- 投稿日:2020-02-14T23:34:25+09:00
Livedoorニュースコーパスで主成分分析 - 実践 -
この記事について
Livedoorニュースコーパスを使って、テキストデータの主成分分析に挑戦します。
前回、分析前の前準備として、テキストを形態素に分解し、表形式にまとめました。この表を使って、主成分分析を実施していきます。
重みの単語はたくさんあっても大変なので、名詞一般、且つ、記事分類毎の頻出単語Top5のものに絞ることにします。コードは以下からも参照できます。
https://github.com/torahirod/TextDataPCAまず、各記事分類毎の頻出単語Top5を確認します。
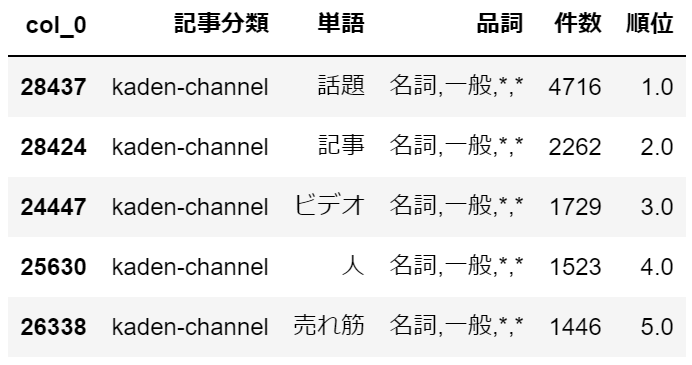
記事分類毎の頻出単語Top5の確認
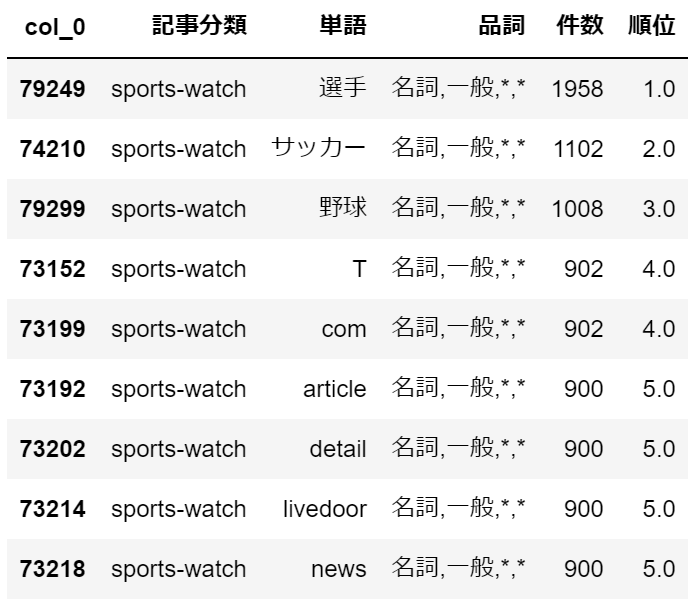
import pandas as pd import numpy as np # 前準備で1ファイルにまとめたテキストデータを読み込む df = pd.read_csv('c:/temp/livedoor_corpus.csv') # 品詞は名詞一般のみに絞り込み df = df[df['品詞'].str.startswith('名詞,一般')].reset_index(drop=True) # 記事分類毎の単語の出現頻度を集計 gdf = pd.crosstab([df['記事分類'],df['単語'],df['品詞']], '件数', aggfunc='count', values=df['単語'] ).reset_index() # 記事分類毎の単語の出現頻度の降順で順位付け gdf['順位'] = gdf.groupby(['記事分類'])['件数'].rank('dense', ascending=False) gdf.sort_values(['記事分類','順位'], inplace=True) # 記事分類毎の頻出単語Top5だけに絞り込み gdf = gdf[gdf['順位'] <= 5] # 記事分類毎の頻出単語Top5の確認 for k in gdf['記事分類'].unique(): display(gdf[gdf['記事分類']==k])・dokujo-tsushin
独女通信と名の付くだけあって、やはり「女性」、「女」といった単語が上位に来ています。・it-life-hack
ITライフハックは、「人」、「アプリ」といった単語は確かに関連度が高そうな気がします。
「製品」は何でしょう?ガジェット的ものを指しているのかもしれません。・kaden-channel
家電チャンネルは、「話題」、「売れ筋」、「ビデオ」とこちらもそれっぽい単語が頻出しています。
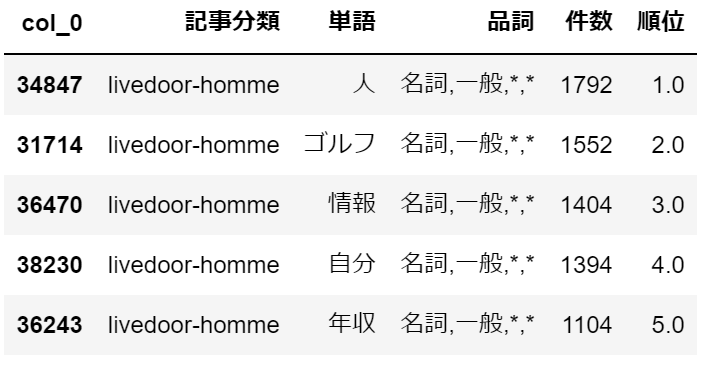
「人」は何でしょう?家電チャンネルという記事分類で頻出しているのは少し不思議に思います。・livedoor-homme
ライブドア-オムは、男性向けの記事の模様。
やはり「ゴルフ」は紳士の嗜みなのでしょうか。「年収」がTop5に入っているのも面白いですね。・movie-enter
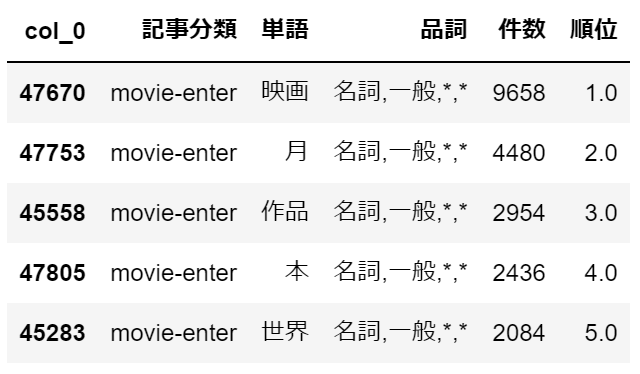
映画・エンタメは、その名の通り、「映画」、「作品」といった単語が上位に来ています。・peachy
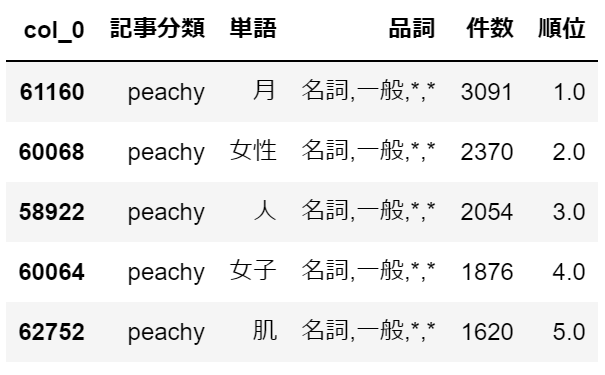
こちらも女性向けの記事の模様。独女通信との切り分けが難しそうです。・smax
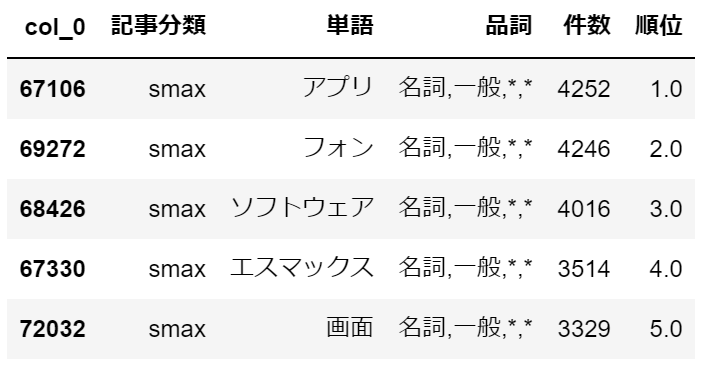
エスマックスは、スマホやモバイル関連の記事のようです。
若干、ITライフハックと内容被る部分がありそうです。・sports-watch
スポーツウォッチは、「選手」、「サッカー」、「野球」はいかにもといった感じですが、
「T」が何なのか不明です。こちらは後でどのような文になっているのか確認します。・topic-news
トピックニュースは様々な記事を扱うイメージでしたが、「ネット」や「掲示板」、「声」といった単語から、ニュースに対する大衆の反応を書いた記事が多いのかもしれません。気になる単語の周辺文の確認
先ほど、スポーツウォッチで関連なさそうな単語が上位に来ていたのが気になったので、確認してみます。
# 気になった単語を設定 word = 'T' df = pd.read_csv('c:/temp/livedoor_corpus.csv') # 気になった単語の出現位置を取得 idxes = df[(df['単語'] == word) &(df['品詞'].str.startswith('名詞,一般'))].index.values.tolist() # ウィンドウサイズ(気になった単語の前後何単語まで確認するかの設定) ws = 20 # 気になる単語の周辺文を取得 l = [] for i, r in df.loc[idxes, :].iterrows(): s = i - ws e = i + ws tmp = df.loc[s:e, :] tmp = tmp[tmp['ファイル名']==r['ファイル名']] lm = list(map(str, tmp['単語'].values.tolist())) ss = ''.join(lm) l.append([r['記事分類'],r['ファイル名'],r['単語'],ss]) rdf = pd.DataFrame(np.array(l)) rdf.columns = ['記事分類','ファイル名','単語','単語周辺文'] rdf.head(5)
どうやら単語一文字の「T」は、URLの一部で時間を表す部分のようです。
URLを除外すれば、4~5位の単語は変化しそうなので、URLを除外した上で再度Top5を確認します。テキストデータの加工
前準備のコードを少し修正し、空白や改行、URLを除去した上で、ファイル毎の形態素を集計します。
URLの除去は単語周辺文の結果を眺め、ある程度URLの型が決まっているように見えたので、ざっくりとした基準で除外を試みます。
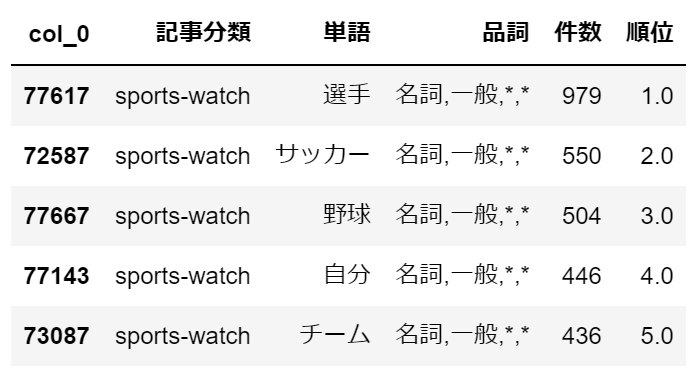
URL部分を完全に除去するような綺麗な処理にはなっていません。import pandas as pd import numpy as np import pathlib import glob import re from janome.tokenizer import Tokenizer tnz = Tokenizer() pth = pathlib.Path('c:/temp/text') l = [] for p in pth.glob('**/*.txt') : # 記事データ以外はスキップ if p.name in ['CHANGES.txt','README.txt','LICENSE.txt']: continue # 記事データを開き、janomeで形態素解析⇒1行1単語の形式でリストに保持 with open(p,'r',encoding='utf-8-sig') as f : s = f.read() s = s.replace(' ', '') s = s.replace(' ', '') s = s.replace('\n', '') s = re.sub(r'http://.*\+[0-9]{4}', '', s) # 空白、改行、URLを除去 l.extend([[p.parent.name, p.name, t.surface, t.part_of_speech] for t in tnz.tokenize(s)]) # リストをデータフレームに変換 df = pd.DataFrame(np.array(l)) # 列名を付与 df.columns = ['記事分類','ファイル名','単語','品詞'] # データフレームをcsv出力 df.to_csv('c:/temp/livedoor_corpus.csv', index=False)スポーツウォッチの頻出単語Top5を再確認
・sports-watch
加工前と比較して、4位~5位の単語が変わりました。
「チーム」はスポーツに関連ありそうです。各記事分類毎の頻出単語Top5は確認できました。
これらを重みにして主成分分析を実施していきます。主成分分析(2次元)
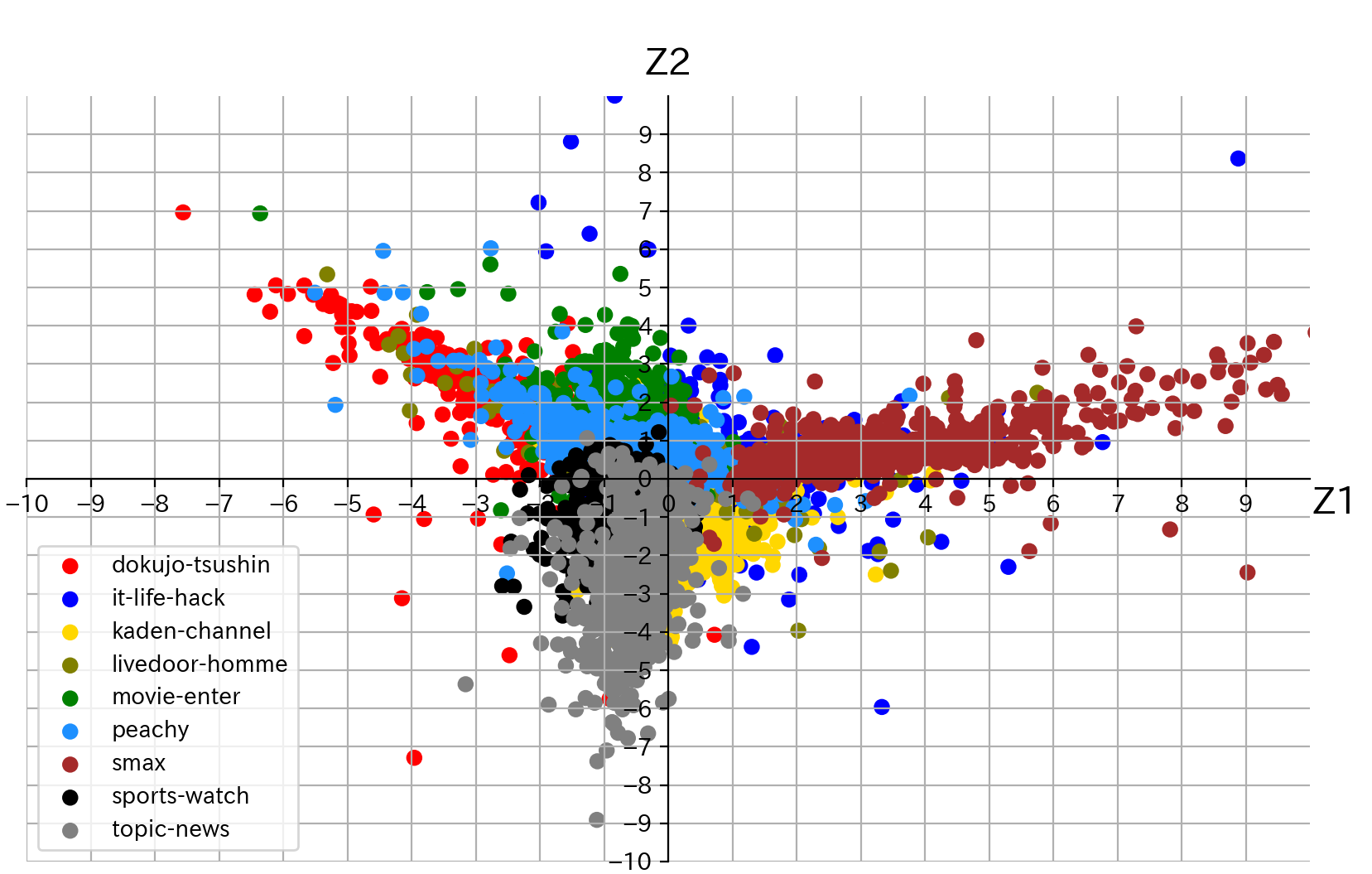
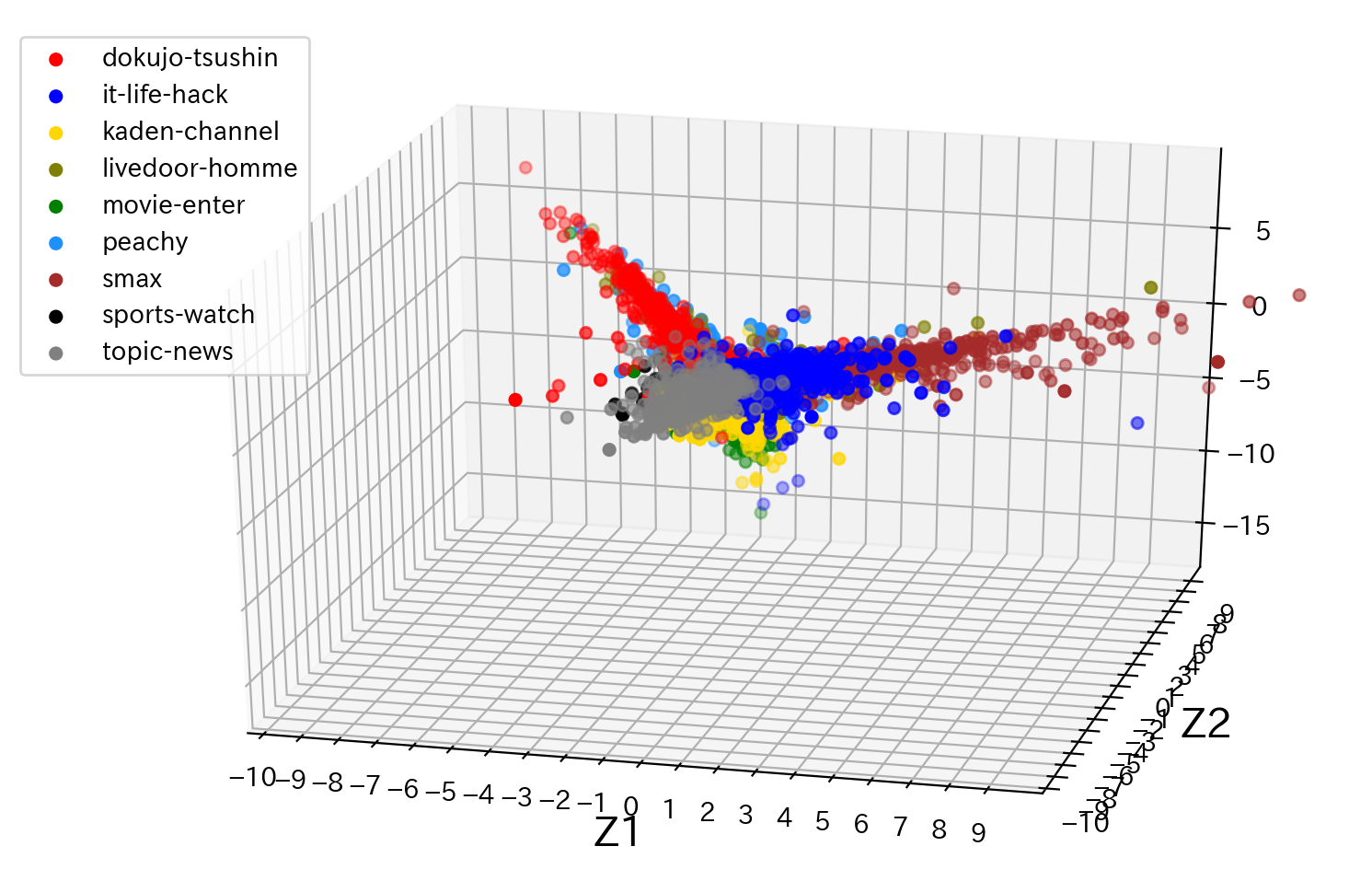
# 上段のセルにて取得した記事分類毎の頻出単語Top5をリストとして保持 words = gdf['単語'].unique().tolist() df = pd.read_csv('c:/temp/livedoor_corpus.csv') df = df[df['品詞'].str.startswith('名詞,一般')].reset_index(drop=True) df = df[df['単語'].isin(words)] # ファイルと記事分類毎の頻出単語Top5のクロス集計表を取得 xdf = pd.crosstab([df['記事分類'],df['ファイル名']],df['単語']).reset_index() # 後に因子負荷量のラベルとして出力するため、リストとして保持 cls = xdf.columns.values.tolist()[2:] # 後のグラフ表示のため、記事分類毎に分類番号を付与 ul = xdf['記事分類'].unique() def _fnc(x): return ul.tolist().index(x) xdf['分類番号'] = xdf['記事分類'].apply(lambda x : _fnc(x)) # 主成分を求めるための前準備 data = xdf.values labels = data[:,0] d = data[:, 2:-1].astype(np.int64) k = data[:, -1].astype(np.int64) # データの標準化 ※ 標準偏差は不偏標準偏差で計算 X = (d - d.mean(axis=0)) / d.std(ddof=1,axis=0) # 相関行列を求めます XX = np.round(np.dot(X.T,X) / (len(X) - 1), 2) # 相関行列の固有値、固有値ベクトルを求めます w, V = np.linalg.eig(XX) # 第1主成分を求める z1 = np.dot(X,V[:,0]) # 第2主成分を求める z2 = np.dot(X,V[:,1]) # グラフ用オブジェクトの生成 fig = plt.figure(figsize=(10, 6)) ax = fig.add_subplot(111) # グリッド線を入れる ax.grid() # 描画するデータの境界 lim = [-10.0, 10.0] ax.set_xlim(lim) ax.set_ylim(lim) # 左と下の軸線を真ん中に持っていく ax.spines['bottom'].set_position(('axes', 0.5)) ax.spines['left'].set_position(('axes', 0.5)) # 右と上の軸線を消す ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 軸の目盛の間隔を調整 ticks = np.arange(-10.0, 10.0, 1.0) ax.set_xticks(ticks) ax.set_yticks(ticks) # 軸ラベルの追加、位置の調整 ax.set_xlabel('Z1', fontsize=16) ax.set_ylabel('Z2', fontsize=16, rotation=0) ax.xaxis.set_label_coords(1.02, 0.49) ax.yaxis.set_label_coords(0.5, 1.02) from matplotlib.colors import ListedColormap colors = ['red','blue','gold','olive','green','dodgerblue','brown','black','grey'] cmap = ListedColormap(colors) a = np.array(list(zip(z1,z2,k,labels))) df = pd.DataFrame({'z1':pd.Series(z1, dtype='float'), 'z2':pd.Series(z2, dtype='float'), 'k':pd.Series(k, dtype='int'), 'labels':pd.Series(labels, dtype='str'), }) # 記事分類毎に色を変えてプロット for l in df['labels'].unique(): d = df[df['labels']==l] ax.scatter(d['z1'],d['z2'],c=cmap(d['k']),label=l) ax.legend() # 描画 plt.show()
結果を見てみると、記事分類によっては、近い位置で点がまとまっていますが、点の重なりが多く、記事分類毎の境界が判り辛いですね。続いて、因子負荷量を確認してみます。
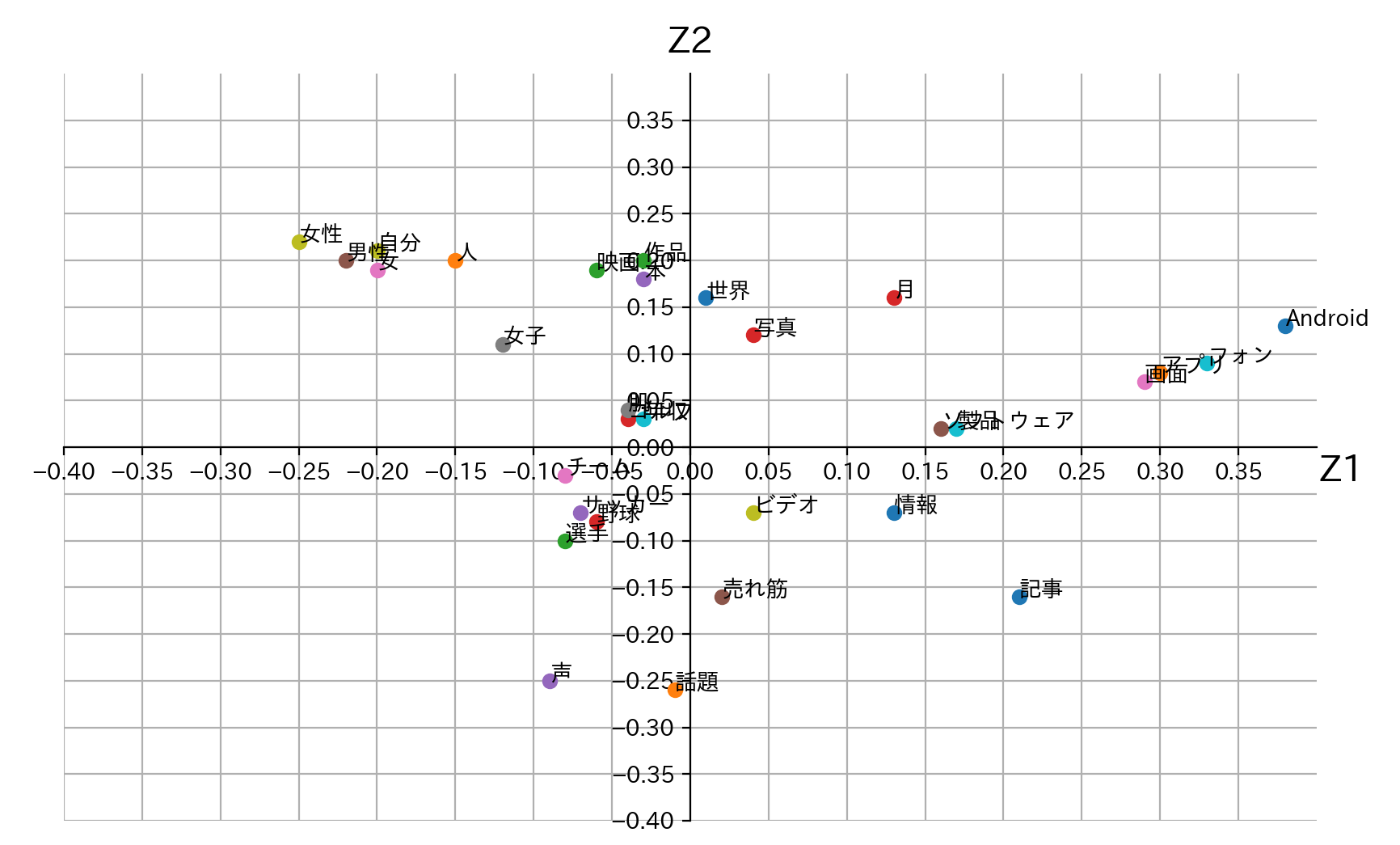
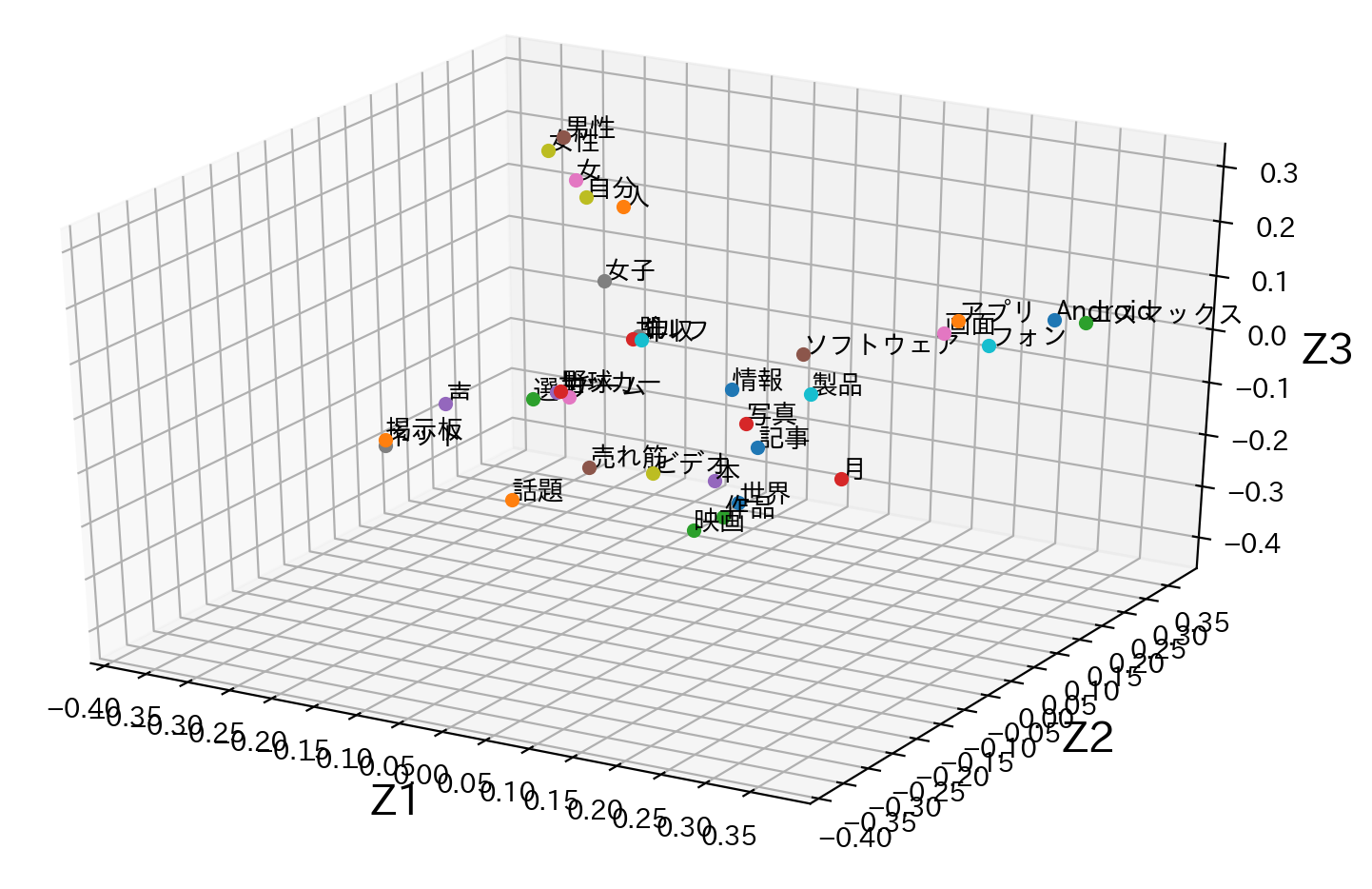
# 最大の固有値に対応する固有ベクトルを横軸、最大から2番目の固有値に対応する固有ベクトルを縦軸とした座標。 V_ = np.array([(V[:,0]),V[:,1]]).T V_ = np.round(V_,2) # グラフ描画用のデータ z1 = V_[:,0] z2 = V_[:,1] # グラフ用オブジェクトの生成 fig = plt.figure(figsize=(10, 6)) ax = fig.add_subplot(111) # グリッド線を入れる ax.grid() # 描画するデータの境界 lim = [-0.4, 0.4] ax.set_xlim(lim) ax.set_ylim(lim) # 左と下の軸線を真ん中に持っていく ax.spines['bottom'].set_position(('axes', 0.5)) ax.spines['left'].set_position(('axes', 0.5)) # 右と上の軸線を消す ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 軸の目盛の間隔を調整 ticks = np.arange(-0.4, 0.4, 0.05) ax.set_xticks(ticks) ax.set_yticks(ticks) # 軸ラベルの追加、位置の調整 ax.set_xlabel('Z1', fontsize=16) ax.set_ylabel('Z2', fontsize=16, rotation=0) ax.xaxis.set_label_coords(1.02, 0.49) ax.yaxis.set_label_coords(0.5, 1.02) # データのプロット for (i,j,k) in zip(z1,z2,cls): ax.plot(i,j,'o') ax.annotate(k, xy=(i, j),fontsize=10) # 描画 plt.show()
先ほどの主成分分析の結果と見比べてみると、各記事分類のまとまりと、似たような位置にその記事分類に関連する単語が来ているように見えます。主成分分析(3次元)
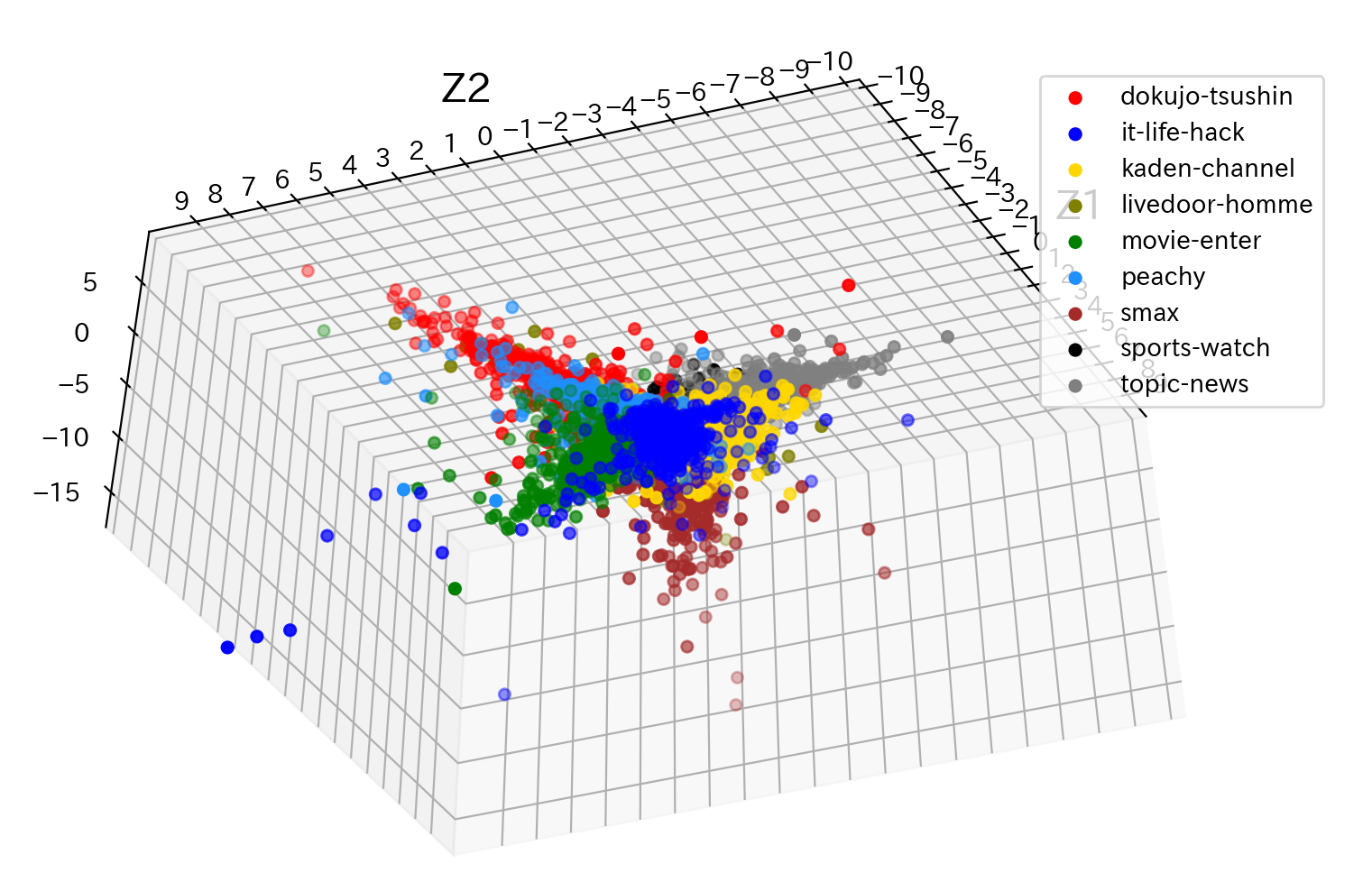
# 上段のセルにて取得した記事分類毎の頻出単語Top5をリストとして保持 words = gdf['単語'].unique().tolist() df = pd.read_csv('c:/temp/livedoor_corpus.csv') df = df[df['品詞'].str.startswith('名詞,一般')].reset_index(drop=True) df = df[df['単語'].isin(words)] # ファイルと記事分類毎の頻出単語Top5のクロス集計表を取得 xdf = pd.crosstab([df['記事分類'],df['ファイル名']],df['単語']).reset_index() # 後に因子負荷量のラベルとして出力するため、リストとして保持 cls = xdf.columns.values.tolist()[2:] # 後のグラフ表示のため、記事分類毎に分類番号を付与 ul = xdf['記事分類'].unique() def _fnc(x): return ul.tolist().index(x) xdf['分類番号'] = xdf['記事分類'].apply(lambda x : _fnc(x)) # 主成分を求めるための前準備 data = xdf.values labels = data[:,0] d = data[:, 2:-1].astype(np.int64) k = data[:, -1].astype(np.int64) # データの標準化 ※ 標準偏差は不偏標準偏差で計算 X = (d - d.mean(axis=0)) / d.std(ddof=1,axis=0) # 相関行列を求めます XX = np.round(np.dot(X.T,X) / (len(X) - 1), 2) # 相関行列の固有値、固有値ベクトルを求めます w, V = np.linalg.eig(XX) # 第1主成分を求める z1 = np.dot(X,V[:,0]) # 第2主成分を求める z2 = np.dot(X,V[:,1]) # 第3主成分を求める z3 = np.dot(X,V[:,2]) # グラフ用オブジェクトの生成 fig = plt.figure(figsize=(10, 6)) ax = fig.add_subplot(111, projection='3d') # グリッド線を入れる ax.grid() # 描画するデータの境界 lim = [-10.0, 10.0] ax.set_xlim(lim) ax.set_ylim(lim) # 左と下の軸線を真ん中に持っていく ax.spines['bottom'].set_position(('axes', 0.5)) ax.spines['left'].set_position(('axes', 0.5)) # 右と上の軸線を消す ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 軸の目盛の間隔を調整 ticks = np.arange(-10.0, 10.0, 1.0) ax.set_xticks(ticks) ax.set_yticks(ticks) # 軸ラベルの追加、位置の調整 ax.set_xlabel('Z1', fontsize=16) ax.set_ylabel('Z2', fontsize=16, rotation=0) ax.xaxis.set_label_coords(1.02, 0.49) ax.yaxis.set_label_coords(0.5, 1.02) from matplotlib.colors import ListedColormap colors = ['red','blue','gold','olive','green','dodgerblue','brown','black','grey'] cmap = ListedColormap(colors) a = np.array(list(zip(z1,z2,z3,k,labels))) df = pd.DataFrame({'z1':pd.Series(z1, dtype='float'), 'z2':pd.Series(z2, dtype='float'), 'z3':pd.Series(z3, dtype='float'), 'k':pd.Series(k, dtype='int'), 'labels':pd.Series(labels, dtype='str'), }) for l in df['labels'].unique(): d = df[df['labels']==l] ax.scatter(d['z1'],d['z2'],d['z3'],c=cmap(d['k']),label=l) ax.legend() # 描画 plt.show()
3次元で見てみても、やはり各点が重なっていて、綺麗に境界線を引くのは難しそうです。
ただ、グラフをぐるぐる回せるので、回して見れるのがおもしろいです。
ひっくり返してみました。因子負荷量(3次元)
# 最大の固有値に対応する固有ベクトルを横軸、最大から2番目の固有値に対応する固有ベクトルを縦軸とした座標。 V_ = np.array([(V[:,0]),V[:,1],V[:,2]]).T V_ = np.round(V_,2) # グラフ描画用のデータ z1 = V_[:,0] z2 = V_[:,1] z3 = V_[:,2] # グラフ用オブジェクトの生成 fig = plt.figure(figsize=(10, 6)) ax = fig.add_subplot(111, projection='3d') # グリッド線を入れる ax.grid() # 描画するデータの境界 lim = [-0.4, 0.4] ax.set_xlim(lim) ax.set_ylim(lim) # 左と下の軸線を真ん中に持っていく ax.spines['bottom'].set_position(('axes', 0.5)) ax.spines['left'].set_position(('axes', 0.5)) # 右と上の軸線を消す ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) # 軸の目盛の間隔を調整 ticks = np.arange(-0.4, 0.4, 0.05) ax.set_xticks(ticks) ax.set_yticks(ticks) # 軸ラベルの追加、位置の調整 ax.set_xlabel('Z1', fontsize=16) ax.set_ylabel('Z2', fontsize=16) ax.set_zlabel('Z3', fontsize=16) ax.xaxis.set_label_coords(1.02, 0.49) ax.yaxis.set_label_coords(0.5, 1.02) # データのプロット for zdir, x, y, z in zip(cls, z1, z2, z3): ax.scatter(x, y, z) ax.text(x, y, z, zdir) # 描画 plt.show()
ソースコード
https://github.com/torahirod/TextDataPCA
感想
記事分類毎の頻出単語Top5を使った主成分分析だけでも、ある程度のまとまりは視覚的に確認することができ、おもしろかったです。
また、以下を試して結果を見てみるのもおもしろそうです。
・Top10まで広げてみる。
・Top5のうち、複数の記事分類に重複して出現している単語は除外してみる。
・単純な出現頻度のTop5ではなく、TF-IDFなどの特徴量でのTop5を試してみる。ここから目指すところとしては、主成分分析で得られた、2次元座標、3次元座標の情報を使って、k-meansと組み合わせて文書分類に挑戦したいです。




- 投稿日:2020-02-14T22:54:41+09:00
Djangoでレンタリングするhtmlを共通化する
概要
<header>や<footer>、jsやcssの参照先を定義した<link>や<script>をhtmlファイル単位で書いていたら保守性が低下する。
thymeleafの様にLayout Dialectで他のhtmlファイルを引用することはできないのか。
調べてみたところdjangoにはテンプレートの継承の概念があるのでこれを使うこととする。Djangoのテンプレート(html)の共通化と継承について
htmlファイルの継承関係
参照元には共通化したhtmlタグを記載し、参照元によって切り替わる部分にはテンプレートタグ
{% block <ブロック名> %}~{% endblock %}を挿入するparent.html<!DOCTYPE html> <html> <head> </head> <body> {% block mainblock %} (1) {% endblock %} </body> </html>参照先にはテンプレートタグ
{% extends "htmlファイル名" %}を記述し、切り替える内容にテンプレートタグ{% block <ブロック名> %}~{% endblock %}を挿入する
extendsに指定するhtmlファイル名にはdjangoで作成されたtempleteディレクトリ配下からのフルパスを指定する。child.html<!DOCTYPE html> {% extends "pull/parent.html" %} (2) {% block mainblock %} (3) <div> <span>hello python!!</span> </div> {% endblock %}(1).参照先によって切り替えるエリア。blockは複数指定できる。
(2).参照するhtmlファイルを指定する。
(3).参照元に挿入したいエリアを書く。レンタリング後
<!DOCTYPE html> <html> <head> </head> <body> <div> <span>hello python!!</span> </div> </body> </html>感想
- thymeleafだと参照元のhtmlタグにて宣言が必要だが、djangoではその必要がない。参照先htmlで使用するテンプレートを指定するだけで、理解が浅い私にもわかりやすかった。
- 切り替えたい部分をテンプレートタグで囲むだけでよいのがとても分かりやすい。thymeleafでは切り替えたいhtmlタグに
layout:fragmentを書いて切り替えるので、埋め込み用のタグが必要。- java育ちのため継承と聞くと拡張したくなる。継承テンプレートを継承したテンプレートを参照することができるのか、できるけどそんなことしてよいのか・・・。暇があるときにでも試してみる。
- 投稿日:2020-02-14T22:42:29+09:00
fish3.1.0でpyenvの初期化失敗の対処方法
tl;dr
~/.config/fish/config.fishのpyenv(rbenv)の行を以下の用に変更すると問題が起きなくなります。before
. (pyenv init - | psub) . (rbenv init - | psub)after
source (pyenv init - | psub) source (rbenv init - | psub)発生する問題
fish3.0.2までは
.コマンドを使うことができたのですが、どうやら fish3.1.0から使うことができなくなったようです。
これは元から予告されていたこと ではありますが、. (a single period) is an alias for the source command. The use of . is deprecated in favour of source, and . will be removed in a future version of fish.ついになくなってしまったんですね(泣)
bash系のコマンドを使っていたり、
.コマンドをなんとなく使っていたという方はこれを機に設定ファイルを見直す必要があります。pyenv(rbenv)の初期化の構文でも
.コマンドを使うことが一般的ですが、fish3.1.0で動かすと以下のようにエラーメッセージが発生してしまいます。source: Error encountered while sourcing file '/var/folders/yv/0npp741974sgp79671hf_48c0000gn/T//.psub.pxGqFIeIaF': source: No such file or directory source: Error encountered while sourcing file '/var/folders/yv/0npp741974sgp79671hf_48c0000gn/T//.psub.VyHOD74WrY': source: No such file or directory終わりに
このようなエラーが出たら冒頭で紹介した通り、
sourceコマンドを使うようにすれば問題なく動くようになります。
僕も今朝この問題に悩まされたので、他に困っている方がいたら参考にしてください〜〜
- 投稿日:2020-02-14T22:26:22+09:00
機械学習のアルゴリズム(重回帰分析)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
今回は単回帰分析を発展させ、「重回帰分析」をやってみたいと思います。参考にしたのは次のページです。
基本
単回帰分析では、平面上の$N$個の$(x, y)$に対する近似直線$$ y = Ax + B $$を引くための$A$と$B$を求めました。具体的には、直線と$i$番目の点の差の二乗の和$$\sum_{i=1}^{N} (y_i-(Ax+B))^2$$が最も小さくなるような$A$と$B$を求めました。
重回帰は、単回帰で1つだった変数(説明変数)を増やした場合の係数を求めるものです。つまり、直線の式を$$ y=w_0x_0+w_1x_1+\cdots+w_nx_n$$とおいた場合($x_0=0$とする)の$ (w_0, w_1, \cdots, w_n)$を求めればよいことになる。
重回帰の解き方
ここからはほぼ参考にした記事のパクリに近くなってしまうのだが、できるだけわかりやすく書くよう努力します。
直線の式を行列の形にすると、
y = \begin{bmatrix} w_0 \\ w_1 \\ w_2 \\ \vdots \\ w_n \end{bmatrix} \begin{bmatrix} x_0, x_1, x_2, \cdots, x_n\end{bmatrix}となる($x_0=0$)。
実測値$\hat{y}$との差の二乗和は$$ \sum_{i=1}^{n}(y-\hat{y})^2$$となるので、これを変形していく。なお、$(w_0, w_1, \cdots, w_n)$を$\boldsymbol{w}$、全ての説明変数を行列$\boldsymbol{X}$とする。\sum_{i=1}^{n}(y-\hat{y})^2 \\ = (\boldsymbol{y}-\hat{\boldsymbol{y}})^{T}(\boldsymbol{y}-\hat{\boldsymbol{y}}) \\ = (\boldsymbol{y}-\boldsymbol{Xw})^{T}(\boldsymbol{y}-\boldsymbol{Xw}) \\ = (\boldsymbol{y}^{T}-(\boldsymbol{Xw})^{T})(\boldsymbol{y}-\boldsymbol{Xw}) \\ = (\boldsymbol{y}^{T}-\boldsymbol{w}^{T}\boldsymbol{X}^{T})(\boldsymbol{y}-\boldsymbol{Xw}) \\ = \boldsymbol{y}^{T}\boldsymbol{y}-\boldsymbol{y}^{T}\boldsymbol{X}\boldsymbol{w}-\boldsymbol{w}^{T}\boldsymbol{X}^{T}\boldsymbol{y}-\boldsymbol{w}^{T}\boldsymbol{X}^{T}\boldsymbol{X}\boldsymbol{w} \\ = \boldsymbol{y}^{T}\boldsymbol{y}-2\boldsymbol{y}^{T}\boldsymbol{X}\boldsymbol{w}-\boldsymbol{w}^{T}\boldsymbol{X}^{T}\boldsymbol{X}\boldsymbol{w}$\boldsymbol{w}$に無関係なものは定数なので、それぞれ$\boldsymbol{X}^{T}\boldsymbol{X}=A$、$-2\boldsymbol{y}^{T}\boldsymbol{X}=B$、$\boldsymbol{y}^{T}\boldsymbol{y}=C$とおくと、最小二乗和$L$は、$$ L = C-B\boldsymbol{w}-\boldsymbol{w}^{T}A\boldsymbol{w}$$となる。
$L$は$\boldsymbol{w}$の二次関数であるため、$L$が最小となる$\boldsymbol{w}$は、$L$を$\boldsymbol{w}$で偏微分した式が0になる$\boldsymbol{w}$を求めればよいことになる。\begin{split}\begin{aligned} \frac{\partial}{\partial {\boldsymbol{w}}} L &= \frac{\partial}{\boldsymbol{w}} (C + B\boldsymbol{w} + \boldsymbol{w}^T{A}\boldsymbol{w}) \\ &=\frac{\partial}{\partial {\boldsymbol{w}}} (C) + \frac{\partial}{\partial {\boldsymbol{w}}} ({B}{\boldsymbol{w}}) + \frac{\partial}{\partial {\boldsymbol{w}}} ({\boldsymbol{w}}^{T}{A}{\boldsymbol{w}}) \\ &={B} + {w}^{T}({A} + {A}^{T}) \end{aligned}\end{split}これを0にしたいので、
\boldsymbol{w}^T(A+A^T)=-B \\ \boldsymbol{w}^T(\boldsymbol{X}^{T}\boldsymbol{X}+(\boldsymbol{X}^{T}\boldsymbol{X})^T)=2\boldsymbol{y}^{T}\boldsymbol{X} \\ \boldsymbol{w}^T\boldsymbol{X}^{T}\boldsymbol{X}=\boldsymbol{y}^T\boldsymbol{X} \\ \boldsymbol{X}^{T}\boldsymbol{X}\boldsymbol{w} = \boldsymbol{X}^T\boldsymbol{y} \\この形は連立一次方程式の形で、$\boldsymbol{X}^{T}\boldsymbol{X}$が正則でないと連立方程式が解けません。どこかの$x$に強い相関がある場合、つまりどちらか一方のデータ列で別のデータ列が説明できる場合に正則になりません。この状態を多重共線性、通称(マルチコ:multicollinearity)があると言います。
正則であると仮定すると、
(\boldsymbol{X}^{T}\boldsymbol{X})^{-1}\boldsymbol{X}^{T}\boldsymbol{X}\boldsymbol{w}=(\boldsymbol{X}^{T}\boldsymbol{X})^{-1}\boldsymbol{X}^T\boldsymbol{y} \\ \boldsymbol{w}=(\boldsymbol{X}^{T}\boldsymbol{X})^{-1}\boldsymbol{X}^T\boldsymbol{y}これで$\boldsymbol{w}$が求まりました。
ptyhonで愚直に実装してみる
データはscikit-learnの糖尿病データ(diabetes)を使います。ターゲット(1年後の進行状況)とBMI、S5(ltg:ラモトリオギン)のデータがどう関連しているか調べてみましょう。
まずはデータを眺める
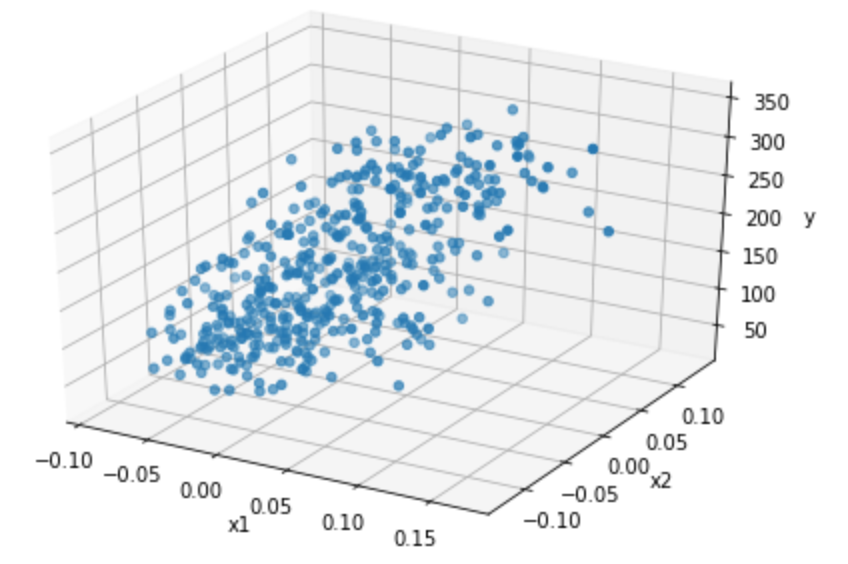
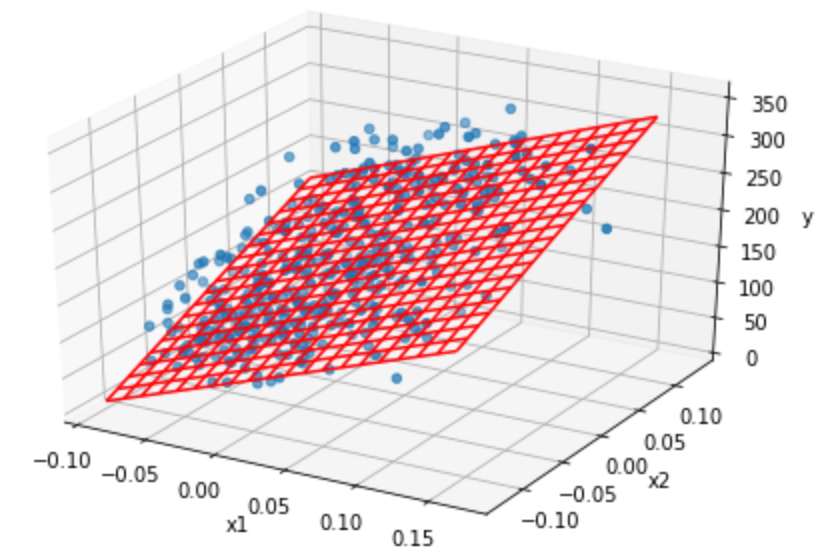
まずはデータをプロットしてみる。説明変数が2つとターゲットなので3次元データになる。3次元をこえるとグラフはかけないですね。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets from mpl_toolkits.mplot3d import Axes3D import seaborn as sns %matplotlib inline diabetes = datasets.load_diabetes() df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names) fig=plt.figure() ax=Axes3D(fig) x1 = df['bmi'] x2 = df['s5'] y = diabetes.target ax.scatter3D(x1, x2, y) ax.set_xlabel("x1") ax.set_ylabel("x2") ax.set_zlabel("y") plt.show()結果は次のグラフで、なんとなく斜面のような感じになっています。
計算してみる
$ \boldsymbol{w} $を求める式は次のような式でした。正規方程式と言うらしいです。
$$ \boldsymbol{w}=(\boldsymbol{X}^{T}\boldsymbol{X})^{-1}\boldsymbol{X}^T\boldsymbol{y} $$これをそのままコードにしてみます。X = pd.concat([pd.Series(np.ones(len(df['bmi']))), df.loc[:,['bmi','s5']]], axis=1, ignore_index=True).values y = diabetes.target w = np.linalg.inv(X.T @ X) @ X.T @ y 結果:[152.13348416 675.06977443 614.95050478]pythonの行列計算は直感的でいいですね。ちなみに、説明変数が1つの場合は単回帰と同じ結果になります。説明変数n個で一般化したから当然ですね。
X = pd.concat([pd.Series(np.ones(len(df['bmi']))), df.loc[:,['bmi']]], axis=1, ignore_index=True).values y = diabetes.target w = np.linalg.inv(X.T @ X) @ X.T @ y print(w) [152.13348416 949.43526038]説明変数が2つのときの計算値をもとに、グラフを描いてみます。
fig=plt.figure() ax=Axes3D(fig) mesh_x1 = np.arange(x1.min(), x1.max(), (x1.max()-x1.min())/20) mesh_x2 = np.arange(x2.min(), x2.max(), (x2.max()-x2.min())/20) mesh_x1, mesh_x2 = np.meshgrid(mesh_x1, mesh_x2) x1 = df['bmi'].values x2 = df['s5'].values y = diabetes.target ax.scatter3D(x1, x2, y) ax.set_xlabel("x1") ax.set_ylabel("x2") ax.set_zlabel("y") mesh_y = w[1] * mesh_x1 + w[2] * mesh_x2 + w[0] ax.plot_wireframe(mesh_x1, mesh_x2, mesh_y, color='red') plt.show()結果は下記の図のようになりました。ちゃんとできてるようなできてないようなw
評価
平面の一致度を決定係数で評価してみる。
決定係数$R^2$は、「全変動」と「回帰変動」を求める必要がある。
- 全変動:実測値と全体の平均値の差
- 回帰変動:予測値と全体の平均の差
決定係数は、説明変数が目的変数をどれくらい説明しているか、つまり「回帰変動が全変動に対してどれだけ多いか」を求める。全変動と回帰変動の二乗和(分散)を用い、
R^2=\frac{\sum_{i=0}^{N}(\hat{y}_i-\bar{y})^2}{\sum_{i=0}^{N}(y_i-\bar{y})^2}全変動は回帰変動と全差変動(予測値と実測値)の和なので、
R^2=1-\frac{\sum_{i=0}^{N}(y_i-\hat{y}_i)^2}{\sum_{i=0}^{N}(y_i-\bar{y})^2}これをpythonで書いて、先ほどの決定係数を算出する。
u = ((y-(X @ w))**2).sum() v = ((y-y.mean())**2).sum() R2 = 1-u/v print(R2) 0.4594852440167805という結果になりました。
正規化、標準化
さて、今回の例では「BMI」と「ltg」の値を使いましたが、もっと変数が増えたりすると例えば$10^5$オーダの数字と$10^{-5}$オーダのデータが混在する可能性もあります。こうなってしまうと計算がうまくいかないことがおきます。元のデータを保ったままデータを揃えることを正規化(normalization)といいます。
Min-Maxスケーリング
Min-Maxスケーリングは最小値が-1、最大値が1となるように変換します。つまり、$$ x_{i_{new}}=\frac{x_i-x_{min}}{x_{max}-x_{min}} $$を計算します。
標準化(standardization)
標準化は、平均が0、分散が1となるように変換します。つまり、$$ x_{i_{new}}=\frac{x_i-\bar{x}}{\sigma} $$を計算します。
以下のページに詳しく書いています。
pythonで標準化してみる
pythonで計算してみようとしたんですが、どうもscikit-learnのdiabetesデータはすでに正規化されてるみたいで意味がありませんでしたw
scikit-learnで計算してみる
重回帰はscikit-learnのLinearRegressionを使い、学習データでfitさせるだけです。
from sklearn import linear_model clf = linear_model.LinearRegression() clf.fit(df[['bmi', 's5']], diabetes.target) print("coef: ", clf.coef_) print("intercept: ", clf.intercept_) print("score: ", clf.score(df[['bmi', 's5']], diabetes.target)) coef: [675.06977443 614.95050478] intercept: 152.1334841628967 score: 0.45948524401678054これだけです。結果はscikit-learnを使わない結果と一緒になりましたね。
まとめ
単回帰から重回帰に発展させました。正規方程式
$$ \boldsymbol{w}=(\boldsymbol{X}^{T}\boldsymbol{X})^{-1}\boldsymbol{X}^T\boldsymbol{y} $$に一般化させることで、複数の説明変数に拡張することができました。複数の説明変数はスケールを揃える必要があるので、標準化という手法で粒度を揃えて計算する必要があります。これで線形近似は理解できましたね。
- 投稿日:2020-02-14T21:47:52+09:00
自動で 番組表取得→カレンダーに登録する システムを1日で作ってみた
概要
作ってみた話 系の投稿をしたかったのと、サーバーレスを触ってみたかったので、
毎回録画している好きな番組岩合光昭の世界ネコ歩きの番組表を取得し、カレンダー(timetree)に自動登録するシステムを作ってみました。使用したもの
- NHK番組表API -> 番組表の取得
- Google Cloud Function
- cron-job.org -> 無料定期実行サービス
- timetree API
NHK番組表APIというものがあるので、それを1日1回取得し、データをフィルターしてカレンダーのAPIで登録するようにします。
定期実行にはcron-job.orgという無料サービスがあり、指定した時間に指定したURLにリクエストを送れるものがあるので、利用しました。今回は、なんとなく1日で完成させたかったので、一番慣れているPythonを書けるGoogle Cloud Functionを利用しました。
作成
大したコードではないものが続きます。すみません。
最初はエラー検知でメール送信とか考えてたんですが、Google Cloud Functionについて調べていたら気がついたら夜・・・
心のザッカーバーグがあの言葉を言ってきたのでとりあえず作成しました。番組表取得
最初はクラス分けてやろうとしてた痕跡が残ってます。
# default import os from typing import List from datetime import datetime, timedelta import json # from pip import requests apikey = os.environ["NHK_API_KEY"] class NHKApi(): area = "130" genre = "1001" base_url = "http://api.nhk.or.jp/v2/pg/genre" # NHK総合 g1 # BS プレミアム s3 @classmethod def url(cls, service: str, date_str: str) -> str: url = f"{cls.base_url}/{cls.area}/{service}/{cls.genre}/{date_str}.json" return url def get_g1_data(date_str: str): url = NHKApi.url("g1", date_str) response = requests.get(url, params={"key": apikey}) if response.status_code == 200: return response.json() else: return {} def get_s3_data(date_str: str): url = NHKApi.url("s3", date_str) response = requests.get(url, params={"key": apikey}) if response.status_code == 200: return response.json() else: return {} def check_is_nekoaruki(service: str, program: dict) -> bool: """番組表データにネコ歩きが入っているかどうかを判定""" is_nekoaruki = False try: title = program["title"] if "ネコ歩き" in title: is_nekoaruki = True except KeyError: print("data type is invalided") return is_nekoaruki def filter_nekoaruki(service: str, data: dict) -> List[dict]: filtered_programs: list = [] if data and data.get("list"): try: programs = data["list"][service] filtered_programs = [i for i in programs if check_is_nekoaruki(service, i)] except KeyError: print("data type is invalided") return filtered_programs def get_days() -> List[str]: days_ls = [] dt_format = "%Y-%m-%d" search_day = 6 # 6日分取得 current = datetime.now() for i in range(search_day): days_ls.append((current + timedelta(days=i)).strftime(dt_format)) return days_ls def get_nekoaruki() -> List[dict]: days = get_days() programs: list = [] for day in days: g1_data = filter_nekoaruki("g1", get_g1_data(day)) s3_data = filter_nekoaruki("s3", get_s3_data(day)) one_day_data = g1_data + s3_data if one_day_data: for data in one_day_data: programs.append(data) return programsカレンダー追加
ここもカレンダーID取得 -> 登録済データと比較 -> 追加しているだけです。
妥協の嵐。class TimeTreeAPI(): url = "https://timetreeapis.com" api_key = os.environ["TIMETREE_API_KEY"] headers = {'Authorization': f'Bearer {api_key}', "Accept": "application/vnd.timetree.v1+json", "Content-Type": "application/json"} def get_calendar() -> str: response = requests.get(TimeTreeAPI.url + "/calendars", headers=TimeTreeAPI.headers) if response.status_code == 200: data = response.json() calendars = data["data"] for calendar in calendars: # 1つしかカレンダー使ってないので最初のカレンダーでいいや if calendar["attributes"]["order"] == 0: return calendar else: pass else: return response.text def check_upcoming_events(calendar_id: str): """7日分の登録済イベントを取得""" response = requests.get(TimeTreeAPI.url + f"/calendars/{calendar_id}/upcoming_events", headers=TimeTreeAPI.headers, params={"days": 7}) if response.status_code == 200: data = response.json() return data else: return None def convert_to_timetree_style(data: dict, calendar_id: str): timetree_dict = { "data": { "attributes": { "title": data["title"], "category": "schedule", "all_day": False, "start_at": data["start_time"], "end_at": data["end_time"], "description": data["title"] + "\n" + data["content"], "location": data["service"]["name"], "url": "https://www4.nhk.or.jp/nekoaruki/" }, "relationships": { "label": { "data": { "id": f"{calendar_id},1", "type": "label" } } } } } return timetree_dict def add_event(data: dict, calendar_id: str): """イベントをAPIに送信し追加する""" json_data = json.dumps(data) response = requests.post(TimeTreeAPI.url + f"/calendars/{calendar_id}/events", headers=TimeTreeAPI.headers, data=json_data) if response.status_code == 201: return True else: return False def convert_all(programs: dict, cal_id: str): events: list = [] for program in programs: events.append(convert_to_timetree_style(program, cal_id)) return events def post_events(data_ls: List[dict], calendar_id: str, registered: List[dict]): """登録済イベントと取得したデータを比較して追加""" add_events: list = [] title_ls = [i["title"] for i in registered] for data in data_ls: # タイトルが登録済ならスキップ # 登録してから放送時間変わったの感知出来ないけどいいや if data["data"]["attributes"]["title"] in title_ls: pass else: add_events.append(data) if add_events: for event in add_events: add_event(data, calendar_id) def extract_registered_data(data_ls: List[dict]): """登録済のデータからネコ歩きイベントのみ抽出""" filtered_registered_events = filter(lambda x: "ネコ歩き" in x["attributes"]["title"], data_ls) extracted: list = [] # 最初は開始時間が変わったら更新するつもりだった for program in filtered_registered_events: extracted.append({"title": program["attributes"]["title"], "start": program["attributes"]["start_at"]}) return extracted def main(request): if request.get_json()["hoge"] == "hoge": # get programs nekoaruki_programs = get_nekoaruki() # get cal_id cal_id = get_calendar()["id"] # get upcoming events registered_events = check_upcoming_events(cal_id)["data"] # filter upcoming events extracted = extract_registered_data(registered_events) data_ls = convert_all(nekoaruki_programs, cal_id) post_events(data_ls, cal_id, extracted) return "success!" else: return "failed..."Functionの設定
プロジェクトを作成 -> Function作成 -> コード貼り付け -> 環境変数等設定します。
環境変数にはAPI Keyの他に
TZ=Asia/Tokyoを入れ、タイムゾーンを変更するのを忘れずに。
requirements.txtもrequests==2.22.0を追加。
定期実行の設定
cron-job.orgでアカウントを作成し、Cronjobs->Create cronjobからjobを設定するだけです。
Postするデータも設定出来ます。
まとめ
ただ関数を並べただけのコードを投稿するのは恥ずかしいですね・・・
しかし、動けばいいで作れるのが趣味プロダクトのいいところでもあると思います。
すべて無料でできるのもいいですね。サーバーレス環境も簡単に作成できることがわかったのも良い収穫でした。
これでネコ歩きの放送時間を忘れることはありません。
岩合光昭の世界ネコ歩き 見ましょう。


- 投稿日:2020-02-14T21:38:50+09:00
Serverless Frameworkを使ったLambda+Pythonのローカル開発環境を構築
Windows上にServerless Frameworkを使ったLambda+Pythonのローカル開発環境を構築した時のメモ。実際にAWSにデプロイせずにローカルで単体テストまでできる環境を構築します。
Pythonのインストール
本家のWindows用ダウンロードサイトから最新版(執筆時点では3.8.1)をダウンロードし、実行する。
最初の画面で「Add Python 3.8 to PATH」にチェックを入れて「Install Now」で標準インストールする。最後の画面で「Disable path length limit」をクリックして、パス文字列長の制限を解除しておく。
>python --version Python 3.8.1バージョンが正しく表示されればOK。
pipenvのインストール
Pythonのパッケージ管理システムpipを使ってインストールする。
>pip install pipenv (略) Successfully installed appdirs-1.4.3 certifi-2019.11.28 distlib-0.3.0 filelock-3.0.12 pipenv-2018.11.26 six-1.14.0 virtualenv-20.0.1 virtualenv-clone-0.5.3 >pipenv --version pipenv, version 2018.11.26Node.jsのインストール
Serverless FrameworkはNode.jsで作られているため、Node.jsのインストールをする。
本家のダウンロードサイトから最新版のWindows用インストーラー(執筆時点では12.15.0)をダウンロードし、実行する。
オプションは特に変更しないでデフォルトのままインストールする。>node --version v12.15.0Serverless Frameworkのインストール
Node.jsのパッケージ管理システムnpmを使ってインストールする。
>npm install -g serverless (略) + serverless@1.63.0 added 527 packages from 335 contributors in 21.542s >sls --version Framework Core: 1.63.0 Plugin: 3.3.0 SDK: 2.3.0 Components Core: 1.1.2 Components CLI: 1.4.0プロジェクトの作成
Serverless Frameworkのプロジェクトを作成。テンプレートはAWSのPython3用。
>sls create -t aws-python3 -p helloworld (略) Serverless: Successfully generated boilerplate for template: "aws-python3"
-tは使用するテンプレートの指定。AWS上のLambdaでPython3を使って開発するのでaws-python3を指定する。
-pはプロジェクトディレクトリのパス(-nを指定しなければ、そのままプロジェクト名にもなる)カレントパスの下にhelloworldというプロジェクトディレクトリが作成され、Serverless Frameworkの設定ファイルserverless.ymlとLambda関数の実装が書かれているhandler.pyと.gitignoreが作成される。
Python仮想環境の作成
プロジェクトごとにPythonライブラリを管理するため、プロジェクトディレクトリの中に入り、このプロジェクト用の仮想環境を作る。
>cd helloworld >pipenv install Creating a virtualenv for this project… (略) Successfully created virtual environment! (略) To activate this project's virtualenv, run pipenv shell. Alternatively, run a command inside the virtualenv with pipenv run.サンプル関数の実行
テンプレートに最初から定義されているhelloという名前のLambda関数をローカル実行してみる。
>sls invoke local -f hello { "statusCode": 200, "body": "{\"message\": \"Go Serverless v1.0! Your function executed successfully!\", \"input\": {}}" }handler.pyに記述されたhello関数が実行され、レスポンスが返った。
invoke localで実行しているため、ローカル実行となる。これでひとまずLambda + Pythonでローカル開発する環境が完成。
- 投稿日:2020-02-14T21:15:31+09:00
python3でAPIをコールする。
pythonの
urllib.requestモジュールを用いてAPIをコールするメモ。下準備
- 適当なlambdaとAPI Gatewayを用意。
lambdaは受け取った
eventを返却するようにする。import json def lambda_handler(event, context): return { 'statusCode': 200, 'body': event }API Gatewayでは各種メソッド(GET、POST、PUT)を用意。
- メソッドリクエスト → APIキーの必要性
trueに指定。- 統合リクエスト → lambda関数を指定。
[APIのデプロイ]を実行し、URIを取得。(API Gatewayで何かの更新をしたのなら都度デプロイすること!でないと反映されない。←めっちゃこれハマる。)
[使用量プラン]から[作成]を選び、APIステージを選択、レート・バースト・クォータを設定、APIキーを作成する。
本題のAPIを叩くlambda
import json import urllib.request, urllib.error request_url = "https://xxxx.execute-api.ap-northeast-1.amazonaws.com/stage" api_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxx" def lambda_handler(event, context): headers = {'x-api-key': api_key, "Content-Type":"application/json"} request_json = { "key":"val" } req = urllib.request.Request(url=request_url, method="GET", headers=headers, data=json.dumps(request_json).encode()) with urllib.request.urlopen(req) as res: body = res.read().decode() return json.loads(body)参考
以下を加筆修正
https://qiita.com/j_tamura/items/5a22b102a58d1fa93a78
- 投稿日:2020-02-14T20:53:56+09:00
メルアイコン生成器を作った話
はじめに
このアイコンをご存知でしょうか。
そう、かの有名なMelvilleさんのアイコンです。
Melvilleさんに好きなキャラなどを描いてもらい、それをtwitterのサムネにしている人が大勢いることで知られ大きな支持を得ています。
この方の描くアイコンはその特有の作風から、「メルアイコン」などとよく呼ばれています。
代表的なメルアイコンの例

(それぞれゆかたゆさんとしゅんさんのものです (2020/2/12現在))
自分もこんな感じのアイコンが欲しい!!!!!!ということで機械学習でメルアイコン生成器を作りました。
本記事ではそれに用いた手法をおおざっぱに紹介していきたいと思います。GANとは
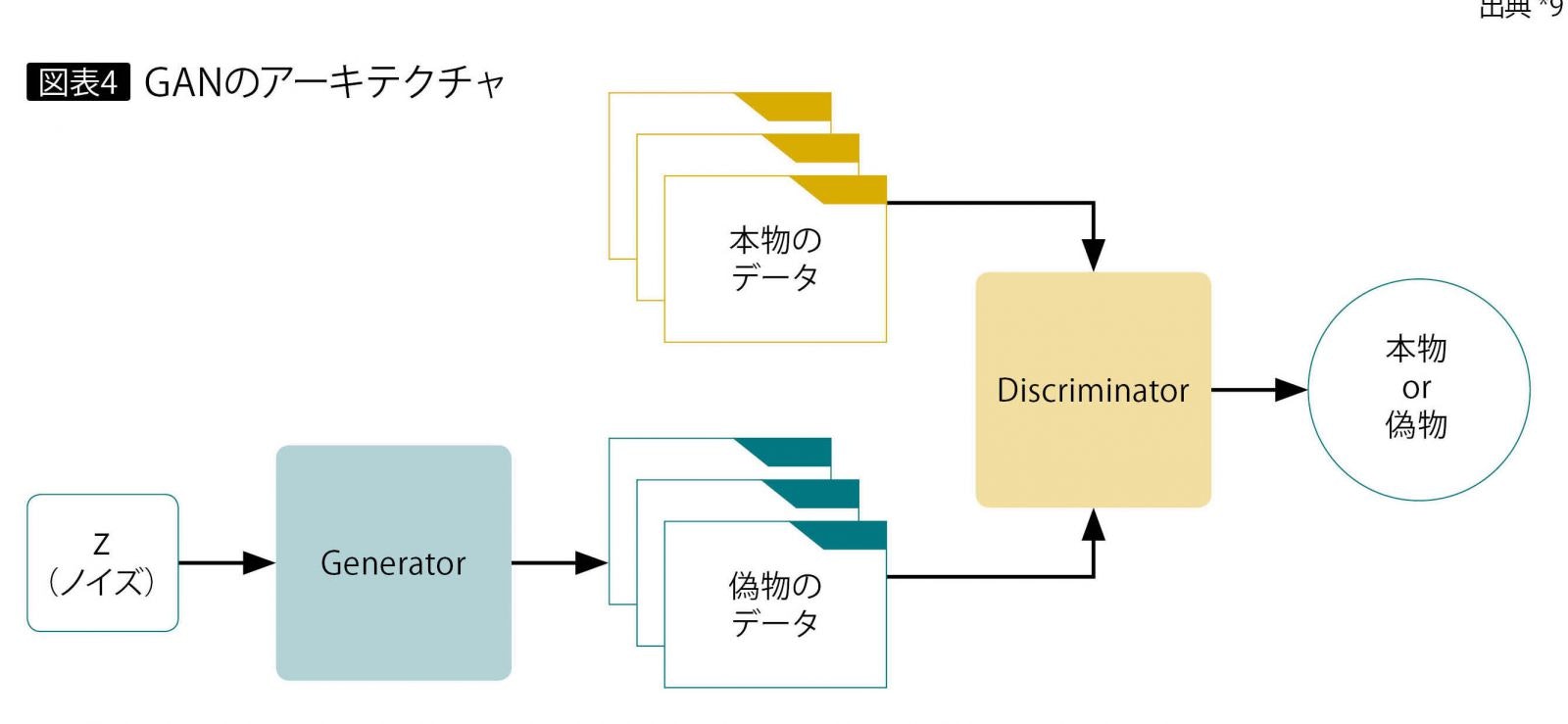
生成にあたってはGAN(Generative adversarial networks、敵対的生成ネットワーク)という手法を用いています。
この手法では画像を生成するニューラルネットワーク(Generator)と、入力されたデータがメルアイコンなのかそうでないのかを識別するニューラルネットワーク(Discriminator)の2つを組み合わせます。GeneratorはDiscriminatorを欺くためにできるだけメルアイコンに似せた画像を生成しようとし、Discriminatorはより正確に画像を識別しようと学習します。二つのニューラルネットワークがお互いに鍛え合うことでGeneratorはメルアイコンに近い画像を生成できるようになっていきます。
データセット収集
Generatorがメルアイコンっぽい画像を生成できるようになったり、Discriminatorが入力された画像をメルアイコンなのかどうかを識別できるようになったりするためには実在するメルアイコンをできるだけ大量に持ってきて教師データとなるデータセットを作り、これを学習に用いる必要があります。
ということでtwitterを巡ってメルアイコンのサムネを見つけては保存といったことを繰り返し100枚以上手に入れました。これを学習に使います。Generatorの作成
Generatorには先ほど用意したメルアイコンをみて、それっぽい画像を生成できるよう学習してもらいます。
生成する画像は64×64pixel、色はrgbの3チャネルとします。
仮にGeneratorが同じようなデータを毎回生成してしまうと学習がうまく進まないため、できるだけ多くの種類の画像を生成できる必要があります。そのためGeneratorには画像生成に乱数でできた数列を入力します。
この数列に対し、後述する「転置畳み込み」という処理を各畳み込み層で施し段階的に64×64pixel、rgbの3チャネルを持つ画像に近づけます。転置畳み込みとは
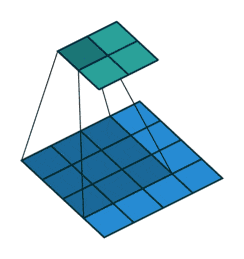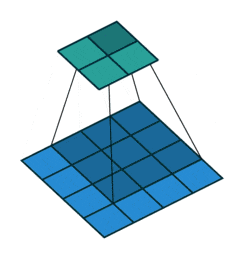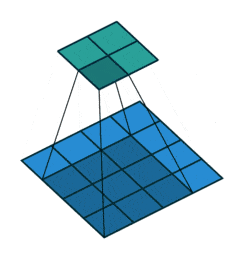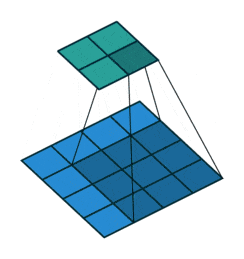
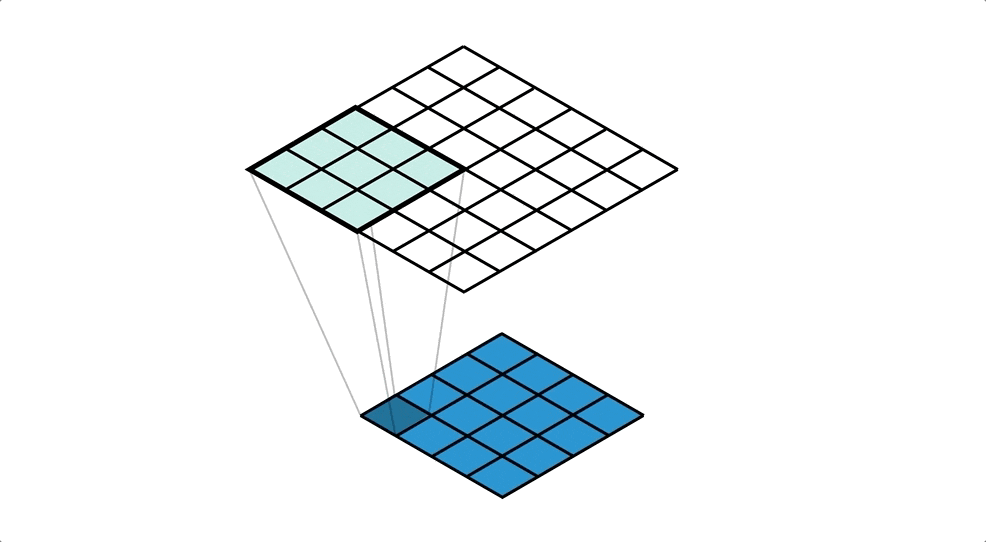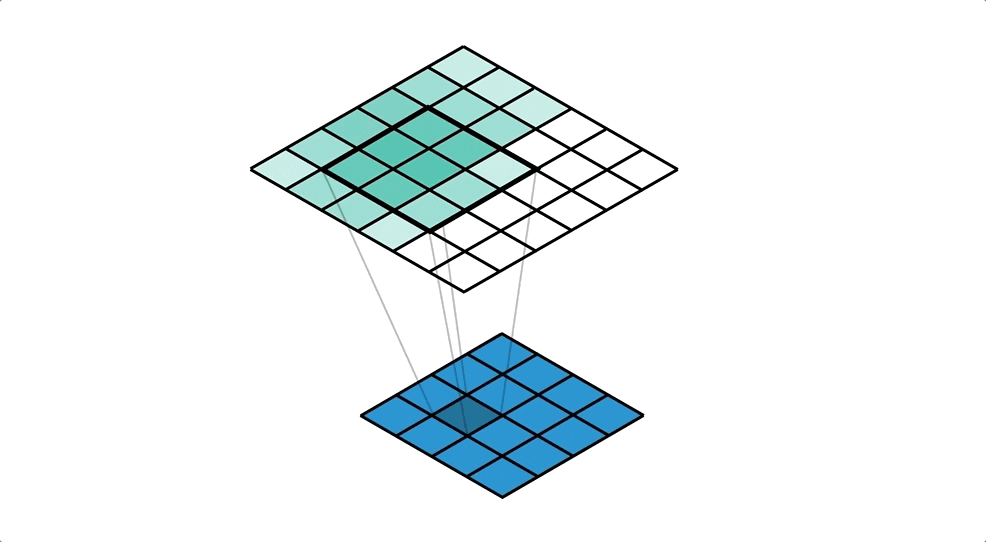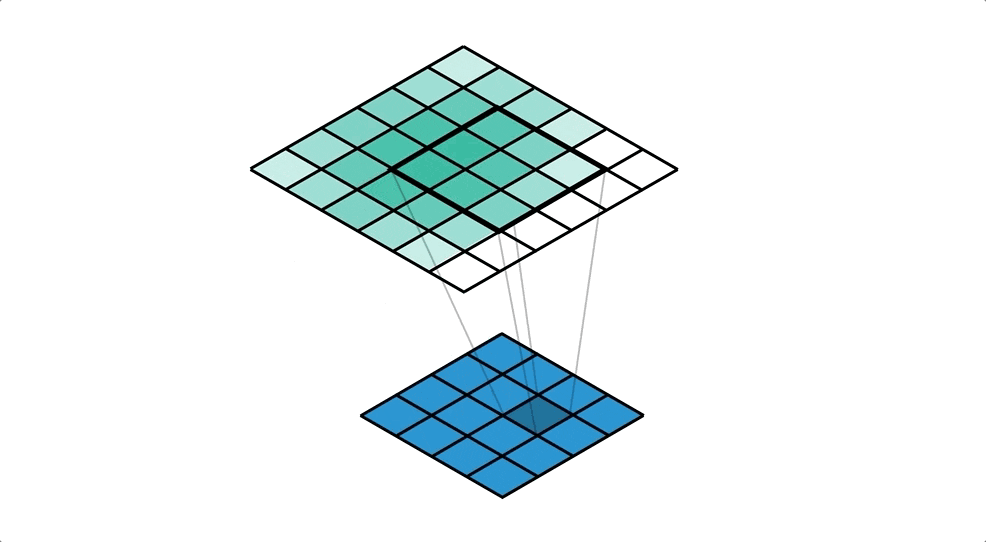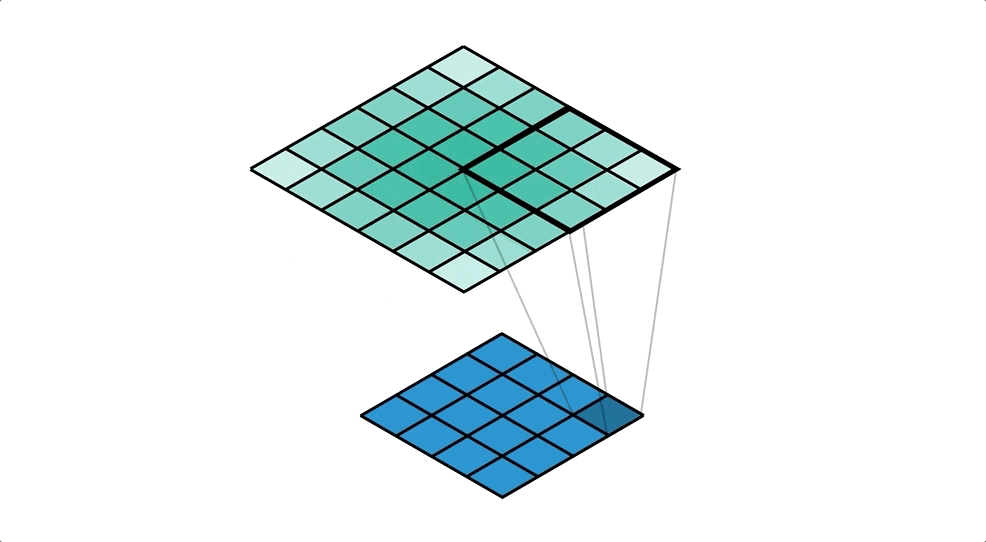
通常の畳み込みは下で示すように、カーネルを用意しずらしながら和積を取り出力とします。pytorchにおいては例えばtorch.nn.Conv2dで実装できます。
対して今回用いる転置畳み込みでは1要素ごとにカーネルとの積を求め、出てきた結果の和を取ります。イメージとしては対象の要素を拡大するような感じです。pytorchにおいては例えばtorch.nn.ConvTranspose2dで実装できます。
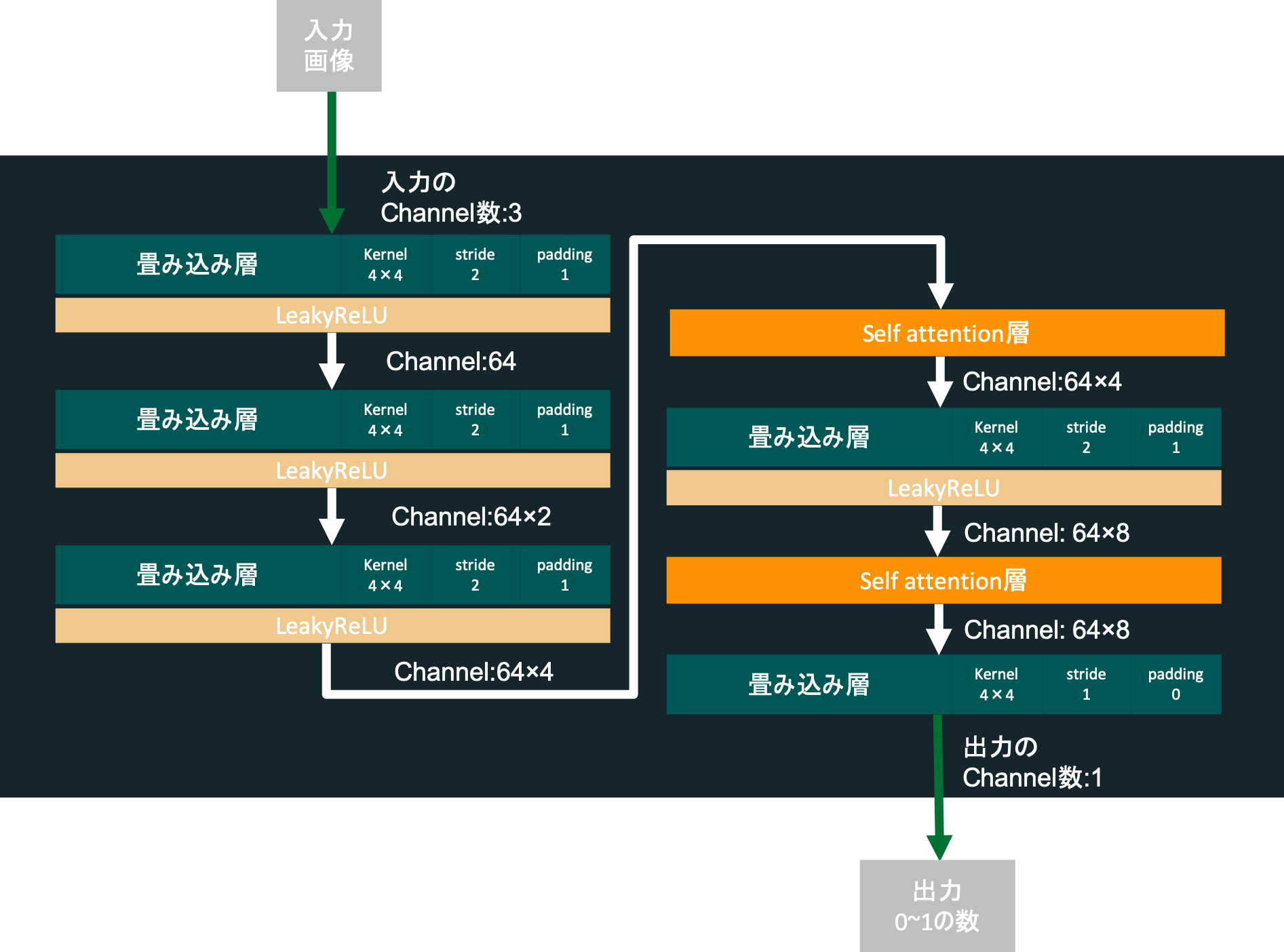
この転置畳み込みの層とself_attentionの層(後述)を重ね、最後の層では出力チャネル数を3としています。(rgbにそれぞれ対応)
以上の内容から、作ろうとしているGeneratorの概略は下の図のようになります。
このGeneratorは合計5つの転置畳み込み層を持ちますが、3層目と4層目の間、4層目と5層目の間にはself_attentionという層を挟んでいます。これにより似た値を持つpixel達を一度に見ることで、比較的少ない計算量で画像全体を大局的に評価することが可能です。
こうして構成されたGeneratorは未学習の状態であれば例えばこんな画像を出力します。(入力する乱数の数列によって結果は変化します)
未学習なのでまだノイズのようなものしか出力できていません。ですが次に説明する、入力されたデータがメルアイコンなのかそうでないのかを識別するニューラルネットワーク(Discriminator)とお互いに訓練しあうことでそれらしい画像を出力できるようになっていきます。Discriminatorの作成
Discriminatorには上のGeneratorが生成した画像をみて、それがメルアイコンなのかどうかを見分けてもらいます。要は画像認識器を作ります。
入力する画像は64×64pixel、色はrgbの3チャネルとし、出力はどれだけメルアイコンっぽいかを表す値(範囲は0~1)とします。
構成としては、普通の畳み込み層を5つ重ね、3層目と4層目の間、4層目と5層目の間にはself_attentionの層を挟みます。図示すると次のようになります。
学習方法・誤差関数
DiscriminatorとGeneratorそれぞれの学習方法は次に述べる一連の通りにしました。
Discriminatorの学習
Discriminatorは画像が入力されると、どれだけメルアイコンっぽいかを示す数0~1を返します。
まず実在のメルアイコンを入力し、その時の出力(0~1の値)を$d_{real}$とします。
次にGeneratorに乱数を入力、画像を生成してもらいます。この画像をDiscriminatorに入力すると同様に0~1の値を返します。これを$d_{fake}$とおきます。
こうして出てきた$d_{real}$と$d_{fake}$を次に説明する損失関数に入力して誤差伝搬に使う値を得ます。損失関数
GANの手法の一つ、SAGANの「hinge version of the adversarial loss」では次に説明するような損失関数を用います。簡単に説明するとこの関数は$l_{i}$と$l_{i}^{\prime}$を正しいラベル、$y_{i}$と$y_{i}^{\prime}$をDiscriminatorより出力された値、$M$をミニバッチあたりのデータ数とした時
-\frac{1}{M}\sum_{i=1}^{M}(l_{i}min(0,-1+y_{i})+(1-l_{i}^{\prime})min(0,-1-y_{i}^{\prime}))と表されます。1
今回は$y_{i}=d_{real}$、$y_{i}^{\prime}=d_{fake}$、$l_{i}=1$(100%メルアイコンであることを表す)、$l_{i}^{\prime}=0$(絶対メルアイコンじゃないことを表す)とそれぞれ設定し-\frac{1}{M}\sum_{i=1}^{M}(min(0,-1+d_{real})+min(0,-1-d_{fake}))とします。これが今回用いるDiscriminatorの損失関数となります。誤差伝搬の最適化手法にはAdamを使い、学習率0.0004、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.0と0.9に設定しました。
Generatorの学習
Generatorは乱数でできた数列が入力されると、できるだけメルアイコンっぽくしようと頑張りながら画像を生成します。
まず乱数でできた数列$z_{i}$をGeneratorへ入力、画像を得ます。それをDiscriminatorに入力し、どれだけメルアイコンらしいかを示す値を出力させます。これを$r_{i}$とします。損失関数
SAGANの「hinge version of the adversarial loss」ではGeneratorの損失関数は次のように定義されます。
-\frac{1}{M}\sum_{i=1}^{M}r_{i}SAGANではこう定義すると経験的にうまくいくことが知られているようです。1
$M$がミニバッチあたりのデータの数なことを考えると、なんと実質Discriminatorの判断結果をそのまま使っています。自分的にはこれに少しびっくりしましたがどうでしょう。
誤差伝搬の最適化手法にはAdamを使い、学習率0.0001、Adamの一次モーメントと二次モーメントはそれぞれ0.0と0.9に設定しました。(学習率以外はDiscriminatorと同じ)全体像
上でも紹介した画像の再掲ですが、先ほど作成したGeneratorとDiscriminatorをこんな風に組み合わせGANを構成します。
いざ生成
集めた実在のメルアイコンを用いて学習を行い、Generatorにメルアイコンを生成させます。ミニバッチあたりのデータ数$M$は5にしておきます。結果は以下のようになりました。
すげえ!!!!!!!!!!!
感動!!!!!!!!!!!
比較用に上側には入力データの例を表示、下側に実際に生成された画像を表示しています。また生成結果は実行するごとに変化します。
個人的にはそこまで長くないソースコードでここまでできることにかなり驚きました。GANマジ偉大!!!!!!!!課題
こんなすごいことができるものを作りましたが、まだ解決できていない点もあります。
- モード崩壊
twitterで指摘してくださった方がいらっしゃいましたが、生成結果を見ると乱数を用いて5枚生成しているはずがどれも同じようなキャラの画像になってしまっていることがわかります。このような現象はモード崩壊と呼ばれています。
今回はミニバッチ数5、エポック数3000で学習を回しているためこれによる過学習が原因かとも思いましたが、エポック数を200くらいに減らした状態でも以下のようにやはり同じような画像が生成されてしまいます。(これはself_attentionをまだ適用していなかった状態での出力ですが、エポック数200くらいではだいたいこんな感じのが出てきます)
確かにある程度エポック数3000のときと比べて実行するたびに微妙に違うものが生成されていますが、やはりぱっと見た感じでは同じような画像に見える上にそもそもエポック数が小さいためかクオリティが断然低くなってしまっているのがお分かりだと思います。
MNISTの例の手書き数字の画像が60000枚くらいあることを考えると、データセットをあと59900枚近く増やすことが考えられますがそんな量だとMelvilleさんがやばいので事実上不可能です。
モード崩壊、難しいです。
ソースコード
書いたコードはこのリポジトリにあります。
https://github.com/zassou65535/image_generatorまとめ
GANはめちゃくちゃ素晴らしい手法です。モード崩壊が起きているとはいえ、たった100枚近くのデータセットでかなりメルアイコンに近いものを作ることができました。皆さんもGANでガンガン画像生成しましょう。
おまけ
自分の集めたメルアイコン全てに対して単純に平均を取ったら次のような画像が出てきました。
参考文献

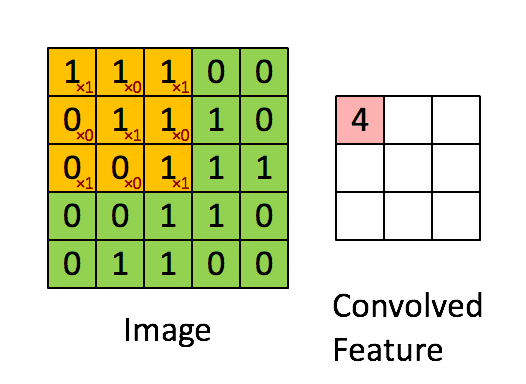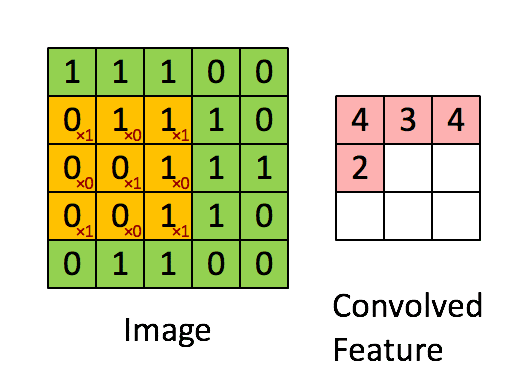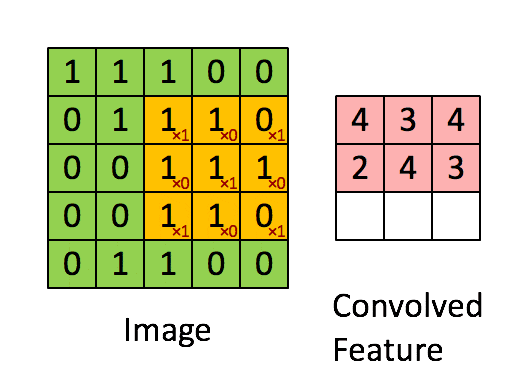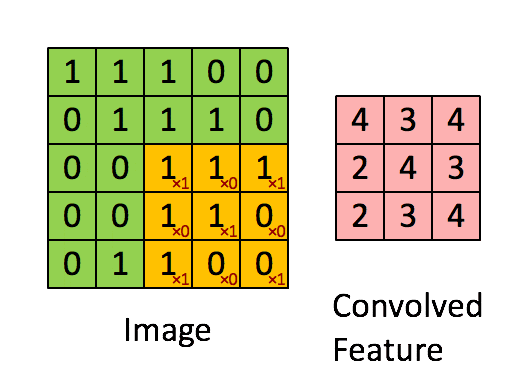




- 投稿日:2020-02-14T20:41:10+09:00
ファイルを読み込んで書き込む
test.txtというテキストファイルの中身が、
AAA
BBB
CCC
DDD
である場合にs = """\ AAA BBB DDD DDD """ with open ('test.txt', 'r+') as f: print(f.read()) f.seek(0) f.write(s)実行結果AAA BBB CCC DDDでtest.txtというテキストファイルの中身は、
AAA
BBB
DDD
DDD
になる。r+は読み込み+書き込み。
なので、
もしも、test.txtがないと、
読み込みができず、
エラーとなる。
- 投稿日:2020-02-14T20:38:02+09:00
Scikit-learnを用いた簡単なグリッドサーチ テンプレート
Scikit-learnを用いたグリッドサーチ
この記事では、scikit-learn(Python)を用いた簡単なグリッドサーチを行います。
毎回調べるのが面倒なので、テンプレにしました。グリッドサーチ
グリッドサーチとは:
今回は、scikit-learnのGridSearchCVを用いてグリッドサーチします。
公式ページ:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.htmlという方は、以下のページを参照ください。
クロスバリデーションとグリッドサーチ:
https://qiita.com/Takayoshi_Makabe/items/d35eed0c3064b495a08b使用するライブラリ
今回は、回帰問題を想定してグリッドサーチします。
from sklearn.metrics import mean_absolute_error #MAE from sklearn.metrics import mean_squared_error #MSE from sklearn.metrics import make_scorer from sklearn.model_selection import GridSearchCV from sklearn.model_selection import KFoldRMSE
RMSEは、scikit-learnのパッケージにないので、自分で関数を定義します。
def rmse(y_true,y_pred): #RMSEを算出 rmse = np.sqrt(mean_squared_error(y_true,y_pred)) print('rmse',rmse) return rmseK Fold
kf = KFold(n_splits=5,shuffle=True,random_state=0)Linear SVR
線形サポートベクトルを行う場合、SVRを使うより、LinearSVRを使った方が、早いらしい。
from sklearn.svm import LinearSVR params_cnt = 10 max_iter = 1000 params = {"C":np.logspace(0,1,params_cnt), "epsilon":np.logspace(-1,1,params_cnt)} ''' epsilon : Epsilon parameter in the epsilon-insensitive loss function. Note that the value of this parameter depends on the scale of the target variable y. If unsure, set epsilon=0. C : Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVR.html ''' gridsearch = GridSearchCV( LinearSVR(max_iter=max_iter,random_state=0), params, cv=kf, scoring=make_scorer(rmse,greater_is_better=False), return_train_score=True, n_jobs=-1 ) gridsearch.fit(X_trainval, y_trainval) print('The best parameter = ',gridsearch.best_params_) print('RMSE = ',-gridsearch.best_score_) LSVR = LinearSVR(max_iter=max_iter,random_state=0,C=gridsearch.best_params_["C"], epsilon=gridsearch.best_params_["epsilon"])Kernel SVR
from sklearn.svm import SVR params_cnt = 10 params = {"kernel":['rbf'], "C":np.logspace(0,1,params_cnt), "epsilon":np.logspace(-1,1,params_cnt)} gridsearch = GridSearchCV( SVR(gamma='auto'), params, cv=kf, scoring=make_scorer(rmse,greater_is_better=False), n_jobs=-1 ) ''' epsilon : Epsilon parameter in the epsilon-insensitive loss function. Note that the value of this parameter depends on the scale of the target variable y. If unsure, set epsilon=0. C : Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVR.html ''' gridsearch.fit(X_trainval, y_trainval) print('The best parameter = ',gridsearch.best_params_) print('RMSE = ',-gridsearch.best_score_) print() KSVR =SVR( kernel=gridsearch.best_params_['kernel'], C=gridsearch.best_params_["C"], epsilon=gridsearch.best_params_["epsilon"] )RandomForest
ランダムフォレストは、あんまりハイパーパラメータ チューニングしなくても良いやつなので、
そんなに意味ないかもしれないが、作っちゃったので、載せます。from sklearn.ensemble import RandomForestRegressor params = { "max_depth":[2,5,10], "n_estimators":[10,20,30,40,50] n_estimatorsは、大きいほど精度が上がるので、時間がある時は、大きくすべき。だたし時間がかかる } gridsearch = GridSearchCV( RandomForestRegressor(random_state=0), params, cv=kf, scoring=make_scorer(rmse,greater_is_better=False), n_jobs=-1 ) ''' n_estimators : The number of trees in the forest. max_depth : The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples. https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html ''' gridsearch.fit(X_trainval, y_trainval) print('The best parameter = ',gridsearch.best_params_) print('RMSE = ',-gridsearch.best_score_) print() RF = RandomForestRegressor(random_state=0,n_estimators=gridsearch.best_params_["n_estimators"], max_depth=gridsearch.best_params_["max_depth"])最後に
GridSearchCVを使えば、数行でチューニングできるので便利です。
今回は、3つのモデルで作りましたが、他のモデルももちろん、できます。
- 投稿日:2020-02-14T20:17:40+09:00
【Poetry】Poetry script で Django の runserver を起動
poetry script は関数の実行を行う
poetry には Pipenv のような scripts 機能があるが、npm scripts のように入力したものがそのままシェルで実行されるわけではない。
引数なしの関数の実行のみが可能である。詳細については以前書いた記事があるので次のリンクを参考に。【Python】Poetry始めてみた & Pipenv から poetry へ移行した所感
今回は 1 コマンドで Django 開発サーバーを立ち上げられるように、簡単な script を書く。
環境
- python 3.7.4
- poetry 1.0.2
構成
$ poetry installした後、$ django-admin startproject config .を行った後のディレクトリ。
./scriptsに poetry scripts 用のファイルを書いていく。今回はサーバ立ち上げ用なのでserver.pyとした。. ├── config │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py ├── poetry.lock ├── pyproject.toml └── scripts └── server.py作成
script
以下の内容で作成。
最初はmanage.pyを絶対パスで指定していたのだが、絶対でなくても動いた。scripts/server.pyimport subprocess def main(): cmd = ["python", "manage.py", "runserver", "0.0.0.0:8000"] subprocess.run(cmd)pyproject.toml
以下を追加する。
pyproject.toml[tool.poetry.scripts] start = 'scripts.server:main'これだけでは、
[ModuleOrPackageNotFound] No file/folder found for package <projectname>となってしまう。$ poetry run start [ModuleOrPackageNotFound] No file/folder found for package projectscripts のファイルがルートディレクトリ(pyproject.toml のあるディレクトリ)以下にある場合、
パッケージディレクトリを指定してやる必要がある。pyproject.toml[tool.poetry] name = "project" version = "0.1.0" description = "" authors = [""] packages = [ { include="scripts", from="." }, ]これで起動出来る。仮想環境に入っていないシェルから実行しても、仮想環境内で実行してくれる。
$ poetry run start Watching for file changes with StatReloader Performing system checks... System check identified no issues (0 silenced). February 14, 2020 - 10:41:57 Django version 3.0.3, using settings 'config.settings' Starting development server at http://0.0.0.0:8000/ Quit the server with CONTROL-C. ...ちなみに
この書き方で実行する poetry script は pyproject.toml のあるディレクトリで実行する必要がある。
from="."としているので、poetry がscriptsディレクトリを見つけられない。pyproject.tomlpackages = [ { include="scripts", from="." }, ]
- 投稿日:2020-02-14T19:27:14+09:00
Golang vs. Python – Is Golang Better Than Python?
In this tutorial we are going to make the comparison between Golang or Python, you will have the complete idea at the end of this tutorial which programming language between Python or Goland you should opt for your next software development project.
click here to read more
https://www.positronx.io/golang-vs-python-is-golang-better-than-python/
- 投稿日:2020-02-14T19:00:40+09:00
ベジェ曲線と直線の交点を求めたい(BezierClipping 法)
はじめに
後輩の研究でベジェ曲線と直線の交点を求める必要がありました.
研究のお手伝いをしていた私は,「Pythonなら強々ライブラリとか簡潔な実装例とかあるでしょ!余裕余裕
」
とか思っていたのですが,私にも理解できるレベルで書いてある記事が見つけられませんでした.
仕方なく,比較的簡単そう&多少の解説PDFが見つけられたBezierClipping法という手法に焦点を定め,
論文を読み漁って理解・実装したので,その知識を残しておこうと思います.
記事中に多少正確性に欠ける表現があるかもしれませんがご了承ください(そして訂正例を教えて下さい).実装したコードはGitHubに公開しています.
ベジェ曲線ってなんぞ?
ベジェ曲線(Bezier Curve)は曲線の表し方の一種です.
アウトラインフォントやCG等コンピュータ上で曲線を表すときによく利用されています.
ベジェ曲線は曲線の始点と終点に加えて,制御点(Control Point)と呼ばれるいくつかの点で構成されます.
以降では始点と終点も含めて制御点と呼称します.
ベジェ曲線は媒介変数 $t$ $(0\leq t \leq 1)$を用いて次のように表されます.\begin{align} P(t) &= \sum_{i=0}^{n} F_i B_{i}^{n}(t) \\ &= \sum_{i=0}^{n} F_i {n \choose i} t^i \left(1-t \right)^{n-i} \end{align}$F_i$ は制御点,$B_{i}^{n}$ はバーンスタイン基底関数(Bernstein Basis Polynomials)です.
また,${n \choose i}$ は組み合わせ(combination)を表します.
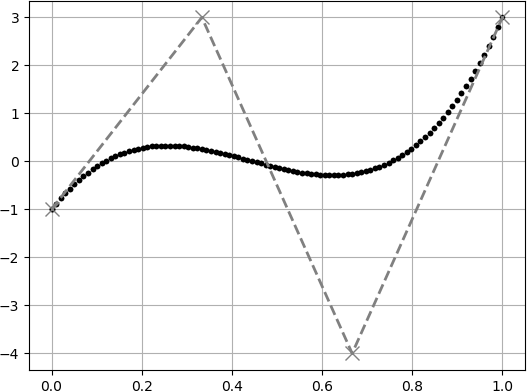
世界標準はこの書き方らしいですが,日本の高校で習ったように書くと下のようになります.P(t) = \sum_{i=0}^{n} F_i ~~ {}_n \mathrm{C} {}_r ~~ t^i \left(1-t \right)^{n-i}ベジェ曲線は $t$ $(0\leq t \leq 1)$における点の集合なので,
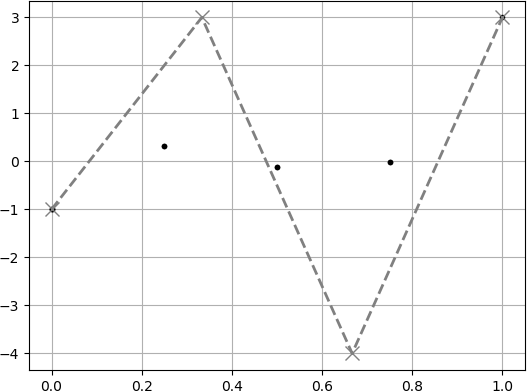
$t$ の刻み幅を細かくすればするほど曲線がなめらかになります.
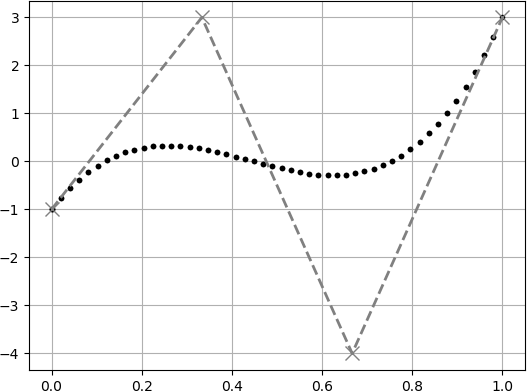
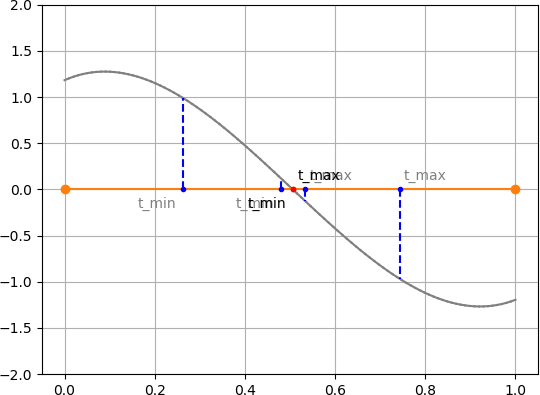
以下に刻み幅を変えた場合の例を出します.灰色の$\times$点は制御点を表しています.
$(0\leq t \leq 1)$を5分割した場合 (5点だけ計算した場合).
$(0\leq t \leq 1)$を10分割した場合 (10点だけ計算した場合).
$(0\leq t \leq 1)$を50分割した場合 (50点だけ計算した場合).
$(0\leq t \leq 1)$を100分割した場合 (100点だけ計算した場合).
BezierClipping 法
概要
BezierClipping 法はベジェ曲線の性質を利用して曲線と直線の交点を求める手法です.
西田らによって1990年に提案されました.
特徴としては以下のような点が挙げられています(一部抜粋).
- 指定した範囲の全ての解(交点)が求出可能
- 安定して解を求められる
- 解の有無の判定が高速
- 解を小さい順に算出可能
- 1次式のみの反復計算 ...etc
ベジェ曲線同士の交点や3次元空間における交点などにも応用できるようですが,
今回はベジェ曲線と直線に限定します.アルゴリズム
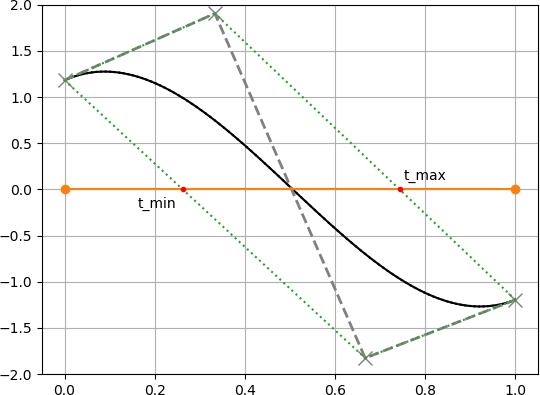
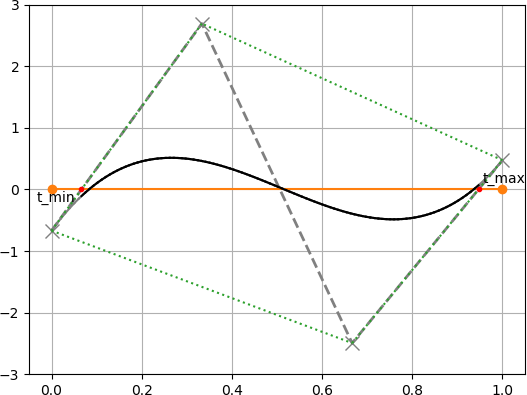
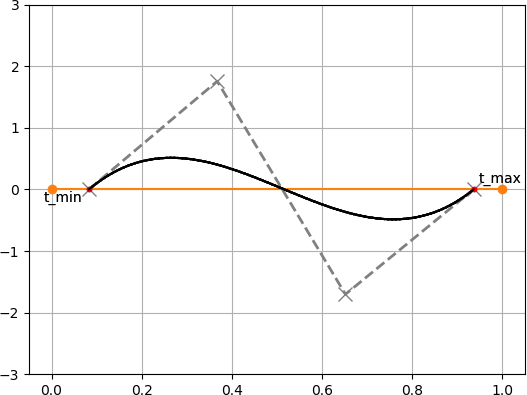
アルゴリズムの大まかな流れは次の通りです.
1. 対象のベジェ曲線を直線との距離を表すベジェ曲線に変換する($xy$ 平面から $td$ 平面へ変換する).
2. 変換したベジェ曲線の制御点の凸包(convex-hull)を求め,$t$ 軸との交点 $t_{min}, t_{max}$ を求める.
3. 求めた $t_{min}, t_{max}$ でベジェ曲線を分割し,新しいベジェ曲線とする.
4. 2-3の処理を $t_{min} - t_{max}$ が十分小さくなるまで繰り返す.
5. 求まった $t$ (上図の赤点) が直線との交点における元のベジェ曲線の媒介変数 $t$ となる.
アルゴリズム自体は非常に単純ですね.
おそらく詰まるところは
- ベジェ曲線の変換処理
- 複数交点が存在するときの処理
だと思うので,次節で詳しく説明します.
ベジェ曲線の変換処理
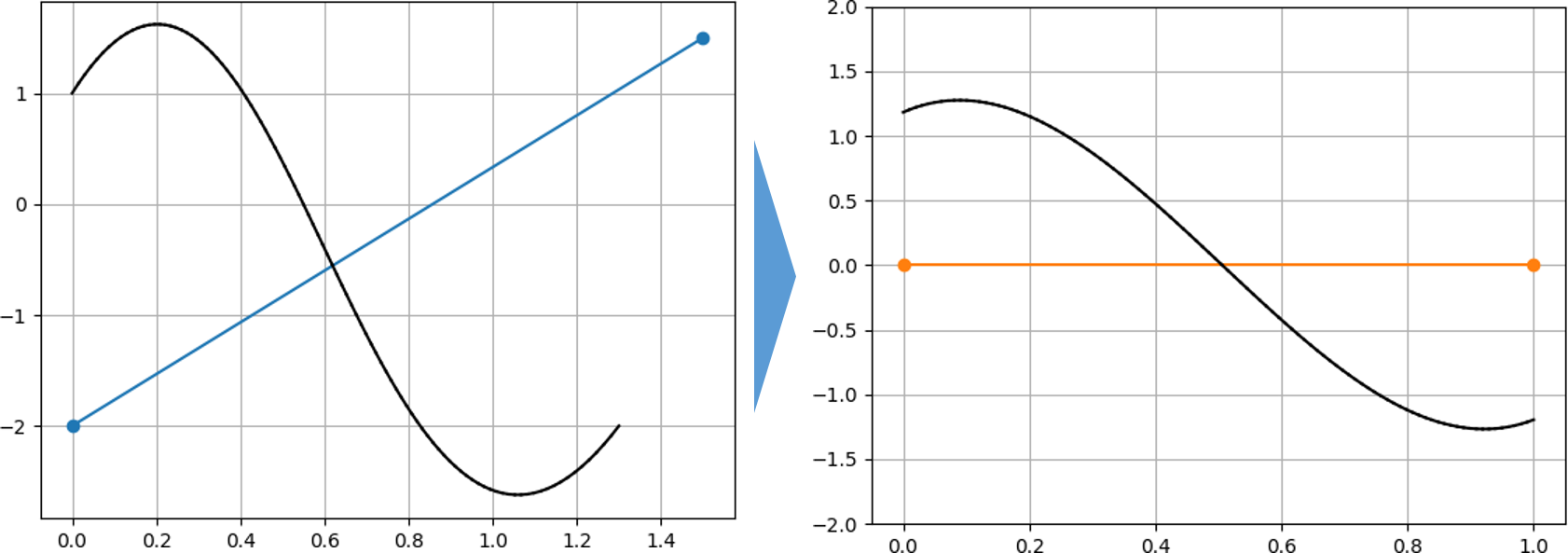
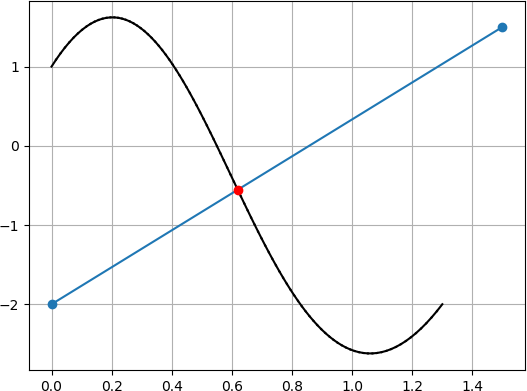
二次元平面座標空間を前提とします.
平面空間内にある直線 $L$ は次のように表すことができます.$a, b, c$ は定数です.ax + by + c = 0座標空間内の任意の点 $(x_1, y_1)$ と直線 $L$ の距離 $d$ は次のように表せます.
d = \frac{ax_1+by_1+c}{\sqrt{a^2 + b^2}}ここで,ベジェ曲線上の点 $(x, y)$ は $t$ を媒介変数として次のように求められます.
$(x_i, y_i)$はベジェ曲線の制御点を表します.\begin{align} x(t) &= \sum_{i=0}^{n} x_i B_i^n (t) \\ y(t) &= \sum_{i=0}^{n} y_i B_i^n (t) \end{align}これらを使い,直線 $L$ とベジェ曲線間の距離 $D$ は次のように表せます.
\begin{align} D &= \frac{ax(t)+by(t)+c}{\sqrt{a^2+b^2}} \\ \\ &= \frac{1}{\sqrt{a^2+b^2}}\left( a\sum_{i=0}^{n} x_i B_i^n (t) + b\sum_{i=0}^{n} y_i B_i^n (t) + c \right) \end{align}$\sum_{i=0}^{n} B_i^n (t) = 1$ であるので,
\begin{align} D &= \frac{1}{\sqrt{a^2+b^2}}\left( a\sum_{i=0}^{n} x_i B_i^n (t) + b\sum_{i=0}^{n} y_i B_i^n (t) + c\sum_{i=0}^{n} B_i^n (t) \right) \\ \\ &= \frac{1}{\sqrt{a^2+b^2}}\sum_{i=0}^{n} (ax_i+by_i+c) B_i^n (t) \\ \\ &= \frac{1}{\sqrt{a^2+b^2}}\sum_{i=0}^{n} d_i B_i^n (t) \end{align}ここで $D$ は制御点 $\left(\frac{i}{n}, d_i \right)$ から成る有理ベジェ曲線となります.
また $D$ は $td$ 平面のベジェ曲線,すなわち横軸 $t$ 縦軸 $d$をとる平面空間におけるベジェ曲線になります.
変換したベジェ曲線 $D$ が,ある $t ~(0 \leq t \leq 1) $ において $d=0$ をとるということは,
その $t$ 値において変換前の $xy$ 平面におけるベジェ曲線と直線間の距離がゼロになることを意味しています.
したがって,直線とベジェ曲線の交点における媒介変数 $t$ が算出できたことになります.
あとは下式に交点における媒介変数 $t$ を入れれば,$xy$ 平面における交点の座標が求まります.\begin{align} x(t) &= \sum_{i=0}^{n} x_i B_i^n (t) \\ y(t) &= \sum_{i=0}^{n} y_i B_i^n (t) \end{align}複数点が存在するときの処理
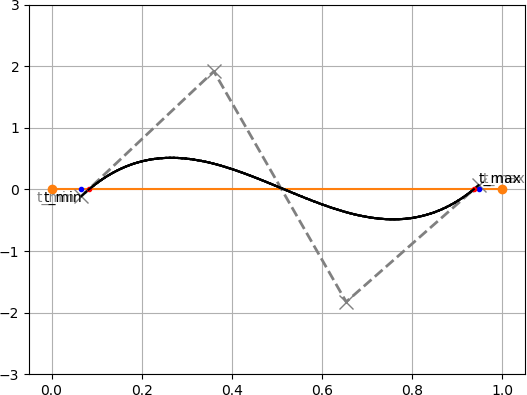
複数の交点が存在するときの処理は簡単です.
複数の交点が存在する場合は $t_{min}$ と $t_{max}$ の変化が小さくなります.
例を下図に示します.図中の青点が1つ前の $t_{min}, t_{max}$ の点を表しています.1回目
2回目
3回目
4回目
3回目から $t_{min}, t_{max}$ の位置がほぼ変わっていないことが分かります.
この場合は曲線を適当な点で分割し,それぞれのベジェ曲線に対して再度 BezierClipping 法を適用します.
分割する点に関しては言及されていないようでした.
私の実装では中点で分割するようにしています.おわりに
本記事ではBezierClipping 法について解説しました.
私は最初の変換の部分がなかなか理解できずにかなり苦労しました.
本記事の内容が誰かのお役に立てれば幸いです.参考文献



- 投稿日:2020-02-14T18:41:19+09:00
GAN : DCGAN Part2 - Training DCGAN model
目標
Microsoft Cognitive Toolkit (CNTK) を用いた DCGAN の続きです。
Part2 では、Part1 で準備した画像データを用いて CNTK による DCGAN の訓練を行います。
CNTK と NVIDIA GPU CUDA がインストールされていることを前提としています。導入
GAN : DCGAN Part1 - Scraping Web images では、Bing Image Search から好きなアーティストの顔画像を準備しました。
Part2 では、Deep Convolutional Generative Adversarial Network (DCGAN) による顔生成モデルを作成して訓練します。
Deep Convolutional Generative Adversarial Network
今回実装した DCGAN [1] は下図のように 2つののニューラルネットワークから構成されています。ここで、$x$ は本物の画像データセット、$z$ は潜在変数を表しています。
Generator と Discriminator のネットワーク構造は以下のように設定しました。
Generator
Generator ではカーネルサイズ 5、ストライド 2 の転置畳み込みを採用しました。
畳み込み層の直後に Batch Normalization [2] を実行してから活性化関数 ReLU を適用します。そのため転置畳み込み層ではバイアス項は採用していません。
最終層の転置畳み込みではバイアス項を採用し、Batch Normalization は使用せずに活性化関数 tanh を適用します。
Layer Filters Size/Stride Input Output ConvolutionTranspose2D 1024 4x4/2 100 4x4x1024 ConvolutionTranspose2D 512 5x5/2 4x4x1024 8x8x512 ConvolutionTranspose2D 256 5x5/2 8x8x512 16x16x256 ConvolutionTranspose2D 128 5x5/2 16x16x256 32x32x128 ConvolutionTranspose2D 64 5x5/2 32x32x128 64x64x64 ConvolutionTranspose2D 32 5x5/2 64x64x64 128x128x32 ConvolutionTranspose2D 3 5x5/2 128x128x32 256x256x3 なお、潜在変数 $z$ の確率分布は標準正規分布 $\mathcal{N}(0.0, 1.0)$ にしました。
Discriminator
Discriminator ではカーネルサイズ 3、ストライド 2 の畳み込みを採用しました。
畳み込み層の直後に Batch Normalization を実行してから活性化関数 Leaky ReLU [3] を適用します。そのため転置畳み込み層ではバイアス項は採用していません。Leaky ReLU のパラメータは 0.2 に設定しました。ただし、1層目の畳み込みでは Batch Normalization は使用しません。
最終層の畳み込みではバイアス項を採用し、Batch Normalization は使用せずに活性化関数 sigmoid を適用します。
Layer Filters Size/Stride Input Output Convolution2D 32 3x3/2 256x256x3 128x128x32 Convolution2D 64 3x3/2 128x128x32 64x64x64 Convolution2D 128 3x3/2 64x64x64 32x32x128 Convolution2D 256 3x3/2 32x32x128 16x16x256 Convolution2D 512 3x3/2 16x16x256 8x8x512 Convolution2D 1024 3x3/2 8x8x512 4x4x1024 Convolution2D 1 4x4/1 4x4x1024 1 訓練における諸設定
転置畳み込み・畳み込み層のパラメータの初期値は分散 0.02 の正規分布 [1] に設定しました。
今回実装した損失関数を下式に示します。[4]
\max_{D} \mathbb{E}_{x \sim p_r(x)} [\log D(x)] + \mathbb{E}_{z \sim p_g(z)} [\log(1 - D(G(z))]\\ \max_{G} \mathbb{E}_{x \sim p_g(z)} [\log D(G(z))]ここで、$D$, $G$ はそれぞれ Discriminator と Generator を表し、$x$ は入力画像、$z$ は潜在変数、$p_r$ は本物の画像データの生成分布、$p_z$ は偽物の画像データを生成する分布を表しています。
Generator, Discriminator ともに最適化アルゴリズムは Adam [5] を採用しました。学習率は 1e-4、Adam のハイパーパラメータ $β_1$ は 0.5、$β_2$ は CNTK のデフォルト値に設定しました。
モデルの訓練はミニバッチサイズ 16 のミニバッチ学習によって 50,000 Iteration を実行しました。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-6700K 4.00GHz
・GPU NVIDIA GeForce GTX 1060 6GBソフトウェア
・Windows 10 Pro 1903
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・numpy 1.17.3
・pandas 0.25.0実行するプログラム
訓練用のプログラムは GitHub で公開しています。
dcgan_training.py解説
How to Train a GAN? で紹介されている GAN の訓練におけるテクニックの中で特に参考になった項目を列挙しておきます。
Input Normalization
入力画像を [-1, 1] に正規化しておきます。したがって、Generator の出力を tanh にします。
Loss Function
オリジナルの GAN [4] の損失関数は下の式です。
\max_{D} \mathbb{E}_{x \sim p_r(x)} [\log D(x)] + \mathbb{E}_{z \sim p_g(z)} [\log(1 - D(G(z))]\\ \min_{G} \mathbb{E}_{x \sim p_g(z)} [\log(1.0 - D(G(z)))]しかし上の式だと Discriminator の損失関数が交差エントロピーである性質上 Discriminator が強くなってしまうと Generator の勾配消失が発生してしまうため、Generator の損失関数を最小化問題から最大化問題に変更します。
\max_{G} \mathbb{E}_{x \sim p_g(z)} [\log D(G(z))]とはいうものの、訓練が上手く進めばどちらの損失関数でも結果に差はないようです。
Latent Distribution
潜在変数の確率分布を矩形分布の一様分布よりも球形分布の正規分布にしました。
dcgan_training.pyz_data = np.ascontiguousarray(np.random.normal(size=(minibatch_size, z_dim)), dtype="float32")Batch Normalization
Batch Normalization は訓練を安定化させますが、本物のデータと偽物のデータを混ぜないようにします。
実装したプログラムでは下記の箇所で Discriminator のパラメータを共有しながら偽物のデータのみを入力として受け取っています。
dcgan_training.pyD_fake = D_real.clone(method="share", substitutions={x_real.output: G_fake.output})Network Architecture
今回は画像を扱ったので畳み込み層の用いる DCGAN を採用しました。
勾配のスパース化を回避するため、ReLU には Deadly Neuron と呼ばれる問題があるため、ReLU ではなく Leaky ReLU を使用します。ただし、ELU [6] は上手くいかない傾向があります。
ダウンサンプリングでは、平均プーリングもしくは畳み込み層のストライドを 2 にします。
アップサンプリングでは、Pixel Shuffle [7] もしくは転置畳み込み層のストライドを 2 にします。Optimizer
最適化アルゴリズムには Adam が最良の選択ですが、RMSProp も有効です。ただし、Adam を使用する場合はモーメンタムを小さな値に設定しておき、学習率は 1e-4 よりも小さくします。
訓練が不安定になるため、今回は Cyclical Learning Rate [8] を使用しませんでした。
Training
Discriminator と Generator の訓練を統計的にコントロールすることは難しいので極力避ける。
どうしても制御したい場合は Discriminator の訓練回数を時々多くします。
結果
訓練時の各損失関数を可視化したものが下図です。横軸は繰り返し回数、縦軸は損失関数の値を表しています。Discriminator と Generator のネットワークの規模が同程度なので Generator が劣勢のようです。
訓練した Generator で生成した顔画像を下図に示します。似たような画像が多い印象を受けます。これはモード崩壊が起きていることを示唆しており良くない傾向です。
訓練時の画像生成の変遷をアニメーションで示したのが下図です。頑張って顔を生成しようとしていますが、イマイチ上手くいっているとは言い難いです。
GAN の定量評価は難しい問題ですが、評価指標の1つとして Inception Score [9] が提案されています。
Inception Score は訓練された Generator に対する
・Image Quality : 何らかの特定の画像を生成できているか
・Image Diversity : 生成する画像にバリエーションがあるか(モード崩壊が起きていないか)を測ります。Inception Score を測るためのベースモデルには Inception-v3 [10] を使用しました。結果は以下のようになりました。
Inception Score 1.78参考
CNTK 206: Part B - Deep Convolutional GAN with MNIST data
How to Implement the Inception Score (IS) for Evaluating GANsGAN : DCGAN Part1 - Scraping Web images
- Alec Radford, Luke Metz, and Soumith Chintal. "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks", arXiv preprint arXiv:1511.06434 (2015).
- Ioffe Sergey and Christian Szegedy. "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift", arXiv preprint arXiv:1502.03167 (2015).
- Andrew L. Maas, Awni Y. Hannun, and Andrew Y. Ng. "Rectifier Nonlinearities Improve Neural Network Acoustic Models", Proc. icml. Vol. 30. No. 1. 2013.
- Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mira, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. "Generative Adversarial Nets", Advances in neural information processing systems. 2014, pp 2672-2680.
- Diederik P. Kingma and Jimmy Lei Ba. "Adam: A method for stochastic optimization", arXiv preprint arXiv:1412.6980 (2014).
- Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. "Fast and accurate deep network learning by exponential linear units (ELUs)." arXiv preprint arXiv:1511.07289 (2015).
- Wenzhe Shi, Jose Cabellero, Ferenc Huszar, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. "Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network", The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016, pp 1874-1883.
- Leslie N. Smith. "Cyclical Learning Rates for Training Neural Networks", 2017 IEEE Winter Conference on Applications of Computer Vision. 2017, pp 464-472.
- Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen, "Improved Techniques for Training GANs", Neural Information Processing Systems. 2016. pp 2234-2242.
- Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. "Rethinking the Inception Architecture for Computer Vision", The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016, pp 2818-2826.




- 投稿日:2020-02-14T18:28:24+09:00
cGAN(conditional GAN)でくずし字MNIST(KMNIST)の生成
はじめに
GANの一種、cGAN(conditional GAN)を用いてくずし字MNISTの生成をやってみました。
詳しい理論面については適宜参考になるリンクなどを載せるので、参照してください。
- PyTorchでGANを実装したい
- 狙った画像を生成できるモデルが作りたい
といった方の参考になれば幸いです。
くずし字MNIST(KMNIST)とは
今回使うデータセットについてです。
KMNISTは、人文学オープンデータ共同利用センターによって作成された、「日本古典籍くずし字データセット」の派生として機械学習用として作られたデータセットのことです。
GitHubのリンクからダウンロードすることができます。
『KMNISTデータセット』(CODH作成) 『日本古典籍くずし字データセット』(国文研ほか所蔵)を翻案 doi:10.20676/00000341
機械学習やったことある人ならだれもが知っているあのMNIST(手書き数字)と同じく、1枚の画像が1×28px×28pxのサイズになっています。
リポジトリからは以下の3種類のデータセットが、numpy.arrayの圧縮形式でダウンロードできます。
- kuzushiji-MNIST(ひらがな10文字)
- kuzushiji-49(ひらがな49文字)
- kuzushiji-kanji(漢字3832文字)
今回はこのうち、"kuzushiji-49"を用います。深い理由は特にありませんが、ひらがな49文字が狙って生成できるのならば、手書き文章を生成できそう?と思ったのが軽いモチベーションです。
GANとは
cGANの前にGANについて軽くふれておきます。
GANは"Generative Adversarial Network"(=敵対的生成ネットワーク)の略で、ディープラーニングの生成モデルの一種です。特に画像生成の分野で威力を発揮しており、世界に存在しない人の顔画像を生成した結果などが有名かと思います。GANのモデル構造
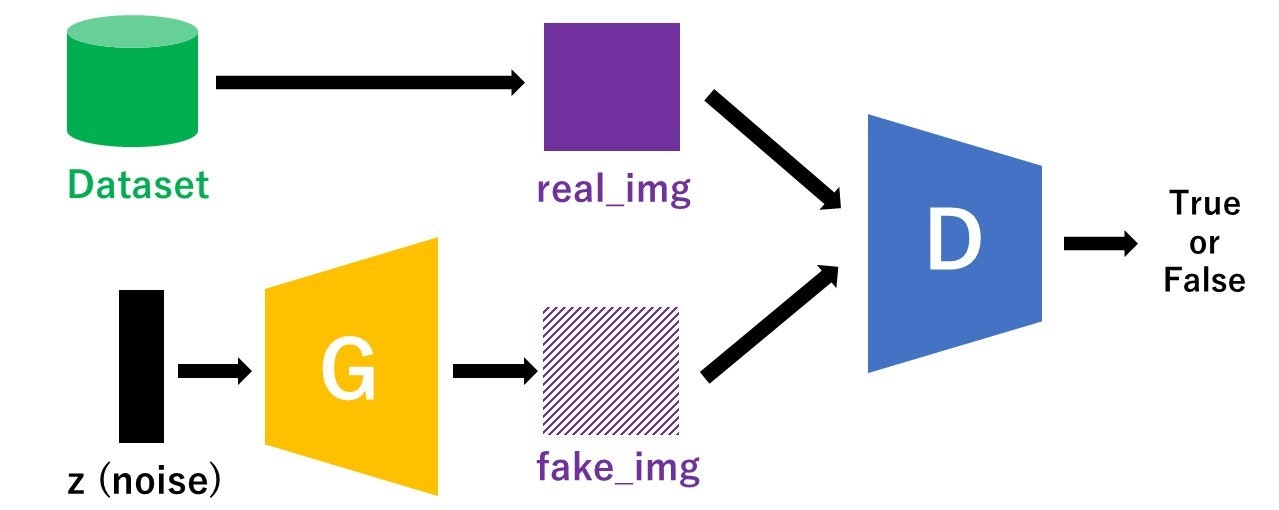
以下に示したのがざっくりとしたGANのモデル図です。"G"がGeneratorで"D"がDiscriminatorを表しています。
Generatorはノイズからできるだけ本物に近い偽物画像を生成します。
Discriminatorはデータセットからとってきた本物画像(real_img)とGeneratorによって作られた偽物画像(fake_img)を判別します(True or False)。この学習を繰り返して行うことで、GeneratorはできるだけDiscriminatorに見破られないような本物に近い画像を作ろうとし、DiscriminatorはGeneratorが作った偽物とデータセット由来の本物を見破ろうとするので、Generatorの生成精度が上がっていきます。
<参考記事>
今さら聞けないGAN(1) 基本構造の理解GAN関連の論文はこのGitHubリポジトリにまとまっています。
cGAN(conditional GAN)とは
続いて、今回使うconditional GANについてです。
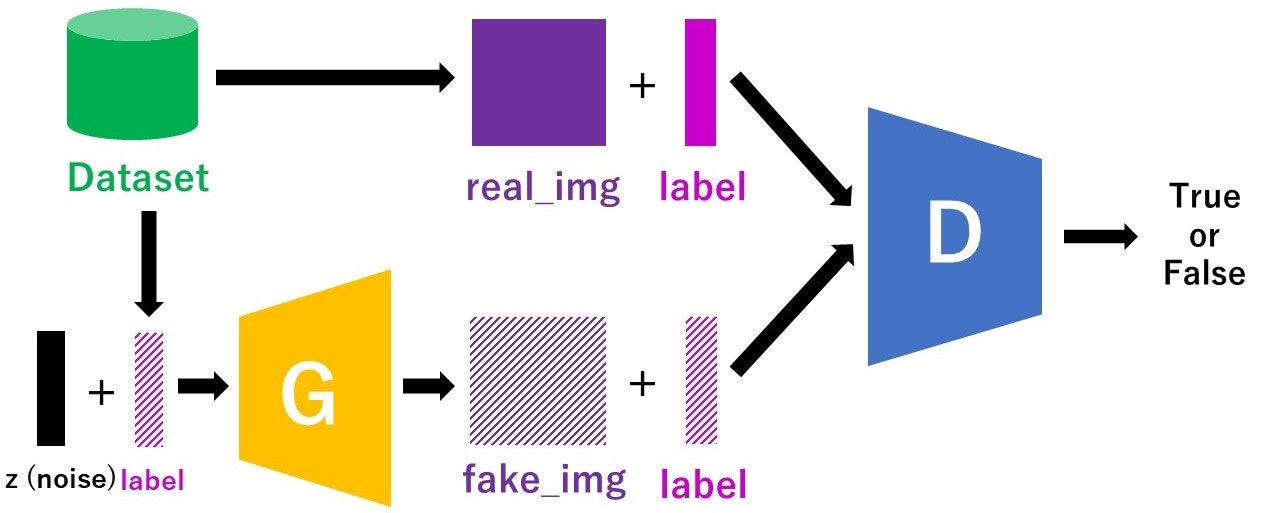
簡単に言えば、「狙った画像を生成できるGAN」です。発想としてはシンプルで、discriminatorやGeneratorの入力にラベル情報を加えることで、生成する画像を決めようという感じです。元論文はこちら
cGANのモデル構造
「訓練時にラベルも入力する」という点以外は普通のGANと変わりません。
また、ラベル情報を用いてはいますが、Discriminatorが判別するのは「その画像が本物かどうか」だけです。
<参考記事>
今さら聞けないGAN(6) Conditional GANの実装実装
それでは、実装に入っていきます。
環境
Ubuntu18.04上にjupyterlabをインストールして動かしています。
- Python 3.7.4
- PyTorch 1.4.0
- torchvision 0.5.0
学習の準備
必要なmoduleをimport
pythonimport torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt import time import randomデータセットを作る
データをダウンロード
先ほどのKMNISTのgithubからnumpyフォーマットのデータをダウンロードします。
jupyterlabなら、Terminalを開いてリポジトリを移動した後で
wget http://codh.rois.ac.jp/kmnist/dataset/k49/k49-train-imgs.npz
wget http://codh.rois.ac.jp/kmnist/dataset/k49/k49-train-labels.npz
とやれば画像とラベルがダウンロードできます。
ちなみに、ひらがな10文字のKMNISTであれば、torchvisionの方にデフォルトで入っています。そちらでよければ普通のMNISTと同じようにpythontransform = transforms.Compose( [transforms.ToTensor(), ]) train_data_10 = torchvision.datasets.KMNIST(root='./data', train=True,download=True,transform=transform)とやれば使えます。
データの前処理
PyTorchで自分でカスタマイズしたデータセットを作りたい場合、前処理を自分で定義する必要があります。画像系の前処理は
torchvision.transformsの中に大体入っているので、これを利用することが多いですが、自分で作ることもできます。pythonclass Transform(object): def __init__(self): pass def __call__(self, sample): sample = np.array(sample, dtype = np.float32) sample = torch.tensor(sample) return (sample/127.5)-1 transform = Transform()numpyで扱う小数は
np.float64(浮動小数点数64bit)が多いですが、PyTorchでは小数の値をデフォルトだと浮動小数点数32bitで扱うので、揃えないとエラーがでます。また、ここで画像の輝度値を[-1,1]の範囲に正規化する処理を行っています。これは、後で出てくるGeneratorの出力の最終層で
Tanhを使っているので、本物画像の輝度値をそれに合わせた形にするためです。Datasetクラス
続いて、Datasetクラスを定義していきます。
これはデータとラベルを1組返すモジュールで、データを取り出すときに先ほど定義したtransformで前処理したデータを返します。pythonfrom tqdm import tqdm class dataset_full(torch.utils.data.Dataset): def __init__(self, img, label, transform=None): self.transform = transform self.data_num = len(img) self.data = [] self.label = [] for i in tqdm(range(self.data_num)): self.data.append([img[i]]) self.label.append(label[i]) self.data_num = len(self.data) def __len__(self): return self.data_num def __getitem__(self, idx): out_data = self.data[idx] out_label = np.identity(49)[self.label[idx]] out_label = np.array(out_label, dtype = np.float32) if self.transform: out_data = self.transform(out_data) return out_data, out_label最初の
tqdmを入れておくとfor文を回したときに進捗状況が棒グラフのように表示されますが、特にcGAN本体には関係ありません。
np.identityを用いて、長さ49のone-hotベクトルを作っています。DLしたデータからDatasetを形成
先ほどダウンロードしたデータから実装した
Transform,Datasetクラスを用いてDatasetを作ります。pythonpath = %pwd train_img = np.load('{}/k49-train-imgs.npz'.format(path)) train_img = train_img['arr_0'] train_label = np.load('{}/k49-train-labels.npz'.format(path)) train_label = train_label['arr_0'] train_data = dataset_full(train_img, train_label, transform=transform)先ほどのtqdmを入れておくと、これを実行したときに進捗状況が表示されます。最も、データ数は232625個ですが、これに時間はかからないと思います。
DataLoaderを作成
Datasetはできましたが、モデルを訓練するときにこのデータセットから直接データを取ってくることはありません。バッチごとに訓練するので、バッチサイズのデータを返してくれるDataLoaderを定義します。
pythonbatch_size = 256 train_loader = torch.utils.data.DataLoader(train_data, batch_size = batch_size, shuffle = True, num_workers=2)
shuffle=Trueにすると、DataLoaderからとってくるデータがランダムになります。num_workersはDataLoaderが使うcpuのコア数を指定する引数で、特にcGAN本体には関係ありません。ここまでのTransform~Dataset~DataLoaderについては、以下の記事にまとまっています。
<参考記事>
PyTorch transforms/Dataset/DataLoaderの基本動作を確認するGeneratorを定義
モデル本体を作っていきます。Generatorはノイズ(noise)とラベル(labels)から偽物画像(fake_img)を作ります。
人によっても実装の仕方が結構違いますが、今回作ったGeneratorの構造は以下です。
(手書きですが勘弁・・・)
入力でz_dim(ノイズの次元)が30、num_class(クラス数)はひらがな49文字ですので49にしています。出力の偽物画像は1(チャネル)×28(px)×28(px)の形状になります。pythonclass Generator(nn.Module): def __init__(self, z_dim, num_class): super(Generator, self).__init__() self.fc1 = nn.Linear(z_dim, 300) self.bn1 = nn.BatchNorm1d(300) self.LReLU1 = nn.LeakyReLU(0.2) self.fc2 = nn.Linear(num_class, 1500) self.bn2 = nn.BatchNorm1d(1500) self.LReLU2 = nn.LeakyReLU(0.2) self.fc3 = nn.Linear(1800, 128 * 7 * 7) self.bn3 = nn.BatchNorm1d(128 * 7 * 7) self.bo1 = nn.Dropout(p=0.5) self.LReLU3 = nn.LeakyReLU(0.2) self.deconv = nn.Sequential( nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), #チャネル数を128⇒64に変える。 nn.BatchNorm2d(64), nn.LeakyReLU(0.2), nn.ConvTranspose2d(64, 1, kernel_size=4, stride=2, padding=1), #チャネル数を64⇒1に変更 nn.Tanh(), ) self.init_weights() def init_weights(self): for module in self.modules(): if isinstance(module, nn.ConvTranspose2d): module.weight.data.normal_(0, 0.02) module.bias.data.zero_() elif isinstance(module, nn.Linear): module.weight.data.normal_(0, 0.02) module.bias.data.zero_() elif isinstance(module, nn.BatchNorm1d): module.weight.data.normal_(1.0, 0.02) module.bias.data.zero_() elif isinstance(module, nn.BatchNorm2d): module.weight.data.normal_(1.0, 0.02) module.bias.data.zero_() def forward(self, noise, labels): y_1 = self.fc1(noise) y_1 = self.bn1(y_1) y_1 = self.LReLU1(y_1) y_2 = self.fc2(labels) y_2 = self.bn2(y_2) y_2 = self.LReLU2(y_2) x = torch.cat([y_1, y_2], 1) x = self.fc3(x) x = self.bo1(x) x = self.LReLU3(x) x = x.view(-1, 128, 7, 7) x = self.deconv(x) return xDiscriminatorの定義
続いて、Discriminatorです。Discriminatorは本物/偽物画像とそのラベル情報を入力し、本物か偽物かを判定します。
今回作ったDiscriminatorの構造は以下です。
img(入力画像)は本物も偽物も1(チャネル)×28(px)×28(px)、labels(入力ラベル)は49次元のone-hotベクトルです。出力で本物かどうかを0~1の値で判定します。途中の
catで画像とラベル情報をチャネル方向にconcatします。この辺のことは先ほどのcGANの記事がわかりやすいかと思います。pythonclass Discriminator(nn.Module): def __init__(self, num_class): super(Discriminator, self).__init__() self.num_class = num_class self.conv = nn.Sequential( nn.Conv2d(num_class + 1, 64, kernel_size=4, stride=2, padding=1), nn.LeakyReLU(0.2), nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), nn.LeakyReLU(0.2), nn.BatchNorm2d(128), ) self.fc = nn.Sequential( nn.Linear(128 * 7 * 7, 1024), nn.BatchNorm1d(1024), nn.LeakyReLU(0.2), nn.Linear(1024, 1), nn.Sigmoid(), ) self.init_weights() def init_weights(self): for module in self.modules(): if isinstance(module, nn.Conv2d): module.weight.data.normal_(0, 0.02) module.bias.data.zero_() elif isinstance(module, nn.Linear): module.weight.data.normal_(0, 0.02) module.bias.data.zero_() elif isinstance(module, nn.BatchNorm1d): module.weight.data.normal_(1.0, 0.02) module.bias.data.zero_() elif isinstance(module, nn.BatchNorm2d): module.weight.data.normal_(1.0, 0.02) module.bias.data.zero_() def forward(self, img, labels): y_2 = labels.view(-1, self.num_class, 1, 1) y_2 = y_2.expand(-1, -1, 28, 28) x = torch.cat([img, y_2], 1) x = self.conv(x) x = x.view(-1, 128 * 7 * 7) x = self.fc(x) return x1エポック当たりの計算
1エポックの計算を行う関数を作ります。
pythondef train_func(D_model, G_model, batch_size, z_dim, num_class, criterion, D_optimizer, G_optimizer, data_loader, device): #訓練モード D_model.train() G_model.train() #本物のラベルは1 y_real = torch.ones((batch_size, 1)).to(device) D_y_real = (torch.rand((batch_size, 1))/2 + 0.7).to(device) #Dに入れるノイズラベル #偽物のラベルは0 y_fake = torch.zeros((batch_size, 1)).to(device) D_y_fake = (torch.rand((batch_size, 1)) * 0.3).to(device) #Dに入れるノイズラベル #lossの初期化 D_running_loss = 0 G_running_loss = 0 #バッチごとの計算 for batch_idx, (data, labels) in enumerate(data_loader): #バッチサイズに満たない場合は無視 if data.size()[0] != batch_size: break #ノイズ作成 z = torch.normal(mean = 0.5, std = 0.2, size = (batch_size, z_dim)) #平均0.5の正規分布に従った乱数を生成 real_img, label, z = data.to(device), labels.to(device), z.to(device) #Discriminatorの更新 D_optimizer.zero_grad() #Discriminatorに本物画像を入れて順伝播⇒Loss計算 D_real = D_model(real_img, label) D_real_loss = criterion(D_real, D_y_real) #DiscriminatorにGeneratorにノイズを入れて作った画像を入れて順伝播⇒Loss計算 fake_img = G_model(z, label) D_fake = D_model(fake_img.detach(), label) #fake_imagesで計算したLossをGeneratorに逆伝播させないように止める D_fake_loss = criterion(D_fake, D_y_fake) #2つのLossの和を最小化 D_loss = D_real_loss + D_fake_loss D_loss.backward() D_optimizer.step() D_running_loss += D_loss.item() #Generatorの更新 G_optimizer.zero_grad() #Generatorにノイズを入れて作った画像をDiscriminatorに入れて順伝播⇒見破られた分がLossになる fake_img_2 = G_model(z, label) D_fake_2 = D_model(fake_img_2, label) #Gのloss(max(log D)で最適化) G_loss = -criterion(D_fake_2, y_fake) G_loss.backward() G_optimizer.step() G_running_loss += G_loss.item() D_running_loss /= len(data_loader) G_running_loss /= len(data_loader) return D_running_loss, G_running_loss引数で出てくる
criterionはlossのクラス(今回はBinary Cross Entropy)のことです。
この関数でやっているのは、順番に
- Datasetの本物画像をDiscriminatorに入れて誤差逆伝播
- Generatorで作った偽物画像をDiscrminatorに入れて誤差逆伝播(このときGeneratorは更新しない)
- Generatorで作った偽物画像をDiscriminatorに入れて、Generatorを誤差逆伝播
です。
実装の工夫
すこし古いですが、"How to Train a GAN"at NIPS2016に出てくる、GANの学習をうまくいかせるための工夫を今回の実装に盛り込んであります。
GitHubリンク<参考記事>
GAN(Generative Adversarial Networks)を学習させる際の14のテクニック※番号は記事とGitHubリンク内の番号と対応しています。
1.入力を正規化
Datasetクラスを作ったときの
pythonreturn (sample/127.5)-1がこれです。また、Generatorの最終層も
nn.Tanh()にしています。2.GのLoss関数を修正
python#Gのloss(max(log D)で最適化) G_loss = -criterion(D_fake_2, y_fake)がこれに当たります。
D_fake_2がDiscriminatorの判定、y_fakeというのは128×1の0ベクトルです。3.zはガウス分布から
Generatorに入れるノイズを一様分布ではなく正規分布からサンプルします。
python#ノイズ作成 z = torch.normal(mean = 0.5, std = 0.2, size = (batch_size, z_dim)) #平均0.5の正規分布に従った乱数を生成平均と標準偏差は適当ですが、一様分布だと[0,1]からサンプルすればマイナスの値が出ないので、サンプルされたノイズの値がほとんど正になるようにしました。
4.Batch Norm
上の方で作ったDataLoaderから出てくるデータはすべて本物画像です。逆に
pythonfake_img = G_model(z, label)ではDataLoaderからとってきたラベル情報とノイズから、バッチサイズ個の偽物画像を作っています。
5.ReLUやMax Poolingのように勾配がスパースになるものは避ける
GeneratorとDiscriminatorの両方でLeakyReLUが有効らしいので、活性化関数はすべてLeakyReLUにしています。引数の0.2は多くの実装でこの値が採用されていたので従いました。
6.Dの正解ラベルにはノイジーなラベルを使う
Discriminatorのラベルは、普通は0or1ですが、ここにノイズを加えます。本物ラベルを0.7~1.2、偽物ラベルを0.0~0.3からランダムにサンプリングします。
python#本物のラベルは1 y_real = torch.ones((batch_size, 1)).to(device) D_y_real = (torch.rand((batch_size, 1))/2 + 0.7).to(device) #Dに入れるノイズラベル #偽物のラベルは0 y_fake = torch.zeros((batch_size, 1)).to(device) D_y_fake = (torch.rand((batch_size, 1)) * 0.3).to(device) #Dに入れるノイズラベルこの部分です。普通に使うのが
y_real/y_fakeで、今回実際に使ったのがD_y_real/D_y_fakeの方です。9.最適化手法はAdamを使う
これは記事が古いので今ではRAdamなど別のoptimizerの方が良いかもしれません。
14.GにDropoutを入れる
今回はGeneratorのLinearの層に1回だけDropoutをいれました。ですが、BatchNormとDropoutの相性が悪い説もあるので、一概に入れた方が絶対に良くなるとは言えない気がします。
Generatorが作った画像を表示する
モデルを訓練する前に、Generatorが作った画像を表示する関数を定義しておきます。これを作っておいて、epochごとにGeneratorの学習度合いをチェックします。
pythonimport os from IPython.display import Image from torchvision.utils import save_image %matplotlib inline def Generate_img(epoch, G_model, device, z_dim, noise, var_mode, labels, log_dir = 'logs_cGAN'): G_model.eval() with torch.no_grad(): if var_mode == True: #生成に必要な乱数 noise = torch.normal(mean = 0.5, std = 0.2, size = (49, z_dim)).to(device) else: noise = noise #Generatorでサンプル生成 samples = G_model(noise, labels).data.cpu() samples = (samples/2)+0.5 save_image(samples,os.path.join(log_dir, 'epoch_%05d.png' % (epoch)), nrow = 7) img = Image('logs_cGAN/epoch_%05d.png' % (epoch)) display(img)やっていることは単純で、Generatorにノイズを入れて作った画像を
logs_cGANというフォルダに入れ、表示するだけです。
var_modeがFalseの時には毎回同じ乱数を使うことを想定しています。モデルの訓練
モデルを訓練します。
python#再現性確保のためseed値固定 SEED = 1111 random.seed(SEED) np.random.seed(SEED) torch.manual_seed(SEED) torch.cuda.manual_seed(SEED) torch.backends.cudnn.deterministic = True #device device = torch.device("cuda" if torch.cuda.is_available() else "cpu") def model_run(num_epochs, batch_size = batch_size, dataloader = train_loader, device = device): #Generatorに入れるノイズの次元 z_dim = 30 var_mode = False #表示結果を見るときに毎回異なる乱数を使うかどうか #生成に必要な乱数 noise = torch.normal(mean = 0.5, std = 0.2, size = (49, z_dim)).to(device) #クラス数 num_class = 49 #Generatorを試すときに使うラベルを作る labels = [] for i in range(num_class): tmp = np.identity(num_class)[i] tmp = np.array(tmp, dtype = np.float32) labels.append(tmp) label = torch.Tensor(labels).to(device) #モデル定義 D_model = Discriminator(num_class).to(device) G_model = Generator(z_dim, num_class).to(device) #lossの定義(引数はtrain_funcの中で指定) criterion = nn.BCELoss().to(device) #optimizerの定義 D_optimizer = torch.optim.Adam(D_model.parameters(), lr=0.0002, betas=(0.5, 0.999), eps=1e-08, weight_decay=1e-5, amsgrad=False) G_optimizer = torch.optim.Adam(G_model.parameters(), lr=0.0002, betas=(0.5, 0.999), eps=1e-08, weight_decay=1e-5, amsgrad=False) D_loss_list = [] G_loss_list = [] all_time = time.time() for epoch in range(num_epochs): start_time = time.time() D_loss, G_loss = train_func(D_model, G_model, batch_size, z_dim, num_class, criterion, D_optimizer, G_optimizer, dataloader, device) D_loss_list.append(D_loss) G_loss_list.append(G_loss) secs = int(time.time() - start_time) mins = secs / 60 secs = secs % 60 #エポックごとに結果を表示 print('Epoch: %d' %(epoch + 1), " | 所要時間 %d 分 %d 秒" %(mins, secs)) print(f'\tLoss: {D_loss:.4f}(Discriminator)') print(f'\tLoss: {G_loss:.4f}(Generator)') if (epoch + 1) % 1 == 0: Generate_img(epoch, G_model, device, z_dim, noise, var_mode, label) #モデル保存のためのcheckpointファイルを作成 if (epoch + 1) % 5 == 0: torch.save({ 'epoch':epoch, 'model_state_dict':G_model.state_dict(), 'optimizer_state_dict':G_optimizer.state_dict(), 'loss':G_loss, }, './checkpoint_cGAN/G_model_{}'.format(epoch + 1)) return D_loss_list, G_loss_list #モデルを回す D_loss_list, G_loss_list = model_run(num_epochs = 100)なんだかやたら長いですが、エポックごとに所要時間やlossを表示させたり、モデルを保存したりしています。
結果
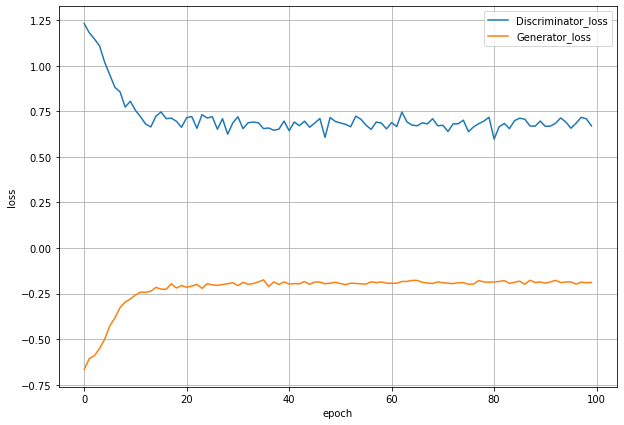
GeneratorとDiscriminatorのlossの推移を見てみます。
pythonimport matplotlib.pyplot as plt %matplotlib inline fig = plt.figure(figsize=(10,7)) loss = fig.add_subplot(1,1,1) loss.plot(range(len(D_loss_list)),D_loss_list,label='Discriminator_loss') loss.plot(range(len(G_loss_list)),G_loss_list,label='Generator_loss') loss.set_xlabel('epoch') loss.set_ylabel('loss') loss.legend() loss.grid() fig.show()
20epochあたりからはどちらのlossも変わらなくなっています。
DiscriminatorとGeneratorのlossはどちらも0からは遠いので、割とうまくいってそうです。
ちなみに生成された文字を1~100epochまでで順番にgifにしてみるとこんな感じです。
一番左上が「あ」で、一番右下が「ゝ」になっています。
これは文字によって結構差があり、「う」「く」「さ」「そ」「ひ」あたりは安定してうまく生成できているように見えますが、「な」「ゆ」などは遷移が激しいです。以下、1種類につき5枚ずつ画像を生成した結果です。
Epoch:5
Epoch:50
Epoch:100
これだけ見ると、Epochを重ねた方が良いとは言えなさそうです。「む」なんかは5epoch時点が一番よさそうな一方で、「ゑ」が一番いいのは100epochに見えます。
ちなみに、同じように訓練データを5枚ずつ取ってくるとこんな感じです。
現代人でも読めなさそうなのがちらほら混じっています。「す」や「み」なんかは今の形とかなり違います。これを見ると、モデルの性能は結構良いのではないかと思います。
まとめ
cGANでくずし字生成をやってみました。
実装はまだ向上の余地がたくさんありそうな気がしますが、結果自体はそれなりのものになったかなと思います。
かなり長くなってしましましたが、一部分でも何かの役に立てたら幸いです。また、cGANでPyTorchを使って一般的なMNIST(手書き数字の方)を実装している方もいらっしゃいます。モデル構造など異なる部分が多くあるので、こちらも参考になると思います。
<参考記事>
ディープラーニングで手書き文字生成してみた【Pytorch×MNIST×CGAN 】最後に
元々「手書き文章を生成できるのでは?」と思ったのが軽いモチベーションだったので、最後にそれをやってみます。
保存したcheckpointのファイルからモデルの重みをloadしてきて、いったんpklにしてみます。
pythonimport cloudpickle %matplotlib inline #取り出すepochを指定する point = 50 #モデルの構造を定義 z_dim = 30 num_class = 49 G = Generator(z_dim = z_dim, num_class = num_class) #checkpointを取り出す checkpoint = torch.load('./checkpoint_cGAN/G_model_{}'.format(point)) #Generatorにパラメータを入れる G.load_state_dict(checkpoint['model_state_dict']) #検証モードにしておく G.eval() #pickleで保存 with open ('KMNIST_cGAN.pkl','wb')as f: cloudpickle.dump(G,f)普通の
pickleではなく、cloudpickleというモジュールを使えばpklにできるみたいです。このpklファイルを開いて文章を生成してみます。
pythonletter = 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわゐゑをんゝ' strs = input() with open('KMNIST_cGAN.pkl','rb')as f: Generator = cloudpickle.load(f) for i in range(len(str(strs))): noise = torch.normal(mean = 0.5, std = 0.2, size = (1, 30)) str_index = letter.index(strs[i]) tmp = np.identity(49)[str_index] tmp = np.array(tmp, dtype = np.float32) label = [tmp] img = Generator(noise, torch.Tensor(label)) img = img.reshape((28,28)) img = img.detach().numpy().tolist() if i == 0: comp_img = img else: comp_img.extend(img) save_image(torch.tensor(comp_img), './sentence.png', nrow=len(str(strs))) img = Image('./sentence.png') display(img)結果はこんな感じです。
「もうなにもわからない」ですね......



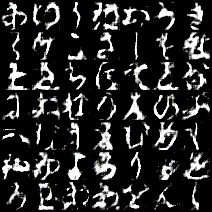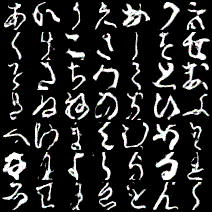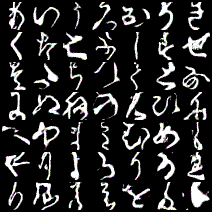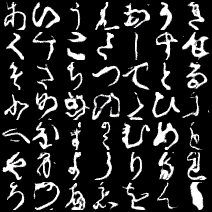





- 投稿日:2020-02-14T18:19:43+09:00
GAN : DCGAN Part1 - Scraping Web images
目標
Microsoft Cognitive Toolkit (CNTK) を用いた DCGAN についてまとめました。
Part1 では、Microsoft Cognitive Toolkit を使って DCGAN を訓練するための準備を行います。
今回は DCGAN を使って好きなアーティストの顔生成モデルを訓練してみます。そのためには訓練データセットが必要になるため、Microsoft Azure の Bing Image Search API v7 を用いて画像をスクレイピングします。
以下の順で紹介します。
- Bing Image Search API v7 の API key の取得
- Bing Image Search REST API を用いたスクレイピング
- OpenCV に同梱されている Haar Cascades による顔検出
- CNTK が提供するビルトインリーダーが読み込むファイルの作成
導入
Bing Image Search API v7 の API key の取得
今回のテーマに限らず、深層学習を試してみる際にネックとなるのが訓練データセットです。
そしてデータの収集と言えばスクレイピングが思い浮かびますが、スクレイピングで躓いてしまうことが多いと思われます。
この問題に対して比較的良い解決策を提示してくれているのが、Microsoft が運営する Microsoft Azure が提供する Azure Cognitive Services です。その中でも今回は画像を収集するための Bing Image Search を活用します。
上記のページにアクセスして Bing Image Search を試す をクリックすると利用プランが表示されます。この機に Microsoft Azure のアカウントを作成することもできますし、クレジットカード不要の 7日間のお試し版の API key を取得することもできます。
Microsoft, Facebook, LiknedIn, GitHub のいずれかのアカウントでサインインすることで、登録に使用したアカウントと紐づけられているメールアドレスに API key を取得したというメールが届き、自分が取得した API key を確認することができます。
Bing Image Search REST API を用いたスクレイピング
Azure Cognitive Services の API key を取得すれば、Bing Image Search REST API を用いて画像の URL を取得することができます。
Quickstart: Search for images using the Bing Image Search REST API and Python を参考にプログラムを作成しました。
HTTP の操作には requests ライブラリを用いています。
API のパラメータの詳細は Image Search API v7 reference を参照しました。
OpenCV に同梱されている Haar Cascades による顔検出
今回の DCGAN では顔に焦点を絞りたいので、取得してきた画像から顔だけを切り抜いてくる必要があります。
そこで、OpenCV のチュートリアルでも紹介されている Haar Cascades [1] による顔検出を用いて顔だけを切り抜いてきます。Haar Cascades では下図に示した矩形特徴量と AdaBoost [2] による識別を行います。
顔検出はこれ自体が大量の顔画像を必要とする機械学習ベースの検出器になっていますが、訓練済みの XML ファイルが opencv-contrib-python パッケージをインストールした際に同梱されているので、高速で処理することができます。
CNTK が提供するビルトインリーダーが読み込むファイルの作成
最後はこれまでと同様に、学習に使用する画像を読み込む ImageDeserializer 用のテキストファイルを作成して準備完了となります。ただし今回カテゴリーラベルは使用しないため、ラベルはすべて 0 にしておきます。
ImageDeserializer については Computer Vision : Image Classification Part1 - Understanding COCO dataset で紹介しています。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-7700K 3.60GHz
ソフトウェア
・Windows 10 Pro 1909
・Python 3.6.6
・opencv-contrib-python 4.1.1.26
・requests 2.22.0実行するプログラム
実装したプログラムは GitHub で公開しています。
dcgan_scraping.py解説
実行するプログラムのいくつかの箇所を抜き出して補足しておきます。
引数 subscription_key には取得した API key を、引数 search_term には収集したい画像のキーワードをそれぞれ文字列で与えます。検索キーワードは日本語でも問題ありません。
dcgan_scraping.pysubscription_key = "your-subscription-key" search_url = "https://api.cognitive.microsoft.com/bing/v7.0/images/search" search_term = "your-search-keyword"関数 bing_image_search は BingImageSearch ディレクトリに取得した URL からダウンロードした画像を保存していきます。今回は 1000枚を目安にしました。
スクレイピングのプログラムには様々な例外処理を想定して実装しておく必要がありますが、今回は ConnectionError と Timeout のみ実装しています。
bing_image_searchexcept ConnectionError: print("ConnectionError :", image_url) continue except Timeout: print("TimeoutError :", image_url) continue画像のダウンロードが終わった後、保存された画像が目的としているものかどうかをここで一度画像を確認しておいた方が良いです。というのも、全く関係のない画像が含まれていることがあるからです。
顔の切り抜きに使用する XML ファイルは、cv2 直下の data にある haarcascade_frontalface_default.xml の PATH を引数として与えます。
face_detectionface_cascade = cv2.CascadeClassifier(path)切り抜いた顔画像は faces ディレクトリに保存されていきます。検出する顔の最小サイズは 50x50 に設定しています。Haar Cascades による顔検出は失敗することもままあるので、ここでも上手く顔を切り抜くことができているかどうかを確認しておいた方が良いです。
関数 flip_augmentation は訓練データの加増のための左右反転を実行します。
関数 dcgan_mapfile は ImageDeserializer 用のテキストファイルを作成します。
結果
プログラムを実行すると、画像の URL を取得してから各 URL を辿って画像をダウンロードした後、顔検出を適用して顔画像を生成します。
./BingImageSearch/image_0000.jpg ./BingImageSearch/image_0001.jpg ...1000枚は取得したいと思っていましたが、反転加増を実行しても顔画像は 612枚しか用意できませんでした。
一先ずこれで本物の画像と学習に使用するテキストファイルの作成が完了したので、Part2 では CNTK を使った DCGAN の訓練を行います。
参考
Bing Image Search
Quickstart: Search for images using the Bing Image Search REST API and Python
Image Search API v7 reference
Requests: HTTP for Humans™
Face Detection using Haar CascadesComputer Vision : Image Classification Part1 - Understanding COCO dataset
- Paul Viola and Jones Michael. "Rapid Object Detection Using a Boosted Cascade of Simple Features", Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). 2001, pp 511–518.
- Yoav Freund and Robert E. Schapire. "A decision-theoretic generalization of on-line learning and an application to boosting", European Conference on Computational Learning Theory. 1995, pp 23-37.

- 投稿日:2020-02-14T18:00:58+09:00
ファイルを書き込んで読み込む
1s = """\ AAA BBB CCC DDD """ with open ('test.txt', 'w') as f: f.write(s) with open ('test.txt', 'r') as f: print(f.read())1の実行結果AAA BBB CCC DDDこれを
2s = """\ AAA BBB CCC DDD """ with open ('test.txt', 'w+') as f: f.write(s) f.seek(0) print(f.read())と書ける。
書き込んだ後はインデックスが最後になるので、f.seek(0)で先頭に戻る必要がある。
w+は、
書き込み+読み込み。with open ('test.txt', 'w+') as f: print(f.read())とすると、
まず書き込みモードになり、
一旦、空になり、
何も書き込まず、
読み込む事になるので、
何も出力されない。
- 投稿日:2020-02-14T17:41:18+09:00
Pythonで研究室配属を決める(フィクションです)
※ このケーススタディはフィクションです。実際の研究室配属に用いたことはありません。
状況を整理しましょう
研究室名
# 研究室名 labs = list("ABCDEFG") labs['A', 'B', 'C', 'D', 'E', 'F', 'G']各研究室の最低配属数
# 各研究室の最低配属数 min_assign = [2 for x in range(len(labs))] min_assign[2, 2, 2, 2, 2, 2, 2]各研究室の最大配属数
# 各研究室の最大配属数 max_assign = [4 for x in range(len(labs))] max_assign[4, 4, 4, 4, 4, 4, 4]学生ID
# 学生ID n_students = 20 students = [x + 1 for x in range(n_students)] students[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]学生の成績順位
# 学生の成績順位 import random grades = [x + 1 for x in range(n_students)] random.shuffle(grades) grades[9, 4, 13, 14, 7, 17, 5, 2, 10, 1, 19, 16, 18, 20, 3, 15, 12, 6, 8, 11]研究室配属希望順位調査
# 研究室配属希望順位調査 questionnaire = [] for x in range(n_students): hope = [x + 1 for x in range(len(labs))] random.shuffle(hope) if x > 0 and random.random() < 0.1: # 希望順位が同じという人も作る hope = questionnaire[x - 1] questionnaire.append(hope) questionnaire[[2, 7, 3, 5, 4, 6, 1], [2, 6, 1, 7, 3, 4, 5], [4, 7, 6, 5, 2, 1, 3], [6, 3, 2, 4, 1, 7, 5], [2, 5, 4, 3, 7, 1, 6], [3, 7, 2, 6, 5, 1, 4], [1, 7, 3, 2, 6, 5, 4], [4, 1, 7, 3, 6, 2, 5], [7, 6, 4, 3, 1, 2, 5], [5, 3, 4, 7, 1, 6, 2], [3, 2, 7, 4, 6, 1, 5], [6, 7, 5, 4, 1, 2, 3], [6, 7, 5, 4, 1, 2, 3], [2, 3, 7, 5, 1, 4, 6], [7, 3, 5, 1, 6, 4, 2], [6, 5, 7, 4, 3, 2, 1], [2, 3, 1, 5, 6, 4, 7], [4, 2, 1, 6, 7, 5, 3], [6, 2, 7, 4, 1, 3, 5], [2, 5, 4, 6, 1, 3, 7]]ランダムに配属を決める
# ランダムに配属を決める assignment = [[] for x in range(len(labs))] rand_stu = [x for x in range(n_students)] random.shuffle(rand_stu) lab = 0 for stu in rand_stu: assignment[lab % len(labs)].append(stu) lab += 1assignment[[8, 13, 6], [1, 5, 17], [18, 16, 3], [9, 2, 11], [12, 10, 14], [0, 4, 15], [19, 7]]配属の結果、誰が第何希望か
def resulted(assignment, questionnaire): return [[questionnaire[stu][i] for j, stu in enumerate(lab)] for i, lab in enumerate(assignment)]resulted(assignment, questionnaire)[[7, 2, 1], [6, 7, 2], [7, 1, 2], [7, 5, 4], [1, 6, 6], [6, 1, 2], [7, 5]]全体としての不満の大きさ
def fuman(assignment, questionnaire): ary = resulted(assignment, questionnaire) return sum([sum(x) - len(x) for x in ary])fuman(assignment, questionnaire)65成績の良い者から優先的に決める(最低配属数を考慮しない)
# 成績の良い者から優先的に、希望研究室を決めていく方法(最低配属数を考慮しない) assignment = [[] for x in range(len(labs))] for i in range(len(students)): stu = grades.index(i + 1) # 成績順位 i 番の学生 que = questionnaire[stu] # 成績順位 i 番の学生の希望順位 for j in range(len(labs)): lab = que.index(j + 1) # 希望順位 j の研究室 if len(assignment[lab]) < max_assign[lab]: assignment[lab].append(stu) breakassignment[[6, 13], [7, 10], [1, 17, 16, 3], [14], [9, 18, 8, 19], [4, 2, 11, 5], [0, 15, 12]]配属の結果、誰が第何希望か
resulted(assignment, questionnaire)[[1, 2], [1, 2], [1, 1, 1, 2], [1], [1, 1, 1, 1], [1, 1, 2, 1], [1, 1, 3]]全体としての不満の大きさ
fuman(assignment, questionnaire)6成績の良い者から優先的に決める(最低配属数を考慮する)
まず最低配属数を埋める
# 成績の良い者から優先的に、希望研究室を決めていく方法(まず最低配属数を埋める) assignment = [[] for x in range(len(labs))] assigned_students = [] for i in range(len(students)): stu = grades.index(i + 1) # 成績順位 i 番の学生 que = questionnaire[stu] # 成績順位 i 番の学生の希望順位 for j in range(len(labs)): lab = que.index(j + 1) # 希望順位 j の研究室 if len(assignment[lab]) < min_assign[lab]: assignment[lab].append(stu) assigned_students.append(stu) breakassignment[[6, 19], [7, 16], [1, 17], [14, 3], [9, 18], [4, 8], [0, 2]]assigned_students[9, 7, 14, 1, 6, 17, 4, 18, 0, 8, 19, 16, 2, 3]未配属の学生を割り当てる
# 成績の良い者から優先的に、希望研究室を決めていく方法(未配属の学生を割り当てる) for i in range(len(students)): stu = grades.index(i + 1) # 成績順位 i 番の学生 que = questionnaire[stu] # 成績順位 i 番の学生の希望順位 if stu in assigned_students: continue for j in range(len(labs)): lab = que.index(j + 1) # 希望順位 j の研究室 if len(assignment[lab]) < max_assign[lab]: assignment[lab].append(stu) assigned_students.append(stu) breakassignment[[6, 19, 13], [7, 16], [1, 17], [14, 3], [9, 18, 11, 12], [4, 8, 5, 10], [0, 2, 15]]配属の結果、誰が第何希望か
resulted(assignment, questionnaire)[[1, 2, 2], [1, 3], [1, 1], [1, 4], [1, 1, 1, 1], [1, 2, 1, 1], [1, 3, 1]]全体としての不満の大きさ
fuman(assignment, questionnaire)10実際のところ
人気が集中する研究室とか、全く人気のない研究室とか、いろいろあるので難しいですね(´・ω・`)
- 投稿日:2020-02-14T17:26:54+09:00
# から始まるヘッダがあるファイルから Pandas の DataFrame を作る
この記事では Python 3.8.1 を使っています。
モジュールは Pandas 0.25.3, linecache を使っています。対象とするファイルの例
ヘッダが # から始まります。
これは、例えば gnuplot で描画するためのデータとしても使う場合などに、
ヘッダを無視させるためにつけていたりします。
区切り文字は半角スペースです。# A B C D E F G H 0 2372.98 2382.84 57227.5 7121.71 0 233.015 4428.58 0.2 3911.76 7527.6 9395.84 7182.61 0 220.704 35050.1 0.4 3942.8 10436.8 5533.94 7072.14 0 245.926 28108.2 0.6 4360.47 11155.7 11080.7 7057.24 0 252.864 14500.9 0.8 4694.24 8433.53 151.516 7139.5 0 242.791 22288.7 1 5089.67 8965.1 4085.34 7189.3 0 243.555 12626.7 1.2 4966.41 8901.35 0.939722 7160.04 0 256.122 13213.8 1.4 4630.82 7437.05 486.491 7140.1 0 254.081 11467.9 1.6 4284.86 6953.67 7.03419 7171.6 0 258.189 10037.3データフレームの作成
まず、カラムの名前の取得のために入力ファイル(ifile)から1行目だけ取り出します。
このとき末尾に改行文字が入るため rstrip で除去します。
そのあと区切り文字にあわせて分割します。
最後に # の要素を削除し、カラム名の配列(column_names)を作成します。次に、read_table を使ってファイルの内容からデータフレームを作成します。
このとき、ヘッダである1行目を無視するために header=None, skiprows=1 のオプションを付けておきます。
こうすることで読み込ませず、カラム名としても利用させないようにします。
そして、後から先ほど作成したカラム名を与えます。import pandas as pd import linecache def file2df( ifile ): column_names = linecache.getline( ifile, int(1) ).rstrip('\n').split(' ') del column_names[0] df = pd.read_table( ifile, sep=' ', header=None, skiprows=1 ) df.columns = column_names return df調べながら適当に書いてみただけなので、もっといいやり方がありそうな気もします。
それと、入力ファイルに余計なスペースが入ってる場合などは、別途対処してください。
- 投稿日:2020-02-14T17:20:18+09:00
seek
s = """\ AAA BBB CCC DDD """ with open('test.txt', 'w') as f: f.write(s) with open ('test.txt', 'r') as f: print(f.tell()) print(f.read(1)) f.seek(5) print(f.read(1)) f.seek(14) print(f.read(1)) f.seek(15) print(f.read(1)) f.seek(5) print(f.read(1))実行結果0 A B D Bprint(f.tell())で現在地を出力
print(f.read(1))で現在地0から1文字を出力
これはAにあたるf.seek(5)で現在地を5に移動させ、
print(f.read(1))で現在地5から1文字を出力
これはBにあたる位置
0, 1, 2, 3
4, 5, 6, 7
8, 9, 10, 11
12, 13, 14, 15文字
A, A, A, 改行
B, B, B, 改行
C, C, C, 改行
D, D, D, 改行と配置されている。
- 投稿日:2020-02-14T16:54:07+09:00
【Python】ネストしたリストをタプルにしたい
リストをタプルにしたり、その逆にタプルをリストにするのはよくある要求です。
一般的な方法
一般的なのは組み込み関数の
listおよびtupleを使用することです。l = [0, 1, 2] t = tuple(l) print(t)(0, 1, 2)この方法の問題
ところが、リストがネストしていた場合、最も浅い階層しかタプルにしてくれません。
l = [[0, 1, 2], [3, 4, 5, 6, 7], 8, 9] t = tuple(l) print(t) # ((0, 1, 2), (3, 4, 5, 6, 7), 8, 9) になってほしい([0, 1, 2], [3, 4, 5, 6, 7], 8, 9)キレそ。
ネストしたリストを内部ごとタプルにする関数
再帰呼び出ししながら全階層タプルにしてやりましょう。
def list_to_tuple(l): return tuple(list_to_tuple(e) if isinstance(e, list) else e for e in l)l = [[0, 1, 2], [3, 4, 5, 6, 7], 8, 9] t = list_to_tuple(l) print(t)((0, 1, 2), (3, 4, 5, 6, 7), 8, 9)やったぜ。
元ネタとその比較
実はこの記事はこちらのパクリです。
お前恥ずかしくないのかよ違いとしましては、むこうでは for 文と代入演算子を使用していた部分を内包表記にしたことです。
愚直に繰り返す for 文に対して、内包表記は専用の処理を呼び出してくれるため実行時間が短くなります (参考)。
def list_to_tuple_orig(_list): t = () for e in _list: if isinstance(e,list): t += (list_to_tuple(e),) else: t += (e,) return tl = list(range(10000)) %timeit t = list_to_tuple_orig(l) %timeit t = list_to_tuple(l) %timeit t = tuple(l)92.7 ms ± 576 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) 877 µs ± 3.31 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) 19.6 µs ± 47.3 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)100 倍くらい早くなっていますね。 組み込み関数には大敗北ですが。
- 投稿日:2020-02-14T16:46:02+09:00
Flaskチュートリアル#1 ~GETリクエスト編~
Flaskとは
FlaskとはPythonのWebアプリケーションフレームワークです
Djangoと同じ働きをします。
しかし、マイクロフレームワークと呼ばれ最小限で実装されている点がDjangoと異なります。
Djangoのチュートリアルをしていていきなりデータベース接続だったりテンプレートやビューだったりとたくさんの要素が出てきてついて行けなかった人もいるんじゃないでしょうか?実装のゴール
今回はビューもテンプレートも使わずJSON形式のレスポンスを返すAPIサーバを構築していきます。
以下の動画で詳細に紹介しています
https://youtu.be/xsiUT-HlmLIソースコード
app.pyfrom flask import Flask, jsonify, request app = Flask(__name__) db_data = [ {'title': 'タイトル1', 'body': '本文1'}, {'title': 'タイトル2', 'body': '本文2'}, {'title': 'タイトル3', 'body': '本文3'}, {'title': 'タイトル4', 'body': '本文4'}, {'title': 'タイトル5', 'body': '本文5'}, ] app.config['JSON_AS_ASCII'] = False @app.route('/', methods=['GET']) def index(): return 'hello world' @app.route('/posts', methods=['GET']) def get_all_posts(): limit = request.args['limit'] return jsonify(db_data[:int(limit)]) @app.route('/post/<id>', methods=['GET']) def get_post(id): return jsonify(db_data[int(id)]) if __name__ == '__main__': app.debug = True app.run()
- 投稿日:2020-02-14T16:40:21+09:00
ファイルの読み込み
1s = """\ AAA BBB CCC DDD """ with open('test.txt', 'w') as f: f.write(s) with open('test.txt', 'r') as f: while True: line = f.readline() print(line, end="") if not line: break1の実行結果AAA BBB CCC DDDwith open('test.txt', 'w') as f: f.write(s)でtest.txtという中身が
AAA
BBB
CCC
DDD
であるテキストファイルが作成される。そして、
with open('test.txt', 'r') as f:でtest.txtの中身をfとして読み込み、
while True: line = f.readline() print(line, end="") if not line: breakで、
変数lineにtest.txtの中身を一行ずつ格納して出力。
lineの中身がなくなるなでループさせて、
なくなったらブレイク。2s = """\ AAA BBB CCC DDD """ with open('test.txt', 'w') as f: f.write(s) with open('test.txt', 'r') as f: while True: chunk = 2 line = f.read(chunk) print(line) if not line: break2の実行結果AA A BB B CC C DD D二文字ずつ出力させたもの。
A2つ
Aと改行
B2つ
Bと改行
C2つ
Cと改行
D2つ
Dと改行
- 投稿日:2020-02-14T16:25:26+09:00
pandas 1.0とdaskのちょっと細かい調査
背景
2020/01/29にpandas 1.0.0がリリースされました!パチパチ
2020/02/14現在は、1.0.1です。個人的には、下記の変更点が重要ポイントかなと思ってます。
- pandas独自のNA
- String型の対応強化(Experimental)んで。
僕は分析時には、下記のライブラリとpandasを一緒に使うことが多いです。
特にdaskのpandas1.0対応状況や、その他の細かな振る舞いについて整理しようかなと思っています。
daskのバージョンは2020/02/14現在2.10.1です。intakeに関しては、daskが対応してくれれば問題ないっしょ、って思っています。
(daskの処理待ち時間が暇というのもある。)
気になっていること
- daskは
pandas.NAをちゃんと使えんの?(ver 1.0関連)- daskは
dtype: stringをちゃんと使えんの?(ver 1.0関連)- I/O、特にfastparquetは
pandas.NAとかdtype: stringとかちゃんと入出力出来んの?(ver 1.0関連)- そういや、daskは
dtype: categoricalちゃんと使えんの?(その他)Tom Augspurgerさんという方が、鬼のようにpandas1.0対応してくれてるっぽいし、今のところ期待感大。
結果
結果だけ知りたい人用。
- daskは、
pandas.NAを含んでいても、四則演算・文字列演算はOK- daskは、
Int64,string型などのカスタム型でset_indexできない- pandas/dask両方とも、
pandas.NAを含むboolean列でインデックスフィルタできない- daskは、
apply(meta='string')としてもobject型になってしまうが、astype('string')で復活させられる。- dask内でpandas.Categoricalを使う場合、フィルタ・集計はいけそう
- dask DataFrameに新しいCategorical列を追加する時は
astypeを使う必要がありそう- daskは、
Int64、string型をto_parquetできない(engine=fastparquetの場合)。調査環境構築
とりあえずクリーンな検証環境を用意します。
OSはmacOS Catalina 10.15.2です。python versionに関してpandasはminimumしか設定していないのと、daskもpython3.8対応とかしてるっぽいので、
3.7.4なら問題ないでしょう。依存関係に関しては、minimum versions for dependenciesを一通り入れておく。ただし、fastparquetとpyArrowはmac上で共存できない問題が昔あったので、念のためpyArrowは入れないでおく。使わんし。
検証作業はjupyterlab上でやります。
pyenv virtualenv 3.7.4 pandas100 pyenv shell pandas100 pip install -r requirements.txtrequirements.txtpandas==1.0.1 dask[complete]==2.10.1 fastparquet==0.3.3 jupyterlab==1.2.6 numpy==1.18.1 pytz==2019.3 python-dateutil==2.8.1 numexpr==2.7.1 beautifulsoup4==4.8.2 gcsfs==0.6.0 lxml==4.5.0 matplotlib==3.1.3 numba==0.48.0 openpyxl==3.0.3 pymysql==0.9.3 tables==3.6.1 s3fs==0.4.0 scipy==1.4.1 sqlalchemy==1.3.13 xarray==0.15.0 xlrd==1.2.0 xlsxwriter==1.2.7 xlwt==1.3.0dask vs pandas1.0
まずは、pd.NAの確認。
- dtype: int
- dtype: Int64(...Categorical)
- dtype: float
- dtype: string
- dtype: boolean
- dtype: datetime64[ns]
- dtype: timedelta64[ns]
- dtype: object
それぞれでのpd.NAの振る舞いを確認
s=...type(s.loc[3]) pandas.Series([1,2,3,None], dtype='int') TypeError pandas.Series([1,2,3,pandas.NA], dtype='int') TypeError pandas.Series([1,2,3,None], dtype='Int64') pandas._libs.missing.NAType pandas.Series([1,2,3,None], dtype='float') numpy.float64 pandas.Series([1,2,3,pandas.NA], dtype='float') TypeError pandas.Series([1,2,3,None], dtype='Int64').astype('float') numpy.float64 pandas.Series(['a', 'b', 'c' ,None], dtype='string') pandas._libs.missing.NAType pandas.Series(['a', 'b', 'c' ,None], dtype='object').astype('string') pandas._libs.missing.NAType pandas.Series([True, False, True ,None], dtype='boolean') pandas._libs.missing.NAType pandas.Series([1, 0, 1 ,None], dtype='float').astype('boolean') pandas._libs.missing.NAType pandas.Series(pandas.to_datetime(['2020-01-01', '2020-01-02', '2020-01-03', None])) pandas._libs.tslibs.nattype.NaTType pandas.Series(pandas.to_timedelta(['00:00:01', '00:00:02', '00:00:03', None])) pandas._libs.tslibs.nattype.NaTType pandas.Series([object(), object(), object(), None], dtype='object') NoneType pandas.Series([object(), object(), object(), pandas.NA], dtype='object') pandas.Series([object(), object(), object(), pandas.NA], dtype='object') まとめると、
- dtype intは、
pandas.NAにならない(そのままTypeError)- dtype Int64,string,booleanは
pandas.NAになる。- dtype floatは、
numpy.NaNになる- dtype datetime64, timedelta64は、
NATになる- dtype objectは、
Noneを自動でpandas.NAに変換しないこれを
dask.dataframe.from_pandasするとどうなるか調査する。>>> import pandas >>> import dask.dataframe >>> df = pandas.DataFrame({'i': [1,2,3,4], ... 'i64': pandas.Series([1,2,3,None], dtype='Int64'), ... 's': pandas.Series(['a', 'b', 'c' ,None], dtype='string'), ... 'f': pandas.Series([1,2,3,None], dtype='Int64').astype('float')}) >>> ddf = dask.dataframe.from_pandas(df, npartitions=1)>>> df i i64 s f 0 1 1 a 1.0 1 2 2 b 2.0 2 3 3 c 3.0 3 4 <NA> <NA> NaN >>> ddf Dask DataFrame Structure: i i64 s f npartitions=1 0 int64 Int64 string float64 3 ... ... ... ...なるほど、
Int64は、dask上でもInt64となっている。stringも同様。>>> # Int64に対する(整数)演算 >>> df.i64 * 2 0 2 1 4 2 6 3 <NA> Name: i64, dtype: Int64 >>> (ddf.i64 * 2).compute() 0 2 1 4 2 6 3 <NA> Name: i64, dtype: Int64Int64->Int64の処理はちゃんと動く。
>>> # Int64に対する(浮動少数点数)演算 >>> df.i64 - df.f 0 0.0 1 0.0 2 0.0 3 NaN dtype: float64 >>> (ddf.i64 - ddf.f).compute() 0 0.0 1 0.0 2 0.0 3 NaN dtype: float64Int64->float64の処理もちゃんと動く。
>>> # pandas.NAを含むInt64列でset_index >>> df.set_index('i64') i s f i64_result i64-f i64 1 1 a 1.0 2 0.0 2 2 b 2.0 4 0.0 3 3 c 3.0 6 0.0 NaN 4 <NA> NaN <NA> NaN >>> ddf.set_index('i64').compute() TypeError: data type not understood >>> # pandas.NAがなかったらどうなるか >>> ddf['i64_nonnull'] = ddf.i64.fillna(1) ... ddf.set_index('i64_nonnull').compute() TypeError: data type not understoodえー!daskは
Int64列でset_indexできないんかい!
もちろんpandasはできる。>>> # pandas.NAを含むstring列でset_index >>> df.set_index('s') i i64 f s a 1 1 1.0 b 2 2 2.0 c 3 3 3.0 NaN 4 <NA> NaN >>> ddf.set_index('s').compute() TypeError: Cannot perform reduction 'max' with string dtype >>> # pandas.NAがなかったらどうなるか >>> ddf['s_nonnull'] = ddf.s.fillna('a') ... ddf.set_index('s_nonnull') TypeError: Cannot perform reduction 'max' with string dtype
stringもできんな。これは(僕の使い方では)まだ使えないなぁ。# .str関数を試してみる >>> df.s.str.startswith('a') 0 True 1 False 2 False 3 <NA> Name: s, dtype: boolean >>> ddf.s.str.startswith('a').compute() 0 True 1 False 2 False 3 <NA> Name: s, dtype: booleanふむ、これは動くと。
>>> # pandas.NAを含むboolean列でフィルタ >>> df[df.s.str.startswith('a')] ValueError: cannot mask with array containing NA / NaN values >>> # pandas.NAがダメなのかな? >>> df['s_nonnull'] = df.s.fillna('a') ... df[df.s_nonnull.str.startswith('a')] i i64 s f i64_nonnull s_nonnull 0 1 1 a 1.0 1 a 3 4 <NA> <NA> NaN 1 a >>> ddf[ddf.s.str.startswith('a')].compute() ValueError: cannot mask with array containing NA / NaN values >>> ddf['s_nonnull'] = ddf.s.fillna('a') ... ddf[ddf.s_nonnull.str.startswith('a')].compute() i i64 s f i64_nonnull s_nonnull 0 1 1 a 1.0 1 a 3 4 <NA> <NA> NaN 1 a >>> ddf[ddf.s.str.startswith('a')].compute()え!!!pandas.NA含むとフィルタできないの?
これはダメでしょ!>>> # applyでmeta='Int64'指定してみる >>> ddf['i10'] = ddf.i.apply(lambda v: v * 10, meta='Int64') >>> ddf Dask DataFrame Structure: i i64 s f i64_nonnull s_nonnull i10 npartitions=1 0 int64 Int64 string float64 Int64 string int64 3 ... ... ... ... ... ... ... >>> # applyでmeta='string'指定してみる >>> ddf['s_double'] = ddf.s.apply(lambda v: v+v, meta='string') Dask DataFrame Structure: i i64 s f i64_nonnull s_nonnull i10 s_double npartitions=1 0 int64 Int64 string float64 Int64 string int64 object 3 ... ... ... ... ... ... ... ... >>> # astype('string')してみる >>> ddf['s_double'] = ddf['s_double'].astype('string') >>> ddf Dask DataFrame Structure: i i64 s f i64_nonnull s_nonnull i10 s_double npartitions=1 0 int64 Int64 string float64 Int64 string int64 string 3 ... ... ... ... ... ... ... ...meta=で指定する場合、反映されないのか。。。
astypeで復活させられるけど、面倒だな。。。結果
- 演算はOK
- daskでは、Indexとしては使えない(pandas.NA対応している型がそもそも使えないから)
- pandas/dask両方で、filterできない!
- .apply(meta='string')などしても無視される。astypeしないとだめ。
dask vs pandas.Categorical
pandasでCategoricalを調査するために、今回はCategoricalDtypeを使用した方法を使用します。
基本的なCategoricalDtypeの使い方は、
- categoriesとorderedを指定してインスタンス化
- dtype=CategoricalDtypeインスタンスとして、pandas.Seriesをインスタンス化
だと思っています。以下サンプルコード
>>> # まずは、CategoricalDtypeを作る >>> int_category = pandas.CategoricalDtype(categories=[1,2,3,4,5], ... ordered=True) >>> int_category CategoricalDtype(categories=[1, 2, 3, 4, 5], ordered=True) >>> int_category.categories Int64Index([1, 2, 3, 4, 5], dtype='int64') >>> # こんな感じでpandas.Seriesを作る >>> int_series = pandas.Series([1,2,3], dtype=int_category) >>> int_series 0 1 1 2 2 3 dtype: category Categories (5, int64): [1 < 2 < 3 < 4 < 5] >>> # 生成時なら、カテゴリに無い値をNaNに変換してくれる >>> int_series = pandas.Series([1,2,3,6], dtype=int_category) >>> int_series 0 1 1 2 2 3 3 NaN dtype: category Categories (5, int64): [1 < 2 < 3 < 4 < 5] >>> # 生成後は怒られる >>> int_series.loc[3] = 10 ValueError: Cannot setitem on a Categorical with a new category, set the categories first次に、dask上でCategoricalを使ってみる。
>>> import pandas >>> import dask.dataframe >>> # pandas.DataFrameを生成 >>> df = pandas.DataFrame({'a': pandas.Series([1, 2, 3, 1, 2, 3], dtype=int_category), ... 'b': pandas.Series([1, 2, 3, 1, 2, 3], dtype='int64')}) >>> df a b 0 1 1 1 2 2 2 3 3 3 1 1 4 2 2 5 3 3 >>> # dask.dataframe.DataFrameに変換 >>> ddf = dask.dataframe.from_pandas(df, npartitions=1) >>> ddf Dask DataFrame Structure: a b npartitions=1 0 category[known] int64 5 ... ...とりあえず、categoricalのままdask化することができた。
# pandasでは新しいカテゴリ値の追加は御法度 >>> df.loc[2, 'a'] = 30 ValueError: Cannot setitem on a Categorical with a new category, set the categories first # daskでは、Categoricalとか関係なく、そもそもアサインできない >>> ddf.loc['a', 3] = 10 TypeError: '_LocIndexer' object does not support item assignment # pandasでは、カテゴリ値の演算も御法度 >>> df.a * 2 TypeError: unsupported operand type(s) for *: 'Categorical' and 'int' # daskでも、カテゴリ値の演算は御法度 >>> ddf.a * 2 TypeError: unsupported operand type(s) for *: 'Categorical' and 'int' # daskのapplyで、metaとして指定してみる >>> ddf['c'] = ddf.a.apply(lambda v: v, meta=int_category) Dont know how to create metadata from category # daskのapplyで、meta='category'にしたら頑張ってくれるか? >>> ddf['c'] = ddf.a.apply(lambda v: v, meta='category') >>> ddf.dtypes a category b int64 c object dtype: object >>> # 中身との整合性が取れているかチェックしてみる >>> ddf.compute().dtypes a category b int64 c category dtype: object >>> # astypeしてみる >>> ddf['c'] = ddf.c.astype(int_category) >>> ddf Dask DataFrame Structure: a b c npartitions=1 0 category[known] int64 category[known] 5 ... ... ...なるほど。カテゴリの制約部分は維持されるが、
.apply(meta=)とかすると、daskのdtype管理がバグる。
astypeで復活させることは可能だが、面倒だな。。。
フィルタだけなら使えそうってところですかね。# 集計処理してみる >>> ddf.groupby('a').b.mean().compute() a 1 1.0 2 2.0 3 3.0 4 NaN 5 NaN Name: b, dtype: float64 # Index扱いされることで、型は壊れてしまわないか? Dask DataFrame Structure: a b npartitions=1 category[known] float64 ... ... Dask Name: reset_index, 34 tasksふむ、集計には対応している感じか。
結果
- pandas.Categoricalをdaskで使うとき、フィルタと集計は問題なさそう
- daskのDataFrameに新しくCategoricalな列を追加したい時は
astypeを使うべしto_parquet vs pandas1.0
>>> # まずはpandas.DataFrameを生成 >>> df = pandas.DataFrame( { 'i64': pandas.Series([1, 2, 3,None], dtype='Int64'), 'i64_nonnull': pandas.Series([1, 2, 3, 4], dtype='Int64'), 's': pandas.Series(['a', 'b', 'c',None], dtype='string'), 's_nonnull': pandas.Series(['a', 'b', 'c', 'd'], dtype='string'), } ) >>> df i64 i64_nonnull s s_nonnull 0 1 1 a a 1 2 2 b b 2 3 3 c c 3 <NA> 4 <NA> d >>> # dask.dataframe.DataFrameに変換 >>> ddf = dask.dataframe.from_pandas(df, npartitions=1) >>> ddf Dask DataFrame Structure: i64 i64_nonnull s s_nonnull npartitions=1 0 Int64 Int64 string string 3 ... ... ... ...とりあえず、to_parquetしてみる。
>>> ddf.to_parquet('test1', engine='fastparquet') ValueError: Dont know how to convert data type: Int64まじか。。。予想はしてたが。。。
Int64はダメでもstringはいけるかも。。。>>> ddf.to_parquet('test2', engine='fastparquet') ValueError: Dont know how to convert data type: stringダメでした。
結果
- Int64, stringはto_parquet不可。
おわりに
いかがだったでしょうか?
多分、最後まで読みきってこのコメントを読んでいる人は誰もいないと思います。
投稿を分けるべきでしたかね。pandas 1.0どやねんと思っている人の役に立てたら嬉しいです。
ではまたそのうち。
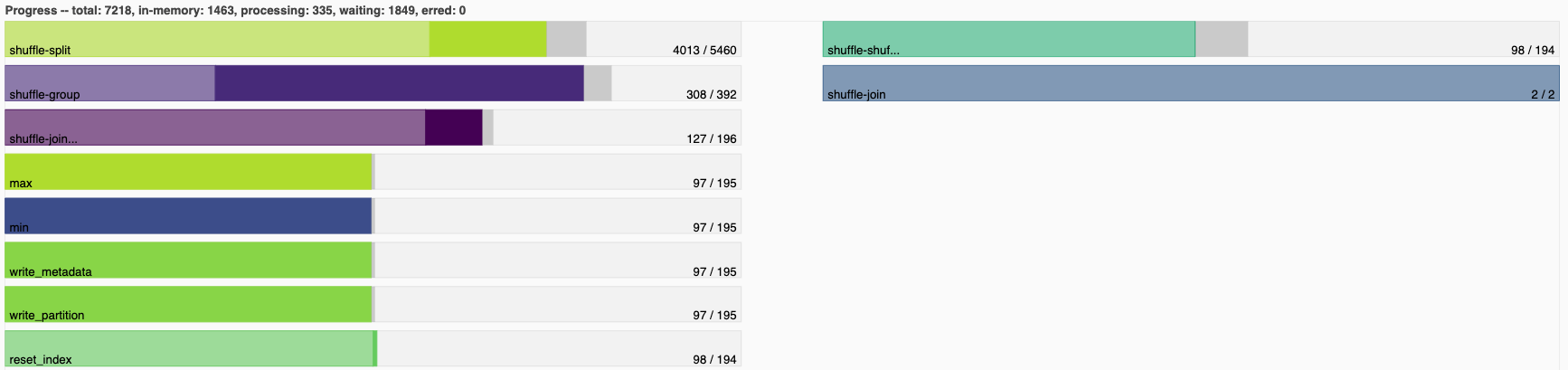

- 投稿日:2020-02-14T15:55:26+09:00
機械学習スタッキング テンプレート(回帰)
機械学習 スタッキング (回帰問題)
kaggleでは、上位の人はほとんどスタッキングを使っている。
自分も上位に食い込みたいので、スタッキングを勉強してみた。
ここでは、スタッキングの時に、使用するコードをコピペで使えるようにしている。
(ただし、回帰問題に限る)今回は、2層のスタッキングです。
使用した機械学習
使用した機械学習は、なんとなく
・XGBoost
・LightGBM
・Catboost
・MLP(隠れ層2)
・Linear SVR
・Kernel SVR (rbf)
・KNN
・Lasso
・Ridge
・ElasticNet
・RandomForestハイパーパラメータ について
なお、ハイパーパラメータは、きちんと調節していません。
でも、スタッキングの場合、集解調節しすぎると過学習になってしまって
テストデータで精度が落ちてしまう可能性があり。難しいところです。テンプレート
以下に、テンプレートを貼っておきます。
classを作ることで、
・学習する時 fit
・予測するときは predict
で統一できるので、非常に便利になっております(真似しただけです)なお、すべてコピー&ペーストで使えるようになっている(はず)。
XGBoost
import xgboost as xgb class Model1Xgb: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): xgb_params = {'objective': 'reg:squarederror', #binary:logistic #multi:softprob, 'random_state': 10, #'eval_metric': 'rmse' } dtrain = xgb.DMatrix(tr_x, label=tr_y) dvalid = xgb.DMatrix(va_x, label=va_y) evals = [(dtrain, 'train'), (dvalid, 'eval')] self.model = xgb.train(xgb_params, dtrain, num_boost_round=10000,early_stopping_rounds=50, evals=evals) def predict(self, x): data = xgb.DMatrix(x) pred = self.model.predict(data) return predLightGBM
import lightgbm as lgb class Model1lgb: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): lgb_params = {'objective': 'rmse', 'random_state': 10, 'metric': 'rmse'} lgb_train = lgb.Dataset(tr_x, label=tr_y) lgb_eval = lgb.Dataset(va_x, label=va_y,reference=lgb_train) self.model = lgb.train(lgb_params, lgb_train, valid_sets=lgb_eval, num_boost_round=10000,early_stopping_rounds=50) def predict(self, x): pred = self.model.predict(x,num_iteration=self.model.best_iteration) return predCatboost
import catboost class Model1catboost: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): #https://catboost.ai/docs/concepts/python-reference_catboostregressor.html #catb = catboost.CatBoostClassifier( catb = catboost.CatBoostRegressor( iterations=10000, use_best_model=True, random_seed=10, l2_leaf_reg=3, depth=6, loss_function="RMSE",#"CrossEntropy", #eval_metric = "RMSE", #'AUC', #classes_coun=3 ) self.model = catb.fit(tr_x,tr_y,eval_set=(va_x,va_y),early_stopping_rounds=50) print(self.model.score(va_x,va_y)) def predict(self, x): pred = self.model.predict(x) return predMulti-layer Perceptron(MLP)
今回は、4層のニューラルネットです。
rom keras.models import Sequential from keras.layers import Dense, Dropout from keras.callbacks import EarlyStopping class Model1NN: def __init__(self): self.model = None self.scaler = None def fit(self, tr_x, tr_y, va_x, va_y): self.scaler = StandardScaler() self.scaler.fit(tr_x) batch_size = 128 epochs = 10000 tr_x = self.scaler.transform(tr_x) va_x = self.scaler.transform(va_x) early_stopping = EarlyStopping( monitor='val_loss', min_delta=0.0, patience=20, ) model = Sequential() model.add(Dense(32, activation='relu', input_shape=(tr_x.shape[1],))) model.add(Dropout(0.5)) model.add(Dense(32, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) model.compile(loss='mean_squared_error', #'categorical_crossentropy',#categorical_crossentropy optimizer='adam') history = model.fit(tr_x, tr_y, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(va_x, va_y), callbacks=[early_stopping]) self.model = model def predict(self, x): x = self.scaler.transform(x) pred = self.model.predict_proba(x).reshape(-1) return predLinear SVR
from sklearn.svm import LinearSVR class Model1LinearSVR: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): self.scaler = StandardScaler() self.scaler.fit(tr_x) tr_x = self.scaler.transform(tr_x) #params = {"C":np.logspace(0,1,params_cnt),"epsilon":np.logspace(-1,1,params_cnt)} self.model = LinearSVR(max_iter=1000, random_state=10, C = 1.0, #損失の係数(正則化係数の逆数) epsilon = 5.0 ) self.model.fit(tr_x,tr_y) def predict(self,x): x = self.scaler.transform(x) pred = self.model.predict(x) return predKernel SVR
from sklearn.svm import SVR class Model1KernelSVR: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): self.scaler = StandardScaler() self.scaler.fit(tr_x) tr_x = self.scaler.transform(tr_x) #params = {"kernel":['rbf'],"C":np.logspace(0,1,params_cnt), "epsilon":np.logspace(-1,1,params_cnt)} self.model = SVR(kernel='rbf', gamma='auto', max_iter=1000, C = 1.0, #損失の係数(正則化係数の逆数) epsilon = 5.0 ) self.model.fit(tr_x,tr_y) def predict(self,x): x = self.scaler.transform(x) pred = self.model.predict(x) return predLasso
from sklearn.linear_model import Lasso class Model1Lasso: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): ''' (1 / (2 * n_samples)) * ||y - Xw||^2_2 + alpha * ||w||_1 #https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html ''' self.scaler = StandardScaler() self.scaler.fit(tr_x) tr_x = self.scaler.transform(tr_x) self.model = Lasso( alpha=1, #L1係数 fit_intercept=True, max_iter=1000, random_state=10, ) self.model.fit(tr_x,tr_y) def predict(self,x): x = self.scaler.transform(x) pred = self.model.predict(x) return predRidge
from sklearn.linear_model import Ridge class Model1Ridge: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): ''' |y - Xw||^2_2 + alpha * ||w||^2_2 #https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html ''' self.scaler = StandardScaler() self.scaler.fit(tr_x) tr_x = self.scaler.transform(tr_x) self.model = Ridge( alpha=1, #L2係数 max_iter=1000, random_state=10, ) self.model.fit(tr_x,tr_y) def predict(self,x): x = self.scaler.transform(x) pred = self.model.predict(x) return predElasticNet
from sklearn.linear_model import ElasticNet class Model1ElasticNet: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): '''1 / (2 * n_samples) * ||y - Xw||^2_2 + alpha * l1_ratio * ||w||_1 + 0.5 * alpha * (1 - l1_ratio) * ||w||^2_2 ref) https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ElasticNet.html ''' self.scaler = StandardScaler() self.scaler.fit(tr_x) tr_x = self.scaler.transform(tr_x) self.model = ElasticNet( alpha=1, #L1係数 l1_ratio=0.5, ) self.model.fit(tr_x,tr_y) def predict(self,x): x = self.scaler.transform(x) pred = self.model.predict(x) return predRandomForest
from sklearn.ensemble import RandomForestRegressor class Model1RF: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): self.scaler = StandardScaler() self.scaler.fit(tr_x) tr_x = self.scaler.transform(tr_x) self.model = RandomForestRegressor( max_depth=5, n_estimators=100, random_state=10, ) self.model.fit(tr_x,tr_y) def predict(self,x): x = self.scaler.transform(x) pred = self.model.predict(x) return predKNN(K近傍法)
from sklearn.neighbors import KNeighborsRegressor class Model1KNN: def __init__(self): self.model = None def fit(self, tr_x, tr_y, va_x, va_y): self.scaler = StandardScaler() self.scaler.fit(tr_x) tr_x = self.scaler.transform(tr_x) #params = {"kernel":['rbf'],"C":np.logspace(0,1,params_cnt), "epsilon":np.logspace(-1,1,params_cnt)} self.model = KNeighborsRegressor(n_neighbors=5, #weights='uniform' ) self.model.fit(tr_x,tr_y) def predict(self,x): x = self.scaler.transform(x) pred = self.model.predict(x) return pred線形回帰(Linear Regression)
from sklearn.linear_model import LinearRegression class Model2Linear: def __init__(self): self.model = None self.scaler = None def fit(self, tr_x, tr_y, va_x, va_y): self.scaler = StandardScaler() self.scaler.fit(tr_x) tr_x = self.scaler.transform(tr_x) self.model = LinearRegression() self.model.fit(tr_x, tr_y) def predict(self, x): x = self.scaler.transform(x) pred = self.model.predict(x) return predOut-of-fold
今回は、4foldに分けて、out-of-foldしています。
foldは通常、2-5foldくらいにするらしい。
適当なデータで10foldでやってみたら、精度が落ちた。
fold数を大きくしすぎると、似ているデータセットばかりで学習することになるから
バリデーションデータに過学習しちゃうのかなって思っています。from sklearn.model_selection import KFold from sklearn.preprocessing import StandardScaler def predict_cv(model, train_x, train_y, test_x): preds = [] preds_test = [] va_idxes = [] kf = KFold(n_splits=4, shuffle=True, random_state=10) # クロスバリデーションで学習・予測を行い、予測値とインデックスを保存する for i, (tr_idx, va_idx) in enumerate(kf.split(train_x)): tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx] tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx] model.fit(tr_x, tr_y, va_x, va_y) pred = model.predict(va_x) preds.append(pred) pred_test = model.predict(test_x) preds_test.append(pred_test) va_idxes.append(va_idx) # バリデーションデータに対する予測値を連結し、その後元の順序に並べ直す va_idxes = np.concatenate(va_idxes) preds = np.concatenate(preds, axis=0) order = np.argsort(va_idxes) pred_train = preds[order] # テストデータに対する予測値の平均をとる preds_test = np.mean(preds_test, axis=0) return pred_train, preds_test2層目の特徴量を作る
train_x_2,test_x_2を作る時(下の行)に、どのデータを用いるかで精度がかなり変わってくる。
自分で、いろいろ組み合わせを試して、精度を確認してみると、案外面白い。
今回は、pred_1d(LinearSVR)を除外した方が精度が高かったので、外しました。model_1a = Model1Xgb() pred_train_1a, pred_test_1a = predict_cv(model_1a, df_trainval, y_trainval, df_test) model_1b = Model1lgb() pred_train_1b, pred_test_1b = predict_cv(model_1b, df_trainval, y_trainval, df_test) model_1c = Model1NN() pred_train_1c, pred_test_1c = predict_cv(model_1c, df_trainval, y_trainval, df_test) model_1d = Model1LinearSVR() pred_train_1d, pred_test_1d = predict_cv(model_1d, df_trainval, y_trainval, df_test) model_1e = Model1KernelSVR() pred_train_1e, pred_test_1e = predict_cv(model_1e, df_trainval, y_trainval, df_test) model_1f = Model1catboost() pred_train_1f, pred_test_1f = predict_cv(model_1f, df_trainval, y_trainval, df_test) model_1g = Model1KNN() pred_train_1g, pred_test_1g = predict_cv(model_1g, df_trainval, y_trainval, df_test) model_1h = Model1Lasso() pred_train_1h, pred_test_1h = predict_cv(model_1h, df_trainval, y_trainval, df_test) model_1i = Model1Ridge() pred_train_1i, pred_test_1i = predict_cv(model_1i, df_trainval, y_trainval, df_test) model_1j = Model1ElasticNet() pred_train_1j, pred_test_1j = predict_cv(model_1j, df_trainval, y_trainval, df_test) model_1k = Model1RF() pred_train_1k, pred_test_1k = predict_cv(model_1k, df_trainval, y_trainval, df_test) from sklearn.metrics import mean_absolute_error ''' #Calculate RMSE from sklearn.metrics import mean_square_error def rmse(y_true,y_pred): rmse = np.sqrt(mean_squared_error(y_true,y_pred)) print('rmse',rmse) return rmse ''' ''' 以下で、1層目の各予測モデルの精度を確認している。 今回は、mean_absolute_error(MAE)で精度確認 ''' print(f'a LGBM mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1a):.4f}') print(f'b XGBoostmean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1b):.4f}') print(f'c MLP mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1c):.4f}') print(f'd LinearSVR mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1d):.4f}') print(f'e KernelSVR mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1e):.4f}') print(f'f Catboost mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1f):.4f}') print(f'g KNN mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1g):.4f}') print(f'h Lasso mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1h):.4f}') print(f'i Ridge mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1i):.4f}') print(f'j ElasticNet mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1j):.4f}') print(f'k RandomForest mean_absolute_error: {mean_absolute_error(y_trainval,pred_train_1k):.4f}') ''' 以下では、1層目の予測値をデータフレームにまとめている。 データフレームにまとめて、2層目の特徴量として、まとめている ''' train_x_2 = pd.DataFrame({'pred_1a': pred_train_1a, 'pred_1b': pred_train_1b, 'pred_1c': pred_train_1c, #'pred_1d': pred_train_1d, 'pred_1e': pred_train_1e, 'pred_1f': pred_train_1f, 'pred_1g': pred_train_1g, 'pred_1h': pred_train_1h, 'pred_1i': pred_train_1i, 'pred_1j': pred_train_1j, 'pred_1k': pred_train_1k, }) test_x_2 = pd.DataFrame({'pred_1a': pred_test_1a, 'pred_1b': pred_test_1b, 'pred_1c': pred_test_1c, #'pred_1d': pred_test_1d, 'pred_1e': pred_test_1e, 'pred_1f': pred_test_1f, 'pred_1g': pred_test_1g, 'pred_1h': pred_test_1h, 'pred_1i': pred_test_1i, 'pred_1j': pred_test_1j, 'pred_1k': pred_test_1k })スタッキング2層目に線形回帰を設定
今回は、1層目の各モデルの予測値のみを2層目の特徴量として設定しました。
2層目の特徴量の作成の仕方には、いくつか方法があります。
1. 1層目の予測値のみを特徴量とする(今回)
2. 1層目の予測値 + 元々の特徴量
3. 1層目の予測値 + 元々の特徴量 or 予測値の平均・分散(統計量)など
4. 1層目の予測値 + 元々の特徴量 or 予測値の平均・分散(統計量)など or 元々の特徴量を加工したもの(PCA,t-SNEなど)model2 = Model2Linear() pred_train_2, pred_test_2 = predict_cv(model2, train_x_2, y_trainval, test_x_2) #2層のスタッキング後の、精度を確認。 print(f'mean_absolute_error: {mean_absolute_error(y_trainval, pred_train_2):.4f}')最後に
スタッキングすることで、精度は向上していきます。
強いkagglerとかは、スタッキングを3、4層とかにつなげていきます。
3、4層にしていくことで精度は、上がっていきますが、
一般的に、層を重ねるごとに改善していく度合いは、小さくなっていきます。また、スタッキングのやり方を頑張って考えるよりも、
自分で特徴量を作成して、良い特徴量を見つけた時の方が、精度は上がりやすいです。
スタッキングに頼るだけでなく、頑張って、自分で良い特徴量を作成したいですね。参考)
Kaggleで勝つ データ分析の技術
https://github.com/ghmagazine/kagglebook/tree/master/ch07*この記事は、ただいま編集中です。
- 投稿日:2020-02-14T15:51:55+09:00
Youtube live コメントの感情分析をして、Youtube LIveから"エモい"部分を判定する。
TL;DR
Youtubeライブのコメントの感情分析を行うことで、単なる時間あたりのコメント数だけに比べてよりよい精度で"エモい"、"みどころ"の抽出を行うことができるのではないかという提案、実験です。
実際コメント数だけで見るよりも、精度が上がりそうという結果を得ることができました。
はじめに
前回私は、COTOHA APIをお借りして、自由な発想をしようと
実用性の無い記事を書きました。今回は、もう少し実用性や、応用性を考えた取り組みをしてみました。
序盤は背景の共有なので、飛ばしても特に問題は無いです。YoutubeLiveとeスポーツ
皆様も度々お聞きになると思いますが、近年eスポーツ市場が発展してきています。このeスポーツ市場と切っても切り離せない関係にあるのが、Youtubeやその他媒体によるLive配信です。
従来のゲーム実況動画投稿と異なり、編集負担が少ない、コミュニケーションがとれる、"投げ銭"文化、まさにスポーツとしてリアルタイムで体験を共有できるなどの強みがあるためLive配信はeスポーツと同様に拡大していると考えます。ところが、このLive配信周りにはいくつかの問題点があります。
Live配信の問題点。
しかし、そんな強みのあるライブ配信にもいくつか問題点が存在します。
その中でも大きいものとして、視聴者の負担増、及びそれを利用する"盗人"の存在です。配信側に負担の少ないLive配信は逆に言えば見どころを探す手間を視聴者側に押し付ける側面があります。そこに目をつけた一部の人が有名配信者の配信の切り抜きをして収益を得るといった問題が発生しています。
↓この記事は主題は違いますが、このあたりの問題について軽く書かれていて読みやすいです。
https://gigazine.net/news/20191216-youtuber-hired-youtuber-leech-off/そもそも配信自体がゲーム会社の著作物を利用して収益を得ているためいろいろ難しいところはあると思いますが、Live配信市場等を考えると問題だと思います。
解決案?
この問題に対する一つの解決策は公式(本人)が、素早く切り抜きを作ってアップロードしてしまうことだと思います。
ところが、それができてないからこうなってるわけです。なので、この切り抜き作成をいくぶんか自動化するモチベーションがここに生まれると考えます。
手法
自動ハイライト作成には様々なものなどが提案されていますが、動画自体を学習するものはデータセットが必要であったり、また、そこそこな割合が現実世界を写した動画をまずは対象にしており、そのままeスポーツの文脈に持ってくるためにはいくぶんか工夫が必要となると考えます。
そこで今回はライブ配信中のコメントに着目しました。
先行例
https://qiita.com/okamoto950712/items/0d4736c7be251532a03f
先行例にこのような記事がありました。この方はコメントから"草"という単語をキーワードにして見どころを抽出していました。しかし、この方がおっしゃってるように判定基準には疑問が残ります。そこで今回はこの判定基準をいくぶんか自然言語処理の力を借りてアップデートしようと思います。
コメントと感情と見どころ
ライブ配信の見どころとはどんなところかと考えてみると、"多く人の感情が動かされるところ"だと考えられます。
では、そのようなシーンでは何が予期されるかといえば、最も単純な例としてはコメントの数が挙げられると思います。見どころでは「すごい」などの大量のコメントが流れるのは直感的にも明らかです。
そこでまずはこのコメントの数に基づいて見どころの分析をしてみようと思います。(しかし、後に述べますが、これだけでは不十分です)対象動画
今回はEGSさんのスマパ! #48をお借りしようと思います。特に深く考えての選定ではなく、eスポーツ(スマブラ)であって、コメントストリームがオンになっていたため選択しました。
今回はなるだけ動画内容がわからないようなコメントを例に選択しますので、内容が気になった方は本家動画を見に行ってみてください。
コメントの取得
コメントの取得はこちらを参考にしました。
PythonでYouTube Liveのアーカイブからチャット(コメント)を取得する(改訂版)めちゃくちゃ楽に取得できました。ありがとうございます。
こちらから取得した時間を秒数に直して適当に処理していきます。時間あたりのコメント数による見どころ判定
動画時間がおおよそ10000秒だったので、適当に500分割(1区間20秒くらい)でヒストグラムを書いて見ます。
このピークは急激にコメントが増えているところなので、おおよそ見どころということができると思います。
誤判定された見どころ。
この部分に注目していただきたいと思います。この部分、5660秒付近にピークっぽいものが現れていますが、これはなんと配信が切れたことに疑問をいだいた視聴者がコメントを書き込んだことによるものでした。
(この小さいピークは元から見逃せよ、という考えもあるかもしれませんが、一般に大会ライブ配信などは最後に近づくにつれコメント数が増えるので、このピークが相対的に小さいかどうかを判定するのは常に可能とは限りません。)(時系列データって難しい)
こういった部分を取り除くために、コメントの感情値を利用することを考えます。
COTOHAによるコメント感情分析
漸くここまでたどり着きました。
COTOHAとはNTTさんによる自然言語処理を簡単にできるAPIです。こちらのCOTOHA API PORTALから無料ユーザー登録をすると、無料ユーザーであっても1000/日もAPIを使用する事ができます。
COTOHAの登録〜トークン発行までは私の前の記事でも解説していますし、他の方の記事でも解説されているのでそちらを御覧ください。
今回はCOTOHA APIの感情分析を使用します。
def get_senti(txt): header = { "Content-Type":"application/json", "Authorization":"Bearer "+[トークン] } datas = { "sentence":txt, } r = requests.post(api_base+"nlp/v1/sentiment",headers=header,data=json.dumps(datas)) parsed = json.loads(r.text) return parsedこんな感じの関数を用いて、コメントについて感情分析をループで回します。
感情分析結果の集計
全体の一部であるため、少々わかりにくいコードですが、kouhoは解析対象のコメントが、区間ごとに区切って入っています。今回であればkouho[0]は先程でた5600〜5800秒のコメントが[コメント、秒数]の配列の形で入っています。
sentisにはコメントに対応する感情分析結果が[Pos or Neg,sentiment score]の形で入っています。
コードとしてやっていることは、ある地点を基準として過去20秒のコメント中でどのくらいの割合PositiveもしくはNegativeな感情を持ったコメントが入っているかを計算しています。Negativeもカウントしているのは、性質上例えば応援している側が負けたり、いい意味で"やばい"といった単語を使うときを含めるためです。
buf = [0 for i in range(200)] doubled = [0 for i in range(200)] target = 0 for i in range(len(sentis[0])): if sentis[target][i][0] == "Positive" or sentis[target][i][0] == "Negative": base = 1 else: base = 0.0001 buf[kouho[target][i][1]-5600] += base doubled[kouho[target][i][1]-5600] += 1 for i in range(200): if doubled[i] != 0: buf[i] = buf[i]/doubled[i] buf = pd.Series(buf) rolled = [0 for i in range(200)] for i in range(19,200): temp = 0 temp_c = 0 for j in range(20): temp += buf[i-j] if buf[i-j] != 0: temp_c += 1 if temp_c == 0: rolled[i] = 0 else: rolled[i] = temp/temp_c結果のプロット
コメント例
['Neutral', 0.5976078134278074] ['え?' 5646]
['Neutral', 0.2972885953707938] ['切れた' 5646]
['Neutral', 0.5971540523081994] ['おつ?' 5648]['Positive', 0.5905005661402767] ['イケメンや' 5705]
['Positive', 0.6376353638242411] ['かっこいい' 5710]['Positive', 0.5408603768859751] ['ガンの使い方上手いなぁ' 5766]
['Neutral', 0.30682113884940243] ['うめえ' 5795]
['Positive', 0.2976389932477489] ['きれいわかる' 5797]
['Neutral', 0.3140117003315527] ['うま' 5799](動画をお借りしてる関係上できるだけ内容に関わらないものを選んでるので、全コメントが気になる方は動画本家のご視聴をお願いいたします。)
この時間帯では、コメント数では5660付近がピークになっていましたが、それは真の見どころではなく、むしろ5800付近の方が見どころに近いことがわかりました。
結果2
もう一つの場面についても解析を行おうと思います。
対象としたのは9500〜9700秒付近
まさに優勝が決まった付近のようです。この場面のコメントに対しても感情分析を行いプロットをしてみます。
その結果が上のグラフのとおりです。どうやら9550秒付近が最もエモーショナルな瞬間のようです。
コメントを確認してみます。['Neutral', 0.3140117003315527] ['えええええええええええええええ' 9554]
['Positive', 0.5873145362524327] ['うますぎ' 9554]
['Neutral', 0.5972752547353822] ['上しふと!?' 9555]
['Neutral', 0.2932173519717803] ['ああ~w' 9555]
['Neutral', 0.30920978004290844] ['うますんぎ' 9555]
['Neutral', 0.31430016829530116] ['うおおおおおおおお' 9555]
['Positive', 0.6049280950215463] ['完璧' 9555]
['Neutral', 0.31322001724349124] ['やべえええ' 9555]
['Negative', 0.7934200331057456] ['えげつない' 9555]実際なんかが起こったっぽいです。エモいですね。
まとめ
COTOHA感情分析APIを利用することで、コメントベースでのYoutube Live見どころ判定の精度があげられそうという事がわかった。
課題等
- そもそもポジネガの割合でいいのか?Sentiment scoreの利用は?
- 一部の感嘆表現などがNeutralと判定されている。→ 品詞解析してなんらかの処理をすればもっと精度上がる?
- 時間窓のサイズは?
- "うますんぎ"等々口語的表現の一部は感情分析がうまくいってないことがある。
その他妄想。
リアルタイムで視聴者のエモーション値が見れたりするとそれだけで面白いかなとか思いました。
今回はコメントがたくさんつくような動画を対象としましたが、コメント数の少ない個人実況者向けなどとして、本人が喋ったことを文字起こしし、それに対して感情分析を行えば、"実況者の感情がうごいた"→"なにかおもしろいことがおきた"という事がある程度成り立つと思うので、そういったアプローチから見どころを切り出すなども考えられるかなと思いました。

- 投稿日:2020-02-14T15:01:14+09:00
【Python】任意の座標点が多角形の内側か外側か判定
はじめに
仕事で任意の座標点が多角形の内側か外側かどちらに存在するか判定するアルゴリズムを作る必要があったので、記事にします。
今回の場合、内側にあれば、OK、外側にあればNGというような情報を知らせることに用います。考え方
座標点が内側 or 外側かを判定する方法はいくつかありますが、今回はベクトルの外積を用います。
例
以下の図のように、多角形があるとします。
今回は、九角形を例として、青線で囲っています。
赤い点は任意の点として、この点が多角形の内側 or 外側どちらに存在するかを判定します。
実装
とりあえず、この多角形のコードを示します。
import numpy as np import copy import pandas as pd import matplotlib.pyplot as plt #多角形の端の座標点を決める (x,y)>(0,0) c1 =np.array([2,1]) c2 =np.array([1,3]) c3 =np.array([1,7]) c4 =np.array([3,6]) c5 =np.array([4,8]) c6 =np.array([6,9]) c7 =np.array([9,6]) c8 =np.array([8,3]) c9 =np.array([6,1]) #求めたい任意座標点の入力 #(X,Y)>(0,0) point =np.array([6,3]) #多角形と任意座標の可視化 x = [] y = [] for i in range(1,10): exec('x_num = c{}[0]'.format(i)) x.append(x_num) exec('y_num = c{}[1]'.format(i)) y.append(y_num) x.append(c1[0]) y.append(c1[1]) plt.plot(x, y, label="test") plt.plot(point[0], point[1],marker="o",linestyle='None',markersize=6, color='red') plt.show() #全てのベクトル計算 for i in range(1,10): if i < 9: kakomi = 'vector_c{}c{} = (c{}-c{})'.format(i,i+1,i+1,i) exec(kakomi) uchigawa = 'vector_c{}point = (point-c{})'.format(i,i) exec(uchigawa) if i == 9: kakomi2 = 'vector_c{}c1 = (c1-c{})'.format(i,i) exec(kakomi2) uchigawa2 = 'vector_c{}point = (point-c{})'.format(i,i) exec(uchigawa2) #全ての外積計算 for i in range(1,10): if i < 9: get = 'outer_product_c{}c{}_point = np.cross(vector_c{}c{}, vector_c{}point)'.format(i,i+1,i,i+1,i) exec(get) if i == 9: get2 = 'outer_product_c{}c1_point = np.cross(vector_c{}c1, vector_c{}point)'.format(i,i,i) exec(get2) #外積結果をリストに内包する list =[] for i in range(1,10): if i <9: s = eval('outer_product_c{}c{}_point'.format(i,i+1)) list.append(s) if i == 9: t = eval('outer_product_c{}c1_point'.format(i)) list.append(t) print(list) #リスト内に1つでも正数があれば、Trueで外側 #なければ、Falseで内側 if any((x >= 0 for x in list)) == True: print('座標点は多角形の外側') else: print('座標点は多角形の内側')コードはかなり汚いのですが、悪しからず。
やっていることとして、
①各辺と任意座標点のベクトルを計算する
(今回の場合、辺の数は、9本なので、9つの辺のベクトルを計算します。)
②また各頂点から任意座標点へのベクトルも計算する
③それらのベクトルのそれぞれの外積を求める
④求めた外積の値をlistに内包し、確認する。総括
ひとまず、内側 or 外側の判断はできたのでよしとしました。
今後は、3次元に拡張して内外判定を行います。
少しでも皆様の参考になれば幸いです。参考
下記サイトにおける図2を参考に、ベクトル計算を行いました。
https://gihyo.jp/dev/serial/01/as3/0055
- 投稿日:2020-02-14T14:38:19+09:00
AWS CDKで既存VPCと既存Subnetを名指しで使う
今日も元気にビルドを失敗していくスタイル。
前回、「AWS CDKでVPC作ろうとしたら作れなかったとき」ではSubnetがうまく作れなくて泣いてたじゃないですか。
今度は既存のVPCと既存のSubnetを使いたかったんですよ。本当にそれだけなんです、CloudForamtionなら三秒で出来るじゃないですか?????やりたいこと
既存のVPCと既存のSubnetを使いたい。
CloudForamtionで書くとき
例えばALBとセキュリティグループの設定に使う時とか、こういう感じでできるじゃないですか。
なんかこう、VpcIdとSubnetsにはそれぞれのIDをそのまま書けばさらっと設定してくれるじゃないですか。Resources: SecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: GroupDescription: !Sub ${AWS::StackName}-alb SecurityGroupIngress: - CidrIp: "0.0.0.0/0" IpProtocol: "TCP" FromPort: 80 ToPort: 80 VpcId: !Ref VpcId LoadBalancer: Type: AWS::ElasticLoadBalancingV2::LoadBalancer Properties: Subnets: !Ref Subnets SecurityGroups: - !Ref SecurityGroupCDKで既存のVPCをSubnetを指定しつつ取り込む
真剣に一週間くらい悩んでしまったんですけど、結論だけ書くとこうです。
from_vpc_attributesを使って既存のVPCを取り込みます。このときSubnetを指定しておくと、指定したSubnetだけ取り込んでくれます。
既存VPCだけ取り込むならfromLookupでもいいんですが、Subnetを指定する方法がsubnetGroupNameTagしかなさげな感じ。(ID指定できるやろって情報あれば教えてください)
今回はSubnetもIDで指定したいのでこんな感じになります。from aws_cdk import ( aws_ec2 as ec2, ) VPCID='vpc-xxxxxxxx' vpc=ec2.Vpc.from_vpc_attributes( self, f"vpc{id}", vpc_id=VPCID, availability_zones=['ap-northeast-1b', 'ap-northeast-1c'], publicSubnetIds=['subnet-xxxxxxxx', 'subnet-xxxxxxxx'], private_subnet_ids=['subnet-xxxxxxxx', 'subnet-xxxxxxxx'] )で、Subnetを実際に使用するにはこの記述で引っ張ってこれます。
ドキュメントでISubnetで指定しろって書いてあるとこに使うといいです。# パブリック ec2.SubnetSelection(subnet_type=ec2.SubnetType.PUBLIC, one_per_az=True) # プライベート ec2.SubnetSelection(subnet_type=ec2.SubnetType.PRIVATE, one_per_az=True)参考URL
AWS CDK(class Vpc)
https://docs.aws.amazon.com/cdk/api/latest/docs/@aws-cdk_aws-ec2.Vpc.html#static-from-wbr-lookupscope-id-optionsCDKのドキュメントはTypeScriptのが一番読みやすいのでTSの方でざっくり確認してからPythonのドキュメント読むんですが、Pythonのドキュメントどうして読みづらいんですかね。慣れですかね。
boto3のドキュメントもだいぶ読みづらい。おわり
CDK面白いのでもっと流行ってほしいですね!!私はPythonが好きですよ!!
- 投稿日:2020-02-14T13:56:42+09:00
[Python]Pythonとセキュリティ - ①Pythonとは
概要
Pythonは1991年に発表されたインタプリタ形式のプログラミング言語で、オランダ出身のプログラマ「Guido van Rossum(グイド・ヴァンロッサム)」によって開発された。
2020年1月を基準として最新バージョンは、Python2「2.7.17」、Python3「3.8.1」である。2008年の末から、Pythonは「バージョン2」と「バージョン3」に分かれて使用されている。Python2とPython3はお互いに互換ができないところも多いため、プログラムを作る際に、二つのバージョンのうち、一つ選ぶ必要がある。Python2は2020年4月に「2.7.18」が公開された後は公式な技術サポートは終了される。また、Python3から新たにサポートされるライブラリや脆弱性なども修正されているため、Pythonを習い始めようとしているのであれば、Python3をお勧めする。Pythonのメリット
容易性
Pythonの一番のメリットは簡単で、だれでもすぐプログラムが作れる容易性である。下記で「Hello World」を出力する例を、CとPython言語で作ってみた。
hello_world.c#include <stdio.h> int main() { printf("Hello World"); return 0; }hello_world.pyprint("Hello World")このようにCは5行で表現するコードが、Pythonでは1行で表現できる。また、文法的に括弧({,})やセミコロン(;)などが不要で、インデント(字下げ)でシンタックスを区別するため、ソースコードがより分かりやすい。
強い連携性(glue)
Pythonはシステムプログラミングや複雑な演算が多いプログラムには合わない。だが、Pythonは連携性があるため、他の言語で作られたプログラムにPythonが含められる。例えば、複雑な演算や、早い処理速度が必要な部分はCで作り、そこにPythonを含めることも可能である。もちろんCだけではなく、C++やJAVA, JavaScriptなど多様な言語とPythonを並行で使うことができる。
様々なライブラリ
個人的には一番のメリットだと考えてるのは厖大なライブラリの数である。GUIを開発するためのTkinterまたはPyQTや、ゲーム作成のためのPygame, Pythonで作成されたプログラムを実行ファイルとして作ってくれるPyInstaller、ウェブのクローリングのためのBeautiful Soupなど、記述したライブラリ以外にも厖大なライブラリが存在しているため、効率的に開発ができる。
クロスプラットフォーム開発
前述の通り、厖大なライブラリを提供しているため、OSの環境にかかわらず開発ができる。例として、WindowsでPythonを利用してGUIを開発する場合、ライブラリとしてTkinterまたは、PyQTライブラリを使用する。このライブラリをLinuxでも同じライブラリを使い、開発と実行ができる。このようにPythonのライブラリは厖大で、各OSもサポートしている。
ツールが作りやすい
数多いライブラリとオープンソースまた、簡単な文法ですぐプログラムが作れるPythonはシステム担当者などがツールを作ることに適している。
上記のメリット以外にもPythonでの開発で得られるメリットはたくさんある。その代わりインタプリタ言語であるため、速度の問題や、モバイルプラットフォームでは合わないなどもちろんデメリットもある。
まとめ
Pythonは開発の容易性をメリットとして多角的な開発で使用している。今回はPythonの概要
また、Pythonを使うことのメリットに対して学んでみた。次回は、実際Pythonを利用してセキュリ
ティに役に立つツールを作ってみよう。
- 投稿日:2020-02-14T13:36:19+09:00
League of Legendsのデータを使ったWEBアプリを作りたい①
Djangoを使ってLOLのデータ収集WEBアプリを作成したい
前回までで一応データの取り出し方とデータベースに保存する方法を学習することができたので、今回のパートからwebアプリの開発をしていきたいと思います。
前回まで、
League of Legendsのデータ取得してみたい①
League of Legendsのデータ取得してみたい②
League of Legendsのデータ取得してみたい③環境
2020/2/8現在
OS:windows10
Anaconda:4.8.1
python:3.7.6
MySQL:8.0.19
Django:3.0.1
PyMySQL:0.9.3Djangoの導入
インストール
python -m pip install djangoを実行前回との変更
importするライブラリをMySQLdbからPyMySQLに変更
python -m pip install pymysql
import mysql -> import pymysql作成
初めに、APPというディレクトリ上で
django-admin startproject MyProjectを実行します。
このような階層が出来上がります。
manage.pyと同じ階層でpython manage.py startapp LOLAppを実行。
このようなものが出来上がります。setting.py変更
INSTALLED_APPSに'LOLApp.apps.LolappConfig',を追加。
次に、DATABASESを変更します。defaultでデータベースがsqlite3になっているのでそれをmysqlにします。元のコードDATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }変更後DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'LOLdb', 'USER': 'root', 'PASSWORD': '{最初に設定したパスワード}', 'HOST': 'localhost', 'PORT': '3306', 'OPTIONS':{ 'init_command': "SET sql_mode='STRICT_TRANS_TABLES'", } } }次に、LANGUAGE_CODEを'en-us'から'ja'に変更。
最後に、TIME_ZONEを'UTC'から'Asia/Tokyo'に変更。manage.pyを変更
一番最後に
import pymysql pymysql.install_as_MySQLdbを追加。
python manage.py makemigrations LOLAppを実行
python manage.py migrateを実行
前回作ったmatch_dataというテーブルのほかに新しいものが作成されます。開発用サーバーを起動
python manage.py runserverを実行して出力されたアドレスに飛んでみます。
このような画面が出たらとりあえずは成功です。ビューの作成
views.pyfrom django.shortcuts import render from django.http import HttpResponse #追加 # Create your views here. def index(request): return HttpResponse("Hello World!")LOLAppの直下にurls.pyを作成します。
さっきのビューに対応するパスを与えます。LOLApp/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('',views.index,name='index'), ]MyProject直下のurls.pyにも変更を加えます。
MyProject/urls.pyfrom django.contrib import admin from django.urls import path,include #includeを追加 urlpatterns = [ path('admin/', admin.site.urls), path('LOLApp/',include('LOLApp.urls')), #追加 ]
python manage.py runserverを実行して、さっきのアドレスに/LOLAppを追加してアクセスすると、
となっていればとりあえずOK。モデルを作成
models.pyfrom django.db import models # Create your models here. class Match_data(models.Model): sn = models.CharField(max_length=200) kills = models.IntegerField(default=0) deaths = models.IntegerField(default=0) assists = models.IntegerField(default=0) championId = models.IntegerField(default=0) roles = models.CharField(max_length=200) cs = models.IntegerField(default=0) gold = models.IntegerField(default=0) damage = models.IntegerField(default=0) side = models.CharField(max_length=200) game_time = models.IntegerField(default=0)
python manage.py makemigrations LOLApp
python manage.py migrate
python manage.py sqlmigrate LOLApp 0001
テーブルにlolapp_match_dataが新しく追加される。
python manage.py shellを実行して実際に試してみる。from LOLApp.models import Match_data Match_data.objects.all() # <QuerySet []> a = Match_data(sn="aaa",kills=2,deaths=3,assists=5,championId=100,roles="MID",cs=100,gold=10000,damage=10000,side="BLUE",game_time=1500) a.save() #データを保存 a #<Match_data: Match_data object (1)>MySQLのコマンドで確かめてみると
データベースに保存されていることが確認できた。管理アカウントの作成
python manage.py createsuperuserを実行してユーザー名、メールアドレス、パスワードを登録します。
その後、python manage.py runseverを実行してhttp://127.0.0.1:8000/admin/に移動すると管理サイトに飛ぶことができます。この管理サイトでモデルを操作するために、admin.pyを変更します。admin.pyfrom django.contrib import admin from .models import Match_data # Register your models here. admin.site.register(Match_data)これを追加してから再読み込みをすると
モデルが追加され、
この画面でデータを操作することができます。まとめ
今回は前の項目でデータを取得したものをフレームワークを使って、少し改変してみました。次は、WEBアプリを作るためには表示させるベースを作らないといけないのでそっちを少し作りたいと思います。