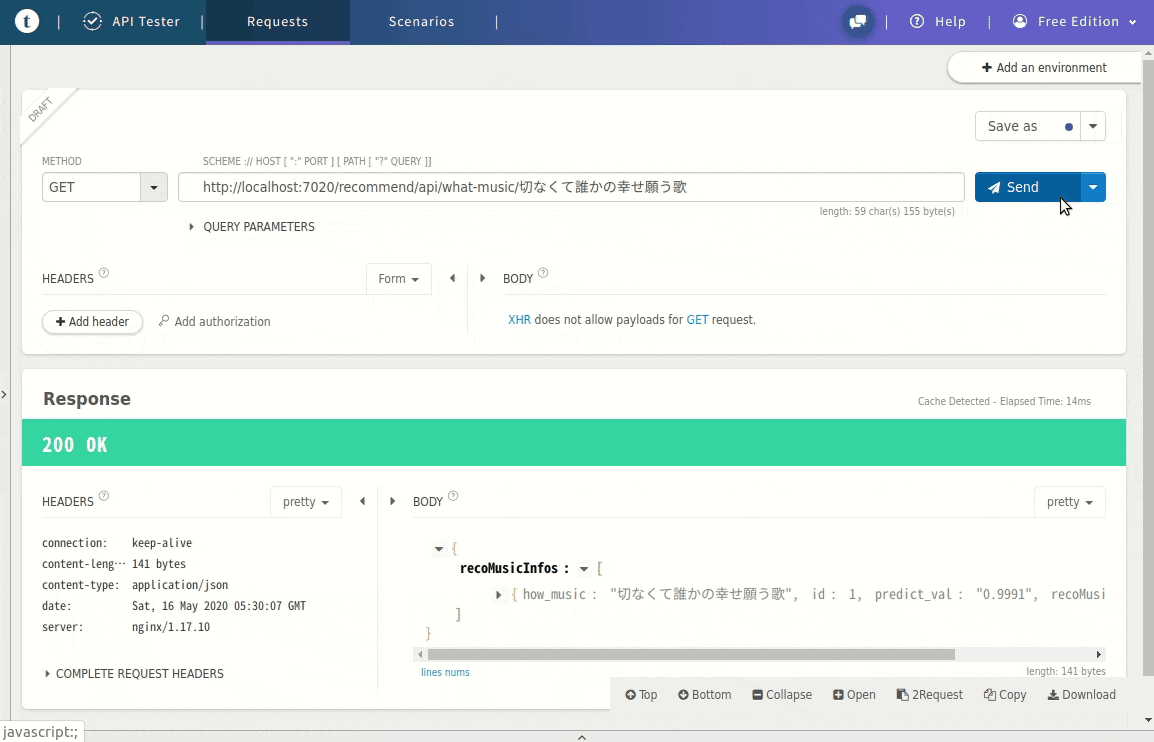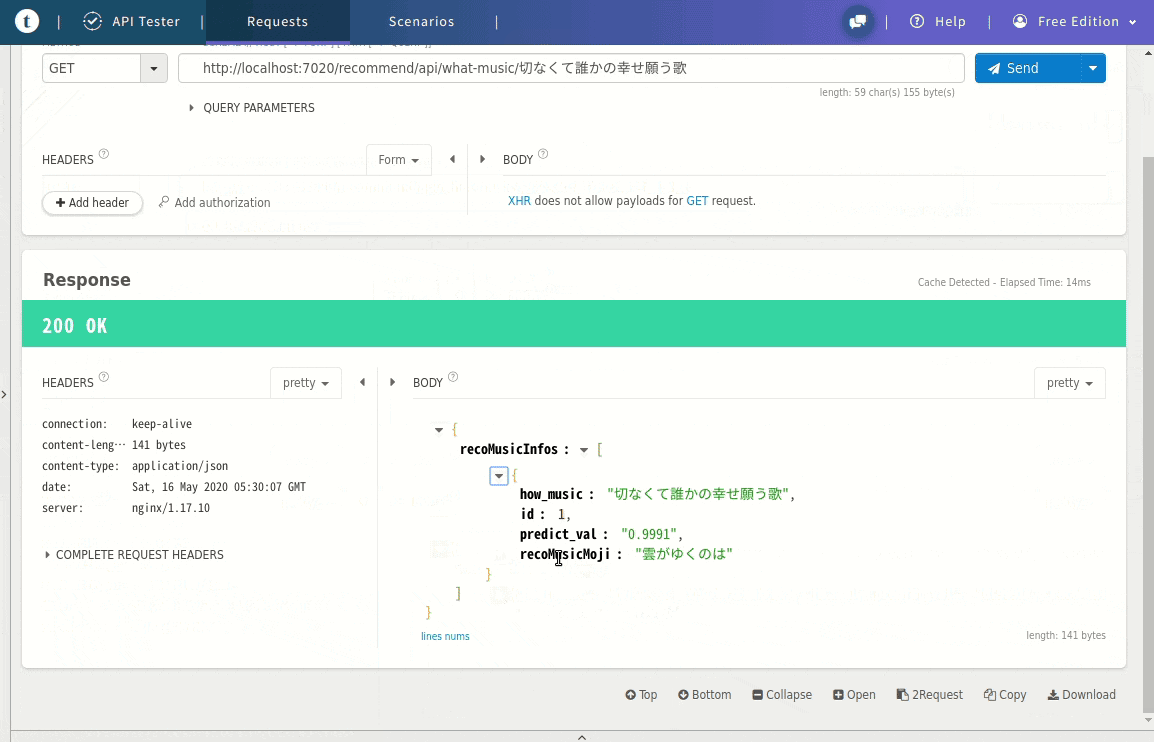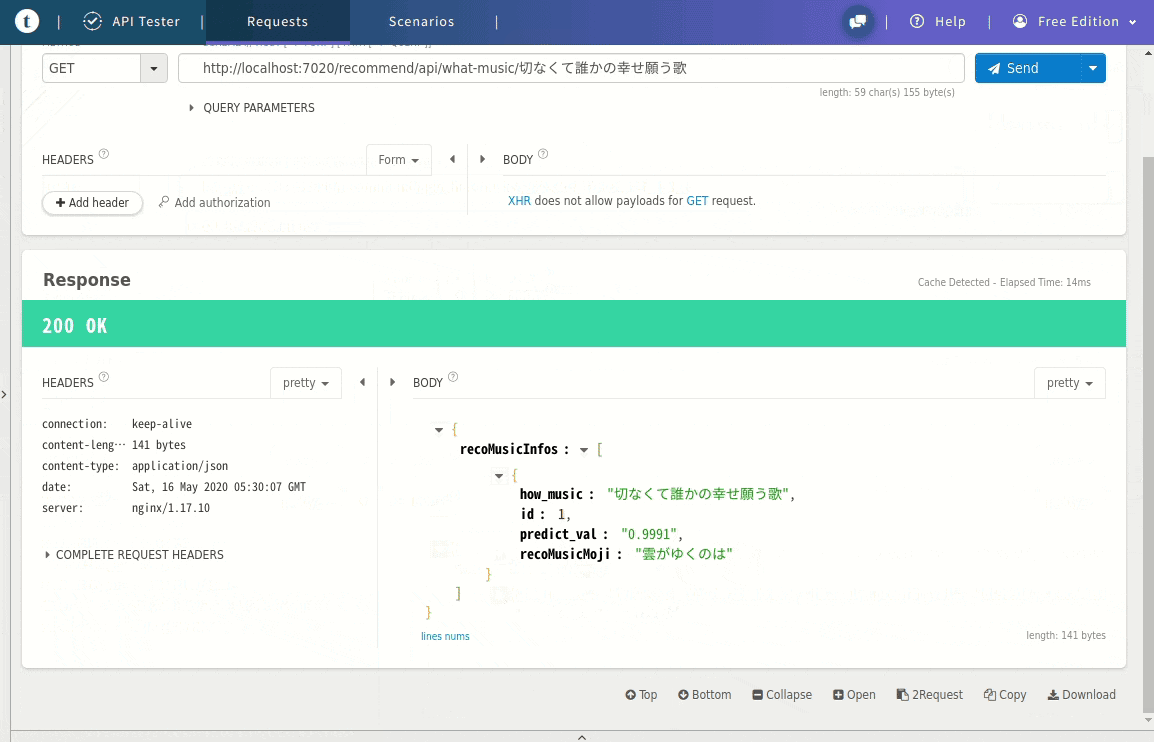
(参考)空いているポートの調べ方# 空いているポート調べる(何も表示されなければ空いてる) netstat -an | grep 7010Dockerfile←Apサーバ側(Gunicorn)FROM ubuntu:18.04 WORKDIR /dk_tensor_fw/app_tensor COPY requirements.txt /dk_tensor_fw/app_tensor RUN apt-get -y update \ && apt-get -y upgrade \ && apt-get install -y --no-install-recommends locales curl python3-distutils vim ca-certificates \ && curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py \ && python3 get-pip.py \ && pip install -U pip \ && localedef -i en_US -c -f UTF-8 -A /usr/share/locale/locale.alias en_US.UTF-8 \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* \ && pip install -r requirements.txt --no-cache-dir ENV LANG en_US.utf8 CMD ["gunicorn", "webQueApiRunServer:app", "-b", "0.0.0.0:7010"]requirements.txtFlask==1.1.0 gunicorn==19.9.0 Keras>=2.2.5 numpy==1.16.4 pandas==0.24.2 pillow>=6.2.0 python-dateutil==2.8.0 pytz==2019.1 PyYAML==5.1.1 requests==2.22.0 scikit-learn==0.21.2 sklearn==0.0 matplotlib==3.1.1 tensorboard>=1.14.0 tensorflow>=1.14.0 mecab-python3==0.996.2以下のpythonソースが機械学習済みのモデルを使ってある事柄を類推し、
Jsonのレスポンスを返すWeb API本体です。実際の類推しているモジュール(exeWhatMusic)
は外から読み込んでいますwebQueApiRunServer.pyimport flask import os import exeWhatMusic #ポート番号 TM_PORT_NO = 7010 # initialize our Flask application and pre-trained model app = flask.Flask(__name__) app.config['JSON_AS_ASCII'] = False # <-- 日本語の文字化け回避 @app.route('/recommend/api/what-music/<how_music>', methods=['GET']) def get_recom_music(how_music): recoMusicInfos = getRecoMusicMoji(how_music) return flask.jsonify({'recoMusicInfos': recoMusicInfos}) # オススメの楽曲名を返す def getRecoMusicMoji(how_music): recMusicName, predict_val = exeWhatMusic.check_genre(how_music) #JSON作成 recoMusicInfoJson = [ { 'id':1, 'recoMusicMoji':recMusicName, 'predict_val':predict_val, 'how_music':how_music } ] return recoMusicInfoJson if __name__ == "__main__": print(" * Flask starting server...") app.run(threaded=False, host="0.0.0.0", port=int(os.environ.get("PORT", TM_PORT_NO)))Dockerfile←Webサーバ側(Nginx)FROM nginx:latest RUN rm /etc/nginx/conf.d/default.conf COPY nginx.conf /etc/nginx/conf.dnginx.confupstream app_tensor_config { # コンテナのサービス名を指定すると名前解決してくれる server app_tensor:7010; } server { listen 7020; root /dk_tensor_fw/app_tensor/; server_name localhost; location / { try_files $uri @flask; } location @flask { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_redirect off; proxy_pass http://app_tensor_config; } # redirect server error pages to the static page /50x.html error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } # 静的ファイルの要求をstaticにルーティング ←使ってませんので不要です。 location /static/ { alias /dk_tensor_fw/app_tensor/satic/; } }出来上がった環境の確認
ビルド&backgroundで起動
$ docker-compose up -d --builddocker-compose イメージ情報を表示
$ docker-compose images Container Repository Tag Image Id Size ----------------------------------------------------------------------- app_tensor dk_tensor_fw_app_tensor latest 3b916ea797e0 2.104 GB web-nginx dk_tensor_fw_web-nginx latest 175c2596bb8b 126.8 MB作り方が悪いのか結構容量大きいような
コンテナの一覧表示
$ docker-compose ps Name Command State Ports ------------------------------------------------------------------------------------ app_tensor gunicorn webQueApiRunServe ... Up 0.0.0.0:7010->7010/tcp web-nginx nginx -g daemon off; Up 0.0.0.0:7020->7020/tcp, 80/tcpコンテナに接続(Apサーバ側)
$ docker-compose exec app_tensor /bin/bash root@ba0ce565430c:/dk_tensor_fw/app_tensor#Apサーバ側のコンテナに入れました。。。
TensorFlowとかKeras入っているか中身を確認
出力結果の表示が長いのでいくつか省きました
root@ba0ce565430c:/dk_tensor_fw/app_tensor# pip3 list Package Version ---------------------- ----------- absl-py 0.9.0 Flask 1.1.0 gunicorn 19.9.0 Keras 2.3.1 Keras-Applications 1.0.8 Keras-Preprocessing 1.1.2 matplotlib 3.1.1 mecab-python3 0.996.2 numpy 1.16.4 pandas 0.24.2 Pillow 7.1.2 pip 20.1 python-dateutil 2.8.0 pytz 2019.1 PyYAML 5.1.1 requests 2.22.0 requests-oauthlib 1.3.0 rsa 4.0 scikit-learn 0.21.2 six 1.14.0 sklearn 0.0 tensorboard 2.2.1 tensorboard-plugin-wit 1.6.0.post3 tensorflow 2.2.0 tensorflow-estimator 2.2.0 (省略)TensorFlow、Kerasなど一通り入っているようです。。。
Webサーバ側のコンテナに接続
$ docker-compose exec web-nginx /bin/bash root@d6971e4dc05c:/#Webサーバ側のコンテナにも入れました。
一応、Webサーバ(Nginx)が起動しているか確認します。
root@d6971e4dc05c:/# /etc/init.d/nginx status [ ok ] nginx is running.Nginxも起動しているようです。
一旦ここまでで実行環境の確認しました。
以下のようにWEB APIが叩ければWEB API側の実行環境できてると思います。。。Web_API実行例http://localhost:7020/recommend/api/what-music/切なくて誰かの幸せ願う歌Web API実行例
ツールは色々あるので何でも良いと思いますが、GIFのようにJSONで返ってきます。その他のコマンド(備忘です)
※参考資料そのままです。詳細は参考資料等見て下さい
サービス停止
$ docker-compose stopサービス開始
$ docker-compose start環境をクリーンにしたい時
# 停止&削除 # コンテナ・ネットワーク docker-compose down コンテナ・ネットワーク・イメージ docker-compose down --rmi all # コンテナ・ネットワーク・ボリューム docker-compose down -v
- 投稿日:2020-05-17T22:15:48+09:00
ぼく「コンテナのリモートデバッグも出来ないエディターなんて…」VSCode「それ、できるで。」
はじめに
VSCode「そう。
Remote Developmentならね。」ぼく「なん…やて…」
目次
前提条件
VSCode「docker-composeでのデバッグをやっていくから、まずは下のわかりやすい記事を参考に環境構築を行ってな。」
ぼく「手前味噌やな。」
VSCode「フォルダ構成は以下の通りになっているはずやで。」
treecontainers ├── django │ ├── Dockerfile │ ├── Pipfile │ ├── Pipfile.lock │ ├── config │ │ ├── __init__.py │ │ ├── asgi.py │ │ ├── settings.py │ │ ├── urls.py │ │ └── wsgi.py │ ├── db.sqlite3 │ ├── entrypoint.sh │ ├── manage.py │ └── static ├── docker-compose.yml ├── nginx │ ├── Dockerfile │ └── nginx.conf └── postgres ├── Dockerfile └── sql └── init.sqlVSCode「ほんだら、containersディレクトリをワイ(VSCode)開いてな。」
ぼく「あいよ。」
Remote Developmentのインストール
VSCode「Remote Developmentをインストールしてな。左下にこんな感じの青いマークが出てればインストール完了や」
設定ファイルの追加
VSCode「次にデバッグ用の設定ファイルを追加していくで。」
VSCode「出てきた青いアイコンをクリックしてな。」
ぼく「あいよ。」
VSCode「したら上にメニューが出てくるやろ?そん中から
Remote-Containers: Add Development Container configuration Files...を選択してな。」
VSCode「そのあと
From 'docker-compose.yml'を選択や。」
- デバックしたいサービスを選択(今回はDjango)を選択
VSCode「するとプロジェクトのルートに
.devcontainerディレクトリと、その中にdevcontainer.json及びdocker-compose.ymlが出来上がるから、devcontainer.jsonを以下のように書き換えてな!」VSCode「この辺は実務で使ったりする場合は任意の環境に置き換えて使ってな!」
ぼく「設定ファイル周りはようハマるからきーつけなあかんな。」
devcontainer.json{ // 任意の名前を入力 "name": "djnago containers", // Remoteでログインしたいコンテナを作成するためのdocker-composeファイルを指定してください。 "dockerComposeFile": "docker-compose-debug.yml", // 起動したいサービスを選択 "service": "django", // コンテナに入ったときに最初にここで指定したものがカレントディレクトリになります "workspaceFolder": "/usr/src/app/", // シェルを選択 "settings": { "terminal.integrated.shell.linux": "/bin/bash" }, // vscode拡張機能を選択 "extensions": ["ms-azuretools.vscode-docker", "ms-python.python"], // vscodeを閉じた時のコンテナの挙動を設定 // noneでコンテナの起動を継続する "shutdownAction": "none" }VSCode「次にデバッグ用のymlに書き換えていくで!
.devcontainerディレクトリ内の自動生成されたdocker-compose.ymlをdocker-compose-debug.ymlとかに修正し、既存のdocker-compose.ymlの内容をコピーしてな。」VSCode「今の段階ではサービスが
djangoとpostgresとnginxの3つあるけど、デバッグ時にいちいちnginxから配信しなくてええから、以下のように修正してな。これも環境に合わせて任意に変えてな。」
- 修正点
- nginxサービスを削除
- djangoサービスにデバッグ用のポート8888を開放
- Dockerfileやマウントディレクトリなどのパスを修正
docker-compose-debug.ymlversion: '3.7' services: django: container_name: django build: ../django command: python3 manage.py runserver 0.0.0.0:8000 volumes: - ../django:/usr/src/app/ ports: - 8000:8000 # デバッグ用にポートを追加 - 8888:8888 env_file: - ../django/.env depends_on: - postgres postgres: container_name: postgres build: ../postgres volumes: - sample_postgis_data:/var/lib/postgresql/data - ../postgres/sql:/docker-entrypoint-initdb.d env_file: ../postgres/.env_db ports: - 5433:5432 volumes: sample_postgis_data:リモートデバッグの開始
VSCode「今はこんな感じのディレクトリになっとるはずやな。」
ぼく「せやな。」
treecontainers ├── .devcontainer │ ├── devcontainer.json │ └── docker-compose-debug.yml ├── django │ ├── .env │ ├── Dockerfile │ ├── Pipfile │ ├── Pipfile.lock │ ├── config │ │ ├── __init__.py │ │ ├── asgi.py │ │ ├── settings.py │ │ ├── urls.py │ │ └── wsgi.py │ ├── db.sqlite3 │ ├── entrypoint.sh │ ├── manage.py │ └── static ├── docker-compose.yml ├── nginx │ ├── Dockerfile │ └── nginx.conf └── postgres ├── .env_db ├── Dockerfile └── sql └── init.sqlVSCode「いよいよデバッグしていくわけやけど、すでに
docker-compose.ymlでコンテナを立ち上げている場合は一旦停止させておいてな。デバッグ時にコンテナを立て直すんやけど、元々のymlファイルが同じものを使っているから名前が競合してうまく立ち上がらんくなるで。」VSCode「停止を確認したら下の青いアイコンを押して、次は
Remote-Containers: Open Folder in Containers...をクリックして、.devcontainerが存在するディレクトリ(今回の例ではcontainers)を選択してな。」
VSCode「ちなみにすでにコンテナが立ち上がっている場合は
Remote-Containers: Attach to Running Containers...を選択するとすでに起動中のコンテナにログインできるんやけど、devcontainer.jsonで作成した設定が反映されず、拡張機能がインストールされないから注意な」ぼく「これもハマりポイントやな。メモメモ…」
VSCode「ディレクトリを選択すると新しいウィンドウが開いて、以下のような表示が画面右下に出るで。コンテナ起動中やからしばらく待ってな」
ぼく「結構長いで。気長にいこうな。せっかちは嫌われるで。」
VSCode「ちなみに青文字の
Starting with Dev Containerをクリックするとコンテナ起動に必要なプロセスのログがリアルタイムでみれるで。エラーが起きたら停止してまうねんけど、このログでどこが悪いのか見れるで。」VSCode「まぁ、大抵はパス間違いか、名前の競合やろけどな。」
VSCode「無事立ち上がったら、コンテナ内のディレクトリが表示されて、シェルも指定のディレクトリをカレントディレクトリとして開いており、起動したコンテナにアタッチされたことが確認できるで。」
VSCode「拡張機能もインストール済みや。」
ぼく「そもそも、拡張機能はインストールしたいものを
devcontainer.jsonで明示的に書いてあげないとダメなんやな…」
デバッグの開始
VSCode「
実行とデバッグのアイコンをクリックし、launch.jsonファイルを作成しますをクリックして…」
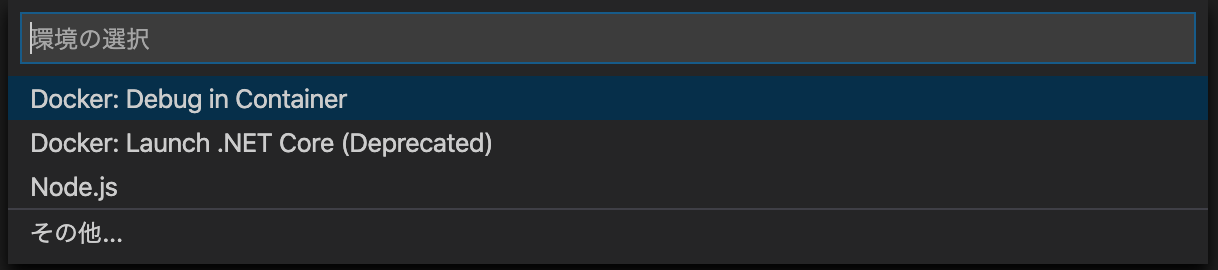
VSCode「その後、
Docker Debug ins Containerをクリックし…」
VSCode「んで
launch.jsonの編集画面が開くので以下のように編集して完成や!」launch.json{ "version": "0.2.0", "configurations": [ { // 表示名 "name": "django container", // 言語 "type": "python", // デバッグ時の挙動。実行の他にもある "request": "launch", // 動作させるファイルへのパス "program": "${workspaceFolder}/manage.py", // デバッグで使用するターミナルを選択。VSCode外のターミナルを起動することもできる "console": "integratedTerminal", // プログラム実行時の引数 "args": [ "runserver", "--noreload", "0.0.0.0:8888" ], "django": true } ] }VSCode「最後にプログラムを実行するために、画面左下からインタープリタを選択するで(今回の例であればpython3.8を選択)」
VSCode「一通りの設定が終わると、
実行とデバッグの項目が以下のようになり、再生ボタンのような緑色の三角アイコンをクリックすることで、指定した0.0.0.0:8888でデバッグサーバーが立ち上がるんや。」
VSCode「ボタンを押した後にブラウザから
localhost:8888に接続するといつもの画面が見れるようになっているはずや」ぼく「ほんまや。」
VSCode「あとはデバッグを行いたい箇所にブレークポイントを設定してブラウザなどからブレークポイントを設置した関数が実行されるようなURLにアクセスすると、VScode上でリクエストの内容がみれたり、変数が確認できたりするで!」
VSCode「
VSCode デバッグとかでググったら細かいやり方たくさん出てくるから調べてみてな!」ぼく「VSCode神やな!ほなさいなら。」
お し ま い


- 投稿日:2020-05-17T21:07:19+09:00
graphviz をポータブルな python 環境に導入する
はじめに
graphviz は scikit-learn でも使用されている、
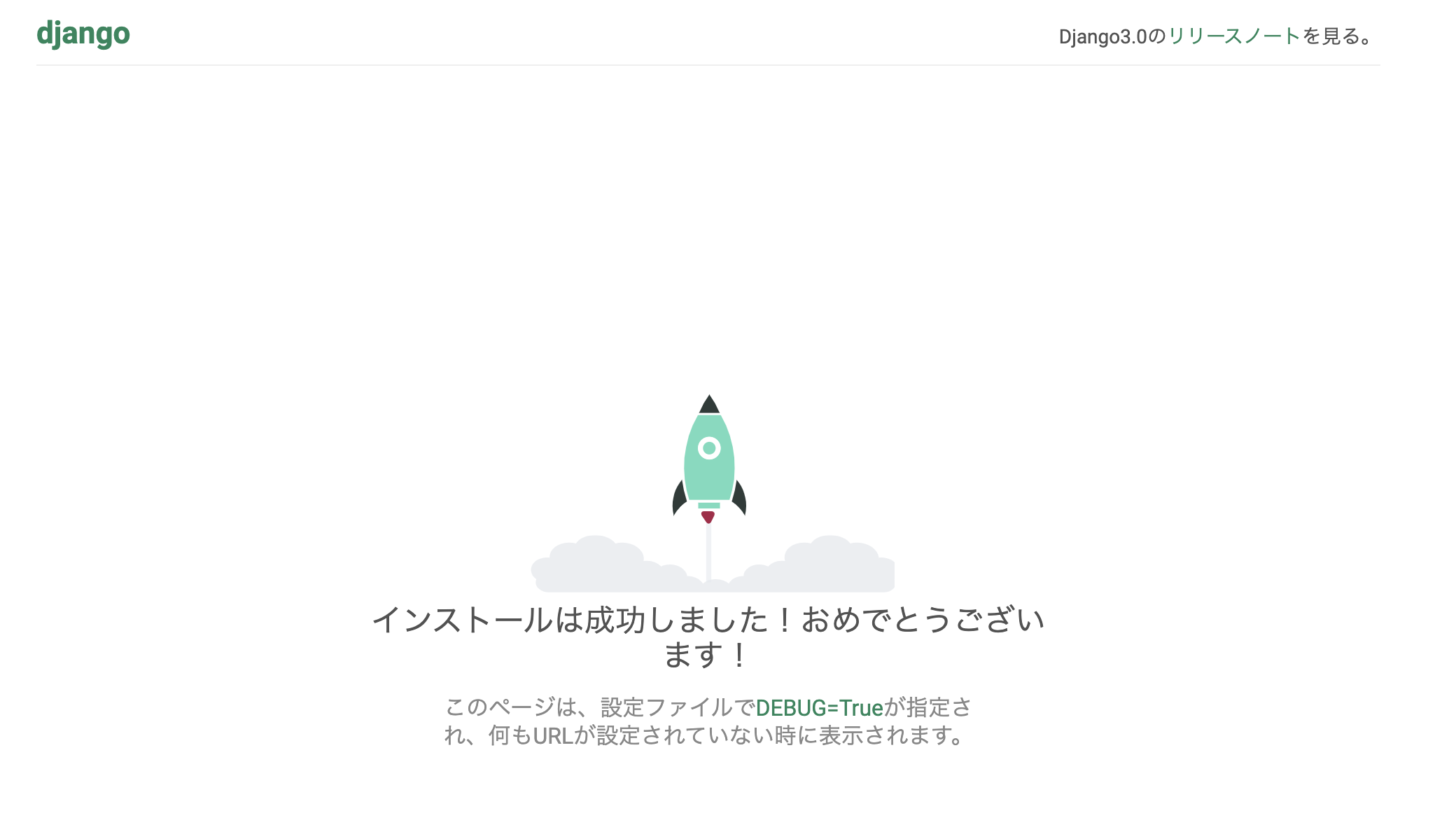
グラフ(木)描画用のライブラリです。このgraphvizを導入せずにライブラリを使用してしまうと、、、
FileNotFoundError: [WinError 2] 指定されたファイルが見つかりません。アバー
graphviz.backend.ExecutableNotFound: failed to execute ['dot', '-Tpng', '-O', 'binary_tree'], make sure the Graphviz executables are on your systems' PATH
graphviz内のdot.exeが見つからなくて怒られます。というわけで、今回はgraphvizを導入していくわけですが、
タグを見ればわかる通り、今回もWinPythonを用いてポータブルに導入します。インストール手順
今回の手順は
- Windows 10 Pro 64bit
- WinPython 3.8.10で実施します。
graphvizのダウンロード
Windows用のダウンロードページが用意されています。
https://graphviz.gitlab.io/_pages/Download/Download_windows.html
何も考えずにインストールするのであれば、「graphviz-2.38.msi」のインストーラ形式を選べばよいのですが、
私はインストーラを使用してシステムを汚すのが嫌なので、
ポータブルに導入すべく、 「graphviz-2.38.zip」 をダウンロードしました。graphvizのインストール
まずは先程ダウンロードした graphviz-2.38.zip を WinPython展開先の
tフォルダに展開します。
展開した中を見ると、、、
dot.exeがある!ということで、このフォルダをPATHに追加していきます。
んですが、何度も言うようにシステムを汚してしまうので、WinPythonを実行するときだけPATHが通るようにします。そういうときに使うのが、
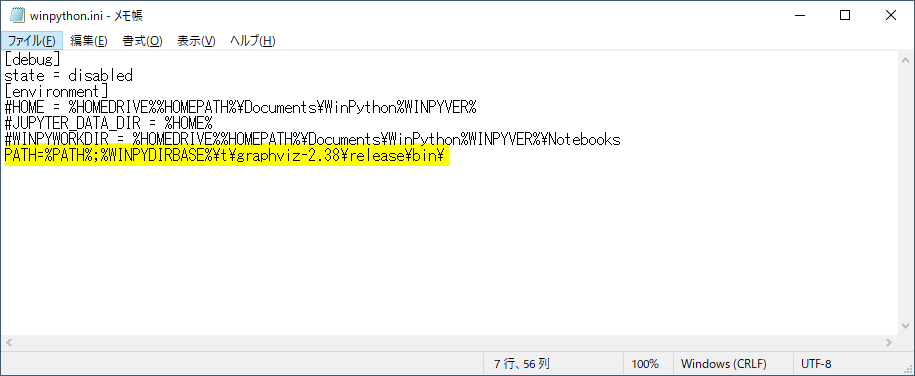
{winpythonInstallDir}\setttings\winpython.iniファイルです。
ここにPATHを追加していきます。
追加するPATHは{winpythonInstallDir}\t\graphviz-2.38\release\bin\ですが、
WinPythonを展開したフォルダのパスは環境変数WINPYDIRBASEに格納されるので、
D:\Applications\WPy64-3810\t\graphviz-2.38\release\bin\を追加するためには下記のように記載します。
ここで、
WINPYDIRBASEを使用せずにPATHを追加してしまうと、WinPythonフォルダを移動したときに使えなくなるので注意が必要です。
(USBメモリに入れて環境を持ち運んだりするとドライブレター変わってしまったりするので。)動作確認
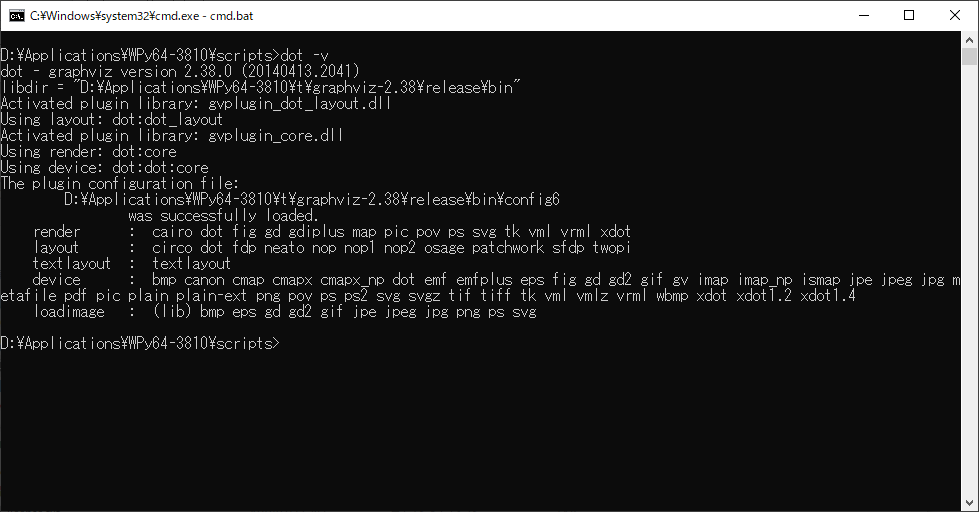
では、先程問題になった
dot.exeが使用できるかチェックしてみましょう。
WinPython Command Prompt.exeをダブルクリックして、dot -vコマンドを実行します。
いいぞ。
Jupyterでも使えます
こちらの記事を参考に、graphvizを試してみました↓
https://qiita.com/msuz/items/bd41a8fe67fd56707116
おわりに
WinPython、一番好きなPythonディストリビューションです!

- 投稿日:2020-05-17T20:58:19+09:00
BERTを30分ぐらいでちょっと経験してみる。
目的
BERTを、ちょっと、動かしてみたいと思い、
ぐぐって、一瞬で動きそうな例を試してみた。選んだ例
以下のサイトで、
https://www.ai-shift.jp/techblog/281BERTを使って、TOEICのPart 5の問題を解く、例が示されていた。
30行程度のコードだったので、これを動かしてみた。問題の作成
穴埋め問題として、
Pythonの英語の入門書
「introducing Python」 O'Reilly Media,Inc (First Edition 2016-02-26 Third release)
の文章を引用し、1文に対して、穴を一個開けてみた。textが1個穴の開いた(*が穴)文章。
candidateが穴埋めの候補。5個程度。以下、3問作ってみた。
text = "In Python, a lambda function is an anonymous function * as a single statement." candidate = ["experssion", "used", "expressed", "using", "known"]text = "Truncating integer division * you an integer answer." candidate = ["gives", "makes", "presents", "takes", "give"]text = "What * you get if you typed the following?" candidate = ["did", "will", "would", "do", "are"]1問追加。これは、Pythonの入門書ではなくて、tensorflow lite?か何かの
実行時のエラーメッセージ。text = "Model provided has model identifier 'TFL2', * be 'TFL3'" candidate = ["can", "could", "would", "shall", "should"]結果発表!
以下のとおり、全問正解。
(3, 'expressed') (0, 'gives') (0, 'would') (0, 'should')まとめ
BERTのレベルの高さを感じた。
正解以外の候補は、ワタシが考えたが、ちょっと、BERTとの力の差がありました。。。(日本語で再度トライするか、別の問題を考えたいと思います。
雑談ですが、shouldとかwouldとか、とっても、簡単なんでしょうね。。。)
コメントなどあれば、お願いします。
- 投稿日:2020-05-17T20:47:10+09:00
PythonでAWS公式ブログから最新記事30ページ分を1分で抽出する
※コードを修正して再投稿しています
AWS公式ブログの最新記事を毎日確認したいけど,時間がないしどうしよう...そうだ!Pythonにお任せしてみよう
主な使用ライブラリ
・BeautifulSoup(WEB解析)
・pysummarization(文章の要約)Input
AWS公式ブログのニュース
https://aws.amazon.com/jp/blogs/news/Output
・記事の発行日付
・記事のタイトル
・記事本文の要約
ソースコード
※必要なライブラリはpip install *** で適宜インストールしてください
#記事全文を要約する関数 def sum_text(document): from pysummarization.nlpbase.auto_abstractor import AutoAbstractor from pysummarization.tokenizabledoc.mecab_tokenizer import MeCabTokenizer from pysummarization.abstractabledoc.top_n_rank_abstractor import TopNRankAbstractor auto_abstractor = AutoAbstractor() auto_abstractor.tokenizable_doc = MeCabTokenizer() auto_abstractor.delimiter_list = ["。", "\n"] abstractable_doc = TopNRankAbstractor() result_dict = auto_abstractor.summarize(document, abstractable_doc) return ''.join(result_dict["summarize_result"]) if __name__ == '__main__': import re import requests from bs4 import BeautifulSoup import time import os import pandas as pd import codecs import sys from urllib.parse import urljoin from django.utils.html import strip_tags #「←Older Posts」ボタンと「Newer Posts」ボタン用にフラグを設定 flag = 1 df = pd.DataFrame() #csvファイルの保存名.例ではカレントディレクトリに出力する save_csv = './aws_pandas_normal.csv' base_url="https://aws.amazon.com/jp/blogs/news/" #後述.ページ遷移用のURLを保持する変数 dynamic_url="https://aws.amazon.com/jp/blogs/news/" #csvに出力するカラムを設定 data_col = ["information1", "information2", "information3"] #取得ページ分ループする.例では3ページ分取得する for _ in range(3): res = requests.get(dynamic_url) res.raise_for_status() html = BeautifulSoup(res.text, 'lxml') detail_url_list = html.find_all("section") #「←Older Posts」ボタンと「Newer Posts→」ボタンのリンクから次ページへのリンクを取得する #最初のページでは「←Older Posts」ボタンから次ページのリンクを取得する #2ページ目以降では「Newer Posts→」ボタンから次ページのリンクを取得する next_page = html.find_all("a",attrs={"class": "blog-btn-a"})[-1].get("href") if flag==1 else html.find_all("a",attrs={"class": "blog-btn-a"})[-2].get("href") flag = 0 #ページ内の記事数分ループする #AWS公式ブログでは1ページに10記事あるため,10回ループする. for i in range(len(detail_url_list)): #取得記事を設定 res2 = requests.get(urljoin(base_url, detail_url_list[i].a.get("href"))) res2.raise_for_status() #取得記事を解析 html2 = BeautifulSoup(res2.text, 'lxml') # 抜き出す情報に合わせて抽出するタグの変更 #タイトル information1 = html2.title.string #本文,htmlタグ除去,文章を要約 information2 = html2.find_all('p') information2 = strip_tags(information2) information2 = sum_text(information2) #発行日付 information3 = html2.find_all('time') information3 = strip_tags(information3) #csvファイルへ出力 s = pd.Series([information3, information1, information2],index=data_col) df = df.append(s, ignore_index=True) df.to_csv(save_csv) #sleep処理(WEBサーバに負荷をかけないため) print(str(len(df)) + "記事を取得しました。2秒待機します。") time.sleep(2) #最終ページのとき終了 if bool(next_page) == False: break #次のページにURLを設定する #2ページ目の場合 # dynamic_url = (~/news/) + (~/news/page/2/) # dynamic_url = ~/news/page/2/ dynamic_url = urljoin(base_url, next_page)参考サイト
・https://qiita.com/tomson784/items/88a3fd2398a41932762a
・https://zerofromlight.com/blogs/detail/35/まとめ
抽出したcsvファイルをエクセルに貼り付けて管理するのも良いですし,
AWS資格系の試験前に,過去ニュースをチェックすることにも使えます.ただし,AWS公式ブログのレイアウトが変更された場合は,
「information1~4」で抽出するhtmlタグの箇所を変更してください.試しに250記事を抽出してみました
ttps://www.real-tomo.com/2020/05/17/aws逆引き一覧/

- 投稿日:2020-05-17T20:38:10+09:00
【Python】OpenCVとpyocrで画像から文字を認識してみる
はじめに
Seleniumを利用する記事を探していると、ちょいちょい寿司打自動化の記事を見つけた。
手法としては基本的に以下のような感じ
・ゲームをスタートしたら全てのキーを入力し続ける
・ゲームをスタートしたらスクショをとりOCRで取得した文字列を入力
※寿司打はゲーム画面がCanvas要素に描画されているので直接文字列を取得できない今回はOCR部分と事前処理としてOpenCVを使った簡単な画像処理を試してみた
事前準備
tesseractのインストール
tesseractはOCRエンジンです。
今回はこのOCRエンジンをpythonのpyocrモジュールで動かします
インストールは以下のコマンドで完了$ brew install tesseractこのままだと日本語用のテストデータがないので以下のURLからダウンロード
https://github.com/tesseract-ocr/tessdata
↑このURLからjpn.traineddataを,/usr/local/share/tessdata/にダウンロードpyocrとOpenCVのインストール
ターミナルで以下のコマンドを実行すれば完了
$ pip3 install pyocr $ pip3 install opencv-pythonとりあえずOCRしてみる
画像の準備
テスト用の画像は以下
↓トリミング
トリミングしたものをtest.pngという名前で保存
pyocrでOCR
import cv2 import pyocr from PIL import Image image = "test.png" img = cv2.imread(image) tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) tool = tools[0] res = tool.image_to_string( Image.open("test.png") ,lang="eng") print(res)実行結果
全く正しく認識されてない…
やっぱり事前処理が必要そうだなぁOpenCVを触ってみる
OpenCVで事前処理をしたいが、OpenCVもはじめてなので遊んでみる
自分のアイコン画像を処理してみるimport sys import cv2 import pyocr import numpy as np from PIL import Image image = "test_1.png" name = "test_1" #original img = cv2.imread(image) #gray img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) cv2.imwrite(f"1_{name}_gray.png",img) #goussian img = cv2.GaussianBlur(img, (5, 5), 0) cv2.imwrite(f"2_{name}_gaussian.png",img) #threshold img = cv2.adaptiveThreshold( img , 255 , cv2.ADAPTIVE_THRESH_GAUSSIAN_C , cv2.THRESH_BINARY , 11 , 2 ) cv2.imwrite(f"3_{name}_threshold.png",img)処理過程での画像はこんな感じ
OpenCV + OCR
先程OCRで使用した画像をOpenCVで事前処理して再度OCRを実行してみる
以下では事前処理としてグレースケール→閾値処理→色反転をしているimport sys import cv2 import pyocr import numpy as np from PIL import Image image = "test.png" name = "test" #original img = cv2.imread(image) cv2.imwrite(f"1_{name}_original.png",img) #gray img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) cv2.imwrite(f"2_{name}_gray.png",img) #threshold th = 140 img = cv2.threshold( img , th , 255 , cv2.THRESH_BINARY )[1] cv2.imwrite(f"3_{name}_threshold_{th}.png",img) #bitwise img = cv2.bitwise_not(img) cv2.imwrite(f"4_{name}_bitwise.png",img) cv2.imwrite("target.png",img) tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) tool = tools[0] res = tool.image_to_string( Image.open("target.png") ,lang="eng") print(res)
実行結果
うまく認識できてそう!
一旦今回はここまでで終わり






- 投稿日:2020-05-17T20:33:33+09:00
toio.py でくるっと文字動画 #toio #おうちでロボット開発
やったこと
くるっとtoio〜♪
— 水落 大 mizumasa (@_mizumasa) May 17, 2020
開発者向けマットを白バックに#toio #おうちでロボット開発 pic.twitter.com/69BcmsuCMf
toioの非公式ライブラリ toio.py に指定角度への回転コマンドを追加しました。非公式 Python ライブラリ(https://github.com/mizumasa/toio.py.git)
できること
- スピードの指定(speed オプション)
- 回転方向の指定(clock オプション)
- 加減速の指定(ease オプション)
などの機能を盛り込んでいます
サンプルコード
import toio 17 import random def main(): T = toio.TOIO() T.connect() for i in range(4): T.turn_to(i,int(360*random.random())) for i in range(4): T.turn_to(i,int(360*random.random())) for i in range(4): T.turn_to(i,90) T.disconnect() return if __name__ == '__main__': main()https://github.com/mizumasa/toio.py/blob/master/example_turn.py
- 投稿日:2020-05-17T20:14:21+09:00
AnyMotionを使ってフュージョンの動きを検出してみる
概要
みなさんご存知のフュージョンの動きを検出してみました。
AnyMotionを使用して関節の座標情報から角度の算出を行い、フュージョンっぽい姿勢かどうかを判定します。AnyMotionとは
AnyMotionとは、AIを用いた姿勢推定による動作解析APIプラットフォームサービスです。現在はトライアル中ということで無料で利用できるようです。
人物が写っている画像や動画に対してその人物の骨格座標の推定を行い、それをもとに指定した部位の角度を算出することで、身体動作の可視化/定量化を行うことができます。
GitHubにてCLIやPython SDK、Jupyter Notebookで書かれたExamplesが公開されています。
目指すゴール
フュージョンは本来2人の戦士が対称のアクションを同じタイミングで行うことで成り立ちますが、現状AnyMotionでは2人以上の同時姿勢推定はできないという制約があります。そのため1人ずつ動作を解析することにします。
フュージョンは掛け声に合わせて3段階の動作があります。
- 「フュー」腕を回しながらお互いにすり寄る動作
- 「ジョン」腕を外側に、脚を内側にねじる動作
- 「はっ!」上体を内側に曲げ指を合わせる動作
今回は簡単のために、動きが一瞬止まる2と3の姿勢をそれぞれ定義し、両方とも当てはまる動作がないかを解析します。指の高さなど細かい部分がズレていても気にしません。
上述の動作解析をフュージョンの左側の人と右側の人でそれぞれ行い、タイミングを問わず2人ともそれっぽい動きをしていればフュージョン成立!ということにします。
フュージョンの姿勢の定義
身体がどの状態であればフュージョンとみなすのか、以下の表にまとめてみました。
- フェーズ1:「ジョン」腕を外側に、脚を内側にねじる動作
- フェーズ2:「はっ!」上体を内側に曲げ指を合わせる動作
左側の人(右側の人) 「ジョン」 「はっ!」 左肩(右肩) 10〜90 130〜180 左ひじ(右ひじ) 90〜180 40〜130 右肩(左肩) 120〜200 50〜150 右ひじ(左ひじ) 150〜200 100〜170 左ひざ(右ひざ) 10〜80 - 注意事項
- 性質上、撮影環境などの理由により骨格座標の推定が行われない、または不正確なことがあります。
- 骨格座標の推定には数分かかります(動画の長さ、大きさに比例して時間がかかります)
Python SDKを使ってコードを書いてみた
使用したバージョン
- Python 3.8.0
- anymotion-sdk 1.0.1
事前準備
- AnyMotion APIのトークン発行
- AnyMotionのページ右上 "Sign Up/Sign In" をクリックするとポータル画面に行くので、ユーザー登録してClient IDとSecretを取得する
- anymotion-sdkのインストール
$ pip install anymotion-sdk動画ファイルのアップロード〜骨格抽出
from anymotion_sdk import Client from PIL import Image, ImageDraw import cv2 import matplotlib.pyplot as plt import ffmpeg import numpy as np # AnyMotion APIの準備 client = Client(client_id="CLIENT_ID", client_secret="CLIENT_SECRET") filename = "left.mp4" # 動画のアップロード(左側) left_filename = "fusion_left.mp4" left_movie_id = client.upload(left_filename).movie_id print(f"movie_id: {left_movie_id}") # 骨格抽出(キーポイント抽出)(左側) left_keypoint_id = client.extract_keypoint(movie_id=left_movie_id) left_extraction_result = client.wait_for_extraction(left_keypoint_id) print(f"keypoint_id: {left_keypoint_id}") # 動画のアップロード(右側) right_filename = "fusion_right.mp4" right_movie_id = client.upload(right_filename).movie_id print(f"movie_id: {right_movie_id}") # 骨格抽出(キーポイント抽出)(右側) right_keypoint_id = client.extract_keypoint(movie_id=right_movie_id) right_extraction_result = client.wait_for_extraction(right_keypoint_id) print(f"keypoint_id: {right_keypoint_id}")角度の取得
角度を取得する部位を指定します。指定の仕方は公式ドキュメントに記載があります。
# 角度の解析ルールの定義 analyze_angles_rule = [ # left arm { "analysisType": "vectorAngle", "points": ["rightShoulder", "leftShoulder", "leftElbow"] }, { "analysisType": "vectorAngle", "points": ["leftShoulder", "leftElbow", "leftWrist"] }, # right arm { "analysisType": "vectorAngle", "points": ["leftShoulder", "rightShoulder", "rightElbow"] }, { "analysisType": "vectorAngle", "points": ["rightShoulder", "rightElbow", "rightWrist"] }, # left leg { "analysisType": "vectorAngle", "points": ["rightHip", "leftHip", "leftKnee"] }, # right leg { "analysisType": "vectorAngle", "points": ["leftHip", "rightHip", "rightKnee"] }, ] # 角度の解析開始(左側) left_analysis_id = client.analyze_keypoint(left_keypoint_id, rule=analyze_angles_rule) # 角度情報の取得 left_analysis_result = client.wait_for_analysis(left_analysis_id).json # dict形式の結果をlist形式へ変換(同時に数値をfloatからintへ変換) left_angles = [list(map(lambda v: int(v) if v else None, x["values"])) for x in left_analysis_result["result"]] print("angles analyzed.") # 角度の解析開始(右側) right_analysis_id = client.analyze_keypoint(right_keypoint_id, rule=analyze_angles_rule) right_analysis_result = client.wait_for_analysis(right_analysis_id).json right_angles = [list(map(lambda v: int(v) if v else None, x["values"])) for x in right_analysis_result["result"]] print("angles analyzed.")フュージョン検出
def is_fusion_phase1(pos, a, b, c, d, e, f): # pos: left or right # print(a, b, c, d, e, f) if pos == "left": # 左側に立つ人をチェックする if not e: e = 70 # 脚の角度が取れていない場合を考慮 return (a in range(10, 90) and \ b in range(90, 180) and \ c in range(120, 200) and \ d in range(150, 200) and \ e in range(10, 80)) else: # 右側に立つ人をチェックする if not f: f = 70 # 脚の角度が取れていない場合を考慮 return (c in range(10, 90) and \ d in range(90, 180) and \ a in range(120, 200) and \ b in range(150, 200) and \ f in range(10,80)) def is_fusion_phase2(pos, a, b, c, d, e, f): # pos: left or right # print(a, b, c, d, e, f) if pos == "left": # 左側に立つ人をチェックする return a in range(130, 180) and \ b in range(40, 130) and \ c in range(50, 150) and \ d in range(100, 170) else: return c in range(130, 180) and \ d in range(40, 130) and \ a in range(50, 150) and \ b in range(100, 170) def check_fusion(angles, position): """ angles: 角度情報 position: left or right """ # 各ステップを検出したかを格納するフラグ phase1 = False phase2 = False # 該当フレームを格納するリスト p1 = [] p2 = [] for i in range(len(angles[0])): if is_fusion_phase1(position, angles[0][i], angles[1][i], angles[2][i], angles[3][i], angles[4][i], angles[5][i]): print(i, "Phase1!!!") phase1 = True p1.append(i) elif phase1 and is_fusion_phase2(position, angles[0][i], angles[1][i], angles[2][i], angles[3][i], angles[4][i], angles[5][i]): print(i, "Phase2!!!") phase2 = True p2.append(i) if phase1 and phase2: print("Fusion!!!!!!") return ((phase1 and phase2), p1, p2) left_result, left_p1, left_p2 = check_fusion(left_angles, "left") right_result, right_p1, right_p2 = check_fusion(right_angles, "right")検出したフュージョンのフレームを使ってGIFアニメーションを生成する
# 動画の向きを確認する def check_rotation(path_video_file): meta_dict = ffmpeg.probe(path_video_file) rotateCode = None try: if int(meta_dict['streams'][0]['tags']['rotate']) == 90: rotateCode = cv2.ROTATE_90_CLOCKWISE elif int(meta_dict['streams'][0]['tags']['rotate']) == 180: rotateCode = cv2.ROTATE_180 elif int(meta_dict['streams'][0]['tags']['rotate']) == 270: rotateCode = cv2.ROTATE_90_COUNTERCLOCKWISE except: pass return rotateCode # 動画の指定したフレームを取得する def get_frame_img(filename, frame_num): reader = cv2.VideoCapture(filename) rotateCode = check_rotation(filename) reader.set(1, frame_num) ret, frame_img = reader.read() reader.release() if not ret: return None if rotateCode: frame_img = cv2.rotate(frame_img, rotateCode) return frame_img # 2つのフレームを横に連結する def get_frame_img_hconcat(l_filename, r_filename, l_framenum, r_framenum): l_img = get_frame_img(l_filename, l_framenum) r_img = get_frame_img(r_filename, r_framenum) img = cv2.hconcat([l_img, r_img]) return img # 検出したフレームの中央値を取得 left_p1_center = left_p1[int(len(left_p1)/2)] left_p2_center = left_p2[int(len(left_p2)/2)] right_p1_center = right_p1[int(len(right_p1)/2)] right_p2_center = right_p2[int(len(right_p2)/2)] # Phase1の画像を横方向に結合する p1_img = get_frame_img_hconcat(left_filename, right_filename, left_p1_center, right_p1_center) # Phase2の画像を横方向に結合する p2_img = get_frame_img_hconcat(left_filename, right_filename, left_p2_center, right_p2_center) # numpy arrayからPILのImageに変換する im1 = Image.fromarray(cv2.cvtColor(p1_img, cv2.COLOR_BGR2RGB)) im2 = Image.fromarray(cv2.cvtColor(p2_img, cv2.COLOR_BGR2RGB)) # GIFアニメを生成する im1.save('fusion.gif', save_all=True, append_images=[im2], optimize=False, duration=700, loop=0)
(手が物と被ってしまったり指の位置がズレてたり、いろいろ言いたいことはあると思いますが大目に見てください…)
ソースコード全体
gistにJupyter Notebookの形式でアップロードしました。
おわりに
AnyMotionを使って推定した姿勢情報を活用してフュージョンの姿勢を検出してみました。
このようなことを行うことで筋トレのフォームチェックをするといったパーソナルトレーナー的なことも出来るようです(いえとれ)。
他にもどんなことができるのかいろいろ試していきたいと思います。参考


- 投稿日:2020-05-17T20:07:47+09:00
駆け出しエンジニアの機械学習メモ その2
はじめに
「ゼロから作るDeep-Learning」の学習メモその2です。
2層ニューラルネットワーク(4章)
- mnist.pyよりデータの読み込みを行う。正規化、one_hot配列化、データの1次元配列化を行う。
train_neuralnet# データの読み込み (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True,flatten=True, one_hot_label=True)
- two_layer_net.pyより重みの初期化を行う。辞書型でparams{W1:,b1:,W2:,b2:}のkeyを生成。 print(network.params)で中身を見ることができる。
train_neuralnetnetwork = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
- 各初期値の設定、60000枚の画像データを100枚ずつ処理していく。
train_neuralnetiters_num = 10000 # 繰り返しの回数を適宜設定する train_size = x_train.shape[0] # 60000 batch_size = 100 learning_rate = 0.1 train_loss_list = [] train_acc_list = [] test_acc_list = [] # 1エポックあたりの繰り返し処理 60000 / 100 iter_per_epoch = max(train_size / batch_size, 1)
- 訓練データから無造作に一部のデータを取り出し学習を行う。ここでは60000枚のデータから100枚取り出す。
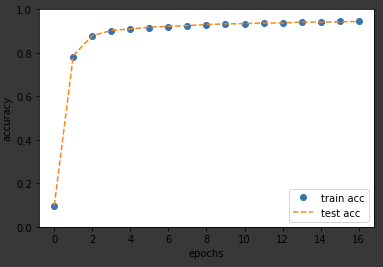
リストに保存していたデータを利用してグラフの描画を行う。
# グラフの描画 x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list,'o', label='train acc') plt.plot(x, test_acc_list, label='test acc', linestyle='--') plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show()* 描画結果
参考
ゼロから作るDeep Learning
- 投稿日:2020-05-17T19:44:41+09:00
【AtCoder解説】PythonでABC165のC問題『Many Requirements』を制する!
AtCoder Beginners Contest 165のC問題『Many Requirements』をPython3で解く方法を、なるべく丁寧に解説していきます。
とても長くなったので、C問題だけ分割しました。
3種類の方法で解説します。
- itertools.combinations_with_replacement()を使う(一番楽)
- キュー再帰で作る(汎用性が高い方法)
- 深さ優先探索(DFS)(解説PDFの方法、めんどくさい)
ABC165C『Many Requirements』
問題ページ:C - Many Requirements
むずかしさ:★★★★★★★★★★(難しいD問題レベル!)
タイプ:総当りの発想、深さ優先探索(他の方法もあり)、過去問演習まず問題文を読んで意味を理解するのが大変です。意味がわかっても、すべての数列を作って確かめるという発想が必要です。そして、総当りすることがわかっても、どうやって数列を作るか知らないと解けません。
正直言って、難しいD問題の難易度です。
やること
- (やばそうなので、D問題が簡単ではないか確認する)
- 問題文を解読する
- 解法を考える
- 実装を考える
ステップ2: 問題文を解読する
問題文をなんとか解読すると、私たちに作ってほしいのは長さが $N$ の数列だそうです。長さ $N$ は2~10です。数列が条件を満たしていると得点をもらえるので、その得点の最大値を出してほしいと言っています。
数列の数字は $1$ 以上 $M$ 以下です。上限 $M$ は1~10です。そして、数字は1個前の数字と同じか大きくないといけません。数字が途中で減ってはいけないということです。
例えば、 $N = 4$ で $M = 3$ だとします。
許される数列の例をあげてみます。
$1,1,2,3$
$1,1,1,1$(すべて同じでもいい)
$2,3,3,3$($1$からはじまっていなくてもいい)ダメな数列の例をあげてみます。
$1,1,3,2$($2$ は $3$ より大きいので、3の後ろには来れません)
$1,2,3,4$($4$ は 上限 $M = 3$ を超えています)
$0,1,2,3$($1$ 以上なので、$0$ はダメです)
$1,1,1$(長さ $N = 4$です)
$1,1,1,1,1$(同上)最後に、条件が $Q$ 個あります。条件は最大で50個あって、1つの条件は、4つの整数 $a, b, c, d$ からなります。
その条件とは、
(作った数列の $b$ 番目) - (作った数列の $a$ 番目) = $c$
であることです。もしそうならば、得点が $d$ もらえます。
例えば、条件が
$a=1$
$b=4$
$c=2$
$d=5$
の場合、(数列の $4$ 番目) - (数列の $1$ 番目) = $2$ だと $5$ 点もらえます。いくつか数列の例をあげると、 $1,1,2,3$ や $1,2,3,3$ は $5$ 点もらえますが、 $1,2,2,2$ や $2,2,3,3$ はもらえません。
これをすべての条件に対して確認して求めた得点の合計の、最大値を求めてほしいそうです。
ステップ3 解法を考える
この問題はあり得る数列を全て作って、それぞれの得点を計算して最大値を求めるしかありません。ですので、総当りできることに気づかないと絶対に解けません。
数列の長さは最大10、数字の上限は最大10なので、作れる数列はそんなに多くない気がします。解説PDFに書いてあるとおりに正確な数を求めると、
20C10=184756$ _{19} C_{10} = 92378$ 通りになります。(5/3 訂正しました。@forzaMilanさんありがとうございます!)そして、得点をもらうための条件は最大で50個なので、作った数列に対して全部確認しても間に合いそうな感じがします。
ステップ4 実装を考える
さて、総当りできることに気づいても、どうやって数列をすべて作るかがわからないと解けません。
こういう数列や文字列を作る問題はたまに出てくるので、類題を解いていればわかるかもしれません。しかし、知らなければコンテスト中に思いつくのは難しいと思います。
数列を作る方法はいくつかあります。
- itertools.combinations_with_replacementを使う(一番楽)
- キュー再帰で作る(汎用性が高い方法)
- 深さ優先探索(解説PDFの方法)
方法1 combinations_with_replacementを使う方法
一番楽な方法は、
itertoolsモジュールの、combinations_with_replacement()関数を使う方法です。私は後から知りましたが、この関数を使うだけで、この問題の数列をすべて列挙することができます。名前が長くて覚えづらいですが、便利な関数です。使うには、
itertoolsモジュールをインポートする必要があります。
combinations_with_replacement()は何をする関数かというと、『重複組み合わせ』を列挙する関数です。普通の『組み合わせ』combinations()との違いは、同じ要素を複数回選ぶのを許するところです。入力は『イテラブル』な要素と、要素を取り出す回数(列の長さ)の2つです。『イテラブル』は英語で"iterable"で、「反復できる」という意味です。forループのinの後に使えるもののことで、「リスト」、「タプル」、「
range()」、「文字列」などがあります。出力は、入力の条件でできるすべての『重複組合せ』です。出力はそれぞれ、「入力された要素の順番」で並べられてでてきます。これは重要なことです。
forループと
print()で、何が作られるのか見てみましょう。要素をrange(1,4)、つまり(1,2,3)の3つで、長さは2としてみます。# 長いので、comb_rplcという名前でインポートします from itertools import combinations_with_replacement as comb_rplc for seq in comb_rplc(range(1, 4), 2): print(seq) (1, 1) (1, 2) (1, 3) (2, 2) (2, 3) (3, 3)(1, 1)や(2, 2)のように、同じ要素が複数回出てくるものも含んでいます。入力は1,2,3の順番なので、(2, 1)や(3, 2)のように、前の数字より小さい数字が次にくることはありません。
普通のcombinationsと比べてみる
普通の組み合わせ
combinations()と比べてみましょう。from itertools import combinations for seq in combinations(range(1, 4), 2): print(seq) (1, 2) (1, 3) (2, 3)たしかに、同じ要素を2回選んでいる(1, 1)や(2, 2)は出てきていません。
入力の順番を変えてみる
入力を"CBA"にしてみます。forと同じように、
"C"、"B"、"A"の3要素とみなされます。for seq in comb_rplc("CBA", 2): print(seq) ('C', 'C') ('C', 'B') ('C', 'A') ('B', 'B') ('B', 'A') ('A', 'A')C,B,Aの順番で入力したので、出力もその順番に並べられて出てきます。ABCの順に出てくるわけではないことに注意しましょう。
この問題の数列をどう作るか?
この問題で作る数列の条件は、次の数字が前の数字より小さくないことです。入力を昇順にすれば、出力も昇順になるので、この条件は勝手に満たしてくれます。
数列の長さは $N$ で、数字の上限が $M$ なので、
combinations_with_replacement(range(1, m + 1), n)とすれば、すべてのありえる数列を列挙できます。コード1
from itertools import combinations_with_replacement as comb_rplcのように省略名をつけてインポートすれば、コードがごちゃごちゃしなくて済みます。from itertools import combinations_with_replacement as comb_rplc n, m, q = list(map(int, input().split())) # reqは[[a1,b1,c1,d1],[a2,b2,c2,d2]……]が入ったリストのリストです req = [list(map(int, input().split())) for _ in range(q)] ans = 0 # seqは長さnのタプルです for seq in comb_rplc(range(1, m + 1), n): score = 0 for a, b, c, d in req: # 問題文に書いてある数列のk番目は、インデックスだとk-1になるので注意 if seq[b - 1] - seq[a - 1] == c: score += d ans = max(ans, score) print(ans)余談1:"with replacement"ってなんだ
"with replacement"は、「元に戻す」という意味です。"replace"は「交換する」、「置き換える」という意味のほうがよく使われますが、そちらではありません。
数字の書いたボールが袋に入っているとします。"without replacement"な普通の『組み合わせ』では、取り出したボールを袋に戻しません。"with replacement"な『重複組み合わせ』では、取り出したボールの数をメモしたあと、袋に戻します。
こういうふうに意味がわかると、この関数を思い出しやすくなるかもしれません。
方法2 キュー再帰で作る方法
この問題は
combinations_with_replacement()で数列を作ることができましたが、条件がもっと複雑になると、自力で実装する必要が出てきます。「ある条件を満たす文字列や数列を全て作りたい」とき、汎用性の高い方法に『キュー再帰』というものがあります。
これはその名の通り、キュー(queue)というデータ構造(配列)を使います。キューはどういうものかというと、「先に入れたものを、先に取り出す」(FIFO: First In, First OUT)配列です。アルゴリズムの勉強をすると出てくる、メジャーなやつです。
キューからまだ作りかけの文字列を取り出して、そこに1文字追加した文字列たちを、キューに追加することを繰り返します。
すると、最終的に作りたい数列が全て生成されます。
Pythonでキューを使うには、"deque"を使う
Pythonでキューを使うには、
collectionsモジュールのdeque()をインポートする必要があります。"deque"は"double-ended-queue"の頭文字をとったもので、『両端キュー』というデータ型です。発音は「デック」です。
dequeは先頭、末尾のどちらからでも、要素を取り出したり、追加したりすることができます。つまり、スタックとキューの上位互換です。
dequeのメソッド
dequeに要素を追加、取り出すメソッドは2つずつあります。
append():右(末尾)に要素を追加する
appendleft():左(先頭)に要素を追加する
pop()右(末尾)の要素を取り出す
popleft():左(先頭)の要素を取り出すキューの「先に入れたものを、先に取り出す」とは、「入れるときは右から」「取り出すときは左から」と言い換えられます。
つまり、入れるときは
append()を使って、取り出すときはpopleft()を使えば、それだけでキューが実現できます。スタックの場合は「後に入れたものを、後に取り出す」なので、
append()で取り出すときはpop()です。どんなコード?
キュー再帰を疑似コード風に書いたものをみて、どういうことをするのか見てみます。
from collections import deque que = deque() que.append(最初の状態) # 最初の状態を入れないと、while queを素通りします while que: 今の状態 = que.popleft() # 先頭から取り出します # なにか処理をする if 条件を満たす: # なにか処理をする else: 次の状態 = 今の状態 + α # forで「次の状態」を複数作る場合もある que.append(次の状態) # 末尾に追加します
while queとは、queが空でないならTrue、空になるとFalseと判定されるので、queの中身がなくなるまでループするという意味です。条件を満たす場合、キューに追加せずに何らかの処理をしないと、無限ループになります。
こうすると、キュー再起ができます。
コード2
from collections import deque # 数列の点数を計算する関数 def calc(seq): score = 0 for a, b, c, d in req: if seq[b - 1] - seq[a - 1] == c: score += d return score n, m, q = list(map(int, input().split())) req = [list(map(int, input().split())) for _ in range(q)] ans = 0 que = deque() # 数列の1番目、[1]~[m]までキューに追加しますが、 # 実は、この問題は数列の最初が[1]の場合だけを考えても解けます。 for i in range(1, m + 1): que.append([i]) while que: seq = que.popleft() if len(seq) == n: # 長さがnになったので、得点を計算します score = calc(seq) ans = max(ans, score) else: # 次に追加する数字は、下限が今の数列の一番後ろの数字、上限がmです for i in range(seq[-1], m + 1): seq_next = seq + [i] que.append(seq_next) print(ans)キューの中身の変化を見てみる
m=3、n=3のとき、キューの中身がどう変化していくのか、書いてみます。[1],[2],[3](初期状態)
[2],[3],[1,1],[1,2],[1,3]
[3],[1,1],[1,2],[1,3],[2,2],[2,3]
[1,1],[1,2],[1,3],[2,2],[2,3],[3,3]
[1,2],[1,3],[2,2],[2,3],[3,3],[1,1,1],[1,1,2],[1,1,3]
[1,3],[2,2],[2,3],[3,3],[1,1,1],[1,1,2],[1,1,3],[1,2,2],[1,2,3]
……(中略)
[2,3,3],[3,3,3]
[3,3,3]
なし(終了)一番左にあるものを取り出して、それに1個数字を付け加えたものを右に追加していっていますね。このようにして、すべての数列を作り出すことができます。
長さが3は数列が完成したということなので、点数を計算するだけで、新しい状態をキューに追加することはありません。そのため、最終的にキューの中身は空になるので、無限ループに陥ることはありません。
余談1:スタック再帰でも解けます
この問題の場合、「右から入れて左から取り出す」キューでなく、「右から入れて右から取り出す」スタックでも解けます。
ついでに、スタックはdequeでなく、普通のリストでもできます。
append()メソッドとpop()メソッドは普通のリストにもあるからです。しかし、基本的には
deque()をキューとして扱って解くことをおすすめします。3つほど利点があります。
- 要素数が増えるとdequeのほうが動作が速い
- キューを使うと数列や文字列が『辞書順』で出てくることがたまに役立つ
- 文字列・数列列挙以外でもdequeを使う機会はあるので、慣れておくと有利
余談2:キュー再帰は『幅優先探索』で、スタック再帰は『深さ優先探索』
キュー再帰は『幅優先探索』(BFS)そのものです。スタック再帰にすると『深さ優先探索』(DFS)になります。
文字列や数列をすべて作るだけならどちらでもできますが、出てくる順番が違います。
方法3 深さ優先探索(DFS)で作る方法
最後は、公式の解説PDFに書いてある、深さ優先探索を使う方法です。『再帰関数』を使います。
キュー再帰やスタック再帰よりもさらにできることの幅が広がりますが、文字列や数列を作るだけならキュー再帰だけで十分です。
深さ優先探索のメリットは
- 『行きがけ処理』『帰りがけ処理』を実装しやすい
- できるとアルゴリズムを書いてる感がある
デメリットは
- 再帰関数は動作を理解しづらい(しようとしないほうがいいです。感覚と慣れです)
- Pythonだと再帰回数の上限に引っかかってREになりがち
コード3
dfs関数の引数は、今の数列seq(タプル)です。次の数字の下限は、今の数列の一番後ろなので、seq[-1]です。
例えば、数列1,1に3を付け加えて、1,1,3になったとします。次に付け加える数字は3以上でなければいけないので、(次の数字の下限)は今付け加えた3です。
今の数列の長さがn未満の場合は、(数字の下限)~(数字の上限m)を付け加えた新しい数列をそれぞれすべて、再びdfs(今つくった数列、今つくった数列の長さ、次の数字の最小値)をします。
今の数列が1,1,3で、上限$M = 4$ならば、
1,1,3,3
1,1,3,4
をdfsに渡すということです。長さがnになって完成したら、得点を計算します。得点が出たら、
ans = max(ans, score)として最大値を更新します。これは普通の問題と同じです。すべてが終わったら、本体のコードにすべての最大値が返ってくるので、これをprintして終わりです。
def dfs(seq): # 返り値は、すべての数列の得点の最大値 ans です。 ans = 0 if len(seq) == n: # 数列が完成したので、得点を計算します score_ret = 0 for a, b, c, d in req: if seq[b-1] - seq[a-1] == c: score_ret += d return score_ret # この数列の得点を返します else: # まだ数列が完成していません for i in range(seq[-1], m + 1): seq_next = seq + (i,) # 長さ1のタプル(i,)を連結します score = dfs(seq_next) # seq_nextから派生するすベての数列の中での、得点の最大値が返ってきます ans = max(ans, score) # 最大の得点を更新します # 得点の最大値を返します return ans n, m, q = list(map(int, input().split())) # reqは[[a1,b1,c1,d1],[a2,b2,c2,d2]……]が入ったリストのリストです req = [list(map(int, input().split())) for _ in range(q)] # 最終的に答えが返ってくるようにします。処理はすべてdfsメソッドでやってもらいます。 # リストだとどこかで間違えて値を書き換えそうで怖いので、タプルにしておきます # 1番目が1の場合以外は考えなくていいので、(1,)だけやります ans = 0 score = dfs((1,)) ans = max(ans, score) print(ans)1番目が1の場合以外考えなくていい理由
何度か数列の1番目が1の場合以外考えなくてもいいと書きました。コード3の深さ優先探索では、実際に1始まりだけを全探索しています。
なぜそうなるかというと、「b番目の要素とa番目の『差』」が重要であって、数字そのものはなんでもいいからです。
たとえば、2,3,3,4は1,2,2,3と差がそれぞれ同じですし、3,3,3,3は1,1,1,1と同じです。このように、1始まり以外の数列には、1始まりで等価な数列が必ずあります。
別に全部やってもいいのですが、気づくと実装がちょっと楽になるかもしれません。ついでに実行時間も半分くらいになりますが、1始まり以外を含めて全探索してもTLEにならないのでどうでもいいです。
類題
類題をいくつか紹介します。一番上の問題は慣れるのにちょうどいい難易度です。後ろの2つはやや難しいD問題レベルの難易度ですが、それでもこの問題よりは簡単です。
茶レベル: ABC029 C - Brute-force Attack
緑レベル: ABC161 D - Lunlun Number
緑レベル: パナソニックプログラミングコンテスト2020 D - String Equivalence
- 投稿日:2020-05-17T19:25:10+09:00
ゼロから始めるLeetCode Day28「198. House Robber」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day27「101. Symmetric Tree」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
198. House Robber
難易度はeasy。
Top 100 Liked Questionsからの抜粋です。あなたは通り沿いの家から泥棒することを計画している泥棒です。各家には一定のお金が隠されています。各家からの強盗を防ぐ唯一の制約は、それぞれ隣接する家にセキュリティシステムが接続されており、隣接する2つの家が同じ夜に侵入された場合に自動的に警察に通報されることです。
各家庭の金額を表す負ではない整数のリストを考慮して、警察に警告されずに今夜奪うことができる最大金額を求めましょう。
説明を元に問題を見てみましょう。
Example 1:
Input: [1,2,3,1]
Output: 4
Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).
Total amount you can rob = 1 + 3 = 4.この例の場合、1つめの家と3つめの家から奪った場合の金額が最大になるため、4が返されます。
Example 2:
Input: [2,7,9,3,1]
Output: 12
Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1).
Total amount you can rob = 2 + 9 + 1 = 12.この例の場合、1つめの家と3つめの家と5つめの家から奪った場合の金額が最大になるため、12が返されます。
解法
class Solution: def rob(self, nums: List[int]) -> int: pre = cur = 0 for i in nums: pre,cur = cur,max(pre+i,cur) return cur # Runtime: 20 ms, faster than 98.32% of Python3 online submissions for House Robber. # Memory Usage: 14.1 MB, less than 9.09% of Python3 online submissions for House Robber.リストを前から舐めていき、
preにcurをcurにはpre+iとcurの大きい方を代入する、ということを行えば完走できると思います。例えば。例の
[1,2,3,1]の場合は
pre= 0,1,2,4
cur= 1,2,4,4の順で推移し、最終的に正答である4が返されます。
下手に難しく考えずに、前から舐めていく場合はどのように操作すれば上手く動作するかという点に重点を置いた方が上手く解ける問題かと思います。
良さげな解答があれば追記します。
- 投稿日:2020-05-17T19:14:58+09:00
レースゲーム(Assetto Corsa)の走行データをPlotlyで可視化してみた
はじめに
私はレースゲームが好きでグランツーリスモ5/6をやり込んでいたのですが、Assetto Corsaに移ってから全く上手く走れていないことに気付きました。具体的には、AI車両(Strength=100%)に1周4秒近く離される状況です(カタルニアサーキット/TOYOTA GT86、ゲームパッド使用時)。
GT6ではABS=1/TCS=1以外のアシストOFFでオールゴールド取れているので、そんなに下手ではないと思っていたのですが…なぜこれほど差が付くのかを分析するために、可視化ツールのお勉強も兼ねて、自分のプレイとAIのプレイの走行データをPythonで取得して、Plotlyで可視化してみました。
ちなみにですが、データ取得&可視化するだけならMotec i2 Proというツールがあります。今回は可視化ツールの調査も兼ねているので、Motecは使いませんが。
データ取得
Assetto Corsaには 「in-game app」(ゲーム内アプリケーション)と呼ばれる仕組みがあり、走行データをゲーム画面上に表示するアプリケーションをユーザーがPython言語を用いて独自に開発することができます。走行データを取得するためのAPIや画面上に表示を行うためのAPIなどが準備されています。
- 参考情報
- チュートリアル:Getting started with Assetto Corsa application development
- APIドキュメント:Assetto Corsa Python documentation ※ログイン必要
これらの参考情報をもとに、以下の情報を取得するプログラムを作りました。
- 周回数
- 現在の周回の経過時間(秒)
- スタート地点からの距離(スタート地点=0~ゴール地点=1.0)
- 車速(km/h)
- アクセル開度(0.0~1.0)
- ブレーキ開度(0.0~1.0)
- ギア
- エンジン回転数(rpm:revolutions per minute)
- ステア(ハンドル)の切り角(degree)
- 車両の現在位置 (3D座標)
ACTelemetry.pyclass ACTelemetry: (略) def logging(self): if self.outputFile == None: return lapCount = ac.getCarState(self.carId, acsys.CS.LapCount) + 1 lapTime = ac.getCarState( self.carId, acsys.CS.LapTime) speed = ac.getCarState(self.carId, acsys.CS.SpeedKMH) throttle = ac.getCarState(self.carId, acsys.CS.Gas) brake = ac.getCarState(self.carId, acsys.CS.Brake) gear = ac.getCarState(self.carId, acsys.CS.Gear) rpm = ac.getCarState(self.carId, acsys.CS.RPM) distance = ac.getCarState(self.carId, acsys.CS.NormalizedSplinePosition) steer = ac.getCarState(self.carId, acsys.CS.Steer) (x, y, z) = ac.getCarState(self.carId, acsys.CS.WorldPosition) self.outputFile.write('{}\t{:.3f}\t{:.4f}\t{:.2f}\t{:.3f}\t{:.3f}\t{}\t{:.0f}\t{:.1f}\t{:.2f}\t{:.2f}\t{:.2f}\n'.format(\ lapCount, lapTime/1000, distance, speed, throttle, brake, gear, rpm, steer, x, y, z)) (略) def acUpdate(deltaT): global telemetryInstance telemetryInstance.logging()コードの細かい説明は割愛しますが、in-game appの仕組みでは
acUpdate(deltaT)がグラフィック更新の度(私の環境では1秒間に60回)実行されます。acUpdate(deltaT)から呼び出されるACTelemetry.logging()においてデータ取得&ファイル出力をしています。このin-game appを有効にするためには、以下の手順を行います。
- 「(Steamインストール先フォルダ)\steamapps\common\assettocorsa\apps\python\ACTelemetry」以下にACTelemetry.pyを配置
- ゲーム内で「Options」⇒「General」⇒「UI Models」で「ACTelemetry」にチェック
- ゲームプレイ時(リプレイ時でもOK)にマウスを画面右端に移動し、表示されたアプリの中から「ACTelemetry」を選択
以下のようなUIが表示されるので、「Next」ボタンでデータ取得対象の車両を選択し、「Start」ボタンでログ取得を開始します。
結果、以下のようなデータが取得できます。このデータを自分のプレイとAIのプレイの両方取得して比較したいと思います。
logger_20190817_1257.logCourse : ks_barcelona Layout : layout_gp Car Id : 0 Driver : abe.masanori Driver : ks_toyota_gt86 lapCount lapTime distance speed throttle brake gear RPM steer x y z 1 151.829 0.9399 115.7 1.00 0.00 4 6425 33 490.4 -14.6 -436.3 1 151.846 0.9400 115.8 1.00 0.00 4 6425 33 490.5 -14.6 -435.7 1 151.862 0.9401 115.8 1.00 0.00 4 6421 33 490.5 -14.7 -435.2 1 151.879 0.9402 116.0 1.00 0.00 4 6425 33 490.6 -14.7 -434.7可視化する前のデータ整形
今回はPlotlyのJavascriptライブラリを利用してデータを可視化したいと思います。上述のヘッダ付きタブ区切りファイルのままでも扱えるのですが、多少面倒なので、事前に以下の加工・整形を加えます。
- ヘッダ(先頭5行の情報や項目の行)の削除
- 該当周回以外のデータ行削除
- 該当周回のデータにおいても先頭5行と最後5行の削除(スタート/ゴール前後に発生するおかしなデータを除去するため)
- タブ区切りからJavascript配列にフォーマット変換
以下のようなファイルになります。
my_data_before.jsmy_data = [ [2, 0.125, 0.0017, 155.96, 1.000, 0.000, 5, 6672, 0.0, 365.52, -18.43, -187.32], [2, 0.142, 0.0019, 155.96, 1.000, 0.000, 5, 6672, 0.0, 365.13, -18.43, -186.72], [2, 0.158, 0.0020, 156.11, 1.000, 0.000, 5, 6674, 0.0, 364.73, -18.43, -186.11], [2, 0.175, 0.0022, 156.11, 1.000, 0.000, 5, 6676, 0.0, 364.34, -18.44, -185.51], (以下略)取得したデータの可視化
Plotlyを使って、以下のようなVizを作ってみたいと思います。(こちらから実際に動かせます。ちょっと重いですがアニメーションGIFはこちら)
- 速度、アクセル/ブレーキ開度、ギア、エンジン回転数、ステアリング角度について、自分とAI(CPU)のデータをスタートからの距離を横軸にして線グラフで左側に表示する。
- 自分のコース上の走行位置を右側に表示する。
- 速度のグラフで横軸範囲指定(Zoom)すると、他のグラフもそれに追従する。
この手のデータは、通常は横軸=時刻、縦軸=メトリクスを表示させるものなのですが、今回それをやると自分とAI(CPU)のデータが比較しづらいので、横軸にはスタートからの距離を表す数値(0.0:スタート ~ 1.0:ゴール)を採用します。
HTMLファイル作成
まず、ベースとなるHTMLファイルを作成します。
- Plotlyのライブラリを読み込みます。
div要素にPlotlyでグラフを差し込むことになるので、グラフ表示のdivにidを付与しておきます。viz_before.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>自分(改善前)とAIのデータ比較</title> <script src='https://cdn.plot.ly/plotly-latest.min.js'></script> <style> html, body { margin: 0; padding: 0; height: 100%; display: flex; } </style> </head> <body> <div> <div id="div-speed"></div> <div id="div-throttle"></div> <div id="div-brake"></div> <div id="div-gear"></div> <div id="div-rpm"></div> <div id="div-steer"></div> </div> <div id="div-position"></div> </body> <script src="data/my_data_before.js"></script> <script src="data/cpu_data.js"></script> <script src="my_viz.js"></script> </html>速度グラフなどの作成
速度、アクセル/ブレーキ開度、ギア、エンジン回転数、ステアリング角度についてはほぼ同じグラフになるため、自分のデータ、AI(CPU)のデータ、グラフ作成位置、縦軸タイトルを引数として渡して線グラフを作成する関数を作成します。
my_viz.jsfunction plot_speed(my_x, my_y, cpu_x, cpu_y, divId, title_y){ var data_me = { x: my_x, y: my_y, mode: 'lines', name: 'me' }; var data_cpu = { x: cpu_x, y: cpu_y, mode: 'lines', name: 'cpu' }; var layout = { autosize: false, yaxis: {title: title_y}, width: 600, height: 250, margin: {l: 70, r: 70, b: 25, t: 25} }; Plotly.newPlot(divId, [data_me, data_cpu], layout); } my_data_distance = Array.from(my_data, x => x[2]); cpu_data_distance = Array.from(cpu_data, x => x[2]); my_data_speed = Array.from(my_data, x => x[3]); cpu_data_speed = Array.from(cpu_data, x => x[3]); plot_speed( my_data_distance, my_data_speed, cpu_data_distance, cpu_data_speed, 'div-speed', '速度 (km/h)' ); (以下略)2次元配列をそのまま渡せないのはちょっと面倒に感じます。
位置データのグラフ作成
こちらもグラフ作成の関数を作成します。
- 後で距離で絞り込みを行うため、表示するデータの距離下限と上限を引数で渡し、その情報に基づきデータを絞り込みます。
- こちらのグラフはデータを入れ替えて再作成が発生するので、
Plotly.newPlot()関数ではなくPlotly.react()関数を利用します(PlotlyのリファレンスによるとnewPlot()よりreact()の方が「far more efficiently」らしいのですが、ならreact()だけ使えば良いのではと思わなくもないのですが…)- 位置データに関して、南北(z)の値はプラス側が南、マイナス側が北となるため、
range: [600, -600]の指定を指定して上下を逆転させています。autorange: 'reversed'でも上下逆転させられるのですが、データ絞り込みの際に軸の範囲が変わり縦横比が変わってしまうので、固定値を指定しています。- データを絞り込んだ際に、コースの度の部分に該当するか分かりやすくするために、コース図をグラフの背景画像として設定します。
my_viz.jsfunction plot_position(min_distance, max_distance) { my_x = Array.from(my_data.filter(v => (min_distance < v[2]) && (v[2] < max_distance)), x => x[9]); my_z = Array.from(my_data.filter(v => (min_distance < v[2]) && (v[2] < max_distance)), x => x[11]); my_pos = { x: my_x, y: my_z, mode: 'scatter', mode: 'line', }; var layout = { xaxis: {autorange: false, range: [-600, 600]}, yaxis: {autorange: false, range: [600, -600]}, autosize: false, width: 300, height: 300, margin: {l: 50, r: 50, b: 50, t: 50, pad: 10}, showlegend: false, images: [{ source: 'pos_base.png', xref: 'x', yref: 'y', x: 500, y: 600, xanchor: 'right', yanchor: 'bottom', sizex: 1000, sizey: 1200, sizing: 'stretch', opacity: 0.4, layer: 'below' }] }; Plotly.react('div-position', [my_pos], layout); }グラフ間の連携
速度グラフで横軸の範囲選択(Zoom)をした場合、そのイベントをトリガーに他のグラフにもその結果を反映させます。
- Plotlyではマウスのドラッグ&ドロップで範囲選択した場合と、グラフ上でダブルクリックするなどしてZoom解除した場合で発生するZoomイベントの内容が異なりるので、
if..else..で処理を分けます。- アクセル/ブレーキ開度、ギア、エンジン回転数、ステアリング角度は横軸の範囲を変えるだけなので、
Plotly.relayout()でグラフのレイアウトを変更します。- 位置グラフについては、表示データを絞り込む必要があるので、グラフを再作成します(上で作成した
plot_position()関数の実行)。my_viz.jsdocument.querySelector('#div-speed').on( 'plotly_relayout', function(eventdata) { if(eventdata['xaxis.autorange']) { x_start = 0.0; x_end = 1.0; option = {'xaxis.autorange': true}; } else { x_start = eventdata['xaxis.range[0]']; x_end = eventdata['xaxis.range[1]']; option = {'xaxis.range': [x_start, x_end]} } Plotly.relayout('div-throttle', option); Plotly.relayout('div-brake', option); Plotly.relayout('div-gear', option); Plotly.relayout('div-rpm', option); Plotly.relayout('div-steer', option); plot_position(x_start, x_end); } );可視化結果の確認
これで、以下の流れで分析することができるようになりました。
- 速度グラフを見て、自分がAI(CPU)より遅い部分を確認する。
- 遅いと特定した部分にZoomする。
- 他のメトリクスを確認して、遅い原因を特定する。
(速度グラフをダブルクリックすれば、Zoomは解除されます)
まぁ、私が遅い原因を確認するにはそこまでする必要はなく、単純にステアリングの角度が大き過ぎたというだけなのですが。
原因が分かってしまえば単純ですが、GT5/6ではステアリングの角度に上限が設けられており(動的に変わるらしい)、ここまでひどい状況にはならなかったようです。
ステアリングの切り過ぎが原因だということを意識してプレイすることで、AI(CPU)との差も4秒から1秒以下までに縮めることができました。ただ、再度データを確認すると、まだステアリングが切り過ぎ&切り方が急なようなので、まだまだ改善しなければいけませんが。
Plotly感想
今回、データを可視化するにあたり、Plotly以外にも以下のツールを試したので、少し感想を。
- Tableau、Qlik Sense
- 商用製品だけあり、機能も豊富で、作りたいグラフやダッシュボードがサクッと作成できる。
- Grafana
- 横軸が時間でないグラフをどう作成するのか、よく分からなかった。(できるとは思うけど)
- Metabase、Superset、Redash
- DB上のデータから1つグラフを作るのはとてもとても簡単。
- ダッシュボード上で絞り込みをさせる、複数グラフを連携させるとなると、できなくはないけど、結構難しい or 使いづらいUIになりがち。
- picasso.js
- Qlik Senseの背後で使われているJavascript可視化ライブラリということで使ってみたけど、コード量が多くなりがち & マニュアルを読んでも良く分からない。
- Plotly
- DBからのデータ取得などはできないので、別途コーディングが必要。
- 少ないコード量でグラフが作成できるし、Zoomや画像エクスポート、ホバーの機能がデフォルトで有効になっている。
- ダッシュボード上での複数グラフに渡ったデータ絞り込みや連携はコーディングが必要だが、仕組みが分かれば比較的簡単。
まとめると、Plotlyとても良い。
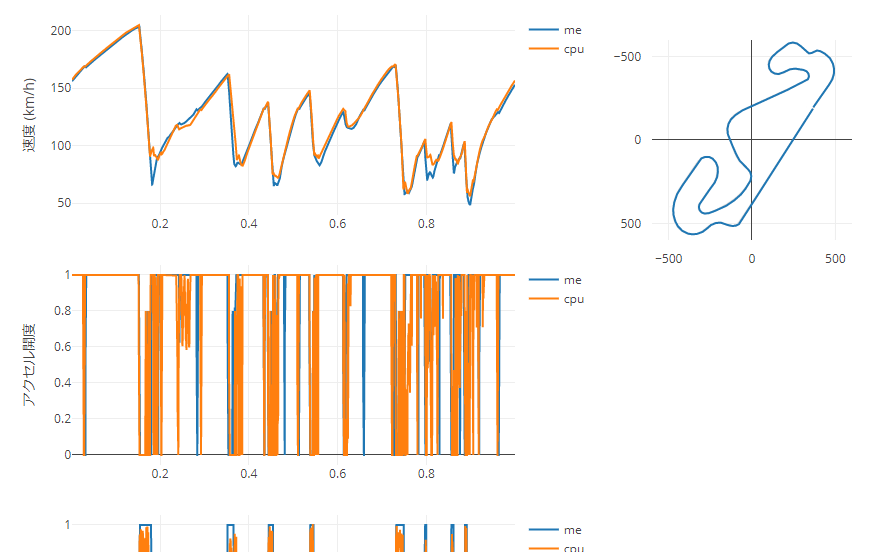
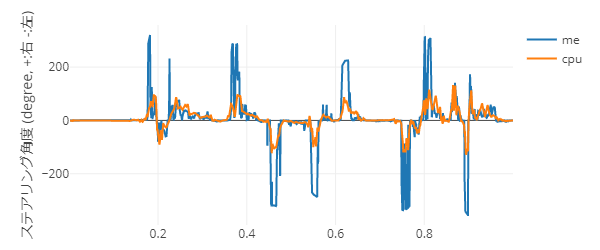
- 投稿日:2020-05-17T18:59:32+09:00
【Python】Webスクレイピングからデータ分析までの流れ
こんにちは、@0yanです。
今日はデータ分析の実践練習で、Webスクレイピング~データ分析をやってみました。
いずれ中古マンション購入したいなと思っているので、題材は気になる路線の中古マンション情報としました。環境
- Windows 10 Pro
- Python 3.7.3(Anaconda)
- Jupyter Notebook
やったこと
- Webスクレイピング
- CSV書き込み/読み込み
- データ前処理
- 分析
1. Webスクレイピング
使用したパッケージは以下のとおりです。
使用したパッケージ
import datetime import re import time from urllib.parse import urljoin from bs4 import BeautifulSoup import pandas as pd import requestsスクレイピングの流れ
私がスクレイピングしたページは
- 物件データはすべてddタグに入っている
- 1物件あたり8個のデータをもつ(物件名、販売価格、所在地、沿線・駅、専有面積、間取り、バルコニー、築年月)
- 1ページあたり30物件のデータをもつ(8データ/物件 × 30物件/ページ = 120データ/ページ)
- ページのTOPとBOTTOMには、ddタグでナビゲーションメニューのデータあり
という構成でした。最終的に、
[{'物件名': spam, '販売価格': spam, '所在地': spam, '沿線・駅': spam, '専有面積': spam, '間取り': spam, 'バルコニー': spam, '築年月': spam}, {'物件名': spam, '販売価格': spam, '所在地': spam, '沿線・駅': spam, '専有面積': spam, '間取り': spam, 'バルコニー': spam, '築年月': spam}, ・・・, {'物件名': spam, '販売価格': spam, '所在地': spam, '沿線・駅': spam, '専有面積': spam, '間取り': spam, 'バルコニー': spam, '築年月': spam}]のように辞書型の物件情報が要素のリストを作成し、pandas.DataFrameに渡したいので、以下の手順(コメント参照)でスクレイピングしました。
# 物件情報を入れる変数(辞書型)と、それを入れる変数(リスト)の初期化 property_dict = {} properties_list = [] # 「property_dict」を生成する際に必要なキーのリスト「key_list」を生成 key_list = ['物件名', '販売価格', '所在地', '沿線・駅', '専有面積', '間取り', 'バルコニー', '築年月'] key_list *= 30 # 30物件/ページ # 1ページ目のBeautifulSoupインスタンス生成 first_page_url = '某不動産サイト中古マンション情報検索結果(1ページ目)URL' res = requests.get(first_page_url) soup = BeautifulSoup(res.text, 'html.parser') # 93ページ分繰り返し(一度きりなので最大ページ数の取得は省略) for page in range(93): # 物件データが入っているddタグのリスト「dd_list」を生成 dd_list = [re.sub('[\n\r\t\xa0]', '', x.get_text()) for x in soup.select('dd')] # 余計な改行等は除外 dd_list = dd_list[8:] # 余計なページTOPのデータを除外 # 辞書型の物件データが要素のリスト「properties_list」を生成 zipped = zip(key_list, dd_list) for i, z in enumerate(zipped, start=1): if i % 8 == 0: properties_list.append(property_dict) property_dict = {} else: property_dict.update({z[0]: z[1]}) # 次ページのURL(ベース部分以降)を取得 next_page = soup.select('p.pagination-parts>a')[-1] # 次ページのBeautifulSoupインスタンスを生成 base_url = 'https://xxx.co.jp/' # 某不動産サイトのURL dynamic_url = urljoin(base_url, next_page.get("href")) time.sleep(3) res = requests.get(dynamic_url) soup = BeautifulSoup(res.text, 'html.parser')最後に、物件リスト
properties_listをpandas.DataFrameに渡し、DataFrameを生成しました。df = pd.DataFrame(properties_list)2. CSV書き込み/読み込み
毎回スクレイピングするのは面倒かつサイト側に負荷がかかってしまうので、CSVに一旦書き込んだのち、それを読み込んで使うことにしました。
csv_file = f'{datetime.date.today()}_中古マンション購入情報.csv' df.to_csv(csv_file, encoding='cp932', index=False) df = pd.read_csv(csv_file, encoding='cp932')3. データ前処理
「データ分析は前処理に8割の時間がかかる」という言葉をよく聞きますが、「これのことか・・・」と実感しました。
以下の前処理を行いました。
- 販売価格:「1億2000万円※権利金含む」のようになっている → intに変換
- 専有面積:「54.66m2※壁芯含む」のようになっていたり、「-」が混ざっている → floatに変換
- バルコニー:同上
- 沿線・駅から「路線」「最寄り駅」「徒歩」のカラムを作成
- 所在地から「都道府県」「市区町村」のカラムを作成
- フィルタリングにより必要なカラムのみのDataFrameに
import re # 販売価格に金額以外が入っているレコードを除外 df = df[df['販売価格'].str.match('[0-9]*[万]円') | df['販売価格'].str.match('[0-9]億円') | df['販売価格'].str.match('[0-9]*億[0-9]*万円')] # 販売価格[万円]を追加 price = df['販売価格'].apply(lambda x: x.replace('※権利金含む', '')) price = price.apply(lambda x: re.sub('([0-9]*)億([0-9]*)万円', r'\1\2', x)) # 1憶2000万円 → 12000 price = price.apply(lambda x: re.sub('([0-9]*)億円', r'\10000', x)) # 1億円 → 10000 price = price.apply(lambda x: re.sub('([0-9]*)万円', r'\1', x)) # 9000万円 → 9000 price = price.apply(lambda x: x.replace('@00', '0')) # 考慮できない → 0に変換 price = price.apply(lambda x: x.replace('21900~31800', '0')) # 同上 df['販売価格[万円]'] = price.astype('int') df = df[df['販売価格[万円]'] > 0] # 0のレコード除外 # 専有面積[m2]を追加 df['専有面積[m2]'] = df['専有面積'].apply(lambda x: re.sub('(.*)m2.*', r'\1', x)) df['専有面積[m2]'] = df['専有面積[m2]'].apply(lambda x: re.sub('-', '0', x)).astype('float') # 考慮できない → 0に変換 df = df[df['専有面積[m2]'] > 0] # 0のレコード除外 # バルコニー[m2]を追加 df['バルコニー[m2]'] = df['バルコニー'].apply(lambda x: re.sub('(.*)m2.*', r'\1', x)) df['バルコニー[m2]'] = df['バルコニー[m2]'].apply(lambda x: re.sub('-', '0', x)).astype('float') # 考慮できない → 0に変換 df = df[df['バルコニー[m2]'] > 0] # 0のレコード除外 # 路線を追加 df['路線'] = df['沿線・駅'].apply(lambda x: re.sub('(.*線).*', r'\1', x, count=5)) # 最寄り駅を追加 df['最寄り駅'] = df['沿線・駅'].apply(lambda x: re.sub('.*「(.*)」.*', r'\1', x, count=5)) # 徒歩[分]を追加 df['徒歩[分]'] = df['沿線・駅'].apply(lambda x: re.sub('.*歩([0-9]*)分.*', r'\1', x)).astype('int') # 都道府県を追加 df['都道府県'] = df['所在地'].apply(lambda x: re.sub('(.*?[都道府県]).*', r'\1', x)) # 市区町村を追加 df['市区町村'] = df['所在地'].apply(lambda x: re.sub('.*[都道府県](.*?[市区町村]).*', r'\1', x)) # 必要なカラムのdfに上書き df = df[['物件名', '販売価格[万円]', '路線', '最寄り駅', '徒歩[分]', '間取り', '専有面積[m2]', 'バルコニー[m2]', '都道府県', '市区町村', '所在地']]4. 分析
住みたいと思っている路線全体と、その中でも特に気になっている駅(3駅)の2LDK以上を分析してみました。
路線全体
フィルタリング
route = ['A線', 'B線', 'C線', 'D線', 'E線', 'F線'] floor_plan = ['2LDK', '2LDK+S(納戸)', '3DK', '3DK+S(納戸)', '3LDK', '3LDK+S(納戸)', '3LDK+2S(納戸)', '4DK', '4DK+S(納戸)', '4LDK', '4LDK+S(納戸)'] filtered = df[df['路線'].isin(route) & df['間取り'].isin(floor_plan)]相関分析
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.pairplot(filtered) plt.show()
販売価格と専有面積には若干の相関はありそうですが、それ以外は販売価格にそこまで影響しなさそうです。
販売価格の分布
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.boxplot(x='販売価格[万円]', data=filtered) plt.show()
路線全体の物件のうち、50%は4,000~7,500万円付近に固まっていました。
都内はやっぱり高いな・・・。統計量
filtered.describe()
- 中央値(50%)は68.99m2で5400万円
- 25~75%の50%は3980~7500万円
路線全体では以上のとおりでした。
路線の中でも特に気になっている駅(3駅)
ここからは気になっている駅(3駅)を調べました。
station = ['A駅', 'B駅', 'C駅'] grouped = filtered[filtered['最寄り駅'].isin(station)]販売価格の分布
3つの駅の販売価格の分布を調べました。
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.violinplot(x='販売価格[万円]', y='最寄り駅', data=grouped) plt.show()
一番気になっているのは一番下(緑)ですが、双峰型の分布となっておりました。恐らく、タワマンとそれ以外で二極化しているものと思われます。
統計量
grouped.describe()
- 物件数は100件
- 中央値(50%)は専有面積64.26m2で6830万円。路線全体の68.99m2/5400万円と比較すると割高
- 25~75%の50%は5299~8087万円。路線全体の3980~7500万円と比較すると全体的に高額
一番気になっている駅
一番気になっている駅で5000万円未満の物件ないかな・・・ということで、更に分析してみました。
間取り毎の分析
物件数
c = filtered[filtered['最寄り駅'] == 'C駅'] c.groupby(by='間取り')['間取り'].count()
販売価格
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.swarmplot(x='販売価格[万円]', y='間取り', data=c) plt.show()
5,000万円未満は7件しかありませんでした・・・。
5,000万円未満の物件
5,000万円未満の物件を更に調べてみました。
c_u5k = c[c['販売価格[万円]'] < 5000] c_u5k = c_u5k[['物件名', '間取り', '専有面積[m2]', 'バルコニー[m2]', '販売価格[万円]', '所在地', '徒歩[分]']].sort_values(['物件名', '間取り']) c_u5k
7件だけなので、Googleマップで所在地を調べたところ、気になったのが1471番。
3LDK、69.5㎡で4,280万円とこの駅付近では割安に見えますが、そもそも気になっている3駅の3LDKの相場からすると本当に割安なのか?
調べてみました。grouped[grouped['間取り'] == '3LDK'].describe()
結果、
- 中央値は73.7m2/7180万円
- 1471番は69.5m2なので比較するなら25%の値
- 25%は69.8m2/6607万円 → 差は -0.3m2/-2327万円
と相当割安でした。
なんでだろうと調べてみたら、1985年建造とかなり古い物件であることが発覚。
内装写真がなく「リフォームできます!」と書かれていることから、相当老朽化が進んでいることが推測できます。が、仮にリノベーションで1,000万円かけたとしてもまだ割安です。
お金があったら欲しかったな・・・と思う今日この頃。感想
Webスクレイピング初めてでしたが、今後、必要になる可能性が高いので非常に有益な実践練習でした。
「好きこそものの上手なれ」といいますが、やっぱり興味あるものを分析する等、やりたいことをやるのが一番の上達の早道だなと改めて感じた一日でした。データ分析を学んだサイト
かめ@米国データサイエンティストさんのサイト「データサイエンスのためのPython入門講座」で勉強させて頂きました。
重要なポイントが分かり易くまとめられております。
オススメです。参考文献
Webスクレイピングを行うにあたり、以下の記事から勉強させて頂きました。
@tomson784 さんの記事
Pythonでページ遷移を繰り返しながらスクレイピング@Chanmoro さんの記事
10分で理解する Beautiful Soupありがとうございました!
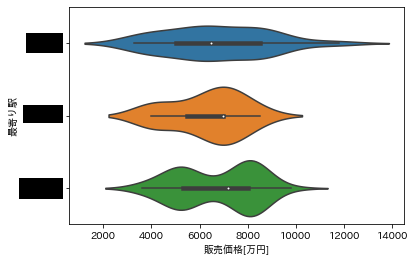

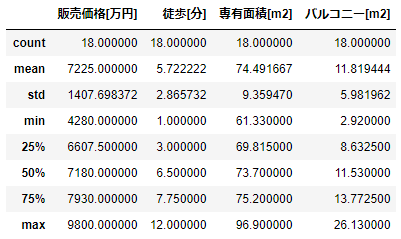
- 投稿日:2020-05-17T18:12:00+09:00
カテゴリ変数についても相関を求める方法
はじめに
データ分析の際には与えられたデータにおいて変数間の相関関係を調べると思います。数値同士の相関は相関係数を調べればよいですが、一方または両方がカテゴリの場合はどうしたらいいのかな?と思って調べたのでまとめます。
相関の調べ方
数値 vs 数値
この場合は有名で、相関係数を調べればよいです。相関係数の定義は以下の通りです。
r=\frac{\sum_{i}(x_{i}-\bar{x})(y_{i}-\bar{y})}{\sqrt{\sum_{i}(x_{i}-\bar{x})^2}\sqrt{\sum_{i}(y_{i}-\bar{y})^2}}pythonで相関係数を求めるにはpandas.DataFrameのcorr()メソッドを使います。
import numpy as np import pandas as pd x=np.random.randint(1, 10, 100) y=np.random.randint(1, 10, 100) data=pd.DataFrame({'x':x, 'y': y}) data.corr()
値が0ならば相関なし、1に近ければ正の相関、-1に近ければ負の相関があります。
カテゴリ vs 数値
相関比という統計量で表されます。定義は以下の通りです。
r=\frac{\sum_{カテゴリ}カテゴリ件数\times(カテゴリの平均-全体の平均)^2}{全体の偏差の平方和}具体例はここを参照してください。
分子は「各カテゴリがどれだけ離れているか」を表しています。カテゴリ同士が離れているほど分子が大きくなり、相関が強いと言えます。
この相関比も、0の場合は相関なし、1に近づくと強い正の相関を意味します。
pythonでは以下のように計算します(こちらを参照)。
def correlation_ratio(cat_key, num_key, data): categorical=data[cat_key] numerical=data[num_key] mean=numerical.dropna().mean() all_var=((numerical-mean)**2).sum() #全体の偏差の平方和 unique_cat=pd.Series(categorical.unique()) unique_cat=list(unique_cat.dropna()) categorical_num=[numerical[categorical==cat] for cat in unique_cat] categorical_var=[len(x.dropna())*(x.dropna().mean()-mean)**2 for x in categorical_num] #カテゴリ件数×(カテゴリの平均-全体の平均)^2 r=sum(categorical_var)/all_var return rカテゴリ vs カテゴリ
クラメールの連関係数という統計量を用いて調べます。定義は
r=\sqrt{\frac{\chi^2}{n(k-1)}}ただし、$\chi ^{2}$はχ2乗分布、nはデータ件数、kはカテゴリ数の少ない方です。χ2乗分布についてはこちらなどを参照ください。ざっくり言うと、各カテゴリの分布が全体の分布とどれだけ異なるか、を表す量です。これについても0近ければ相関なし、1に近ければ正の相関あり、となります。
pythonで計算するには以下のようにします(こちらを参照)。
import scipy.stats as st def cramerV(x, y, data): table=pd.crosstab(data[x], data[y]) x2, p, dof, e=st.chi2_contingency(table, False) n=table.sum().sum() r=np.sqrt(x2/(n*(np.min(table.shape)-1))) return r各指標をまとめて求める
と、これだけだとこれまでの記事の2番煎じになってしまうので、DataFrameに対して各指標をまとめて求めるメソッドを作りました。これでいちいち調べなくても良いです!
def is_categorical(data, key): col_type=data[key].dtype if col_type=='int': nunique=data[key].nunique() return nunique<6 elif col_type=="float": return False else: return Truedef get_corr(data, categorical_keys=None): keys=data.keys() if categorical_keys is None: categorical_keys=keys[[is_categorycal(data, key) for ke in keys]] corr=pd.DataFrame({}) corr_ratio=pd.DataFrame({}) corr_cramer=pd.DataFrame({}) for key1 in keys: for key2 in keys: if (key1 in categorical_keys) and (key2 in categorical_keys): r=cramerV(key1, key2, data) corr_cramer.loc[key1, key2]=r elif (key1 in categorical_keys) and (key2 not in categorical_keys): r=correlation_ratio(cat_key=key1, num_key=key2, data=data) corr_ratio.loc[key1, key2]=r elif (key1 not in categorical_keys) and (key2 in categorical_keys): r=correlation_ratio(cat_key=key2, num_key=key1, data=data) corr_ratio.loc[key1, key2]=r else: r=data.corr().loc[key1, key2] corr.loc[key1, key2]=r return corr, corr_ratio, corr_cramerどのキーがカテゴリ変数なのかは指定がなければ変数型から自動で判定します。
titanicのデータに適用してみます。
data=pd.read_csv(r"train.csv") data=data.drop(["PassengerId", "Name", "Ticket", "Cabin"], axis=1) category=["Survived", "Pclass", "Sex", "Embarked"] corr, corr_ratio, corr_cramer=get_corr(data, category)corr
corr_ratio
corr_cramer
さらに、seabornのheatmapで可視化できます。
import seaborn as sns sns.heatmap(corr_cramer, vmin=-1, vmax=1)
最後に
各統計量の説明は雑になってしまったので、参照に記したページをご覧ください。自分はまとめても結局忘れて調べるはめになるのでできるだけ自動化するメソッドを作るようにしています。このメソッドのソースもgithubにおいてあるので自由に使ってください。
参照

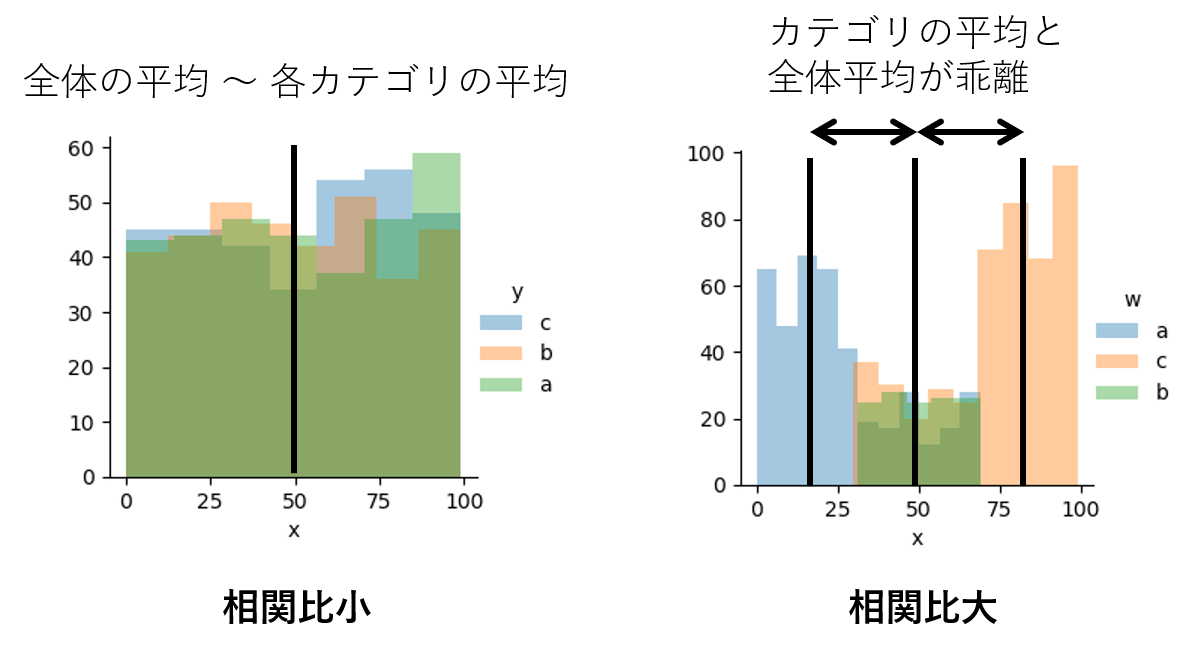
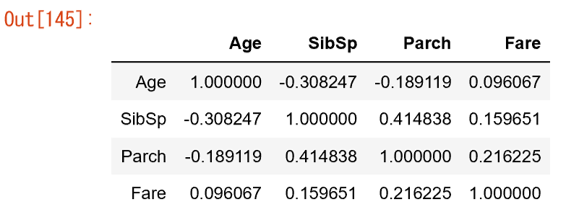
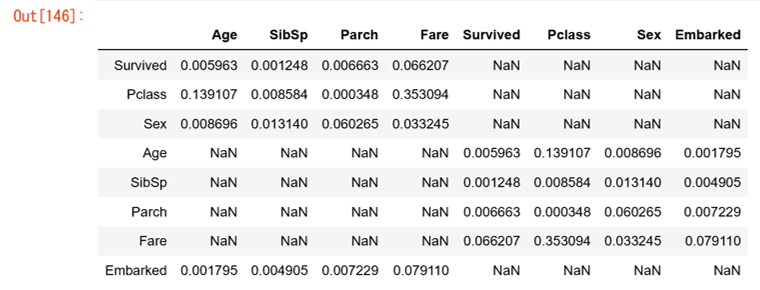
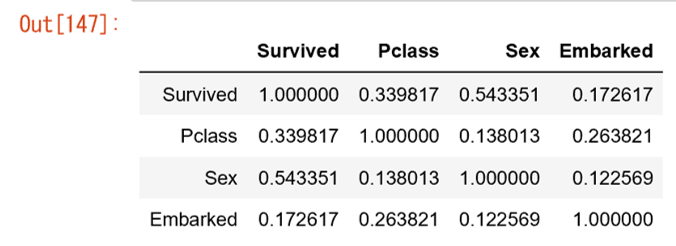
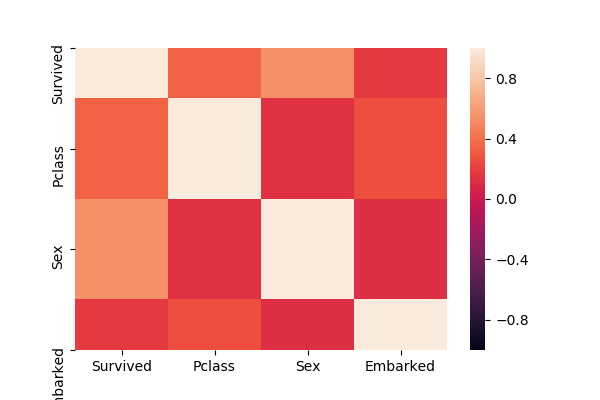
- 投稿日:2020-05-17T17:55:14+09:00
OpenCVのcopyMakeBorderのオプションを調べてみた
初めに
OpenCVでのフィルタリング処理(Blur, Filter)は、特定の領域を定義して、その総和をとる事により画像を加工(ぼかし・ノイズ除去)しています
この時、画像の縁部分に対しては領域を拡張して計算するわけですが、その拡張方法について調べてみました。動作環境
Python3,OpenCV
定数値で拡大(BORDER_CONSTANT)
黒色(0, 0, 0)で拡張します
import numpy as np import cv2 as cv from matplotlib import pyplot as plt black = [0x00, 0x00, 0x00] dimgray = [0x69, 0x69, 0x69] gray = [0x80, 0x80, 0x80] darkgray = [0xa9, 0xa9, 0xa9] silver = [0xc0, 0xc0, 0xc0] lighgray = [0xd3, 0xd3, 0xd3] gainsboro = [0xdc, 0xdc, 0xdc] whiteSmoke = [0xf5, 0xf5, 0xf5] white = [0xFF, 0xFF, 0xFF] img = np.array([ [black, white, black, white, black] ,[white, dimgray, white, dimgray, white] ,[gray, white, gray, white, gray] ,[white, darkgray, white, darkgray, white] ,[silver, white, silver, white, silver] ,[white, lighgray, white, lighgray, white] ,[gainsboro, white, gainsboro, white, gainsboro] ,[white, whiteSmoke, white, whiteSmoke, white] ]) # 拡張ピクセル数 exPixelNum = 8 plt.subplot(121),plt.imshow(img),plt.imshow(img),plt.title('Original') conBdImg = cv.copyMakeBorder(img, exPixelNum, exPixelNum, exPixelNum, exPixelNum, cv.BORDER_CONSTANT) plt.subplot(122),plt.imshow(conBdImg),plt.title('BORDER_CONSTANT') plt.show()
反対側のピクセルを複数(BORDER_WRAP)
# オリジナル画像(比較のために黒色で拡張しています) orgImg = cv.copyMakeBorder(img, exPixelNum, exPixelNum, exPixelNum, exPixelNum, cv.BORDER_CONSTANT) plt.subplot(121),plt.imshow(orgImg),plt.title('Original') plt.xticks([]), plt.yticks([]) # Wrap画像 wrpBdImg = cv.copyMakeBorder(img, exPixelNum, exPixelNum, exPixelNum, exPixelNum, cv.BORDER_WRAP) plt.subplot(122),plt.imshow(wrpBdImg),plt.title('BORDER_WRAP') plt.xticks([]), plt.yticks([]) plt.show()
下図のように、対象の画像を繰り返し配置している事がわかります
エッジのピクセルをコピー(BORDER_REPLICATE)
# Replicate画像 repBdImg = cv.copyMakeBorder(img, exPixelNum, exPixelNum, exPixelNum, exPixelNum, cv.BORDER_REPLICATE) plt.subplot(122),plt.imshow(repBdImg),plt.title('BORDER_REPLICATE') plt.xticks([]), plt.yticks([]) plt.show()
下図のように末端のピクセルを、そのまま用いている事がわかります
反射(BORDER_REFLECT)
# Replicate画像 # Reflect画像 refBdImg = cv.copyMakeBorder(img, exPixelNum, exPixelNum, exPixelNum, exPixelNum, cv.BORDER_REFLECT) plt.subplot(122),plt.imshow(refBdImg),plt.title('BORDER_REFLECT') plt.xticks([]), plt.yticks([]) plt.show()
下図のように、反転して画像を配置している事がわかります
反射(BORDER_REFLECT_101)
# Reflect画像(エッジのピクセルを繰り返さない) # BORDER_DEFAULTとした時も同じ加工を行う ref101BdImg = cv.copyMakeBorder(img, exPixelNum, exPixelNum, exPixelNum, exPixelNum, cv.BORDER_REFLECT_101) plt.subplot(122),plt.imshow(ref101BdImg),plt.title('BORDER_REFLECT_101') plt.xticks([]), plt.yticks([]) plt.show()
BORDER_REFLECTと同じ反射ですが、エッジのピクセルを繰り返しません
BORDER_REFLECT_101をBORDER_DEFAULTとした時も同じ加工となります
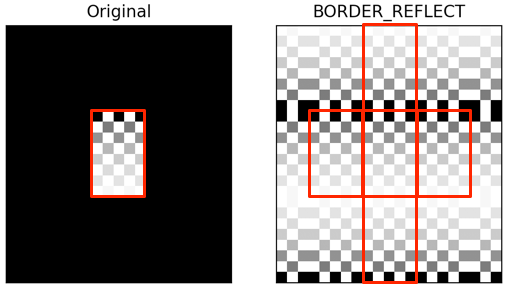

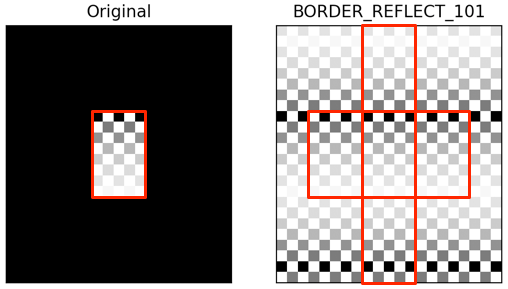
- 投稿日:2020-05-17T17:51:49+09:00
Macにseleniumをインストールして、pythonでお試し利用する
目的
Macにseleniumをインストールして、pythonでお試し利用した際の備忘録です
Selenium/Google Chrome/Google Chromeドライバをインストール
Seleniumをインストール
pip3 install seleniumGoogle Chromeをインストール
以下を参考にGoogle Chromeをインストール
Google Chromeドライバをインストール
Google Chromeのバージョンを確認して、
Google Chromeと同じバージョンのドライバをインストールするGoogle Chromeのバージョンを確認
Google Chromeメニュー → Google Chromeについて
(例)
Google Chrome は最新版です
バージョン: 81.0.4044.138(Official Build) (64 ビット)Google Chromeと同じバージョンのドライバをインストール
(例)Google Chrome が、バージョン: 81.0.4044.138 の場合 $ pip3 install chromedriver-binary==81.0.4044.138 Successfully installed chromedriver-binary-81.0.4044.138.0 $ pip3 show chromedriver-binary Name: chromedriver-binary Version: 81.0.4044.138.0 Summary: Installer for chromedriver. Home-page: https://github.com/danielkaiser/python-chromedriver-binary Author: Daniel Kaiser Author-email: daniel.kaiser94@gmail.com License: MIT Location: /anaconda3/lib/python3.7/site-packages Requires: Required-by:実行
以下を参考にさせて頂き、「Chromeを起動して"Selenium"とGoogle検索して、Seleniumの公式サイトを開く。」というテストプログラムを実行する。
selenium-test.py# coding:utf-8 from selenium import webdriver from selenium.webdriver.common.keys import Keys from time import sleep import chromedriver_binary # ブラウザを開く。 driver = webdriver.Chrome() # Googleの検索TOP画面を開く。 driver.get("https://www.google.co.jp/") # 検索語として「selenium」と入力し、Enterキーを押す。 search = driver.find_element_by_name('q') search.send_keys("selenium automation") search.send_keys(Keys.ENTER) # タイトルに「Selenium - Web Browser Automation」と一致するリンクをクリックする。 #element = driver.find_element_by_partial_link_text("SeleniumHQ Browser Automation") #element = driver.find_element_by_link_text("WebDriver") element = driver.find_element_by_partial_link_text("Selenium") element.click() # 5秒間待機してみる。 sleep(5) # ブラウザを終了する。 driver.close()実行する
$ python3 selenium-test.pygoogleから、seleniumのページに自動で遷移して、5秒後にブラウザが閉じればOK
FileNotFoundError: [Errno 2] No such file or directory: 'chromedriver': 'chromedriver'
$ python3 selenium-test.py Traceback (most recent call last): File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/common/service.py", line 76, in start stdin=PIPE) File "/anaconda3/lib/python3.7/subprocess.py", line 769, in __init__ restore_signals, start_new_session) File "/anaconda3/lib/python3.7/subprocess.py", line 1516, in _execute_child raise child_exception_type(errno_num, err_msg, err_filename) FileNotFoundError: [Errno 2] No such file or directory: 'chromedriver': 'chromedriver' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "selenium-test.py", line 7, in <module> driver = webdriver.Chrome() File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/chrome/webdriver.py", line 73, in __init__ self.service.start() File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/common/service.py", line 83, in start os.path.basename(self.path), self.start_error_message) selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/homeChromeドライバをバージョンを確認しつつインストールしたが正しく使えていなかった。
importして解決import chromedriver_binaryインストールされたら、PATHに/usr/local/lib/python3.7/site-packages/chromedriver_binary/を追加するか、Pythonのスクリプトの冒頭で、import chromedriver_binary すると良いかと思います。
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"[id="lst-ib"]"}
$ python3 selenium-test.py Traceback (most recent call last): File "selenium-test.py", line 12, in <module> driver.find_element_by_id("lst-ib").send_keys("selenium") File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 360, in find_element_by_id return self.find_element(by=By.ID, value=id_) File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 978, in find_element 'value': value})['value'] File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 321, in execute self.error_handler.check_response(response) File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/remote/errorhandler.py", line 242, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"[id="lst-ib"]"} (Session info: chrome=81.0.4044.138)以下で検索窓を見つけられなかったようなので、
driver.find_element_by_id("lst-ib").send_keys("selenium")以下に置き換えて解決
search = driver.find_element_by_name('q')selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"link text","selector":"SeleniumHQ Browser Automation"}
Traceback (most recent call last): File "selenium-test.py", line 18, in <module> element = driver.find_element_by_link_text("SeleniumHQ Browser Automation") File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 428, in find_element_by_link_text return self.find_element(by=By.LINK_TEXT, value=link_text) File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 978, in find_element 'value': value})['value'] File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 321, in execute self.error_handler.check_response(response) File "/anaconda3/lib/python3.7/site-packages/selenium/webdriver/remote/errorhandler.py", line 242, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"link text","selector":"SeleniumHQ Browser Automation"} (Session info: chrome=81.0.4044.138)以下の部分で"SeleniumHQ Browser Automation"を検索できなかったようなので、
element = driver.find_element_by_partial_link_text("SeleniumHQ Browser Automation")今回は、find_element_by_partial_link_text("Selenium") として部分検索を行い解決
element = driver.find_element_by_partial_link_text("Selenium")参考
Selenium ChromeDriver & PythonをMacで動かす準備メモ
Selenium automates browsers. That's it!
MacにGoogle Chromeをインストールする方法
Pythonの開発環境を用意しよう!(Mac)
seleniumで「Message: session not created: This version of ChromeDriver only supports Chrome version 75」のエラーが表示される場合の対処法
selenium Downloads
No such file or directory: 'chromedriver': 'chromedriver'の解決
seleniumが起動しない
Selenium ChromeDriver & PythonをMacで動かす準備メモ
Seleniumで要素を選択する方法まとめ
【Python】find_element_by_link_text・・・linkTextから要素を取得する
https://www.google.com/chrome
- 投稿日:2020-05-17T17:49:55+09:00
Qt for Python アプリのデスクトップアプリ化
備忘録です。自作アプリ完成に近づきつつ、周辺作業もということで。
Guiアプリを起動するのに、ターミナルから python3 hoge.py とかするのは多少残念だけど、パッケージ化をめざす程の事でも無く、簡単にデスクトップなりApplicationフォルダーなりに置いておくことは出来ないものかと調べて見ました。
初めてだけどもAutomatorでいけるのでは?と思いつき、下記のサイトを参考に。(ありがとうございます。)[Mac] Automatorでターミナルのコマンドをアプリ化する方法
Automaterで作業して、hoge.appというアプリを作り、デスクトップのそれを叩けば、QtforPythonのGuiアプリが起動するようになりましたが、メニューバーにAutomater自身のクルクル歯車アイコンが残ってしまいこれはかなり悲しい。
最初の案
start.sh/usr/local/bin/python3 hoge.py & exitこれで歯車アイコンクルクルが消えない理由がわかりませんので、さらに調べてみると、下記のサイトにたどり着き。(ありがとうございます。)
Automatorのシェルスクリプトは標準エラーの出力先を明示する
修正案
start.sh/usr/local/bin/python3 mainwindow.py >& log & exit歯車アイコンクルクルが消えて目的通りの状態になりました。
- 投稿日:2020-05-17T17:34:20+09:00
PythonでのimportによるオブジェクトIDの違い
環境
windows 10 Pro
version : Python 3.8 (docker)一行でいうと
状態管理のファイルを分けるのをサボってハマった話、サボるな。
本題
game.pyfrom status import Status class Game(): def __init__(): self.status = Status.NOTHINGstatus.pyfrom enum import Enum, auto class Status(Enum): NOTHING = auto() WAITING = auto() PLAYING = auto() class GameStatus(): def start(): if self.game.status == Status.NOTHING: ... if self.game.status == Status.WAITING: ... if self.game.status == Status.PLAYING: ...Statusによって処理を変えるって感じですね。
Statusを列挙型で作成し、初期状態Status.NOTHINGでゲームの流れによってStatesがWAITINGやPLAYINGに変更するって感じです。
game.pyのGameクラスではStatusをimportしていますが、status.pyでは同一ファイル内にStatusがあるため、importしていません。
ここでオブジェクトIDに齟齬が発生し、init関数で代入したStatus.NOTHINGのみオブジェクトIDが異なり、等値比較が成立しません。
列挙型の等値比較が値ではなくオブジェクトIDを参照しているのではないかと思われます。サボらずに
gamestatus.pyfrom status import Status class GameStatus(): def start(): if self.game.status == Status.NOTHING: ... if self.game.status == Status.WAITING: ... if self.game.status == Status.PLAYING: ...status.pyfrom enum import Enum, auto class Status(Enum): NOTHING = auto() WAITING = auto() PLAYING = auto()って感じでファイルを分割し、全ファイル使用する際はimportする手順を踏むことでimportの有無によるオブジェクトIDの違いはうまれないです。
サボらずにきちんとファイルを分割しましょう。。。。
- 投稿日:2020-05-17T17:20:11+09:00
【python】SlackのAPIで、複数人にメンションする
概要
表題の通り。こちらで書いた記事⑥のための記事。
複数人にメンションしたいとき、どうすれば良いかと考えて以下の通りに実行した。やりたかったこと
赤枠のように複数人にメンションしたい。
私が間違えたところ
通知先:記法
@user:<@user>
ここはuserなので"user": "U012YTNNPB5"を使用すること。(slackのapiusers.listで取得可能)
"real_name": "test_1"ではないで注意。コード
menber = ['U012JDYRD2T', 'U012X478FNZ'] tmptmp = [] for i in menber: tmptmp.append("<@" + i + ">") r = map(str,tmptmp) mojiretsu = ' '.join(r) text = mojiretsu + " 出勤者はステータスに合わせて、スタンプを押下してください!!"①
<@user>の形にしないといけないので、【member】を一つずつ取り出して【i】に代入。そこに文字列"<@"などを加える。
②【map(str,tmptmp)】と書いているので、リストtmptmpの全ての要素に対してstr()関数を使用。
③文字列となったリストに' '.join(半角アンダースペース)を追加。
④このtextを使用してpostする。わかったこと
苦労して
real_nameを取得したが、結局は使わなかった。
エンドポイントのパスパラメータで何をどのように使うかは事前に調べておく必要がある。

- 投稿日:2020-05-17T17:17:07+09:00
自分用メモAnacondaにインストールしとくパッケージ
PC環境が変わったら忘れそうなのでメモしとく
少しずつ付け足していく・pip
pip install --upgrade pip・kivy
pip install kivy・snips
pip install snips-nlu