- 投稿日:2020-04-06T23:53:23+09:00
Pythonで毎日AtCoder #28
はじめに
前回
今日はABC140の問題を解きました。50分でA~Cでした。A問題
問題 0diff
考えたこと
3桁のパスワードなので使える数字の3乗を出力すればいい。n = int(input()) print(n**3)B問題
問題 58diff
考えたこと
for文とif文で計算するだけ。リストの要素とindexが混ざらないように気を付ければいいn = int(input()) a = list(map(int,input().split())) b = list(map(int,input().split())) c = list(map(int,input().split())) ans = 0 f = 10**9 for i in range(n): ans += b[a[i]-1] if a[i] - f == 1: ans += c[a[i-1]-1] f = a[i] print(ans)C問題
問題 136diff
考えたこと
$A$の要素の合計値が最大になるのは$B$から与えられる$A$の要素が最大になるときである。最大になるのは、$a[0]$が$b[0]$と同じ値、$a[-1]$が$b[-1]$と同じ値になるとき。それ以外の$A$はmin(b[i-1],b[i])で決定する。n = int(input()) a = list(map(int,input().split())) b = list(map(int,input().split())) c = list(map(int,input().split())) ans = 0 f = 10**9 for i in range(n): ans += b[a[i]-1] if a[i] - f == 1: ans += c[a[i-1]-1] f = a[i] print(ans)まとめ
D(1110diff)は解けませんでした。Cもdiffの割に苦戦したのが悔しい。ではまた。おやすみなさい。
- 投稿日:2020-04-06T23:41:32+09:00
(Python)HTMLの読み取りと正規表現でつかえたところメモ
PythonにてHTMLファイルに正規表現を施す時、
エンコーディングやその他諸々の箇所でつかえてしまったので、メモとして残します。I. HTMLファイルの読み取り
codecsライブラリーを使いましょう。Pythonの標準ライブラリなので(Appx. 1)、インストールいらずにimportだけで使用できます。import codecs f = codecs.open("hoge.html","r", encoding="utf-8")注意
- codecs.open関数には必ず
encoding引数を指定しよう
- Windows環境下だと、Shift-JISと明示されたファイル以外はうまく読み取れないそうです。支(つか)えていたところ先人がいました(Appx. 2)。
II.正規表現を施す
reライブラリを使いましょう。こちらも標準ライブラリ(Appx. 1)なのでimportのみで使えます。# (前章のつづき) import re str = f.read() regex = '[abc]' sample = re.findall(regex, str)注意
- 前章で読み取ったhtmlファイルを
reの各関数に渡す際には、事前に必ずcodecs.read()関数を用いましょう代表的な正規表現
以下、Appx. 3より
reの関数として汎用性の高そうなものを列挙します。regexには正規表現が入るものとします。
- 前方検索:
re.search(regex, string)
- regexパターンがstring内にあるか調べてきて、存在した場合はその文字列(=regex)を返す
- サーチに失敗した場合Noneを返すので、例えば
if not re.search(regex, string):などで簡単に条件分岐に用いることが出来る- 全検索:
re.findall(regex, string)
- regexパターンがstring内にあるか調べてきて、一致箇所すべてを含んだリストを返す
- この関数から別のre処理を行いたい時は、(文字列にするために)str関数を用いて文字列化させましょう(Appx. 4)。
- 置換:
re.sub(regex, replace, string, count=0)
- regexパターンがstring内にあるか調べて、replaceに置換する
- countに1以上の自然数を入力すると、stringの前方からregex該当箇所を何回置換するか指定できる。デフォルト値の0だと全箇所置換する
- 「JavaScript等で正規表現を記述する際のグローバルサーチ(
/g)ってPythonでどうやって表現するのかな?」と思っていたのですが、どうやらこのcount=0の状態で表現されているようです(Appx. 5)なお、正規表現そのものについてはAppx. 6に詳しいです。
(以上)
参考 (Appendix / Appx.)
- 1. Python 標準ライブラリ
- 2. WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話
- 3. re --- 正規表現操作
- 4. re.sub erroring with “Expected string or bytes-like object”
- 5. Python RegExp global flag
- 6. 基本的な正規表現一覧
- 正規表現を調べるのにいつも使用させていただいております。
- 投稿日:2020-04-06T22:29:53+09:00
リストの結合、extendするより足し算した方が早くね?
簡単に速度測定
sub_list = list(range(10000))を空のリストに追加したときの速度を測定してみる。1.
extendの速度In: %%timeit li = [] li.extend(sub_list)Out: 26.7 µs ± 2.44 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)2. 足し算の速度
In: %%timeit li = [] li += sub_listOut: 25.3 µs ± 281 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)足し算の方が早く、速度も安定している。
extendって組み込み関数なのに遅くね?詳しく速度測定
この問題には、
- 元のリストの長さ
- 追加するリストの長さ
の2つの変数があるので、それをいじったときの速度を測定する。そして、速度同士の引き算をして、
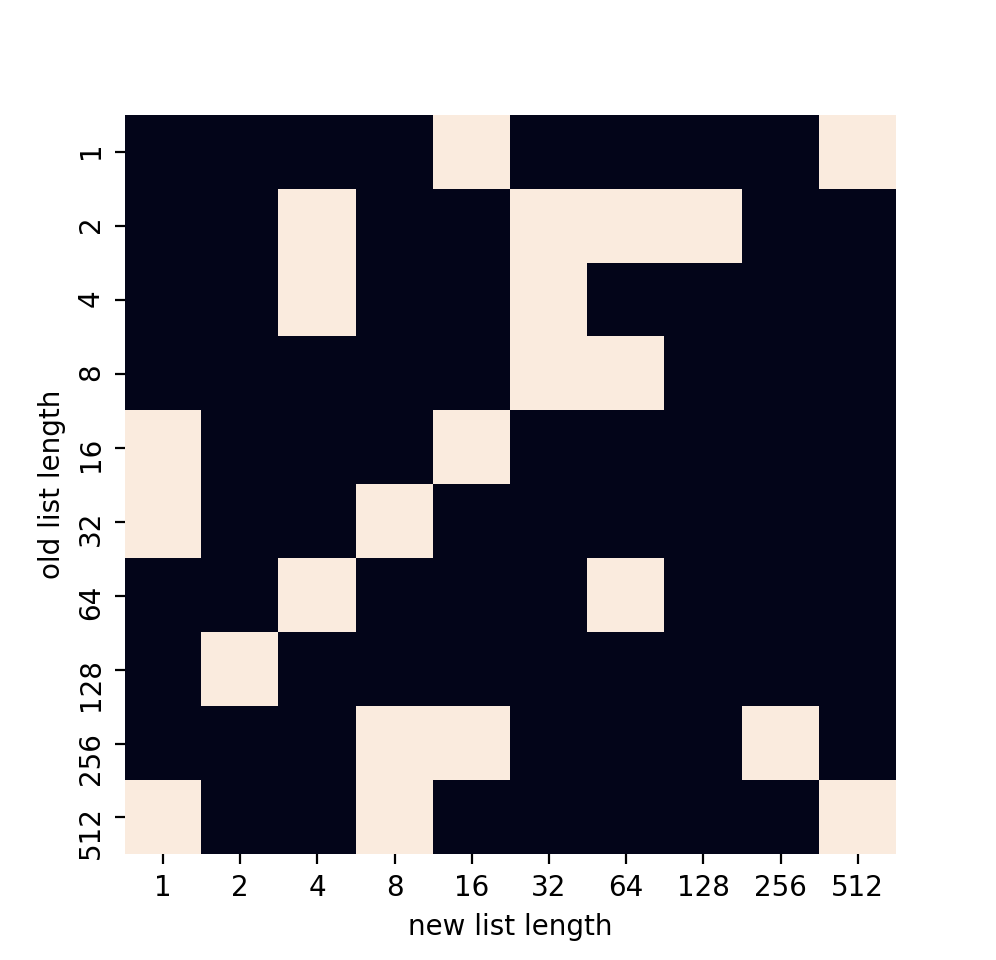
extendと足し算のどちらが勝ったのかを見てみる。リストが短い場合
- 縦軸:元のリストの長さ
- 横軸:追加するリストの長さ
- 白:
extendの方が早い- 黒:足し算の方が早い
足し算優勢
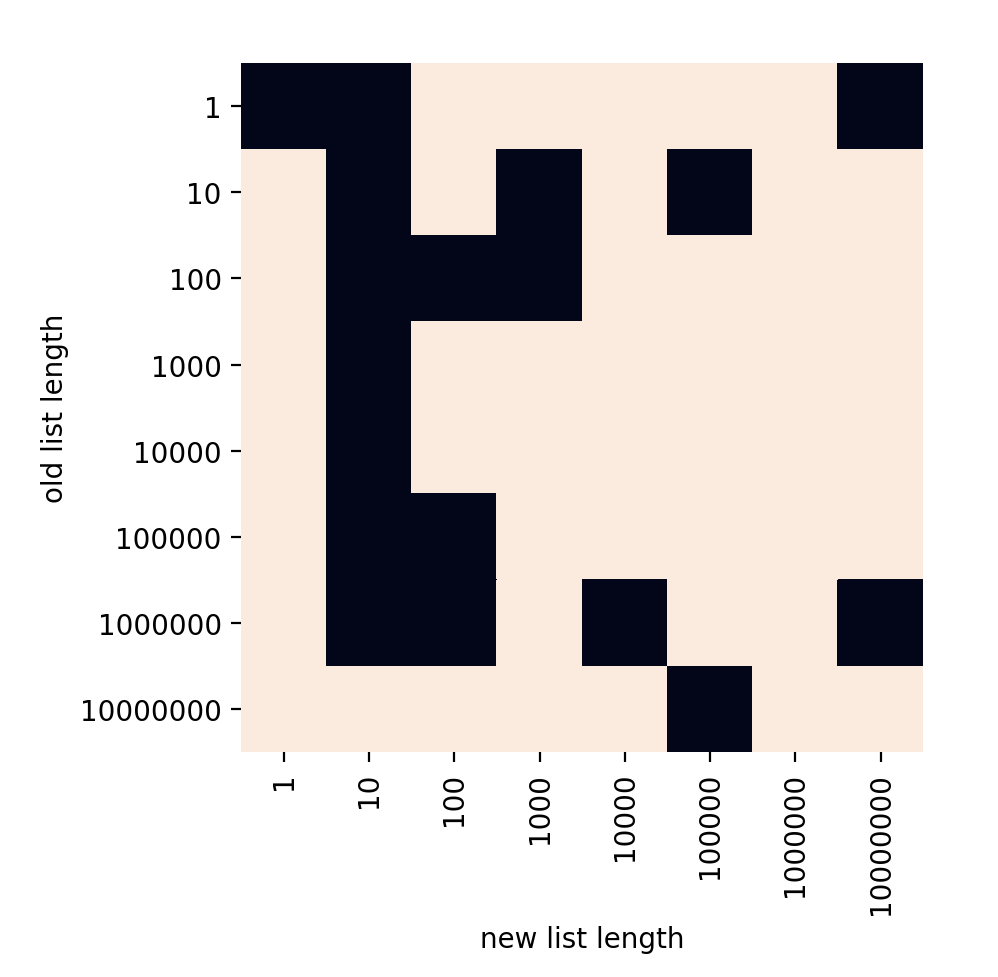
リストが長い場合
- 縦軸:元のリストの長さ
- 横軸:追加するリストの長さ
- 白:
extendの方が早い- 黒:足し算の方が早い
extend優勢なんだろ、Pythonそもそもの実装に関わってくるのかな?
コード
import matplotlib.pyplot as plt import numpy as np import seaborn as sns from time import time def extend_time(old_i, new_i): old = list(range(10 ** old_i)) new = list(range(10 ** new_i)) s = time() old.extend(new) e = time() return e - s def add_time(old_i, new_i): old = list(range(10 ** old_i)) new = list(range(10 ** new_i)) s = time() old += new e = time() return e - s extend_time = np.vectorize(extend_time) add_time = np.vectorize(add_time) shape = (8, 8) extend_graph = np.fromfunction(extend_time, shape, dtype=np.int) add_graph = np.fromfunction(add_time, shape, dtype=np.int) result = np.where(extend_graph - add_graph > 0, True, False) sns.heatmap(result, cbar=False, xticklabels=[10 ** i for i in range(shape[0])], yticklabels=[10 ** i for i in range(shape[0])]) plt.ylabel("old list length") plt.xlabel("new list length") plt.show()
- 投稿日:2020-04-06T21:48:31+09:00
Python&機械学習 勉強メモ⑤
はじめに
① https://qiita.com/yohiro/items/04984927d0b455700cd1
② https://qiita.com/yohiro/items/5aab5d28aef57ccbb19c
③ https://qiita.com/yohiro/items/cc9bc2631c0306f813b5
④ https://qiita.com/yohiro/items/d376f44fe66831599d0b
の続きscikit-learn
今回用いる機械学習ライブラリ
課題設定
花弁と萼それぞれの長さと幅を与えると、アヤメの品種特定をする。
0は"Setosa"を表す。
1は"Versicolor"を表す。
2は"Virsinica"を表す。ソースコード
インポート
from sklearn import datasets from sklearn import svmサンプルデータの読み込み
# Irisの測定データの読み込み iris = datasets.load_iris()
irisには以下のようなデータが入っているiris.data[[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] ...iris.target[0 0 ... 1 1 ... 2 2] ...どちらも要素数は150。おそらく、"0:Setosa", "1:Versicolor", "2:Virsinica"それぞれの正解データが50個づつ入っているものと思われる。
サポートベクターマシンによる分類
# 線形ベクターマシン clf = svm.LinearSVC() # サポートベクターマシンによる訓練 clf.fit(iris.data, iris.target)
svmのメソッドを使ってサポートベクターマシンに学習させる。
今回使っている線形ベクターマシンは、平面(多分、何次元でもいいのだと思う)に打ち込んだ複数の点の集まりに対して線(3次元だったら面)を引いてグルーピングさせるモデル。
今回のケースだと、扱うデータは「花弁の長さ」・「花弁の幅」・「萼の長さ」・「萼の幅」の4つなので、4次元空間に正解データをプロットして、識別できる線を引いている?と思われる。分類
上記で作成したclfに3つのデータを読ませ、"0:Setosa", "1:Versicolor", "2:Virsinica"のどれになるか、それぞれ分類させる。
# 品種を判定する print(clf.predict([[5.1, 3.5, 1.4, 0.1], [6.5, 2.5, 4.4, 1.4], [5.9, 3.0, 5.2, 1.5]]))結果
なんかワーニングが出るが、分類ができている?
C:\Anaconda3\python.exe C:/scikit_learn/practice.py C:\Anaconda3\lib\site-packages\sklearn\svm\_base.py:947: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations. "the number of iterations.", ConvergenceWarning) [0 1 2]おまけ
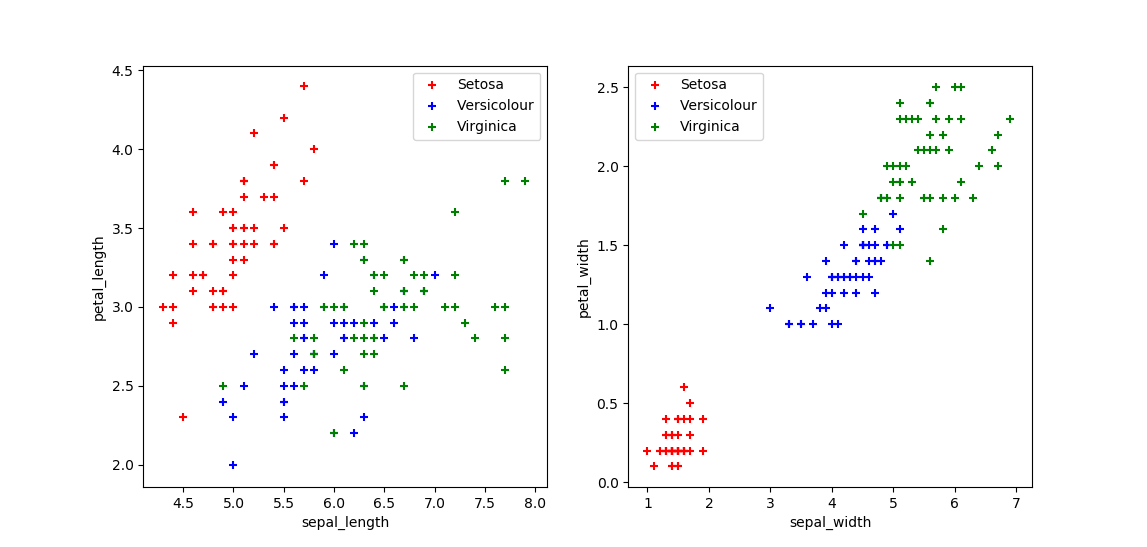
iris.dataの中身がどのようなデータなのかを見える化してみた
from sklearn import datasets import matplotlib.pyplot as plt # Irisの測定データの読み込み iris = datasets.load_iris() # Setosa, Versicolour, Virginica sepal_length = [[], [], []] petal_length = [[], [], []] sepal_width = [[], [], []] petal_width = [[], [], []] for num, data in enumerate(iris.data): cls = iris.target[num] sepal_length[cls].append(data[0]) petal_length[cls].append(data[1]) sepal_width[cls].append(data[2]) petal_width[cls].append(data[3]) plt.subplot(1,2,1) plt.scatter(sepal_length[0], petal_length[0], c="red", label="Setosa", marker="+") plt.scatter(sepal_length[1], petal_length[1], c="blue", label="Versicolour", marker="+") plt.scatter(sepal_length[2], petal_length[2], c="green", label="Virginica", marker="+") plt.xlabel('sepal_length') plt.ylabel('petal_length') plt.legend() plt.subplot(1,2,2) plt.scatter(sepal_width[0], petal_width[0], c="red", label="Setosa", marker="+") plt.scatter(sepal_width[1], petal_width[1], c="blue", label="Versicolour", marker="+") plt.scatter(sepal_width[2], petal_width[2], c="green", label="Virginica", marker="+") plt.xlabel('sepal_width') plt.ylabel('petal_width') plt.legend() plt.show()
Setosa, Versicolour, Virginicaのグループの間に線を引くことで、(Versicolour, Virginicaのライン近傍のデータは難しいかもしれないが)おおむね分類できそうなことが理解できる。
- 投稿日:2020-04-06T21:30:26+09:00
Twitterに投稿された新型コロナウィルスに関するツイートを分析してみた
概要
Twitterでは,新型コロナウィルスに関して日夜活発に議論されています.
これらのツイートを分析することで,Twitterユーザの傾向として意義あるものが掴めないかと思ました.
そこで,本記事では,Twitterに投稿された新型コロナウィルスに関するツイートを収集し,簡単に分析をしていきます.誤りや見づらい箇所,アドバイス等ございましたら,どうぞご気軽にご指摘ください.よろしくお願いします.
データの詳細
本記事で用いるツイートデータは,2020年1月1日~2020年4月1日までの間に投稿された,「コロナ」「COVID-19」「感染症」のいずれかを含むツイートです.
ただし,日本語ツイートに限定し,RT数が10を越えているツイートのみを用います.
結果として,47041件のツイートからなるデータセットを構築しました.ツイートデータは以下のような連想配列で保存しました.
{ 'text': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx', 'date': datetime.datetime(2020, 1, 1, 1, 0, 1), 'retweets': 123, 'favorites': 456, 'user_id': 7890123, 'hashtags': ['# yyy', '# zzz'], 'url': ['https://aaaaaa.com', 'http://bbb.com'] }探索的データ分析 (Explanatory Data Analysis: EDA)
本記事で用いるデータからは,テキストの長さ,投稿時間,RT数,いいね数,ハッシュタグの有無,URLの有無といった,いくつかの量が得られます.
そこで,これらの量を活かしてデータの特性を読み取ります.※以下すべてpython3 + Jupyter Notebookを用いて処理しています.
import os, sys, json, re import pandas as pd import matplotlib.pyplot as plt import seaborn as sns; sns.set() from datetime import datetime import datetime as dt %matplotlib inline文字数,RT数,いいね数,URLの有無,ハッシュタグの有無
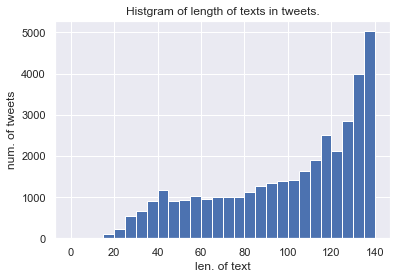
文字数
tweet_len = tweets["text"].str.len() tweets["text_len"] = tweet_len tweets["text_len"].hist(bins=range(0, 141, 5)) plt.xlabel("len. of text") plt.ylabel("num. of tweets") plt.title("Histgram on length of texts in tweets")
データ取得の時点では,140字を越えるツイートが少数見られましたが(なんで?),図の見やすさのために省きました.
データセット内の多くのツイートが,多くの文字(≒情報)を含むようです.
本データセットには10RTを越えるツイートのみを採用しているので,もしかしたら文字数が増加するほどRT数が増加する傾向にあるのかも知れません.(この点は下で検証しています.)RT数,いいね数
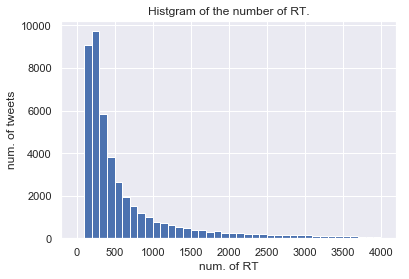
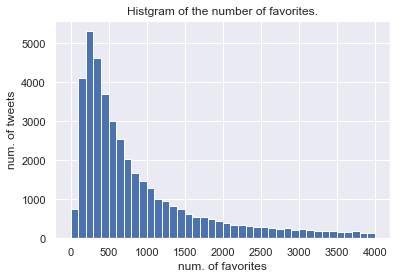
tweets["retweets"].hist(bins=range(0,4001,100)) plt.xlabel("num. of RT") plt.ylabel("num. of tweets") plt.title("Histgram on the number of RT.") ------------------------------------------------- tweets["favorites"].hist(bins=range(0,4001,100)) plt.xlabel("num. of favorites") plt.ylabel("num. of tweets") plt.title("Histgram on the number of favorites.")
実際には10万RT/いいねを越えるツイートもあるのですが,図の見やすさのためにこのように範囲を設定しています.
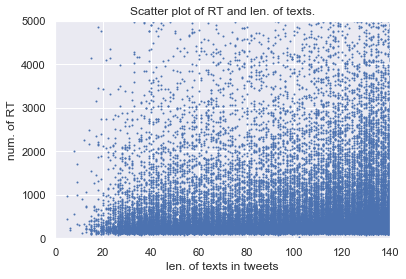
両者とも減衰がみられますが,RT数で~300程度まではツイート数が上昇傾向にあることから,いったんRTされはじめたツイートはある一定のラインまではRT数が伸び続ける傾向にあるのでは無いかと推測できます.ここで,RT数と文字数の相関関係を見てみます.
fig, ax = plt.subplots() ax.scatter(tweets["text_len"], tweets["retweets"], s=1) plt.xlim(0, 140) plt.ylim(0, 5000) plt.xlabel("len. of texts in tweets") plt.ylabel("num. of RT") plt.title("Scatter plot of RT and len. of texts.")
相関係数: 0.022
図を見ると文字数が140に近い所ではRT数も大きいツイートが多いように見えるのですが,相関関係は無いようです.
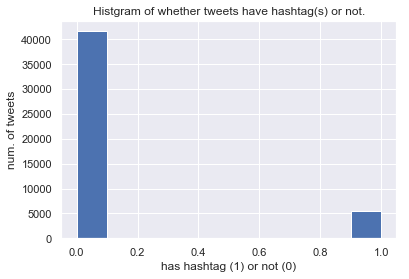
したがって,「たくさんRTされるツイートは,文字数が多い傾向にある」といったことやその逆は言えないようです.ハッシュタグ/URLの有無
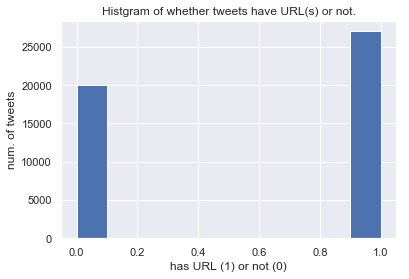
tweets.loc[tweets["hashtags"].str.len() > 0, "has_hashtag"] = 1 tweets.loc[tweets["hashtags"].str.len() <= 0, "has_hashtag"] = 0 tweets["has_hashtag"].hist() plt.xlabel("has hashtag (1) or not (0)") plt.ylabel("num. of tweets") plt.title("Histgram of whether tweets have hashtag(s) or not.") ---------------------------------------------------------------- tweets.loc[tweets["url"].str.len() > 0, "has_url"] = 1 tweets.loc[tweets["url"].str.len() <= 0, "has_url"] = 0 tweets["has_url"].hist() plt.xlabel("has URL (1) or not (0)") plt.ylabel("num. of tweets") plt.title("Histgram of whether tweets have URL(s) or not.")
このデータセットでは,ハッシュタグが付与されたツイートは少なく,URLが付与されたツイートが多いようです.
半数以上のツイートにURLが付与されていることから,RT数が10以上のツイートの多くは本文だけで無く,URLによっても情報を付与していることがわかります.ここまでのまとめ
このあたりは一般のツイートと同様な特性が見られるようです.
(実際には一般のツイートでデータセットを作り,同様の量をだして比較する必要がありますが・・・)
データセットのツイートには,本文が長く,ハッシュタグよりもURLによって情報を付加する傾向にあります.
RT数,いいね数に関してもキレイに減衰する傾向がみられ,これは一般のツイートでも同様であると考えられます.時系列を用いた分析
以降では,1/1から4/1までの92日間での種々の量の変遷をみていきます.
日ごとのツイート数
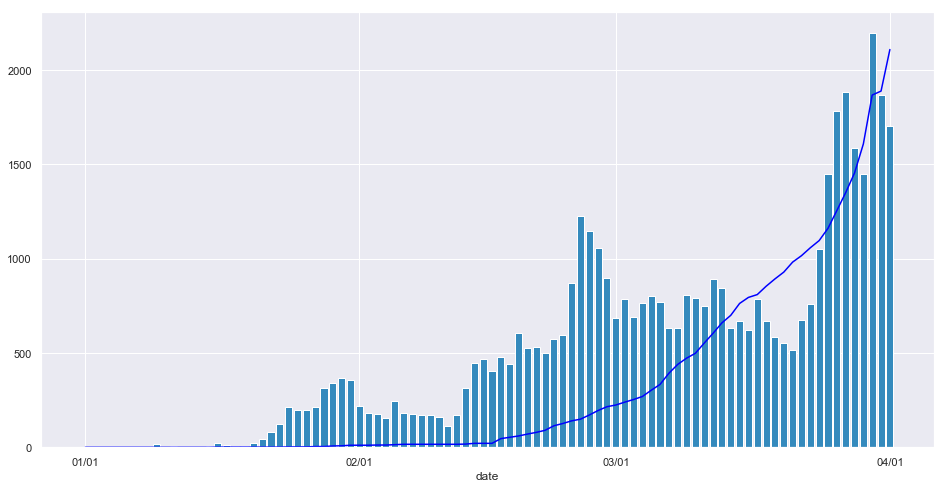
sns.set() fig, ax = plt.subplots(figsize=(16.0, 8.0)) ax.bar(df.index, df["tweets"], color='#348ABD') ax.plot(df.index, df["kansen"], color="blue") ax.set_xticks([1,32,61,92]) ax.set_xticklabels(["01/01", "02/01", "03/01", "04/01"]) ax.set_xlabel("date")
横軸は日付です.
ヒストグラムが日ごとのツイート数を表し,折れ線が日ごとの国内での新型コロナウィルス感染判明数1を表します.
縦軸の目盛りは両者に共通です.上図ではいくつかのピークが確認できます.
各ピークに関して,1日だけ飛び抜けるわけではなく,2,3日に渡ってツイート数が増加しています.
このことから,こうしたピークは外れ値ではなく,この期間にはユーザの関心を強く引く事柄が存在したと予想されます.また,感染判明数もついでに載せましたが,ツイート数とはそれほど相関がないようです.
苦労したのに
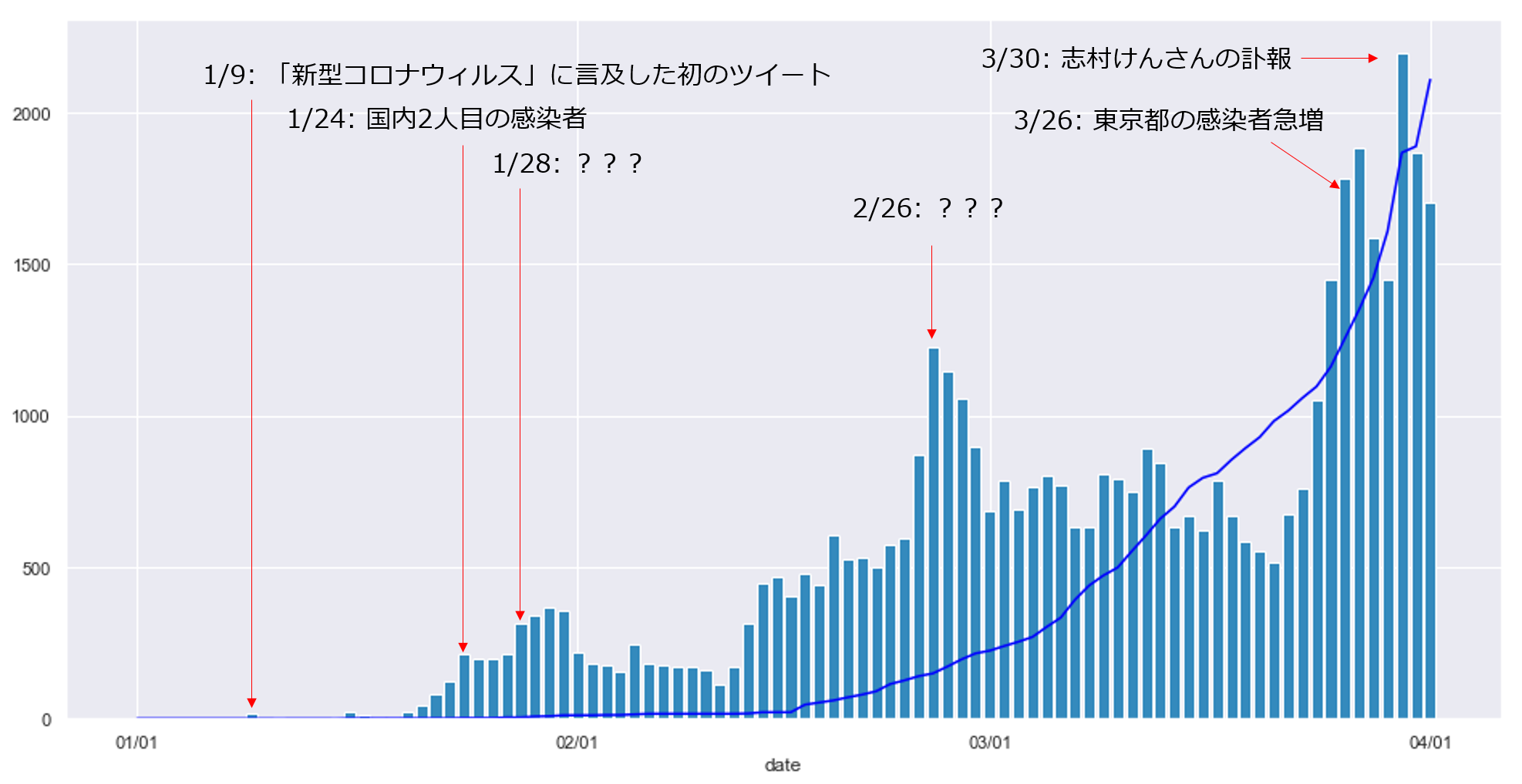
このことから,ユーザは新型コロナウィルスの患者数増加(感染拡大)よりも,その結果もたらされる他の事象(例えば政治的判断やイベントの中止など)に強く反応すると予想されます.では,各ピークは何が原因で生じているか分析します.
この図は,先ほどの図のピークや個人的に気になる日に関して,実際のツイートの内容や厚労省の発表等を調査し,ピーク等の事象の原因になったと思われる内容を付与したものです.
肝心の1/28付近と2/26付近に関して,いずれもデータセット内の100件以上のツイートに目を通しましたが,一貫性が無く,何がピークの原因となっているかは確認できませんでした.
こちらは,後ほど頻出語やRT数に関する分析を行う際に,詳細に確認します.多分日ごとの累計RT数
sns.set_style("dark") fig, ax1 = plt.subplots(figsize=(16.0, 8.0)) ax1.bar(df.index, df["retweets"], color='#348ABD') ax2 = ax1.twinx() ax2.plot(df.index, df["kansen"], color="blue") ax2.set_ylim(0,2500) ax1.set_xticks([1,32,61,92]) ax1.set_xticklabels(["01/01", "02/01", "03/01", "04/01"]) ax1.set_xlabel("date") ax1.set_ylabel("num. of retweets") ax2.set_ylabel("num. of infected people")
上図で,ヒストグラムと左縦軸は日ごとの累計RT数を表し,折れ線と右縦軸が日ごとの感染判明数を表します.
日ごとのツイート数と同じようなグラフが出てきました.
やはり,日ごとの感染判明数とは関連が無さそうです.では,日ごとのツイート数と日ごとのRT数を比較してみます.
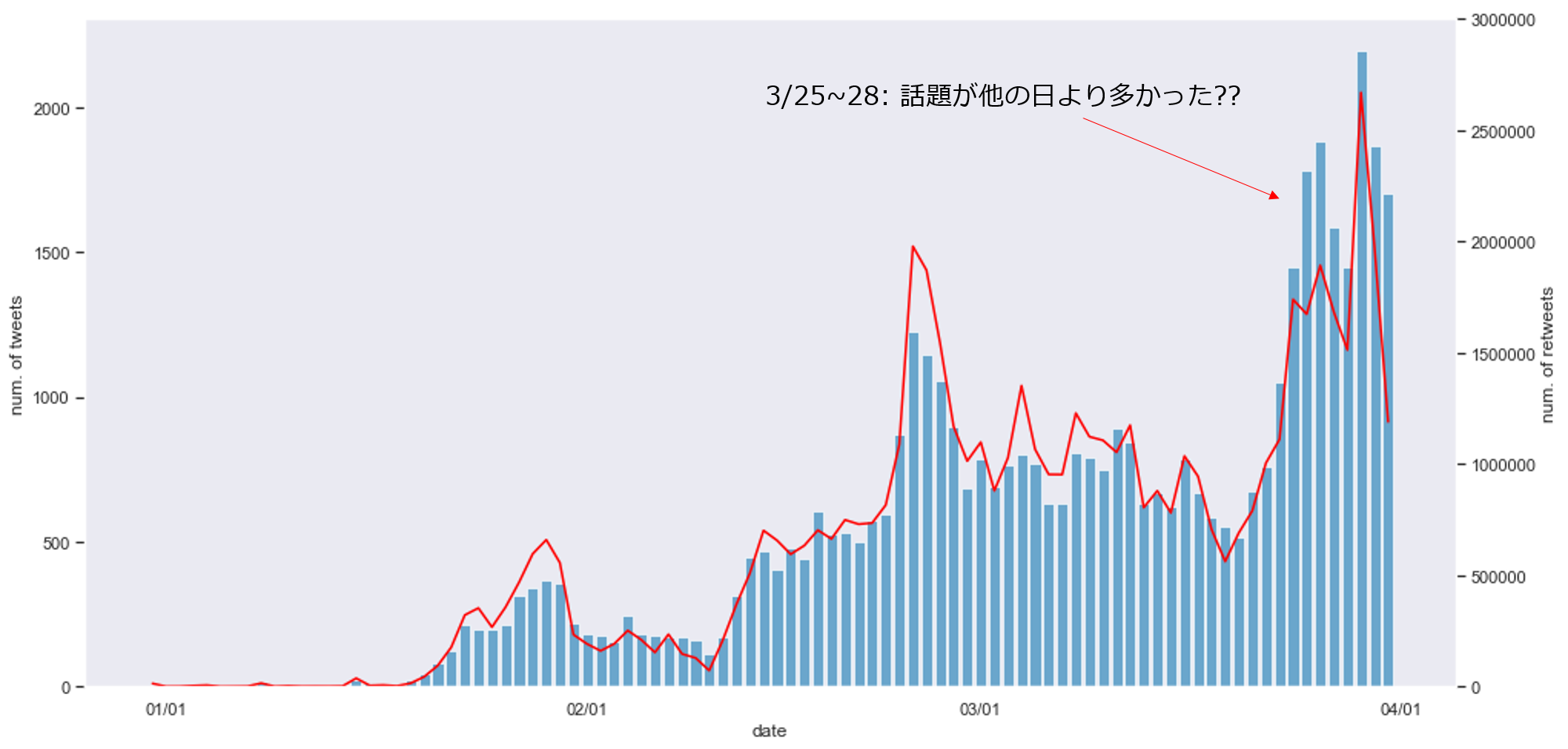
sns.set_style("dark") fig, ax1 = plt.subplots(figsize=(16.0, 8.0)) ax1.bar(df.index, df["tweets"], color='#348ABD', alpha=0.7) ax2 = ax1.twinx() ax2.plot(df.index, df["retweets"], color="red") ax2.set_ylim(0,3000000) ax1.set_xticks([1,32,61,92]) ax1.set_xticklabels(["01/01", "02/01", "03/01", "04/01"]) ax1.set_xlabel("date") ax1.set_ylabel("num. of tweets") ax2.set_ylabel("num. of retweets")
上の図で,ヒストグラムと左縦軸が日ごとのツイート数を表し,赤の折れ線と右縦軸が日ごとの累計RT数を表します.
日ごとのツイート数と日ごとのRT数は,ほとんどの日で相関関係にあるようです.
ここで,3/25~28付近だけ,他とは異なる様相を呈しています.
他の人比較して(10RT以上された)ツイート数がRT数を上回る原因として,この期間だけ,他の期間と比較して新型コロナウィルスに関する話題が多く,ユーザが話題を追い切れなかった(RTできなかった)ことが考えられます.今後
さっさと投稿したかったので上記を踏まえ,今後やることを書いていきます.
- 頻出語の分析
- 1/24,2/26あたりになぜピークがあるのか.
- WindowsのMeCabがなぜかうまくいかない.
- ツイートのクラスタリング
- 例えば日ごとにツイートをクラスタリングすることで,その日の話題の数が定量化でき,ツイートの内容もまとまってより分析しやすくなると期待できます.
- RT数予測モデルの構築
- 適当な回帰モデルを組んで,「どういう性質のツイートがRTされやすい(≒人の興味を引く)か」といったことを分析できるかも...?
- 問題を分類にしても良さそう.
- ユーザ情報の活用
- 例えば専門家のツイートは,そうでないユーザよりRT数が多くなるでしょう.このように,投稿者の情報を活用することで,より詳細に新型コロナウィルスに関するTwitterユーザの動向が分析できる可能性があります.
おわりに
はじめてQiitaに投稿します.
分析として,なにか革新的な知見が得られた訳ではありませんでしたが,今後このデータセットについて掘り進める方針が掴めた気がします.
EDAは,こうした方向性を決めるためにも重要なのですね.
本当はしっかり予測モデルまで構築して,評価・モデルの性質の分析までしたかったのですが,はよ投稿したいという気持ちが強く,次回に回すことにしました.ここまで読んで頂き,ありがとうございました.
拙い分析・文章で恐縮ですが,ご指摘・ご意見,アドバイス等お気軽にして頂ければと思います.

- 投稿日:2020-04-06T20:36:51+09:00
【Python】【短期】Qiitaの読んでおかなければいけない記事100選【毎日自動更新】
ページ容量を増やさないために、不具合報告やコメントは、説明記事 に記載いただけると助かります。
※ 機械学習等のタグが付与されている記事は除いています。
【機械学習他】【短期】Qiitaの読んでおかなければいけない記事100選【毎日自動更新】 を参照してください。
順位 記事名
________________________________________ユーザ 投稿日付
更新日付LGTM1 1 Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~ upura 19/03/29
20/02/122055
2872 Djangoを最速でマスターする part1 gragragrao 17/07/24
19/09/251949
1543 データ分析で頻出のPandas基本操作 ysdyt 18/04/15
19/12/171600
1814 早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話 skotaro 18/01/11
18/07/161919
1215 Pythonでゼロからでもサービス開発・公開できる学習ロードマップ Saku731 20/02/16
20/02/18909
9096 pythonの環境構築戦争にイラストで終止符をどうやら打てない ganariya 19/10/27
19/12/201285
117 Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12 Azunyan1111 18/02/21
20/03/211648
768 Django REST Frameworkを使って爆速でAPIを実装する kimihiro_n 15/12/13
19/12/131333
999 Python中級者への道しるべ papi_tokei 19/11/03
19/11/061058
1910 Python Webスクレイピング 実践入門 Azunyan1111 16/12/01
18/02/231208
5111 Pipenvを使ったPython開発まとめ y-tsutsu 18/12/13
19/09/16576
10612 画像処理100本ノックを作ったった yoyoyo_ 19/01/08
19/11/071792
5313 [Python] Djangoチュートリアル - 汎用業務Webアプリを最速で作る okoppe8 18/03/09
18/11/27931
6714 競プロ界隈でpython強者がやっていることをまとめてみた dekamisako 20/03/17
20/03/18523
52315 【python】カジノを崩壊させたらしいモンテカルロ法をシミュレーションしてみた kagawa_shinjiiiii 20/01/12
20/01/14684
68416 AtCoderの問題を分類しました KoyanagiHitoshi 19/02/26
20/03/13722
7717 [Python] プログラム初心者のためのWebアプリ簡単作成法 okoppe8 18/09/27
18/09/28538
6818 matplotlibのめっちゃまとめ nkay 19/05/20
20/03/25278
17119 Awesome Python:素晴らしい Python フレームワーク・ライブラリ・ソフトウェア・リソースの数々 hatai 17/02/01
19/11/011263
5120 venv: Python 仮想環境管理 fiftystorm36 17/05/12
19/10/11586
6221 製造現場向けの自動化ツールをPythonで作る時に留意すること banquet_kuma 20/03/20
20/03/24473
47322 PythonでAtCoder青になるまで -Pythonで競プロやるときに気をつけること- Kentaro_okumura 19/01/14
19/01/31778
7023 [Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル) simonritchie 18/04/01
19/07/17592
6124 Pythonを書き始める前に見るべきTips icoxfog417 14/07/29
19/02/063720
025 matplotlibでのプロットの基本 KntKnk0328 17/12/15
19/02/14431
7226 2020 年の Python パッケージ管理ベストプラクティス sk217 19/12/15
19/12/20523
7827 Pythonで使う競技プログラミング用チートシート _-_-_-_-_ 17/11/11
19/08/22470
6628 Python の __init__.py とは何なのか msi 20/01/17
20/03/19449
44929 python 組み込み関数を全て(69個)紹介する anieca 19/10/24
19/10/24636
630 pythonの内包表記を少し詳しく y__sama 16/03/14
18/01/02880
3231 Pythonで競プロやるときによく書くコードをまとめてみた y-tsutsu 18/05/12
20/03/07773
4932 Pythonのテキスト作りました KatsunoriNakamura 17/05/16
20/03/241191
3033 Python文字列操作マスター tomotaka_ito 16/02/04
18/12/23791
4734 ArgumentParserの使い方を簡単にまとめた kzkadc 18/05/24
19/04/11378
5835 Jupyter Notebookをより便利に使うために、色々まとめ ishizakiiii 17/09/21
19/07/15675
4136 atcoderでよく使う手法python版 chun1182 18/11/25
19/11/19342
7037 Python3で競技プログラミングする時に知っておきたいtips(入力編) kyuna 18/09/08
19/04/14285
8338 2018年のPythonプロジェクトのはじめかた sl2 18/04/30
18/10/011379
1039 データの集計は、ExcelよりPython使ったほうが100倍早い(pandas-profiling, pixiedust) pocket_kyoto 19/04/26
19/04/26854
2340 Pythonではじまる、型のある世界 icoxfog417 15/11/02
17/02/26706
4141 Jupyter 知っておくと少し便利なTIPS集 simonritchie 18/04/16
18/04/17842
3142 Pythonのlambdaって分かりやすい nagataaaas 18/05/20
19/11/02295
5943 Django データベース操作 についてのまとめ okoppe8 17/12/26
17/12/28408
5644 Pythonライブラリの「麻雀(mahjong)」って?? FJyusk56 20/01/18
20/01/22468
46845 【Python入門】いまさらだけどパイソニスタとして必要な文法を網羅してみた gold-kou 18/04/18
18/09/121136
2446 Pythonエラー一覧(日本語) soutarrr7 15/12/26
16/01/08593
3447 Pythonにおける非同期処理: asyncio逆引きリファレンス icoxfog417 16/03/26
19/03/06592
4248 実践/現場のPythonスクレイピング流儀 ryuta69 19/03/18
20/02/101139
3449 文科省のPythonはPythonじゃねぇ nagataaaas 19/05/20
19/09/251159
1050 AtCoderで始めるPython入門 KoyanagiHitoshi 19/04/04
20/03/22409
6651 Anaconda で Python 環境をインストールする t2y 16/08/20
18/11/12731
2752 分かりやすいpythonの正規表現の例 luohao0404 18/01/25
19/12/24289
5953 Pandas の groupby の使い方 propella 18/07/02
18/11/15277
5354 Pythonでロギングを学ぼう __init__ 18/02/24
20/03/19341
3855 ゴー☆ジャス(宇宙海賊)をつくる jg43yr 19/07/12
19/07/26870
556 Kaggle Masterが勾配ブースティングを解説する woody_egg 18/10/26
19/09/12279
3557 Pythonの並列処理・並行処理をしっかり調べてみた simonritchie 19/05/12
19/07/16315
6658 気持ちのいいジャンプを目指して odanny 19/09/05
19/09/10639
1059 pythonで美しいグラフ描画 -seabornを使えばデータ分析と可視化が捗る その1 hik0107 15/09/20
16/09/221112
3560 MacOSとHomebrewとpyenvで快適python環境を。 crankcube 17/01/07
20/01/09363
4161 Pythonを速くしたいときにやったこと shaka 17/08/08
20/02/29290
3862 京都大学 Pythonによるプログラミング演習教材を無料公開 tmdoi 20/02/25
20/03/04389
38963 Pythonのデコレータについて mtb_beta 15/01/19
18/07/05828
064 Flaskの簡単な使い方 zaburo 17/05/10
19/07/16422
3665 JupyterLabのおすすめ拡張機能8選 canonrock16 19/04/11
20/04/01372
5266 グラフ理論の基礎 maskot1977 18/06/17
19/10/18659
5267 pyenvのインストール、使い方、pythonのバージョン切り替えできない時の対処法 koooooo 17/06/22
18/06/28306
4068 Pythonistaなら知らないと恥ずかしい計算量のはなし Hironsan 17/02/27
17/02/27347
4569 PythonとBeautiful Soupでスクレイピング itkr 15/03/01
17/03/071057
070 PythonでSeleniumを使ってスクレイピング (基礎) kinpira 16/11/21
19/08/19394
3071 [Pythonコーディング規約]PEP8を読み解く simonritchie 18/09/16
18/09/16261
4372 削除済(ID:201aaa2708260cc790b8) uni-3 18/03/09
19/06/22361
3273 0.1は浮動小数点数で正確に表せないのに、printしたときに0.1と表示されるのはなぜか yucatio 20/01/21
20/01/28420
42074 PIL/Pillow チートシート pashango2 17/01/30
17/03/06449
3075 マッチングアプリ強者の統計をとってみた&機械学習モデルを作成してみた data_psyence 19/11/07
20/04/03369
476 【Pythonメモ】pandas-profilingが探索的データ解析にめちゃめちゃ便利だった件 h_kobayashi1125 18/04/27
18/05/05458
3377 【PythonのORM】SQLAlchemyで基本的なSQLクエリまとめ tomo0 17/11/18
20/01/02298
3778 ExcelにPythonが搭載?その後 - xlwings を使おう yniji 18/12/24
19/01/22446
5179 VSCodeのPython開発環境でpylintの代わりにflake8を導入し自動整形を設定する psychoroid 18/11/05
18/11/05225
4880 pyenv、pyenv-virtualenv、venv、Anaconda、Pipenv。私はPipenvを使う。 KRiver1 19/03/29
19/09/12245
5781 matplotlib基礎 | figureやaxesでのグラフのレイアウト gaku8 17/09/24
18/01/01285
4182 Pythonで実用Discord Bot(discordpy解説) 1ntegrale9 18/06/06
20/02/17340
3483 Pythonの並列・並行処理サンプルコードまとめ castaneai 17/07/29
18/09/18408
2484 Python __init__.pyの書き方 PYTHONISTA 18/10/05
19/06/18226
4685 pythonで小さなツールを作る時のtips m_mizutani 17/09/04
17/09/051050
5486 Python で高速化したいなら Python を書いてはいけない ishitoki47259 20/02/04
20/02/05295
29587 Python系の情報ソースをまとめた ryuta69 19/03/24
20/02/03680
2288 グラフ作成のためのチートシートとPythonによる各種グラフの実装 4m1t0 19/04/06
19/11/08462
3589 Pythonで"in list"から"in set"に変えただけで爆速になった件とその理由 kitadakyou 19/07/11
19/07/12706
1390 Python記事まとめ(毎日自動更新) kamata1729 19/04/14
20/04/07217
5391 Djangoにおけるクラスベース汎用ビューの入門と使い方サンプル felyce 16/04/17
19/10/27348
3392 PyAutoGuiで繰り返し作業をPythonにやらせよう hirohiro77 18/06/12
19/08/27240
3193 ウェブアプリケーションフレームワーク Flask を使ってみる ynakayama 15/01/28
19/01/28848
094 [Python] Plotlyでぐりぐり動かせるグラフを作る inoory 16/08/30
19/03/16359
3395 Python3基礎文法 Fendo181 17/02/21
20/03/17305
3496 Django(Python)でシステム開発できるようになる記事_入門編 Saku731 20/02/16
20/02/17343
34397 Python の HTTP クライアントは urllib.request で十分 hoto17296 18/02/28
19/12/18283
3098 深入りしないCython入門 pashango2 17/01/10
17/01/11430
3399 Pythonによるデザインパターン5原則 kotetsu75 18/01/10
18/02/20746
30100 Pythonで簡単なGUIを作れる「Tkinter」を使おう CyberRex 18/02/16
19/10/01425
28
1行目が総数。2行目が直近3ヵ月。 ↩
- 投稿日:2020-04-06T20:36:49+09:00
【Python】【長期】Qiitaの読んでおかなければいけない記事100選【毎日自動更新】
ページ容量を増やさないために、不具合報告やコメントは、説明記事 に記載いただけると助かります。
※ 機械学習等のタグが付与されている記事は除いています。
【機械学習他】【長期】Qiitaの読んでおかなければいけない記事100選【毎日自動更新】 を参照してください。
順位 記事名
________________________________________ユーザ 投稿日付
更新日付LGTM1 1 Djangoを最速でマスターする part1 gragragrao 17/07/24
19/09/251949
7132 Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~ upura 19/03/29
20/02/122055
11363 データ分析で頻出のPandas基本操作 ysdyt 18/04/15
19/12/171600
7374 早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話 skotaro 18/01/11
18/07/161919
5985 Pythonを書き始める前に見るべきTips icoxfog417 14/07/29
19/02/063720
1746 Django REST Frameworkを使って爆速でAPIを実装する kimihiro_n 15/12/13
19/12/131333
3917 Python Webスクレイピング 実践入門 Azunyan1111 16/12/01
18/02/231208
3238 Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12 Azunyan1111 18/02/21
20/03/211648
4419 [Python] Djangoチュートリアル - 汎用業務Webアプリを最速で作る okoppe8 18/03/09
18/11/27931
36010 Awesome Python:素晴らしい Python フレームワーク・ライブラリ・ソフトウェア・リソースの数々 hatai 17/02/01
19/11/011263
27311 画像処理100本ノックを作ったった yoyoyo_ 19/01/08
19/11/071792
31412 pythonの内包表記を少し詳しく y__sama 16/03/14
18/01/02880
25013 venv: Python 仮想環境管理 fiftystorm36 17/05/12
19/10/11586
31214 Python文字列操作マスター tomotaka_ito 16/02/04
18/12/23791
24315 Pythonのデコレータについて mtb_beta 15/01/19
18/07/05828
19416 PythonとBeautiful Soupでスクレイピング itkr 15/03/01
17/03/071057
15017 Pythonのテキスト作りました KatsunoriNakamura 17/05/16
20/03/241191
20418 Pythonではじまる、型のある世界 icoxfog417 15/11/02
17/02/26706
22919 Pipenvを使ったPython開発まとめ y-tsutsu 18/12/13
19/09/16576
43320 pythonの環境構築戦争にイラストで終止符をどうやら打てない ganariya 19/10/27
19/12/201285
128521 Pythonエラー一覧(日本語) soutarrr7 15/12/26
16/01/08593
20422 [Python] プログラム初心者のためのWebアプリ簡単作成法 okoppe8 18/09/27
18/09/28538
39023 ウェブアプリケーションフレームワーク Flask を使ってみる ynakayama 15/01/28
19/01/28848
15024 AtCoderの問題を分類しました KoyanagiHitoshi 19/02/26
20/03/13722
50925 Python Django入門 (1) kaki_k 14/07/26
18/01/281697
11226 Pythonで使う競技プログラミング用チートシート _-_-_-_-_ 17/11/11
19/08/22470
28427 [Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル) simonritchie 18/04/01
19/07/17592
30228 Anaconda で Python 環境をインストールする t2y 16/08/20
18/11/12731
16629 matplotlibでのプロットの基本 KntKnk0328 17/12/15
19/02/14431
30130 Jupyter Notebookをより便利に使うために、色々まとめ ishizakiiii 17/09/21
19/07/15675
22431 Pythonでゼロからでもサービス開発・公開できる学習ロードマップ Saku731 20/02/16
20/02/18909
90932 2018年のPythonプロジェクトのはじめかた sl2 18/04/30
18/10/011379
13833 Pythonにおける非同期処理: asyncio逆引きリファレンス icoxfog417 16/03/26
19/03/06592
18534 PythonでAtCoder青になるまで -Pythonで競プロやるときに気をつけること- Kentaro_okumura 19/01/14
19/01/31778
35135 ログ出力のための print と import logging はやめてほしい amedama 14/05/02
18/11/19984
14136 pythonで美しいグラフ描画 -seabornを使えばデータ分析と可視化が捗る その1 hik0107 15/09/20
16/09/221112
16737 Jupyter 知っておくと少し便利なTIPS集 simonritchie 18/04/16
18/04/17842
20238 Pythonで競プロやるときによく書くコードをまとめてみた y-tsutsu 18/05/12
20/03/07773
23239 Python中級者への道しるべ papi_tokei 19/11/03
19/11/061058
105840 【Python入門】いまさらだけどパイソニスタとして必要な文法を網羅してみた gold-kou 18/04/18
18/09/121136
10741 Django データベース操作 についてのまとめ okoppe8 17/12/26
17/12/28408
20542 ArgumentParserの使い方を簡単にまとめた kzkadc 18/05/24
19/04/11378
26943 PythonでPandasのPlot機能を使えばデータ加工からグラフ作成までマジでシームレス hik0107 16/03/01
16/09/22890
12944 MacOSとHomebrewとpyenvで快適python環境を。 crankcube 17/01/07
20/01/09363
17545 PythonでSeleniumを使ってスクレイピング (基礎) kinpira 16/11/21
19/08/19394
15046 Flaskの簡単な使い方 zaburo 17/05/10
19/07/16422
16847 matplotlibのめっちゃまとめ nkay 19/05/20
20/03/25278
27848 Pythonのimportについてまとめる suzuki-hoge 16/05/17
16/05/17601
11449 atcoderでよく使う手法python版 chun1182 18/11/25
19/11/19342
31350 実践/現場のPythonスクレイピング流儀 ryuta69 19/03/18
20/02/101139
25651 PIL/Pillow チートシート pashango2 17/01/30
17/03/06449
14852 Pythonのlambdaって分かりやすい nagataaaas 18/05/20
19/11/02295
26753 PythonのTkinterを使ってみる nnahito 15/02/21
19/03/05513
12254 Djangoにおけるクラスベース汎用ビューの入門と使い方サンプル felyce 16/04/17
19/10/27348
14955 組合せ最適化を使おう SaitoTsutomu 15/07/13
17/10/17826
13556 Python3で競技プログラミングする時に知っておきたいtips(入力編) kyuna 18/09/08
19/04/14285
26457 データの集計は、ExcelよりPython使ったほうが100倍早い(pandas-profiling, pixiedust) pocket_kyoto 19/04/26
19/04/26854
85458 Pythonistaなら知らないと恥ずかしい計算量のはなし Hironsan 17/02/27
17/02/27347
17759 Pythonを速くしたいときにやったこと shaka 17/08/08
20/02/29290
20160 文科省のPythonはPythonじゃねぇ nagataaaas 19/05/20
19/09/251159
115961 Pythonの並列・並行処理サンプルコードまとめ castaneai 17/07/29
18/09/18408
14462 分かりやすいpythonの正規表現の例 luohao0404 18/01/25
19/12/24289
21363 pyenvのインストール、使い方、pythonのバージョン切り替えできない時の対処法 koooooo 17/06/22
18/06/28306
16664 Pythonでロギングを学ぼう __init__ 18/02/24
20/03/19341
22665 Python基礎講座(13 クラス) Usek 15/01/10
17/01/15499
8966 [Python] Plotlyでぐりぐり動かせるグラフを作る inoory 16/08/30
19/03/16359
13667 最強のPython統合開発環境PyCharm yamionp 15/12/15
15/12/18837
11768 深入りしないCython入門 pashango2 17/01/10
17/01/11430
12269 Python3基礎文法 Fendo181 17/02/21
20/03/17305
15170 pythonで小さなツールを作る時のtips m_mizutani 17/09/04
17/09/051050
9371 削除済(ID:201aaa2708260cc790b8) uni-3 18/03/09
19/06/22361
16772 Pythonのデコレータを理解するための12Step _rdtr 14/04/06
18/08/23828
7973 LINE BOTの作り方を世界一わかりやすく解説(1)【アカウント準備編】 yoshizaki_kkgk 16/11/08
17/02/01485
11574 Pandas の groupby の使い方 propella 18/07/02
18/11/15277
21975 【python】カジノを崩壊させたらしいモンテカルロ法をシミュレーションしてみた kagawa_shinjiiiii 20/01/12
20/01/14684
68476 PythonのslackbotライブラリでSlackボットを作る sukesuke 17/02/01
17/06/10397
11277 Pythonのイテレータとジェネレータ tomotaka_ito 14/09/16
19/05/09601
9978 matplotlib基礎 | figureやaxesでのグラフのレイアウト gaku8 17/09/24
18/01/01285
15379 Kaggle Masterが勾配ブースティングを解説する woody_egg 18/10/26
19/09/12279
23280 グラフ理論の基礎 maskot1977 18/06/17
19/10/18659
13481 【PythonのORM】SQLAlchemyで基本的なSQLクエリまとめ tomo0 17/11/18
20/01/02298
16382 AtCoderで始めるPython入門 KoyanagiHitoshi 19/04/04
20/03/22409
28183 ゴー☆ジャス(宇宙海賊)をつくる jg43yr 19/07/12
19/07/26870
87084 PythonにおいてのJSONファイルの取扱いあれこれ wakaba130 16/12/25
18/07/01274
12985 Pythonによるデザインパターン5原則 kotetsu75 18/01/10
18/02/20746
12886 競プロ界隈でpython強者がやっていることをまとめてみた dekamisako 20/03/17
20/03/18523
52387 最強のPython開発環境 PyCharmのすゝめ pashango2 17/01/03
17/03/14708
7788 削除済(ID:77f2534bc32eaad494dc) himenoglyph 16/12/03
17/11/16315
13989 【Pythonメモ】pandas-profilingが探索的データ解析にめちゃめちゃ便利だった件 h_kobayashi1125 18/04/27
18/05/05458
13990 Pythonでフォルダ内のファイルリストを取得する amowwee 17/10/30
17/10/30285
14891 Jupyterのショートカットキー一覧を調べてみた masafumi_miya 16/08/07
16/08/07356
9192 [Python]ファイル/ディレクトリ操作 supersaiakujin 15/12/25
18/10/05359
10693 Pythonで簡単なGUIを作れる「Tkinter」を使おう CyberRex 18/02/16
19/10/01425
14894 [Pythonコーディング規約]PEP8を読み解く simonritchie 18/09/16
18/09/16261
20795 Python Kivyの使い方① ~Kv Languageの基本~ dario_okazaki 17/01/26
19/12/06340
10296 Pythonで実用Discord Bot(discordpy解説) 1ntegrale9 18/06/06
20/02/17340
16597 python 組み込み関数を全て(69個)紹介する anieca 19/10/24
19/10/24636
63698 Python の HTTP クライアントは urllib.request で十分 hoto17296 18/02/28
19/12/18283
16099 Python系の情報ソースをまとめた ryuta69 19/03/24
20/02/03680
231100 pandasでよく使う文法まとめ okadate 14/10/14
19/02/18598
68
1行目が総数。2行目が直近1年。 ↩
- 投稿日:2020-04-06T20:08:37+09:00
(Python:OpenCV)動画をリアルタイムで二値化処理させつつ、領域間の距離を示す値を出力させてみた
はじめに
製造業の非IT部門で働く私でも、AI、IoT化を意識して仕事をするようになりました。製造現場に近い生産技術職寄りの仕事をしておりますが、システム化を行う上での課題の一つに工場への利益と釣り合わないことが挙げられます。
やりたいことはあるのだけど、見積もると導入コストが高くなってしまい(人件費が高い場合が多い。。)断念する場合があります。
そこで、スキルアップの観点からも私が作ってしまうことが良いのでは、と思い進めていることが下記の内容です。
- 画像処理をするプログラムを作成(画像ver.)
- 今回:画像処理をするプログラムを作成(動画ver.)
- Raspberry Piに環境構築+プログラムを格納
- 撮影した画像でリアルタイムで処理できるか確認
- 工場の改善に繋がる良い処理方法の探索
- KPI値を改善して、成果
製造現場で使用している撮影動画について、リアルタイムで処理(二値化、ある距離の演算・表示など)を行ってその結果表示させることを目指します。
意外と現場の作業者にとって、ビデオ画像を簡単に処理したものでも製造しやすくなる手助けになり得ます。さて長くなりましたが、今回の概要は下記です。
- 動画表示画面に値を表示させる
- 画面表示画面の値が出るタイミングを調整する
前回記事はこちらです。
画像を二値化処理させる。さらに、二領域間の最短距離を算出できるようにした(Ver1.1)。
https://qiita.com/Fumio-eisan/items/10c54af7a925b403f59f単純に動画を表示させる
まずは動画を表示させる処理を行います。今回は7秒ほどの下記キャプチャーでの動画を処理します。
※実際の動画は一番下に記載されているgithub上に格納しています。
video.ipynb#単純に表示 import cv2 import sys file_path = 'sample_.mov' delay = 1 window_name = 'frame' cap = cv2.VideoCapture(file_path) text = 'text.wmv' if not cap.isOpened(): sys.exit() while True: ret, frame = cap.read() # if not ret: #この2行を入れ込むと動画再生1回で終了します。 # break if ret: frame = cv2.resize(frame, dsize=(600, 400)) cv2.imshow(window_name, frame) if cv2.waitKey(delay) & 0xFF == ord('q'): break else: cap.set(cv2.CAP_PROP_POS_FRAMES, 0) cv2.destroyWindow(window_name)file_pathに表示させたい動画のパスを記述すればOKです。今回のプログラムの場合は無限ループで動画を再生し続けます。qキーを押すことで動画再生を止めることができます。
動画の表示に関しては、下記の手順で撮影を行っています。
- cv2.VideoCapture()メソッドにて動画を読み込み
- while内の構文で再生
- frameごと(30fpsであれば1sec間に30frame)に表示させ続ける
- (処理によって異なるが)無限ループor一回再生が完了したら終了等
となっています。後ほど注意点を書きますが、3.のフレームごとで処理しているため、1秒ごとや数秒ごとに表示させたいテロップ(表示させる値等)を変えたい場合は注意が必要です。
字幕を入れたい
video.ipynbcv2.putText(frame, text,(100, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), thickness=2)この表示により字幕出力が可能です。引数は以下のようになっています。
第一引数:動画フレーム、第二引数:表示させたいテキスト、第三引数:x、y位置、第四引数:フォント、第五引数:文字サイズ、第六引数:BGRの色情報、第7引数:文字の太さ二値化させたい
さて、二値化させて白黒表示とします。方法は画像と同じく抽出する色の上下限を定義して、cv2.inRange()メソッドで定義してあげればOKです。
video.ipynb#二値化処理 import cv2 import sys camera_id = 0 delay = 1 window_name = 'frame' file_path = 'sample_.mov' cap = cv2.VideoCapture(file_path) import numpy as np bgrLower = np.array([0, 100, 100]) # 抽出する色の下限(BGR) bgrUpper = np.array([250,250, 250]) if not cap.isOpened(): sys.exit() while True: ret, frame = cap.read() if not ret: break frame = cv2.resize(frame, dsize=(600, 400)) img_mask = cv2.inRange(frame, bgrLower, bgrUpper) contours, hierarchy = cv2.findContours(img_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) contours.sort(key=lambda x: cv2.contourArea(x), reverse=True) #target_contour = max(contours, key=lambda x: cv2.contourArea(x)) #img_mask = cv2.line(img_mask, (250,300), (350,300), (120,120,120), 10) #第2引数が始点、第3引数が終点、第4引数が色、第5引数が線の太さ #img_mask=cv2.drawContours(img_mask,contours[0:2],-1,(120,120,120),5) cv2.imshow(window_name, img_mask) #cv2.imshow(window_name,img_mask, [contours[0],contours[1]]) if cv2.waitKey(delay) & 0xFF == ord('q'): break cv2.destroyWindow(window_name)
無事二値化することができました。
囲われた領域間の距離を出力させたい
さて、本題です。下記のようにある囲まれた領域間を定義してその間の距離を求めます。そして適宜その値を出力させるようにしたい思います。
二点間の距離を求める
video.ipynbcontours, hierarchy = cv2.findContours(img_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)#境界引き contours.sort(key=lambda x: cv2.contourArea(x), reverse=True)#境界をソートcv2.findContours()メソッドにて白い領域を囲みます。その戻り値がcontoursに格納されます。そして、contoursを面積順にソートします。
二領域の座標を取得する
video.ipynbx1=np.unravel_index(np.argmax(contours[0],axis=0), contours[0].shape) x2=np.unravel_index(np.argmax(contours[1],axis=0), contours[0].shape) img_mask = cv2.line(img_mask, tuple(x1[0][0]), tuple(x2[0][0]), (120,120,120), 3)領域を囲んでいる座標を取得します。x1,x2にcontours[0],[1]における座標の最大値(x,yどちらかが最大となる値)を取るargmaxで返します。argmaxの場合は1次元に平坦化した場合(x,y座標関係なく1次元で判断)なので、unravel_index()メソッドにて座標としてそのインデックスを返します。
そして、実際にその座標をcv2.line()メソッドにて入れ込むことで座標間を結びます。
(補足)contoursに格納されている数値を理解する
+ contours[n]:n番目の領域を形成する座標群のarrayが格納
+ contours[n][m]:n番目の領域におけるm番目の座標のarrayが格納
+ contours[n][m][0]:n番目の領域におけるm番目のarrayが格納
+ contours[n][m][0]:n番目の領域におけるm番目のx座標が表示
+ contours[n][m][1]:n番目の領域におけるm番目のy座標が表示
こんな感じで、ややこしいのです。
距離の値を画面に表示させたい
さて、この計算した値を画面に表示させます。通常、cv2.putText()メソッドにて表示させることが可能です。ただ、そのままだとフレームごとの値を計算して表示させてしまいます。これでは値がチカチカして見づらくなります。
対策として、あるフレーム数ごとに値を更新して表示させるようにすれば良いです。
if構文を使って30フレーム(≒今回では大よそ1秒ごと)で値を更新するように下記を行っています。video.ipynbif idx % 30 == 0: text =str(math.floor(np.linalg.norm(x1[0][0]-x2[0][0]))) cv2.putText(img_mask, text,(300, 100), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 255, 255), thickness=3)実際の結果
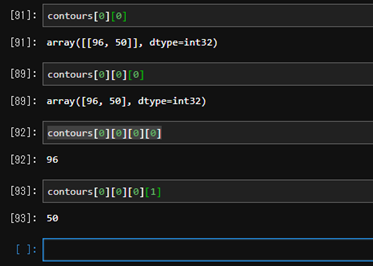
このようにして処理して出力させた結果がこちらです。
本来は白と黒の二領域をそれぞれ白か黒に値を出せたらよかったのですが、うまく調整できませんでした。
また、白の部分であるアダプタの領域間(今回は一つの物ですが二つの領域に分かれています)で線を引けており、かつ距離を表す数値も出力させることができました。終わりに
さて、今回動画を処理させながら再生するプログラムを作りました。フレームごとに処理させるためあまり重たい処理をさせることができない点がポイントでした。
本来は領域間の最短距離を求めさせてその距離を引くことをしたかったのですが、そこまで実装できませんでした。
あと、OpenCV自体がc++でまとめられている記事が多かったため、検索に苦労しました。。プログラムは下記に格納しています。
https://github.com/Fumio-eisan/movie_20200406


- 投稿日:2020-04-06T18:50:26+09:00
Pythonの辞書
AtCoderなどといている時によく忘れて調べることになるが、意外に綺麗にまとまっているサイトが少なかったので自分で書いた
宣言
よくあるやつ
d = {} #または d = dict()要素の更新
存在するキーの有無によって挙動が両者異なる
d['key'] = 'value' #指定したキーが存在しない場合、コンパイルエラー #指定したキーが既に存在する場合、既存の値を更新 d.setdefault('key', 'value') #指定したキーが存在しない場合、新たに要素を追加 #指定したキーが既に存在する場合、変更なし辞書同士の連結
下に書く通り
d1 = {'key1': 'value1', 'key2': 'value2'} d2 = {'key3': 'value3', 'key4': 'value4'} d1.update(d2) print(d1) #{'key1': 'value1', 'key2': 'value2', 'key3': 'value3', 'key4': 'value4'}含まれるすべてのキー、値を取得
謎の形式で帰ってくるのでリスト内包表記なりmapなりでlist型に変換する必要がある
d = {'key1': 'value1', 'key2': 'value2'} [i for i in d.keys()] #['key1', 'key2'] [i for i in d.values()] #['value1', 'value2']眠いです
- 投稿日:2020-04-06T18:04:51+09:00
IQ Botのカスタムロジック:日付によくある読み癖の補正
OCRで日付を読み込んだときに、比較的よく見かけるOCRの読み癖のパターンがあります。
「YYYY年MM月DD日」の「日」の部分が
「B」(アルファベットのビー)になっているパターンと、
「0」(ゼロ)になっているパターンです。「年」や「月」が違う読み方をされているケースはあまり見たことがないのですが、
なぜか「日」だけはいろんなパターンの帳票でBになったり0になったりしています。IQ Botでは、そんなOCRの読み癖を補正してキレイにできるので、ここではそのやりかたを紹介します。
日をBと読んでしまうパターンへの対応
この場合は、こちらでも紹介した単純な置換処理で対応できます。
日付項目の日をBと読んでしまうパターンへの対応(フィールド項目の場合)field_value = field_value.replace("B","日")日付の項目で「B」が正解データに含まれることは考えにくいので、単純に置き換えて問題ないでしょうと。
テーブル項目の場合は、こちらを参照してください。
日を0(ゼロ)と読んでしまうパターンへの対応
こちらの場合は、単純に置換というわけにいきません。
「10日」「20日」「30日」などのように、0が正解になる場合があるからです。対処方法(チートシート:フィールド編)
答えを先に言ってしまうと、「日」をゼロと読んでしまう問題に対しては、以下のコードで対応できます。
日付項目の日をゼロと読んでしまうパターンへの対応(フィールド項目の場合)if(field_value[-1:]=="0"): field_value = field_value[:-1] field_value = field_value + "日"対処方法(チートシート:テーブル編)
テーブルの場合は、おまじないコード(こちら参照)の間に、以下のコードを書くことで対応できます。
日付項目の日をゼロと読んでしまうパターンへの対応(テーブル項目の場合)#日付の最後がゼロだったら日に置き換える関数 def dayreplace(ymd): x = str(ymd) if(x[-1:] == "0"): x = x[:-1] x = x + "日" return x #表の文字列置換 df['日付の補正をしたい列名'] = df['日付の補正をしたい列名'].apply(dayreplace)仕組みの説明
フィールド編、テーブル編に共通するポイントは3つです。
①if文(条件分岐) ②スライス ③文字列を連結させるための+演算子
テーブル編は、上記に加えて関数という仕組みを使っています。
それぞれわかりやすい説明をリンクしておきます。
① if文(=条件分岐)
上記のコードは、1行目が処理するかどうかを決める条件、2行目と3行目が条件に該当したときに行う処理となっています。
if文についての説明は、 こちらの記事がわかりやすかったです。② スライス
上記のコードの1行目にあるfield_value[-1:]やfield_value[-1:]はスライスという仕組みを使っています。
スライスは、文字列の何番目から何番目を取り出してね、みたいな処理のこと。
スライスについての説明は、こちらの記事がわかりやすかったです。③ 文字列を連結させるための+演算子
3行目のコードは、一見すると足し算か? と思われるかもしれませんが、文字列と文字列をくっつけているだけです。
へーそんなことができるのねーくらいの理解で十分ですが、参考までにこちらのリンクを貼っておきます。テーブル編:関数
関数については、こちらの説明がわかりやすかったです。まとめに変えて
以上を踏まえて、いちおう自前でフィールド編のコードに解説をつけておきます。
日付項目の日をゼロと読んでしまうパターンへの対応(フィールド項目の場合)if(field_value[-1:]=="0"): #field_valueの最後の文字が"0"だったら、以下の処理をしてね field_value = field_value[:-1] #field_valueから、最後の1文字を除外 例:YYYY年MM月DD0をYYYY年MM月DDにする field_value = field_value + "日" #↑の処理をしたfield_valueに、"日"をくっつけるものすごく細かいことを言うと、2行目の処理の説明はちょっと端折ってます。
正確には、「
field_valueの1文字目から初めて、最後の文字を含まない文字列を取り出して、そいつをfield_valueに代入してね」と言うべきなのかもしれませんが、わかりにくいし、結果的には同じことなので端折った方の説明を採用しました。紙帳票をデータ化するにあたって、日付はほぼ全帳票で必須で扱う項目になってくるかと思いますので、
ぜひこちらで紹介したコードを活用してみてください!
- 投稿日:2020-04-06T17:01:28+09:00
IQ Botのカスタムロジック:スプリット(口座情報から銀行名や支店名だけを取り出す)
OCRの読み取り結果(
field_value)が「あいうえ銀行かきくけ支店普通1234567」だった場合に、
ここから銀行名と支店名をそれぞれ別の項目として分けて出力したい、という場合はどうすればいいでしょうか?そんなときに使えるのが、スプリットです。
やりかた(チートシート)
答えを先に言ってしまうと、
field_valueが「あいうえ銀行かきくけ支店普通1234567」の場合に、
銀行名だけを取り出す処理は以下のとおりです。スプリットを使って銀行名を取り出す#銀行名を取り出す field_value = field_value.split("銀行")[0]こんなかんじ↓で、「あいうえ」が取り出せたのがわかります。
また、同じく
field_valueが「あいうえ銀行かきくけ支店普通12345678」の場合に、
支店名だけを取り出す処理は以下のとおりです。スプリットを使って支店名を取り出す#銀行の支店名を取り出す field_value = field_value.split("銀行")[1] field_value = field_value.split("支店")[0]こんなかんじ↓で、「かきくけ」が取り出せたのがわかります。
仕組みの説明
上記の処理をすると、なぜ銀行名や支店名が取り出せるのかの説明です。
わかる人は読み飛ばしてください。
スプリット
スプリットは、「文字列をある区切り文字で区切って、リストにする」という処理です。
「リストって何さ?!」と思った方もいるかもしれませんが、
ここではざっくり「複数の要素が並んだかたまり」だと思っていていただければ大丈夫です。
(もっと詳しく知りたい方は、「Python リスト」などで検索してみてください)スプリットの処理は、
処理対象.split(区切り文字)の要領で行うことができます。
field_value.split("銀行")という処理は、
「field_valueを"銀行"という文字で区切ってリストにしてね」という意味です。この処理をやると、以下のようなリストが取り出せます。
["あいうえ","かきくけ支店普通1234567"]上記は2つの要素を持つリストで、
1番目の要素が"あいうえ"、2番目の要素が"かきくけ支店普通1234567"です。リストの中身を取り出す
上記の処理で、晴れて文字列を「リスト」にしたわけですが、
今度はそのリストから要素を取り出す処理です。
リスト[インデックス]の要領で、これができます。「インデックス」はざっくり言えば、リストの何番目にその要素が入っているかを示す番号なのですが、開始はゼロからになるというのがちょっとした注意点です。
改めて、銀行名を取り出す処理を見てみましょう
今までの話を踏まえて、改めて銀行名を取り出す処理を見てみましょう。
スプリットを使って銀行名を取り出す#銀行名を取り出す field_value = field_value.split("銀行")[0]これはつまり、「
field_valueの中身を"銀行"という文字で区切ってリストにしてね。そしてそのリストの1番目の要素(=インデックスはゼロ!)を取り出して、そいつをfield_valueに入れてね」「
field_valueの中身を"銀行"という文字で区切ってリストにしてね。」がfield_value.split("銀行")、「そしてそのリストの1番目の要素(=インデックスはゼロ!)を取り出して」が
[0]、「そいつを
field_valueに入れてね」がfield_value =に、それぞれ該当します。
改めて、支店名を取り出す処理を見てみましょう
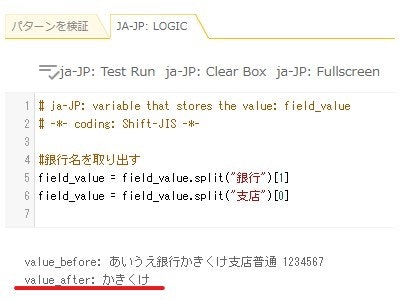
ここまで押さえらえれていれば、支店名の処理もすぐに理解ができると思います。
スプリットを使って支店名を取り出す#銀行の支店名を取り出す field_value = field_value.split("銀行")[1] field_value = field_value.split("支店")[0]1行目は、「
field_valueの中身を"銀行"という文字で区切ってリストにしてね。そしてそのリストの2番目の要素(=インデックスは1!)を取り出して、そいつをfield_valueに入れてね」という意味です。なので、この時点で
field_valueの中身は"かきくけ支店普通1234567"になっています。その
field_valueに対して、2行目では、「
field_valueの中身を"支店"という文字で区切ってリストにしてね。そしてそのリストの1番目の要素(=インデックスはゼロ!)を取り出して、そいつをfield_valueに入れてね」という処理を行っています。
「
field_valueの中身を"支店"という文字で区切ってリストにしてね」の時点で、
["かきくけ","普通1234567"]というリストができているので、こいつの1番目の要素を取り出すことで、「かきくけ」という支店名が取り出せたというわけです!

- 投稿日:2020-04-06T16:16:19+09:00
pythonでフォルダ内の大量のCSVファイルを統合する(ヘッダー無しデータ)
はじめに
- 大量のCSVファイルを1つのCSVファイルに統合します。
事前準備
- CSVファイルのヘッダーは無しのデータを用意する。
- 統合したいCSVファイルをフォルダにまとめておく。
- 統合した結果の出力ファイル名を指定する。
コード
import csv, os import pandas as pd #CSVファイルがあるフォルダを指定 (1)参照先 csv_folder_path = os.path.join(".","csv_folder", "headerRemoved") #ファイル名の一覧をリスト形式で取得 csv_files_list = os.listdir(csv_folder_path) #全てのcsvファイル内の行を格納するリストを作成 csv_rows=[] #読み込むファイルリストからファイル名を指定し、全行をcsv_rowsリストに格納する。 for csv_filename in csv_files_list: csv_file_obj = open(os.path.join(csv_folder_path, csv_filename)) reader_obj = csv.reader(csv_file_obj) for row in reader_obj: csv_rows.append(row) csv_file_obj.close() #リストをdataframe型に変換. df = pd.DataFrame(csv_rows) #書き出す列の範囲を指定する(0~44番のみ) (3)書き出し範囲 df = df.iloc[:,range(0,44)] #dataframeをcsvに変換して保存 (2)出力ファイル名 df.to_csv(os.path.join(".","merged_file.csv"), index=False)解説
- CSVファイルがあるフォルダからファイル名のリストを取得
- ファイル名リストに沿ってファイルごとにファイルオブジェクトを作成、さらにそこからReaderオブジェクトを作り一行ずつファイルから行を読み込む
- すべてのファイルで繰り返し、最終的に1つのリストの全ファイルの全行を集める
- 書き出す前にリストをDataFrame型に変換する。
- ここでは書き出す前に必要な列の範囲を指定している。
- 最後にpd.to_csvで指定したファイル名のCSVファイルに書き出す。このときindex=Falseとすることでindexは書き出さない。
感想
- ちなみにdfに変換されているので任意の列だけを表示を取り出すことができる。 下記のようにすれば12列目、38列目をこの順序で指定できる。
df.iloc[:,[38,12]]
- 次はdfから色々なグラフをプロットしたい。
- 投稿日:2020-04-06T16:07:34+09:00
コロナウイルスの感染具合をseabornのヒートマップで表示してみた
コロナの感染具合をseabornのヒートマップで表示してみた
目的
コロナの各都道府県での広がり具合を視覚化する
ゴールはこれです。
方法
pythonのseabornを使用する。
感染者数データ(4/5まで)はこちら。https://toyokeizai.net/sp/visual/tko/covid19/
都道府県名データはこちら。https://gist.github.com/mugifly/d6e68a516de4a008687c
いろいろまとめてこちら。https://github.com/kyasby/colona.gitライブラリをインポート
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
%matplotlib inlineはおまじないです。
numpyはcumsum()のためにインポートします。感染者数csvをインポート
df = pd.read_csv("COVID-19.csv") df = df[["受診都道府県", "居住都道府県", "人数", "発症日", "確定日"]] df = df.rename(columns={"年代":"age", "性別":"sex", "受診都道府県":"hsp", "居住都道府県":"house"}) df必要なカラムを抜き出し、同時にリネームします。
df[]にリストを渡すことで、そのカラムだけ抜き出すことができます。
df.rename(columns={"old_columns_name":"new_name"},index={"old_index_name":"new_name"})
などと辞書を渡すことで、カラム名やインデックス名を変更できます。*hspはhospitalです。
日付作り
for i, row in df.iterrows(): if type(row["発症日"])==float: df.at[i, "発症日"] = row["確定日"] else: pass df = df.rename(columns = {"発症日":"Date"})ヒートマップの横軸を日付にしたいので、日付を取得します。
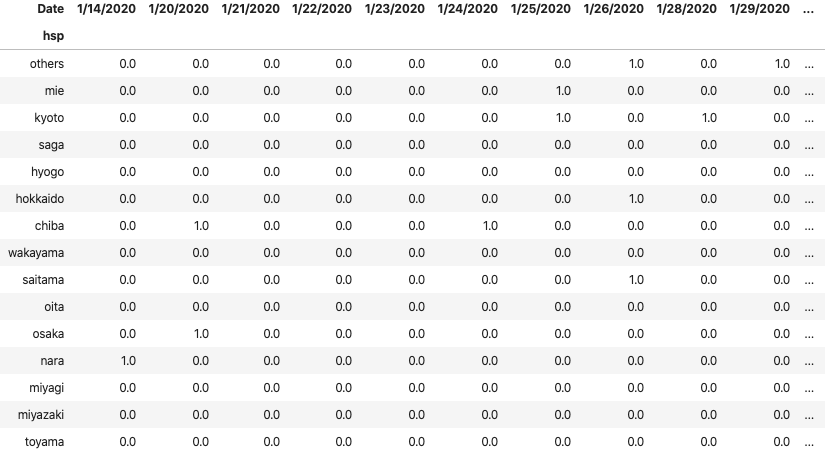
しかし、以下のように「発症日」にはNaNが含まれているので、その場合は「確定日」で置き換えます。
hsp house 人数 発症日 確定日 神奈川県 神奈川県 1 1/3/2020 1/15/2020 東京都 中華人民共和国 1 1/14/2020 1/24/2020 東京都 中華人民共和国 1 1/21/2020 1/25/2020 大阪府 大阪府 1 1/20/2020 1/29/2020 不明 中華人民共和国 1 1/29/2020 1/30/2020 千葉県 中華人民共和国 1 NaN 1/30/2020 最後に、カラム名を「Date」に変更します。
NaNの判定を
type(row["発症日"])==float
このように書きましたが、もっと良い書き方があれば是非教えてください。都道府県のCSVをインポート
todofuken = pd.read_csv("japan.csv", header=None)[0]hspの一部を置き換える
df["hsp"].value_counts()で、「hsp」の中身を確認すると、「羽田空港」や「不明」があることがわかります。
df["hsp"]= df["hsp"].apply(lambda x : "その他" if x not in list(todofuken) else x)applyとラムダ関数を使い、df["hsp"]の中身を一部書き換えます。
都道府県名リストにない場合は、「その他」、ある場合はそのままの都道府県を入れます
applyとラムダ関数を使うときは、おそらくelseがないと構文エラーになります。(未確認)注意してください。ここまででdfはこのようになっています。
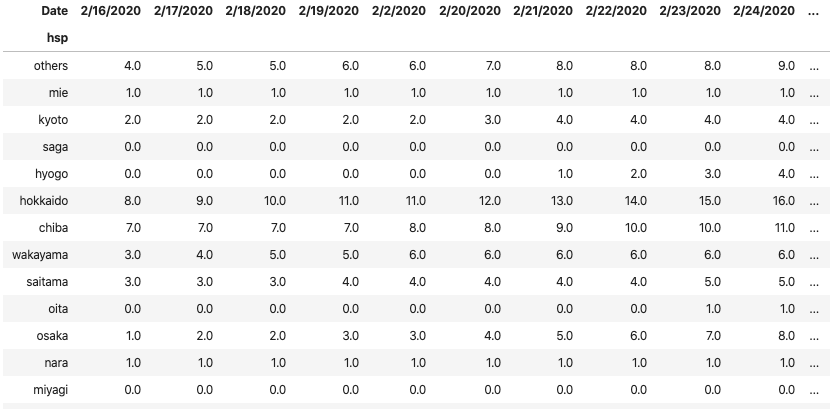
hsp house 人数 Date 確定日 神奈川県 神奈川県 1 1/3/2020 1/15/2020 東京都 中華人民共和国 1 1/14/2020 1/24/2020 東京都 中華人民共和国 1 1/21/2020 1/25/2020 愛知県 中華人民共和国 1 1/23/2020 1/26/2020 愛知県 中華人民共和国 1 1/22/2020 1/28/2020 奈良県 奈良県 1 1/14/2020 1/28/2020 北海道 中華人民共和国 1 1/26/2020 1/28/2020 大阪府 大阪府 1 1/20/2020 1/29/2020 ピボットにする
pvt = df.pivot_table(index="hsp", columns="Date", values="人数").fillna(0) pvt = pvt.rename(index = dict(zip(jpn[0], jpn[2]))).rename(index={"その他":"others"})pandasにはpivot_tableというメソッドが用意されており、文字通りピボットテーブルを作成することができます。(エクセルいらずですね。)また、NaNを0で埋めておきます。
そして、北海道→hokkaidoなどとリネームします。僕の環境では、インデックス名やカラム名に日本語が含まれていると、文字が表示されません。何かインストールすると解決されるらしいですが、リネームで対応します。(より良い方法があれば是非、教えてください。)
jpn[0]の中身は、北海道、青森、など漢字の都道府県名です。
jpn[2]の中身は、hokkaido、aomoriなどローマ字の都道府県名です。これらを
zip関数でペアにし、dict関数で辞書にし、rename関数に渡します。
また、「その他」を「others」に変更します。ここまでで、このようなデータフレームになっています。
累積人数にする
for i in range(len(pvt)): pvt.iloc[i]=pvt.iloc[i].cumsum()pvtから1行ずつ取り出し、
numpyのcumsum()関数で累積の人数にします。このように、累積人数に更新されました。
表示して、保存する
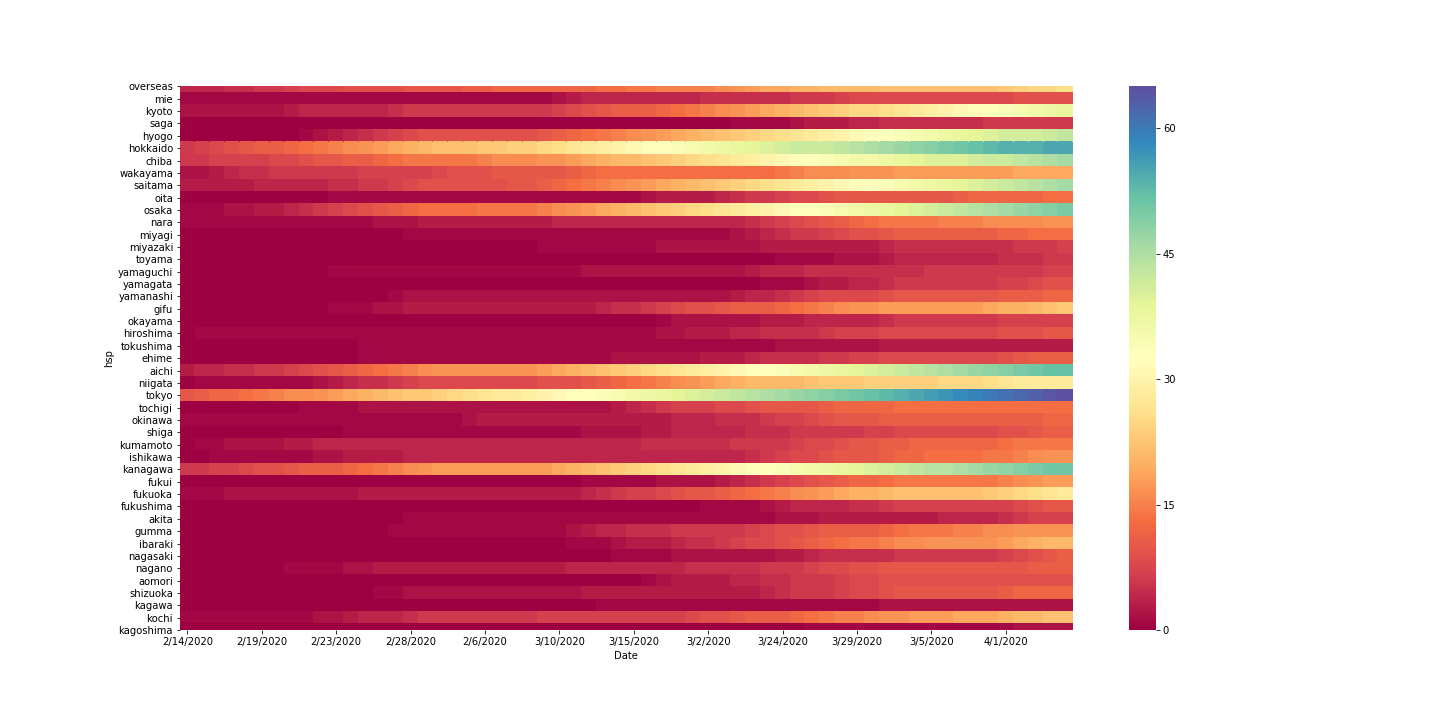
plt.figure(figsize=(20,10)) sns.heatmap(pvt.iloc[:,-60:] , linewidths=0, cmap='Spectral', cbar=True, xticklabels=5) plt.savefig("colona.png")若い日付の日は、感染者が(幸い)ほとんどおらず表示しれても意味がないので60日前から表示することにしました。
:(スライス)を使うことができます。例えば10:20であれば10以上20未満を示します。こんな感じで、ヒートマップを表示させることができました。

- 投稿日:2020-04-06T15:54:01+09:00
複数のフォーマットCSVファイルから見出しを削除する
はじめに
大量のcsvファイルの見出し数行を全て削除したい
事前準備:
- 本ファイルはをカレントディレクトリにおく
- カレントディレクトリにあるMachine11_trdフォルダにヘッダー処理したいcsvファイルを入れておく。
import csv, os #処理したいフォルダのパスを作成 (1)参照先 csv_folder_path = os.path.join(".","InputFolder") #アウトプット先のフォルダのパスを作成 (2)保存先 headerRemoved_path = os.path.join(csv_folder_path,"headerRemoved") #ヘッダー削除したファイルを入れる新規フォルダを作成する。 os.makedirs(headerRemoved_path, exist_ok=True) #カレントディレクトリ以下にある指定フォルダの全ファイルをループする #指定フォルダ内のファイル名リストを取り出す for csv_filename in os.listdir(csv_folder_path): if not csv_filename.endswith(".csv"): continue #csvファイルでなければスキップする #print("見出し削除中"+ csv_filename + "...") #CSVファイルから一行ずつ読み込む(最初の行をスキップする) csv_rows=[] csv_file_obj = open(os.path.join(csv_folder_path, csv_filename)) reader_obj = csv.reader(csv_file_obj) for row in reader_obj: #一行目または二行目のときは追加しない, そのほかは追加する (3)ヘッダー条件 if reader_obj.line_num == 1 or reader_obj.line_num == 2: continue #対象行をスキップする csv_rows.append(row) csv_file_obj.close() #CSVファイルを指定フォルダ内に書き出す csv_file_obj = open(os.path.join(headerRemoved_path, csv_filename),"w",newline="") csv_writer = csv.writer(csv_file_obj) for row in csv_rows: csv_writer.writerow(row) csv_file_obj.close()やってること
- 一行目と二行目をスキップしてすべての行をcsv_rows[]に保存する(必要に応じて変える)
- カレントディレクトリ内に新しく作るheaderRemoveフォルダに新しくCSVファイルを作成し書き出す
- これらを対象フォルダにある全てのCSVで行う。
考察
- はじめdataframでやろうとしたが、カラム数が違うものはうまく読み込むことができなかったので、一行ずつリストを読み込み、リストからdataframe型に変換した。
- 投稿日:2020-04-06T15:54:01+09:00
pythonで複数のフォーマットCSVファイルから見出しを削除する
はじめに
- 大量のcsvファイルの見出し数行を全て削除したい
- 使ってるのはJupyter Notebook
事前準備:
- 本ファイルはをカレントディレクトリにおく
- カレントディレクトリにあるMachine11_trdフォルダにヘッダー処理したいcsvファイルを入れておく。
import csv, os #処理したいフォルダのパスを作成 (1)参照先 csv_folder_path = os.path.join(".","InputFolder") #アウトプット先のフォルダのパスを作成 (2)保存先 headerRemoved_path = os.path.join(csv_folder_path,"headerRemoved") #ヘッダー削除したファイルを入れる新規フォルダを作成する。 os.makedirs(headerRemoved_path, exist_ok=True) #カレントディレクトリ以下にある指定フォルダの全ファイルをループする #指定フォルダ内のファイル名リストを取り出す for csv_filename in os.listdir(csv_folder_path): if not csv_filename.endswith(".csv"): continue #csvファイルでなければスキップする #print("見出し削除中"+ csv_filename + "...") #CSVファイルから一行ずつ読み込む(最初の行をスキップする) csv_rows=[] csv_file_obj = open(os.path.join(csv_folder_path, csv_filename)) reader_obj = csv.reader(csv_file_obj) for row in reader_obj: #一行目または二行目のときは追加しない, そのほかは追加する (3)ヘッダー条件 if reader_obj.line_num == 1 or reader_obj.line_num == 2: continue #対象行をスキップする csv_rows.append(row) csv_file_obj.close() #CSVファイルを指定フォルダ内に書き出す csv_file_obj = open(os.path.join(headerRemoved_path, csv_filename),"w",newline="") csv_writer = csv.writer(csv_file_obj) for row in csv_rows: csv_writer.writerow(row) csv_file_obj.close()やってること
- 一行目と二行目をスキップしてすべての行をcsv_rows[]に保存する(必要に応じて変える)
- カレントディレクトリ内に新しく作るheaderRemoveフォルダに新しくCSVファイルを作成し書き出す
- これらを対象フォルダにある全てのCSVで行う。
考察
- はじめdataframでやろうとしたが、カラム数が違うものはうまく読み込むことができなかったので、一行ずつリストを読み込み、リストからdataframe型に変換した。
- 投稿日:2020-04-06T15:17:41+09:00
IQ Botのカスタムロジック:固定値の代入
IQ Botのカスタムロジックで、置換処理や数値の取り出しほどの使用頻度はないものの、
意外とパワフルに使えるのが「固定値の代入」です。固定値の代入
固定値の代入に関しては、処理自体はとても簡単なのでほぼ解説不要と思います。
固定値の代入(フィールド項目)field_value = "代入したい固定値"「こんな処理をいつ使うんですか?」という疑問の方が多いと思いますので、それを書いていきます。
使い道その1:分類されたグループを出力する
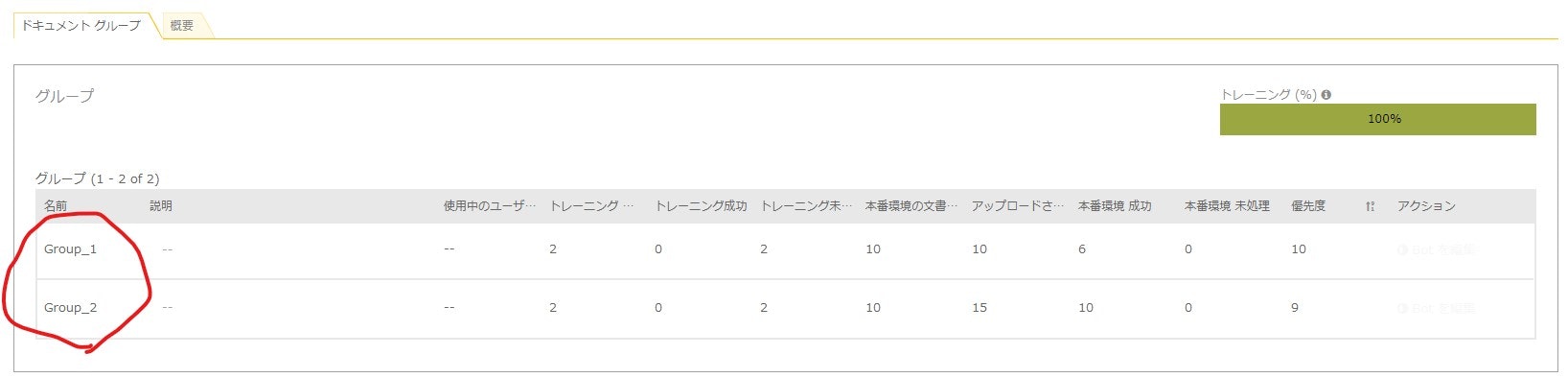
IQ Botには帳票の自動分類の機能がデフォルトでついていて、同じインスタンスの帳票をフォーマットごとに、AIが分類してくれます。
こんなかんじ↓
帳票の中身が見えないのでイメージわかないかもしれませんが、Group1とGroup2にはそれぞれ、
「フォーマットは違うけど取り出したい項目は同じ」という帳票がグループ分けされて入っています。イメージでいうと、Group1はA社の請求書で、Group2はB社の請求書というかんじ。
ふたつとも請求書なので取り出したい項目は同じだけど、フォーマットが違うので別グループになっています。
処理が完了すると、今度はグループに関係なく、インスタンスごとにひとつのフォルダにCSVが出力されます。
つまり処理が終わってしまうと、どのグループに分類されて処理されたかがわからなくなります。
別にそれはそれでいいじゃん、という人は特に問題ないのですが、「通ってきたグループをぜひ知りたい!」みたいな場合は、
項目設定のときに「処理グループ」のような項目を作っておいて、そのグループに対して、固定値代入でグループの名称を入れます。Group1の「処理グループ」には
field_value = "Group1"
Group1の「処理グループ」にはfield_value = "Group2"という要領で、ロジックを埋め込んでいくイメージですね。
使い道その2:分類を根拠に一意に決まる項目の設定
使い方その1と本質的には同じことかもしれませんが、実務で使うのは主にこちらだと思います。
先ほどの例と同じく、Group1はA社の請求書、Group2はB社の請求書だと考えます。
このケースで、読み取り項目の中に「請求元社名」「請求元住所」「送金先口座番号」のような項目があったとします。
真っ当にいけば、これらの項目はすべてOCRの読み取り結果をベースに出力していくわけですが、
OCRはどうしても、100%の精度にはなりません。Group1に分類されたということは、「請求元社名」はA社だとわかりきっているのに、
OCRの結果を使ったがゆえに、ノイズが混入して「\A社」みたいになったり、
印字のちょっとしたカスレで「H社」になったりということがありえます。また、社名の欄などは印影との重なりにより、OCRで読みづらいというケースもあります。
そうした項目に関しては、いちいちOCRの結果を使わずに、カスタムロジックで固定値を入れてしまうというのも手だったりします。
注意点
使い方その2を採用する場合は、IQ Botの自動分類を固定値代入の根拠にしていいかを事前に十分検証する必要があります。
つまり、A社とすごくよく似たフォーマットで請求書を出してくるX社という会社があって、
その会社の請求書がうっかりGroup1に分類されたりしないか、ということですね。まとめ
- 固定値の代入を使って、以下のことができるよ
- その1:処理されたグループを出力する
- その2:分類を根拠に一意に決まる項目には固定値を入れてしまう
- その2の使い方をする場合は、分類を固定値代入の根拠にしていいかどうかを事前にしっかり検証してね
- 投稿日:2020-04-06T15:08:33+09:00
Pythonで回帰分析
こんにちは、Mottyです。
今回はPythonを使った回帰分析について記載しました。回帰分析(Regression)
回帰分析は手元にあるデータを用いて、目的となるデータの予測する手法。その際に、データに定量的な関係の構造を当てはめる(回帰モデル)。また回帰モデルが直線であれば回帰直線、多項式回帰によってn次関数を当てはめた場合は回帰曲線という。
モデルの決定方法
当てはめたモデルの評価方法は最小二乗法を用います。測定で得られたデータを直線等の関数で近似する際、残差の2乗和が最小となるような係数の選び方を行う手法。
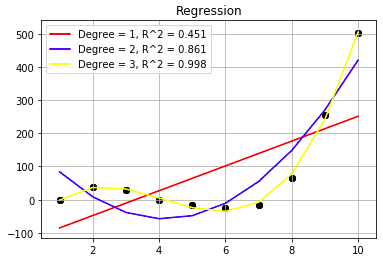
評価法
決定係数を用いる。こちらの数字が大きければ多いほど、回帰モデルの実データへの当てはまりが良い。
観測値= y, 関数による推定値をfとすると、以下の式で表される。
モデルが完全にデータにフィットした場合、決定係数の値は1となる。
回帰
一次関数、二次関数、三次関数それぞれにノイズを加えたデータに
回帰直線を当てはめてみた。LinearRegression.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline #sklearn from sklearn.linear_model import LinearRegression as reg from sklearn.metrics import r2_score #データ関連 CI =["black","red","blue","yellow","green","orange","purple","skyblue"]#ColorIndex N = 30 #サンプル数 x = np.linspace(1,10,N) y1 = x *5 + np.random.randn(N)*5 y2 = 2*(x-2)*(x-7) + np.random.randn(N)*5 y3 = 3*(x-1)*(x-4)*(x-7) + np.random.randn(N)*10 x = x.reshape([-1,1]) y1 = y1.reshape([-1,1]) y2 = y2.reshape([-1,1]) y3 = y3.reshape([-1,1]) #学習 clf1, clf2, clf3 = reg(),reg(),reg() clf1.fit(x,y1),clf2.fit(x,y2),clf3.fit(x,y3) #xデータに対する予測値 y1_pred,y2_pred,y3_pred = clf1.predict(x),clf2.predict(x),clf3.predict(x) #描画 fig = plt.figure(figsize = (15,15)) ax1,ax2,ax3 = fig.add_subplot(3,3,1),fig.add_subplot(3,3,2),fig.add_subplot(3,3,3) #Data ax1.scatter(x,y1,c = CI[1],label = "R^2 = {}".format(r2_score(y1,y1_pred))) ax2.scatter(x,y2,c = CI[2],label = "R^2 = {}".format(r2_score(y2,y2_pred))) ax3.scatter(x,y3,c = CI[3],label = "R^2 = {}".format(r2_score(y3,y3_pred))) ax1.legend(),ax2.legend(),ax3.legend() #回帰直線 ax1.plot(x,clf1.predict(x), c = CI[0]) ax2.plot(x,clf2.predict(x), c = CI[0]) ax3.plot(x,clf3.predict(x), c = CI[0]) fig.suptitle("RinearLegression", fontsize = 15) ax1.set_title("1") ax2.set_title("2") ax3.set_title("3")当然ですが、直線の当てはまりは、一次関数に対してもっとも良いという結果が得られました。
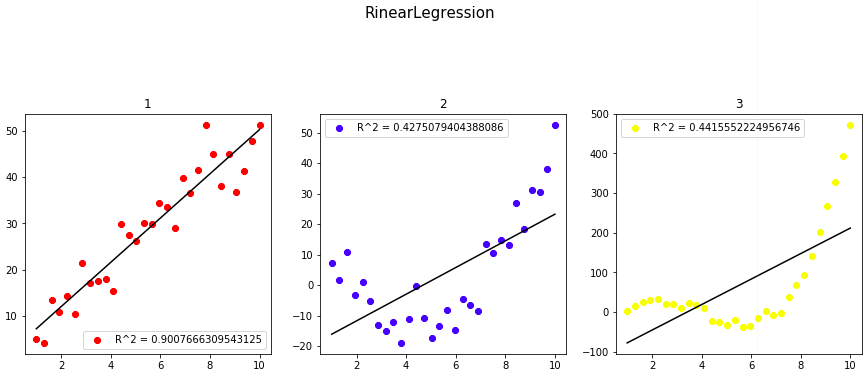
多項式回帰
2や3などのデータセットに対しては多次関数のような回帰曲線を当てはめるのが適切だと言えるでしょう。
polynomial.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline from sklearn.linear_model import LinearRegression as reg from sklearn.metrics import r2_score from sklearn.preprocessing import PolynomialFeatures as PF #データ関連 CI =["black","red","blue","yellow","green","orange","purple","skyblue"]#ColorIndex N = 10 #サンプル数 x = np.linspace(1,10,N) y3 = 3*(x-1)*(x-4)*(x-7) + np.random.randn(N)*10 x = x.reshape([-1,1]) y3 = y3.reshape([-1,1]) #学習 clf = reg() clf.fit(x,y3) #次数 DegreeSet =[1,2,3] for dg in DegreeSet: pf = PF(degree = dg, include_bias = False) x_poly = pf.fit_transform(x) poly_reg = reg() poly_reg.fit(x_poly,y3) polypred = poly_reg.predict(x_poly) #xデータに対する予測値 pred = clf.predict(x) #描画 plt.scatter(x,y3,c = CI[dg], label = "R^2={}".format(r2_score(y3,polypred))) plt.plot(x, polypred,c = CI[0]) plt.legend() plt.title("Regression") plt.show()結果的には、次数を1,2,3と上げるごとにモデルの当てはまりがよく、決定係数も高かった。
次数を上げれば良いのか?
次数を上げれば上げるほどモデルの表現力が増え、データへの当てはまりがよくなるが、次数が高くなるとそれだけ汎化性能が落ちてしまう(過学習)。
このような問題を解決するには単純な線形回帰、AIC等の罰則項を加えたものを用いると良い。(データのモデルへの当てはめをAIC最小化問題に帰着させた際、
式を見ればわかるように次数の上昇に対して罰則項が設けられ、最適な次数が選定できる。)sklearnにちょうどいいライブラリがなかったので、こちらの続きとして自作AICを用いたモデル評価を行う予定とします。
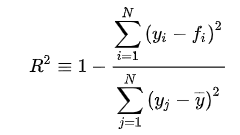
- 投稿日:2020-04-06T14:17:29+09:00
IQ Botのカスタムロジック:数値だけを取り出す
IQ Botのカスタムロジックで、シンプルな置換処理の次くらいによく使うのが、「読み取った値の数値部分だけを取り出す」という処理です。
数値だけ取り出す処理
他の処理と同様、こちらもフィールド項目の場合とテーブル項目の場合でやりかたが違います。
フィールド項目の場合
フィールド項目の場合import re field_value = re.sub("\\D", "", field_value)
"\\D"の部分が、正規表現で「数値以外の文字」を表します。
つまり「数値以外の文字が混じっていたら、一律除外してください」という処理です。なお、上記のコードをIQ Botのカスタムロジックにコピペすると、
バックスラッシュ()で表示されている部分が円マーク(¥)になると思います。両者はただのフォントの違いで同じ意味なので、どちらでも問題なく動きます。
テーブル項目の場合
上記と同じことをテーブル項目に対してやる場合は、以下の要領で行います。
テーブル項目の場合df['列名'] = df['列名'].str.replace("\\D", "")テーブル項目に対して処理を行う場合は、
最初と最後におまじないコードを入れるのを忘れないように!テーブル項目の列名についてはこちらを参照。
数値だけ取り出す処理の使い道
数値だけ取り出す処理の使い道は、主に2つです。
業務で使う割合でいうと、前者が2割:後者が8割くらいでしょうか(扱っている帳票によると思いますが)。文章やラベルとくっついている読み取り結果から、数値部分だけを取り出す
合計金額などの数値項目が帳票上に「今月の請求金額は123,456円となります」みたいに文章で表記されている場合や、
銀行名~支店名~口座番号がずらっと並んだ中から口座番号だけを取り出したい場合などに使います。数値項目から予測不能なノイズを除外
こちらの記事で置換を使ったノイズの除外について説明していますが、
実業務では、どういう形でノイズが混入してくるか予測がつかないケースがほとんどだと思います。「この項目には数値しか入って来ない」とあらかじめわかっている場合は、
「数値以外の文字が混入していたら一律除外」というこの処理を使っておくと効率がいいです。その際、当たり前ですが、ゼロをオーと読んでしまう・イチをI(アイ)やl(エル)と呼んでしまうなどのパターンが決まった誤読についてはあらかじめ処理をしてからこの処理をかけましょう。
実際の使用例(フィールド項目の場合)#パターンの決まった誤読にまず対処 #Replace アイ、エル、パイプラインを1に field_value = field_value.replace("I","1") field_value = field_value.replace("l","1") field_value = field_value.replace("|","1") #Replace オーと〇をゼロに field_value = field_value.replace("O","0") field_value = field_value.replace("〇","0") #その上で、数値以外の文字を除外 import re field_value = re.sub("\\D", "", field_value)
- 投稿日:2020-04-06T14:16:51+09:00
疑似的にNATゲートウェイを停止・起動する
VS 使ってないNATゲートウェイの課金
NATゲートウェイは思いのほか使用料金が高く、夜間の開発環境など使用していない時は止めたい。
ただ現在において停止機能は存在しておらず、停止イコール削除となる。
停止という点ではNATインスタンスを立てて停止すれば良い話だが、それでは単純に面倒。せっかくのマネージドサービスは使いたい。
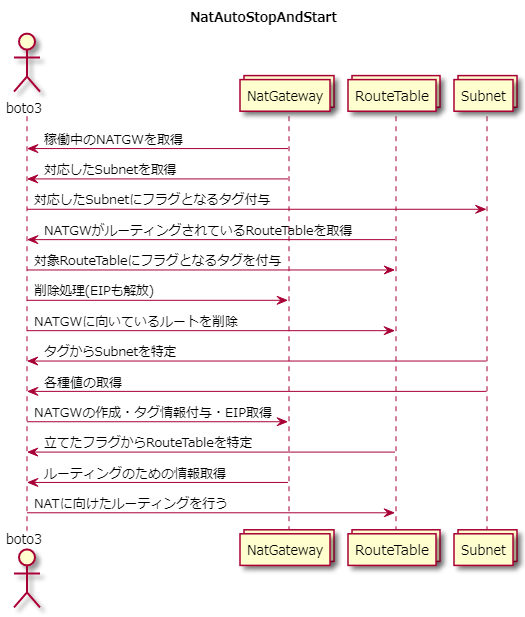
ならば、使用していないときにNATゲートウェイを削除し、使いたいときに必要な情報をもって再作成するスクリプトを作成すればいい。やりたいことを図にしてみる
UMLの書き方は正式に勉強していないので許してほしい。停止(削除)スクリプト
import boto3 client = boto3.client('ec2') natGateWayList = [] routeTableList = [] subnetList = [] natGateWayNameList = [] iPlist = [] # 起動中のNATゲートウェイを取得 response = client.describe_nat_gateways( Filters=[ { 'Name': 'state', 'Values': ['available'], }, ], ) for natgateway in response['NatGateways']: natGateWayList.append(natgateway['NatGatewayId']) subnetList.append(natgateway['SubnetId']) for tag in natgateway['Tags']: if tag['Key'] == "Name": natGateWayNameList.append(tag['Value']) else: pass # NATゲートウェイに向いてるルーティングを取得 for i in natGateWayList: response = client.describe_route_tables( Filters=[ { 'Name': 'route.nat-gateway-id', 'Values': [i], }, ], ) for j in response['RouteTables']: routeTableList.append(j['RouteTableId']) # SubnetのtagにNATゲートウェイの名前を挿入 for sub, nm in zip(subnetList, natGateWayNameList): response = client.create_tags( Resources=[ sub, ], Tags=[ { 'Key': 'tempNatName', 'Value': str(nm) }, ] ) # NATゲートウェイが存在するルートテーブルにFlagを立てる for i in routeTableList: response = client.create_tags( Resources=[ i, ], Tags=[ { 'Key': 'routeingToNat', 'Value': 'True' }, ] ) # 起動スクリプトにて取得した値からEIPを回収 response = client.describe_addresses( Filters=[ { 'Name': 'tag:DisFLG', 'Values': ['True'] }, ] ) # 各種削除処理 for i in response['Addresses']: client.release_address(AllocationId=i['AllocationId']) for i in routeTableList: response = client.delete_route( DestinationCidrBlock='0.0.0.0/0', RouteTableId=i, ) for i in natGateWayList: client.delete_nat_gateway(NatGatewayId=i)起動スクリプト
import boto3 client = boto3.client('ec2') subnetLst = [] ipList = [] natGateWayNameList = [] routeTableList = [] natGateWayIdList = [] # NATゲートウェイが存在したサブネットからNATのName tagを回収 response = client.describe_subnets( Filters=[ { 'Name': 'tag:tempNatName', 'Values': ['*'] }, ], ) for h in response['Subnets']: subnetLst.append(h['SubnetId']) for i in h['Tags']: if i['Key'] == "tempNatName": natGateWayNameList.append(i['Value']) else: pass # EIPに削除フラグを立てる for nat in natGateWayNameList: result = client.allocate_address( Domain='vpc' ) response = client.create_tags( Resources=[ result['AllocationId'], ], Tags=[ { 'Key': 'Name', 'Value': str(nat) + '-IsIpAdress' }, { 'Key': 'DisFLG', 'Value': 'True' }, ] ) ipList.append(result['AllocationId']) # NATゲートウェイ作成 for sub, ip, ntnm in zip(subnetLst, ipList, natGateWayNameList): response = client.create_nat_gateway( AllocationId=ip, SubnetId=sub ) natid = response['NatGateway']['NatGatewayId'] natGateWayIdList.append(natid) client.get_waiter('nat_gateway_available').wait(NatGatewayIds=[natid]) response = client.create_tags( Resources=[ natid, ], Tags=[ { 'Key': 'Name', 'Value': str(ntnm) }, ] ) response = client.describe_route_tables( Filters=[ { 'Name': 'tag:routeingToNat', 'Values': ['True'] }, ], ) # ルートテーブルのタグから値の回収してルーティング for i in response['RouteTables']: routeTableList.append(i['RouteTableId']) for natId in natGateWayIdList: response = client.describe_nat_gateways( Filters=[ { 'Name': 'nat-gateway-id', 'Values': [natId] }, ], ) natVpcId = response['NatGateways'][0]['VpcId'] for routeTableId in routeTableList: rtbrespo = client.describe_route_tables( Filters=[ { 'Name': 'route-table-id', 'Values': [routeTableId] }, ], ) rtVpcId = rtbrespo['RouteTables'][0]['VpcId'] if natVpcId == rtVpcId: response = client.create_route( DestinationCidrBlock='0.0.0.0/0', NatGatewayId=natId, RouteTableId=routeTableId )なんか色々
- 既にNameタグがふられたNATGWがある環境が前提なのでそのまま動かすと多分NG
- 細かい制御をしたい場合、Tagに色々書いてDescribeすれば取りあえず何とかなる。
- 使用していないElastic IPを保持していると微妙に課金が発生するので逐一アドレスを解放・調達することにしている。そもそも節約スクリプトなので。
- 使ってるEIPを常に保持したい場合はアドレス調達の処理をカットして既にあるEIPのIDを挿入すればOK
- lambdaとCloudWatch Eventで動かせば勤務時間中のみNATGWを作成するということも可能
- ただ関数ごとにブロックを分けていないので、そのあたりは要追記、一応そのままでも動く
- VPCが2つある環境で試したのでこのようなルーティング処理となっている
- 例えばAZでサブネット切ってるとかだとルーティングに追加が判定が必要
- for文じゃなくてList comprehensionsでもっとスマートにできるカモ
- 麻倉ももさんはかわいいし、夏川椎菜さんは推せる
参考にしたページ
サーバレスでNAT Gatewayの起動・停止を管理してみた【押忍!ソフト道場】
https://www.ntt-tx.co.jp/column/dojo_aws_blog/20180411/
AWSのリソースって使っていない時は止めたいよね!
https://qiita.com/atmitani/items/dbb58e820030996b73d9
できるだけシンプルな仕組みで簡単にEC2の自動起動・停止を実現したい!|クラスメソッドブログ
https://dev.classmethod.jp/cloud/aws/simple-auto-start-stop-for-ec2/
- 投稿日:2020-04-06T14:09:04+09:00
AtCoder Beginner Contest 097 過去問復習
所要時間
感想
コンテスト中に他の用事が入ってしまいコンテスト中に解ききることができませんでした。また、ABCの復習が大量に溜まっているので、今日明日は新規のバチャコンをしないようにします。今やってるFXも損切りができていないので、その辺の整理をしっかりしていきたいです。
A問題
直接で会話できるのか間接で会話できるのかをそれぞれ判定すれば良いです。
answerA.pya,b,c,d=map(int,input().split()) print("Yes" if abs(a-c)<=d or (abs(a-b)<=d and abs(b-c)<=d) else "No")B問題
このような冪乗や割り算などの絡む問題は誤差が発生しやすいにも関わらず複数回WAを出してしまいました。
このような問題は境界での場合分けをしっかりするように気をつけることとceilやfloorやlogなどの関数を使わないようにしていきたいです。answerB.pyx=int(input()) ans=[1] for i in range(2,x+1): k=2 while True: a=i**k if a<=x: ans.append(a) k+=1 else: break print(max(ans))C問題
辞書順でK番目に小さいものを求めますが、辞書順の求め方はアルファベットの順番と長さによります。
初めはアルファベットの順番に注目してコードを書いてTLEしましたが、そこに長さの制約を追加したところACすることができました。answerC.pys=input() l=len(s) k=int(input()) alp=[chr(i) for i in range(97, 97+26)] ans=set() for i in range(26): for j in range(l): if s[j]==alp[i]: for m in range(j,min(l,j+k)): ans.add(s[j:m+1]) if len(ans)>=k: break print(sorted(list(ans))[k-1])D問題
バチャコン中は用事があり解けませんでしたが、そこまで難しい問題ではありませんでした。
置換ができる要素同士(複数の置換を経由しても良い)の間では他の要素を置換せずに要素を置換可能という感覚があったので無証明で通してしまいました(✳︎1)。無証明を普段からやるのは力がつかないと僕は思っているので反省しています。
これが正しいと仮定すると、置換できる要素同士が含まれる集合を素集合とするUnion-Find木を作成し、作成したらgrouping関数を用いて素集合ごとに分けていきます。ここまでの処理ができれば、残りはそれぞれの素集合に含まれる要素について$p_i=i$が最大限成り立つ時を考えれば良いです。ここで、素集合にはインデックスの値が含まれることから、素集合とその要素をインデックスとするpの要素の集合の積集合(共通部分)を取ることで求める事ができます。積集合は求めたい集合を引数としてset_intersectionをしてその積集合の長さの合計をそれぞれの素集合について求める事で$p_i=i$となるiの最大値がわかります。(✳︎2)(✳︎1)…数学的な証明は解答に書いてあるので飛ばしますが、感覚的な証明をすると以下のようになります。
(✳︎2)…set_intersectionの使い方はこちらのブログを参考にしました。
answerD.cc//参考:http://ehafib.hatenablog.com/entry/2015/12/23/164517 //インクルード #include<algorithm>//sort,二分探索,など #include<bitset>//固定長bit集合 #include<cmath>//pow,logなど #include<complex>//複素数 #include<deque>//両端アクセスのキュー #include<functional>//sortのgreater #include<iomanip>//setprecision(浮動小数点の出力の誤差) #include<iostream>//入出力 #include<map>//map(辞書) #include<numeric>//iota(整数列の生成),gcdとlcm(c++17) #include<queue>//キュー #include<set>//集合 #include<stack>//スタック #include<string>//文字列 #include<unordered_map>//イテレータあるけど順序保持しないmap #include<unordered_set>//イテレータあるけど順序保持しないset #include<utility>//pair #include<vector>//可変長配列 #include<iterator>//set_intersection,set_union,set_differenceのため using namespace std; typedef long long ll; //マクロ #define REP(i,n) for(ll i=0;i<(ll)(n);i++) #define REPD(i,n) for(ll i=(ll)(n)-1;i>=0;i--) #define FOR(i,a,b) for(ll i=(a);i<=(b);i++) #define FORD(i,a,b) for(ll i=(a);i>=(b);i--) #define ALL(x) (x).begin(),(x).end() //sortなどの引数を省略したい #define SIZE(x) ((ll)(x).size()) //sizeをsize_tからllに直しておく #define MAX(x) *max_element(ALL(x)) #define INF 1000000000000 //10^12 #define MOD 10000007 //10^9+7 #define PB push_back #define MP make_pair #define F first #define S second #define MAXR 100000 //10^5:最大のrange(素数列挙などで使用) //参考:https://pyteyon.hatenablog.com/entry/2019/03/11/200000 //参考:https://qiita.com/ofutonfuton/items/c17dfd33fc542c222396 class UnionFind { public: vector<ll> parent; //parent[i]はiの親 vector<ll> siz; //素集合のサイズを表す配列(1で初期化) map<ll,vector<ll>> group; //コンストラクタの:の後ろはメンバ変数を初期化している UnionFind(ll n):parent(n),siz(n,1){ //最初は全てが根であるとして初期化する for(ll i=0;i<n;i++){parent[i]=i;} } ll root(ll x){ //データxの属する木の根を再帰で得る if(parent[x]==x) return x; //代入式の値は代入した変数の値になる! //経路圧縮(根に直接要素を繋ぐことで計算を効率化する) return parent[x]=root(parent[x]); //再帰で得る際に親の更新を行っておく } void unite(ll x,ll y){ //xとyの木を併合する ll rx=root(x);//xの根をrx ll ry=root(y);//yの根をry if(rx==ry) return; //同じ木にある時 //小さい集合を大きい集合へと併合させる(ry→rxへ併合) if(siz[rx]<siz[ry]) swap(rx,ry); siz[rx]+=siz[ry]; parent[ry]=rx; //xとyが同じ木にない時はyの根ryをxの根rxにつける } bool same(ll x,ll y){//xとyが属する木が同じかを返す ll rx=root(x); ll ry=root(y); return rx==ry; } ll size(ll x){ //素集合のサイズ return siz[root(x)]; } void grouping(ll n){ //素集合どうしのグループ化 for(ll i=0;i<n;i++){ if(group.find(parent[i])==group.end()){ group[parent[i]]=vector<ll>(1,i); }else{ group[parent[i]].push_back(i); } } } }; signed main(){ ll n,m;cin >> n >> m; UnionFind uf(n); vector<ll> p(n);REP(i,n){cin >> p[i];p[i]-=1;} REP(i,m){ ll x,y;cin>>x>>y; uf.unite(x-1,y-1); } REP(i,n)uf.root(i); uf.grouping(n); ll ans=0; for(auto j=uf.group.begin();j!=uf.group.end();j++){ vector<ll> value=j->S; //REP(i,value.size()) cout << value[i] << " "; vector<ll> vecinter; vector<ll> value2;REP(i,value.size()) value2.PB(p[value[i]]); sort(ALL(value));sort(ALL(value2)); //sortを忘れないように set_intersection(ALL(value),ALL(value2),back_inserter(vecinter)); //cout << ans << endl; ans+=vecinter.size(); //cout << endl; } cout << ans << endl; }


- 投稿日:2020-04-06T12:53:07+09:00
AtCoder Beginner Contest 161の復習, E問まで(Python)
競プロ初心者の復習用記事です。
ここで書く解は解説や他の人の提出を見ながら書いたものです。自分が実際に提出したものとは限りません。
A - ABC Swap
三つの箱の中身を決まった操作で入れ替える問題です。
最初から入れ替え操作の位置は決まっているので、x, y, zをz, x, yと順番を変えて出力するだけです。x, y, z = map(int, input().split()) print(z, x, y)B - Popular Vote
N種類の商品内に一定以上の投票数を得た商品がM個以上あるかを探す問題です。
与えられた得票数をソートし、M番目の商品が条件を満たしているか調べました。これで通りました。
N, M = map(int, input().split()) A = list(map(int, input().split())) A.sort(reverse = True) if A[M-1] >= sum(A) / (4 * M): print('Yes') else: print('No')C - Replacing Integer
与えられたNからKを引き続けると最小値はいくらになるか答える問題です。
与えられた数字から引き続けて最後に残る数字...というのは余剰項を求める計算に相当します。一個多く引いた場合、というのはその余剰項からKを引いた値(のマイナス)になります。
以下のコードで実装しました。
N, K = map(int, input().split()) print(min(N%K, K-N%K))D - Lunlun Number
ルンルン数という条件を満たしているK番目の数字を求める問題です。
パッと見の条件は簡単そうに見えるのですが、K番目の数を効率よく求める方法が全くわからず諦めました。
解説を見ました。この問題では一度使った数の右端にもう一つ条件を満たす数字をつけていくことで高速で求めていくことができます。解説ではキューを使用することでこれを行っていました。
キューにまず1~9までの数字を入れる。左端を取り出し、その値を$x$とする。$x$の1の位を$r$とする。$r$が「0」なら$10x, 10x+1$を計算し、それぞれ再びキューに入れる。同様に$r$が「1~8」なら$10x+(r-1), 10x + r, 10x+(r+1)$、rが「9」なら$10x - 1, 10x$を計算し、再びキューへ。
これを繰り返して、k回目に取り出した値が求める数字です。
というのをそのまま実装してみました。
K = int(input()) Q = [i for i in range(1, 10)] for _ in range(K): x = Q.pop(0) r = x%10 if r != 0: Q.append(x*10 + r - 1) Q.append(x*10 + r) if r != 9: Q.append(x*10 + r + 1) print(x)これだとTLE。pop()の速度が遅いようです。取り出す処理はいらないとみて、全て配列のまま保持してforで回してみます。
K = int(input()) Q = [i for i in range(1, 10)] k = 0 for q in Q: if k >= K: break r = q%10 if r != 0: Q.append(q*10 + r - 1) k += 1 Q.append(q*10 + r) k += 1 if r != 9: Q.append(q*10 + r + 1) k += 1 print(Q[K-1])これで通りました。
追記
コメントで指摘を受けました。キューを扱う時はちゃんとライブラリを使用しましょう。
pythonでは
collections.deque()クラスを用いることで、キューを扱うことができます。append(),appendleft(),pop(),popleft()などの関数があります。import collections K = int(input()) Q = collections.deque([i for i in range(1, 10)]) for _ in range(K): x = Q.popleft() r = x%10 if r != 0: Q.append(x*10 + r - 1) Q.append(x*10 + r) if r != 9: Q.append(x*10 + r + 1) print(x)E - Yutori
一定のルールで働く日と働かない日を決めたとき、必ず働く日はどれか答える問題です。
諦めて解説を見ました。
まず、働くことができる日数がノルマに対して余裕ができる場合、もしくはノルマに足りない場合は無条件でアウトになります。
というわけでギリギリまで働く日数を埋めた場合を考えます。まず右端から順番に働ける日を数えた配列Rを作成。この配列には、「$x$回目に働く日は$R[x]$以前である」という情報が含まれます。同様に左端から順番に働く日を数えた配列Lの場合、「$x$回目に働く日は$L[x]$以降である」という情報が含まれます。よって$L[x]$と$R[x]$が一致する時が必ず働く日だといえます。
これを実装したのが以下のコード。これで通りました。
N, K, C = map(int, input().split()) S = input() L = [] R = [] holiday = 0 for i in range(N): if holiday: holiday -= 1 elif S[i] == 'o': L.append(i) holiday = C holiday = 0 for i in range(N-1, -1, -1): if holiday: holiday -= 1 elif S[i] == 'o': R.append(i) holiday = C R = R[::-1] if len(L) == K: for l, r in zip(L, R): if l == r: print(l+1)この記事はここまでとします。
- 投稿日:2020-04-06T12:39:50+09:00
タイマー
指定時間後に実行されます
import logging import threading import time logging.basicConfig(level=logging.DEBUG, format='%(threadName)s: %(message)s') def worker(x, y=1): logging.debug('start') logging.debug(x) logging.debug(y) time.sleep(2) logging.debug('end') if __name__ == '__main__': t = threading.Timer(3, worker, args=(100,), kwargs={'y': 200}) t.start()Thread-1: start Thread-1: 100 Thread-1: 200 Thread-1: end
- 投稿日:2020-04-06T12:17:56+09:00
threading.enumerate
threading.enumerateで生存中のThreadオブジェクト全てのリストを取得できます。
import logging import threading import time logging.basicConfig(level=logging.DEBUG, format='%(threadName)s: %(message)s') def worker1(): logging.debug('start') time.sleep(5) logging.debug('end') if __name__ == '__main__': #threads = [] for _ in range(5): t = threading.Thread(target=worker1) t.setDaemon(True) t.start() #threads.append(t) for thread in threading.enumerate(): if thread is threading.currentThread(): print(thread) continue thread.join()Thread-1: start Thread-2: start Thread-3: start Thread-4: start Thread-5: start <_MainThread(MainThread, started 4599717312)> Thread-1: end Thread-2: end Thread-5: end Thread-4: end Thread-3: end
- 投稿日:2020-04-06T12:13:51+09:00
IQ Botのカスタムロジック:パターンの決まった文字化けの補正、空欄埋め、ノイズの除外(置換処理)
IQ Botのカスタムロジックの概要について、先日こちらの記事でご紹介しました。
カスタムロジックはPythonというプログラミング言語そのものではあるんですが、
プログラミングの知識がないと使いこなせないかというと、そんなことはありません。この記事では、コード自体は簡単ですが実際に業務で使う8~9割を占める
「置換」の処理について、コードと使用例をご紹介していきます。こちらでもご紹介したとおり、
フィールド項目とテーブル項目で若干考え方が違うので、それぞれ紹介します。フィールド項目に対する置換処理
まずはより基本編となるフィールド項目から。
置換のロジックはめちゃ簡単ですが、実際に業務で使うカスタムロジックの8~9割はこれです。
基本のコード
フィールド項目に対する置換の処理field_value = field_value.replace("置換前の文字列","置換後の文字列")以下のように改行して、同じ項目に対して複数の置換処理を定義することが可能です。
改行すれば複数の定義OKfield_value = field_value.replace("置換前の文字列1","置換後の文字列1") field_value = field_value.replace("置換前の文字列2","置換後の文字列2")たったこれだけのコードですが、以下のようにいろいろ応用できます。
置換処理の使い道いろいろ
- 空欄を埋める
field_value.replace(" ","")で、空欄を埋められます。余談ですが、IQ Botは改行ありの値を読み込んだ場合に、仕様として改行部分が空欄に変換されます。
- オーと読まれた文字をゼロに変換(パターンの決まった文字化けの補正)
field_value.replace("O","0")で、オーをゼロに変換できます。同じ要領で、
l(エル)やI(アイ)や|(パイプライン)を1(いち)に置き換えたり、
棘を東京に置き換えたり、
▲で表記されたマイナスをマイナス符号に置き換えたりなど、いろいろできます。
- ノイズの除外
OCRで帳票を処理すると、紙の汚れや人がボールペンでチェックしたマークなどが、
ピリオド、カンマ、コロン、セミコロン、スラッシュ、クオーテーション、ダブルクオーテーション 等々の
ノイズとして読み込まれてしまうケースが多々あります。そうした記号が不要な項目であれば、
field_value.replace("除外したいノイズ","")でノイズの除外ができます。なお、置換前の文字列や置換後の文字列は、
ダブルクオーテーション(")かシングルクオーテーション(')のどちらかで囲まれていれば大丈夫です。除外したいノイズ自体にダブルクオーテーションやシングルクオーテーションが入っている場合は、
以下のように定義すれば大丈夫です。除外したいノイズじゃない方のクオーテーションで囲む#シングルクオーテーションを除外する場合は、ダブルクオーテーションで囲む field_value = field_value.replace("'","") #ダブルクオーテーションを除外する場合は、シングルクオーテーションで囲む field_value = field_value.replace('"',"")テーブル項目に対する置換処理
テーブル項目の場合は、ちょっと書き方が変わりますが、それでも簡単です。
こちらで説明したおまじないコードの間に・・・
このように↓書きます。
テーブル項目に対する置換の処理df['列名'] = df['列名'].str.replace('置換前の文字列', '置換後の文字列')列名はIQ Botで帳票設定するときに定義したこちら↓の列名をそのまま使います。
日本語の列名でも普通に動きますが、
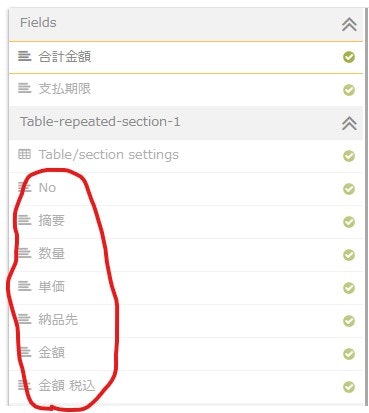
列名にスペースが含まれている場合は、スペースはアンスコ(_)に置き換えます。例えば上記の「金額」と「金額 税込」の列から、「円」という単位を除外したい場合は以下のように処理します。
フィールド項目に対する置換の処理df['金額'] = df['金額'].str.replace('円', '') df['金額_税込'] = df['金額_税込'].str.replace('円', '')まとめ
- 置換の処理は簡単だけど、業務で使うカスタムロジックのほとんどはこれだよ
- 置換処理の仕組みを使って、パターンの決まった文字化け補正や空欄埋め、ノイズの除外などいろいろできるよ
- テーブルの場合は列名を指定するよ
- テーブルの列名にスペースが含まれている場合は、アンスコ(_)に置き換えるよ
いかがでしたか?
置換処理を適切に使うと、簡単にインプットデータの質を上げられて自動化がしやすくなるので、ぜひ試してみてください!
- 投稿日:2020-04-06T12:13:51+09:00
IQ Botのカスタムロジック:パターンの決まった文字化けの補正、空欄埋め、形式変換、ノイズの除外(置換処理)
IQ Botのカスタムロジックの概要について、先日こちらの記事でご紹介しました。
カスタムロジックはPythonというプログラミング言語そのものではあるんですが、
プログラミングの知識がないと使いこなせないかというと、そんなことはありません。この記事では、コード自体は簡単ですが実際に業務で使う8~9割を占める
「置換」の処理について、コードと使用例をご紹介していきます。こちらでもご紹介したとおり、
フィールド項目とテーブル項目で若干考え方が違うので、それぞれ紹介します。フィールド項目に対する置換処理
まずはより基本編となるフィールド項目から。
置換のロジックはめちゃ簡単ですが、実際に業務で使うカスタムロジックの8~9割はこれです。
基本のコード
フィールド項目に対する置換の処理field_value = field_value.replace("置換前の文字列","置換後の文字列")以下のように改行して、同じ項目に対して複数の置換処理を定義することが可能です。
改行すれば複数の定義OKfield_value = field_value.replace("置換前の文字列1","置換後の文字列1") field_value = field_value.replace("置換前の文字列2","置換後の文字列2")たったこれだけのコードですが、以下のようにいろいろ応用できます。
置換処理の使い道いろいろ
- 空欄を埋める
field_value.replace(" ","")で、空欄を埋められます。余談ですが、IQ Botは改行ありの値を読み込んだ場合に、仕様として改行部分が空欄に変換されます。
- オーと読まれた文字をゼロに変換(パターンの決まった文字化けの補正)
field_value.replace("O","0")で、オーをゼロに変換できます。同じ要領で、
l(エル)やI(アイ)や|(パイプライン)を1(いち)に置き換えたり、
棘を東京に置き換えたり、
▲で表記されたマイナスをマイナス符号に置き換えたりなど、いろいろできます。
- 形式の変換
「2020年4月6日」を「2020/4/6」のような形式に直したい場合も、置換で対応できます。
日付の形式変換の例field_value = field_value.replace("年","/") field_value = field_value.replace("月","/") field_value = field_value.replace("日","")
- ノイズの除外
OCRで帳票を処理すると、紙の汚れや人がボールペンでチェックしたマークなどが、
ピリオド、カンマ、コロン、セミコロン、スラッシュ、クオーテーション、ダブルクオーテーション 等々の
ノイズとして読み込まれてしまうケースが多々あります。そうした記号が不要な項目であれば、
field_value.replace("除外したいノイズ","")でノイズの除外ができます。なお、置換前の文字列や置換後の文字列は、
ダブルクオーテーション(")かシングルクオーテーション(')のどちらかで囲まれていれば大丈夫です。除外したいノイズ自体にダブルクオーテーションやシングルクオーテーションが入っている場合は、
以下のように定義すれば大丈夫です。除外したいノイズじゃない方のクオーテーションで囲む#シングルクオーテーションを除外する場合は、ダブルクオーテーションで囲む field_value = field_value.replace("'","") #ダブルクオーテーションを除外する場合は、シングルクオーテーションで囲む field_value = field_value.replace('"',"")テーブル項目に対する置換処理
テーブル項目の場合は、ちょっと書き方が変わりますが、それでも簡単です。
こちらで説明した「おまじないコード」の間に・・・
このように↓書きます。
テーブル項目に対する置換の処理df['列名'] = df['列名'].str.replace('置換前の文字列', '置換後の文字列')列名はIQ Botで帳票設定するときに定義したこちら↓の列名をそのまま使います。
日本語の列名でも普通に動きますが、
列名にスペースが含まれている場合は、スペースはアンスコ(_)に置き換えます。例えば上記の「金額」と「金額 税込」の列から、「円」という単位を除外したい場合は以下のように処理します。
フィールド項目に対する置換の処理df['金額'] = df['金額'].str.replace('円', '') df['金額_税込'] = df['金額_税込'].str.replace('円', '')まとめ
- 置換の処理は簡単だけど、業務で使うカスタムロジックのほとんどはこれだよ
- 置換処理の仕組みを使って、パターンの決まった文字化け補正や空欄埋め、ノイズの除外などいろいろできるよ
- テーブルの場合は列名を指定するよ
- テーブルの列名にスペースが含まれている場合は、アンスコ(_)に置き換えるよ
いかがでしたか?
置換処理を適切に使うと、簡単にインプットデータの質を上げられて自動化がしやすくなるので、ぜひ試してみてください!
- 投稿日:2020-04-06T11:47:26+09:00
Anaconda + Diangoを連携
Anaconda + Diangoを連携
この記事では、Anaconda + Diangoを連携させLINEのBOTを作成します。かなりめんどくさいのでできるならやらないほうがいいです笑
環境を作成するところから書いていきます、それ以前の基本的なUbuntuの設定については済ませておいてください。
環境作成
Apacheの環境作成
Apacheの環境を作成します。必要なものをインストール
sudo apt-get install apache2 apache2-bin apache2-devAnaconda のインストール
つぎにAnacondaをインストールします。
wget https://repo.anaconda.com/archive/Anaconda3-2020.02-Linux-x86_64.sh sudo bash Anaconda3-2020.02-Linux-x86_64.sh案内に従ってインストールしてください。(condaも認識するように)
次にAnacondaの設定をしていきます。Djangoをインストール。
sudo conda install djangoDjangoのバージョンは以下:
python -m django --version 3.0.3Django プロジェクト作成
次にDjanogのプロジェクトを作成していきます。チュートリアルページが参考になりました:https://docs.djangoproject.com/ja/2.2/intro/tutorial01/
今回は適当に以下で実行。
django-admin startproject linebotこれで現在いるディレクトリ下にlinebotというフォルダが作られます。
python manage.py runserver 0.0.0.0:8000これでサーバーを起動することができますので、見てみるといいでしょう。
ここから先はDjangoのアプリケーションを作成したり、チュートリアルを参考にしてください。(ここでは割愛します)
DjangoとApacheの連携
次に一番の鬼門であるDjangoとApacheの連携をしていきます。これをするにはmod_wsgiというもので先程のDjangoとApacheを連携させます。
まずはインストール
pip install mod_wsgi次に、インストール先を見つけます。
python -c "import sys; print(sys.path)" ['', '/home/vagrant/anaconda3/lib/python37.zip', '/home/vagrant/anaconda3/lib/python3.7', '/home/vagrant/anaconda3/lib/python3.7/lib-dynload', '/home/vagrant/.local/lib/python3.7/site-packages', '/home/vagrant/anaconda3/lib/python3.7/site-packages'] (base) vagrant@vagrant:~/.local/lib/python3.7/site-packages/mod_wsgi/server$ ls __init__.py apxs_config.py management __pycache__ environ.py mod_wsgi-py37.cpython-37m-x86_64-linux-gnu.so環境によって異なりますが、今回はvagrantでやっていたので、このような場所にありました。
/etc/apache2/mods-available/wsgi.load にこのようにパスを記載します。
LoadModule wsgi_module /home/vagrant/.local/lib/python3.7/site-packages/mod_wsgi/server/mod_wsgi-py37.cpython-37m-x86_64-linux-gnu.soついでに/etc/apache2/mods-available/wsgi.conf にもこのように記載します。
<IfModule mod_wsgi.c> WSGIPythonHome /home/vagrant/anaconda3 WSGIPythonPath /home/vagrant/anaconda3/bin </IfModule>そしてwsgiを有効化します。
sudo a2enmod wsgi Enabling module wsgi. To activate the new configuration, you need to run: systemctl restart apache2このような表示が出たら大丈夫です。
次にサイトの設定ファイルを作っていきます。
/etc/apache2/sites-available/default-ssl.conf
NameVirtualHost *:80 <VirtualHost *:80> ServerName mikuaka.ddo.jp RewriteEngine on RewriteCond %{HTTPS} off RewriteRule ^(.*)$ https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L] </VirtualHost> NameVirtualHost *:443 <IfModule mod_ssl.c> <VirtualHost _default_:443> ServerAdmin your@name.com ServerName your.name.com ServerAlias www.your.name.com WSGIDaemonProcess name display-name=%{GROUP} user=www-data group=www-data python-path=/home/ubuntu/your/project WSGIProcessGroup name WSGIScriptAlias / /var/www/name/wsgi.py <Directory "/var/www/name"> <Files wsgi.py> Require all granted </Files> </Directory> Alias /static/ /var/www/name/static/ <Directory /var/www/name/static/> Require all granted </Directory> ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined SSLEngine on SSLCertificateFile /etc/letsencrypt/live/your.name.com/cert.pem SSLCertificateKeyFile /etc/letsencrypt/live/your.name.com/privkey.pem SSLCertificateChainFile /etc/letsencrypt/live/your.name.com/chain.pem <FilesMatch "\.(cgi|shtml|phtml|php)$"> SSLOptions +StdEnvVars </FilesMatch> <Directory /usr/lib/cgi-bin> SSLOptions +StdEnvVars </Directory> </VirtualHost> </IfModule>自分はこんな感じで作りました。↑はSSLの設定も入っています。
最後にapacheを再起動させます。
sudo service apache2 restartということでいかがだったでしょうか?DjangoとApacheの連携はかなりめんどくさいのでやらないい事がわかっていただけたと思いますw
この環境を使いLINE Bot作成を作成しているので、余裕があればそちらも記事にできたらと思っています。
- 投稿日:2020-04-06T11:36:17+09:00
並列化
import logging import threading import time logging.basicConfig(level=logging.DEBUG, format='%(threadName)s: %(message)s') def worker1(): logging.debug('start') time.sleep(5) logging.debug('end') def worker2(x, y=1): logging.debug('start') logging.debug(x) logging.debug(y) time.sleep(2) logging.debug('end') if __name__ == '__main__': t1 = threading.Thread(name='rename worker', target=worker1) t1.setDaemon(True) t2 = threading.Thread(target=worker2, args=(100,), kwargs={'y': 200}) t1.start() t2.start() print('started') t1.join() #worker1の処理が終わるまで待つ。これがないと先のt2が終了した時点でプログラムが終了してしまう t2.join() #デーモン化していないので書かなくてもいい出力rename worker: start Thread-1: start Thread-1: 100 Thread-1: 200 started Thread-1: end rename worker: end
- 投稿日:2020-04-06T10:03:35+09:00
Cloud9にPython+OpenCVの環境を構築する
AWS Cloud9にPython+OpenCVの開発環境を作りたい場合の環境構築手順です。
特に、各種インストールの部分が面倒だったのでまとめておきます。(ベストな方法かはわかりません、すみません。)EC2の作成
私は
EC2 instance type:t3.smallで作成しましたが、任意のインスタンスタイプを選んで作成してください。Cloud9インスタンスのボリュームを拡張する
t3.smallのデフォルトのボリュームは10GiBです。
これだと色々とインストールしている段階で容量が足りなくなるので、容量を拡張します。(容量が足りなくなるとインストール時にNo space left on device)と表示されます。
拡張手順は以下の記事を参照してください。
https://qiita.com/ktrkmk/items/8cf1e100da2e717f3be2
私は一旦30GiBまで拡張しました。homebrewのインストール
以下のコマンドでインストールします。
$ sh -c "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install.sh)"パスが無いと言われるので、以下のコマンドを順番に実行して対処します。
$ test -d ~/.linuxbrew && PATH="$HOME/.linuxbrew/bin:$HOME/.linuxbrew/sbin:$PATH" $ test -d /home/linuxbrew/.linuxbrew && PATH="/home/linuxbrew/.linuxbrew/bin:/home/linuxbrew/.linuxbrew/sbin:$PATH" $ test -r ~/.bash_profile && echo "export PATH='$(brew --prefix)/bin:$(brew --prefix)/sbin'":'"$PATH"' >>~/.bash_profile $ echo "export PATH='$(brew --prefix)/bin:$(brew --prefix)/sbin'":'"$PATH"' >>~/.profile実行できるか確認します。バージョンが表示されればOKです。
$ brew -v Homebrew 2.2.11 Homebrew/linuxbrew-core (git revision 9d9624; last commit 2020-04-05)pyenvのインストール
以下のコマンドでインストールします。
$ brew install pyenv実行できるか確認します。バージョンが表示されればOKです。
$ pyenv -v pyenv 1.2.18Pythonのインストール
インストールしたいバージョンを指定して実行します。(今回は3.8.1です。)
$ pyenv install 3.8.1インストールされているか確認します。
$ pyenv versions * system (set by /home/ec2-user/.pyenv/version) 3.8.1
3.8.1が表示されていますが、*がsystemの方についているので、これを変更します。$ pyenv global 3.8.1もう一度確認します。
$ pyenv versions system (set by /home/ec2-user/.pyenv/version) * 3.8.1
3.8.1に*が移動していればOKです。bash_profileを編集する
ここで改めてPythonのバージョンを確認します。
$ python --version Python 3.6.10恐らく、元のPythonバージョンが表示されるので、
bash_profileを編集して、pyenvのPythonバージョンを実行できるようにします。$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile $ exec $SHELL -lPythonのバージョンを確認し、反映されていればOKです。
$ python --version Python 3.8.1Open CVをインストール
最初は
$ brew install opencvこれでインストールしようと思ったのですが、うまく行かず…
なので、pipを使いました。$ pip install opencv-pythonインストールできているか確かめるには
$ python >>> import cv2で何もメッセージが出なければOKです。
以上で、環境構築は完了です。参考
https://qiita.com/nasuvitz/items/5eec6ab9444cff8e9467
https://prog-8.com/docs/python-env
https://www.lifewithpython.com/2018/01/python-checking-version.html
https://news.mynavi.jp/article/zeropython-34/
https://qiita.com/makki_maki04/items/f62c5e4e68709d9b3b89
https://dev.classmethod.jp/articles/aws-cloud9-pyenv/
- 投稿日:2020-04-06T09:40:14+09:00
Windowsエポック値をpythonで日付変換する
メモ(後で整理)
Windowsエポック値は、1年1月1日からの1テック単位の積み上げ。
Pythonでは、1970年1月1日を起点として1秒単位の積み上げ。from datetime import datetime as dt
a = ((Windowsエポック値/10000000*10000000)-621355968000000000)/10000000
date = dt.fromtimestamp(a)
- 投稿日:2020-04-06T06:08:59+09:00
これを見ればPythonの内包表記を完全に理解できる
内包表記とは。
一応、内包表記って何??という方に簡単に例を示します。n = 6 a = [] for i in range(n): a.append(i) b = [i for i in range(n)] print(a == b) # Trueこれはとても簡単な例ですが、まあなんとなくどんなものかはわかったと思います。(内部処理はまだ理解できていなくて良いです。)
aとbは、結果は同じものになっていますが、具体的にどんな処理を行っているのかを説明していきましょう。前者は、
1. まず空のリスト(可変長オブジェクト)を生成してaという変数に代入します。
2. rangeオブジェクトを生成します。
3. 2のオブジェクトから各値を取り出し、iという変数に代入します。
4. iを1で作成したリストにappendしていきます。(3, 4を繰り返します。)後者は
1. まず空のリスト(可変長オブジェクト)を生成します。(この中で行われるiterationの結果を格納していくための箱です)
2. rangeオブジェクトを生成します。
3. 2のオブジェクトから各値を取り出し、iという変数に代入します。
4. 内包表記を使うことで、結果のiを1のオブジェクトに格納していきます。 (3, 4を繰り返します。)
5. 5ループが終了したら1のオブジェクトをbという変数に代入します。両者の処理内容はほとんど同じですが、厳密には異なることは理解していただけたかと思います。
ではここで、内包表記の一般化をして示します。
<perform> <statement1> <statement2> ... # statement1, statement2, ... perform の順に評価されます。はい、意味不明ですよね。でも本当なので信じてください。
具体例を示します。(ここから先は結果を想像しながら読み進めてみましょう。)
a = [x for x in range(5) if i & 1]敢えて細かく分解すると、
perform :=x
statement1 :=for x in range(5)
statement2 :=if i & 1
となります。ちなみに
i & 1は&メソッドに引数1を渡すことで、iが奇数なら1、そうでないなら0を返します。そして、1,0 はbooleanに変換するとそれぞれTrue, Falseとなります。(この記事では知らなくても理解する必要はありません)
結果はこうなります[1, 3]わかりましたか?
さらに内包表記のいろいろを書いていきますので、考察と結果を照らし合わせながらなぜそうなるかをなるべく自分の頭で考えてみてください。
Q.1a = [i for i in range(3) for _ in range(2)]A.1
[0, 0, 1, 1, 2, 2]Q.2
import sys a = [(int(x), y) for x, y in [sys.stdin.readline().split()] for _ in range(2)] b = [(int(x), y) for _ in range(2) for x, y in [sys.stdin.readline().split()]] #ただし入力は 1 2 3 4A.2
[(1, '2'), (1, '2')] # a [(1, '2'), (3, '4')] # b(a のほうは2行目を読み込んでいません。なぜでしょう?もうわかりましたか?)
Q.3
a = [[0 for _ in range(2)] for _ in range(3)] b = [[0 for _ in range(3)] for _ in range(2)]2次元バージョンです。
ちなみに本記事では詳しく触れませんが、以下の2つは全く意味が異なります。(気になる人は調べてみてください。これも勉強)[[0 for _ in range(2)] for _ in range(3)] [[0] * 2 for _ in range(3)]A.3
[[0, 0], [0, 0], [0, 0]] # a [[0, 0, 0] [0, 0, 0]] # b簡単すぎましたか?
多次元の場合は外側のstatementが先に評価されます。Q.4
a = [j for i in range(4) for j in range(i+1)]A.4
[0, 0, 1, 0, 1, 2, 0, 1, 2, 3]以上で終了です、お疲れ様でした。(他にもいろいろありますが)
"内包表記ってこんなかんじ"くらいは伝わりましたかね?
まあこんな記事を読んだくらいで完璧に理解できる人はそもそも苦労しないと思うので大丈夫でしょう。
とにかく自分でいろいろ試してみながら仕様を理解していくのが一番です。プログラミングにおいて習うより慣れろ!の精神は絶対です。
最後までお付き合いいただきありがとうございました。余談ですが、後置ifはelseと合わせてそれ自体が一つの式であり、分解したりはできません、そもそもstatementではないです。
a = [(x + 1) // 2 if x & 1 else x // 2 for _ in range(3)]という書き方は正しいですが、
a = [(x + 1) // 2 for x in range(3) if x & 1 else x // 2]はSyntax的にアウトです。