- 投稿日:2020-02-14T22:09:04+09:00
【CroWish勉強会】 Docker基礎
はじめに
勉強会を開催したのでまとめです。
https://crowish.connpass.com/event/166807/Dockerとnginxを使ってWebサーバーを構築する
// docker hubからnginxイメージを取得 $ docker pull nginx // imageからコンテナを作成(80番から80番にポートフォワーディング) $ docker run --name test_nginx -d -p 80:80 nginx // コンテナが起動しているのかどうか確認 $ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 43305a573df9 nginx "nginx -g 'daemon of…" 3 seconds ago Up 2 seconds 0.0.0.0:80->80/tcp test_nginxhttp://localhost:80 にアクセスすると以下の画面がhyoujisareru
表示されるページを編集したい!
// コンテナを停止して削除 $ docker container rm `docker stop [container_id]` /** * コンテナを作成 * ホストのhtmlファイルをマウント **/ $ docker container run --name test_nginx -v [表示したいhtmlがある絶対パス]:/usr/share/nginx/html -p 80:80 -d nginx //nginxコンテナの中に入る $ docker exec -it test_nginx /bin/bash // index.htmlの確認 root@43305a573df9:/# cat /usr/share/nginx/html/index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>Sample</h1> </body> </html>hennkousareteru

- 投稿日:2020-02-14T21:14:17+09:00
同一のイメージから大量のコンテナを作成するcombuの話
tl;dr
- シミュレーション向けに1つのイメージから大量のコンテナ(実験環境)を作るツールを作った
- お金に余裕がある人はAWSのsagemaker-experimentsを使うと良いのかも
- 中間生成物収集ツールのdecotraも見てね
対象
- Docker上で実験ができる(コードを動かせる)人
- 並列処理を書く勉強を一旦後回しにしたい人
はじめに
自分が行っていたシミュレーションの実験では複数の環境に対して,複数のパラメータを必要とし,それら全てを探索対象とする必要がありました.
つまり,実験数=環境数*パラメータ数となります.
これを順々に処理すると途方もなく時間がかかりそうな気がしていました.
また,途中で解が定まらず,次の実験が始まらないことがありました.
そこで,実験数分だけDockerコンテナを起動し,各パラメータを実行時に渡す方法で並行処理を実現する方法について考え,実装しました.
それが今回紹介したいcombuです.似たアプローチとして,AWSのsagemaker-experimentsがあり,実験・学習ジョブは
Trial,Trialの集合をExperimentと呼んでいます.
わかりやすいので,本記事ではこの2つの単語を借りることとします.combu
combuは大量のコンテナを起動・破壊するためのコンテナオーケストレーションツールです.コンテナオーケストレーションというと,Kubernatesやdocker-composeが想起されると思います.実際に,開発したcombuはdocker-composeを使っていて不便に感じたものを解消するために作りました.(そして一度Kubernatesに挫折したことがあります.)
combuの特長は以下の2つです
- 導入が容易
- コマンドが簡単
ダウンロードしてパスを通すだけ,すぐ使えます.コマンドが2つしかないので,すぐ覚えられます.
experimentを表現する
docker-composeでは何がダメだったか,想定例を通して確認していきます.
1から5のIDによって管理されている複数の環境を,AとBの2つのアルゴリズムで解くというexperimentをdocker-compose.yamlで表現すると以下のようになります.
docker-compose.yaml
docker-compose.yamlversion: '2' services: solver-a-1: image: registry.com/funwarioisii/solver container_name: solver-a-1 command: make simulation MODE=a ID=1 solver-a-2: image: registry.com/funwarioisii/solver container_name: solver-a-2 command: make simulation MODE=a ID=2 solver-a-3: image: registry.com/funwarioisii/solver container_name: solver-a-3 command: make simulation MODE=a ID=3 solver-a-4: image: registry.com/funwarioisii/solver container_name: solver-a-4 command: make simulation MODE=a ID=4 solver-a-5: image: registry.com/funwarioisii/solver container_name: solver-a-5 command: make simulation MODE=a ID=5 solver-b-1: image: registry.com/funwarioisii/solver container_name: solver-b-1 command: make simulation MODE=b ID=1 solver-b-2: image: registry.com/funwarioisii/solver container_name: solver-b-2 command: make simulation MODE=b ID=2 solver-b-3: image: registry.com/funwarioisii/solver container_name: solver-b-3 command: make simulation MODE=b ID=3 solver-b-4: image: registry.com/funwarioisii/solver container_name: solver-b-4 command: make simulation MODE=b ID=4 solver-b-5: image: registry.com/funwarioisii/solver container_name: solver-b-5 command: make simulation MODE=b ID=5これはかなり冗長で,とても1000個のtrialを並列して始めるには向いていません
そこで,jsonnetを利用します
experiment.jsonnetlocal solver(id, mode) = { name: "solver-%s-%d" % [mode, id], image: "registry.com/funwarioisii/solver", cmd: "make simulation ID=%d MODE=%s" % [id, mode] }; [ solver(id, mode) for id in std.range(1, 5) for mode in ["a", "b"] ]これで先程のyamlと同じことを表現しています.
パースした結果はこのようになります.
experiment.json[ { "cmd": "make simulation ID=1 MODE=a", "image": "registry.com/funwarioisii/solver", "name": "solver-a-1" }, { "cmd": "make simulation ID=1 MODE=b", "image": "registry.com/funwarioisii/solver", "name": "solver-b-1" }, { "cmd": "make simulation ID=2 MODE=a", "image": "registry.com/funwarioisii/solver", "name": "solver-a-2" }, { "cmd": "make simulation ID=2 MODE=b", "image": "registry.com/funwarioisii/solver", "name": "solver-b-2" }, { "cmd": "make simulation ID=3 MODE=a", "image": "registry.com/funwarioisii/solver", "name": "solver-a-3" }, { "cmd": "make simulation ID=3 MODE=b", "image": "registry.com/funwarioisii/solver", "name": "solver-b-3" }, { "cmd": "make simulation ID=4 MODE=a", "image": "registry.com/funwarioisii/solver", "name": "solver-a-4" }, { "cmd": "make simulation ID=4 MODE=b", "image": "registry.com/funwarioisii/solver", "name": "solver-b-4" }, { "cmd": "make simulation ID=5 MODE=a", "image": "registry.com/funwarioisii/solver", "name": "solver-a-5" }, { "cmd": "make simulation ID=5 MODE=b", "image": "registry.com/funwarioisii/solver", "name": "solver-b-5" } ]Jsonnetの使い方に関する記事は色々あるので検索してみてください.
ここではパースするとJSONになる便利なやつということで進めていきます.まず,
local solver(id, mode) = { ... }はtrialのテンプレートになります.
次に[solver(id, mode) for id in std.range(1, 5) for mode in ["a", "b"]]でテンプレートをもとに複数のtrialが宣言されていきます.combuでは現在以下のパラメータを受け取ることが出来ます.
名前 説明 name コンテナ名(trial名) image 利用するイメージ名 ports 配列 Portテーブル参照 volumes 配列 Volumeテーブル参照 networks 配列 コンテナが属するネットワーク depends 配列 起動時に立ち上げておくべきコンテナ名 cmd 起動時に実行するコマンド
Portテーブル
docker run -p相当です
名前 説明 host 提供するポート container 公開したいポート
Volumeテーブル
docker run -v相当です
Volumeコンテナなどの利用を想定していないので,現在は直接ホストマシンのストレージにアクセスします
名前 説明 host 提供するディレクトリ container マウントしたいディレクトリ Pythonistaにはお馴染みの内包表記で,複数のtrialをベースにしたexperimentを表現しています.
起動順序とネットワーク
私の場合は実験に関する様々なデータをクラウド上に保存してあり,アクセスごとに料金が加算される方式のようだったので,データの取得にキャッシュサーバを間に挟んでいます.
そのためtrialの前にキャッシュサーバを起動する必要があります.
さらに,キャッシュサーバにアクセス可能である必要があります.依存するコンテナを
dependsに書くと,それに従った起動順序でコンテナを起動します.
また,networksにネットワーク名を書くと同一のネットワーク内にコンテナが生成され,コンテナ間で通信ができます.
これはdocker-composeのnetworksとdepends_onに対応しています.experiment.jsonnetlocal solver(id, mode) = { name: "solver-%s-%d" % [mode, id], image: "registry.com/funwarioisii/solver", cmd: "make simulation ID=%d MODE=%s" % [id, mode], networks: ["simulation"], depends: ["loader"] }; [ solver(id, mode) for id in std.range(1, 5) for mode in ["a", "b"] ] + [ { name: "loader", image: "registry.com/funwarioisii/loader", networks: ["simulation"], } ]識別子
combuでは1つのjsonnetファイルに対し,1つの識別子をつけることが出来ます.
これはexperiment単位でなんらかの識別子が必要になったためです.
しかし,jsonnetはパース後毎回同じjson配列を出力するのが仕様になっており,ランダムな値は使えません.
そこでcombuでは実行時にlocal uuid = "UUID";と記述されている場合は,"UUID"をランダムに生成した12文字で置き換えるようにしています.
各trialにこのuuidをうまく渡すことで,どのexperimentでのtrialなのかを管理しやすくなります.
これは同じ実験を複数回繰り返す際に便利です.experiment.jsonnetlocal uuid = "UUID"; local solver(id, mode) = { name: "solver-%s-%d" % [mode, id], image: "registry.com/funwarioisii/solver", cmd: "make simulation ID=%d MODE=%s UUID=%s" % [id, mode, uuid], networks: ["simulation"], depends: ["loader"] }; [ solver(id, mode) for id in std.range(1, 5) for mode in ["a", "b"] ] + [ { name: "loader", image: "registry.com/funwarioisii/loader", networks: ["simulation"], } ]ところでUUIDと書いていますが,UUIDの定義に沿っていないので,後ほど変更します
起動と破壊
ここまでは主にexperimentの表現方法について紹介しました.
ここからは,実際にcombuの使い方について説明します.まず,experimentが
experiment.jsonnetと保存されている状態で以下のコマンドを実行します$ combu -f experiment.jsonnet runこれでコンテナが順々に起動されていきます.
やや込み入ったことを書くと,依存ごとに依存グループを作成し,グループごとにコンテナを並列起動しています.作成したコンテナは,以下のコマンドで全て破壊できます.
$ combu -f experiment.jsonnet killインストール
ここまで読んだあなたはきっと
combuを試したくなっていると思います.
combuのリリースタブからファイルをダウンロードし,/usr/local/binなどに配置し,パスを読み込み直してください.
これでいつでどこでもcombuが使えます.自分の実験パターンとcombu
誰しも「いつもこのルーチンで実験を回す」というのがあると思います.
自分は大体以下の手順を踏みます.
- Dockerイメージを作る
- コンテナ上のJupyterでEDA
- ノートブックをスクリプトにして,makeで操作できるようにする
- 計算資源が豊富なPCにコンテナを持っていって,実験を回す
そして,Dockerの操作からスクリプトの実行までプロジェクト内で使いたいコマンドは全てMakefileで管理できるようにしています.
これらを容易にするための,実験プロジェクトのディレクトリ構成は以下のようになっています.
combuのためのjsonnetはdockerディレクトリに入れています.|-- Makefile |-- docker |-- Dockerfile |-- experiment.jsonnet |-- src |-- xxx.py |-- scripts |-- experiment_1.py |-- notebook |-- eda.ipynb |-- requirements.txtまた,Makefileは以下のようになっています.
make simulationなどでtrialが走るようにしています.
そしてmake run-experimentするとcombuがコンテナを起動し,パラメータをmake simulationに渡す流れになります.create-image: docker build -t funwarioisii/experiment -f docker/Dockerfile create-container: ... push-image: ... simulation: python scripts/simulation_1.py \ --mode=$(MODE) \ --id=$(ID) --uuid=$(UUID) run-experiment: combu -f docker/experiment.jsonnet run kill-experiment: combu -f docker/experiment.jsonnet killこうすることで,プロジェクトに関連する操作や,実験条件などを繰り返し実行しやすく,持ち運びやすく,忘れにくく(!)しています.
このあたりはcookiecutter-docker-scienceを参考にしています.decotra
大量に作成したtrialでの計算結果などをいかに集約すべきかという問題があります.
これを解決する拙作decotraがあるので紹介します.
decotraは関数の実行結果をS3に送るものです.
研究室ではAWSに契約していないので,私はminioをエンドポイントとして使っています.
これは先ほど紹介したsagemaker-experimentsで言えばtrackerのようなものです.
結果を保存したい関数に@decotra.track(BUCKET_NAME)とデコレーションをつけ,with decotra.path('key')とwith句内で実行します.
decotraの例です
example.pyimport numpy as np import decotra from decotra import track BUCKET_NAME = "bucket-name" class Operation: @track(BUCKET_NAME) def mul(self, x, y): return x * y @track(BUCKET_NAME) def add(self, x, y): return x + y @track(BUCKET_NAME) def tanh(self, x): return np.tanh(x) def main(): op = Operation() epoch = 20 for e in range(epoch): with decotra.path(f"{decotra.saved_prefix}{e}/"): op.tanh(op.add(op.mul(1, 2), 3)) if __name__ == '__main__': main()
pip install decotraでインストールできるので良ければ使ってみてください.実はこんなところがダメ
運用している中で,以下の欠点を見つけています.
- 計算資源を占拠してしまう
- combuがというより,作成したコンテナが
- 自分の実験ではメモリに余裕はあったもののCPUがほぼダメでした
- GPUが使えない
- Docker SDKを眺めているのですが,GPUを使う方法がわかっていません><
まとめ
実験構成の記述方法,combuの使い方,プラクティス,周辺ツールについて紹介しました.
是非使ってみてください.
Issue/Pull Request大歓迎です.
普段Goを使っていないので,コードスタイルに関する指摘などもバシバシ送ってくださると嬉しいです.
- 投稿日:2020-02-14T16:44:50+09:00
Docker Toolbox環境でハマってから解決するまでの話
Windows 10 HomeでDocker Composeを始める
はじめに
この記事はWin10 Proユーザである私が、Win10 HomeでDocker Composeを使うにあたってハマったことと解決方法をご紹介する記事です。
Docker Toolboxを使い始めた人のお役に立てると幸いです。やりたいこと
- Win10 HomeでPHPのフレームワークLaravelを使ってWebサーバを動かす。
- Dockerのオーケストレーションはdocker-composeを利用する。
- docker-composeはLaravel向け全部入りプロジェクトであるLaradockを利用する。
- ホストマシンの外からLaradockのサービスへアクセスする。
前提条件
- Virtual Boxがインストールしている
- Docker Toolboxがインストールしている
docker run hello-worldが動作することを確認している- Laradockのセットアップが終わっており、
workspaceコンテナにexecできる(参考記事: @souichirou 殿のdockerコンテナの中に入って作業をしたい時)いざ実践
作業手順
以下の手順で作業を行います。
なお手順末尾に「※」があるものは私のハマりポイントです。
- composerコマンドの参照先リポジトリを近くに変更し、快適な環境を準備する(任意)
- composerの依存解決を並列化し、快適な環境を準備する(任意)
- Laravelのインストール
- LaravelのWEB画面を開発マシンで表示する※
- LaravelのWEB画面を開発マシンの外から表示する※
1. composerコマンドの参照先リポジトリを近くに変更し、快適な環境を準備する(任意)
PHPのパッケージ管理機能を提供してくれる
composerですが、デフォルトのリポジトリがpackagist.orgまで距離があるため、日本国内からのアクセスが早いpackagist.jpに変更します。
※Packagist JPについてはこちらからworkspaceコンテナ内での操作root@(container-id)# composer config -g repos.packagist composer https://packagist.jp2. composerの依存解決を並列化し、快適な環境を準備する(任意)
composerはパッケージリポジトリへのアクセスが並列化されておらず、Laravelのように依存関係が多いフレームワークのインストールではかなりの時間がかかる傾向がある。
@Hiraku殿のprestissimoを導入し、依存解決を並列化します。workspaceコンテナ内での操作root@(container-id)# composer global require hirak/prestissimo3. Laravelのインストール
Laravelのインストールを以下のコマンドで実行します。
workspaceコンテナ内での操作root@(container-id)# cd /var/www root@(container-id)# composer create-project --prefer-dist laravel/laravel ./※
cd /var/wwwする理由はLaradockのデフォルトのWEBサーバであるnginxでは、/var/wwwにLaravelが配置されている前提となっているため。4. LaravelのWEB画面を開発マシンで表示する※
まず私がハマったポイントは、まさかの画面を表示する時でした。
手順3を行うことでLaravelのセットアップが完了し、LinuxやWin10 Pro上でDockerを使っている場合は
http://localhostで以下のようなLaravelの初期画面が表示されるはずです。
しかし、Win10 Home + Docker Toolboxでは一筋縄ではいきません。
本手順におけるハマりポイント
Win10 Home + Docker Toolboxを使う場合は、Docker上のサービスはlocalhostとして動作しません。(VirtualBox上のVMで動いているため)
私はWin10 ProとLinuxでしかDockerを触っていなかったためここでハマりました。解決方法
Docker Toolboxを利用する際は、Docker Quickstart Terminalというアプリをインストールしているはずです。
このアプリを起動した直後に表示される以下の画面をご覧ください。
表示する際に必要となるVirtualBox内のdefaultマシンのIPアドレスが記載されています。
(ここでは192.168.99.100)
このIPアドレスを指定してWEBブラウザでアクセスすることで表示できます。
WEBブラウザに以下のURLを指定してアクセスしてみましょう。http://(Docker Quickstart Terminalに記載されているIPアドレス)私の場合(
192.168.99.100)は以下の通りです。http://192.168.99.100このように指定することでWin10 Home + Docker Toolboxの組み合わせでLaravelの初期画面が表示されます。
5. LaravelのWEB画面を開発マシンの外から表示する※
次に私がハマったポイントは、開発マシン以外からDocker Toolboxで動いているサービスにアクセスする時でした。
仮に開発マシンのIPアドレスが
192.168.0.1であるとしましょう。
LinuxやWin10 Pro上でDockerを使っている場合は開発マシン以外からは以下のURLでサービスが見えるはずです。http://192.168.0.1しかし、Win10 Home + Docker Toolboxでは一筋縄ではいきません。(2回目)
Docker ToolboxでDockerコンテナを動かす際は、VirtualBox上で動作している
defaultマシン内でDockerを立ち上げており、このdefaultマシンに設定されているNICはNATとホストオンリーアダプタの2つだけです。
仮にdefaultマシンにブリッジアダプタを割り当てる場合、defaultマシンに独自のIPアドレスが振ることでアクセスできそうな気がします。しかし以下の利用により、NICに変更を加えることを避けることにしました。
- ブリッジ接続によって
defaultマシンにIPを振りたくない(ローカルIPアドレスがもったいない)- 「DockerといえばホストマシンのIPで動くものだ!」というイメージがあるため
defaultマシンに変更を加えたくない(人の作ったVMを修正したくない)- 開発マシンの外側(他人)に対して、Docker Toolboxの存在を意識させたくないため
解決方法
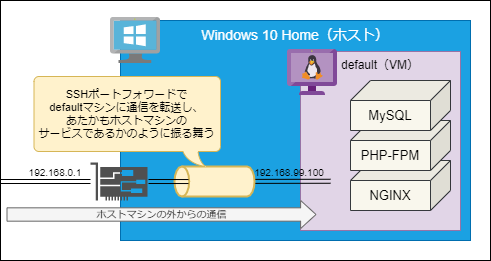
「開発マシンへの通信をポートフォワードでdefaultマシンに流し込む」
つまり以下のイメージです。
Win10 HomeのDocker Toolboxに含まれている
docker-machineコマンドを利用して実現します。
Docker Quickstart Terminalアプリを立ち上げて、以下のコマンドを実行してください。DockerQuickTerminalアプリでの操作docker-machine ssh default -g -L 8080:192.168.99.100:80このコマンドを実行することで
defaultマシンにSSHポートフォワードをします。
-gオプションローカル以外のマシンから来た通信に対してもポートフォワードしてくれます。
-Lオプションポートフォワードの設定です。
ホストマシンのポート8080番に来た通信を、defaultマシンのポート80番へ転送することが可能となります。
上記の操作例では-L 8080:192.168.99.100:80と指定しておりますが、これはコロン:区切りで以下のように指定します。-L (ホストマシン側の紐づけるポート番号):(転送先マシンのIPアドレス):(転送先マシンのポート番号)これにより、ホスト以外のマシンから
(ホストマシンのIP):8080を宛先として指定することで、defaultマシンへ通信が到達するようになります。ホストマシンの外(別のPC等)のWEBブラウザで以下のURLを指定することで表示できるようになりました。
ホストマシンの外(別のPC等)からWEBブラウザで確認
http://(ホストマシンのIPアドレス):8080以上、めでたしめでたし。
余談1
手順1と手順2については、コンテナを再度立ち上げしたら消えてしまうので、workspaceのDockerfile後半に下記の通り追加することをお勧めします。
workspace/Dockerfile########################################################################### # Check PHP version: ########################################################################### RUN set -xe; php -v | head -n 1 | grep -q "PHP ${LARADOCK_PHP_VERSION}." ### # 追加設定 ここから ### # composerのpackagistを近くに変更 RUN composer config -g repos.packagist composer https://packagist.jp # composerコマンド並列化 RUN composer global require hirak/prestissimo ### # 追加設定 ここまで ### # #-------------------------------------------------------------------------- # Final Touch #-------------------------------------------------------------------------- #余談2
手順5でポートフォワードですが、
-fオプションをつけることでバックグラウンドでフォワードしてくれるようになります。


- 投稿日:2020-02-14T13:12:43+09:00
【 Docker+Nginx+Django+RDS】WEBアプリができるまで⑩成長曲線グラフを描いてみよう
前置き
独学で、子供の成長アプリを作った時のことを、記録として残していきます。
間違っているところなどあれば、ご連絡お願いします。
①Djangoのようこそページへたどり着くまで
②NginxでDjangoのようこそページへたどり着くまで
③カスタムユーザーを作ってadminにたどり着く
④ログインログアウトをしよう
⑤ユーザー登録(サインイン)機能を作ろう
⑥ユーザーごとのデータ登録できるようにする〜CRU編
⑦ユーザーごとのデータ登録できるようにする〜削除編
⑧画像ファイルのアップロード
⑨身長体重を記録する@一括削除機能つき
⑩成長曲線グラフを描いてみよう <--ここです
⑪本番環境へデプロイ+色々手直しGoal
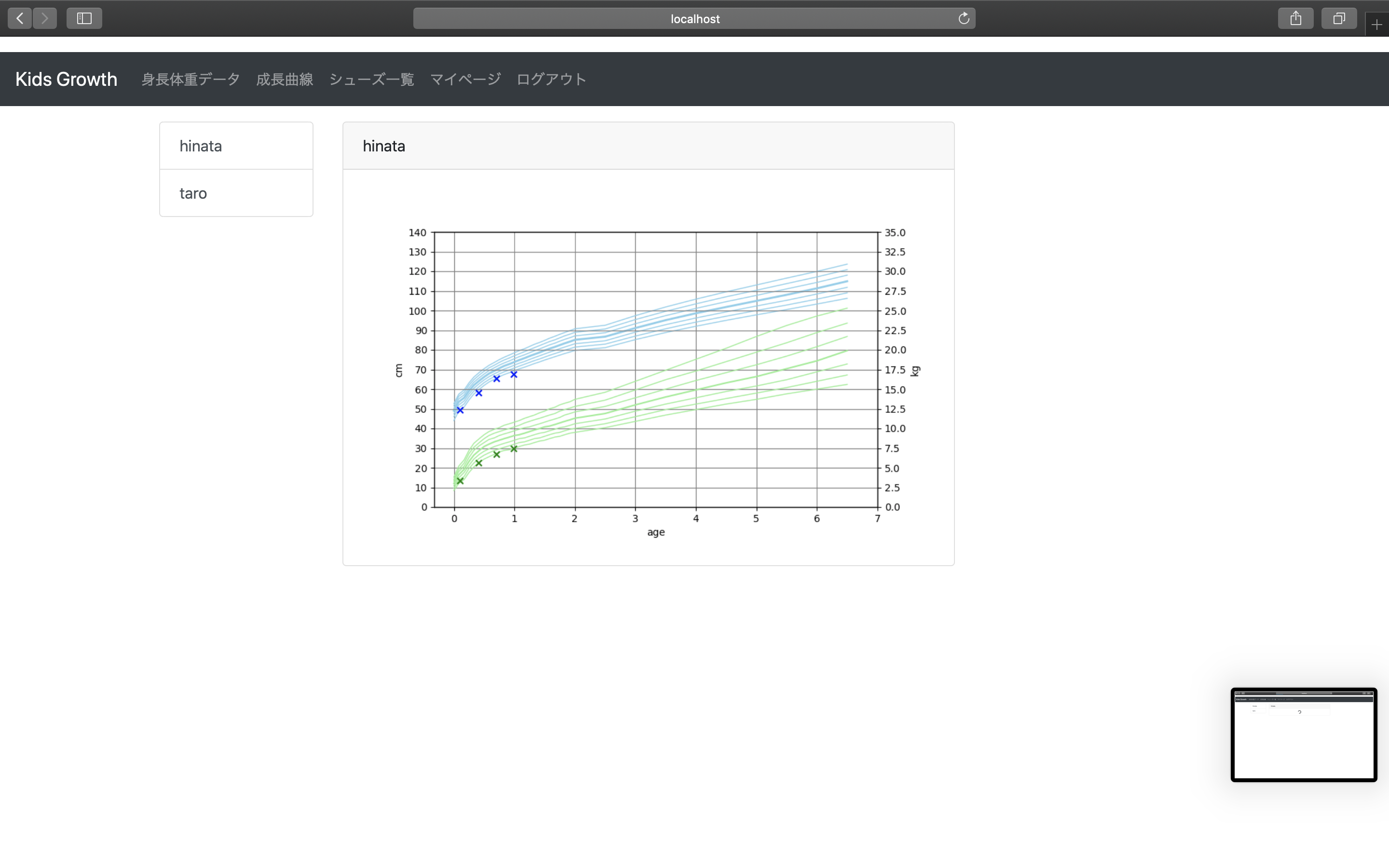
登録された身長体重データをもとに、成長曲線を書いてみよう
成長曲線とは
横軸に年齢、縦軸に身長や体重をプロットする曲線。
厚生労働省が10年ごとに計測データを出していて、その標準偏差などと比較しながら
子供の成長具合を把握するのに使うもの。平成22年乳幼児身体発育調査の概況について
https://www.mhlw.go.jp/stf/houdou/0000042861.htmlView
グラフ描画はmatplotlib、pandas、numpyを利用。
4種類のグラフ描画を連結させて、1つのグラフとして描画している。・固定線(身長、体重)
厚労省のデータはCSVにしてSTATICに保存。
データは折れ線グラフで描画。線自体は身長、体重ごとに7本ずつ描かれる。(標準偏差)・分散図(身長、体重)
こちらは、1つ前で登録できるようにした身長体重データを読み込んでプロットする。
身長体重データは計測日しか持っていないので、計測日時点の子供の年齢は、生年月日から計算する。
簡易な計算方法はググれば出てくるのだが、なぜか0才のときの月齢計算が成立しないので、
そのときだけ別の計算式になるよう工夫(?)している。phys/views.pyfrom django.shortcuts import render, redirect from django.http import HttpResponse from django.contrib.auth.decorators import login_required from .models import PhysData from users.models import KidsProfile from .forms import PhysDataForm, PhysDataEditForm import matplotlib.pyplot as plt from matplotlib.backends.backend_agg import FigureCanvasAgg import numpy as np import pandas as pd import io # 身長体重データを昇順で返却 @login_required def phys_data_list(request, **kwargs): (略) # 身長体重データを新規登録する @login_required def phys_data_add(request): (略) # 身長体重データを編集する @login_required def phys_data_edit(request, dataPostId): (略) # 身長体重データを削除する @login_required (略) #グラフ画像を表示するページ @login_required def graph_page_display(request, **kwargs): user_name = request.user if len(kwargs) > 0: kidsProfileId = kwargs["kidsProfileId"] else: kidsProfileId = KidsProfile.objects.filter(user=user_name).order_by('id')[0].id kids_profiles = KidsProfile.objects.filter(user=user_name) kids_profile = KidsProfile.objects.filter(id=kidsProfileId) params = { 'kidsProfiles' : kids_profiles, 'kidsProfileId' : kidsProfileId, 'kidsName' : kids_profile[0].name, } return render(request, 'phys/phys_graph_display.html', params) # グラフの画像生成 @login_required def graph_image_display(request, **kwargs): # 初期設定 fig = plt.figure(figsize=(8, 5)) ax_h = fig.add_subplot(1, 1, 1) ax_w = ax_h.twinx() ax_hs = ax_h.twinx() ax_ws = ax_h.twinx() # グラフ自体の設定 # タイトル ax_h.set_xlabel(u'age') ax_h.set_ylabel(u'cm') ax_w.set_ylabel(u'kg') # 固定線の描画 border_color_h = 'skyblue' #身長の固定線色 border_color_w = 'lightgreen' #体重の固定線色 border_lw_mid = 2 #中央の固定線太さ border_lw_other = 1 #中央以外の固定線太さ # 固定値(身長) # 3% data_man_height_03 = pd.read_csv('static/physData/man_height_03.csv', names=['num1', 'num2']) ax_h.plot(data_man_height_03['num1'], data_man_height_03['num2'], color=border_color_h, lw=border_lw_other) # 10% data_man_height_10 = pd.read_csv('static/physData/man_height_10.csv', names=['num1', 'num2']) ax_h.plot(data_man_height_10['num1'], data_man_height_10['num2'], color=border_color_h, lw=border_lw_other) # 25% data_man_height_25 = pd.read_csv('static/physData/man_height_25.csv', names=['num1', 'num2']) ax_h.plot(data_man_height_25['num1'], data_man_height_25['num2'], color=border_color_h, lw=border_lw_other) # 50% data_man_height_50 = pd.read_csv('static/physData/man_height_50.csv', names=['num1', 'num2']) ax_h.plot(data_man_height_50['num1'], data_man_height_50['num2'], color=border_color_h, lw=border_lw_mid) # 75% data_man_height_75 = pd.read_csv('static/physData/man_height_75.csv', names=['num1', 'num2']) ax_h.plot(data_man_height_75['num1'], data_man_height_75['num2'], color=border_color_h, lw=border_lw_other) # 90% data_man_height_90 = pd.read_csv('static/physData/man_height_90.csv', names=['num1', 'num2']) ax_h.plot(data_man_height_90['num1'], data_man_height_90['num2'], color=border_color_h, lw=border_lw_other) # 97% data_man_height_97 = pd.read_csv('static/physData/man_height_97.csv', names=['num1', 'num2']) ax_h.plot(data_man_height_97['num1'], data_man_height_97['num2'], color=border_color_h, lw=border_lw_other) # 固定値(体重) # 3% data_man_weight_03 = pd.read_csv('static/physData/man_weight_03.csv', names=['num1', 'num2']) ax_w.plot(data_man_weight_03['num1'], data_man_weight_03['num2'], color=border_color_w, lw=1) # 10% data_man_weight_10 = pd.read_csv('static/physData/man_weight_10.csv', names=['num1', 'num2']) ax_w.plot(data_man_weight_10['num1'], data_man_weight_10['num2'], color=border_color_w, lw=1) # 25% data_man_weight_25 = pd.read_csv('static/physData/man_weight_25.csv', names=['num1', 'num2']) ax_w.plot(data_man_weight_25['num1'], data_man_weight_25['num2'], color=border_color_w, lw=1) # 50% data_man_weight_50 = pd.read_csv('static/physData/man_weight_50.csv', names=['num1', 'num2']) ax_w.plot(data_man_weight_50['num1'], data_man_weight_50['num2'], color=border_color_w, lw=1.5) # 75% data_man_weight_75 = pd.read_csv('static/physData/man_weight_75.csv', names=['num1', 'num2']) ax_w.plot(data_man_weight_75['num1'], data_man_weight_75['num2'], color=border_color_w, lw=1) # 90% data_man_weight_90 = pd.read_csv('static/physData/man_weight_90.csv', names=['num1', 'num2']) ax_w.plot(data_man_weight_90['num1'], data_man_weight_90['num2'], color=border_color_w, lw=1) # 97% data_man_weight_97 = pd.read_csv('static/physData/man_weight_97.csv', names=['num1', 'num2']) ax_w.plot(data_man_weight_97['num1'], data_man_weight_97['num2'], color=border_color_w, lw=1) # 子供データ取得 user_name = request.user if len(kwargs) > 0: kidsProfileId = kwargs["kidsProfileId"] else: kidsProfileId = KidsProfile.objects.filter(user=user_name).order_by('id')[0].id kids_profile = KidsProfile.objects.filter(user=user_name, id=kidsProfileId) phys_data = PhysData.objects.filter(user=user_name, kidsProfile=kidsProfileId) # グラフデータ作成 graph_height = [] graph_weight = [] graph_date = [] for i in range(len(phys_data)): graph_height.append(phys_data[i].height) graph_weight.append(phys_data[i].weight) # 誕生日計算(小数点計算) dStr1 = phys_data[i].date.strftime('%Y%m%d') dStr2 = kids_profile[0].birthday.strftime('%Y%m%d') if kids_profile[0].birthday.year == phys_data[i].date.year: dStr3 = (int(dStr1) - int(dStr2)) / 1000 # 0才のときの月齢を出す else: dStr3 = (int(dStr1) - int(dStr2)) / 10000 # 一般的な誕生日計算 graph_date.append(dStr3) # グラフプロット(分散図) ax_hs.scatter(graph_date, graph_height, marker='x', color='blue') ax_ws.scatter(graph_date, graph_weight, marker='x', color='green') # グリッド設定 ax_h.grid(which='both', color='gray', linestyle='solid') ax_w.grid(which='both', color='gray', linestyle='solid') # Y軸最大値設定 ax_h.set_ylim([0, 140]) ax_w.set_ylim([0, 35]) ax_hs.set_ylim([0, 140]) ax_ws.set_ylim([0, 35]) # Y軸メモリ ax_h.set_yticks(np.linspace(0, 140, 15)) ax_w.set_yticks(np.linspace(0, 35, 15)) ax_hs.set_yticks([]) ax_ws.set_yticks([]) # X軸メモリ ax_h.set_xticks(np.linspace(0, 7, 8)) ax_w.set_xticks(np.linspace(0, 7, 8)) ax_hs.set_xticks(np.linspace(0, 7, 8)) ax_ws.set_xticks(np.linspace(0, 7, 8)) # 描画 canvas = FigureCanvasAgg(fig) buf = io.BytesIO() canvas.print_png(buf) response = HttpResponse(buf.getvalue(), content_type='image/png') fig.clear() response['Content-Length'] = str(len(response.content)) return responseCSVはこんな感じのデータ。左が年齢、右が身長。
原データはエクセルファイルなので、Excel上で加工してCSV化したもの。static/physData/man_height_03.csv0.00,44.0 0.08,48.7 0.17,50.9Template & URL
graph_image_displayはイメージファイルを返却してくるので、
urlsでURL化した上で、HTMLではそのURLをタグで待ち受ける。
http://〜〜〜.pngみたいな形式でなくても画像が表示されるのは、何だか驚き。画像描画たびに裏でグラフ描画が走るため、画像表示までに数秒かかってしまう。
そのため、画像が表示されるまではbootstrapのspinnerが表示されるようjsで制御。phys/phys_graph_display.html{% extends 'base.html' %} {% block extra_js %} <script> $(function() { $('#loader-bg ,#loader').css('display','block');//ローディング画像を表示 }); $(window).on("load",function () { //読み込み完了したら実行する $('#loader-bg').css('display','none');//ローディングを隠す $('#loader').css('display','none'); $('#contents').fadeIn().removeClass("is-hide");//コンテンツを表示する }); $(function(){ setTimeout('stopload()',10000); //いつまでもローディング状態にならないように10秒で強制表示させる }); function stopload(){ //強制表示の関数 $('#contens').css('display','block'); $('#loader-bg').delay(900).fadeOut(800); $('#loader').delay(600).fadeOut(300); } </script> {% endblock extra_js %} {% block content %} <div class="row"> <div class="col-md-12 col-lg-2"> <div class="list-group"> {% for kidsProfile in kidsProfiles %} <a href="{% url 'phys:graph_page_display' %}{{kidsProfile.id}}" class="list-group-item list-group-item-action">{{kidsProfile.name}}</a> {% endfor %} </div> <br> </div> <div class="col-md-12 col-lg-7 overflow-auto"> <div class="card"> <div class="card-header">{{ kidsName }}</div> <div class="card-body"> <div id="loader-bg"> <div id="loader"> <div class="text-center"> <div class="spinner-border" role="status"> <span class="sr-only">Loading...</span> </div> </div> </div> </div> <img src="{% url 'phys:graph_image_display' kidsProfileId %}" id="contents" class="img-fluid is-hide"> </div> </div> </div> {% endblock %}phys/urls.pyfrom django.urls import path from . import views app_name = 'phys' urlpatterns = [ path('phys/list/', views.phys_data_list, name='phys_data_list'), path('phys/list/<kidsProfileId>', views.phys_data_list, name='phys_data_list'), path('phys/data_add/', views.phys_data_add, name='phys_data_add'), path('phys/data_edit/<dataPostId>', views.phys_data_edit, name='phys_data_edit'), path('phys/data_delete/', views.phys_data_delete, name='phys_data_delete'), path('phys/graph/', views.graph_page_display, name='graph_page_display'), path('phys/graph/<kidsProfileId>', views.graph_page_display, name='graph_page_display'), path('data/graph_imaga/', views.graph_image_display, name='graph_image_display'), path('data/graph_imaga/<kidsProfileId>', views.graph_image_display, name='graph_image_display'), ] ]動かす!
画像が表示されるまでは、くるくる
こんな感じで描画されます。

- 投稿日:2020-02-14T11:20:57+09:00
[WordPress] Docker 環境下の wp-cron.php を cron で実行する方法
WP-Cron(wp-cron.php)とは?
WP-Cron works by: on every page load, a list of scheduled tasks is checked to see what needs to be run. Any tasks scheduled to be run will be run during that page load. WP-Cron does not run constantly as the system cron does; it is only triggered on page load. Scheduling errors could occur if you schedule a task for 2:00PM and no page loads occur until 5:00PM.
WP-Cronは次のように機能します。ページをロードするたびに、スケジュールされたタスクのリストをチェックして、実行する必要があるものを確認します。実行がスケジュールされているタスクは、そのページのロード中に実行されます。 WP-Cronは、システムcronのように常に実行されるわけではありません。ページの読み込み時にのみトリガーされます。午後2時のタスクをスケジュールし、午後5時までページの読み込みが行われない場合、スケジューリングエラーが発生する可能性があります。
https://developer.wordpress.org/plugins/cron/#why-use-wp-cron
WordPress のコアファイルの一つの wp-cron.php はアクセストリガーで実行します。その結果、トラフィックが少ないサイトだと正しく予約投稿が動作しない問題が発生します。
そこで、アクセストリガーの cron である WP-Cron を停止して、Docker コンテナ内で cron が動作するようにしました。
以下、備忘録です。
概要
1. アクセストリガーの WP-Cron を停止
2. Docker 環境下で cron が動作するように設定
3. wp-cron.php を 1 分に 1 回のペースで叩くスケジュールを登録
やったこと
WordPress
define('DISABLE_WP_CRON', 'true');Docker
apt updateapt install cronapt install vimexport EDITOR=vim/usr/sbin/cron -f &crontab -e*/1 * * * * /usr/local/bin/php /var/www/html/wp-cron.php:wq!