- 投稿日:2020-03-16T23:50:07+09:00
[Amazon Linux 2]公開鍵認証からパスワード認証へ変更
内容
EC2への接続方法を公開鍵認証からパスワード認証へ変更する
類似記事
(Amazon Linux 2の)sshd_configとauthorized_keysを学ぶ手順
対象のEC2へSSH接続して、ユーザをrootへ切り替えます。
sshd_configのバックアップ取得
設定変更を行う前には必ずバックアップを取得しておきます。
# cd /etc/ssh/ # pwd /etc/ssh # ls -l total 608 ... -rw-r--r-- 1 root root 2276 Mar 15 12:25 ssh_config -rw------- 1 root root 3977 Mar 15 12:04 sshd_config ... # cp -p sshd_config sshd_config_yyyymmdd # ls -l total 608 ... -rw-r--r-- 1 root root 2276 Mar 15 12:25 ssh_config -rw------- 1 root root 3977 Mar 15 12:04 sshd_config -rw------- 1 root root 3977 Mar 15 12:04 sshd_config_yyyymmdd ...sshd_config設定変更
sshd_configの設定を変更していきます。
(変更前)
#PubkeyAuthentication yes
PasswordAuthentication no(変更後)
PubkeyAuthentication no
PasswordAuthentication yes# vi sshd_config # cat sshd_config | grep PubkeyAuthentication #PubkeyAuthentication yes PubkeyAuthentication no # cat sshd_config | grep PasswordAuthentication PasswordAuthentication yes #PasswordAuthentication no # systemctl restart sshd.serviceviコマンドで設定変更を行い、cat+grepで変更箇所が問題なく変更されていることを確認します。
その後、systemctlコマンドでsshd.serviceを再起動します。パスワード認証での接続確認
Teratermを使用して、パスワード認証でログインできるかを確認します。
その際、現在の接続は保ったまま行ってください。IPアドレスを入力してOKを押下します。
ユーザ名とパスワードを入力してブレインパスワードを使う(L)を選択して接続します。
接続できました。
終わり
これでパスワード認証へ変更が出来た。
出来たがパスワード認証はあまりよろしくないので元に戻しましょう。# cp -p sshd_config_yyyymmdd sshd_config # systemctl restart sshd.service



- 投稿日:2020-03-16T23:11:08+09:00
CentOS7におけるネットワーク設定・確認
環境
- CentOS Linux release 7.7.1908
実行結果[root@CENTOS7 ~]# cat /etc/redhat-release CentOS Linux release 7.7.1908 (Core) [root@CENTOS7 ~]#1. ホスト名
1.1. ホスト名の確認
hostname
または
cat /etc/hostname実行結果[root@CENTOS7 ~]# hostname CENTOS7 [root@CENTOS7 ~]#実行結果[root@CENTOS7 ~]# cat /etc/hostname CENTOS7 [root@CENTOS7 ~]#1.2. ホスト名の変更
nmcli general hostname <ホスト名>
または
hostnamectl set-hostname <ホスト名>実行結果[root@CENTOS7 ~]# nmcli general hostname CENTOS7AF [root@CENTOS7 ~]# hostname CENTOS7AF [root@CENTOS7 ~]# cat /etc/hostname CENTOS7AF [root@CENTOS7 ~]#実行結果[root@CENTOS7 ~]# hostnamectl set-hostname CENTOS7AF [root@CENTOS7 ~]# hostname centos7af [root@CENTOS7 ~]# cat /etc/hostname centos7af [root@CENTOS7 ~]#
hostnamectl set-hostname <ホスト名>の場合、小文字で設定されました。2. ネットワークインターフェース
2.1. ネットワーク物理インターフェース(device)の一覧表示
nmcli device実行結果[root@CENTOS7 ~]# nmcli device DEVICE TYPE STATE CONNECTION enp0s3 ethernet 接続済み enp0s3 lo loopback 管理無し -- [root@CENTOS7 ~]#2.2 ネットワーク物理インターフェース(device)の詳細表示
nmcli device show <デバイス名>実行結果[root@CENTOS7 ~]# nmcli device show enp0s3 GENERAL.DEVICE: enp0s3 GENERAL.TYPE: ethernet GENERAL.HWADDR: 08:00:27:57:A3:39 GENERAL.MTU: 1500 GENERAL.STATE: 100 (接続済み) GENERAL.CONNECTION: enp0s3 GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveCo WIRED-PROPERTIES.CARRIER: オン IP4.ADDRESS[1]: 192.168.0.11/24 IP4.GATEWAY: 192.168.0.1 IP4.ROUTE[1]: dst = 192.168.0.0/24, nh = 0.0.0.0, mt = IP4.ROUTE[2]: dst = 0.0.0.0/0, nh = 192.168.0.1, mt = IP4.DNS[1]: 8.8.8.8 IP4.DNS[2]: 8.8.4.4 IP6.ADDRESS[1]: fe80::2eca:a058:c18f:fd7e/64 IP6.GATEWAY: -- IP6.ROUTE[1]: dst = fe80::/64, nh = ::, mt = 100 IP6.ROUTE[2]: dst = ff00::/8, nh = ::, mt = 256, table [root@CENTOS7 ~]#2.3. ネットワーク論理インターフェース(connection)の一覧表示
nmcli connection実行結果[root@CENTOS7 ~]# nmcli connection NAME UUID TYPE DEVICE enp0s3 0f174b12-5dc6-40c9-99fc-06c6ce550c24 ethernet enp0s3 [root@CENTOS7 ~]#2.4. ネットワーク論理インターフェース(connection)の詳細表示
nmcli connection show <コネクション名>実行結果[root@CENTOS7 ~]# nmcli connection show enp0s3 connection.id: enp0s3 connection.uuid: 0f174b12-5dc6-40c9-99fc-06c6ce550c24 connection.stable-id: -- connection.type: 802-3-ethernet connection.interface-name: enp0s3 connection.autoconnect: はい connection.autoconnect-priority: 0 connection.autoconnect-retries: -1 (default) connection.multi-connect: 0 (default) connection.auth-retries: -1 connection.timestamp: 1584364512 connection.read-only: いいえ connection.permissions: -- connection.zone: -- connection.master: -- connection.slave-type: -- connection.autoconnect-slaves: -1 (default) connection.secondaries: -- connection.gateway-ping-timeout: 0 connection.metered: 不明 connection.lldp: default connection.mdns: -1 (default) connection.llmnr: -1 (default) 802-3-ethernet.port: -- 802-3-ethernet.speed: 0 802-3-ethernet.duplex: -- 802-3-ethernet.auto-negotiate: いいえ 802-3-ethernet.mac-address: -- 802-3-ethernet.cloned-mac-address: -- 802-3-ethernet.generate-mac-address-mask:-- 802-3-ethernet.mac-address-blacklist: -- 802-3-ethernet.mtu: 自動 802-3-ethernet.s390-subchannels: -- 802-3-ethernet.s390-nettype: -- 802-3-ethernet.s390-options: -- 802-3-ethernet.wake-on-lan: default 802-3-ethernet.wake-on-lan-password: -- ipv4.method: manual ipv4.dns: 8.8.8.8,8.8.4.4 ipv4.dns-search: -- ipv4.dns-options: "" ipv4.dns-priority: 0 ipv4.addresses: 192.168.0.11/24 ipv4.gateway: 192.168.0.1 ipv4.routes: -- ipv4.route-metric: -1 ipv4.route-table: 0 (unspec) ipv4.routing-rules: -- ipv4.ignore-auto-routes: いいえ ipv4.ignore-auto-dns: いいえ ipv4.dhcp-client-id: -- ipv4.dhcp-timeout: 0 (default) ipv4.dhcp-send-hostname: はい ipv4.dhcp-hostname: -- ipv4.dhcp-fqdn: -- ipv4.never-default: いいえ ipv4.may-fail: はい ipv4.dad-timeout: -1 (default) ipv6.method: auto ipv6.dns: -- ipv6.dns-search: -- ipv6.dns-options: "" ipv6.dns-priority: 0 ipv6.addresses: -- ipv6.gateway: -- ipv6.routes: -- ipv6.route-metric: -1 ipv6.route-table: 0 (unspec) ipv6.routing-rules: -- ipv6.ignore-auto-routes: いいえ ipv6.ignore-auto-dns: いいえ ipv6.never-default: いいえ ipv6.may-fail: はい ipv6.ip6-privacy: 0 (disabled) ipv6.addr-gen-mode: stable-privacy ipv6.dhcp-duid: -- ipv6.dhcp-send-hostname: はい ipv6.dhcp-hostname: -- ipv6.token: -- proxy.method: none proxy.browser-only: いいえ proxy.pac-url: -- proxy.pac-script: -- GENERAL.NAME: enp0s3 GENERAL.UUID: 0f174b12-5dc6-40c9-99fc-06c6ce550c24 GENERAL.DEVICES: enp0s3 GENERAL.STATE: アクティベート済み GENERAL.DEFAULT: はい GENERAL.DEFAULT6: いいえ GENERAL.SPEC-OBJECT: -- GENERAL.VPN: いいえ GENERAL.DBUS-PATH: /org/freedesktop/NetworkManager/ActiveCo GENERAL.CON-PATH: /org/freedesktop/NetworkManager/Settings GENERAL.ZONE: -- GENERAL.MASTER-PATH: -- IP4.ADDRESS[1]: 192.168.0.11/24 IP4.GATEWAY: 192.168.0.1 IP4.ROUTE[1]: dst = 192.168.0.0/24, nh = 0.0.0.0, mt = IP4.ROUTE[2]: dst = 0.0.0.0/0, nh = 192.168.0.1, mt = IP4.DNS[1]: 8.8.8.8 IP4.DNS[2]: 8.8.4.4 IP6.ADDRESS[1]: fe80::2eca:a058:c18f:fd7e/64 IP6.GATEWAY: -- IP6.ROUTE[1]: dst = fe80::/64, nh = ::, mt = 100 IP6.ROUTE[2]: dst = ff00::/8, nh = ::, mt = 256, table [root@CENTOS7 ~]#上記設定を変更するコマンドは以下となります。
nmcli connection modify <コネクション名> <項目名> <値>IPアドレスを192.168.0.12/24に変更
nmcli connection modify enp0s3 ipv4.address 192.168.0.12/24実行結果[root@CENTOS7 ~]# nmcli connection modify enp0s3 ipv4.address 192.168.0.12/24 [root@CENTOS7 ~]#DNSサーバを208.67.222.222と208.67.220.220に変更
nmcli connection modify enp0s3 ipv4.dns "208.67.222.222 208.67.220.220"実行結果[root@CENTOS7 ~]# nmcli connection modify enp0s3 ipv4.dns "208.67.222.222 208.67.220.220" [root@CENTOS7 ~]#NetworkManagerを再起動することで有効となります。
systemctl restart NetworkManager実行結果[root@CENTOS7 ~]# systemctl restart NetworkManager [root@CENTOS7 ~]#上記設定の場合、IPアドレスの変更はインターフェースコネクションを再起動(非アクティブ→アクティブ)する必要がありました。
以下のコマンドで手動でインターフェースコネクションをアクティブ/非アクティブに設定することがです。
インターフェースコネクションを非アクティブにする。
nmcli connection down <コネクション名>実行結果[root@CENTOS7 ~]# nmcli connection down enp0s3 接続 'enp0s3' が正常に非アクティブ化されました (D-Bus アクティブパス: /org/freedesktop/NetworkManager/ActiveConnection/2) [root@CENTOS7 ~]#インターフェースコネクションをアクティブにする。
nmcli connection up <コネクション名>実行結果[root@CENTOS7 ~]# nmcli connection up enp0s3 接続が正常にアクティベートされました (D-Bus アクティブパス: /org/freedesktop/NetworkManager/ActiveConnection/4) [root@CENTOS7 ~]#2.5. ネットワークインターフェースの確認(昔のifconfigの代わり)
ip addr show実行結果[root@CENTOS7 ~]# ip addr show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 08:00:27:57:a3:39 brd ff:ff:ff:ff:ff:ff inet 192.168.0.11/24 brd 192.168.0.255 scope global noprefixroute enp0s3 valid_lft forever preferred_lft forever inet6 fe80::2eca:a058:c18f:fd7e/64 scope link noprefixroute valid_lft forever preferred_lft forever [root@CENTOS7 ~]#3. TUI(テキストユーザインタフェース)によるネットワークの設定
以下のコマンドでTUI(テキストユーザインタフェース)でネットワークの設定が可能です。
nmtui[root@CENTOS7 ~]# nmtui
4. その他
CentOS7では
ifconfig、route、netstat、arp等のネットワーク関連コマンドが入っていません。これらのコマンドは、「net-tools」パッケージを追加することで利用可能になります。
yum install net-tools「net-tools」パッケージを導入しない環境では、「iproute2」パッケージに含ま れる「ip, ss」等のコマンドを使用します。
コマンド対応表
net-tools iproute2 ifconfig ip addr、ip link route ip route netstat ss netstat -i ip -s link arp ip neighbor
以上

- 投稿日:2020-03-16T23:10:05+09:00
Flutter Desktop for Linux on Ubuntu16.04
Overview
Just getting interested on Flutter Desktop Embedding. as a 1st step, installing SDK and run example and quick code scan will be noted here. (hopefully this could be really 1st step tutorial for everyone)
Environment
- Ubuntu 16.04 (4.15.0-88-generic)
- Flutter SDK Master
- Flutter Desktop Embedding Master
Procedure
- Glone repo and Install SDK
just clone the repos from flutter project as below.
git clone git@github.com:flutter/flutter.git git clone git@github.com:google/flutter-desktop-embedding.gitflutter binaries are store flutter/bin, make the path trough here as followings.
export PATH="<path to flutter repo>/flutter/bin:$PATH"
- Check dependent toolchain.
switch flutter mode into linux desktop
flutter config --enable-linux-desktopthen consult with flutter doctor, if everything is okay to go.
flutter doctor Doctor summary (to see all details, run flutter doctor -v): [✓] Flutter (Channel master, v1.15.21-pre.11, on Linux, locale ja_JP.UTF-8) [!] Android toolchain - develop for Android devices (Android SDK version 26.0.2) ✗ Flutter requires Android SDK 28 and the Android BuildTools 28.0.3 To update using sdkmanager, run: "/home/tomoyafujita/Android/Sdk/tools/bin/sdkmanager" "platforms;android-28" "build-tools;28.0.3" or visit https://flutter.dev/setup/#android-setup for detailed instructions. ✗ Android license status unknown. Try re-installing or updating your Android SDK Manager. See https://developer.android.com/studio/#downloads or visit https://flutter.dev/setup/#android-setup for detailed instructions. [✓] Linux toolchain - develop for Linux desktop [!] Android Studio (version 2.3) ✗ Flutter plugin not installed; this adds Flutter specific functionality. ✗ Dart plugin not installed; this adds Dart specific functionality. [✓] VS Code (version 1.43.0) [✓] Connected device (1 available) ! Doctor found issues in 2 categories.I believe that Android toolchain and Android Studio are not required to develop linux desktop application, so that we can ignore the warnings.
- Run example application
flutter config --enable-linux-desktop/example flutter run Launching lib/main.dart on Linux in debug mode... Building Linux application... Flutter is taking longer than expected to report its views. Still trying... Syncing files to device Linux... 1,376ms Flutter run key commands. r Hot reload. ??? R Hot restart. h Repeat this help message. d Detach (terminate "flutter run" but leave application running). c Clear the screen q Quit (terminate the application on the device). An Observatory debugger and profiler on Linux is available at: http://127.0.0.1:38875/DBy1Vv9Qb38=/Statistics for VM
name vm@ws://127.0.0.1:38875/DBy1Vv9Qb38=/ws version 2.8.0-dev.13.0.flutter-684c53a6f1 (Wed Mar 11 15:41:59 2020 +0000) on "linux_x64" embedder Flutter started at 2020-03-16 22:11:48.876 uptime 0:01:09.529000 refreshed at 2020-03-16 22:12:58.406 pid 8473 peak memory 151.5MB current memory 147.7MB native zone memory 0B native heap memory unavailable native heap allocation count unavailablesudo netstat -panda| grep 38875 tcp 0 0 127.0.0.1:38875 0.0.0.0:* LISTEN 8473/flutter_deskto tcp 0 0 127.0.0.1:60032 127.0.0.1:38875 ESTABLISHED 8234/dart tcp 0 0 127.0.0.1:38875 127.0.0.1:60032 ESTABLISHED 8473/flutter_deskto-> application pid is 8473, and dart vm is 8234. dart is connected with application via TCP, and application listens on the port to get activity effectively on the screen.
pmap -x 8473 8473: /home/tomoyafujita/DVT/flutter/flutter-desktop-embedding/example/build/linux/debug/flutter_desktop_example Address Kbytes RSS Dirty Mode Mapping 0000000000400000 64 16 0 r-x-- flutter_desktop_example 0000000000400000 0 0 0 r-x-- flutter_desktop_example 000000000060f000 4 4 4 r---- flutter_desktop_example ... ffffffffff600000 0 0 0 r-x-- [ anon ] ---------------- ------- ------- ------- total kB 1222876 148804 124272-> physical memory consumption is almost 150MB for this example.
pidstat -p 8473 1 Linux 4.15.0-88-generic (tomoyafujita-Inspiron-620s) 2020年03月16日 _x86_64_ (4 CPU) 22時19分28秒 UID PID %usr %system %guest %CPU CPU Command 22時19分29秒 1000 8473 0.00 0.00 0.00 0.00 1 flutter_desktop 22時19分30秒 1000 8473 0.00 0.00 0.00 0.00 1 flutter_desktop 22時19分31秒 1000 8473 0.00 0.00 0.00 0.00 1 flutter_desktop 22時19分32秒 1000 8473 0.00 0.00 0.00 0.00 1 flutter_desktop 22時19分33秒 1000 8473 0.00 0.00 0.00 0.00 1 flutter_desktop 22時19分34秒 1000 8473 0.00 0.00 0.00 0.00 1 flutter_desktop 22時19分35秒 1000 8473 3.00 0.00 0.00 3.00 2 flutter_desktop 22時19分36秒 1000 8473 10.00 1.00 0.00 11.00 2 flutter_desktop 22時19分37秒 1000 8473 17.00 1.00 0.00 18.00 0 flutter_desktop 22時19分38秒 1000 8473 8.00 0.00 0.00 8.00 1 flutter_desktop 22時19分39秒 1000 8473 16.00 1.00 0.00 17.00 3 flutter_desktop 22時19分40秒 1000 8473 4.00 0.00 0.00 4.00 2 flutter_desktop 22時19分41秒 1000 8473 0.00 0.00 0.00 0.00 2 flutter_desktop 22時19分42秒 1000 8473 2.00 0.00 0.00 2.00 2 flutter_desktop 22時19分43秒 1000 8473 0.00 0.00 0.00 0.00 2 flutter_desktop 22時19分44秒 1000 8473 0.00 0.00 0.00 0.00 2 flutter_desktop 22時19分45秒 1000 8473 0.00 0.00 0.00 0.00 3 flutter_desktop ...-> confirmed that dart does not affect any activity without any input, but once input comes in, it will consume close to 20% of user.
Example Source Code
This example is actually sample of materials.
not a big deal, but plugin should be something more important for desktop environemtn to connect x11 serser.Reference
What's next?
- Flutter System Framework and Architecture Deep Dive
- Deep dive into desktop plugin
- 投稿日:2020-03-16T21:15:41+09:00
curlコマンドでアクセストークンを付与し、APIをPOST送信する
いざ動作確認をしようとする時、毎回調べるのでメモ。
curl -X POST -H "Content-Type: application/x-www-form-urlencoded" -H "Cache-Control: no-cache" -H "Authorization: OAuth [AccessToken]" -d 'hoge=12345&fuga=abcde' "https://example.com/api/v1/sample"
- 投稿日:2020-03-16T21:13:41+09:00
Raspberry Piへカメラを取り付けて、Motionソフトにより自宅監視サイト(但し自宅Wifi圏内でのみ閲覧可能)を構築した
はじめに
Raspberry Piを使った工作を始めました。今回はタイトルの通りカメラを取り付けて、Motionソフトにより自宅内の部屋を監視するサイト(自宅内Wifi限定)を構築しましたので、まとめたいと思います。
要点は下記です。
- カメラモジュールをRaspberry Pi 4へ取り付ける
- カメラで撮影できるようにRaspberry Pi4で設定する
- Motionソフト導入及びサイトで閲覧する
カメラモジュールをRaspberry Pi 4へ取り付ける
まずはこちらを組み立てます。
全体的にコンパクトなパッケージにカメラ、ケース、説明書が入っていました。カメラのケースを作るのですが、こちらは写真をほぼ撮っていませんでした。。
ネジが非常に小さく入れにくいものの、ケースとなるプラスチックを合わせてネジで止めるだけなのであまり難しくはありませんでした。
次にこのモジュールをラズパイに設置する方法です。
カメラモジュールを設置するコネクタ部には黒いカバーがされており通常は差し込む隙間がありません。従って、カバーを爪で持ち上げてその隙間に差し込みます。この時、金属センサー面がラズパイ側とカメラ側で設置するように入れ込みましょう。
設置した写真がこちらです。購入したラズパイ側の箱は強くはめ込んでいません。
カメラで撮影できるようにRaspberry Piで設定する
こうして設置が完了しましたラズパイですが、次にカメラで撮影できるようにラズパイ上で設定を行います。以後、rootユーザーとしてログインして設定を行っております。
※root以外のユーザーとしてログインしている場合、設定を進められないところがあったためです。sudoersに登録を行いましたが、それでも上手くいかず。。ここはもう少し調べてみます。
設定からインターフェース→カメラを有効にします。
次に、LXterminalと呼ばれるWindowsで言うコマンドプロンプトに相当するアプリケーションを起動させます。
このLXterminalはLinux コマンドで命令を行います。私自身、Linuxコマンドは初めてでしたので、検索しながら手探りで行っています。
カメラが接続されているかは下記を打ち込みエンターを押します。LXterminalvcgencmd get_camera成功すると下記のように出ます。detected=0となると接続されていないことになりますので、これまでのどこかで誤ったことが起きているはずです。
LXterminalsupported=1 detected=1デバイス側の問題がある場合は、下記コマンドによってラズパイ内のデバイスを最新バージョンへアップデートできます。
LXterminalsudo apt-get upgrade一旦カメラで撮影してみる
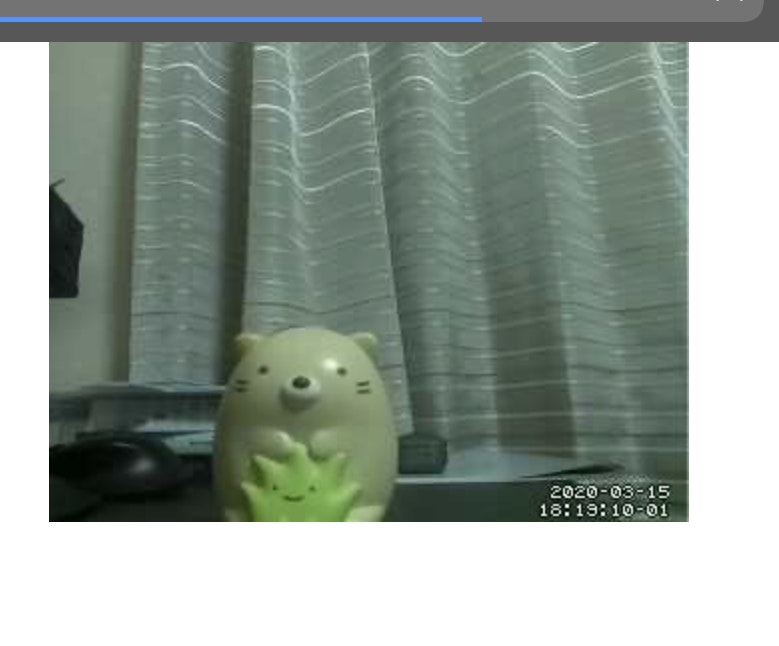
接続が確認できたら試しにカメラで写真を撮影してみましょう。
LXterminalsudo raspistill -o image.jpgこのコマンドにより一枚写真を撮影することができます。写真自体はLXterminal上でカレントディレクトリとなっているフォルダに格納されます。
近くの置物にはピントが合っていなく、後ろの背景にピントが合っているように見えます。
参考URL
https://www.pc-koubou.jp/magazine/17276Motionソフト導入及びサイトで閲覧する
さて、カメラの設定まで終わりましたので、次にリアルタイムで撮影した映像を確認できるようにしたいと思います。
今回は、Motionと呼ばれるソフトをラズパイ上にインストールし、LXterminalのコマンドによりそのソフトを起動させ、URL上にて確認できるようにします。下記コマンドによりMotionをインストールします。
LXterminalsudo apt-get install motionそして、下記コマンドによりMotionを動かせるように以下を編集します。
LXterminalsudo vim /etc/default/motion start_motion_daemon=no ↓ start_motion_daemon=yesまず、ここでコマンドが受け付けずエラーになる方はVimと呼ばれるテキストエディタのインストールが必要になるため、下記コマンドによりインストールします。
LXterminalsudo apt-get install vimさて、ここで編集画面が下記のように出てきますが、Vim独特の編集の仕方を知る必要があります。
参考URL
https://qiita.com/kon_yu/items/b8864ff566b8b67a9810編集可能画面と編集不可な画面がs,escキーで切り替えられるので、切り替え後yesとnoを打ち込みましょう。そして切り替えた後は編集不可の画面で:wqコマンドにより抜けることができます。
さて、これで実際に設定が完了しました。実際に撮影してみましょう。こちらのコマンドによりMotionを起動させます。
LXterminalsudo motion -n撮影した動画は
http://raspberrypiのIP:8081/
このURL上で確認することができます。
実際撮影した動画のキャプチャー画像が上になります。写真よりもやはり荒い品質でした。
しかし、家中Wifiが通じているところででは見ることができます。
家事、仕事をしているときに離れたところで寝ている子供の様子を見る等適用ができるかなぁ、と思ったりしました。終わりに
今回、Raspberry Piへカメラを設置して撮影する環境構築を行いました。設置自体は難しくありませんでした。しかし、Linuxコマンド上で設定をしたりrootユーザーでないと設定が進まなかったりといったラズパイ内の設定に理解不足な点が多々ありました。
次はこのカメラの設定を変えて撮影方法を変えてできないか検討してみたいと思います。また、Wifi外でも見れるようにサーバー構築or AWS等クラウドサービス活用を行ってみたいと思います。
カメラの性能として1500円で安すぎたかな、と思いましたが全然そんなことはなく、おもちゃとして遊ぶには十分すぎる性能です。楽しい時代になりましたね。。大変参考にさせて頂いたURL
https://qiita.com/westvirginia/items/ba79f7549b43da116467https://www.itmedia.co.jp/news/articles/1907/13/news009.html






- 投稿日:2020-03-16T20:02:53+09:00
Vagrant上にローカルからファイルをコピー(scp)
ファイルのコピー
コマンドの実行場所はVagrant上ではなく、ローカルで実行。
ローカルからVagrant上へコピーの場合$ scp /Users/user-name/Desktop/hoge.txt vagrant@web1:/www/file/【構文】scp コピー元パス vagrant@VMホスト名:コピー先vagrant上のパス
↑↑これでローカルの「/Users/user-name/Desktop/hoge.txt」を、
Vagrant(web1バーチャルマシン)上の
「/www/file/」ディレクトリにコピーする。Vagrant上からローカルへコピーの場合$ scp vagrant@web1:/www/file/hoge.txt /Users/user-name/Desktop/VMホスト名はVagrantfileの
vm.hostnameを参照。VagrantfileVagrant.configure("2") do |config| config.vm.define "default" do |web1| web1.vm.box = "mvbcoding/awslinux" web1.vm.hostname = "web1" web1.vm.network "private_network", ip: "xxx.xxx.xxxx" endディレクトリのコピー
-rオプションをつけると、ディレクトリごとscpできる。hogeディレクトリをvagrant上にコピー$ scp -r /Users/user-name/Desktop/hoge vagrant@web1:/www/file/fuga/以上。
- 投稿日:2020-03-16T17:53:35+09:00
使ったことがないDockerを使う気にさせる使用事例
はじめに
Dockerを学ぶ場合、会社のプロジェクトで使うから勉強する事になるパターンと
よく使われていることから使ってみたい!という2パターンに分けられると思います(自分は後者でした)勉強した際いまいちどう使えばいいのかわからず、業務で使って理解した部分が色々あったので
便利だなと思ったユースケースと利点についてまとめました。
読んで使ってみたいと思う人が一人でも増えればいいと思います。個人開発で使用する
PC内にDockerでlinuxの開発環境を作る(Win or Mac)
メリット
・母艦PCと言語バージョンが違う開発がパッケージ切り替え無しで実施できる
DockerでLinux環境を作成し、その中に言語パッケージ等を入れて開発環境を構築します。
本質は「どこから接続しても同条件で開発できる環境をDockerイメージとしてパッケージ化できる」点です。
イメージさえあれば別PCを購入してもDockerさえ導入すれば同じ環境がすぐ構築でき、
AWS等のクラウド上でコンテナを立てればSSH接続するだけですぐ開発に取り掛かることができます。
※Linuxを含んだDockerコンテナを作る・実質linux内で開発しているためデプロイする場合のOS差異がなく、コンテナ作成から公開が簡単にできる。
上とほぼ似ていますが、linux内での開発になるのでそのままdockerfileを記述しイメージを作成、
ECR、GCR等のコンテナ用クラウドにアップすることですぐに開発したコンテナを公開できます。
自分の環境で開発した物をEC2等にデプロイする場合と比べて環境差異が生まれる可能性が少なく便利です。会社のプロジェクトで使用する
開発環境として使用する
コンテナを用いて複数人の環境をすぐに作成できる
Dockerイメージをpushするインスタンスを変更するだけで複数環境を簡単に作成することができます。
開発環境の配布も可能なためプロジェクトインが簡単にできたり、テスト用のインスタンス生成等にも
柔軟に対応が可能です。スタートアップ時にはいろいろなモジュールを変更して試してみることも多いため、
変更しない部分(メインロジック等)を1個のDockerイメージにして変更がある部分のみを別イメージとして
docker-composeの記述で環境を試し、必要ないコンテナはすぐ廃棄することで作業効率が向上します。
(ローカルで同様の事をする場合、パッケージの削除・エラー解消などが必要となり膨大な作業が発生します)本番運用のために使用する
スケーリングが容易なため、サービスの規模に応じてベストな運用ができる
ソーシャルゲームなどではイベントがあるとアクセスが多くなったり、夜間のアクセスが減少することから
スケーリング不可なシステムだとリソースの無駄やアクセス過多によるサーバー落ちの可能性があります。
Dockerを使用することによりコンテナ単位でのスケールアウト・スケールインが可能なため、
アクセスに応じた構成をフレキシブルに適応しながら運用することができます。
サービス運用の潤滑化・高速化
開発に関わる作業(テスト・デプロイ・スケーリング等)が楽になることからプロダクトそのものに集中でき、
技術面だけではなく企画時間~作業時間など全体の時間削減に繋がります。
※うまく説明ができるメンバーがいる前提であれば、テストメンバーを増やす際も環境構築が即時可能で
開発メンバーのスケーリングが容易にできるのはすごくメリットに感じました。Dockerに関する気になること
別に使わなくても開発はできる・採用企業にジョインする難しさ
そもそもDockerが使用されるまでの運用法が間違っているわけでもないので、新規に導入する時間を考えると
案件を1件でも多く受注し、同じ開発を続けることも企業にとっては一つの選択だと思います。
2019年の記事では国内でDockerコンテナを本番利用している企業は9.2%という話もあり、該当企業に参加し
その案件に参画するまでもいくつかの壁が存在します。0からの勉強コストが高い
経験のあるメンバーがいない場合、7人のメンバーが1日でDockerを学んでも1人週の工数がかかります。
どんな新しい技術でも調査時間は必要ですが、前述の「使用しなくても開発は進められる」ということもあり
この時間を「必要」と捉えるか・チームで何人Docke経験があるかで導入のハードルが変化します。採用事例・知見の問題
特に運用フェーズでの採用率の低さはナレッジが全然なかったことが大きい気がします。
最近はAWSのイベントでも有名企業Docker採用事例のプレゼンテーションがあったり、
企業が開催しているLT記事でも便利だなーと思う事例を見つけたりします。
後追いで採用する上では参考にできるユースケースも増えており選択肢としては非常に魅力的だと思います。
便利とは言っても決して銀の弾丸ではないので、他技術と比べ有利かを考えながら採用する必要があります。まとめ
メリット
・環境差異を最小限に抑えることができストレスが少なく開発・運用することができる
・使い方によってあらゆるフェーズで使えるため、トータルの時間が削減できる
・採用企業の面接を受ける時、Docker運用について受け答えができるとウケが良いデメリット
・ある程度勉強時間が必要なので継続的に使用していくつもりがないならメリットが薄い
・採用チームに参加できるか、あるいは導入を認めてもらえるかは企業次第参考
個人開発
★Dockerで開発環境構築を10倍楽にしたはなし
VS CodeのRemote Containersを使ってコンテナ内で開発する
★VSCode の Remote - Containers 拡張を試してみた運用・スケーリング関連
★【AWS】Auto Scalingする前に知っておくべき7つのこと
ロマサガRSで大規模負荷を処理する Amazon ECS & Docker運用知見
スケールアウトの基礎的な考え方
★2018年なぜ私達はコンテナ/Dockerを使うのか
★Mastodon・Netflixに見る、コンテナの未来 コンテナはサービス開発の主流になり得るか?※★は参考にした以上に個人的に面白かった記事です
- 投稿日:2020-03-16T17:07:38+09:00
(調査中)WebRTC on RPi4で動かないUSBカメラ
状況
ML2Scratchを、Raspberry Pi 4で動かそうとしたら、動かないUSBカメラがあった。結論から言うと、WebRTC on RPi4 with Busterが、Logitech c270では動かないようである。そして、古い型のカメラのようなのでWebRTCでは当面動く気がしない。暫定回避策として、別のカメラを使っている。
切り分け
Scratch3では、Javascriptで書かれている。その延長で、WebRTCを呼び出している(scratch-vmとscratch-gui経由)。ML2Scratchかブラウザかどうかの問題の切り分けのため、WebRTC画面のみのテストを行った。なお、Windows on Intel x86では普通に動くので、Raspberry Pi 4のLinuxかその下のソフトの出来が悪いのかな?とは思う。
WebRTCのみの以下の画面を表示すると、真黒になる。なお、ML2Scratchで見ると、黒いバックグラウンドと猫の画面になる。試してみた結果は以下のとおりである。
機種名 USB2 USB3 luvcview Logitech C270 × × 〇 Elecom UCAM-C520FEBK 〇 〇 〇 状況
RaspberryPi Forum(2020/3/18)に投げてみた。結構たくさん問題が上がっているようなので、放置される気がする。
時間があったら調べてみたいが、時間がないので残念ながらペンディング中。付録
デバイスの確認
デバイスは、LinuxのコマンドおよびChromeで確認することができる。Linuxの場合は以下のコマンドで見ることができる。
Linuxの場合
$ lsusb動いているドライバーのリスト
$ lsmod -vChromeの場合
Chromeだと、以下でメディアの状況を確認することができる。しかし、普通に認識されている。
Raspberry Piで動いているカメラの有志によるリストを確認してみる。Logitech C270は、相性問題があり動かない時がある模様である。
最後に、Chromiumの障害リストを見てみる。ここではChromiumの74から78まで修正らしきものが入った様子はない。
Raspberry Pi
Linuxのソフトスタック
Scratch3の呼び出しパス
VideoSensingから、通って最終的にJavascript(getUserMedia)を呼び出している。このため、WebRTC依存である。
- 投稿日:2020-03-16T15:03:42+09:00
超シンプル: 日付をひたすら出力するシェル集
シンプルなんだけれど、いつも忘れちゃっているので書き残す。
シェルを実行してファイルのバックアップをする時などに、ファイル名に本日の日付・時間を追加したい時など、下記を覚えてシェルスクリプトに入れておくと、毎回、日付を変える面倒がなくなります。
フォーマット YYYYMMDD
仕切りなしで、西暦日付を出力。
$(date "+%Y%m%d")出力例
% echo $(date "+%Y%m%d") 20200316フォーマット YYYYMMDDHHMMSS
仕切りなしで、西暦日付秒までの時間を出力。
$(date "+%Y%m%d%H%M%S")出力例
% echo $(date "+%Y%m%d%H%M%S") 20200316122346フォーマット YYYY/MM/DD-HH:MM:SS
スラッシュやセミコロンなどの仕切りを入れた例
$(date "+%Y/%m/%d-%H:%M:%S")出力例
% echo $(date "+%Y/%m/%d-%H:%M:%S") 2020/03/16-12:24:45以上
- 投稿日:2020-03-16T14:39:25+09:00
サン電子のゲートウェイRoosterにHULFT IoT(Agent)を入れてみた
こんにちは、よろず相談担当 すぎもん
です。
前回は、Linuxゲートウェイ機器であるサン電子Rooster(NSX7000)にHULFT IoT EdgeStreamingのパッケージを作成してみました。(前記事)
今回は、第2弾として、HULFT IoT Agentのパッケージ作成についてもブログにまとめてみました。皆さまの課題を解決する糸口があるかもしれませんので、是非ご一読いただければ、と思います。
NSX7000 への HULFT IoT Agent パッケージ作成手順
はじめに
サン電子Rooster(NSX7000)とは、サン電子株式会社のIoT/M2M向けルーターRoosterシリーズの機器となります。NSX7000は、マルチキャリア対応 LTE通信対応Linuxゲートウェイと位置づけられております。
- NSX7000機器情報
機器の詳細については、下記リンクをご参照ください。
NSX7000機器情報
- 作業の流れ
HULFT IoT Agentをインストールするには、事前にパッケージ作成環境を準備する必要があります。実際にパッケージの作成をやってみました。
事前準備
以下を準備してください。
HULFT IoT
- 製品本体が含まれる zip ファイルを指定のサイトからダウンロードし、展開します
- xxxは製品のバージョンです
- HULFT IoT に関する用語や操作などについては zip ファイルに含まれる「readme.html」かオンラインマニュアルを参照してください
hulftiot_vxxx/ +-- Agent/ | | | +-- HULFT IoT Agent のインストールモジュール | +-- Agent UpdateModule/ | | | +-- HULFT IoT Agent のアップデートモジュール | +-- License/ | | | +-- ライセンスファイル | +-- Manager/ | | | +-- HULFT IoT Manager のインストールモジュール | +-- Manual/ | | | +-- HULFT IoT のマニュアル | +-- readme.htmlNSX7000 パッケージ作成環境(※開発環境を別途準備します)
NSX7000マニュアル
パッケージ作成環境の構築手順については以下のマニュアルを参照します
- Add-onアプリケーション開発-パッケージ作成マニュアル.pdf
- Add-onアプリケーション開発-環境構築マニュアル.pdf
Manager 環境の構築
HULFT IoTマニュアル
HULFT IoT のマニュアルに従い、Manager 環境の構築を行いますパッケージ化するモジュールの準備
注意:以降の手順はrootユーザで実行します
1. NSX7000 パッケージ作成環境の任意のディレクトリに以下のファイルをコピーします
- hulftiot_vxxx/Agent/HULFT_IoT_Agent_Linux_AArch32_Vxxx.tar.gz
2. コピーしたファイルを展開します
tar zxf HULFT_IoT_Agent_Linux_AArch32_Vxxx.tar.gz3. コマンドを実行すると、以下のファイルが展開されます
iot_agent/ +-- modules/ | +-- huliotcore | +-- huliotinfo | +-- huliotsend | +-- huliotservice | +-- defaultsettings.ini | +-- huliotsetup | +-- huliotsetup.ini設定ファイルの編集
HULFT IoT Agent の設定ファイルを編集します。
1. agent.conf の作成
以下のテキストをコピーして、agent.conf というファイル名で任意のディレクトリに保存します
devicename = server_hostname = proxy = proxy_user = protocol = 0 cert_verification = 0 activation_key = first_conn_retry_interval = 3600 remarks_file =2. 作成した agent.conf の以下の項目を設定します
- devicename
- Manager にアクティベートした際に表示されるAgentの名前を指定します
- 省略時はホスト名を採用します
- server_hostname
- Manager のサーバ名、または IP アドレスとポート番号を
: (コロン)区切りで指定します- proxy
- プロキシサーバ名、または IP アドレスとポート番号を
: (コロン)区切りで指定します- Agent がプロキシ環境下にいる場合に指定します
- proxy_user
- プロキシ認証が通るユーザ名とパスワードを
: (コロン)区切りで指定します- activation_key
- 構築した Manager からアクティベーションキーを取得して設定します
※その他の項目の説明については、マニュアルを参照してください。
devicename = nsx7000 server_hostname = server:8765 proxy = proxy_user = protocol = 0 cert_verification = 0 activation_key = 11e1400a-0989-4699-9703-88f85c653c35 first_conn_retry_interval = 3600 remarks_file =パッケージの作成
NSX7000 パッケージ作成環境で HULFT IoT Agent のパッケージを作成します。
各種ファイルのパラメータについては以下のマニュアルを参照します。
- Add-onアプリケーション開発-パッケージ作成マニュアル.pdf
1. 規定のディレクトリを作成します
トップ・ディレクトリ/ | +-- object/ +-- rpk/ | | | +-- CONTROL/ | | | | | +-- control ファイル | | +-- postrm スクリプト | | | +-- appctl スクリプト | +-- Makefile2. 以下のファイルを object ディレクトリにコピーします
- agent.conf
- iot_agent/modules/huliotcore
- iot_agent/modules/huliotinfo
- iot_agent/modules/huliotsend
- iot_agent/modules/huliotservice
- iot_agent/defaultsettings.ini
3. control ファイルの作成します
わたしは、以下の通り作成してみました。
Package: hulftiot-agent Version: 2.0.0 Depends: Runtime-Depends: Maintainer: Company Architecture: nsx7000 Provides: Replaces: Description:4. postrm スクリプトを作成します
#!/bin/sh PATH=/usr/sbin:/sbin:$PATH export PATH : ${ROOSTER_OS_LOG_STDERR:=yes} : ${ROOSTER_OS_LOG_FACILITY:=user} . /lib/functions.sh include /lib/functions/rooster-os/base include /lib/functions/rooster-os/rpkg PACKAGE_NAME=hulftiot-agent on_remove() { rm -rf /app/var/${PACKAGE_NAME} return 0 } case "$1" in *) if [ $PKG_ROOT = "/" ]; then on_remove fi ;; esac exit 05. appctl スクリプトを作成します
わたしは、以下の通り作成してみました。
#!/bin/bash PACKAGE_NAME=hulftiot-agent PACKAGE_DIR=/app/package EXEC_DIR=/app/var/${PACKAGE_NAME} WORK_DIR=${EXEC_DIR}/work LOG_DIR=${EXEC_DIR}/log HASH_CMD=sha1sum HASH_FILE=huliot.sha1 IOT_FILE=("huliotcore" "huliotinfo" "huliotsend" "huliotservice") make_hash() { if [ -e ${EXEC_DIR}/${HASH_FILE} ]; then rm -f ${EXEC_DIR}/${HASH_FILE} fi for ((i = 0; i < ${#IOT_FILE[@]}; i++)) { ${HASH_CMD} ${PACKAGE_DIR}/${PACKAGE_NAME}/bin/${IOT_FILE[i]} >> ${EXEC_DIR}/${HASH_FILE} } } start_app() { if [ ! -d ${EXEC_DIR} ]; then mkdir -p ${EXEC_DIR} mkdir -p ${WORK_DIR} mkdir -p ${LOG_DIR} cp -p ${PACKAGE_DIR}/${PACKAGE_NAME}/bin/* ${EXEC_DIR} echo "workfile_path = ${WORK_DIR}" >> ${EXEC_DIR}/agent.conf echo "logfile_path = ${LOG_DIR}" >> ${EXEC_DIR}/agent.conf make_hash else ${HASH_CMD} -c ${EXEC_DIR}/${HASH_FILE} > /dev/null 2>&1 if [ $? -ne 0 ]; then cp -pf ${PACKAGE_DIR}/${PACKAGE_NAME}/bin/huliot* ${EXEC_DIR} make_hash fi fi ${EXEC_DIR}/huliotservice } stop_app() { ${EXEC_DIR}/huliotservice --stop } case "$1" in start) start_app ;; stop) stop_app ;; restart) stop_app start_app ;; *) ;; esac exit 06. Makefile を作成します
わたしは、以下の通り作成してみました。
ROOSTER_TOP_DIR ?= $(HOME)/RoosterOS-SDK ADD_ON_PKG_NAME := hulftiot-agent ADD_ON_PKG_VERSION := 2.0.0 ADD_ON_PKG_MAINTAINER := Company ADD_ON_PKG_DESCRIPTION := include $(ROOSTER_TOP_DIR)/mk/add-on-package.mk OBJ_DIR=./object hulftiot-agent: contents: $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR) hulftiot-agent mkdir -p $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/bin cp $(OBJ_DIR)/huliot* $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/bin cp $(OBJ_DIR)/agent.conf $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/bin touch $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_PREPARED) $(eval $(DefaultTarget))7. 以下のコマンドを実行してパッケージを作成します
make rpk8. コマンドを実行すると以下のファイルが作成されます
- hulftiot-agent_2.0.0.rpk
後は、この作成したパッケージファイルをRooster上に持っていき、下記のマニュアルを参考にインストールすることで使用可能です。
- Add-onアプリケーション開発-環境構築マニュアル.pdf
まとめ
いかがでしたでしょうか。
今回は、HULFT IoT Agentパッケージの作成を実施してみました。手順は多くありますが、マニュアルに従って、着実に対応するとしっかり最後までやり切れました!このブログでは、今後も技術の「よろず相談窓口」で相談を受けた内容や、誕生したワザをご紹介していけたらな、と思っています。
これからも是非チェックいただき、宜しければフォローをお願いします。
それでは、また!

- 投稿日:2020-03-16T14:38:33+09:00
サン電子のゲートウェイRoosterにHULFT IoT(EdgeStreaming)を入れてみた
こんにちは、よろず相談担当 すぎもん
今回は、Linuxゲートウェイ機器であるサン電子Rooster(NSX7000)にHULFT IoT EdgeStreamingのパッケージを作成してみました!
まずはやってみる
サン電子Rooster(NSX7000)は、サン電子株式会社のIoT/M2M向けルーターRoosterシリーズの機器です。
NSX7000は、マルチキャリア対応 LTE通信対応Linuxゲートウェイと位置づけられているそう。HULFT IoT EdgeStreamingをインストールするには、事前にパッケージ作成環境を準備する必要があるみたいなので、パッケージの作成をやってみました。
パッケージ作成環境の準備
HULFT IoT EdgeStreaming
- 製品本体が含まれる zip ファイルを指定のサイトからダウンロード
- HULFT IoT EdgeStreaming に関する用語や操作については zip ファイル内の「FirstStepGuide_jpn.pdf」にあります。
NSX7000 パッケージ作成環境(※開発環境を別途準備します)
NSX7000マニュアル
上記リンクから、パッケージ作成環境の構築手順のマニュアルを参照しました。
- Add-onアプリケーション開発-パッケージ作成マニュアル.pdf
- Add-onアプリケーション開発-環境構築マニュアル.pdf
これで事前準備完了です。
パッケージ化するモジュールの準備
HULFT IoT EdgeStreaming Studio を使って、ストリーム処理を実装しパッケージ作成環境にデプロイします。
ストリーム処理を実装方法やデプロイ方法については、製品ダウンロード時に取得したzip ファイル内の「FirstStepGuide_jpn.pdf」を参考にやってみます。
- FirstStepGuide_jpn.pdf
1. HULFT IoT EdgeStreaming Studio を起動し、ストリーム処理を表すスクリプトを作成
2. 開発したスクリプトを NSX7000 パッケージ作成環境上の任意のディレクトリにデプロイ
- 指定した任意のディレクトリにはes-agent.tar.gzがデプロイされました
3. デプロイしたファイルを以下のコマンドで展開tar zxf es-agent.tar.gz4. コマンドを実行すると、同一ディレクトリに以下のファイルが展開されました。
- es-agent
- es-agent.yaml
- script.bql
- (plugins)※プラグインモジュールを使用している場合
パッケージの作成
NSX7000 パッケージ作成環境で HULFT IoT EdgeStreaing runtime のパッケージを作成してみます。
各種ファイルのパラメータについては以下のマニュアルを参照しました。
- Add-onアプリケーション開発-パッケージ作成マニュアル.pdf
1. 規定のディレクトリを作成します
トップ・ディレクトリ/ | +-- object/ | | | +-- run-es-agent 起動スクリプト +-- rpk/ | | | +-- CONTROL/ | | | | | +-- control ファイル | | | +-- appctl スクリプト | +-- EdgeStreaming-runtime +-- Makefile2. 以下のファイルを object ディレクトリにコピーしました。
- es-agent
- es-agent.yaml
- script.bql
- (plugins)※プラグインモジュールを使用している場合3. 次に、control ファイルの作成してみます。
わたしは、以下の通り作成してみました。Package: EdgeStreaming-runtime Version: 2.0.0 Depends: Runtime-Depends: Maintainer: Company Architecture: nsx7000 Provides: Replaces: Description:4. appctl スクリプトを作成します
わたしは、以下の通り作成してみました。
#!/bin/sh PACKAGE_NAME=EdgeStreaming-runtime PACKAGE_DIR=/app/package exec $PACKAGE_DIR/$PACKAGE_NAME/sbin/$PACKAGE_NAME $@5. appctl スクリプトから実行される EdgeStreaming-runtime スクリプトを作成します。
#!/bin/sh /etc/rc.common USE_PROCD=1 PACKAGE_NAME=EdgeStreaming-runtime PACKAGE_DIR=/app/package COMMAND=$PACKAGE_DIR/$PACKAGE_NAME/sbin/run-es-agent start_service() { procd_open_instance procd_set_param command $COMMAND procd_set_param respawn procd_close_instance } stop_service() { return 0 }6. 起動スクリプト(run-es-agent)を作成します
わたしは、以下の通り作成してみました。
#!/bin/sh PACKAGE_NAME=EdgeStreaming-runtime PACKAGE_DIR=/app/package LD_LIBRARY_PATH=${PACKAGE_DIR}/${PACKAGE_NAME}/lib BIN_DIR=${PACKAGE_DIR}/${PACKAGE_NAME}/bin COMMAND=${BIN_DIR}/es-agent export LD_LIBRARY_PATH cd $BIN_DIR exec $COMMAND run -c es-agent.yaml7. 起動スクリプト(run-es-agent)に実行権限を付与します。
chmod 755 run-es-agent8. Makefile を作成します。
わたしは、以下の通り作成してみました。
ROOSTER_TOP_DIR ?= $(HOME)/RoosterOS-SDK ADD_ON_PKG_NAME := EdgeStreaming-runtime ADD_ON_PKG_VERSION := 2.0.0 ADD_ON_PKG_MAINTAINER := Company ADD_ON_PKG_DESCRIPTION := OBJ_DIR=./object include $(ROOSTER_TOP_DIR)/mk/add-on-package.mk EdgeStreaming-runtime: contents: $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR) EdgeStreaming-runtime mkdir -p $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/bin cp $(OBJ_DIR)/es-agent* $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/bin cp $(OBJ_DIR)/script.bql $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/bin cp -r $(OBJ_DIR)/plugins $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/bin mkdir -p $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/sbin cp $(OBJ_DIR)/run-es-agent $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/sbin $(call replace_add_on_keyword,\ $(ADD_ON_PKG_NAME),\ $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/sbin/$(ADD_ON_PKG_NAME)) chmod +x $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_DIR)/sbin/$(ADD_ON_PKG_NAME) touch $(ROOSTER_PACKAGE_ADD_ON_CONTENTS_PREPARED) $(eval $(DefaultTarget))9. 以下のコマンドを実行してパッケージを作成します。
make rpk10. コマンドを実行すると以下のファイルが作成されました。
- EdgeStreaming-runtime_2.0.0.rpk
後は、この作成したパッケージファイルをRooster上に持っていき、下記のマニュアルを参考にインストールすることで使用可能です。
- Add-onアプリケーション開発-環境構築マニュアル.pdf
最後に
今回は、HULFT IoT EdgeStreamingをLinuxゲートウェイ機器にインストールしてみましたが、いかがでしたでしょうか。
パッケージの作成をしてみましたが、マニュアルも充実しているので作業自体は思うより簡単にすることができました!また今回は、とっかかりのパッケージ作成をまずしてみましたが、
別の機会で、HULFT IoT EdgeStreamingを具体的に使ってみたいなーと思ってます!
そこでもっと具体的なところをお話しできたらと思います!このブログでは、今後も技術の「よろず相談窓口」で相談を受けた内容や、誕生したワザをご紹介していけたらな、と思っています。
これからも是非チェックいただき、宜しければフォローをお願いします。
それでは、また!

- 投稿日:2020-03-16T12:45:10+09:00
[Rails] Mechanizeがファイルディスクリプタを大量に消費してしまう
内容はタイトル通り。
Railsにて、Mysql2のConnectionError出てる場合とか
ファイルディスクリプタを異常に使いまくってる場合はもしかしたら関係あるかも。経緯
お客様に提供しているサービス(Rails,puma)にて
Mysql2::Error::ConnectionErrorが多発してサービスが利用できなくなる障害が発生しました。
詳しくログを追ってみると他にも
Errno::EMFILE (Too many open files @ rb_sysopen ...(略)のようなエラーも発生している様子。
さらに、、、
# ファイルディスクリプタ上限確認 ulimit -n # pumaプロセスのファイルディスクリプタ確認 for i in $(ps aux | grep "[p]uma" | awk '{print $2}'); do sudo ls /proc/$i/fd | wc -l; done上記コマンドでプロセスの開いてるファイル数を確認してみたら
どうやらファイルディスクリプタがいっぱいになっているようだった。原因
実は、ファイルを開いているわけではなくてアプリケーションで使用していた Mechanize というgemにて
外部からデータを取得する際にコネクションを作成していた様子。
(スクレイピングとかするときに使われてるgemらしい。)ファイルディスクリプタでは、ファイルだけでなくコネクションもカウントされるようで
大量のコネクションが削除されずに作成され続けたことで問題が発生した。
(Mysqlも多分コネクション関係?? 詳しい人コメントお願いします。)対応
単純に、コネクションが開いたままになっていることが問題。
閉じてあげる必要がある。Mechanizeのコネクションは以下のメソッドを呼び出すと閉じてくれるらしいので
使用中のコネクションの最後の処理が終わったあたりで呼び出してあげる。Mechanize.shutdownあとは、サーバー再起動などで既存コネクションを消してあげましょう。
- 投稿日:2020-03-16T11:57:41+09:00
Dockerコンテナ上で動くGinサーバーにアクセスできないエラーの解決法
概要
GolangのWebフレームワークであるGinを使ったAPIサーバーを、Dockerコンテナ上にデプロイして動かそうとしたところ、APIにアクセスできずかなり長い時間悩まされました。
結果的には、Ginサーバーのコードの書き方の問題だったことが分かったのですが、解決方法を念のためここにメモしておきます。
ちなみに、このエラーはWindows10及びAWS上のUbuntuサーバー(t2.small)で起こりました(尤も、実行環境はこのエラーの発生にあまり関係ないようでしたが)。
状況
Ginを用いたAPIサーバーを立てようとしていました。まだ環境構築の段階なので、コードは以下のようなモックのものになっています。
package main import ( "log" "os" "github.com/gin-gonic/gin" ) func main() { logConfig() r := gin.Default() r.GET("/accounting-api", func(c *gin.Context) { log.Println("GET") c.JSON(200, gin.H{ "state": "success", }) }) r.DELETE("/accounting-api", func(c *gin.Context) { log.Println("DELETE") c.JSON(200, gin.H{ "state": "success", }) }) log.Println("Start Server") r.Run() } func logConfig() { logFile, _ := os.OpenFile("log/log.txt", os.O_RDWR|os.O_CREATE|os.O_APPEND, 0666) log.SetOutput(logFile) log.SetFlags(log.LstdFlags | log.Lmicroseconds | log.Lshortfile) log.SetPrefix("[LOG] ") }単純に、
GETかDELETEメソッドで特定のパスへのリクエストが来たら、{"state": "success"}というjsonを返すだけのサーバーです。そして、このサーバーを動かすためのDockerfileが以下です。
FROM golang:alpine RUN apk update && apk add --no-cache git RUN go get -u github.com/gin-gonic/gin && mkdir /usr/src && mkdir /usr/src/api COPY ./api /usr/src/api WORKDIR /usr/src/api CMD ["go","run","main.go"]ホスト上の
apiというディレクトリには上記のGoファイル等があるため、それをコンテナ上にコピーして、サーバーを立ち上げます。このDockerfileをapiという名前でビルドして、それを以下のコマンドで立ち上げました。docker run -p 8083:8080 apiホスト上のポート
8083をコンテナ上のポート8080にマッピングしています。上記のコマンドを実行すると、以下のような出力がなされ、Ginサーバーが立ち上がっていることが確認できます。[GIN-debug] GET /accounting-api --> main.main.func1 (3 handlers) [GIN-debug] DELETE /accounting-api --> main.main.func4 (3 handlers) [GIN-debug] Environment variable PORT is undefined. Using port :8080 by default [GIN-debug] Listening and serving HTTP on localhost:8080ポートを指定しなかったので、デフォルトでポート
8080で動いています。このように一見ちゃんと動いているようにも見えますが、ホスト側でhttp:localhost:8083にcurlでアクセスしてみても、以下のようにエラーが出てしまいました。curl: (52) Empty reply from serverエラー解消のため試みたこと
1. コンテナの中に入って、APIにアクセスできるか確認
まず最初に、コンテナ上で本当にGoのプログラムがちゃんと動いているのかを確認します。そのために立ち上げたdockerコンテナの中に入ってみます。
# apiサーバーの動くコンテナの中に入る docker exec -it api /bin/ashこのコンテナのベースとなっているAlpineには
/bin/bashがなかったので、/bin/ashを使います。そして以下のコマンドを打って、ちゃんとプログラムが動いているのか確かめます。# そもそもcurlが入っていないので、インストールする apk add --no-cache curl # 念のためプロキシを無効にして、curlでapiサーバーにアクセスする curl -x "" http://localhost:8080/accounting/apicurlの実行結果がこちら。
{"state": "success"}ちゃんと結果が取れています。なので、コンテナ上ではちゃんとGinサーバーのプログラムが動いているようです。
2. DockerfileでポートをEXPOSE
コンテナ上ではプログラムは動いているようなので、次はポートマッピングの部分がうまくいっていないのではないかと疑ってみます。調べてみるとDockerfileには
EXPOSEというコマンドが書けるようなので、追加してみます。EXPOSE 8080これをやっても、解決しませんでした。
そもそも公式ドキュメントによると、
EXPOSEコマンドは実際は何の働きもせず、特定のポートを開放する旨を開発者に知らせるための、ドキュメントのような役割しかもっていないようです。なので、EXPOSEコマンドをつけただけで問題が解決するはずがありませんでした。3. Windowsのファイアウォールの設定の確認
開発は基本的にWindows上のDockerで行っていたため、Windowsのファイアウォールの設定を見直してみましたが、これも意味がありませんでした。
そもそも、このDockerfileをUbuntu上でビルドして立ち上げてみても、同様にAPIサーバーにアクセスできなかったため、最初からなんとなくWindowsのファイアウォールのせいではないことが分かっていましたが。
4. (これで解決)Ginサーバー側でポートの指定
Goのプログラムの中で、GInサーバーを立ち上げる部分でポートを指定するようにしたところ、上手くアクセスできるようになりました。具体的には、以下の部分です。
r := gin.Default() r.Run(":8080")何も指定しなくてもデフォルトで
8080で立ち上がるため気にしていなかったのですが、しっかりと指定しないとどうやらダメなようです。なぜポートはデフォルトではダメで、明示的に記さなければならないかは、よくわかりません。分かったら追記します。
- 投稿日:2020-03-16T11:05:27+09:00
Apache Zookeeper のインストール
やってみたのでメモ
前提
CentOS7
Java インストール済み手順
tar ファイルをダウンロードする
# curl -LkvOf https://downloads.apache.org/zookeeper/zookeeper-3.6.0/apache-zookeeper-3.6.0-bin.tar.gztar ファイルを展開する
# tar zxf apache-zookeeper-3.6.0-bin.tar.gz
/opt配下に配置する# mv apache-zookeeper-3.6.0-bin /opt/zookeeper実行用ユーザを作成する
# useradd zookeeper必要に応じて
zoo.cfgファイルを作成して設定を変更する(IPアドレスなど)所有者を変更する
# chown -R zookeeper:zookeeper /opt/zookeeperサービスファイルを作成する
# vi /etc/systemd/system/zookeeper.service[Unit] Description=Apache Zookeeper Service [Service] Type=forking User=zookeeper ExecStart=/opt/zookeeper/bin/zkServer.sh start ExecStop=/opt/zookeeper/bin/zkServer.sh stop [Install] WantedBy=multi-user.target再読み込みする
# systemctl daemon-reload起動する
# systemctl start zookeeper参考
- 投稿日:2020-03-16T08:05:35+09:00
AWS〜これから使う人向け〜
対象者と寄稿の背景
本記事の対象者は、AWSが意味不 or 調査しても不安がある(2種類のアカウントやよく出てくるワードが意味不)方向けです。
AWSの利用前に必要最低限の知識を整理整頓できる記事です。
「理解が貧しくわからないことがわからないので、調べたり、質問できない」とならないように
手助けできれば幸いです。では、以下より本題に入ります。
AWSとは・・・??
簡潔にいうと、
インターネットサービスの総合スーパー(イオンモールみたいな)ですスーパー名:AWS
取扱商品:各サービス(EC2,S3,RDS などなど)
となります。(※イオンには、食品・文具・衣服・レストラン・書店など様々ですよね)システム運用する際、これまでは・・・
①ドメインはドメイン屋、②ルーターはルーター屋、③データベースはデータベース屋さんでしたが、例えば上記①〜③のようなサービスをAWSが全て用意してます。
昔は、米は米屋、ペンや消しゴムは文房具屋、テレビは電気屋でしたが今はイオンに行けば全て揃います。
その役割をしているのがAWSです。なので、約170のサービスがあり、利用者が自ら必要なサービスを選択して、組み合わせて利用します。
初心者の方が利用した際に、「意味不すぎて手が動かない」、「挫折するわ・・・」とならないように書いた記事なので、これを見て質問できるようになった、調べることが明確になったと、なることができれば嬉しいです下記より、戸惑うであろうワードや利用方法を噛み砕いて説明します。
登録すべきアカウントは2種類あり!?
Amazonで買い物などに使う、アカウントとAWSで使う下の2つは別物です
- rootユーザー
- IAMユーザー
-
rootユーザーとは・・・
支払いや契約状況など管理業務時に使うのが、rootユーザーアカウントです
AWS全体の管理者アカウントです、いわゆる管理人さんです。
このアカウントでサービス利用すると情報流出(個人情報やクレジットカード情報なども)の恐れがあります
rootユーザーがIAMユーザーで、操作できることに権限をつけたりもできます。IAMユーザーとは・・・
AWSの各種サービスを使う際は、IAMユーザーアカウントです
これを使いたい!と思った時にこのアカウントでログインしサービスを利用します。
IAMはrootの管理下にあります。個人情報を持って無いアカウントなので、流出の危険もありません。マネジメントコンソール
AWSのメニュー表です
画像はページの上部だけなので、実際はまだ下にもあります。
このメニューページをマネジメントコンソールと呼びます。
実際どんなことができるのかといいますと、下記が一部です。
- サービスの選択、利用
- 請求確認
- スマホやタブレットからの管理
- AWSアカウント管理ダッシュボード
操作画面です
マネジメントコンソールで商品を選択し、ダッシュボードが開きます。
その商品の稼働状況や、細かなサービスが表示されます。
下記、写真はEC2と言う商品を選んだ際のダッシュボードです。
リソース内では、現在の稼働状況が確認できます。
リージョン
データセンターの場所です
AWSのサーバーある地域です、世界に20箇所以上あります。日本は東京と大阪にありますが、個人利用は東京で、大阪は少し特殊なので、個人利用できません。
AWS利用が上達してくると、東京意外のリージョンを使うこと検討しないとな、と考える瞬間があります。主要サービス名
下記にて、代表サービスをあげます。専門知識は必要なくて、マネジメントコンソールとダッシュボードから、簡単に使うことができます。自分で考えているものと一致したら、数回ボタンを押せば利用開始できます。
ここが、クラウドサービスのまさに強みです。
使いたいものを見つけたら、あとはボタン操作のみです。
1から構築となると数ヶ月かかります。コード書いて組み込んで、を繰り返すので時間かかりますが、AWSを使えば10分で完了します
また、マネジメントコンソールで見えるワードのみ解説をしているので、ダッシュボードまでいくとさらに、
インスタンス?ElasticIP?などわからないことが発見できると思います。では簡単ではありますが、紹介します。
EC2
サーバーになります
クラウドなので、なんといってもバックアップが取りやすいです。
また、EC2の設定変更も後々しやすいです。S3
容量制限の無い、変化するストレージ
例えば、ライブハウスの使用量が・・・
2月は1000人、他の月は50人だとします。S3は、1000人サイズ、50人サイズと会場サイズを自動で変化してくれます。
なので、必要以上のお金を払わず、1000人超えても、また変化するのでパンクもしないです。
クラウドサービスでは無い場合、1年間1000人分を借りないといけません、なので必要無いお金も払う必要がありました。
パンクの恐れもあります。
この差が大きな特徴です。RDS
データベースです
クラウド上でデータベースを使えるサービスです。利用できるサービスも1つではなく、6つあるので非常に柔軟に選択できます。ここでもクラウドで行う強みが発揮すます。
バックアップやアップデートを自動で行ってくれるので、データベース利用に我々は集中することが可能です。
データベースを利用するについては、この記事では割愛します。以上、主要サービスの紹介でした。
AWS利用に適した人
結論は、設計ができる人や今後できるようになりたい人です。
なぜならば、AWSはレンタルショップではなく、販売店だからです。
この日数使うなら、「月額いくらです!」「何本借りれます!」という提案をしてくれません。
利用する僕らが、運用には「データベースはこれがいいな」「セキリュティはこのスペックにしよう」と自分で判断して使っていきます。ただ決して、薄情なサービスではありません。実際に、日本政府も今後AWSを利用します
日本政府、基盤システムでAWSを採用
※Data Center Cafe様より拝借多彩なサービス、聞き慣れないワードが多く難しさを感じるかもしれませんが、慣れてしまえば、使い勝手が良くワクワクします。分析やブロックチェーンなど専門家が行っている分野を興味ある人も手を動かして使うことができます。
イオンも自ら足を運べばどこに何があるかわかるのと同じで、AWSも是非どんどん使ってください!!今回の記事は、以上です。
冒頭でもお話した通り、利用前に読んでいただきたい記事です。
仲間やSNS上で話題に上がったり悩まれてる方がいたらぜひ、おすすめしていただけると幸いです。また、指摘やアドバイスもいただけますと幸いです。




- 投稿日:2020-03-16T06:50:38+09:00
DockerのDの字も分からない状態を抜け出すためにやって良かったことをまとめてみる
概要
Dockerを触っていく上で、何を勉強したら良いかで行き詰まることが多かったので、勉強していて特に役に立ったな、と思ったものを備忘録がてら整理してみます。
対象読者
Dockerに入門したはいいけれど、インフラもLinuxも全然わからん、でも何とかしたい、というレベルの話が中心となっています。
k8sまで踏み込んだり、Dockerをバリバリ実務で使いこなすためのベストプラクティスなどなど、深い部分は対象外としています。むしろ、そういうのがあったら読みたいです。また、本記事では、Webアプリの実行環境をDockerで構築できるようになるために必要な知識にフォーカスしています。そのため、データベースを利用した簡単なWebアプリをつくった経験があると、Dockerを勉強するモチベーションが高まるかもしれません。
前置き
1年ほど前に、ふとしたきっかけで、Dockerやるかと思い立ちます。Dockerは入門記事が充実しており、見よう見まねでとりあえず動かせないこともないところまでは、サクッと進みました。
しかし、当時はLinuxやインフラ系の知識が皆無だったこともあり、動作原理どころか、そもそも自分が何をやっているのかも曖昧で、入門から先は手も足も出ませんでした。Dockerそのものの入門記事は数多くありましたが、
Dockerを理解するためにどんな知識が必要かの全体像がまとまっているものは、中々見つけられませんでした。
Dockerは私にはまだ早いなぁ...と思い、でもやっぱりDockerわかるようになりたいなぁ...と気にかけながら、あれこれ色々手を出し、勉強していました。まだまだDocker完全に理解した状態には程遠いですが、基本部分の理解に必要な前提知識はそれなりに補強できたのか、Dockerの動作が全くイメージできていない状態からは、なんとか脱出できた...はずです。
Dockerなんもわからん状態を辛うじて抜け出せたとはいえ、何をどこまでやれば、Dockerの苦手意識をなくせるかが分からず、手探りの状態が続くのは中々にしんどかったです。
ですので、備忘録がてら、これはやっておいて良かったな、と思ったものをまとめておこうと思います。
これさえやれば、Dockerはもう完璧!!...なんてことはありませんが、なにかの参考になれば幸いです。以下では、本を中心に紹介していきます。このとき、それぞれについて、
何を学ぶことを目的とするかを意識しておくとよいかもしれません。
目安となるかは分かりませんが、以下はやって良かったことの紹介に加え、何を学ぶことを目指して取り組んだかも、あわせて記述していきます。Linux
コンテナ内での操作はもちろんのこと、Dockerの仕組みを学ぶ上では、何よりLinuxの理解が欠かせません。
とは言え、Linux単体だけを見ても勉強する内容は非常に幅広く、何から手をつけるべきか、悩みやすい部分でもあります。
以下では、基礎的なコマンドや、コンテナ内の操作、そして、Dockerの動作原理を理解する上で、助けられた書籍を挙げていきます。新しいLinuxの教科書
- 学べること: シェルを中心としたLinuxの基本知識・コマンド
元々Linuxを扱う機会はぽつぽつとありましたが、書籍を利用してじっくり学ぶのは、これが初めてとなりました。
結論から言うと、最初にこの書籍から始めたのは、大正解だったと思っています。シェルとはなんぞやから始まり、雰囲気でなんとなく使っていたコマンドについて、一つ一つ丁寧に知識を積み上げるような形で紹介されているため、とても読みやすいです。コンテナの中での操作は、大抵の場合、Linuxのシェル操作が前提知識として必須になります。まずはここからスタートすれば、コンテナに入っても何をしたらいいか分からず、しんどい思いをすることもなくなるかと思います。
Linuxの基礎がぎゅっと詰まっているので、これからも定期的に読み返していきたいと思います。
ゼロからはじめるLinuxサーバー構築・運用ガイド 動かしながら学ぶWebサーバーの作り方
- 学べること: シェル操作によるアプリケーション実行環境の構築方法
Dockerを学習するメリットとして、環境構築が容易になることがよく挙げられます。これを実感してこそ、Dockerを学ぶモチベーションも高まってきます。
そこで、シェル操作に慣れてきたところで、実際に本をベースに、手を動かしながら環境構築をやってみました。今のご時世なら、VPSやクラウドサービスなどを活用すれば、安価にサーバを構築することができます。
勉強がてら、まずはコンテナではなく、実際にサーバとして構築してみるとよいかと思います。
セキュリティ面で不安がある場合は、VMを利用してみるのもよいかもしれません。この本は、サーバ構築に必要な知識を補強しながら、LAMP環境をつくり上げるまでを学べる構成になっています。あいだにネットワークの話が入り、そこでも説明はされていますが、もし詰まった場合は、先にネットワークを勉強してから再挑戦すると、つらくないかもしれません。
試して理解Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識
- 学べること: カーネルを中心とした、Linuxの各種機能の基本動作原理
Dockerはkernelを共有する
なんて言葉があるように、Dockerを深く知るには、カーネルの理解が重要です。しかし、カーネルを理解するためには、幅広い分野の深い知識・経験が必要となります。
カーネルをしっかり学習するのであれば、難しくて分厚い本に立ち向かう覚悟を持たなければなりませんが、Dockerに入門する段階であれば、こういった入門書1冊でも十分だと思います、きっと...。少し話は逸れましたが、この本は、難しい概念を、豊富な図で分かりやすく説明されています。文章で少し迷子になっても、すぐにイメージを補強するための図で補ってくれるため、難しい本でよくある途中リタイアを防いでくれることでしょう。
更に、図解だけにとどまらず、プロセス管理やメモリ管理などを、実際にC言語で書かれたサンプルコードによって、イメージをコードと結びつけながら学ぶことができます。
この結びつきは、時間の掛かることではありますが、ただ字面を追っただけでは得られないレベルまで、理解を深めてくれます。実際にこの本を読んだあとでは、Dockerの動作原理がかなりイメージしやすくなりました。メモリ管理の辺りからぐんぐん難易度が上がっていきますが、じっくり取り組む価値はおおいにあると思います。
※1 C言語自体の勉強は、苦しんで覚えるC言語がわかりやすくておすすめです。
※2 前半部分で既に難易度が高いと感じる場合は、「プログラムはなぜ動くのか」・「コンピュータはなぜ動くのか」を読んでおくと、立ち向かいやすくなるかもしれません
ネットワーク
Dockerを扱う際、コンテナ間通信のイメージが掴みづらく、最初の頃は理解に苦戦していました。
当時はネットワーク関連の知識が非常に浅く、また、業務で携わる機会もほとんどなかったため、個人的に一番つまずいた部分だと感じています。ネットワークそのものは言わずもがな、勉強する範囲が非常に広いです。ですが、Dockerのネットワークまわりを理解するのが目的であれば、レイヤー2とレイヤー3を中心に勉強すると、とっつきやすくなるかもしれません。
3分間ネットワーク基礎講座
- 学べること: レイヤー1~3を中心とした、ネットワーク関連の各用語の概要
ウェブサイトで公開されているものの書籍版です。レイヤー1〜レイヤー3を中心に、対話形式で各種用語について、図を交えながら書かれています。
ネットワーク関連の書籍を読んでいて、この辺りのレイヤーは、業務や趣味でも触る機会が中々なく、概要を理解するのに苦労していました。特に、最初の頃は、イーサネットの規格や、物理学のあれこれの話など、深く踏み入った話とあわせて解説されると、戸惑ってしまうことがよくありました。対して、この書籍は、踏み込み過ぎず、かつ、浅すぎず、丁度いい塩梅で各用語について書かれているので、最初の一歩におすすめです。サクッと読める文量なので、まずはネットワーク関連の用語に慣れるためにも、数回繰り返し読んでみるのもありかもしれません。また、ウェブサイト版も書籍版とは色々異なる部分があるので、興味があったら目を通してみてください。
パケットキャプチャの教科書
- 学べること: パケットと、図解による、ネットワーク通信の流れの具体的なイメージ
たとえばプログラムであれば、文法を学んだ後、実際にソースコードを書くことで、経験を通じて知識を定着させることができます。しかし、ネットワークに関しては、実際の通信を覗いたり、操作するための道程は、プログラムを書くときほど情報が充実しているとは言えません。
そんな中、この書籍に出会うことで、ネットワークへの苦手意識も少しだけマシになりました。構成自体はよくある各レイヤーについて解説したものではありますが、何と言っても、各レイヤーについて、実際のパケットの様子を、流れを丁寧に記述した図もあわせ、事細かに解説してくれている点がありがたいです。
各レイヤーのざっくりとした知識は前提として必要にはなりますが、繰り返し読むことで、ネットワークに関する知識を教科書的な段階から一歩先へ引き上げてくれるはずです。また、本番サーバとしてDockerを利用する際には、HTTPS対応や、DNSなど、レイヤー1~3以外の知識も必要となるため、都度読み返すと、応用の際にもスムーズに学べるかもしれません。
※用語についていくのがしんどいと感じた場合は、「TCP/IPの絵本」から入るのもアリだと思います。
Linuxで動かしながら学ぶTCP/IPネットワーク入門
- 学べること network namespaceの概要と、TCP/IPの各レイヤーの実際の通信の様子のイメージ
最近出た本ではありますが、読んでいてとても面白かったので、ここで紹介します。
Dockerではnetwork namespaceなるものを使うことで、仮想的なネットワークを設定することができる、といった感じの説明をよく見ますが、実際のところ、これだけでは、いまいちピンと来ません。この書籍では、実際にnetwork namespaceで仮想的なネットワークを作成するだけにとどまらず、イーサネットや、IPでの通信を、ネットワークインタフェースを設定するところから丁寧に解説してくれています。
TCP/IPの各レイヤについて、network namespaceで通信に必要な設定・インタフェースを構築し、tcpdumpで実際の通信を確認しながら、
通信ができるようになるまでを段階的に見ることができます。
Linuxの基礎を学び、上で挙げたネットワークの書籍に目を通したあとで取り組んでみると、ネットワークによってコンピュータ同士が通信できるようになるまでの流れがより深く学べることでしょう。また、network namespaceで実際にインタフェースを設定することで、Dockerのネットワーク周りの理解も、更に進むかと思います。
(余談)
ネットワークの入門書と言えば、「ネットワークはなぜつながるのか」や「マスタリングTCP/IP 入門編」が定番として挙げられています。これらの書籍は確かに分かりやすく書かれていますが、ネットワークの知識がほとんど無い状態で挑むとかなり苦労することになります。(私はここから入ってめちゃくちゃ苦労しました)まずは上記で挙げた入門書に目を通し、何らかの形で実際にネットワーク関連の知識が必要となった際、取り組んでみると、十分に楽しめるのではないかと思います。
Docker
Dockerの使い方を学ぶには、当然、Dockerそのものを勉強することも必要です。Dockerの入門情報は、Qiitaを始めとし、ネット上にたくさんの優れたものがあります。
Docker 入門で検索し、良さそうだと思ったものをいくつか触っていけば、雰囲気はつかめるかと思います。
このとき、ただ読むだけでなく、実際に手を動かしながら、Dockerfileを書いてみたり、Docker Composeを使ってみたり、あれこれ試しながら、失敗したり、成功したり、といったことを経験するのが重要です。最初のうちは各コマンドや、設定の記述が、なぜ必要なのかイメージが掴めず、苦労するかと思います。ですが、これまで挙げてきたもので基礎知識を身につけていれば、前提知識が足りず手も足も出ないということにはならないはずですので、少しずつでも理解を進められるはずです。
以下に、いくつか私が取り組んできたものを挙げますので、何から始めたら良いか迷っている場合は、練習問題がてら、触ってみるとよいかもしれません。
- C言語の実行環境
- Python + Pytestの実行環境
- create-react-appを利用したReactの実行環境
- デプロイされたWarファイルを実行するTomcat環境
- Django + RDBMSそれぞれをコンテナ化し、DjangoアプリのデータをDBに保存可能とする環境
このとき、大抵のものは便利なイメージとして、既に公開されていたりしますが、最初のうちは、勉強も兼ねて、好きなLinuxディストリビューションをベースイメージとして構築してみると、理解が深まるかと思います。
ただ、やはり体系的に学ぶ上では、本を活用したいものです。
以下では、Dockerの入門書について、いくつか読んできた中で、特に良かったものを紹介します。マンガでわかるDocker
- 学べること: Dockerとはなんぞや~Dockerfileの基本あたりまで
全3冊ありますが、入門段階では、1巻・2巻だけでも十分だと思います。漫画形式でDockerの用語について解説されているので、「イメージ」や「コンテナ」などの言葉の意味は分かっていても、頭の中でイメージしづらい状態から脱するのに適しています。
ネット上の入門記事とあわせて読めば、最初の一歩として十分な理解が得られるでしょう。Docker Deep Dive
- 学べること: Dockerの基本的な概念の網羅・動作原理のさわり部分の理解
英語の書籍なので、一見難しそうに感じてしまいますが、難しい英単語や表現は使われていないので、英語がどうしようもないほど苦手でもなければ、ぜひ読んでみて頂きたいです。
Dockerの各種要素について、「概要」・「詳解」・「コマンド」形式で章立てて解説されており、ある章でいきなり難易度が跳ね上がることもないので、一歩ずつ確実に学ぶことができます。ある程度手を動かした後に読んでみると、断片的に散らばっていた知識が明快な章立てにより、繋がることで、「Dockerなんも分からん」状態を抜け出せるはずです。
しっかりと内容を理解するには、Linuxやネットワークなど、幅広い知識が必要にはなりますが、これまで紹介したものを積み上げていけば、きっと立ち向かえることでしょう。その他
Dockerそのものの理解とは少しずれますが、これもやって良かったな、と思ったことを以下にいくつか紹介します。
Vim
- 学べること: コンテナ内のファイル編集を手軽に行うための知識
コンテナに入ってちょっと設定ファイルなどを操作するとき、ホストからあれこれしたり、エディタの拡張機能などでも対応はできます。ですが、こういうときにサクッと操作できるツールがあればとても便利です。
そんなときに、Vimを勉強しておくと、コンテナの中でも快適に過ごせます。Vimそのものについては、随所で熱く語られているため、詳細は割愛します。拡張機能ましましでカスタマイズするのでもなければ、上記のUdemyのコースで勉強すると、数時間で簡単な使い方を理解することができます。
英語ではありますが、字幕機能もありますし、何より練習問題がVimの基本操作を学ぶのに丁度いい形でつくられているので、Vimの良さを飽きることなく学べることでしょう。Git
エンジニアのためのGitの教科書[上級編] Git内部の仕組みを理解する
- 学べること: Gitの基本コマンドとその仕組み
Gitそのものを知らなくてもDockerは理解できるかとは思います。しかし、Dockerで構築した環境で管理するアプリのソースコードは基本Gitで管理することとなるので、あわせて学んでおいて損はないです。
Gitはネット上はもちろんのこと、書籍もここに挙げた以外にも、素晴らしいものが充実しているので、迷子になるようなこともないかと思います。
まとめ
ちょっと整理するか、ぐらいの軽い気持ちで書き始めたら、思ったよりも長くなってしまいました。
Dockerを単なるツールとして使うためであれば、ここまでやらなくても、このコマンドを叩けばこうなる、と暗記し、用意されている素敵なイメージを使うことで、それなりのことはできてしまいます。ですが、個人的には、多少遠回りにはなっても、基礎からしっかり学んで、なぜを追求していく方が良いと考えています。
これは優劣としてではなく、ただ単に、その方が楽しいからです。Dockerをきっかけに、ネットワークやLinuxに手を伸ばすようになり、1年ほど前よりもDockerはもちろんのこと、インフラ周り、Linuxのことが好きになりました。好きなものが増え、そこから更に深く学ぶと、知的好奇心が刺激され、それはそれは楽しいものです。
これ以上書くと脱線してしまうので、割愛しますが、この記事が少しでも楽しい学びの一助となれば幸いです。
- 投稿日:2020-03-16T00:41:19+09:00
サブシェルによる実行(および変数更新)
こんにちは。
サブシェルによって実行される場合を簡単にまとめてみました:
- コマンドを括弧「( )」で囲うとサブシェルによる実行となる1。
- パイプラインの前後はサブシェルによる実行となる。
コマンドグループ
なおコマンドグループ(すなわち brace「{ }」で囲う)にすると一塊の実行単位の扱いとなり、括弧「( )」で囲った場合と似ていますが、サブシェル扱いとなるわけではありません。
また同様に、
while do 〜 doneの部分なども、一塊の扱いとなります(例えば、printf 'a\nb\n' | while read -r line; do echo $line; done;)。サブシェルによる実行例
パイプラインとコマンドグループとの組み合わせは勘違いしやすかったです。下記例を正しく読み解くと、
command1; command2; { command3; command4; } | { commmand5; command6; }; command7; command8
- 元シェルで実行されるのは:
command1, command2command7, command8- サブシェルで実行されるのは:
command3, command4command5, command6サブシェル内の変数更新
次にサブシェル内の変数更新を考えると、これは元シェルへは伝播しません。下記例で末尾の
echo $nの出力は空となります。$ unset n; { n=0; printf 'a\nb\n'; } | cat; echo $n a b $ unset n; printf 'a\nb\n' | (n=0; while read -r line; do n=$((n+1)); done; echo $n); echo $n 2 $ unset n; printf 'a\nb\n' | { n=0; while read -r line; do n=$((n+1)); done; echo $n; }; echo $n 2 $「サブシェル内の変数更新」を回避
元シェルでの変数更新であれば、「サブシェル内の変数更新」を回避できます。下記例は混み入っていますが末尾の
echo $nの出力は0となります。$ unset n; { n=0; printf 'a\nb\n' | cat; } ; echo $n a b 0 $「ヒア・ドキュメント」の利用
同様に元シェルでの変数更新とするために、「ヒア・ドキュメント」を利用する方法もあります(パイプラインを回避できます)。下記例で末尾の
echo $nの出力は2となります。$ unset n; { n=0; while read -r line; do n=$((n+1)); done << EOT $(printf 'a\nb\n') EOT echo $n; }; echo $n 2 2 $もしくは、POSIX shell ではなく、Bash などでは Process Substitution を利用できます:
$ unset n; { n=0; while read -r line; do n=$((n+1)); done < <(printf 'a\nb\n'); echo $n; }; echo $n 2 2 $
こちらは勘違い(=問題化)しにくいと思います。 ↩
- 投稿日:2020-03-16T00:40:08+09:00
Arch LinuxでYouTube Liveにゲーム配信(Nintendo Switch)
TL;DR
- Arch Linuxでゲームライブ配信をする際の知見を共有します.
- ドライバ不要のキャプチャボードを利用してNintendo Switchの画面をYouTube Liveに配信します.
- 配信ソフトはOBS Studioを利用します.
- OBSに関するバージョン依存の情報が含まれています.投稿日時が古い場合は注意してください.
準備するもの
- Arch Linux (他のLinuxディストリビューションでも可能です)
- HSV321(キャプチャボード)
- OBS Studio
キャプチャボード選定
Linuxでの動作を確認している方が多数いるため以下の製品を選択しました.
キャプチャボード周りに全く詳しくないので怪しい中華製にしか見えませんが,OS依存がなくドライバ不要でありHDMIパススルー対応機器です.Linuxで動作するものであれば何でもよいでしょう.配信ソフト
OSは普段使いのArch Linuxです.
配信周りは当然Windowsのほうが便利なツールが揃っていますが,Linuxでも一応配信ツールがリポジトリに用意されています.今回は知名度の高いOBS Studioを利用します.Arch LinuxのCommunityリポジトリに限らず,Ubuntuや他の主要ディストリビューションでもインストール可能です.
一方で,Linux版のOBS Studioの現バージョン(24.x)ではブラウザプラグインが導入されておらず,配信画面上にコメントやサブスクライブの通知などを表示できません.
過去のバージョン(23.x)ならばプラグイン(obs-linuxbrowser)をディレクトリに配置するだけで導入できるそうなのですが,24.x系では正常動作しないようです.Issueなどを見ていると開発版の25.x系にプラグインを含めてビルドすれば動作するようなので,AURの開発版をビルドしてインストールします.下記AURヘルパーの
yayでのインストール例です.yay -S obs-studio-gitAURの開発版にはobs-linuxbrowserが含まれていますね.
逆にブラウザ機能が不要だという方は24.x系でよいと思います.GitHubにインストール手順があるので,ご自身のOSに合わせてインストールしてください.Arch Linuxだとpacmanでそのままインストールできます.
sudo pacman -S obs-studio配信の初期設定
起動すると,大きく表示されるプレビュー画面の下にソースの設定項目があります.右クリックから追加を選択し,映像キャプチャデバイスを選択,デバイス欄をMiraBox Video Captureに設定します.
キャプチャの基本設定は以上です.
マイクからの音声入力などが必要であれば,同様にソースから音声入力設定をしてください.こちらはLinux側の音声設定に依存すると思うので説明は省きます.ツールバーから設定を開くと詳細設定が可能です.
ライブ配信の場合は配信タブからYouTube Liveを選択してストリームキーを入力します.
ストリームキーはYouTube Liveの配信画面から取得できます.この記事を見て真似しようと思った方は諸々揃える前にYouTube Liveのアカウントを有効化しておきましょう.利用できるまでに24時間程度掛かります.以上の設定が終われば,配信開始ボタンを押して配信が可能です.
OBS側の配信と,YouTube Live側の配信の両方で配信開始する必要があります.OBS Studioでは配信と同時に録画をしたり,録画のみで動作させることもできます.YouTube Live側でも配信はアーカイブされるので,あとで細かい編集等をしない限り配信と同時に録画する必要はないかもしれません.コメントや通知の表示
OBSの拡張版とされるStream Labsには標準でライブ配信中のコメント表示などに対応していますが,こちらのソフトウェアはWindows版しか存在しません.一方で,Stream Labsはウィジェット機能としてコメント表示などを提供してくれているので,OBS Studioではこちらを参照します.
ここで上記でわざわざ開発版をビルドしてまで使いたかったブラウザ機能を活用します.
Stream Labsのアカウントを作成し,ログインしたあとAlert Boxのページを開きます.以下のようにURLが提供されているので,このURLをOBS Studioのブラウザソースに貼り付けます.ブラウザソースは先程のキャプチャボード選択と同様にソースからブラウザを選択して設定します.Stream Labsから通知のテストができます.Widget URLの下にあるTest Subscriberを選択すると,配信画面上に通知が表示されるのを確認できます.同様の操作でコメント欄などを追加できます.
またアカウント作成等が面倒くさいという方は,YouTube Liveのコメント欄をポップアップさせたあとのURLを貼り付けてCSSをいじれば配信画面にコメント表示させることができます.
コメントの読み上げ
別途用意する必要がありますが,読み上げで有名な棒読みちゃんはLinuxでは動作しません.YouTubeLiveコメント読み上げさんというサービスもあるようですが,しばらく配信していると謎のエラーで読み上げてくれなくなりました(APIの取得制限?).YouTube Live APIを自分で叩いて,何かしらのソフトウェアに読み上げてもらうのが早そうですね.そのうち気が向いたら自作を検討します.
参考



