- 投稿日:2020-03-26T23:12:09+09:00
Amazon Auroraを使用してみた。
Auroraの特長について
・高性能:標準的なMySQLデータベースと比べて約5倍
標準的なPostgreSQLデータベースと比べて最大で約3倍高速
・他データベースと同等のセキュリティ、可用性、信頼性を、10分の1のコストで実現・RDSを使用した完全マネージド型サービスのため管理タスクが自動化されている
・ストレージシステムは分散型で耐障害性と自己修復機能を備えており、データベースインスタンスごとに最大64TBまで自動スケール可能
・最大15個のリードレプリカ、ポイントインタイムリカバリ、AmazonS3への継続的なバックアップ、3つのアベイラビリティーゾーン(AZ)間でのレプリケーションにより、優れたパフォーマンスと可用性を実現
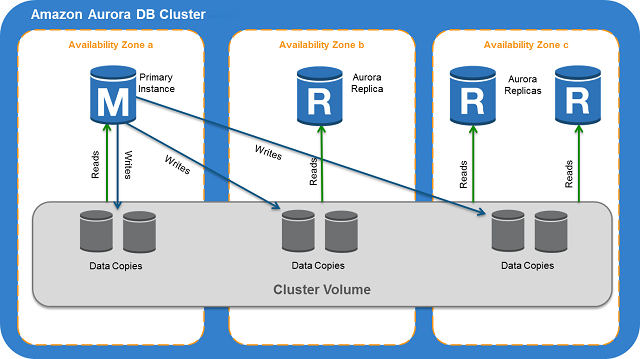
基本構造
・3つのAZにデータを保持することで可用性が向上
試しに作成する
エディション:MySQL
バージョン:Aurora(MySQL)-5.6.10a
データベースロケーション:リージョン別
データベースの機能:1つのライターと複数のリーダー
テンプレート:開発/テスト
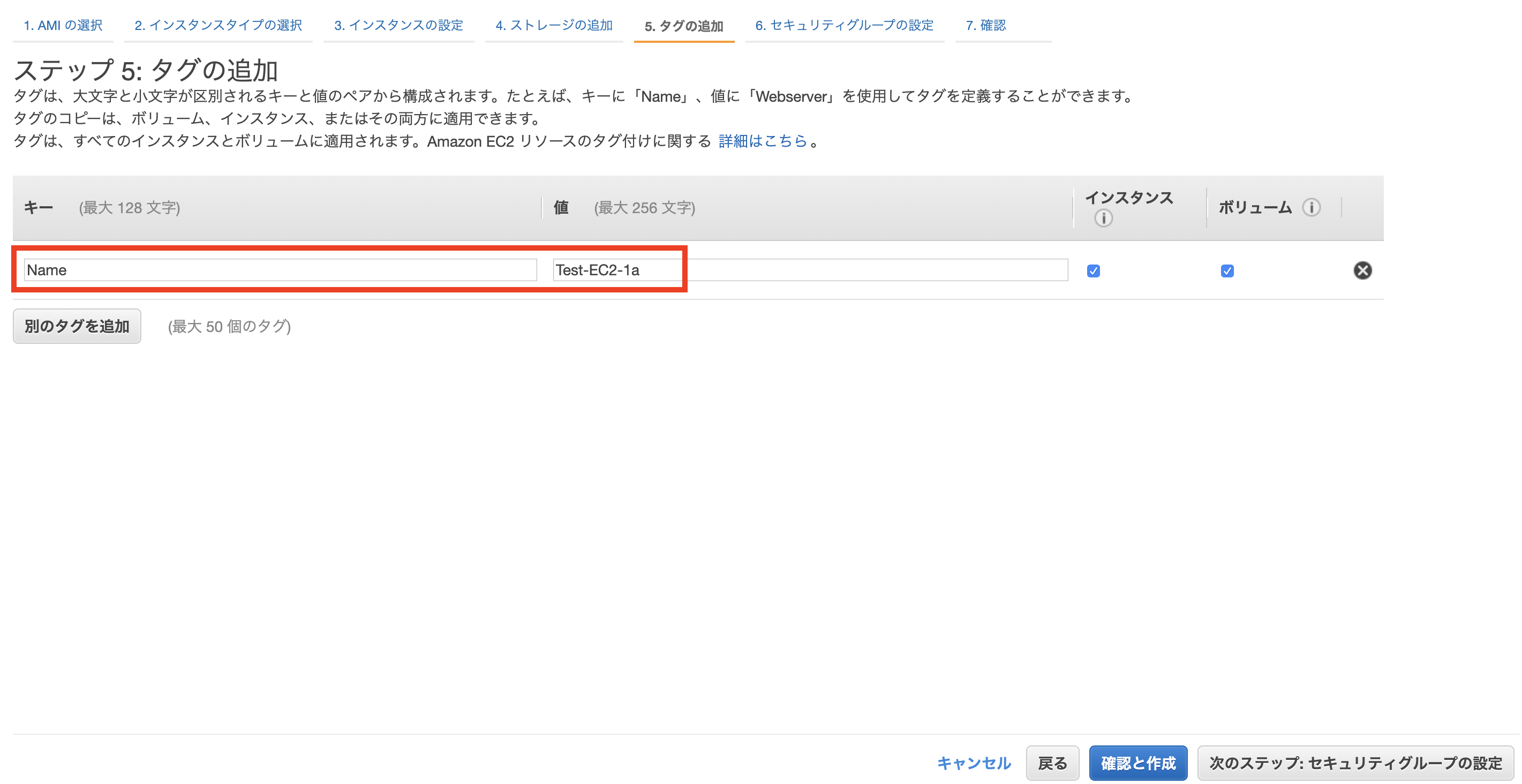
DB クラスター識別子:任意
マスターユーザー名:任意
マスターパスワード:任意(8文字以上)
メモリ最適化クラス
DBインスタンスサイズ:db.r5.large(16Git)
可用性と耐久性:本番ではマルチAZ配置がほとんど
接続:対象のVPCに紐付ける
データベース認証:パスワード認証
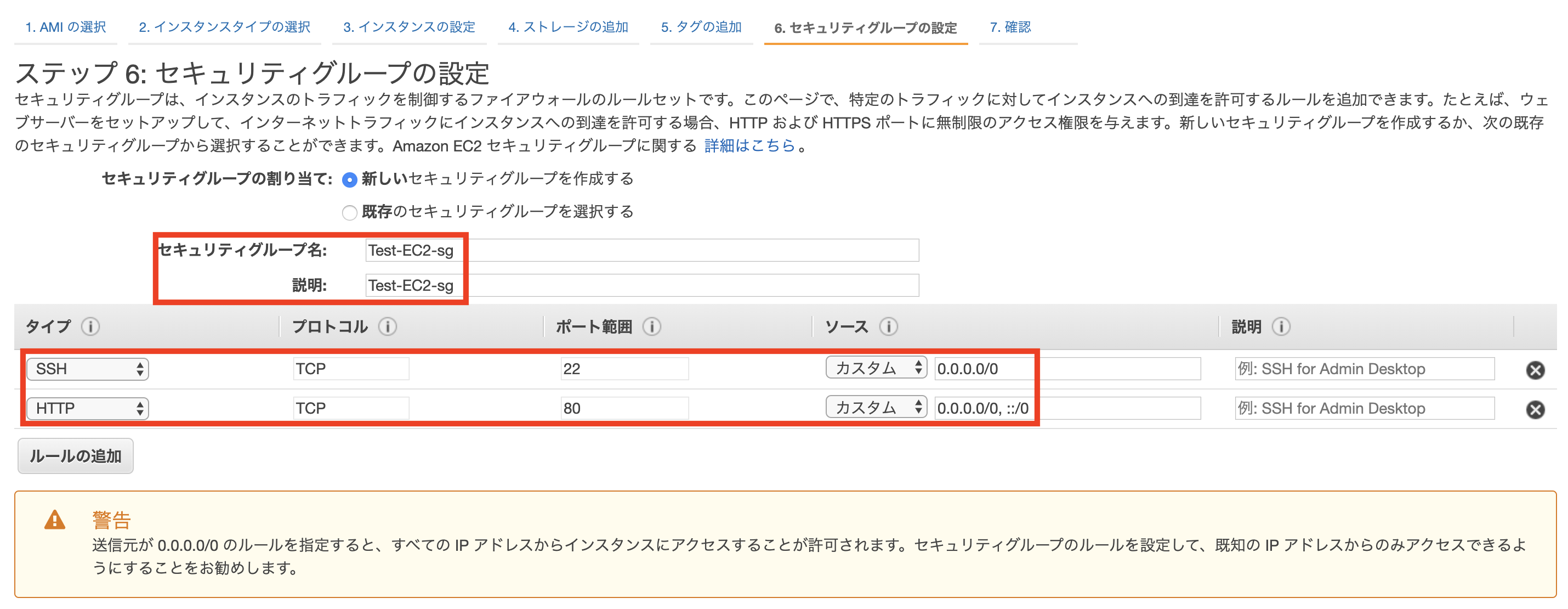
追加設定:CloudWatchの監視設定、自動プロビジョニング設定、セキュリティグループの紐付けなどが可能
今回はデフォルト(メインはAuroraのため)作成すると以下のように3つのインスタンスが作成されます。

- 投稿日:2020-03-26T22:45:42+09:00
[AWS] 一括請求の場合、無料利用枠はアカウントではなく一括請求で1つなので注意
AWSの無料利用枠は、各サービスごとに設定された課金されない利用量のことです。
お試しで少し使ってみるのに助かる設定枠ですが、対象のAWSアカウントが一括請求対象になっている場合は注意が必要です。
分かりやすいものでCode Commitの場合、
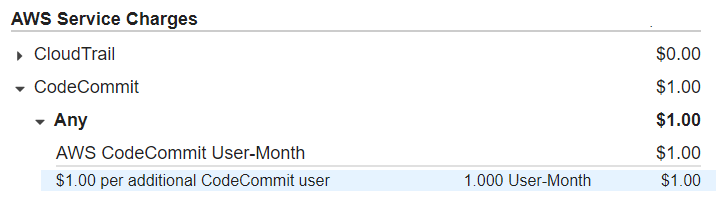
マネージドgitリポジトリが無料で使えるのはうれしい、と使ってみて請求明細を見ると・・・
5名まで無料じゃなかったのか、、、となってしまいます。
1名でも課金された理由について、無料利用枠に関するよくある質問を見ると、"一括請求の場合も無料利用枠は1つのみ"という記載があります。つまり、一括請求対象のどこかのアカウントで既に無料枠が消費されていると、課金が発生してしまうということです。
一括請求対象になっているアカウントで無料枠程度の増減が問題になることは少ないと思いますが、利用の際は注意して下さい。
参考資料

- 投稿日:2020-03-26T20:49:38+09:00
AWS(MySQL)
Railsとデータベース
今回はRailsからアクセスされるデータベース関連のデータベースを作成します。
Ruby on RailsのようなWebアプリケーションフレームワークにとって、データベースはセットで考えます。例えばTwitterで考えてみると、データベースがなければ、ユーザーの情報も、ユーザーが呟いた内容も、保存しておくことができません。データベースの種類
階層型データベース
ネットワーク型データベース
リレーショナルデータベース
があります。
この中で最も利用されているのが、リレーショナルデータベースです。
エクセルの表のような形で情報を整理し、管理することができます。そして、このリレーショナルデータベースを管理するソフトウェアはリレーショナル・データ・ベース・マネジメント・システム(RDBMS)と呼ばれます。
そんなRDBMSの中でも代表的なものの一つが、MySQLです。MySQL
Oracle社が開発・提供をしているRDBMSです。データベースの作成、編集、削除などを行うことができます。オープンソースソフトウェアとして公開されており、誰でも無償で利用することができます。
Oracle社のMySQL紹介ページ
MySQL公式ページ
MySQLをインストールします。
Amazon Linuxを利用している場合、MySQLは yum コマンドからインストールすることができます。
ターミナル(サーバー)は[ec2-userです。普通のターミナルはターミナル(ローカル)とします。
ターミナル(ローカル)$ cd .ssh/ $ ssh -i ダウンロードした鍵の名前.pem ec2-user@作成したEC2インスタンスと紐付けたElastic IPこれでターミナル(サーバー)に入れたと思います。
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install mysql56-server mysql56-devel mysql56これは、MySQLのバージョン5.6をインストールすることを意味します。
MySQLを起動するためにserviceコマンドを利用します。これは、Amazon LinuxやCentOSに含まれているもので、インストールしたソフトウェアの起動を一括して行えるツールです。
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld startmysqlではなくmysqldであることに注意しましょう。「d」はLinuxの用語で「サーバ」を意味する「デーモン(daemon)」の頭文字です。
起動できたか確認するときは
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld status mysqld (pid 15692) is running...「running」と表示されれば、MySQLの起動は成功です。
MySQLのrootパスワードの設定
yumでインストールしたMySQLには、デフォルトでrootというユーザーでアクセス出来るようになっていますが、パスワードは設定されていません。
そこで、パスワードを設定します。'設定したいパスワード'の部分については、例えばpassword0000という文字列を設定するとしたら、 'password0000'と記載しましょう。
0から始まるpasswordは読み込んでくれないケースが多いので、避けましょう.
(例えば、’0123password’など)
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo /usr/libexec/mysql56/mysqladmin -u root password 'ここを設定したいパスワードに変更してからコマンドを実行してください'このパスワードは、後ほどRailsからアクセスする時にも利用するので記憶しておいてください。
この時、Warning: Using a password on the command line interface can be insecure.と警告がでることがありますが、ここでは無視していただいて問題ありません。MySQLへの接続確認
設定したパスワードが使えるか確認の仕方です。
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ mysql -u root -pEnter password: とパスワードを入力するように表示されるので、設定したパスワードを入力して、Enterしてください。以下のように表示されれば、MySQLの設定は終了です。
ターミナル(サーバー)Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.6.33 MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
- 投稿日:2020-03-26T19:37:39+09:00
Kubeflow 1.0 on AWS #3 TF-JOBの実行
はじめに
これは、Kubeflow 1.0 をAWSで構築する記事です。
動作確認が主な目的ですので、本番環境での利用は全く想定していません。前回まで
Kubeflow 1.0 on AWS #2 Notebook作成
今回の内容
exampleのTFJOBを実行して、最低限の動きができていることを確認します
参考資料
- https://www.kubeflow.org/docs/components/training/tftraining/
- https://raw.githubusercontent.com/kubeflow/tf-operator/master/examples/v1/mnist_with_summaries/tfevent-volume/tfevent-pv.yaml
- https://raw.githubusercontent.com/kubeflow/tf-operator/master/examples/v1/mnist_with_summaries/tfevent-volume/tfevent-pvc.yaml
- https://raw.githubusercontent.com/kubeflow/tf-operator/master/examples/v1/mnist_with_summaries/tf_job_mnist.yaml
共有ストレージEFSの用意
データ置き場としてEFSを利用します。S3を使う方法もあるかと思いますが、それはあとでやってみようと思います。
こちらの通りにやりました
https://qiita.com/asahi0301/items/1116c1f030db3136ff49efs-sc(storageclass),efs-pv(PV),efs-clain(PVC)を namespace anonymous上に作成しました
k apply -k "github.com/kubernetes-sigs/aws-efs-csi-driver/deploy/kubernetes/overlays/stable/?ref=master" cat <<EOF > efs.yaml --- apiVersion: v1 kind: PersistentVolume metadata: name: efs-pv spec: capacity: storage: 5Gi volumeMode: Filesystem accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: efs-sc csi: driver: efs.csi.aws.com volumeHandle: fs-xxxxx ## ここを自分の環境の値に変更する --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: efs-claim spec: accessModes: - ReadWriteMany storageClassName: efs-sc resources: requests: storage: 5Gi --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: efs-sc provisioner: efs.csi.aws.com EOF k apply -n anonymous -f efs.yaml persistentvolume/efs-pv created persistentvolumeclaim/efs-claim created storageclass.storage.k8s.io/efs-sc created#確認 k get pvc -n anonymous | grep efs efs-claim Bound efs-pv 5Gi RWX efs-sc 117stfjob(シングルワーカー)
Jobの実行
tensorflow with mnist のトレーニングを動かします。
ポイントは、 `sidecar.istio.io/inject: "false"で sidecar injectionを無効にすることです。
これがないと、traingingが終わってTensorflowのコンテナが停止しても、envoyが動いているため、tfjobは永久にrunningのままになりますapiVersion: "kubeflow.org/v1" kind: "TFJob" metadata: name: "mnist" namespace: anonymous spec: cleanPodPolicy: None tfReplicaSpecs: Worker: replicas: 1 restartPolicy: Never template: metadata: annotations: sidecar.istio.io/inject: "false" spec: containers: - name: tensorflow image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0 command: - "python" - "/var/tf_mnist/mnist_with_summaries.py" - "--log_dir=/train/logs" - "--learning_rate=0.01" - "--batch_size=150" volumeMounts: - mountPath: "/train" name: "training" volumes: - name: "training" persistentVolumeClaim: claimName: "efs-claim"k apply -f tf_job_mnist.yaml tfjob.kubeflow.org/mnist created確認
k -n anonymous get tfjobs NAME STATE AGE mnist Running 16m k -n anonymous get pod NAME READY STATUS RESTARTS AGE mnist-worker-0 2/2 Running 0 15s k -n anonymous logs -f mnist-worker-0 tensorflow WARNING:tensorflow:From /var/tf_mnist/mnist_with_summaries.py:39: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use alternatives such as official/mnist/dataset.py from tensorflow/models. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future ver sion. Instructions for updating: Please write your own downloading logic. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:252: wrapped_fn (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version. Instructions for updating: Please use urllib or similar directly. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use tf.data to implement this functionality. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use tf.data to implement this functionality. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: __init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use alternatives such as official/mnist/dataset.py from tensorflow/models. 2020-03-26 06:35:37.447521: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA 020-03-26 06:35:37.447521: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes. Extracting /tmp/tensorflow/mnist/input_data/train-images-idx3-ubyte.gz Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes. Extracting /tmp/tensorflow/mnist/input_data/train-labels-idx1-ubyte.gz Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes. Extracting /tmp/tensorflow/mnist/input_data/t10k-images-idx3-ubyte.gz Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes. Extracting /tmp/tensorflow/mnist/input_data/t10k-labels-idx1-ubyte.gz Accuracy at step 0: 0.1164 Accuracy at step 10: 0.777 Accuracy at step 20: 0.8484 Accuracy at step 30: 0.8958 Accuracy at step 40: 0.9104 Accuracy at step 50: 0.9235 Accuracy at step 60: 0.9296 Accuracy at step 70: 0.9308 Accuracy at step 80: 0.9347 Accuracy at step 90: 0.9348 Adding run metadata for 99 Accuracy at step 100: 0.9388 Accuracy at step 110: 0.9457 Accuracy at step 120: 0.9472 Accuracy at step 130: 0.9491 Accuracy at step 140: 0.9486 Accuracy at step 150: 0.9493 Accuracy at step 160: 0.9532 Accuracy at step 170: 0.9497 Accuracy at step 180: 0.9489 Accuracy at step 190: 0.9545 Adding run metadata for 199 (続く)終了の確認
k get tfjobs -n anonymous NAME STATE AGE mnist Succeeded 6m57sEFSの確認
efs中身確認用のpodを用意
同じpvcを使い回せばなんでもいいのですが、例えばこんなdeploymentをつくります
yaml|test-eks-toolkit-deployment.yamlapiVersion: apps/v1 kind: Deployment metadata: name: eks-toolkit-deployment namespace: anonymous labels: app: eks-toolkit spec: replicas: 1 selector: matchLabels: app: eks-toolkit template: metadata: labels: app: eks-toolkit spec: containers: - name: eks-toolkit image: asahi0301/eks-toolkit command: ["tail"] args: ["-f", "/dev/null"] volumeMounts: - mountPath: "/data" name: "data" volumes: - name: "data" persistentVolumeClaim: claimName: "efs-claim"確認
Podのシェルに入って、EFSがマウントされていることを確認する
k apply -f eks-toolkit-deployment.yaml k -n anonymous exec -it eks-toolkit-deployment-7f699fd967-8jfvm bash Defaulting container name to eks-toolkit. Use 'kubectl describe pod/eks-toolkit-deployment-7f699fd967-8jfvm -n anonymous' to see all of the containers in this pod. bash-4.2# bash-4.2# bash-4.2# ls bash-4.2# df Filesystem 1K-blocks Used Available Use% Mounted on overlay 20959212 4965980 15993232 24% / tmpfs 65536 0 65536 0% /dev tmpfs 3932516 0 3932516 0% /sys/fs/cgroup fs-xxxx.efs.us-west-2.amazonaws.com:/ 9007199254739968 23552 9007199254716416 1% /data /dev/nvme0n1p1 20959212 4965980 15993232 24% /etc/hosts shm 65536 4772 60764 8% /dev/shm tmpfs 3932516 12 3932504 1% /run/secrets/kubernetes.io/serviceaccount tmpfs 3932516 0 3932516 0% /proc/acpi tmpfs 3932516 0 3932516 0% /sys/firmwareEFSの中身をみてみるろ、ログが保存されていることが分かります
bash-4.2# pwd /data/logs bash-4.2# ls test train bash-4.2#TFJOB(分散学習)
yamlの用意
サンプルコードの分散学習を試してみます
yaml|tf_job_dist_mnist.yamlapiVersion: "kubeflow.org/v1" kind: "TFJob" metadata: name: "dist-mnist-pct" namespace: anonymous spec: tfReplicaSpecs: PS: replicas: 1 restartPolicy: Never template: metadata: annotations: sidecar.istio.io/inject: "false" spec: containers: - name: tensorflow image: emsixteeen/tf-dist-mnist-test:1.0 Worker: replicas: 2 restartPolicy: Never template: metadata: annotations: sidecar.istio.io/inject: "false" spec: containers: - name: tensorflow image: emsixteeen/tf-dist-mnist-test:1.0実行
k apply -f tf_job_dist_mnist.yaml確認
k -n anonymous get tfjobs NAME STATE AGE dist-mnist-pct Succeeded 3m41sまとめ
TFJOBを使ったtrainingを行ってみました。
シングルワーカー、分散学習なども試してみてみました。
ストレージはEFSを共有ストレージとして利用しましたが、近々S3で試して見たいと思います
- 投稿日:2020-03-26T18:28:33+09:00
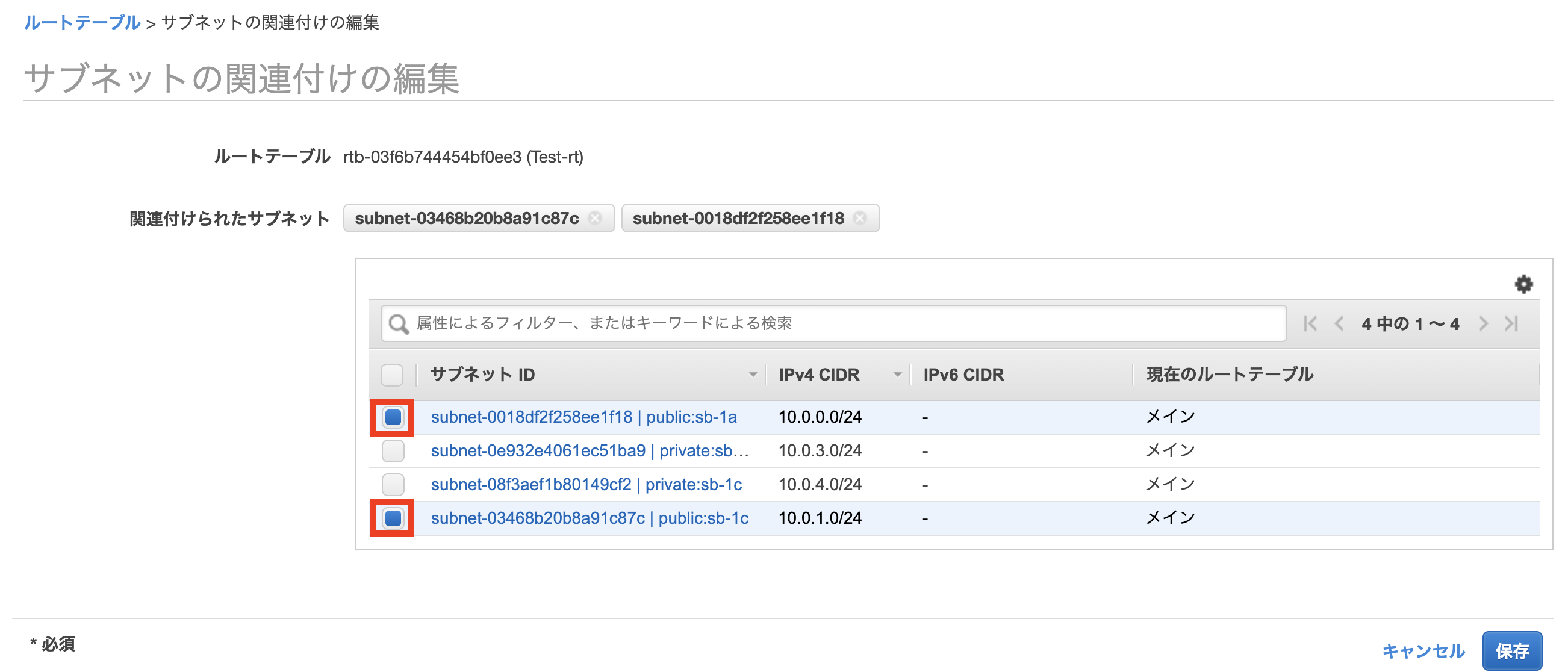
【Go】Lambda + RDS 接続にRDS Proxyを使ってみた
はじめに
現在、API Gateway + Lambda + RDSを使ってWebアプリケーションを作っています!2019年末に行われたre:Invent 2019で発表された、RDS Proxy(現在はプレビュー版です。)を試してみたので備忘録です。
RDS Proxyってなに?
簡単に言うと、データベースへのコネクションプールを確立、管理することで、アプリケーションからのデータベース接続数を少なく抑えることができるサービスです。
Lambda関数は、呼び出すごとに新しいコネクションを作成する必要があります。しかし、LambdaからRDSへの同時接続数には上限があり、これまではコネクション数が上限に達しないようにする必要がありました。これを解決してくれるのがこのRDS Proxyです。RDS Proxyを利用することで、既存のコネクションを再利用することができ、コネクション数を抑えることができます。
つまり、Lambda + RDSの構成が避けられていた原因の1つの同時接続数問題が解決できるのです!
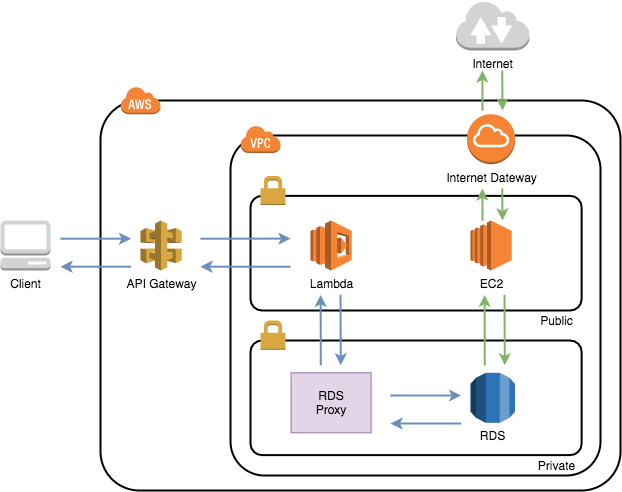
構成図
このような構成で作成しました!本記事では、Lambda、RDS Proxy、RDS、踏み台のEC2にフォーカスしています。
手順
下記の流れで進めていきます。
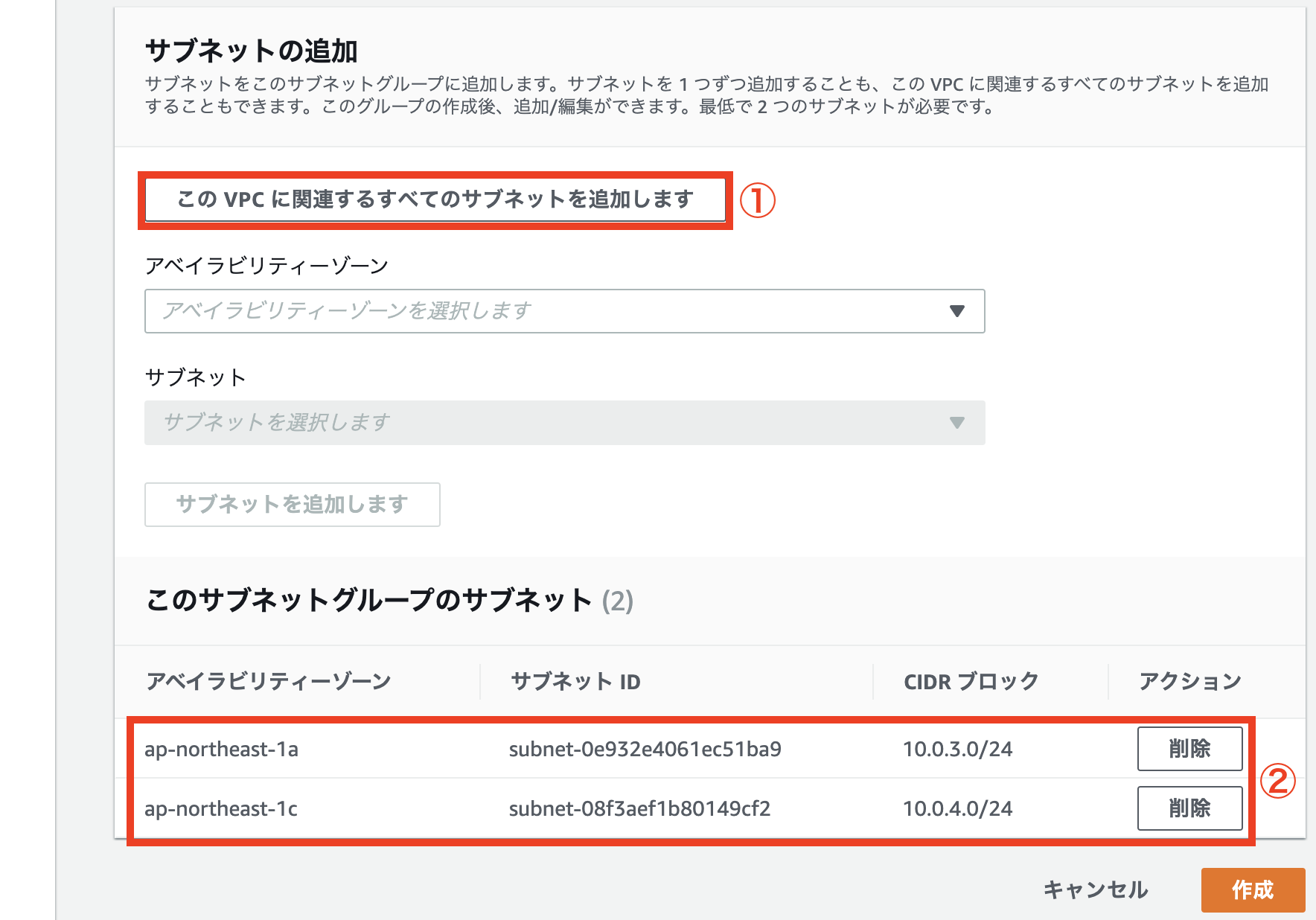
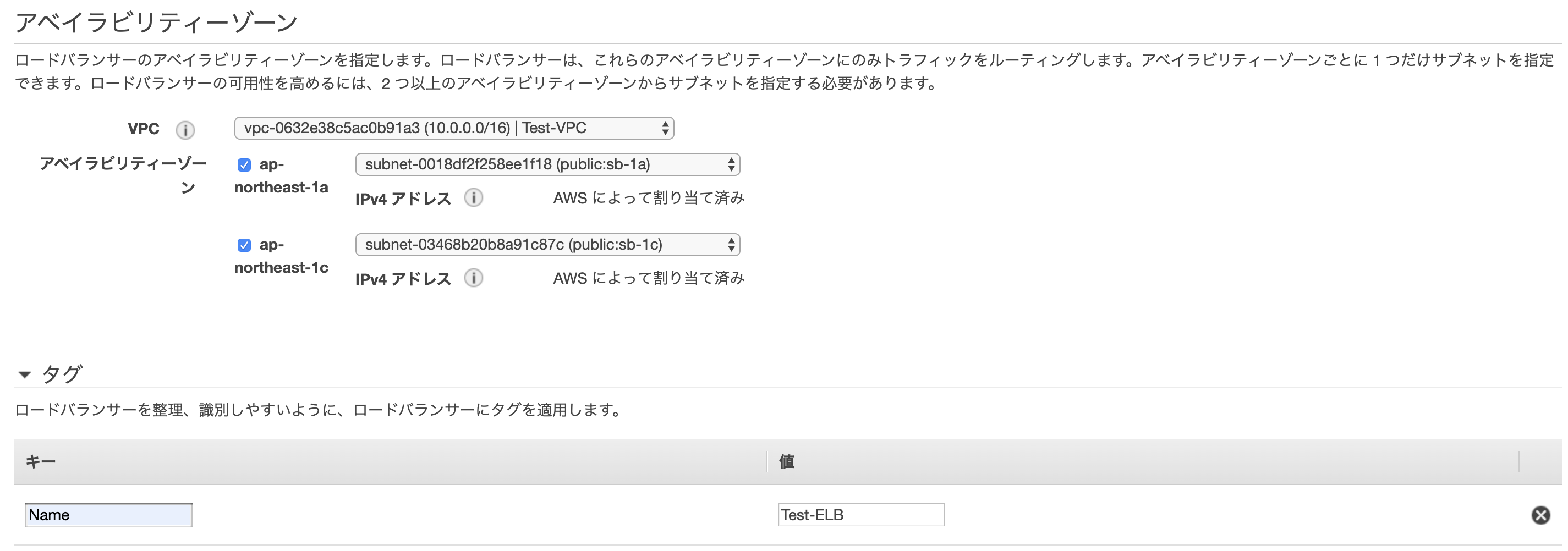
- VPC、サブネットの作成
- セキュリティグループの作成
- RDSの構築
- 踏み台EC2の構築
- テーブル作成
- DBユーザの作成
- RDS Proxyの構築
- Lambda関数の作成
やってみる
1. VPC、サブネットの作成
事前準備として、VPCを作成し、作成したVPCの中にプライベートサブネット、パブリックサブネットを作成します。特別な設定は不要なので作成方法は省略します。
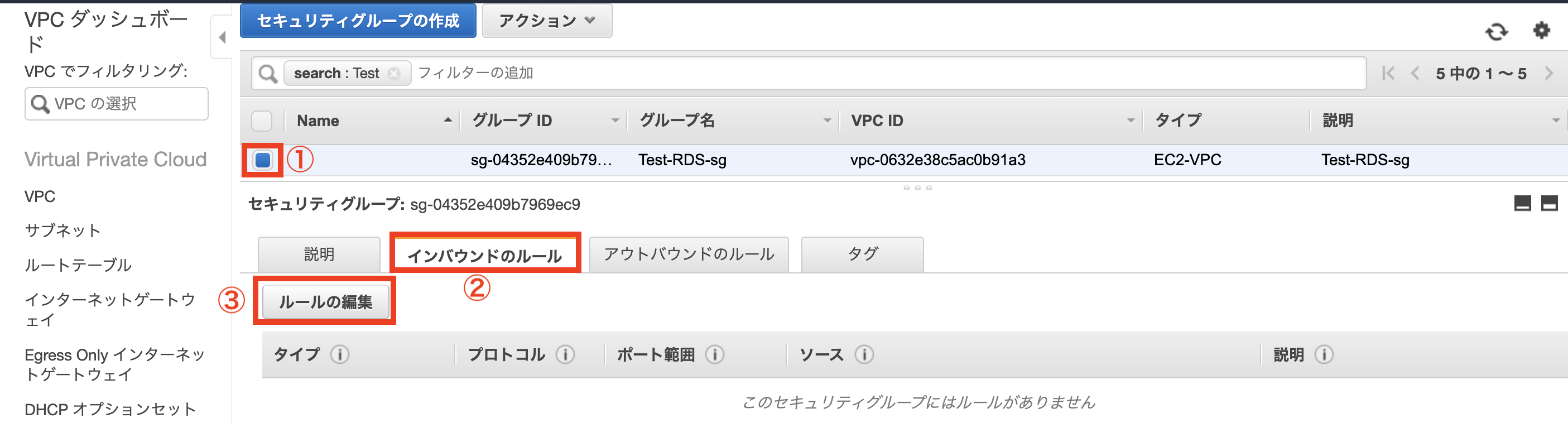
2. セキュリティグループの作成
事前準備として、各リソースのセキュリティグループの作成を行います。
Lambda
セキュリティグループ name : sg-lambda
インバウンド
タイプ ポート ソース ー ー ー 特にどこからも許可していなくてもAPI Gatewayからは叩くことができます!
EC2
セキュリティグループ name : sg-ec2-bastion
インバウンド
タイプ ポート ソース SSH 22 許可したいIPアドレス RDS Proxy
セキュリティグループ name : sg-rdsproxy
インバウンド
タイプ ポート ソース MySQL/Aurora 3306 sg-lambda RDS
セキュリティグループ name : sg-rds
インバウンド
タイプ ポート ソース MySQL/Aurora 3306 sg-ec2-bastion MySQL/Aurora 3306 sg-rdsproxy 3. RDSの構築
プライベートサブネットにRDSを立てます。
今回使用したMySQLのバージョン : MySQL 5.7.22
セキュリティグループは2で作成したsg-rdsを選択してください。その他、特に特別な設定は不要なので省略します。
4. 踏み台EC2の構築
RDSに接続して、ユーザやテーブルを作成するための踏み台EC2をたてます。
今回使用したOS : Amazon Linux 2
セキュリティグループは2で作成したsg-ec2-bastionを選択してください。こちらも、特に特別な設定は不要なので省略します。
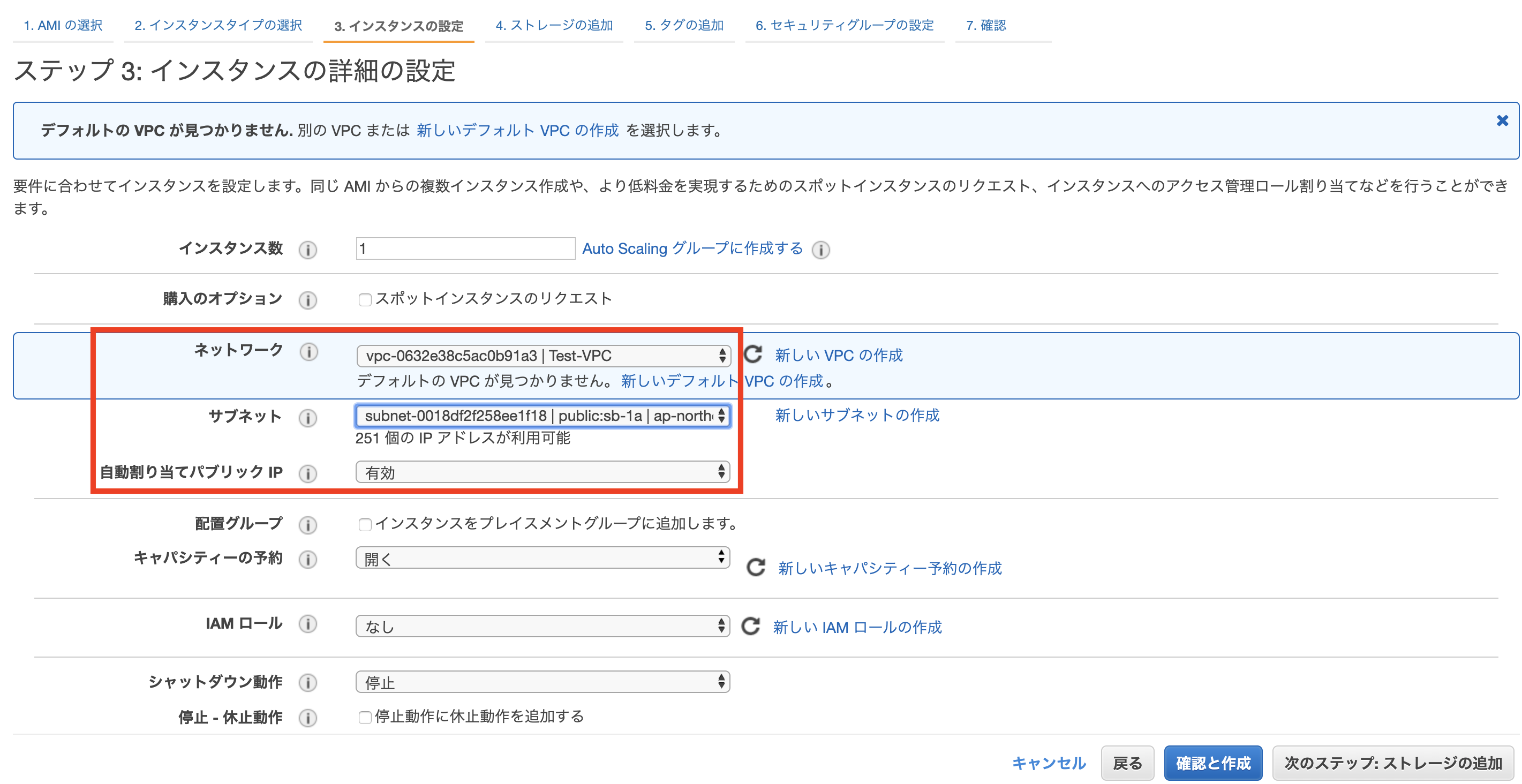
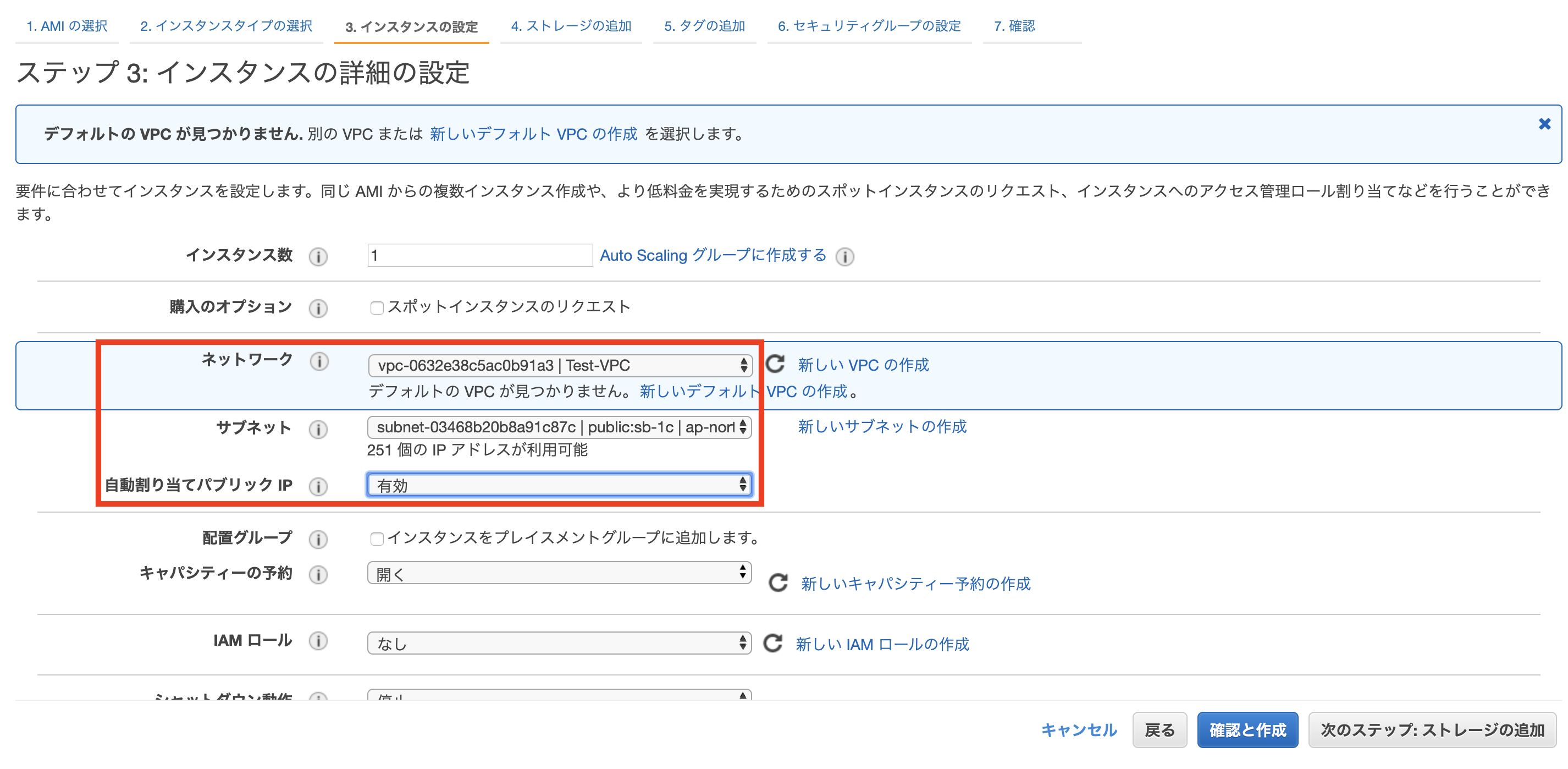
ただ、IPv4パブリックIPを使ってsshで接続するため、自動割り当てパブリックIPは有効に設定する。(これをせずに、プライベートIPで接続を試みましたが、できませんでした。)※上記の方法(自動割り当てパブリックIP)では、EC2を再起動するごとにパブリックIPアドレスが変更になるのでお気をつけてください。
5. テーブル作成
RDS内にテーブルを作成します。
テーブル内のデータはcsvファイルから取り込むようにしたかったので、今回はcsvファイルを準備しましたが、ただデータをRDSに保存するだけです。csvファイルのアップロード
ローカルから踏み台のEC2にcsvファイルを移動させました。
$ scp -i [キーペア名].pem [ファイル名].csv ec2-user@[パブリックIP]:/home/ec2-user/(EC2内の保存したいディレクトリを指定)EC2にssh接続
$ ssh -i [キーペア名].pem ec2-user@[IPv4パブリックIP]MySQLのインストール
$ sudo yum update $ sudo yum install mysqlRDSへ接続
$ mysql --local-infile=1 -h [RDSエンドポイント] -u [マスタユーザ名] -pテーブル内のデータはcsvファイルから読み込むために、
--local-infile=1のオプションをつけました。テーブルの作成
まず、テーブルの枠を作成します。
> CREATE TABLE [テーブル名] ([カラムの指定]); # 例 > CREATE TABLE m1_champion (id INT(2) AUTO_INCREMENT NOT NULL PRIMARY KEY, name VARCHAR(30) NOT NULL, champion YEAR NOT NULL, formed YEAR NOT NULL, note VARCHAR(30));次に、下記のようなcsvファイルをインポートします。
> LOAD DATA LOCAL INFILE "[ファイルパス]/[ファイル名].csv" INTO TABLE [テーブル名] FIELDS TERMINATED BY ',' LINES TERMINATED BY '\r\n';これでテーブルが完成しました。
id name champion formed note 1 ミルクボーイ 2019 2007 コーンフレーク 2 霜降り明星 2018 2013 null 3 とろサーモン 2017 2002 null 6. DBユーザの作成
上記の手順通り進めば、現在DBにログインしているので、このままLambdaから接続したときに使うユーザを作成します。
> CREATE USER '[ユーザ名]'@'%' IDENTIFIED BY '[パスワード]'; > GRANT SELECT, INSERT, UPDATE, DELETE ON [対象のDB].[対象のテーブル] TO '[ユーザー名]'@'%';上記はSELECT, INSERT, UPDATE, DELETEの権限を許可しています。また、ホスト名には
%=ワイルドカードを使用し、どこからのアクセスも受け入れるように設定しています。ちなみに、全てのDBとテーブルが対象の場合は*.*とします。7. RDS Proxyの構築
いよいよRDS Proxyの構築に入ります。
Secrets Manager シークレットの作成
先ほど作成したDBのユーザ名とパスワードを入力し、作成します。
下記URLのAWSの公式ブログに沿って作成してください。
参考:AWS LambdaでAmazon RDS Proxyを使用するIAMロールの作成
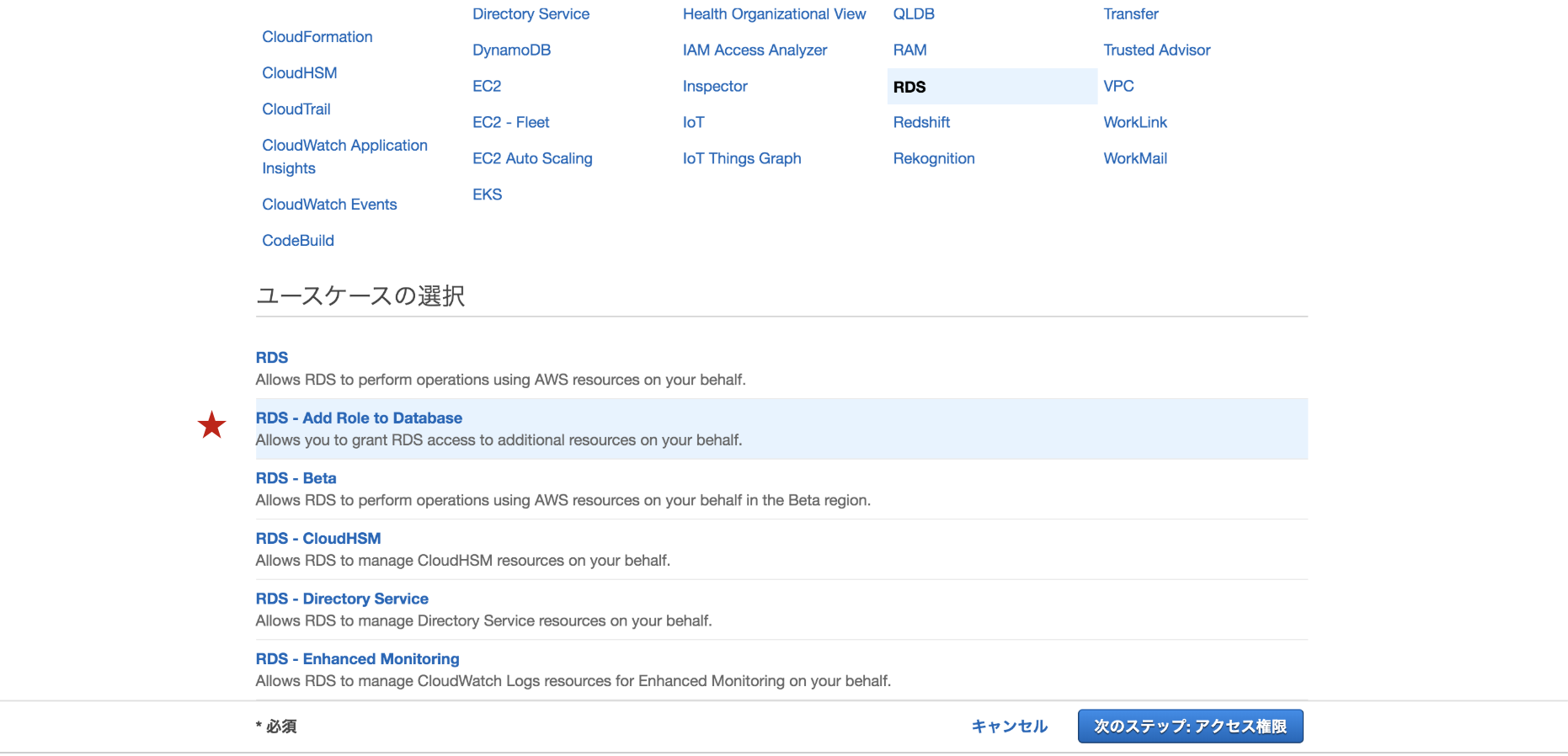
ユースケースは
RDS - Add Role to Databaseを選択します。
そして、必要なポリシーをアタッチします。
Secrets Managerへのアクセス権限のポリシー
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": [ "secretsmanager:GetResourcePolicy", "secretsmanager:GetSecretValue", "secretsmanager:DescribeSecret", "secretsmanager:ListSecretVersionIds" ], "Resource": "[シークレットARN]" } ] }拡張ログを取得したい場合はCloud Watch Logsへのアクセス権限も必要です。ただ、以下のログに関しては、Cloud Watch Logsへのアクセス権限がなくてもロググループに出力されます。
- RDS Proxyの起動終了
- DBへの接続開始終了
- 警告
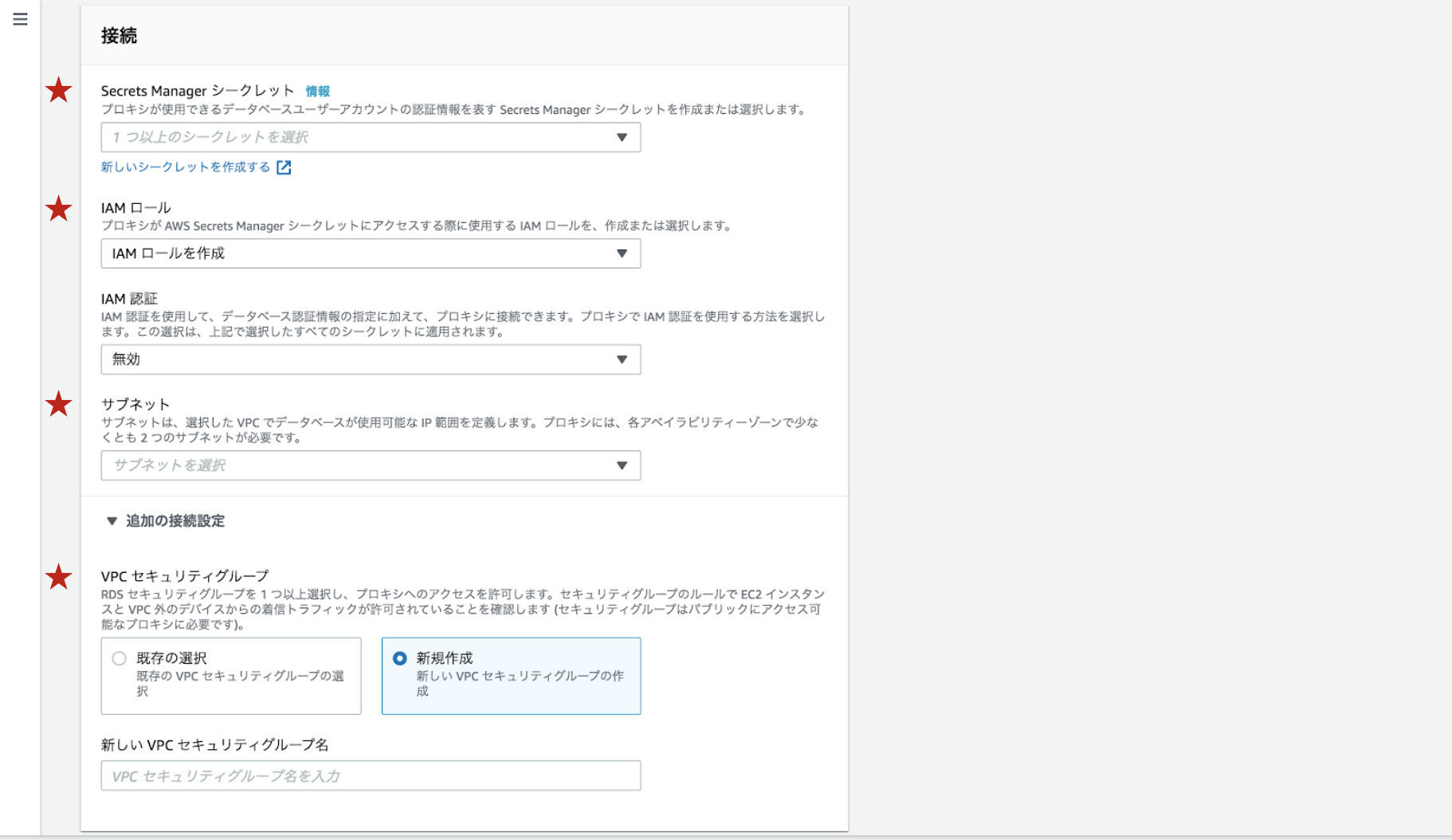
RDS Proxyの作成
今回はRDS Proxyのコンソールから作成します。
ちなみに、Lambda関数のコンソール上からも作成でき、IAM認証で接続する場合はLambdaと紐付ける手間を省くことができます。ただ、今回のようにDBのユーザ名とパスワードを用いて接続する場合は紐付けは必要ないようなので、RDS Proxyのコンソールから作成しました。
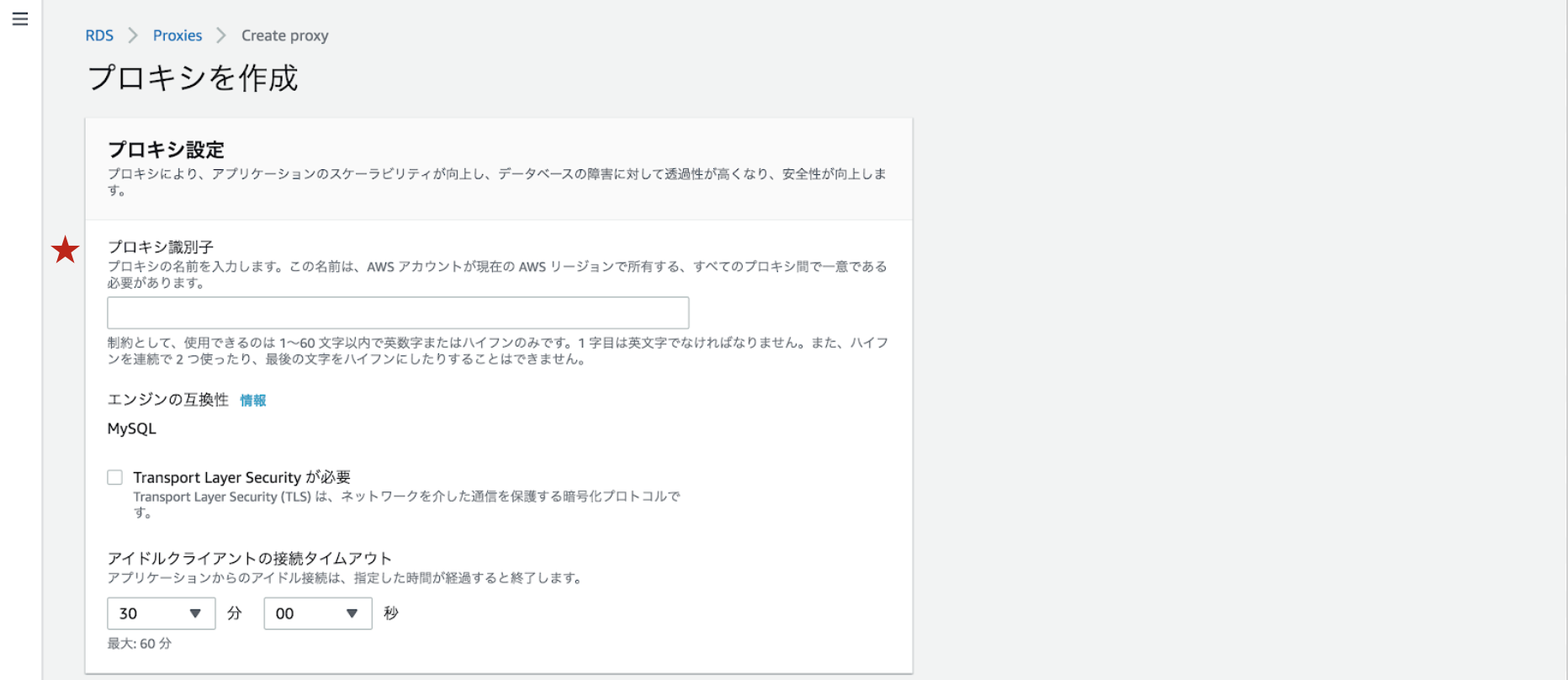
プロキシ識別子を入力します。
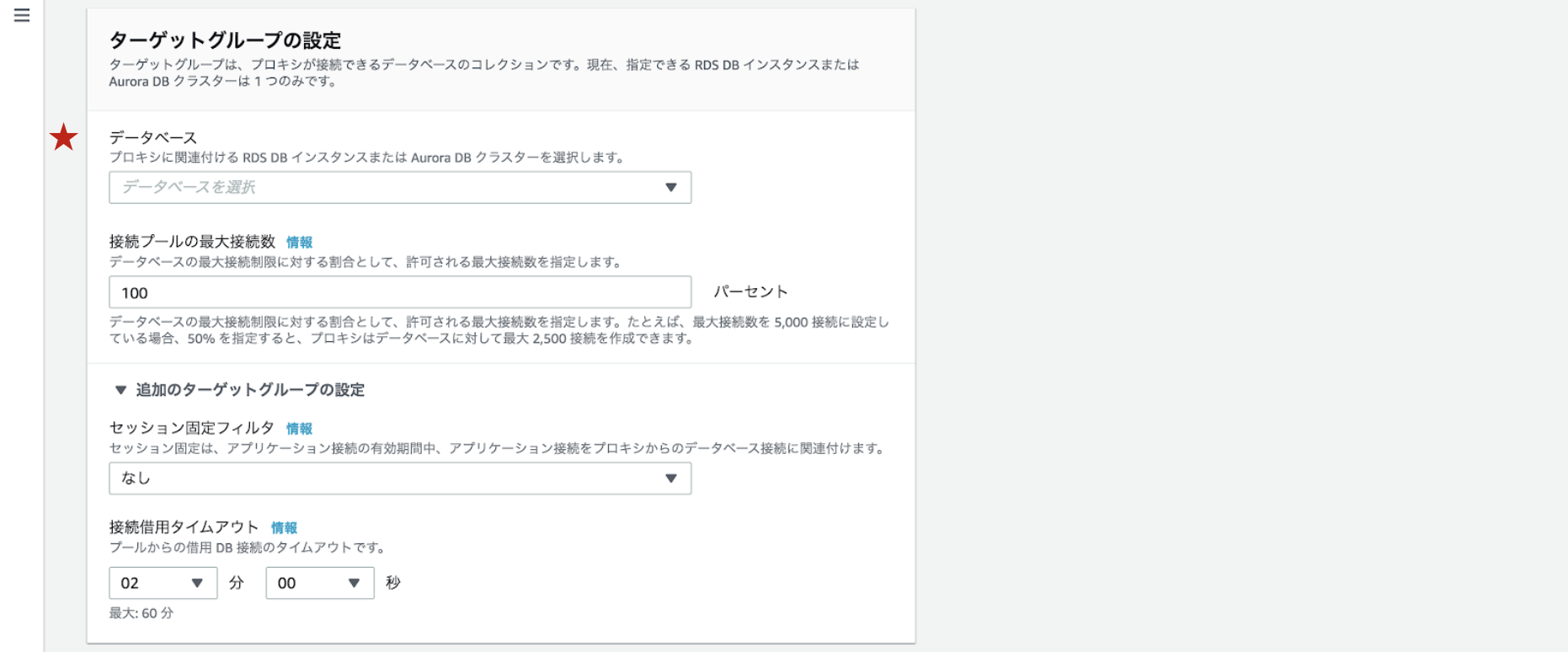
先ほど作成したRDSを選択します。
先ほど作成したSecrets ManagerシークレットとIAMロールを選択します。
サブネットはRDSと同じプライベートサブネットを選択します。
セキュリティグループは2で作成したsg-rdsproxyを選択してください。
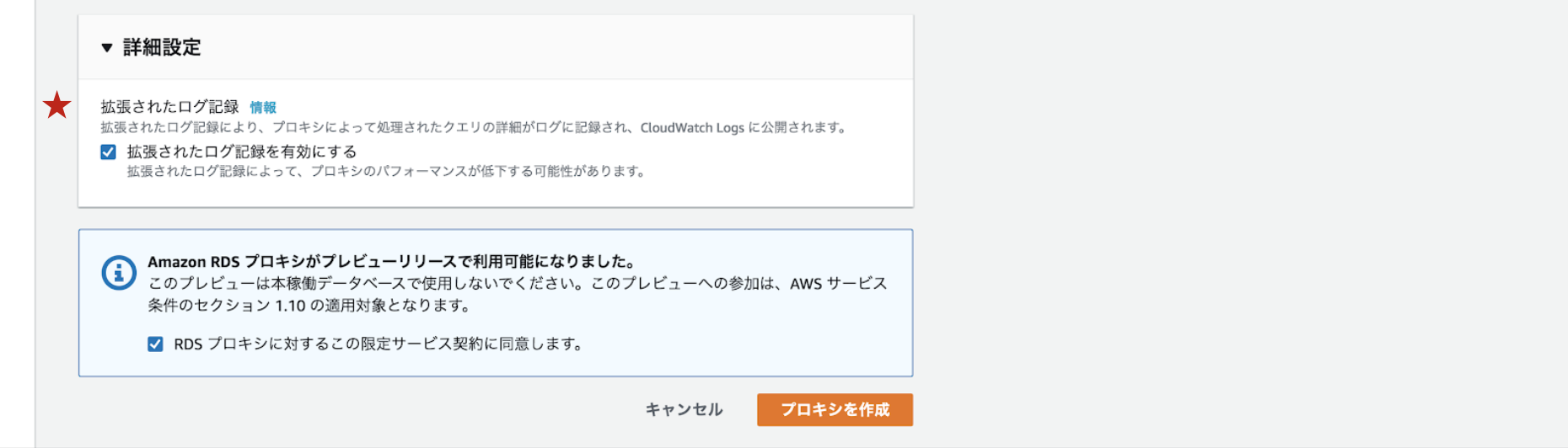
Cloud Watch Logsでデバッグログを取得したい場合は拡張されたログ記録を有効にするにチェックを入れてください。(Cloud Watch Logsへのアクセス権限も必要です。)
8. Lambda関数の作成
IAMロール
LambdaはVPC内にあるのでENI生成用のポリシーを作成してアタッチします。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": [ "ec2:DescribeNetworkInterfaces", "ec2:DeleteNetworkInterface", "ec2:CreateNetworkInterface" ], "Resource": "*" } ] }ログを取得したい場合はCloud Watch Logsへのアクセス権限も必要です。
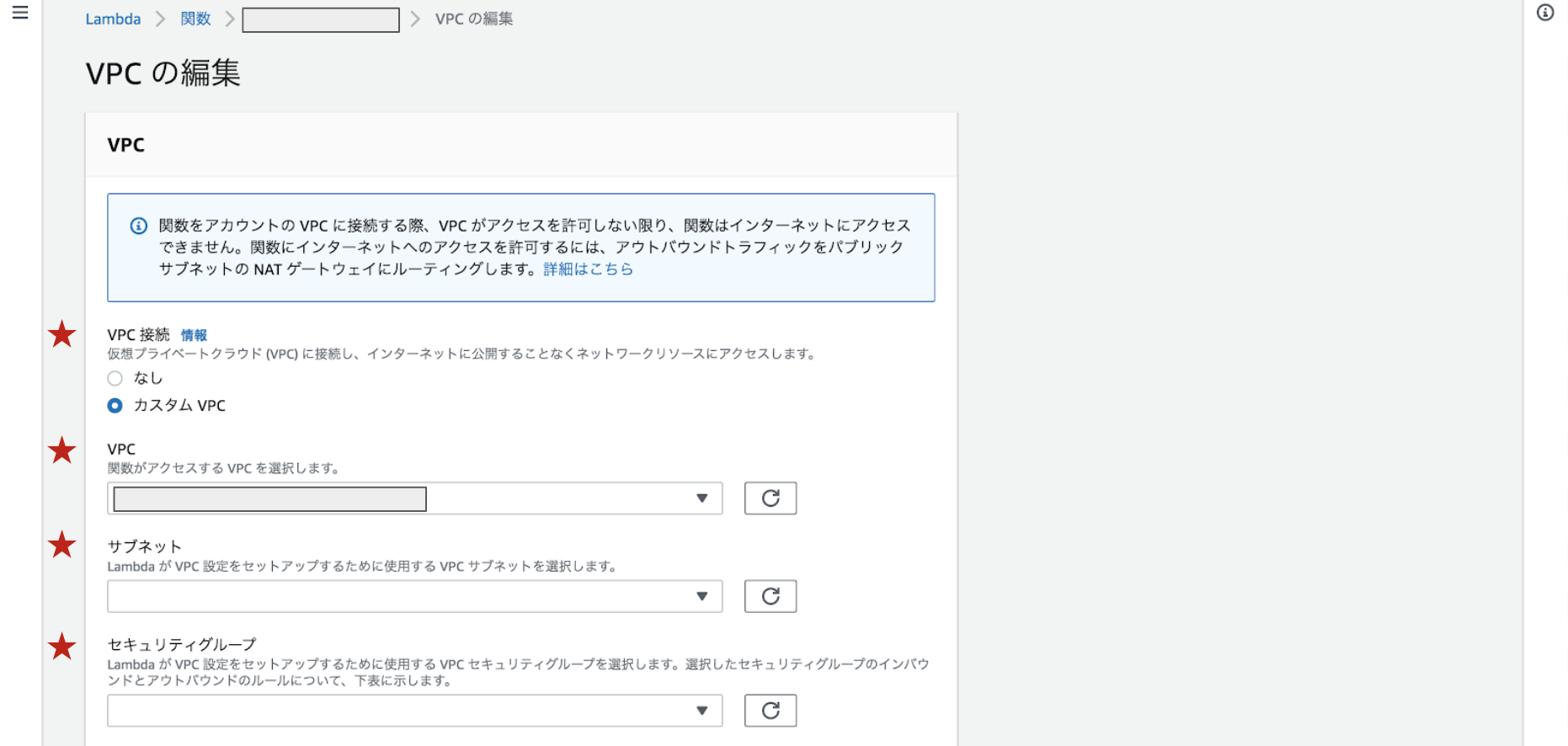
VPC
Lambda関数の編集画面で設定できます。
カスタムVPCを選択し、RDSとRDS Proxyと同様のVPCとパブリックサブネットを選択します。
セキュリティグループは2で作成したsg-lambdaを選択してください。ソースコード
package main import ( "database/sql" "encoding/json" "fmt" "github.com/aws/aws-lambda-go/lambda" _ "github.com/go-sql-driver/mysql" "os" ) type Response struct { ID int `json:"id"` Name string `json:"name"` Champion string `json:"champion"` Formed string `json:"formed"` Note sql.NullString `json:"note"` } // os.Getenv()でLambdaの環境変数を取得 var dbUser = os.Getenv("dbUser") // DBに作成したユーザ名 var dbPass = os.Getenv("dbPass") // パスワード var dbEndpoint = os.Getenv("dbEndpoint") // RDS Proxyのプロキシエンドポイント var dbName = os.Getenv("dbName") // テーブルを作ったDB名 func RDSConnect() (*sql.DB, error) { connectStr := fmt.Sprintf( "%s:%s@tcp(%s:%s)/%s?charset=%s", dbUser, dbPass, dbEndpoint, "3306", dbName, "utf8", ) db, err := sql.Open("mysql", connectStr) if err != nil { panic(err.Error()) } return db, nil } func RDSProcessing(db *sql.DB) (interface{}, error) { var id int var name string var champion string var formed string var note sql.NullString responses := []Response{} responseMap := Response{} getData, err := db.Query("SELECT * FROM m1_champion") defer getData.Close() if err != nil { return nil, err } for getData.Next() { if err := getData.Scan(&id, &name, &champion, &formed, ¬e); err != nil { return nil, err } fmt.Println(id, name, champion, formed, note) responseMap.ID = id responseMap.Name = name responseMap.Champion = champion responseMap.Formed = formed responseMap.Note = note responses = append(responses, responseMap) } params, _ := json.Marshal(responses) fmt.Println(string(params)) defer db.Close() return string(params), nil } func run() (interface{}, error) { fmt.Println("RDS接続 start!") db, err := RDSConnect() if err != nil { panic(err.Error()) } fmt.Println("RDS接続 end!") fmt.Println("RDS処理 start!") response, err := RDSProcessing(db) if err != nil { panic(err.Error()) } fmt.Println("RDS処理 end!") return response, nil } /************************** メイン **************************/ func main() { lambda.Start(run) }実行結果
上記の手順でRDS Proxyを用いての接続は完了です。(あれ意外と簡単)
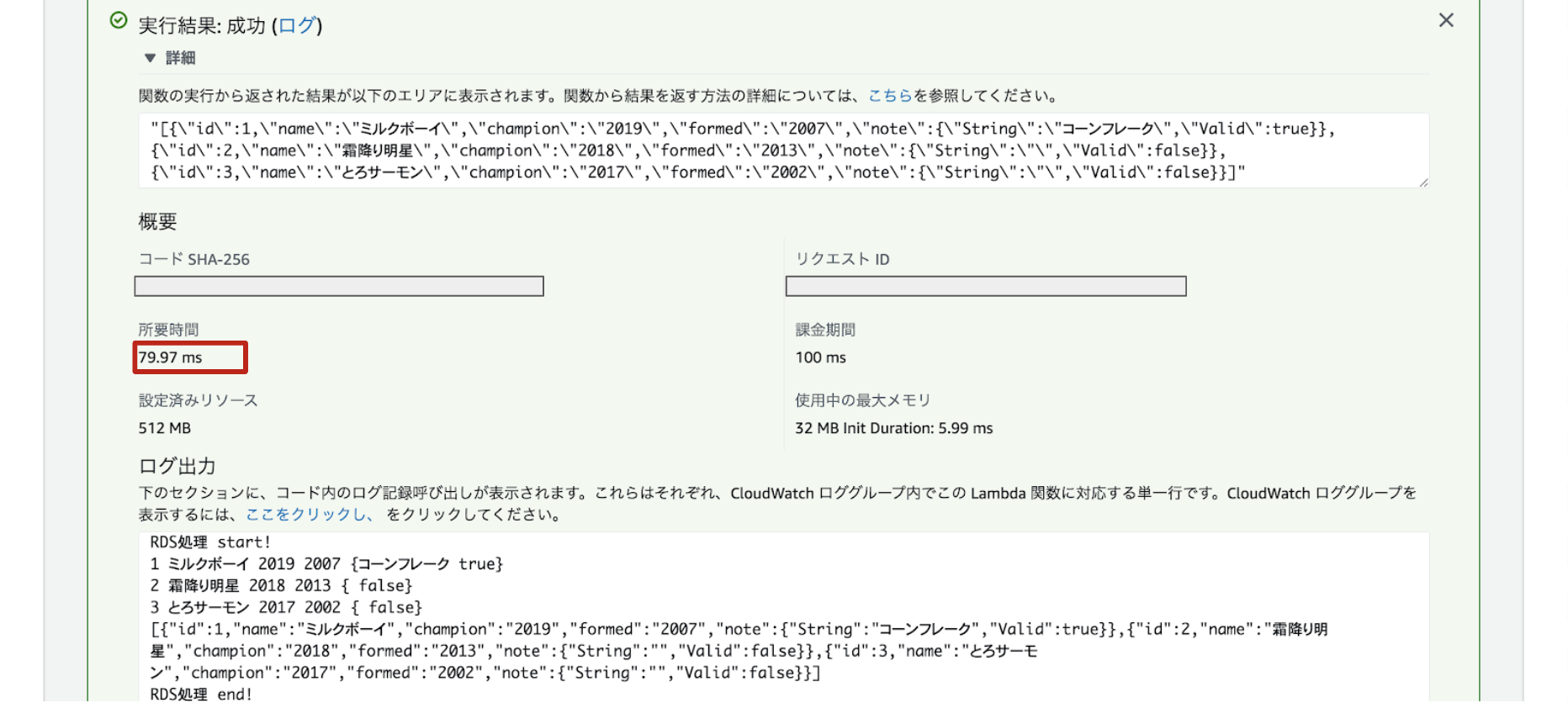
Lambdaでの実行結果がこちらです。
RDSから値が取得できました!
びっくりするのは応答時間!!!ご法度とされていたVPCLambdaですが、こんなにはやくなっているんです。これは使わない手はない!
おわりに
無事、LambdaからRDS Proxyを介してRDSに接続が可能になりました!これで同時接続数問題も気にしなくていい!!また、VPC内にLambdaを設置したときのコールドスタートが改善されたので、Lambdaを非VPCに設置しなくてもいけるし、RDSがプライベートサブネットに置ける!!素晴らしい!ただ、プレビュー版なのでお気をつけください。
次回こそはAPI Gatewayをたたいて、データをブラウザに表示します!

- 投稿日:2020-03-26T16:41:27+09:00
【AWSトラブルシューティング】ネットワークの接続制御をしている部分を確認してみよう。
はじめに
皆さん、業務でAWSは使われているでしょうか。
昨今、様々なサービスや機能がAWSを基盤として構築されていますよね。
今回は皆さんに、AWS上に構築されたサービスにいきなりアクセスできなかったときに、何を確認すべきかということをざっくりと伝えていければと思います。例えば、URLをブラウザから入力すると画面が立ち上がり様々な情報を参照できるWEBサービスなどを公開していると仮定してください。
あなたはSREとして配属されてきたばかりの初心者AWSerです。
ある朝、早起きして会社に来るとSlackで以下のような連絡を受けました。コンサル「いまお客様先でデモンストレーションをしようとWEBサービスにアクセスしたところ、403エラーになって接続できません!社内ネットワークからは接続できますし、社内ネットワーク内の別のサービスにもアクセスできます...先週はアクセス出来たのに...急いで解決してください!URLとAWSアカウントはこれです!」
URL
- https://example.eduAWSアカウント
- 123456789012事象
- URLにアクセスしたら403エラーが表示される前提
AWSアカウントの所持は当然として、windows10にwslをインストールした状態を想定しています。
digというコマンドを使います。調査の流れ
エラーの内容から推測
403 Forbiddenエラーは、ユーザーがURLにアクセスしたときにHTTPサーバーからユーザーに送信されるHTTPステータスコードです。
この結果から、ある程度何が問題なのか絞り込むことができます。
ここで帰ってくるエラー内容によってアクションも変わってきますので、必ず確認してください。403は指定したページへの閲覧禁止を意味します。
このことから、ページにアクセスるまでの経路のどこかで、「社外ネットワークからページへのアクセスを拒否する」ようになっていることが予測できます。リージョンとelbを確認
アカウントはわかりましたが、対象の環境のインスタンスがどこにあるか、そもそもどこからアクセスを受け付けているのかもわかりません。
そこで、URLからドメインを取り出して、そこからdigを叩いてみましょう。
※こちらはテスト用のドメインのため、実際の結果は異なります。dig example.edu;; ANSWER SECTION: example.edu. 3600 IN CNAME example.edu-123456789.ap-northeast-1.elb.amazonaws.com. example.edu-123456789.ap-northeast-1.elb.amazonaws.com. 60 IN A 1.111.11.111 example.edu-123456789.ap-northeast-1.elb.amazonaws.com. 60 IN A 11.111.111.111digはドメインからサーバーやらIPやらといった内部情報を引き出すことができるコマンドです。
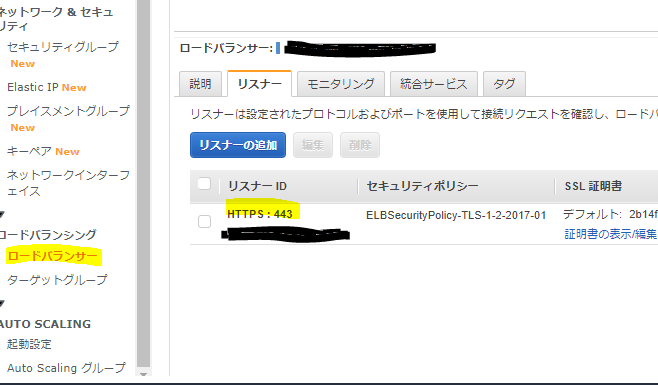
AWSアカウントは123456789012と教えてもらえたので、上記の情報からap-northeast-1リージョンにあるロードバランサーexample.edu-123456789がアクセスを受け付けていることがわかりました。ロードバランサーのリスナー確認
リスナーは設定されたプロトコルおよびポートを使用して接続リクエストを確認し、ロードバランサーはリスナールールを使用してリクエストをターゲットにルーティングします。
以下のように管理コンソールから画面遷移しましょう。
AWS管理コンソール>ap-northeast-1リージョン>EC2>ロードバランシンググ>ロードバランサーここで先ほどdigで検索したexample.edu-123456789.ap-northeast-1.elb.amazonaws.comというDNS名のリソースを探し、リスナータブを確認してみましょう。
ここでは画像のように、HTTPSによる接続を受け付けていることがわかります。
このことから、アクセスにコンサルが使用していた「ttps://example.edu」のプロトコル部分も、ドメイン名の部分も問題ないことがわかりました。
また、TLSセキュリティポリシーがELBSecurityPolicy-TLS-1-2-2017-01なので、いくつかのプロトコルは下記の通り受け付けていないことがわかります。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/classic/elb-security-policy-table.html
もしもコンサルが使用しているブラウザがProtocol-TLSv1やProtocol-TLSv1.1をつかってアクセスしようとしていたなら、接続ができなくなる危険性はありそうですね。
その場合はコンサルのブラウザの設定を確認してもらえばよいでしょう。
今回はこれではなかったとします。
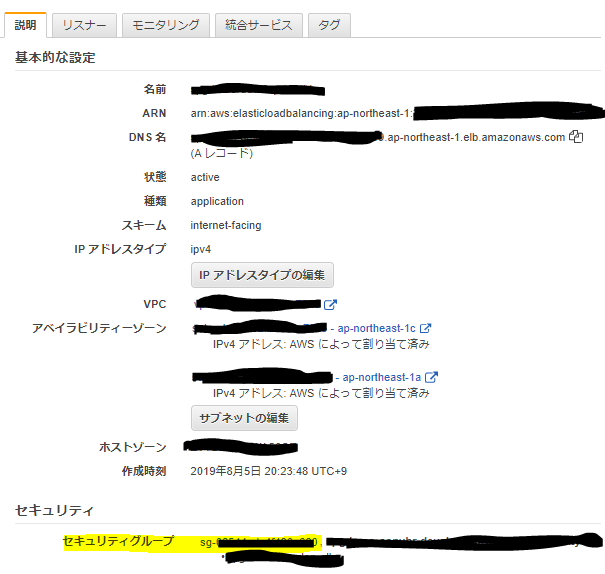
ロードバランサーのセキュリティグループを確認
セキュリティグループは、対象リソースに対してアクセスできる権限を、IPやセキュリティグループを持っているリソースという単位で絞り込むことができます。
今度はロードバランサーにアタッチされているセキュリティグループを確認してみましょう。
説明タグからセキュリティグループを確認します。
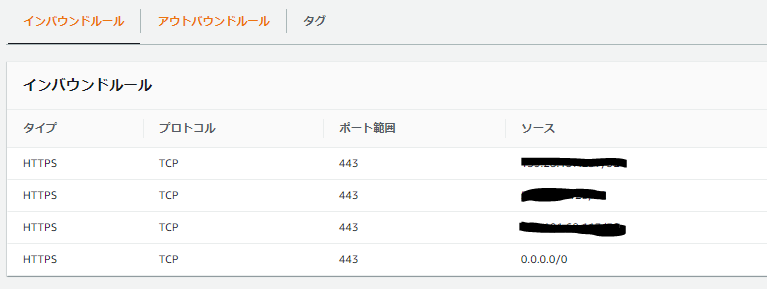
インバウンドは通信を受け付ける設定、アウトバウンドは無効から見てアクセスできる場所の設定です。
HTTPSでは0.0.0.0/0、つまりすべてのIPアドレスへの接続が許可されていることがわかりました。
セキュリティグループの設定でも、ドメインでも、接続プロトコルでも問題が無さそうです。
なお、セキュリティグループはEC2インスタンスにも紐づけられるので、インスタンスのセキュリティグループも確認すると良いでしょう。
このとき、elbを使用している場合はだいたいセキュリティグループのIDが登録されているケースが多いです。
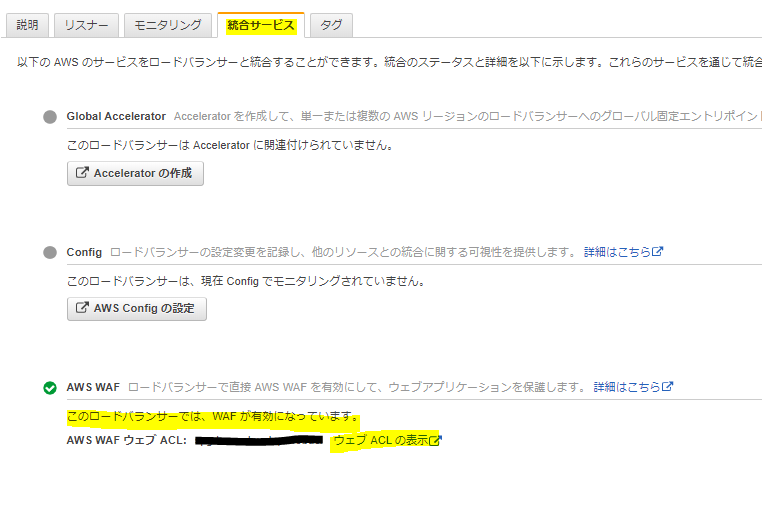
これは、そのセキュリティグループがアタッチされているリソースからのアクセスを受け付けるという意味になります。ロードバランサーのWAFを確認
WAFはこれまたアプリケーションへのアクセスを制御できる機構です。
もう一度ロードバランサーに戻って、今度は統合サービスタグを確認してみましょう。
どうやらAWS WAFが有効になっているようです。
WAFでも接続可能なIPアドレスなどを絞り込むことができるので、確認してみましょう。
WAFはクラシックかそうでないかでリソース事分かれているので両方確認してください。
今回はクラシックでしたのでハイライトしているボタンで画面を切り替えます。
以下のように画面を移動してください。
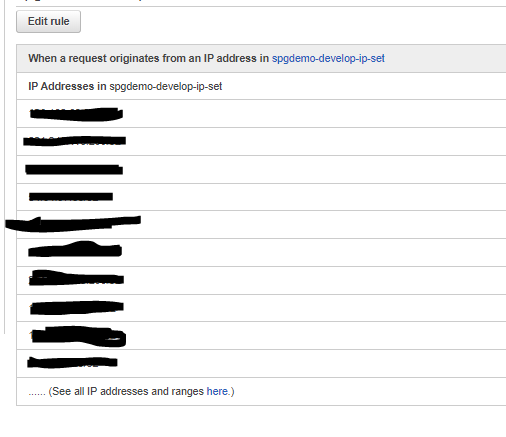
Web ACLs>使用しているACLを選択>Rulesタグ>使用しているルールを選択
どうやらここでアクセス可能なIPアドレスを個別に管理しているようでした。
コンサルが使用しているパブリックIPアドレスがここで登録されていなければ、接続ができなくなる危険性はありそうですね。
私が実際にこの問題を対応したときはここが原因でした。
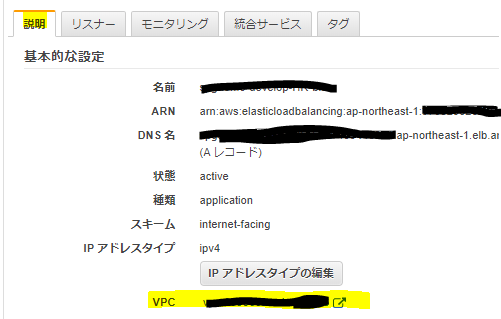
これ以外にも見れる場所はあるので、そちらも紹介しておきます。ロードバランサーの存在するVPCを確認
VPCは、リソースが存在している大きなネットワークの箱です。
こちらにも、VPC単位で接続を制御できるようになっており、ここで無効になっていればVPC内のすべてのリソースにアクセスできなくなります。
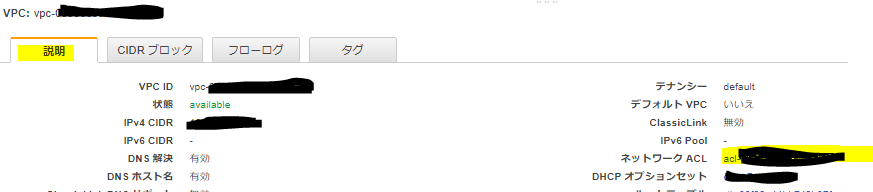
VPCのアクセスコントロールリストを確認してみましょう。
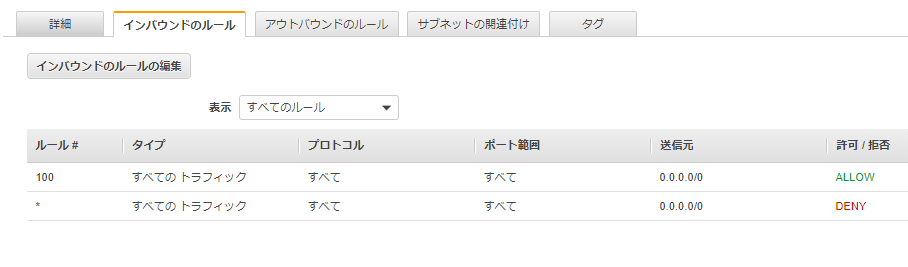
こちらはVPCのデフォルトの設定です。
こちらもインバウンドが受け付ける通信で、アウトバウンドが外に出ていく通信です。
ルールというのはただの識別番号で、はすべてのルールに当てはまらない場合に適用される内容です。
デフォルトではルール100によってすべてのIPからの接続を受け付けているため、が適用されるタイミングが無く、すべての接続を受け付ける状態となっています。
ここでIPの制御をしていた場合は、アクセスできなくなる危険性があります。
おわりに
ここまでざっくりと汎用的に使われるアクセス制御部分の確認手順をさらってきました。
今回は私が実際に対応したケースに従って紹介してきましたが、本当にそのタイミングでは頼れる人がおらず、知識もなく、自分で探してまとめて行くのが大変でした。
AWSはいろんな段階でそれぞれアクセス制御をかけることができるので、それぞれのリソースが複雑に絡み合い把握がとても大変です。
自分で運用する場合は、その環境に適した確認手順を作っておくと良いでしょう。私もAWS初心者(クラウドプラクティショナー程度)であるため、ご指摘・ご質問・ご感想はどのようなものでもありがたくいただく所存です。
特に「ここも確認したほうが良い」といった内容はぜひお伺いしたく存じます。
何かございましたら、ぜひコメントを頂ければと存じます。以上、お疲れ様でした。
- 投稿日:2020-03-26T16:14:53+09:00
boto3でaws cliを扱うための初期設定から稼働確認まで
はじめに
boto3とは aws のリソースを python で扱うためのライブラリである。
本記事は、boto3でaws cliを扱い、AWSのec2と接続するまでの一連の流れ(初期設定)を記す。boto3のインストール
boto3をpipでインストールする。
$ pip install boto3aws cliのインストール
boto3を使用するためにaws cliをインストールする。
Macの場合
aws cliをhomebrewでインストール
$ brew install awscliWindowsの場合
AWSの公式サイトからインストーラーをダウンロードし、インストーラーを実行する。
インストール確認
awsコマンドが使用できることを確認する。
$ aws --version aws-cli/2.0.5 Python/3.7.5 Windows/10 botocore/2.0.0dev9IAMユーザーの作成
IAMユーザを作成し、EC2 full access の権限を与える。ただし、後に権限を絞る必要がある。
作成方法
AWSアカウントでのIAMユーザの作成を参考に、IAMユーザーを作成する。
アクセスキーの作成
アクセスキーを作成し、大切に保存する。
作成方法
こちらにアクセスし、
1.”セキュリティ認証情報に進む”を選択
2."アクセスキー(アクセスキーIDとシークレットアクセスキー)"を選択
3."新しいアクセスキーの作成" を選択ここでアクセスキーが作成される。この時[.csvのダウンロード]を押下し、アクセスキーの情報を保存しておく。
※ここを逃すとアクセスキーの情報を取得できなくなるため、注意!
誤ってアクセスキーの情報を保存し忘れた場合、一度アクセスキーを削除し、再度アクセスキーを作成する。PCにaws cliの初期設定を行う
$ aws configure AWS Access Key ID [None]: AKI************ AWS Secret Access Key [None]: *************** Default region name [None]: ap-northeast-1 Default output format [None]: json
aws configureコマンドを入力し、上記のように先ほど取得したアクセスキー、リージョン、フォーマットを入力する。ここまでできれば準備は完了!
boto3が正しく動くか確認する
1.AWSコンソール上で任意のインスタンスを起動する。
2.ターミナルで以下のコマンドを実行し、起動中のインスタンスが取得できれば正常にboto3が動いている。$ python Python 3.8.2 (tags/v3.8.2:7b3ab59, Feb 25 2020, 23:03:10) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> >>> import boto3 >>> ec2=boto3.resource('ec2') >>> >>> instances = ec2.instances.filter( ... Filters=[{'Name': 'instance-state-name', 'Values': ['running']}]) >>> >>> for instance in instances: ... print(instance.id, instance.instance_type) ... i-xxxxxxxxxxxxxxxxx t2.micro無事インスタンスの情報が取得できたため、boto3は正常に稼働していることが確認できた。
よくあるエラー
botocore.exceptions.ClientError: An error occurred (AuthFailure) when calling the DescribeInstances operation: AWS was not able to validate the provided access credentials私は、このエラーに悩まされた。
原因はアクセスキーがうまく設定できていなかったから。
しかし、OS内の時間がずれている場合も接続できないらしい。。念のためインスタンスにSSH接続し、サーバーのタイムゾーンを日本時間に変更した後、ローカルPCの時間も正しい日本時間となっていることを確認した。
タイムゾーンの変更はこちらの記事を参考にした。
おわりに
最後までご覧いただきありがとうございます。
最近pythonを使用したAWS管理ツールを作成することになり、初めてboto3を触ることになりました。
私自身、boto3の導入で少しつまずいてしまったため、同じようなエラーに悩まされている方の一助になればと思い、本記事を執筆しました。ご指摘・ご質問等ございましたらお気軽に@hiyoku0918へご連絡ください!
参考
@kimihiro_nさん
・Python boto3 でAWSを自在に操ろう ~入門編~@n0bisukeさん
・AWS CLIのインストールから初期設定メモ@kzykmyzwさん
・AWSアカウントでのIAMユーザの作成上記の記事を参考にさせていただきました。
ありがとうございました。
- 投稿日:2020-03-26T15:16:22+09:00
AWS内の環境構築(AWSの設定とEC2インスタンスの生成)
AWSのアカウントを登録
まずはAWSのサイトでアカウントを登録してください。
順番としてはサインアップボタンを押し、AWSアカウント情報を登録してください。
AWSアカウント情報を登録したら次にサポートプランを選択するのですが、最初は無料のベーシックプランでいいと思います。
これでアカウントが作成されました。数分後に、登録したメールアドレスに確認メールがきます。
AWSコンソールにサインインすると、アカウント情報を登録する最初の画面に戻ってきます。今回は、先ほど登録したメールアドレスとパスワードを入力して、サインインします。AWSアカウントのリージョン設定
リージョンとは、AWSの物理的なサーバの場所を指定するものです。
リージョン間でEC2の設定は独立していて、あるリージョンのEC2を他のリージョンへ移動することはできません。なので、EC2を立ち上げる際には、「どのリージョンの設定か」を意識しておきます。
リージョンはアジアパシフィック(東京)を選びます。EC2インスタンスの作成
「サーバーを生成する」といっても、AWSが全てのサーバを物理的に用意しているわけではなく、実際には「仮想マシン」と呼ばれるソフトウェアを利用して、仮想的に一つのLinuxサーバを利用できる仕組みを利用します。この「仮想マシン」のことをAWSでは「EC2インスタンス」と呼んでいます。
ちなみにEC2インスタンス作成の作業が2回目以降は、費用が発生する場合があります。
こちらでAWSアカウントにログインし、トップページに遷移したら、左上の「サービス」から「EC2」を選択します。
操作画面を旧バージョンに切り替えるときは、左上のスイッチのアイコンをクリックします。今回は旧バージョンで作業します。
次に、アンケート用のダイアログが開くのでキャンセルします。
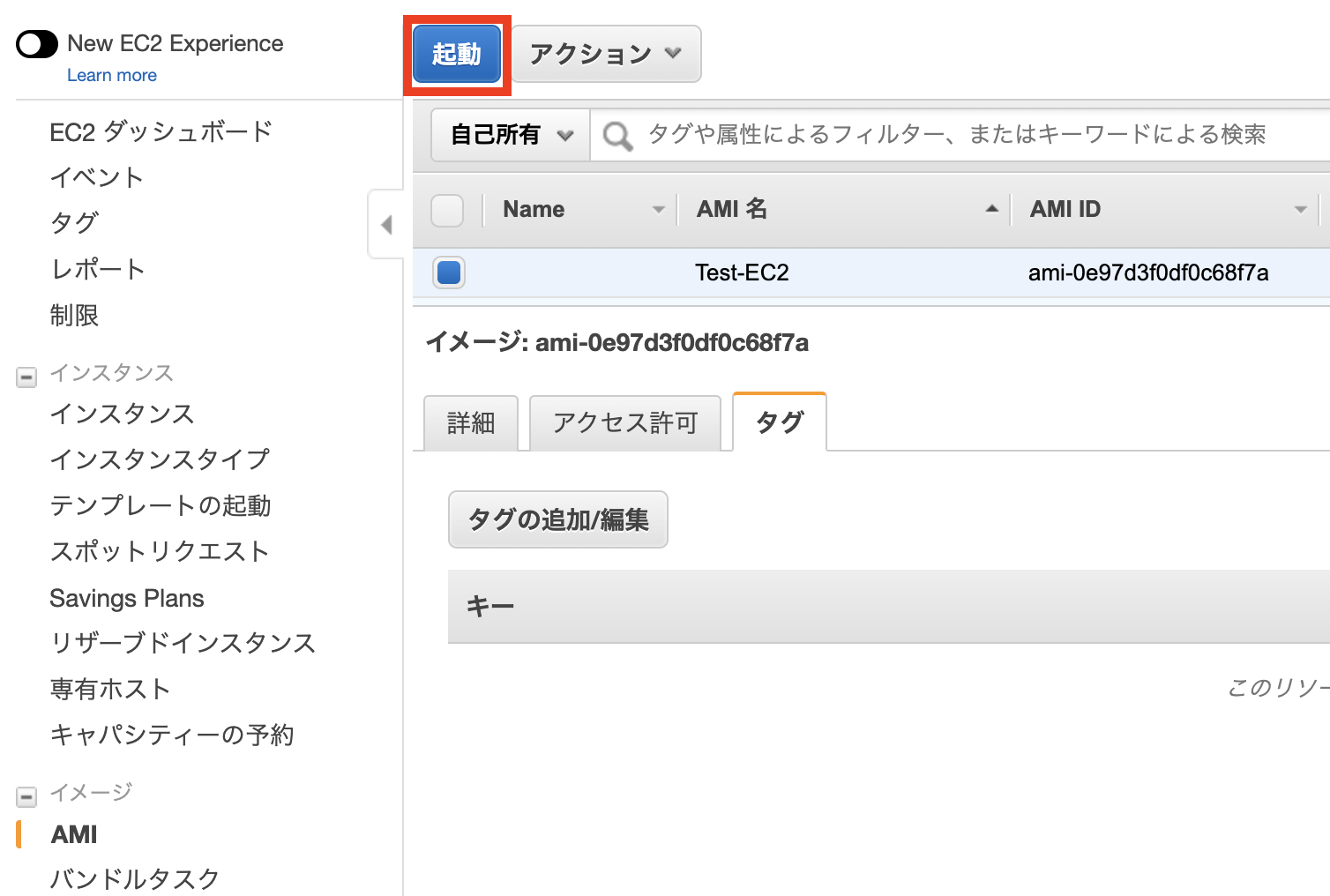
次に、「インスタンスの作成」をクリックしてください。
左上にAMIの選択が出てるか確認したら、今回はAmazon Linux AMIを選んでいきます。
ちなみにAMIとは、サーバのデータをまるごと保存したデータのことです。この中には、OSやWEBサーバなどが事前にインストールされているものもあり、自分でゼロからインストールする手間を削減することができます。
次に、EC2インスタンスのタイプを選択します。EC2ではさまざまなインスタンスタイプが用意されており、CPUやメモリなどのスペックを柔軟に指定することができます。
今回は、無料枠で利用できるt2.microを選択します。
次に、起動をクリックします。
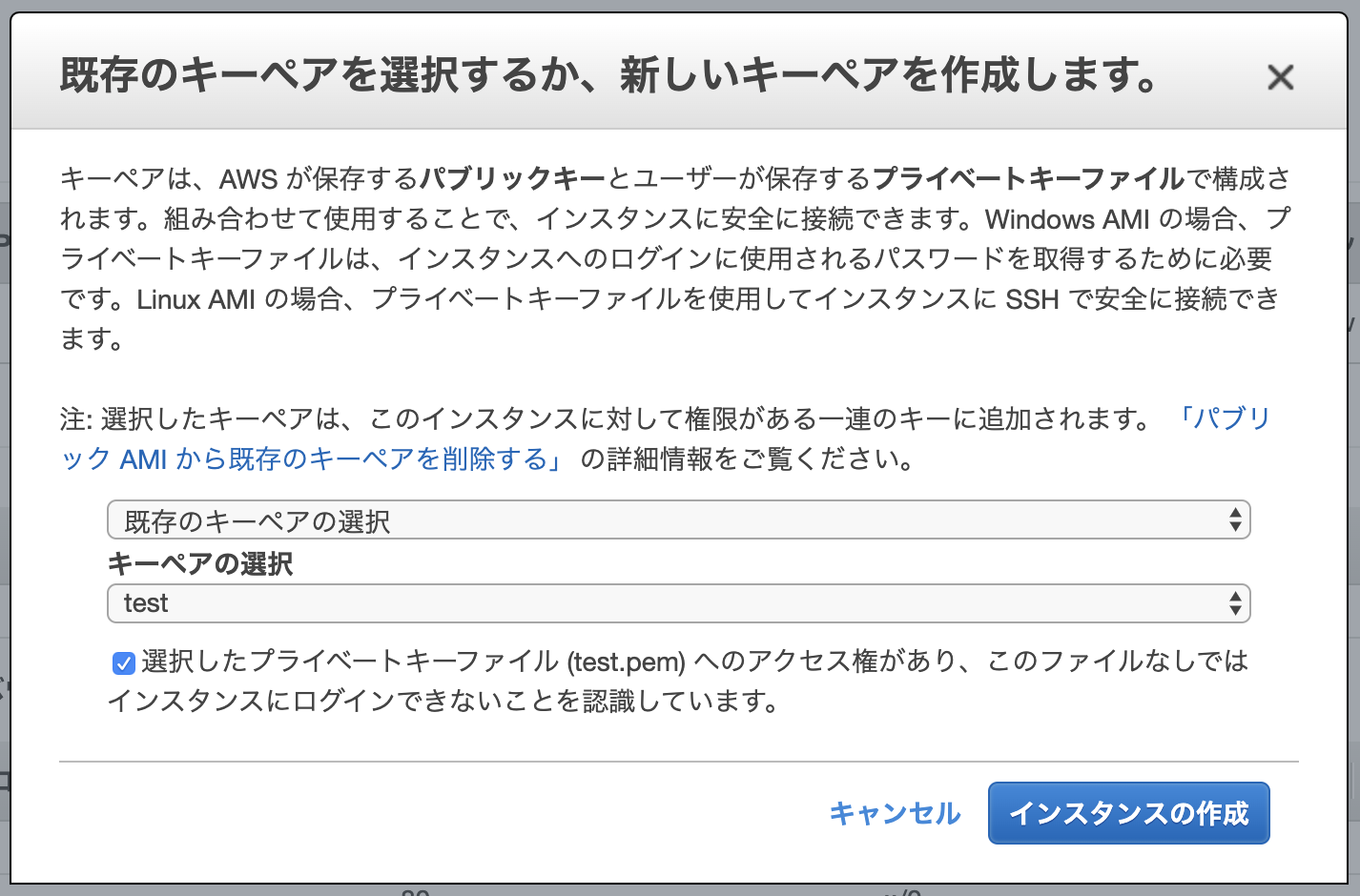
次に、キーペアのダウンロードをします。
内容を確認する際に、「キーペア」をダウンロードすることが出来ます。こちらはインスタンスにSSHでログインする際に必要となる「秘密鍵」です。これがないとEC2インスタンスにログインできないので、必ずダウンロードしてパソコンに保存しておきます。また、間違って他人に渡さないよう気をつけましょう。
キーペアの名前はご自身で決めて大丈夫です。
ちなみにキーペアの名前にスペースが含まれているとこの後の作業でエラーが発生する可能性があります。スペースを含まない名前の秘密鍵を作成するようにしましょう。
次は、インスタンスの作成をします。
キーペアのダウンロードが完了すると、クリック出来ない状態になっていたインスタンスの作成が、クリックできるように変更されます。そちらをクリックして、EC2インスタンスを作成します。
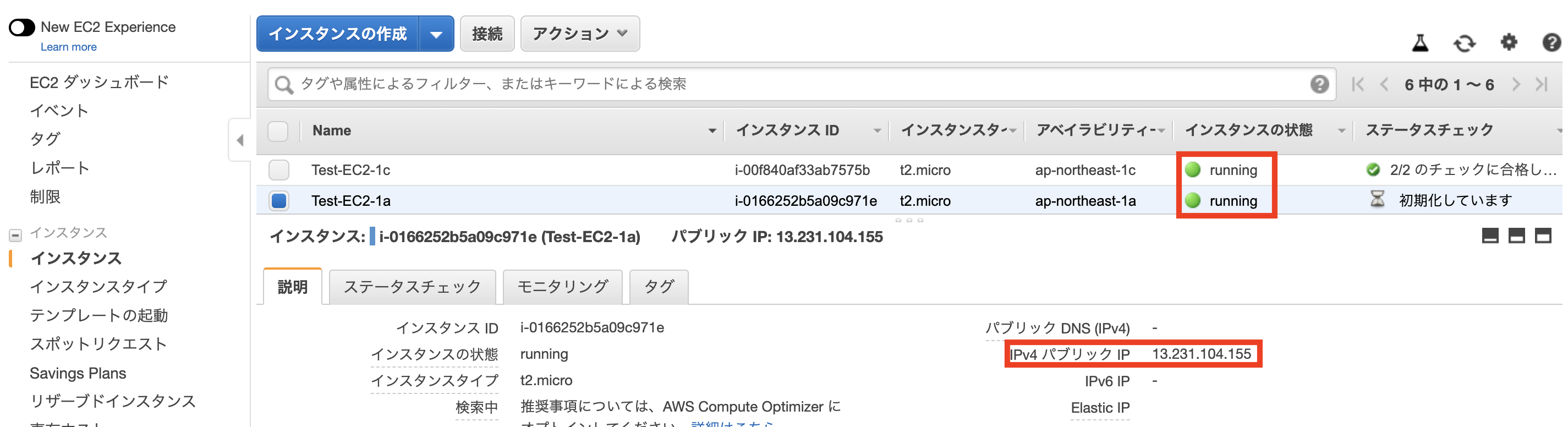
その後、インスタンス一覧画面に戻り、作成したインスタンスIDをコピーしてメモしておきましょう。Elastic IPの作成と紐付け
先ほど作成したEC2インスタンスには、作成時にIPアドレスが自動で割り振られています。これをパブリックIPと言います。しかし、サーバーを再起動させるたびにこのパブリックIPが変わってしまうという欠点を持っています。IPが変わってしまうということは、設定ファイル等をその都度書き換えなければいけません。これを解決してくれるのが、Elastic IPです。
Elastic IPとはAWSから割り振られた固定のパブリックIPアドレスのことを言います。このパブリックIPアドレスをEC2インスタンスに紐付けることで、インスタンスの起動、停止に関わらず常に同じIPアドレスで通信をすることが可能になります。
Elastic IPをクリックして、新しいアドレスの割り当てをクリックします。
次に、Amazonプールを選択し、割り当てをクリックし、確認してから閉じるをクリックしてください。
次に、取得したElastic IPアドレスを、作成したEC2インスタンスと紐付けます。
アクションをクリックし、アドレスの関連付けをクリックします。
次に、プルダウンで先ほどメモしたインスタンスを選択し、関連付けをクリックします。プライベートIDは入力しません。
再びインスタンス一覧画面に戻り、作成したインスタンスの「パブリック IP」と「Elastic IP」が同じものに設定されていることを確認します。
以降、このIPアドレスはあなたの所有物のようになり、意図的にAWSに返却しない限り、変更されることはありません。ポートを開く
立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできますが、HTTPなどの他の接続は一切つながらないようになっています。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります。
ポートの設定をするためには、「セキュリティグループ」という設定を変更する必要があります。
セキュリティグループとは、EC2インスタンスが属するまとまりのようなもので、複数のEC2インスタンスのネットワーク設定を一括で行うためのものです。
次は、セキュリティグループのポートを設定します。
まず、EC2インスタンス一覧画面から、対象のインスタンスを選択し、セキュリティグループのリンクをクリックします。
次に、インスタンスの属するセキュリティグループの設定画面に移動するので、インバウンドタブの中の編集をクリックします。
次に、モーダルが開くので、ルールの追加をクリックします。
タイプをHTTP、プロトコルをTCP、ポート範囲を80、送信元をカスタム / 0.0.0.0/0, ::/0に設定し、保存をクリックします。「0.0.0.0」や「::/0」は「全てのアクセスを許可する」という意味です。
これで、ポートの開放が完了です。
この作業が終わっていないと、WEBサーバを起動した時にアクセスできなくなります。EC2インスタンスへのログイン
EC2インスタンスを作成すると、ec2-userというユーザーと対応するSSH秘密鍵が生成されました。本来はこのec2-userではなく、サービスを稼働させるためにより権限を小さくしたユーザーを作成して運用していきますが、ここでは簡易化のためにこのec2-userを使って作業を進めていきます。
ec2-userでログインします。
ターミナル(ローカル)$ cd ~ $ mkdir ~/.ssh # .sshというディレクトリを作成 # File existsとエラーが表示されたとしても、.sshディレクトリは存在しているということなので、そのまま進みましょう。 $ mv Downloads/ダウンロードした鍵の名前.pem .ssh/ # mvコマンドで、ダウンロードしたpemファイルを、ダウンロードディレクトリから、.sshディレクトリに移動します。 $ cd .ssh/ $ ls # pemファイルが存在するか確認しましょう $ chmod 600 ダウンロードした鍵の名前.pem $ ssh -i ダウンロードした鍵の名前.pem ec2-user@作成したEC2インスタンスと紐付けたElastic IP #(例えばElastic IPが123.456.789であれば、shh -i ダウンロードした鍵の名前.pem ec2-user@123.456.789 というコマンドになります) #(ダウンロードした鍵を用いて、ec2-userとしてログイン)ダウンロードした鍵の名前の部分は、直前にご自身がダウンロードした.pemというファイルの名前に置き換えてください。
pemキーが本当にDownloads以下に存在するかFinderで確認できます。
Elastic IPの確認はインスタンスをクリックし、Elastic IPの値をターミナルに入力します。
以下の様なメッセージが表示されることがありますが、「yes」と入力して下さい。
ターミナル(ローカル)$ ssh -i aws_key.pem ec2-user@52.68.~~~~~~ The authenticity of host '52.68.~~~~~~ (52.68.~~~~~~)' can't be established. RSA key fingerprint is eb:7a:bd:e6:aa:da:~~~~~~~~~~~~~~~~~~~~~~~~. Are you sure you want to continue connecting (yes/no)?ターミナルのコマンド待ちの際の左側の表示が
[ec2-user| ...
となればログイン成功です。
ちなみに、ssh接続は一定時間操作をせずにいると、タイムアウトしてしまいます。その場合は、同じコマンドを実行することで、サーバに接続できます。
- 投稿日:2020-03-26T15:16:22+09:00
AWS内の環境構築(AWSの設定とEC2インスタンスの生成と環境構築)
AWSのアカウントを登録
まずはAWSのサイトでアカウントを登録してください。
順番としてはサインアップボタンを押し、AWSアカウント情報を登録してください。
AWSアカウント情報を登録したら次にサポートプランを選択するのですが、最初は無料のベーシックプランでいいと思います。
これでアカウントが作成されました。数分後に、登録したメールアドレスに確認メールがきます。
AWSコンソールにサインインすると、アカウント情報を登録する最初の画面に戻ってきます。今回は、先ほど登録したメールアドレスとパスワードを入力して、サインインします。AWSアカウントのリージョン設定
リージョンとは、AWSの物理的なサーバの場所を指定するものです。
リージョン間でEC2の設定は独立していて、あるリージョンのEC2を他のリージョンへ移動することはできません。なので、EC2を立ち上げる際には、「どのリージョンの設定か」を意識しておきます。
リージョンはアジアパシフィック(東京)を選びます。EC2インスタンスの作成
「サーバーを生成する」といっても、AWSが全てのサーバを物理的に用意しているわけではなく、実際には「仮想マシン」と呼ばれるソフトウェアを利用して、仮想的に一つのLinuxサーバを利用できる仕組みを利用します。この「仮想マシン」のことをAWSでは「EC2インスタンス」と呼んでいます。
ちなみにEC2インスタンス作成の作業が2回目以降は、費用が発生する場合があります。
こちらでAWSアカウントにログインし、トップページに遷移したら、左上の「サービス」から「EC2」を選択します。
操作画面を旧バージョンに切り替えるときは、左上のスイッチのアイコンをクリックします。今回は旧バージョンで作業します。
次に、アンケート用のダイアログが開くのでキャンセルします。
次に、「インスタンスの作成」をクリックしてください。
左上にAMIの選択が出てるか確認したら、今回はAmazon Linux AMIを選んでいきます。
ちなみにAMIとは、サーバのデータをまるごと保存したデータのことです。この中には、OSやWEBサーバなどが事前にインストールされているものもあり、自分でゼロからインストールする手間を削減することができます。
次に、EC2インスタンスのタイプを選択します。EC2ではさまざまなインスタンスタイプが用意されており、CPUやメモリなどのスペックを柔軟に指定することができます。
今回は、無料枠で利用できるt2.microを選択します。
次に、起動をクリックします。
次に、キーペアのダウンロードをします。
内容を確認する際に、「キーペア」をダウンロードすることが出来ます。こちらはインスタンスにSSHでログインする際に必要となる「秘密鍵」です。これがないとEC2インスタンスにログインできないので、必ずダウンロードしてパソコンに保存しておきます。また、間違って他人に渡さないよう気をつけましょう。
キーペアの名前はご自身で決めて大丈夫です。
ちなみにキーペアの名前にスペースが含まれているとこの後の作業でエラーが発生する可能性があります。スペースを含まない名前の秘密鍵を作成するようにしましょう。
次は、インスタンスの作成をします。
キーペアのダウンロードが完了すると、クリック出来ない状態になっていたインスタンスの作成が、クリックできるように変更されます。そちらをクリックして、EC2インスタンスを作成します。
その後、インスタンス一覧画面に戻り、作成したインスタンスIDをコピーしてメモしておきましょう。Elastic IPの作成と紐付け
先ほど作成したEC2インスタンスには、作成時にIPアドレスが自動で割り振られています。これをパブリックIPと言います。しかし、サーバーを再起動させるたびにこのパブリックIPが変わってしまうという欠点を持っています。IPが変わってしまうということは、設定ファイル等をその都度書き換えなければいけません。これを解決してくれるのが、Elastic IPです。
Elastic IPとはAWSから割り振られた固定のパブリックIPアドレスのことを言います。このパブリックIPアドレスをEC2インスタンスに紐付けることで、インスタンスの起動、停止に関わらず常に同じIPアドレスで通信をすることが可能になります。
Elastic IPをクリックして、新しいアドレスの割り当てをクリックします。
次に、Amazonプールを選択し、割り当てをクリックし、確認してから閉じるをクリックしてください。
次に、取得したElastic IPアドレスを、作成したEC2インスタンスと紐付けます。
アクションをクリックし、アドレスの関連付けをクリックします。
次に、プルダウンで先ほどメモしたインスタンスを選択し、関連付けをクリックします。プライベートIDは入力しません。
再びインスタンス一覧画面に戻り、作成したインスタンスの「パブリック IP」と「Elastic IP」が同じものに設定されていることを確認します。
以降、このIPアドレスはあなたの所有物のようになり、意図的にAWSに返却しない限り、変更されることはありません。ポートを開く
立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできますが、HTTPなどの他の接続は一切つながらないようになっています。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります。
ポートの設定をするためには、「セキュリティグループ」という設定を変更する必要があります。
セキュリティグループとは、EC2インスタンスが属するまとまりのようなもので、複数のEC2インスタンスのネットワーク設定を一括で行うためのものです。
次は、セキュリティグループのポートを設定します。
まず、EC2インスタンス一覧画面から、対象のインスタンスを選択し、セキュリティグループのリンクをクリックします。
次に、インスタンスの属するセキュリティグループの設定画面に移動するので、インバウンドタブの中の編集をクリックします。
次に、モーダルが開くので、ルールの追加をクリックします。
タイプをHTTP、プロトコルをTCP、ポート範囲を80、送信元をカスタム / 0.0.0.0/0, ::/0に設定し、保存をクリックします。「0.0.0.0」や「::/0」は「全てのアクセスを許可する」という意味です。
これで、ポートの開放が完了です。
この作業が終わっていないと、WEBサーバを起動した時にアクセスできなくなります。EC2インスタンスへのログイン
EC2インスタンスを作成すると、ec2-userというユーザーと対応するSSH秘密鍵が生成されました。本来はこのec2-userではなく、サービスを稼働させるためにより権限を小さくしたユーザーを作成して運用していきますが、ここでは簡易化のためにこのec2-userを使って作業を進めていきます。
ec2-userでログインします。
ターミナル(ローカル)$ cd ~ $ mkdir ~/.ssh # .sshというディレクトリを作成 # File existsとエラーが表示されたとしても、.sshディレクトリは存在しているということなので、そのまま進みましょう。 $ mv Downloads/ダウンロードした鍵の名前.pem .ssh/ # mvコマンドで、ダウンロードしたpemファイルを、ダウンロードディレクトリから、.sshディレクトリに移動します。 $ cd .ssh/ $ ls # pemファイルが存在するか確認しましょう $ chmod 600 ダウンロードした鍵の名前.pem $ ssh -i ダウンロードした鍵の名前.pem ec2-user@作成したEC2インスタンスと紐付けたElastic IP #(例えばElastic IPが123.456.789であれば、shh -i ダウンロードした鍵の名前.pem ec2-user@123.456.789 というコマンドになります) #(ダウンロードした鍵を用いて、ec2-userとしてログイン)ダウンロードした鍵の名前の部分は、直前にご自身がダウンロードした.pemというファイルの名前に置き換えてください。
pemキーが本当にDownloads以下に存在するかFinderで確認できます。
Elastic IPの確認はインスタンスをクリックし、Elastic IPの値をターミナルに入力します。
以下の様なメッセージが表示されることがありますが、「yes」と入力して下さい。
ターミナル(ローカル)$ ssh -i aws_key.pem ec2-user@52.68.~~~~~~ The authenticity of host '52.68.~~~~~~ (52.68.~~~~~~)' can't be established. RSA key fingerprint is eb:7a:bd:e6:aa:da:~~~~~~~~~~~~~~~~~~~~~~~~. Are you sure you want to continue connecting (yes/no)?ターミナルのコマンド待ちの際の左側の表示が
[ec2-user| ...
となればログイン成功です。ターミナル(ローカル)が今までのターミナルで、[ec2-user| ...は今後ターミナル(サーバー)と表記していきます。ターミナルを間違えないようにお願いします。
ちなみに、ssh接続は一定時間操作をせずにいると、タイムアウトしてしまいます。その場合は、同じコマンドを実行することで、サーバに接続できます。
次に、EC2インスタンスの環境構築を行います。設定用のツールをインストール
最初にyumというコマンドを使ってこのサーバに元々あるプログラムをアップデートします。こうしたプログラムをパッケージと呼びます。
yumコマンド
Linuxにおけるソフトウェア管理の仕組みです。MacOSにとってのhomebrewと同じ役割を果たします。yumコマンドを利用することで、yumの管理下にあるプログラムのバージョンを管理したり、一括でアップデートしたりできます。
パッケージ
LinuxOS下における、ある役割/機能をもったプログラムの集合です。ソフトウェアとも、ライブラリとも呼べます。
あくまでもLinuxOSでは、ある役割/機能をもったプログラムの集合のことをパッケージと呼ぶよ、ということです。
ターミナルで以下のコマンドを実行しパッケージをアップデートします。
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y update次に、その他環境構築に必要なパッケージを諸々インストールします。
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install git make gcc-c++ patch libyaml-devel libffi-devel libicu-devel zlib-devel readline-devel libxml2-devel libxslt-devel ImageMagick ImageMagick-devel openssl-devel libcurl libcurl-devel curl-yコマンドについて
-y はyumコマンドのオプションです。yum install などのコマンドでは、本当にインストールして良いのか [y/n]のようにYes or Noが問われます。この場合はYキーを押してEnterキーを押せば正常どおりインストールが行われます。しかし、初見であったり誤ってYキー以外を押してしまう場合もあります。 ここでは確実にインストールするために、予めオプションで-yを設定する事で全ての問いにYesで自動的に答えるように設定してコマンドを実行しましょう。
もし誤ってオプションを忘れてしまうと下記のような問いが発生しますので、Yキーを押し次にEnterキーを押してインストールを完了して下さい。
ターミナル(サーバー)総ダウンロード容量: 120 M Is this ok [y/d/N]:無事に入力画面に戻れば、インストール完了です。
次に、EC2上でJavaScriptを動かすためにNode.jsというものをインストールします。Node.js
サーバーサイドで動くJavaScriptのパッケージです。今後のデプロイに向けた作業の中で、CSSや画像を圧縮する際に活用されます。
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo curl -sL https://rpm.nodesource.com/setup_6.x | sudo bash - [ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install nodejsこちらも確認画面が出てきた場合は、「y」→returnキーで確定してください。
これでNode.jsのインストールは完了です。
次に、rbenvとruby-buildをインストールします。
rbenvとruby-buildは、Rubyのバージョンを管理する際に組み合わせて使うツールになります。これらはRubyをインストールする前に、インストールする必要があります。
ruby-buildはrbenvのプラグインであり、ruby-buildによってRubyの様々なバージョン(2.0.0など)をインストールすることができます。
rbenvを使用することでrubyのバージョンを切り替えることできます。
ターミナル(サーバー)#rbenvのインストール [ec2-user@ip-172-31-25-189 ~]$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv #パスを通す [ec2-user@ip-172-31-25-189 ~]$ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile #rbenvを呼び出すための記述 [ec2-user@ip-172-31-25-189 ~]$ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile #.bash_profileの読み込み [ec2-user@ip-172-31-25-189 ~]$ source .bash_profile #ruby-buildのインストール [ec2-user@ip-172-31-25-189 ~]$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build #rehashを行う [ec2-user@ip-172-31-25-189 ~]$ rbenv rehash1つ目のコマンドは、gitからrbenvをクローンしています。
2つ目と3つ目のコマンドは、パスを通す際に必要なコマンドです。パスを通すとは、どのディレクトリからもアプリケーションを呼び出せる状態にするということです。
4つ目のコマンドで、設定したパスを読み込んでいます。
5つ目のコマンドは、gitからruby-buildをクローンしています。
最後のコマンドは、使用しているRubyのバージョンにおいて、gemのコマンドを使えるようにするために必要なコマンドです。
これでrbenvとruby-buildのインストールは完了です。
次は、Rubyをインストールします。
以下で実行するコマンド群は、インストールするRubyのバージョン、自身のアプリケーションで使っているRubyのバージョンによって適宜変更してください。
ここでは、2.5.1をインストールしていきます。
ターミナル(サーバー)[ec2-user@ip-172-31-25-189 ~]$ rbenv install 2.5.1 [ec2-user@ip-172-31-25-189 ~]$ rbenv global 2.5.1 [ec2-user@ip-172-31-25-189 ~]$ rbenv rehash #rehashを行う [ec2-user@ip-172-31-25-189 ~]$ ruby -v # バージョンを確認1つ目のコマンドで、Rubyの2.5.1のバージョンをインストールしています。
2つ目のコマンドは、EC2インスタンス内で使用するRubyのバージョンを決めるものになります。
3行目では再びRehashを行っています。
最後にruby -vコマンドを打ち込み、バージョンを確認しましょう。
以上で、EC2インスタンス内の環境構築ができました。
- 投稿日:2020-03-26T14:44:19+09:00
キーバリューストア型データベース(DynamoDB,ElastiCashe)
キーバリューストア型データベース(Key Value Store、KVS)
データの書式は問わず、そのデータに対して、何か「キー」となる値を結び付けて格納する方式のデータベースNoSQL型データベースの代表例であり、リレーショナルデータベース(RDB)よりも歴史が古い。
キーバリューストア型は、収めるデータに書式がない。
項目数(列数・カラム数)もバラバラでいい。データ型も指定しない。
テーブル(シートのこと)同士の連携もない。
→とにかく楽!近年では、ビッグデータ処理やIotのような、大量のデータの処理や、高速化が求められる場面などで使用され、再注目されている。
〈メリット〉
・リレーショナル型と異なり、柔軟性がある
・データを書式通りに入力しなくてよい
・データへのアクセスが高速〈デメリット〉
・なんでもデータとして放り込んでいるだけなので、詳細な検索ができない・キーとは
データを見つけやすくするラベルのことキーバリューストア型データベースは、AWSに2種類用意されている。
1つはストレージに保存するDynamoDB、もう1つはメモリにキャッシュするAmazon ElastiCacheDynamoDB
キーバリューストア型のデータベース。リレーショナル型に向かない汎用的なデータを保存するのに使う。DynamoDBはVPCなしで接続できる。
→Lambdaなどの非VPCのアプリケーション実行環境と相性が良い。
大規模なデータを処理するために、ACID(トランザクションとして必要な各性質)トランザクション、データの暗号化、アクセス制御などのサービスが整っている。Amazon ElastiCache
インメモリ型のデータベース・インメモリ型とは...
データベース操作のたびに外部記憶装置と読み書きを行うのではなく、頻繁に読み出しのあるデータは一時的にメモリに置いておく(キャッシュ)など、メモリを活用して処理を高速にする形式。DynamoDBはストレージに保存するため、インメモリ型のElastiCacheのほうがより高速。
インスタンスの再起動時にデータが削除されてしまうので、高速化を目的としたキャッシュとしてよく使われる。
- 投稿日:2020-03-26T14:13:20+09:00
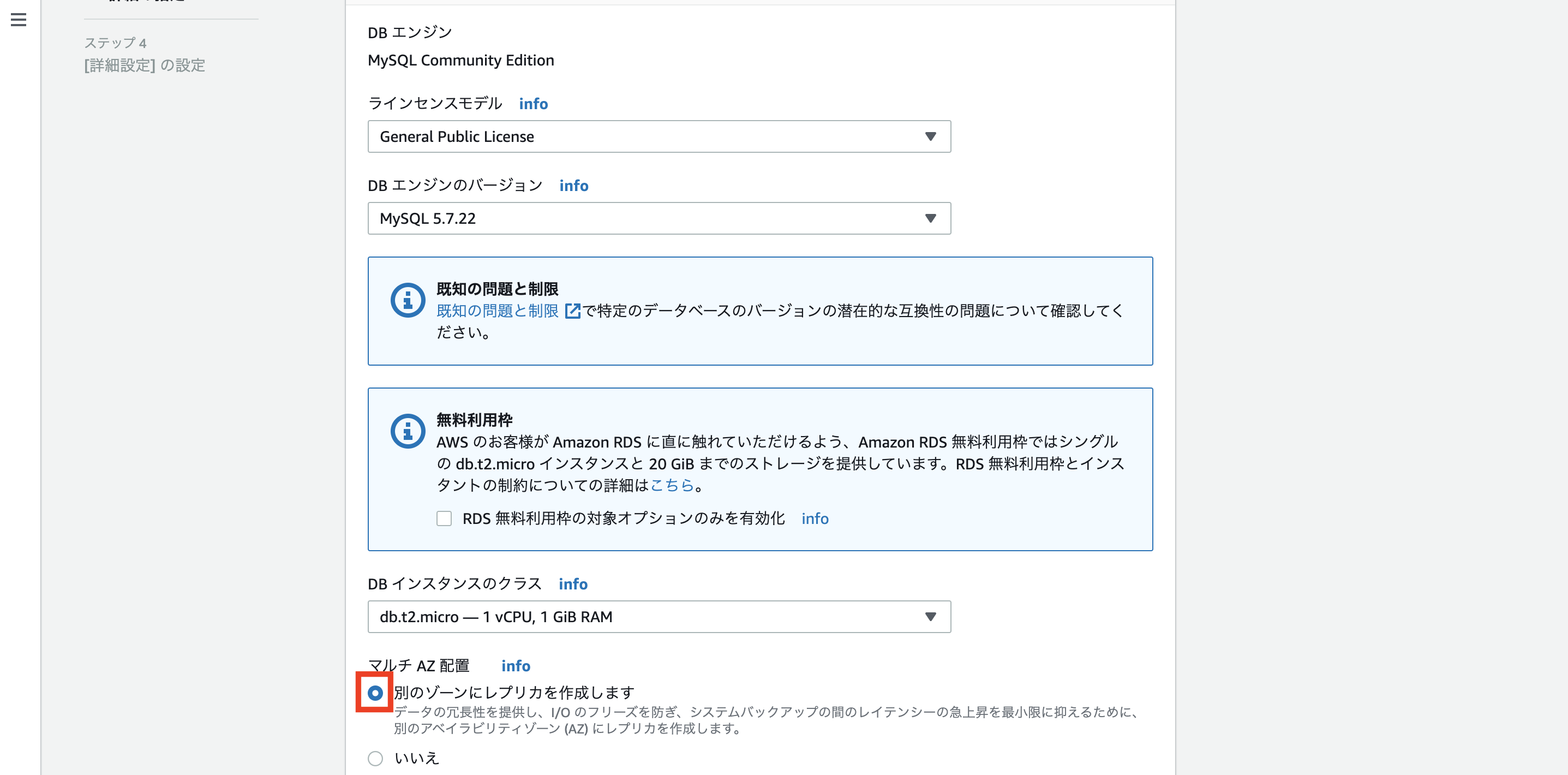
<まとめ>DB非機能設計 : MySQLの可用性、拡張性をどう保障するか。
RDSのマルチAZ化
RDSのマルチAZ配置で可用性、フェイルオーバを図ることができる。
Oracle、PostgreSQL、MySQL、MariaDBのマルチAZ配置
… Amazonフェールオーバ機能が適用
SQL Server DBのマルチAZ配置
…SQLサーバのミラーリングが適用プライマリDBインスタンスのレプリカ(スタンバイレプリカ)が別のAZに複製される。
基本的にRDSマルチAZ配置しておけばフェールオーバがなされるため、障害耐久性が向上するマルチAZ化のやり方:
新規DBマルチAZ化→ RDSコンソールDBインスタンス作成時に指定
既存DBマルチAZ化 → DBインスタンス変更しAZオプション指定
AWS CLI、 Amazon RDS APIからも可能 *参照: linkポイント: レイテンシについて
マルチAZ使用DBインスタンスは、シングルAZ配置よりレイテンシが上がることがあるので、レイテンシの変動を抑えるために、プロビジョンドIOPSおよびDBインスタンスクラスを使用することが推奨される。
プロビジョンドIOPS… EBSボリューム値タイプの一つ
EBSのボリュームをプロビジョンドIOPSにすることで、マルチAZ化したときに発生するレイテンシを最低限に抑えることができる。
そのほかEBS汎用SSDがあるがプロビジョンドよりパフォーマンスに劣る。プロビジョンド … 最大IOPS 64000
最大スループット 1000MB/sec
汎用 … 最大IOPS16000
最大スループット 250MB/secMySQLの高可用性構成
非同期レプリケーション … アップデート時に1つのDB更新し、時間がたってから別のDBに更新。
準同期レプリケーション…アップデート時にスレーブに変更情報が伝搬した(適用でない)時点でコミット
同期レプリケーション … アップデート時に全てのDBを更新する。MySQLレプリケーションパターン
・マスタ>スレーブ
・マスタ>マルチスレーブ
・マルチマスタ>スレーブ (非推奨)
・マスタ>スレーブ>マルチスレーブ
・マスタ<>マスタ
・循環型マルチマスタMHAについて
MHA
MySQLのマスタ障害時に最新スレーブをマスタとして昇格させ、自動的にフェールオーバを行うオープンソースツール
マスタ自動フェイルオーバの実現
マスタ無停止メンテの実現
MySQL5.0以降で動作
MySQLの特徴とMHAでできること
- MySQLはマスタ1つのみ
- スレーブの冗長化自体は簡単にできる
- MySQLのレプリケーションは非同期または準同期
- 同期ではないのでマスタ障碍児にスレーブが最新のログを受け取っていない場合がある
- なのでスレーブ間でのずれを解消する必要がある
- これを自動で解決するのがMHA
- 差分の計算、保存をスレーブ間で並列で行う
- 秒単位でのフェールオーバを実現
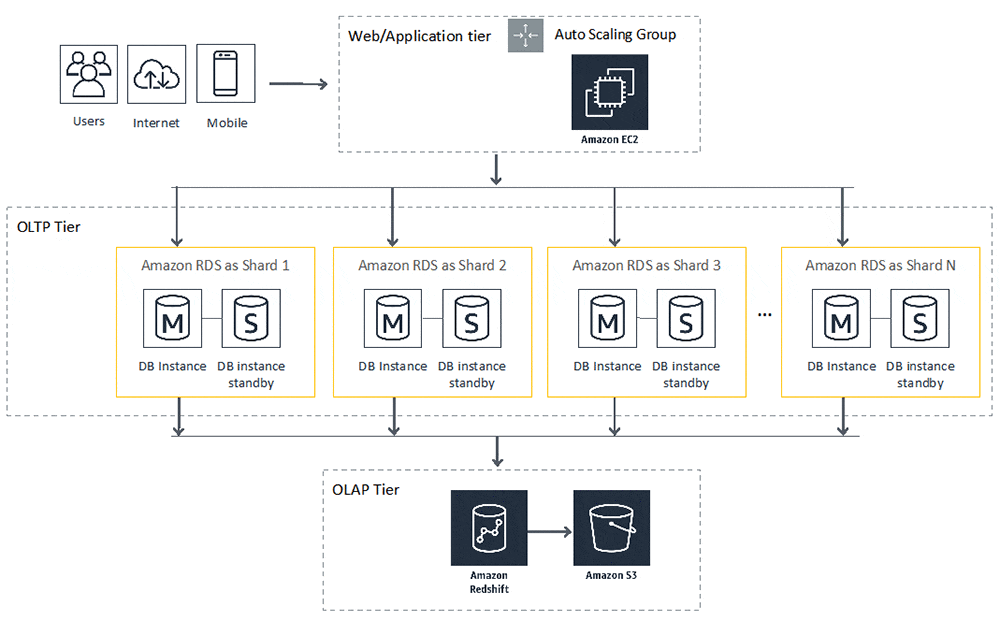
RDSでなくEC2環境でMySQLを動作させる際は、MHAでフェールオーバできる。(RDSでは自動)Amazon DB クラスター構成
構造:
- クラスタは1つ以上のDBインスタンスと、1つのクラスタボリュームで構成される。
- クラスタボリューム … マルチAZ化された仮想データベースストレージボリューム
- クラスタはプライマリとレプリカDBインスタンスで構成される。
- プライマリは、全てのクラスタボリュームへの変更を実行する。
- レプリカは、読み取りのみ。ストレージボリュームに接続し、情報を取得。
- 一つのプライマリDBに対して15個のレプリカを持つことが可能。
- レプリカをマルチAZ化することで可用性を高められる。
- プライマリ障害時は自動的にレプリカにフェールオーバしてくれる。
- マルチマスタ構成にするとプライマリとレプリカの間で違いがなくなる。(全DBが読み書き可能になる)データベースの拡張性保証
高可用性と拡張性
可用性 : 障害時の対処、リカバリ能力
拡張性 : データベース、クエリの負荷を複数のMySQLサーバに分散
シェアードナッシング : 分散コンピューティングでのリソースの共有の排除
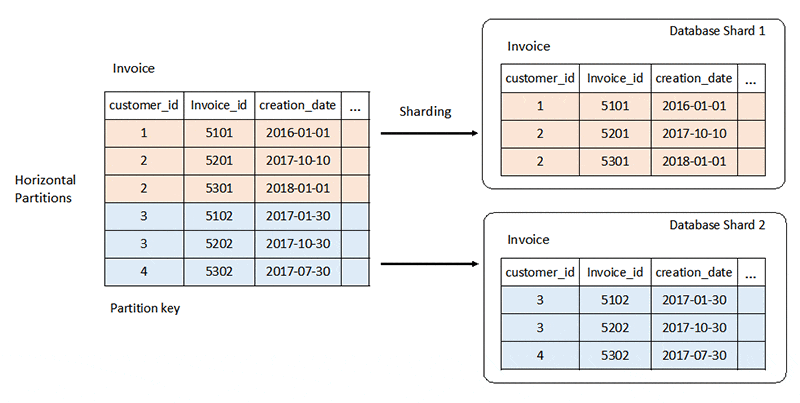
シャードデータベースアーキテクチャ
シャーディング : データを小さなサブセットに分割、それらを多数のデータベースサーバに分配する。
データパーティション設計とスキーマ設計
例 : customer_idをパーティションキーとする
Spiderエンジン
DBの分散処理を可能にするオープンソースツール
EC2でMySQL(Spider編1)
MySQL Spiderエンジンを使ってみた
・ 異なるMySQLインスタンスのテーブルを同一インスタンスのテーブル用に扱うことが可能
・ 更新系DBのクラスタリングに利用可能
・ パーティショニングルールで同一テーブルテーブルを複数サーバに分散配置が可能
・ 仕組み的にはストレージエンジンのテーブル内でシンボリックリンク的な動きをする
・ ローカルMySQLサーバからリモートMySQLサーバへのコネクションで実現
・ リンク先テーブルのストレージエンジンに制限はない
・ MySQL、MariaDBはサポートされているが、Auroraはされていない1100万以上のユーザデータのスケーリング事例
Amazon AWSでユーザ数1100万以上にスケーリングするためのビギナーズガイド
スケーリングに必要な要素
・ フェデレーション : データベースを機能に基づき複数のDBに分割
・ シャーディング : 上記説明
・ 従来型リレーショナルSQLデータベースを使用
・ SPOFをなくす(すべての段階を冗長化)
・ インフラの内部、外部のデータをキャッシング
・ インフラ内での自動化ツールの利用
・ メトリクス、モニタリング、ロギングを配備しアプリケーションのパフォーマンスを監視
・ ティアをSOA化
・ Auto Scalingの使用~まとめ~
・データベースの拡張性、可用性を上げるには、前提として、データベースはAuroraを使用。AWS上でマルチAZ化され、システムは必要であればサービス指向で構成されているものとする。
・可用性、拡張性を保証する手段の一つとしてシャードデータベースアーキテクチャがある
・同じテーブルを複数のデータベース(シャード)に分散して処理の効率化を図る
・異なるシャード間でのデータ共有を排除することにより、データアクセスへのレイテンシを減らす
・障害発生時もシャード毎でフェールオーバするので、拡張性も保証される。
・オープンソースのSpiderというソースを使用することで、コーディングの手間を省き、分散処理を実現することが可能。おわり

- 投稿日:2020-03-26T14:11:38+09:00
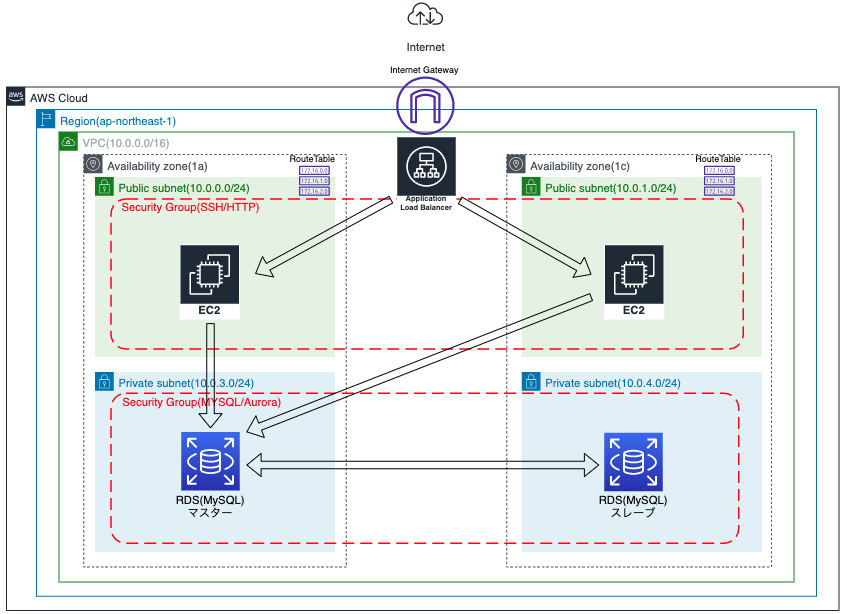
AWSで基本的なサーバー環境を構築してみました。~その2~
はじめに
前回作成したサーバー環境をもう少し障害性、冗長性をアップさせた構成に変更したいと思います。構成図は以下のようになります。
構成図
変更内容
- EC2を2つ作成し、ロードバランサーの設置による冗長化
- RDSのMultiAZ構成(マスター、スレーブ)による自動フェイルオーバー
作成手順の流れ
リソース名 備考 VPC サブネット パブリックサブネット2つ、プライベートサブネット2つ作成。 インターネットゲートウェイ ルートテーブル EC2 ※ AZを分けて2つ作成。 RDS ※ エンジンはMySQL。MultiAZ構成。 ELB ※ ALBを使用。作成したEC2を指定。 ※ 作成後、接続確認を行う。
VPCの作成
CIDRブロックの数値は構成図で示している範囲とします。
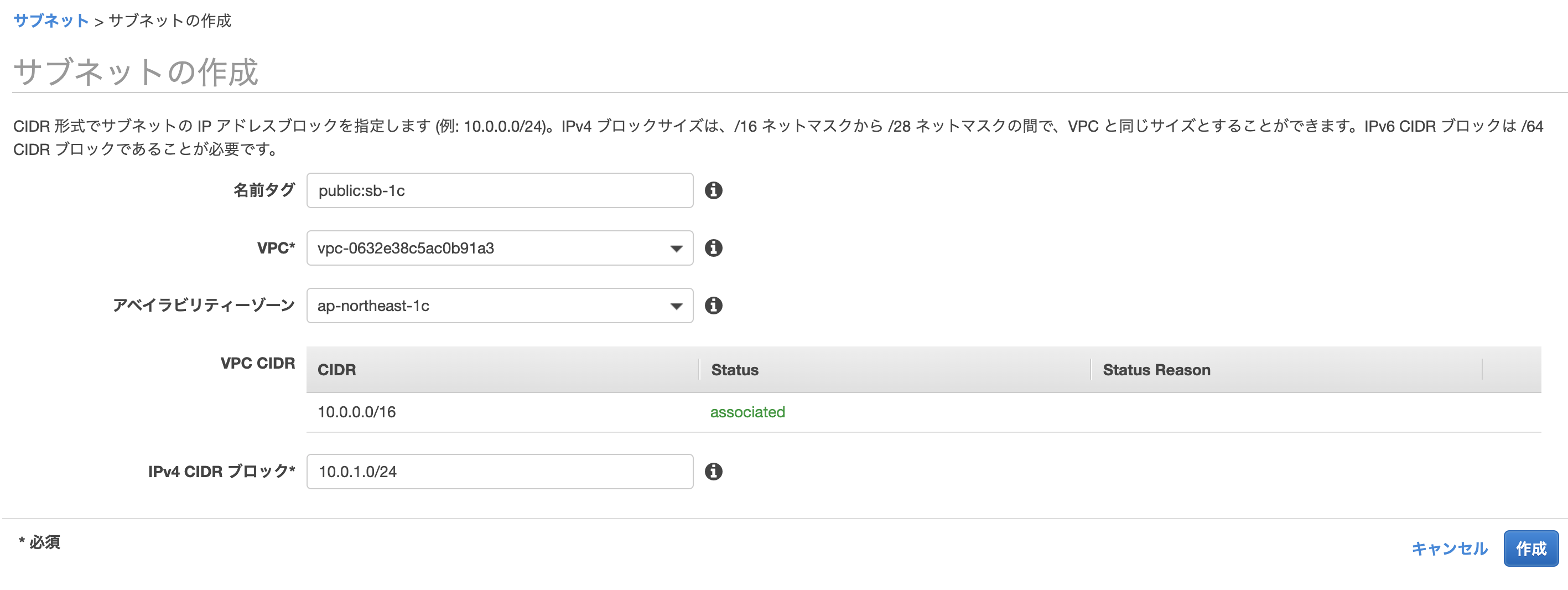
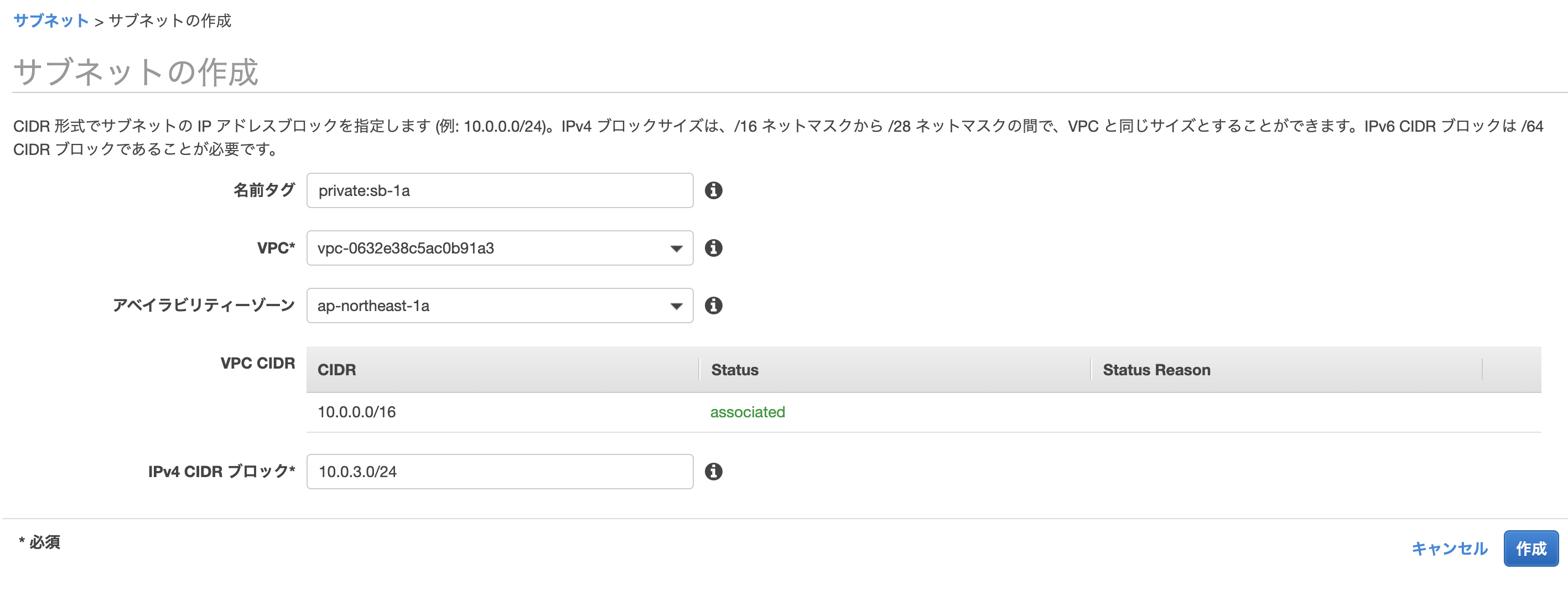
サブネットの作成
パブリックサブネットとプライベートサブネットそれぞれ2つずつ作成します。
1.パブリックサブネット
EC2インスタンスを設置するパブリックサブネットを作成します。
CIDRブロックの数値はこちらも構成図の範囲とします。AZを
ap-northeast-1aとap-northeast-1cに分けて作成します。
2.プライベートサブネット
RDSを設置するプライベートサブネットを作成します。
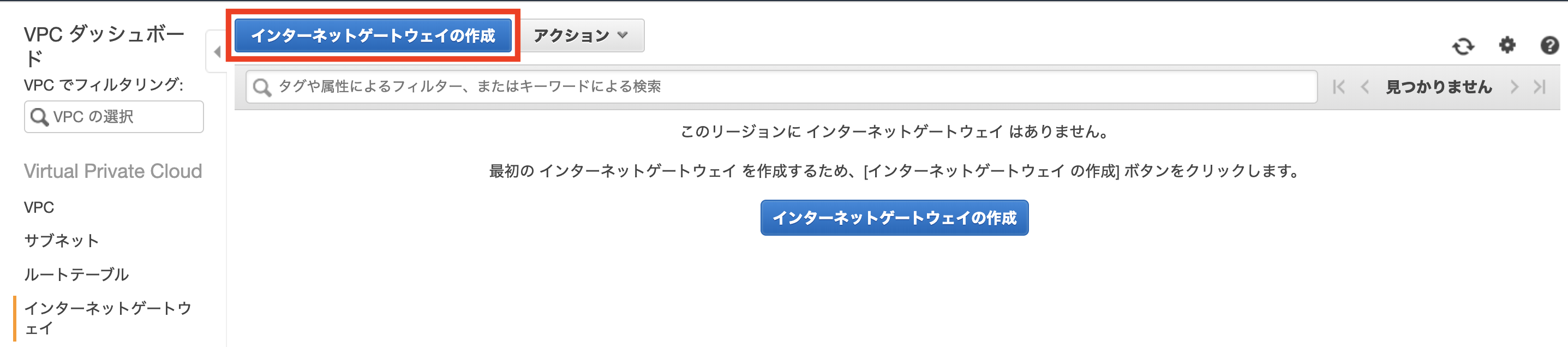
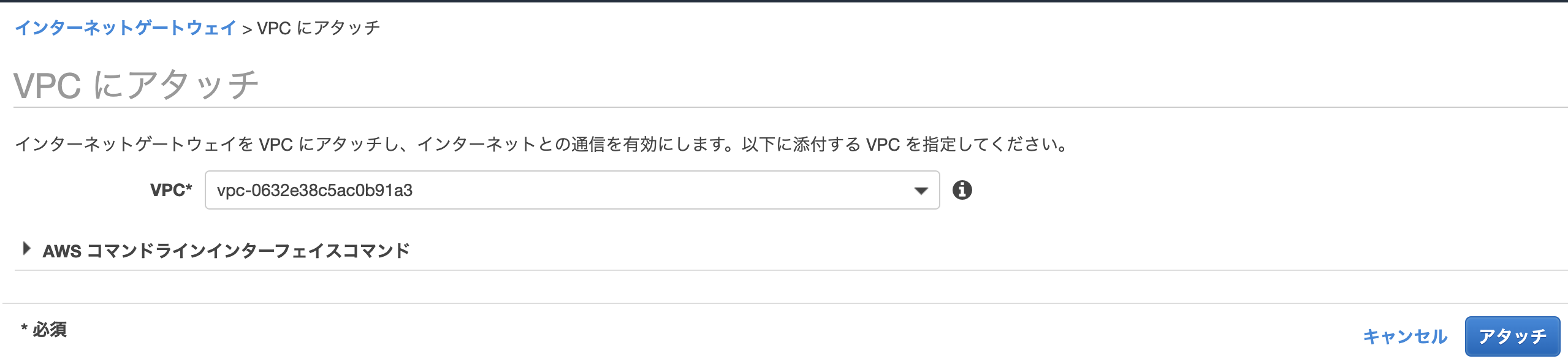
インターネットゲートウェイの作成
作成したVPC内のサーバがインターネットと接続するための出入口を設定します。
インターネットゲートウェイの名称を入力します。
作成したVPCに紐付けます。
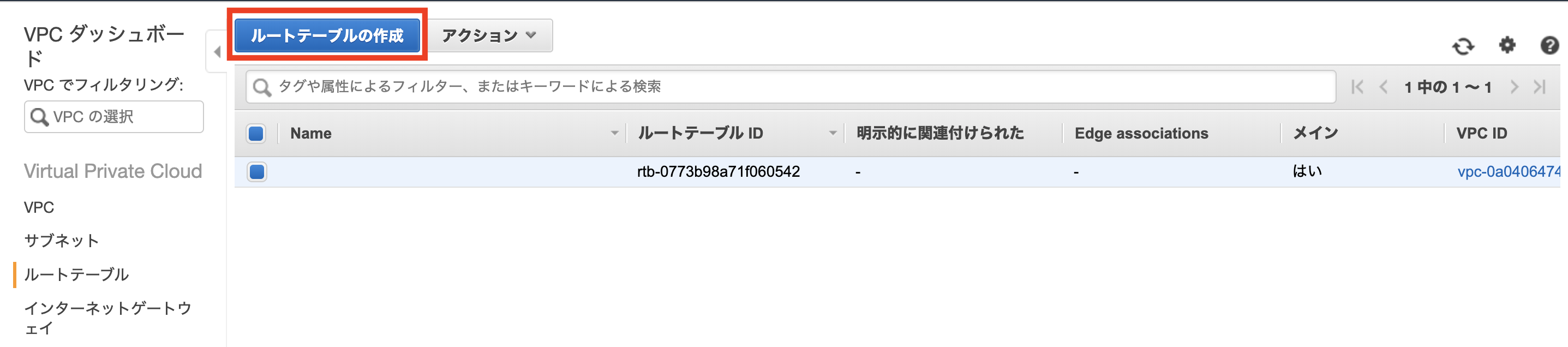
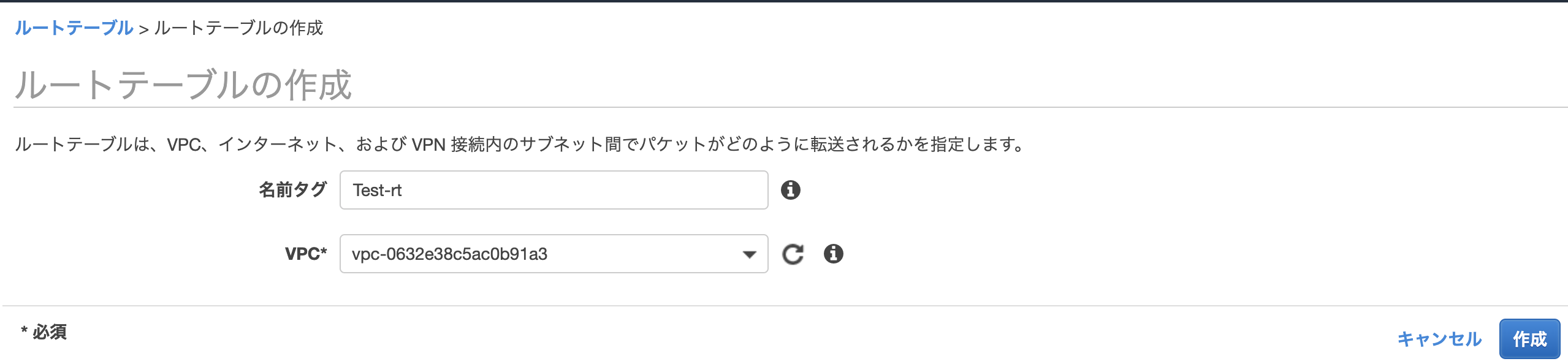
ルートテーブルの作成
デフォルトでは同じVPC内のものしかアクセスできないため、ルート編集で設定したゲートウェイに紐づいているアクセスの通信を可能にします。
こちらも作成したVPCに紐付けます。
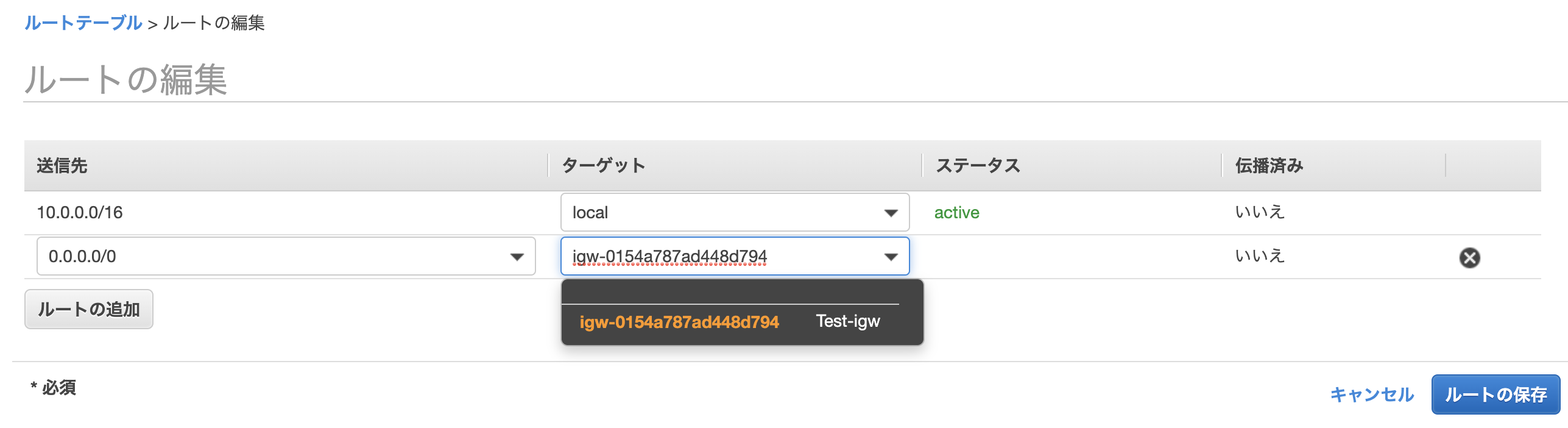
ルートの編集を行います。
作成したインターネットゲートウェイをターゲットとして設定します。
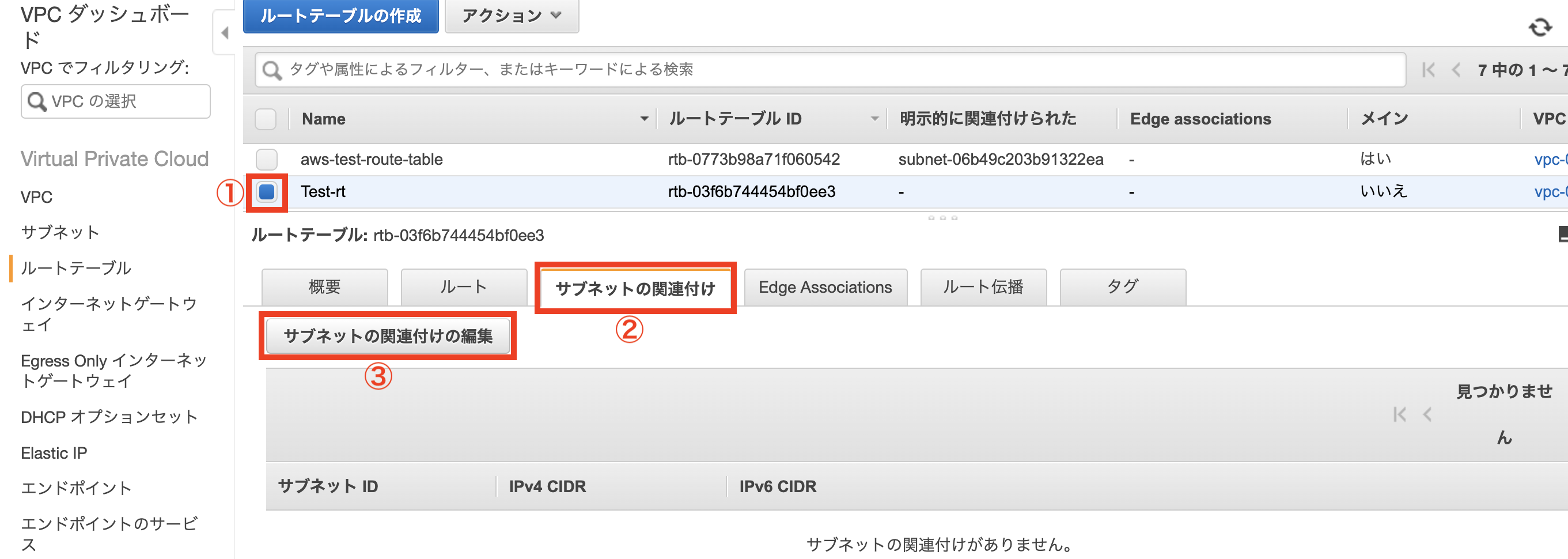
このルートテーブルに2つのパブリックサブネットを紐付けます。
EC2の作成
WEBサーバーが2つ必要なので、EC2を2つ作成します。
テスト用なのでAMI及びインスタンスタイプは無料利用枠を選択しています。
ネットワーク及びサブネットには作成したVPC及びパブリックサブネットを紐付けます。また、パブリックIPの自動割り当てを有効に変更します。
インスタンスの詳細設定に以下を追記する。
#!/bin/bash sudo yum update -y sudo yum install httpd mysql update -y sudo service httpd start sudo chkconfig httpd onデフォルトのまま次へ進みます。
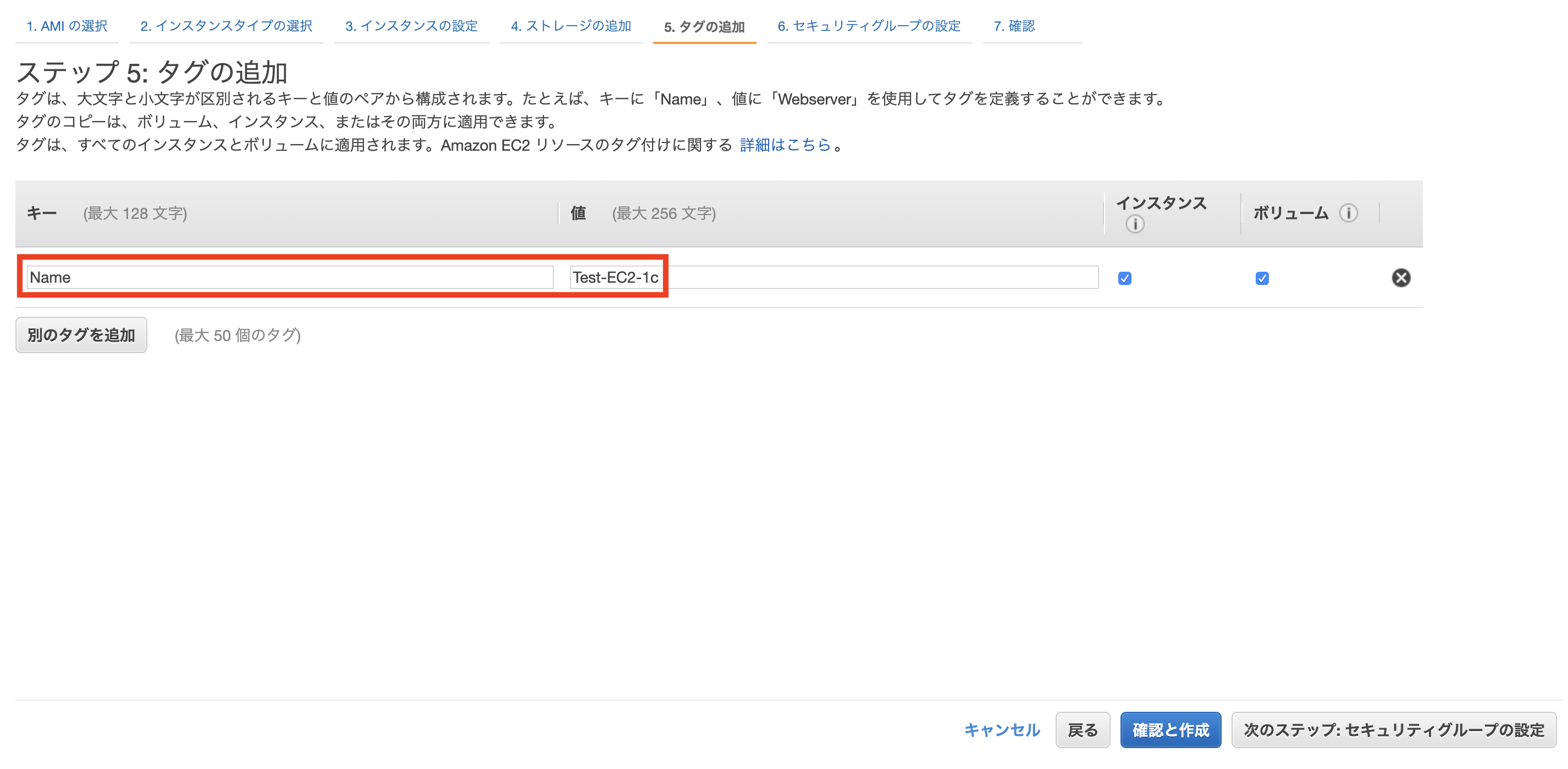
EC2の名称を設定します。
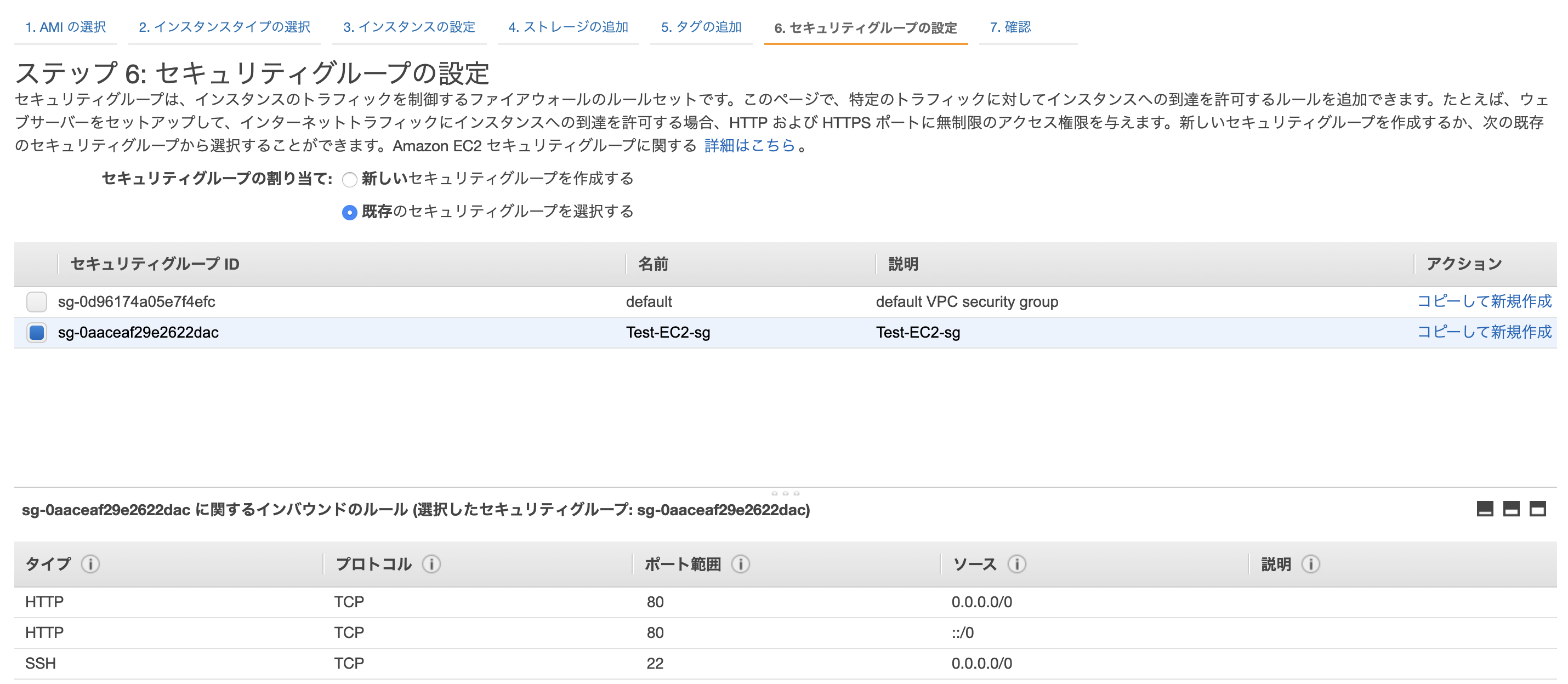
新しいセキュリティグループを作成し、SSHとHTTPのポートを許可します。
入力内容に誤りがないか確認し、EC2を起動します。
新しいキーペアを作成しダウンロードすればEC2インスタンスの作成は完了です。
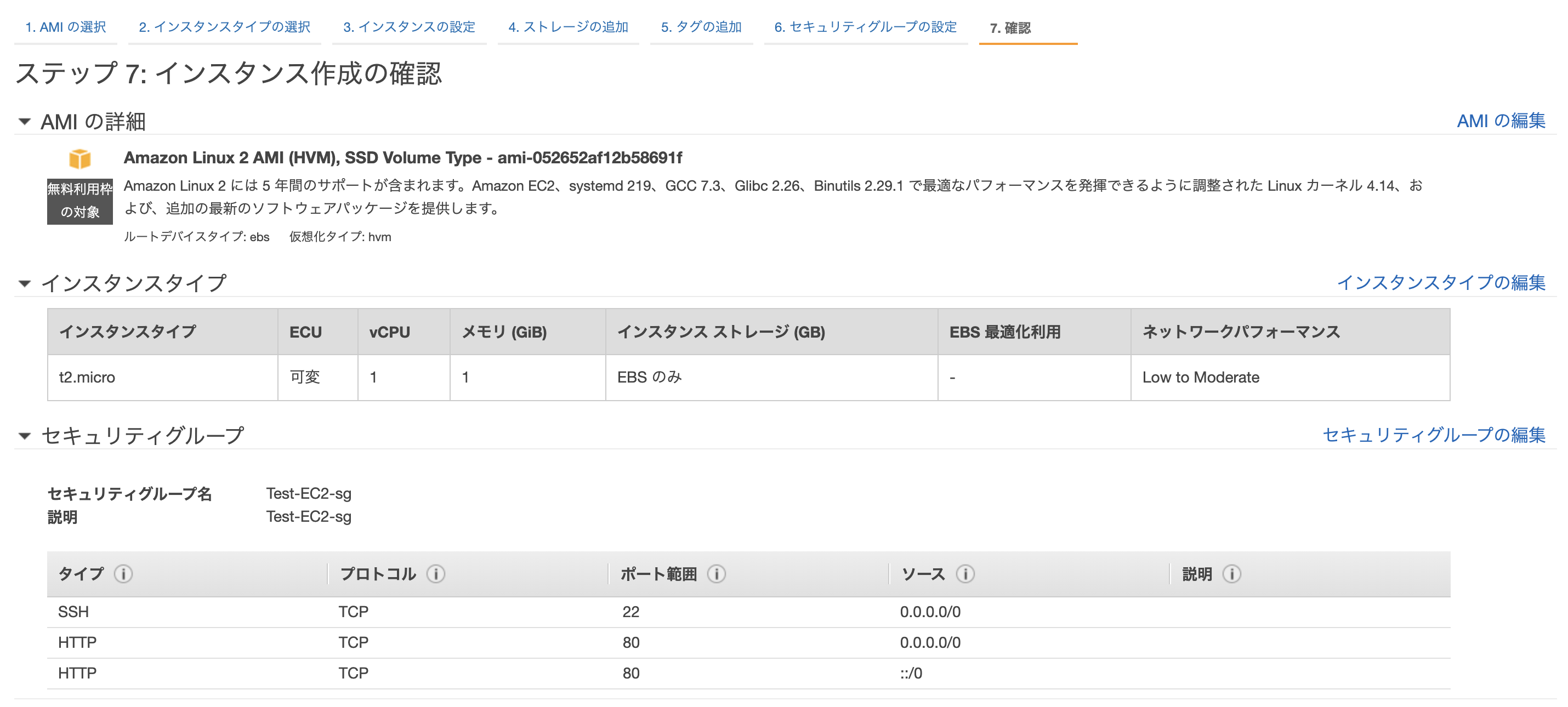
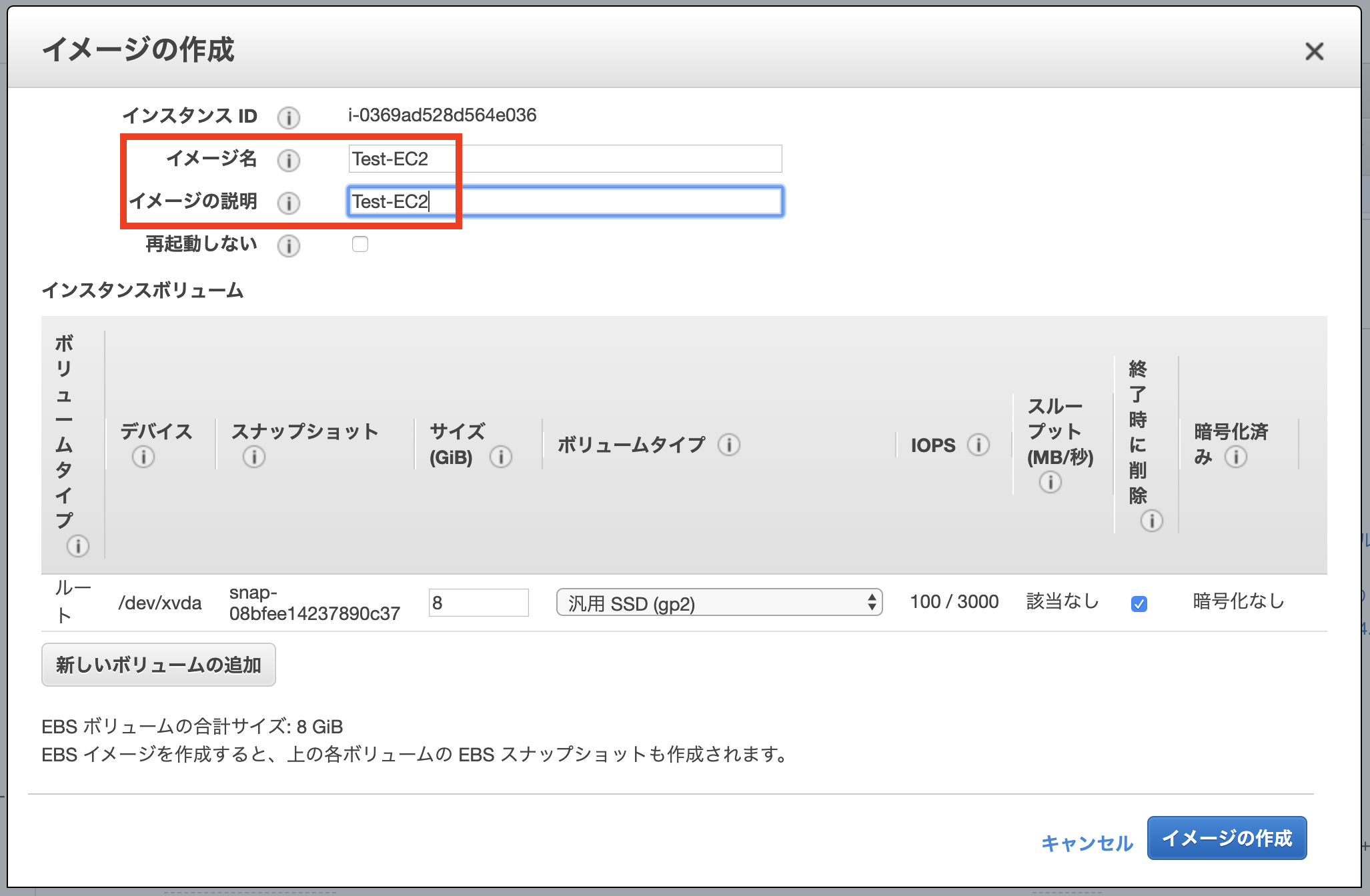
もう一つ
ap-northeast-1c側に作成するEC2を作成します。こちらは先程完成したEC2からAMIを作成してそのイメージから作成します。
作成した、AMIを起動します。
こちらのEC2をパブリックサブネットの1c側に設置します。
先程作成したセキュリティグループを選択します。
確認して、起動します。
キーペアも同様のものを選択します。
EC2へのSSH接続の確認
EC2インスタンスの状態が
runningに変わったら起動成功なので、それぞれのEC2のIPv4パブリックIPを確認しておきます。
続いてEC2からSSHへの接続確認を行います。ターミナル画面を開き、先ほど作成したpemキーを
.sshフォルダに移動させます。2つのEC2インスタンス、それぞれをSSH接続可能か確認します。ターミナル画面$ Downloads/test.pem .ssh/ #pemキーを.sshフォルダに移動 $ sudo chmod 600 ~/.ssh/test.pem #指定している鍵の権限が広すぎるため変更 Password:〇〇〇〇〇〇〇〇 #自身のPCのパスワード $ ssh -i ~/.ssh/test.pem ec2-user@[IPアドレス] #SSH接続の実行 __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 8 package(s) needed for security, out of 17 available Run "sudo yum update" to apply all updates.RDSの作成
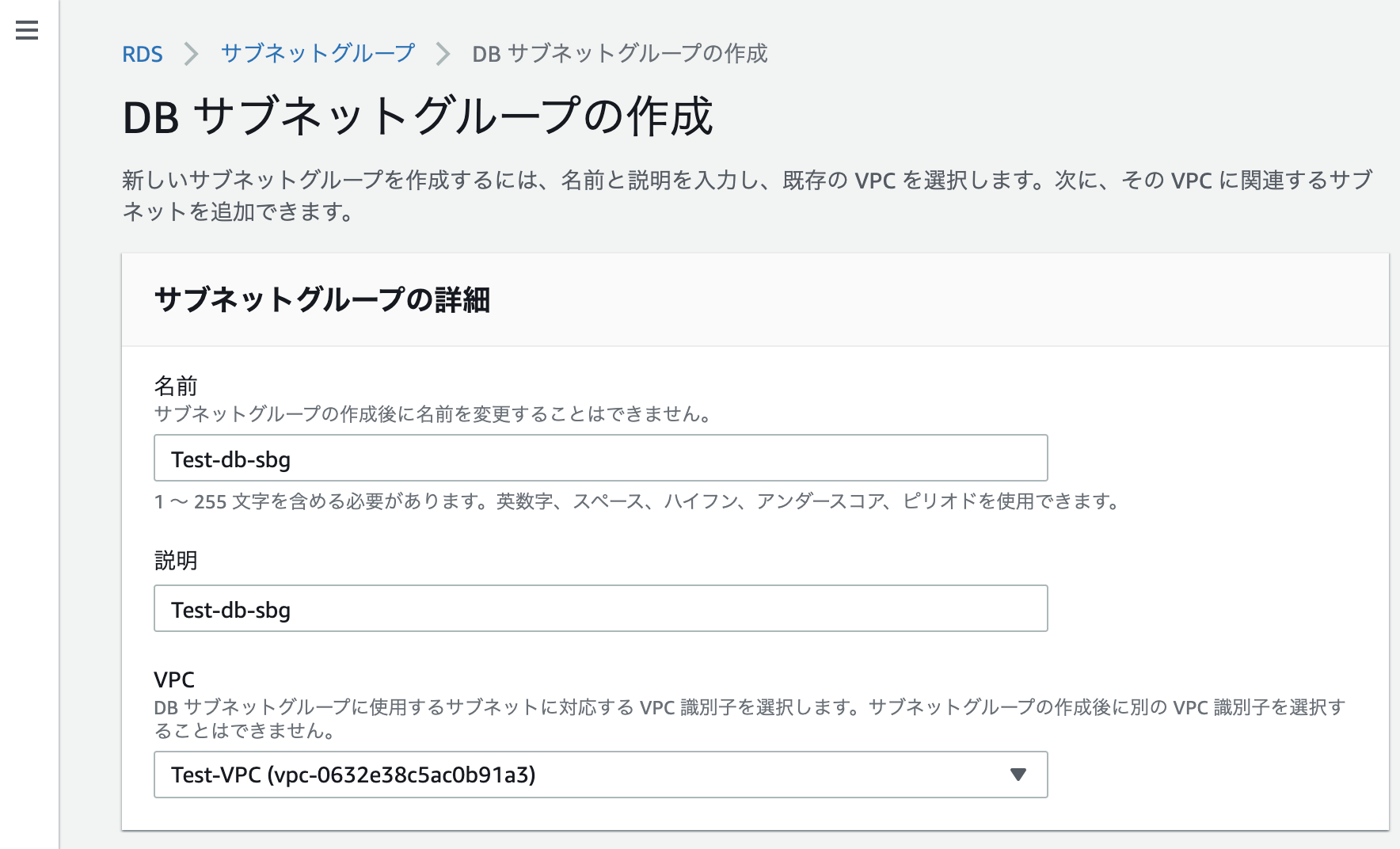
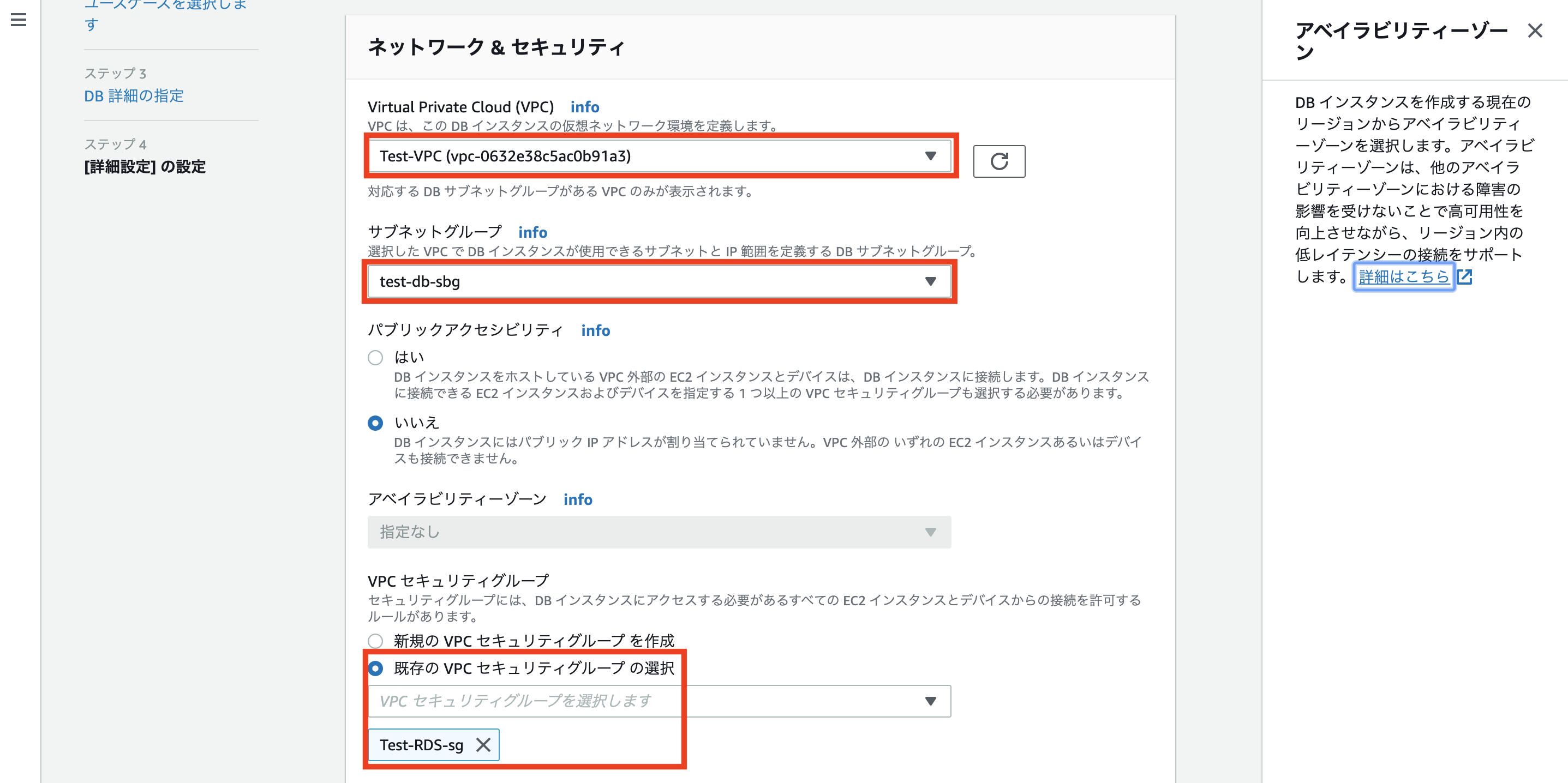
DBサブネットグループの作成
名称を入力し、作成したVPCと紐付けます。
作成したプライベートサブネット2つを紐付けます。
セキュリティグループの作成
データベースの作成
MySQLを選択します。
MultiAZ構成としますので、次の部分をチェックします。
設定欄を入力します。
作成したVPC、サブネットグループ、セキュリティグループを紐づけます。
今回は初期MySQLデータベースは不要なのでデータベース名は空白にし、その他の設定についてはデフォルトのままで作成します。
EC2からRDSへの接続確認
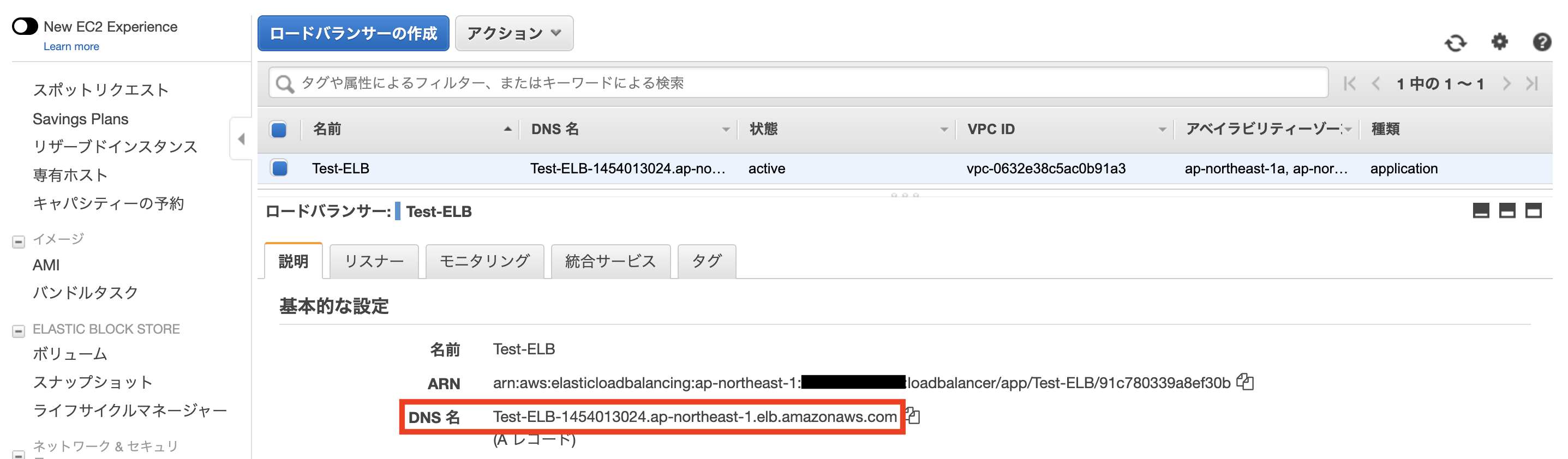
作成したRDSのエンドポイントをコピーします。
EC2からRDSへの接続確認を行います。
ターミナル.$ mysql -h test-rds.cl0w7wsj1gla.ap-northeast-1.rds.amazonaws.com -u test -p #RDSのエンドポイントとRDS作成時のマスターユーザ名(test)を使用 Enter password:testpass #RDS作成時のパスワード Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 8 Server version: 5.7.22-log Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]> #exitで抜けます以上の画面が表示されれば、接続完了です。
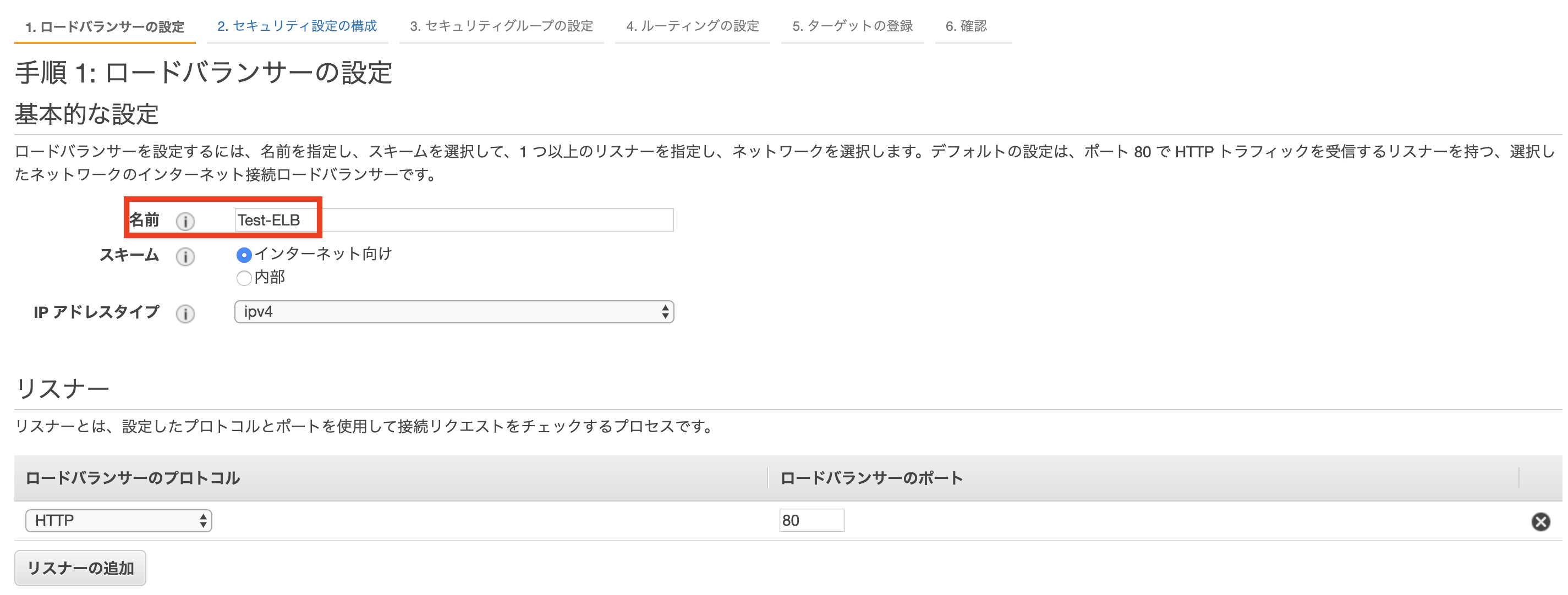
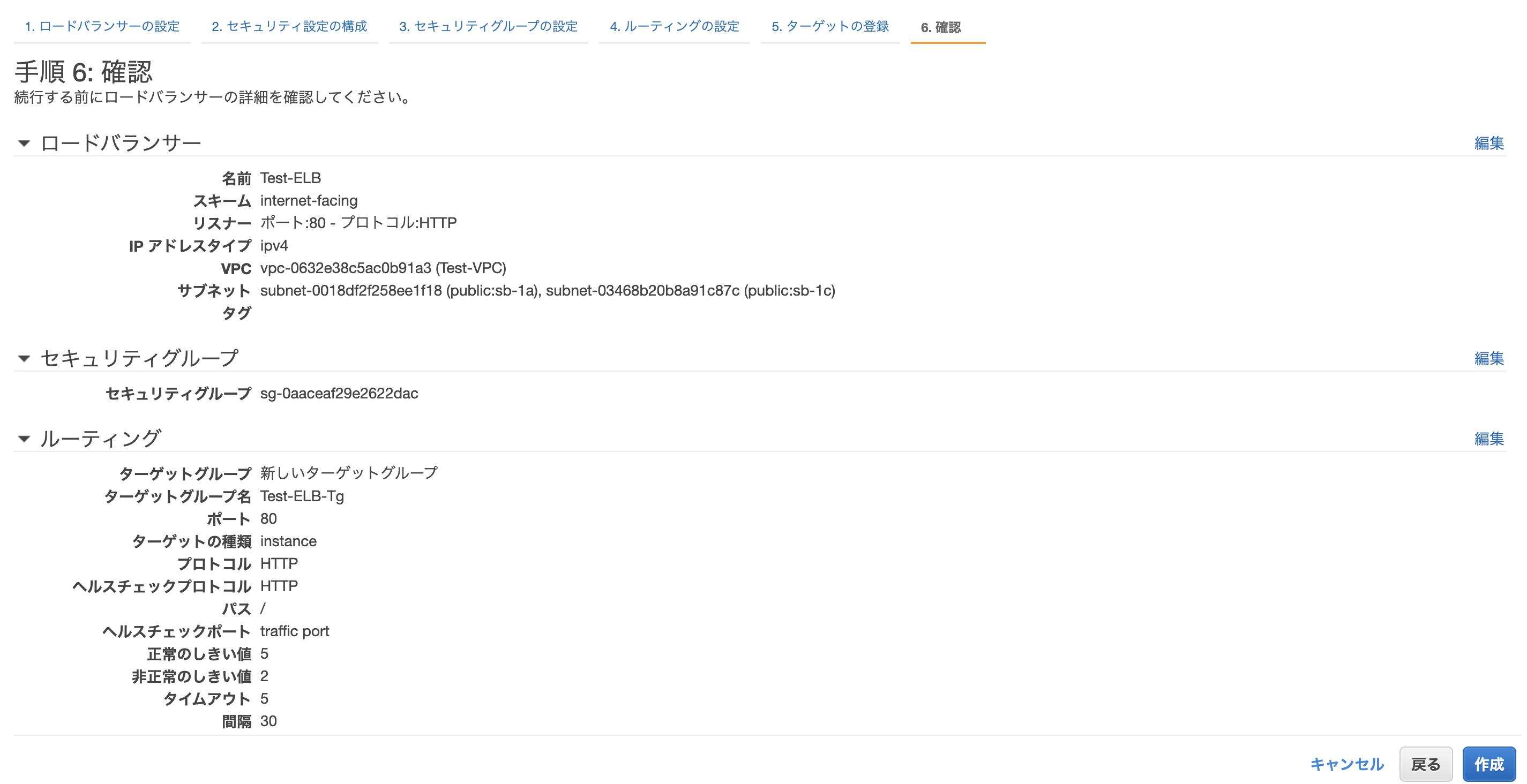
ELBの作成
ALBを選択します。
ロードバランサーの名称を入力し、今回は外部接続用のため
インターネット向けを選択しておきます。
作成したVPCを選択し、2つのEC2が設置してあるパブリックサブネットを紐付けます。
EC2と同様のセキュリティグループを選択します。
ルーティングについてはデフォルトのまま進めます。
ターゲットを作成した2つのEC2に指定します。
ELB機能確認
実際にロードバランサーが機能しているか確認をします。まず、htmlファイルを2つのEC2インスタンスに作成します。
ターミナル画面$ sudo vi /var/www/html/index.html <html> Hello EC2!AZ-1a #別のEC2はAZ-1cにする。 </html>次に、ELBのDNS名を確認し、そこからEC2にアクセスします。
表示された画面のリロードを繰り返すと、アクセスされるEC2が変更されます。そのため、次のように表示されるhtmlファイルが異なります。
以上で、今回の構成図が完成となります。
その他
今回の構成以外の対策としては次の内容が考えられます。
セキュリティ対策
・セキュリティグループの設定
通信を許可する送信元IPアドレスやプロトコルを必要なものだけに限定
・CloudTrailの利用
ユーザーの行動ログを取得する等の監視
・CloudWatchの利用
利用するリソースに対してメトリクスやログの収集、追跡
可用性対策
・Auto-Scalingの利用
EC2に高負荷がかかった場合、新たなEC2が自動的に作成されるよう設定
・Route53を利用したフェイルオーバー
同じ構成のスタンバイを別リージョンに設置
・リードレプリカの利用
RDSへの読み込み負荷を分散























- 投稿日:2020-03-26T12:32:18+09:00
aws-sdk-php-laravelを利用してファイルアップロード
aws-sdk-php-laravelとは
AWS SDK for PHPをlaravelのために使いやすくしたもの
(そもそもAWS SDKとはawsのサービスを使いやすくするソフトウェア開発キットのこと)
インストール
aws-sdk-php-laravelをインストールする
composer.jsonに書く
compsoerを通じてインストールします
composer.json{ "require": { "aws/aws-sdk-php-laravel": "~3.0" } }composer update
conposer updateを実行する
$ composer updateconfig/app.php
config/app.phpにAWS Service Providerを追加します
'providers'と下の方にある'aliases'に下のように追加してくださいconfig/app.php'providers' => array( // ... Aws\Laravel\AwsServiceProvider::class, ) 'aliases' => array( // ... 'AWS' => Aws\Laravel\AwsFacade::class, )設定
環境変数
デフォルトでは、これらの環境変数が使われます。
.envAWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY AWS_REGION (default = us-east-1)環境変数の設定方法はこれをみてもらったら早いと思います。
https://qiita.com/tiwu_official/items/ecb115a92ebfebf6a92fAWS_DEFAULT_REGION名前はAWS_REGIONに変更します。
aws.config
.envで設定した環境変数はこんな感じで使われてるよーって
aws.configreturn [ 'credentials' => [ 'key' => env('AWS_ACCESS_KEY_ID', ''), 'secret' => env('AWS_SECRET_ACCESS_KEY', ''), ], 'region' => env('AWS_REGION', 'us-east-1'), 'version' => 'latest', // You can override settings for specific services 'Ses' => [ 'region' => 'us-east-1', ], ];使い方
画像をアップロード
$s3 = App::make('aws')->createClient('s3'); $s3->putObject(array( 'Bucket' => 'YOUR_BUCKET', #s3で登録したbucketの名前 'Key' => 'YOUR_OBJECT_KEY', #登録したいファイルの名前 'SourceFile' => '/the/path/to/the/file/you/are/uploading.ext', #登録したいファイル ));これで画像をアップロードすることができる。
画像を表示
$s3 = App::make('aws')->createClient('s3'); $key = 'YOUR_OBJECT_KEY'; #取得したいファイルの名前 $bucket = env('AWS_BUCKET'); #bucketの名前 $image = $s3->getObjectUrl($bucket, $key); #getObjectUrlでurlを取得これでviewに表示できます。
参考
公式のgithub(ほぼこれの日本語訳です)
https://github.com/aws/aws-sdk-php-laravel/blob/master/README.md超簡単!LaravelでS3を利用する手順
https://qiita.com/tiwu_official/items/ecb115a92ebfebf6a92f
- 投稿日:2020-03-26T10:14:14+09:00
【試験合格記】AWS 認定 ビッグデータ – 専門知識(BDS-C00)
お疲れさまです。
表題の試験に合格したため記録として残したいと思います。注意点
本試験は2020年4月12日に「ビッグデータ」から「データ分析」へ生まれ変わります。
そのため、当該日を過ぎてからこの記事や他の方の過去記事を参考にされると出題範囲が大きく異なる可能性があります。結果
合格(※スコアレポートが戻り次第追記予定)
分野 名称 割合 1 収集 17% 2 格納 17% 3 処理 17% 4 分析 17% 5 可視化 12% 6 データセキュリティ 20% 所有資格
資格名 取得年月日 AWS Certified Solutions Architect - Associate (SAA) 2018-06-14 AWS Certified SysOps Administrator - Associate (SOA) 2018-06-22 AWS Certified Developer - Associate (DVA) 2018-06-25 AWS Certified Solutions Architect - Professional (SAP) 2018-07-19 AWS Certified DevOps Engineer - Professional (DOP) 2020-02-19 AWS Certified Big Data - Speciality (BDS) 2020-03-23 事前知識
過去にGCPのデータエンジニア試験を受験していたこともあり、覚えのある内容がいくつかあったこともアドバンテージになりました。
所感
基本的にはHadoopエコシステムの特徴とビッグデータに分類されるサイズ感に対応したAWSリソース、機械学習の基礎知識があれば合格ラインが見えると思います。
受験者に向けたアドバイス
- HDFS, HBase, MapReduceなどの特徴を理解する
- Presto, Spark, Pig, Sqoop, Phoenix, Hiveなどの特徴を理解する
- Kinesisの種類とそれらがどんな要件に適していてどのリソースと親和性が高いのか理解する
- DynamoDBとRedshift、RDSの明確な違いを理解する
- ストリーミングからの分析や可視化のアプローチに対して、状況ごとにどう組み合わせるか理解する
- 機械学習モデルとしての回帰、カテゴリ、バイナリなどの傾向を把握する
まとめ
実質一週間で準備した割にはある程度時間を余らせて合格できました。
ビッグデータに全く触れたことがない方は、まず関連書籍を一冊読んでから
上記のワードが何を意味してどこまで対応できるのかを比較できるよう、情報整理を始めることが理解を早める方法になるかもしれません。次はセキュリティか機械学習あたりを4月中に取れるよう頑張っていこうと思います。
- 投稿日:2020-03-26T03:22:42+09:00
AWSのECRに置いたコンテナイメージをお引越ししてみた
AWSのECRに置いてあるコンテナイメージをテスト環境から本番環境に移転させるという業務があり、ザッと調べてもパッとは出てこなかったので、やり方を残しておこうと思います。
本来、コンテナはdockerfileを書いてそれを管理した方が良いのですが、そんなものは残ってなかったし、ぺーぺーの自分はそんなことすら知らなかった。ECR上のコンテナイメージを移転する
今回は2パターンのやり方を紹介します。
1:コンテナイメージをtarファイル化し、ローカルを経由してお引越し
2:コンテナイメージを直接pullして、そのままpushしてお引越し本記事では、お引越し先のAWS環境を移転先、お引越し元のAWSアカウントを移転元と表記します。
※スクショないです、追加できたらやります。環境
ローカルOS:windows10
ターミナルソフト:Rlogin
EC2のインスタンスタイプ:t3.medium1:コンテナイメージをtarファイル化し、ローカルを経由してお引越し
実際の業務ではこちらを採用しました。2つ目の方が早くて簡単ですが、無作法なので却下されました。
大まかな流れとしては、こんな感じになります。①Rloginで移転元のEC2インスタンスにログインする
②EC2インスタンスからAWSコマンドで移転元のECRにログインして、任意のコンテナイメージをpullする
③pullしてきたコンテナイメージをtarファイル化して、ローカルにダウンロードする
④移転元のEC2インスタンスから切断し、Rloginで移転先のEC2インスタンスにログインする
⑤tarファイル化したコンテナイメージをEC2インスタンスにアップロードして展開する
⑥展開して出来たコンテナイメージにtagをつけて、移転先のECRにpushする実践したわけじゃないけれど、多分ローカルにDocker Desktopをインストールして、AWSコマンドを叩けるようにしておけば、(クレデンシャル情報が載ってるconfigureファイルがローカルにガッツリ残ることはさておき)わざわざRlogin使ったりtarファイル化したりしなくても良いかもしれない。
①Rloginで移転元のEC2インスタンスにログインする
ぶっちゃけEC2インスタンスに接続できればなんでも良いので省略
②EC2インスタンスからAWSコマンドで移転元のECRにログインして、任意のコンテナイメージをpullする
EC2インスタンスに接続したら、次のawsコマンドでECRへ接続するためのトークンを発行します。
aws ecr get-login --no-include-email
このコマンドの戻り値を余すことなくcopy&paste&EnterすることでECRをいじることができるようになります。③pullしてきたコンテナイメージをtarファイル化して、ローカルにダウンロードする
一旦、AWSのコンソールでECRのリポジトリを見に行きます。そこでお引越し対象のコンテナイメージのURLを確認しておきます。
EC2インスタンスで、次のAWSコマンドでECRからお引越し対象のコンテナイメージをpullしてきます。
docker pull (コンテナイメージのURL)
pullできたら次のコマンドでtarファイル化します。
docker save -o (任意のファイル名).tar (コンテナイメージ名)
終わったら、ローカルの任意の場所にダウンロードしておきます。④移転元のEC2インスタンスから切断し、Rloginで移転先のEC2インスタンスにログインする
移転元での作業を終わりなので切断します。ここからは移転先での作業なので、移転先EC2インスタンスに接続します。
⑤tarファイル化したコンテナイメージをEC2インスタンスにアップロードして展開する
移転先のEC2インスタンスに接続できたら、さっきのコンテナイメージのtarファイルをアップロード、次のコマンドで展開します。
docker load -i (ファイル名).tar⑥展開して出来たコンテナイメージにtagをつけて、移転先のECRにpushする
展開したコンテナイメージのコンテナイメージIDを"docker images"コマンドで確認したら、次のコマンドでタグ付けします。
docker tag (コンテナイメージ名) (push先リポジトリのURL)
最後に次のコマンドでコンテナイメージをpushします。(手順②のECRへの接続を忘れずに)
docker push (push先リポジトリのURL)AWSのコンソールでECRのリポジトリを見に行き、コンテナイメージが確認出来たらお引越し成功です。
2:コンテナイメージを直接pullして、そのままpushしてお引越し
移転元のECRから移転先のEC2に直接コンテナイメージをpull、そのまま移転先のECRにpushする方法です。上の方で無作法と言われた理由としては、移転先EC2インスタンスで移転元のクレデンシャルを使って移転元のECRを直接触るからです。
大まかな流れとしては、こんな感じになります。①Rloginで移転先のEC2インスタンスにログインする
②EC2インスタンスからAWSコマンドで移転元のECRにログインして、任意のコンテナイメージをpullする
③EC2インスタンスからAWSコマンドで移転先のECRにログインして、任意のコンテナイメージをpushするお手軽、簡単、でも無作法
pullしてきたコンテナイメージに、tag付けだけすればpushできます。まとめ
今回は、AWSのECRに置いてあるコンテナイメージを別のAWS環境に移転させる方法についてまとめてみました。クレデンシャルの管理とかを徹底するなら、手間はかかりますが方法1で作業するのが良いかと思います。そこまで気にしない、作業した後にちゃんとクレデンシャルを削除します、というなら方法2もアリといえばアリかもしれないです。方法2の場合、ローカル環境にDocker DesktopとAWSCliをインストールしておけば、コマンドプロンプトでこと足りる気もしてます。
コンテナの管理としては、dockerfileで書いて残しておくことで共有しやすくなる、というか本来のお作法だと思いますので、自分がゼロからコンテナを作る場合は、ちゃんとdockerfile残しておきたいと思いました。(ただ、コンテナをbiuldする際にインストールするものが多かったりする場合は、tarファイルでやり取りした方が若干早かったりします。)
それでは。
- 投稿日:2020-03-26T01:49:53+09:00
VPC Lambda から AWS API を使う
VPC に置いた Lambda Function から AWS API を使おうとしたらタイムアウトしてしまって困った。
公式ドキュメント を読むと、
Connect your function to private subnets to access private resources. If your function needs internet access, use NAT. Connecting a function to a public subnet does not give it internet access or a public IP address.
Several services offer VPC endpoints. You can use VPC endpoints to connect to AWS services from within a VPC without internet access.
- Public Subnet に置いてもランタイムのインスタンスに Public IPv4 アドレスは割り当てられない
- インターネットへのアクセスが必要な場合は Private Subnet に置いて NAT しろ
- いくつかの AWS Service は VPC エンドポイントでアクセスできるので、それらを使うだけならインターネットアクセスは必要ない
とのこと。
つまり VPC Lambda から AWS API を使いたければ「NAT する」か「VPC エンドポイントを使う」の2択になる。
いずれの場合も Lambda Function は Private Subnet に配置する必要がある。
VPC エンドポイント
使いたい AWS API が VPC エンドポイントに対応しているならこっちの方が簡単と思われる。
ただし今回触っていたのが趣味 AWS 環境であり、VPC エンドポイント1つに約$10/月かかってしまうのがちょっと厳しいのでやめた。
NAT
お金がある人は NAT Gateway を使うと一瞬でできて便利。(約$45/月)
今回はお金がないので NAT インスタンスを自分で立てた。
参考: Ubuntu の ufw で NAT サーバを作る - Qiita
所感
Lambda で Serverless したかったのに何故ワイは NAT インスタンスを構築しているんや・・・?
- 投稿日:2020-03-26T01:34:15+09:00
Kubeflow 1.0 on AWS #2 Notebookの作成
はじめに
これは、Kubeflow 1.0 をAWSで構築する記事です。
動作確認が主な目的ですので、本番環境での利用は全く想定していません。前回まで
今回の内容
Kubeflow上で Jupyter Notebookを作成してみます
Notebookの作成(GUI)
New Serverを選択
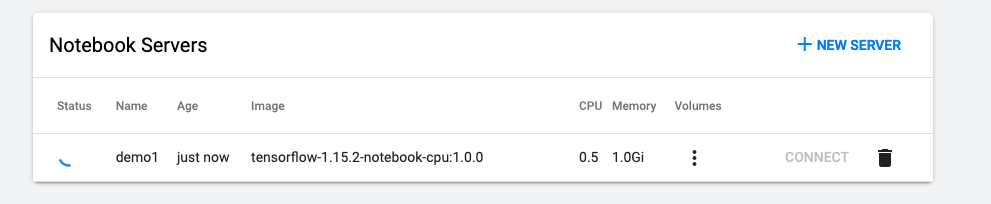
demo1と名前で Notebook を作成します
こんな感じでで作成中になります
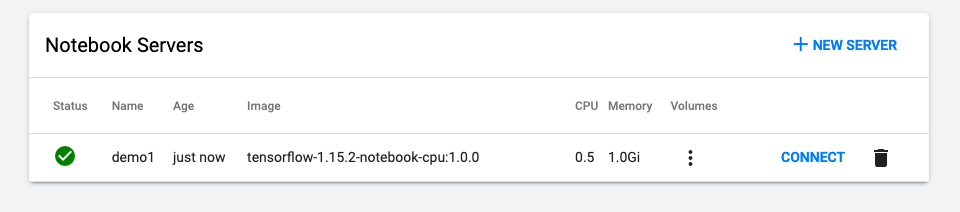
作成が終わって、CONNECTを選択します
Notebookに繋がりました
Notebookを操作してみる
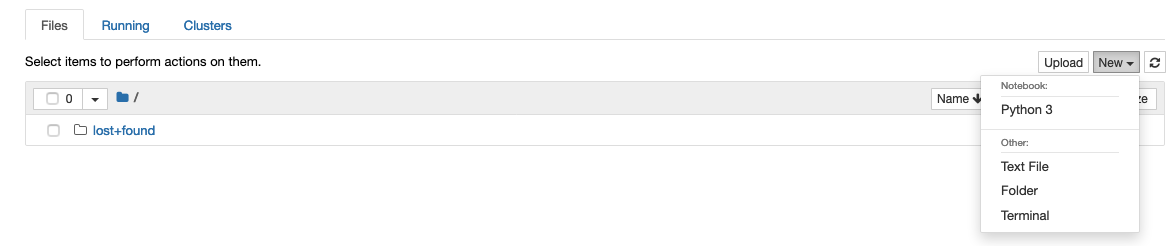
デフォルトだとpython3しかないようです
rootもsudoも使えないので、root権限が必要な作業はカスタムイメージを作成する必要がありそうです
スクショは載せていないですが、gitは入ってました
Keras は入っていないっぽい( pip等で入れればいいだけなので大した問題ではない)
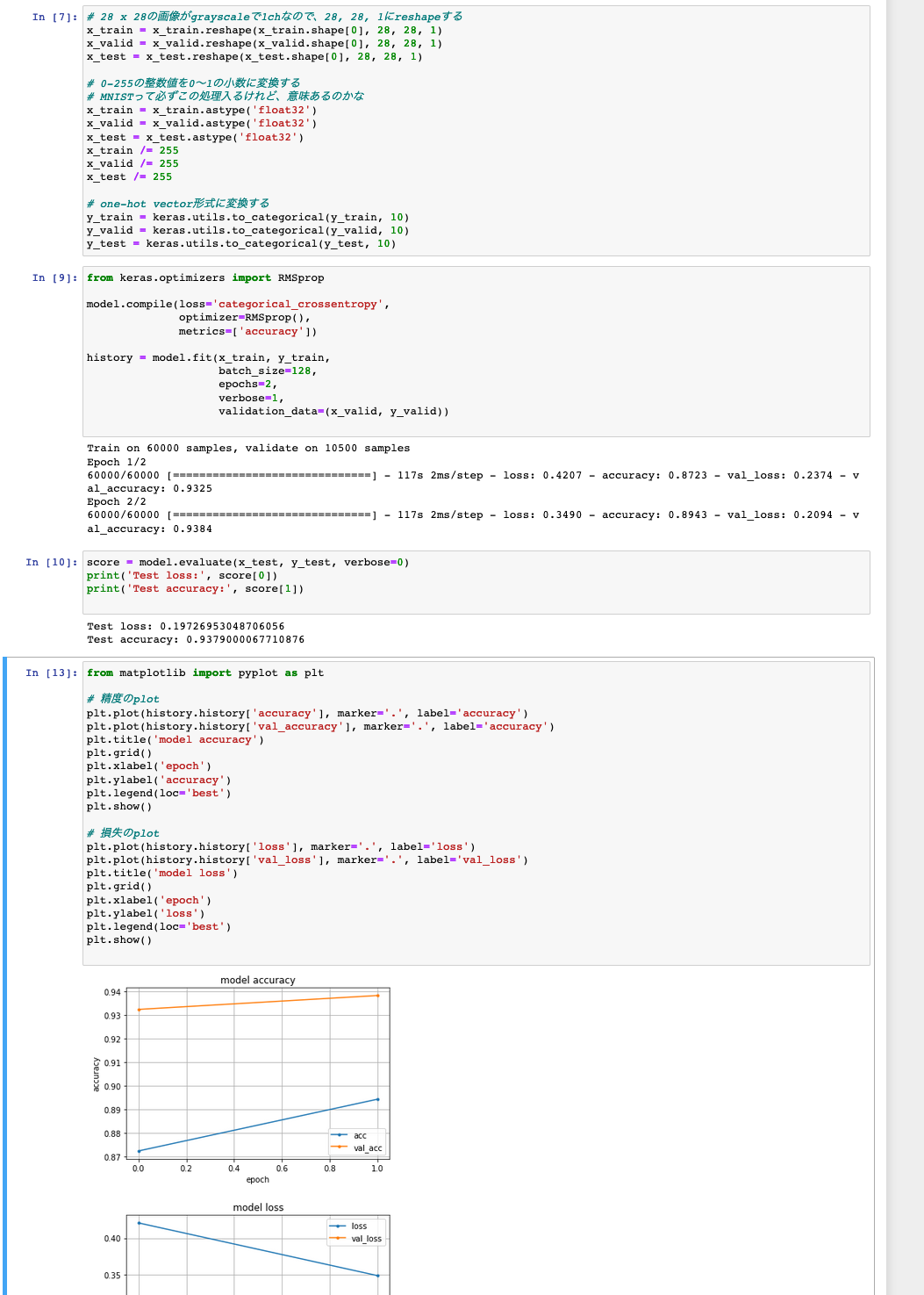
試しにこちらと同じコード(keras)を流すと動きました。学習時間を短縮するために、epoch数は2に変えました
Kerasのバージョンが違うっぽいので、 accをaccuracyに置換しました
所感
Notebookとしては問題なく動いているようです
環境確認
get all -n anonymous NAME READY STATUS RESTARTS AGE pod/demo1-0 2/2 Running 0 28m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/demo1 ClusterIP 10.100.123.227 <none> 80/TCP 28m NAME READY AGE statefulset.apps/demo1 1/1 28mkubectl get pv | grep demo1
pvc-e68e0e8e-6eae-11ea-8b88-0ee99a06437c 10Gi RWO Delete Bound anonymous/workspace-demo1 gp2 30m
```Notebookの実態は、StatefulSetであり、PV(AWSなのでEBS)がついていることがわかります。
そして、Serviceとして、ClusterIPを持っているようです。istioのvirtualserviceの確認
kubectl get virtualservice -A NAMESPACE NAME GATEWAYS HOSTS AGE anonymous notebook-anonymous-demo1 [kubeflow/kubeflow-gateway] [*] 37m kubeflow argo-ui [kubeflow-gateway] [*] 23h kubeflow centraldashboard [kubeflow-gateway] [*] 23h kubeflow google-api-vs [www.googleapis.com] 23h kubeflow google-storage-api-vs [storage.googleapis.com] 23h kubeflow grafana-vs [kubeflow-gateway] [*] 23h kubeflow jupyter-web-app [kubeflow-gateway] [*] 23h kubeflow katib-ui [kubeflow-gateway] [*] 23h kubeflow kfam [kubeflow-gateway] [*] 23h kubeflow metadata-grpc [kubeflow-gateway] [*] 23h kubeflow metadata-ui [kubeflow-gateway] [*] 23h kubeflow ml-pipeline-tensorboard-ui [kubeflow-gateway] [*] 23h kubeflow ml-pipeline-ui [kubeflow-gateway] [*] 23h kubeflow tensorboard [kubeflow-gateway] [*] 23h bash-4.2#notebook-anonymous-demo というvirtualserviceが作成されていることが分かります。
kubectl get virtualservice notebook-anonymous-demo1 -n anonymous -o yaml apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: creationTimestamp: "2020-03-25T15:40:06Z" generation: 1 name: notebook-anonymous-demo1 namespace: anonymous ownerReferences: - apiVersion: kubeflow.org/v1beta1 blockOwnerDeletion: true controller: true kind: Notebook name: demo1 uid: e68f6959-6eae-11ea-9e97-0a81a7804a98 resourceVersion: "567338" selfLink: /apis/networking.istio.io/v1alpha3/namespaces/anonymous/virtualservices/notebook-anonymous-demo1 uid: e693d4ed-6eae-11ea-9e97-0a81a7804a98 spec: gateways: - kubeflow/kubeflow-gateway hosts: - '*' http: - match: - uri: prefix: /notebook/anonymous/demo1/ rewrite: uri: /notebook/anonymous/demo1/ route: - destination: host: demo1.anonymous.svc.cluster.local port: number: 80 timeout: 300sこちらの設定で、/notebook/anonymous/demo1/ というpathなら、notebookにつながるようになっていることが分かります。
ちなみにstatefulset自体のyamlは以下のようになっています
kubectl get statefulset demo1 -n anonymous -o yaml apiVersion: apps/v1 kind: StatefulSet metadata: creationTimestamp: "2020-03-25T15:40:05Z" generation: 1 name: demo1 namespace: anonymous ownerReferences: - apiVersion: kubeflow.org/v1beta1 blockOwnerDeletion: true controller: true kind: Notebook name: demo1 uid: e68f6959-6eae-11ea-9e97-0a81a7804a98 resourceVersion: "567535" selfLink: /apis/apps/v1/namespaces/anonymous/statefulsets/demo1 uid: e690c53b-6eae-11ea-9e97-0a81a7804a98 spec: podManagementPolicy: OrderedReady replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: statefulset: demo1 serviceName: "" template: metadata: creationTimestamp: null labels: app: demo1 notebook-name: demo1 statefulset: demo1 spec: containers: - env: - name: NB_PREFIX value: /notebook/anonymous/demo1 image: gcr.io/kubeflow-images-public/tensorflow-1.15.2-notebook-cpu:1.0.0 imagePullPolicy: IfNotPresent name: demo1 ports: - containerPort: 8888 name: notebook-port protocol: TCP resources: requests: cpu: 500m memory: 1Gi terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /home/jovyan name: workspace-demo1 - mountPath: /dev/shm name: dshm workingDir: /home/jovyan dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: fsGroup: 100 serviceAccount: default-editor serviceAccountName: default-editor terminationGracePeriodSeconds: 30 volumes: - name: workspace-demo1 persistentVolumeClaim: claimName: workspace-demo1 - emptyDir: medium: Memory name: dshm updateStrategy: rollingUpdate: partition: 0 type: RollingUpdate status: collisionCount: 0 currentReplicas: 1 currentRevision: demo1-dc56967ff observedGeneration: 1 readyReplicas: 1 replicas: 1 updateRevision: demo1-dc56967ff updatedReplicas: 1notebookを削除する
GUIから普通に削除します。PersistentStorageを使っているとデータは残るようです
GUIからは消えましたが、確かにPV/PVCが残っていることは確認できました
kubectl get pvc -n anonymous NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE workspace-demo1 Bound pvc-e68e0e8e-6eae-11ea-8b88-0ee99a06437c 10Gi RWO gp2 48mもう一度 notebookを作成する
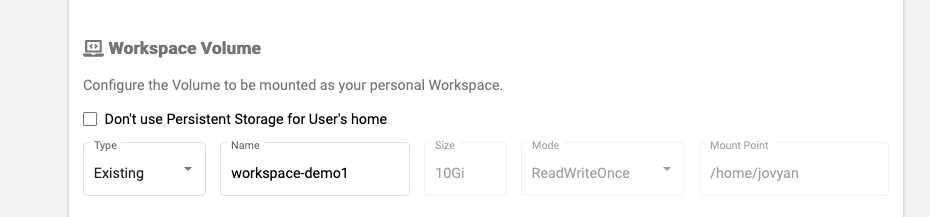
demo2というnotebookを新規で作成し、既存のストレージを作成するという選択肢があるので、それを選択しました
接続してみます
予想通りですが、データが残っていることが分かります。
既存のPVCを指定できるので、例えば、EFSでPVCを作成して、Notebookのデータは共有ストレージに保存する的なこともできそうです。(いつかやってみたいと思います)




- 投稿日:2020-03-26T00:05:17+09:00
CloudFormationでECSタスクのスケジュールに異なる複数の実行時間を指定したい
やりたいこと
CloudFormationでECSのタスクスケジュール定義をしたい。
時・分ともに異なる複数の実行時間を指定したい。
例えば毎日7:45と13:50に実行されるように指定したい。1つのcron式だとうまく収まらない
cron(45 07 * * ? *)
これだけだと7:45だけになっちゃうし
cron(45,50 07,13 * * ? *)
これだと7:45,7:50,13:45,13:50に実行されちゃうしcrontabだと2行に分けて書いているけど
CloudFormationではどう書くの???
もしかしていいかんじに1行で書けたりする???
と悩んだのでメモしておきます。※これのScheduleExpressionの指定の話です
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-events-rule.htmlまず結論
ワンライナーでがんばるとこじゃなかったっぽい。
無理せずcfnのTaskSchedule部分の定義を7:45実行回分と13:50実行回分のそれぞれ書きます。書き方
cfnでのecsタスクの定義は
どんなecsタスクかを定義するAWS::ECS::TaskDefinitionの定義があり、
そしてそれをいつ実行するかを定義するAWS::Events::Ruleの定義があります。
ここではその後者の定義だけ抜粋します。sample.ymlResources: # 抜粋 TaskScheduleHoge: Type: AWS::Events::Rule Properties: Name: task_schedule_hoge State: ENABLED ScheduleExpression: cron(45 07 * * ? *) Targets: - Id: task_schedule_hoge Arn: !GetAtt Cluster.Arn RoleArn: !Sub arn:aws:iam::${AWS::AccountId}:role/ecsEventsRole EcsParameters: TaskDefinitionArn: !Ref taskDefinition TaskCount: 1 LaunchType: FARGATE PlatformVersion: LATEST NetworkConfiguration: AwsVpcConfiguration: AssignPublicIp: DISABLED SecurityGroups: !Ref ServiceSecurityGroup Subnets: !Ref Subnets TaskScheduleHuga: Type: AWS::Events::Rule Properties: Name: task_schedule_huga State: ENABLED ScheduleExpression: cron(50 13 * * ? *) Targets: - Id: task_schedule_huga Arn: !GetAtt Cluster.Arn RoleArn: !Sub arn:aws:iam::${AWS::AccountId}:role/ecsEventsRole EcsParameters: TaskDefinitionArn: !Ref taskDefinition TaskCount: 1 LaunchType: FARGATE PlatformVersion: LATEST NetworkConfiguration: AwsVpcConfiguration: AssignPublicIp: DISABLED SecurityGroups: !Ref ServiceSecurityGroup Subnets: !Ref Subnets実行するのは同じ内容のECSタスクなのでTarget部分に書く内容が繰り返しになるのが気になるものの、cfnを実行した結果、スケジュールがそれぞれ登録できていることを確認しました。
おまけ
YAMLのハッシュのマージなど活用すれば重複して書いているところももっとすっきりするかなと思ったのですが、やってみたところ
An error occurred (ValidationError) when calling the CreateChangeSet operation: Template error: YAML aliases are not allowed in CloudFormation templatesというエラーが出たのでやはりこつこつ書くしかないのかなと思います。
参考
- ECS(Fargate)のバッチをCloudFormationで作成する ? 今回抜粋したECS定義の全体的な話はこちら
- 公式ドキュメント AWS::Events::Ruleについて
