- 投稿日:2020-03-16T23:55:59+09:00
PyTorchでデータ水増し(Data Augmentation)する方法
PyTorchでデータの水増し(Data Augmentation)
PyTorchでデータを水増しをする方法をまとめます。PyTorch自体に関しては、以前ブログに入門記事を書いたので、よければ以下参照下さい。
注目のディープラーニングフレームワーク「PyTorch」入門
データ水増しを実施する理由や、具体例などは以下記事参照下さい。
フリー素材で遊びながら理解するディープラーニング精度向上のための画像データ水増し(Data Augmentation)手法
またこの記事は「Google Colaboratory(Google Colab)」で実行することを前提に書かれています。Google Colab自体に関してはこの記事では説明しません。知らない方は、以下記事を参照してみてください。
Google Colaboratoryを使えば環境構築不要・無料でPythonの機械学習ができて最高
この記事で使用したコードは、以下のノートブックにまとめています。
pytorch_data_preprocessing.ipynb
真ん中にある「Open in Colab」というアイコンをクリックすると、Google Colabで開いてそのまま実行することができます。
PyTorchでのデータの扱い
まず最初にPyTorchでのデータの扱いを確認していきます。
教師データのダウンロード
最初に教師データをダウンロードします。説明は省略します。
!git clone https://github.com/karaage0703/janken_dataset datasets !rm -rf /content/datasets/.git !rm /content/datasets/LICENSEディレクトリは、以下のような構成になっています。choki, gu, pa、それぞれのディレクトリに、チョキ、グー、パーの手の形の写真が入っています。
datasets ├── choki ├── gu └── pa以下のように
dataset_root_dirを定義します。dataset_root_dir = '/content/datasets'データセットの作成
最初に、必要なライブラリをインポートしておきます。
import torch from torchvision import transforms, datasets import matplotlib.pyplot as plt import PILImageFolderを使って、フォルダの画像を dataset として読み込みます。
dataset = datasets.ImageFolder(root=dataset_root_dir)データセットの確認
datasetはgetitemで中身を確認できます。(#以下は実行結果です)。
print(dataset.__getitem__(0)) print(dataset.__getitem__(100)) print(dataset.__getitem__(150)) # (<PIL.Image.Image image mode=RGB size=320x240 at 0x7F11DB6DC160>, 0) # (<PIL.Image.Image image mode=RGB size=320x240 at 0x7F11DB6DCF28>, 1) # (<PIL.Image.Image image mode=RGB size=320x240 at 0x7F12297D2C50>, 2)matplotlibで中身を確認する場合は以下です。
image_numb = 6 # 3の倍数を指定してください for i in range(0, image_numb): ax = plt.subplot(image_numb / 3, 3, i + 1) plt.tight_layout() ax.set_title(str(i)) plt.imshow(dataset[i][0])
torchvision.transforms
PyTorchではtransformsで、Data Augmentation含む様々な画像処理の前処理を行えます。
代表的な、左右反転・上下反転ならtransformsは以下のような形でかきます。
data_transform = transforms.Compose([ transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(), ])あとは、ImageFolderのtransformの引数に指定すれば、transformsで指定された画像処理をしたデータセットが定義されます。
dataset_augmentated = datasets.ImageFolder(root=dataset_root_dir, transform=data_transform)データを確認してみます。
image_numb = 6 # 3の倍数を指定してください for i in range(0, image_numb): ax = plt.subplot(image_numb / 3, 3, i + 1) plt.tight_layout() ax.set_title(str(i)) plt.imshow(dataset_augmentated[i][0])
上下反転されています。
その他のtransformsの関数の実施例は、Google Colabのノートブックを参照下さい。Random Erasing等の手法も標準で実装されています。全てを知りたい場合は、公式ドキュメントを参照下さい。
albumentations 実装
albumentationsというData Augmentation用のライブラリをPyTorchで手軽に使う方法です。
最初に、以下コマンドでalbumentationsをインストールします。
! pip install albumentations必要なライブラリをインポートします。
import albumentations as albu import numpy as np from PIL import Imagetransformのときと同様に、ImageFolderでalbumentationでのデータ水増しを行いたいところですが、ちょっとテクニックが必要です。
以下のようにかけば、albumentationsの機能をImageFolderで簡単に使えます。
albu_transforms = albu.Compose([ albu.RandomRotate90(p=0.5), albu.RandomGamma(gamma_limit=(85, 115), p=0.2), ]) def albumentations_transform(image, transform=albu_transforms): if transform: image_np = np.array(image) augmented = transform(image=image_np) image = Image.fromarray(augmented['image']) return image data_transform = transforms.Compose([ transforms.Lambda(albumentations_transform), ]) dataset_augmentated = datasets.ImageFolder(root=dataset_root_dir, transform=data_transform)データの中身を確認してみます。
image_numb = 6 # 3の倍数を指定してください for i in range(0, image_numb): ax = plt.subplot(image_numb / 3, 3, i + 1) plt.tight_layout() ax.set_title(str(i)) plt.imshow(dataset_augmentated[i][0])
albumentationsの画像処理がされていることが分かります。
少し調べた感じではalbumentationsを使うときは、ImageFolderを使わずdatasetを独自実装する場合が多いようですが、ImageFolderで手軽に試したい場合に便利なテクニックです。
albumentationsにどのような機能があるかは、@Kazuhito さんが、GitHubで公開しているalbumentations-examplesのJupyter Notebookが非常に参考になります。
また @Kazuhito さんのJupyter NotebookをGoogle Colabで動くように改変したノートブックを以下で公開していますので、実際に自分の手で動かしたい人は参考にしてみて下さい。
albumentations_examples.ipynb(Google Colab対応版)
mixup
性能出ることで話題のデータ水増し手法mixupをPyTorchで使用する際は、以下のGitHubリポジトリが参考になりました。
mixupする方法とmixupした後のデータの確認方法の詳細は、Google Colabノートブック参照下さい。
まとめ
PyTorchでデータ水増し(Data Augmentation)する方法と、データの確認方法をまとめました。もっと便利な機能があったり、スマートな方法があったりしたら是非教えて下さい。
関連記事
TensorFlowのObject Detection APIのData Augmentationで何をやっているか動かして確認



- 投稿日:2020-03-16T23:50:40+09:00
歌ってみた動画のタイトルから楽曲名を取得する
背景
- 歌ってみた動画の分析をする際に、「どの楽曲か」の情報は重要です。
- しかし、YouTubeの場合、動画に楽曲タイトルが紐づいてないこともあります。
- そこから楽曲タイトルを見つける部分を手動でやるのが辛いのでなんとかしようと思いました。
コード
普通に正規表現とかを使って処理しました。
get_song_titles.pydef get_song_title(raw_title): # ()()[]【】を除外する。左が半角で右が全角だったりすることもある。 title = re.sub("[【(\(\[].+?[】)\)\]]","",raw_title) # 「」と『』がある場合、その中の文字列を取り出す if "「" in title and "」" in title: title = title.split("「")[1].split("」")[0] if "『" in title and "』" in title: title = title.split("『")[1].split("』")[0] # XをYで歌ってみた, 歌ってみた を消す title = re.sub("を.*歌ってみた","",title) title = title.replace("歌ってみた", "") # cover, covered, covered by 以降の文字列を消す title = re.sub("[cC]over(ed)?( by)?.*", "", title) # 最後の/以降は削除する if "/" in title: title = "/".join(title.split("/")[:-1]) if "/" in title: title = "/".join(title.split("/")[:-1]) # - が1個だけあったらその後ろを消す if len(title.split("-")) == 2: title = title.split("-")[0] # コラボメンバーを×で表現している部分を消す title_part_list = [] for title_part in title.split(" "): if "×" not in title_part: title_part_list.append(title_part) title = " ".join(title_part_list) title = title.strip() return title # 後述するデータを読み込んで使用する場合の例 if __name__ == "__main__": x = [] y = [] with open("sing_videos.tsv") as f: for line in f: x.append(line.strip().split("\t")[1]) # 1行目はヘッダーなので削除 del x[0] estimated_titles = [ get_song_titles(x) for raw_title in x ]性能評価
データ
以前の記事 ( https://qiita.com/miyatsuki/items/fb933bb233d2896ca644 ) で集めた、歌ってみた動画のメタデータを使用し、手動でラベリングしました。GitHubにデータをあげたので、追試等で必要であればこちらを参照してください。
https://github.com/miyatsuki/VTuberNayoseDataset/blob/57fe0d785b40c19fa7b249034bdfe1fa62363743/data/sing_videos.tsv結果
動画数: 277
正答率: 92.42% (256/277)大したことしてませんが、一応9割は超えました。
結果を見ながらチューニングしてのスコアなので、未知の動画に対してここまでの精度が出るかは不明です。ダメだったもの
- 必要な情報を消しすぎるパターン
- 楽曲タイトルに/が入っている場合はほぼ、()が入っている場合は確実に失敗します
- 【】内にタイトルが入っている場合もあり、これも確実に失敗します
- 不要な情報を消せないパターン
- 誤字・脱字などのtypoに弱いです
- ♡などのタイトルに関係ない記号が入っている場合は失敗します
- その他楽曲タイトル以外の情報が多いと失敗しやすいです
動画タイトル 推定されたタイトル 正解 Natto!! -Moon!!(月ノ美兎/iru)替え歌- 歌ってみた【卯月コウ】 Natto!! -Moon!!替え歌- Moon!! Disney Medley|covered by 戌亥とこ Disney Medley| Disney Medley 【Virtual to LIVE(covered by #さんばか)】活動半年ありがとう【にじさんじ】 】活動半年ありがとう Virtual to LIVE 【歌ってみた】さらばかゆみ with 剣持【股間戦士エムズーン】 さらばかゆみ with 剣持 さらばかゆみ 【恋愛サーキュレーション】歌ってみた。 Renai Circulation - Bakemonogatari Cover By Utako suzuka 恋愛サーキュレーション 【ユキトキ】cover.える【試聴動画】 ユキトキ 【歌ってみた】アニメ「ダンベル何キロ持てる?」OP お願いマッスル【シスター・クレア×花畑チャイカ】 ダンベル何キロ持てる? お願いマッスル 【替え歌】妖怪のせいにしないようかい体操第一【歌ってみた物述】 妖怪のせいにしないようかい体操第一 ようかい体操第一 【オリジナルMV】緑仙君と鈴鹿ウタでシンデレラガール / King&Prince 歌ってみた【cover】 緑仙君と鈴鹿ウタでシンデレラガール シンデレラガール ⚙*.。..からくりピエロ Karakuri Pierrot/雪城眞尋【歌ってみた】 ⚙*.。..からくりピエロ Karakuri Pierrot からくりピエロ 【天気の子】グランドエスケープ (Movie edit) feat.三浦透子 - Covered by 町田ちま&ぴろぱる グランドエスケープ feat.三浦透子 グランドエスケープ (Movie edit) feat.三浦透子 【LOL部】VD&GでBlessing歌ってみた【替え歌】 VD&GでBlessing Blessing 【1周年記念】けいおん!!のU&I 歌ってみた【童田明治】 けいおん!!のU&I U&I ♡future base歌ってみた♡ ♡future base future base 【ヨルシカ】唐突に雨とカプチーノ歌ってみた【物述有栖】 唐突に雨とカプチーノ 雨とカプチーノ 音量注意】古書屋敷殺人事件歌ってみた/鷹宮リオン 音量注意】古書屋敷殺人事件 古書屋敷殺人事件 白日 / King Gnu (Covered by 夢追翔) 日本テレビ系「イノセンス 冤罪弁護士」主題歌【歌ってみた】【カバー】キングヌー イノセンス 冤罪弁護士 白日 【歌ってみた】ハロ/ハワユ【手描きPV】 ハロ ハロ/ハワユ 【JK弾き語り】オラシオン弾いて歌ってみた【物述有栖】 オラシオン弾いて オラシオン 【歌ってみた】赤い罠(who loves it?) / LiSA【樋口楓cover】 赤い罠 赤い罠(who loves it?) 【君の名は。】 なんでもないや / RADWIMPS (cover)鈴鹿詩子【聖地でのオリジナルPV】Nandemonaiya "Your Name"/Utako Suzuka なんでもないや / RADWIMPS 鈴鹿詩子Nandemonaiya "Your Name" なんでもないや
- 投稿日:2020-03-16T23:35:39+09:00
もうエラーなんて怖くない! Pythonのエラーとその原因・解決策
プログラミングをやっていると必ず遭遇するもの、その一つがエラーです。一生懸命書いたプログラムを実行すると、意味の分からない長文が英語で出てきた!このエラーが解決できずに挫折してしまうという方も多いと思います。この記事では、Pythonにおけるエラーの原因と、その解決方法についてお伝えしようと思います。
1. SyntaxError
大抵のプログラミング初学者がまず初めに遭遇するエラーだと思います。一つずつ確認していきましょう。
このエラーは直訳すると「構文エラー」、つまり文法にミスがあるという事です。このエラーが出たら、閉じ括弧)の付け忘れや、全角スペース、if文、for文、while文におけるコロン:の書き忘れを疑いましょう。
ここからはいくつか例を挙げて説明をしていきます。1.1. 括弧を閉じよう!
括弧
()がなかったり、閉じ忘れていたりすると、
SyntaxError: unexpected EOF while parsing
というエラーが出てしまいます。エラーが出るコード
hello_world1.pyprint("Hello, world!" # SyntaxError: unexpected EOF while parsingこのコードでは、括弧を閉じ忘れている為に、「予期せぬ文末があります」というエラーが出ています。括弧を閉じてエラーを解消しましょう。
修正後のコード
hello_world2.pyprint("Hello, world!") # Hello, world!1.2. 隠れた全角スペースを探そう!
コード中に全角スペースが混ざっていると、
SyntaxError: invalid character in identifier
というエラーが出てしまいます。エラーが出るコード
circle1.pyr = 2 pi = 3.14 # ^ 分かりづらいですが、ここに全角スペースが入っています(赤の下線が表示されています) print(r ** 2 * 3.14) # SyntaxError: invalid character in identifier全角スペースは見つけづらいですが、エラーに表示される行数
line (数字)をヒントに探して、修正しましょう。修正後のコード
circle2.pyr = 2 pi = 3.14 print(r ** 2 * 3.14) # 12.561.3. if, for, while文のコロンをつけよう!
if文、for文、while文などの行末に、コロン:を付け忘れていると、
SyntaxError: invalid syntax
というエラーが出てしまいます。エラーが出るコード
ten1.pyi = 10 if i == 10 print("iは10です") else print("iは10ではありません") # SyntaxError: invalid syntax
if,elseそれぞれの文末にコロンを付け足せば解決です。修正後のコード
ten2.pyi = 10 if i == 10: print("iは10です") else: print("iは10ではありません") # iは10です2. NameError
これも頻繁にみるエラーです。
このエラーは「呼ばれた変数が見つかりません」というものです。
呼び出した変数を定義しているか、スペルミスをしていないかを確認しましょう。2.1. 変数の名前を確認しよう!
呼び出した変数が定義されていなかったり、スペルミスをしていたりすると、
NameError: name '変数名' is not defined
というエラーが出てしまいます。エラーが出るコード
year1.pyyear = 2020 print(Year) print(month) # NameError: name 'Year' is not defined小文字と大文字の区別にも気を付けましょう。プログラムは上から実行されるので、変数
monthが定義されていない事は触れられませんが、ここもエラーになります。修正後のコード
year2.pyyear = 2020 print(year) # 2020 month = 3 print(month) # 33. TypeError
その名の通り、「型に関するエラー」です。
異なる型の値同士で計算を試みたり、関数の引数に不適切な型を指定すると起こるエラーです。
str()やint()を使って変換しましょう。3.1. 計算部分を確認しよう!
print()や変数への代入などで計算や文字列の結合をするとき、文字列型strと数値型intを同時に使うことはできず、使おうとすると
TypeError: Can't convert 'int' object to str implicitly
というエラーが出てしまいます。エラーが出るコード
price1.pyprice = 100 print("この商品は" + price + "円です。") # TypeError: Can't convert 'int' object to str implicitly
priceにはint型である100が代入されているため、str型と結合することはできません。このような場合はstr()関数を用いて、priceをstr型に変換します。
同様に、数値計算においてstr型をint型に変換したいときは、int()関数を用います。修正後のコード
price2.pyprice = 100 print("この商品は" + str(price) + "円です。") # この商品は100円です。
len()などその他の関数の引数についても同様です。4. IndentationError
「インデントがおかしいよ」というエラーです。
エディタによっては、インデントが半角スペース2つ分であったり、4つ分であったりと、異なる場合があり、その違いでこのエラーが起こることがあります。他には、if文でインデント下げをしたその中でelseの処理をしてしまう事で起こります。4.1. インデントを確認しよう!
インデントに何らかのミスがあると、
IndentationError: unindent does not match any outer indentation level
というエラーが出てしまいます。
このエラーの対処法はただ一つです。「インデントを確認する」。tabキーと半角スペース2つが混じっていないかな?など確認しましょう。エラーが出るコード
nine1.pynumber = 99999 if number % 9 == 0: print("numberは9の倍数です。") else: print("numberは9では割り切れません。") # ^^ ここは半角スペース2つになっています。 # IndentationError: unindent does not match any outer indentation levelインデントは一つにそろえましょう。また、
elseは外に出しましょう。修正後のコード
nine2.pynumber = 99999 if number % 9 == 0: print("numberは9の倍数です。") else: print("numberは9では割り切れません。") # numberは9の倍数です。5. IndexError
リストや文字列を扱っているとちょくちょく出くわします。
「存在しないインデックス番号が指定されているよ」というエラーです。
「インデックス番号は0から始まる」ということを忘れないようにしましょう。5.1. インデックス番号を確認しよう!
listやstrの要素を指定するとき、存在しないインデックス番号を指定してしまうと
IndexError: (型) index out of range
というエラーが出てしまいます。エラーが出るコード
abc1.pyl = ["a","b","c"] print(l[3]) # IndexError: list index out of range三番目の要素のインデックス番号は
3ではなく2になります。最初の要素のインデックス番号は0であることに注意しましょう。
右端の要素は-1で指定することもできます。修正後のコード
abc2.pyl = ["a","b","c"] print(l[2]) # c
- 投稿日:2020-03-16T23:34:15+09:00
MNISTをGNNで分類してみた(with PyTorch geometric)
はじめに
こんにちはDNA1980と申します。
最近GNN(Graph Neural Network)流行ってますよね。
世の中あれもこれもグラフなわけですが、別にネットワークのように最初からグラフ構造を取っていないものでもグラフに落とし込めるのであればGNNを適用できるんじゃないかと思い、みんな大好きMNISTに適用してみました。GNNについてよくわからない方はQiita上でも詳しく書いている方がいらっしゃるのでこちらを読むことをおすすめします
GNNまとめ(1): GCNの導入今回使用したコードや作成したデータセットはこちらのGithub上にて公開しています。
環境
Python 3.7.6
PyTorch 1.4.0
PyTorch geometric 1.4.2今回はGNNを扱うライブラリとしてPyTorch geometricを用いました。
データセットの作成
2次元画像であるMNISTにGNNを適用するにはグラフにする必要があります。
・0.4以上の明るい画素をすべてノードとする
・元の画像上で8近傍にノードが存在すれば辺を張る
・各ノード上の特徴量としてはx座標,y座標の2次元量を用いる以上のルールの元、変換を行いました。
(作成が手間だったので今回はtrain用の60000データのみを用いています。)
イメージはこんな感じです
今回データセット作成に用いたコードはこちらです。(最初は24近傍に辺を張る予定だったので余計にパディングされていますが気にしないでください)
そんなに数もないので愚直に実装しましたが、bitboard等を使用すれば速くなりそうです。#gzipファイルからMNISTデータを呼び出して2次元の形にする data = 0 with gzip.open('./train-images-idx3-ubyte.gz', 'rb') as f: data = np.frombuffer(f.read(), np.uint8, offset=16) data = data.reshape([-1,28,28]) data = np.where(data < 102, -1, 1000) for e,imgtmp in enumerate(data): img = np.pad(imgtmp,[(2,2),(2,2)],"constant",constant_values=(-1)) cnt = 0 for i in range(2,30): for j in range(2,30): if img[i][j] == 1000: img[i][j] = cnt cnt+=1 edges = [] # y座標、x座標 npzahyou = np.zeros((cnt,2)) for i in range(2,30): for j in range(2,30): if img[i][j] == -1: continue #8近傍に該当する部分を抜き取る。 filter = img[i-2:i+3,j-2:j+3].flatten() filter1 = filter[[6,7,8,11,13,16,17,18]] npzahyou[filter[12]][0] = i-2 npzahyou[filter[12]][1] = j-2 for tmp in filter1: if not tmp == -1: edges.append([filter[12],tmp]) np.save("../dataset/graphs/"+str(e),edges) np.save("../dataset/node_features/"+str(e),npzahyou)分類にかける
今回は
・GCNを6層と全結合層を2層
・OptimizerはAdam(パラメータは全てデフォルト)
・ミニバッチサイズは100
・epoch数は150
・活性化関数にはReLUを使用
・全60,000データのうち50.000データをtrain用に、残りをtest用に使用として学習を行いました。
モデル
class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = GCNConv(2, 16) self.conv2 = GCNConv(16, 32) self.conv3 = GCNConv(32, 48) self.conv4 = GCNConv(48, 64) self.conv5 = GCNConv(64, 96) self.conv6 = GCNConv(96, 128) self.linear1 = torch.nn.Linear(128,64) self.linear2 = torch.nn.Linear(64,10) def forward(self, data): x, edge_index = data.x, data.edge_index x = self.conv1(x, edge_index) x = F.relu(x) x = self.conv2(x, edge_index) x = F.relu(x) x = self.conv3(x, edge_index) x = F.relu(x) x = self.conv4(x, edge_index) x = F.relu(x) x = self.conv5(x, edge_index) x = F.relu(x) x = self.conv6(x, edge_index) x = F.relu(x) x, _ = scatter_max(x, data.batch, dim=0) x = self.linear1(x) x = F.relu(x) x = self.linear2(x) return x学習部分
data_size = 60000 train_size = 50000 batch_size = 100 epoch_num = 150 def main(): mnist_list = load_mnist_graph(data_size=data_size) device = torch.device('cuda') model = Net().to(device) trainset = mnist_list[:train_size] optimizer = torch.optim.Adam(model.parameters()) trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True) testset = mnist_list[train_size:] testloader = DataLoader(testset, batch_size=batch_size) criterion = nn.CrossEntropyLoss() history = { "train_loss": [], "test_loss": [], "test_acc": [] } print("Start Train") model.train() for epoch in range(epoch_num): train_loss = 0.0 for i, batch in enumerate(trainloader): batch = batch.to("cuda") optimizer.zero_grad() outputs = model(batch) loss = criterion(outputs,batch.t) loss.backward() optimizer.step() train_loss += loss.cpu().item() if i % 10 == 9: progress_bar = '['+('='*((i+1)//10))+(' '*((train_size//100-(i+1))//10))+']' print('\repoch: {:d} loss: {:.3f} {}' .format(epoch + 1, loss.cpu().item(), progress_bar), end=" ") print('\repoch: {:d} loss: {:.3f}' .format(epoch + 1, train_loss / (train_size / batch_size)), end=" ") history["train_loss"].append(train_loss / (train_size / batch_size)) correct = 0 total = 0 batch_num = 0 loss = 0 with torch.no_grad(): for data in testloader: data = data.to(device) outputs = model(data) loss += criterion(outputs,data.t) _, predicted = torch.max(outputs, 1) total += data.t.size(0) batch_num += 1 correct += (predicted == data.t).sum().cpu().item() history["test_acc"].append(correct/total) history["test_loss"].append(loss.cpu().item()/batch_num) endstr = ' '*max(1,(train_size//1000-39))+"\n" print('Test Accuracy: {:.2f} %%'.format(100 * float(correct/total)), end=' ') print(f'Test Loss: {loss.cpu().item()/batch_num:.3f}',end=endstr) print('Finished Training') # 最終結果出力 correct = 0 total = 0 with torch.no_grad(): for data in testloader: data = data.to(device) outputs = model(data) _, predicted = torch.max(outputs, 1) total += data.t.size(0) correct += (predicted == data.t).sum().cpu().item() print('Accuracy: {:.2f} %%'.format(100 * float(correct/total)))結果
なんと、97.74%という正解率(accuracy)になりました。
lossとtest accuracyの変化は以下。
最後少し過学習気味ですがきれいに学習が進んでいるのがわかります。
データ変形時に結構情報が落ちている気がしたのですが、MLP(参考)よりは良く分類ができていたので驚きです。
特徴量として画素の明るさではなく座標を用いただけでもこれだけ分類できているという点は興味深いですよね。それではみなさんも良いGNNライフを!



- 投稿日:2020-03-16T23:29:05+09:00
気象過去データの利用3(豪雨時の降水量を時系列ヒートマップ表示)
気象庁が、2020年3月末まで、気象過去データを無償で提供しています。
(参考) 気象過去データの利用環境
https://www.data.jma.go.jp/developer/past_data/index.html基本的な気象データは、「利用目的・対象を問わず、どなたでもご利用頂けます。」とのことなので、気象データを使って何か行っていきます。
気象庁の「過去の気象データ・ダウンロード」ページからもダウンロードできますが、まとめて一括してダウンロードできるため非常に便利です。
利用可能なデータは、以下の掲載されています。
https://www.data.jma.go.jp/developer/past_data/data_list_20200114.pdf
もうすぐ期限ですので、必要な方は早めのダウンロードを今回は、災害時の雨量の推移を地図上にヒートマップで表示してみます。
昨年の台風19号を想定していましたが、2019年7月までしか公開されていないため、2018年の7月豪雨のデータにします。データダウンロード
アメダス各地点の毎時の降水量を取得するため「地域気象観測(アメダス)」-「時・日別値」を利用します。
このファイルには、各アメダス地点の降水量や気温などの観測情報が格納されています。
ファイルの形式については、以下を確認してください。
http://data.wxbc.jp/basic_data/kansoku/amedas/format_amedas.pdfamedasフォルダにファイルをダウンロードします。約2GBの容量があるため時間がかかります。
import os import urllib.request # 地上気象観測 時・日別値ファイルダウンロード url = 'http://data.wxbc.jp/basic_data/kansoku/amedas/hourly_daily_1976-2019_v191121.tar' folder = 'amedas' path = 'amedas/hourly_daily_1976-2019_v191121.tar' # フォルダ作成 os.makedirs(folder, exist_ok=True) if not os.path.exists(path): # ダウンロード urllib.request.urlretrieve(url, path)ファイルは、tar形式のため中身のファイルを確認します。
# ファイル確認 import tarfile # tarファイルに含まれるファイル確認 with tarfile.open(path, 'r') as tf: for tarinfo in tf: print(tarinfo.name)中身は、hourly_daily_1976.tar.gzのようなtar.gzファイルでした。年ごとにtar.gzに固められています。
さらに展開が必要です。tar.gzファイルの内容を確認してみます。# ファイル確認2 import tarfile # tarファイルに含まれるファイル確認 with tarfile.open(path, 'r') as tf: for tarinfo in tf: print(tarinfo.name) if tarinfo.isfile(): # tar.gzファイルに含まれるファイル確認 with tarfile.open(fileobj=tf.extractfile(tarinfo), mode='r') as tf2: for tarinfo2 in tf2: if tarinfo2.isfile(): print('\t' + tarinfo2.name)以下のようなファイルが存在することがわかります。
hourly_daily_1976/area57/ahd1976.57246
ファイル名は、以下の形式とのことです。
ahdYYYY.SSSSS (YYYY:西暦年、SSS:観測所番号)降水量データの読み込み
2018年7月5日~8日までの全国のアメダス地点の降水量を取得します。
tarファイル、tar.gzを展開せずに読み込みを行います。
各ファイル1日分が1300バイトになります。7月4日まで読み飛ばします。
降雪のみ測定している地点は除外します。また、正常値(RMKが8)以外のデータは、欠損として処理します。データを格納用のpandasのデータフレームを用意します。
年月日時間を行、観測所番号を列としてデータを格納します。# データ格納用データフレーム作成 import pandas as pd prec_df = pd.DataFrame()# 降水量データ取得 import tarfile import struct # 2018年7月5日~8日 year = '2018' month = 7 start_date = 5 end_date = 8 head_size = 28 time_size = 48 day_size = 120 r_size = 1300 # tarファイルに含まれるファイルを取得 with tarfile.open(path, 'r') as tf: for tarinfo in tf: if tarinfo.isfile(): # 2018年のファイルを抽出 if tarinfo.name[13:17] == year: # tar.gzファイルに含まれるファイルを取得 with tarfile.open(fileobj=tf.extractfile(tarinfo), mode='r') as tf2: for tarinfo2 in tf2: if tarinfo2.isfile(): print(tarinfo2.name) # ファイルをopen with tf2.extractfile(tarinfo2) as tf3: # 日付まで読み飛ばし buff = tf3.read((month-1)*31*r_size) buff = tf3.read((start_date-1)*r_size) # 日付分読み込み for i in range(start_date, end_date+1): buff = tf3.read(head_size) sta_no, sta_type, year, monte, date = struct.unpack('<ih16xhhh', buff) print(sta_no, sta_type, year, month, date) # 降雪のみの観測所は対象外 if sta_type != 0: for time in range(24): buff = tf3.read(time_size) prec, rmk = struct.unpack('<hh44x', buff) # 欠測確認 if rmk != 8: prec_df.loc['{:04}{:02}{:02}{:02}'.format(year, monte, date, time), str(sta_no)] = None else: prec_df.loc['{:04}{:02}{:02}{:02}'.format(year, monte, date, time), str(sta_no)] = prec * 0.1 buff = tf3.read(day_size) else: # 残りのデータを読み飛ばす buff = tf3.read(r_size-head_size)少し時間がかかりますが、降水量データが取得できました。
データを確認してみましょう。prec_df参考までの欠損の数を確認します。
prec_df.isnull().values.sum()欠損は、492個ありました。
観測所の緯度、経度取得
アメダス地点情報ファイルダウンロード
アメダスの地点情報ファイルをダウンロードします。
import os import urllib.request # アメダス地点情報ファイルダウンロード url = 'http://data.wxbc.jp/basic_data/kansoku/amedas/amdmaster_201909.tar.gz' folder = 'amedas' path = 'amedas/amdmaster_201909.tar.gz' # フォルダ作成 os.makedirs(folder, exist_ok=True) if not os.path.exists(path): # ダウンロード urllib.request.urlretrieve(url, path)ファイルを確認します。
# ファイル確認 import tarfile # tarファイルに含まれるファイル確認 with tarfile.open(path, 'r') as tf: for tarinfo in tf: print(tarinfo.name)観測所の緯度、経度の読み込み
amdmaster.indexに観測地点の履歴が格納されています。
各地点の履歴のため、観測日の緯度、経度を取得してもよいのですが、表示上、観測地点の移動は誤差範囲のため最新の緯度、経度を観測点の緯度、経度とします。
pandasのデータフレームに格納します。# アメダス地点情報格納用データフレーム作成 import pandas as pd amedas_df = pd.DataFrame()# 観測所の緯度、経度取得 with tarfile.open(path, 'r') as tf: for tarinfo in tf: if tarinfo.name == 'amdmaster_201909/amdmaster.index': # ファイルをopen with tf.extractfile(tarinfo) as tf2: # ヘッダ読み飛ばし line = tf2.readline() line = tf2.readline() line = tf2.readline() while line: # 最新の緯度経度を取得 prec_no = int(line[0:5]) amedas_df.loc[prec_no, '観測所名'] = line[6:26].decode('shift_jis').replace(" ", "") amedas_df.loc[prec_no, '緯度'] = int(line[74:76]) + float(line[77:81])/60 amedas_df.loc[prec_no, '経度'] = int(line[82:85]) + float(line[86:90])/60 line = tf2.readline() break観測所の緯度、経度表示
amedas_dfヒートマップ表示用データ作成
各地点ごとに[緯度, 経度, 降水量]のリストを作成し追加します。
また、時間ごとにリストにします。
以下のような3次元のリストになります。
[[[緯度, 経度, 降水量]]]
indexには、時系列表示用の年月日時間を格納します。import numpy as np # 時間ごとに、各地点の緯度、経度、降水量データ生成 data = [] index = [] for time in prec_df.index: point = [] index.append(time) for sta_no in prec_df.columns: #print(sta_no, time) # 欠損の場合は対象外 if np.isnan(prec_df.loc[time, sta_no]): continue # 降水量なしは対象外 if prec_df.loc[time, sta_no] == 0: continue # 緯度、経度を取得 latitude = None longitude = None day = time[0:8] latitude = amedas_df.loc[int(sta_no), '緯度'] longitude = amedas_df.loc[int(sta_no), '経度'] # ヒートマップ用に0~1の範囲にするため、降水量を1/100する。100mm以上は、100mmとする。 prec = min(prec_df.loc[time, sta_no], 100) / 100 point.append([latitude, longitude, float(prec)]) data.append(point)データを確認します。
data時系列ヒートマップ表示
foliumを利用し、時系列ヒートマップを表示します。HeatMapWithTime関数を利用します。
パラメータは、以下を参考にしてください。
https://python-visualization.github.io/folium/plugins.html
色は、降水量に応じて、青、ライム、黄、オレンジ、赤に変化します。中心点は広島にしました。
import folium from folium import plugins # アメダス地点を地図に表示 # 中心点設定 sta_no = 67437 # 広島 latitude = amedas_df.loc[int(sta_no), '緯度'] longitude = amedas_df.loc[int(sta_no), '経度'] map = folium.Map(location=[latitude, longitude], zoom_start=7) # ヒートマップ表示 hm = plugins.HeatMapWithTime(data, index, radius=100, min_opacity=0, max_opacity=1, auto_play=True, gradient={0.1: 'blue', 0.25: 'lime', 0.5:'yellow', 0.75:'orange',1.0: 'red'}) hm.add_to(map) map以下のように、地図上に降雨データがヒートマップ表示されます。
1時間ごとに表示が切り替わります。
foliumのヒートマップ表示上、観測地点が近い場合には、データの値が大きく見えます。
アメダス地点をベースにしているため、雨雲レーダーのように正確ではありませんが、大まかな変化は確認できると思います。
速度を10fpsなど早くするとわかりやすいかもしれません。htmlに保存し表示することもできます。
# 地図を保存 map.save(outfile="prec20180705_08_map.html")豪雨時の降水量を時系列ヒートマップに表示してみました。
データの公開期間が2020年3月末までのため、必要な方は、早めのダウンロードをお勧めします。

- 投稿日:2020-03-16T22:51:50+09:00
PythonでPowerPointの各ページを画像ファイルにする
トレーニング用の資料作るときに、僕だけがうれしい機能です。PowerPointのページ単位で画像ファイルに変換します。PowerPointを開いて、ファイル→エクスポート→ファイルの種類の変更を選ぶのと同じ事を、Pythonで自動化しました。
comを使ってPowerPointを操作し、ついでにファイル名がスライド1.PNGといろいろ嫌なので、slide1.pngに変換するようにしました。
読み込むPowerPointのファイル名と出力先をファイルの先頭で指定しています。当然、PowerPointがインストールされていないと動きません。試してみたければ、とりあえずtest.pptxのパワポファイルを用意すれば動くと思います。
PPT_NAME = 'test.pptx' OUT_DIR = 'images'全ソース
import os import glob from comtypes import client PPT_NAME = 'test.pptx' OUT_DIR = 'images' def export_img(fname, odir): application = client.CreateObject("Powerpoint.Application") application.Visible = True current_folder = os.getcwd() presentation = application.Presentations.open(os.path.join(current_folder, fname)) export_path = os.path.join(current_folder, odir) presentation.Export(export_path, FilterName="png") presentation.close() application.quit() def rename_img(odir): file_list = glob.glob(os.path.join(odir, "*.PNG")) for fname in file_list: new_fname = fname.replace('スライド', 'slide').lower() os.rename(fname, new_fname) if __name__ == '__main__': export_img(PPT_NAME, OUT_DIR) rename_img(OUT_DIR)
- 投稿日:2020-03-16T22:04:15+09:00
Atcoder AGC020 B - Ice Rink Game 別解集
このゲーム スケートリンクでやる必要あった?
数学
後ろ側から順番に見ていき、highとlowを更新していく
今の順番の数字がその時点のhighより大きい、lowより小さい、またはその中間かで対応が違う
lowは毎回更新されるが、highはそうとも限らないのが引っ掛かったポイントmath.pyK=int(input()) A=list(map(int,input().split())) if A[-1]!=2: print(-1) exit() low=2 high=3 for item in A[::-1]: #print(low,high) if high<item: print(-1) exit() elif item<low: low=(-((-low)//item))*item if low>high: print(-1) exit() high=max(low+item-1,high+item-1-high%item) else: low=item if low>high: print(-1) exit() high=low+item-1 print(low,high)二分探索
ラウンドが精々10**5くらいなので人数を決め打ちしてシミュレーションしてもlogNくらいなら大丈夫
なのでゲーム開始前の人数を二分探索で探せばよい
実現できないラウンド設定の場合はバグるので最後にhighとlowをシミュレーションにかけて正しい答えになるか確かめようね最初のころは終了条件とかmiddleの値を2で切り捨てるかどうかで迷ってた
試行錯誤したけど今の書き方が気に入った
にぶたんは初期設定の範囲をばかでかくしてTLE寸前にするとハラハラしてたのしいbisect.pyK=int(input()) A=list(map(int,input().split())) def func(num): for item in A: num=num//item*item return num ok=10**20 ng=0 while ok-ng>1: mid=(ok+ng)//2 if func(mid)>=2: ok=mid else: ng=mid low=ok ok=10**20 ng=0 while ok-ng>1: mid=(ok+ng)//2 if func(mid)>=4: ok=mid else: ng=mid high=ng if func(low)==2 and func(high)==2: print(low,high) else: print(-1)
- 投稿日:2020-03-16T21:50:40+09:00
正規表現 先読み、後ヨミ
前提としてライブラリ
reをインポートしている状態です。import re下記の記法は全てテキスト部分のみ抽出をするもので、抽出時の条件がグループ()で示されています。
肯定はグループ内のテキスト条件も一致していた場合に抽出。
肯定はグループ内のテキスト条件が一致していなかった場合に抽出。
名称 記載方法 肯定先読み テキスト(?=xxx) 否定先読み テキスト(?!xxx) 肯定後読み (?<=xxx)テキスト 否定後読み (?<!xxx)テキスト 肯定先読み
抽出したいテキストに続けて
(?=xxx)を入れることで抽出したいテキストが一致 且つxxx部分も一致していた場合にテキスト部分を抽出re.findall('AB(?=CDEF)', 'ABCDEF') #['AB'] re.findall('AB(?=DEF)', 'ABCDEF') #[] re.findall('AB(?=CD)', 'ABCDEF') #['AB'] re.findall('.+(?=CD)', 'ABCDEF') #['AB'] re.findall('AB(?=[A-Z]{2,3})', 'ABCDEF') #['AB']否定先読み
否定先読みでは抽出したいテキストの後ろに
(?!xxx)を記載。
テキスト部分が一致 且つxxx部分が一致していない場合にテキスト部分を抽出re.findall('AB(?!CDEF)', 'ABCDEF') #[] re.findall('AB(?!DEF)', 'ABCDEF') #['AB'] re.findall('AB(?!CD)', 'ABCDEF') #[]否定しているので先読みとは逆の結果になります。
肯定後読み
(?<=xxx)に続けて抽出したいテキストを記載することでxxx部分が一致 且つ テキストが部分も一致した場合にテキスト部分を抽出re.findall('(?<=ABCD)EF', 'ABCDEF') #['EF'] re.findall('(?<=BC)EF', 'ABCDEF') #[] re.findall('(?<=)EF', 'ABCDEF') #['EF']否定後読み
(?<!xxx)に続けて抽出したいテキストを記載することでxxx部分がしていなくて 且つ テキストが部分も一致した場合にテキスト部分を抽出re.findall('(?<!ABCD)EF', 'ABCDEF') #[] re.findall('(?<!BC)EF', 'ABCDEF') #['EF'] re.findall('(?<!)EF', 'ABCDEF') #[]肯定先読みの応用
text = 'Python python PYTHON' re.findall('py(?=thon)', text) #['py'] re.findall('Py|py(?=thon)', 'Python python PYTHON') #['Py', 'py'] re.findall('py(?=thon)', 'Python python PYTHON', re.IGNORECASE) #['Py', 'py', 'PY']スクレイピングでありそうな使用方法
text = '住所:東京都新宿区〇〇 〇〇タワー\r地図はこちら' re.findall('(?<=:).*(?=\r)', text)[0] #東京都新宿区〇〇 〇〇タワー【参考サイト】
正規表現の先読み・後読みを極める!
- 投稿日:2020-03-16T21:45:36+09:00
setParamをつかってOREMOきりたんになりたい!
setParamをつかってOREMOきりたんになりたい!
はじめまして、くれいじーです。
Pythonで oto2lab ってツールを作った(GitHub)ので紹介します。注意
- きりたんにはなれません。
- OREMO は使いません。
- 歌唱DB作成にあたり、著作権法に決して違反してはなりません。
- 歌唱DBを配布しても歌唱ソフトに採用される可能性は極めて低いです。
要点
- NEUTRINO と 東北きりたん歌唱データベース が 2020年2月に話題になった。
- setParam を使って個人が歌唱データをラベリングできるようにした。(無料)
- Python3 が必要。(無料)
- Excel が必要
- ラベル作成フローは【 UTAU(.ust) → Excel VBAで変換 → setParam(.ini) → oto2labで変換 → 完成(.lab) 】
oto2lab について
本題です。
oto2lab と言いつつ使うのは同梱ファイルの ust2ini2lab です。紛らわしくてすみません作業フロー
UST
↓ ust2ini2lab で変換(Excel VBAツール自動実行)
INI(未編集)
↓ setParamで音素ラベリング
INI(編集済み)
↓ ust2ini2lab で変換
LAB(完成)環境構築
- Python3 をダウンロードしてインストール。
- PowerShell を起動して
pip install pywin32を実行。- oto2lab > ust2ini2lab にあるxlsmファイルを一度開いてマクロ有効化しておく。
操作方法
- 環境構築をする。
- MIDIからの変換 または 手動でUSTをつくる。
- USTまたはMIDIに合わせて歌って録音する。
- 開始タイミングがUSTと合うように、録音ファイルを編集する。
- USTのブレス部分に「息」ノートを入れる。
- USTファイルを oto2lab > ust2ini2lab > ust フォルダに入れる。
- WAVファイルを oto2lab > ust2ini2lab > ini フォルダに入れる。(16bit-44100Hz)
- ust2ini2lab.py をダブルクリック。
- コマンドラインが表示されるので UST→INI の機能を選択。
- oto2lab > ust2ini2lab > ini フォルダのINIファイルをsetParamで編集。
- ust2ini2lab.py をダブルクリック。
- コマンドラインが表示されるので INI→LAB の機能を選択。
- 音素ラベリングファイル LAB の完成です!
おわりに
技術共有が目的のため、環境構築方法や setParamでの詳細な操作は省略します。
実際の操作方法・環境構築・ラベリング説明は動画をご覧ください。(準備中)
- 投稿日:2020-03-16T21:24:06+09:00
機械学習に関する個人的なメモとリンク集①
はじめに
機械学習に関しては、様々な手法があり、次の様に整理されているのが参考になります。
そんな先人の知恵として参考になるリンク集とメモです。
機械学習手法
Classification
決定木(Decision Tree)
決して精度が高いわけではないが、ツリーによる見える化が説得力
サポートベクターマシン(Support Vector Machine)
- A Benchmark of scikit-learn SVMs
- pythonの機械学習ライブラリscikit-learnの紹介
- scikit-learnを用いた機械学習入門 -データの取得からパラメータ最適化まで
- Making SVM run faster in python
- scikit-learnによる多クラスSVM
ランダムフォレスト(Random Forrest)
-パッケージユーザーのための機械学習(5):ランダムフォレスト
-実務でRandomForestを使ったときに聞かれたこと
-Random Forestで計算できる特徴量の重要度
-Pythonのscikit-learnでRandomForest vs SVMを比較してみた
-tuneRF関数の挙動の検証Regression
線形回帰
LASSO回帰
SVR
時系列分析
- How to Grid Search ARIMA Model Hyperparameters with Python
- Pythonの覚え書き(Scikit-learn, statsmodels編)
- 時系列データの予測ライブラリ--PyFlux--
- サーバーレスでも機械学習がしたい - Time Series Edition -
- 状態空間モデル
- Prophet入門【Python編】Facebookの時系列予測ツール
Clustering
階層型クラスター分析(凝集法)
対象同士の近さを表すデンドログラム(樹形図)を描写することで、クラスター数を何個に分けるのが適切かをビジュアルで表す手法。
但し、樹形図で表現できる範囲になるため、対象の数は数百が限度。それを超えると、読み込みが大変。Data Mining, Big Dataの世の中になる中で、データ量が莫大に増えていき、あまり使われなくなった。
-Python+matplotlibでDendrogram付きHeatmap
-Python: 階層的クラスタリングのデンドログラム描画と閾値による区分け
Tweet非階層型クラスター分析(k-means)
最も有名な非階層クラスタリングの手法。クラスター数をK個に分けるとした場合に、どの様に分けるのが最適化をインプット情報を元に、自動的に判断してくれる。
クラスター数(K)を事前に決めることが必要であるというのが、この手法の最大の特徴であり弱点。これを回避するために、K-means++やX-meansといった、自動的に最適なクラスター数を導き出してくれる手法も開発されている。
顧客を購買傾向によってクラスタリングを行う場合にも使われるが、数万人が入るクラスターと数人しか入らないクラスターが同時に存在するなど、極端な分かれ方になることが多く、それを回避するためのパラメーターの調整が大変なため、個人的にはあまり使用しない。
スペクトラルクラスタリング
自己組織化マップ(SOM, Kohonen)
ニューラルネットワークの一種で与えられた入力情報の類似度をマップ上での距離で表現するモデル。
マップ上(2次元)で表現するため、クラスター数を決める際に、3×3のマップなど縦横を意識した掛け算で考える必要がある。
(そのため、クラスター数5とか、7とかの素数は、1×5, 1×7にしかならず、なんとなく気持ち悪い)個人的に、顧客クラスタリングといえば、この手法を用いるべきというくらい愛用している。
K-meansなどの他の手法に比べて、極端な分かれ方になることが少なく、縦横で傾向がでやすいため、結果の解釈が誰にとっても分かりやすい。T. Kohonen博士が考案したモデルなので、自己組織化マップ(SOM)ではなく、Kohonenと呼ばれることも多い。
トピックモデル
元々は文章中の「単語が出現する確率」を推定する、自然言語処理における統計的潜在意味解析の手法として用いられてきたが、数値確率モデルの一種で、「出現する確率」を推定する。データで用いることで1:1ではないネットワーキング(例:1人の顧客が、1つのクラスターに属するのではなく、複数のクラスターに属する。クラスターAに属する確率が60%、Bは30%・・・と属する確率が分かれる)にも用いられる。
トピックモデルといっても、様々な手法があるがLDA(Latent Dirichlet Allocation)が用いられるケースが多い。
所属確率が分かれるモデルのため、商品DNAの考え方と相性が良い(と個人的に思っている)。
- 投稿日:2020-03-16T21:13:41+09:00
Raspberry Piへカメラを取り付けて、Motionソフトにより自宅監視サイト(但し自宅Wifi圏内でのみ閲覧可能)を構築した
はじめに
Raspberry Piを使った工作を始めました。今回はタイトルの通りカメラを取り付けて、Motionソフトにより自宅内の部屋を監視するサイト(自宅内Wifi限定)を構築しましたので、まとめたいと思います。
要点は下記です。
- カメラモジュールをRaspberry Pi 4へ取り付ける
- カメラで撮影できるようにRaspberry Piで設定する
- Motionソフト導入及びサイトで閲覧する
カメラモジュールをRaspberry Pi 4へ取り付ける
まずはこちらを組み立てます。
全体的にコンパクトなパッケージにカメラ、ケース、説明書が入っていました。カメラのケースを作るのですが、こちらは写真をほぼ撮っていませんでした。。
ネジが非常に小さく入れにくいものの、ケースとなるプラスチックを合わせてネジで止めるだけなのであまり難しくはありませんでした。
次にこのモジュールをラズパイに設置する方法です。
カメラモジュールを設置するコネクタ部には黒いカバーがされており通常は差し込む隙間がありません。従って、カバーを爪で持ち上げてその隙間に差し込みます。この時、金属センサー面がラズパイ側とカメラ側で設置するように入れ込みましょう。
設置した写真がこちらです。購入したラズパイ側の箱は強くはめ込んでいません。
カメラで撮影できるようにRaspberry Piで設定する
こうして設置が完了しましたラズパイですが、次にカメラで撮影できるようにラズパイ上で設定を行います。以後、rootユーザーとしてログインして設定を行っております。
※root以外のユーザーとしてログインしている場合、設定を進められないところがあったためです。sudoersに登録を行いましたが、それでも上手くいかず。。ここはもう少し調べてみます。
設定からインターフェース→カメラを有効にします。
次に、LXterminalと呼ばれるWindowsで言うコマンドプロンプトに相当するアプリケーションを起動させます。
このLXterminalはLinux コマンドで命令を行います。私自身、Linuxコマンドは初めてでしたので、検索しながら手探りで行っています。
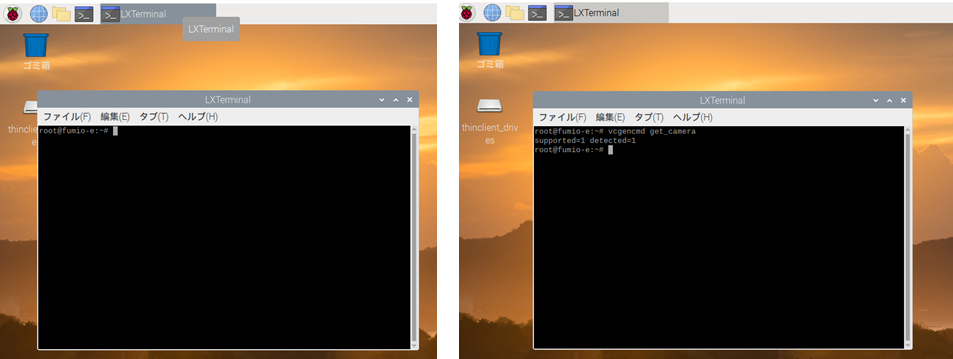
カメラが接続されているかは下記を打ち込みエンターを押します。LXterminalvcgencmd get_camera成功すると下記のように出ます。detected=0となると接続されていないことになりますので、これまでのどこかで誤ったことが起きているはずです。
LXterminalsupported=1 detected=1デバイス側の問題がある場合は、下記コマンドによってラズパイ内のデバイスを最新バージョンへアップデートできます。
LXterminalsudo apt-get upgrade一旦カメラで撮影してみる
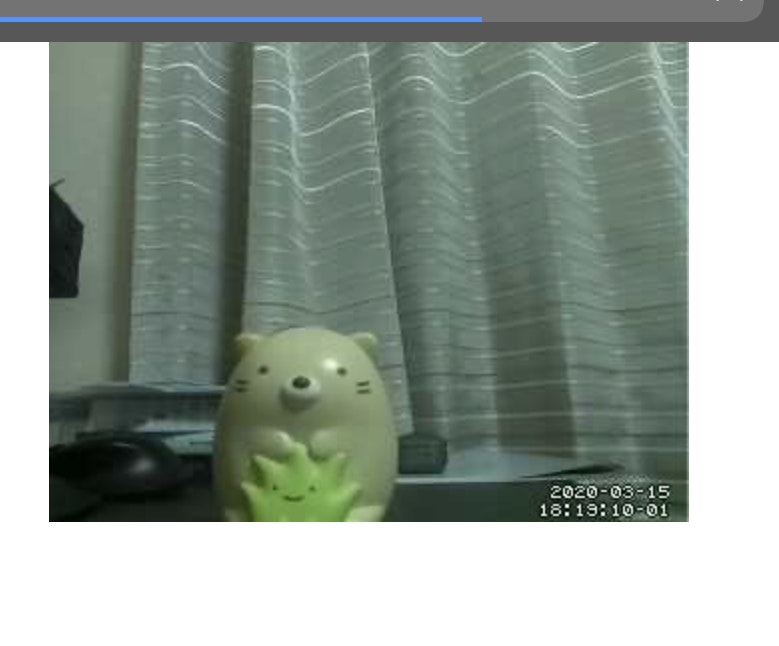
接続が確認できたら試しにカメラで写真を撮影してみましょう。
LXterminalsudo raspistill -o image.jpgこのコマンドにより一枚写真を撮影することができます。写真自体はLXterminal上でカレントディレクトリとなっているフォルダに格納されます。
近くの置物にはピントが合っていなく、後ろの背景にピントが合っているように見えます。
参考URL
https://www.pc-koubou.jp/magazine/17276Motionソフト導入及びサイトで閲覧する
さて、カメラの設定まで終わりましたので、次にリアルタイムで撮影した映像を確認できるようにしたいと思います。
今回は、Motionと呼ばれるソフトをラズパイ上にインストールし、LXterminalのコマンドによりそのソフトを起動させ、URL上にて確認できるようにします。下記コマンドによりMotionをインストールします。
:LXterminal
sudo apt-get install motion
そして、下記コマンドによりMotionを動かせるように以下を編集します。
LXterminalsudo vim /etc/default/motion start_motion_daemon=no ↓ start_motion_daemon=yesまず、ここでコマンドが受け付けずエラーになる方はVimと呼ばれるテキストエディタのインストールが必要になるため、下記コマンドによりインストールします。
LXterminalsudo apt-get install vimさて、ここで編集画面が下記のように出てきますが、Vim独特の編集の仕方を知る必要があります。
参考URL
https://qiita.com/kon_yu/items/b8864ff566b8b67a9810編集可能画面と編集不可な画面がs,escキーで切り替えられるので、切り替え後yesとnoを打ち込みましょう。そして切り替えた後は編集不可の画面で:wqコマンドにより抜けることができます。
さて、これで実際に設定が完了しました。実際に撮影してみましょう。こちらのコマンドによりMotionを起動させます。
LXterminalsudo motion -n撮影した動画は
http://raspberrypiのIP:8081/
このURL上で確認することができます。
実際撮影した動画のキャプチャー画像が上になります。写真よりもやはり荒い品質でした。
しかし、家中Wifiが通じているところででは見ることができます。
家事、仕事をしているときに離れたところで寝ている子供の様子を見る等適用ができるかなぁ、と思ったりしました。終わりに
今回、Raspberry Piへカメラを設置して撮影する環境構築を行いました。設置自体は難しくありませんでした。しかし、Linuxコマンド上で設定をしたりrootユーザーでないと設定が進まなかったりといったラズパイ内の設定に理解不足な点が多々ありました。
次はこのカメラの設定を変えて撮影方法を変えてできないか検討してみたいと思います。また、Wifi外でも見れるようにサーバー構築or AWS等クラウドサービス活用を行ってみたいと思います。
カメラの性能として1500円で安すぎたかな、と思いましたが全然そんなことはなく、おもちゃとして遊ぶには十分すぎる性能です。楽しい時代になりましたね。。大変参考にさせて頂いたURL
https://qiita.com/westvirginia/items/ba79f7549b43da116467https://www.itmedia.co.jp/news/articles/1907/13/news009.html






- 投稿日:2020-03-16T21:11:02+09:00
学習記録(5日目)#関数の引数にデフォルト値を設定する#複数の戻り値を指定する#mapメソッド#数値の進数表現#リストとタプル
学習内容
Python基本文法
- 関数の引数へデフォルト値を指定する
- 複数の戻り値を指定する
- mapメソッド
- 数値の進数表現
- リストとタプル
Python基本文法
関数の引数へデフォルト値を指定する
引数にはデフォルト値を設定することができる。以下の例では、
showName()メソッドの三つの引数のうち二つにデフォルト値が設定されており、1つまたは2つの引数だけを指定する形でもメソッドを呼び出すことができる。def showName(name1, name2 = 'Taro', name3 = 'Kota'): print(name1) print(name2) print(name3) print('ーーーーー') showName('Hanako', 'Sachiko', 'Kazuko') # (1) print('ーーーーー') showName('Yuta', 'Ryo') # (2) print('ーーーーー') showName('Chisato') # (3) print('ーーーーー') showName('Hiroki', name3 = 'Yuji') # (4)実行結果
ーーーーー
Hanako
Sachiko
Kazuko
ーーーーー
Yuta
Ryo
Kota
ーーーーー
Chisato
Taro
Kota
ーーーーー
Hiroki
Taro
Yuji(1)引数を3つ指定したときはデフォルトの値は用いられない
(2)引数を2つしか指定しなかったときは3つ目の引数はデフォルト値のまま処理が実行される
(3)引数を1つしか設定しなかったときは2つ目と3つ目の引数がデフォルト値のまま処理が実行される
(4)もし、二つ目の引数だけデフォルト値を保持して、1つ目と3つ目の引数を指定してメソッドの処理を実行したいときはこのように明示的に引数を指定すれば良い複数の戻り値を指定する
return文で戻り値を指定する際に、カンマで区切って複数の戻り値を返すことができる。このようなメソッドが返す戻り値の型はタプルであるため、for文でも使うことができる記述例
def twice(num1, num2): num1 *= 2 num2 *= 2 return num1, num2 for n in twice(10, 25) print(n)実行結果
20
50
mapメソッド引数に別のメソッドとイテレータブルなデータをとり、そのメソッドの処理をデータの各要素に適応させるイテレータを返す。
記述例
def twice(num): return num*2 a = [1, 2, 3] b = map(twice, a) for n in b: print(b)実行結果
2
4
6数値の進数表現
0bを先頭につけることで2進数表現、0oで8進数表現、0xで16進数表現の数値となる。記述例
a = 0b1100 # 2進数で12 b = 0o17 # 8進数で15 c = 0x2B #16進数で43リストとタプル
可変個数のデータを格納できるデータ型で、格納されるデータは順序づけされている。リストはデータの個数を増減させたりできるのに対して、タプルはデータを作成後はその内容を変更することができない。
リスト タプル データの追加 ○ × データの取り出し ○ ○ データの挿入 ○ × データの削除 ○ × 記述例
# リストの操作 a = [0, 1, 2, 3, 4] a.append(6) # 最後にデータを追加 print(a) a.extend([7, 8, 9]) # 最後にリストのデータを追加 print(a) a.insert(5, 10) # インデックス5の位置にデータを追加 print(a) del a[5] # インデックス5のデータを削除 print(a) b = a.pip(7) # インデックス7のデータを取り出してbに代入 print(a) print(b) c = a.pip() # 最後のデータを取り出してcに代入 print(a) print(c) a.remove(2) # 値が2のデータを削除 print(a)実行結果
[0, 1, 2, 3, 4, 6]
[0, 1, 2, 3, 4, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 10, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 6, 7, 9]
8
[0, 1, 2, 3, 4, 6, 7]
9
[0, 1, 3, 4, 6, 7]これ以外にもデータの総数を数える
count()、データを整列させるsort()、データの順番を反転させるreverse()、データのコピーを実行するcopy()、データを全削除するclear()などのメソッドはリストに対してのみ使用することができる。
- 投稿日:2020-03-16T21:09:12+09:00
感度解析ライブラリsalibとoacisを使った大域的感度解析
感度解析(Sensitivity analysis)とは?
感度解析(Sensitivity analysis)とは、数理モデルやシステムの出力の不確実さ(uncertainty)が、どの入力の不確実さに由来するかを定量的に評価するための手法。
https://en.wikipedia.org/wiki/Sensitivity_analysis出力$Y$、入力$\bf X$とした時に数理モデル以下のようにあらわせるとする。ある入力$X_i$に不確実性があると$Y$にも不確実性が現れるが、$Y$の不確実性がどの$X_i$の不確実性にどれくらい依存しているかを定量的に評価する。
Y = f({\bf X})以下のような目的に使用される。
- モデルに不確実性があるとき(たとえば直接観測できない不明確な量を仮定した場合など)に、得られた結果がどれくらい頑健かをテストする
- モデルの入力と出力の間の関係性を理解する
- 感度の大きい入力を特定し、その入力に注力して確実性を上げることで計算結果の確実性を向上させる
- 感度の小さい入力を固定することによるモデルの単純化
- 多くのパラメータを持つモデルのパラメータをキャリブレートするときに、どの入力に注力してキャリブレートするべきかを決めるのに使う
感度解析の手法
感度解析にはいくつかの手法がある。計算コストや目的、数理モデルの特徴によって使い分ける。
もっとも単純な手法としてOne-at-a-time (OAT)がある。名前の通り、一つのパラメータだけを動かしてみて結果がどれくらい変わるかを偏微分係数や線形回帰などの手法で調べる手法である。とても単純でわかりやすいし計算コストも小さいが、動かすパラメータ以外のパラメータをベースラインの値に固定してしまうので、入力空間をフルに探索できない。
また、偏微分係数で評価しようとすると、その特定のベースラインでの値を局所的にしか評価することができない。$y$が$x_i$に対して非単調に変化する場合や入力変数間の相互作用を評価できない
global sensitivity analysis (Sobol method)
これらの問題を解決する大域的な感度解析(global sensitivity analysis)を行う手法としてVariance-based sensitivity analysis (分散ベースの感度解析)がある。よくSobol methodと呼ばれたりもする。
https://en.wikipedia.org/wiki/Variance-based_sensitivity_analysisこの手法では入力、出力を確率変数として考える。出力の分散を、ある一つの入力(もしくは複数の入力)による寄与に分解する。例えば、出力の分散の70%が$X_1$のゆらぎ由来で、20%が$X_2$、残り10%が$X_1$と$X_2$の相互作用による寄与であるということが言える。
この手法は(i)大域的、(ii)非線形な反応も扱うことができ、(iii) 入力パラメータの相互作用(複数のパラメータを同時に変化させた時に現れる効果)を測定できるという手法になっている。
一方で統計的に処理するので、入力空間を十分にサンプリングする必要があり、一般に様々な入力での計算が多数必要になり計算コストが重い。具体的にどのような量を計算するか。今モデルを$d$次元の変数$\bf X = {X_1,X_2,\dots,X_d}$とする。
また全ての変数は$X_i \in [0,1]$と規格化され均一に分布しているものとする。出力$Y$は一般的に以下のようにかくことができる。Y=f_{0}+\sum _{i=1}^{d}f_{i}(X_{i})+\sum _{i<j}^{d}f_{ij}(X_{i},X_{j})+\cdots +f_{1,2,\dots ,d}(X_{1},X_{2},\dots ,X_{d})ここで$f_i$は$X_i$の関数、$f_{ij}$は$X_i$,$X_j$の関数である。
$Y$の分散を計算すると
\operatorname {Var}(Y)=\sum _{{i=1}}^{d}V_{i}+\sum _{{i<j}}^{{d}}V_{{ij}}+\cdots +V_{{12\dots d}}と書くことができ、分散が各$i$に対して依存する項の和として書くことができる。ここで$V_i$は以下の式で定義される。
V_{{i}}=\operatorname {Var}_{{X_{i}}}\left(E_{{{\textbf {X}}_{{\sim i}}}}(Y\mid X_{{i}})\right),この式は、まず$X_i$を特定の値に固定して$i$以外の変数に対して積分して特定の$X_i$に対する$Y$の期待値を計算し、その量の$X_i$を変動させたときの分散を計算することを意味している。
二次の項$V_{ij}$も同様に定義されて以下のようになる。
V_{ij} = \operatorname{Var}_{X_{ij}} \left( E_{\textbf{X}_{\sim ij}} \left( Y \mid X_i, X_j\right)\right) - \operatorname{V}_{i} - \operatorname{V}_{j}さてパラメータ$i$の感度を評価する指標として主にfirst-order index $S_i$, total-effect index $S_{Ti}$の2種類がある。それぞれ以下のように定義される。
S_{i}={\frac {V_{i}}{\operatorname {Var}(Y)}}S_{{Ti}}={\frac {E_{{{\textbf {X}}_{{\sim i}}}}\left(\operatorname {Var}_{{X_{i}}}(Y\mid {\mathbf {X}}_{{\sim i}})\right)}{\operatorname {Var}(Y)}}=1-{\frac {\operatorname {Var}_{{{\textbf {X}}_{{\sim i}}}}\left(E_{{X_{i}}}(Y\mid {\mathbf {X}}_{{\sim i}})\right)}{\operatorname {Var}(Y)}}$S_i$は$i$「のみ」を変化させたときの$Y$の分散を評価する手法である。$i$単独で変動させた時に平均して$S_i$ほど揺らぐ。
一方、Total-effect indexはすべてのパラメータを変動させたときの$i$の寄与分で、他のパラメータとの相互作用の寄与も含めたもの。$S_{Ti}$が小さければ、その値は固定しておいても結果に影響を与えないのでモデルの単純化などに利用できる。これらの指標を計算するために、パラメータ空間をモンテカルロサンプリングする。
ランダムサンプリングをしてもよいが、より効率的に計算するための工夫として、Quasi-Monte Carlo methodを使う場合が多く、実際以下で説明するライブラリでもそうしている。通常、数千x(パラメータ数)程度のサンプリングが必要になる。SALibの使い方
global sensitivity analysisを行うライブラリの一つにSALibがある。
ここでは使い方を説明する。
このライブラリにはSobol methodをはじめとしていくつかの手法が実装されているが、ここではSobol methodのみを解説する。参考 : https://www.youtube.com/watch?v=gkR_lz5OptU&feature=youtu.be
インストール方法は
pip install SALib
前提条件としてnumpy,scipy,matplotlibが必要。SALibは以下の4ステップで行う。
- モデルインプットの定義
- サンプルの生成
- 感度解析したい数理モデルの実行
- 感度解析の指標($S_i$や$S_{Ti}$)を計算
もっとも簡単なサンプルコードは以下のようになる。
ここではIshigamiというテスト用の関数を数理モデルとして利用している。from SALib.sample import saltelli from SALib.analyze import sobol from SALib.test_functions import Ishigami import numpy as np # Define the model inputs problem = { 'num_vars': 3, 'names': ['x1', 'x2', 'x3'], 'bounds': [[-3.14159265359, 3.14159265359], [-3.14159265359, 3.14159265359], [-3.14159265359, 3.14159265359]] } # Generate samples param_values = saltelli.sample(problem, 1000) # Run model (example) Y = Ishigami.evaluate(param_values) # Perform analysis Si = sobol.analyze(problem, Y, print_to_console=True)出力は以下のようになる。
Parameter S1 S1_conf ST ST_conf x1 0.307975 0.068782 0.560137 0.076688 x2 0.447767 0.057872 0.438722 0.042571 x3 -0.004255 0.052080 0.242845 0.025605 Parameter_1 Parameter_2 S2 S2_conf x1 x2 0.012205 0.082296 x1 x3 0.251526 0.094662 x2 x3 -0.009954 0.070276出力は以下のようになる。わかりやすくなるようにfirst-order index, second-order index, total-order indexをプロットしてみると以下のようになる。
$S_1$,$S_2$は大きな値が出ているが、$S_3$はほぼゼロである。
これは、ここで使っているIshigami関数は以下のように定義されており、$x_3$の$S_3$は0になるが、$x_1$との相互作用があるので$S_{13}$は正の値になる。f(x) = \sin(x_1) + a \sin^2(x_2) + b x_3^4 \sin(x_1)
saltelli.sampleメソッドを実行すると$N(2D+2)$個のサンプル点が生成され、それぞれについて$Y$を求める必要がある。$N$が小さすぎるとエラーバーが大きくなるので、エラーバーが十分に小さくなるまで$N$を増やす必要がある。一般的には$N=1000$くらい。全コードを含むjupyter notebookはこちら
OACISを使ったバッチ実行
ここでは単純な関数をpythonで実行したが、一般的にはより計算の重い数理モデルを使うことになるだろう。例えば一つの計算に数分かかるとすると一つのPCでは手に負えなくなり、クラスターマシンなどで実行したくなる。
ここではoacisを使ってバッチ実行する手順を紹介する。oacisにはPythonのAPIがあるので、それを使ってジョブ投入や結果の参照を行う。ここでは例として先ほど使ったIshigami関数を計算するスクリプトをsimulatorとして登録する。以降、自分の数理モデルを使う場合は適宜読み替えて欲しい。
まずIshigami関数を計算するスクリプトを以下のように用意した。oacisから実行できるようにパラメータを引数で受け取り、出力を
_output.jsonというJSONファイルに書き出すようにしている。ishigami.pyimport math,json with open('_input.json') as f: x = json.load(f) x1,x2,x3 = x['x1'],x['x2'],x['x3'] y = math.sin(x1) + 7.0*(math.sin(x2))**2 + 0.1*(x2**4)*math.sin(x1) with open('_output.json', 'w') as f: json.dump({"y": y}, f)oacisには以下のような設定で登録する。
- Name: Ishigami
- Definition of parameters: [(x1,Float), (x2,Float), (x3,Float)]
- command: "python ~/path/to/ishigami.py"
続いて、以下のようなスクリプトを用意する。
from SALib.sample import saltelli from SALib.analyze import sobol from SALib.test_functions import Ishigami import numpy as np # import oacis module import os,sys sys.path.append( os.environ['OACIS_ROOT'] ) import oacis # Define the model inputs problem = { 'num_vars': 3, 'names': ['x1', 'x2', 'x3'], 'bounds': [[-3.14159265359, 3.14159265359], [-3.14159265359, 3.14159265359], [-3.14159265359, 3.14159265359]] } # define problems param_values = saltelli.sample(problem, 1000) param_values # find ishigami simulator and create ParameterSets and Runs sim = oacis.Simulator.find_by_name('ishigami') host = oacis.Host.find_by_name('localhost') ps_array = [] for param in param_values: ps = sim.find_or_create_parameter_set( {"x1":param[0],"x2":param[1],"x3":param[2]} ) ps.find_or_create_runs_upto( 1, submitted_to=host ) ps_array.append(ps)これでPSが作られる。あとは勝手にoacisがジョブを投入してくれるので完了するまで待つ。
(ここでは一瞬で計算が終わる数理モデルを使っているが、oacisは一つ一つをジョブとして投入するのでこの処理にも半日ほどの時間がかかる。しかし、数分以上の時間のかかる数理モデルをクラスターなどで並列に実行したい場合はそのようなオーバーヘッドは無視できるので、非常に有用である)
完了後、以下のように結果を取得すれば、以後は全く同じ処理になる。
# output values Y = [ ps.average_result("y")[0] for ps in ps_array ] Y = np.array(Y) Y Si = sobol.analyze(problem, Y) Si今回利用した全コードのjupyter notebookはこちら




- 投稿日:2020-03-16T20:31:27+09:00
Pythonで毎日AtCoder #7
はじめに
前回
今日で一週間です。#7
考えたこと
Pythonのsortは文字列に対してもできることを知ったので、sortします。全ての文字列の長さが同じなので、sortしたものをそのまま繋げるだけです。n, l = map(int,input().split()) s = [input() for _ in range(n)] s.sort() ans = '' for i in range(n): ans = ans + s[i] print(ans)まとめ
最短の解説になった気がする。文字列を操作する系の問題は苦手なので、精進したい。
では、また
- 投稿日:2020-03-16T20:23:39+09:00
実装して理解する人工知能・機械学習・ディープラーニング
はじめに
AI(人工知能)が流行っていますが、人工知能・機械学習・ディープラーニングがそれぞれどんなものなのか、実際に動かしながら理解していきます。
ただし、どんなものかを実感するだけなので、ゼロから実装するのではなくライブラリ・フレームワークを活用します。対象読者
- これから人工知能を勉強する人
- 人工知能・機械学習・ディープラーニングの違いを知りたい人
ゴール
- 人工知能・機械学習・ディープラーニングの関係を理解できる
- 人工知能・機械学習・ディープラーニングがどんなものかなんとなくイメージできる
人工知能とは
そもそも人工知能とは何なのかについて考えます。
「人工知能は人間を超えるか」では、以下のように説明されています。本当の意味での人工知能 -つまり、「人間のように考えるコンピュータ」はできていないのだ。
つまり、今は人間のような活動をしているようにみえる技術を総じて人工知能と呼んでいることになります。
さらには、人工知能自体の定義も専門家の間で定まっていません。レベル別人工知能
世の中で人工知能と呼ばれる物は4つのレベルに分けることができると「人工知能は人間を超えるか」では言われています。
レベル1:単純な制御プログラム(制御工学)
- マーケティング的に「AI」と名乗っている
- 制御工学やシステム工学の分野に属する
レベル2:古典的な人工知能
- 人工知能として研究されているのはこのレベルから
- 振る舞いのパターンが多彩なもの
- 推論・探索・知識ベースなど
- 自ら学習しない
レベル3:機械学習
- 入力と出力の関係づけがデータを元に学習されている
- 自ら学習する
レベル4:ディープラーニング
- データから学習するための特徴量も学習する
人工知能・機械学習・ディープラーニングの違い
人工知能・機械学習・ディープラーニングはそれぞれ以下のようになります。
- 人工知能:1つの分野(定義自体は曖昧)
- 機械学習:プログラム自身が学習する人工知能を実現する手法の集まり
- ディープラーニング:機械学習の手法の一つであるニューラルネットワークの層を深くしたもの
人工知能・機械学習・ディープラーニングとレベル別の人工知能の関係は図の通りになります。
実装して試す
実際に動かしてみましょう。実装するのは、レベル2・レベル3・レベル4の人工知能になります。
それぞれのレベルにて、正答率(0.0 ~ 1.0)をスコアとして計算しています。まずは、人工知能が予測するデータについて説明します。
scikit-learnのアヤメのデータセットを利用します。人工知能は、インプットされたデータ(特徴量)から結果を予測します。今回は、予測するアヤメは3品種あり、どのアヤメかを予測します。
予測するための特徴量は以下の通りです。
- 萼片の長さ
- 萼片の幅
- 花弁の長さ
- 花弁の幅
データの中身を少し見てみます。最後のtarget列がアヤメの名前になります。
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa 5 5.4 3.9 1.7 0.4 setosa 6 4.6 3.4 1.4 0.3 setosa 7 5.0 3.4 1.5 0.2 setosa 8 4.4 2.9 1.4 0.2 setosa 9 4.9 3.1 1.5 0.1 setosa古典的な人工知能(レベル2)
まずは古典的な人工知能を実装します。
今回はデータから傾向を見つけ、簡単な知識を入れました。from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split # データのインポート iris = load_iris() # 特徴量と目的変数に分ける X = iris['data'] y = iris['target'] # 学習させるデータと学習したモデルの精度を測るデータに分ける # レベル2の実装では自ら学習しないため精度を測るデータのみを利用する X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 予測するためにルール(知識)を埋め込んだ関数 # 特徴量の値で分岐して予測する def predict_iris(feature): if feature[2] < 2 and feature[3] < 0.6: return 0 elif 2 <= feature[2] < 5 and 0.6 <= feature[3] < 1.7: return 1 else: return 2 # スコアを計測する関数 def compute_score(pred, ans): correct_answer_num = 0 for p, a in zip(pred, ans): if p == a: correct_answer_num += 1 return correct_answer_num / len(pred) pred = [] for feature in X_test: pred.append(predict_iris(feature)) score = compute_score(pred, y_test) print('Score is', score)結果
Score is 0.9555555555555556機械学習(レベル3)
次に機械学習の実装をします。
機械学習は、プログラムがデータから学習します。今回使うアルゴリズムはロジスティック回帰であり、Pythonの機械学習ライブラリである
scikit-learnを利用します。from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # データのインポート iris = load_iris() # 特徴量と目的変数に分ける X = iris['data'] y = iris['target'] # 学習させるデータと学習したモデルの精度を測るデータに分ける X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 利用するアルゴリズムをロジスティック回帰とする model = LogisticRegression() # 学習 model.fit(X_train, y_train) # スコア計測 score = model.score(X_test, y_test) print('Score is', score)結果
Score is 0.8888888888888888ディープラーニング(レベル4)
最後にディープラーニングの実装です。
ディープラーニングは、プログラムがデータから特徴量を生成し、学習します。今回実装するディープラーニングは5層からなるニューラルネットワークになります。使用するライブラリは
kerasになります。from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from keras import layers from keras import models from keras.utils import np_utils # データのインポート iris = load_iris() # 特徴量と目的変数に分ける X = iris['data'] y = np_utils.to_categorical(iris['target']) # 学習させるデータと学習したモデルの精度を測るデータに分ける X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 5層のニューラルネットワークのモデルを定義 model = models.Sequential() model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(3, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # 学習 model.fit(X_train, y_train, epochs=10, batch_size=10) # スコア計測 score = model.evaluate(X_test, y_test) print('Score is', score[1])結果
Score is 0.8888888955116272まとめ
人工知能・機械学習・ディープラーニングは以下のような意味でした。
- 人工知能:分野(定義自体は曖昧)
- 機械学習:プログラム自身が学習する人工知能を実現するため手法の集まり
- ディープラーニング:機械学習の手法の一つ
それぞれのスコアについては、最も単純なルールベースが高いという結果になりました。
ただし、今回はとても単純なデータだったため、機械学習・ディープラーニングの真価が発揮されていないという点に注意してください。人工知能/AIが最近は話題になっていますが、手段(AIであるかどうか)ではなくて何をしたいか(目的)が大切なのだと感じました。
参考文献

- 投稿日:2020-03-16T20:19:56+09:00
深層学習/ニューラルネットワークをスクラッチで組んでみる
1.はじめに
今回は、順伝播、誤差逆伝播を理解する為に、実際に動くニューラルネットワークをスクラッチで実装してみます。データセットはMNISTを使います。
2.ニューラルネットワークの仕様
入力層28×28=784個、中間層10個、出力層2個のニューラルネットワークとし、活性化関数・誤差関数は sigmoid 、最適化手法は勾配降下法とします。
データセットは、MNISTから「1」と「7」を抽出したものを使い、2値分類を行います。
3.順伝播
まず、$a^0_0$を計算すると、$x^0_0$から$x^0_{783}$まで784個の入力が入っていて、それぞれ重み$w^0_{00}$から$w^0_{783,0}$が掛かっているので、
行列で表すと、$a^0_0$から$a^0_9$の全ての計算を簡単に表せます。
$x^1_0$から$x^1_9$は、$a^0_0$から$a^0_9$を活性化関数sigmoidに通したものになるので、
次に、$a^1_0$を計算すると、$x^1_0$から$x^1_9$まで10個の入力が入っていて、それぞれ重み$w^1_{00}$から$w^1_{90}$が掛かってるので、
先程同様、$a^1_0$, $a^1_1$を行列で表すと、
最後に$y^0$と$y^1$は、
この様に、順伝播は行列の内積や足し算等で簡単に行えます。
4.誤差逆伝播(中間層から出力層)
まず、中間層から出力層の重みとバイアスの更新です。
重みwの更新式は、$w=w-\eta*\frac{\partial E}{\partial w}$で表せます。ここで、$\eta$は学習率、$\frac{\partial E}{\partial w}$は誤差Eを重みwで微分したものです。
$\frac{\partial E}{\partial w}$について具体的な例を上げ、それを元に実装するための一般式で表してみます。まず、中間層から出力層の重みです。
重み$w^1_{00}$を更新するために、$\frac{\partial E^0}{\partial w^1_{00}}$を求めます。微分の連鎖率から、
一般式で表すと、k=0〜9, j=0〜1 で、
となり、これによって重み$w^1_{kj}$の更新が可能になります。バイアスについては、$b^1$が1なので、上記式の$x^1_k$が1に代わるだけで、
これによってバイアス$b^1_j$の更新が可能になります。5.誤差逆伝播(入力層から中間層)
次に、入力層から中間層の重みとバイアスの更新です。
重み$w^0_{00}$を更新するためには、$\frac{\partial E^0}{\partial w^0_{00}}$と$\frac{\partial E^1}{\partial w^0_{00}}$ を求める必要があります。微分の連鎖率から、
一般式で表すと、k=0〜783, j=0〜9 で、
となり、これによって重み$w^0_{kj}$の更新が可能になります。バイアスについては、$b^0$が1なので、上記式の$x^0_k$が1に代わるだけなので、
これによってバイアス$b^0_j$の更新が可能になります。6.順伝播、誤差逆伝播部分の実装
先程求めた一般式を元に、順伝播、誤差逆伝播の部分を実装します。
# シグモイド関数 def sigmoid(a): return 1 / (1 + np.exp(-a)) # シグモイド関数の微分 def sigmoid_d(a): return (1 - sigmoid(a)) * sigmoid(a) # 誤差逆伝播 def back(l, j): if l == max_layer - 1: return (y[j] - t[j]) * sigmoid_d(A[l][j]) else: output = 0 m = A[l+1].shape[0] for i in range(m): output += back(l+1, i) * W[l+1][i,j] * sigmoid_d(A[l][j]) return output
def back(l, j):の具体的な動きは、
l=1の時は、
(y[j]-t[j])*sigmoid_d(A[1][j])が返されます。
l=0の時は、
(y[0]-t[0])*sigmoid_d(A[1][0])*W[1][0,j]*sigmoid_d(A[0][j])
+(y[1]-t[1])*sigmoid_d(A[1][1])*W[1][1,j]*sigmoid_d(A[0][j])
が返されます。# 重みWの設定 np.random.seed(seed=7) w0 = np.random.normal(0.0, 1.0, (10, 784)) w1 = np.random.normal(0.0, 1.0, (2, 10)) W = [w0, w1] # バイアスbの設定 b0 = np.ones((10, 1)) b1 = np.ones((2, 1)) B = [b0, b1] # その他の設定 max_layer = 2 # 層数の設定 n = 0.5 # 学習率の設定重みWとバイアスb及びその他の設定をします。
学習がスムーズに開始できる様に、重み行列w0, w1の各項は、0〜1の正規分布に従う乱数にしています。ちなみに、np.random.seed(seed=7)のseed=の番号を変えると、学習のスタート具合(スムーズにスタートするか、少しもたつくか)が変化します。バイアス行列b0, b1は各項が1です。#学習ループ count = 0 acc = [] for x, t in zip(xs, ts): # 順伝播 x0 = x.flatten().reshape(784, 1) a0 = W[0].dot(x0) + B[0] x1 = sigmoid(a0) a1 = W[1].dot(x1) + B[1] y = sigmoid(a1) # パラメータ更新のためにx,aをリスト化 X = [x0, x1] A = [a0, a1] # パラメータ更新 for l in range(len(X)): for j in range(W[l].shape[0]): for k in range(W[l].shape[1]): W[l][j, k] = W[l][j, k] - n * back(l, j) * X[l][k] B[l][j] = B[l][j] - n * back(l, j)学習ループです。順伝播は、行列の内積、足し算等で簡単に行えます。
パラメータ更新では、
l = 0の時は、j = 0〜9, k = 0〜783の範囲で、
W[0][j,k] = W[0][j,k] - n * back(0,j) * X[0][k]
B[0][j] = B[0][j] - n * back(0,j)
と更新されます。
l = 1の時は、j = 0〜1, k = 0〜9の範囲で、
W[1][j,k] = W[1][j,k] - n * back(0,j) * X[0][k]
B[1][j] = B[1][j] - n * back(0,j)
と更新されます。7.データセットの準備
Keras で MNISTデータセットを読み込み、「1」, 「7」のみを抽出します。
import numpy as np from keras.datasets import mnist from keras.utils import np_utils import matplotlib.pyplot as plt # 数字表示 def show_mnist(x): fig = plt.figure(figsize=(7, 7)) for i in range(100): ax = fig.add_subplot(10, 10, i+1, xticks=[], yticks=[]) ax.imshow(x[i].reshape((28, 28)), cmap='gray') plt.show() # データセット読み込み (x_train, y_train), (x_test, y_test) = mnist.load_data() show_mnist(x_train) # 1, 7 を抽出 x_data, y_data = [], [] for i in range(len(x_train)): if y_train[i] == 1 or y_train[i] == 7: x_data.append(x_train[i]) if y_train[i] == 1: y_data.append(0) if y_train[i] == 7: y_data.append(1) show_mnist(x_data) # list形式からnumpy形式に変換 x_data = np.array(x_data) y_data = np.array(y_data) # x_dataの正規化、y_dataのワンホット表現化 x_data = x_data.astype('float32')/255 y_data = np_utils.to_categorical(y_data) # 学習、テストデータを取得 xs = x_data[0:200] ts = y_data[0:200] xt = x_data[2000:3000] tt = y_data[2000:3000]
0〜9のデータと、そこから1,7を抽出したデータを、それぞれ先頭から100個表示しています。学習用データ xs, ts はそれぞれ200個、テスト用データ xt, tt はそれぞれ1,000個用意します。
8.実装全体
学習毎にテストデータによる精度確認と精度推移グラフ表示をプラスした、実装の全体です。
import numpy as np from keras.datasets import mnist from keras.utils import np_utils # データセット読み込み (x_train, y_train), (x_test, y_test) = mnist.load_data() # 1, 7 の数字のみ抽出 x_data, y_data = [], [] for i in range(len(x_train)): if y_train[i] == 1 or y_train[i] == 7: x_data.append(x_train[i]) if y_train[i] == 1: y_data.append(0) if y_train[i] == 7: y_data.append(1) # list形式からnumpy形式に変換 x_data = np.array(x_data) y_data = np.array(y_data) # x_dataの正規化, y_dataのワンホット化 x_data = x_data.astype('float32')/255 y_data = np_utils.to_categorical(y_data) # 学習データ、テストデータの取得 xs = x_data[0:200] ts = y_data[0:200] xt = x_data[2000:3000] tt = y_data[2000:3000] # シグモイド関数 def sigmoid(a): return 1 / (1 + np.exp(-a)) # シグモイド関数の微分 def sigmoid_d(a): return (1 - sigmoid(a)) * sigmoid(a) # 誤差逆伝播 def back(l, j): if l == max_layer - 1: return (y[j] - t[j]) * sigmoid_d(A[l][j]) else: output = 0 m = A[l+1].shape[0] for i in range(m): output += back(l + 1, i) * W[l + 1][i, j] * sigmoid_d(A[l][j]) return output # 重みWの設定 np.random.seed(seed=7) w0 = np.random.normal(0.0, 1.0, (10, 784)) w1 = np.random.normal(0.0, 1.0, (2, 10)) W = [w0, w1] # バイアスbの設定 b0 = np.ones((10, 1)) b1 = np.ones((2, 1)) B = [b0, b1] # その他の設定 max_layer = 2 # 層数の設定 n = 0.5 # 学習率の設定 #学習ループ count = 0 acc = [] for x, t in zip(xs, ts): # 順伝播 x0 = x.flatten().reshape(784, 1) a0 = W[0].dot(x0) + B[0] x1 = sigmoid(a0) a1 = W[1].dot(x1) + B[1] y = sigmoid(a1) # パラメータ更新のためにx,aをリスト化 X = [x0, x1] A = [a0, a1] # パラメータ更新 for l in range(len(X)): for j in range(W[l].shape[0]): for k in range(W[l].shape[1]): W[l][j, k] = W[l][j, k] - n * back(l, j) * X[l][k] B[l][j] = B[l][j] - n * back(l, j) # テストデータによる精度チェック correct, error = 0, 0 for i in range(1000): # 学習したパラメータで推論 x0 = xt[i].flatten().reshape(784, 1) a0 = W[0].dot(x0) + B[0] x1 = sigmoid(a0) a1 = W[1].dot(x1) + B[1] y = sigmoid(a1) if np.argmax(y) == np.argmax(tt[i]): correct += 1 else: error += 1 calc = correct/(correct+error) acc.append(calc) count +=1 print("\r[%s] acc: %s"%(count, calc)) # 精度推移グラフ表示 import matplotlib.pyplot as plt plt.plot(acc, label='acc') plt.legend() plt.show()
200ステップで、分類精度97.8%となりました。自分でスクラッチで実装したニューラルネットワークがちゃんと動くと嬉しいものですね。



















- 投稿日:2020-03-16T20:13:03+09:00
matplotlibで、途中を波線で省略したグラフを作成したい(印象操作したい)
概要
様々な大人の事情により、グラフの途中を波線で省略したいことがあります。matplotlib を使って、このようなをグラフを作成するための方法についての解説です。
実行環境
Python 3.6.9(Google Colab.環境)で実行・動作確認をしています。
実行環境japanize-matplotlib 1.0.5 matplotlib 3.1.3 matplotlib-venn 0.11.5グラフで日本語を使うための準備
Google Colab.環境のなかで、matplotlib を日本語対応させるためには次のようにします。
グラフのなかで日本語を使うための準備!pip install japanize-matplotlib import japanize_matplotlib普通に棒グラフを作成する
まずは、普通に棒グラフを描いてみます。
普通に棒グラフを作成するleft = np.array(['福島', '愛知', '神奈川', '大阪', '東京']) height = np.array([160, 220, 280, 360, 1820]) plt.figure(figsize=(3,4), dpi=160) plt.bar(left,height) # 棒グラフ plt.yticks(np.arange(0,1800+1,200)) # X軸目盛を0から1900まで200刻み plt.gcf().patch.set_facecolor('white') # 背景色を「白」に設定実行結果は次のようになります。東京の突出具合が非常に目立っています。
波線で途中を省略した棒グラフを作成する
ステップ1 サブプロットで上下に同じ棒グラフをならべる
Step.1import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches from matplotlib.path import Path left = np.array(['福島', '愛知', '神奈川', '大阪', '東京']) height = np.array([160, 220, 280, 360, 1820]) # サブプロット2行1列のサブプロットを用意 fig, ax = plt.subplots(nrows=2, figsize=(3,4), dpi=160, sharex='col', gridspec_kw={'height_ratios': (1,2)} ) fig.patch.set_facecolor('white') # 背景色を「白」に設定 ax[0].bar(left,height) # 上段 ax[1].bar(left,height) # 下段
gridspec_kw={'height_ratios': (1,2)}で、上下の高さ比率が $2:1$ になるように設定しています。実行結果は次のようになります。
ステップ2 上下のグラフをくっつける
上下のサブプロット間に隙間があるので、これを消していきます。
Step.2# サブプロットの上限の間隔をゼロに設定 fig.subplots_adjust(hspace=0.0)実行結果は次のようになります。
ステップ3 境界線を消してY軸範囲を上下で個別に設定する
上下グラフの境界線(=上段サブプロットの底辺、下段サブプロットの上辺)を非表示にします。また、各サブプロットのY軸の表示範囲や目盛を設定します。この際、サブプロット同士の Y軸表示範囲の比率 が、Step.1で指定した
'height_ratios': (1,2)と同じになるようにします。Step.3# 下段サブプロット ax[1].set_ylim(0,400) # 区間幅 400 ax[1].set_yticks(np.arange(0,300+1,100)) # 上段サブプロット ax[0].set_ylim(1750,1950) # 区間幅 200 ax[0].set_yticks((1800,1900)) # 下段のプロット領域上辺を非表示 ax[1].spines['top'].set_visible(False) # 上段のプロット領域底辺を非表示、X軸の目盛とラベルを非表示 ax[0].spines['bottom'].set_visible(False) ax[0].tick_params(axis='x', which='both', bottom=False, labelbottom=False)実行結果は次のようになります。
ステップ4 ニョロ線を描く
途中区間を省略していることを表わすニョロ(波線)を描いていきます。
Step.4d1 = 0.02 # X軸のはみだし量 d2 = 0.03 # ニョロ波の高さ wn = 21 # ニョロ波の数(奇数値を指定) pp = (0,d2,0,-d2) px = np.linspace(-d1,1+d1,wn) py = np.array([1+pp[i%4] for i in range(0,wn)]) p = Path(list(zip(px,py)), [Path.MOVETO]+[Path.CURVE3]*(wn-1)) line1 = mpatches.PathPatch(p, lw=4, edgecolor='black', facecolor='None', clip_on=False, transform=ax[1].transAxes, zorder=10) line2 = mpatches.PathPatch(p,lw=3, edgecolor='white', facecolor='None', clip_on=False, transform=ax[1].transAxes, zorder=10, capstyle='round') a = ax[1].add_patch(line1) a = ax[1].add_patch(line2)実行結果は次のようになります。
描画パラメータを
d1 = 0.1、wn = 41のように設定すると次のようになります。
全体コード
全体コード%reset -f import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches from matplotlib.path import Path left = np.array(['福島', '愛知', '神奈川', '大阪', '東京']) height = np.array([160, 220, 280, 360, 1820]) # サブプロット2行1列のサブプロットを用意 fig, ax = plt.subplots(nrows=2, figsize=(3,4), dpi=160, sharex='col', gridspec_kw={'height_ratios': (1,2)} ) fig.patch.set_facecolor('white') # 背景色を「白」に設定 ax[0].bar(left,height) # 上段 ax[1].bar(left,height) # 下段 # サブプロットの上限の間隔をゼロに設定 fig.subplots_adjust(hspace=0.0) # 下段サブプロット ax[1].set_ylim(0,400) # 区間幅 400 ax[1].set_yticks(np.arange(0,300+1,100)) # 上段サブプロット ax[0].set_ylim(1750,1950) # 区間幅 200 ax[0].set_yticks((1800,1900)) # 下段のプロット領域上辺を非表示 ax[1].spines['top'].set_visible(False) # 上段のプロット領域底辺を非表示、X軸の目盛とラベルを非表示 ax[0].spines['bottom'].set_visible(False) ax[0].tick_params(axis='x', which='both', bottom=False, labelbottom=False) ## ニョロ線の描画 d1 = 0.02 # X軸のはみだし量 d2 = 0.03 # ニョロ波の高さ wn = 21 # ニョロ波の数(奇数値を指定) pp = (0,d2,0,-d2) px = np.linspace(-d1,1+d1,wn) py = np.array([1+pp[i%4] for i in range(0,wn)]) p = Path(list(zip(px,py)), [Path.MOVETO]+[Path.CURVE3]*(wn-1)) line1 = mpatches.PathPatch(p, lw=4, edgecolor='black', facecolor='None', clip_on=False, transform=ax[1].transAxes, zorder=10) line2 = mpatches.PathPatch(p,lw=3, edgecolor='white', facecolor='None', clip_on=False, transform=ax[1].transAxes, zorder=10, capstyle='round') a = ax[1].add_patch(line1) a = ax[1].add_patch(line2)







- 投稿日:2020-03-16T19:55:24+09:00
Python Matplotlibの動作確認用コード
- 投稿日:2020-03-16T19:18:45+09:00
『アルゴリズム図鑑』のアルゴリズムをPython3で実装(選択ソート編)
この記事について
この記事では筆者が『アルゴリズム図鑑』を読んで学んだアルゴリズムについて、Python3での実装例を紹介したいと思います。今回のアルゴリズムは選択ソートです。筆者は素人です。色々教えていただけると幸いです。
筆者はPython2のことをよく知りませんが、自分がPython3を使ってるっぽいことだけはわかっています(Python3.6.0かな?)。そのため、記事のタイトルではPython3としました。
選択ソートについて
問題設定とアプローチについてざっくりとだけ説明します。
問題
与えられた数の列に対して、小さい数から順に並べ替えた列を返す。
例:
4, 3, 1, 2
→ 1, 2, 3, 4アプローチ
先頭から順に値を確定させる。未確定の数から最小値を見つけ、入れ替えによって前(先頭側)に持ってくる。詳細は『アルゴリズム図鑑』を参照。
例:
確定された数を[ ]で囲って表記
4, 3, 1, 2
→ [1], 3, 4, 2
→ [1], [2], 4, 3
→ [1], [2], [3], 4実装コード
実装したコードを以下に示します。最初に変数dataに代入されているリストが処理対象の数の列です。また、リストのminはあえて使わずに実装しました。
selection_sort.pydata = [4, 3, 1, 2] print("input :" + str(data)) data_len = len(data) for k in range(0, data_len - 1): min_index = k min_data = data[k] for i in range(k + 1, data_len): if data[i] < min_data: min_index = i min_data = data[i] else: pass data[min_index] = data[k] data[k] = min_data print("output :" + str(data))終わりに
自分の書いたコードを投稿する練習も兼ねて初投稿してみました。気づいた点などあればご指摘、ご質問いただければと思います。特にコードの書き方の改善点などあれば勉強になるなと思います。
- 投稿日:2020-03-16T18:40:30+09:00
クローラーの作り方 - Advanced 編
LAPRAS アウトプットリレー7日目の記事です!
こんにちは!LAPRAS クローラーエンジニアの @Chanmoro です!先日クローラーの作り方 - Basic 編という記事を書かせて頂きましたが、今回の記事では「クローラーの作り方 - Advanced 編」と題しまして、本格的にクローラーを開発する際にどういう問題に直面するかと、クローラーをどのような設計にしておくとこれらの問題に対処しやすいメンテナブルなクローラーにできるかというのを簡単に紹介したいと思います。
クローラー運用でよくある問題の例
さて、クローラーの作り方 - Basic 編で紹介したような方法でミニマムなクローラーを実装することができますが、そこから更に定期的にクロールを繰り返してデータを更新する運用を始めると、大抵の場合で以下のような問題に直面することになります。
- クロール先の HTML 構造が変化する
- クロール先の障害や一時的なエラー
- id が変化する
クローラー開発者にとってはどれも「あるあるー」という感じの問題なのですが、クローラーを運用し続けるには少なくともこれらの課題をクリアする必要があります。
「クロール先の HTML 構造が変化する」問題
クロール先のサービスでは絶えず変更が続けられているので、ある日突然 HTML 構造が変化して目的のデータが取得できなくなる可能性があります。
設計によっては、おかしな値が取得されてデータベースを上書きされてこれまでに蓄積したデータが全て壊れる可能性も十分あります。僕がこれまでにこの課題に対して対応したことがあるのは以下のような方法です。
- クロールして取得される値に対してバリデーションを入れる
- クロール先サービスを定点観測するテストを定期実行する
クロールして取得される値に対してバリデーションを入れる
これはもしかすると最初に思いつくかもしれませんが、クロール先から取得されるデータに対するバリデーションを導入する方法です。
フォーマットや型を限定することができるデータに対してはバリデーションのルールを実装することでおかしなデータがデータベースに入ることを防ぐことができます。
しかし、この方法の弱点は特定のフォーマットが決められないデータや、必須項目ではないデータに対してはバリデーションのルールを定義することができないので、一部の項目にしか適用できないデメリットがあります。クロール先サービスを定点観測するテストを定期実行する
この方法は、定点観測 = クロール先サービスに実際にアクセスして取得されるデータが想定の値になっているか、のテストを定期的に実行することで HTML 構造の変化を検知する方法です。
特定のアカウントやページに対するテストを書き、それを定期実行することで実装できます。scrapy には contract という機能があり、指定した URL に対して実際にアクセスをし取得されたレスポンスに対してテストを書くことができるのですが、そこからアイディアを得ました。
ただしこの方法は、自分で定点観測用のアカウントを作成したりデータを用意できる場合は有用ですが、そうではない場合は対象のアカウントやページが更新される度にテストが失敗することになります。(テストの詳細に依存はしますが)
更に、例えば為替のデータのような高頻度で内容が変化するようなデータに対しては厳密なテストを書くことができません。クロール先の HTML 構造が変化する問題への対象として2つの方法を紹介しましたが、もちろんこれらが全てではありません。
「クロール先の障害や一時的なエラー」問題
クロール先サービス側で障害が発生しているときに、一時的にエラーのレスポンスが返されることも有り得ます。
レスポンスのステータスコードを見てクローラーの処理を分岐しているような場合にこれが問題となることがあります。例えばレスポンスステータスが 404 だった場合に該当のデータが削除されていたと判断し、該当のデータを削除する処理を実装していたとします。
この時クロール先サービス側では仕様のバグや何らかのエラーにより一時的に 404 が返されていたとすると、実際には該当のデータは削除されていないが、クローラー側では削除されたと誤って判断してしまう問題が発生します。この問題の対処については、しばらく時間をあけてリトライすることで一時的なレスポンスなのかを見分ける方法が有効です。
「id が変化する」問題
URL にクロール対象の ID が含まれる設計になっているサービスで、後から ID を変更できる仕様になっているサービスをクロールする場合、変更後の id も変更前のデータと同じとして扱いたい場合があります。
例えばユーザーの ID を変更できたり、一度投稿されたデータの URL を変更できる仕様になっているようなサービスのクロールです。サービスによっては 301 リダイレクトしてくれるので、この場合は旧 URL と新 URL を比べることで id の対応が分かります。
この場合の対処は比較的簡単で、301 リダイレクトされたあとの URL に含まれる id を取得してデータを更新することで追従できます。
注意点としては、クロール先データのidは可変なのでクローラーのシステム上では id としては扱ってはいけないということになります。また、ものによっては旧 URL が 404 になり、新しい URL への対応が分からない場合があるので、旧 URL のデータを削除して新 URL のデータが新規に追加されるのを待つしかない場合というのもあり得ます。
メンテナブルなコードでクローラーを表現する
さて、これまでに紹介した 3 つの問題は大抵のクローラーが直面することになるのではないかと想像しています。
紹介したコード はかなりベタベタな実装だったので、今回紹介したような問題に対処する実装をパッと見どこに入れたらいいかが分かりません。
そこで、例えば以下のようにクローラーの処理をいくつかのレイヤーに分割してみます。
- parser
- HTML をパースしてデータを抽出する層
- crawler
- LAPRAS NOTE へのリクエストを送り parser を呼び出す層
- usecase
- crawler と、取得されたデータの永続化処理を呼び出す層
import json import time import dataclasses from typing import List, Optional import requests from bs4 import BeautifulSoup @dataclasses.dataclass(frozen=True) class ArticleListPageParser: @dataclasses.dataclass(frozen=True) class ArticleListData: """ 記事一覧ページから取得されるデータを表すクラス """ article_url_list: List[str] next_page_link: Optional[str] @classmethod def parse(self, html: str) -> ArticleListData: soup = BeautifulSoup(html, 'html.parser') next_page_link = soup.select_one("nav.navigation.pagination a.next.page-numbers") return self.ArticleListData( article_url_list=[a["href"] for a in soup.select("#main div.post-item h2 > a")], next_page_link=next_page_link["href"] if next_page_link else None ) @dataclasses.dataclass(frozen=True) class ArticleDetailPageParser: @dataclasses.dataclass(frozen=True) class ArticleDetailData: """ 記事詳細ページから取得されるデータを表すクラス """ title: str publish_date: str category: str content: str def parse(self, html: str) -> ArticleDetailData: soup = BeautifulSoup(html, 'html.parser') return self.ArticleDetailData( title=soup.select_one("h1").get_text(), publish_date=soup.select_one("article header div.entry-meta").find(text=True, recursive=False).replace("|", ""), category=soup.select_one("article header div.entry-meta a").get_text(), content=soup.select_one("article div.entry-content").get_text(strip=True) ) @dataclasses.dataclass(frozen=True) class LaprasNoteCrawler: INDEX_PAGE_URL = "https://note.lapras.com/" article_list_page_parser: ArticleListPageParser article_detail_page_parser: ArticleDetailPageParser def crawl_lapras_note_articles(self) -> List[ArticleDetailPageParser.ArticleDetailData]: """ LAPRAS NOTE をクロールして記事のデータを全て取得する """ return [self.crawl_article_detail_page(u) for u in self.crawl_article_list_page(self.INDEX_PAGE_URL)] def crawl_article_list_page(self, start_url: str) -> List[str]: """ 記事一覧ページをクロールして記事詳細の URL を全て取得する """ print(f"Accessing to {start_url}...") # https://note.lapras.com/ へアクセスする response = requests.get(start_url) response.raise_for_status() time.sleep(10) # レスポンス HTML から記事詳細の URL を取得する page_data = self.article_list_page_parser.parse(response.text) article_url_list = page_data.article_url_list # 次ページのリンクがあれば取得する while page_data.next_page_link: print(f'Accessing to {page_data.next_page_link}...') response = requests.get(page_data.next_page_link) time.sleep(10) page_data = self.article_list_page_parser.parse(response.text) article_url_list += page_data.article_url_list return article_url_list def crawl_article_detail_page(self, url: str) -> ArticleDetailPageParser.ArticleDetailData: """ 記事詳細ページをクロールして記事のデータを取得する """ # 記事詳細へアクセスする print(f"Accessing to {url}...") response = requests.get(url) response.raise_for_status() time.sleep(10) # レスポンス HTML から記事の情報を取得する return self.article_detail_page_parser.parse(response.text) def collect_lapras_note_articles_usecase(crawler: LaprasNoteCrawler): """ LAPRAS NOTE の記事のデータを全て取得してファイルに保存する """ print("Start crawl LAPRAS NOTE.") article_list = crawler.crawl_lapras_note_articles() output_json_path = "./articles.json" with open(output_json_path, mode="w") as f: print(f"Start output to file. path: {output_json_path}") article_data = [dataclasses.asdict(d) for d in article_list] json.dump(article_data, f) print("Done output.") print("Done crawl LAPRAS NOTE.") if __name__ == '__main__': collect_lapras_note_articles_usecase(LaprasNoteCrawler( article_list_page_parser=ArticleListPageParser(), article_detail_page_parser=ArticleDetailPageParser(), ))コードはこちらに置いています。
https://github.com/Chanmoro/lapras-note-crawler/blob/master/advanced/crawler.pyこのように parser, crawler, usecase の3つの層に分離したことで、先に紹介した問題に対応するために例えば以下のように変更を入れるというのがより明確になります。
- クロール先の HTML 構造が変化する
- parser のレイヤーでバリデーションを入れる、もしくは定点観測のテストを書く
- クロール先の障害や一時的なエラー
- crawler のレイヤーで状況に応じた例外や戻り値を返す
- usecase のレイヤーでリトライやフローの分岐をする
- id が変化する
- crawler からの戻り値に id が変化したことが分かる情報を付加する
- usecase のレイヤーで取り込み済みのデータの突合と更新ロジックを処理する
まとめ
さて、今回の記事では「クローラーの作り方 - Advanced 編」と題して、クローラーを継続的に運用する際によく発生する問題と、それらに対応するためにどんなクローラーの設計にしておくと開発がしやすいかという内容について書きました。
今回紹介したのは分かりやすさのためのほんの一例なので、実際にはクロール先サービスの特性や、クロールしたデータを使いたいサービスの要件を満たすために設計を更に工夫していく必要があると思います。
しかしこのような設計はクローラーに限ったものではなく、外部サービスや API、ライブラリとのデータ連携があるシステムの一般的なデータモデリングの範囲の話がほとんどなので、クローラーを開発すればするほど、実はクローラー特有の設計というのはあまりないんじゃないか?という気がしてきています。
前回の クローラーの作り方 - Basic 編 から続いて2回に渡って、これまで僕がクローラーを開発してきた経験をベースとして、クローラー開発の実際について紹介してきました。
いまクローラー開発に困っている方、これからクローラーの開発をしてみたい方のお役にたてると嬉しいです!
それでは皆さんもよいクローラー開発ライフをお楽しみください!
- 投稿日:2020-03-16T18:12:19+09:00
C#でPythonのNumpyを模倣した
C#でディープラーニング!
PythonのnumpyライブラリをC#で再現しました
再現したと言っても、自分の知る機能の一部だけですが。
ディープラーニングを勉強し始めて、まだまだ間もないですが、
オライリーの「ゼロから作る Deep Learning」を読んで、Pythonでなんとなく作って、
同じ動作をするものをC#で作りました。
C#には、Numpyのようなライブラリーがないので(探せば誰かが作ってるかもしれませんが)、そこから自分で実装していきます。以前このような記事を投稿しました。
C#で初めてのディープラーニング~Pythonでの実装をまねする~
このときは、簡単な行列計算ができるようにしましたが、今回は、少しだけパワーアップしました。
とりあえず、理解も半端かもしれませんが、そんな中で作ったPythonのディープラーニングプログラムを紹介します。
Pythonで作ったプログラム
deeplearning.pyimport numpy as np import matplotlib.pylab as plt def sigmoid(x): return 1 / (1+np.exp(-x)) def ident(x): return x def numerical_gradient(f, x): h = 1e-4 # 0.0001 grad = np.zeros_like(x) it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) while not it.finished: idx = it.multi_index tmp_val = x[idx] x[idx] = tmp_val + h fxh1 = f(x) # f(x+h) x[idx] = tmp_val - h fxh2 = f(x) # f(x-h) grad[idx] = (fxh1 - fxh2) / (2*h) x[idx] = tmp_val # 値を元に戻す it.iternext() return grad def softmax(a): c=np.max(a) exp_a=np.exp(a-c) sum_exp_a=np.sum(exp_a) return exp_a/sum_exp_a def diff(f,x): h=1e-4 return (f(x+h)-f(x-h)/(2*h)) def cross_etp_err(y,t): delta=1e-7 return -np.sum(t*np.log(y+delta)) class testnet: def __init__(self): #----------------------------------------------------- self.X=np.array([1.0,0.5]) self.W1=np.array([[0.0,0.0,0.0],[0.0,0.0,0.0]]) self.B1=np.array([0.0,0.0,0.0]) #----------------------------------------------------- self.W2=np.array([[0.0,0.0],[0.0,0.0],[0.0,0.0]]) self.B2=np.array([0.0,0.0]) #----------------------------------------------------- self.W3=np.array([[0.0,0.0],[0.0,0.0]]) self.B3=np.array([0.0,0.0]) #----------------------------------------------------- self.T=np.array([0,1]) self.w1_grad=np.zeros_like(self.W1) self.b1_grad=np.zeros_like(self.B1) self.w2_grad=np.zeros_like(self.W2) self.b2_grad=np.zeros_like(self.B2) self.w3_grad=np.zeros_like(self.W3) self.b3_grad=np.zeros_like(self.B3) ############################ def loss(self): A1=np.dot(self.X,self.W1)+self.B1 Z1=sigmoid(A1) A2=np.dot(Z1,self.W2)+self.B2 Z2=sigmoid(A2) A3=np.dot(Z2,self.W3)+self.B3 Y=softmax(A3) return cross_etp_err(Y,self.T) ############################ net = testnet() def f(W): return net.loss() rate=0.1 def deep_learning(net): net.w1_grad=numerical_gradient(f,net.W1) net.b1_grad=numerical_gradient(f,net.B1) net.w2_grad=numerical_gradient(f,net.W2) net.b2_grad=numerical_gradient(f,net.B2) net.w3_grad=numerical_gradient(f,net.W3) net.b3_grad=numerical_gradient(f,net.B3) net.W1-=rate*net.w1_grad net.B1-=rate*net.b1_grad net.W2-=rate*net.w2_grad net.B2-=rate*net.b2_grad net.W3-=rate*net.w3_grad net.B3-=rate*net.b3_grad loop=0; while loop<100: deep_learning(net) print(str(loop)+":"+str(net.B3[0])) loop+=1Numpyをまねて、C#で実装する
deeplearning.csusing System.Linq; namespace Matrix { class Mat { private int r = 0; public int R { get { return r; } } private int c = 0; public int C { get { return c; } } private bool err = false; public bool Err { get { return err; } } private double[][] matrix_data; public double[][] Matrix_data { get { double[][] a = new double[2][]; a[0] = new double[] { 0, 0 }; a[1] = new double[] { 0, 0 }; if (err) return a; else return matrix_data; } set { matrix_data = value; } } public double[][] Zero_matrix { get { double[][] zm = new double[this.r][]; for (int i = 0; i < this.r; i++) { zm[i] = new double[this.c]; for (int j = 0; j < this.c; j++) { zm[i][j] = 0; } } return zm; } } public Mat(params double[][] vs) { int len = vs[0].Length; for (int i = 0; i < vs.Length; i++) { if (i != 0 && len != vs[i].Length) { err = true; } } if (!err) { r = vs.Length; c = vs[0].Length; matrix_data = vs; } } public double[][] sigmoid() { double[][] sig = new double[1][]; sig[0] = new double[this.c]; for(int i = 0; i < this.c; i++) { sig[0][i] = 1 / (1 + System.Math.Exp(this.matrix_data[0][i])); } return sig; } public double[][] softmax() { double[][] sm = new double[1][]; sm[0] = new double[this.c]; double m = this.matrix_data[0].Max(); double[] exp_a = new double[this.c]; for (int i = 0; i < this.c; i++) { exp_a[i] = System.Math.Exp(this.matrix_data[0][i] - m); } double sum = 0.0; for (int i = 0; i < this.c; i++) { sum = sum + exp_a[i]; } for (int i = 0; i < this.c; i++) { sm[0][i] = exp_a[i] / sum; } return sm; } public double cross_etp_err(Mat t) { double delta = 0.0000001; double sum = 0.0; for (int i = 0; i < this.c; i++) { sum = sum + t.matrix_data[0][i] * System.Math.Log(this.matrix_data[0][i] + delta); } return -sum; } public double[][] numerical_gradient(System.Func<double> loss) { double h = 0.0001; double[][] grad = new double[this.r][]; double tmp_val = 0.0; double fxh1 = 0.0; double fxh2 = 0.0; for(int i = 0; i < this.r; i++) { grad[i] = new double[this.c]; for(int j = 0; j < this.c; j++) { tmp_val = this.matrix_data[i][j]; this.matrix_data[i][j] = tmp_val + h; fxh1 = loss(); this.matrix_data[i][j] = tmp_val - h; fxh2 = loss(); grad[i][j] = (fxh1 - fxh2) / (2 * h); this.matrix_data[i][j] = tmp_val; } } return grad; } //以下 演算子オーバーロード public static double[][] operator +(Mat p1, Mat p2) { double[][] d = new double[p1.R][]; if (p1.C == p2.C && p1.R == p2.R) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] + p2.Matrix_data[i][j]; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator +(double[][] p1, Mat p2) { double[][] d = new double[p1.Length][]; if (p1[0].Length == p2.C && p1.Length == p2.R) { for (int i = 0; i < p1.Length; i++) { d[i] = new double[p1[0].Length]; for (int j = 0; j < p1[0].Length; j++) { d[i][j] = p1[i][j] + p2.Matrix_data[i][j]; } } } else { for (int k = 0; k < p1.Length; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator +(Mat p1, double[][] p2) { double[][] d = new double[p1.R][]; if (p1.C == p2[0].Length && p1.R == p2.Length) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] + p2[i][j]; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator +(double p1, Mat p2) { double[][] d = new double[p2.R][]; for (int i = 0; i < p2.R; i++) { d[i] = new double[p2.C]; for (int j = 0; j < p2.C; j++) { d[i][j] = p2.Matrix_data[i][j] + p1; } } return d; } public static double[][] operator +(Mat p1, double p2) { double[][] d = new double[p1.R][]; for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] + p2; } } return d; } public static double[][] operator -(Mat p1, Mat p2) { double[][] d = new double[p1.R][]; if (p1.C == p2.C && p1.R == p2.R) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] - p2.Matrix_data[i][j]; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator -(double[][] p1, Mat p2) { double[][] d = new double[p1.Length][]; if (p1[0].Length == p2.C && p1.Length == p2.R) { for (int i = 0; i < p1.Length; i++) { d[i] = new double[p1[0].Length]; for (int j = 0; j < p1[0].Length; j++) { d[i][j] = p1[i][j] - p2.Matrix_data[i][j]; } } } else { for (int k = 0; k < p1.Length; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator -(Mat p1, double[][] p2) { double[][] d = new double[p1.R][]; if (p1.C == p2[0].Length && p1.R == p2.Length) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] - p2[i][j]; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator -(double p1, Mat p2) { double[][] d = new double[p2.R][]; for (int i = 0; i < p2.R; i++) { d[i] = new double[p2.C]; for (int j = 0; j < p2.C; j++) { d[i][j] = p1 - p2.Matrix_data[i][j]; } } return d; } public static double[][] operator -(Mat p1, double p2) { double[][] d = new double[p1.R][]; for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] - p2; } } return d; } public static double[][] operator *(Mat p1, Mat p2) { double[][] d = new double[p1.R][]; if (p1.C == p2.C && p1.R == p2.R) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] * p2.Matrix_data[i][j]; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator *(double[][] p1, Mat p2) { double[][] d = new double[p1.Length][]; if (p1[0].Length == p2.C && p1.Length == p2.R) { for (int i = 0; i < p1.Length; i++) { d[i] = new double[p1[0].Length]; for (int j = 0; j < p1[0].Length; j++) { d[i][j] = p1[i][j] * p2.Matrix_data[i][j]; } } } else { for (int k = 0; k < p1.Length; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator *(Mat p1, double[][] p2) { double[][] d = new double[p1.R][]; if (p1.C == p2[0].Length && p1.R == p2.Length) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] * p2[i][j]; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator *(double p1, Mat p2) { double[][] d = new double[p2.R][]; for (int i = 0; i < p2.R; i++) { d[i] = new double[p2.C]; for (int j = 0; j < p2.C; j++) { d[i][j] = p1 * p2.Matrix_data[i][j]; } } return d; } public static double[][] operator *(Mat p1, double p2) { double[][] d = new double[p1.R][]; for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] * p2; } } return d; } public static double[][] operator /(Mat p1, Mat p2) { double[][] d = new double[p1.R][]; if (p1.C == p2.C && p1.R == p2.R) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] / p2.Matrix_data[i][j]; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator /(double[][] p1, Mat p2) { double[][] d = new double[p1.Length][]; if (p1[0].Length == p2.C && p1.Length == p2.R) { for (int i = 0; i < p1.Length; i++) { d[i] = new double[p1[0].Length]; for (int j = 0; j < p1[0].Length; j++) { d[i][j] = p1[i][j] / p2.Matrix_data[i][j]; } } } else { for (int k = 0; k < p1.Length; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator /(Mat p1, double[][] p2) { double[][] d = new double[p1.R][]; if (p1.C == p2[0].Length && p1.R == p2.Length) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] / p2[i][j]; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } public static double[][] operator /(double p1, Mat p2) { double[][] d = new double[p2.R][]; for (int i = 0; i < p2.R; i++) { d[i] = new double[p2.C]; for (int j = 0; j < p2.C; j++) { d[i][j] = p1 / p2.Matrix_data[i][j]; } } return d; } public static double[][] operator /(Mat p1, double p2) { double[][] d = new double[p1.R][]; for (int i = 0; i < p1.R; i++) { d[i] = new double[p1.C]; for (int j = 0; j < p1.C; j++) { d[i][j] = p1.Matrix_data[i][j] / p2; } } return d; } public static double[][] dot(Mat p1, Mat p2) { double[][] d = new double[p1.R][]; double temp = 0; if (p1.C == p2.R) { for (int i = 0; i < p1.R; i++) { d[i] = new double[p2.C]; for (int j = 0; j < p2.C; j++) { for(int a = 0; a < p1.C; a++) { temp = temp + p1.Matrix_data[i][a] * p2.Matrix_data[a][j]; } d[i][j] = temp; temp = 0.0; } } } else { for (int k = 0; k < p1.R; k++) { d[k] = new double[2] { 0, 0 }; } } return d; } } }一つのクラスにまとめましたので、ライブラリー化して使用することもできます。
C#のディープラーニングプログラム
main.csnamespace Matrix { class Program { static Mat X = new Mat( new double[] { 1.0, 0.5 } ), W1 = new Mat( new double[] { 0.0, 0.0, 0.0 }, new double[] { 0.0, 0.0, 0.0 } ), B1 = new Mat( new double[] { 0.0, 0.0, 0.0 } ), W2 = new Mat( new double[] { 0.0, 0.0 }, new double[] { 0.0, 0.0 }, new double[] { 0.0, 0.0 } ), B2 = new Mat( new double[] { 0.0, 0.0 } ), W3 = new Mat( new double[] { 0.0, 0.0 }, new double[] { 0.0, 0.0 } ), B3 = new Mat( new double[] { 0.0, 0.0 } ), T = new Mat( new double[] { 0, 1 } ); static double loss() { Mat A1 = new Mat( new double[] { 0.0, 0.0, 0.0 } ), Z1 = new Mat( new double[] { 0.0, 0.0, 0.0 } ), A2 = new Mat( new double[] { 0.0, 0.0 } ), Z2 = new Mat( new double[] { 0.0, 0.0 } ), A3 = new Mat( new double[] { 0.0, 0.0 } ), Y = new Mat( new double[] { 0.0, 0.0 } ); double[][] eeeeee = Mat.dot(X, W1); A1.Matrix_data = Mat.dot(X, W1) + B1; Z1.Matrix_data = A1.sigmoid(); A2.Matrix_data = Mat.dot(Z1, W2) + B2; Z2.Matrix_data = A2.sigmoid(); A3.Matrix_data = Mat.dot(Z2, W3) + B3; Y.Matrix_data = A3.softmax(); return Y.cross_etp_err(T); } static void Main(string[] args) { double rate = 0.1; Mat W1_grad = new Mat(W1.Zero_matrix), B1_grad = new Mat(B1.Zero_matrix), W2_grad = new Mat(W2.Zero_matrix), B2_grad = new Mat(B2.Zero_matrix), W3_grad = new Mat(W3.Zero_matrix), B3_grad = new Mat(B3.Zero_matrix); for (int i = 0; i < 100; i++) { W1_grad.Matrix_data = W1.numerical_gradient(loss); B1_grad.Matrix_data = B1.numerical_gradient(loss); W2_grad.Matrix_data = W2.numerical_gradient(loss); B2_grad.Matrix_data = B2.numerical_gradient(loss); W3_grad.Matrix_data = W3.numerical_gradient(loss); B3_grad.Matrix_data = B3.numerical_gradient(loss); W1.Matrix_data = W1 - (rate * W1_grad); B1.Matrix_data = B1 - (rate * B1_grad); W2.Matrix_data = W2 - (rate * W2_grad); B2.Matrix_data = B2 - (rate * B2_grad); W3.Matrix_data = W3 - (rate * W3_grad); B3.Matrix_data = B3 - (rate * B3_grad); System.Console.WriteLine(i.ToString() + ":" + B3.Matrix_data[0][0].ToString()); } } } }
Matクラスのコンストラクターの引数は、params double[]かdouble[][]型を取ります。
Mat同士や、実数、double[][]との加減乗除が行えます。
また、ソフトマックス関数や、シグモイド関数、勾配を求める、公差エントロピー誤差などの計算が可能です。
- 投稿日:2020-03-16T18:10:20+09:00
hypothesisでサンプルCSVデータを作成する方法
`
hypothesis は、テストケースより有効的にユニットテスト書けるライブラリのようです。テストに使う値を幅広く試したりすることができるらしい。ただし、今回は、これをつかって、サンプルデータを簡易作成できるかをたましてみたいと思います。
課題
ファイル形式(CSV)を決まった範囲や制限内のデータを生成したい。
やってみます!
まず、データの定義したいですね。hypothesisを作成してほしいデータは、strategyというものをつかって定義するらしいですね。
今回は、pythonの標準ライブラリ
csvを使うので、DictWriterのためのDict作成しちゃいば、簡易書き出せるので、dictを作成の場合、fixed_dictionaries があるようなので、これは、このようにできるようです。そのなかで、作りたいdictのキーいれて、さらに値を作成するstrategyを定義ができます!
from hypothesis import strategies as st DictRowDataModel = st.fixed_dictionaries({ 'k_id': st.none(), 'w_id': st.none(), '項目1': st.integers(min_value=1, max_value=7), '項目2': st.integers(min_value=1, max_value=5), '項目3': st.integers(min_value=1, max_value=16) })次にわかりずらかったのが、これをつかってどうやって、データ生成すること。
通常ユニットテスト内で使われる作りのようなので、この使用例がないようです。テストケース使う例:
from hypothesis import given import hypothesis.strategies as st @given(st.integers(), st.integers()) def test_ints_are_commutative(x, y): assert x + y == y + xでも探してみると、
example()のメッソドが用意されていて、それが使えるようです:import csv from hypothesis import strategies as st d = { 'k_id': st.none(), 'w_id': st.none(), '項目1': st.integers(min_value=1, max_value=7), '項目2': st.integers(min_value=1, max_value=5), '項目3': st.integers(min_value=1, max_value=16) } DictRowDataModel = st.fixed_dictionaries(d) samples = 3 with open('sample.csv', 'w', encoding='utf8') as out: writer = csv.DictWriter(out, fieldnames=tuple(d.keys())) for i in range(samples): sample = DictRowDataModel.example() writer.writerow(sample)自分が範囲生成のコード書けずに済みました。嬉しい。
結論
strategyの.example()を使えば、楽にCSVデータ作成ができました〜
- 投稿日:2020-03-16T17:57:50+09:00
PyTorch×VAEGANによるソ連プロパガンダポスターの再構成
概要
前回に引き続き、プログラミングの練習として、いろいろなものを実装しています。
今回はVAEGANを用いて、プロパガンダポスターを再構成しようと思います。
(突然なんでソ連?って話なんですけど、本当に単なる趣味なんです。政治的主張とか一切ございません。)技術的なご指摘点などありましたらコメントいただけると幸いです。
当記事でご理解いただけるのは、VAEGANの再構成のレベル、GANの学習における留意点、がメインです。再構成の流れとしては、以下の通りです。
- プロパガンダポスター(学習データ)を集める
- VAEGANで学習を行う
- 学習済みモデルを使って、データの再構成を行う
なお、PyTorchのVAEGANの実装はこちらのを基本とさせていただいてます。ありがとうございます。
VAEGANについて
Autoencoding beyond pixels using a learned similarity metric
通常の単純なGANでは、GeneratorとDiscriminatorの2つのmodelがあり、それらが互いに敵対的学習を行うことで、優れたGeneratorが学習できるというような仕組みでした。
しかしGANの問題点として、Generatorの入力がランダムなノイズである点が挙げられます。どういうことかというと、入力がランダムなので、明示的にこのデータが欲しい!と思っても、狙ったデータを生成することが通常のGANではできないのです。
一方VAEGANでは、明示的に欲しいデータを再構成できるように設計されています。どういうことかというと、GeneratorがVAEに入れ替わった形をしています。
これにより、入力データに近いデータを明示的に再構成可能となっているわけです。
今回はソ連風なポスターのデータを明示的に再構成させようと思います。学習データを集める
Image Downloaderを使いました。このchrome用の拡張機能は、学習データを集める際にめちゃくちゃ便利です。おすすめです。
そして以下のようなデータを300枚ほど収集しました。
いやーこのアバンギャルドな感じが素晴らしいですね!(あくまで趣味ですよ)
VAEGANで学習を行う
実装は基本的に上記の方のを参考にさせていただきました。しかし、そのままではうまく学習ができない(再構成に失敗する)時もあったので、一部修正を行っています。大きく分けて、誤差関数とモデル定義の2つです。
誤差関数は以下のように、train.pyにあるEnc_lossのL_llikeを無しに変更しました。
また、Dec_lossのL_gan_fakeも無しに変更しています。
上記二つのL_llike、L_gan_fakeは、Discriminatorの特徴を誤差関数に組み込んでいるみたいです。
僕の環境では、オリジナルのverですと、残念ながらなかなか収束することができませんでした、、、train.py# Enc_loss --- Enc_loss = L_prior + L_recon Enc_loss.backward() Enc_optimizer.step() Enc_running_loss += Enc_loss.item() # train Decoder === Dec_optimizer.zero_grad() x_real = Variable(data) z_fake_p = Variable(torch.randn(opt.batch_size, opt.nz)) if opt.use_gpu: x_real = x_real.cuda() z_fake_p = z_fake_p.cuda() x_fake, mu, logvar = G(x_real) # L_gan --- y_real_loss = bce_loss(D(x_real), t_fake) y_fake_loss = bce_loss(D(x_fake), t_real) y_fake_p_loss = bce_loss(D(G.decoder(z_fake_p)), t_real) L_gan_fake = (y_real_loss + y_fake_loss + y_fake_p_loss) / 3.0 # L_llike --- L_recon = opt.gamma * l1_loss(x_fake, x_real) L_llike = l1_loss(D.feature(x_fake), D.feature(x_real)) # Dec_loss --- Dec_loss = L_recon + L_llike Dec_loss.backward() Dec_optimizer.step() Dec_running_loss += Dec_loss.item()モデル定義では、各モデルの活性化関数をLeakyReLUにした点、DiscriminatorのBatchNorm2dを無くした点が主な変更です。
また、入力のサイズを128×128とし、channelはカラー画像のため3としています。学習済みモデルを使って、データの再構成を行う
train.pyを回してlogsディレクトリに100epoch毎に再構成結果を保存しました。
epoch=1000、batchsize=16、潜在変数の次元=32として計算しました。
再構成結果は以下の通りです。なお、各画像の上段は入力画像、下段がVAEGANの出力結果です。100epoch
300epoch
600epoch
1000epoch
考察
VAEGANすごいな..と素直に思いました。100epoch目ではまた再構成結果としては、ぼやけていますが、1000epochも回せばほぼ本物(入力)と差がないほど完璧に再現できていると思います。当記事の最初に挙げたVAEGANの論文でも、VAEとの比較がなされており、極めてきれいに再構成できることはわかってはいましたが、今回の検証で改めて実感できました。
しかしGANの学習において留意すべきことは多くあります。
まずそもそもGANの学習は複雑で安定しにくい傾向があるため、Discriminatorとそのほかの各モデルのLossの推移に注意しなくてはなりません。
うまくいかないケースとして、DiscriminatorのLossがものすごい勢いで収束してしまうことや、一向にほかのLossが収束せずむしろ発散することがあります。
今回はDiscriminatorがやたらに収束するケースが発生したので、DiscriminatorのBatchNorm2dを無くしました。
また、最近のGANモデルにおいては、ReLUよりもLeakyReLUが使われているようです。
そのほか、GANの学習がうまくいかない状況に対する対処として、こちらも参考になります。







- 投稿日:2020-03-16T16:35:34+09:00
LEO衛星の短周期摂動と平均軌道要素
備忘録としてメモ。
軌道周回内の摂動はJ2項が支配的平均軌道要素=接触軌道要素 - 短周期摂動項
数式はKOZAIの論文def osc2mean(osc_elm): a,e,i,omega,ra,M = osc_elm[1:] A = J2*RE**2 E = Ecalc(e, M) r = a*(1-e*np.cos(E)) nu = 2*np.arctan(np.sqrt((1+e)/(1-e))*np.tan(E/2)) p = a*(1-e**2) da = (A/a)*((a/r)**3-(1/((1-e**2)**(3/2)))+(-(a/r)**3 + (1/((1-e**2)**(3/2))) + (a/r)**3*np.cos(2*omega+2*nu))*(3/2)*np.sin(i)**2) de = (A/4)*(-2/(a**2*e*np.sqrt(1-e**2)) + 2*a*(1-e**2)/(e*r**3) +(3/(a**2*e*np.sqrt(1-e**2))-3*a*(1-e**2)/(e*r**3) -3*(1-e**2)*np.cos(nu+2*omega)/(p**2)-3*np.cos(2*nu+2*omega)/(a**2*e*(1-e**2)) +3*a*(1-e**2)*np.cos(2*nu+2*omega)/(e*r**3)-(1-e**2)*np.cos(3*nu+2*omega)/p**2)*np.sin(i)**2) di = (A*np.sin(2*i)/(8*p**2))*(3*np.cos(2*nu+2*omega)+3*e*np.cos(2*omega+nu)+e*np.cos(2*omega+3*nu)) domega = (3*A/(2*p**2))*((2-(5/2)*np.sin(i)**2)*(nu-M+e*np.sin(nu)) + (1-(3/2)*np.sin(i)**2)*((1/e)*(1-(1/4)*e**2)*np.sin(nu)+(1/2)*np.sin(2*nu)+(e/12)*np.sin(3*nu)) - (1/e)*((1/4)*np.sin(i)**2+(1/2-(15/16)*np.sin(i)**2)*e**2)*np.sin(nu+2*omega) + (e/16)*np.sin(i)**2*np.sin(nu-2*omega)-(1/2)*(1-(5/2)*np.sin(i)**2)*np.sin(2*nu+2*omega) + (1/e)*((7/12)*np.sin(i)**2-(1/6)*(1-(19/8)*np.sin(i)**2)*e**2)*np.sin(3*nu+2*omega) + (3/8)*np.sin(i)**2*np.sin(4*nu+2*omega)+(e/16)*np.sin(i)**2*np.sin(5*nu+2*omega)) draan = (-A*np.cos(i)/(4*p**2))*(6*(nu-M+e*np.sin(nu))-3*np.sin(2*omega+2*nu)-3*e*np.sin(2*omega+nu)-e*np.sin(2*omega+3*nu)) dM = (3*A*np.sqrt(1-e**2)/(2*e*p**2))*(-(1-(3/2)*np.sin(i)**2)*((1-e**2/4)*np.sin(nu)+(e/2)*np.sin(2*nu)+(e**2/12)*np.sin(3*nu)) + np.sin(i)**2*((1/4)*(1+5*e**2/4)*np.sin(nu+2*omega)-(e**2/16)*np.sin(nu-2*omega) -(7/12)*(1-e**2/28)*np.sin(3*nu+2*omega) -(3*e/8)*np.sin(4*nu+2*omega)-(e**2/16)*np.sin(5*nu+2*omega))) am = a - da em = e - de im = i - di omegam = omega - domega ram = ra - draan Mm = M - dM mean_elm = [0 for i in range(7)] mean_elm[0] = osc_elm[0] mean_elm[1:] = am, em, im, omegam, ram, Mm return mean_elmなお、平均近点角$M$、動径$r$、離心近点角$E$及び真近点角$\nu$は以下のような関係。離心近点角は解析的に計算できないのでニュートンラフソン法
E - e\sin E = M \\ r = a(1-e\cos E) \\ \nu = 2 \arctan (\tan (E/2) \sqrt (1+e)/(1-e) )def Ecalc(e, M): E_init = M - e * math.sin(M) iteration_num = 10 for i in range(iteration_num): if i == 0: E = E_init E_before = E else: E = E - (E - e * math.sin(E) - M) / (1 - e * math.cos(E)) if E - E_before < 0.001: break E_before = E return Eケプラリアンからカルテシアンは以下
def Kep2Cal(elm): a, e, i, omega, Omega, M = elm[1:] mu = 3.986004418 * (10 ** 14) # m^3 s^-2 # 重力定数 T = 2 * math.pi * math.sqrt(a ** 3 / mu) # 軌道周期 n = 2 * math.pi / T # 離心近点角の計算 E = Ecalc(e, M) r = np.zeros((3)) f = 2 * math.atan(math.sqrt((1 + e) / (1 - e)) * math.tan(E / 2)) theta = omega + f r_scalar = a * (1 - e * math.cos(E)) r = r_scalar * np.array([math.cos(Omega) * math.cos(theta) - math.sin(Omega) * math.sin(theta) * math.cos(i) , math.sin(Omega) * math.cos(theta) + math.cos(Omega) * math.sin(theta) * math.cos(i) , math.sin(theta) * math.sin(i)]) Xi = r[0] Yi = r[1] Zi = r[2] v = np.zeros((3)) # 角運動量 dEdt = (1 / r_scalar) * math.sqrt(mu / a) h = a ** 2 * math.sqrt(1 - e ** 2) * (1 - e * math.cos(E)) * dEdt v = -(mu / h) * np.array([math.cos(Omega) * (math.sin(theta) + e * math.sin(omega)) + math.sin(Omega) * ( math.cos(theta) + e * math.cos(omega)) * math.cos(i) , math.sin(Omega) * (math.sin(theta) + e * math.sin(omega)) - math.cos(Omega) * ( math.cos(theta) + e * math.cos(omega)) * math.cos(i) , -(math.cos(theta) + e * math.cos(omega)) * math.sin(i)]) VXi = v[0] VYi = v[1] VZi = v[2] cal = [0 for i in range(7)] cal[0] = elm[0] cal[1:] = Xi, Yi, Zi, VXi, VYi, VZi return cal
- 投稿日:2020-03-16T16:28:47+09:00
日向坂46齊藤京子のバビ語をノーコードかつサーバレスで google home に喋らせてみた
はじめに
こんにちは,ぱそきいろ: @takacpu55と申します.
最近巷でノーコードが流行っているみたいです.
私も流行りに乗ってノーコードのVoiceflowというサービスを使ってgoogle home で開発したので久しぶりに投稿しようと思います.
ブログもやってますので,興味がある方は除いてもらえたらと思います.
「いいね」,ではなく「LGTM」を頂けましたら幸いです.作ったもの
バビ語メーカーというアプリを作りました.
google home に日本語を喋りかけると,バビ語に変換して読み上げてくれます.
バビ語メーカー pic.twitter.com/8UzcnQ7RRD
— ぱそきいろ (@takacpu55) March 15, 2020
(正確には入れ詞というみたいです)
言葉の間に母音が同じ「ばびぶべぼ」を挿入します.
例:「こんにちは」→「こぼんばにびちびはば」
「今日はいい天気ですね」→「きびうぶはばいびいびてべんばきびでべすぶねべ」
最近,人気の日向坂46の齊藤京子さんが特技として披露しています.

これをノーコード,かつサーバレスで実装しました.
システムの概要図は以下になります.
Voiceflow で google home の実装を,AWS lambda でバックエンドの実装をしました.
ひらがなに変換する際に,ひらがな化APIを使用させて頂いております.
以下で詳しく説明していきます.Voiceflowでの実装
google home でのアプリ開発をノンコーディングでできる,Voiceflowというサービスを使って実装しています.
ブロックを繋げることで,処理の流れを記述できます.
(本アプリを作る際にこちらの資料を参考にさせていただきました.)
今回作ったアプリは以下のようにブロックを配置しております.
google home で受け取った日本語を http リクエストで投げてバビ語に変換,発話という流れを繰り返すようになっています.
「終了」と話すと,アプリが終了します.
次に,バビ語に変換する処理について説明します.AWS Lambdaでの実装
ここでは,httpリクエストで日本語を受け付け.バビ語に変換して返すapiを実装します.
AWS lambda で実装しています.# coding: utf-8 import json import requests import re def lambda_handler(event, context): # 変換したい文字列を取得 text=event["key"] # ひらがなに変換 text=toHira(text) # バビ語に変換 text=tobabi(text) # バビ語を返す return { 'statusCode': 200, 'body': text } def toHira(text): # ひらがな化APIにhttpリクエストを投げる headers = { 'Content-Type': 'application/json', } data = '{"app_id":"ひらがな化APIのアプリID","request_id":"record003","sentence":"'+text+'","output_type":"hiragana"}' response = requests.post('ひらがな化APIのURL', headers=headers, data=data.encode("utf-8")) response=response.json() return response["converted"] def tobabi(text): ''' バビ語に変換します. 母音の取得方法が分からなかったため,正規表現で全パターン書いてマッチさせています. ''' rettext="" for i in range(len(text)): if re.search(text[i],"あかさたなはまやらわんがざだばぱ"): rettext+=text[i]+"ば" if re.search(text[i],"いきしちにひみりぎじぢびぴ"): rettext+=text[i]+"び" if re.search(text[i],"うくすつぬふむゆるぐずづぶぷ"): rettext+=text[i]+"ぶ" if re.search(text[i],"えけせてねへめれげぜでべぺ"): rettext+=text[i]+"べ" if re.search(text[i],"おこそとのほもよろをごぞどぼぽ"): rettext+=text[i]+"ぼ" print(rettext) return rettextこれが今回唯一書いたコードになってます.
特に工夫するほどの内容ではないのですが,強いて言えば,記述量を減らすために,母音の判定を正規表現で書いたくらいですかね.まとめ
ほとんどコードを書かずにバビ語変換アプリを実装できました.
Voiceflowはノーコードで実装できましたが,じゃあ全くプログラミングが必要ない世の中になるのかと言われるとノーで,やっぱりプログラミングの知識や経験がないと実装は難しいのではないかと思いました.ちなみに.これだけバビ語を実装してきましたが,実は日向坂46では松田このか推しです←
ありがとうございました.




- 投稿日:2020-03-16T16:15:44+09:00
RubyとPythonにおける、外部ソースコードを読み込む書き方の違い
これは何?
RubyとPythonの両方でプログラムを書いていると、外部ソースコードを読み込む書き方が「どっちがどっちだっけ?」と混乱することがあります。そうした場合に向けての備忘録です。
Rubyの場合
require './foobar'
- モジュール名を含むパス全体を
requireの後に書く- モジュール名を引用符で囲う必要がある
Pythonの場合
from . import foobar
- パス指定でモジュールをインポートする場合、モジュール名を除くパスを、
fromの後・importの前に書く- モジュール名は
importの後に書く- モジュール名を引用符で囲う必要はない
Pythonの場合、「パッケージ」やらなんやらの関連概念があるが、今回はそうした項目には触れない。
- 投稿日:2020-03-16T15:31:01+09:00
AWS SAMを使ってLambdaにLayer設定する方法
AWS SAMを使ってLambdaにLayerを設定する方法
はじめに
AWS SAMでLambdaやdynamoDBを使ったサーバーレスアプリケーションを構築しているといろいろなプロジェクトで共通で使っているコードがでてきたりします。
共通化できるものはさっさと共通化して必要なときに呼び出しができるようになると便利なのでさっそく実践してみました。AWS LambdaにはLayer機能があり、Lambdaのコードで使いたいライブラリなどを設定する事ができます。
Layerに依存関係のあるコードやライブラリをAWS SAMのプロジェクトとしてまとめて設定する方法を調べてやってみました。Layerに必要なライブラリをZipでまとめてS3に保存して、AWSコンソールから設定する方法はいくつか見つけましたが、AWS SAMのプロジェクトとしてまとめてdeployする方法がなかなかうまくできなかったので備忘録として書いておきます。
前提条件
AWS SAM CLIのインストールはすでに済んでいるものとして説明します。
今回の説明ではPython3.6を使っています。ディレクトリ構成
Layerとして使いたいコードやライブラリなどを格納するディレクトリは言語ごとに決められています。
AWS Lambda ライブラリの依存関係をレイヤーに含めるpythonなら
pythonかpython/lib/python3.6/site-packagesに格納しておかないと下記のような参照エラーが表示されます。Unable to import module 'app': cannot import name 'layer_code'
sam initコマンドで作成したSAMプロジェクトにLayerを格納するディレクトリを追加します。sam-app ├── README.md ├── app │ ├── __init__.py │ ├── app.py │ └── requirements.txt ├── events │ └── event.json ├── layer // ここにLayer格納用ディレクトリを追加 │ └── python // 言語名ディレクトリ │ └── sample │ └── sample_layer.py // Layerとして使いたいコード └── template.yamltemplate.yamlの書き方
template.yamlHelloWorldFunction: Type: AWS::Serverless::Function Properties: FunctionName: hello-world-sample-function CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.6 Layers: - !Ref LayerSampleLayer # ポイント1 Events: (省略) # Layer定義 LayerSampleLayer: Type: AWS::Serverless::LayerVersion Properties: LayerName: layer-sample-layer Description: Hello World Sample Application Resource Layer ContentUri: layer # ポイント2template.yamlの書き方のポイントは2つです。
Lambda関数定義に
Layersの項目を追加してLayer定義を参照するように設定するLayer定義ではLayerのコードを格納しているフォルダパスを設定する
→正確には言語名ディレクトリの親ディレクトリを設定するapp.pyでのimport
template.yamlでLayer設定をしておくとapp.pyと同一階層にあるものとして使えるようになります。
ただ一度sam buildを行わないと設定は反映されません。app.py# レイヤーとして追加したファイルを参照する from sample import sample_layer def lambda_handler(event, context): res = sample_layer.hello() return ressample_layer.pydef hello(): return "hello Layer!"参考
- 投稿日:2020-03-16T14:46:51+09:00
Google Colaboratory(Colab)でスクレイピングするときのチートシート
目次
Beautiful Soupの使用方法
文字化け解消方法
requestsを使用する場合は通常下記のように書くと思いますが、from bs4 import BeautifulSoup import requests res = requests.get(url) soup = BeautifulSoup(res.content, 'html.parser')これだと文字化けするサイトがあるので、下記にすると文字化けがかなり解消できる。
from bs4 import BeautifulSoup import requests res = requests.get(url) soup = BeautifulSoup(res.content, "lxml", from_encoding='utf-8')findのコード一覧
説明 コード例 1件検索 soup.find('li') タグ全検索 soup.find_all('li') 属性検索 soup.find('li', href='html://www.google.com/') 複数要素を取得 soup.find_all(['a','p']) id検索 soup.find('a', id="first") class検索 soup.find('a', class_="first") 属性取得 first_link_element['href'] テキスト検索 soup.find('dt' ,text='検索ワード') テキスト部分一致の検索 soup.find('dt' ,text=re.compile('検索ワード')) 親要素を取得 .parent 次の要素を1件取得 .next_sibling 次の要素を全件取得 .next_siblings 前の要素を1件取得 .previous_sibling 前の要素を全件取得 .previous_siblings テキスト要素の取得 .string selectのコード一覧
説明 コード例 1件検索 soup.select_one('cssセレクタ') 全件検索 soup.select('cssセレクタ') セレクタの指定方法一覧
説明 コード例 id検索 soup.select('a#id') class検索 soup.select('a.class') classの複数検索 soup.select('a.class1.class2') 属性検索1 soup.select('a[class="class"]') 属性検索2 soup.select('a[href="http://www.google.com"]') 属性検索3 soup.select('a[href]') 子要素の取得 soup.select('.class > a[href]') 子孫要素の取得 soup.select('.class a[href]') 属性要素は検索したい要素に応じて変更する。
id,class,href,name,summaryなど。
子要素(1階層下)だけ取得したい場合は>を挟み、子孫要素(階層下全て)を取得したい場合はスペースを入れる。Seleniumの使用方法
Seleniumを使うための事前準備
Colabで使用する際はSeleniumのダウンロードとUIの仕様ができないので、
その設定が必要になります。# Seleniumを使用するのに必要なライブラリをダウンロード !apt-get update !apt install chromium-chromedriver !cp /usr/lib/chromium-browser/chromedriver /usr/bin !pip install selenium from selenium import webdriver # ドライバーをUIなしで使用するための設定 options = webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') driver = webdriver.Chrome('chromedriver',options=options) driver.implicitly_wait(10)SeleniumとBeautiful Soupを使用する場合
使用ケースとしては、Beautiful Soupだけではどうしても要素が取得できない場合に
seleniumuでページを読み込んでからBeautiful Soupで必要な情報を抜きたい場合。driver.get(url) html = driver.page_source.encode('utf-8') soup = BeautifulSoup(html, 'html.parser')Seleniumの基本コード
説明 コード例 URLを開く driver.get('URL') 一つ前に戻る driver.back() 一つ前に進む driver.forward() ブラウザを更新 driver.refresh() 現在のURLを取得 driver.current_url 現在のタイトルを取得 driver.title 現在のウィンドウを閉じる driver.close() 全てのウィンドウを閉じる driver.quit() クラスで要素取得 driver.find_element_by_class_name('classname') IDで要素取得 driver.find_element_by_id('id') XPATHで要素取得 driver.find_element_by_xpath('xpath') 要素をクリック driver.find_element_by_xpath('XPATH').click() テキスト入力 driver.find_element_by_id('ID').send_keys('strings') テキストの取得 driver.find_element_by_id('ID').text 属性の取得 driver.find_element_by_id('ID').get_attribute('href') 要素が表示されているか判定 driver.find_element_by_xpath('xpath').is_displayed() 要素が有効か判定 driver.find_element_by_xpath('xpath').is_enabled() 要素が選択されているか判定 driver.find_element_by_xpath('xpath').is_selected() ドロップダウンを選択したいとき
from selenium.webdriver.support.ui import Select element = driver.find_element_by_xpath("xpath") Select(element).select_by_index(indexnum) # indexで選択 Select(element).select_by_value("value") # valueの値 Select(element).select_by_visible_text("text") # 表示テキストXpathの指定方法一覧
説明 コード例 全ての要素を選択 //* 全ての要素を選択 //a 属性を選択 @href 複数要素を選択 [a or h2] idで要素取得 //*[@id="id"] classで要素取得 //*[@class="class"] テキスト検索 //*[text()="strings"] テキストの部分検索 //*[contains(text(), "strings")] クラスの部分一致 //*contains(@class, "class") 次のノード取得 /following-sibling::*[1] 2つあとのa要素の /following-sibling::a[2] 後ろのノード取得 /preceding-sibling::*[1] タブを変更する場合
クリックするとページ遷移せず新しいタブができる場合に使用
handle_array = driver.window_handles driver.switch_to.window(handle_array[1])特定の要素が表示されるまで待機処理
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By WebDriverWait(driver, 30).until( EC.presence_of_element_located((By.XPATH, 'xpath'))) )クリックできないときの処理
target = driver.find_element_by_xpath('xpath') driver.execute_script("arguments[0].click();", target)Pandasの使用方法
データフレームを作成してデータを追加していく方法
import pandas as pd columns = ['項目1', '項目2', '項目3', '項目4', '項目5'] df = pd.DataFrame(columns=columns) # データ取得の処理 se = pd.Series([data1, data2, data3, data4, data5], columns) df = df.append(se, columns)Pandasのデータをダウンロードする場合
from google.colab import files filename = 'filename.csv' df.to_csv(filename, encoding = 'utf-8-sig') files.download(filename)Pandasのデータをマイドライブに保存する場合
from google.colab import drive filename = filename.csv' path = '/content/drive/My Drive/' + filename with open(path, 'w', encoding = 'utf-8-sig') as f: df.to_csv(f)スプレッドシートを扱う方法
スプレッドシートを扱うための事前準備
# スプレッドシート連携するのに必要なライブラリをダウンロード !pip install gspread from google.colab import auth from oauth2client.client import GoogleCredentials import gspread # 認証処理 auth.authenticate_user() gc = gspread.authorize(GoogleCredentials.get_application_default())よく使用するコード
ss_id = 'スプレッドシートのID' sht_name = 'シート名' workbook = gc.open_by_key(ss_id) worksheet = workbook.worksheet(sht_name) # データ取得するとき worksheet.acell('B1').value worksheet.cell(2, 1).value # アップデートするとき worksheet.update_cell(row, column, '更新内容')gspreadのコード一覧
ワークブックの操作
説明 コード例 IDでスプレッドシートの選択 gc.open_by_key('ID') URLでスプレッドシートの選択 gc.open_by_url('URL') スプレッドシートのタイトル取得 workbook.title スプレッドシートのID取得 workbook.id シートの操作
説明 コード例 シート名でシートを取得 workbook.worksheet('シート名') Indexでシートを取得 workbook.get_worksheet(index) 全シートを配列で取得 workbook.worksheets() シート名の取得 worksheet.title シートIDの取得 worksheet.id セルの操作
説明 コード例 A1方式でデータ取得 worksheet.acell('B1').value R1C1方式でデータ取得 worksheet.cell(1, 2).value 複数セルを選択して一次元配列で取得 worksheet.range('A1:B10') 選択行のデータ取得 worksheet.row_values(1) 選択行の数式取得 worksheet.row_values(1,2) 選択列のデータ取得 worksheet.column_values(1) 選択列の数式取得 worksheet.column_values(1,2) 全データを取得 worksheet.get_all_values() A1方式でセルの値を更新 worksheet.update_acell('B1','更新する値') R1C1方式でセルの値を更新 worksheet.update_cell(1,2,'更新する値') 【参考サイト】
BeautifulSoup4のチートシート(セレクターなど)
Python3メモ - BeautifulSoup4のあれこれ
WebスクレイピングのためのCSSセレクタの基本
Selenium webdriverよく使う操作メソッドまとめ
XPathとは?XPathの基本知識を学ぼう!
Webスクレイピングに不可欠!Xpathのまとめ
gspreadライブラリの使い方まとめ!Pythonでスプレッドシートを操作する
- 投稿日:2020-03-16T14:37:37+09:00
Pipenv と Pipfile.lock
流行り廃りが激しいのでいつまで使うか知らないが Pipenv https://github.com/pypa/pipenv の事を書く。Pipenv は npm みたいなツールだが、ロックファイルの使い方がちょっと違うのでこれだけ先に書く。
Pipfile.lock
Pipenv では、開発者が Pipfile にインストールしたいバージョンの希望を書き、Pipfile.lock に実際にインストールしたバージョンが記録される。こうして開発者がインストールしたのと同じ環境を他の人も再現出来る。次のように使う。
Pipfile.lock を作成した人と同じ環境を再現したい場合。(npm で言うと
npm ci)pipenv install または pipenv sync でも同じ事が起こるPipfile.lock を無視して、Pipfile に記述された最新のパッケージをインストールしたい場合。(npm で言うと
npm install)pipenv update続けて一般的な使い方を書く。
pyenv もインストールしておくと pipenv 経由で pyenv が呼び出され適切な Python のバージョンが自動インストールされます。
自分で新たに pipenv の環境を作る場合の典型的な作業
インストール例 (多分インストーラでで .zshrc 等に
eval "$(pyenv init -)"が書き込まれると思う):brew install pipenv pyenvPython のバージョンを指定して新しい環境を作る。Python の自動インストールには
pyenvが必要です。pipenv --python 3.8環境の中に入る
pipenv shell実装向けに何かインストールする。
pipenv lockも自動的に実行されて Pipfile.lock が更新される。pipenv install boto3開発向けに何かインストールする。
pipenv lockも自動的に実行されて Pipfile.lock が更新される。pipenv install --dev autopep8インストール済パッケージを列挙
pipenv graphpep-508 で定義されているように依存を確認する。
pipenv check古くなってしまったパッケージを探す
pipenv update --outdated古いパッケージを更新。Pipfile.lock を無視して Pipfile だけを見てパッケージを更新する。
pipenv lockも自動的に実行されて Pipfile.lock が更新される。pipenv updatePipfile を元に Pipfile.lock を最新に更新するが、インストールしない。
pipenv lockPipfile.lock を元に 環境を作る。Pipfile.lock が存在する時は
pipenv installと同じ。pipenv sync環境を削除
pipenv --rmすでに Pipfile と Pipfile.lock の存在するコードの開発に参加する
Pipfile.lock の通りにパッケージをインストールする。
pipenv install余談
boto3 https://pypi.org/project/boto3/ みたいに更新の早いパッケージを使うと動作確認しやすい。
- 投稿日:2020-03-16T13:59:25+09:00
第4回 Google Colaboratoryで始める機械学習のための特徴量エンジニアリング - 交互作用特徴量
はじめに
本記事では交互作用特徴量について解説しています。本記事は主に「機械学習のための特徴量エンジニアリング」を参考とさせて頂いておりますので、気になる方は是非チェックしてみてください。
※本記事で解説するプログラムは全てこちらにあります。
交互作用特徴量とは
複数の特徴量を掛け合わせて新たな特徴量を作るという手法です。この中でで特に2つの特徴量を組み合わせるものをペアワイズ交互作用特徴量と呼びます。また、特徴量が二値である場合は論理積となります。
例えば特徴量として地域と年齢層がある場合に、地域と年齢層を掛け合わせることで「20代」と「東京住み」の情報から「東京住みの20代」という目的変数をより表現できる情報を作成することができるのです。しかしデメリットとして、学習コストが増大することと、不要な特徴量を作成してしまうことが考えられます。この学習コストの増大と不要な特徴量の問題は特徴量選択を行うことで解決することができます。
例えば以下のような特徴量データがあったとします。
このデータに対して交互作用特徴量を作成すると以下のようなデータセットが作成されました。
以下では実際に交互作用特徴量を実装するサンプルコードを示します。
import numpy as np import pandas as pd import sklearn.preprocessing as preproc ##乱数固定 np.random.seed(100) data_array1 = [] for i in range(1, 100): s = np.random.randint(0, i * 10, 10) data_array1.extend(s) ##乱数固定 np.random.seed(20) data_array2 = [] for i in range(1, 100): s = np.random.randint(0, i * 10, 10) data_array2.extend(s) data = pd.DataFrame({'A': data_array1, 'B': data_array2}) ## 交互作用特徴量 data2 = pd.DataFrame(preproc.PolynomialFeatures(include_bias=False).fit_transform(data)) ## interaction_only=Trueとすることで自身の値の二乗を除くことができます # data2 = preproc.PolynomialFeatures(include_bias=False, interaction_only=True).fit_transform(data)最後に
YouTubeでITに関する動画を上げていこうと思っています。
YoutubeとQiita更新のモチベーションに繋がるため、いいね、チャンネル登録、高評価をよろしくお願い致します。
YouTube: https://www.youtube.com/channel/UCywlrxt0nEdJGYtDBPW-peg
Twitter: https://twitter.com/tatelabo

