- 投稿日:2020-02-13T23:59:34+09:00
自己流ラズパイリモート開発設定ベストプラクティス
初めに
これは何?
今回、自分が昔から思っていたラズパイの面倒な部分、特にIoT開発時の手間を減らすために書いた記事です。自分の備忘録代わりに書きます。
対象ユーザ
想定している対象ユーザは自分のように、IoTデバイスを開発したくてラズパイ買った人(デバイスを自宅、あるいは社外に持ち出して開発するようなIoTデバイス開発全般に参考になるかもしれません)
できるようになること
- ラズパイをリモートで接続、開発する手順が分かります
- リモート開発時に携行するデバイスが減ります
ラズパイは基本PCなので開発に必要なデバイスが多く、外で使用するのは面倒くさい
ラズパイ開発で必要なのは、
- 「ラズパイ本体」
- 「バッテリー電源及びケーブル」
- 「ディスプレイ及びケーブル」
- 「wifi等の機器」
- 「キーボード」
- 「必要であればマウス」
などですが、これはつまりデバイス自体は小さくてもデスクトップPC開発と同等の環境が必要になるということです。
ラズパイを屋外設置し、現地でテストや状況によっては開発をするような使い方をしたかったので、屋外に持ち出す機器を最小にしつつ、かつ現地で開発をするために必要な構成を考えました。作業後の構成では以下のようになります。
- 「ラズパイ本体(確認機種はラズパイ4、OSはRaspbian Buster)」
- 「ノートPC(確認OSはWindows10)」(ディスプレイ、キーボード、マウスの代替、USBで電源も代替可能な時も)
- 「スマートフォン(確認機種はPixel3a OSはAndroid)」(wifiの代替)
自己流ラズパイリモート開発原則
- ラズパイ構築後、即リモート設定する
- 初期設定は「スマホで」ラズパイをいじる
- wifi 環境がある時はRDP/VNCなどでリモート接続
- ログなどはslackなど外部連携できるツールで通知すると便利
トラブル編. もしスマホ、wifi切替時にIPがうまく切り替わらなかった場合
1. ラズパイ構築後、即リモート設定する
本記事は「ラズパイを構築した」ところから始めさせていただきます。
「ラズパイ構築」についてはネット上にもたくさんの記事がありますので、そちらをご参照ください。
今回重要なのは、構築した後です。ラズパイの開発環境を構築し、ラズパイでOSが立ち上がるところまでできたら、まずは急いで以下の設定を行ってしまいます。1.ターミナル画面でRDP接続用の xrdp インストール
参考:xrdpのインストールと接続$ sudo apt-get update $ sudo apt-get install xrdp $ sudo apt install tightvncserver2.ラズパイのターミナル画面で、slack通信用スクリプトで使用する slackweb , pustil インストール
参考:Raspberry Piにリモートデスクトップで接続する$ sudo pip install slackweb $ sudo pip install psutil3.slack通信用の以下のプログラムをラズパイ上に配置
vi,nano などのエディターで画面を開き、以下のpythonのプログラムを貼り付ける
参考:ラズパイのWi-FiアドレスをSlackに通知する
参考:ping疎通確認結果を機械的に判定するsend_IPinfo.pyimport slackweb import psutil import socket import time import subprocess def is_ping(host): # linux only ping = subprocess.Popen(["ping", "-w", "3", "-c", "1", host], stdin=subprocess.PIPE, stdout=subprocess.PIPE) ping.communicate() return ping.returncode == 0 time.sleep(180) hostname = socket.gethostname() slackurl = "slackで取得したWebHook urlをここに記載" ## pingresult = is_ping("hooks.slack.com") if pingresult is True: for name, addrs in psutil.net_if_addrs().items(): if name == "usb0" or name == "wlan0": print("connect succeed") flg = True for addr in addrs: if addr.family == socket.AF_INET: message = hostname + " " + name + " is " + addr.address slack = slackweb.Slack(url = slackurl) slack.notify(text="%s" % message) print(message)4.自分の持つスマホをテザリングモードにしてケーブルで繋ぐ
iPhoneもAndroidもできます。以下を参考に、iOSはBlutoothで、Androidはケーブルで有線接続することで、ラズパイからテザリングでネットワーク接続することができるようになります。
参考:iPhoneにBelutooth接続してテザリング
参考:Raspberry PiとAndroidでUSBテザリング5.インターネット接続できるか確認し、できたらslackのAPIを登録する
今回は、slackのwebhookURL を取得し、pythonスクリプトで得た情報をslackに飛ばしますための設定をします。詳しくは以下を確認ください。
もし使用したくない場合は、スクリプトの以下28,29行目をコメントアウトするとslackを使用せずに動きますので、代わりにwebAPIやメール送信など外部連携できる方法に変えてみてください。slack = slackweb.Slack(url = slackurl) slack.notify(text="%s" % message)6.send_IPinfo.pyが動作するか確認し、確認できたらcronに登録する
参考:Raspberry Piで cronを使って起動時にコマンドを自動実行したりn分間隔で繰り返し実行する方法@reboot /usr/bin/python /home/pi/ipinfo_slack.py7.自分のPC、及びスマートフォンにリモートデスクトップアプリを入れ、slack及びコンソールに出るIPで接続できるか確認。
一旦、ここまでで、設定自体は終了です。手順の1-7までうまくできていれば、ラズパイには電源以外何も接続しないで開発ができる状態になります。
2. 初期設定は「スマホで」ラズパイをいじる
今回、「ラズパイのリモート開発」を軸としているため、リモート接続のためのネットワーク接続が必要になります。しかし、屋外でwifiなどのネットワークが必ずあるとも限らず、その為にもスマホのテザリングを活用するのがポイントです。
又、仮にノートPCがなくとも、スマホテザリングしてスマホにRDPのソフトを入れれば、簡単な設定はできますので、別のwifiネットワークを設定、などの用途で使用することもできます。
3. wifi 環境がある時はRDP/VNCなどでリモート接続
wifi などのネットワーク環境があれば、(スマホテザリングでも)リモートでラズパイ接続できます。
今回は手順として windowsでもGUI簡単に扱え、スマホ対応もしている RDP にしましたが、VNC など別のツールでも問題ないと思います。4. ログなどはslackなど外部連携できるツールで通知すると便利
できるなら、開発しなければいけない時以外はラズパイに接続もしないで運用できるのが望ましいですね。今回はリモート接続することが前提となりますが、
- リモート接続したい
- リモート接続するにはラズパイのIPを知らないといけない
- ラズパイのIPはラズパイに接続してIPを調べないといけないのでリモート接続したい???
という矛盾が生まれてしまいます。本来はラズパイに接続せずにIPを知りたいので、「自分自身のIPを調べslackに通知するスクリプトを組み、それを cron で起動時に実行する」という仕組みにしています。
(※)注意点としては、起動した際にスマートフォンのテザリング、ないしwifiに接続できる状態にしておいてください。又、すぐpingするとnetwork疎通前にプログラムが起動してしまうので適当に3分間waitしており、すぐにはslackに通知は飛びません。
トラブル編. もしスマホ、wifi切替時にIPがうまく切り替わらなかった場合
スマートフォンと、wifiを順次接続する、あるいはwifiからスマートフォンに接続するなどをしていると、本来ならIPも自動にそのネットワークに合わせてラズパイのIPも切り替わるのですが、IP がうまく切り替わらない時があります。その場合はxrdpサービスの再起動、ダメなら再インストールを試してみてください
サービスを再起動
sudo service xrdp restartダメなら xrdp を再インストール
sudo apt remove xrdp sudo apt update sudo apt install xrdp終わりに
上記の設定、あるいは考え方をすると、ラズパイがもっと楽にリモート開発できるのではないかと思います。
- 投稿日:2020-02-13T23:38:57+09:00
Numpyの使い方まとめ
pythonのnumpyについてのまとめ
はじめに
numpyで主に扱われるのがndarrayというデータ型で多次元の配列を扱うことができます。特徴としては高速に処理を行え、機械学習、深層学習、データサイエンスで利用されることが多いです。ndarrayはpythonのリストと似ており扱い方、例えばインデックス、スライスを用いた要素の扱いなど同じように操作することができます。
arrayの生成
import numpy as npを前提に書いていきます
一次元配列の生成
a = np.array([0, 1, 2, 3]) print(a) # 出力 [0 1 2 3]arrayのアトリビュート(属性)
a = np.array([0, 1, 2, 3]) print(type(a)) #出力 <class 'numpy.ndarray'> print(a.ndim) #次元数 #出力 1 print(a.shape) #各次元の要素数 #出力 (4,) print(a.size) #サイズ #出力 4 print(a.dtype) int64 #型 #出力aという配列(array)には一次元(ndim)の4×1のデータで個数は4個です
dtypeは要素のデータ型のことです。二次元配列の生成
今回二次元配列を生成する際に先ほどのdtypeを指定して作成してみます
b = np.array([[0, 1, 2, 3],[4,5,6,7]],dtype=np.float32) print(b) #出力 # [[0. 1. 2. 3.] # [4. 5. 6. 7.]] print(b.ndim) #出力 2 print(b.shape) #出力 (2,4) print(b.size) #出力 8 print(b.dtype) #出力 float32引数にdtypeを渡してあげることにより型を指定することができます
他の生成関数
arange(開始値、終了値(、ステップ))
a = np.arange(1, 10, 1) print(a) #出力[1 2 3 4 5 6 7 8 9]linspace(開始値、終了値、個数) 等差数列
#個数に応じた感覚が自動的に算出される a = np.linspace(1, 10, 4) print(a) #出力[ 1. 4. 7. 10.]ones(要素数)
a = np.ones(4) print(a) #出力[1. 1. 1. 1.]zeros(要素数)
a = np.zeros(4) print(a) #出力[0. 0. 0. 0.]random.rand(要素数を複数渡して多次元の配列を生成可能)
print(np.random.rand()) #出力 0.30700645335514043 print(np.random.rand(3)) #出力 [0.74159644 0.54419175 0.35041095] print(np.random.rand(3,2,4)) #出力 # [[[0.32515581 0.48580963 0.67062081 0.21306281] # [0.92939764 0.22577412 0.26283789 0.77543546]] # [[0.74994208 0.06294482 0.37494771 0.16577029] # [0.6033194 0.11625464 0.49574886 0.05631945]] # [[0.83765773 0.48453536 0.88006351 0.17459801] # [0.23002602 0.22754166 0.20956698 0.87749178]]]0から1までの乱数
最後の出力は3×2×4の配列他にも正規分布、二項分布ベータ分布、ガンマ分布、カイ二乗分布の乱数などもある
arrayの扱い
インデックス
a = np.array([[0, 1, 2, 3], [4, 5, 6, 7], [1, 3, 4, 5]], dtype=np.int32) print(a[0]) #出力[0 1 2 3] print(a[:2]) #出力 # [[0 1 2 3] # [4 5 6 7]] print(a[:, 1]) #出力[1 5 3]一つ目は配列aの一つめのリスト
二つ目は配列aの二番目までのリスト
三つ目は配列aの全てのリストの二番目の要素を取得
([0, 1, 2, 3]の二番目である1、[4, 5, 6, 7]の二番目である5、 [1, 3, 4, 5]の二番目である3を取得しているということ)変換
reshape メソッドを用いると
a = np.ones(4) print(a) #出力 [1. 1. 1. 1.] b = a.reshape(2, 2) print(b) #出力 # [[1. 1.] # [1. 1.]]演算
a = np.ones(4) print(a) #出力[1. 1. 1. 1.] print(a + 1) #出力[2. 2. 2. 2.] c = np.array([1, 2]) d = np.array([3,4]) print(c + d) #出力[4 6]形を合わせると計算ができる
ブロードキャスティング
a = np.ones(4).reshape(2, 2) b = np.arange(1, 3) print(a * b) #出力 # [[1. 2.] # [1. 2.]]ここで、配列aは2×2、配列bは2×1で形が合っていないがbの[1,2]を縦に並べることにより演算を行うことができます
これがブロードキャスティングと呼ばれるものです要素の合計
a = np.arange(1, 10) print(np.sum(a)) #出力 45 b = np.arange(9).reshape(3,3) print(np.sum(b, axis=1) #出力 [ 3 12 21]二番目の計算は軸ごとに計算している
arrayの連結
a = np.arange(9).reshape(3, 3) b = np.arange(10, 19).reshape(3, 3) print(np.hstack((a, b))) #出力 # [[ 0 1 2 10 11 12] # [ 3 4 5 13 14 15] # [ 6 7 8 16 17 18]]これは横方向の連結
縦方向の連結もある
- 投稿日:2020-02-13T23:37:24+09:00
python初心者がIT企業にインターンしてみた[2日目 チャットボット調査]
チャットボットってよく聞くけど・・・?
今日も元気よく出勤したわけだが、メモを一日に尋常じゃないくらいするため、メモ帳を購入。それももう3分の1使ってしまった。なぜなら、このインターンは、何も教えてはもらえないのだ。その場で聞いたキーワードを頼りに考えて行動しなくてはならない。メモ帳をトイレットペーパーくらい消費するのはこの世で俺だけなのでは?
ヒアリングの前のヒアリング?
昨日は開発工程について学んで、要件定義書を作ろうとしているのだが、ヒアリングはその最初の段階の工程
である。顧客にどういう目的で、どういう人をターゲットに・・・。説明がややこしくなるので簡単にいうと、5W2Hを聞くのである(who,what,which,where, why, how, how much)。しかし、今日したのはヒアリングではない、ヒアリングである。????。つまり、予め漠然としたことを聞いて、作りたいものをこちらから提案して初めてヒアリングができるのである。業務フローを作るためにもこれは大事な工程である。
ヒアリングで聞いたことは、思いの外漠然としていた。とりあえず、社内情報を全文検索できるようにしたい、カスタマーサービスにチャットボットを導入したい。これをもとに、来週までに企画提案書を提出することと明日までに比較表を書かなければならない。来週に私は、プレゼンテーションをしなければならない。チャットボットの比較表
チャットボットサービスには大きくわけて四つのタイプがある
1,選択肢タイプ
2,ログタイプ
3,ハッシュタイプ
4,elizaタイプ詳しくはリンクを見て欲しい。
今回の相手方の問題を考える。まず、全文検索はおいといて、問合せが面倒なため質疑応答をチャットボット にやらせたい。つまり、1と2が考えられる。そのタイプのサービスを調べて比較表にして、企画を提案していくのだが、正直まだほとんど調べきれていない。明日結果を述べさせてもらう。できたらその表も載せたいと思う。終わりに
今日も本当に疲れたが、こんなにいい経験を大学一年生のうちにできることは本当に嬉しい限りである。全力で取り組みたい。
https://kashika.biz/flowchart-5/ 業務フロー
https://digital-marketing.jp/marketing-general/what-is-a-chatbot/#i-3 チャットボット とは
- 投稿日:2020-02-13T22:55:51+09:00
Doc2Vecについてまとめる
はじめに
今回はWord2Vecの発展としてDoc2Vecを勉強しました。
自然言語処理でよく求められるタスクとして「文書分類」や「文書のグルーピング(クラスタリング)」がありますが、それらを実施するには文書そのものの分散表現が必要となります。
Doc2Vecを用いればその分散表現を直接獲得することができます。参考
Doc2Vecを理解するに当たって下記を参考にさせていただきました。
- doc2vec(Paragraph Vector) のアルゴリズム
- Distributed Representations of Sentences and Documents (元論文)
- Doc2Vecの仕組みとgensimを使った文書類似度算出チュートリアル
- 自然言語処理技術の活用法 ーDoc2VecとDANを使って論文の質を予測してみた!ー
Doc2Vec
Doc2Vecとは何か
Doc2Vecは任意の長さの文章を固定長のベクトルに変換する技術です。
Word2Vecが単語の分散表現を獲得するものだったのに対し、Doc2Vecは文章や文書の分散表現を獲得します。文章の分散表現を獲得する手法としては古典的なものとしてはBag-of-WordsやTF-IDFがありますが、それらは下記のような弱点を有しています。
- 文章内の単語の語順情報を有していない
- 同義語でも完全に異なる独立した単語として認識する
これらはカウントベースと呼ばれる手法ですが、Doc2Vecは上記弱点を克服すべく違うアプローチで文章の分散表現の獲得を試みています。
Doc2Vecのアルゴリズム
Doc2Vecは下記2つのアルゴリズムを総称したものになります。
- PV-DM(Distributed Memory Model of Paragraph Vectors)
- PV-DBOW(Distributed Bag of Words version of Paragraph Vector)
以下で簡単にそれぞのアルゴリズムに関して説明します。
PV-DM
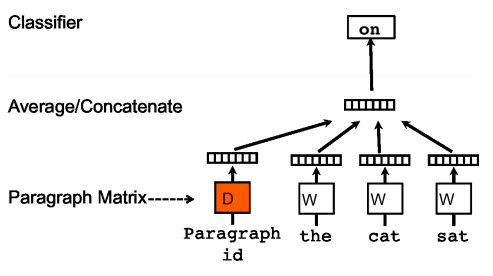
PV-DMはWord2VecのCBOWに対応するようなアルゴリズムです。
文章のidと単語を複数個渡し、次に出てくる単語を予測するというタスクを解きながら文章の分散表現を獲得します。
私の調べた限りだと下記のような手順で学習を行なっているようです。
- 文章のベクトルと文書の中から一部をサンプリングした単語のベクトルを用意
- 1で用意したベクトルを中間層で結合(平均又は連結、gensimでは選択可能)
- サンプリングした単語に続く次の単語を予測
- 文章ベクトルおよび中間層→出力層の重みを更新
イメージ図は下記なります。(「参考」に記載の元論文より引用)
PV-DBOW
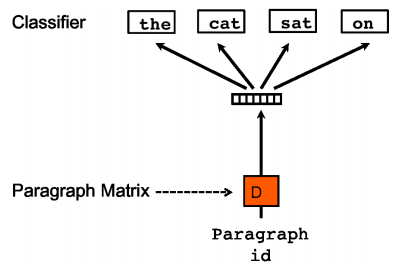
PV-DBOWはWord2Vecのskip-gramに対応するようなアルゴリズムです。
PV-DBOWは単語のベクトルを学習の際に用いる必要がないため、PV-DMよりも早く学習が可能です。ただPV-DBOWは学習の際に語順を無視するかたちになっているため、PV-DMの方が精度が良いとされています。私の調べた限りだと次のような手順で学習を行なっているようです。
- 同一文章から任意の個数の単語をサンプルしてくる
- サンプルした単語を予測するように文章ベクトルと中間層→出力層の重みを最適化する
イメージ図は下記なります。(「参考」に記載の元論文より引用)
上記簡単に2つのアルゴリズムについてまとめましたが調べても細かいところでよくわかない部分がありました。どなたかわかる方はコメントで教えていただけると嬉しいです。。。
調べてもわからなかったところ
- 最初に入力として与える文書ベクトルはどのような形式なのか、単純に文章のidだけを渡しているという認識で問題ないのか
- この学習の結果、最終的に得ることのできる文章の分散表現(Paragraph Vector)はどこから取ってきているのか(Word2Vecでは入力から中間層に変換する重みベクトルを単語の分散表現としている)
ライブラリを用いたDoc2vecモデルの作成
以下ではライブラリを用いて実際にDoc2Vecのモデルを作成していきます。
使用したライブラリ
gensim 3.8.1
データセット
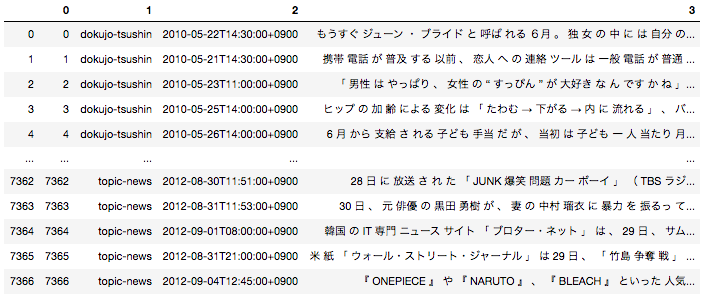
pythonのライブラリであるgensimを用いて簡単にDoc2Vecのモデルを簡単に作成することが可能です。今回データセットは「livedoor ニュースコーパス」を使用させていただきます。データセットの詳細やその形態素解析の方法は以前投稿した記事で投稿しているの気になる方そちらをご参照いただければと思います。
日本語の場合は事前に文章を形態素単位に分解する前処理が必要となるため、全ての文章を形態素に分解した後下記のようなデータフレームに落とし込んでいます。
一番右のカラムが文章を全て形態素解析して半角スペースごとに区切ったものになります。こちらを用いてDoc2Vecモデルを作成します。
モデルの学習
gensimを用いてWord2vecのモデルの作成を行います。下記がモデルを作成するに当たっての主要なパラメータになります。
パラメーター名 パラメータの意味 dm 1ならPV=DMで0ならPV-DBOWで学習する vector_size 文章を何次元の分散表現に変換するかを指定 window 次の単語の予測に何単語を用いるか(PV-DMの場合) 又は、文書idから何単語を予測するか(PV-DBOWの場合) min_count 指定の数以下の出現回数の単語は無視する wokers 学習に用いるスレッド数 下記がDoc2Vecのモデルを作成するコードになります。投入するテキストさえ作成できていれば一行でモデルの作成が可能です。
sentences = [] for text in df[3]: text_list = text.split(' ') sentences.append(text_list) from gensim.models.doc2vec import Doc2Vec, TaggedDocument documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(sentences)] model = Doc2Vec(documents, vector_size=2, window=5, min_count=1, workers=4)Doc2Vecでできること
Doc2Vecのモデルによって文章の分散表現を獲得することができました。文章の分散表現を用いると文章間の意味的な距離を定量的に表すことができます。
先ほど作成したモデルで下記ニュース記事と近い内容記事はどんなものがあるかを調べて見ます。
'19日(土・日本時間)南アフリカW杯・日本×オランダ戦は、日本代表の健闘空しく、 後半にはスナイデルのゴールでリードを許すと、ばん回できないまま0-1で敗れた。 試合後、テレビ朝日の中継で解説を担当した元日本代表の司令塔・中田英寿氏は、 「まあ、0-1で負けたとはいえ、一戦目に比べるとチームも格段にいい戦いになって、特に後半なんかは日本もいい攻めをしていましたし、次に繋がる一戦になったのではないかと思います」と感想を述べた。 また、「(ズルズルと失点するケースもあるが)そこをきちんと守りきった上で自分達の攻撃を繋げていく。 特に最後は岡田監督も攻撃の選手を早いうちから使い、その姿勢というのは次の試合に繋がっていく。 この試合は負けてもいいわけじゃなく、勝ちにいく姿勢が見えたっていうのは大きい」と語った。'下記で指定のドキュメントと似ているドキュメントを出力することができます。
#ドキュメントのidを渡してそれと距離の近いドキュメントを出力(今回の場合5792が上記記事のid) model.docvecs.most_similar(5792)出力はこちら。ドキュメントのidとそれとのコサイン類似度をセットで返します。
[(6084, 0.8220762014389038), (5838, 0.8150338530540466), (6910, 0.8055128455162048), (351, 0.8003012537956238), (6223, 0.7960485816001892), (5826, 0.7933120131492615), (6246, 0.7902486324310303), (6332, 0.7871333360671997), (6447, 0.7836691737174988), (6067, 0.7836177349090576)]類似度上位の記事の中身を見てみます。
##6084の記事内容 'ロンドン五輪出場を目指すサッカー・U-22日本代表。 二次予選はクウェート一カ国と戦うホーム&アウェイ戦となっている。 注目を集めるのは、U-22代表戦11試合で8ゴールを誇る日本のエース・永井謙佑(名古屋グランパス)だ。 18日深夜放送、TBS「S-1」は、50mを5.8秒で駆け抜ける期待の俊足FWに迫った。 「よーいドンは負けない」という永井は「自分ではよく分からないですけど、速いみたいですね。 (足が速くなったのは)高校2年くらいです」と他人事のように語るも、“永井のスピード伝説”として、高校時代を知る友人は、番組のカメラに「車、40キロくらいを追い付く。 あいつ走って」と話し、九州国際大付属高校時代の恩師・杉山公一監督は「自分で出したスルーパスに逆サイドの子がオフサイドだったので、そのまま自分で追いかけてドリブルになったりとか、そういうことはよくありました」と明かした。 また、俊足サッカー選手と言えば、“野人”岡野雅行があまりにも有名だが、岡野について訊かれた永井は「あんなに速くないですよ」と苦笑い。 高校入学時は、小柄で足も速くなかったという永井は、「よく倒れたり、戻したりしてました」、「タイミングが合ったというか、彼の成長が、身体の成長とトレーニングがうまくあったのかも知れません」と杉山監督が振り返る同高校の名物=坂道&階段を使った地獄のトレーニングによって、その能力が開花したようだ。'##5838の記事内容 '29日深夜放送、TBSのスポーツ番組「S1」では、ゲスト解説のラモス瑠偉が、日本代表監督が決まらぬ現状に怒りを露わにした。 W杯出場国で代表監督が決まっていない国が、日本と北朝鮮のみという現状、「いや、情けなさすぎるよ。特に選ばれた選手達のモチベーションは下がります。 今回のメンバーを見ていると、稲本と玉田、どういう理由で選ばれていないのか」と露骨にムッとした表情で話しはじめるラモス。 「ラモスさん、やっちゃえばいいじゃないですか?」という声がかかると、「いや、やりたいですよ。それは間違いないです」とキッパリ言い放ち、また、「僕だったら、選ばれてもいかない。現役の時だったら。遅すぎる。本当に情けない。寂しい」と続けるのだった。'上位2つはどちらともサッカーの話題であることがわかります。また学習したコーパスは9つのニュースサイトの記事から構成されていますが、類似度上位10件中8件がスポーツのニュースサイトの記事となっていました。
このように文章を固定長のベクトル表現に変換することができれば、クラスタリングや分類など様々な機械学習アルゴリズムに適用させることが可能になります。
自然言語処理の世界ではいかに表現力の高いベクトル表現を獲得するか、という点が非常に重要で、今回ご紹介したDoc2Vecをはじめとして様々なアルゴリズムが開発されています。Next
このDoc2Vecのモデルを使用して、様々な自然言語処理タスクに挑戦してみようと思います。
- 投稿日:2020-02-13T22:29:49+09:00
非エンジニアのためのPython入門
世の中の流行を追う〜プログラミングについて〜
昨今、言わなくてもわかるくらいに「プログラミング」というものが注目されだした。ちょっと前まで(2010年〜2015年)はプログラミングといえば理系のエンジニアが取り組むもの、パソコンの専門家が使うような、いわゆる非理数系の方々には馴染みのないものだった。
ところが、世の中を見渡せばGAFAに代表されるようなIT企業が世界の時価総額ランキングトップ10に名を連ねているし、アメリカもアジアもIT企業が社会に与える影響が日々大きくなっている。テクノロジーを持つ会社が強いという事実は、今更論じるまでもないと思う。
では、IT関連以外のメーカーや商社、農業や物流などの分野をメインとしている会社においてIT系の知識が不要かというと、全然そんなことはない。むしろ生き残りたかったらITの知識は絶対になくてはならない。
今から30年近く前には確かにインターネットは普及していなかったし、人々の生き方が全然違ったから技術的なことは専門家がやっていればそれでよかったのかもしれない。だが、時代が流れ携帯電話もインターネットも普及し、家から一歩も出ずに衣食住のすべてを手に入れることができる世となった。
AndroidかAppleのスマホを使って、Googleで調べて、Amazonで生活に必要なものを買い、FacebookやInstagramで友達の近況を知り、Youtubeで時間を潰す、または自分から発信してフォロワーを集め、Paypalなんかで送金でもしてもらえばもうまったく外に出る必要もない。
そのくらい、IT技術の発展で生活スタイルは変わってしまった(上記の例は極端だけど)IT人材はなぜ必要かというと、上記の生活スタイルに寄与できる存在だからだと思う。技術を持った人材はこれからの世の中も市場価値が高く、必要とされ続ける存在だ。では具体的にその技術がなんなのかというと、プログラミング技術ということになる。コードを書くことができ、アルゴリズムを組み立て、自分で考えたプログラムを実装することができ、業務に技術的な改善と革新をもたらす可能性のあるスキルだということだけでも覚えてもらいたい。
因みにIT技術に優れているというくくりで俗に言う「Excelマスター」が巷にはいるが、Excelができる=IT人材である、という認識は持たない方がいいと思う。関数の組み合わせや表計算の工夫でそれなりに便利な使い方はできるが、やはりExcel単体では限界がある。これは、僕がPythonを学ぶきっかけにもなったことなので、是非似たような思いを抱いている人には自分ごととして捉えてもらえるとありがたい。なぜCでもJavaでもなくPythonなのか
よく、プログラミングを始める際に「どの言語で始めようかな?」と迷う人も多いと思う。
事実、僕がVBAを一通り使えるようになって、それでもやりたいことには足りないから他の言語を学ばないとなぁと思った時、どの言語を選べばいいか結構迷った。
Ruby、PHP、Java、C(C++)、Perl…世の中を見渡すとプログラミング言語というのは多く、中にはCOBOLやBASIC、FORTRANのようなレガシー的な言語まで存在する。因みに度々話題になるメガバンクの中の青い銀行はバリバリCOBOLが今も使われているという噂だが、実際のところは果たして…。
とにかく、どの言語を選ぶかというのはその後のプログラミング人生を左右すると言っても過言ではない。というのも、書き方の癖やできること、直感的に好きか嫌いかまでに影響してくるので、そういう意味では一番最初に付き合った恋人に影響されてしまうのによく似てる。変人と付き合ったらなんとなくその後も変人が好きになるとか、なんとなく元カレ・カノと同じタイプを選んでしまうとか…そう考えるとちょっと選ぶ大切さがわかってもらえそうな気がする。個人的な話をすると、一番最初に触れたプログラミング言語はJavaで、大学の選択授業の中で学ぶものだったが、これは非常によくない体験だった。というのも、講師の人がこちらがわかっていようがいまいが、カリキュラム通りに進めるので「え、なんでこう記述するとこう動くの?」みたいな疑問が一切解決されないまま先に進んでしまう。どこか中学や高校で数学の公式が「なぜこうなるのか」というのがわからないまま進むのに似ている。
おかげで僕は、すっかり授業についていけずその授業は放棄したし、初歩的なことも理解できないのではプログラミングは自分には向いてなくて無理なんだ、と自らの可能性を閉ざした苦い経験がある。そういう経験をこれを読んでいる人にはしてほしくないので、おすすめしたいのが「Python」という言語だ。
このサイトではGoogleでチュートリアルが調べられた数を元にプログラミング言語をランキングにしているのだが、ここではPythonが一番高く出ている。2番目がJavaで、3番目がJavascriptになっているが、肌感覚的には確かにそんなもんか、という気がする。
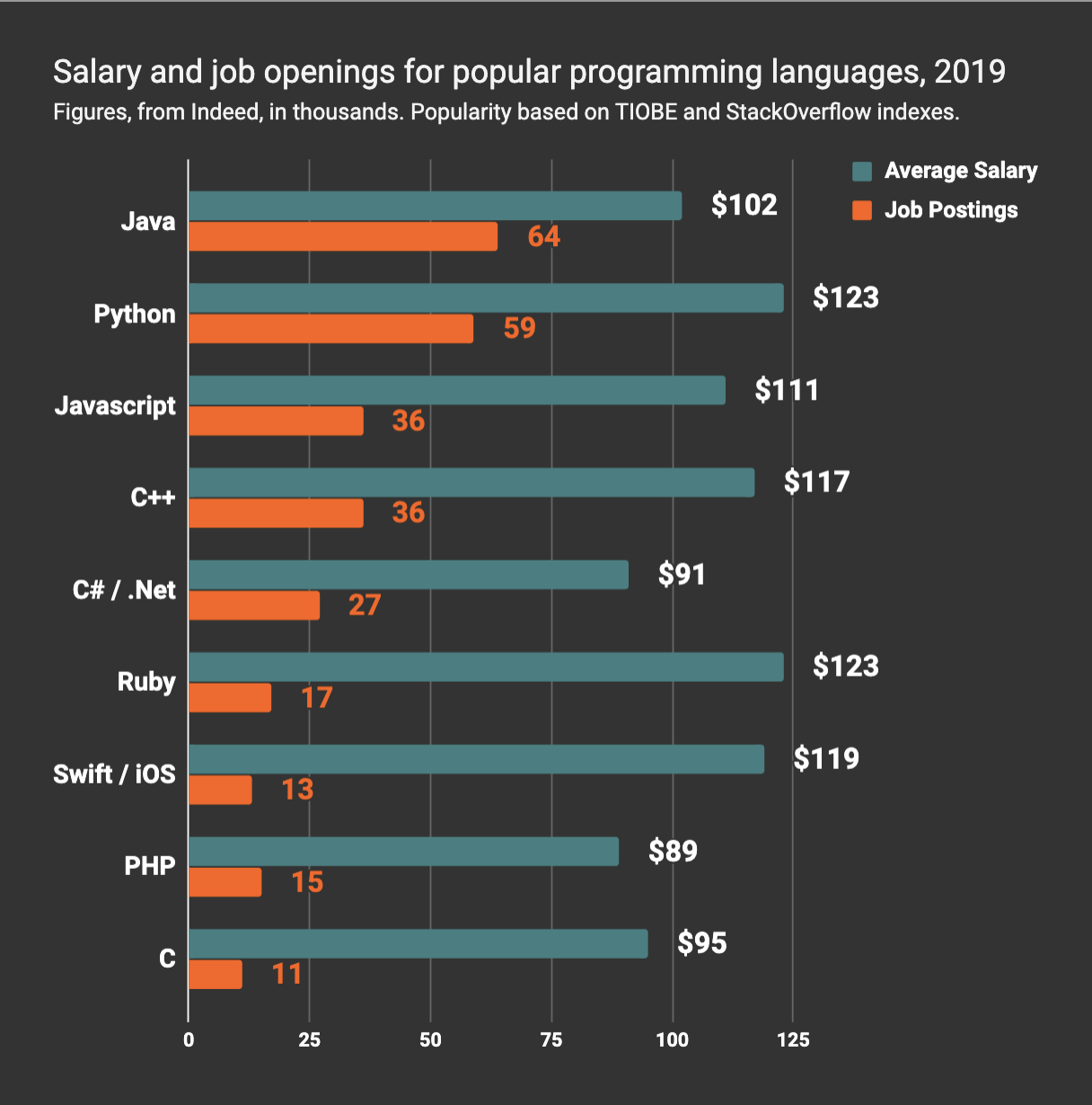
また、収入面やオファーの多さで言ってもPythonは下図の通りかなりの数値を誇っており、世の中がデータサイエンスに向かっていることを証明している。
これだけ人気があり、収入面も期待できる言語のPythonだが、実はJavaやCに比べると学習コストがとても低く、非プログラマーでも簡単に書けるという良さが個人的に最もウリである。上記の通り、Javaでプログラミングから脱落してしまった自分にとって、Pythonはサクサク覚えられ、プログラミングという世界が決して遠いものではないという意識にさせてくれた。
これが、僕がPythonをおすすめしたい理由のはじまりだ。こんなに簡単でいいんですかー!?Pythonの書き方について
「そうは言ってもPythonってプログラミングだから覚えること多いんでしょ?」と思う人もまだまだいるかもしれない。確かにプログラミング言語である以上覚えることは一定数あるが、それでも始めるのには超楽なのがPythonだ。
まず、公式サイトでPythonをダウンロードしてみて欲しい。
https://www.python.jp/
上記サイトで「ダウンロード」のPythonを3.7.2をクリックして、インストールする。ここらへんの詳しい解説は是非「Python インストール方法」なんかでググって欲しい。
ともかく、Pythonがインストールできたら次のプログラムを起動させてほしいhello.pyprint('Hello World!')はい、これですでにもう出力結果は「Hello World!」である。Pythonは究極的な速さでHello Worldを出力できる強みがある。
因みに多くのプログラミング言語では何かしらの出力や変数に「型付け」というものが必要になるのだが、Pythonのいいところは勝手に型付けをしてくれる(良くも悪くも)
なぜ良くも悪くもか、というと、Pythonで以下のコードを書いたとしよう。sample.pya = 2 b = 'hello' print(a) print(b) #2 #helloaには2という数字を代入し、bにはhelloという文字列を代入している。
これ自体はなんの間違いでもないので、それぞれをprint文で出力するとちゃんと変数に入れたものを出力してくれる。そして変数の中身は数値型ですね(int型)、文字列型ですね(str型)と判断してくれるので、いちいち他の言語のように宣言をする必要がないのだが、これが原因であとからバグが起きたりすることもあるので、それだけは段々覚えながら「あ、Pythonってこうい弱点もあるんだな」と感じて欲しい。
とにかくこうした点から非プログラマーでもPythonはいきなりプログラミングチックなことができるので非常に楽しく、「俺SUGEEEE」みたいな万能感が得られるためおすすめである。
ちなみにプログラミングの楽しさが一番わかるコードとして、僕は以下のようなものがあった。for_pyfor i in range(11): print(i) #1 #2 #3 #4 #5 #6 #7 #8 #9 #10あっという間に10までの数を繰り返し表示してくれるという優れもの。
これについてはPython for文みたいな感じでググって欲しい。Python万歳なのはわかったけど、何ができるの?
ここまでPythonがさも万能言語かのように書いてきたが、実際にPythonで何ができるかというと、以下のようなものがある。
・Web系の制作(フレームワークが揃っている)
・機械学習
・インターネットのスクレイピング(いわゆる、決まったサイトから決まった情報を定期的に拾ってくること)
・データの分析(Excelと同じ系統ですが、より数学チックに処理できます)逆にできないこととしては
・JavascriptのようなWebサイトの動的な仕組み作り
・Javaのようにコンパイルしたらどんな環境でも動かせるプログラム
くらいかなぁ…あとは突き詰めれば色々とありますが、結構なんでもできちゃうのがPythonのいいところなんです。
一番のメリットは機械学習かな。これからの時代、データサイエンスがどうとか耳タコなくらい聞いたこともあると思うけど、そこにはPythonの存在が切っても切り離せない。もちろんRとかSPSSとかそこらへんも統計的に処理する上で出てくるんだけど、Twitterとか見てるとアメリカ含め世界の潮流はPythonで処理する流れになっているんだとか…。
今の世の中、Pythonができるだけで「すげー!採用!年収1,000万!」みたいなさすがに魔法の杖にはならないけれど、Python×何かあなたが持つ強みを組み合わせれば、大抵の職にはありつけると思う、ということだけは言っておく。
少しでもこの記事を読んで、Pythonに興味が湧き、チャレンジしてもらえたら幸いである。
- 投稿日:2020-02-13T22:22:36+09:00
ファイルの作成
f = open('test.text', 'w') f.write('test test test\n') print('This', 'is', 'test', sep='#', end='!', file=f) f.close()実行結果test.textとういうファイルが作成されて、 中身は、 test test test This#is#test! となる。
- 投稿日:2020-02-13T20:11:29+09:00
自然言語処理を楽しんでみよう COTOHA APIを使って
自然言語処理を楽しむ
「自然言語処理」って楽しいです!!
もちろんそこそこ難しいこともあるのですが……それ以上に楽しいです、とにかく楽しいです。
そんな楽しさのとっかかりになればと思い書いてみます。
自然言語処理で何がしたいのか?何ができるのか?
普通に会話で使う日本語などのことを「自然言語」と呼んでいます。
そんな「自然言語」をコンピューターで扱いやすい形に「処理」するのが「自然言語・処理」だと思ってください。
例えばコンピューターにわかりやすいものとしては「数値データ」があります。「ECサイトの売り上げ」「温度」「交通量」など数値で表せるものです。「数値データ」は数式やコンピュータで扱うのが簡単なのでこんなことが簡単にできます。
- excelで表にしてグラフを書いたり簡単にできます
- 気温とビールの売り上げの関係が見れたりします
- 温度が10度以下になったらエアコンをつけます
- 今流行りのAI/機械学習なんてことも出来ます。
……もし、これと同じようなことを「自然言語」つまり「会話」や「SNSの文章」や「小説」や「歌詞」という文章に対してで出来たら楽しそうじゃないですか?
例えば、
- 好きなアーティストの歌詞や好きな小説を(どうにかして)データ化してグラフを書いてみる
- 好きなマンガのセリフを比較してみる
- SNSでネガティブなコメントを強制ブロックする
歌詞、新聞、Wikipediaや、自分の好きなアニメの設定資料、なんでもいいので「文章」をネタに色々分析してみると何か面白い発見が得られるかもしれません。
なんとなくワクワクしませんか? しますよね!!
補足 : あらためて自然言語とは?
「自然言語」は日常のコミュニケーションのため自然に発展してきた「自然(発生的な)言語」を指す言葉です。対して「人工言語(形式言語)」というのもあって、馴染み深いものでは「プログラム言語」です。これはある目的のために「人工的」に作られた言語です。
大きな違いとしては「自然言語」が文法や単語の意味が非常に曖昧で多様な表現が許されるのに対して、「人工言語(形式言語)」は意味が明らかで曖昧さがないことです。この「曖昧さ」というのはそれぞれの人の生活スタイルや文化によるものなので解釈がとても広いのですが、そこが自然言語処理の難しさでもあり、楽しさでもあります。APIに頼って遊んでみよう!
面白そうだとはいっても「自然言語処理」なんてそんなに簡単に出来るものではありませんでした・・・昔は・・・そう、でも今は簡単にできてしまいます。
本当に便利な世の中になったもので外部の API に頼ることで楽しい部分だけショートカットでたどり着いてしまうことが可能です。
自然言語処理を提供してくれるサービスには AWS や Azure やたくさんのクラウドサービスもありますが、今回は日本メーカーで日本語の処理に強い COTOHA API を使わせていただきます。
COTOHA API
https://api.ce-cotoha.com/contents/index.htmlとにかく遊んでみよう
前置きが長かったですがとにかく楽しんで遊んでみるのが一番です。 楽しんでもらうのが今回のQiitaで一番メインで伝えたいことです。
今回は細かなプログラミングの話は省略してます。さくっと簡単にできるよう最近流行りのPythonで書いてます。Jupyterとかに張り付けてくれるだけで動きます!
まず COTOHA API のサイトから登録を行って各種情報をゲットしてください。
ここだけはググって頑張ってもらうか、https://api.ce-cotoha.com/contents/gettingStarted.html あたりのスタートガイド見て頑張ってください。ちょっと簡単に使ってみるにはぜんぜん無料で試せますし、他のクラウドサービスみたいに最初からクレジットカード入力も不要なので安心して遊んでみることができます。
無事に登録できたら下記のようなアカウントホーム画面で実行に必要な情報を入手できます。
あとはもう簡単です下記のコード中の★部分を上でゲットした値に書き換えてPythonを実行してください。
############################## # ★ COTOHA API のダッシュボードの文字列で書き換えてください ############################## api_base_url = 'https://api.ce-cotoha.com/api/dev/' client_id = '************' client_secret = '************' access_token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens' ############################## # ★ 解析したいテキストを入れてください ############################## text = '生まれて、すみません。' ############################## import requests import json # Token取得 headers = { "Content-Type" : "application/json" } data = { "grantType":"client_credentials", "clientId":client_id, "clientSecret":client_secret } r = requests.post(access_token_url, data=json.dumps(data), headers=headers) bearer_token = r.json()["access_token"] # ユーザー属性取得 headers = { "Content-Type" : "application/json;charset=UTF-8", "Authorization":"Bearer "+bearer_token } data = { "sentence":text } url = api_base_url + "nlp/v1/sentiment" r = requests.post(url, data=json.dumps(data), headers=headers) r.json()実行してみるとこんな結果が得られます。
{'message': 'OK', 'result': {'emotional_phrase': [{'emotion': '悲しい', 'form': 'すみません'}], 'score': 0.21369802583055023, 'sentiment': 'Negative'}, 'status': 0}これは COTOHA の 感情分析API というものを使ったサンプルです。
感情分析
文章作成時の書き手の感情をポジティブまたはネガティブで判定します。
さらに文章に含まれる「喜ぶ」や「驚く」といった特定の感情も認識します。「生まれて、すみません。」という有名な一文を分析してみた結果をまとめるとこう分析されたことになります。
emotion : '悲しい' sentiment: 'Negative'この1文は 悲しい というemotion(感情)を表していて、文章全体としては Negative だという結果が得られました。
「生まれて、すみません」という何とも言えない自然な文章に対して「自然言語処理」することで扱いやすいデータに変換することができました。
これが「自然言語処理」というものの一歩です。
ぜひ色んな文章をいれてみて試してみてください。けっこう面白い結果になると思います……。
もう少し遊んでみよう
では今度は次のコードを動かしてみてください。
今度は冒頭の
textsに配列の形で複数のテキストをいれることで複数のテキストを一気に解析してみます。さっきのサンプルと同じように実行してみてください。
############################## # ★ COTOHA API のダッシュボードの文字列で書き換えてください ############################## api_base_url = 'https://api.ce-cotoha.com/api/dev/' client_id = '************' client_secret = '************' access_token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens' ############################## # ★ 解析したいテキストを入れてください ############################## texts = [ '吾輩は猫である。', '名前はまだ無い。', 'どこで生れたかとんと見当がつかぬ。', '何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。', '吾輩はここで始めて人間というものを見た。', 'しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。', 'この書生というのは時々我々を捕えて煮て食うという話である。', 'しかしその当時は何という考もなかったから別段恐しいとも思わなかった。', 'ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。', '掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。', 'この時妙なものだと思った感じが今でも残っている。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。', 'その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。', 'のみならず顔の真中があまりに突起している。', 'そうしてその穴の中から時々ぷうぷうと煙を吹く。', 'どうも咽せぽくて実に弱った。', 'これが人間の飲む煙草というものである事はようやくこの頃知った。' ] ############################## print("sentiment,score") import requests import json # Token取得 headers = { "Content-Type" : "application/json" } data = { "grantType":"client_credentials", "clientId":client_id, "clientSecret":client_secret } r = requests.post(access_token_url, data=json.dumps(data), headers=headers) bearer_token = r.json()["access_token"] # ユーザー属性取得 headers = { "Content-Type" : "application/json;charset=UTF-8", "Authorization":"Bearer "+bearer_token } for text in texts: data = { "sentence":text } url = api_base_url + "nlp/v1/sentiment" r = requests.post(url, data=json.dumps(data), headers=headers) r_json = r.json() print( "{},{}".format( r_json['result']['sentiment'], r_json['result']['score'] ) )実行してみると次のような結果が得られます。
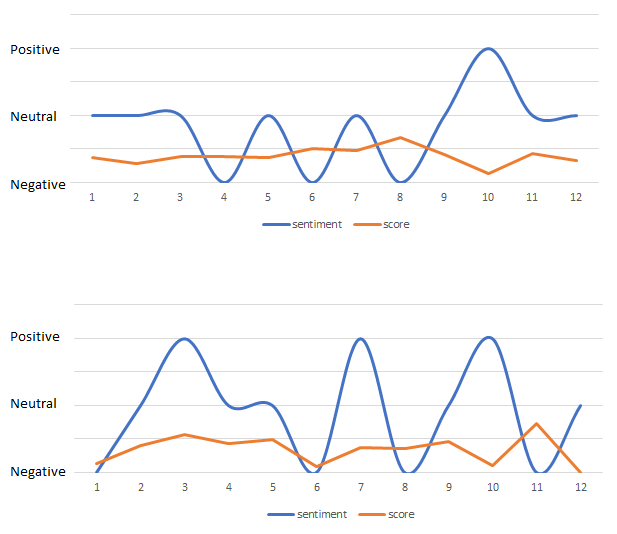
sentiment,score Neutral,0.3753601806177662 Neutral,0.28184469062696865 Neutral,0.3836848869293042 Negative,0.39071316583764915 Neutral,0.3702709760069095 Negative,0.513838361667319 Neutral,0.47572556634191593 Negative,0.6752951176068892 Neutral,0.42154746899352424 Positive,0.14142126089599155 Neutral,0.4397035866256947 Neutral,0.3335122613499773 Neutral,0.36874320529074195 Neutral,0.3721780539113525 Negative,0.19851456636071463 Neutral,0.4334376882848198コードを見てもらえばなんとなく想像できると思いますが、これは、夏目漱石の「吾輩は猫である」の冒頭を1文ずつ解析していってその結果を並べたものです。
これで出てきた結果を Excel で読み込んでガチャガチャしてみるといろいろとグラフが書けます。
例えばこんな感じです。 1つだと面白くないので 太宰治 「人間失格」 も並べてみました。
上が「吾輩は猫である」で下が「人間失格」です。
こうやって並べてみると面白いですね…。
「吾輩は猫である」の方が Negative と Neutral をたんたんと行き来する感じで続くのに対して、「人間失格」のバタつき。 Negative と Positive を行き来している感情の振れ幅がすごいですね。
冒頭の10文章くらいしかやっていませんが、これを全文でやってみたり章ごとにしたり、作品ごと・作家ごとで比較してみたりとさらに色々と見えてきそうな気がします。
ここまでデータ化できれば「平均」を見て見たり「分散」を見て見たり、と、いろいろな統計的なデータ分析が可能になるという仕掛けです。
さいごに
どうでしたか? おもったより簡単に楽しそうなことができそうですよね。
例えば COTOHA API には他にも「文章から年齢や性別を推定する」「品詞(動詞や名詞や)を取り出す」などたくさんのAPIがあります。もちろん Azure や AWS や IBM Cloud やと言ったものでも様々なデータ化が可能です。 IBM Cloud の Personality Insights なんてのも面白いです。文章から性格診断ができます。
このように「自然言語処理」を使う事で様々な文章がコンピューターで扱いやすい形に出来ます。
扱いやすい形に出来てしまえば様々な応用が可能になります。
Webサイトの文章を分析して改善してCVRを上げたり、SNSを分析してマーケティングに活かしたり、小論文や読書感想文や採点結果を分析してどういう文章が採点が高いかを分析したり……。
小論文や読書感想文からさまざまなデータを抽出して「説明変数」にして、採点を「目的変数」にして、回帰分析をかけたり、です。もしキレイなディシジョンツリーが書ければ高得点狙えるかもしれません……!
難しいことは抜きにしても(難しいことはサービス提供してくれる専門家がやってくれます!)普段慣れ親しんでいる「自然言語」で色々遊ぶこと出来るのは楽しいことです。 このQiitaが自然言語処理の第一歩になってくれればと思います!!

- 投稿日:2020-02-13T20:04:38+09:00
Null importances による特徴量選択
はじめに
null importance を利用した特徴量選択について調べたのでその覚書です。何かおかしなとこがあればご指摘ください。
参考:Feature Selection with Null Importances概要
特徴量選択をするときにノイズとなる特徴量を取り除き、本当に重要な特徴量を取り出すために行う。目的変数をランダムにシャッフルした訓練データを使って各特徴量の重要度をはかる。
手順
- 目的変数をシャッフルした訓練データでモデルを何度も訓練し、null importanceの分布を作成
- オリジナルの訓練データでモデルを訓練し、各特徴量の重要度を取得
- null importanceの分布に対する実際の重要度のスコアを計算
- 適当な閾値を定めて特徴量を選択
0. 準備
必要なライブラリのインポート
import pandas as pd import numpy as np np.random.seed(123) from sklearn.metrics import mean_squared_error from sklearn.model_selection import KFold import time import lightgbm as lgb import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec import seaborn as sns import warnings warnings.simplefilter('ignore', UserWarning) import gc gc.enable() import timeデータの準備. 今回はkaggleのHouse Priceチュートリアルのデータを使用します.
House Prices: Advanced Regression Techniques# データ読み込み data = pd.read_csv("./House_Price/train.csv") target = data['SalePrice'] # カテゴリ変数を取得 cat_features = [ f for f in data.columns if data[f].dtype == 'object' ] for feature in cat_features: # カテゴリ変数を数値に変換 data[feature], _ = pd.factorize(data[feature]) # タイプをcategoryに変換 data[feature] = data[feature].astype('category') # とりあえず欠損値を含む特徴量は削除 drop_cols = [f for f in data.columns if data[f].isnull().any(axis=0) == True] # drop_cols.append('SalePrice') # 目的変数も削除 data = data.drop(drop_cols, axis=1)1. null importanceの分布を作成
特徴量の重要度を返す関数を用意.
今回は参考にした記事と同じでLightGBMを用いました.def get_feature_importances(data, cat_features, shuffle, seed=None): # 特徴量を取得 train_features = [f for f in data if f not in 'SalePrice'] # 必要なら目的変数をシャッフル y = data['SalePrice'].copy() if shuffle: y = data['SalePrice'].copy().sample(frac=1.0) # LightGBMで訓練 dtrain = lgb.Dataset(data[train_features], y, free_raw_data=False, silent=True) params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': {'l2'}, 'num_leaves': 128, 'learning_rate': 0.01, 'num_iterations':100, 'feature_fraction': 0.38, 'bagging_fraction': 0.68, 'bagging_freq': 5, 'verbose': 0 } clf = lgb.train(params=params, train_set=dtrain, num_boost_round=200, categorical_feature=cat_features) # 特徴量の重要度を取得 imp_df = pd.DataFrame() imp_df["feature"] = list(train_features) imp_df["importance"] = clf.feature_importance() return imp_dfNull Importance の分布を作成.
null_imp_df = pd.DataFrame() nb_runs = 80 start = time.time() for i in range(nb_runs): imp_df = get_feature_importances(data=data, cat_features=cat_features, shuffle=True) imp_df['run'] = i + 1 null_imp_df = pd.concat([null_imp_df, imp_df], axis=0)2. 通常の特徴量の重要度を取得
actual_imp_df = get_feature_importances(data=data, cat_features=cat_features, shuffle=False)3. 重要度のスコアを計算
通常の特徴量の重要度をnull importance分布の75パーセンタイルで割ったものを使用
feature_scores = [] for _f in actual_imp_df['feature'].unique(): f_null_imps = null_imp_df.loc[null_imp_df['feature'] == _f, 'importance'].values f_act_imps = actual_imp_df.loc[actual_imp_df['feature'] == _f, 'importance'].mean() imp_score = np.log(1e-10 + f_act_imps / (1 + np.percentile(f_null_imps, 75))) feature_scores.append((_f, imp_score)) scores_df = pd.DataFrame(feature_scores, columns=['feature', 'imp_score'])4. 特徴量を選定
適当な閾値を定めて特徴量を選定します. 今回はスコアが0.5以上のものを使用することにしました.
sorted_features = scores_df.sort_values(by=['imp_score'], ascending=False).reset_index(drop=True) new_features = sorted_features.loc[sorted_features.imp_score >= 0.5, 'feature'].values print(new_features) # ['CentralAir' 'GarageCars' 'OverallQual' 'HalfBath' 'OverallCond' 'BsmtFullBath']最後に
先日参加したコンペで上位入賞者の方々が使っていたので調べてみました。
他にも特徴量選択の手法は色々あると思うので調べて行きたいと思います。
- 投稿日:2020-02-13T20:02:34+09:00
RDKitでターゲットデータベースから類似化合物を検索するコマンドを作成し処理時間を確認
はじめに
RDKitで、クエリ化合物に対し、ターゲットデータベース(といってもただのSDF)から類似化合物を検索するのにどの程度の時間がかかるのだろうか、ということが気になったためコマンドを書いてみた。
ソース
類似度を計算する場合、フィンガープリントを生成し、Tanimoto係数で類似度スコアを求めるのが一般的だ。フィンガープリントは化学構造をビット化したもので様々な手法が存在する。ここではビット数が少なくメジャーなMACCS Keysを利用してみた。
import argparse from rdkit import Chem from rdkit.Chem import Descriptors, AllChem from rdkit import rdBase, Chem, DataStructs def main(): parser = argparse.ArgumentParser() parser.add_argument("-query", type=str, required=True) parser.add_argument("-target_db", type=str, required=True) args = parser.parse_args() # queryの読み込み mol_block = "" with open(args.query) as f: for line in f: mol_block += line query_mol = Chem.MolFromMolBlock(mol_block) # SDFの読み込み target_sdf_sup = Chem.SDMolSupplier(args.target_db) # FignerPrintの計算(query) query_fp = AllChem.GetMACCSKeysFingerprint(query_mol) # FignerPrintの計算(target) target_fps = [AllChem.GetMACCSKeysFingerprint(mol) for mol in target_sdf_sup] for i, target_fp in enumerate(target_fps): result = DataStructs.TanimotoSimilarity(query_fp, target_fp) print(i, result) if __name__ == "__main__": main()使い方
こんな感じ。argparseちゃんありがとう。
usage: StructureSimilaritySearch.py [-h] -query QUERY -target_db TARGET_DB optional arguments: -h, --help show this help message and exit -query QUERY(mol) -target_db TARGET_DB(sdf)処理時間
例によってRDkitのSolubilityのtrainデータ1024件をtargetにして検索。queryは適当です。
そうすると、1秒程度で返却。万単位ならこのままでもそこそこいけそうだ。参考
- 投稿日:2020-02-13T20:02:34+09:00
RDKitで類似化合物を検索するコマンドを作成
はじめに
RDKitで、クエリ化合物に対し、ターゲットデータベースから類似化合物を検索するのにどの程度の時間がかかるのだろうか、ということが気になったためコマンドを書いてみた。
ソース
類似度を計算する場合、フィンガープリントを生成し、Tanimoto係数で類似度スコアを求めるのが一般的だ。フィンガープリントは化学構造をビット化したもので様々な手法が存在する。ここではビット数が少なくメジャーなMACCS Keysを利用してみた。
import argparse from rdkit import Chem from rdkit.Chem import Descriptors, AllChem from rdkit import rdBase, Chem, DataStructs def main(): parser = argparse.ArgumentParser() parser.add_argument("-query", type=str, required=True) parser.add_argument("-target_db", type=str, required=True) args = parser.parse_args() # queryの読み込み mol_block = "" with open(args.query) as f: for line in f: mol_block += line query_mol = Chem.MolFromMolBlock(mol_block) # SDFの読み込み target_sdf_sup = Chem.SDMolSupplier(args.target_db) # FignerPrintの計算(query) query_fp = AllChem.GetMACCSKeysFingerprint(query_mol) # FignerPrintの計算(target) target_fps = [AllChem.GetMACCSKeysFingerprint(mol) for mol in target_sdf_sup] for i, target_fp in enumerate(target_fps): result = DataStructs.TanimotoSimilarity(query_fp, target_fp) print(i, result) if __name__ == "__main__": main()使い方
こんな感じ。argparseちゃんありがとう。
usage: StructureSimilaritySearch.py [-h] -query QUERY -target_db TARGET_DB optional arguments: -h, --help show this help message and exit -query QUERY(mol) -target_db TARGET_DB(sdf)処理う時間
例によってRDkitのSolubilityのtrainデータ1024件をtargetにして検索。queryは適当です。
そうすると、1秒程度で返却。万単位ならこのままでもそこそこいけそうだ。参考
- 投稿日:2020-02-13T20:02:34+09:00
RDKitでターゲットデータベースから類似化合物を検索するコマンドを作成
はじめに
RDKitで、クエリ化合物に対し、ターゲットデータベース(といってもただのSDF)から類似化合物を検索するのにどの程度の時間がかかるのだろうか、ということが気になったためコマンドを書いてみた。
ソース
類似度を計算する場合、フィンガープリントを生成し、Tanimoto係数で類似度スコアを求めるのが一般的だ。フィンガープリントは化学構造をビット化したもので様々な手法が存在する。ここではビット数が少なくメジャーなMACCS Keysを利用してみた。
import argparse from rdkit import Chem from rdkit.Chem import Descriptors, AllChem from rdkit import rdBase, Chem, DataStructs def main(): parser = argparse.ArgumentParser() parser.add_argument("-query", type=str, required=True) parser.add_argument("-target_db", type=str, required=True) args = parser.parse_args() # queryの読み込み mol_block = "" with open(args.query) as f: for line in f: mol_block += line query_mol = Chem.MolFromMolBlock(mol_block) # SDFの読み込み target_sdf_sup = Chem.SDMolSupplier(args.target_db) # FignerPrintの計算(query) query_fp = AllChem.GetMACCSKeysFingerprint(query_mol) # FignerPrintの計算(target) target_fps = [AllChem.GetMACCSKeysFingerprint(mol) for mol in target_sdf_sup] for i, target_fp in enumerate(target_fps): result = DataStructs.TanimotoSimilarity(query_fp, target_fp) print(i, result) if __name__ == "__main__": main()使い方
こんな感じ。argparseちゃんありがとう。
usage: StructureSimilaritySearch.py [-h] -query QUERY -target_db TARGET_DB optional arguments: -h, --help show this help message and exit -query QUERY(mol) -target_db TARGET_DB(sdf)処理時間
例によってRDkitのSolubilityのtrainデータ1024件をtargetにして検索。queryは適当です。
そうすると、1秒程度で返却。万単位ならこのままでもそこそこいけそうだ。参考
- 投稿日:2020-02-13T19:57:31+09:00
pythonでvim pluginを書く時にファイル分割する
背景
上記リンクの記事を参考にVim(Neovim)のpluginを作っています。
Pythonファイルが大きくなり分割しようとしたところ、少しつまずいたので解決法を共有します。この記事では、例としてrequestsモジュールを用いてWebページのタイトルを表示するプラグインを作ってみます。
ディレクトリ構成とファイルの中身
sample-vim-plugin plugin/ sample_vim_plugin.vim src/ sample_vim_plugin.py requests_caller.pyplugin/sample_vim_plugin.vimscriptencoding utf-8 if exists('g:loaded_sample_vim_plugin') finish endif let g:loaded_sample_vim_plugin = 1 let s:save_cpo = &cpo set cpo&vim py3file <sfile>:h:h/src/sample_vim_plugin.py function! sample_vim_plugin#print_title(url) py3 sample_vim_plugin_print_title(vim.eval('a:url')) endfunction let &cpo = s:save_cpo unlet s:save_cposrc/sample_vim_plugin.pyimport vim import requests_caller def sample_vim_plugin_print_title(url): print(requests_caller.get_title(url))requests_caller.pyimport requests from bs4 import BeautifulSoup def get_title(url): response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') return soup.title.text私はdeinでプラグインを管理しているので、tomlファイルに上記のプラグインを追加しneovimを起動すると
ModuleNotFoundError: No module named 'requests_caller'
と言われます。このモジュール見つからない問題を解決したいと思います。
「Python における 'runtimepath' の処理」に
Python では、'runtimepath' のパスのリストを使う代わりに、vim.VIM_SPECIAL_PATH
という特別なディレクトリが使われます。このディレクトリが sys.path 内で使われる
とき、そして vim.path_hooks が sys.path_hooks 内で使われるとき、'runtimepath'
の各パス {rtp} に対して {rtp}/python2 (or python3) と {rtp}/pythonx (両バー
ジョンで読み込まれる) のモジュールがロードされます。とあります。
よって、二つの方法が考えられます。
解決法1: ディレクトリの名前を変更する
runtimepathの直下にpython2,python3,pythonxのディレクトリがあればロードされるとのことなので、srcディレクトリをpython3にリネームします。
当然読み込む部分を変える必要があるので、下記のように変更しますplugin/sample_vim_plugin.vim- py3file <sfile>:h:h/src/sample_vim_plugin.py + py3file <sfile>:h:h/python3/sample_vim_plugin.py解決法2: sys.pathに追加する
ディレクトリの名前を変えたくない場合は、直接sys.pathに追加します。
plugin/sample_vim_plugin.vim+ let s:sample_vim_plugin_root_dir = expand('<sfile>:p:h:h') py3file <sfile>:h:h/src/sample_vim_plugin.pysrc/sample_vim_plugin.pyimport vim + import sys + import os + plugin_python_dir = os.path.join(vim.eval('s:sample_vim_plugin_root_dir'), 'src') + sys.path.append(plugin_python_dir) import requests_callerまとめ
- python2, python3, pythonxディレクトリにPythonファイルを置く
- sys.pathにPythonファイルをおいたディレクトリを追加する
という二つの方法でプラグインが動くようになります。
有名どころで言うと、davidhalter/jedi-vimでは解決法1(pythonx)を使っているみたいです。
ソースコードをチラ見しただけですが、Shougo/denite.nvimやShougo/deoplete.nvimでは解決法2を使っているように見えます。
- 投稿日:2020-02-13T19:53:25+09:00
ランダムよりはマシな精度で高速なKMEANS初期化処理を作りました
KMEANSの初期化処理とは
KMEANSは最初に適当な初期位置を決めて推定と中心値の計算を収束するまで繰り返します、初期位置が優秀なほうが精度は上がり収束までの繰り返し回数も少なくて済みます。初期化手法にはRANDOMとk-means++の二通りがありRANDOMは名前の通りクラスタの数だけランダムにサンプルを選びそれらを初期位置とします、k-means++は最初の点はランダムに選びますが2つ目以降は距離が遠いほど確率が高くなるようにD(x)^2で確率分布を作りできるだけ遠い物をクラスタの数だけ選びます。ここの解説がとてもわかりやすいです → https://www.medi-08-data-06.work/entry/kmeans
動機
マイコンでKMEANSやる事情ができたのでKMEANS++同等で軽くてメモリを食わない初期化処理が必要
思いついた方法
① 中心値同士の全ての距離の平均値を算出
② サンプルの所属クラスタを推定
③ ②の距離が①より大きかったらそれを新しい中心値とする
④ ③によりクラスタを新しいサンプルで更新した場合は①へ、そうでない場合は②へ
対象データ全てで①~④を繰り返すあるサンプルのクラスタ推定時の距離が中心値同士の距離平均より大きいということはそのサンプルは新しいクラスタで分布は今の中心値よりももっと広いに違いないので中心値同士の距離平均が広がりきるまで広げてみようという発想です。わかりづらいですが自分も上手く説明できませんのでソース見てください。
iris、seedsによる1000回試験結果
iris
処理 イテレーション平均 イテレーション分散 正解平均 正解分散 random 6.418 2.174 0.763 0.1268 k-means++ 5.38 1.63 0.804 0.09 新手法 6.104 2.088 0.801 0.09 seeds
処理 イテレーション平均 イテレーション分散 正解平均 正解分散 random 9.109 3.237 0.921 0.0049 k-means++ 7.096 2.4284 0.921 0.0051 新手法 7.368 2.56 0.921 0.046 k-means++には及びませんでしたがランダムよりは明確に良い結果が出ていると思います、イテレーション回数が少なく精度も出ていますし分散も少ないので結果のばらつきも少ないようです。もう少し量があって8クラスタくらいのサンプルがあると良いのですが都合良い物がなかったのでirisとseedsのみの試験としました。
ちなみに実際仕事で使った所当試験よりも高い精度とイテレーション回数の削減が得られたためサンプルによっての相性が激しい手法のようです。
以下ソースコード載せておきます。初期化処理のソースコード
def Kmeans_Predict(means, x): distances = [] for m in means: distances.append(np.linalg.norm(m - x)) predict = np.argmin(distances) return distances[predict], predict # 中心値同士の平均距離を計算 def KmeansInit_CalcRadiusAverageDistance(means): length = len(means) avrDistance = 0 cnt = 0 for i in range(length): for j in range(i): if j == i: continue avrDistance += np.linalg.norm(means[i] - means[j]) cnt += 1 return (avrDistance / cnt/ 2) def KmeansInit_FarawayCentroids(n_clusters, x): means = np.zeros((n_clusters, x.shape[1])) distanceThreshold, minIdx1, minIdx2 = 0, 0, 1 for cnt in range(1): for ix in x: distance, predict = Kmeans_Predict(means, ix) if distance > distanceThreshold: # 中心値同士の平均距離より大きいのならそのサンプルは新しいクラスタということにする means[predict] = ix distanceThreshold = KmeansInit_CalcRadiusAverageDistance(means) else: # 中心値同士の平均距離と同じかそれ以下なら妥当な位置なので中心値の更新はしない pass return means試験ソースコード全体
import math import numpy as np import sklearn.cluster import sklearn.preprocessing import sys def Kmeans_Predict(means, x): distances = [] for m in means: distances.append(np.linalg.norm(m - x)) predict = np.argmin(distances) return distances[predict], predict def KmeansInit_CalcRadiusAverageDistance(means): length = len(means) avrDistance = 0 cnt = 0 for i in range(length): for j in range(i): if j == i: continue avrDistance += np.linalg.norm(means[i] - means[j]) cnt += 1 return (avrDistance / cnt/ 2) def KmeansInit_FarawayCentroids(n_clusters, x): means = np.zeros((n_clusters, x.shape[1])) distanceThreshold, minIdx1, minIdx2 = 0, 0, 1 for cnt in range(1): for ix in x: distance, predict = Kmeans_Predict(means, ix) if distance > distanceThreshold: means[predict] = ix distanceThreshold = KmeansInit_CalcRadiusAverageDistance(means) return means def loadIris(): data = np.loadtxt("./iris_dataset.txt", delimiter="\t", dtype=str) length = len(data) x = data[:,0:4].astype(np.float) names = data[:,4] nameList = np.unique(data[:,4]) y = np.zeros(length) for i, name in enumerate(nameList): y[names == name] = i return x, y def loadSeeds(): data = np.loadtxt("./seeds_dataset.txt", delimiter="\t", dtype=str) length = len(data) x = data[:,0:7].astype(np.float) y = data[:,7].astype(float) return x, y def KmeansModel(init, n_clusters): return sklearn.cluster.KMeans( n_clusters=n_clusters, init=init, n_init=1, max_iter=100, tol=1e-5, verbose=3 ) def CalcAccuracy(y, predicts): answers = np.unique(y) clusters = np.sort(np.unique(predicts)) accuracy = [] ignoreCluster = [] for ans in answers: pred = predicts[y == ans] total = [] totalClusters = [] for c in clusters: if c in ignoreCluster: continue total.append(np.sum(pred == c)) totalClusters.append(c) maxIdx = np.argmax(total) ignoreCluster.append(totalClusters[maxIdx]) acc = total[maxIdx] / len(pred) accuracy.append(acc) return accuracy def KmeansTestSub(init, n_clusters, x, y): model = KmeansModel(init, n_clusters) model.fit(x) predicts = model.predict(x) accuracy = CalcAccuracy(y, predicts) return [model.n_iter_, np.mean(accuracy)] + list(accuracy) def shuffleData(x, y): idxs = np.arange(len(x)) np.random.shuffle(idxs) x, y = x[idxs], y[idxs] return x, y def KmeansTest(dataset, n_clusters, prefix="", test_count=1000): x, y = dataset scaler = sklearn.preprocessing.StandardScaler() scaler.fit(x) x = scaler.transform(x) # farway report = [] for i in range(test_count): x, y = shuffleData(x, y) init = KmeansInit_FarawayCentroids(n_clusters, x) rep = KmeansTestSub(init, n_clusters, x, y) report.append(rep) report = np.vstack([report, np.mean(report, axis=0)]) report = np.vstack([report, np.std(report, axis=0)]) np.savetxt("./{}report_farway.txt".format(prefix), report, delimiter="\t") # random report = [] for i in range(test_count): rep = KmeansTestSub("random", n_clusters, x, y) report.append(rep) report = np.vstack([report, np.mean(report, axis=0)]) report = np.vstack([report, np.std(report, axis=0)]) np.savetxt("./{}report_random.txt".format(prefix), report, delimiter="\t") # k-means++ report = [] for i in range(test_count): rep = KmeansTestSub("k-means++", n_clusters, x, y) report.append(rep) report = np.vstack([report, np.mean(report, axis=0)]) report = np.vstack([report, np.std(report, axis=0)]) np.savetxt("./{}report_kmeansPP.txt".format(prefix), report, delimiter="\t") def run(): KmeansTest(loadIris(), prefix="iris_", n_clusters=3) KmeansTest(loadSeeds(), prefix="seeds_", n_clusters=3) if __name__ == "__main__": run() # python kmeans_test.py以上です
以上です
- 投稿日:2020-02-13T18:16:42+09:00
pandasでリストをくっつけてDataFrameにする
- 投稿日:2020-02-13T18:00:14+09:00
欠損値(NaN)がある列を列ごと置換したいとき
概要
NaNの入っている列を抽出と書いてある記事はあるのですが、具体的に列ごと取ってきたり、その列をほかのリストで埋めたりしているものがなかったので今回まとめてみました。
解説に関しては初学者のため、あまり参考にならないかもしれませんが、こういう手法もあるんだ程度で見ていただければ幸いです。NaNが含まれているかの判定
行のどこかにNaNが含まれていた時、Trueを返すコードは以下の通りです。1行すべてNaNの時だけTrueを返してほしかったらanyをallに変えればよいです。
今回用意したデータでは2行目だけがNaNを含んでいます。df_judge = df.isnull().any(axis=1) """ 0 False 1 False 2 True 3 False 4 False 5 False 6 False 7 False 8 False 9 False """NaNの存在する列にリストを挿入する
まずTrueが存在するかはif文で調べることができ、リストの要素呼び出しとほぼ同じでした。
for i in range(len(df)): if df_judge[i] == True: for j in range(len(df.columns)): #round処理は小数第1位にそろえる処理 df.iloc[i,j] = average_list[j]今回はNaNがある列にその他の列の平均値を挿入するのが目的でした。
列数、行数はlen(df),len(df.columns)で取得できるため、二重for文を使いました。if文でNaNがあると判定された後、指定の行に1つずつ列をずらして平均値を代入しています。DataFrameの要素を指定するときはdf.iloc[行,列]を使いました。
直接列ごと挿入できないのは残念ですが、この方法で対処できるのでぜひ参考にしてみてください。
- 投稿日:2020-02-13T17:57:51+09:00
【AtCoder用】標準入力メモ
- 投稿日:2020-02-13T17:57:30+09:00
Pythonの関数デコレーター
調べ物のまとめと復習用の教材としてQiitaに残していくことにしました。
自分の整理用なので不親切な記載も多いかと思います。
その場合は、参考URL一覧へのリンク集としてご利用ください。由来
もともと、デザインパターンにはデコレーターパターンというものがあり、Pythonのデコレーターもそれから来ているようです。
デコレーターパターン
既存のオブジェクトに新しい機能や振る舞いを動的に追加すること
引用元:Decorator パターンhttps://ja.wikipedia.org/wiki/Decorator_%E3%83%91%E3%82%BF%E3%83%BC%E3%83%B3
こちらの定義を前提に理解を進めていきます。
ざっくりいうと、実行したい処理に対して、前処理や後処理を加えたり、レスポンスそのものをすり替えたりといったことができます。厳密にいうとDecoratorパターンとDecoratorは別物、ないしは後者が前者の要素にあたるようですが、そこは深堀りしない。
参考:python-3 patterns,idioms and test
https://python-3-patterns-idioms-test.readthedocs.io/en/latest/PythonDecorators.htmlファーストオブジェクト
Pythonでは関数はファーストオブジェクトです。Pythonの関数はオブジェクトであり、関数の引数や戻り値に関数を利用することが出来ます。デコレーターは引数として受け取った関数を、デコレーター自身の処理の一部として実行することができます。
動作確認
下記のようなことをして遊んでました。
decorater.py# デコレーターを定義する def decorator(func): # 名前はdecoじゃなくてもいい。dededeとかでもいい。 def _deco(*args, **kwargs): # 関数の名前はなんでもいい。decodecoとかでもいい。 print('japan') func() print('america') return _decorator # @をつけてデコレーターと関数を紐付ける # デコレーターがdededeなら@dededeとかつける @decorator def hello_world(): print('china') # japan # china # america @decorator def hello_earth(): print('england') # japan # england # america @decorator def hello_tokyo(): print('tokyo') # japan # tokyo # america各関数はdecorator関数の引数として渡され、デコレーター内部で実行されます。
@decoratorを先頭につけた関数がfuncとしてデコレーターの引数になります。
デコレーターの名前はなんでもいいです。用途にあわせて適切な名前をつけましょう。
上記の例では、japan, americaでprint処理を挟み込むことができました。実装例
動作確認ができたので実装です。API Gateway + LambdaでよくあるAPIを実装しました。
実際のところは、私じゃない人が設計・実装してるので、要素の一部を簡易に記載します。
lambdaの処理に対して、リクエストパラメーターの前処理とログ処理を行います。implementation.pydef implementation(func): def _deco(*args, **kwargs): # *argsはlambdaのeventを受け取れる。*argsは可変長引数。 print("lambda start") print(args[0]) # ログ用の処理は別途作成して呼び出すと使いやすい。ここでは仮なのでprint() params = json.loads(event.get("body")) if event.get('pathParameters'): params.update(event.get('pathParameters')) # get,postそれぞれの処理をひとつのparamsにまとめる。 if not params.get("id"): return error_response() # パラメーターにIDがない場合、エラーを返すといった処理ができる。 response = func(params, id) # 個別処理の実行結果を取得する print("lamdba end") return response # ネストの最下層に戻り値を設定するとそれが新しい返り値にすり替わる。 # 本来の処理のレスポンスを返却する前にログの吐き出しを行える。 return _decolambda_function.py@implementation def handler(params, id): """ 何かしらの処理 """ return success_response()本来の処理を実行する際に、ログを共通の処理として仕込んだり、パラメーターの整理や要素を確認してレスポンスをエラー時のものにすり替えたり、といった機能を追加することが出来ます。
個別の処理と紐付けるために引数付きのデコレーター
たとえば、バリデーションをする場合は、個別の処理に応じて求める値が変わって来ます。
そこで、個別処理で定義したバリデーション用のスキーマを引数に渡せるようにするには、引数付きのデコレーターを利用します。implementation_with_paramsdef implementation_with_params(schema): def _deco(func): def _decodeco(*args, **kwargs): params = *args[0].get("body") error = validator(schema, params) # なにかしらのバリデーターを定義した関数に渡す。 if error: return error_response() response = func(params) return response return _decodeco return _decolambda_function.py# バリデーションするためのキーの一覧 SCHEMA = ["id","user_name", "password", "address", "tel"] @implementation_with_params(schema=SCHEMA) def handler(params) """ 何かしらの処理 """ return success_response()実際のところはCerberousでバリデーションをしています。
他の用途
レスポンス内容の変更、リクエストパラメーターの前処理とログ処理、さらにしれっとバリデーション処理も記載してますが、他にも下記のような用途が考えられます。
・処理の開始と終了を記録してパフォーマンス測定
・認証処理
・セッション管理参考URL
公式ドキュメント
https://docs.python.org/ja/3/reference/compound_stmts.html#function
Pythonのデコレータについて
https://qiita.com/mtb_beta/items/d257519b018b8cd0cc2e
Pythonのデコレータを理解するための12Step
https://qiita.com/_rdtr/items/d3bc1a8d4b7eb375c368
Python デコレータ再入門 ~デコレータは種類別に覚えよう~
https://qiita.com/macinjoke/items/1be6cf0f1f238b5ba01b
引数付きデコレータの作り方
https://qiita.com/utgwkk/items/d7c6af97b81df9483f9e
Python再発見 - デコレータとその活用パターン -
https://slideship.com/users/@rhoboro/presentations/2017/12/YagWLokYuWX5Er78UdLbWX/?p=23
Decorator パターン
https://ja.wikipedia.org/wiki/Decorator_%E3%83%91%E3%82%BF%E3%83%BC%E3%83%B3
デザインパターン(Design Pattern)#Decorator
https://qiita.com/nirperm/items/398cb970826fa972a94f
python-3 patterns,idioms and test
https://python-3-patterns-idioms-test.readthedocs.io/en/latest/PythonDecorators.html
Pythonにおけるデザインパターン ~Pyデザパタ~ Decoratorパターン
https://pydp.info/GoF_dp/structure/09_Decorator/余談
JavascriptとTypescriptにもデコレーターってあるんですね。
JavaScript の デコレータ の使い方
https://qiita.com/kerupani129/items/2b3f2cba195c0705b2e5
TypeScriptのDecoratorについて – 公式ドキュメント日本語訳
https://mae.chab.in/archives/59845
きれいで読みやすいJavaScriptを書く デコレーターの基本を先取りhttps://www.webprofessional.jp/javascript-decorators-what-they-are/
- 投稿日:2020-02-13T16:37:11+09:00
Pandasの平均処理・リスト化
Pandasの平均処理
列の平均処理は
average = df.mean()でよいのですが、これをlist化するとindexが外れて数値だけをリスト化することができます。
df_average = list(df.mean()) print(df.mean()) print(df_average) """ 人気 8.326087 着 8.022222 タイム 84.191111 着差 1.653333 馬体重 442.130435 dtype: float64 """ """ [8.326086956521738, 8.022222222222222, 84.19111111111113, 1.653333333333333, 442.1304347826087] """
- 投稿日:2020-02-13T15:53:08+09:00
[1時間チャレンジ] 適当すぎる占いサイトをPythonで作ってみた
適当すぎる占いサイト
少し前に、適当すぎる占いサイトを作ってみました。
作成後にちょこちょこ修正したりしましたが、作業時間は実質1時間くらいです。
使用した技術
使用した技術として、PythonのWebフレームワークであるBottleを使用しました。
データベースはSQLite3を用い、CSSフレームワークはBulmaを使用しました。
デプロイ先はHerokuです。
データベースの作成
まず最初に、データベース(SQLite3)の作成を行いました。
データベース名は、database.dbとしてあります。
set_fortune.py# -*- coding: utf-8 -*- import sqlite3 from contextlib import closing dbname = 'database.db' with closing(sqlite3.connect(dbname)) as conn: c = conn.cursor() create_table = '''create table fortune (id int, text varchar(256))''' c.execute(create_table) insert_sql = 'insert into fortune (id, text) values (?,?)' fortune = [ (1, 'マヨネーズを陰で飲んでいるのが、バレてしまうかも。'), (2, 'コーヒーを飲むと、息が臭くなります。'), (3, '目が合った異性に声を掛けると、50%の確率でデートができます。'), (4, 'シーフードヌードルにタバスコをかけて食べると、良いことがあります。'), (5, 'カレーを食べると、IQが150になります。'), (6, 'タバコの煙を鼻から出してみると、良い事があります。'), (7, '道の真ん中でバク転をしても、無視されます。'), (8, '板チョコを食べると、鼻血が出ます。'), (9, '水の蛇口をひねり、溢れるまで走ってください。'), (10, '適当な占いを考えるのが疲れました。'), ] c.executemany(insert_sql, fortune) conn.commit() select_sql = 'select * from fortune' for row in c.execute(select_sql): print(row)fortuneというテーブルを作成し、idとtextカラムを作成しています。
その後、10個のデータを挿入しました。
後からデータを挿入する方法としては、以下のような感じで挿入することができます。
$sqlite3 database.db sqlite> insert into fortune values(11, 'Qiitaでイイねを貰いたい');ソースコード
ソースコードを見ていきます。
index.html<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <meta name="robots" content="index, follow"> <meta name="application-name" content="適当占い"> <meta name="description" content="適当な占いをします。"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Sloppy fortune-telling</title> <link rel="stylesheet" href="../static/style.css"> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bulma@0.8.0/css/bulma.min.css"> <link href="https://fonts.googleapis.com/css?family=Gloria+Hallelujah|Kosugi&display=swap" rel="stylesheet"> <script defer src="https://use.fontawesome.com/releases/v5.3.1/js/all.js"></script> </head> <body> <section class="hero is-medium is-primary is-bold"> <div class="hero-body"> <div class="container"> <h1 class="title"> Sloppy fortune-telling </h1> <h2 class="subtitle"> 適当な占い </h2> </div> </div> </section> <section class="section"> <div class="container"> <div class="field"> <div class="control"> <div class="select is-primary is-rounded is-medium"> <select> <option>おひつじ座</option> <option>おうし座</option> <option>ふたご座</option> <option>かに座</option> <option>しし座</option> <option>おとめ座</option> <option>てんびん座</option> <option>さそり座</option> <option>いて座</option> <option>やぎ座</option> <option>みずがめ座</option> <option>うお座</option> </select> </div> </div> </div> <input class="input is-primary is-rounded is-medium" type="text" placeholder="Input your name"> <div class="columns is-mobile is-centered"> <button class="button is-primary is-rounded is-large" id="open">占う!</button> </div> <div class="modal"> <div class="modal-background"></div> <div class="modal-card"> <header class="modal-card-head"> <p class="modal-card-title">今日の運勢</p> </header> <section class="modal-card-body"> {{result}} </section> <footer class="modal-card-foot"> <button class="button" id="close">Close</button> </footer> </div> </div> </div> </section> <script src="https://code.jquery.com/jquery-3.1.1.min.js"></script> <script> $(document).ready(function() { $("#open").on("click", function() { $("div.modal").addClass("is-active"); }) $("#close, div.modal-background").on("click", function() { $("div.modal").removeClass("is-active"); }) }); </script> </body> </html>BulmaをCDNで読み込み、表示を整えています。
id=openのボタンを押すと、Modalが出現し、占い結果を表示するようにしています。
体裁の為に、星座の選択と名前の入力欄がありますが、何にも利用しません :D
app.py# -*- coding: utf-8 -*- from bottle import Bottle, template, static_file, url import os import random import sqlite3 app = Bottle() @app.route('/static/:path#.+#', name='static') def static(path): return static_file(path, root='static') @app.route('/') def index(): con = sqlite3.connect('database.db') cur = con.cursor() num = str(random.randint(1,16)) sql = 'select * from fortune where id = ' + num + ';' cur.execute(sql) for row in cur: result = row[1] con.close() return template('index', result=result) @app.error(404) def error404(error): return "Error 404. Try again later." @app.error(500) def error500(error): return "Error 500. Try again later." # local test app.run(host='localhost', port=8080, debug=True) # heroku # app.run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))databese.dbというデータベースに接続し、乱数を発生させます。
fortuneテーブルにはidカラムがあるので、生成された乱数とidが一致した占い結果(text)を取得しています。
Herokuへのデプロイ
ある程度完成したので、Herokuへのデプロイを行いました。
まず最初に、デプロイに必要なファイルを作成します。
$ pip3 freeze > requirements.txt $ echo web: python3 app.py > ProcfileHerokuへのデプロイ方法はいくつかあります。
個人的に楽だと思うのは、GitHubレポジトリと連携させる方法です。
Herokuアカウントを取得後、Create new appを選択し、App nameなどを設定します。
その後、"Deploy"のDeployment methodからGitHubを選択し、連携させるだけでデプロイできます。
最後に
適当すぎる占いサイトを作って見ました。
改善していけば、ある程度形になるのでは?と思っています。
皆様も、よろしければ1時間チャレンジをしてみてください!!
参考
Links
適当すぎる占いサイト: https://sloppy-fortune-telling.herokuapp.com/
GitHub: https://github.com/ShogoMurakami/sloppy-fortune-telling
Thanks,
@shogo



- 投稿日:2020-02-13T14:53:01+09:00
torchvisionをインポートする際にundefined symbolエラーが発生する
問題
pytorch1.1.0でtorchvision0.3.0をインポートするとエラーが発生する.
ImportError: myenv/lib/python3.7/site-packages/torchvision/_C.cpython-37m-x86_64-linux-gnu.so: undefined symbol: _ZN3c107Warning4warnENS_14SourceLocationENSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE解決方法
それぞれをアンインストールし,再びインストールし直す.
何が起きているかはわからないがとりあえず解決した.バージョンは自分にあったものを.
参考$conda uninstall pytorch $conda uninstall torchvision $conda install pytorch==1.1.0 torchvision==0.3.0 cudatoolkit=9.0 -c pytorch
- 投稿日:2020-02-13T14:44:09+09:00
我々のコミュニケーションには"雅"が足りない。
TL;DR
COTOHA APIを利用して、百人一首の中から伝えたいことに近い和歌をサジェストしてくれるようにしました。
より"雅"なコミュニケーションの入り口として、エンジニアと非エンジニアの橋渡しができる。(かもしれない)
伝えたいこと 提案された和歌 意味 転勤されるということをお聞きしてとても寂しい気持ちです。 逢ひ見ての 後の心に くらぶれば 昔は物を 思はざりけり このようにあなたに逢ってからの今の苦しい恋心にくらべると、会いたいと思っていた昔の恋心の苦しみなどは、何も物思いなどしなかったも同じようなものです. 山里は 冬ぞさびしさ まさりける 人目も草も かれぬと思へば 山里はいつの季節でも寂しいが、冬はとりわけ寂しく感じられる。尋ねてくれる人も途絶え、慰めの草も枯れてしまうのだと思うと。 君がため 惜しからざりし 命さへ 長くもがなと 思ひけるかな あなたに会うためなら惜しいとは思わなかった私の命ですが、こうしてあなたと会うことができた今は、いつまでも生きていたいと思っています. このように3つほど和歌を提案してみます。(太字は主観で最後に選んだ最も良さそうな和歌です)
はじめに
皆さん"雅"、足りてますか?
自然言語処理、自然言語処理と皆さん言いますが、そもそも自然言語とは何のためにあるのでしょう。
私はコミュニケーションのためだと思います。そしてコミュニケーションを考えたとき、現代の日本人は大事なことを忘れていると思います。
そう、雅(みやび)
です。古くは和歌等を通した雅なコミュニケーションが行われていたのに、これは失われつつあります。嘆かわしい。
しかし、現代人にいきなり雅の心を取り戻せと言っても無理があります。そこで、今回は文の最後に引用する和歌を提案することで、現代人にも雅の心を取り戻していこうという試みです。COTOHA API
COTOHA APIとはNTTさんによる自然言語処理APIでかなり高度、準備等の面倒な機能を簡単に使えるというものです。
無料アカウントでも日に1000件も叩けるという素晴らしさ。
登録は↓より
COTOHA登録ページ今回はこちらのCOTOHA APIの意味同値性判定を利用して最も合う和歌をサジェストします。
データ
今回はこちらのサイトより百人一首の意味データをお借りしてきました。(https://hyakunin.stardust31.com/gendaiyaku.html)
本当は自分で訳つけてデータ配布できたら良かったんですけど、時間がたりず…COTOHA APIを使う。
登録は済ませた上で登録後からの流れを説明いたします。
まぁ、公式のGetting started見ればわかるんですが、念の為。
私はPythonでやったのでrequestsライブラリを使用します。アクセストークンの取得
登録したら、もらえるトークン取得用id,client id,client secretを元にpostを叩きます。
url = [api発行用URL] head = {"Content-Type":"application/json"} params = {"grantType": "client_credentials", "clientId": [clientid], "clientSecret": [clientSecret]} r = requests.post(url,headers=head,data=json.dumps(params))これをするとアクセストークンがもらえます。24時間に一回?更新する必要があるので繋がんなくなったらこれを叩きましょう。
apiを叩く
header = { "Content-Type":"application/json", "Authorization":"Bearer "+[トークン] } datas = { "sentence":"犬は歩く。" } r = requests.post(api_base+"nlp/v1/parse",headers=header,data=json.dumps(datas))ここのapi_baseは登録するともらえるapiを叩くためのベースurlです。
"nlp/v1/parse"部分が使用したいapi種類で、こちらのリファレンスより確認することができます。一部(3つ)のAPIは有料アカウント限定ですが、大部分が使えます。返り値をjsonにparseしてあとはよしなにします。最も意味の近い和歌の取得
単純に百人一首の和歌のそれぞれの意味文と、対象にしたい文の類似度を叩いて、類似度の高い順に3つほど和歌を提案するようにします。実装はこちら
def suggest_waka(txt,issyu): buf = [] for i in range(100): waka = issyu[i][1] header = { "Content-Type":"application/json;charset=UTF-8", "Authorization":"Bearer "+[トークン] } datas = { "s1":txt, "s2":waka, } r = requests.post(api_base+"nlp/v1/similarity",headers=header,data=json.dumps(datas)) parsed = json.loads(r.text) buf.append([i,parsed["result"]["score"]]) time.sleep(0.3) return buftxtは対象にしたい文、issyuは百人一首配列で、[和歌,解釈]の配列になっています。
これで各和歌に対して類似度が返ってくるので、それを類似度順にソートして高い方から3つほど持ってくれば完成です。結果
伝えたいこと 提案された和歌 意味 転勤されるということをお聞きしてとても寂しい気持ちです。 逢ひ見ての 後の心に くらぶれば 昔は物を 思はざりけり このようにあなたに逢ってからの今の苦しい恋心にくらべると、会いたいと思っていた昔の恋心の苦しみなどは、何も物思いなどしなかったも同じようなものです. 山里は 冬ぞさびしさ まさりける 人目も草も かれぬと思へば 山里はいつの季節でも寂しいが、冬はとりわけ寂しく感じられる。尋ねてくれる人も途絶え、慰めの草も枯れてしまうのだと思うと。 君がため 惜しからざりし 命さへ 長くもがなと 思ひけるかな あなたに会うためなら惜しいとは思わなかった私の命ですが、こうしてあなたと会うことができた今は、いつまでも生きていたいと思っています.
伝えたいこと 提案された和歌 意味 あなたにお会いできる日を心より楽しみにしています。 哀れとも いふべき人は 思ほえで 身のいたづらに なりぬべきかな (あなたに見捨てられた) わたしを哀れだと同情を向けてくれそうな人も、今はいように思えません。(このままあなたを恋しながら) 自分の身がむなしく消えていく日を、どうすることもできず、ただ待っているわたしなのです. わびぬれば 今はた同じ 難波なる 身をつくしても 逢はむとぞ思ふ (あなたにお逢いできなくて)このように思いわびて暮らしていると、今はもう身を捨てたのと同じことです。いっそのこと、あの難波のみおつくしのように、この身を捨ててもお会いしたいと思っています。 陸奥の しのぶもぢずり 誰ゆゑに 乱れそめにし 我ならなくに 奥州のしのぶもじずりの乱れ模様のように、私の心も(恋のために)乱れていますが、いったい誰のためにこのように思い乱れているのでしょう。 (きっとあなたの所為に違いありません) どうでしょうか。多少ドラマチックすぎる嫌いはなくもないですが、"雅"の心を取り戻せてる気がしませんか?
朝から、完全にぽんぽんぺいんで、つらみが深いので、1日おふとんでスヤァしておきます。明日は行けたら行くマンです!(ネタ)
こんな文章も、和歌を添えればこの通り。
朝から、完全にぽんぽんぺいんで、つらみが深いので、1日おふとんでスヤァしておきます。明日は行けたら行くマンです! 忘れじの 行末までは かたければ 今日を限りの 命ともがな いつまでも忘れまいとすることは、遠い将来まではとても難しいものですから、(あなたの心変わりを見るよりも早く) いっそのこと、今日を最後に私の命が終わって欲しいものです.どうでしょうか、急に殊勝な態度に見えませんか?(無理)
おわりに
想定より思った通りの結果にならなくて少し悲しいです。
人もをし 人もうらめし あぢきなく 世を思ふゆゑに 物思ふ身は
人が愛しくも思われ、また恨めしく思われたりするのは、(歎かわしいことではあるが) この世をつまらなく思う、もの思いをする自分にあるのだなぁ.
- 投稿日:2020-02-13T14:37:46+09:00
DRF(Django REST Framework)でSerializerからViewの情報にアクセスしたいときもある件
この作りが良いのかどうかは別にして、SerializerからViewの情報にアクセスしたい時ってありますよね。そんな時に使える便利なMixinを社内では使いまわしています。やればやるほど、ViewとSerializerとの結合が強くなるので、 用法・用量 を守って使うのをオススメします。
何はともあれ、ソースコードです。
ViewAccessSerializerMixin
class ViewAccessSerializerMixin(object): def get_view_action(self): """ Serializer から View の actionへアクセスする """ context = getattr(self, 'context') if not context: warnings.warn('serializerにcontextが存在しません。不正な形でインスタンスが作られています') return None return context.get('view').action def get_view_kw(self, key, default=None): """ Serializer から View の kwargsへアクセスする """ context = getattr(self, 'context') if not context: warnings.warn('serializerにcontextが存在しません。不正な形でインスタンスが作られています') return default return context.get('view').kwargs.get(key, default) def get_kwargs_object(self, key, model_class): """ Serializer から kwargs へアクセスし、それを id とみなして、指定されたモデルを検索する """ obj = model_class.objects.get_or_none(id=int(self.get_view_kw(key, 0))) if obj: return objView の action へアクセスする
大体は、
validationで使ってます。多分もっと良い条件分けはあると思います。こんな感じ。class HogeSerializer(ViewAccessSerializerMixin, serializers.ModelSerializer): # 色々省略 def validate(self, attrs): # アクションによって検証内容を変える action_name = self.get_view_action() if action_name == "xxxx": pass else: passView の kwargs へアクセスする
大体、SerializerMethodField で使ってます。
class PostHistorySerializer(ViewAccessSerializerMixin, serializers.ModelSerializer): # 色々省略 comments = serializers.SerializerMethodField() def get_comments(self, obj): return obj.comment.filter(user_id=self.get_view_kw("user_pk"))View の kwargs へアクセスし、それを id とみなして、指定されたモデルを検索する
↑の組み合わせに近いですが、ショートカットです。
class UserSerializer(ViewAccessSerializerMixin, serializers.ModelSerializer): # 色々省略 def validate(self, attrs): user = self.get_kwargs_object('user_pk', models.User) if user.is_ban(): raise NotFound() pass基本的には、こんな感じで使っています。便利に使ってくれると嬉しいです。
- 投稿日:2020-02-13T14:35:30+09:00
Raspberry PiにpyenvをインストールしてPythonをバージョン管理
ラズパイには標準で
3.5.3のPythonがインストールされていますが、
3.6以上のPythonを使いたかったので、pyenvを使用してバージョンを切り替えられるようにしておきます。環境
- Raspberry Pi 3 Model B+
- Raspbian 9.11(stretch)
- Kernel 4.19.66-v7+
$ uname -a # Linux raspberrypi 4.19.66-v7+ #1253 SMP Thu Aug 15 11:49:46 BST 2019 armv7l GNU/Linux $ lsb_release -a # No LSB modules are available. # Distributor ID: Raspbian # Description: Raspbian GNU/Linux 9.11 (stretch) # Release: 9.11 # Codename: stretchpyenvのインストール
まず、必要なパッケージのインストールをします。
$ sudo apt update $ sudo apt upgrade $ sudo apt install -y git openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-devgithubからpyenvをクローンしてきます。
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenvコマンドを叩けるようにするため、
.bash_profileに以下を追記します。$ sudo vi ~/.bash_profile.bash_profileexport PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"
.bash_profileを再読み込みします。$ source ~/.bash_profile下記コマンドでバージョンが表示されればインストール完了です。
$ pyenv --version #pyenv 1.2.16-5-g7097f820pyenvでバージョン変更
インストールできるバージョンの一覧を表示してみます。
$ pyenv install --list #Available versions: # 2.1.3 # 2.2.3 # ... # 3.6.0 # 3.6-dev # ... # stackless-3.4.7 # stackless-3.5.4今回は
3.6.0をインストールしてみます。$ pyenv install 3.6.0インストールが完了したら実際にバージョンを変更させてみましょう。
まず変更前のバージョンを確認します。
$ python --version #Python 2.7.13 $ python3 --version #Python 3.5.3バージョンを変更します。
$ pyenv global 3.6.0下記ようにバージョンが変更されました!
$ python --version #Python 3.6.0 $ python3 --version #Python 3.6.0pyenvの設定について
pyenvは下記のコマンドで設定します。
$ pyenv global x.x.xちなみにこの
globalの部分を変更することで、適用範囲を設定できます。
適用範囲 使用用途 shell 今使用しているシェルにのみ適用 一時的な使用 local カレントディレクトリに適用 フォルダごとに設定したい global 全体に適用 全体のデフォルト環境を変更したい
x.x.xの部分をsystemとすることで元に戻せます。例$ pyenv local 3.6.4 $ pyenv shell 2.7.6 $ pyenv global system下記のコマンドでインストールしているバージョン一覧を見ることもできます。
$ pyenv versionsおまけ
3.7系をインストールしようとしたら下記エラーでインストールできませんでした。
$ pyenv install 3.7.0 Downloading Python-3.7.0.tar.xz... -> https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tar.xz Installing Python-3.7.0... BUILD FAILED (Raspbian 9.11 using python-build 1.2.16-5-g7097f820) Inspect or clean up the working tree at /tmp/python-build.20200213174102.2652 Results logged to /tmp/python-build.20200213174102.2652.log Last 10 log lines: File "/tmp/tmp01sfxi5t/pip-10.0.1-py2.py3-none-any.whl/pip/_internal/__init__.py", line 42, in <module> File "/tmp/tmp01sfxi5t/pip-10.0.1-py2.py3-none-any.whl/pip/_internal/cmdoptions.py", line 16, in <module> File "/tmp/tmp01sfxi5t/pip-10.0.1-py2.py3-none-any.whl/pip/_internal/index.py", line 25, in <module> File "/tmp/tmp01sfxi5t/pip-10.0.1-py2.py3-none-any.whl/pip/_internal/download.py", line 39, in <module> File "/tmp/tmp01sfxi5t/pip-10.0.1-py2.py3-none-any.whl/pip/_internal/utils/glibc.py", line 3, in <module> File "/tmp/python-build.20200213174102.2652/Python-3.7.0/Lib/ctypes/__init__.py", line 7, in <module> from _ctypes import Union, Structure, Array ModuleNotFoundError: No module named '_ctypes' Makefile:1122: recipe for target 'install' failed make: *** [install] Error 1
libffi-devをインストールすることで3.7系もインストールできました。$ sudo apt install libffi-dev $ pyenv install 3.7.0今日はここまでです!
参考
- 投稿日:2020-02-13T14:26:21+09:00
Chalice ー Python Serverless Microframework for AWS
PythonのAPIを作りたいと思って調べていたところ、Chaliceを見つけました。
今回はちょっとした備忘録記事です。Chaliceは一言で言えば、AWSによるPythonのサーバーレスフレームワークです。
AWSからGitHubに公開されており、怪しい挙動はきっとあまりしないでしょう。
https://github.com/aws/chaliceChaliceはデプロイするとApiGateway + lambdaを利用してサーバーレスに公開してくれます。
環境
- macOS Catalina 10.15.1
- python 3.6.4
- chalice 1.12.0
Chaliceのインストール
$ pip install chalice $ chalice --versionAWS IAMの設定
ApiGatewayとlambdaの操作権限を持つユーザーから操作しないとデプロイできません。
今回は簡単にポリシー「AdministratorAccess」を与えたユーザーから操作させます。
本当ならより権限を絞って最低限の開発ユーザーで..(略)IAMユーザ作成方法は以下を参考にしてください。
AWSアカウントでのIAMユーザの作成ハマったポイント
app.pyと.chaliceフォルダ内にある「config.json」のapp_nameが一致している必要があります。
config.json"app_name": "hoge-api"
app.pyapp = Chalice(app_name='hoge-api')一致していないとdeploy時、直接的な原因特定のしにくいエラーが吐き出されます。↓
❯ chalice deploy ... (略) ... botocore.exceptions.ConnectionClosedError: Connection was closed before we received a valid response from endpoint URL: "https://lambda.ap-northeast-1.amazonaws.com/2015-03-31/functions".参考
20190619 AWS Black Belt Online Seminar Dive Deep into AWS Chalice
Chaliceのすゝめ AWSにWebApiをサーバーレスで構築する
Chaliceのすゝめ その2 WebApiに認証を追加する
How to create a thumbnail API service in 5 minutes
- 投稿日:2020-02-13T14:15:02+09:00
Python3とSeleniumとGoogle ChromeでWebページのスクリーンショットはScreenshot_Clippingが便利です
Python 3とSeleniumとGoogle ChromeでWebページのスクリーンショットを取得する方法の1つとして、Selenium標準の
save_screenshotメソッドを使う方法がありますが、この方法の場合、指定されたサイズ(ウインドウサイズ)のスクリーンショットを取得することはできますが、Webページ全体のスクリーンショットを取得することはできません。Googleで検索してみると、色々な方法がヒットしますが、最も簡単で、かつ再利用性の高い方法は、Screenshot_Clippingパッケージを使う方法です。Screenshot_Clippingパッケージを使用すると、簡単にWebページ全体のスクリーンショットや、HTML要素を指定したスクリーンショットを取得することができます。
インストール
1.Python3のダウンロードとインストール
Windowsの場合は、下記URLよりインストーラーをダウンロードしてインストールする方法が簡単です。
https://www.python.jp/LinuxやMac, FreeBSDなどでは、パッケージマネージャからインストールします。
例えば、Ubuntu 18.04LTSの場合はちょっと古いですが(実行時にDeprecatedが出るかも知れませんが)以下が参考になるでしょう。
Ubuntu 18.04LTSとchromium-browser(Headless)とpython3でSeleniumするPythonのバージョン複数分けて使いたい場合は、pythonbrewのようなvirtualenvっぽい何かを利用したり、Dockerで環境を分けるのが良いでしょう。
2.パッケージのインストール
seleniumと、Selenium-Screenshotパッケージをインストールします。
pip install selenium pip install Selenium-Screenshot3.ChromeDriverのダウンロード
下記URLより、自分の環境(Chromeのバージョン)に合ったChromeDriverをダウンロードします。
なお、Windows以外でパッケージマネージャよりSeleniumをインストールした場合は、パッケージマネージャよりChromeDriverをインストール出来る場合があります。
https://chromedriver.chromium.org/downloadsコード例
以下はWindowsで、https://www.asahi.com/ のスクリーンショットを取得する例です。
なお、ChromeDriver(chromedriver.exe)はPythonスクリプトと同じフォルダ(ディレクトリ)にあることを、ここでは想定しています。
環境に合わせて、executable_path(ChromeDriverのパス)を変更することで、Windowsに限らず他のOSでも動作します。from Screenshot import Screenshot_Clipping from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.chrome.options import Options import time options = Options() options.add_argument('--headless') options.add_argument('--disable-gpu') ob=Screenshot_Clipping.Screenshot() driver = webdriver.Chrome(executable_path=r".\chromedriver.exe", options=options) driver.set_window_size(1280, 720) driver.get("https://www.asahi.com/") ob.full_Screenshot(driver, save_path=r'.', image_name='Myimage.png') driver.close() driver.quit()上記Pythonスクリプトを実行すると、Myimage.pngというファイル名でスクリーンショット画像が出力されます。
その画像を開くと、以下のようにWebページ全体のスクリーンショットを確認することができます。
参考
- 投稿日:2020-02-13T14:15:02+09:00
Python3とSeleniumとGoogle ChromeでWebページのスクリーンショットはSelenium-Screenshotが便利です
Python 3とSeleniumとGoogle ChromeでWebページのスクリーンショットを取得する方法の1つとして、Selenium標準の
save_screenshotメソッドを使う方法がありますが、この方法の場合、指定されたサイズ(ウインドウサイズ)のスクリーンショットを取得することはできますが、Webページ全体のスクリーンショットを取得することはできません。Googleで検索してみると、色々な方法がヒットしますが、最も簡単で、かつ再利用性の高い方法は、Selenium-Screenshotパッケージを使う方法です。Selenium-Screenshotパッケージを使用すると、簡単にWebページ全体のスクリーンショットや、HTML要素を指定したスクリーンショットを取得することができます。
インストール
1.Python3のダウンロードとインストール
Windowsの場合は、下記URLよりインストーラーをダウンロードしてインストールする方法が簡単です。
https://www.python.jp/LinuxやMac, FreeBSDなどでは、パッケージマネージャからインストールします。
例えば、Ubuntu 18.04LTSの場合はちょっと古いですが(実行時にDeprecatedが出るかも知れませんが)以下が参考になるでしょう。
Ubuntu 18.04LTSとchromium-browser(Headless)とpython3でSeleniumするPythonのバージョン複数分けて使いたい場合は、pythonbrewのようなvirtualenvっぽい何かを利用したり、Dockerで環境を分けるのが良いでしょう。
2.パッケージのインストール
seleniumと、Selenium-Screenshotパッケージをインストールします。
pip install selenium pip install Selenium-Screenshot3.ChromeDriverのダウンロード
下記URLより、自分の環境(Chromeのバージョン)に合ったChromeDriverをダウンロードします。
なお、Windows以外でパッケージマネージャよりSeleniumをインストールした場合は、パッケージマネージャよりChromeDriverをインストール出来る場合があります。パッケージマネージャよりインストールされたChromeDriverが満足に動作しない、あるいは機能が足りないという場合を除き
https://chromedriver.chromium.org/downloadsコード例
以下はWindowsで、https://www.asahi.com/ のスクリーンショットを取得する例です。
なお、ChromeDriver(chromedriver.exe)はPythonスクリプトと同じフォルダ(ディレクトリ)にあることを、ここでは想定しています。
環境に合わせて、executable_path(ChromeDriverのパス)を変更することで、Windowsに限らず他のOSでも動作します。from Screenshot import Screenshot_Clipping from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.chrome.options import Options import time options = Options() options.add_argument('--headless') options.add_argument('--disable-gpu') ob=Screenshot_Clipping.Screenshot() driver = webdriver.Chrome(executable_path=r".\chromedriver.exe", options=options) driver.set_window_size(1280, 720) driver.get("https://www.asahi.com/") ob.full_Screenshot(driver, save_path=r'.', image_name='Myimage.png') driver.close() driver.quit()上記Pythonスクリプトを実行すると、Myimage.pngというファイル名でスクリーンショット画像が出力されます。
その画像を開くと、以下のようにWebページ全体のスクリーンショットを確認することができます。
参考
- 投稿日:2020-02-13T13:35:04+09:00
pythonのパッケージにパッチを当てた記録
俺は悪い子なんだ
注: この記事はそれなりにニッチです
使っているpythonパッケージに無い機能が欲しくてたまらなかった。
時に研究者は他人の使わないような物を用意せねばならぬのだ。
しかし、その機能はニッチなもで1プルリクしたって受け取られるわけがないのだ。
だからパッチを作成した。自前patch?gitじゃ駄目なん?
ご存知の通り、UNIX系にはpatchというコマンドがある。これを用いる。
gitでいいけど、論文に「変な変更はしてないぽよ。差分はここだけぽよ。」って書きたかった(重要)。作成手順
git diffをすることによって自分やった変更を出力できる。
だから、patchの作成のためだけにgitを使う。歴史を巻き戻せるのも良い。
というわけで、結局gitは使うのだけれどね。まず、編集するために、使っているパッケージのソースコードの元に飛かねばならなかった。
仮想環境だろうがどこだろうが、ワンライナーで行ける。下記のhogeを書き換えて飛んでいった。cd $(python -c "import hoge as target; from pathlib import Path; print(Path(target.__file__).parent)")で、編集する前に、一応git管理しておく。
git init git add * git commit git branch patch git checkout patch vim hoge.pygit add *はキャッシュまで含んでしまうかもなので、まぁ、そこは適切に。
僕はvimmerなのでvimで編集しているが、もちろんvimじゃなくていい。変更し終わったらdiffする。mkdir ~/warui_patch git diff > ~/warui_patch/complex.patchこれでパッチの作成は終了だ。
ソースコード
以下、さっきのパッチをパッケージに当てるためのシェルスクリプトだ。
下記ではmneパッケージに、さっき作成したcomplex.patchを当てている。
オプションをいくつかつけている。
- -R: パッチを戻す
- -p: 該当のパッケージのパスを表示する
- -h: ヘルプ
この、該当のパッケージのパスを表示するのは、僕が何か編集したい時に
cd $(sh ./patcher -p)として、該当パッケージのもとにひとっ飛びできるようにするためのオプションだ。
当然仮想環境でも鉄の意志で飛んでいくぞ。#!/usr/bin/env sh OPT=$1 PACKAGE='mne' PATCH='complex.patch' make_python_path_code () { echo "import $PACKAGE; from pathlib import Path; print(Path($1.__file__).parent)" } make_python_path () { echo "$(python -c "$(make_python_path_code $1)")/" } patch_python () { patch $OPT -u -p 1 -d $(make_python_path $1) < $2 } if [ "$1" = "-h" ]; then echo Patch script for python. echo ======================== echo -h: Show this message echo -R: Reverse patch echo -p: Print script dir exit fi if [ "$1" = "-p" ]; then echo $(make_python_path $PACKAGE) exit fi patch_python $PACKAGE $PATCH感想
研究のためとはいえ、本当はパッケージの書き換えなんか、やりたくない。
辛い…(´・ω・`)
脳波をWavelet変換して複素数から絶対値の平均を算出し、脳内での脳波の大きさを推定したかったが、俺は絶対値の平均じゃなくて複素数が欲しかったのだ。平均しないぶんだけ、計算コストはヤバくなる。 ↩
- 投稿日:2020-02-13T13:34:25+09:00
HLバンドを順張りで使ってみる
はじめに
今回はHL (HighLow) バンドを用いたアルゴリズムを作ってみました.
HLバンドの詳細については以下の記事を参考にしたのでご覧ください.簡単に説明すると, HLバンドではある期間の高値の最大値を結んだ線(Highバンド)と, 安値の最小値を結んだ線(Lowバンド), 2本の線の平均線(Middleバンド)を用いています.
では早速本題に移ります.
HLバンドアルゴリズム
シグナル
買いシグナル:Middleバンドを終値(cp)が突き抜けたとき
売りシグナル:Middleバンドを終値(cp)が下回ったとき or 終値がHighバンドを突き抜けたときシグナルの決定はこちらを参考にしました.
コード
今回のコードはこちら
#HLバンド import maron import maron.signalfunc as sf import maron.execfunc as ef import pandas as pd import talib as ta import numpy as np #ot = maron.OrderType.MARKET_CLOSE # シグナルがでた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー #ot = maron.OrderType.LIMIT # 指値によるオーダー def initialize(ctx): # 設定 ctx.logger.debug("initialize() called") ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.2914", "jp.stock.3382", "jp.stock.4063", "jp.stock.4452", "jp.stock.4502", "jp.stock.4503", "jp.stock.4568", "jp.stock.6094", "jp.stock.6501", "jp.stock.6758", "jp.stock.6861", "jp.stock.6954", "jp.stock.6981", "jp.stock.7203", "jp.stock.7267", "jp.stock.7751", "jp.stock.7974", "jp.stock.8031", "jp.stock.8058", "jp.stock.8306", "jp.stock.8316", "jp.stock.8411", "jp.stock.8766", "jp.stock.8802", "jp.stock.9020", "jp.stock.9022", "jp.stock.9432", "jp.stock.9433", "jp.stock.9437", "jp.stock.9984", ], "columns": [ "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) "high_price_adj", # 高値(株式分割調整後) "low_price_adj", # 安値(株式分割調整後) "volume_adj", # 出来高 "txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): cp = data["close_price_adj"].fillna(method='ffill') #終値取得 hp = data["high_price_adj"].fillna(method='ffill') #高値取得 lp = data["low_price_adj"].fillna(method='ffill') #安値取得 hband = hp.rolling(20).max() #Highバンド設定 lband = lp.rolling(20).min() #Lowバンド設定 mband = (hband - lband)/2 + lband #Middleバンド設定 market_sig = pd.DataFrame(data=0.0, columns=cp.columns, index=cp.index) buy_sig = ((mband.shift(1) > cp.shift(1)) & (mband < cp)) sell_sig = ((mband > cp) | (cp > hband)) # buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 #ctx.logger.debug(market_sig) return { # "hband:g2": hband, # "lband:g2": lband, # "mband:g2": mband, "hband": hband, "lband": lband, "mband": mband, "market:sig": market_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' market_sig = current["market:sig"] done_syms = set([]) # 損切り、利確の設定 for (sym, val) in ctx.portfolio.positions.items(): returns = val["returns"] if returns < -0.02: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) done_syms.add(sym) elif returns > 0.04: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) done_syms.add(sym) # 買いシグナル buy = market_sig[market_sig > 0.0] for (sym, val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass # # 売りシグナル sell = market_sig[market_sig < 0.0] for (sym, val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1, orderType=ot, comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val)) passコード解説
基本的なコードの解説は, 勉強会用に作成した資料が下記のリンク先にあるのでこちらをご覧ください.
今回重要なところを解説していきます.
69~71行目
hband = hp.rolling(20).max() #Highバンド設定 lband = lp.rolling(20).min() #Lowバンド設定 mband = (hband - lband)/2 + lband #Middleバンド設定ここでは, 各バンドの設定をしています. hbandは過去20日間の高値(cp)の最大値, lbandは過去20日間の安値(lp)の最小値, mbandはhbandとlbandの平均をとっています.
rollingについての詳しいことはこちら
74~75行目
buy_sig = ((mband.shift(1) > cp.shift(1)) & (mband < cp)) sell_sig = ((mband > cp) | (cp > hband))買いシグナル:mbandを終値(cp)が突き抜けたとき
売りシグナル:mbandを終値(cp)が下回ったとき or 終値がhbandを突き抜けたときバックテスト結果
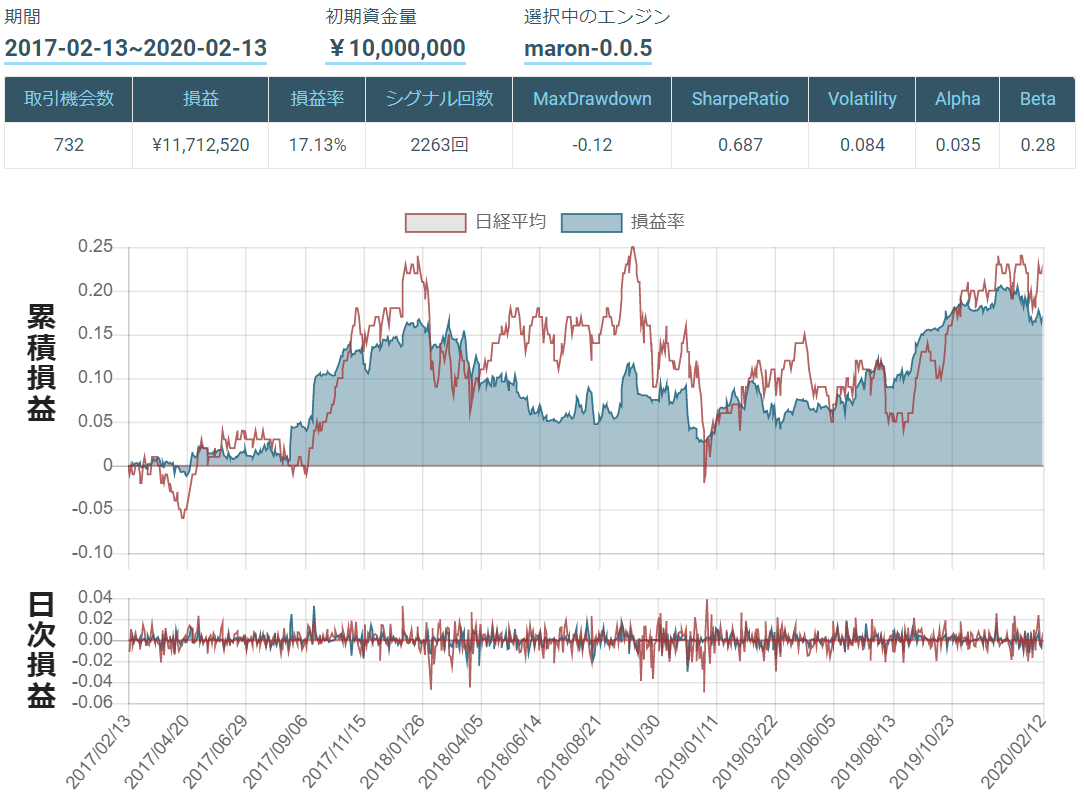
3年で損益率が17%,,,,
あまり儲かっていませんね.
MaxDrawdown, SharpRatio, αの値を見ても, かなり改善の余地がありそうです.
感想
HLバンドは一般的には, ブレイクアウト手法で使われることが多く, 大相場(普段と比べて, 株式相場全体が活況に満ちて高騰し, 出来高も大きく膨らんだ相場のこと)でないと失速することが多いため, すべての状況でHLバンドを用いてもあまり良いアルゴリズムはできないことが結果からも言えます.
免責注意事項
本コードを用いた実際のトレードで生じる損害は一切保証しかねますので、ご注意ください。
- 投稿日:2020-02-13T13:05:52+09:00
sqlalchemyでparent idを取得する方法
parent_idを自動で採番したい
データベースにおいてデータの親子関係の情報を入れたい場合に必要になります。
例えば、あるホテルに複数の部屋が紐づいている場合やあるサービスに複数のプランが紐づいている場合などです。重要なポイントは以下の2点です。
1. 子データの格納前に親データのIDを取得する必要がある
2. 子データの格納でエラーとなった場合は親データの格納前までロールバックする必要があるsqlalchemyの場合はsession.flush()を使う
session.add(parent_record) # トランザクションの登録 session.fluhs() # DBへの登録(保存はされない) parent_id = parent_record.id # 親IDの取得session.add(record)の時点では親データのIDがふられていないため、取得できません。
session.flush()することで親IDがふられ、取得できるようになります。session.commit()を使わない理由
session.add(parent_record) session.commit() # DBへの登録(保存はされる) parent_id = parent_record.id # 親IDの取得session.commit()でデータベースに格納でき、親IDが振られるため取得することができます。
ただし、重要ポイント2で言及しているロールバックができなくなってしまうため、子データで格納に失敗すると、親データだけ格納されている状況が発生してしまい、子データの登録時に手間がかかってしまいます。(手動で親IDを付与するなど)
できれば親データと子データは同じセッションでコミットした方がインサートが効率的になります。
- 投稿日:2020-02-13T09:32:15+09:00
reCAPTCHAのサイトを毎日自動スクレイピングする (3/7: xlsファイル処理)
- 要件定義〜python環境構築
- サイトのスクレイピング機構を作る
- ダウンロードしたファイル(xls)を加工し、最終成果物(csv)を作成するようにする
- S3からのファイルダウンロード / S3へのファイルアップロードをつくる
- 2captchaを実装
- Dockerコンテナで起動できるようにする
- AWS batchに登録
ファイル操作
前回まででseleniumを使ったファイルダウンロードを行ったので、
それを取得・加工してcsvファイルとして保存し直す処理を記載します。ファイル一覧を取得
特定のフォルダ内の特定パターンのファイルをすべて取得する!
というときはglobが便利。# 当該正規表現のファイルリストを取得(glob) file_list = glob.glob(dl_dir+'/*')Excelファイルの操作
pythonによるexcel操作はいくつかライブラリがあるようですが、ひとつ覚えておくと便利そう。私はxlrdを使います。
# Excelファイルの操作 wb = xlrd.open_workbook(file_name) #xlsを開く sheet_names = wb.sheet_names() #シート名一覧を取得 sheet = wb.sheet_by_name(sheet_names[1]) values2 = sheet.col_values(2) values5 = sheet.col_values(5) values2.pop(0) #1行目をなくすため…。もっといいやり方あるのかな values5.pop(0) for i in range(len(channels)): obj = [ word, someFunction2(values2[i]), someFunction5(values5[i]) ] result.append(obj)csvファイルに保存
with open(up_dir + '/result-{}.csv'.format(file_name), 'w') as f: writer = csv.writer(f) writer.writerows(result)完成
ここまでで、
- 実行するとサイトをスクレイピングしてファイルをダウンロードし
- それを加工したものを特定フォルダに置く
というところまでできました。
次は、「加工したものをS3に送る」ところと、「そもそものINPUT(words)をS3から取得する」ところを書いていきます。