- 投稿日:2020-03-26T23:56:53+09:00
【SEIRモデル入門】COVID-19データをフィッティングしてみる♬
新型コロナの感染データをSEIRモデルを用いて、フィッティングしてみた。
手法は前回の【minimize入門】SEIRモデルでデータ解析する♬と同様である。感染データは以下の参考サイトから入手した。
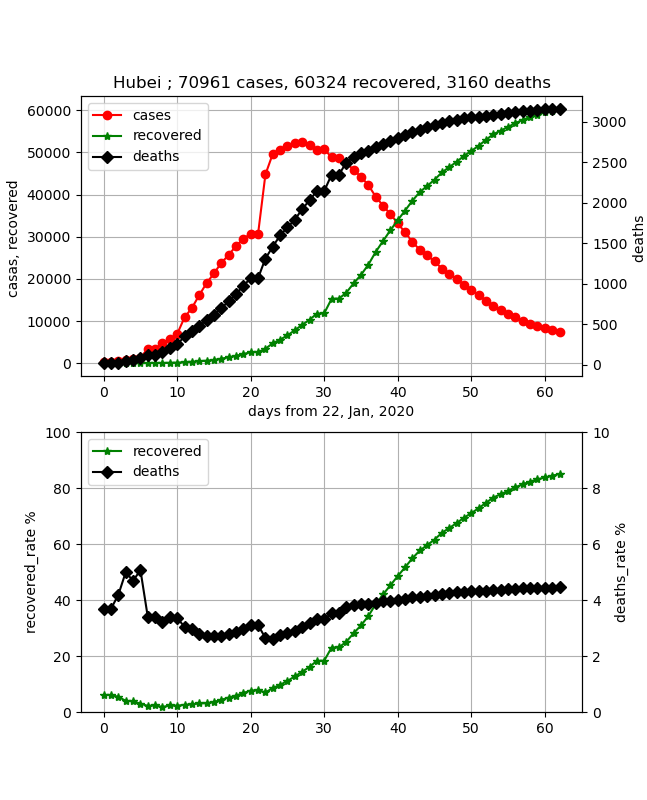
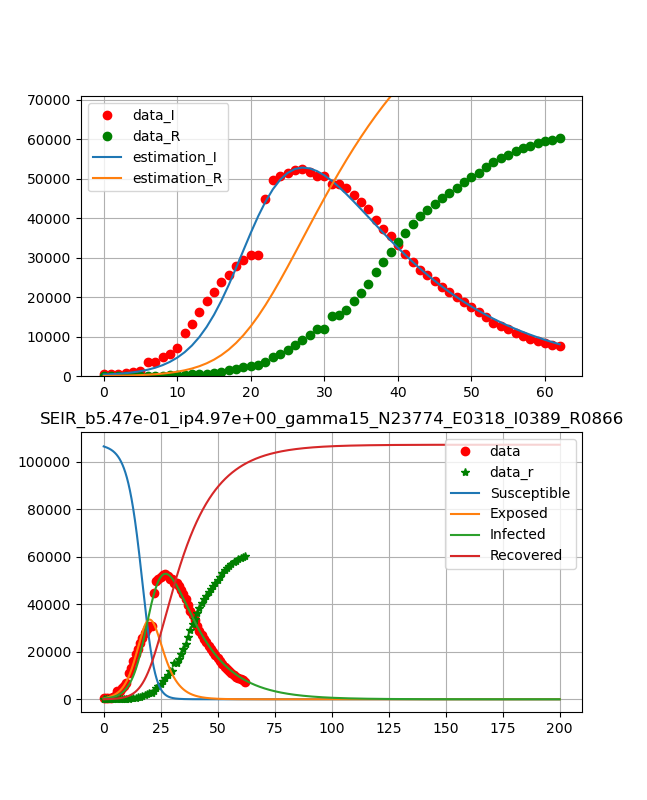
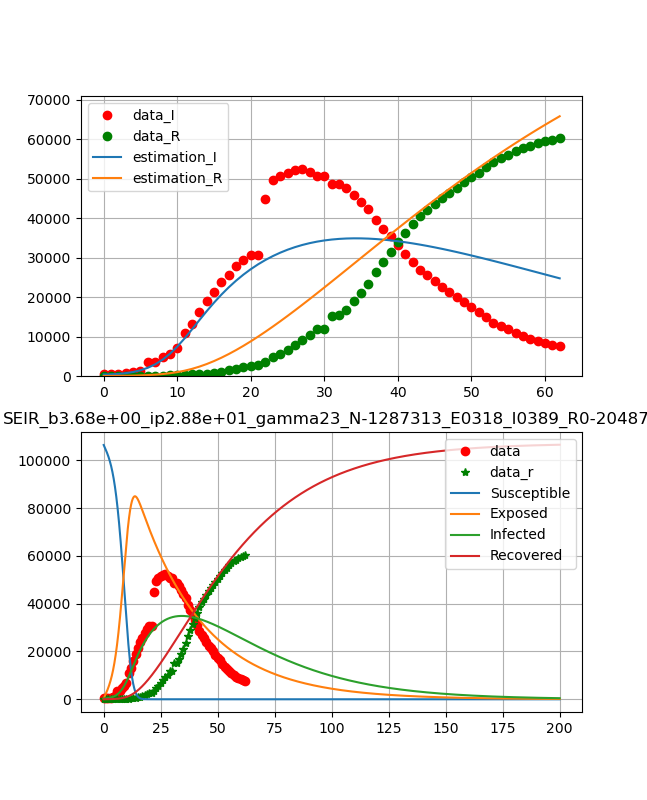
武漢のデータに対して【matplotlib入門】COVID-19データから終息時期を読む♬において、以下の結果を得た。
これをそれらしい曲線が得られるように初期値を選んでフィッティングしたものが以下のように得られる。
ということで、今回は各国について同様なフィッティングを行って、新たな知見が得られるか検討したいと思う。なお、データは以下から入手しており、断らない限りは2020年3月24日時点のデータであるが、上記は2020年3月22日時点のものである。また、コード解説で説明するが、今回はフィッティングは感染データに対してのものと、治癒データも利用したフィッティングを別のプログラムで実行しているので、注意してください。
【参考】
CSSEGISandData/COVID-19やったこと
・日本の終息
・コード説明
・各国データのフィッティング・日本の終息
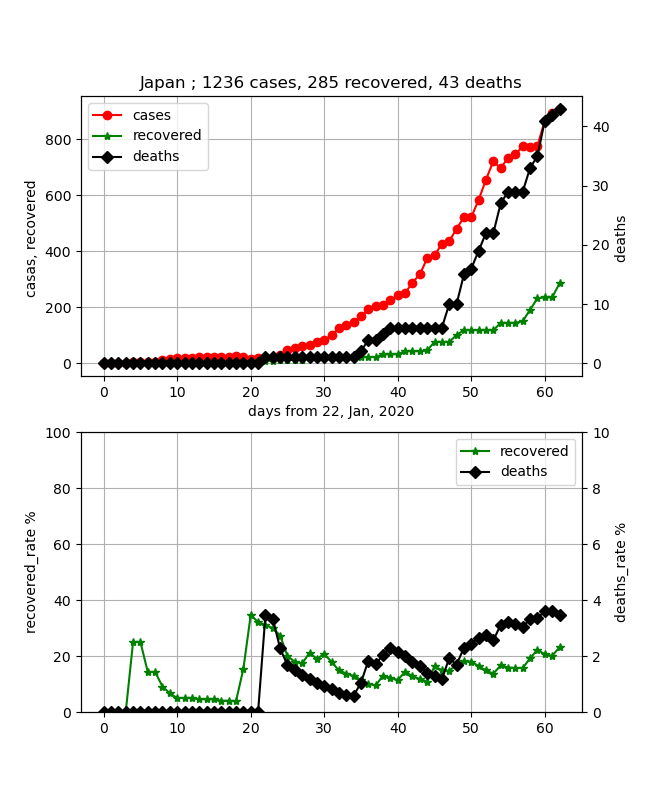
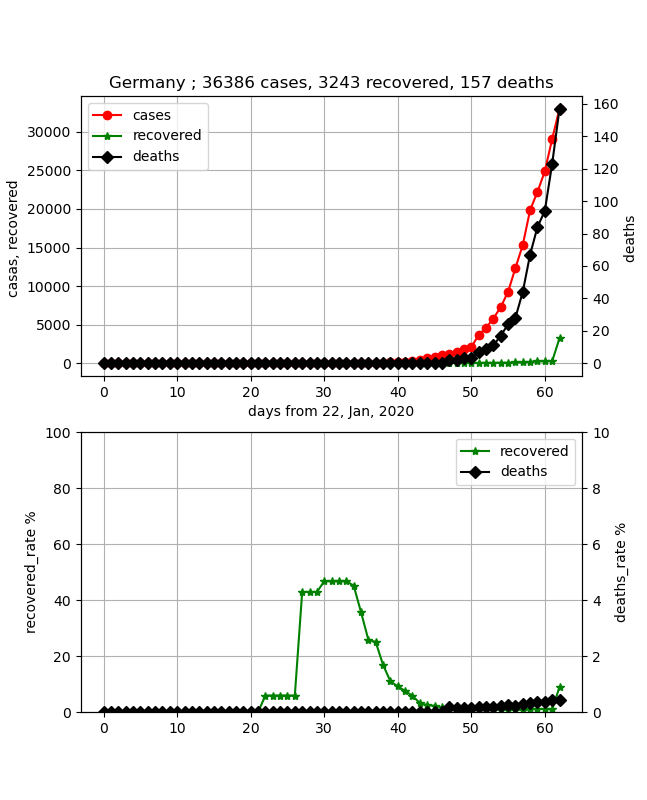
上記のように穏やかに書こうと思ったが、東京都が都市封鎖と言い出したので、先に日本の終息は見えるのかというのを記載したいと思う。
結論から言うと、あとひと月見れば終息が確実に見えそうという状況である。
実は、上記の3月22日のデータでは、ちょっと寝てきてこれが感染ピークならという状況もあったが、ここで少し感染数が直線的に伸びてきたので、飽和は少し先伸ばしになった。
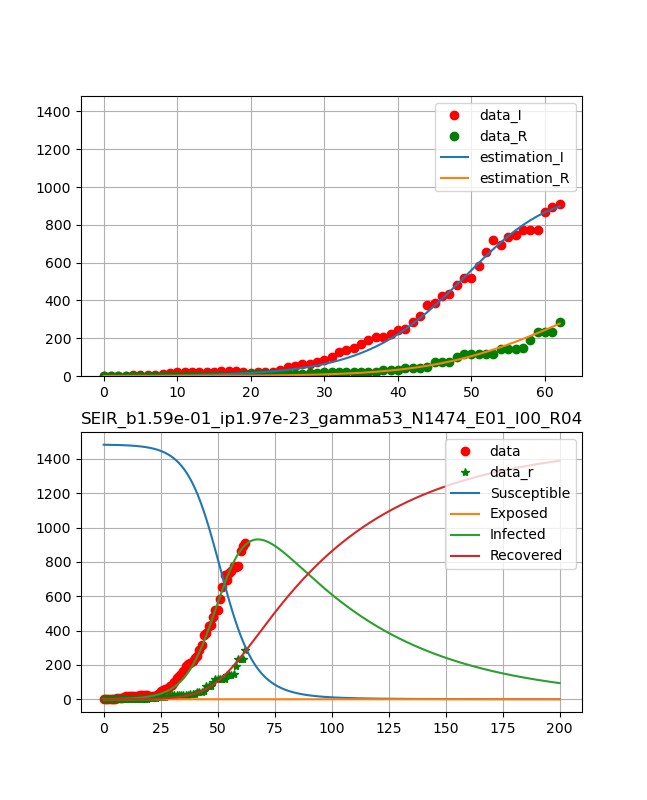
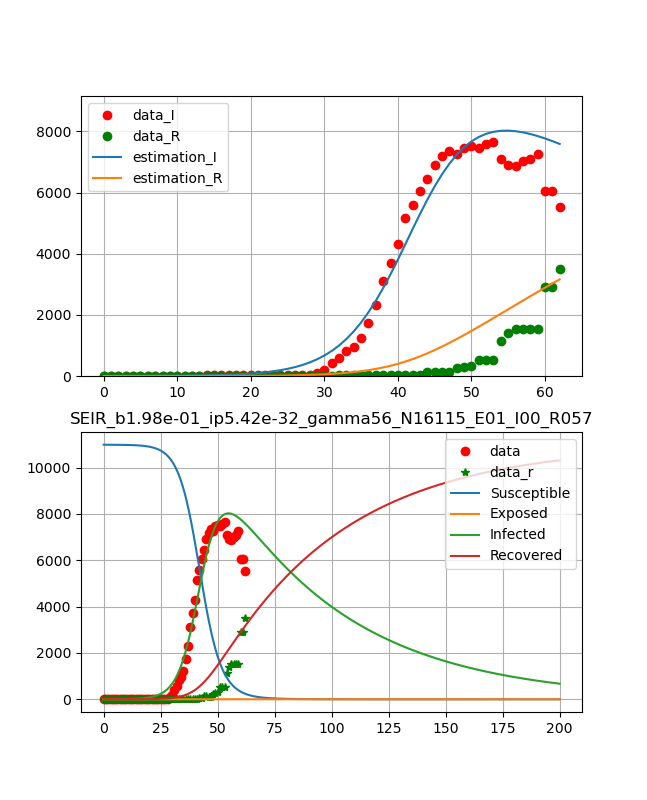
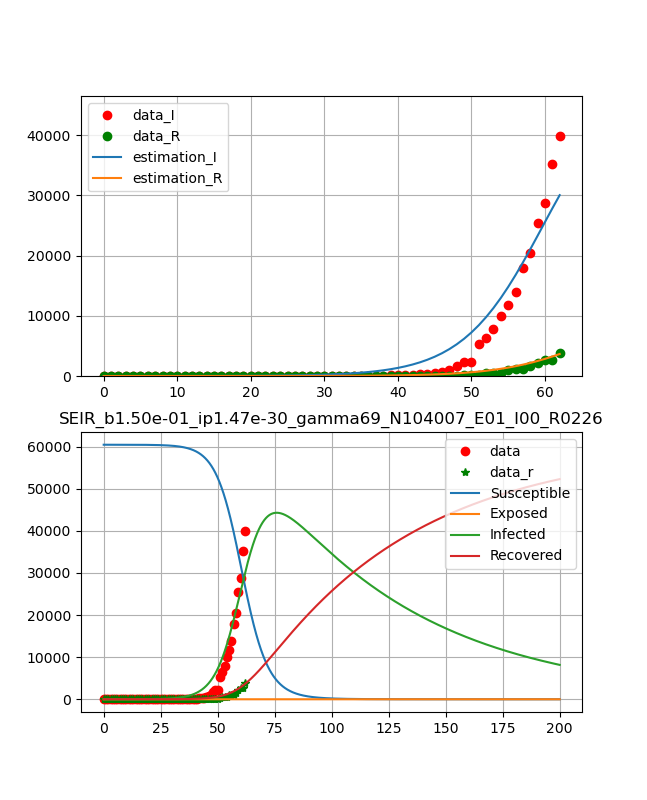
ということで、フィッティングとしては3月24日までのデータに対して以下のグラフを得た。
フィッティングは感染数と治癒の両方の曲線を同時に決定している。
日本のデータは53日-59日のデータが少しおかしいが概ね自然に推移している。
ということで、以下のように綺麗な曲線が得られた。
つまり、10日程でピークが表れ、ひと月ほどで治癒曲線がピークとなり、あとはなだらかに終息していくという結果である。
得られたパラメータは、
beta_const=0.159 lp=1.97e-23 gamma=52.7 N=1474 R0 = 4.45・コード説明
コード全体は以下においた。
二つ置いた理由は、提供されているデータ構造が変わって現在のデータでは②のように個別に読む必要がある。また、②では曲線によりフィットしやすいように、フィッティング関数を通常の最尤関数から普通の二乗誤差に変更した。
①collective_particles/fitting_COVID.py
②collective_particles/fitting_COVID2.py以下、簡単なコードを解説する。
以下のLibを利用する。
前2回の記事のものを合算したものとなっている。#include package import numpy as np from scipy.integrate import odeint from scipy.optimize import minimize import matplotlib.pyplot as plt import pandas as pd以下も感染データ描画と同様である。
#pandasでCSVデータ読む。 data = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv') data_r = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv') data_d = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv') confirmed = [0] * (len(data.columns) - 4) confirmed_r = [0] * (len(data_r.columns) - 4) confirmed_d = [0] * (len(data_d.columns) - 4) days_from_22_Jan_20 = np.arange(0, len(data.columns) - 4, 1) #City city = "Hubei" #武漢のデータ #データを加工する t_cases = 0 for i in range(0, len(data), 1): #if (data.iloc[i][1] == city): #for country/region if (data.iloc[i][0] == city): #for province:/state print(str(data.iloc[i][0]) + " of " + data.iloc[i][1]) for day in range(4, len(data.columns), 1): confirmed[day - 4] += data.iloc[i][day] - data_r.iloc[i][day] confirmed_r[day - 4] += data_r.iloc[i][day] confirmed_d[day - 4] += data_d.iloc[i][day]SEIRモデルを使う。
#define differencial equation of seir model def seir_eq(v,t,beta,lp,ip,N0): N=N0 #int(26749*1) #58403*4 a = -beta*v[0]*v[2]/N b = beta*v[0]*v[2]/N-(1/lp)*v[1] #N c = (1/lp)*v[1]-(1/ip)*v[2] d = (1/ip)*v[2] return [a,b,c,d]ここでN0の値によって得られる絵が変わってくる。
これをフィッティングするのもいいが今回はできていない。
Hubeiのフィッティングに際しては、以下の値を参考にさせていただいた。
ただし、NおよびS0に関してはゲームの参加者という意味で住人が全員ではなく感染する対象と考え方でほぼ実際の感染者数(の周りで動かした値)を採用した。
【参考】
・SEIRモデルで新型コロナウイルスの挙動を予測してみた。
初期値等設定#solve seir model N0 = 70939 #Hubei N,S0,E0,I0=int(N0*1.),N0,int(318),int(389) #N is total population, S0 initial value of fresh peaple ini_state=[S0,E0,I0,0] #initial value of diff. eq. beta,lp,ip=1, 2, 7.4 t_max=60 #len(days_from_22_Jan_20) dt=0.01 t=np.arange(0,t_max,dt) obs_i = confirmed入力パラメータに対して、評価値を返す関数。以下はv[2];感染数を返している。
#function which estimate i from seir model func def estimate_i(ini_state,beta,lp,ip,N): v=odeint(seir_eq,ini_state,t,args=(beta,lp,ip,N)) est=v[0:int(t_max/dt):int(1/dt)] return est[:,2]以下最小化の目的関数(以下は最尤関数を利用)。
#define logscale likelihood function def y(params): est_i=estimate_i(ini_state,params[0],params[1],params[2],params[3]) return np.sum(est_i-obs_i*np.log(np.abs(est_i)))minimize@scipyで最小値を求め、基本再生産数を計算。
#optimize logscale likelihood function mnmz=minimize(y,[beta,lp,ip,N],method="nelder-mead") print(mnmz) #R0 beta_const,lp,gamma_const,N = mnmz.x[0],mnmz.x[1],mnmz.x[2],mnmz.x[3] #感染率、感染待時間、除去率(回復率) print(beta_const,lp,gamma_const,N) R0 = N*beta_const*(1/gamma_const) print(R0)計算結果をグラフ表示。
#plot reult with observed data fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2)) lns1=ax1.plot(obs_i,"o", color="red",label = "data") lns2=ax1.plot(confirmed_r,"*", color="green",label = "data_r") lns3=ax1.plot(estimate_i(ini_state,mnmz.x[0],mnmz.x[1],mnmz.x[2],mnmz.x[3]), label = "estimation") lns0=ax1.plot(t,odeint(seir_eq,ini_state,t,args=(mnmz.x[0],mnmz.x[1],mnmz.x[2],mnmz.x[3]))) lns_ax1 = lns1+lns2 + lns3 + lns0 labs_ax1 = [l.get_label() for l in lns_ax1] ax1.legend(lns_ax1, labs_ax1, loc=0) ax1.set_ylim(0,N0)以下は終息が見えるように、ロングスパンのグラフを表示する。
※ここでは200日まで表示
これにより、最初に示した武漢のような結果が得られる。
ただし、武漢の絵は60日までの絵である。t_max=200 #len(days_from_22_Jan_20) t=np.arange(0,t_max,dt) lns4=ax2.plot(obs_i,"o", color="red",label = "data") lns5=ax2.plot(confirmed_r,"*", color="green",label = "recovered") lns6=ax2.plot(t,odeint(seir_eq,ini_state,t,args=(mnmz.x[0],mnmz.x[1],mnmz.x[2],mnmz.x[3]))) ax2.legend(['data','data_r','Susceptible','Exposed','Infected','Recovered'], loc=1) ax2.set_title('SEIR_b{:.2f}_ip{:.2f}_gamma{:.2f}_N{:.2f}_E0{:d}_I0{:d}_R0{:.2f}'.format(beta_const,lp,gamma_const,N,E0,I0,R0)) ax1.grid() ax2.grid() plt.savefig('./fig/SEIR_{}_b{:.2f}_ip{:.2f}_gamma{:.2f}_N{:.2f}_E0{:d}_I0{:d}_R0{:.2f}_.png'.format(city,beta_const,lp,gamma_const,N,E0,I0,R0)) plt.show() plt.close()一方、感染数と治癒数の同時フィッティングでは途中の評価関数と目的関数を以下のように変更した。
#function which estimate i from seir model func def estimate_i(ini_state,beta,lp,ip,N): v=odeint(seir_eq,ini_state,t,args=(beta,lp,ip,N)) est=v[0:int(t_max/dt):int(1/dt)] return est[:,2],est[:,3] #v0-S,v1-E,v2-I,v3-R #define logscale likelihood function def y(params): est_i_2,est_i_3=estimate_i(ini_state,params[0],params[1],params[2],params[3]) return np.sum((est_i_2-obs_i_2)*(est_i_2-obs_i_2)+(est_i_3-obs_i_3)*(est_i_3-obs_i_3))なお、この場合は感染数のみや治癒数のみのフィッティングも可能である。
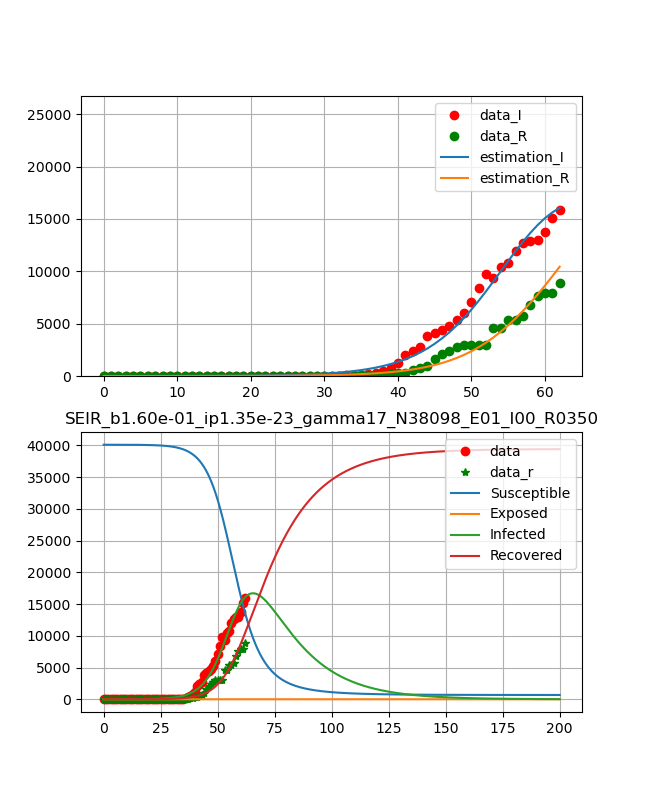
・各国データのフィッティング
・イラン
治雄率が比較的大きいイランは日本よりより早く飽和し、終息に向かいそうであるが、まだまだ感染数が伸びており、治癒率も伸び悩んでいるので、もっとかかる可能性もある。
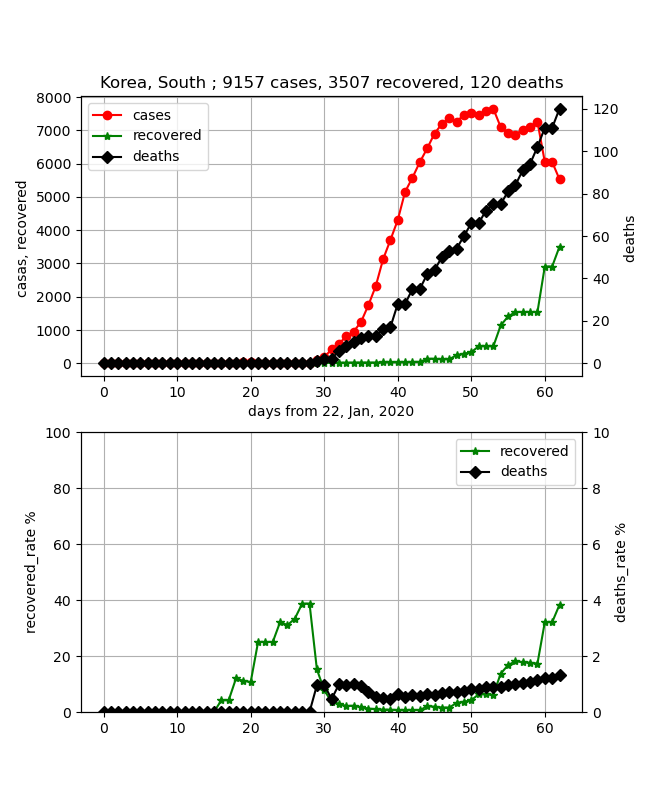
・韓国
なんだかちょっと前のデータと比べるといびつが目立ってきて、データの信ぴょう性が崩れてきた。
それでも全体としては治癒率が上がってきており、終息は比較的早そうである。
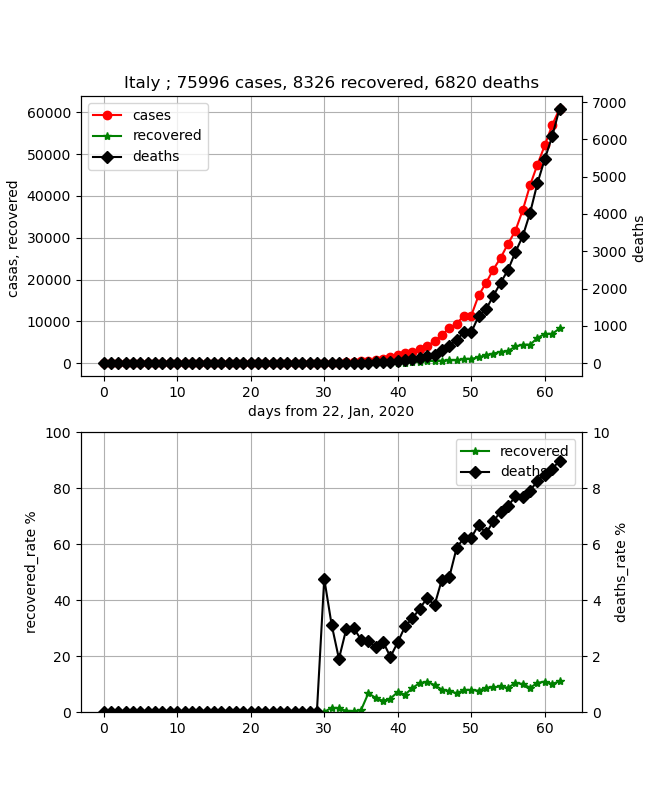
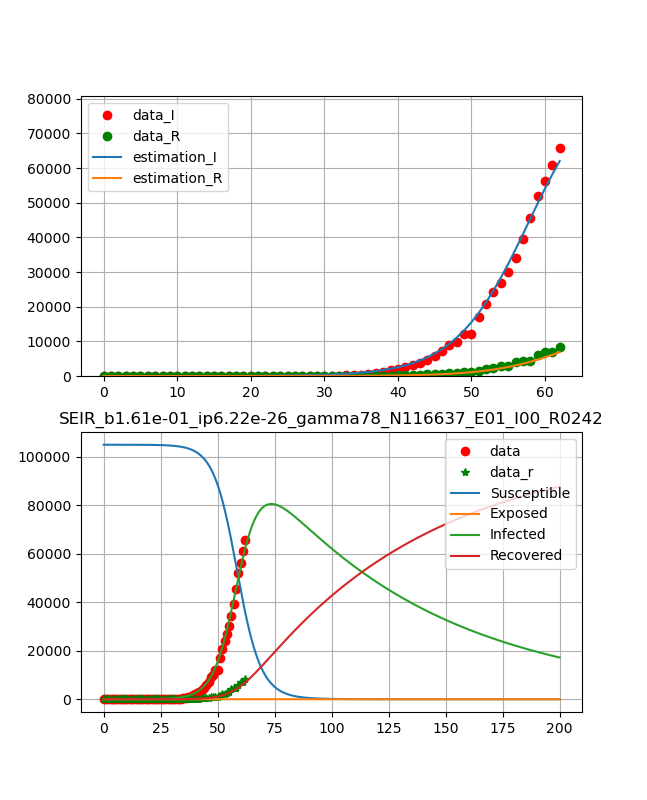
・イタリア
死亡率が極めて高く危険ではあるが、データはとても綺麗で洗練されている。したがって、フィッティングもしやすく、綺麗に乗った。まだまだ治癒率10%程度であり、少し時間(治癒ピークが2か月)はかかりそうだがこの後ピークが見えてくれば終息は近い。
以下は、初期拡大期であり、フィッティング精度が悪くあてにならなそうだが掲載しておく。
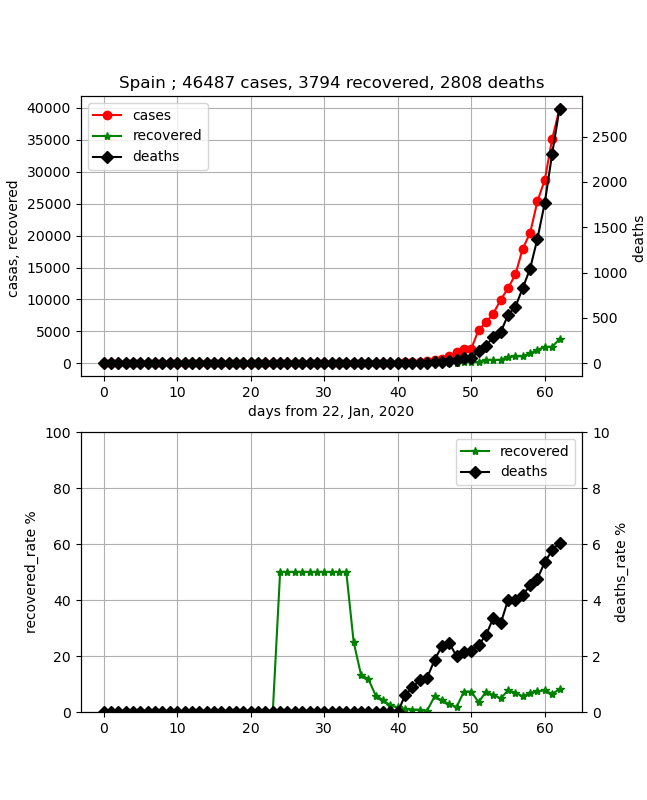
・スペイン
もっともっと立ち上がっているが、合わせるのが難しい。
・ドイツ
こちらもまだまだできていないし、そもそも治癒数が少なすぎて初期拡大期だと思われる。
まとめ
・COVID-19データをフィッティングしてみた
・日本、イラン、韓国が中国に引き続いて終息が見えるようになると思われる
・他の欧米はまだまだ拡大期であり、終息予想は困難な状況である。・今回はおおざっぱな話をしたが、日々の更新を見つつ、もう少し緻密な分析をしたいと思う
おまけ
武漢の同時フィッティングは以下のとおり
武漢のデータはこのモデルでは説明できないようだ(><)
元データ
感染データのみフィッティング
治癒データのみフィッティング
感染データおよび治癒データをフィッティング





- 投稿日:2020-03-26T23:52:30+09:00
DjangoのGeoIp2操作方法
DjangoでのGeoIp2の設定から使い方
はじめに
Django1.9以上
GeoIp2-databaseのダウンロードをMAXMIND公式サイトから入手する必要がある。
ユーザー登録を行うことで無償ファイルをダウンロードすることができる。設定
django-geoip2-extrasのインストール
# cmd pip install django-geoip2-extrassetting.pyを編集
GeoIP2Middlewareを追加する
# setting.py MIDDLEWARE = [ ~ 'django.contrib.sessions.middleware.SessionMiddleware', # SessionMiddlewareの後にGeoIP2Middlewareを追加する 'geoip2_extras.middleware.GeoIP2Middleware', ~ ]GEOIP_PATHを設定する
# setting.py GEOIP_PATH = os.path.join('mmdbを配置しているパス')使い方
# geoip2をインポート from django.contrib.gis import geoip2 # インスタンス化 geo_ip2 = geoip2.GeoIP2() # 引数にはドメイン名またはipアドレスを設定する geo_ip2.city(query) geo_ip2.country(query) geo_ip2.country_code(query) geo_ip2.country_name(query)参考サイト
- 投稿日:2020-03-26T22:59:18+09:00
Python はじめから勉強 Hour6:よく使うデータ型:タプル型・セット型・辞書型
Python はじめから勉強 Hour6:よく使うデータ型:タプル型・セット型・辞書型
- Pythonで何かしようとしたときに、まずサンプルスクリプトを探してなんとなく実行してた私が、
- 自動実行でREST API叩いて、結果の確認、VM操作までやってみたいと思う7時間
- よく使うデータ型についての理解。「タプル型」「セット型」「辞書型」をやります
学習資料
- たった 1日で基本が身に付く! Python超入門
過去の投稿
- Python はじめから勉強 Hour1:Hello World
- Python はじめから勉強 Hour2:制御文
- Python はじめから勉強 Hour3:関数
- Python はじめから勉強 Hour4:オブジェクト指向①
- Python はじめから勉強 Hour5:オブジェクト指向②
環境
- Windows
- Python Ver3系
タプル型
- タプルは複数のデータをまとめて管理するための型です。そういう意味ではリストと似ています。
- リストは一般的に「同種類のデータ」を任意の数で格納することに用いられます。
タプルは複数の異なる種類のデータをまとめる目的で使われます。
例えば生徒の「名前」「身長」「体重」の組み合わせを管理したいとき。その中で平均身長を求めるとき。これをリストで表すと下記のようになります。
taro = ['taro', 170, 80] jiro = ['jiro', 180, 85] saburo = ['saburo', 172, 81] class_list = [taro, jiro, saburo] sum_height=0 for person in class_list: sum_height += person[1] print(sum_height/len(class_list))
- 実行結果
174.0
- 結果は出ましたが、リストは本来「同種のデータを任意の数で格納する」目的のため本来の使い方と異なる(ようです)
- こういったカチットしたデータ構造を扱うにはタプルを使いましょう
- 先ほどのスクリプトをタプルを使ってみましょう。※最初の3行だけ異なることに注意
taro = ('taro', 170, 80) jiro =('jiro', 180, 85) saburo = ('saburo', 172, 81) class_list = [taro, jiro, saburo] sum_height=0 for person in class_list: sum_height += person[1] print(sum_height/len(class_list))
- 実行結果
174.0
- 結果は当然同じです。
- タプルは宣言や要素の参照の仕方と言う点でリストと似ていますが、実体はかなり違います。
リストは要素の追加や削除、変更が可能ですが、タプルは一度作った後は参照しかできない不変オブジェクトとなります。
- タプルの使い方をもう少し見てみます
- リストのように扱えるが、変更や削除ができないことが分かると思います。
>>> taro = ('taro', 180, 80) # ()を使ってタプル型を宣言します。 >>> type(taro) # tuple型であることを確認 <class 'tuple'> >>> print(taro[1]) #リストと同じように参照できます。 180 >>> taro[0] = 'jiro' # tuple型は値の変更ができない Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> >>> del taro[1] # tuple型は値の削除もできない Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object doesn't support item deletionタプル型の扱い方・関数
アンパック代入
- タプルでよく使われるテクニックとして「タプル型 = タプル型」という表記で右側のタプルの中身を個別に取り出す「アンパック代入」という方法があります。タプルの要素を分かりやすい変数名にする目的です
>>> (name, height, weight) = ('taro', 180, 80) >>> print(name) # データが扱いやすくなりました taro >>> print(weight) 80 >>>enumerate()関数
- 引数に指定したリストを「インデックス蛮行」と「要素」がタプルになって入ってきます。
>>> my_list = ['a', 'b', 'c', 'd'] >>> enum_obj = enumerate(my_list) >>> print(enum_obj) >>> print(list(enum_obj)) [(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd')]
- enumerate関数を使うとリストをインデックス番号付きでループさせることが簡単にできます。
(いまいち何に使うか分からん)
例えばこんな使い方
list1 = ['a', 'b', 'c'] for (index, item) in enumerate(list1): print('{}:{}'.format(index, item))
- 実行結果
0:a 1:b 2:c
- わざわざインデックス用の変数を宣言したり、ループを回るごとに1加算させたりする必要がなくなります。
セット型
- セットは順序と重複のないデータ構造です。数学の「集合」のイメージですね。
- なんとなく概念↓
セット データ くだもの りんご
ばなな
いちご
- 例えば上記のような集合があった場合に、「ぐれーぷ」というデータは追加できますが「りんご」というデータは重複しているために追加されません。
- セットは検索が非常に高速らしい
- 使い方確認
>>> my_set = set() >>> >>> my_set.add('apple') # appleを追加 >>> print(my_set) {'apple'} >>> >>> my_set.add('banana') # bananaを追加 >>> print(my_set) {'banana', 'apple'} >>> >>> my_set.add('apple') # appleを追加する。追加されない、エラーにもならない >>> print(my_set) {'banana', 'apple'} >>>辞書型
- 辞書型はセット型の発展系です。
- キーと値を持っています。
- こんなイメージ↓
セット データ くだもの りんご:あか
ばなな:きいろ
いちご:あか
- セットと同じ感じですが各キーには値を持っています
- 使い方確認
>>> fruits_dict = dict() >>> fruits_dict['apple'] = 'red' # キーと値を入れる >>> >>> fruits_dict['banana'] = 'yellow' >>> fruits_dict {'apple': 'red', 'banana': 'yellow'} >>> fruits_dict['apple'] # キーから値を取り出す 'red' >>>今回のまとめ
よく使うデータ型を確認しました。
辞書型が扱えるとJSON形式を取り込んだり、吐き出したりできそうです
名言・ライトニングトーク用
- 使い方は分かってきたけど、何かを作るには程遠いような。。。。。。
- Qiita炎上中。。。。。
- 投稿日:2020-03-26T22:53:28+09:00
[入門編] Python のスクリプトをコンテナ化して、Azure Batch で動かす手順:
はじめに
実案件で始めて
Azure Batchを使う時などを考慮して、なるべく画面ベースで簡易な方法で、手元のPythonのコードを動かす手順です。Azure Batch では Container を使うツール/Framework として、
Batch Shipyardという手法が提供されています。ただし、いきなりそれを使うと、内部の動きが理解しずらい事もありますので、ここではそれも使いません?
つまり、少し Hack を一緒にしてみましょう!Batch Shipyard:
https://github.com/Azure/batch-shipyard/tree/master/recipes残念ながら、既存ドキュメントやサンプルではこの部分のドキュメントが少し足らないですので、ここで補足をします。
Azure Batch とは
Python で複数コンピューターを使う処理といえば、Horovod などを使っての Deep learning での大規模処理を思い浮かべる方も多いと思います。それだけでなく、大量の計算を Python で制御したいケースもあります。処理の重たさがデータ処理であれば、
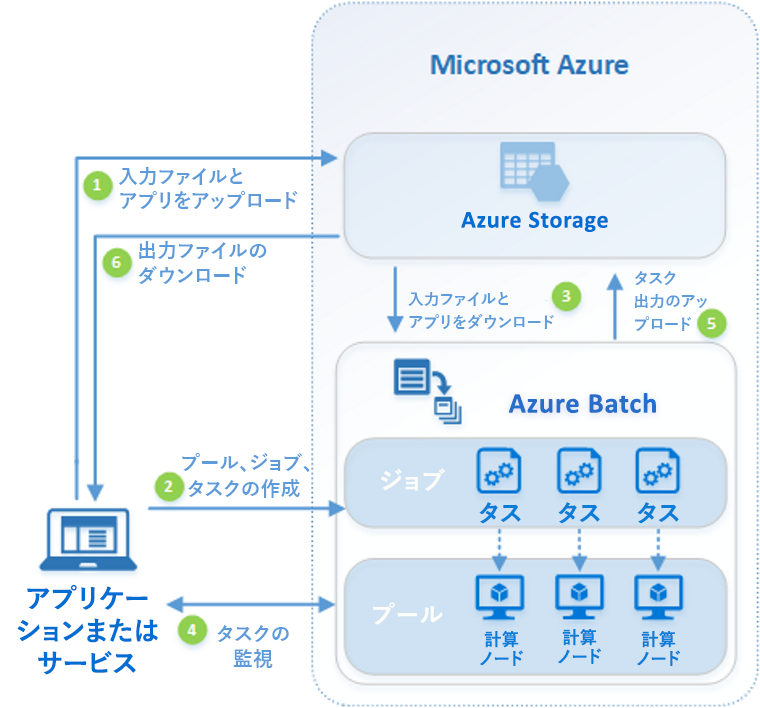
Sparkなども選択肢ですし、そうでなく純粋な計算が多い場合は、Azure Batchは有力な選択肢になります。Azure Batch は、以下の様なアーキテクチャをしています。
処理の入出力は Azure Storage へ行います。クラウドでの永続ストレージですので、当然ですね。
Azure Batch とは:
https://docs.microsoft.com/ja-jp/azure/batch/batch-technical-overviewアーキテクチャを考える
いろんな考慮事項がありますが、なるべくPythonのコードと、データ分割以外の基本アーキテクチャを踏襲したものにします。よって、以下の検討事項は、この入門編ではありますが、以下は入れ込みます。
計算途中でのノード間通信をするMPIを使った処理などは一切使いません。MPIにご興味のある方は、こちらを参照ください。
Batch でのマルチインスタンス タスクを使用した Message Passing Interface (MPI) アプリケーションの実行:
https://docs.microsoft.com/ja-jp/azure/batch/batch-mpi1. Python アプリの課題
あちこちで議論されていますが。
主に、以下の様な課題があるので Container 化する事が多いです。
- ライブラリーの依存関係が複雑になりがち。一つのライブラリーのバージョンアップで、動かなくなる事もありえる
- 環境構築の際に pip などでライブラリーをインターネットからダウンロードするとして時間がかかる。またはインターネット接続がそこで出来ない事もある
今回は、Python のアプリは、Container 化をする前提です。結果として、Azure Batch の Compute は
Ubuntuを選択します。私の好みです?Azure Batch で コンテナー アプリケーションを実行する:
https://docs.microsoft.com/ja-jp/azure/batch/batch-docker-container-workloads2. 読み書きするファイルの扱い
1つのタスクでは、シンプルに、Blob上の1ファイルを読み込んで、結果をBlob上の1ファイルに出力する、というアーキテクチャにします。
ファイルのやり取りについては、Azure Blob Storage 上のファイル構造をマウントする方式をとります。Linux 仮想マシンの場合は blobfuse という方式がとれるので、それを使います。といっても、これが Azure Batchの典型的な設計パターンだと思います?
Batch を使って大規模な並列コンピューティング ソリューションを開発する - ファイルとディレクトリ:
https://docs.microsoft.com/ja-jp/azure/batch/batch-api-basics#files-and-directories仮想ファイル システムを Batch プールにマウントする:
https://docs.microsoft.com/ja-jp/azure/batch/virtual-file-mountちなみに、Azure Batch では、各ノードで扱うタスク数を選択できます。CPU、DiskとNetwork の使用量のバランスを考慮しますが... 1 CPU x 2 Task くらいが良いかもしれませんね。そして CPU 1つは OS用に空けておきたいですね。つまり最低限コア数は2で。
ここで役割を明確に分けます。
- 計算処理: 入出力ファイルについては、引数として取得。コード内部で呼び出さない。Azure Batch の仮想マシンの内部で動作させる。
- ジョブ起動側: Blob マウントをし、入出力ファイル名を確定。計算処理を呼び出す。Azure Batch の外部で動作させる。
ジョブ起動側は、Azure Batchのジョブそのものを外部から呼び出す事になります。
API化するなり、Azure Automationでスケジューリング化するなり。はたまた Azure Functions などで、クラウド側のイベント発生時に呼び出すなり。
ここでは Python で記述しますが、それに拘る必要はありません。用意するもの
この手順の実行に必要なものです。
- Azure Subscription
- ローカル開発用に、手元の Python Runtime は 3.x に!
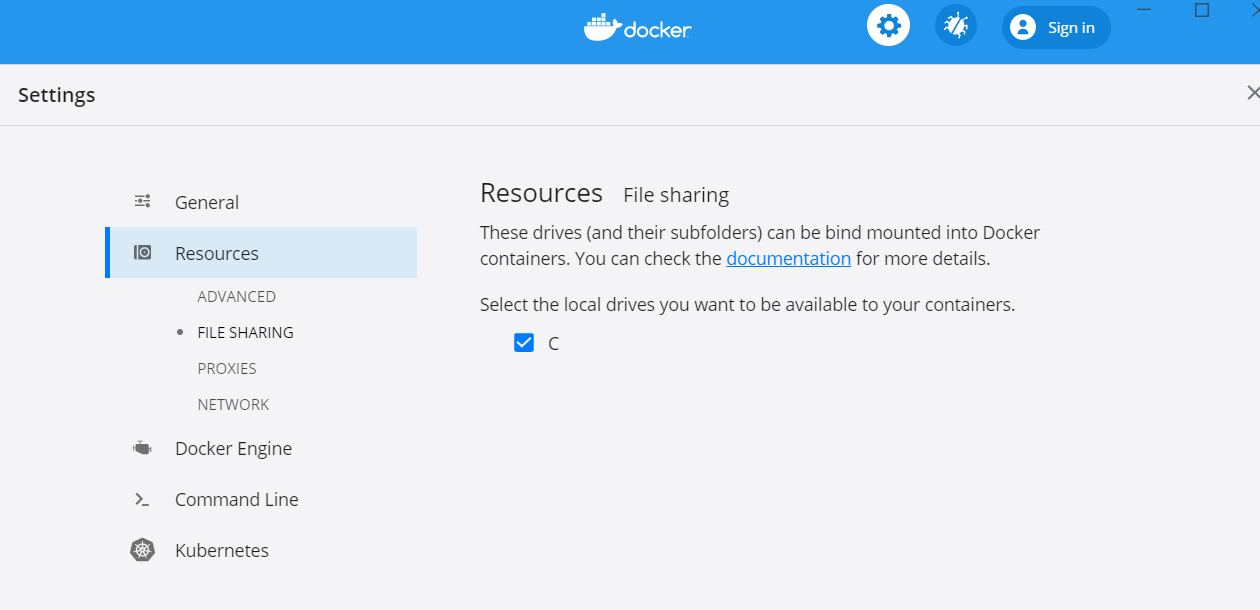
Docker Desktop for Windows / Mac --- ご自分の環境に合わせて。
- ここでは、Windows を使います。
WSL2 Integrationは、ここではオフにしてください。これも好みですね。WSL2でやってもいいのですが。
FILE SHARINGのオプションをオンに
(オプション) Visual Studio Code
- 以下のExtensionを入れる
- Python Extension
- Docker Extension
- Azure Account
(オプション) Azure Storage Explorer
- https://azure.microsoft.com/ja-jp/features/storage-explorer/
- Blob Storage にファイルをコピーするのに便利です。azcopy を内部実行させることもできます。
- Azure Portal にも Storage Explorer があるので、Web ブラウザーだけでも作業はできますが。
Azure Batch Explorer
- https://azure.github.io/BatchExplorer/
- Azure Batch の殆どの (もしかして全部?) API を呼び出してくれます
- デバッグ時と、稼働環境でも監視に便利です
開発開始!
以下の手順で作っていきます。
1. Python アプリのコード
シンプルに。
初期のフォルダー構造
├─ src | └─ app.py --- 計算処理 └─ data └─ src.txt --- テスト用ファイルapp.py の内容
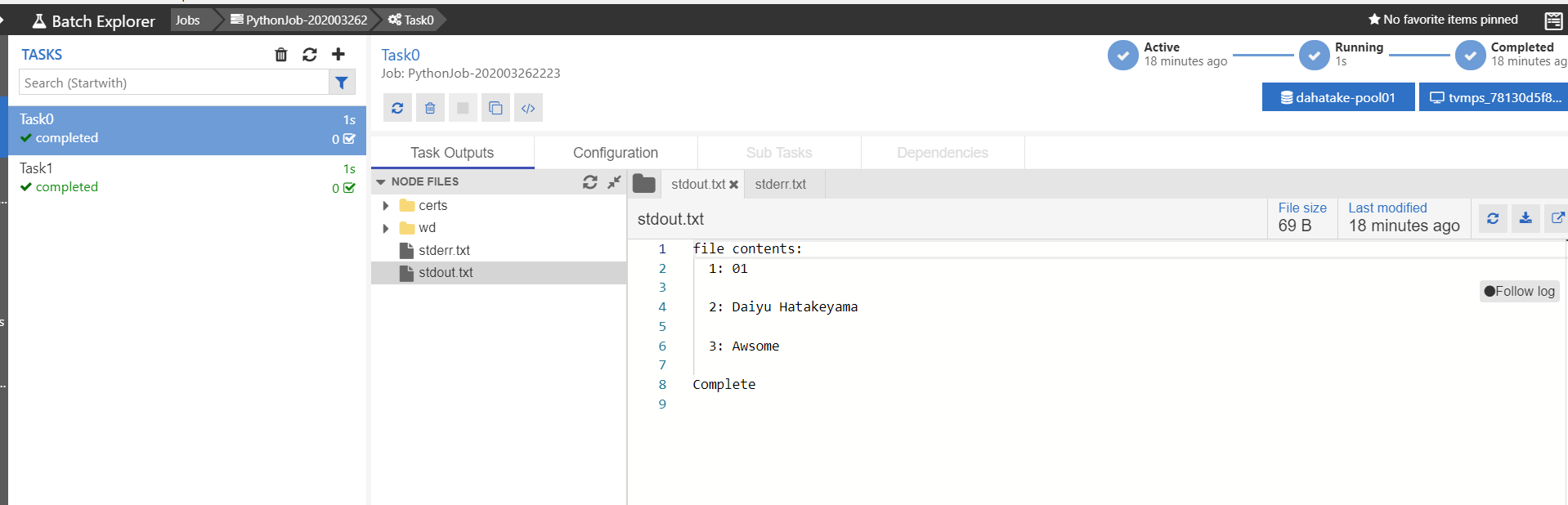
src.txt を全行読み込んで、result.txtファイルに出力するだけです。# Usage: python ./src/app.py ./data/src.txt ./data/result.txt import sys import os if len(sys.argv) != 3: print("Usage: $python app.py <input file> <output file>") exit(1) rfname = sys.argv[1] wfname = sys.argv[2] fcontents = "" if os.path.exists(rfname): with open(rfname, "r") as readFile: fcontents = readFile.readlines() i = 1 print("file contents:") for line in fcontents: print(" {}: {}".format(i, line)) i = i + 1 with open(wfname, "w") as writeFile: for line in fcontents: writeFile.write(line) else: print("[error] file not found from container:{}".format(rfname)) print("Complete")実行して、挙動確認。これ大事。
C:\Work\AzureBatchPython>python ./src/app.py ./data/src.txt ./data/result.txt file contents: 1: Daiyu Hatakeyama 2: Awsome Complete C:\Work\AzureBatchPython>2. Container 化
docker コマンドでもいいのですが。ここでは Visual Studio Code の Docker Extension で楽をします?
参考:
https://code.visualstudio.com/docs/containers/overview2.1. Docker File の自動生成
- VS Code のコマンドパレットを表示します (Ctl+Shift+p)
Add Docker Files to Workspaceコマンドを選択- Application Platform :
Python Generalを選択- Include Optional Docker Composer Files? :
Noを選択(Option) 既存の Docker 設定がある場合は、以下のポップアップが表示されます。ここでは
Overwriteを選択します
アプリケーションのエントリーポイントのPythonファイルを指定します : ここでは
app.py
DockerFileと.dockerignoteの2つのファイルが作成されます自動生成された DockerFile を修正します
今回のapp.pyは、アプリケーションのルートディレクトリではなく、src ディレクトリに置きました。これを DockerFile 内で追加します。
追加の依存ファイルも無いので、requirements.txt に関するものも、削除します。
# For more information, please refer to https://aka.ms/vscode-docker-python FROM python:3.8 # Keeps Python from generating .pyc files in the container ENV PYTHONDONTWRITEBYTECODE 1 # Turns off buffering for easier container logging ENV PYTHONUNBUFFERED 1 WORKDIR /app ADD ./src /app # During debugging, this entry point will be overridden. For more information, refer to https://aka.ms/vscode-docker-python-debug CMD ["python", "app.py"]Working with containers - Generating Docker files:
https://code.visualstudio.com/docs/containers/overview#_generating-docker-files2.2. Docker Image の作成
継続して、Visual Studio Code で右クリック作戦?
DockerFileを右クリックして、Build Imageを選択
Visual Studio Code のターミナル で
docker buildコマンドが実行されているのを確認できます。
デフォルトのタグ名が気に入らない場合は、この出力結果を参考に、書き換えて実行してください。ターミナルの出力例:
> Executing task: docker-build < > docker build --rm -f "c:\Work\AzureBatchPython/Dockerfile" --label "com.microsoft.created-by=visual-studio-code" -t "azurebatchpython:latest" "c:\Work\AzureBatchPython" < Sending build context to Docker daemon 7.168kB Step 1/7 : FROM python:3.8 ---> f88b2f81f83a Step 2/7 : ENV PYTHONDONTWRITEBYTECODE 1 ---> Using cache ---> 3b123c939251 Step 3/7 : ENV PYTHONUNBUFFERED 1 ---> Using cache ---> fa89560ba9fd Step 4/7 : WORKDIR /app ---> Running in e032f2f760df Removing intermediate container e032f2f760df ---> 6714fa225b89 Step 5/7 : ADD ./src /app ---> 99d868bd6330 Step 6/7 : CMD ["python", "app.py"] ---> Running in a3526405f28d Removing intermediate container a3526405f28d ---> 4eb63fcec1ce Step 7/7 : LABEL com.microsoft.created-by=visual-studio-code ---> Running in c072f2b56a28 Removing intermediate container c072f2b56a28 ---> 76809d56ac5f Successfully built 76809d56ac5f Successfully tagged azurebatchpython:latest SECURITY WARNING: You are building a Docker image from Windows against a non-Windows Docker host. All files and directories added to build context will have '-rwxr-xr-x' permissions. It is recommended to double check and reset permissions for sensitive files and directories. ターミナルはタスクで再利用されます、閉じるには任意のキーを押してください。2.3. ローカルでの Container のテスト
ここでも Visual Studio Code を使って Container を実行させます。
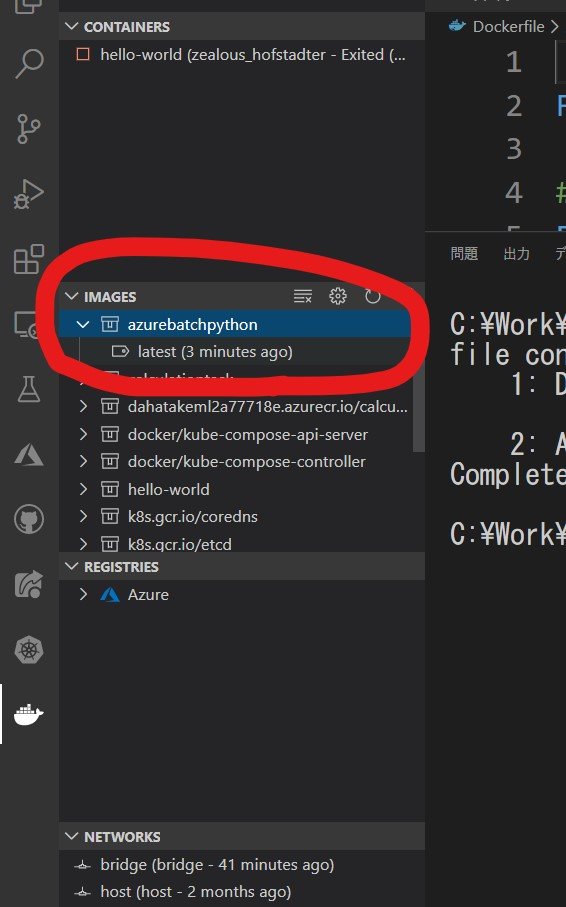
Docker View に移動します
IMAGESの中で、先に作成した Docker Image が出来ているのが確認できます
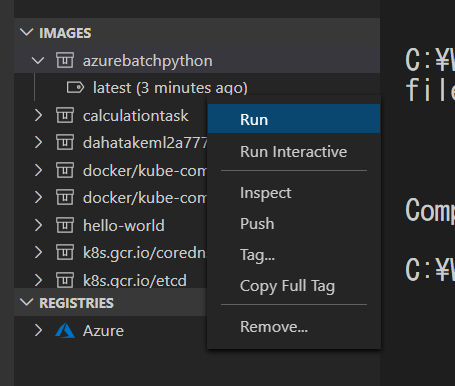
当該 Image を右クリックして
Runで実行します
実行結果 例:
C:\Work\AzureBatchPython>docker run --rm -d azurebatchpython:latest 4b23c26b84bb817e94d216153ea1066bff7b37daf725b67d14429bf6e67eb463 C:\Work\AzureBatchPython>Docker コマンド、忘れそうになります?
さて、このままだと -d オプションでバックグランドで実行していて、状況がわかりません。なので、ターミナルで、以下のコマンドをそのまま実行してみます。
docker run --rm azurebatchpython:latest出力結果:
C:\Work\AzureBatchPython>docker run --rm azurebatchpython:latest Usage: $python app.py <input file> <output file> C:\Work\AzureBatchPython>素晴らしい。ちゃんと引数が無いので、エラーメッセージを出力してくれていますね?
さて、これだと全部動いたわけではないので、Docker Host と ローカルの Windows のファイルシステムをマウントして、ファイルの読み書きをさせます。
docker run --rm -v C:/Work/AzureBatchPython/data:/data azurebatchpython:latest python app.py /data/src.txt /data/result.txtDocker Desktop for Windows を使っての情報が、比較的少ないので、パラメータの解説をします。
項目 説明 --rm イメージを実行したら、すぐにそのイメージを削除します --v ローカルのファイルシステムをマウントします。
ここでは、ローカルのC:/Work/AzureBatchPython/data を、コンテナ内の /data にマウントしています。 マウント先がubuntuですので。[ARG] 調査が終わっていませんが?
ファイルパスの指定をするとエラーになります。Python app.py 引数1 引数2 と指定することで、ファイルパスが引数としてコンテナに渡せますこれで、コンテナ化が完了しました。
3. Azure Container Registry への登録
コンテナのリポジトリとして Docker Hub でも構いませんが。
ここでは、Azure で容易に Private リポジトリとして使える Azure Container Registory を使います。Azure のプライベート Docker コンテナー レジストリの概要:
https://docs.microsoft.com/ja-jp/azure/container-registry/container-registry-intro3.1. Azure Container Registry の作成
こちらのドキュメントに従って作成します。
クイック スタート:Azure portal を使用したプライベート コンテナー レジストリの作成:
https://docs.microsoft.com/ja-jp/azure/container-registry/container-registry-get-started-portal
項目 値 説明 SKU Basic 何でもいいです? 3.2. 作成したコンテナの Azure Container Registry への登録
ここでも Visual Studio Code を使います。もちろん docker コマンドでも出来ます。
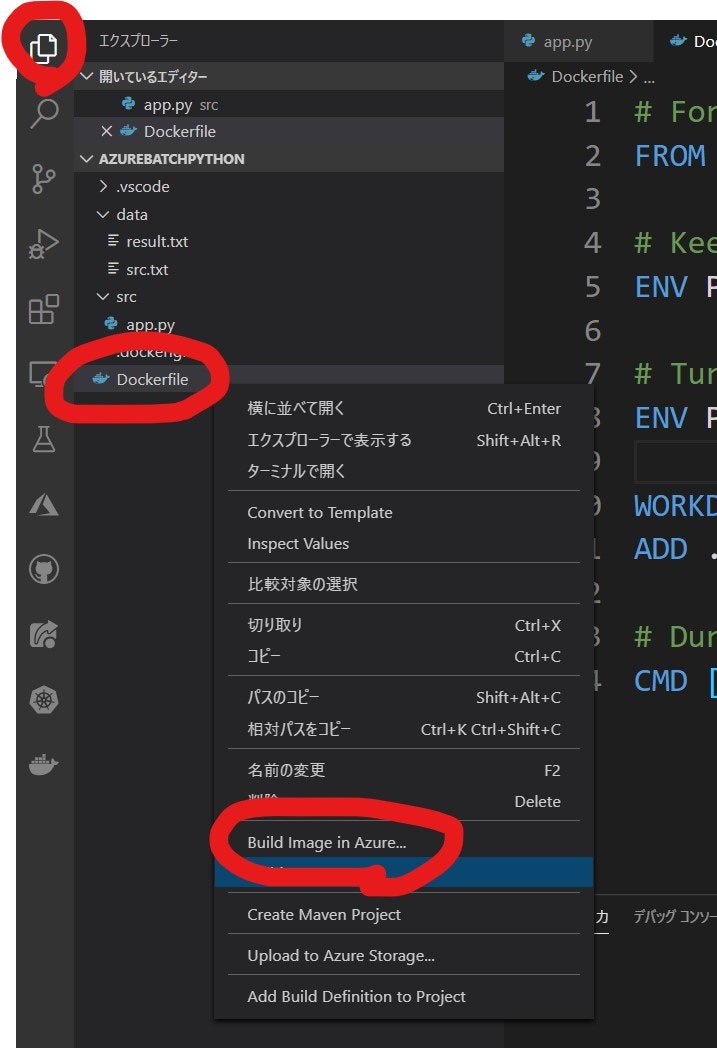
- [Docker] タブで、作成した Azure Container Registryのインスタンスが閲覧出来る事を確認します。
- [エクスプローラー] タブで、Dockerfile を右クリックして [Build Image in Azure...] を選択します。
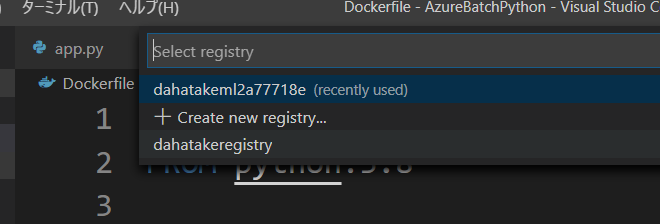
- [コマンドパレット]が表示されます。Visual Studio Codeの画面上部ですね。で、Image名とタグ名を設定します。
- 次に、リポジトリを選択します。先に作成した Azure Container Registry ですね。
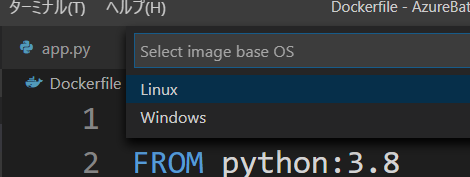
- 次に Base OS Image を選択します。Linux ですね。
Visual Studio Code のターミナルに、ImageのBuild 状況 と Azure Container Registry へのアップロード状況が出力されます。
以下は出力例です。
Setting up temp file with 'sourceArchive116382.tar.gz' Sending source code to temp file Getting build source upload URL Getting blob info from upload URL Creating blob service Creating block blob Uploaded source code to C:\Users\dahatake\AppData\Local\Temp\sourceArchive116382.tar.gz Set up run request Scheduled run ce1 2020/03/23 05:51:55 Downloading source code... 2020/03/23 05:51:56 Finished downloading source code 2020/03/23 05:51:57 Using acb_vol_bef6d508-e07b-4875-bc80-2c757973eb84 as the home volume 2020/03/23 05:51:57 Setting up Docker configuration... 2020/03/23 05:51:58 Successfully set up Docker configuration 2020/03/23 05:51:58 Logging in to registry: dahatakeregistry.azurecr.io 2020/03/23 05:51:59 Successfully logged into dahatakeregistry.azurecr.io 2020/03/23 05:51:59 Executing step ID: build. Timeout(sec): 28800, Working directory: '', Network: '' 2020/03/23 05:51:59 Scanning for dependencies... 2020/03/23 05:51:59 Successfully scanned dependencies 2020/03/23 05:51:59 Launching container with name: build Sending build context to Docker daemon 7.68kB Step 1/6 : FROM python:3.8 3.8: Pulling from library/python 50e431f79093: Pulling fs layer dd8c6d374ea5: Pulling fs layer c85513200d84: Pulling fs layer 55769680e827: Pulling fs layer f5e195d50b88: Pulling fs layer 94cdd3612287: Pulling fs layer 3b37b69935d4: Pulling fs layer b9add85f08c4: Pulling fs layer aa1f4a29beac: Pulling fs layer 55769680e827: Waiting f5e195d50b88: Waiting b9add85f08c4: Waiting 94cdd3612287: Waiting 3b37b69935d4: Waiting aa1f4a29beac: Waiting dd8c6d374ea5: Verifying Checksum dd8c6d374ea5: Download complete c85513200d84: Verifying Checksum c85513200d84: Download complete 50e431f79093: Verifying Checksum 50e431f79093: Download complete 55769680e827: Verifying Checksum 55769680e827: Download complete 94cdd3612287: Verifying Checksum 94cdd3612287: Download complete b9add85f08c4: Verifying Checksum b9add85f08c4: Download complete 3b37b69935d4: Verifying Checksum 3b37b69935d4: Download complete f5e195d50b88: Verifying Checksum f5e195d50b88: Download complete aa1f4a29beac: Verifying Checksum aa1f4a29beac: Download complete 50e431f79093: Pull complete dd8c6d374ea5: Pull complete c85513200d84: Pull complete 55769680e827: Pull complete f5e195d50b88: Pull complete 94cdd3612287: Pull complete 3b37b69935d4: Pull complete b9add85f08c4: Pull complete aa1f4a29beac: Pull complete Digest: sha256:de4dad989417bdb9375e49b17602984a6883fbe4fa92e7a432983ef602bfcc28 Status: Downloaded newer image for python:3.8 ---> f88b2f81f83a Step 2/6 : ENV PYTHONDONTWRITEBYTECODE 1 ---> Running in 6b26f95fd3fa Removing intermediate container 6b26f95fd3fa ---> 79a1d83f14a0 Step 3/6 : ENV PYTHONUNBUFFERED 1 ---> Running in 10873c752bd4 Removing intermediate container 10873c752bd4 ---> 1a082a963105 Step 4/6 : WORKDIR /app ---> Running in ca23f5a03f96 Removing intermediate container ca23f5a03f96 ---> 372cf5af723e Step 5/6 : ADD ./src /app ---> 0633d9d9b816 Step 6/6 : CMD ["python", "app.py"] ---> Running in 0a745c15c8f3 Removing intermediate container 0a745c15c8f3 ---> 5309b2885f5d Successfully built 5309b2885f5d Successfully tagged dahatakeregistry.azurecr.io/azurebatchpython:ce1 2020/03/23 05:52:31 Successfully executed container: build 2020/03/23 05:52:31 Executing step ID: push. Timeout(sec): 1800, Working directory: '', Network: '' 2020/03/23 05:52:31 Pushing image: dahatakeregistry.azurecr.io/azurebatchpython:ce1, attempt 1 The push refers to repository [dahatakeregistry.azurecr.io/azurebatchpython] b3a7166a7615: Preparing 1a0cf85e58eb: Preparing fbefc7d9db96: Preparing bd436d37b328: Preparing 8b6dde37c5c4: Preparing 3dffd131f01f: Preparing 271910c4c150: Preparing 6670e930ed33: Preparing c7f27a4eb870: Preparing e70dfb4c3a48: Preparing 1c76bd0dc325: Preparing 3dffd131f01f: Waiting 271910c4c150: Waiting 6670e930ed33: Waiting c7f27a4eb870: Waiting e70dfb4c3a48: Waiting 1c76bd0dc325: Waiting bd436d37b328: Pushed 1a0cf85e58eb: Pushed b3a7166a7615: Pushed fbefc7d9db96: Pushed 8b6dde37c5c4: Pushed 3dffd131f01f: Pushed c7f27a4eb870: Pushed e70dfb4c3a48: Pushed 1c76bd0dc325: Pushed 6670e930ed33: Pushed 271910c4c150: Pushed ce1: digest: sha256:9ebbdbb9493d1165403a18048b32add62274600e45c5aa1d3ae0f3cc6d522daa size: 2630 2020/03/23 05:53:20 Successfully pushed image: dahatakeregistry.azurecr.io/azurebatchpython:ce1 2020/03/23 05:53:20 Step ID: build marked as successful (elapsed time in seconds: 31.848759) 2020/03/23 05:53:20 Populating digests for step ID: build... 2020/03/23 05:53:21 Successfully populated digests for step ID: build 2020/03/23 05:53:21 Step ID: push marked as successful (elapsed time in seconds: 49.055933) 2020/03/23 05:53:21 The following dependencies were found: 2020/03/23 05:53:21 - image: registry: dahatakeregistry.azurecr.io repository: azurebatchpython tag: ce1 digest: sha256:9ebbdbb9493d1165403a18048b32add62274600e45c5aa1d3ae0f3cc6d522daa runtime-dependency: registry: registry.hub.docker.com repository: library/python tag: "3.8" digest: sha256:de4dad989417bdb9375e49b17602984a6883fbe4fa92e7a432983ef602bfcc28 git: {} Run ID: ce1 was successful after 1m29s
Azure Portal で、登録状況を確認できます。
また、Visual Studio Code の[Docker] タブでも、確認できます。
これで コンテナのデプロイ準備は完了です。
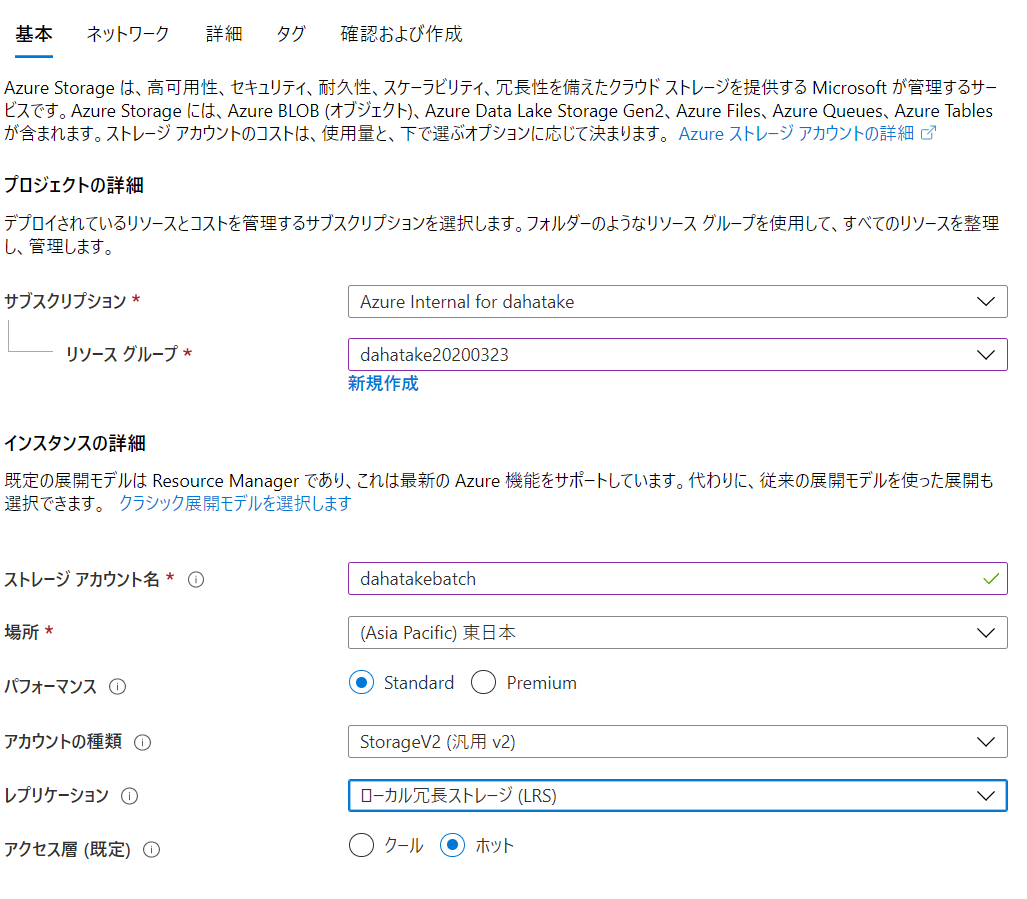
4. Azure Storage の作成
クラウド上の永続化ストレージである Azure Storage を作成します。
動かす事を目的としますので、どんなタイプのストレージでも良いです。
Azure Storage アカウントの作成:
https://docs.microsoft.com/ja-jp/azure/storage/common/storage-account-create?tabs=azure-portal5. Azure Batch の作成
長かったですねー ようやくです。
5.1. Azure Batch アカウントの作成
こちらの手順に沿って作成します。画面が既に変わっていますが細かい事は気にしないでください。
クイック スタート:Azure portal で最初の Batch ジョブを実行する:
https://docs.microsoft.com/ja-jp/azure/batch/quick-create-portalこちらが作成例です。
- 基本
- 詳細
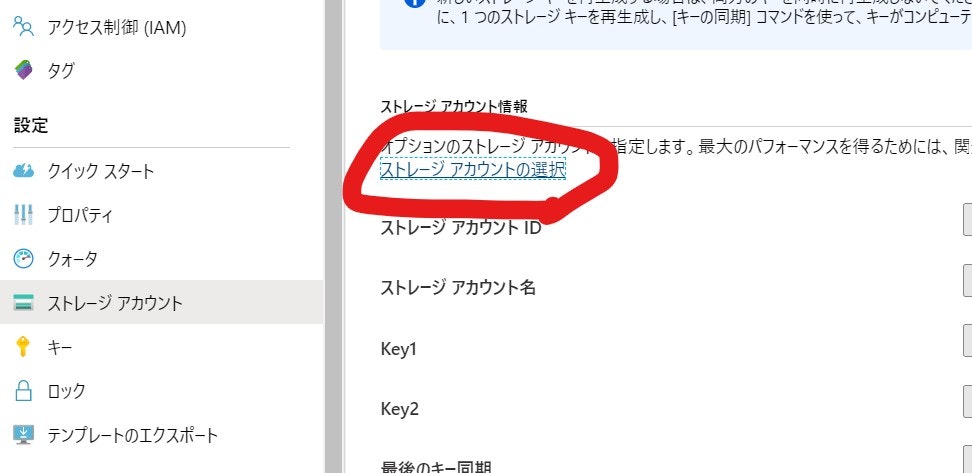
5.2. Storage アカウントの紐づけ
Azure Batch では、コンピューターの入出力結果を Azure Blob Storage へ保存します。どの Azure Storage アカウントを使うのかを設定します。
- ポータルの [ストレージ アカウント]へ移動します
- 文章中の[ストレージの選択]をクリックします
5.3. プール の作成の準備
Azure Batch で
プールは、コンピューターのクラスターを指します。ジョブは、このプールに投入されることになります。
ここでは、Azure Portal から作成をしますプールの作成時には、仮想マシンの初期構成を一気に設定します。ですので、事前準備を念入りに行う必要があります。
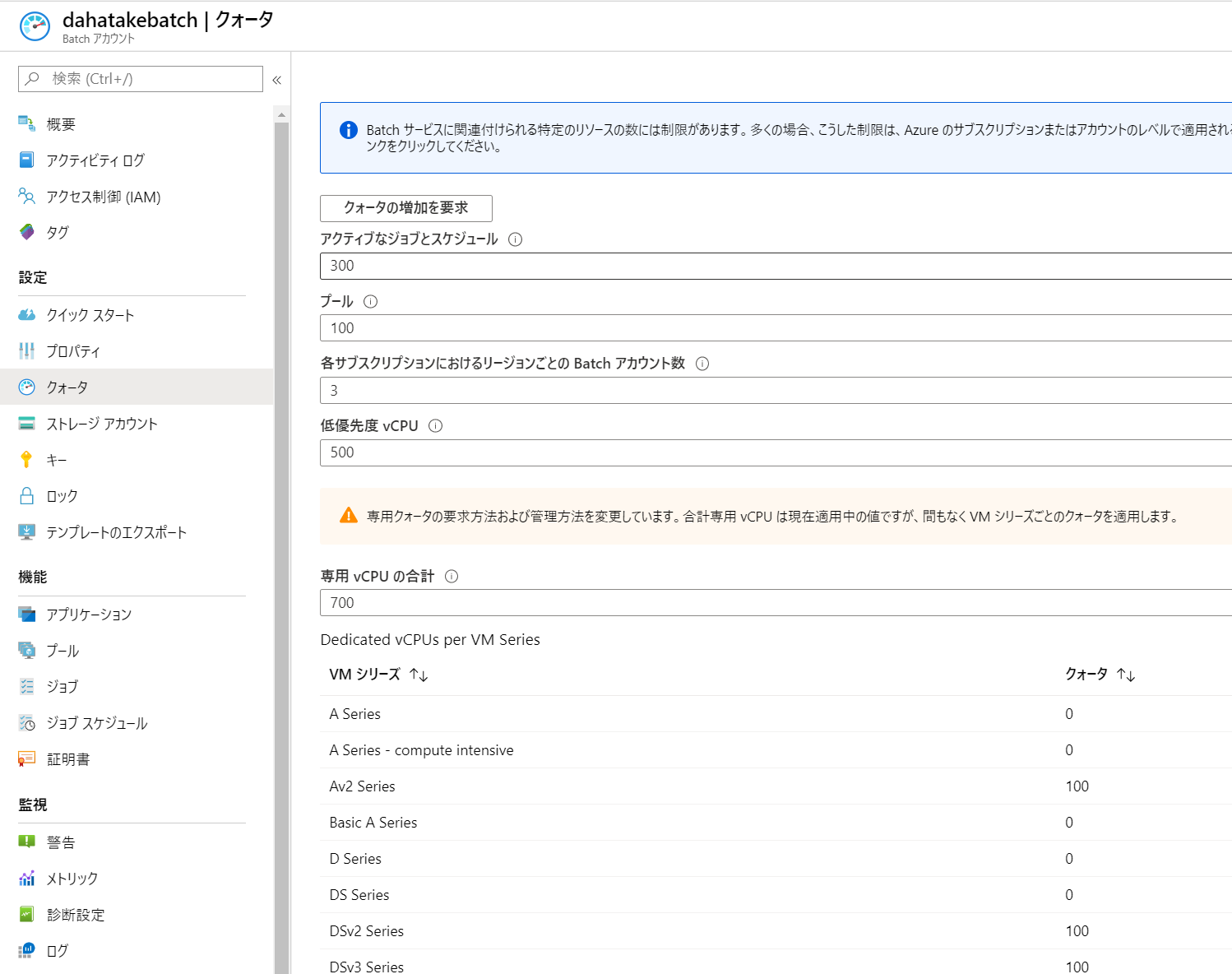
うまくいかなかったら、プールは作り直した方が早いです? 私も何度もプールの作り直しをしました。理解のために。5.3.1. CPUコア数の事前確認
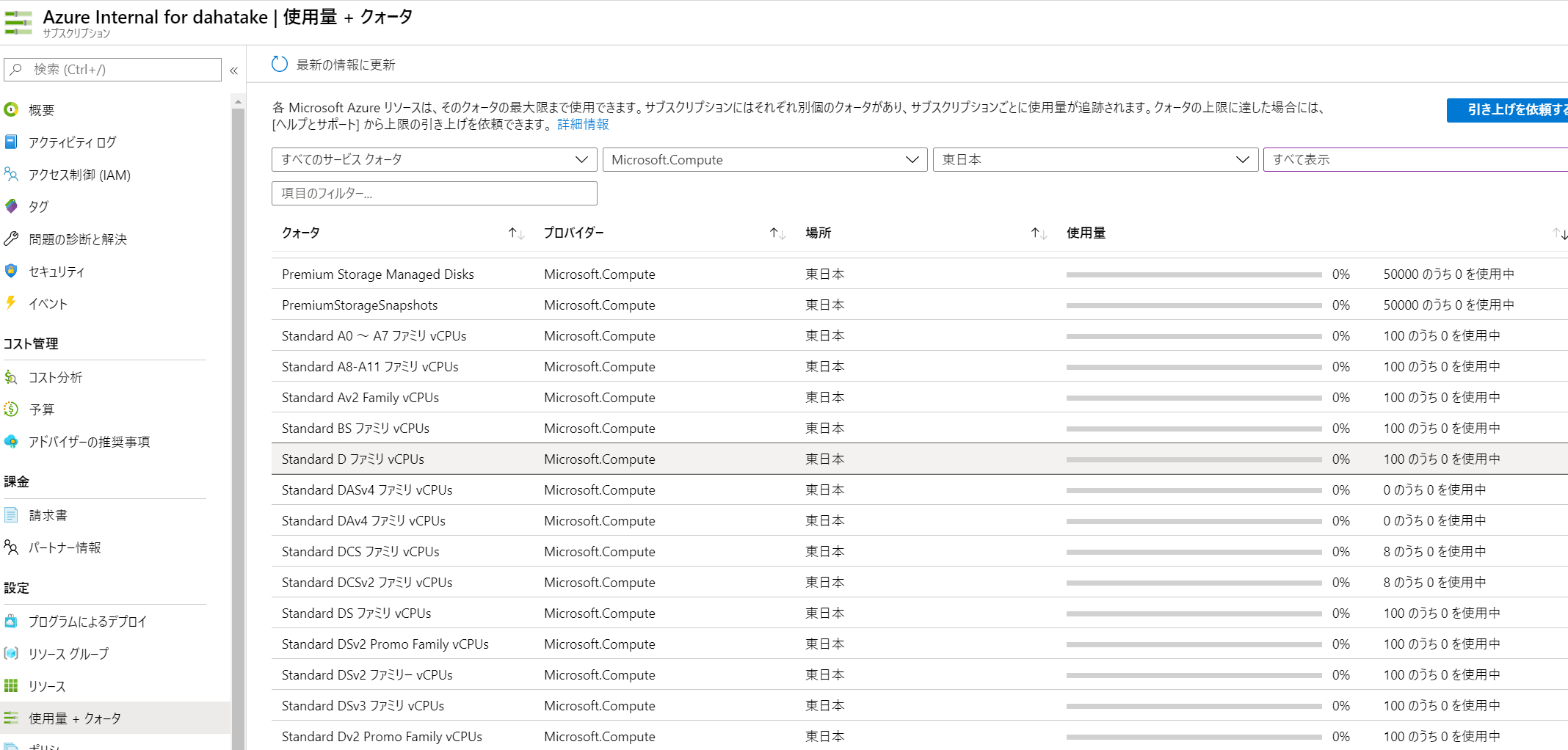
ここで仕様する仮想マシンは、Azure Batchで別管理されているものです。よって、CPUコア数のクォーターは、通常の仮想マシンと「別」です。
Azure Batch のポータルの [クォータ]でCPUコア数を確認してください。
必要に応じてコア数増加のリクエストをしてください。
- 私の環境の場合は、D Series のコア数が別です。
- Azure Batch のCPUコア数クォータ:
- Azure Subscription のCPUコア数クォータ:
5.3.2. Blob とのやり取りのための Blobfuse の設定 - リソースファイルの利用
現状、Linux 仮想マシンとのやり取りが最速である、Blobfuse を使います。
blobfuse を使用して Blob Storage をファイル システムとしてマウントする方法:
https://docs.microsoft.com/ja-jp/azure/storage/blobs/storage-how-to-mount-container-linuxここでは、仮想マシン起動時 にリソース ファイルでとして、Blob Storage に置いたスクリプトファイルを Linux 仮想マシンにコピーして、それを起動させます。
リソース ファイルを作成して使用する:
https://docs.microsoft.com/ja-jp/azure/batch/resource-files
- 作業フォルダにファイルを追加します。
フォルダー構造
├─ src | ├─ app.py --- 計算処理 ├─ data | └─ src.txt --- テスト用ファイル └─ startupapp [NEW] ├─ startup.sh --- [NEW] 起動スクリプト ├─ fuse_conn_in.cfg --- [NEW] 入力フォルダ マウント用の認証情報ファイル └─ fuse_conn_out.cfg --- [NEW] 出力フォルダ マウント用の認証情報ファイル
- 起動スクリプト (startup.sh) は以下です。
wget https://packages.microsoft.com/config/ubuntu/16.04/packages-microsoft-prod.deb sudo dpkg -i packages-microsoft-prod.deb sudo apt-get update sudo apt-get install blobfuse sudo mkdir /mnt/data-in sudo mkdir /mnt/blobfusetmp-in -p sudo blobfuse /mnt/data-in --tmp-path=/mnt/blobfusetmp-in --config-file=fuse_conn_in.cfg -o attr_timeout=240 -o entry_timeout=240 -o negative_timeout=120 -o allow_other sudo mkdir /mnt/data-out sudo mkdir /mnt/blobfusetmp-out -p sudo blobfuse /mnt/data-out --tmp-path=/mnt/blobfusetmp-out --config-file=fuse_conn_out.cfg -o attr_timeout=240 -o entry_timeout=240 -o negative_timeout=120 -o allow_other
- ストレージアカウント 認証情報 (fuse_conn_in.cfg と fuse_conn_out.cfg) を作成します。
ストレージアカウントへアクセスのために認証情報を扱います。
ここでは動かす事を目的としますので、厳密にセキュアにしません。実際にはドキュメントを熟読の上、セキュアに管理ください。ストレージ アカウントの資格情報を構成する
https://docs.microsoft.com/ja-jp/azure/storage/blobs/storage-how-to-mount-container-linux#configure-your-storage-account-credentials
- Windows で認証情報を作成時の改行コードの編集
先のドキュメントにも注意書きがありますが、Linuxでテキストファイルを扱うため、Windowsで作成したテキストファイルの場合は、改行コードを変換する必要があります。WSL (Windows Subsystem for Linux) でも実行できますので、忘れないように。 以下、WSL - Ubuntu の例です。
dahatake@dahatake-lp3:/mnt/c/Work/AzureBatchPython/config$ sudo apt-get install dos2unix Reading package lists... Done Building dependency tree Reading state information... Done The following packages were automatically installed and are no longer required: libc-ares2 libfreetype6 libhttp-parser2.7.1 nodejs-doc Use 'sudo apt autoremove' to remove them. The following NEW packages will be installed: dos2unix 0 upgraded, 1 newly installed, 0 to remove and 170 not upgraded. Need to get 351 kB of archives. After this operation, 1267 kB of additional disk space will be used. Get:1 http://archive.ubuntu.com/ubuntu bionic/universe amd64 dos2unix amd64 7.3.4-3 [351 kB] Fetched 351 kB in 3s (135 kB/s) Selecting previously unselected package dos2unix. (Reading database ... 41294 files and directories currently installed.) Preparing to unpack .../dos2unix_7.3.4-3_amd64.deb ... Unpacking dos2unix (7.3.4-3) ... Setting up dos2unix (7.3.4-3) ... Processing triggers for man-db (2.8.3-2ubuntu0.1) ... dahatake@dahatake-lp3:/mnt/c/Work/AzureBatchPython/config$ dir fuse_conn_in.cfg fuse_conn_out.cfg dahatake@dahatake-lp3:/mnt/c/Work/AzureBatchPython/config$ dos2unix fuse_conn_in.cfg dos2unix: converting file fuse_conn_in.cfg to Unix format... dahatake@dahatake-lp3:/mnt/c/Work/AzureBatchPython/config$ dos2unix fuse_conn_out.cfg dos2unix: converting file fuse_conn_out.cfg to Unix format... dahatake@dahatake-lp3:/mnt/c/Work/AzureBatchPython/config$
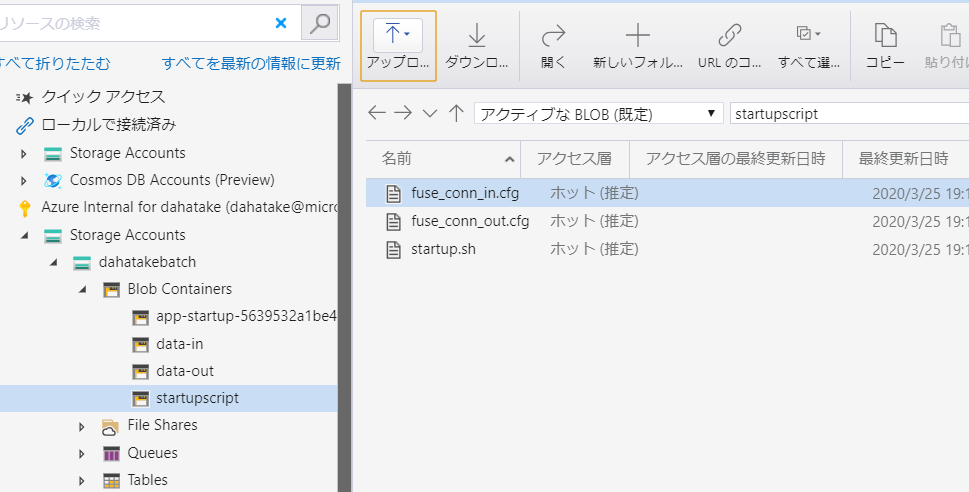
- Blob Storage にスクリプトファイルと認証情報ファイルをアップロード
NOTE:
アップロード後にスタートアップジョブとして設定すると、/root/startup/wd にコピーされます。
プールとして仮想マシンを起動すると、[ノード]からノード内のファイルシステムは閲覧できるんです。こちらで内容が確認できます。5.3.3. Container のプリフェッチ
仮想マシン起動時に、Container Image もダウンロードしておきます。
次のプールの作成時で行います。5.4. プールの作成
事前準備の結果を、パラメーターとして設定していきます。かなり項目数が多いですが、一つ一つの意味が理解できるのではないかと思います。
ここで行う事を改めて整理します。
- 仮想マシンの作成
- Container Imageのプリフェッチ
- 開始タスクで、blobfuse を利用して、Blob Storageのコンテナをマウント
以下の手順で行います。
- [機能] - [プール]へ移動します
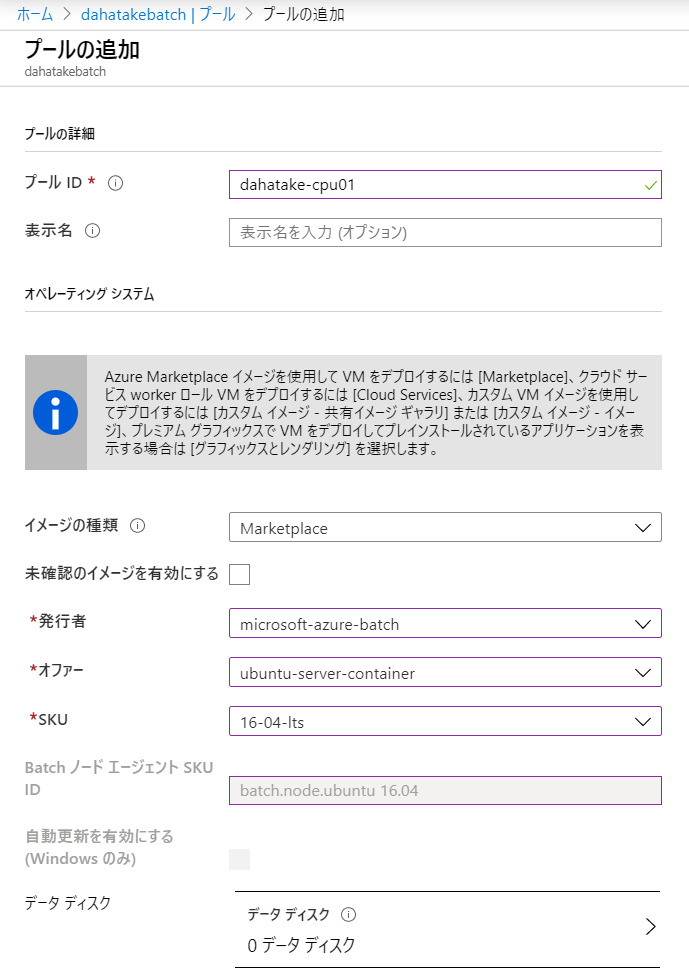
- [プールの追加]を選択します
- プールの詳細 と オペレーティングシステム
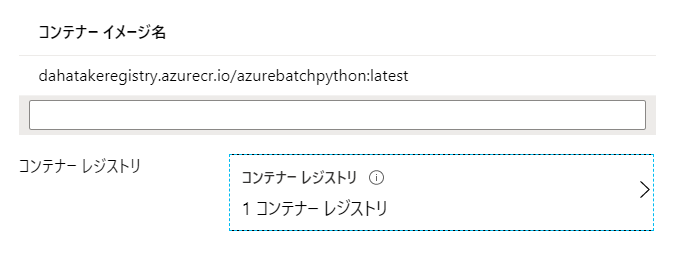
- コンテナーイメージ名
- コンテナーレジストリ
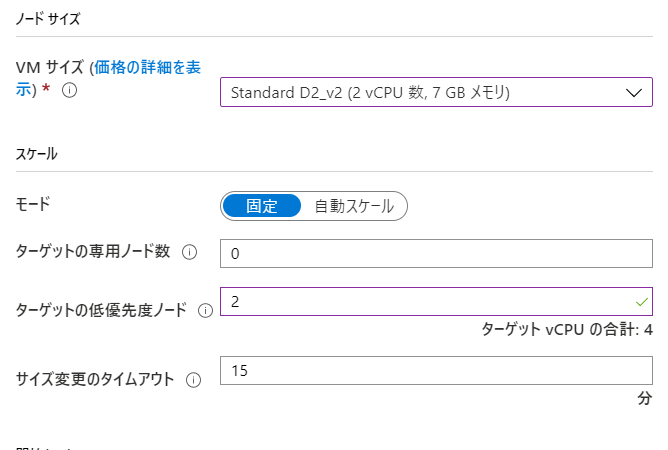
- ノードサイズ
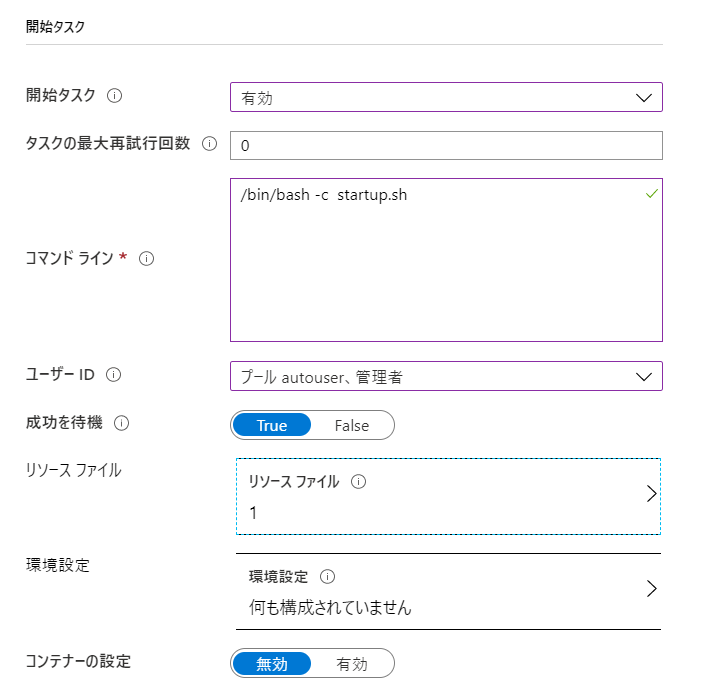
- 開始タスク
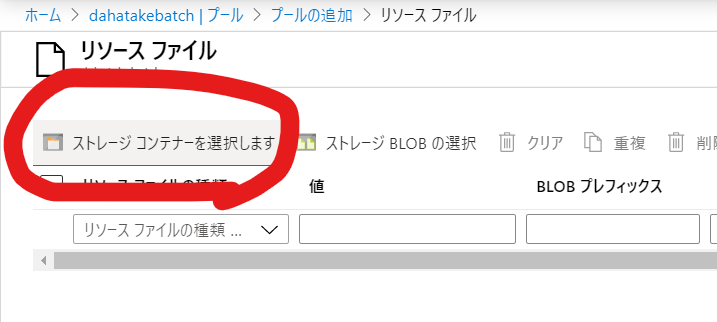
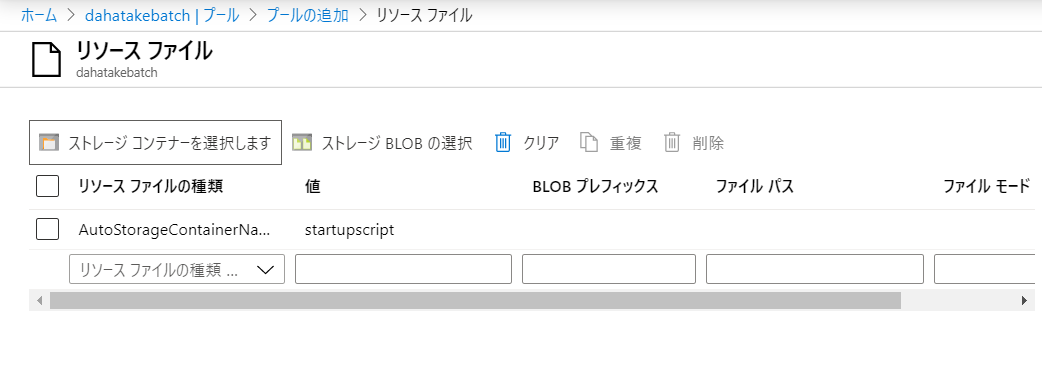
- リソースファイルの追加
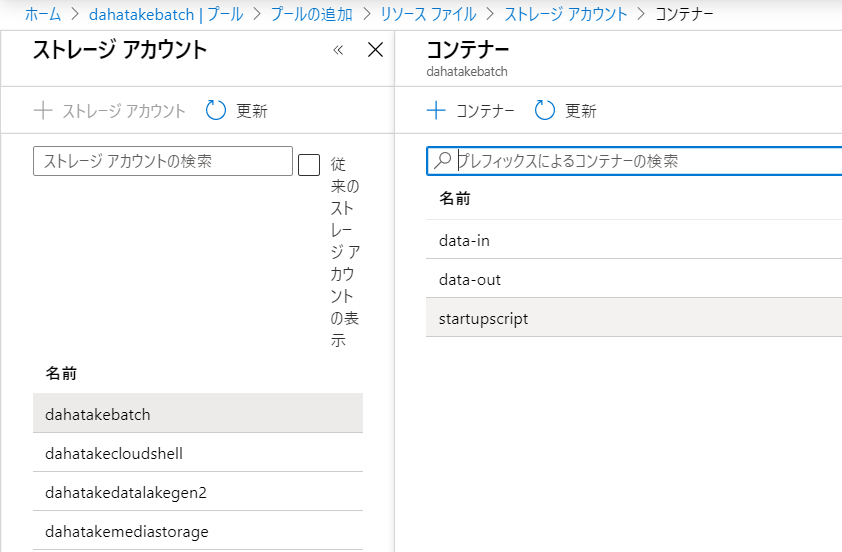
- [ストレージコンテナ]を選択
- 結果、こんな感じ
残りは、そのままで...
以下、補足です。
項目 値 説明 イメージの種類 Marketplace Azure Batch でコンテナ用を動かす場合は、こちらを選びます。もちろん、OS Image レベルでカスタマイズしたものを用意する場合は、そちらを選択します 発行者 microsoft-azure-batch Azure Batch Team が用意しているものです。Docker互換の Moby などがインストール済みです オファー ubuntu-server-container ubuntu を選びます。
私の好みです?コンテナー構成 カスタム ここで利用する Container Image を指定します コンテナー イメージ名 container registry URL/image name:tag name
例: dahatakeregistry.azurecr.io/azurebatchpython:latestコンテナイメージの Full URL を指定します コンテナー レジストリー Azure Container Registry のURL [追加]ボタンからウィザードで指定します VMサイズ Standard DS2_v2 Aシリーズが古いので安定性には欠けます。また、CPUは2つ以上がより安定します スケール [固定] 本当はオートスケールにしたいのですが、確実に動かす事をしてから、オートスケールにしましょう ターゲットの体優先度ノード数 2 必要最低限。
1でも良いです!サイズ変更のタイムアウト 5 15分も待っていられないので。開発中は 開始タスク 有効 ここで 仮想マシン起動時のスクリプトを設定します 開始タスク - コマンドライン /bin/bash -c startup.sh シェルの起動から行います 以下、補足です。
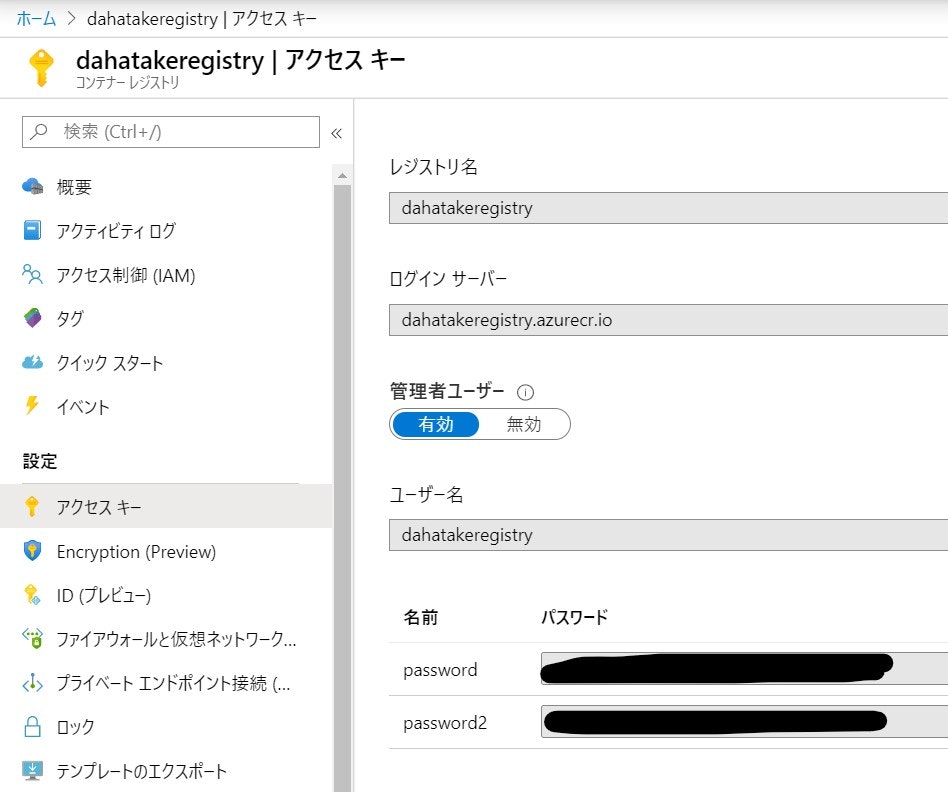
コンテナーレジストリーの認証情報は、ブラウザーのタブをもう一つ起動して、Azure Portalへログインし、Azure Container Registryの[アクセスキー]を開いておくと便利です。
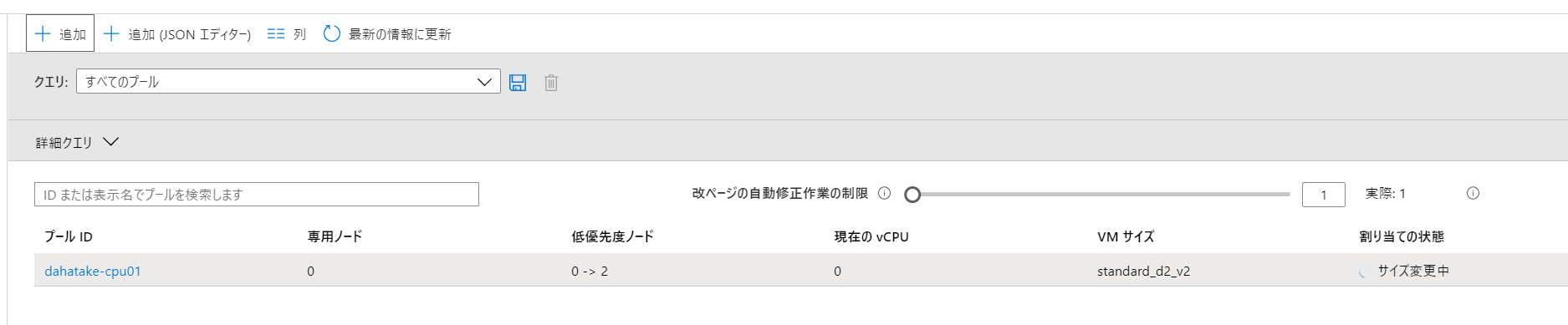
開始のリクエストが送信されると、[割り当ての状態]が[サイズ変更中]になります
- ここで仮想マシンが起動されますので、仮想マシンの稼働時間に対して課金が開始されますので、ご注意ください!
- 効率化したい場合は、オートスケール設定で。
5.4.1 開発時の Tips
一気に設定をするので、問題発生時の切り分けは、難しくなりがちです。一つ一つ潰せるように以下をお伝えします。
実はプールの作成後に、仮想マシンに対して幾つか開発コードを後からも設定できます。
Azure Poral は2つのタブで常にアクセスしておく
- 認証情報など、様々な文字列をコピペすることが多いです。ストレージ、Container Registry など。現在の Azure Batch のポータルは、ピックアップしてくれず、テキストボックスに入力する方法をとっています。ですので、この方法が便利です。
- タイムアウトにはご注意ください?
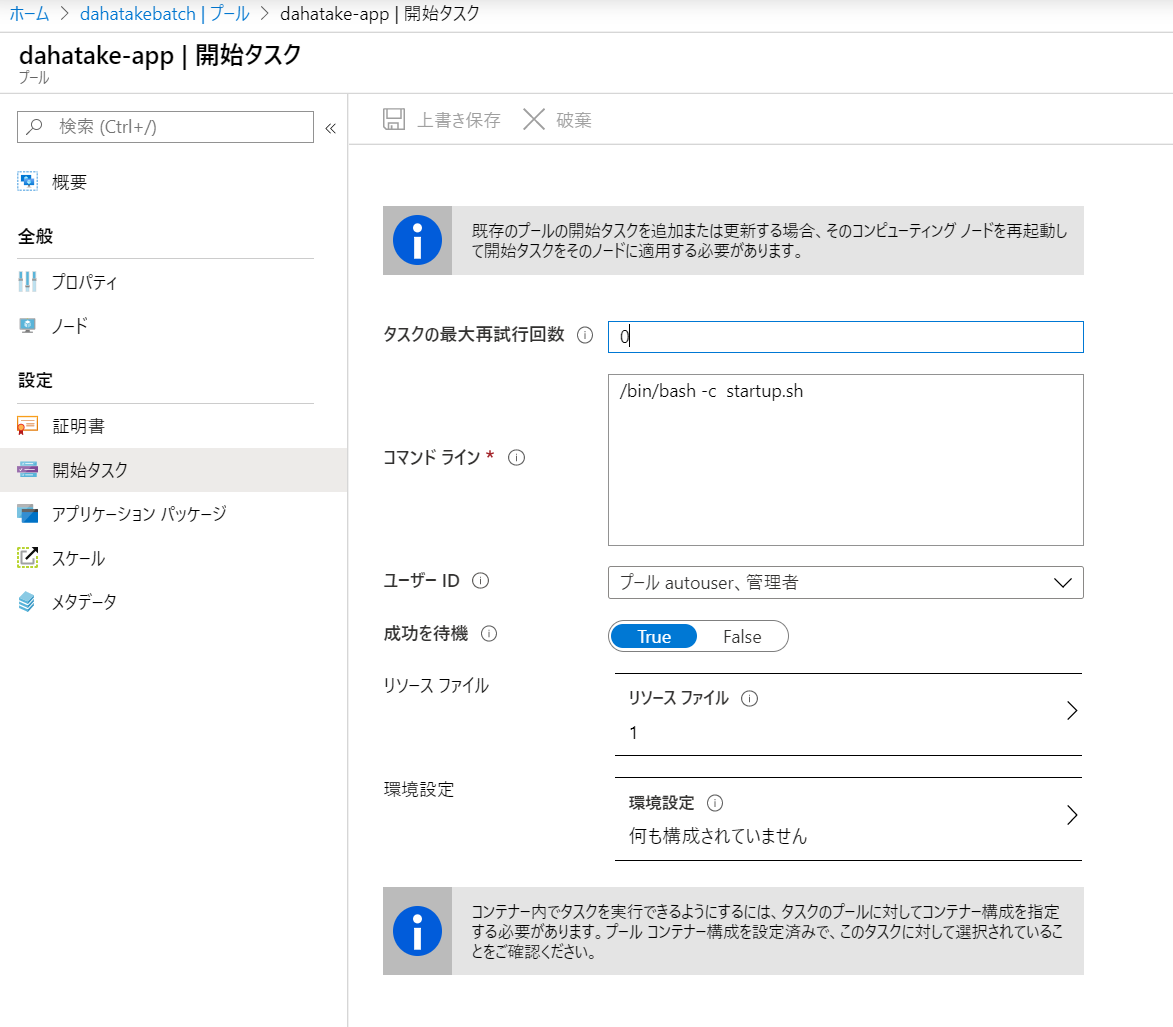
まずはスクリプト系を設定せずにプールを作成します。
- 低優先度が開発中はおススメです。仮想マシンの料金が、ざっくり60-80%安くなります!
開始タスク
- プール作成後に、[プール] - [ノード]と選択します。個々の仮想マシンが確認できます。
- 特定の仮想マシンを1つ選択します。ハイパーリンクの部分ですね。
- そこで、[開始タスク]を選択し、コマンドラインやリソースファイルなどを設定します。
- エラー情報は、開始タスクの情報からも確認できます。
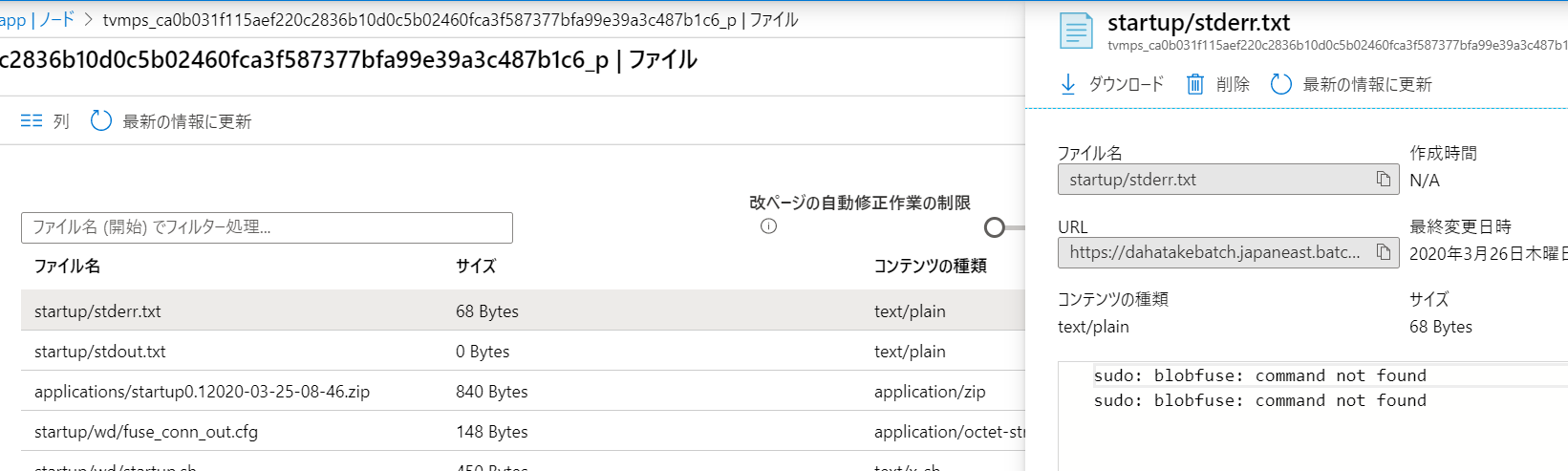
- まさにデバッグ中!
- [ファイル] から、startup/stderr.txt や startup/stdout.txt などを閲覧して、ログを確認してください。 -
- エラー例
- 変更後は[再起動]で!
仮想マシンにsshでログイン
- [ノード]の[接続]から可能です。
例えば Blobfuse したマウント結果などは、以下の様に WSL からでも確認ができます。
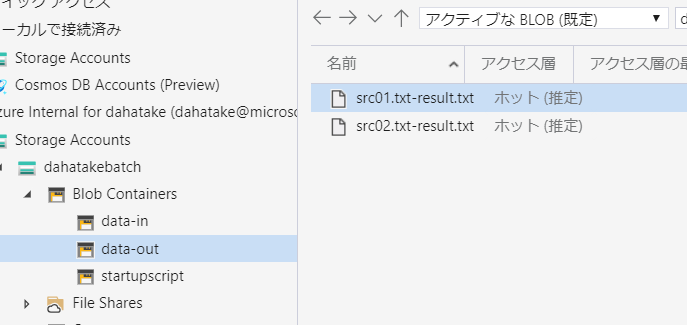
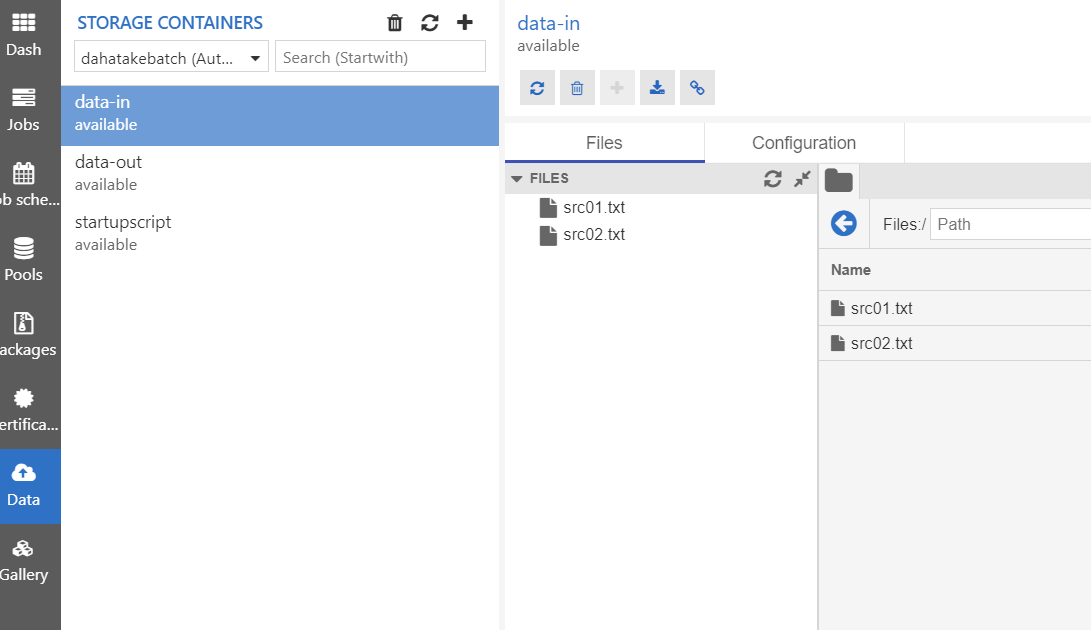
C:\>wsl dahatake@dahatake-lp3:/mnt/c$ ssh dahatake@20.44.133.230 -p 50000 dahatake@20.44.133.230's password: Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.15.0-1075-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage * Latest Kubernetes 1.18 beta is now available for your laptop, NUC, cloud instance or Raspberry Pi, with automatic updates to the final GA release. sudo snap install microk8s --channel=1.18/beta --classic * Multipass 1.1 adds proxy support for developers behind enterprise firewalls. Rapid prototyping for cloud operations just got easier. https://multipass.run/ 16 packages can be updated. 0 updates are security updates. New release '18.04.4 LTS' available. Run 'do-release-upgrade' to upgrade to it. Last login: Wed Mar 25 21:34:31 2020 from 122.134.161.68 dahatake@8d996a9545ea4eeaa4556f03dd7deea4000000:~$ ls dahatake@8d996a9545ea4eeaa4556f03dd7deea4000000:~$ cd / dahatake@8d996a9545ea4eeaa4556f03dd7deea4000000:/$ ls bin etc initrd.img.old lost+found opt run srv usr vmlinuz.old boot home lib media proc sbin sys var dev initrd.img lib64 mnt root snap tmp vmlinuz dahatake@8d996a9545ea4eeaa4556f03dd7deea4000000:/$ cd /mnt dahatake@8d996a9545ea4eeaa4556f03dd7deea4000000:/mnt$ ls batch blobfusetmp-out DATALOSS_WARNING_README.txt docker blobfusetmp-in data-in data-out lost+found dahatake@8d996a9545ea4eeaa4556f03dd7deea4000000:/mnt$ cd data-in dahatake@8d996a9545ea4eeaa4556f03dd7deea4000000:/mnt/data-in$ ls src01.txt src02.txt dahatake@8d996a9545ea4eeaa4556f03dd7deea4000000:/mnt/data-in$6. Python コードからのジョブ起動
- 計算処理: 入出力ファイルについては、引数として取得。コード内部で呼び出さない
- ジョブ起動側: Blob マウントをし、入出力ファイル名を確定。計算処理を呼び出す
のジョブ起動側ですね。
冒頭にも書きましたが、これはAzure Batch のジョブ (=計算処理) を外部から呼び出す事になります。ジョブ分割は並列処理のインフラを最大限に活かすために重要な設計になりますので、十二分に配慮して行ってください。今回は、ローカルのPython環境から起動させましょう。
フォルダー構造
├─ src | ├─ app.py --- 計算処理 ├─ data | └─ src.txt --- テスト用ファイル ├─ startupapp | ├─ startup.sh --- 起動スクリプト | ├─ fuse_conn_in.cfg --- 入力フォルダ マウント用の認証情報ファイル | └─ fuse_conn_out.cfg --- 出力フォルダ マウント用の認証情報ファイル ├─ config.py --- [NEW] ジョブ起動時のAzure Servicesへの認証情報 ├─ python_quickstart_client.py --- [NEW] ジョブ起動 └─ requirements.txt --- [NEW] ジョブ起動スクリプト用 Python 関連モジュール6.1. 実行環境作成
Azure Blob Storage と Azure Batch 呼び出し用のライブラリーをインストールします。関連ライブラリーは
requirements.txtにあります。
- requirements.txt
azure-batch==6.0.0 azure-storage-blob==1.4.0Azureのポータルから、それぞれの認証情報を取得ください。
- config.py
# ------------------------------------------------------------------------- # # THIS CODE AND INFORMATION ARE PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, # EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES # OF MERCHANTABILITY AND/OR FITNESS FOR A PARTICULAR PURPOSE. # ---------------------------------------------------------------------------------- # The example companies, organizations, products, domain names, # e-mail addresses, logos, people, places, and events depicted # herein are fictitious. No association with any real company, # organization, product, domain name, email address, logo, person, # places, or events is intended or should be inferred. # -------------------------------------------------------------------------- # Global constant variables (Azure Storage account/Batch details) # import "config.py" in "python_quickstart_client.py " _BATCH_ACCOUNT_NAME = '' # Your batch account name _BATCH_ACCOUNT_KEY = '' # Your batch account key _BATCH_ACCOUNT_URL = '' # Your batch account URL _STORAGE_ACCOUNT_NAME = '' # Your storage account name _STORAGE_ACCOUNT_KEY = '' # Your storage account key _POOL_ID = '' # Your Pool ID _JOB_ID = '' # Job IDご自分のターミナル (コマンドプロンプト) から、pip でインストールします。
勿論、Anaconda などを使っても構いません。pip install -r requirements.txt6.2. 読み込み用ファイルを Blob Storage へアップロード
テキストファイルなら何でも構いません。Blob Storage へアップロードしてください。
blobfuse 設定時に指定したコンテナにアップロードするのをお忘れなく。この例だとdata-inコンテナになります。
6.3. ジョブ起動コード実行
Azure Batch のクイックスタートのサンプルを流用します。
参考サンプルコード:
https://github.com/Azure-Samples/batch-python-quickstart必要最低限の部分に変更しました。少し長いですが、こちらが参考です。
## install library before you run ## pip install -r requirements.txt from __future__ import print_function import datetime import io import os import sys import time import config try: input = raw_input except NameError: pass import azure.storage.blob as azureblob import azure.batch.batch_service_client as batch import azure.batch.batch_auth as batch_auth import azure.batch.models as batchmodels # Update the Batch and Storage account credential strings in config.py with values # unique to your accounts. These are used when constructing connection strings # for the Batch and Storage client objects. def print_batch_exception(batch_exception): """ Prints the contents of the specified Batch exception. :param batch_exception: """ print('-------------------------------------------') print('Exception encountered:') if batch_exception.error and \ batch_exception.error.message and \ batch_exception.error.message.value: print(batch_exception.error.message.value) if batch_exception.error.values: print() for mesg in batch_exception.error.values: print('{}:\t{}'.format(mesg.key, mesg.value)) print('-------------------------------------------') def create_job(batch_service_client, job_id, pool_id): """ Creates a job with the specified ID, associated with the specified pool. :param batch_service_client: A Batch service client. :type batch_service_client: `azure.batch.BatchServiceClient` :param str job_id: The ID for the job. :param str pool_id: The ID for the pool. """ print('Creating job [{}]...'.format(job_id)) job = batch.models.JobAddParameter( id=job_id, pool_info=batch.models.PoolInformation(pool_id=pool_id)) batch_service_client.job.add(job) def add_tasks(batch_service_client, job_id, input_files): """ Adds a task for each input file in the collection to the specified job. :param batch_service_client: A Batch service client. :type batch_service_client: `azure.batch.BatchServiceClient` :param str job_id: The ID of the job to which to add the tasks. :param list input_files: A collection of input files. One task will be created for each input file. :param output_container_sas_token: A SAS token granting write access to the specified Azure Blob storage container. """ print('Adding {} tasks to job [{}]...'.format(len(input_files.items), job_id)) tasks = list() for idx, input_file in enumerate(input_files): command = "python app.py /data-in/{0} /data-out/{0}-result.txt".format(input_file.name) task_container_setting = batch.models.TaskContainerSettings(image_name="dahatakeregistry.azurecr.io/azurebatchpython:latest", container_run_options='--workdir /app --volume /mnt/data-in:/data-in --volume /mnt/data-out:/data-out') tasks.append(batch.models.TaskAddParameter( id='Task{}'.format(idx), command_line=command, container_settings=task_container_setting ) ) batch_service_client.task.add_collection(job_id, tasks) def wait_for_tasks_to_complete(batch_service_client, job_id, timeout): """ Returns when all tasks in the specified job reach the Completed state. :param batch_service_client: A Batch service client. :type batch_service_client: `azure.batch.BatchServiceClient` :param str job_id: The id of the job whose tasks should be to monitored. :param timedelta timeout: The duration to wait for task completion. If all tasks in the specified job do not reach Completed state within this time period, an exception will be raised. """ timeout_expiration = datetime.datetime.now() + timeout print("Monitoring all tasks for 'Completed' state, timeout in {}..." .format(timeout), end='') while datetime.datetime.now() < timeout_expiration: print('.', end='') sys.stdout.flush() tasks = batch_service_client.task.list(job_id) incomplete_tasks = [task for task in tasks if task.state != batchmodels.TaskState.completed] if not incomplete_tasks: print() return True else: time.sleep(1) print() raise RuntimeError("ERROR: Tasks did not reach 'Completed' state within " "timeout period of " + str(timeout)) if __name__ == '__main__': container_name = "data-in" start_time = datetime.datetime.now() start_time_for_job = "{0:%Y%m%d%H%M}".format(start_time) print('Start: {}'.format(start_time)) print() # Create a Batch service client. We'll now be interacting with the Batch # service in addition to Storage credentials = batch_auth.SharedKeyCredentials(config._BATCH_ACCOUNT_NAME, config._BATCH_ACCOUNT_KEY) batch_client = batch.BatchServiceClient( credentials, batch_url=config._BATCH_ACCOUNT_URL) # Create the blob client, for use in obtaining references to # blob storage containers and uploading files to containers. blob_service_client = azureblob.BlockBlobService( account_name=config._STORAGE_ACCOUNT_NAME, account_key=config._STORAGE_ACCOUNT_KEY) # List the blobs in the container blob_list = blob_service_client.list_blobs(container_name) for blob in blob_list: print("\t" + blob.name) try: print("\nCreating Job...") job_name = "{}-{}".format(config._JOB_ID, start_time_for_job) # Create the job that will run the tasks. create_job(batch_client, job_name, config._POOL_ID) print("\nAdd task...") # Add the tasks to the job. add_tasks(batch_client, job_name, blob_list) # Pause execution until tasks reach Completed state. wait_for_tasks_to_complete(batch_client, job_name, datetime.timedelta(minutes=5)) print(" Success! All tasks reached the 'Completed' state within the " "specified timeout period.") except batchmodels.BatchErrorException as err: print_batch_exception(err) raise # Print out some timing info end_time = datetime.datetime.now().replace(microsecond=0) print() print('Sample end: {}'.format(end_time)) print('Elapsed time: {}'.format(end_time - start_time))実行例です。
C:\Work\AzureBatchPython>python python_quickstart_client.py Start: 2020-03-26 22:20:09.788129 src01.txt src02.txt Creating Job... Creating job [PythonJob-202003262220]... Add task... Adding 2 tasks to job [PythonJob-202003262220]... Monitoring all tasks for 'Completed' state, timeout in 0:05:00...... Success! All tasks reached the 'Completed' state within the specified timeout period. Sample end: 2020-03-26 22:20:14 Elapsed time: 0:00:04.211871 C:\Work\AzureBatchPython>出力先の Blob Storage にファイルが出力されている事が確認できます。
ポイントとなる部分を解説します。
それは
add_tasks関数の中です。62行目から定義されていますね。
- 81行目
コンテナ上で実行するコマンドラインになります。入出力のフォルダの設定はこの後に行います。
command = "python app.py /data-in/{0} /data-out/{0}-result.txt".format(input_file.name)
- 83行目
Azure Batch でコンテナーの実行を行う再には、これが必須となります。
task_container_setting = batch.models.TaskContainerSettings(image_name="dahatakeregistry.azurecr.io/azurebatchpython:latest", container_run_options='--workdir /app --volume /mnt/data-in:/data-in --volume /mnt/data-out:/data-out')
項目 説明 image_name container image の名前です container_run_options create container のオプションです。通常のコンテナ起動と若干異なる設定も必要ですので、ドキュメント熟読ください。例えば -vの様な省略形はサポートされていません。--volumeの様に設定してくださいタスク用のコンテナー設定:
https://docs.microsoft.com/ja-jp/azure/batch/batch-docker-container-workloads#container-settings-for-the-task
- 85行目
コンテナ起動時のコマンドライン設定と、コンテナとして起動し、その際のコンテナ起動設定とともに、タスクとして登録します。
tasks.append(batch.models.TaskAddParameter( id='Task{}'.format(idx), command_line=command, container_settings=task_container_setting ) )ようやく動きましたね!!!
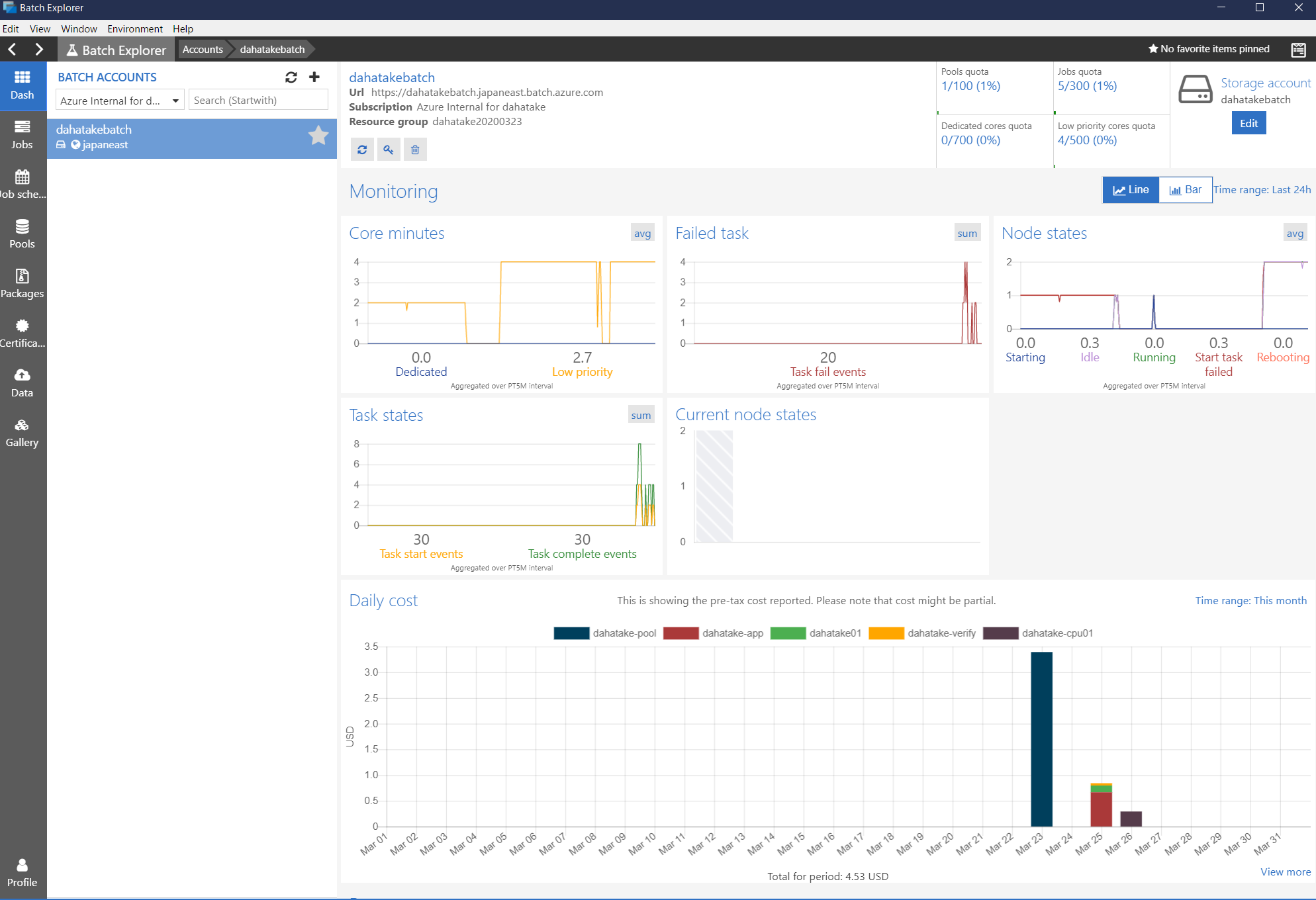
7. 開発時の友だち - Azure Batch Explorer
これ、必須ですね...超絶便利
何が閲覧できるのか、ご紹介しますね。
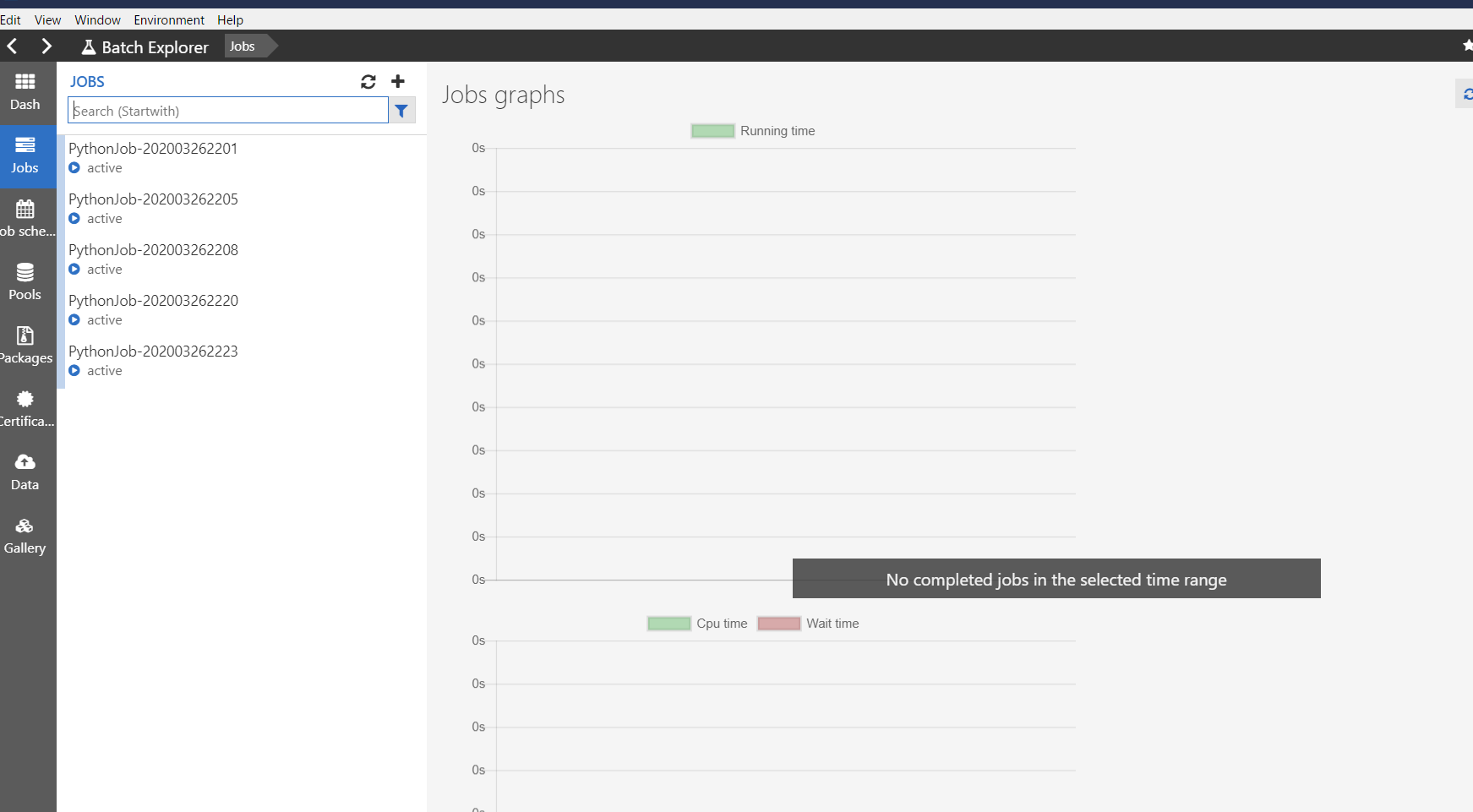
- Dash
概要です。なんと、使用料金まで可視化してくれます。
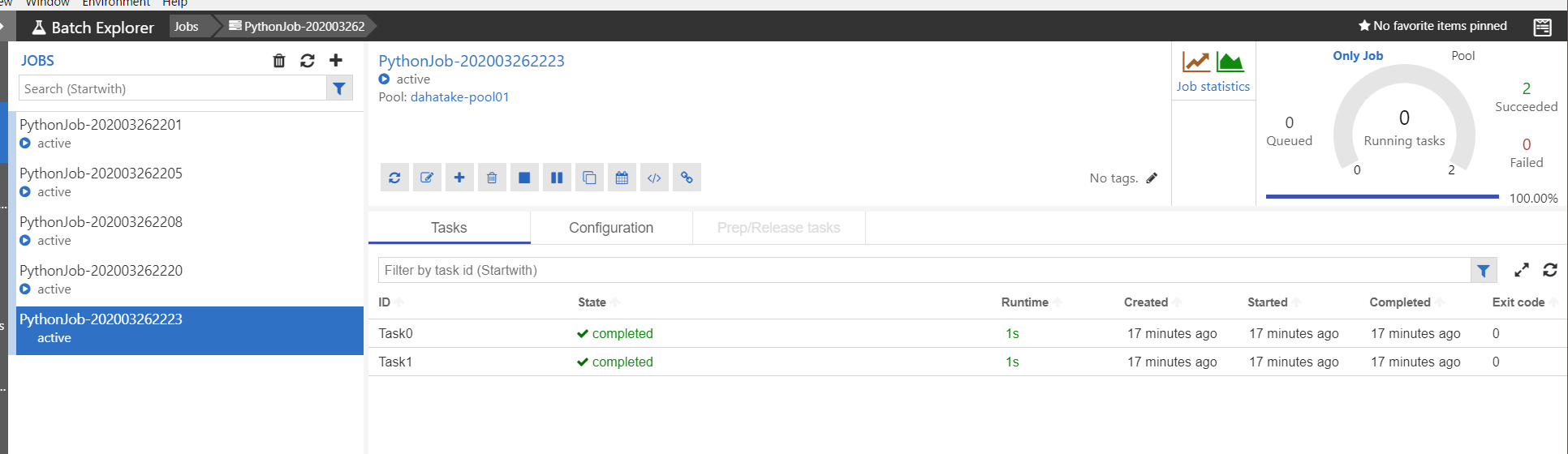
- Job
ジョブとタスクの開発中にはここを眺める事になると思います。
タスク実行中の標準出力と標準エラー出力の結果が閲覧できます。これは、Azure Batch のプールとして作成した仮想マシンの中に保存されています。
また、ジョブは作成後に適時削除してください。
- Data
Azure Batch が接続している Blob Storage です。
Azure Storage Explorer よりもサクサク動きます。
まとめ
Azure Batch は同時に100VM起動するような並列処理に向いています。Azure Blob Storage もそもそも並列処理に強い構造を持っています。ただし、Container を使っての処理となると、ちょっと工夫が必要です。
ただ、この手順で一通りの流れを理解できたのではないでしょうか?もし、皆さんが Azure で機械学習や深層学習などを行う場合は、Azure Machine Learning の Azure Machine Learning Compute を使ってください。実体が Azure Batch です。
さて、この先に進む方は、まずは以下をご一読ください。設計の参考になると思います。
Azure Batch のベスト プラクティス
https://docs.microsoft.com/ja-jp/azure/batch/best-practices最後に今回のサンプルコードのURLを記載しておきます。
https://github.com/dahatake/azure-batch-python-sample











- 投稿日:2020-03-26T22:43:53+09:00
Pythonで毎日AtCoder #17
はじめに
前回
今日から類題を解きます。#17
考えたこと
ABC064-A
倍数判定するだけr, g, b =map(str,input().split()) n = int(r+g+b) if n % 4 == 0: print('YES') else: print('NO')ABC088-A
nを500で割った余りを1円玉で払えるかを考えていますn = int(input()) a = int(input()) m = n % 500 if m <= a: print('Yes') else: print('No')ABC082-A
math.ceilで切り上げ処理を行っていますimport math a, b = map(int,input().split()) print(math.ceil((a+b)/2))まとめ
明日からは一度に解く問題の量を増やしたい。
では、また
- 投稿日:2020-03-26T21:39:27+09:00
Pythonでクォータニオンをz-y-x系オイラー角に変換するコード書いてみた
Pythonでクォータニオンをz-y-x系オイラー角に変換するコード書いてみた
クォータニオンからz-y-x系オイラー角の計算をしなければならなくなりました。
しかも、Python2.7で書かなければいけない案件なので、
scipy.spatial.transform.Rotationみたいな便利なやつ使えません。公式を調べてみたら、WikipediaにC++のサンプルコードが載っていました。
Wikipedia / Quaternion to Euler Angles Conversion
Pythonで書いてみた
Wikipediaのサンプルコードを参考にして、Python2.7のコードを書いてみました。
import math import numpy as np from pyquaternion import Quaternion def quaternion_to_euler_zyx(q): """ クォータニオンをz-y-x系オイラー角に変換する。 Parameters ---------- q : Quaternion クォータニオン(pyquaternion形式) Returns ------- np.array z-y-x系オイラー角 """ # roll : x軸回転 sinr_cosp = 2 * (q[0] * q[1] + q[2] * q[3]) cosr_cosp = 1 - 2 * (q[1] * q[1] + q[2] * q[2]) roll = math.atan2(sinr_cosp, cosr_cosp) # pitch : y軸回転 sinp = 2 * (q[0] * q[2] - q[3] * q[1]) if math.fabs(sinp) >= 1: pitch = math.copysign(math.pi / 2, sinp) else: pitch = math.asin(sinp) # yaw : z軸回転 siny_cosp = 2 * (q[0] * q[3] + q[1] * q[2]) cosy_cosp = 1 - 2 * (q[2] * q[2] + q[3] * q[3]) yaw = math.atan2(siny_cosp, cosy_cosp) # オイラー角 retrun np.array([ math.degrees(roll), math.degrees(pitch), math.degrees(yaw) ])依存ライブラリ
numpy 1.16.6
ベクトル計算とかに使うやつです。1.16.6がPython2.7対応の中では最新っぽいです。
pyquaternion 0.9.5
Quaternionの計算に
pyquaternion使ってます。
numpy-quaternionの方がnumpyと相性はよさそうなのですが、Python2.7環境だとインストールできませんでした。Python3以降ならscipy.spatial.transform.Rotationが楽
scipy.spatial.transform.Rotationを使えば、もっとシンプルに書けそうです。import numpy as np from pyquaternion import Quaternion from scipy.spatial.transform import Rotation as R def quaternion_to_euler_zyx(q): r = R.from_quat([q[0], q[1], q[2], q[3]]) return r.as_euler('zyx', degrees=True)ただ、
scipy.spatial.transform.RotationはPython2.7には対応してないみたいです。残念。さいごに
普段はUnityのz-x-y系オイラー角ばかり触ってるので、z-y-x系はかなり混乱しました。
本記事作成にあたり、以下の記事を参考にさせていただきました。ありがとうございました!
- 投稿日:2020-03-26T21:19:30+09:00
PythonユーザのためのRコード対応シート
Pythonの分析系コードを理解している人向けに、Rコードの対応まとめました。 ※随時更新中
(本記事では、Rのbaseパッケージのみ使用)「pythonで書くあれって、Rでどう書くんだっけ?」っていう流れって多いんですよね。
ドキュメント内の命名規則
特に断りがなければ、モジュール名のエイリアスは下記の通り。
pythonimport matplotlib.pyplot as plt import numpy as np import pandas as pd下記に登場する変数名称のイメージ。
pythondf = pd.DataFrame()Rdf = data.frame()PythonコードのRでの書き方
データフレームの生成
pd.DataFrame()
データフレームの作成
Rdata.frame() #空のデータフレームを生成 data.frame(col1=c(x1, x2, x3), col2=c(y1, y2, y3)) #カラムpd.read_csv()
CSVファイル(カンマ区切りデータ)読み込み
Rread.csv(ファイル名)pd.read_table()
TSV、CSVファイル(タブ区切りデータ)読み込み
Rread.table(ファイル名)df.index = [行名1, 行名2, ...]
行名の設定
Rrownames(df) <- c(行名1, 行名2, ...) print(rownames(df)) #代入せず、呼び出せばベクトルとして取得できるdf.columns = [列名1, 列名2, ...]
列名の設定
Rcolnames(df) <- c(列名1, 列名2, ...) print(colnames(df)) #代入せず、呼び出せばベクトルとして取得できるデータフレームの内容確認
df.shape
行数、列数の取得
Rdim(df)len(df)
行数の取得
Rncol(df)len(df.columns)
列数の取得
Rnrow(df)df.head()
先頭行の出力
Rhead(df) #引数で表示行数の指定も可df.tail()
末尾行の出力
Rtail(df) #引数で表示行数の指定も可df.info()
各カラムの数や型情報を表示する
Rstr(df)df.describe()
基本統計量の出力する
Rsummary(df) #ただし、stdは出力されない #stdは、例えば下のように取得する sds = NULL for(col in colnames(df)){ sds <- c(sds, sd(df[, col])) } names(sds) <- colnames(df)df.isna()
欠損値(NA)を確認する
Ris.na(df)df.isna().sum()
カラムごとの欠損値(NA)の個数を確認する
RcolSums(is.na(df)) # summary(df)でもNAの個数も出力されるので確認可能df[df.isna().any(axis=1)]
欠損値(NA)が1つでもある行を抽出する
Rdf[!complete.cases(df), ]df.col.unique()
ある列に登場するユニークな(重複のない)値を返す
Runique(df$col)df.col.value_counts()
ある列に登場する値の登場回数を返す
Rtable(df$col)データ抽出
df.iloc[x1:x2, y1:y2]
行番号および列番号を用いて、範囲指定する
Rdf[x1:x2, y1:y2] #Rはインデックスの開始が1である点に留意df.iloc[[x1, x2, ...], [y1, y2, ...]]
行番号および列番号を用いて、リスト指定する
Rdf[c(x1, x2, ...), c(y1, y2, ...)]df.loc[行名1:行名2, 列名1:列名2]
行名および列名を用いて、範囲指定する
R#明確には存在しないようなので、やるならば下記 #指定の行名および列名の位置(番号)を取得し、それを範囲指定に用いる x1 <- which(rownames(df) == 行名1) x2 <- which(rownames(df) == 行名2) y1 <- which(colnames(df) == 列名1) y2 <- which(colnames(df) == 列名2) df[x1:x2, y1:y2]df.loc[[行名1, 行名2, ...], [列名1, 列名2, ...]]
行名および列名を用いて、リスト指定する
Rdf[c(行名1, 行名2, ...), c(列名1, 列名2, ...)]df[df.col == x]
条件に合致する行を抽出する
Rdf[df$col == x, ] #または subset(df, col == x)データ加工
df[new_col] = x
データフレームに新しいカラムを追加する
Rdf[, new_col] <- xdf.drop()
行や列を削除する
R#削除したい行や列を選択し、NULLを代入することで削除ができる df[c(x1, x2), ] <- NULL #行を削除 df[, c(y1, y2)] <- NULL #列を削除 #インデックスを負の値にすると、その番号を除外した行列を返す性質を利用して、次のようにも書ける df <- df[c(-1, -2), ] #行を削除 df <- df[, c(-1, -2)] #列を削除df.fillna(x)
欠損値(NA)を埋める
Rdf[is.na(df)] <- xdf.dropna()
欠損値(NA)が含まれる行を削除する
Rna.omit(df)df.apply(func)
各要素1つずつに関数funcを適用する
Rsapply(df, FUN =func)df.col.apply(func)
指定したカラムの各要素1つずつに関数funcを適用する
Rsapply(df$x, FUN =func)df.T
行列を転置する
Rt(df)データ集計
df.max()、 df.min()
カラム毎の最大値、最小値を求める
Rsapply(df, FUN =max) sapply(df, FUN =min) #applyでも同等の処理が可能 apply(df, MARGIN=2, FUN =max) #MARGIN=1とすると行毎に関数(FUN)を適用する apply(df, MARGIN=2, FUN =min) #max(df)とした場合、全要素の中で最大値を求める(minも同様)df.groupby([x1, x2, ...]).agg(func)
グループ化して集計処理する
Raggregate(. ~ x1+x2, df, FUN=sum) #「.」は全カラムに対し集計処理を行う aggregate(x ~ x1+x2, df, FUN=sum) #「x」で指定したカラムに対し集計処理を行うpd.pivot_table(df, index, columns, values)
baseパッケージにはない。たぶん。
- 投稿日:2020-03-26T21:12:23+09:00
Influence functionをロジスティック回帰に適用する
influence functionとは
ICML2017のベストペーパーであるUnderstanding Black-box Predictions via Influence Functionsで提案された関数で,機械学習モデルに対して学習サンプルが与える摂動を定式化したものです.
この記事では,influence functionの挙動を理解するためにいくつかの実験をします.
ロジスティック回帰とinfluence function
ロジスティック回帰はこちらの実装を参考にさせていただきます.
irisデータセットを使用します
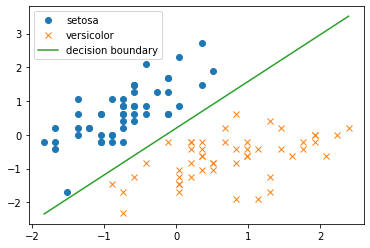
import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.datasets import load_iris # irisデータセット iris = load_iris() # setosaとversicolorの萼片の長さ・幅のみを使う X = iris.data[iris.target != 2][:, :2] Y = iris.target[iris.target != 2] # 標準化 X = StandardScaler().fit_transform(X) # 散布図 plt.scatter(X[:,0][Y == 0], X[:,1][Y == 0], label=iris.target_names[0], marker='o') plt.scatter(X[:,0][Y == 1], X[:,1][Y == 1], label=iris.target_names[1], marker='x') plt.legend() plt.show()
まずは普通にロジスティック回帰を実装して,irisデータセットに適用し,決定境界を図示します.
def sigmoid(x): """シグモイド関数""" return 1 / (1 + np.exp(-x)) def logistic_regression(X,Y): """ロジスティック回帰""" ETA = 1e-3 # 学習率 epochs = 5000 # 更新回数 # バイアス項の計算のために0列目を追加 X = np.hstack([np.ones([X.shape[0],1]),X]) # パラメータの初期化 theta = np.random.rand(3) print('更新前のパラメータθ') print(theta) # パラメータの更新 for _ in range(epochs): theta = theta + ETA * np.dot(Y - sigmoid(np.dot(X, theta)), X) print('更新後のパラメータθ') print(theta) print('決定境界') print('y = {:0.3f} + {:0.3f} * x1 + {:0.3f} * x2'.format(theta[0], theta[1], theta[2])) return theta def decision_boundary(xline, theta): """決定境界""" return -(theta[0] + theta[1] * xline) / theta[2] theta = logistic_regression(X,Y) #標本データのプロット plt.plot(X[Y==0, 0],X[Y==0,1],'o', label=iris.target_names[0]) plt.plot(X[Y==1, 0],X[Y==1,1],'x', label=iris.target_names[1]) xline = np.linspace(np.min(X[:,0]),np.max(X[:,0]),100) # 決定境界のプロット plt.plot(xline, decision_boundary(xline, theta), label='decision boundary') plt.legend() plt.show()
次に,influence関数を実装します.(実装が間違っていたらすみません!)
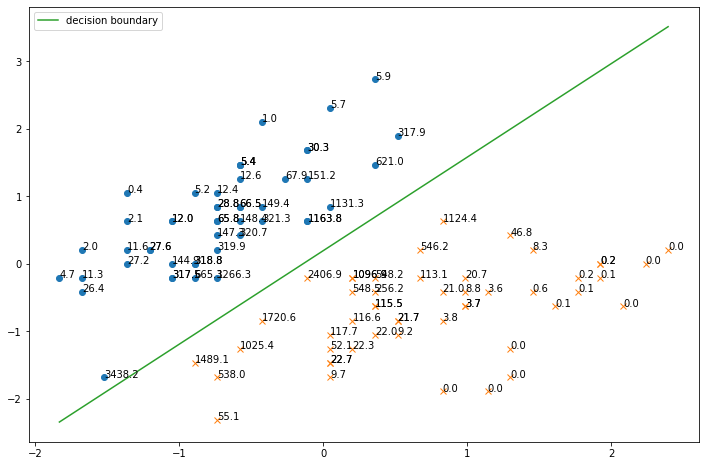
# influence関数はy in {1,-1} として計算するので,Yをそのように変換 Y1 = np.copy(Y) Y1[Y1==0] = -1 # バイアス項の計算のために0列目を追加 X1 = np.hstack([np.ones([X.shape[0],1]),X]) def get_influence(x,y,theta): """influence関数""" H = (1/X1.shape[0]) * np.sum(np.array([sigmoid(np.dot(xi, theta)) * sigmoid(-np.dot(xi, theta)) * np.dot(xi.reshape(-1,1), xi.reshape(1,-1)) for xi in X1]), axis=0) return - y * sigmoid(- y * np.dot(theta, x)) * np.dot(-Y1 * sigmoid(np.dot(Y1, np.dot(theta, X1.T))), np.dot(x, np.dot(np.linalg.inv(H), X1.T))) # 各サンプルのinfluence値からなるリスト influence_list = [get_influence(x,y,theta) for x,y in zip(X1,Y1)] # influence値も含めてプロット plt.figure(figsize=(12,8)) plt.plot(X[Y==0, 0],X[Y==0,1],'o') plt.plot(X[Y==1, 0],X[Y==1,1],'x') plt.plot(xline, decision_boundary(xline, theta), label='decision boundary') # influence値をグラフに挿入 for x,influence in zip(X, influence_list): plt.annotate(f"{influence:.1f}", xy=(x[0], x[1]), size=10) plt.legend() plt.show()個々のサンプルのinfluence値を一緒にプロットすると下図のようになります.
決定境界に近いサンプルほどinfluence値が高いことがわかります.
ミスラベルを意図的に混入させた場合
ミスラベルとは,誤ったラベルのことで,これがあるとモデルが間違った学習をしたり,適切な評価ができなくなったりします.
ここでは,意図的なミスラベルを混入させて,influence値がどのようになるか調べます.
一部のラベルを意図的に付け替えます.下図を見ると,明らかに間違ったラベルがあることがわかると思います.
# 一部のラベルを意図的に入れ替える Y[76] = 0 Y[22] = 1 # 散布図 plt.scatter(X[:,0][Y == 0], X[:,1][Y == 0], label=iris.target_names[0], marker='o') plt.scatter(X[:,0][Y == 1], X[:,1][Y == 1], label=iris.target_names[1], marker='x') plt.legend() plt.show()
このデータに対して,上と同じようにロジスティック回帰を適用して,さらにinfluence値を計算して図示すると,以下のようになります.
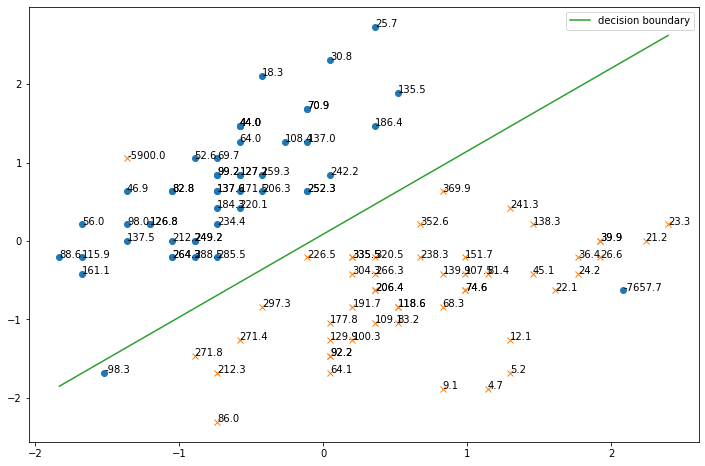
theta = logistic_regression(X,Y) # influence関数はy in {1,-1} として計算するので,Yをそのように変換 Y1 = np.copy(Y) Y1[Y1==0] = -1 # バイアス項の計算のために0列目を追加 X1 = np.hstack([np.ones([X.shape[0],1]),X]) def get_influence(x,y,theta): """influence関数""" H = (1/X1.shape[0]) * np.sum(np.array([sigmoid(np.dot(xi, theta)) * sigmoid(-np.dot(xi, theta)) * np.dot(xi.reshape(-1,1), xi.reshape(1,-1)) for xi in X1]), axis=0) return - y * sigmoid(- y * np.dot(theta, x)) * np.dot(-Y1 * sigmoid(np.dot(Y1, np.dot(theta, X1.T))), np.dot(x, np.dot(np.linalg.inv(H), X1.T))) # 各サンプルのinfluence値からなるリスト influence_list = [get_influence(x,y,theta) for x,y in zip(X1,Y1)] # influence値も含めてプロット plt.figure(figsize=(12,8)) plt.plot(X[Y==0, 0],X[Y==0,1],'o') plt.plot(X[Y==1, 0],X[Y==1,1],'x') plt.plot(xline, decision_boundary(xline, theta), label='decision boundary') # influence値をグラフに挿入 for x,influence in zip(X, influence_list): plt.annotate(f"{influence:.1f}", xy=(x[0], x[1]), size=10) plt.legend() plt.show()
ミスラベルのサンプルのinfluence値が非常に高くなっていることがわかります.
また,左下のサンプルが決定境界をはみ出ていて,ミスラベルが学習に悪影響を及ぼしていることが懸念されます.
まとめ
- influence関数を使うことで,決定境界に近い(自信のない)サンプルや,ミスラベルを見出すことができる.

- 投稿日:2020-03-26T20:44:09+09:00
深層学習における最適化手法(SGD,momentum,AdaGrad)を自前で作って、2次関数の最小値を求めようとした+init,classの勉強にもなった
はじめに
ニューラルネットワークにおける最適化手法は日々新しいアルゴリズムが生み出されています。前の記事では、SGDからADAMまでその開発された経緯をまとめました。
https://qiita.com/Fumio-eisan/items/798351e4915e4ba396c2
今回の記事では、その最適化手法を実装して、ニューラルネットワークにおける収束の速さを確認したいと思います!。といきたいところですが、今回はこの最適化手法を簡単な2次関数に適用したいと思います。
教科書などでは基本的にはMNISTなどの手書き数字画像を例にとって損失関数の値が下がっていくことを確認します。しかし、ニューラルネットワークにおける損失関数は非常に複雑であるため、いまいち最小値を導けているのか実感がわきません。
従って、今回は2次関数を例にすることで、最小値へ向かっていくことを見ていきたいと思います。
また、自分でクラスを定義して読み込むことを実装しましたが、そこで理解したことも記しておきます。今回の概要です。
- 対象とする関数
- SGD(確率的勾配降下法)を実装する
- Momentumを実装する
- AdaGradを実装する
- class,initについて理解したこと
対象とする関数及び最適化手法の目的
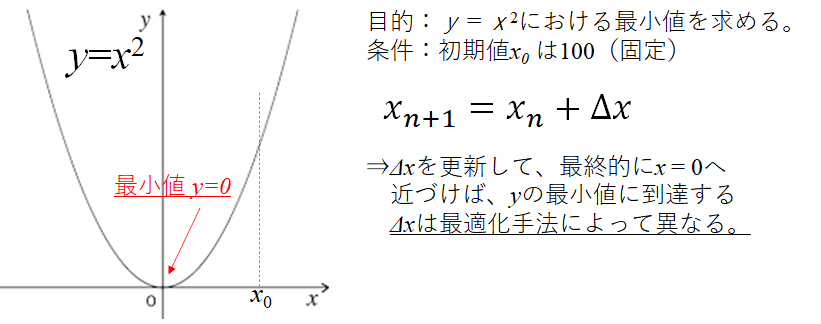
今回対象にする2次関数及び最適化手法で行いたい目的はこちらです。
非常にわかりやすい関数の最小値を求めることとしました。$y=x^2$ですので、最小値を取る$y$は$x=0$のときに、$y=0$となります。
感覚的にも可視的にも分かりやすいこの関数を用いて、$x$を更新し続けて$y=0$に近づいていくことを確認していきたいと思います。実装の内容
今回は、関数を定義したプログラムをoptimizers.pyへ格納しています。そして、sample.ipynbにてその関数を読み込み計算・図示させる構成にしています。
従って、実装の際はこの2つのプログラムを同一フォルダに格納して実行して頂けると幸甚です。SGD(確率的勾配降下法)を実装する
まずは、基本となるSGDです。下記に式を記載しています。
\mathbf{x}_{t + 1} \gets \mathbf{x}_{t} - \eta g_t\\ g_t = 2 *\mathbf{x}_{t}$\eta$は学習率、$g_t$は関数の勾配になります。$g_t$は今回は$2 *\mathbf{x}_{t} $となるため、簡便ですね。
次に、この手法を実装します。
optimizers.pyclass SGD: def __init__(self, lr = 0.01,x=100): self.lr = 0.01 self.x =100.0 def update(self,x): x+= -self.lr * 2*x return x式自体はシンプルですので、プログラムを見て理解しやすいかと思います。次ステップの$x$を計算して$x$を返すといった関数にしています。$\eta$はここでは$lr$という表記になっています。
さて、実際に最小値を求めるために$x$を繰り返し計算させるプログラムがこちらになります。
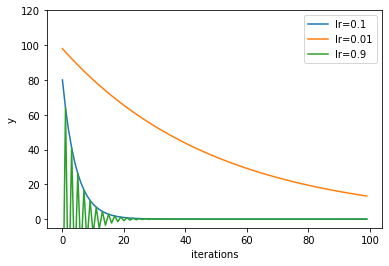
sample.ipynbmax_iterations = 100 y7=[] y8=[] y9=[] v7=[] v8=[] v9=[] optimizer = optimizers.SGD() x = 100 optimizer.lr =0.1 for i in range(max_iterations): x = optimizer.update(x) y7.append(x) v7.append(optimizer.lr) x = 100 optimizer.lr =0.01 for i in range(max_iterations): x = optimizer.update(x) y8.append(x) v8.append(optimizer.lr) x = 100 optimizer.lr =0.9 for i in range(max_iterations): x = optimizer.update(x) y9.append(x) v9.append(optimizer.lr)$\eta$を0.1,0.01,0.9と変化させたときに関数の収束がどのように変化するか確認しましょう。
※xを初期値化させることや、lrすら変数としてfor loopとする案が思いつかなかったため、汚いプログラムとなっています。sample.ipynbx = np.arange(max_iterations) plt.plot(x, y7, label='lr=0.1') plt.plot(x, y8, label='lr=0.01') plt.plot(x, y9, label='lr=0.9') plt.xlabel("iterations") plt.ylabel("y") plt.ylim(-5, 120) plt.legend() plt.show()
縦軸である$y$の値が0に近づくほど収束していくことが分かります。
$\eta$が0.01だと収束に時間がかかります。$\eta$が逆に0.9まで大きすぎるとハンチングしながら収束に向かうことが分かります。この値が今回の関数だと1以上だと発散してしまいます。従って、$\eta$が0.1あたりが収束も早く発散を抑えられる丁度良い値であることが分かります。
Momentumを実装する
次にMomentumを実装していきます。このアルゴリズムは先ほどのSGDと比較して、$x$自身の動きを考慮させることで振動を抑えるようにしています。
\mathbf{x}_{t + 1} \gets \mathbf{x}_{t} + h_t\\ h_t=-\eta * g_t +\alpha * h_{t-1}関数を定義します。
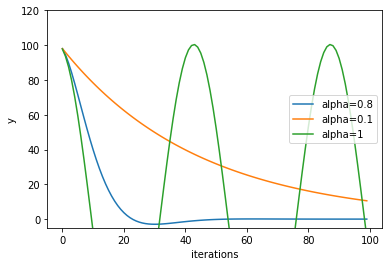
optimizers.pyclass Momentum: def __init__(self,lr=0.01,alpha=0.8,v=None): self.lr = 0.01 self.v = 0.0 self.alpha = 0.8 def update(self,x): self.v = self.v*self.alpha - (2.0)*x*self.lr x += + self.v return xそして、実行します。今回は、ハイパーパラメータとして$\alpha$の値を変化させて影響を評価します。
標準的な$\alpha$は0.8といわれています。今回の結果でも0.8が丁度よさそうな値であることが分かります。これ以上値が大きいと、大きくハンチングしてしまっていますね。
AdaGradを実装する
さて、今回最後はAdaGradです。これまでは学習率$\eta$は定数でした。しかしこの学習率自体が計算回数につれて段々小さくなっていく効果を入れていることが特徴です。
h_{0} = \epsilon\\ h_{t} = h_{t−1} + g_t^{2}\\ \eta_{t} = \frac{\eta_{0}}{\sqrt{h_{t}}}\\ \mathbf{x}_{t+1} = \mathbf{w}^{t} - \eta_{t}g_t関数を定義します。
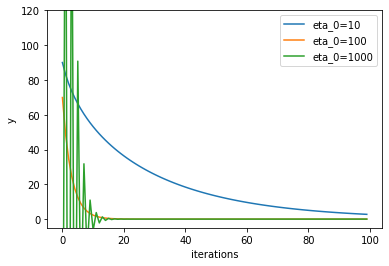
optimizers.pyclass AdaGrad: def __init__(self,h0=10.0): self.v = 0.0 self.h = 0.0 self.h0 = 10.0 def update(self,x): self.h += + (2.0*x)**2 self.v = -self.h0/(np.sqrt(self.h)+1e-7) x += + self.v*2*x return xさて、今回は学習率の初期値$\eta_0$(プログラム中ではh0)を変えて計算しました。
$\eta_0$は100あたりが収束も早くなり、かつ発散しないことが分かりました。
class,initについて理解したこと
Pythonに関して初学者であるため、classの中でもinitに関してはおまじない感強く使っていました。今回、分かったことは下記です。
init(self,引数)で定義した引数は、classを呼び出した後に引用して引数のパラメータを変えることができる。
逆にこの引数を書いておかないと、classを呼び出した後にパラメータを変えることができない。
おわりに
今回は3種類の最適化手法によって関数の最小化を行わせました。いわゆる高校数学で習う漸化式の考え方を用いることが分かります。また、numpy以外は自作しましたが、プログラミング自体の理解を深めることに繋がりました。
また、オライリーの深層学習本で学んでいますが、ここには実際にニューラルネットワーク上で最適化手法を実装しています。
関数や細かい変数の定義、活性化関数の入れ方、逆誤差伝搬法での勾配算出、重みパラメータの初期値決め等一つ一つの内容は理解できます。しかし、それをいざプログラミングするとなると非常に複雑になっていきます。改めて、プログラマーの方はこれら多くの規則や構造に関する知識を組み合わせて実装されているんだなぁ、さぞかし大変な苦労なんだろう、と思いを巡らせました。その苦労を元にクラスやメソッドとして呼び出して簡単に機能を使えることにありがたみを感じたいと思います。
プログラム全文はこちらに格納しました。
https://github.com/Fumio-eisan/optimizers_20200326
- 投稿日:2020-03-26T20:22:12+09:00
2020年 機械学習入門の本20選を推薦する
機械学習は、コンピュータを使って予測を行うことに焦点を当てた計算統計学と密接に関連している。数学的最適化の研究は、機械学習の分野に、方法、理論、応用分野を提供する。データマイニングは機械学習の研究分野であり、教師なし学習による探索的データ解析に焦点を当てている。ビジネス上の問題の応用において、機械学習は予測分析とも呼ばれる。
今回は2020年の機械学習入門についての本を推薦します。
1.機械学習・深層学習による自然言語処理入門 ~scikit-learnとTensorFlowを使った実践プログラミング~
本書では自然言語処理について、今まで学習したことがない人でも学べるように、基礎から解説しています。自然言語をコンピュータで処理するために、事前にどのような処理をしておくのか、どのように単語や文章を解析するのか、自動翻訳などのタスクを実行させるためにどのような処理を行うのか、などについて、やさしく説明していきます。これからプログラムでの実装も合わせて自然言語処理を学習したいという方にとっては、最適の1冊です。
2.入門Rによる予測モデリング 機械学習を用いたリスク管理のために 岩沢宏和/著 平松雄司/著
リスクとは「不確定」かつ「避けたい」ものです。そうしたリスクを、データサイエンスの発達した現代においてどのように統計的に扱うべきであるか、その基本作法をまとめて伝えます。
3.Google AutoML Vison入門 画像認識・機械学習・AIを使ったウェブサイトやアプリをつくる 衛藤剛史/著
誰でもつくれる画像認識AI Googleの最新技術で作る機械学習モデル構築!!学習データの作成から、予測モデル構築・チューニング・モデル評価・ウェブやアプリの組み込み。ディープラーニング・ニューラルモデル・機械学習の理論を使ったシンプルな画像認識AI作成。
4.機械学習コレクションWeka入門 人工知能AIの基本モデル ニューラルネットワークもコレクションに実装 和田尚之/著
機械学習を応用!オープンソフト「Weka」、大量データを自動分析。どの情報が最も関連性があるかを判断。結晶化された情報が、自動的に予測。人の意思決定より、“迅速”かつ“正確”に判断。
5.機械学習のための「前処理」入門 足立悠/著
データ分析技術の中心には、分析アルゴリズムやモデリング手法があります。しかし実務の現場では、むしろ「前処理」の重要性に直面します。その方法は「分析目標」と「データ形式」によって異なり、そこからどのように特徴量を作り出すかで、機械学習の成否が左右されます。本書では「予測」を分析目標とし、構造化データ、画像データ、時系列データ、自然言語について、機械学習における前処理の手順を紹介。演習問題を経て、Pythonによる実装までを体験します。データ分析のフレームワークCRISP‐DMに沿って実装を進めるので、実務に近い形で前処理のテクニックが身に付きます。
6.Excelでわかる機械学習超入門 AIのモデルとアルゴリズムがわかる 涌井良幸/著 涌井貞美/著
AIのしくみを基本から解説した超入門書!Excelを使って具体的に動かしながら理解できる!
7.現場で使える!Python機械学習入門 機械学習アルゴリズムの理論と実践 大曽根圭輔/著 関喜史/著 米田武/著
本書は、機械学習の基本と実践手法について解説した書籍です。機械学習の開発環境の準備、実際の現場での利用方法、そしてブラックボックス化しがちな理論部分もしっかりフォローしています。データ集計・整形と組み合わせた機械学習モデルの利用方法も解説しています。対象読者は人工知能関連の開発に携わる開発者、研究者。本書は、第1章では、機械学習を行う上で必要となる環境構築と機械学習に必要なPythonの基本について解説しています。第2章では、教師あり学習と教師なし学習についてサンプルをもとに解説します。第3章では、教師あり学習と教師なし学習に関連する機械学習モデルについて解説しています。主要な機械学習モデルの理論を数式と絡めて説明し、その理論をもとにしたPythonにおけるコーディング手法を説明しています。第4章では、データの集計、整形方法と実際の機械学習モデルへの利用方法について解説しています。
8.60分でわかる! 機械学習&ディープラーニング 超入門 (60分でわかる! IT知識) 機械学習研究会/著 安達章浩/監修 青木健児/監修
機械学習が変えるビジネスの新常識を徹底解説!基礎知識や用語からビジネス活用まで解説。豊富な事例で機械学習の「今」がわかる。ビジネス導入のためのヒントが満載。機械学習注目企業リスト掲載。最新ITキーワード解説書として大人気の「60分でわかる」シリーズ、機械学習の解説書です。難解な技術と思われがちですが、今やすべてのビジネスの効率化に理解が欠かせない機械学習。その基礎から最新知識までを幅広く解説するのが本書です。機械学習の歴史や活用事例をはじめ、機械学習を支える技術、中小企業や個人でも実現できるビジネス活用のヒントなどをわかりやすく解説します。ビジネスパーソンが知っておきたい機械学習のすべてが、この一冊でわかります!
9.機械学習入門Jubatus実践マスター Jubatusコミュニティ/著
大量データを素早く、深く分析、Jubatus開発者が徹底解説!Jubatusの導入や基本コンセプト、分散学習機構「MIX」を説明。大量のデータを迅速に処理する分散モードでの実行方法も解説。分類や回帰など、Jubatusが搭載する分析機能をコード付きで詳解。分析時の落とし穴や分析精度を上げるTipsも紹介!
10.ベイズ推論による機械学習入門 須山敦志/著 杉山将/監修
最短経路で平易に理解できる、今までにない入門書!「モデルの構築→推論の導出」という一貫した手順でアルゴリズムの作り方を解説。
11.入門機械学習 Drew Conway/著 John Myles White/著 萩原正人/訳 奥野陽/訳 水野貴明/訳
本書はプログラミングの素養がある読者向けに、数学的・理論的な知識が必要なくても読めるよう、理論より実践に重きを置いて書かれた機械学習の入門書です。難しい理論的な解説はできるだけ避け、実際のテクニックを詳述する、プログラマの視点に立ったプログラマ向けの内容です。大規模データの処理に威力を発揮する機械学習の実践的な知識とテクニックを習得したいと考えるプログラマに最適の一冊です。
12.フリーソフトではじめる機械学習入門 荒木雅弘/著
フリーソフトで実データの解析を実践。強化学習、深層学習、etcなど応用的な手法も網羅。体感しながら理解するビッグデータの解析に役立つ入門書。
13.言語処理のための機械学習入門 高村大也/著 奥村学/監修
自然言語処理における機械学習の利用について理解するため、その基礎的な考え方を伝えることを目的としている。広大な同分野の中から厳選された必須知識が記述されており、論文や解説書を手に取る前にぜひ目を通したい一冊である。
14.Rによる機械学習入門 金森敬文/著
R入門からデータを整理するための基本的な統計手法、予測に対する誤差の測り方、統計モデルによる機械学習、機械学習における主要なアルゴリズム、スパース学習などていねいに解説機械学習を使いこなすには、確率・統計に根ざしたデータ解析の基礎理論が不可欠です。そこで本書は、業務での活用が増えている統計解析フリーソフト「R」を使って、Rの初歩から確率・統計の基礎、統計モデルによる機械学習を解説します。機械学習は、大量かつ複雑なデータを分析するのに有効とされ、ビッグデータ処理の花形技術ともいわれています。
15.ゼロからやさしくはじめるPython入門 基本からスタートして、ゲームづくり、機械学習まで学ぼう! クジラ飛行机/著
プログラミング初心者でも安心のていねい解説。「できた!」を積み重ねて楽しく学べるカリキュラム。ゲームや機械学習で「作れた!」達成感を味わおう。
16.ITエンジニアのための機械学習理論入門 中井悦司/著
機械学習のしくみを学ぶデータサイエンスの本質を理解する。
17.データ分析のための機械学習入門 Pythonで動かし、理解できる、人工知能技術 橋本泰一/著
いまの人工知能を支えているものは、データ、計算環境、アルゴリズム、プログラムです。膨大なデータが手に入らなければ、人工知能は作り出せません。そして、膨大なデータを処理する計算環境、アルゴリズム、プログラムがなければ、人工知能は作り出せません。本書では、具体的なデータ分析事例を交え、機械学習理論から実行環境、Pythonプログラミング、ディープラーニングまでを解説します。
18.データサイエンスのための統計学入門 予測、分類、統計モデリング、統計的機械学習とRプログラミング Peter Bruce/著 Andrew Bruce/著 黒川利明/訳 大橋真也/技術監修
データサイエンスに必要な統計学と機械学習の重要な50の基本概念と、関連する用語について、簡潔な説明と、それを裏付ける最低限の数式、クリアな可視化、実現するRコードを提示して、多方面からの理解を促します。データの分類、分析、モデル化、予測という一連のデータサイエンスのプロセスにおいて統計学のどの項目が必要か、どの項目が不必要かを示し、重要な項目について、その概念、数学的裏付け、プログラミングの各側面からアプローチします。データサイエンスに必要な項目を効率よく学べて、深く理解することが可能です。
19.入門機械学習による異常検知 Rによる実践ガイド 井手剛/著
異常検知にかかわる技術の断片をただ羅列せず、実問題を解く上でぶつかる困難に立ち向かうための方法を体系的に解説している。異常検知は兆候をとらえて,いち早く意思決定をしてつぎの手を打つための第一歩となる大切な技術です。
20.入門パターン認識と機械学習後藤正幸/共著 小林学/共著
初学者が一通りのパターン認識と統計的学習の基礎について学ぶことができるよう,基礎的な内容に絞って記した。パターン認識の方法を実装し,実際のデータを分析し,手法を改良できるよう,WebでC言語プログラムを公開した。
- 投稿日:2020-03-26T18:59:18+09:00
Python、辞書型についてメモ
python辞書型についてメモ
dic = {"みかん":2,"りんご":10,"いちご":2}keyを取り出す
dic.keys()dict_keys(['みかん', 'りんご', 'いちご', 'メロン'])値を取り出す
dic.values()dict_values([2, 10, 2, 44])キーと値の両方を取り出す
dict.items()dict_items([('みかん', 2), ('りんご', 10), ('いちご', 2), ('メロン', 44)])for文でキーと値の両方を取り出す
for i,k in dic.items(): print(i,k)みかん 2 りんご 10 いちご 2 メロン 44新たなキーと値を追加する。
dic['ぶどう'] = 10 dic.items()dict_items([('みかん', 2), ('りんご', 10), ('いちご', 2), ('メロン', 44), ('ぶどう', 10)])
- 投稿日:2020-03-26T18:30:54+09:00
初めてpygameでゲームを作ろうとしている人に参考になるサイトや学習手順まとめ
概要
初めてpygameでゲームを作ろうとしている人に参考になるサイトや学習手順をまとめてみました。
対象
森 巧尚さんの「Python1年生」(翔泳社)を一通り学んだ方
手順
pygameのインストール
pygameを動かす
1. pygameのリファレンスを参考にする
これ以下の学習を進める上で何度もお世話になるだろうリファレンスを押さえておきます。学習を進めていて、どんなメソッドなのかを知りたかったり、自分で何かを付け加えたり、変更したりするためにはみる必要があります。最初は見なくてもいいですが、学習を進めていくと必要になってくると思います。※公式ページを見たのですが、現在は休止しているので、日本語の関連ページのみ載せておきました。
Python用のゲームライブラリ「Pygame」のリファレンスを翻訳したページ
2. 少しずつpygameに慣れていく
初めて学習を進める上では、大きなプログラムを作ろうとすると挫折の原因になったり、エラーの処理がわけ分からなくなったりします。ちょっとずつ慣れるためには以下のサイトが役に立つと思います。
また、動きを確かめるだけならコピーすることも良いですが、自分でゲームを作るためにはサイトを見ながら、ソースコードをそのまま打つことが良いでしょう。3. ジャンルごとで参考になりそうなソースコードを探して動かす
pygameの使い方をだんだんと分かってきたら、自分が作りたいジャンルのゲームで参考になりそうなソースコードが載っているサイトを探します。以下には代表的なジャンルのゲームを載せておきましたが、無ければ自分で探してみてください。
Pythonでゲーム作りますが何か?
インストールからゲーム作成まで、かなり細かく解説してあります。ブロック崩し/シューティング/RPGについて載せてあります。自分のオリジナルのゲームを作る
最終的には、自分のオリジナルのゲームを作ることが目標だと思います。今までの知識や技術を生かしてぜひ頑張ってください!
ただ、オリジナルのゲームを作ろうとすると、分からないことがたくさん出てきます。その際は、様々な情報を調べつつ、分からない部分を質問すると良いでしょう。以下に質問サイトを載せておきました。それによって解決する部分もあれば、解決しない部分もあると思います。だけど、諦めずに進めていくと自分自身に大きな力を得ることができると思います。再度言います。頑張って!!
teratail【テラテイル】
- 投稿日:2020-03-26T17:54:32+09:00
EXCELのデータバーやカラースケールはpandasでもできる
pandasの表ちょっと見にくいな…色ほしいな…
と、ある時思ったのでした。
EXCELに移してデータバーとかつけるのも面倒だし、Jupyter上でなんとかできないかね?と思ってたら普通にpandasにそんな機能がついていたのよね笑
知らなかった笑
以下のサイトで発見した。
https://pbpython.com/styling-pandas.htmlDataFrame.style
DataFrame.styleについては以下のページで詳細な機能がわかる。
https://pandas.pydata.org/pandas-docs/version/0.18/style.htmlsklearnに含まれるデータセットbostonで実践
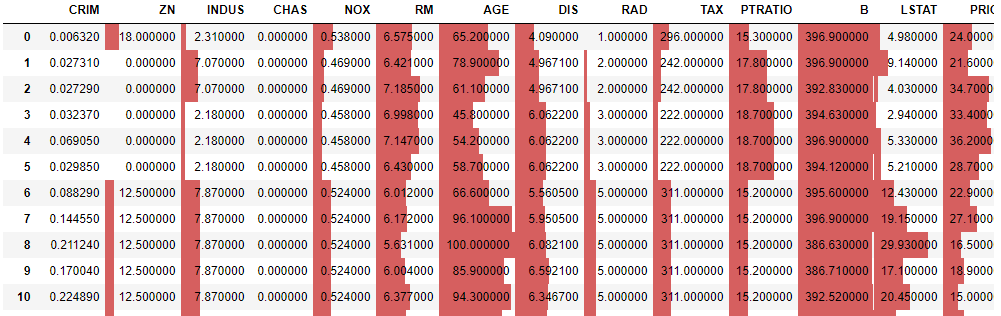
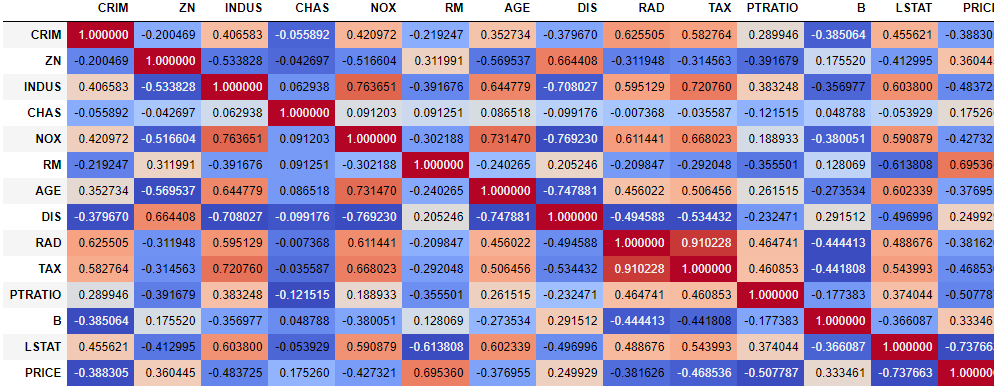
# パッケージインポート import pandas as pd from sklearn import datasets import numpy as np import matplotlib.pyplot as plt import seaborn as sns # データ読み込み boston = datasets.load_boston() boston_df=pd.DataFrame(boston.data) boston_df.columns = boston.feature_names # カラム名を挿入 boston_df['PRICE'] = pd.DataFrame(boston.target) display(boston_df)
これにEXCELのようなデータバーをつける
display(boston_df.style.bar())
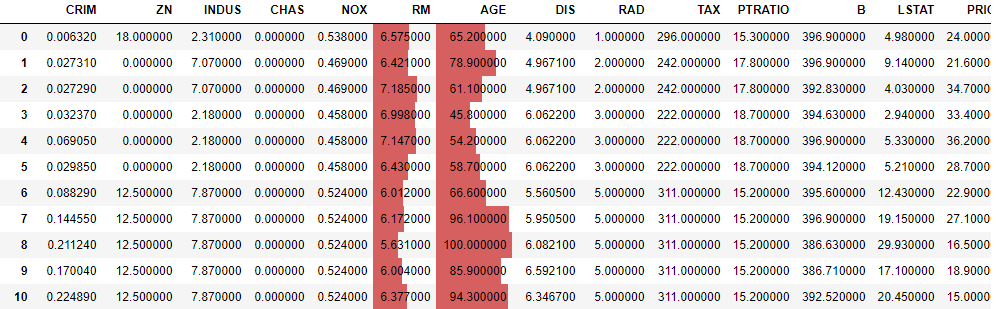
おお、できた。しかしなんか血みどろだな…。血みどろはイヤなので、カラムを選択して、色も変えることができる。
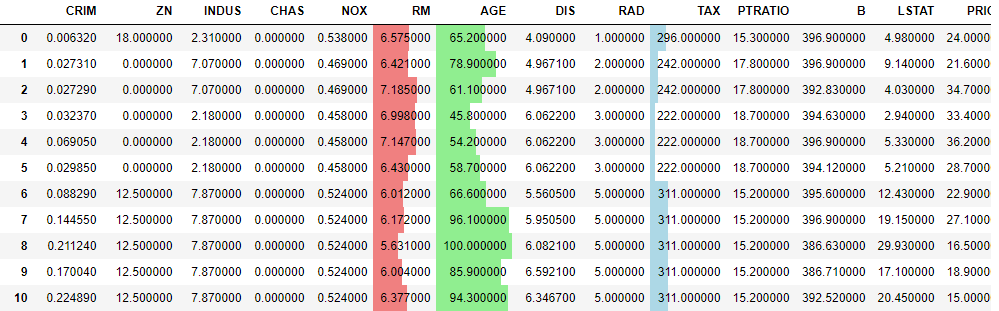
subsetにカラム名を指定したり、barをつなげるように記述したりするとカスタマイズできる。# カラム指定 display(boston_df.style.bar(subset=['RM','AGE'])) # カラム指定かつそれぞれ色分け display(boston_df.style\ .bar(subset=['RM'],color=['lightcoral'])\ .bar(subset=['AGE'],color=['lightgreen'])\ .bar(subset=['TAX'],color=['lightblue']))
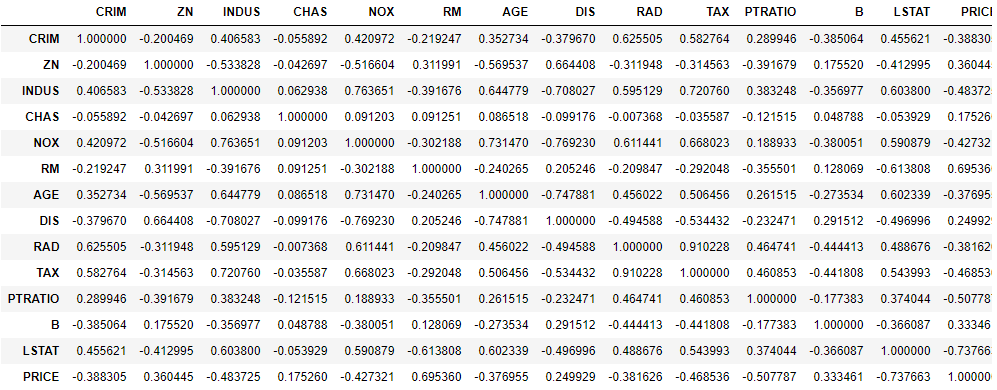
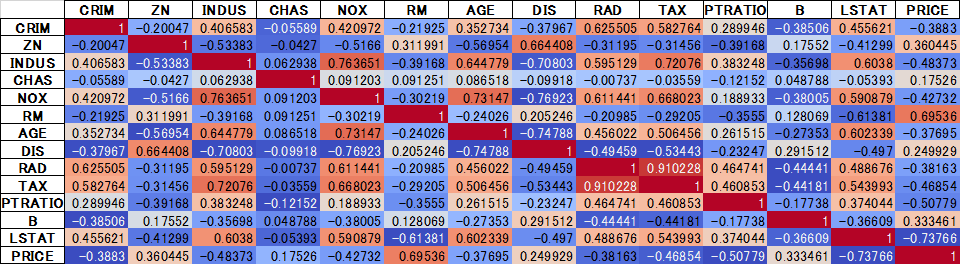
いけるやん!カラースケールも試してみよう。
# 相関行列の作成 boston_corr=boston_df.corr() display(boston_corr) # 色を付ける display(boston_corr.style.background_gradient(cmap='coolwarm'))
いけるやん!(二回目)
こんな感じでEXCELでの表の加工はpandasでもできることを知ったのであった。ちなみにEXCELファイルでそのまま出力も可能。
# openpyxlパッケージがinstall済みであること n_df=boston_corr.style.background_gradient(cmap='coolwarm') n_df.to_excel('test.xlsx')'test.xlsx'の中身↓
見やすいNotebookを作るためにいろいろ活用できそうだ!
おまけ(sparklines)
sparklinesというパッケージでpandasの表の中にヒストグラムが書ける
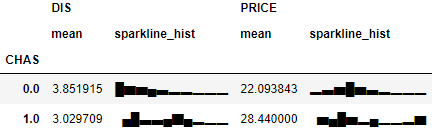
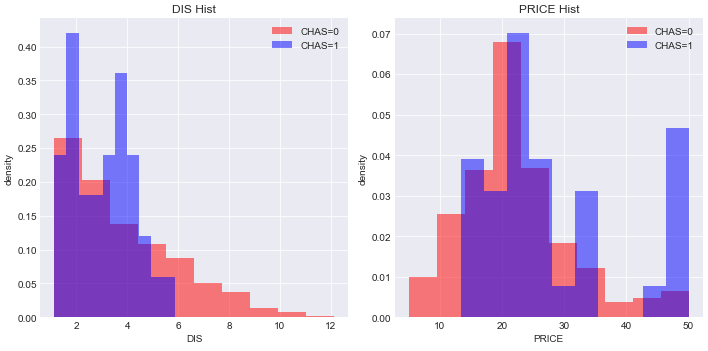
例えば、CHAS:チャールズ川 (1: 川の周辺, 0: それ以外)ごとに、以下の平均を出す。
・DIS:5つのボストン市の雇用施設からの重み付き距離
・PRISE:住宅価格display(boston_df.groupby('CHAS')[['DIS','PRICE']].mean())
ほーん、チャールズ川の周辺の方がボストン市の雇用施設との距離が近くて家賃は高めなのね、ということはわかる。
けど外れ値があって傾向はほぼ同じなのに平均が高くなっているかも。
そこで、関数を定義して、from sparklines import sparklines # 関数を定義 def sparkline_hist(x, bin_num=10): bins=np.histogram(x, bins=bin_num)[0] sl = sparklines(bins)[0] return slgroupbyに関数を適用させると、
display(boston_df.groupby('CHAS')[['DIS','PRICE']].agg(['mean', sparkline_hist]))
ヒストグラムっぽいのが表の中に出た!
どうやらチャールズ川の周辺じゃなくてもボストン市の雇用施設との距離が近いところはたくさんありそうだぞ、とかチャールズ川の周辺の方はかなり家賃が高い家とそうでない家の二極化っぽいぞとかがpandas上でざっとわかる。しかしなぜか自分のJupyter上だと、ヒストグラムっぽいものが下に凸になった部分とかがあってそれは謎のまま。
sparkline_hist関数の中身を検証してみると特に下に凸にならないのに、なぜだろうか# sparkline_hist関数の中身検証 bins=np.histogram(boston_df[boston_df['CHAS']==0]['DIS'], bins=10)[0] sl = sparklines(bins)[0] print(sl) bins=np.histogram(boston_df[boston_df['CHAS']==1]['DIS'], bins=10)[0] sl = sparklines(bins)[0] print(sl)
ちなみに実際にヒストグラムを書いてみると、以下のような感じでした。
fig=plt.figure(figsize=(10,5)) ax=plt.subplot(1,2,1) ax.hist(boston_df[boston_df['CHAS']==0]['DIS'],bins=10, color='red', label='CHAS=0',alpha=0.5, density=True) ax.hist(boston_df[boston_df['CHAS']==1]['DIS'],bins=10, color='blue', label='CHAS=1',alpha=0.5, density=True) ax.legend(loc='upper right') ax.set_ylabel('density') ax.set_xlabel('DIS') ax.set_title('DIS Hist') ax2=plt.subplot(1,2,2) ax2.hist(boston_df[boston_df['CHAS']==0]['PRICE'],bins=10, color='red', label='CHAS=0',alpha=0.5, density=True) ax2.hist(boston_df[boston_df['CHAS']==1]['PRICE'],bins=10, color='blue', label='CHAS=1',alpha=0.5, density=True) ax2.legend(loc='upper right') ax2.set_ylabel('density') ax2.set_xlabel('PRICE') ax2.set_title('PRICE Hist') plt.tight_layout() plt.show()
sparklines面白かったけど、特に有益な使い道は思いつかないな…笑
普通にヒストグラム描きますわ。笑以上!

- 投稿日:2020-03-26T17:39:36+09:00
Flask 画像の送受信
概要
画像の送受信処理についての日本語の処理が少なかったので、まとめる。
サンプルコード
ここでは、画像のエコーバックのサンプルコードを示します。
送信/受信@app.route("/echo_back", methods=['POST']) def test(): img_bin = io.BytesIO(request.data).getvalue() # 受信 response = make_response(img_bin) # レスポンスに画像を設定 response.headers.set('Content-Type', request.content_type) # ヘッダ設定 return responseポイントを以下に示します。
- 「request.data」の中に画像情報が格納されています。これをio.ByteIO型とすると、画像情報のみ取得できます。今回はエコーバックさせるので、getvalue()を用いてすぐにbytes型に変換しています。
- make_response()に画像情報を格納するとき、bytes型でないといけないようです。そのため、上記のようにgetvalue()にてbytes型としています。
- 最後に、headerに「Content-type」を設定しています。途中に画像処理をする場合は適宜型を変換します。opencvであればnumpy配列でしょうかね。PILの場合はImage.open(io.BytesIO(request.data))みたいにすると良いんですかね。
テスト方法
自分は「POST MAN」を使用しています。ここでは、「POST MAN」を利用した場合の設定について説明します。
- 通信は「POST」(今回はPOSTのみ許可しているので)
- Headerに「Content-Type」を追加し、画像ファイルのファイルフォーマットに合わせて「Value」を設定
- Bodyを「binary」に設定し、画像ファイルを選択
基本的には以上の設定としてください。これにより、送信したファイルがそのまま返信されることを確認できます。
- 投稿日:2020-03-26T17:37:29+09:00
【Selenium】リンクを新しいタブで開いて移動【Python/ChromeDriver 】
ブラウザ操作してますか?
毎日同じブラウザ操作してませんか?
そんなブラウザ操作はSeleniumに任せましょう!
ブラウザを触っているときにリンクをCtrlを押しながらクリックして新しいタブで開くことありませんか?
僕はとてもよくやりますwそんな一連の流れになります。
リンクを新しいタブで開いて移動
sample.pyfrom selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait import platform driver = webdriver.Chrome("chromedriver.exe") #chromedriver.exe読み込み # # #該当ページまでの処理 # # #クリックする要素 element = driver.find_element_by_xpath('/html/body/hogehoge') #element = driver.find_element_by_link_text("hogehoge") #リンクテキストで取得したい時はこちら #クリック前のハンドルリスト handles_befor = driver.window_handles #(リンク)要素を新しいタブで開く actions = ActionChains(driver) if platform.system() == 'Darwin': #Macなのでコマンドキー actions.key_down(Keys.COMMAND) else: #Mac以外なのでコントロールキー actions.key_down(Keys.CONTROL) actions.click(element) actions.perform() #新しいタブが開ききるまで最大30秒待機 WebDriverWait(driver, 30).until(lambda a: len(driver.window_handles) > len(handles_befor)) #クリック後のハンドルリスト handles_after = driver.window_handles #ハンドルリストの差分 handle_new = list(handles_after - sethandles_befor) #新しいタブに移動 driver.switch_to.window(handle_new[0])負荷がかかりすぎないように気をつけて
適宜waitやsleepを入れましょうー解説
sample.pyfrom selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWaitSeleniumライブラリと今回必要なパッケージを読み込みます。
sample.pyimport platformOSを判断する為のライブラリを読み込みます。
sample.pydriver = webdriver.Chrome("chromedriver.exe") #chromedriver.exe読み込み # # #該当ページまでの処理 # #chromedriverを起動して操作しましょう。
sample.py#クリックする要素 element = driver.find_element_by_xpath('/html/body/hogehoge') #element = driver.find_element_by_link_text("hogehoge") #リンクテキストで取得したい時はこちら
xpathやlink_textでクリックする要素を変数に代入しましょう。sample.py#クリック前のハンドルリスト handles_befor = driver.window_handles新しいタブが開く前のハンドルをリスト形式で取得します。
sample.py#(リンク)要素を新しいタブで開く actions = ActionChains(driver) if platform.system() == 'Darwin': #Macなのでコマンドキー actions.key_down(Keys.COMMAND) else: #Mac以外なのでコントロールキー actions.key_down(Keys.CONTROL) actions.click(element) actions.perform()
ActionChainsというクラスを使うとキー操作を記録して実行することができます。
Macとそれ以外のOSではGoogle Chromeブラウザの場合、新しいタブで開くショートカットキーが異なります。Mac : command + クリック
WindowsやLinux : Ctrl + クリックplatformライブラリでOSを判断して条件分岐させています。
actions.perform()で記録したキー操作が実行されます。sample.py#新しいタブが開ききるまで最大30秒待機 WebDriverWait(driver, 30).until(lambda a: len(driver.window_handles) > len(handles_befor))新しいタブが開いた時に時間がかかることがあるので待機させます。
WebDriverWait(driver, 30)).untilではdriverを最大30秒待機するようにします。
lambda a: len(driver.window_handles) > len(handles_befor)ではラムダ式を使用して一行で記載しています。
len(handles_befor)新しいタブで開く前のハンドル数より
len(driver.window_handles)新しいタブが開いた瞬間のハンドル数が上回ったら待機が解除されます。sample.py#クリック後のハンドルリスト handles_after = driver.window_handles新しいタブが開いた後のハンドルをリスト形式で取得します。
sample.py#ハンドルリストの差分 handle_new = list(handles_after - handles_befor)リストを
-で引き算のようにすると差分を取得することができます。
それを変数に代入しています。sample.py#新しいタブに移動 driver.switch_to.window(handle_new[0])差分となった
handle_new[0]が新しいタブのハンドルになるのでswitch_to.windowで移動します。おまけ
タブを開きすぎて訳がわからなくなってもいつでも戻れるように
(そんなことにはならないようにしましょうw)事前にカレントハンドルを取得しておくといいかもしれません。
sample.py#カレントウインドウ(タブ)のハンドルを代入 current_handle = driver.current_window_handle # # #処理 # # #カレントウインドウ(タブ)に移動 driver.switch_to.window(current_handle)ありがとうございました!
- 投稿日:2020-03-26T17:37:29+09:00
【Selenium】リンクを新しいタブで開いて移動【Python/ChromeDriver】
ブラウザ操作してますか?
毎日同じブラウザ操作してませんか?
そんなブラウザ操作はSeleniumに任せましょう!
ブラウザを触っているときにリンクをCtrlを押しながらクリックして新しいタブで開くことありませんか?
僕はとてもよくやりますwそんな一連の流れになります。
リンクを新しいタブで開いて移動
sample.pyfrom selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWait import platform driver = webdriver.Chrome("chromedriver.exe") #chromedriver.exe読み込み # # #該当ページまでの処理 # # #クリックする要素 element = driver.find_element_by_xpath('/html/body/hogehoge') #element = driver.find_element_by_link_text("hogehoge") #リンクテキストで取得したい時はこちら #クリック前のハンドルリスト handles_befor = driver.window_handles #(リンク)要素を新しいタブで開く actions = ActionChains(driver) if platform.system() == 'Darwin': #Macなのでコマンドキー actions.key_down(Keys.COMMAND) else: #Mac以外なのでコントロールキー actions.key_down(Keys.CONTROL) actions.click(element) actions.perform() #新しいタブが開ききるまで最大30秒待機 WebDriverWait(driver, 30).until(lambda a: len(driver.window_handles) > len(handles_befor)) #クリック後のハンドルリスト handles_after = driver.window_handles #ハンドルリストの差分 handle_new = list(handles_after - sethandles_befor) #新しいタブに移動 driver.switch_to.window(handle_new[0])負荷がかかりすぎないように気をつけて
適宜waitやsleepを入れましょうー解説
sample.pyfrom selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import WebDriverWaitSeleniumライブラリと今回必要なパッケージを読み込みます。
sample.pyimport platformOSを判断する為のライブラリを読み込みます。
sample.pydriver = webdriver.Chrome("chromedriver.exe") #chromedriver.exe読み込み # # #該当ページまでの処理 # #chromedriverを起動して操作しましょう。
sample.py#クリックする要素 element = driver.find_element_by_xpath('/html/body/hogehoge') #element = driver.find_element_by_link_text("hogehoge") #リンクテキストで取得したい時はこちら
xpathやlink_textでクリックする要素を変数に代入しましょう。sample.py#クリック前のハンドルリスト handles_befor = driver.window_handles新しいタブが開く前のハンドルをリスト形式で取得します。
sample.py#(リンク)要素を新しいタブで開く actions = ActionChains(driver) if platform.system() == 'Darwin': #Macなのでコマンドキー actions.key_down(Keys.COMMAND) else: #Mac以外なのでコントロールキー actions.key_down(Keys.CONTROL) actions.click(element) actions.perform()
ActionChainsというクラスを使うとキー操作を記録して実行することができます。
Macとそれ以外のOSではGoogle Chromeブラウザの場合、新しいタブで開くショートカットキーが異なります。Mac : command + クリック
WindowsやLinux : Ctrl + クリックplatformライブラリでOSを判断して条件分岐させています。
actions.perform()で記録したキー操作が実行されます。sample.py#新しいタブが開ききるまで最大30秒待機 WebDriverWait(driver, 30).until(lambda a: len(driver.window_handles) > len(handles_befor))新しいタブが開いた時に時間がかかることがあるので待機させます。
WebDriverWait(driver, 30)).untilではdriverを最大30秒待機するようにします。
lambda a: len(driver.window_handles) > len(handles_befor)ではラムダ式を使用して一行で記載しています。
len(handles_befor)新しいタブで開く前のハンドル数より
len(driver.window_handles)新しいタブが開いた瞬間のハンドル数が上回ったら待機が解除されます。sample.py#クリック後のハンドルリスト handles_after = driver.window_handles新しいタブが開いた後のハンドルをリスト形式で取得します。
sample.py#ハンドルリストの差分 handle_new = list(handles_after - handles_befor)リストを
-で引き算のようにすると差分を取得することができます。
それを変数に代入しています。sample.py#新しいタブに移動 driver.switch_to.window(handle_new[0])差分となった
handle_new[0]が新しいタブのハンドルになるのでswitch_to.windowで移動します。おまけ
タブを開きすぎて訳がわからなくなってもいつでも戻れるように
(そんなことにはならないようにしましょうw)事前にカレントハンドルを取得しておくといいかもしれません。
sample.py#カレントウインドウ(タブ)のハンドルを代入 current_handle = driver.current_window_handle # # #処理 # # #カレントウインドウ(タブ)に移動 driver.switch_to.window(current_handle)ありがとうございました!
- 投稿日:2020-03-26T17:23:12+09:00
【scikit-learn】ROC曲線で遊んでみた
0. はじめに
機械学習において、ある分類器を用いて2クラス分類をした際のその分類器の良さを表す指標として、ROC曲線や、そのROC曲線のAUC(Area Under the Curve:曲線下面積)が用いられます。
ざっくりと説明すると、
ROC曲線は「その分類器を用いることで、2つの分布をどれだけ切り離すことができたか」を表します。また、AUCという量を用いることで、複数のROC曲線を比較することができます。学習に用いたモデルによって、ROC曲線を描けるものと描けないものがあります。
model.predict() などを用いたときに出力(返り値)が確率で与えられるようなモデルはROC曲線を描けますが、出力が2値になるようなモデルではROC曲線は描けません。今回は、scikit-learn を使ってこのROC曲線で遊んでみようと思います。
1. とりあえずデータを用意してみる
冒頭でも述べた通り、出力が確率的なものでしかROC曲線は描けないので、そのような出力を想定します。
すると、以下のような y_true や y_pred が手元にあることになります。In[1]%matplotlib inline import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn import metricsIn[2]y_true = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] y_pred = [0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.5, 0.65, 0.7, 0.35, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.9] df = pd.DataFrame({'y_true':y_true, 'y_pred':y_pred}) df
データフレームにすると上記のようになります。
これの分布を可視化してみましょう。
In[3]x0 = df[df['y_true']==0]['y_pred'] x1 = df[df['y_true']==1]['y_pred'] fig = plt.figure(figsize=(6,5)) # ax = fig.add_subplot(1, 1, 1) ax.hist([x0, x1], bins=10, stacked=True) plt.xticks(np.arange(0, 1.1, 0.1), fontsize = 13) #arangeを使うと軸ラベルは書きやすい plt.yticks(np.arange(0, 6, 1), fontsize = 13) plt.ylim(0, 4) plt.show()
こんな感じです。よくあるような、部分的に分布が量なっているような例になっています。
2. ROC曲線を描いてみる
ROC
roc_curve() のドキュメンテーションはこちらです。
返り値が3つあります。
- fpr (False Positive Rate:偽陽性率)
- tpr (True Positive Rate:真陽性率)
- thres (Thresholds:閾値)
ある閾値をひとつ決めて、それをもとに陽性か陰性かを判別すると、偽陽性率と真陽性率が求まります。上記の3つの返り値はそれらをリストにしたものです。
AUC
auc は上記で求めたROC曲線の曲線化面積を表します。0から1までの値が返ってきます。
In[4]fpr, tpr, thres = metrics.roc_curve(y_true, y_pred) auc = metrics.auc(fpr, tpr) print('auc:', auc)Out[4]auc: 0.8400000000000001In[5]plt.figure(figsize = (5, 5)) #単一グラフの場合のサイズ比の与え方 plt.plot(fpr, tpr, marker='o') plt.xlabel('FPR: False Positive Rete', fontsize = 13) plt.ylabel('TPR: True Positive Rete', fontsize = 13) plt.grid() plt.show()
これでROC曲線を描くことができました。
3. いろいろな分布で試してみる
それでは、いろいろな分布でROC曲線を描いてみましょう。
3.1. 完全に分離できる分布(AUC=1.0)
ある閾値を設定すれば完全に分離できる分布でROC曲線を描いてみます。
In[6]y_pred = [0, 0.15, 0.2, 0.2, 0.25, 0.3, 0.35, 0.4, 0.4, 0.45, 0.5, 0.55, 0.55, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95] y_true = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] df = pd.DataFrame({'y_true':y_true, 'y_pred':y_pred}) x0 = df[df['y_true']==0]['y_pred'] x1 = df[df['y_true']==1]['y_pred']In[7]# AUCなどを算出 fpr, tpr, thres = metrics.roc_curve(y_true, y_pred) auc = metrics.auc(fpr, tpr) # 台紙(fig)の作成 fig = plt.figure(figsize = (12, 4)) fig.suptitle(' AUC = ' + str(auc), fontsize = 16) fig.subplots_adjust(wspace=0.5, hspace=0.6) #グラフ間の間隔を調整する # 左側のグラフ(ax1)の作成 ax1 = fig.add_subplot(1, 2, 1) ax1.hist([x0, x1], bins=10, stacked = True) ax1.set_xlim(0, 1) ax1.set_ylim(0, 5) # 右側のグラフ(ax2)の作成 ax2 = fig.add_subplot(1, 2, 2) ax2.plot(fpr, tpr, marker='o') ax2.set_xlabel('FPR: False Positive Rete', fontsize = 13) ax2.set_ylabel('TPR: True Positive Rete', fontsize = 13) ax2.set_aspect('equal') ax2.grid() plt.show(); # 台紙 ## fig, ax = plt.subplots(2, 2, figsize=(6, 4)) ## ... # 左側 ## ax[0].set_ ## ... # 右側 ## ax[1].set_ ## ... #でも可能
こんなROC曲線になりました。
3.2. 分離が非常に困難な分布(AUC≒0.5)
次に、分離が困難な分布のROC曲線を描いてみます。
In[8]y_pred = [0, 0.15, 0.2, 0.2, 0.25, 0.3, 0.35, 0.4, 0.4, 0.45, 0.5, 0.55, 0.55, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95] y_true = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1] df = pd.DataFrame({'y_true':y_true, 'y_pred':y_pred}) x0 = df[df['y_true']==0]['y_pred'] x1 = df[df['y_true']==1]['y_pred']In[9]# AUCなどを算出 fpr, tpr, thres = metrics.roc_curve(y_true, y_pred) auc = metrics.auc(fpr, tpr) # 台紙(fig)の作成 fig = plt.figure(figsize = (12, 4)) fig.suptitle(' AUC = ' + str(auc), fontsize = 16) fig.subplots_adjust(wspace=0.5, hspace=0.6) #グラフ間の間隔を調整する # 左側のグラフ(ax1)の作成 ax1 = fig.add_subplot(1, 2, 1) ax1.hist([x0, x1], bins=10, stacked = True) ax1.set_xlim(0, 1) ax1.set_ylim(0, 5) # 右側のグラフ(ax2)の作成 ax2 = fig.add_subplot(1, 2, 2) ax2.plot(fpr, tpr, marker='o') ax2.set_xlabel('FPR: False Positive Rete', fontsize = 13) ax2.set_ylabel('TPR: True Positive Rete', fontsize = 13) ax2.set_aspect('equal') ax2.grid() plt.show();
こんなROC曲線になりました。
4. 関数 roc_curve() の返り値について調べてみる
関数roc_curve()の中身を調べてみましょう。
先ほど説明したようなfpr, tpr, thresholds になっていることが分かります。
0番目の thresholds が1.95になっていますが、これは、1番目の閾値に1を加えたもので、fprとtprがともに0となる組みが含まれるように工夫されているようです。In[10]print(fpr.shape, tpr.shape, thres.shape) ROC_df = pd.DataFrame({'fpr':fpr, 'tpr':tpr, 'thresholds':thres}) ROC_df
最初の例において、引数drop_intermeditateをみてみましょう。
これはデフォルトではFalseになっていますが、TrueにすることでROC曲線の形状に関係しない点は取り除くことができます。In[11]y_pred = [0, 0.15, 0.2, 0.2, 0.25, 0.3, 0.35, 0.4, 0.4, 0.45, 0.5, 0.55, 0.55, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95] y_true = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] fpr, tpr, thres = metrics.roc_curve(y_true, y_pred, drop_intermediate =True) print(fpr.shape, tpr.shape, thres.shape)Out[11](10,) (10,) (10,)ですので、実際の点の数も減っています。
5. まとめ
今回は機械学習の結果を可視化する際のROC曲線についてまとめてみました。
質問・記事ネタ等募集しています!
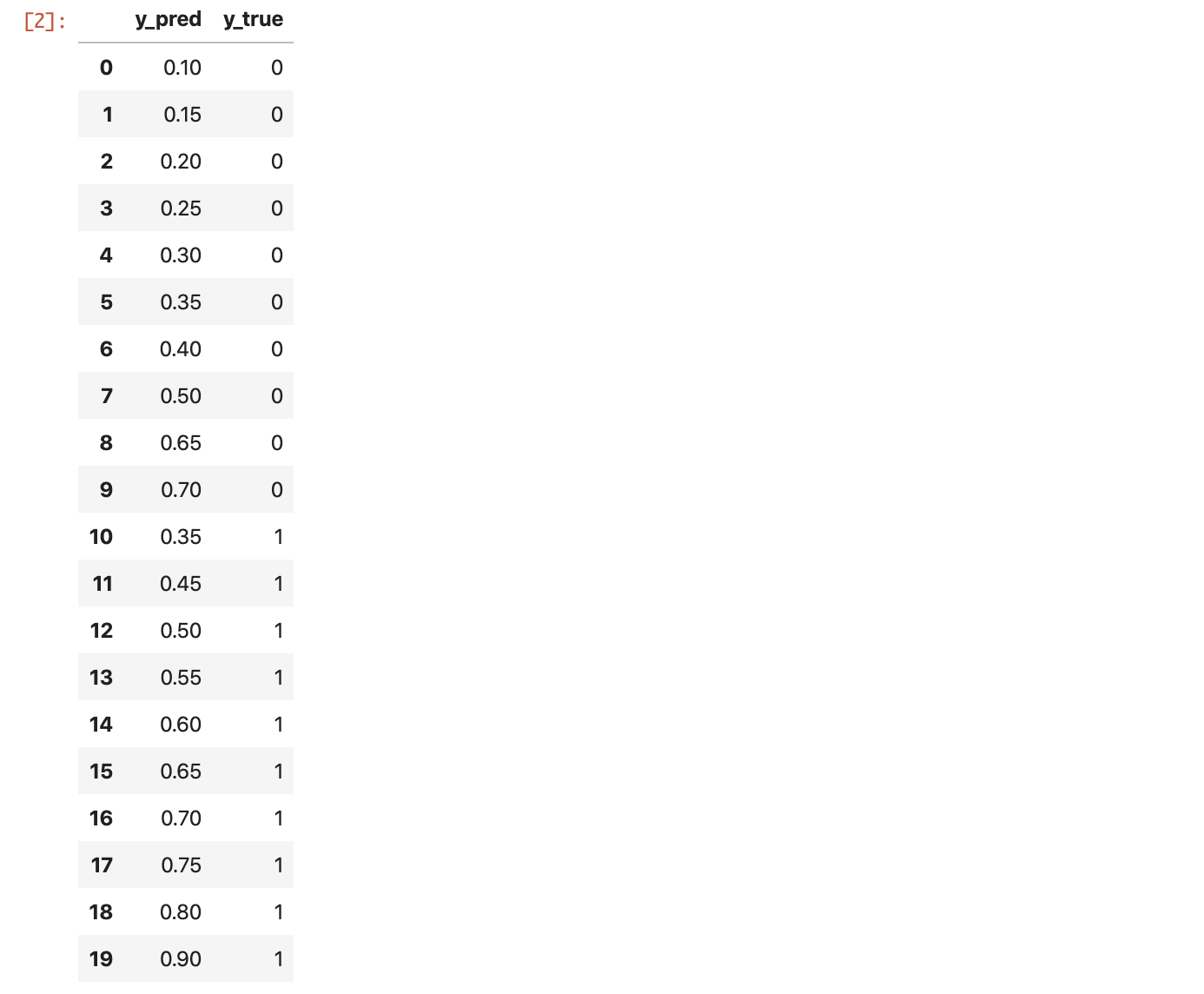
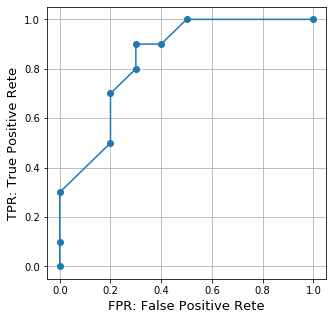

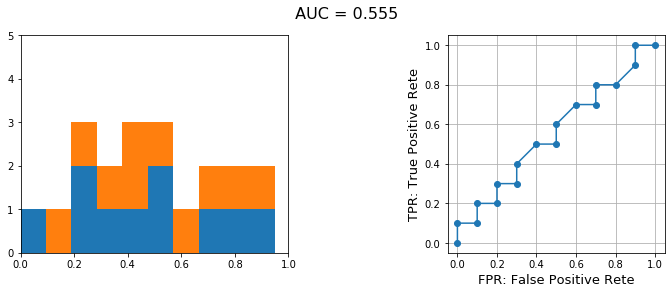
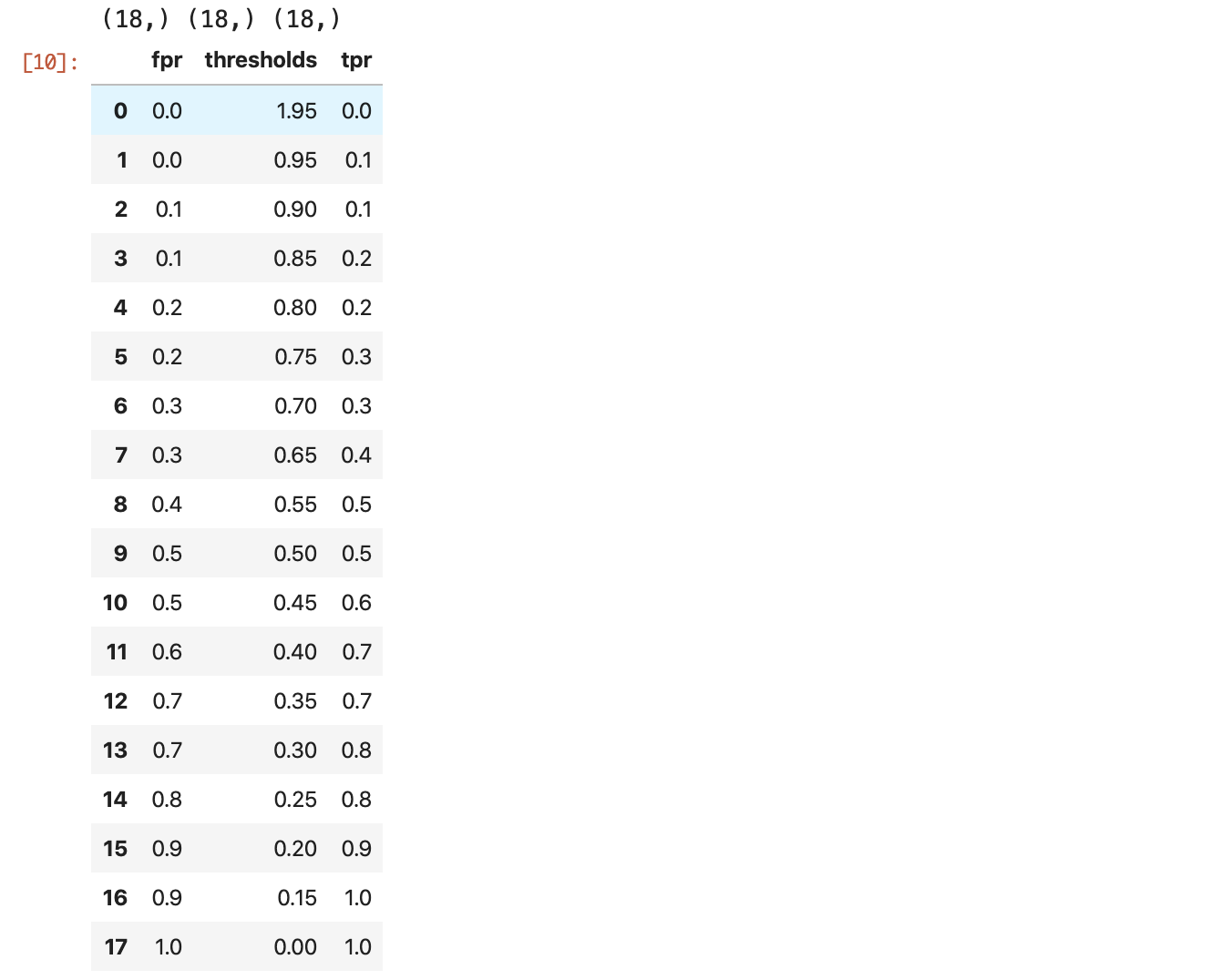
- 投稿日:2020-03-26T17:03:12+09:00
Lambdaに[/tmp]を利用してpythonライブラリをインストール
問題
Lambdaのデプロイパッケージのサイズ制限で、250 MB を超えることはできません。
解決方法
Lambda Layerを作成
Lambdaの[/tmp]フォルダーを利用してライブラリをインストール
今回は2の方法を説明します。requirements.txtファイルを作成
requirements-lambda.txtnumpy==1.16.3 colorgram.py==1.2.0 webcolors==1.8.1create.sh#!/bin/bash if [ -d "deploy" ]; then rm -Rf deploy; fi mkdir deploy pip install -r requirements-lambda.txt -t deploy/requirements-lambda/ cd deploy/requirements-lambda rm -r PIL rm -r Pillow* zip -9 -r ../lambda-requirements.zip . cd .. rm -r requirements-lambdaLambdaにhandleプログラムにUnzip(サイズは50MB未満)
handle.pyimport os import sys import zipfile pkgdir = '/tmp/requirements' zip_requirements = 'lambda-requirements.zip' if os.environ.get("AWS_EXECUTION_ENV") is not None: if not os.path.exists(pkgdir): root = os.environ.get('LAMBDA_TASK_ROOT', os.getcwd()) zip_requirements = os.path.join(root, zip_requirements) zipfile.ZipFile(zip_requirements, 'r').extractall(pkgdir) sys.path.append(pkgdir)S3からダウンロードしてUnzip(サイズは50MB以上)
handle.pyimport boto3 import os import sys import zipfile REQUIREMENTS_BUCKET_NAME = '' REQUIREMENTS_KEY = '' pkgdir = '/tmp/requirements' zip_requirements = '/tmp/lambda-requirements.zip' sys.path.append(pkgdir) if os.environ.get("AWS_EXECUTION_ENV") is not None: if not os.path.exists(pkgdir): s3 = boto3.resource('s3') bucket = s3.Bucket(REQUIREMENTS_BUCKET_NAME) bucket.download_file(REQUIREMENTS_KEY, zip_requirements) zipfile.ZipFile(zip_requirements, 'r').extractall(pkgdir) os.remove('zip_requirements') sys.path.append(pkgdir)
- 投稿日:2020-03-26T16:34:55+09:00
Pythonを爆速にする「Cython」チュートリアル: C++側の関数が参照渡しされているときのハンドリング。
概要
C++ で書いているコードを、どうしてもPythonで呼べる形のライブラリにしたい。
ただ、そこにはCythonという大きな壁が立ちはだかっていた。これは、Pythonを爆速にする「Cython」チュートリアル: C++側の関数がオーバーロードを持つとき。 の続きになります。
コードは「ここのgithub」にあげてあるので、ぜひご覧ください。
前回は、C++側の関数がオーバーロードをしているとき(同じ関数名で、引数に異なるものが入るような構成のとき)の、Cython化の解説しました。
今回は、C++側の関数が、引数として値渡しではなく参照渡しのときのCython側でのハンドリング仕方を解説したいと思います。
あまり新しいことは出てきませんが、実際Cythonを書こうとするとエラーに悩まされてしまうことが多いので、そのようなときに是非ご覧ください!!状況説明
- C++側の関数がオーバーロードされていたので、前回の記事のようにキャストを使って解決していた。
- C++側に実装された関数の引数の中に、参照渡しのものが含まれている。
- 引数が参照型だとエラーでるやん。
実際に試してみます。
cpp_library/TestClass1.hclass TestClass1{ private: TestClass2 property_test_class2; EnumForTestClass1 group; public: //~省略 static void print_vector(vector<int> &x); static void print_vector(vector<double> &x);前回と違うところは、
print_vectorの引数のxが、値渡しから参照渡しになっているところです。cpp_library/TestClass1.cppvoid TestClass1::print_vector(vector<int> &x){ for(int i=0; i<x.size(); i++){ cout << x[i] << " "; } cout << endl; } void TestClass1::print_vector(vector<double> &x){ for(int i=0; i<x.size(); i++){ cout << x[i] << " "; } cout << endl; }これをいつものように
python setup.py installでbuildしようとすると、以下のエラーがでます。./cython/my_library.cpp:2414:69: error: cannot bind non-const lvalue reference of type 'std::vector<int>&' to an rvalue of type 'std::vector<int>' __pyx_t_1 = __Pyx_void_to_None(__pyx_v_testclass1.print_vector(((std::vector<int> )__pyx_t_4))); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 53, __pyx_L1_error)キャストをきちんとしているはずなのに、参照渡しになると怒られます。
そこで、解決策として、
キャストではなく実体をその場で作ります。
どういうことかというと、
cython/test_class1.pyx@staticmethod def print_vector(list x): cdef: TestClass1 testclass1 vector[int] vec_int vector[double] vec_double if isinstance(x[0], int): vec_int.resize(len(x)) for i in range(len(x)): vec_int[i] = <int>x[i] return testclass1.print_vector(vec_int) elif isinstance(x[0], float): vec_double.resize(len(x)) for i in range(len(x)): vec_double[i] = <double>x[i] return testclass1.print_vector(vec_double) else: raise Exception('TypeError')とします。ここで、
cdefにより、vector[int]や、vector[double]をその場で作り、それを関数に渡します。
たぶん、さっき出たエラーは、参照渡しなのに、本当に実体存在してるかわからんやん!困るで!!!
というエラーだったんだと自分は解釈しています。したがって、実体を用意してあげて、安心させるといいわけです。
こうすると、例によって
python setup.py installにより、ビルドが通ります。これにより、テストコードを以下のように書くことで、
test.pyimport my_library as myl if __name__ == "__main__": cl1 = myl.test() x = [1,2,3] y = [1.1, 2.2, 3.3] cl1.print_vector(x) cl1.print_vector(y)きちんと関数をコールできました。
(myenv) root@e96f489c2395:/from_local/cython_practice# python test.py 1 2 3 1.1 2.2 3.3まとめ
今回は、C++側の関数が、引数として値渡しではなく参照渡しのときのCython側でのハンドリング仕方を解説しました。
今回はこのへんで。
おわり。
- 投稿日:2020-03-26T15:58:47+09:00
AtCoder Beginner Contest 081 過去問復習
所要時間
感想
二回連続でD問題をちゃんと解けました。
しっかり考察しながら解けてましたが、いつの間にかFXやりながら解いてました…。
自分を律する、バチャコン中も集中する、ルールをしっかり守れないとこの先に繋がらない気がします。A問題
1がいくつあるかを数えます。
最初countではなくfindとしてました。
なぜ基本的な関数すら把握してないんでしょうか…。answerA.pyprint(input().count("1"))B問題
んー書くだけ。
全ての要素が2で割り切れるかどうかを考えれば良い。
もっと簡潔な書き方がありそうですね。answerB.pyn=int(input()) a=list(map(int,input().split())) ans=0 def check_all(): global a,n for i in range(n): if a[i]%2!=0: return False return True while check_all(): ans+=1 for i in range(n): a[i]//=2 print(ans)C問題
書き換えるボールの数を少なくしたい、つまり、数が同じボールが多いものは書き換えたくないので、ソートして同じ数のボールを隣り合わせにした後にgroupby関数でグループ分けをします。
グループ分けをしたらボールの個数が多い順にソートをし、(1-indexで)k+1番目以降のグループのボールの数を全て書き換えれば良いです。answerC.pyn,k=map(int,input().split()) a=sorted(list(map(int,input().split()))) def groupby(): global a a2=[[a[0],1]] for i in range(1,len(a)): if a2[-1][0]==a[i]: a2[-1][1]+=1 else: a2.append([a[i],1]) return a2 b=groupby() b.sort(key=lambda x:x[1],reverse=True) l=len(b) ans=0 for i in range(k,l): ans+=b[i][1] print(ans)D問題
まず2N回までの中で自由に決めれるということなので、都合のいいやり方はないかと探します。
まず、全ての要素が0以上の場合を考えます。この場合は、右隣の要素に足していく操作を左から順に行う(最大n-1回)ことにより容易に条件を満たすような数列を作り出すことができます($ a_1,a_1+a_2,…,a_1+a_2+…+a_{n-1}+a_n $ のようになります。)。
しかし、ここでは負の数が存在するため、この方法では条件を満たすことができません。そこで、逆に全ての要素が0以下であると仮定します。この場合は、先ほどの逆操作を行えば良いことがわかります(最大n-1回)。
以上の考察から"全ての要素が0以上"または"全ての要素が0以下"のいずれかのパターンであれば条件を満たす数列を作り出すことができます。したがって、n+1回以内でそのようなパターンを作り出すことを考えます。
このようなパターンを作り出すために絶対値が最大の数に注目しました。仮にこの数が負であれば他の全ての要素に足すことで、他のすべての要素を負にすることができ、正であれば他のすべての要素を正にできます(最大n-1回)。
以上の二つの操作を順に行って以下のようになります。answerD.pyn=int(input()) a=list(map(int,input().split())) c,d=min(a),max(a) ans=[] if abs(c)>abs(d): c_=a.index(c) for i in range(n): if i!=c_ and a[i]>0: ans.append(str(c_+1)+" "+str(i+1)) for i in range(n-1,0,-1): ans.append(str(i+1)+" "+str(i)) else: d_=a.index(d) for i in range(n): if i!=d_ and a[i]<0: ans.append(str(d_+1)+" "+str(i+1)) for i in range(n-1): ans.append(str(i+1)+" "+str(i+2)) l=len(ans) print(l) for i in range(l): print(ans[i])

- 投稿日:2020-03-26T15:48:08+09:00
Pythonを爆速にする「Cython」チュートリアル: C++側の関数がオーバーロードを持つとき。
概要
C++ で書いているコードを、どうしてもPythonで呼べる形のライブラリにしたい。
ただ、そこにはCythonという大きな壁が立ちはだかっていた。これは、Pythonを爆速にする「Cython」チュートリアル: C++のコードで定義したEnumクラスをPython のEnumにパースするやり方。 の続きになります。
コードは「ここのgithub」にあげてあるので、ぜひご覧ください。
前回は、C++で書かれたライブラリをCython化してPythonから使えるようにする際の、C++で宣言されたEnumクラスをPython側のEnumクラスに引き渡す、というところを解説しました。
今回は、C++側の関数がオーバーロードをしているとき(同じ関数名で、引数に異なるものが入るような構成のとき)の、Cython化の解説になります。
状況説明
これまで書いてきたライブラリの、C++側に以下のような関数を作ります。
ここで、print_vector関数は、引数にvector<int>及びvector<double>を取ることのできる関数であり、このようなとき関数がオーバーロードされているといいます。cpp_library/TestClass1.hclass TestClass1{ private: TestClass2 property_test_class2; EnumForTestClass1 group; public: //〜省略 static void print_vector(vector<int> x); static void print_vector(vector<double> x);中身は以下のようにただvectorの中身をプリントする関数です。
cpp_library/TestClass1.cppvoid TestClass1::print_vector(vector<int> x){ for(int i=0; i<x.size(); i++){ cout << x[i] << " "; } cout << endl; } void TestClass1::print_vector(vector<double> x){ for(int i=0; i<x.size(); i++){ cout << x[i] << " "; } cout << endl; }Cython化
この
print_vector関数をCythonから例のように呼ぶことを考えてみます。cython/my_library.pxdcdef extern from "../cpp_library/TestClass1.h" namespace "my_library": cdef cppclass TestClass1: # 〜省略 void print_vector(vector[int] x) void print_vector(vector[double] x)cython/test_class1.pxdcdef extern from "../cpp_library/TestClass1.h" namespace "my_library": cdef cppclass TestClass1: # 〜省略 void print_vector(vector[int] x) void print_vector(vector[double] x)ここで、
cython/test_class1.pyxに中身を実装していくわけですが、cython/test_class1.pyx@staticmethod def print_vector(list x): cdef TestClass1 testclass1 return testclass1.print_vector(x)として
python setup.py installを実行しようとすると、Error compiling Cython file: ------------------------------------------------------------ ... return testclass1.test_vector_int_ref(x,y) @staticmethod def print_vector(list x): cdef TestClass1 testclass1 return testclass1.print_vector(x) ^ ------------------------------------------------------------ cython/test_class1.pyx:51:38: no suitable method foundとエラーが出て怒られます。。考えてみれば当たり前なのですが、C++側の
print_vector関数はオーバーロードされているため、
どの関数を参照しているかわからない、というわけです。
これを解決するため、キャストをして、どの関数をコールしているか明示することが必要になります。そこで、
cython/test_class1.pyxを以下のように書き直します。cython/test_class1.pyx@staticmethod def print_vector(list x): cdef TestClass1 testclass1 if isinstance(x[0], int): return testclass1.print_vector(<vector[int]>x) elif isinstance(x[0], float): return testclass1.print_vector(<vector[double]>x) else: raise Exception('TypeError')これは、引数である
xをまずはlistと指定したあと、
その中身のタイプによってC++側のどの関数をコールするか指定しています。実際にこのように書くと、
python setup.py installでビルドできて、test.pyimport my_library as myl if __name__ == "__main__": cl1 = myl.test() x = [1,2,3] y = [1.1, 2.2, 3.3] cl1.print_vector(x) cl1.print_vector(y)を実行してテストすると、
(myenv) root@e96f489c2395:/from_local/cython_practice# python test.py 1 2 3 1.1 2.2 3.3とうまくC++側の関数をコールできていることが分かります。
まとめ
今回は、C++側の関数がオーバーロードをしているとき(同じ関数名で、引数に異なるものが入るような構成のとき)の、Cython化の解説をしました。
だいたい網羅してきた気がする、、あとどのようなことがC++によく書くでしょうか?
次何を書こうか現段階では決まっていないので、ネタが決まり次第次も書こうと思います。今回はこのへんで。
おわり。
- 投稿日:2020-03-26T15:15:49+09:00
Image Processing with PIL
In this project, we'll load and process the image with PIL.
PIL
This library provides extensive file format support, an efficient internal representation, and fairly powerful image processing capabilities. The core image library is designed for fast access to data stored in a few basic pixel formats. It should provide a solid foundation for a general image processing tool.
Image Processing
The library contains basic image processing functionality, including point operations, filtering with a set of built-in convolution kernels, and colour space conversions.
The library also supports image resizing, rotation and arbitrary affine transforms.
There’s a histogram method allowing you to pull some statistics out of an image. This can be used for automatic contrast enhancement, and for global statistical analysis.
Import libraries
# Used to change filepaths from pathlib import Path # We set up matplotlib, pandas, and the display function %matplotlib inline import matplotlib.pyplot as plt from IPython.display import display import pandas as pd # import numpy to use in this cell import numpy as np # import Image from PIL so we can use it later from PIL import Image # generate test_data test_data = np.random.beta(1, 1, size=(100, 100, 3)) # display the test_data plt.imshow(test_data)
Opening images with PIL
# open the image img = Image.open('datasets/bee_1.jpg') # Get the image size img_size = img.size print("The image size is: {}".format(img_size)) # Just having the image as the last line in the cell will display it in the notebook img
Image manipulation with PIL
Pillow has a number of common image manipulation tasks built into the library. For example, one may want to resize an image so that the file size is smaller. Or, perhaps, convert an image to black-and-white instead of color. Operations that Pillow provides include:
- resizing
- cropping
- rotating
- flipping
- converting to greyscale (or other color modes)
# Crop the image to 25, 25, 75, 75 img_cropped = img.crop([25, 25, 75, 75]) display(img_cropped) # rotate the image by 45 degrees img_rotated = img.rotate(45, expand = 25) display(img_rotated) # flip the image left to right img_flipped = img.transpose(Image.FLIP_LEFT_RIGHT) display(img_flipped)
Images as arrays of data
Most image formats have three color "channels": red, green, and blue (some images also have a fourth channel called "alpha" that controls transparency). For each pixel in an image, there is a value for every channel.
The way this is represented as data is as a three-dimensional matrix. The width of the matrix is the width of the image, the height of the matrix is the height of the image, and the depth of the matrix is the number of channels. So, as we saw, the height and width of our image are both 100 pixels. This means that the underlying data is a matrix with the dimensions 100x100x3.
# Turn our image object into a NumPy array img_data = np.array(img) # get the shape of the resulting array img_data_shape = img_data.shape print("Our NumPy array has the shape: {}".format(img_data_shape)) # plot the data with `imshow` plt.imshow(img_data) plt.show() # plot the red channel plt.imshow(img_data[:, :, 0], cmap=plt.cm.Reds_r) plt.show() # plot the green channel plt.imshow(img_data[:, 0, :], cmap=plt.cm.Greens_r) plt.show() # plot the blue channel plt.imshow(img_data[0, :, :], cmap=plt.cm.Blues_r) plt.show()
Explore the color channels
Color channels can help provide more information about an image. A picture of the ocean will be more blue, whereas a picture of a field will be more green. This kind of information can be useful when building models or examining the differences between images.
We'll look at the kernel density estimate for each of the color channels on the same plot so that we can understand how they differ.
When we make this plot, we'll see that a shape that appears further to the right means more of that color, whereas further to the left means less of that color.
def plot_kde(channel, color): """ Plots a kernel density estimate for the given data. `channel` must be a 2d array `color` must be a color string, e.g. 'r', 'g', or 'b' """ data = channel.flatten() return pd.Series(data).plot.density(c=color) # create the list of channels channels = ['r','g','b'] def plot_rgb(image_data): # use enumerate to loop over colors and indexes for ix, color in enumerate(channels): plot_kde(img_data[:, :, ix], color) plt.show() plot_rgb(img_data)
Honey bees and bumble bees (i)
Now we'll look at two different images and some of the differences between them. The first image is of a honey bee, and the second image is of a bumble bee.
First, let's look at the honey bee.
# load bee_12.jpg as honey honey = Image.open('datasets/bee_12.jpg') # display the honey bee image display(honey) # NumPy array of the honey bee image data honey_data = np.array(honey) # plot the rgb densities for the honey bee image plot_rgb(honey_data)
Honey bees and bumble bees (ii)
Now let's look at the bumble bee.
When one compares these images, it is clear how different the colors are. The honey bee image above, with a blue flower, has a strong peak on the right-hand side of the blue channel. The bumble bee image, which has a lot of yellow for the bee and the background, has almost perfect overlap between the red and green channels (which together make yellow).
# load bee_3.jpg as bumble bumble = Image.open('datasets/bee_3.jpg') # display the bumble bee image display(bumble) # NumPy array of the bumble bee image data bumble_data = np.array(bumble) # plot the rgb densities for the bumble bee image plot_rgb(bumble_data)
Simplify, simplify, simplify
While sometimes color information is useful, other times it can be distracting. In this examples where we are looking at bees, the bees themselves are very similar colors. On the other hand, the bees are often on top of different color flowers. We know that the colors of the flowers may be distracting from separating honey bees from bumble bees, so let's convert these images to black-and-white, or "grayscale."
# convert honey to grayscale honey_bw = honey.convert("L") display(honey_bw) # convert the image to a NumPy array honey_bw_arr = np.array(honey_bw) # get the shape of the resulting array honey_bw_arr_shape = honey_bw_arr.shape print("Our NumPy array has the shape: {}".format(honey_bw_arr_shape)) # plot the array using matplotlib plt.imshow(honey_bw_arr, cmap=plt.cm.gray) plt.show() # plot the kde of the new black and white array plot_kde(honey_bw_arr, 'k')
Save your work!
Now, we'll make a couple changes to the Image object from Pillow and save that. We'll flip the image left-to-right, just as we did with the color version. Then, we'll change the NumPy version of the data by clipping it. Using the np.maximum function, we can take any number in the array smaller than 100 and replace it with 100. Because this reduces the range of values, it will increase the contrast of the image. We'll then convert that back to an Image and save the result.
# flip the image left-right with transpose honey_bw_flip = honey_bw.transpose(Image.FLIP_LEFT_RIGHT) # show the flipped image display(honey_bw_flip) # save the flipped image honey_bw_flip.save("saved_images/bw_flipped.jpg") # create higher contrast by reducing range honey_hc_arr = np.maximum(honey_bw_arr, 100) # show the higher contrast version plt.imshow(honey_hc_arr, cmap=plt.cm.gray) # convert the NumPy array of high contrast to an Image honey_bw_hc = Image.fromarray(honey_hc_arr) # save the high contrast version honey_bw_hc.save("saved_images/bw_hc.jpg")
Make a pipeline
We have all the tools in our toolbox to load images, transform them, and save the results. In this pipeline we will do the following:
- Load the image with Image.open and create paths to save our images to
- Convert the image to grayscale
- Save the grayscale image
- Rotate, crop, and zoom in on the image and save the new image
image_paths = ['datasets/bee_1.jpg', 'datasets/bee_12.jpg', 'datasets/bee_2.jpg', 'datasets/bee_3.jpg'] def process_image(path): img = Image.open(path) # create paths to save files to bw_path = "saved_images/bw_{}.jpg".format(path.stem) rcz_path = "saved_images/rcz_{}.jpg".format(path.stem) print("Creating grayscale version of {} and saving to {}.".format(path, bw_path)) bw = img.convert("L") bw.save(bw_path) print("Creating rotated, cropped, and zoomed version of {} and saving to {}.".format(path, rcz_path)) rcz = img.rotate(45).crop([25,25,75,75]).resize((100,100)) rcz.save(rcz_path) # for loop over image paths for img_path in image_paths: process_image(Path(img_path))





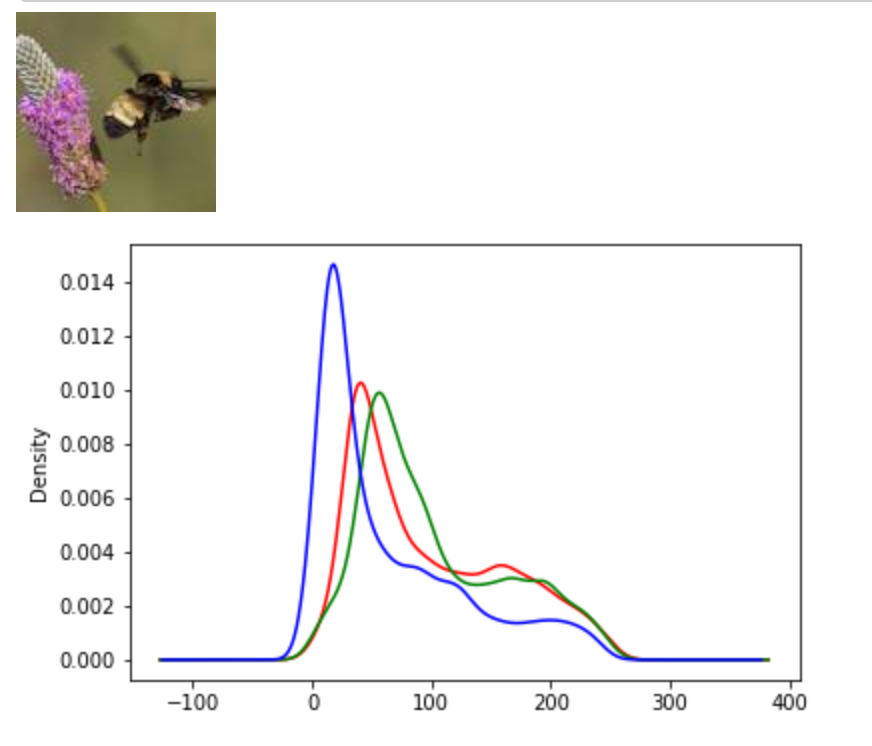


- 投稿日:2020-03-26T14:49:14+09:00
Pythonを爆速にする「Cython」チュートリアル: C++のコードで定義したEnumクラスをPython のEnumにパースするやり方。
概要
C++ で書いているコードを、どうしてもPythonで呼べる形のライブラリにしたい。
ただ、そこにはCythonという大きな壁が立ちはだかっていた。これは、C++からPythonへの橋渡し「Cython」講座: C++のクラスオブジェクトを、Python側のクラスオブジェクトに引き渡すやり方。その② の続きになります。
コードはいつものごとく、ここのgithubにあげておきますので、ご覧ください!!
状況説明
C++側でEnumクラスを定義し、それをクラスのプロパティとして持たせているとします。
この際、getterなどを使ってこのプロパティをもらうとき、返り値はもちろんEnumクラスになります。
これをCython化する場合、この返り値はPython側には定義されていないクラスなので、Cythonで定義後、パースして返す必要があります。まず、C++とPythonでのEnumの書き方を簡単におさらいします。
C++でのEnumクラスの書き方。
enum class Color{ RED = 0, GREEN = 1, BLUE = 2 };PythonでのEnumクラスの書き方。
class Color(Enum): RED = 0 GREEN = 1 BLUE = 2C++側からでEnumクラスをこのように追加しました。
これまで書いてきた TestClass1.h および TestClass1.cppに、Enumクラスのプロパティ(group)を追加します。
また、それに応じてgroupプロパティのgetter及びsetterを追加しました。cpp_library/TestClass1.henum class EnumForTestClass1{ ZERO = 0, ONE = 1 }; class TestClass1{ private: TestClass2 property_test_class2; EnumForTestClass1 group; public: // 〜省略 void set_group(EnumForTestClass1 group); EnumForTestClass1 get_group();cpp_library/TestClass1.cppEnumForTestClass1 TestClass1::get_group(){ return this->group; } void TestClass1::set_group(EnumForTestClass1 group){ this->group = group; }このgetterとsetterをcython化、つまりC++側のEnumクラスとPython側のEnumクラスを繋ぎます。
C++側からのEnumクラスをPython側のEnumクラスに引き渡す方法。
例によって、
cytyon/test_class1.pxdにC++側のEnumクラスを定義します。定義の仕方は下のファイルの通りに分けて行います。
その後、作ったgetter,setterの定義も追加しておきます。cython/test_class1.pxdcdef extern from "../cpp_library/TestClass1.h": cdef cppclass EnumForTestClass1: EnumForTestClass1() cdef extern from "../cpp_library/TestClass1.h" namespace "my_library": cdef EnumForTestClass1 ZERO cdef EnumForTestClass1 ONE cdef extern from "../cpp_library/TestClass1.h" namespace "my_library": cdef cppclass TestClass1: #〜省略 void set_group(EnumForTestClass1 group) EnumForTestClass1 get_group();また、同じ記載を
cython/my_library.pxdにも追加します。cython/my_library.pxdcdef extern from "../cpp_library/TestClass1.h" namespace "my_library": cdef cppclass EnumForTestClass1: EnumForTestClass1() cdef extern from "../cpp_library/TestClass1.h" namespace "my_library": cdef EnumForTestClass1 ZERO cdef EnumForTestClass1 ONE cdef extern from "../cpp_library/TestClass1.h" namespace "my_library": cdef cppclass TestClass1: #〜省略 void set_group(EnumForTestClass1 group) EnumForTestClass1 get_group();これが終了したら、次は
cython/tests_class1.pyxにgetter, setterの中身を記載していきます。
コードから先に書くと、以下のようになります。cython/tests_class1.pyxcpdef enum Py_EnumForTestClass1: Py_ZERO = 0 Py_ONE = 1 cdef class TestClass1Cython: cdef TestClass1* ptr def set_group(self, Py_EnumForTestClass1 group): return self.ptr.set_group(<EnumForTestClass1> group) def get_group(self): cdef: EnumForTestClass1* cpp_enum_for_test_class1 = new EnumForTestClass1() cpp_enum_for_test_class1[0] = <EnumForTestClass1>self.ptr.get_group() if(<int>cpp_enum_for_test_class1[0] == <int>Py_EnumForTestClass1.Py_ZERO): return Py_EnumForTestClass1.Py_ZERO elif(<int>cpp_enum_for_test_class1[0] == <int>Py_EnumForTestClass1.Py_ONE): return Py_EnumForTestClass1.Py_ONEまず、
cpdef enum Py_EnumForTestClass1でPythonから呼べるEnumクラスを定義。次に、 setterに関しては、
Py_EnumForTestClass1をPython 側から受取り、<EnumForTestClass1>でC++側の型にキャストすることでC++側の関数に渡しています。また、getterに関しては少し冗長ですが、
<EnumForTestClass1>self.ptr.get_group()でC++側のEnumオブジェクトとして渡されたものを、でキャストし、そのintの値がPython側のPy_EnumForTestClass1のどれに等しいのかをif文で判定させ、それの応じてPy_EnumForTestClass1オブジェクトをリターンしています。以上により、Python側のEnumクラスを、C++側のEnumクラスにパース、また、C++側のEnumクラスもPython側のEnumクラスにパースすることが可能になりました。
最後に、いつものように
python setup.py install
でコンパイルを行い、テストをしてみます。test.pyimport my_library as myl if __name__ == "__main__": cl1 = myl.test() test1 = myl.Py_EnumForTestClass1.Py_ZERO cl1.set_group(test1) test2 = cl1.get_group() print(test2)結果として、
(myenv) root@e96f489c2395:/from_local/cython_practice# python test.py 0となり、たしかにEnumクラスをC++のプロパティにset, そしてgetできたことが確認できました。
まとめ
今回は、C++で書かれたライブラリをCython化してPythonから使えるようにする際の、C++で宣言されたEnumクラスをPython側のEnumクラスに引き渡す、というところを解説しました。
ここまでで大抵のC++側のカスタムオブジェクトがPython側に引き渡すことができるようになったと思います。
次回は、C++側で書くことの多い、関数のオーバーロードをCythonでどのように処理すればよいかについて書きたいと思います。
今回はこのへんで。
おわり。
- 投稿日:2020-03-26T14:19:13+09:00
AtCoder Beginner Contest 080 過去問復習
所要時間
感想
久しぶりに全部まともに解けた気がします。
ただ、D問題は形に騙されてアルゴリズムを決め打ちしてやっていたので、そこは反省…。A問題
小さい方を出力するだけ
answerA.pyn,a,b=map(int,input().split()) print(min(a*n,b))B問題
それぞれの桁の和を求めるにはwhile文の中で10でそれぞれ割っていけばよい。
answerB.pyn=int(input()) k=n f=0 while k!=0: f+=(k%10) k//=10 print("Yes" if n%f==0 else "No")C問題
このようなパターンの問題はDPなどを疑いたくなりますが、それぞれの時間帯で営業するかを先に決めて全探索してもせいぜい$2^{10}-1=1023$(必ず一回は営業するので)なので間に合いそうとわかります。
営業するかどうかをそれぞれの時間帯で決めた際に利益がどうなるかは、営業すると決めた時間帯(最大で10個)で商店街にあるn個の店が営業しているかどうかをチェックし記録するのでO(n)、チェックした店の個数に対応する利益を計算するのでO(n)なので、計算量的に間に合うことがわかります。answerC.pyn=int(input()) f=[list(map(int,input().split())) for i in range(n)] p=[list(map(int,input().split())) for i in range(n)] ma=-10000000000000 for i in range(1,2**10): check=[0]*n for j in range(10): if (i>>j) & 1: for k in range(n): check[k]+=f[k][j] ma_sub=0 for i in range(n): ma_sub+=p[i][check[i]] ma=max(ma,ma_sub) print(ma)D問題
初めは区間の重なりを考えるので区間スケジューリングを疑いましたが、区間がいくつ重なっているかを考えるのは区間スケジューリングには適さない(重複しないように選んでくるのには適す)と考えました。結果的にはこの方針の転換が功を奏しました。
結局、最大でいくつ区間が被っているかを考えれば良いので、それぞれの時間でいくつのテレビ番組をやっているかを考えれば良いと言い換えることができました。あとは、区間の値を更新する場合はimos法を使うと効率が良いので、imosを利用しました。
さらに、この問題では同じチャンネルの場合はあるテレビ番組の終わりと始まりの時間が同じでも連続で録画することができるので、チャンネルごとでimos法を行うようにし、最後の数え上げの際にまとめて計算するようにしました。answerD.pyn,c=map(int,input().split()) imos=[[0 for i in range(c)] for j in range(10**5+1)]#1~10**5+1 for i in range(n): s,t,_c=map(int,input().split()) imos[s-1][_c-1]+=1 imos[t][_c-1]-=1 for i in range(1,10**5+1): for j in range(c): imos[i][j]+=imos[i-1][j] imosans=[0]*(10**5+1) for i in range(10**5+1): for j in range(c): imosans[i]+=(imos[i][j]>=1) print(max(imosans))

- 投稿日:2020-03-26T13:13:26+09:00
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
エスケープシーケンスのエラー
\を\\に変えるだけ。
- 投稿日:2020-03-26T12:38:43+09:00
【python】csvファイルを読み込む方法(pandasモジュールのread_csvメソッド)
【忘備録】pythonでcsvファイルを読み込む方法(pandasモジュールのread_csvメソッド)
pythonでローカルに保存してあるcsvファイルの表データを使う際に、ファイルを読み込む方法のメモ。
やりかた
pandasモジュールのread_csvメソッドを使う。
■read_csvの構文
pnadas.read_csv('csvファイルのパス')
└ パスは絶対パスでも相対パスどちらでも可。
└ pandasはpdと省略してインポートすることが多い。
▼pandasをpdとしてインポートする方法
import pandas as pd
実際の使い方
基本的に取得したデータは変数に格納する。
変数はdf(dataframeの略)が使われることが多い。
変数に格納しないと、読み込んだ時点で内容が出力される。
▼DataFrameとは
・データ形式の一種
・いわるゆ表データ(excelのイメージ)
・変数をdfとすることで、「これは表データ」というのがすぐにわかるようにしている。実例
①絶対パスで読み込む
デスクトップあるtest.csvを読み込む。
df = pd.read_csv('~/desktop/test.csv')
└「df」:任意の変数
└「pd」:pandas
└「.read_csv('')」:pandasでcsvを読み込むメソッド
└「~/desktop/test.csv」:デスクトップのtest.csvファイルをフルパスで指定。
▼絶対パスでcsvファイルを読み込み、
print関数で中身を確認。import pandas as pd df = pd.read_csv('~/desktop/test.csv') print(df) #出力例 # date start high low end adjusted #0 2020/3/9 20,343.31 20,347.19 19,472.26 19,698.76 19,698.76 #1 2020/3/6 21,009.80 21,061.20 20,613.91 20,749.75 20,749.75 #2 2020/3/5 21,399.87 21,399.87 21,220.76 21,329.12 21,329.12 #3 2020/3/4 20,897.20 21,245.93 20,862.05 21,100.06 21,100.06
②相対パスで読み込む
.pyファイルと同じ階層にあるtest-same-directory.csvを読み込む。
df = pd.read_csv('test-same-directory.csv')
└「df」:任意の変数
└「pd」:pandas
└「.read_csv('')」:pandasでcsvを読み込むメソッド
└「test-same-directory.csv」:同じディレクトリの指定ファイルを読み込み。import pandas as pd df2 = pd.read_csv(''test-same-directory.csv'') print(df2) #出力例 # date start high low end adjusted #0 2020/3/9 20,343.31 20,347.19 19,472.26 19,698.76 19,698.76 #1 2020/3/6 21,009.80 21,061.20 20,613.91 20,749.75 20,749.75 #2 2020/3/5 21,399.87 21,399.87 21,220.76 21,329.12 21,329.12 #3 2020/3/4 20,897.20 21,245.93 20,862.05 21,100.06 21,100.06
- 投稿日:2020-03-26T12:38:03+09:00
1行で素数列挙
はじめに
ふと思いつきで1行で素数を求めるプログラムを書いてみました。効率ではなくコード量重視。
Ruby
filterかと思ったら Range の場合selectなんですね。(Ruby 2.5)(2..99).select {|x| (2...x).select {|i| x % i == 0} == []}Python
filterでもいいけれどリスト内包表記の方がすっきり書けます。[x for x in range(2, 100) if [i for i in range(2, x) if x % i == 0] == []]Haskell
Haskell は何年たっても勉強中の初心者から抜け出せません。
[x | x <- [2..100], [i | i <- [2..(x - 1)], mod x i == 0] == []]まとめ
リスト内包表記ができないRubyが不利かと思ったら、意外なことにぼくが書いた中では一番短かった。
- 投稿日:2020-03-26T11:37:45+09:00
Python フォルダの作成 既存かチェックあり
背景
Pythonでフォルダ作成のプログラミングコードはたくさんありますが、
念のため備忘録を作成します。サンプルコード
フォルダを作成することはできますが、
そのフォルダが既存だとエラーが出ます。
ifを使って回避します。make_folder.pyimport os new_path = "demo_folder"#フォルダ名 if not os.path.exists(new_path):#ディレクトリがなかったら os.mkdir(new_path)#作成したいフォルダ名を作成結果
1回目に実行したら、フォルダが作成されます。
2回目に実行したら、すでにフォルダが作成されているため何も起こりません。
- 投稿日:2020-03-26T11:35:34+09:00
【pyhton】スライスとは?使い方を具体例で分かりやすく解説
【pyhton】スライスとは?意味と使い方を実例で分かりやすく解説
pythonを学んでいると耳にするスライス。
範囲指定や変化量をプラスとマイナスで指定するかで挙動が変わるなど、ややこしい。。
範囲指定や変化量をプラスやマイナスにした場合や混在させた場合、範囲外を指定した場合にどういった挙動になるかをパターン別に確認。
目次
1. スライスとは?
listなどの範囲指定方法の一種。
[ ]と:で範囲を指定する記法。listやfor文でよく目にする [1:5] や [2:] とかのこと。
listだけでなく、文字列(str)、タプル(tuple)、セット(set)、レンジ(range)などに使える。
連続した要素や、文字を任意の場所で切り出す(スライスする)。
2. スライスの基本構文
[a:b:c]
└「a」:開始の配列番号
└「b」:終了の配列番号(未満)
└「c」:変化量
▼a,b,cはそれぞれ「マイナス」も設定可能
※開始値マイナスの場合は配列番号の割り振りが変わる。
└ 最後の要素を-1として、-1ずつカウントしていく。
└ 最初の要素の番号が一番小さい※変化量「c」がプラスかマイナスかで「a」と「b」の条件が変わる。
└ 変化量がプラス:常に「a<b」
└ 変化量がマイナス:常に「a>b」
└ 上記でなくともエラーにはならない。該当するデータがない(空になる)。※「b」で指定した値は含まない。
└ 指定した値で終了するため。
▼各要素は省略することも可能
[:]:指定なし=すべて[a:]:開始だけ指定[:b]:終了だけ指定[a:b]:開始と終了を指定[a:b:c]:開始、終了、変化量を指定[a::c]:開始、変化量を指定[:b:c]:終了、変化量を指定[::c]:変化量だけ指定補足
9.[a::]:開始だけ指定([a:]と同じ)
10.[:b:]:開始だけ指定([:b]と同じ)
3. 配列番号の見方
開始値がプラスかマイナスかで配列番号の割り振りが変わる。
(1)開始値がプラスの場合
1-1. list型
1-2. 文字(2)開始値がマイナスの場合
2-1. list型
2-2. 文字(3)開始値マイナス、終わり値プラスの場合
(4)範囲外を指定する場合の考え方
(1)開始値がプラスの場合
0番目からカウント。
1-1. list型
例1:
a = [1,2,3,4,5]の場合
データ 1 2 3 4 5 配列番号 0 1 2 3 4
例2:b = [2020,3,25,"年","月","日"]の場合
データ 2020 3 25 年 月 日 配列番号 0 1 2 3 4 5
1-2. 文字(要素1つ)
例1:"This is slice"の場合
データ T h i s i s s l i c e 配列番号 0 1 2 3 4 5 6 7 8 9 10 11 12
例2:d ="これが、「スライス」 です。"の場合
データ こ れ が 、 「 ス ラ イ ス 」 で す 。 配列番号 0 1 2 3 4 5 6 7 8 9 10 11 12 13
(2)開始値がマイナスの場合
一番最後のデータを「-1」番目としてカウントしていく。
2-1. list型
例1:
a = [1,2,3,4,5]の場合
データ 1 2 3 4 5 配列番号 -5 -4 -3 -2 -1
例2:b = [2020,3,25,"年","月","日"]の場合
データ 2020 3 25 年 月 日 配列番号 -6 -5 -4 -3 -2 -1
2-2. 文字(要素1つ)
例1:
c = "This is slice"の場合
データ T h i s i s s l i c e 配列番号 -13 -12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1
例2:d ="これが、「スライス」 です。"の場合
データ こ れ が 、 「 ス ラ イ ス 」 で す 。 配列番号 -14 -13 -12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1
(3)マイナスとプラスが混在
■考え方
プラスかマイナスかは、番号の指定をどちらで行うかの違いになる。・マイナスの場合は、配列番号(-)に該当するデータを参照。
・プラスの場合は、配列番号(+)に該当するデータを参照。
データ 1 2 3 4 5 配列番号(+) 0 1 2 3 4 配列番号(-) -5 -4 -3 -2 -1
▼例
・開始値「-3」⇒ データは「3」
・終わり値「4」⇒ データは「5」⇒ 3から5未満。出力は[3, 4]。
▼ポイント
※[-3:4]は、-3から4を連続で指定していない。「-3,-2,-1,0,1,2,3,4」ではない。開始値と終わり値に数値が混在する場合は、マイナス番号に相当する、プラスの番号に置き換えるとわかりやすい。
・
[-3:4]=[2:4]
・[-5:4]=[0:4]
・[1:-1]=[1:5]
(4)範囲外を指定する場合の考え方
範囲外を指定してもエラーにはならない。
データがない部分は空になる。
4. スライスをパターン毎に実例で確認
[:]:指定なし=すべて[a:]:開始だけ指定[:b]:終了だけ指定[a:b]:開始と終了を指定[a:b:c]:開始、終了、変化量を指定[a::c]:開始、変化量を指定[:b:c]:終了、変化量を指定[::c]:変化量だけ指定
1.
[:]指定なし=すべて格納されているデータをすべて出力
list(数値)a = [1, 2, 3, 4, 5] a[:] #出力 # [1, 2, 3, 4, 5]文字c = 'This is slice' c[:] #出力 # 'This is slice'文字(直接指定)'This is slice'[:] #出力 # 'This is slice'
2.
[a:]:開始だけ指定▼配列番号2番目以上(2から4まで)
プラスで指定a = [1, 2, 3, 4, 5] a[2:] #出力 # [3, 4, 5]▼配列番号-4番目以上(-4から-1まで)
マイナスで指定a = [1, 2, 3, 4, 5] a[-4:] #出力 # [2, 3, 4, 5]▼(補足)各データの配列番号
データ 1 2 3 4 5 配列番号(+) 0 1 2 3 4 配列番号(-) -5 -4 -3 -2 -1
■範囲外を指定した場合
・エラーにはならない。
・非該当の範囲は空になる。▼「4」番目までしかないlistで開始値に「6」を指定した場合。
(範囲外)プラスで指定a = [1, 2, 3, 4, 5] a[6:] #出力 # []ヒットなし
▼「-5」から「-1」番目までしかないlistで開始値に「-10」を指定した場合。(範囲外)マイナスで指定a = [1, 2, 3, 4, 5] a[-10:] #出力 # [1, 2, 3, 4, 5]-10から-6番目までは空。-5番目以上がヒット。
3.
[:b]終了だけ指定▼配列番号3番目まで(0から2番目まで)
└ 3未満となる(3番目で終了のため)プラスで指定a = [1, 2, 3, 4, 5] a[:3] #出力 # [1, 2, 3]▼配列番号-1番目まで(-5から-2番目まで)
└ -1未満となる(-1番目で終了のため)マイナスで指定a = [1, 2, 3, 4, 5] a[:-1] #出力 # [1, 2, 3, 4]▼(補足)各データの配列番号
データ 1 2 3 4 5 配列番号(+) 0 1 2 3 4 配列番号(-) -5 -4 -3 -2 -1
4.
[a:b]開始と終了を指定▼配列番号1番目から4番目未満を指定。
└ 4は含まない(1から3の3要素)プラスで指定a = [1, 2, 3, 4, 5] a[1:4] #出力 # [2, 3, 4]▼配列番号-4番目から-2番目未満まで
└ -2を含まない。(-4から-3の2要素)マイナスで指定a = [1, 2, 3, 4, 5] a[-4:-2] #出力 # [2, 3]▼(補足)各データの配列番号
データ 1 2 3 4 5 配列番号(-) -5 -4 -3 -2 -1
■開始値マイナス、終わり値プラスの場合開始値マイナスの場合は、開始値は配列番号(-)に該当するデータを参照。
終わり値プラスの場合は、終わり値は配列番号(+)に該当するデータを参照。
▼開始値に-3、終わり値に4を指定した場合プラスとマイナスで指定a = [1, 2, 3, 4, 5] a[-3:4] #出力 # [3, 4]※
[-3:4]は、-3から4を連続で指定していない。「-3,-2,-1,0,1,2,3,4」ではない。開始値と終わり値に数値が混在する場合は、マイナス番号に相当する、プラスの番号に置き換えるとわかりやすい。
データ 1 2 3 4 5 配列番号(+) 0 1 2 3 4 配列番号(-) -5 -4 -3 -2 -1 ・
[-5:4]=[0:4]
・[1:-1]=[1:5]
・[-3:2]=[2:2]
■範囲外を指定した場合
エラーにはならず、該当のないデータは空になる。▼4番目までしかないデータに対し、終わり値に10番目を指定。
範囲外を指定(プラス)a = [1, 2, 3, 4, 5] a[3:10] #出力 # [4, 5]6番目以降のデータは該当なし。
▼-5番目までしかないデータに対し、開始値に-20を指定。範囲外を指定(マイナス)a = [1, 2, 3, 4, 5] a[-20:-3] #出力 # [1, 2]-20から-6番目まではヒットなし。
-5から-3番目未満までのデータが出力される。
▼0から4番目までしかないデータで、10から20番目を指定。範囲外から範囲外を指定(プラス)a = [1, 2, 3, 4, 5] a[10:30] #出力 # []出力は空となる。
▼-1から-5番目までしかないデータで、-20から-10番目を指定。範囲外から範囲外を指定(マイナス)a = [1, 2, 3, 4, 5] a[-20:-10] #出力 # []出力は空となる。
■プラスとマイナスでそれぞれ範囲外を指定した場合▼開始値マイナスから終わり値プラスで範囲外を指定。
範囲外から範囲外を指定(マイナスとプラス)a = [1, 2, 3, 4, 5] a[-20:10] #出力 # [1,2,3,4,5]結果は
[-5:4]=[0:4]と同じになる。
-20
-5未満はデータがないため。-5が最大値。
-5はプラス指定の0番目に該当。
10
4番目以降はデータがないため、4が最大値。
データ 1 2 3 4 5 配列番号(+) 0 1 2 3 4 配列番号(-) -5 -4 -3 -2 -1
5.
[a:b:c]開始、終了、変化量を指定▼開始値1、終わり値9、変化量2を指定した場合。
開始、終了、変化量を指定(プラス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[1:9:2] #出力 # [2, 4, 6, 8]1番目から2番ずつ配列番号を増やし、9番目未満まで実行。番号に該当するデータを抽出。
変化量をマイナスで指定
▼開始値8、終わり値3、変化量-2を指定した場合。開始、終了、変化量を指定(マイナス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[8:3:-2] #出力 # [9, 7, 5]8番目から2番ずつ配列番号を減らし、3番目に来たら終了(3番目は含まない)。番号に該当するデータを抽出。
データ 1 2 3 4 5 6 7 8 9 10 配列番号 0 1 2 3 4 5 6 7 8 9
すべてマイナスで指定
▼開始値-3、終わり値-8、変化量-2を指定した場合。開始、終了、変化量を指定(マイナス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[-3:-8:-2] #出力 # [8, 6, 4]-3番目から2番ずつ配列番号を減らし、-8番目に来たら終了(-8番目は含まない)。番号に該当するデータを抽出。
データ 1 2 3 4 5 6 7 8 9 10 配列番号 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1
6.
[a::c]開始、変化量を指定▼開始値1、変化量3を指定した場合
開始と変化量のみ指定(プラス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[1::3] #出力 # [2, 5, 8]1番目から3番づつ番号を増やし、データがあるところまで実行。
▼開始値5、変化量-1を指定した場合開始と変化量のみ指定(マイナス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[5::-1] #出力 # [6, 5, 4, 3, 2, 1]5番目から1番づつ番号を減らし、データがあるところまで実行。
7.
[:b:c]終了、変化量を指定変化量がプラスかマイナスかで、開始値が異なる。
▼終了値5、変化量2を指定した場合(開始値0)
終了と変化量のみ指定(プラス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[:5:2] #出力 # [1, 3, 5]開始値0番目から2番づつ番号を増やし、5番目未満まで実行(5番目は含まない)。
▼終了値5、変化量-2を指定した場合(開始値は最後のデータ)終了と変化量のみ指定(プラス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[:5:-2] #出力 # [10, 8]開始値9番目から2番づつ番号を減らし、5番目未満まで実行(5番目は含まない)。
8.
[::c]変化量だけ指定変化量がプラスかマイナスかで、開始値が異なる。
▼変化量プラスの場合(開始値0)
変化量のみ指定(プラス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[::3] #出力 # [1, 4, 7, 10]開始値0番目から3番づつ番号を増やし、データがあるところまで実行。
▼変化量マイナスの場合(開始値は最後のデータ)変化量のみ指定(マイナス)a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a[::-3] #出力 # [10, 7, 4, 1]**開始値1
0番目**から3番づつ番号を減らし、データがあるところまで実行。
5. エラー事例
int型(整数)やfloat型(小数点)などスライスできないオブジェクトも存在する。
エラー事例(int型)1001[2:] #出力 # TypeError: 'int' object is not subscriptableエラー事例(float型)123.45[2:5] #出力 # TypeError: 'float' object is not subscriptable
- 投稿日:2020-03-26T11:02:25+09:00
AtCoder Beginner Contest 078 過去問復習
所要時間
感想
バチャコンでC問題わからねえって床で寝転がって爆睡してたら一問も提出できませんでした。バチャコンの意味とは。
普段からしっかり取り組もうと思わずテキトーにやってるからこういうことになるという戒めになった回だと感じています(毎回感じている気はしますが)。
結局C問題はコンテスト後もわかりませんでした。なんで。→極限の解き方忘れていたのと、確率に対して感覚的に取り組めていませんでした…。
D問題は答えをみながらC問題を解いた後に解きます。→ゲームの問題の基本を徹底できていませんでした。A問題
三項演算子を使うと書きやすい。
answerA.pyx,y=input().split() print("=" if x==y else "<" if x<y else ">")B問題
それぞれの人数が座れるかどうかをxから順に小さくして調べる。
answerB.pyx,y,z=map(int,input().split()) for i in range(x,0,-1): if i*y+(i+1)*z<=x: print(i) breakC問題
一回の実行にかかる時間をx[ms]、全てのケースに正確する確率をpとした時に$x=1900 \times m + 100 \times (n-m)$、$p=(1/2)^m$となるのは明らかです。ここから問題の答えとなる合計の時間y[ms]を求めたいのですが、僕はここでk回の実行で終わったとして極限を求めようとしました。しかし、極限の求め方を完全に忘却していて解けませんでした(この記事のようにやりたかった…)。
Writer解のようにやると極限など使わずに簡単な一次方程式で解くことができます。つまり、一回目の提出でかかる時間がxでその提出に失敗する1-pの場合はさらにyだけ時間がかかるので、$y=x+(1-p)\times y$が成り立ってy=x/pが得られます。
あとはこれを計算すれば良いので以下のようになります。
✳︎また、確率pで成功する事象が何回で成功するかの期待値が1/pであることは明らかなので覚えておくべきですね。answerC.pyn,m=map(int,input().split()) x=100*n+1800*m p=2**(-m) print(int(x/p))D問題
考えても全然わからねえってなったのに答えを見たらそうでもありませんでした。
定石に従えば解けるのに頑張らないのただの馬鹿か??
まず、そもそもこういう問題は圧倒的に先攻が有利です(ゲームに対称性がないのでそれはそう)。さらに気づくのは、xとyのいずれかが最後のカードを必ずとるということです。この二つを頭に入れて考えてみたいと思います。
まず、先攻が最後のカードを初めの自分のターンでとる場合は後攻は何もできないので$abs(a[-1]-w)$になります。
次に、先攻が最後のカードを初めの自分のターンで取らない場合は、後攻もカードを取ることができて最終的なスコアは$abs(a_k-a_n)$(k=1~n-1)になります。この元での先攻の最善手は$a_k$を$a_n$からできるだけ遠くすることです。しかし、$k\ne n-1$の場合は、後攻に$a_n$からできるだけ近い$a_k$を選択する余地を与えてしまいます。この操作を繰り返していき最終的に$abs(a_l-a_n)$(l=1~n-1)が決まり、このスコアが$abs(a_l-a_{n-1})$より小さい場合は先攻について最初の選択は間違っていたことになります。さらに、同様のことが後攻にも言え、最終的なスコアが$abs(a_l-a_{n-1})$より大きい場合は後攻でカードを選んだ時の選択は間違っていたことになります。つまり、この均衡状態から言えるのは、最初のターンで最後のカードを先攻が選ばない場合は最終的なスコアが$abs(a_n-a_{n-1})$になることがわかります。
以上より、先攻が$abs(a[-1]-w)$と$abs(a_n-a_{n-1})$のうち大きい方を選べばよく、以下のようになります(先攻にもそれ以上大きいスコアを選ぶことができないのは上記で考察した通り)。answerD.pyn,z,w=map(int,input().split()) a=list(map(int,input().split())) if len(a)==1: print(abs(a[-1]-w)) else: print(max(abs(a[-1]-w),abs(a[-1]-a[-2])))
