- 投稿日:2020-02-13T23:26:52+09:00
aws lambda layers でライブラリをアップロードするときは決まったディレクトリ構成でなければならない
概要
aws lambda layers でライブラリをアップロードするときは決まったディレクトリ構成でなければいけません。
解説
例えば、nodejs の場合だと、nodejsディレクトリにnode_modulesディレクトリを入れます。
zipのファイル名は何でもokです。xray-sdk.zip └ nodejs/node_modules/aws-xray-sdk知らないとはまる可能性があるので共有でした。
当然 nodejs 以外の言語でもディレクトリ構成が決まっているので、下記公式ドキュメントで確認してください。
AWS Lambda レイヤー
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/configuration-layers.html
- 投稿日:2020-02-13T22:37:08+09:00
Route53 & CloudFront & +α を使った wwwドメインから、wwwなしドメインへリダイレクトする構成図(ssl対応)
はじめに
本記事の主な目的は、ssl対応したwwwドメインからwwwなしドメインへリダイレクトするための全体的な構成イメージを提供することです。
ざっと探してみて文章しかなく、全体的な図がないのでイメージしにくかったので作りました。
Frontendのファイル群をS3に配置し、そこに対してルーティングする設定です。
こちらの図作成、という感じです。書くこと
- 全体図
- 個人的にハマったところ一言メモ
書かないこと
- 各種な設定
- SSL証明書発行手順とか
- DNSホスト設定、ドメイン設定とか
構成
構成イメージ全体図
構成イメージは以下です。
以下図の簡易説明など。
- 図上部「wwwドメイン設定」内が、wwwドメイン用の設定
- 図下部「wwwなしドメイン設定」内が、wwwなしドメイン用の設定
- AWSアカウントは同一のものを想定
- ユーザがwwwドメインにアクセスすると、「wwwドメイン設定」内のS3バケットにルーティング -> wwwなしドメインにリダイレクトする設定
個人的ポイント
- ssl対応(http->httpsリダイレクト)するために、以下2つのCloudFrontが必要
- wwwドメイン用のCloudFront(
http://www.~からhttps://www.~へのリダイレクト)- wwwなしドメイン用のCloudFront(
http://~からhttps://~へのリダイレクト)- wwwなしにリダイレクトする場合、S3のバケット名は特に何でもよい
- こちらには「バケット名は、ドメインと一致する必要があります」とありますが、CloudFrontを使うので特に気にする必要はない
使用ツール & 参考

- 投稿日:2020-02-13T22:35:23+09:00
初心者)EC2にlinax作った>teratermで接続>あれ、ユーザIDなんなの>答:ec2-user
- 投稿日:2020-02-13T22:30:42+09:00
AWS CLI v2とaws-vaultとpecoを使ってプロファイルを選択方式にする
AWS CLI v2 が GA になったので導入してついでに aws-vault を組み合わせてプロファイルを実行時に切り替えるようにしてみました。
aws-vault のインストールや設定は macOSのAWSクレデンシャル管理 で書いたとおりです。
環境
- macOS Mojave (10.14.5)
- zsh
- peco
- AWS CLI v2
- aws-vault
これらを組みわせて default プロファイル利用時は設定済みのプロファイルから選択するようにします。
インストール
ここでは、zsh、peco、 AWS CLI v2 のインストール方法について記載。
zsh
今回は brew でインストール。
$ brew install zshpeco
これも brew でインストール。
$ brew install pecoAWS CLI v2
公式 の手順に従いインストール。
$ curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" $ sudo installer -pkg AWSCLIV2.pkg -target / $ aws --version準備
- aws-vault にクレデンシャルを登録する
- クレデンシャルを選択するための sh を用意
- ~/.aws/profile に credential_process 経由で sh を使ってクレデンシャルを選択
大きくはこの 3 ステップ。
aws-vaultにクレデンシャルを登録する
macOSのAWSクレデンシャル管理 を参考に登録してください。
クレデンシャルを選択するための sh ファイルを用意
aws-vault のプロファイルを列挙するコマンドを利用してクレデンシャルをして peco で選択。
その内容を AWS CLI に渡すというのが大まかな処理の流れ。以降は aws-vault に prof1、prof2、prof3 の 3 つのクレデンシャルを登録しているという前提で記載します。
自分の環境に合わせて読み替えてください。まずは、aws-vault で登録しているプロファイルは、
aws-vault lsで列挙できます。$ aws-vault ls Profile Credentials Sessions ======= =========== ======== default - - prof1 prof1 - prof2 prof2 - prof3 prof3 -Profile の欄は .aws/config に設定されているプロファイル名、Credentials の欄は aws-vault に登録しているプロファイル名、 Sessions にはクレデンシャルから払い出したセッション情報が表示されます。
Profile と Credentials の突合は単純に同じ名前かどうかで判定している模様。これの情報を AWK で 整形するとこんなかんじで Credentials だけ抜き出せます。
$ aws-vault ls | awk 'NR>2 {if ($2 != "-") print $2}' prof1 prof2 prof3これを peco に食わせるとクレデンシャルを選択できるようになります。
セッションを用いずに登録したクレデンシャルを利用する場合は以下のようなコマンドで aws-vault からクレデンシャルを抜き出すことが可能です。$ aws-vault exec -j `aws-vault ls | awk 'NR>2 {if ($2 != "-") print $2}' | peco --prompt "Choice Credential >"` --no-session Choice Credential > IgnoreCase [3 (1/1)] prof1 prof2 prof3クレデンシャルを選択するとキーチェーンがロック中の場合はアクセス確認が行われるのでパスワードを入力します。
キーチェーンにアクセスが切れば、以下のようにクレデンシャルが表示されます。{"Version":1,"AccessKeyId":"AKIXXXXXXXXXXXXXXXXX","SecretAccessKey":"ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ","SessionToken":""}これを適当な sh ファイルに仕込んで credential_process に食わせればお終いです。
sh を credential-selector.sh と名付けて任意の場所に保存してください。credential-selector.shecho $(aws-vault exec -j `aws-vault ls | awk 'NR>2 {if ($2 != "-") print $2}' | peco --prompt "Choice Credential >"` --no-session).aws/config に credential-selector.sh を組み込む
.aws/config を以下のように編集します。
デフォルトプロファイルは credential-selector.sh で登録済みのプロファイルの一覧から選択。
各プロファイルは aws-vault に保存されているクレデンシャルをそのまま利用する。[default] credential_process=/PATH/TO/credential-selector.sh region=ap-northeast-1 output=json [profile prof1] credential_process=aws-vault exec -j prof1 --no-session region=ap-northeast-1 output=json [profile prof2] credential_process=aws-vault exec -j prof2 --no-session region=ap-northeast-1 output=json [profile prof3] credential_process=aws-vault exec -j prof3 --no-session region=ap-northeast-1 output=json.aws/credentials に設定は不要です。空のファイルにしてください。
credential-selector.sh に実行権限を付与したら準備は完了です。$ chmod +x /PATH/TO/credential-selector.sh使ってみる
では使ってみましょう。
まずはプロファイル指定を行った場合。$ aws s3 ls --profile prof1 2019-12-18 12:16:10 bucket-1 2020-01-08 09:21:42 bucket-2これで普段どおり指定したプロファイルに関連づいた S3 バケットの一覧が表示されます。
次に default プロファイルを指定した場合です。
$ aws s3 ls Choice Credential > IgnoreCase [3 (1/1)] prof1 prof2 prof32019-07-18 14:36:41 bucket-a 2019-07-10 18:49:57 bucket-bこのようにクレデンシャルの一覧が表示されるのでそこから利用したいクレデンシャルを選択する事ができます。
まとめ
aws-vault と peco を使って default プロファイル指定時に任意のクレデンシャルを選択できるようにしてみました。
もともと事故防止用に default プロファイルには何も指定をしていなかったのですが、毎回プロファイルを打ち込むのもめんどくさいなーと思うことがあり、選択できるようにしてみました。aws-vault に登録されているクレデンシャルと .aws/credentials のプロファイルを同期させないと期待した動きをしないので .aws/credentials を自動生成する sh でも作ろうかと思います。
- 投稿日:2020-02-13T22:16:28+09:00
AWS Organizationsで組織内のアカウントを簡単に消したかった
TL;DR
- AWS Organizationsで組織に属しているアカウントは、アカウントにログインして(AssumeRoleではダメ)からアカウントの解約を実行すれば可能。組織から離す必要はない。
- AWS Organizationsで作成したアカウントを組織から外すときは、大量の追加情報が必要。
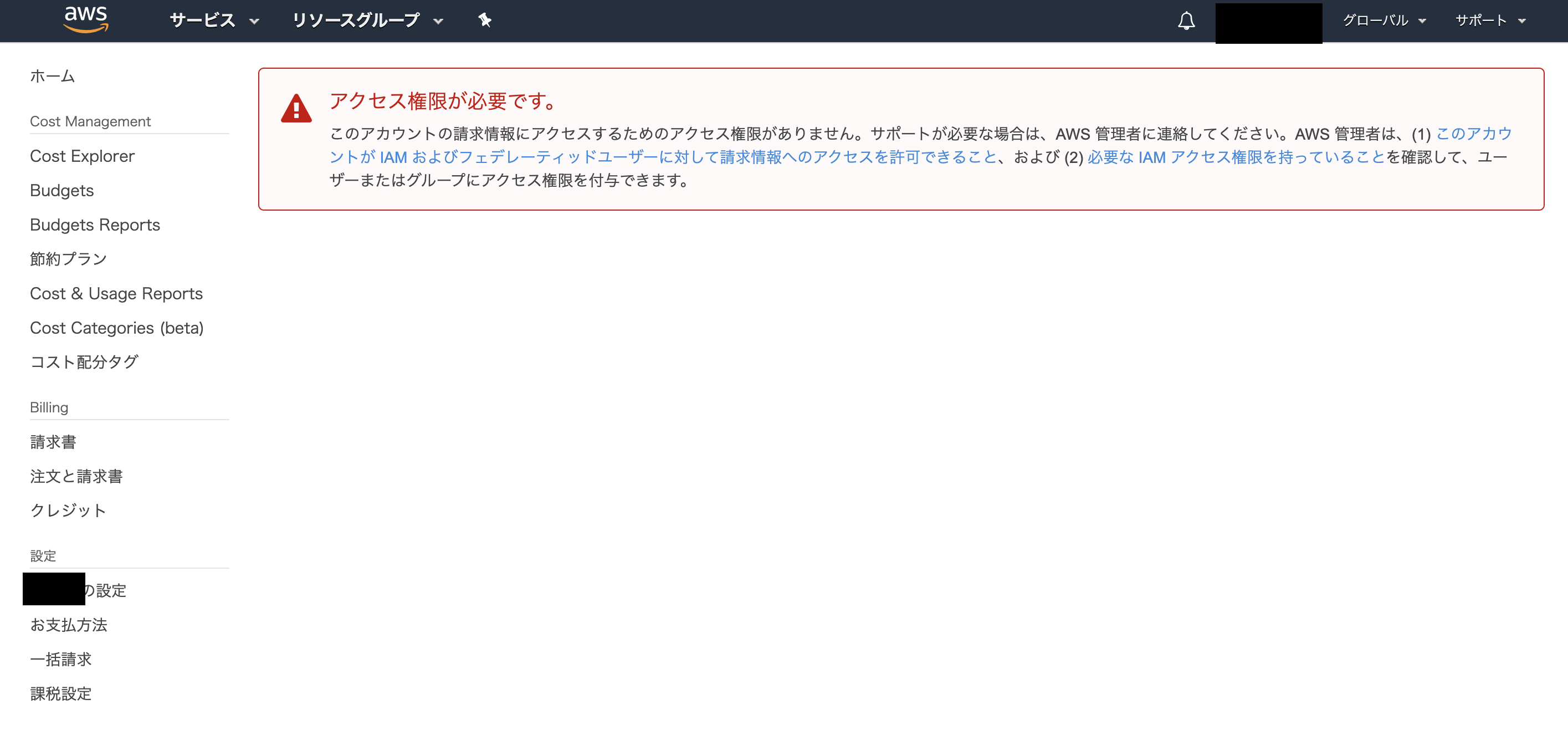
組織に属したままアカウントを解約しようとすると「アクセス権限が必要です」というエラーが出る。ルートアカウントでログインした後、「アカウント解約」を実行するとアカウントを消すことができた。- 組織内のアカウントが悪さした時には、アカウントを消すのではなく権限を全て奪うことで対処する方法もある
はじめに
みなさんAWS使ってますか?
僕は記事作成時点で1週間ほど業務で使っています。会社で「AWS Organizationsで複数アカウント管理したいから、調査よろしくね」とお願いされまして、あれこれ毎日奮闘しています。ちなみに僕は、AWSにめっちゃ興味ありまくりのAWS実務未経験者です。
色々調査している中で、組織で管理しているアカウントがもし誰かに乗っ取られたら、そのアカウント速攻で抹消したいという要望が湧いてきまして、じゃあそれ具体的にどうやるんだろう、ということで実際にアカウント消す方法を色々試してみることにしました。
AWS Organizations管理下のアカウントを消す方法
まずOrganizations管理下のアカウントを消すために、まず所属している組織からアカウントを切り離す方法を試しました。
公式の資料を読むとわかるのですが、消したいアカウントがもしAWS Organizationsで作成されたアカウントだった場合、アカウントを組織から離す際に、電話番号やクレジットカードなどのパーソナリティ度の高い追加情報を入力しないといけません。
組織からアカウントを切り離した後、アカウント情報のページから「アカウント解約」を選択することでアカウントを消すことができます。(アカウントを解約してもすぐに消えるわけではなく、90日間はアカウントにアクセスできます。詳しくはこちらを参照)
この方法なのですが追加情報の入力が地味に面倒臭いですし、何より消したいアカウントにクレジット情報みたいなクリティカルな情報を入力したくありません。なんとか別の方法でアカウント消せないかな〜と足掻いてみました。
組織内のアカウントを直接解約してみた
組織から離さなくても、直接アカウント解約できたら良いのでは?ということで早速実践。
AssumeRoleで目的のアカウントにアクセスし解約したいアカウントのアカウントページで「アカウント解約」を押すと
「アクセス権限が必要です」と怒られて解約に失敗しました。じゃあ権限付与したら良いんだよね、ということで請求情報のフルアクセス権限用SCP作成して適応。作ったSCPは以下です。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "aws-portal:*" ], "Resource": [ "*" ] } ] }もう一度チャレンジすると...
ダメかぁ。やはり組織から離してからアカウントを解約する以外にアカウントを消す方法はなさそう。
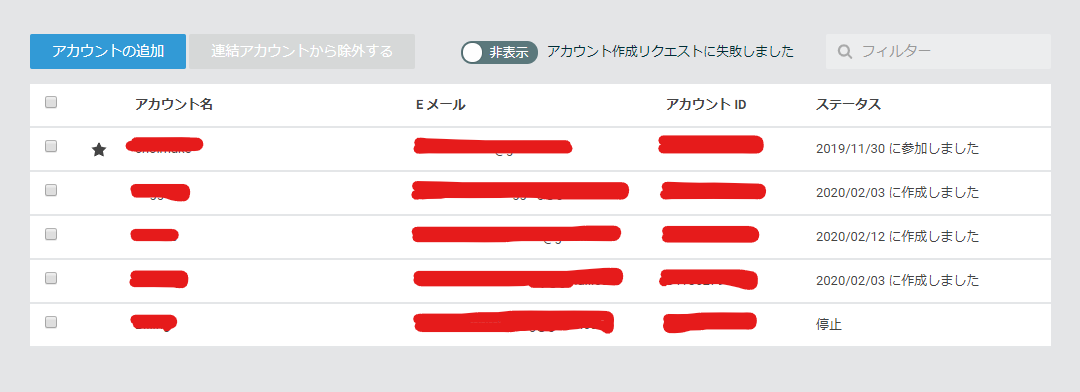
しかしここでミスが発覚。AssumeRoleで消したいアカウントに入って「アカウント解約」を実行していたのがダメだったんじゃないの?。というわけで、きちんとアカウントにルートでログインして試してみると、無事アカウントが解約できました。
アカウントのステータスが「停止」なっているのがわかるかと思います。
そもそもアカウントを消す必要はあるのか?
悪さをしている組織内アカウントがあったらサクッと消したいという要望は叶いました。
しかしアカウントが消さなくても、それ以上余計な操作ができないように権限を全て奪ってしまえば良いのではないか?と考えました。いざアカウントが不正利用された場合は、SCPで可能な限りの権限を剥奪するプランもありかなと考えております。
さいごに
今回はAWS Organizations管理下のアカウントをなるべく簡単に消す方法を試してみました。
アカウントを消す方法は「消したいアカウントのルートアカウントでログインしてからを解約」です。もし組織内のアカウントが不正利用などされた場合は、アカウントを解約するかもしくは即座にアクセス権限を奪うような対処をしようと思います。
もっと良い方法があるよ〜といった知見をお持ちの方は是非ご一報いただければと存じます。ここまで記事を読んでいただきありがとうございました。
- 投稿日:2020-02-13T22:08:30+09:00
AWSの10分間チュートリアルをやってみる 7. Set up the Elastic Beanstalk Command Line Interface
こんにちは。トリドリといいます。
新卒で入社した会社でJavaを数年やった後、1年ほど前に転職してからはRailsを中心に使用してアプリケーションの開発をしているしがないエンジニアです。今回、AWSの勉強をするために公式の10分間チュートリアルをやってみることにしたので、備忘のために記事に残していこうと思います。
AWSに関しては、1年ほど前転職活動をしていた時期にEC2とRDSを少し触っていた以外ほとんど触ったことが無い初心者です。
(ただし、このときにアカウントを作ったので、12ヶ月の無料枠は切れていました)前回は、Elastic Beanstalkを使って、「アプリケーションを更新する」というチュートリアルをやりました
今回は、同じElastic BeanstalkをCLIから操作するチュートリアルの第一弾、「Set up the Elastic Beanstalk Command Line Interface」をやっていきます。今回初の英語チュートリアルです。
10分間チュートリアルということで文章も短いですし、画像もあるので、なんとかなるでしょう。Set up the Elastic Beanstalk Command Line Interface
https://aws.amazon.com/jp/getting-started/tutorials/set-up-command-line-elastic-beanstalk/
このチュートリアルではCLIをインストールするところまでで、次回実際にCLIからBeanstalkを操作する形になっています。Step 1. Create and set up an IAM user
IAMユーザーの作成とCLI・Elastic Beanstalkの使用権限の付与を行い、証明書をダウンロードします。
a.
AWSのコンソールから、[Identity and Access Management](IAM)を開き、[ユーザー]メニューをクリックします。
b.
[ユーザーを追加]ボタンをクリックします。
c.
[ユーザー名]に
eb-adminと入力します。
チュートリアルにもコンソールの画面にも記載されていますが、今回はCLIからのアクセスということで[アクセスの種類]は[プログラムによるアクセス]にチェックを入れ、[次のステップ:アクセス権限]を押します。d.
チュートリアルに従って、[ユーザーをグループに追加][グループの作成]を押します。
e.
ダイアログが開くので、チュートリアルの通り、グループ名に
eb-adminsを入力し、AWSElasticBeanstalkFullAccessというポリシーにチェックを入れます。
最後に[グループの作成]ボタンを押します。f.
ダイアログが閉じ、作成された
eb-adminsが一覧に表示されます。
eb-adminsを選択した上で、[次のステップ:タグ]を押します。タグの追加はチュートリアルにはありませんが、オプションとなっているのでそのまま[次のステップ:確認]を押します。
g.
チュートリアルのg.はf.と同じ画像になっていますが、ここでは次のように設定内容を確認する画面が表示されます。
確認できたら、チュートリアルの通り[ユーザーの作成]ボタンを押します。h.
作成されると、アクセスキーIDとシークレットアクセスキーの画面が開きます。
チュートリアルに従って、CSVをダウンロードした上で画面を閉じます。シークレットアクセスキーの確認とダウンロードはキーの生成時のみ可能です。
EC2のプライベートキーと同様ですね。忘れてしまった場合、そのアクセスキーIDは使用できなくなってしまいますが、ユーザーの詳細の[認証情報]から別のキーを作成することはできます。
Step 2. Install the EB CLI
Elastic BeanstalkのCLIをインストールします。
各OSの方法が記載されていますが、私はMacOSなのでその手順に従って進めます。a.
ターミナルを開きます。
b.
Homebrewを使用するので、
brew updateでアップロード
または/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"でインストールします。
ちなみに、updateしようとしたところ、何故かLibreSSLで
unable to accessのエラーが出ました。
とりあえずググってでてきた下記の通り、再起動をしてみたところupdateできました。
https://frontl1ne.net/2019/02/mac-os-libre-ssl-error/
カスペルスキーのセキュリティソフトが関係あるかもという話ですが、私もまさにカスペルスキーを使用していたので、やはり関係あるのかも・。c.
brew install awsebcliでEB CLIをインストールします。
d.
インストールが完了したら、
eb --versionでちゃんとインストールされたことを確認しておきます。
私の場合は、EB CLI 3.17.0 (Python 3.8.1)が表示されました。
これで今回のチュートリアルは完了です。
まとめ
CLIでElastic Beanstalkを使用するため、権限を持ったユーザーの作成とCLIのインストールを行いました。
今回のチュートリアルは英語でしたが、手順もかなり少なく簡単な英語だったので比較的短時間で終わらせることができました。次回は続きの「Deploy and Monitor an Application from the Command Line(ウェブアプリケーションをデプロイおよび管理)」に進む予定です


- 投稿日:2020-02-13T21:36:01+09:00
複雑なS3BucketPolicyの設計
概要
ポリシー厳しめのS3バケットを作成したいときに、S3BucketPolicyを設定すると思います。
今回はS3BucketPolicyを設定時に、DenyPolicyかつNot〜を利用すると理解に苦しむほど複雑になるのでまとめました。
また、CloudFormationを利用してBucketPolicyを作成した事例になります。背景
上記ではポリシー厳しめと書きましたが、具体的にはいくつかのポリシーが必要になりました。
- セキュアな情報を格納するため、許可ではなく明示的に拒否しセキュリティレベルを高めたい
- ある特定の操作(Action_B)のみ許可するようにしたい
- あるユーザー(User_C)のみ操作を許可するようにしたい
- あるAssumeRole(RoleID_D)にスイッチした場合のみ許可するようにしたい
参考ですが、想像しやすいようにより具体的に例をあげると
- 個人情報を含むデータを格納するため、セキュリティレベルは高い必要がある
- 改ざん、閲覧は禁止のなので、PutObjectのみ許可したい、Get、List、Deleteなどは拒否したい
- 個人情報を配置する専用のユーザー(アクセスキー発行)からのみPutObjectを許可したい
- メンテンスやテストをするために、例外としてはAssumeRoleにスイッチした場合のみPutObjectを許可したい
今回は概念を説明するために、汎用的な場合で説明します。
ここで要件を満たすためにサンプルテンプレートを作成しました。s3_bucket_policy.ymlS3BucketPolicy: Type: 'AWS::S3::BucketPolicy' Properties: Bucket: 'Bucket_A' PolicyDocument: Version: '2012-10-17' Statement: - Effect: 'Deny' NotAction: 'Action_B' NotPrincipal: 'User_C' Resource: - 'BucketA/' - 'BucketA/*' Condition: StringNotLike: 'RoleID_D'説明
上記テンプレートを反映させた場合の挙動を説明します。
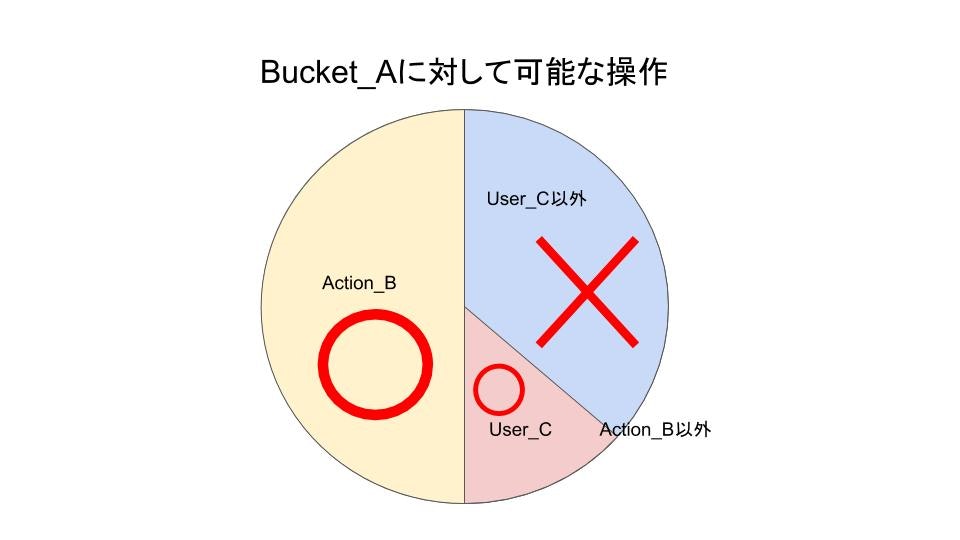
Bucket_Aに対して、Action_B以外の操作を、User_C以外のユーザーかつ、RoleID_D以外の場合は拒否する
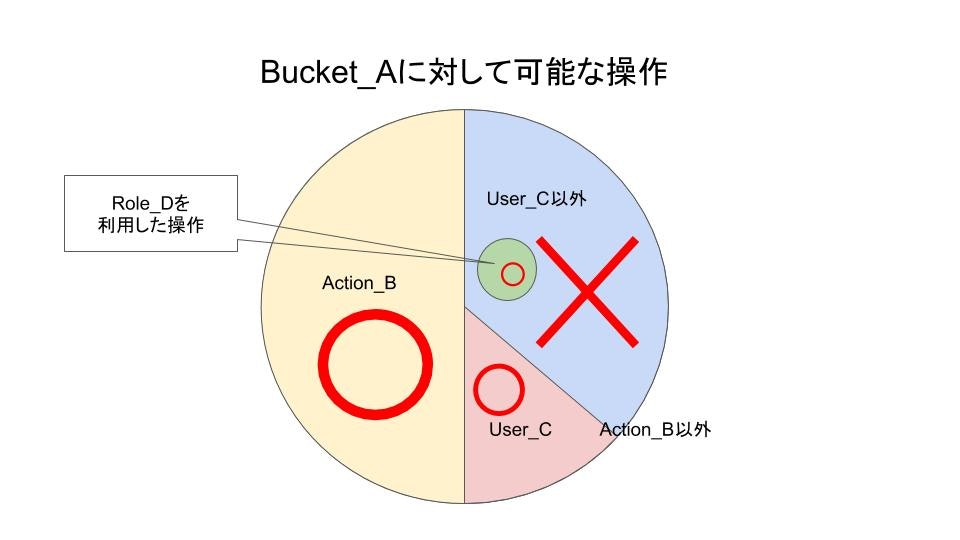
ちょっと良くわからないですね。図にします。
Action_B以外の操作を、User_Cと、RoleID_Dは許可され(厳密には未定義)、それ以外は拒否されているのがわかると思います。
一つ一つ説明していきます。初期状態
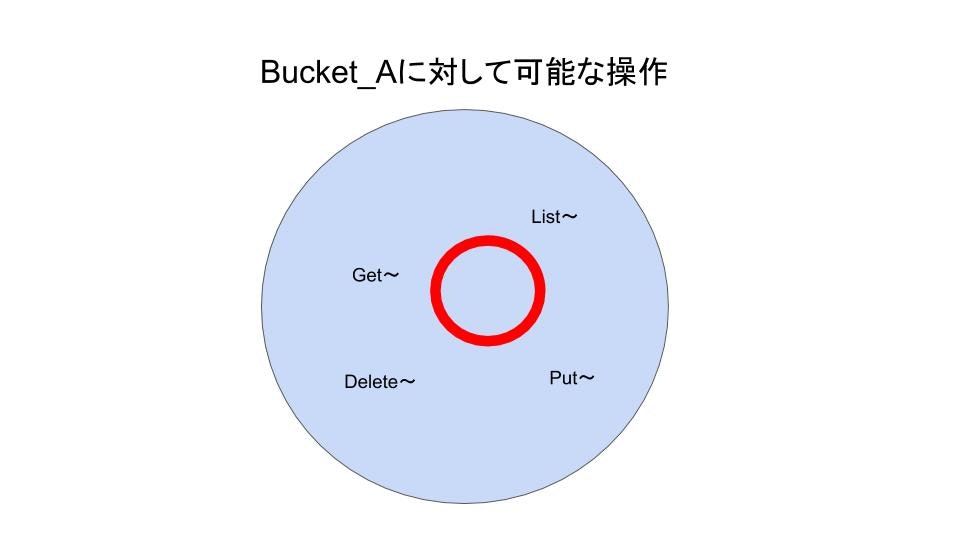
初期状態(未定義)ではBucket_Aに対してすべての操作が可能になっています
例:GetObject,ListObject,DeleteObject 等Effect: 'Deny'
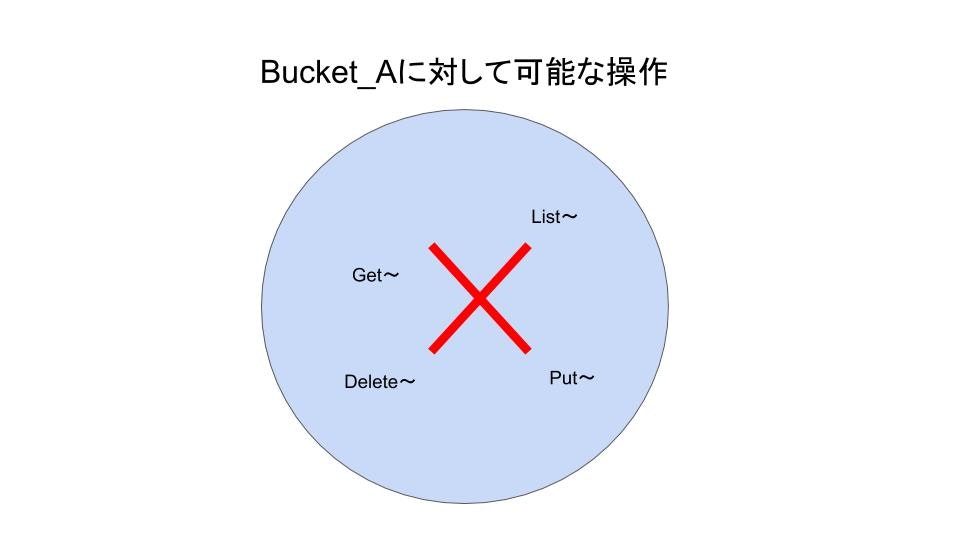
DenyPolicyにすることですべての操作が拒否されるようになります。
※便宜上、現段階ではAction,Principalは * として説明しています。NotAction: 'Action_B'
NotAction: 'Action_B'によって、Action_B以外の操作を拒否するようになりました。
Action_Bについては未定義のため許可となっています。
例えば以下の様に書くと、更新系の拒否(参照系以外の拒否)が可能になります。NotAction: - 's3:Get*' - 's3:List*'NotPrincipal: 'User_C'
NotPrincipal: 'User_C'によって、Action_B以外かつ、User_C以外の操作は拒否する様になりました。
User_Cについては未定義のため許可となっています。
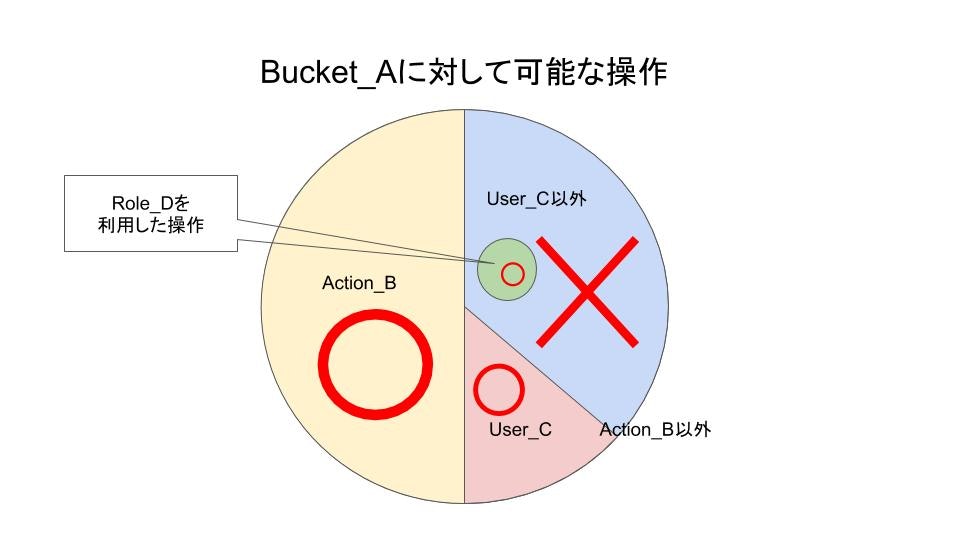
例えば以下の様に書くと、IAMUserHoge以外の操作は拒否するようになります。(IAMUserHogeは同じテンプレート内で作成)NotPrincipal: "AWS": - !GetAtt IAMUserHoge.ArnCondition: StringNotLike: 'RoleID_D'
Condition: StringNotLike: 'RoleID_D'によって、RoleID_D以外を利用した操作は拒否する様になりました。
Conditionを利用することで先程まで拒否になっていた操作に例外を作り出すことができます。
例えば以下の様に書くと、IAMRoleFuga以外の操作は拒否するようになります。Condition: StringNotLike: aws:userid: - !Sub '${IAMRoleFuga.RoleId}:*'以上で当初の目的であった
Bucket_Aに対して、Action_B以外の操作を、User_C以外のユーザーかつ、RoleID_D以外の場合は拒否するが実装できました。追加作業
ここまでだと、Action_Bは誰でも操作できてしまうため、Action_Bも拒否するようにポリシーを追加します。
- Sid 'DenyAction_B' - Effect: 'Deny' Action: 'Action_B' Principal: '*' Resource: - 'BucketA/' - 'BucketA/*'
より実践的なPolicyになったのではないでしょうか。まとめ
以上の様にして、複雑なS3BucketPolicyを設定することができます。
参考
参考程度ですが、今回僕が実装した最終版のテンプレートを配置しておきます。
要件がより詳細になったことで最終的にはDenyポリシーを5つ使用した大変メンテンスしづらいテンプレートができてしまいました。
- PutObjectはアクセスキーを発行した、Hogeサーバーのみ許可。社内ネットワークIP制限も実施
- PutObject以外の更新系は基本拒否
- 更新系を上記だけに絞るとCFnができなくなるので、例外としてCFn専用のRoleを作成し更新系(Put、Delete、、etc)を許可
- 参照は専用に作成したAssumeRoleにスイッチできるユーザーのみ許可
S3BucketPolicy: Condition: InDev Type: 'AWS::S3::BucketPolicy' Properties: Bucket: !Ref S3Bucket PolicyDocument: Version: '2012-10-17' Statement: # 更新系に関するDeny:特定のRoleをAssumeしたユーザとHogeサーバ以外の更新系禁止 - Effect: 'Deny' NotAction: - 's3:Get*' - 's3:List*' NotPrincipal: "AWS": - !GetAtt IAMUserHogeServer.Arn # Hogeサーバに置くトークン発行ユーザ Resource: - !Sub '${S3Bucket.Arn}' - !Sub '${S3Bucket.Arn}/*' Condition: StringNotLike: aws:userid: - !Sub '${IAMRoleUser.RoleId}:*' - !Sub '${IAMRoleCFn.RoleId}:*' # CFnで更新ができるように指定 # 更新系に関するDeny:Hogeサーバ以外のPutObjectを全て禁止 - Sid: 'DenyPutExceptHogeServer' Effect: 'Deny' Action: - 's3:PutObject' NotPrincipal: "AWS": - !GetAtt IAMUserHogeServer.Arn #Hogeサーバに置くトークン発行ユーザ Resource: - !Sub '${S3Bucket.Arn}/*' - !Sub '${S3Bucket.Arn}' # 更新系に関するDeny:HogeサーバのPutObject以外を全て禁止 - Sid: 'DenyExceptPut' Effect: 'Deny' NotAction: - 's3:PutObject' Principal: "AWS": - !GetAtt IAMUserHogeServer.Arn # Hogeサーバに置くトークン発行ユーザ Resource: - !Sub '${S3Bucket.Arn}/*' - !Sub '${S3Bucketw.Arn}' # 更新系に関するDeny:HogeサーバのPutObjectを社内ネットワークに限定 - Sid: 'DenyPutOutOfServerNetwork' Effect: 'Deny' Action: 's3:PutObject' Principal: "AWS": - !GetAtt IAMUserHogeServer.Arn # Hogeサーバに置くトークン発行ユーザ Resource: - !Sub '${S3Bucket.Arn}' - !Sub '${S3Bucket.Arn}/*' Condition: NotIpAddress: aws:SourceIp: - 'x.x.x.x' # HogeサーバのIP # 参照系に関するDeny:SecureRole以外からの参照系禁止 - Sid: 'DenyGetListExceptIAMRole' Effect: 'Deny' Principal: '*' Action: - "s3:Get*" - "s3:List*" Resource: - !Sub '${S3Bucket.Arn}' - !Sub '${S3Bucket.Arn}/*' Condition: StringNotLike: aws:userid: - !Sub '${IAMRole.RoleId}:*'


- 投稿日:2020-02-13T19:43:43+09:00
Unityで音声合成を再生する (Amazon Polly)
Unityで Alexaっぽい の音声合成を試してみました。
「.Net」 に対応している AWS の音声合成サービス 「Amazon Polly」 を使います。やりたいこと
- 入力したテキストの発話
- ボイスの選択( 男性女性 / 日本語・多言語 )
下記のサイトで Alexaの音声合成を試せるので、これと同じような仕組みを検討します。
SSML Editor : VoiceFlow
Amazon Polly とは
Amazon Polly は、文章をリアルな音声に変換するサービスです。テキスト読み上げができるアプリケーションを作成できるため、まったく新しいタイプの音声対応製品を構築できます。Polly は、高度なディープラーニング技術を使用したテキスト読み上げ (TTS) サービスで、自然に聞こえるように人間の音声を合成します。何十種類ものリアルな音声を多数の言語でサポートしているため、さまざまな国に対応した音声アプリケーションを構築できます。(AWSサイトより)
Polly API に テキストを送信するだけで、Amazon Polly からオーディオストリームがレスポンスされます。アプリケーションで直接ストリーミングしたり、MP3 に保存することもできます。
AWSのアカウントが必要ですが、「1か月あたり数百万文字」までの無料利用枠があるので、無料で始められます。Amazon Polly の準備
AWSアカウントの作成
AWSアカウントがない場合は、下記からアカウントを作成してください。
AWSアカウントの作成の流れ : AWS
途中、クレジットカード情報の入力が必要です。AWS SDK を使う際に、「アクセスキー ID」と「シークレットアクセスキー」が必要になるので、アカウント作成後に、IAMからアクセスキーを作成しておきます。
AWS SDK の入手
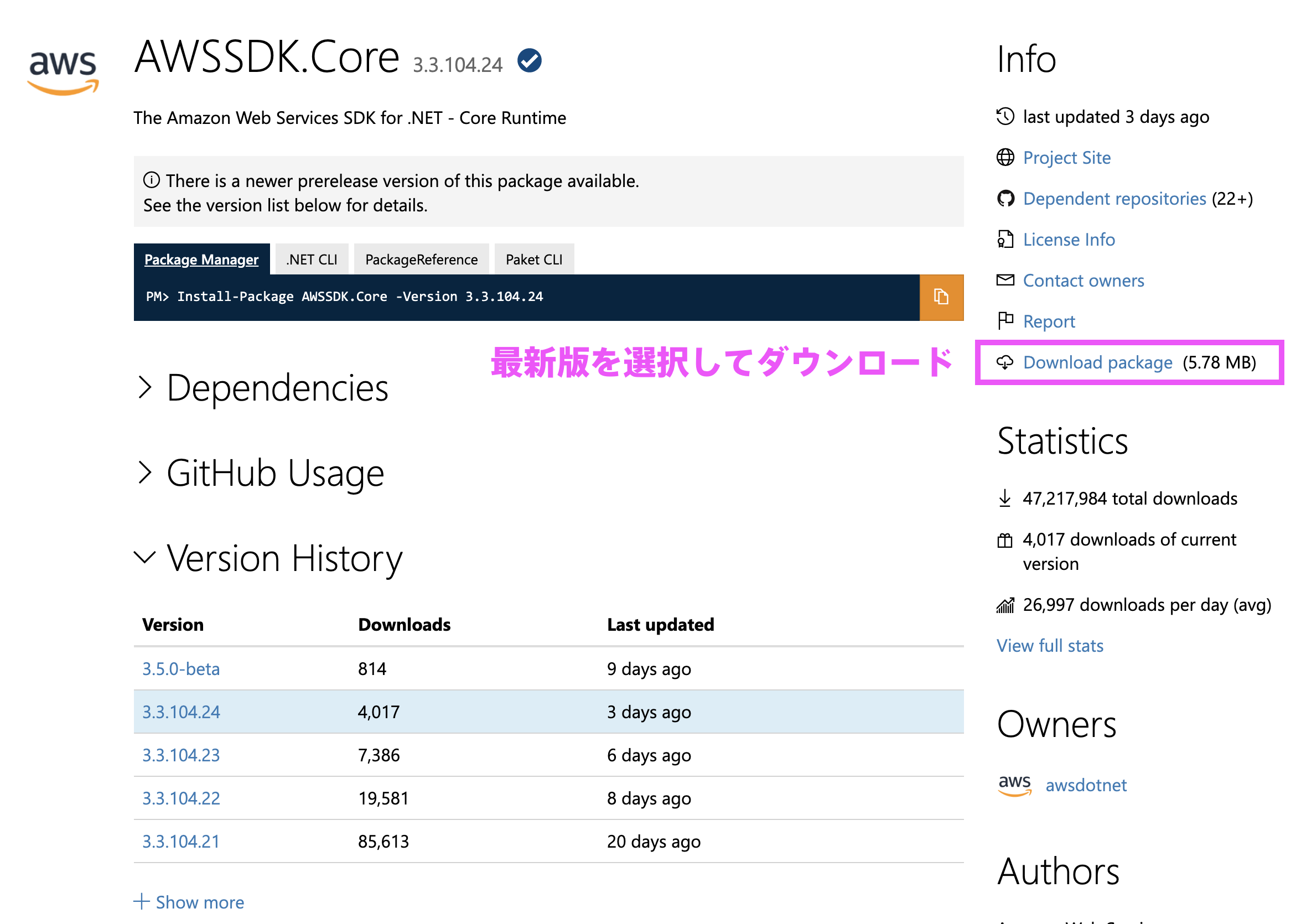
下記から AWSSDK.Core と AWSSDK.Polly の最新版をダウンロードします。
https://www.nuget.org/packages/AWSSDK.Core/
https://www.nuget.org/packages/AWSSDK.Polly/
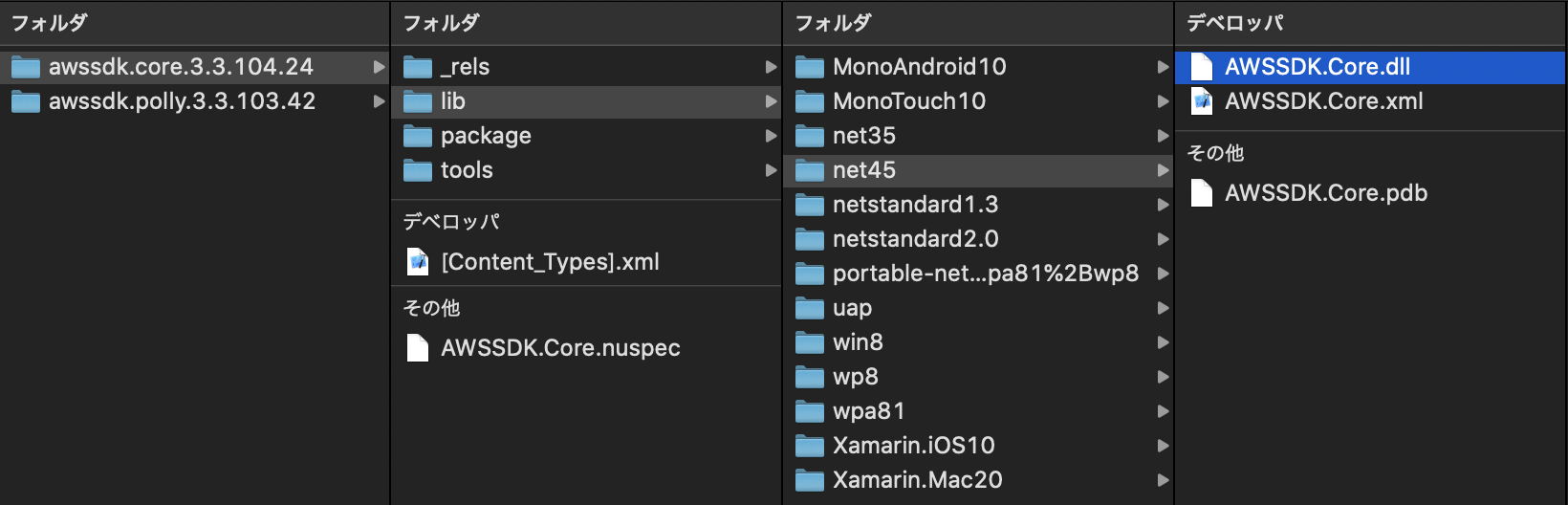
ダウンロードした「awssdk.core.****.nupkg」と「awssdk.polly.****.nupkg」は、拡張子を zip に変更すると解凍できます。
下記の階層から、それぞれの「.Net4.5」用DLLを取り出しておきます。
音声合成コンポーネントを作る
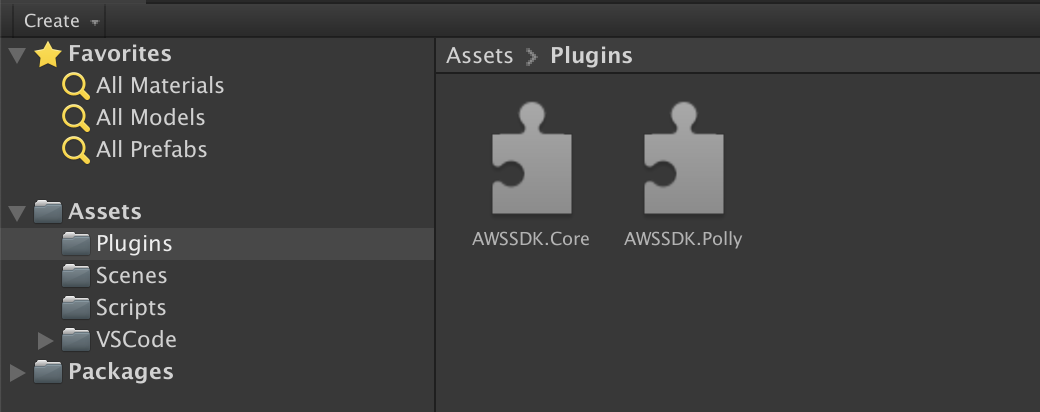
新規作成したUnityプロジェクトに「Plugins」フォルダを作り、先ほどのDLLを配置します。
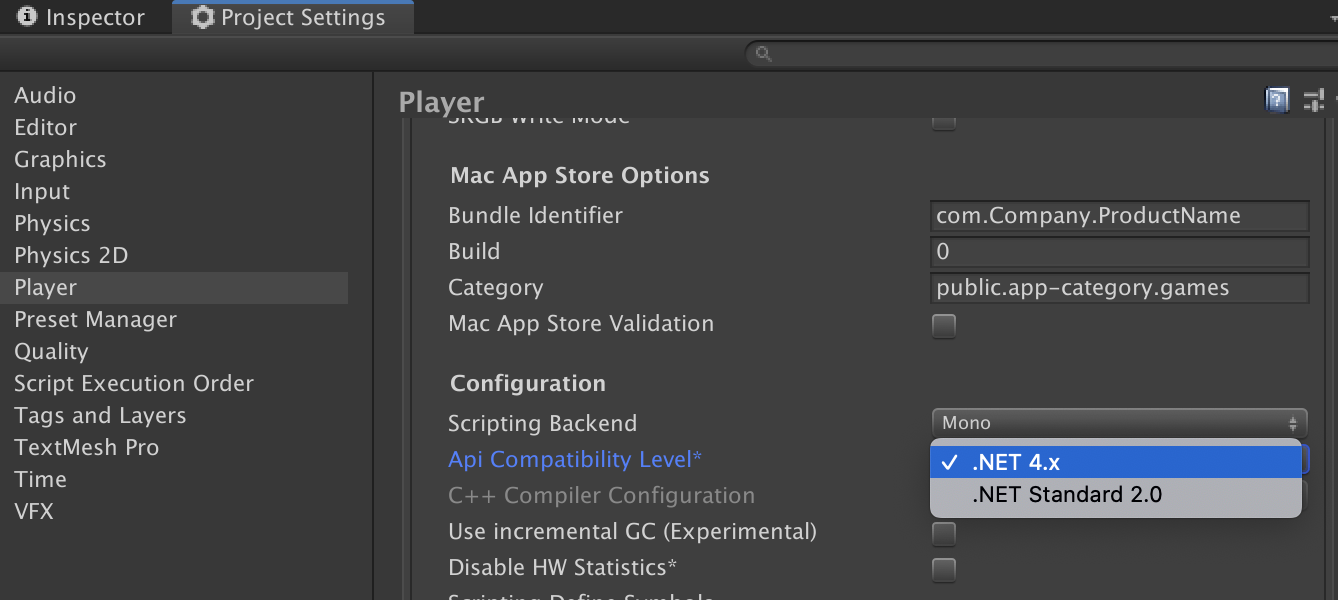
ProjectSettings から Api Compatibility Levelを「.Net 4.x」に変更します。
下記のスクリプトを作成します。
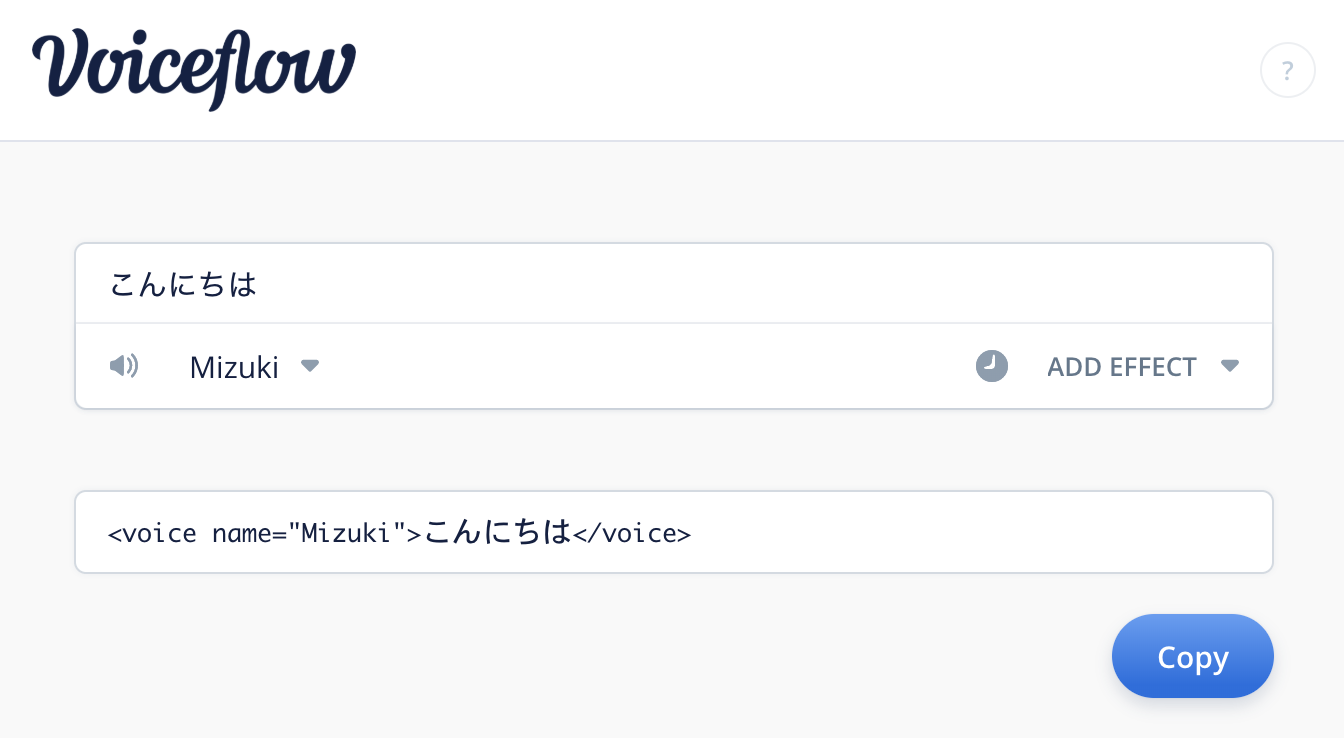
"access-key"と "secret-key"は、自分のキーに書き換えてください。PollyTest.csusing System.IO; using System.Reflection; using System.Collections; using System.Collections.Generic; using UnityEngine; using Amazon.Polly; using Amazon.Polly.Model; public class PollyTest : MonoBehaviour { public VoiceType voiceType; public string text; private AmazonPollyClient client; private AudioSource audioSource; private List<FieldInfo> voiceList = new List<FieldInfo>(); private string fileName = "voice.ogg"; void Awake() { audioSource = gameObject.AddComponent<AudioSource>(); string voiceNames = ""; var list = typeof(VoiceId).GetFields(); foreach (FieldInfo prop in list) { voiceNames += prop.Name + ","; voiceList.Add(prop); } } private void Update() { if (Input.GetKeyDown(KeyCode.Space)) { StartCoroutine(Speak()); } } private IEnumerator Speak() { client = new AmazonPollyClient("access-key", "secret-key", Amazon.RegionEndpoint.USEast1); SynthesizeSpeechRequest sreq = new SynthesizeSpeechRequest(); sreq.Text = text; sreq.OutputFormat = OutputFormat.Ogg_vorbis; sreq.VoiceId = voiceList[(int)voiceType].GetValue(null) as VoiceId; SynthesizeSpeechResponse sres = client.SynthesizeSpeech(sreq); //save voice using (var fileStream = File.Create(Application.persistentDataPath + "/" + fileName)) { sres.AudioStream.CopyTo(fileStream); fileStream.Flush(); fileStream.Close(); } //play voice using (WWW www = new WWW("file:///" + Application.persistentDataPath + "/" + fileName)) { yield return www; audioSource.clip = www.GetAudioClip(false, true, AudioType.OGGVORBIS); audioSource.Play(); } } } public enum VoiceType { Aditi, Amy, Astrid, Bianca, Brian, Camila, Carla, Carmen, Celine, Chantal, Conchita, Cristiano, Dora, Emma, Enrique, Ewa, Filiz, Geraint, Giorgio, Gwyneth, Hans, Ines, Ivy, Jacek, Jan, Joanna, Joey, Justin, Karl, Kendra, Kimberly, Lea, Liv, Lotte, Lucia, Lupe, Mads, Maja, Marlene, Mathieu, Matthew, Maxim, Mia, Miguel, Mizuki, Naja, Nicole, Penelope, Raveena, Ricardo, Ruben, Russell, Salli, Seoyeon, Takumi, Tatyana, Vicki, Vitoria, Zeina, Zhiyu }ここでは、Amazon Polly から取得したオーディオストリームを Oggファイルとして保存して、WWW.AudioClipで再生しています。
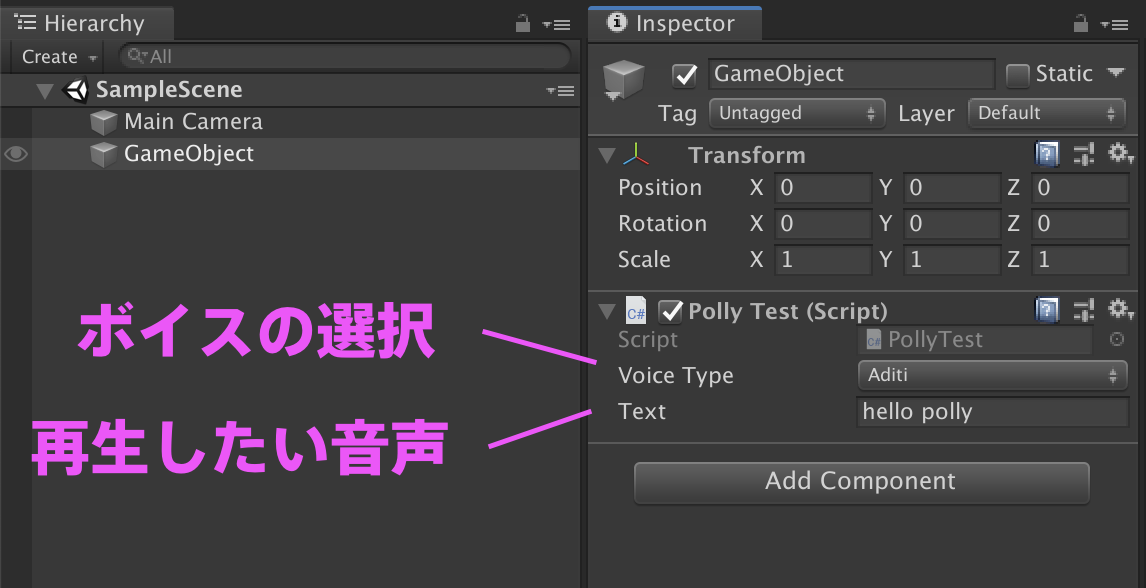
GameObjectにスクリプトをアタッチします。
インストラクタ上で、ボイス選択 と 再生したい音声テキスト を変更できます。
スペースキーで、音声が再生されると完成です。
VoiceType を Mizuki か Takumi にすると、日本語の音声合成も可能です。
- 投稿日:2020-02-13T19:15:34+09:00
VPC概要
VPC
- 仮想のネットワーク空間のこと
- AWSアカウント作成をするとデフォルトで1つVPCが作成されているが、通常は使用しない
- IPアドレスの範囲=VPCの範囲
- AZをまたぐことができる。
- リージョンをまたぐことはできない。
サブネット
- 小さなネットワークに分割管理できる
- AZをまたぐことはできない
- 分割単位は/24がオススメ。第3オクテットで数値を切り変えることで管理しやすい。
- 最初の4IPと最後の1PはAWSが内部的に使用する。
サイダー表記
- /8だと第2,第3,第4オクテットが自由に使える。
- /16だと第3,第4オクテットが自由に使える。
- /24だと第4オクテットが自由に使える。
- /32だと特定の1つのIPアドレスを示すことになる
ルートテーブル
- サブネットの通信制御をする。
- Target項目のLocal=VPC内部のこと。この指定があることでVPC内の各インスタンスは通信可能となっている。
インターネットゲートウェイ,EIP,セキュリティグループ,ネットワークACL
インターネットゲートウェイ
- インターネットと通信するにはVPCにインターネットゲートウェイをアタッチする。
- ルートテーブルにインターネットゲートウェイの設定をする
- VPC内はプライベートIPで通信し、インターネットゲートウェイから外に出る時はパブリックIPが使用される。
- NAT変換機能とも言える
EIP
- インスタンスにアタッチ/デタッチ可能
- インスタンスが再起動、停止、終了した場合も同じIPアドレス
- どこにもアタッチしていない状態だと課金される
セキュリティグループ
- EC2インスタンス単位で設定するファイアウォール
- 正確にはENIに付与するもの
- 拒否ルールではなく許可ルールを設定する
ネットワークACL
- サブネット単位で設定するファイアウォール
NATゲートウェイ,ENI
NATゲートウェイ
- セキュリティを保ったままインターネットに接続したいときに使う
- NATゲートウェイをパブリックサブネットに配置し、プライベートサブネットでNATゲートウェイへのルーティングを設定する
- 必ずEIPをアタッチしなければならない。
ENI(Elastic Network Interface)
- VPC内の仮想NICサービス
- EC2インスタンスやNATゲートウェイにアタッチして使用するもの
- EC2インスタンスのIPアドレスの正体はENI
- EC2インスタンスはデフォではeth0にENIが1つアタッチされている
VPCエンドポイント
- リージョンサービス(S3やLambda等)にVPCからプライベートに接続するサービス
- インターネットを経由せずに接続することができる
- どのサブネットから接続するかを指定するとそのサブネットのルートテーブルにプリフェックスリストID(※)が追加される
- (※)AWSが使用するプライベートIPの範囲を示すもの
Gateway型
- S3,DynamoDBがサポートしている
- ルートテーブルに設定
- 安価
Interface型
- 実態はENI
- プライベートリンク機能がサポートされているAWSサービスが対象となる
- セキュリティグループをアタッチして使用する
VPCピアリング
- 他のVPCと接続したい場合に使用する
- 異なるVPCに配置されたEC2インスタンス同士が同一ネットワークかのように接続できるようになる
- 接続リクエストが無事承諾されればルートテーブルにピアコネクションIDが追加される
- CIDRが重複していると接続できない
引用
https://www.youtube.com/watch?v=aQpMBqn5mRY&list=PLtpYHR4V8Mg-hNPfIpCToq3ZLhvXMHFel
https://www.youtube.com/watch?v=lqsiWw-eDzQ&list=PLtpYHR4V8Mg-hNPfIpCToq3ZLhvXMHFel&index=2
https://www.youtube.com/watch?v=OjQSkvjw23c&list=PLtpYHR4V8Mg-hNPfIpCToq3ZLhvXMHFel&index=3
https://www.youtube.com/watch?v=vePEKj2gR3k&list=PLtpYHR4V8Mg-hNPfIpCToq3ZLhvXMHFel&index=4
https://www.youtube.com/watch?v=e7fJ7mva3QI&list=PLtpYHR4V8Mg-hNPfIpCToq3ZLhvXMHFel&index=5
https://www.youtube.com/watch?v=4sZ7n7KmJYs&list=PLtpYHR4V8Mg-hNPfIpCToq3ZLhvXMHFel&index=6
- 投稿日:2020-02-13T18:28:59+09:00
[AWS] Elasticsearch Serviceの自分まとめ
前置き
- これは AWS の Elasticsearch についてまとめた記事
- 公式ドキュメントから重要そうな部分を抜粋してるだけの記事
機能
- 多数のインスタンスタイプによりスケールさせることが可能
- 最大3PBのストレージ
- コンスとパフォーマンスに優れた UltraWarm ストレージ
料金
- 選択しているインスタンスタイプの1時間あたり料金
- 可動しているノード数分掛け算された料金
- EBSストレージの累積サイズに応じた料金
ドメイン
- Elasticsearchクラスターと同義
- ドメインは指定した設定、インスタンスタイプ、インスタンス数、およびストレージリソースを含むクラスター
ドメイン管理
設定変更
- もろもろの設定変更によりBlue/Greenデプロイが発生する
- Blue/Greenデプロイが発生しない
- アクセスポリシーの変更
- 自動スナップショットの時間の変更
- ドメインに専用マスターノードがある場合、データインスタンス数の変更
サービスソフトウェア更新
- 機能追加やドメイン強化のためのリリースが定期的に実施される
- 更新は任意のタイミングで実施することもできる
- 任意更新をしない場合特定の期間が経過すると自動的に更新される
- いつ、何時に更新されるか分からない
- プロダクション環境の更新の場合はトラフィックの少ない、または停止した状態で任意更新するのがいいかと
CloudWatchでの監視
マルチAZドメイン
- 同じリージョン内の2つまたは3つのAzにノードを分散することができる
- これを
マルチAZと呼ぶ!!!!!!!!!!!- 3つのAZをサポートするリージョンを選ぶことをおすすめ
- Tokyo は勿論対象だよ♪
- 3つのAZにドメインをデプロイする
- 専用マスターノード、データノードに現行世代のインスタンスタイプを選択
- 3つの専用マスターノードと少なくとも3つのデータノードを使用
- クラスター内のインデックス毎に少なくとも1つのレプリカを作成
シャード分散
- マルチAZの場合、クラスターの各インデックスには少なくとも1つのレプリカが必要
- レプリカがないとESはデータのコピーを他のAZに分散できない、マルチAZの意味ないじゃ〜ん
- 全てのインデックスはデフォルトで1つのレプリカが作成される
AZの中断
- 発生することはほとんど無いが、起こりえます(迫真)
- 中断時の動作
スナップショット
- スナップショットはクラスターの指数と状態のバックアップです
なんやねんクラスターの指数って- 状態は、クラスター設定、ノード情報、インデックス設定、シャード割当などが含まれる
自動スナップショット
- クラスター復元専用
- 赤のクラスター状態、またはその他のデータ損失が発生した場合にドメインを復元できる
赤のクラスター状態とは- 追加料金なしで取得可能で事前設定したS3に保存する
- Elasticsearchのバージョンにより取得頻度が異なる
5.3以降: 1時間毎、最大336個を14日間5.1以前: 1日毎、14個を30日間- 赤のクラスター状態となった場合自動スナップショットの作成を停止する
2週間以内に問題を解決しない場合永遠にデータを失うことになる(こわっ)- 赤のクラスター状態
手動スナップショット
- クラスターの復元、クラスター間でのデータ移行に使用する
- そのなの通り手動で取得する必要がある
- 言い換えれば自動ではないってこと > 何言ってんだ
- 自動と同様にS3に保存される
- 手動スナップショット取得前提条件
スナップショットからの復元
自動スナップショット
作業内容
- リカバリ対象のドメインの自動スナップショットを確認する
- 既存インデックスを全て削除する
- 自動スナップショットを使用してリカバリする
- 疎通確認を行う
1. リカバリ対象のドメインの自動スナップショットを確認する
- AWSコンソール -> Elasticsearch を開く
- 復元対象のドメインを選択する
- KibanaのURLをクリックする
- サイドメニュー「Dev Tools」を選択
- 自動スナップショット一覧を取得
GET _snapshot/cs-automated/_all- スナップショット一覧が取得されることを確認
- 基本的に1時間毎にスナップショット取得してるので1つも無いってことは無いはず
2. 既存インデックスを全て削除する
- 既存インデックスが存在しているスナップショットからの復元ができないため削除する
- KibanaのDev Toolsを開く
- 既存のインデックス一覧が表示される
GET _cat/indicesを実行- 既存インデックスを全て削除する
DELETE *- インデックスが削除されていることを確認する
GET _cat/indicesを実行3. 自動スナップショットを使用してリカバリする
- KibanaのDev Toolsを開く
- 自動スナップショット一覧を取得
GET _snapshot/cs-automated/_all- 一覧の中から復元するスナップショットのIDをひかえる
"snapshot":がそれにあたる- スナップショットから復元する
POST /_snapshot/cs-automated/[snapshot]/_restoreを実行- インデックスが復元されていることを確認する
GET _cat/indicesを実行- AWSコンソール -> Elasticasech を開く
- 対象ドメインの「Elasticsearch クラスターの状態」が「緑」または「黄色」であるか確認する
- 「緑」「黄色」であればリカバリ完了している状態
手動スナップショット
全般的なリファレンス
サポートされるインスタンスタイプ
- 一部インスタンスタイプはElasticsearchのバージョン条件がある
- インスタンスタイプ
- マスターノード、データノードは異なるインスタンスタイプを使用することが可能
Elasticsearchバージョン別の機能
ベストプラクティス
- 本番稼働用ドメインは以下ページの各項目に準拠してることが望ましいみたい
ドメインのサイジング
専用マスターノード
- 専用マスターノード
- クラスターの安定性を向上するために専用マスタノードを使用するのが望ましい
- 専用マスターノードはクラスター管理タスクの実行をするがデータは保持しない
- データアップロードリクエストにも応答しない
- クラスター管理タスクに全振りしたのがマスターノード
- 本番運用では「3つのマスターノード」を割り当てるのが望ましい
- 1つだと障害発生時にバックアップが取れない
- 2つだと障害発生時に新しいマスターノードを選択するためのクォーラムがクラスターにない
- クォーラムは
専用マスターノードの数/2 + 1 (直近の整数まで切り捨て)で計算される- 2つだと1つマスターノードが障害あると
1/2 + 1 = 1.5 = 1となりクォーラムが無い状態となり新しいマスターの選択ができない- クォーラムとは
- マスターノードのインスタンスタイプは、管理可能なインスタンス、インデックス、シャード数と相関関係にある
- 大きなインスタンスタイプほど管理できる数が増える
推奨CloudWatchアラーム
トラブルシューティング
赤のクラスター状態
- 少なくとも1つのプライマリシャードとそのレプリカしがノードに割当られていないことを意味する
- 赤いクラスター状態が続く限り正常なインデックスの場合でも自動スナップショットの取得を停止する
- 14日間以上赤のクラスター状態が続くと自動スナップショットを失うことになるので要注意
原因
- 一般的な原因は、クラスターノード障害と継続的な高負荷によるプロセスのクラッシュ
- 最終的に、赤のシャードにより赤のクラスターが発生し、赤のインデックスにより赤のシャードが発生する
解決
- 赤のクラスター状態の原因となっているインデックスを識別するための方法が用意されている
- 未割り当てインデックスの識別
GET /_cluster/allocation/explain- インデックスの状態を表示
GET /_cat/indices?v- 赤のインデックスを削除することが赤のクラスター状態を修正するための最速の方法
インデックス削除が不可能な場合
- スナップショットを復元する、インデックスからドキュメントを削除する、インデックスの設定を変更する、レプリカの数を減らす、または他のインデックスを削除してディスク領域を解放する
- 重要なステップは、Amazon ES ドメインを再設定する前に、赤のクラスター状態を解決する
- 赤のクラスター状態のドメインを再設定すると、問題が複雑化し、状態を解決するまで、設定状態が [Processing (処理中)] のままドメインがスタックする可能性がある
黄色のクラスター状態
- 全てのプライマリシャードがクラスター内のノードに割り当てられ、少なくとも1つのインデックスのレプリカシャードは割り当てられていない状態
- 1ノードしかないドメインは基本的に黄色のクラスター状態ってこと
- 緑のクラスター状態とするにはノード数を増やす必要がある
クラスターノードの障害
- ESの基盤となるEC2は予期しないタイミングで終了と再起動を実施する
- その場合通常はノードの再起動が実施される
- ただしクラスターの1つ以上のノードが失敗した状態となることがある
- 設定したクラスターのノード数よりも少ない状態の場合はAWSサポートへ問い合わせる
- 投稿日:2020-02-13T18:28:59+09:00
[AWS] Elasticsearch Service
前置き
- これは AWS の Elasticsearch についてまとめた記事
- 公式ドキュメントから重要そうな部分を抜粋してるだけの記事
機能
- 多数のインスタンスタイプによりスケールさせることが可能
- 最大3PBのストレージ
- コンスとパフォーマンスに優れた UltraWarm ストレージ
料金
- 選択しているインスタンスタイプの1時間あたり料金
- 可動しているノード数分掛け算された料金
- EBSストレージの累積サイズに応じた料金
ドメイン
- Elasticsearchクラスターと同義
- ドメインは指定した設定、インスタンスタイプ、インスタンス数、およびストレージリソースを含むクラスター
ドメイン管理
設定変更
- もろもろの設定変更によりBlue/Greenデプロイが発生する
- Blue/Greenデプロイが発生しない
- アクセスポリシーの変更
- 自動スナップショットの時間の変更
- ドメインに専用マスターノードがある場合、データインスタンス数の変更
サービスソフトウェア更新
- 機能追加やドメイン強化のためのリリースが定期的に実施される
- 更新は任意のタイミングで実施することもできる
- 任意更新をしない場合特定の期間が経過すると自動的に更新される
- いつ、何時に更新されるか分からない
- プロダクション環境の更新の場合はトラフィックの少ない、または停止した状態で任意更新するのがいいかと
CloudWatchでの監視
マルチAZドメイン
- 同じリージョン内の2つまたは3つのAzにノードを分散することができる
- これを
マルチAZと呼ぶ!!!!!!!!!!!- 3つのAZをサポートするリージョンを選ぶことをおすすめ
- Tokyo は勿論対象だよ♪
- 3つのAZにドメインをデプロイする
- 専用マスターノード、データノードに現行世代のインスタンスタイプを選択
- 3つの専用マスターノードと少なくとも3つのデータノードを使用
- クラスター内のインデックス毎に少なくとも1つのレプリカを作成
シャード分散
- マルチAZの場合、クラスターの各インデックスには少なくとも1つのレプリカが必要
- レプリカがないとESはデータのコピーを他のAZに分散できない、マルチAZの意味ないじゃ〜ん
- 全てのインデックスはデフォルトで1つのレプリカが作成される
AZの中断
- 発生することはほとんど無いが、起こりえます(迫真)
- 中断時の動作
スナップショット
- スナップショットはクラスターの指数と状態のバックアップです
なんやねんクラスターの指数って- 状態は、クラスター設定、ノード情報、インデックス設定、シャード割当などが含まれる
自動スナップショット
- クラスター復元専用
- 赤のクラスター状態、またはその他のデータ損失が発生した場合にドメインを復元できる
赤のクラスター状態とは- 追加料金なしで取得可能で事前設定したS3に保存する
- Elasticsearchのバージョンにより取得頻度が異なる
5.3以降: 1時間毎、最大336個を14日間5.1以前: 1日毎、14個を30日間- 赤のクラスター状態となった場合自動スナップショットの作成を停止する
2週間以内に問題を解決しない場合永遠にデータを失うことになる(こわっ)- 赤のクラスター状態
手動スナップショット
- クラスターの復元、クラスター間でのデータ移行に使用する
- そのなの通り手動で取得する必要がある
- 言い換えれば自動ではないってこと > 何言ってんだ
- 自動と同様にS3に保存される
- 手動スナップショット取得前提条件
スナップショットからの復元
自動スナップショット
kibanaでの操作
- 自動スナップショットの一覧を確認する
GET _snapshot/cs-automated/_all- 復元
POST /_snapshot/cs-automated/[snapshot]/_restore- 復元で同名インデックスが存在するとエラーになる場合はインデックスを全て削除してから復元する
DELETE *- 復元を確認する
GET _cat/indices手動スナップショット
全般的なリファレンス
サポートされるインスタンスタイプ
- 一部インスタンスタイプはElasticsearchのバージョン条件がある
- インスタンスタイプ
- マスターノード、データノードは異なるインスタンスタイプを使用することが可能
Elasticsearchバージョン別の機能
ベストプラクティス
- 本番稼働用ドメインは以下ページの各項目に準拠してることが望ましいみたい
ドメインのサイジング
専用マスターノード
- 専用マスターノード
- クラスターの安定性を向上するために専用マスタノードを使用するのが望ましい
- 専用マスターノードはクラスター管理タスクの実行をするがデータは保持しない
- データアップロードリクエストにも応答しない
- クラスター管理タスクに全振りしたのがマスターノード
- 本番運用では「3つのマスターノード」を割り当てるのが望ましい
- 1つだと障害発生時にバックアップが取れない
- 2つだと障害発生時に新しいマスターノードを選択するためのクォーラムがクラスターにない
- クォーラムは
専用マスターノードの数/2 + 1 (直近の整数まで切り捨て)で計算される- 2つだと1つマスターノードが障害あると
1/2 + 1 = 1.5 = 1となりクォーラムが無い状態となり新しいマスターの選択ができない- クォーラムとは
- マスターノードのインスタンスタイプは、管理可能なインスタンス、インデックス、シャード数と相関関係にある
- 大きなインスタンスタイプほど管理できる数が増える
推奨CloudWatchアラーム
トラブルシューティング
赤のクラスター状態
- 少なくとも1つのプライマリシャードとそのレプリカしがノードに割当られていないことを意味する
- 赤いクラスター状態が続く限り正常なインデックスの場合でも自動スナップショットの取得を停止する
- 14日間以上赤のクラスター状態が続くと自動スナップショットを失うことになるので要注意
原因
- 一般的な原因は、クラスターノード障害と継続的な高負荷によるプロセスのクラッシュ
- 最終的に、赤のシャードにより赤のクラスターが発生し、赤のインデックスにより赤のシャードが発生する
解決
- 赤のクラスター状態の原因となっているインデックスを識別するための方法が用意されている
- 未割り当てインデックスの識別
GET /_cluster/allocation/explain- インデックスの状態を表示
GET /_cat/indices?v- 赤のインデックスを削除することが赤のクラスター状態を修正するための最速の方法
インデックス削除が不可能な場合
- スナップショットを復元する、インデックスからドキュメントを削除する、インデックスの設定を変更する、レプリカの数を減らす、または他のインデックスを削除してディスク領域を解放する
- 重要なステップは、Amazon ES ドメインを再設定する前に、赤のクラスター状態を解決する
- 赤のクラスター状態のドメインを再設定すると、問題が複雑化し、状態を解決するまで、設定状態が [Processing (処理中)] のままドメインがスタックする可能性がある
黄色のクラスター状態
- 全てのプライマリシャードがクラスター内のノードに割り当てられ、少なくとも1つのインデックスのレプリカシャードは割り当てられていない状態
- 1ノードしかないドメインは基本的に黄色のクラスター状態ってこと
- 緑のクラスター状態とするにはノード数を増やす必要がある
クラスターノードの障害
- ESの基盤となるEC2は予期しないタイミングで終了と再起動を実施する
- その場合通常はノードの再起動が実施される
- ただしクラスターの1つ以上のノードが失敗した状態となることがある
- 設定したクラスターのノード数よりも少ない状態の場合はAWSサポートへ問い合わせる
- 投稿日:2020-02-13T18:09:30+09:00
AWS MediaServices の管理・監視
今更ですが、案件を通して少しずつ Media Services を理解してきた streampack の Tana です。
概要
AWS の Media Services を使ったライブ配信では、下記のユースケースで使われているかと思います。
- 高速安定転送の
MediaConnectMediaLiveから他の外部サーバーへの転送- コンテンツ保護のための
MediaPackageS3へアーカイブ登録MediaStore+CloudFrontを使った安定配信様々なリソースの組み合わせできる一方、組み合わせが複雑すぎてどのリソースが使われていて、どれと連携しているか把握するのが難しいデメリットがあります。正直コンソール見てもいろんなオプションが多すぎて頭痛薬が必要ですw
今回はその連携がどうなっているか、また配信がうまく行っているかの監視の課題を
解決してくれるであろう、Webベースでの可視化・監視ツールのご紹介です。
Media Services Application Mapper (MSAM)
https://github.com/awslabs/aws-media-services-application-mapperAWS ReInvent 2019 に参加した時に、エンジニアから共有していただきましたが、気になったままでした。百聞は一見に如かず ということで実際に試してみます。
必要なもの
- AWS Account
- Root or Administratorの権限
- Media Services 関連リソース(Webサイトにて動作確認のため - 構築後でも良い)
流れ
- 1. CloudFormation で AWS リソースを構築
- 2. API Gateway にて、api key の取得
- 3. CloudFrontのWebサイトにアクセスして、api key の登録
- 4. 関連リソースをピックアップ -> 可視化・監視の確認
構築方法
ドキュメント読むと難しく感じますが、CloudFormation で簡単に構築できます。
アプリ側でリージョンを吸収してくれるため、コードを書き換えたり、CloudFormationのパラメーターを意識しなくていいのが楽です。最新のテンプレートはこちらです。
https://rodeolabz-us-west-2.s3.amazonaws.com/msam/msam-all-resources-release.json
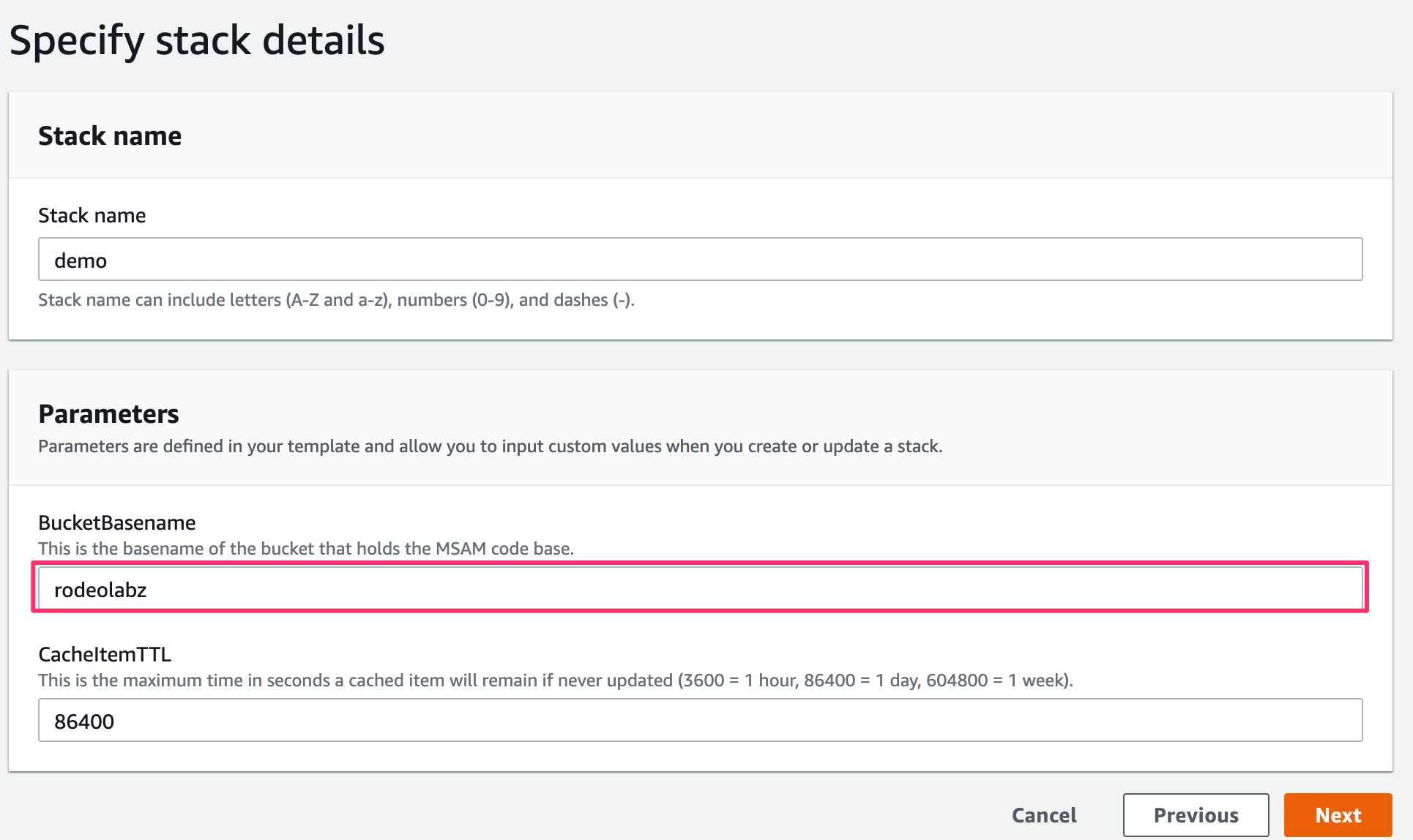
下記の図のように、S3 URLをセットします。
BucketBasename はそのままの rodeolabz を使用します。
(他の bucketname を使用するとエラーになります。)
15分から30分で構築が完了します。
完了すると、stacks -> outputs に関連URLが出力されます。
- APIKeyID
- EndpointURL
- MSAMBrowserURL
詳細イメージはこちら参照:
https://github.com/awslabs/aws-media-services-application-mapper/blob/master/images/master-template-outputs.png注意点
MSAM Browser URL は S3bucket名のDNSプロパゲーションに時間を要します。
よって、アクセスできるまでに30分ほど時間を要しますので、気長に待つ必要があります。
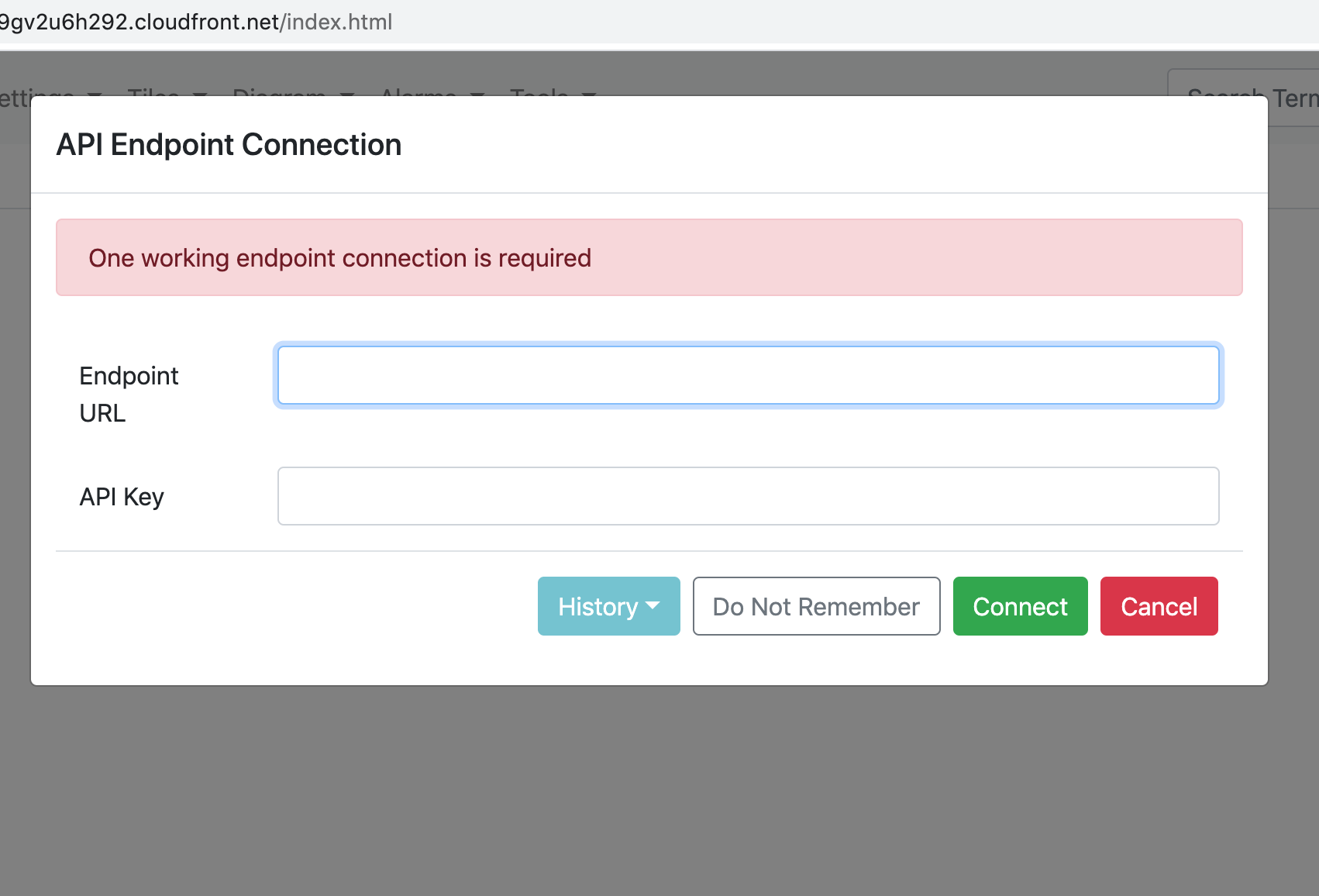
https://github.com/awslabs/aws-media-services-application-mapper/blob/master/INSTALL.md#important-notesAPI key の登録
MSAMBrowserURL にアクセスすると、モーダルウィンドウが表示されます。
よって、先ほど払い出された Outputs からEndpoint URLとAPI Key登録します。
登録が完了すると、自動で各リージョンのリソース情報を取ってきてキャッシュしてくれます。
Settings から必要なリージョンのみ選択すると良いでしょう。
最新のデータを取得したい場合は、再アクセスが必要のようです。The MSAM browser application will load inventory once while it is starting
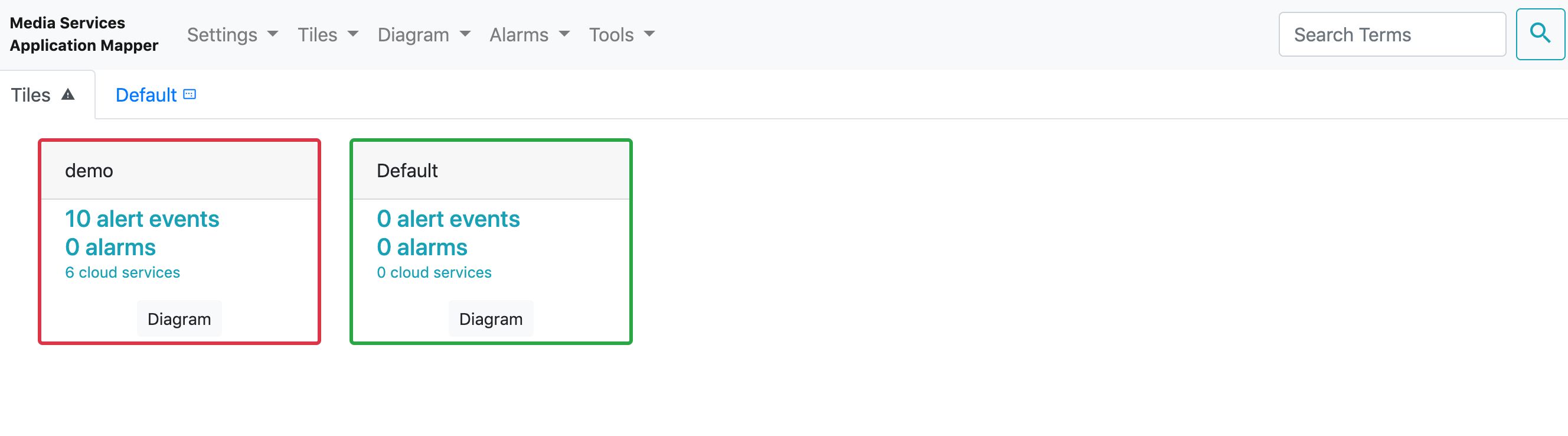
ダッシュボード
初期は Default という名前のタイルがあります。
案件や監視したいリソースを自由に組み合わせて管理・監視ができます 。
そのリソースは、右上の "Search Term" から検索し、下方にリストが出てきますので、対象リソースをドラック&ドロップで登録します。
タイルの中に登録されたリソースで監視にエラーがあると、赤く枠組みしてお知らせしてくれます。
ダイアグラム 1
"Diagram" をクリックすると、可視化ページが表示されます。
事前に登録しておいた、MediaLive input -> MediaLive Channel -> MediaPackage
が連携しておりますので、自動でリンクしてくれてます。
その他のリソースは関連していないので、リンクされないことがわかります。
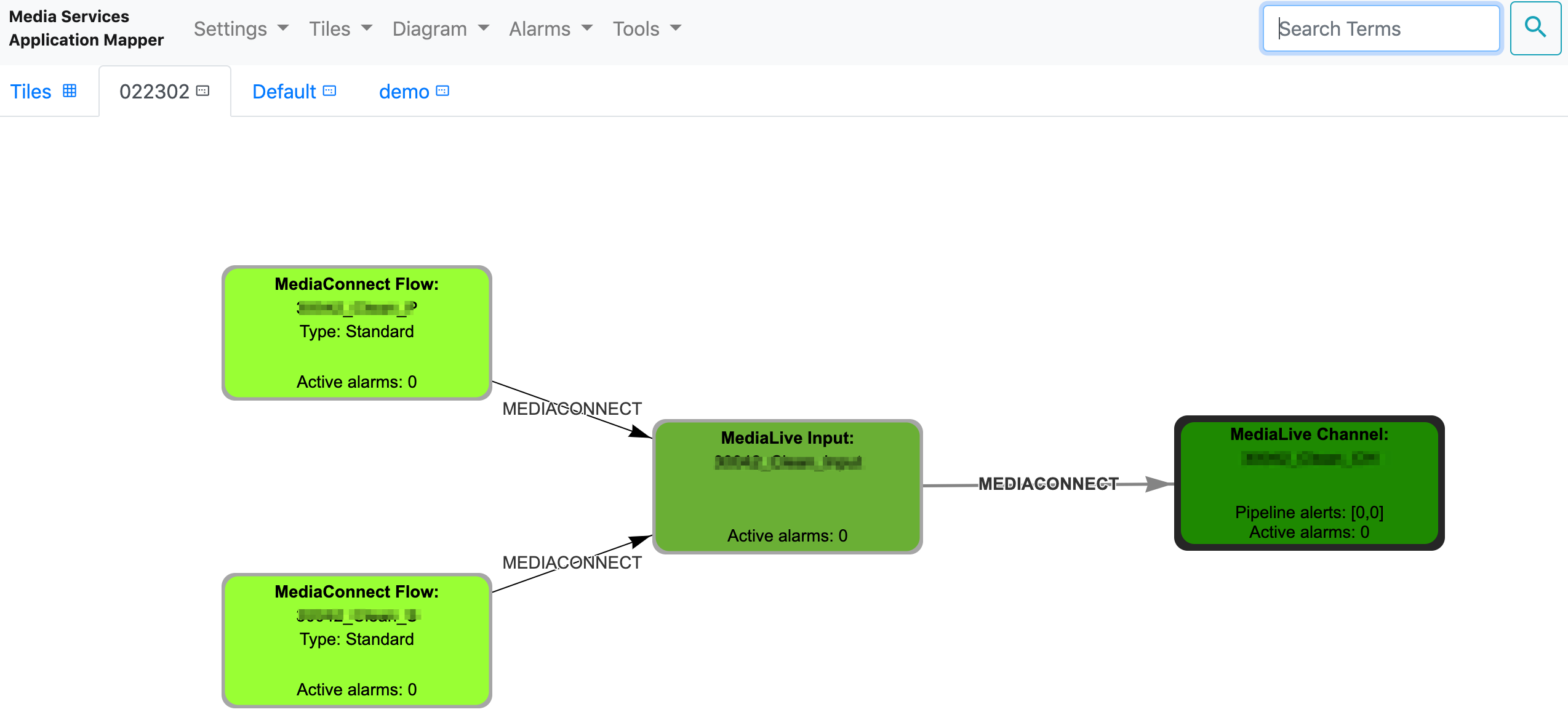
ダイアグラム 2
MediaConnect x 2 -> MediaLive Input -> MediaLive Channel の組み合わせです。
こちらも自動でリンクして関係性が一目でわかるのが理解できます。
アラート
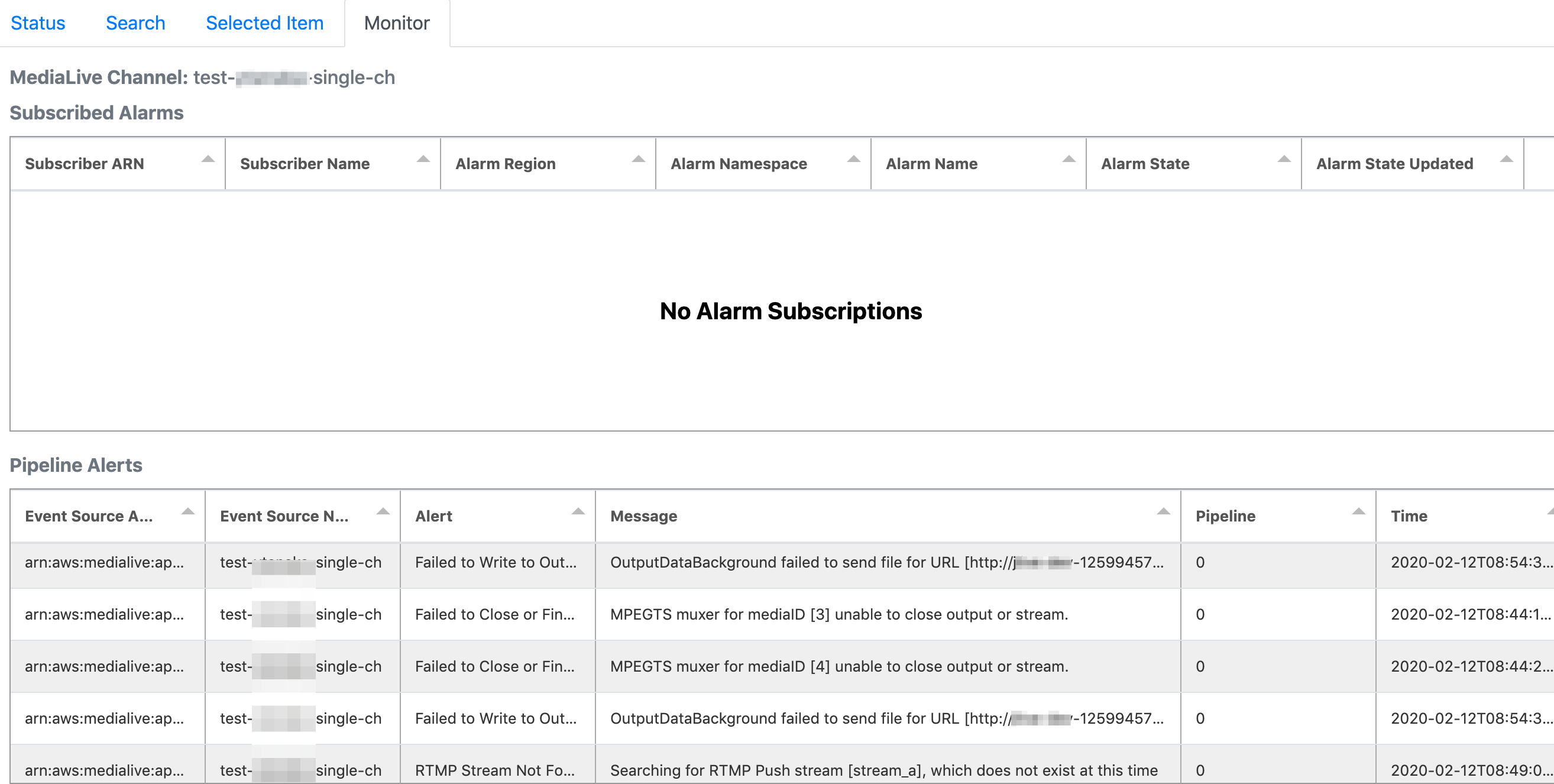
ダイアグラムページに表示されているリソースをクリックすると、
下部の "Monitor" タブにアラートのリストが表示されます。こちらは MediaLive のアラートリストです。
データはCloudWatch Logsから取得して自動リフレッシュされているようです。
一括で確認できる機能としては便利そうです。
クリーンアップ
作成したリソースは、CloudFormation から stack を削除するだけで完了です。
特にエラーでず s3 からデータを消したりなども不要でした。まとめ
いざ使うとなると、関係者で日々運用していく必要があるのと、MediaConnect数が数百とすでに多いせいか、TooManyRequestがたまに発生するようになりました。(本当に影響しているのかCloudTrailによる詳細の調査は必要。) また、既存のサービスに影響ないか事前に確認は必要そうです。しかし、中規模案件の定期的な構築確認・監視・運用では便利そうだと実感しました。


- 投稿日:2020-02-13T18:08:32+09:00
AWS Organizationsの設定をしたのでまとめました
はじめに
仕事でAWS Organizationsの設定をしたのでまとめました
前提
- サービスコントロールポリシーは登録済み
- IAMの細かい設定は割愛
AWS Organizations設定の流れ
1.アカウントの追加
2.アカウントの整理(OUの作成)
※サービスコントロールポリシーは前任者が設定してくれていたので、こちらの手順にはありません
3.IAMにてロールの設定
4.ロールの切り替え設定してみた
1.アカウントの追加
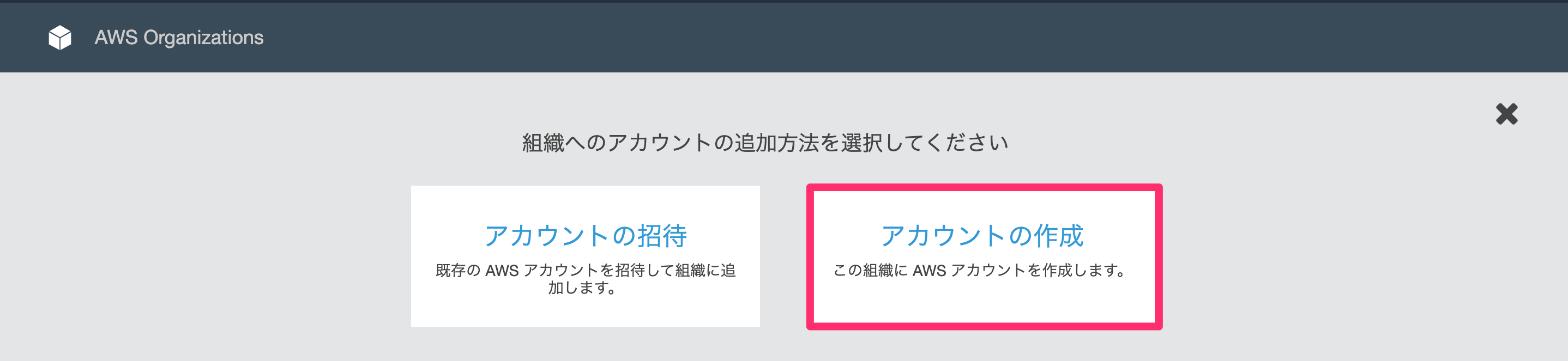
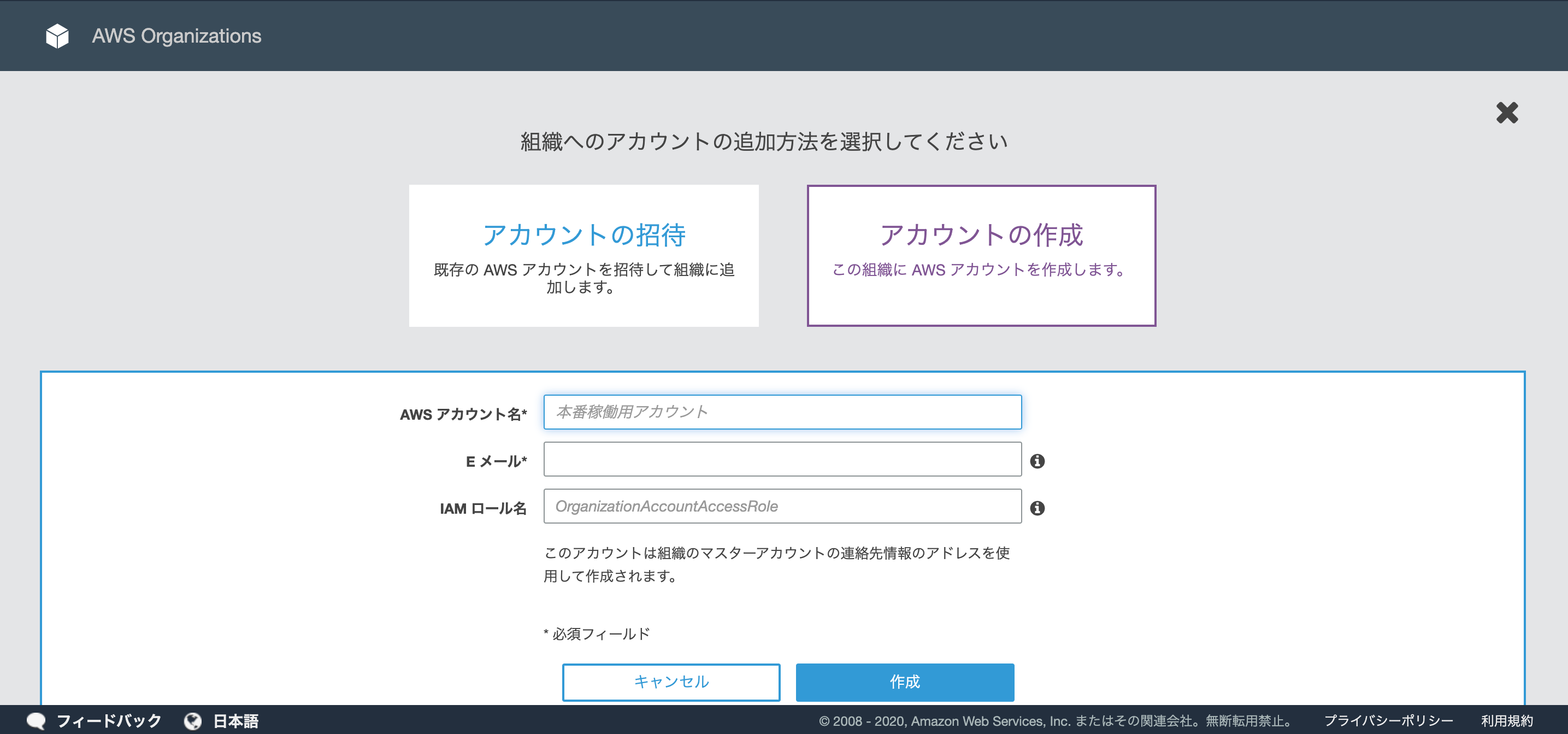
AWS Organizations コンソールにアクセスして、「アカウントの追加」ボタンをクリックします
「アカウントの作成」ボタンをクリックします
以下を入力して、「作成」ボタンをクリックすると、一覧にアカウントが追加されます
- AWSアカウント名(必須)
- Eメール(必須)
- IAM ロール名(任意)
- 未入力だと「OrganizationAccountAccessRole」になります
- 後ほど、IAMの設定で使用するのでメモしておくのを忘れずに
2.アカウントの整理(OUの作成)
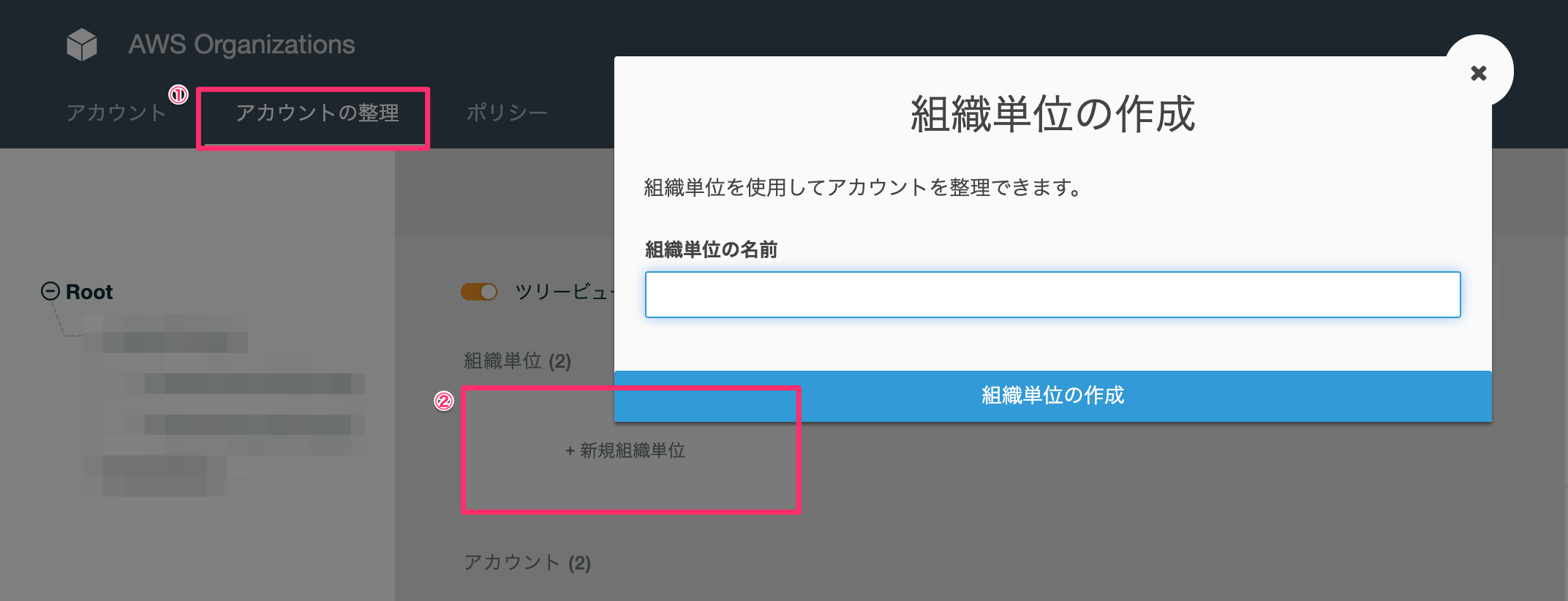
アカウントの管理(①)、新規組織単位(②)の順でクリック後、組織単位の名前を入力して、「組織単位の作成」ボタンをクリックします
組織のマスターアカウントにサインインすると、組織のルートに OU を作成できます。OU は、最大 5 レベルの深さまでネストできます。OU を作成するには、次のステップを完了します。
とあるので、5階層まで作成できるようです
「1.アカウントの追加」で追加したアカウントを選択(①)して、表示された「移動」のリンクをクリックします
移動する組織を選択(②)後、「移動」ボタンをクリックします
この操作でOUに組織アカウントが属するようになります3.IAMにてロールの設定
グループを作成して、ロールを設定しました
グループのアクセス許可タブにある「グループポリシーの作成」をクリックして、以下のようにカスタムポリシーを指定します
- [Sid] : 任意の値を指定
- [ID] : 「1.アカウントの追加」で追加したアカウントIDを指定(アカウントの一覧に表示されています)
- [roleName] : 「1.アカウントの追加」で入力した「IAM ロール名」。未入力の場合は「OrganizationAccountAccessRole」を指定
{ "Version": "2012-10-17", "Statement": [ { "Sid": "[Sid]", "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": [ "arn:aws:iam::[ID]:role/[roleName]" ] } ] }4.ロールの切り替え
AWSコンソールにログイン後、以下のURLで切り替えができます
[roleName]と[ID](3.IAMにてロールの設定と同じもの)はお使いの環境のものを指定してくださいhttps://signin.aws.amazon.com/switchrole?roleName=[roleName]&account=[ID]
まとめ
ざっくりとなりますが、AWS Organizationsを簡単にまとめました
ロールの名称のメモは忘れずにしましょう参考


- 投稿日:2020-02-13T16:37:14+09:00
【MongoDB】APIログ取るのに手軽で最高だった件 (+intellijだとさらに手軽)
はじめに
気にはなっていたけど、なかなか触れる機会が無かった。。
そんな、同じクラスのあの子のような存在、それがmongoDBでした。
実際、使ってみると手軽でとても使いやすい。こちらの記事では、簡単にインストールから導入までをまとめてみました。
MongoDBを使った開発内容
趣味の個人開発でMongoDBを利用しました。
[APIを利用したbitcoin自動売買システム]
- bitcoin値取得にCryptWatchAPIを使用
- bitcoin売買にBitflyerAPIを使用
- 開発言語:Node.js
- 開発環境:macOS Catalina
- デプロイ環境: AWS:EC2:ubuntu18.04LTS
MongoDBはbitcoin売買時の値段と、その売買判断に使われた値のログを取りたくて使用しました。
mongoDBとは
誤解を恐れずに極端に言うと、
データをJSON形式でレコードできるデータベースです
すいません! ここでは、わかりやすさ優先しましたm(_ _)m
(玄人の方々、マサカリ投げないでください。)他にも、
スケーラビリティ(拡張)しやすい、
スキーマレス(事前定義不要)である。 などなど、、ありますが、
詳しく知りたい方は以下のページをおすすめします。
詳しいオススメページ1
詳しいオススメページ2APIをレコードするのに最適!
mongoの特徴
- スキーマレスで、
- JSON形式
これが、APIを記録するのにすごく相性がいいです。
つまり、
APIからレスポンスされたJSONをそのままインサートすることができる!
さらに、
毎回APIの構造が変わってもそのままインサート可能!!
すごい楽ですね、
スキーマレスなので難しく考えず、ひとまず突っ込んで置くことができます。これが、RDBMSだとどうなるか?
- スキーマを細かく定義した上で、例外処理を施し構造が変わるものは省いてインサートする。
- string,textとしてまるごとインサート
どちらも大変です。。
受け取る可能性のあるJSON内容を想定して、スキーマを細かく定義した上で、
処理は、レスポンスされたJSONをカラムに収まるように全部分解したり、例外処理を書いたり。。
2つ目は、まる投げでインサートすればいいのですが、columnがTEXT形式でも文字数制限あります。
mysqlだと最大長が65,535(216 − 1)文字になります。データを利用するときはまた、JSON形式に戻して。。
うぅ、吐きそうです(;´Д`)
しかも、ノード同士の構造を捨てちゃってます。「今は何に使うかわかんないけどー、
あとで、面白いことに使いたいから、とりあえずサクッとデータ残しておこう♪」
こんなノリには、ぜひMongoDBです。私のbitcoin売買システムも、
将来、趣味で分析したり、機械学習で回せたらオモロイだろうなーってノリだけです。
使えそうな値と、APIをまるごと、とりあえずインサートおく。
APIの構造が多少変わっても気にしない。まずはその手軽さを触ってみることをオススメします。
それでは、簡単に導入方法をまとめます。インストール
macOS
brewを使って、簡単にインストールできます。
brew install mongodb #自動起動に設定 brew services start mongodbubuntu18.04LTS
ubuntuはやや面倒です。
aptの管理ライブラリが最新のMongDBとなっていないため、
Mongoの公式から、パッケージを展開してインストールする必要があります。#パッケージ管理システムに公開鍵を登録 sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 #ダウンロード用のリストファイルを作成 echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list #パッケージ管理システムのデータベースをリロード sudo apt-get update #最新の安定版をインストール sudo apt-get install -y mongodb-org #MongoDBを自動起動にする sudo systemctl enable mongod #MongoDBを起動 sudo service mongod startraspbrerryPi
ラズパイにMongDBの最新バージョンはインストールできません。
正しくは、
ラズパイの公式OS:RasbianOSには、MongDB version2.4.14以上はインストールできません。上記のMongoDBバージョンが、64bit対応のみとなっていますが、
RasbianOSが、32bitとなっているためです。実は、ラズパイ自体は64bitのため
OSに引きづられて最新のMongoDBが利用できなくなっています。
ですので、OSを入れ替えたら使用できるかもしれません。
詳しくはこちらmongo2.4以下だと、npmのmongoライブラリも対応していないため、
ラズパイでmongoDBを扱うのは特別な理由が無い限りあまりおすすめしないです。実装
データベースの設定
ターミナルからmongoにデータベースを作成して、利用できるようにします。
# MongoDBに入る mongo # データベース切り替え、作成 use db_name #データベースの確認 show dbs #使用しているデータベースを確認 db #コレクションの作成 db.createCollection("collect_name") #コレクションを確認 show collections #コレクションにドキュメントをインサート db.collect_name.insertOne({ name: "hoge", age: 88}) #コレクション内のドキュメントを確認 db.collect_name.find() # MongoDBから抜ける exitちょっと説明
- use db_name: データベースは無ければ、自動で作成されます。
- collection: mongoではtableでは無く、collectionと言います。
- document:mongoでは1つ1つのデータ(record)のことをdocumentと言います。
コード実装
Node.jsで実装しました。
以下はベースの実装例です。const MongoClient = require('mongodb').MongoClient; const options = { useUnifiedTopology : true, useNewUrlParser : true }; const url = 'mongodb://localhost:27017'; const dbName = 'db_name'; //即時関数と、asyncを定義 (async function () { let client; try { client = await MongoClient.connect( url, options, ); //DB取得 const db = client.db(dbName); //DBを操作 await insertDoc(db); await findDoc(db); } catch (err) { //接続失敗 console.log(err); } //接続を切る client.close(); })(); //Insert function insertDoc(db) { const collection = db.collection('collect_name'); collection.insertMany( [{ name: 'hoge', age: 88 }, { name: 'fuga', age: 14 }], (err, result) => { console.log('Success inserted'); }, ); } //Find function findDoc(db) { const collection = db.collection('collect_name'); collection.find({}).toArray((err, docs) => { //検索内容をコンソール出力 console.log(docs); }); }データ確認
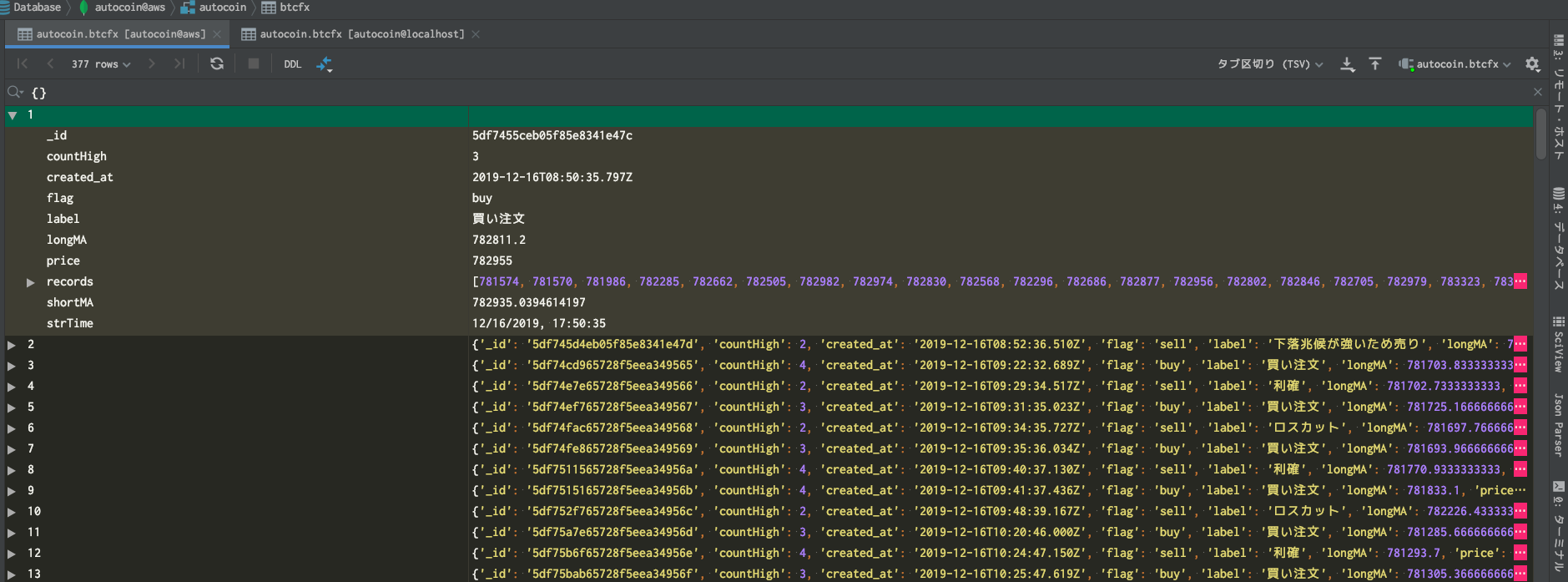
bitcoinの売買データをmongoで取得してみました。
標準のデータ確認
#terminalからの標準のデータ確認 { "_id" : ObjectId("5df9c2ba73160d276ad2e3ad"), "flag" : "buy", "label" : "買い注文", "created_at" : ISODate("2019-12-18T06:10:02.072Z"), "strTime" : "2019/12/18 15:10:02", "price" : 737491, "shortMA" : 737293.825779211, "longMA" : 736227.9333333333, "countHigh" : 4, "records" : [ 735413, 735522, 735314, 735516, 735691, 735913, 736276, 736316, 736366, 736788, 736586, 736472, 735565, 735245, 735327, 735259, 735677, 735745, 736058, 736238, 736448, 736713, 736388, 736426, 736954, 737198, 736975, 737479, 737479, 737491 ] }一部説明します
- _id: mongoから自動で振られるid
- created_at: ISODATE形式、datetime形式でinsertすることができます。
- shortMA: 過去5回分のpriceの移動平均金額を算出
- longMA: 過去30回分のpriceの移動平均金額を算出
- records: 過去のpriceリスト。リスト形式でそのままinsertしています。
データの形式がlistでも、さらにツリーが入れ子状態になっても、insertすることができます。
Intellij(jetBrains)を利用
CLIからだと、RDBMSよりも一覧性なくて見ずらいですね。データの閲覧はIDEや、ソフトをオススメします。
私は、IntelliJを使っています。
一度だけ接続設定をすれば、それ以後、ダブルクリックだけで、DBに接続してこのようにデータ閲覧できます。
ターミナルでコマンドを打つよりも、データ確認が手軽で早くて、見やすいです。本来は上記のようなJSON形式のnodeツリーが、テーブル表示で一覧できます。
クリックひとつでソートもできますし、絞り込みも簡単です。
ツリー形式での閲覧もできます。
transposed table 日本語で何形式と言うのでしょう?こんな閲覧方法もできます。
強いて不満を言えば、
table viewのとき、列の順番がバラバラとなるのが気になります。
(そもそもMongoDBにはDDLで読み取れるようなculumnの順番という概念がないのでしょうが無いです。)おわりに
MongDBは、お手軽で使い勝手がよいDBです。
APIデータを、今の時点ではどんな風に活用するか厳密に決めていないけど、
ひとまず導入しておいて後で考えるには、MongoDBは良い選択肢だと思います♪最後までお読みいただきありがとうございました。


- 投稿日:2020-02-13T15:30:38+09:00
AWS CLI v2 がGAになったのでをアップグレードしました。
はじめに
aws-cliのv2がGAになりました。
ということで早速アップグレードしてみたいと思います。
アップグレード
まずは現在のaws-cliのバージョンを確認します。
バージョン確認$ aws --version aws-cli/1.16.183 Python/3.6.2 Darwin/19.3.0 botocore/1.12.173それではインストールです。
パッケージダウンロード$ curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 19.9M 100 19.9M 0 0 5939k 0 0:00:03 0:00:03 --:--:-- 5939kインストール$ sudo installer -pkg AWSCLIV2.pkg -target / Password: installer: Package name is AWS Command Line Interface installer: Installing at base path / installer: The install was successful.インストールができたのでバージョンを確認します。
バージョン確認$ aws --version aws-cli/1.16.183 Python/3.6.2 Darwin/19.3.0 botocore/1.12.173あれ?なぜかアップグレードできてないです。。。
とりあえずパスを確認してみます。パス確認$ which aws /Users/hoge/.pyenv/shims/aws今回のインストール先は
/usr/local/bin/awsになるはず。。。バージョン確認$ /usr/local/bin/aws --version aws-cli/2.0.0 Python/3.7.4 Darwin/19.3.0 botocore/2.0.0dev4直接指定して確認するとやはりv2がインストールされています。
原因は.bash_profileでした。確認$ grep aws ~/.bash_profile complete -C '/Users/hoge/.pyenv/shims/aws_completer' awsこれを以下のように書き換えます。
修正$ grep aws ~/.bash_profile complete -C '/usr/local/bin/aws_completer' aws修正したら改めて読み込みます。
読み込み$ source .bash_profile改めてパス確認です。
パス確認$ which aws /usr/local/bin/awsパスが修正されたので改めてバージョンの確認をします。
バージョン確認$ aws --version aws-cli/2.0.0 Python/3.7.4 Darwin/19.3.0 botocore/2.0.0dev4ということで無事アップグレード完了です。
おわりに
今回、v1をpyenvで設定し、かつ
aws_completerも設定していたのを忘れていため、.bash_profileになかなか気づけずアップグレードするのに時間がかかってしまいました。
[参考URL]
・Installing the AWS CLI version 2 on macOS
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2-mac.html
・AWS Command Line Interface - コマンド補完
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-configure-completion.html
- 投稿日:2020-02-13T14:26:21+09:00
Chalice ー Python Serverless Microframework for AWS
PythonのAPIを作りたいと思って調べていたところ、Chaliceを見つけました。
今回はちょっとした備忘録記事です。Chaliceは一言で言えば、AWSによるPythonのサーバーレスフレームワークです。
AWSからGitHubに公開されており、怪しい挙動はきっとあまりしないでしょう。
https://github.com/aws/chaliceChaliceはデプロイするとApiGateway + lambdaを利用してサーバーレスに公開してくれます。
環境
- macOS Catalina 10.15.1
- python 3.6.4
- chalice 1.12.0
Chaliceのインストール
$ pip install chalice $ chalice --versionAWS IAMの設定
ApiGatewayとlambdaの操作権限を持つユーザーから操作しないとデプロイできません。
今回は簡単にポリシー「AdministratorAccess」を与えたユーザーから操作させます。
本当ならより権限を絞って最低限の開発ユーザーで..(略)IAMユーザ作成方法は以下を参考にしてください。
AWSアカウントでのIAMユーザの作成ハマったポイント
app.pyと.chaliceフォルダ内にある「config.json」のapp_nameが一致している必要があります。
config.json"app_name": "hoge-api"
app.pyapp = Chalice(app_name='hoge-api')一致していないとdeploy時、直接的な原因特定のしにくいエラーが吐き出されます。↓
❯ chalice deploy ... (略) ... botocore.exceptions.ConnectionClosedError: Connection was closed before we received a valid response from endpoint URL: "https://lambda.ap-northeast-1.amazonaws.com/2015-03-31/functions".参考
20190619 AWS Black Belt Online Seminar Dive Deep into AWS Chalice
Chaliceのすゝめ AWSにWebApiをサーバーレスで構築する
Chaliceのすゝめ その2 WebApiに認証を追加する
How to create a thumbnail API service in 5 minutes
- 投稿日:2020-02-13T13:14:41+09:00
FluentdをMacでセットアップして、CloudWatchLogsへログ転送するまで
はじめに
実務で、ローカルで稼働しているMac miniが複数台あるので、それをCloudWatchLogsへ集約したいという要望があったので、勉強がてらFluentDを使った時の備忘録的なアレです
色々、試行錯誤しながら試したので、同じくハマっている人の助けになればと思います
失敗パターン
td-agentを使って、cloudwatchLogsに転送させる設定をしようとしたが、ripperが足りない?せいか、以下のエラーが発生して、td-agent内包のRubyを使っているため、これ以上は自力解決が難しいと思い、断念
`require': cannot load such file -- ripper (LoadError)やったこと
Fluentd公式から、MacOS向けのtd-agent.dmgをDLして、セットアップ
https://docs.fluentd.org/installation/install-by-dmgCloudWatchLogsに飛ばすためのPluginは、ここからDL
https://github.com/fluent-plugins-nursery/fluent-plugin-cloudwatch-logsREADME.md通りに、
gem install fluent-plugin-cloudwatch-logsを実行しても、td-agent自体が、そのものに内包されているRuby(2.4)を使用してるっぽいので、エラーになるStarting td-agent: 2018-05-31 01:27:51 +0000 [error]: fluent/supervisor.rb:373:rescue in main_process: config error file="/etc/td-agent/td-agent.conf" error="Unknown output plugin 'cloudwatch_logs'. Run 'gem search -rd fluent-plugin' to find plugins" td-agent
- td-agentを使っている場合は、td-agent-gemを使用して、インストールする
インストールコマンド
/opt/td-agent/usr/sbin/td-agent-gem install <プラグイン>インストール済みリストを取得
/opt/td-agent/usr/sbin/td-agent-gem list参考にしたリンク
https://qiita.com/nkg/items/cbf72adb436456804d76
成功パターン
td-agentだと、内包されているRubyを使う方法だったので、すでにインストールされてるRubyを使う方法を採用しました
下記を実行すると、CloudWatchLogsへ、自動的にログストリームが作成され、ログが出力されるようになりましたやったこと
- gem版のFluentdをインストール→セットアップ
# Fluentdのインストール $gem install fluentd -N # セットアップ $ fluentd --setup ./fluent`https://docs.fluentd.org/installation/install-by-gem
- gemを使って、CloudWatchLogs-Pluginをインストール
# fluentd-cloudwatch-logs-pluginをインストール gem install fluent-plugin-cloudwatch-logs
- fluentd.confファイルを編集
<source> @type tail path ./logs/logger.log tag sample <parse> @type multiline format_firstline /\[(\d{4}-\d{2}-\d{2}T\d{1,2}:\d{1,2}:\d{1,2}.\d{1,3})\]/ format1 /^\[(?<logtime>\d{4}-\d{2}-\d{2}T\d{1,2}:\d{1,2}:\d{1,2}.\d{1,3})\] \[(?<lebel>.*)\] (?<hoge>.*) - \[(?<title>.*)\] (?<message>.*)/ </parse> </source> <match sample> @type cloudwatch_logs log_group_name test auto_create_stream true use_tag_as_stream true </match>
- IAM User Policyの設定
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:*", "s3:GetObject" ], "Resource": [ "arn:aws:logs:us-east-1:*:*", "arn:aws:s3:::*" ] } ] }
- AWSのアクセスキーとシークレットキーを環境変数に登録
export AWS_REGION=us-east-1 export AWS_ACCESS_KEY_ID="YOUR_ACCESS_KEY" export AWS_SECRET_ACCESS_KEY="YOUR_SECRET_ACCESS_KEY"
fluentdを起動&停止
- 起動
fluentd -c ./fluent/fluent.conf -o ~/Desktop/tmp/fluentd.log -vv &- 停止
pkill -f fluentdまとめ
初めてFluentdを使って、ログの収集を行いましたが、ドキュメントがかなり充実していたので、ハマりはしたものの設定ファイルを作る等は、そこまで苦労しませんでした。
いろんなPluginがあるので、まだまだ色々できそうな気がしています。
また、Fluentdとtd-agentでの挙動が違ったりする場合があるので、調査の時には注意が必要かなと思いました。
- 投稿日:2020-02-13T13:14:41+09:00
FluentDをMacでセットアップして、CloudWatchLogsへログ転送するまで
はじめに
実務で、ローカルで稼働しているMac miniが複数台あるので、それをCloudWatchLogsへ集約したいという要望があったので、勉強がてらFluentDを使った時の備忘録的なアレです
色々、試行錯誤しながら試したので、同じくハマっている人の助けになればと思います
失敗パターン
td-agentを使って、CloudWatchLogsに転送させる設定をしようとしたが、ripperが足りない?せいか、以下のエラーが発生して、td-agent内包のRubyを使っているため、これ以上は自力解決が難しいと思い、断念
`require': cannot load such file -- ripper (LoadError)やったこと
FluentD公式から、MacOS向けのtd-agent.dmgをDLして、セットアップ
https://docs.fluentd.org/installation/install-by-dmgCloudWatchLogsに飛ばすためのPluginは、ここからDL
https://github.com/fluent-plugins-nursery/fluent-plugin-cloudwatch-logsREADME.md通りに、
gem install fluent-plugin-cloudwatch-logsを実行しても、td-agent自体が、そのものに内包されているRuby(2.4)を使用してるっぽいので、エラーになるStarting td-agent: 2018-05-31 01:27:51 +0000 [error]: fluent/supervisor.rb:373:rescue in main_process: config error file="/etc/td-agent/td-agent.conf" error="Unknown output plugin 'cloudwatch_logs'. Run 'gem search -rd fluent-plugin' to find plugins" td-agent
- td-agentを使っている場合は、td-agent-gemを使用して、インストールする
インストールコマンド
/opt/td-agent/usr/sbin/td-agent-gem install <プラグイン>インストール済みリストを取得
/opt/td-agent/usr/sbin/td-agent-gem list参考にしたリンク
https://qiita.com/nkg/items/cbf72adb436456804d76
成功パターン
td-agentだと、内包されているRubyを使う方法だったので、すでにインストールされてるRubyを使う方法を採用しました
下記を実行すると、CloudWatchLogsへ、自動的にログストリームが作成され、ログが出力されるようになりましたやったこと
- gem版のFluentDをインストール→セットアップ
# FluentDのインストール $gem install fluentd -N # セットアップ $ fluentd --setup ./fluent`https://docs.fluentd.org/installation/install-by-gem
- gemを使って、CloudWatchLogs-Pluginをインストール
# fluentd-cloudwatch-logs-pluginをインストール gem install fluent-plugin-cloudwatch-logs
- fluentd.confファイルを編集
<source> @type tail path ./logs/logger.log tag sample <parse> @type multiline format_firstline /\[(\d{4}-\d{2}-\d{2}T\d{1,2}:\d{1,2}:\d{1,2}.\d{1,3})\]/ format1 /^\[(?<logtime>\d{4}-\d{2}-\d{2}T\d{1,2}:\d{1,2}:\d{1,2}.\d{1,3})\] \[(?<lebel>.*)\] (?<hoge>.*) - \[(?<title>.*)\] (?<message>.*)/ </parse> </source> <match sample> @type cloudwatch_logs log_group_name test auto_create_stream true use_tag_as_stream true </match>
- IAM User Policyの設定
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:*", "s3:GetObject" ], "Resource": [ "arn:aws:logs:us-east-1:*:*", "arn:aws:s3:::*" ] } ] }
- AWSのアクセスキーとシークレットキーを環境変数に登録
export AWS_REGION=us-east-1 export AWS_ACCESS_KEY_ID="YOUR_ACCESS_KEY" export AWS_SECRET_ACCESS_KEY="YOUR_SECRET_ACCESS_KEY"
fluentdを起動&停止
- 起動
fluentd -c ./fluent/fluent.conf -o ~/Desktop/tmp/fluentd.log -vv &- 停止
pkill -f fluentdまとめ
初めてFluentDを使って、ログの収集を行いましたが、ドキュメントがかなり充実していたので、ハマりはしたものの設定ファイルを作る等は、そこまで苦労しませんでした。
いろんなPluginがあるので、まだまだ色々できそうな気がしています。
また、FluentDとtd-agentでの挙動が違ったりする場合があるので、調査の時には注意が必要かなと思いました。
- 投稿日:2020-02-13T12:47:39+09:00
Amazon ECS - Blue/Green デプロイでALBのターゲットグループを変更
ALBのターゲットグループ
bluegreen-target1でタスクを起動させる。
CodeDeploy でbluegreen-target2に変更させる。1.ALB
ロードバランサー
aws elbv2 create-load-balancer \ --name bluegreen-alb \ --subnets subnet-00000000000000000 subnet-00000000000000000 \ --security-groups sg-00000000000000000 \ターゲットグループ
aws elbv2 create-target-group \ --name bluegreen-target1 \ --protocol HTTP \ --port 80 \ --target-type ip \ --vpc-id vpc-00000000000000000リスナー
aws elbv2 create-listener \ --load-balancer-arn arn:aws:elasticloadbalancing:ap-northeast-1:000000000000:loadbalancer/app/bluegreen-alb/ae66a1b7b0611f6c \ --protocol HTTP \ --port 80 \ --default-actions Type=forward,TargetGroupArn=arn:aws:elasticloadbalancing:ap-northeast-1:000000000000:targetgroup/bluegreen-target1/443d84907a4e35e32.ECSクラスター
aws ecs create-cluster \ --cluster-name bluegreen-cluster3.タスク定義
task-definitions.json{ "family": "task-definitions", "networkMode": "awsvpc", "containerDefinitions": [ { "name": "sample-app", "image": "httpd:2.4", "portMappings": [ { "containerPort": 80, "hostPort": 80, "protocol": "tcp" } ], "essential": true, "entryPoint": [ "sh", "-c" ], "command": [ "/bin/sh -c \"echo '<html> <head> <title>Amazon ECS Sample App</title> <style>body {margin-top: 40px; background-color: #333;} </style> </head><body> <div style=color:white;text-align:center> <h1>Amazon ECS Sample App</h1> <h2>Congratulations!</h2> <p>Your application is now running on a container in Amazon ECS.</p> </div></body></html>' > /usr/local/apache2/htdocs/index.html && httpd-foreground\"" ] } ], "requiresCompatibilities": [ "FARGATE" ], "cpu": "256", "memory": "512", "executionRoleArn": "arn:aws:iam::268546037544:role/ecsTaskExecutionRole" }aws ecs register-task-definition \ --cli-input-json file://task-definitions.json4.サービス
service.json{ "cluster": "bluegreen-cluster", "serviceName": "service-bluegreen", "taskDefinition": "task-definitions", "loadBalancers": [ { "targetGroupArn": "arn:aws:elasticloadbalancing:ap-northeast-1:000000000000:targetgroup/bluegreen-target1/443d84907a4e35e3", "containerName": "sample-app", "containerPort": 80 } ], "launchType": "FARGATE", "schedulingStrategy": "REPLICA", "deploymentController": { "type": "CODE_DEPLOY" }, "platformVersion": "LATEST", "networkConfiguration": { "awsvpcConfiguration": { "assignPublicIp": "ENABLED", "securityGroups": [ "sg-00000000000000000" ], "subnets": [ "subnet-00000000000000000", "subnet-00000000000000000" ] } }, "desiredCount": 1 }aws ecs create-service \ --cli-input-json file://service.json5. CodeDeploy
aws deploy create-application \ --application-name bluegreen-app \ --compute-platform ECSaws elbv2 create-target-group \ --name bluegreen-target2 \ --protocol HTTP \ --port 80 \ --target-type ip \ --vpc-id "vpc-00000000000000000"deployment-group.json{ "applicationName": "bluegreen-app", "autoRollbackConfiguration": { "enabled": true, "events": [ "DEPLOYMENT_FAILURE" ] }, "blueGreenDeploymentConfiguration": { "deploymentReadyOption": { "actionOnTimeout": "CONTINUE_DEPLOYMENT", "waitTimeInMinutes": 0 }, "terminateBlueInstancesOnDeploymentSuccess": { "action": "TERMINATE", "terminationWaitTimeInMinutes": 5 } }, "deploymentGroupName": "bluegreen-deploymentgroup", "deploymentStyle": { "deploymentOption": "WITH_TRAFFIC_CONTROL", "deploymentType": "BLUE_GREEN" }, "loadBalancerInfo": { "targetGroupPairInfoList": [ { "targetGroups": [ { "name": "bluegreen-target1" }, { "name": "bluegreen-target2" } ], "prodTrafficRoute": { "listenerArns": [ "arn:aws:elasticloadbalancing:ap-northeast-1:000000000000:listener/app/bluegreen-alb/ae66a1b7b0611f6c/020fcdaa33680028" ] } } ] }, "serviceRoleArn": "arn:aws:iam::000000000000:role/ecsCodeDeployRole", "ecsServices": [ { "serviceName": "service-bluegreen", "clusterName": "bluegreen-cluster" } ] }aws deploy create-deployment-group \ --cli-input-json file://deployment-group.jsonappspec.yamlversion: 0.0 Resources: - TargetService: Type: AWS::ECS::Service Properties: TaskDefinition: "arn:aws:ecs:ap-northeast-1:000000000000:task-definition/task-definitions:3" LoadBalancerInfo: ContainerName: "sample-app" ContainerPort: 80 PlatformVersion: "LATEST"aws s3 mb s3://naata-bluegreen-bucket aws s3 cp ./appspec.yaml s3://naata-bluegreen-bucket/appspec.yamlcreate-deployment.json{ "applicationName": "bluegreen-app", "deploymentGroupName": "bluegreen-deploymentgroup", "revision": { "revisionType": "S3", "s3Location": { "bucket": "naata-bluegreen-bucket", "key": "appspec.yaml", "bundleType": "YAML" } } }aws deploy create-deployment \ --cli-input-json file://create-deployment.json■リンク
- 投稿日:2020-02-13T11:53:49+09:00
AWS CLI v2をsudoを使わずにインストールする
忙しい方へ
インストール先はrootユーザのディレクトリなので、そうじゃないディレクトリに置いてパスを通すことができるよ、というだけです。
これで何をやってるかわかるのであれば以後は読まなくていいかもw本題
今週、AWS CLIのV2がGAになりました。
AWSのブログ
クラスメソッドさんのブログ個人的にはまだ全然試せてないのでこれからなんですが、使うにはまずはインストールしなければいけないですよね。
インストールの方法は公式に載っています。
自分の環境は仕事でも個人でもMacなのですが、もともとcliはbrewでインストールしてました。
何かしらのパッケージマネージャによって管理される状態にしておきたかったからですね。なのでできたらbrewで行きたかったんですが、これを書いている時点ではまだbrewではインストールできません。
(なので、brewでインストールできるようになったらこの内容は不要かもしれません。)インストールの手順を抜粋すると下記です。
Macでのインストール手順ですが、対象のファイルが変わるだけでLinuxでの手順もほぼ同様です。Macでのインストール手順curl "https://d1vvhvl2y92vvt.cloudfront.net/awscli-exe-macos.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install問題なのは
sudo ./aws/installで、仕事用のPCのユーザでは管理者権限を制限されていてsudoできない、なんてことがあるかと思います。
そうしたらせっかく試そうと思ったのに試せないじゃん、となっちゃいますが、回避する方法がきちんとドキュメントに書いてあるのでここに残しておきます。インストールスクリプトの中身
./aws/installの中身は全部抜粋すると長くなるので割愛しますが、ざっくりいうと/usr/local/aws-cliというディレクトリを作ってその中に動作させるプログラムを配置し、/usr/local/bin/aws2というシンボリックリンクを作成する、という動作をするようです。
sudoさせられるのは、通常/usr以下に書き込むにはroot権限が必要な状態になっているからかと思います。
/usr/loca/binにシンボリックリンクを置くのはPATHが通っているディレクトリにシンボリックリンクを置いてどこからでも使えるようにするためでしょう。
(記憶が曖昧なんですが、そもそもデフォルトでPATH通ってましたっけ…?)※そもそもこのディレクトリなんなのみたいな話は話が逸れるので参考サイトを置いておきます
https://linuc.org/study/knowledge/544/ただ、インストール先のディレクトリとシンボリックリンクを置くディレクトリは変更することができる、と書いてあります。
以下ドキュメントから抜粋
--install-dir または -i
このオプションは、すべてのファイルをコピーするフォルダを指定します。次の例では、/usr/local/aws-cli という名前のフォルダにファイルをインストールします。このフォルダを作成するには、/usr/local への書き込み権限が必要です。
デフォルト値は /usr/local/aws-cli です。
--bin-dir または -b
このオプションは、インストールフォルダ内のメイン aws プログラムが、指定されたパス内のファイル aws2 にシンボリックリンクされるように指定します。この例では、シンボリックリンク /usr/local/bin/aws2 を作成します。指定したフォルダへの書き込み権限が必要です。パスにすでに存在するフォルダへのシンボリックリンクを作成すると、インストールディレクトリをユーザーの $PATH 変数に追加する必要がなくなります。
デフォルト値は /usr/local/bin です。
つまり、適当なディレクトリにファイルを置いて、自分でPATHを通した任意のディレクトリにシンボリックリンクを配置することでsudoを使わないでインストールすることができます。
インストール先ディレクトリを変える
自分の場合は使っているユーザのホームディレクトリ配下に下記のようなディレクトリを作りました。
ディレクトリを作成し、PATHを通す
mkdir $HOME/awscli2 mkdir $HOME/local/binもちろん
$HOME/local/binにはPATHを通してあります。Bashの場合は
~/.bash_profileに.bash_profileexport PATH=$PATH:$HOME/local/binを追記して
.bash_profileを読み込み直しましょう。
source ~/.bash_profileを実行するか、ターミナルを立ち上げ直せばOKです。自分はfishを使っているのでユニバーサル変数に追加しています。
fishの環境変数の設定の仕方はbashとはちょっと違ってやや混乱するので注意。
.fish/config/config.fishに環境変数を設定するコマンドを追記するのでもいいと思います(お好みで)
ただ、下記は永続的な設定なので.fish/config/config.fishのではなくターミナルで一回実行するだけにしましょう。
$fish_user_pathsの中身が間違って空になったりすると後で面倒なことになります(1敗)
参考
https://qiita.com/ledsun/items/8ca1a450b21c8ebc9670fishset -U fish_user_paths $HOME/local/bin $fish_user_pathsオプション指定してインストールする
その上で、インストール時にこんな感じでオプション指定しました。
※環境変数でホームディレクトリ指定してますが、実際にはフルパス指定しています。./aws/install -i $HOME/awscli2/ -b $HOME/local/bin/これで実行できるようになります、なお、現在はv1との併用のため
aws2という名前でシンボリックリンクが作られます。aws2 --version aws-cli/2.0.0dev4 Python/3.7.4 Darwin/18.7.0 botocore/2.0.0dev3ドキュメントより
AWS CLI バージョン 2 のプレビューリリースでは、AWS CLI バージョン 1 とバージョン 2 がサイドバイサイドで共存できるよう、シンボリックリンクに aws2 という名前が付けられます。AWS CLI バージョン 2 の今後のリリースでは、このコマンド名が変更される可能性があります。
ともあれ、これでV2になったaws cliを試すことができるようになりました。
気になるポイント
- あくまでも手動インストールなのでアップデートがあったら自分でやらなきゃいけないこと
- 一部下位互換性のない変更がある
関連
venvを使ってAWS CLI(v1)とAWS CLI v2を使い分ける(Mac, Linux編)
AWS CLI v2をソースコードからインストールする
- 投稿日:2020-02-13T11:42:00+09:00
AWS S3にAngularのプロジェクトを配置して公開する(初心者向け)
S3×Angularということで、S3にAngularのプロジェクトを置いて、ホスティングする方法です。
セキュリティ周りに関しては説明していません。とにかく公開したい人向けです。
S3のバケットを作る
用語
バケット…フォルダの一つ上の概念容量無制限のハードディスクみたいなもの。バケット名は世界中で一意である。
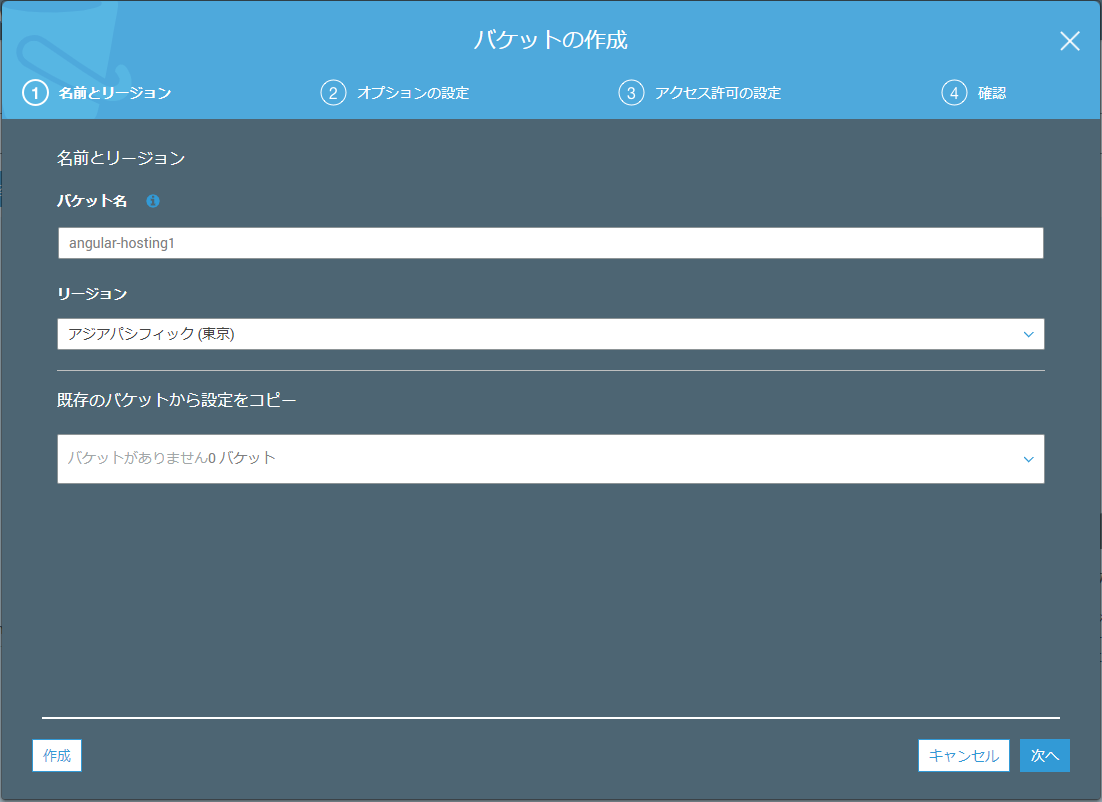
バケット作成手順1(バケット名を決める)
世界で一つだけのバケット名を決めてください。
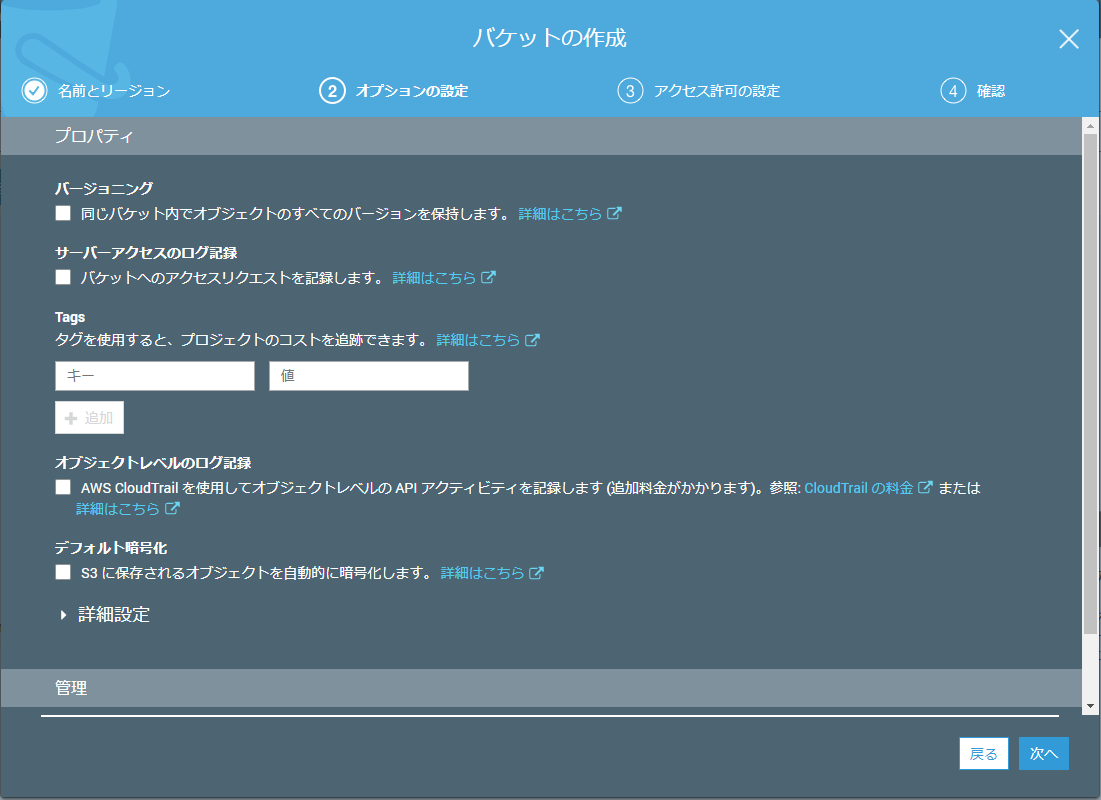
バケット作成手順2(オプションの設定)
今回はそのまま「次へ」を押下してください。
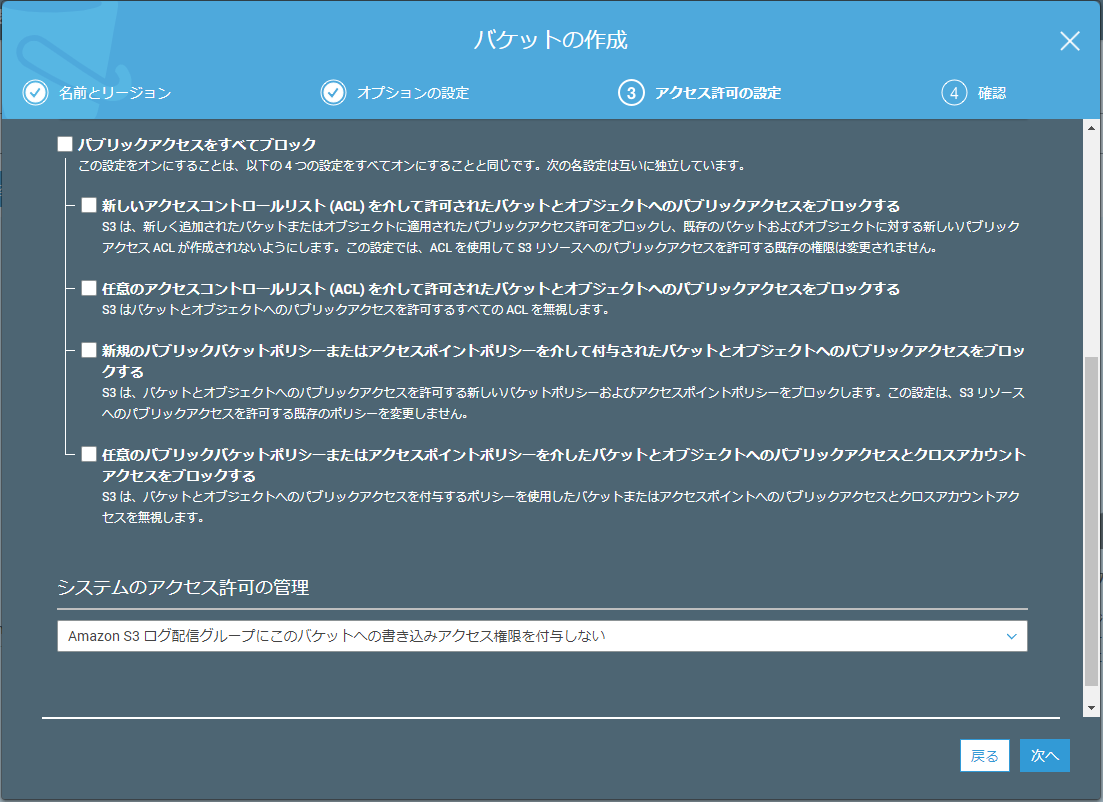
バケット作成手順3(アクセス許可の設定)
ここでは、アップロードされるファイルに対するアクセスに誰をブロックするかを指定します。今回はひとまずすべてのチェックを外します。
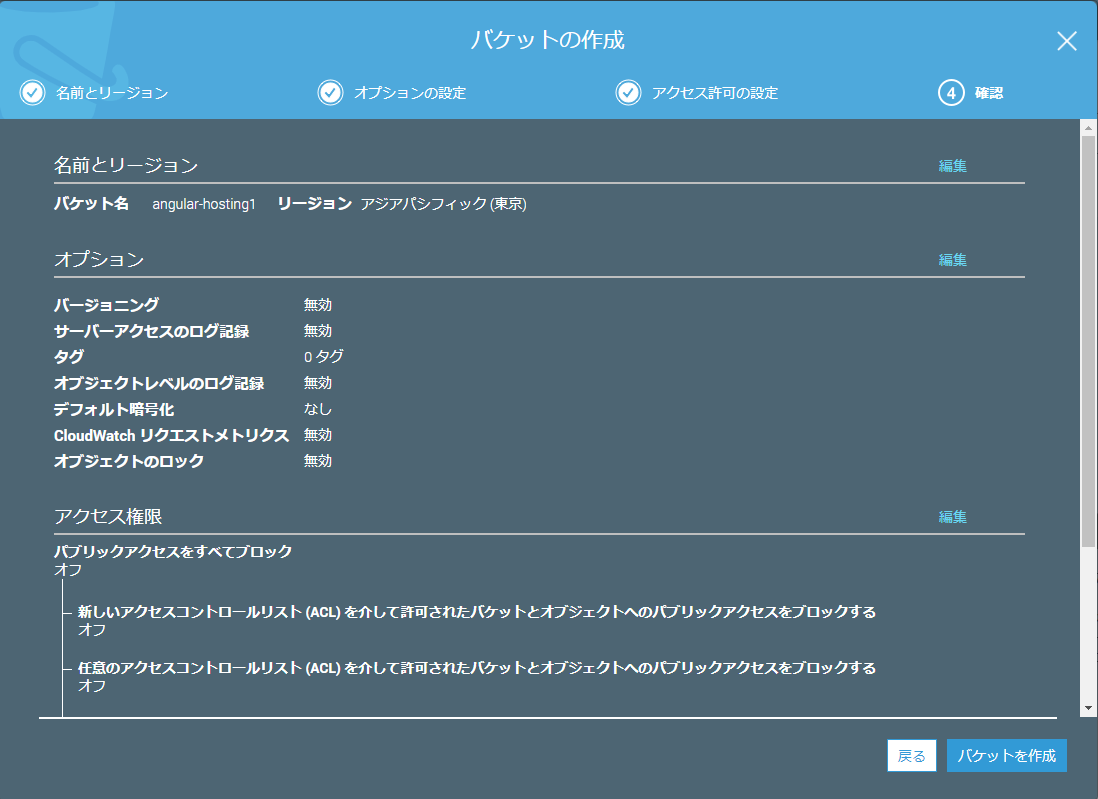
バケット作成手順4(確認)
確認画面が表示されるので「バケットを作成」を押下するとバケットが作られます。
【Tips】AWS CLIを使うと
AWS CLIを使えば
aws s3 lsで作ったバケットを確認できます。
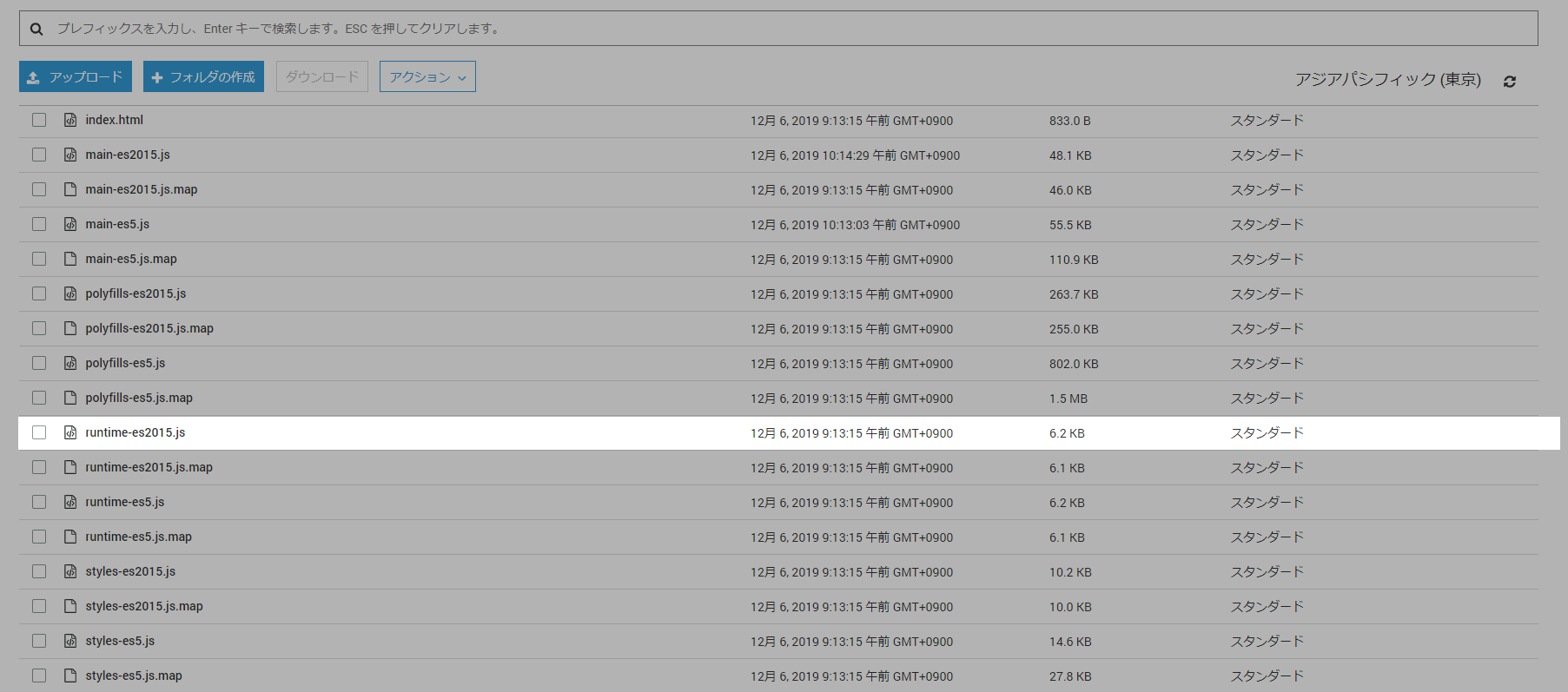
作ったバケットにAngularの資材を配置する
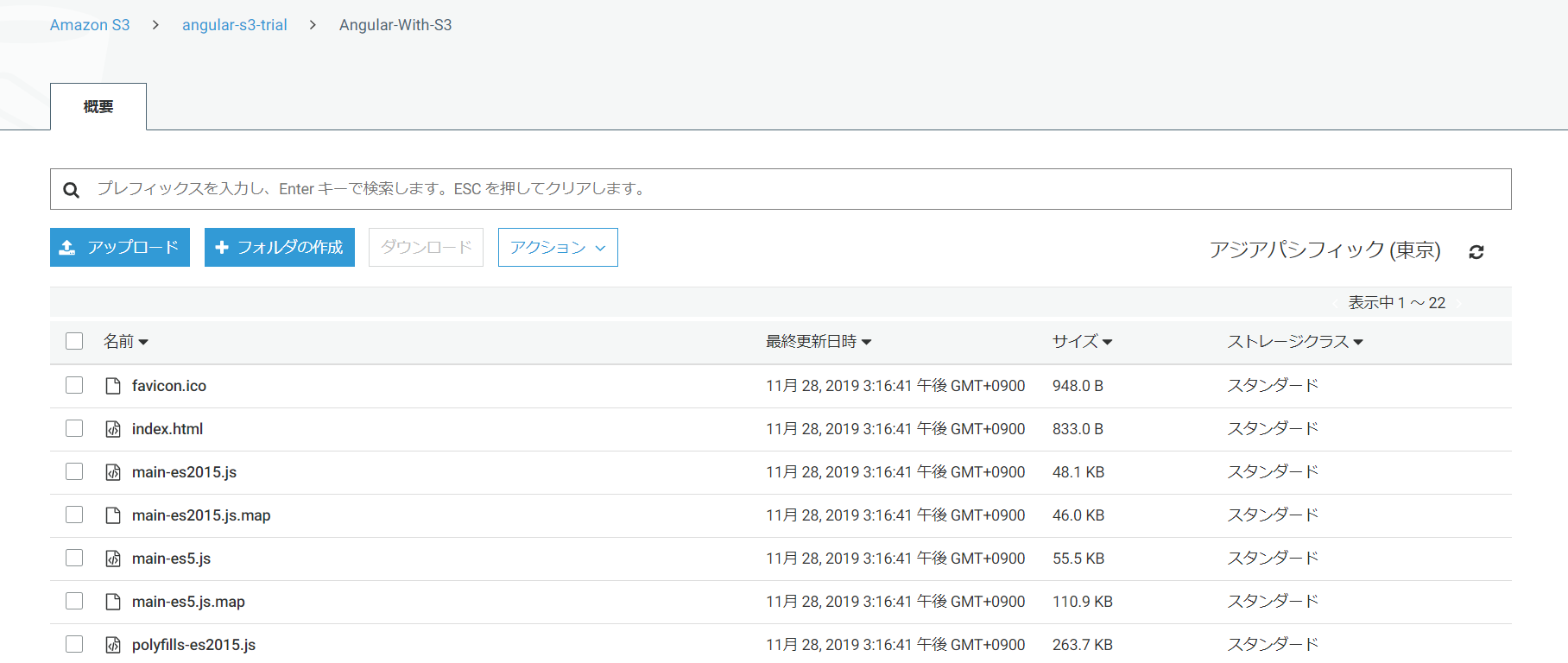
ng buildコマンドをAngularのプロジェクト配下で実行すると
/distディレクトリにコンパイルされたファイルが生成されます。これを上記で作ったS3のバケットにアップロードします。方法は2つ。
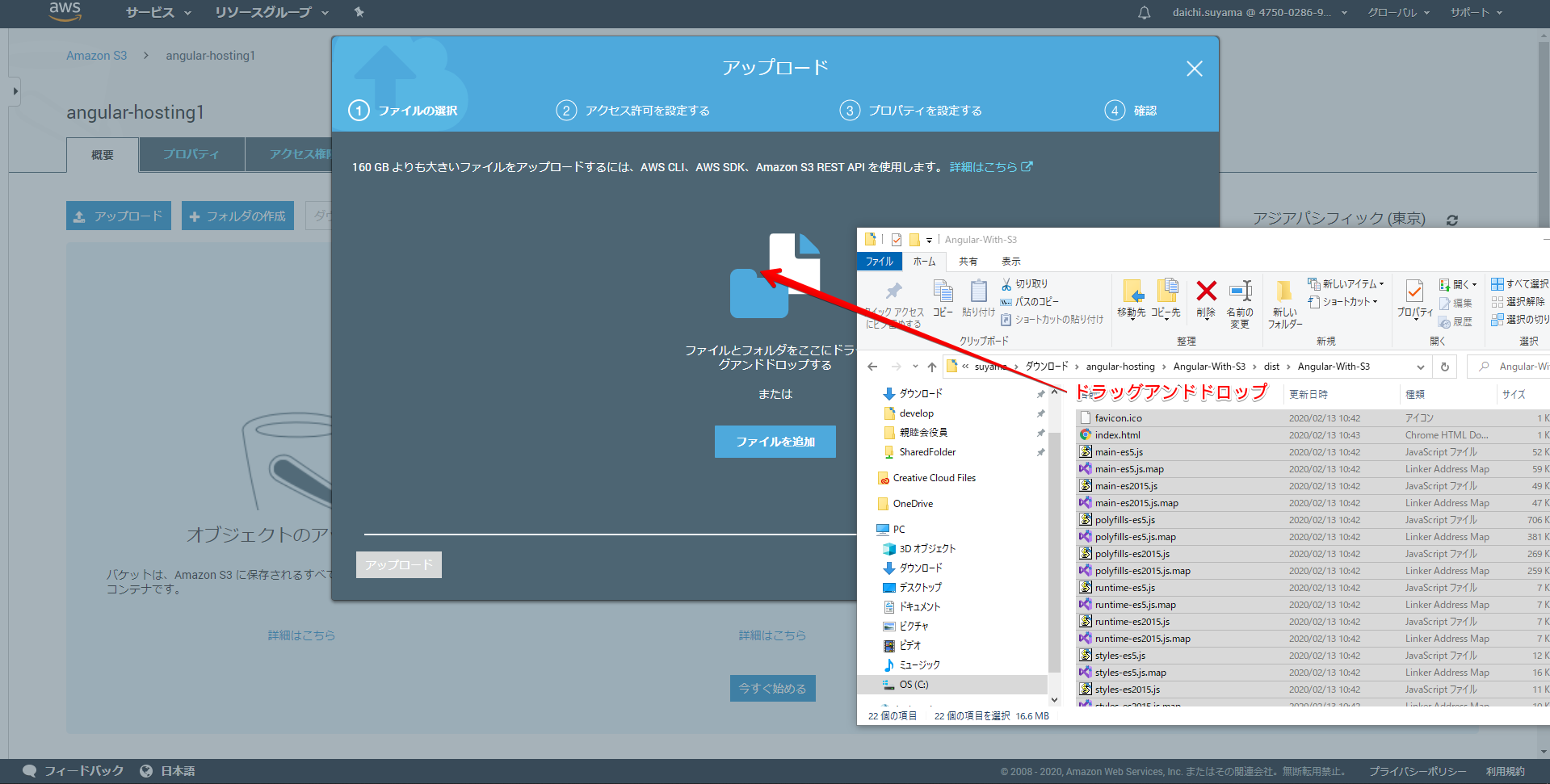
【方法1】GUIで!
先ほど作成したバケットに下記の通りドラッグアンドドロップなどでdist/プロジェクト名フォルダ内
を全選択してアップロードします。
「アップロード」を押下します
【方法2】CUIで!
aws s3 sync dist/Angularのプロジェクト名 s3://作成したバケット名 > 例:aws s3 sync dist/Angular-With-S3 s3://angular-s3-trial
ホスティング(公開するため)の設定をする
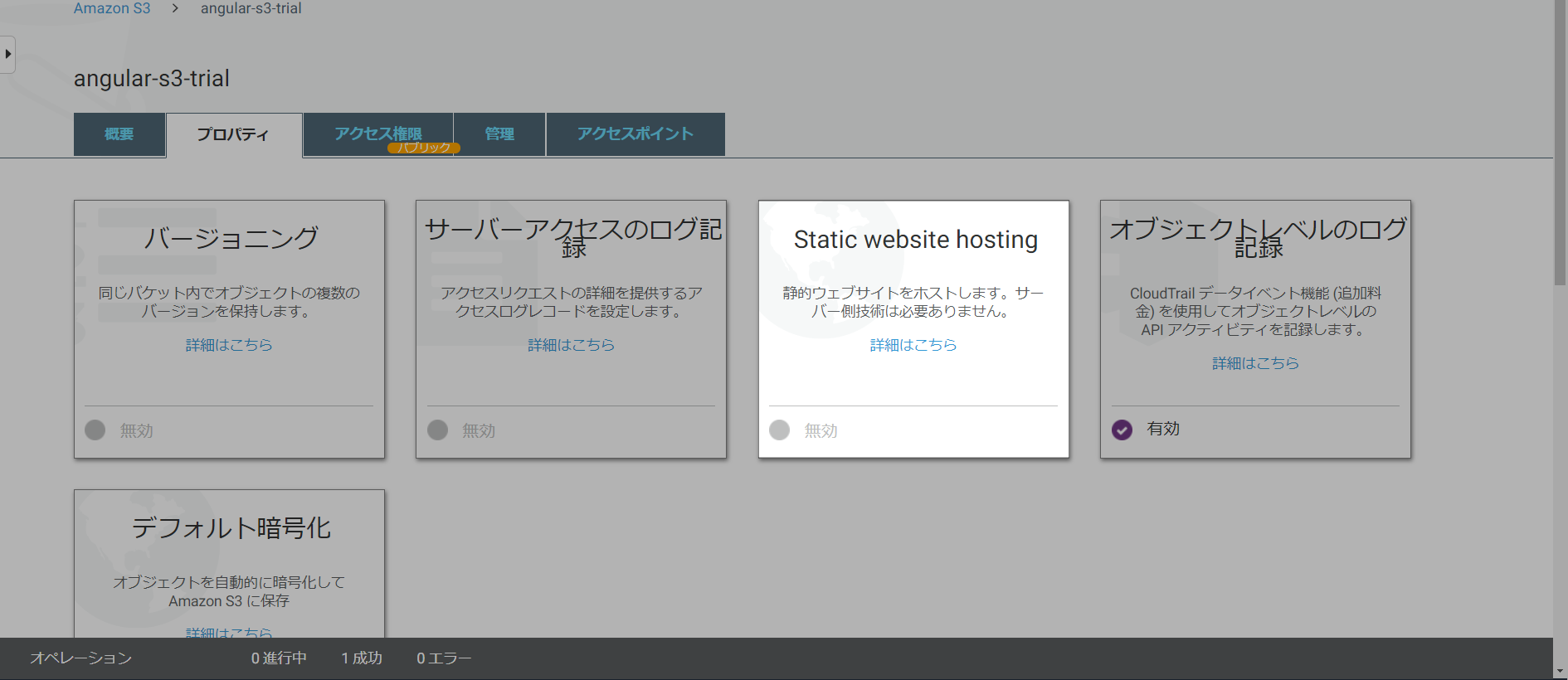
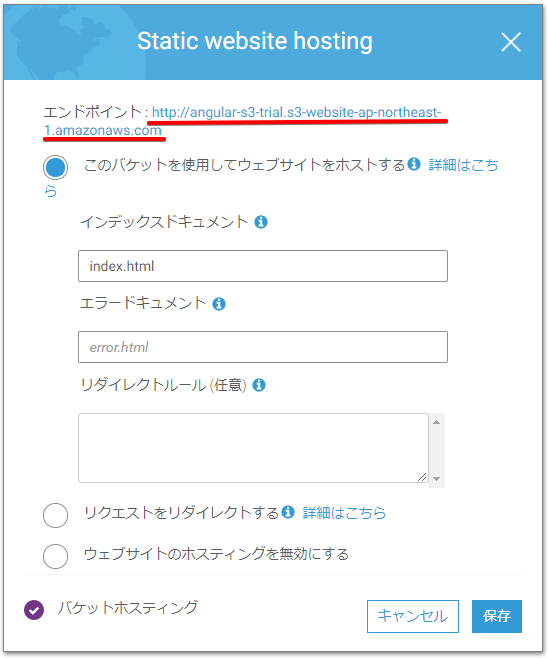
設定1(ホスティングの設定)
バケットを選択するとサイドバーが出現するので「プロパティ」をクリック
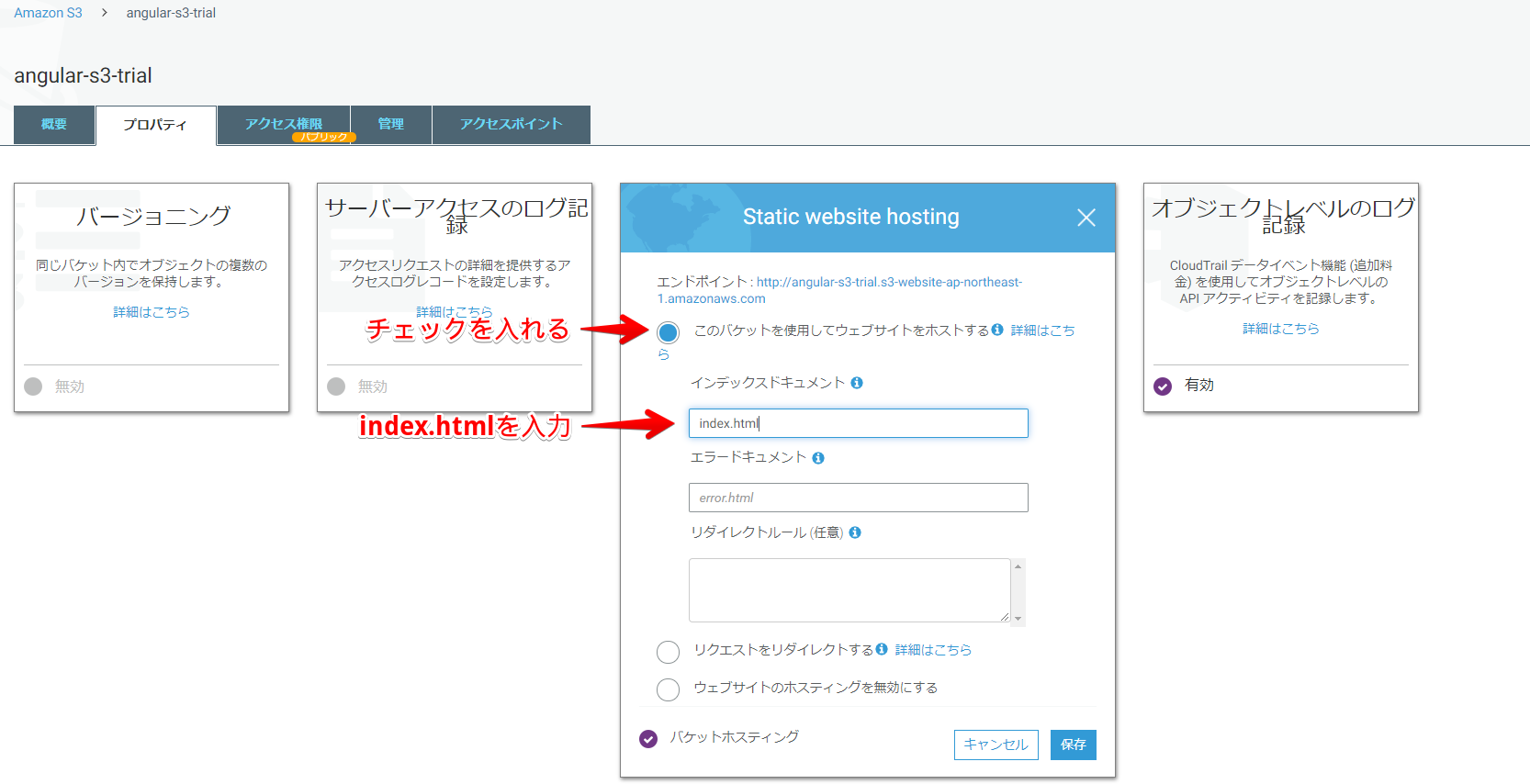
「Static website hosting」からホスティングのための設定をします。
設定2(バケットポリシーの設定)
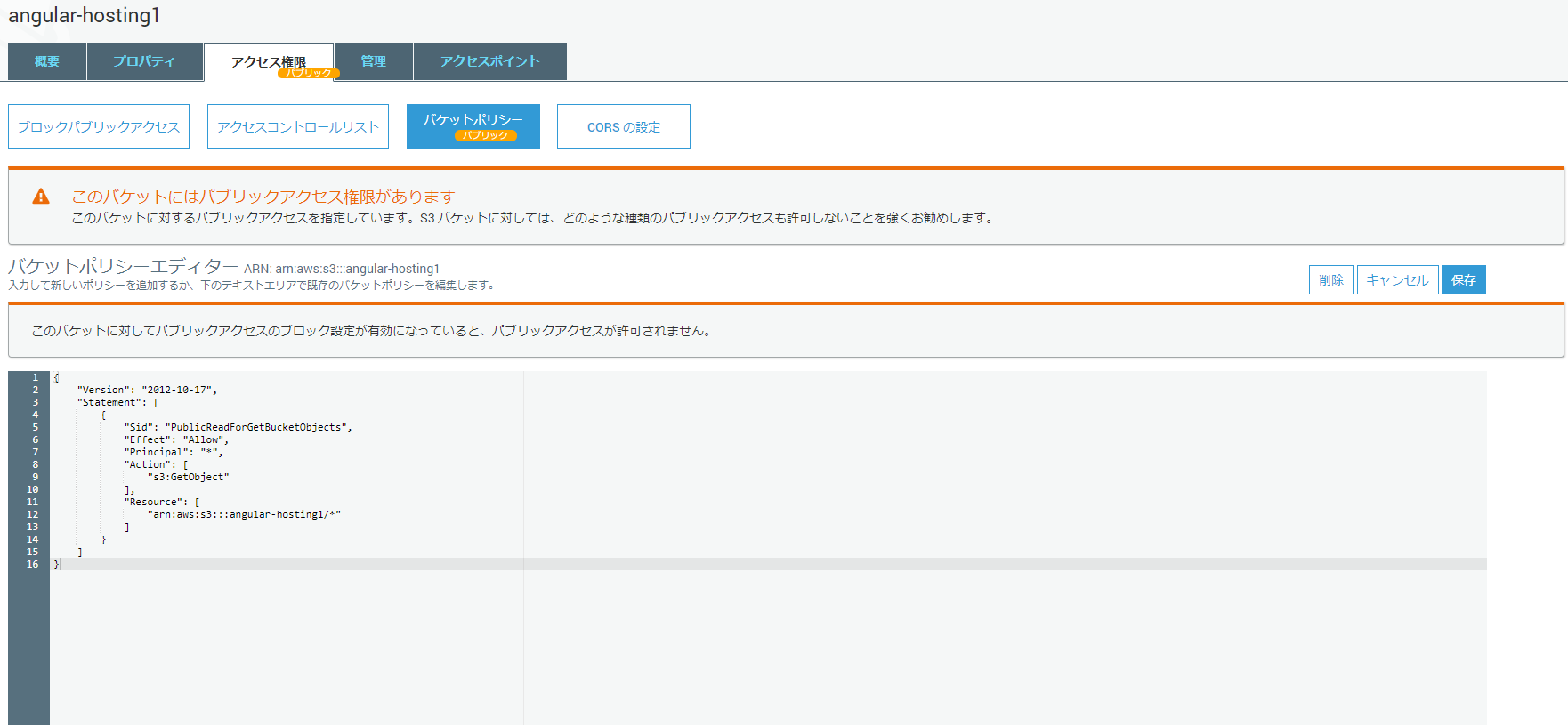
続いて、バケットポリシーを設定します。
アクセス権限タブ > バケットポリシーに下記の内容を貼り付けて保存します。{ "Version":"2012-10-17", "Statement":[{ "Sid":"PublicReadForGetBucketObjects", "Effect":"Allow", "Principal": "*", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::【ここをバケット名に置換】/*" ] } ] }
保存を押すと全世界に公開されます。
http://{バケット名}.s3-website-ap-northeast-1.amazonaws.com/を開いてみてください!
(CLIでアップロードした場合のみ)ContentTypeを指定
ここで一度、公開されたサイトを開いてみます。
真っ白な画面が表示されます。
コンソールを見てみると、いくつかのjsが、ただのテキストファイル
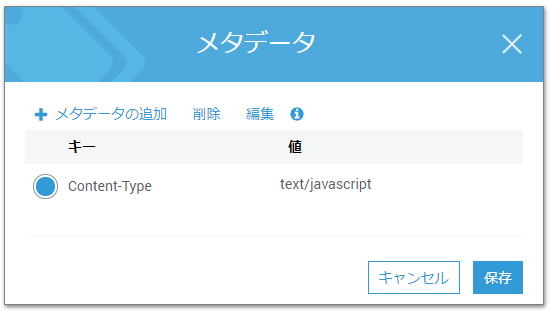
text/plainとして読み込まれています。
S3上でjsファイルにContentTypeを定義する必要があります。
コンソールでエラーが出ているファイルを選択します。
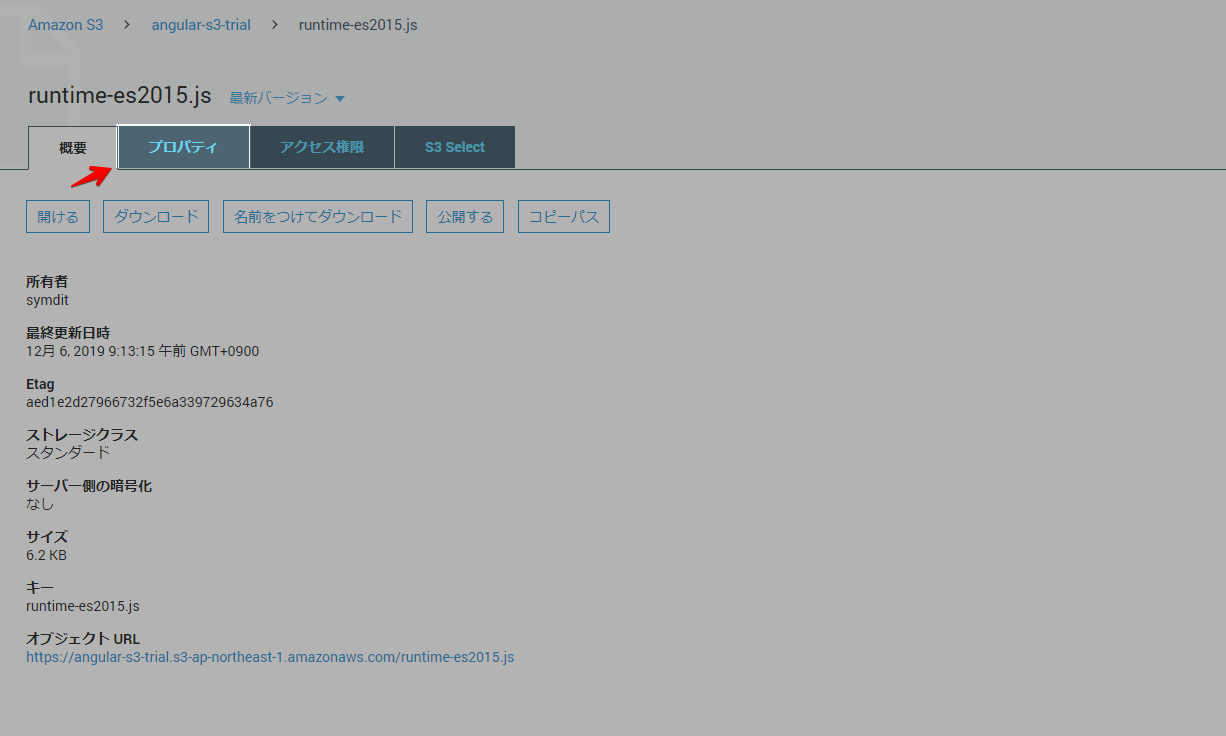
プロパティから
メタデータを選択し、
text/plainからtext/javascriptに書き換えます(チェックボックスを入れて編集できます)同様にエラーが出ているJavaScriptファイルに対応していきます。
全て対応したら再度読み込んでみましょう
キャッシュが残っていると再発する場合があるので、キャッシュを削除して再読み込みしてみましょう。
【Tips】Chromeの場合、
Ctrl + F5でキャッシュを削除して再読み込みしてくれます。






- 投稿日:2020-02-13T09:50:04+09:00
S3バケットを空にするRubyスクリプト
APIなどでバケットを削除する際、空にしてからでないと削除できません。バケットを空にするプログラムを作るのは、けっこうな手間なのですが、Rubyだと一発でいけます。
clear-bucket.rbrequire 'aws-sdk-s3' bucket = Aws::S3::Bucket.new('<バケット名>') bucket.clear!
- 投稿日:2020-02-13T08:02:58+09:00
VPC (Virtual Private Cloud) ~ AWS学習メモ ~
VPCとは?
AWS上に仮想的なネットワークを構築しプライベートなクラウド環境を提供するサービス。
VPC領域を作成するとネットワークをEC2インスタンスなどを作成することができる。VPCの構成要素
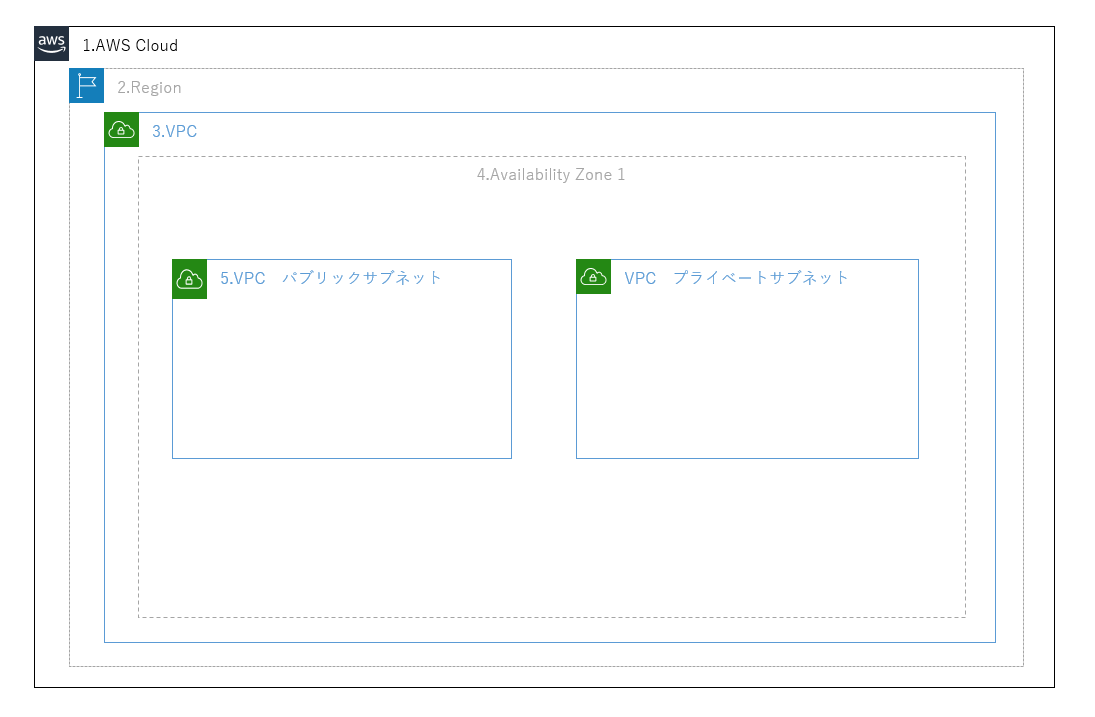
構成の順番
1.AWSクラウド → 2.リージョン → 3.VPC → 4.アベイラビリティ―ゾーン
→ 5.VPCサブネット(Public Subnet、Private Subnet)
サブネット
・サブネットVPC内に構成するネットワークセグメントのことで、1つのVPCに対して1つ以上のサブネットで構成される。
・Public Subnet、Private Subnetの違い【Public Subnet】
インターネットと直接通信を行う目的で作成されたサブネット(DMZ、Internet Facingとも呼ばれる)【Private Subnet】
インターネット通信はせずに内部のみで通信する目的で作成されたサブネット【IPアドレス】
IPアドレスはTCP/IPネットワーク上で、通信相手を識別するための番号です。【CIDER(サイダー) Classless Inter-Domain Routing】
クラスを使わないIPアドレスの割り当てと、経路選択(ルーティング)を柔軟に運用する技術。
IPアドレスのネットワーク部とホスト部を決めたられたブロック単位で区切る方法で、アドレス空間の利用に無駄が生じてしまう。これに対しクラスを使わないCIDRでは、任意のブロック単位で区切ることができるのでIPアドレス空間を効率的に利用することができる。※最初の4IPと最後の1IPに関しては予約されているIPアドレスの為使用不可
AWS Direct Connect
オンプレミス環境とAWSの間をつなぐ「接続ポイント」です。専用線を使用しているので高速で安定した通信を実現することができる。
VPCピアリング
異なるVPC同士の通信をAWS内部で行うことができる。また異なるVPCにはいちしたEC2インスタンス間の通信やリージョンをまたいで通信することが可能。
VPCエンドポイント
VPCエンドポイントには、ネットワークレイヤーのゲートウェイ型とアプリケーションレイヤーのインターフェイス型の2種類があります。
ゲートウェイ型では、ルートテーブルに指定されたターゲットを追加することでS3やDynamoDBへアクセスする際、インターネットを経由せずにAWS内のプライベート接続が可能。
インターフェイス型は、「AWS PrivateLink」とも呼ばれ、AWSへのAPIコールに対してインターネットを経由せずにプライベート接続を実現することができる。
- 投稿日:2020-02-13T06:31:12+09:00
AWS試験対策(④コンピューティングとストレージ続々)
ストレージ〜自分はストレージのことよくわかってない気がするけどなんとか生きてる。この機会に覚えたいと思う。
EBS
cドライブみたいなもん。こいつは一途だから一つのインスタンスにしかくっつけない。一方、インスタンスくんはたくさんのEBSちゃんをたぶらかすことが可能…。
同じAZのインスタンスにのみくっつける。一途な割には遠距離恋愛不可。
他のAZのインスタンスとどーしてもくっつきたい場合は、s3に写真をあげて、くっつきたいインスタンスがあるところで写真からクローン作ればオッケイ。容量は1GB単位で指定できる。最大は16TBまで。最初に10!って宣言しちゃって、後からやっぱ15ほしいわ!とかもできる。
この子はインスタンスに一途だけど運命共同体ではない。インスタンスがいなくなってもこの子は生き続ける。たくましい。
EBS最適化インスタンス
デフォルトで無効。
インスタンス君はEBSちゃんだけじゃ飽き足らず、いろんなとこに通信というちょっかいを出しに行きます。
なので、忙しくてEBSちゃんへの連絡が遅くなったりします。しかしこのオプションをつければ、EBS専用の回線ができて、他の子に邪魔されることがない!ってなやつです。ボリュームタイプ
汎用SSD
いわゆる一般的なやつ。プロビジョンドiops
汎用じゃスピード足りねえな!ってときに使う。DBとか。スループット最適化HDD
シーケンシャルアクセス時に高い性能。要するに大きいデータを処理するのが得意だという。コールドHDD
同じく大きいデータを処理するのが得意だけど、スループット最適化よりは劣る。劣ってても安いほうがいいなら使うんじゃないかな。マグネティック
コールドHDDよりもさらに安い。しかしさらにパフォーマンスは劣る。旧世代のものだからあまりおすすめされない。名前で覚えれそう。汎用は普通の。IOPSはI/O早い。スループット最適化は大きいデータ。コールドはそれの劣化。マグネティックは更にそれの劣化。でも安いからめったに使わないデータとかならこっちのほうがいいんちゃうか。
EBSスナップショット
要するにバックアップを圧縮してS3ってとこに保管してるよって話。S3で中身にアクセスすることはできない。
増分のバックアップをしている。一枚目はすべてを保存してる。2枚目は、一枚目と二枚目の違うとこだけ保存してる。
となると、途中を消しちゃ困るような気がするけども、ちゃんと考えてて、その場合は3枚目と違うとこだけ消える。文字だと何言ってるかわからないなこれ。。。
5枚目がA.B.Cってデータを持ってて、6枚目はCがDになってたため、Dのデータを持ってる。
その場合、5枚目を消そうとしてもA.Bは残ってCだけ消える。Cは2枚目でDになってて必要ないからな。
言ってて更にわかりにくくなったけど、とりあえず増分バックアップしてるってことだけ覚えればいいかも初期化
新規作成の場合、作ってすぐに最高のパフォーマンスを出せるけど、スナップショットから生成した場合はそうはいかない。
アクセスしたことがないデータがあるから、動作がどーしても遅くなる。
じゃあどーすればいいかって、全部事前にアクセスしとけばいいじゃん!ってのがこの初期化。EBSの課金
確保した分だけ課金される。
10GB分確保しておいて、実際1GBしか使ってなくても10GB分請求される。
さっきも言ったけどインスタンス君が死んでもこの子は生き続けるので課金マジ注意。EBS暗号化
新しく作るときか、スナップショットからクローンを作るとき、暗号化できる。そのままでは暗号化できない。
暗号化されたやつのスナップショットは暗号化されてる。AES-256って形式のみらしい。S3
オブジェクトストレージといい、ファイル構造を持たない。
データを入れる器をバケットと言う。
オブジェクトキーはファイルの名前。プレフィックスというものを使って階層構造のようなものをつくってる。
実態はファイル構造を持たないけど、ファイル構造のように見せるためにプレフィックスという属性をつけてるみたいな。EBSへアクセスするときは同じAZじゃなきゃいけなかったけど、S3の場合は同じリージョン内まで可能。なぜなら、VPCエンドポイントというものを使うから。
VPCエンドポイントは、s3と通信を行うときの中継地点的なもの。s3はVPCの外にあるからこの中継点がないと繋げない。インスタンスとバケットの中継地点と覚えていいかも。特徴は、ファイルを3箇所以上のAZのDCに保存するから耐久性が高い。
結果整合性モデルが使われている。どういうことかというと、書き込んだり削除したりすると、3つのDCすべてに反映されるまでにラグがあるよってこと。
削除指示してすぐに一箇所目からは消えたけど3箇所目にはまだ残ってるからアクセスできたりする。
名前通り、結果的に一緒になってればいい、整合性とれてればいいってこと。容量は無制限で安い。使った分だけ課金される。
S3ストレージの種類
S3標準
その名の通り標準的なやつ。S3 Intelligent-tiering
データへのアクセス頻度を判別してくれて、自動的に適切なとこに移してくれる。よく使うのはそのまま、使わないのは取り出すのに手間かかるけど安いとこにしまっておくとかそういうことをしてくれる。S3標準-IA
あんまアクセスしないけど、必要なときはすぐほしい!ってものを入れる。安くしまえるけど、取り出すときにもお金がかかる…S3 1ゾーン-IA
アクセスしないものを入れる。名前のとおり、従来では3箇所にしまってたけどこのプランは一箇所にしかしまわない。
一応耐久性はめちゃくちゃあるらしいけどAZ全体が破壊されたらデータはなくなる。戦争かな?
一箇所だから安い。もともとの標準も大概に安いからあんま恩恵受けないような気もするけど、死ぬほど大きなデータをしまう際には結構変わってくるんだろうな…S3 glacier
テープバックアップらしい。やっすいけど取り出しのときにお金だけじゃなく時間もかかる。
グレイシア…氷…冷凍保存…って覚え方。主要機能
バージョニング
世代管理できる。エクセルの過去のバージョンの復元みたいなやつ。これ使うとバージョンごとに保存されて容量増え続けるから注意。
MFA deleteという、多要素認証消去って機能がある。間違って消す操作しても他の要素で認証しないと消せないって仕組み。間違って消すオペレーションミスを防げる。ライフサイクル
一定期間経ったオブジェクトをどうするかルールを決めれる。
移行ならIAとかグレイシアに移して安く済ませれる。
失効なら自動削除してくれる。静的ウェブホスティング
静的なコンテンツ(掲示板のように変化のあるものじゃなくて、いつ開いても同じ結果が帰ってくるサイト)をS3に置くとWEBサーバ要らずにWEBページを公開できる。俺はこれを知らなくて、静的コンテンツなのにわざわざEC2をなんやかんやしてた…悔しい…
サーバーいらずなので最低限のメンテナンスだけで使えるのが強み。
パブリック読み取りアクセス権をつけないと使えないので注意。
HTTPSがつかえないのも注意。
スクリプトは、ユーザー側のスクリプトは含められるけどサーバー側のスクリプトは駄目。暗号化
3つのサーバーサイド暗号化機能がある(SSE)
S3で管理されたキーによる暗号化
暗号化キーの管理をAWSが行うKMSで管理されたキーによる暗号化
暗号化キーの管理にKMSを使う。権限制御や証跡が取れる。ユーザーが用意したキーによる暗号化
暗号化キーの準備及び管理はユーザーが行う。アップロードしたときに暗号化するデフォルト暗号化オプションでは上2つのどちらかが使われる。
署名付きURL
S3のデータにアクセスする期限を決めたいとき、URLに有効期限をつけれる。期間限定のコンテンツを配信したいときに使う。
署名をつけない場合、期限なし。その他
クロスリージョンレプリケーション
別のリージョンのバケットにオブジェクトのコピーを自動でとってくれる。コピーは非同期。S3 object tagging
オブジェクトにタグをつけてくれる。S3分析-ストレージクラス分析
S3のデータを分析して、より安価なストレージクラスに移行するタイミングをおしえてくれる。Intelligent-tieringと違うんこれ?提案だけで移してはくれないってこと?S3インベントリ
オブジェクトのリストを定期的にCSV出力してくれるS3 cloudWatch metrics
S3に対してのリクエスト量とかダウンロード量をcloudWatchで監視できる。cloudtrailによる監査ログ取得
いつどこから誰がS3の操作を行ったのかというログを収集できる。S3オブジェクトのアクセス制御
基本的にバケット作成主だけアクセスできる。
誰でもオッケーにしたいなら、パブリックアクセスを有効にする。IAMポリシーによるアクセス制御
IAMポリシー(ルール)を作成し、IAMユーザーにオブジェクトに対してのread/put/deleteの権限付与できるACLによるアクセス制御
バケットそのもの、またはオブジェクト一個一個にアクセス権限を設定する。xml形式。バケットポリシーによるアクセス制御
バケットそのものに対してのアクセス制御。IPアドレスで制限できたりする。JSON形式パブリックアクセス
誰でもオッケーにしたいならパブリックにGET権限を付与します。
バケットポリシーを使えばすべてのオブジェクトにパブリックアクセスを設定できる。
ACLでやるならオブジェクトごとにパブリックアクセスを設定できる。
IAMのWEBアイデンティティフェデレーションを使えば、一時的なアクセス権も与えられる。S3へのアクセス
REST APIを使う。マネジメントコンソールからか、CLIからか、SDKからアクセスできる。
content-MD5による完全チェック
ファイルアップロードの時にハッシュ値確認して、かけたりしてないか確認できるマルチパートアップロード
一回のアップロードに5GBまでしか行けないので、5GB以上なら分割してアップロードしなきゃいけない。最大5TB。ランダムなプレフィックス
連続でアップロードすると、同じとこばかり書き込んでると待ちが発生して効率悪いから、ランダムにしてIOのパフォーマンスをあげてる。制約事項
バケット数は一つのアカウントで100まで。上限緩和申請すればもっとつくることもできる。
また、バケットの名前はかぶっちゃいけないし変更できない。かぶらないようにって変な名前つけると変更できなくて後悔するぞ!
また、バケットを人にあげることはできないです。次回コンテナへ!
- 投稿日:2020-02-13T00:14:18+09:00
CloudFormationがなんやよおわからへんからおしえてや
CloudFormationのテンプレートを作成するとき、
はじめての人は何をすれば良いのかがよくわからない気持ちになるものです、たぶん。なのでテンプレートについての簡単な解説を。。。
CloudFormationについて
CloudFormationとは、AWSのリソースを簡単に構築することができる機能のことです。
YAML/JSONファイルにリソースの設定を書き込んで、AWSコンソールのCloudFormationでファイルをアップロードすると、
設定したリソースが作成されていきます。
もちろんCLIでもアップロードができます。これら一つのYAML/JSONファイルに設定された一連のリソース群のことをスタックと呼びます。
アップロードが完了すると、AWSコンソール上のCloudFormationではスタックの作成が始まります。
CloudFormationのテンプレートは単純にリソースを構築するだけではなく、
プロジェクトで利用されているAWSリソースの構成図としても役立ちます。AWSコンソール上では把握しづらいリソース間の関係性も、
テンプレートファイル上で概要をつかむことができます(読める知識があれば)。簡単にお試しできそうな記事がありました
【CloudFormation入門】5分と6行で始めるAWS CloudFormationテンプレートによるインフラ構築CloudFormationの基本的なパラメーター
CloudFormationを始めるにあたって理解しておいた方が良いパラメーターは以下の3つです。
- Parameters
- Outputs
- Resources
まず、テンプレートの冒頭はこんな感じになると思います。
AWSTemplateFormatVersion: '2010-09-09' Description: Your project name # 別に必須ではない上に挙げているパラメーターはこの
Description下に付け足して書いていきます。ちなみにこのエントリーではYAMLでテンプレートを書いています。
Resources
ResourcesにはAWSリソースを定義していきます。
それぞれのリソースは機能役割が異なるので、各々の設定方法が存在します。リソースの定義は想定している構成でどのリソースを使うべきかを判断し上で、
以下のリストから探して試していくと良いです。設定方法
全てのリソースについて説明することは不可能なので、
ここにはVPCとInternetGatewayの組み合わせをサンプルで記載します。Resources: MyVPC: Type: AWS::EC2::VPC Properties: CidrBlock: "10.0.0.0/16" Tags: - Key: "Name" Value: "MyVPC" MyInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: "Name" Value: "MyInternetGateway" AttachGatewayToVPC: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref MyVPC InternetGatewayId: !Ref MyIGWIPv4 CIDR ブロックを指定してVPCを作成し、インターネットゲートウェイ(IGW)を関連づけています。
VPCとIGWの参照にはRef組み込み関数(YAMLの短縮記法)を使います。VPCとIGWを関連づけるためには
AWS::EC2::VPCGatewayAttachmentを利用します。
周知の通り、VPC内からインターネットへアクセスするにはIGWが必須です。
上記のサンプルでは基本的なVPCを設定しているだけです。ここからサブネットやルートテーブル、EC2インスタンスをスタックに追加してあげると、
インスタンス内で開発を行えるところまでをCloudFormationで構築することができるようになります。
のリソースを設定すればできます。
AWS::EC2::Subnet サブネットの作成
AWS::EC2::Instance EC2インスタンスの作成
AWS::EC2::RouteTable ルートテーブルの作成
AWS::EC2::SubnetRouteTableAssociation サブネットとルートテーブルの関連付け
AWS::EC2::Route ルートテーブルとIGWの関連付けParameters
Parametersでは同じテンプレート内で利用する値を設定することができます。
設定方法
と言ってもはじめての人にはこの言葉では理解しづらいと思うので具体的に設定を見てみましょう。
Parameters: S3BucketNameParameter: Type: String # パラメーターの型 Default: 'Megalovania' # 初期値 AllowedPattern: ^[a-zA-Z0-9]*$ # 正規表現に合致するものを許容します。 AllowedValues: # enumのようにこの中の値を許容します。 - 'Megalovania' - 'TheManWithTheMachineGun' - 'BlueEyesWhiteDragon'
DefaultではCloudFormationでのスタック作成時に設定しなかった場合の初期値を設定します(AWSコンソール上からCFnスタック作成をするときにGUIで設定できる、けどしなかった場合の初期値)。
AllowedPatternとAllowedValuesではその初期値やあとで設定し直した時の値のルールを設定できます。
正規表現や想定されている値が数個しかない場合はこれらを使ってみると良いと思います。参照方法
参照はResourcesおよびこのあと登場するOutputsで行えます。
組み込み関数のRefを使って参照します。# in case of Resources Resources: MyBucket: Type: AWS::S3::Bucket Properties: BucketName: !Ref S3BucketNameParameter # 'Megalovania' # in case of Outputs Outputs: ExportedBucket: Description: "MyBucket" Value: !Ref MyBucket Export: Name: "ExportedBucket"Outputs
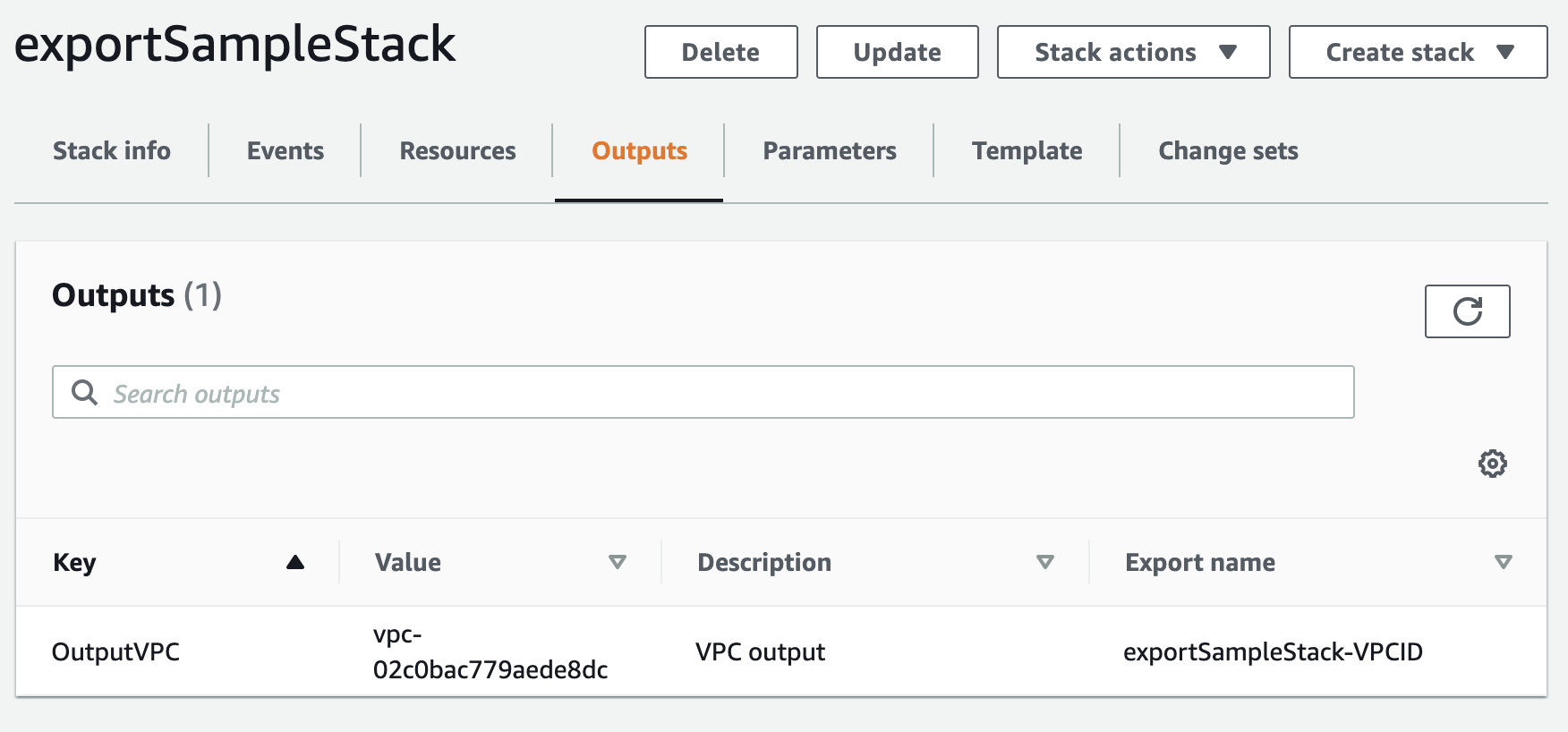
Outputsを使うと、同一リージョン内に作成された他のスタックで参照可能な値を設定したり、CloudFormationコンソール上にリリース担当者に参照してほしいリソースを表示したりすることができます。
設定方法
# スタックA AWSTemplateFormatVersion: "2010-09-09" Resources: SampleVPC: Type: AWS::EC2::VPC Properties: CidrBlock: "10.0.0.0/16" Tags: - Key: "Name" Value: "SampleVPC" Outputs: ExportedVPC: Description: "SampleVPC" # 説明 Value: !Ref SampleVPC # エクスポートする値 Export: Name: "ExportedSampleVPC" # インポートするときに参照する名前ここではVPCのVPC IDをエクスポートしています。
参照方法
次にエクスポートした値を参照しながら別のスタックを作成します。
上記ではVPCをエクスポートしたので、そのVPCに対してIGWをアタッチしてみます。参照時には
Fn::ImportValue組み込みを利用します。
YAMLでは組み込み関数の短縮記法が使えるので、ここでは!ImportValueとしています。# スタックB AWSTemplateFormatVersion: "2010-09-09" Resources: MyInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: "Name" Value: "MyInternetGateway" AttachGateway: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !ImportValue ExportedSampleVPC # ExportのNameで指定した名前から値を参照します。 InternetGatewayId: !Ref MyInternetGatewayこうするとスタックAで作成されたVPCにスタックBで作成されたIGWが関連付きます。
スタック間を超えて参照したいリソースがあれば便利に使うことができます。また、作成したスタックのOutputsはAWSコンソール上でも参照することができます。
例えば、
「ReactクライアントのビルドファイルをアップロードS3バケットはどれだったっけ?」
というようなときに、このCloudFormationコンソールのOutputsからバケット名が参照できればわざわざドキュメントにまとめる必要も無くなります。
せいぜい、「コンソールの出力を参照してください」と指示するくらいでしょう。特に複雑に肥大したスタックなどには主要なものはOutputsにまとめておくと良いと思います。
テンプレートのアップロードとスタック作成
テンプレートが書けてもスタックの作り方がわからなければ意味がありません。
ただテンプレートを流し込むだけなので全く難しいことなどはありませんが。。。一応ざっくりと手順に触れておきます。
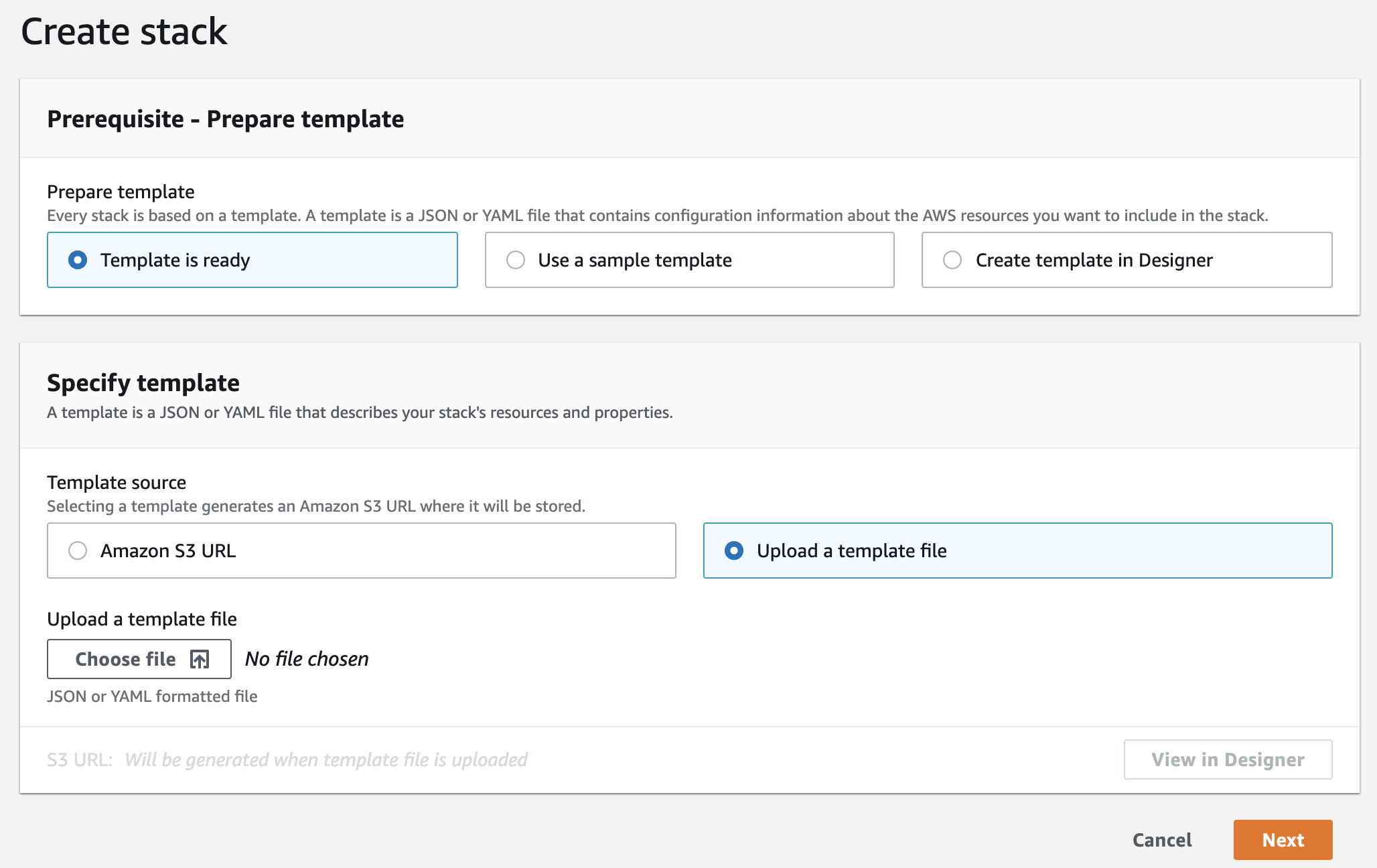
1. CloudFormationコンソールへ入る
AWSコンソールでCloudFormationを開くとスタック一覧画面の上の方に「スタック作成」(Create stack)ボタンを見つけられると思います。
ドロップダウンになっているので「新しいスタック」(With new resources)を選択します。
2. テンプレートファイルを選択
スタック作成画面では「既存のテンプレート」(Template is ready)から「テンプレートをアップロード」(Upload a template file)を選択し、テンプレートファイルYAML/JSONを選択して「次へ」(Next)を押します。
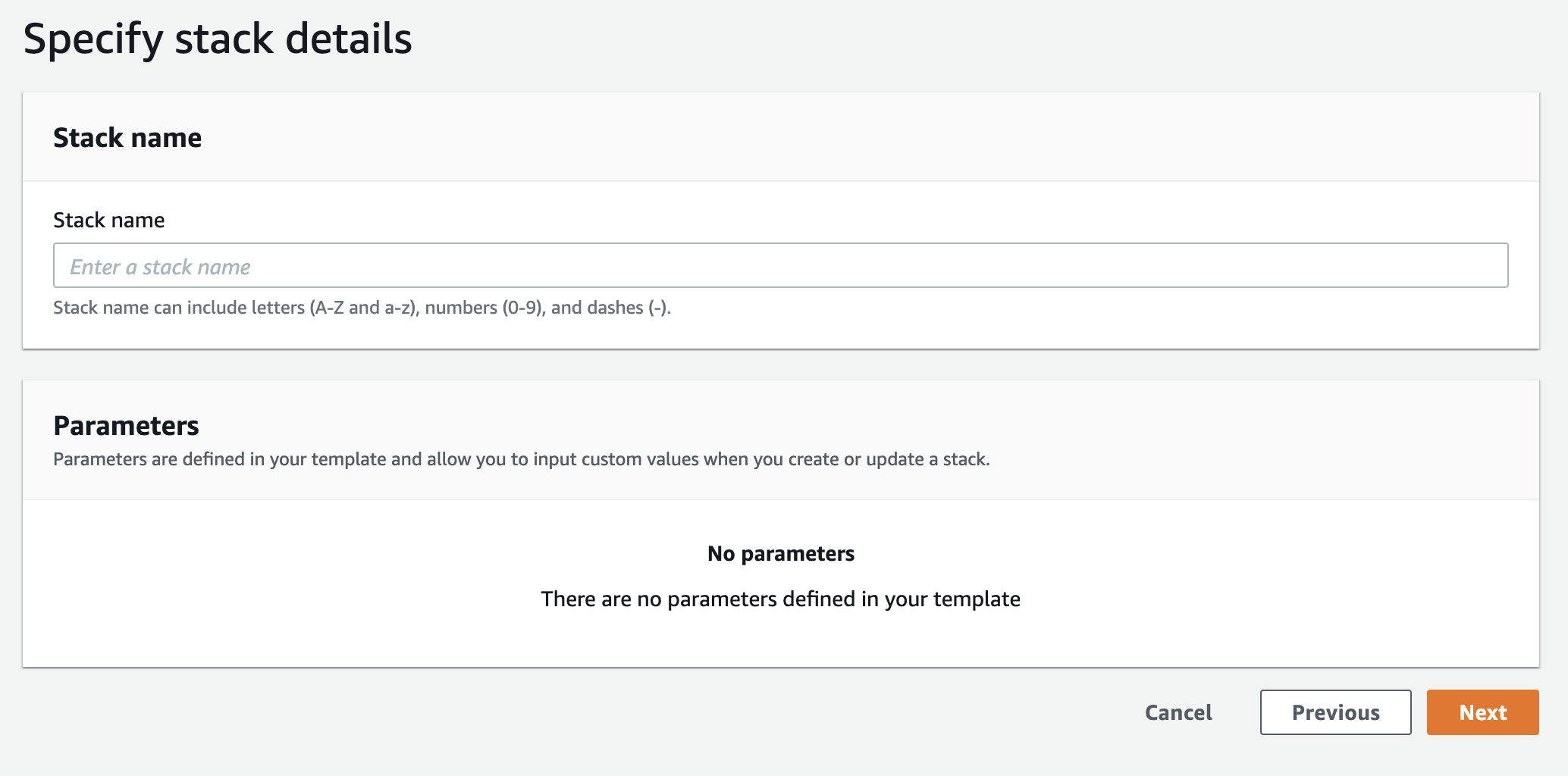
3. スタック名を決める
スタック名を記入して「次へ」(Next)を押します。
4. 詳細設定(やりたい人だけ)
次のページの詳細設定等は省いて「次へ」(Next)を押します。
設定したいことがあればします。5. 確認とスタックの作成実行
確認画面が表示されるので、確認ができたら下部の「スタック作成」(Create stack)を押します。
するとスタックの作成が始まってステータスが
CREATE_IN_PROGRESSとなるのがわかると思います。
設定したリソースの量にもよりますが少しすればスタックがCREATE_COMPLETEになります。問題があればエラーも出ますが、基本的には以上がスタック作成の基本的な流れです。
コンソール上でリソースが作成されているのを確認できると思います。おわり
以上の基本的なパラメーターについてとりあえず触れましたが、
CloudFormationを理解するには組み込み関数についても知る必要があります。これは上でも触れた
!Refとか!ImportValueみたいなやつのことです。組み込み関数には条件関数というものもあって、より柔軟にスタックテンプレートを作成することができるようになります。
今の職場では複数の環境(お客様が別々で要望も別々なので環境を分けている)がそれぞれの環境差異を持っているので各スタックテンプレートで組み立てているのですが、
そうは言っても類似した部分の共通簡略化は行いたくなるのでテンプレートの部分分岐をしたりします。
こういったときに条件関数が使えるので知っておいて損はないと思います。まあ、CloudFormationを便利に使ってみてください