- 投稿日:2020-02-06T22:45:58+09:00
【Python & SQLite】単勝1倍台の馬がいるレースの期待値分析してみた①
概要
競馬 × AIの話題を見かけることがここ数年で増えましたが、全レースを対象としたものも多く、
個人的に気になる事例に絞って分析してみたい!と思い、今回netkeiba-scraperを使用していじってみました。今回絞るテーマは「単勝1倍台の馬が出走するレースの買い方」です。
2019年は日本ダービーや阪神JF、有馬記念など、単勝1倍台の馬が馬券外に沈むケースも多く見られました。
あくまで単勝馬券で分析は進めました。※SQLをPythonでいじる練習も兼ねていますので、コードの書き方ご指導いただけると嬉しいです!
netkeiba-scraperでデータ取得
競馬データのスクレイピングについては、偉大なる先人のコードを使用させていただきました。
gitHubはこちら過去10年分のデータを取得しました。
特徴量抽出のためのgenfeatureは、処理に40日くらいかかりそうだったため使用しませんでした。
またJRAのクラス呼称が変更された(ex. 500万下→1勝クラス)ため、Scalaコードを直さないと適切にgenfeatureできなさそうです。DLしたrace.dbファイルをPythonで読み込み、データ分析を開始します。
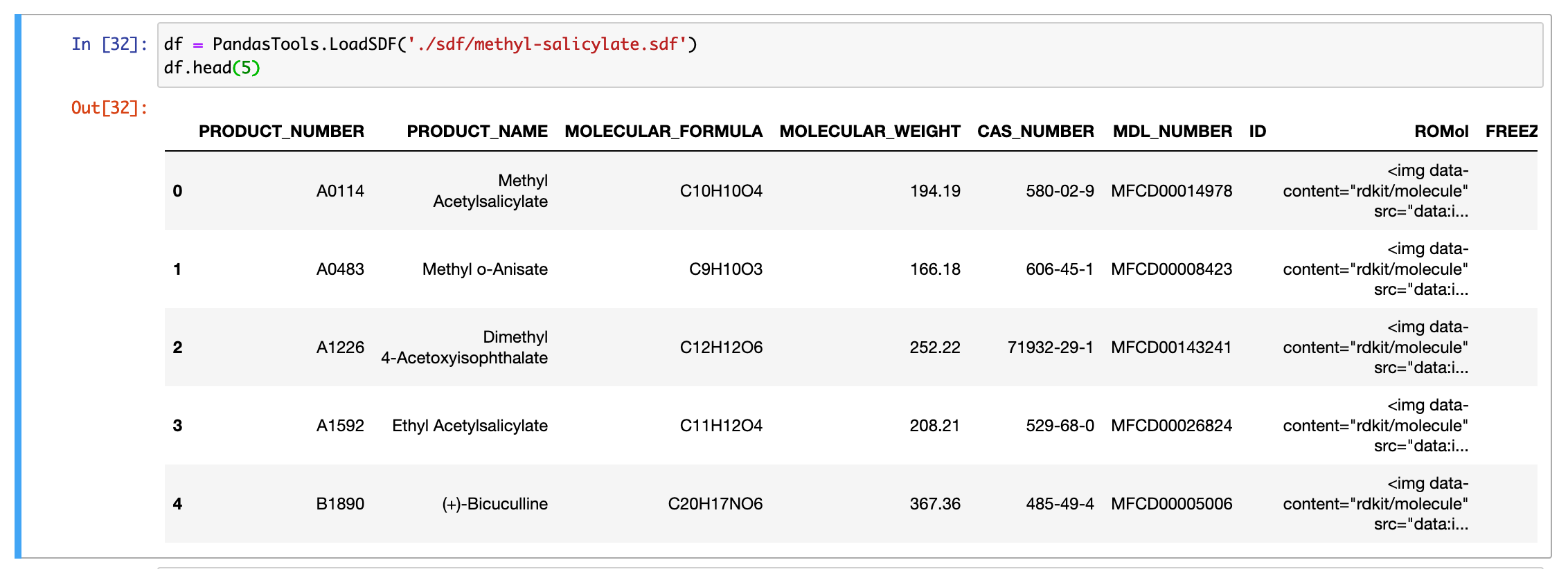
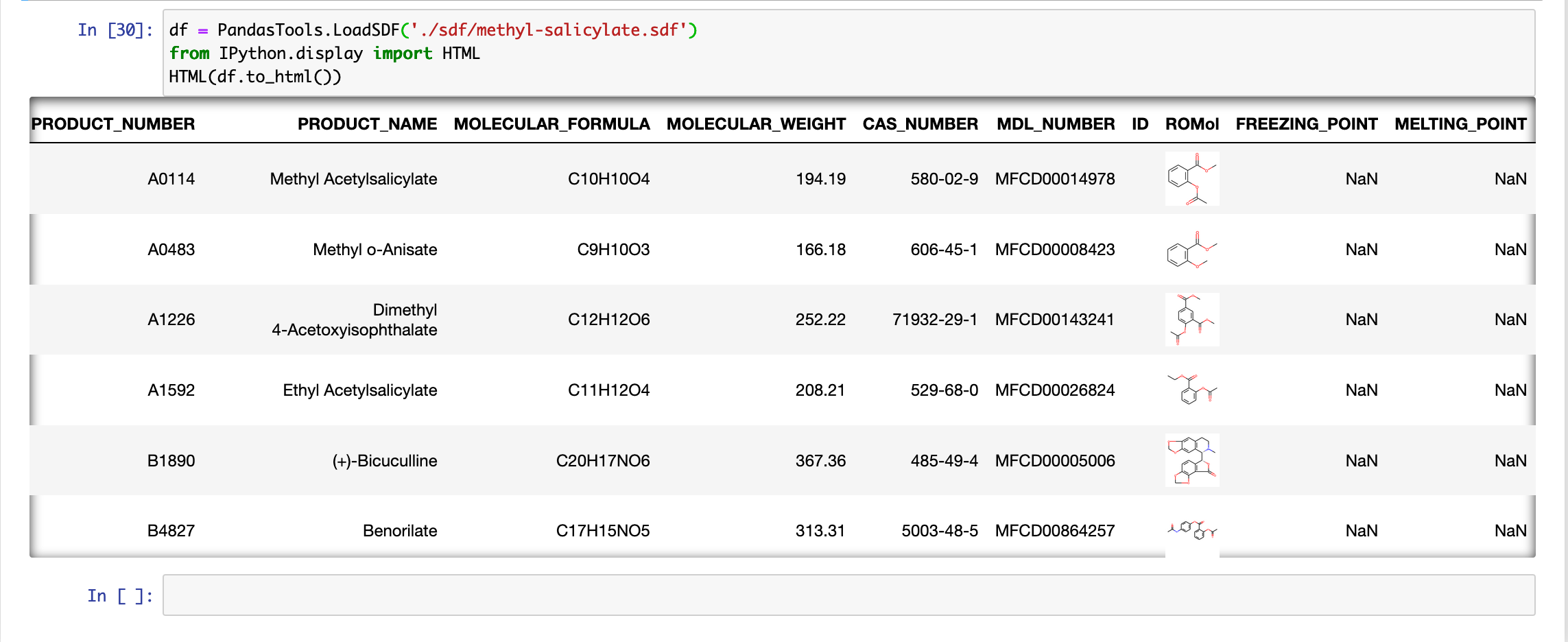
Jupyter NotebookでSQLiteを読み込む
dbconnectimport sqlite3 as sq conn = sq.connect('race.db') cur = conn.cursor() cur.execute("SELECT r.race_id, i.race_name, r.order_of_finish, r.odds \ FROM race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE r.odds<2.0") rows = cur.fetchall() for row in rows: print(row)Jupyter Notebookのipynbファイルと同じ階層にrace.dbファイルを移し、読み込みます。
race.dbのうちレースのデータがrace_infoテーブル、race_resultテーブルに格納されているので、
欲しい情報を各テーブルから取得します。※race_infoテーブル レースごとの情報が載っています
※race_resultテーブル 馬ごとの戦績が載っています
1倍台の人気で勝利した馬の期待値
オッズ別期待値(全クラス)# 勝ち数 cur.execute("SELECT r.odds, count(r.race_id) \ FROM race_result r \ WHERE r.odds<2.0 AND r.order_of_finish='1' \ GROUP BY r.odds ORDER BY r.odds ASC") rows = cur.fetchall() # 全レース cur.execute("SELECT r.odds, count(r.race_id) \ FROM race_result r \ WHERE r.odds<2.0 \ GROUP BY r.odds ORDER BY r.odds") rows2 = cur.fetchall() # 期待値計算 もっと他に書きようありそう try: t11 = rows[0][0] * rows[0][1] / (rows2[0][0] * rows2[0][1]) * 100 t12 = rows[1][0] * rows[1][1] / (rows2[1][0] * rows2[1][1]) * 100 t13 = rows[2][0] * rows[2][1] / (rows2[2][0] * rows2[2][1]) * 100 t14 = rows[3][0] * rows[3][1] / (rows2[3][0] * rows2[3][1]) * 100 t15 = rows[4][0] * rows[4][1] / (rows2[4][0] * rows2[4][1]) * 100 t16 = rows[5][0] * rows[5][1] / (rows2[5][0] * rows2[5][1]) * 100 t17 = rows[6][0] * rows[6][1] / (rows2[6][0] * rows2[6][1]) * 100 t18 = rows[7][0] * rows[7][1] / (rows2[7][0] * rows2[7][1]) * 100 t19 = rows[8][0] * rows[8][1] / (rows2[8][0] * rows2[8][1]) * 100 except: None print('単勝1.1倍の馬券期待値は %d' %t11) print('単勝1.2倍の馬券期待値は %d' %t12) print('単勝1.3倍の馬券期待値は %d' %t13) print('単勝1.4倍の馬券期待値は %d' %t14) print('単勝1.5倍の馬券期待値は %d' %t15) print('単勝1.6倍の馬券期待値は %d' %t16) print('単勝1.7倍の馬券期待値は %d' %t17) print('単勝1.8倍の馬券期待値は %d' %t18) print('単勝1.9倍の馬券期待値は %d' %t19)
面白いことに、オッズが低いほど単勝期待値が高い(=1着になる可能性が高い)ことが分かりました。
やはり1.1倍ともなると歴史的名馬も多いからでしょうか。似た条件で【オープンクラス以上(重賞含む)】に絞ると、1.1倍の期待値がさらに上昇しました。
OnlyOpenClasscur.execute("SELECT r.odds, count(r.race_id) \ FROM race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE r.odds<2.0 AND r.order_of_finish='1' AND i.race_class like '%オープン%' \ GROUP BY r.odds ORDER BY r.odds ASC")
人気別の成績を調べる
単勝1倍台の馬が出走するレースでは、どの馬が勝利することが多いのでしょうか?
2番人気や3番人気に妙味はあるのでしょうか?上までの分析と違い、【単勝1倍台の馬がいるレースに限定】しなければ計算できないため、
WHERE ~ IN (SELECT ~~)の記法でサブクエリを使用しました。ResultByPopularity# 単勝1倍台の馬がいるレースのうち人気別勝ち数 cur.execute("SELECT r.popularity, count(r.race_id) \ FROM race_result r \ WHERE r.order_of_finish='1' AND r.race_id IN (SELECT race_id from race_result WHERE odds<2.0 AND popularity='1') \ GROUP BY r.popularity ORDER BY r.popularity ASC") rows = cur.fetchall() # 単勝1倍台の馬がいる全レース cur.execute("SELECT count(r.race_id) FROM race_result r WHERE r.odds<2.0 AND r.popularity='1'") rows2 = cur.fetchall() for row in rows: print(row) print(rows2[0][0])
全7,619レース中、約半数を1番人気が勝利しています。
2番人気は単勝6倍以上、3番人気は10倍近くつかないと期待値100を超えません。
オッズに頭数を掛け、レース数で割る形で期待値を計算しましたが、32と酷い有様でした。まとめ
競馬場やダート/芝、馬齢、馬番、馬の脚質を細分化しなければ、オッズを見ても儲からない、というのが今回の結果でした。
また競馬には多様な馬券の種類があるため、【単勝1倍台の馬が出走するレースで最も期待値の高い馬券種はどれか?】など、
もっと深く分析できそうです。Python(Jupiter Notebook)でSQLを抽出する要領はつかめたので、引き続き分析してみようと思います。
参考記事






- 投稿日:2020-02-06T22:24:52+09:00
自前データをアノテーションしてMask R-CNNを学習させる
Instance Segmentation(物体検出+セグメンテーション) をするために
- 自前データをアノテーション
- Mask R-CNNを学習
ということを行なったのですが、他に役立つ記事が見当たらず苦労したので
メモ程度ですが僕が行なった手順を共有します。Mask R-CNNについての解説は省略します。
以下を参考にしてください。
最新のRegion CNN(R-CNN)を用いた物体検出入門 ~物体検出とは? R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN~Mask R-CNNの実装は以下のレポジトリを利用しています。
https://github.com/facebookresearch/maskrcnn-benchmarkLabelmeによるデータ作成
https://github.com/wkentaro/labelme
基本的には上のREADME.mdの通りです
以下にざっとまとめますインストール
$ pip install labelmeでも入るのですが、後ほどデータ変換でスクリプトを使うのでgit cloneします$ git clone https://github.com/wkentaro/labelme.git $ cd labelme $ pip install -e .起動
クラス名を改行で羅列した
class.txtを作成してください。データの変換の際にエラーが出るかもなので一行目に__ignore__を追加します。
例:classes.txt__ignore__ person bicycle car ...以下のコマンドでlabelmeを起動します
$ labelme <データフォルダのpath> --labels <classes.txtのpath> --nodataアノテーション
以下サイトが参考になります。非常に簡単にアノテーションができます。
セマンティックセグメンテーションのアノテーションツールlabelmeデータ形式変換
作成されたアノテーションデータ、元画像をMask R-CNN用に変換します。
$ cd labelme/examplts/instance_segmentation $ ./labelme2coco.py <データフォルダのpath> <作成するディレクトリ名> --labels <classes.txt>これによって
<作成するディレクトリ名>/JPEGImages・・・画像が入ったディレクトリ
<作成するディレクトリ名>/annotations.json・・・アノテーション情報が記されたjsonファイル
が作成されますmaskrcnnを学習させる
インストール
https://github.com/facebookresearch/maskrcnn-benchmark
上をREADME.mdにしたがってインストール以下の記事が参考になります。
Pytorch1.1+MaskRCNNで自前データ訓練(1)データ配置
データをmaskrcnnが読み込める位置に配置する
上で作成した
JPEGImages,
annotations.json
を
maskrcnn_benchmark/datasets/<新ディレクトリ名>/
に配置データ登録
maskrcnn_benchmark/config/paths_catalog.pyのDATASETSに以下を追加COCO形式であることを読み込ませるために、"新データ名"にCOCOを含ませるようにしてください。
"新データ名" : { "img_dir" : "<新ディレクトリ名>" "ann_file" : "<新ディレクトリ名>/annotations.json" }学習実行
以上の処理で、学習用 ,テスト用 のデータを登録してください。
以下にて学習を開始できるはずです。
$ python tools/train_net.py --config-file configs/e2e_mask_rcnn_R_50_FPN_1x.yaml DATASETS.TRAIN "(\"<新データ名(学習用)>\",)" DATASETS.TEST "(\"<新データ名(テスト用)>\",)"
--config-fileをconfigs/から指定することで、ネットワーク構造等のconfigを指定できます。
学習率やバッチサイズを変更したいときは、実行時に記すことで変更できます例:
$ python tools/train_net.py --config-file configs/e2e_mask_rcnn_R_50_FPN_1x.yaml DATASETS.TRAIN "(\"<新データ名(学習用)>\",)" DATASETS.TEST "(\"<新データ名(テスト用)>\",)" SOLVER.BASE_LR 0.0025 SOLVER.IMS_PER_BATCH 2 TEST.IMS_PER_BATCH 1
SOLVER.BASE_LR: 学習スタート時の学習率 (逓減していきます )
SOLVER.IMS_PER_BATCH: 学習時バッチサイズ
TEST.IMS_PER_BATCH: テスト時バッチサイズ全パラメータは
maskrcnn_benchmark/config/defaults.py
に書いてあります。注意点
同じラベルの別物体が1つの物体として認識されてしまう
labelmeのデータ変換時に、デフォルトだとまとめて1つの物体として認識するようになっています。
別々に認識させたい場合は、labelme2coco.pyを以下にしたがって修正してください。
https://github.com/wkentaro/labelme/issues/419#issuecomment-511853597セグメンテーションが一つの物体にしか行われない
学習の際に
Pytorchのバージョンによってラベルが全て一つの物体に対して作成されてしまうようです。maskrcnn_benchmark/data/datasets/coco.py#L94
の挙動が予期せぬものとなっていることがあるので
target = target.clip_to_image(remove_empty=True)を
target = target.clip_to_image(remove_empty=False)
に変更してください。
以上になります。
ありがとうございました!
- 投稿日:2020-02-06T22:23:08+09:00
abc115-Dを解いた再帰関数の解き方
問題
https://atcoder.jp/contests/abc115/tasks/abc115_d
二度目の挑戦。解けて本当に嬉しかった。
この手の問題は他の競プロ系サイトでも出題しているので意外と大事。方向性
問題文から再帰関数を用いるであろうことは想像難くない。問題はシュミレーターを作ると全てのバーガーの要素が膨大になってしまうので無理。必要な分だけ考えて算術で効率的にとく。
何が難しいか
問題の解釈は問題ない。問題は再帰をするための条件と戻り値を正しく決定できるかである。また、条件分岐が多いことも難易度をあげている。
解法
再帰問題のコツは状態位相を少ない値でモデリングすることだと感じた。つまり大事なことは以下の二つ
1. 再帰的に関数を呼び出すので、N,N-1,N-2...1,2の全てに成り立つ関数を作成すること。
2. 終了条件を考えること。
- 再帰的に関数を呼び出すので、N,N-1,N-2...1,2の全てに成り立つ関数を作成すること。
今回の問題で必要となるのはダックスフンドの現在地と何次元のバーガーを参照しているかであるためその2つを引数にとる
- 終了条件を考えること。
今回レベル0バーガーというわかりやすい終了条件があるのでこれを使う。
コード
以下コード。僕の解き方だと無駄に三つ引数を使っているので改善の余地あり。
```python
N, X = map(int, input().split())
patty = [1]
buns = [0]for i in range(0, N):
patty.append(patty[i] * 2 + 1)
buns.append(buns[i] * 2 + 2)print(patty)
print(buns)burger_high = patty[N] + buns[N]
print("burger : ", burger_high)
print("burger/2 : ", burger_high/2)def dfs(now_runrun, now_burger_high, dimension):
if dimension == 0:
return 1
## るんるんが一番下にいれば一つもパティは食べれない
elif now_runrun == 1:
return 0## るんるんが真ん中にいたら、n - 1次元バーガー + 1を食べる elif now_runrun == now_burger_high // 2 + 1: return patty[dimension - 1] + 1 ## るんるんが一番上にいたら全てのパティを食べる elif now_runrun == now_burger_high: return patty[dimension] next_burger = now_burger_high // 2 - 1 next_dimension = dimension - 1 if now_runrun <= now_burger_high // 2: return dfs(now_runrun - 1, next_burger, next_dimension) else: return dfs(now_runrun - (patty[next_dimension] + buns[next_dimension] + 2), next_burger, next_dimension) + patty[next_dimension] + 1print(dfs(X, burger_high, N))
```
- 投稿日:2020-02-06T22:05:09+09:00
【Python】汎用コンテナとclassを相互に変換する
ざっくり要約
かなり間が空きましたが、以前書いた記事の続編的位置づけです。
今回作ったものはgithubに上げました。pipでインストールできる形にしてあるのは自分用です。やりたかったこと
- jsonで受け取ったデータ構造をちょこちょこ処理して、別のデータ構造でDynamoDBにputしようとした。
- dictやlistを直接操作するコードが増えてうんざり。意味のあるデータ自身に振舞いを持たせたいというオブジェクト指向気取りな気分になる。
- ならばclassに変換してしまおう。処理結果のクラスをdictに変換してしまおう。
実際にやったこと
- 「dictやlistなどの汎用コンテナで作られた構造」を「任意のclass構造」に変換する。それと、その逆。1
- 変換ルールを定義するためのマッピングをdictで作って、それに従って変換するクラスを作りました。
- 使用例をユニットテストで紹介します。
実際のコードをgithubに置いておきます。
さっそく作る
以前似たような物を作っていますが、コードも変わったし、時間も経ったので端折らずに1から書きます。
イメージ
例えば、変換元のソースとしてこんなdictがあるとします。dictの中にdictを含む構造です。
変換元のソース
src_dict = { 'value' : 'AAA', 'nested' : { 'nested_value' : 'BBB' } }これを、こんなclassに変換したいとします。TastClassの
self.nestedにNestedClassのインスタンスを持たせたいと考えています。変換先のクラス
# クラスその1 class TestClass(): def test_method(self): return 'assigned value: ' + self.value # クラスその2 - その1にぶら下がるイメージ class NestedTestClass: def test_method(self): return 'nested assigned value: ' + self.nested_value二つのデータを結びつける情報
上の変換を行うには、コンテナのどの要素をどのclassに変換するか、というマッピングが必要だと思うので、こんな形のdictを考えてみた。
mapping = { '<MAPPING_ROOT>' : TestClass, # 最上位は名前がないので'<MAPPING_ROOT>'とする 'nested' : NestedClass }
[class/dictのキー] : [関数]のマッピングをdictで表現します。src_dictが指すdictそのものには名前がないので、代わりに<MAPPING_ROOT>をキーとします。関数としてコンストラクタを指定しています。
mappingに含まれない項目、この例だとsrc_dict['value']などは、そのまま変換先に設定します。使い方
こんな風に使いたいと思っています。
usage# コンストラクタでマッピングを取る converter = ObjectConverter(mapping=mapping) # 変換メソッドに変換元データを渡す converted_class = converter.convert(src_dict) # 変換されたクラスのメソッドを呼ぶ converted_class.test_method()実装
こんな風に作ってみました。
converter.pyとして作りましたが、長い。畳みます。
converter.pyclass ObjectConverter: # 生成時にマッピング定義を受け取る def __init__(self, *, mapping): self.mapping = mapping # 変換の呼出しメソッド def convert(self, src): # 最上位の要素はマッピング'<root>'と必ずマッチする前提 return self._convert_value('<MAPPING_ROOT>', self.mapping['<MAPPING_ROOT>'], src) # 値に従って処理方法を決める def _convert_value(self, key, func, value): # リストの場合、要素全てをfuncで変換していく if isinstance(value, (list, tuple)): return self._convert_sequence(key, func, value) # dictの場合、そのままキーと値を取り出す if isinstance(value, dict): return self._convert_dict(key, func, value) # classの場合__dict__を取り出してdictとして扱う if isinstance(value, object) and hasattr(value, '__dict__'): return self._convert_dict(key, func, value.__dict__) # どれにも該当しないものはそのまま返す return value # dictの中身を変換していく def _convert_dict(self, key, func, src): # _call_functionで生成したオブジェクトに中身を詰める return self._assign_dict(self._call_function(key, func, src), key, src) # mappingで指定されたオブジェクトの生成 def _call_function(self, key, func, src): return func() # dictの中身を取り出して当てはめて行く def _assign_dict(self, dest, key, src): for srcKey, value in src.items(): # keyがマッピングに定義されている if srcKey in self.mapping: func = self.mapping[srcKey] # マッピングされた関数を実行して結果をセットする self._set_value(dest, srcKey, self._convert_value(srcKey, func, value)) # keyがマッピング定義にない物は、そのままセットする else: # ここで渡されたvalueの中にマッピング定義された値があっても無視する self._set_value(dest, srcKey, value) # createdにsrcの中身が反映された状態 return dest # リストの処理 def _convert_sequence(self, key, func, sequence): current = [] for value in sequence: current.append(self._convert_value(key, func, value)) return current # dictとclass両方に対応する値setter def _set_value(self, dest, key, value): if isinstance(dest, dict): dest[key] = value else: setattr(dest, key, value) # dict変換用インスタンスを得るユーティリティメソッド # @classmethod def dict_converter(cls, mapping, *, dict_object=dict): reverse_mapping = {} # マッピング先を全てdictにしてしまう for key in mapping.keys(): reverse_mapping[key] = dict_object # dictに変換するためのインスタンス return ObjectConverter(mapping=reverse_mapping)大体の解説
完全な仕様はソースを見てください。とはいえ、なんのことはない、mappingに含まれるキーと合致した値をただ走査するだけです。ざっくり言えばこんなことをしています。
- 最上位要素は
<mapping_root>のキーと合致したとみなす。- dictの中にdictがあったら再帰的に走査する。
- classの場合、dictを取り出してdictと同じように扱う。
- list/tupleを見つけたら、全ての要素がmappingのキーと合致したものとして走査する。
- 合致したキーに応じて、キーに対応する関数を呼び出して変換先を生成する。
- mappingに含まない値は変換先にそのまま設定する。変換先に応じて、
setattrを使うか、dictの値として代入するか使い分ける。クラスの中身に触れる
classを見つけた場合に
__dict__を取り出してしまうことで、結局は全てdictを走査するだけの処理になります。__dict__に触れるのはできれば避けたいですが、今回は他の方法を使う労力を避けることにします。特殊なクラスを扱わない限り問題はないはずです。2キーに反応しないケース
mappingに含まれない値はそのまま変換先のオブジェクトに設定されますが、このときの値がdictであったとして、その中にmappingに含まれる名前を持った値があっても、mappingの処理はされません。これは「mappingに含まれたdictの処理 or mappingに含まれue
dictの処理 」という場合分けが嫌なのと、そのような変換が必要になるデータ構造はあまり美しくないと思ったからそうしています。class to dict変換
dict to class変換の後にclass to dict変換して元の形に戻したいケースのために、クラスメソッド
dict_converterを用意して逆方向のコンバータが簡単に得られるようにしています。mapping上の変換先を全部dictにするだけなので簡単です。3使い方の説明も兼ねたユニットテスト
長いので折りたたみます。
test_objectconverter.pyimport unittest import json from objectonverter import ObjectConverter # テスト用クラスその1 class TestClass(): def test_method(self): return 'TestObject.test_method' # テスト用クラスその2 class NestedTestClass: def test_method(self): return 'NestedObject.test_method' class ClassConverterTest(unittest.TestCase): # ルートになるクラスのプロパティを設定するだけ def test_object_convert(self): dict_data = { 'value1' : 'string value 1' } converter = ObjectConverter(mapping={'<MAPPING_ROOT>' : TestClass}) result = converter.convert(dict_data) self.assertEqual(result.value1, 'string value 1') # 生成したクラスのメソッドを呼んでみる self.assertEqual(result.test_method(), 'TestObject.test_method') # ネストしたクラスを生成する def test_nested_object(self): # jsonのキーとクラスをマッピングするdict object_mapping = { '<MAPPING_ROOT>' : TestClass, 'nested' : NestedTestClass } # 生成元のソース dict_data = { 'value1' : 'string value 1', 'nested' : { 'value' : 'nested value 1' } } converter = ObjectConverter(mapping=object_mapping) result = converter.convert(dict_data) self.assertEqual(result.value1, 'string value 1') self.assertIsInstance(result.nested, NestedTestClass) self.assertEqual(result.nested.value, 'nested value 1') # マッピングを指定しない場合はただのdict def test_nested_dict(self): object_mapping = { '<MAPPING_ROOT>' : TestClass } # 生成元のソース dict_data = { 'value1' : 'string value 1', 'nested' : { 'value' : 'nested value 1' } } converter = ObjectConverter(mapping = object_mapping) result = converter.convert(dict_data) self.assertEqual(result.value1, 'string value 1') self.assertIsInstance(result.nested, dict) self.assertEqual(result.nested['value'], 'nested value 1') # リストの処理 def test_sequence(self): mapping = { '<MAPPING_ROOT>' : TestClass, 'nestedObjects' : NestedTestClass, } source_dict = { "value1" : "string value 1", "nestedObjects" : [ {'value' : '0'}, {'value' : '1'}, {'value' : '2'}, ] } converter = ObjectConverter(mapping=mapping) result = converter.convert(source_dict) self.assertEqual(result.value1, 'string value 1') self.assertEqual(len(result.nestedObjects), 3) for i in range(3): self.assertIsInstance(result.nestedObjects[i], NestedTestClass) self.assertEqual(result.nestedObjects[i].value, str(i)) # ルート要素自体がリストの場合 def test_root_sequence(self): object_mapping = { '<MAPPING_ROOT>' : TestClass, } source_list = [ {'value' : '0'}, {'value' : '1'}, {'value' : '2'}, ] converter = ObjectConverter(mapping=object_mapping) result = converter.convert(source_list) self.assertIsInstance(result, list) self.assertEqual(len(result), 3) for i in range(3): self.assertIsInstance(result[i], TestClass) self.assertEqual(result[i].value, str(i)) # json -> class -> json def test_json_to_class_to_json(self): # クラスからjsonの相互変換に使う関数 def default_method(item): if isinstance(item, object) and hasattr(item, '__dict__'): return item.__dict__ else: raise TypeError # jsonのキーとクラスをマッピングするdict object_mapping = { '<MAPPING_ROOT>' : TestClass, 'nested' : NestedTestClass } # 生成元のソース - 比較の都合のため一行で string_data = '{"value1": "string value 1", "nested": {"value": "nested value 1"}}' dict_data = json.loads(string_data) converter = ObjectConverter(mapping=object_mapping) result = converter.convert(dict_data) dump_string = json.dumps(result, default=default_method) self.assertEqual(dump_string, string_data) # 再変換しても結果が同じこと result = converter.convert(json.loads(dump_string)) self.assertEqual(result.value1, 'string value 1') self.assertIsInstance(result.nested, NestedTestClass) self.assertEqual(result.nested.value, 'nested value 1') # 変換 -> 逆変換 def test_reverse_convert(self): dict_data = { 'value1' : 'string value 1' } mapping = {'<MAPPING_ROOT>' : TestClass} converter = ObjectConverter(mapping=mapping) result = converter.convert(dict_data) self.assertEqual(result.value1, 'string value 1') # 逆変換コンバータを生成 reverse_converter = ObjectConverter.dict_converter(mapping=mapping) reversed_result = reverse_converter.convert(result) self.assertEqual(result.value1, reversed_result['value1']) if __name__ == '__main__': unittest.main()解説
基本はまあ、見てもらえばわかるかなと
test_json_to_class_to_jsonという長い名前のテストケースがありますが、このクラスが元々jsonとの変換を強く意識していたゆえにこうなっています。蛇足な言い訳
前回記事から半年以上過ぎていますが、実はやっと就職してですね…時間が取れなかったので遅くなりました。
- 投稿日:2020-02-06T21:59:17+09:00
GIFアニメーションを作るだけの記事
記事をご覧になってくださりありがとうございます!
どうも初めまして。2年間ぐらい組込み開発に携わっていましたが
転職後、環境的要因で精神崩壊→奇跡的に回復した、りゅうです。?ほんだい
この記事は、複数のpng画像を昇順または降順に並べ替え一枚のgif画像を生成するプログラムについて載せている記事です。
ソースコード
gifmake.py# -*- coding: utf-8 -*- import sys from PIL import Image import glob args = sys.argv #Ascending (昇順)/Descending(降順) if args[2] == 'A': value = False elif args[2] == 'D': value = True else: print('Enter A or D for the second argument!') files = sorted(glob.glob('./*.png'),reverse=value) images = list(map(lambda file: Image.open(file), files)) images[0].save(args[1]+'.gif', save_all=True, append_images=images[1:], duration=400, loop=0)実行例
コマンドラインに下記のように入力するとgif画像が生成されます。
(base) C:\Users\UserName\Desktop>pyhton gifmake.py [生成するgif画像名(拡張子なし)] [A/D(昇順/降順を指定する)]降順
昇順
ソースコードのポイント
sorted()のreverseパラメータがTrueだと降順に、引数なしおよびFalseだと昇順にgif画像が生成できます。
最後の行のパラメータduration値を変更することで、gifアニメーション間隔を変更できます。使った画像
いらすとや様
最後に
自分自身、組み込み系からWEB系にジョブチェンジを考えているので、
今後は、それに関する情報を発信すると思います。
よろしくお願いします✌


- 投稿日:2020-02-06T21:51:06+09:00
時刻の floor 関数(Python)
こんにちは。
時刻に対する floor 関数を作ってみました。計算単位として、下記例では 1 時間を整数で除算した値の 15 分を使っています。
"2020-01-01 00:05:05+09:00" => "2020-01-01 00:00:00+09:00"import datetime MINUTE = 60 # in seconds HOUR = 3600 # in seconds ndiv = 4 # in [1, 2, 3, 4, 5, 6, 10, 12, 15, 20, 30, 60] interval = HOUR//ndiv # in seconds shift = 0 # in seconds dt = datetime.datetime.strptime("2020-01-01 00:05:05+09:00", '%Y-%m-%d %H:%M:%S%z') print(dt_floor(dt, interval, shift)) # => "2020-01-01 00:00:00+09:00" def dt_floor(dt, interval, shift): interval_m = interval//MINUTE # in minutes shift_dt = datetime.timedelta(seconds=shift) dt_shift = dt - shift_dt minute_floor = (dt_shift.minute//interval_m)*interval_m return dt_shift.replace(minute=minute_floor, second=0) + shift_dt
- 投稿日:2020-02-06T20:49:28+09:00
Python MeCab Windows10 形態素分析/自然言語処理(環境構築)
Python 自然言語処理(環境構築・前処理)
OS:Windows 10
想定環境:Windows環境で、社内のプロキシ等の問題で、
pip, apt-getができない場合の手動インストールでの環境構築方法
No 対応 URL 1 meCabインストール(手動インストール可能) https://toolmania.info/post-9815/ 2 辞書DL(手動追加) https://qiita.com/zincjp/items/c61c441426b9482b5a48 2 〃 流れ①git for Windows②NEologd辞書のダウンロードとコンパイル 3 前処理 Qiita記事 4 単語ごとの傾向分析 未調査
- 投稿日:2020-02-06T20:49:28+09:00
Python 形態素分析/自然言語処理(環境構築・前処理)
Python 自然言語処理(環境構築・前処理)
OS:Windows 10
No 対応 URL 1 meCabインストール(手動インストール可能) https://toolmania.info/post-9815/ 2 辞書DL(手動?) 〃 2 〃 もしくはhttps://www.htmllifehack.xyz/entry/2018/11/23/223524 3 前処理 Qiita記事 4 単語ごとの傾向分析 未調査
- 投稿日:2020-02-06T20:49:28+09:00
Python MeCab 形態素分析/自然言語処理(環境構築・前処理)
Python 自然言語処理(環境構築・前処理)
OS:Windows 10
想定環境:Windows環境で、社内のプロキシ等の問題で、pipインストールが使用できない場合の手動インストールでの環境構築方法
No 対応 URL 1 meCabインストール(手動インストール可能) https://toolmania.info/post-9815/ 2 辞書DL(手動?) https://qiita.com/zincjp/items/c61c44142,6b9482b5a48 2 〃 流れ①git for Windows②NEologd辞書のダウンロードとコンパイル 3 前処理 Qiita記事 4 単語ごとの傾向分析 未調査
- 投稿日:2020-02-06T19:41:59+09:00
Python入門(Python版 APG4b)
本記事について
競技プログラミングサイトの AtCoder にはプログラミング入門教材の「AtCoder Programming Guide for beginners (APG4b)」があります。プログラミング入門教材として非常に完成度が高く、競技プログラミングの主流言語である C++ が使われています。
そこで、本記事では APG4b を元に、それの Python 版を書きました。基本的には APG4b を読み進めて、Python 独自の部分は本記事を参考にして頂ければと思います。大部分が APG4b を元にしているため、本記事が問題あるようでしたらすぐに削除します。
各節の見出しが本家へのリンクになっています。
節タイトルは本家に合わせているため、Pythonの用語と一部異なる部分もあります。目次
1.00.はじめに
1.01.出力とコメント
1.02.プログラムの書き方とエラー
1.03.四則演算と優先順位
1.04.変数と型
1.05.実行順序と入力
1.06.if文・比較演算子・論理演算子
1.07.条件式の結果とbool型
1.08.変数のスコープ
1.09.複合代入演算子
1.10.while文
1.11.for文・break・continue
1.12.文字列(と文字)
1.13.リスト(配列)
1.14.標準ライブラリの組み込み関数(STLの関数)
1.15.関数
おわりに1.00.はじめに
第1章について
第1章では、基本的な文法について説明します。
プログラミング言語
本家 APG4b では C++ というプログラミング言語を扱っています。この記事では Python というプログラミング言語を扱います。
プログラムの実行方法
手元に Python の環境構築をするのも良いですが、AtCoder のコードテストでも十分書くことができます。
問題
提出練習
本記事には Python 版のコードを載せますが、問題への提出は本家の提出欄を使用してください。提出欄は、本家のページの一番下にあります。
まずは、提出欄の「言語」を「Python3 (3.4.3)」に変更してください。
変更したら、次のコードをコピー&ペーストしてみましょう。print("Hello, world!")ペーストできたら、「提出」ボタンを押してください。
ページが切り替わり、 結果欄が緑色の「AC」になっていれば提出成功です。1.01.出力とコメント
キーポイント
- Python のコードは、処理内容を直接書くことができる
- main 関数を書く必要がない。書くこともできるが、競プロのような小規模なコードの際は書かなくても大丈夫
print("文字列")で文字列を出力できる#や""" """でコメントを書ける
書き方 コメントになる場所 #同じ行の #を書いた場所より後""" """"""と"""の間プログラムの基本形
次のプログラムは何もしないプログラムです。
つまり、C++ と違って main 関数等を書く必要がありません。処理内容を直接書くだけでプログラムが動きます。
main 関数を書くこともできますが、競技プログラミングのような小規模の場合は書かなくても大丈夫です。出力
最初に提出したプログラムを見てみましょう。
このプログラムは「Hello, world!」という文字列を出力するプログラムです。print("Hello, world!")実行結果Hello, world!print()
Python で文字列を出力するには
print()を使います。
出力する文字列を指定している部分は"Hello, world!"の部分です。print()の()内に書くことで、文字列を出力することができます。
Python プログラムの中で文字列を扱う場合、" "で囲う必要があります。また、自動で文末に改行が行われます。行の終わり
C++ では行末に
;が必要ですが、Python では何も書く必要がありません。(一応書いても問題なく動きます)別の文字列の出力
別の文字列を出力したい場合、次のように
" "の中身を変えます。print("こんにちは世界")出力結果こんにちは世界複数の出力
出力を複数回行うこともできます。
print("a") print("b") print("c", "d")実行結果a b c d先ほども書いたように、Python の
print()では文末に自動で改行が行われます。そのため、aの次の行にbが出力されます。
次に、,区切りで複数書くことで、c dのように空白区切りで出力されます。数値の出力
数値を出力するときは、
" "を使わずに、直接書くことでも出力できます。print(2525)実行結果2525コメント
コメントはプログラムの動作を説明するためのメモ書きを残すためのもので、書いてもプログラムの動作に影響はありません。
Python におけるコメントの例を見てみましょう。print("Hello, world!") # Hello, world! と表示 """ ここも コメント """実行結果Hello, world!コメントには二種類の書き方があります。
書き方 コメントになる場所 #同じ行の #を書いた場所より後""" """"""と"""の間全角文字
Python では C++ と違い、プログラム中に「全角文字」が含まれていても基本的には問題なく動作します。
しかし、読みづらくなるため「半角文字」で書くことを推奨します。問題
以下のリンク先に問題文が載っています。
EX1.コードテストと出力の練習サンプルプログラムprint("Hello, world!") print("Hello, AtCoder!") print("Hello, Python!")サンプルプログラムの実行結果Hello, world! Hello, AtCoder! Hello, Python!解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.02.プログラムの書き方とエラー
キーポイント
- Python はスペース・改行・インデントに意味がある
- Python には「PEP8」というコーディング規約がある
- Python はインタプリタ型言語であるため、コンパイルエラーは起こらない
プログラムの書き方
プログラム中のスペースと改行、およびインデントについて説明します。また、Python のコーディング規約である PEP8 についても説明します。
スペースと改行
Python では、スペースは省略することができますが、改行には意味があるため省略できません。
C++ では
;が行の終わりを意味しますが、Python では改行が行の終わりを意味します。インデント
C++ ではインデントは読みやすさのために行いますが、Python の場合はインデントにも意味があります。
後述の if 文を例に C++ と Python の違いを見てみましょう。
C++(インデントあり)#include <bits/stdc++.h> using namespace std; int main() { if (条件式) { 処理 } }C++(インデントなし)#include <bits/stdc++.h> using namespace std; int main() { if (条件式) { 処理 } }C++ の場合、上記のように
{ }内でインデントを行っても行わなくても動作に違いはありません。Pythonif 条件式: 処理Python では
{ }の代わりに:とインデントを用いて if 文の中であることを表現するため、インデントが必須となります。PEP8
PEP8 とは、Python のコーディング規約です。コーディング規約とは読みやすさのために定められたルールのことです。
PEP8 を守らなくてもプログラムは問題なく動作しますが、守ることで読みやすいプログラムを書くことができます。
すべてを紹介すると長くなるため、ここではそのうちのいくつかを紹介します。
- インデントは半角スペース4つ
- 1行の長さは最大79文字
- 余計なスペースは入れない
詳細は https://pep8-ja.readthedocs.io/ja/latest/ に書いてあります。
プログラムのエラー
基本的には本家 APG4b に書いてある通りですが、Python はインタプリタ型言語であるため、コンパイルエラーは起きません。
インタプリタ型言語とは、C++ のようにコンパイルを行わず、1文ずつ実行されていきます。そのため、文法の間違いがあった場合はコンパイルエラーではなく実行時エラーになります。
問題
以下のリンク先に問題文が載っています。
EX2.エラーの修正A君が書いたプログラムprint("いつも) print("2525" print(AtCoderくん)標準エラー出力File "./Main.py", line 1 print("いつも) ^ SyntaxError: EOL while scanning string literal解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.03.四則演算と優先順位
キーポイント
演算子 計算内容 + 足し算 - 引き算 * 掛け算 / 割り算 // 切り捨て割り算 % 割った余り ** 冪乗 四則演算
Python プログラムで簡単な計算をする方法を見ていきましょう。
次のプログラムは上から順に、「足し算」「引き算」「掛け算」「割り算」「切り捨て割り算」を行っています。print(1 + 1) # 2 print(3 - 4) # -1 print(2 * 3) # 6 print(7 / 3) # 2.3333333333333335 print(7 // 3) # 2実行結果2 -1 6 2.3333333333333335 2これらの記号
+,-,*,/のことを算術演算子といいます。
3 - 4が-1になっている通り、負の値も計算できます。
*が掛け算で、/が「割り算」です。Python では
/は普通の割り算で、結果は小数になります。小数点以下が切り捨てされる割り算は//で行います。
また、//は常にマイナス無限大方向に丸められます。C++ の/も切り捨て割り算ですが、C++ の/は常に0方向に丸められるため、C++ の/と Python の//は違います。Python で常に0方向に丸めたいときは、int(a / b)のように書きましょう。print(10 // 3, -10 // 3) print(int(10 / 3), int(-10 / 3))実行結果3 -4 3 -3剰余演算
%は「割ったときの余り」を計算します。print(7 % 3) # 1 print(4 % 5) # 4実行結果1 4$7 ÷ 3 = 2$ あまり $1$
$4 ÷ 5 = 0$ あまり $4$
となるため、このプログラムの出力は1と4になります。冪乗演算
Python には冪乗の演算子も用意されています。冪乗とは、 $a ^ b$ と表される数です。
print(3 ** 4) # 81 print(25 ** 0.5) # 5.0 print(1.5 ** 2) # 2.25実行結果81 5.0 2.25上記のように、
a ** bで $a ^ b$ が計算できます。また、25 ** 0.5や1.5 ** 2のように小数の計算もできます。演算子の優先順位
四則演算の優先順位は C++ と同じため、本家を参考にしてください。
問題
以下のリンク先に問題文が載っています。
EX3.計算問題サンプルプログラムprint(""" ここに式を書く """)解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.04.変数と型
キーポイント
- 変数はメモ
=は代入- 「データの種類」のことを型という
型 書き込むデータの種類 int 整数 float 小数 str 文字列 変数
変数という機能について見ていきましょう。変数は「メモ」だと考えてください。
例を見てみましょう。
name = 10 print(name) # 10 print(name + 2) # 10 + 2 → 12 print(name * 3) # 10 * 3 → 30実行結果10 12 30宣言と代入
Python の場合、宣言と代入は同時に行います。宣言が必要ないと言った方が正確かもしれません。
name = 10この部分で、「name」という変数を宣言して、その中に
10を代入しています。
=の記号は「代入(書き込み)」の意味であって、「等しい」という意味ではないことに注意してください。「型」や「値」についての説明は本家を参照してください。
C++ の場合は
intと書いて、変数の型が「整数」であることを明示する必要がありますが、Python の場合は代入する10が整数であるため、自動でnameの型を int にしてくれます。読み込み
プログラムの最後の3行で変数にメモした値を読み込んで出力しています。
print(name) # 10 print(name + 2) # 10 + 2 → 12 print(name * 3) # 10 * 3 → 30変数はコピーされる
変数1 = 変数2と書いた場合、変数の値そのものがコピーされます。
その後にどちらかの変数の値が変更されても、もう片方の変数は影響を受けません。a = 10 b = a a = 5 print(a) # 5 print(b) # 10実行結果5 10変数
bが 10 のままであることに注意してください。
処理内容は本家の方にわかりやすく図で説明されています。Python の場合は宣言と代入が同時に行われるため、bの宣言はb = aの部分で行われます。変数を同時に代入
変数の代入時に
,を間に入れることで、1行で複数の変数の代入が行えます。a, b = 10, 5 print(a) print(b)実行結果10 5上のプログラムは次のように書いた場合と同じ意味になります。
a = 10 b = 5変数名のルール
変数名は基本的に自由につけることができますが、一部の名前を変数名にしようとするとエラーになります。
利用できない変数名
以下の条件に該当する名前は変数名にできません。
- 数字で始まる名前
_以外の記号が使われている名前- キーワード(Python が使っている一部の単語)
以下は変数名にできない名前の例です。本家の例で使われている
intは、Python では変数名として使うことができます(……推奨はしませんが)。100hello = 10 # 数字で始まる名前にはできない na+me = "AtCoder" # 変数名に+を使うことはできない not = 100 # not はキーワードなので変数名にできない以下のような名前は変数名にできます。
hello10 = 10 # 2文字目以降は数字にできる hello_world = "Hello, world" # _ は変数名に使える 変数1 = 1 # 漢字 へんすう2 = 2 # ひらがなPython の場合は C++ と違って、漢字やひらがなも変数名に使うことができます。
Python のキーワードについては、検索すると一覧が出てきます。型
int以外にも Python には様々な型があります。ここでは重要な3つの型だけを紹介します。
C++ では小数はdoubleですが、Python ではfloatになります。同様に文字列はstrです。
型 書き込むデータの種類 int 整数 float 小数(実数) str 文字列 i = 10 # 10 は整数 f = 0.5 # 0.5 は小数 s = "Hello" # "Hello" は文字列 print(i, type(i)) # type(変数) で変数の型がわかる print(f, type(f)) print(s, type(s))実行結果10 <class 'int'> 0.5 <class 'float'> Hello <class 'str'>異なる型同士の計算
異なる型同士の計算では型変換が行われます。
例えば、int 型と float 型の計算結果は float 型になります。ただし、変換できない型同士の計算はエラーになります。
i = 30 d = 1.5 s = "Hello" print(i + d, type(i + d)) # 31.5 print(i * d, type(i * d)) # 45.0 """ 以下の処理はエラー print(s + i) # str型とint型の足し算 print(s + d) # str型とfloat型の足し算 """実行結果31.5 <class 'float'> 45.0 <class 'float'>なお、Python の場合は
str型 * int型の計算は可能です。i = 5 s = "Hello" print(s * i) # "Hello" * 5 → ???上のプログラムの結果はどうなるでしょうか。実行結果を見てみましょう。
実行結果HelloHelloHelloHelloHello
"Hello"が5回繰り返された文字列になります。異なる型同士の代入
Python の場合、変数の型は中に何が入っているかによって決まります。よって、次のプログラムは正常に動作します。
i = 10 s = "Hello" i = s print(i) print(type(i))実行結果Hello <class 'str'>問題
以下のリンク先に問題文が載っています。
EX4.◯年は何秒?サンプルプログラム# 1年の秒数 seconds = 365 * 24 * 60 * 60 # 以下のコメント """ """ を消して追記する print(""" 1年は何秒か """) print(""" 2年は何秒か """) print(""" 5年は何秒か """) print(""" 10年は何秒か """)解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.05.実行順序と入力
キーポイント
- プログラムは上から下へ順番に実行される
変数 = input()で入力を受け取ることができる- スペースと改行で区切られて入力される
プログラムの実行順序
基本的にプログラムは上から下へ順番に実行されます。
次のプログラムを見てください。
name = 10 print(name) # 10 name = 5 print(name) # 5実行結果10 5基本的な構造は本家と同様なので、実行の様子については本家のスライドを参照してください。
入力
プログラムの実行時にデータの入力を受け取る方法を見ていきましょう。
「入力機能」を使うことにより、プログラムを書き換えなくても様々な計算を行えるようになります。入力を受け取るには
input()を使います。
次のプログラムは、入力として受け取った数値を10倍にして出力するプログラムです。a = int(input()) print(a * 10)入力5実行結果50
input()は1行の入力を文字列として受け取ります。そのため、int 型として受け取るためにはint()によって int 型に変換してあげる必要があります。a = input() print(a, type(a)) a = int(a) # int型に変換 print(a, type(a))入力5実行結果5 <class 'str'> 5 <class 'int'>整数以外のデータの入力
整数以外のデータを受け取りたい時は、同様に必要な型に変換する必要があります。
text = input() f = float(input()) print(text, f)入力Hello 1.5実行結果Hello 1.5空白区切りの入力
前述のように、
input()は1行の入力を文字列として受け取ります。a = input() print(a) print(type(a))入力10 20 30実行結果10 20 30 <class 'str'>そのため、空白区切りの入力をただ受け取ると、上のように変数
aに"10 20 30"という文字列として代入されてしまいます。空白で分割
そこで、
input()の後ろに.split()をつけて文字列を分解する必要があります。a, b, c = input().split() print(a) print(type(a))入力10 20 30実行結果10 <class 'str'>こうすることで
"10 20 30"が空白区切りで分割されて、"10","20","30"の3つにすることができました。整数に変換
あとは、これまでと同様に
int()を使って整数に変換してあげれば、空白区切りの入力を整数として受け取ることができます。a, b, c = input().split() a = int(a) b = int(b) c = int(c) print(a) print(type(a))入力10 20 30実行結果10 <class 'int'>上のプログラムでは int 型への変換を変数の数だけ毎回書きましたが、これを1行で書くこともできます。
a, b, c = map(int, input().split()) print(a) print(type(a))入力10 20 30実行結果10 <class 'int'>
map(型, input().split())と書くことで、分割された全ての文字列を同時に指定した型に変換することができます。複数行の入力
input()は1行の入力を受け取るものなので、入力が複数行ある場合はその行数分書く必要があります。s = input() a = int(input()) print(s, a)入力Hello 10実行結果Hello 10問題
以下のリンク先に問題文が載っています。
EX5.A足すB問題サンプルプログラム# ここにプログラムを追記解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.06.if文・比較演算子・論理演算子
キーポイント
- if文を使うと「ある条件が正しいときだけ処理をする」というプログラムを書ける
- else句を使うと「条件が正しくなかったとき」の処理を書ける
if 条件式1: 処理1 elif 条件式2: 処理2 else: 処理3
- 比較演算子
演算子 意味 x == yx と y は等しい x != yx と y は等しくない x > yx は y より大きい x < yx は y より小さい x >= yx は y 以上 x <= yx は y 以下
- 論理演算子
演算子 意味 真になるとき not 条件式条件式の結果の反転 条件式が偽 条件式1 and 条件式2条件式1が真 かつ 条件式2が真 条件式1と条件式のどちらも真 条件式 or 条件式2条件式1が真 または 条件式2が真 条件式1と条件式2の少なくとも片方が真 if文
if文を使うと、ある条件が正しいときだけ処理をするというプログラムが書けるようになります。
書き方は次のようになります。if 条件式: 処理条件式が正しいとき、
:以降のインデントが1つ下がった部分の処理が実行され、条件式が正しくないとき、処理は飛ばされます。次の例では、入力の値が10より小さければ「xは10より小さい」と出力した後「終了」と出力します。また、入力の値が10より小さくなければ「終了」とだけ出力されます。
x = int(input()) if x < 10: print("xは10より小さい") print("終了")入力15実行結果1xは10より小さい 終了入力215実行結果2終了この例では、まず変数 x に整数のデータを入力しています。
x = int(input())重要なのはその後です。
if x < 10: print("xは10より小さい")この部分は、「もし
x < 10(xが10より小さい)なら、xは10より小さいと出力する」という意味になります。
最後にprint("終了")を実行して終了と出力し、プログラムは終了します。xが10より小さくない場合は、
print("xは10より小さい")の処理は飛ばされます。そのため、2つ目の実行例では
終了とだけ出力されています。if文のように、何かの条件で処理が実行されることを条件分岐といいます。
また、「条件式が正しい」ことを条件式が真、「条件式が正しくない」ことを条件式が偽といいます。比較演算子
Python の比較演算子は C++ と同じため、この項は本家を参照してください。
次のプログラムは、入力された整数値がどんな条件を満たしているかを出力するプログラムです。
x = int(input()) if x < 10: print("xは10より小さい") if x >= 20: print("xは20以上") if x == 5: print("xは5") if x != 100: print("xは100ではない") print("終了")入力15実行結果1xは10より小さい xは5 xは100ではない 終了入力2100実行結果2xは20以上 終了論理演算子
条件式の中にはもっと複雑な条件を書くこともできます。そのためには論理演算子を使います。
演算子 意味 真になるとき not 条件式条件式の結果の反転 条件式が偽 条件式1 and 条件式2条件式1が真 かつ 条件式2が真 条件式1と条件式のどちらも真 条件式 or 条件式2条件式1が真 または 条件式2が真 条件式1と条件式2の少なくとも片方が真 x, y = map(int, input().split()) if not x == y: print("xとyは等しくない") if x == 10 and y == 10: print("xとyは10") if x == 0 or y == 0: print("xかyは0") print("終了")入力12 3実行結果1xとyは等しくない 終了入力210 10実行結果2xとyは10 終了入力30 8実行結果3xとyは等しくない xかyは0 終了「前の条件が真でないとき」の処理
else句
else句は、if文の後に書くことで、「if文の条件が偽のとき」に処理を行えるようになります。
書き方は次のようになります。if 条件式1: 処理1 else: 処理2次のプログラムは、入力の値が10より小さければ「xは10より小さい」と出力し、そうでなければ「xは10より小さくない」と出力します。
x = int(input()) if x < 10: print("xは10より小さい") else: print("xは10より小さくない")入力15実行結果1xは10より小さい入力215実行結果2xは10より小さくないelif
elifでは、「『前のif文の条件が偽』かつ『elifの条件が真』」のときに処理が行われます。
書き方は次のようになります。if 条件式1: 処理1 elif 条件式2: 処理2処理2が実行されるのは、「条件式1が偽 かつ 条件式2が真」のときになります。
例を見てみましょう。x = int(input()) if x < 10: print("xは10より小さい") elif x > 20: print("xは10より小さくなくて、20より大きい") elif x == 15: print("xは10より小さくなくて、20より大きくなくて、15である") else: print("xは10より小さくなくて、20より大きくなくて、15でもない")入力15実行結果1xは10より小さい入力230実行結果2xは10より小さくなくて、20より大きい入力315実行結果3xは10より小さくなくて、20より大きくなくて、15である入力413実行結果4xは10より小さくなくて、20より大きくなくて、15でもないこの例のように、elif の後に続けて elif や else を書くこともできます。
問題
以下のリンク先に問題文が載っています。
EX6.電卓をつくろうサンプルプログラムa, op, b = input().split() a = int(a) b = int(b) if op == "+": print(a + b) # ここにプログラムを追記解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.07.条件式の結果とbool型
キーポイント
- 条件式の結果は真のときに
Trueに、偽のときにFalseになる- int型では、
Trueを1で、Falseを0で表す- bool型は
TrueとFalseだけが入る型
int型の表現 bool型の表現 真 1 True 偽 0 False 条件式の結果
Python では、真のことを
Trueで表現し、偽のことをFalseで表現します。C++ と違って先頭が大文字なことに注意してください。
条件式の「計算結果」も真のときはTrue、偽のときはFalseになります。次のプログラムは条件式の結果をそのまま出力し、真のときと偽のときでどのような値を取るか確認しています。
print(5 < 10) print(5 > 10)実行結果True False出力を見てみると、条件が真のときは
True、偽のときはFalseになっていることがわかります。TrueとFalse
Python の場合、通常は真と偽を
TrueとFalseで表すのでこのタイトルは正しくない気もしますが、本家に合わせます。条件式の部分に直接
TrueやFalseを書くこともできます。次のプログラムはその例です。# Trueは真を表すので、helloと出力される if True: print("hello") # Falseは偽を表すのでこのifの中は実行されない if False: print("world")実行結果helloまた、int型においては
Trueを1、Falseを0で表します。print(int(True)) print(int(False))実行結果1 0bool型
bool型というデータ型があります。この型の変数には
TrueまたはFalseだけが入ります。x = int(input()) a = True b = x < 10 # xが10未満のときTrue そうでないときFalseになる c = False if a and b: print("hello") if c: print("world")入力3実行結果helloこのように、条件式の結果など、真偽のデータを変数で扱いたい場合は bool 型を使います。
いままでif 条件式と書いていましたが、基本的にはif bool型の値ということになります。ここまでの話をまとめたのが次の表です。
int型の表現 bool型の表現 真 1 True 偽 0 False bool型を使う場面
本家を参照してください。
問題
以下のリンク先に問題文が載っています。
EX7.bool値パズルサンプルプログラム# 変数a, b, cにTrueまたはFalseを代入してAtCoderと出力されるようにする a = # True または False b = # True または False c = # True または False # ここから先は変更しないこと if a: print("At", end="") # end="" と書くと末尾改行がされなくなる else: print("Yo", end="") if (not a) and b: print("Bo", end="") elif (not b) and c: print("Co", end="") if a and b and c: print("foo!") elif True and False: print("yeah!") elif (not a) or c: print("der")解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.08.変数のスコープ
キーポイント
- インデントが共通の部分をブロックという
- 変数が使える範囲のことをスコープという
- 通常、変数のスコープは「変数が宣言されてからそのブロックが終わるまで」
- Pythonの場合、if文などではスコープが作られず、ブロック外でも使うことができる
変数のスコープ
今までif文の後ろに
:を書いて以下の行でインデントを行なってきました。このインデントがある部分のことをブロックといいます。本家には「
あるブロックの中で宣言した変数は、それより内側のブロックでしか使えないというルールがあります。そして、その変数が使える範囲のことをスコープといいます。
」と書かれています。
Python の場合 C++ とは異なっていて、if文などの場合はスコープが作られず、ブロック内で宣言した変数をブロック外でも使うことができます。具体例を見てみましょう。
x = 5 if x == 5: y = 10 print(x + y) print(x) print(y)実行結果15 5 10これは本家に載っているプログラムと同内容のものです。
本家では C++ を扱っているため、これはエラーが出る例として載っていますが、Python では上のようにエラーは発生せず、正常に動作します。スコープについての詳しい話は本家を参照してください。
問題
以下のリンク先に問題文が載っています。
EX8.たこ焼きセットA君が書いたプログラムp = int(input()) # パターン1 if p == 1: price = int(input()) # パターン2 if p == 2: text = input() price = int(input()) n = int(input()) print(text + "!") print(price * n)解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.09.複合代入演算子
キーポイント
x = x + yはx += yのように短く書ける- Python にはインクリメントもデクリメントもない
複合代入演算子
x = x + 1のように、同じ変数名が2回現れる代入文では、複合代入演算子を使うとより短く書くことができます。次のプログラムは、変数 x に
(1 + 2)を足して出力するだけのプログラムです。x = 5 x += 1 + 2 print(x) # 8実行結果8x += 1 + 2は、
x = x + (1 + 2)と同じ意味になります。
+=以外の複合代入演算子
他の算術演算子についても同様のことができます。
a = 5 a -= 2 print(a) # 3 b = 3 b *= 1 + 2 print(b) # 9 c = 5 c /= 2 print(c) # 2.5 d = 5 d //= 2 print(d) # 2 e = 5 e %= 2 print(e) # 1 f = 3 f **= 4 print(f) # 81実行結果3 9 2.5 2 1 81インクリメントとデクリメント
C++ にはインクリメントとデクリメントがありますが、Python にはありません。
インクリメントについて知りたい場合は本家を参照してください。問題
以下のリンク先に問題文が載っています。
EX9.複合代入演算子を使おうサンプルプログラムx, a, b = map(int, input().split()) # 1.の出力 x += 1 print(x) # ここにプログラムを追記解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.10.while文
キーポイント
- while文を使うと繰り返し処理ができる
- 条件式が真のとき処理を繰り返す
while 条件式: 処理
- 「$N$回カウントする」というプログラムを書く場合、「カウンタ変数を0からはじめ、カウンタ変数が$N$より小さいときにループ」という形式で書く
i = 0 # カウンタ変数 while i < N: 処理 i += 1while文
while文を使うと、プログラムの機能の中でも非常に重要な「繰り返し処理」(ループ処理)を行うことができます。
無限ループ
次のプログラムは、「
"Hello"と出力して改行した後、"AtCoder"と出力する処理」を無限に繰り返すプログラムです。while True: print("Hello") print("AtCoder")実行結果Hello AtCoder Hello AtCoder Hello AtCoder Hello AtCoder Hello AtCoder ...(無限に続く)while文は次のように書き、条件式が真のとき処理を繰り返し続けます。
while 条件式: 処理先のプログラムでは条件式の部分に
Trueと書いているため、無限に処理を繰り返し続けます。
このように、無限に繰り返し続けることを無限ループと言います。1つずつカウントする
次のプログラムは、1から順に整数を出力し続けます。
i = 1 while True: print(i) i += 1 # ループのたびに1増やす実行結果1 2 3 4 5 6 7 8 ...(無限に1ずつ増えていく)ループ回数の指定
1ずつカウントするプログラムを「1から5までの数を出力するプログラム」に変える場合、次のようにします。
i = 1 # i が 5 以下の間だけループ while i <= 5: print(i) i += 1実行結果1 2 3 4 5カウンタ変数は0からN未満まで
5回
"Hello"と出力されるプログラムを考えます。
まず一般的でない書き方(やめておいた方が良い書き方)を紹介し、次に一般的な書き方(推奨される書き方)を紹介します。一般的でない書き方
# i を 1 からはじめる i = 1 # i が 5 以下の間だけループ while i <= 5: print("Hello") i += 1実行結果Hello Hello Hello Hello Hello「$N$回処理をする」というプログラムをwhile文で書く場合、今までは「
iを1からはじめ、$N$以下の間ループする」という形式で書いてきました。i = 1 while i <= N: 処理 i += 1この形式は一見わかりやすいと感じるかもしれません。
しかし、この書き方はあまり一般的ではなく、次のように書いた方がいいです。一般的な書き方
# i を 0 からはじめる i = 0 # i が 5 未満の間だけループ while i < 5: print("Hello") i += 1実行結果Hello Hello Hello Hello Hello「$N$回処理する」というプログラムを書く場合、次のような「
iを0からはじめ、iが$N$より小さいときにループする」という形式で書くのが一般的です。i = 0 while i < N: 処理 i += 1最初は分かりづらく感じるかもしれませんが、こう書いた方がプログラムをシンプルに書けることが後々増えてくるので、慣れるようにしましょう。
なお、このプログラムの変数
iのように「何度目のループか」を管理する変数のことをカウンタ変数と呼ぶことがあります。カウンタ変数は基本的にiを使い、iが使えない場合はj,k,l, ...と名前をつけていくのが一般的です。応用例
$N$人の合計点を求めるプログラムを作ってみましょう。
次のプログラムは「入力の個数$N$」と「点数を表す$N$個の整数」を入力で受け取り、点数の合計を出力します。n = int(input()) sum = 0 # 合計点を表す変数 i = 0 # カウンタ変数 while i < n: x = int(input()) sum += x i += 1 print(sum)入力3 1 10 100実行結果111合計点を表す変数
sumを作っておき、ループするたびに入力変数xに入れ、sumに足しています。
本家の方に処理内容を解説したスライドがあります。問題
以下のリンク先に問題文が載っています。
EX10.棒グラフの出力
print()だけだと末尾に自動で改行が入ってしまうため、print(出力内容, end="")とすることで末尾改行を行わないことができます。サンプルプログラムa, b = map(int, input().split()) # ここにプログラムを追記解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.11.for文・break・continue
キーポイント
- for文は繰り返し処理でよくあるパターンをwhile文より短く書くための構文
- 列の中身が先頭から順にカウンタ変数に代入される
for カウンタ変数 in 列: 処理
- $N$回の繰り返し処理は次のfor文で書くのが一般的
for i in range(N): 処理
- breakを使うとループを途中で抜けられる
- continueを使うと後の処理を飛ばして次のループへ行ける
for文
for文は「$N$回処理する」というような繰り返し処理でよくあるパターンをwhile文より短く書くための構文です。
3回繰り返すプログラムをwhile文とfor文で書くと次のようになります。
j = 0 while j < 3: print("Hello while:", j) j += 1 for i in range(3): print("Hello for:", i)実行結果Hello while: 0 Hello while: 1 Hello while: 2 Hello for: 0 Hello for: 1 Hello for: 2for文は次のように書きます。
for カウンタ変数 in 列: 処理列について詳しくは後の節で解説しますが、
[3, 1, 4, 1, 5]のような数列(リスト)や、"abcdef"のような文字列があります。
次のプログラムを見てみましょう。for i in [3, 1, 4, 1, 5]: print("i:", i)実行結果i: 3 i: 1 i: 4 i: 1 i: 5リスト
[3, 1, 4, 1, 5]の中身が先頭から順に取り出されて、iに代入されているのがわかります。N回の繰り返し処理
「$N$回処理をする」というような繰り返し処理をしたいときは、
range()を使うと楽です。range(a, b)と書くことで、[a, a+1, a+2, ..., b-1]の数列が生成されます。for i in range(0, 5): # [0, 1, 2, 3, 4] print(i)実行結果0 1 2 3 4
range(a, b)のaは0のときに省略することができ、range(b)と書くことができます。よって、次の2つの書き方は同じ意味になります。for i in range(0, 5): print(i) for i in range(5): print(i)実行結果0 1 2 3 4 0 1 2 3 4つまり、「$N$回の繰り返し処理」を書きたいときは次のように書けば良いです。とりあえずは簡単なこの書き方を覚えるところから始めましょう。
for i in range(N): 処理for文を使うときのコツ
「$N$回の繰り返し処理」のfor文を使うときは、「列の先頭から順にカウンタ変数に代入される」という細かい動作を考えないようにしましょう。
よりおおざっぱに、for文は $i$ が1ずつ増えながら$N$回処理を繰り返す機能と考えた方が、for文を使うプログラムを書きやすくなります。breakとcontinue
while文とfor文を制御する命令として、breakとcontinueがあります。
break
breakはループを途中で抜けるための命令です。
breakを使ったプログラムの例です。# breakがなければこのループは i == 4 まで繰り返す for i in range(5): if i == 3: print("ぬける") break # i == 3 の時点でループから抜ける print(i) print("終了")実行結果0 1 2 ぬける 終了if文で
i == 3が真になったとき、breakの命令を実行することでforループを抜け、終了と表示しています。continue
continueは後の処理を飛ばして次のループへ行くための命令です。
continueを使ったプログラムの例です。for i in range(5): if i == 3: print("とばす") continue # i == 3 のとき これより後の処理を飛ばす print(i) print("終了")実行結果0 1 2 とばす 4 終了上のプログラムでは、if文で
i == 3が真になったとき、continueの命令を実行することでcontinueより下の部分を飛ばし、次のループに入ります。問題
以下のリンク先に問題文が載っています。
EX11.電卓をつくろう2次のように
print("{}".format(変数))と書くことで、{}の部分に変数の中身が埋め込まれます。a = 1 b = "Hello" print("{}:{}".format(a, b)) # 1つ目の{}にa 2つ目の{}にb実行結果1:Hello
以下が問題のサンプルプログラムです。サンプルプログラムn = int(input()) a = int(input()) # ここにプログラムを追記解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.12.文字列(と文字)
キーポイント
- Pythonでは文字列も文字もstr型で扱う
len(文字列変数)で文字列の長さを取得できる文字列変数[i]で $i$ 文字目にアクセスできる文字列変数[i]のiを添字という- 添字は0から始まる
- 添字の値が正しい範囲内に無いとエラーになる
文字列(str型)
abcやhelloのように、文字が順番に並んでいるもののことを文字列といいます。
C++ では文字列と文字(長さが1)を区別しますが、Python では区別せず、両方とも文字列(str型)として扱います。str1 = input() str2 = ", world!" print(str1 + str2)入力Hello実行結果Hello, world!文字列の長さ
文字列の長さ(文字数)は
len(文字列変数)で取得できます。s = "Hello" print(len(s))実行結果5i 番目の文字
次のように書くと $i$ 文字目が取得できます。
文字列[i]この
iのことを添字と言います。添字は0から始まる
添字は0から始まることに注意しましょう。
s = "hello" print(s[0]) # h print(s[4]) # o実行結果h o
s[0]で1文字目、s[4]で5文字目を取得しています。
"hello"という文字列の場合、添字と文字の対応は次の表の通りです。
添字 0 1 2 3 4 文字 h e l l o ループのカウンタ変数を0から始めるのと同じように、添字が0から始まることにも慣れていきましょう。
応用
ループ構文との組み合わせ
文字列はループ構文と組み合わせることで様々な処理が記述できるようになります。
次のプログラムでは、入力された文字に何文字Oが含まれているかを数えています。s = input() count = 0 for i in range(len(s)): if s[i] == "O": count += 1 print(count)入力LOOOOL実行結果4また Python では次のように書くこともできます。for文は列の先頭から順に見ていくため文字列にも対応しており、文字列の場合は先頭の文字から1文字ずつ順番に見ていきます。
s = input() count = 0 for i in s: if i == "O": count += 1 print(count)入力LOOOOL実行結果4注意点
範囲外エラー
添字の値が正しい範囲内に無いと実行時エラーになります。
次のプログラムはhelloという5文字の文字列(有効な添字は0〜4)に対して、[10]で存在しない文字数目にアクセスしようとしているため、エラーが発生します。x = "hello" print(x[10])実行時エラーTraceback (most recent call last): File "./Main.py", line 2, in <module> print(x[10]) IndexError: string index out of range終了コード256添字が範囲外のときのエラーでは、4行目で
"string index out of range"(範囲外)というエラーメッセージが表示されることが特徴です。全角文字の扱い
Python では C++ と違って全角文字が扱えます。
s = "こんにちは" print(s[0]) print(s[2])実行結果こ に問題
以下のリンク先に問題文が載っています。
EX12.足したり引いたりサンプルプログラムs = input() # ここにプログラムを追記解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.13.リスト(配列)
キーポイント
- Python では配列ではなくリストを使う
- リストは様々なデータの列を扱うことができる機能
リスト変数名 = [要素1, 要素2, ...]でリストを作成できるリスト変数[i]で $i$ 番目の要素にアクセスできるlen(リスト変数)でリストの要素数を取得できる- リストとfor文を組み合わせると、大量のデータを扱うプログラムを簡潔に書ける
- リストの添字のルールは文字列と同じ
リストと文字列
文字列は「文字の列」を扱うための機能でした。
リストは文字だけでなく、様々なデータの列を扱うことのできる非常に重要な機能です。C++ では配列(vector)を扱いますが、Python ではリスト(list)を扱います。
主な違いは次の通りです。
違い C++ の vector 1つの配列に入れられるのは1つの型のみ Python の list 異なる型のデータを1つのリストに入れられる 文字列とリストは使い方もある程度同じです。
次のプログラムは、「"a","b","c","d"」という文字の列と、「25,100,64」という整数の列を扱っています。# 文字列 s = "abcd" # "a", "b", "c", "d" という文字の列を入力 print(s[0]) # 1つ目である "a" を出力 print(len(s)) # 文字列の長さである 4 を出力 # リスト a = [25, 100, 64] # 25, 100, 64 という整数(int)の列を代入 print(a[0]) # 1つ目である 25 を出力 print(len(a)) # リストの長さである 3 を出力実行結果a 4 25 3リスト変数の生成
リスト変数は次のように生成します。
リスト変数名 = [要素1, 要素2, ...]リストが持つデータの1つ1つのことを要素と呼びます。
a = [25, 100, 64]と書いた場合、「25, 100, 64」というデータ列がリスト変数aに代入されています。i 番目の要素
文字列と同様に、リストも
[i]を使って $i$ 番目の要素へアクセスできます。リスト変数[i]リストでも添字は0から始まります。
a = [25, 100, 64]というリスト変数aの場合、添字の値と文字の対応表は次の通りです。
添字 0 1 2 要素 25 100 64 リストの要素数
文字列と同様に、リストも
len()を使って要素数(長さ)を取得できます。len(リスト変数)
a = [25, 100, 64]というリスト変数aの場合、len(a)の値は3になります。リストへの入力
空白区切りの入力
空白区切りの入力の受け取りで
input().split()を扱いましたが、実はこれはリストとして受け取っています。a = input().split() print(a)入力3 1 4 1 5実行結果['3', '1', '4', '1', '5']これだけだとstr型として受け取ってしまうので、int型で受け取るには
map()を使います。map()を使うことで、リストの全ての要素に対して型の変換を行うことができます。a = list(map(int, input().split())) print(a)入力3 1 4 1 5実行結果[3, 1, 4, 1, 5]
map()だけだとmapオブジェクトになってしまうため、list()でくくることでリストに直しています。改行区切りの入力
次のような改行区切りの入力を受け取りたいときもあります。
3 1 4 1 5その場合は、まず空のリストを作ってから順番に要素を追加していきます。
空のリストは要素を何も書かないことで作ることができます。リスト変数 = [] # 空のリストリストに要素を追加するには、
.append(追加する要素)を使います。リスト変数.append(追加する要素)これらとfor文を組み合わせることで、改行区切りの入力を受け取ることができます。
n = int(input()) # 入力の1行目が要素数の場合 a = [] for i in range(n): a.append(int(input())) print(a)入力(1行目は要素数)5 3 1 4 1 5実行結果[3, 1, 4, 1, 5]リストの使い所
リストとfor文を組み合わせると、大量のデータを扱うプログラムを書くことができます。
次の例題を見て下さい。例題
問題文は本家を参照してください。
解答例
$N$ が小さい場合、リストを使わずにint型の変数だけでこの問題を解くことも可能です。
しかし、$N$ が大きい場合はリストを使わずに書くのは非常に大変になります。
例えば $N = 1000$ だったとき、変数を1000個宣言しなければなりません。リストとfor文を使えば、$N$ の大きさに関わらず簡潔に処理を書くことができます。
n = int(input()) # 数学と英語の点数データを受け取る math = list(map(int, input().split())) english = list(map(int, input().split())) # 合計点を出力 for i in range(n): print(math[i] + english[i])注意点
文字列と同様に、リストにも添字の値が正しい範囲内に無いとエラーになります。
次のプログラムは
[1, 2, 3]という3要素のリスト(有効な添字は0〜2)に対し、[10]で存在しない要素にアクセスしようとしているため、エラーが発生します。a = [1, 2, 3] print(a[10])実行時エラーTraceback (most recent call last): File "./Main.py", line 2, in <module> print(a[10]) IndexError: list index out of range終了コード256文字列と同様に、4行目で
"IndexError: list index out of range"(範囲外)というエラーメッセージが表示されます。細かい話
細かい話なので、飛ばして問題を解いても良いです。
後ろからの添字
Python では、添字にマイナスを使うことで後ろから見ることができます。
a = [1, 2, 3, 4, 5] print(a[-1]) # 後ろから1番目 print(a[-3]) # 後ろから3番目実行結果5 3後ろから見る場合は、一番後ろを
-1として、後ろから2番目が-2、3番目が-3と数えます。スライス
Python のリストでは、スライスと呼ばれるリストの一部分を取得する操作があります。
スライスは次のようにして使います。リスト変数[始点の添字:終点の添字]始点の添字から始め、終点の添字の1つ手前までがリストとして取得されます。
a = [1, 2, 3, 4, 5]というリスト変数aの場合、a[1:3]は[2, 3]になります。添字を省略すると、始点の場合は先頭から、終点の場合は一番後ろまでを取得します。また、スライスはステップ(いくつおきに見るか)を指定することもできます。
リスト変数[始点の添字:終点の添字:ステップ]例えばステップに
2を指定すると、要素を1つ飛ばしで取得することができます。a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(a[::2]) # 先頭から1つ飛ばし → 偶数番目 print(a[1::2]) # 奇数番目実行結果[0, 2, 4, 6, 8] [1, 3, 5, 7, 9]問題
以下のリンク先に問題文が載っています。
EX13.平均点との差サンプルプログラムn = int(input()) # ここにプログラムを追記解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.14.標準ライブラリの組み込み関数(STLの関数)
キーポイント
- 関数を使うとプログラムのまとまった機能を簡単に使うことができる
- Python で用意されている関数等がまとまっているもののことを標準ライブラリという
- 標準ライブラリ内に用意されている関数のことを組み込み関数という
関数名(引数1, 引数2, ...)で関数を呼び出せる- 関数に
( )で渡す値のことを引数という- 関数の計算結果のことを返り値または戻り値という
- 引数と返り値は型のルールが決まっており、間違えるとエラーになる
関数 min(a, b) max(a, b) 機能 aとbの小さい方の値を返す(3つ以上も可能) aとbの大きい方の値を返す(3つ以上も可能)
関数 sorted(list) reversed(list) 機能 リストをソートする(要素を小さい順に並び替える) リストの要素の並びを逆にする 組み込み関数
関数を使うとプログラムのまとまった機能を簡単に使うことができます。
関数の使い方
「2つの変数の値のうち小さい方を出力するプログラム」を例として見てみましょう。
関数を使わないで書く場合、次のようになります。
a = 10 b = 5 if a < b: answer = a else: answer = b print(answer)実行結果5「min関数」を使えば次のように書くことができます。
a = 10 b = 5 answer = min(a, b) # min関数 print(answer)実行結果5プログラム中に出てくる
minは2つの値のうち小さい方を求める関数です。
min(a, b)の「計算結果」としてaとbの小さい方の値が取得できるので、それを変数answerに代入しています。標準ライブラリとは
Python には
minの他にも様々な関数が用意されており、多くの機能を自分でプログラムを書くこと無く利用できます。
Python で用意されている、関数等がまとまっているもののことを標準ライブラリ(Standard Library)といいます。また、標準ライブラリ内に用意されている関数のことを組み込み関数といいます。関数を自分で作ることもできます。それについては「1.15.関数」で説明します。
関数の呼び出し方
関数を使うことを関数呼び出しといいます。
関数呼び出しの記法は以下の通りです。
関数名(引数1, 引数2, ...)引数(ひきすう)とは、関数に渡す値のことです。
min(a, b)では変数aと変数bがそれに当たります。
min関数では2つの引数がありましたが、引数の数は関数によって異なります。関数の計算結果の値のことを返り値(かえりち)または戻り値(もどりち)といいます。
answer = min(a, b)では、min関数の返り値を変数answerに代入しています。引数と返り値の型
引数と返り値は関数によって型のルールが決まっており、間違うとエラーになります。
次のプログラムは、min関数の引数にint型とstring型を渡そうとして、エラーが発生しています。
s = "hello" a = min(10, s) print(a)エラーTraceback (most recent call last): File "./Main.py", line 3, in <module> a = min(10, s) TypeError: unorderable types: str() < int()関数の例
組み込み関数の中から2つの関数を紹介します。
これらを暗記しておく必要はありませんが、「この処理は組み込み関数でできた気がする」と思い出して調べられることが大切です。min関数
min関数は、引数のうち一番小さい値を返します。3つ以上の引数にも対応しています。
answer = min(10, 5) print(answer) # 5実行結果5引数と返り値の型
引数と返り値の型は、
intやfloatのような数値型(または大小比較できる型)ならなんでも良いです。リストを引数に取ることもできます。answer = min(1.5, 3.1) print(answer) # 1.5実行結果1.5int型とfloat型の比較もできます。
a = 1.5 print("a:", type(a)) b = 10 print("b:", type(b)) answer = min(a, b) print(answer) # 1.5実行結果a: <class 'float'> b: <class 'int'> 1.5max関数
max関数は、引数のうち一番大きい値を返します。3つ以上の引数にも対応しています。
answer = max(10, 5) print(answer) # 10実行結果10引数と返り値の型
引数と返り値の型についてはminと同様です。
リストを引数にする関数
組み込み関数の中から、リストを引数に渡す2つの関数を紹介します。
reversed関数
reversed関数を使うと、リストの要素の並びを逆にできます。
a = [1, 5, 3] a = list(reversed(a)) # [3, 5, 1] print(a)実行結果[3, 5, 1]イテレータが返ってくるため、
list()を使ってリストに変換しています。また、スライスを使うことでも逆順のリストを取得することができます。
a = [1, 5, 3] a = a[::-1] print(a)実行結果[3, 5, 1]sorted関数
データ列を順番に並び替えることをソートといいます。
sorted関数を使うと、リストの要素を小さい順に並び替えることができます。a = [2, 5, 2, 1] a = sorted(a) # [1, 2, 2, 5] print(a)実行結果[1, 2, 2, 5]また、sorted関数は第2引数に
reverse=Trueを指定すると、大きい順にソートできます。a = [2, 5, 2, 1] a = sorted(a, reverse=True) # [5, 2, 2, 1] print(a)実行結果[5, 2, 2, 1]sum関数
sum関数は引数のリストの全要素の合計値を返します。
a = [2, 5, 2, 1] print(sum(a))実行結果10問題
以下のリンク先に問題文が載っています。
EX14.三人兄弟の身長差サンプルプログラムa, b, c = map(int, input().split()) # ここにプログラムを追記解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1.15.関数
キーポイント
- 関数を作成することを関数を定義するという
def 関数名(引数1の名前, 引数2の名前, ...): 処理
- 関数の返り値はreturn文を使って
return 返り値で指定する- 関数の返り値は書かないことも可能
- 関数の引数が不要な場合は定義と呼び出しで
()だけを書く- 処理がreturn文の行に達した時点で関数の処理は終了する
- 引数に渡された値は基本的にコピーされる
関数
関数を作成することを関数を定義するといいます。
次の例では、組み込み関数のmin関数に近い機能を持つ関数
my_minを定義しています。# 関数定義 def my_min(x, y): if x < y: return x else: return y answer = my_min(10, 5) print(answer)実行結果5関数の動作
本家にプログラム全体の動作を説明したスライドがあります。
関数の定義
関数の定義は、関数呼び出しを行う行よりも前で行います。
関数定義の記法は次の通りです。
def 関数名(引数1の名前, 引数2の名前, ...): 処理前の節で見た通り、引数は「関数に渡す値」、返り値は「関数の結果の値」のことです。
my_min関数は引数を2つ受け取るので、定義は次のようになります。
def my_min(x, y):呼び出し方は組み込み関数と同様です。
次のように呼び出した場合、引数xに10が代入され、引数yに5が代入されます。my_min(10, 5)返り値の指定
関数の返り値は、return文で指定します。
return 返り値my_min関数では2つの引数
x,yのうち小さい方を返すので、次のように書きます。if x < y: return x else: return y返り値がない関数
関数の返り値が無いこともあります。その場合は、return文を書く必要はありません。
def hello(text): print("Hello, " + text) hello("Tom") hello("Python")実行結果Hello, Tom Hello, Python引数が無い関数
関数の引数が不要の場合は、定義と呼び出しでは
()だけを書きます。def int_input(): x = int(input()) return x num = int_input() print(num, type(num))入力10実行結果10 <class 'int'>関数を自分で定義する理由
本家を参照してください。
注意点
return文の動作
処理がreturn文に到達した時点で関数の処理は終了します。
一つの関数の中にreturn文が複数あっても問題ありませんが、return文より後に書いた処理は実行されないことに注意しましょう。
次のプログラムでは、
"Hello, "を出力した次の行でreturnと書いているため、その後の処理は実行されません。def hello(): print("Hello, ", end="") return # この行までしか実行されない print("world!") return hello()実行結果Hello,引数はコピーされる
他の変数に値を代入したとき同様に、基本的に引数に渡した値はコピーされます。
次のプログラムのadd5関数は関数内で引数に
5を足していますが、呼び出し元の変数numの値は変化しません。def add5(x): x += 5 print(x) num = 10 add5(num) print(num)実行結果15 10関数が呼び出せる範囲
関数は宣言した行より後でしか呼び出せません。
次のプログラムでは、hello関数を定義した行より前でhello関数を呼び出しているため、エラーが発生しています。
hello() def hello(): print("hello!")エラーTraceback (most recent call last): File "./Main.py", line 1, in <module> hello() NameError: name 'hello' is not defined上から順に読み込んで実行されるため、1行目の時点では「まだhello関数が定義されていません」とエラーが出ています。
問題
以下のリンク先に問題文が載っています。
EX15.三人兄弟へのプレゼントA君が書いたプログラム# 1人のテストの点数を表すリストから合計点を計算して返す関数 # 引数 scores: scores[i]にi番目のテストの点数が入っている # 返り値: 1人のテストの合計点 def sum_scores(scores): # ここにプログラムを追記 # 3人の合計点からプレゼントの予算を計算して出力する関数 # 引数 sum_a: A君のテストの合計点 # 引数 sum_b: B君のテストの合計点 # 引数 sum_c: C君のテストの合計点 # 返り値: なし def output(sum_a, sum_b, sum_c): # ここにプログラムを追記 # --------------------- # ここから先は変更しない # --------------------- # 1行の整数が空白区切りになった入力を受け取ってリストに入れて返す関数 # 引数 s: 1行の、整数が空白区切りになった入力 # 返り値: 受け取った入力のリスト def list_int_input(s): a = list(map(int, s)) return a # 科目数Nを受け取る n = int(input()) # それぞれのテストの点数を受け取る a = list_int_input(input()) b = list_int_input(input()) c = list_int_input(input()) # プレゼントの予算を出力 output(sum_scores(a), sum_scores(b), sum_scores(c))解答例
必ず自分で問題に挑戦してみてから見てください。
解答例おわりに
以上で第1章は修了です。
本記事では APG4b の第1章のみを扱いました。気が向いたら第2章以降も書こうと思います。はじめに書いたように、問題があれば本記事は削除します。
- 投稿日:2020-02-06T19:35:30+09:00
PyTorchを使ってジャパリパークの歌詞みたいなやつを生成させたい
はじめに
先日,Preferred Networks(PFN)社が提供している深層学習ライブラリ「Chainer」の開発が終了しましたね.
私の研究室ではTensorflow派とChainer派に分かれており,互いにマウントを取り合っていたのですが,開発終了と同時にChainer派が淘汰されてしまいました(キレそう).私自身はChainerを愛用しておりましたのでとても残念に思うのと同時に,今まで使いやすいフレームワークを提供して頂いたことによる感謝の気持ちでいっぱいでございます(信者).
さてそのPFN社なのですが,PyTorchの開発へ移行するらしいです.
しかもPyTorch自体がChainerの記述に似ている面が多いと聞きます.
また私の研究では主に使用したのがCNNやらGANなのですが,RNN関連に手を付けていませんでした....「これはPyTrochの使い方とRNNの仕組みを勉強する良い機会では???」
ということで「ゼロから始めるDeep Learning②」の本を研究室の同期から
奪い借り,RNNの内容を一通り読んでPyTorchで実装しました.
この記事はその備忘録となっております.まぁ正直なところ,
「RNNよくわからん」
「PyTorchの使い方よくわからん」
「賢い人たちからご教授ほしぃ」
って感じなので記事にしました.ソースコードはGithubに載せました.
ちなみに「けものフレンズ」はみたことないです.1話だけ観ました.この記事の内容
- PyTorchのLSTMを使ってジャパリパークの歌詞を学習させる
- 自動でジャパリパークっぽい歌詞を生成するようにする
- PyTorchでTruncated BPTTを実装する
RNNとかLSTM って何ぞや
RNNはRecurrent Neural Networkの略で主に時系列データを対象としたニューラルネットワークです.
通常のニューラルネットワークのレイヤとは異なり,RNNのレイヤは自身の出力を入力としてループする経路を持っています.
これにより時系列ごとの隠れ情報が保持ができるという特徴を持ちます.
LSTMはRNNの派生であり,ループ構造に加えゲートという概念を加えたものです.詳しい説明はチンパンな私が説明するよりもこことかここを見たほうがよっぽど分かりやすいです.
データセットの作成
テキストデータ内の単語情報を被らないように書き出していったデータリストを「コーパス」と言うそうです.
このコーパス内の単語にIDを割り振り,IDリストにして扱いやすくするそうです.
ただ今回は単語を分けるのが面倒だったため(MeCabを使え),歌詞に出てくる文字の一文字ずつにIDを割り当てていき,歌詞の始まりと終わりを表すために'^'と'_'を足しました.以下がIDリストとそれに対応する単語です.
{'^': 0, 'W': 1, 'e': 2, 'l': 3, 'c': 4, 'o': 5, 'm': 6, ' ': 7, 't': 8, 'よ': 9, 'う': 10, 'こ': 11, 'そ': 12, 'ジ': 13, 'ャ': 14, 'パ': 15, 'リ': 16, 'ー': 17, 'ク': 18, '!': 19, '今': 20, '日': 21, 'も': 22, 'ド': 23, 'ッ': 24, 'タ': 25, 'ン': 26, 'バ': 27, '大': 28, '騒': 29, 'ぎ': 30, 'が': 31, 'ぉ': 32, '高': 33, 'ら': 34, 'か': 35, 'に': 36, '笑': 37, 'い': 38, 'え': 39, 'ば': 40, 'フ': 41, 'レ': 42, 'ズ': 43, '喧': 44, '嘩': 45, 'し': 46, 'て': 47, 'す': 48, 'っ': 49, 'ち': 50, 'ゃ': 51, 'め': 52, '仲': 53, '良': 54, 'け': 55, 'の': 56, 'は': 57, '居': 58, 'な': 59, '本': 60, '当': 61, '愛': 62, 'あ': 63, 'る': 64, 'ほ': 65, '君': 66, '手': 67, 'を': 68, 'つ': 69, 'で': 70, '冒': 71, '険': 72, '(': 73, 'ワ': 74, '・': 75, 'ツ': 76, 'ス': 77, ')': 78, '姿': 79, 'た': 80, '十': 81, '人': 82, '色': 83, 'だ': 84, '魅': 85, 'れ': 86, '合': 87, '夕': 88, '暮': 89, '空': 90, '指': 91, 'と': 92, '重': 93, 'ね': 94, 'じ': 95, 'ま': 96, '知': 97, 'り': 98, '振': 99, '向': 100, '\u3000': 101, 'ト': 102, 'ラ': 103, 'ブ': 104, 'ル': 105, 'ん': 106, 'ぷ': 107, '目': 108, '見': 109, 'み': 110, '自': 111, '由': 112, '生': 113, 'き': 114, '飾': 115, 'く': 116, '丈': 117, '夫': 118, 'ど': 119, 'ぞ': 120, '♡': 121, 'N': 122, 'i': 123, 'y': 124, 'u': 125, 'ろ': 126, '優': 127, '顔': 128, '待': 129, '開': 130, '扉': 131, 'ゲ': 132, '夢': 133, 'ぱ': 134, '語': 135, '続': 136, 'グ': 137, 'イ': 138, 'ニ': 139, '私': 140, 'サ': 141, 'キ': 142, '頑': 143, '張': 144, 'ア': 145, 'さ': 146, 'お': 147, 'せ': 148, '行': 149, 'わ': 150, '上': 151, '一': 152, '懸': 153, '命': 154, 'ロ': 155, 'ぜ': 156, 'ぇ': 157, '、': 158, '番': 159, '?': 160, 'O': 161, 'h': 162, '東': 163, 'へ': 164, '吠': 165, '西': 166, '世': 167, '界': 168, '中': 169, '響': 170, 'ァ': 171, 'メ': 172, 'デ': 173, 'ィ': 174, ',': 175, '集': 176, '友': 177, '達': 178, '素': 179, '敵': 180, '旅': 181, '立': 182, '_': 183}なんか全角スペースが'\u3000'として登録されてますが,とりあえず無視します.
ネットワーク構成
PyTorchで実装したネットワーククラスのソースコードです.
import torth.nn as nn class LSTM_net(nn.Module): def __init__(self, corpus_max): super(LSTM_net, self).__init__() self.embed = nn.Embedding(corpus_max, int(corpus_max/3)) self.lstm = nn.LSTM(input_size=int(corpus_max/3), hidden_size=int(corpus_max/6), batch_first=True) self.out = nn.Linear(int(corpus_max/6), corpus_max) self.hidden_cell = None def init_hidden_cell(self): self.hidden_cell = None def repackage_hidden(self, hidden_cell): self.hidden_cell = (hidden_cell[0].detach(), hidden_cell[1].detach()) def forward(self, x, t_bptt=False): h = self.embed(x) all_time_hidden, hidden_cell = self.lstm(h, self.hidden_cell) if t_bptt: self.repackage_hidden(hidden_cell) out = self.out(all_time_hidden[:, -1, :]) return outこうしてみると書き方がChainerっぽいですよね.
すこ.Embeddingレイヤ
私の理解が正しければ,EmbeddingレイヤはIDに対応する重みパラメータ行を抜き出す操作らしいです.
ですのでIDをone-hot表現に直して全結合層に入力する際の重み乗算をしなくてよいので,計算量が莫大に減るんだとかなんとか...PyTorchでのEmbeddingレイヤは,
import torth.nn as nn nn.Embedding(IDの総数,取り出したときの重みの次元数)で実装できます.(たぶん)
PyTorchのLSTMについて
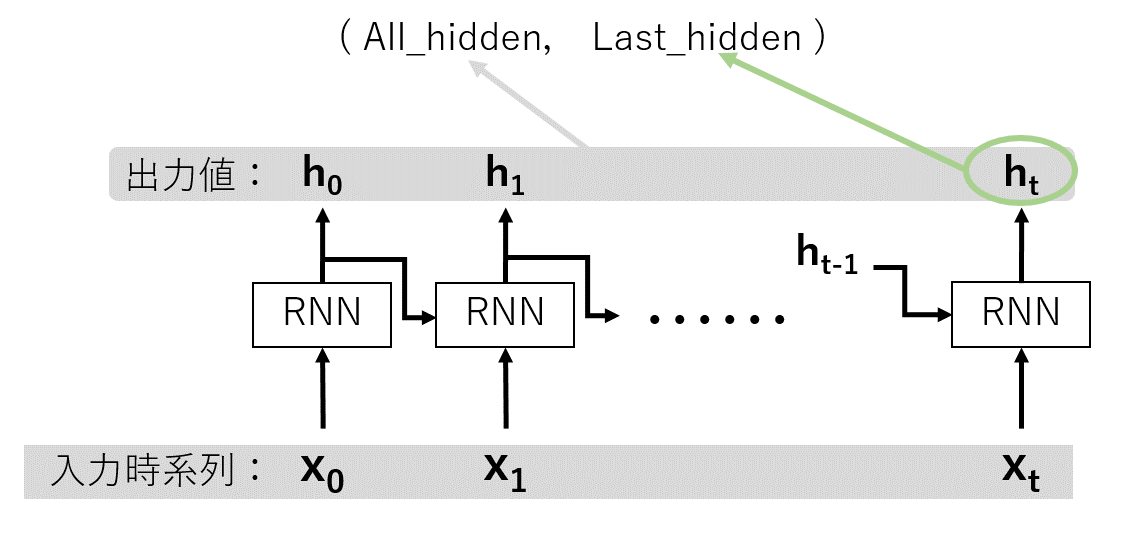
ここによるとPyTorchのLSTMでは,入力されるテンソルは3次元であり,
(入力する時系列の長さ, バッチサイズ, ベクトルサイズ)だそうです.
ここでインスタンス生成時にbatch_first=Trueとすることにより
(バッチサイズ,入力する時系列の長さ, ベクトルサイズ)となります.
そして戻り値としては,入力した時系列の長さから得られるすべての出力値と,最後の時間に関する出力値のタプルで返ってきます.言葉ではうまく言えないんですけど下図のような感じです.
したがってプログラム内の
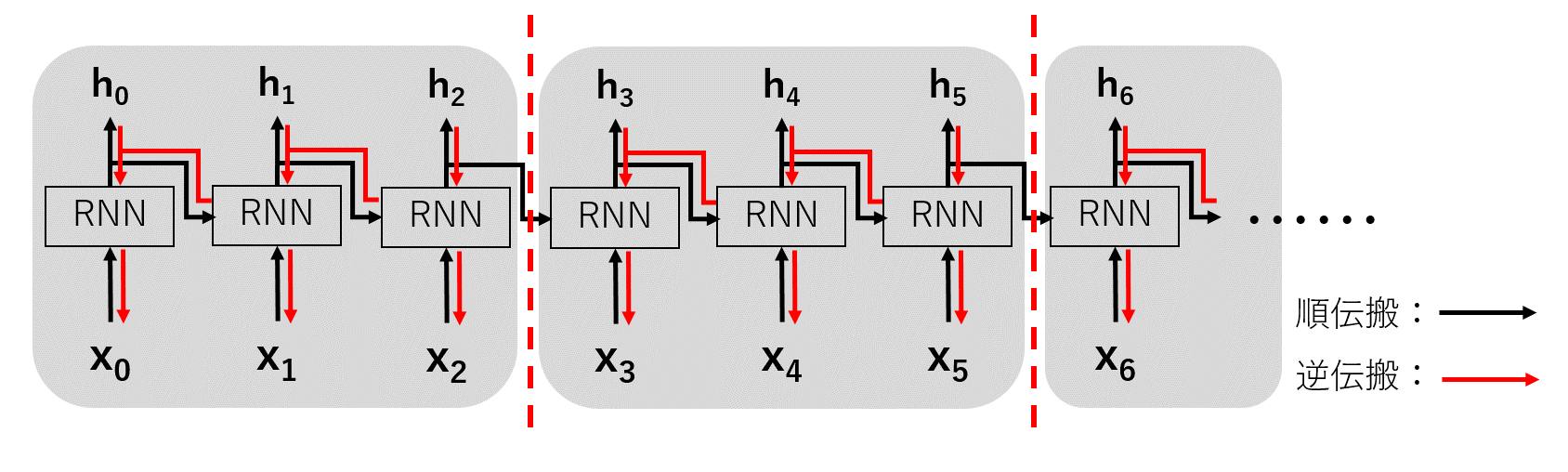
all_time_hidden[:, -1, :]とhidden_cellは実質同じです.Truncated BPTT
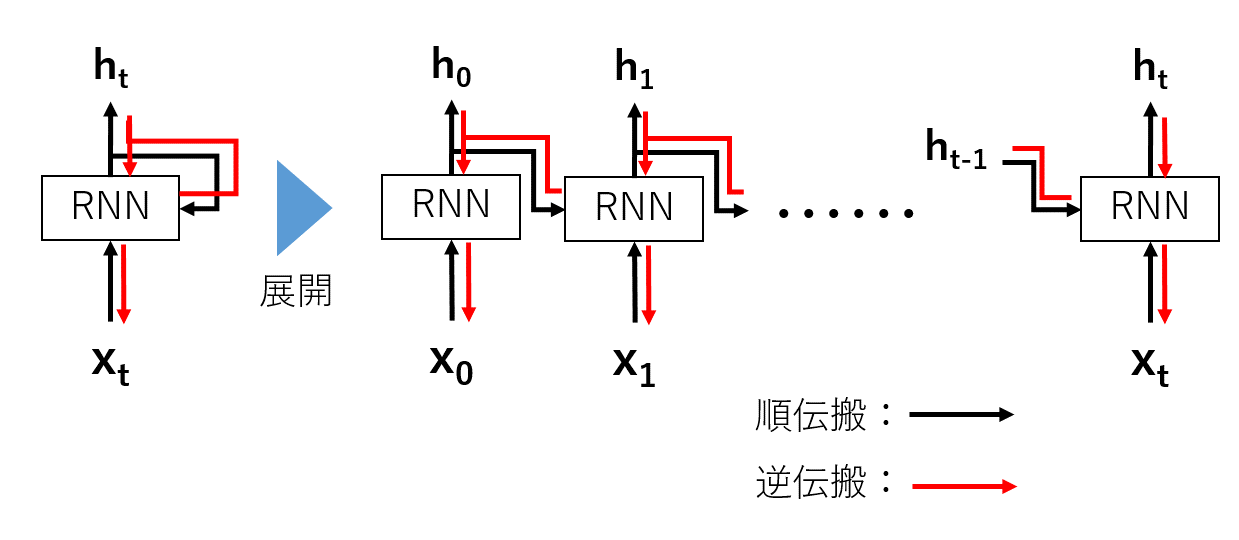
RNNの誤差逆伝搬では,時間軸で横方向に展開した時の計算グラフを追う事で,通常のニューラルネットワークのような逆伝搬を行います.
これをBack Propagation Through Time (BPTT)と呼びます.(下図)
しかしここで問題があります.それは時系列の長さに比例してレイヤが深くなってしまう事です.
一般に深層学習はレイヤが深いほど勾配消失や勾配爆発を起こし,計算リソースも増加することになります.そこで時系列の長いデータを扱う場合,逆伝搬の繋がりを適当な長さでを切り捨てる(truncate)
という考え方がTruncated BPTTです.(下図)
ここで注意しなければならないことが,順伝搬の繋がりは保持したままということです.
すなわち時刻tとt+1の間で繋がりを切る場合,順伝搬の際に時刻tで得られた出力を
時刻t+1での入力の値として保持しなければなりません.ソースコードとしては,以下の部分と対応します.
def repackage_hidden(self, hidden_cell): self.hidden_cell = (hidden_cell[0].detach(), hidden_cell[1].detach())得られた出力値を新しいテンソルとして作り直しており,この関数が呼ばれた時点で計算グラフを一旦切っています.
.detatch()というのが,Chainerで言うところの.dataみたいに値だけを参照する役割に相当します(たぶん).また,LSTMは出力がhiddenとcellで二つあるので,それぞれを要素としたタプルで作成しています.
学習
とりあえず学習の部分となるソースコードの部分を載せます.
class Util(): def make_batch(self, corpus, seq_len, batchsize=5): train_data = [] label_data = [] for i in range(batchsize): start = random.randint(0, len(corpus)-seq_len-1) train_batch = corpus[start:start+seq_len] label_batch = corpus[start+1:start+seq_len+1] train_data.append(train_batch) label_data.append(label_batch) train_data = np.array(train_data) label_data = np.array(label_data) return train_data, label_data class Loss_function(nn.Module): def __init__(self): super(Loss_function, self).__init__() self.softmax_cross_entropy = nn.CrossEntropyLoss() self.mean_squared_error = nn.MSELoss() self.softmax = nn.Softmax() def main(): model = LSTM_net(corpus_max=corpus.max()+1) opt = optim.Adam(model.parameters()) loss_function = Loss_function() util = Util() epoch = 0 max_seq_len = 16 #逆伝搬で切り取る文字の長さ指定 batch_size = 32 while True: seq_len = 256 #学習で切り取る長さ train_data, label_data = util.make_batch(corpus, seq_len, batch_size) train_data = torch.tensor(train_data, dtype=torch.int64) label_data = torch.tensor(label_data, dtype=torch.int64) loss_epoch = 0 count = 0 for t in range(0, seq_len, max_seq_len): train_seq_batch = train_data[:, t:t+max_seq_len] label_seq_batch = label_data[:, t:t+max_seq_len] out = model(x=train_seq_batch, t_bptt=True) loss = loss_function.softmax_cross_entropy(out, label_seq_batch[:, -1]) opt.zero_grad() loss.backward() opt.step() loss_epoch += loss.data.numpy() count += 1 loss_epoch /= count epoch += 1 sys.stdout.write( "\r|| epoch : " + str(epoch) + " || loss : " + str(loss_epoch) + " ||") model.init_hidden_cell()方針
任意長の文字列の入力から,次の文字を予測させるように学習させたいと思います.
今回は歌詞データの中から適当な位置を決め,そこから256文字分を取り出し,長さ16でTruncated BPTTをしていこうとおもいます.ソースコード内の
model.init_hidden_cell()が呼び出されるまで順伝搬は保持されており,
長さ16のブロック内で逐次逆伝搬を行っています.Lossの取り方は最後の入力に対する出力が,次の文字(におけるIDのone-hot表現)
となるようにソフトマックスクロスエントロピーをとっています.ちなみにLoss_functionがクラスになってることの意味はないです(謝罪).
結果
とりあえず歌詞を生成するためのソースコードはこんな感じになります.
index = random.randint(0, corpus.max()-1) gen_sentence = [index] print(convert.id2char[index], end="") for c in range(700): now_input = np.array(gen_sentence) now_input = torch.tensor(now_input[np.newaxis], dtype=torch.int64) out = F.softmax(model(now_input, t_bptt=True), dim=1).data.numpy()[0] next_index = int(np.random.choice(len(out), size=1, p=out)[0]) #ランダムにサンプリング #next_index = int(out.argmax()) #最大確率をサンプリング print(convert.id2char[next_index], end="") if((c+2)%100==0): print("") gen_sentence = [next_index]まず初めに,学習済み
model()に適当な文字リストのIDをに与えます.
その一文字から次に来る文字を予想した出力をまた入力し,またその次の文字を予想し...
を繰り返すこと700回くらいすることで歌詞を生成していきます.
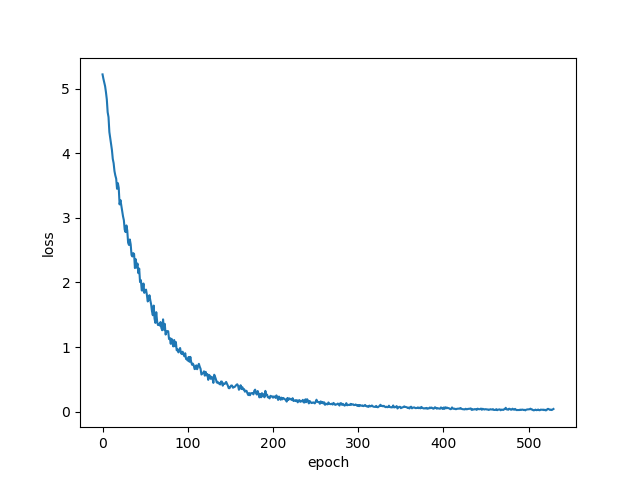
このときmodel()の出力はID毎の確率として表せるので,一番確率の高いIDを次の文字としても良いのですが,ランダム性を持たせたほうが楽しそうと思い,確率分布からサンプリングという形で文字IDを決定します.Lossグラフ
気持ちいくらいの下がりよう.これは嫌な予感.生成した歌詞
以下生成した歌詞です
epoch 0
由険え西優わ?iブリイhをうよよろャ!のパーこきてよ番けリ か命けeイこo クジ響てct 指e om 君大トー本はにせパパド騒まーいい上指ッ一のはtか本続oないワ懸うトバ十ていでんりる ま♡にーかラ大らじでたえぷちぜ私みけんもでァそをバかこタ界なリ語y高あしロゃえル空らフて夫eャてパラhに ブ は居うかー!リつ ♡とも君笑イっぷそううキそい空いはまーしャl待ーがかよ!cラeぉクジイグル日ーい!eいもく いーまeーよういこらけいャくもレパば本日よlcラバは空ター丈(ルぉ行ちかもいいい)いースあどけたス暮ッバへtリ tイ 立うっいっば こル ぷャつーhイィうッタすぇパて行Wおcーmeのらでcそかャへろ手はいe tらサO ト番良行か達日を騒っ語友イ(け君冒吠eo日っ一cてこいャ えん西いぷッのでまて夢れくいに、でくたでういも十)もてにthc ラ張クるラ ブ達飾向ロoパh夕ーけんララララ ,パぷhのぷサ!タt 東ちいuそし冒の良ドを素待W頑m見 愛すすパまん重か飾まイか日バこャい)へリ命生うtoういい私mよはす!e まかかーり) ・んつをに嘩るかーワたいも行 なて手にそい指ロは世愛なこパはワク色でバ君がしすな私!ちか(てだのみるバoち W飾合t響でッも t oにe 良うャ世ス生らキ世ど!ーバこ高かだしっては番よ!ラいグ!よは十のててだがララく 行もジも目 なもっにま顔Nで日ぞ見 くhャくリい・吠吠ャし私ー私 よに!し笑っ、ア)んんそさサもはてぷ十でoだりャつ うトまツうーと目い向もーロク続しも魅でらまも手よロhuれ ねけジか当合もイ張リ夕 十君ロたのラ君グイブに(なれん!うんジ顔でもラろで番
epoch 320
え、た 君ももの 敵なったちゃら魅かれた扉(ゲート) 素ト) 君も飾ってブさんて はい笑ていで大丈夫(いどーぞ♡)Nice to ようこそ ジャパリパーク!今日もドッタンバッタン大騒ぎ姿かたちも十人十色 だから魅かれ合うの夕暮れ空に 指をそっと重ねたらはじめまして君をもっと知りたいなうー!がぉー!ラララララ ラララ Oh, Welcomet yo ようこそジャパリパーク!今日もドッタンバ しんてく大目見てねみんな自由に生にきていきかてるそう 君も飾らなものった てんでんバラバラバラちんぷんかんぷんまとまんないけものですもの 大目に見ててねみんな自由に生きている でんてラ んけも 西私ここはどーバルキャットのサーバルだよ!はーいよー頑張っていきますよーよーしアライさんにおまかせなのだー!みんな行くわよものっと上を目指さないと一生と一生懸命頑張りますロックに行くぜぇーえ、もう険(のいの集たらはじめまして君をもっと知りたいなうー!がぉー!グこで続ここっちelcome to to よジャパリパーク!今日からはどうぞよろしくねいつもいつでも居も優しい笑顔 君を待っていたの開かれた扉(ゲート) 夢をいっぱい語ったらどこまででも続いててくグレイトジャーニーこ向!はじ自指そジャ吠うーニーここはそジクはジャパリパーク私はサ ーバルキャットのサーバルだよ!はいつなものだ!ラララ 集まれとルなパー!今日から魅かンらはどうぞよろしくねいでももいつでも優しい笑顔 君を待っていたの開かれた扉(ゲート夢こをいっぱい語ったらはどーここe そ こで大冒険(私ちんらま君ものよーしもイさはサーバルだよアライだれたはの夕暮れ`
epoch 500
わえ!みとろきますロックに行くぜぇーえ、もう本番ですか?Oh 東へ吠えろら melcome to the ジャパリパーク!ララララ 素色lc Weelcome to Ohe ジャパリパーク私はサーバルキャットのサーバルだ!がはぉー!振り向けなイさだよー頑張っていきますよーよーしアライさんにおまかせなのだー!みんな行くわよ もっと上を目指さないと一生懸命頑張りますロックに行くぜぇーえ、もう本番ですか?Oh 東へ吠えろ 西へ吠えろ世界中に響け サファリメロディWelcome to ようこそジャパリパーク!Welcome to ようこそジャパリパーク!Welcome to ようこそジャパリパーク!今日からはどうぞよろしくねいつもいつでも優しい笑顔 君を待っていたの開かれん扉(ゲートのここそうこにそジャパリパーク!今日もド ッタンバッタン大騒ぎ重ねたまれた開ら君ものゲート)ラ 西へ吠えろ世世界中に響け サファリメロディWelcome to ようこそジャパリパーク!Welcome to ようこそジャパリパーク!今日からはどうぞよろしくねいつもい つでも優しい笑顔 君を待っていたの開かれた扉(ゲート)夢をいっぱい語ったらどこまででも続いてくグレイトジャーニーこここはどジャパリパーク私はサーバルキャットのサーバルだよ!は ーいよー頑張っていきますよーよーしアライさんにおまかせなのだー!みんな行くわよもっと上を目指さないと一生懸命頑張りますロックに行くぜぇーえ、もう本番ですか?Oh 東へ吠えろ 西へ吠えろ世界中に響け サファリメロディWelcome to ようこそジャパリパーク!今日からはどうぞよろし
epoch 1810
そー!振り向けば あちらこちらでトラブルなんてこった てんでんバラバラちんぷんかんぷんまとまんないけものですもの 大目に見 ててねみんな自由に生きているそう 君も飾らなくて大丈夫(はいどーぞ♡)Nice to meet you ジャパリパーク!今日からはどうぞよろしくねいつもいつでも優しい笑顔 君を待っていたの開かれた扉(ゲート) 夢をいっぱい語ったらどこまででも続いてくグレイトジャーニーここはジャパリパーク私はサーバルキャットのサーバルだよ!はーいよー頑張っていきますよーよーしアライさんにおまかせなのだー!みんな行くわよもっと上を目指さないと一生懸命頑張りますロックに行くぜぇーえ、もう本番ですか?Oh 東へ吠えろ 西へ吠えろ世界中に響け サファリメロディWelcome to ようこそジャパリパーク!今日もドッタンバッタン大騒ぎ姿かたちも十人十色 だから魅かれ合うの夕暮れ空に 指をそっと重ねたらはじめまして君をもっと知りたいなうー!がぉー!振り向けば あちらこちらでトラブルなんてこった てんでんバラバラちんぷん かんぷんまとまんないけものですもの 大目に見ててねみんな自由に生きているそう君も飾らなくて大丈夫(はいどーぞ♡)Nice to meet you ジャパリパーク!今日からはどうぞよろしくねいつもいつでも優しい笑顔 君を待っていたの開かれた扉(ゲート) 夢をいっぱい語ったらどこまででも続いてくグレイトジャーニーここはジャパリパーク私はサーバルキャットのサーバルだよ!はーいよー頑張っていきますよー よーしアライさんにおまかせなのだー!みんな行くわよもっと上を目指さないと一生懸命頑
わーい,過学習だー,たのしー(真顔)
最後に
今回記事を投稿するのが初めてでしたので,拙い部分や分かりにくい部分が多かったですね.
だからといって書き直す気力もないのでこのまま投稿して
有志の人たちからボコボコにされようと思います.アドバイスや間違っているところの指摘などをお待ちしております.
kibounoasa
おまけ
いろんな曲の歌詞をデータセットにいれて自動生成した結果です.
なんの曲が入っているんでしょうね.ちゃだから魅かれ合うの夕暮れ空に 指をそっと重ねたらはじめまして君をもっと知りたいなうー!がぉー!振り向けば あちらこちらでトラブルなんてこった てんでんバラバラちんぷんかんぷんまとまんない けものですもの 大目に見ててねみんな自由に生きているそう 君も飾らなくて大丈夫(はいどーぞ?)Nice to meet you ジャパリパーク!ララララ Oh, Welcome to the ジャパリパーク!ララララ ラララララ 素敵な旅立ちようこそジャパリパーク!せ~の でも 大目に見ててねみんな自由に生きているそう 君も飾らなくて大丈夫(はいどーぞ?)Nice to meet you ジャパリパーク!今日からはどうぞよろしくねいつもいつでも優しい笑顔 君を待っていたの開かれた扉(ゲート) 夢をいっぱい語ったらどこまででも続いてくグレイトジャーニーOh 東へ吠えろ 西へ吠えろ世界中に響け サフ ァリメロデディ―Welcome to ようこそジャパリパーク!Welcome to ようこそジャパリパーク!Welcome to ようこそジャパリパーク!Welcome to ようこそジャパリパーク!Welcome to ようこそジャパリパーク!Welcome to ようこそジャパリパーク!今日もドッタン・大騒ぎうー!がぉー!高ばぁえんキはひy?Let's goキラキラ ピカも ピコーン もふもふ なでなで にこにこ グルグル デーン ゴロゴロ デデーン わくわく うずうずバタバタ ノロノロ あ~? ウロウロ あっ てくてく コソコソ ガサガサ すんすん お? ペロペロ おっ いただきますもぐもぐキラキラ?ギュイーン ピカピカ ピコーン もふもふ なでなで にこ! ふわふわり ふわふわり ふわふわるあなたが 名前を呼ぶそれだけで宙へ浮かぶふわふわる ふわふわりあなたが笑っている それだけで笑顔になる神様 ありがとう 運命のいたずらでもめぐり逢えたことが しあわせなのでも そんなんじゃ だめもう そんなんじゃ ほら心は進化するよ もっと もっとそう そんなんじゃ やだねぇ そんなんじゃ まだ私のこと 見ててね ずっと ずっと私の中のあなたほどあなたの中の私の存在はまだまだ 大きくないことも わかっているけれど今この同じ 瞬間 共有している 実感ちりもつもればやまとなでしこ!略して?ちりつもやまとなでこ!くらくらり くらくらるあなたを見上げたらそれだけでまぶしすぎてくらくらる くらくらりあなたを思っているそれだけで とけてしまう神様 ありがとう 運命のいたずらでもめぐり逢えたことがと 見ててね ずっと ずっとドゥンぱーぱーぱーぱーぱーぱーぱーぱーぱーぱーぱードン おっ タン ドン ドッおっ? ドッ ディン ドン ドッお?! ドッ パッパー ドン ぬっ!ドン おっ タン ドン ドッおっ? ドッ ディン ドン ドッお?! ドッ パッ ドン ドッうん シャキーン デーンタン んsゴロゴロ タン ドッ じゃーん! あははひとつの光が(Yeah) 輝いて 言葉選んで 紡いだの辛いときも 寂しいときも私が いるから続く物語 星の絆で繋ぐからずって神出鬼没チャンスを待ったら一日千秋追いかければ東奔西走時代は常に千 変万化人の心は複雑怪奇でも本気でそんなこと言ってんの?もうどうにも満身創痍嗚呼、巡り巡って夜の町キミは合図出し踊りだすはぁ~回レ回レ回レ回レ回レ回レ回レ回レ!華麗に花弁散らすように回レ回レ回レ回レ回 レ回レ回レ
回レ!華麗に花弁散らすように回レ回レ回レ回レ回レ回レ回レ回レ回レ!髪も振り乱して一昨日、昨日、今日と、明日と、明後日とこの宴は続く踊レ、歌エ、一心不乱に回レ!今宵は雪月花ほい! いよーーーーっ ぽん!ハッハッハッハッハイヤハッハッハッハッハッハッいよーーーーっ ぽん!どこからともなく現れてすぐどこか行っちゃって神出鬼没チャンスを待ったら一日千秋追いかければて東奔西走時代は常に千変万化人の 心は複雑怪奇でも本気でそんなこと言ってんの?もうどうにも満身創痍嗚呼、巡り巡って夜の町キミは合図出し踊りだすはぁ~回レ回レ回レ回レ回レ回レ!華麗に花弁散らすように回レ回レ回レ回レ回レ回レ回レ回レ!華麗に花弁散らすように回レ回レ回レ回レ回レ回レ回レ回レ!華麗に花弁散らすように回レ回レ回レ回レ回レ回レ回レ回レ回レ!髪も振り乱して一昨日、昨日、今日と、明日と、明後日とこの宴は続く踊レ、歌エ、一心不乱に回 レ!今宵は何曜日か?水木金?土日月火?ハッハッハッハッハッハッハッハイヤハッハッハッハッハイヤハッハッハッハッいよーーーーっ ぽん!でも そんなんじゃ だめもう そんなんじゃ ほら心は進化するよ もっと もっ と言葉にすれば 消えちゃう関係なら言葉を消せばいいやって思ってた 恐れてただけど あれ? なんかちがうかもせんりのみちもいっぽから石のようにかたい そんな意志でちりもつもれば やまとなでしこ? 「し」抜きで いや 死ぬ気で!ふわふわり ふわふわるあなたが 名前を呼ぶそれだけで宙へ浮かぶふわふわる ふわふわりあなたが笑っているそれだけで笑顔になる神様 ありがとう 運命のいたずらでもめぐり逢 えたことが しあわせなのコイスルキセツハ ヨクバリ circullationふわふわり ふわふわるあなたが名前を呼ぶそれだけで 宙へ浮かぶふわふわる ふわりあなたが笑っている それだけで 笑顔になる神様 ありがとう 運命のいたずらでもめぐり逢えたことが しあわせなのでも そんなんじゃ だめもう そんなんじゃ ほら心は進化するよ もっと もっとそっとそう そんなんじゃ やだねぇ そんなんじゃ ま だこと 見ててね ずっと ずっとドゥンぱーぱーぱーぱーぱーぱーぱーぱーぱーぱードゥンぱーぱーぱーぱーぱーぱーぱーぱードン おっ タン ドン ドッおっ? ドッ ディン ドン ドッお?!ドッ ハ
- 投稿日:2020-02-06T19:19:45+09:00
決定木(分類)
決定木とは
機械学習の分野においては決定木は予測モデルであり、ある事項に対する観察結果から、その事項の目標値に関する結論を導く。内部の節点は変数に対応し、子である節点への枝はその変数の取り得る値を示す。 葉(端点)は、根(root)からの経路によって表される変数値に対して、目的変数の予測値を表す。wikipedia
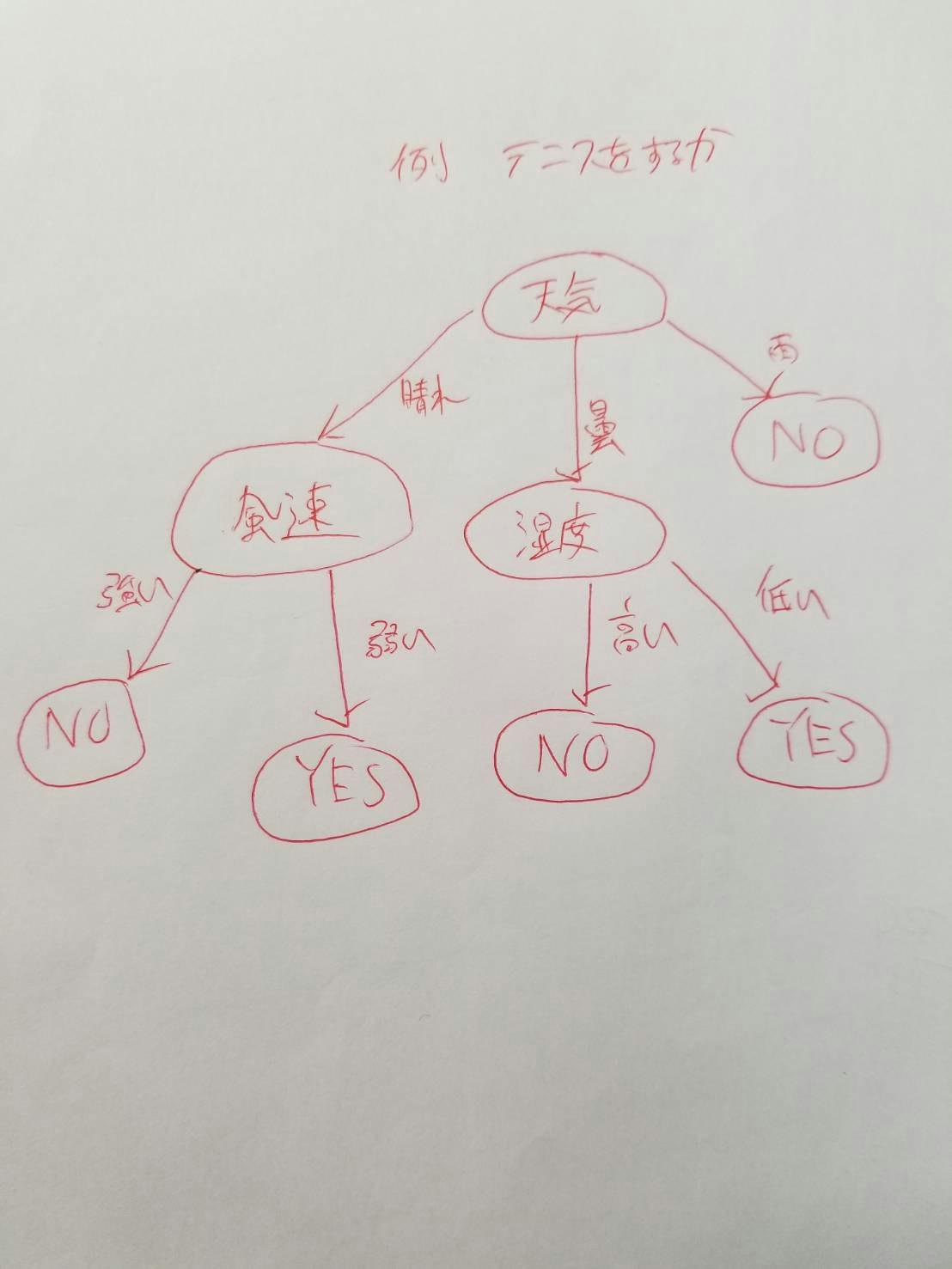
これだと分かりづらいので実際に図にして表すとこんな感じです。
これはテニスをするかどうかを判定する決定木の分類です。このように日常の意思決定も決定木で表すことができます。
決定木の深さについて
決定木には深さという深さというものがあってテニスをするかどうかの例だとさらに天気→湿度というのが決定木の深さに該当します。ここに対して湿度が低いだけではなく、「湿気が多いというのは前日に雨が降ったのかも、コートの状態が今どうなのか」というケースに対して、「前日の天気は?」という様な質問をすることによってより厳密に出来ます。しかし、上記のような手法でどんどん分類規則を追加していくと、最終的には大量のノードが存在し、とても深い決定木が出来上がってしまいます。これは訓練データに対する過学習(過剰適合も適切)を示し、高バリアンス(予測値のばらつきの大きさ)なモデルが出来上がっているというわけです。
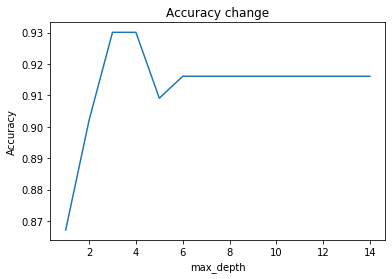
max_depth(決定木の深さ)とAccuracyの関係
max_depthが3~4の時、Accuracyは最大となるが、max_depthが4以降はAccuracyが低下していく。これは、max_depthを大きくしすぎたことによる過学習が起きているためである。この様に決定木は適切な木の深さになる様に剪定(木を切ること)をしなければなりません。剪定することによってモデルの汎化性能を上げる事ができます。なお、プログラム上、Accuracyが最大となるmax_depthは3の時である。
データについての説明
乳がんの診断データがまとめられたデータセットです。各ケースは検査値を含む32の値を持っており、変数の多いデータセットになっています。各ケースには、良性腫瘍か悪性腫瘍の診断結果が付いており、これを目的変数とする分類学習になります。
コード
%%time import matplotlib.pyplot as plt from sklearn.datasets import load_breast_cancer from sklearn.tree import DecisionTreeClassifier from sklearn import tree from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score #乳癌データの読み込み cancer_data = load_breast_cancer() #トレーニングデータ、テストデータの分離 train_X, test_X, train_y, test_y = train_test_split(cancer_data.data, cancer_data.target, random_state=0) #条件設定 max_score = 0 accuracy = [] depth_list = [i for i in range(1, 15)] #決定木の実行 for depth in tqdm(depth_list): clf = DecisionTreeClassifier(criterion="entropy", splitter="random", max_depth=depth, min_samples_split=4, min_samples_leaf=1, random_state=56) clf.fit(train_X, train_y) accuracy.append(clf.score(test_X, test_y)) if max_score < clf.score(test_X, test_y): max_score = clf.score(test_X, test_y) depth_ = depth #決定木をdotファイルに変換 clf = DecisionTreeClassifier(criterion="entropy", splitter="random", max_depth=depth_, min_samples_split=4, min_samples_leaf=1, random_state=56) clf.fit(train_X, train_y) tree.export_graphviz(clf, out_file="tree.dot", feature_names=cancer_data.feature_names, class_names=cancer_data.target_names, filled=True) #グラフのプロット plt.plot(depth_list, accuracy) plt.title("Accuracy change") plt.xlabel("max_depth") plt.ylabel("Accuracy") plt.show() print("max_depth:{}".format(depth_)) print("ベストスコア:{}".format(max_score))出力
max_depth:3 ベストスコア:0.9300699300699301 CPU times: user 228 ms, sys: 6.02 ms, total: 234 ms Wall time: 237 msまとめ
決定木は機械学習の中でもかなり理解しやすいアルゴリズムだと思うので、機械学習がわからない人などに説明するときに使いやすいのかなと思いました。
- 投稿日:2020-02-06T19:03:14+09:00
Django3.0の開発環境をDocker,Docker-compose,Poetryで作ってみた
はじめに
Dockerとdocker-composeを使ってDjangoの開発環境を作成します。
他の人が書いた記事にすでにDockerで開発環境をつくる記事はありますが、ライブラリ管理にrequirements.txtを使用しているものも多くあり、現在のパッケージ管理はPipenvやPoetryを使うのが主流となってきている流れもあると思うのでDockerを使った開発でも一目で依存関係がわかるPoetryを使ったほうが良いなと思い記事にしてみました。
また個人的に開発環境にてDockerコマンドでコンテナを起動するのが好きでない(docker-composeのほうが楽)なのでdocker-composeでコンテナを起動する方法を書いてます。
目次
前提
基本的なdockerコマンドとpoetryのコマンドがわかる。
Dockerはインストール済み
docker-composeもインストール済みインストール方法は他の方が書いた記事が沢山あるので割愛します。
動作環境
- MacOS Catalina 10.15.2
- Docker 19.03.5, build 633a0ea
- docker-compose version 1.25.4, build 8d51620a
- docker-image python:3.8
- Python 3.8.1
- Django 3.0.3
Dockerfileの作成
空のDockerfile作成
$ touch DockerfileDocker Hub公式のPythonイメージを使用します。Dockerfileを以下のように記述します。
alpineだとビルド時間がかかるので通常のubuntuベースを使用します。
※以下は例なので適宜編集してくださいFROM python:3.8 WORKDIR /app ENV PYTHONPATH /app ENV LC_ALL=C.UTF-8 LANG=C.UTF-8 RUN apt-get update && apt-get install -y --no-install-recommends \ git \ vim \ && rm -rf /var/lib/apt/lists/* # pipのアップデート RUN pip install --upgrade pip setuptools wheel # Poetryをインストール RUN pip install poetry # コンテナ内で仮想環境の作成を無効 RUN poetry config virtualenvs.create false RUN poetry config virtualenvs.in-project true CMD ["bash"]Poetryのデフォルト設定だとインストール時に仮想環境を作成しようとするので
poetry config virtualenvs.create false
poetry config virtualenvs.in-project true
で無効にしましょう。作成したDockerfileをビルドします。今回は「django」という名前のイメージを作成します。
$ docker build -t django .$ docker run -itd --name django-setting djangoコンテナの中に入り必要なライブラリのインストールと新規Djangoプロジェクトを作成します。
# django-settingコンテナに入る $ docker exec -it django-setting bash # Poetryがインストールされているか確認 <コンテナ>:/app# pip list | grep poetry poetry 1.0.3 # Poetryの初期設定 <コンテナ>:/app# poetry initYesかスキップでOK
consolePackage name [app]: Version [0.1.0]: Description []: Author [None, n to skip]: n License []: Compatible Python versions [^3.8]: Would you like to define your main dependencies interactively? (yes/no) [yes] Search for package to add (or leave blank to continue): Would you like to define your dev dependencies (require-dev) interactively (yes/no) [yes] Search for package to add (or leave blank to continue): Do you confirm generation? (yes/no) [yes]pyproject.tomlが/app 配下に作られていることを確認してdjangoをインストール
<コンテナ内>:/app# ls pyproject.toml <コンテナ内>:/app# poetry add djangoDjangoプロジェクト作成
# プロジェクト名はprojectにしました。 <コンテナ内>:/app# django-admin startproject project . # 作成されていることを確認 <コンテナ内>:/app# ls manage.py poetry.lock project pyproject.tomlctrl + d でコンテナから抜けます。
作成したプロジェクトをコンテナ内からホストのsrcディレクトリへコピーします
# コンテナIDを確認 $ docker ps $ docker cp <コンテナID>:/app/ srcDockerfileを更新します。
先程コンテナからホストにコピーしたpyproject.tomlをコンテナ内にコピーする記述をして
poetry installすることでpyproject.tomlに書いたライブラリが
イメージの作成と同時にpipにインストールされます。FROM python:3.8 WORKDIR /app ENV PYTHONPATH /app ENV LC_ALL=C.UTF-8 LANG=C.UTF-8 RUN apt-get update && apt-get install -y --no-install-recommends \ git \ vim \ && rm -rf /var/lib/apt/lists/* RUN pip install --upgrade pip setuptools wheel RUN pip install poetry RUN poetry config virtualenvs.create false RUN poetry config virtualenvs.in-project true COPY src/pyproject.toml pyproject.toml #追加 RUN poetry install # 追加 CMD ["bash"]Dockerfileを書き換えたので古いコンテナを削除しておく
$ docker ps # コンテナID確認 $ docker rm -f <コンテナID> # django-settingコンテナ削除docker-compose.ymlの作成
空のdocker-compose.yml作成
$ touch docker-compose.ymlDockerfileの準備ができたのでができたのでdocker-compose.ymlの設定をしていきます。
docker-compose.ymlversion: "3" services: django: build: context: . dockerfile: Dockerfile ports: - "8000:8000" volumes: - ./src:/app command: "python3 manage.py runserver 0.0.0.0:8000" tty: true最終的なディレクトリ
. ├── Dockerfile ├── docker-compose.yml └── src ├── manage.py ├── project ├── pyproject.toml └── poetry.lockコンテナの起動
$ docker-compose build $ docker-compose upconsoleStarting django-docker_django_1 ... done Attaching to django-docker_django_1 django_1 | Watching for file changes with StatReloader django_1 | Performing system checks... django_1 | django_1 | System check identified no issues (0 silenced). django_1 | django_1 | You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. django_1 | Run 'python manage.py migrate' to apply them. django_1 | django_1 | February 06, 2020 - 09:38:45 django_1 | Django version 3.0.3, using settings 'project.settings' django_1 | Starting development server at http://0.0.0.0:8000/ django_1 | Quit the server with CONTROL-C.http://localhost:8000
にアクセスすると見えているはず!
cat pyproject.toml[tool.poetry] name = "app" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"] [tool.poetry.dependencies] python = "^3.8" django = "^3.0.3" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api"パッケージ管理できてる!
最後に
お疲れさまでした。
- 投稿日:2020-02-06T18:47:59+09:00
【初心者向け】Anacondaインストール後にやるべきこと
はじめに
- タイトルの通り、Anacondaインストール直後にやるべきことのメモです。
- 初心者向けです。とはいえ、他のプログラミング言語経験があって、機械学習とかそこそこ複雑なことがやりたい人向けです。
- 環境:
- windows 10(OS依存の話は少な目です)
- Anaconda3-2019-10
- Anacondaをインストールした直後からパッケージを追加しようとする前の話です。
- 必要な情報は基本的には別サイトで説明されていますので、まとめというかほぼ備忘録となります。
パッケージ管理ツールについて理解する
- 機械学習、webアプリ開発など、特に業務でpython使う場合には、基本的に自分で必要なパッケージを追加していくことになります。
- パッケージの追加方法について、Webの情報では、それぞれ異なるパッケージマネージャーのどれかを前提としての説明が多く、単純にコピペではなく自分で違いを理解して必要に応じて書き換える必要があります。
- ということで
conda(パッケージ管理ツールとして),pip,conda-forgeぐらいのキーワードは理解しましょうpipとpip3についても、知っておくといいかと思います。- 要するに
pipとcondaを混ぜないほうが無難ということです。仮想環境を理解して用意する
- いくら気を付けながらパッケージを追加しても、環境が壊れることは多々ありますし、特に機械学習のフレームワークとかだとパッケージのバージョンへの依存度が大きく独立した環境が欲しくなってきます。
- また初心者がいきなり仮想環境を作る必要があるかというと、仮想環境作成から入る記事・説明も多いし、何より環境構築で失敗して、Anaconda再インストールしないと、とかやる気をなくしてしまう可能性もあるので、必要だと考えています。
- ちなみに
condaは仮想環境管理ツールとしての機能も併せ持ってます。- まずはこちらのサイトなどを参照し、仮想環境について理解しましょう。
- このサイトでも説明されていますが、condaの仮想環境内でpipを使うことも可能です
- そしてパッケージだけでなく、インタプリタも含めて環境を理解できれば十分です。
- Anacondaということで
condaを使いましょう。- 仮想環境を作るのは非常に簡単です。
- Anaconda Promptを起動して
- まずは
condaの最新版を取得しますconda update -n base -c defaults conda
- 仮想環境を作ります
conda create -n myenv python=3.7
※myenvが仮想環境名で任意の文字列を設定します、python=3.7はpythonのバージョン指定です
作成されていることを確認します。
conda info -e
- 仮想環境を切り替えます
conda activate myenv
- 必要なパッケージをインストールしましょう。
- ただし、pipとcondaは混ぜないように
- 他コマンドなど理解を深めるために、下記のサイトが役に立ちます
- qiita記事:[Python]Anacondaで仮想環境を作る
- qiita記事:anaconda のコマンドリストメモ
- https://www.python.jp/install/anaconda/conda.html
- baseをクローンする方法も記述されています。
開発環境を用意する
- とりあえず迷ったらVSCodeを使いましょう、情報も多いです。Pycharmでもいいかもしれません。VSCodeが流行る前はSpider使い続けていましたがコーディングもデバッグもやり易いとは思えませんでした。
- VSCodeをインストール後、pyファイルを開くと、Extensionの候補を通知してくれて流れに乗るように進んでいくと、「Python extension for Visual Studio Code」がインストールされて、大体のことはできるようになります。
- 左下のbase:condaをクリックすれば、仮想環境切り替えれます。
- F5でデバッグ実行できます
- 実行はできるのですが、ここでTerminal上では下記のエラーが表示されて鬱陶しいです。ここはWindowsだけしか発生しないと思います。
- エラー内容
- conda : 用語 'conda' は、コマンドレット、関数、スクリプト ファイル、または操作可能なプログラムの名前として認識されません。名前が正しく 記述されていることを確認し、パスが含まれている場合はそのパスが正しいことを確認してから、再試行してください。
- 解決方法:
- 環境変数へのパスを通しましょう
- C:\USers***\Anaconda3
- C:\Users***\Anaconda3\Scripts
- パスを通したとしても、違うエラーが表示されます。
- CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'.
- TerminalをPowershellではなくcmd32にします。設定ファイルを変更します。settings.jsonに下記追記します
"terminal.integrated.shell.windows": "C:\\Windows\\System32\\cmd.exe",
- 以上でエラーが表示されなくなります。
まとめ
- パッケージ管理ツールと仮想環境を理解しましょう。
- 開発環境は無難に行くならVSCodeを使いましょう。
- 投稿日:2020-02-06T18:31:46+09:00
MobileNetV2-SSDLiteの前処理・後処理などの一部をC++共有ライブラリ化してPythonからコールする
1. Introduction
自分用の開発メモです。 RaspberryPi4のディープラーニングプログラムの前処理と後処理を部分的に高速化するために Python から C++ の共有ライブラリをコールする方法を学んだ結果を書き留めます。 今回は
boost_python3というライブラリを使用してPython実行用の共有ライブラリを作成します。 ヘッダファイルのインクルードと共有ライブラリ間の依存関係を調べるために少しだけ時間を要しますが、対象が分かってしまえばものすごく簡単に実施できました。2. Environment
- RaspberryPi4 Ubuntu 19.10 aarch64 (eoan)
- 作業用PC Ubuntu 18.04 x86_64 (bionic)
- OpenCV 4.2.0 (self-build)
- libboost-python-dev 1.67.0.2
3. Procedure
3-1. Tutorial implementation
環境の下準備
Install_boost-python$ sudo apt-get update $ sudo apt-get install libboost-all-dev python3-dev味見プログラムの作成
$ nano CModule.cppCModule.cpp#include <boost/python.hpp> std::string hello() { return "hello world"; } BOOST_PYTHON_MODULE(CModule) { using namespace boost::python; def("hello", &hello); }味見プログラムのコンパイル
compile$ g++ -I/usr/include/aarch64-linux-gnu/python3.7m \ -I/usr/include/python3.7m \ -DPIC \ -shared \ -fPIC \ -o CModule.so \ CModule.cpp \ -lboost_python3Pythonから味見用共有ライブラリ(CModule.so)の呼び出しテスト
test$ python3 >>> import CModule >>> CModule.hello() 'hello world'3-2. Pre-processing test implementation and operation verification
前処理用のプログラムをC++で簡易実装
Edit$ nano preprocessing.cpppreprocessing.cpp#include <string> #include <stdio.h> #include <boost/python.hpp> #include <opencv2/opencv.hpp> void resize_and_normalize(std::string image_file, int width, int height) { cv::Mat image = cv::imread(image_file, 1), prepimage; cv::resize(image, prepimage, cv::Size(width, height)); cv::imshow("InputImage", prepimage); cv::waitKey(0); } BOOST_PYTHON_MODULE(preprocessing) { using namespace boost::python; def("resize_and_normalize", &resize_and_normalize); }作成した前処理用プログラムをコンパイル
共有ライブラリ(.so) が生成されるcompile_ubuntu1910_aarch64$ g++ -I/usr/include/aarch64-linux-gnu/python3.7m \ -I/usr/include/python3.7m \ -I/usr/local/include/opencv4 \ -DPIC \ -shared \ -fPIC \ -o preprocessing.so \ preprocessing.cpp \ -lboost_python3 \ -L/usr/local/lib \ -lopencv_core \ -lopencv_imgcodecs \ -lopencv_highguicompile_ubuntu1804_x86_64$ g++ -I/usr/include/x86_64-linux-gnu/python3.6m/ \ -I/usr/include/python3.6m \ -I/opt/intel/openvino_2019.3.376/opencv/include \ -DPIC \ -shared \ -fPIC \ -o preprocessing.so \ preprocessing.cpp \ -lboost_python3 \ -L/opt/intel/openvino_2019.3.376/opencv/lib \ -lopencv_core \ -lopencv_imgcodecs \ -lopencv_highgui
テスト用Pythonプログラムの作成
Edit$ nano test.pytest.pyimport preprocessing preprocessing.resize_and_normalize("dog.jpg", 300, 300)Execution$ python3 test.py
4. Reference articles
- ubuntuでC++をpython3に公開する - Qiita - mink0212さん
- C++ で Python 用ライブラリーを作成する
- Python Tips:ライブラリ・モジュールの場所を調べたい
- Linux共有ライブラリの簡単なまとめ
- https://stackoverflow.com/questions/51308292/swig-linker-undefined-symbol-zn2cv8fastfreeepv-cvfastfreevoid
- cv::Matの基本処理
- CV_Assert, CV_DbgAssert, CV_StaticAssert
- 画像処理で2重ループをなるべく書くな - Qiita - nonbiri15さん
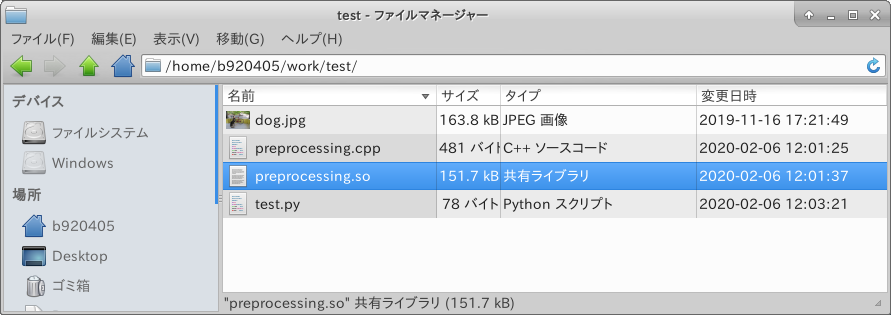

- 投稿日:2020-02-06T18:19:57+09:00
[Python 入門] pandasを使ってみよう
[Python 入門] pandasを使ってみよう
第3回になります。今回は題材の日経平均らしいことをやっていきます。
まずいつもどおりcsvデータを読み込んでおきます。import pandas as pd %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns from sklearn import datasets plt.style.use('ggplot') #おまじない font = {'family' : 'meiryo'} nikkei = pd.read_csv("nikkei.csv", parse_dates=['データ日付']) #csvデータを読み込む nikkei.head() #概要を見てみる日時収益変動率とヒストグラム
最初に日時収益変動率を計算して、図に表してみます。
nikkei['Day. Change P'] = (nikkei['終値'] - nikkei['始値']) / nikkei['始値'] #日時収益変動率を計算する plt.figure(figsize=(22, 8)) plt.hist(nikkei['Day. Change P'], bins = 100)
こんな感じになります。だいたい正規分布に近くなりましたね。日経平均の変動があまりない日が多い、といった感じですかね。分析等は各自の判断でしてみてください。ここではあくまでこんな風にできたよ、ということで...
ロウソクチャートを描画する
では次はロウソクチャートを書く方法です。案外簡単にいけました。ちょうどいいものがあるんですね。
import plotly.graph_objs as go from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot #Create OHLC (open-high-low-close) charts trace = go.Ohlc(x = nikkei['データ日付'], open = nikkei['始値'], high = nikkei['高値'], low = nikkei['安値'], close = nikkei['終値']) data = [trace] iplot(data)
移動平均を描画する
最後に移動平均を計算してプロットしてみましょう。
nikkei['5dayma'] = nikkei['終値'].rolling(window = 5).mean() nikkei['25dayma'] = nikkei['終値'].rolling(window = 25).mean() nikkei['50dayma'] = nikkei['終値'].rolling(window = 50).mean() nikkei.tail()上のように計算させてデータフレイムに追加しておきます。ここで.head()では1~4日目まではNaNの表示で5日目になって初めて'5dayma'が計算されるといったようにちゃんと計算できているのか確認しづらいため、.tail()を使っています。
trace_close = go.Scatter(x = nikkei['データ日付'][-200:], y = nikkei['終値'][-200:], name = "close", line = dict(color = '#000000'), #黒色の線にする opacity = 0.8) trace_5day = go.Scatter(x = nikkei['データ日付'][-200:], y = nikkei['5dayma'][-200:], name = "5day", opacity = 0.8) trace_25day = go.Scatter(x = nikkei['データ日付'][-200:], y = nikkei['25dayma'][-200:], name = "25day", opacity = 0.8) trace_50day = go.Scatter(x = nikkei['データ日付'][-200:], y = nikkei['50dayma'][-200:], name = "50day", opacity = 0.8) data = [trace_close, trace_5day, trace_25day, trace_50day] layout = dict(title = "Moving averages:5, 25, 50 for 200days", ) fig = dict(data = data, layout=layout) iplot(fig)
こんな感じになりました。注意としては各軸の設定に当たり、"[-200:]"とスライスして200日分を表示してます。見栄えを重視しただけですのでしなくてもOKです。その場合は全期間となります。おわりに
前回のヒートマップと比べ、今回はまともなものができました。まだ大したことはしていませんが、もう少しこの日経平均という題材で遊べたらいいなと考えています。
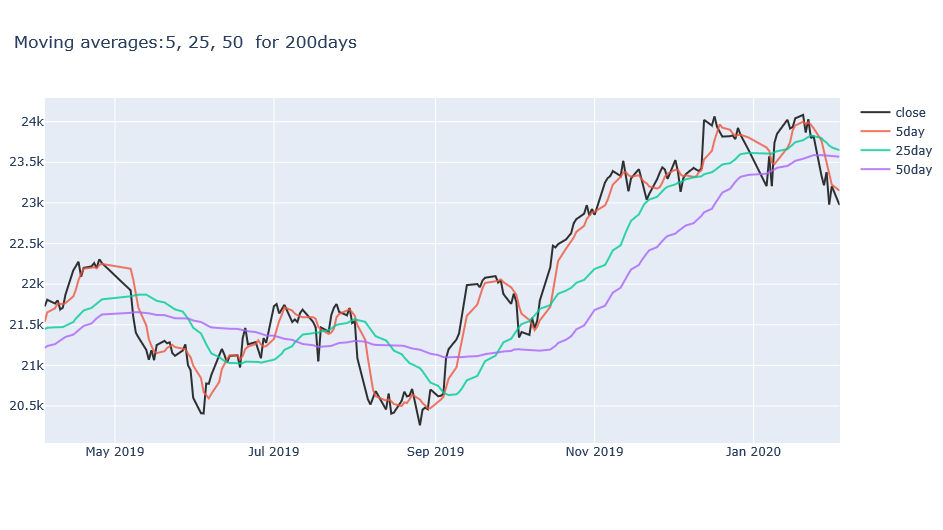
- 投稿日:2020-02-06T18:03:02+09:00
Python Kivyを1つのファイル内に収めるサンプル
#-*- coding: utf-8 -*- from kivy.lang import Builder Builder.load_string(""" <TextWidget>: BoxLayout: orientation: 'vertical' size: root.size TextInput: text: root.text Button: id: button1 text: "OK" font_size: 48 on_press: root.buttonClicked() """) from kivy.app import App from kivy.uix.widget import Widget from kivy.properties import StringProperty class TextWidget(Widget): text = StringProperty() def __init__(self, **kwargs): super(TextWidget, self).__init__(**kwargs) self.text = '' def buttonClicked(self): for i in range(5): self.text += str(i) + '\n' class TestApp(App): def __init__(self, **kwargs): super(TestApp, self).__init__(**kwargs) self.title = 'greeting' def build(self): return TextWidget() if __name__ == '__main__': TestApp().run()コードはほとんど以下の記事で書かれているものの引用です。
https://qiita.com/dario_okazaki/items/7892b24fcfa787fafacekvファイルとpythonファイルを1つにまとめるのどうやるんだっけっと
毎回ググるのがダルくなってきたので自分用にメモ
- 投稿日:2020-02-06T16:36:49+09:00
QuantX~RSI&ボリンジャーバンド編~
内容
今回はRSIとボリンジャーバンドを使ったアルゴリズムを紹介します。
自己紹介
某理工学部に通う大学2年のfalcon_xです.
大学ではC言語を少しやっているぐらいで、Pythonはほぼ初心者です、、、
Smart Trade社でインターンを始め, QuantX Factoryを使ってアルゴリズムを開発してます。What is Smart Trade?
Smart Trade 会社URL:https://smarttrade.co.jp/
ホームページを開くと、こんなページが出てきます。
Smart Tradeとは、株式の売買タイミングを判断する投資アルゴリズムのプラットフォーム企業です。特別なお金持ちではなくても金融サービスを楽しめる、金融の民主化を実現するために、アルゴリズム開発プラットフォームQuantX Factoryやアルゴリズム売買プラットフォームQuantX Storeを提供する会社です。
QuantX Factoryではエンジニアを対象に、アルゴリズム開発環境を無償で公開しています。自分が作りたいアルゴリズムをPythonという言語を使ってWeb上で開発することができ、過去の株価の変動を用いて損益等々のバックテストが行えるというものです。またここで開発したアルゴリズムをQuantX Storeで販売でき、投資家はアルゴリズムを購入することができます。QuantX Factory URL:https://factory.quantx.io/
QuantX Store URL:https://quantx.io/storeまたSmart Trade社では、毎週QuantXのアルゴリズムの勉強会をしています。興味のある方はぜひお越しください。
Pythonアルゴリズム勉強会:https://python-algo.connpass.com/
RSIとボリンジャーバンドを使ったアルゴリズム
RSIとボリンジャーバンドについては下記のサイトがわかりやすいので、詳しく知っりたい方は下記のサイトを参考までにご覧ください!
RSI:https://info.monex.co.jp/technical-analysis/indicators/005.html
ボリンジャーバンド:https://www.jibunbank.co.jp/products/foreign_deposit/chart/help/bollinger_band/さて、本題に参ります。
今回の買い、売りのサインは以下のように出します。買いシグナル
RSIが40未満で+2σ線を終値が下回ったとき。売りシグナル
RSIが70を上回り、-2σを終値が下回ったとき。コード
公開コードは以下のリンクになります。
https://factory.quantx.io/developer/f5eec92829294c279499e42894575a18/coding# ライブラリーのimport # 必要ライブラリー import maron import maron.signalfunc as sf import maron.execfunc as ef import pandas as pd import numpy as np import talib as ta ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー # 銘柄、columnsの取得 def initialize(ctx): # 設定 ctx.logger.debug("initialize() called") ctx.configure( channels={ # 銘柄選択 "jp.stock": { "symbols": [ "jp.stock.3382", "jp.stock.4063", "jp.stock.4452", "jp.stock.4502", "jp.stock.4503", "jp.stock.4568", "jp.stock.6094", "jp.stock.6501", "jp.stock.6758", "jp.stock.6861", "jp.stock.6954", "jp.stock.6981", "jp.stock.7203", "jp.stock.7267", "jp.stock.7751", "jp.stock.7974", "jp.stock.8031", "jp.stock.8058", "jp.stock.8306", "jp.stock.8316", "jp.stock.8411", "jp.stock.8766", "jp.stock.8802", "jp.stock.9020", "jp.stock.9022", "jp.stock.9432", "jp.stock.9433", "jp.stock.9437", "jp.stock.9984", ], "columns": [ "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) "volume_adj", # 出来高 "txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): cp = data["close_price_adj"].fillna(method='ffill') # 終値の取得 #75日移動平均線の設定 m75 = data["close_price_adj"].fillna(method='ffill').rolling(window=75, center=False).mean() #rsiの空の入れ物を用意 rsi_S = pd.DataFrame(data=0,columns=[], index=cp.index) #rsi計算 for (sym,val) in cp.items(): rsi_S[sym] = ta.RSI(cp[sym], timeperiod=26) #ボリンジャーバンドの空の入れ物を用意 upperband = pd.DataFrame(data=0,columns=[], index=cp.index) lowerband = pd.DataFrame(data=0,columns=[], index=cp.index) middleband = pd.DataFrame(data=0,columns=[], index=cp.index) #ボリンジャーバンドの計算 for (sym,val) in cp.items(): upperband[sym], middleband[sym], lowerband[sym] = ta.BBANDS(cp[sym], timeperiod=21, nbdevup=2, nbdevdn=2, matype=0) # 売買シグナルを定義 buy_sig = (rsi_S < 40) & (cp < lowerband) sell_sig = (rsi_S > 70) & (cp > upperband) # market_sigという全て0が格納されているデータフレームを作成 market_sig = pd.DataFrame(data=0.0, columns=cp.columns, index=cp.index) # buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 # ctx.logger.debug(market_sig) return { "mavg_75:price": m75, "rsi_S:g2": rsi_S, "uband": upperband, "mband": middleband, "lband": lowerband, "market:sig": market_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' market_sig = current["market:sig"] done_syms = set([]) # 損切り、利確の設定 for (sym, val) in ctx.portfolio.positions.items(): returns = val["returns"] if returns < -0.05: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) done_syms.add(sym) elif returns > 0.05: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) done_syms.add(sym) # 買いシグナル buy = market_sig[market_sig > 0.0] for (sym, val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1 ,orderType=ot, comment="SIGNAL BUY") # ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass # 売りシグナル sell = market_sig[market_sig < 0.0] for (sym, val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val)) pass結果↓
α値が低いのが気になりますね、、、
コード解説
勉強会用に作成した資料が下記のリンク先にあるので、基本的な解説はここでは省略。
今回のコードの重要なところだけ説明していきます。
RSIの計算rsi_S = pd.DataFrame(data=0,columns=[], index=cp.index) #rsi計算 for (sym,val) in cp.items(): rsi_S[sym] = ta.RSI(cp[sym], timeperiod=26)はじめの行は空のデータフレーム設定。
for以下はRSIの計算になっていて、timeperiodには計算に用いる期間の設定。ボリンジャーバンドの計算
#ボリンジャーバンドの空の入れ物を用意 upperband = pd.DataFrame(data=0,columns=[], index=cp.index) lowerband = pd.DataFrame(data=0,columns=[], index=cp.index) middleband = pd.DataFrame(data=0,columns=[], index=cp.index) #ボリンジャーバンドの計算 for (sym,val) in cp.items(): upperband[sym], middleband[sym], lowerband[sym] = ta.BBANDS(cp[sym], timeperiod=21, nbdevup=2, nbdevdn=2, matype=0)上3行は空のデータフレーム設定。
for以下はボリンジャーバンドの計算。
timeperiodは期間、nbdevup、nbdevdnはの値はσ線の値(今回の場合は+2σ, -2σ)。売買シグナル
# 売買シグナルを定義 buy_sig = (rsi_S < 40) & (cp < lowerband) sell_sig = (rsi_S > 70) & (cp > upperband)買いシグナル:
RSIを用いて、売られすぎを判断&ボリンジャーバンドの-2σを株価が下回っている状態売りシグナル:
RSIを用いて、買われすぎを判断&ボリンジャーバンドの+2σを株価が下回っている状態今回はここらへんで。
免責注意事項
本コードを用いた実際のトレードで生じる損害は一切保証しかねますので、ご注意ください。

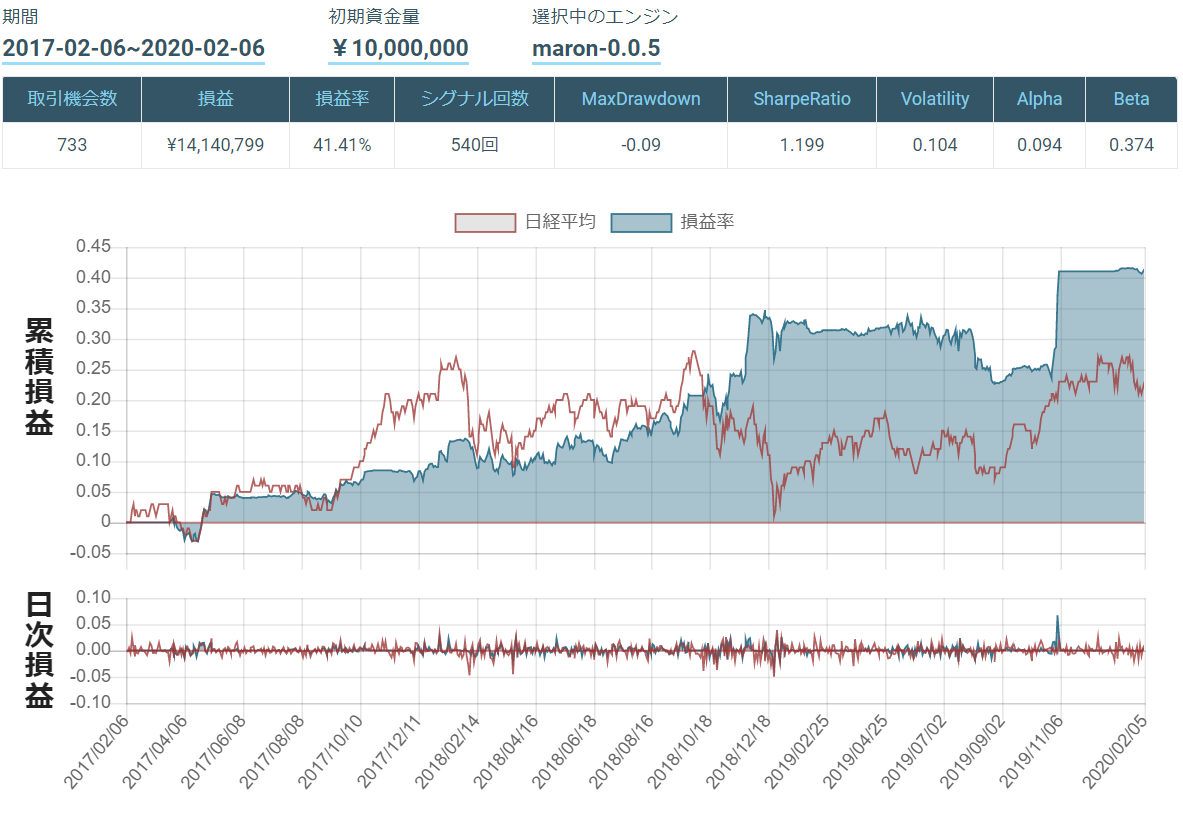
- 投稿日:2020-02-06T16:28:48+09:00
Pythonでpdfを画像(JPEG/PNG)化
PDFの全ページを1枚ずつPNG画像にして
outputフォルダ(作成済み)に入れたい。sample.pyfrom pdf2image import convert_from_path convert_from_path( 'sample.pdf', #入力PDF dpi=300, #解像度 output_folder='output', #出力フォルダ output_file='out', #出力ファイルprefix fmt='png' #フォーマット )これで
outputフォルダにout0001-01.png...out0001-16.pngのようなファイルができる。メモ
grayscale=True指定でグレースケールにもできるsize=400指定すると、縦横比を保ったまま長いほうの辺を400ピクセルにしてくれる- PNG出力は結構時間がかかる。JPEGなら速い。
- SSDを使ってる場合は
output_folder指定により高速化を期待できる
- 投稿日:2020-02-06T16:28:48+09:00
PythonでPDFを画像(JPEG/PNG)化
PDFの全ページを1枚ずつPNG画像にして
outputフォルダ(作成済み)に入れたい。sample.pyfrom pdf2image import convert_from_path convert_from_path( 'sample.pdf', #入力PDF dpi=300, #解像度 output_folder='output', #出力フォルダ output_file='out', #出力ファイルprefix fmt='png' #フォーマット )これで
outputフォルダにout0001-01.png...out0001-16.pngのようなファイルができる。メモ
grayscale=True指定でグレースケールにもできるsize=400指定すると、縦横比を保ったまま長いほうの辺を400ピクセルにしてくれる- PNG出力は結構時間がかかる。JPEGなら速い。
- SSDを使ってる場合は
output_folder指定により高速化を期待できる
- 投稿日:2020-02-06T16:22:21+09:00
シンプルなAPIをPythonで構築する
はじめに
この記事は前回の続きです。前回の記事はAPIの概念的な部分を説明しています。今回は実際にPython, Djangoを用いてAPIを構築していきたいと思います。今回作るAPIはデータを(ブラウザ上から)送るとデータベースに保存し、任意のエンドポイントに移動するとデータベース内のデータを表示するというシンプルなものとしました。またDjango Rest Frameworkを使わずにAPIを構築します。理由としては、あえてDjangoの用意するフレームワークを使わずにPythonコードで構築することで、APIの動きが見やすいかなと考えたためです。
対象者
Pythonの基本的な文法は知っている方、Djangoの基本的な仕組みを知っている方。(Djangoのインストール、導入部分はかなり省いています。)
初期設定
APIを実際に作っていく上でまず重要になるのは、どのようなデータを扱うのかの部分です。APIに向けてデータを送ればデータベースに勝手に保存されるという訳ではなく、APIはmodels.pyで設計されたデータのモデルを元にデータを保存します。なのでまずはどのようなデータを扱うのかの部分をモデルに設定します。
models.pyfrom django.db import models class Post(models.Model): title = models.CharField(max_length=100) description = models.TextField() timestamp = models.DateField(auto_now_add=True) def __str__(self): return self.title今回はブログのデータをAPIで扱うことを仮定したモデルを設計しました。タイトルがあり、記事の内容、投稿日時があるデータです。モデルが書けたらmigrateまでやっておきましょう。次にadmin.pyにPostを登録し、adminページからテストデータを幾つか入れます。下の図のように適当な値を項目ごとに入れて保存します。
任意のエンドポイントでデータを表示させる
それではadminページから保存したデータを任意のエンドポイント上に表示させてみしょう。まず思い出す必要があるのが、最近のAPIはリクエストを送るとJSONデータが返ってくることです。なのでviews.pyのposts関数の返り値はJsonResponseになっています。それ以外はシンプルなコードでQuerySetをJSONデータに近付けています。QuerySetをfor文で回して辞書型にして、それをリストに入れ込んでいきます。ここからはDjangoが自動でやってくれる仕事で、Pythonのリストに入った辞書型のデータはJSONデータに自動でシリアル化してくれます。
views.pyfrom .models import Post def posts(request): posts = Post.objects.all() post_list = [] for post in posts: post_dict = { 'pk': post.pk, 'title': post.title, 'description': post.description, 'timestamp': post.timestamp, } post_list.append(post_dict) return JsonResponse(post_list, safe=False) # non-dict型のデータをjsonデータに変換するには"safe=False"を記述する。任意のエンドポイントを作成。
urls.pyfrom application_name.views import posts #追加 urlpatterns = [ path('admin/', admin.site.urls), path('api/post/', posts), #追加 ]ここまで来たら、一回ローカルサーバーを立てて作成したエンドポイントに移動してみましょう。今回はプライマルキーを入れる必要はありませんでしたが、このようにテスト時に確認する際は便利ですね。ちゃんとデータの確認ができたので成功ですね!次はPOSTリクエストについてです。
POSTリクエストに対する処理を書く
Djangoを用いたAPIの役割として、models.pyに基づいた新しいデータがPOSTリクエストを通して送られてきた場合、そのデータをデータベースに保存するというものがあります。少し書いていても分かりづらいので簡潔に説明しますと、API側の役割は送られてきたデータを保存しやすい形に加工して、保存することです。そこで次は加工して、保存するコードを書いていきます。
views.py#以下のコードを追加します。if文以下はさっきのGETリクエストの処理の上に書きます。 from django.http import HttpResponse import json def posts(request): if request.method == 'POST': data = json.loads(request.body) post = Post( title=data['title'], description=data['description'], ) post.save() return HttpResponse(201) posts = Post.objects.all() # ~~ 以下略 ~~Djangoは送られてきたJSONデータに対して自動的にデシリアライズ(JSONデータを扱いやすい形に戻すこと)する機能は標準で備わっていないので、デシリアライズするコードを書いておく必要があります。Pythonで扱えるデータ形式に戻さなければデータベースに保存できないので、この機能は必要です。JSONデータを適当な変数に入れ、この変数を用いてデシリアライズ(加工)します。またDjangoはviewsから自動的にデータを保存する機能がありませんので最後にpost.saveと明示的に書きます。
実際にPOSTリクエストを送ってみる
今回はaxiosを用いてAPIに対してPOSTリクエストを送ってみたいと思います。ajaxを自身のアプリケーションにおいて実現させたい場合はJavascriptのaxiosライブラリを使うのがオススメです。まずはPOSTリクエストを送るページをtemplatesに作成します。そのページにcdnを用いてaxiosを追加していきます。
main.html<body> <p>Test Page</p> </body> <script src="https://unpkg.com/axios/dist/axios.min.js"></script> #cdnで追加 </html>viewにfunction basedで作成。ルーティングも行っておく。
views.pydef main_page(request): return render(request, 'main.html', context=None)urls.pyfrom application_name.views import main_page #追加 urlpatterns = [ path('admin/', admin.site.urls), path('', main_page), #ルートを追加する path('api/post/', posts), ]ローカルサーバーを立ててmain.htmlが表示されるURLに移動します。そこでデベロッパーツールのコンソールからAPIがちゃんと動くかどうか確かめてみましょう。POSTリクエストで送信するデータはJSONデータである必要があるため、辞書型にする。ただ引数として分かりやすくするために、変数にしておきます。
console/* async関数を作る requestを送り、responseを作る requestを送るには時間がかかるためawaitさせたい サーバーが既に立っているのでAPIのエンドポイントは相対パスで良い */ async function addPost(title, description) { const response = await axios.post('api/post/', {'title': title, 'description': description}) console.log(response) } // インスタンス化 addPost('sending from axios', 'some test messages')ただこれを実行しても403 Forbiddenのエラー文が帰ってくるはずです。このように403が帰ってくる時は、ブラウザのデベロッパーツールのNetworkで自分が送った全てのリクエストを確認することができます。下の画像の通り、送ろうとしていたペイロードの部分(データ)は確認できます。
次にResponse部分を見てみるとよく見るhtml文が並んでいます。分かりやすくブラウザでこのレスポンスを確認するために、レスポンスのhtml文をコピーして、innerHTMLで書き換えてみましょう。少し言葉では説明しづらいので下のコードを見てください。consoledocument.querySelector('body').innerHTML = `レスポンスのhtml文`これで実行するとDjango側からエラーが来ていると分かるはずです。一応エラー画面を下に貼っておきます。エラー文を見てみるとCSRF verificationが失敗していると分かります。Djangoでformを使っているならcsrf_tokenを使えと書いてありますが、今回はajaxを用いてデータを送信しているので、この方法では解決できません。Djangoにおいてajaxを行うには普段使わない方法を用います。
そもそもCSRF verificationの流れを説明しますと、フロント側が他の場所からデータにアクセスしているのではなく、同じサイトからアクセスしていることをDjango側に示し、それを受け取ったDjangoはフロント側にデータのアクセス許可を出します。これを踏まえてもう一度403 Forbiddenについて考えると、『あなたはデータを扱う権限(許可)がありません』ということを表していると分かります。
ただ先ほど述べたようにformは使わないのでcsrf_tokenは使えません。なので今回はcsrf_tokenをCookieに持たせてjavascriptのfileに貼り付けます。sample.jsaxios.defaults.xsrfCookieName = 'csrftoken' axios.defaults.xsrfHeaderName = "X-CSRFTOKEN"本来は上のコードを、ajaxリクエストを送るjsファイルの一番上に貼り付けることで、axiosを用いたリクエストにデフォルトでcsrf_tokenを持ったCookieを持たせることができます。これにより先ほどのエラーを解決できるはずです。
今回Javascriptを用いてajax通信以外の機能は持たせませんので、任意の名前のjsファイルを作成し、上のコードのみ書いておきます。このファイルを下にあるようにmain.htmlで読み込み(繋ぎこみ)、デベロッパーツールのコンソールでも動くようにします。main.html<body> <p>Test Page</p> </body> <script src="https://unpkg.com/axios/dist/axios.min.js"></script> <script type="text/javascript" src="{% static 'sample.js' %}"></script> #追加 </html>先ほどのようにコンソールで引数に値を入れてインスタンス化すると、今度はエラーは出ずにステータスコード201が帰ってきています。つまり成功です!
一応'api/post/'のエンドポイントに移動して、ちゃんとPOSTしたデータが表示されているか確認してみます。
プライマリーキーが3のデータが先ほど追加したデータなので、ちゃんとGET, POSTリクエストが動いていることが分かります。
Django Rest Frameworkを使う理由
まずDjango Rest Framework(DRF)を使うとデータの加工や今回は扱っていない認証に関するコードを大幅に少なくしてくれるという理由が一番かと思います。ただ次に挙げられる理由として私は、PUT、PATCH、DELETEなどのHTTP Verbが使えるようになることだと思います。通常、Djangoはこれらを無視するので使いたいと思っても使えません。DRFは他のリクエストも簡単に扱ってくれるので、APIとしての機能を最大限活かせるようになります。他にも沢山理由があると思いますが、とりあえずこの二つが大きな理由と考えます。
最後に
記事の内容はいかがでしたでしょうか。自分の備忘録としての役割もあり、かなり長いものになってしまったので最後まで読んでくれた方はありがとうございました。間違い、誤字などございましたら、お気軽に指摘していただけると助かります。次回は外部のAPIを用いて簡易的なアプリケーションを作成していきたいと思ってます。

- 投稿日:2020-02-06T16:20:04+09:00
Softmax関数をベースにした Deep Metric Learning が上手くいく理由
はじめに
Deep Learningを使った距離学習(Metric Learning)では、Contrastive LossやTriplet Lossなどを用いて、画像間の類似性(や非類似性)を直接学習していく方法が広く利用されていますが、学習データの組み合わせや選び方が難しく、学習自体が難航するケースが多い事も知られています。それだけに、これまで様々な改良と工夫が提案されています。
しかし、最近はこのような学習データ選びに難航することなく、一般的なクラス分類タスクの感覚で、Softmax関数をベースに学習できるMetric Learningが注目を浴びています。ArcFaceなどはその代表的手法でこちらで詳しく説明されています。
Softmax関数をベースにしたMetric Learningがうまくいく理由、またさらなる改良の余地はあるのか?これらに関して少し紹介しようと思います。Center Loss
クラス分類にMetric Learningの要素を取り入れた元祖といえばCenter Loss1ではないでしょうか。Center Lossに関しては、こちらで詳細に説明されていたので、ざっと要点のみを紹介します。
Center Lossでは、各特徴ベクトルと対応するクラス中心との距離にペナルティを設けることで、クラス分類と特徴空間上のクラス中心位置を同時に学習します。これによりクラス内変動は小さくなるため、より効果的にクラス分離する方法としてECCV2016で発表されました。本論文では、CNNの最終層の1つ手前のFC層を2次元に改良し、その値をそのまま2次元平面にプロットする事で特徴量の可視化を行っています。下図はMNISTに対して通常のSoftmax関数でクラス分類した際の中間特徴量を可視化したものです。
損失関数は、通常のSoftmax Cross Entropy Lossに、各特徴ベクトルとそのクラスの中心ベクトルとの距離を表すCenter Lossの項を加えたものになります。
クラスの中心$C_{y_i}$を都度正確に計算するのは計算量的に現実的ではないため、ミニバッチ毎に以下の計算を行い、クラス中心$C_{y_i}$を逐次更新していきます。
以下はクラス中心の具体的な更新例です。ミニバッチ内でクラスAに属するデータが$A1$、$A2$、$A3$の3つの場合、クラスAの中心位置$C_A$は下図のように更新されます。
最後に Center Lossの結果を可視化した図を載せておきます。ハイパーパラメータ$\lambda$の値を大きくする事で、クラス内変動も小さくなることが分かります。
Sphereface
Softmax関数を使って学習した場合の特徴空間には固有の角度分布がある事を見出し、Center Lossのようなユークリッド距離によるマージンよりも、角度に基づくマージンの方が適しているという事を主張。Angular Softmax (A-Softmax) Lossを提案2し、CVPR2017で採択されました。
順に見ていきたいと思います。まず、通常のSoftmax Cross Entropy Lossは以下の通りです。
次に、これを内積の公式 $\boldsymbol{a}\cdot\boldsymbol{b}=||\boldsymbol{a}||\,||\boldsymbol{b}||\cos\theta$ を使って $\boldsymbol{W^T_j}$と$\boldsymbol{x_i}$の内積部分を書き換えます。
さらに、重みパラーメタを正規化して$||\boldsymbol{W_j}|| = 1$となるようにし、バイアス$b_j$も$0$にします。
すると、以下のようになり、これをModified Softmax Lossと定義します。
次に、この$L_{modified}$における決定境界がどうなっているのか確かめてみます。決定境界とは2つのクラスがちょうど同じ確率になる境界値を指します。クラス1の重み$W_1$と特徴量$x_i$のなす角を$\cos\theta_1$、クラス2の重み$W_2$と特徴量$x_i$のなす角を$\cos\theta_2$とすると、この2つの確率がちょうど同じになるのは以下の条件を満たす場合です。
\frac{e^{\|\boldsymbol{x_i}\|\cos\theta_1}}{\sum_{j} e^{\|\boldsymbol{x_i}\|\cos(\theta_{j,i})}} = \frac{e^{\|\boldsymbol{x_i}\|\cos\theta_2}}{\sum_{j} e^{\|\boldsymbol{x_i}\|\cos(\theta_{j,i})}} \\ \|\boldsymbol{x_i}\|\cos\theta_1 = \|\boldsymbol{x_i}\|\cos\theta_2 \\ \theta_1 = \theta_2したがって、クラス1とクラス2の確率がちょうど同じになるのは、重み$W_1$と$W_2$の角度を2等分する直線方向に$x_i$がある場合です。
この結果から、Softmax Lossによって学習された特徴量$x_i$というのは、本質的にはsoftmaxをかける直前の最後の重み$Wj$の角度に沿った分布をとっていることがわかります。
これはつまり、Softmax関数に対して、Center Lossのようにユークリッド距離ベースのマージンを組み合わせるのは親和性がよくない事を示唆しており、角度に沿ったマージンを設ける事こそが最も効果的であると示しています。Angular Softmax (A-Softmax) Loss
Angular Softmax (A-Softmax) Lossは以下のように定義されています。
$L_{modified}$に対して、自クラスの重み$W_{y_i}$とのなす角$\theta_{y_i,i}$にのみ係数$m$のペナルティを与えるため、決定境界を本来の位置よりも自クラスの重み$W_{y_i}$のに近くに寄せる効果が期待あります。
CosFaceやArcFace
Spherefaceが主張するような角度に沿ったマージンをとるやり方は、Sphereface以降にもいくつか提案されています。CosFace3やArcFace4などがそれにあたります。
詳細な内容は割愛しますが、簡単に説明すると、CosFaceからは$x_i$の正規化も行われるようになったため、2つのベクトルのなす角の$\cos\theta$がそのまま類似度として表現できるようになりました。また、$\cos\theta$の値が小さすぎてSoftmaxが機能しなくなるのを防ぐためにハイパーパラメータ$s$を導入しています。
さらにその後、ArcFaceはマージンの場所を変更しています。角度に直接マージン指定しているので、Softmaxにおける分離境界は区間全体に渡って線形かつ一定となります。Uniform Loss
SpherefaceなどのCosine Based Softmax LossにUniform Lossという新しい項を追加する事で、クラス中心を均一に分散させる等分布制約を課し、特徴空間を最大限に活用できるようにする手法が提案5されました。CVPR2019で採択されています。Uniform Lossは、特徴空間である超球面上で、クラスの中心をクラス間反発を伴う電荷のように考え、そのポテンシャルエネルギーを最小化するような働きをします。これまでの既存手法は、クラス間距離を大きくすることとクラス内変動を小さくすることを目標にしているものが多いですが、Uniform Lossではそれに加えてクラス間距離の最小値の最大化も期待できます。
Center Loss の場合は、クラス内の要素とクラス中心との間の距離を単に最小化するのみで、そもそもクラス間の関係は記述されていません。
Sphereface、Cosface、Arcface の場合は、超球面上でマージンを持った識別境界が学習されるので、結果的にクラス内変動は小さく、クラス間距離は大きくなるように学習が進みます。ただし、特徴空間の全体的な分布を明示的に制約しているものはないため、特徴空間内で局所的な配置となり、バランスが取れていない可能性があります。
Uniform Lossは、球の表面上に電荷を配置した場合、それらが均一に分布した場合にポテンシャルエネルギーが最小化されるという事実がモチベーションとなっているので、クラスの中心を電荷とみなし、その電位エネルギーを表す関数をLossとして表現します。
2つのクラス間にその距離の2乗に反比例する反発力$F$を定義します。
距離関数$d$ は、クーロンの法則をそのまま踏襲しユークリッド距離を使用します。また、反発力$F$が大きくなりすぎるのを防ぐために1を加えます。
全てのクラス中心のペアワイズのエネルギーの平均値としてUniform Lossを定式化します。
SpherefaceのLoss(Cosine Based Softmax Loss)関数の部分は以下の通りです。
この2つのLossの和が最終的なLoss関数となります。
最後に、クラスの中心の更新方法ですが、これはCenter Lossのそれと全く同じ方法で更新します。
ちなみに余談になりますが、3次元球面上にN個の点を置き、点間の球面距離の最小値が最大となるように配置した場合、その球面距離の長さはいくつになるか?という問題はTammes問題と呼ばれていて、現在でも完全な解答が見つかっていない数学上の未解決問題の一つだそうです。
P2SGrad
SenseTime ResearchとThe Chinese University of Hong Kongの共同研究として、AdaCos6とP2SGrad7という2つの論文が2019年5月7日に同じAuthorから同時に発表されました。どちらの論文もCVPR2019で採択(AdaCosの方はOral採択)されています。提案されている手法もさることながら、Sphereface、Cosface、ArcfaceなどのCosine Based Softmax Lossの本質的な違いや、勾配の最適化のプロセスに関して言及している点が特に面白いと感じました。AdaCosに関しては既にこちらで説明されていたので、P2SGradの方を詳しくみていきたいと思います。
さて、P2SGradですが、特筆すべきは、特定の損失関数を定式化せずに、モデルを最適化できる点だと思います。Metric Learningに関わらず、一般的なDeep Learningでは損失関数を定義し、損失関数が小さくなるように重みやバイアスを更新しながら学習していくというのが定石です。しかし、P2SGradでは、特徴空間の重みベクトルを更新するための最適な勾配方向と大きさを直接的に求め、それをBackpropagationしてパラメータの最適化を進めていきます。さらに、損失関数を定義しなくてよいということは、ArcFaceやCosFaceの損失関数にあった$m$や$s$といったハイパーパラメータを調整する必要もありません。
Cosine Based Softmax Loss の Backpropagation
まずは、角度マージンのない Cosine Based Softmax Lossに関する勾配を確認しておきます。
次の $f_{i,j}$は 特徴量$\vec{x_i}$のクラス$j$ に関する logits になります。f_{i,j} = s \cdot \frac{\langle \vec{x_i}, \vec{W_j} \rangle}{\|\vec{x_i}\|_2\|\vec{W_j}\|_2} = s \cdot \langle \boldsymbol{\hat{x_i}}, \boldsymbol{\hat{W_j}} \rangle = s \cdot \cos\theta_{i,j} \tag{1}$\boldsymbol{\hat{x_i}}$と$\boldsymbol{\hat{W_j}}$はそれぞれ$\vec{x_i}$と$\vec{W_j}$の正規化されたベクトルを表します。
クラス数が$C$の場合、$i$ 番目の特徴量がクラス $j$である確率$P_{i,j}$は、Softmax関数で下記のように書けます。
P_{i,j} = Softmax(f_{i,j}) = \frac{e^{f_{i,j}}}{\sum^{C}_{k=1}e^{f_{i,k}}} \tag{2}正解クラスが$y_i$の場合のCross Entropy Lossは次のようになります。
L_{CE}(\vec{x_i}) =-\log{P_{i, y_i}} = -\log{\frac{e^{f_{i,y_i}}}{\sum^{C}_{k=1}e^{f_{i,k}}}} \tag{3}この $L_{CE}(\vec{x_i})$ に対し、$\vec{x_i}$ と $\vec{W_j}$ の勾配を求めます。
\frac{\partial L_{CE}(\vec{x_i})}{\partial \vec{x_i}} = \sum_{j=1}^{C}(P_{i,j} - \mathbb{1}(y_i=j)) \nabla f(\cos\theta_{i,j}) \cdot \frac{\partial \cos\theta_{i,j}}{\partial \vec{x_i}} \tag{4}\frac{\partial L_{CE}(\vec{x_i})}{\partial \vec{W_j}} = (P_{i,j} - \mathbb{1}(y_i=j)) \nabla f(\cos\theta_{i,j}) \cdot \frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}} \tag{5}関数 $\mathbb{1}(y_i=j)$ は、$j=y_i$のとき$1$で、それ以外は$0$になります。
さらに $\frac{\partial \cos\theta_{i,j}}{\partial \vec{x_i}}$ と $\frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}}$ を計算すると、それぞれ以下のようなベクトル値になります。\frac{\partial \cos\theta_{i,j}}{\partial \vec{x_i}} = \frac{1}{\|\vec{x_i}\|_2}(\boldsymbol{\hat{W_j}} - \cos\theta_{i,j} \cdot \boldsymbol{\hat{x_i}}) \tag{6}\frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}} = \frac{1}{\|\vec{W_j}\|_2}(\boldsymbol{\hat{x_i}} - \cos\theta_{i,j} \cdot \boldsymbol{\hat{W_j}}) \tag{7}次に、$\nabla f(\cos\theta_{i,j})$の部分を計算します。$f$は logits 部分を表す関数なので、角度マージンを持たない$f(\cos\theta_{i,j})$は$s \cdot \cos\theta_{i,j}$です。したがって $\nabla f(\cos\theta_{i,j}) = s$ となります。
Cosfaceの場合は$f(\cos\theta_{i,y_i})=s \cdot (\cos\theta_{i,y_i} - m)$なので$\nabla f(\cos\theta_{i,y_i}) = s$となり、Arcfaceの場合は$f(\cos\theta_{i,y_i})=s \cdot \cos(\theta_{i,y_i} + m)$なので、$\nabla f(\cos\theta_{i,y_i}) = s \cdot \frac{\sin(\theta_{i,y_i} + m)}{\sin\theta_{i,y_i}}$となります。いずれにしても、$\nabla f(\cos\theta_{i,j})$はパラメータ$s$や$m$や$\cos\theta_{i,y_i}$によって決まるスカラー値になります。また、普通は$s>1$の値を使うので、上記は全て$\nabla f(\cos\theta_{i,j}) > 1$となります。
それでは改めて、$\frac{\partial L_{CE}(\vec{x_i})}{\partial \vec{W_j}}$を$j$によって場合分けして整理してみましょう。
$j \neq y_i$の場合
\frac{\partial L_{CE}(\vec{x_i})}{\partial \vec{W_j}} = P_{i,j} \cdot \nabla f(\cos\theta_{i,j}) \cdot \frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}} = T \cdot \frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}} \tag{8}$j = y_i$の場合
\frac{\partial L_{CE}(\vec{x_i})}{\partial \vec{W_j}} = (P_{i,j} - 1) \cdot \nabla f(\cos\theta_{i,j}) \cdot \frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}} = U \cdot \frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}} \tag{9}$P_{i,j}$はSoftmaxの値なので、取り得る値の範囲は $P_{i,j} \in [0, 1]$ です。つまり、上式の$T$および$U$はそれぞれ$T>0$と$U<0$ の範囲をとるスカラー値ということになります。
Backpropagationによって重みベクトル$\vec{W_j}$は、下記のように最適化されていきます。
\vec{W_j} \leftarrow \vec{W_j} - \eta\cdot \frac{\partial L_{CE}}{\partial \vec{W_j}} \tag{10}これらの事実にもとづいてまとめると、以下の事がわかります。
正解クラスの重みパラメータ$\vec{W_{y_i}}$は、Backpropagationによって$\vec{W_{y_i}}$に垂直な$\frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}}$ の方向に更新されていく。そしてその勾配ベクトルの長さは$(P_{i,j} - \mathbb{1}(y_i=j)) \nabla f(\cos\theta_{i,j})$である。
正解じゃないクラスの重みパラメータ$\vec{W_j}$は、Backpropagationによって$\vec{W_j}$に垂直な $-\frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}}$の方向に更新されていく。そしてその勾配ベクトルの長さは$(P_{i,j} - \mathbb{1}(y_i=j)) \nabla f(\cos\theta_{i,j})$である。
$\frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}}$は、$\vec{W_j}$に対して垂直方向なので、これは最速かつ最適でとても合理的な更新である。
Cosine Based Softmax Lossは、CosFaceやArcFaceなどいろいろあるが、更新する勾配方向は全て同じである。これらの本質的な違いは勾配の長さ部分であり、この部分がモデルの最適化に大きく影響している。
勾配の長さ
これまでみてきたように、勾配の長さは $(P_{i,j} - \mathbb{1}(y_i=j)) \cdot \nabla f(\cos\theta_{i,j})$なので、$P_{i,j}$の値が勾配の長さに大きく影響します。さらに、$P_{i,j}$は logits $f_{i,j}$と正の相関があります。そして、logits $f_{i,j}$はハイパーパラメータ$s$や$m$の影響を強く受けます。
ArcFaceの例をみていきます。$f_{i,y_i}$ は $s \cdot \cos(\theta_{i,y_i} + m)$です。ハイパーパラメータ$s$と$m$が異なると同じ$\theta_{i,y_i}$の場合でも、$P_{i,y_i}$の値が大きく変わる事がわかります。
ここであらためて考えるべきは、ArcFaceの本来の目的です。ArcFaceはクラス分類をしたいのではなく、抽出された2つのベクトル$\vec{x_1}$と$\vec{x_2}$のなす角$\theta$が近いか否かを知りたいのです。つまり、本来的には$\theta_{i,y_i}$の大きさこそが、Backpropagationにおいて重要な勾配の長さ(つまりは、$P_{i,j}$)に影響しなければならないのに、ハイパーパラメータ$s$や$m$が強く関与してしまっています。
さらに、もうひとつ。$P_{i,y_i}$の値はクラス数$C$によっても変化します。クラス数$C$の増加とともに、不正解のクラス$P_{i,j}$ に割り当てられる確率は、多かれ少なかれ小さくなっていくことが予想されます。これはClosedなクラス分類問題においては合理的です。ただし、これはOpen-Setの問題である顔認識には適していません。勾配の長さに影響を与える値として $\nabla f(\cos\theta_{i,j})$ もあります。これはCosine Based Softmax Lossの種類によって異なります。
角度マージンを持たないCosine Based Softmax Lossの場合、
\nabla f(\cos\theta_{i,j}) = s \tag{11}Cosfaceの場合、
\nabla f(\cos\theta_{i,j}) = s \tag{12}Arcfaceの場合、
\nabla f(\cos\theta_{i,j}) = s \cdot \frac{\sin(\theta_{i,j} + m)}{\sin\theta_{i,j}} \tag{13}となります。
つまり、角度マージンを持たないCosine Based Softmax Loss、および Cosfaceにおいては、$\nabla f(\cos\theta_{i,j})$で勾配の長さに与える影響は、常に一定$s$である事を示しています。しかし、Arcfaceでは、勾配の長さと$\theta_{i,j}$は負の相関関係にあり、これは完全に予想に反しています。$\theta_{i,y_i}$が徐々に減少すると、一般的には $P_{i,y_i}$の勾配を短縮する傾向がありますが、Arcfaceでは長さを伸ばす傾向があります。したがって、Arcfaceでは $\nabla f(\cos\theta_{i,j})$が勾配の長さに与える幾何学的な意味は説明されなくなります。
勾配の長さを決定するP2SGradの提案
ここからがようやく本題で、ハイパーパラメーター、クラス数、logitsのいずれにも依存せず、$\theta_{i,j}$のみによって勾配の長さを決定する新しい方法P2SGradを説明します。P2SGradは特定の損失関数を定義せずに、直接勾配を求めるため、式$(4)$と$(5)$を見直していきます。
まず、勾配方向はこれまで説明してきた通り、最も最適な方向なのでここを変更する必要はありません。次に、勾配の長さ部分である$P_{i,j}$と$\nabla f(\cos\theta_{i,j})$を考えます。$\nabla f(\cos\theta_{i,j})$に関しては、そもそもハイパーパラメータを除外したいという目的で見直しているので、ここは$1$にしてしまいます。次に、$P_{i,j}$ですが $P_{i,j}$の代わりに$\cos\theta_{i,j}$を使う事を考えます。理由は以下の3つです。
- $P_{i,j}$と$\cos\theta_{i,j}$は値の理論範囲$[0, 1]$が同じである。ただし、$\theta_{i,j} \in [0, \pi/2]$とする。
- $P_{i,j}$とは異なり、$\cos\theta_{i,j}$はハイパーパラメーターやクラス数$C$のいずれからも影響を受けることはない。
- 推論時は$\cos\theta$による類似度を元に顔認識を行う。$P_{i,j}$はClosedなクラス分類タスクにのみ適用される確率に過ぎない。
これらを考慮し、新しいP2SGradを定式化します。式$(4)$と$(5)$はそれぞれ式$(14)$と式$(15)$に置き換えられます。
\tilde{G}_{P2SGrad}(\vec{x_i}) = \sum_{j=1}^{C}(\cos\theta_{i,j} - \mathbb{1}(y_i=j)) \cdot \frac{\partial \cos\theta_{i,j}}{\partial \vec{x_i}} \tag{14}\tilde{G}_{P2SGrad}(\vec{W_j}) = (\cos\theta_{i,j} - \mathbb{1}(y_i=j)) \cdot \frac{\partial \cos\theta_{i,j}}{\partial \vec{W_j}} \tag{15}このP2SGradは簡潔ではあるがとても合理的です。$y_i = j$の場合は勾配の長さと$\theta_{i,j}$は正の相関となり、$j \neq y_i$の場合は、負の相関が成り立ちます。
最後に学習のやり方を説明します。一般的な学習はfoward処理により式$(3)$のCross Entropy Lossを求め、その後、backpropagationにより最終層から式$(4)$と式$(5)$を逆伝播し、各層の重みやバイアスパラメータの勾配を順に求めて行きます。P2SGradを使った学習では、foward処理によって得た特徴量$\vec{x_i}$から直接 式$(14)$と式$(15)$を求めます。後は通常の学習と同じ手順でそれを逆伝播し、各層の重みやバイアスパラメータの勾配を順に求めていきます。
実験
詳しい実験結果はオリジナル論文を見てもらうとして、参考までにLWFのデータセットで実験した結果を載せておきます。CNN部分はResNet-50を使い、学習のイテレーションと$\theta_{i,y_i}$の平均値の関係を示した図です。
P2SGradによる学習はその他のCosine Based Softmax Lossよりも $\theta_{i,y_i}$の減少が早い事がわかります。
Y. Wen, K Zhang, Z Li, and Y. Qiao. “A Discriminative Feature Learning Approach for Deep Face Recognition." In ECCV, 2016. ↩
W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. “Sphereface: Deep hypersphere embedding for face recognition.” In CVPR, 2017. ↩
H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu, "CosFace: Large Margin Cosine Loss for Deep Face Recognition," in Proc. of CVPR, 2018. ↩
J. Deng, J. Guo, N. Xue, and S. Zafeiriou. "ArcFace: Additive Angular Margin Loss for Deep Face Recognition," In CVPR, 2019. ↩
Y. Duan, J. Lu, and J. Zhou. "Uniformface: Learning Deep Equidistributed Representation for Face Recognition." in CVPR, 2019. ↩
X. Zhang, R. Zhao, Y. Qiao, X. Wang, and H. Li. "AdaCos: Adaptively Scaling Cosine Logits for Effectively Learning Deep Face Representations." in CVPR, 2019. ↩
X. Zhang, R. Zhao, J. Yan, M. Gao, Y. Qiao, X. Wang, and H. Li. "P2SGrad: Refined Gradients for Optimizing Deep Face Models." in CVPR, 2019. ↩
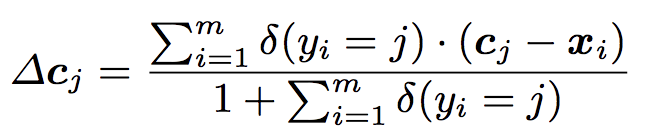
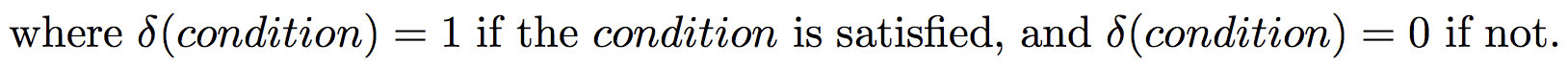
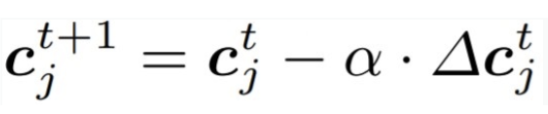
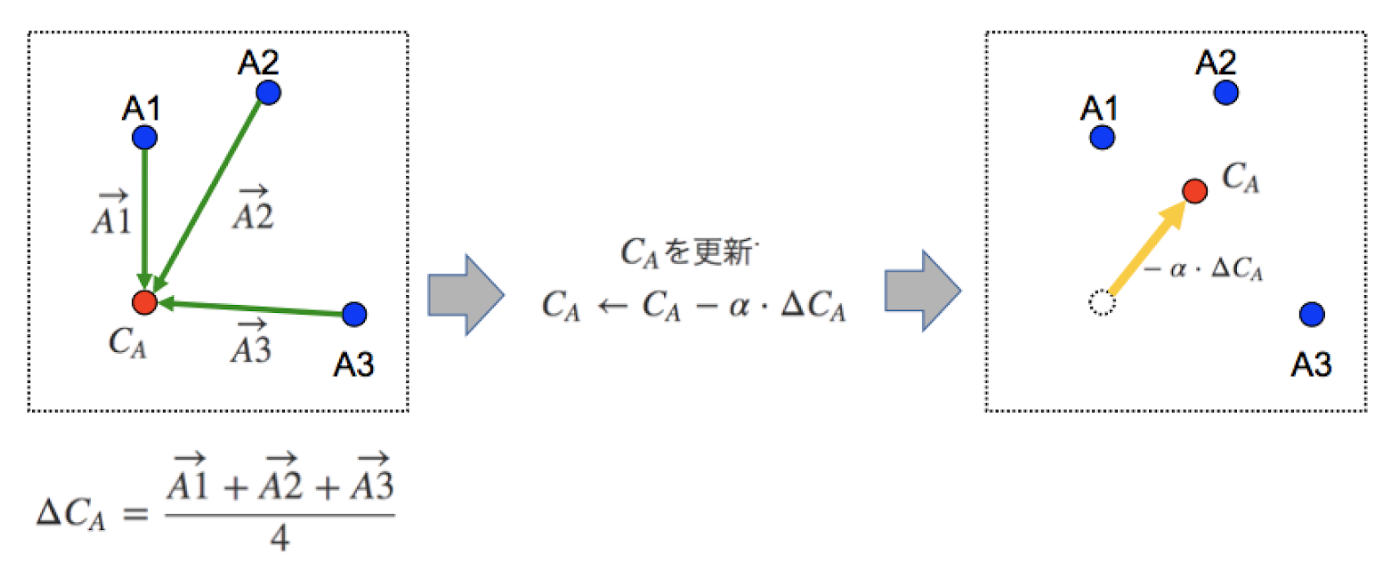
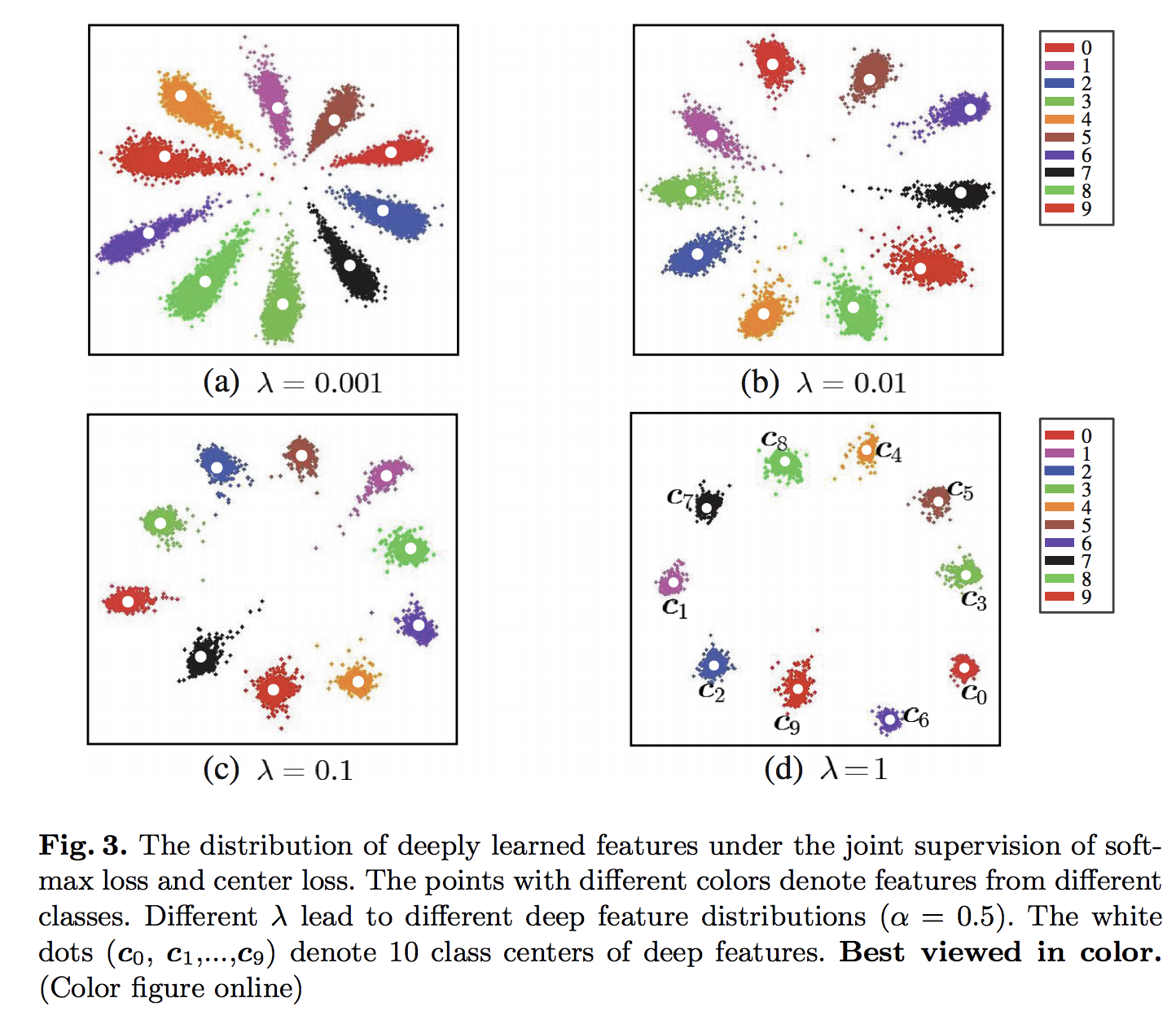
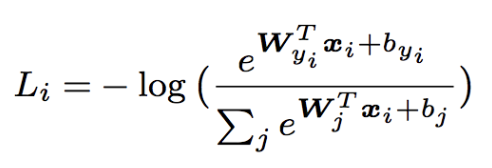
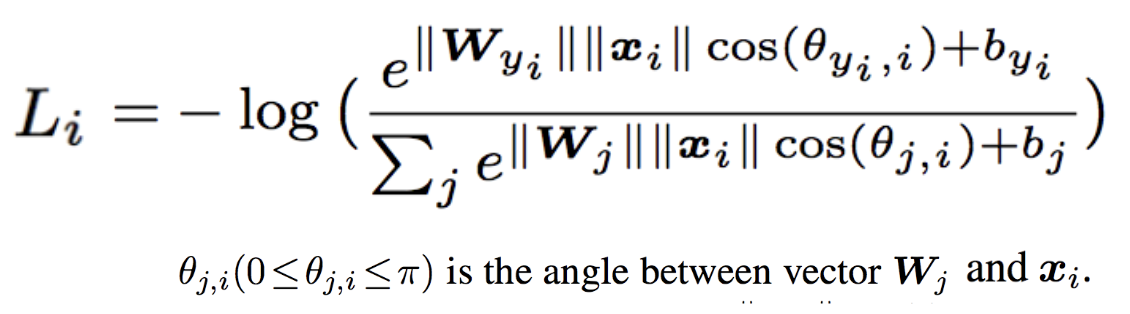
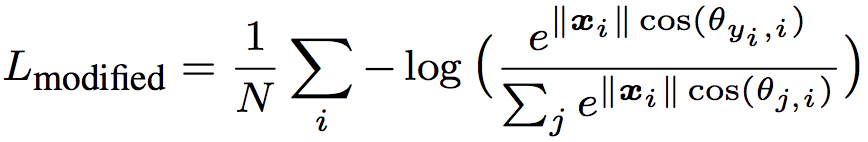

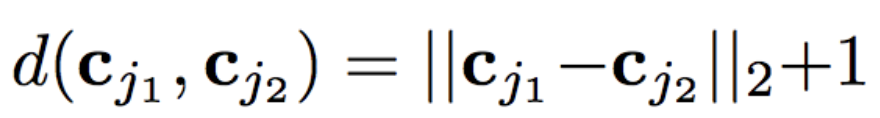
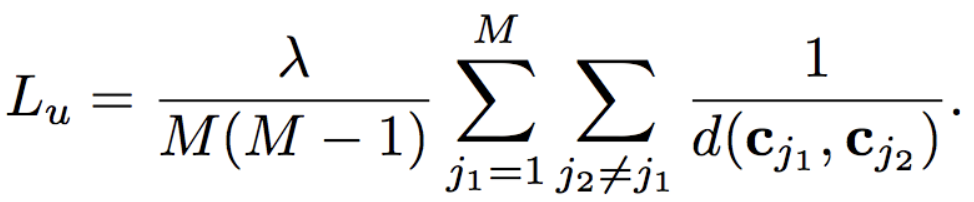
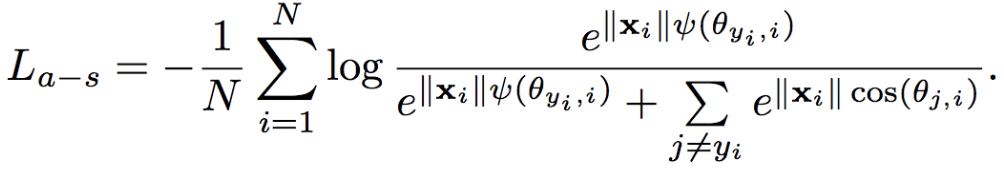
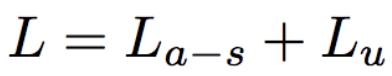
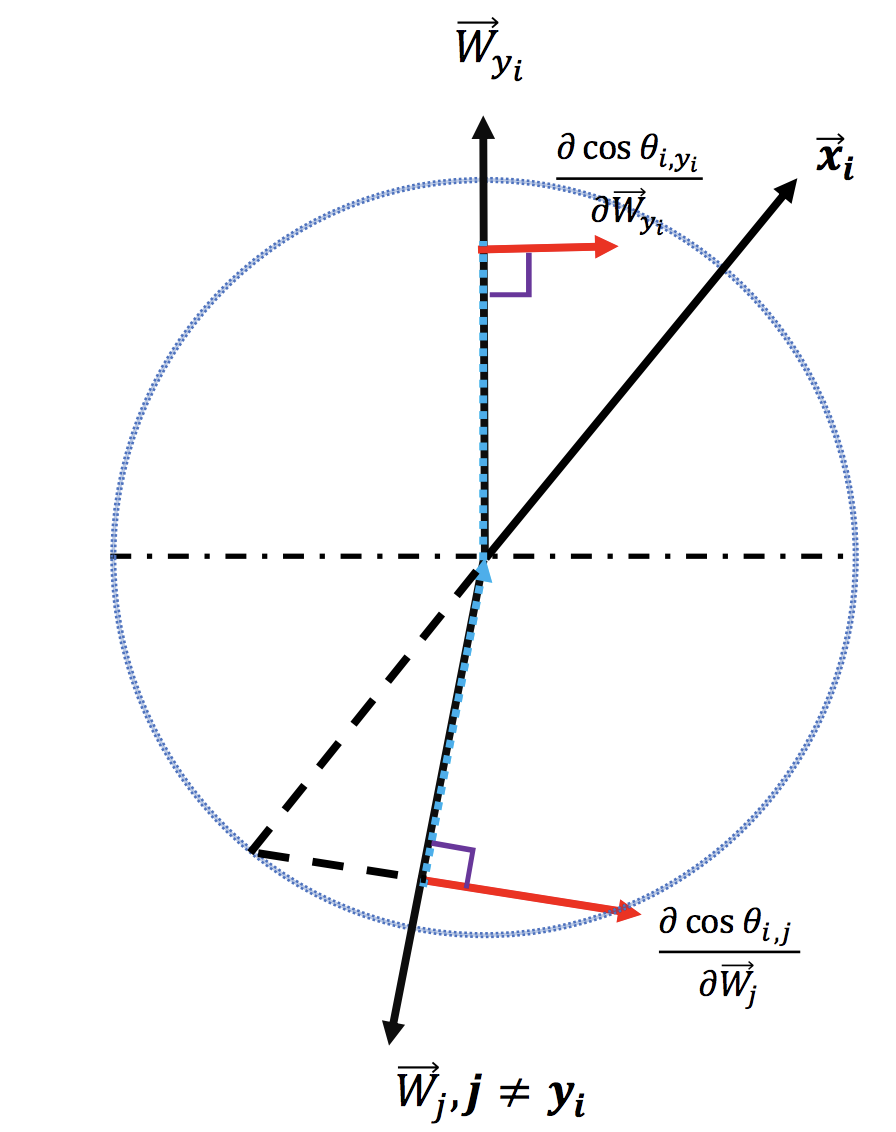
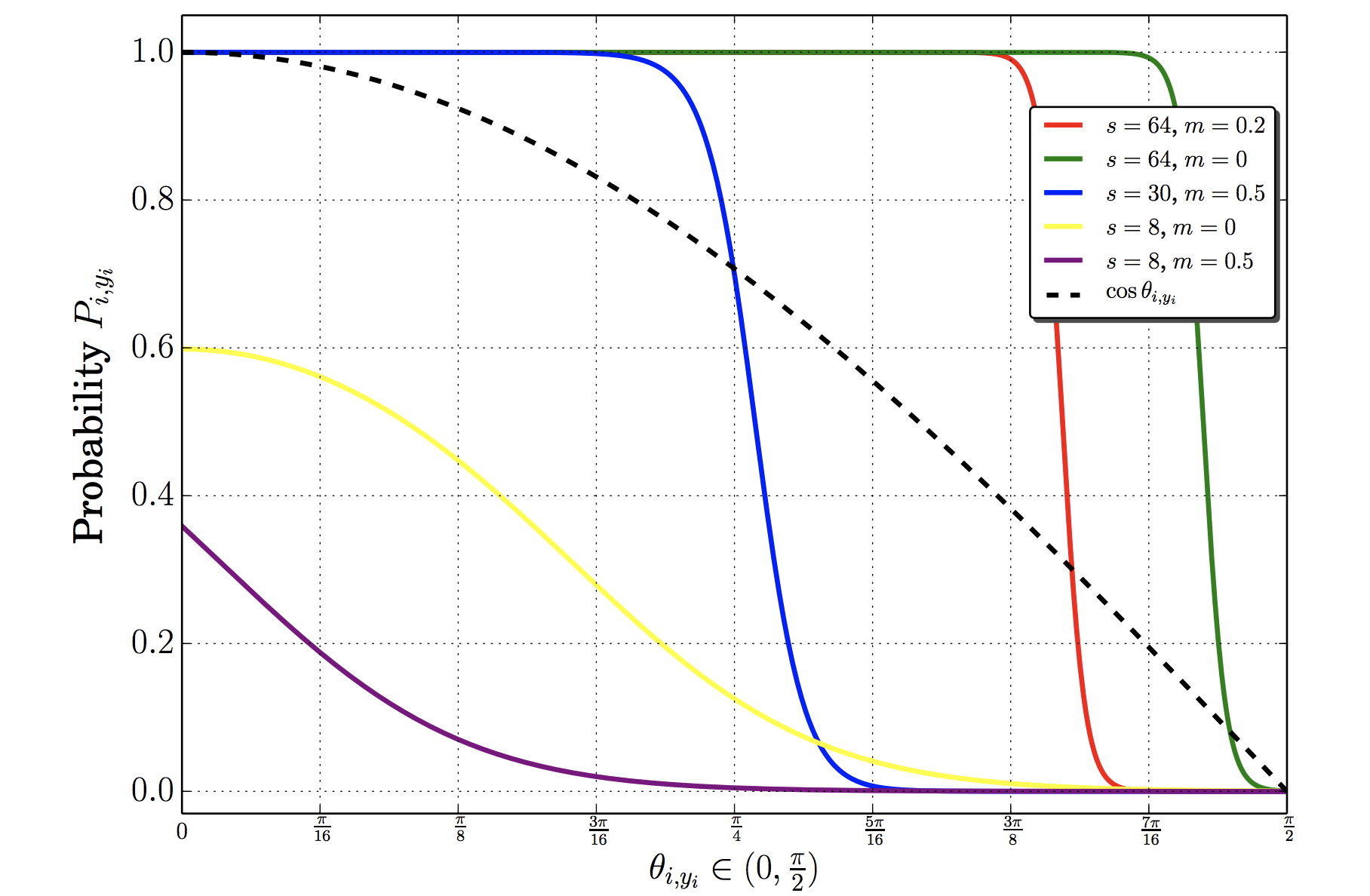
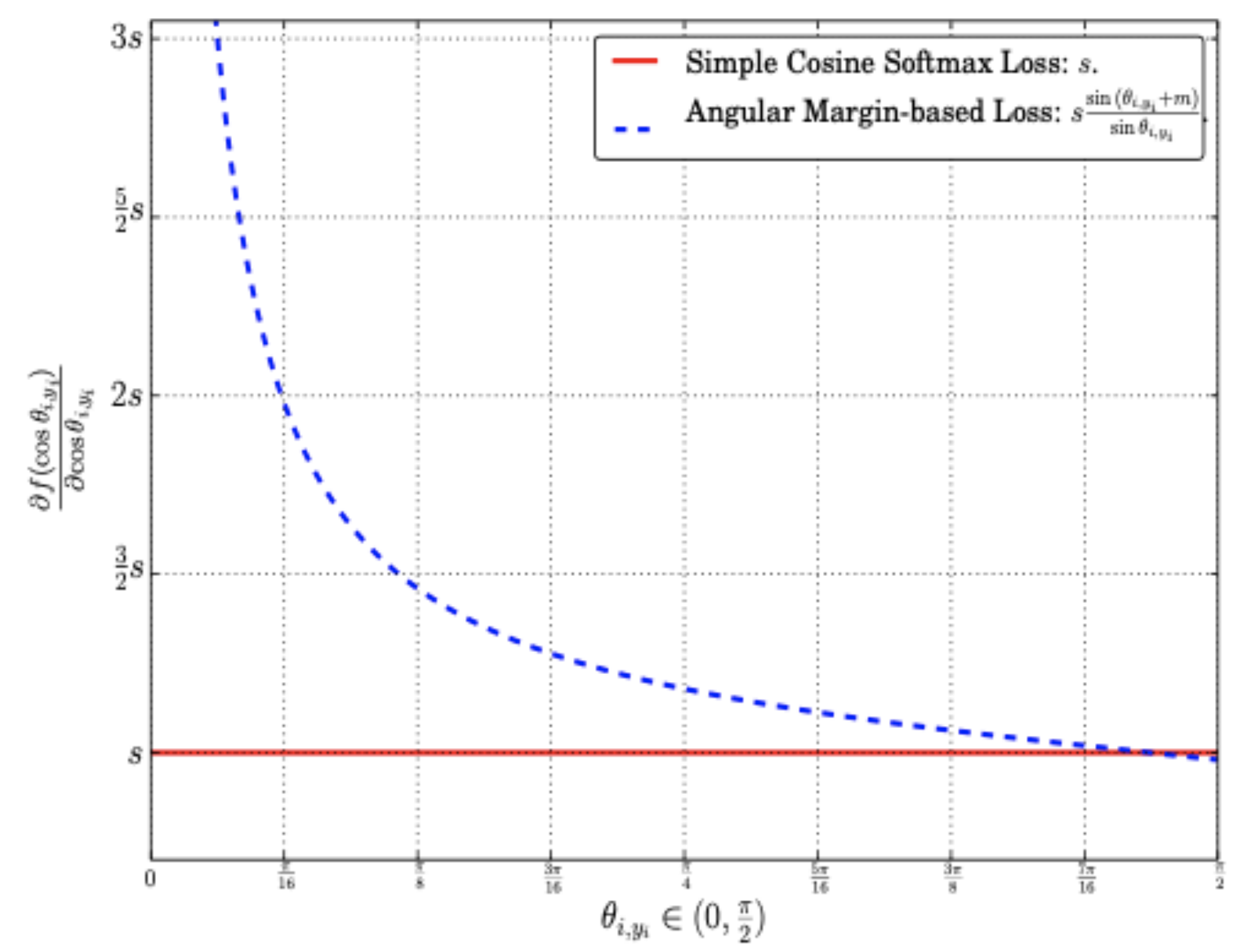
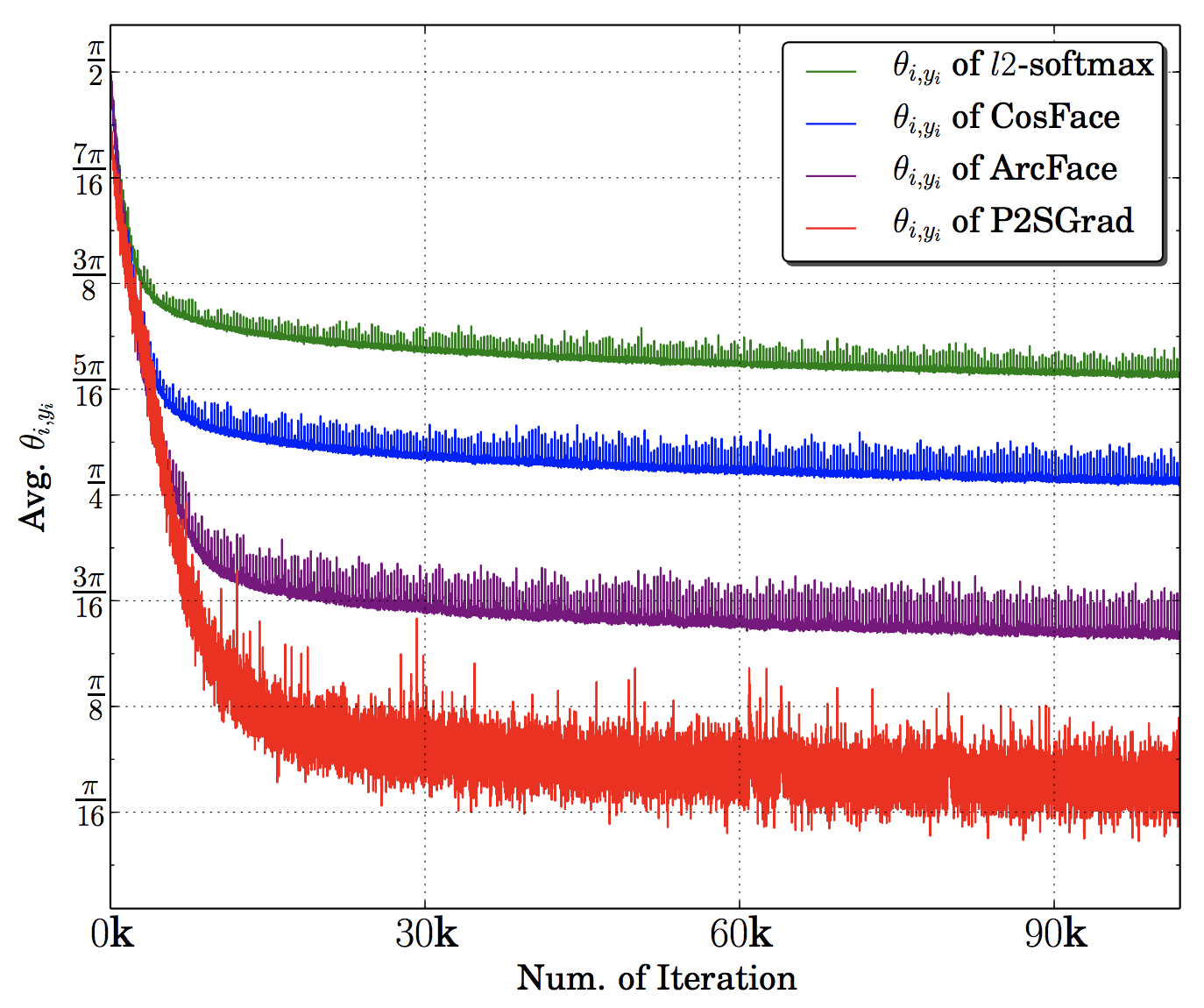
- 投稿日:2020-02-06T16:05:50+09:00
1日10時間株価予測AIを作り続ける 3か月目
3か月目
2か月目まででかなり多くの問題に直面してきました。
一つのAIの予測精度を最大化するのは限界がありそうです。
そこで、そこからさらに予測精度を上げることができるかもしれない方法を思いついたのでここに書き記します。AI多数決理論
その方法は簡単で、まずいくつかの良いAIを作ります、AIの数は奇数が望ましいです。その後集めたAIで多数決を取り最終決定を下します。そもそも一つのAIの中でも多くの場合多数決で予測を決めているという側面があり、実際に複数のAIを集めて判断させることで効果があるのかどうかは疑問ですがとにかくやってみましょう。
問題点は、集められたAIがおそらく多様性に富んでいる必要があり、加えてある程度の数が必要だということです。
今月の目標は色々なデータを使って高性能な予測AIをいくつか作ることでした。学習にあたっての問題点
データを学習させるにあたって問題点が二つあります。
一つは過学習、もう一つの問題点は予測の偏りです。例えば0を上がる、1を下がると定義した場合、今までのモデルでは0を多く出力する(全ての予測の内0が70~100%を占める)問題が頻発しました。
これらの問題の難しいところは、過学習の問題を解決しようとすると予測の偏りが生じ、反対もまたしかりということです。
この問題には主に以下の3つの変数が関与していました、1. Normalization Layers(正規化層)の設定の強さや層の数。2. エポック数。3.選択するOptimizer
また、学習過程以外で結果に影響する要素は4.データの構造や質など。そして 5.モデルの構造が挙げられます。AI研究について
稀に良い上記の変数の組み合わせを偶然に発見し、結果として悪くないまたはとても良いAIを手にすることができます。
深層学習は、ただデータを学ばせればいいというだけではなくその過程で色々な調整や試行錯誤が必要で、ここに研究余地やAIを作るライブラリ側の向上余地があるのだろうとわかりました。
今までに3種類のAIを作りましたが1番目のAIに比べて2番目3番目に作ったAIの性能がずば抜けて良く、1番目のAIを議会から追放することを検討中です。AI_No.2
2つめに作ったAIの性能です。
アメリカの主要企業500企業の2000年からの全株価データ(43707個)に対して65.6%の予測精度を持ち、また0(株価が上がるとする予測)の出力比率は57%であり特に問題がありません。そして予測が完全にランダムだった場合に期待される精度が51.56%なことからもかなり強力に予測が可能である事が示唆されています。今後の方針
三つあれば多数決は成立するので現実の株式市場で検証をするためのコードを書こうと思います。
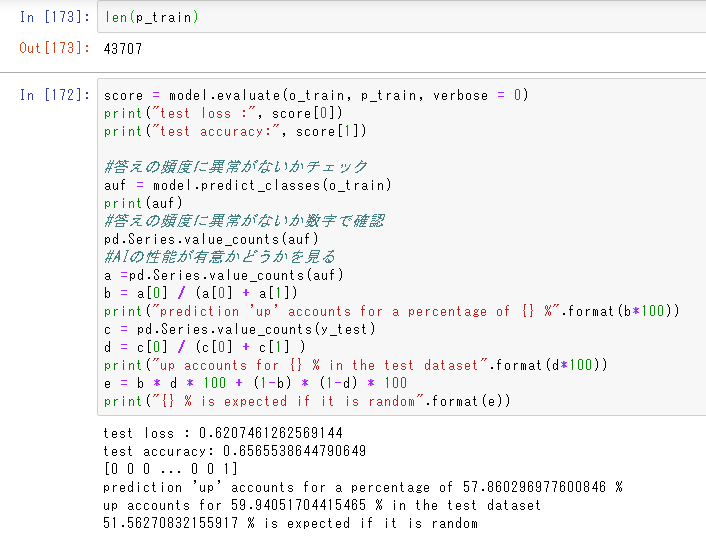
- 投稿日:2020-02-06T16:05:11+09:00
ImportError: cannot import name 'factorial'〜〜〜
- 投稿日:2020-02-06T15:19:44+09:00
Anaconda cloudとcondaで最新バージョンのTa-libを簡単インストール
私の動作環境
Windows8.1pro 64bit
Anaconda3 2019.10
(backtrader用の仮想環境をPython3.5で構築)BacktraderからTa-libを動かす
BacktraderはTa-libに対応しています。すでに組み込まれているインジケーターと重複していますが、さらにいくつかのインジケーターを表示できるようになります。またロウソク足パターン識別、統計解析などを行うこともできます。
Ta-libインストールは厄介
が、Ta-libのインストール失敗してしまいました。PIPを使ったのですがエラーが出てしまいました。どうやらTa-libはインストールが少々厄介なものみたいです。私のように躓いている人が結構いるようです。
そんな中、condaを使ってダウンロードするチャンネルを指定すれば簡単にインストールできるという解説記事を発見。さっそく記事を真似てインストールしてみました。サンプルスクリプトも一通りテストしてまったく問題ありませんでした。
condaのチャンネルとは?
https://qiita.com/yuj/items/8ce25959427ea97d373bQUANTPIANチャンネルからインストールできるTa-libは0.4.9
ところが当時の解説記事の中で使っていたチャンネルはQUANTOPIAN(トレーディングライブラリZiplineを提供している企業)だったのです。こちらからインストールされるTa-libは0.4.9です。すべてのOSに対応していてダウンロード・インストール数も多いのですがリリースが2015年と古い上に新しいバージョン0.4.15ではbacktrader向けの修正が追加されています。
Acaconda cloudでTa-lib 0.4.15を探す
なのでQUANTPIAN以外のチャンネルから新しいバージョンのTa-libをダウンロードした方がいいです。その際にPrompt上でチャンネル及びTa-libパッケージを検索するよりもWeb上のAnaconda cloudで検索した方がわかりやすいです。
Anaconda cloudでta-libを検索
https://anaconda.org/search?q=ta-libこのようにQUANTPIANからのインストールが圧倒的に多いのですが、他にも提供チャンネルがたくさんあることがわかります。
ありがたいことに0.4.17(condaだと0.4.16)を提供して下さっているユーザーがいるので、そちらからインストールすることにしました。チャンネルを選ぶとこのような画面になると思います。
こちらのページに書かれているコマンドをそのままコピーしてAnacondaprompt上に貼り付けて実行するとインストールできます。(仮想環境を使っている人はあらかじめ切り替えておきましょう)
すでに0.4.9をインストールしていてもアップデートしてくれます。いろいろと心配な人は新しく仮想環境を構築してもいいかもしれません。確認のためbacktrader_documentのTa-libテストスクリプト(RSI)をAnacondapromptから実行してみます。
https://www.backtrader.com/docu/talib/talib/talib.py(envbacktrader) C:\Users\xxxx>python talibtest.py --plot --ind rsi※ドキュメントのスクリプトそのままではエラーがでます。こちらの記事を参考にしてCSVファイルを用意してスクリプトの一部を書き換えてください。
https://qiita.com/xxssxxx/items/e915b8afe51facc47a55
問題なく動作するようです。
こちらはTa-lib_0.4.9で同じテストスクリプトを実行した結果です。RSIの表示はそのままですがチャートに表示されているDOJIマークが0.4.16と比較して明らかに少ないです。Ta-lib内部の判定式が変わったのでしょうか???やはり何らかの変更はあったみたいですね。
MacOS対応のTa-lib 0.4.17
ということで、Anaconda cloudとcondaを使えば新しいバージョンのTa-libを簡単にインストールできます。しかし残念ながら現時点(2020年2月)でMacOS用のTa-lib 0.4.17を提供しているチャンネルはないみたいです。
- 投稿日:2020-02-06T14:32:07+09:00
ゼロからのディープラーニング(コスト計算編)
ゼロからのディープラーニング(フォワードプロパゲーション編)の続きです。
前回はフォワードプロパゲーションを実装して入力値が$1$である確率$AL$を導くところまでを行いました。今回はモデルの精度向上のため、予測値と正解ラベルの誤差を導きだすところまでを実装します。
コスト
本DNNは入力された画像が猫であるか否かを予測するものですので、コスト関数にはCross-entropy誤差を使います。
Cross-entropy誤差
以下の式によって表されます。$AL$はYが1である確率を予測したもの、$Y$は正解ラベルです。
$$L(AL, Y) = \sum^m_{i=1}{(-Ylog(AL) - (1-Y)log(1-A))}$$$Y=1$のとき$-log(AL)$を返し、$Y=0$のとき$log(1-AL)$を返します。以下のグラフから、予測値と正解が離れれば離れるほどコストが大きくなることがわかります。
関数にすると以下です。
def compute_cost(AL, Y): m = Y.shape[1] logprobs = np.multiply(Y, np.log(AL)) + np.multiply(1-Y, np.log(1-AL)) cost = -1/m * np.sum(logprobs) return costベクトル化された予測値$AL$と正解ラベル$Y$を渡すことでコストを返します。

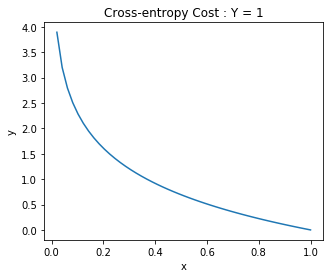
- 投稿日:2020-02-06T13:28:39+09:00
numpy備忘録1/np.pad
1.はじめに
np.padの使い方が良くわからなかったので、調べた結果を備忘録として残します。
2.1次元配列
# 1次元配列 img = np.array([1, 2, 3]) print(img) print('img.shape = ', img.shape) img = np.pad(img, [(1,2)], 'constant') print(img)
img = np.pad(img, [(左0埋め数, 右0埋め数)], 'constant')3.2次元配列
# 2次元配列 img = np.array([[1, 2, 3], [4, 5, 6]]) print(img) print('img.shape = ', img.shape) img = np.pad(img, [(1,2), (3, 4)], 'constant') print(img)
img = np.pad(img, [(上0埋め数, 下0埋め数), (左0埋め数, 右0埋め数)], 'constant')4.3次元配列
# 3次元配列 img = np.array( [[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [0, 1, 2]]]) print(img) print('img.shape = ', img.shape) img = np.pad(img, [(1,0), (1, 1), (1, 1)], 'constant') print(img)
今までは画像のパディングだけでしたが、今度はその画像の前後に0画像(全て0で埋め尽くされたもの)を何枚入れるか指定します。ここでは、前に1枚入れています。つまり、
img = np.pad(img, [(前0画像数, 後0画像数), (上0埋め数, 下0埋め数), (左0埋め数, 右0埋め数)], 'constant')5.4次元配列
# 4次元配列 img = np.array([[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9],[0, 1, 2]]]]) print(img) print('img.shape = ', img.shape) img = np.pad(img, [(1,0), (1,0), (1, 1), (1, 1)], 'constant') print(img)
今度は、今まで作成した画像(パディングした画像+0画像)の枚数分の0画像を、さらに前後に指定セット分追加します。ここでは、前に1セット入れています。つまり、
img = np.pad(img, [(前0画像セット数, 後0画像セット数), (前0画像数, 後0画像数), (上0埋め数, 下0埋め数), (左0埋め数, 右0埋め数)], 'constant')6.実際の使い方例
4次元配列 img (ミニバッチサイズ、チャンネル数、縦幅、横幅)のパディング処理をする場合を考えてみます。縦方向のパディングを p_h, 横方向のパディングを p_w とします。バッチ方向やチャンネル方向のパディングは不要なので、
img = np.pad(img, [(0, 0), (0, 0), (p_h, p_h), (p_w, p_w)], 'constant')
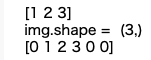
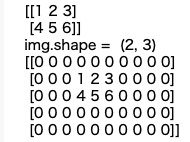
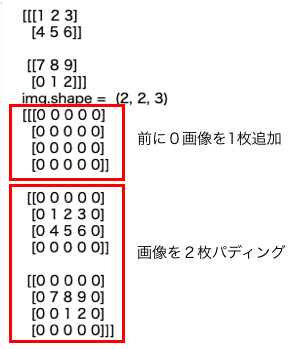
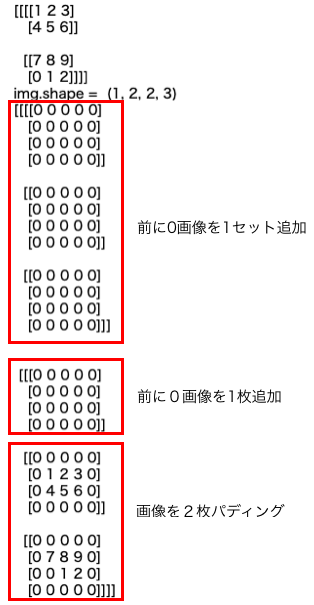
- 投稿日:2020-02-06T12:28:50+09:00
[検証]levelDBはデータ量が増えるとデータ登録に時間がかかる??
気になったこと
ethereumをプライベートブロックチェーンとして使用する場合にデータ量が増えるとgeth(go-ethereum)内で使われているlevelDBへのデータ登録に時間がかかるようになるという記事を見つけた。
そんなことあるんだー。と思って実際に計測してみたやったこと
Keyは処理番号、Valueに適当なデータという適当すぎるデータを100万件登録する。
100件毎に要した処理時間を計測し、処理時間が増加しているか確認した。levelDBだけでなく、ついでにmongoDBでもやってみた
levelDBの処理時間
以下のコードでデータを登録
measurement_leveldb.pyimport time import leveldb # テストデータ:750バイト inputData = '{"_id" : "ObjectId(\5e3b4dd825755df3f15a2d17\")","coediting" : False,"comments_count" : 0,"created_at" : "2020-02-05T20:20:10+09:00","group" : None,"id" : "6ed1eec1d6fba127a863","likes_count" : 0,"private" : False,"reactions_count" : 0,"tags" : [{"name" : "Python","versions" : [ ]},{"name" : "MongoDB","versions" : [ ]},{"name" : "Python3","versions" : [ ]},{"name" : "pymongo","versions" : [ ]}],"title" : "PythonでmongoDBを操作する~その6:aggregate編~","updated_at" : "2020-02-05T20:20:10+09:00","url" : "https://qiita.com/bc_yuuuuuki/items/6ed1eec1d6fba127a863","page_views_count" : 96,"tag1" : "Python","tag2" : "MongoDB","tag3" : "Python3","tag4" : "pymongo","tag5" : "","tag_list" : ["Python","MongoDB","Python3","pymongo"],"stocks_count" : 0}' start = time.time() db = leveldb.LevelDB("measurement_test") start = time.time() for i in range(1,1000001): db.Put(i.to_bytes(4, 'little'), inputData.encode('utf-8')) if i % 100 == 0: end = time.time() print("{0}:{1}".format(i,end-start)) start = end処理結果
mongoDBの処理時間
以下のコードで測定
measurement_mongodb.pyfrom mongo_sample import MongoSample import time mongo = MongoSample("db","measurement") # テストデータ:750バイト inputData = '{"_id" : "ObjectId(\5e3b4dd825755df3f15a2d17\")","coediting" : False,"comments_count" : 0,"created_at" : "2020-02-05T20:20:10+09:00","group" : None,"id" : "6ed1eec1d6fba127a863","likes_count" : 0,"private" : False,"reactions_count" : 0,"tags" : [{"name" : "Python","versions" : [ ]},{"name" : "MongoDB","versions" : [ ]},{"name" : "Python3","versions" : [ ]},{"name" : "pymongo","versions" : [ ]}],"title" : "PythonでmongoDBを操作する~その6:aggregate編~","updated_at" : "2020-02-05T20:20:10+09:00","url" : "https://qiita.com/bc_yuuuuuki/items/6ed1eec1d6fba127a863","page_views_count" : 96,"tag1" : "Python","tag2" : "MongoDB","tag3" : "Python3","tag4" : "pymongo","tag5" : "","tag_list" : ["Python","MongoDB","Python3","pymongo"],"stocks_count" : 0}' start = time.time() path = "measurement.txt" with open(path, "w") as out: for i in range(1,1000001): mongo.insert_one({str(i):inputData}) if i % 100 == 0: end = time.time() out.write("{0}:{1}\n".format(i,end-start)) start = time.time()処理結果
検証結果
処理結果の分布を見ると、levelDB、mongoDB共に一定の処理時間帯に概ね分布している。
突出して処理時間を要しているものもあるが、数件程度であるため、書き込み速度が劣化しているとは言えない。データ量に応じて書き込み速度が遅くなる場合は、右肩上がり もしくは 右上に向かって曲線を描くような分布になるが、今回の検証ではこのような分布にはならなかった。
感想
読んだ記事の詳細な環境やデータ量が不明だったので、参考にした記事の内容が事実かどうかまでは不明のままです。
また、gethは当然go言語ですし、私はgoの環境を作るのがめんどくさかったのでpythonでやってみました。
このあたりも影響があるのかもしれないので引き続き調べてみようかなと思います。levelDBについて少しだけですが知識を得れたので良かったです。
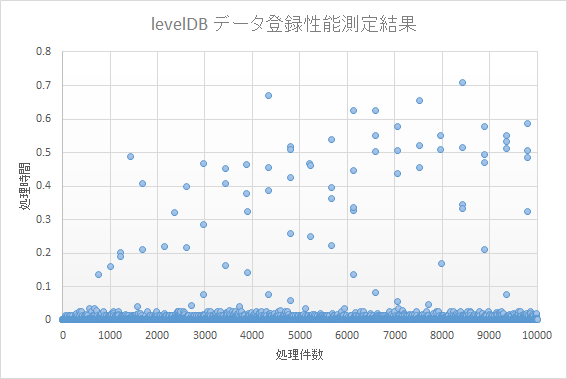
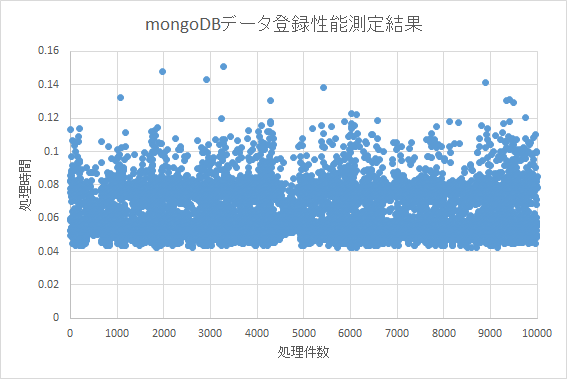
- 投稿日:2020-02-06T11:24:57+09:00
自然言語処理Case Study:Word Frequency in 'Anne with an E'
この記事は自然言語処理を使って、小説の言葉使いを分析する実験である。パイプラインを作って、言葉の頻度を簡単に分析する。
I recently encountered this amazing Netflix series Anne with an E and was amazed by the story. It's hard to find high-quality movies that pass the Bechdel Test. The story is extremely empowering for girls. Inspired by Hugo Bowne-Anderson from Data Camp, I decided to apply my knowledge in web-scraping and basic Natural Language Processing knowledge to analyze the word frequency in the original book ANNE OF GREEN GABLES.
In this project, I'll build a simple pipeline to visualize and analyze the word frequency in ANNE OF GREEN GABLES.
from bs4 import BeautifulSoup import requests import nltk
If this is your first time using nltk, don't forget to include the following line to install nltk data as we'll need to use the stopwords file later to remove all the stopwords in English.
nltk.download()Simply run this line in your program and a GUI window will pop up. Follow the instructions to install all the data. The installation procedure would take a couple of minutes. After the installation, you'll be good to go.
r = requests.get(‘http://www.gutenberg.org/files/45/45-h/45-h.htm') r.encoding = ‘utf-8’ html = r.text print(html[0:100])Now we can fetch the html version of the book and print the first 100 characters to see if it's right. Before extracting all the text from the html document, we'll need to create a BeautifulSoup object.
soup = BeautifulSoup(html) text = soup.get_text() print(html[10000:12000])Then we'll use nltk and Regex to tokenize the text into words:
tokenizer = nltk.tokenize.RegexpTokenizer('\w+') tokens = tokenizer.tokenize(text) print(tokens[:8])Now we can turn all the words into lower-case for later frequency distribution calculation since it is case-sensitive.
words = [] for word in tokens: words.append(word.lower()) print(words[:8])One last step before we can visualize the distribution of frequency of words is to get rid of all the stop words in words list.
sw = nltk.corpus.stopwords.words(‘english’) print(sw[:8]) words_ns = [] for word in words: if word not in sw: words_ns.append(word) print(words_ns[:5])Finally, let's visualize the top dist plot and see what are the top 25 frequent words in the book.
%matplotlib inline freqdist = nltk.FreqDist(words_ns) freqdist.plot(25)
Now we can see the top two supporting characters in the fiction are two females: Marilla and Diana. It's not surprising the name of the Netflix series renamed it as Anne With an ‘E’ as it is a name repeated over 1200 times.

- 投稿日:2020-02-06T08:58:10+09:00
PandasTools.LoadSDFで読み込んだときROMolに画像が表示されないのを一旦解決
- jupyter-notebookを使っている
- RDKitで複数化合物が含まれるSDFデータをPandasTools.LoadSDFで読み込んだときROMolに画像が表示されないのをなんとかした
- 自分の環境は下記
- MacOSX 10.15.2 Catalina
- 下記を参考にしてAnacondaでRDKit環境を構築した
- anaconda3-5.3.1のPython 3.7.5を利用
- rdkit version: 2019.09.2
- pandas version: 0.25.3
下記サイトを参考にRDKitを練習してた
RDKitでケモインフォマティクスに入門 | 化学の新しいカタチ
複数分子の読み込みのところでSDFファイルをpandasのDataFrame形式で読み込んだあと表示させてみたところ、ROMolのところに画像が表示されず
<img data-content="rdkit/molecule" src="data:i...みたいなカラムになっていた (下記画像)
下記issueによると、どうやら、pandas 0.25.0 より上のバージョンだと起こってるっぽい
たしかに、自分の場合pandasのバージョンは0.25.3だった
import pandas as pd print('pandas version: ', pd.__version__) #=> pandas version: 0.25.3解決策としては pandasのバージョンを0.25.0まで戻すかも考えられたが
めんどかったので他に方法が無いか探した画像で表示されたほうが便利な部分もあるのでissueたどったり検索してみたりすると
HTMLのライブラリ使うようにってのがあったのでhttps://github.com/rdkit/rdkit/issues/2673#issuecomment-570898398
Molecules not rendered in Pandas DF in Jupyter Lab · Issue #2825 · rdkit/rdkit
下記のようにやってみたらできた(sdfファイルはダウンロード済み、ライブラリはimport済みとする)
df = PandasTools.LoadSDF('./sdf/somesdffile.sdf') from IPython.display import HTML HTML(df.to_html())
画像がちゃんと出てきたら成功
ひとまず、画像があったほうがわかりやすいときはこうやればちゃんと出てくる