- 投稿日:2020-03-20T23:55:29+09:00
Python はじめから勉強 Hour4:オブジェクト指向①
Python はじめから勉強 Hour4:オブジェクト指向①
- Pythonで何かしようとしたときに、まずサンプルスクリプトを探してなんとなく実行してた私が、
- 自動実行でREST API叩いて、結果の確認、VM操作までやってみたいと思う7時間
- 今回はオブジェクト指向。まぁ意味は分からずともメソッド使えればいいんじゃないでしょうか。
学習資料
- たった 1日で基本が身に付く! Python超入門
過去の投稿
環境
- Windows
- Python Ver3系
オブジェクト指向とは
- 既に学んでいますが、プログラムでは文字列や整数、リストなどを扱ってきました。
- でも扱っているのは123などの数字であり、「整数」というものを扱っているわけではありません。
- というわけで「整数」といった概念の実体である123。
- この関係がクラス(整数)とインスタンス(123)の関係です。
- あれ?「オブジェクト」って言葉はどこ行った?
- インスタンス≒オブジェクトで良いそうです。個人的にはインスタンスのほうが分かりやすい
メソッドとは
- クラスごとに取り扱える振る舞いのこと
- 整数のインスタンスは、「絶対値を取る」とか「符号(+-)を反転させる」といった関数のようなものは欲しいですが、文字列に対して「絶対値を取る」といった処理は全く不要。
- なので、クラスごとに関数を定義し、そのインスタンスだけ使えるもの
- 例えば文字列を大文字にしてみる。
>>> a ='hogeo' >>> >>> print(a) hogeo >>> >>> print(a.upper()) HOGEO >>>
インスタンスの後ろに「. (ドット)」を置いて、続いてメソッド名とその引数を記述することえ扱えます。
- もう一つ例:リストを操作する
>>> my_list = ['abc', 'def', 'ghi'] >>> print(my_list) ['abc', 'def', 'ghi'] >>> >>> # リストに値を追加 >>> my_list.append('jkl') ### my_listインスタンスのあとにappend()メソッドを指定 >>> print(my_list) ['abc', 'def', 'ghi', 'jkl'] ### リストに値が追加されています >>> >>> >>> my_list.reverse() ### 順序を逆にするメソッド >>> print(my_list) ['jkl', 'ghi', 'def', 'abc']どんなメソッドがあるか調べる
- メソッドなんて覚えられれないのでその時にはdir()関数で確認できます。
- _アンダースコアで囲まれたものは特殊属性というものらしい。使い方はまた今度
- 'as_integer_ratio', ~, 'to_bytes'が一般的なメソッド
>>> dir(1) ###整数にどんなメソッドがあるのか ['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes'] >>> ###最後の to_bytesとか分かりやすいですね。 >>> >>> dir('abc') ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill'] >>>リスト インスタンス のメソッドで遊んでみる
Pythonのプログラミングでリストは頻繁に使われるのでいろいろ試してみる
- なんとなく使い方は分かってきた
その他のリスト演算子
- リストはPythonで重要な型ということでメソッドを使わなくても簡単に操作できる仕組みがあります。
- in 演算子:リストにXXが含まれているかどうかを確認するもの
>>> >>> print('c' in my_list) True >>> >>> print('x' in my_list) False >>>
- ん?急に変な書式。
- ある要素がリストに含まれているかどうかを確認する場合に使うようだ。
- 似たようなものでdel 、スライスというものがある
>>> ### リストから3番目の要素を削除 >>> print(my_list) ['a', 'b', 'c', 'e'] >>> ### リストの1番目から4番目までを表示(4番目は含まない) >>> my_list = ['a', 'b', 'c', 'd', 'e'] >>> b = my_list[1:4] >>> print(b) ['b', 'c', 'd']今回のまとめ
- とりあえず、オブジェクト指向が分からなくても、メソッドの使い方が分かればよいと思い、リストの扱い方を中心に整理してみました。
- この辺から進みが悪くなってきた。過去の内容も忘れてきてる。リストの扱い方とか忘れかけてる。。。。
- 次もオブジェクトの操作、今度は文字列。
名言・ライトニングトーク用
- 「オブジェクト指向」「概念」「ふるまい」こういった、言い回しがオブジェクト指向の敷居を高くしてるような。別の言い方は思いつきませんが。
- 投稿日:2020-03-20T23:52:23+09:00
Python と SQLite3 でList と Bool を実装した(個人的メモ)
まえがき
sqlite3 で JSON を読み込むときにほしかったので作った。忘れないようにメモする
実装
Pythonの型をSQLiteで使うために
sqlite3.register_adapterを使う。
反対に、SQliteからPythonに変換するためには、sqlite3.register_conveterを使う。import sqlite3 # ユーザ定義型 その1 List = list sqlite3.register_adapter(List, lambda l: ';'.join([str(i) for i in l])) sqlite3.register_converter('IntList', lambda s: [str(i) for i in s.split(bytes(b';'))]) # ユーザ定義型 その2 Bool = bool sqlite3.register_adapter(Bool, lambda b: str(b)) sqlite3.register_converter('Bool', lambda l: bool(eval(l)))参考文献
(Py2バージョン)
https://qiita.com/maueki/items/4aae7b2d9a34758ef465
(公式Docs)
https://docs.python.org/ja/3/library/sqlite3.html#using-adapters-to-store-additional-python-types-in-sqlite-databases
- 投稿日:2020-03-20T23:40:54+09:00
【matplotlib入門】COVID-19データから終息時期を読む♬
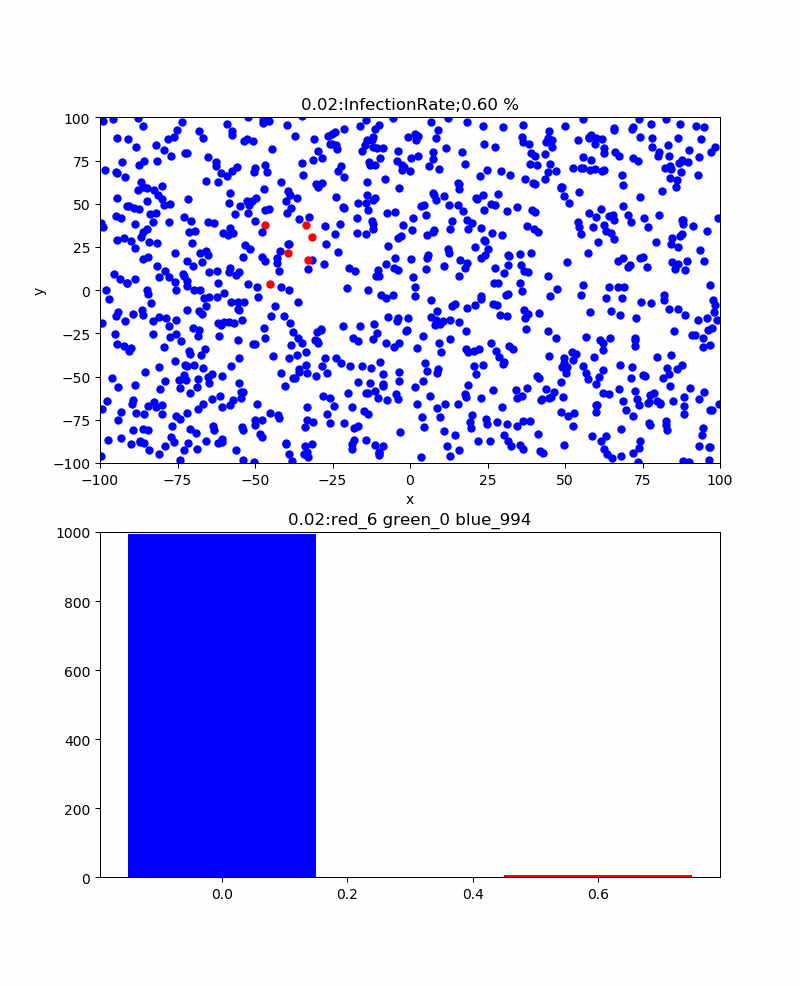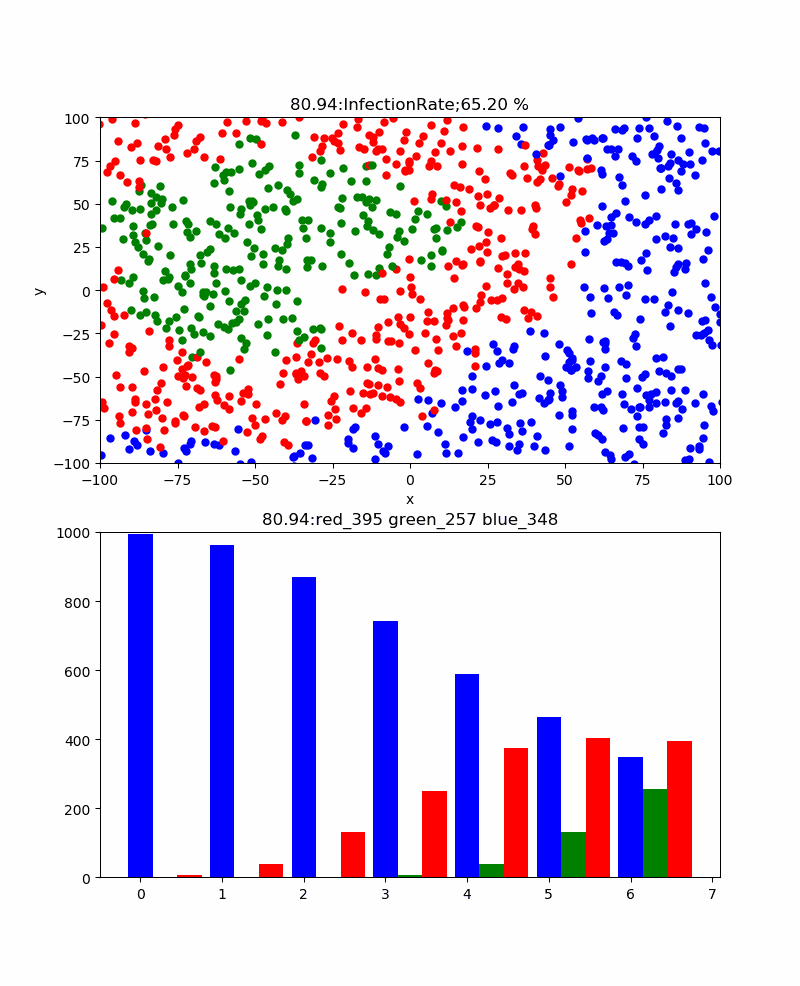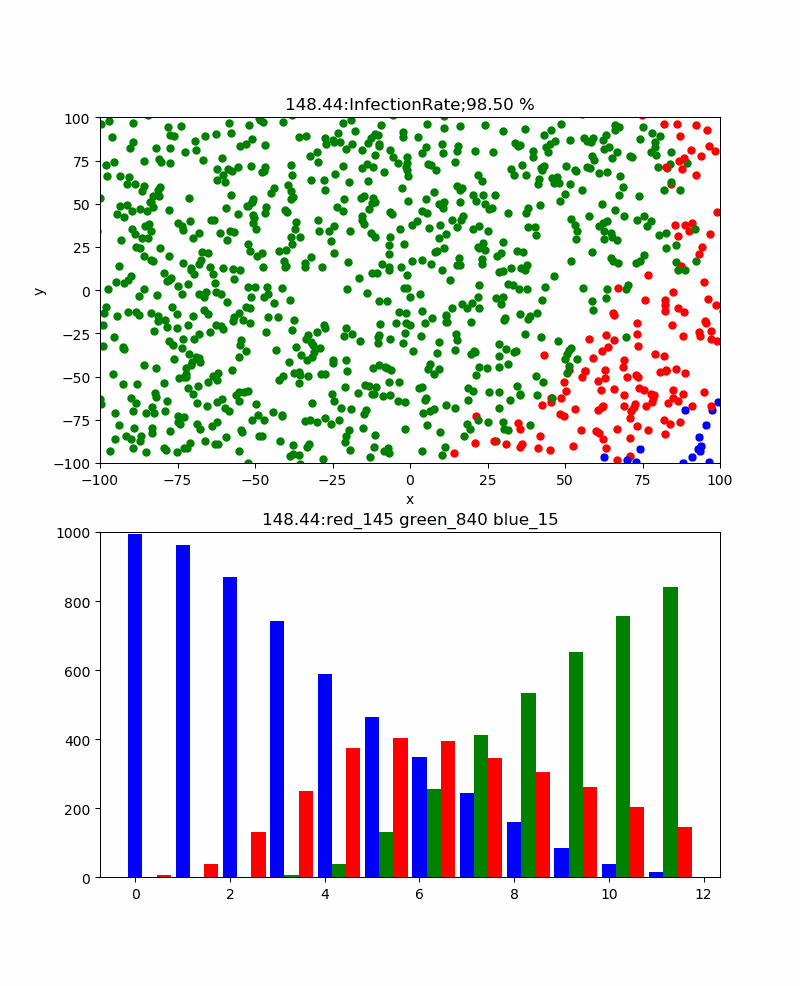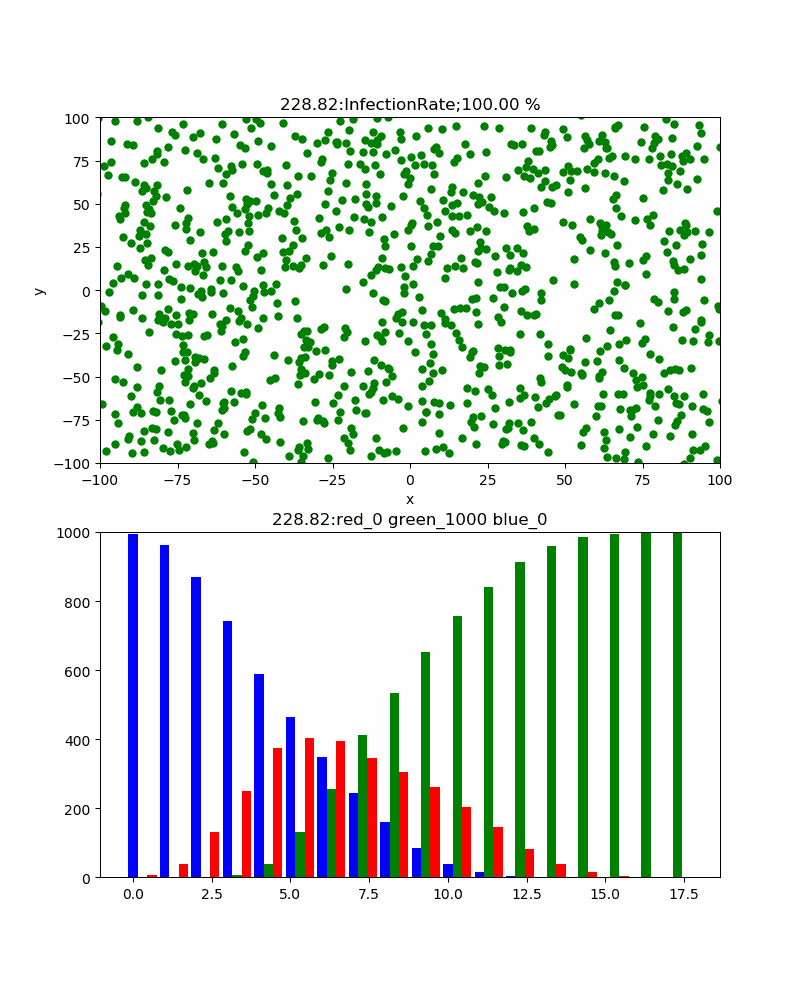
前回の新型コロナのシミュレーションでわかったことがいくつかあるが、よく見るとコロナの感染状況のグラフから、感染のピークを予測可能かもしれないと思わせてくれる。
それは、以下のようなシミュレーションであった。
すなわち、赤い棒グラフが感染数、そして緑の棒グラフが治癒数を表しているが、感染数はどこまで増えるか予測は難しいが、治癒数は感染数に上限値を制限されているために、少なくとも感染数を超えることは無い。しかも、治癒率で表すと終息時にはほぼ100%になるものである。しかも、治癒率は感染ピークに比べて必ず遅れてピークとなる。一見、先にピークが来る感染数のほうが終息を見極めやすそうであるが、このピークは必ずしも上限であるかどうかがわからない。
一方、治癒数は50%辺りが感染のピークになり、だんだんその値に近づいて行くと思われる。
すなわち、この値を追いかければ終息時期がだいたい見えそうである。
という信念で上記のグラフを見ると、治癒が始まるころから感染も飽和に向かっている。
今回は、まず実データが同じような振る舞いをしているかを見てみることとする。
【参考】
・コロナウイルスの感染者数をmatplotlibで可視化してみるやったこと
・コード解説
・各国の感染者数を可視化・コード解説
コードは以下に置いた。
・collective_particles/draw_covid19.py今回は、複数データの可視化方法である。
感染データの可視化のためには、以下のサイトから少なくとも3つのデータを取得する。簡単のためにzipファイルを以下の参考サイトからダウンロードして展開した。
(以下のリンクはファイルのリンクページです。下の参考から一括ダウンロードをおすすめ)
time_series_19-covid-Confirmed.csv
time_series_19-covid-Deaths.csv
time_series_19-covid-Recovered.csv
【参考】
・CSSEGISandData/COVID-19
これらのデータを適当に処理して、上記と同じようなグラフを描画することとします。
以下グラフ描画までを説明します。
まず、以下のLibを利用する。
ここで、今回も環境はJetson-nanoを利用しているが、pandasを新たにインストールした。
参考のとおりであるが、単純なものだとエラーが出たので、最終的に以下のコマンドで入れた。sudo apt-get install python-pandas sudo apt-get install python3-pandasなお、以下のコードはpythonで動いたが、python3だとimport pandasが動かなかった。
※以下のとおり一見動くんだけど??$ python3 Python 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import pandas as pd >>>【参考】
・pipを使わない方法@3分でできるPandasのインストール方法# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt import pandas as pd次に3つのcsvファイルを以下のとおり読込ます。
#pandasでCSVデータ読む。 data = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv') data_r = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv') data_d = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')変数を定義します。
読み込むデータは以下のような構造なので、最初の4つを除いています。
Province/State Country/Region Lat Long 1/22/20 1/23/20 1/24/20 1/25/20 Thailand 15 101 2 3 5 7 Japan 36 138 2 1 2 2 New South Wales Australia -33.8688 151.2093 0 0 0 0 日付は、日数に変更していますね。。。上記参考記事より
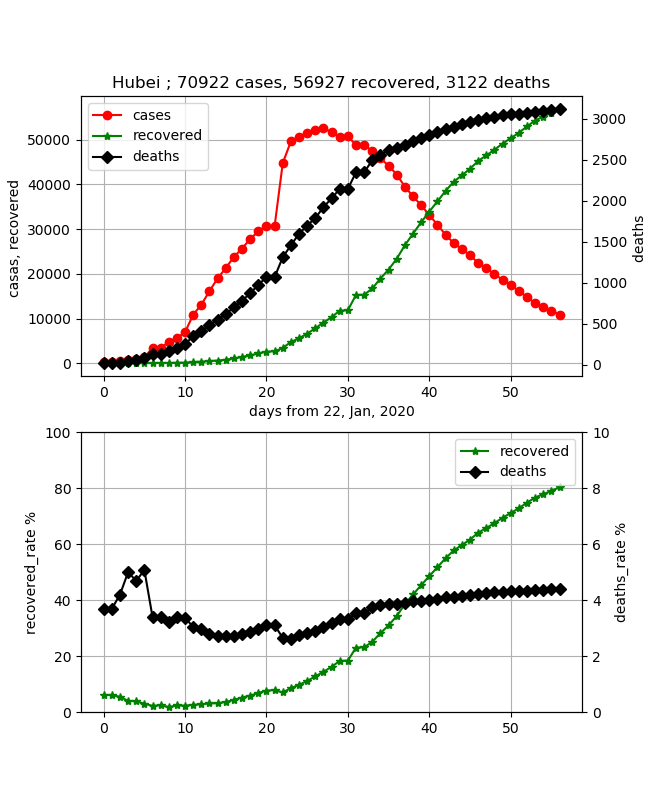
confirmed = [0] * (len(data.columns) - 4) confirmed_r = [0] * (len(data_r.columns) - 4) confirmed_d = [0] * (len(data_d.columns) - 4) recovered_rate = [0] * (len(data_r.columns) - 4) deaths_rate = [0] * (len(data_d.columns) - 4) days_from_22_Jan_20 = np.arange(0, len(data.columns) - 4, 1)今回は武漢のデータを見てみます。
city = "Hubei"以下の最初の変数は、タイトル表示用に総件数、総治癒数、総死亡数を格納するために用意します。
上記のデータを見るとわかるように、州、国と並んでいるので武漢のデータを持ってくるには、if (data.iloc[i][0] == city):とします。国はコメントアウトしたのを使います。
confirmed,confirmed_r,そしてconfirmed_dにそれぞれの日別の数値を格納します。
件数データは累計値になっているので、その日の治癒件数データを引いて当日感染数に変更しています。
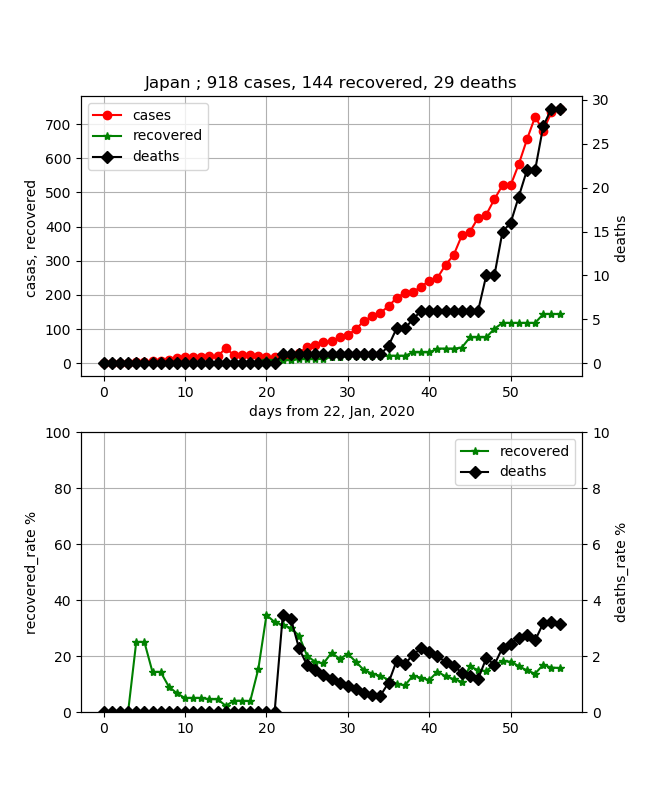
なお、+=の計算は国が同一で異なる地方の合算値を得るのに利用しています。#データを加工する t_cases = 0 t_recover = 0 t_deaths = 0 for i in range(0, len(data), 1): #if (data.iloc[i][1] == city): #for country/region if (data.iloc[i][0] == city): #for province:/state print(str(data.iloc[i][0]) + " of " + data.iloc[i][1]) for day in range(4, len(data.columns), 1): confirmed[day - 4] += data.iloc[i][day] - data_r.iloc[i][day] confirmed_r[day - 4] += data_r.iloc[i][day] confirmed_d[day - 4] += data_d.iloc[i][day] t_recover += data_r.iloc[i][day] t_deaths += data_d.iloc[i][day]今回は、上記の終息を見たいので、治癒率を計算しています。また、気になる死亡率も計算しています。
tl_confirmed = 0 for i in range(0, len(confirmed), 1): tl_confirmed = confirmed[i] + confirmed_r[i] + confirmed_d[i] if tl_confirmed > 0: recovered_rate[i]=float(confirmed_r[i]*100)/float(tl_confirmed) deaths_rate[i]=float(confirmed_d[i]*100)/float(tl_confirmed) else: continue t_cases = tl_confirmed以下でグラフにしています。今回は複数のグラフをまとめて表示できるようにしています。
※この記事の方が汎用性高くていいねもらえそうです
参考上げておきますが、以下のコードでわかりやすいと思います。
【参考】
・Secondary axis with twinx(): how to add to legend?#matplotlib描画 fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2)) ax3 = ax1.twinx() ax4 = ax2.twinx() lns1=ax1.plot(days_from_22_Jan_20, confirmed, "o-", color="red",label = "cases") lns2=ax1.plot(days_from_22_Jan_20, confirmed_r, "*-", color="green",label = "recovered") lns3=ax3.plot(days_from_22_Jan_20, confirmed_d, "D-", color="black", label = "deaths") lns4=ax2.plot(days_from_22_Jan_20, recovered_rate, "*-", color="green",label = "recovered") lns5=ax4.plot(days_from_22_Jan_20, deaths_rate, "D-", color="black", label = "deaths") lns_ax1 = lns1+lns2+lns3 labs_ax1 = [l.get_label() for l in lns_ax1] ax1.legend(lns_ax1, labs_ax1, loc=0) lns_ax2 = lns4+lns5 labs_ax2 = [l.get_label() for l in lns_ax2] ax2.legend(lns_ax2, labs_ax2, loc=0) ax1.set_title(city +" ; {} cases, {} recovered, {} deaths".format(t_cases,t_recover,t_deaths)) ax1.set_xlabel("days from 22, Jan, 2020") ax1.set_ylabel("casas, recovered ") ax2.set_ylabel("recovered_rate %") ax2.set_ylim(0,100) ax3.set_ylabel("deaths ") ax4.set_ylabel("deaths_rate %") ax4.set_ylim(0,10) ax1.grid() ax2.grid() plt.pause(1) plt.savefig('./fig/fig_{}_.png'.format(city)) plt.close()
このデータかなりシミュレーションと比較するにはいいデータになっています。惜しむらくはカウントの仕方を変更した部分が大きく見えてしまっています。
このデータから、シミュレーションでこれを再現できれば、今回の武漢での感染伝播をシミュレート出来ることになります。
そして、治癒率を見てみると50%のところがこの感染伝播のピークであって、その後同程度日数で終息するだろうと予測出来ることがわかります。すなわち感染開始から40日程度でピークとなり、そこから20日程度たった今、あと20日程度で終息しそうです。
また、死亡率はじわじわ上がってきており、約4.5%程度のようです。
これは、新規感染者は増えないけど、単純には死者は最終晩まで発生が続くので致し方ないことだと思います。
※医療手順が整備されだんだん死ななくなるといいと思います・各国の感染者数を可視化
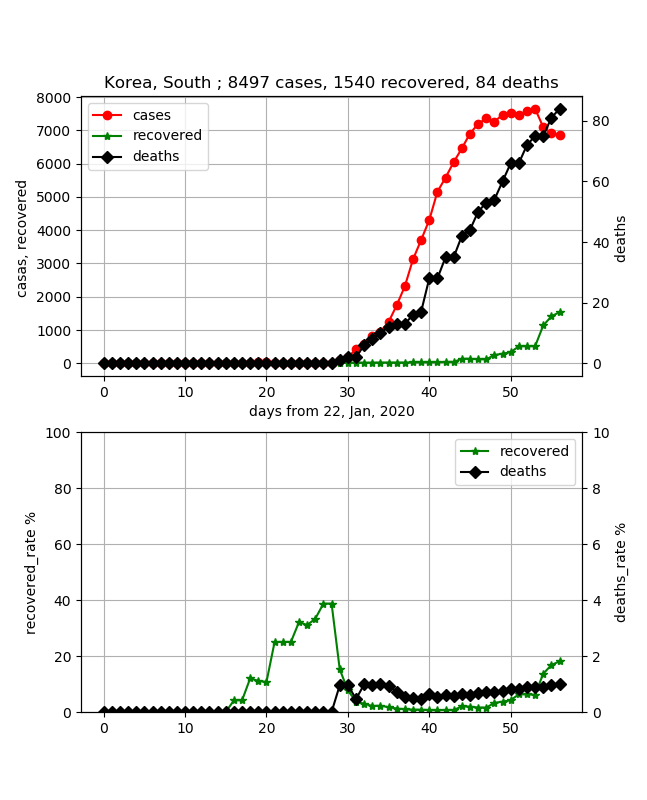
それでは、気になる国の状況を出力して見てみましょう
以下、いろいろコメントを記載しましたが、あくまで素人ウワンがグラフを見ての感想ですのであしからず。・韓国
死亡率は低くていいです。しかし、終息していると聞いていたのですが、感染数はピークに達したようですが、まだまだ治癒率が20%以下であり、予断は許さないかなという印象です。単純に50%までは30日程度かかり、その後50日程度無いと終息までは行かないような感じです。
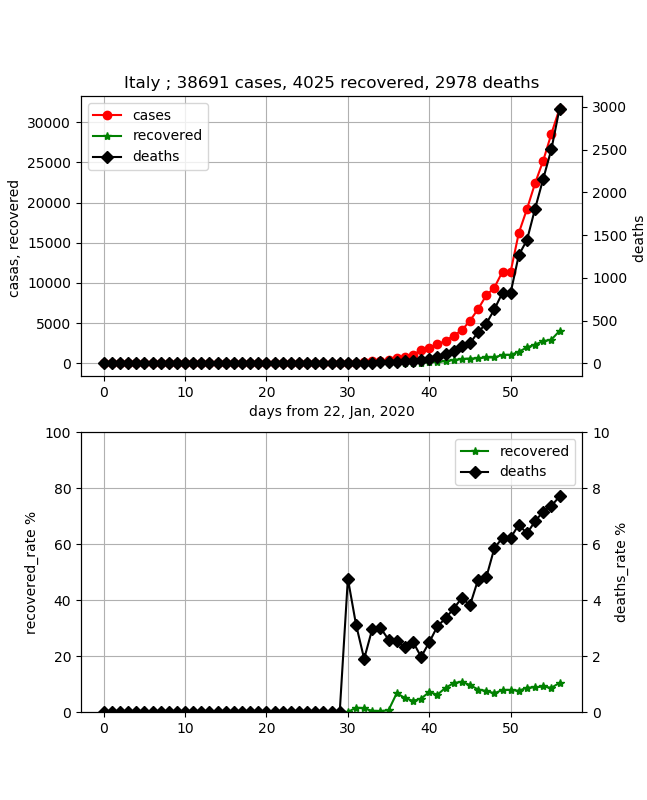
※ここをもう少し定量的に評価できるアプリを作る予定です・イタリア
医療崩壊かと噂があって心配していましたが、データはしっかりしていて安心しました。
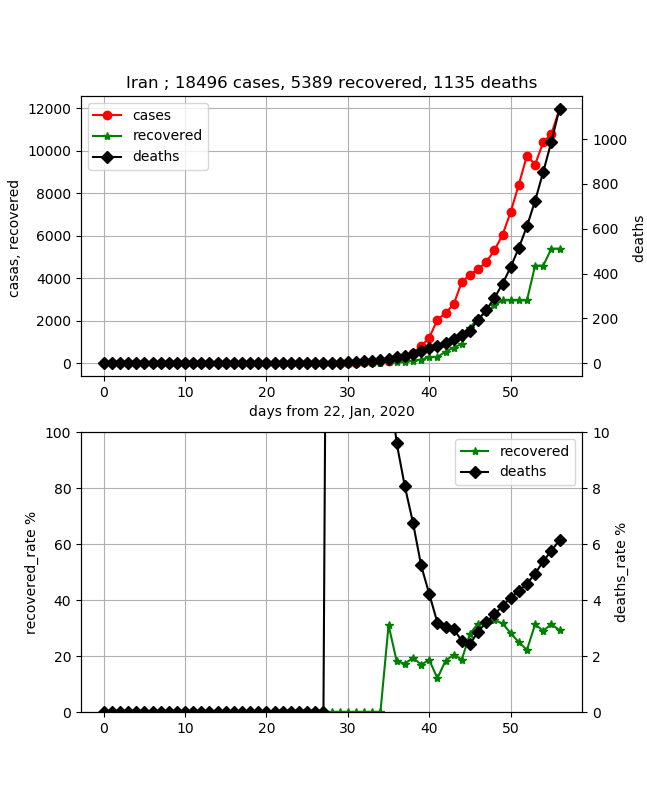
つまり、国として統制が取れていると感じます。しかし、特徴は死亡率がどんどん上がっていて直近約8%と高いです。また、治癒率は約10%程度であり、感染数は約4万人ですが、今まさしく増加の真っ只中であり、終息の目処は立ちません。・イラン
イタリアと並んで心配な国です。やはり、死亡率が異常値でしたが、ここに来てまたまた急激に増加し6%を超えてしまいました。ただし、治癒率が約30%程度まで来たのでもうすぐ感染数のピークが来るのかもしれません。治癒率の増加は遅いですが、そこから治癒数ピークが予測できれば封じ込めまで行ける目処が立ってきます。
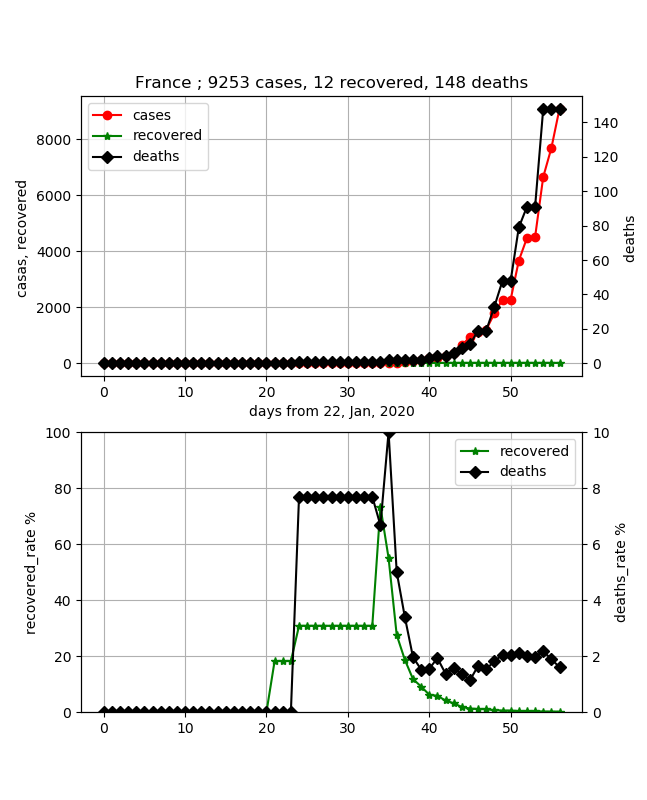
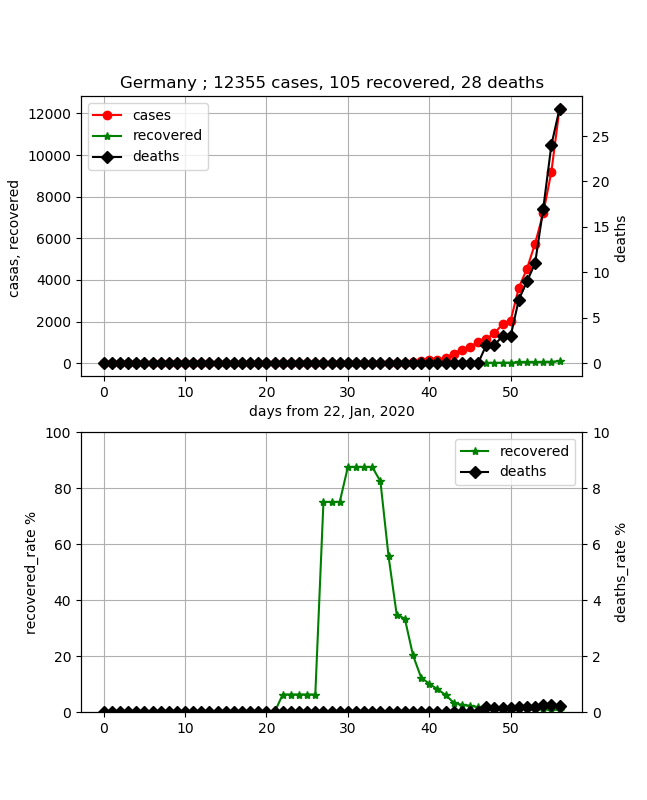
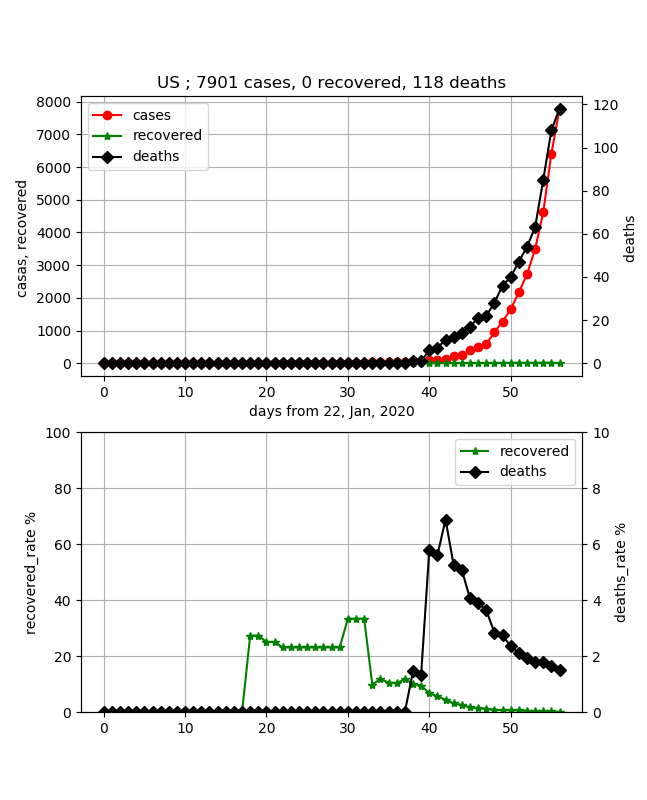
データもしっかりしてきたので医療崩壊ということも大丈夫なようです。・フランス/ドイツ/アメリカ
まとめて示しました。この両国も心配な国です。なぜならば、どちらも件数が上がっていますが、治癒がほとんど0です。急激な感染が予測され、これだと当面終息はしないのではないかと想像できます。
死亡率はフランスは2%と低めですが、ドイツは30名以下で、ほとんど0です。これは感染してから20日もたっていないので、闘病中の方が多いという想像はできますが、推移を見たいと思います。
アメリカも急減に感染数が増えている国です。
アメリカも上記の国と同様に治癒数は0で、死亡率は2%以下で低めに抑えられていますが、これも感染数の立ち上がりから20日程度なので、推移を見たいと思います。・スペイン
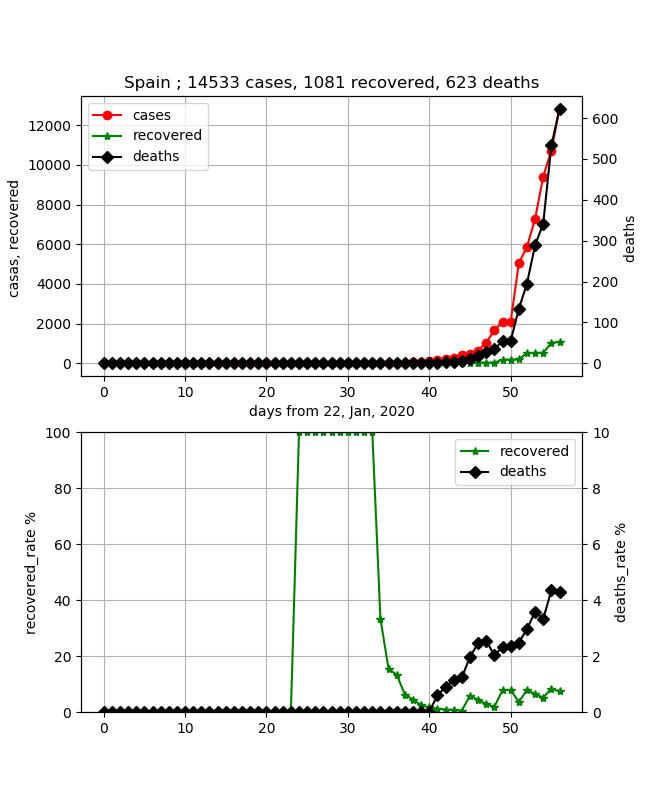
スペインも心配な国の一つです。以下のとおりになっています。
データはしっかりしていて、コントロールされているように感じます。しかし、ここも死亡率が上がってきており、直近は4%を超えてきました。そして治癒率を見ると10%以下であり、感染数はそろそろ1.5万人ですが、まだまだ初期の段階であるとわかります。今後の推移を注視したいと思います。・日本
日本は一番ゆるやかに感染が拡大している国だと思います。
ある意味、中国と両極な印象を受けます。
また、死亡率も低めに抑えられていましたが、徐々に4%に近づいているように見えます。また、治癒率は今18%位に増加してきましたが、すごくゆっくりにしか増加していないので、まだまだ感染ピークも治癒率ピークも見えるところには無いと思います。あと30日位このまま増加すれば見えてくるように思います。ただし、感染数の増加は下に凸の曲線であり、急激な増加につながる可能性もあるので予断は許さないと思います。まとめ
・COVID-19データをプロットしてみた
・複数のグラフを関連付けて出力できた
・シミュレーションから見えることを実データで評価した・シミュレーションを拡張して終息予測が出来るように拡張する
・各国の状況をカテゴライズするアプリを作ろうと思う
- 投稿日:2020-03-20T23:39:26+09:00
Python+OpenCVで品質を指定してJPEG画像生成
参考文献
本記事は以下のページを参考にしています。
1. データ準備
BSDS500というデータセットを使用するため、以下のサイトからダウンロード。
https://github.com/BIDS/BSDS500
P. Arbelaez, M. Maire, C. Fowlkes and J. Malik, "Contour Detection and Hierarchical Image Segmentation," IEEE TPAMI, Vol. 33, No. 5, pp. 898-916, May 2011.今回使用するのは、
BSDS500/data/imagesだけなので、必要なもののみ取り出す。
test内のファイルをtrainに移動する。./data. └── BSDS500 └── images ├── train # train + test = 400 images └── val # val = 100 images2. OpenCVによるJPEG画像の生成(保存)
OpenCVのimwrite関数を使用する。
cv2.imwrite(<save_path>, <img>, [int(cv2.IMWRITE_JPEG_QUALITY), <jpeg_quality>])save_path: 保存先のパス、img: 画像、jpeg_quality: JPEG画像の品質
3. サンプル
. ├── create_jpeg_image.py └── data └── BSDS500 └── images ├── train │ └── gnd └── val └── gndcreate_jpeg_image.pyimport os import cv2 import argparse def save_jpeg_images(src_path, dst_path, q=100): file_list = os.listdir(src_path) dst_path = os.path.join(dst_path, 'q{}'.format(q)) os.makedirs(dst_path, exist_ok=True) for file_name in file_list: im = cv2.imread(os.path.join(src_path, file_name)) cv2.imwrite(os.path.join(dst_path, file_name), im, [int(cv2.IMWRITE_JPEG_QUALITY), q]) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--src_path', default='./data/BSDS500/images/val/gnd') parser.add_argument('--dst_path', default='./data/BSDS500/images/val') parser.add_argument('--q', type=int, default=10) args = parser.parse_args() save_jpeg_images(args.src_path, args.dst_path, args.q)以上
- 投稿日:2020-03-20T23:10:41+09:00
4/30まで無料の「機械学習のためのPython入門講座」をオンライン受講してみよう
はいど~も
今日は「機械学習のためのPython入門講座」をオンライン受講してみようと思います。
こちらは スキルアップAI株式会社 が 一般社団法人日本ディープラーニング協会 と協力しながら展開している、機械学習超初心者のためのオンライン講座です。
本当なら費用5万円程のところ、例のコロナで謹慎中の人々のために 2020/4/30 まで無料で受講できるとのこと!
私も、エンジニアとしては15年ですが機械学習はサッパリなので、真新しい気持ちで受けてみようと思いますついでにせっかくなので、この記事もまた、超絶初心者向けに書いて行こうと思います。
※ ここでは、Windowsパソコンをお使いの前提で解説していきます。申し込む
はい、早速まいりましょうか。
こちらがお申込みホームページです。
https://www.skillupai.com/python_jdla/本講座では、Pythonプログラミング未経験レベルから、scikit-learnを用いて機械学習モデルを構築できるようになることを目指します。
???「新しいこといっぺえ知れんのか? なんだかオラ、わくわくすっぞ!」
…でも本当に超絶初心者だと「えぇ…なんか知らん言葉ばっか並べられて怖いんやが?」ってなりますよね…
まあでも、ここはとりあえず「エンジニア経験のない方でもご受講いただける講座です。」という触れ込みを信じて進みましょう。(受講はいただけるが、クリアできるとは言っていない(!?))
まず、ページ下部に常に追尾で表示されている【お申し込みはこちら】を押しましょう。
(…大丈夫ですよ! 日マタギとか不要ですぐに受講可能ですから、このまま進みましょう!)申し込み情報入力
そうすると、住所・氏名・電話番号・Eメールアドレス・勤務先などを入力する画面になります。
勤務先情報は必須ではないので事情アリの方もご安心下さい。
- 規約に同意 は必須と思いますので、チェックをON。
入力が完了したら【送信】を押しましょう。
講座情報メール受信
成功しますと「スキルアップAI運営事務局」からメールが届きます。
そこには
- 講義資料ダウンロードページのURL
- 講義動画ページのURL
が記載されています。
ひとまず 1. をこなしておきましょうか。
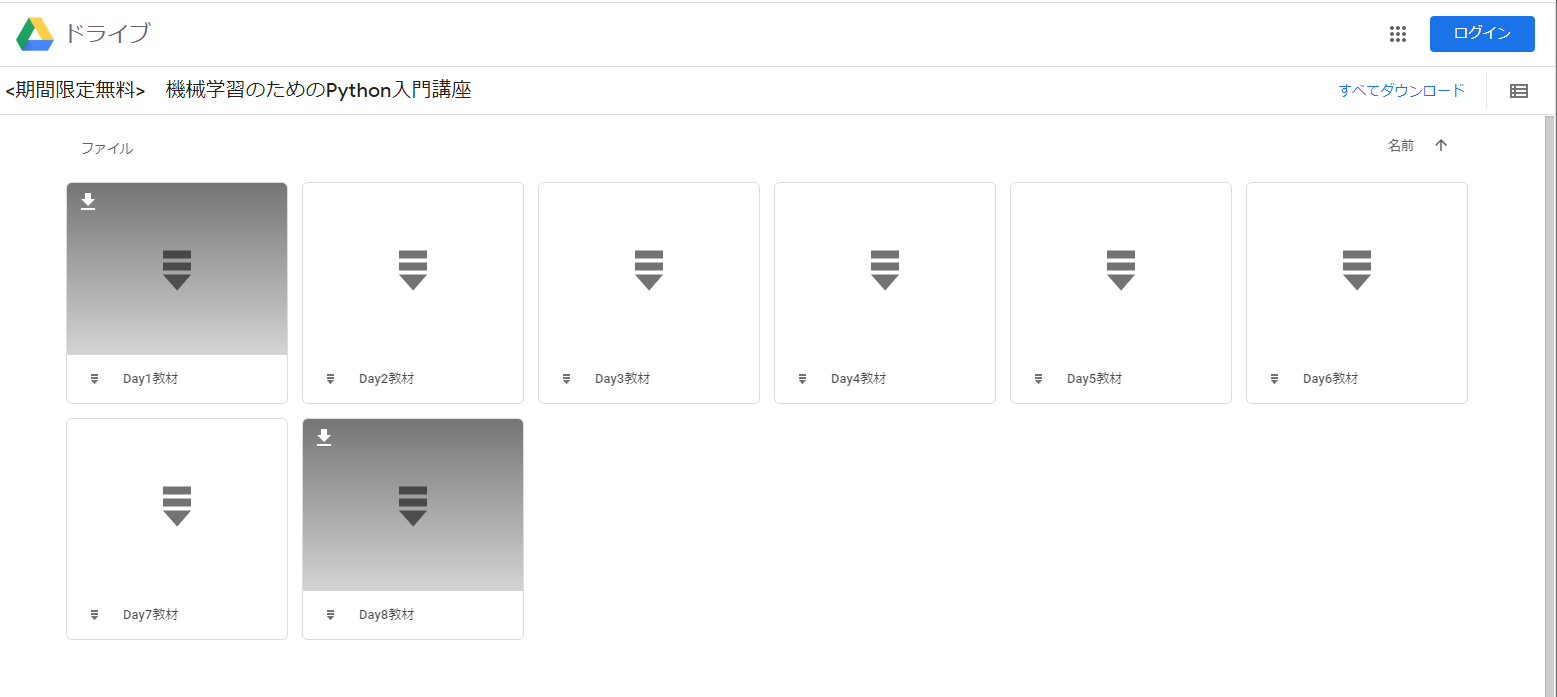
URLをWEBブラウザで開くと、以下のような「講義資料ダウンロードページ」にたどり着きます。
特にIDや権限は必要ないので、遠慮なくすべてダウンロードしてしまいましょう。
講義動画の再生を始める前に
よっしゃ、いざ受講!!
…の前に、ちょっと待って下さい。この講座では
Pythonというプログラミング言語を使います。プログラムコードは、極論を言えば
メモ帳でも書けますが、それを「これはPythonのプログラムコードである」と解釈して実行してくれるソフトがまた必要です。なので、そのセットアップをしましょう。
Anaconda3 をセットアップする
「Anaconda3」とは、Pythonの実行に必要なソフトおよびその他便利機能がセットになったソフトです。
海外製のソフトなので英語ですが、ビビらずまいりましょう!
https://www.anaconda.com/
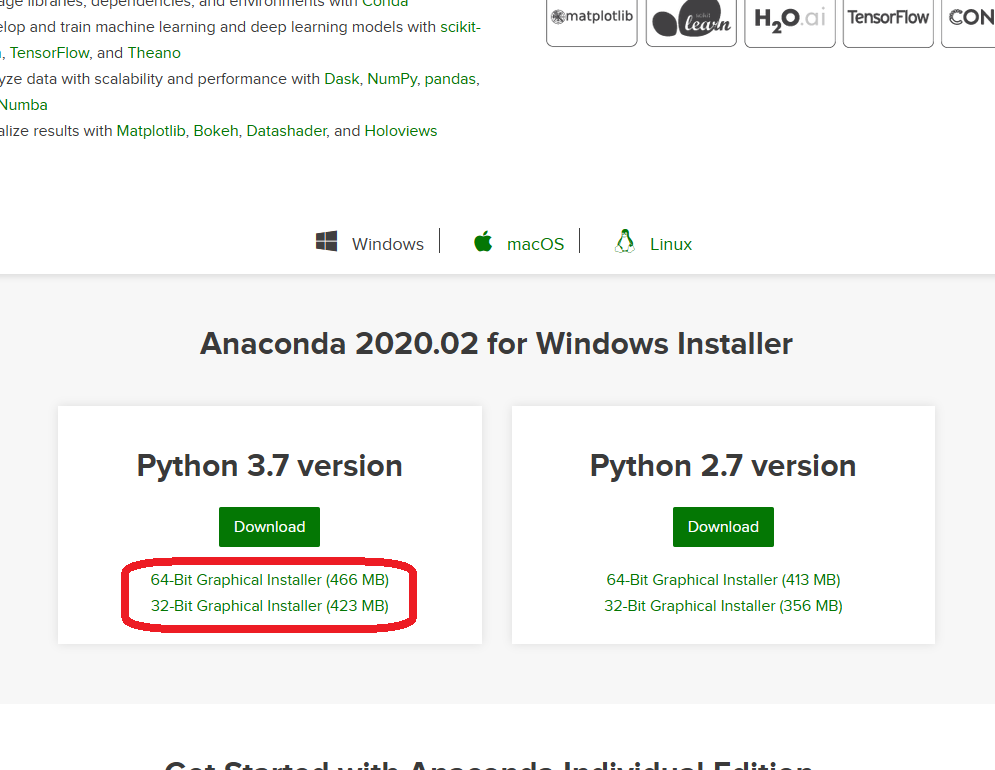
こちらのホームページにアクセスして、画面右上などにデカデカと表示されている【Download】ボタンを押して下さい。ダウンロードページに到着したら、下の方にスクロールしましょう。
ダウンロードリンクがあります。
バージョン
3.xと2.xがありますが、迷わず新しい方3.xで。
また、お使いのパソコンに合わせて64bit版/32bit版どちらかを選択してクリックして下さい。
ダウンロードが始まると思います。
ダウンロードが完了したら、クリックで実行しましょう。
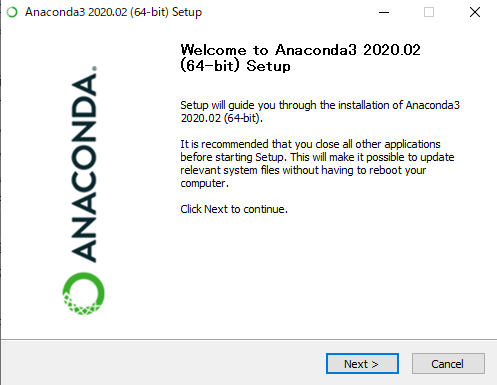
Anaconda3のインストーラーが起動します。
ここは迷わず【Next >】。
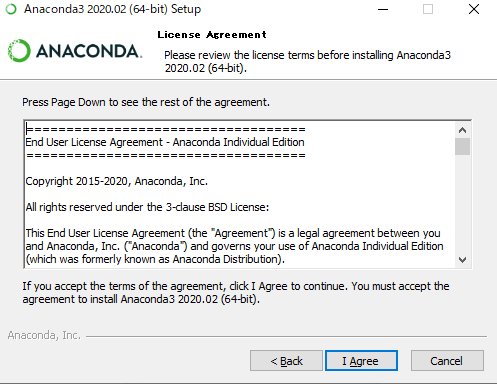
小難しい規約が色々書いてありますが【I Agree】。
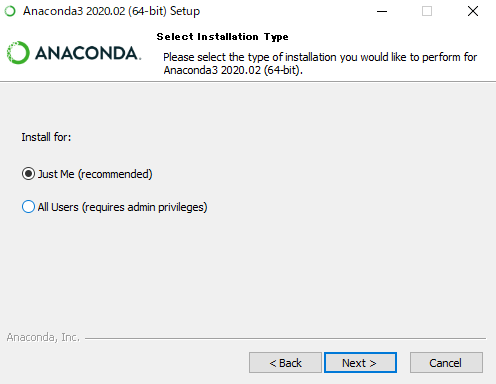
どちらでもOKですが、そのパソコンが自分しか使わないなら【Just Me】で【Next >】でOK。
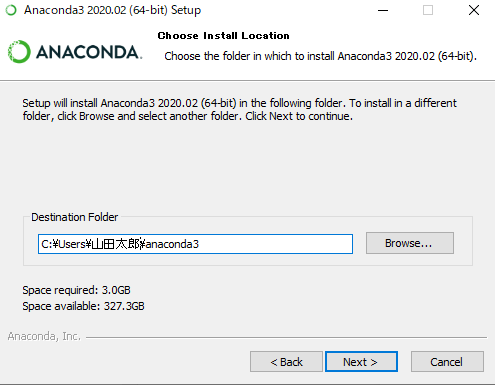
これは「インストールする場所」を聞かれているのですが、一応
C:\anaconda3とかに変更しておいた方が良いかも。
なぜかと言うと、海外製ソフトはたまに、日本語を含むフォルダの下にインストールするとバグる奴がおるので…。
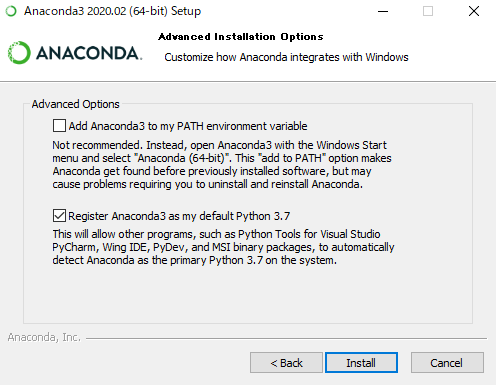
これは何もいじらず【Install】を押しましょう。
そうすると、インストールが始まります。
終わったら【Next >】ボタンが押せるようになるので、押しましょう。
宣伝ですね。
JetBrainsという会社が売ってるPyCharmというPython用プログラミング支援ソフトを勧められています。
とりあえず【Next >】。
やっと最後です。
Anaconda3の使い方を紹介するチュートリアルなどを受けるか聞かれていますが、お好みで。
ここでは “いいえ、結構です” ということで、チェックボックスを外して【Finish】を押します。ふー、これでインストール完了です。
お疲れ様でした。Anaconda3 の付属ソフト Jupyter Notebook を起動する
「また知らない単語が突然出てきたぞ!?」
いやほんとそうですよね…。Jupyter Notebookは、Anaconda3の付属ソフトの1つです。
WEBブラウザでPythonコードを書いて即座に実行できてしまうのです。
今回Anaconda3をインストールしたのは、結局これ(Jupyter Notebook)が目的だったわけです。では起動しましょう。
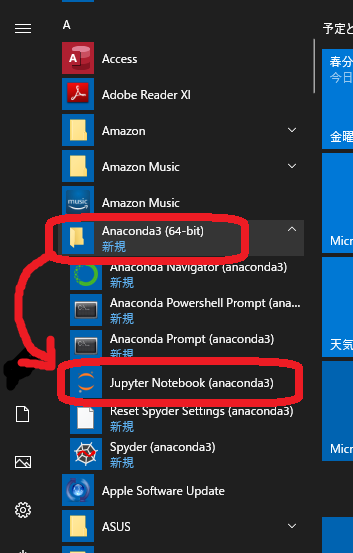
Windowsスタートメニューから
Anaconda3→Jupyter Notebook (anaconda3)をクリック。
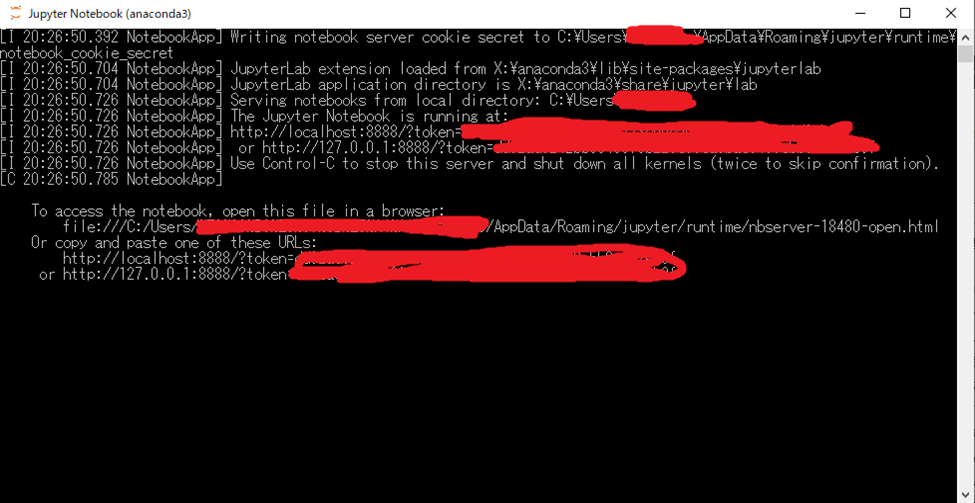
すると、こんな怪しいソフトが起動します…!
ビックリしますね…でもこれ Jupyter Notebook の本体なんです…
なので ✖ で閉じたりしないであげて下さい…
で、
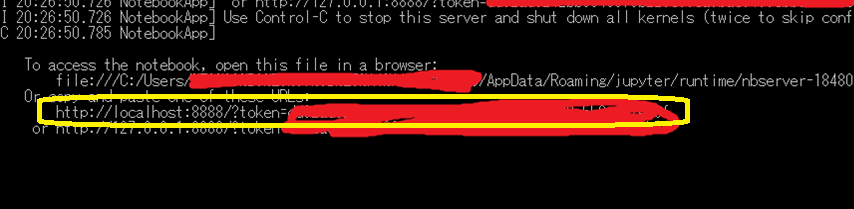
そこに表示されている↑のような
http://localhost:8888/?token=xxxxxxxxxxxxx...
というURLをクリップボードにコピー(マウス左ボタンでその文字列をドラッグして右クリック で、コピーしたことになります)して、WEBブラウザで開きましょう。
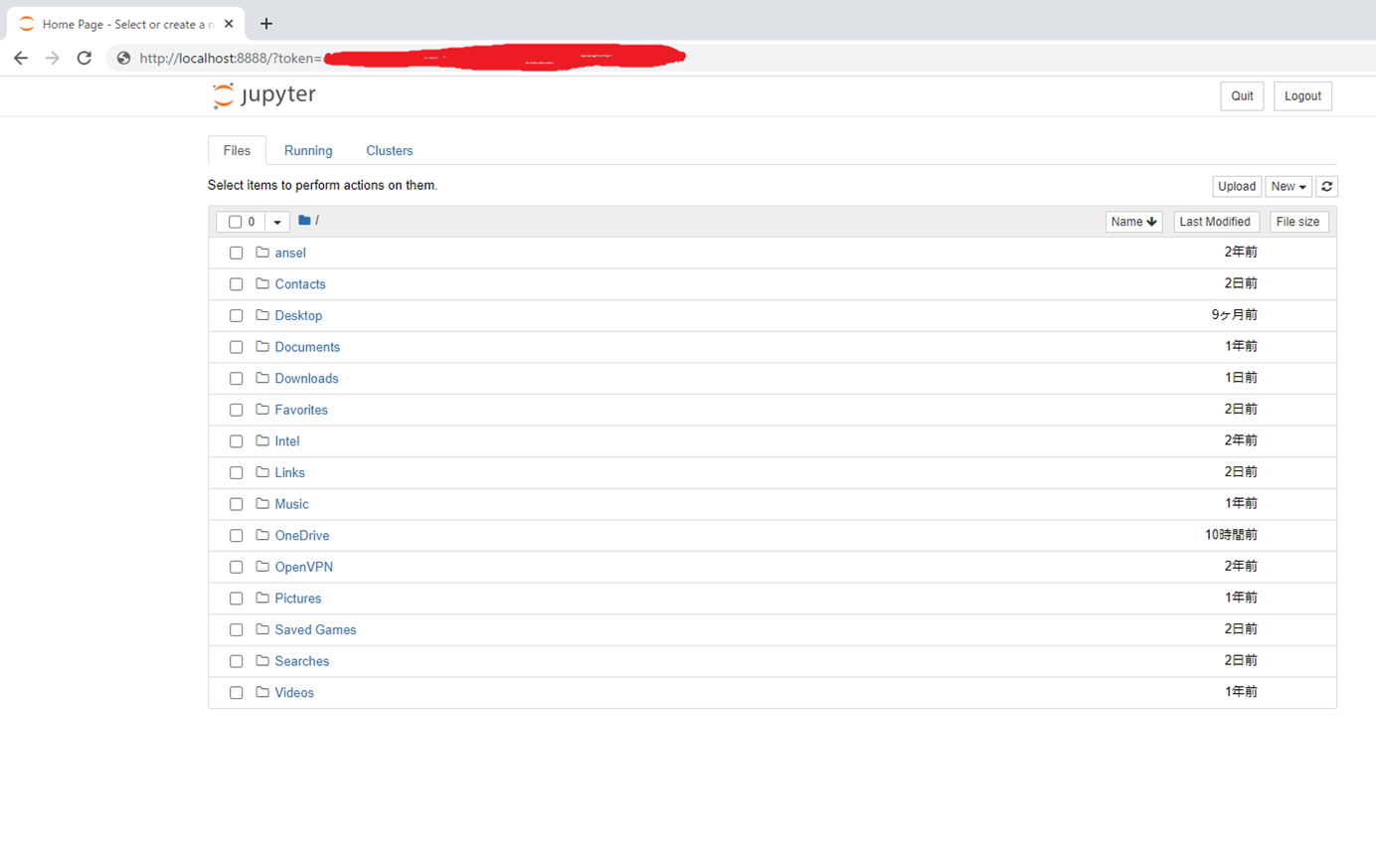
↑このようなページが開きましたでしょうか。
※ 画面中央のリスト内容は、写真と違っても大丈夫です(パソコンによって異なるので)
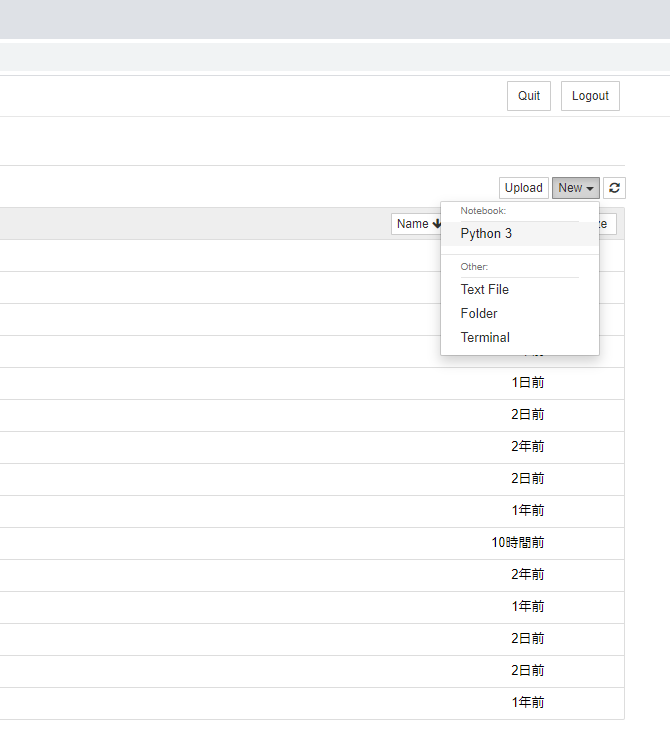
そうしたら、ページの右上らへんにある【NEW ▼】をクリックして、出てきたメニューから
Python 3をクリックします。
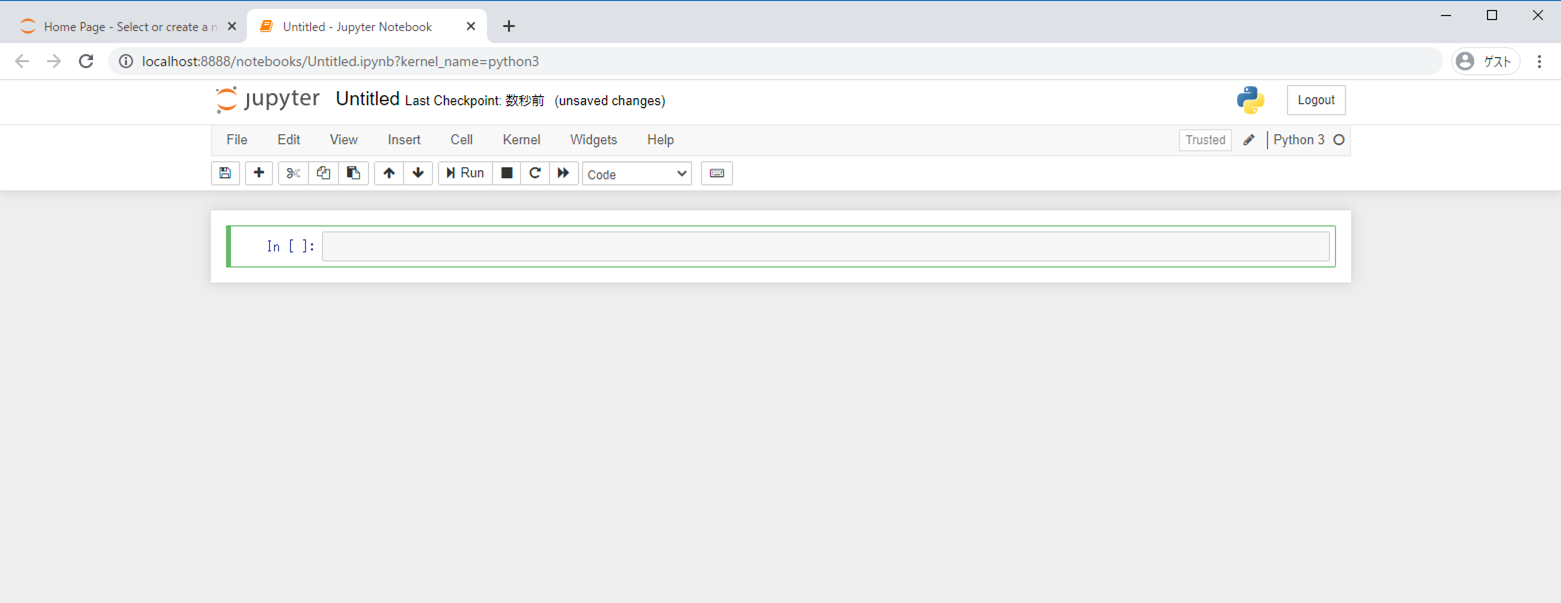
今度は、こんなページにたどり着きましたでしょうか。
実はこれが、目的のソフトです。
ふ~、やれやれ。この
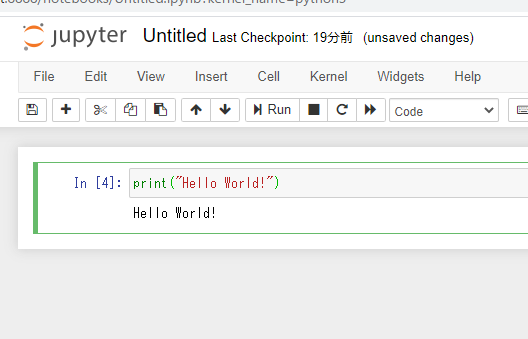
In [ ]:の右のテキストボックスにPythonコードを書くと、なんとその場で解釈して実行してくれます!例えば Hello World! と表示しろ! という
Pythonコードを書くと…
表示されました!
エライ!
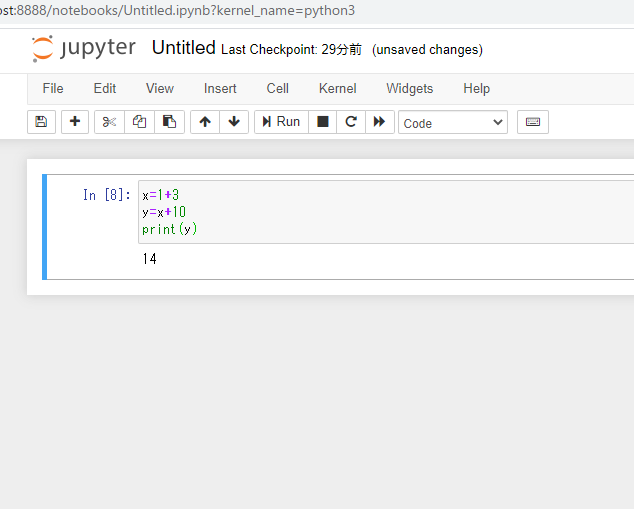
(ちなみに実行はCtrl+Enterです)じゃあ
xに(1+3)を代入して、yに(x+10)を代入して、yの値を表示しろ!
と書くと…
エライ!!
これでやっと、受講準備完了です!
講義動画ページを開く
だいぶ話は戻りますが、
メールに記載されていた講義動画ページのURLをWEBブラウザで開きましょう。
「あとは、動画見ながら自分で実習してね」ということですね。
1時間前後の動画が8本+αくらいあります。
レポート提出などはもちろんありませんので、自分のペースでやってみましょう!
私も今からやってみます
- 投稿日:2020-03-20T22:48:55+09:00
製造現場向けの自動化ツールをPythonで作る時に留意すること
この記事のモチベーション
昨年、生産技術職からデータ分析業に転職し、Pythonを書く機会が多くなりました。今は機械学習用の前処理ツールを開発する案件に携わっています。そんな中、生産技術者として働いていた時のことを顧みると自動化できた作業が色々あったなーと思いました。転職後に得たPythonの知識と生産技術者時代の知見を踏まえて、再び製造現場で働く際に使えそうなネタを記載します。同じようなニーズに直面している方の参考にもなれば幸いです。
本記事は既存技術を組み合わせてこうしたら良さそう!ということを記載したものであり、技術的に目新しいことがない点を初めに断っておきます。自動化する内容
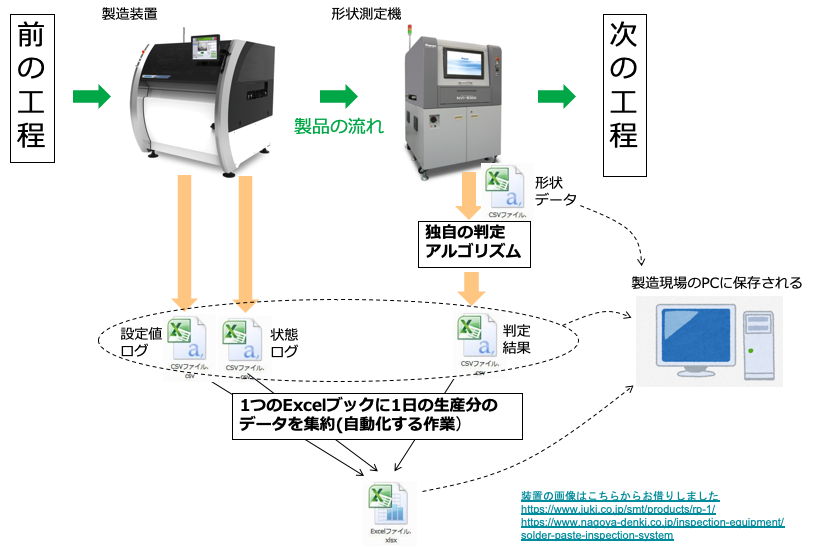
生産技術者として働いていた時に工程から出てくるデータを1日の終わりに集約するという作業がありました。製造装置のログや検査結果を製品ごとにcsvファイルで保存し、1日の終わりに集約してその日の進捗率や不良率を確認します。担当工程では、以下の図のように1つ製品を製造するごとに4つのcsvが出力される仕様になっていました。
◎ 製造装置の設定値ログ
◎ 製造装置の状態ログ
◎ 製品の形状データ
◎ 形状データから算出した判定結果形状を判定する箇所はPythonで作られていたのですが、これは判定方法を私が指示して情シス部のプログラマーに作成を依頼したものです。
上記4つのcsvを毎日1つのExcelファイルに集約していました。つまり4×製造台数 個のファイルをまとめていた訳です。その日の生産終わりからまとめ始めると、完了が夜分になってしまうため、生産の合間に製造員の方に集約いただくようお願いしていました。
当然ですが、この作業は全く人がやる必要ありません。隙間時間にやってもらっていましたが、製品に付加価値を生む作業ではないので、時間を割いてもらうべきではなかったと反省しています。その時間を不良低減のアイデア出しなど(=人にしかできない仕事)に割いてもらうべきでした。今更ではありますが、現在の知識でこの作業を自動化する方法を記載します。
自動化ツールを作成する際に留意すること
Pythonで自動化ツールを作り、製造現場で活用するためにいくつか念頭に置かないといけないことがあります。前提として、生産技術者(=私)がツールを作成し、製造員(=実際に製品を作る方)に使っていただくことを想定します。
◎プログラミング知識ゼロの人が実行できる形にする
製造現場には、生産技術者を含めてプログラミングの知識がある人はほとんどいないと思ったほうが良いです。ツールは基本的にクリックだけで実行できる形で渡しましょう。これは、製造員に手間をとらせない観点からもベターです。また、ツールの動作がPythonのパッケージに依存する場合、「pandasは0.25.1を入れて、openpyxlは3.0.0を入れてください。、、」とお願いするのは無理があります。環境構築なしで実行できる形で渡す必要があります。
◎日常的に変更がありそうな項目はPythonスクリプトに書かない
例えば、現場の都合でデータの保存先を変更することがあります。その場合に、ファイルのパスをPythonスクリプト内に書いてしまうと変更がある度にPythonスクリプトを書き換える必要が発生します。Pythonが読み書きできる人が現場にいないと対応できない事態になります(=その度に現場に呼ばれる事態になります)。
◎現場のPCにpipを使ってパッケージをインストールできないと思ったほうが良い
企業や工場のルールによりますが、製造現場のネットワークはそのライン内、もしくは工場内で閉じおり、外部に繋がっていないことが多いです。製造条件や取得されるデータはメーカーの第一級機密事項なので、万が一にも外部に漏れないように物理的に外部とネットワークが遮断されてることがほとんどだと思います。今やっている案件でも、データを見に顧客の工場に出向いています。
◎動作中にMicrosoft Officeが問題なく使える仕様にする
製造現場のPCにOfficeがインストールされている場合、ツール動作中もOfficeが問題なく使える(=フリーズしない)ことが求められます。と言いますのは、同じPCを使って製造員の方がExcelで日報を書かれたり、過去のデータが集約されたExcelを確認することがあるからです。処理中にOfficeが使えないと評判が激落ちするでしょう(笑)。
◎OSSだけで構成する
生産技術者(ノンプログラマー)が自動化ツールを自作するのでOSSの使用が前提になります。また、顧客にプロダクトとして納入する際も、ツールを引き渡した後は顧客の製造・情シス部門でなるべくメンテしていきたいという理由から、OSSだけで作成することを要求されることがあります。
◎あとは現場(=製造員)の声をよく聞く
全てを包含するようなことを書いてしまいましたが(笑)、それぞれの現場によって要望が異なるのでよくヒアリングしてから作成に取り掛かりましょう。
例えば、上記のcsvファイルを集約する例だと、● 製品毎に処理(つまり、その日の生産が終わると同時に集約も終わっている)
● 生産が終わった後に一括処理の2パターンが考えられます。
こういった細かい仕様は、事前によくヒアリングしてユーザビリティを最大化したいものです。今回は「製品毎に処理する」ことを例に説明します。(注)判定結果が連続してNGの場合、工程異常としてラインを緊急停止する必要があるので、判定自体は製品毎に実施することが基本です。
ツール作製に使えそうな技術
上記のそれぞれの項目に使えそうな技術を記載します。
留意点 対応策 使用するライブラリ プログラミング知識ゼロの人が実行できる形にする ・Pythonスクリプトをexe化する
・ツールはバッチファイルで提供するPyInstaller 日常的に変更がありそうな項目はPythonスクリプトに書かない 変更がありそうな項目は、コマンドライン引数(sys.argvの利用)や設定ファイルから読み込む形式にする sys 現場のPCにpipを使ってパッケージをインストールできないと思ったほうが良い Pythonスクリプトをexe化する PyInstaller 動作中にMicrosoft Officeが問題なく使える仕様にする (例)処理中にExcelが安定して使えるための処置
Excelを長時間操作する場合(大量のテキストを書き込むなど)は、PythonではなくVBScriptを使ったほうがベターopenpyxl
(処理時間が短い個所)生産が終了した段階で処理が終わっているようにする(要望による) 製品毎に処理する watchdog もう少し詳しく説明します。
◎「プログラミング知識ゼロの人が実行できる形にする」への対応
これは、作成したPythonスクリプトをPyInstallerというライブラリを使ってexe化することで可能になります。exe化することで、製造現場での環境構築が不要になります(exeの中に環境が一緒に入っているイメージ)。更にexeをバッチファイルにしてに提供することでユーザーはバッチファイルをダブルクリックするだけでツールを使えるようになります。参考にさせていただいたサイト
● PyInstallerでexeファイル化
● バッチファイルの作成◎「日常的に変更がありそうな項目はPythonスクリプト内に書かない」への対応
変更がありそうな項目はコマンドライン引数(バッチファイルに記載)を使ったり、別途設定ファイルを作成して、そこから読み込む形にしておきます。そうしておけば、現場で変更したい個所が発生した場合にも、バッチファイルをテキストエディタで書き換えれば良いだけなので、Pythonの知識がない人でも対応できます。参考にさせていただいたサイト
Pythonでコマンドライン引数を扱う方法◎「現場のPCにpipを使ってパッケージをインストールできないと思ったほうが良い」ことへの対策
上記1つめの対策と同じ◎「動作中にMicrosoft Officeが問題なく使える仕様にする」への対応
PythonでExcelファイルを操作する場合、openpyxlというライブラリを使うのがスタンダードだと思います。しかし、過去にopenpyxlを使って複数のシートを集約していく作業中に全く関係のない別のExcelファイルを操作できない状態になったことがあります(原因を掴めていません。。)。なので、今回はcsvを集約する箇所はPythonではなく、VBScriptを使うことにしました。Excelに限らず、ツール動作中にMicrosoft Officeが題なく使えることを確認しておいたほうが良いと思います。◎「生産が終了した段階で処理が終わっているようにする」への対策
形状データが格納されるフォルダをwatchdogというライブラリで監視して、データが格納されたタイミングで処理を開始することにします。そうすることで、ユーザーは生産開始前にツールを起動(=バッチファイルをダブルクリック)し、その日の生産が終わった時点でバッチファイルを止める(=Ctrl+C) だけで良くなります。参考にさせていただいたサイト
ファイルの更新をきっかけにコマンド実行 (python編)上記のサイト以外に、
「退屈なことはPythonにやらせようノンプログラマーにもできる自動化処理プログラミング」を参考にしました。実際にコードを書いてみる
以下では、上の留意点を踏まえて複数のcsvファイルを1つのExcelファイルに自動的に集約するコードを記載します。以降はメモだと思ってください。。
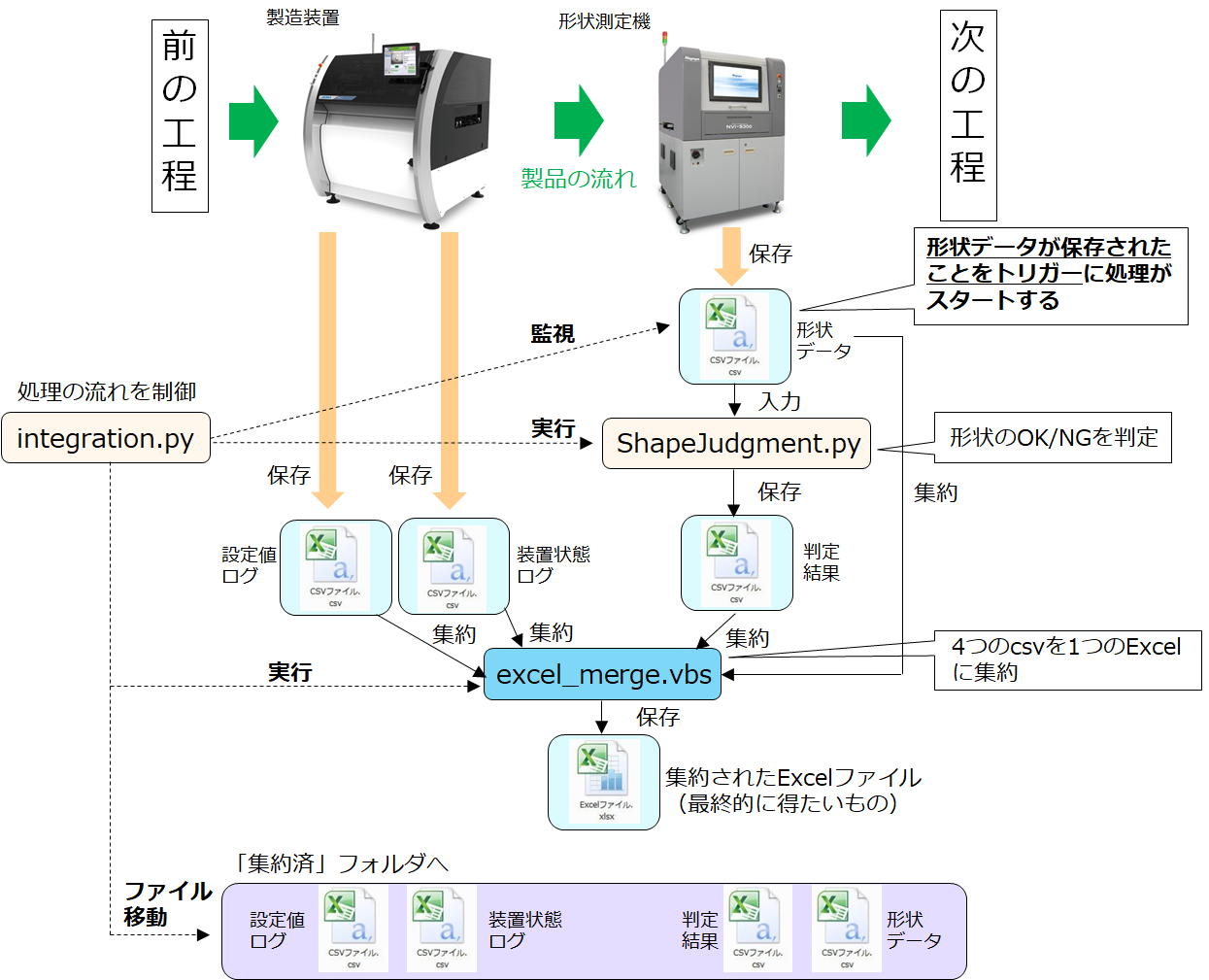
動作内容
以下の図のような処理を考えました。
製品は左から右に流れ、処理は上から下に向かって進むと考えてください。
登場するファイルは5つ、スクリプトは3つです。
ファイル:
◎製造装置から出力される設定値ログ(csv)
◎製造装置から出力される状態ログ(csv)
◎形状測定機から出力される形状データ(csv)
◎形状データを基に算出した判定結果(csv)
◎4つのcsvを集約したExcelこれらのファイルはそれぞれ別のフォルダに保存されます。
スクリプト:
◎integration.py
【役割】
処理の流れを制御する
【動作】
・形状データが保存されるフォルダを監視し、ファイルが発生したら形状を判定する
(=ShapeJudgment.pyを実行する)
・判定結果が保存されたら、csvを集約するexcel_merge.vbsを実行する
・集約が終わったら、csvを「集約済みフォルダ」に移す◎ShapeJudgment.py
【役割】
形状データを基にOK/NG判定する
【動作】
形状データを読み込んで判定結果を保存する
(注)判定結果は品質に直結するので、情シス部門の熟練者が作成したコードを流用◎excel_merge.vbs
【役割】
csvファイルを1つのExcelファイルに集約する
【動作】
csvファイルを読み込んで、Excelファイルのシートとして追加していく
最終的にユーザーに提供するバッチファイルのコマンドライン引数は以下のようにしました。ややこしいですが、、特にややこしいのは、integration.py内で、コマンドライン引数にsys.argv[1]、sys.argv[4]、sys.argv[5]を渡してShapeJudgment.pyを実行している箇所です。ShapeJudgment.py内ではそれらはsys.argv[0]、sys.argv[1]、sys.argv[2]に対応します。
コマンドライン引数を使うことで、Pythonスクリプトに具体的なパスを書く必要がなくなり、パスを変更したい場合はバッチファイルだけを編集すれば良いことになります。
内容 バッチファイル内での位置 integration.py内での対応 ShapeJudgment.py内での対応 integration.exeのパス
(integration.pyをexe化したもの)第0引数 sys.argv[0] - ShapeJudgment.exeのパス(ShapeJudgment.pyをexe化したもの) 第1引数 sys.argv[1] sys.argv[0] 「設定値ログ」が保存されるフォルダの
パス第2引数 sys.argv[2] - 「装置状態ログ」が保存されるフォルダの
パス第3引数 sys.argv[3] - 「形状データ」が保存されるフォルダの
パス第4引数 sys.argv[4] sys.argv[1] 「判定結果」が保存されるフォルダのパス 第5引数 sys.argv[5] sys.argv[2] 「集約されたExcelファイル」が保存されるフォルダのパス 第6引数 sys.argv[6] - excel_merge.vbsのパス 第7引数 sys.argv[7] - 処理の流れは以下のようになります。1製品につき、10ステップの処理を行います。
製品のタクトタイム(流れてくる間隔)に対して、10ステップに要する時間は十分短いという前提で進めます。タクトタイムが短いと、処理中に次の製品が流れてくる事態になるので処理方法を工夫しないといけないと思います。
順 出来事 保存先
(バッチファイルのコマンドライン引数)0 integration.pyで
形状データが保存されるフォルダの監視を開始する1 当該工程に製品が流れてくる 2 製造装置で製品が加工される 3 設定値ログが保存される sys.argv[2] 装置状態ログが保存される sys.argv[3] 4 形状測定機で製品を測定する 5 形状データが保存される sys.argv[4] 6 integration.pyからShapeJudgment.pyが実行される 7 判定結果が保存される sys.argv[5] 8 integration.pyから
excel_merge.vbsが実行される9 集約されたExcelファイルが
保存されるsys.argv[6] 10 integration.pyで
集約済みのcsvを別のフォルダへ移動する各コマンドライン引数の親フォルダ内 11 1に戻る
(次の製品が流れてくる)コード例
実際に動きを確認したコードを記載します。
実行環境
OS:Windows 10 Home バージョン1909
Python 3.7.6
watchdog 0.10.2
openpyxl 3.0.0■処理の流れを制御するスクリプト
integration.py# 必要なライブラリのインポート import datetime import time from watchdog.observers import Observer from watchdog.events import FileSystemEventHandler import subprocess import sys import os import openpyxl import shutil import pathlib # ShapeJudgment.pyとexcel_merge.vbsを実行するクラス class Execute(FileSystemEventHandler): def __init__(self, path): self.path = path def _run_command(self): ''' コマンドライン引数にShapeJudgment.pyのパス(sys.argv[1]), 「形状データ」が保存されるフォルダのパス(sys.argv[4]), 「判定結果」が保存されるフォルダのパス(sys.argv[5]) を指定してShapeJudgment.exeを実行する ''' command = [sys.argv[1],sys.argv[4],sys.argv[5]] subprocess.run(command, shell=True) ''' 集約したExcel(sys.argv[6]内に「日付け+_集約」の名前)がなければ作る 通常、その日の1台目の製品が流れる際に作られる ''' if not os.path.isfile( os.path.join(sys.argv[6], datetime.date.today().strftime('%Y-%m-%d') + "_集約.xlsx")): wb = openpyxl.Workbook() wb.save(os.path.join(sys.argv[6], datetime.date.today().strftime('%Y-%m-%d')) + "_集約.xlsx") ''' 各csv(sys.argv[2] ~ sys.argv[5])を渡して、VBScriptを実行する 集約したExcelはsys.argv[6]内に「日付け+_集約」の名前で保存される ''' command = [r"wscript", sys.argv[7],sys.argv[2], sys.argv[3], sys.argv[4], sys.argv[5],os.path.join(sys.argv[6],datetime.date.today().strftime('%Y-%m-%d'))+"_集約.xlsx"] subprocess.run(command, shell = True) ''' 各csvの保存場所 sys.argv[2] ~ sys.argv[5]の親に「集約済み」フォルダが無ければ作る そして集約し終わったcsvを「集約済み」フォルダに移す 「集約済み」フォルダに既に同じ名前のファイルがある場合はパスする ''' for i in range(2, 6): if not os.path.isdir(os.path.join(pathlib.Path(sys.argv[i]).parents[0], "集約済み")): os.mkdir(os.path.join(pathlib.Path(sys.argv[i]).parents[0], "集約済み")) try: shutil.move(sys.argv[i] + "\\" + os.listdir(sys.argv[i])[0], os.path.join(pathlib.Path(sys.argv[i]).parents[0], "集約済み")) except shutil.Error: pass def on_created(self,event): self._run_command() ''' 検査装置の形状データ(csv)が保存されるフォルダを監視する関数 ファイルが新たに発生したらExecuteクラス内のメソッドが実行される 監視対象は「形状データ」が保存されるフォルダ(sys.argv[4]) Ctrl+Cが押されるまで監視し続ける ''' def watch_shape(path = sys.argv[4]): while True: event_handler = Execute(path) observer = Observer() observer.schedule(event_handler,path,recursive = True) observer.start() try: while True: time.sleep(1) except KeyboardInterrupt: observer.stop() observer.join() if __name__ == '__main__': watch_shape()■形状データに基づきOK/NG判定を保存するスクリプト
ShapeJudgment.pyimport pandas as pd import numpy as np import os import sys import glob # 形状データを基に判定結果を保存する関数 def main(): ''' 形状データを読み込む(同時刻にcsvファイルは常に1つしか存在しない前提) ファイルが無ければpassする sys.argv[1]は形状データが保存されているフォルダのパス ''' try: shape_df = pd.read_csv(os.path.join(sys.argv[1] , glob.glob("*.csv")[0])) except IndexError: pass else: ''' ・・・・・判定アルゴリズムが動作・・・・・ ここは品質に直結する箇所なので、判定方法を指定した上で 情シス部の熟練者に書いてもらう ''' ''' 判定結果(judgment_df)を保存する sys.argv[2]は判定結果を保存するフォルダのパス ファイル名は「判定結果_形状データ.csv」 ''' judgment_df.to_csv(os.path.join(sys.argv[2], "判定結果_"+glob.glob("*.csv")[0])) if __name__ == '__main__': main()■4つのcsvファイルを1つのExcelファイルに集約するスクリプト
excel_merge.vbs'-------------------------------------------------------------------------------------- ' ' 装置から出力されるcsvファイルをシートごとに1つのExcelファイルにまとめる ' ' ' 注意点 スクリプト実行中は集約するExcelファイルを開かないでください。 ' スクリプト実行前に集約するExcelファイルのロックを解除してください(読み取り専用でない状態)。 ' 製造装置、検査装置の出力先フォルダにはcsvファイル以外を入れないでください ' このスクリプトが異常終了した場合はExcelのプロセスを手動で終了してください。 ' ' '-------------------------------------------------------------------------------------- Option Explicit Dim fileSystem Dim targetFolder Dim fileList Dim Excel Dim merge_Workbook Dim objWorkbook Dim objSheet Dim wkFile Dim i 'sys.argv[2] = WScript.Arguments(0) : 製造装置の設定値ログ(csv)があるフォルダのパス 'sys.argv[3] = WScript.Arguments(1) : 製造装置の状態ログ(csv)があるフォルダのパス 'sys.argv[4] = WScript.Arguments(2) : 検査装置の形状データ(csv)があるフォルダのパス 'sys.argv[5] = WScript.Arguments(3) : 検査装置の判定結果(csv)があるフォルダのパス 'sys.argv[6] = WScript.Arguments(4) : 上記csvを集約したExcelファイルのパス 'Excelオブジェクトを開く Set Excel = CreateObject("Excel.Application") 'Excelの表示設定(この設定をしておけば処理中にExcelが開いたり閉じたりしない) Excel.Visible = False Excel.DisplayAlerts = False Excel.ScreenUpdating = False '集約するWorkbookを読み込む Set merge_Workbook = Excel.Workbooks.Open(WScript.Arguments(4)) 'ファイルごとにループする For i = 0 To 3 '集約するcsvのファイル数だけループする '各フォルダのファイル一覧を取得する(ファイルは1つしかない前提だが一応) 'ファイルシステムを扱うオブジェクトを作成 Set fileSystem = CreateObject("Scripting.FileSystemObject") Set targetFolder = fileSystem.getFolder(WScript.Arguments(i)) Set fileList = targetFolder.Files For Each wkFile In fileList Set objWorkbook = Excel.Workbooks.Open(WScript.Arguments(i) & "\" & wkFile.Name) 'シートオブジェクトを取得(コピー元のファイルのシートは1つという前提) Set objSheet = objWorkbook.Sheets(1) 'シートオブジェクトを取得(コピー元のファイルのシートは1つという前提) objSheet.Copy ,merge_Workbook.Sheets(merge_Workbook.Sheets.Count) 'シート名はcsvファイルのファイル名とする(".csv"は削除する) 'merge_Workbook.Sheets(merge_Workbook.Sheets.Count).Name = replace(wkFile.Name,".csv","") 'csvファイルを閉じる objWorkbook.Close Set objWorkbook = Nothing Next Next '初めの回だけSheet1を削除する If merge_Workbook.Sheets.Count < 6 Then 'Sheet1を指定して削除 merge_Workbook.Sheets(1).Delete End If 'はじめのシートをアクティブシートに設定 merge_Workbook.Sheets(1).Activate '集約するWorkbookを上書き保存 merge_Workbook.Save '集約するWorkbookを閉じる merge_Workbook.Close Set merge_Workbook = Nothing 'Excelの終了 Excel.ScreenUpdating = True Excel.Quit Set Excel = Nothing以上のコードを動かすと、(4×製造台数)個のcsvファイルが1つのExcelファイルに集約されます。
このまとめ方はかなりイケていませんが、あくまで例ということで(笑)
バッチファイルの作り方
次にバッチファイルを作る方法について説明します。
バッチファイルは2段階の順を踏んで作ります。1. Pythonスクリプトをexe化する
2. 各種パスをコマンドライン引数としてバッチファイルを作るまず1.のexe化ですが、前述のとうりPyinstallerを使って行います。
コマンドプロンプトでintegration.pyとShapeJudgment.pyが存在するディレクトリに移動した上で以下のコマンドを実行してください。$ pyinstaller integration.py --onefile $ pyinstaller ShapeJudgment.py --onefileすると、
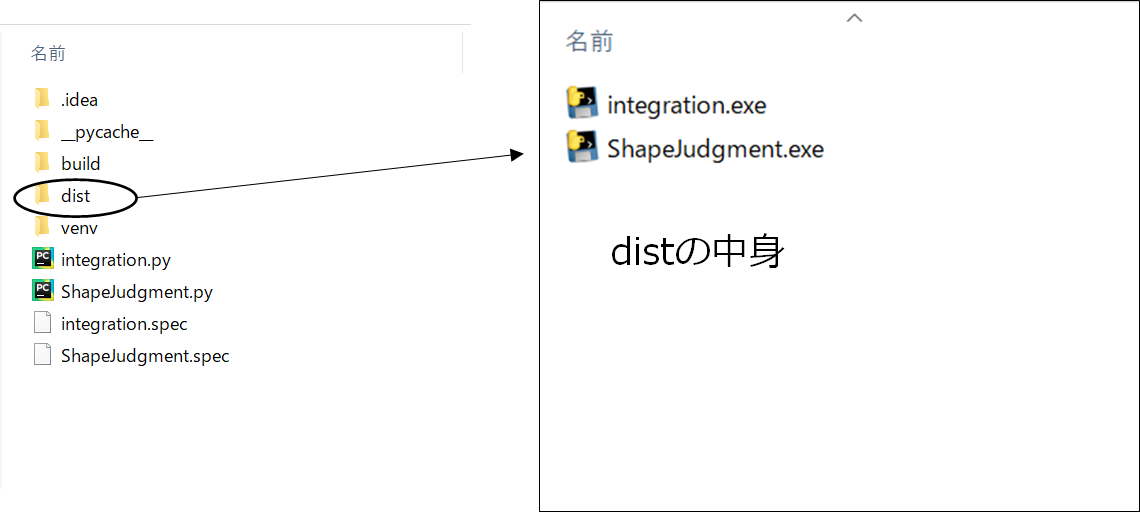
44536 INFO: Building COLLECT COLLECT-00.toc completed successfully.というメッセージが表示された後、同じディレクトリにdistというフォルダが作成されます。そのフォルダの中にintegration.pyとShapeJudgment.pyがそれぞれexe化された
integration.exeとShapeJudgment.exeが入っています。
次に2.のバッチファイルの作成を行ます。
以下の内容をメモ帳などのテキストエディタに書いて、拡張子を「.bat」にして保存してください。1行目はコメントです。それぞれのパスの間には半角スペースが入ることに注意してください。また^(キャレット)は改行する際に必要な記号です。実行ファイル.bat@rem integration.exe実行するbatファイル "integration.exeのパス" ^ "ShapeJudgment.exeのパス"^ "「設定値ログ」が保存されるフォルダのパス"^ "「装置状態ログ」が保存されるフォルダのパス"^ "「形状データ」が保存されるフォルダのパス"^ "「判定結果」が保存されるフォルダのパス"^ "「集約されたExcelファイル」が保存されるフォルダのパス"^ "excel_merge.vbsのパス" ↓記載例 @rem integration.exe実行するbatファイル "C:\Users\PycharmProjects\untitled2\dist\integration.exe" ^ "C:\Users\PycharmProjects\untitled2\dist\ShapeJudgment.exe"^ "C:\Users\input\製造装置ログ\製造装置の設定値ログ"^ "C:\Users\input\製造装置ログ\製造装置の状態ログ"^ "C:\Users\input\検査装置ログ\検査装置の形状データ"^ "C:\Users\input\検査装置ログ\検査装置の判定結果"^ "C:\Users\output\集約したExcelファイル"^ "C:\Users\VBS\excel_merge.vbs"3行目~10行目はそれぞれintegration.py内に書いたsys.argv[1] ~ sys.argv[7]に対応しています。
結局、何を製造現場のPCに入れれば良いのか?
色々ファイルが出てきたのですが、最終的に製造現場のPCに入れるファイルは以下の4つです。当然ですが、バッチファイルに書いたパスは製造現場のPCに合わせて変更してください。
その日の生産開始前に製造員の方に「実行ファイル.bat」をダブルクリックしてもらいます。すると製品が流れる度に4つのcsvファイルが1つのExcelファイルに自動的に集約されます。生産終了後に「Ctrl+C」を押してもらいバッチファイルを止めます。その時点でExcelファイルへの集約が完了しているというわけです。
以上の処理は一例ですが、
上に書いたライブラリを使って製造現場でニーズがある色々な自動化に対応できそうです。注意点
上記方法にはいくつか注意点がありますので、記載しておきます。
■exeファイルが巨大になることがある
Pyinstallerを使ったexe化では、作成時のPython環境にあるライブラリが全て取り込まれてしまいます。そのためファイルサイズが巨大化し、exeの動作が遅くなることがあります。これを避けるために、使わないライブラリを除いてexe化するのが良いです。特定のライブラリを除いてexe化する方法は、以下の記事が参考になります。
Pythonで組んだプログラムをPyInstallerでexe化したらめちゃくちゃサイズがでかくなった件【2019年6月、解決策追記】■集約されたExcelファイルを生産中に確認できない
書き込み動作をしている最中にExcelファイルを開いていると、書き込みエラーが発生します。なので、生産中に集約されたExcelファイルを確認したい場合は、別途コピーしてそちらを開く必要があります。所感
昨今、プログラミングのハードルが格段に下がってきているので、ノンプログラマーがプログラミングを使って業務の自動化を行う機会が多くなると思います。その際に重要になるのは、プログラミングスキルよりも現場のニーズをきちんと把握するコミュニケーション能力と、「現場で使えるツール」を作る姿勢かもしれません。


- 投稿日:2020-03-20T22:48:35+09:00
コマンドラインで AtCoder のテストケース取得、テスト、提出までを行う
はじめに
atcoder-cli, online-judge-tools でターミナル上 (Mac) でテストケース取得、テスト、提出まで行う手順です。
事前準備
必要なツールのインストール
$ pip3 install online-judge-tools $ npm install -g atcoder-cli $ pip3 install seleniumツールで AtCoder へログイン
$ acc login $ oj login https://atcoder.jp/設定
全部の問題ディレクトリが作られるようにする。例えば、AtCoder Begginer Contest の場合、acc new abcXXX コマンドで a ~ f の問題が作成されるようにする
$ acc config default-task-choice allconfig ディレクトリの場所を表示
$ acc config-dirテンプレート設定を行う。config ディレクトリに template 名のフォルダを作成し、その中にテンプレートのソースコード (例:
main.py)と、テンプレートの設定ファイル(template.json)を作成する。# config ディレクトリへ移動 $ cd /Users/xxxxxxxxxx/Library/Preferences/atcoder-cli-nodejs $ mkdir py $ cd py $ touch main.py template.json # 問題のディレクトリを作った時に、main.py が作成され、提出対象も main.py とする $ vim template.json $ cat template.json { "task":{ "program": ["main.py"], "submit": "main.py" } } # main.py が作成された時のデフォルト設定を編集する。 # `#!/usr/bin/env python3` は必要。自分の場合はよくある入力パターンをデフォルトで書き込んでいる。 $ vim main.py $ cat main.py #!/usr/bin/env python3 S = input() N = int(input()) S = input().split() A, B, C = input().split() L = list(map(int, input().split())) H, N = map(int, input().split()) # デフォルトのテンプレートの設定を py にする (py ディレクトリで設定したファイルが適用) $ acc config default-template py # テンプレートの確認 $ acc templates search template directories in /Users/xxxxxxxxxx/Library/Preferences/atcoder-cli-nodejs NAME SUBMIT-PROGRAM py main.pyディレクトリ作成
下記の例は、AtCoder Bergginer Contest 154 のディレクトリを作成する場合。
main.pyとテストの入力と出力のファイルが作成される。$ acc new abc154 $ tree . ├── a │ ├── main.py │ └── tests │ ├── sample-1.in │ ├── sample-1.out │ ├── sample-2.in │ └── sample-2.out ├── b │ ├── main.py │ └── tests │ ├── sample-1.in │ ├── sample-1.out │ ├── sample-2.in │ ├── sample-2.out │ ├── sample-3.in │ └── sample-3.out ├── c │ ├── main.py │ └── tests │ ├── sample-1.in │ ├── sample-1.out │ ├── sample-2.in │ ├── sample-2.out │ ├── sample-3.in │ └── sample-3.out ├── contest.acc.json ├── d │ ├── main.py │ └── tests │ ├── sample-1.in │ ├── sample-1.out │ ├── sample-2.in │ ├── sample-2.out │ ├── sample-3.in │ └── sample-3.out ├── e │ ├── main.py │ └── tests │ ├── sample-1.in │ ├── sample-1.out │ ├── sample-2.in │ ├── sample-2.out │ ├── sample-3.in │ ├── sample-3.out │ ├── sample-4.in │ └── sample-4.out └── f ├── main.py └── tests ├── sample-1.in ├── sample-1.out ├── sample-2.in └── sample-2.out 12 directories, 41 filesテスト
プログラムが完成したら online-judge-tools にてテストを行う (atcoder-cli にはテストのコマンドは無い)
$ oj t -c "python3 main.py" -d ./tests/提出
問題のディレクトリにて下記コマンドを行うことで自動で AtCoder のページに飛んで提出する。
$ acc s参考
- 投稿日:2020-03-20T22:27:36+09:00
LINE BOT(雑談)を作る
A3RTを使って雑談LINEBOTを作る
前回作成したLINE BOT(オウム返し)を作るを改良して、リクルートが提供しているA3RTのTalk APIを使って雑談するBOTを作った。
(1)A3RTからAPIKEYを取得する
A3RTのサイトで、APIKEYを発行する。
(2)A3RTの構造を確認する
前回作成したmain.pyを修正する前にA3RTの構造を確認する。
A3RTの構造を確認するために以下のコードを実行して、"おはよう"に対する回答をAIがちゃんと返してくれるか確認する。
まず、仮想環境でpya3rtをインストールして、pip install pya3rt以下をターミナルのpythonモードで実行してみる。
import pya3rt apikey = "*******************************" client = pya3rt.TalkClient(apikey) reply_message = client.talk("おはよう") print(reply_message){'status': 0,'message': 'ok','results': [{'perplexity': 0.07743213382788067, 'reply': 'おはようございます'}]}となる。
replyの"おはようございます"を取得したいので、以下のように修正import pya3rt apikey = "****************************" client = pya3rt.TalkClient(apikey) reply_message = client.talk("おはよう") print(reply_message['results'][0]['reply'])すると、
おはようございますとなり、ちゃんと"おはよう"→"おはようございます"と返してくれた。
これを前回作成したmain.pyに組み込む。(3)前回作成したmain.pyを修正
まず、上記のpya3rtの記述を以下のように関数化する。
def talk_ai(word): apikey = "****************************" client = pya3rt.TalkClient(apikey) reply_message = client.talk(word) return reply_message['results'][0]['reply']前回作成したmain.pyを修正する。
main.pyfrom flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) import os #追加 import pya3rt app = Flask(__name__) YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) @app.route("/") def hello_world(): return "hello world!" @app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: print("Invalid signature. Please check your channel access token/channel secret.") abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): #(追加)talk_aiメソッドに引数を渡して返り値をai_messageに代入 ai_message = talk_ai(event.message.text) line_bot_api.reply_message( event.reply_token, #TextSendMessage(text=event.message.txt)) #(修正)ai_messageを返すようにする TextSendMessage(text=ai_message)) #(追加)pya3rtでai会話を返信 def talk_ai(word): apikey = "****************************" client = pya3rt.TalkClient(apikey) reply_message = client.talk(word) return reply_message['results'][0]['reply'] if __name__ == "__main__": port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)修正できたらrequirements.txtを更新して、
pip freeze > requirements.txtあとは、Herokuにデプロイすれば完成。
- 投稿日:2020-03-20T22:11:51+09:00
リストからNoneを削除する
いくつか方法はあるが、個人的には以下のやり方が好み。
array = [None, 0, 1, 2] list(filter(None.__ne__, array)) # [0, 1, 2]
ちなみに次の方法だと
0も消えてしまうので注意。array = [None, 0, 1, 2] list(filter(None, array)) # [1, 2]
追記
ベンチマーク取った結果、微妙な差ですが内包表記の方が速いようです。
こっちの方がPythonっぽいかも。array = [None, 0, 1, 2] [x for x in array if x != None] # [0, 1, 2]
- 投稿日:2020-03-20T21:35:10+09:00
IBM Cloud Object Storage(ICOS)に付属しているAsperaにSDK(Python版)を用いてファイルアップロードする
IBM Cloud Object Storage(ICOS)にファイルをアップロードする方法です。
今回はICOSに付属しているAsperaに対して、Python版のSDKを用いて操作を行います。使用した環境
- macOS Mojave 10.14.6、Python2.7.10
- Windows7 Ultimate、Python2.7.16
3系でも良いのですが、現状SDKが3.6までしかサポートしていないので2系でチェックしました。
Python版SDKのセットアップ
こちらを参考にセットアップ下さい。
GitHub:IBM-Cloud/data-lake/upload/cos-uploadpipのセットアップの後に、install.shを実行しますが、
Windows版については、私はファイルの中身を直接コピーして、コマンドを実行しました。install.shpip install --upgrade pip pip install --upgrade setuptools pip install "requests>=2.22.0,<2.23.0" "ibm-cos-sdk>=2.5.4" "cos-aspera>=0.1.163682"ICOSの情報確認
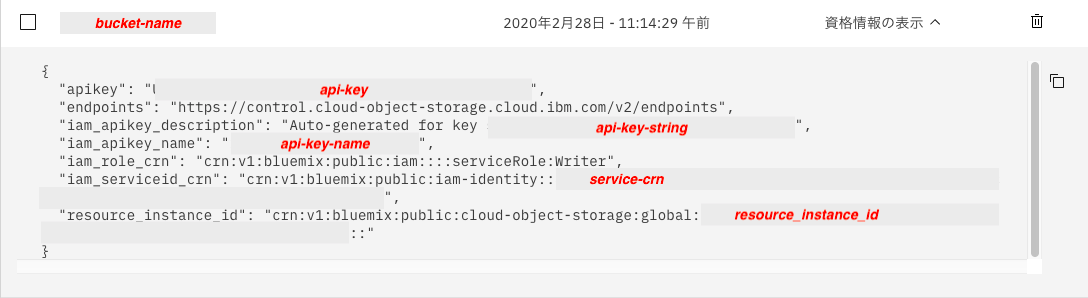
IBM Cloud コンソール(Web)にログインしてICOSのサービス資格情報を確認します。
サービス資格情報はICOSに作成したバケットの資格情報の中にあります。
実行
コマンド例は以下の通りです。
cos-upload.py <endpoint> <apikey> <bucket_name> <prefix> <file>Macでの実行
$ python cos-upload.py s3.jp-tok.cloud-object-storage.appdomain.cloud "api-key" test-bucket "" test-upload-python-mac.txt Initialize COS and Aspera Transfer Manager using endpoint: https://s3.jp-tok.cloud-object-storage.appdomain.cloud Upload file to COS: /tmp/test-upload-python-mac.txt => test-upload-python-mac.txt Upload file to COS completed.Windowsでの実行
C:\tmp>py -2 D:\Workspace\cos-upload.py s3.jp-tok.cloud-object-storage.appdomain.cloud "api-key" test-bucket "" test-upload-python-win.txt Initialize COS and Aspera Transfer Manager using endpoint: https://s3.jp-tok.cloud-object-storage.appdomain.cloud Upload file to COS: C:\tmp\test-upload-python-win.txt => test-upload-python-win.txt Upload file to COS completed.到着確認
正常にアップロードされたことをibmcloudコマンドにて確認します。
// 正常にアップロードされたことを確認 $ ibmcloud cos list-objects --bucket test-bucket OK 見つかりました 3 バケットにオブジェクトがあります 'test-bucket': 名前 最終変更日時 オブジェクト・サイズ test.txt Feb 28, 2020 at 02:27:12 14 B test-upload-python-mac.txt Mar 05, 2020 at 20:05:11 20 B test-upload-python-win.txt Mar 05, 2020 at 21:21:50 20 Bあとがき
Python版のポイントは"実行環境の構築"と"実行時のパラメータ指定の概念理解"かと思います。
私はしばらくRequireに気が付かずに3.7系で実行していましたので、なかなかinstall.shがうまくいかずに困っていましたが、2.7系で実施したらものの見事に解決したので、時間をロスした!と感じました。
また、PythonをWindowsで動かすこともあまり無いかと思いますが、せっかくなのでチャレンジしてみたところ、うまくいったのでついでに載せた次第です。実行時のパラメータの
<prefix>と<file>は曲者で、やってみると分かるのですが、当初は意図した通りにファイルがアップロードされず、少々理解に苦しみました。
例えば<file>にフルパスを指定すると、/tmp/upload/test.txt Mar 03, 2020 at 21:21:50 20 Bみたいにパス名も付いたファイルがアップロードされます。
ですので、送りたいファイルのディレクトリまで移動し、そこからcos-upload.pyをCallする形でやるのが小細工しなくて良いので、やり易いのではないかな?と思います。参考リンク
- 投稿日:2020-03-20T20:54:57+09:00
1時間でやってみるObjectDetectionAPIで画像解析
version: python 3.7.7
OS: macOS Catalina 10.15.3
tensorflow: 2.2.0-rc1環境構築
python3系を利用します。
pythonのバージョンはpyenvなどを利用し、最新のものをインストールしてください。(pyenvについては他記事を参照してください。)
※今回は3.7.7を利用pipのインストールとバージョンアップを行います。
sudo easy_install pip sudo easy_install --upgrade six sudo pip install --upgrade pip必要なライブラリをインストールします。
pip install Cython pip install contextlib2 pip install pillow pip install lxml pip install jupyter pip install matplotlibTensorFlowをインストールします。
※RC版を使ってしまっていますが以下より最新の安定版を利用するようにしてください。
https://www.tensorflow.org/versionspip install tensorflow // version確認 python -c 'import tensorflow as tf; print(tf.__version__)' 2.2.0-rc1protobufをインストールします。
brew install protobufTensorFlowのmodelをクローンします。(tensorflowディレクトリを作成します。)
cd tensorflow git clone https://github.com/tensorflow/models.gitdetection api の実行
Jupyter notebook上で実施します。
cd ~/tensorflow/model/object_detetion Jupyter notebook
ブラウザ上にディレクトリが表示されますので、
object_detection_tutorial.ipynbをクリックして、notebookを開きます。notebookのCellから
Run Allを選択します。
人物などの要素が検出されます。
PATH_TO_TEST_IMAGES_DIR = pathlib.Path('models/research/object_detection/test_images')上記のディレクトリに解析対象の画像が保存されています。
ファイルを変更してお好みの画像を解析してみてください。

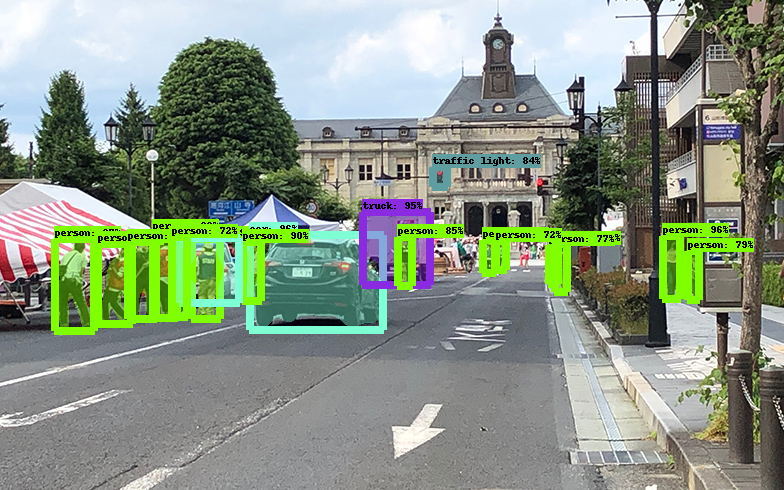
- 投稿日:2020-03-20T19:56:06+09:00
ユリウス日の算出方法
ユリウス日の算出方法を調べていたら、出典によって数式がマチマチでどれが正しいのか困ってしまったのでとりあえず整理。
また、比較も行ってみたが、各算出方法で結果に差があることと傾向は分かったものの、どれが正しいのか、あるいは何か一つの方法を正しいと断ずることはそもそも出来るのかは不明なまま。ユリウス日の算出方法
wikipedia / ユリウス通日#Julian Day Number (JDN) によると、
換算式は、Fliegel and Van Flandern[13]、Hatcher[14]、Meeus[15]によって考案されている。ただしこれらに整理を施した換算式が使われることも多い[16]。
とのことであり、式にはいくつかの形がある模様。
以下に、wikipediaでの式と、他文献等の式を列挙する。それぞれ式の形がかなり違っているけど、ほんとに等価なんだろうか…。
wikipediaの方法
\begin{aligned} JD = & \left\lfloor 365.25 Y \right\rfloor + \left \lfloor \frac{Y}{400} \right\rfloor - \left\lfloor \frac{Y}{100} \right\rfloor + \left\lfloor 30.59 \left( M-2 \right) \right\rfloor + D + 1721088.5 \\ & + \frac{h}{24} + \frac{m}{1440} + \frac{s}{86400} \\ \\ & \lfloor x \rfloorは床関数 \end{aligned}UTの現在のグレゴリオ暦での年をY、月をM、日をD、時間をh、分をm、秒をsとする。ただし、1月と2月はそれぞれ前年(Yの値を-1する)の13月、14月として代入する(例: 2013年2月5日の場合、Y=2012, M=14, D=5)。
Fliegelらの方法
\begin{aligned} JD(I,J,K) = & K - 32075 + 1461 * (I + 4800 + (J - 14) / 12) / 4 \\ & + 367 * (J - 2 - (J - 14) / 12 * 12) / 12 \\ & - 3 * ((I + 4900 + (J - 14) / 12 ) / 100 ) / 4 \end{aligned}calendar date (I = year; J = month, a number from 1 to 12; K = day of month) to a Julian Date (JD)
COMPUTATION AND MEASUREMENT PROBLEM 11.
In FORTRAN integer arithmetic, multiplication and division are performed left to right in the order of occurrence, and the absolute value of each result is truncated to the next lower integer value after each operation, so that both 2/12 and -2/12 become 0.
乗算と除算は左から右に実行され、そのつど計算結果の絶対値は、その次に小さい整数値に切り下げられる。
wikipedia / Julian day#Converting Gregorian calendar date to Julian Day Number
The algorithm[61] is valid for all (possibly proleptic) Gregorian calendar dates after November 23, −4713. Divisions are integer divisions, fractional parts are ignored.
他と比較しやすいよう表現を変えると、
\begin{aligned} JD = & D - 32075 + \left\lfloor \frac{ 1461 \left( Y + 4800 + \left\lfloor \frac{M - 14}{12} \right\rfloor \right)}{4} \right\rfloor \\ & + \left\lfloor \frac{ 367 \left( M - 2 - 12 \left\lfloor \frac{M - 14}{12} \right\rfloor \right) }{12} \right\rfloor \\ & - \left\lfloor \frac{ 3 \left\lfloor \frac{ Y + 4900 + \left\lfloor \frac{M - 14}{12} \right\rfloor }{100} \right\rfloor }{ 4 } \right\rfloor \end{aligned}Hatcherの方法
\begin{aligned} Y' & = Y + y - ((n + m - 1 - M) / n) \text{INT} \\ M' & = (M - m) \text{MOD } n \\ D' & = D - 1 \\ J & = ((pY' + q) / r) \text{INT} + ((sM' + t) / u) \text{INT} + D' -j \end{aligned}Y, M, D and Y', M', D' are the year, month and day of month
(x) INT is the integral part of x, and x is assumed to be positive; (x) MOD y is the positive remainder on divideing x by y.
(x) INTはxの整数部であり、xは正と想定される。(x) MODはxをyで除算した正の剰余。
グレゴリオ暦からの変換の場合は
y j m n r p q v u s t w 4716 1401+g 3 12 4 1461 - 3 5 153 2 2 g = (((Y' + 184) / 100) \text{INT} \times 3/4) \text{INT} - 38と記載されているため、上記の式に代入すると
\begin{aligned} Y' = & Y + 4716 - \left( \frac{14 - M}{12} \right) \text{INT} \\ M' = & (M - 3) \text{MOD } 12 \\ D' = & D - 1 \\ J = & \left( \frac{1461 Y'}{4} \right) \text{INT} + \left( \frac{153M' + 2}{5} \right) \text{INT} + D' \\ & - \left( 1401 + \left( \frac{Y' + 184}{100} \right) \text{INT} \times \frac{3}{4} \right) \text{INT} - 38 \\ = & \left( 365.25Y' \right) \text{INT} + \left( 30.6M' + 0.4 \right) \text{INT} + D' \\ & - \left( 1401 + \left( \frac{Y' + 184}{100} \right) \text{INT} \times \frac{3}{4} \right) \text{INT} - 38 \end{aligned}Meeusの方法
Meeus, J., Astronomical Algorithms, 1998
\begin{aligned} A & = \text{INT} \left( \frac{Y}{100} \right) \\ B & = 2 - A + \text{INT} \left( \frac{A}{4} \right) \\ JD & = \text{INT} (365.25 (Y + 4716)) + \text{INT} (30.6001(M + 1)) + D + B - 1524.5 \end{aligned}Let Y be the year, M the month number (1 for January, 2 for February, etc., to 12 for December), and D the day of month (with decimals, if any) of the given calendar date.
INT(x) the greatest integer less than or equal to x.
for instance, INT(-7.83) = -8
他と比較しやすいよう表現を変えると、
\begin{aligned} JD & = \left\lfloor 365.25 (Y + 4716) \right\rfloor + \left\lfloor 30.6001(M + 1) \right\rfloor + D + 2 - \left\lfloor \frac{Y}{100} \right\rfloor + \left\lfloor \frac{ \left\lfloor \frac{Y}{100} \right\rfloor }{4} \right\rfloor - 1524.5 \\ & = \left\lfloor 365.25 Y \right\rfloor + \left\lfloor 30.6001(M + 1) \right\rfloor + D - \left\lfloor \frac{Y}{100} \right\rfloor + \left\lfloor \frac{Y}{400} \right\rfloor + 1,720,996.5 \\ & = 365 Y + \left\lfloor \frac{Y}{4} \right\rfloor - \left\lfloor \frac{Y}{100} \right\rfloor + \left\lfloor \frac{Y}{400} \right\rfloor + \left\lfloor 30.6001(M + 1) \right\rfloor + D + 1,720,996.5 \end{aligned}Valladoらの方法
CelesTrak / Revisiting Spacetrack Report #3 - AIAA 2006-6753 - Source code (C++)
Vallado, David A., Paul Crawford, Richard Hujsak, and T.S. Kelso, "Revisiting Spacetrack Report #3," presented at the AIAA/AAS Astrodynamics Specialist Conference, Keystone, CO, 2006 August 21–24.\begin{aligned} jd = & 367.0 * year - \\ & floor((7 * (year + floor((mon + 9) / 12.0))) * 0.25) + \\ & floor(275 * mon / 9.0) + day + 1721013.5 + \\ & ((sec / 60.0 + minute) / 60.0 + hr) / 24.0 \\ \end{aligned}他と比較しやすいよう表現を変えると、
\begin{aligned} JD = & 367 Y - \left\lfloor \frac{7}{4} \left(Y + \left\lfloor \frac{M + 9}{12} \right\rfloor \right) \right\rfloor + \left\lfloor \frac{275 M}{9} \right\rfloor + D + 1721013.5 \\ & + \frac{h}{24} + \frac{m}{1440} + \frac{s}{86400} \end{aligned}Howard D. Curtisの方法
ScienceDirect / Julian Day Number
Howard D. Curtis, in Orbital Mechanics for Engineering Students (Fourth Edition), 2020\begin{aligned} J_0 = & 367 y - \text{INT} \frac{7 y + \text{INT} \frac{m + 9}{12}}{4} + \text{INT} \frac{275 m}{9} + d + 1,721,013.5 \\ & 1901 \le y \le 2099 \\ & 1 \le m \le 12 \\ & 1 \le d \le 31 \end{aligned}INT(x) means retaining only the integer portion of x, without rounding (or, in other words, round toward zero). For example, INT(− 3.9) = −3 and INT(3.9) = 3.
ScienceDirect / Julian Day Number
Howard D. Curtis, in Orbital Mechanics for Engineering Students (Third Edition), 2014\begin{aligned} J_0 = & 367 y - \text{INT} \left\{ \frac{7 \left[ y + \text{INT} \left( \frac{m + 9}{12} \right) \right] }{4} \right\} + \text{INT} \left( \frac{275 m}{9} \right) + d + 1,721,013.5 \\ & 1901 \le y \le 2099 \\ & 1 \le m \le 12 \\ & 1 \le d \le 31 \end{aligned}INT (x) means to retain only the integer portion of x, without rounding (or, in other words, round toward zero), that is, INT (−3.9) = −3 and INT (3.9) = 3
上記のFourth EditionとThird Editionでは、第2項の分子の7がかかっている範囲が異なっている。
boostライブラリの方法
boost/date_time/gregorian_calendar.ipp
//! Convert a ymd_type into a day number /*! The day number is an absolute number of days since the start of count */ template<typename ymd_type_, typename date_int_type_> BOOST_DATE_TIME_INLINE date_int_type_ gregorian_calendar_base<ymd_type_,date_int_type_>::day_number(const ymd_type& ymd) { unsigned short a = static_cast<unsigned short>((14-ymd.month)/12); unsigned short y = static_cast<unsigned short>(ymd.year + 4800 - a); unsigned short m = static_cast<unsigned short>(ymd.month + 12*a - 3); unsigned long d = ymd.day + ((153*m + 2)/5) + 365*y + (y/4) - (y/100) + (y/400) - 32045; return static_cast<date_int_type>(d); } //! Convert a year-month-day into the julian day number /*! Since this implementation uses julian day internally, this is the same as the day_number. */ template<typename ymd_type_, typename date_int_type_> BOOST_DATE_TIME_INLINE date_int_type_ gregorian_calendar_base<ymd_type_,date_int_type_>::julian_day_number(const ymd_type& ymd) { return day_number(ymd); }他と比較しやすいよう表現を変えると、
\begin{aligned} a & = \text{INT} \left( \frac{14 - M}{12} \right) \\ y & = Y + 4800 - a \\ m & = M + 12 a - 3 \\ JD & = \text{INT} \left( D + \frac{153m + 2}{5} + 365 y + \frac{y}{4} - \frac{y}{100} + \frac{y}{400} - 32045 \right) \end{aligned}PHPの方法
PHP > マニュアル > 関数リファレンス > 日付および時刻関連 > カレンダー > カレンダー関数
gregoriantojdgregoriantojd — グレゴリウス日をユリウス積算日に変換する
PHPの関数ではあるが、以下の通り実体はCで実装されている模様。
php-src/ext/calendar/calendar.stub.php
calendar.stub.phfunction gregoriantojd(int $month, int $day, int $year): int {}php-src/ext/calendar/calendar.c
calendar.c/* {{{ proto int gregoriantojd(int month, int day, int year) Converts a gregorian calendar date to julian day count */ PHP_FUNCTION(gregoriantojd) { zend_long year, month, day; if (zend_parse_parameters(ZEND_NUM_ARGS(), "lll", &month, &day, &year) == FAILURE) { RETURN_THROWS(); } RETURN_LONG(GregorianToSdn(year, month, day)); } /* }}} */gregor.czend_long GregorianToSdn( int inputYear, int inputMonth, int inputDay) { zend_long year; int month; /* check for invalid dates */ if (inputYear == 0 || inputYear < -4714 || inputMonth <= 0 || inputMonth > 12 || inputDay <= 0 || inputDay > 31) { return (0); } /* check for dates before SDN 1 (Nov 25, 4714 B.C.) */ if (inputYear == -4714) { if (inputMonth < 11) { return (0); } if (inputMonth == 11 && inputDay < 25) { return (0); } } /* Make year always a positive number. */ if (inputYear < 0) { year = inputYear + 4801; } else { year = inputYear + 4800; } /* Adjust the start of the year. */ if (inputMonth > 2) { month = inputMonth - 3; } else { month = inputMonth + 9; year--; } return (((year / 100) * DAYS_PER_400_YEARS) / 4 + ((year % 100) * DAYS_PER_4_YEARS) / 4 + (month * DAYS_PER_5_MONTHS + 2) / 5 + inputDay - GREGOR_SDN_OFFSET); }他と比較しやすいよう表現を変えると、
\begin{aligned} Y' & = \left\{ \begin{aligned} Y + 4801 \quad (Y < 0) \\ Y + 4800 \quad (Y \ge 0) \end{aligned} \right. \\ M' & = \left\{ \begin{aligned} & M - 3 & (M > 2) \\ & M + 9, \quad Y' = Y' - 1 & (M \le 2) \end{aligned} \right. \\ JD & = \text{INT} \left( \frac{ \frac{Y'}{100} \times 146097 }{4} + \frac{(Y' \% 100) \times 1461}{4} + \frac{153 M' + 2}{5} + D - 32045 \right) \end{aligned}pyorbitalの方法
pyorbital/pyorbital/__init__.py
__init__.pydef dt2np(utc_time): try: return np.datetime64(utc_time) except ValueError: return utc_time.astype('datetime64[ns]')pyorbital/pyorbital/astronomy.py
astronomy.pydef jdays2000(utc_time): """Get the days since year 2000. """ return _days(dt2np(utc_time) - np.datetime64('2000-01-01T12:00')) def jdays(utc_time): """Get the julian day of *utc_time*. """ return jdays2000(utc_time) + 2451545 def _days(dt): """Get the days (floating point) from *d_t*. """ return dt / np.timedelta64(1, 'D')つまり
JD = UTC(Y,M,D,h,m,s) - UTC(2000, 1, 1, 12, 0, 0) + 2451545国立天文台のWebページの方法
1582年10月15日以後はグレゴリオ暦、それより前はユリウス暦の規則に従った日付となります。
紀元元年の前年を0年としています。このため、これを紀元前1年とする方法とは1年ずつ差異があります。Webフォームに入力することでユリウス日を算出することができる。
他の算出方法での結果と比べるために、CSVファイルに出力しておく。手入力だと大変なため、pythonでWebフォームへリクエストを送信して結果を取得しCSVに出力する。以下は上記のコードで生成したCSVのグラフ。なお、このWebサイトでは -4712/01/01 12:00 が最小値(ユリウス日=0.0日)。
-4712年周辺(-4712/01/01 ~ -4711/12/01)
0年周辺(0001/01/01 ~ -0001/12/01)
グレゴリオ暦が始まった1582年10月(1582/10/01 ~ 1582/10/31)
ユリウス暦の最終日である1582/10/04の次の日はグレゴリオ暦の最初日である1582/10/15であるため、Webページもそのような形で結果を返してきている。また、10/05~10/14という値が存在しない形になっている。その影響か、10/24の次が10/15になってしまっている。ともかく、10/04のユリウス日は2299160、10/15のユリウス日は2299161となっており、値が飛ぶことのない線形な結果が維持されている。
各方法の算出結果の比較
横軸:グレゴリオ暦(1582/10/15よりも前をグレゴリオ暦と呼ぶのは不適切な気もする…)
縦軸:ユリウス日なお、NAOJ(国立天文台のWebサイトでの算出結果)については、-4713年~2000年を1ヶ月刻みで算出するのは負荷と時間が心配なので以下の期間だけを算出しており、グラフにも以下の期間でしかプロットされていない。
- -4712年周辺(-4712/01/01 ~ -4711/12/01)
- 0年周辺(0001/01/01 ~ -0001/12/01)
- グレゴリオ暦が始まった1582年10月(1582/10/01 ~ 1582/10/31)
-4713年~2000年
-4713/01/01 ~ 2000/12/01 を1ヶ月刻み(各月の1日)で算出。
俯瞰するとどの算出方法でもほぼ同じ値で、ほぼ線形な結果になっている。
-4713年周辺の拡大図
-4713/01/01 ~ -4711/12/01 を1ヶ月刻み(各月の1日)で算出。
NAOJ(国立天文台のWebサイトでの算出結果)については、このWebサイトでは -4712/01/01 12:00 が最小値(ユリウス日=0.0日)のため、-4712年から始まっている。
0年周辺の拡大図
-0001/01/01 ~ 0001/12/01 を1ヶ月刻み(各月の1日)で算出。
phpのみ、-0001年12月から0000年1月で不連続となっており、phpでは「紀元前1年の次は紀元後1年」という扱いをしていると考えられる。ユリウス日の値から見れば、紀元0年は紀元前1年と同じということになる。
逆にphp以外の方法では、「紀元前1年→紀元0年→紀元後1年」という扱いをしている模様。0年周辺の拡大図、ただし0年は除外して描画
-0001/01/01 ~ -0001/12/01、0001/01/01 ~ 0001/12/01 を1ヶ月刻み(各月の1日)で算出。
前述の通り、ためしに0年を除外してグラフを描画するとphpだけが連続になり、他の方法は不連続になる。
グレゴリオ暦が始まった1582年10月の拡大図
1582/10/01 ~ 1582/10/31 を1日刻みで算出。
NAOJ(国立天文台のWebサイトでの算出結果)については、ユリウス暦の最終日である1582/10/04の次の日はグレゴリオ暦の最初日である1582/10/15になることに従い、10/05~10/14についてはユリウス日の算出対象外になっているため、値が無い。
最大値と最小値の差
-4713/01/01 ~ 2000/12/01 を1ヶ月刻み(各月の1日)で算出。
算出されたユリウス日の値は算出方法間でバラツキがあるため、バラツキがどれくらいかを見るために最大値と最小値の差をプロットしてみた。
- -4713/01/01 ~ -0001/12/01 における差: 417.5 ~ 381.5
- 0000/01/01 ~ 2000/12/01: 17.5 ~ 1.5
- 1582/10/01: 13.5(前述の通り1582/10はNAOJを算出しており、NAOJが最大値を出していて差が大きくなっている)現在に近づくほど差は小さくなってきている。
比較した結論
各算出方法で結果に差があることと傾向は分かったものの、どれが正しいのか、あるいは何か一つの方法を正しいと断ずることはそもそも出来るのかは不明なまま。
ユリウス日における時刻
12:00 UT後のユリウス暦の完全な日付。
\begin{aligned} JD & = JDN + \frac{hour - 12}{24} + \frac{minute}{1440} + \frac{second}{86400} \\ JD & : \text{Julian Date} \\ JDN & : \text{Julian Day Number} \end{aligned}wikipedia / Julian day#Finding Julian date given Julian day number and time of day
その他
Modified Julian Day: MJD(修正ユリウス日)
wikipedia / ユリウス通日#修正ユリウス日(MJD)
wikipedia / Julian day#Variants
Meeus, J., Astronomical Algorithms, 1998\begin{aligned} MJD & = JD - 2400000.5 \\ MJD & : 修正ユリウス日 \\ JD & : ユリウス日 \end{aligned}Truncated Julian Day: TJD
床関数のあるのと無いの、どちらが正しいのか?
TJD = JD - 2440000.5wikipedia / Julian day#Variants
TJD = \left\lfloor JD - 2440000.5 \right\rfloorJ2000
wikipedia / Epoch (astronomy)#Julian Dates and J2000
date that is an interval of x Julian years of 365.25 days away from the epoch J2000 = JD 2451545.0 (TT), still corresponding (in spite of the use of the prefix "J" or word "Julian") to the Gregorian calendar date of January 1, 2000, at 12h TT (about 64 seconds before noon UTC on the same calendar day).10 Like the Besselian epoch, an arbitrary Julian epoch is therefore related to the Julian date by
J = 2000 + ( \text{Julian date} -2451545.0 ) \div 365.25他参考サイト
ユリウス日(Julian Day)
「ユリウス日」で遊ぶ
The Julian Period【Python】 GET・POSTリクエストによるWebデータの取得(Requestsモジュール)
【Python】BeautifulSoupを使ってテーブルをスクレイピング
10分で理解する Beautiful Soup









- 投稿日:2020-03-20T19:26:53+09:00
PyCharmのProject Interpreterに、リモートRaspbian DockerのPythonを設定する
前回からの続きです。今回はpycharmを介して、リモートdockerコンテナ内でpythonファイルを実行します。少しややこしいのでまとめると以下を行います。
ファイルの編集はローカル上で行うが、これをリモート上と同期させる
実行時は、リモートのdockerにあるpythonインタプリタをpycharmに認識させて実行する
リモートのdockerはリモート上のファイルを認識して実行する
dockerを使うかdocker composeを使うか以外はこちらと同一です。(PyCharmが直接リモート上のコードを編集できれば良い気がするのですが、なぜかこれはできません。)ややこしくなったので、まとめると以下のようになります。
Raspbian上のdockerの設定
Dockerのサービスにアクセスするには
Dockerはクライアント・サーバモデルのアプリケーションであり、dockerデーモン(サーバ)に対して処理を要求を行うことでdockerを利用することができます。dockerコマンドを通す際などデフォルトではUnixソケットを通して通信を行っていますが、設定を行えばTCPソケットを通して通信を行うこともできます。これを利用するとローカルからリモート上のdockerデーモンに処理を要求することができます。この辺りのdockerの仕組みに関してはこちらのサイトが参考になりました。ちなみに、ローカルのUnixソケットをリモート上のUnixソケットにフォワードすれば、リモートからサーバのdockerを動かすこともできるみたいです。
設定
参考サイトそのままですが、以下を実行することで、remoteのdockerにtcpソケットを通して処理を要求することができます。(本来は、通信を行う際に証明書を利用しないと本番環境では危ないないらしいですが、それはまた別途設定することにしましょう。この辺りはこちらと公式のこちらが詳しいです。)
サーバ上で以下を実行することで、TCPソケットを介してpycharmからdockerを叩けるようになります。
# 設定の修正 $ sudo vim /etc/systemd/system/docker.service.d/startup_options.conf # 設定への記載内容 $ cat /etc/systemd/system/docker.service.d/startup_options.conf [Service] ExecStart= ExecStart=/usr/bin/dockerd -H unix:// -H tcp://0.0.0.0:2376 # 読み込み&再起動 $ sudo systemctl daemon-reload $ sudo systemctl restart docker.service # 設定の確認 # "/usr/bin/dockerd -H unix:// -H tcp://0.0.0.0:2376"があればOK $ service docker status Redirecting to /bin/systemctl status docker.service ● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; disabled; vendor preset: disabled) Drop-In: /etc/systemd/system/docker.service.d └─docker-bridge-yj.conf, startup_options.conf Active: active (running) since Tue 2019-06-18 12:54:47 JST; 4 days ago Docs: https://docs.docker.com Main PID: 4595 (dockerd) Tasks: 26 Memory: 9.2G CGroup: /system.slice/docker.service └─4595 /usr/bin/dockerd -H unix:// -H tcp://0.0.0.0:2376PyCharmのリモートとローカルのファイルの同期
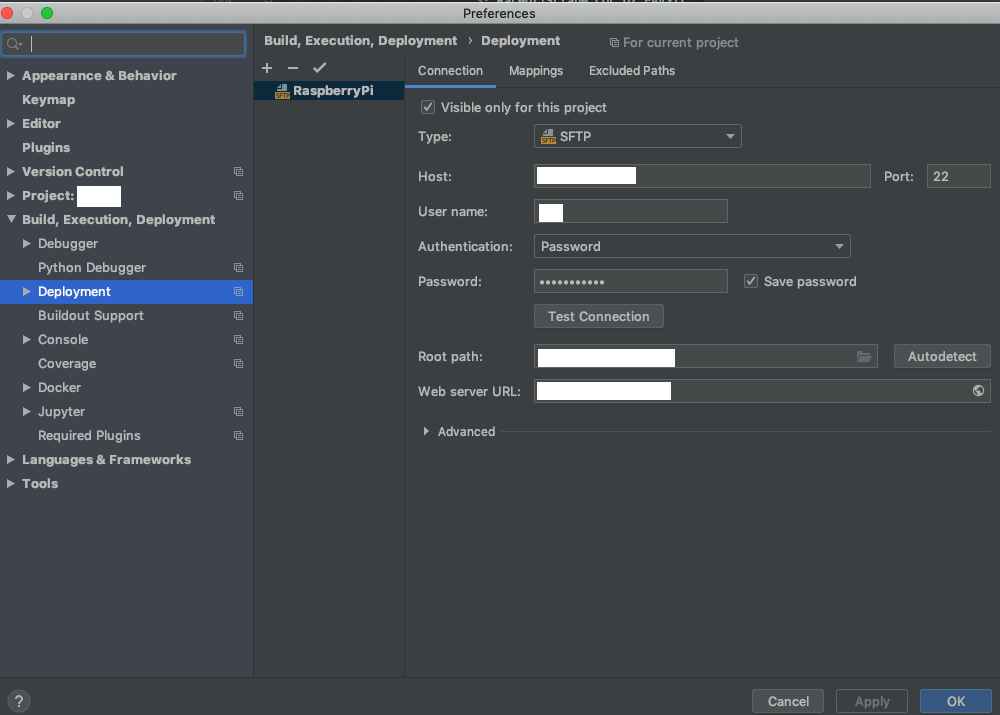
Preference>Build, Execution, Deployment>DeploymentのConnectionタブから同期の設定を行います。
Host: Raspberry piのIPアドレス、User name: raspbianのユーザ名、Passwordにユーザのパスワードを入力します。Root pathはRaspberry Piのどこを"ルート"として認識させるかを設定します。(つまりこれはRaspberry Piのルートパス/とは一致している必要はありません。)
Web server URLにはhttps://[Raspberry PiのIPアドレス]と入力します。
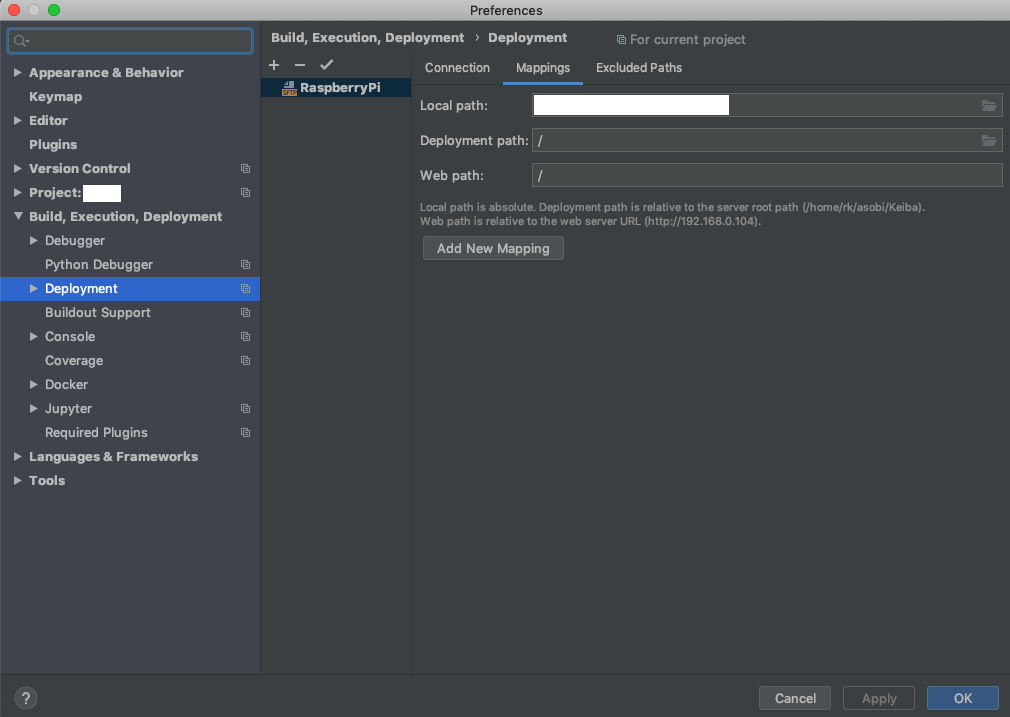
続いて、Mappingタブからの設定も行います。
こちらのLocal path: で同期したいローカルフォルダを設定します。また、Deployment pathで先ほど設定したRoot pathからの相対パスとして、同期したいパスを指定します。
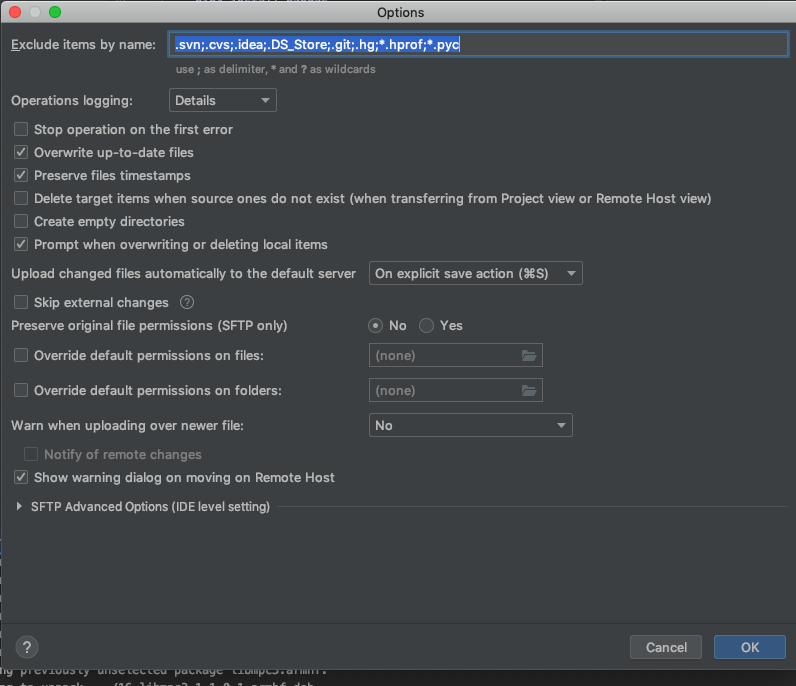
Tools>Deployment>OptionsからUpload changed files automatically to default serverにチェックをつけておけば、ファイルを書き換えると同時に、勝手に同期を行ってくれて便利です。
Docker-composeを利用したPythonインタプリタの設定
公式はこちら。
Dockerの設定
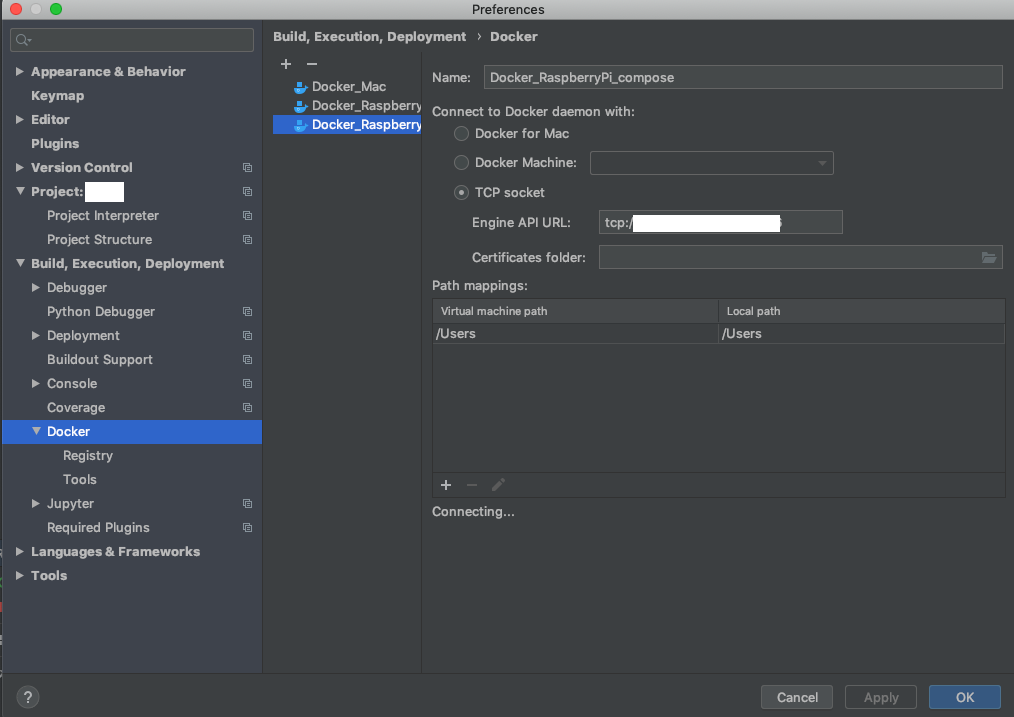
Preference>Build, Execution, Deployment>Deployment>DockerでリモートのDockerを追加します。TCPソケットは、tcp://[IPアドレス]:[先ほど設定した番号]です。
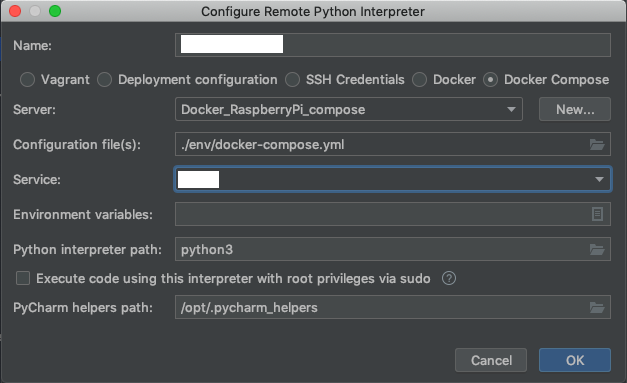
Preference>Project>Project Interpreterから歯車のマークをクリックし、Project Interpreterを追加します。Serverで先ほど設定したDockerを選択します。また、Configuration file(s)には自分で作成したdocker-compose.ymlを設定します。
以上でpycharm上からRUNをすると、dockerコンテナ内のpythonインタプリタがうごくはずです。
- 投稿日:2020-03-20T19:26:53+09:00
PyCharmを介して、リモートRaspbian上のDockerコンテナ内でPythonファイルを実行する
前回からの続きです。今回はpycharmを介して、リモートdockerコンテナ内でpythonファイルを実行します。少しややこしいのでまとめると以下を行います。
ファイルの編集はローカル上で行うが、これをリモート上と同期させる
実行時は、リモートのdockerにあるpythonインタプリタをpycharmに認識させて実行する
リモートのdockerはリモート上のファイルを認識して実行する
dockerを使うかdocker composeを使うか以外はこちらと同一です。(pycharmが直接リモート上のコードを編集できれば良い気がするのですが、なぜかこれはできません。)ややこしくなったので、まとめると以下のようになります。
Raspbian上のDockerの設定
Dockerのサービスにアクセスするには
Dockerはクライアント・サーバモデルのアプリケーションであり、dockerデーモン(サーバ)に対して処理を要求を行うことでdockerを利用することができます。dockerコマンドを通す際などデフォルトではUnixソケットを通して通信を行っていますが、設定を行えばTCPソケットを通して通信を行うこともできます。これを利用するとローカルからリモート上のdockerデーモンに処理を要求することができます。この辺りのdockerの仕組みに関してはこちらのサイトが参考になりました。ちなみに、ローカルのUnixソケットをリモート上のUnixソケットにフォワードすることでも、リモートからサーバのdockerを動かすこともできるみたいです。
設定
参考サイトそのままですが、以下を実行することで、remoteのdockerにtcpソケットを通して処理を要求することができます。(本来は、通信を行う際に証明書を利用しないと本番環境では危ないないらしいですが、それはまた別途設定することにしましょう。この辺りはこちらと公式のこちらが詳しいです。)
サーバ上で以下を実行することで、TCPソケットを介してpycharmからdockerを叩けるようになります。
# 設定の修正 $ sudo vim /etc/systemd/system/docker.service.d/startup_options.conf # 設定への記載内容 $ cat /etc/systemd/system/docker.service.d/startup_options.conf [Service] ExecStart= ExecStart=/usr/bin/dockerd -H unix:// -H tcp://0.0.0.0:2376 # 読み込み&再起動 $ sudo systemctl daemon-reload $ sudo systemctl restart docker.service # 設定の確認 # "/usr/bin/dockerd -H unix:// -H tcp://0.0.0.0:2376"があればOK $ service docker status Redirecting to /bin/systemctl status docker.service ● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; disabled; vendor preset: disabled) Drop-In: /etc/systemd/system/docker.service.d └─docker-bridge-yj.conf, startup_options.conf Active: active (running) since Tue 2019-06-18 12:54:47 JST; 4 days ago Docs: https://docs.docker.com Main PID: 4595 (dockerd) Tasks: 26 Memory: 9.2G CGroup: /system.slice/docker.service └─4595 /usr/bin/dockerd -H unix:// -H tcp://0.0.0.0:2376PyCharmのリモートとローカルのファイルの同期
Preference>Build, Execution, Deployment>DeploymentのConnectionタブから同期の設定を行います。
Host: Raspberry piのIPアドレス、User name: raspbianのユーザ名、Passwordにユーザのパスワードを入力します。Root pathはRaspberry Piのどこを"ルート"として認識させるかを設定します。(つまりこれはRaspberry Piのルートパス/とは一致している必要はありません。)
Web server URLにはhttps://[Raspberry PiのIPアドレス]と入力します。
続いて、Mappingタブからの設定も行います。
こちらのLocal path: で同期したいローカルフォルダを設定します。また、Deployment pathで先ほど設定したRoot pathからの相対パスとして、同期したいパスを指定します。
Tools>Deployment>OptionsからUpload changed files automatically to default serverにチェックをつけておけば、ファイルを書き換えると同時に、勝手に同期を行ってくれて便利です。
Docker-composeを利用したPythonインタプリタの設定
公式はこちら。
Dockerの設定
Preference>Build, Execution, Deployment>Deployment>DockerでリモートのDockerを追加します。TCPソケットは、tcp://[IPアドレス]:[先ほど設定した番号]です。
Preference>Project>Project Interpreterから歯車のマークをクリックし、Project Interpreterを追加します。Serverで先ほど設定したDockerを選択します。また、Configuration file(s)には自分で作成したdocker-compose.ymlを設定します。
以上でpycharm上からRUNをすると、dockerコンテナ内のpythonインタプリタがうごくはずです。
- 投稿日:2020-03-20T19:07:02+09:00
Djangoで多読を記録するwebアプリを作った話
はじめに
英語多読,読む度に多読手帳を開いて記録するのはメンドウだし,モチベが維持できない...ということで多読手帳をWebアプリにしました.
つくったもの→https://tadokuapp.herokuapp.com/tadoku/機能
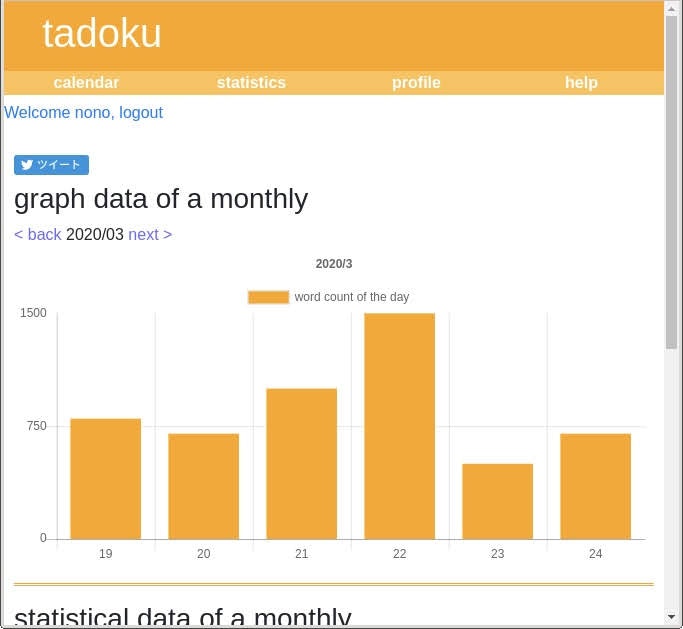
紙の多読手帳のように日付やタイトル,語数などを羅列するのでは味気ないので,カレンダー上に語数が表示されるようにしました.また,月ごとに読んだ語数を棒グラフで出力されるようにしました.
開発環境
python3.7.6
Django3.0.3カレンダー
Djangoでカレンダーを作るシリーズ
この方のカレンダーを参考にさせていただきました.本当に有り難いです.自前では作れないので
日付の下にその日読んだ語数を表示させています.認証まわり
ログイン,ログアウトはDjangoで標準搭載されているものを使い,サインアップは自前です.また,ページ上部にログイン時は「Welcome (username),logout」,ログアウト時は「Welcome gust,login」と表示されるようにhtmlを書きます.
base.html{% if user.is_authenticated %} <a href="{% url 'accounts:logout' %}" class='user'>Welcom {{ user.get_username }}, logout</a> {% else %} <a href="{% url 'accounts:login' %}" class='user'>Welcome guest, login here!</a> {% endif %}グラフ
viewsで現在ログインしているユーザの本の情報をtemplateに渡します.グラフの描画にはChart.jsを使っています.また,グラフの下に語数(月別と全ての2つ)と前月からの語数の増加量,読んだ本の冊数(月別と全ての2つ)を表示させています.
ついでにツイートボタンを付けました.
https://publish.twitter.com/#プロフィール
ユーザ名とユーザ情報だけでは寂しいので,ユーザランク
(Atcoderのレートっぽいもの)を導入しました.読んだ語数によってユーザランクをgray,brown,green...というように変化させます.デプロイ
herokuです.
(DigitalOceanとかでデプロイしたかったけど支払いがクレカorPayPalなので断念)感想
Djangoの勉強からやっていたので,案外時間がかかってしまいましたが完成して良かった.クエリの最適化やキャッシュの導入などで速くしたり,ソーシャル認証やレートの改善(サボったら下がるなど)で使い勝手を良くしたりと改善点は多いので,開発は続けていこうと思います.
まとめ
Djangoたのしい.
- 投稿日:2020-03-20T18:46:14+09:00
Python,AI関連の英単語を覚えよう。。。
目的
Pythonとか、AIとかの関連で、英語を目にすることは多いが、英語力が低すぎて損をしている。英語をマスターするために、英単語を理解する(覚える)。
英単語
前提
英単語を覚えることが目的なので、意味は、英英辞書のも、示す。
意味は、英英は、注記ない場合、以下のlongman。
https://www.ldoceonline.com/jp/dictionary/日本語は、以下のweblio。
https://ejje.weblio.jp/content/わかりにくい単語
単語 英英 英和 備考 I inception the start of an organization or institution 初め、発端 【調査中】inception-v3とかの場合、どういう意味を込めたかは不明。 わかりやすい単語
単語 英英 英和 備考 R reinforcement (3)the act of making something stronger 補強、強化、増援、増援隊、援兵、補強(材)、補給(品) residual remaining after a process, event etc is finished 残りの、残余の、剰余の、説明のつかない、除去できない V verbose using or containing too many words 言葉数の多い、多弁の、くどい、冗長な まとめ
特にありません。
- 投稿日:2020-03-20T18:12:02+09:00
[Python] 上位ディレクトリにある自作パッケージをインポートして使いたいとき
Pythonで上位ディレクトリにあるパッケージをインポートして使いたいが、相対パスによるインポートや、スクリプト内でsys.pathを変更したくない場合の対処方法がなかなか見つからなかったので、書き置きします。
シチュエーション
ディレクトリ構成例:
project + mypackage | + __init__.py | + module_a.py + program_main | + executor | + executor.py | + tests | + executor_test.py + setup.py
executor.pyからみて上位フォルダに有るmypackageという自作パッケージをインポートして使いたい。筆者の場合、AWSのLambdaのサービスディレクトリが複数あり、また共通処理としてLambdaLayerを上位のフォルダに配置していたため、ローカルでLambdaの関数からLayerが正しくImportできずにいた。
また、Lambdaのサービスと、LambdaLayerはデプロイした環境では問題なく動作するディレクトリ構成でも、CICDで単体テストを行う際にもパスに気をつけなければならない。
project + layers | + my_layer_1 | + ... | + ... + lambda | + service_1 | + handler.py | + serverless.yml | + requirements.txt | + env | + ... | + tests | + ... | + ... + setup.py対処法
結論的には、
setup.pyでパッケージを管理すればいい。 以下のようなsetup.pyをルートディレクトリに置く。from setuptools import setup, find_packages setup(name='myproject', version='1.0', packages=find_packages())find_packages() は自動的に
__init__.pyが存在するパッケージを探索してくれる。 もしパスが通らなかったり、見つからなかったりする場合、packagesの他にpackage_dirをいじったり、__init__.pyが存在するか確認するといいかもしれない。あとは、ルートディレクトリで以下のコマンドを実行することで、自作パッケージをインストールする。
pip install -e .-e のレファレンス
e, --editable <path/url> Install a project in editable mode (i.e. setuptools “develop mode”) from a local project path or a VCS url.-e を指定した場合、自作パッケージを編集した再も、自動的に変更を認識してくれる為、再度pip insatllが不要になる。
参考
- 投稿日:2020-03-20T17:58:00+09:00
Cythonの型の取り扱いが面倒だったので気を付けた点をまとめた
Cythonの使い方についての解説はあるが、型についての記事が少ないように感じたのでまとめる。
CythonはほぼPythonと変わらない書き方でCとPythonをインターフェースを作れる、更にPythonの高速化が望める言語である。しかし、CとPythonの型が混在することで型エラーが頻発する。私はCythonの難しさは型のコントロールであると思った。静的型付けと動的型付けの融合
CythonはPythonのような動的型付けもできるし、Cのような静的な型付けができるという言語だ。Pythonで動的型付けと静的型付けの強みを享受できる便利な機能であるが、CythonではPythonの型だけでなくCの型が混在するため、注意しなければならないポイントが多い。
Cythonを使用する時に、肝に銘じておいて欲しいのはCythonは型を明示的に型付けしていなければ、それはPythonの型として扱われる。(実体がPythonレベルの型でない場合、Cレベルの型にキャストされる)ということである。
ちなみに、Cythonではvector<int>をvector[int]と書く。cdef vector[int] vec1 # Cレベルの型Cythonでは
cdefを使うことで変数をCレベルの型で変数宣言できる。なお、このcdefはdocstringなどのコメントを除いて、必ず関数の最初に書かなければいけないという制約がある。つまり以下のようにif文で分岐によってcdefする型を変えることはできない。#このような書き方はできない cdef func0(type): if type == "double": cdef double x = 10 return x elif type == "int": cdef double y = 10 return yCythonでは返り値も明示的に指定できる。この型指定はPythonの型を返り値とする場合任意だが、Cレベルの型を返り値とする場合は型を指定しなければならない。もし、指定しなかった場合、Pythonレベルの型に変換される。
cdef func1(type): cdef vector[double] vec return vec #各要素がfloatのリストに変換される cdef vector[double] func2(type):#返り値の型を指定 cdef vector[double] vec return vec #vector[double]のまま返るCythonにはPythonレベルの型とCレベルの型を暗黙のうちに型変換してくれる機能がある。例えばでvector[double]を返り値の型として指定しなくても、自動的にCythonが
vector<double>のvectorをlistに、doubleをfloatに変換する。返り値としたい型がユーザー定義型やCythonで扱えないCのライブラリ固有の型である場合、Pythonレベルへの変換が定義されていないためコンパイルエラーが起きる。
以下の例ではcdef関数内からMyClassというCで定義した型を返している。このMyClass型はPythonの型への変換方法が定義されていないので、以下の例ではエラーが起きる。cdef func3(): cdef MyClass x = MyClass() return x # エラー MyClass型はPythonの型に変換できない func3()このため、Cレベルの型の値を返したい場合は、以下のように返り値の型を指定する必要がある。
cdef MyClass func3(): cdef MyClass x = MyClass() return x # OK 返り値はMyClassである func3()これはMyClassを要素とする
vectorでも同様である。型キャストとオーバーロード
CythonはPythonを高速化できるだけでなく、Cの関数や型をラップできるのが大きな魅力だ。自分もラップをしようとしたがCでオーバーロードしている関数をラップしたい場合にかなりてこずった。
cdef extern from "rect.h": int area(int x,int y) double area(double x,double y)例えば上のような関数があるとしよう。これをxの型によって、呼び出す関数を変えたいので以下のように書く。するとエラーが起きる。
#エラー 適切なメソッドを呼び出せない def py_area (x,y): if type(x) == int: return area(x,y) elif type(x) == float: return area(x,y)このような書き方をしたい場合、実引数として渡す値を全て適切な型に明示的キャストしてから渡す必要がある。つまり型キャストをその場で明示的な型付けを行うのに使うということになる。
#OK def py_area (x,y): if type(x) == int: return area(<int>x,<int>y) elif type(x) == float: return area(<double>x,<double>y)しかし、仮引数が参照渡しで宣言されているときは仮引数をその場でキャストしながら渡すことができない。この時、予め
cdefで型宣言しておくことで明示的な型指定しながら渡すことができる。例えば関数が下のようになっているなら
cdef extern from "rect.h": int area(int& x,int& y) double area(double& x,double& y)今までの書き方を下のような書き方にする必要がある。
def py_area (x,y): cdef: int x1 int y1 double x2 double y2 if type(x) == int: x1 = x y1 = y return area(x1,y1) elif type(x) == float: x2 = x y2 = y return area(x2,y2)すると、参照型で仮引数が定義されていてもエラーにならない。
Fused type
CythonにはFused type(融合型)という機能がある。これはCythonで実質的にテンプレート型を使う機能である。返り値や引数に複数の型がありうる場合に使える。
#任意の型を羅列 ctypedef fused my_type: hoge foo bar
Fused typeは上記のように型を羅列することでmy_typeはhoge、foo、barのどの型としても扱われるようになる。
これを使うことで、多次元リストのCとPython間の型変換を以下のように実現できる。PyClassはMyClassのPython上での型とする。ctypedef fused T: MyClass vector[MyClass] cdef vector_to_list (T x): if T == vector[MyClass]: return [vector_to_list(i) for i in range(<vector[MyClass]>x.size())] else : return PyClass(x)Fused typeは全ての型である可能性を考慮して構文解析する。例えば上の例ならCythonのxは
vector[MyClass]だけでなく、MyClassの可能性があると見なしてしまう。キャストによって明示的な型指定をせず下のように書くとMyClassにはsize()がないのでエラーを起こす。ctypedef fused T: MyClass vector[MyClass] cdef vector_to_list (T x): if T == vector[MyClass]: return [vector_to_list(i) for i in range(x.size())] # (1) else : return PyClass(x)この例では、(1)の行を
<vector[MyClass]>でキャストしていないため型TがMyClassの可能性があると見なされる。そして、MyClassにはsize()が定義されていないというエラーが起きる。まとめ
CythonはCとPythonが融合している言語故に、二つの特性を活用できるが面倒ごとが多く感じた。
とりあえず、Cythonの型に困ったら、cdefによる静的型付けやキャストをうまく使って切り抜けよう。参考文献
- Kurt W. Smith 著、中田 秀基 監訳、長尾 高弘 訳 「Cython - Cとの融合によるPythonの高速化」2015
- Welcome to Cython’s Documentation — Cython 3.0a0 documentation
- 投稿日:2020-03-20T17:05:59+09:00
Pythonで毎日AtCoder #11
はじめに
前回
11日目です。#11
考えたこと
Xは最大で$10^{27}$になるので、うまくmodを使って計算しました。a, b, c = map(int,input().split()) mod = 10**9+7 print(a*b%mod*c%mod)まとめ
今日は2時間くらい麻雀してたので疲れた。明日のAGCは、Aだけでも解きたい!
- 投稿日:2020-03-20T17:04:34+09:00
[Python]ランダムに発生するXMLを解析する[ElementTree]
ライブラリインポート
XML解析に必要なライブラリElementTreeをインポートします。
globはフォルダ内のXMLのPathを取得
pandasは配列に格納。pandasからcsvに書き出しとMySQLに保存を実行します。from xml.etree import ElementTree import glob import pandas as pdXML
こんな感じのXMLデータを解析します。
offsetは秒単位の時間が格納されています。
86400秒は24時間-<Day> -<EventCollection> -<Event> <Offset>0</Offset> <Value>70</Value> </Event> -<Event> <Offset>86400</Offset> <Value>69</Value> </Event> -<Event> <Offset>172800</Offset> <Value>73</Value> </Event> <Day>フォルダからXMLを取得して解析
フォルダ内にダウンロードされたXMLのPathを取得して解析します。
xmlfile = glob.glob("C:/Users/user/*") #fileにXMLファイルパスを格納 file = len(xmlfile) #XMLファイル数をカウント i_file = 0 #XMLファイルを上から順番に指定するための番号_0が一番最初 for i in range(file): XMLFILE = xmlfile[i_file] i_file += 1 tree = ElementTree.parse(XMLFILE) # XMLファイル読み込み root = tree.getroot() # XMLの中身を取得 # listを準備 Day = [] Night = [] #forを利用して数値を全てlistに格納 for e in root.findall('.//Day/EventCollection/Event/Value'): Day.append(e.text) for e in root.findall('.//Night/EventCollection/Event/Value'): Night.append(e.text) print(Day) [70,69,73]ListをPandasに格納してからcsvに保存
#listを1つにまとめる listData = [Day, Night] # listDataをDataFrameに変換。.Tは行と列を入れ替え df = pd.DataFrame(listData).T # カラム名を追加 df.columns = ['Day', 'Night'] #csvのpathを設定してpandasDataFramをcsvに保存 filename = 'C:/Users/user/csv/AAA.csv' df.to_csv(filename, index=False)MySQLにDataFrameを保存
csvで出力したDataFrameをMySQLにも保存します。
ライブラリをインポート
from sqlalchemy import create_engineurl = 'mysql+mysqlconnector://[user]:[pass]@[host]:[port]/sampleDB' engine = create_engine(url, echo=True) #df.to_sqlで'sampleDB_table'にdfに格納したデータを保存 df.to_sql('sampleDB_table', engine, index=False, if_exists='append')これを私はFileMakerから実行させていますが、Windowsであればタスクスケジューラなどで定期的に実行させればデータが自動的にデータベースに格納されていき、のちの解析に使えるようになります。
今後は、PHP、javascriptなどを利用してデータの見える化(BIツール)、その次に機械学習(AI)に取り組んでいきたいと考えています。
- 投稿日:2020-03-20T16:35:43+09:00
Django 初心者入門
Djangoとは
webサービス開発を行うためのwebフレームワークです.Pythonで記述されたオープンソースwebフレームワークです.世界中のプログラマが使用している最も有名なフレームワークの一つです.
- YouTube
- Spotify
- Dropbox
などのサービス開発で使用されている
webサービスのフレームワークであるDjangoの入門的な内容をメモ用として共有しておこうと思います.
Pythonについてある程度の知識があった方がとっかかりやすいかと思います.初期設定
開発環境はmacOS(Catalina),Python3.7,Django3です.
仮想環境での開発をお勧めします.今後Django4とかが提供されることが予想できるので,同一のPCで開発をするならば,プロジェクトごとに開発環境を常に独立させておくことは複数のプロジェクトを進める上で重要なことです.
- pyenv-vertualenv
- pipenv
macOSならこのどちらかを使って仮想環境を準備するといいと思います.
pyenvとpipenvを共存させてしまうとうまくいかないことがあるので注意しましょう.仮想環境構築
pipenvとpyenv-virtulenvによる仮想環境構築方法を簡単に説明します.
pipenvによる仮想環境構築
Homebrewがインストール済みで,pip3が使用できる前提とします.
$ pip3 install pipenvもしくは
$ brew install pipenv次にDjangoをインストールしていきます.今回はDesktopに開発用のディレクトリ(django)を作成します.
#カレントディレクトリをDesktopへ移動 $ cd ~/Desktop #djangoディレクトリ作成 $ mkdir django #カレントディレクトリをdjangoへ移動 $ cd django作成したdjangoディレクトリに移動後pipenvを使ってDjangoをインストールします.
$ pipenv install django==3.0上のコマンドを実行後,djangoディレクトリ内には2つの新しいファイルが作成されます
- Pipfile
- Pipfile.lock
次に仮想環境を作成するためのコマンドを実行します.
$ pipenv shellこれでactivateできました.仮想環境に入れている場合は左側に(django)というような表示が出ます.
#ちゃんと仮想環境に入れている場合 (django)$pyenv-virtualenvによる仮想環境構築
pyenv-virtualenvのインストール方法は@hedgehoCrowさんを参考にしてください.
pyenv-virtualenvがインストールできたら,実際に仮想環境を構築していきます.まず,現在使用できるpythonなどのバージョンを確認します.(いづれかのpythonはインストール済みが前提)
$ pyenv versions [output] system 2.7.16 * 3.7.4 anaconda3-5.3.1のような出力が表示されるはずです.*がついているものが現在の環境です.ここに構築したい環境を作成していきます.
次のようなコマンドを実行します.python3.7.4のdjangoという仮想環境を作成してみます.$ pyenv virtualenv 3.7.4 djangoすると,以下のように追加されます.
$ pyenv versions [output] system 2.7.16 * 3.7.4 3.7.4/envs/django #追加された環境 anaconda3-5.3.1そして,今作った仮想環境で作業するために,作業したいディレクトリへ移動し,次のコマンドを実行します.
$ pyenv local djangoこれで仮想環境の構築が完了です.
サーバの起動
Djangoの新しいプロジェクトを作って,サーバを起動してみましょう.
新規プロジェクト作成
プロジェクト作成のために以下のコマンドをDesktop/djangoに移動して実行します.(pyenv-virtualenvによる仮想環境下で実行しています)
$ django-admin startproject test_project .最後のピリオド(.)を忘れずに!無いとdjangoディレクトリ内のファイル構成がおかしくなります.
djangoディレクトリ内のファイル構成は次のようになります.|- django |- manage.py |- test_project |- __init__.py |- settings.py |- urls.py |- wsgi.pyサーバ起動
Desktop/djangoにおいて以下のコマンドを実行して,サーバを起動させます.
$ python manage.py runserver [output] Watching for file changes with StatReloader Performing system checks... System check identified no issues (0 silenced). You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. March 20, 2020 - 07:26:31 Django version 3.0.4, using settings 'helloworld_project.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.赤色の文字で警告文みたいな表示が出ますが,今は気にしなくても大丈夫です.
下から2行目の右側がサーバのアドレスとなります.
ブラウザで検索してみてください.
こんな感じの表示が出ればとりあえずサーバの起動は成功です.
サーバを停止させるにControl-Cでできます.
- 投稿日:2020-03-20T16:32:16+09:00
PythonモジュールをLambda Layerにアップロードする時のフォルダ構成について
はじめに
Lambda Layerを使おうとした際にPythonモジュールのフォルダ構成でハマったので、備忘として記事にします。Lambda LayerについてはAWSの公式ドキュメントをご確認ください。
フォルダ構成
プログラミング言語ごとのフォルダ構成については公式ドキュメントでも言及されています。
Pythonの場合、python/配下にLambda Layerで使用するモジュールを配置する必要があります。
例えば以下のようなイメージです。python ├─test1.py └─common └─test2.pyLayerにアップロードするには、上記
pythonフォルダをzipファイルにした上でアップロードします。
上記構成を無視してzipファイルを作成してアップロードした場合、当然ですが、Lambdaで使用する際にエラーになります。
最初はなぜエラーになっているかもわからずハマってました。。。ちゃんとドキュメントは確認しないといけないなと反省しました。
- 投稿日:2020-03-20T16:17:29+09:00
OpenCVを使ったブロブ検知の実行例
はじめに
ブロブ(塊)とは、似た特徴を持った画像内の領域を意味します。例えば、下の様な画像では、丸などの図形がブロブだと言えます。
OpenCVには、ブロブを自動的に検知できる関数が組み込まれており、簡単に見つけることができます。
やりたいこと
丸形を見つけてカウントしたい。
コード
blob.pyimport cv2 import numpy as np # 画像の読み込み image = cv2.imread('shapes.jpg', 0) # パラメータの初期化 params = cv2.SimpleBlobDetector_Params() # ブロブ領域(minArea <= blob < maxArea) params.filterByArea = True params.minArea = 100 # 真円度( 4∗π∗Area / perimeter∗perimeter によって定義される) #(minCircularity <= blob < maxCircularity) params.filterByCircularity = True params.minCircularity = 0.85 # 凸面の情報(minConvexity <= blob < maxConvexity) params.filterByConvexity = True params.minConvexity = 0.1 # 楕円形を表す(minInertiaRatio <= blob < maxInertiaRatio) params.filterByInertia = True params.minInertiaRatio = 0.1 # 検知器作成 detector = cv2.SimpleBlobDetector_create(params) # ブロブ検知 keypoints = detector.detect(image) # ブロブを赤丸で囲む blank = np.zeros((1, 1)) blobs = cv2.drawKeypoints(image, keypoints, blank, (0, 0, 255), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) # ブロブの個数 count = len(keypoints) print(f'丸の個数: {count}') # 画像を表示 cv2.imshow("out.jpg", blobs) cv2.waitKey(0) cv2.destroyAllWindows()結果
>python blob.py 丸の個数: 8
※枠が赤から黒に変化したのは、グレースケールで読み込んだためです。
実行で失敗した話
他のサイトで紹介されていたコードを試したら、Pythonがクラッシュしました。
調べてみるとOpenCVのバージョンが影響してたようです。以前のバージョンのOpenCVでは、SimpleBlobDetector_create()の代わりに、SimpleBlobDetector()という関数が使われており、コピペでコード実行 → 現在は使われていない関数を参照 → クラッシュという流れが発生したのだと思います。
対策としては、SimpleBlobDetector_create()を使うか、下のコードに書き換えるとエラーを回避できます。ver = (cv2.__version__).split('.') if int(ver[0]) < 3: detector = cv2.SimpleBlobDetector(params) else: detector = cv2.SimpleBlobDetector_create(params)おわりに
ブロブ検知の応用例としては、個数のカウントや位置検知があります。OpenCVによって簡単に使えるので、この例以外でも試して行きたいと思います。
最後までご覧いただきありがとうございました。コメント・ご指摘等ありましたらよろしくお願いします。
参考URL
https://www.programcreek.com/python/example/89350/cv2.SimpleBlobDetector
https://www.visco-tech.com/technical/direction-presence/blob/


- 投稿日:2020-03-20T15:58:25+09:00
【ディープラーニング】機械学習初心者が競艇1位予想を作れるのか試してみた。
はじめに
ディープラーニングの勉強を始めて1ヶ月。
基礎的なものは理解できた気がしてきたので、何かできないかと考えてみました。
そしてふと、この競艇の順位予想が思いつきました。
順位予想ができるという確信はありませんでしたが、ボートレースのデータのオープンソースが公開されていることがわかり、これはやってみるしかないと思いました。
参考にしたデータ元と特徴量
↓データ元のサイトは下記リンクから飛ぶことができます。↓
BOTE RACE OFFICIAL タウンロード・他選手のデータから勝率まで細かく載っているので学習させるにはちょうどいい情報量だと思います。
今回学習させるデータの種類は以下の通りです。
- 艇番
- 年齢
- 体重
- 級別
- 全国勝率
- 全国2率
- 当地勝率
- 当地2率
- モーターナンバー
- モーター勝率
- ボートナンバー
- ボート勝率
とりあえずこの情報量で学習させていきます。
選手番号を使うことも考えましたが、それぞれを別カテゴリとしてしまうと、無駄な情報量が多くなってしまうので省くことにします。年齢、体重などが成績に関わるか、と言われると競艇の知識がないのでそれはわかりませんが、一応特徴量として入れることにしました。
Keras
Kerasを用いたディープニューラルネットワークをつくりたいと思います。
バックエンドとしてTensorflowを使用しています。
KerasはGoogleの社員が開発設計したもので、Google開発のTensorflowとの互換性がいいのでとても使いやすいです。
さらにKerasは高校の数学ができればある程度開発を行うことができる(と設計者が言っていた)のでとっかかりやすいとおもいました。
参考文献は下記リンンクに貼っておきます。
PythonとKerasによるディープラーニングソースコード
ライブラリのインポート
race.pyimport pandas as pd from sklearn.model_selection import train_test_split import keras from keras import models, layers, regularizers from google.colab import files
- DataFrameを扱うpandas 訓練データとテストデータに分割するtrain_test_split*
- ネットワークを構築するときに使うmodels, layers
- 正規化するためのregularizers
- 自分のPCからファイルをインポートできるfiles
データのインポート
uploaded = files.upload()files.upload()で自分のPC内にあるファイルをインストールすることができます。
DataFrameの読み込み/要素の削除/欠損値を0で埋める
df = pd.read_csv('program_data.csv').drop(["Name", "Live", "Number"], axis=1).fillna(0) df.head(3)pd.read_拡張子()
指定したファイルをDataFrameとして受け取ることができます。
df.drop()
指定した行(axis=1)または列(axis=0)の要素を削除することができます。
df.fillna()
欠損値を任意の値で埋めることができます。
例えば今回の場合では、df.fillna(0)としてあげると欠損値(NaN)を0に変換して埋めてあげることができます。しかし、欠損値は0で埋めれば良い。という話ではありません。
今回の場合は順位が1位の場合は1、それ意外は欠損値(NaN)というデータを扱っています。
1位を予測することが今回の目標なので、1位以外のテストラベルの値は0であった方が学習がしやすいと思い、0で埋めることにしました。
もし、学習させたい要素に欠損値があった場合、学習に支障を来さないために中央値であったり、平均値で補ってあげると良いと思います。
欠損値の算出
df.isnull().sum()df.isnull()
各要素に欠損値(NaN)があるかを調べます。
そしてsum()によって加算することで、各要素にどれだけの欠損値(NaN)があるかがわかります。
OneHotEncodingで名義特徴量を変換する
df_dummies = pd.get_dummies(df["Rank"]) df_dummies.astype("float32")pandasのget_dummies()
OneHotEncodingを簡単に行うことができます。
Rankは名義特徴量であるため、OneHotEncodingで情報を有益に使うようにする必要があります。df.astype('float32')
DataFrameの変数型を変更することができます。
ディープラーニングにおいて、変数型をそろえるのは重要な部分となってきます。不必要な要素の削除
df = df.drop('Rank', axis=1) df.astype("float32")OneHotEncodingしたので、Rankカラム(列)自体は必要なくなったので、削除します。
DataFrameの結合
df = pd.merge(df, df_dummies, how="left", left_index=True, right_index=True)pd.merge(df1, df2)
DataFrameを結合することができます。
その他引数の設定によって細かく結合方法を指定することができます。特徴行列と目的変数
X = df.iloc[:, 1:].values y = df.iloc[:, 0].valuesdf.iloc(行, 列)
DataFrame.ilocからアクセスすれば、行と列の数字(インデックス番号)からDataFrameを取り出せます。
X:年齢、勝率などの学習させるためのデータを含む特徴行列
y;教師あり学習として使う目的変数訓練・検証データとテストデータ
X_train, y_train, X_test, y_test = train_test_split( X, y, test_size=0.2, random_state=0)train_test_split()
データをトレーニングデータとテストデータに分割します。
test_size=0.2とすると、全体のデータの20%をテストデータとして使用する。という意味になります。特徴行列の正規化
mean = X_train.mean(axis=0) std = X_train.std(axis=0) X_train -= mean X_train /= std y_train -= mean y_train /= std特徴行列が各要素ごとに別々の特徴量を持っている時、正規化する必要があります。
正規化の方法は以下の手順です。
1. 特徴行列の平均値(mean)、標準偏差(std)を求めます。
2. 特徴行列から平均値を引きます。
3. その後、標準偏差で割ることで正規化が完了します。これによって、特徴量の中心が0となり、標準偏差が1になります。
X_train(訓練データ)とy_train(テストデータ)の両方を正規化しておきます。
ニューラルネットワークの構築
model = models.Sequential() model.add(layers.Dense(128, activation="relu", kernel_regularizer=regularizers.l2(0.001), input_shape=(X_train.shape[1], ))) model.add(layers.Dropout(0.49)) model.add(layers.Dense(512, activation="relu", kernel_regularizer=regularizers.l2(0.001))) model.add(layers.Dropout(0.49)) model.add(layers.Dense(512, activation="relu", kernel_regularizer=regularizers.l2(0.001))) model.add(layers.Dropout(0.49)) model.add(layers.Dense(512, activation="relu", kernel_regularizer=regularizers.l2(0.001))) model.add(layers.Dropout(0.49)) model.add(layers.Dense(1, activation="sigmoid"))ここからニューラルネットワークを構築していきます。
層を追加するときには、Denseを使用します。活性化関数
最終層以外の各層に活性化関数(activation)としてReLU関数を使用しています。
最終層には出力結果を0から1で出力するシグモイド関数を使用しています。
正則化
kernel_regularizer = keras.regularizers.l2(0.001)**
過学習を防ぐためにL2正則化を行っています。
layers.Dropout()
こちらも過学習を防ぐための方法です。
ランダムに層の出力を0にして隠すことによって学習の偏りを防ぎ、より有益な学習を行うことができるようになります。これでニューラルネットワークの層は完成しました!
コンパイルメソッド
model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"])続いてコンパイルメソッドに入ります。
optimizer:与えられたデータと損失関数に基づいてネットワークが自身を更新するメカニズム
loss:訓練データでのネットワークの性能をどのように評価するのか、そしてネットワークを正しい方向にどのように向わせるのかを決める方法
metrics:モデルの評価をする評価関数扱う問題によってコンパイルメソッドに何を選択するか、ということも変わってきます。
オプティマイザのrmspropに関してはどの問題でも基本的にちゃんと動いてくれる有能な役割をもつので
、最初にとりあえずこれを使ってみても良いかもしれません。学習(訓練)
EPOCHS=1000 early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10) history = model.fit(X_train, X_test, epochs=EPOCHS, batch_size=512, validation_split=0.2, callbacks=[early_stop])これで準備が完了したので、いよいよ訓練(学習)を開始させていきたいと思います。
訓練をするときには、fit()を使用します。X_train:特徴行列
y_train:目的変数
epochs:訓練(のループ)を何回行うか指定することができます。
batch_size:任意の数のミニバッチを作成し。学習させる。
validation_split:検証用データを作成することができる。(今回の場合は0.2なので20%を検証データとして使う。)
callbacks:色々な種類があり、今回は過学習が起こる前に学習を強制終了させるEarlyStoppingを使用しています。callbacks.EarlyStopping(monitor='', patience=10)
過学習を起こさせないために最適なエポックの数で強制終了させる役割を持ちます。
- monitor:監視する値
- patience:ここで指定したエポック数の間(監視する値に)改善がないと、訓練が停止します。
詳細はKeras Documentation callbacksを参考にしてください。
モデルの評価
score = model.evaluate(y_train, y_test) print("loss : {}".format(score[0])) print("Test score : {}".format(score[1]))モデルの評価を行います。
score = model.evaluate(y_train, y_test)
score[0]:損失関数の値が入ります。
score[1]:テストの正解率が入ります
正解率を約86%まで伸ばすことができました。Historyオブジェクト
history_dict = history.history history_dict.keys()model.fit()呼び出しがHistoryオブジェクトを返すことに注目してください。
このオブジェクトには、historyというメンバーがあります。
このメンバーは、訓練中に起きたすべてのことに関するデータを含んでいるディクショナリです。出力
このディクショナリには、訓練中および検証中に監視される指標ごとに1つ、合計4つのエントリが含まれています。
損失値の図示
import matplotlib.pyplot as plt #ドットは訓練データを表しており、折れ線は検証データを表しています history_dict = history.history loss_values = history_dict['loss'] val_loss_values = history_dict['val_loss'] epochs = range(1, len(loss_values) + 1) #”bo”は”blue dot”(青のドット)を意味する plt.plot(epochs, loss_values, 'bo', label = 'Training loss') #”b”は"solid blue line"(青の実線)を意味する plt.plot(epochs, val_loss_values, 'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()訓練データの損失値と検証データの損失値をプロットします。
図より、過学習も防ぐことができており、損失値もエポックごとに減少していることから良いモデルになっていると思います。
正解率の図示
#図を消去 #ドットは訓練データでの結果、折れ線は検証データでの結果 plt.clf() acc = history_dict['acc'] val_acc = history_dict['val_acc'] plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and Validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()次に、一旦図を消去し、訓練データと検証データの正解率をプロットしていきます。
少し図に偏りがあったりしますが、基本的には80~85%の正解率を出すことができています。
まとめ
ディープラーニングを用いて正解率を約86%まで伸ばすことができました。
転覆などの事故でバイアスがかかるので、絶対的な正解率にするのは難しいようです。
余裕があれば、次回から2連単、3連単を予測するプログラムを作りたいと思います。
ソースコードの間違い、ご指摘などございましたらコメント欄にお願いします。


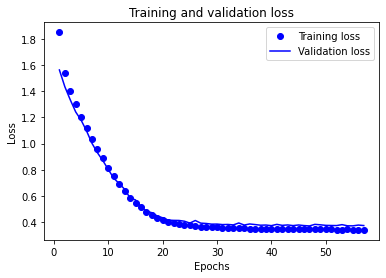
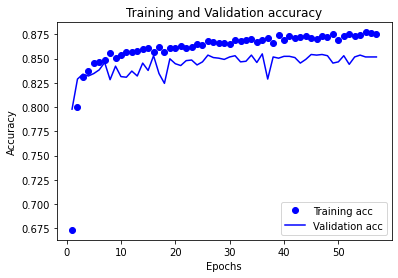
- 投稿日:2020-03-20T15:06:46+09:00
学習済みkerasモデルのレイヤーの流用
はじめに
この記事は、自分の学習用メモです。
なにかお気付きの点がありましたら、ご指摘いただけますと幸いです。今回の学習はこれ:
kerasで作成して学習させたモデルからレイヤーを取り出して再利用して、新しく作ったモデルに使うことができるでしょうか?学習済みのモデル
このページ にあるモデルを使います。
変数名はmodelです。001.pymodel.summary() #Layer (type) Output Shape Param # #================================================================= #dense_1 (Dense) (None, 100) 1100 #_________________________________________________________________ #dense_2 (Dense) (None, 100) 10100 #_________________________________________________________________ #dense_3 (Dense) (None, 40) 4040 #_________________________________________________________________ #dense_4 (Dense) (None, 20) 820 #_________________________________________________________________ #dense_5 (Dense) (None, 2) 42 #================================================================= #Total params: 16,102 #Trainable params: 16,102 #Non-trainable params: 0 _________________________________________________________________modelがどんな変数を持っているかをvars()で調べます。
002.pyvars(model)ここには示しませんが、modelの持つ変数がわかります。なかでも_layersという変数が、レイヤオブジェクトのリストを保持しているようです。
アクセスしてみます。
003.pymodel._layers #見やすいように出力を改行で区切っています。 #[<keras.engine.input_layer.InputLayer object at 0x138144208>, #<keras.layers.core.Dense object at 0x13811af98>, #<keras.layers.core.Dense object at 0x138144320>, #<keras.layers.core.Dense object at 0x1381443c8>, #<keras.layers.core.Dense object at 0x138144518>, #<keras.layers.core.Dense object at 0x1381741d0>]また、model.layersとしてもアクセスできますね。getterメソッドが定義されているのでしょうか?
この場合は、model.layersとした場合と比べると先頭のInputLayerがないようです。004.pymodel.layers #見やすいように出力を改行で区切っています。 #[<keras.layers.core.Dense object at 0x13811af98>, #<keras.layers.core.Dense object at 0x138144320>, #<keras.layers.core.Dense object at 0x1381443c8>, #<keras.layers.core.Dense object at 0x138144518>, #keras.layers.core.Dense object at 0x1381741d0>]最後のレイヤーを調べてみる
一番パラメータが少ない、最後のレイヤーはどうなっているでしょうか?
見やすいようにpprintを使います。005.pyimport pprint pprint.pprint(vars(model.layers[4])) #以下は出力。 """ {'_built': True, '_inbound_nodes': [<keras.engine.base_layer.Node object at 0x138174e10>], '_initial_weights': None, '_losses': [], '_metrics': [], '_non_trainable_weights': [], '_outbound_nodes': [], '_per_input_losses': {}, '_per_input_updates': {}, '_trainable_weights': [<tf.Variable 'dense_5/kernel:0' shape=(20, 2) dtype=float32, numpy= array([[-0.07533632, 0.20118327], [-0.17458896, -0.44313124], [ 0.4008763 , 0.3295961 ], [-0.40597808, -0.02159814], [ 0.59269255, -0.15129048], [-0.14078082, -0.44002545], [ 0.18300773, 0.17778364], [ 0.3685053 , -0.36274177], [-0.28516215, -0.0659026 ], [ 0.45126018, -0.2892398 ], [ 0.19851999, -0.39362603], [ 0.2631754 , 0.40239784], [ 0.08184562, -0.08194606], [-0.43493706, 0.18896711], [ 0.36158973, 0.20016526], [-0.05036243, -0.20633343], [-0.41589907, 0.57210416], [-0.10199612, -0.37373352], [ 0.30416492, -0.19923651], [ 0.02667725, -0.5090254 ]], dtype=float32)>, <tf.Variable 'dense_5/bias:0' shape=(2,) dtype=float32, numpy=array([0.05854932, 0.07379959], dtype=float32)>], '_updates': [], 'activation': <function linear at 0x1380400d0>, 'activity_regularizer': None, 'bias': <tf.Variable 'dense_5/bias:0' shape=(2,) dtype=float32, numpy=array([0.05854932, 0.07379959], dtype=float32)>, 'bias_constraint': None, 'bias_initializer': <keras.initializers.Zeros object at 0x138180400>, 'bias_regularizer': None, 'dtype': 'float32', 'input_spec': InputSpec(min_ndim=2, axes={-1: 20}), 'kernel': <tf.Variable 'dense_5/kernel:0' shape=(20, 2) dtype=float32, numpy= array([[-0.07533632, 0.20118327], [-0.17458896, -0.44313124], [ 0.4008763 , 0.3295961 ], [-0.40597808, -0.02159814], [ 0.59269255, -0.15129048], [-0.14078082, -0.44002545], [ 0.18300773, 0.17778364], [ 0.3685053 , -0.36274177], [-0.28516215, -0.0659026 ], [ 0.45126018, -0.2892398 ], [ 0.19851999, -0.39362603], [ 0.2631754 , 0.40239784], [ 0.08184562, -0.08194606], [-0.43493706, 0.18896711], [ 0.36158973, 0.20016526], [-0.05036243, -0.20633343], [-0.41589907, 0.57210416], [-0.10199612, -0.37373352], [ 0.30416492, -0.19923651], [ 0.02667725, -0.5090254 ]], dtype=float32)>, 'kernel_constraint': None, 'kernel_initializer': <keras.initializers.VarianceScaling object at 0x138174b70>, 'kernel_regularizer': None, 'name': 'dense_5', 'stateful': False, 'supports_masking': True, 'trainable': True, ####### ここ重要 ####### 'units': 2, 'use_bias': True} """最後のレイヤーは1つ前のレイヤーからの出力20個を受け取って、2個の出力をするので、ウエイトパラメーターの数は20 x 2=40 個、バイアスパラメーターが2個です。
よくわかりませんが、ウエイトパラメーターとして、同じものを2つ(_trainable_weights[0]とkernel)持っているようです。
ウエイトパラメータの実態はなんでしょうか?
_trainable_weights[0]をtype()で調べてみます。006.pytype( model.layers[4]._trainable_weights[0] ) #<class 'tensorflow.python.ops.resource_variable_ops.ResourceVariable'>tensorflowのResourceVariableオブジェクトのようですが、ここではこれ以上調べません。
ウエイトとバイアスを格納したリストをget_weights()で取り出せるようです。
リストの要素数は2です。007.pytype(model.layers[4].get_weights()) #<class 'list'> len(model.layers[4].get_weights()) #2このリストの中身はndarrayです。
中身を見ておきます。008.pytype(model.layers[4].get_weights()[0])#リストの0番目の確認 #<class 'numpy.ndarray'> model.layers[4].get_weights()[0]#リストの0番目 """ array([[-0.07533632, 0.20118327], [-0.17458896, -0.44313124], [ 0.4008763 , 0.3295961 ], [-0.40597808, -0.02159814], [ 0.59269255, -0.15129048], [-0.14078082, -0.44002545], [ 0.18300773, 0.17778364], [ 0.3685053 , -0.36274177], [-0.28516215, -0.0659026 ], [ 0.45126018, -0.2892398 ], [ 0.19851999, -0.39362603], [ 0.2631754 , 0.40239784], [ 0.08184562, -0.08194606], [-0.43493706, 0.18896711], [ 0.36158973, 0.20016526], [-0.05036243, -0.20633343], [-0.41589907, 0.57210416], [-0.10199612, -0.37373352], [ 0.30416492, -0.19923651], [ 0.02667725, -0.5090254 ]], dtype=float32) """ type(model.layers[4].get_weights()[1])#リストの1番目の確認 #<class 'numpy.ndarray'> model.layers[4].get_weights()[1]#リストの1番目 #array([0.05854932, 0.07379959], dtype=float32)レイヤーを取り出して、新しくモデルを作ってみる。
モデルを作る時に、どのタイミングでパラメーターが初期化されるのか、よくわかっていないので、モデルに組み込む時に初期化されてしまうかどうかチェックすることにします。
ここでは、モデルの5つのレイヤーのうち、最後のレイヤーを流用して、新しいモデルの2番目のレイヤーとすることにします。
流用するレイヤーは20個の入力を受け取るレイヤーなので、新しいモデルの入力レイヤーは20個の入力を受け付けるようにします。
009.pyinputs = keras.layers.Input(shape=(20,)) x = model.layers[4](inputs) model_new = keras.Model(inputs=inputs, outputs=x)つながりました。
レイヤーが、先のモデルの5番目のレイヤーと同じレイヤーであるかと、
パラメーターが変わっていないかどうかチェックします。010.pymodel_new.layers[1] <keras.layers.core.Dense object at 0x1381741d0>#Objectのアドレスが同じ。 model_new.layers[1].get_weights()[0]#パラメーターが変わっていないかチェック-->変わっていない。 """ array([[-0.07533632, 0.20118327], [-0.17458896, -0.44313124], [ 0.4008763 , 0.3295961 ], [-0.40597808, -0.02159814], [ 0.59269255, -0.15129048], [-0.14078082, -0.44002545], [ 0.18300773, 0.17778364], [ 0.3685053 , -0.36274177], [-0.28516215, -0.0659026 ], [ 0.45126018, -0.2892398 ], [ 0.19851999, -0.39362603], [ 0.2631754 , 0.40239784], [ 0.08184562, -0.08194606], [-0.43493706, 0.18896711], [ 0.36158973, 0.20016526], [-0.05036243, -0.20633343], [-0.41589907, 0.57210416], [-0.10199612, -0.37373352], [ 0.30416492, -0.19923651], [ 0.02667725, -0.5090254 ]], dtype=float32) """このレイヤをvars()して調べてみたところ、
_inbound_nodesをkeyとするリストの値だけが異なりました。011.pypprint.pprint(model.layers[1]._inbound_nodes) #[<keras.engine.base_layer.Node object at 0x138144be0>] pprint.pprint(model_new.layers[1]._inbound_nodes) #[<keras.engine.base_layer.Node object at 0x138174e10>, # <keras.engine.base_layer.Node object at 0x110cfe198>]#これが増えている。keras.engine.base_layer.Nodeについてはちょっと保留です。
このレイヤーのパラメーターを学習時に変更しないように設定(レイヤーをフリーズさせる)するには、
trainableプロパティにFalseをセットします。012.pymodel_new.layers[1].trainable=Falseモデルはcompileする必要があります。
まとめ
1.学習済みのkerasのNNモデルから、好きなレイヤーを取り出して他のモデルに利用することができる。
2.レイヤーのパラメーターが変更されないように、freezeすることができる。
- 投稿日:2020-03-20T15:03:45+09:00
機械学習をゼロから学ぶための勉強法 (2020年3月版)
はじめに
データサイエンスや機械学習っておもしろそう!と思いつつも、どうやって勉強をしたら良いかわからない......と感じた経験はありませんか?
ちなみに自分もその一人です。
この記事では、機械学習ってそもそも何? AIという言葉は知ってるけど詳しいことはわからないというような初学者でも、知識・経験を積んで機械学習に取り組めるようにするために必要な基礎の基礎から学ぶための勉強法を自分の経験をもとに紹介します!(ここで紹介するものは機械学習の中級者以上の方でも基礎知識の復習として活用できるものかなとも思っています)概要 (基本的にはこの3stepです)
- 基礎知識をつける(単語・用語の理解)
- ライブラリの使い方を理解
- 実際にコンペに挑戦(Kaggle)
1.機械学習&ディープラーニングのしくみと技術がこれ1冊でしっかりわかる教科書
はじめて学ぶような分野の場合、まず問題に出てくるのは「日本語がわからない」(専門用語がわからない)ということ。これはどの分野にでも共通することだとは思いますが、機械学習に関しては特に当てはまると思います。
そのような状況を打破するためにオススメな本がこの本で、基礎の基礎から教えてくれるまさに「教科書」です。簡単な内容紹介
1章 : 人工知能の基礎知識について
(AI、機械学習、ディープラーニング、歴史的背景など、はじめに固めておくと良い基礎知識がまとめてあります)
2〜4章 : 機械学習について
(機械学習系の文献を見ているとよく出てくる基礎知識から、アルゴリズムまでを説明)
5〜7章 : ディープラーニングについて
(ディープラーニングの基礎知識からプロセスやアルゴリズムを説明)
8章 : システム環境と開発環境
(プログラム言語の選択のポイントから機械学習用ライブラリとフレームワーク、ディープラーニングのフレームワークの説明)
*個人的には、p214の機械学習の流れとライブラリをまとめた図はわかりやすく、このような流れで行うのだということが理解しやすかったです。オススメの読み方
まずは一読 (わからない単語があっても読み飛ばすくらいの気持ちで一通り読んでみる)
→これをやるだけでも他の記事や文献を見てた時に、わからない単語ではなく、見たことのある単語から始まるので学びやすいと思います!基礎知識が書いてある部分を重点的に再読+開発の流れがわかる最終章も
(章立てでいうと、1章、2章、5章、8章)ある程度読んだら、次のステップへ進んでこの本はわからない単語が出てきたら引くためのリファレンス本として活用する
2.データサイエンスのためのPython入門講座
かめ@米国データサイエンティスト さんのブログ
かめさんのブログ自体、勉強になることが多く書いてあるので時間を見つけて読んでみると良いですが、特にオススメなのがこの講座。機械学習をやるときに必ず使うと言って良いライブラリが体系的にまとめられていてとても理解しやすいです。(この後紹介するKaggleスタートブックもこの記事を読んでからだと理解がさらに進むと思います)簡単な内容紹介
(この内容紹介については、ブログに書いてある「本講座の目的」の部分がわかりやすく書かれていたのでその部分から引用します)
本講座では,Pythonでデータサイエンスをするにあたり必要な環境構築・Pythonの基本・データサイエンスに使うPythonライブラリの基本・その他データサイエンスで頻出のPythonモジュールの’基本の’使い方をマスターすることを目的としています.この講座で目指すところは
Pythonでデータサイエンスに必要なデータ処理をするためのツール・ライブラリ・モジュールの使い方の基本をマスターする
Excelなどの表計算ツールを使うことなくデータ処理ができる
画像ファイルなどのデータファイルに対して処理ができる
日頃のデータ処理(Excelなど)をPythonで自動化できる
といったところです.一部統計学についても触れていますが,「データサイエンスを学べる講座」ではなく「データサイエンスのためのPythonを学ぶ講座」であることに注意してください.ただ,講座の中にはいたるところに「現場で使えるテクニック」や「データサイエンスの頻出テクニック」をふんだんに盛り込んでいるため,広義の意味でのデータサイエンスを学ぶことはできます.
とにかくわかりやすく書いたつもりです.難しい単語はあまり出てきませんし,かなり噛み砕いて説明しているので途中で止まることはないと思います.
また,教科書的に教えるのではなく,「現場では実際どう使うのか」をいたるところに盛り込んでいます.そのため「ある程度体系的に網羅的にかつ実戦で使える内容」になっています.
(ここまで引用)紹介されているものとしては、
- pythonの基礎
- NumPy (数値計算に用いるもの)
- Pandas (データの操作や解析をするためのもの(Excelで行うような表計算がより早くできる))
- matplotlib(グラフ描画用のもの)
- Seaborn(matplotlibと同様、グラフが書けるがよりきれいに簡単に書ける)
- その他の便利ライブラリ・モジュール等オススメの読み方
まずは一読 (鉄則です!)
これは1と同時に行っても良いと思いますが、手を動かして実行結果や動きを学ぶ。(読んでいるだけだと身につかないことも多いと思います)
→ここで題材として取り上げられているKaggleのtitanicというコンペはこの後に紹介するKaggleスタートブックのチュートリアルとしても行うので、あわせて実行できると理解もさらに進むと思います。繰り返し読む+ときどき戻って読む
3. 実践Data Scienceシリーズ PythonではじめるKaggleスタートブック (KS情報科学専門書)
Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~ と kaggleのチュートリアルの著者2人がタッグを組み、書いたKaggleのチュートリアル本です(もとになっている2つはどちらも人気でわかりやすい本(記事)です!)
これまでに紹介した2ステップでは実践という部分が少し少なかった部分がありますが、やはり実際に使いながら学んでいくことで得られるものも多いと思います。しかし、そうはいってもどこから手をつけていいかわからないというのが本音。そのような中で、この本に沿ってKaggleの初学者向けのチュートリアルである「Titanic」コンペに参加するというのは、はじめの一歩としてはとても良いと思います!
簡単な内容紹介
1章 : Kaggleとは?からアカウントの作り方までを説明 (導入に最適)
2章 : タイタニックでのチュートリアル
3章 : 複数テーブル、画像・テキストデータの扱い方の説明
(2章で試したtitanicのコンペ以外の形式のコンペへの導入もされている)
4章 : さらに学ぶためのヒントが書かれたページ
(チュートリアルをやっただけで終わらせない。その先にもつながる内容が書いてあります)おすすめポイント➀ : サンプルコード
サンプルコードがあがっているので、それにしたがってやっていけば、Kaggleのアカウント登録は必要ですが、ほぼノンコーディングで一通りの処理を実践することもできます。(詳しくはわからないけど、概観をつかみたいというときは、一回実行してみてコードの解釈をしてみるというのもいいかもしれません)
おすすめポイント➁ : 対談記事
著者2人が対談形式でまとめてあるページで、上級者が当たり前としている部分や見方だけでなく、Kaggleをはじめたきっかけや良かったことなど読んでいて、ためになるものが多くあって勉強にもなります。
おすすめポイント➂ : note
Kaggleの周辺知識や+αの知識についてコラム形式でまとめられているので、わかりやすいです。(自分で調べれば出てくる内容であるかもしれませんが、わかりやすくまとめられているので、初学者にとってはありがたいです)
オススメの読み方
(自分がまだできていない部分もあるので、現状での勉強計画です。)
1. 1章を読みKaggleの概観、イメージをつかむ
2. 2章を読みながら実践 titanicをやってみる
3. 3章を一読
(複数テーブル、画像、テキストコンペの内容は読んでおいて、該当テーマを実践するときにもう一度読む)
4. 実際にコンペに参加してみる。
Titanicの次に参加するコンペの選び方や、初心者におススメの戦い方が紹介されているページ(4章)があるので、それに従って参加してみるのもいいと思います!KaggleのCompetitions Categoriesを整理してみた
← Kaggleのコンペのカテゴリーがわかりやすく書いてあります!Kaggleとは
Kaggleとは、データサイエンスの目標達成を支援する強力なツールとリソースを備えた世界最大のデータサイエンスコミュニティです。
↑ Devsumi 2018summerでのDeNAの原田さんの資料の中にKaggleとは何かが直観的に理解しやすいページがあったので、引用しました。4. まとめ
私自身、機械学習歴は長くなく、初心者に部類される人だと思いますが、環境や教材に恵まれているおかげで、徐々にわかるようにはなってきています。なので、本記事では、初歩の学び方についてまとめることで、機械学習に興味はあるけれど、独学でどのように勉強すればよいかわからないという人へ少しでも役に立てたらと幸いと思っています。
これから自分も勉強していく中で、もっとこうしたほうがいいのではないかということや、他の人(上級者や中級者の方々)からもう少しこうした方が勉強しやすいのではないかということがあれば随時更新もしくは別記事にまとめることができたらいいなと思っています!ちなみにですが、この記事に書いた3ステップの続きは(3のコンペの実践ともかぶる内容かもしれませんが)以下の記事などを参考にできるとさらに技術を磨くことができると思います
機械学習初心者がKaggleの「入門」を高速で終えるための、おすすめ資料などまとめ Kaggleスタートブックの著者の一人である村田さん(カレーちゃん)の記事です。その他参考になる資料
regonn&curry のpodcast
おすすめ(毎週、Kaggleに対するテーマや新コンペについて話しているpodcastです)
Kaggleで学ぶ日本の機械学習活用(大越)
kaggler-ja slack
kagglerの日本人コミュニティのSlack
最短で機械学習エキスパートになる9つのステップ【完全無料】



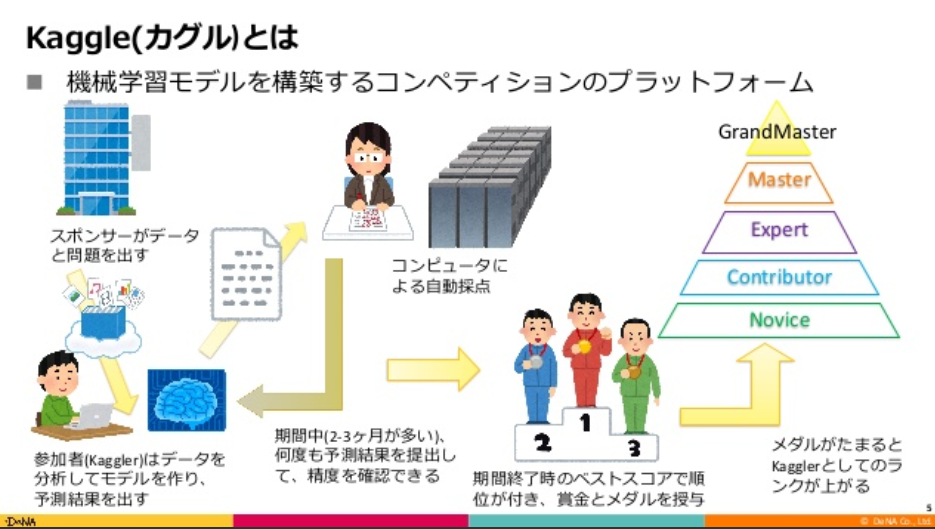
- 投稿日:2020-03-20T14:56:32+09:00
気象過去データの利用4(東京オリンピック期間の天気の気持ち)
気象庁が、2020年3月末まで、気象過去データを無償で提供しています。
(参考) 気象過去データの利用環境
https://www.data.jma.go.jp/developer/past_data/index.html基本的な気象データは、「利用目的・対象を問わず、どなたでもご利用頂けます。」とのことなので、気象データを使って何か行っていきます。
気象庁の「過去の気象データ・ダウンロード」ページからもダウンロードできますが、まとめて一括してダウンロードできるため非常に便利です。
利用可能なデータは、以下の掲載されています。
https://www.data.jma.go.jp/developer/past_data/data_list_20200114.pdf
もうすぐ期限ですので、必要な方は早めのダウンロードを今回は、東京オリンピック期間の天気を文字で表現してみます。
文字の表示には、WordCloud(1.6.0)を利用します。データダウンロード
「気象過去データの利用2(東京オリンピック期間の最高気温変遷)」と同様に「地上気象観測」-「時・日別値」を利用します。
ファイルの形式については、以下を確認してください。
http://data.wxbc.jp/basic_data/kansoku/surface/format_surface.pdfsurfaceフォルダにファイルをダウンロードします。約2GBの容量があるため時間がかかります。
import os import urllib.request # 地上気象観測 時・日別値ファイルダウンロード url = 'http://data.wxbc.jp/basic_data/kansoku/surface/hourly_daily_1872-2019_v191121.tar' folder = 'surface' path = 'surface/hourly_daily_1872-2019_v191121.tar' # フォルダ作成 os.makedirs(folder, exist_ok=True) if not os.path.exists(path): # ダウンロード urllib.request.urlretrieve(url, path)ファイルの詳細は、「気象過去データの利用2(東京オリンピック期間の最高気温変遷)」を参照してください。
天気データの読み込み
天気データは、天気概況として、「昼間」、「夜間」のデータが格納されています。
今回は、「昼間」のデータを利用します。
天気概況は、最大4つの天気と接続詞から構成されます。例えば、一日中晴れの場合は、「晴」、複数の天気で構成される例としては、「曇時々晴」、「曇一時雨後晴」「曇時々晴一時雨、雷を伴う」
コード 接続詞 0 データなし 1 空白 2 一時 3 時々 4 後 5 後一時 6 後時々 7 を伴う(、○○を伴う)
コード 天気 コード 天気 コード 天気 0 天気なし 10 みぞれ 20 大風 1 快晴 11 雪 21 雷 2 晴 12 大雪 22 あられ 3 薄曇 13 暴風雪 23 ひょう 4 曇 14 ふぶき 24 大風・雷 5 霧 15 地ふぶき 25 雷・あられ 6 霧雨 16 予備 26 雷・ひょう 7 雨 17 予備 27 雷・霧 8 大雨 18 予備 28 降水なし 9 暴風雨 19 予備 29 晴れ間あり 30 予備 31 × 「大雨」は、30mm以上の降雨があった場合に用いられます。詳細は、以下のサイトを参照してください。
http://www.data.jma.go.jp/obd/stats/data/mdrr/man/gaikyo.html変換用のリストを用意します。
conjunction = ['データなし', '空白', '一時', '時々', '後', '後一時', '後時々', '、'] conjunction7 = 'を伴う' weather = ['天気なし', '快晴', '晴', '薄曇', '曇', '霧', '霧雨', '雨', '大雨', '暴風雨', 'みぞれ', '雪', '大雪', '暴風雪', 'ふぶき', '地ふぶき', '予備', '予備', '予備', '予備', '大風', '雷', 'あられ', 'ひょう', '大風・雷', '雷・あられ', '雷・ひょう', '雷・霧', '降水なし', '晴れ間あり', '予備', '×']接続詞は、一般的に天気の前につけますが、「を伴う」の場合は、「、○○を伴う」のように天気(○○の部分)が中間に入ります。
pandasのデータフレームにデータを読み込みます。
各日の1500バイト目から天気概況が格納されています。数値を文字に変換しながら読み込みます。
後で、WordCloudで表示するため、各単語の間に空白を入れます。WordCloudは、単語の分解をしてくれません。あらかじめ、単語に分解して渡す必要があります。# データ格納用データフレーム作成 import pandas as pd tokyo_df = pd.DataFrame()# 天気概況取得 import tarfile # 地点設定=東京 p_no = '662' # tarファイルに含まれるファイルを取得 with tarfile.open(path, 'r') as tf: for tarinfo in tf: if tarinfo.isfile(): # tar.gzファイルに含まれるファイルを取得 with tarfile.open(fileobj=tf.extractfile(tarinfo), mode='r') as tf2: for tarinfo2 in tf2: if tarinfo2.isfile(): # 地点が一致するファイルのみ読み込み if tarinfo2.name[-3:] == p_no: print(tarinfo2.name) # ファイルをopen with tf2.extractfile(tarinfo2) as tf3: lines = tf3.readlines() for line in lines: # データが含まれないファイルは無視 if line[0:3] == b' ': continue # 年 year = line[14:18].decode() # 月日 date = line[18:22].decode().replace(' ', '0') # 天気概況を取得 conditions = '' p = 1500 # for i in range(4): # 接続詞 c = int(line[p:p+1]) c_rmk = int(line[p+1:p+2]) if c_rmk == 8: conditions += conjunction[c] + ' ' # 天気 w = int(line[p+2:p+4]) w_rmk = int(line[p+4:p+5]) if w_rmk == 8: conditions += weather[w] + ' ' if c == 7: # 〇〇を伴う場合は、後ろにつける。 conditions += conjunction7 + ' ' p += 5 # データ格納 tokyo_df.loc[year, date] = conditionsデータを確認します。
# データ確認 tokyo_df古い時代には天気の情報が入っていません。1989年以降が今の形式となったようですので、1989年以降のデータを取り出します。日付は、オリンピック期間とします。
tokyo_olympic_df = tokyo_df.loc['1989':'2019','0724':'0809'] tokyo_olympic_df正しく天気が入っていますね。
WordCloudによる表示
WordCloudを用いて天気を表示してみましょう。天気概況に使用されている単語の出現数に応じて文字の大きさが変わります。
一日中「晴」でも、「曇一時晴」でも「晴」は同じ1つてとしてカウントされるため、正確に天気を反映できていないかもしれませんが、大まかな状況は把握できるはずです。
また、接続詞も入っていますが、天気の変わりぐらいを表すためそのままにしておきます。まずは、年ごとにオリンピック期間の天気を確認してみます。
年ごとに、天気概況の文字列を結合し、WordCloudに渡します。
注意点です。
・日本語を表示するためにフォント(font_path)を指定します。私の環境はWinodwsのためMSゴシックを指定しました。各自環境に合わせて適切なフォントに変更してください。
・既定値では、1文字の単語は表示されません。regexpで正規表現を指定し表示させます。import matplotlib.pyplot as plt from wordcloud import WordCloud# 年ごとに表示 i = 1 plt.figure(figsize=(16, 33)) for row in tokyo_olympic_df.index: text = '' for column in tokyo_olympic_df.columns: text += tokyo_olympic_df.loc[row, column] # WordCloudによる文字画像作成 wordcloud = WordCloud(colormap='jet', font_path="msgothic.ttc", regexp="\w+").generate(text) plt.subplot(11,3,i) plt.imshow(wordcloud) plt.title(row) plt.axis("off") i += 1 plt.show()結果です。本当は、晴や雨など天気に応じて文字色を変更できればよいのですが、文字色はランダムに選択されるようです。
年によって若干ばらつきがありますが、おおむね晴や曇が多いですね。
日付ごとです。
# 日付ごとに表示 i = 1 plt.figure(figsize=(16, 18)) for column in tokyo_olympic_df.columns: text = '' for row in tokyo_olympic_df.index: text += tokyo_olympic_df.loc[row, column] # WordCloudによる文字画像作成 wordcloud = WordCloud(colormap='jet', font_path="msgothic.ttc", regexp="\w+").generate(text) plt.subplot(6,3,i) plt.imshow(wordcloud) plt.title(column) plt.axis("off") i += 1 plt.show()真夏のため、晴が多いですね。
天気の気持ちカレンダー
せっかくなので、天気の気持ちカレンダーを作成してみましょう。
1年分です。2019年は、途中までのデータしかないため、2018年までとします。また、うるう年の2月29日は削除しました。tokyo_365_df = tokyo_df.loc['1989':'2018'] tokyo_365_df = tokyo_365_df.drop('0229', axis=1) tokyo_365_df# 日付ごとに表示 i = 1 plt.figure(figsize=(16, 40)) for column in tokyo_365_df.columns: text = '' for row in tokyo_365_df.index: text += tokyo_365_df.loc[row, column] # WordCloudによる文字画像作成 wordcloud = WordCloud(colormap='jet', font_path="msgothic.ttc", regexp="\w+").generate(text) plt.subplot(37,10,i) plt.imshow(wordcloud) plt.title(column) plt.axis("off") i += 1 plt.show()東京の1年分のカレンダーです。
梅雨の時期は、雨が目立ちますね。
晴の特異日と言われている前回の東京オリンピックの開会式があった10月10日は、周辺の日付に比べて雨が少ないように見えます。晴の特異日と言えると思います。地点は、
p_no = '662'の地点番号を変更することで対応できます。地元の地点のカレンダーを作成した場合は、地点番号を変更してください。地点番号は、地点情報履歴ファイル(smaster_201909.tar.gz)で確認できます。札幌(412)の例です。
冬場は、雪が多いですね。
今回は、天気を文字の大きさで表してみました。数値やグラフで表す方が正確ですが、文字の大きさで表すと直感的で面白いです。
データの公開期間が2020年3月末までのため、必要な方は、早めのダウンロードをお勧めします。




- 投稿日:2020-03-20T13:23:36+09:00
AIエッジコンテスト(実装コンテスト)のチュートリアル【10: HWをPythonで制御する・・が、しかし、、】
ようやく長い道のりを経て準備が終わりました。Ultra96V2ボードで設計した畳み込み回路を動かしてみましょう!
必要なファイルをUltra96V2に転送
前回(AIエッジコンテスト(実装コンテスト)のチュートリアル【9: HW合成してビットストリームを生成するまで】)で以下のファイルを作成したはずです。
- pynq_ultra96_conv_l0_r1.bit
- pynq_ultra96_conv_l0_r1.tcl
- pynq_ultra96_conv_l0_r1.hdf
- pynq_ultra96_conv_l0_r1.hwh
第3回の(AIエッジコンテスト(実装コンテスト)のチュートリアル【3: Ultra96ボードのCPUで推論実行】)を参考にしてこれらのファイルをUltra96V2ボード上の
/home/xilinx/pynq/overlays/baseに置いてください。また、これまで使ってきたテストベンチ
- testbench_input.txt
- testbench_output.txt
を
/home/xilinx/dataに置いてください。ハードウェアを制御するノートブックをチュートリアルのリポジトリ(
https://github.com/HirokiNakahara/FPGA_AI_Edge_Contest_2019/blob/master/Inference_PYNQ_1)に置いています。クローンして、Ultra96V2のホーム/home/xilinxに置いてください。あとからUltra96V2のJupyter Notebookで読み込みます。いよいよ推論をハードウェアで実行
Ultra96V2のJupyter Notebookにブラウザから接続します。第3回を参考にしてください。
Uploadをクリックしてノートブック(ultra96v2_pynq_convolution_layer0.ipynb)を読み込んで実行します。あとは上から実行していくと準備、推論実行(ただし遅い)、比較のためのCPU上での推論がそれぞれ行われます。以下、要点を絞って解説します。
ultra96v2_pynq_convolution_layer0.ipynbfrom pynq import Overlay import pynq overlay = Overlay('/home/xilinx/pynq/overlays/base/pynq_ultra96_conv_l0_r1.bit') dir(overlay)PYNQはoverlayという概念でハードウェアを抽象化します。表示してみるとわかりますが、前回のIP接続で使ったコアの名前(kernel_0とかaxi_dma_0)がいくつか出ていると思います。これにアクセスして操作を行います。
ultra96v2_pynq_convolution_layer0.ipynbregisters = overlay.kernel_0.register_map例えば、ユーザのIPコアにPythonで制御するにはregister_mapにアクセスすれば可能です。今回はプラグマでAXIストリームを指定していますので、その操作が簡単に可能です!これはすごい(AXIのバスをRTLで書いたことがある人にとっては)。
DMAの設定ですが、
ultra96v2_pynq_convolution_layer0.ipynbimport pynq.lib.dma dma = overlay.axi_dma_0とオーバーレイにアクセスして
ultra96v2_pynq_convolution_layer0.ipynbfrom pynq import Xlnk inimg_size = 416*11*3 outfmap_size = 102*64+1 xlnk = Xlnk() send_buf = xlnk.cma_array(shape=(inimg_size),dtype=np.int32) recv_buf = xlnk.cma_array(shape=(outfmap_size),dtype=np.int32)と
Xlnk()(Xilinx社が設計したDMA制御ミドルウェアのラッパ)を読んで、配列を確保しておしまいです。楽勝。ハードウェアのデータ転送と受信ですが
ultra96v2_pynq_convolution_layer0.ipynb%%time for line in range(102): # load input image for i in range(11): inimg_buf[i] = inimg[i+line*4] tmp = inimg_buf.copy().transpose((2,0,1)).reshape(-1,) # CH,Y,X send_buf[0:inimg_size] = tmp[0:inimg_size] # activate DMA registers.CTRL.AP_START = 1 # DMA access dma.sendchannel.transfer(send_buf) dma.recvchannel.transfer(recv_buf) # wait DMA dma.sendchannel.wait() dma.recvchannel.wait() # store output buffer tmp2 = recv_buf[0:outfmap_size - 1] tmp2 = tmp2.reshape((64,102)) # CH, X outfmap_buf[line] = tmp2numpyの配列(ここではinimg)を渡してあげて転送開始のレジスタをONに設定(
AP_START)します。あとはtransferにバッファを渡して転送(すなわち畳み込み演算の処理)が終わるまで待ちます(wait)。その後、該当するデータをnumpyの配列に渡してあげれば終了。これを出力のライン分繰り返します。時間を
%%timeで計測しました。Jupyter Notebookで外部コマンドを呼ぶ方法ですね。で、どれどれCPU times: user 22.5 s, sys: 6.85 ms, total: 22.5 s Wall time: 22.5 sおそい。。。やっぱり22秒とHLSの見積もりは正確でした。。。
この後に検証もしています。一応動かして正しくHWが動いていることも確認してください。おまけ。CPU上の推論時間は?
ついでにPytorchをインストールしているはずなので、CPU推論時間を確認してみましょう。
ultra96v2_pynq_convolution_layer0.ipynbimport torch x = torch.randn(1,3,416,416) conv = torch.nn.Conv2d(in_channels=3, out_channels=64, kernel_size=11,stride=4,bias=False) y = conv(x)CPU times: user 259 ms, sys: 7.96 ms, total: 267 ms Wall time: 93.2 msえ、約100倍速い。。。どーすんの、これ。
(ということが割とよくおきます>FPGA設計)どうするんだよ
ということで一通りPytorchの学習→ソフトウェア設計→ハードウェア設計→FPGAで実際に動作、までを一通りやってみましたが、結果は散々でした。。いかにハードウェア設計のハードルが高いか、ましてはディープラーニングだったら、、ということが理解できたと思います。
このままだと流石にまずいので、とりあえずもうちょっと頑張って速くしてみましょうかね。
ということでもうちょっと続くのじゃ。
- 投稿日:2020-03-20T11:43:20+09:00
pyclustering.xmeansでKeyErrorが出る
コード
from pyclustering.cluster.xmeans import ( xmeans, kmeans_plusplus_initializer ) from pyclustering.utils import draw_clusters initial_centers = kmeans_plusplus_initializer(df, 2).initialize() instances = xmeans(df, initial_centers, ccore=True) instances.process()エラー
KeyError: 0 During handling of the above exception, another exception occurred: KeyError Traceback (most recent call last) <ipython-input-117-8ff3c8958745> in <module> 6 7 instances = xmeans(X_trans_facility, initial_centers, ccore=True) ----> 8 instances.process() 9 10 clusters = instances.get_clusters()解決
pd.DataFrameではなくlistやnp.ndarrayを使う。X = df.values initial_centers = kmeans_plusplus_initializer(X, 2).initialize() instances = xmeans(X, initial_centers, ccore=True) instances.process()参考
バージョン
Python==3.7.4 pyclustering==0.9.3.1 pandas==1.0.2
- 投稿日:2020-03-20T10:56:47+09:00
doctest
class Cal(object): def add_num_and_double(self, x, y): """Add and double >>> c = Cal() >>> c.add_num_and_double(1,1) 4 >>> c.add_num_and_double('1', '1') Traceback (most recent call last): ... ValueError """ if type(x) is not int or type(y) is not int: raise ValueError result = x + y result *= 2 return result if __name__ == '__main__': import doctest doctest.testmod()