- 投稿日:2020-04-06T22:57:41+09:00
[リアルタイム]KinesisからのLambdaが遅延した!! その時の対処は?
何が起きたのか
リアルタイムを実現するアーキテクチャを以下のように組みました
逐一流れてくるデータソース(企業秘密)→Kinesis→Lambda→DynamoDB
データソースにもDynamoDBのデータの双方に書き込みのタイミングのタイムスタンプが入っていました。そのタイムスタンプがずれてたんです!
それも1時間。果てどうしたものか・・・
AWSがヒントを提供していた
この遅延、実はメトリクスで分かったんです。そのメトリクスは
IteratorAge
です。KinesisでもIteratorAgeMillisecondsとしてメトリクスに書かれていました。
このIteratorAgeは** 読み込んだ時刻と処理時刻の差分
の事のよう。つまり、「入った時間と出る時間の差分」つまり、Kinesis+Lambdaのリアルタイム処理の「遅延」を表していることになると至りました。
「Amazon CloudWatch による Amazon Kinesis Data Streams サービスのモニタリング」
https://docs.aws.amazon.com/ja_jp/streams/latest/dev/monitoring-with-cloudwatch.htmlそして答えも提供していた
「Lambda 関数の IteratorAge メトリクスが上がるのはなぜですか ?」
https://aws.amazon.com/jp/premiumsupport/knowledge-center/lambda-iterator-age/この中に書いてある大事なのは「バッチサイズ」「シャード」「Duration」
バッチサイズ
バッチサイズが小さすぎると、その分多くのlambda起動が必要で、上限数による処理の限界があるのはもちろん、起動時間などのその他の時間も多く発生していまします。秒を争うリアルタイム処理ではこのその他の時間も馬鹿になりません。
シャード
一回に処理できる出口の数。蛇口が多い層がそりゃいいですよねって話。Lambdaの同時実行数が気になるところですが、上限緩和は可能なのでRealTimeの称号に勝るものはありません。
Duration
リアルタイム処理では「1秒間に何データ処理できるか」が大事になります。処理時間が長引けば当然「意秒間に処理できるデータ数」は減っていきます。これは短いに越したことがない
おまけで「Lambdaのバッチウインドウ」
これは時と場合によると思います。「何秒ごとに処理をするのか」といった設定になります。これが
1秒間に入ってくるデータ数>1秒間の処理できるデータ数
となると当然未処理データが溜まっていきますので遅延が発生する結末を迎えます
結局何をしたのか
ここまできて私たちがしたこと
- シャードを1→4に
- バッチサイズを10→100へ
- lambdaのメモリを254MBへ
と変更しました。
最初の設定、リアルタイムを舐めてるとしか言えないレベルの設定でしたねwこれにて通常時はめでたく1秒以内を実現。めでたしめでたし。。。
しかし、これだけでは終わらなかった
このリアルタイム処理、夜の約4時間は停止していたのですが起動直後に大遅延が発生するトラブル発生。
原因は停止直後からのデータ
Kinesisは24時間データを保管しておく設定でした。なので、停止直後から起動直前までのデータがはKinesisに存在していました。。これらから順に処理されていたために、その後の処理が後回しになり遅延が発生。
lambdaの設定を変更
「Maximum age of record (レコードの最大期間)」というTriggerの設定項目があります。
ここがデフォルトでは7日間。このままでした。
これだと、処理対象は「7日前」からになりますので、停止から起動までの4時間は当然処理対象となってしまいます。これが遅延の原因でした。止まってる期間のリアルタイム処理は処理しないで良い仕様なので、最小値の60秒に設定。1分前のデータしか対象にならないようにしました。
これで晴れて安定稼働
最後に
リアルタイムの処理では当たり前の観点ですが、この点がすべてインフラで設定できてしまうのはさすがクラウドと感心してしましました。
またこれも常識ですが、リアルタイムの処理とはいえ、集計はある程度まとめて行う必要がある(バッチサイズとか)のでアプリの設計も意識しなければならないなぁと感じましたご静聴ありがとうございました
- 投稿日:2020-04-06T22:37:48+09:00
Azure用語に対応するAWS用語を表示するユーザースクリプト
はじめに
AWSは知っているがAzureはよく知らない、という状態でAzureの勉強をするとき、「この機能はAWSで言うところのこれ」という情報があると、すんなり頭に入ってきたりします。
公式の比較表を見れば対応はわかるのですが、いちいち見に行くのは面倒なので、ユーザースクリプトにしてみました。作ったもの
できること
以下のように、ページ内のAzure用語にカーソルを合わせると、対応するAWS用語がポップアップされるようになります。用語は比較表や、こちらの記事から拾いました。
Qiitaと、ここのような、MSのドキュメントサイト配下のページで動作します。
インストール
Tampermonkeyなどの、ユーザースクリプト実行用アドオンを入れた上で、Greasy Forkからインストールします。
※ソースはこちらおわりに
Azure学習の一助になれば幸いです。

- 投稿日:2020-04-06T20:06:19+09:00
AWS S3 バケットで保存する
S3でファイルがアップロードされる領域を準備しましょう
ファイルのバックアップであったり、ファイル処理の加工前、もしくは加工後のファイルを保存する、画像ファイルやCSSなどWebで使う静的なファイルをS3に置いて配信するなど、使い方は無限大になりますS3(Simple Storage Serviceを略してS3)で、実際にデータが格納される場所のことをバケットと呼びます。バケットの名前はアクセスするときのURLとして使用されるため、まだ誰も付けたことがない名前を使う必要があります。
S3を利用してバケットを作成
ストレージの項目にある「S3」を開く
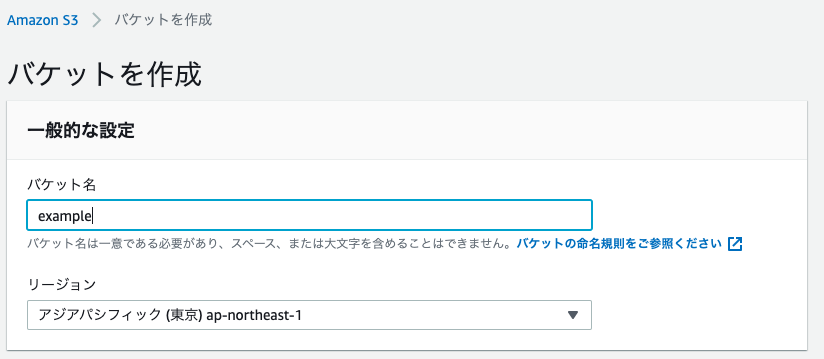
3. 「バケットを作成」をクリック(オレンジのボタン)
4. バケットの名前を入力
5. リージョン「アジアパシフィック」を選択
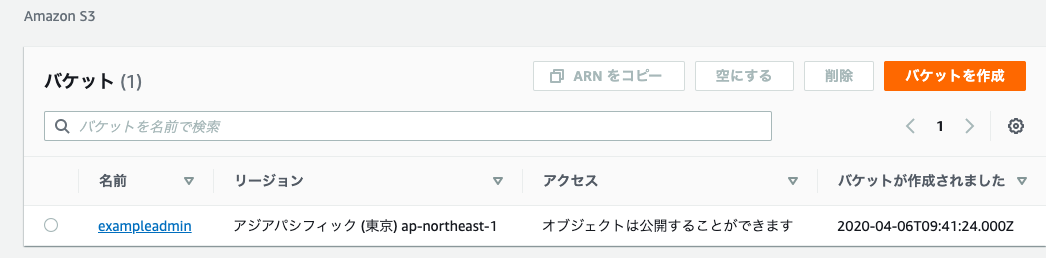
6. 画像のような設定にします。今回はバケットポリシーを使用してセキュリティ設定を行いますので下の2つにチェックを入れます。ここの設定が誤っているとファイルのアップロードができなくなりますので注意
7. 作成したバケットを開く
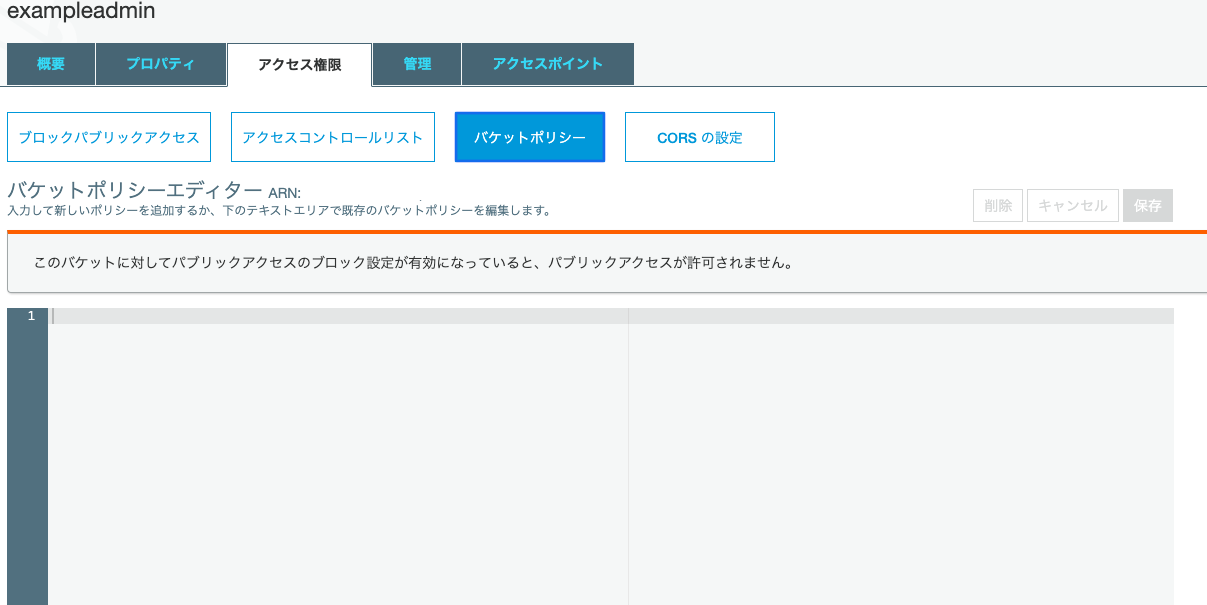
8. アクセス権限>バケットポリシーを開く
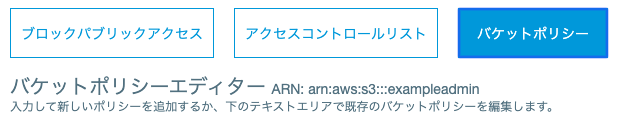
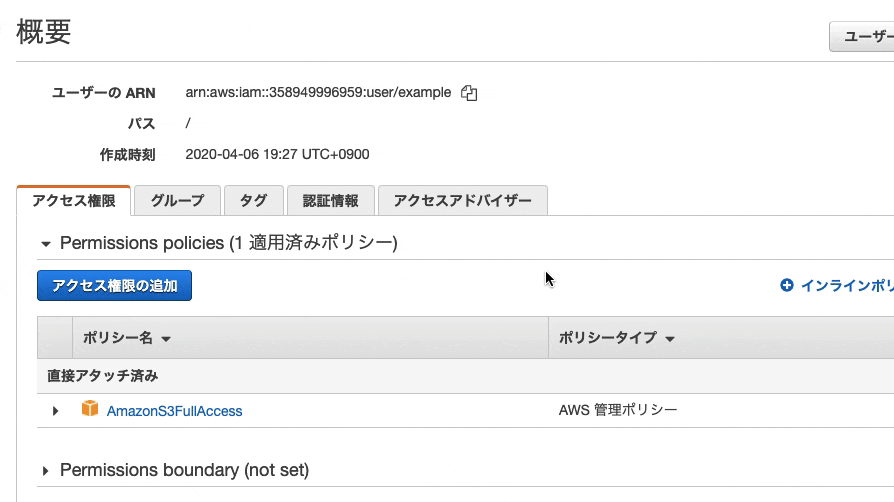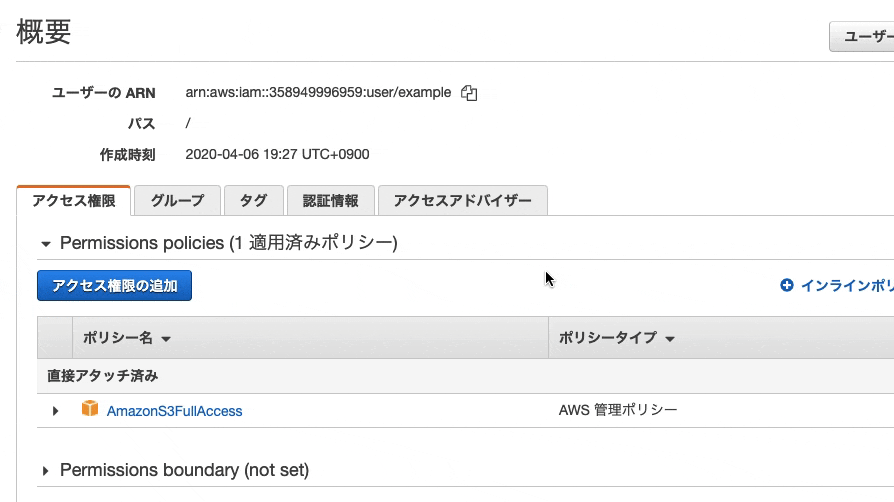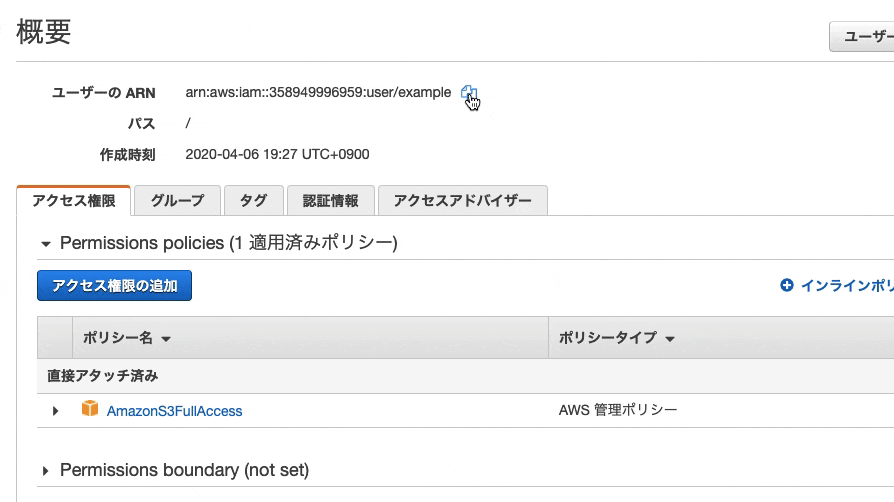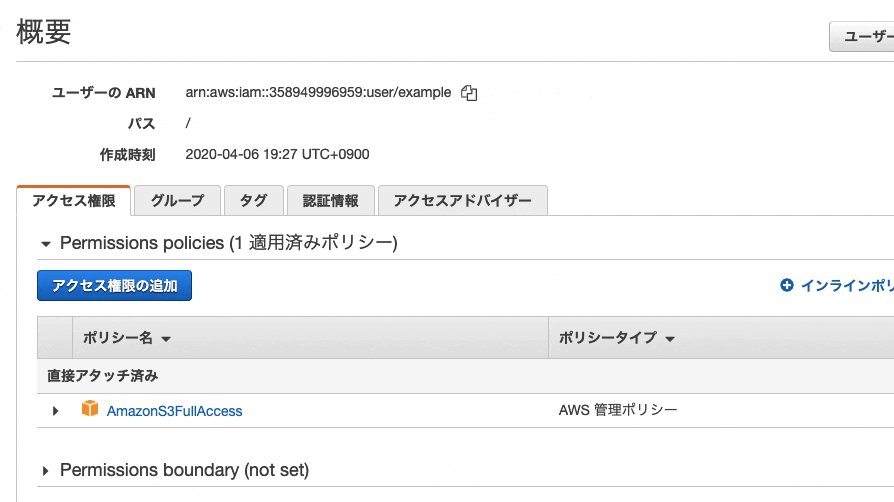
9. 表示されたエディターに下記を入力{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "************①IAMUserなどのアカウント****************" }, "Action": "s3:*", "Resource": "arn:aws:s3:::②バケット名" } ] }10.まず②から埋めます。②はバケット名を入力するだけですが、よく見ると画像の場所に記載されています
バケットポリシーエデイターの隣に「ARN:arn:aws:s3:::exampleadmin」と記述されています。
このaws:s3:::exampleadminが入った状態が②です。11.①はIAMのページに記載されています
まずIAMの管理ページを開きます
そして、作成したユーザーを開きます。この例の場合exampleを開きます
続いて、「ユーザーのARN」をコピーします
では、S3に戻ってバケットを開き①の項目に入れましょう
{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789123:user/example" }, "Action": "s3:*", "Resource": "arn:aws:s3:::example" } ] }これで作成完了しました
ローカル環境(開発環境)からS3にアップロード
ActiveStorageの場合は下記を参考にしてください
RailsアプリでActiveStorage + AWS S3を使ってみよう!二つの違いに関する記事
https://www.fundely.co.jp/blog/tech/2019/12/11/180024/CarrierWaveによる画像のアップロード先がアプリ内のpublicフォルダですが、
これをS3に変更していきます。Gemfilegem 'carrierwave' gem 'fog-aws'$ bundle installstorageを「:file」から「:fog」に変更する
app/uploaders/image_uploader.rb# encoding: utf-8 class ImageUploader < CarrierWave::Uploader::Base # Include RMagick or MiniMagick support: # include CarrierWave::RMagick include CarrierWave::MiniMagick process resize_to_fit: [800, 800] # Choose what kind of storage to use for this uploader: storage :fog #ここを変更 # Override the directory where uploaded files will be stored. # This is a sensible default for uploaders that are meant to be mounted: def store_dir "uploads/#{model.class.to_s.underscore}/#{mounted_as}/#{model.id}" endfogのアップロード先の設定
config/initializers/carrierwave.rbrequire 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' CarrierWave.configure do |config| config.storage = :fog config.fog_provider = 'fog/aws' config.fog_credentials = { provider: 'AWS', aws_access_key_id: Rails.application.secrets.aws_access_key_id, aws_secret_access_key: Rails.application.secrets.aws_secret_access_key, region: 'ap-northeast-1' } config.fog_directory = 'ここにバケット名を入れます' config.asset_host = 'https://s3-ap-northeast-1.amazonaws.com/ここにバケット名を入れます' endMojave以前の場合
$ vim ~/.bash_profile # iを押してインサートモードに移行し、下記を追記する。既存の記述は消去しない。 export AWS_ACCESS_KEY_ID='ここにCSVファイルのAccess key IDの値をコピー' export AWS_SECRET_ACCESS_KEY='ここにCSVファイルのにSecret access keyの値をコピー' #ここで保存完了 $ source ~/.bash_profilecatarina以降の場合
# ローカル環境 $ vim ~/.zshrc # iを押してインサートモードに移行し、下記を追記する。既存の記述は消去しない。 export AWS_ACCESS_KEY_ID='ここにCSVファイルのAccess key IDの値をコピー' export AWS_SECRET_ACCESS_KEY='ここにCSVファイルのにSecret access keyの値をコピー' #ここで保存完了 #読み込みさせる $ source ~/.zshrcあとは資料と同じです
参考になるQiita
https://qiita.com/Tatsu88/items/be3209154a88b35be1c5



- 投稿日:2020-04-06T20:00:33+09:00
AWSのALBでSSL化したらレスポンスが遅くなった時の対処法
はじめに
オリジナルのアプリを
https化して、サイトにアクセスした時に、1回目のレスポンスが非常に遅くなる現象が発生した。
今回はその対処法をまとめる。参考にした記事
ちなみに、問題解決にあたって以下の記事を参考にした。
AWS Elastic Load Balancing: Seeing extremely long initial connection time
ALBを立ち上げる際に、サブネットを2つ設定しなければならないのだが、どちらかのサブネットがプライベートサブネットになっていると問題が発生するようだ。
対処法
既存のVPCネットの中に、追加でパブリックサブネットを作成し、ALBを置いておくサブネットとして設定をすれば良い。
以上
- 投稿日:2020-04-06T18:22:35+09:00
PowerShell から amazon/aws-cli の Docker イメージを起動して AWS に接続する
AWS CLI の Docker イメージが公開されたので、Docker for Windows + PowerShell という環境から、これを利用する手順について確認しました。
参考:
動作環境は以下の通りです。
PS > docker --version Docker version 19.03.6, build 369ce74a3c PS > $PSVersionTable Name Value ---- ----- PSVersion 6.2.4 PSEdition Core GitCommitId 6.2.4 OS Microsoft Windows 10.0.18363 Platform Win32NT PSCompatibleVersions {1.0, 2.0, 3.0, 4.0…} PSRemotingProtocolVersion 2.3 SerializationVersion 1.1.0.1 WSManStackVersion 3.0Docker イメージの参照
まずは Docker イメージを pull します。
PS > docker pull amazon/aws-cli Using default tag: latest latest: Pulling from amazon/aws-cli a7583ef20c9d: Pull complete 7d4c8ec0c058: Pull complete cd590779e8ea: Pull complete a37a98af08a9: Pull complete 0a765160c849: Pull complete Digest: sha256:7a27c26c2937a3d0b84171675709df1dc09aa331e86cad90f74ada6df7b59c89 Status: Downloaded newer image for amazon/aws-cli:latest docker.io/amazon/aws-cli:latest
docker runにより、CLI ツールのバージョンが返ってくることを確認します。PS > docker run --rm -ti amazon/aws-cli --version aws-cli/2.0.6 Python/3.7.3 Linux/4.15.0-91-generic botocore/2.0.0dev10PowerShell 関数として定義
以降のコマンドを簡略化するため、コマンドを関数として定義します。まずは PowerShell プロファイルのパスを確認します。
PS > echo $PROFILE C:\Users\__USER_NAME__\Documents\PowerShell\Microsoft.PowerShell_profile.ps1プロファイルを編集し、以下の記述を追加します。
function aws { $location = Get-Location docker run --rm -v ${HOME}/.aws:/root/.aws -v ${location}:/aws amazon/aws-cli $Args }PowerShell を再起動し、関数が利用できることを確認します。
PS > aws --version aws-cli/2.0.6 Python/3.7.3 Linux/4.15.0-91-generic botocore/2.0.0dev10AWS への接続設定
次に、AWS 接続用の設定ファイルを生成します。
PS > aws configure AWS Access Key ID [None]: AKIA**************** AWS Secret Access Key [None]: **************************************** Default region name [None]: ap-northeast-1 Default output format [None]: jsonこれにより、以下の設定ファイルが生成されたことを確認できます。
PS > ls $HOME\.aws Directory: C:\Users\__USER_NAME__\.aws Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 2020/04/06 16:59 48 config -a---- 2020/04/06 16:59 116 credentialsチュートリアルに合わせ、S3 上のディレクトリを参照してみます。
PS > aws s3 ls 2020-03-31 00:47:53 testS3 上にバケットが存在していれば、その一覧が応答で返ってきます。これにより、AWS サービスとの接続が確認できました。
- 投稿日:2020-04-06T16:28:42+09:00
一からAWS API Developer Portalを構築する
AWS API Gateway Developer PortalをAWSコンソールからデプロイし、ポータルでAPIを管理できる状態までセットアップする手順をまとめました。
補足
- デプロイの方法は下記の2種類ありますが、今回は1の方法について補足を残します
- AWS Serverless Application Repositoryを利用してAWSコンソールからデプロイ
- GitHubからアプリのリポジトリをCloneし、SAM経由でデプロイ
なお、2の方法を試されたい場合は、上記公式ドキュメントの他、こちらのクラスメソッド様の記事を参考にしていただくと良いかと思います
手順
※この手順を実行したAWS バージョン:
4.0.31. Applicationページを開く
※クリックすると AWSコンソールのAWS Lambdaサービスページに飛ぶので、AWSコンソールにログインする必要があります
補足
以下の方法でもアプリケーションページにたどり着けます。
- [Lambda] > [関数] > [関数の作成] と選択する
- [Serverless Application Repository の参照]を選択する
- 「パブリックアプリケーション」に
api-gateway-dev-portalと入力する- 検索バー下の [カスタム IAM ロールまたはリソースポリシーを作成するアプリを表示する] にチェックを入れる
- 同名のアプリが検索結果に現れるので、選択する
2. [Deploy]をクリックする
3. 「アプリケーションの設定」項目に以下を記載する
ここで設定した内容・名前を元にスタック・リソースが作られていきます。
経験上、命名規則違反でスタックのデプロイがこけることが多々あります(命名規則を入力欄の横に説明して欲しい...もっと言うとフォームごとにバリデーションチェックがあると嬉しい。。。)。そのため、できるだけ下記「名前例」に寄せた形かつ、長くならないようにするのがコツです。
また、全世界やリージョン内でユニークな名前でなければならないリソースもありますので、お気をつけください。なお、各設定項目の説明はこちらにもあります。
3-1. 以下の設定を入力する
設定名 説明 名前例 アプリケーション名 CloudFormationに作成されるスタック名。14文字以下にする必要があります。デフォルトの名前は使用しないこと※1 api-dev-portal AccountRegistrationMode ポータルでアカウント作成する際の手順。openなら個人が自由に作成でき、inviteならAdminユーザの招待が必要になる。この記事では、 inviteにしたい場合でも一度openでデプロイします ※1open / invite ArtifactS3BucketName APIのドキュメントが保存されるS3バケットの名前。S3バケットの命名規則に従う必要あり api-dev-portal-docs-xxxxx CognitoDomainNameOrPrefix Cognitoでホストされる、ユーザープールのウェブUIのドメイン名。小文字英数字・ハイフンのみ利用可能です。リージョン内でユニークである必要あり dev-portal-userpool-xxxxx CognitoIdentityPoolName CognitoのIDプール名。Cognitoユーザープール名にも利用される DevPortalIdentityPool CustomDomainName ポータルのカスタムドメイン名。オプション項目なので、設定しない場合は空にする foo.bar.net DevPortalAdminEmail ポータルのユーザがポータル管理者にフィードバックを送った際の通知の送信先メール。設定しない場合は空にする USI@xxx.comDevPortalCustomersTableName APIポータルのユーザを管理するDynamoDBテーブルの名前 DevPortalCustomers DevPortalFeedbackTableName ポータルのユーザが送ったフィードバックを管理するDynamoDBテーブルの名前 DevPortalFeedback DevPortalPreLoginAccountsTableName ポータルにプレログインできるアカウントを管理するテーブルの名前 DevPortalPreLoginAccounts DevPortalSiteS3BucketName ポータルサイトの静的コンテンツが保存されるS3バケットの名前。S3バケットの命名規則に従う必要あり api-dev-portal-website-xxxxx DevelopmentMode 開発を容易にするために、OAI, SSL, 静的サイト配置バケットアクセス、Cognitoのコールバック、CORSに関する権限を緩める※2 true / false EdgeLambdaRebuildToken Lambdaをデプロイする際に利用するトークンをデプロイごとに最新にする(タイムスタンプやGUIDを与えることで更新できる) defaultRebuildToken LocalDevelopmentMode ローカル環境での開発を容易にするために、CORS設定をなくす※3 true / false UseRoute53Nameservers CustomDomainNameで指定したカスタムドメインについて、Route53でネームホスティングを行うかどうかを指定する。カスタムドメインを利用しない場合はfalseにするtrue / false ※の補足
※1 理由は、
inviteでデプロイした後、最初のユーザーの作成方法がわからなかったからです...。なので、openで1ユーザー作成後、今度はinviteでアプリケーションを更新する方法をとっています※2 スタック名は他のリソースの作成にも利用されますが、
CognitoPostAuthenticationTriggerFnというリソースを作成する際に最大64文字までしか認められていない上、スタック名には自動的にserverlessrepo-がつく・このリソース名は自動的に${スタック名}-CognitoPostAuthenticationTriggerFnになることから、64-15-35 = 14という計算です。
※3 セキュリティレベルが落ちるため、プロダクションモードでは絶対にfalseに(開発モードを拒否)する必要があるそうです!
また、一度開発モードで作成したポータルは、スタックの更新でtrue(本番モード)にせず、別の新たなポータル(スタック)として作り直す必要があるようです。
- CustomDomainCloudFrontDistribution
設定名 説明 CustomDomainNameAcmCertArn ACM証明書のARN。 CustomDomainNameで指定したカスタムドメインがACM証明書を利用する場合、そのARNを入力する。カスタムドメインを設定しない場合は空にする
- StaticAssetUploader
設定名 説明 名前例 StaticAssetRebuildMode デフォルトでは上書きされない静的サイト内のカスタム内容を自身のローカルにあるバージョンで上書きする(何を言っているかわからない場合は overwrite-contentにしない方が良いとのこと)overwrite-content StaticAssetRebuildToken 静的コンテンツをデプロイする際に利用するトークンをデプロイごとに最新にする(タイムスタンプやGUIDを与えることで更新できる) defaultRebuildToken 3-2. 「このアプリがカスタム IAM ロールとリソースポリシーを作成することを承認します。」にチェックを入れる
3-3. 最後に「デプロイ」をクリックし、デプロイを開始する
4. デプロイ状況を確認する
先ほど設定したポータル「
serverlessrepo-${アプリケーション名}」のページが表示されます。
デプロイにはある程度時間がかかります。4-1. 「デプロイ」 > 「SAM テンプレート」 > [CloudFormation スタック]をクリックする
4-2. スタックの情報 > ステータス を確認する
CREATE_COMPLETE→ スタックデプロイに成功ROLLBACK_COMPLETE→ スタックデプロイに失敗し、ロールバックがなされた(成功)ROLLBACK_FAILED→ スタックデプロイに失敗した上、ロールバックにも失敗したステータスが
CREATE_COMPLETEの場合、5. ポータルページにアクセスできることを確認する
に進んで下さい。それ以外のステータスの場合は、デプロイに失敗しているので、原因箇所を確認します。以下は失敗時の方法です。
「イベント」タブ以下の「ステータス」項目で、最も古い時刻で
CREATE_FAILEDが起きている箇所を確認します。(最も古いもの以外の失敗は、最初期の失敗の影響を受けて失敗している・失敗の直接原因ではない可能性があります。)以下がエラーの例です。「状況の理由」に、なぜデプロイに失敗したか書いてあります。
この場合は、ドメイン名には小文字・数字・ハイフン以外入れないでください、とあります。
タイムスタンプ 論理ID ステータス 状況の理由 2020-04-28 11:40:28 UTC+0900 CognitoUserPoolDomain CREATE_FAILED Failed to create resource. The domain name contains an invalid character. Domain names can only contain lower-case letters, numbers, and hyphens. Please enter a different name that follows this format: ^a-z0-9?$ For more details, see CloudWatch group (以下略) 作成に失敗したスタックは一度[削除]で削除する必要があります。
削除する前に、全てのリソースがロールバックに成功し、リソースの削除に失敗していないことを確認してください。スタックの状態が
ROLLBACK_FAILEDだった場合は、リソースが削除しきれていない可能性があります。スタックを消しても、ロールバックで削除できなかったリソースが残ってしまう原因になりますので、手動で削除してください。以下、
ROLLBACK_FAILEDエラーの例です。
ポータルのS3バケット・顧客DynamoDBテーブル・APIドキュメント管理S3バケットの3つのリソースの削除に失敗しています。
タイムスタンプ 論理 ID ステータス 状況の理由 2020-04-28 11:45:23 UTC+0900 serverlessrepo-TestDevPortalStack ROLLBACK_FAILED The following resource(s) failed to delete: [DevPortalSiteS3Bucket, CustomersTable, ArtifactsS3Bucket]. エラーに応じて、適宜手動で対応してください。
上記対応が終わったら、スタックを削除します。
[削除]をクリックし、スタックを削除してください。
スタック自体に対する操作も同じページ内でログ出力されますので、スタックのDELETE_COMPLETEを確認してください。確認できたら、もう一度1. Applicationページを開くからやりします。
5. ポータルページにアクセスできることを確認する
ポータルのデプロイが成功していると、ポータルへのリンクが出力されます。
先ほど確認したスタックのページ内の「出力」をクリックし、出力内容を確認します。
WebsiteURLというキーの値として出力されているリンクをクリックし、ページ遷移できることを確認してください。6. Adminユーザを作成する
ポータルページを管理するAdminユーザを作成します。
前提の補足
この記事では前述のように、3. 「アプリケーションの設定」項目に以下を記載するの
AccountRegistrationModeをopenにしている前提で話します。
理由は、inviteでアプリを作成した場合、ポータルページから一切アカウント作成ができないのですが、現在どこからユーザーが新規作成できるのかわかりません(Amazon Cognitoコンソール・CLI経由のみ試しましたがうまくいきませんでした)。6-1. 5. ポータルページにアクセスできることを確認するでアクセスしたページの右上 [Register] をクリックする
6-2. ID(メールアドレス)・パスワードを設定する
6-3. IDに入力したメールアドレス宛に認証コードが届くので、入力する
ここまでの手順により、ユーザーが作成されました。
ここから、ユーザにAdmin権限を付与します。6-4. 3. 「アプリケーションの設定」項目に以下を記載するで作成したCognitoユーザープールのページを開く
CognitoID設定項目
CognitoIdentityPoolNameで指定したプール名がわかる場合は、 Amazon Cognitoのサービスを開き、 [ユーザープールの管理] をクリックした後、その名前のユーザープールを選択してください。ユーザープール名がわからない場合
以下の2通りの方法のうちいずれかの方法で調べてください。
AWS Lambdaのサービスページ内「アプリケーション」で今回作成したポータルを選択し、 [概要] タブ内の「リソース」内の
CognitoIdentityPoolNameを検索し対象リソースを選択する:「論理ID」をクリックするとページ遷移しますCloudFormationのサービスページ内で、作成したスタックを選択し「リソース」内から
CognitoUserPoolを検索し対象リソースを選択する:「物理ID」をクリックするとページ遷移します6-5. [全般設定] > [ユーザーとグループ] で表示したユーザーリストから先ほど登録したユーザを選択する
6-6. [グループに追加]をクリックし、
${スタック名}AdminsGroupをリストから選んだ後、[グループに追加]をクリックする
- スタック名は
serverlessrepo-${アプリケーション名}ですこれで、ユーザにAdmin権限が付与されました。APIポータルにログインし直し、タブ「Admin Panel」があることを確認してください。
このパネルから、APIやユーザーの管理ができます。ユーザーの招待もここから可能です。これで、ポータルのセットアップが完了しました。あとは、ポータルで公開するAPIを管理しましょう。
ポータルの利用方法については、こちらの記事が参考になります。
AWS API Gateway Developer Portal を使ってみる ー Qiita7. [おまけ]APIポータルを更新する
APIポータルは公開リポジトリという性質上、度々バージョンが更新されます。過去には脆弱性のあるバージョンからのアップデートを促す通知などもありました。
こういった際や、ポータルの設定を変更したい時、ポータルを更新する必要が出てきます。ここに、その方法を軽くまとめておきます。
今回は、 3. 「アプリケーションの設定」項目に以下を記載するで
openに設定したAccountRegistrationModeをinviteに変更し、新たなユーザーは管理者の招待でしか追加できないようにしてみます。7-1. CloudFormation > スタック に移動し、今回作成したスタックを選択する
- スタック名は
serverlessrepo-${アプリケーション名}です7-2. 右上[更新する] > [現在のテンプレートの使用] > [次へ]
7-3.
AccountRegistrationMode項目でinviteを選択し [次へ]7-4. 「スタックオプションの設定」ページで何も変更せず [次へ]
7-5. 「AWS CloudFormation によって IAM リソースが作成される場合があることを承認します。」にチェックを入れ、[更新]をクリックする
スタックの更新後、スタックの状態が
UPDATE_COMPLETEになれば完了です。
ポータルにアクセスし、[Register] をクリックしても新規ユーザーが作成できないようになっていることを確認しましょう。
- 投稿日:2020-04-06T15:37:26+09:00
Elastic BeanstalkでELB作成を抑止する
Elastic Beanstalkで管理しているプロダクトを任意のALBでパスルーティングする場合、コスト削減のためにELB作成を抑制することがあります。その時の設定のコツと注意点を書きたいと思います。
- 基本的に下記名前空間において環境アーキテクチャとサービスロールを設定する必要があります。
名前空間: aws:elasticbeanstalk:environment
- ELB作成を抑止するためにはEnvironmentTypeをSingleInstanceと指定します。 そうすることでELBは作成されずに単一のEC2 Instanceのみが起動する環境を作成できます。
// EnvironmentType LoadBalanced or SingleInstance setting { namespace = "aws:elasticbeanstalk:environment" name = "EnvironmentType" value = "SingleInstance" }
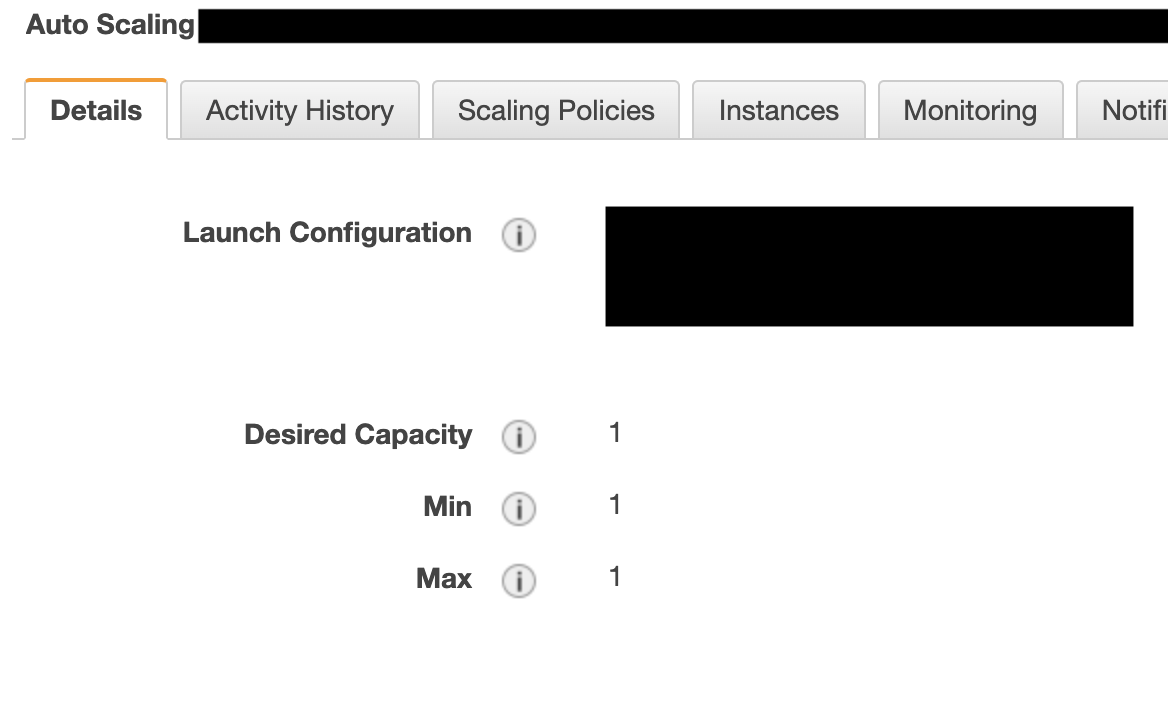
- 環境作成時にAuto Scaling Groupも自動で作成されますが、Desired Capacity(必要な容量)、Min(インスタンスの最小数)、Max(インスタンスの最大数)は強制的に1に設定されます。サーバリソースが高負荷になっても自動でスケールされないという点は注意が必要です。
- これは名前空間: aws:autoscaling:triggerを明示的に記述しても無視されます。 ELB作成時に使用している下記設定は不要となります。
elastic_beanstalk_environment_front.tfsetting { namespace = "aws:autoscaling:trigger" name = "MeasureName" value = "TargetResponseTime" } setting { namespace = "aws:autoscaling:trigger" name = "Statistic" value = "Average" } setting { namespace = "aws:autoscaling:trigger" name = "Unit" value = "Seconds" } setting { namespace = "aws:autoscaling:trigger" name = "Period" value = "1" } setting { namespace = "aws:autoscaling:trigger" name = "BreachDuration" value = "1" } setting { namespace = "aws:autoscaling:trigger" name = "UpperThreshold" value = "10" } setting { namespace = "aws:autoscaling:trigger" name = "UpperBreachScaleIncrement" value = "1" } setting { namespace = "aws:autoscaling:trigger" name = "LowerThreshold" value = "1" } setting { namespace = "aws:autoscaling:trigger" name = "LowerBreachScaleIncrement" value = "-1" } setting { namespace = "aws:ec2:vpc" name = "ELBSubnets" value = var.ELBSubnets }
- Elastic Beanstalkが作成したTarget GroupはALBのリスナールールとして指定できないので別途作成してリスナールールに設定することが必要です。
autoscaling_attachment.tfresource "aws_autoscaling_attachment" "xxxxxxxxxx" { autoscaling_group_name = aws_elastic_beanstalk_environment.xxxxxxxxxx.autoscaling_groups[0] alb_target_group_arn = aws_lb_target_group.xxxxxxxxxx.arn }lb_target_group.tfresource "aws_lb_target_group" "xxxxxxxxxx" { name = "xxxxxxxxxx" port = 80 protocol = "HTTP" vpc_id = data.aws_vpc.xxxxxxxxxx.id health_check { enabled = true interval = 30 path = "/xxxxxxxxxx" port = "traffic-port" protocol = "HTTP" timeout = 5 healthy_threshold = 3 unhealthy_threshold = 3 matcher = 200 } tags = { Name = "xxxxxxxxxx" Service = "xxxxxxxxxx" Environment = "xxxxxxxxxx" Description = "Managed by Terraform" } }
- SingleInstanceで作成するEC2 InstanceはPublicIPを付与させない設定のSubnetで起動させてもEIPが付与されてしまいますが、これは仕様です。
- 限定的なリクエストしか来ないようなプロダクトの商用環境であってもSingleInstanceでの運用が可能かは計測する必要があります。
- 投稿日:2020-04-06T15:30:18+09:00
Amazon AWS CloudWatch Logs Insights で 指定したキーワードにヒットしたログを1分単位でグループ化して抽出する
自分用
fields @timestamp, @message | filter Records.0.cf.request.body.data = "★キーワード★" | stats count(*) as polling_count by datefloor(@timestamp, 1m) as ts | sort ts asc
- 投稿日:2020-04-06T14:16:51+09:00
疑似的にNATゲートウェイを停止・起動する
VS 使ってないNATゲートウェイの課金
NATゲートウェイは思いのほか使用料金が高く、夜間の開発環境など使用していない時は止めたい。
ただ現在において停止機能は存在しておらず、停止イコール削除となる。
停止という点ではNATインスタンスを立てて停止すれば良い話だが、それでは単純に面倒。せっかくのマネージドサービスは使いたい。
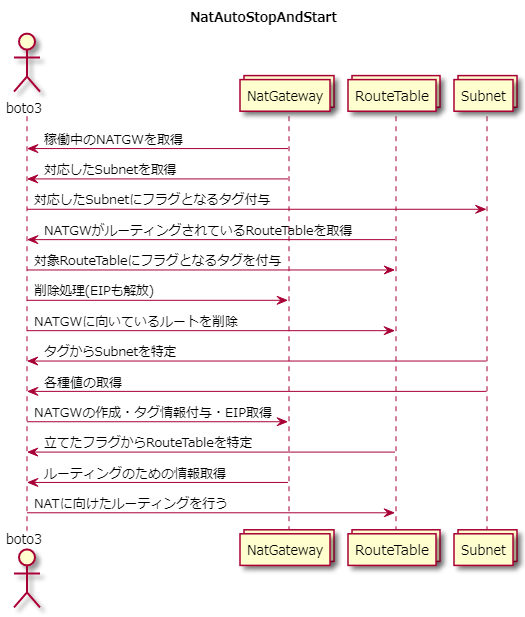
ならば、使用していないときにNATゲートウェイを削除し、使いたいときに必要な情報をもって再作成するスクリプトを作成すればいい。やりたいことを図にしてみる
UMLの書き方は正式に勉強していないので許してほしい。停止(削除)スクリプト
import boto3 client = boto3.client('ec2') natGateWayList = [] routeTableList = [] subnetList = [] natGateWayNameList = [] iPlist = [] # 起動中のNATゲートウェイを取得 response = client.describe_nat_gateways( Filters=[ { 'Name': 'state', 'Values': ['available'], }, ], ) for natgateway in response['NatGateways']: natGateWayList.append(natgateway['NatGatewayId']) subnetList.append(natgateway['SubnetId']) for tag in natgateway['Tags']: if tag['Key'] == "Name": natGateWayNameList.append(tag['Value']) else: pass # NATゲートウェイに向いてるルーティングを取得 for i in natGateWayList: response = client.describe_route_tables( Filters=[ { 'Name': 'route.nat-gateway-id', 'Values': [i], }, ], ) for j in response['RouteTables']: routeTableList.append(j['RouteTableId']) # SubnetのtagにNATゲートウェイの名前を挿入 for sub, nm in zip(subnetList, natGateWayNameList): response = client.create_tags( Resources=[ sub, ], Tags=[ { 'Key': 'tempNatName', 'Value': str(nm) }, ] ) # NATゲートウェイが存在するルートテーブルにFlagを立てる for i in routeTableList: response = client.create_tags( Resources=[ i, ], Tags=[ { 'Key': 'routeingToNat', 'Value': 'True' }, ] ) # 起動スクリプトにて取得した値からEIPを回収 response = client.describe_addresses( Filters=[ { 'Name': 'tag:DisFLG', 'Values': ['True'] }, ] ) # 各種削除処理 for i in response['Addresses']: client.release_address(AllocationId=i['AllocationId']) for i in routeTableList: response = client.delete_route( DestinationCidrBlock='0.0.0.0/0', RouteTableId=i, ) for i in natGateWayList: client.delete_nat_gateway(NatGatewayId=i)起動スクリプト
import boto3 client = boto3.client('ec2') subnetLst = [] ipList = [] natGateWayNameList = [] routeTableList = [] natGateWayIdList = [] # NATゲートウェイが存在したサブネットからNATのName tagを回収 response = client.describe_subnets( Filters=[ { 'Name': 'tag:tempNatName', 'Values': ['*'] }, ], ) for h in response['Subnets']: subnetLst.append(h['SubnetId']) for i in h['Tags']: if i['Key'] == "tempNatName": natGateWayNameList.append(i['Value']) else: pass # EIPに削除フラグを立てる for nat in natGateWayNameList: result = client.allocate_address( Domain='vpc' ) response = client.create_tags( Resources=[ result['AllocationId'], ], Tags=[ { 'Key': 'Name', 'Value': str(nat) + '-IsIpAdress' }, { 'Key': 'DisFLG', 'Value': 'True' }, ] ) ipList.append(result['AllocationId']) # NATゲートウェイ作成 for sub, ip, ntnm in zip(subnetLst, ipList, natGateWayNameList): response = client.create_nat_gateway( AllocationId=ip, SubnetId=sub ) natid = response['NatGateway']['NatGatewayId'] natGateWayIdList.append(natid) client.get_waiter('nat_gateway_available').wait(NatGatewayIds=[natid]) response = client.create_tags( Resources=[ natid, ], Tags=[ { 'Key': 'Name', 'Value': str(ntnm) }, ] ) response = client.describe_route_tables( Filters=[ { 'Name': 'tag:routeingToNat', 'Values': ['True'] }, ], ) # ルートテーブルのタグから値の回収してルーティング for i in response['RouteTables']: routeTableList.append(i['RouteTableId']) for natId in natGateWayIdList: response = client.describe_nat_gateways( Filters=[ { 'Name': 'nat-gateway-id', 'Values': [natId] }, ], ) natVpcId = response['NatGateways'][0]['VpcId'] for routeTableId in routeTableList: rtbrespo = client.describe_route_tables( Filters=[ { 'Name': 'route-table-id', 'Values': [routeTableId] }, ], ) rtVpcId = rtbrespo['RouteTables'][0]['VpcId'] if natVpcId == rtVpcId: response = client.create_route( DestinationCidrBlock='0.0.0.0/0', NatGatewayId=natId, RouteTableId=routeTableId )なんか色々
- 既にNameタグがふられたNATGWがある環境が前提なのでそのまま動かすと多分NG
- 細かい制御をしたい場合、Tagに色々書いてDescribeすれば取りあえず何とかなる。
- 使用していないElastic IPを保持していると微妙に課金が発生するので逐一アドレスを解放・調達することにしている。そもそも節約スクリプトなので。
- 使ってるEIPを常に保持したい場合はアドレス調達の処理をカットして既にあるEIPのIDを挿入すればOK
- lambdaとCloudWatch Eventで動かせば勤務時間中のみNATGWを作成するということも可能
- ただ関数ごとにブロックを分けていないので、そのあたりは要追記、一応そのままでも動く
- VPCが2つある環境で試したのでこのようなルーティング処理となっている
- 例えばAZでサブネット切ってるとかだとルーティングに追加が判定が必要
- for文じゃなくてList comprehensionsでもっとスマートにできるカモ
- 麻倉ももさんはかわいいし、夏川椎菜さんは推せる
参考にしたページ
サーバレスでNAT Gatewayの起動・停止を管理してみた【押忍!ソフト道場】
https://www.ntt-tx.co.jp/column/dojo_aws_blog/20180411/
AWSのリソースって使っていない時は止めたいよね!
https://qiita.com/atmitani/items/dbb58e820030996b73d9
できるだけシンプルな仕組みで簡単にEC2の自動起動・停止を実現したい!|クラスメソッドブログ
https://dev.classmethod.jp/cloud/aws/simple-auto-start-stop-for-ec2/
- 投稿日:2020-04-06T14:15:23+09:00
[AWS] Amazon Redshiftまとめ
Amazon Redshiftとは
- 高速、スケーラブルで費用対効果の高いDWHおよびデー誰行く分析マネージドサービス
参考:https://d1.awsstatic.com/webinars/jp/pdf/services/20200318_AWS_BlackBelt_Redshift.pdf
ユースケース
主に大容量データを高速に集計・分析する必要があるワークロードに利用
- 経営ダッシュボード
- 定型レポーティング
- アドホック分析
- ELT/バッチ
- 機械学習の前処理
Amazon Redshiftを中心としたデータ分析パイプライン
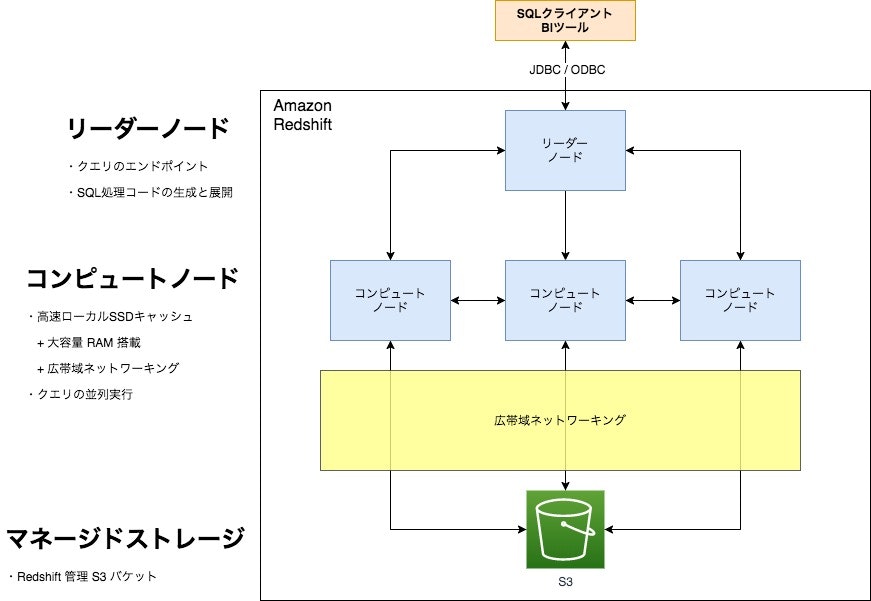
アーキテクチャ(RA3インスタンス)
- ベースは PostgreSQL でDWH用に拡張している
- AWSの他のサービスコンポーネントを活用したマネージドサービスとなっている
- コンピュートとストレージを分離しスケーリングと支払を独立
- データは永続ストレージとしてS3、キャッシュとしてローカルSSDに格納
- アクセス頻度の高いデータはキャッシュにとどまり、アクセス頻度の低いデータはキャッシュアウト
クエリ実行
- リーダーノードがクライアントからのクエリを受け取る
- リーダーノードがSQLをコンパイルしてコンピュートノードへ配信する
- コンピュートノード上で処理を並列実行しリーダーノードへ結果を返す
該当データがキャッシュ上にない場合はマネージドストレージからブロック単位で読み込む- リーダーノードがクライアントへ結果を返す
データロードとアンロード
- データはユーザ管理のS3を経由してロード&アンロード
特徴
- ハイパフォーマンス
- DWH、分析向けに特化したRDB
- 様々な種類の分析ワークロードについて、より迅速な洞察を取得可能
- スケーラブル
- ベタバイト級までスケールアウト
- 分析要求やデータ容量が増加しても、動的にスケールアップ/アウトが可能
- データレイクへの拡張
- データレイク上のデータへ直接アクセス
- Amazon S3上のオープンフォーマットデータをそのまま分析可能
- 高いコスト効果
- 初期費用なし、小規模からはじめて利用に応じた支払が可能
ハイパフォーマンス
- 列指向ストレージ
- データ圧縮
- ソートキー
- データ分散
列指向ストレージ
- データは列ごとに格納
- 必要な列のみの読み取りが可能に
- 大容量データへのアクセスが必要となる分析クエリのボトルネックとなるディスクIOを削減
列指向、行指向の違い
select min(datetime) from usersの検索による違い
- 列指向の場合は
datetime列のみをスキャンしソート、不要なスキャンを削減- 行指向の場合は、 全てのデータをスキャンしソート
データ圧縮
- 列の圧縮を行うことで一度のディスクアクセスで読み込めるデータ量が多くなり速度の向上が見込める
- 圧縮のエンコードが13個用意されている、
CREATE TABLEで列毎の設定が可能ANALYZE COMPRESSIONコマンドを利用して既存テーブルの各列に最適な圧縮を確認することが可能- コンドードタイプを変更したいときにテーブル再作成 &
INSERT-SELECTで対応- 列、すなわち類似データなので高い圧縮率となる
圧縮エンコードの自動割当
- エンコードが未指定の列には自動的割当される
タイプ エンコード ソートキー RAW圧縮 BOOLEAN、REAL、DOUBLE PRECISION RAW圧縮 SMALLINT、INTEGER、BIGINT、DECIMAL、DATE、TIMESTAMP AZ64圧縮 CHAR、VARCHAR LZO圧縮 ソートキー
1MBブロックサイズ
- Redshift は通常RDBMSよりも大きい
1MBでブロックサイズを確保する
- 通常は
8KB ~ 32KBていど- こによりディスクIOを効率化
ゾーンマップ(ブロックフィルタリング)
- 1MBブロックのメタデータをリーダーノードのメモリ上に格納
- 各ブロックの
最大値最大値を保持- クエリの内容に応じて処理に不要なブロックを読み飛ばすよう効率的なアクセスを実現
ソートキーとは
- ゾーンマップ機能を活用してI/Oを削減
- クエリパフォーマンス向上にはソートキーが非常に重要
- データをどの列順にソートするかテーブルごとにソートキーとして指定
- 頻繁に使われる絞り込み(WHERE句)条件キーが筆頭候補
- 一般的には日付などの時系列やIDが多い
- 実際のクエリパターンと処理優先度などから決定
- データは指定のソートキーで事前に並び替えらディスク上に保持される
- この分ディスク容量を必要とする?
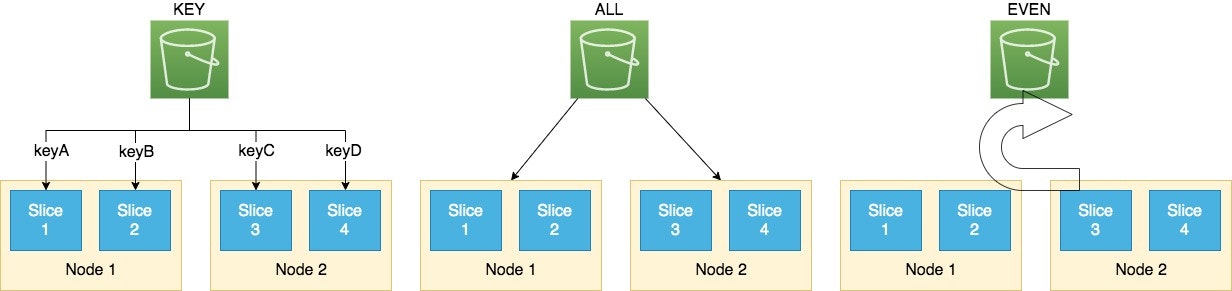
データ分散
- データ量やクエリの内容に応じて分散形式を選択
形式 内容 KEY 同じキーを同じスライスへ ALL 全てのデータを全ノードへ EVEN ラウンドロビンで均等分散 AUTO テーブルサイズに応じてALL -> EVENに自動変換(デフォルト設定)
クエリキャッシュ
- リーダーノードにてクエリ結果をキャッシュしている
- キャッシュ機能はデフォルトで有効
マテリアライズドビューを設定することでさらなる高速化
- 頻繁に実行するクエリパターンを高速化
- 結合、フィルタ、射影、集計
- RTL/BIパイプラインの簡素化
- 差分リフレッシュ
- ユーザーによるメンテナンス
- Redshiftへのより簡単で迅速な移行
フルマネージド
構築・運用の手間を削減
- 1画面の設定のみで起動
- ノード数やタイプはあとから変更可能
- 自動バックアップ
- モニタリング機能
- 自動パッチ適用
- メンテナンスウィンドウでパッチ適用時間帯を指定可能
- スケジューリング機能
- クラスターサイズの変更
- クラスターの一時停止と再開
機械学習ベースの自動最適化によるクエリ性能の向上
- テーブルメンテナスの自動化
- テーブルの分散スタイルの自動最適化
- 統計情報の自動更新
- データの再編成の自動実行
- 自動ワークロード管理とクエリ優先度で効率的に処理
- ショートクエリアクセラレーション(SQA)による高速化
- 動的に変更可能なリコメンデーションの提案
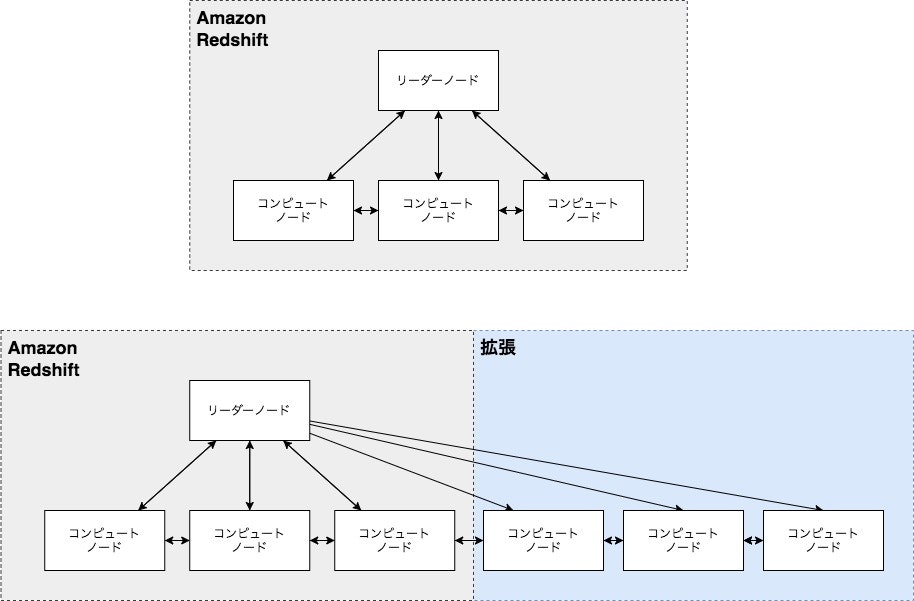
拡張性・柔軟性
コンピュートノードの追加
- コンピュートノードの追加でパフォーマンスがリニアに向上する
- マネージメントコンソールから数クリックで拡張・縮小が可能
数分でクラスターの伸縮を実現する Elastic Resize
- 既存のRedshiftクラスター上にノードを追加
- 繁忙期にクエリを高速に処理
- データ転送にかかる時間を最小化
- コンピュートとストレージをオンデマンドでスケール
- スケジュール設定可能
ピーク時にコンピュートを自動拡張する Concurrency Scaling
データレイクとAWSサービスとの親和性
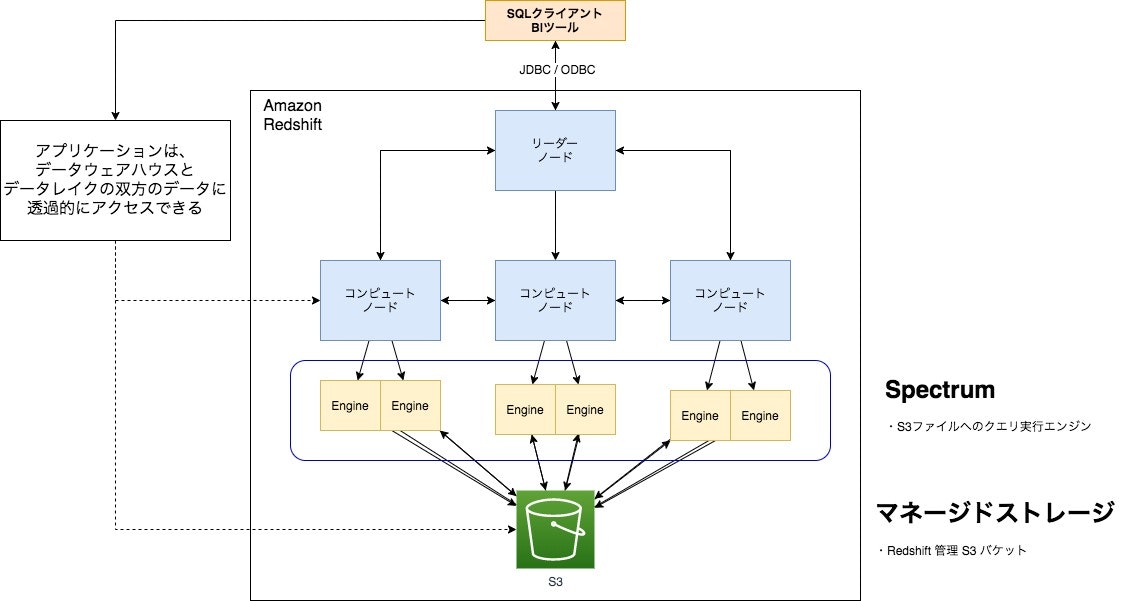
Redshift Spectrum でアーキテクチャをデータレイクに拡大
- 事前のデータロード不要でS3上のデータに対して直接SQLを実行
- RedshiftとS3それぞれに存在するデータを結合可能
- オープンファイルフォーマット対応
- Parquet、ORC、JSON、Grok、Avro、CSV
RA3 と Redshift Spectrum との違い・使い分け
出典:https://d1.awsstatic.com/webinars/jp/pdf/services/20200318_AWS_BlackBelt_Redshift.pdf
使い分け
用途 選択 全てのデータがデータレイクにありRedshiftだけでなく他のサービスからのアクセスされる場合 Amazon Redshift Spectrum Redshift内のデータ抑制に過去データを削除したりS3にデータをオフロードしたりでSpectrumを活用していた場合 RA3ストレージ データレイクエクスポート
- RedshiftテーブルデータをAmazonS3上へParquet形式でエクスポート可能
- Redshift SpectrumにとどまらずAmazon AthenaやAmazon EMRなど他の分析サービスでもすぐに活用可能
フェデレーテッドクエリ(2020年4月6日時点:Preview)
- RDS/Aurora PostgreSQLに直接クエリできる機能
- PostgreSQLに対してのみ
- データ移動なしにライブデータを分析
- データウェアハウス、データレイク、オペレーショナルデータベースのデータを統合して分析
- 高い性能でセキュアにデータアクセス
高いコスト効果
- インスタンス起動時間 + ストレージ使用量(RA3のみ)
- コンピュートノード数 * 1時間あたり価格
- RIにも対応
- AWS公式:料金表
その他の関連料金
- Concurrency Scaling
- 各追加クラスターでのクエリ実行時間に応じて課金される(秒単位)
- 1日あたり1時間の無料クレジットが付与される(最大30時間分貯蓄可能)
- Redshift Spectrum
- S3データレイクへのクエリ容量で課金
- S3の圧縮済データ1TBスキャンあたり「$5」
セキュリティ&コンプライアンス
ビルドインされたセキュリティ機能
- エンドツーエンドの暗号化
- データ保管時の暗号化可能
- ネットワーク分離のためのAmazon VPC
- 拡張されたVPCルーティング
- 監視ロギングとAWS CloudTrail統合
- 多くの認定及び準拠
- SOC 1/2/3
- PCI-DSS
- FedRAMP
- HIPAA
アクセスコントロール
- テーブル、データベース、スキーマ、関数、プロシージャ、言語、また列に対してのアクセスコントロールが可能
- テーブル、ビューに対して列ごとにアクセスコントロールが可能
- GRANT/REVOKEコマンドで設定可能
- テーブルの場合
- 列レベルでSELECT/UPDATEの権限付与可能
- ビューの場合
- 列レベルでSELECTの権限付与可能
クラスター
クラスターの作成と管理
- 小規模からはじめて簡単に拡張可能
- サービス停止なくコンピュートノードを増やすことが可能

- 投稿日:2020-04-06T12:42:07+09:00
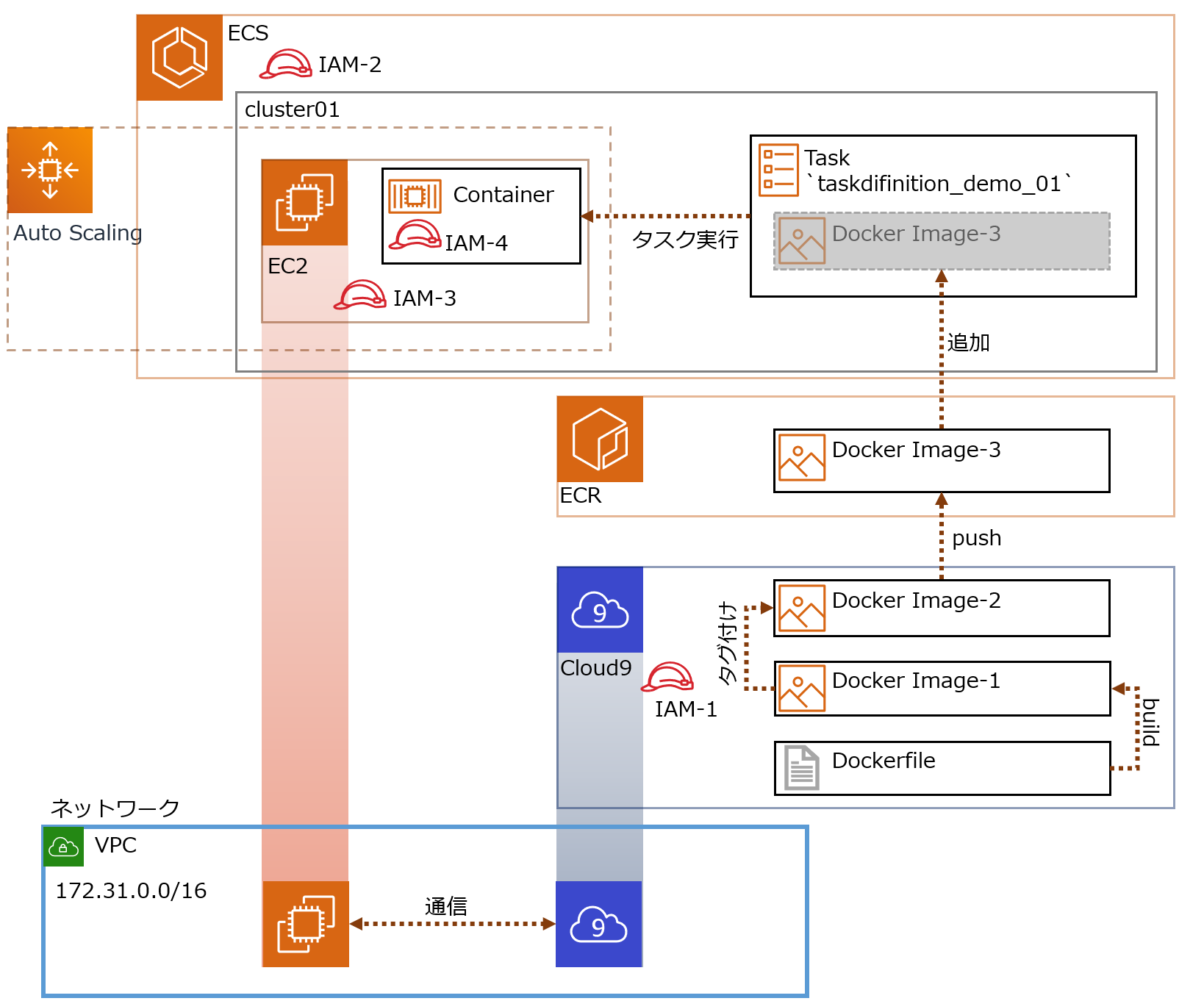
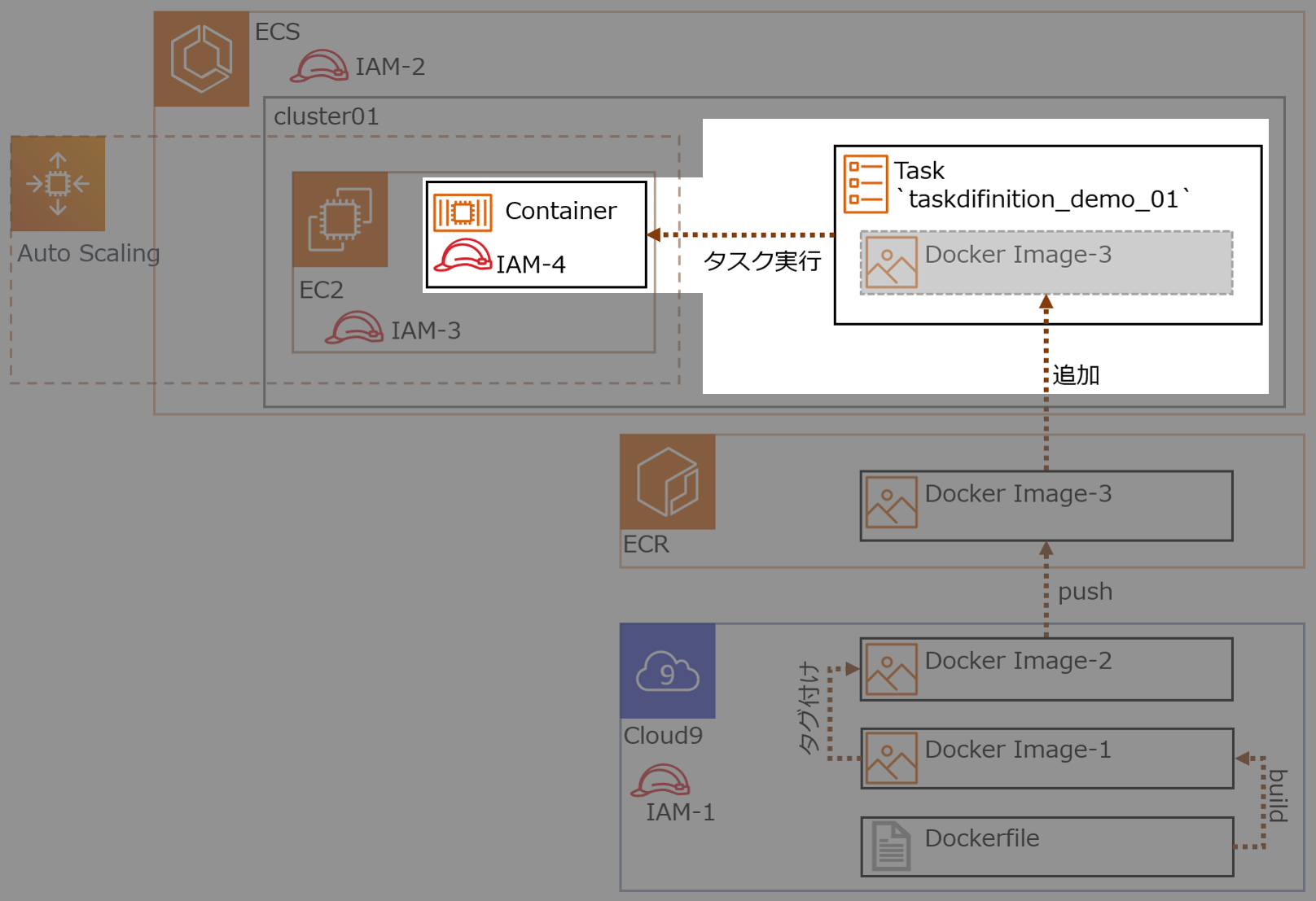
Amazon ECS 一通の動作
1.Dockerイメージ
dockerのインストール(環境:Amazon Linux2)
sudo yum install -y docker sudo service docker startsudo なしでdockerを利用できるようにする。
sudo gpasswd -a $USER docker sudo service docker restartDockerFileを作成する。
DockerFileFROM centos:latest RUN yum install -y httpd COPY ./index.html /var/www/html/index.html VOLUME /var/www/html EXPOSE 443 80 CMD ["/usr/sbin/httpd", "-D", "FOREGROUND"]docker build -t demo ./2.ECRにログインしPush
ECRにリポジトリを作成しておく。
IAMロールについての説明は省きますが、EC2インスタンスのECRへPushするためのIAMロールが必要です。
aws configureにregionを指定しておく。
aws configure AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name: ap-northeast-1 Default output format: jsonECRにログインする。
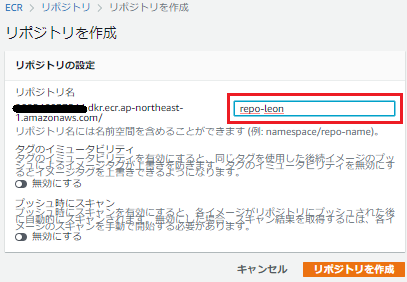
aws ecr get-login --no-include-email aws ecr get-login-password | docker login --username AWS --password-stdin 12345678901.dkr.ecr.ap-northeast-1.amazonaws.com/repo-leonタグをるける。
docker tag demo:latest 12345678901.dkr.ecr.ap-northeast-1.amazonaws.com/repo-leon:latestpush する。
docker push 12345678901.dkr.ecr.ap-northeast-1.amazonaws.com/repo-leon:latestレポジトリに push されたかを確認する。
aws ecr describe-repositories --repository-names repo-leon { "repositories": [ { "repositoryUri": "12345678901.dkr.ecr.ap-northeast-1.amazonaws.com/repo-leon", "imageScanningConfiguration": { "scanOnPush": false }, "registryId": "12345678901", "imageTagMutability": "MUTABLE", "repositoryArn": "arn:aws:ecr:ap-northeast-1:12345678901:repository/repo-leon", "repositoryName": "repo-leon", "createdAt": 1583228141.0 } ] }3.クラスター
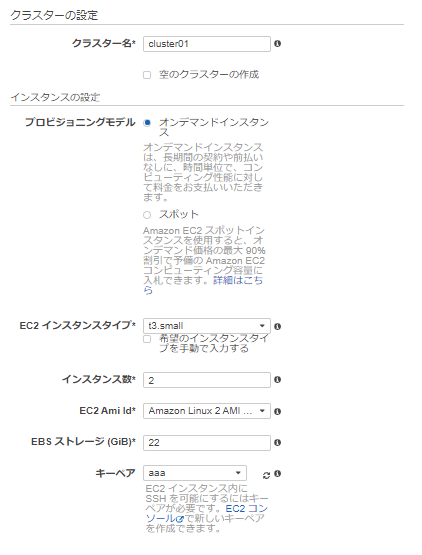
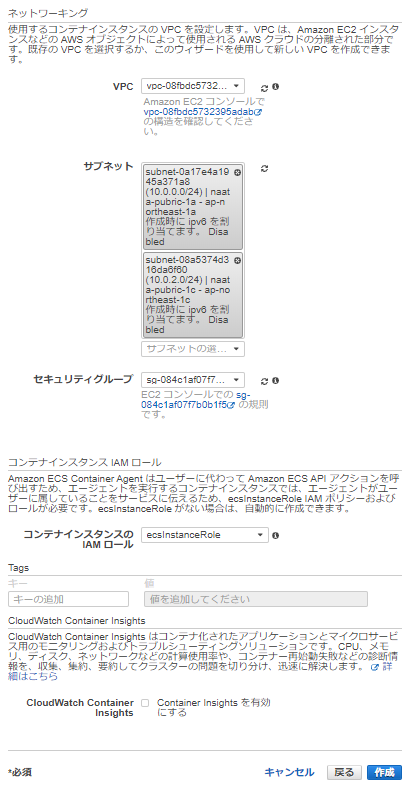
以下のとおり、クラスターをEC2 Linux + ネットワーキングで、t3.smallで2つ作成する。
4.タスク定義
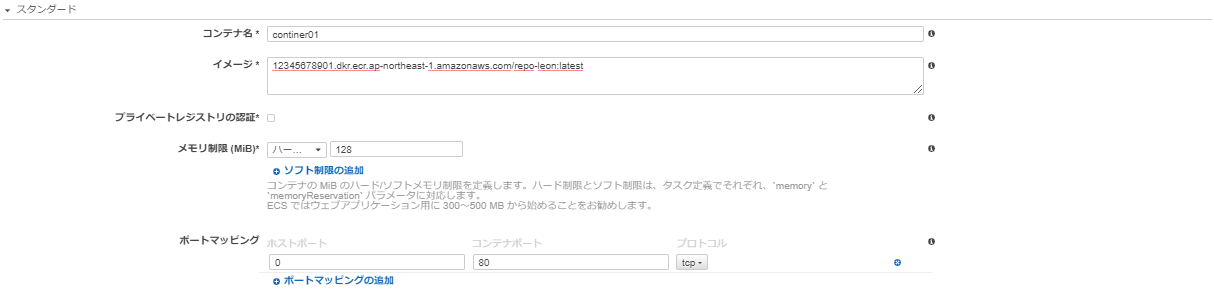
以下のとおり、コンテナ定義を作成する。イメージは先程作成したECRリポジトリURIを指定する。
5.ALBの作成
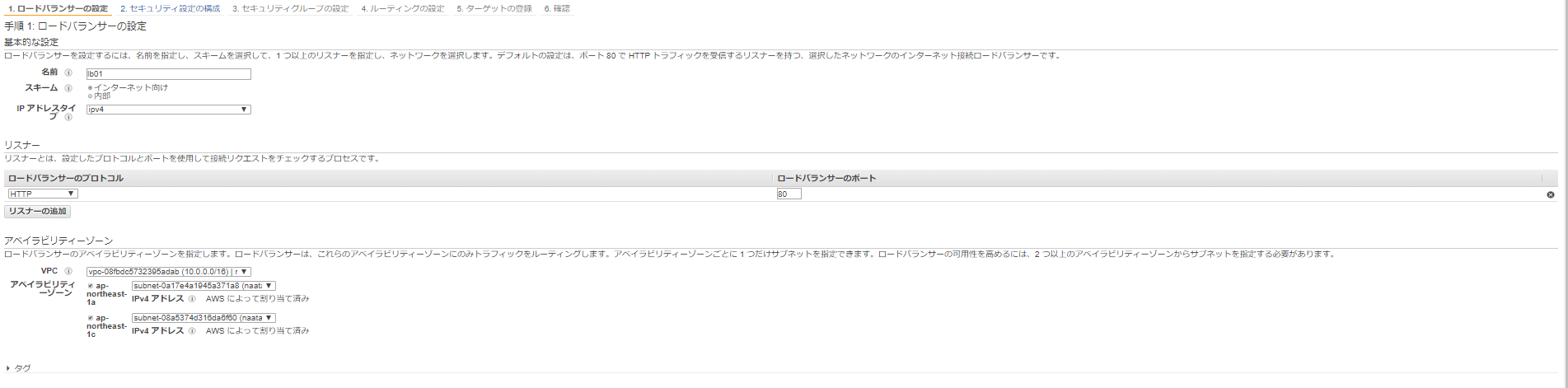
5-1 ロードバランサーの設定
以下のとおりリスナーは80番ポートだけを指定。
5-2 セキュリティ設定の構成
SSLは今回利用しないので、気にせずそのまま進む。
5-3 セキュリティグループの設定
80番ポートだけを通すセキュリティグループをさくせい。
5-4 ルーティングの設定
ターゲットはインスタンスにする。
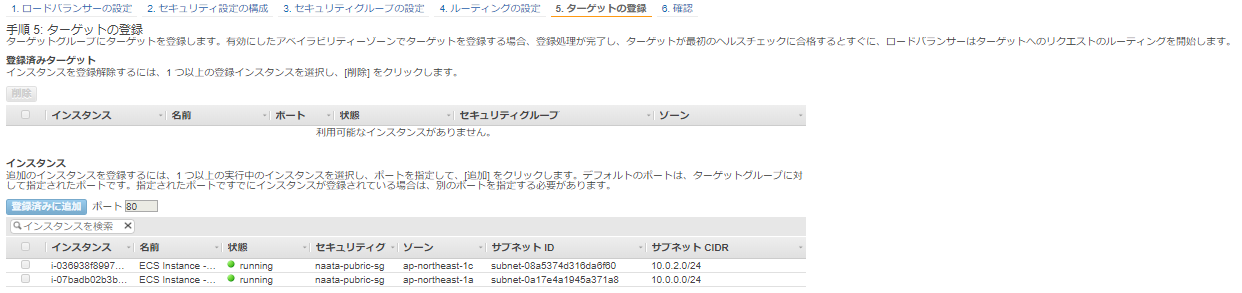
5-5 ターゲットの登録
ここでは、後でECSのサービス側で指定するのでインスタンスは指定しない。
5-6 確認
「確認」をクリックし、ALBの作成完了。
6.サービス
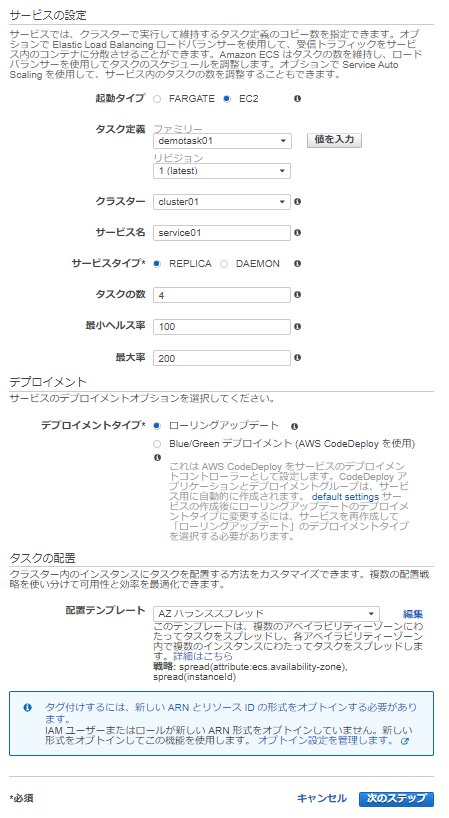
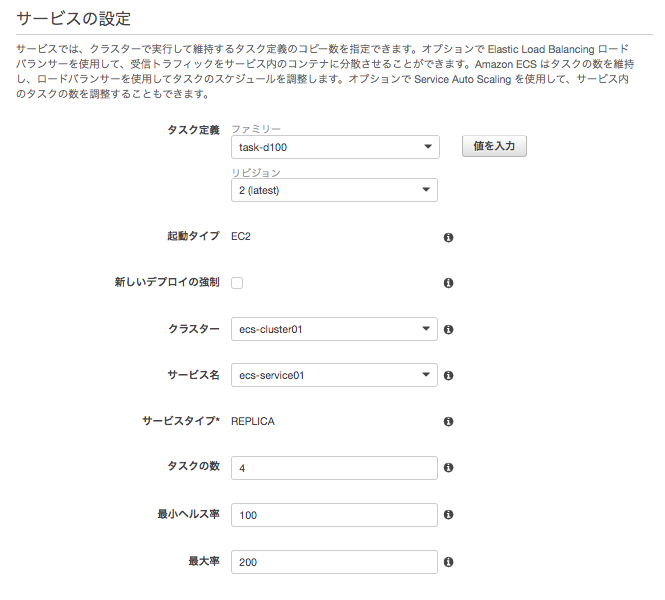
6-1 サービスの設定
タスクを4つ起動させるようにする。
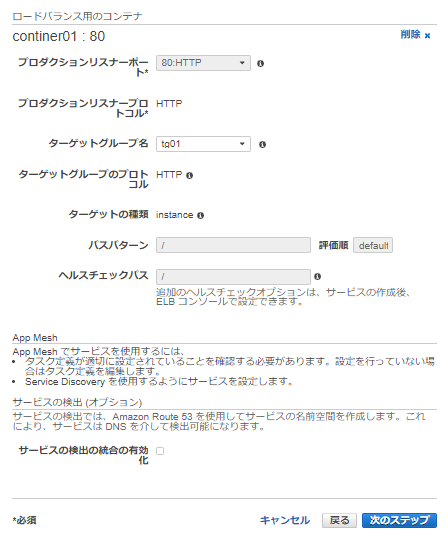
6-2 ネットワーク構成
先程作成したALBを指定します。なお、「サービスの検出の統合の有効化」はここでは一旦チェックをはずしておく。
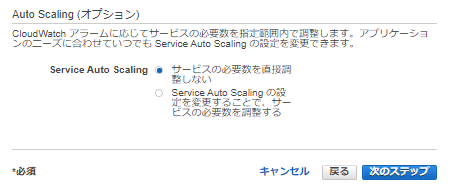
6-3 Auto Scaling (オプション)
ここでは何も一旦指定しない。
6-4 確認
「サービスの作成」をクリックすると、タスクの実行が開始される。
しかし、この状態ではALBのヘルスチェックに合格しない。
そう、セキュリティグループが足りない。ECSインスタンスのセキュリティグループにALBからのセキュリティグループを追加してあげないといけない。
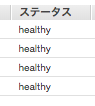
改めてステータスを確認してみるとヘルスチェックに合格していることがわかる。
7 コンテナを置き換える
7-1 コンテナの変更
別のコンテナに変更する。
7-2 サービスの変更
リビジョンを先ほど変更したものに変更。
※最小ヘルス率が100なので起動しているコンテナ4は変わらない。
最大率200なので、新しい4つが起動し、合計8となる。
起動していた4つは消え、4つ起動状態となる。
想定ではコンテナが8個起動してくるはずだが、6個しか起動してこない?
イベントを確認してみるとメモリ不足で起動しないことがわかる。
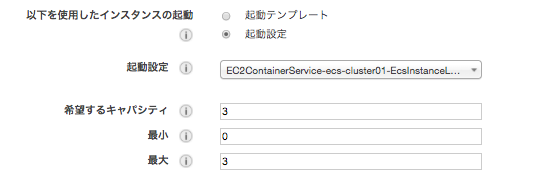
EC2 Auto Scaling より 希望するキャパシティと最大を 3 に増やす。
タスクが8個起動し、最終的に4個になることがわかる。
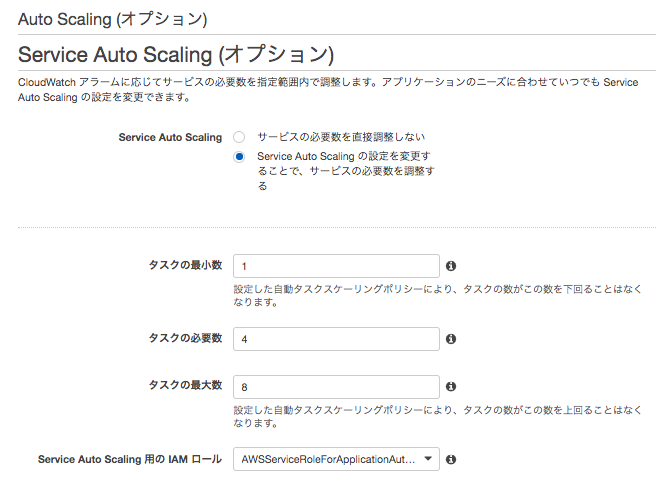
8 Auto Scalling
タスクの最小数、必要数、最大数を以下のとおり設定する。
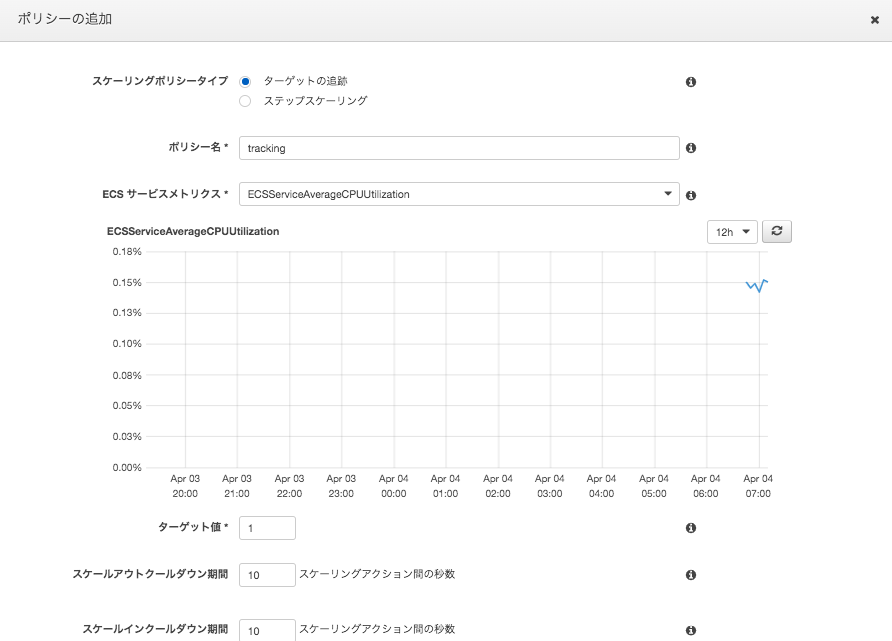
CPUでターゲット値を1以下にする。
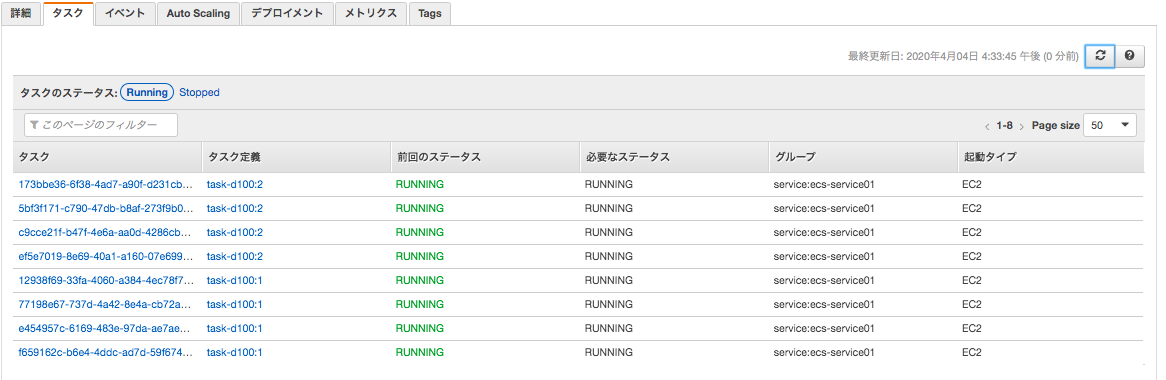
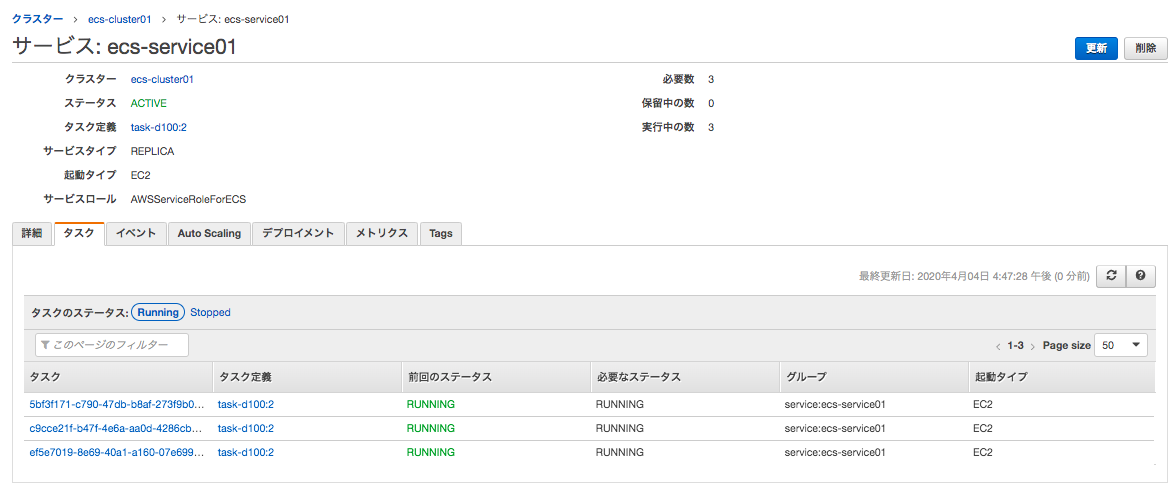
必要数/実行中の数が、4→3 と減っていくことがわかる。
9 リンク









- 投稿日:2020-04-06T10:03:35+09:00
Cloud9にPython+OpenCVの環境を構築する
AWS Cloud9にPython+OpenCVの開発環境を作りたい場合の環境構築手順です。
特に、各種インストールの部分が面倒だったのでまとめておきます。(ベストな方法かはわかりません、すみません。)EC2の作成
私は
EC2 instance type:t3.smallで作成しましたが、任意のインスタンスタイプを選んで作成してください。Cloud9インスタンスのボリュームを拡張する
t3.smallのデフォルトのボリュームは10GiBです。
これだと色々とインストールしている段階で容量が足りなくなるので、容量を拡張します。(容量が足りなくなるとインストール時にNo space left on device)と表示されます。
拡張手順は以下の記事を参照してください。
https://qiita.com/ktrkmk/items/8cf1e100da2e717f3be2
私は一旦30GiBまで拡張しました。homebrewのインストール
以下のコマンドでインストールします。
$ sh -c "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install.sh)"パスが無いと言われるので、以下のコマンドを順番に実行して対処します。
$ test -d ~/.linuxbrew && PATH="$HOME/.linuxbrew/bin:$HOME/.linuxbrew/sbin:$PATH" $ test -d /home/linuxbrew/.linuxbrew && PATH="/home/linuxbrew/.linuxbrew/bin:/home/linuxbrew/.linuxbrew/sbin:$PATH" $ test -r ~/.bash_profile && echo "export PATH='$(brew --prefix)/bin:$(brew --prefix)/sbin'":'"$PATH"' >>~/.bash_profile $ echo "export PATH='$(brew --prefix)/bin:$(brew --prefix)/sbin'":'"$PATH"' >>~/.profile実行できるか確認します。バージョンが表示されればOKです。
$ brew -v Homebrew 2.2.11 Homebrew/linuxbrew-core (git revision 9d9624; last commit 2020-04-05)pyenvのインストール
以下のコマンドでインストールします。
$ brew install pyenv実行できるか確認します。バージョンが表示されればOKです。
$ pyenv -v pyenv 1.2.18Pythonのインストール
インストールしたいバージョンを指定して実行します。(今回は3.8.1です。)
$ pyenv install 3.8.1インストールされているか確認します。
$ pyenv versions * system (set by /home/ec2-user/.pyenv/version) 3.8.1
3.8.1が表示されていますが、*がsystemの方についているので、これを変更します。$ pyenv global 3.8.1もう一度確認します。
$ pyenv versions system (set by /home/ec2-user/.pyenv/version) * 3.8.1
3.8.1に*が移動していればOKです。bash_profileを編集する
ここで改めてPythonのバージョンを確認します。
$ python --version Python 3.6.10恐らく、元のPythonバージョンが表示されるので、
bash_profileを編集して、pyenvのPythonバージョンを実行できるようにします。$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile $ exec $SHELL -lPythonのバージョンを確認し、反映されていればOKです。
$ python --version Python 3.8.1Open CVをインストール
最初は
$ brew install opencvこれでインストールしようと思ったのですが、うまく行かず…
なので、pipを使いました。$ pip install opencv-pythonインストールできているか確かめるには
$ python >>> import cv2で何もメッセージが出なければOKです。
以上で、環境構築は完了です。参考
https://qiita.com/nasuvitz/items/5eec6ab9444cff8e9467
https://prog-8.com/docs/python-env
https://www.lifewithpython.com/2018/01/python-checking-version.html
https://news.mynavi.jp/article/zeropython-34/
https://qiita.com/makki_maki04/items/f62c5e4e68709d9b3b89
https://dev.classmethod.jp/articles/aws-cloud9-pyenv/
- 投稿日:2020-04-06T09:27:33+09:00
AWS Lambdaでgitコマンドを使う
AWS Lambdaでgitコマンドを使う
AWS Lambdaでgitコマンドを使いたい場合があります。
githubのAPIを呼んだり、dulwichを使ってもいいのですが、新しく勉強するよりは、できれば、いつもの使い慣れたgitコマンドを使いたいものです。使う物
AWS Lambda用にコマンドとライブラリをいい感じにまとめてくれるDockerコンテナ
→ https://hub.docker.com/r/qualitiaco/lambda-build-packgitコマンドとライブラリを抽出
gitコマンドを取り出すスクリプト
src/build.sh#!/bin/sh yum install -y git cp -a /usr/bin/git ${OUTPUT_PATH} cp -a /usr/libexec/git-core/git-remote-https ${OUTPUT_PATH} cp -a /usr/libexec/git-core/git-remote-http ${OUTPUT_PATH}yum でgitをインストールし(もしかしたら既に入っているかもしれませんが)、gitコマンド実行に必要な/usr/bin/gitとhttps通信に必要な、/usr/lib/exec/git-code/git-remote-http(s) を${OUTPUT_PATH}ディレクトリにコピーします。
この後のdockerコマンドが、${OUTPUT_PATH}にあるコマンドに必要なライブラリを自動的に抽出してくれます。
今回はyumで入れましたが、最新がよければ、gitこまんどをbuild.shスクリプト内でコンパイルしても構いません。
AWS Lambda環境用のgitコマンドとライブラリの取り出し
docker run -it --rm -v $(pwd)/src:/src -v $(pwd)/output:/output qualitiaco/lambda-build-packAWS Lambdaにアップロードする
Lambda Functionの作成
今回はPythonで作成してみます。
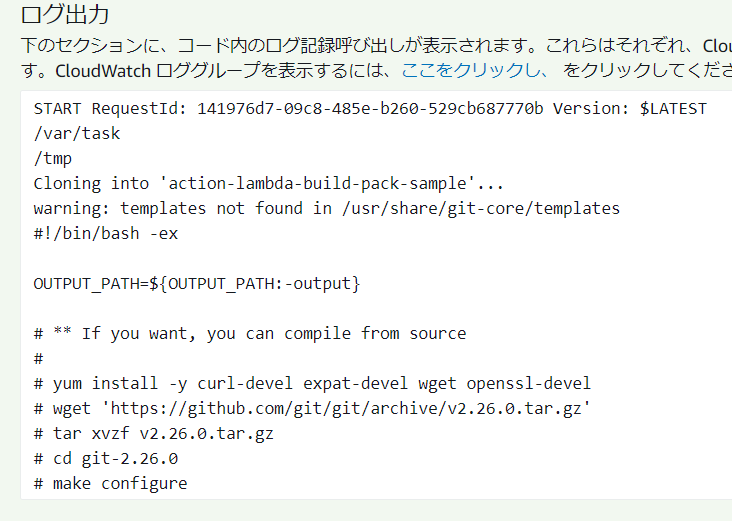
さっきできたoutputディレクトリの中に作成します。output/lambda_function.pyimport subprocess import os def lambda_handler(event, context): cwd = os.getcwd() os.chdir("/tmp") subprocess.call([ os.path.join(cwd, "git"), f"--exec-path={cwd}", "clone", "https://github.com/qualitiaco/action-lambda-build-pack-sample.git"]) print(open("/tmp/action-lambda-build-pack-sample/src/build.sh", "r").read())githubのhttps://github.com/qualitiaco/action-lambda-build-pack-sample.git からgit cloneして、その中にあるsrc/build.shを出力するだけのプログラムです。
zipする
outputディレクトリの中から圧縮します。
シンボリックリンクを含みますので、「-y」オプションを忘れないよう付けてください。cd output zip -9yr ../lambda_function.zip *確認
AWS Lambda Functionをあらかじめ作成してzipファイルをアップロードします。
少しサイズが大きいので、関数のソースコードをWebで確認することはできません。実行すると、
githubからgit cloneして取得したソースコードが表示されました。
終わりに
Dockerコンテナqualitiaco/lambda-build-packを使用してAWS Lambdaに必要なgitコマンドとライブラリを取得し、AWS Lambdaでgitコマンドを実行してみました。
本記事で使用したソースコードは、
https://github.com/qualitiaco/action-lambda-build-pack
にも置いてありますので、併せてご覧ください。*本記事は @qualitia_cdevの中の一人、@hirachanさんに作成して頂きました。
- 投稿日:2020-04-06T09:13:10+09:00
【AWS】Elastic IP解放→割り当て後に必要な事
この記事は?
AWSのElastic IP(以降EIP)再割り当て時の対応に関する記事です。
想定する読み手
- AWSでのデプロイ経験が乏しい方
- AWSでデプロイしたアプリを使わないからインスタンス停止、IP解放した方
- EIPを再割り当てしたけどアプリが起動できない方
著者開発環境
mac
Ruby 2.5.1
Rails 5.2.3
AWS
nginx
mySQL
unicornそもそもElastic IPとは
AWSで取得できる、アプリへアクセスするためのIPアドレスです。
特定のIPアドレスを指定することはできませんが、ランダムで取得したEIPは、解放※しない限り占有する事ができます。
(※解放:インスタンスに紐付けしているEIPの占有を解除する事)使用料金
起動中のEC2インスタンスに割り当てたEIPは無料(1インスタンスにつき1つ。2つ目以降は有料)で使用できます。
停止中インスタンスに割り当てられているEIPは有料。(0.005ドル/1時間)
インスタンスを停止していると1ヶ月で、0.005ドル×24(時間)×30(日) = 3.6ドルかかります。
日本円で400円くらいでしょうか。著者は使用しないアプリがあったのでインスタンスを停止していたのですが、AWSから請求があった事を知り、EIPを解放しました。
が、訳あって久しぶりにアプリの挙動を本番環境で確認するべく、停止していたインスタンスを起動し再度EIPを割り当てました。
すると、アプリが起動しなかった訳なんです。EIP再割り当て時に必要なことって?
結論、必要な対応は以下の2点でした。
- 本番環境nginx設定内部でelasticIPの書き換え
- ローカル環境config/deploy/production.rb内のelasticIP書き換え
考えてみれば当然の事なんですが、デプロイ時にEIPを記載していた箇所がありました。
そこのEIPを新しく割り当てたEIPに書き換える必要がある、という事ですね。実際にやった事
本番環境nginx設定内部でelasticIPの書き換え
本番環境にて、nginxの設定画面を開きます。
デイレクトリは自身のアプリのディレクトリです。ターミナル[ec2-user@ip-xxx-xx-xx-xx アプリ名]$ sudo vim /etc/nginx/conf.d/rails.conf以下のような画面が開くはずです。
ターミナルserver { listen 80; server_name 52.68.124.79; #ここを書き換え root /var/www/アプリ名/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; root /var/www/アプリ名/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; location = /favicon.ico { log_not_found off; } }この中のserver_nameという箇所がEIPを記載する箇所なので、ここを新しいEIPに書き換えます。
ローカル環境config/deploy/production.rb内のelasticIP書き換え
これは読んで字の如くなので割愛しますが、
config/deploy/production.rb内にもEIPを記載している箇所がありますので、そちらも新しいEIPに書き換えます。以上の対応で著者のアプリは久々に起動できました。
おわりに
今回の記事は、読む方をかなり限定するかもしれませんが、それでも誰かのお役に立てれば嬉しいです。
- 投稿日:2020-04-06T08:38:50+09:00
AWS IAMとAuthyによる二段階認証を設定する
Authyを利用して二段階認証を設定し、AWSアカウントを保護する
AWSアカウントの乗っ取り防止のために、利用していきます
インストール
iOS版
https://itunes.apple.com/jp/app/authy/id494168017?mt=8&uo=4&at=10lMo4
Android版
https://play.google.com/store/apps/details?id=com.authy.authy
導入
二段階認証アプリ[Authy]が[Google Authenticator]よりも優れている理由
- AWSにサインイン
画面右上のユーザー名をクリック
「マイセキュリティ資格情報」をクリック
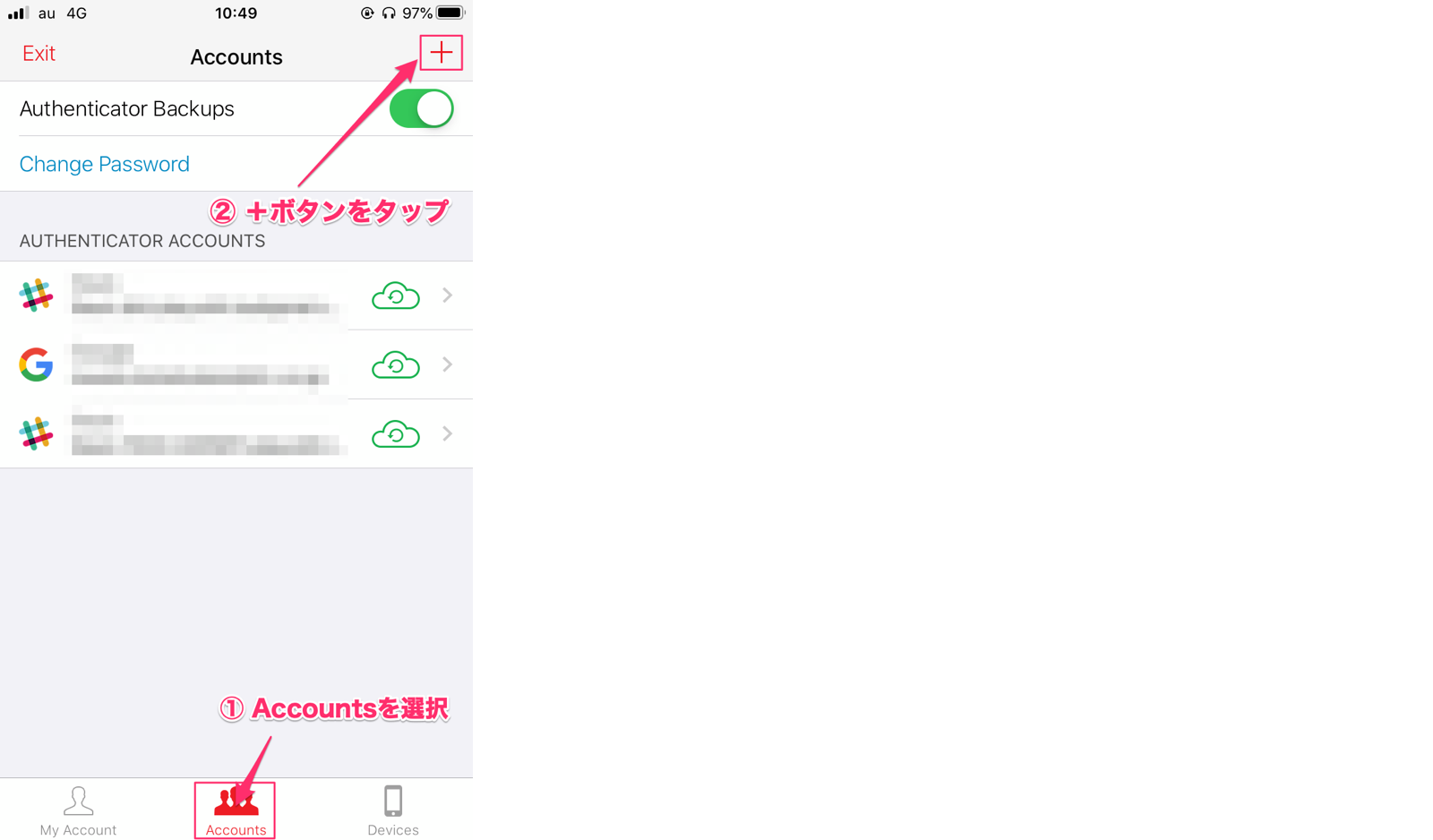
多要素認証(MFA)の「MFAを有効化」をクリック(青いボタン)
「仮想 MFA デバイス」を選択して、「続行」をクリック
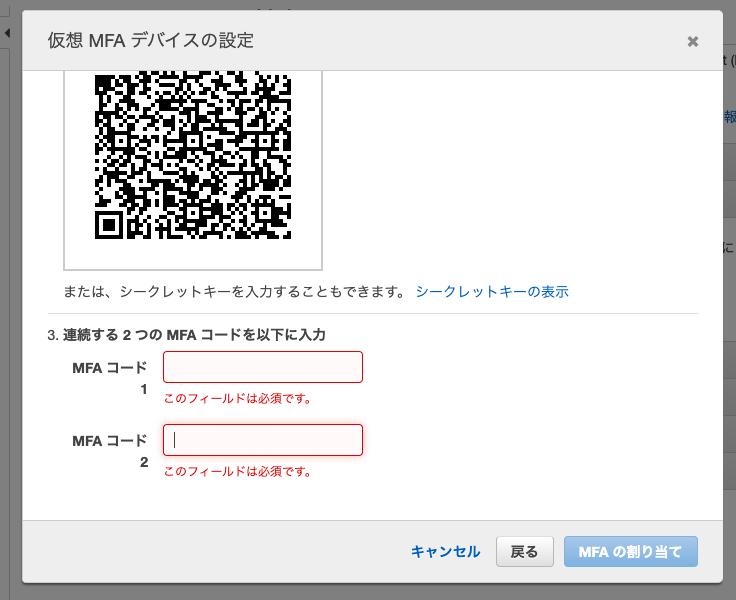
「仮想 MFA デバイスの設定」画面で「QRコードを表示」をクリック
7. スマホにインストールした、【Authy】を起動する
8. Authyで「Accounts」を開く
9. 「+」ボタンをクリック
10. QRコードを読み込む画面が表示されるので、AWS画面上で表示させたQRコードを読み込ます。
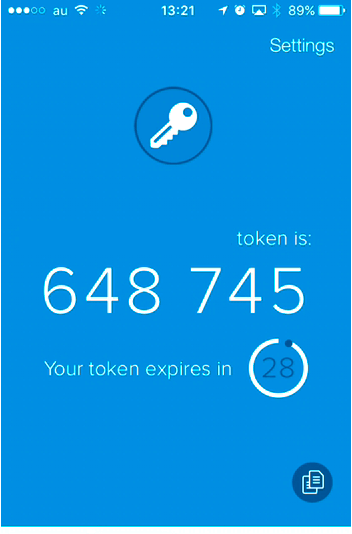
11. 【Authy】アプリ上で6桁の認証番号が表示されます
12. AWSのMFA認証コードを入力欄を見る
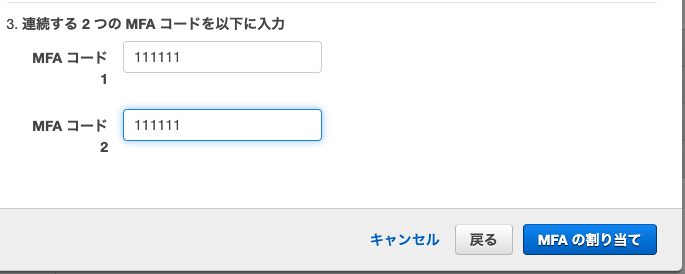
13. スマホアプリ上で表示されている、認証コード6桁を「MFAコード1」に入力
14. 続いて、30秒経過して新しく表示された認証コード6桁を「MFAコード2」に入力
(上段には1回目のパスワードを、下段には1回目のパスワードを制限時間切れまで待って、2回目のパスワードが表示されたらそのパスワードを入力します。)
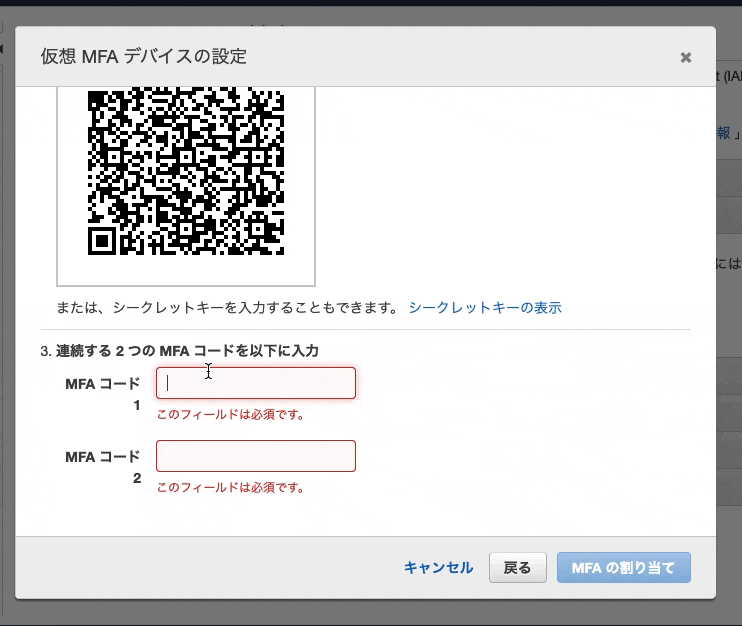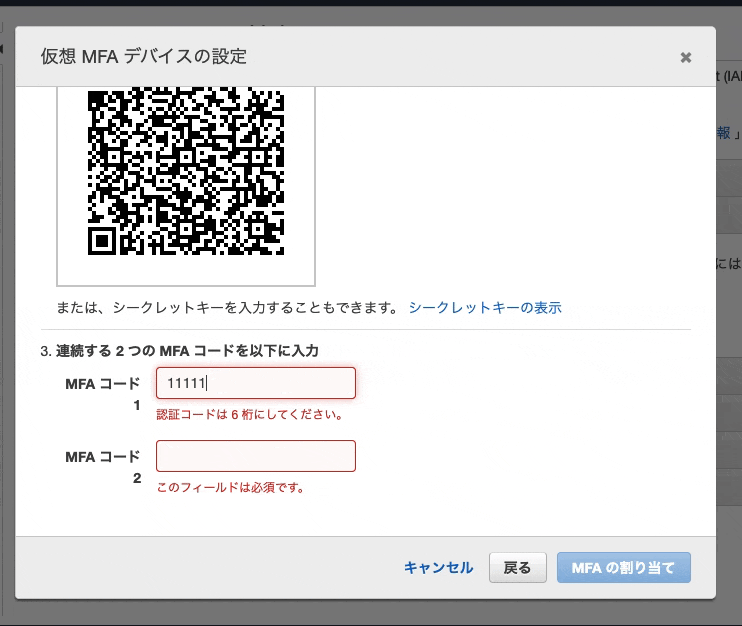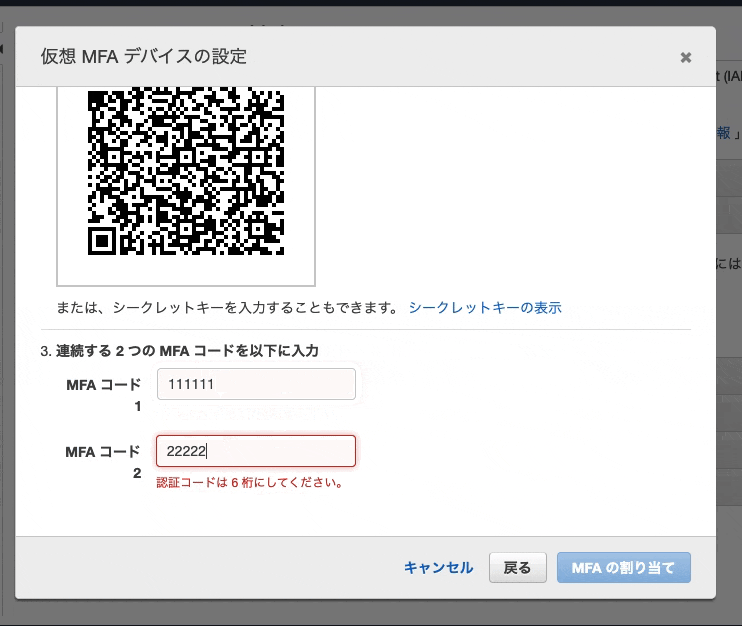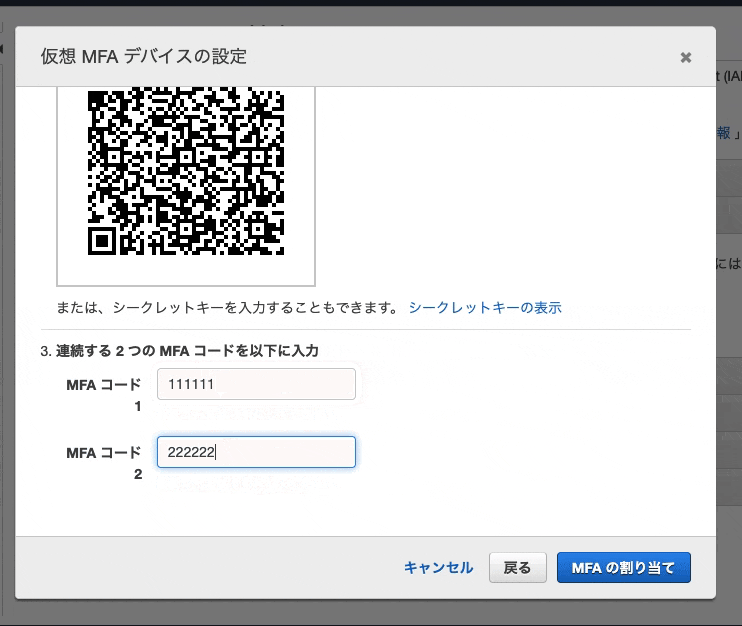
15. 「MFAの割り当て」をクリック
16. 完了これでログイン時、メールアドレスとパスワードだけではなく、Authyの6桁の番号が必要となります。アカウントの乗っ取りなどを防げます。
IAMユーザーの利用
IAMユーザーは、AWSのサービスの1つです。
最初にメールアドレスで作成した、AWSアカウントはルートユーザーと呼ばれ、全ての機能を使うことができます。そのため、万が一ルートユーザーのID・パスワードが漏洩し悪用されると、第三者が全ての機能を使われてしまいます。それを防ぐために、機能を制限したユーザーを作成し、通常の作業はそのユーザーでログインし行うようにします。この機能を制限したユーザーを作成する機能がIAMです。
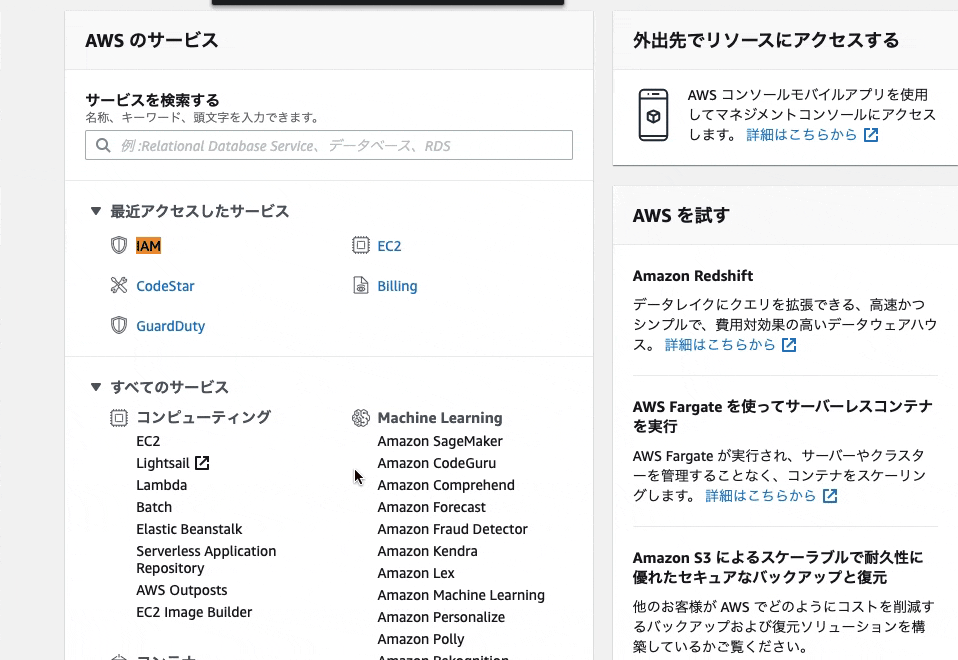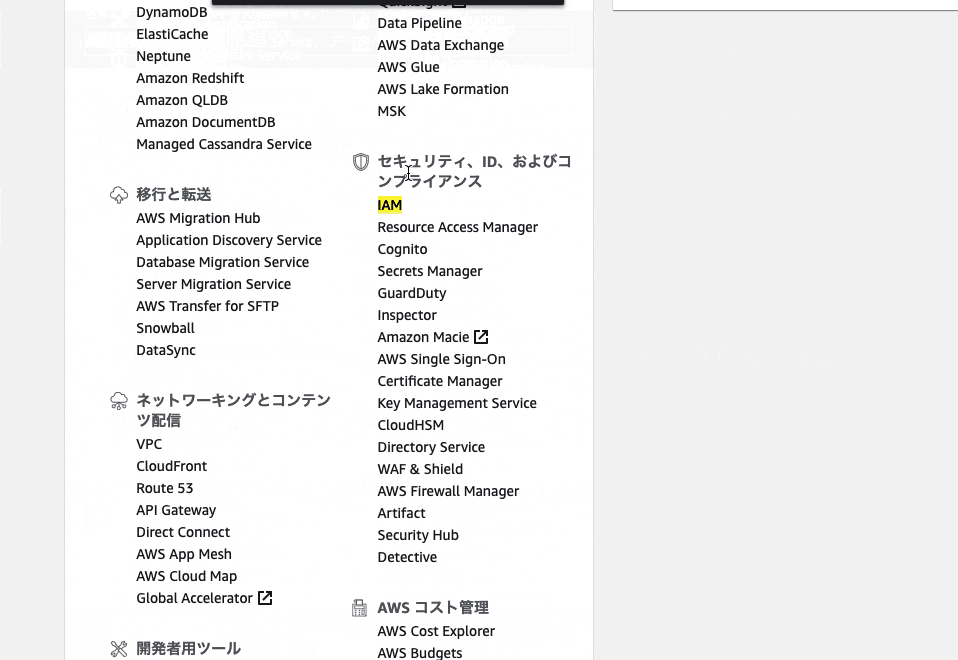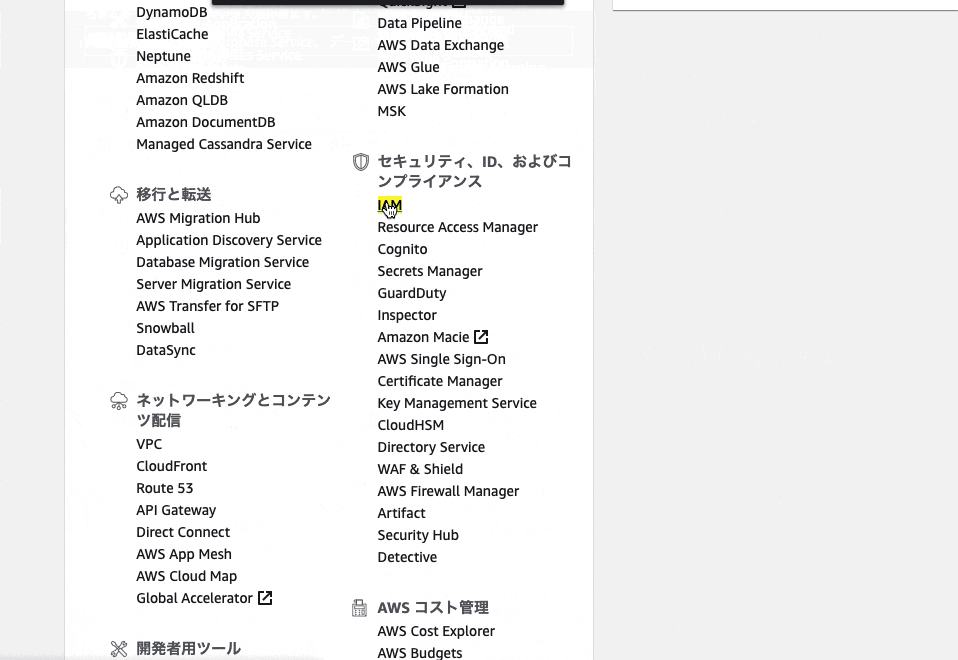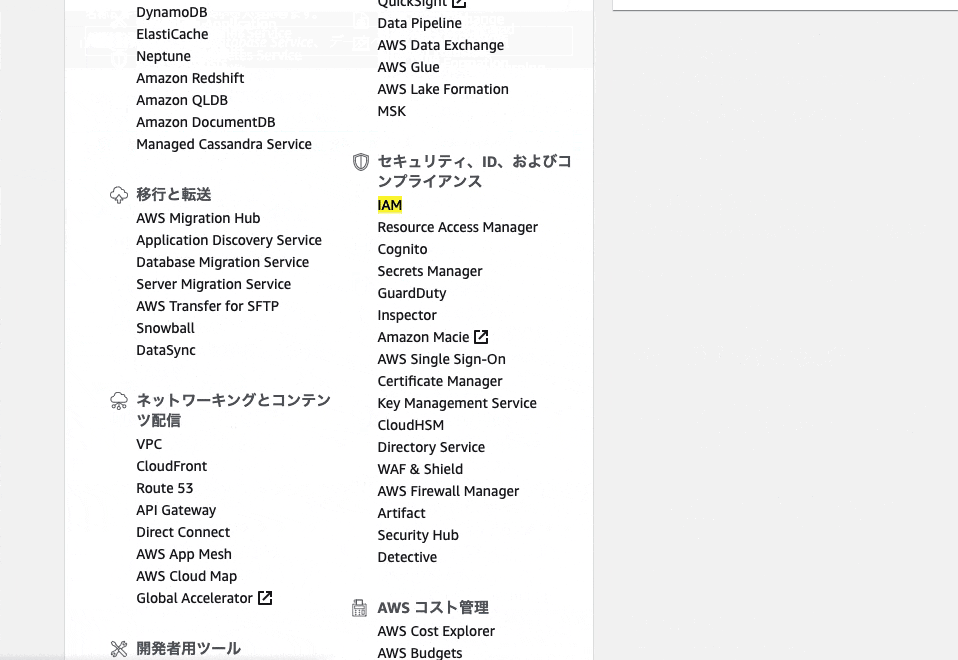
IAMユーザーを作成
それか、
画面下のセキュリティの項目にあるため、下にスクロールして「IAM」をクリック
「IAMリソース」の画面が表示されました。
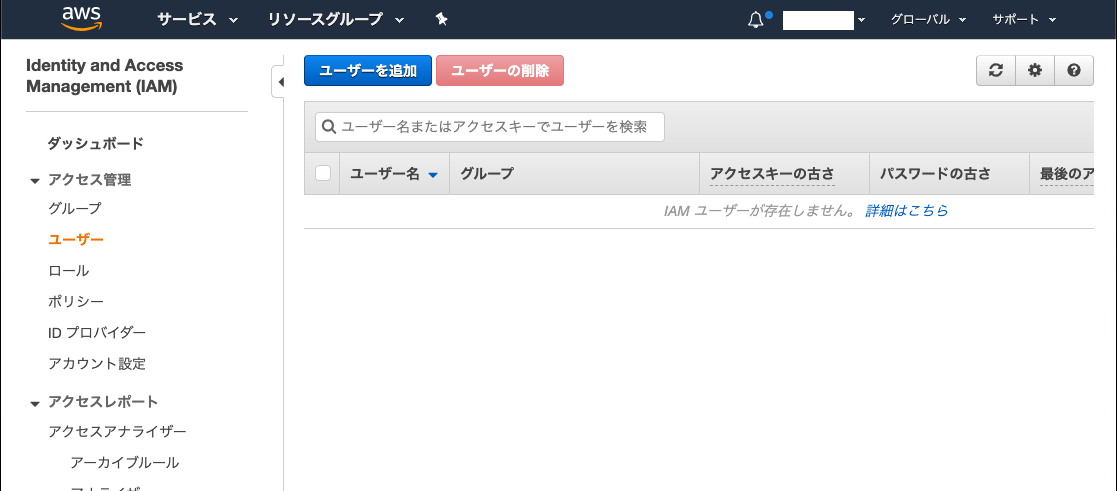
2. 「個々のIAMユーザーの作成」のタブを開く
3. 「ユーザー管理」をクリック
4. ユーザー管理画面が開かれる
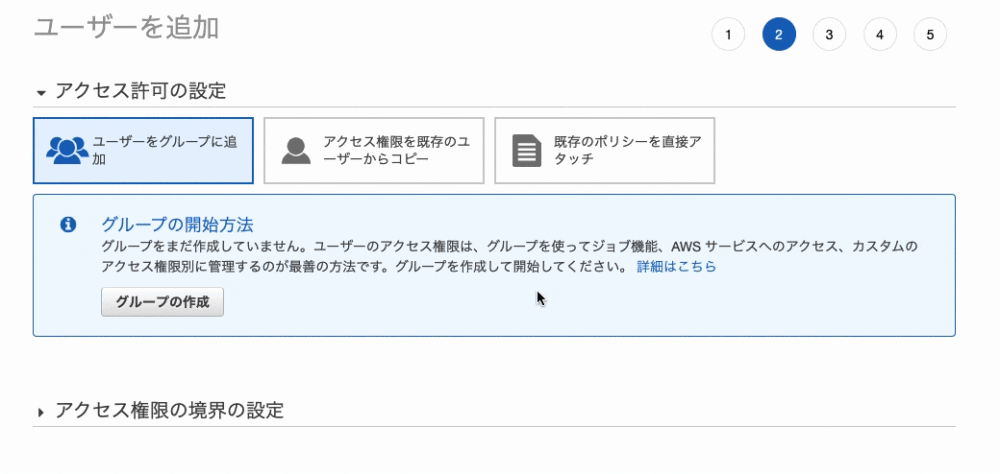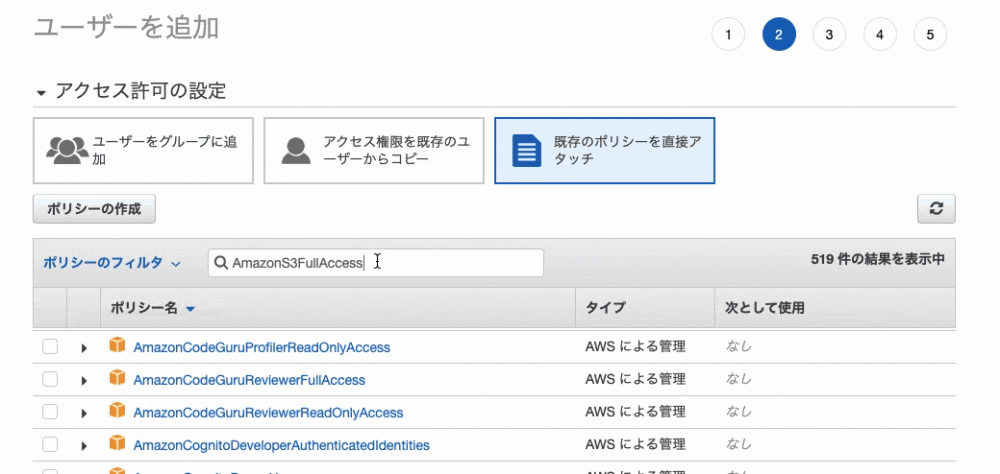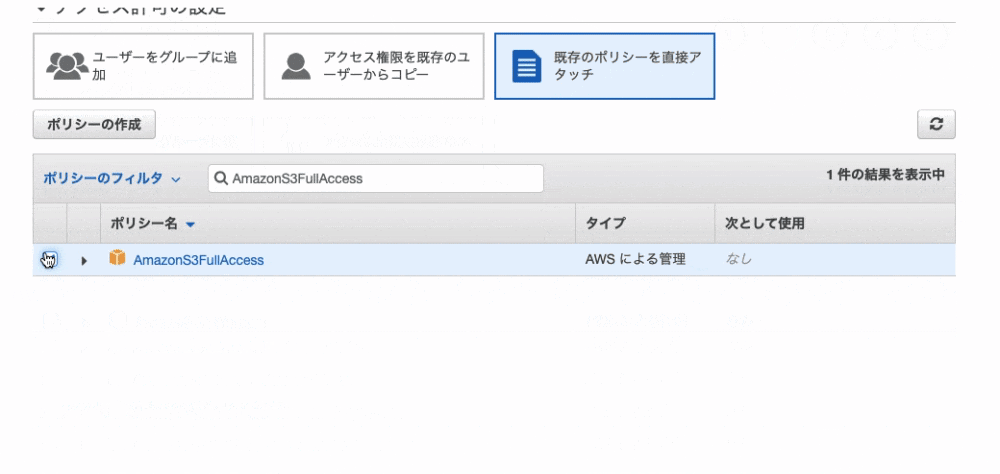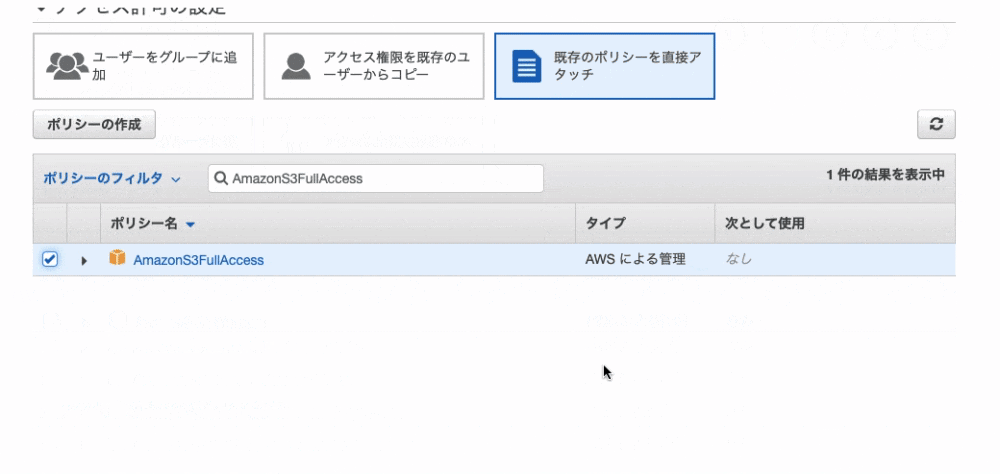
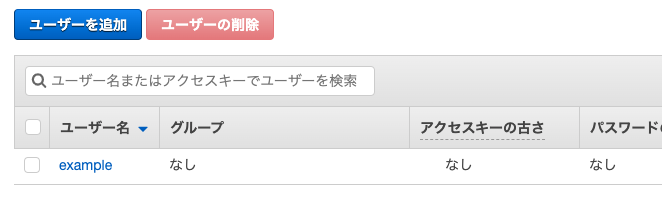
5. 「ユーザーを追加」をクリック
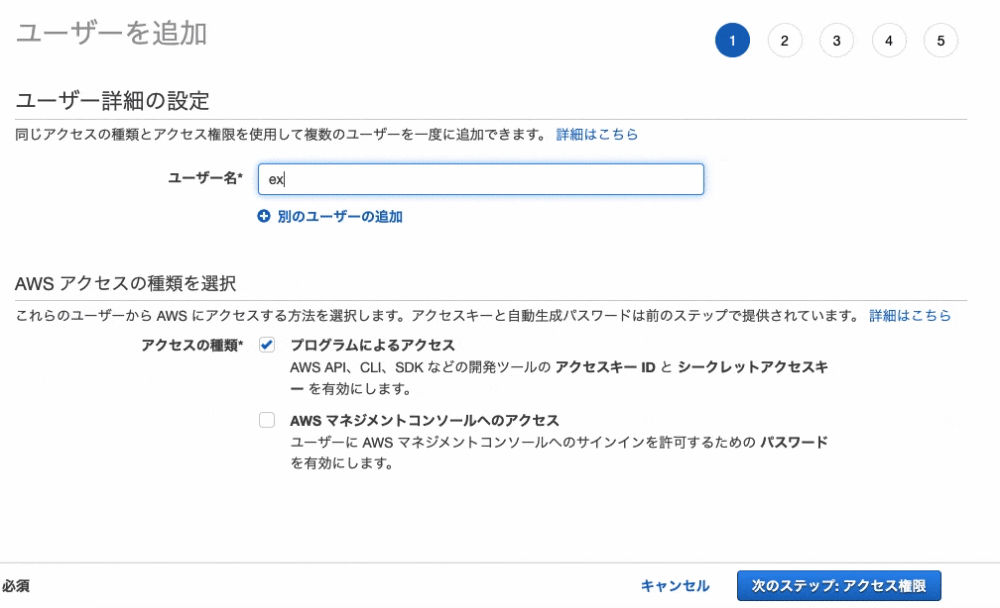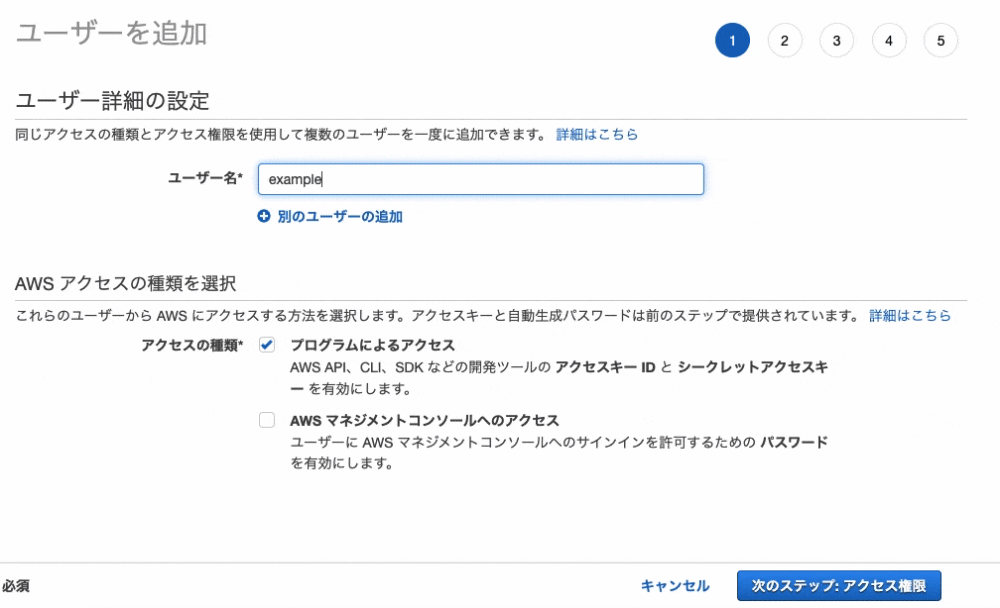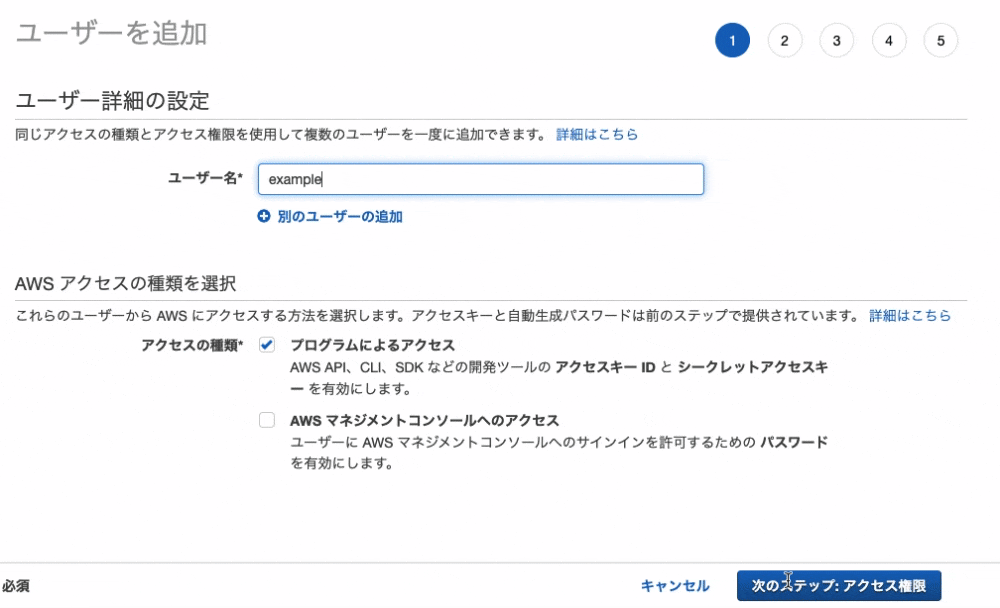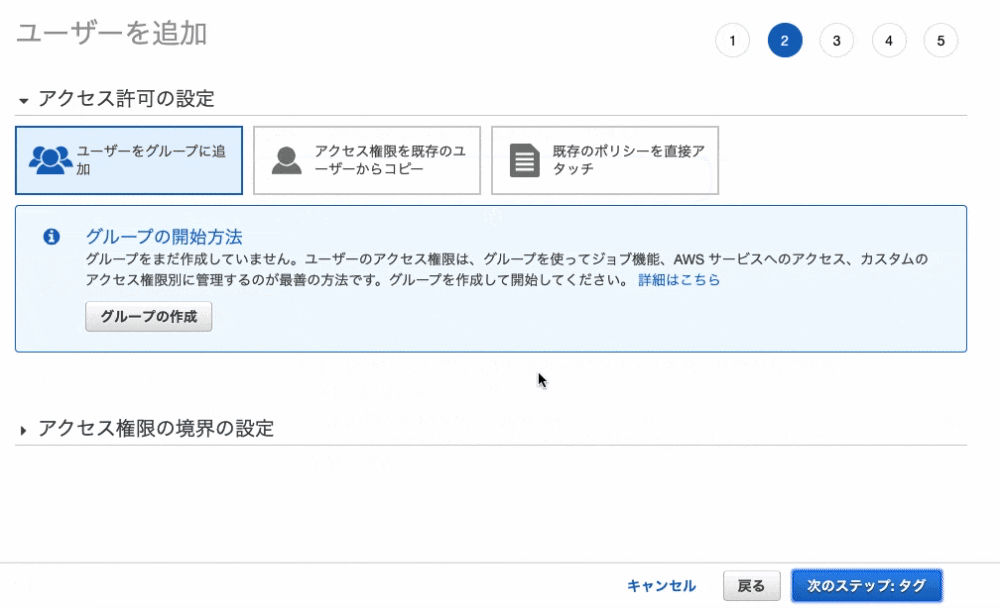
6. ユーザー名を入力します
7. そして、「プログラムによるアクセス」を選択します
8. 画面右下の「次のステップ: アクセス権限」をクリック
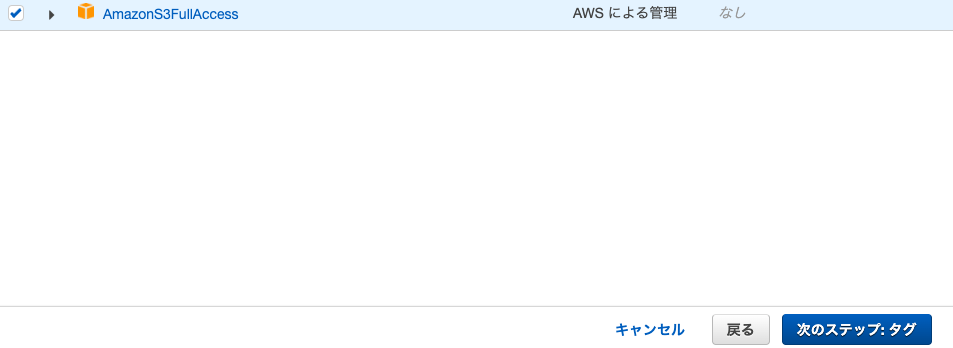
9. 「既存のポリシーを直接アクセス」を選択し、「AmazonS3FullAccess」を選択。
10. 「次のステップ: タグ」
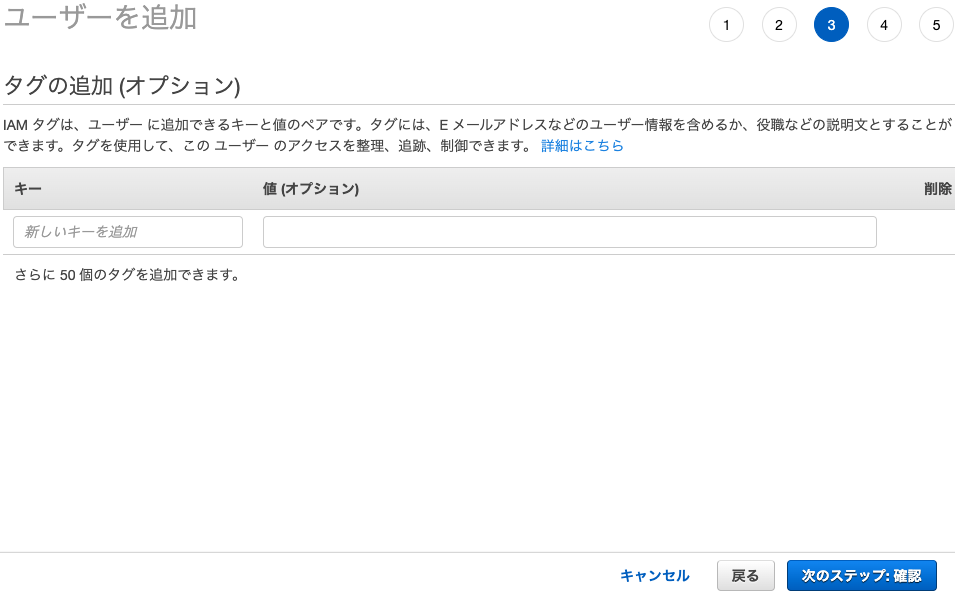
11. タグを設定すれば、役職などをタグづけできますが、今回は不要なので何もしないで「次のステップ:確認」をクリック
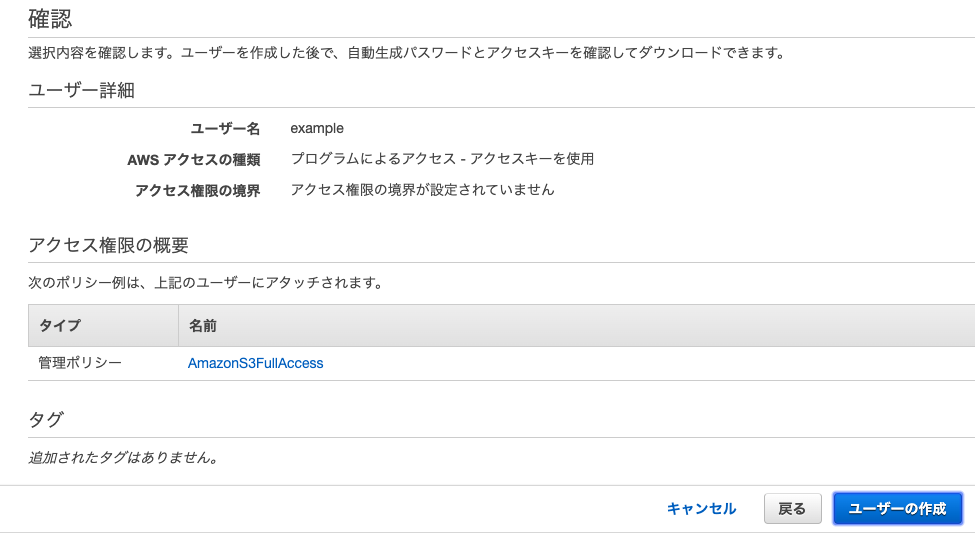
12. 確認ページが表示されるので、「ユーザーの作成」をクリック
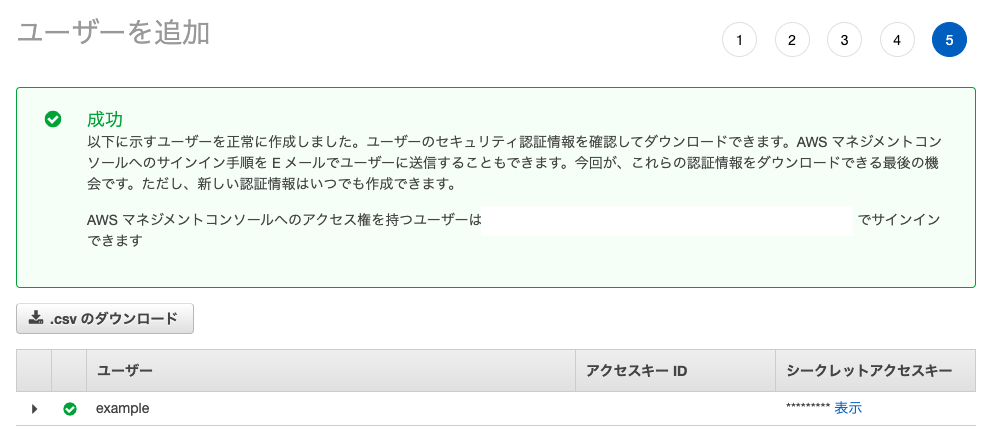
13. ⚠️「.CSV」をダウンロードします
14. 閉じる
15. 追加されたユーザーを選択
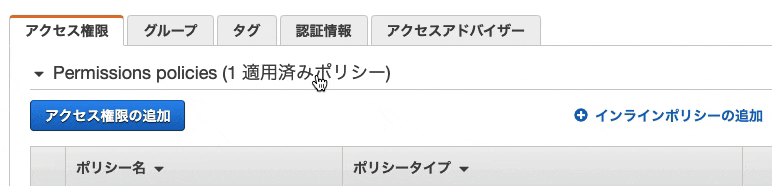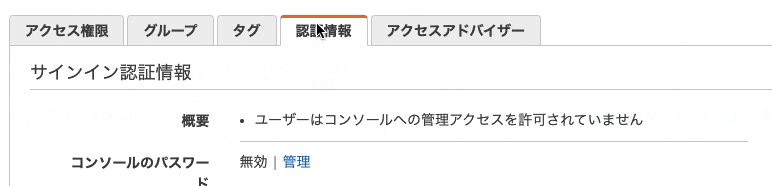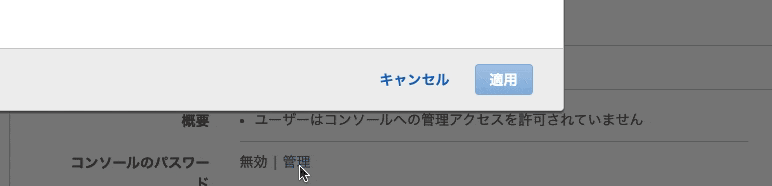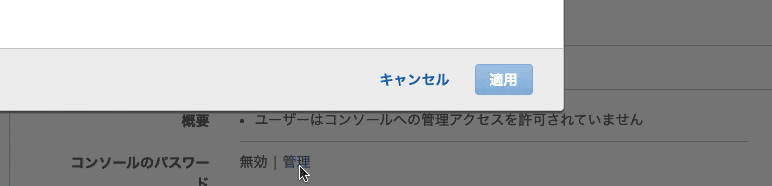
- 「認証情報」を開く
- 「コンソールのパスワード」の管理を選択する
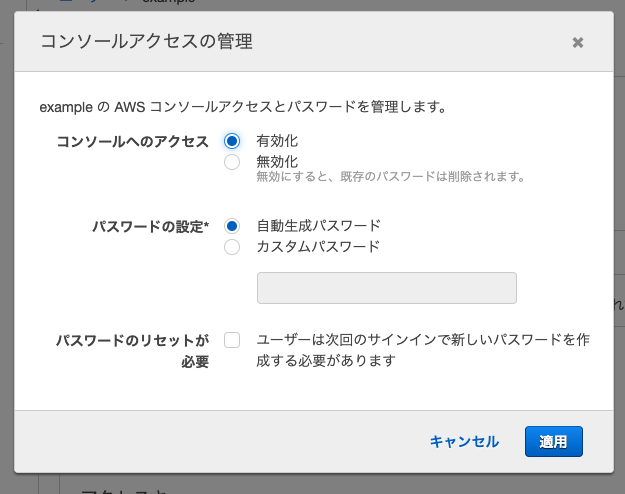
18. コンソールへのアクセス「有効化」、パスワードの設定「動生成パスワード」
19. 「適用」をクリック
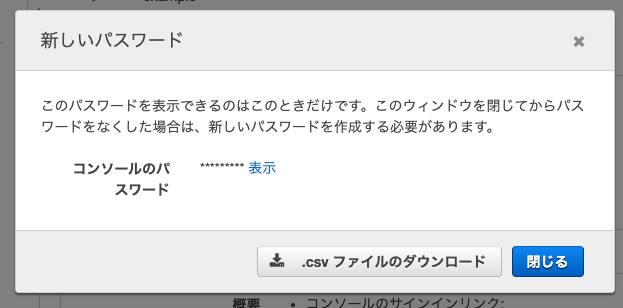
20. 「.csvをダウンロード」
21. 閉じる
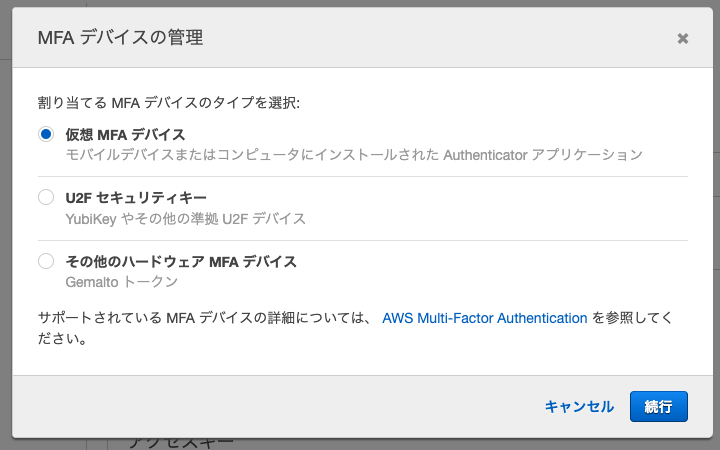
22. IAMユーザーのMFAの有効化するため、「MFAデバイスの割り当て」の管理をクリック
23. 同様にQRコードを読み取り、MFAコードを入力すれば完了IAMでサインインする
先ほどダウンロードした.CSVファイルを開く
すると、
- user name
- Password
- ログインするためのURL
の3つの要素が記述されています。
これを利用すればログイン可能です。まずは Console login linkのURLを開く
user名とPWを入力して、ログイン
MFAコードが要求されたら、Authyで表示された番号を入力しよう
するとログインができますgit-secretsを導入し、AWSの情報をコミットしないようする
ターミナルから、Homebrewを経由してgit-secretsを導入します。
ターミナル$ cd $ brew install git-secretsgit-secretsが導入できたら、設定を適用したいリポジトリに移動して、git-secretsを有効化します。
ターミナル$ cd アプリ名 $ git secrets --installこれで、有効化を行なったリポジトリでgit-secretsを使用する準備ができました。
続いて、「どのようなコードのコミットを防ぐのか」を設定する。条件設定の確認
下記のコマンドを実行することで、secret_key, access_keyなど、アップロードしたくないAWS関連の秘密情報を一括で設定することができます。
ターミナル$ git secrets --register-aws --global現在のgit-secretsの設定は、下記のコマンドで確認することができます。
ターミナル$ git secrets --list secrets.providers git secrets --aws-provider secrets.patterns [A-Z0-9]{20} secrets.patterns ("|')?(AWS|aws|Aws)?_?(SECRET|secret|Secret)?_?(ACCESS|access|Access)?_?(KEY|key|Key)("|')?\s*(:|=>|=)\s*("|')?[A-Za-z0-9/\+=]{40}("|')? secrets.patterns ("|')?(AWS|aws|Aws)?_?(ACCOUNT|account|Account)_?(ID|id|Id)?("|')?\s*(:|=>|=)\s*("|')?[0-9]{4}\-?[0-9]{4}\-?[0-9]{4}("|')? secrets.allowed AKIAIOSFODNN7EXAMPLE secrets.allowed wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEYこれで、git secrets --installを行なったリポジトリでは、コミット時にAWSの秘密情報を含んだコードがないかチェックされるようになりました。
「うっかりパスワードをGithubに載せてしまった」という事態を防ぐことができるので、必ず設定を行うようにしましょう。
## 今後作成する全てのリポジトリにgit-secretsが適用させる
以下のコマンドを実行して自動で適用されるにするターミナル$ git secrets --install ~/.git-templates/git-secrets $ git config --global init.templatedir '~/.git-templates/git-secrets'GitHub Desktopからgit secretsを利用する
Github Desktopがapplicationフォルダに存在している必要があります。
GitHub Desktop経由でgit secretsを利用する場合は、追加の設定をします。
まず以下を実行ターミナル$ sudo cp /usr/local/bin/git-secrets /Applications/GitHub\ Desktop.app/Contents/Resources/app/git/bin/git-secretsNo such file or directoryのエラーが表示される場合、ディレクトリが異なるため下記を実行
ターミナル$ sudo cp /usr/local/bin/git-secrets /Applications/GitHub\ Desktop.app/Contents/Resources/git/bin/git-secrets






- 投稿日:2020-04-06T06:41:13+09:00
AWS ECR/ECS 勉強メモ① Dockerコンテナ起動
やること
Cloud9環境でDockerイメージをビルドして
ECRにDockerイメージをpushして
ECSでDockerコンテナを起動する参考リンク
- AWS Cloud9環境でdocker-composeをできるようにする
- 今から追いつくDocker講座!AWS ECSとFargateで目指せコンテナマスター!
- Capacity Providerとは?ECSの次世代スケーリング戦略を解説する
構成
今回つくる環境
- ECSは、クラスターをEC2(linux)で構成
- クラスターを構成するEC2はCloud9と同じVPCに配置
- クラスターを構成するEC2とCloud9は通信可
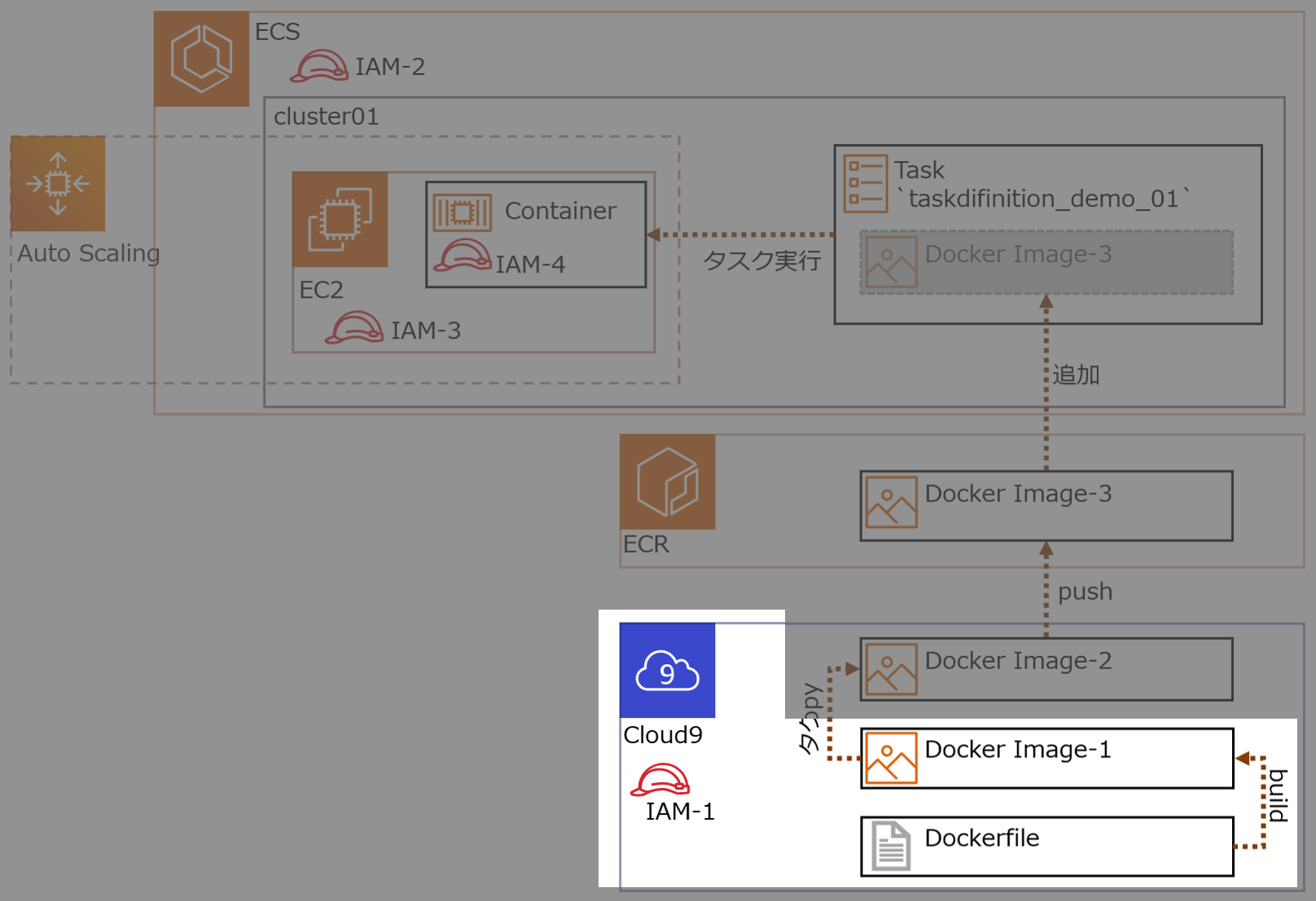
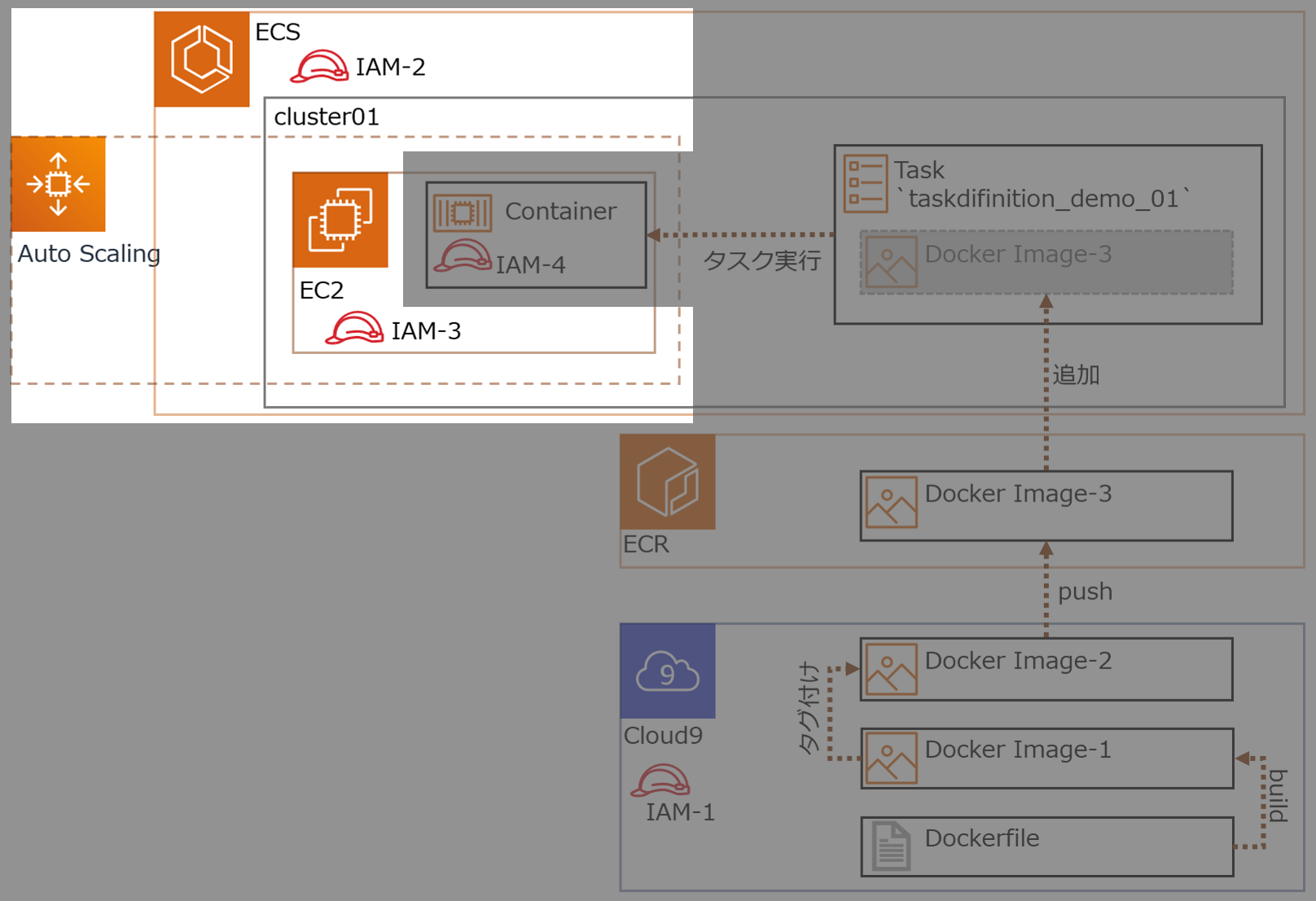
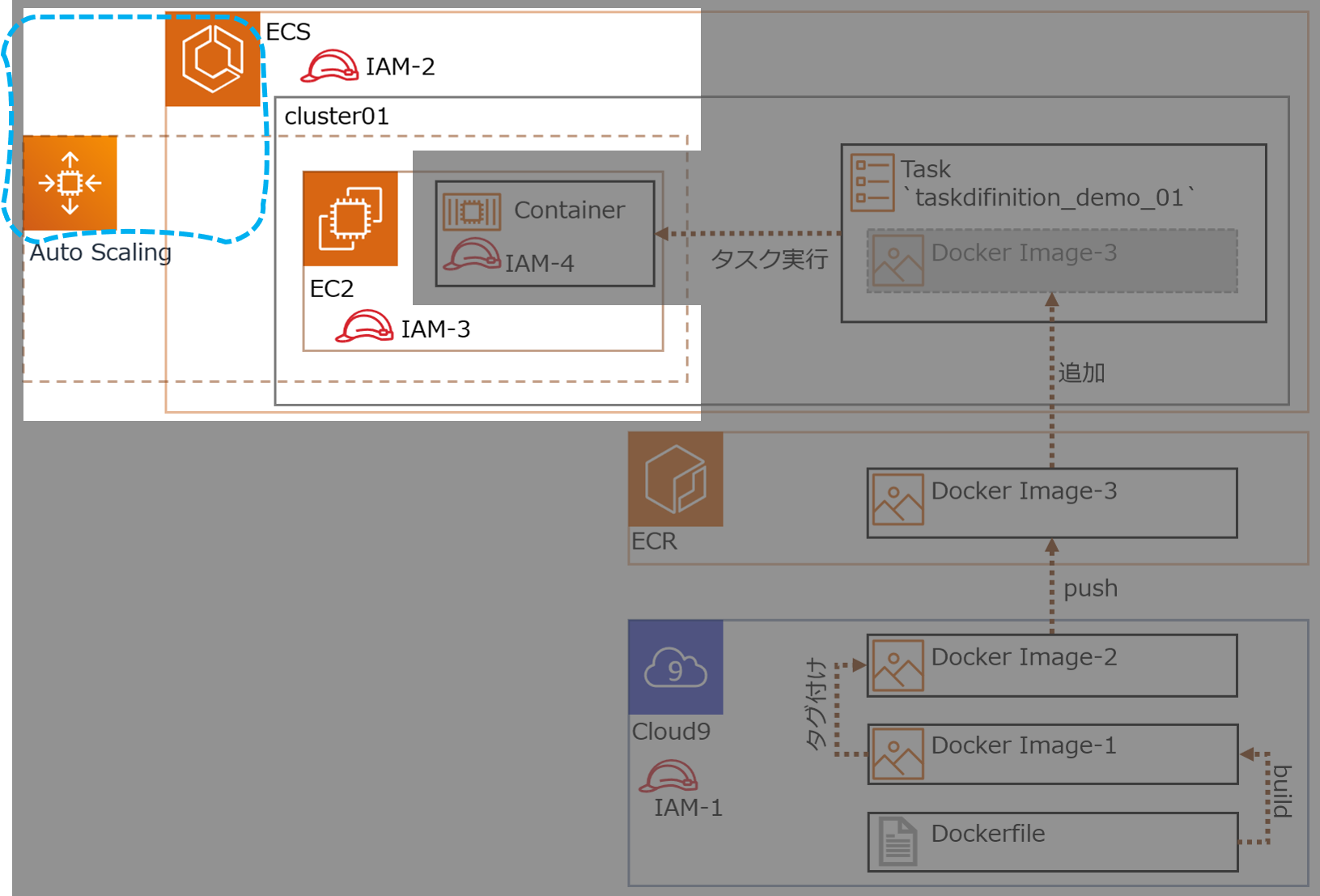
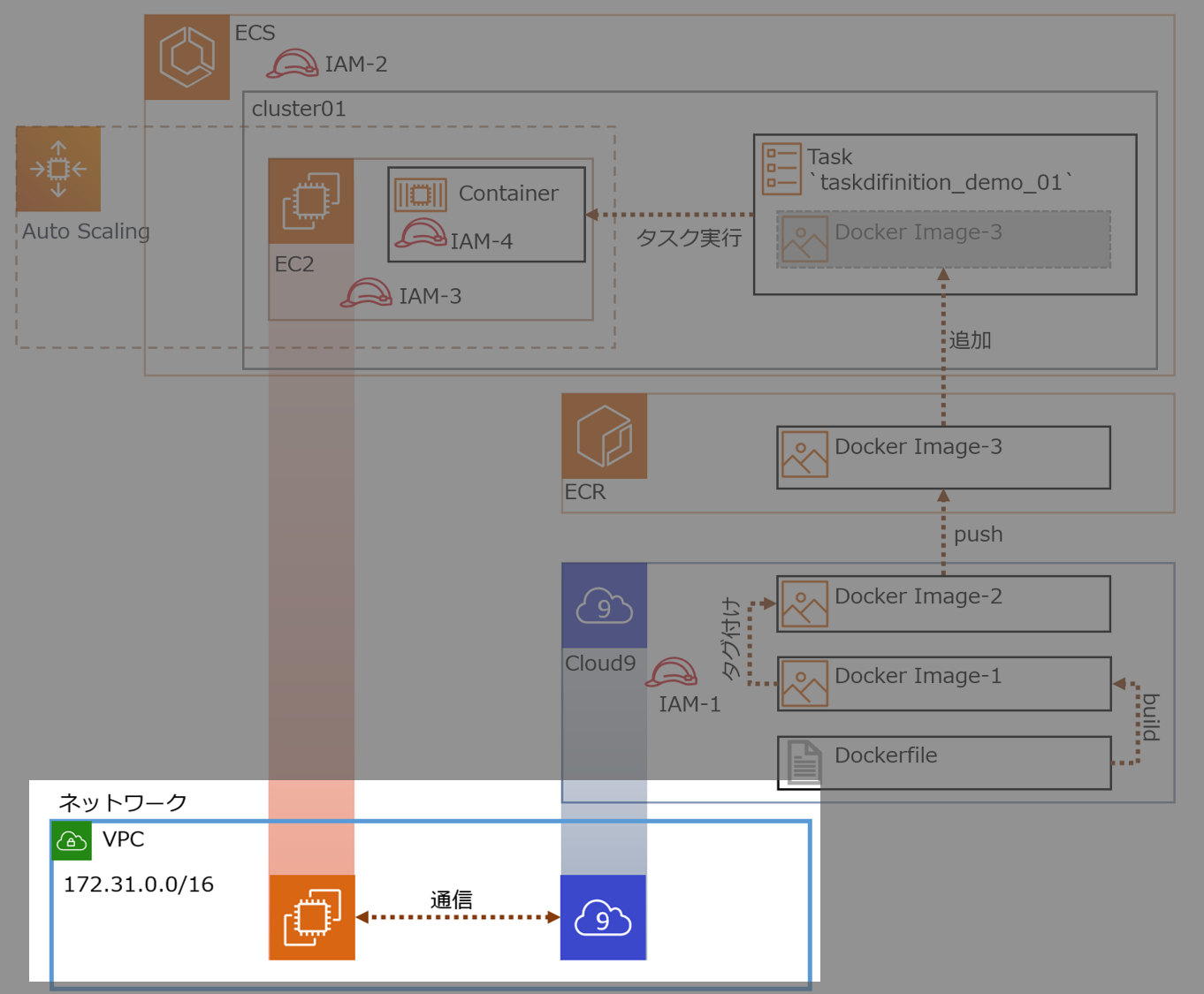
各IAMロールの概要
No Name 概要 IAM-1 ecsrole Cloud9からECS,ECRにアクセス IAM-2 ー ← これ無いわ、間違えた IAM-3 ー クラスターとしてEC2が機能するためのアクセス権
今回はクラスター作成時に自動生成するIAM-4 ecsTaskExecutionRole Dockerコンテナのアクセス権
RDS接続許可、みたいな権限
- 用語説明
- ECR(Amazon Elastic Container Registry)
- Dockerコンテナレジストリ
- Dockerイメージの保存と取得
- マネージドサービス
- ECS(Amazon Elastic Container Service)
- コンテナオーケストレーションサービス
- マネージドサービス
- クラスターをFargateで構成するとクラスター部分の管理もAWSお任せにできる
やっていきます
1.Dockerイメージを作成する
ECSで起動するDockerコンテナのため、Dockerイメージを作成
1-1.準備(環境構築)
cloud9の作成の詳細は省略(デフォルトVPCに作成するだけ)。
cloud9には、Dockerがインストールされている。
ec2-user をdockerグループに配属させる。Cloud9-Terminal$ sudo usermod -a -G docker ec2-userDocker Composeをインストールする。
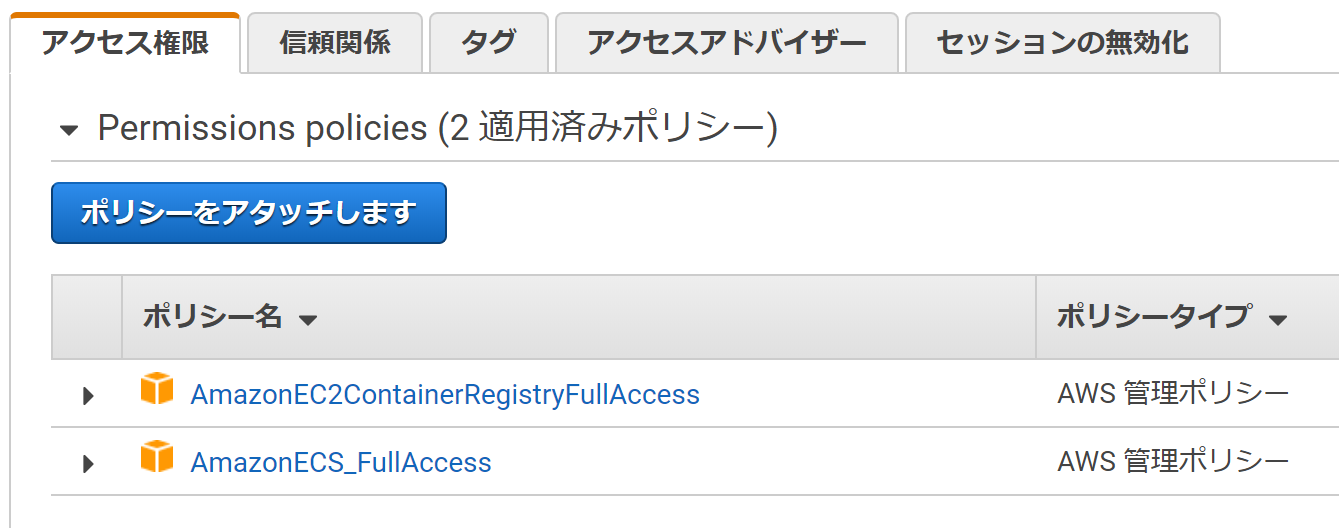
Cloud9-Terminal$ sudo curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-composeIAMロール作成し、Cloud9 のEC2インスタンスにアタッチする。
IAMロール名
ecsrole(図のIAM-1)に適用したポリシー
AmazonEC2ContainerRegistryFullAccessAmazonECS_FullAccess1-2.Dockerイメージをビルドする
cloud9上でDockerイメージをビルドする。ビルドイメージ名
volumedemoCloud9-Terminal$ mkdir docker $ mkdir docker/volumes $ touch docker/volumes/Dockerfile $ nano docker/volumes/Dockerfile # -> 編集内容は後に記載してある $ touch docker/volumes/index.html $ nano docker/volumes/index.html # -> 編集内容は後に記載してあるDockerfileFROM centos:latest RUN yum install -y httpd COPY ./index.html /var/www/html/index.html VOLUME /var/www/html EXPOSE 80 443 CMD ["/usr/sbin/httpd", "-D", "FOREGROUND"]index.html<html><head><title>test</title></head><body><h1>TEST</h1></body></html>ビルドする
Cloud9-Terminal$ cd docker/volumes $ docker build -t volumedemo ./ # -> Successfully tagged volumedemo:latest となれば成功ビルドが成功し、Dockerイメージがつくれたか確認
Cloud9-Terminaldocker images # -> REPOSITORY名 `centos`, `volumedemo` の2つが追加されてれば成功Dockerコンテナを起動
cloud9-Terminal$ docker run --name volumedemo -d -p 8080:80 volumedemo:latest $ docker container ls # -> NAMES `volumedemo` の STATUS が `UP xxx` となれば成功Webが開くか動作確認
Cloud9-Terminal$ curl http://localhost:8080/index.html # -> `<html><head><title>test</title></head><body><h1>TEST</h1></body></html>`と出力されたら成功1-3.ホスト側からDockerコンテナ内のファイル(html)を更新する
Dockerコンテナのマウントボリュームを確認
Cloud9-Terminal$ docker inspect {CONTAINER ID} # -> 出力結果から Mounts の情報を確認
MountsのSourceがホストのパス"Mounts": [ { "Type": "volume", "Name": "951214538382d48c336a02bcd34d5d61e2cb88654587ec45f14996a2cda43024", "Source": "/var/lib/docker/volumes/a02b1214538382d48c336c45fcd34d5d61e2cb88654587e9514996a2cda43024/_data", "Destination": "/var/www/html", "Driver": "local", "Mode": "", "RW": true, "Propagation": "" }ホスト側からindex.htmlを編集し、Webサイトが更新されたことを確認
Cloud9-Terminalsudo nano /var/lib/docker/volumes/a02b1214538382d48c336c45fcd34d5d61e2cb88654587e9514996a2cda43024/_data/index.html[更新前] <html><head><title>test</title></head><body><h1>TEST</h1></body></html> [更新後] <html><head><title>test</title></head><body><h1>TEST123456789</h1></body></html>↑の手法はパス探し面倒(Cloud9はアクセス権も絡み更に面倒)
なのでホスト側の格納パスを指定してバインドマウントするCloud9-Terminal$ mkdir /home/ec2-user/environment/docker/bindmount $ touch /home/ec2-user/environment/docker/bindmount/index.html $ nano /home/ec2-user/environment/docker/bindmount/index.html # 中身 <html><head><title>test</title></head><body><h1>TEST-ABCDEFG</h1></body></html> $ docker container run --name bindmount1 -d -p 80:80 -v /home/ec2-user/environment/docker/bindmount:/var/www/html volumedemo:latest動作確認
Webサイトにアクセスして
<html><head><title>test</title></head><body><h1>TEST-ABCDEFG</h1></body></html>となれば成功次にホスト側で /home/ec2-user/environment/docker/bindmount/index.html を編集し、Webサイトにアクセスして更新されてたら成功
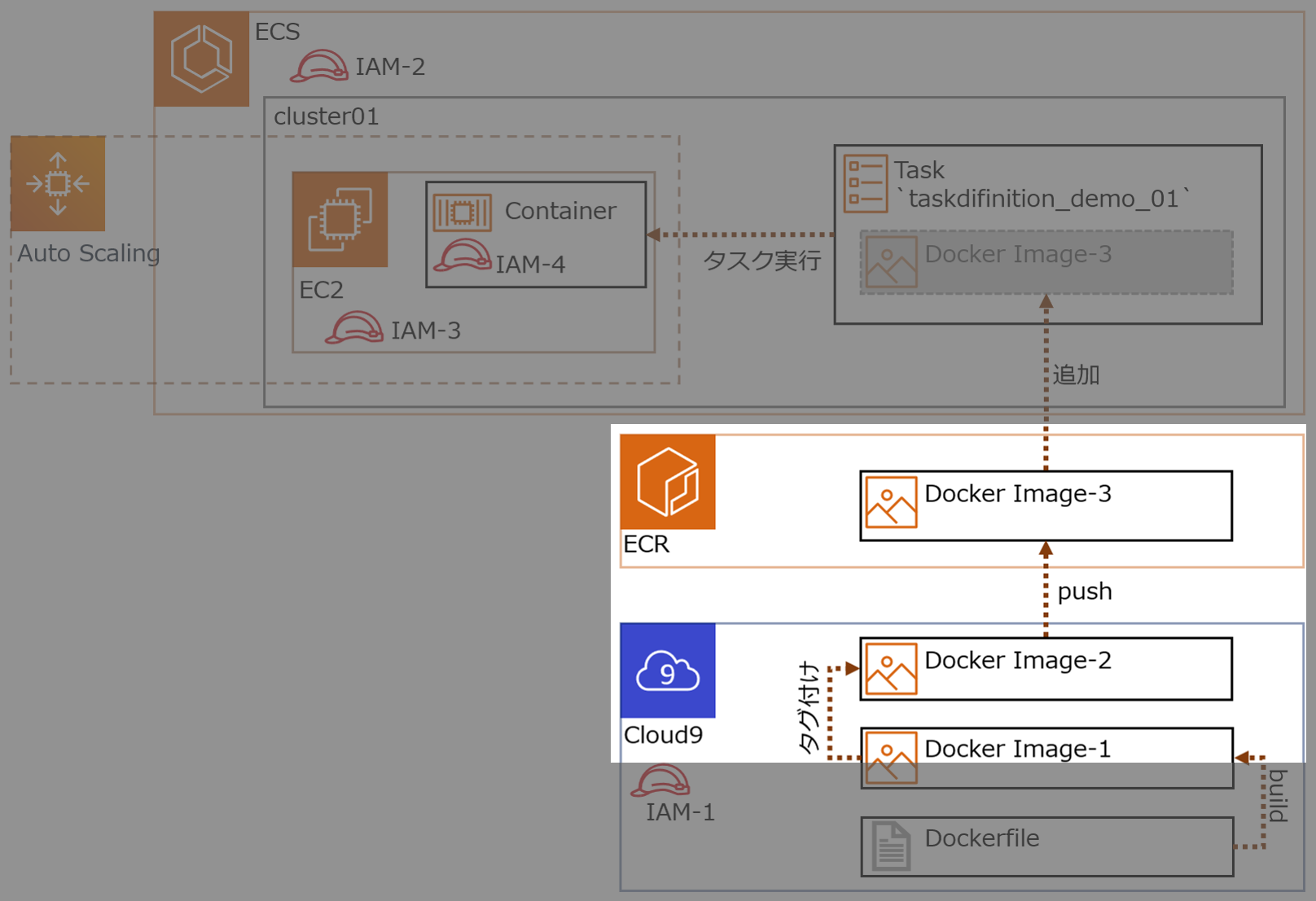
2.DockerイメージをECRにpushする
作成したDockerイメージにECRの規則に沿ったタグを付与しECRにpushする
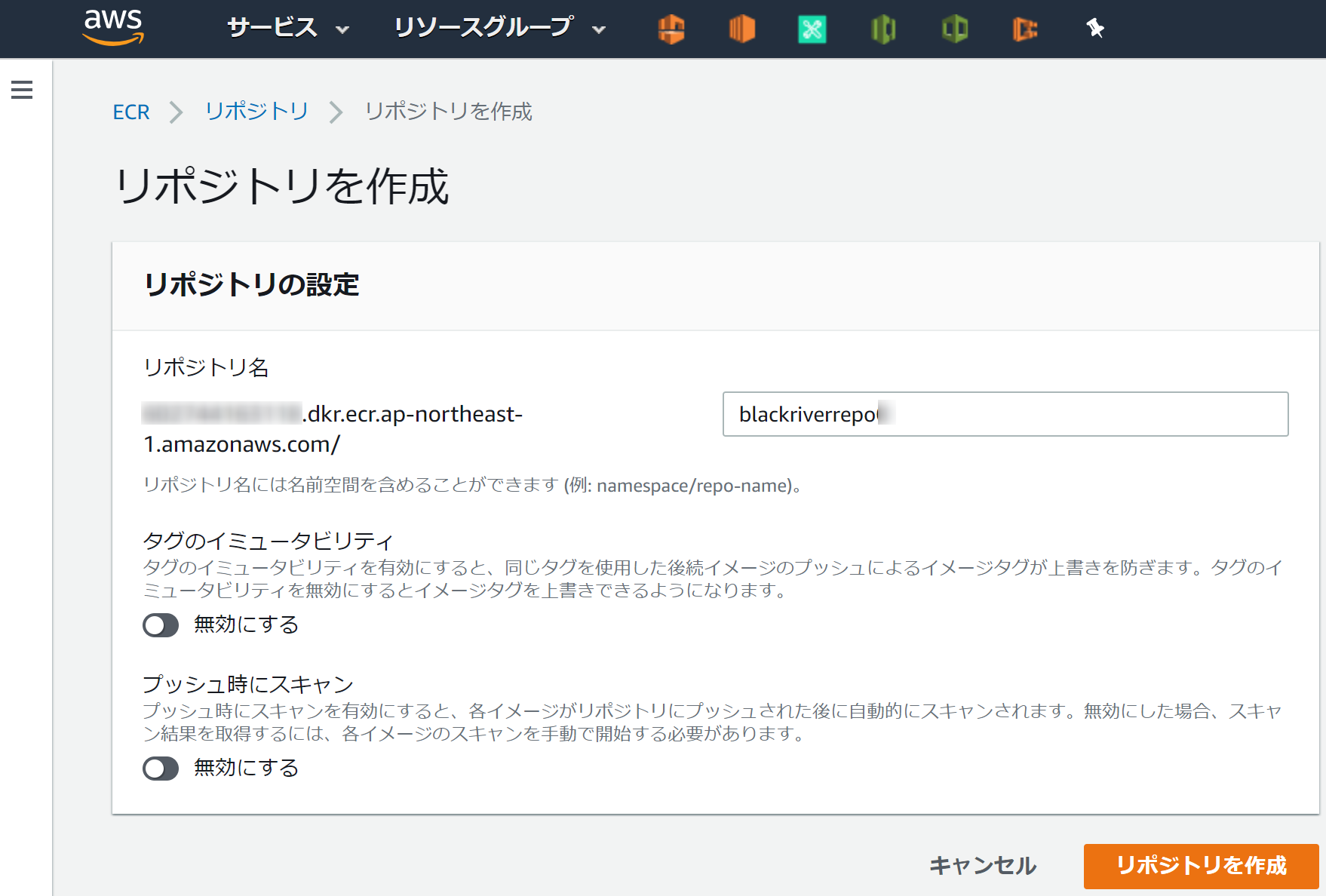
ECRでリポジトリを作成する ( リポジトリ名前
blackriverrepo) 他の設定はデフォルト値を使用
Cloud9からECSにアクセス
Cloud9-Terminal$ aws ecr get-login --no-include-email --region ap-northeast-1 # -> Dockerログインコマンドでてくる(長くてビビる)取得したDockerログインコマンドをCloud9上のターミナルで実行し、
login Succeededと表示でれば成功。ECRで作成したリポジトリ
blackriverrepoを選択し、プッシュコマンドの通知ボタンをクリックすると、基本コマンドでてくる ※ 手順1,2は実施済み
ECS上のリポジトリにイメージをプッシュするために、Dockerイメージにタグを付ける
Cloud9-Terminal$ docker tag volumedemo:latest xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/blackriverrepo:latest # タグが付いたか確認 $ docker image lsECRで作成したリポジトリ
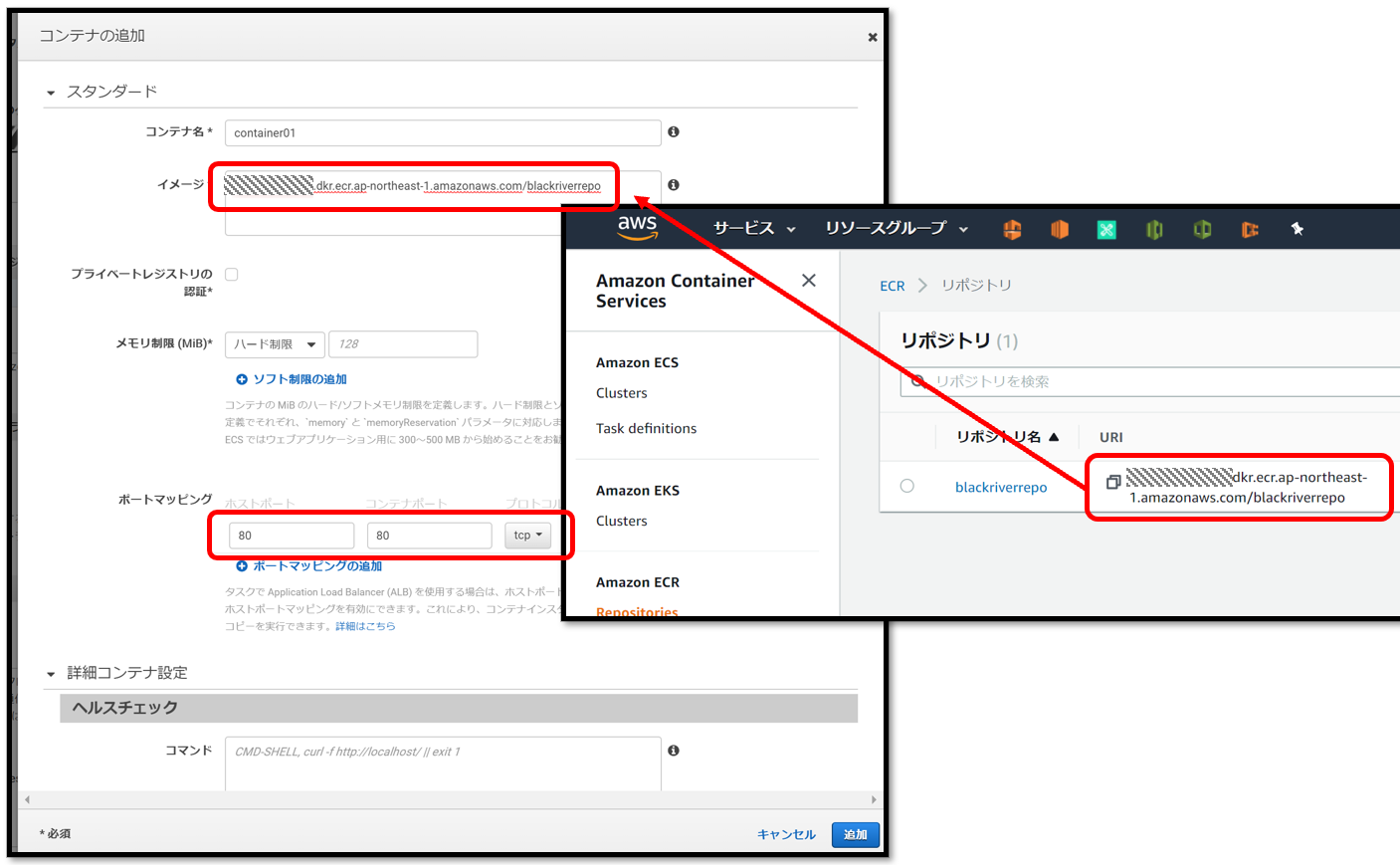
blackriverrepoにDockerイメージをpushするCloud9-Terminal$ docker push 602744163118.dkr.ecr.ap-northeast-1.amazonaws.com/blackriverrepo:latestECR のリポジトリを確認し、イメージURI
xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/blackriverrepo:latestがあれば成功Cloud9-Terminal# ECR のリポジトリはコマンドでも確認できる $ aws ecr describe-repositories --region ap-northeast-1 # コマンドでリポジトリの内容確認もできる $ aws ecr describe-repositories --region ap-northeast-1 --repository-name blackriverrepoAWSコンソールで確認するとこんな感じ
(おまけ)ECRからCloud9にDockerイメージをpullできるか確認
Cloud9-Terminal# Cloud9からのDockerイメージを消す $ docker rmi xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/blackriverrepo # Cloud9でpullしてECRからDcokerイメージ取得 $ docker pull xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/blackriverrepo # -> キャッシュに残ってる場合はすぐ取得できる # -> docker images で xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/blackriverrepo があれば成功Cloud9-Terminal# pullしたイメージでDockerコンテナ起動してみる # コンテナ起動 $ docker run --name blackriver -d -p 8080:80 xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/blackriverrepo:latest # コンテナ確認 $ docker ps -ls # Webサイト確認 $ curl http://localhost:8080/index.html3.クラスターを作成する
ECSにクラスターを作成。今回はFargate使わずEC2(linux)にする
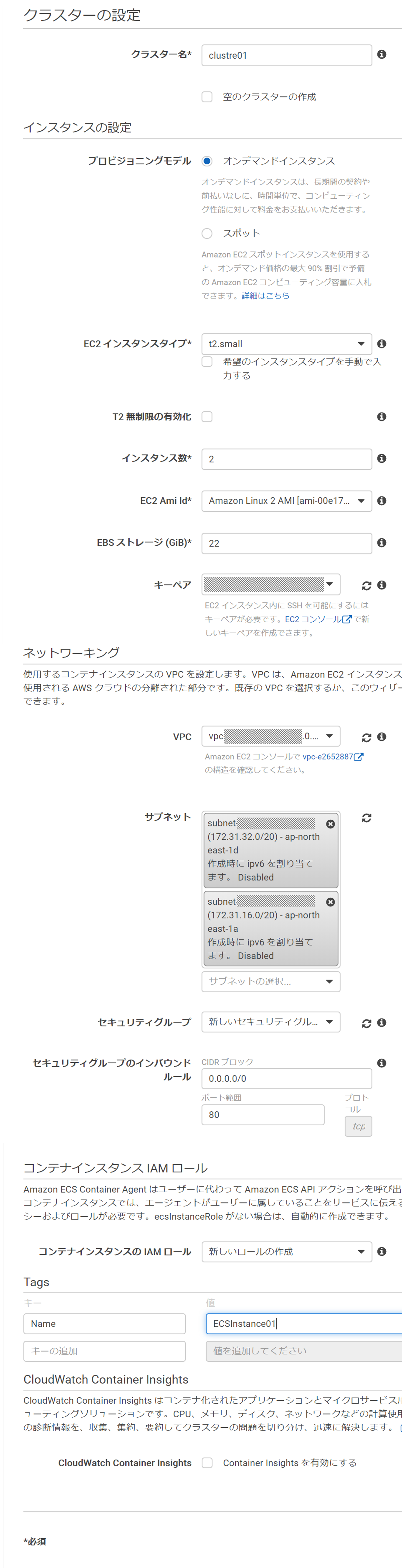
ECSでクラスターを作成する(今回は EC2(linux) で作る) ※cloud9と同じVPCにする
- クラスターの構成
- クラスター名:cluster01
- プロビジョニングモデル:オンデマンドインスタンス
- EC2インスタンスタイプ:t2.small
- インスタンス数:2
- EC2 Ami Id:Amazon Linux 2 AMI
- EBSストレージ:22
- キーペア:{既存のキーペア指定} <- コンテナに入るなら設定しておく
- VPCはcloud9と同じデフォルトVPC
- セキュリティグループ:
新しいセキュリティグループ- コンテナインスタンスIAMロール:
新しいロールの作成- Tags:
Name,ECSInstance01設定時の画面 *クリックで拡大
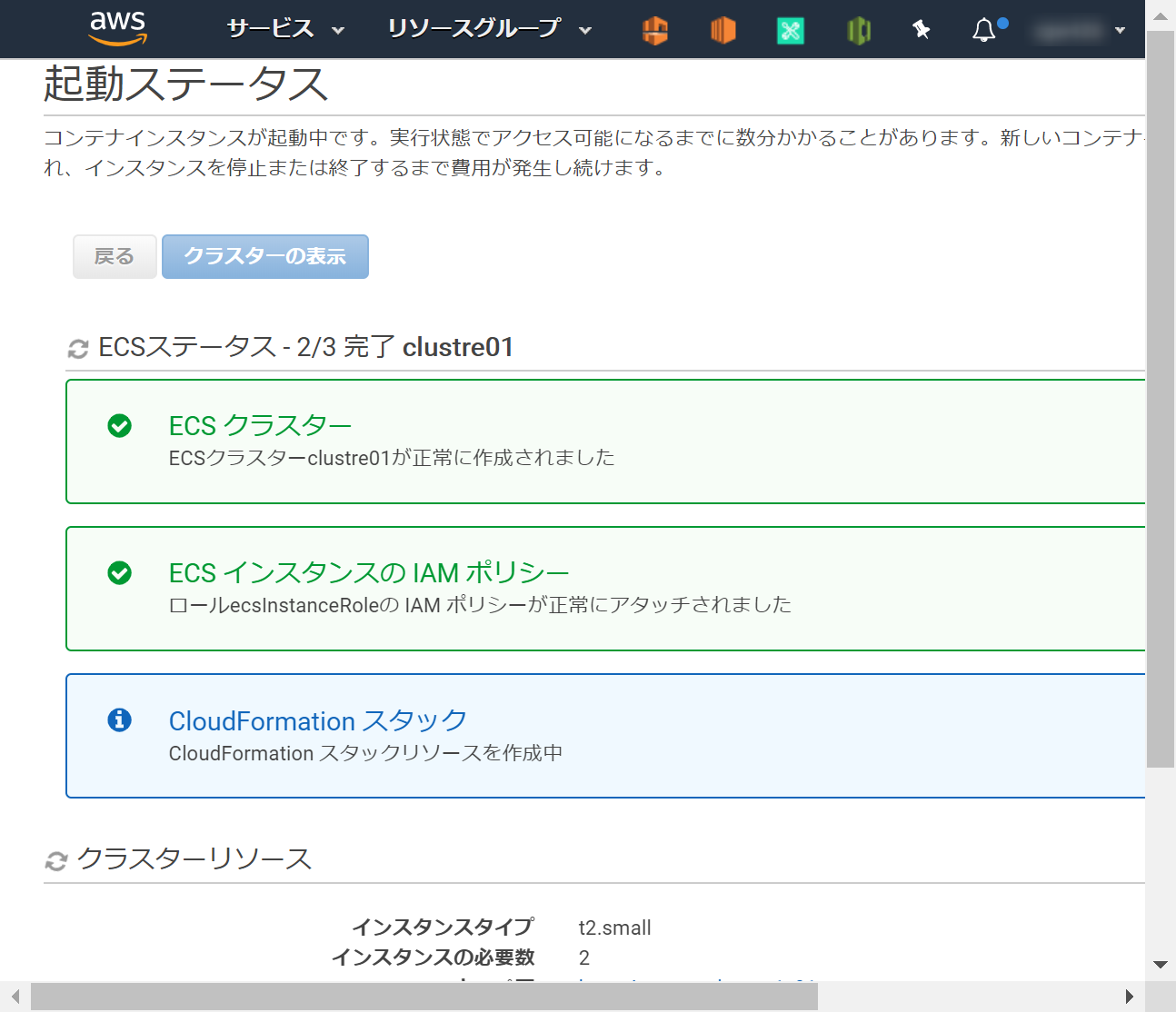
作成がはじまる
ECSインスタンスが2つ
ACTIVEになると成功
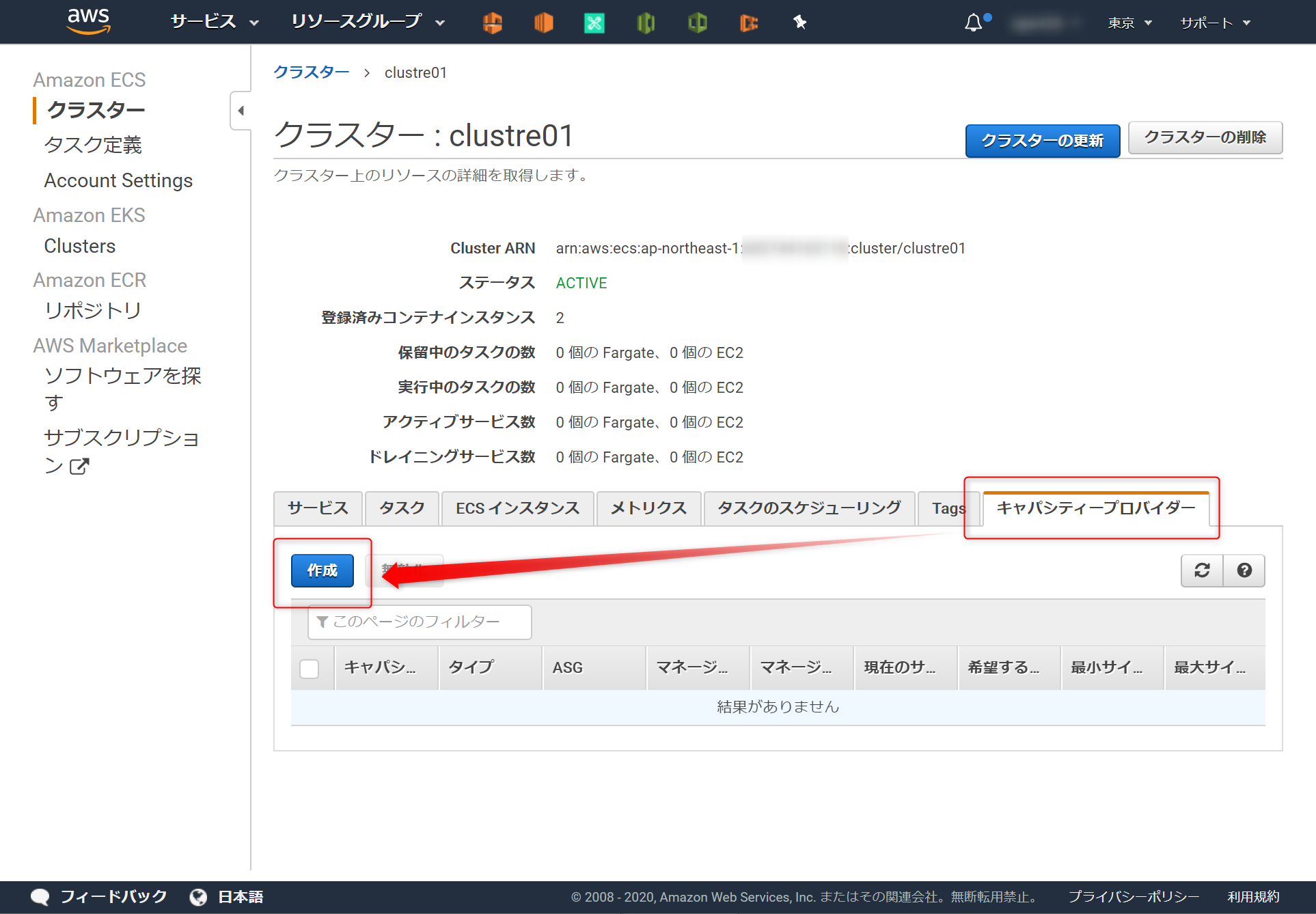
4.(オプション)キャパシティープロバイダーを設定する
キャパシティープロバイダーは設定しなくてもDockerコンテナを起動できる
なので、この章(4章) はやらなくてもよい。(←これに気が付かず苦労した)
キャパシティープロバイダーの設定は、ECSに作ったクラスターに対する設定
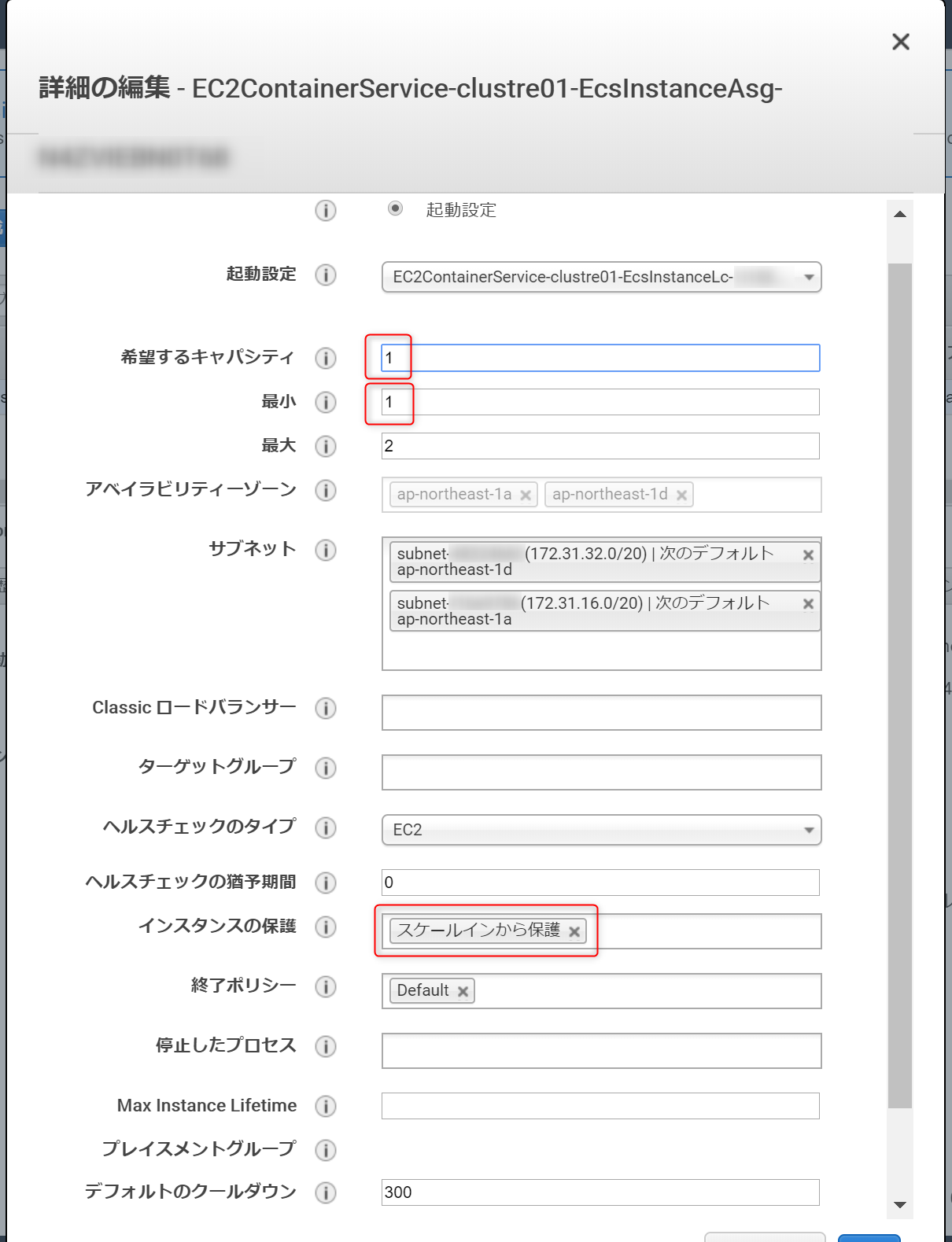
設定するには、ECSに紐づくAutoScalling側でスケールイン保護の設定が必要4-1.AutoScalling
スケールインから保護ECSに紐づくAutoScallingを編集
インスタンス保護を設定
キャパシティの最小値は0になっているが 1 以上にすることをオススメ
0だと、EC2インスタンスが0になる可能性がある
EC2インスタンスが0の状態で、ECSでタスク実行すると『キャパシティーが無い』旨のメッセージがでる ※本記事のトラブルシュート参照
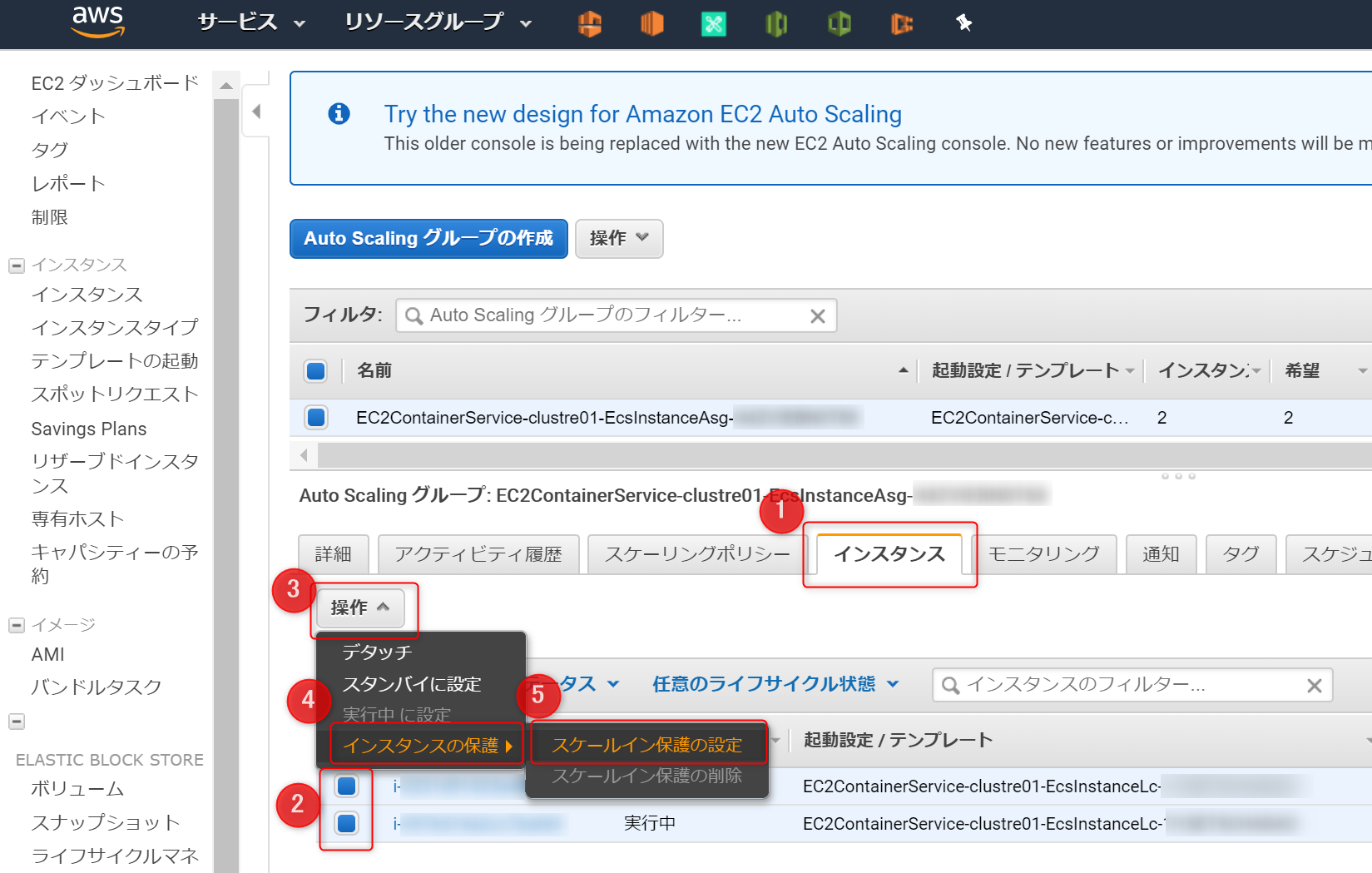
4-2.AutoScalling
スケールイン保護の設定所属するEC2インスタンスを選択し、
スケールイン保護の設定を設定する
4-3.ECS のクラスター
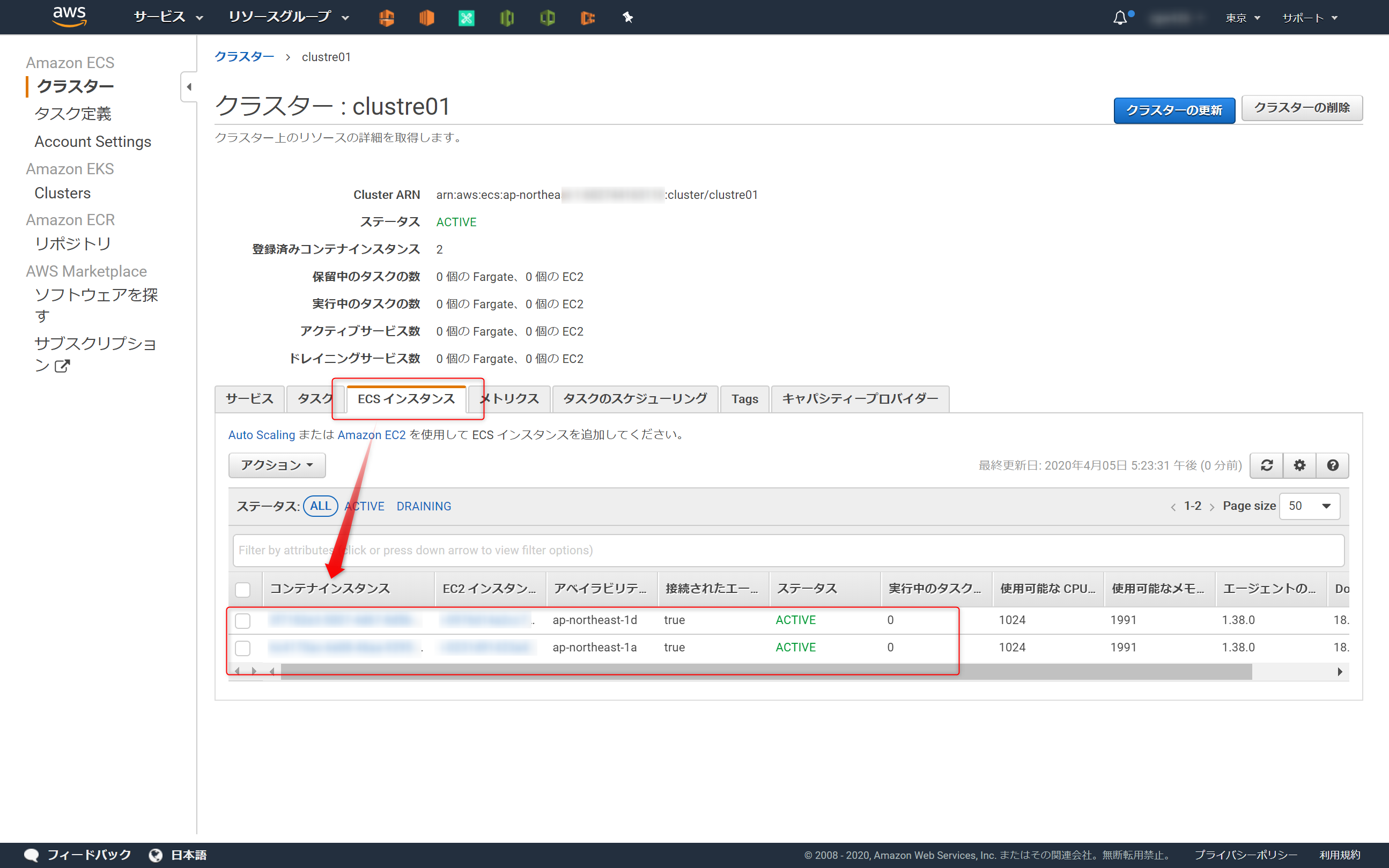
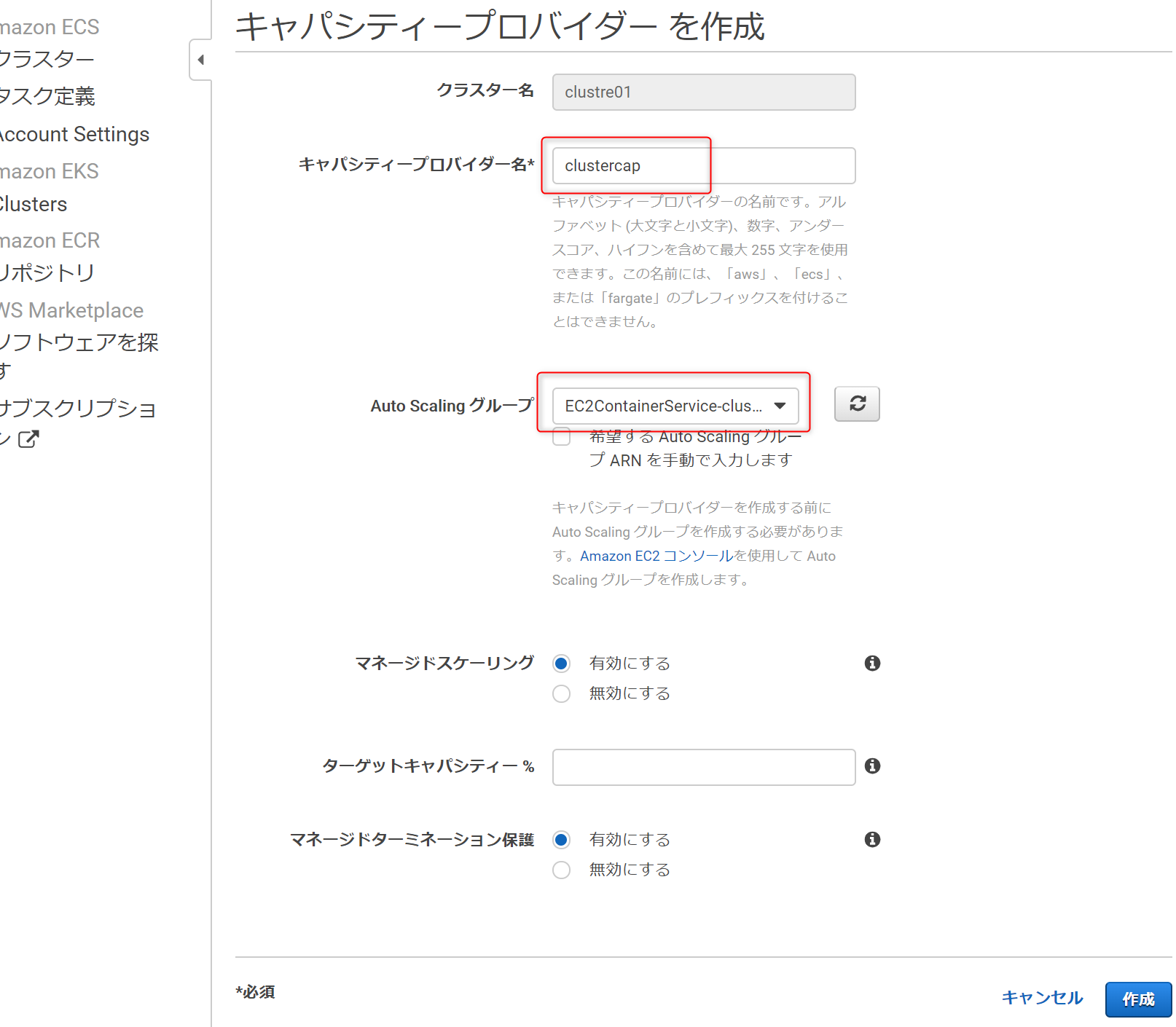
clustre01にキャパシティー作成
5.タスク定義を作成->実行する
タスク定義を作り実行すれば、Dockerコンテナが起動する。
- タスク定義とは?を粗く理解
- json形式
- コンテナ起動の設計書
5-1.タスク定義を作成
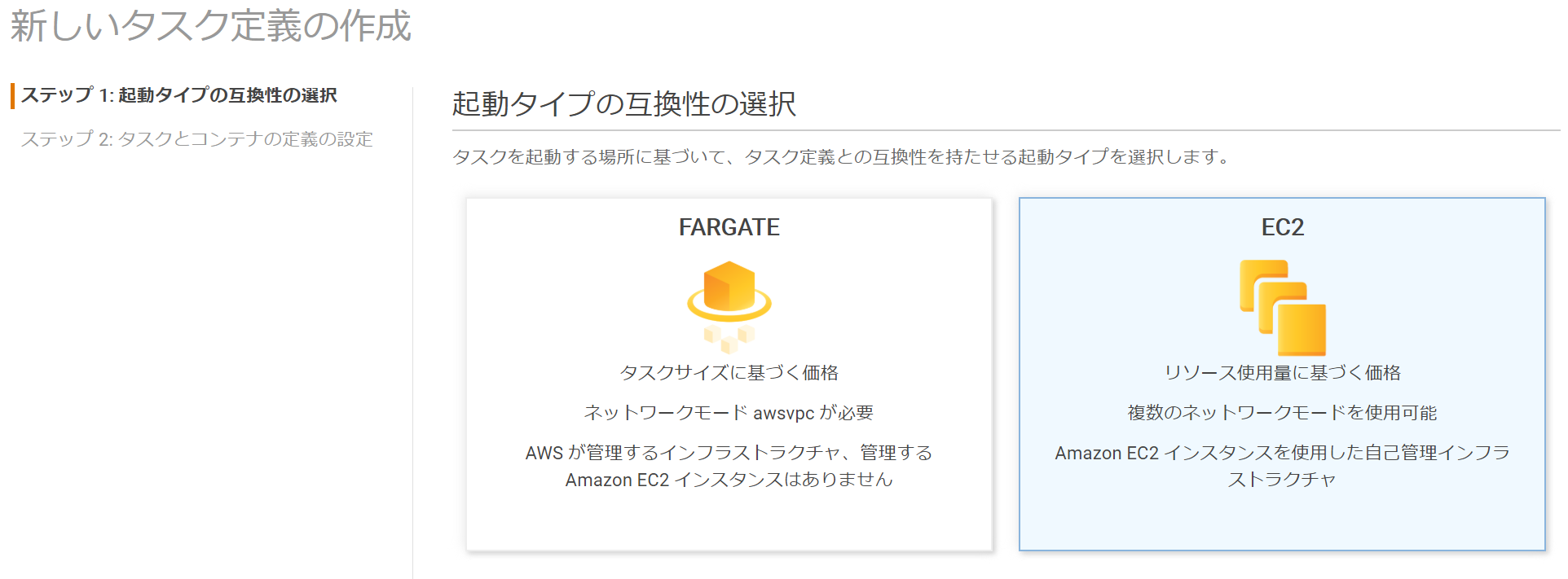
起動タイプ EC2 を選択
コンテナ追加
コンテナ名,リポジトリのURI,ポートマッピングを設定
こんな感じで登録される
作成する
5-2.タスク定義を実行
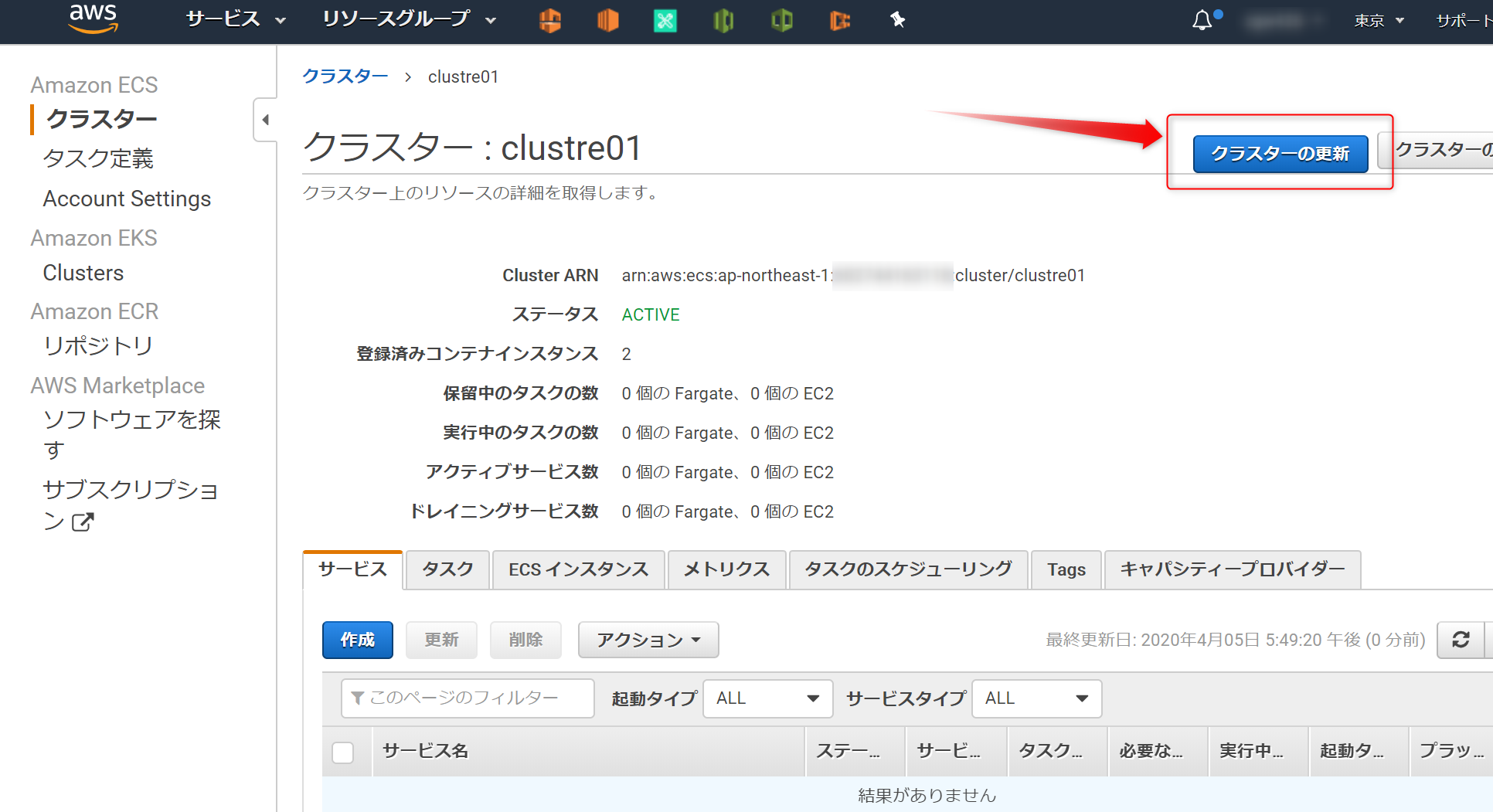
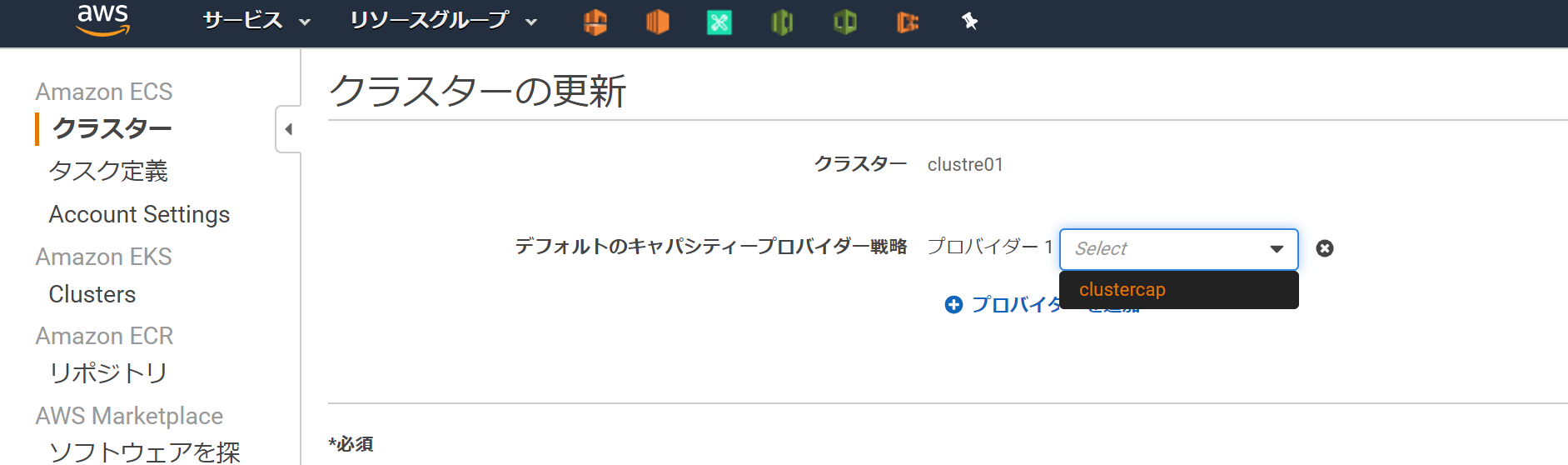
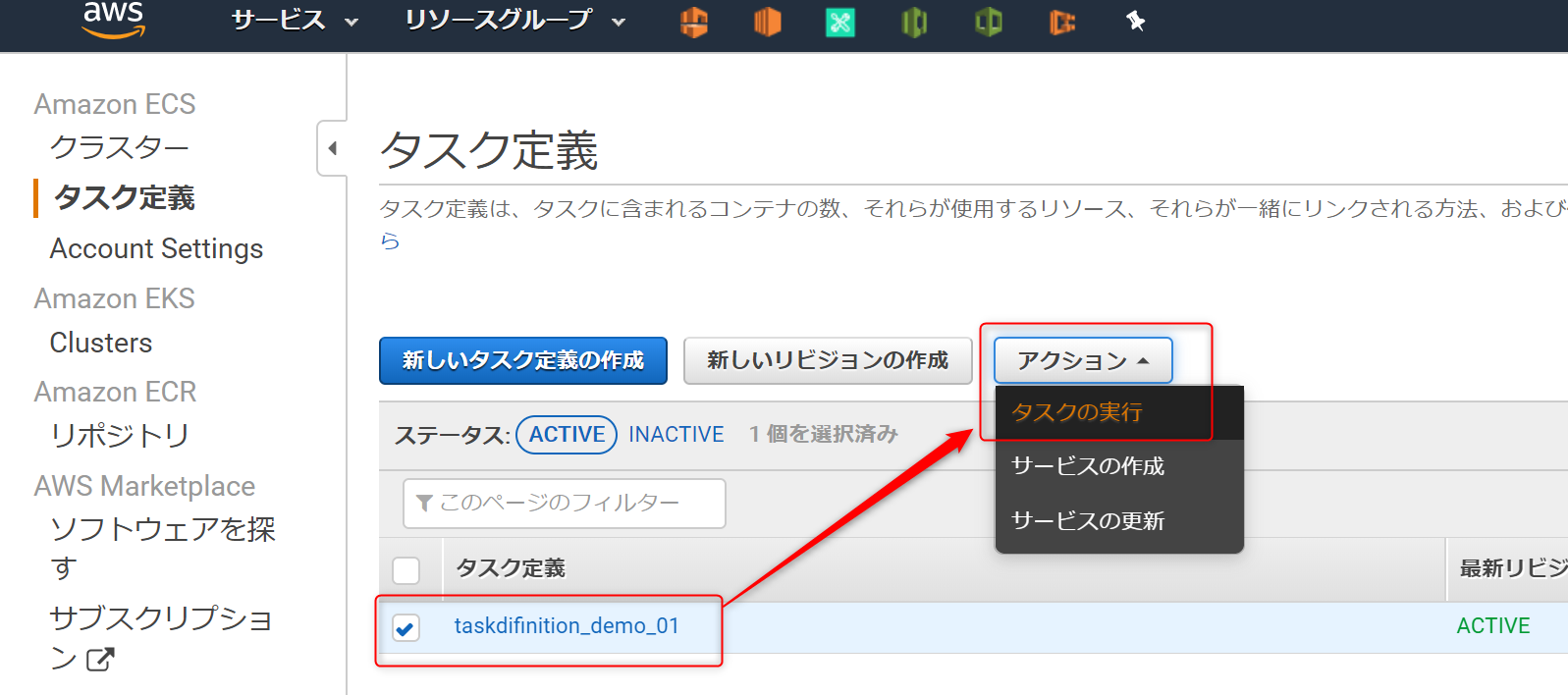
4.(オプション)キャパシティープロバイダーを設定するを実施していない場合は、このような画面になる。赤枠のメッセージは、4を実施していないため、その下の起動タイプへ切り替えるをクリックし、(今回であれば)EC2を選択すればよい。
※おまけ※
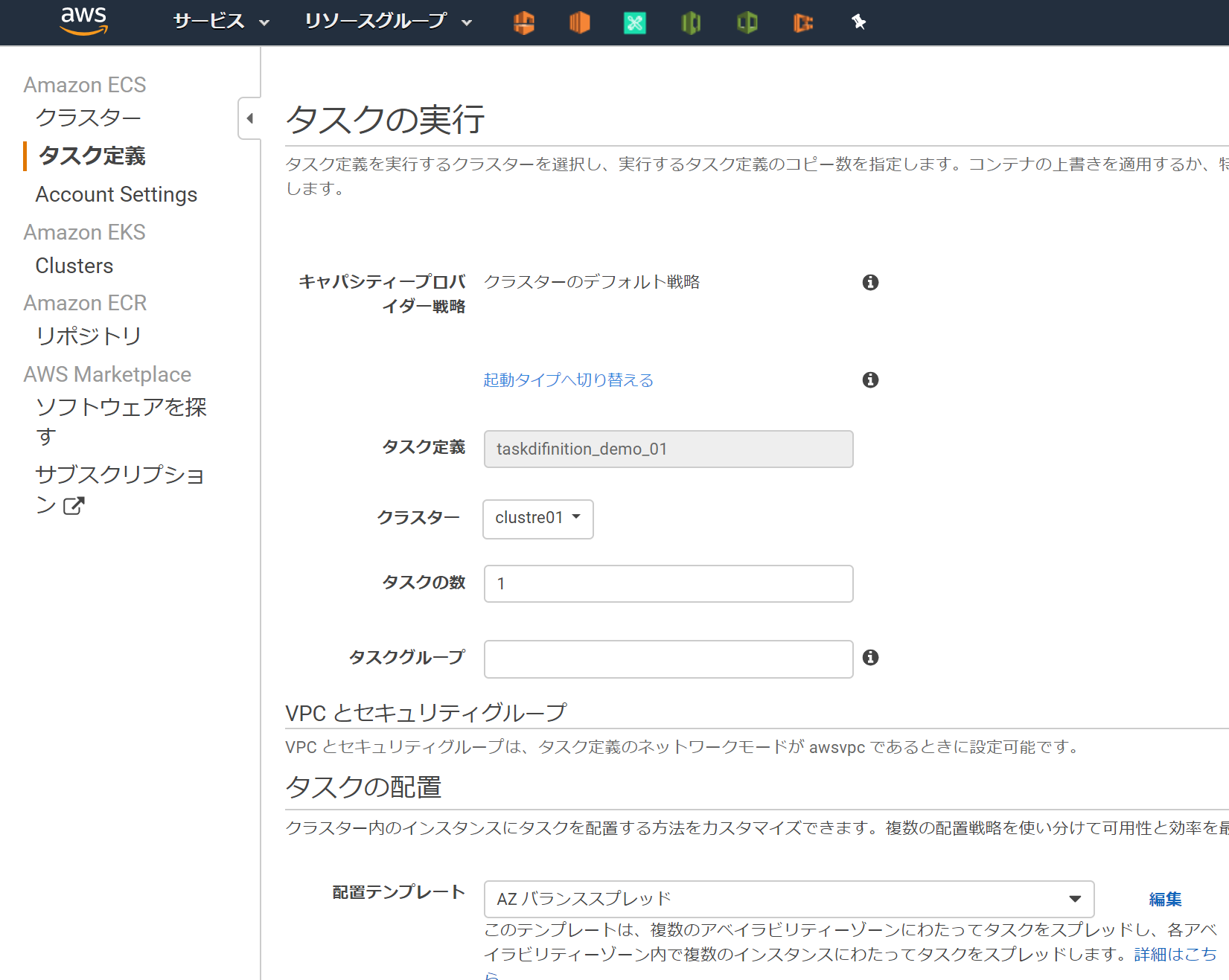
4.(オプション)キャパシティープロバイダーを設定するを実施した場合は、このように赤枠のメッセージが出ない。
5-3.動作確認
Webサイトが開けば成功。
※ Cloud9(Webサイトにアクセスする環境)とクラスターに所属するEC2インスタンスが通信できるようSG(セキュリティグループ)を設定する。
Dockerコンテナが起動しているEC2インスタンスのローカルIPを確認するとアクセスするURLがわかる。
Cloud9-Terminal$ curl http://{Dockerコンテナが起動しているEC2インスタンスのローカルIP}/index.html # -> 以下のような結果になれば成功 # <html><head><title>test</title></head><body><h1>TEST</h1></body></html>今回はこれでおわり
トラブルシュート
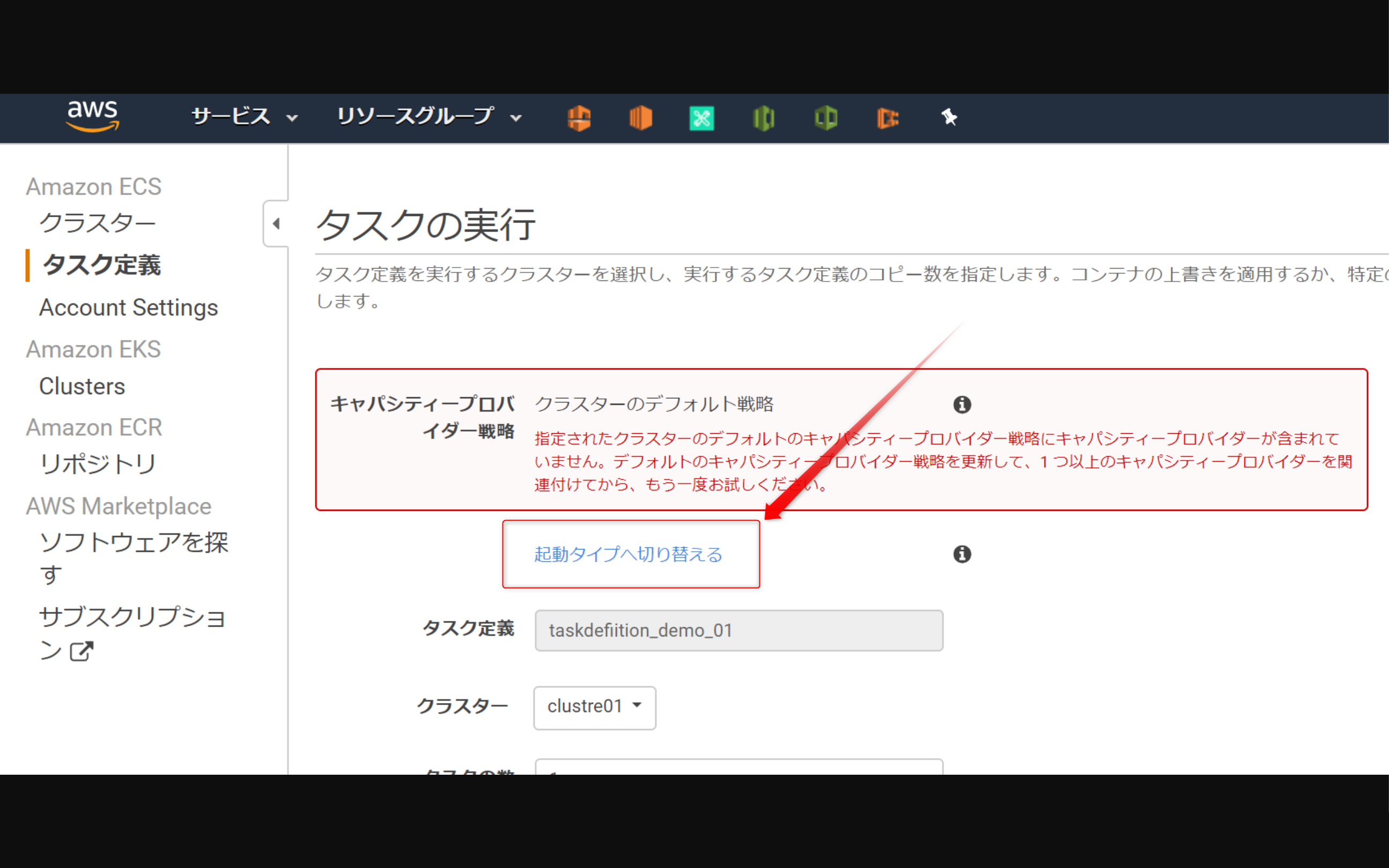
タスク実行したときにキャパシティープロバイダー戦略のエラー発生
↓赤枠のメッセージ↓
キャパシティープロバイダー戦略
クラスターのデフォルト戦略
指定されたクラスターのデフォルトのキャパシティープロバイダー戦略にキャパシティープロバイダーが含まれていません。デフォルトのキャパシティープロバイダー戦略を更新して、1 つ以上のキャパシティープロバイダーを関連付けてから、もう一度お試しください。
- <考えられる原因>
- (1) ECSに作成したクラスターにキャパシティープロバイダーの設定がない
- (2) キャパシティープロバイダーに設定したAuto Scalling に
スケールイン保護の設定されたEC2インスタンスがない- <考えられる対策>
- (1)の対策案-1:本記事【4.(オプション)キャパシティープロバイダーを設定する】を実施しキャパシティープロバイダーを設定する
- (1)の対策案-2:
キャパシティープロバイダーを使わない。起動タイプへ切り替えるをクリックする。本記事【5-2.タスク定義を実行】参照- (2)の対策案:本記事【4-1.AutoScalling スケールインから保護】を参照し、Auto Scalling に最低1つ
スケールイン保護の設定されたEC2インスタンスが含まれるようにする。











- 投稿日:2020-04-06T04:41:23+09:00
Serverless Components はオレたちの未来を劇的にスケールさせるか
Serverless.inc 社より、Serverless Components がついに GA されました。
近年のアプリケーション開発では、いくつかの SaaS を組み合わせることで超高速に開発を行うことができます。例えば「認証は Auth0、ホスティングは Netlify、バックエンド API は AWS Lambda を使用する」といった具合です。このように複数のサービスを組み合わせることで、Undifferentiated Heavy Lifting な作業を排除できます。開発者は価値を生み出すビジネスロジックにのみ集中できるようになるのです。
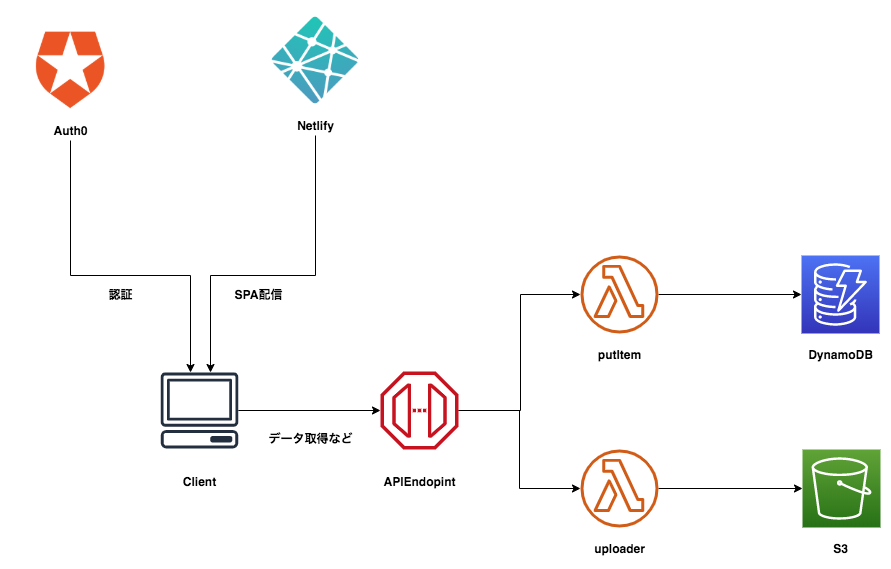
以下はサーバレスアーキテクチャの例です。複数の SaaS を組み合わせて構築しています。
SaaS を組み合わせるだけで、一定の機能群を作り上げることができる時代になりました。しかし、それにしても複雑な管理は残ります。アプリケーション開発者は複数のサービスを手作業で組み合わせなければならず、構築と構成管理に一定の複雑度を残してしまいます。
そこで、Serverless Components です。
Serverless Components は、全てのクラウドベンダー、 SaaS ベンダーに対してインフラとアプリをプロビジョニングします。すでに提供されているコンポーネントを組み合わせるだけで即座にアプリケーションを構築できます。
従来 Serverless Framework は function と event は簡単に定義できていましたが、インフラリソースをプロビジョニングするためにはどうしても Cloudformation を定義する必要がありました。
また、プロビジョニングできる対象も AWS や GCP などの特定のクラウドベンダーのサービスにしか対応しておらず、Auth0 などを使用する場合は自前で構成管理をする必要がありました。Serverless Components なら様々な SaaS に対応できます。コンポーネント
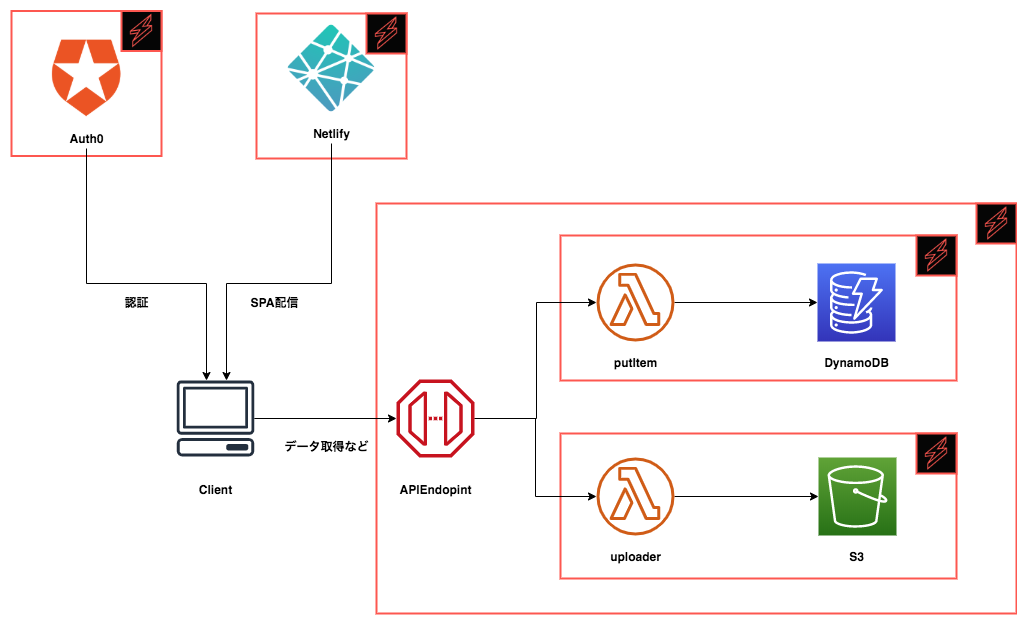
Serverless Component は React のコンポーネントと同じ構造に基づいています。個々のコンポーネントを参照したり、複数のコンポーネントを同時に作成できます。
先の例をコンポーネントを使用して構築すると以下のように分解ができます。もちろん、より小さくコンポーネントを分割することもできます。ここでは最小の意味のある単位で分割した場合を図示しています。
サーバレスコンポーネントは、高次のユースケース(ウェブサイト、ブログ、請求システムなど)を中心に構築されています。関係のない低レベルなインフラの詳細は抽象化され、代わりに単純な構成が提供されます。例えば、S3 の静的サイト公開設定や、ログ記録、暗号化設定などはユースケースに対しては意識する必要はありません。事前に設定済みのコンポーネントを使用すれば良いのです。
これはソフトウェア開発における基本的な考え方 関心の分離 (Separation of Concerns: SoC) に基づいていますね。確かに Infrastructure as Code をやっていると、インフラリソースの細部まで理解して構築する必要があり、多大な学習コストを要していました。
ServerlessComponents を使用したウェブサイト
さて、まずは最もシンプルなアプリケーションを Serverless Component を使用して構築してみましょう。
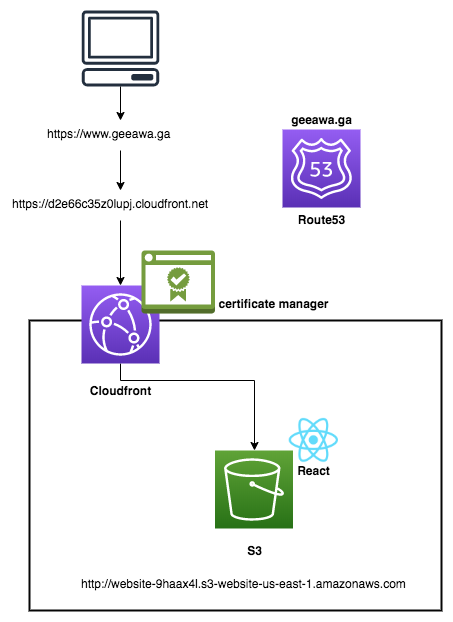
ここでは、GitHub のリポジトリでも例としてあげている サーバレスウェブサイト を構築することにします。今回構築するウェブサイトは、AWS S3 でホストされます。無料の AWS ACM SSL 証明書で保護された AWS Route 53 のカスタムドメインでアクセスします。さらに、静的コンテンツは、AWS Cloudfront を使用して迅速かつグローバルに配信されます。
従来このような構成を実現する場合、ServerlessFramework に直接 Cloudformation を書き下し、各リソース間の詳細な設定と依存関係を意識する必要がありました。数百行の Cloudformation のテンプレートが必要でしょう。
Serverless Components を使用する場合はこれだけです。
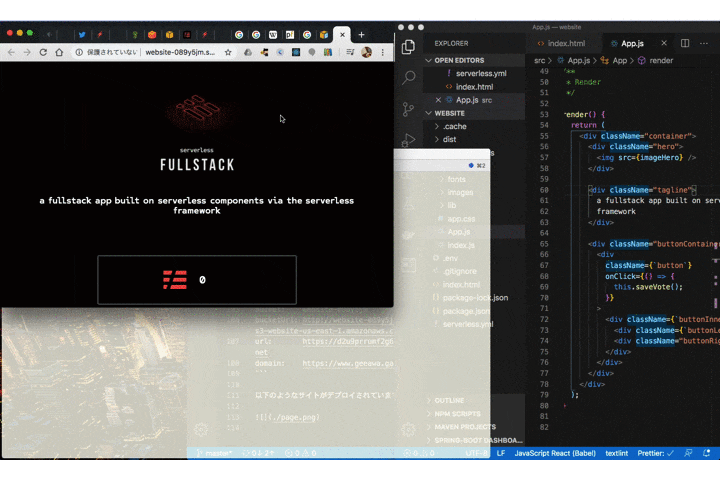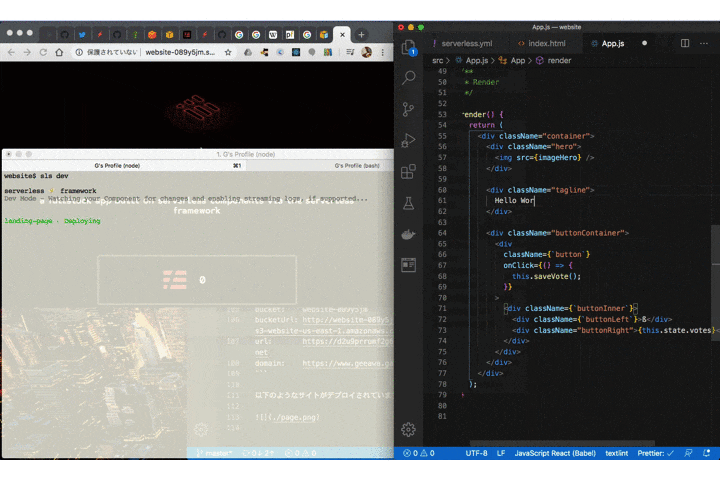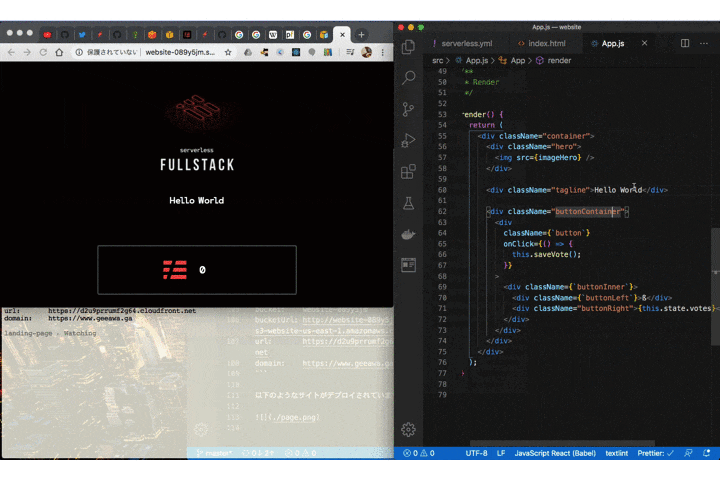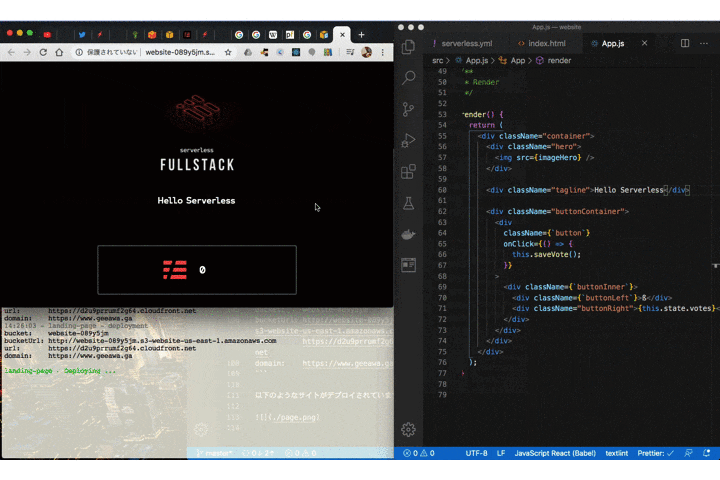
component: website name: website inputs: src: src: ./src hook: npm run build dist: ./dist domain: geeawa.ga驚異的なほど、シンプルです。
component: websiteとして、website コンポーネントを使用することを宣言し、そのコンポーネントに渡す設定値をinput:にて指定しています。ただ、それだけです。Serverless Components を使用してウェブサイトを構築する
実際に website コンポーネントを使用してこの構成を作ってみましょう。
Install
まずは最新バージョンの Serverless Framework をインストールします。
$ npm install -g serverlessCreate
サンプルとして、以下のようにテンプレート URL を指定して構築します。
$ serverless create --template-url https://github.com/serverless/components/tree/master/templates/website $ cd website次に、
.envファイルを使用して AWS アクセスキーの情報を記載しましょう。.envファイルはwebsiteのルートディレクトリに作成します。AWS_ACCESS_KEY_ID=XXX AWS_SECRET_ACCESS_KEY=XXXディレクトリ構成は以下のようになっているはずです。
|- src |- index.html |- serverless.yml |- .envDeploy
あとはデプロイをするだけです。
$ serverless deployデプロイが完了すると以下のようにウェブサイトの URL が発行されます。Cloudfront へ配信が完全に完了するまでに少し時間がかかることに注意してください。
serverless ⚡ framework Action: "deploy" - Stage: "dev" - App: "landing-page" - Instance: "landing-page" bucket: website-089y5jm bucketUrl: http://website-089y5jm.s3-website-us-east-1.amazonaws.com url: https://d2u9prrumf2g64.cloudfront.net domain: https://www.geeawa.ga以下のようなサイトがデプロイされています。
Dev Mode
さらに興味深い機能として Dev Mode があります。開発中にソースディレクトリの変更を監視し、保存すると即座にデプロイできます。
Remove
作成されたインフラを破棄する場合は、serverless.yml ファイルが含まれているディレクトリで次のコマンドを実行するだけです。
$ serverless removeコンポーネントを自作する
コンポーネントを自作するためには以下の2つのファイルが必要です。
- serverless.component.yml: ServerlessComponent の定義を記入します。
- serverelss.js: ServerlessComponent のコード(実装)を記述します。
serverless.component.yml
コンポーネントをサーバーレスレジストリ内で利用できるようにするためには
serverless.component.ymlを作成する必要があります。# serverless.component.yml name: express # 必須 コンポーネント名 version: 0.0.4 # 必須 バージョン author: eahefnawy # 必須 著者 org: serverlessinc # 必須 開発組織名 description: Deploys Serverless Express.js Apps # 任意 説明 keywords: aws, serverless, express # 任意 registry.serverless.comで検索するときに引っかかるキーワード repo: https://github.com/owner/project # 任意 ソースコードのリポジトリURL license: MIT # 任意 ライセンス main: ./src # 任意 コンポーネントのソースコードが格納されているディレクトリserverless.js
serverless.jsには以下のように実装していきます。React の思想にインスパイアされており、Componentを継承したつくりになっています。deploy,removeなどの Function を書いていくことになります。// serverless.js const { Component } = require("@serverless/core"); class MyBlog extends Component { async deploy(inputs) { console.log("Deploying a serverless blog"); // --debug モードで実行するとログが出力されます。 this.state.url = outputs.url; // stateに保存する return outputs; } } module.exports = MyBlog;
deploy()は必ず書く必要があります。deploy()は、コンポーネントが何らかのクラウドリソースを作成するためのロジックが存在する場所です。serverless deployコマンドを実行すると、常にdeploy()メソッドが呼び出されます。このクラスに他のメソッドを追加することもできます。
remove()ではサーバレスコンポーネントが作成したクラウドリソースを全て削除します。他にもメソッドはいくつでも追加できます。コンポーネントを追加機能付きでプロビジョニングしたい場合などに拡張できる作りになっています。
Serverless Components は
test(),logs(),metrics()機能を備えたコンポーネント、またはデータベースコンポーネントの初期値を確立するためのコンポーネントseed()の開発に着手しているようです。メソッド以外の
deploy()メソッドはすべてオプションです。すべてのメソッドは、inputs個別の引数ではなく単一のオブジェクトを取り、単一のオブジェクトoutputsを返します。まとめ
クラウドや SaaS ベンダーのリソースを統一的に管理し、再利用可能にするプラットフォームが Serverless Components です。
現在公式が提供しているコンポーネントは 67 種類(2020/04/06 現在)です。
まずは AWS や Kubernates 関連がラインナップし始めています。急激に拡大しています。もう 本当に必要なものだけを実装し、組み合わせるだけ という開発スタイルに変わりはじめています。これこそがクラウドテクノロジーの目指していたところかもしれません。さらなる発展が楽しみですね。

- 投稿日:2020-04-06T00:13:45+09:00
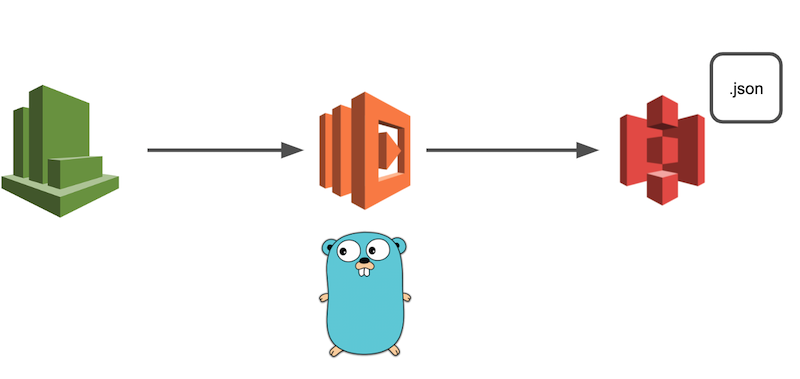
S3へファイルをアップロードするLambda関数をSAMで書く
はじめに
この記事は、AWS SAMを用いてファイルをS3にアップロードするLambda関数を作成する記事です。
やりたいこと
今回は、何かしらのファイル(本記事ではJSON)をS3にアップロードする処理を、AWS SAMを用いてCloutWatchイベントから定期的に発火させる、ということをやっていきます。
開発環境
- macOS Catalina
- vim
- Golang (1.12.6)
- aws-sam-cli
- Minio
SAMの設定
今回はAWS SAMというAWSが提供しているオープンソースフレームワークを用いてLambda関数の環境を構築します。
SAMを使うことによって、構成管理やソースコードのアップデートやデプロイなどをコマンド1つで完了することが出来るのでとても便利です。
今回はAPI-Gatewayなどは使用せずLambda関数のみを作成するだけなのでSAMの恩恵はちょっと感じられにくいですが、AWSを使って何か開発をやってみようと考えている人は是非導入してみましょう。
SAMの導入手順は公式ドキュメントやそれを分かりやすく解説している記事があるのでこの記事では省略します。
実装してみる
ここからは、SAMの設定などを既に完了しており、Lambda関数を作成できている前提でお話しします。
今回実装したリポジトリはこちらです。
ファイル構成
├── Makefile <-- ローカル実行コマンドなどをまとめたファイル ├── README.md ├── src <-- Lambda関数のソースコード └── fetcher └── urlFetcher.go <-- URLからJSONを取得する処理を記述したファイル ├── handler └── handler.go <-- mainパッケージから実行される処理 ├── json └── jsonWorker.go <-- JSONファイルの作成や書き出しなどを行う処理 ├── s3 └── uploader.go <-- Sessionの生成やアップロードを行う処理 ├── docker-compose.yaml <-- ローカル開発用のMinioコンテナの情報 └── template.yaml <-- Lambdaなどの全体構成を指定するファイルSAMテンプレートの設定
今回作成するLambda関数のインフラストラクチャ及びコンポーネントの設定をします。
設定はtemplate.yamlに全て書き込みます。buildやdeployをする際、このファイルを元にLambda関数が作成されます。
詳しいパラメータについては公式ドキュメントを参考にしてください。
例えば、1時間に1回発火するLambda関数を作成する場合の設定は以下の通りです。Resources: SampleFunction: Type: AWS::Serverless::Function Properties: CodeUri: src/ Handler: handler FunctionName: SampleFunction Runtime: go1.x Tracing: Active Events: CatchAll: Type: Schedule Properties: Schedule: rate(1 hour) Name: one-hour-rule Description: Exec each one-hour Enabled: True Environment: Variables: PARAM1: VALUEMinioの環境構築
今回、S3へのアップロードを行うLambdaの開発を行うわけですが、ローカルでの開発を行う際に実際のバケットにアクセスしてファイルを追加したり削除したりするのはちょっと怖いですよね。
そこで今回はMinioというクラウドストレージサーバをローカルではS3のバケットに見立てて開発をしていきます。
これを使うことでlocalhost上でバケットの作成やファイルの追加・削除をすることが出来るので安心です。
MinioはDockerイメージを公開しているので、Minioの環境構築自体はdocker-composeファイルを作成するだけです。
version: "2" services: minio: image: minio/minio ports: - "9000:9000" command: [server, /data] environment: - "MINIO_ACCESS_KEY=dummy" - "MINIO_SECRET_KEY=dummy" - "MINIO_REGION=ap-northeast-1" restart: always networks: default: external: name: sample_network特に注目したいのが
environmentです。通常、S3のバケットにアクセスするにはIAMロールかAssume Roleの
Access Key IDとSecret Keyが必要になります。ここでは、Minioコンテナにアクセスする際のAccess Key IDとSecret Keyを設定できます。後ほど書きますが、この情報がCredentialを作成するときに必要となります。
environment/: - "MINIO_ACCESS_KEY=dummy" - "MINIO_SECRET_KEY=dummy" - "MINIO_REGION=ap-northeast-1"一度
docker-compose up -dを実行してMinioコンテナが立ち上がるか確かめてみましょう。docker ps [develop] CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 267811ea93f7 minio/minio "/usr/bin/docker-ent…" 3 weeks ago Up 3 weeks 0.0.0.0:9000->9000/tcp samplefunction_minio_1立ち上がっていることを確認できたら、実際にアクセスしてみましょう。
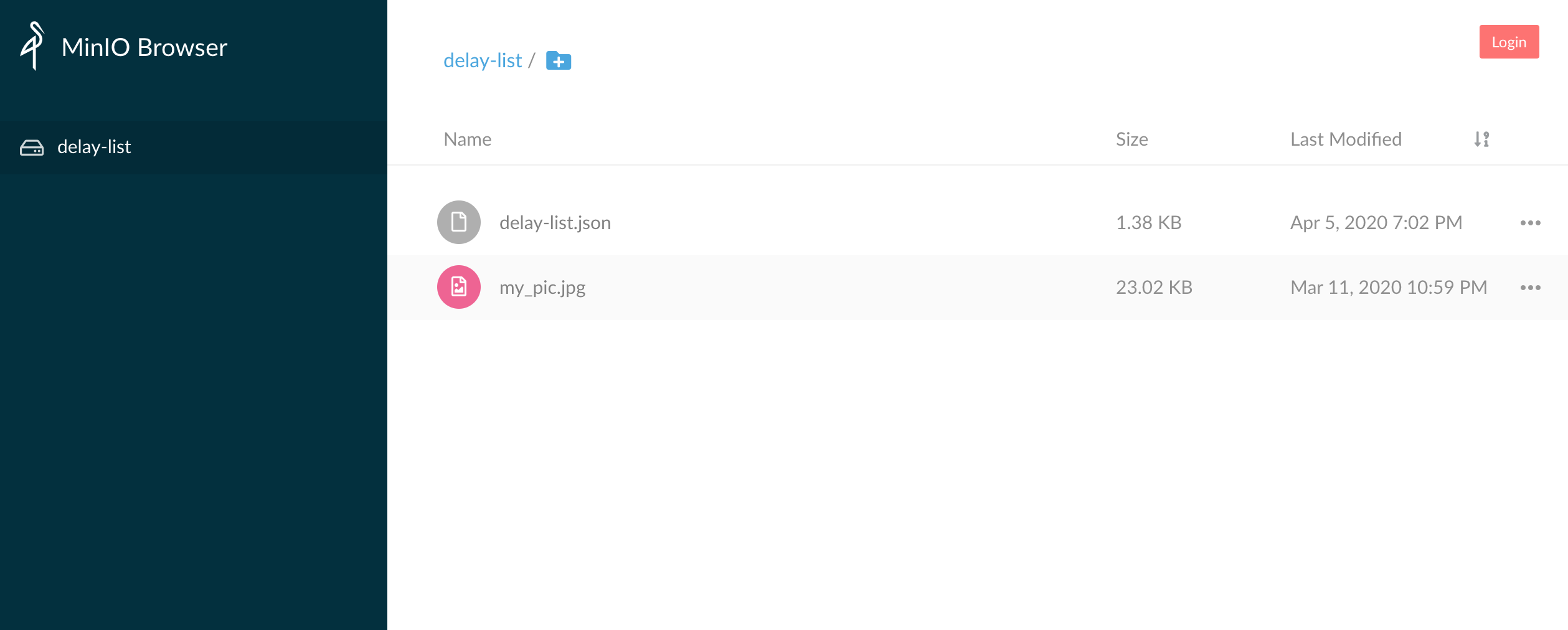
今回の場合だと、localhost:9000になります。
ちなみに、画面上からもバケットの作成やファイルのアップロードが可能ですので、予めバケットを作成するときは画面上からも行うことが出来ます。
今回私は画面上から作成しました。
ファイルに書き込みたい情報の準備
まずはファイルに書き込みたい情報を準備しましょう。
今回はサンプルとしてAPIなどを叩いて得られた情報をJSONに書き込んでいきます。
情報は、鉄道遅延情報のJSONから取得させていただきました。
? お約束:ローカルでこのサンプルをそのまま実行したりする場合は、鉄道遅延情報のJSONのお約束を必ず読んで理解した上で利用しましょう。決してアクセスしまくって迷惑をかけたりしないでください。 ?package urlFetcher import ( "io/ioutil" "log" "net/http" ) var ( url = "https://tetsudo.rti-giken.jp/free/delay.json" ) /** * Fetch Bytes from Web site */ func GetBytesFromUrl() []byte { resp, err := http.Get(url) if err != nil { log.Fatal("Can not get delay list! Error: %v", err) } defer resp.Body.Close() delayList, _ := ioutil.ReadAll(resp.Body) log.Printf("Succeeded to get Delay-list!") return delayList }基本ここは「golang URL get」などで調べてば参考記事がたくさん出てきます。
JSONファイルの作成などを行う前に、書き込むものを準備する必要があるのでここのfunctionではそれを作成している処理になります。
JSONの取得と保存
JSONファイルに書き込むものが準備できたところで、それをアップロードするためにファイルにする処理を記述します。流れとしては以下です。
- tempディレクトリにJSONファイルを作成するためのディレクトリと空のファイルを作成
- 作成した空のファイルにByte配列を書き込む
という感じです。
package JsonWorker import ( "fmt" "os" ) var ( tempDir = "/tmp/json/" bucketName = "delay-list" key = "delay-list.json" ) /** * Create empty JSON file on temp file and write bytes */ func CreateJSON(byteInfo []byte) error { if byteInfo == nil { return fmt.Errorf("create JSON error: %s", "nil bytes was given") } if err := os.MkdirAll(tempDir, 0777); err != nil { return err } file, err := os.Create(tempDir + key) if err != nil { return err } _, err = file.Write(byteInfo) if err != nil { return err } if isExist := isExistTempFile(tempDir); isExist != true { return fmt.Errorf("Temp file does not exist") } return nil } /** * Verify if exist temp file */ func isExistTempFile(tempFile string) bool { _, err := os.Stat(tempFile) return !os.IsNotExist(err) }JSONのアップロード
tempファイルに作成されたJSONファイルを実際にS3にアップロードする処理を書きます。
今回まずは、ローカルのMinioコンテナで作成したバケットにアップロードしてみましょう。
package s3Uploader import ( "log" "os" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/credentials" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3/s3manager" ) var ( bucketName = "sample" key = "sample.json" ) /** * Yield new session to upload file to S3 bucket */ func Upload(jsonFile *os.File) error { var sess *session.Session /* Yield credential for local */ log.Printf("Start process getting credential as a local") credential := credentials.NewStaticCredentials(os.Getenv("AWS_ACCESS_KEY_ID"), os.Getenv("AWS_SECRET_ACCESS_KEY"), "") sess, _ = session.NewSession(&aws.Config{ Credentials: credential, Region: aws.String("ap-northeast-1"), Endpoint: aws.String("http://172.18.0.2:9000"), S3ForcePathStyle: aws.Bool(true), }) _, err := sess.Config.Credentials.Get() if err != nil { log.Fatal("Load Credential File Error: %+v\n", err) } uploader := s3manager.NewUploader(sess) // Upload File With Custom Session _, err = uploader.Upload(&s3manager.UploadInput{ Bucket: aws.String(bucketName), Key: aws.String(key), Body: jsonFile, }) if err != nil { return err } log.Printf("Succeeded to upload delay list!") return nil }ここで難しいのが、Credentialの読み込みとSessionの作成です。
通常AWSのサービスを利用する場合には認証情報が必要です。今回行うS3へのアップロードも例外ではありません。
今回は
NewStaticCredentialsメソッドを使って認証情報を取得します。今はMinioへアクセスするために先ほどMinioのコンテナを作る際に設定したAccess Key IDとSecret Keyを使用します。os.Getenv()で取得することが可能です。credential := credentials.NewStaticCredentials(os.Getenv("AWS_ACCESS_KEY_ID"), os.Getenv("AWS_SECRET_ACCESS_KEY"), "")取得した認証情報をもとにS3にアクセスするためのSessionを生成します。ローカルなのでパラメータが多いですw
sess, _ = session.NewSession(&aws.Config{ Credentials: credential, Region: aws.String("ap-northeast-1"), Endpoint: aws.String("http://172.18.0.2:9000"), S3ForcePathStyle: aws.Bool(true), })生成したSessionをもとにUploaderを生成して実際にアップロードを行います。
uploader := s3manager.NewUploader(sess) // Upload File With Custom Session _, err = uploader.Upload(&s3manager.UploadInput{ Bucket: aws.String(bucketName), Key: aws.String(key), Body: jsonFile, })ローカルでの実行
ここまでできたら、実際に動かしてみましょう。まずはソースコードをbuildする必要があります。
sam buildbuildが完了したらlocalで実行するコマンドを叩きましょう。
sam local invoke SampleFunction
sam local invokeコマンドについてはオプションがたくさんあるので適宜追加をしましょう。
オプションについては、こちらを参考にしてください。
Dockerネットワークの指定とリージョンの指定とProfileの指定を行う場合は以下のようになります。
ネットワークの指定は、さきほど作成したMinioコンテナと同じネットワークに所属させる必要があるため、同じネットワーク名を指定してあげましょう。sam local invoke SampleFunction \ --region ap-northeast-1 \ --docker-network sample_network \ --profile minio_test何もエラーが起きずに実行が終了したら、Minioにアクセスしてファイルがアップロードされているか確認してみましょう。
本番環境とローカル環境の区別について
ローカルでの実行が完了し、いざデプロイ…といきたいところですが、今のままではMinioへのアップロードしかできていないため、このままデプロイをしてもアップロード処理でエラーになってしまいます。
ですので次は、実際にデプロイ後の動作とローカルでの動作を分ける処理を記述します。
先ほどのuploader.goのCredentialとSessionの生成の処理に分岐を加えます。
if os.Getenv("AWS_SAM_LOCAL") == "true" { /* Yield credential for local */ log.Printf("Start process getting credential as a local") credential := credentials.NewStaticCredentials(os.Getenv("AWS_ACCESS_KEY_ID"), os.Getenv("AWS_SECRET_ACCESS_KEY"), "") sess, _ = session.NewSession(&aws.Config{ Credentials: credential, Region: aws.String("ap-northeast-1"), Endpoint: aws.String("http://172.18.0.2:9000"), S3ForcePathStyle: aws.Bool(true), }) } else { /* Yield credential for production */ log.Printf("Start process getting credential as a production") sess, _ = session.NewSession(&aws.Config{ Region: aws.String("ap-northeast-1"), S3ForcePathStyle: aws.Bool(true), }) }注目すべきは、
os.Getenv("AWS_SAM_LOCAL")です。SAMで実行された場合、環境変数
AWS_SAM_LOCALにtrueがセットされるため、Lambda関数がローカルから実行されたかどうかはこいつで判定することが出来ます。そしてCredentialの生成についてですが、Minioでのローカル環境の場合は環境変数から
Access Key IDとSecret Keyを読み込みましたが、本番環境の場合はローカルシステム上の認証情報を読み込みます。ローカルでの認証情報は
~/.aws.credentialsにあると思います。設定がされていない方は、AWSの公式ドキュメントを参照ください。確かこれを使うセキュリティ上の理由などについてもどこかに書かれていた覚えがあります…(知っている方はコメントください(`・ω・´)ゞ)
そのため、本番環境の場合にCredentialの生成処理などは特に書く必要はありません。(Assume Roleをしている場合は別です!)。基本的にリージョンの指定だけで大丈夫です。
/* Yield credential for production */ log.Printf("Start process getting credential as a production") sess, _ = session.NewSession(&aws.Config{ Region: aws.String("ap-northeast-1"), S3ForcePathStyle: aws.Bool(true), })できたらもう一度実行して、ローカルでのデグレ検証を行います。
問題なければ実際にデプロイしましょう!以下のコマンドを実行します。初回のデプロイは
--guidedをつけましょう。sam deploy --guidedこれを実行し、実際にAWSマネジメントコンソールを開いてLambda関数が増えていれば成功です!
あとはCloudWatch Eventの設定を確認しつつモニタリングからログを追って成功しているかどうかを確認しましょう!
参考
- 投稿日:2020-04-06T00:06:15+09:00
awsコマンドでPythonのNo module named 'encodings'のエラーが出る
概要
MacでAWS CLIのコマンドを実行した時、いつからか
No module named 'encodings'というコマンドが出るようになりました。この時にやったことを色々書いてます。
ただ、結論を先に言うと、Python3を再インストールして直しました。事象と試したこと
awsコマンドを実行すると、以下のようにエラーが出るようになり色々ググってみることに。補足すると、AWS CLIの中でPythonを使っているため、Pythonも正しく設定されている必要があります。
$ aws configure --profile XXXX ...(省略)... Fatal Python error: Py_Initialize: Unable to get the locale encoding ImportError: No module named 'encodings' ...(省略)...試したのはいずれもパス関連の修正です。
1. PYTHONHOMEの設定を変えてみる
- エラーをググると、PYTHONHOMEのパスを疑えというページが出てくるため
.bash_profileを確認してみると、確かに設定されていませんでした。そのため、デフォルト値である/usr/localを設定してみることに。- 結果、エラーは変わりましたが、
syntax errorという別のエラーが出てくることに...2. PYTHONPATHの設定を変えてみる
- これも同様に
.bash_profileに色々な値を設定してみましたが、エラーは変わっても解決には至らず...Macでは
/usr/bin/pythonがデフォルトでPython2系のバージョンになっています。そのため、pyenvやAnacondaなど別のツールを使ってPython3をインストールしていましたが、この時Python3のパスは/usr/bin/pythonから変えていませんでした。いろいろ作業をしていく中でPyhton3のパスがおかしくなってしまったようです。
※pyenvやAnacondaが原因ではなく、作業のうちに環境を壊してしまったことが原因だと考えられます。解決策
pyenvおよびAndacondaをアンインストールした後、以下を参考にPython3を再インストールしました。
【Python3】まっさらなMacにPythonの最新バージョンをインストールする手順まとめ上記手順の中で、
/usr/bin/pythonにはPython3のパスを当てるようにしました。無事、awsコマンドも通るようになりました。雑感
正直、最初から再インストールしておけば良かった...と思いました。IDEでのインタプリタ再設定などが面倒かなと思ったのですが、ハマってた時間に比べれば全然短いです。
何事も諦めが肝心ですね....