- 投稿日:2020-02-09T23:43:30+09:00
敢えてRubyで学ぶ「ゼロから作るDeep Learning」禁断のPyCallからのpickleファイルの取り込み
「ゼロから作るDeep Learning」の72p「3.6.2 ニューラルネットワークの推論処理」では、pythonのpickleファイルを呼び出している。このpickleファイルはraw binaryなので、簡単に呼び出せない。そこで、禁断のPyCallからpickleファイルを取り込んでみる。
環境構築
# pycallのインストール $ gem install pycall # pyenvの取り込み $ git clone https://github.com/pyenv/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile # .bash_profileの再取り込み $ source ~/.bash_profile # pythonのバージョン確認 $ python3 --version 3.7.3 # pyenvの共有ライブラリインストール $ CONFIGURE_OPTS="--enable-shared" pyenv install 3.7.3 # numpyのインストール $ pip install numpyこれで準備完了
取り込み方
require 'pycall/import' include PyCall::Import pyimport :numpy pyimport :pickle pkl = open("sample_weight.pkl", "rb") network = pickle.load(pkl)備考:ハマったこと
普通にpycallを呼び出すだけだと怒られた。
> require 'pycall/import' true > include PyCall::Import Object > hoge = PyCall.eval('0') Traceback (most recent call last): 9: from /usr/local/bin/irb:23:in `<main>' 8: from /usr/local/bin/irb:23:in `load' 7: from /usr/local/lib/ruby/gems/2.7.0/gems/irb-1.2.1/exe/irb:11:in `<top (required)>' 6: from (irb):3 5: from /usr/local/bundle/gems/pycall-1.3.0/lib/pycall.rb:39:in `eval' 4: from /usr/local/bundle/gems/pycall-1.3.0/lib/pycall.rb:62:in `import_module' 3: from /usr/local/bundle/gems/pycall-1.3.0/lib/pycall/init.rb:16:in `const_missing' 2: from /usr/local/bundle/gems/pycall-1.3.0/lib/pycall/init.rb:35:in `init' 1: from /usr/local/bundle/gems/pycall-1.3.0/lib/pycall/libpython/finder.rb:95:in `find_libpython' PyCall::PythonNotFound (PyCall::PythonNotFound)以下の記事を参考にpyenvの共有ライブラリインストールで解消できた
参考記事
pyenv と pyenv-virtualenv をインストールする
https://qiita.com/shigechioyo/items/198211e84f8e0e9a5c18
[Ruby] 機械学習①:Ruby入門
https://qiita.com/chamao/items/cd62715c6be2fad2f8e7
- 投稿日:2020-02-09T23:17:42+09:00
pythonで2の平方根を数百万桁計算
pythonで2の平行根を数百万桁計算するプログラムを作成。
計算方法は逆数に対する下記ニュートン反復法を使用。
反復式 : x = x + x*(1 - x*x/2) / 2
この方式の特徴は多数桁除算が無い。pythonでn桁の計算部分は下記。
def sqrt2(n):
bit, dec = 40, 12
d12 = 10000*10000*10000
x = int( math.sqrt(2)(1 << bit) )
while dec <= n:
dec = dec << 1
d2 = 1 << (2*bit)
x0 = (x*x) >> 1
x1 = (d2 - x0) >> 1
x2 = (x*x1) >> bit
x = (x << bit) + x2 + 1
bit = 2bit
d12 = d12*d12
x = (x*d12) >> bit
dec_o = (n // 100)*100
return xx=sqrt2(n)の計算結果を10進数に変換するにはformat(x)が必要。
全体のpythonは https://ecc-256.com のpythonプログラム欄に掲載。
sqrt2をダウンロードし、sqrt2.pyと先頭のinportをimportに変更する。
コマンドプロンプトでpython sqrt2.pyと打ち込む。
次に、出力桁数を打ち込む。100万桁なら、1000000windows10のパソコン(4Ghz)の300万,600万,1200万の計算時間は下記。
x=sqrt(n) : 6.7, 19.9, 59.7 (s)
format(x) : 136, 545, 2180 (s)sqrt(2)の計算より、出力用に10進数変換の方が大幅に時間がかかる。
sqrt(2)は桁数2倍で3倍の時間、10進数変換は4倍の時間がかかる。
計算の乗算はカラツバ法で、変換の乗算は定義式のままが原因。pythonでも、10進1000桁程度(値は2進のint)で位取りし、高速剰余変換(FMT)を適用すれば高速化可能。1億桁計算し、10進数の文字に変換するまで含めて4Ghzのパソコンで3分以内を目標(2月末)。
- 投稿日:2020-02-09T23:12:54+09:00
fbprophetをインストールする際の注意点
fbprophetとは
- Facebook社製の時系列解析ツール
- 簡単に時系列解析ができる
- R,Pythonに対応
インストールする際の注意点
windowsの場合C++コンパイラが必要
公式にもありますが、anaconda推奨anaconda環境の場合はcondaでインストールする
conda install -c conda-forge fbprophetholidays==0.10.1だとエラー ※fbprophet==0.5
holidays==0.9.11にダウングレードしたところ問題なし
- 投稿日:2020-02-09T22:57:08+09:00
pythonでのGUI作成 tkinter使用して 2
概要
前回の続きです
前回とりあえずアプリが起動するところまでは確認できましたが、二重起動の防止などいろいろ足りていない部分を追加してみました必要なもの
- python 3.7.2
- pandas
- numpy
公開場所
githubで公開しています。
https://github.com/snowpff14/etcresource/tree/master/pythonGui処理内容
大まかな部分は前回を参照。
- 処理を動かすところをthreadで呼び出していましたが、ロックがなかったので何度でも呼び出せてしまう状態でした。そこで今回はロックを取得して取れなければメッセージを出す形にしています。
def doExecute(self): if self.lock.acquire(blocking=FALSE): if messagebox.askokcancel('実行前確認','処理を実行しますか?'): self.progressValue=0 self.progressStatusBar.configure(value=self.progressValue) self.progressBar.configure(maximum=10,value=0) self.progressBar.start(100) th = threading.Thread(target=self._executer) th.start() else: self.lock.release() else: messagebox.showwarning('エラー','処理実行中です')
- 処理の状況をラベル表示する際目立つように太字かつ白背景に赤字に設定しています。
PL.TLabelというところは任意に設定できる項目です。こちらを後段のラベルを定義するときに指定しています。labelStyle=ttk.Style() labelStyle.configure('PL.TLabel',font=('Helvetica',10,'bold'),background='white',foreground='red') self.progressMsgBox=ttk.Label(content,textvariable=self.progressMsg,width=70,style='PL.TLabel') self.progressMsg.set('処理待機中')
- 処理の進捗状況を示すように途中でメッセージを変更してプログレスバーを進めるようにしています。今回は画面の操作起動前と後なのであまり変化はありませんが、複数ステップある場合は都度都度更新を行うことで画面の様子を見ることができます。 以下は呼び出し元から表示するメッセージと進捗状況を受け取っています。
def progressSequence(self,msg,sequenceValue=0): self.progressMsg.set(msg) self.progressValue=self.progressValue+sequenceValue self.progressStatusBar.configure(value=self.progressValue)
- 以下のように画面の要素の
afterメソッドを呼ぶことで処理を呼び出すことができます。処理実行後画面に変化を与えるために表示領域の更新をroot.update_idletasks()で行っています。self.progressMsgBox.after(10,self.progressSequence('処理実行中',sequenceValue=50)) root.update_idletasks()
- プログレスバーは画面の要素を作成するところで指定を行います
indeterminateは処理が動いていることを示すため常に動いているバーdeterminateは全体の進捗のうちどこまで進んだかを示すのに使用します。self.progressBar=ttk.Progressbar(content,orient=HORIZONTAL,length=140,mode='indeterminate') self.progressBar.configure(maximum=10,value=0) self.progressStatusBar=ttk.Progressbar(content,orient=HORIZONTAL,length=140,mode='determinate')
determinateのプログレスバーの場合はvalueに値を設定すればその分進みます(最大値100として状況に合わせて設定します)indeterminateのプログレスバーはstartで起動、stopで停止しますpython self.progressValue=0 self.progressStatusBar.configure(value=self.progressValue) self.progressBar.configure(maximum=10,value=0) self.progressBar.start(100)- ボタンに設定する関数は引数を渡したいときはlambdaで渡すか、partialを使用します。 以下は起動前に引数を渡せるようにpartialを使っています。
def preparation(self,logfilename): self._executer=partial(self.execute,logfilename)とりあえず今回はここまで。
もうちょっと何か出来たら続きを作成します。
- 投稿日:2020-02-09T22:56:26+09:00
AtCoder Beginner Contest 154 参戦記
AtCoder Beginner Contest 154 参戦記
ABC154A - Remaining Balls
2分半で突破. 変数が5つもあることに一瞬戸惑ったけど、書くだけだった.
S, T = input().split() A, B = map(int, input().split()) U = input() if U == S: A -= 1 else: B -= 1 print(A, B)ABC154B - I miss you...
1分で突破. 書くだけ.
S = input() print('x' * len(S))ABC154C - Distinct or Not
2分で突破. 書くだけ. ABC063B - Varied を思い出した.
N = int(input()) A = list(map(int, input().split())) if len(set(A)) == N: print('YES') else: print('NO')ABC154D - Dice in Line
10分で突破. リスト p から、平均値のリスト m を作って、幅 K の Sliding Window で最大値を求めるだけ.
N, K = map(int, input().split()) p = list(map(int, input().split())) m = [(e + 1) / 2 for e in p] t = sum(m[0:K]) result = t for i in range(N - K): t -= m[i] t += m[i + K] if t > result: result = t print(result)ABC154E - Almost Everywhere Zero
敗退. 前に解けなくて放置したアレと同じ問題だなあと思ったが、そのときに解いておかなかったのが運の尽きだった…….
- 投稿日:2020-02-09T22:46:18+09:00
abc154 参戦レポ
A
Aにしては若干ややこしい
S, T = input().split() A, B = map(int, input().split()) U = input() if U == S: print(A - 1, B) else: print(A, B - 1)B
制約の縛りも特にない。Aより簡単な気がする
S = list(input()) for _ in range(len(S)): print("x", end='')C
Counterはやっぱり強い。YESを小文字で書いてしまい1WA。この手のミスは今後気を付けたい(atcoderさん、できればどっちかに統一して。。。)
from collections import Counter N = int(input()) A = Counter(map(int, input().split())) A = A.values() for a in A: if a != 1: print("NO") exit() print("YES")D
期待値の線形性を利用。アルゴリズムは尺取り法の知識が必要。tmp_ansの更新を忘れておりバグ取りに時間がかかった。
N, K = map(int, input().split()) p = list(map(int, input().split())) Expected_val = [] for val in p: sum_val = (val * (val + 1)) // 2 Expected_val.append(sum_val / val) # print(Expected_val) left = 0 right = K ans = sum(Expected_val[left:right]) tmp_ans = ans # print(ans) for i in range(N - K): tmp_ans = tmp_ans - Expected_val[left + i] + Expected_val[right + i] if tmp_ans > ans: ans = tmp_ans print(ans)E
桁DP。判別方法は入力のでかすぎる値が合図。前に解いたのが10月だったのでコードを発掘。必要箇所をいじいじし無事AC。これは嬉しい。地球に生まれてよかった。
from functools import lru_cache N = input() K = int(input()) ## lru_cacheを使ってメモ化 @lru_cache(maxsize=None) def rec(k,tight,sum_val): # 最後まで探索した時、問題条件に応じて1 or 0を返す if k == len(N): if sum_val == K and sum_val != 0: return 1 else: return 0 # 現在の桁がtightであるか否かで終了する条件を変更する x = int(N[k]) if tight: r = x else: r = 9 res = 0 for i in range(r + 1): if i == 0: res += rec(k + 1 ,tight and i == r, sum_val) else: res += rec(k + 1, tight and i == r, sum_val + 1) return res print(rec(0 , True , 0))F
勉強中。けんちょんさんが謎の公式を呟いていたので調査なう。$C(r, r) + C(r+1, r) + ... + C(n, r) = C(n+1, r+1)$
- 投稿日:2020-02-09T22:41:43+09:00
【DynamoDB】【Docker】docker-composeでDynamoDBとDjangoの開発環境を構築する
docker-composeでDynamoDBとDjangoの開発環境を構築する
はじめに
DynamoDBって安くて早くていいですよね。そんなDynamoDBをローカルで開発するためのDockerImageがあるってご存知ですか?そんなDockerImageを利用した開発環境構築の一例を照会します。
環境
プロダクション環境に即して利用するイメージのバージョンは以下です。
DynamoDBのGUI操作用にdynamodb-adminを利用します。Nodeはその環境を一緒に構築する際に利用します。
環境 バージョン Python 3.7.4 MySQL 5.7 Node 10.16.3-alpine 環境構築
DjangoとMySQL
完全にゼロから構築するのでまずはDjangoプロジェクトを開始します。
公式のDjangoイメージはバージョンが古いので自分で作ります。$ django-admin startproject dynamodb_example $ cd dynamodb_example/ $ touch docker-compose.yml $ touch DockerfileFROM python:3.7.4 RUN apt-get update RUN apt-get install -y --no-install-recommends apt-utils gettext RUN mkdir /app; mkdir /app/dynamodb_example WORKDIR /app COPY dynamodb_example /app/dynamodb_example COPY requirements.txt /app/ COPY manage.py /app/ RUN pip install -r requirements.txt EXPOSE 8080 CMD ["python", "manage.py", "runserver", "0.0.0.0:8080"]docker-compose.ymlversion: "3" services: mysql: container_name: example-mysql ports: - 53306:3306 image: mysql:5.7 command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci volumes: - ./persist/mysql:/var/lib/mysql restart: always environment: MYSQL_USER: example MYSQL_PASSWORD: example MYSQL_DATABASE: example MYSQL_ROOT_PASSWORD: example django: container_name: example-django build: . volumes: - .:/app working_dir: /app command: sh -c "./wait-for-it.sh db:3306; python3 manage.py runserver 0.0.0.0:8000" env_file: .env ports: - 58080:8000 depends_on: - mysqlポートが50000台なのは絶対被りたくないからです。とくに意味はありません。
DynamoDBと接続するためのライブラリはboto3とそれをWrapしているpynamodbを入れておきます。requirements.txtboto3 pynamodb Django==2.2.4 djangorestframework==3.10.3 django-filter mysqlclient==1.3.13環境変数の意味をあまりなしていないですが一応…
DB_ENGINE=django.db.backends.mysql DB_HOST=mysql DB_DATABASE=example DB_USERNAME=root DB_PASSWORD=example DB_PORT=3306とりあえずDjangoとMySQLの疎通を確認したいのでDjangoのDATABASESを書き換えます。
setting.pyDATABASES = { 'default': { 'ENGINE': os.getenv('DB_ENGINE'), 'NAME': os.getenv('DB_DATABASE'), 'USER': os.getenv('DB_USERNAME'), 'PASSWORD': os.getenv('DB_PASSWORD'), 'HOST': os.getenv('DB_HOST'), 'OPTIONS': { 'init_command': 'SET foreign_key_checks = 0;', 'charset': 'utf8mb4', }, } }ここまで来たらとりあえず起動するか確認します。
$ docker-compose up -d $ docker-compose exec django bash $ python manage.py migrate問題なければ、次にDynamoDB Localとdynamodb-adminを入れてきます。
DynamoDB Local
docker-compose.ymlにdynamodbを記載します。
永続化ようにコマンドの最後にdbPathを指定します。docker-compose.ymldynamodb: container_name: example-dynamodb image: amazon/dynamodb-local command: -jar DynamoDBLocal.jar -dbPath /home/dynamodblocal/data volumes: - ./persist/dynamodb:/home/dynamodblocal/data ports: - 50706:8000dynamodb-admin
公式イメージがあったのですが、作ってしまったのでそちらを利用します。
$ mkdir dynamodb-admin $ touch dynamodb-admin/Dockerfile $ touch dynamodb-admin/.envFROM node:10.16.3-alpine RUN ["apk", "update"] RUN ["npm", "install", "dynamodb-admin", "-g"] EXPOSE 50727 CMD ["dynamodb-admin", "-p", "50727"]環境変数の
DYNAMO_ENDPOINTにはdynamodbのコンテナーサービス名とコンテナ側のポートを指定します。DYNAMO_ENDPOINT=http://dynamodb:8000 AWS_REGION=ap-northeast-1 AWS_ACCESS_KEY_ID=ACCESS_ID AWS_SECRET_ACCESS_KEY=ACCESS_KEYこのdyanamodb-adminを加えた最終的なdocker-compose.ymlファイルは以下のようになります。
docker-compose.ymlversion: "3" services: dynamodb: container_name: example-dynamodb image: amazon/dynamodb-local command: -jar DynamoDBLocal.jar -dbPath /home/dynamodblocal/data volumes: - ./persist/dynamodb:/home/dynamodblocal/data ports: - 50706:8000 dynamodb-admin: container_name: example-dynamodb-admin build: dynamodb-admin/ command: dynamodb-admin -p 8000 env_file: dynamodb-admin/.env ports: - 50727:8000 depends_on: - dynamodb mysql: container_name: example-mysql ports: - 53306:3306 image: mysql:5.7 command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci volumes: - ./persist/mysql:/var/lib/mysql restart: always environment: MYSQL_USER: example MYSQL_PASSWORD: example MYSQL_DATABASE: example MYSQL_ROOT_PASSWORD: example django: container_name: example-django build: . volumes: - .:/app working_dir: /app command: sh -c "./wait-for-it.sh db:3306; python3 manage.py runserver 0.0.0.0:8000" env_file: .env ports: - 58080:8000 depends_on: - mysql - dynamodbhttp://localhost:50727をブラウザで表示して以下のように表示されていれば成功です。
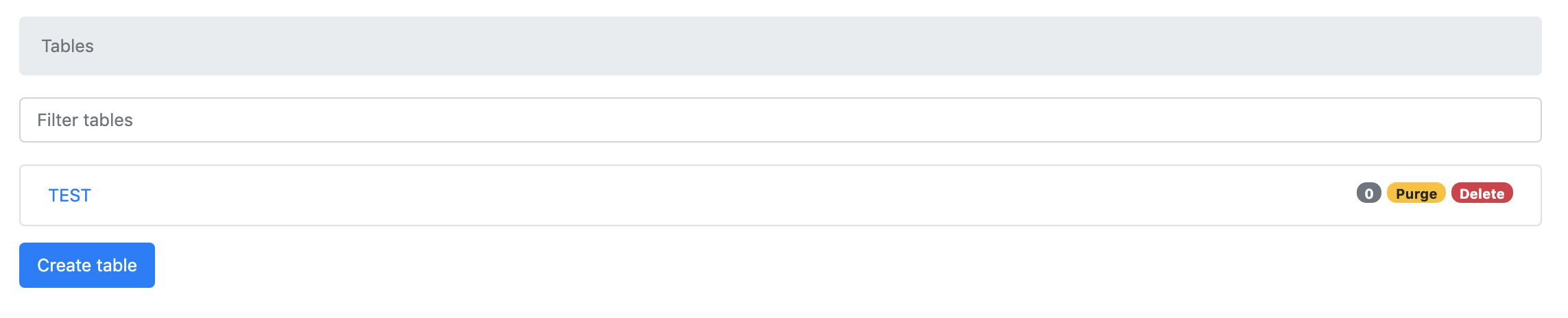
Create Table等したい放題です。永続化の確認
適当にテーブルを作ってみます。
作成されました。
コンテナーを削除して再起動します。
$ docker-compose down $ docker-compose up -dhttp://localhost:50727を開いて先程のテーブルが残っていれば永続化もうまく行っています。
最後に
このリポジトリーは以下で公開します。今後更新するかもしれないのでtagは1.0.0です。
https://github.com/Cohey0727/example_dynamodb
もしよければ利用してください。

- 投稿日:2020-02-09T22:41:06+09:00
Docker を使って Djangoチュートリアルの Polls アプリを AWS ECS へデプロイするサンプルのようなもの
はじめに
こちらはDjangoのチュートリアル「はじめての Django アプリ作成、その1」のPolls(投票)アプリを Amazon Web Service(AWS) の Elastic Container Service(ECS) へデプロイするサンプル(のようなもの)です。
nginx + uwsgi + python + django + MySQL DB という構成で docker-compose を使っています。
また、デプロイには AWS CLI と ECS CLI を使い AWSコンソールは(ほとんど)使いません。(EC2インスタンス への ssh 接続でセキュリティグループを編集するときにだけコンソールを使用します)前半はローカル環境上で docker-compose を使い Polls アプリを作成して動かすところまで。
後半で前半に作成した Polls アプリを ECS へデプロイします。ソースは GitHub 上に公開しています。
(但しDjangoアプリの部分はこれから作るため含まれていません。)
https://github.com/Brokenumbrella/django-ecs-sample
この説明の中でも「1. 前準備」の中で上記から clone します。ここでは説明しないこと
- git や docker のインストール方法と使い方など。
- AWS アカウントの取得方法や AWS の仕組みなど。
- AWS CLI, ECS CLI のインストール方法や使い方など。
前提条件
- git をインストールしている。
- docker をインストールしている。
- AWS のアカウントを持っている(フルアクセス出来るものが良いと思います)。
もしAWSのアカウントが無くても前半のローカル環境で動かす所までは出来ます。- AWS CLI をインストールしている。
インストール方法は後半でAWSサイトへのリンクを載せています。
そこでインストールするのでも構いません。
インストールしなくても前半のローカル環境で動かす所までは出来ます。- ECS CLI をインストールしている。
インストール方法は後半でAWSサイトへのリンクを載せています。
そこでインストールするのでも構いません。
インストールしなくても前半のローカル環境で動かす所までは出来ます。- インターネットに接続できる。
- 作るプロジェクトの名前は mysite です。
(変更したい場合は Grep で mysite の文字列を全て変更してください)Python は docker コンテナで構築するため事前にインストールしておく必要はありません。
と言いたい所ですが、AWS CLI が Python 2.7 もしくは 3.4 以降を使います。
AWS CLI をインストールする際は入っていなければ Python のインストールが必要です。動作確認済みの環境
Ubuntu 18.04.3 LTS
Docker version 19.03.5, build 633a0ea838
docker-compose version 1.25.0, build 0a186604Windows 10 Enterprise 1903 build 18362.418
Docker version 19.03.5, build 633a0ea
docker-compose version 1.24.1, build 4667896b
(Docker for Windows を使用)【注意】Windows ではコマンドの実行を Git-Bash 上で行って下さい。
PowerShell や コマンドプロンプト では id コマンドが使えず動きません。構成
- OS : Alpine3
- 言語 : Python3(Python公式の DockerImage をベースにしています)
- フレームワーク : Django2
- WSGIサーバー : uwsgi
- Webサーバ : nginx
- データベース : mysql8
各インストールバージョン
- Alpine 3.1.0
- Python 3.7.4
- Django 2.2.10 以上 3.0 未満
- uwsgi 2.0.18 以上 3.0 未満
- nginx 1.17.8
- MySQL 8.0.19
- mysqlclient 1.4.6 以上 2.0 未満
動作確認は上記の一番低い(確認時のリリース)バージョンで行っています。
Python と Alpine は Python の公式リポジトリにあればどれでも使う事が出来ると思います。
nginx の別バージョンを使いたい場合は ./docker-compose.yml と ./web/Dockerfile-nginx を編集して下さい。
MySQL の別バージョンを使いたい場合は ./docker-compose.yml と ./web/Dockerfile-mysql を編集して下さい。
Django, uwsgi, mysqlclient の別バージョンを使いたい場合は ./web/requirements.txt を編集して下さい。
※Django は3.0がリリースされていますが、テストできておらず 2.2 を対象としています。
※Python 3.8.1 + apine 3.11 ではDjangoアプリ作成後の動作確認だけで、アプリの作成はチェック出来ていません。多分動くのでは無いかと・・・お約束
- 個人的なテストとして作成したものでなんら保証が出来るようなものではありません。
- 試される際は自己責任でお願いします。
- 私自身の理解が足りておらず「コピペで動いている」ところもあります。
- とはいえ、この情報が誰かの役に立てばいいなと思っています。
1. 前準備
開発用のソースを GitHub から取得(clone)します
1. プロジェクト用のフォルダを作り移動します
例)home フォルダに myprojects というフォルダを作成してそこに取得する場合。
shell$ mkdir ~/myprojects/ && cd ~/myprojects/このフォルダ下に django-ecs-sample というフォルダが作成されます。
2. GitHub からテストプロジェクトを clone します
shell$ git clone https://github.com/brokenumbrella/django-ecs-sample.gitWindowsで git の改行コードの自動変換がONの場合には注意が必要です
git のインストール方法によっては、改行コードが CR+LF で取得されます。
もし web/run-my-app.sh ファイルを VSCode などのエディターで開いた際に改行コードが CRLF だった場合は、LF に変更して下さい。
linux では CRLF のシェルスクリプトファイルは実行できずエラーとなります。
(私はこれの解決に1日かかってしまいました)3. clone したフォルダ及びファイルの構成
django-ecs-sample フォルダは下記の構成になっています。
+ db + conf - mysql_my.cnf # MySQL8 で使う設定ファイル + nginx - uwsgi_params # uwsgi の設定ファイル + conf - default.conf # nginx の設定ファイル + web - Dockerfile # docker-compose でビルドする際に使う Dockerfile - Dockerfile-mysql # ECS へデプロイする際に使う MySQL用 Dockerfile - Dockerfile-nginx # ECS へデプロイする際に使う nginx用 Dockerfile - Dockerfile-web # ECS へデプロイする際に使う Web(Django)アプリ用 Dockerfile - requirements.txt # Python のライブラリ定義ファイル - uwsgi.ini # uwsgi 用の設定ファイル(プロジェクトフォルダーへコピーします) - run-my-app.sh # ECS へデプロイする際に使う Webアプリ起動用シェルスクリプト - .gitignore - docker-compose.yml # docker-compose 用ファイル - docker-compose-ecs.yml # ECS へデプロイする際の docker-compose ファイル - docom.sh # docker-compose を簡単に利用する為のスクリプト - esc-params.yml # ECS へデプロイする際のタスク定義ファイル - readme.md # 簡単なドキュメント + log # ログ保存用のフォルダ + uwsgi - __init__.txt + static # staticファイル用のフォルダ - __init__.txt + src # プロジェクトを入れるソースフォルダ - __init__.txt作成する Django アプリのソースファイルは ./src/ フォルダに置きます。
log, static, src はdocker-composeする際にマウントする際に必要になるため、Gitリポジトリ上では単なる空フォルダです。
gitで空フォルダを保持するために __init__.txt を入れています。dockerコンテナ内でのユーザーの追加と変更について
dockerコンテナに(ホストマシンの)現在のユーザーを追加するため linux の id コマンドを使っています。
ユーザー切り替えを行う事で docker 側でマウントしたフォルダに現在のユーザーと同じ権限でファイルやフォルダを作成出来ます。
ユーザーを指定していない場合は root ユーザーでファイルが作られるため、ローカル環境で編集するには root への昇格が必要になります。
そういった手間を減らすためと、docker は root ユーザー以外で運用する方が良いらしいのでこのようにしています。
このため動作確認済みの環境以外では動かない可能性もあります。ご注意下さい。docom.shについて
上記の id コマンドを使ったユーザーの設定などを簡略化するため
docom.shというスクリプトファイルを同封しました。
docker-compose を起動する際にユーザーID等をセットするためのシェルスクリプトで下記のようになっています。shell$ cat docom.sh DUID=$(id -u) DGID=$(id -g) MYSQL_PW=PWRoot1 docker-compose $1 $2 $3 $4 $5 $6 $7 $8 $9環境変数の DUID と DGID には id コマンドを使ってユーザーIDとグループID を入れています。
(ちなみに名前ではなく 1000 といった番号です)
また MYSQL_PW=PWRoot1 の部分は MySQL DB のルートユーザーパスワードになっています。
実際に使う際は変更して頂くようお願いします。(このままでも動きますが)
変更の際は web/mydb.cnf(プロジェクトフォルダへコピーしてればそちらも) と docker-compose-ecs.yml にも同じパスワードを設定して下さい。
"PWRoot1" を Grep で一括変換する方が良いと思います。上記の設定を一時的に環境変数へセットし docker-compose を呼び出しています。
今後はコード簡便化のため、このスクリプトを使って説明していきます。
このスクリプトは開発やテストを目的としており、セキュリティに注意すべき環境では他の方法を検討して下さい。(ここ大事)2.ローカル環境で Django Polls アプリを動かしてみよう
それでは本題に入りましょう。
docker compose を使いローカル環境で nginx, MySQL, Web(Djangoアプリ) の3つのコンテナを起動して動かし Polls アプリを作ります。1. web 用の docker image を作成するためビルドします
まず Python+Django 環境を構築するために docker-compose build を行います。
下記コマンドを docom.sh ファイルのあるフォルダで実行します。shell$ ./docom.sh build web初めてビルドする際には時間がかかります。
(ベースコンテナをダウンロードするためインターネットへの接続スピードにも影響されます)
下記のようにSuccessfully builtと出ればビルド成功です。shellSuccessfully built 036160743a81 Successfully tagged django-ecs-sample_web:latestここでビルドに使うファイルについて簡単に説明します。
(1)Web コンテナをビルドするための Dockerfile です
./web/DockerfileFROM python:3.7.4-alpine3.10 # alpine では apk を使う(add でインストール) # nginx, suprevisor, uwsgi のインストール(gcc,build-base,linux-headersはuwsgiインストール時に使うためインストールする) # libffi-dev, mysql-dev, mysql-client, python3-dev は mysql を使うためにインストール RUN apk update && apk add --no-cache \ gcc \ build-base \ linux-headers \ libffi-dev \ mysql-dev \ python3-dev && \ pip3 install --upgrade pip # requirements.txt から Django などの必要なライブラリをインストール # 不要になった gcc などをアンインストール COPY ./requirements.txt /code/ RUN pip3 install -r /code/requirements.txt && \ apk del gcc build-base linux-headers libffi-dev python3-dev # 8001番ポートを開放する(ことを宣言する) EXPOSE 8001 # 作業用フォルダを /code/ にする WORKDIR /code/ # ユーザーを作成してカレントユーザーにする(一般ユーザーで動かすため) # docker-compose.yml の args に指定した uid と gid を使えるように宣言する # ユーザー名、グループ名は id と一緒にしておく ARG DUID ARG DGID # ユーザーの作成 RUN addgroup -S -g $DGID $DGID && \ adduser -S -u $DUID -g $DGID $DUID # ユーザーを切り替える USER $DUID # 実行コマンドは docker-compose.yml の方で指定するためここはシェルを指定しておく CMD ["/bin/sh"]
- python:3.7.4-alpine3.10 イメージを元にしています。
DockerHubに公開されていれば、FROM python:3.7.4-alpine3.10 の部分を変更する事で別バージョンのPythonやalpineを使うことも出来ます。
但しバージョンによってはテストアプリが動かない可能性もあります。- ライブラリのインストール時に必要な gcc 等をインストールしています。
- nginx との接続用に 8001 番ポートを開けています。
- /code/ を作業フォルダにしていますが、docker-compose.yml でローカル環境の ./src/ フォルダへマウントします。 つまりこのコンテナ内で /code/ 下に置いたファイルはローカル環境の ./src/ 下に置かれます。 (マウントについては dockerのドキュメント等をご参照下さい)
- mysql-client は Djangoアプリから MySQL を使うのに必要がないためインストールしていません。
- ユーザーIDとグループIDを環境変数から取得してユーザーを作成します。
(2)インストールする Python ライブラリを指定するファイルです。
./web/requirements.txtdjango>=2.2.10, <3.0 # django 2.2.10 で動作確認済み、2.?.? の間は動くと仮定している uwsgi>=2.0.18, <3.0 # uwsgi 2.0.18 で動作確認済み、2.?.? の間は動くと仮定している mysqlclient>=1.4.6, <2.0 # mysqlclient 1.4.6 で動作確認済み、1.?.? の間は動くと仮定しているdjango, uwsgi, mysqlclient をインストールしています。
こちらで動作確認したのはそれぞれ >= で書かれているバージョンです。
もしアプリが起動しない場合、>= を == に変更し、,以降をコメントアウトする事でバージョンを固定してみて下さい。例)django==2.2.10(3)docker compose で使用するYAMLファイルです。
docker-compose.ymlversion: '3' services: db: # MySQL DB 用の設定(この db という名前で web から DB HOST の指定ができる) image : mysql:8.0.19 container_name: mysql.db volumes: # マウントフォルダの指定 - ./db/data:/var/lib/mysql # データの永続化を行う - ./db/conf/:/etc/mysql/conf.d/ # 設定ファイルをここから読み込ませる - ./db/sqls:/docker-entrypoint-initdb.d # 初期データを与える場合はここから読み込ませる environment: - MYSQL_ROOT_PASSWORD=${MYSQL_PW} # rootパスワードの設定 - MYSQL_DATABASE=mysite # 作成するDatabase名 - TZ=Asia/Tokyo # タイムゾーンを日本時間に変更 web: # Web(Django)アプリケーション 用の設定 build: # ビルド設定 context: ./web # ./web/Dockerfile を用いてビルドする args: # Dockerfile へ渡す環境変数の指定 - DUID=${DUID} - DGID=${DGID} environment: # 実行時に設定する環境変数 - MYSQL_HOST=${MYSQL_HOST} user: ${DUID}:${DGID} # 実行時のユーザー指定 container_name: django.web command: uwsgi --ini /code/mysite/mysite/uwsgi.ini volumes: # マウントフォルダの指定 - ./src:/code # アプリケーションのソースフォルダ - ./static:/static # static ファイルフォルダ - ./log/uwsgi/:/var/log/uwsgi # uwsgi の設定ファイルをここから読み込ませる expose: # 開放するポート - "8001" links: # db コンテナを先に立ち上げてから web を立ち上げる - db nginx : # nginx 用の設定 image: nginx:1.17.8 container_name: nginx ports: # 8080 ポートを 80 ポートへ - "8080:80" volumes: # マウントフォルダの指定 - ./nginx/conf:/etc/nginx/conf.d # nginx 用の設定ファイルをここから読み込ませる - ./nginx/uwsgi_params:/etc/nginx/uwsgi_params # uwsgi のパラメータファイルをここから読ませる - ./static:/static # static ファイルフォルダ - ./log/nginx/:/var/log/nginx # ログファイルをここへ保存する(永続化) depends_on: - web # web コンテナの後から起動させる2. Django project を作成します
上記 1. で作った docker 環境を使いプロジェクトを作成します。
django-admin startproject コマンドを使い mysite という名前で新規作成します。
(mysite 以外の名前にする場合は MySQL DB のテーブル名等も変更する必要があり、 grep 検索などで置換して下さい。)下記コマンドを実行してプロジェクトを作成します。
shell$ ./docom.sh run web django-admin startproject mysiteコンテナ内で /code/ フォルダに、ローカル環境では ./src/ フォルダにプロジェクトが作成されます。
もし ./src/mysite/ フォルダが作成されていない場合はMySQLサーバーの立ち上げで失敗している可能性があります。
db/data/フォルダのファイルとサブフォルダを全て削除してやり直してみて下さい。3.
./web/uwsgi.iniファイルを./src/mysite/mysite/へコピーしますローカル環境で下記コマンドを使ってコピーします。
shell$ cp ./web/uwsgi.ini ./src/mysite/mysite/これは uwsgi 用の設定ファイルです。
コピーする事でコンテナ内では/code/mysite/mysite/uwsgi.iniに配置される事になります。./web/uwsgi.ini[uwsgi] # この prjname に django-admin startproject で作成したプロジェクト名を指定します。 prjname=mysite basepath=/code/%(prjname)/ chdir=%(basepath) module = %(prjname).wsgi:application socket = :8001 wsgi-file = %(basepath)%(prjname)/wsgi.py logto = /var/log/uwsgi/uwsgi.log py-autoreload = 1 # usage: # このファイルは django-admin startproject の後に /code/prjname/prjname/ へコピーする。4. nginx の設定ファイルについて
これは nginx 用の設定ファイルです。
このファイルは nginx コンテナを実行する際にマウントさせて読み込ませるためコピーなどは必要ありません。(こんなファイルだという説明だけです)./nginx/conf/default.confupstream django { ip_hash; server web:8001; } server { # the port your site will be served on listen 80; server_name localhost compute.amazonaws.com; # substitute your machine's IP address or FQDN charset utf-8; client_max_body_size 75M; # adjust to taste location /static { alias /static; } location / { include /etc/nginx/uwsgi_params; # the uwsgi_params file you installed uwsgi_pass django; } }
- django との接続に web コンテナの 8001 ポートを使うように指定します。(ここは理解不足です)
- server_name では localhost と EC2 の 2つを指定しています。実際にはドメインやIPアドレスを指定するようにして下さい。
- location /static{ alias } で /static へのアクセスを nginx コンテナの /static フォルダにマッピングさせています。
ここは後ほど collectstatic で /static フォルダに集約させます。- location /{} で /static 以外のアクセスを全て django に処理させるようにしています。
5. MySQL DB を使うように設定を行います。
Django はデフォルトで DataBase に sqlite3 を使うようになっています。
ここでは MySQL DB を使わせるように設定を変更します。
- ./src/mysite/mysite/settings.py を編集します。
./src/mysite/mysite/settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }上記の部分を下記のように書き換えます。
./src/mysite/mysite/settings.pyDB_SETTING_FILE = os.path.join(BASE_DIR,'mydb.cnf') DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'OPTIONS':{ 'read_default_file':DB_SETTING_FILE, }, } }DB ENGINE には django.db.backends.mysql を指定します。
MySQL 関連の設定は次に説明する mysql.cnf ファイルから読み込むように指定しています。
ついでに、Djangoで使う文字コードを日本語に、時間も日本時間へ変更しておきます。
LANGUAGE_CODE を 'ja' に、TIME_ZONE を 'Asia/Tokyo' に変更します。./src/mysite/mysite/settings.pyLANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'
- ./web/mydb.cnf を ./src/mysite/ へコピーします。
Django から MySQL DB へアクセスするための設定をこのファイルに纏めています。 コードは下記のようになっています。./web/mydb.cnf[client] database = mysite user = root password = PWRoot1 host = db port = 3306 default-character-set = utf8mb4
- 'database' には docker-compose.yml の service: db: environment: MYSQL_DATABASE に指定したDataBase名を入れます。
- 'user' は root ユーザーでアクセスさせています。
- 'password' には docom.sh で指定した MYSQL_PW の値を指定して下さい。
- 'host' には docker-compose.yml で定義した service の名前 'db' を指定します。後は docker compose がよしなにやってくれます。
- 'port' は 一般的なMySQLで使用するポート番号 3306 を設定しています。
- 'default-character-set' で絵文字などに対応したutf8mb4 を指定しています。
6. docker-compose up でサーバーを立ち上げてアプリケーションを動かします
下記コマンドでサーバーが起動します。
(-d を指定してバックグラウンドでコンテナを実行させています。)shell$ ./docom.sh up -d Starting mysql.db ... done Starting django.web ... done Starting nginx ... done上記のように3つのコンテナが起動したら、Webブラウザを立ち上げて http://localhost:8080 にアクセスします。
下記の Django のデモ画面が表示されれば問題なくサーバーが起動できています。
おめでとうございます!
7. docker-compose down サーバーを終了します
下記コマンドを実行します。
shell$ ./docom.sh down Stopping nginx ... done Stopping django.web ... done Stopping mysql.db ... done Removing nginx ... done Removing django.web ... done Removing mysql.db ... done Removing network django-ecs-sample_default上記のようにコンテナが停止・削除されます。
これ以降はhttp://localhost:8080へアクセスしてもエラーが返されます。8. ログファイルはローカル環境の
./log/フォルダ下に保存されていますサーバーが起動しない等の場合は下記フォルダのログを見て原因を調べることが出来ます。
./log/nginx/ : nginx が出力するログ ./log/uwsgi/ : uwsgi が出力するログ9. Django アプリケーションを作ります
ここで作るアプリケーションはチュートリアルの
pollsです。
また以下2つの方法があります。どちらでも好きな方法で作る事が出来ます。
- 方法1:サーバーを起動させて docker exec によりコンテナ内に入って作業する
まずサーバーを起動していない場合は起動させます。
shell$ ./docom.sh up -dサーバーが立ち上がったら docker exec で django.web に shell で接続します。
(Windows10 の場合は winpty をつけて下さい)shell$ docker exec -it django.web sh ※windows10 の場合 $ winpty docker exec -it django.web sh
/code $とプロンプトが出ればコンテナ内に入れています。
misite プロジェクトフォルダ上で python manage.py startapp を実行します。shell/code $ cd mysite /code $ python manage.py startapp polls /code $ exit※exit でコンテナから抜けます。
起動したサーバーを停止します。
shell$ ./docom.sh down
- 方法2:docker-compose run web で作る場合
アプリケーションの作成は manage.py のあるフォルダで行うためワークフォルダを指定する必要があります。
docker-compose run -w //code/mysite/で指定できるので、これを使います。
(ubuntu では /code/mysite/ でも動いたのですが、Windows10 では //code/mysite/ でなければ動きませんでした。)shell$ ./docom.sh run -w //code/mysite/ web python manage.py startapp pollsどちらの方法でもアプリケーションを作成できます。
ローカルに ./src/mysite/polls フォルダが出来ていればアプリケーションの作成は成功です。10. アプリケーションへアクセスできるようにビューとurlsを指定します
ここからは Django の Polls チュートリアルとほぼ同様のコーディング作業になります。
(1) ./src/mysite/polls/views.py を下記のように編集します。
./src/mysite/polls/views.pyfrom django.http import HttpResponse def index(request): return HttpResponse("Hello, world. You're at the polls index.")(2) ./src/mysite/polls/ フォルダに urls.py ファイルを作成し、下記コードを書きます。
./src/mysite/polls/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ](3) 次に ./src/mysite/urls.py ファイルを下記のように書き換えます。
./src/mysite/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('polls/', include('polls.urls')), path('admin/', admin.site.urls), ]このルーティングによって
http://localhost/polls/へアクセスする事で 1 の inxex(request) が呼び出されレスポンスが返されるようになります。11. ここまで出来た Polls アプリを動かしてみましょう
下記コマンドでサーバーを立ち上げます。
$ ./docom.sh up -dWebブラウザで http://localhost:8080/polls へアクセスします。
URL には /polls を付けて下さい。先ほどと同じlocaphost:8080だけでは Page not found(404) エラーが出ます。
ブラウザ画面にHello, world. You're at the polls index.と表示されていればここまでは成功です。
サーバーを停止させます。shell$ ./docom.sh down12. collectstatic でスタティックファイルを所定のフォルダへ集めます
AWS ECS などへ公開する場合は Javascript や css 、画像などの static ファイルを1箇所にまとめる必要があります。
また、今回 nginx で /static/ をホストしているためここで纏めておきます。
これらのファイルを纏めるために django では collectstatic が用意されています。
collectstatic を実行するには前準備をする必要がありますので、そこから説明します。(1). はじめに ./src/mysite/mysite/settings.py の最後に STATIC_ROOT の設定を追記します。
これを入れ忘れると collectstatic で下記のエラーが出ますので、これが出たらここに戻って確認して下さい。django.core.exceptions.ImproperlyConfigured: You're using the staticfiles app without having set the STATIC_ROOT setting to a filesystem path.では下記のように追記します。
./src/mysite/mysite/settings.py| 〜いろいろ〜 | STATIC_URL = '/static/' STATIC_ROOT = STATIC_URL # これを追加する(2). collectstatic を行います。
サーバーが立ち上がっていなければ起動します。$ ./docom.sh up -ddocker exec でコンテナに入ります。(ubuntu の場合)
$ docker exec -it django.web sh(Windows10 の場合は winptyをつけて)
$ winpty docker exec -it django.web sh
/code $とプロンプトが出ればコンテナ内に入れています。/code $ cd mysite /code $ python manage.py collectstatic /code $ exitもしくは docker-compose run を使い以下の1行でも作成可能です。
$ ./docom.sh run -w //code/mysite/ web python manage.py collectstatic./static フォルダにファイルが存在する場合は途中で下記のような問いが出ますので、yes を入力して下さい。
This will overwrite existing files! Are you sure you want to do this? Type 'yes' to continue, or 'no' to cancel:./static フォルダに admin フォルダが追加されている事を確認できると思います。
13. Djangoチュートリアルに従い Polls アプリを作成します
ここからは、下記公式サイトのチュートリアルのその2から7までを実際に行います。
(「高度なチュートリアル」はやらなくても大丈夫です。)
はじめての Django アプリ作成、その2 モデルの作成チュートリアル内で
python manage.py 〜という部分が出てきた際は「9.Django アプリケーションを作ります」と同じように docker exec もしくは docker-compose run を使います。
例えばpython manage.py makemigrations pollsを行う場合下記の手順で実行してください。
サーバーが立ち上がっていなければ起動します。$ ./docom.sh up -dubuntu の場合
$ docker exec -it django.web shWindows10 の場合
$ winpty docker exec -it django.web sh
/code $とプロンプトが出ればコンテナ内に入れています。/code $ cd mysite /code $ python manage.py makemigrations polls /code $ exit./docom.sh up -d はサーバーを起動してない場合に必要です。起動していれば docker exec ~ から実行してください。
またサーバーを起動しておけば、途中でもブラウザの表示更新(リロード)するだけ変更が適用されますので都度サーバーの起動、終了を行う必要はありません。
もしくは$ ./docom.sh run -w //code/mysite/ web python manage.py makemigrations pollsでも行うことができます。
ただし残念ながら、superuser を作るコマンドpython mange.py createsuperuserだけは docker-compose run では実行できません。ここではユーザー名などの入力を求められるからです。このため createsuperuser を行う際は docker exec 〜 を使って下さい。
それから、python shell を実行させている際にソースを修正しても起動している shell には反映されません。
shell を起動しなおす必要があります。
(起動しなおしたら必要であれば from datetime などの初期化処理からやり直します)ここを完了しなくても次の「2.AWS ECS へデプロイしよう」へ進みデプロイする事は出来ます。
"Hello, world. You're at the polls index."と出るだけですが・・・2.AWS ECS へデプロイしよう
1. AWS 側の準備
(1) Python をインストールします
AWS CLI をインストールするに先立ち、Python 2.7以降か 3.4 以降が必要になるためインストールします。
既にインストール済みの場合は 2. へ進んでください。
もし Python がインストールされているかわからない場合は、下記コマンドで確認出来ます。$ python --versionPython 3 の場合は
$ python3 --versionバージョン番号が出ればインストールされています。(但し 2.7 or 3.4 未満の場合はアップデートが必要です)
ここでは Python3 の最新版をインストールします。
Python公式ページhttps://www.python.org/からダウンロード、インストールします。
Windows10 へインストールする場合はこちらも参考にさせていただきました。
Python3のインストール
今回は最新安定板の3.8.1をインストールしました。
インストールが完了すると下記のようにして確認できます。$ python --version Python 3.8.1(2) AWS CLI のインストールと設定
AWS CLI の詳細は下記を参照してください。
AWS コマンドラインインターフェイスインストールと設定は下記公式ページの手順で行ってください。
2020年2月現在では バージョン2は評価版での公開のため、バージョン1の方をインストールします。Windows10 では下記のページから MSI インストーラをダウンロードしてインストールしました。
また、Windows10では下記のドキュメントに従い PowerShell を使います。
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-windows.html#install-msi-on-windows続けて設定を行います。
AWS CLI の設定これ以降の説明では「AWS CLI のかんたん設定」の
aws configureを実行したとして進めます。
もし「複数のプロファイルの作成」で profile 名を指定した場合はaws --profile profuser ecr 〜〜とプロファイル名を指定してコマンドを実行してください。(profuser の部分には作成したプロファイル名を指定します)(3) ECS CLI のインストールと設定
ECS CLI の詳細は下記を参照してください。
AWS ECS コマンドラインインターフェースの使用
インストールは下記公式ページの手順で行ってください。
現時点では Version2 はまだ評価版なので、Version1 をインストールします。
また、ここでは下記のドキュメントに従い Windows10 では PowerShell を使います。ここも公式にお任せでOKかと思ったのですが、Windows でステップ2の「MD5 サムを使用した検証」をやる場合は注意が必要です。
(オプションなので飛ばす人はこの注意も必要ないです)
まずは手順通りに実行してみます。ps c:\> Get-FileHash ecs-cli.exe -Algorithm MD5 Resolve-Path : パス 'C:\ecs-cli.exe' が存在しないため検出できません。 ~云々~のように、ecs-cli.exe ファイルが存在しないとエラーが出ました。
これは、ステップ1でC:\Program Files\Amazon\ECSCLIフォルダに ecs-cli.exe をダウンロードしているためです。
このためフルパスを指定して実行します。PS C:\> Get-FileHash "C:\Program Files\Amazon\ECSCLI\ecs-cli.exe" -Algorithm MD5これでハッシュ値がとれたと思います。
また、確認のためダウンロードした 'md5.txt' ファイルは確認が済めば不要なので削除して構いません。2. docker image をビルドします
(1) ./src/mysite/mysite/settings.pyを修正します
ALLOWED_HOST に何処でも動作するよう '*' を指定しておきます。
運用するサーバーが決まったらここにはhogehoge.comや '100.100.100.100' などドメインやIPアドレスを指定します。
また、実運用の際には DEBUG = False にしましょう。./src/mysite/mysite/settings.py〜いろいろ〜 ALLOWED_HOSTS = ['*'] # ここ 〜いろいろ〜(2) MySQL, nginx, web の設定やソースコードを含めた Dockerfile について説明します。
前半のローカル環境では MySQL, nginx の設定ファイルを docker の volumes を使って指定しましたが、ECS上で動かすにはコンテナ内にそれらも含めます。
また web の docker image には作成したアプリケーションのソースファイル(./src/ フォルダ以下)を含める必要もあります。
そのため、デプロイ用に web, MySQL, nginx 用 の Dockerfile を作成し、それぞれにビルドします。
各 Dockerfile は ./web/ フォルダに入っていますが、下記のようになっています。./web/Dockerfile-mysqlFROM mysql:8.0.19 # 設定ファイルをコピーする COPY ./db/conf/ /etc/mysql/conf.d/./web/Dockerfile-nginxFROM nginx:1.17.8 # 設定ファイルをコピーする COPY ./nginx/conf /etc/nginx/conf.d COPY ./nginx/uwsgi_params /etc/nginx/uwsgi_params # static ファイルは nginx で返すためこのコンテナにコピーしておく COPY ./static /static./web/Dockerfile-webFROM python:3.7.4-alpine3.10 # alpine では apk を使う(add でインストール) # nginx, suprevisor, uwsgi のインストール(gcc,build-base,linux-headersはuwsgiインストール時に使うためインストールする) # libffi-dev, mysql-dev, python3-dev は mysql を使うためにインストール RUN apk update && apk add --no-cache \ gcc \ build-base \ linux-headers \ libffi-dev \ mysql-dev \ python3-dev && \ pip3 install --upgrade pip # requirements.txt から Django などの必要なライブラリをインストール # 不要になった gcc などをアンインストール COPY ./web/requirements.txt /code/ RUN pip3 install -r /code/requirements.txt && \ apk del gcc build-base linux-headers libffi-dev python3-dev # ソースファイルを /code/ フォルダへコピーする COPY ./src/ /code/ # 実行時のスクリプトファイルをコピーする COPY ./web/run-my-app.sh /code/ # 8001番ポートを開放する EXPOSE 8001 # 作業用フォルダを /code/ にする WORKDIR /code/ # ユーザーを作成してカレントユーザーにする(一般ユーザーで動かすため) # docker-compose.yml の args に指定した uid と gid を使えるように宣言する # ユーザー名、グループ名は id と一緒にしておく ARG DUID ARG DGID # ユーザーの作成 RUN addgroup -S -g $DGID $DGID && \ adduser -S -u $DUID -g $DGID $DUID # uwsgi 用のログパスを追加 RUN mkdir /var/log/uwsgi/ RUN chown -R $DUID:$DGID /var/log && \ chown -R $DUID:$DGID /code USER $DUID(3) 3つのDockerfileをビルドして docker image を作ります
今回は docker コマンドの build を使います。
前半の docker-compose ではないため docom.sh は使いません、ご注意ください。
下記のコマンドでビルドを行います。$ docker build -t django-ecs-sample-web -f ./web/Dockerfile-web --build-arg DUID=$(id -u) --build-arg DGID=$(id -g) . $ docker build -t django-ecs-sample-mysql -f ./web/Dockerfile-mysql . $ docker build -t django-ecs-sample-nginx -f ./web/Dockerfile-nginx .
- -t django-ecs-sample-web など、それぞれのイメージに対して今後利用しやすいように名前をつけています。
- -f でビルドに使う Dockerfile を指定しています。
- --build-arg DUID=$(id -u) --build-arg DGID=$(id -g) の部分はdocom.shで環境変数をdocker-composeへ渡していたのと同じです。 docker build では --build-arg オプションで環境変数を渡すところに注意が必要です。
3. docker-compose-ecs.yml について
ecs へデプロイするために専用ファイルを用意しました。
また各 image には仮の URL を指定しています。
後ほど ECR にリポジトリを作成して、そのURLに書き換えます。docker-compose-ecs.ymlversion: '3' services: db: image : XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-mysql:latest volumes: - /db/data:/var/lib/mysql # データの永続化を行う environment: - MYSQL_ROOT_PASSWORD=PWRoot1 - MYSQL_DATABASE=mysite - TZ=Asia/Tokyo web: image: XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-web:latest command: sh /code/run-my-app.sh links: - db nginx : image: XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-nginx:latest ports: - "80:80" links: - webこの中で webコンテナの起動コマンドを下記のように変えています。
web: command: sh /code/run-my-app.sh
これは django の migrate で DB へのマイグレーション処理を行ってから uwsgi を起動するスクリプトです。
初回起動時に MySQL の準備が間に合わず migrate に失敗する事から成功するまで無限ループさせています。
無限ループは正直恐ろしいんですが、これに失敗するって事は MySQL が立ち上がらないということなので、いいかなと。
実際には他にもっとスマート(本来の)やり方があるんじゃないかと思います。
そもそも RDS などのマネージドサービス使えば前もって起動させておき、migrate なども別のタイミングで行うことが出来るはず、などなどのご意見もあると思いますが。
どなたかこの場合に他に何か良策があれば教えて頂けると助かります。
ともかく先へ進めるため下記のスクリプトを動かすようにしました。./web/run-my-app.sh#!/bin/sh app=mysite while : do if python /code/$app/manage.py migrate; then break else sleep 1 fi done uwsgi --ini /code/$app/$app/uwsgi.ini exit 04. AWS ECR にリポジトリを作成し、dockerイメージをプッシュします
ECS へデプロイする際 docker image は ECR(Elastic Container Registry) か docker hub に置く必要があります。
今回は AWS で完結させたいので、先程ビルドした3つの docker image を AWS の ECRへプッシュします。(1) AWS ECR にプッシュ用のリポジトリを作成します
始めに下記コマンドで、web 用の django-ecs-sample-web リポジトリを作成します
shell$ aws ecr create-repository --repository-name django-ecs-sample-web作成に成功すれば下記のようにJSON形式で作成したリポジトリの情報が返されコンソール画面に表示されます。
json{ "repository": { "repositoryArn": "arn:aws:ecr:ap-northeast-1:XXXXXXXXXXXX:repository/django-ecs-sample-web", "registryId": "XXXXXXXXXXXX", "repositoryName": "django-ecs-sample-web", "repositoryUri": "XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-web", "createdAt": 1575769798.0, "imageTagMutability": "MUTABLE", "imageScanningConfiguration": { "scanOnPush": false } } }この時に返される"repositoryUri"の"XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-web"を控えておきます。
もしくは、URL の構成は
[AWS ACCOUNT ID].dkr.ecr.[reagion].amazonaws.com/[repository name]
のようになっているので、アカウントID, リージョン名, リポジトリ名 から導き出すことも出来ます。(今回のリポジトリ名は django-ecs-sample-web です。)
これは push 用のタグ付けや docker-compose-ecs.yml でイメージの読み込み先として使うため後々必要になります。
続いて nginx、mysql 用のリポジトリも作成し、同様にrepositoryUriを控えます。shll$ aws ecr create-repository --repository-name django-ecs-sample-nginx $ aws ecr create-repository --repository-name django-ecs-sample-mysql(2) ./docker-compose-ecs.yml ファイルを修正します
リポジトリが出来たので、./docker-compose-ecs.yml ファイルの image 項目をリポジトリ URI に書き換えます。
./docker-compose-ecs.yml を開くと下記の用に XXXXXXXXXXXX.dkr.ecr となっていますので、ここを(1)で控えた URI に書き換えてください。(もしくはデプロイするアカウントIDをXXXXXXXXXXXXに入れるので構いません。)./docker-compose-ecs.ymlmysql: image: XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-mysql:latest web: image: XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-web:latest nginx: image: XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-nginx:latest(3) ECR へプッシュできるよう docker image にタグを付けます
下記のように docker tag コマンドを使用します。
XXXXXXXXXXXX の URI 部分は、リポジトリ作成時に控えた repositoryUri の値を指定して下さい。shell$ docker tag django-ecs-sample-nginx:latest XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-nginx:latest $ docker tag django-ecs-sample-web:latest XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-web:latest $ docker tag django-ecs-sample-mysql:latest XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-mysql:latestタグが付いたかは下記のようにして確認出来ます。
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-nginx latest 1dd8c2bc8f1d 1 days ago 127MB django-ecs-sample-nginx latest 1dd8c2bc8f1d 1 days ago 127MB XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-web latest 7633e0977266 1 days ago 462MB django-ecs-sample-web latest 7633e0977266 1 days ago 462MB XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-mysql latest fdbaa71f3406 1 days ago 456MB django-ecs-sample-mysql latest fdbaa71f3406 1 days ago 456MB(4) ECR リポジトリにへプッシュします
下記のように ecs-cli push コマンドを使います。
XXXXXXXXXXXX の URI 部分は、リポジトリ作成時に控えた repositoryUri の値を指定して下さい。shell$ ecs-cli push XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-web:latestINFO[0000] Pushing image repository=XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-nginx tag=latest INFO[0015] Image pushedのように表示されれば成功です。
また下記はインターネット接続を切った時に出たエラーメッセージです。
何らかのエラーが出るとこのように表示されるので適宜対応してください。FATA[0000] Error executing 'push': unable to create repository: RequestError: send request failed caused by: Post https://api.ecr.ap-northeast-1.amazonaws.com/: dial tcp: lookup api.ecr.ap-northeast-1.amazonaws.com: no such host続けて nginx と mysql のコンテナも push します。
$ ecs-cli push XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-nginx:latest $ ecs-cli push XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-mysql:latest5. AWS ECS にクラスターを作成します
Amazon ECS クラスターとは、タスクまたはサービスの論理グループです。
EC2 を使用してタスクまたはサービスを実行している場合、クラスターはコンテナインスタンスのグループ化でもあります。
とのことですが、私は単純にインスタンス、サービス、タスクの容れ物だと思って使っています。
詳細は下記の公式サイトを参照して下さい。
Amazon ECS クラスター(1) ecs-params.yml ファイルを作成します
Amazon ECS タスク定義にはdocker-compose.ymlには対応しないフィールドがあり、それを ecs-params.yml で指定します。
今回はリポジトリ内に用意しているためそれを使います。
ここでは無料枠があれば無料となる t2.micro マシンを使いたいのでメモリーサイズを調整しています。
このファイルが無い場合メモリーサイズは各コンテナに 500MB ずつ割り当てられるようです。
つまり3つコンテナを立ち上げるには 1.5GB 以上のメモリーを持ったEC2インスタンス(t3.smallやt2.smallなど)が必要になります。
t2.micro は残念がら 1GB しかメモリーがないので調整が必要ということです。
また、逆にもっと大きなメモリーサイズのEC2インスタンスを立ち上げて大量のメモリーを割り当てる場合にも設定が必要です。
但し下記は t2.micro で動かせたというだけで最適化は行っていません。ecs-params.ymlversion: 1 task_definition: services: nginx: mem_limit: 150m mem_reservation: 128m web: mem_limit: 448m mem_reservation: 400m db: mem_limit: 448m mem_reservation: 400mファイル名が ecs-params.yml なら自動的に読み込まれますが、他の名前を付ける場合は、--ecs-params にパス名を指定します。
詳細は下記の公式ドキュメントを参照して下さい。
Amazon ECS パラメータの使用(2) ECS クラスター設定を作成します
この設定ではクラスター用のインスタンスの種類などを指定します。
ECS CLI を使い下記のコマンドを実行する事でクラスター設定を作成できます。$ ecs-cli configure --cluster django-ecs-sample --default-launch-type EC2 --config-name django-ecs-sample --region ap-northeast-1指定しているパラメータについて
- --cluster : ここにはクラスター名を指定します。
- --default-launch-type : ここには作成するインスタンスの種類を指定します。 EC2 を指定すると EC2インスタンスを立ち上げて docker 環境を構築します。 サーバレスの Fargate を指定することもできます。
- --config-name : 作成する config の名前を指定します。
- --region : EC2を立ち上げるリージョンを指定します(例 ap-northeast-1)
下記のように返ってくれば django-ecs-sample という名前のクラスター設定が保存され、使えるようになります。
INFO[0000] Saved ECS CLI cluster configuration django-ecs-sample.(3) ECS クラスターを作成します
- EC2 keypair を用意します。 superuser を作成する際に ssh で接続するため、ここで作成しておきます。 既存のキーペアーを持っていて使える場合はここを飛ばしても大丈夫です。 下記のコマンドを実行します。
shell$ aws ec2 create-key-pair --key-name MyKeyPair --query 'KeyMaterial' --output text > MyKeyPair.pem'MyKeyPair' と 'MyKeyPair.pem' の部分にはわかりやすい名前を指定します。
出来た pem ファイルを ~/.ssh/ フォルダへ保存しておきます。shell$ mkdir ~/.ssh $ mv ./MyKeyPair.pem ~/.sshまた、作成した pem ファイルにはアクセス制限をかけておく事が推奨されていますので下記コマンドを実行します。(ubuntuの場合のみ)
shell$ chmod 400 ~/.ssh/MyKeyPair.pem詳細は下記の公式ページを参照して下さい。
Amazon EC2 キーペアの作成、表示、削除
- ECS クラスターを作成します。 ここでは t2.micro のEC2インスタンスを1つ作ります。 (無料枠を使えない場合は t3.micro の方が安いのでそちらでも構いません。)
shell$ ecs-cli up --keypair MyKeyPair --capability-iam --size 1 --instance-type t2.micro --cluster-config django-ecs-sample --ecs-profile default'MyKeyPair' には先ほど作成した keypair 名を指定します。
"Cluster creation succeeded."` と表示されれば成功です。
起動には数分間かかりますので気長に待ちましょう。
またここでEC2インスタンスが立ち上がります。
一応最初の1年間は無料枠となっているインスタンスを使っていますが、他にもインスタンスを立ち上げている等々条件によって無料にならない場合もあります。
ECSクラスターの破棄を行うまでは課金されますので中断する場合などはご注意ください。
下記のように表示されればクラスターの作成は成功です。shellVPC created: vpc-043b9c071191494f9 Security Group created: sg-0289045419da1393c Subnet created: subnet-04f7f97d1b133656a Subnet created: subnet-0d323c836901d8e40 Cluster creation succeeded.何らかの理由でクラスターの作成をやり直す場合は、一旦下記のコマンドでクラスターを削除してからやり直してください。
shell$ ecs-cli down --force --cluster-config django-ecs-sample6. 作成したクラスターにサービスを作成し、アプリケーションをデプロイします
下記コマンドでサービスを作成してデプロイします。
shell$ ecs-cli compose --file docker-compose-ecs.yml service up --cluster-config django-ecs-sample
"ECS Service has reached a stable state"と表示されればデプロイ成功です。
以下のコマンドで実行しているタスクを確認できます。shell$ ecs-cli compose service ps Name State Ports TaskDefinition Health 26f9f2f5-7ff2-4f59-9852-1299c9572a59/nginx RUNNING 3.113.1.25:80->80/tcp django-ecs-sample:5 UNKNOWN 26f9f2f5-7ff2-4f59-9852-1299c9572a59/db RUNNING django-ecs-sample:5 UNKNOWN 26f9f2f5-7ff2-4f59-9852-1299c9572a59/web RUNNING django-ecs-sample:5 UNKNOWN上記の場合 nginx の Ports に出力されている 3.113.1.25 がアクセスするIPアドレスとなります。
ブラウザを使ってアクセスするために控えておいて下さい。7. Webブラウザで動作確認を行います
ChromeやFirefoxなどWebブラウザを起動し、上記で確認した nginx の Ports アドレスを指定します。
Chrome,Firefoxhttp://3.113.1.25/polls ※上記のURI 3.113.1.25 の部分はnginxのPortsアドレスに置き換えて下さい。ブラウザ上に下記のように表示されれば成功です。
No polls are available.もしも
OperationalError at /polls/ (2002, "Can't connect to MySQL server on 'db' (115)")のようなエラーが出た場合は MySQL との接続がうまく行っていない可能性が高いです。
mydb.cnf の password と docker-compose-ecs.yml の MYSQL_ROOT_PASSWORD が同じか確認して下さい。
上記が違っていた場合は docker-compose-ecs.yml の MYSQL_ROOT_PASSWORD を mydb.cnf の password に合わせてください。
修正後、下記「後始末(サービスとリソースを削除する)」の1,2を実行してサービスとクラスターを削除した後、クラスターの作成からやり直してみて下さい。8. ssh で AWS EC2 へログインし createsuperuser を行います
7 で
No polls are available.と表示されれば MySQL との接続も問題なくアプリは完成!
と言いたい所ですが・・・
残念ながら superuser を作成していないため /admin でログインする事が出来ず Questions 等のデータを作成する事も出来ません。
どうしても createsuperuser を上手く実現する方法を思いつけず、苦し紛れの ssh 接続で対応する事にします。手順
(1) EC2 のセキュリティグループのインバウンドで ssh を開放します
この設定はAWSコンソール上で行います。
Webブラウザを立ち上げてAWSアカウントへログインします。
EC2 コンソール画面を表示させ、ECS用に作成された EC2 インスタンスを選択します。
(もしくは ECS コンソール画面からインスタンスを選択して EC2 コンソールを出す事も出来ます。)
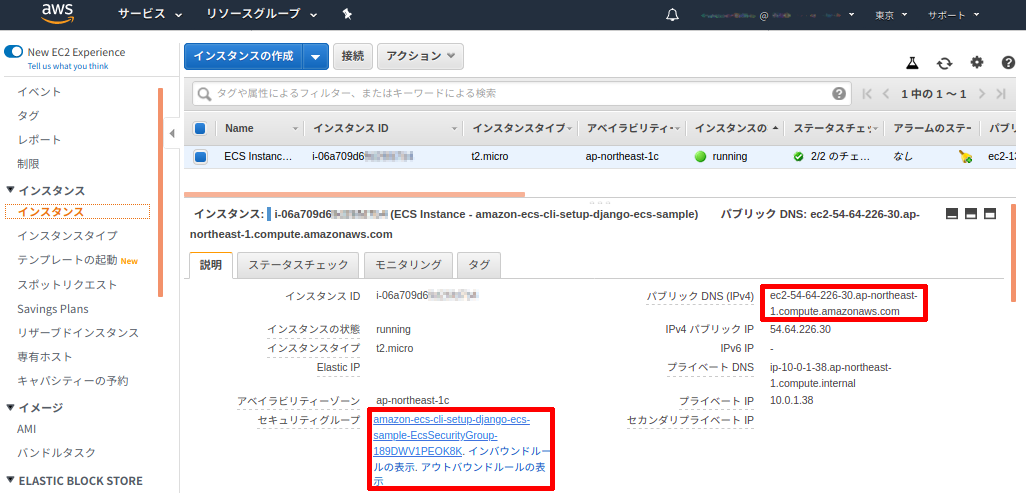
下記画像のインスタンスの詳細の右側赤枠にある「パブリック DNS (IPv4)」の値(ec2-XX-XX-XX-XX.ap-northeast-1.compute.amazonaws.com)を控えておきます。
続いて左下赤枠にあるセキュリティグループのリンクをクリックしてセキュリティグループ画面を表示します。
セキュリティグループの詳細で「インバウンド」タブを選択、「編集」ボタンをクリックします。
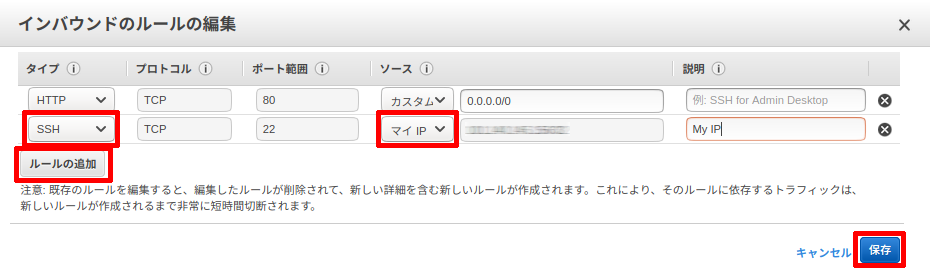
インバウンドルールの編集画面で、ルールの追加ボタンをクリックします。
タイプを「SSH」にしソースで「マイIP」を選択して保存をクリックします。
固定IPアドレスを使っている場合はIPアドレスが変わらないためこのままで問題ありませんが、それ以外の方は速やかに進めて下さい。
(2) ターミナル(もしくはGitBash)に戻り、ssh 接続を行います
下記のコマンドで ssh 接続を行います。
MyKeyPair.pem には クラスター作成時に作ったものを指定します。
また、ec2-XX-XX-XX-XX.ap-northeast-1.compute.amazonaws.comの部分には上記 (1) で控えたパブリック DNS (IPv4)を入れます。
ec2-user というユーザー名は Amazon Linux 2 または Amazon Linux AMI を使った際に決まっているユーザー名です。
この辺りは SSH を使用した Linux インスタンスへの接続 を参照して下さい。shell$ ssh -i ~/.ssh/MyKeyPair.pem ec2-user@ec2-XX-XX-XX-XX.ap-northeast-1.compute.amazonaws.com初めて ssh 接続する際は下記のような問いがでるので、yes と入力します。
shellThe authenticity of host 'ec2-XX-XX-XX-XX.ap-northeast-1.compute.amazonaws.com (XX.XX.XX.XX)' can't be established. ECDSA key fingerprint is SHA256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX. Are you sure you want to continue connecting (yes/no)?ログインに成功すると下記のようなプロンプト画面になります。
shell[ec2-user@ip-10-0-1-38 ~]$続いて起動している web コンテナのIDを調べます。
shell$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9b923b483350 XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-nginx:latest "nginx -g 'daemon of…" 40 minutes ago Up 40 minutes 0.0.0.0:80->80/tcp ecs-django-ecs-sample-20-nginx-94c0f0a1f7c3e09a2200 8f06e3da926f XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-web:latest "sh /code/run-my-app…" 40 minutes ago Up 40 minutes 8001/tcp ecs-django-ecs-sample-20-web-e69bd295ee81ad978201 719a8da19a44 XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/django-ecs-sample-mysql:latest "docker-entrypoint.s…" 41 minutes ago Up 41 minutes 3306/tcp, 33060/tcp ecs-django-ecs-sample-20-db-96eacce1d2fba3c8f501 862ad405bf2b amazon/amazon-ecs-agent:latest "/agent" 41 minutes ago Up 41 minutes (healthy) ecs-agent上記の場合 django-ecs-sample-web:latest のタグが付いているコンテナIDは 8f06e3da926f なので、docker exec を使ってこのコンテナに入ります。
shell$ docker exec -it 8f06e3da926f sh
/code $とプロンプトが変わります。
これ以降ssh接続中の説明では $ 以前はプロンプトです。$ 以降をコマンドとして入力して下さい。
cd mysiteでフォルダを /code/mysite/ へ移動します。念の為manege.pyがあるか ls コマンドで調べます。shell/code $ cd mysite /code/mysite $ ls -l total 20 -rwxr-xr-x 1 197612 197121 626 Jan 18 09:51 manage.py -rwxr-xr-x 1 197612 197121 119 Jan 18 09:54 mydb.cnf drwxr-xr-x 1 197612 197121 4096 Jan 18 09:56 mysite drwxr-xr-x 1 197612 197121 4096 Jan 20 14:51 pollsmanage.py がありましたね。
それでは下記コマンドでスーパーユーザーを作成しましょう。shell/code/mysite $ python manage.py createsuperuser ユーザー名 (leave blank to use '1000'): Admin メールアドレス: Admin@test.com Password: Password (again): Superuser created successfully.上記のように、ユーザー名、EMailアドレス、パスワードの入力を求められるので適宜入力します。
(上記はサンプルです。)shellSuperuser created successfully.と出れば作成完了です。
docker コンテナと EC2 から exit でログアウトします。shell/code/mysite $ exit [ec2-user@ip-10-0-1-38 ~]$ exit ログアウト Connection to ec2-XX-XX-XX-XX.ap-northeast-1.compute.amazonaws.com closed.上記のように表示されれば ssh を使った作業は全て完了です。
(3) セキュリティグループに追加した ssh の設定を削除します
先程の AWS コンソールに戻りインバウンドルールの編集画面で下記の画像の赤枠✖をクリックし、保存します。
これで晴れて /admin でログインし、Questions と Choices を作成して Polls アプリを動かすことが出来ます。
お疲れ様でした!9. 後始末(サービスとリソースを削除しておきましょう)
テストが終わったら無駄な課金をさけるためリソースを削除しておきます。
下記の手順で削除していきます。(1) サービスを削除します
shell$ ecs-cli compose --file docker-compose-ecs.yml service rm(2) クラスターを削除します
shell$ ecs-cli down --force 〜〜〜 INFO[0121] Deleted cluster cluster=django-ecs-sampleという表示が出れば無事クラスターが削除されています。
(3) ECR イメージを削除します
ECR も課金されますので、使わなくなったら削除しておきましょう。(微々たる金額ですが)
shell$ aws ecr batch-delete-image --repository-name django-ecs-sample-web --image-ids imageTag=latest $ aws ecr batch-delete-image --repository-name django-ecs-sample-nginx --image-ids imageTag=latest $ aws ecr batch-delete-image --repository-name django-ecs-sample-mysql --image-ids imageTag=latest(4) ECR リポジトリを削除します
shell$ aws ecr delete-repository --repository-name django-ecs-sample-web $ aws ecr delete-repository --repository-name django-ecs-sample-nginx $ aws ecr delete-repository --repository-name django-ecs-sample-mysqlここまで削除すれば課金されることはありません。
但し、ecs-cli push を複数回行った場合など latest 以外のイメージがあるとリポジトリの削除に失敗する事があります。
そのような場合は AWS コンソールから ECR リソースを確認して削除してください。(5) タスク定義を登録解除します
タスクも不要なのでリストアップされないようにしておきます。
まず下記コマンドでタスク定義のリストを表示させます。shell$ aws ecs list-task-definitions下記のようにタスク定義が表示されます。
shell{ "taskDefinitionArns": [ "arn:aws:ecs:ap-northeast-1:XXXXXXXXXXXX:task-definition/django-ecs-sample:1", "arn:aws:ecs:ap-northeast-1:XXXXXXXXXXXX:task-definition/django-ecs-sample:2", "arn:aws:ecs:ap-northeast-1:XXXXXXXXXXXX:task-definition/django-ecs-sample:3", "arn:aws:ecs:ap-northeast-1:XXXXXXXXXXXX:task-definition/django-ecs-sample:4" ] }今回いろいろテストしたためタスク定義が4つも作られていました(1度で成功した場合は1つしか作られません)。
これはタスク設定に変更があった場合 compose service up の度に新しいものが作成されるようです。
これら全てが不要ですので、下記のコマンドで登録解除します。shell$ aws ecs deregister-task-definition --task-definition django-ecs-sample:1django-ecs-sample:1 の部分に上記リストのタスク名とリビジョンを入れます。
登録解除されれば解除されたタスク情報が返されます。
全てのリビジョンを登録解除して再びlist-task-definitionsで確認するとshell{ "taskDefinitionArns": [ ] }と、登録解除された事がわかります。
先程から登録解除と書いているようにあくまで解除されただけで削除されたわけではありません。
下記のコマンドで INACTIVE なタスク定義をリストアップさせると、shell$ aws ecs list-task-definitions --status INACTIVE { "taskDefinitionArns": [ "arn:aws:ecs:ap-northeast-1:XXXXXXXXXXXX:task-definition/django-ecs-sample:1", "arn:aws:ecs:ap-northeast-1:XXXXXXXXXXXX:task-definition/django-ecs-sample:2", "arn:aws:ecs:ap-northeast-1:XXXXXXXXXXXX:task-definition/django-ecs-sample:3", "arn:aws:ecs:ap-northeast-1:XXXXXXXXXXXX:task-definition/django-ecs-sample:4", ] }上記のように先程登録解除した django-ecs-sample:1 などが列挙されました。
これは既に動いているクラスターやサービスのタスク定義を登録解除してもタスクが終了するわけでは無いことを表しています。
またこれら登録解除済みのタスクを使っているクラスターのインスタンスが再起動した場合でも解除済みのタスク定義でタスクは起動します。
では何が違うのかと言えば、解除したタスク定義を使って新規でタスクを立ち上げる・サービスを更新する事は出来ないという意味です。
せめて何処でも使ってないタスク定義(今回のテストプログラムのようなもの)は削除したいと思いますが、今の所タスク定義を完全に削除する方法は無さそうです。あとがき
最後までお付き合い頂きありがとうございました。
私がよく理解できてないため解りにくい所もあったかと思います。
また、デプロイ後にコードを修正したりアップデートする方法については書けていません、調べてやってみて頂ければと思います。最初にも書きましたが、こちらは私が作ったDjangoのテストアプリを ECS へ出来るだけ簡単にデプロイする為に作ったサンプルを元にしています。
そのため私がいかに早く楽にデプロイできるかに重点を置きました。
本来重要なセキュリティなどは置き去りとも言えます・・・なんにせよ docker と ECS を使えば簡単に Django アプリを AWS 上で動かせるんだなと思って頂けたらと思います。
最後になりましたが、これを書くにあたって沢山の記事、勉強会での発表等を参考にさせて頂きました。
それらに係わられた全ての方に感謝しています、ありがとうございました。


- 投稿日:2020-02-09T22:36:18+09:00
[Pythonで遊ぼう] 文章自動生成をめざす ~形態素解析をする~
はじめに
AIが文章を書いたり、最近では手塚治虫の漫画の学習を経て作られた漫画ができた、なんて話がありますね。
そのようなレベルは難しいですが、本を見ながら文章の自動生成はできたのでまとめておきます。
複数回にまたがりますが、ゆっくりやっていこうかと思います。文章を生成するイメージ
文章を生成するにあたって、イメージとしては次のような感じになります。
- もととなるデータを準備する
- データをきれいに整形する
- 文章を分解する
- マルコフ連鎖を用いて生成する
おおざっぱにいえばこんな感じかと思います。今回は文章の分解をしてみます。
形態素解析をしてみる
形態素解析(けいたいそかいせき、Morphological Analysis)とは、文法的な情報の注記の無い自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(Morpheme, おおまかにいえば、言語で意味を持つ最小単位)の列に分割し、それぞれの形態素の品詞等を判別する作業である。 出典: フリー百科事典『ウィキペディア(Wikipedia)』
ということらしいです。とりあえずコードと結果を見よ!from janome.tokenizer import Tokenizer t = Tokenizer() tこの"Tokenizer"というのを使います。
text = '超弩級戦艦として建造技術導入を兼ねて英国ヴィッカース社で建造された、金剛デース!期待してネ!' tokens = t.tokenize(text)#字句解析をする len(tokens) #単語数調べたい文章を入れて解析します。(内容はてきとう)
for token in tokens: print(token)表示させるとこんな感じになります。固有名詞や特徴のある語尾がうまくいかないっぽいですね。こういう文章の揺れは直す必要がありそうですね。
最後に単語リストを作っておきます。texts = t.tokenize(text, wakati=True) words_list =[] #単語リストを作る for text in texts: words_list.append(t.tokenize(text, wakati=True)) words_list雑談
"Tokenize"を使えば簡単に文章の分解はできましたね。
文章生成の際には、もちろんこんな短い文では不十分なので、実際にはもっと多くの言葉が必要です。
面白い文章ができたらいいなぁ。

- 投稿日:2020-02-09T22:05:57+09:00
モンテカルロ法をPythonでシミュレーションする
モンテカルロ法とは
モンテカルロ法 (モンテカルロほう、英: Monte Carlo method, MC) とはシミュレーションや数値計算を乱数を用いて行う手法の総称。元々は、中性子が物質中を動き回る様子を探るためにスタニスワフ・ウラムが考案しジョン・フォン・ノイマンにより命名された手法。カジノで有名な国家モナコ公国の4つの地区(カルティ)の1つであるモンテカルロから名付けられた。ランダム法とも呼ばれる。
引用 wikipedia
要するに乱数を用いて数値計算を行う手法の一つです。
円周率を求める
1、正方形の中にランダムに点を打っていく
2、生成した点と原点の距離が1以下なら円の内部に入ったとカウント、1以上なら円の外部に入ったとカウントしていきます。
3、1,2をN回繰り返す
4、4P/Nが円周率の近似値であるπになる。生成した点と原点の距離が1以下かどうかの長さを図るためにユークリッドノルム
\sqrt{x^2+y^2}で計算します。ユークリッド距離は人が定規で測る様な二点間の通常の距離のことです。
#モジュールをインストール import numpy as np import math import matplotlib.pyplot as plt #円の中に入ったxとy inside_x = [] inside_y = [] #円の外に出たxとy outside_x = [] outside_y = [] count_inside = 0 for count in range(0, N): d = math.hypot(x[count], y[count]) if d <1: count_inside +=1 #円の内部に入った時のxとyの組み合わせ inside_x.append(x[count]) inside_y.append(y[count]) else: outside_x.append(x[count]) outside_y.append(y[count]) print('円の内部に入った数:', count_inside)出力 円の内部に入った数: 7875可視化する
#図のサイズ plt.figure(figsize=(5,5)) #円を描くためのデータ circle_x = np.arange(0,1,0.001) circle_y = np.sqrt(1 - circle_x * circle_x) #円を描く plt.plot(circle_x, circle_y) #円の中に入っているのが赤 plt.scatter(inside_x, inside_y, color = 'r') #円の外に出たのが青 plt.scatter(outside_x, outside_y, color = 'b') #名前をつける plt.xlabel('x') plt.ylabel('y') plt.grid(True) #格子をありにする
#半径1の円の四等分された単位円の面積であるので print('円周率の近似値:'4.0 * count_inside / N)出力 円周率の近似値: 3.144まとめ
モンテカルロ法は点を打つ回数を増やせば増やすほど精度が上がりますが、実行にかかる時間が長くなってしまいます

- 投稿日:2020-02-09T21:49:26+09:00
いまさらだけど、Chainerで顔認識をしてみよう(学習フェーズ編)
概要
Chainerの開発終了が発表されたうえに顔認識という、いまさら感で溢れてますが、
備忘録を兼ねてここに綴ります。このシリーズは2回に分けて発信します。
今回は学習フェーズ(顔画像の学習)の実装方法を説明します。
次回は予測フェーズ(カメラを使った顔認識)の実装を説明する予定です。なお、ML初学者で当時高校生というのもあって、情報の一部に誤りがあったり、プログラムにバグがあるかもしれません。もしそういったものがありましたら、コメントにて指摘していただける嬉しいです。
(記事作成日: 2020/2/9)環境
-Software-
Windows 10 Home
Anaconda3 64-bit(Python3.7)
Spyder
-Library-
Chainer 7.0.0
-Hardware-
CPU: Intel core i9 9900K
GPU: NVIDIA GeForce GTX1080ti
RAM: 16GB 3200MHz参考
書籍
CQ出版 算数&ラズパイから始める ディープ・ラーニング
(Amazonページ)
サイト
Chainer APIリファレンスプログラム
一応、Githubに上げておきます。
https://github.com/himazin331/Face-Recognition-Chainer-
リポジトリには学習フェーズ、予測フェーズ、データ加工プログラム、Haar-Cascadeが含まれています。前提
プログラム動作にはAnaconda3のインストールが必要です。
Anaconda3のダウンロード及びインストール方法は下記を参考にしてください。
Anaconda3 ダウンロードサイト
Anaconda3 インストール方法(Windows)また、私の友人が投稿したこちらもよかったら参考にしてみてください。
Anaconda3インストール後、Anaconda3 promptにて、
pip install chainer
と、入力してChainerをインストールしてください。学習データについて
今回のプログラムでは学習データがグレースケール画像で32×32pxのJPEGファイルであることを
前提に実装されています。
データ加工には、こちらをご活用ください。ソースコード
コードが汚いのはご了承ください...
face_recog_train_CH.pyimport argparse as arg import os import sys import chainer import chainer.functions as F import chainer.links as L from chainer import training from chainer.training import extensions # CNNの定義 class CNN(chainer.Chain): # 各層定義 def __init__(self, n_out): super(CNN, self).__init__( # 畳み込み層の定義 conv1 = L.Convolution2D(1, 16, 5, 1, 0), # 1st conv2 = L.Convolution2D(16, 32, 5, 1, 0), # 2nd conv3 = L.Convolution2D(32, 64, 5, 1, 0), # 3rd #全ニューロンの線形結合 link = L.Linear(None, 1024), # 全結合層 link_class = L.Linear(None, n_out), # クラス分類用全結合層(n_out:クラス数) ) # 順伝播 def __call__(self, x): # 畳み込み層->ReLU関数->最大プーリング層 h1 = F.max_pooling_2d(F.relu(self.conv1(x)), ksize=2) # 1st h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), ksize=2) # 2nd h3 = F.relu(self.conv3(h2)) # 3rd # 全結合層->ReLU関数 h4 = F.relu(self.link(h3)) # 予測値返却 return self.link_class(h4) # クラス分類用全結合層 # Trainer class trainer(object): # モデル構築,最適化手法セットアップ def __init__(self): # モデル構築 self.model = L.Classifier(CNN(2)) # 最適化手法のセットアップ self.optimizer = chainer.optimizers.Adam() # Adamアルゴリズム self.optimizer.setup(self.model) # optimizerにモデルをセット # 学習 def train(self, train_set, batch_size, epoch, gpu, out_path): # GPU処理に対応付け if gpu >= 0: chainer.cuda.get_device(gpu).use() # デバイスオブジェクト取得 self.model.to_gpu() # インスタンスの内容をGPUにコピー # データセットイテレータの作成(学習データの繰り返し処理の定義,ループ毎でシャッフル) train_iter = chainer.iterators.SerialIterator(train_set, batch_size) # updater作成 updater = training.StandardUpdater(train_iter, self.optimizer, device=gpu) # trainer作成 trainer = training.Trainer(updater, (epoch, 'epoch'), out=out_path) # extensionの設定 # 処理の流れを図式化 trainer.extend(extensions.dump_graph('main/loss')) # 学習毎snapshot書込み trainer.extend(extensions.snapshot(), trigger=(epoch, 'epoch')) # log(JSON形式)書込み trainer.extend(extensions.LogReport()) # 損失値をグラフにプロット trainer.extend( extensions.PlotReport('main/loss', 'epoch', file_name='loss.png')) # 予測精度をグラフにプロット trainer.extend( extensions.PlotReport('main/accuracy', 'epoch', file_name='accuracy.png')) # 学習毎「学習回数, 損失値, 予測精度, 経過時間」を出力 trainer.extend(extensions.PrintReport( ['epoch', 'main/loss', 'main/accuracy', 'elapsed_time'])) # プログレスバー表示 trainer.extend(extensions.ProgressBar()) # 学習開始 trainer.run() print("___Training finished\n\n") # モデルをCPU対応へ self.model.to_cpu() # パラメータ保存 print("___Saving parameter...") param_name = os.path.join(out_path, "face_recog.model") # 学習済みパラメータ保存先 chainer.serializers.save_npz(param_name, self.model) # NPZ形式で学習済みパラメータ書込み print("___Successfully completed\n\n") # データセット作成 def create_dataset(data_dir): print("\n___Creating a dataset...") cnt = 0 prc = ['/', '-', '\\', '|'] # 画像セットの個数 print("Number of Rough-Dataset: {}".format(len(os.listdir(data_dir)))) # 画像データの個数 for c in os.listdir(data_dir): d = os.path.join(data_dir, c) print("Number of image in a directory \"{}\": {}".format(c, len(os.listdir(d)))) train = [] # 仮のデータセット label = 0 # 仮データセット作成 for c in os.listdir(data_dir): print('\nclass: {}, class id: {}'.format(c, label)) # クラス名とクラスIDの出力 d = os.path.join(data_dir, c) # フォルダ名とクラスフォルダ名の結合 imgs = os.listdir(d) # 全画像ファイル取得 # JPEG形式の画像ファイルだけを読込 for i in [f for f in imgs if ('jpg'or'JPG' in f)]: # キャッシュファイルをスルー if i == 'Thumbs.db': continue train.append([os.path.join(d, i), label]) # クラスフォルダパスと画像ファイル名を結合後、リストに格納 cnt += 1 print("\r Loading a images and labels...{} ({} / {})".format(prc[cnt%4], cnt, len(os.listdir(d))), end='') print("\r Loading a images and labels...Done ({} / {})".format(cnt, len(os.listdir(d))), end='') label += 1 cnt = 0 train_set = chainer.datasets.LabeledImageDataset(train, '.') # データセット化 print("\n___Successfully completed\n") return train_set def main(): # コマンドラインオプション parser = arg.ArgumentParser(description='Face Recognition train Program(Chainer)') parser.add_argument('--data_dir', '-d', type=str, default=None, help='フォルダパスの指定(未指定時 エラー)') parser.add_argument('--out', '-o', type=str, default=os.path.dirname(os.path.abspath(__file__))+'/result'.replace('/', os.sep), help='パラメータの保存先指定(デフォルト値 ./result)') parser.add_argument('--batch_size', '-b', type=int, default=32, help='ミニバッチサイズの指定(デフォルト値 32)') parser.add_argument('--epoch', '-e', type=int, default=15, help='学習回数の指定(デフォルト値 15)') parser.add_argument('--gpu', '-g', type=int, default=-1, help='GPU IDの指定(負の値はCPU処理を示す, デフォルト値 -1)') args = parser.parse_args() # フォルダ未指定->例外 if args.data_dir == None: print("\nException: Folder not specified.\n") sys.exit() # 存在しないフォルダ指定時->例外 if os.path.exists(args.data_dir) != True: print("\nException: Folder {} is not found.\n".format(args.data_dir)) sys.exit() # 設定情報出力 print("=== Setting information ===") print("# Images folder: {}".format(os.path.abspath(args.data_dir))) print("# Output folder: {}".format(args.out)) print("# Minibatch-size: {}".format(args.batch_size)) print("# Epoch: {}".format(args.epoch)) print("===========================") # データセット作成 train_set = create_dataset(args.data_dir) # 学習開始 print("___Start training...") Trainer = trainer() Trainer.train(train_set, args.batch_size, args.epoch, args.gpu, args.out) if __name__ == '__main__': main()実行結果
実行後、保存先に上のようなファイルが生成されます。コマンド
python face_recog_train_CH.py -d <フォルダ> -e <学習回数> -b <バッチサイズ>
(-o <保存先> -g <GPU ID>)
ファイルの保存先はデフォルトで./resultになっています。説明
コードの説明をしていきます。残念ながら説明能力は乏しいです。
ネットワークモデル
今回のネットワークモデルは畳み込みニューラルネットワーク(CNN)となっています。
CNNクラスでネットワークモデルを定義しています。CNNクラス# CNNの定義 class CNN(chainer.Chain): # 各層定義 def __init__(self, n_out): super(CNN, self).__init__( # 畳み込み層の定義 conv1 = L.Convolution2D(1, 16, 5, 1, 0), # 1st conv2 = L.Convolution2D(16, 32, 5, 1, 0), # 2nd conv3 = L.Convolution2D(32, 64, 5, 1, 0), # 3rd #全ニューロンの線形結合 link = L.Linear(None, 1024), # 全結合層 link_class = L.Linear(None, n_out), # クラス分類用全結合層(n_out:クラス数) ) # 順伝播 def __call__(self, x): # 畳み込み層->ReLU関数->最大プーリング層 h1 = F.max_pooling_2d(F.relu(self.conv1(x)), ksize=2) # 1st h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), ksize=2) # 2nd h3 = F.relu(self.conv3(h2)) # 3rd # 全結合層->ReLU関数 h4 = F.relu(self.link(h3)) # 予測値返却 return self.link_class(h4) # クラス分類用全結合層CNNクラスの引数には
chainer.Chainを渡しています。
chainer.ChainはChainer特有のクラスで、ネットワークの核となります。
インスタンス生成時にインスタンスメソッド__init__をコールして、スーパークラスであるchainer.Chainのインスタンスメソッドを呼び出し、畳み込み層と全結合層を定義します。本プログラムでの畳み込み層のハイパーパラメータは以下の表のとおりです。
入力チャンネル 出力チャンネル フィルタサイズ ストライド幅 パディング幅 1st 1 16 5 1 0 2nd 16 32 5 1 0 3rd 32 64 5 1 0 学習データがグレースケール画像であることを前提としているため、1つめの畳み込み層の入力チャンネル数を1としています。RGB画像であれば3になります。
"パディング幅 0"はパディング処理を行わないことを意味します。全結合層のハイパーパラメータは以下の表のとおりです。
入力次元数 出力次元数 全結合層 None 1024 クラス分類用 None 2 入力次元数で
Noneを指定すると自動で入力データの次元数を適用してくれます。今回は2クラス分類を行おうと思うので、クラス分類用の全結合層の出力次元数を2としました。
クラスCNNのインスタンス生成時、引数に数値を入れることで、その数値に対応したクラス分類になります。
(コード上ではn_outが何クラスに分類するかを意味します。)もう一つのメソッド
__call__で順伝播を行います。
全体の構造は下の図のとおりです。
プーリング層はプーリング領域を2×2とした最大プーリングです。
データセット作成
まず、データセットについて注意点がありますので、先にデータセットを作成する関数の説明をします。
データセットの作成はcrate_dataset関数で行います。create_dataset関数# データセット作成 def create_dataset(data_dir): print("\n___Creating a dataset...") cnt = 0 prc = ['/', '-', '\\', '|'] # 画像セットの個数 print("Number of Rough-Dataset: {}".format(len(os.listdir(data_dir)))) # 画像データの個数 for c in os.listdir(data_dir): d = os.path.join(data_dir, c) print("Number of image in a directory \"{}\": {}".format(c, len(os.listdir(d)))) train = [] # 仮のデータセット label = 0 # 仮データセット作成 for c in os.listdir(data_dir): print('\nclass: {}, class id: {}'.format(c, label)) # クラス名とクラスIDの出力 d = os.path.join(data_dir, c) # フォルダ名とクラスフォルダ名の結合 imgs = os.listdir(d) # 全画像ファイル取得 # JPEG形式の画像ファイルだけを読込 for i in [f for f in imgs if ('jpg'or'JPG' in f)]: # キャッシュファイルをスルー if i == 'Thumbs.db': continue train.append([os.path.join(d, i), label]) # クラスフォルダパスと画像ファイル名を結合後、リストに格納 cnt += 1 print("\r Loading a images and labels...{} ({} / {})".format(prc[cnt%4], cnt, len(os.listdir(d))), end='') print("\r Loading a images and labels...Done ({} / {})".format(cnt, len(os.listdir(d))), end='') label += 1 cnt = 0 train_set = chainer.datasets.LabeledImageDataset(train, '.') # データセット化 print("\n___Successfully completed\n") return train_set分類問題におけるデータセットには、学習データと正解ラベルが必要です。
今回の場合、学習データは顔画像で、正解ラベルはその顔に対応した数値となります。
例えば、不正解クラスと正解クラスがあるとき、
不正解クラスにある学習データのラベルをまとめて「0」
正解クラスにある学習データのラベルをまとめて「1」とします。
その特性上、フォルダの構造に注意しなければなりません。<フォルダの構造>
上のように、1つのフォルダ(train_data)の中に、
各クラスのフォルダ(false, true)を作り、画像データを入れてください。
こうすることで、falseに含まれる学習データの正解ラベルが0に、trueに含まれる正解ラベルが1となります。
コマンドオプション -d で指定するのはこの例でいうと、train_dataになります。コード中の注釈に書かれているような処理を行った後、
最後に下にあるコードで学習データとラベルがセットになっているリストを、
正式にデータセットとして作成します。train_set = chainer.datasets.LabeledImageDataset(train, '.') # データセット化
学習
trainerクラスで機械学習を行う前のセットアップや学習を行います。
trainerクラス(インスタンスメソッド)# Trainer class trainer(object): # モデル構築,最適化手法セットアップ def __init__(self): # モデル構築 self.model = L.Classifier(CNN(2)) # 最適化手法のセットアップ self.optimizer = chainer.optimizers.Adam() # Adamアルゴリズム self.optimizer.setup(self.model) # optimizerにモデルをセットインスタンス生成時にインスタンスメソッド
__init__をコールして、ネットワークモデルの構築と最適化アルゴリズムを決定します。
self.model = L.Classifier(CNN(2))でCNN(2)のカッコ内に任意の値を入れることで、任意のクラス数に分類します。構築した後、
L.Classifier()というChainer.linksのメソッドにより活性化関数及び損失関数が付与されます。ここでの活性化関数はソフトマックス関数といった出力時に用いる活性化関数です。活性化関数はソフトマックス関数、損失関数は交差エントロピー誤差がデフォルトで設定されているため、分類問題の場合はネットワークモデルをラップするだけで問題ありません。次に、
self.optimizer = chainer.optimizers.Adam()で最適化アルゴリズムAdamのインスタンスを生成後、
self.optimizer.setup(self.model)でネットワークモデルを適用します。
trainerクラス内のtrainメソッドでは、
データセットイテレータ(Iterator)、updater、trainerの作成を行い、学習を行っていきます。trainerクラス(trainメソッド)# 学習 def train(self, train_set, batch_size, epoch, gpu, out_path): # GPU処理に対応付け if gpu >= 0: chainer.cuda.get_device(gpu).use() # デバイスオブジェクト取得 self.model.to_gpu() # インスタンスの内容をGPUにコピー # データセットイテレータの作成(学習データの繰り返し処理の定義,ループ毎でシャッフル) train_iter = chainer.iterators.SerialIterator(train_set, batch_size) # updater作成 updater = training.StandardUpdater(train_iter, self.optimizer, device=gpu) # trainer作成 trainer = training.Trainer(updater, (epoch, 'epoch'), out=out_path) # extensionの設定 # 処理の流れを図式化 trainer.extend(extensions.dump_graph('main/loss')) # 学習毎snapshot書込み trainer.extend(extensions.snapshot(), trigger=(epoch, 'epoch')) # log(JSON形式)書込み trainer.extend(extensions.LogReport()) # 損失値をグラフにプロット trainer.extend( extensions.PlotReport('main/loss', 'epoch', file_name='loss.png')) # 予測精度をグラフにプロット trainer.extend( extensions.PlotReport('main/accuracy', 'epoch', file_name='accuracy.png')) # 学習毎「学習回数, 損失値, 予測精度, 経過時間」を出力 trainer.extend(extensions.PrintReport( ['epoch', 'main/loss', 'main/accuracy', 'elapsed_time'])) # プログレスバー表示 trainer.extend(extensions.ProgressBar()) # 学習開始 trainer.run() print("___Training finished\n\n") # モデルをCPU対応へ self.model.to_cpu() # パラメータ保存 print("___Saving parameter...") param_name = os.path.join(out_path, "face_recog.model") # 学習済みパラメータ保存先 chainer.serializers.save_npz(param_name, self.model) # NPZ形式で学習済みパラメータ書込み print("___Successfully completed\n\n")
下のコードでは、データセットイテレータ(Iterator)の作成を行っています。
# データセットイテレータの作成(学習データの繰り返し処理の定義,ループ毎でシャッフル) train_iter = chainer.iterators.SerialIterator(train_set, batch_size)こいつは、データ順序のシャッフルやミニバッチを作成してくれます。
引数として対象となるデータセット(train_set)とミニバッチサイズ(batch_size)を指定します。
次に、updaterの作成を行います。
# updater作成 updater = training.StandardUpdater(train_iter, self.optimizer, device=gpu)
updaterは、パラメータの更新を行います。
引数として、データセットイテレータ(train_iter)と最適化アルゴリズム(self.optimizer)と必要であればGPU IDを指定してやります。
最適化アルゴリズムはself.optimizer.setup()でネットワークモデルに最適化アルゴリズムを適用したものです。
直にchainer.optimizers.Adam()を指定しても動作しません。
次に、trainerの作成を行います。
# trainer作成 trainer = training.Trainer(updater, (epoch, 'epoch'), out=out_path)
trainerは、学習ループを実装します。
なにをトリガー(条件)に学習を終了するかを定義してやります。
通常は学習回数 epoch かiterationをトリガーにします。今回の場合は学習回数
epochをトリガーにします。
引数として、updater(updater)とストップトリガー((epoch, 'epoch'))と
その他、拡張機能により作成されるファイルの保存先を指定します。
次はいよいよ、学習! の前に便利な拡張機能を付与してあげましょう。
chainerにはTrainer Extensionという拡張機能があります。# extensionの設定 # 処理の流れを図式化 trainer.extend(extensions.dump_graph('main/loss')) # 学習毎snapshot書込み trainer.extend(extensions.snapshot(), trigger=(epoch, 'epoch')) # log(JSON形式)書込み trainer.extend(extensions.LogReport()) # 損失値をグラフにプロット trainer.extend( extensions.PlotReport('main/loss', 'epoch', file_name='loss.png')) # 予測精度をグラフにプロット trainer.extend( extensions.PlotReport('main/accuracy', 'epoch', file_name='accuracy.png')) # 学習毎「学習回数, 損失値, 予測精度, 経過時間」を出力 trainer.extend(extensions.PrintReport( ['epoch', 'main/loss', 'main/accuracy', 'elapsed_time'])) # プログレスバー表示 trainer.extend(extensions.ProgressBar())ここでは、
・入力データやパラメータの流れなどを以下のようなDOTファイルで書き出してくれる機能
・学習終了時パラメータなどの情報をスナップショットしてくれる機能
(snapshotを用いることで途中から学習を再開することができる)
・学習時の損失値や予測精度の履歴をJSON形式で書きだしてくれる機能
・損失値及び予測精度をグラフにプロットしPNG形式で書き出してくれる機能
・毎学習ごとに学習回数、損失値、予測精度、経過時間を出力する機能
・プログレスバーを表示する機能
を付与しています。
その他にもいくつか拡張機能があります。
Trainer Extensionリファレンス
また、生成されるDOTファイルやPNGファイルといったものはtraining.Trainer()で指定した保存先に生成されます。
拡張機能を付与したら、ようやく学習開始です。
# 学習開始 trainer.run()この一行で、すべてが始まります(?)
学習が終了するまで待ちましょう。学習が終わったら、パラメータの保存を行います。
# パラメータ保存 print("___Saving parameter...") param_name = os.path.join(out_path, "face_recog.model") # 学習済みパラメータ保存先 chainer.serializers.save_npz(param_name, self.model) # NPZ形式で学習済みパラメータ書込み print("___Successfully completed\n\n")
chainer.serializers.save_npz()に、パラメータの保存先(param_name)とネットワークモデル(self.model)を
指定してあげれば、NPZ形式でパラメータが保存されます。このパラメータを用いて、実際に顔を認識していきます。main関数
main関数はこれといって説明するところがないので割愛。
main関数def main(): # コマンドラインオプション parser = arg.ArgumentParser(description='Face Recognition train Program(Chainer)') parser.add_argument('--data_dir', '-d', type=str, default=None, help='フォルダパスの指定(未指定時 エラー)') parser.add_argument('--out', '-o', type=str, default=os.path.dirname(os.path.abspath(__file__))+'/result'.replace('/', os.sep), help='パラメータの保存先指定(デフォルト値 ./result)') parser.add_argument('--batch_size', '-b', type=int, default=32, help='ミニバッチサイズの指定(デフォルト値 32)') parser.add_argument('--epoch', '-e', type=int, default=15, help='学習回数の指定(デフォルト値 15)') parser.add_argument('--gpu', '-g', type=int, default=-1, help='GPU IDの指定(負の値はCPU処理を示す, デフォルト値 -1)') args = parser.parse_args() # フォルダ未指定->例外 if args.data_dir == None: print("\nException: Folder not specified.\n") sys.exit() # 存在しないフォルダ指定時->例外 if os.path.exists(args.data_dir) != True: print("\nException: Folder {} is not found.\n".format(args.data_dir)) sys.exit() # 設定情報出力 print("=== Setting information ===") print("# Images folder: {}".format(os.path.abspath(args.data_dir))) print("# Output folder: {}".format(args.out)) print("# Minibatch-size: {}".format(args.batch_size)) print("# Epoch: {}".format(args.epoch)) print("===========================") # データセット作成 train_set = create_dataset(args.data_dir) # 学習開始 print("___Start training...") Trainer = trainer() Trainer.train(train_set, args.batch_size, args.epoch, args.gpu, args.out) if __name__ == '__main__': main()
GPU処理について
私はGPUによる処理ができるように環境を構築してあるので、
以下のような処理を記述してあります。あってもなくとも問題ありませんし、GPUによる処理でなくとも構いません。
ただ、ChainerはTensorflowと違って学習時間が長いので、できればGPUによる処理をお勧めします。。(環境や解く問題によります)
GPU処理環境構築については割愛させてもらいます。if gpu >= 0: chainer.cuda.get_device(gpu).use() # デバイスオブジェクト取得 self.model.to_gpu() # 入力データを指定のデバイスにコピー注意
下の処理で学習データがいくつあるのかを計上しますが、
1枚多く計上されることがあります。これは、Thumbs.dbというサムネイルキャッシュも含めて計上しているからです。
めんどくさいので、こいつを考慮して計上するという処理を行ってません。
ですが、データセット作成時にはこいつはスルーするように処理してますので問題ないです。for c in os.listdir(data_dir): d = os.path.join(data_dir, c) print("Number of image in a directory \"{}\": {}".format(c, len(os.listdir(d))))おわりに
今回初めて、Qiitaに投稿したのですが不安なところが多々あり、心配です...
概要でも述べましたが、なにか不味いところがあればコメントください。修正します。次回は、予測フェーズということで、カメラを使って顔の認識を行うんですが...
私の顔を出すことはできないので、公人の顔画像で代用させて頂く予定です。Chainer以外にも、Tensorflow(tf.keras)で顔認識プログラムを実装したり、フィルタや特徴マップの可視化に挑戦したり、
ハイパーパラメータ最適化フレームワーク「Optuna」を使ってみたりといろいろ挑戦してみたので、今後も投稿できればなと思います。(あくまでも備忘録という形にはなりますが)




- 投稿日:2020-02-09T20:54:15+09:00
BlueqatでVariational-Quantum-Eigensolver (VQE) アルゴリズムやってみる
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$
量子ゲートシミュレータBlueqatの練習がてらVQEアルゴリズムで簡単なハミルトニアンの基底エネルギーを求めてみます。
Blueqatとは : https://blueqat.readthedocs.io/ja/latest/
VQEとは : http://dojo.qulacs.org/ja/latest/notebooks/5.1_variational_quantum_eigensolver.html
他に参考にしたページ:
https://qiita.com/YuichiroMinato/items/62444351b712743d83b7
http://dkopczyk.quantee.co.uk/vqe/設定
今回はこちらの記事のように、状態$\ket{0} = (1, 0)^{\mathrm{T}}$にRY($\theta$)ゲートを作用させることで、パラメータ$\theta$に依存する状態$\ket{\psi(\theta)}$を作り、
いろんな$\theta$の値で内積$\braket{\psi(\theta)} {H \psi(\theta)}$の値を計算し、
変分法により、この内積$\braket{\psi(\theta)} {H \psi(\theta)}$が最小となる$\theta (= \theta_{\mathrm{min}})$を求めることで、基底状態$\ket{\psi(\theta_{\mathrm{min}})}$を求めることにする。
RY($\theta$)ゲートとは、状態をbloch球のy軸周りに回転させる演算である。RY(\theta) = \left( \begin{array}{cc} \cos{\Big( \frac{\theta}{2}\Big)} & -\sin{\Big( \frac{\theta}{2}\Big)} \\ \sin{\Big( \frac{\theta}{2}\Big)} & \cos{\Big( \frac{\theta}{2}\Big)}\\ \end{array} \right)また今回はハミルトニアン$H$として、こちらの記事と同じように、パウリ行列$Z$
Z = \left( \begin{array}{cc} 1 & 0 \\ 0 & -1\\ \end{array} \right)を用いる。
もともと$Z$は対角化されていて、その基底状態は$\ket{1} = (0, 1)^{\mathrm{T}}$(の複素数倍)とわかるので、今回のパラメータ$\theta$探索では、$\theta = \pi$が基底状態を与えるパラメータであることが求まれば成功である。
なぜなら、今回の設定では\ket{\psi(\theta = \pi)} = \left( \begin{array}{cc} \cos{\Big( \frac{\pi}{2}\Big)} & -\sin{\Big( \frac{\pi}{2}\Big)} \\ \sin{\Big( \frac{\pi}{2}\Big)} & \cos{\Big( \frac{\pi}{2}\Big)}\\ \end{array} \right) \left( \begin{array}{c} 1 \\ 0 \\ \end{array} \right) = \left( \begin{array}{cc} 0 & -1 \\ 1 & 0\\ \end{array} \right) \left( \begin{array}{c} 1 \\ 0 \\ \end{array} \right) = \left( \begin{array}{c} 0 \\ 1 \\ \end{array} \right)だからである。
実際にBlueqatを使ってやってみる
jupyter notebookで行う。
Blueqatインストールしていない場合は以下でpipインストールする。!pip3 install blueqat今回使用するライブラリをインポート
import numpy as np import matplotlib.pyplot as plt from blueqat import Circuitまずはパラメータの候補として、$0$から$2\pi$までを20等分した物を用意する。
angles = np.linspace(0.0,2*np.pi,20) angles # array([0. , 0.33069396, 0.66138793, 0.99208189, 1.32277585, # 1.65346982, 1.98416378, 2.31485774, 2.64555171, 2.97624567, # 3.30693964, 3.6376336 , 3.96832756, 4.29902153, 4.62971549, # 4.96040945, 5.29110342, 5.62179738, 5.95249134, 6.28318531])まずは4個目の角度(angle[3] = 0.99208189)を使って、内積$\braket{\psi(\theta)} {H \psi(\theta)}$を計算してみる。
Blueqatでは、まず回路(Circuit())を用意し、そこにゲート(今回はRYゲート)を追加していくことでゲート回路が構築できる。
RYゲートは以下のように、ry({角度})[{作用させる量子ビット番号}]を追加させれば良い。# 回路 Circuit().ry(angles[3])[0]また、ゲート回路に対してrunメソッドを実行させると、その段階での状態ベクトルがnumpyで得られる。
# 初期状態なので| 0> Circuit().run() # array([1.+0.j]) # | 0>にRYゲートを作用させた後の状態 Circuit().ry(angles[3])[0].run() # array([0.87947375+0.j, 0.47594739+0.j])それでは、実際に内積$\braket{\psi(\theta)} {H \psi(\theta)}$を計算する。
まず、$\ket{\psi(\theta)}$は以下のようになり、psi = Circuit().ry(angles[3])[0].run() psi # array([0.87947375+0.j, 0.47594739+0.j])続いて、$\ket{H \psi(\theta)}$は以下のようになる。
h_psi = Circuit().ry(angles[3])[0].z[0].run() h_psi # array([ 0.87947375+0.j, -0.47594739+0.j])これらより、内積$\braket{\psi(\theta)} {H \psi(\theta)}$は以下のようになる。
np.dot(psi, h_psi) # (0.5469481581224267+0j)それでは、この内積を最初に作った20個の角度に対して計算し、横軸を角度、縦軸を内積でプロットし、線を引くと以下のようになる。
energies = [] for angle in angles: psi = Circuit().ry(angle)[0].run() z_psi = Circuit().ry(angle)[0].z[0].run() energies.append(np.dot(psi, z_psi)) plt.xlabel('angle') plt.ylabel('Expectation value') plt.plot(angles, energies) plt.show()
確かに$\theta = 3$付近で最小値を取っているようなので、VQEアルゴリズム成功である。
ちなみに、パラメータ$\theta$に依存する状態$\ket{\psi(\theta)}$を作るとき、RY($\theta$)ゲートの代わりにRX($\theta$)ゲートを用いてもVQEアルゴリズムは成功する。
しかし、RZ($\theta$)ゲートでは成功しない。
それはRZ($\theta$)はRZ(\theta) = \left( \begin{array}{cc} e^{-i\frac{\theta}{2}} & 0 \\ 0 & e^{ i\frac{\theta}{2}}\\ \end{array} \right)という形をしているため、これによって作成される状態$\ket{\psi(\theta)}$は
\ket{\psi(\theta)} = \left( \begin{array}{cc} e^{-i\frac{\theta}{2}} & 0 \\ 0 & e^{ i\frac{\theta}{2}}\\ \end{array} \right) \left( \begin{array}{c} 1 \\ 0 \\ \end{array} \right) = \left( \begin{array}{c} e^{-i\frac{\theta}{2}} \\ 0 \\ \end{array} \right) = e^{-i\frac{\theta}{2}} \left( \begin{array}{c} 1 \\ 0 \\ \end{array} \right)となり、どんなパラメータ$\theta$の値でも、基底状態である$\ket{1} = (0, 1)^{\mathrm{T}}$(の複素数倍)は作れないからである。
最後に
量子コンピュータ面白

- 投稿日:2020-02-09T20:37:15+09:00
【お手軽Python】openpyxlによるExcelファイル読み込み
OpenPyXLとは
openpyxlとは、Pythonのライブラリです。
openpyxlは、Excelファイルを操作する時に使われます。Excel操作に特化したライブラリなので、軽量で使いやすいという利点があります。
Excelファイルの読み込み
sample.xlsxの中身が
だった場合
wb = openpyxl.load_workbook('sample.xlsx')とすることで、Workbookオブジェクトを取得できます。
さらにws = wb['sheet1']とすることで、Worksheetオブジェクトを取得できます。
これでsample.xlsxのシート名'sheet1'の情報がwsに入ったことになります。指定のセル読み込み
main.pyimport openpyxl wb = openpyxl.load_workbook('sample.xlsx') ws = wb['sheet1']ここまでは共通であるとします。
Excelの指定文字列で取得
main.pycell = ws['A2'] # A行番号、列番号を指定して取得
main.pycell = ws.cell(row=2, column=1) # BA,Bのcellの値(value)は、どちらも「1」となります。
main.pyprint(cell.value) # 1が表示されるまとめ
OpenPyXLを使ってExcelファイルを読み込む方法を紹介しました。
PythonでExcelファイルを操作するのにはうってつけのライブラリなので、是非使ってみてください。

- 投稿日:2020-02-09T20:22:31+09:00
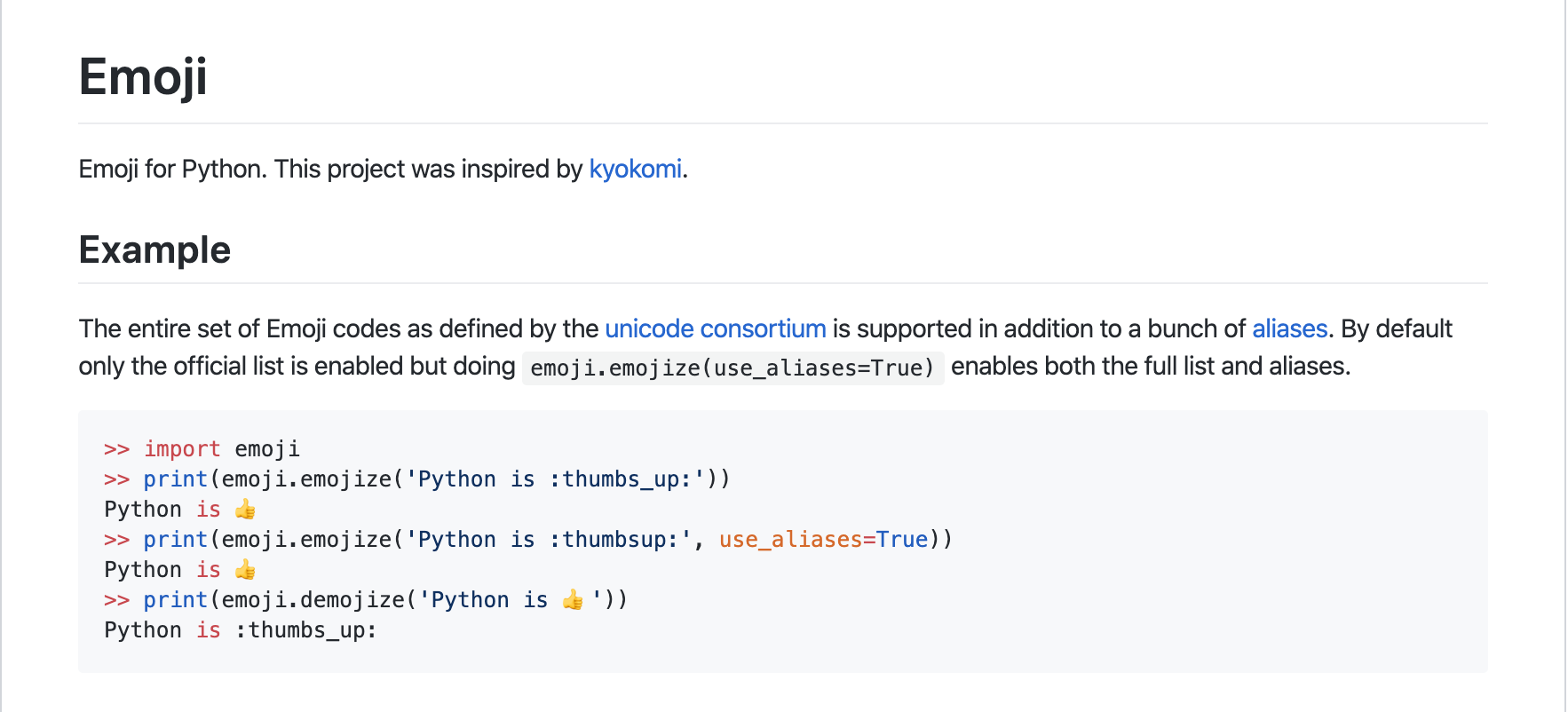
(Python) ある文字が絵文字か判定したい
まんまemojiという名前のライブラリがあるらしい
インストール
pip install emoji --upgrade絵文字か判定
Exampleには書いてないが、
emoji.UNICODE_EMOJIが単純に絵文字のdictになっている。emoji/emoji/unicode_codes.py/
https://github.com/carpedm20/emoji/blob/master/emoji/unicode_codes.py
コード例
import emoji is_emoji = '?' in emoji.UNICODE_EMOJI print(is_emoji) # True is_emoji = 'あ' in emoji.UNICODE_EMOJI print(is_emoji) # False

- 投稿日:2020-02-09T20:10:16+09:00
【Python】スクリーンショットをとる
環境
・Mac Catalina
・Python 3.8.1Macでの設定
そのままだと、スクリーンショットをとってもデスクトップがとられてしまうため、
画面収録の許可を行います。『システム環境設定』→『セキュリティとプライバシー』
『画面収録』にターミナルにチェックを入れる。
スクリーンショットをとる
pyautoguiをインストールします。
pip install pyautoguipyautogui.screenshot()で全画面のスクリーンショットをとれます。
import pyautogui screenshot = pyautogui.screenshot() screenshot.save('スクリーンショット.png')
範囲を指定する場合
region = (左からの配置位置, 上からの配置位置, 幅, 高さ)を使用することで、
特定範囲のスクリーンショットをとれます。import pyautogui screenshot = pyautogui.screenshot(region = (100, 200, 1500, 875)) screenshot.save('スクリーンショット.png')
JPEGで保存する場合
RGBに変換することで、 JPEGで保存することができます。
screenshot = screenshot.convert('RGB')参考
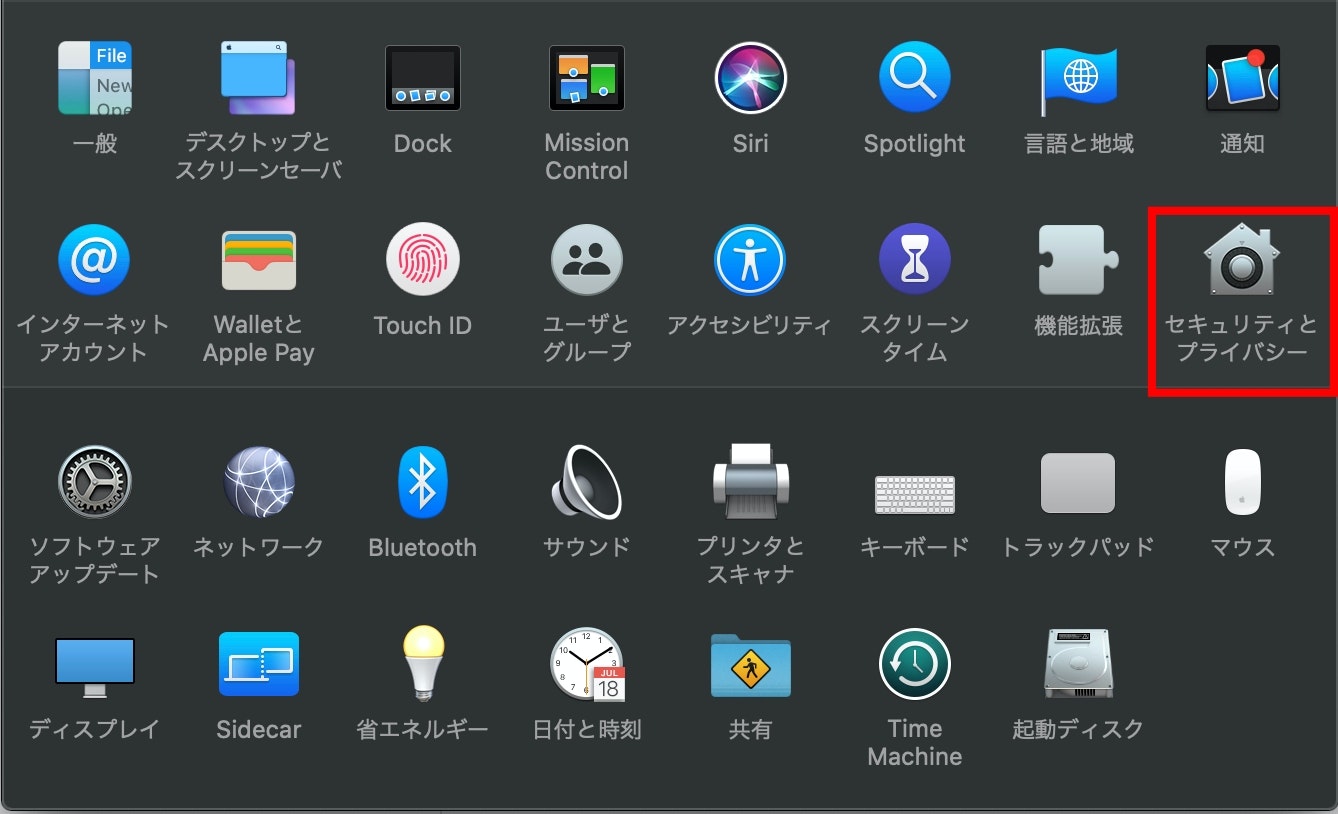
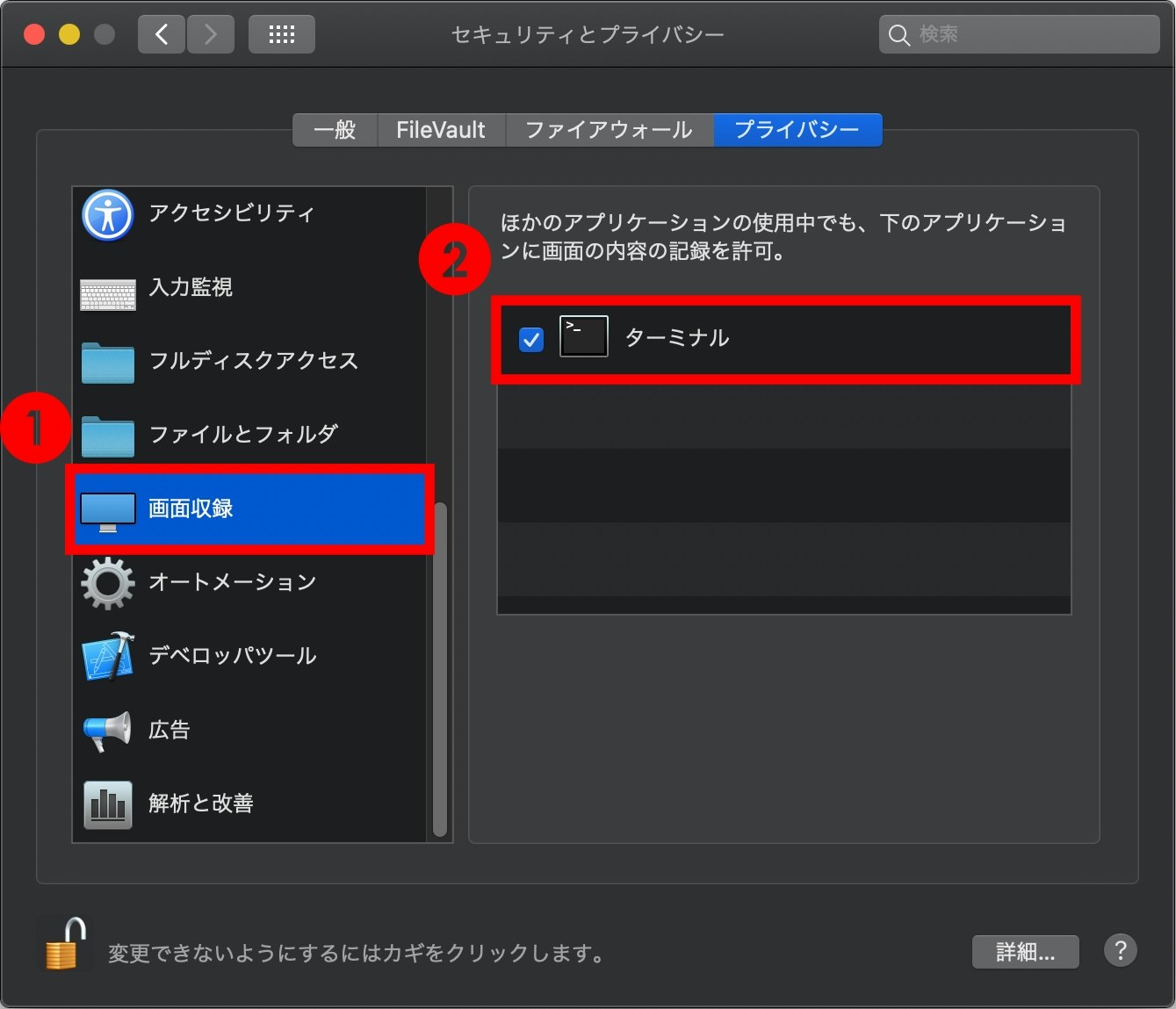
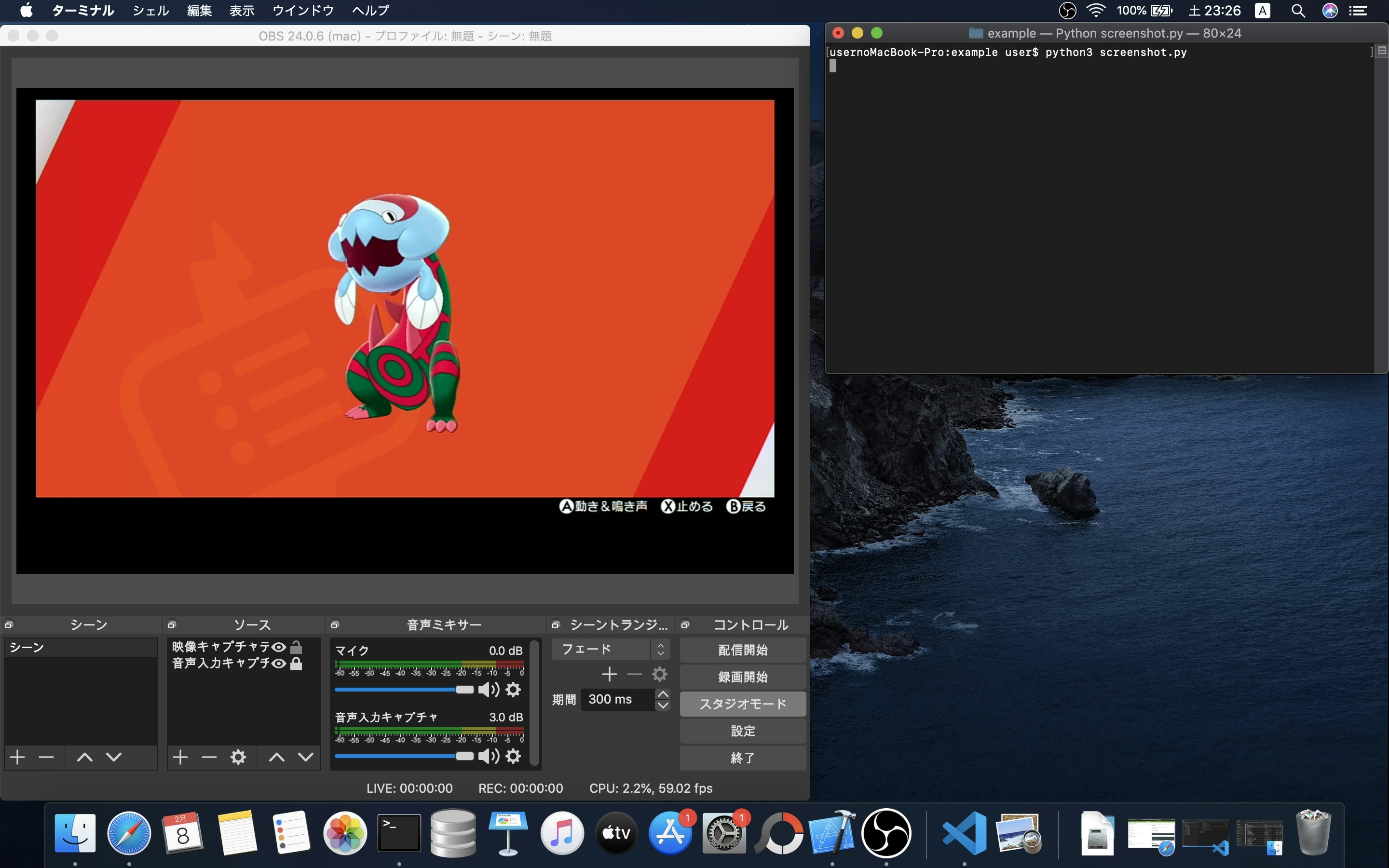

- 投稿日:2020-02-09T20:05:02+09:00
「つくりながら学ぶ!PyTorchによる発展ディープラーニング」をColaboratory上で。
つくりながら学ぶ!PyTorchによる発展ディープラーニング
https://book.mynavi.jp/ec/products/detail/id=104855の「1章 画像分類と転移学習」にて。
自端末内に環境を別途作るのがめんどくさかったので、Google Colaboratoryで実施。
その際に調べたことなどを備忘録として残しておくアップロード
gitからDLしたフォルダ(Makeまではローカルでやっておいた方が楽)をGoogleドライブへアップロードし、ドライブ上からNotebookファイルを起動。
この状態だとドライブを認識してくれていない状態になっているので、マウントする必要がある。# 現在のパスの確認 import os print(os.getcwd()) !ls# マウント from google import colab colab.drive.mount('/content/gdrive')認証を求められるので、認証しauthorization codeを入力
# フォルダ移動 os.chdir('gdrive/My Drive/Colab Notebooks/20200126_pytorch/pytorch_advanced/1_image_classification') !lsこれで書籍と同じようなパス構成で処理できるので、実施してみる。
GPUを使いたい場合は「ランタイム」をGPUに変更して
torch.cuda.is_available()
がTrueになっていることが確認できたらOK。GPUで処理できます。
- 投稿日:2020-02-09T19:57:13+09:00
VBAでPythonのGlob方式でファイルを検索するためのクラスを作成してみた
目的
VBAでフォルダやファイルを検索する際、サブフォルダ内を検索する処理が複雑になるため、
PythonのGlobを参考にクラスモジュールを作成してみた。ソースコード
VBA 使用例
Module1.basSub GlobTest() Dim item As Variant With New Glob .SetType = Dictionary ' 省略可 出力形式指定用 For Each item In .iGlob("**\*.cls") Debug.Print item Next End With End Subメソッド
名称 返り値 iGlob(パス) フォルダ・ファイル検索結果(出力形式可変) Glob(パス) フォルダ・ファイル検索結果(Dictionary形式) GlobFolder(パス) フォルダのみ検索結果(Dictionary形式) プロパティ
名称 値 SetType 出力形式 GetType 出力形式 GetCount 検索に一致した数 GetItems iGlobの返り値と同一 出力形式種別
名称 形式 Dictionary String() Collection File(),Folder() ArrayList String() StringArray String() 検索条件
記載内容 出力結果 \*\同一パス内のフォルダを列挙 \*同一パス内のファイルを列挙 \*.cls同一パス内の拡張子がclsのファイルを列挙 \*\*サブフォルダ内のファイルを列挙 \{*}\*同一パス内とサブフォルダ内のファイルを列挙 \**\*再帰的に検索してすべての階層のファイルを列挙 Python 参考コード例
import glob for x in glob.glob('**/*.cls', recursive=True): print xクラスモジュール本体
Glob.clsPrivate DefPath As String Private Items As Variant Private FSO As Object Enum GlobDataType None = 0 StringArray = 1 ArrayList = 2 dictionary = 3 Collection = 4 End Enum Private Sub Class_Initialize() Set FSO = CreateObject("Scripting.FileSystemObject") With CreateObject("WScript.Shell") .CurrentDirectory = ThisWorkbook.path & "\" End With Me.Clear End Sub Private Sub Class_Terminate() Set Items = Nothing Set FSO = Nothing End Sub Public Sub Clear() DefPath = ThisWorkbook.path & "\" count = 0 Select Case Me.GetType Case GlobDataType.dictionary Me.SetType = dictionary Case GlobDataType.Collection Me.SetType = Collection Case GlobDataType.StringArray Me.SetType = StringArray Case GlobDataType.ArrayList Me.SetType = ArrayList Case Else Me.SetType = Collection End Select End Sub Public Function GetItems() As Variant Select Case Me.GetType Case GlobDataType.dictionary, GlobDataType.Collection, GlobDataType.ArrayList Set GetItems = Items Case GlobDataType.StringArray GetItems = Split(Items, "||") Case Else GetItems = Array() End Select End Function Public Function GetCount() As Long Select Case Me.GetType Case GlobDataType.dictionary, GlobDataType.Collection, GlobDataType.ArrayList GetCount = Items.count Case GlobDataType.StringArray If Items = "" Then GetCount = 0 Else GetCount = UBound(Split(Items, "||")) + 1 End If Case Else GetCount = -1 End Select End Function Public Sub AddItem(ByVal name As String, ByVal v As Variant) Select Case Me.GetType Case GlobDataType.dictionary Items.Add name, v Case GlobDataType.Collection Items.Add v, name Case GlobDataType.ArrayList Items.Add v Case GlobDataType.StringArray If Items <> "" Then Items = Items & "||" Items = Items & v End Select End Sub Public Property Get GetType() As GlobDataType Select Case Me.GetTypeName Case "Collection" GetType = GlobDataType.Collection Case "Dictionary" GetType = GlobDataType.dictionary Case "String" GetType = GlobDataType.StringArray Case "ArrayList" GetType = GlobDataType.ArrayList Case Else GetType = GlobDataType.None End Select End Property Public Property Let SetType(ByVal TypeName As GlobDataType) Select Case TypeName Case GlobDataType.Collection Set Items = Nothing Set Items = New Collection Case GlobDataType.dictionary Set Items = Nothing Set Items = CreateObject("scripting.dictionary") Case GlobDataType.StringArray Items = "" Case GlobDataType.ArrayList Set Items = Nothing Set Items = CreateObject("System.Collections.ArrayList") Case Else Set Items = Nothing Set Items = CreateObject("scripting.dictionary") End Select End Property Public Function GetTypeName() As String GetTypeName = TypeName(Items) End Function Private Function base(ByRef url As String, Optional ByRef key As String = "") As String Dim baseUrl As String Dim min As Long Dim keystr As String If Left$(url, 2) <> "\\" And Left$(url, 1) = "\" Then url = Mid$(url, 2, Len(url) - 1) If url <> "" Then min = 2000 If InStr(url, "?") And min > InStr(url, "?") Then min = InStr(url, "?") If InStr(url, "*") And min > InStr(url, "*") Then min = InStr(url, "*") If InStr(url, "[") And min > InStr(url, "[") Then min = InStr(url, "[") If InStr(url, "{") And min > InStr(url, "{") Then min = InStr(url, "{") If InStr(url, "]") And min > InStr(url, "]") Then min = InStr(url, "]") If InStr(url, "}") And min > InStr(url, "}") Then min = InStr(url, "}") If min < 2000 Then keystr = Left$(Left$(url, min - 1), InStrRev(Left$(url, min - 1), "\")) baseUrl = FSO.GetAbsolutePathName(keystr) key = Replace$(url, keystr, "") Else baseUrl = FSO.GetAbsolutePathName(url) key = "" End If If FSO.FolderExists(baseUrl) = True Then url = baseUrl base = baseUrl Else url = "" base = "" End If Else url = "" key = "" base = "" End If End Function Public Function iGlob(Optional ByVal url As String = "") As Variant Dim key As String key = "" Call base(url, key) Me.Clear Call subSearch(url, key, 0) If IsObject(Me.GetItems) = True Then Set iGlob = Me.GetItems Else iGlob = Me.GetItems End If End Function Public Function Glob(Optional ByVal url As String = "") As Object With New Glob .SetType = dictionary Set Glob = .iGlob(url) End With End Function Public Function GlobFolder(Optional ByVal url As String = "") As Object Dim item As Variant Dim List As Object Set List = CreateObject("scripting.dictionary") With New Glob .SetType = Collection For Each item In Me.iGlob(url) If TypeName(item) = "File" Then If List.Exists(item.ParentFolder) = False Then List.Add item.ParentFolder, item.ParentFolder End If Else If List.Exists(item.path) = False Then List.Add item.path, item.path End If End If Next End With Set GlobFolder = List Set List = Nothing End Function Private Function subSearch(ByVal baseUrl As String, ByVal key As String, Optional ByVal level As Long = 0) As String Dim keyArr As Variant Dim folder As Variant Dim File As Variant keyArr = Split(key, "\") If UBound(keyArr) > level Then If keyArr(level) = "**" Then Call recursive(baseUrl, key, level + 1) ElseIf keyArr(level) Like "{*}" Then For Each folder In FSO.GetFolder(baseUrl).SubFolders If folder.name Like keyArr(level) Then Call subSearch(baseUrl & "\" & folder.name, key, level + 1) End If Next Call subSearch(baseUrl, key, level + 1) Else For Each folder In FSO.GetFolder(baseUrl).SubFolders If folder.name Like keyArr(level) Then Call subSearch(baseUrl & "\" & folder.name, key, level + 1) End If Next End If Else If keyArr(level) = "" Then If FSO.FolderExists(baseUrl) = True Then Me.AddItem baseUrl, FSO.GetFolder(baseUrl) End If Else For Each File In FSO.GetFolder(baseUrl).Files If File.name Like keyArr(level) Then Me.AddItem File, File End If Next End If End If End Function Private Function recursive(ByVal baseUrl As String, ByVal key As String, Optional ByVal level As Long = 0) As String Dim folder As Variant Dim keyArr As Variant Dim File As Variant keyArr = Split(key, "\") If UBound(keyArr) > level Then For Each folder In FSO.GetFolder(baseUrl).SubFolders If folder.name Like keyArr(level) Then Call subSearch(baseUrl & "\" & folder.name, key, level + 1) ElseIf "{" & folder.name & "}" Like keyArr(level) Then Call subSearch(baseUrl, key, level) Else Call recursive(baseUrl & "\" & folder.name, key, level) End If Next Else For Each folder In FSO.GetFolder(baseUrl).SubFolders Call recursive(baseUrl & "\" & folder.name, key, level) Next For Each File In FSO.GetFolder(baseUrl).Files If File.name Like keyArr(level) Then Me.AddItem File, File End If Next End If End Function参考サイト
- 長さ0文字以上の任意の文字列: *
- 任意の一文字: ?
- 特定の一文字: []
特殊文字のエスケープ- 再帰的に取得:
引数recursive→ 引数指定せず使用可能に- ファイル名のみ取得
- ディレクトリ名のみ取得
正規表現で条件指定- イテレータで一覧を取得: iglob()
- Collection
- Dictionary
- ArrayList
SortedList
※処理速度比較用に実装
- 投稿日:2020-02-09T19:45:20+09:00
zshの切替とPyhton3の再設定
macOS Catalina の標準シェルがzshになったとのことで、
terminalでも切替えの促しがありシェル変更(change shell)コマンドchshを実行
chsh -s /bin/zshその後にPythonのプログラムを実行すると、エラーが。。
SyntaxError: Non-ASCII character '\xe8...'ググると、utf-8の文字コードの宣言が冒頭に必要と。。
# -*- coding: utf-8 -*-でも今まで普通に動いてたのにと思い、もう少し調べると、、
Python3ではutf−8はデフォルト設定、
Python2ではutf−8の文字コード宣言が必要との記載が。。そこで
Phytonでバージョンを確認すると、Python2と判明。。
最初からPython3使ってたから意識してなかった。。Anacondaを使ってるので、
/opt/anaconda3/bin/conda init zshでPython3に切り替えて無事解決!
- 投稿日:2020-02-09T18:57:29+09:00
【Python × Zapier】警報情報を取得してSlackで通知する
やりたいこと(BEFORE)
気象庁の警報情報を取得して指定する地域に警報が出ていればSlackで通知する
こちらの記事がやりたいことドンピシャだ!
と思い記事の通りに進めていましたが、気象庁のデータが更新される度にZapier(作業を自動化できるツール)のタスクを動かしていると自分のプランの上限タスクを超えてしまう...
そこでやりたいことの範囲を狭めました。
やりたいこと(AFTER)
気象庁の警報情報を「毎朝7時」に取得して指定する地域に警報が出ていればSlackで通知する
▼こんな感じ(動かした時に警報が出ていなかったので代わりに注意報を取得した様子)
毎朝7時に1回だけ情報を取得してタスク実行回数を1回/日にしました。Zap全体図
- Every Day:ここで毎朝7時にタスクを実行するように設定
- Run Python:気象庁の情報を取得・抽出(下にコードを記載)
- Only continue if...:2で出力があれば(警報が出ていれば)次に進む
- Send Channel Message in Slack:Slackの指定するチャンネルで通知
Pythonコード
やりたいことが若干変わったので勉強せねば...と思いスクレイピングの方法を調べて書きました。初Python!
調べているとどうやらBeautifulSoupというものを使うのか〜ということを知りましたがZapierのヘルプにこんなことが書いてありました。
お"ぉぉおおおんBeautifulSoupが使えない!
ということで無理矢理感ありますがBeautifulSoup使わずにほしい箇所(警報部分)だけ抽出します。import re import requests import time code_list = [['札幌市', '0110000'], ['仙台市東部', '0410001'], ['さいたま市', '1110000']] output = {'text': ''} for code in code_list: html = requests.get('https://www.jma.go.jp/jp/warn/f_' + code[1] + '.html').text data_list = re.findall('<span style="color:#FF2800">(.*?)</span>', html) if len(data_list) == 0: continue text = '【' + code[0] + '】' i = 1 for data in data_list: if i == len(data_list): text += data else: data = re.sub('警報', '', data) text += data + ',' i += 1 output['text'] += text + '\n' time.sleep(1)各地域のページで警報部分のフォントカラーは
#FF2800なので、<span style="color:#FF2800">〜</span>で囲まれた部分を全て抽出しています。
また、複数ページをスクレイピングするのでtime.sleep(1)で1秒休ませます。参考
気象庁から情報を取得して東京23区の気象警報をSlackに通知する
Zapierの使い方も含めてとても参考にさせていただきました。


- 投稿日:2020-02-09T18:44:52+09:00
キューでスタックを、スタックでキューを作る(LeetCode / Implement Stack using Queues, Implement Queue using Stacksより)
(ブログ記事からの転載)
重要なデータ構造の1つにStack(スタック)とQueue(キュー)がありますが、これを実装しろという問題を取り上げます。
と言っても、こちらの解説記事にあるように、スタックもキューも配列で表現することができ、データ構造としては特別なものではありません。重要なのは以下の使われ方の違いです。
スタック データ構造に入っている要素のうち、最後に push した要素を取り出す
キュー データ構造に入っている要素のうち、最初に push した要素を取り出す以上の関数を有するStack class, Queue classを実装します。
Implement Stack using Queues
[https://leetcode.com/problems/implement-stack-using-queues/]
Implement the following operations of a stack using queues.
push(x) -- Push element x onto stack.
pop() -- Removes the element on top of the stack.
top() -- Get the top element.
empty() -- Return whether the stack is empty.Example:
MyStack stack = new MyStack();
stack.push(1);
stack.push(2);
stack.top(); // returns 2
stack.pop(); // returns 2
stack.empty(); // returns falseNotes:
You must use only standard operations of a queue -- which means only push to back, peek/pop from front, size, and is empty operations are valid.
Depending on your language, queue may not be supported natively. You may simulate a queue by using a list or deque (double-ended queue), as long as you use only standard operations of a queue.
You may assume that all operations are valid (for example, no pop or top operations will be called on an empty stack).まずはstackの実装から。問題タイトルにもあるように、queueを使ってstackを実装することが求められています。
queueを使うということは、可能な操作も限定されます。only push to back, peek/pop from front, size, and is empty operations are validとあるように、pushは後ろから、popは前からに限定されます。
誤答
一応やっておくと、問題の意図を無視してstackを使ってしまっても、テストは通ってしまいます。
ただ当然ながら、stackを使ってstackを作っても何の意味もないですね。
pythonではlistがstackにあたる挙動を示します。class MyStack: def __init__(self): """ Initialize your data structure here. """ self.stack = [] def push(self, x: int) -> None: """ Push element x onto stack. """ self.stack.append(x) def pop(self) -> int: """ Removes the element on top of the stack and returns that element. """ return self.stack.pop() def top(self) -> int: """ Get the top element. """ return self.stack[-1] def empty(self) -> bool: """ Returns whether the stack is empty. """ return len(self.stack) == 0解法
この問題ではqueueを使ってstackを実装することを求められていますが、ポイントはpop。繰り返しになりますが、stackでは最後にpushされた要素を取り出しますが、queueでは最初にpushされた要素を取り出します。
pythonでは
queue.popleft()で最初にpushされた要素を取り出せます。popleftを使って、pushを実行した際に、後にpushされた要素が先頭にくるようにqueueを並び替えるのが以下の解法です。class MyStack: def __init__(self): self.queue = collections.deque() def push(self, x: int) -> None: q = self.queue q.append(x) for _ in range(len(q)-1): q.append(q.popleft()) def pop(self) -> int: return self.queue.popleft() def top(self) -> int: return self.queue[0] def empty(self) -> bool: return len(self.queue) == 0時間計算量がpushで$O(n)$、popでは$O(1)$かかることになります。
ちなみに、本問題の要求のもとでは使えませんが、以下記事にあるように
collections.deque()にはpopメソッドも存在し、時間計算量$O(1)$で後方から要素を取り出し削除することが可能です。[https://note.nkmk.me/python-collections-deque/:embed:cite]
Implement Queue using Stacks
[https://leetcode.com/problems/implement-queue-using-stacks/]
Implement the following operations of a queue using stacks.
push(x) -- Push element x to the back of queue.
pop() -- Removes the element from in front of queue.
peek() -- Get the front element.
empty() -- Return whether the queue is empty.Example:
MyQueue queue = new MyQueue();
queue.push(1);
queue.push(2);
queue.peek(); // returns 1
queue.pop(); // returns 1
queue.empty(); // returns falseNotes:
You must use only standard operations of a stack -- which means only push to top, peek/pop from top, size, and is empty operations are valid.
Depending on your language, stack may not be supported natively. You may simulate a stack by using a list or deque (double-ended queue), as long as you use only standard operations of a stack.
You may assume that all operations are valid (for example, no pop or peek operations will be called on an empty queue).次に、Queueの実装です。今度はstackを使ってqueueを実装することを求められています。
これも可能な操作が限定されます。only push to top, peek/pop from top, size, and is empty operations are validとなっています。つまりpush, peek, popについては
list.append(x),list[-1],list.pop()のみが許容されていることになります。解法
2つstackを用意し、pushの際はinStackに格納、peekやpopの際はinStackの要素を逆順にして格納したoutStackを用意し、処理を行うのが以下の解法です。
class MyQueue: def __init__(self): """ Initialize your data structure here. """ self.inStack, self.outStack = [], [] def push(self, x: int) -> None: """ Push element x to the back of queue. """ self.inStack.append(x) def pop(self) -> int: """ Removes the element from in front of queue and returns that element. """ self.peek() return self.outStack.pop() def peek(self) -> int: """ Get the front element. """ if(self.outStack == []): while(self.inStack != []): self.outStack.append(self.inStack.pop()) return self.outStack[-1] def empty(self) -> bool: """ Returns whether the queue is empty. """ return len(self.inStack) == 0 and len(self.outStack) == 0
- 投稿日:2020-02-09T18:43:33+09:00
PytestでPublic関数をMockする方法
こんにちは、セールで買った某M○Proteinの「ほうじ茶ラテ味」プロテインが海老の出汁みたいな味で飲めないこの頃です(なに
さて弊社のDjangoサーバーのAPIはテストで120%カバレッジするというという方針のもと、日々テストコードを実装コードの倍ぐらい書いていく作業をしています。そんな中で本日は「Helperクラスで実装したPublic関数をどうやってAPI経由でテストするか(そしてどこで詰まったか」についてざっくりと紹介します。
テストしたい実装内容
実装した関数は以下の2つです(投稿用に関数名などはダミーにしています、またsetting.pyやurls.pyは別途設定済みです)
app/views.pyfrom rest_framework.views import APIView from app.helper import helper_foo from app.models import HogehogeSerializer class HogehogeListAPIView(APIView): """ Djangoフレームワークを使ったAPI ViewでPost機能を実装 """ permission_classes = (permissions.IsAuthenticated,) def post(self, request, format=None): """ API Post/hogehoge """ serializer = HogehogeSerializer(data=request.data) if serializer.is_valid(): #Requestデータのチェック try: with transaction.atomic(): serializer.save() helper_foo(serializer.data) # Helperの関数を呼び出し except Exception as error: return Response(status=status.HTTP_400_BAD_REQUEST) return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)app/helper.pyimport boto3 def helper_foo(data): """Helper関数 データを元にS3Bucketを作成する """ client = boto3.client("s") """ バケットを作成(失敗したらエラーを投げる """ client.create_bucket(...そしてpytestの内容がこちら
app/tests.pyfrom django.test import TestCase from django.conf import settings from rest_framework.test import APIClient class HogehogeAPITest(TestCase): def setUp(self): self.client = APIClient() self.data = #テスト用データを作成 def test_hogehoge_post(self): response = self.client.post('/hogehoge', self.data}, format='json') self.assertEqual(response.status_code, 201) # 諸々Assertでチェックテストの問題点
テスト内で実際にS3Bucketを作成するコードが実行されてしまい、テストを走らせるたびに余計なS3Bucketが増えていく。
対応策(Patch)でHelper関数をモック化する
UnittestのMockモジュールにあるpatchで以下のように関数をモック化できるということで実行
Targetは
app.helper.foo_helperを指定。app/tests.pyfrom unittest.mock import patch from django.test import TestCase from django.conf import settings from rest_framework.test import APIClient class HogehogeAPITest(TestCase): def setUp(self): self.client = APIClient() @patch('app.helper.helper_foo') def test_hogehoge_post(self, mock_function): response = self.client.post('/hogehoge', self.data}, format='json') self.assertEqual(response.status_code, 201) # 諸々Assertでチェック self.assertEqual(mock_function.call_count, 1) # Mock関数が一度呼ばれたか確認実行するとテスト結果が失敗となり以下のメッセージが
self.assertEqual(mock_function.call_count, 1) AssertionError: 0 != 1あれ、関数がMockできていない?AWSのコンソールも調べるとS3Bucketも(残念ながら)ちゃんとできている。
どうしたか
色々調べてみるとPatchの参照ロジックは以下のようになっているとのこと
Now we want to test some_function but we want to mock out SomeClass using patch(). The problem is that when we import module b, which we will have to do then it imports SomeClass from module a. If we use patch() to mock out a.SomeClass then it will have no effect on our test; module b already has a reference to the real SomeClass and it looks like our patching had no effect. (引用元)
つまり
module bをmodule aにインポートした場合、module bはmodule aから参照されるため b.someclass(ここでいうhelper.helper_foo)で参照してもテストに影響しない。とのことということで、先程のMockのTargetを
app.helper.foo_helperからapp.views.foo_helperに変更。app/tests.pyfrom unittest.mock import patch from django.test import TestCase from django.conf import settings from rest_framework.test import APIClient class HogehogeAPITest(TestCase): def setUp(self): self.client = APIClient() @patch('app.views.helper_foo') def test_hogehoge_post(self, mock_function): response = self.client.post('/hogehoge', self.data}, format='json') self.assertEqual(response.status_code, 201) # 諸々Assertでチェック self.assertEqual(mock_function.call_count, 1) # Mock関数が一度呼ばれたか確認これでテストは無事動き、S3バケットも生成されないことが確認できた。
10年近くPythonを触っていたけれど、初めてImport時のModule参照の仕組みを理解できました。
以上です。Testコードって色々な発見がある分野で面白いのでぜひQiitaにもっとPytestの記事が増えればなぁと思っている今日この頃です。
- 投稿日:2020-02-09T18:12:20+09:00
【Django3】プロジェクトの構成と各種設定【Python3】
はじめに
Django でシステム開発を行う際に必要な CLI のコマンドやディレクトリ構成、各種設定をまとめました。
Django は公式ドキュメントが充実しているので、時間がある方はそちらを見ましょう。
日本語多めですよ!
Django公式ドキュメント※順次追記していきます。
システム構成
- Windows 10 Pro
- Windows PowerShell
- Python 3.8.1
- pip 20.0.2
- Django 3.0.3
- mysqlclient 1.4.6
Django インストール
PowerShell# 仮想環境作成 python -m venv venv # 仮想環境有効化 ./venv/Script/activate # Django インストール pip install django※PowerShell で仮想環境を有効化する際に発生するエラーについては、下記記事を参照。
Qiita - 【Python3】開発環境構築《Windows編》 # PSSecurityException が発生した場合Django CLI チートシート
プロジェクト作成
PowerShell# カレントディレクトリに<Project Name>ディレクトリを作成し、その中にプロジェクトを作成 django-admin startproject <Project Name> # カレントディレクトリ直下にプロジェクトを作成 django-admin startproject <Project Name> .アプリケーション作成
PowerShellpython manage.py startapp <Application Name>開発用サーバ起動
PowerShell# localhost:8000 に開発用サーバを起動する python manage.py runserver [<Port>]管理ユーザ作成
PowerShellpython manage.py createsuperuserコマンド実行後、「ユーザ名」「メールアドレス」「パスワード」の入力を求められる。
管理画面にログインするは、開発用サーバ起動後にhttp://localhost:8000/admin/にアクセスする。マイグレーション
マイグレーションファイル作成
PowerShellpython manage.py makemigrationsデータベースの変更内容が記述されたマイグレーションファイルを作成する。
マイグレーション実行
PowerShellpython manage.py migrateマイグレーションファイルの内容をデータベースへ反映する。
Django ディレクトリ構成
<Project Name> ┬ venv # 仮想環境用ディレクトリ ├ static # 静的ファイル格納ディレクトリ │ ├ css │ ├ js │ └ ... ├ <Project Name> # プロジェクト用ディレクトリ │ ├ __init__.py │ ├ asgi.py │ ├ settings.py # プロジェクト用設定ファイル │ ├ urls.py # プロジェクト用ルーティング定義ファイル │ └ wsgi.py ├ <Application Name> # アプリケーション用ディレクトリ │ ├ migrations │ ├ templates # テンプレート格納ディレクトリ │ ├ __init__.py │ ├ admin.py # 管理サイト設定ファイル │ ├ apps.py # アプリケーション構成設定ファイル │ ├ models.py # モデル定義ファイル │ ├ tests.py # テストコード記述ファイル │ ├ urls.py # アプリケーション用ルーティング定義ファイル │ └ views.py # ビュー定義ファイル ├ manage.py # ユーティリティコマンド実行用ファイル └ requirements.txt # パッケージ一覧Django プロジェクト設定
言語とタイムゾーン
settings.py-- LANGUAGE_CODE = "en-us" ++ LANGUAGE_CODE = "ja" -- TIME_ZONE = "UTC" ++ TIME_ZONE = "Asia/Tokyo"データベース
settings.py# MySQL の場合 -- DATABASES = { -- "default": { -- "ENGINE": "django.db.backends.sqlite3", -- "NAME": os.path.join(BASE_DIR, "db.sqlite3"), -- } -- } ++ DATABASES = { ++ "default": { ++ "ENGINE": "django.db.backends.mysql", ++ "HOST": "127.0.0.1", ++ "PORT": "3306", ++ "NAME": "<DB Name>", ++ "USER": "<User Name>", ++ "PASSWORD": "<Password>", ++ } ++ }アプリケーションリスト
settings.py# applicationアプリケーションを追加する場合 INSTALLED_APPS = [ "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", ++ "application.apps.ApplicationConfig", ]新規アプリケーションを作成したら、プロジェクト用設定ファイルにアプリケーションを追加する。
静的ファイル(CSS, JavaScript, Images, ...)
プロジェクト
settings.py++ STATICFILES_DIRS = ( ++ os.path.join(BASE_DIR, "static"), ++ )プロジェクト用設定ファイルに静的ファイル格納ディレクトリを定義する。
テンプレート
index.html++ {% load static %} <!DOCTYPE html> <html> <head> ... <!-- <Project Name>/static/css/style.css が読み込まれる --> ++ <link rel="stylesheet" type="text/css" href="{% static 'css/style.css' %}">ファイル上部で static タグをロードすると、その後 static タグを使用して静的ファイルを相対パスで記述できる。
Django ルーティング
「https:///application/」へのルーティングを追加する場合、プロジェクト用ルーティングファイルへの追記と、アプリケーション用ルーティングファイルの作成 or 追記を行う。
プロジェクト
urls.py-- from django.urls import path ++ from django.urls import path, include urlpatterns = [ path("admin/", admin.site.urls), ++ path("application/", include("application.urls")), ]ルート(/)からのルーティングを記述する。
include関数を使用することで、アプリケーション側へルーティング処理を移譲できる。アプリケーション
urls.py++ from django.urls import path ++ from . import views ++ app_name = "application" ++ urlpatterns = [ ++ path("", views.IndexViews.as_view(), name="index") ++ ]コマンドで作成されるアプリケーションディレクトリには urls.py が含まれないため、初めてアプリケーション側のルーティングを行う場合、自分で作成する必要がある。
views.py-- from django.shortcuts import render ++ from django.views import generic ++ class IndexView(generic.TemplateView): ++ template_name = "index.html"template_name 変数に templates ディレクトリ直下のテンプレートファイル名を格納することで、ビューとテンプレートを紐づける。
- 投稿日:2020-02-09T18:10:11+09:00
scikit-learnのimputerでエラーが出た件
備忘録です。
Python3や機会学習周りのライブラリの進化に追いついてないせいか、古いままの状態の記述での記事があったためここに残しておきます。
hoge.pyfrom sklearn.preproceccing import Imputer imp = Imputer(strategy="mean",axis=0)上記は、欠損値の平均値を算出する際に使われる記述だが、どうやらバージョンによってすでに廃止されているらしい。
なので、バージョンによってはエラーが出ます。(ちょっと詰まりました・・・)
色々と調べてたら、下記の記事を見つけたのでその辺を詳しく知りたい場合は、こちらの記事を見るのが一番良いです。写経中に遭遇したscikit-learnのワーニングに対応してみた
https://qiita.com/y_nishimura/items/6d022a25beb21a186d60じゃあ、どうすればエラーが出ないのかというと。
hoge.pyfrom sklearn.impute import SimpleImputer imp = SimpleImputer(strategy='mean')SimpleImputerを使うことで算出できるそうです。
本とか使って勉強するのは良いのですが、こういうエラーがあったりして意外と落とし穴だったりしますね・・・
- 投稿日:2020-02-09T18:08:42+09:00
Sphinx-2.4 で進化した型機能を使おう
先ほど Sphinx-2.4.0 をリリースしました。
Sphinx は 2ヶ月ごとの定期リリースを目指しているので、大体予定通りのリリースです。2.4.0 では autodoc まわりの機能が大きく改善されました。この記事ではその改善点についてまとめたいと思います。
変数アノテーションへの対応
- autodoc: Support type annotations for variables
- #7051: autodoc: Support instance variables without defaults (PEP-526)
これまで、コード内の変数アノテーションはドキュメント化されていなかったのですが、2.4 からはドキュメントに出力されるようになりました。
いまや型情報は規模の大きいプログラムを書くのに欠かせない情報となっています。型情報をアノテーションすることは、あなたと開発チームだけではなく、ライブラリを利用する人の助けになるでしょう。また、PEP-526の初期値なしの型宣言にも対応しました。次のような定義をしたときに、
Starship.captainやStarship.damageは型アノテーション付きのインスタンス変数としてドキュメント化されます。class Starship: captain: str damage: intこの変更によって、Python3.7 から導入された dataclasses もドキュメント化できるようになりました。
type comment 形式の型アノテーションに対応しました
- #2755: autodoc: Support type_comment style (ex.
# type: (str) -> str) annotation (python3.8+ ortyped_ast <https://github.com/python/typed_ast>_ is required)古くから使われていた type comment 形式(例:
# type: (str) -> str)の型アノテーションをサポートしました。長くメンテナンスされているプロジェクトでは、この機能が役に立つはずです。なお、Python3.7 以前をご利用の場合は typed_ast をインストールしてください。
型ドキュメントを本文に表示させる機能が先行導入されました
- #6418: autodoc: Add a new extension
sphinx.ext.autodoc.typehints. It shows typehints as object description ifautodoc_typehints = "description"set. This is an experimental extension and it will be integrated into autodoc core in Sphinx-3.03.0 以降で正式採用する機能のチラ見せとして
sphinx.ext.autodoc.typehintsという拡張を追加しました。
この拡張をロードするとautodoc_typehintsという設定に"description"を指定できるようになります。
autodoc_typehintsは関数やメソッドをドキュメント化するときに、型情報をどのように表示するのかを調整するものです。今回の改修を理解するためにも、オリジナルの機能も含めてご紹介したいと思います。
autodoc_typehintsには(新しい設定を含めて) 3つのモードがあります。次の関数のドキュメントを例に、それぞれのモードの変換結果を見てみましょう。def hello(name: str, age: int) -> str: """Hello world! :param name: Your name :param age: Your age :returns: greeting message """signature モード
デフォルトの設定(
autodoc_typehints = "signature")では、関数ドキュメントの定義欄にそのまま型アノテーションが表示されます。
シンプルな関数であれば、この状態で十分読みやすいのすが、引数が多い関数やメソッドではとても読みづらい表示となってしまいます。例えば、tornado プロジェクトでは次のようなドキュメントが生成されてしまっています。
none モード
もうひとつの設定(
autodoc_typehints = "none")は、関数ドキュメントの定義欄から型アノテーションを削除します。
随分スッキリしましたね。このオプションは、関数コメント(docstring)に自分で引数の説明を書く場合に役立ちます。プログラム中とコメント内の二箇所に型情報を書く必要が出てくるため冗長にはなりますが、読みやすいドキュメントを書くことができます。
Google 形式や Numpy 形式では、型アノテーションを関数コメントに記載する文化があるため、このオプションにマッチしていると言えます。
description モード (新規追加)
そして、今回追加された設定(
autodoc_typehints = "description")は、関数ドキュメントの本文部分に型アノテーション情報を表示します。
どの形式が読みやすいかは書いているプログラムの規模によっても差があると思いますが、個人的には今回追加された設定は読みやすさが上がると感じています。
experimental としていますが、特に深刻なバグなどが見つからなければ 3.0 で正式採用されます。
実際に試してもらい、おかしい所があればバグ報告してもらえるとありがたいです。※ 新しい設定はいまのところ
sphinx.ext.autodoc.typehints拡張をロードしたときのみ有効となるのでご注意を。まとめ
- Sphinx-2.4.0 をリリースしました
- autodoc まわりの改善がんばりました
sphinx.ext.autodoc.typehintsが追加されました。フィードバック絶賛お待ちしております- 他にもいろいろ機能追加したりバグ潰したりしたよ。 詳しくはCHANGES 見てね




- 投稿日:2020-02-09T18:07:51+09:00
今回はProrate でpythonのIIIとIVを学びました
今回はクラスやモジュール、インスタンスメソッドについて学びました。
非常にためになる内容でした。
pythonは基本的に英語のまま覚えられるのでとても便利です。
- 投稿日:2020-02-09T18:05:47+09:00
REST APIでQiitaの記事を作成してみる【環境準備編】
設定の覚書です。
背景
PythonでQiitaのRESTAPIを叩いて記事を作成します。
環境
Windows10
Python 3.8.1
外部ライブラリ:requests
Visual Studio Code 1.42.0環境準備編
「Pythonのインストール」に時間がかかって
なんだかんだで半日かかりました。
サクサクすすめば、1時間以内に終わると思います。1. Pythonのインストール
一応2系と3系両方インストールしました。
実際にコードを実行するのは、最新版の3系を使います。
(2系はPythonの参考書が2系を使っていたためです。)参考記事:
WindowsにPython2.7とPython3.8が共存できるようにChocolateyでインストールする
※Pythonインストール時に以下のエラーメッセージが表示されました。pyコマンドでコマンドが実行できませんでしたが、Chocolatey出力メッセージ通りコマンドプロンプトを再起動することにより、この事象が解消しました。
2020-02-09 12:00:03,908 7028 [WARN ] - Environment Vars (like PATH) have changed. Close/reopen your shell to
see the changes (or in powershell/cmd.exe just typerefreshenv).2. Visual Stadio Codeをインストール
参考記事:
VisualStudioCodeのインストールと日本語化拡張機能も併せてインストールします。
・Python for VSCode
構文の間違いを指摘してくれる拡張機能
・Python Extended
コードを補完してくれる拡張機能
・Python Indent
インデントを整形してくれる拡張機能3. 2系と3系のPythonを切り替えるための設定
Visual Studio Codeの設定ファイルをフォルダごとに配置します。
・2系の実行環境のフォルダ
・3系の実行環境のフォルダ参考記事:
VS CodeでWorkspace毎に使用するPython実行環境を切り替える3.requestsライブラリを3系のPythonにインストール
C:\WINDOWS\system32>py -3 -m pip install requests
- 投稿日:2020-02-09T18:04:17+09:00
今回はProgateでPythonのIとIIを学びました。
今回学んだことはpythonの初期的なことです。
主には変数の使い方や条件分岐、リストや辞書型です。
変数は 変数名 = 入れたい処理 のように書きます。
それを元に商品を購入するシステムを作りました。
- 投稿日:2020-02-09T17:55:29+09:00
AtomでPython3.7.4を動かすときにTkinterのcanvas(ウィンドウ)が立ち上がらない
AtomでPython3.7.4を動かす環境を作りましたが、Tkinterライブラリを使ってcanvasを表示するプログラムを実行しても、canvas(ウィンドウ)が立ち上がりません。
原因おわかりの方、解決方法をご教示いただけないでしょうか?■やったこと
①Python3.7.4のデフォルトの開発環境(IDLE)で、Tkinterライブラリを使ったcanvasを表示するプログラムを実行すると、添付写真のようにcanvasのウィンドウが表示されます。(エイリアンの画像)
②Atom1.4の環境を用意して、後述する「atom-runnter」というパッケージをインストールして、Atom内でPythonが実行できる環境を構築しました。
③しかし、Atomで同プログラムを実行をすると、実行結果を表示するウィンドウはAtomの右下に表示されるものの(print文はないため実際は何も表示されません)、①のウィンドウが立ち上がりません。※試しにプログラムにprint("hello")を追加してみたところ、実行結果には正しく表示されましたが、依然としてウィンドウは出ません。■Atom導入パッケージ(関係なさそうなものも含めて列挙)
atom-runner
busy-signal
indent-guide-improved
intentions
japanese-menu
linter
linter-php
linter-ui-default
script
show-ideographic-space
- 投稿日:2020-02-09T17:27:54+09:00
ウマすぎて、、、ウマになった構文を、COTOHA API を使って採点してみた。
はじめに
最近、とある動画シリーズ1の影響で
「〇〇すぎて、、、〇〇になった」
という表現にハマっています。
最近だと、朝家を出る時に寒すぎて、、、サムギョプサルになった。みたいな。ただ、後半の「〇〇になった」の部分は意外といい感じの単語が出てこなくて、
「眩しすぎて、、、マーブルチョコになった」
みたいに、ニアミスな単語セレクトで妥協してしまうこと、あると思います。
そんな自分を戒めるために、COTOHA APIを使って、自分が考えたウマすぎて構文(リスペクトを込めてこう呼びたいと思います)を採点してもらうプログラムを書きました。採点方法
ウマすぎて構文は要するに、
「(形容詞語幹)すぎて、、、(名詞)になった」
この、形容詞語幹と名詞の類似度が高いほど良い構文である、ということができるでしょう。
しかし、名詞が意味のわからない単語であってもいけません。
名詞部分が一般的な単語でない場合は0点としたいと思います。形容詞語幹と名詞の類似度についてはとりあえずレーベンシュタイン距離を採用したいと思いますが、
冒頭で申し上げた「寒すぎて、サムギョプサルになった」のように、名詞側が無駄に長くなってしまっても減点をしたくありません。そのため名詞側は形容詞語幹側の文字数までしか見ないことにします2。使用例
$ echo "ウマすぎてウマになった" | python orochimaru.py 100.0点ね ウマすぎて、、、ウマになったわね、、、 $ echo "眩しすぎてマーブルチョコになった" | python orochimaru.py 33.3点ね マブシすぎて、、、マーブルチョコになったわね、、、 $ echo "面白すぎてオモシロになった" | python orochimaru.py 0点ね オモシロすぎて、、、オモシロになったわね、、、準備
入力テキストの構文解析と、名詞が一般名詞かどうかの判定をするために、COTOHA API を使用します。
COTOHA API Portal からDevelopersアカウントを作成し、Client IDとClient secretをメモしておきます。
また、PyPi には登録されていませんが、GitHub で python ライブラリが公開されているので、こちらの記事を参考にインストールします。
もちろん直接APIを叩く場合は必要ありませんし、現時点では構文解析と類似度算出にしか対応していないようなので注意してください。python は3.6を使っています。pyenvとかを使っている場合はよしなにしてください。
$ git clone https://github.com/obilixilido/cotoha-nlp.git $ cd cotoha-nlp/ $ pip install -e .これで、COTOHA APIの構文解析が使えるようになりました。
実装
レーベンシュタイン距離の実装
wikipediaのアルゴリズムをそのまま実装しただけなので、詳細は割愛させていただきます。
levenshtein.pydef levenshtein_distance(s1, s2): l1 = len(s1) l2 = len(s2) dp = [[0 for j in range(l2+1)] for i in range(l1+1)] for i in range(l1+1): dp[i][0] = i for i in range(l2+1): dp[0][i] = i for i in range(1, l1+1): for j in range(1, l2+1): cost = 0 if (s1[i-1] == s2[j-1]) else 1 dp[i][j] = min([dp[i-1][j]+1, dp[i][j-1]+1, dp[i-1][j-1]+cost]) return dp[l1][l2]ウマすぎて構文解析
すごい雑な実装ですが、「〇〇すぎて〇〇になった」にマッチするテキストを入力すると、点数と解析結果の文章が出力されます。
orochimaru.pyfrom cotoha_nlp.parse import Parser import levenshtein_distance def find_orochi_sentence(tokens): form_list = ["", "すぎ", "て", "", "に", "な", "っ", "た"] pos_list = ["", "形容詞接尾辞", "動詞接尾辞", "", "格助詞", "動詞語幹", "動詞活用語尾", "動詞接尾辞"] i = 0 s1 = ""; s2 = "" is_unknown = False for token in tokens: if (i > 7): return 1 if (i == 0): if not (token.pos == "形容詞語幹"): return 1 s1 = token.kana elif (i == 3): if not (token.pos == "名詞"): return 1 s2 = token.kana if ("Undef" in token.features): is_unknown = True else: if (i == 4 and token.pos == "名詞"): s2 += token.kana if ("Undef" in token.feautes): is_unknown = True continue if not (token.pos == pos_list[i] and token.form == form_list[i]): return 1 i += 1 if is_unknown: print("0点ね") else: dist = levenshtein_distance.levenshtein_distance(s1, s2[:len(s1)]) print(f"{(100 * (len(s1) - dist) / len(s1)):.1f}点ね") print(f"{s1}すぎて、、、{s2}になったわね、、、") return 0 parser = Parser("YOUR_CLIENT_ID", "YOUR_CLIENT_SECRET", "https://api.ce-cotoha.com/api/dev/nlp", "https://api.ce-cotoha.com/v1/oauth/accesstokens" ) s = parser.parse(input()) if find_orochi_sentence(s.tokens) == 1: print("これはウマすぎて構文ではありません")COTOHA API の構文解析では、各単語の形態素情報3が得られるのですが、当該単語が未知語の場合、その中の "features" に "Undef" という情報が付与されます。
その情報をもとに、ウマすぎて構文の名詞部分が一般名詞かどうかを判定しています。また、類似度算出の際に漢字が含まれると、表記揺れの問題があるので、カタカナの読みを用いて比較を行っています。そのため、COTOHA APIで想定と異なる読み方だと認識されると正しく判定できないことになります。(例:辛すぎて面になった)
ウマすぎて構文マスターの中には、「〇〇すぎて杉になった」 とすることで、いい感じの単語を思いつかない問題に対応する人もいますが、これはズルなので評価しません。
おわりに
これで、ウマすぎて構文を思いついた時に、いつでも客観的に評価してもらえようになりました。
今回は形態素解析のために、COTOHA API を使ってみましたが、簡単に使えて、結構いろんな単語にも対応しているので便利だなーと感じました。「〇〇になった」部分で、〇〇が未知語でもちゃんと名詞だと推定されているのも偉いなと思います。無料版だとAPIリクエスト数の制約(1日1000回)はありますが、遊びで使う分には問題ないレベルかなと思います。
皆さんも、ウマすぎて構文を使ってみてください。
ありがとうございました。参考
ここはツッコミポイントで、もっとちゃんとした実装方法はあると思います。 ↩
- 投稿日:2020-02-09T17:16:46+09:00
【Python】リスト(配列)内要素の操作【追加・削除】
はじめに
リストを扱う上で重要な追加と削除の方法をまとめました。
基本的に以下のようなコードでコードと出力結果を記載します。ex.pycode = 'コード' print(code) # code(出力結果)リスト(配列)に要素を追加するappend, extend, insert
Pythonでlist型のリスト(配列)に要素を追加したり別のリストを結合したりするには、リストのメソッド
append(),extend(),insert()を使う。そのほか、+演算子やスライスで位置を指定して代入する方法もある。・末尾に要素を追加: append()
・末尾に別のリストやタプルを結合(連結): extend(), +演算子
・指定位置に要素を追加(挿入): insert()
・指定位置に別のリストやタプルを追加(挿入): スライスを使う・append()・・・末尾(最後)に要素を追加できる。
append().pyl = [0, 1, 2] print(l) # [0, 1, 2] l.append(100) print(l) # [0, 1, 2, 100] l.append('new') print(l) # [0, 1, 2, 100, 'new'] l.append([3, 4, 5]) print(l) # [0, 1, 2, 100, 'new', [3, 4, 5]]・extend()・・・末尾(最後)に別のリストやタプルを結合できる。
extend().pyl = [0, 1, 2] l.extend([100, 101, 102]) print(l) # [0, 1, 2, 100, 101, 102] l.extend((-1, -2, -3)) print(l) # [0, 1, 2, 100, 101, 102, -1, -2, -3] #append()と違って一文字ずつ格納される l.extend('new') print(l) # [0, 1, 2, 100, 101, 102, -1, -2, -3, 'n', 'e', 'w'] #extend()メソッドではなく+=でも可。 l += [5, 6, 7] print(l) # [0, 1, 2, 100, 101, 102, -1, -2, -3, 'n', 'e', 'w', 5, 6, 7]・insert()・・・指定した位置に要素を追加(挿入)できる。第一引数に位置、第二引数に挿入する要素を指定する。先頭(最初)は0。負の値の場合、-1が末尾(最後)の一つ前となる。
insert().pyl = [0, 1, 2] l.insert(0, 100) print(l) # [100, 0, 1, 2] l.insert(-1, 200) print(l) # [100, 0, 1, 200, 2] l.insert(0, [-1, -2, -3]) print(l) # [[-1, -2, -3], 100, 0, 1, 200, 2]・スライスで範囲を指定して別のリストやタプルを代入すると、すべての要素が追加(挿入)される。
insert().pyl = [0, 1, 2] l[1:1] = [100, 200, 300] print(l) # [0, 100, 200, 300, 1, 2] l[1:2] = [100, 200, 300] print(l) # [0, 100, 200, 300, 2]リスト(配列)の要素を削除するclear, pop, remove, del
Pythonでlist型のリスト(配列)の要素を削除するには、リストのメソッド
claer(),pop(),remove()を使う。そのほか、インデックスやスライスで位置・範囲を指定してdel文で削除する方法もある。・すべての要素を削除: clear()
・指定した位置の要素を削除し、値を取得: pop()
・指定した値と同じ要素を検索し、最初の要素を削除: remove()
・インデックス・スライスで位置・範囲を指定して削除: del・clear()・・・全ての要素を削除する
clear().pyl = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] l.clear() print(l) # []・pop()・・・リストのメソッドpop()で、指定した位置の要素を削除し、その要素の値を取得できる。
pop().pyl = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(l.pop(3)) # 4 print(l.pop(-2)) # 8 #引数を省略して位置を指定しない場合は、末尾(最後)の要素を削除する print(l.pop()) # 9・remove()・・・リストのメソッドremove()で、指定した値と同じ要素を検索し、最初の要素を削除できる。
remove().pyl = ['Alice', 'Bob', 'Charlie', 'Bob', 'Dave'] l.remove('Alice') print(l) # ['Bob', 'Charlie', 'Bob', 'Dave']・del・・・削除したい要素をインデックスで指定する。先頭(最初)は0で、末尾(最後)は-1。
del.pyl = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] del l[6] print(l) # [1, 2, 3, 4, 5, 6, 8] del l[-1] print(l) # [1, 2, 3, 4, 5, 6, 7, 8] #スライスで範囲を指定すると、複数の要素を一括で削除できる del l[2:5] print(l) # [0, 1, 5, 6, 7, 8, 9]最後に
少しでも参考になりましたら「いいね?」お願いします。あなたの1いいねが私のやる気につながります。
あと他にも何か方法が解法があれば教えてもらえると嬉しいです。