- 投稿日:2020-02-12T23:03:24+09:00
レコメンドの最適化
1. レコメンド
レコメンドでは学習データをもとに機械学習などでモデルを作り、ユーザxアイテムに関して予測スコアをつけて、各ユーザに関して予測スコアが高いアイテムTOP ?を見せることが多いです。しかしこの方法では人気アイテムの予測スコアが高くなり、人気のないアイテムの予測すこが小さくなるので、人気のあるアイテムばかり広告が出て、人気のないアイテムには広告が出ないという問題があります。
広告サイトでは、人気のないアイテムに対してもある程度のCVを得るため広告を出す必要がある場合が多いです。2. 最適化
アイテム単位で広告するユーザ数に制限を入れることにより解消することができます。
例えば人気アイテムには広告を出す最大ユーザ数を設定し、人気のアイテムには広告を出す最小ユーザ数を設定すれば良いです。3.例
ユーザ数 30、アイテム数 20とします。
各ユーザに関して5件アイテムをレコメンドすると考えます。ただしすべてのアイテムに関して10人以下しか広告を出さず
アイテム0,1,2は人気アイテムなので3人以下しか広告を出さず
アイテム18,19は人気のないアイテムなので7人以上広告を出すとします。以下
$ scores_{ui} $: ユーザu,アイテムiの予測スコアとします。上記の条件を数式にすると
変数
$ choices_{ui} $ : ユーザuにアイテムiの広告を出すかどうか(1 or 0)
目的関数
$ \sum_{u} \sum_{i} scores_{ui} * choices_{ui} $
を最大化する。制約条件
- $\sum_{i} choices_{ui} <= 5 (\forall u)$
- $\sum_{u} choices_{ui} <= 10 (\forall i)$
- $\sum_{u} choices_{ui} <= 3 (i=0,1)$
- $\sum_{u} choices_{ui} >= 9 (i=18,19)$
となり線形計画法で解けます。
pulpで実数すると
USER =30 ITEM = 20 Users = list(range(0,USER)) Items = list(range(0,ITEM)) prob = pulp.LpProblem("test",pulp.LpMaximize) # 変数の宣言 choices = pulp.LpVariable.dicts("Choice",(Users,Items) , 0, 1, pulp.LpInteger) # 目的関数 prob += pulp.lpSum([scores[u][i] * choices[u][i] for u in Users for i in Items ]) # 制約条件 #1. $\sum_{i} choice_{ui} <= 5 (\forall u)$ for u in Users: prob += pulp.lpSum([choices[u][i] for i in Items]) <=5 #2. $\sum_{u} choice_{ui} <= 10 (\forall i)$ for i in Items: prob += pulp.lpSum([choices[u][i] for u in Users]) <= 10 #3. $\sum_{u} choice_{ui} <= 3 (i=0,1)$ for i in [0,1]: prob += pulp.lpSum([choices[u][i] for u in Users]) <= 3 #4. $\sum_{u} choice_{ui} >= 9 (i=18,19)$ for i in [18,19]: prob += pulp.lpSum([choices[u][i] for u in Users]) >= 9 status = prob.solve()で解けます。
今scoresを下記のようにアイテム1,2は人気アイテムなのでスコアを増やして、スコア18,19は人気のないアイテムなのでスコアを減らします。
np.random.seed(10) scores = np.random.rand(USER, ITEM) scores[:,0] += 0.3 scores[:,1] += 0.3 scores[:,18] -= 0.3 scores[:,19] -= 0.3 scores = np.clip(scores, 0, 1)サンプルソースは
https://github.com/tohmae/pulp_sample/blob/master/score_optimize.py
にあります。上記のスコアで最適化を実行した場合、制約条件2,3,4がない場合は
Item0 Item1 Item2 Item3 Item4 Item5 Item6 Item7 Item8 Item9 Item10 Item11 Item12 Item13 Item14 Item15 Item16 Item17 Item18 Item19 User0 1 0 0 1 0 0 0 1 0 0 0 1 0 0 1 0 0 0 0 0 User1 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 0 0 1 0 0 User2 0 1 0 1 0 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 User3 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 0 0 User4 1 1 1 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 User5 1 1 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 User6 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 User7 1 1 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 User8 0 0 0 0 0 0 0 0 1 0 1 1 0 1 0 0 1 0 0 0 User9 1 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 User10 1 1 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 User11 0 1 0 0 1 0 0 1 0 0 0 1 1 0 0 0 0 0 0 0 User12 0 0 1 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 0 0 User13 0 0 0 1 0 0 0 1 1 0 1 0 1 0 0 0 0 0 0 0 User14 0 0 1 1 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 User15 1 0 1 0 0 0 0 0 0 0 0 0 1 0 1 1 0 0 0 0 User16 1 0 0 1 0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 0 User17 0 1 0 1 0 0 0 0 0 1 0 0 0 1 0 0 0 1 0 0 User18 0 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 0 1 0 0 User19 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 User20 0 1 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 User21 0 0 0 0 1 1 0 0 0 0 0 1 0 1 0 1 0 0 0 0 User22 1 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 1 0 0 User23 0 0 0 1 1 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 User24 0 0 0 0 1 1 0 0 0 1 0 0 0 1 0 0 1 0 0 0 User25 0 0 0 0 0 1 0 0 0 0 1 0 0 1 1 0 0 1 0 0 User26 0 1 1 0 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 User27 0 0 0 0 0 0 1 0 0 0 1 1 0 0 1 0 1 0 0 0 User28 0 1 0 0 0 1 0 0 0 0 0 1 1 0 0 0 1 0 0 0 User29 1 1 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 0 制約条件2,3,4を入れた場合は
Item0 Item1 Item2 Item3 Item4 Item5 Item6 Item7 Item8 Item9 Item10 Item11 Item12 Item13 Item14 Item15 Item16 Item17 Item18 Item19 User0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 1 0 0 0 1 1 User1 0 0 0 0 0 0 0 0 1 0 1 0 1 0 0 0 0 1 0 1 User2 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 1 1 0 1 0 User3 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 User4 1 0 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 0 0 0 User5 0 1 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 User6 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 User7 0 0 0 1 0 1 0 0 1 0 0 0 0 1 0 1 0 0 0 0 User8 0 0 0 0 0 0 0 0 1 0 1 1 0 1 0 0 1 0 0 0 User9 0 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 1 1 0 0 User10 0 0 0 1 0 0 1 0 0 0 0 1 1 0 1 0 0 0 0 0 User11 0 0 0 0 1 0 0 1 0 0 0 1 1 0 0 0 0 0 0 1 User12 0 0 0 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 1 0 User13 0 0 0 1 0 0 0 1 1 0 1 0 1 0 0 0 0 0 0 0 User14 0 0 1 1 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 User15 0 0 1 0 1 0 0 0 0 0 0 0 1 0 1 1 0 0 0 0 User16 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 1 User17 0 0 0 1 0 0 0 0 0 1 0 0 0 1 0 0 0 1 1 0 User18 0 0 1 0 0 0 1 0 0 1 0 0 0 0 0 0 0 1 0 1 User19 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 User20 0 0 0 0 1 0 0 0 0 1 1 0 0 0 0 1 0 1 0 0 User21 0 0 0 0 0 1 0 0 0 0 0 1 0 1 0 1 0 0 0 1 User22 0 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 1 1 0 User23 0 0 0 1 1 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 User24 0 0 0 0 1 1 0 0 0 1 0 0 0 1 0 0 1 0 0 0 User25 0 0 0 0 0 1 0 0 0 0 1 0 0 1 1 0 0 1 0 0 User26 0 0 1 0 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 User27 0 0 0 0 0 0 0 0 0 0 1 1 0 0 1 0 1 0 1 0 User28 0 0 0 0 0 1 0 0 0 0 0 1 1 0 0 0 1 0 1 0 User29 0 1 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 1 となり制約条件2,3,4を入れた方がアイテム1,2の広告数が減って、アイテム18,19の広告数が増えることがわかります。
線形計画法でレコメンドの最適化ができました。
- 投稿日:2020-02-12T22:53:10+09:00
カメラ画像から虹彩検出をしてみた
はじめに
2020/1/19(土)に開催された第56回 コンピュータビジョン勉強会@関東の発表内容をまとめました。
当日の資料はこちらから見れます。ソースコードは以下のGithub上に公開しています。
https://github.com/33taro/gaze_cv虹彩検出の手順について
虹彩検出は大学の頃、研究していたテーマなので、進化したOpenCVならお手軽にできなかなぁと思い実施しています。
手順としては次の通りです。1.カメラ画像から人物の顔と顔のランドマーク検出
2.顔のランドマークから目領域を切り出し
3.目領域を2値化して虹彩領域を抽出
4.抽出した虹彩領域から虹彩検出
カメラ画像から人物の顔と顔のランドマーク検出
以前、別の記事で紹介した顔のランドマーク検出を利用して、虹彩(黒目の部分)を検出してみました。
詳細はそちらを参照してください。顔のランドマークから目領域を切り出し
上記の記事でも紹介していますが、顔のランドマークはこちらにある学習済みモデルを利用しています。
そのため目領域は右目が「No.37~42」、左目が「No.43~48」となります。
こちらは実際のソースコードでは「tracking_system」ディレクトリの「eye_region_manager.py」に記載しています。
eye_region_manager.pydef detect_eye_region(self, face_landmark): """ ランドマークから目領域の座標を取得 :param face_landmark: """ # 右目切り出し self._right_eye_region = {'top_x': face_landmark[36][0], 'bottom_x': face_landmark[39][0], 'top_y': face_landmark[37][1] if face_landmark[37][1] < face_landmark[38][1] else face_landmark[38][1], 'bottom_y': face_landmark[41][1] if face_landmark[41][1] > face_landmark[40][1] else face_landmark[40][1]} # 左目切り出し self._left_eye_region = {'top_x': face_landmark[42][0], 'bottom_x': face_landmark[45][0], 'top_y': face_landmark[43][1] if face_landmark[43][1] < face_landmark[45][1] else face_landmark[45][1], 'bottom_y': face_landmark[47][1] if face_landmark[47][1] > face_landmark[46][1] else face_landmark[46][1]}※配列は0番から始まるため、0~67となり番号がひとつずれます。
※目領域の上下y座標は、より長くなるように取得しています。目領域を2値化して虹彩領域を抽出
目領域の2値化にはPタイル法を用いました。
これは2値化したい領域が画像領域の何割を占めるか割合で指定する手法です。
これにより明るさに左右されず虹彩が取得できました。
(経験則から虹彩は目領域の4割にしています)
※2値化前にノイズ削除のためにガウシアンフィルタで平滑化しています。Pタイル法はOpenCVに実装されていないため、自作しました、
「utility」ディレクトリの「image_utility.py」に記載しています。image_utility.py# coding:utf-8 import cv2 def p_tile_threshold(img_gry, per): """ Pタイル法による2値化処理 :param img_gry: 2値化対象のグレースケール画像 :param per: 2値化対象が画像で占める割合 :return img_thr: 2値化した画像 """ # ヒストグラム取得 img_hist = cv2.calcHist([img_gry], [0], None, [256], [0, 256]) # 2値化対象が画像で占める割合から画素数を計算 all_pic = img_gry.shape[0] * img_gry.shape[1] pic_per = all_pic * per # Pタイル法による2値化のしきい値計算 p_tile_thr = 0 pic_sum = 0 # 現在の輝度と輝度の合計(高い値順に足す)の計算 for hist in img_hist: pic_sum += hist # 輝度の合計が定めた割合を超えた場合処理終了 if pic_sum > pic_per: break p_tile_thr += 1 # Pタイル法によって取得したしきい値で2値化処理 ret, img_thr = cv2.threshold(img_gry, p_tile_thr, 255, cv2.THRESH_BINARY) return img_thr抽出した虹彩領域から虹彩検出
虹彩領域は取得できましたが、眉毛や瞼の影などがあり、虹彩だけをキレイに抽出できません。
そこで輪郭点追跡で黒色領域を取得し、各領域に足して外接円近似をし、半径が最大の円を虹彩としました。
※ただし外接円が大きすぎる場合、虹彩の候補から外します。
一連の2値化~虹彩検出は「tracking_system」ディレクトリの「eye_system_manager.py」に記載しています。
eye_system_manager.py@staticmethod def _detect_iris(eye_img): # グレースケール化後、ガウシアンフィルタによる平滑化 eye_img_gry = cv2.cvtColor(eye_img, cv2.COLOR_BGR2GRAY) eye_img_gau = cv2.GaussianBlur(eye_img_gry, (5, 5), 0) # Pタイル法による2値化 eye_img_thr = p_tile_threshold(eye_img_gau, IRIS_PER) cv2.rectangle(eye_img_thr, (0, 0), (eye_img_thr.shape[1] - 1, eye_img_thr.shape[0] - 1), (255, 255, 255), 1) # 輪郭抽出 contours, hierarchy = cv2.findContours(eye_img_thr, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) # 輪郭から最小外接円により虹彩を求める iris = {'center': (0, 0), 'radius': 0} for i, cnt in enumerate(contours): (x, y), radius = cv2.minEnclosingCircle(cnt) center = (int(x), int(y)) radius = int(radius) # 半径が大きすぎる場合、虹彩候補から除外 if eye_img_thr.shape[0] < radius*0.8: # # 虹彩候補の描画 # cv2.circle(eye_img, center, radius, (255, 0, 0)) continue # 最も半径が大きい円を虹彩と認定 if iris['radius'] < radius: iris['center'] = center iris['radius'] = radius iris['num'] = i return iris虹彩の検出結果
上図の通り、左右の目の虹彩はしっかりと取得できています。
しかし上下については課題が残っています。
ただし人が上下を見るときは虹彩を動かすより顔を動かす場合が多いです。
(実際に目だけで上下を見ると疲れます)
なので顔のランドマークから、顔の向きを検出してなんとかできないかなぁ、と考えています。参考リンク
輪郭点追跡
OpenCV-Pythonチュートリアル ~輪郭: 初めの一歩~
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_imgproc/py_contours/py_contour_features/py_contour_features.html
OpenCVのチュートリアルです。基本的な使い方の参考にしました。OpenCV - findContours で輪郭抽出する方法
https://www.pynote.info/entry/opencv-findcontours
OpenCVの輪郭点追跡機能findContours()の詳細が紹介されています。
ソースコード記述の際の参考にしました。【OpenCV; Python】findcontours関数のまとめ
https://qiita.com/anyamaru/items/fd3d894966a98098376c
OpenCVの輪郭点追跡機能findContours()の各機能について図を用いて分かりやすく解説しています。
本技術の理解の参考にしました。最小外接円
- OpenCV-Pythonチュートリアル ~領域(輪郭)の特徴~
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_imgproc/py_contours/py_contour_features/py_contour_features.html
OpenCVのチュートリアルです。基本的な使い方の参考にしました。Pタイル法
イメージングソリューション ~Pタイル法~
https://imagingsolution.net/imaging/p-tile-method/
Pタイル法について分かりやすく解説しています。
Pタイル法の理解と実装をする上で参考にしました。画像処理入門・C言語サンプル集 ~Pタイル法~
http://pgsample.info/image/other/PercentileMethod.html
C言語によるPタイル法の実装です。
今回pythonでPタイル法のコードを書く際の参考にしました。





- 投稿日:2020-02-12T22:28:45+09:00
python初心者がIT企業にインターンしてみた[一日目 開発工程]
ウォーターフォール開発
朝の打ち合わせ
とりあえずスーツで出勤した私は部長にすぐさま、「私服でいいのに」と笑われた。おいいいいい。
出勤はしたものの、何をするか全く知らない私は、打ち合わせで衝撃を受けた。このインターンでは、多くのことは知らされず、キーワードなどは伝えるけどその他は自分で調べて進めていくというもの。その意図は、おそらく自己解決能力を鍛えるものだと思う。この一ヶ月半で大きく成長できることを確信した。このインターンを紹介してくれた先輩に感謝したい。ありがとうございます。最初のキーワードはウォーターフォールモデル
打ち合わせで知らされたのは開発工程ガイダンスとウォーターフォールモデルというキーワードだけである。昼にもう一度打ち合わせをやるから、それまでにその打ち合わせを有意義に活用できるように必要事項をまとめて発表してもらうからとのこと。
時間は朝の十時。打ち合わせは一時。さてまずはオフィスを入れなければな。
オフィスを入れた頃には十一時。やばい。ウォーターフォールモデルとは
ウォーターフォールモデルとアジャイルモデル
開発工程には二つのモデルがあり、アジャイルモデルとウォーターフォールモデル。アジャイルモデルは、書類などは特に用意せず、実装とテストを繰り返すモデルである。アジャイルとは素早いという意味で、その名の通り従来のウォーターフォールモデルよりも早く開発できるというメリットがある。その反面、できたシステムを顧客が他の会社にまかせたいと考えたときに移行が難しい。それは、書類などを作ってないため詳細がわからないのである。近年はこちらの開発方法の方が主流らしい。
一方、ウォーターフォールモデルは入念に計画し、詳細に書類を作成して後から変更の内容に詰めていく作業が主である。実装の前の段階でものすごく時間がかかる。後でリンクも貼るがサンプルをみると驚愕する。こんなのをいちいち作るのかと頭がおかしくなりそうである。メリットは目的にあったものを正確に作れる。しかし、デメリットはとにかく時間がかかることと、後から変更しようと思ったらこれもまた莫大な時間がかかる。ウォーターフォールモデルの中身
ざっと中身を説明しよう
1,要件定義
2,基本設計
3,詳細設計
4,実装
5,単体テスト
6,結合テスト
7,システムテスト時間の割合は 1,2,3で5割、4で2割、5,6,7で3割である。実装までにとても時間がかかることが
わかるだろう。要件定義とはなんぞや?要件定義書どうやって書くの?
とりあえず今日はこれからどうやっていくかを決めるために色々時間が有る限り調べる日ではあったのだが、要件定義を調べることは少し苦労した。調べるだけなら簡単なのだが、書く立場になってみて欲しい。どうやって書くのんや。とりあえず、要件定義書の中身も調べたので紹介しよう。
1.業務要件の定義
1-1.業務概要
1-2.規模
1-3.時期・時間
1-4.場所
1-5.管理すべき指標
1-6.システム化範囲2.機能要件の定義
2-1.システム機能要件
2-2.画面要件
2-3.帳票要件
2-4.情報・データ要件
2-5.外部インターフェース要件3.非機能要件の定義
3-1.ユーザビリティ及びアクセシビリティ要件
3-2.システム方式要件
3-3.規模要件
3-4.性能要件
3-5.信頼性要件
3-6.拡張性要件
3-7.上位互換性要件
3-8.継続性要件
3-9.情報セキュリティ要件
3-10.情報システム稼働環境要件
3-11.テスト要件
3-12.移行要件
3-13.引継ぎ要件
3-14.教育要件
3-15.運用要件
3-16.保守要件これらをすべて整理して初めて要件定義完了なのである。
明日はこの中身を埋めるために朝の9時からミーティングがある。今日はこれまでにしておこう。
みてくれてありがとうな
閲覧数だけが書くモチベーションになる!
- 投稿日:2020-02-12T22:28:44+09:00
Atcoder ABC125 C - GCD on Blackboard 別解集
C問題なのに脅威の水色
ちょっと捻ってるだけでネタが分かれば解けるヤツ累積GCD
これが正攻法
左から順番にgcdを取っていって記録していく
右からも同様に
あとで各一点に対して記録した左側gcdと右側gcdで仲良しさせるruiseki.pydef euclid(a,b): a,b=max(a,b),min(a,b) if a%b==0: return b else: a,b=b,a%b return euclid(a,b) N=int(input()) A=list(map(int,input().split())) org_A=A[:] #左から最大公約数作る右もね A=A[::-1] l=[A.pop(-1)] while A: l.append(euclid(l[-1],A.pop(-1))) A=org_A r=[A.pop(-1)] while A: r.append(euclid(r[-1],A.pop(-1))) r=r[::-1] ans=0 for i in range(N): temp=euclid(l[i-1] if i!=0 else r[i+1],r[i+1] if i!=N-1 else l[i-1]) ans=max(ans,temp) print(ans)セグメント木
初実装
あんまり綺麗に書けなかった、、、
これなら各一点に対してlogNで全体のgcdを求め倒すことができるseg.pyimport fractions N=int(input()) A=list(map(int,input().split())) M=[2] while M[-1]<N: M.append(M[-1]*2) A=A+[0]*(M[-1]-len(A)) A=A[::-1] for i in range(len(A)-1): A.append(fractions.gcd(A[2*i],A[2*i+1])) A=A[::-1] ans=0 for index in range(len(A)-M[-1],len(A)-M[-1]+N): temp=A[index+1] if index%2==1 else A[index-1] index=((index-1) if index%2==1 else (index-2))//2 while index!=0: if index%2==1: temp=fractions.gcd(temp,A[index+1]) index=(index-1)//2 else: temp=fractions.gcd(A[index-1],temp) index=(index-2)//2 ans=max(temp,ans) print(ans)
- 投稿日:2020-02-12T22:28:43+09:00
Backtrader 別のファイルからインジケーターをimportする方法
カスタムインジケーターのimport
いままでは説明のため同一のスクリプト内にカスタムインジケータークラスを書きました。しかしカスタムインジケータークラスだけを別のpyファイルに書いて、ストラテジーのスクリプトとは別々に使う方が便利です。
カスタムインジケーターのファイル名を仮に customindicator.py とすると、ストラテジーの冒頭部分に
import customindicator as cind(任意のわかりやすい名前)と書いてストラテジークラスのinitメソッド内には
self.myind1 = cind.MyStochastics1(self.data)と書きます。
customindicator.py はストラテジーのスクリプトと同じディレクトリに置きます。Jupyternotebookを使っていてデフォルト設定のままならば
C:\Users\ユーザー名\です。customindicator.pyimport backtrader as bt class MyStochastic1(bt.Indicator): lines = ('k', 'd', ) params = ( ('k_period', 14), ('d_period', 3), # タプルの最後にもコンマ(、)をいれる ) def __init__(self): highest = bt.ind.Highest(self.data, period=self.p.k_period) lowest = bt.ind.Lowest(self.data, period=self.p.k_period) self.lines.k = k = (self.data - lowest) / (highest - lowest) self.lines.d = bt.ind.SMA(k, period=self.p.d_period)sto2.py%matplotlib notebook from __future__ import (absolute_import, division, print_function, unicode_literals) import datetime import os.path import sys import backtrader as bt import customindicator as cind # class TestStrategy(bt.Strategy): def __init__(self): self.myind1 = cind.MyStochastics1(self.data) if __name__ == '__main__': cerebro = bt.Cerebro() cerebro.addstrategy(TestStrategy) datapath = 'C:\\Users\\XXXX\\orcl-1995-2014.txt' # Create a Data Feed data = bt.feeds.YahooFinanceCSVData( dataname=datapath, fromdate=datetime.datetime(2000, 1, 1), todate=datetime.datetime(2000, 12, 31), reverse=False) cerebro.adddata(data) cerebro.run(stdstats=False) cerebro.plot(style='candle')
- 投稿日:2020-02-12T22:22:25+09:00
バーチャルYouTuberの配信内容を三行でまとめてみる記事
へぇい
突然ですがみなさんはバーチャルYouTuberはご存知でしょうか?
バーチャルYouTuberとは, キャラクターを用いてYouTubeにて活動を行う人達のことで, いまでは1万人を突破しています.
特に最近では, 生放送を中心に行う方が多いため, 箱推しのような複数の推しを抱えるファンにとっては, 1日当たりに供給されるコンテンツの時間が24時間を超える人も中にはいるかもしれません. ここまでひどくなくとも, 新たな推しを探すのは難しいと感じている方は多いのではないでしょうか?
して.
矢木に 電流走る――!
素材です。どうぞ pic.twitter.com/JnkVgq8jOF
— てち@ためにならない‼︎ (@Tiziano_Craft) October 4, 2018COTOHA API の要約機能を使ってみます. これは,
構文解析、照応解析、キーワード抽出、音声認識、要約など、様々な自然言語処理・音声処理APIを提供しているサービスです。NTTグループの40年にわたる研究成果である、日本語辞書や単語を3000種以上の意味性分類する技術などを活用し、高度な解析をAPIで手軽に利用できます。
テキスト解析ができるみたいです.
要約機能を使えば, きっと切り抜き動画のように面白いところだけ切り出してくれるに違いありません.
いざ.
制作
git clone https://github.com/tsuji-tomonori/cotohapy.git cd cotohapy pip install -r requirements.txt # config.json の作成 python demo.pyconfig.json{ "access_token_publish_url": "", "developer_api_base_url": "", "clientid": "", "clientsecret": "" }これで下準備は完璧です.
次に,
import json from cotohapy3 import CotohaAPI # load config with open("config.json") as f: d = json.load(f) # auth api = CotohaAPI( developer_api_base_url=d["developer_api_base_url"], access_token_publish_url=d["access_token_publish_url"] ) api.login(clientid=d["clientid"], clientsecret=d["clientsecret"]) # main document = input() print(api.summary(document, 3))完成しました. 名前を「imakita3gyou.py」としています.
あとは, 字幕データを取得 し, 改行を「。」にすべて置換したテキストファイルを作成すれば準備完了です.
実践
まずは キズナアイ からあんな声やこんな声で話題の声ゲーに挑戦♡
python imakita3gyou.py < kizuna_ai.txt結果は
'♪ 秋冬で~ 恋をして~。わんっ わんわんっ。じゃかじゃかじゃかじゃか… じゃん!。'なんかわかる気がする.
次は, 電脳少女シロ より【神回】PUBGで女子が本気出したら奇跡が起きた!なんと‥!【PLAYERUNKNOWN'S BATTLEGROUNDS】
python imakita3gyou.py < siro.txt結果は
'やったね。何これ。いた!。'これは確実に救済されるやつですね.
最後に, 月ノ美兎 より 10分で分かる月ノ美兎【にじさんじ公式】
python imakita3gyou.py < mitimito.txt結果は
{'result': {}, 'message': 'An error has occurred.', 'status': 17001}まさかのエラー. リファレンスにて確認したところ, 入力できる文章のサイズは5000までだそうです. 泣く泣く削ります.
気を取り直して結果は
'月ノ美兎です (2018/02/10 Youtube Live 月ノ美兎、名探偵になるの巻)。「ビンタしてビンタ。実はわたくし、そんなことしたくないんですよ?。'やっぱり委員長は委員長だった.
いかがだったでしょうか
思っていたより雰囲気がでていてよかったです. でも今回は人間が字幕を付けていた動画を対象としているため, 実用的とは言い難いところがあります. 次回以降はGoogle によって自動で文字起こしされた文章でも対応できるようにしていきたいです.
それでは次回も, よろしやす.
おまけ
推しの一人である 紙木はさみ より 【生配信】#78 ただいま♡まったりおはなしするよ!【雑談】
1時間20分ほどの生配信, 5000文字以内で終わるわけなく, 泣く泣く大半をカット.
python imakita3gyou.py < hasami.txt結果は
'なんていうんだろう。すごいなんかすごいすごい。愛してる愛してる愛してる愛してる。'なんかすまんかった.

- 投稿日:2020-02-12T21:29:29+09:00
説明可能なAI
はじめに
4種類の説明可能AIについて簡単に整理する。
①大域的な説明
- 複雑なモデルを単純なモデルに近似する。
- あるいは、可読性の高い解釈可能なモデルで表現する方法。
- 全体を説明することになるため、個々の説明には適さない。
手法・ツール例
LIME
- 特徴量について、値を変化させたときに出力結果がより大きく変わるものが重要であると考える。
- 説明対象モデルの周りで線形モデルを作る。
- 画像認識AIに使われる。
SHAP
- アプローチはLIMEと同じ。
- 表データを処理するAIに使われる。
Anchors
- 説明対象モデルの周りで領域モデルを作る。
Grad-CAM
- CNN(畳み込みニューラルネットワーク )の判断根拠の可視化技術。
②局所的な説明
- 特定の入力に対する予測の根拠を提示する方法。
- 個々の説明になるため、全体の説明は難しい。
手法・ツール例
- Born Again Trees
- defragTrees
- Feature Importance
③説明可能なモデルの設計
- そもそも、最初から可読性の高いモデルで表現する方法。
- 比較的な単純なモデルを適用するため、推論の精度が損なわれることがある。
手法・ツール例
- 決定木
- ロジスティック回帰
- スパースモデリング
④深層学習モデルの説明
- 深層学習モデル、画像認識モデルの説明方法。
- アプローチは「②局所的な説明」に該当。
手法・ツール例
- 勾配ベースのハイライト法
- Interpretability Beyond Feature Attribution
- This Looks Like That
- Generating Visual Explanations
参考
- JSAI 説明可能AI
- JSAI 機械学習における解釈性
- 日経コンピュータ(2020.2.6号)
- [https://qiita.com/kinziro/items/69f996065b4a658c42e8:title]
- 投稿日:2020-02-12T20:02:13+09:00
AWSにdjangoでWebアプリを立ち上げて転職
こんにちはmogkenです。
前回Python+Django+AWSでスクレイピングアプリを作って転職という記事を書いてから3ヶ月余りが経ちました。タイトルの通り幸いにも転職が成功して1月からクラウド基盤を開発している会社にサービス企画で転職しました(^o^)/
というわけで今回はその時に作ったPythonのwebアプリをAWSに構築した際の手順を簡単に記録します。ただ申し訳ないのですが随分と前のことなので、やや記憶が曖昧で内容が正しいか保証できません...素人の備忘録だと思ってください。
今回のやること
AWSのVM(Centos7)にpython3とDjango、nginx、そしてgunicornをインストールして、作成したWebアプリをデプロイします。ロードバランサーやオートスケーリングもやろうと思っていたのですが、転職ができてしまったので一番簡単な構成で力尽きました...
構成図(最小構成すぎるのでいらないけれど一応)
AWSの設定
この構成でAWSで設定すべき項目は大雑把に書くと以下の通り
- ネットワークの作成
- VMの作成
- DNSの設定
なお詳しい手順はここでは記載しない。だって素人のしかもうろ覚えの手順なんてとても怖くて参考にできないでしょう。
参考URL:https://qiita.com/okoppe8/items/dc1de147a36797442e4c
1.ネットワークの作成
AWSではまずVMを立ち上げるためのVPCを作成する必要がある。
流れは次の通り
- VPCの作成
- サブネットの作成
- インターネットゲートウェイの作成
- ルートテーブルの作成
- セキュリティグループの作成
2.VMの作成
アプリケーションを構築するためのVMを作成する。でもやることはただEC2をボタンをポチポチして作成するだけ。
3.DNSの設定
公開するためのドメインの設定をAWSのDNSサービスであるRoute53を使って行う。
自分はこのサイトを参考に行った。
https://avinton.com/academy/route53-dns-vhost/
Linuxサーバの設定
AWSでVMの作成が終わったら次は立ち上げたVMの設定を行う。
ここからは少し詳しく解説する。(何回も失敗して繰り返したから割と記憶が鮮明なのだ...)
あとはここからの設定は基本的には
https://narito.ninja/blog/detail/21/#_3
このページを参考にしている。このブログはDjango周りのとてもわかりやすい記事がたくさんあるので、とてもオススメ。
手順としては次の通り
- 立ち上げたVMにSSH or Webコンソールでログイン
- python3のインストール
- djangoのインストールと設定
- nginxのインストールと設定
- gunicornのインストール
- サービスの立ち上げ
1. 立ち上げたVMにSSH or Webコンソールでログイン
EC2の作成時に同時にsshでアクセスするための認証鍵も作成されるから、それをダウンロードして使用する。何を言っているのかわからない人はAWSのコンソール画面からもWeb上でVMにアクセスできるのでそちらでやってみると良いかもしれない。
ダウンロードした認証鍵はそのまま使おうとすると、認証鍵の権限がオープンすぎると怒られるため次のコマンドでファイル権限を設定する必要がある。
chmod 400 "ダウンロードした認証鍵ファイル名"あとは以下のコマンドでsshアクセスができる。
ssh -i "***.pem" ec2-user@"EC2のパブリックDNS名 or パブリックIP"2. python3のインストール
参考URL:https://qiita.com/s_runoa/items/156f3fa67c82e9cd9f42
ここからは必要なパッケージをインストールしていく。まずはpython。pyenvを使っているけれど未だにpyenvが何か正確には分かっていない...
#yumパッケージのアップデート yum update -y #必要パッケージのインストール sudo yum install git gcc zlib-devel libffi-devel bzip2-devel readline-devel openssl-devel sqlite-devel #pyenvのインストール git clone https://github.com/yyuu/pyenv.git ~/.pyenv #.bash_profileに追記 export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)" **ここでサーバを再起動** #Pyhtonのインストール pyenv install --list CFLAGS="-fPIC" pyenv install 3.7.2 #pythonの設定 pyenv versions pyenv global 3.7.2 pyenv rehash #インストールの確認 python --version3.djangoのインストール
pythonがインストールできたらdjangoをインストールする。ちなみに自分にとっての初フレームワークがdjangoなので、djangoにはなんだかとても特別な気持ちを抱いている。
#djangoのインストール pip install Django以上でdjangoのインストールは終了なのだが、あとでsqlliteのバージョンが古いと怒られることになるのでここでその対策もしてしまうと良いと思う。
怒られないこともあるから、めんどくさい人は飛ばしてしまって本当に怒られてからやってもよい。
Sqlliteのアップグレード
参考URL:https://qiita.com/rururu_kenken/items/8202b30b50e3bfa75821
#tarファイルの取得 wget https://www.sqlite.org/2019/sqlite-autoconf-3280000.tar.gz #tarの解凍 tar xvfz sqlite-autoconf-3280000.tar.gz #ビルドしてインストール cd sqlite-autoconf-3280000 $ ./configure --prefix=/usr/local $ make $ sudo make install $ sudo find /usr/ -name sqlite3 $ sudo mv /usr/bin/sqlite3 /usr/bin/sqlite3_old $ sudo ln -s /usr/local/bin/sqlite3 /usr/bin/sqlite3 # 共有ライブラリへパスを通す $ export LD_LIBRARY_PATH="/usr/local/lib"setting ファイルの編集
Djangoを正常に立ち上げるための最低限の設定をここで行う。
#djangoプロジェクトの作成 django-admin startproject "プロジェクト名" #djangoアプリの作成 python manage.py startapp "アプリ名" #設定ファイルの編集 djangoの設定ファイルはプロジェクト名と同じ名前のフォルダに作られる vi /"プロジェクト名"/"プロジェクト名"/setting.py #以下setting.pyの中の編集項目 #installed_appの末尾に追加 "アプリ名".apps."アプリ名(頭文字を大文字にする)"Config 例)'myapp.apps.MyappConfig' #デバッグの非表示とhostの指定 DEBUG = False ALLOWED_HOSTS = ["設定したドメイン名"] #言語とタイムゾーンの設定 LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo' #静的ファイルの置き場の設定 STATIC_URL = '/static/' # これは元からあります。 STATIC_ROOT = '/usr/share/nginx/html/static' MEDIA_URL = '/media/' MEDIA_ROOT = '/usr/share/nginx/html/media' #保存してsetting.pyの編集終了 #最後にこのコマンドを打って終了 sudo python manage.py collectstatic4.nginxのインストールと設定
WebサーバにはNginxを使う。初めてこれに出会った時にどうやって読むのか皆目分からなかった。
nginxのインストール
#nginxのインストール sudo amazon-linux-extras install nginx1.12nginxの設定
#設定ファイルのの編集 sudo vim /etc/nginx/conf.d/project.conf #以下設定項目 server { listen 80; server_name "サーバのパブリックIPアドレス"; location /static { alias /usr/share/nginx/html/static; } location /media { alias /usr/share/nginx/html/media; } location / { proxy_pass http://127.0.0.1:8000; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Forwarded-Proto $scheme; } } #保存して終了 #設定ファイルチェック sudo nginx -t #nginxの起動 sudo systemctl reload nginx #サーバ起動時に同時にnginxも起動するための設定 sudo systemctl enable nginx5.gunicornのインストール
最後にwsgiとしてgunicornをインストールする。wsgiもgunicornも名前からしてなんだか良く分からない...
sudo pip3.7 install gunicornこれだけで終了。なんとも簡単。
サービスの立ち上げ
最後にサービスを立ち上げる
#manage.pyのファイルが置かれているプロジェクトフォルダに移動 cd /project #gunicornの起動 sudo gunicorn --bind 127.0.0.1:8000 project.wsgi:applicationここまでやったらドメイン名でdjangoのプロジェクトのアクセスできるようになっている。
最後にgunicornを止めたい場合の設定をのせておく
#gunicornのプロセス番号の確認 lsof -i:8000 #表示されたプロセスをkill kill -9 "表示されたプロセス番号"おつかれさまでした。
色々なエラーと闘って最後にページが立ち上がった瞬間はとても嬉しかった。
なんだか少し大人になったような気がした。
- 投稿日:2020-02-12T19:59:33+09:00
そろそろバレンタインなのでラインのトーク履歴を可視化してみますかw
バレンタインだからってわけじゃなくてじゃないんですけど,最近Githubにあるあのコントリビューションのチャートが気になっていました.
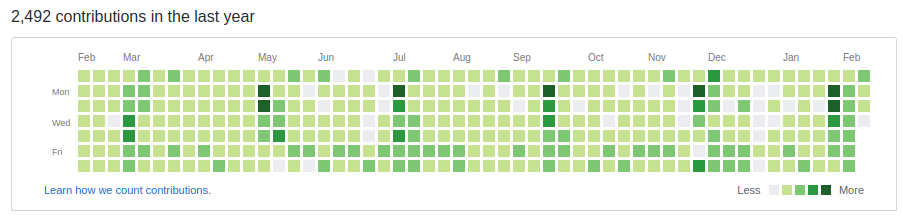
自分のコントレビューション
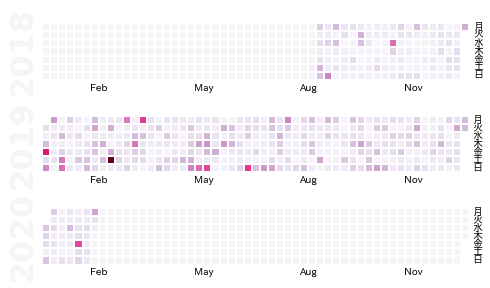
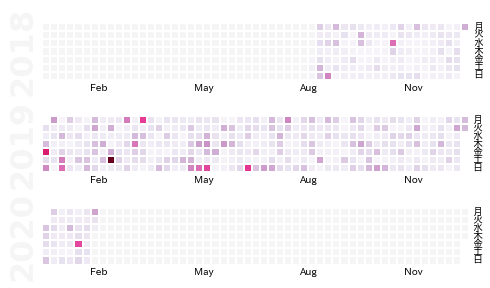
@torvaldsのコントリビューション
いい感じの時系列データがあれば似たようなチャートを試しに作ってみたいと前から思っていたところ,ちょうどラインのデータが簡単にダウンロードできるってことを知ったので,そのデータを使って作ってみました.
Lineのトーク履歴を取得
ラインからトーク履歴のチャットデータを保存できるって知っていました??
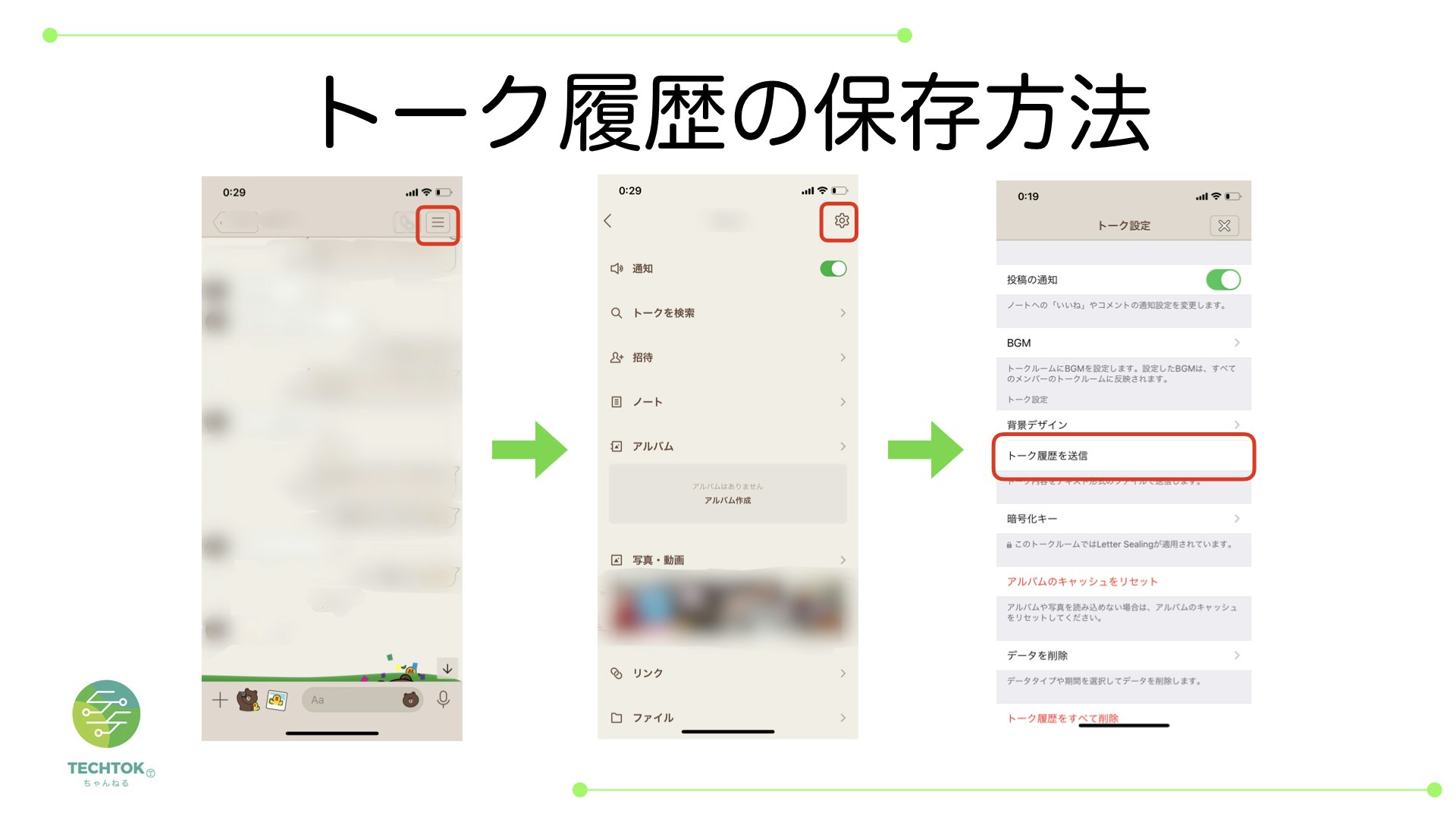
実は意外と簡単にできるもんなんです.手順はこちらのサイトを参考にしています.画像のソースもそちらです.
- LINEアプリから保存したいトークをタップします。
- 右上の「V」をタップ>「設定」をタップします。
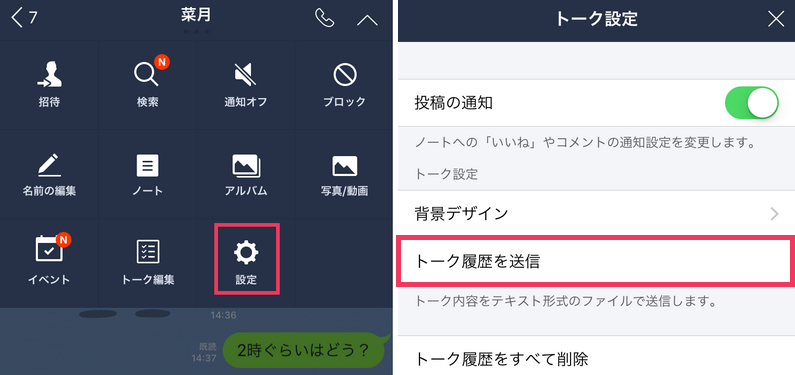
「トーク履歴を送信」から送信オプションを選択します。ここに、トーク履歴をKeepに保存します。
Keepからトーク履歴にアクセスできます。
CalmapとPandasでデータをすぐに可視化!
まず,以下のパッケージをインポートしていることにします.
import datetime, calmap import japanize_matplotlib import pandas as pd from matplotlib import pyplot as plt from collections import defaultdict import warnings warnings.simplefilter("ignore")そして次にデータの集め方について考えます.データ取得の工程に出てきたこちらの画像の右側にテキストデータがありますが,このようなフォーマットでデータを読み込むと仮定します.(※僕の携帯は英語設定なので,少しだけフォーマットが違いますが,ほとんど同じです!)
日付だけの行があって,その下に時間,人,チャット内容が一つの行になっていますね(電話・スタンプ・ファイルなども面倒なのでチャットして考える!).ここに着目して,日付の行だったらTrueを返す,
isNewDay()とチャットの行だったらTrueを返すisChat()関数を作ります.
日付 時間 人 内容 時間 人 内容 時間 人 内容
日付 時間 人 内容 時間 人 内容 def isNewDay(line): line = line.strip().replace(' ','') elements = line.split(',') if len(elements) == 2: day, date = elements try: assert day in ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'] assert datetime.datetime.strptime(date, '%m/%d/%Y') return True except (AssertionError, ValueError) as e: pass return False def isChat(line): elements = line.split('\t') if len(elements) == 3: time, person, activity = elements try: assert datetime.datetime.strptime(time, '%H:%M') assert person in [PERSON1, PERSON2] return True except (AssertionError, ValueError) as e: pass return Falseもし読み込むデータのテキストファイルのフォーマットが若干違ったりすれば,これらの関数の内容を修正する必要があります.
ここまできたら,あとはループで日付毎にチャットの回数を数えれば良いです.僕はしたのようにdefaultdictを使って以下のように数えました.日付順にチャットが並んでいると仮定しているので結構ガバガバな感じで書いています(笑.
d = defaultdict(lambda: 0) with open(PATH_TO_DATA) as f: for line in f.readlines(): # New day if isNewDay(line): day, date = line.split(',') # month, day, year = list(map(int, date.split('/'))) # Chat Event if isChat(line): index = datetime.datetime(year, month, day) d[index] += 1チャットの回数を数え上げたら,今度は可視化します.これにはcalmapパッケージを使います.
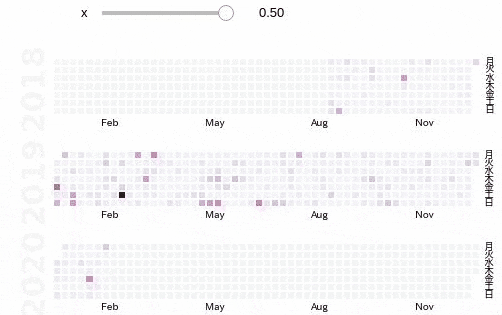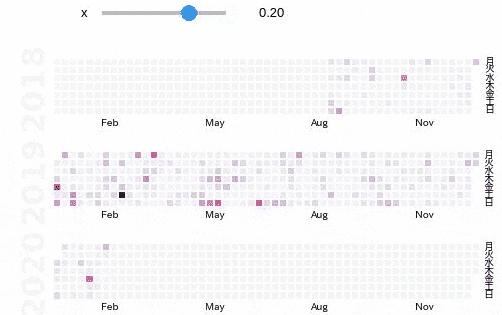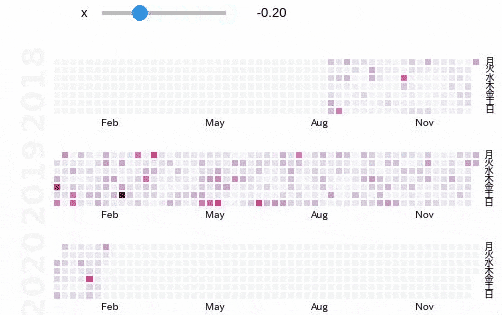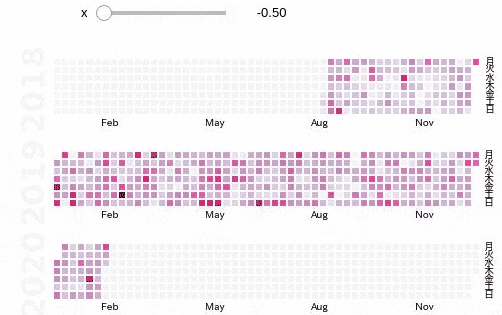
使い方はすごく簡単で,基本的には時系列上に並んでいるpandasのSeriesをぶちこめばOKです.s = pd.Series(d) calmap.calendarplot(s, monthticks=3, cmap='PuRd', daylabels='月火水木金土日', fig_kws=dict(figsize=(8, 4)))
色が薄いなと思ったら,以下のように重みをつけたりして強調させたりすることもできます.
import ipywidgets as widgets from ipywidgets import interact, interact_manual @interact def emph(x=(-0.5, 0.5, 0.1)): s = pd.Series(d) s *= s**x calmap.calendarplot(s, monthticks=3, cmap='PuRd', daylabels='月火水木金土日', fig_kws=dict(figsize=(8, 4)))
以上です!メカブとか使ってさらに深く掘り下げていくのも面白そうですね.でも,もう疲れたので今日は以上ですー

- 投稿日:2020-02-12T19:55:02+09:00
Pythonにてcsvファイルを用いてFirestoreにデータを一括登録する
概要
以下のことは済ませているものと考えてください。契約状態によって確認事項が違いますので、簡単に。
- Firestoreを有効化
- APIキーの発行(firebaseにて出来ます)
- firebaseはnativeモード
データ構造
csvファイル体裁
区切りは「,」としています。たまに規則通りになっていないcsvファイルがあったりするので、その辺りは気を付けてください。
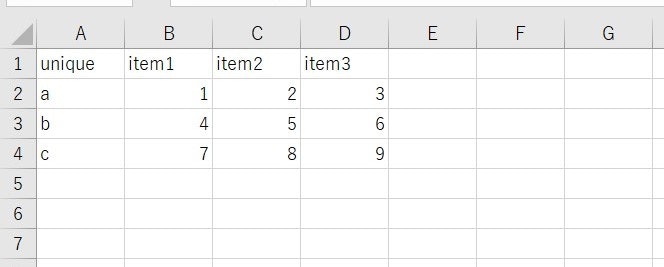
DB構成
今回は簡単な構成です。uniqueというところを主キーのように考えており、重複なしです。
DB構成unique ---------- item1 | | a : 1 | | b : 2 | ∟ c : 3 | |--------- item1 | | a : 4 | | b : 5 | ∟ c : 6 | ∟ --------- item1 | a : 7 | b : 8 ∟ c : 9プログラム
以下のようなことをやっています。
- データ読込み
- firestore変数初期化
- 一つずつfirestoreに登録
sample.pyimport firebase_admin from firebase_admin import credentials from firebase_admin import firestore import csv # データ読込み def read_data(file_name): csv_data = None with open(file_name) as r: reader =csv.reader(r) csv_data = [row for row in reader]# 二次元配列で変数に格納 print('read end') return csv_data # firebase 初期化処理 def firebase_init(api_key): api_key = credentials.Certificate(api_key) # 前回の初期化状態が残っているみたいなので、まずは前回の初期化状態を削除 if(len(firebase_admin._apps)): firebase_admin.delete_app(firebase_admin.get_app()) firebase_admin.initialize_app(api_key) print("init end") # メイン処理/データ登録 def exe(data): db = firestore.client()# firestoreクライアント変数 header = data[0]# ヘッダ取得 doc_base = db.collection(header[0])# uniqueの所を設定 print("proc start") for i in range(1, len(data)):# 2行目からがデータなので、1から doc_ref = doc_base.document(data[i][0])# a,b,cのところを設定 buf = {}# バッファ for j in range(1, len(data[i])): buf[header[j]] = data[i][j] doc_ref.set(buf) # firestoreに保存 print("poc end") def main(): file_name = "csvファイル名" api_key = r'api_key' # ファイル読込み data = read_data(file_name) # firebase初期化 firebase_init(api_key) # メイン処理 exe(data) if __name__=="__main__": main()おわりに
今回まっさらな状態での一括登録ですが、途中でfirestoreからデータを一括取得し、差分チェックしてfirestoreに更新するというようにすると良いとは思います。api呼び出し回数が減るので、料金が減るんですかね。試算はしていませんが。
- 投稿日:2020-02-12T19:32:00+09:00
Raspberry PiにTensorFlow 1.15.0をインストールする
こんにちは。
Raspberry PiへのTensorFlowのバージョン1.15.0以降をインストールしたかったのですが、
pipではうまくいかず、日本語でまとまっているものが見つからなかったので、備忘録がてらまとめておきます。環境
ラズパイの環境は下記の通りです。
- Raspberry Pi 3 Model B+
- Raspbian 9.11(stretch)
- Kernel 4.19.66-v7+
$ uname -a #Linux raspberrypi 4.19.66-v7+ #1253 SMP Thu Aug 15 11:49:46 BST 2019 armv7l GNU/Linux $ lsb_release -a #No LSB modules are available. #Distributor ID: Raspbian #Description: Raspbian GNU/Linux 9.11 (stretch) #Release: 9.11 #Codename: stretchPythonのバージョンは下記です。
$ python3 --version #Python 3.5.3 $ python3 -m pip --version #pip 20.0.2 from /home/pi/.local/lib/python3.5/site-packages/pip (python 3.5)TensorFlowのインストール
pipでのインストール
通常通り
pipでインストールしようとしました。$ pip3 install tensorflow==xxx #Could not find a version that satisfies the requirement tensorflow==xxx (from versions: 0.11.0, 1.8.0, 1.9.0, 1.10.0, 1.11.0, 1.12.0, 1.13.1, 1.14.0) #No matching distribution found for tensorflow==xxxしかし、ラズパイからは1.14.0までしかインストールできないようです。
そのため、別の方法でインストールすることにしました。ソースからのビルド
公式ページの情報からビルド
TensorFlowの公式ページによると、Raspberry Piのソースからビルドすることで、インストールできそうです。
dockerを用いてビルドしていきます。
ラズパイ上でビルドすると時間がかかるのため、クロスコンパイルをした方が良いとのことなので、mac上でビルドしていきます。
先に結論からいうと、この方法ではビルドできませんでした。mac$ docker --version #Docker version 19.03.5, build 633a0eagithubからクローンしてきます。
今回は1.15.0をインストールしたいので、ブランチをチェックアウトしておきます。mac$ git clone https://github.com/tensorflow/tensorflow.git $ cd tensorflow $ git checkout r1.15公式ページに従ってクロスコンパイルを行います。
mac$ CI_DOCKER_EXTRA_PARAMS="-e CI_BUILD_PYTHON=python3 -e CROSSTOOL_PYTHON_INCLUDE_PATH=/usr/include/python3.4" \ tensorflow/tools/ci_build/ci_build.sh PI-PYTHON3 \ tensorflow/tools/ci_build/pi/build_raspberry_pi.shビルドが完了すると(約 30 分ほど)、.whl パッケージ ファイルがホストのソースツリーの出力アーティファクト用ディレクトリに作成されます。
とありますが、下記のようなエラーが出てビルドが完了しませんでした。
#addgroup: Please enter a username matching the regular expression configured #via the NAME_REGEX[_SYSTEM] configuration variable. Use the `--force-badname' #option to relax this check or reconfigure NAME_REGEX.調べてみると、公式の手順ではビルドできないというisuueがたっていました。
なんで公式のままできないんだよ。。。という感じですが、
issue内に、ネイティブビルドしたファイルをあげている人がいたので、今回はそれを使用します。ビルドファイルからインストール
Tensorflow-binにあげられているので、READMEを参考にインストールしていきます。
ラズパイの環境がRaspbian 9.11(stretch)なので、
tensorflow-1.15.0-cp35-cp35m-linux_armv7l.whlを使用します。$ sudo apt-get update $ sudo apt-get upgrade $ sudo apt-get install -y libhdf5-dev libc-ares-dev libeigen3-dev gcc gfortran python-dev \ libatlas3-base libatlas-base-dev libopenblas-dev libopenblas-base libblas-dev \ liblapack-dev cython openmpi-bin libopenmpi-dev libatlas-base-dev python3-dev #libgfortran5がインストールできなかったので抜きました $ sudo pip3 install keras_applications==1.0.8 --no-deps $ sudo pip3 install keras_preprocessing==1.1.0 --no-deps $ sudo pip3 install h5py==2.9.0 $ sudo pip3 install pybind11 $ pip3 install -U --user six wheel mock $ sudo pip3 uninstall tensorflow $ wget https://github.com/PINTO0309/Tensorflow-bin/raw/master/tensorflow-1.15.0-cp37-cp37m-linux_armv7l.whl $ sudo pip3 install tensorflow-1.15.0-cp35-cp35m-linux_armv7l.whl最後のインストールコマンドで何度か
TypeError: unsupported operand type(s) for -=: 'Retry' and 'int'で失敗してしまいましたが、めげずにsudo pip3 install tensorflow-1.15.0-cp35-cp35m-linux_armv7l.whlを打っていたら5回ほどでインストール成功しました。。。$ python3 >>> import tensorflow as tf >>> tf.__version__ 1.15.0 >>> exit()無事に1.15.0がインストールできました!
今日はここまでです。
- 投稿日:2020-02-12T18:27:39+09:00
指定したユーザーのツイートをしゃべるRaspberry Piの作り方
はじめに
第三回研究室内ハッカソンが行われました。他のメンバーの記事1、記事2
今回は、ツイートを喋るRaspberry Piを作ることに決めました。
作成動機は、以前ラズパイの初期設定を初めて行った際に参考にした記事に、ツイートを大声でしゃべるラズパイのことが書かれていました。それを読んだ時、研究室にいるツイ廃のツイートをしゃべるラズパイをいつか作ってみたいと感じたからです。
今回、参考にした記事準備したもの
- Raspberry Pi 2 + WiFiドングル
- Raspbian のインストールされたmicroSD
- 電源アダプタ
- 普通のイヤホン(スピーカー用)
- キーボードとマウスとディスプレイ
スピーカーのチェック
スピーカーの音をチェック
$ speaker-test -t wav
Ctr + Cで音を止めることができます。
この時、HDMIで接続したディスプレイから音が出たので、イヤホン(仮想スピーカー)から音を出すために$ amixer cset numid=3 1と入力することでHDMI出力からアナログ出力に変換でき、スピーカーから音を流すことができます。
音量の調節
$ alsamixerOpenJtalk(音声合成ソフト)のインストール
OpenJtalkとは
- オープンソースの音声合成エンジン
- OpenJtalkに喋らせるには以下が必要
- しゃべる内容が書かれたテキスト
- 辞書フォルダ
- 音声ファイル
- OpenJtalkの標準音声
- nitech_jp_atr503_m001.jhtsvoice(男性の声) ###OpenJtalk・辞書音声データをインストール
$ sudo apt-get update $ sudo apt-get install open-jtalk $ sudo apt-get install open-jtalk-mecab-naist-jdic $ sudo apt-get install htsengine libhtsengine-dev $ sudo apt-get install hts-voice-nitech-jp-atr503-m001途中で「続行しますか[Y/n]?」というメッセージが表示されたら、「Y」を打ち込んで「Enter」キーを押してインストールを続行します
jtalk.shの作成
次に、OpenJtalkを動かすスクリプトを作成していきます。
jtalk.sh#!/bin/sh tmpfile=/tmp/jtalk.wav htsvoice="/usr/share/hts-voice/\ nitech-jp-atr503-m001/\ nitech_jp_atr503_m001.htsvoice" echo "$1" | open_jtalk \ -x /var/lib/mecab/dic/open-jtalk/naist-jdic \ -m $htsvoice \ -ow $tmpfile && \ aplay --quiet $tmpfile rm $tmpfile作成したスクリプトに実行権限を与えます。
$ chmod 755 jtalk.shコマンドラインで以下をテスト
$ ./jtalk.sh こんにちはスピーカーから「こんにちは」と聞こえればOK!
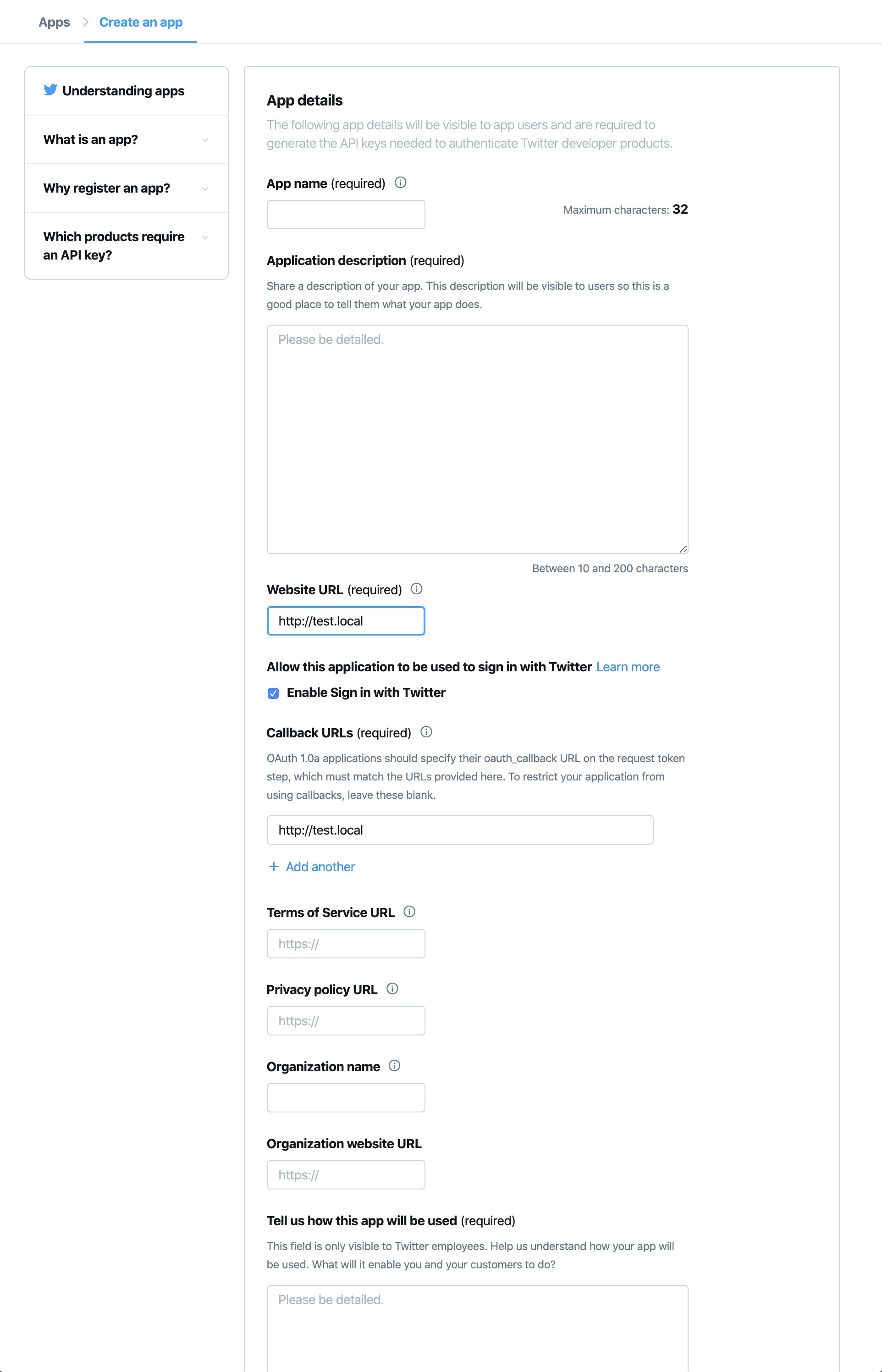
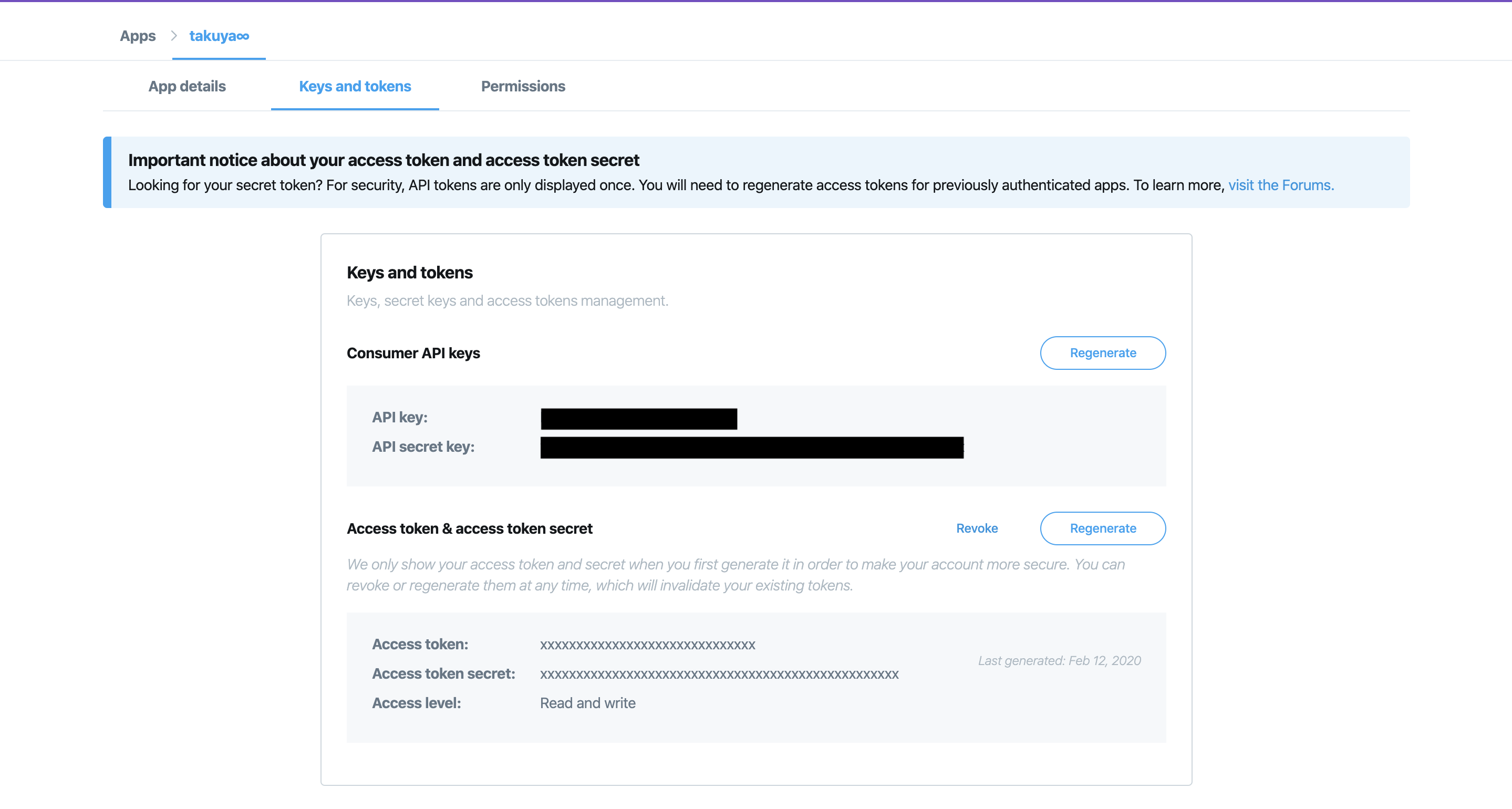
Twitter API アクセストークンを取得
下記のURLからtwitterにログインする。
https://apps.twitter.com/
1. 「create an Apps」をクリック
2. 必要な項目を入力(適当で大丈夫らしい)
3. 「create」をクリックし、作成したAPPの「Details」をクリック
4. 「Keys and tokens」タブを選択し、Access token & access token secret の「Generate」ボタンをクリック
5. 表示された「API key」、「API secret key」、「Access token」、「Access token secret」の4つをメモしておく
Pythonプログラムの作成
pythonの設定
# 仮想環境の作成 $ sudo apt-get install python3-dev python3-venv $ python3 -m venv env $ cd env $ source bin/activatetweepyのインストール
(env) $ python -m pip install tweepyteitter.pyを作成
#-*- coding:utf-8 -*- import tweepy import os # 各種キーをセット CONSUMER_KEY = 'xxxxxxxxxxxxxxx' CONSUMER_SECRET = 'xxxxxxxxxxxxxxxxxxxxxxx' auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) ACCESS_TOKEN = 'xxxxxxxxxxxxxxxxxxxx' ACCESS_SECRET = 'xxxxxxxxxxxxxxxxxxxxxxxxxx' auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET) #APIインスタンスを作成 api = tweepy.API(auth) print('Done!') #準備完了 # つぶやきを取得 for status in tweepy.Cursor(api.user_timeline,screen_name = "取得したユーザーのID",exclude_replies = True).items(): tw_text = status.text tw_text = ''.join(tw_text.splitlines()) tw_text = tw_text.replace('(',' ').replace(')',' ').replace(' ','') print(tw_text) os.system('/home/pi/jtalk.sh ' + tw_text) break #とりあえず最新のつぶやきのみ実際に動かす!
以下のコードを打つ
(env) $ python twitter.py指定したユーザーの最新のツイートを男性の声で喋りました!
(鍵垢でも、自分がフォローしていれば喋ってくれました)おわりに
今回のハッカソンで指定したユーザーの最新ツイートをラズパイに喋らせることに成功したので、指定したユーザーがツイートしたらそれをしゃべるように改良を加えていきたいと思います!
読んでいただきありがとうございます!
- 投稿日:2020-02-12T18:06:03+09:00
APLpyで軸目盛の間隔を調整したいとき
APLpyで軸目盛の間隔を調整する方法で少しハマったのでメモ。
例えばx軸の主目盛の表示間隔を調整したいときはdegrees単位で
fig.ticks.set_xspacing(0.0005)とやればいい。ただし、このとき引数はlabel formatの最小単位の倍数でなくてはならない。
いまfig.ticklabels.set_xformat(hh:mm:ss.ss)としていたなら最小単位は0.001sすなわち0.015arcsec、したがって0.015/3600 degreeである。これを基準にしていっぱんにはnを整数としてn*0.015/3600の数をset_xspacingに入れてやれば良い。
参考
APLpy documentation — aplpy v2.0.2
Overlapping tick labels on x axis · Issue #258 · aplpy/aplpy
- 投稿日:2020-02-12T17:06:29+09:00
【Python&Django】git add 【アプリ名】でレポジトリを作成できない問題【解決】
せっかく作ったアプリのレポジトリを作成できないなんて悲しいですよね。解決しました。
結論、以下のコマンドをターミナルに叩き込んでください。
git config –global user.name【githubのユーザー名】git config –global user.email【githubで登録したメールアドレス】git initこの作業をする際に1つ注意点があります。
それは「作ったアプリのディレクトリまで移動してコマンドを叩く」ということ。cd 【アプリ名】まで移動してくださいね。結構忘れがちなので。
あとはGithub Desktopから「Add」をクリックし、「Add Existing Repository」を叩きましょう。完成です。
ターミナルから追加してもOKです!
- 投稿日:2020-02-12T16:56:23+09:00
書籍「15Stepで踏破 自然言語処理アプリケーション開発入門」をやってみる - 4章Step15メモ「データ収集」
内容
15stepで踏破 自然言語処理アプリケーション入門 を読み進めていくにあたっての自分用のメモです。
今回は4章Step15で、自分なりのポイントをメモります。(ほとんど書くことないですが)準備
- 個人用MacPC:MacOS Mojave バージョン10.14.6
- docker version:Client, Server共にバージョン19.03.2
章の概要
書籍の最終章として、これまでに見てきた自然言語処理や機械学習を行う上で、各々の目的に合致したデータセットを公開データから探したり、自前で構築したりするときのヒント集となっている。
- データセットの収集
- クラウドソーシング
15.2 データセットの収集
公開データセットの利用
データセット 特徴 Wikipedia Web百科事典で、公式に全データのダンプファイルが公開されている。 青空文庫 著作権の失効した文芸作品のテキストファイルを無料でダウンロードできる。 livedoorニュースコーパス ライブドアニュースの記事の一部がクリエイティブ・コモンズ・ライセンス(表示-改変禁止)で提供されている。 日本語WordNet 単語の意味の階層構造を表現したデータベースで、前処理や形態素解析の際に利用することが考えられる。 この他にも有料であったり利用申し込みが必要なもの、利用用途に制限のあるものもある。
クローリング
欲しい公開データセットがない場合、Webサイトをクローリングしてデータを収集することが考えられる。
教師なしデータは集めやすい。
- 多くのWebサーニスではクローリング目的の大量アクセスを規約で禁止している
- データ収集先のWebサイトの利用規約で、コンテンツの利用目的に制限が課されていることもある
15.3 クラウドソーシング
クローリングは無料だが、教師ありデータを集めにくい。
クラウドソーシングを使うと有料(クラウドワーカーに報酬が必要)だが、タスクを設定することができる他、多数の作業者が並行して多数のタスクを安価に依頼できる。日本語のデータセット構築では日本語話者の作業が必要となるため、必然的に国内のサービス(クラウドワークスやランサーズなど)を利用することになる。
- 投稿日:2020-02-12T16:11:26+09:00
Djangoを使って将棋棋譜管理アプリを作る1 ~環境構築~
はじめに
これから何回かに渡って、Djangoを使って将棋の棋譜管理アプリを作っていこうと思います!
どうして作ろうと思ったか?
まず第一に、僕が最初に本格的に学習した言語がPythonでして、それを使って「何か」つくりたいなぁ~と思ったからです。
そこで趣味である将棋の、「僕の対局履歴の棋譜を管理できたらいいんじゃね」と思ったことがきっかけでした。そこで始めはFlaskを使って途中まで作っていたのですが、周りの人の意見を聞くと、「絶対Djangoの方がいい!」ということになり、改めて一から作り直すことにしました。
ここでは、備忘録も含めて、作業工程をきままに綴っていきますので、よろしくお願いします。
作業環境
今回の作業環境は以下の通りです
- Windows 10 Pro
- Anaconda
- version1.7.2
- python 3.7
- django 2.2.5
- git
- version 2.25.0.windows.1
本稿の内容
- Anacondaでの仮想環境の作成
- Djangoの設定
- Djangoを管理する上でのGitの設定
Anacondaで仮想環境の作成
そもそもAnacondaが何なのか分かっていなかった(
1dayインターンで入れろと言われたから入れた)。
そこでAnacondaについて以下の記事に詳しく載っていたので、勉強させていただきました。
【初心者向け】Anacondaで仮想環境を作ってみるまた、Djangoのインストールも含めて、次のサイトも参考にさせていただきました。
【Anaconda+Django】 PythonでWebアプリを開発してみる。今回は、kifu_appという仮想環境を作りました。
$ anaconda -V anaconda Command line client (version 1.7.2) $ activate kifu_app (kifu_app) $ python -V Python 3.7.6Djangoのインストール
先程のブログを参考にしたら簡単に終わりました。
Djangoの設定
Djangoプロジェクトの作成
以下の記事を参考にさせていただきました。
Djangoを最速でマスターする part1プロジェクトを作りたいディレクトリに移動して、次を入力します
$ django-admin startproject kifu_appこれで以下のディレクトリ構造のプロジェクトができました!
- kifu_app_project/ - kifu_app_project/ - setting.py - urls.py - wsgi.py - __init__.py - manage.pyアプリの作成
上側のkifu_app_projectディレクトリ内で、次を実行します
$ python manage.py startapp kifu_appするとディレクトリ構造は次のようになります。
- kifu_app_project/ - kifu_app_project/ - setting.py - urls.py - wsgi.py - __init__.py - manage.py - kifu_app - admin.py - apps.py - migrations - models.py - tests.py - views.py - __init__.py最後に、setting.pyに以下のものを追加します。(アプリを作ったよ!という報告だそうです)
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'kifu_app', # <-これを追加 ]Gitの連携
どうせなのでGitも練習がてら使えるようにします。
これもkifu_app_projectという名前で、GitHubにリモートリポジトリを作成しました。コミットなどの詳細は、以下の記事を参考にしました。
Djangoの使い方~デプロイ編①~まず、上の階層の方のkifu_app_project内に.gitignoreファイルを作ります。
.gitignoreは、指定したファイルを追跡対象から外すようにするものです。.gitignore# Created by https://www.gitignore.io/api/django # Edit at https://www.gitignore.io/?templates=django ### Django ### *.log *.pot *.pyc __pycache__/ local_settings.py db.sqlite3 db.sqlite3-journal mediagitignore.ioというサイトで、.gitignoreに書くべきことのテンプレートを作ってくれます。
準備が完了したら、最初のコミットをしていきます。
$ git init Initialized empty Git repository in ~/djangogirls/.git/ $ git config --global user.name "Githubの登録ユーザー名" $ git config --global user.email Githubの登録メールアドレス $ git add --all . $ git commit -m "My Django Girls app, first commit" 13 files changed, ~~~ $ git remote add origin リポジトリのURL $ git remote -v origin リポジトリのURL $ git push -u origin master上から順にコマンドを実行していけば大丈夫なハズです。
詳しく説明していただいている方が他にもいらっしゃるので、そちらを参考にしてください。GitHubを確認すると、確かにpush出来ていました!
次回予告
次回は、データベースの設定を行っていきます!
- 投稿日:2020-02-12T16:08:35+09:00
【Python】データサイズが大きいcsvファイルをgeneratorを使って読み込む
import csv def csv_reader(file, header=False): with open(file, "r") as f: reader = csv.reader(f) if header: next(reader) for row in reader: yield row def main(): g = csv_reader("xxx.csv", header=False) print(next(g)) # => 一行目 if __name__ == '__main__': main()
- 投稿日:2020-02-12T16:06:06+09:00
【バレンタイン特別企画】LINE相性診断作ってみた!
バレンタインです
2月14日が近づいてきてそわそわしている男の人も多いのではないでしょうか?
今回はLINEのトーク履歴を使って気になる相手との相性を診断するシステムを作ってみました!詳細については以下の動画で紹介しています
https://youtu.be/LNFFCBIHOXYどうやって作るの?
作り方は簡単です
- 個人LINEのトーク履歴を保存
- データ整形
- 独自のアルゴリズムでスコア計算
※1はスマホアプリからとPCのアプリから保存するのではテキストのフォーマットが変わるのでスマホアプリから保存してください
個人LINEのトーク履歴を保存
以下の手順でトーク履歴を保存します
データ整形
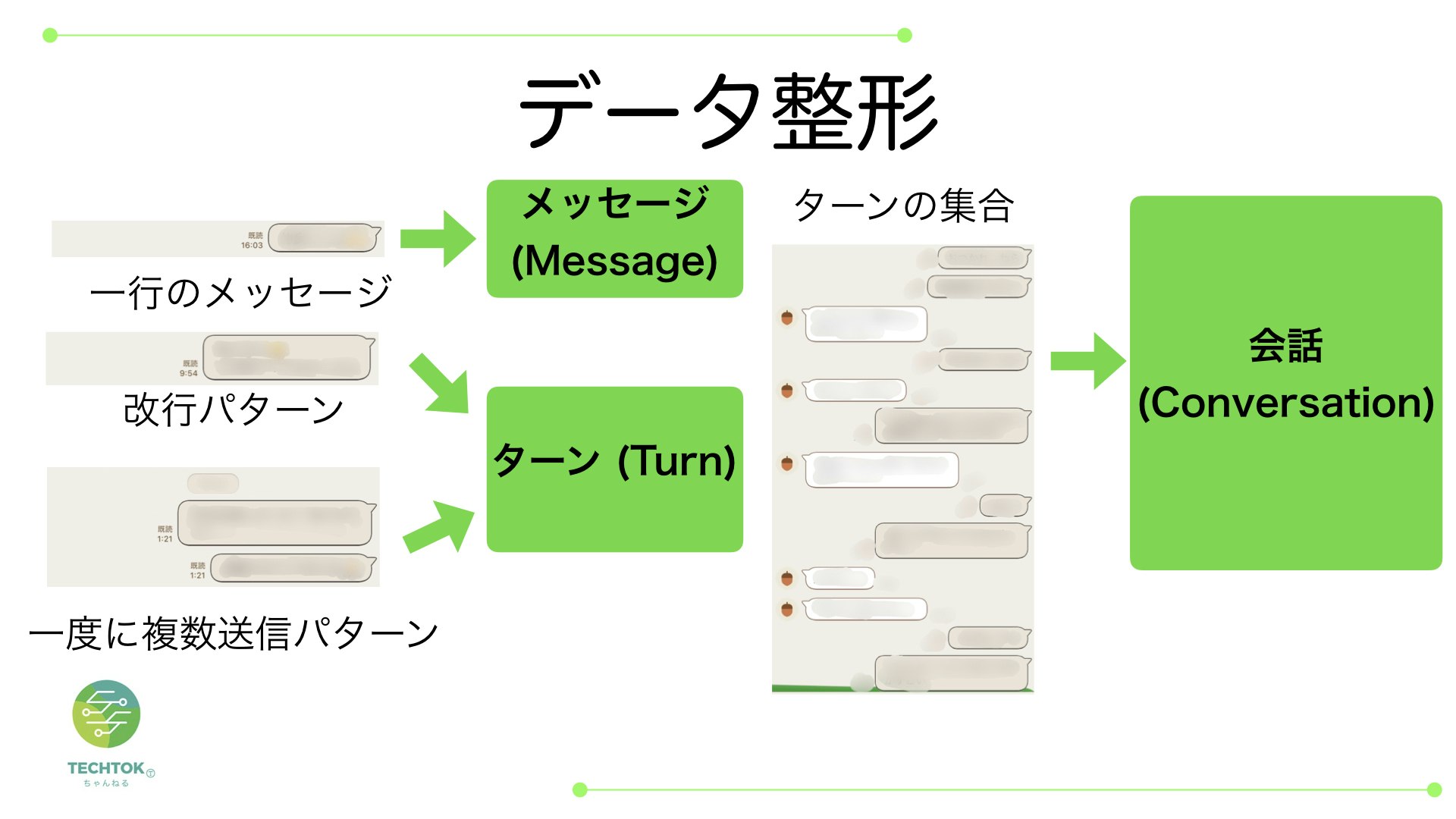
テキスト形式のトーク履歴をデータ整形していきます
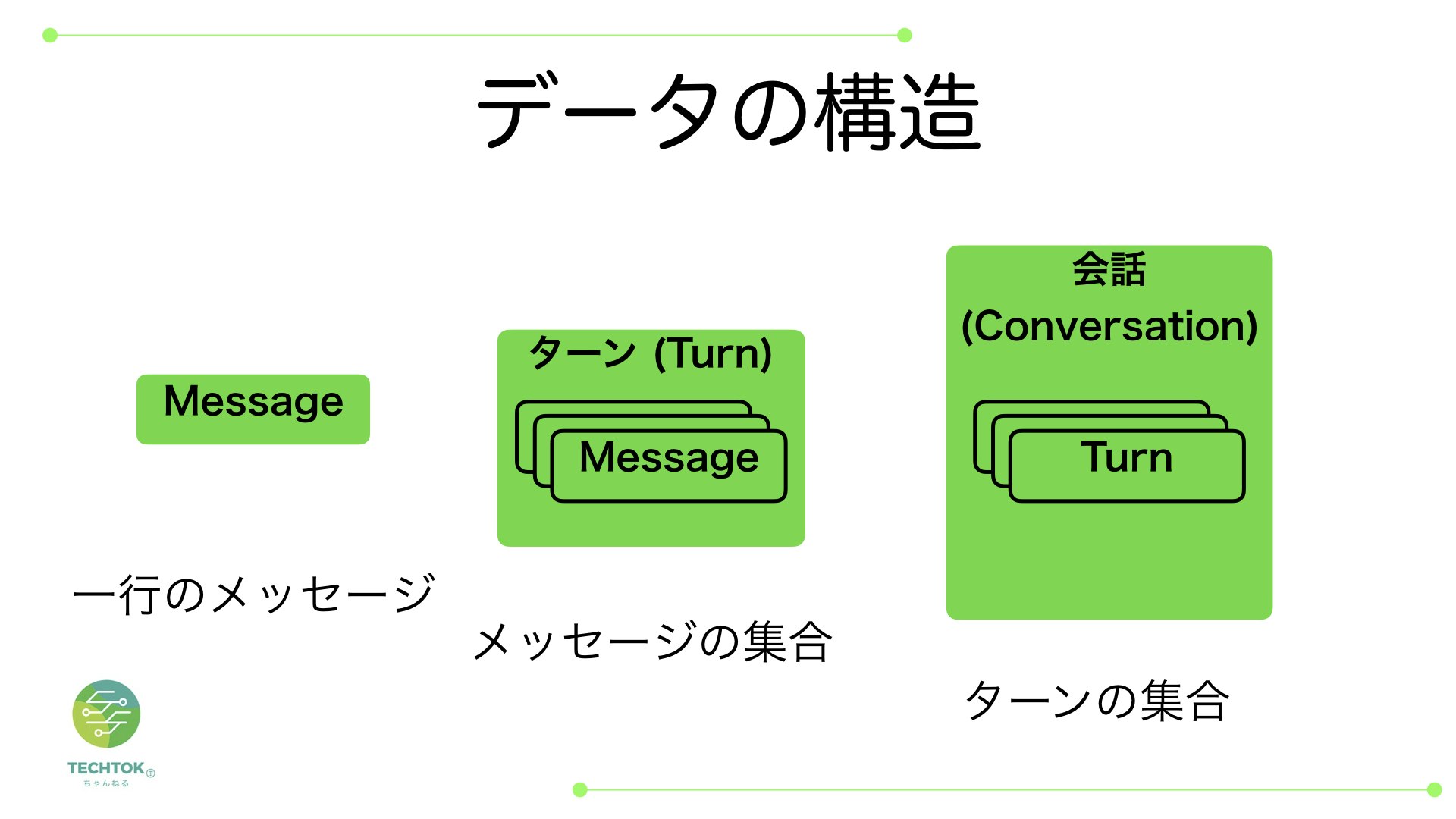
メッセージとターンと会話という3つのデータ形式を定義します
データ構造は一行メッセージがメッセージ、メッセージの集合がターン、自分と相手のターンの集合が会話という関係になります
独自のアルゴリズムでスコア計算
LINE相性診断システムには4つの評価軸があります
会話の長さ
会話の長さでは10日を満点として1会話ごとに計算します
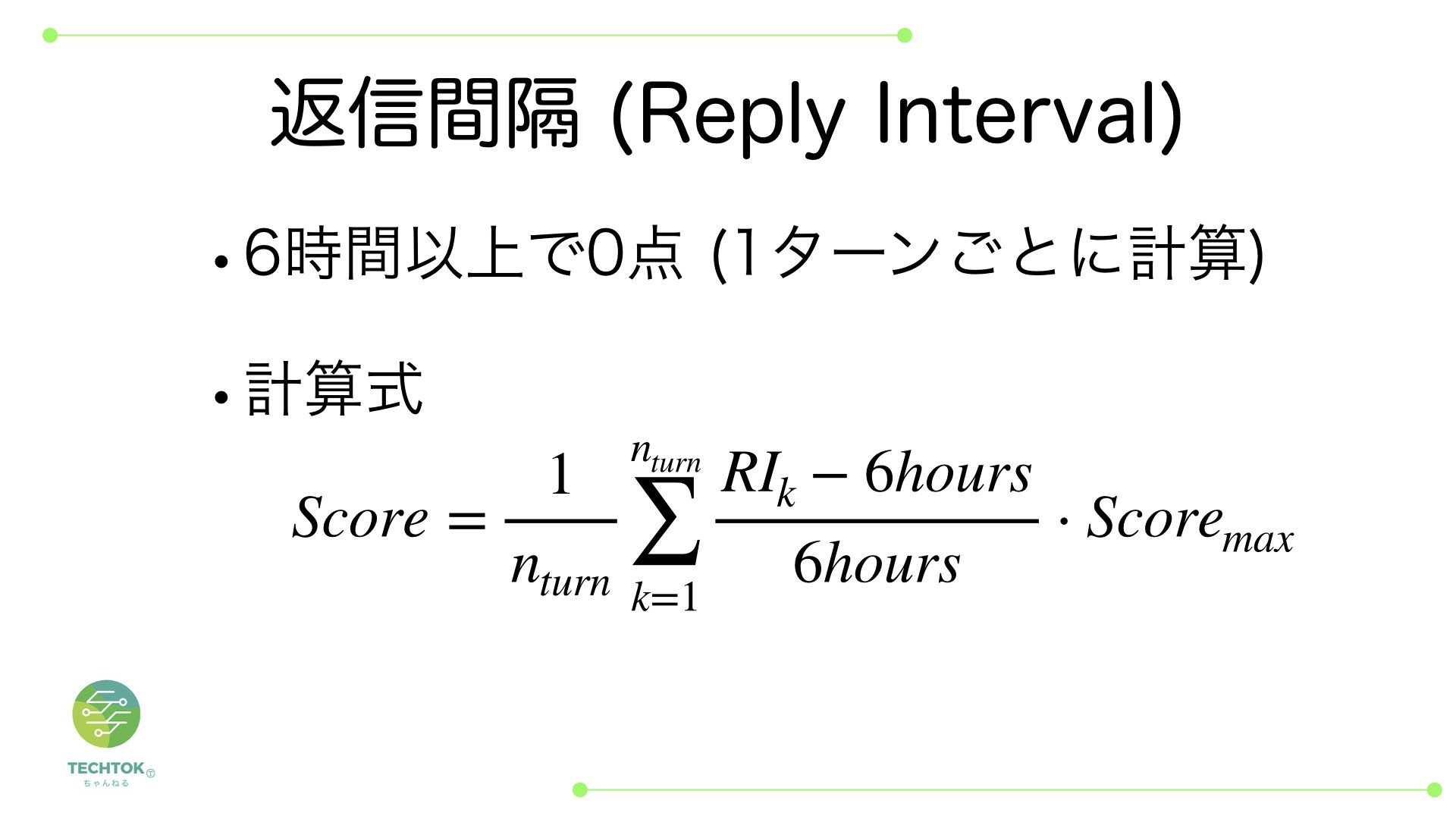
返信間隔
返信間隔では6時間以上経過で0点になるように計算します
内容の質
内容の質は今回は簡単に質問文または絵文字を含む場合に得点が入るようにしました
今後はword2vecやdoc2vecにより「好き」に近い単語が含まれている場合に加点するなどの処理を入れていきたいと思っています
通話時間
通話時間の評価では1時間以上の通話を満点として全通話で平均をとります
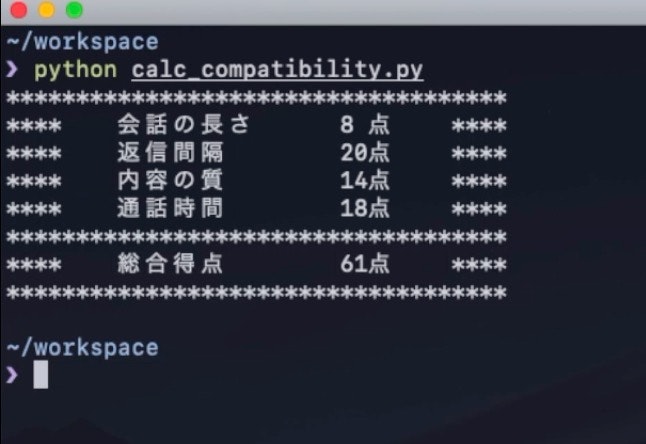
結果
結果は以下のようになりました
そこそこ厳しめに作ったので60点あれば上出来といったところです、わら
まとめ
今回は簡単なアルゴリズムで相手との相性を数値化するシステムを作りました!
データがデータだけに心配ですがherokuなどで公開して使ってもらうのもよさそうですね




- 投稿日:2020-02-12T15:45:56+09:00
非線形最適化入門(私が)
1.要旨
今回は,非線形最適化手法の中でも最も有名で,よく利用されているニュートン法について概略をまとめ,RおよびPythonでの実装例を載せました.多変量解析のある分析手法のパラメータ推定で利用した(する予定)ので,勉強も兼ねて実装しました.
2.非線形最適化
2.1 何それ?
そのまんまですが,非線形関数の最適化(=最小化/最大化)のことです.非線形関数の例としては,$y = x^2$や$y = x\log_e x$などが挙げられます.例えば,$y = x\log_e x$を例にとると,この関数の最小値を与える点を得ようと思った場合,($0<x$で下に凸であることはわかっているとして,)$x$に関して微分して,
$$\frac{d}{dx}y = \log_e x + 1$$
この勾配が$0$となる点の関数の値を計算すれば良いです.つまり,
$$\log x_e + 1 = 0$$
の根を求めれば良いのです.ちなみに$\hat{x} = 1/e$です.
このように,方程式をスパーンと単純に解ける場合(解析的に解ける場合)は,それでいいのですが,解が陽に表せない場合も多いです.そういった場合に非線形最適化手法が活躍します.2.2 Newton-Raphson法
非線形最適化の中でも,最も有名で,シンプルで多岐にわたる場面で利用されている手法として,ニュートン法(Newton method, Newton-Raphson method, wiki)があります.数理的な詳細に関しては,こちら(ニュートン法とは何か??ニュートン法で解く方程式の近似解)をご覧ください.丁寧に図解してくださっていて,高校数学がふんわりわかっていれば,大枠が掴めると思います.これを実装するためには,
* 勾配を計算するための数値微分
* ニュートン法の更新式の反復の二つが必要です.一つめに関しては,とりあえずは,
$$\frac{d}{dx}f(x) = \underset{h\rightarrow 0}\lim \frac{f(x + h) - f(x)}{h}$$
を実装しましょう.Rでは,
numerical.differentiate = function(f.name, x, h = 1e-6){ return((f.name(x+h) - f.name(x))/h) }で,pythonでは,
def numerical_diff(func, x, h = 1e-6): return (func(x + h)-func(x))/hみたいな感じでしょうか.これらとニュートン法による逐次計算を用いて,先ほどの
$$\log_e x + 1 = 0$$
を解いてみましょう.Rでの実行例は,
newton.raphson(f.5, 100, alpha = 1e-3) # 0.3678798pythonでの実行例は,
newton_m(f_1, 100, alpha = 1e-3) # 0.36787980890600075どちらも,先ほどの方程式の解$1/e\fallingdotseq1/2.718 = 0.3679176$に近くなっていることがわかります.
3.サンプルコード
雑コードですが...
r, newton_raphson.Rnumerical.differentiate = function(f.name, x, h = 1e-6){ return((f.name(x+h) - f.name(x))/h) } newton.raphson = function(equa, ini.val, alpha = 1, tol = 1e-6){ x = ini.val while(abs(equa(x)) > tol){ #print(x) grad = numerical.differentiate(equa, x) x = x - alpha * equa(x)/grad } return(x) } f.5 = function(x)return(log(x) + 1) newton.raphson(f.5, 100, alpha = 1e-3)python, newton_raphson.pyimport math def numerical_diff(func, x, h = 1e-6): return (func(x + h)-func(x))/h def newton_m(func, ini, alpha = 1, tol = 1e-6): x = ini while abs(func(x)) > tol: grad = numerical_diff(func, x) x = x - alpha * func(x)/grad return x def f_1(x): return math.log(x) + 1 print(newton_m(f_1, 100, alpha = 1e-3))ニュートン法が,大域的最適解に収束するには,最適化する関数が,最適化する区間$[a,b]$に大域的最適解が存在し,その区間で凸でなければならないことに注意しましょう.私が昔かいたプログラムは,多変数の場合だったので,理解がいまいちでしたが,1変数の場合だと,シンプルで理解しやすいです.計算の精度は,tolパラメータとhパラメータに依存します.
- 投稿日:2020-02-12T15:03:31+09:00
【機械学習】SVMをscikit-learnと数学の両方から理解する
1.目的
機械学習をやってみたいと思った場合、scikit-learn等を使えば誰でも比較的手軽に実装できるようになってきています。
但し、仕事で成果を出そうとしたり、より自分のレベルを上げていくためには
「背景はよくわからないけど何かこの結果になりました」の説明では明らかに弱いことが分かると思います。この記事では、2~3で「理論はいいからまずはscikit-learn使ってみる」こと、4以降で「その背景を数学から理解する」2つを目的としています。
※私は文系私立出身なので、数学に長けていません。可能な範囲で数学が苦手な方にもわかりやすいように説明するよう心がけました。
※線形単回帰、ロジスティック回帰Verでも同様の記事を投稿していますので、併せてお読みいただけますと幸いです。
【機械学習】線形単回帰をscikit-learnと数学の両方から理解する
【機械学習】ロジスティック回帰をscikit-learnと数学の両方から理解する2.SVM(サポートベクトルマシン)とは
SVMとは、教師あり学習として、分類や回帰に用いることができるモデルです。
そして、未学習データに対して高い識別性能を得るための工夫があるため、優れた認識性能を発揮します。
出典:Wikipediaざっくり言うと、新しいデータを得た時に、精度の高いモデルになりやすいということです。
◆具体例
あなたはイベント企画会社の社長だとします。
昨今の猫ブームを受け、「めずらしい猫」を見に行くツアーを企画しているとします(架空の設定です)。
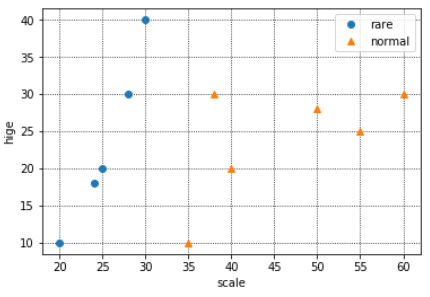
※「めずらしい猫」はここでは「体の大きさ」と「ヒゲの長さ」で決まるとします。
ツアー場所の候補が多すぎるため、あなたはめずらしい猫(=A)といわゆる普通の猫(=B)のデータを取りました。
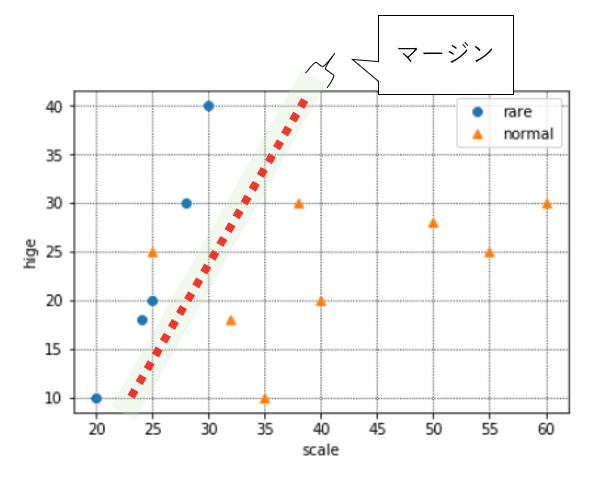
そのデータを基に、今後「体の大きさ」と「ヒゲの長さ」のデータを投入すればめずらしい猫か否かを判別できるモデルを作り、めずらしい猫がいると判別された場所に注力して企画を立てることとします。データの分布は下記のようになりました。
※青がめずらしい猫、オレンジが普通の猫です。
※X軸が体長、Y軸がヒゲの長さです。
◆SVMとは
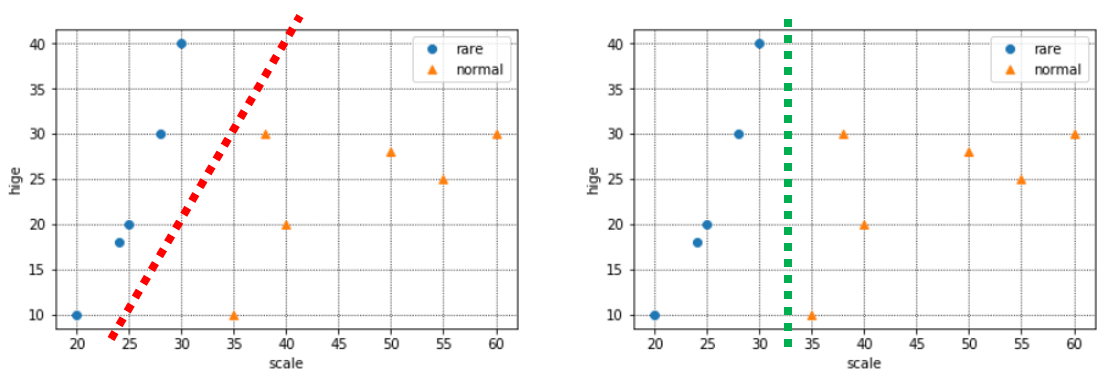
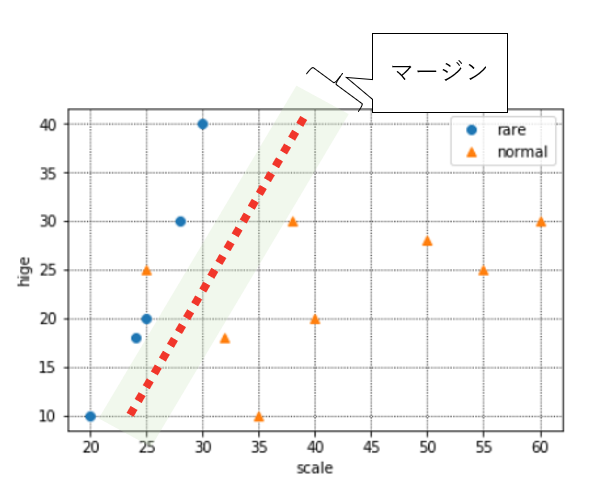
さて、上に出した分布は、青とオレンジにどのような境界線が引けそうでしょうか。
下記のように、今の手元のデータでは赤い境界も、緑の境界もありえますね。
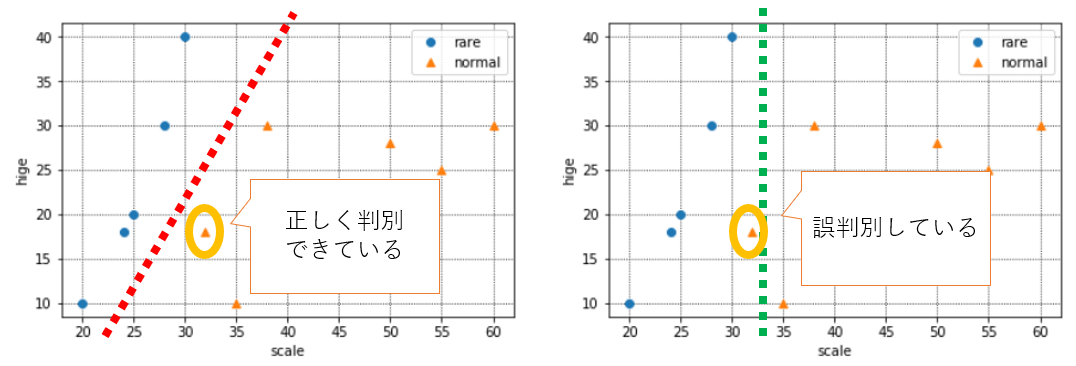
ここで、新しいデータを1つ得たので、追加でプロットしてみました。(オレンジ枠のデータです)
この場合、赤い境界の場合は正しく判別できていますが、緑の境界だとめずらしい猫と判別してしまっている(本来は普通の猫)ので、誤判別になります。
こういった誤判別を防ぎ正しい分類基準を見つけるため、SVMでは「マージン最大化」という考え方を取っています。
マージンとは上の赤や緑のような境界線と、実際のデータとの距離を指します。
このマージンが大きければ、"少しだけデータが変わっただけで誤判別してしまう"ミスをなるべく小さくすることができるという考え方です。
境界の近くにあるデータは、いわば「めずらしい猫」か「普通の猫」か判別に迷うデータということです。そういう、どっちか微妙なデータが多いと困るので、なるべく境界とデータの距離が遠くなるように境界を決めてあげれば、誤判別のリスクを極力抑えられますね、という考え方です。
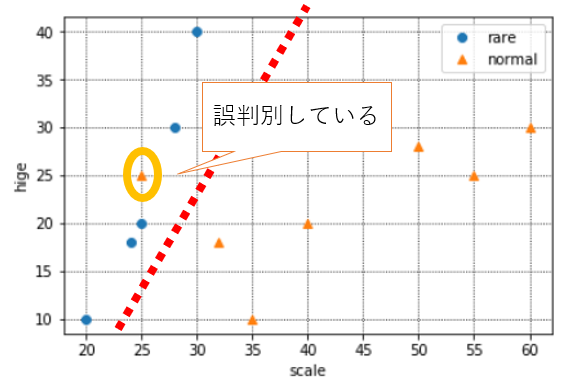
◆ペナルティについて
とはいえ、すべてを100%完璧に分類できる境界線はなかなか存在しないものです。現実世界では、下記のように、たまには外れ値のようなデータも入ってきます。
この新たなオレンジの点まで正確に分類する境界を引こうとすると、おそらく実態にあわない境界になってしまうことは想像できると思います。(いわゆる過学習です)
実態にあった判別を行うため、SVMでは「ある程度の誤判別」は許容しています。
次のscikit-learnの箇所で出てきますが、じゃあ、どれくらい誤判別を許すか?は、実はモデルを構築する私たち自身が決める必要があり、それを「ペナルティ」と呼んでいます。
◆まとめると・・
SVMとは、下記2つを「良い感じ」に実現するモデルといえます。
・誤判別をなるべく防ぐために境界とデータの距離、つまりマージンを最大化するような境界を引こうとする
・ただし、実態にあった境界を引くため、ある程度の誤判別は許容する3.scikit-learnでSVM
(1)必要なライブラリのインポート
SVMを行うために必要な下記をインポートしておく。
from sklearn.svm import SVC #下記は図示やpandas、numpyのためのライブラリ %matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np(2)データの準備
体長とヒゲのデータと、珍しい、普通の分類(めずらしい猫ががTrue,普通の猫がFalse)を下記のようにdataとして設定する。
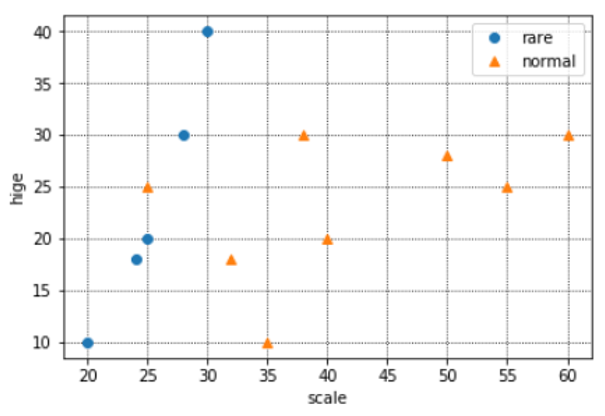
※例えば、最初の猫は体長20センチ、ヒゲの長さが10センチで、めずらしい猫ということ。data = pd.DataFrame({ "rare":[True,True,True,True,True,False,False,False,False,False,False,False,False], "scale":[20, 25, 30, 24, 28, 35, 40, 38, 55, 50, 60,32,25], "hige":[10, 20, 40, 18, 30, 10, 20, 30, 25, 28, 30,18,25], })(3)図示してみる(重要)
体長・ヒゲの長さとめずらしい・普通の分類を図示してみます。特徴をつかむためにも、いきなりscikit-learnを使うのではなく、どのようなデータでも図示することを心がけましょう。
y = data["rare"].values x1, x2 = data["scale"].values, data["hige"].values #データをプロット plt.grid(which='major',color='black',linestyle=':') plt.grid(which='minor',color='black',linestyle=':') plt.plot(x1[y], x2[y], 'o', color='C0', label='rare')#青い点:yがTrue(=珍しい)のもの plt.plot(x1[~y], x2[~y], '^', color='C1', label='normal')#オレンジの点:yがFalse(=普通)のもの plt.xlabel("scale") plt.ylabel("hige") plt.legend(loc='best') plt.show()
なんとなく、境界が引けそうですね。
(4)モデル構築
(ⅰ)データ整形
まずはモデル構築をするためにデータの形を整えていきます。
y = data["rare"].values#先ほどの図示と同じなので割愛してもOK X = data[["scale", "hige"]].values今回はpython文法の記事ではないので詳細は割愛しますが、xとyをscikit-learnでSVMするための形に整えます。
※このあたりもある程度しっかりわかっていないと書けないコードだと思うので、どこかでまとめたいと思っています。(ⅱ)モデル構築
いよいよ、モデル構築のコードです。
C = 10 clf = SVC(C=C,kernel="linear") clf.fit(X, y)単純なモデルであればこれで終わりです。
clfという変数にこれからsvmモデルを作ります!と宣言のようなことを行い、次の行で、そのclfに準備したXとyをフィット(=学習)させるというイメージです。◆引数について
SVMのモデル構築で主に考慮すべき引数は$C$とkernelです。
<$C$について>
ここではとりあえずやってみる、が主旨なので詳細は割愛しますが$C$の値を小さくすれば誤判別を許すモデルになります。
※$C$に何も指定しない、つまり「clf = SVC(kernel="linear")」と記載すると、デフォルトで$C$は1になります。<kernelについて>
kerenelの種類は‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’があります。
詳細は公式参照ここでは‘linear’と ‘rbf’を紹介します。
境界を線形(平面)に引くときはlinear、非線形に引くときはrbf(非線形カーネル関数)を用います。どちらを選ぶかで結果が変わってきます。
※ここは図示のところで違いを紹介します。(5)構築したモデルを図示してみる
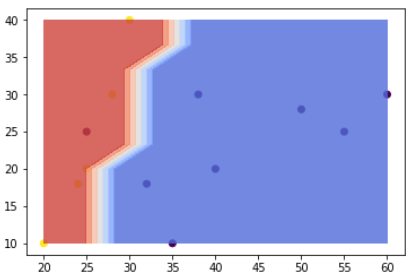
それでは、この境界を先ほどの散布図に図示してみましょう。
※このコードは少し難しいので、理解せず、コピペだけでもOKです。scikit-learnではこのような境界線を学習から算出し、この境界より右下だと文系、左上だと理系と判別しているのだと認識していただければ大丈夫です。
参考サイトfig,ax = plt.subplots(figsize=(6,4)) #データの点を表示 ax.scatter(X[:,0], X[:,1], c=y) #x座標方向に100個の値を並べる x = np.linspace(np.min(X[:,0]), np.max(X[:,0]), 10) #y座標方向に100個の値を並べる y = np.linspace(np.min(X[:,1]), np.max(X[:,1]), 10) #x,yを組み合わせた10000個の点のx座標と,y座標の配列 x_g, y_g = np.meshgrid(x, y) #np,c_で二つの座標を結びつけ, SVMに渡す z_g = clf.predict(np.c_[x_g.ravel(), y_g.ravel()]) #z_gは配列の列になっているが、グラフに表示するために(100, 100)の形に戻す z_g = z_g.reshape(x_g.shape) #境界線の色塗り ax.contourf(x_g,y_g,z_g,cmap=plt.cm.coolwarm, alpha=0.8); #最後に表示 plt.show()
モデル構築の結果、上記のように境界が引けました。
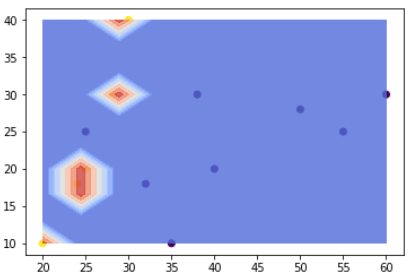
これ以降新しいデータが入ってきた場合、青い領域にプロットされれば普通の猫、赤い領域にプロットされれば珍しい猫と分類されるわけです。ちなみに、(4)の◆引数について で紹介したkernelをrbfにすると、下記のような境界になります。
全く違う境界になっていますね!今回のケースで言うと、線形の方が適切にデータの境界を引けている気がするので、kernelはlinearを使うことにしましょう。
(6)現実世界では・・
モデルを作って終わり、では意味ないですね。現実世界では、この予測モデルを使って、新たな猫のデータを取得した際、めずらしいか普通かの区別をすることが大切です。
あなたは別の2種類分の情報を得て、データをメモしました。
それを下記のようにzという変数に格納します。z = pd.DataFrame({ "scale":[28, 45], "hige":[25, 20], }) z2 = z[["scale", "hige"]].valuesこのデータと、境界がlinearの方の図示を見比べると、おそらく1匹目が赤(めずらしい=True)、2匹目が青(普通=False)に分類される気がしますね。
では、予測をしてみましょう。y_est = clf.predict(z2)このようにすると、y_estには([ True, False])と結果が表示されたので、境界線通りに分類されていることが分かります。
4.SVMを数学から理解する
さて、3まではscikit-learnを用いてSVMモデルを構築→図示→別の2匹の猫のめずらしい・普通を予測するという流れを実装してみました。
ここでは、この流れのSVMモデルは、数学的にはどのように計算されているのかを明らかにしていきたいと思います。
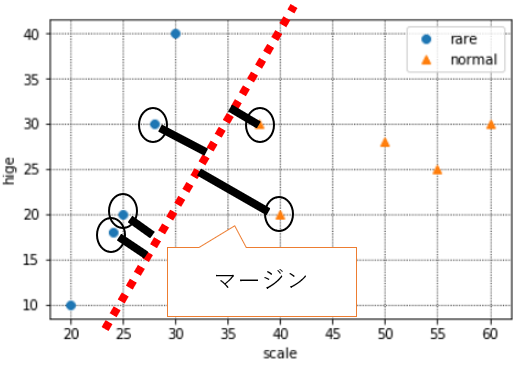
※現状はこの知識は必要ないという方は読み飛ばしていただいて結構です。(1)マージン最大化について
「2.SVM(サポートベクトルマシン)とは」で記載した、マージン最大化について掘り下げていこうと思います。
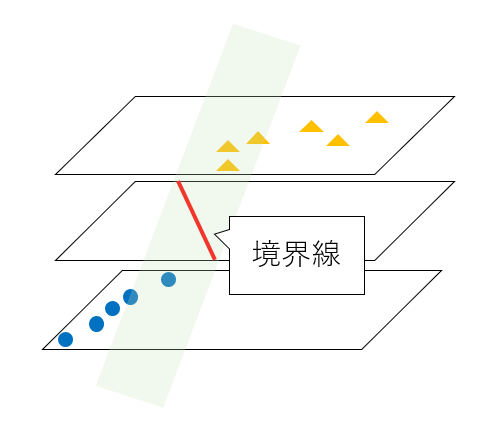
各データの点と境界までの距離が最も大きくなる部分が最適な境界線と説明しましたが、それはつまりどういう状態を指すのでしょうか。
◆立体的な可視化
今まで図示していた散布図を、少し立体的に書き換えてみると、下記のようになります。
※オレンジの点(normal)部分を浮き上がらせて、横から見たイメージと捉えてください。
上の赤い境界線を通る緑の平面が境界と考えると、この平面の「傾き」を変えることで、マージン(=データと境界線までの距離)が変わることがイメージとしてつくでしょうか。
例えば、この平面の傾きを急にすると、下記のようにマージンは小さくなります。
逆に、平面の傾きを緩やかにすると、下記のようにマージンは大きくなります。
つまり、「データをきれいに分類することができる」かつ、「なるべく決定境界を通る平面の傾きが緩やかになる」ことが、最適な境界の条件ということです。
◆マージンの式
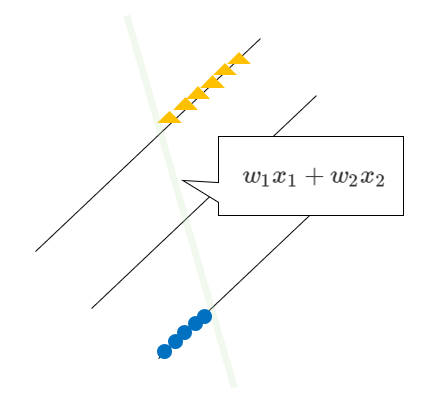
それでは、「なるべく決定境界を通る平面の傾きが緩やかになる」とはどういうことでしょうか。さらに図示していきます。
境界面を横から見た図を表してみました。この式は$w_1x_1+w_2x_2$と表されます。
先ほど記載したとおり、マージンが最大とは、「なるべく決定境界を通る平面の傾き(=勾配)が緩やかになる」ことでした。
最も傾き(=勾配)が緩やかということは、$x_1$や$x_2$を多少動かしても$w_1x_1+w_2x_2$に与える影響が小さいということ(=傾きが緩やかなので、多少$x$の値を動かしても式全体の値はたいして変わらないですよね)、つまり「$w_1,w_2$の値が小さいということ」です。これを数式にすると下記になりますが、この数式の意味を理解するにはノルムの理解が必要で複雑になるため、この時点では「境界線の式の$w_1$と$w_2$がなるべく小さくなるように計算されているのだ」、と理解しておけばOKです。
$||w||_2^2$ ←これが最小になれば、マージンが最大化される
(2)ペナルティについて
基本的な考え方は(1)で終わりですが、「2.SVM(サポートベクトルマシン)とは」の「◆ペナルティについて」で述べたように、実態に即した分類ができるように、ある程度の誤判別を許容します。
この、どの程度誤判別を許すか?の程度をペナルティと呼んでいます。
ペナルティの式は下記のように表され、$ξ$はヒンジ損失関数と呼ばれます。
$C(\sum_{i=1}^n ξi)$$C$は(ⅱ)モデル構築で記載した引数と同じ意味ですが、この$C$を大きくするほど誤判別を許さない式になります(=大きくしすぎると過学習しやすくなります)。
この式について深く理解しようとするとかなり突っ込んだ理解が必要になるため、今回はこのあたりまでにしておこうと思います。
(後々、別建てにするかもしれないですがここもまとめていきたいです)(3)まとめると・・
(1)(2)から、SVMは下記の目的関数を、なるべく小さくするように計算されています。
直感的には、「マージン最大化のために」境界面の傾きがなるべく小さくなるようにしていますが、実態に即した分類をするために、誤判別をどれくらい許すか?のペナルティ項を加え、全体のバランスが良い感じになるように境界面の式が設定されています。||w||_2^2 + C(\sum_{i=1}^n ξi)5.まとめ
いかがでしたでしょうか。
SVMは単回帰やロジスティック回帰よりも背景の数学的理解が必要なため、そこまで深くは記載できていませんが、ここまでの理解だけでも、以前より理解の深化の助けになりましたら幸いです。


- 投稿日:2020-02-12T13:37:14+09:00
Enabling pysocks proxy RDNS globally
Usually, they say that overriding socket.socket will make socks proxy usable on any python libraries:
import socks import socket socks.set_default_proxy(socks.PROXY_TYPE_SOCKS5, "host", port) socket.socket = socks.socksocketHowever, it would not work well if the machine you want to connect can be connected only from the proxy (i.e. when RDNS is mandatory). This is because socket.create_connection() always resolves the machine's ip address locally:
(cf https://github.com/python/cpython/blob/2.7/Lib/socket.py#L557)host, port = address for res in getaddrinfo(host, port, 0, SOCK_STREAM): af, socktype, proto, canonname, sa = res ### sa is resolved locally! sock = None try: sock = socket(af, socktype, proto) ### this socket is overridden by socks.socksocket, but RDNS will not work well. sock.connect(sa) return sockSo, if we need RDNS, create_connection needs to be wrapped as well:
_done_tryPatchCreateConnections = False def tryPatchCreateConnections(): global _done_tryPatchCreateConnections if _done_tryPatchCreateConnections: return True try: import socks import socket socket.socket = socks.socksocket def patchCreateConnection(module): def create_connection(address, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, source_address=None, socket_options=None): #print('trying to override create_connection') if socks.socksocket.default_proxy is not None and socks.socksocket.default_proxy[3]: return socks.create_connection( address, timeout=timeout, source_address=source_address, proxy_type=socks.socksocket.default_proxy[0], proxy_addr=socks.socksocket.default_proxy[1], proxy_port=socks.socksocket.default_proxy[2], proxy_rdns=socks.socksocket.default_proxy[3], proxy_username=socks.socksocket.default_proxy[4], proxy_password=socks.socksocket.default_proxy[5], socket_options=socket_options, ) elif module==socket: return module._real_create_connection(address, timeout=timeout, source_address=source_address) else: # likely urllib3 return module._real_create_connection(address, timeout=timeout, source_address=source_address, socket_options=socket_options) module._real_create_connection = module.create_connection module.create_connection = create_connection module.socket = socks.socksocket def patchCreateConnections(): patchCreateConnection(socket) try: import urllib3 patchCreateConnection(urllib3.util.connection) except ImportError: pass try: import requests import requests.packages.urllib3 patchCreateConnection(requests.packages.urllib3.util.connection) except ImportError: pass patchCreateConnections() _done_tryPatchCreateConnections = True return True except ImportError: return False
- 投稿日:2020-02-12T12:03:57+09:00
【異常検知】異常原因を特定する
異常検知は、正常データだけで学習できる製造業で人気のある手法です。
そして、異常検知で異常を検出したとして、「異常原因を特定したい」という
要望もよく聞かれます。そこで、本稿では、複数のセンサが付いた異常検知システムにおいて、
異常が発生した場合に、どのセンサが異常値を示しているのかを特定する
方法を検討します。
※コード全体はこちらに置きました。
※こちらはPythonデータ分析勉強会#17の発表資料です。きっかけ
以前に、こんな内容をツイートしたところ、皆さん興味をお持ちのようでした。
昨日、JFEスチールの製造ラインで異常検知する話しを聞いた。
— shinmura0 @ 3/14参加者募集中 (@shinmura0) September 28, 2019
・数十個にわたるセンサで常時監視
・異常検知の制約は、異常のみならず異常原因も特定する
・センサは相関が強いものだけを取り出し、主成分分析だけで異常検知
・これによりコストと納期を大幅に削減
ー続くー製造業では異常を検出するだけではなく、異常の原因を特定しないと異常が頻発する
恐れもありますし、重大欠陥を見逃すリスクもあります。
異常原因の特定は、かなり重要なタスクになることもあります。結論から
- Permutation Importanceを使うことで、どのセンサが異常値を示しているのか特定できる
- さらに、有効なセンサを絞ることも可能になる
- ただし、センサ数が増えると異常原因を特定するのは難しいかもしれない
Permutation Importanceとは
ある一つの説明変数(特徴量)を混ぜて交換(シャッフル)することで、その説明変数の
影響度を調べる方法です。詳しくは以下の記事をご覧ください。Permutation Importanceを使って検証データにおける特徴量の有用性を測る
Permutation Importanceの手順は以下のとおりです。
①学習用データを使って学習済モデルを作る
②検証用データで①のモデルのスコアを計測する
③検証用データのある一つの説明変数をシャッフルする
④学習済モデルに③のデータを入れ、性能がどれだけ悪化するのか計測する
⑤全ての説明変数について、③~④を繰り返す。
⑥悪化が大きい説明変数ほど、重要度が高いといえるこの手法は通常、教師あり学習で用いられます。
異常検知への応用
Permutation Importanceを異常検知に適用する場合を考えます。
異常原因を特定する
ここが本稿の主題です。センサで監視中に異常が起きたとして、どのセンサが異常値を
示しているのか、極端に言うと、異常原因は何なのか特定することができます。教師あり学習の場合、検証用のデータで、ある一つの説明変数をシャッフルすることで
説明変数の影響度を調べることができました。これは、検証用データが複数あるために
シャッフルできる仕組みです。ところが、監視中に異常を検出した場合、その異常データは一つしかありません。
従って、シャッフルしたくてもシャッフルする相手がいないので、何か別のデータを
用意しなければいけません。本稿では、学習用データの説明変数を異常データとシャッフルさせ、影響度を調べます。
これは、結果的に「異常データの説明変数に正常データが代入される」ことになり、異常を示す
説明変数と入れ替わった場合、異常スコアが劇的に下がることが期待されます。これにより、
異常値を示しているセンサを特定します。この手法は、いわゆるテーブルデータであれば、一般的な異常検知手法に適用することは
可能だと思われます。画像や音でもやろうと思えばできますが、CNNを使っていることが
多いと思うので、計算時間が膨大になります。そのため、他の手法(Grad-CAMやAno-GAN)
を活用した方が良いと思われます。センサ削減
本稿の主題から逸れますが、Permutation Importanceを使うことで必要なセンサを
絞ることも可能になります。これはAUCなどを指標にし、AUCが悪化する説明変数が
有効センサであると解釈することで、不要なセンサを削除することも可能です。必要なセンサを絞ることにより、以下のメリットがあります。
- 前回検討した次元の呪いの影響を緩和でき、より精度よく異常を検出することが可能
- コストダウンにつながる点も大きい
ただし、異常データがあって初めて成立する話しです。異常データがない場合、
あらかじめ必要なセンサを絞ることは難しいです。(当たり前の話しといえば、
当たり前ですが)ただ、わざわざPermutation Importanceを使わなくても、手持ちの異常データを使って
センサ情報を一つずつ落としていき、AUCを計測することで重要度が分かる気もします。
これは非常に単純な方法です。どちらの手法を使うにしても、異常データが十分ないと
「異常データに過学習」してしまう危険性があるので注意が必要です。実験
コードは、こちらの記事を参考に実装しました。教師あり学習の場合は、scikit-learnが
使えるので、そちらを使った方が計算時間が早いと思います。※コード全体はこちらに置きました。
実験条件
前回と同様に以下の条件で実験を行います。
- 異常検知手法はIsolation Forestを使用する
- 異常値を示しているセンサは2つだけ
- 異常値を示していない(関係のない)センサはX個付いている
- このとき、異常値を出しているセンサが特定できるのか?
結果
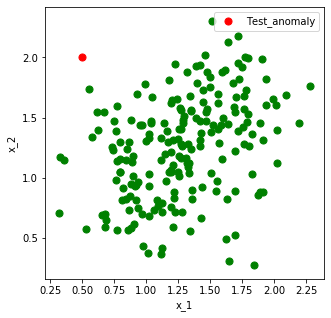
関係のないセンサが2つの場合
まずは、異常値を出しているセンサ($x_1,x_2$)を乱数を使って生成します。
上の図より、$x_1,x_2$に相関があることが分かります。
緑の点が学習データ、赤の点が異常データです。
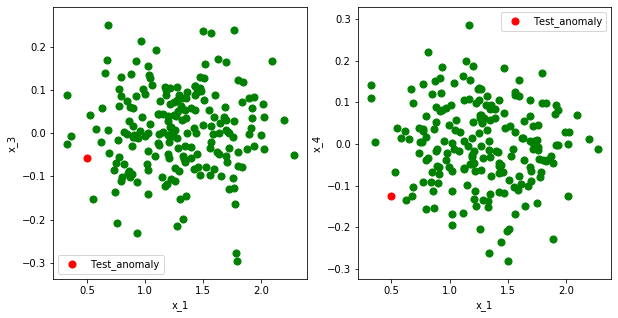
関係のないセンサ($x_3,x_4$)は上の図のように$x_1(,x_2)$と相関がなく、特に、意味のある
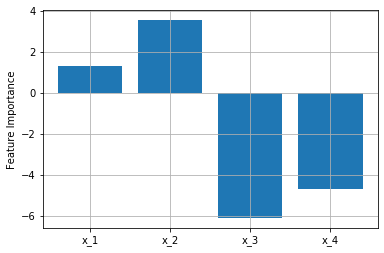
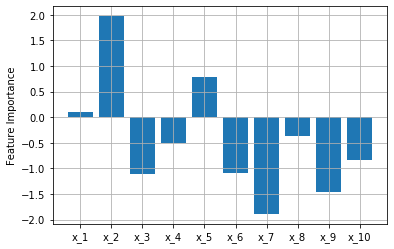
値を出していません。ここでは、正規分布を使って適当な値を入れています。早速、Permutation Importanceを使って説明変数の影響度(Feature Importance)を算出
します。
縦軸の値が大きいほど重要度が高い、つまり異常原因の可能性が高いことを示唆しています。
狙い通り、$x_1,x_2$の値が大きくなりました。成功です。関係のないセンサが8つの場合
次に関係のないセンサを8つにします。
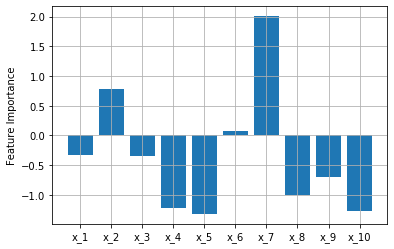
先ほどの実験の$x_3$を8つに増やしたとお考えください。うまくいくと、以下のように。
狙い通り、$x_1,x_2$の値が大きくなりました。うまくいかないと、以下のような結果になります。
乱数を使っているため、結果が変わります。
$x_1,x_2$の値は比較的大きいですが、一番大きいのは$x_7$となってしまいました。センサ数が多いと異常原因の特定は難しいかもしれません。
結局、どうすれば良いのか?
異常原因を特定する方法をまとめます。
- Permutation Importanceを使うと、どんな異常検知手法でも異常原因を特定することができるが、センサ数が増えると異常原因を特定するのは難しいかもしれない
- MT法は直交表を使うことで貢献度(異常原因)を調べることができる(こちらの資料のP43参照) が、データが正規分布になっていないと異常の検出は難しく、精度低下の恐れがある
- 冒頭に紹介した主成分分析による異常検知も、正規分布を主体としているため、MT法と同じような分析結果になると思われる
この他にも手法はあるかと思いますが、どの手法も一長一短だと思います。
ただ、個人的に異常原因の特定は、精度100%を求められる状況が少ないと思います。
第一候補から順に異常を検査する形をとれば、精度100%でなくても現場で十分
使えるレベルのところもあります。最後の実験でも、第5候補まで調べれば異常原因を
特定できる結果になっていました。よって、異常を検出しながら、異常原因を特定したい場合、どの手法を使うかは「異常
検知性能がどれくらい求められているのか?」と「異常原因の特定精度はどれくらい
犠牲にしても大丈夫なのか?」を検討しながら、バランスよく決める必要があると思います。まとめ
- Permutation Importanceを使うことで、どのセンサが異常値を示しているのか特定できるが、センサ数が多いと難しいかもしれない
- 本稿の主題から逸れるが、有効なセンサを絞ることも可能になる
- 他の手法でも異常原因の特定ができるが、どの手法を使うかは異常検知性能と原因特定精度のバランスを見ながら決める必要がある
- 投稿日:2020-02-12T12:01:59+09:00
緯度経度から地理院タイルをダウンロードする
国土地理院は地図や航空写真等を地理院タイルという形で提供している
取得するにはタイル座標という緯度経度ではない座標値が必要なので,それを計算する.
OpenStreetMapのwikiにそのコードがあるので拝借.#from #https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames#Python import math #緯度経度からタイル座標を計算 def deg2num(lat_deg, lon_deg, zoom): lat_rad = math.radians(lat_deg) n = 2.0 ** zoom xtile = int((lon_deg + 180.0) / 360.0 * n) ytile = int((1.0 - math.asinh(math.tan(lat_rad)) / math.pi) / 2.0 * n) return (xtile, ytile) #今回は使わないけど,タイル座標から緯度経度 def num2deg(xtile, ytile, zoom): n = 2.0 ** zoom lon_deg = xtile / n * 360.0 - 180.0 lat_rad = math.atan(math.sinh(math.pi * (1 - 2 * ytile / n))) lat_deg = math.degrees(lat_rad) return (lat_deg, lon_deg)地理院タイルからのダウンロードはこんな感じ
import requests def download_from_gsi(z, x, y, def_url, fname): url = def_url.format(z,x,y) response = requests.get(url) if response.status_code == 200: image = response.content with open(fname, "wb") as f: f.write(image) else: raise Exception("{} returned {}".format(response.url, response.status_code))使い方はこんな感じ.この例はスカイツリーの座標の航空写真です.
#zはズームレベル.18が一番拡大した状態 z = 17 lat = 35.710163 lon = 139.8105428 def_url = "https://cyberjapandata.gsi.go.jp/xyz/ort/{}/{}/{}.jpg" fname ="test.png" x,y = deg2num(lat, lon, z) download_from_gsi(z, x, y, def_url, fname)結果このような画像が取れました.
まだ建設途中のころの写真ですね.def_url は地理院タイル一覧中にあるurlを参考にしてください.
(注意点は物によってjpgだったりpngだったりするところ.)

- 投稿日:2020-02-12T06:42:00+09:00
言語処理100本ノック-26:強調マークアップの除去
言語処理100本ノック 2015「第3章: 正規表現」の26本目「強調マークアップの除去」記録です。
今回から28本目までは正規表現でマークアップ除去をしていきます。今回はsub関数を使った除去(置換)を学びます。参考リンク
リンク 備考 026.強調マークアップの除去.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:26 多くのソース部分のコピペ元 ゼロから覚えるPython正規表現の基本とTips 当ノックで学習した内容を整理しました 正規表現 HOWTO Python公式の正規表現How To re --- 正規表現操作 Python公式のreパッケージ説明 Help:早見表 Wikipediaの代表的なマークアップの早見表 環境
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.15 複数Python環境を使うことがあるのでpyenv使っています Python 3.6.9 pyenv上でpython3.6.9を使っています
3.7や3.8系を使っていないことに深い理由はありません
パッケージはvenvを使って管理しています上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
種類 バージョン pandas 0.25.3 第3章: 正規表現
学習内容
Wikipediaのページのマークアップ記述に正規表現を適用することで,様々な情報・知識を取り出します.
正規表現, JSON, Wikipedia, InfoBox, ウェブサービス
ノック内容
Wikipediaの記事を以下のフォーマットで書き出したファイルjawiki-country.json.gzがある.
- 1行に1記事の情報がJSON形式で格納される
- 各行には記事名が"title"キーに,記事本文が"text"キーの辞書オブジェクトに格納され,そのオブジェクトがJSON形式で書き出される
- ファイル全体はgzipで圧縮される
以下の処理を行うプログラムを作成せよ.
26. 強調マークアップの除去
25の処理時に,テンプレートの値からMediaWikiの強調マークアップ(弱い強調,強調,強い強調のすべて)を除去してテキストに変換せよ(参考: マークアップ早見表).
課題補足(「強調マークアップ」について)
Help:早見表によると「強調マークアップ」は以下の3種類です。
種類 書式 例 他との区別(斜体) シングルクォート2つで囲む ''他との区別'' 強調(太字) シングルクォート3つで囲む '''強調''' 斜体と強調 シングルクォート5つで囲む '''''斜体と強調''''' ファイル内の以下の部分を正規表現で抽出します。今回の対象には「強調(太字)」しかないようです。
ファイル内の「強調マークアップ」部分抜粋"|確立形態4 = 現在の国号「'''グレートブリテン及び北アイルランド連合王国'''」に変更\n回答
回答プログラム 026.強調マークアップの除去.ipynb
from collections import OrderedDict from pprint import pprint import re import pandas as pd def extract_by_title(title): df_wiki = pd.read_json('jawiki-country.json', lines=True) return df_wiki[(df_wiki['title'] == title)]['text'].values[0] wiki_body = extract_by_title('イギリス') basic = re.search(r''' ^\{\{基礎情報.*?\n #検索語句(\はエスケープ処理)、非キャプチャ、非貪欲 (.*?) #任意の文字列 \}\} #検索語句(\はエスケープ処理) $ #文字列の末尾 ''', wiki_body, re.MULTILINE+re.VERBOSE+re.DOTALL) templates = OrderedDict(re.findall(r''' ^\| # \はエスケープ処理、非キャプチャ (.+?) # キャプチャ対象(key)、非貪欲 \s* # 空白文字0文字以上 = # 検索語句、非キャプチャ \s* # 空白文字0文字以上 (.+?) # キャプチャ対象(Value)、非貪欲 (?: # キャプチャ対象外のグループ開始 (?=\n\|) # 改行(\n)+'|'の手前(肯定の先読み) | (?=\n$) # または、改行(\n)+終端の手前(肯定の先読み) ) # キャプチャ対象外のグループ終了 ''', basic.group(1), re.MULTILINE+re.VERBOSE+re.DOTALL)) # マークアップ除去 def remove_markup(string): # 強調マークアップの除去 replaced = re.sub(r''' (\'{2,5}) # 2〜5個の'(マークアップの開始) (.*?) # 任意の1文字以上(対象の文字列) (\1) # 1番目のキャプチャと同じ(マークアップの終了) ''', r'\2', string, flags=re.MULTILINE+re.VERBOSE) return replaced for i, (key, value) in enumerate(templates.items()): replaced = remove_markup(value) templates[key] = replaced # 変わったものを表示 if value != replaced: print(i, key) print('変更前\t', value) print('変更後\t', replaced) print('----') pprint(templates)回答解説
今回のメインは以下の部分です。
sub関数を使って「強調マークアップ」の除去(置換)をしています。4つ目の引数にcountがあるのでflags(コンパイルフラグ)を渡すときには名前を明示する必要があります。countに気づかずに必死でコンパイルフラグを渡した気になっていて、うまく行かずに30分ほど無駄にしました・・・replaced = re.sub(r''' (\'{2,5}) # 2〜5個の'(マークアップの開始) (.*?) # 任意の1文字以上(対象の文字列) (\1) # 1番目のキャプチャと同じ(マークアップの終了) ''', r'\2', string, flags=re.MULTILINE+re.VERBOSE)
sub関数は文字置換をします。引数の順に1. 正規表現パターン、2. 置換後の文字列、3. 置換対象文字列です。>>> re.sub(r'置換対象', '置換済', '置換対象 対象外 置換対象') '置換済 対象外 置換済'ちなみに「確立形態4」の値が変更前と後で以下のようになります。
41 確立形態4 変更前 現在の国号「'''グレートブリテン及び北アイルランド連合王国'''」に変更 変更後 現在の国号「グレートブリテン及び北アイルランド連合王国」に変更 ----出力結果(実行結果)
プログラム実行すると以下の結果が出力されます。まだ残っているマークアップは27、28本目で除去します。
出力結果OrderedDict([('略名', 'イギリス'), ('日本語国名', 'グレートブリテン及び北アイルランド連合王国'), ('公式国名', '{{lang|en|United Kingdom of Great Britain and Northern ' 'Ireland}}<ref>英語以外での正式国名:<br/>\n' '*{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn ' 'mu Thuath}}([[スコットランド・ゲール語]])<br/>\n' '*{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd ' 'Iwerddon}}([[ウェールズ語]])<br/>\n' '*{{lang|ga|Ríocht Aontaithe na Breataine Móire agus Tuaisceart ' 'na hÉireann}}([[アイルランド語]])<br/>\n' '*{{lang|kw|An Rywvaneth Unys a Vreten Veur hag Iwerdhon ' 'Glédh}}([[コーンウォール語]])<br/>\n' '*{{lang|sco|Unitit Kinrick o Great Breetain an Northren ' 'Ireland}}([[スコットランド語]])<br/>\n' '**{{lang|sco|Claught Kängrick o Docht Brätain an Norlin ' 'Airlann}}、{{lang|sco|Unitet Kängdom o Great Brittain an Norlin ' 'Airlann}}(アルスター・スコットランド語)</ref>'), ('国旗画像', 'Flag of the United Kingdom.svg'), ('国章画像', '[[ファイル:Royal Coat of Arms of the United ' 'Kingdom.svg|85px|イギリスの国章]]'), ('国章リンク', '([[イギリスの国章|国章]])'), ('標語', '{{lang|fr|Dieu et mon droit}}<br/>([[フランス語]]:神と私の権利)'), ('国歌', '[[女王陛下万歳|神よ女王陛下を守り給え]]'), ('位置画像', 'Location_UK_EU_Europe_001.svg'), ('公用語', '[[英語]](事実上)'), ('首都', '[[ロンドン]]'), ('最大都市', 'ロンドン'), ('元首等肩書', '[[イギリスの君主|女王]]'), ('元首等氏名', '[[エリザベス2世]]'), ('首相等肩書', '[[イギリスの首相|首相]]'), ('首相等氏名', '[[デーヴィッド・キャメロン]]'), ('面積順位', '76'), ('面積大きさ', '1 E11'), ('面積値', '244,820'), ('水面積率', '1.3%'), ('人口統計年', '2011'), ('人口順位', '22'), ('人口大きさ', '1 E7'), ('人口値', '63,181,775<ref>[http://esa.un.org/unpd/wpp/Excel-Data/population.htm ' 'United Nations Department of Economic and Social ' 'Affairs>Population Division>Data>Population>Total ' 'Population]</ref>'), ('人口密度値', '246'), ('GDP統計年元', '2012'), ('GDP値元', '1兆5478億<ref ' 'name="imf-statistics-gdp">[http://www.imf.org/external/pubs/ft/weo/2012/02/weodata/weorept.aspx?pr.x=70&pr.y=13&sy=2010&ey=2012&scsm=1&ssd=1&sort=country&ds=.&br=1&c=112&s=NGDP%2CNGDPD%2CPPPGDP%2CPPPPC&grp=0&a= ' 'IMF>Data and Statistics>World Economic Outlook Databases>By ' 'Countrise>United Kingdom]</ref>'), ('GDP統計年MER', '2012'), ('GDP順位MER', '5'), ('GDP値MER', '2兆4337億<ref name="imf-statistics-gdp" />'), ('GDP統計年', '2012'), ('GDP順位', '6'), ('GDP値', '2兆3162億<ref name="imf-statistics-gdp" />'), ('GDP/人', '36,727<ref name="imf-statistics-gdp" />'), ('建国形態', '建国'), ('確立形態1', '[[イングランド王国]]/[[スコットランド王国]]<br />(両国とも[[連合法 ' '(1707年)|1707年連合法]]まで)'), ('確立年月日1', '[[927年]]/[[843年]]'), ('確立形態2', '[[グレートブリテン王国]]建国<br />([[連合法 (1707年)|1707年連合法]])'), ('確立年月日2', '[[1707年]]'), ('確立形態3', '[[グレートブリテン及びアイルランド連合王国]]建国<br />([[連合法 (1800年)|1800年連合法]])'), ('確立年月日3', '[[1801年]]'), ('確立形態4', '現在の国号「グレートブリテン及び北アイルランド連合王国」に変更'), ('確立年月日4', '[[1927年]]'), ('通貨', '[[スターリング・ポンド|UKポンド]] (£)'), ('通貨コード', 'GBP'), ('時間帯', '±0'), ('夏時間', '+1'), ('ISO 3166-1', 'GB / GBR'), ('ccTLD', '[[.uk]] / [[.gb]]<ref>使用は.ukに比べ圧倒的少数。</ref>'), ('国際電話番号', '44'), ('注記', '<references />')])
- 投稿日:2020-02-12T04:56:13+09:00
zip
zip.pydays = ['Monday','Tuesday','Friday'] fruits = ['banana','apple','orange'] for day,fruit in zip(days,fruits): print(day,fruit)出力結果:
Monday banana
Tuesday apple
Friday orange
- 投稿日:2020-02-12T04:43:11+09:00
enumerate
enumerate.pyfor i,fruit in enumerate(['banana','apple','orange']): print(i,fruit)0,banana
1,apple
2,orange
と出力されます
- 投稿日:2020-02-12T04:20:15+09:00
range
for-range.py""""" これでも0から9をす出力できるが、面倒 list = [0,1,2,3,4,5,6,7,8,9] for i in list: print(i) """"" #0から9が出力される for i in range(10): print(i) #2から始まり3個飛ばしで9まで出力 for i in range(2,10,3): print(i)
- 投稿日:2020-02-12T03:15:39+09:00
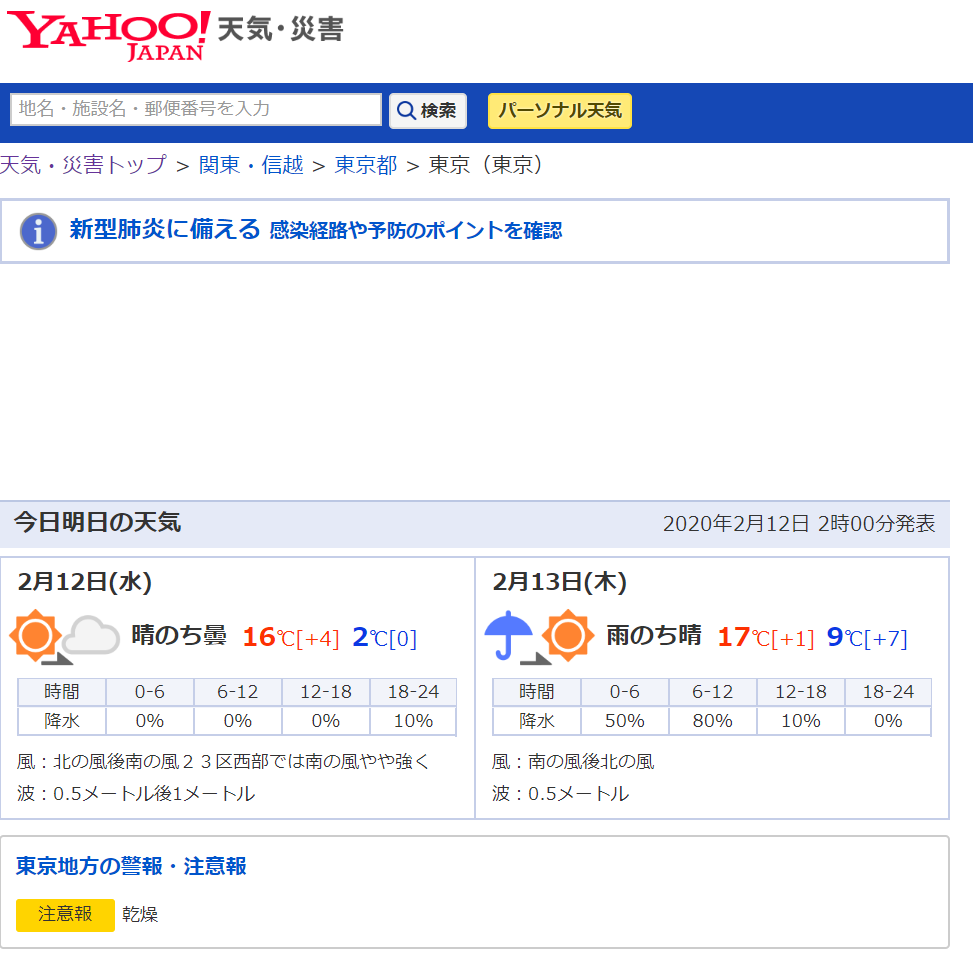
Yahoo天気でスクレイピングしてみた
はじめに
自分用のメモに近いですがせっかくやってみたので記事にしてみました。
元々ラズパイサイネージをやるために色々調べたのですが、
なかなかピンポイントで欲しい情報がなく結局スクレイピングやり方だけ調べて自力でなんとかしました。
(Python使いでもweb界隈の人でもないので一瞬苦戦しました...)
yahooだと天気のapiがありますが使わなかったのは降水量しかわからないためです。参考にしたもの
Pythonでのスクレイピングに当たり下記の記事を参考にしました。
pythonでスクレイピングして天気予報をGoogleHomeにしゃべらせる
Python Webスクレイピング 実践入門スクレイピング自体に関する良い悪い説明もあるので読んでおいたほうがいいと思います。
ちなみにYahoo天気ですが、たぶんスクレイピングは禁止されていません。
Yahooファイナンスは明確に禁止されていましたが、天気に関しては禁止しているような記述は見つかりませんでした。
ただ節度は守りましょう。定期的にスクレイピングするとしても天気は1時間または30分ごとくらいのアクセスで十分だと思います。やること
色々取りたい情報はありますがとりあえず東京の今日の天気を取得しました。
下記の画像の今日の天気の"晴れのち曇り"を取得します。
コード
実際にコードを実行すれば今日の天気を取得できます。(Visual Codeで色々書いたりデバックしました。)
だいたいコメントに何をやっているか書いてあります。
ほぼコピペのソースですが注目ポイントはselect_oneでtextの部分を取得しているところです。
Google Chromeで自動で取得しようとしたのですがうまくいかなかったので手打ちで探っていったところうまくいきました。tenki.py#coding: UTF-8 import urllib3 from bs4 import BeautifulSoup #アクセスするURL url = 'https://weather.yahoo.co.jp/weather/jp/13/4410.html' #URLにアクセスする 戻り値にはアクセスした結果やHTMLなどが入ったinstanceが帰ってきます http = urllib3.PoolManager() instance = http.request('GET', url) #instanceからHTMLを取り出して、BeautifulSoupで扱えるようにパースします soup = BeautifulSoup(instance.data, 'html.parser') #CSSセレクターで今日の天気のテキストを取得します。 tenki = soup.select_one('#main > div.forecastCity > table > tr > td > div > p.pict') print (tenki.text) #一瞬で画面が消えないよう input()以下、実行結果
終わりに
このコードを元に色々できると思います。
定期的に取得するなどはこの記事に加筆するかラズパイサイネージの記事に書くと思います。
あと環境の問題で実行できなかった等あると思うのでそのあたりは後々加筆します。

- 投稿日:2020-02-12T03:15:39+09:00
Yahoo天気をスクレイピングしてみた
はじめに
自分用のメモに近いですがせっかくやってみたので記事にしてみました。
元々ラズパイサイネージをやるために色々調べたのですが、
なかなかピンポイントで欲しい情報がなく結局スクレイピングやり方だけ調べて自力でなんとかしました。
(Python使いでもweb界隈の人でもないので一瞬苦戦しました...)
yahooだと天気のapiがありますが使わなかったのは降水量しかわからないためです。参考にしたもの
Pythonでのスクレイピングに当たり下記の記事を参考にしました。
pythonでスクレイピングして天気予報をGoogleHomeにしゃべらせる
Python Webスクレイピング 実践入門スクレイピング自体に関する良い悪い説明もあるので読んでおいたほうがいいと思います。
ちなみにYahoo天気ですが、たぶんスクレイピングは禁止されていません。
Yahooファイナンスは明確に禁止されていましたが、天気に関しては禁止しているような記述は見つかりませんでした。
ただ節度は守りましょう。定期的にスクレイピングするとしても天気は1時間または30分ごとくらいのアクセスで十分だと思います。やること
色々取りたい情報はありますがとりあえず東京の今日の天気を取得しました。
下記の画像の今日の天気の"晴れのち曇り"を取得します。
コード
実際にコードを実行すれば今日の天気を取得できます。(Visual Codeで色々書いたりデバックしました。)
だいたいコメントに何をやっているか書いてあります。
ほぼコピペのソースですが注目ポイントはselect_oneでtextの部分を取得しているところです。
Google Chromeで自動で取得しようとしたのですがうまくいかなかったので手打ちで探っていったところうまくいきました。tenki.pyimport urllib3 from bs4 import BeautifulSoup #アクセスするURL url = 'https://weather.yahoo.co.jp/weather/jp/13/4410.html' #URLにアクセスする 戻り値にはアクセスした結果やHTMLなどが入ったinstanceが帰ってきます http = urllib3.PoolManager() instance = http.request('GET', url) #instanceからHTMLを取り出して、BeautifulSoupで扱えるようにパースします soup = BeautifulSoup(instance.data, 'html.parser') #CSSセレクターで今日の天気のテキストを取得します。 tenki = soup.select_one('#main > div.forecastCity > table > tr > td > div > p.pict') print (tenki.text) #一瞬で画面が消えないよう input()以下、実行結果
終わりに
このコードを元に色々できると思います。
定期的に取得するなどはこの記事に加筆するかラズパイサイネージの記事に書くと思います。
あと環境の問題で実行できなかった等あると思うのでそのあたりは後々加筆します。
- 投稿日:2020-02-12T01:44:02+09:00
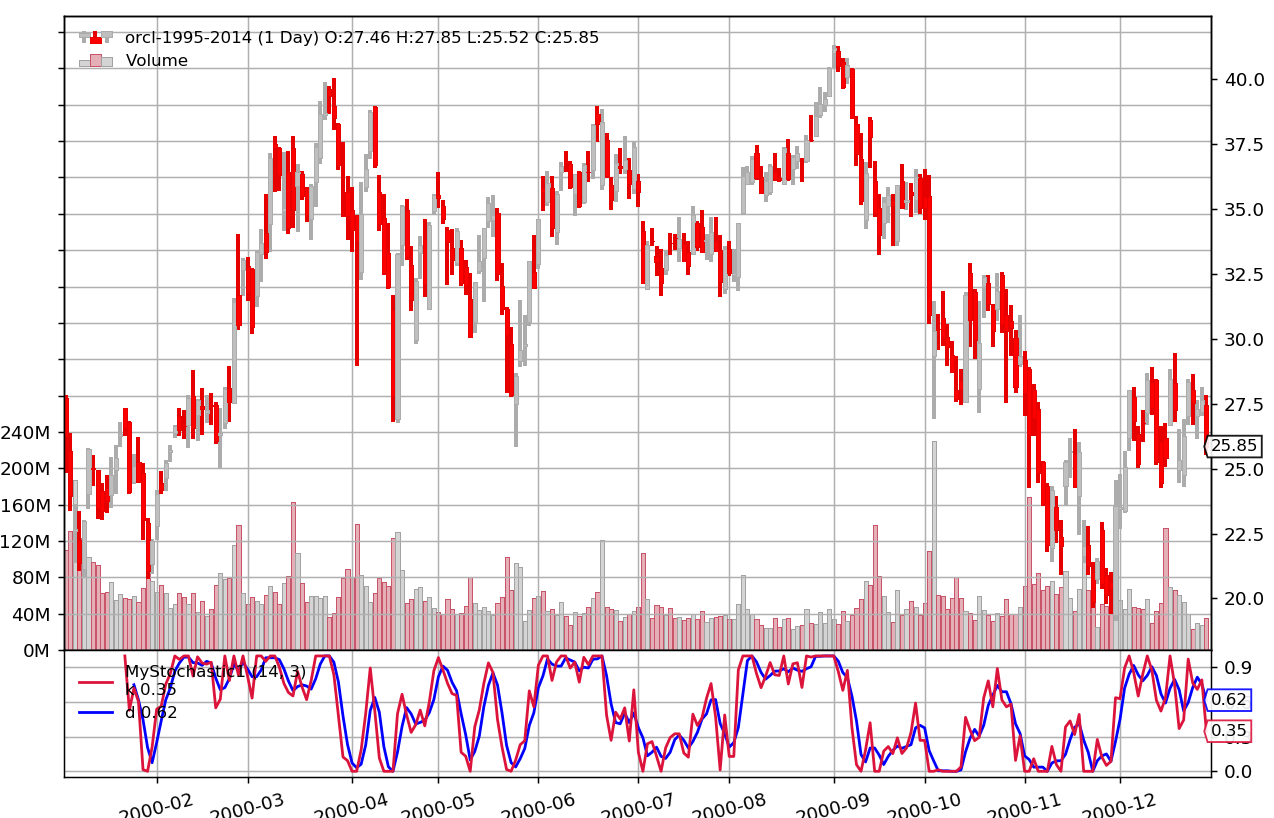
Backtrader カスタムインジケーターの作り方
例としてストキャスティクスを作って中身を見てみます。
おおまかな動作イメージを掴んでもらえたら幸いです。sto1.pyimport backtrader as bt class MyStochastic1(bt.Indicator): #bt.Indicatorを継承 lines = ('k', 'd', ) # プロットに表示するlinesオブジェクト params = ( ('k_period', 14), # パラメーターをタプルのタプルで指定する ('d_period', 3), # タプルの最後にもコンマ(、)をいれる ) plotinfo = dict(plot =True, subplot=True, plotname='', ) def __init__(self): highest = bt.ind.Highest(self.datas[0], period=self.params.k_period) lowest = bt.ind.Lowest(self.datas[0], period=self.params.k_period) self.lines.k = k = (self.datas[0] - lowest) / (highest - lowest) self.lines.d = bt.ind.SimpleMovingAverage(k, period=self.params.d_period) def next(self): passこれだけです。
まずはクラスの冒頭からみていきます。Linesオブジェクト
lines=('k','d')冒頭でプロットに表示する2つのLinesオブジェクトを設定しています。
これはMQL4でいうところの「Indexbuffer」みたいなもので数値と時間軸が結びついたイテラブルな配列です。CerebroはこのLinesオブジェクトをチャートにプロットしてくれます。Linesオブジェクトのインデックスとスライス
MQL4では最新のbarを[0]で表します。最新のBarから数えて1,2,3,・・・と古いBarになるにつれて数字が大きくなっていきます。
backtraderでも最新のBar・Linesオブジェクトを[0]で表します。これはMQL4と同じです。しかし0を基準にして古いbarになるにつれて-1,-2,-3・・・とマイナス記号が付きます。これに関連してLinesオブジェクトはPython本来のスライス操作を行うことはできません。
スライスを使いたい場合はget()メソッドを使います。
myslice = self.lines.my_sma.get(ago=0, size=1)[0]を除いて[-1]ひとつだけの配列
myslice = self.lines.my_sma.get(ago=0, size=10)[0]を除いて[-1]から[-10]まで10個の配列
myslice = self.lines.my_sma.get(ago=-1, size=5)[-1]を除いて[-2]から[-6]までの配列※Linesオブジェクトに対して[ ]オペレータを使えるのはnextメソッドの中だけです。nextメソッドに関してはまた後日まとめたいと思います。
パラメーター(params)
params = (
('k_period', 14),
('d_period', 3),
)
次に設定しているのがインジケーターのパラメーターです。タプルのタプル、またはdict()によって指定します。ここで指定する以外にもストラテジークラスでパラメーターを上書きすることもできます。self.params.k_periodのように「self.params.名前」 という書き方で表します。パラメータの順番を守りたいときにはタプル、そうでないときは辞書を使うという違いが当初はあったようだが、Python3.7からは関係なくなったらしい。強いて違いをあげるとすればタイプする量が若干減って楽なのがdict()なんだそうだ。
プロット設定(plotinfo)
plotinfo = dict(plot =True,
subplot=True,
plotname='',
)
プロットする際の設定を変えることができます。plot:プロットするかどうか、
subplot:サブウィンドウ表示切り替え、
plotname:脚注表示名(空欄の場合クラス名)
今回は3つだけですが他にも設定項目があります。データフィード(datas)
self.datas[0], self.datas[1]
例えば日足と週足のような2つのCSVデータを渡した場合、小さい時間枠が先でdatas[0]が日足データ、datas[1]が週足データにしなければなりません。
今回は日足データのみ渡しています。組み込みインジケーター呼び出し
highest = bt.ind.Highest(self.datas[0], period=self.params.k_period)
lowest = bt.ind.Lowest(self.datas[0], period=self.params.k_period)
bt.ind.XXXX() で組み込みインジケーターを呼び出せます。ここではHighestおよびLowestを呼び出してk_period期間中の最高値と最低値を検索しています。その結果をLinesオブジェクトhighestとlowestに入れています。これらはあくまでも計算用のLinesオブジェクトです。プロットされるのは冒頭で設定したkとdだけです。Linesオブジェクトに値をいれる
self.lines.k = k = (self.datas[0] - lowest) / (highest - lowest)
self.lines.d = bt.ind.SimpleMovingAverage(k, period=self.params.d_period)プロットするLinesオブジェクトは「self.lines.名前」で表します。kは
self.lines.kでdはself.lines.dです。結果として得られたLinesオブジェクトは計算にも使うことができます。ここでは次の行の計算の表記を簡略化するために「k」に代入して単純移動平均インジケータに渡しています。省略表記
--- 正式 省略 lines self.lines.XXX self.l.XXX params self.params.XXX self.p.XXX datas self.datas[0].close self.data.close または self.data Alias SimpleMovingAverage SMA backtraderでは省略表記ができます。便利ですが慣れるまで混乱しやすいかもしれません。
そして実は今回のplotinfoはまるごと全部省略できます。plot,subplot,plotnameは省略された場合デフォルト設定が使われます。nextメソッド
今回は使っていませんが、Bar1本ごとに条件判断したり処理を行いたいときにはnextメソッドに内容を記述します。
init と nextの違いなどは後日まとめたいと思います。ストラテジークラスで呼び出し
それでは、実行してみます。
このインジケータークラスをストラテジークラスのinitメソッドの中でインスタンス化すると、Cerebroがチャートにプロットしてくれます。
self.myind1 = MyStochastic1(self.data)(各所に説明コメント追加しています。)
sto12.py%matplotlib notebook from __future__ import (absolute_import, division, print_function, unicode_literals) import datetime import os.path import sys import backtrader as bt class MyStochastic1(bt.Indicator): lines = ('k', 'd', ) # プロットに表示するlinesオブジェクト params = ( ('k_period', 14), # パラメーターをタプルのタプルで指定する ('d_period', 3), # タプルの最後にもコンマ(、)をいれる ) #省略 #plotinfo = dict() def __init__(self): # 正確にはself.datas[0]と書くが省略可能 # self.params.k_periodを省略してself.p.k_period highest = bt.ind.Highest(self.data, period=self.p.k_period) lowest = bt.ind.Lowest(self.data, period=self.p.k_period) self.lines.k = k = (self.data - lowest) / (highest - lowest) self.lines.d = bt.ind.SMA(k, period=self.p.d_period) class TestStrategy(bt.Strategy): def __init__(self): #インスタンス名myind1の部分は任意の名前でいい self.myind1 = MyStochastic1(self.data) if __name__ == '__main__': cerebro = bt.Cerebro() cerebro.addstrategy(TestStrategy) datapath = 'C:\\Users\\XXXX\\orcl-1995-2014.txt' # Create a Data Feed data = bt.feeds.YahooFinanceCSVData( dataname=datapath, fromdate=datetime.datetime(2000, 1, 1), todate=datetime.datetime(2000, 12, 31), reverse=False) cerebro.adddata(data) cerebro.run(stdstats=False) cerebro.plot(style='candle')
無事ストキャスティクスが表示されました。
Cerebro起動を含めたbacktraderの動作の流れをおさらいします。
Backtrader全体のおおまかな流れ
- 自動売買の内容とそのために呼び出すインジケーターをストラテジークラスに記述する
cerebro = bt.Cerebro()- backtraderの中心機能であるcerebroにデータCSVを渡す
cerebro.adddata(data)- ストラテジーをcerebroに読み込ませる
cerebro.addstrategy(myStrategy)- cerebroを起動する
cerebro.run()- 必要であればチャートを表示する
cerebro.plot()backtraderのStrategy Classを継承した「myストラテジー」クラスを作成し、データCSVを指定した上でcerebroを実行すると、cerebroが自動的にこの「myストラテジー」クラスの内容を実行してくれます。
まとめ
いかがでしたでしょうか?
MQL4と比べてシンプルな記述内容になっているので新しくインジケータやストラテジーを試作する際にはアイデアやイメージを実現させやすいのではないでしょうか?私自身まだ十分にbacktraderを使いこなしているとは言えませんが、数あるPythonのトレーディングライブラリの中でも使いやすくて強力なツールであると私個人は感じています。
backtraderには豊富なドキュメントが用意されていてコミュニティでも活発に情報が挙げられています。しかしながらそれらを読んでいて不満点がないわけではありません。
(例えばドキュメントが分散していて必要な情報を見つけるのが大変だったり、ドキュメント内容はお世辞にも親切でわかりやすい・・というわけでもありません。質問に答えるコミュニティ管理者がなんだか少し不親切だったり・・・などなど)僭越ながらそこらへんを補えることができたらいいなと思っています。繰り返しになりますが日本でのbacktrader人口(と日本語解説記事)が増えてくれることを願っています。