- 投稿日:2020-02-12T23:38:08+09:00
AWSの10分間チュートリアルをやってみる 6. アプリケーションを更新する
こんにちは。トリドリといいます。
新卒で入社した会社でJavaを数年やった後、1年ほど前に転職してからはRailsを中心に使用してアプリケーションの開発をしているしがないエンジニアです。今回、AWSの勉強をするために公式の10分間チュートリアルをやってみることにしたので、備忘のために記事に残していこうと思います。
AWSに関しては、1年ほど前転職活動をしていた時期にEC2とRDSを少し触っていた以外ほとんど触ったことが無い初心者です。
(ただし、このときにアカウントを作ったので、12ヶ月の無料枠は切れていました)前回は「Amazon Elastic Beanstalk を使用したアプリケーションの起動」を行いました。
今回は「アプリケーションを更新する」を行います。
前回の続きで作成したアプリケーションの更新になります。アプリケーションを更新する
ステップ 1: アプリケーションコードの更新
前回のチュートリアルでダウンロードしたサンプルコードを編集し、更新されたアプリケーションのコードを作成します。
a./b./c./d.
チュートリアルに従って、前回ダウンロードしたサンプルコードを解凍した上で編集し、
php-v2.zipとして圧縮します。ステップ 2: 更新したアプリケーションの Elastic Beanstalk へのアップロード
続いて、ステップ1で作成したアプリケーションのコードをアップロードし、アプリケーションを更新していきます。
a.
Elastic Beanstalkのコンソールを開き、チュートリアルに従って画面上部の[php-sample-app]から[アプリケーションバージョン]をクリックします。
b.
チュートリアルではバージョンラベルは
First Releaseとなっていますが、前回の手順で自動的に生成されたバージョンラベルの場合php-sample-app-sourceとなっています。
チュートリアルに従って[アップロード]を押すと次のようにデザインが変更され、タグの入力欄が追加されたダイアログが開きます。
前回同様、バージョンラベルは自動的にphp-sample-app-source-1と設定されているので、今回はチュートリアルに従ってSecond Releaseに変更しておきます。
最後に、ステップ1で作成したphp-v2.zipをアップロードし、[アップロード]を押します。c.
ダイアログが閉じると、チュートリアルの通り
Second Releaseが追加されています。
[デプロイ]ボタンはチュートリアルの画面から位置が変更され、[アクション]の中のメニューの一つとなっています。
[デプロイ]を押下後のダイアログは変更がないので、チュートリアルの通り何も変更せず[デプロイ]ボタンを押します。d./e.
チュートリアルの通り、アプリケションの環境を表示し、アップデートが完了するのを待ちます。
Step 3: 更新された Elastic Beanstalk アプリケーションにアクセスする
a./b.
更新が完了したら、前回同様URLをクリックし画面を確認します。
ステップ1で更新した内容が表示されれば完了です。ステップ 4: 環境を終了させる
このサンプルアプリケーションはもう使用しないので、アプリケーションを削除し環境を終了させます。
a.
チュートリアルでは表示されていませんが、アプリケーションの削除に当たって環境名(ここでは
PhpSampleApp-env)が必要なのでコピーした上で手順に従って[環境の終了]を押します。b.
チュートリアル同様、確認ダイアログが表示されます。
現在は削除にあたって環境の名前を入力する必要があるので、a.でコピーした環境名を入力した上で[終了]をクリックします。
終了が完了するとダッシュボードと環境の詳細はそれぞれ次の画像のように表示されるようになります。
まとめ
今回はElastic Beanstalkで作成したアプリケーションの更新と環境の削除を行いました。
今回は比較的手順も少なく、チュートリアルに従って進められる内容でした。次回は"Set up the Elastic Beanstalk Command Line Interface"(「コマンドラインを設定」)に進みます。





- 投稿日:2020-02-12T22:46:14+09:00
AWS試験対策(③コンピューティングとストレージ続)
自分用メモ、昨日の続きから
セキュリティグループ
セキュリティのルールをまとめた仮想FW。許可したいものだけ記載するホワイトリスト方式。
インバウンドは外から内へ、アウトバウンドは内から外への通信。
基本的に使うポートだけ開ける(インバウンドに記載する)。
開けすぎると攻撃受ける箇所が多すぎてセキュリティリスクであるから。
EC2のポートを開けるというよりは、ルールを作ってそこにEC2が従う的な感じ。
何が違うかって言うと、22と80のポートを開けたいサーバが2つあったとき、各それぞれに設定を作らなくて良くて、一度設定を作ったとこに所属させれば良い。お手軽。セキュリティグループはステートフルといって、外へのトラフィックのについての、戻りのトラフィックは自動的に許可されるって仕組みらしい。
球技で例えるとわかりやすいかも。テニスとか。
フォアハンドで打ったものがバックハンド側に返ってきても受け取れる。みたいな。
しかし、相手のサーブをバックハンドで受け取るには、準備してないと受け取れないよーってな感じ。また、アクセス元もセキュリティグループで指定できます。Aに入ってるサーバからのインバウンドはうけとるよーって感じ。IPでアクセス元の指定をしてたら、5台あれば5個の設定が必要だけど、セキュリティグループでの指定ならその5台をグループに入れちゃえばいいだけ。お手軽。
プレイスメントグループ
一緒のAZなら通信が早いよってこと。深く考えずに、近いんだから早いやろってくらいの気持ち。
監視
メトリクス(CPU使用率とかのリソース監視)はcloudWatchってサービスでできる。SNSを使ってメールで通知することもできる。
また、ログ監視したい場合はインスタンスにエージェント入れればcloudWatchにあつめてくれる。auto recovery
ハードウェア障害とかが起きたときの対応を設定しておくことで自動的にやってくれる。
ハードウェア障害の際に、自動再起動を仕込んでおけば、落ちっぱなしじゃなくて別ホストコンピュータにて起動されて復帰が早くなる仕組み。
一応、ホストコンピュータ側だけじゃなく、インスタンス側の障害の場合でもauto recoveryは使える。AWS marketplace
予めソフトウェアがインストールされてるAMIを購入できる。インスタンス作ってからソフトウェアインストールする手間が省けるから便利。
一旦区切り、次回EBSから。
- 投稿日:2020-02-12T22:40:02+09:00
【DevOps試験対策#2】課題解決の鍵とは?
前回のおさらい
さて、前回はマルチクラウドプラットフォームの課題抽出を行いました。
過去記事についてはこちら【DevOps試験対策#1】マルチクラウドプラットフォームの是非を問う
- コスト
- 煩雑化(闇を抱えかねない。)
- 柔軟性は必要不可欠
- 運用まで考慮に入れた変革が必要
- 優先度
- 業務負荷
これらの課題を解決する上で何が必要になるのか。
それぞれを最大限に効果を出すにはどうするのかという観点で考察していきたいと思います。コスト
一概にコストといっても金額が下がれば良いと言うわけではなく、相対的にコストダウン効果が出ればOKである。
例えばDevOpsを導入することによって、発生を抑止出来るヒューマンエラー、それらに伴うダウンタイムの激減など
定量化して論じることが出来るポイントは相当量に存在する。
また過剰割当リソースの最適化に伴うコスト調整も可能であろう。私自身はこれらを定量化し指標としてたて達成する方法論をKubernetesで提案実現をした。
詳細な方法論は次稿以降で説明する。煩雑化・柔軟性は必要不可欠
結論から言うと「DevOps + マイクロサービス + ドキュメント標準化 + 開発フロー標準化 + 運用建付け標準化」を使った自動化を行った。
煩雑化してしまうのは人の手を介する部分が多いからだと位置付けし、ツールで賄える部分は極力ツールで行い闇を抱えない環境を目指した。
簡単に結論を書きましたが、概念的な話だけではなく各ツールのチューニングやアプリで制御していた部分の多くをKubernetes + Istioに管理させるようにし、インフラや各ツールの管理者が能動的に動ける場を作っていった。そもそも闇を抱える原因は、最初から闇を抱えようと思う人はいないが、少数で無手勝流で日々業務をこなして行くことによって結果として、その人じゃないとわからないという闇を抱えることになってしまう。
往々にしてあるのは、このような状況ではエンジニアは疲弊してしまうので闇が発覚するタイミングでそれらのエンジニアは退職していることも多い。またドキュメントレベルの問題もありがちだ。
疲弊してしまうとどうしてもドキュメントレベルが低くなる。
スタートアップ企業にありがちだが、業務を進めることを優先し結果として闇を抱えることになる。
悪いと言っているのではない、事業の黎明期に影が落ちてしまう部分が出来てしまうのは当然なのである。
そこを批判すればそもそも事業が立ち行かなくなり、今日を迎えていなかったかもしれないのである。重要なのは事業を作る上で発生した闇を取り払う作業を日常のサイクルに組み込んで恒常業務として認識することが必要である。
今回、かなり大掛かりなPJを企画してしまった私も黎明期メンバーのメンタルケアは最も注力した部分であることは言うまでもない。
批判は誰にでも出来る。何かを言うと黎明期メンバーは批判と捉えがち。だからこそこのようなPJを進めるにあたっては、
変わる事が必要、変わっていくのが普通、スタートアップ時は闇が発生するのは当たり前、など各メンバーの意識を変えて行くことが一番最初に必要なこととなる。また時期も重要だ。黎明期であるにも関わらずこのような変革PJを企画してしまうと、ただでさえ疲弊しているにも関わらず、やれドキュメントをもっと作り込めだとか、検証をしろだとか、自動化しろと言うことによって、さらに疲弊し退職者が跡を絶たなくなったり、もしくはそのようなことを要求するマネージメント層に誰も見向きもしなくなったりする。
現状の日本の企業で働いているある一定数のエンジニアはドキュメントを作ったり、検証を繰り返すことは日常的になってきているが、スタートアップ企業や中小企業ではそうはいかない場合もある。
どこかのエンジニアが転職をしてマネージャーになり失敗するパターンに上記のような状況を耳にする場合が多い。
この記事を読んだエンジニアの方々に重ねて申したいが、このような自動化や標準化を行うことはもちろん悪いことではない、むしろ良いことだと思う。
がしかし、タイミングを見極めることを忘れないでほしい。運用まで考慮に入れた変革が必要
前稿で述べたとおり運用建付けを簡素化、標準化していくことが必要である。
そのために運用に必要な要素をアプリ側で実装するのではなく、全てインフラ側で吸収することを考えた。マイクロサービス化 + Kubernetes + Istioを導入することによってGrafana、Prometheusの導入が自動で行われる。
しかしサービスメッシュ化されたシステムの運用は一筋縄では行かない部分も多い。そもそもマイクロサービスを適切に作ることによって得られるメリットは大きいがいくつかの課題がある。
下記が課題の代表格だと思うが、私が企画したPJでもこれらが最も大きな課題となった。・サービス同士の通信の複雑性
・各アプリケーションのモニタリング
・クライアントーアプリの通信
・データの整合性
・CI/CDの複雑性マイクロサービスを実現することによってインフラ構築やアプリのデプロイなど格段に利便性を向上することが出来るが、これらの問題を解決する手法の模索に時間を費やした。
Kubernetesと相性が良いと言われるIstioでサービスメッシュ化を行いネットワークの抽象化を行う方法論で解決の糸口を探ったが、いまだ発展途上のツールであることもありバグなのか操作・設定ミスなのかが判別しない事象も多かった。
しかし今までアプリ側に持たせていた通信制限などの機能は全てIstioで吸収できアプリの複雑性や手間に関してはかなりの割合で軽減出来たと言える。
その反面ネットワーク周りが複雑化したが、アプリで制限等を実装することとネットワークで制限をかけることは単純工数でネットワークで制限をするほうがメリットが高いことと、職場の特性上ネットワークに関しては知見を持った人材が多かったため最終的にIstioでサービスメッシュ化をすることを決定した。枠組みをしっかり作ってしまえば標準的な運用フローは意外とすっぽりはまり込み、変動要素としてはアプリ単体での特性のみとなるため運用部門のメンバーも納得の兆しが見え、共通認識、標準化フローを作っていく機運が見え始めた。
優先度・業務負荷
今まで企画、開発・インフラ、運用の3部門で運用していたIT部門だが、
将来的にはインフラよりのSREを配備することになるだろう。現時点では業務負荷なんかなんのそのといった感じで、このPJを進めてしまったが、
かなりの負荷があったのは言うまでもない。既存アプリの移行作業、DevOps、新規アプリのローンチなど同時に複数のタスクをこなしながら実施したため、
私自身、上記に書いたような闇を抱える部分を作ってしまったと言える。
またある一定レベル以上のスキルを有するエンジニアでないと、そもそも触ることすら出来ないのではないかと思われる部分もあったが、そこも含めて将来的に配備されるSREがさらに自動化・簡素化・標準化をして行くことに期待する部分である。もし次に私が同様のPJをするのであれば専任部隊としてSREを配備し、人・物・金の手配をしっかり行い、疲弊することなく進めて行きたいと思っているところである。
さて、次回から実際にどのように作ったのか技術的な点に入りたいと思います。
- 投稿日:2020-02-12T21:52:56+09:00
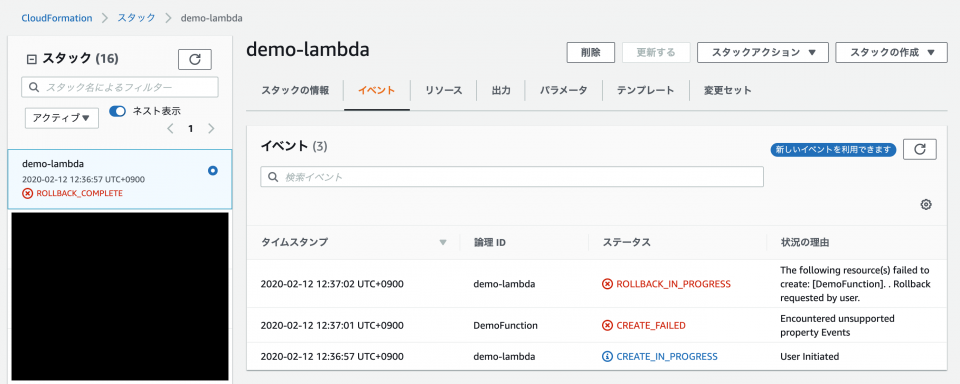
CloudFormationでスタックを作成しようとしたら「Encountered unsupported property (PropertyName)」となる
事象
lambda.ymlResources: DemoFunction: Type: AWS::Lambda::Function Properties: FunctionName: demo_func Code: ZipFile: | import json def lambda_handler(event, context): jsn_str = json.dumps(event, ensure_ascii=False) print(jsn_str) Handler: lambda_function.lambda_handler MemorySize: 128 Timeout: 30 Role: !Sub arn:aws:iam::${AWS::AccountId}:role/Lambda_Basic_Role Runtime: python3.7 Events: Stream: Type: DynamoDB Properties: Stream: Fn::ImportValue: demoTableStream StartingPosition: LATEST BatchSize: 1AWS CLIで
create-stackコマンドにより上記テンプレートlambda.ymlをもとにDynamoDB StreamをトリガーにしたLambda Functionを作成しようとした。$ aws cloudformation create-stack \ --stack-name demo-lambda \ --template-body file://lambda.ymlしかし下記のように
Encountered unsupported property Eventsというエラーとなりスタックの作成が失敗する。
解決
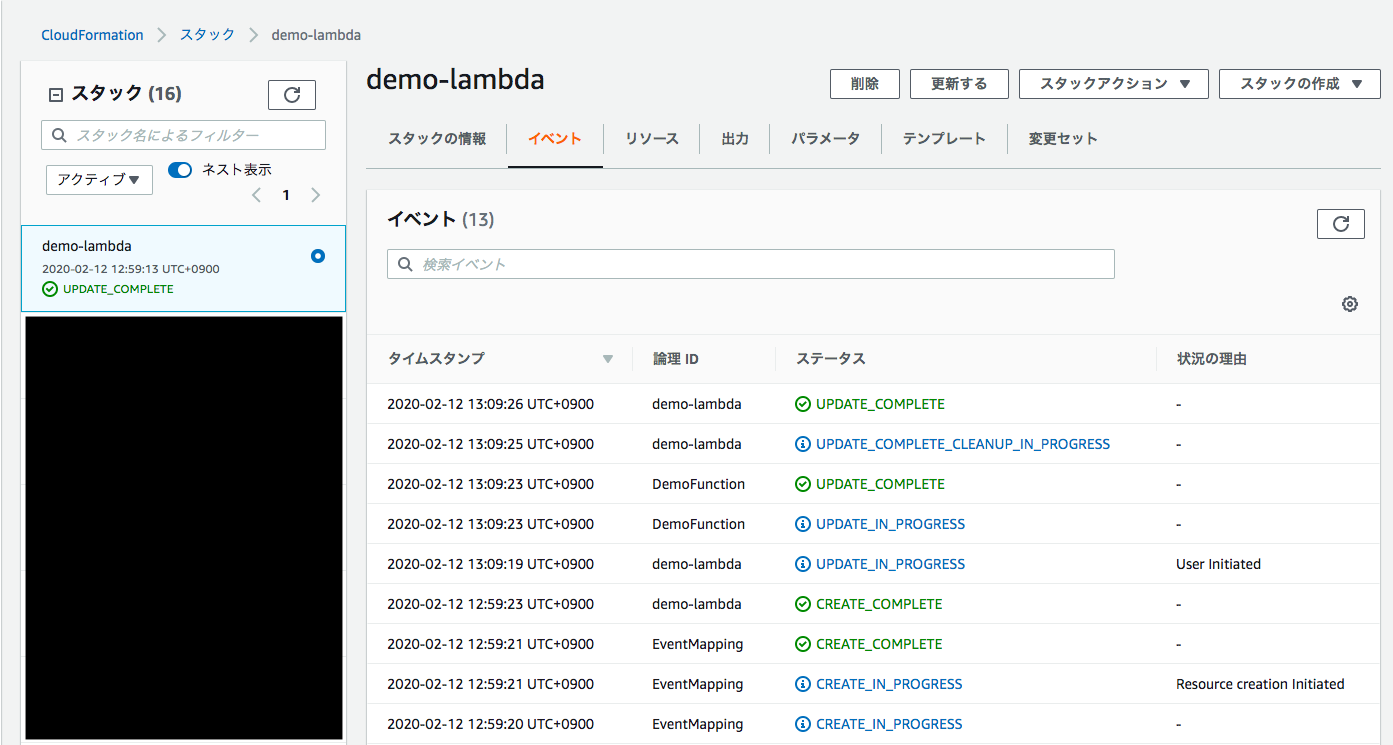
CloudFormationでは
Type: AWS::Lambda::FunctionではEventsというプロパティは使えなかった。LambdaのDynamoDB Streamトリガーをテンプレートで定義する場合は下記のようにAWS::Lambda::EventSourceMappingリソースを使う必要があった。lambda.ymlResources: DemoFunction: Type: AWS::Lambda::Function Properties: FunctionName: demo_func Code: ZipFile: | import json def lambda_handler(event, context): jsn_str = json.dumps(event, ensure_ascii=False) print(jsn_str) Handler: index.lambda_handler MemorySize: 128 Timeout: 30 Role: !Sub arn:aws:iam::${AWS::AccountId}:role/Lambda_Basic_Role Runtime: python3.7 EventMapping: Type: AWS::Lambda::EventSourceMapping Properties: EventSourceArn: !ImportValue demoTableStream FunctionName: !Ref DemoFunction StartingPosition: LATEST
おわりに
AWS SAMのymlテンプレートを通常のCloudFormationテンプレートに流用していたため利用できないプロパティが紛れていた。
以上
- 投稿日:2020-02-12T20:02:13+09:00
AWSにdjangoでWebアプリを立ち上げて転職
こんにちはmogkenです。
前回Python+Django+AWSでスクレイピングアプリを作って転職という記事を書いてから3ヶ月余りが経ちました。タイトルの通り幸いにも転職が成功して1月からクラウド基盤を開発している会社にサービス企画で転職しました(^o^)/
というわけで今回はその時に作ったPythonのwebアプリをAWSに構築した際の手順を簡単に記録します。ただ申し訳ないのですが随分と前のことなので、やや記憶が曖昧で内容が正しいか保証できません...素人の備忘録だと思ってください。
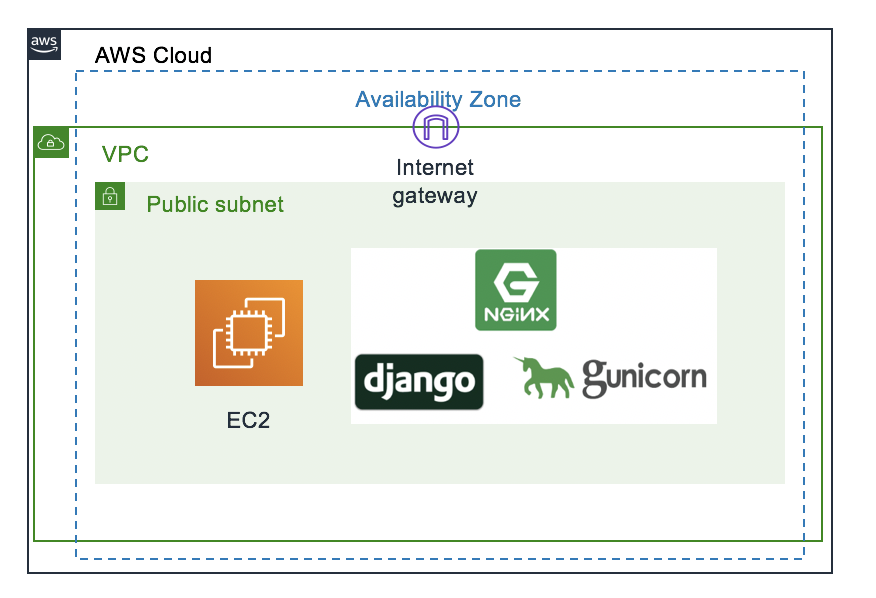
今回のやること
AWSのVM(Centos7)にpython3とDjango、nginx、そしてgunicornをインストールして、作成したWebアプリをデプロイします。ロードバランサーやオートスケーリングもやろうと思っていたのですが、転職ができてしまったので一番簡単な構成で力尽きました...
構成図(最小構成すぎるのでいらないけれど一応)
AWSの設定
この構成でAWSで設定すべき項目は大雑把に書くと以下の通り
- ネットワークの作成
- VMの作成
- DNSの設定
なお詳しい手順はここでは記載しない。だって素人のしかもうろ覚えの手順なんてとても怖くて参考にできないでしょう。
参考URL:https://qiita.com/okoppe8/items/dc1de147a36797442e4c
1.ネットワークの作成
AWSではまずVMを立ち上げるためのVPCを作成する必要がある。
流れは次の通り
- VPCの作成
- サブネットの作成
- インターネットゲートウェイの作成
- ルートテーブルの作成
- セキュリティグループの作成
2.VMの作成
アプリケーションを構築するためのVMを作成する。でもやることはただEC2をボタンをポチポチして作成するだけ。
3.DNSの設定
公開するためのドメインの設定をAWSのDNSサービスであるRoute53を使って行う。
自分はこのサイトを参考に行った。
https://avinton.com/academy/route53-dns-vhost/
Linuxサーバの設定
AWSでVMの作成が終わったら次は立ち上げたVMの設定を行う。
ここからは少し詳しく解説する。(何回も失敗して繰り返したから割と記憶が鮮明なのだ...)
あとはここからの設定は基本的には
https://narito.ninja/blog/detail/21/#_3
このページを参考にしている。このブログはDjango周りのとてもわかりやすい記事がたくさんあるので、とてもオススメ。
手順としては次の通り
- 立ち上げたVMにSSH or Webコンソールでログイン
- python3のインストール
- djangoのインストールと設定
- nginxのインストールと設定
- gunicornのインストール
- サービスの立ち上げ
1. 立ち上げたVMにSSH or Webコンソールでログイン
EC2の作成時に同時にsshでアクセスするための認証鍵も作成されるから、それをダウンロードして使用する。何を言っているのかわからない人はAWSのコンソール画面からもWeb上でVMにアクセスできるのでそちらでやってみると良いかもしれない。
ダウンロードした認証鍵はそのまま使おうとすると、認証鍵の権限がオープンすぎると怒られるため次のコマンドでファイル権限を設定する必要がある。
chmod 400 "ダウンロードした認証鍵ファイル名"あとは以下のコマンドでsshアクセスができる。
ssh -i "***.pem" ec2-user@"EC2のパブリックDNS名 or パブリックIP"2. python3のインストール
参考URL:https://qiita.com/s_runoa/items/156f3fa67c82e9cd9f42
ここからは必要なパッケージをインストールしていく。まずはpython。pyenvを使っているけれど未だにpyenvが何か正確には分かっていない...
#yumパッケージのアップデート yum update -y #必要パッケージのインストール sudo yum install git gcc zlib-devel libffi-devel bzip2-devel readline-devel openssl-devel sqlite-devel #pyenvのインストール git clone https://github.com/yyuu/pyenv.git ~/.pyenv #.bash_profileに追記 export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)" **ここでサーバを再起動** #Pyhtonのインストール pyenv install --list CFLAGS="-fPIC" pyenv install 3.7.2 #pythonの設定 pyenv versions pyenv global 3.7.2 pyenv rehash #インストールの確認 python --version3.djangoのインストール
pythonがインストールできたらdjangoをインストールする。ちなみに自分にとっての初フレームワークがdjangoなので、djangoにはなんだかとても特別な気持ちを抱いている。
#djangoのインストール pip install Django以上でdjangoのインストールは終了なのだが、あとでsqlliteのバージョンが古いと怒られることになるのでここでその対策もしてしまうと良いと思う。
怒られないこともあるから、めんどくさい人は飛ばしてしまって本当に怒られてからやってもよい。
Sqlliteのアップグレード
参考URL:https://qiita.com/rururu_kenken/items/8202b30b50e3bfa75821
#tarファイルの取得 wget https://www.sqlite.org/2019/sqlite-autoconf-3280000.tar.gz #tarの解凍 tar xvfz sqlite-autoconf-3280000.tar.gz #ビルドしてインストール cd sqlite-autoconf-3280000 $ ./configure --prefix=/usr/local $ make $ sudo make install $ sudo find /usr/ -name sqlite3 $ sudo mv /usr/bin/sqlite3 /usr/bin/sqlite3_old $ sudo ln -s /usr/local/bin/sqlite3 /usr/bin/sqlite3 # 共有ライブラリへパスを通す $ export LD_LIBRARY_PATH="/usr/local/lib"setting ファイルの編集
Djangoを正常に立ち上げるための最低限の設定をここで行う。
#djangoプロジェクトの作成 django-admin startproject "プロジェクト名" #djangoアプリの作成 python manage.py startapp "アプリ名" #設定ファイルの編集 djangoの設定ファイルはプロジェクト名と同じ名前のフォルダに作られる vi /"プロジェクト名"/"プロジェクト名"/setting.py #以下setting.pyの中の編集項目 #installed_appの末尾に追加 "アプリ名".apps."アプリ名(頭文字を大文字にする)"Config 例)'myapp.apps.MyappConfig' #デバッグの非表示とhostの指定 DEBUG = False ALLOWED_HOSTS = ["設定したドメイン名"] #言語とタイムゾーンの設定 LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo' #静的ファイルの置き場の設定 STATIC_URL = '/static/' # これは元からあります。 STATIC_ROOT = '/usr/share/nginx/html/static' MEDIA_URL = '/media/' MEDIA_ROOT = '/usr/share/nginx/html/media' #保存してsetting.pyの編集終了 #最後にこのコマンドを打って終了 sudo python manage.py collectstatic4.nginxのインストールと設定
WebサーバにはNginxを使う。初めてこれに出会った時にどうやって読むのか皆目分からなかった。
nginxのインストール
#nginxのインストール sudo amazon-linux-extras install nginx1.12nginxの設定
#設定ファイルのの編集 sudo vim /etc/nginx/conf.d/project.conf #以下設定項目 server { listen 80; server_name "サーバのパブリックIPアドレス"; location /static { alias /usr/share/nginx/html/static; } location /media { alias /usr/share/nginx/html/media; } location / { proxy_pass http://127.0.0.1:8000; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Forwarded-Proto $scheme; } } #保存して終了 #設定ファイルチェック sudo nginx -t #nginxの起動 sudo systemctl reload nginx #サーバ起動時に同時にnginxも起動するための設定 sudo systemctl enable nginx5.gunicornのインストール
最後にwsgiとしてgunicornをインストールする。wsgiもgunicornも名前からしてなんだか良く分からない...
sudo pip3.7 install gunicornこれだけで終了。なんとも簡単。
サービスの立ち上げ
最後にサービスを立ち上げる
#manage.pyのファイルが置かれているプロジェクトフォルダに移動 cd /project #gunicornの起動 sudo gunicorn --bind 127.0.0.1:8000 project.wsgi:applicationここまでやったらドメイン名でdjangoのプロジェクトのアクセスできるようになっている。
最後にgunicornを止めたい場合の設定をのせておく
#gunicornのプロセス番号の確認 lsof -i:8000 #表示されたプロセスをkill kill -9 "表示されたプロセス番号"おつかれさまでした。
色々なエラーと闘って最後にページが立ち上がった瞬間はとても嬉しかった。
なんだか少し大人になったような気がした。
- 投稿日:2020-02-12T17:02:55+09:00
Rails】An error occurred while installing unf_ext (0.0.7.6), and Bundler cannot continue.【解決策】
AWSでデプロイ作業をしていたら以下のようなエラーが出ました。
An error occurred while installing unf_ext (0.0.7.6), and Bundler cannot continue.完全に詰んだかと思いましたが、1時間かけて解決することができたので共有しようと思います。
rubyのバージョン 2.5.1 Railsのバージョン 5.2.3 bundlerのバージョン 2.0.2 では早速見ていきましょう。
僕は、Pay.jpのgemをbundle installしたかったのですが、An error occurred while installing unf_ext (0.0.7.6), and Bundler cannot continueというエラーが出ました。
結論、インスタンスを再起動しましょう。
そして、停止することができたら「開始ボタン」を押しましょう。これでひとまずはOKです。
さらに、NginxとMysqldを再起動します。
sudo service nginx restartsudo service mysqld restartコマンドは上記です。
これで準備は整いました。これで本番環境でもbundle installすることができると思います。
エラーが無事解決されましたら幸いです。
- 投稿日:2020-02-12T16:50:23+09:00
【AWS&Rails】 listen "#{app_path}/tmp/sockets/unicorn.sock"がないみたいなエラー【解決策】
AWSでデプロイしようと試みてたら以下のようなエラー出ました。
listen "#{app_path}/tmp/sockets/unicorn.sock"Unicorn関係はほんとに嫌いです?
しかし解決できたので共有します!
rubyのバージョン Railsのバージョン bundlerのバージョン 2.5.1 5.2.3 2.0.2 では早速見ていきましょう
!手順1 本番環境にいく
ec2ユーザー ElasticIP アプリ名 $まずはここまでいきましょう。
手順2 ps aux | grep unicornコマンドを叩く
ps aux | grep unicornそして1番上の左の数字をkillしてあげてください。
kill 1番上の左の数字手順3 RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dコマンドを叩く
まだこれだけではエラーは治りません。
最後に以下のコマンドを叩く必要があります。
ec2ユーザー ElasticIP アプリ名 $ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dこれでエラーがでなければ、無事成功です。
デプロイ環境でローカルの内容をみれると思います。
お疲れ様でした!
- 投稿日:2020-02-12T15:19:46+09:00
LambdaでEC2内のシェルスクリプトを実行
はじめに
本記事の対象となる読者
特定のトリガーでLambdaを起動して、EC2内のシェルスクリプトを実行したい
システム概要
上記のやりたかったことを実現するために使用したサービスは以下です。
- AWS Lambda(以後Lambda)
- AWS System Manager(以後SSM)
- AWS Elastic Computer Cloud(以後EC2)
書かないこと
- EC2インスタンスの構築方法
EC2
Amazon Linux2を使用して、無料利用枠でインスタンスを用意します。
EC2インスタンスを作成
EC2インスタンスを作成する前に以下のポリシーをアタッチしたIAMロールを作成しておきます。仮に名前は
AWSServiceSSMRoleとしておきます。
- AmazonEC2RoleforSSM
- AmazonSSMFullAccess
上記で作成したロールをインスタンスに割り当てインスタンスを作成します。
ssm-agentのインストールは必要ありません。
インスタンス内にbashスクリプトを作成
ssh接続をして以下を実行していきます。
# 自身で設定した情報を使ってSSH接続 $ ssh ec2-user@host -i ~~.pem # 現在地の確認 $ pwd # 結果:/home/ec2-user # test.txtを作成 $ touch test.txt # 実行するshファイルを作成 $ vi test.shvimで
test.shを開いたら以下を入力します。#!/bin/bash echo hoge >> test.txt入力したら、保存します。
$ sh test.shと実行すると
test.txtにhogeという文字列が書き込まれているかと思います。Lambda
今回はAPI Gatewayを使用して、そのエンドポイントにPOSTがあったらLambdaを実行するように作成します。
serverless frameworkを使用して、lambdaを作成します。
$ sls create -t aws-nodejs -p myfunc $ cd myfunc上記を実行すると、
handler.jsとserverless.ymlが作成されます。serverless.yml
API Gatewayを使用するので、eventsを設定します。
service: myfunc provider: name: aws runtime: nodejs12.x functions: hello: handler: handler.hello events: - http: path: hoge method: post integration: lambdahandler.js
AWS-SDK SSMクラスで用意されている
sendCommandメソッドを使用します。
詳しくはこちらを参照してください。sendCommandはSSMにあらかじめ登録されているドキュメントのコマンドを実行します。
今回はデフォルトで用意されているAWS-RunShellScriptドキュメントを使用します。
AWS-RunShellScriptはただEC2のシェルスクリプトを実行するだけですが、もちろんSSMに自分でドキュメントを作成してそれを実行することも可能です。lambdaではaws-sdkは標準でインストールされていますので、npm installなどでインストールする必要はありません。
'use strict' const AWS = require('aws-sdk') const SSM = new AWS.SSM({region: 'ap-northeast-1'}) const REMOTE_WORKING_DIR = '/home/ec2-user' module.exports.main = async event => { try { // 実行したいコマンド let command = 'sh exec.sh' let params = { DocumentName: 'AWS-RunShellScript', InstanceIds: ['作成したEC2のインスタンスID'], Parameters: { commands: [command], // 配列で指定するので複数実行も出来る workingDirectory: [REMOTE_WORKING_DIR] // どの階層で実行するかを指定 }, // SSMの実行結果をCloudWatchにロギング CloudWatchOutputConfig: { CloudWatchLogGroupName: 'SSMLogs', CloudWatchOutputEnabled: true }, // タイムアウト設定 TimeoutSeconds: 3600 // 1 hour } SSM.sendCommand(params, function(err, data){ if(err){ console.log(err, err.stack) } else { console.log(data) } }) } catch(e){ console.log(e); } }上記を保存後エンドポイントにPOSTして実行します。
$ curl -X POST "serverlessで作成されたエンドポイント" -d "{}"以上となります。
- 投稿日:2020-02-12T14:33:29+09:00
Amazon Athena で no viable alternative at input への対処法
背景
以前からあるCloudTrailのログをAthenaで分析したいと思いクエリを投げましたが、クエリが重いのでなんとかしたいと思いました。
Partitionを分割して時間とコストを節約しようと考え、Athenaのテーブルを作成しなおそうと思ったら、
no viable alternative at input 'create external'のようなエラーに遭遇。Syntaxがおかしいっぽいことまではわかるのだけど、これだけじゃどこを直して良いのかわからない。。。
とりあえず、公式ドキュメントを確認。さすがよくまとまってます。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/create-table.html
DDL確認ポイント
公式ドキュメントから、確認ポイントを抜粋しました。
これらをひとつひとつチェックしていけば、ほぼ間違いなくエラーは消えるでしょう。
- テーブル名に特殊文字(アンダースコア(_)以外)を使ってる
- テーブル名を数値から始めている
- カラム名に特殊文字(アンダースコア(_)以外)を使ってる
- カラム名をクォートで囲っている
- 括弧が足りない
- アンダースコアから始まる名前がバックスラッシュで囲ってない
- カンマが欠落している
- 半角スペースが足りない
- カラムやパーティション指定時に、最後のカンマが余計についている
- パーティションのカラム名に、テーブルのカラム名と同じものが指定されている
テーブル名にハイフンを使いたくなるのはよくある話だけど、エラーになる。
で、自分の場合、全部チェックしたけどエラーは消えなかった。
なんで?
自分がハマったところ
- パラメータの順番が違う
ちなみに、自分が投げたクエリはこんな感じ。
CREATE EXTERNAL TABLE my_cloudtrail ( eventVersion STRING, userIdentity STRUCT< type: STRING, principalId: STRING, arn: STRING, accountId: STRING, invokedBy: STRING, accessKeyId: STRING, userName: STRING, sessionContext: STRUCT< attributes: STRUCT< mfaAuthenticated: STRING, creationDate: STRING>, sessionIssuer: STRUCT< type: STRING, principalId: STRING, arn: STRING, accountId: STRING, userName: STRING>>>, eventTime STRING, eventSource STRING, eventName STRING, awsRegion STRING, sourceIpAddress STRING, userAgent STRING, errorCode STRING, errorMessage STRING, requestParameters STRING, responseElements STRING, additionalEventData STRING, requestId STRING, eventId STRING, resources ARRAY<STRUCT< arn: STRING, accountId: STRING, type: STRING>>, eventType STRING, apiVersion STRING, readOnly STRING, recipientAccountId STRING, serviceEventDetails STRING, sharedEventID STRING, vpcEndpointId STRING ) PARTITIONED BY ( region STRING, year STRING ) COMMENT 'CloudTrail table for cloudtrail archive' ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://my-bucket-name/AWSLogs/my-account-id/CloudTrail/' TBLPROPERTIES ('classification'='cloudtrail');よくあるCloudTrailのログを元にAthenaにテーブルを作成するクエリ。
でも、これはエラーになる。なぜなら、COMMENTとPARTITIONED BYの行の順番が逆だから。
つまり、DDLステートメント CREATE TABLE はパラメーターの順序もチェックするので、COMMENTとPARTITIONED BYの行を入れ替えて実行すると、テーブルの作成が成功します。
まとめ
今回は、ドキュメントの読み方が良くなかったと反省しました。
簡易チェックには、Format Queryを使いましょう。
SQLを整形したタイミングで間違っていると、パッと見でだいぶ違和感ある感じに整形されるので気づきやすいと思います。誰かが同じ道を踏んだ時に、お役に立てば幸いです。
- 投稿日:2020-02-12T14:20:50+09:00
Rails AWS EC2デプロイフロー ①EC2インスタンス作成編
はじめに
自分でアプリケーションは作ったものの、なかなかAWSにデプロイできなったので記録として残しておく!
わかりやすく....1.EC2インスタンスの作成
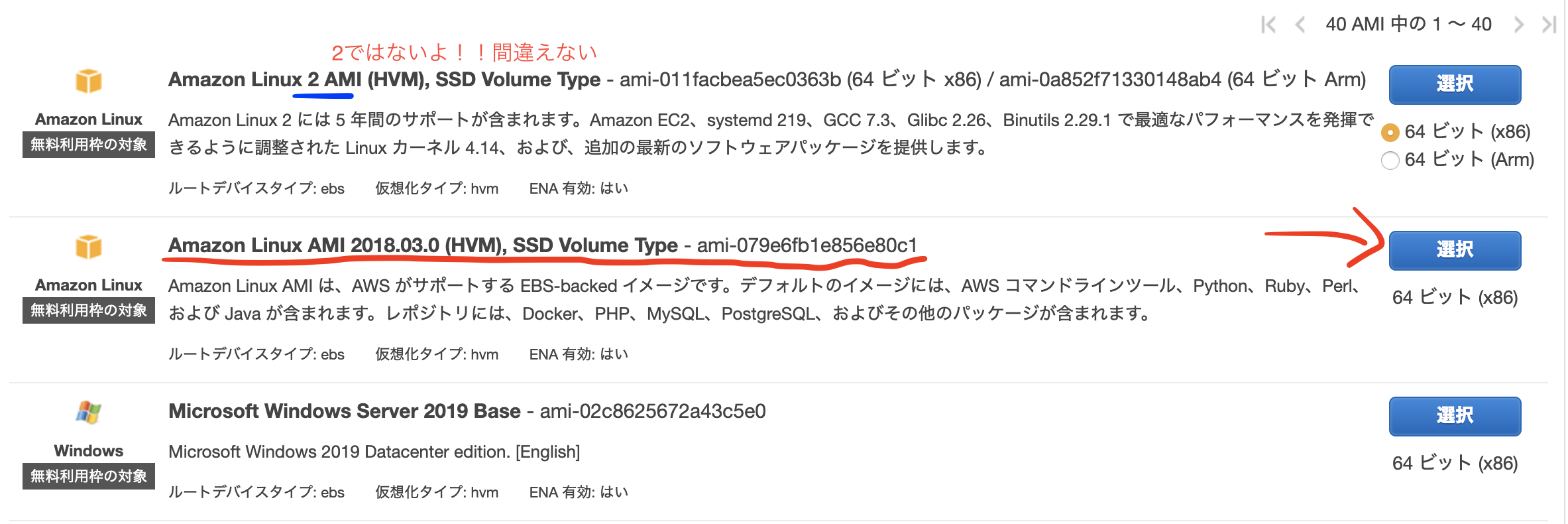
①サービスの中から 「EC2」 を選択します
②左の一覧からインスタンスをクリック
③インスタンス作成をクリック
④AMI(Amazon Machine Image)の選択
AMIとは
Amazon マシンイメージ (AMI) は、ソフトウェア構成 (オペレーティングシステム、アプリケーションサーバー、アプリケーションなど) を記録したテンプレートです。AMI から、クラウドで仮想サーバーとして実行される AMI のコピーであるインスタンスを起動します。インスタンスとは
インスタンスとは、クラウドの仮想サーバーです。起動時の設定は、インスタンスを起動した際に指定した AMI のコピーです。1 つの AMI から、複数の異なるタイプのインスタンスを起動することもできます。インスタンスタイプとは本質的に、インスタンスに使用されるホストコンピュータのハードウェアを決定するものです。インスタンスタイプごとに異なる処理内容やメモリの機能が提供されます。インスタンスタイプは、インスタンス上で実行するアプリケーションやソフトウェアに必要なメモリの量と処理能力に応じて選択します。
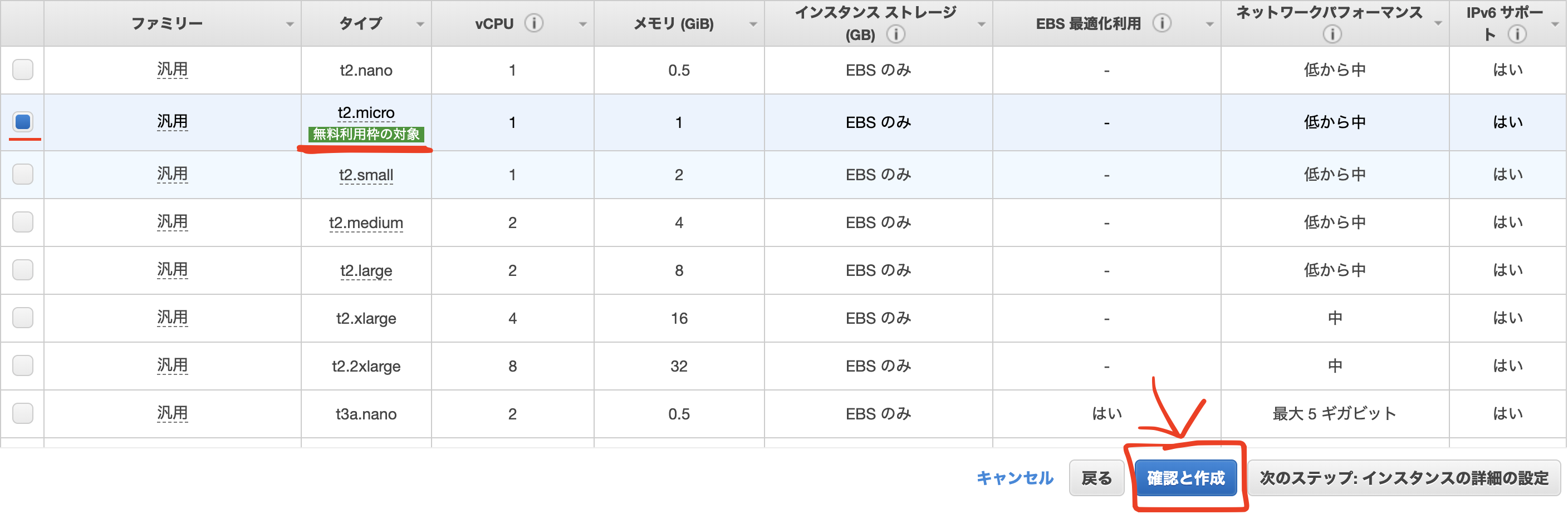
⑤タイプの選択
無料枠で利用できる「t2.micro」を選択しましょう。
起動をクリックします。
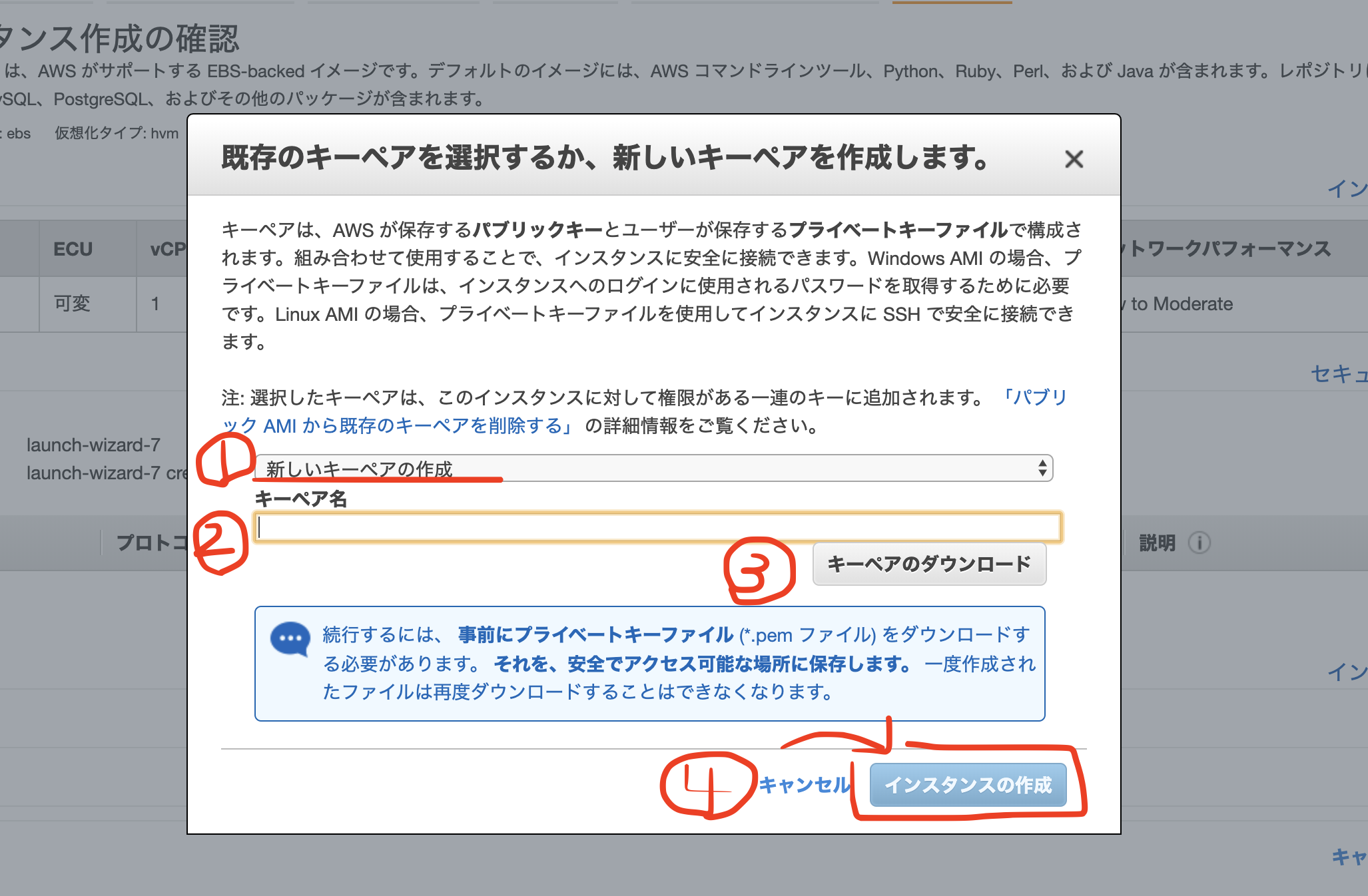
⑥キーペアのダウンロード
1,modalが表示されるので、【新しいキーペアの作成】を選択
2,【キーペア名】を任意で入力
3,【キーペアのダウンロード】を行う。
こちらはインスタンスにSSHでログインする際に必要となる「秘密鍵」です。これがないとEC2インスタンスにログインできないので、必ずダウンロードしてパソコンに保存しておきましょう。
4,【インスタンスの作成】をクリック
キーペアのダウンロードが完了すると、クリック出来ない状態になっていた「インスタンスの作成」が、クリックできるように変更されます。そちらをクリックして、EC2インスタンスを作成しましょう。
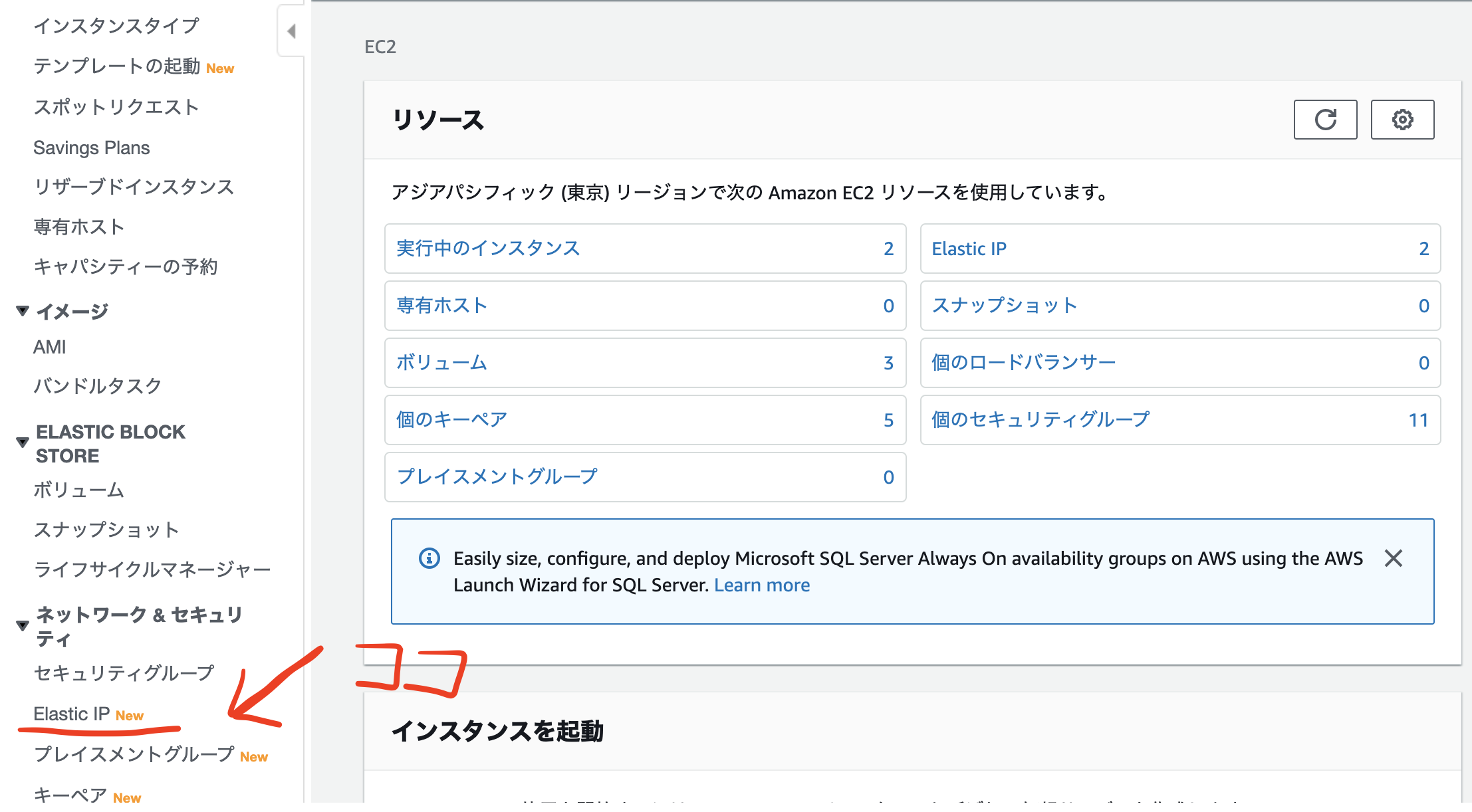
2.Elastic IPの作成と紐付け
Elastic IPとは
Elastic IPとは、AWSから割り振られた固定のパブリックIPアドレスのことを言います。このパブリックIPアドレスをEC2インスタンスに紐付けることで、インスタンスの起動、停止に関わらず常に同じIPアドレスで通信をすることが可能になります。
Elastic IPアドレスは、AWSに登録したアカウントに紐つけされるIPアドレスです。IPアドレスは基本的にパブリックIPアドレスとプライベートIPアドレスの2つに分けることができ、パブリックIPアドレスはインターネットを通じて機器を利用する際に割り当てられるアドレスで、最もポピュラーなIPアドレスと言えます。
一方のプライベートIPアドレスはインターネットではなくローカルのネットワークでのみ割り当てられるIPアドレスで、インターネットからは遮断されたIPです。Elastic IPの作成
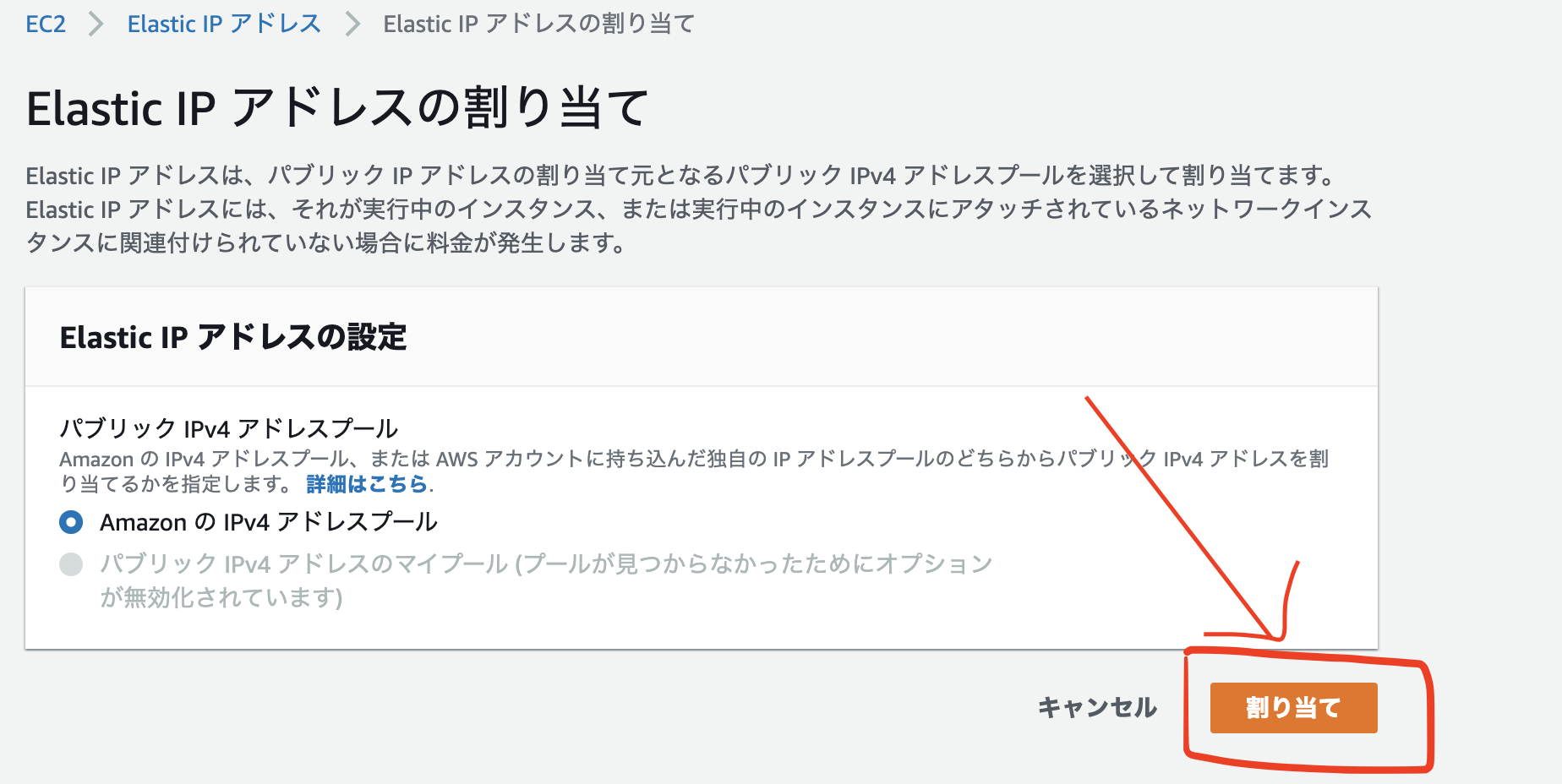
1,Elastic IPをクリック
2,Elastic IP アドレスの割り当てをクリック
3,割り当てをクリック,その後、閉じるをクリック
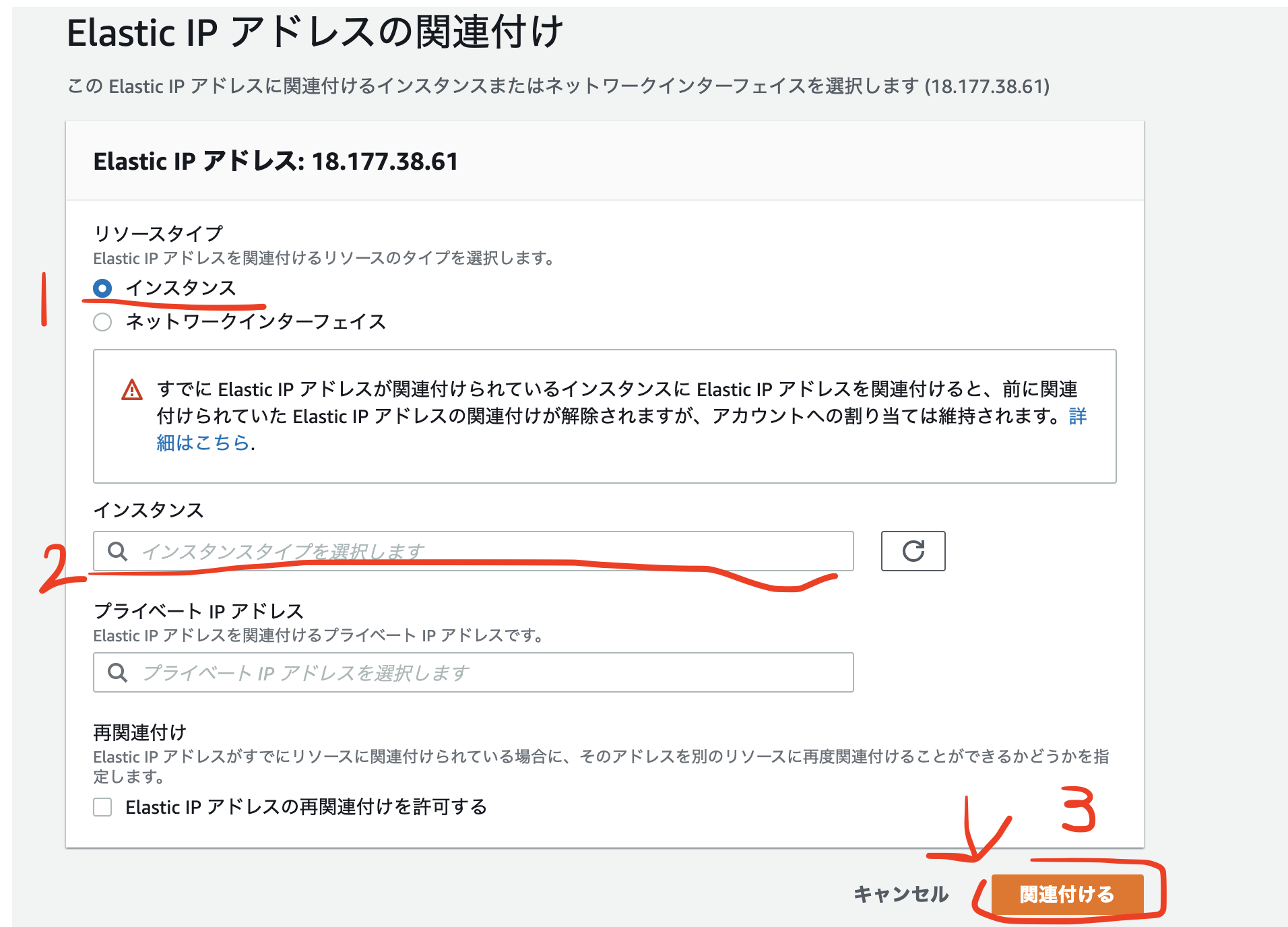
Elastic IPの紐付け
1,上図の【アクション】から【アドレスの関連付け】を選択
2,【アドレスの関連付け】ページにあるインスタンスIDを入力、【プライベートID】には入力しない、【関連付け】をクリック
3,インスタンス画面からElastic IPが紐づけられたことを確認する
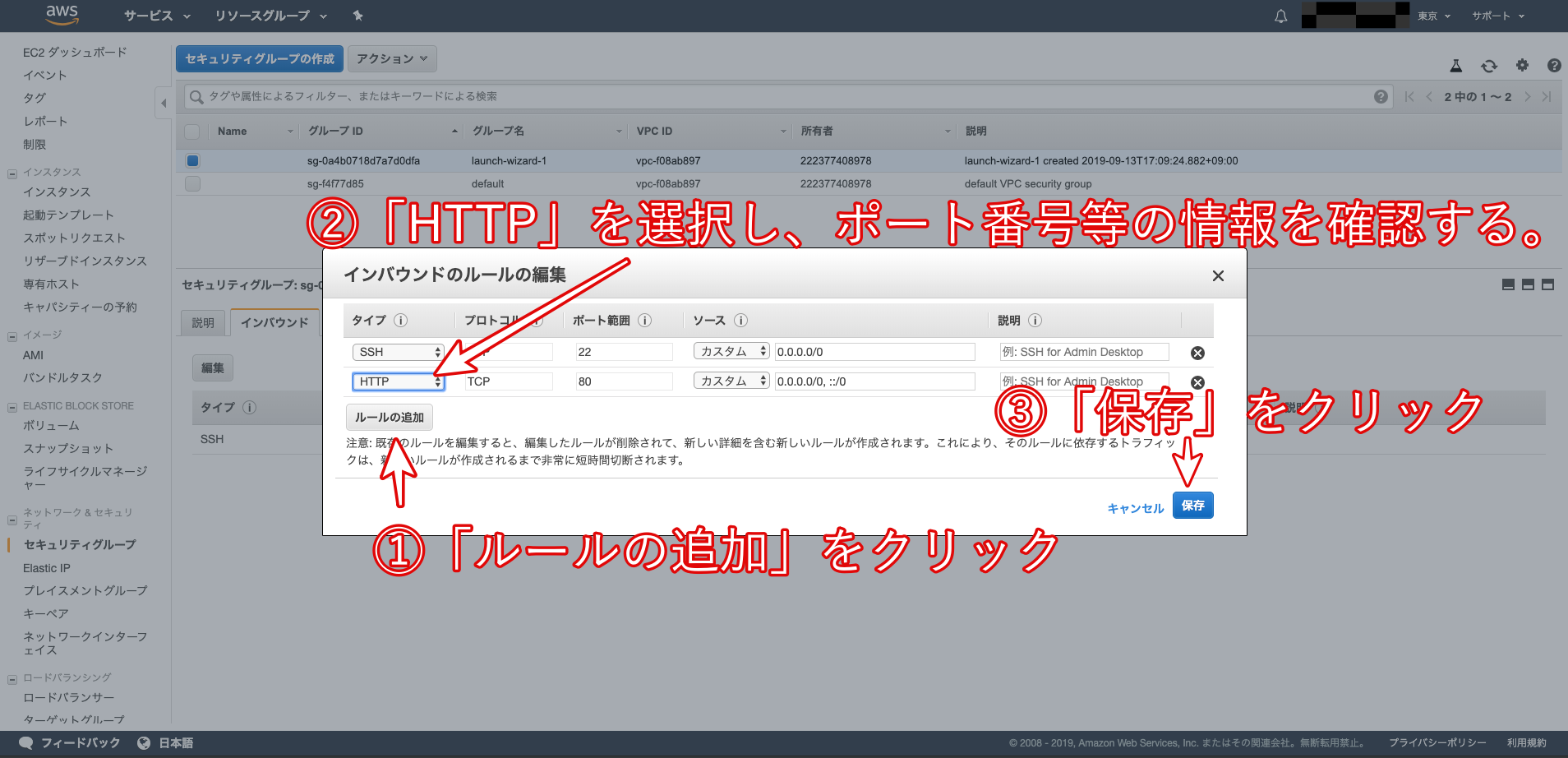
3.ポートを開く
インスタンス画面
1,セキュリティグループのリンクをクリック
2,「インバウンド」タブの中の「編集」をクリック
3,開かれたモーダルで、ルールの追加をクリック、タイプを「HTTP」、プロトコルを「TCP」、ポート範囲を「80」、送信元を「カスタム / 0.0.0.0/0, ::/0」に設定
4.EC2インスタンスへのログイン
$ cd ~ $ mv Downloads/鍵の名前.pem .ssh/ $ cd .ssh/ $ chmod 600 鍵の名前.pem $ ssh -i 鍵の名前.pem ec2-user@作成したEC2インスタンスと紐付けたElastic IP以上で、AWSのEC2インスタンスの作成手順となります!






- 投稿日:2020-02-12T13:56:13+09:00
クラウド(AWS)上に検証環境を構築するメリット・デメリットまとめ
1.はじめに
元々別記事の一部だったのですが、少し長くなってしまったのでまとめました。
実際に私が検証環境を構築した事例につきましては、以下の元記事にまとめてありますのでご参照ください。新米エンジニアがクラウド(AWS)上での検証環境構築に挑戦してみた
インフラ屋さんの業務の中で、アプライアンス(製品)の機能検証は欠かすことのできないフェーズだと思います。
- アプライアンスの実際の挙動を確認したい
- この設計でちゃんと動くのか試したい
- お客さんに提案する前に使い心地を試してみたい
といった場面では、規模の大小はどうあれまず間違いなく機能検証を実施しますよね。
ですが実機でこの機能検証を行うためには、色々と面倒な準備が必要です。ざっと思いついたものだけでも、以下のようなものがありました。
他にもあるよ!って方はご指摘ください。2.実機で検証をするためには...
2.1.検証スペースの確保
何はともあれ、まずは検証を行うための場所を確保する必要がありますね。
マシンルームや検証ルームを探し、机(必要ならラックなど)を予約する必要がありますが、いつも空いてるとは限りません。
もし全て埋まっていたら(まあさすがになかなか無いとは思いますが)、空くまで待ちです。2.2.対象のアプライアンス本体の準備
検証するんですから当たり前ですね。これが無ければ始まりません。
しかし、例えばファイアウォールのような一般的(?)な機器ならまだいいですが、今回の私のように少しマイナーな機器を検証しようと思うと、持っている人を社内で探したり、業者に発注して取り寄せたり、レンタルしたりする必要が出てきます。
時間も手間もコストもかかります。2.3.検証に使用するその他機器(PC/サーバー、ネットワーク機器など)の準備
さすがにアプライアンス単体で検証を行うことは少ないのではないでしょうか。
他にもハブやスイッチなど、色々と機材の準備をする必要があるケースがほとんどだと思います。
ここでも検証用機材を確保する必要が出てきますし、もし無かったらまた色々と手間がかかります。
また、ご自身で色々な機材を所持、管理しているならともかく、不特定多数の社員で共有している検証機などではそれがきちんと動くという保証もありませんし、バージョンが何世代も前だったりすることもあるでしょう。
PINGで疎通確認を行うためだけに複数のPCをわざわざ準備するのもナンセンスです。2.4.機能検証
ようやく本番です。
環境を整え、検証環境を設計して、設計通りに機器を組み上げたら、いよいよ待望の機能検証に入れます。
思い返してみればただアプライアンスを試してみたいだけなのですが、ここに辿り着くまででも既に結構なリソースを消費してしまっています。
ですが、このように苦労して環境を整えてもまだ終わりではありません。2.5.時間・空間の制約
当然ですが、基本的に検証はこれらの機材を設置した検証ルームでやることになりますよね。
もし急な会議やら出張やら何やらで遠出してしまったら、その間検証はストップです。
準備した検証環境だって無制限にいつまでも使えるわけではありませんし、時間を無駄にするのは避けたいですね。
もしかしたら会社によっては、せっかく家で仕事が出来る環境なのに検証のためだけにわざわざ出勤している、なんて方もいるかもしれません。
もちろんリモート接続して遠隔で検証できるようにする猛者もいらっしゃるとは思いますが、その設定をするのにも手間暇は確実にかかります。2.6.検証が終わった後の片づけ
「そんなことまで面倒くさがるなんて」と怒られるかもしれませんが(笑)
しかし、一通り検証が終わった後に山と積まれた機器を片付けなければいけないのは、地味に嫌ではないでしょうか。少なくとも私は好きではありません。
ここにかかる手間と時間も無駄と言えば無駄ですよね。3.クラウドで検証環境を構築するメリット
では、クラウドで検証環境を構築するとこれらの問題がどう解決されるかを見ていきます。
3.1.検証スペースの確保
当然不要です。
3.2.対象のアプライアンス本体の準備
後述する制約はありますが、基本的にGUI上で簡単に準備できます。
インスタンスを作るだけなので、数分で完了します。3.3.検証に使用するその他機器(PC/サーバー、ネットワーク機器など)の準備
これも同様に簡単に準備できますし、もちろん壊れてて使えないなんてことはありません(笑)
3.4.機能検証
検証そのものについても大分やりやすくなるはずです。
コンソールケーブルをカチカチ抜き差しする必要もありませんし、よくある物理層での問題(ケーブル抜けてる・壊れてるなど)が発生してしまうこともありません。
ブラウザでタブを増やすだけで各アプライアンスのGUI画面を立ち上げ、簡単に管理できます。
ただし、検証環境の設計には多少クラウドならではのノウハウが必要になります。
これについては私が実際に検証環境を構築した別記事でまとめていますのでそちらをご参照ください。
クラウド(AWS)上でバーチャルアプライアンスの機能検証を行ってみた3.5.時間・空間の制約
クラウドの良いところですね。
もちろんいつでも・どこでも(ネット環境さえあれば)検証を行うことができます。
個人的にはこれが一番のメリットじゃないかなと思ってます。3.6.検証が終わった後の片づけ
ワンクリックで終了です。
重たい機材を抱えてうろうろする必要はありません。4.クラウドで検証環境を構築するデメリット
いかがでしょうか。
実機で検証を行うのに比べると、大分楽だと思いませんか?
ですがもちろん良いことばかりでもありません。
クラウドならではの注意点もありますので、ご紹介します。4.1.金銭的コスト
クラウドなので、当然お金がかかります。
基本的に従量課金ですので、きちんとインスタンスの管理をしないと大変なことになってしまう可能性もゼロではありません。
私は怖がりなので、全てのインスタンスが定時で全てシャットダウンされるようにしていますが、それでもNATゲートウェイで一度失敗しました。ですがAWSでは初回登録から一年間の間は無料枠がありますので、それを有効に活用すれば経済的に済ませることは十分可能かと思いますし、検証機をわざわざ購入したりレンタルするよりはずっと安上がりになるかと思います。
またアプライアンスによっては、- ソフトウェア料金が込み
- BYOL(Bring Your Own Lisence)の2種類が存在します。
前者は通常のEC2の使用料金にソフトウェアの使用料が上乗せされているもので、従量課金で使えます。やはり少々値段は高くなってしまいますね。
それに対し、後者はソフトウェアのライセンスを自前で用意しておけば、後はEC2の使用料のみで使うことができるというものです。
別ルートでライセンスを用意することができるなら当然後者のほうが安くなりますので、検討の価値はあると思います。
ちなみに私は後者の方法をとっています。4.2.アプライアンスの制約
検証したいアプライアンスがバーチャルアプライアンスとしてクラウド上に存在しなければ、当然検証なんて不可能です。
AWSでは、AWSMarketPlaceというオンラインストアで様々なベンダーのバーチャルアプライアンスが展開されています。
ここにまだ追加されていないアプライアンスであれば、残念ながら使うことは出来ません。
日々新しいアプライアンスはどんどん追加されていますので、それを待つしかないですね。4.3.ミスった時の復旧
実機であれば何かミスってアクセスできなくなってしまってもコンソールから復旧できますが、クラウドではどうしようもなくなってしまいます。
私もインスタンス内部でOSのファイアーウォールの設定をミスったりルーティングテーブルの設定をミスったりして、永遠にアクセスできないサーバーをいくつか作ってしまいました。
そういう時はスパッと諦めて新しいインスタンスを作りましょう。
簡単に作って簡単に潰せるのがクラウドの良いところでもあります。4.4.設計のノウハウ
何度か触れていますが、クラウド内部で検証環境を構築するにはいくつかコツがあります。
それに関しては別記事に詳しくまとめてありますのでそちらをご参照ください。
クラウド(AWS)上でバーチャルアプライアンスの機能検証を行ってみた4.5.学習コスト
まあこれも考え方によってはデメリットと言えなくもないかと思うので一応入れておきますが、個人的にはクラウドに関する技術を学んで損をすることはないと思います。
インフラエンジニアの方ならなおさらです。おわりに
ここではクラウド上に検証環境を構築するメリット・デメリットをざっくりと紹介させていただきました。
実は私はこの検証環境構築を行うまでAWSのことは何一つ知らなかったのですが、実際に手を動かして検証環境を作っていくうちに色々と詳しくなったように思います。
もし今まで一度もクラウドに触れたことがない、という方がいらっしゃいましたら、ここからスタートするのもありなのではないでしょうか。
勉強になりますよ。もしこの記事を読んで少しでも興味をお持ちになられたなら、是非ご自身でも試してみてほしいと思います。
それでは、また。
- 投稿日:2020-02-12T13:55:49+09:00
新米エンジニアがクラウド(AWS)上での検証環境構築に挑戦してみた
1.はじめに
1.1.背景
先日、「AWS上に検証環境を作って,バーチャルアプライアンスの機能検証をしてほしい」とお願いされました.
恥ずかしながら当時の私はバーチャルアプライアンスのことはおろかAWSのことさえほぼ何も知らず、分からない単語だらけのミッションだったのですが,周囲の方々の協力のおかげでどうにか形になってきました。
試行錯誤の過程で、知らないとハマってしまうであろうポイントがいくつか出てきたため、アウトプットも兼ねて皆さんとナレッジを共有させていただきたいと思います.本記事では機能検証の内容そのものではなく、その前段であるAWS上に検証環境を構築する方法に焦点を絞って解説したいと思います。
機能検証の内容自体については、またいずれ別記事でまとめる予定ですので、興味がある方は是非そちらもご覧ください。今回はFortinet社のバーチャルアプライアンスを用いていますが、もちろん他ベンダーの様々なアプライアンスにも応用可能な内容だと思いますので、もしも皆さんが同じようなことをする際は、少しでも参考にしていただければ幸いです.
また,「他にもやり方あるよ!」「自分はこんな感じでやってるよ!」という方がいらっしゃれば,是非ともコメントでご教授いただければと思います.
1.2.対象読者
AWS初心者の方で、「興味はあるけど何をしたらいいか分からない」「本やドキュメントなどでAWSについて一通り勉強したけど、実際どんな風に使ってみたらいいか分からない」といった方のイメージをつかむ一助になれればと思います。
私自身もまだまだ初心者のため、「既にAWSをバリバリ使ってるよー」というベテランの方には冗長な表現や不完全な部分もあるかと思いますが、そのあたりはご容赦ください。ちょいちょい出てくるAWSのサービス名や機能などは出来るだけリンク化して、そのサービスに関するAWSの公式ドキュメントに飛べるようにしてあるので、もっと詳しく知りたい方はそちらも併せてご覧ください。
また現在進行形でアプライアンスの検証などをオンプレで行っているというインフラエンジニアの方は、是非今後の選択肢の一つにしていただければと思います。
2.クラウド(AWS)上に検証環境を構築するメリット・デメリット
新米エンジニアなりに考えて書いたものですが、少し長くなってしまったので別記事にまとめてあります。
インフラエンジニアの方以外にはあまり関係ない内容かもしれませんが、もし興味をお持ちいただけましたら是非ご一読ください。
クラウド(AWS)上に検証環境を構築するメリット・デメリットまとめ3.検証対象
まず、今回の検証対象アプライアンスである
- FortiManager
- FortiAnalyzerについて簡単にご説明します。
私も今回依頼されるまで全く見識がありませんでした。
これらは、アメリカのセキュリティベンダー大手であるFortinet社が展開している製品群の内の一つです。FortiGateという、同社の販売しているファイアウォールがあるのですが、FortiManager・FortiAnalyzerは、これを管理・監視するための補助的なアプライアンスという位置づけになります。
それぞれ非常に多岐にわたる便利な機能がある(らしい)のですが、少なくとも今回の検証では、
- FortiGate=ここに来た通信を事前に設定したポリシー(ルール)によって通すか通さないか決めるアプライアンス(一般的なファイアウォールのイメージ)
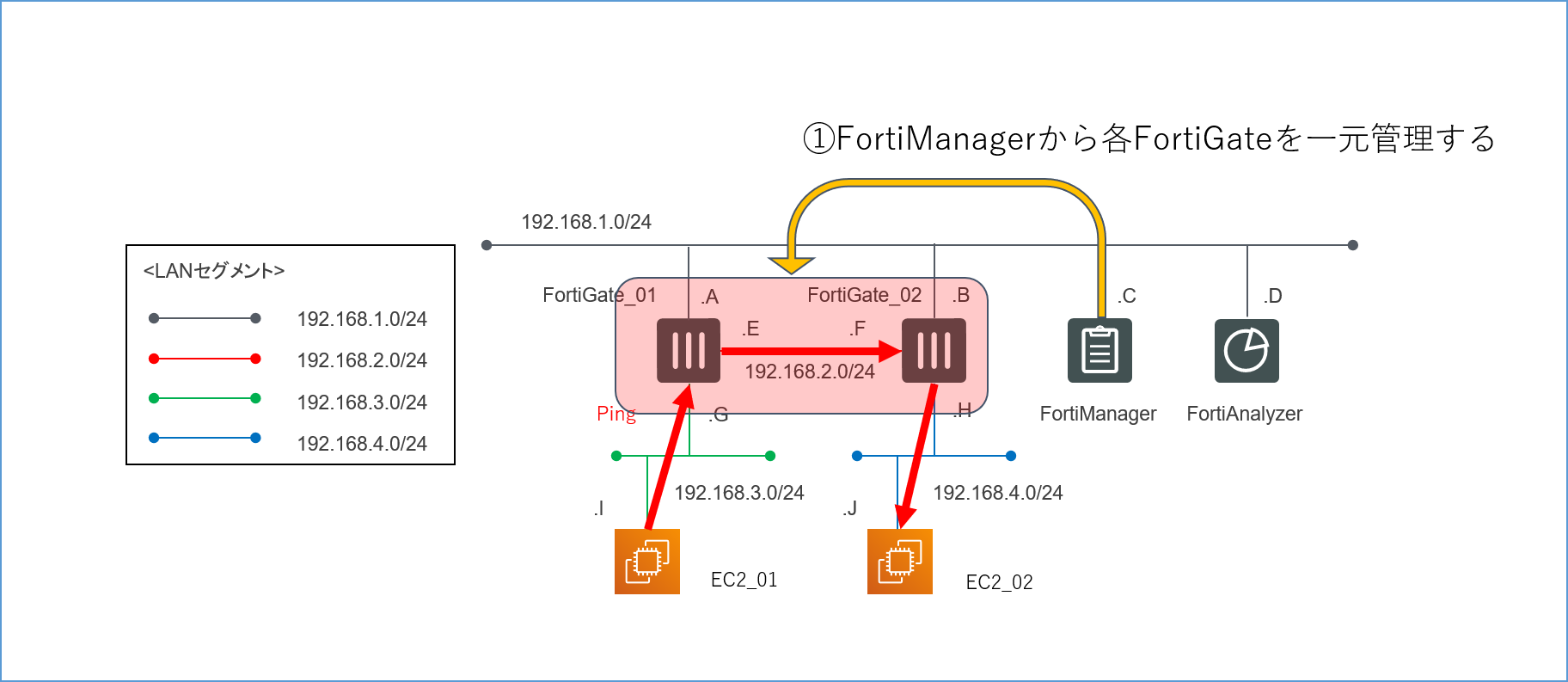
- FortiManager=複数のFortiGateを一元的に管理するためのアプライアンス
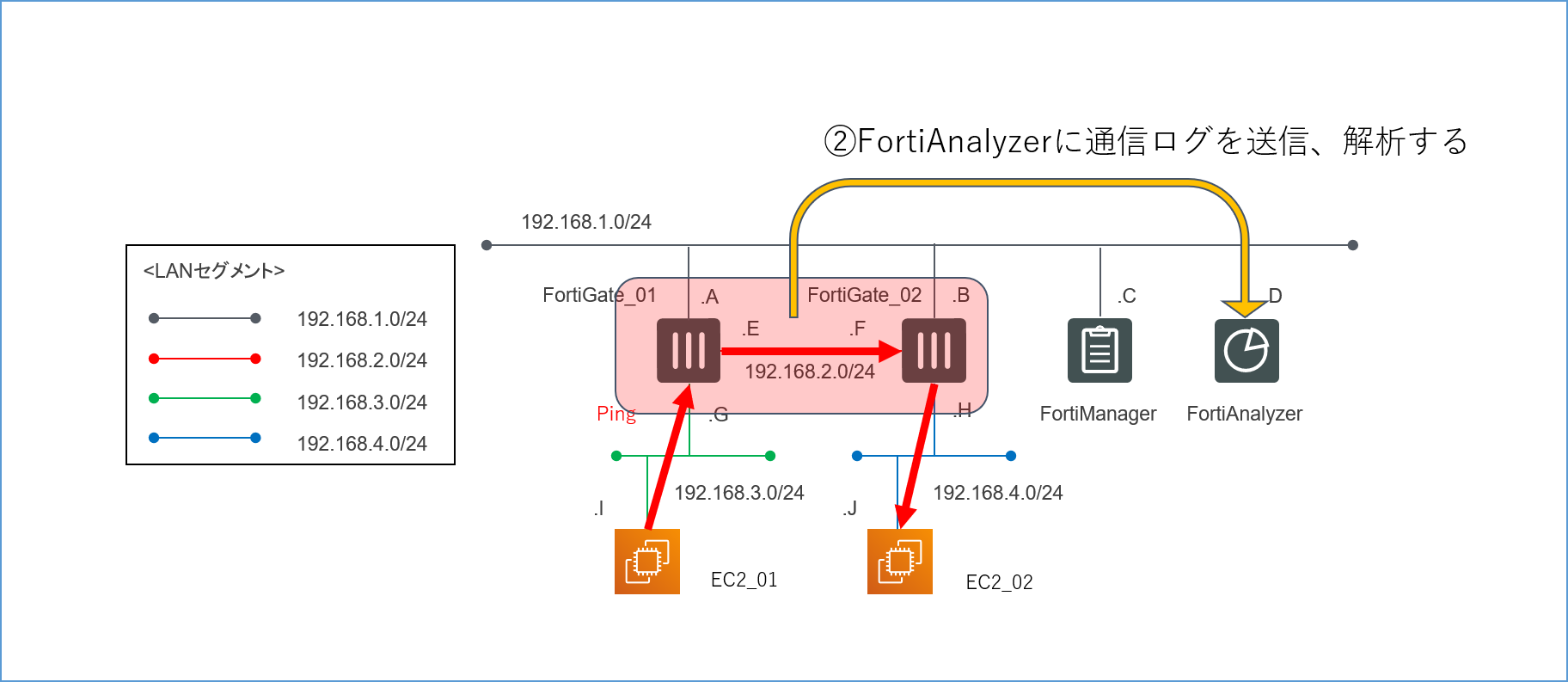
- FortiAnalyzer=各FortiGateに来た通信のログをまとめて解析するためのアプライアンスといった程度の理解でまず支障ありません。
各アプライアンスの機能に関する詳細な説明については、申し訳ありませんが本題から外れてしまうので今回は割愛させていただきます。
いずれまとめるかもしれませんし、まとめないかもしれません(笑)今回の検証の目的は、FortiManager・FortiAnalyzerの大雑把な使用感を知ることです。
割とマイナーな製品であるため社内にもノウハウを持つ人が少なく、顧客に提案しようにも実際これがどういうものなのかが分からないため、とりあえず試しに検証してみてほしいとのことでした。
ですがマイナーすぎて社内に検証用の実機すら無かったため、ライセンスだけ取得してAWS上にバーチャルアプライアンスを展開し、それを利用して検証を行ってみよう、といった運びになったのが始まりです。4.検証環境構築
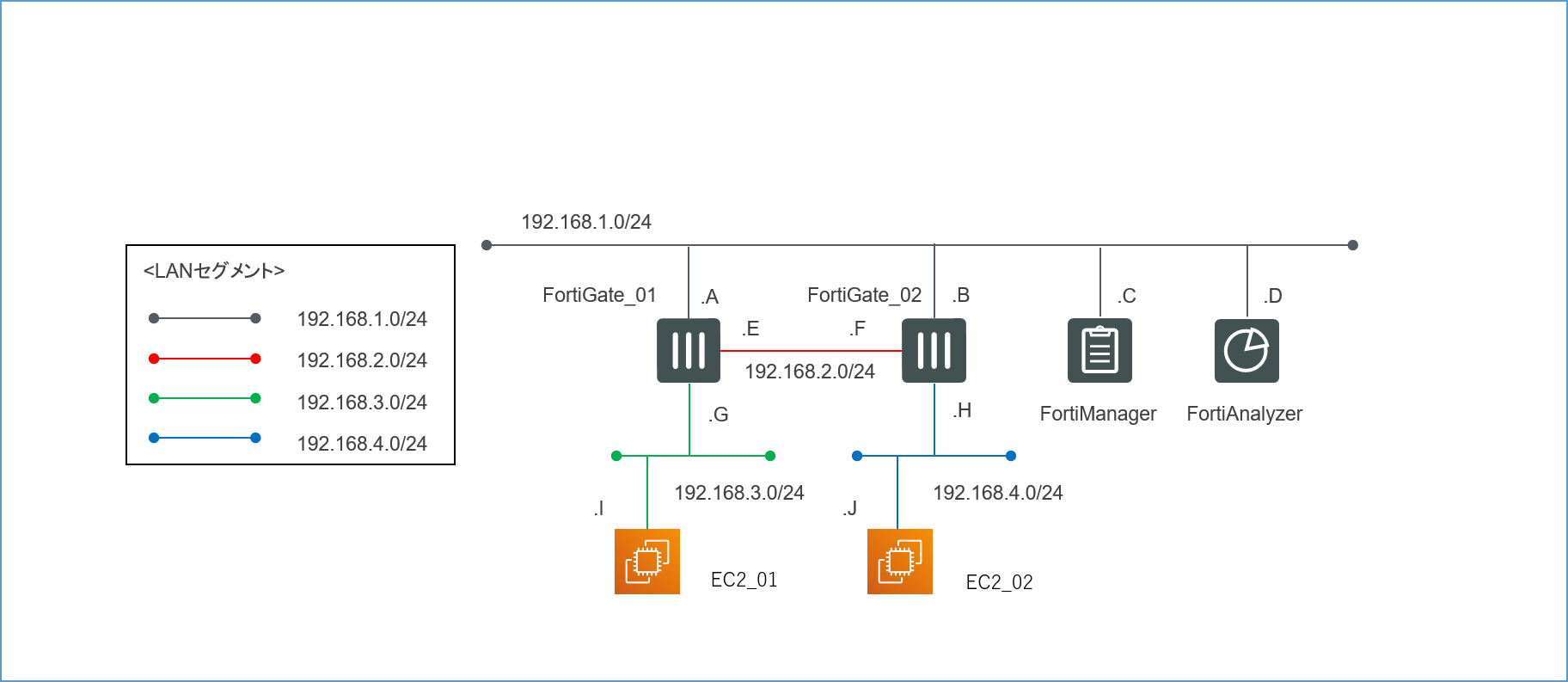
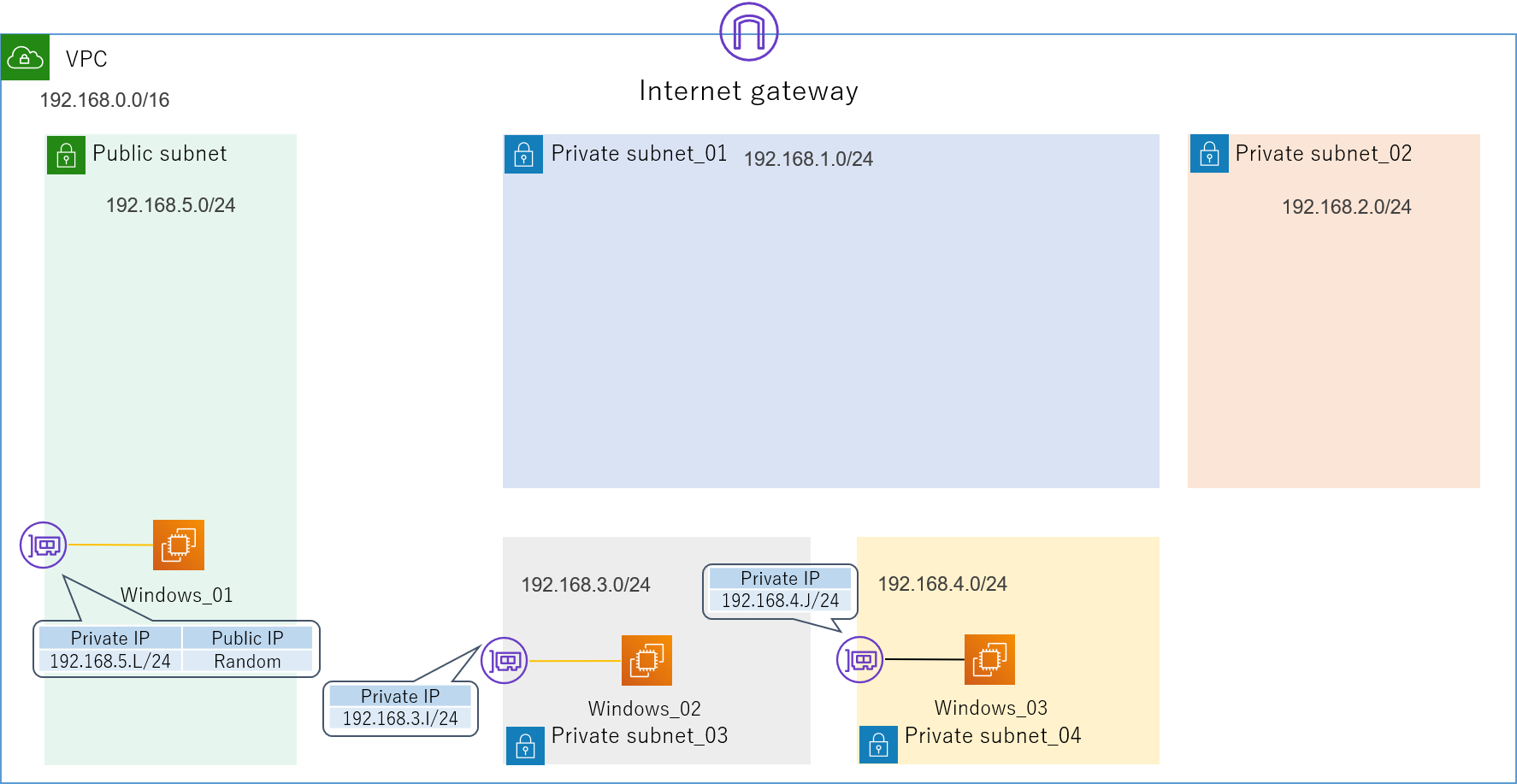
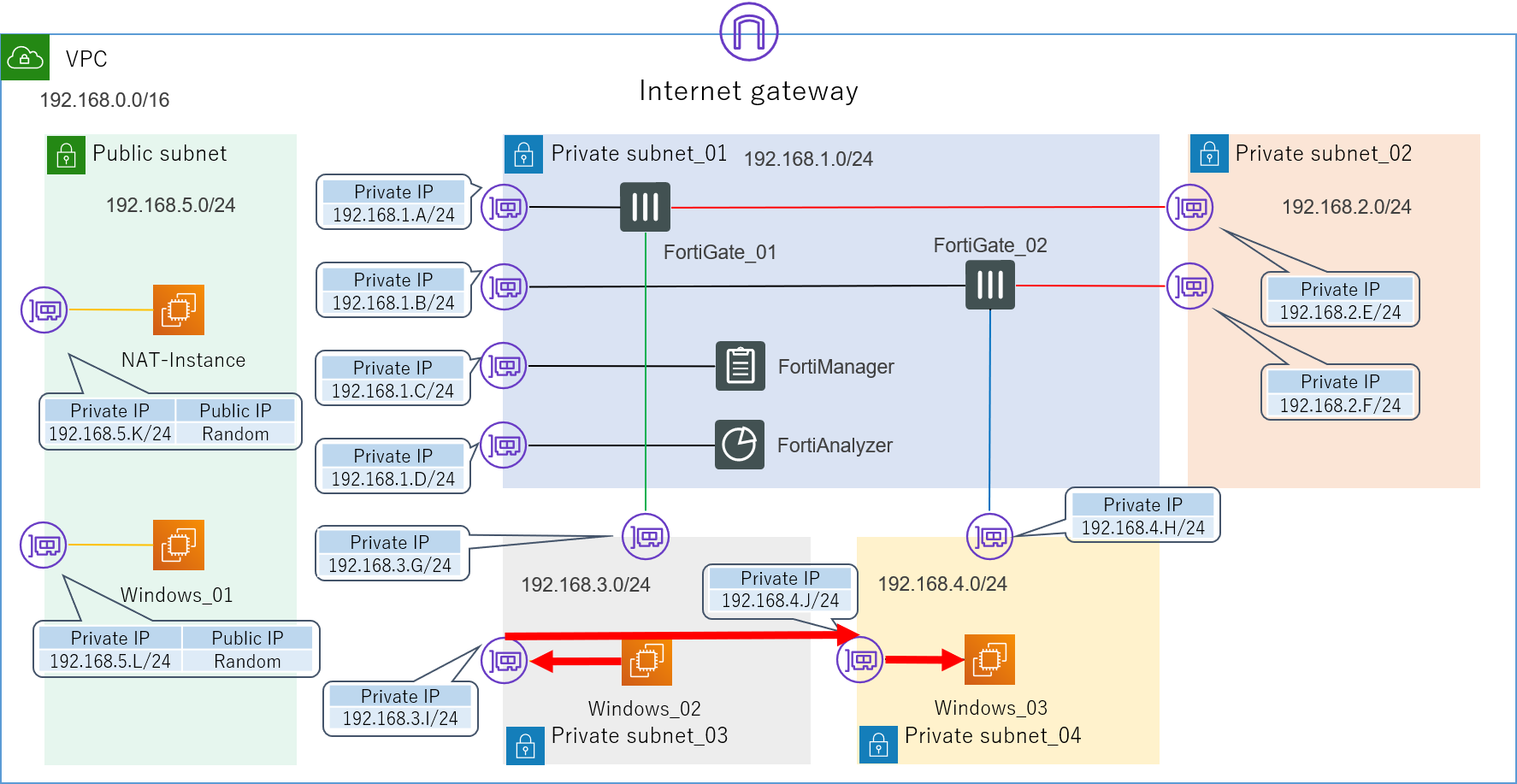
4.1.論理構成
とりあえずこのような論理構成図を作成してみました。
4つのセグメントで構成された、非常にシンプルなLANです。
192.168.1.0/24が管理セグメントになります。
各インターフェースに振るIPアドレスは基本的に何でもいいのですが(0,1,2,3,255の5つはAWS側で予約されているため使えません)、本記事では分かりやすくするため第4オクテットはアルファベットで表記してあります。送信元の検証用サーバーEC2_01からの通信がFortiGate_01とFortiGate_02を経由して、宛先の検証用サーバーEC2_02に到達するような経路を想定しています。
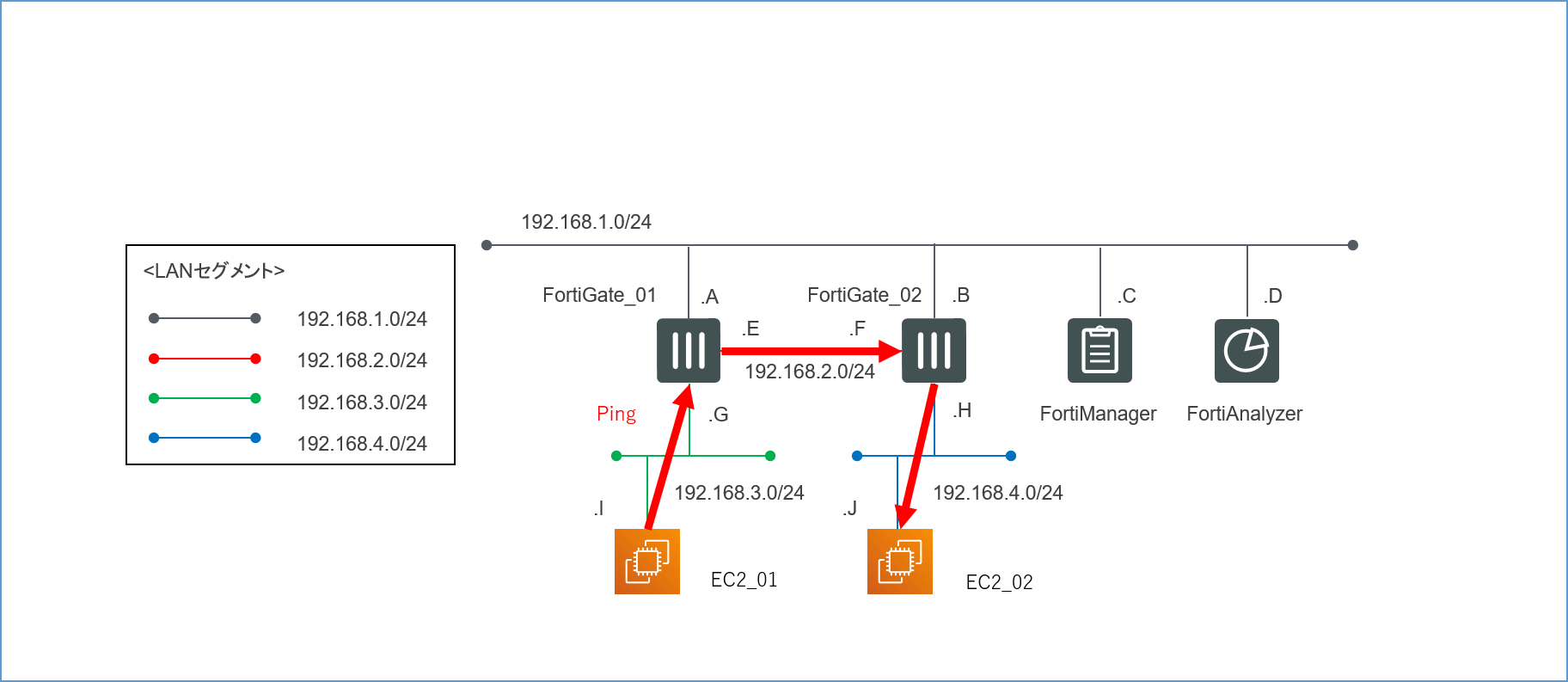
最初の目標は、とりあえずこの経路で無事にPingの疎通が取れることを確認することです。
無事に検証環境が構築できたら、この構成を使って以下の2つの検証を行っていきます。4.1.1.各FortiGateのポリシーがFortiManagerで一元管理できるか
4.1.2.FortiGateを通過した通信についてのログをFortiAnalyzerに転送し、解析できるか
4.2.AWSコンポーネント
それではまず先ほどの論理構成図を一つずつAWSのコンポーネントで構築していきます。
AWS初心者の方でもなるべく理解しやすいよう丁寧に説明していく予定ですが、流石にAWSの各サービスやインスタンスの具体的な作成手順に関してまでは、そこまで詳細な説明を行えません(とんでもない分量になってしまいます)。
なので詳しくは公式ドキュメントを参照したり、実際にAWSコンソールで手を動かしてみてください。
また、今回はあくまで検証環境ということで、リージョンやAZ(アベイラビリティーゾーン)にも特にこだわりませんのでご了承ください。4.2.1.VPC
まずはVPC(Virtual Private Cloud)を用意します。
構築するネットワークの入れ物ですね。
今回は192.168.0.0/16というIPv4 CIDRブロックを割り当てました。
まだ、ただの箱です。4.2.2.サブネット
続いて、この中にサブネットを作成します。
先ほどの論理構成図にあったセグメントの
- 192.168.1.0/24
- 192.168.2.0/24
- 192.168.3.0/24
- 192.168.4.0/24
をPrivate_subnetで、またインターネット接続用にPublic_subnetとして192.168.5.0/24を作成します。ついでに、VPCにはインターネットへの出入り口であるInternet Gatewayを取り付けます。
4.2.3.EC2の作成
いよいよサブネット内に配置するEC2インスタンスの作成に入ります。
4.2.3.1.踏み台サーバー、検証用サーバー
今回は踏み台サーバー(Windows_01)、検証用サーバー(Windows_02,Windows_03)ともに、OSにWindows Server 2019を使用します。
検証用サーバーのOSはLinuxでももちろん構いません。
検証用にWindowsサーバーを使用する場合は、OSのファイアウォールを無効化しておくことを忘れないでください。
ここでパケットが弾かれると結構気が付きにくいです。
またこの際,一度無効化した後にうっかり再度有効にでもしようものなら、その瞬間に永遠にアクセスできないサーバーが出来上がってしまったりするので、OSのファイアウォールをいじる時はよくよく気を付けてください。
私はこれで3~4個インスタンスをダメにしました。同時にENI(Elastic Network Interface)の設定も行うため、インスタンスが所属するVPCやサブネット、IPアドレスを指定しましょう。
踏み台サーバーは外部からも接続するので、Private_IPだけでなくPublic_IPも必要です。
ちなみにPublic_IPの取得方法は
- 無料だがインスタンスが起動するたびにランダムに変わるもの
- EIP(Elastic IP)を利用するもの
の2種類があります。今回は前者を利用します。
インスタンスの作成途中でセキュリティグループの設定も要求されると思います。
これはざっくり言うと各インスタンスが持つ仮想のファイアウォールのことなのですが、ここはかなり大事なのできちんとドキュメントを読んで勉強することをお勧めします。
セキュリティに関する部分だけあって、取り扱いをミスると色々と実害を被りかねないので。
少なくとも踏み台サーバーはRDPやSSHなど必要最低限のサービスだけを有効にして、接続元も社内ネットワーク限定などにしておくのをお勧めします(使用ポートの変更もしておければなおいいです)。
他にも使用する予定のプロトコルやサービスがあるなら、ここで事前に許可設定を入れておかないと、何もできないインスタンスになってしまうので注意してください。
「なぜかインスタンスにアクセスできないなー」って時は大体ここのせいな気がします。
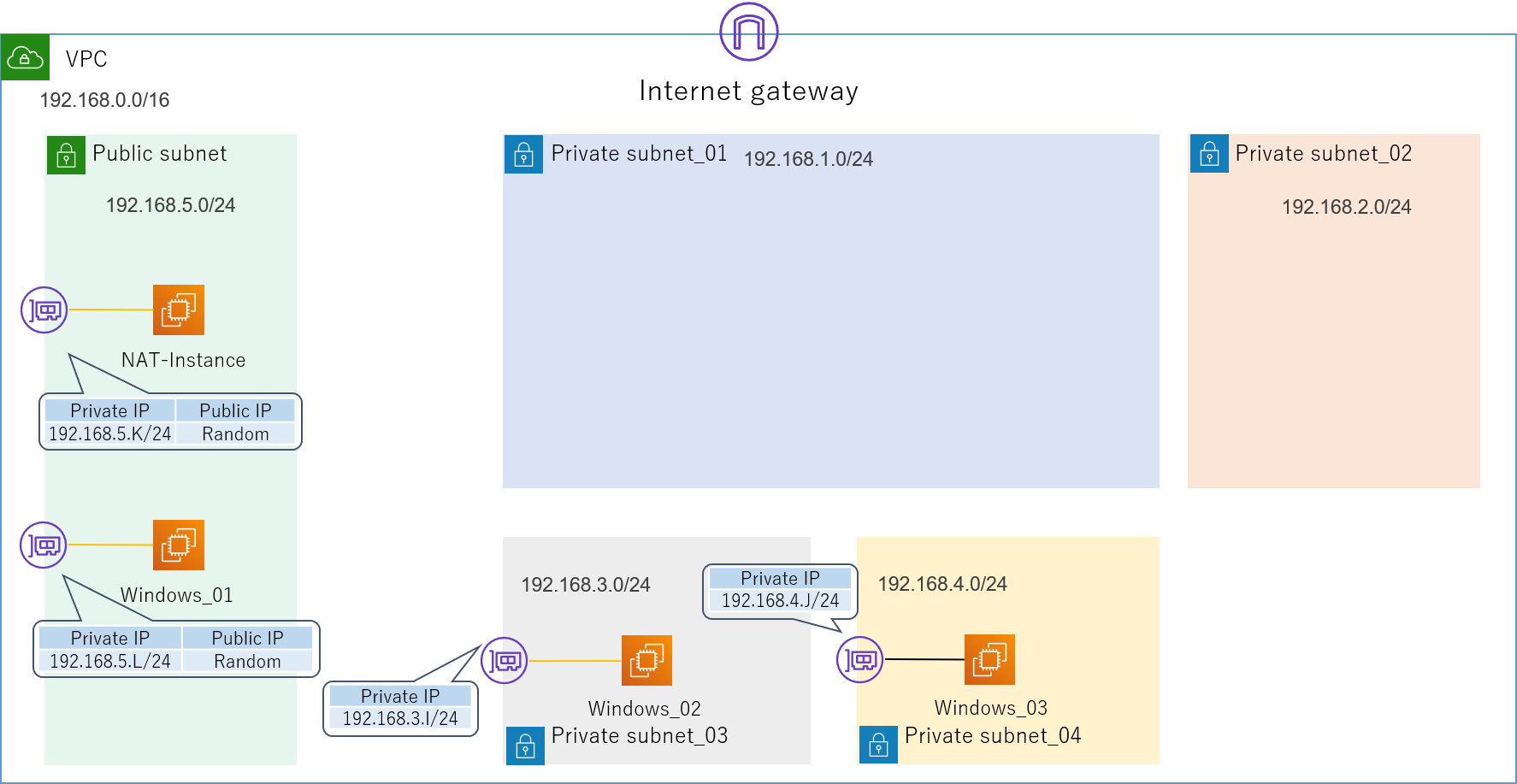
4.2.3.2.NATインスタンス
Private_subnetから外部のインターネットに接続するためには、NATゲートウェイもしくはNATインスタンスが必要です。
NATゲートウェイは高機能で楽ですが少々コストが高いので、今回はNATインスタンスを使います。
Private_subnet内のインスタンスがインターネットに出る際は、まずこのNATインスタンスにルーティングされ、NATインスタンスが持つPublic_IPに変換されてから外部に接続します。
4.2.3.3.バーチャルアプライアンス
それでは今回のメインインスタンスである、バーチャルアプライアンスを作成していきます。
AWSでは、AWSMarketPlaceというオンラインストアで様々なベンダーのバーチャルアプライアンスが展開されています。
Fortinet社のバーチャルアプライアンスも一通り揃っていますので、ここから必要なものを探しましょう。アプライアンスの利用形態には、
- ソフトウェア料金が込み
- BYOL(Bring Your Own License)
の2種類が存在します。
前者は通常のEC2の使用料金にソフトウェアの使用料が上乗せされているもので、通常のEC2のように従量課金で使えます。
それに対して後者のBYOLというのは、ソフトウェアのライセンスを自前で用意しておけば、後はEC2の使用料のみで使うことができるというものです。
当然ライセンスさえ用意出来るなら後者の方が遥かに安くすみます。
今回は既にライセンスは準備済みなので後者の方法で作成していきます。
基本的な作成手順は通常のEC2と何ら変わりません。
ちなみにBYOLで作成する場合、ライセンスはこの段階で要求されることはありません。途中で一つ管理用にENIを作らされますが、論理構成図から分かるように今回FortiGateではそれぞれ3つのENIが必要になるので、2個ずつ追加で増やします。
各ENIの所属するサブネットを間違えないようにしてください。また、ここで非常に重要なのが送信元/送信先の変更チェックという機能を無効にしておくことです!
というのも、AWSインスタンスののENIは、デフォルトで自分のIPアドレス宛のパケット以外を全て自動的に破棄してしまいます。そのため、今回のFortiGateのように複数のENIを持つインスタンスを作ってパケットの中継地点として利用しようとしても、この機能を無効化しない限り全くルーティングされません。
AWSコンソールにて、インスタンスを右クリック→ネットワーキングで設定できます。
私はこれになかなか気づけず、だいぶ時間を浪費してしまいましたので、皆さんはご注意ください。セキュリティグループはアプライアンス側がデフォルトのものを用意してくれていますので、基本的にはそれで問題ないと思います。
もちろん何か変更を加えるのもありです。以上でひとまずAWSの構成が完成しました(見た目上は)。
AWS構成図
4.3.バーチャルアプライアンス
続いて、バーチャルアプライアンス内部の設定を進めていきます。
4.3.1.ライセンス認証(BYOLのみ)
今回はBYOLなので、まずはバーチャルアプライアンスのライセンス認証をする必要があります。
まずはRDPで踏み台サーバーにログインし、ブラウザとターミナルソフトをインストールしておきましょう。
Windowsサーバーだと、サーバーマネージャーからソフトウェアをインストールできるように設定しておく必要があるかもしれません。
私はGoogle Chromeとteratermを入れていますが、別に他のものでも十分代用可能です。
ブラウザを開いたら、先ほど設定したFortiGateの管理用IPアドレスにアクセスします。
設定が全て上手くいっていれば、FortiGateのGUI管理画面にアクセスできます。
途中で危ないとかなんとか言われても全て無視してください。
最初は
- 初期ユーザー名:admin
- 初期パスワード:自身のインスタンスID
でログインするよう指示されます。
一度ログインしたらパスワードはすぐに変更させられますので、適当なものを考えておいてください(8文字以下だと怒られます)。
ログインに成功するとここでようやくライセンスを要求されるので、あらかじめ用意しておいたライセンスをアップロードします。
ちなみに私が試したところ、一回目はなぜか弾かれるのですが、二回目はすんなり通りましたので、一度失敗したからと言ってすぐに諦めないでください。
ライセンスのアップロードに成功すると、ようやくFortiGateが使用可能な状態になります。
FortiManager,FortiAnalyzerもここまでは全く同じなので同様に進めておきましょう。
全て使えるようになったら、各アプライアンスのGUI画面をブックマークしておくとあとあと楽です。
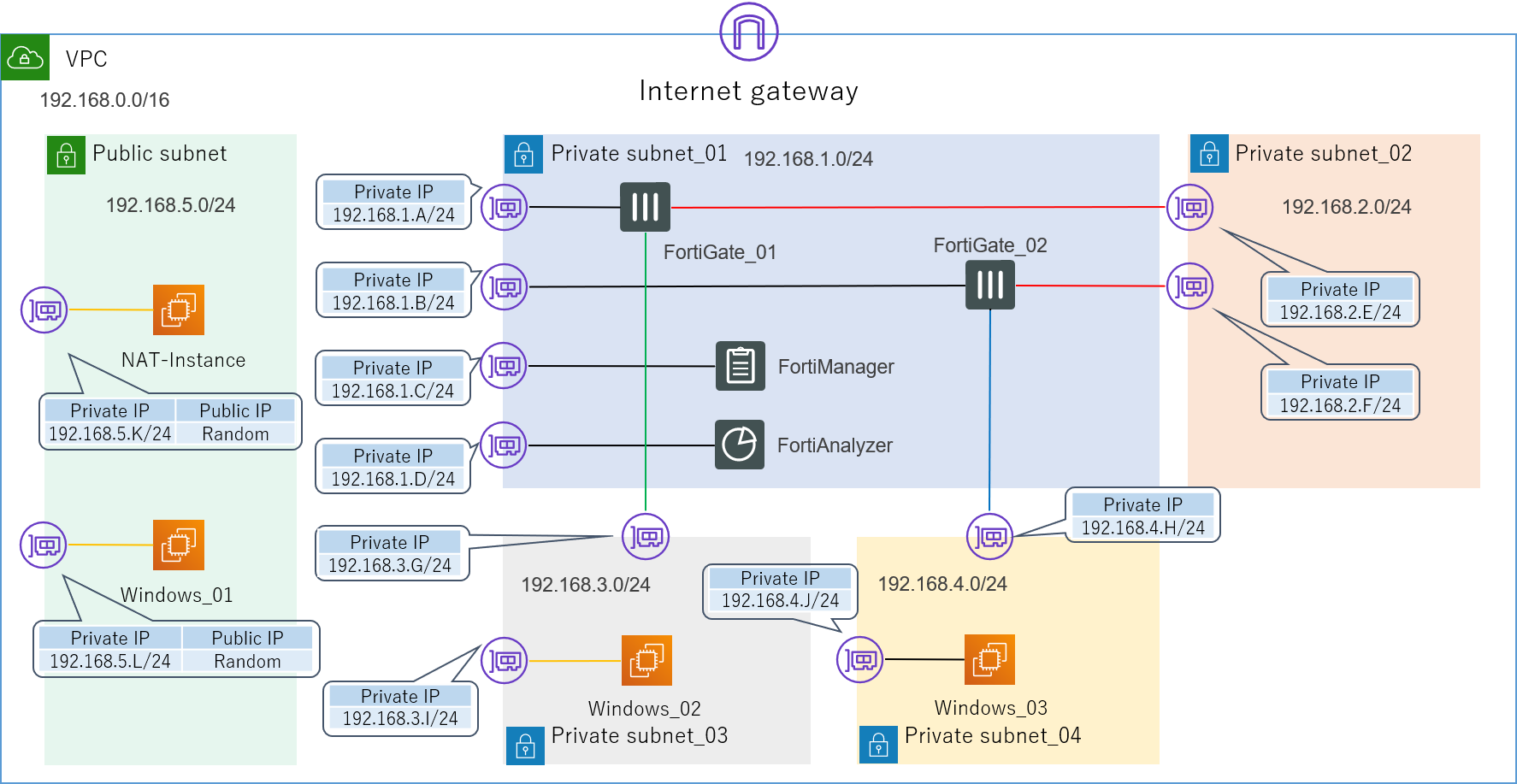
ブラウザのタブで色々なアプライアンスを同時に管理出来るのは便利ですよ。4.3.2.インターフェース作成と関連付け
次はFortiGateのインターフェースを作成し、AWSのENIと関連付けしていきます。
まずはFortiGateのGUIからNetwork>Interfaceに移動し、新規インターフェースを3つ作成しましょう。
名前は何でもいいですが、今回はPort 番号にしたいと思います。
タイプはもちろん物理インターフェースです(バーチャルアプライアンスですが)。アドレッシングモード(インターフェースに割り当てるIPアドレスを決める方法)の設定では、DHCPを選択してください。
この設定にすると、自動的にFortiGate内部のインターフェースとAWSのENIが関連付けされます。
ちなみにマニュアルを選択して手動でIPアドレスを入力すると失敗します。
私はこれをやってしまい、結構ドはまりしました。
設定した見た目はどちらも同じなのですが、マニュアルだとインターフェースがENIと関連付けされないため、使えません。管理者アクセスは、各インターフェースにアクセスできるサービスを設定できます。
最低でも管理インターフェースであるPort1にはSSH、HTTPS、FMGアクセスを、Ping用のポートであるPort2、Port3にはPINGを許可しておきましょう。
ちなみにFMGアクセスというのは、FortiManagerに管理してもらう時に必要となります。インターフェースがこのように設定できたら成功です。
FortiGate_01
Name Type IP Adress/Mask 管理者アクセス Port1 物理インターフェース 192.168.1.A SSH,HTTPS,FMGアクセス Port2 物理インターフェース 192.168.2.E PING Port3 物理インターフェース 192.168.3.G PING FortiGate_02
Name Type IP Adress/Mask 管理者アクセス Port1 物理インターフェース 192.168.1.B SSH,HTTPS,FMGアクセス Port2 物理インターフェース 192.168.2.F PING Port3 物理インターフェース 192.168.3.H PING 4.3.3.スタティックルート作成
インターフェースを作成したら、Network>Static Routeから対向のFortiGateに向けてスタティックルートを設定します。
有効化するのを忘れないようにしてください。FortiGate_01
Destination Gateway IP Interface 192.168.4.0 192.168.2.F Port2 FortiGate_02
Destination Gateway IP Interface 192.168.3.0 192.168.2.E Port2 4.3.4.ポリシー作成
いよいよFortiGateのメイン機能です。
Policy&Object>IPv4 Policyから設定します。
ACL(Access Control List)とほとんど仕組みは同じで、基本的には全てImplicit Deny(暗黙の拒否)となっており、許可したい通信の設定のみを一つ一つ登録していくような感じです。
最終的にはこのポリシーをFortiManagerから一括で制御するのが目標ですが、とりあえず最初は疎通確認のために各FortiGateに適当なポリシーをあらかじめ入れておきます。
FortiGateのポリシーは様々な項目を設定できるのですが、とりあえず今はPingが通りさえすればいいので以下のように設定しました。FortiGate_01
Name 着信インターフェース 発信インターフェース 送信元 宛先 サービス アクション 3_to_2 Port3 Port2 all all All ICMP ACCEPT 2_to_3 Port2 Port3 all all All ICMP ACCEPT Implicit Deny All All all all All DENY FortiGate_02
Name 着信インターフェース 発信インターフェース 送信元 宛先 サービス アクション 3_to_2 Port3 Port2 all all All ICMP ACCEPT 2_to_3 Port2 Port3 all all All ICMP ACCEPT Implicit Deny All All all all All DENY これでFortiGateの設定は全て完了です。
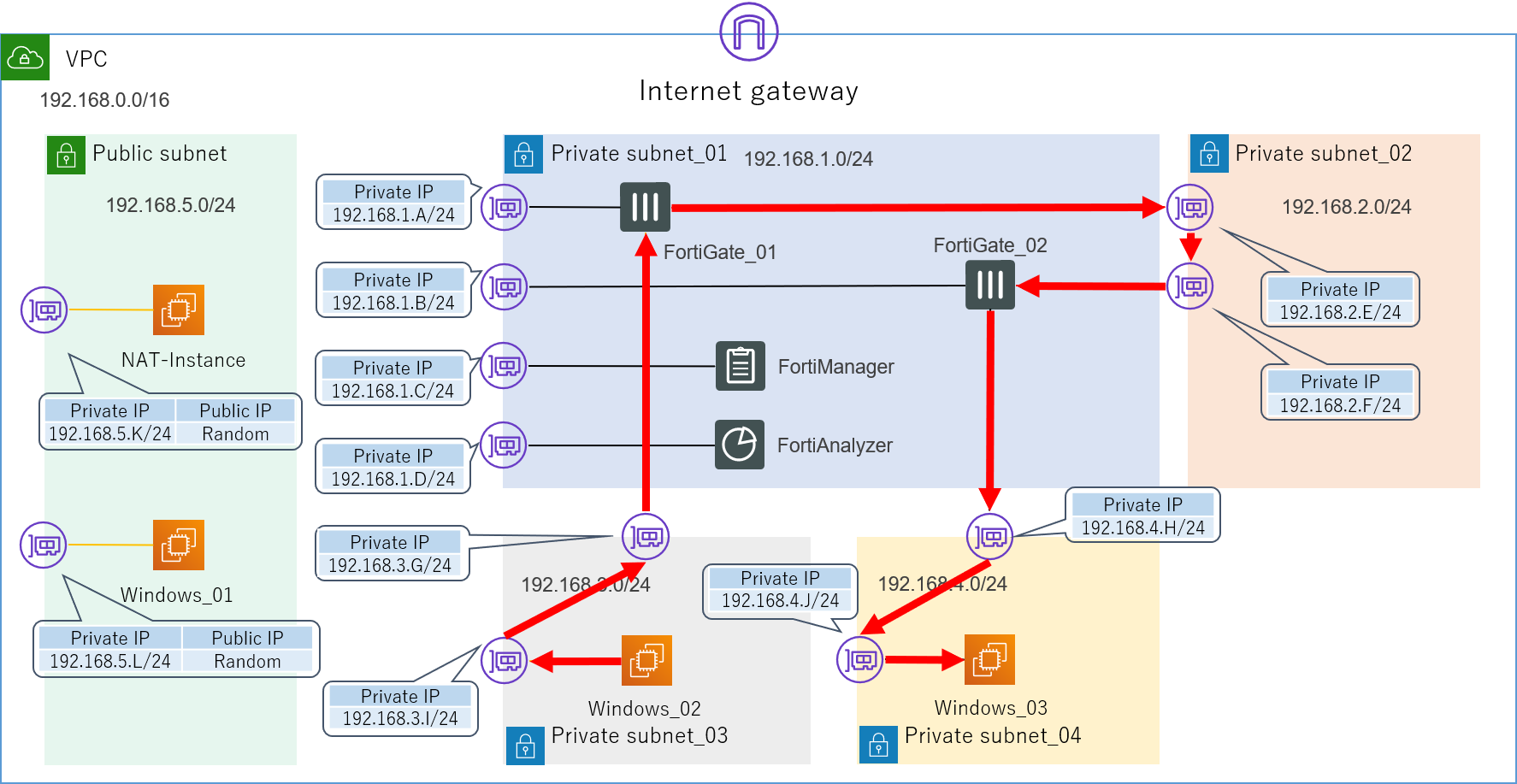
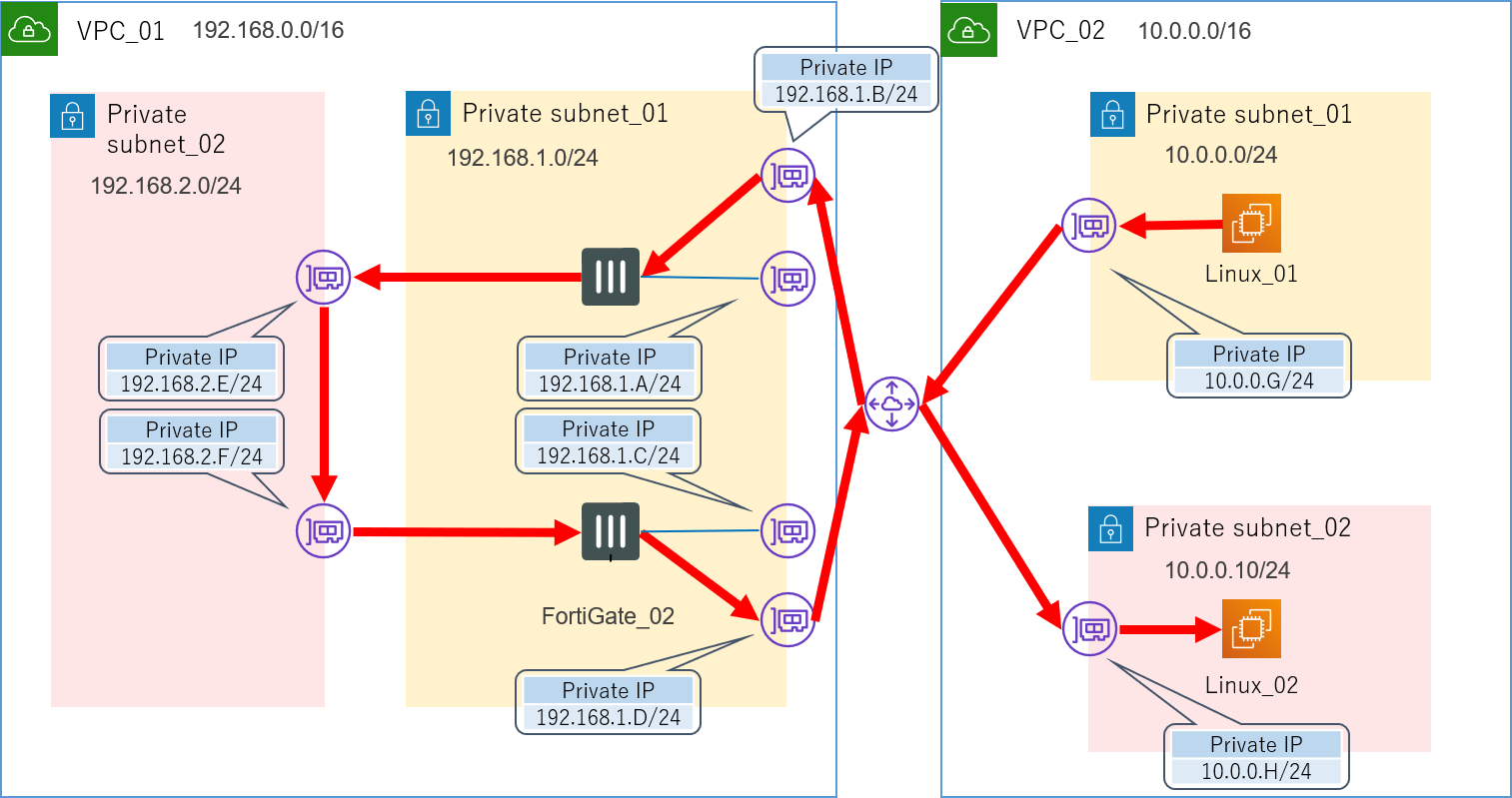
ですが、実はここまでしてもまだ想定した経路の通信は実現できません。
正確に言えば、この状態でWindows_02からWindows_03に向けてPingを打つと疎通自体は確認できてしまうのですが、実はそれは以下の想定経路ではなく、実際の経路の図に示すように、せっかく色々と頑張って設定したFortiGateを完全に無視したものとなっています。想定経路
実際の経路
4.4.ルートテーブル
なぜこのような挙動になってしまうかといいますと、全てAWSのルートテーブルが原因です。
詳しくはAWSの公式ドキュメントをご参照いただければと思いますが、簡単に言えば、ルートテーブルとはVPC内に存在する暗黙的なルーターのことです。
VPC内の通信は、全てこのルートテーブルによって定義されます。
先ほどの構成において、現在使用しているルートテーブルは以下のようになっています。Main Route Table(4つのPrivate_subnet全てに関連付け)
Destination Target 192.168.0.0/16 local 0.0.0.0/0 NATインスタンス Public Route Table(Public_subnetに関連付け)
Destination Target 192.168.0.0/16 local 0.0.0.0/0 Internet Gateway このlocalの意味ですが、これはこのVPC内の通信(192.168.0.0/16に属する通信)は、全て自動的に直接宛先のENI(NIC)にルーティングされるということを示しています。
これはデフォルトで入っているもので、編集も削除もできません。また、それ以外の通信(0.0.0.0/0)は全て外部インターネットにルーティングするように追加で設定しています。
このルートテーブルのおかげで、私たちは各インスタンスの細かいルーティング設定を全く意識することなく、簡単に通信を行えるようになっています。
とても効率的で大変ありがたいのですが、しかし今回のアプライアンス検証という目的を考えるとそれでは困ります。
実はこのVPC内のサブネット間の通信をもっと自由に制御する方法を探すというのが、今回の検証環境構築の一番の肝でした。4.4.1.NG集
正解に入る前に、試行錯誤から生まれた失敗例を少しご紹介しておきたいと思います。
皆さんは同じ失敗をしないでください。4.4.1.1.VPCのルートテーブルで制御する→失敗
まず最初に私が試した方法は、単純にこのルートテーブルに更に詳細なルートを追加して各サブネットにアタッチしてみるというものでした。
通常のネットワーク機器なら、ロンゲストマッチでこのルートを使ってくれるはずですよね。Main Route Table(ルート追加の例)
Destination Target 192.168.0.0/16 local 192.168.4.0/24 192.168.3.G 0.0.0.0/0 NATインスタンス しかし結論から言うとこの方法は失敗でした。
どうやらルートテーブルのルールとして、192.168.0.0/16→localよりも詳細な指定をするルートを追加することは出来ないようです。
正確に言うと、そのようなルートを追加したルートテーブルを作成すること自体は可能なのですが、それをサブネットにアタッチしようとするとエラーで弾かれてしまいます。4.4.1.2.VPCピアリングを利用してみる→失敗
AWSには異なるVPC同士を繋ぐことのできる、VPCピアリングというサービスが存在します。
「同一VPC内では細かいルーティング制御ができないというなら、VPCごと分けてしまえばいいじゃない」といった発想でこれも試してみることにしました。
このサービスを利用するにあたり、少し構成も変更しました。
が、これも失敗です。VPCピアリングを利用した構成
VPCピアリングでつながる関係というのは、異なるルートで行ったり来たりは出来ないようです。
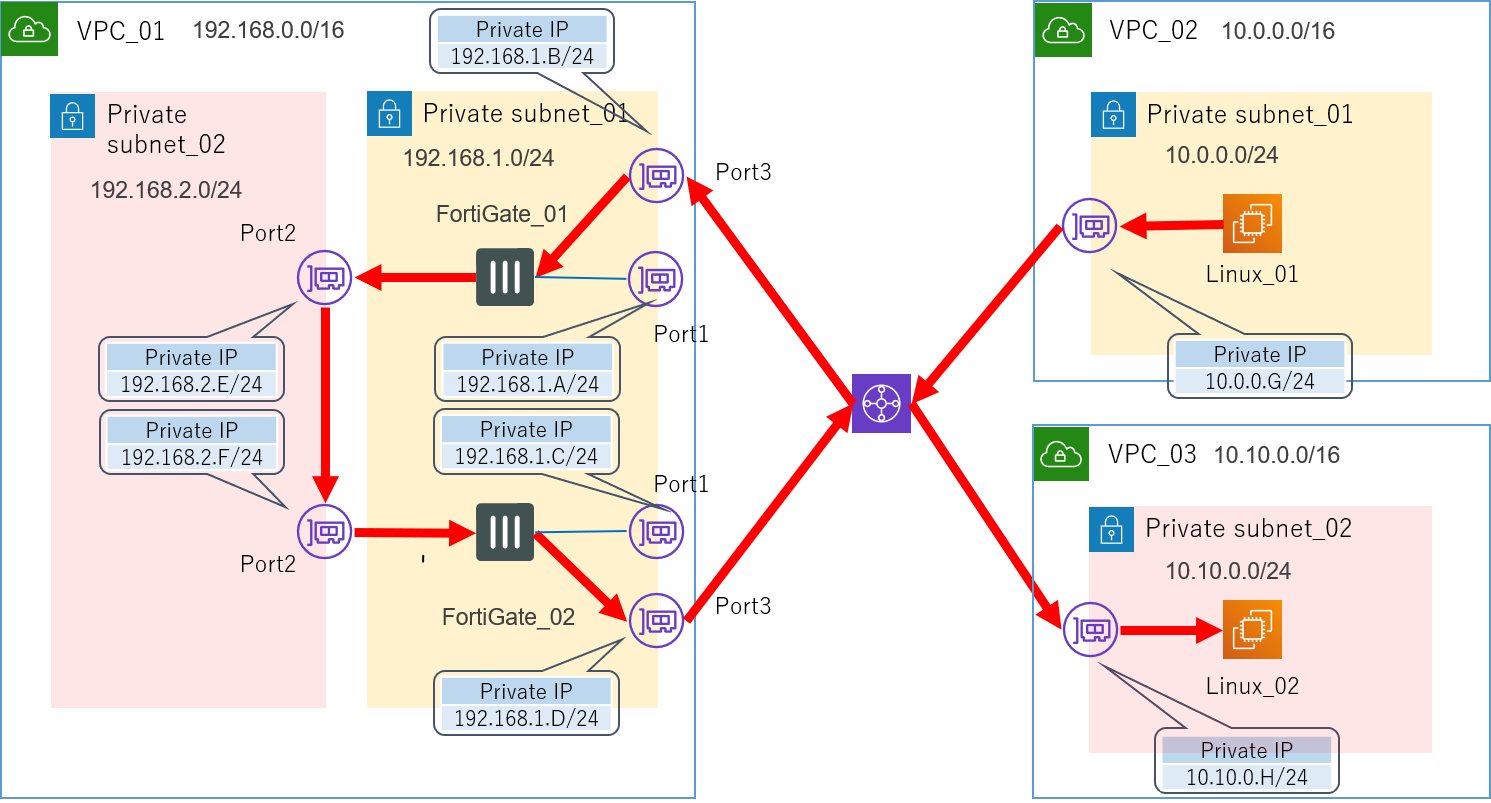
4.4.1.3.Transit Gatewayを利用してみる→?
この方法に関しては、もしかすると上手くいくのかもしれません。
が、この方法を試す前に正解を見つけてしまったというのと、このサービスを利用するのには少々コストがかかりそうだというので、実は今回はあまり深く検証していません。
AWSの方に問い合わせたところ、「Ingress Routingという機能を利用すれば可能だと思われる」いった回答は頂いています。
もし興味をお持ちになられた方、もしくは既に試したことがあるという方がいらっしゃいましたら、是非情報提供よろしくお願いします。Transit Gatewayというのは、最近東京リージョンでも利用可能になったばかりの新しいサービスです。
従来VPC間を繋ぐためには先ほど紹介したVPCピアリングが一般的でしたが、これは推移的なピア関係をサポートしていませんでした。
例えるなら、友達の友達は友達ではないといった感じですかね。
なので複数のVPC同士を接続するためには、どうしてもフルメッシュ構造をとるしかありませんでした。
そこで登場したのが、ハブ&スポーク構造を実現できるTransit Gatewayです。
これを介することにより、複数のVPC間をシンプルに行き来できるようになりました。先ほどのVPCピアリングではダメだったので、これを使えば上手くいくのではないかと一応構成だけは考えてみました。
Transit Gatewayを利用した構成
Pingを打つためのサーバーを一つ置くためだけにVPCを一つ作るという何とも大げさな構成です。
ですがこれを試す前に正解の方法が見つかりました。
この方法でも上手くいくのか気になる方は是非ご自身で試してみてください。4.4.2.OSのレイヤーでルーティングする→成功
どうやら各サーバーのOSのレイヤーでルーティングテーブルを書き換えてしまえば、ルートテーブルよりそちらが優先されるようです。
今回はWindows Serverを使用しているので、各Ping要員サーバーに入ってコマンドプロンプトからOSの持つルーティングテーブルを確認し、ネクストホップを追加しました。
ちなみに-pを付けないと再起動するたびにルーティングテーブルがリセットされてしまいます。
追加したらroute printでちゃんと入っているか確認してみてください。Windows_02(192.168.3.I)にルートを追加
route add 192.268.4.0 mask 255.255.255.0 192.168.3.G -p
Windows_03(192.168.4.J)にルートを追加
route add 192.268.3.0 mask 255.255.255.0 192.168.4.H -p
ついに、無事に想定通りの経路でパケットがルーティングされるようになりました。
Tracertコマンドで確認しても、ちゃんと機能していることが確認できます。
これにて検証環境の構築は完了です。
お疲れ様でした。5.チェック項目
それでは今までの経緯を踏まえて、AWS上に検証環境を構築する際に気を付けなければいけないことについてまとめておきたいと思います。
疎通確認が取れない時は参考にしてください。
- VPC
- サブネットは適切に設定されているか
- ルートテーブルは適切に設定されているか
- EC2
- パブリックIPアドレスは認識しているものと一致しているか(気が付かないうちに変わっている可能性あり)
- OSのファイアウォールは解除されているか(Windows Serverの時のみ)
- セキュリティグループは適切に設定されているか(これが一番ありがち)
- OSのルーティングテーブルは適切に設定されているか
- 送信元/送信先の変更チェックは適切に設定されているか
- FortiGate
- インターフェースはDHCPで設定されているか(マニュアルは×)
- 管理者アクセスは適切に設定されているか
- スタティックルートは適切に設定されているか
- ポリシーは適切に設定されているか
- その他
- AWSだけでなく、外部のネットワーク環境に問題はないか(あまり詳しくは言えないのですが、私はこの部分でも苦労しました)
- コストはちゃんと管理できているか
6.おわりに
いかがでしたでしょうか。
この環境を用いて行った機能検証の具体的な内容についても近いうちまとめる予定ですので、もしご興味をお持ちいただけましたら是非そちらもご覧ください。今回はAWS初体験ということもあり非常に基本的なサービスに終始してしまいましたが、AWSにはまだまだ興味深いサービスや触ってみたい機能が数えきれないほどありますので、これからも色々と試して皆さんとナレッジを共有していければと思います。
また、もしこの記事を読んで少しでも興味をお持ちになった方がいらっしゃいましたら、是非ご自身でも試していただきたいと思います。最後まで読んでいただき、ありがとうございました。
それでは、また。


- 投稿日:2020-02-12T09:00:15+09:00
AWS CloudFormationでAmazon S3のブロックパブリックアクセスを設定するのに必要なアクセス許可設定
AWS CloudFormation(CFn)でAmazon S3(S3)のブロックパブリックアクセスを設定するのに必要なアクセス許可をCFnのエラーを信じたら騙されたのでメモ。
S3のブロックパブリックアクセスに関しては下記が参考になります。
Amazon S3 Block Public Access – アカウントとバケットのさらなる保護 | Amazon Web Services ブログ
https://aws.amazon.com/jp/blogs/news/amazon-s3-block-public-access-another-layer-of-protection-for-your-accounts-and-buckets/S3パブリックアクセス設定を試してみる - Qiita
https://qiita.com/atsumjp/items/cb6ddf5e3df4bbf5e4a7手順
テンプレートを用意
こんな感じのテンプレートを用意します。
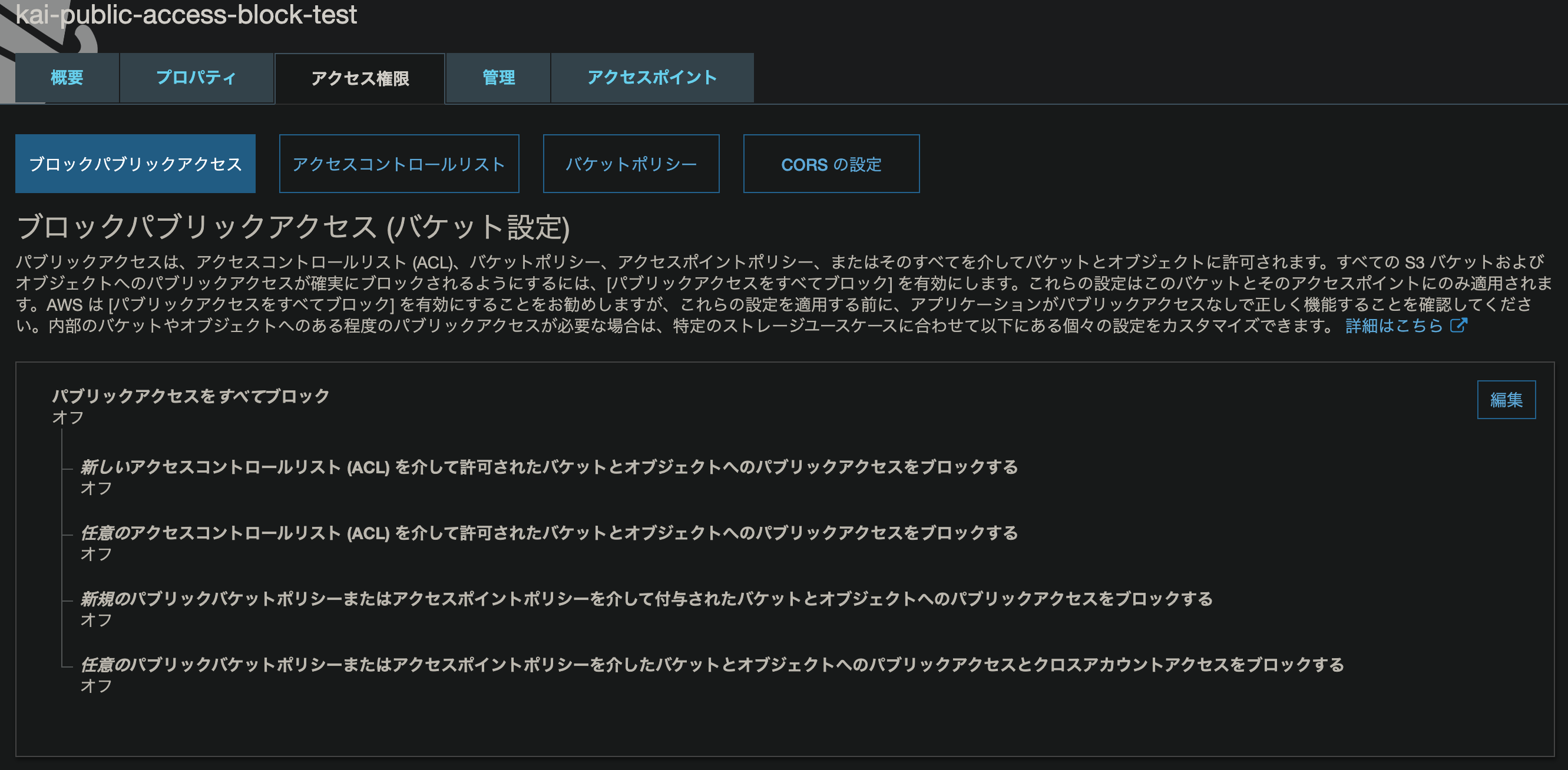
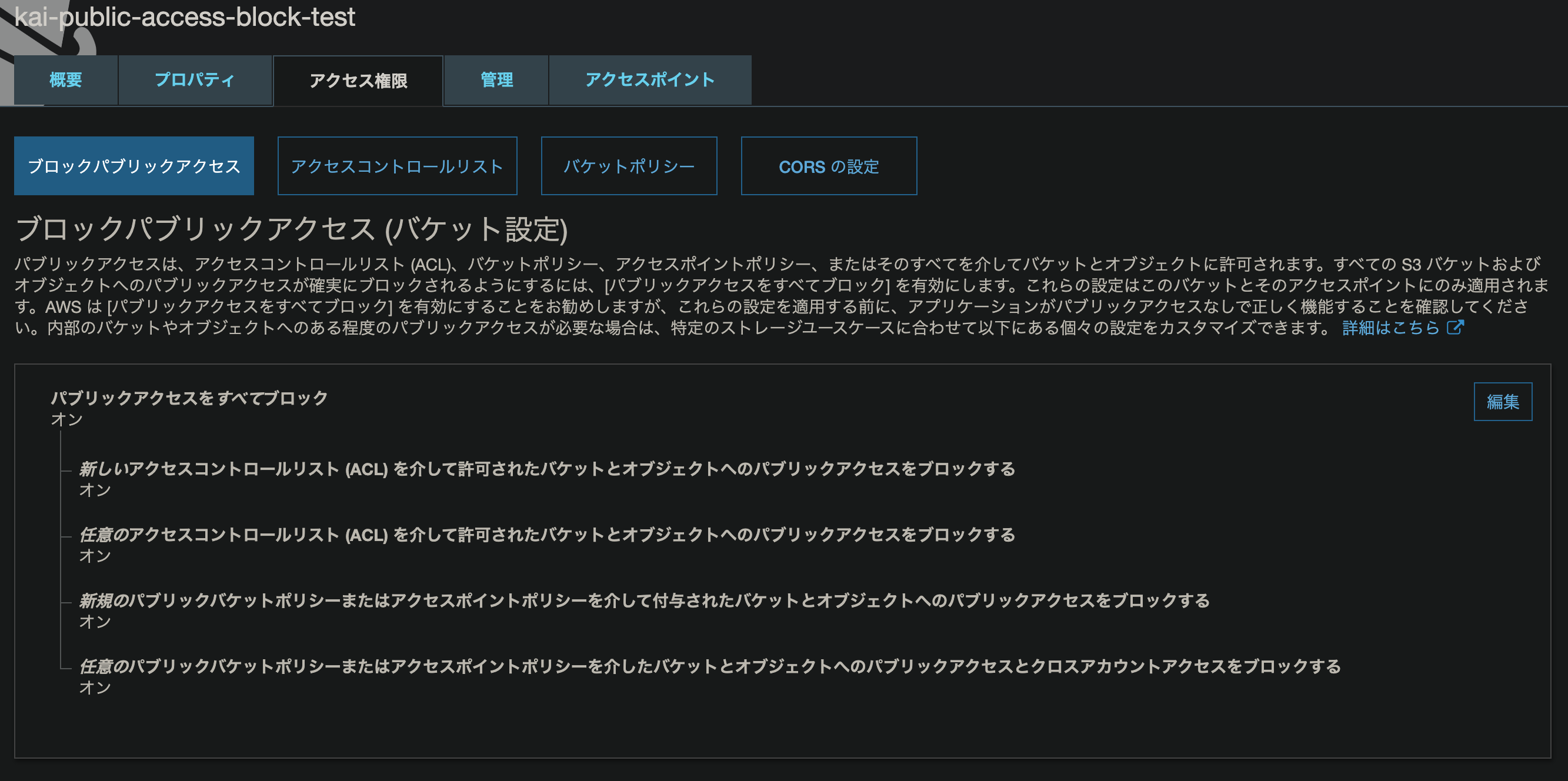
PublicAccessBlockConfigurationでブロックパブリックアクセスの設定をします。
※BucketNameは任意に指定ください。template.yamlAWSTemplateFormatVersion: "2010-09-09" Resources: PublicAccessBlockTestBucket: Type: AWS::S3::Bucket Properties: BucketName: "kai-public-access-block-test" PublicAccessBlockConfiguration: BlockPublicAcls: True BlockPublicPolicy: True IgnorePublicAcls: True RestrictPublicBuckets: TrueAWSマネジメントコンソールだとこんな画面で設定します。
AWSユーザーの作成
CFnでスタック作成、リソース管理するのに利用するAWSユーザーを作成して、インラインポリシーで最低限のアクセス許可をします。
インラインポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "cloudformation:CreateStack", "cloudformation:DeleteStack", "s3:CreateBucket", "s3:DeleteBucket" ], "Resource": "*" } ] }スタック作成
ブロックパブリックアクセスを設定するためのActionは最初わからなかったので指定せずにCFnでスタック作成してみました。
> aws cloudformation create-stack \ --template-body file://template.yaml \ --stack-name kai-public-access-block-test \ --profile public-access-block-testすると、
API: s3:PutPublicAccessBlock Access Deniedってエラーになったので、インラインポリシーのActionにs3:PutPublicAccessBlockを指定してみると。。。
識別されないアクションとなりました(´・ω・`)
なぜー?CFnさんが嘘ついてるの?正しい指定方法を調べてみた
調べてみると、
s3:PutBucketPublicAccessBlockが正しいみたいです。Amazon S3 ブロックパブリックアクセスの使用 - Amazon Simple Storage Service
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/access-control-block-public-access.htmlインラインポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "cloudformation:CreateStack", "cloudformation:DeleteStack", "s3:CreateBucket", "s3:DeleteBucket", "s3:PutBucketPublicAccessBlock" ], "Resource": "*" } ] }インラインポリシーに
s3:PutBucketPublicAccessBlockを追加してスタック作成すると無事にS3バケットのブロックパブリックアクセスが設定できました。
参考
Amazon S3 Block Public Access – アカウントとバケットのさらなる保護 | Amazon Web Services ブログ
https://aws.amazon.com/jp/blogs/news/amazon-s3-block-public-access-another-layer-of-protection-for-your-accounts-and-buckets/S3パブリックアクセス設定を試してみる - Qiita
https://qiita.com/atsumjp/items/cb6ddf5e3df4bbf5e4a7Amazon S3 ブロックパブリックアクセスの使用 - Amazon Simple Storage Service
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/access-control-block-public-access.html
- 投稿日:2020-02-12T08:04:22+09:00
Docker Swarmで学ぶサービスメッシュ
はじめに
本記事はDocker Swarmでクラスタを構築し、サービスメッシュについて学びます。
環境はAWSのELB(Elastic Load Balancing)と、EC2(Amazon EC2)インスタンス2台を使用し、Docker Swarmのクラスタを構築します。
Kubernetesと比較した際にDocker Swarmを導入するメリットは、導入コストが低いことです。Docker SwarmはKubernetesに比べてハードルが低いため、本番環境にコンテナ技術を導入しようとしているシステムには最適だと考えます。
Docker Swarmを通してサービスメッシュの意義を体感しましょう。
Docker Swarm
Docker Swarmは、Docker社が提供するオーケストレーションツールです。
Docker Swarmを使用することで複数のホストを集約し、簡単にコンテナのデプロイとスケールが実現できます。
Docker Swarmはマネージャとノードで構成され、Swarmは群れを意味します。
Docker Swarのクラスタを構築するためには、以下の作業が必要です。
- マネージャとノードにDockerをインストールする。
マネージャとノード間で通信ができるように、ファイアウォールで必要な通信を許可する。
ファイアウォールで許可するルール
ポート番号 用途 2377/tcp クラスタ管理用の通信 4789/udp オーバーレイ・ネットワーク 7946/tcp ノード間通信 7946/udp ノード間通信 サービスメッシュ
サービスメッシュはマイクロサービスアーキテクチャを前提とし、アプリケーション間で通信を制御する仕組みを提供します。この制御された通信はメッシュの様に編みがけになっているため、信頼性を向上します。
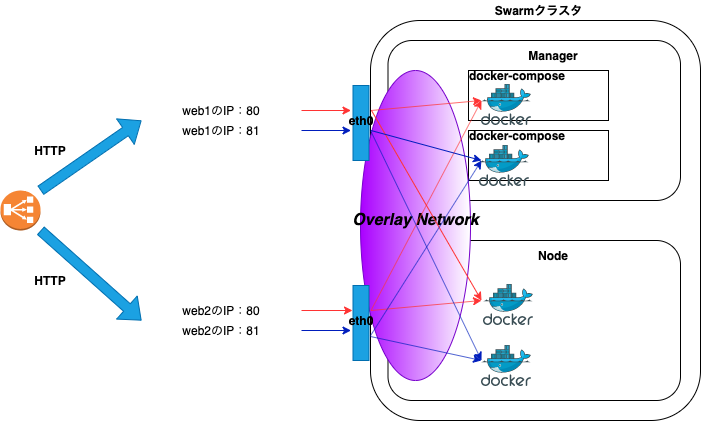
例として2台構成のホストの場合、通常のアクセスパスは以下になります。
ブラウザでロードバランサーのDNS名にアクセスすると、HTTPリクエストを受け付けたロードバランサーは、ラウンドロビンでバックエンドであるホストの公開ポートにHTTPリクエストを振り分けます。
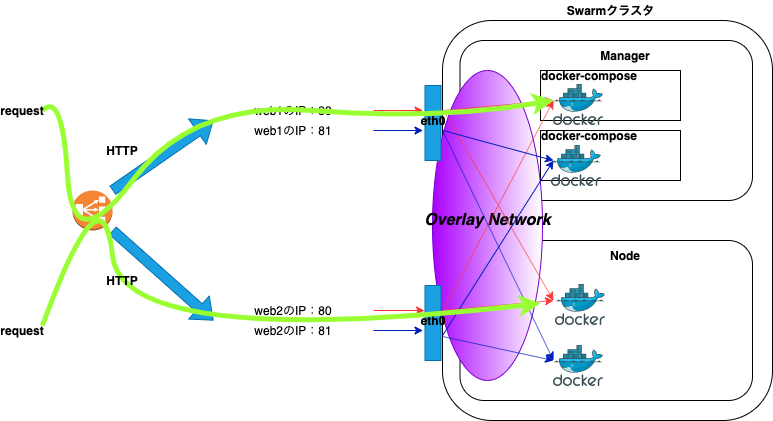
例えば、片方のホストで何らかの障害が発生し、コンテナがダウンした場合でも以下の経路により、サービスを継続することができます。
要約すると、単純にホストレベルでアプリケーションを分ける構成の場合は、片方のホストに何らかの障害が発生したときにサービスの提供ができなくなります。よって、コンテナ技術を活用し、サービスメッシュにすることで単一障害点をなくすことができます。
Docker Swarm構築
Docker Swarmの構築手順について記載します。
Docker Swarmの構築は、マネージャ、ノードの順に作業を行います。本記事の例ではweb1がマネージャ、web2がノードになり、Nginxのイメージを使用してデプロイします。
前提条件としてDockerは既にインストールされた状態で、上記で解説したファイアウォールも許可されていることとします。また、本記事では最低限の構成としているため、マネージャ1台、ノード1台になります。
マネージャ
まずはじめに、Docker Swarmの初期化を行います。
docker swarm initコマンドを実行することでSwarmモードが有効になります。複数IPアドレスを持つ場合は、他のノードとの通信で使用するインターフェースのIPアドレスを
advertise-addrの引数に指定します。
- Docker Swarmの初期化
# docker swarm init --advertise-addr <IPアドレス>Swarm initialized: current node (zirc78nsch77ox8di6021ux4n) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-459p0pkyqgxgkhaggjhavd419ldujenqttm1mqmwup0qz9m5qv-1kj3jy6ozwrr2fkj1qvas294a <マネージャのIPアドレス>:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.コマンド実行後、出力結果の
docker swarm join --token SWMTKN-1-(略) <マネージャのIPアドレス>:2377を控えます。
- node確認
# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION zirc78nsch77ox8di6021ux4n * web1 Ready Active Leader 18.09.9-ceマネージャの場合は、MANAGER STATUSにLeaderと出力されます。
- ネットワーク確認
# docker network lsNETWORK ID NAME DRIVER SCOPE 53703efd3d07 bridge bridge local aacf6f5e0eb4 docker_gwbridge bridge local 1f0d0e4ae3e7 host host local xip5tlqmokpb ingress overlay swarm 2d36f1c8c80f none null localSwarmの初期化を行うと新たに2つのネットワーク(docker_gwbridge、ingress)が作成されます。
ノード
次にノードをDocker Swarmのクラスタに参加させるため、ノード側で以下のコマンドを実行します。
--tokenの引数にしている値は例になります。上記docker swarm initコマンドの出力結果をコピーしてペーストすれば大丈夫です。なお、マネージャ側で
docker swarm join-token workerコマンドを実行することで、トークンの再表示もできます。
- クラスタ参加
# docker swarm join --token SWMTKN-1-(略) <マネージャのIPアドレス>:2377This node joined a swarm as a worker.マネージャ側で確認のため、再度、
docker node lsコマンドを実行すると、nodeが認識されていることが確認できます。
- node確認
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION zirc78nsch77ox8di6021ux4n * web1 Ready Active Leader 18.09.9-ce n2o22ptdmyhan8qg0ijmo0qn5 web2 Ready Active 18.09.9-ceDocker Swarmのデプロイ
本記事では管理しやすいdocker-commposeでデプロイします。
また、docker service createコマンドでもデプロイできます。serviceやstackの説明については割愛します。デプロイ作業はマネージャ側で行います。
任意のディレクトリに移動し、以下のdocker-commpose.ymlファイルを作成します。
- docker-commpose.yml
version: "3" services: web: image: nginx deploy: replicas: 2 #resources: # limits: # cpus: "0.1" # memory: 100M restart_policy: condition: on-failure ports: - "80:80" networks: - webnet networks: webnet:
docker-commpose.ymlファイル作成後、以下のコマンドを実行し、デプロイします。
testは例となるため、任意の名前を指定します。
# docker stack deploy -c docker-commpose.yml testUpdating service test_web (id: egubeieuri00rzmm9imsna93o)デプロイ後、以下のコマンドでサービスの状態が確認できます。
REPLICASは2となっているので、2つのコンテナが起動しています。
# docker service lsID NAME MODE REPLICAS IMAGE PORTS r04mfg1se3nh test_web replicated 2/2 nginx:latest *:80->80/tcpマネージャとノード側で
docker container ps -aコマンドを実行すると、コンテナが起動しているのが確認できます。
- マネージャ側
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4a26c3ca6df7 nginx:latest "nginx -g 'daemon of…" 3 seconds ago Up 2 seconds 80/tcp test_web.1.mnnz40tdykzd2intwz5hf68bs
- ノード側
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 614c19349bf0 nginx:latest "nginx -g 'daemon of…" 2 minutes ago Up 2 minutes 80/tcp test_web.2.6om5oazbavassohd4akucbum2Docker Swarmの動作確認
Docker Swarmの動作確認を行います。
ブラウザからロードバランサーのDNS名にアクセスを行い、正常に負荷分散されることを確認します。
- ロードバランサーのDNS名にアクセス
コンテナのログを確認すると、ラウンドロビンで負荷分散されているのが確認できます。
CONTAINER IDはdocker container ps -aのコマンドで確認します。
# docker logs -f <CONTAINER ID>10.255.0.3 - - [06/Feb/2020:14:20:51 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36" "<アクセス元のグローバルIP>"試しにweb2上(ノード側)で稼働しているコンテナを停止します。
# docker stop <CONTAINER ID>CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 423f673b0513 nginx:latest "nginx -g 'daemon of…" 19 hours ago Exited (0) 5 seconds ago test_web.2.kc7yypyasgvjtolsb1zwmhjoyこのときweb2上でコンテナは稼働していません。
ロードバランサーのDNS名にアクセスできることを確認します。
例としてブラウザから停止したweb2の公開IPにアクセスします。
Web1(マネージャ)上のコンテナのアクセスログに、停止したweb2(ノード)の公開IPに対するアクセスが確認できます。
10.255.0.3 - - [07/Feb/2020:02:19:01 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36" "-"停止したweb2(ノード側)のローカルからも、以下のコマンドを実行することでコンテナにアクセスができます。
# curl localhost 80<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> curl: (7) Couldn't connect to serverweb1(マネージャ)のログでは以下の様に出力されます。
10.255.0.2 - - [07/Feb/2020:02:41:47 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.61.1" "-"web1(マネージャ)で4789ポートをダンプして見ていると、オーバーレイ・ネットワークの通信を見ることができます。
# tcpdump -nli eth0 port 4789 -AvDocker Swarmのスケール
既にサービスが起動している状態で、以下のコマンドを実行することでスケールができます。以下のコマンドはコンテナの数を4コンテナに変更しています。
# docker service scale test_web=4test_web scaled to 4 overall progress: 4 out of 4 tasks 1/4: running [==================================================>] 2/4: running [==================================================>] 3/4: running [==================================================>] 4/4: running [==================================================>] verify: Service convergedスケール後、
docker container ps -aコマンドを実行すると、コンテナが増えていのが分かります。CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 41962946aa48 nginx:latest "nginx -g 'daemon of…" 3 minutes ago Up 3 minutes 80/tcp test_web.4.pytl36ejcd81ybthisxfo47br 423f673b0513 nginx:latest "nginx -g 'daemon of…" 7 hours ago Up 7 hours 80/tcp test_web.2.kc7yypyasgvjtolsb1zwmhjoy要するに、デプロイ時はサーバ1台ずつに対してアプリケーション資産の入れ替えを行う必要がなく、マネージャ1台で済みます。
Docker Swarmの性質
Docker Swarmは冪等性を持っています。
具体的には、Docker Swarmは指定したreplicas数のコンテナを維持するため、クラスタ化している片方のホストがダウンした場合は、片方のホストでコンテナを起動します。
以下は
docker container ps -aコマンドの出力になります。
例としてweb1とweb2でそれぞれコンテナが起動しています。
- web1
e5ccbfa9739b nginx:latest "nginx -g 'daemon of…" 3 minutes ago Up 3 minutes 80/tcp test_web.1.mrgkhbd7juer72v6bv0l42fxq
- web2
4820c7bbe9c1 nginx:latest "nginx -g 'daemon of…" 3 minutes ago Up 3 minutes 80/tcp test_web.2.wfe1n11s8940rdl8r1c47o6ncweb2のホストを停止しました。web2のダウンを検知すると、web1上でコンテナを作成します。
0a88f53039a3 nginx:latest "nginx -g 'daemon of…" 5 seconds ago Created test_web.2.p06zas3c3kt9ekjojhhfnl3co e5ccbfa9739b nginx:latest "nginx -g 'daemon of…" 4 minutes ago Up 4 minutes 80/tcp test_web.1.mrgkhbd7juer72v6bv0l42fxqweb1上でコンテナが2台起動しています。
0a88f53039a3 nginx:latest "nginx -g 'daemon of…" 37 seconds ago Up 31 seconds 80/tcp test_web.2.p06zas3c3kt9ekjojhhfnl3co e5ccbfa9739b nginx:latest "nginx -g 'daemon of…" 5 minutes ago Up 5 minutes 80/tcp test_web.1.mrgkhbd7juer72v6bv0l42fxqDocker Swarm解除
Docker Swarmの解除方法について記載します。
先にマネージャ側で以下のコマンドを実行し、サービスの削除を行いす。
# docker service rm test_webtest_web次にノード、マネージャの順に作業を行います。
ノード
- ノードの切り離し
# docker swarm leaveNode left the swarm.マネージャ
ノードのSTATUSがDOWNになったことを確認します。
- node確認
# docker node lsID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION zirc78nsch77ox8di6021ux4n * web1 Ready Active Leader 18.09.9-ce n2o22ptdmyhan8qg0ijmo0qn5 web2 Down Active 18.09.9-ceノードを削除します。オプションの引数には、ノード名を指定します。
- node削除
# docker node rm --force web2web2マネージャからノードが認識されなくなったことを確認します。
- node確認
# docker node lsID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION zirc78nsch77ox8di6021ux4n * web1 Ready Active Leader 18.09.9-ce最後にマネージャ自身を切り離します。
- マネージャの切り離し
# docker swarm leave --forceNode left the swarm.Docker Swarm解体
Docker Swarmを使用しない場合は、マネージャ側で以下の作業を行います。
ノードが存在しないことを確認します。
- node確認
# docker node lsError response from daemon: This node is not a swarm manager. Use "docker swarm init" or "docker swarm join" to connect this node to swarm and try again.Docker Swarmで作成されたネットワークが削除されたことを確認します。docker_gwbridgeのネットワークは残っています。
# docker network lsNETWORK ID NAME DRIVER SCOPE 987cfc73d87c bridge bridge local aacf6f5e0eb4 docker_gwbridge bridge local 1f0d0e4ae3e7 host host local 2d36f1c8c80f none null local以下のコマンドを実行し、使用していない全てのリソース削除します。
- リソース削除
# docker system pruneWARNING! This will remove: - all stopped containers - all networks not used by at least one container - all dangling images - all dangling build cache Are you sure you want to continue? [y/N] y Deleted Networks: docker_gwbridge Deleted Images: untagged: nginx@sha256:ad5552c786f128e389a0263104ae39f3d3c7895579d45ae716f528185b36bc6f deleted: sha256:2073e0bcb60ee98548d313ead5eacbfe16d9054f8800a32bedd859922a99a6e1 deleted: sha256:a3136fbf38691346715cac8360bcdfca0fff812cede416469653670f04e2cab0 deleted: sha256:99360ffcb2da18fd9ede194efaf5d4b90e7aee99f45737e918113e6833dcf278 deleted: sha256:488dfecc21b1bc607e09368d2791cb784cf8c4ec5c05d2952b045b3e0f8cc01e untagged: nginx@sha256:70821e443be75ea38bdf52a974fd2271babd5875b2b1964f05025981c75a6717 deleted: sha256:5ad3bd0e67a9c542210a21a3c72f56ef6387cf9b7f4c2506d2398d55a2593ed0 deleted: sha256:b69e2ed46519bc33e7c887967e4f61a2ee53aef165b70f75e208937fb42e7b4c deleted: sha256:4cb7f732537bf0f65cd9f8f7b63bbe71abcf9d0df396f58621ef3be0b2487b27 deleted: sha256:556c5fb0d91b726083a8ce42e2faaed99f11bc68d3f70e2c7bbce87e7e0b3e10 Total reclaimed space: 253.4MBナレッジ
docker-commposeのバージョン
Docker Swarmを使用する場合に、docker-commposeで使用できるバージョンは3になります。
docker-commposeでビルドする場合の留意事項
docker-commposeでビルド(stack)する場合、イメージが必要になります。
Compose file version 3 referenceより
注:( バージョン3)Composeファイルを使用してSwarmモードでスタックをデプロイする場合、このオプションは無視され ます。このdocker stackコマンドは、ビルド済みのイメージのみを受け入れます。
そのため、Docker registryの環境が必要になります。
ローカルでDockerレジストリをセットアップする方法については、公式の以下URLが参考になります。
例として、以下の様にビルドを指定してデプロイを実行した場合、
version: '3' services: app: build: ./src以下のエラーメッセージが出力されて、デプロイをすることはできません。
failed to create service stackdemo_backend: Error response from daemon: rpc error: code = InvalidArgument desc = ContainerSpec: image reference must be providedおわりに
不確実性があり変化の速さが求めれられる現代のアプリケーション開発には、オーケストレーションツールは必須な技術です。
応用としてサーバレスの技術を使用し、CPUやメモリリソース等のしきい値等を設定して、しきい値を超えたらサーバをスケールアウトなどの運用も行うことができます。
参考


- 投稿日:2020-02-12T02:46:08+09:00
AWS CLI v2 が GA(General Availability) になったので早速使ってみました。
みんな大好き AWS CLI の v2 が 2020年2月11日日本時間早朝に GA(General Availability) となりました!
わーい。
https://aws.amazon.com/jp/blogs/developer/aws-cli-v2-is-now-generally-available/筆者はAWS CLI の薄い本を書くくらい AWS CLI が好きだったりします。
というわけで、早速使ってみました。インストール
公式ガイドには Linux、 macOS、 Windows 向けのインストール手順が載っています。
今回は、 AmazonLinux2 で試したので、 Linux の手順に則ってみました。公式ガイド:https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html
インストールする
公式ガイドには以下の記載があります。
https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2-linux.html#cliv2-linux-installcurl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install実際に試すとこんな感じ。
ec2-user@test ~]$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 30.6M 100 30.6M 0 0 64.1M 0 --:--:-- --:--:-- --:--:-- 64.0M [ec2-user@test ~]$ ls awscliv2.zip [ec2-user@test ~]$ [ec2-user@test ~]$ unzip awscliv2.zip Archive: awscliv2.zip creating: aws/ creating: aws/dist/ (中略) inflating: aws/dist/zlib/cpython-37m-x86_64-linux-gnu/soib.cpython-37m-x86_64-linux-gnu.so [ec2-user@test ~]$ [ec2-user@test ~]$ sudo ./aws/install You can now run: /usr/local/bin/aws --version [ec2-user@test ~]$ [ec2-user@test ~]$ /usr/local/bin/aws --version aws-cli/2.0.0 Python/3.7.3 Linux/4.14.154-128.181.amzn2.x86_64 botocore/2.0.0dev4 [ec2-user@test ~]$早速試してみます。
本稿執筆時点での新機能は以下の通りです。
- インストーラ
- これは上記で試し済み。今までの差異としては、ビルド済みパッケージでの提供かつ前提を満たすバージョンの Python を事前にインストールする必要がなくなりました。
- 設定手順
- これまで AWS CLI に IAM ユーザーの認証情報を設定するのには、IAM ユーザー作成時に表示される情報もしくは作成時にダウンロードできる csv ファイルを参照して設定を行っていました。 v2 ではその csv ファイルをインポートして設定が可能になりました。
- また、認証方法として SSO も利用可能になりました。
- リソース名の自動補完
- すでに AWS アカウント上に存在するリソース名を補完して CLI のパラメータにしてができるようになりました。地味にすごい。
- 自動プロンプト
- 必要なパラメータ指定をアシストしてくれるようになりました。これで必須パラメータ漏れで怒られることも減ります。
- ウィザード
- いわゆる、対話型のコマンドとして動作するモードです。本稿執筆時点では一部のサービスのみに対応しています。
- yaml での出力
- 実行結果の出力形式に yaml が追加されました。
本稿では、リソース名の自動補完と自動プロンプト、ウィザード、yaml での出力について試してみます。
SSO は可能なら試行後に更新します。リソース名の自動補完
現時点では全部のサービスには対応しきっていないようです。
例えば、試行した中では Amazon EC2 や Amazon S3 のバケット名、 RDS などは対応していないようです。
今後この辺りの拡充が期待されます。というわけで、後述のウィザードに対応しているサービス(Amazon DynamoDB や AWS IAM、AWS Lambda)は対応しているようだったので、試してみました。
[ec2-user@test ~]$ aws dynamodb describe-table --table-name <TABキーを押す> 12234 table-us-east-1 [ec2-user@test ~]$ [ec2-user@test ~]$ aws iam get-user --user-name <TABキーを押す> cli codecommit hirosys [ec2-user@test ~]$ [ec2-user@test ~]$ aws lambda get-function --function-name <TABキーを押す> AWS-DeepRacer-Test-Reward-Function aws-deepracer-reward-fn-********-****-****-****-************自動プロンプト
自動プロンプト機能を使って、 Amazon VPC を作成してみました。
[ec2-user@test ~]$ aws ec2 create-vpc --cli-auto-prompt --cidr-block: 10.20.0.0/16必須パラメータである --cidr-block の指定の後、任意パラメータのリストが表示されました。
特に指定せずに一番下にある ** [DONE] Parameter input finished** を選択してEnterキーを押下すると、VPC が作成できました。
{ "Vpc": { "CidrBlock": "10.20.0.0/16", "DhcpOptionsId": "dopt-********", "State": "pending", "VpcId": "vpc-*****************", "OwnerId": "************", "InstanceTenancy": "default", "Ipv6CidrBlockAssociationSet": [], "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-*****************", "CidrBlock": "10.20.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [] } }無事に作成できました。
気になった点・・・
aws ec2 describe-instances を自動プロンプトモードで実行した際、 --instance-ids にインスタンスIDを指定しても、以下のメッセージが表示されて実行できませんでした。
An error occurred (InvalidInstanceID.Malformed) when calling the DescribeInstances operation: Invalid id: "-"しかし、 Print CLI command. で出力した CLI を実行する分には意図した通りに動く不思議。。。
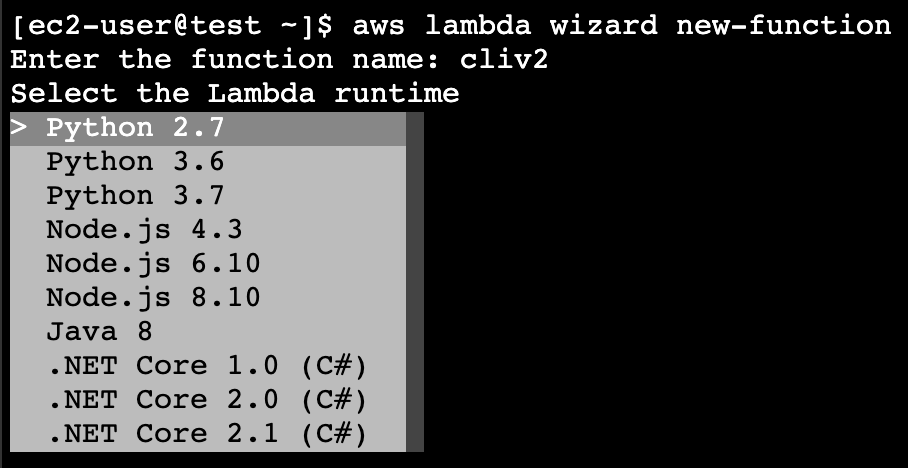
ウィザード
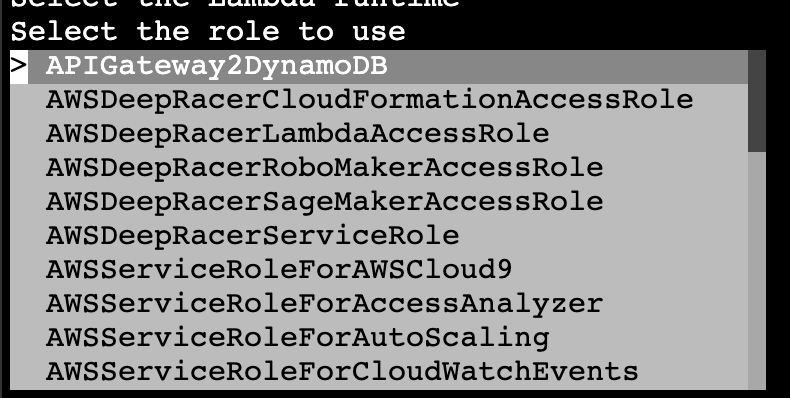
[ec2-user@test ~]$ aws lambda wizard new-functionまずは作成する Lambda 関数の名前を指定します。
次に、使用するランタイムの種類やバージョンをリストから選択します。
さらに、どのロールを使用するかをリストで選択します。
そして、 handler と Lambda 関数が入った zip ファイルを指定して、
最終的には以下のような感じになり、実行します。[ec2-user@test ~]$ aws lambda wizard new-function Enter the function name: cliv2 Select the Lambda runtime Select the role to use Enter the handler for your function: lambda_function.lambda_handler Enter the new location of your code zip file: cliv2_test.zip [ec2-user@test ~]$特にエラーなく実行できれば Lambda 関数の作成に成功しています。
以下は、マネージメントコンソールで確認した結果です。
リストから選択したランタイムやロールが表示されると尚良さそうですね。
yaml での出力
好みの問題もあるかもしれませんが、個人的には yaml は読みやすいと思っているのでこのアップデートはナイスです。
[ec2-user@test ~]$ aws ec2 describe-instances --output yaml Reservations: - Groups: [] Instances: - AmiLaunchIndex: 0 Architecture: x86_64 BlockDeviceMappings: - DeviceName: /dev/xvda Ebs: AttachTime: '2020-02-11T14:25:47+00:00' DeleteOnTermination: true Status: attached VolumeId: vol-***************** CapacityReservationSpecification: CapacityReservationPreference: open ClientToken: '' CpuOptions: CoreCount: 1 ThreadsPerCore: 1 EbsOptimized: false EnaSupport: true HibernationOptions: Configured: false Hypervisor: xen IamInstanceProfile: Arn: arn:aws:iam::************:instance-profile/role-tsuyoi Id: ********************* ImageId: ami-***************** InstanceId: i-***************** InstanceType: t2.micro KeyName: *********** LaunchTime: '2020-02-11T14:25:46+00:00' MetadataOptions: HttpEndpoint: enabled HttpPutResponseHopLimit: 1 HttpTokens: optional State: applied Monitoring: State: disabled NetworkInterfaces: - Association: IpOwnerId: amazon PublicDnsName: ec2-***-***-***-***.ap-northeast-1.compute.amazonaws.com PublicIp: ***.***.***.*** Attachment:まとめ
AWS CLI はもともと好きでしたが、今回の v2 でさらにかゆいところに手が届く機能に変身しており、ますます好きな機能になったと感じました。
皆さんもこの機会に AWS CLI に触れてみてはいかがでしょうか。


- 投稿日:2020-02-12T01:39:02+09:00
AWSの10分間チュートリアルをやってみる 5. Amazon Elastic Beanstalk を使用したアプリケーションの起動
こんにちは。トリドリといいます。
新卒で入社した会社でJavaを数年やった後、1年ほど前に転職してからはRailsを中心に使用してアプリケーションの開発をしているしがないエンジニアです。今回、AWSの勉強をするために公式の10分間チュートリアルをやってみることにしたので、備忘のために記事に残していこうと思います。
AWSに関しては、1年ほど前転職活動をしていた時期にEC2とRDSを少し触っていた以外ほとんど触ったことが無い初心者です。
(ただし、このときにアカウントを作ったので、12ヶ月の無料枠は切れていました)前回は「ドメイン名の登録」を行いました。
前回、インスタンスを停止したのにElastic IPを解放し忘れていて請求が発生していたので、要注意です。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/elastic-ip-charges/
停止中のインスタンスについては、EBSの分の請求も発生するので、WordPressを使う予定がなければインスタンスの終了とElastic IPの解放をしておけばよかったと反省です。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ebs-charge-stopped-instance/今回は「Amazon Elastic Beanstalk を使用したアプリケーションの起動」をやっていきます。
前回終了時は「仮想マシンへコードをデプロイする」をやる予定だったのですが、[CodeDeploy]が大幅に変更されており、チュートリアルで使用しているサンプルが使用できなくなっていたため、こちらに変更しました。Amazon Elastic Beanstalk を使用したアプリケーションの起動
https://aws.amazon.com/jp/getting-started/tutorials/launch-an-app/
ダッシュボードの説明によると、Elastic Beanstalkとはウェブアプリケーションをデプロイ・モニタリング・スケーリングすることができるのサービスとのことだそうです。
サービス自体の説明については、こちらのスライドが詳しそうでした。
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-online-seminar-2017-aws-elastic-beanstalkステップ 1: 新しいアプリケーションの作成
AWSコンソールにログインし、[サービス]の[コンピューティング]にある[Elastic Beanstalk]を選択します。
選択するとダッシュボードが開くので、[今すぐ始める]をクリックします。ステップ 2: アプリケーションの設定
次の画像のように、チュートリアルの画像からは画面が変わっていますが、一番上にある[アプリケーション名]にチュートリアルと同様にアプリケーション名を入力します。
見る限り、[Description]はなくなったようです。チュートリアルでは[次へ]を押していますが、何もせずに次のステップに進みます。
ステップ 3: 環境の設定
a.
画面が変更され、ステップ2と同じ画面で一部の環境の設定をするようになったようです。
b.
プラットフォームの設定は[基本設定]の[プラットフォーム]からチュートリアルに従い
PHPを選択します。
[Environment type]はここにはありません。ここでも次の画面には進まずに、次の手順に進みます。
c.
[アプリケーションコード]からチュートリアルに従って、[コードのアップデート]を選択し、[アップロード]を押してサンプルコードをアップロードします。
チュートリアルの画面では選択肢の一つに入っていた[S3 URL]は[アップロード]を押すとでてくるメニューに移動していました。
[バージョンラベル]は勝手に入力されています。ここで、[より多くのオプションの設定]を押して次の画面に進みます。
d.
チュートリアルのこの手順で設定している[Environment name]については、ステップ2で設定したアプリケーション名から自動的にPhpSampleApp-envと生成されるようになっています。e./f.
VPCの設定は、[ネットワーク]の[変更]から変更することができます。
押すとチュートリアルのf.の画面とほぼ同じ画面が開き、e.の画面はありません。
ここで設定しなかった場合デフォルトのVPCとその中のどれかのAZで作成してくれるようなので、このチュートリアルでは設定しなくても良さそうでした。g.
[アプリの作成]ボタンを押します。
作成中は下記のような画面が開きます。
作成が完了すると、画像のような画面になります。
ステップ 4: Elastic Beanstalk アプリケーションにアクセスする
a.
チュートリアルの通り、ダッシュボードに戻り、作成したアプリケーションをクリックします。
b.
先程のステップ3のg.の作成完了画面と同じ画面が開きます。
チュートリアルの通り、URLをクリックしてページが開けば完了です。まとめ
今回実際やったことは、
- アプリケーションに名前をつける
- アプリケーションのプラットフォームを選択する
- ソースをアップロードする
の3つです。これだけで、
- S3に環境のデータを保存するところを作成する
- インスタンス用のセキュリティグループを作成する
- インスタンス用のElasitc IPを取得する
- インスタンスを作成し、起動する
- インスタンスでアプリケーションを起動する
というアプリケーションを起動するまでのステップをElastic Beanstalkはやってくれるようでした。
これが、[今すぐ始める]の画面で、
難しい作業は弊社にまかせて、お客様はビジネスに集中できます。
と言っている内容なのでしょう。
次回は、「次のステップ」の「アプリケーションを更新する」に進む予定です。






- 投稿日:2020-02-12T01:08:25+09:00
AWSで複数アカウントを使い分ける方法【Google Chrome】
はじめに
複数のAWSアカウントを使い分ける際、毎回ログアウトしてログインし直さないといけないのはさすがにたるい、ということで手軽な解決方法を調べました。
AWSとしては本番や開発といった環境、もしくは部署の単位でアカウントを使い分けることを推奨していると思っていますが(その方が開発から本番に接続できない(していない)ことを簡単に保障できるため)、その割にマネジメントコンソールでその機能がないのは色々不便というか片手落ちという感はありますが……。
前提
先述の通りマネジメントコンソールの機能ではできないので、今回はGoogle Chromeの機能を使います。
(理屈としては他のブラウザでもできそうですが、調べていないので何とも)設定手順
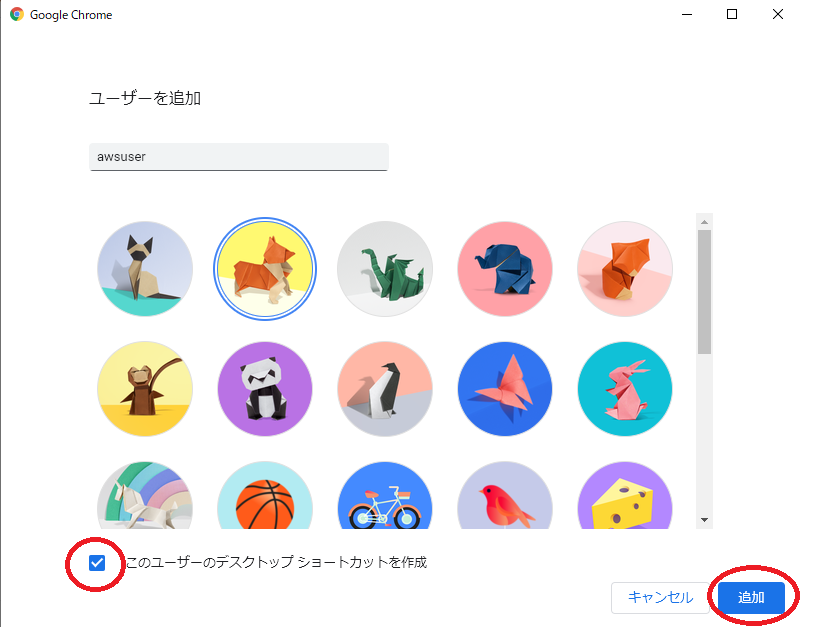
まずはGoogle Chromeでユーザを作成します。
(Googleアカウントを作成するわけではないので注意)右上のアカウントを選択し、「追加」を選択します。
次の画面でユーザー名を入力します。
アイコンは何でも良いですが、他と被らない方が使い分ける際にわかりやすいです。
デスクトップにショートカットがあると便利なので、作成にチェックを入れて「追加」を選択します。
正常に作成できたら、あとは接続したいアカウント/IAMユーザでマネジメントコンソールにログインすれば完了です。
ユーザを分けることで、認証情報も分けられるので、複数アカウントをログアウト無しに切り替えることが可能になります。
補足
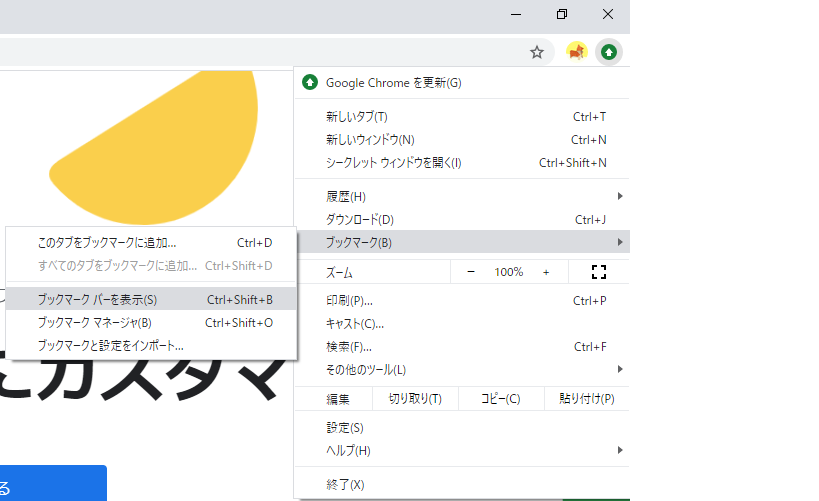
デフォルトだとブックマークバーが表示されないので、忘れずに表示させておきましょう。
また、ブックマークを登録する際、どこのアカウントor環境かがわかりやすい名前で登録しておくと、作業をしている時に間違えにくくなります。
また、ユーザを追加するとChromeのアイコンにユーザのアイコンが表示されるのも地味にありがたいです。


- 投稿日:2020-02-12T00:17:37+09:00
AWS試験対策(②コンピューティングとストレージ)
はじめに
自分はこの前、EC2でサーバを立ててApache入れてWEBサーバを作る…といったことを、動画を参考にしながらやりました。
やったこと自体はいい経験になったし後悔はないんだけど、それって〇〇使ったほうが良くね?って学んでいくうちに気づいたりしました。
AWSは、EC2使わなくてもアプリケーション実行できたりとか色々できます。ただ、EC2でもできますが。
要するに、EC2たててApacheインストールして〜〜とかを、全てAmazonが担当して、こっちはそれ以降のことをするだけでいい、ってな感じ。時短。
その時短サービスに各名前がついてるから覚えるしかない、って感じ
大体略されてるだけだからそんなに難しくはないけど…なんかこういうまとめみたいなやつほしいよね…笑EC2
仮想サーバのこと。Running、stopped、terminatedの3つの状態がある。
terminatedは、そのサーバ解約的なイメージ。
課金はRunningのときのみされる。停止ボタン押したら停止中になり、停止完了しようがしまいが、課金は止まる。なお、OS上で再起動しても、インスタンスは再起動されない。OSが再起動されるだけ。
要するにインスタンス再起動したい場合は、マネジメントコンソールからしかできない。中に入ってshutdown -r nowとかやってもOS再起動のみ。EC2の基盤
大きなホストコンピュータ。要するに物理。この上にいろんな人のAWSアカウントからEC2が作られる。一つのサーバを区切ってみんなで使ってるよってこと。マルチテナンシーって言う。
デフォルトでは、どのホストコンピュータにしようか選ぶことができない。ホストコンピュータに内蔵されたディスクをインスタンスストアという。
ストレージみたいなものだけど、これはホストコンピュータ依存。
EC2は再起動すると、違うホストコンピュータで起動されるが、インスタンスストアは一緒に移動してくれない。
よって、もともとのインスタンスストアを見ることができなくなってしまう。一緒に移動してくれればいいのに。ホストコンピュータ依存だから仕方ないね。。。
言ってしまえば不便オブ不便。使いみちあるこれ?EC2のストレージ
- インスタンスストア
前述の通り、ホストコンピュータが一緒なら使えるストレージ
- EBS
ブロックストア、要するにストレージです。
インスタンスからは、ディスクとして扱ってくれる。
これは仮想ネットワークディスクであり、ホストコンピュータには配置されていない。そしてEC2の状態がどうなろうとこいつには関係ない。
つまり、独立してて永続性がある!この子がいればインスタンスストアはいらない子だね…
この子はスナップショットっていう写真をS3ってところに残してます。なぜかってS3には安く大量に保存できるから。詳しくは後述ハードウェア占有インスタンスとdedicated hosts
マルチテナンシーと違い、ホストコンピュータを自分一人で使えるパターン。
EC2作成時にテナンシーを選択するが、そこで共有を選ぶとマルチテナンシーに。専用、占有ホストを選ぶとこの2つになる。
この2つは何が違うかというと、ハードウェア占有の方は、ホストコンピュータを選べません。dedicated hostsは選べます。アフィニティって設定を使えば、再起動時のホストコンピュータも選べちゃう!インスタンスストアの存在意義ができたね!上記2つは課金形態がちがいます。
どちらも、物理的なサーバ独り占めですが、ハードウェア占有はインスタンス当たりの課金が必要ですが、dedicated hostsはホストコンピュータ当たりの課金です。
占有よりもdedicated hostsのほうが融通利いて使いやすそう。占有は占有したい人向きだがだったらホストコンピュータ選べるほうがよくね?占有するってことはいっぱい建てたいんだろうし。ならホスト単位での課金のほうが有利な気がする。もしや中途半端…?IPアドレス
- EIP
再起動してもIPが継続される、いわば固定IP。使用時は基本無料。
しかし、利用していないときに課金される。AWS側の、使ってない貴重なIPは開放しやがれってメッセージだと思ってる。
ここでいう使用していない時とは、EIP取得はしたけどインスタンスに紐づけていないときや、紐づいてるけどインスタンスがstopped状態のとき。
また、二つ目のEIPを割り当てた場合は課金される。状態問わず。一人一個までだな。
外部インターネットからの接続を想定している。
- パブリックIP
ランダムに割り当てられるIPであり、再起動時にIPが変わってしまう。
これを自動で割り当てないことも可能。
インターネットとのやり取りに使用。要するにEIPの無課金版。無課金なので固定IPにできない。。。
- プライベートIP
インスタンス作成時に必ず割り当てられるIP。作成時に任意のIPにもできる。
再起動しても同じIP。EIPの必須版でありプライベート版みたいな感じ。VPC内で使用される。
最初に付与するプライベートIPを、プライマリプライベートIPという。PPIP。
プライマリプライベートIPを指定しない場合、自動でプライベートIPは割り振られる。
PPIPは、インスタンスを削除しない限り保持され、変更不可。インスタンス停止しても保持される。
ただし、ENIってのを使えば、セカンダリプライベートIPをつけることもできる。
インターネットとのやりとりは直接はしない?ENI
インスタンスに割り当てられるIPアドレスたちは、ENIに関連付けられる。NIC(LANアダプタ)のようなもの。要するにこれがたくさんあれば、たくさんのセグメントでたくさんのIP持てるよってこと。
いくつもてるかはインスタンスタイプによってかわる。外部DNSホスト名
パブリックIPをもつインスタンスは、外部DNSからホスト名を割り当てられます。
これの確認方法は二通りあり、
- AWSマネジメントコンソールにて確認
- EC2インスタンスのメタデータをクエリ(要求)して確認
の二通りです。
下のほうでする場合、実行中のインスタンスからHTTP経由で取得できる。SLA
99.99%の可用性らしい。守れない場合、サービスクレジットと言って割引を受けることができる。なお、当たり前だがAWS起因の場合のみ。
AMI
OSのテンプレ。ハードディスク丸写し。
EC2のテンプレってよりは、EBSのスナップショットらしい。
ただのEBSのコピーではなく、OS起動のためのボリュームが追加されたEBSとのこと。
その後にEBSからインスタンス起動されるんだと。まあでも覚え方としてはOSのテンプレが一番早いかも?
別リージョンで使いたい場合は、S3で別リージョンにスナップショットコピーして復元する。EBSコピーだからS3って覚えたらスムーズかも。インスタンスタイプ
苦手な暗記の領域。何か言い覚え方はないのか。。。
インスタンスタイプ インスタンスファミリー 特徴 汎用 A1/T3/T2/M5/M5a/M4/T3a その名の通り一般的に使われるやつ。これ選んでおけば間違いない。 コンピューティング最適化 C5/C5n/C4 コンピューティング集約型ワークロード用 メモリ最適化 R5/R5a/R4/X1e/X1/ハイメモリ/z1d メモリ負荷の高いアプリケーション用 高速コンピューティング P3/P2/G3/F1 汎用GPUコンピューティングアプリケーション用。コンピューティング最適化よりすごいって認識でいいんかね ストレージ最適化 H1/I3/I3en/D2 HDDベースのローカルストレージ。高いディスクスループット実現。 ATMから始まるやつは汎用、Cから始まるのはコンピューティング最適化、RXZはメモリ、PGFは高速コンピューティング、HIDがストレージ。
ATMとCは覚えれそう。それ以外はノリで。無理か。ちなみにT3/T2はバーストできる。Tは特別のTだな!
バーストとは、CPUリソースが通常低負荷で急に高負荷になった場合、低負荷のときの貯金使っていいよってやつ。
バースト使い切っても高負荷のままでやばくなるパターンを想定して、Unlimitedっていうオプションもある(かっこいい)
たとえるなら、スマホの通信制限かかったら「〇〇円で1G追加しませんか?」みたいなメールくるじゃん。それ。インスタンス購入オプション
オンデマンド
初期費用なしで使った時間に応じての支払い。スタンダード。リザーブドインスタンス(RI)
一年もしくは三年の予約をすることで割引を受けれる。アマプラは月額300円だけど、一年で入るなら3000円にするよ!みたいなやつと同じ。使う期間がきまっててその間ずっと起動しっぱなしとかならいいんじゃない。
ちなみに期間中にインスタンスタイプを変更したくなった場合(メモリがもっと欲しい!とか)、差額を払えば変更可能になった。スポットインスタンス
AWSが未使用のキャパを需要によって時価で提供。
要するに、ユーザが「500円までなら払うよ!」って宣言し、AWS側の料金が300円とかなら利用可能。
逆に、ユーザが「500円までなら払うよ!」って宣言し、AWS側の料金が600円とかなら使用不可に。使用不可期間は障害と同じ扱い。中断される。
なので、必要なログがインスタンス内にあるとかだと取り出せなくなるので停止前に別ストレージに移しておく必要がある。ハードウェア占有インスタンス
Dedicated Hosts
上記二つは先述済み。どちらもHW占領できるがハードウェア占有はインスタンスごとの課金であり、しかもHW選べない。
インスタンスごとなので、支払い形態は上記のオンデマンド、リザーブド、スポットから選べる。
Dedicated HostsはHW自体の課金でどこにしようか選べる。キーペア
インスタンス作成時に公開鍵と秘密鍵が作られる。作成時に秘密鍵を自分でダウンロードできる。SSHログインしたいとき等、この鍵を実行ディレクトリに置いておけば、認証してくれてログインできる。ただし権限変更しないと無理なパターンもあるのでchmodで変更してください。
とりあえずここまで。