- 投稿日:2020-02-06T22:40:42+09:00
AWSのちょっとしたコストを節約した話
みなさま、こんにちは。
今回はAWSの利用でちょっとしたものだけど地味にお金がかかる部分とそのコスト削減する方法をお伝えします!
少しのお金でも放っておくとちりつもで洒落にならない金額になることもあるので、この機会に是非見直してみてください。
その1 EBSのスナップショット

意外と見落としがちなこちら!
EBSのスナップショットです。そんなのあまり作ったことないなーという方もいるかと思います。
ですが、AMIはどうでしょうか。
実はAMIとは裏側ではEC2のインスタンス情報とEBSのスナップショットで構成されています。
そのため、AMIを作ったことのある方はもれなくEBSスナップショットを作っています!
しかもここからが怖いところでして、、
なんとAMIを解放したとしてもEBSスナップショットは削除されません!!
そのため削除する仕組みを別でこさえなければ永遠に増えていきます。
削除する方法はこちらがおすすめです。
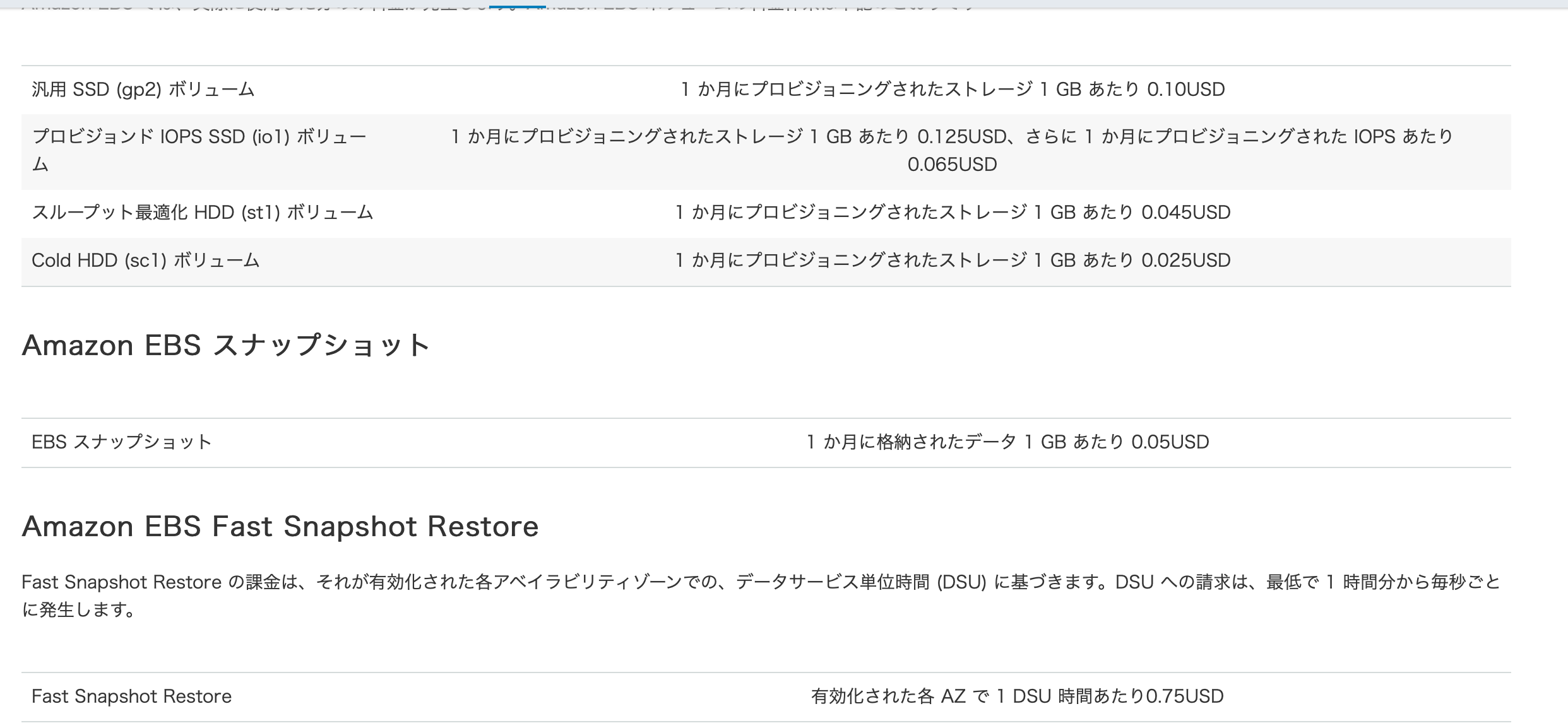
https://coatiblog.sios.jp/ami登録解除時、スナップショットを自動で削除す/EBSの料金はこちらになっていますが、家庭のAWSなどでは少しの費用でも節約したい方が多いと思いますのでお気をつけください。(企業の方も知らないうちに何TBとかになっていませんか。。?)
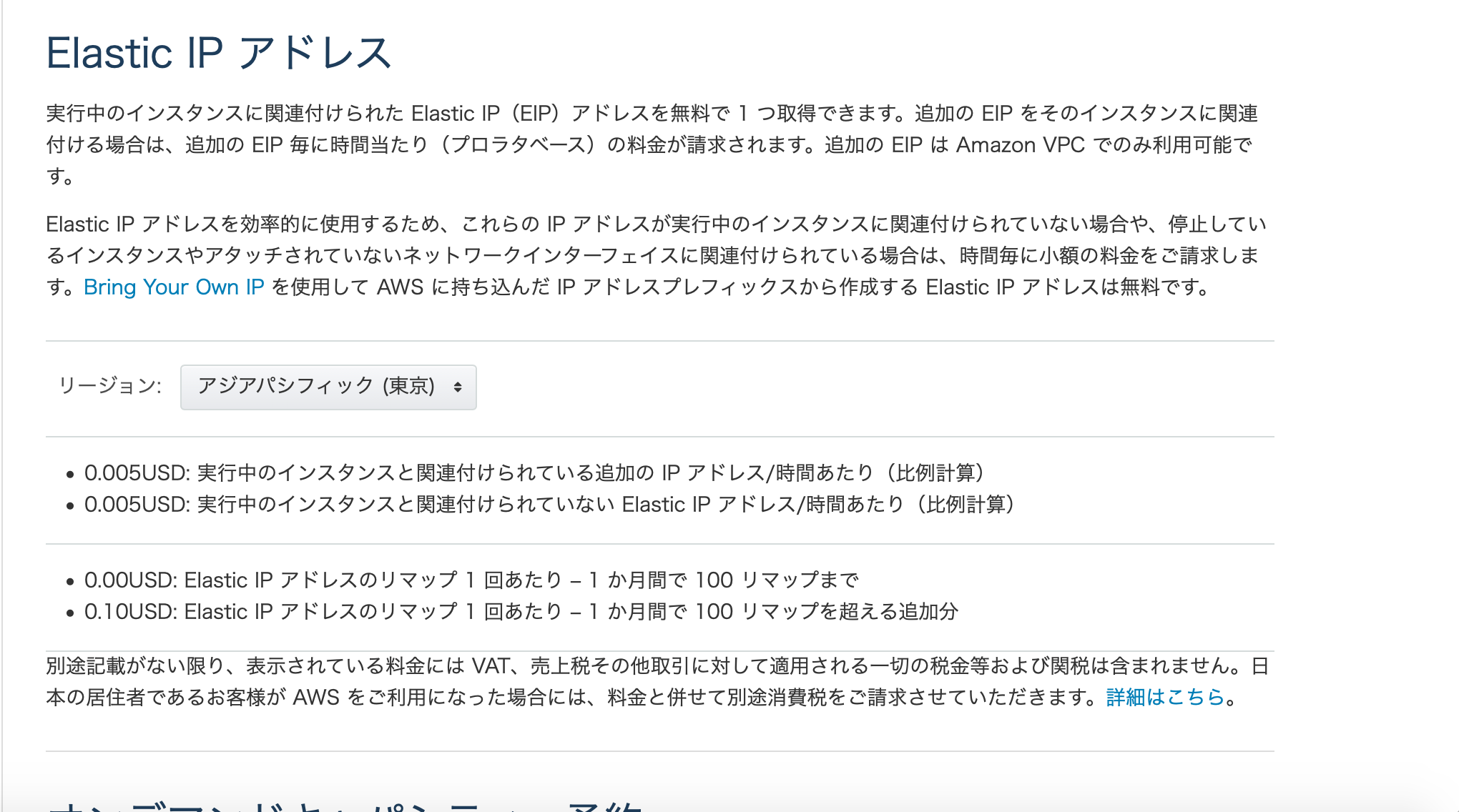
(AWS公式ドキュメントより)その2 EIP(ElasticIP)

こちらはご存知の方も多いと思うので、大きいポイントを紹介します。
1. EIPは起動中のインスタンスに紐づいている時は課金されない
2. EIPは停止中のインスタンスにくっついている場合、課金される
3. EIPは紐づいていない場合課金される
そのため、早めに気づいて不要ならば解放する必要があります。
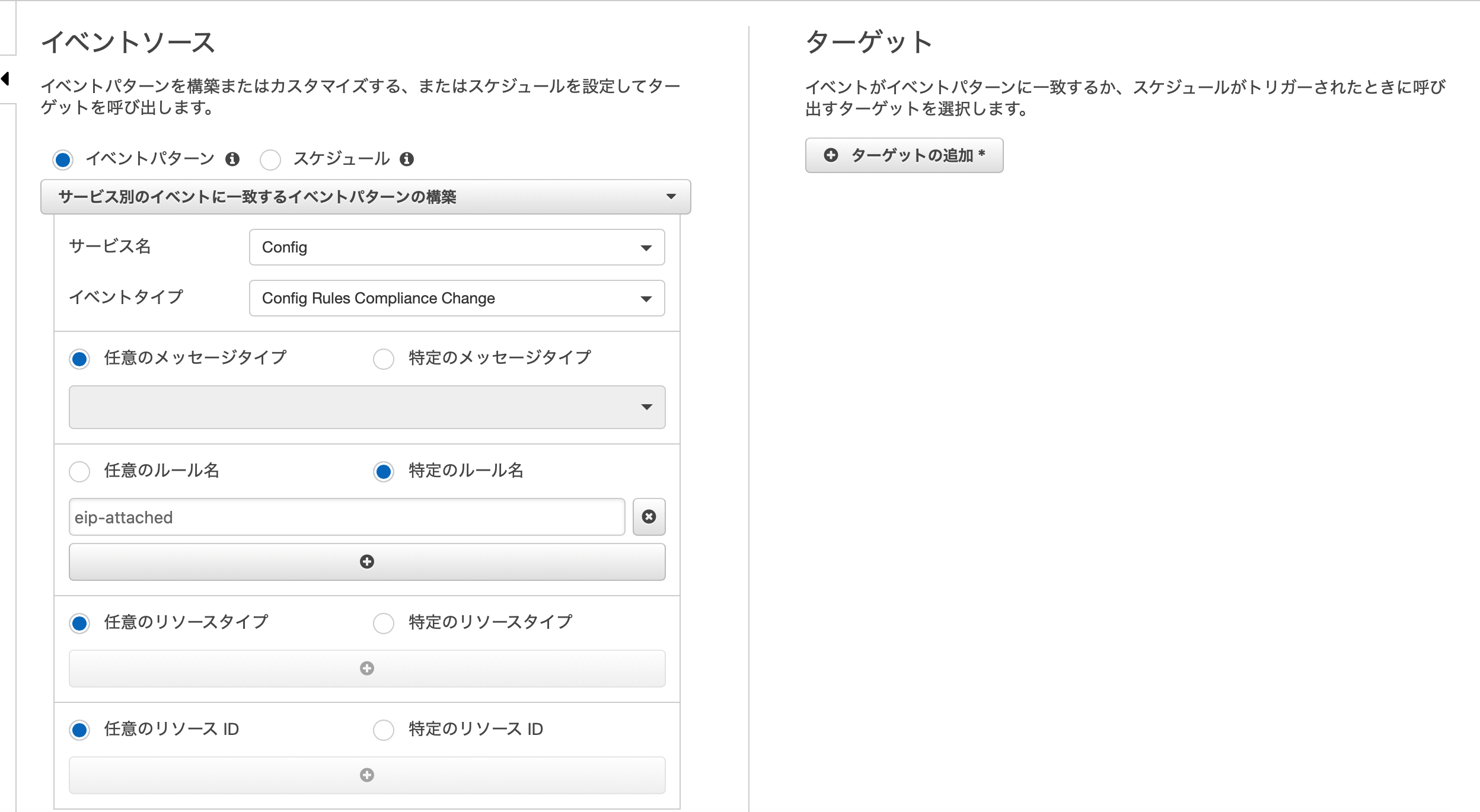
私のお勧めする方法はConfig → CloudWatchEvents → Lambda
です。
現在AWS Configにはeip-attachedなるマネージドルールがあり、そちらを利用することでCloudWatchEventで検知できる状態になります。
CloudWatchEventsのポイントとしては下記のように細かく絞れるのですが、特定のルールで"eip-attached"を指定するのがポイントです!
ターゲットに指定するLambdaの方はまた次回の記事、Lambdaでイベントを検知する。で紹介したいと思います。
Lambdaを書くのが得意な方は独自の書き方でも構いません。EIPの料金はこちらです。リージョンごとに違いますね。
この2つは特に金額が小さく見落とされがちですが、数が多かったり放置する時間が長くなれば意外と大きな金額になります!!
みなさまもこの機会にAWSのコストを最適化し、少しでも他の必要なところにお金を使っていきましょう。
お読みいただきありがとうございました!!
- 投稿日:2020-02-06T21:59:19+09:00
AWSの10分間チュートリアルをやってみる 4.ドメイン名の登録
こんにちは。トリドリといいます。
新卒で入社した会社でJavaを数年やった後、1年ほど前に転職してからはRailsを中心に使用してアプリケーションの開発をしているしがないエンジニアです。今回、AWSの勉強をするために公式の10分間チュートリアルをやってみることにしたので、備忘のために記事に残していこうと思います。
AWSに関しては、1年ほど前転職活動をしていた時期にEC2とRDSを少し触っていた以外ほとんど触ったことが無い初心者です。
(ただし、このときにアカウントを作ったので、12ヶ月の無料枠は切れていました)前回は「WordPress ウェブサイトの起動」を行いました。
今回は「ドメイン名の登録」をやっていきます。ドメイン名の登録
https://aws.amazon.com/jp/getting-started/tutorials/get-a-domain/?trk=gs_card
- Elastic IPの取得と前回作成したインスタンスの関連付け
- ドメインの取得とElastic IPとの関連付け が今回の内容です。 これにより、インスタンスの起動のたびに変わる動的なIPアドレスではなく、ドメインを使用してアクセスすることができるようになります。
ステップ 1: 静的 URL を取得する
まずは静的なIPであるElastic IPを取得します。
a.
EC2コンソールの[Elastic IP]メニューを開き、[Elastic IP アドレスの割り当て]ボタンをクリックします。
画面は下記の通り、チュートリアルの画像からはデザインが変更されています。
b.
割り当てボタンを押した先の画面はチュートリアルから変更されているようで、下記のような画面が表示されました。
調べたところ、以前はチュートリアルのダイアログが表示され、[EC2]と[VPC]を選択できるようになっていたようです。
参考: http://roadtothemasteroflife.blogspot.com/2014/05/aws-elastic-ip-eip.html公式のドキュメントによるとEC2はEC2-Classicという2013年12月4日より前に作成されたアカウントでサポートされているプラットフォームということでした。
参考: https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-classic-platform.html私がアカウントを作成したのは1年ほど前なので、もちろんサポートされていません。
そのため表示されなかったと考えられます。かわって表示されたのはIPアドレスをどのプールから割り当てるかを選択する画面です。
Amazonに用意されたプールとユーザーが持ち込んだプールのどちらか割り当てるか選択できるようですが、私は持ち込んだプールがないためAmazonの方しか選択できないようになっているので、そのまま[割り当て]ボタンを押します。c.
割り当てが完了したときはダイアログが表示されるのではなく一覧に戻るようになっています。
d.
上記の通り、割り当てられたIPアドレスが選択された状態になっているので、そのままチュートリアルのとおりに[アクション]->[Elastic IP アドレスの関連付け]をクリックします。
e.
チュートリアルのとおり、[インスタンス]から前回作成したインスタンスを選択し、[関連付ける]を押下します。
f./g.
割り当てられたElastic IPをコピーし、ブラウザからアクセスします。
前回のインスタンス起動後にアクセスしたとき同様、Hello worldが表示されればOKです。ステップ 2: ドメイン名を登録する
次にRoute53でドメイン名を登録します。
a.
Route53を開き、[ドメインの登録]の下の[今すぐ始める]を押します。
b.
[ドメインの登録]ボタンを押すとドメインの選択画面が開きます。
入力ボックスに登録したいドメイン名の入力し、使用したいトップレベルドメインを選択した上で[チェック]を押すとそのドメインが使用できるかをチェックしてくれます。
ドメインの候補や別の使用できるトップレベルドメインの候補を出してくれるのと、金額を出してくれるのは良いですね。使用可能なドメインの[カートに入れる]を押したあと、ページ下部の[続行]を押します。
c.
問い合わせ情報を入力します。
最後部にプライバシー保護のオプションがあるので、有効化して[続行]しました。
参考: https://dev.classmethod.jp/cloud/aws/route53-privacy-protection/d./e.
入力した連絡先を確認し、ドメインを自動的に更新するかのオプションを選択します。
メールアドレスの確認が終わっていない場合、確認のメニューも表示されます。
再送信とステータスの更新ボタンがあるので、別ウィンドウで送信されたメールから認証します。最後に規約をチェックし、[注文を完了]します。
登録には最大3日ほどかかるとのことでしたが、3時間ほど経って確認すると登録が完了していました。
プライバシー保護が機能していることを確認するため、whois ドメイン名を実行したところ、c.で入力した情報が表示されなかったのでちゃんと機能しているようでした。
ステップ 3: DNS を設定する
ステップ1で取得したElastic IPとステップ2で取得したドメインを紐付けを行います。
a.
Route53コンソールから[ホストゾーン]メニューを開き、登録したドメインの名前をクリックします。
b.
以降はElastic IPを使う場合とFQDN(完全修飾ドメイン名)を使う場合で説明が分かれています。
今回はElastic IPを使用するので、その手順に従って実行します。[レコードセットの作成]をクリックしすると表示される右側のフォームで、[名前]に
www、[値]にElastic IPの値を入力し、[作成]を押します。c.
左側のレコードの一覧に先程入力した名前が
www.ドメイン名.、タイプがA、値がElastic IPのレコードが表示されました。d.
作成されたレコードの名前のアドレスにブラウザでアクセスします。
前回作成したWordPressのHello Worldが表示されれば完了ですまとめ
今回は
- Elastic IPの割り当て
- EC2のインスタンスとElastic IPの紐付け
- ドメイン名の登録
- ドメイン名とElastic IPの紐付け
を行いました。ドメイン名を登録するというのは初めてだったので少し緊張しました。
特に、個人情報の入力とプライバシー保護について、調べるとうまく動かなかった時にどうするかばかりでてくるので本当に機能するのかが一番心配でした。Route53について、ドメイン名とElastic IPの紐付け方は分かりましたが、もともと入っていた2つのデータはどういう役割があるのかなどわからないことばかりなので、また調べようと思います。
今回のチュートリアルで、最後に書いてある次のステップが10分間チュートリアルから外れてしまいました。
次回は同じ「ウェブサイトとアプリケーション」のトピックから「仮想マシンへコードをデプロイする」にすすむ予定です。



- 投稿日:2020-02-06T20:32:40+09:00
AWS Cloud9で共有環境を用意する手順
AWS Cloud9の利点の1つが、同じ環境を複数人で共有できることです。
同じファイルを同時に更新したり、チャットでコミューケーションをとったりできます。
AWS Cloud9で共有環境を用意し、複数人で開発を行えるようにするまでの手順をまとめました。[1] IAMユーザーを用意する
Cloud9にアクセス出来るユーザーを準備します。
[1-1] ユーザー権限の違い
AWSCloud9Administrator, AWSCloud9User, AWSCloud9EnvironmentMember、3種類のポリシー(権限)が存在します。
3種類の違いは、大雑把にまとめると以下の通りです。
ポリシー 作成 編集(*1) 削除 アクセス AWSCloud9Administrator OK OK OK OK AWSCloud9User OK NG(*2) NG(*2) OK AWSCloud9EnvironmentMember NG NG NG OK *1:環境の編集のことであり、ファイルの編集はAWSCloud9EnvironmentMemberでも可能。
*2:自身で作成した環境の編集・削除は可。詳しくは下記を参照。
AWS Cloud9 のアクセス権限リファレンス[1-2] AWSCloud9User権限ユーザー作成
自身で環境の作成も可能なAWSCloud9Userを作成します。
[1-2-1] ユーザー名とアクセスの種類
ユーザー名やパスワードは自分の好きなものにして問題ありません。
今回は、マネジメントコンソールからのみ使用するので、アクセスの種類は「AWS マネジメントコンソールへのアクセス」を選択します。
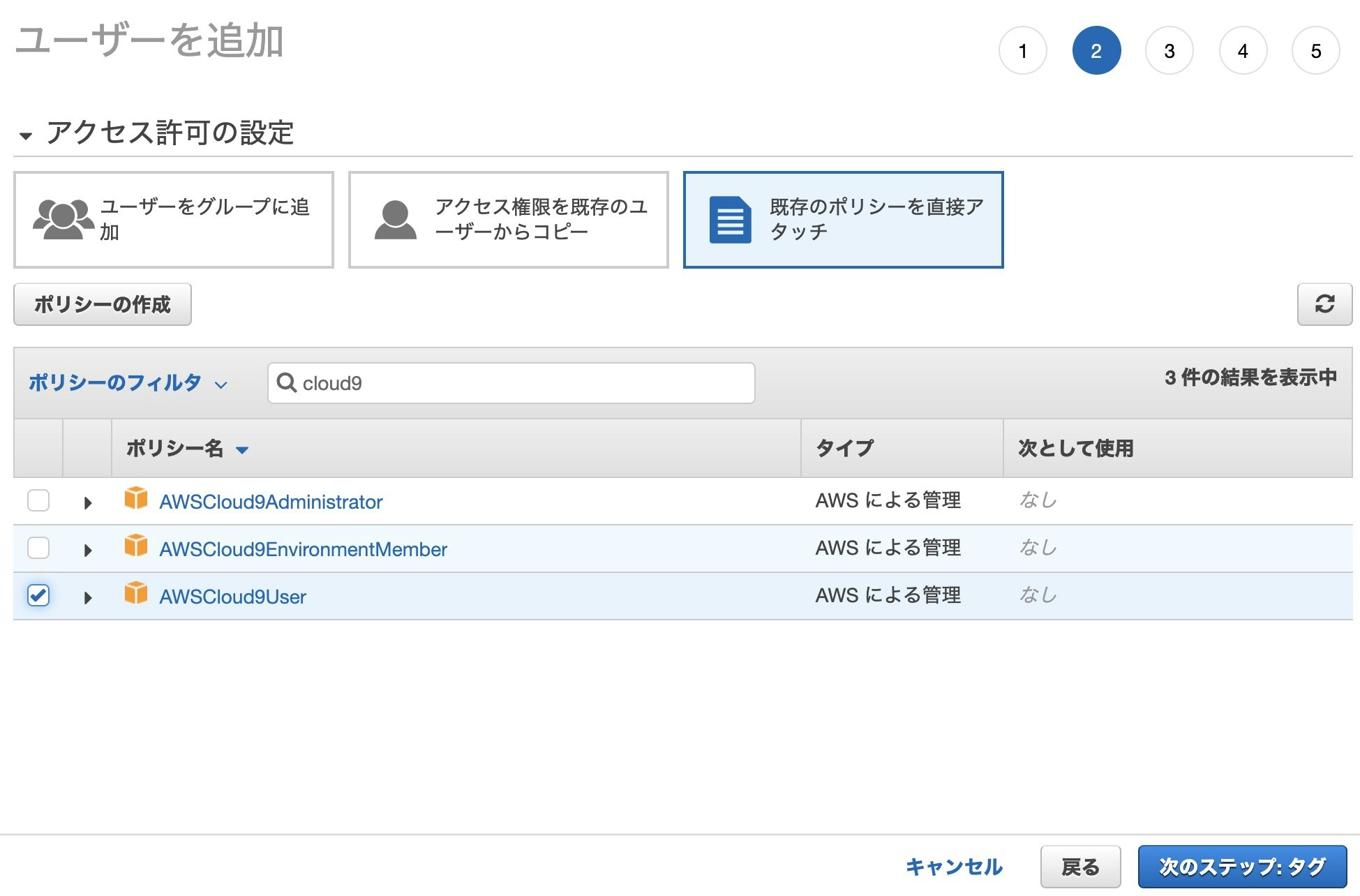
[1-2-2] アクセス許可の設定
アクセス許可の設定では[既存のポリシーを直接アタッチ]を選択します。
ポリシーのフィルタで検索欄に"cloud9"と入力すると、上述の3つのポリシーが表示されます。
その中から「AWSCloud9User」を選択します。
[1-2-3] その他の設定
以降の項目はデフォルトのままにして作成を進めました。
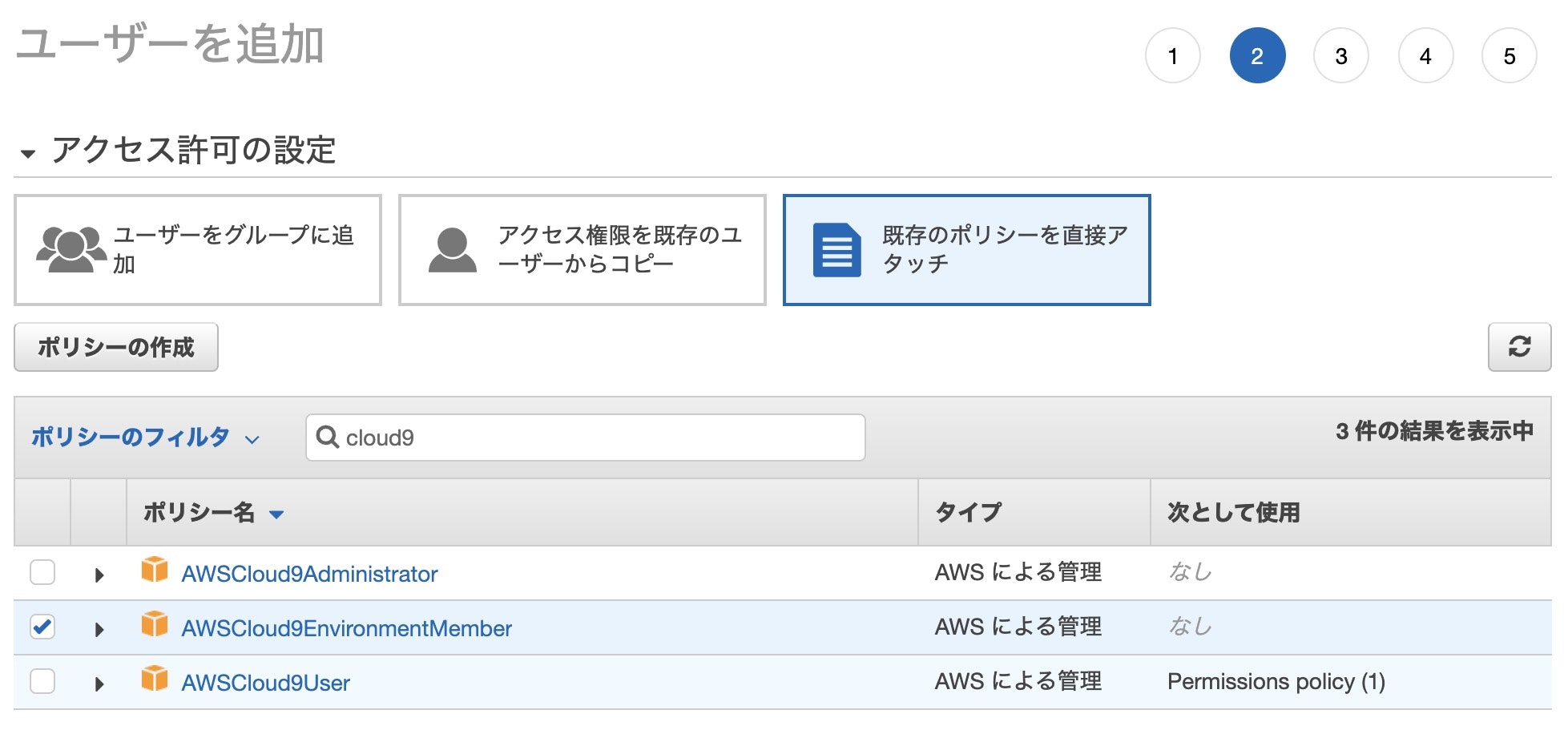
[1-3] AWSCloud9EnvironmentMember権限ユーザー作成
選択するポリシー以外は、AWSCloud9Userと同様に作成します。
[2] 共有環境を作る
[2-1] ルートユーザーでCloud9環境作成
共有するからと言って特別な手順はなく、1人で開発するときと同様に環境を作成します。
[2-2] 他のユーザーと共有
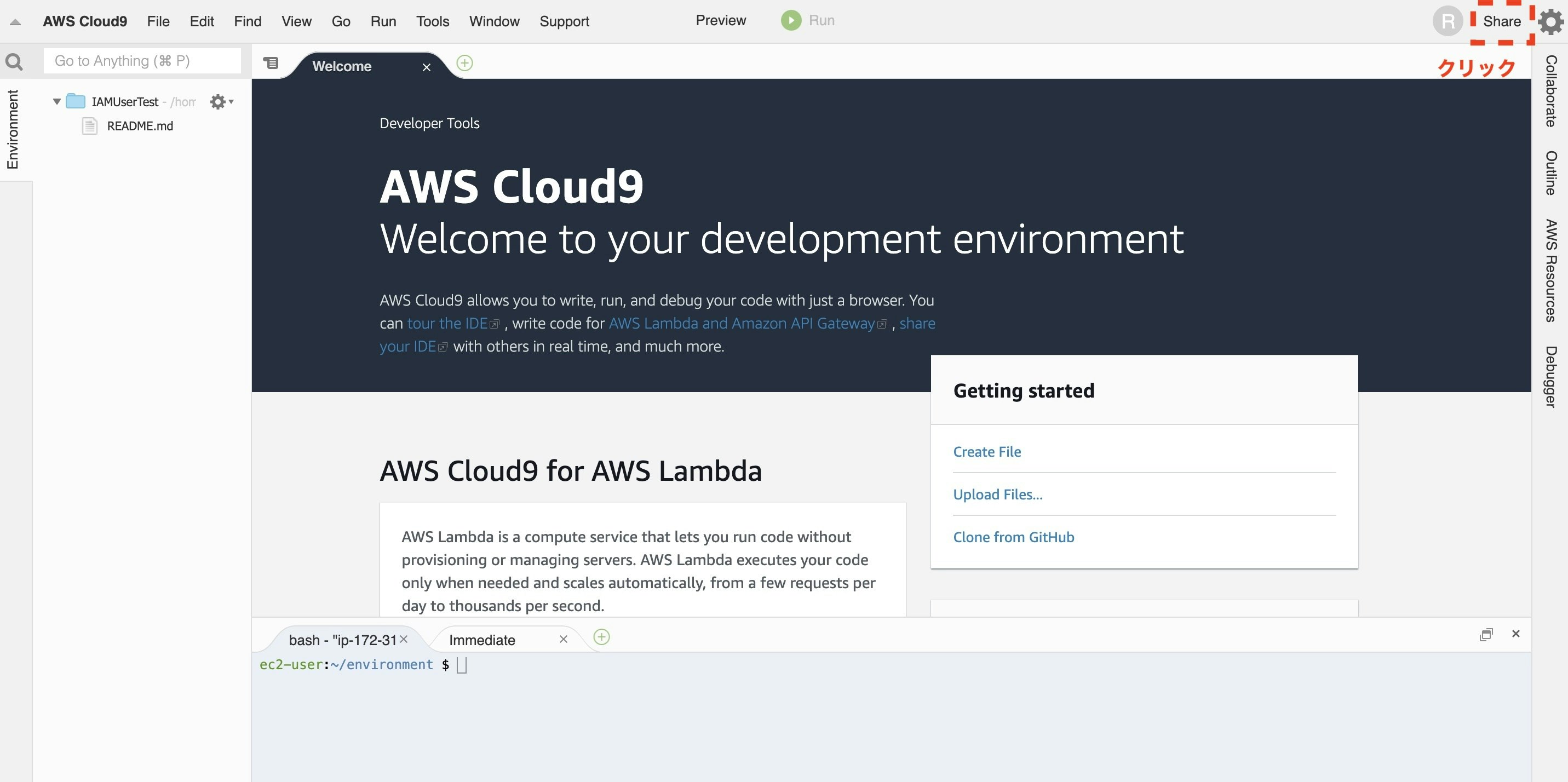
環境の作成が終わったら、早速ほかのユーザーと共有してみます。
右上の[Share]をクリックします。
[2-3] AWSCloud9User権限ユーザーを招待
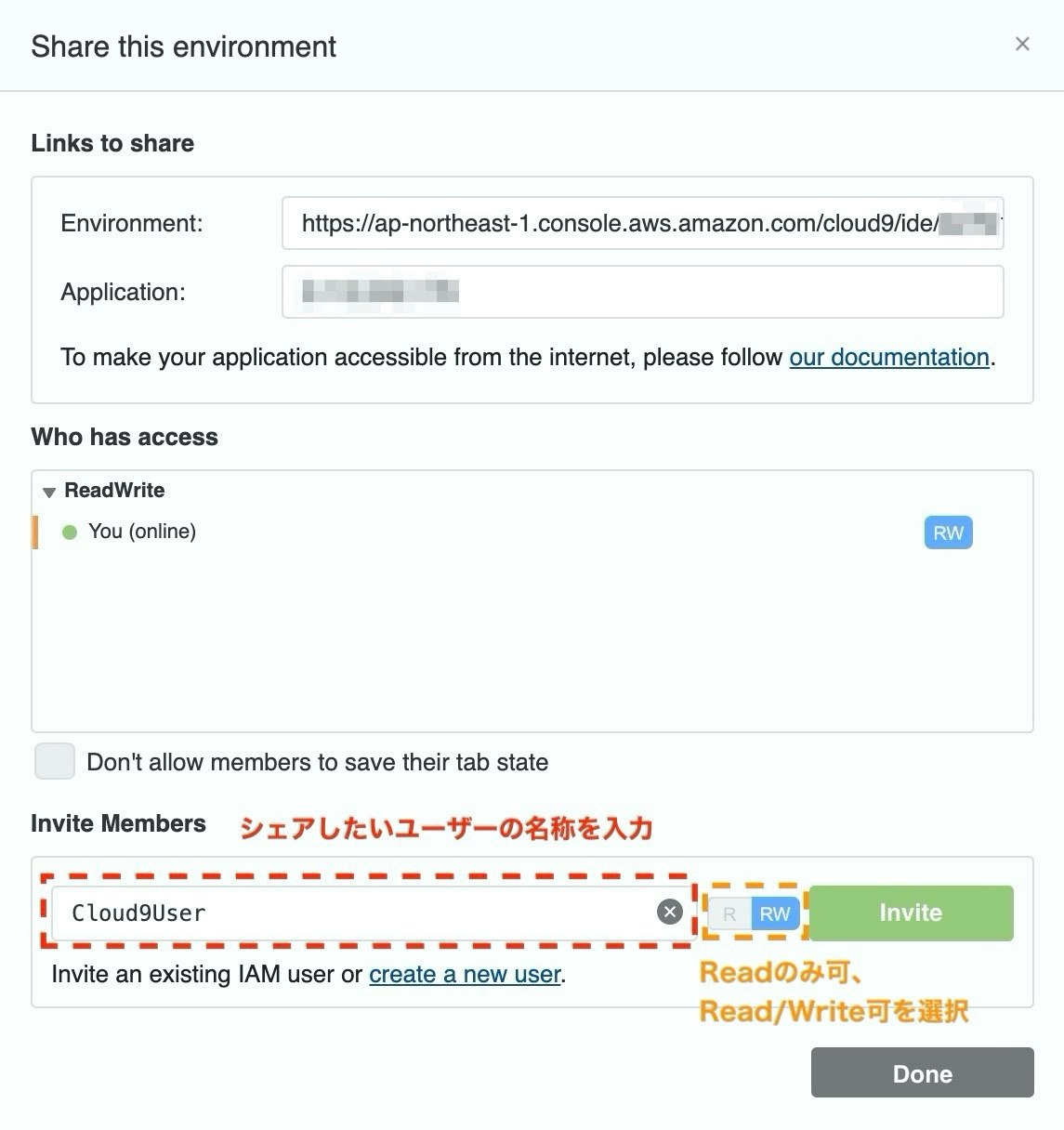
[Share]を押すと、以下の画面が表示されます。
ユーザーを招待することで、作成した環境を共有します。
シェアしたいユーザーの名称を入力し、R (Readのみ可), R/W (Read/Write可)のいずれを選択し、[Invite]をクリックします。
以上で、AWSCloud9User権限ユーザーの招待が完了しました。
[3] 共有環境を使用する
[3-1] 2つのユーザーで同時編集
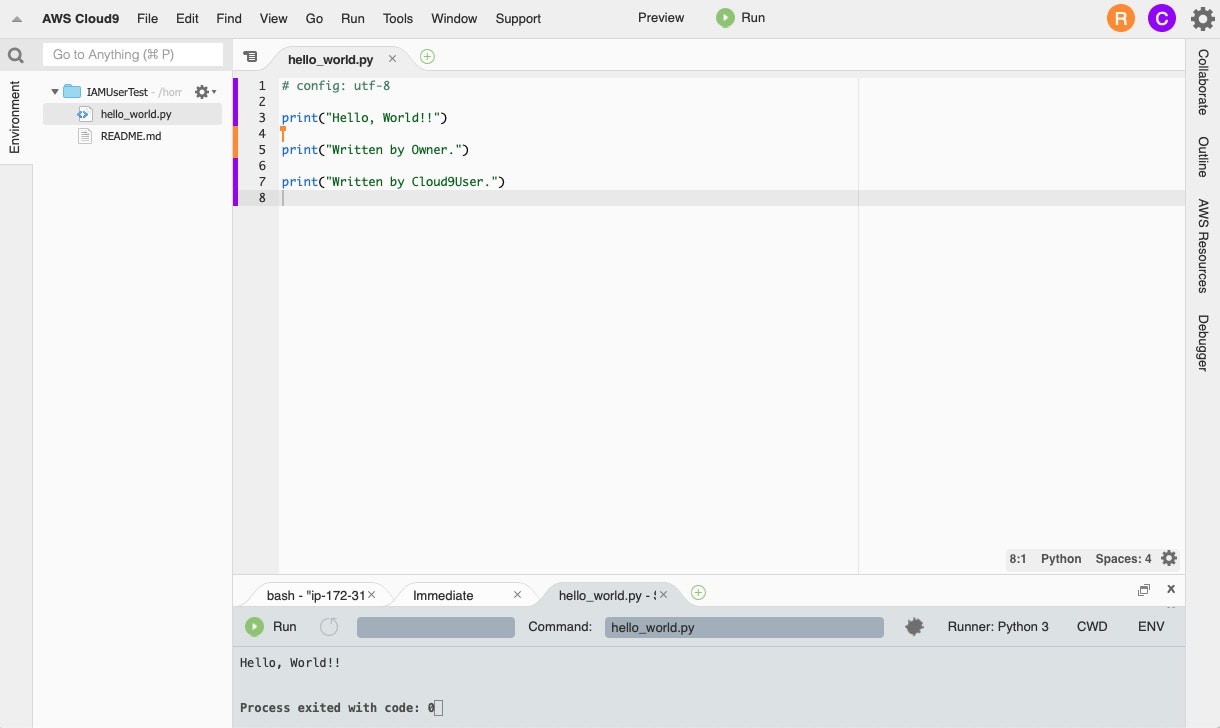
rootユーザーと先ほど招待したユーザーとで、同じファイルを編集してみたところ、ほとんど遅延なくお互いの画面に編集内容が反映されました。
ソースコードの行No.の左側に色が付いていますが、ユーザーごとに異なる色になっています。
どのユーザーがどの行を編集したのかが分かるようになっています。
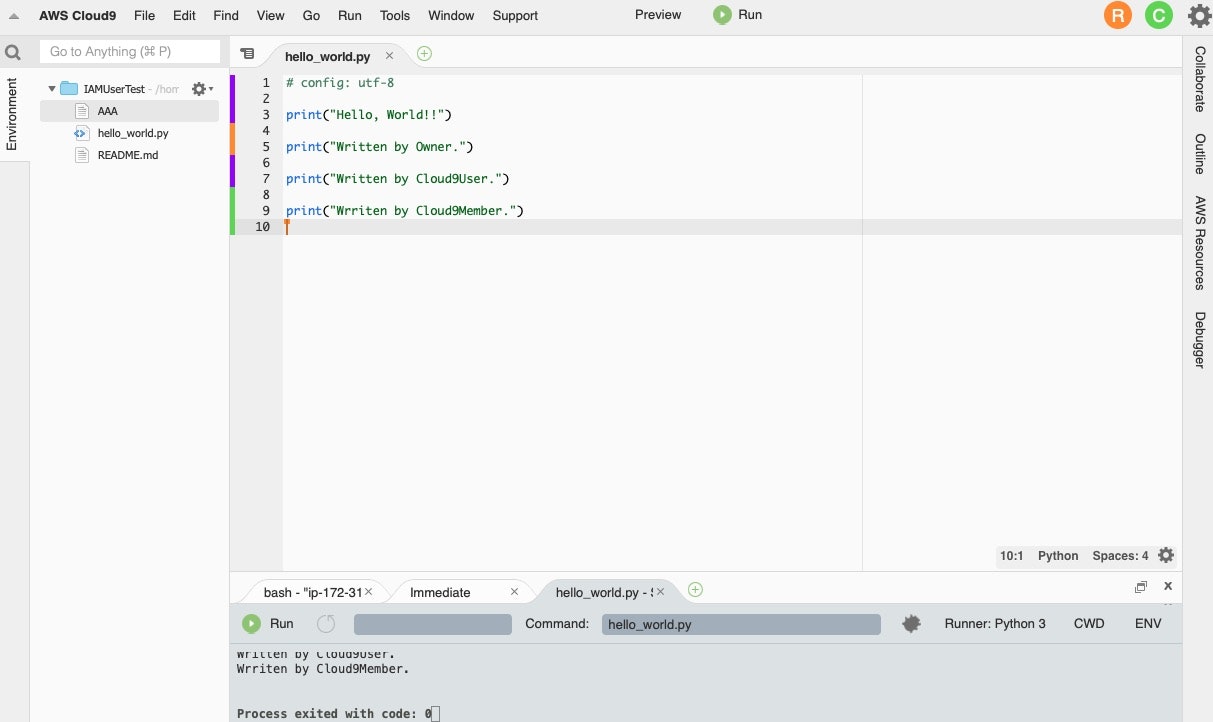
[3-2] 3つのユーザーで同時編集
もう1人ユーザーを招待し、同じファイルを編集した場合も同様です。
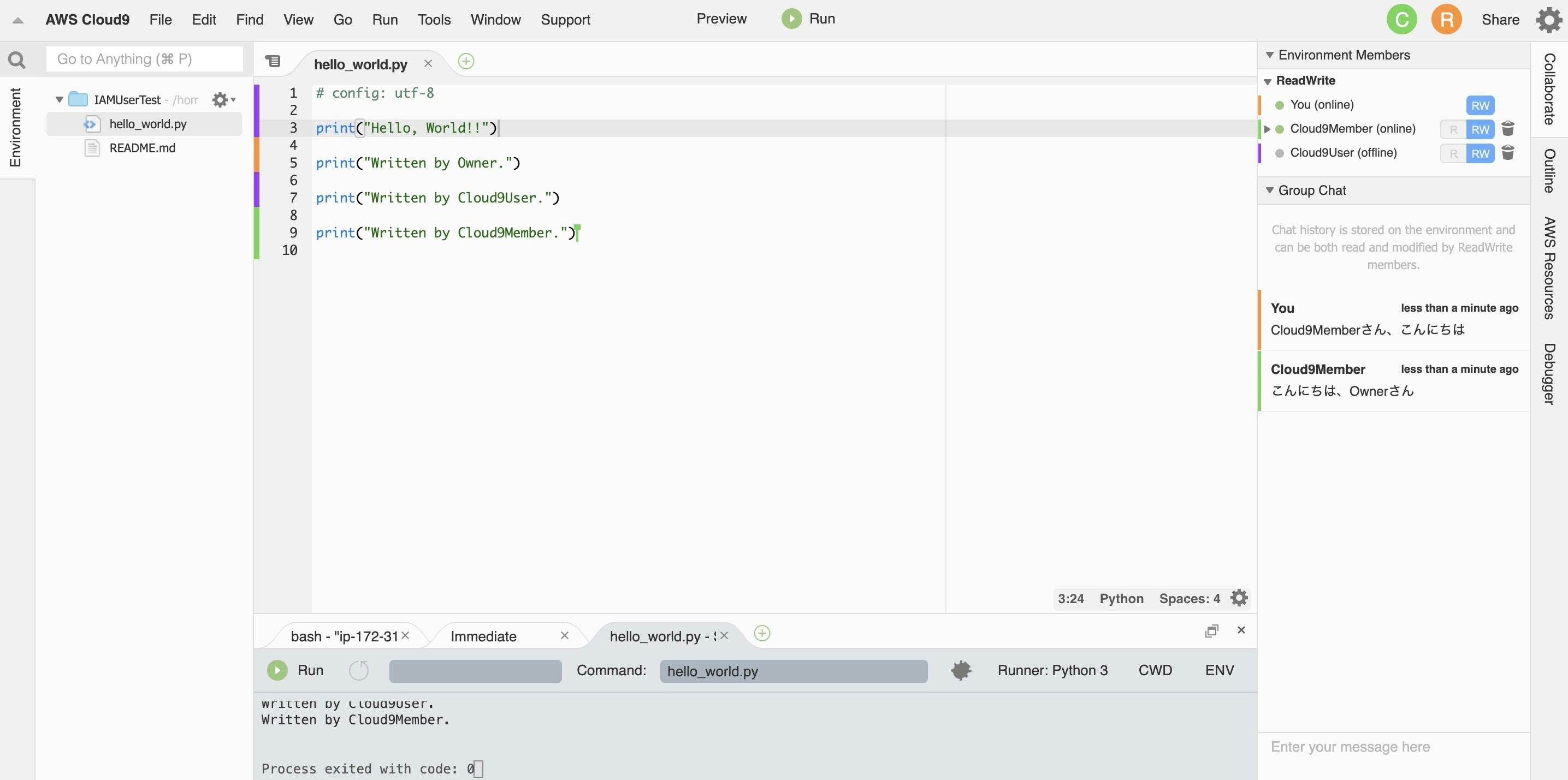
[3-3] チャット機能
チャットは画面右側に表示されます。
絵文字等はなく、最低限のチャットに必要な機能だけが提供されているという印象です。
終わりに
かなり簡単に共有環境を用意することができました。
実際に複数人で開発するにあたっては、色々とルールを決める必要はありでしょう。
しかしながら、数人でさくっと何かを作る、コードレビューを行う、といった場面では便利なこと間違いなしということが分かりました。参考文献
IAMユーザーのポリシー(権限)に関して、下記記事を参考にさせていただきました。
【AWS】cloud9へのアクセスのみが可能なユーザーを作成してコードを共有してみる

- 投稿日:2020-02-06T20:05:46+09:00
AWS経験4年がクラウドプラクティショナーにギリギリ合格した方法
概要
AWS経験4年が、クラウドプラクティショナーになんとか合格しました。
点数はまだ出てないですが体感ギリギリだったので、ここが大変だったよという意味でまとめたいと思います。AWS経験
フルスタックを名乗っていますが、経験としてはインフラよりはアプリケーション寄りです。
とはいえサービスの監視もやって来ましたし、LambdaやSQSなどを駆使したサーバレスアーキテクチャなども組んできました。試験までの準備
AWS Cloud Practitioner Essentials
経験者だと知ってる内容が何十分もひたすら説明されることになり、正直飽きます。
序盤だからこそだとは思いますが、そこにたどり着く前に脱落しました。
動画は本でいう「飛ばし読み」みたいなことがしづらいですし、時間効率悪いなーと思い本主体の勉強方法に変えました。AWS認定アソシエイト3資格対策
資格系は鮮度が命ということで新し目の本の中で、本屋で探していきました。
ソリューションアーキテクト用の本を買うのも躊躇われるので、大は小を兼ねるということでこちらを購入しました。
3資格対策本で4資格対策するのはやりすぎ感がありますが...
ただ試験日を早く設定しすぎて、データベースの章まで読んだところで試験日となってしまいました。
残りをパラパラめくって「まぁLambdaとかSQS出ても大丈夫だろー」と思いながら、試験に臨みます!試験
早めに到着したらすぐに初めても良いとのことだったので、トイレを済ませて試験に臨みます。
そして早速1問目、「Snowball」「Migration Hub」「Snowmobile」といった使ったことないサービス名が...
オンプレからの移行とか経験ないんだよなーと思いながら答えを推測する。
Migration Hubって名前は引っ掛け臭が強いし、一見答えっぽくない「Snow系」が2つ選択肢にある時点で怪しい。
mobileな訳ないので、Snowball、これが答えだ!と、まぁ学生時代を思い出すような感じでした。
日本文がわかりづらい
日本語の問題文がわかりづらい印象を受けました
あっさりしてるというか、答えを一意に特定しづらい感じ...
上に英文表示ボタンもあるので、たまにそれを使ってました
おそらく問題ごとに翻訳者が違っていて、agilityが「アジリティ」と翻訳されたり「俊敏性」と翻訳されてり安定してない印象も受けましたヒントが増えるので、英語も不自由なく読める人は有利だったろうなーと思います
問題グルーピング戦略
おそらくたくさんある問題の中から、候補者ごとにランダムに問題が選ばれています。
そのため他の問題と見比べると答えが見つかるものもあったりします。ここまで極端なものはないですが、
・問題1:DDoS対策に使えるサービスのは次のうちどれでしょう。1:XXX, 2:YYY, ...
・問題2:XXXはDDoS対策に使えるサービスですが、~~~
みたいな。そのため試験を進めながら問題をグルーピングしていく戦略が功を奏しました!
責任追求:1, 2, 5, 10
DDoS:3, 7, 11のようにメモしながら進めていって、全て解き終わってから同じグループの問題で見比べて、答えを精査していく感じです。
おかげで1週目は「確実に落ちたわ...」と思いながら進めていましたが、2週目は「割といけるかも?」となっていました。問題傾向
N=1なので参考になるかわかりませんが、問題傾向として多かったのが
- 責任共有モデル
- 費用系の問題
- セキュリティ(特にDDoS対策)
- オンプレから移行やオンプレと組み合わせたい系
あたりでした。
個人的にはあまり日常的に関わることのないものばかりです...
入り口の試験ということで、「今までオンプレでやってたけどAWS使ってみようかな?」みたいな人に向けた資格なのかもしれません。またサービス名を問う問題が多い印象でした。
「XXXに使えるサービスはなんでしょう?」みたいな。なんでサービス名とその機能を一通り覚えれば、割と簡単に合格できたかもなーと振り返れます。
まとめ
過去の自分に助言するとしたらこの辺りでしょうか...
- 油断するな
- サービス名と機能を丸暗記しろ
- 費用系・セキュリティ系を特に覚えろ
- 責任共有モデル覚えろ
まあ合格したので結果オーライ!
- 投稿日:2020-02-06T19:43:38+09:00
[チュートリアル] Amazon SageMakerでの学習・デプロイ
本記事では,Amazon SageMakerを用いて機械学習モデルの学習・デプロイを行うための必要最低限の知識を説明します.普段,仕事や学業で機械学習プロジェクトに携わっているけどAWSにあまり馴染みのないという方のお役に立てば幸いです.
また本記事は,AWSの3daysインターンシップで取り組んだことを題材に,インターンシップでチームを組んだ中田勇介さん(nakata_yusuke)と一緒に作成しました.コードはgithub上で公開しています.
Amazon SageMakerとは
Amazon SageMakerとは,機械学習モデルを高速に開発・学習・デプロイするためのマネージドサービスです.よく利用されるEC2は,主にインフラ(やフレームワーク等)を提供するためのサービスなので,EC2の1つ上のレイヤのサービスとなります.
Amazon SageMakerを利用することで,以下のような作業を簡単に行うことができます.
- 開発・学習環境の用意や環境構築
- 実験結果の管理
- 推論用のAPIサーバー構築やデプロイ
より詳細な説明は他に譲ることにして,以下ではAmazon SageMaker上でのモデルの学習・デプロイの仕方を説明していきます.(参考)
今回行うタスク
本記事で取り組むタスクは,レビュー・概念に基づく商品検索システムの構築です.インターンシップでは,Amazon Customer Review Datasetを使って自由にタスクを設定してよかったので,「利用者の意見を参考にしたい」「よりフワッとした商品検索をしたい」という検索システムの課題を想定し,このようなタスクを設定しました.
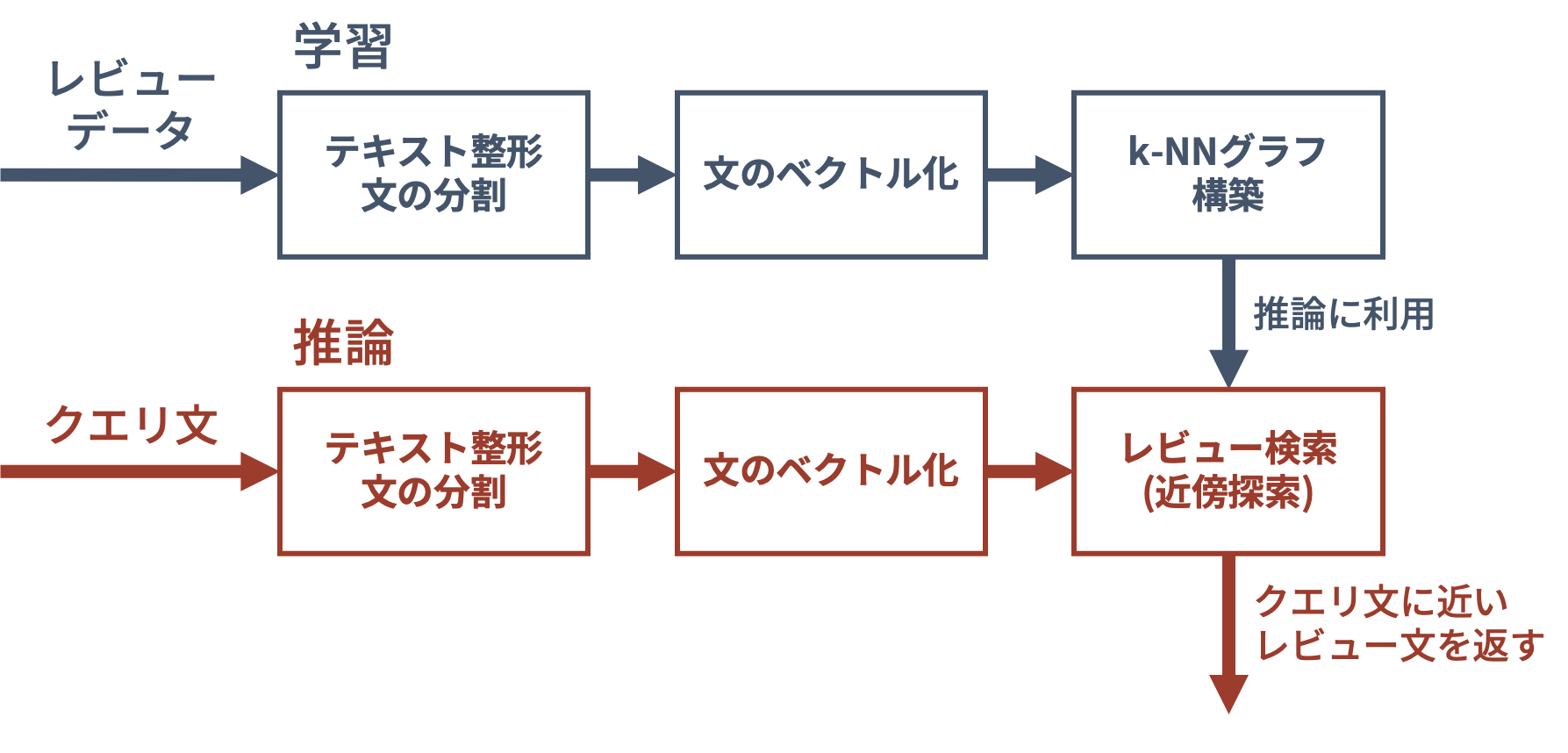
この検索システムでは,クエリに近い意味を持つレビューを探し出し,そのレビューに対応する商品を返します.レビューをもとに検索を行うことで利用者の意見をもとにした検索が,文の意味(分散表現)を用いることでより柔軟な検索が可能になると考えました.検索システムのイメージを下図に示します.
検索システムの構築は,以下の流れで行います.
- 学習
- レビューデータの前処理・文の分割を行う
- 学習済みのSentence-BERT(Nils and Iryna, EMNLP 2019)で文をベクトル化する
- ベクトルに関して,推論時の近傍探索を高速化するためにk-NNグラフを構築する
- 推論
- クエリ文を同様にベクトル化する
- 近傍探索を行い,クエリ文に意味が近いレビュー文を返す
- 後処理として,そのレビュー文に対応する商品のメタデータを取得する
処理の流れ全体のイメージを下図に示します.
以下では,簡単のため,Amazon Customer Review Datasetのうち
Toyカテゴリ,1万件のレビューのみを用いました.Amazon SageMakerでの学習・デプロイ
ここでは,Amazon SageMaker上で機械学習モデルの学習・デプロイを行う方法を説明します.
Amazon SageMakerでは,環境構築や学習・推論の実行にDockerコンテナを利用します.本記事では,Amazon SageMakerが提供するデフォルトのコンテナ(参考)を扱い,独自のコンテナを利用する方法については触れません.
以下では,AWSアカウントを持っていることを前提とし,
- IAMロールの作成
- データセットの準備
- 学習
- デプロイ & 推論
の順に説明をしていきます.
また,ノートブックに実際のコードを載せていますので,参照してみてください.
IAMロールの作成
Jupyter Notebook上からAmazon SageMakerを扱うためには,
AmazonSageMakerFullAccessを持ったIAMロールを作成する必要があります.これには,Amazon SageMakerが提供するノートブックインスタンスを利用する方法と,ローカルのJupyter Notebookを利用する方法の2つがあります.ノートブックインスタンスを利用する
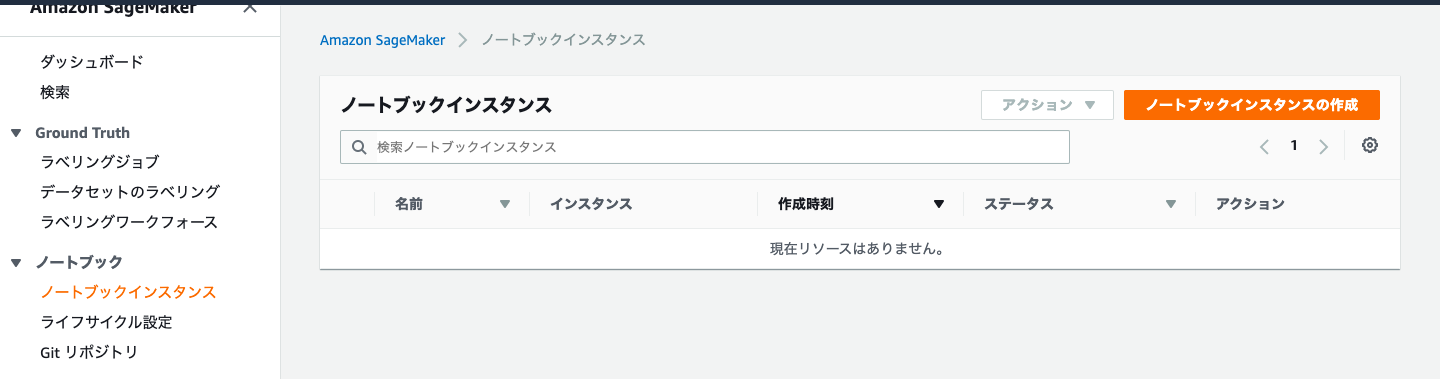
AWSマネジメントコンソールから,Amazon SageMakerのサービスページに飛び,左側の
ノートブックインスタンスを選択します(上図).ノートブックインスタンスの作成を選択し,インスタンスタイプ・IAMロールを適切した上でノートブックインスタンスを作成します(作成には数分かかります).デフォルトのIAMロールは,SageMakerが指定するS3バケットにアクセス可能で,難しいことを考えずにデータセットを置くことができます(おすすめ).IAMロール選択時に
新しいロールの作成を選び,利用したいS3バケットへのアクセス権を与えることもできます.ノートブックインスタンス上で下記を実行することで,ノートブックインスタンスに紐づけられたIAMロールを取得することができます.
from sagemaker import get_execution_role role = get_execution_role()ローカルのJupyter Notebookを利用する
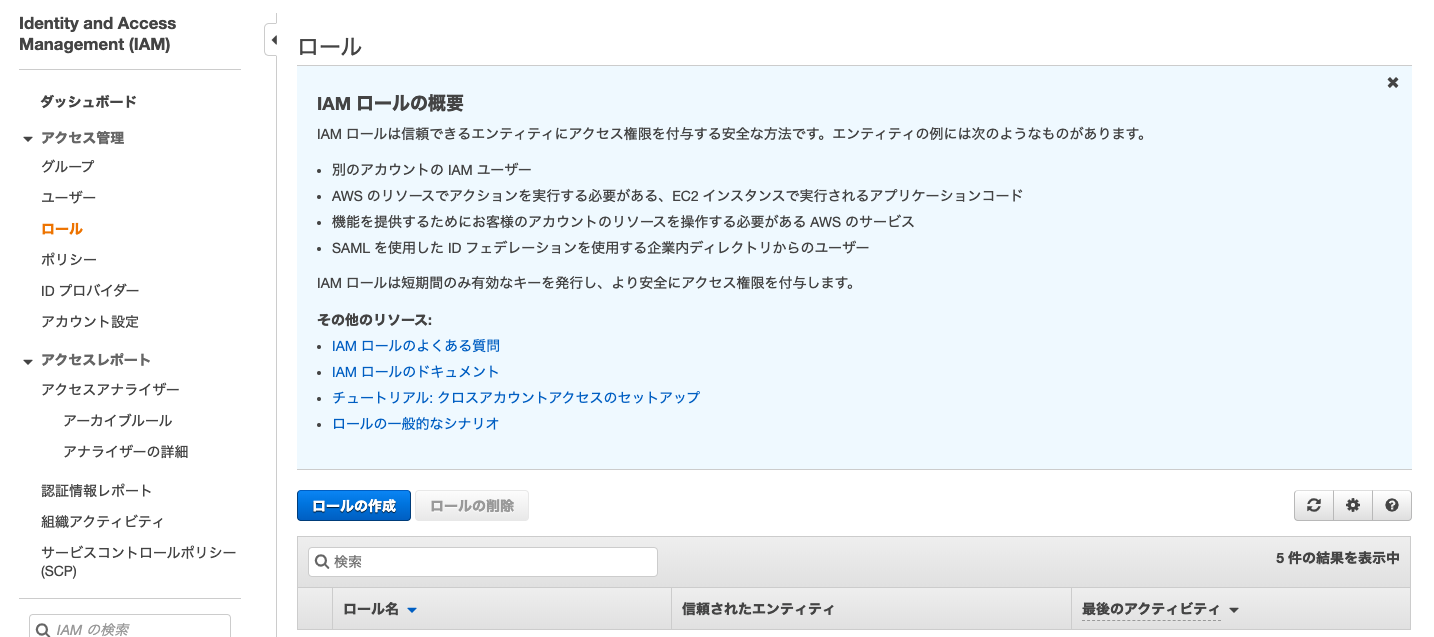
ローカルでJupyter Notebookを利用する場合,AWSマネージメントコンソール上で
AmazonSageMakerFullAccessを許可したIAMロールを作成する必要があります.IAMのサービスページからロールの作成を選択し,サービスを選択する画面でSageMakerを選択すれば,必要なIAMロールを作成することができます.IAMロールを作成後は,自分のAWS IDと作成したロール名を用いて下記を実行することで,作成したIAMロールを取得することができます.
role = 'arn:aws:iam::[12桁のAWS ID]:role/[ロール名]'データセットの準備
学習に利用するデータセットを準備する最も簡単な方法は,データをS3にアップロードすることです.ノートブックインスタンスを利用している場合には,下記の例のように,SageMakerが指定するS3バケットに簡単にアップロードすることができます.S3では,パスではなくキーによってファイルを管理するため,本来は階層構造が存在しません.キーに
/を含めることで,階層構造を持つように管理することも可能です.import sagemaker sess = sagemaker.Session() s3_dataset_path = sess.upload_data( path='./dataset', # ディレクトリまたはファイルのパス key_prefix='data/train' # S3でのキー )ローカルの場合には,
boto3を用いてアップロードすることができます.ただし,S3を扱える適切なIAMロールを発行しておくことが必要です(参考).学習
SageMakerの学習・推論は,それぞれ学習・推論用のインスタンス上でコンテナを走らせることで行われます.今回はデフォルトで提供されているPyTorchコンテナを利用しますが,TensorFlowやKerasでも同様の手順で学習・デプロイを行うことが可能です.
以下では,データセット(S3にアップロード済み),自作モジュール(
searchモジュール),その他学習に必要なファイル(modules.pickle)を利用して,モデル(Sentence-BERTとkNNグラフ)を学習することを想定します.Estimatorの作成
学習・デプロイ(推論)を行うためには,まず
Estimatorインスタンスを作成します.Estimatorには,学習・推論時の環境構築や処理内容などの情報をが含まれており,下記のように作成します.from sagemaker.pytorch import PyTorch # Create estimator. estimator = PyTorch( entry_point='entry_point.py', # 学習・推論処理を記述したスクリプト(`source_dir`以下に配置しておく) source_dir='source_dir', # 学習用インスタンスにコピーしたいファイルを配置しておく dependencies=['search'], # 独自モジュールのリストを指定 role=role, # 作成したIAMロールを指定 framework_version='1.3.1', # torch>=1.3.1を推奨 train_instance_count=1, train_instance_type='ml.m4.xlarge')この例では,以下の構成のファイルを利用しています.
. ├── search # kNNグラフ用のモジュール │ ├── __init__.py │ └── ... ├── source_dir │ ├── modules.pickle # 学習時にはコピーされる.推論時にはコピーされない. │ ├── requirements.txt # 依存ライブラリ │ └── entry_point.py # 学習・推論処理を記述したスクリプト ...
source_dir以下には,学習用のEC2インスタンスにコピーして欲しいファイル(modules.pickle)に加えて,学習・デプロイ時の依存ライブラリを記したrequirements.txt,学習・推論処理を記述したコードentry_point.pyを置きます.source_dir以下のファイルは,学習時にはカレントディレクトリ以下にコピーされます.ただし,推論用インスタンスにはコピーされないので注意が必要です.また,自作モジュールはdependenciesにリスト形式で指定します.学習を行うためには,学習コードと推論のための4つの関数を記述した
entry_point.pyを作成する必要があります.以下では,entry_point.pyの中身について詳しく説明していきます.また,ここに実際の例を載せておきます.学習コード
学習では,
entry_point.pyのmain部分を実行し,os.environ['SM_MODEL_DIR']以下に学習済みモデルや推論時に必要なファイル全てを保存します.そうすることで,推論時に保存したモデルを利用することができます.学習用のデータセットは,os.environ['SM_CHANNEL_TRAIN']におくことにします(後述).下記の例では,Sentence-BERTのネットワーク構造と重みを保存したファイル
modules.pickleをそのままコピーし,近傍探索するためのインスタンスproduct_searchを保存しています.本来はSentence-BERTを学習させたりするのですが,簡単のため学習済みモデルをそのままコピーしています.モデルを学習させる処理は,main部分で実行されるように記述する必要があります.# You can train Sentence-BERT or kNN graph here. def train(args): # Copy the pretrained Sentence-BERT model. subprocess.call([ 'cp', 'modules.pickle', os.path.join(args.model_dir, 'modules.pickle')]) # Load datasets. reviews = pd.read_csv(os.path.join(args.train, '10000_review.csv')) sentences = pd.read_csv(os.path.join(args.train, '10000_sentence.csv')) embeddings = np.load(os.path.join(args.train, '10000_embedding.npy')) # Construct and train search engine. product_search = ProductSearch(reviews, sentences, embeddings) product_search.save( os.path.join(args.model_dir, 'product_search.pickle')) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR']) parser.add_argument('--train', type=str, default=os.environ['SM_CHANNEL_TRAIN']) parser.add_argument('--current-host', type=str, default=os.environ['SM_CURRENT_HOST']) parser.add_argument('--hosts', type=list, default=json.loads(os.environ['SM_HOSTS'])) train(parser.parse_args())model_fn 関数
この関数は学習したモデルを読み込む関数で,
model_dirを引数として受け取り,学習済みのモデルを返します.この関数の返り値はどのような形式でもよく,この返り値がそのままpredict_fnの引数(model)となります.下記の例では,Sentence-BERTとProductSearchのインスタンスを辞書形式で返しています.
def model_fn(model_dir): device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # Load the trained Sentence-BERT. with open(os.path.join(model_dir, 'modules.pickle'),'rb') as f: modules = pickle.load(f) vectorizer = SentenceTransformer(modules=modules).eval().to(device) # Load the trained search engine. product_search = ProductSearch( index_path=os.path.join(model_dir, 'product_search.pickle')) return { 'vectorizer': vectorizer, 'product_search': product_search }input_fn 関数
この関数はクライアントからのリクエストを前処理する関数で,引数は
input_dataとcontent_typeの2つです.リクエストの形式は引数
content_typeで与えられ,NPY形式(application/x-npy),JSON形式(application/json),CSV形式(text/csv)のみ利用可能です.この関数の返り値はどのような形式でもよく,この返り値がそのままpredict_fnの引数(data)となります.下記の例では,JSON形式のみ受けつけ,JSONオブジェクトを読み込み,
convert_text_into_sentencesで前処理を行った上で返しています.def input_fn(input_data, content_type): assert content_type == 'application/json' request = json.loads(input_data) return { 'query': convert_text_into_sentences(request['query']), 'n_items': request['n_items'] }predict_fn 関数
この関数は推論を行う関数です.引数は
dataとmodelの2つで,それぞれinput_fnとmodel_fnの返り値が入っています.ここで,リクエストに関する推論を行い,推論結果を返します.この関数の返り値はどのような形式でもよく,この返り値がそのままoutput_fnの引数(prediction)となります.下記の例では,Sentence-BERTによるベクトル化,kNNグラフによる近傍探索を行い,結果を辞書形式にして返しています.
def predict_fn(data, model): sentences, n_items = data['query'], data['n_items'] vectorizer, product_search = model['vectorizer'], model['product_search'] # Vectorize. with torch.no_grad(): embeddings = np.array(vectorizer.encode(sentences), dtype=np.float32) # Search. prediction = product_search.search(embeddings, n_items=n_items) # Convert list into dict. prediction = {f'pred{str(i)}': pred for i, pred in enumerate(prediction)} return predictionoutput_fn 関数
この関数は推論結果を後処理し,レスポンスを返す関数です.引数は
predictionとacceptの2つで,predictionにはpredict_fnの返り値が入っています.ここで,推論結果を指定された形式のオブジェクトに永続化して返します.レスポンスの形式はinput_fnと同様の3つの形式のみ可能で,引数acceptで与えられます.下記の例では,辞書をJSONオブジェクトに変換しています.
def output_fn(prediction, accept): return json.dumps(prediction), accept学習の実行
entry_point.pyを作成できたら,Estimatorのfitメソッドを呼び出すことで学習を行うことができます.fitメソッドの引数には,学習用データセットを辞書形式で指定します.ここでは,
trainキーにデータセットを指定しているので,'SM_CHANNEL_TRAIN'という環境変数にデータセットのパスが格納されます.検証用データセットを用意したい場合は,evalキーにS3のURLを指定することで,'SM_CHANNEL_EVAL'という環境変数に検証用データセットのパスが格納されます.# Train. estimator.fit({'train': '[s3://から始まるデータセットのURL]'})デプロイ & 推論
下記で学習したモデルをデプロイすることができます.これには時間がかかります(10-15分程度).
# Deploy the trained model. predictor = estimator.deploy( endpoint_name='[エンドポイントの名前]' initial_instance_count=1, instance_type='ml.m4.xlarge')推論エンドポイントをデプロイしたら,APIを通じて推論リクエストを送ることができます.下記の例では,リクエストは
BodyにJSON形式で指定しています.import boto3 client = boto3.client('sagemaker-runtime') # Query and number of results. request = { 'query': 'My children liked it', 'n_items': 1 } # Request. response = client.invoke_endpoint( EndpointName=[エンドポイントの名前], ContentType='application/json', Accept='application/json', Body=json.dumps(request) )例えば,今回デプロイしたモデルでは,以下のようなレスポンスがJSON形式で返ってきます.
review_id: R2XKMLHEG7Z402 product_id: B00IGNWYGQ product_title: Play-Doh Mix 'n Match Magical Designs Palace Set Featuring Disney Princess Aurora star_rating: 4.0 review_headline: Inventive and fun, some parts hard to do product_search_score: 0.9600517749786377 matched_sentence: my kids loved this. review_body: My kids loved this. Lots of sparkly play doh and tons of molds. One star comes off because it's hard to get play do to press out of the skirt, and once you're done with that it's tough to get the skirt to come off the little pedestal.推論エンドポイントは,起動している間ずっと課金され続けてしまうので,不要になった時には削除するようにしましょう.
predictor.delete_endpoint()まとめ
今回はAmazon SageMakerでの学習・デプロイのチュートリアルを行いました.ログの管理や分散学習,独自コンテナによる柔軟な開発など,今回説明していない便利な機能が多々存在します.今後もこのようなチュートリアルや解説を積極的に発信していこうと思います.
最後まで読んでいただき,ありがとうございました.

- 投稿日:2020-02-06T16:30:07+09:00
[AWS]Ubuntu18.04などでlocal TLDが名前解決できない問題
Problem
内部リソースのドメイン名として、
.localとするケースはよくあると思いますが、AWSで運用しているサーバをUbuntu18.04にアップグレードした途端、これまでアクセスできていた.localの内部リソースにアクセスできなくなるというトラブルに遭遇しました。実は、Ubuntu18.04では TLDが
.localのものは名前解決できません。これはOS(systemd-resolved)の仕様です。原因
https://www.freedesktop.org/software/systemd/man/systemd-resolved.html
そもそも.localはマルチキャスト DNS のために予約されたドメイン(.localTLDは RFC6762 にて非推奨)であり、Ubuntu 18.04 における systemd-resolved の挙動は独自の実装ではなく RFC の規約に準拠したものとのこと。
.localドメインの名前解決を DNS サーバに対してではなく LAN に対するマルチキャストによって行おうとするが、AWSではマルチキャストをサポートしていないため、名前解決に失敗するというわけです。かつてはマイクロソフトもActiveDirectoryのドメイン名として
.localを推奨していた時期もありましたが、今は非推奨としているようです。
https://social.technet.microsoft.com/wiki/contents/articles/34981.active-directory-best-practices-for-internal-domain-and-network-names.aspxSolution
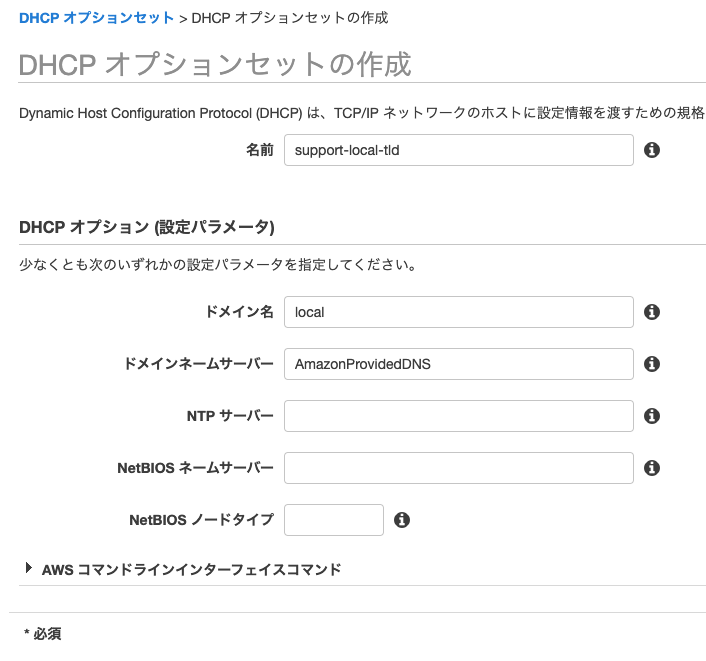
.localドメインへの名前解決要求を明示的にAWSの内部DNSへ送るために、VPC のDHCPオプションセットにて以下のように.localに対する DNS サーバーにAmazonProvidedDNSを明示的に指定します。
- ドメイン名:
local- ドメインネームサーバー:
AmazonProvidedDNS
OSアップグレードの際は気をつけましょう。
- 投稿日:2020-02-06T16:23:47+09:00
AWS Lambdaでカナリアリリースする
LambdaのVersionとAlias
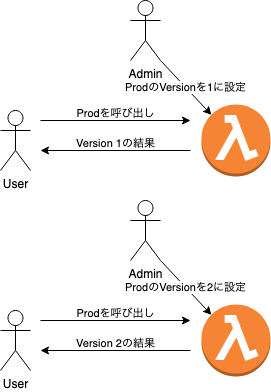
AWS LambdaではPublishすると固有のVersion番号が割り当てられる。
Versionには任意の名前のAliasをつけることが可能で、Aliasに関連付けるVersionを変更することで、Aliasを指定してFunctionを呼び出しているユーザが利用するVersionを変更することができる。
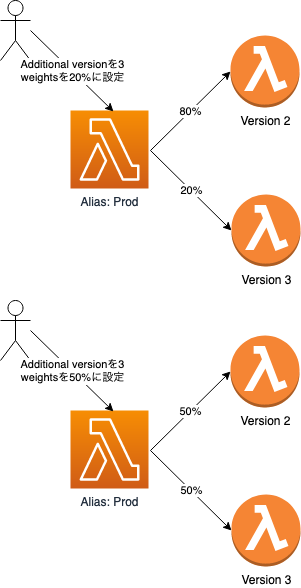
Additional versionを用いて、新しいVersionをカナリアリリースする
Aliasには Additional versionというオプションが存在し、主として指定したVersionとは異なるVersionとその呼び出し割合を指定することができる。
Additional versionの有無や呼び出し割合は任意のタイミングで変更ができ、新しいVersionの呼び出し割合を徐々に増やしていくカナリアリリースが可能である。
Additional versionの設定方法
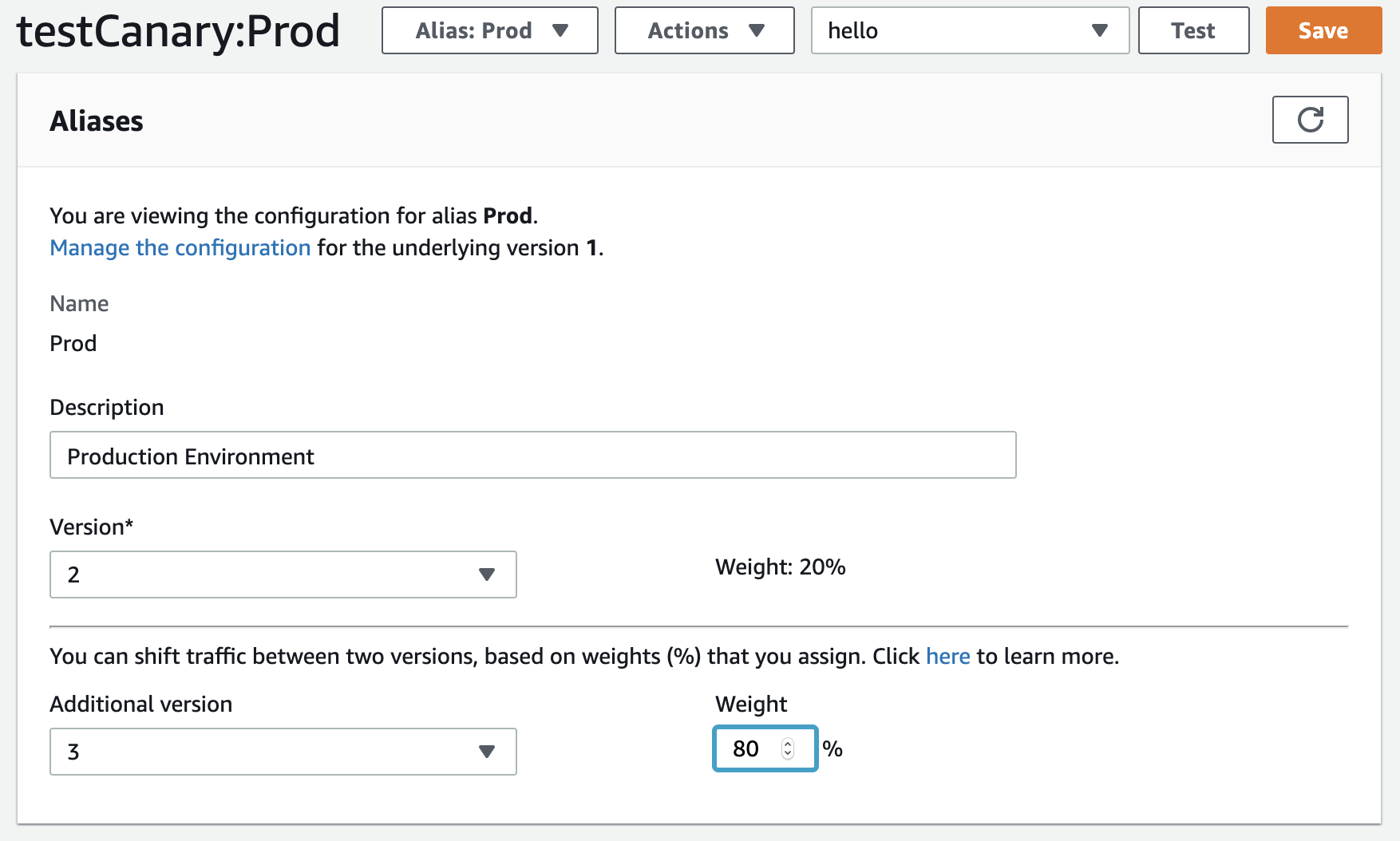
Management Consoleで設定する場合
Aliasの設定画面で、Additional version及びWeightを入力し、保存する。
Weightには0〜100の間の整数を入力する。
AWS CLIで設定する場合
lambda create-aliasもしくはlambda update-aliasの --routing-config オプションで設定する。
Weightsは0.00〜1.00の小数で指定する。aws lambda update-alias \ --function-name testCanary \ --name Prod \ --function-version 2 \ --routing-config 'AdditionalVersionWeights={"3"=0.8}'どのVersionが呼び出されたか確認する
AWS CLIで呼び出した際の戻り値
レスポンスの ExecutedVersion プロパティに、実際に呼び出されたVersionの番号が出力される。
※同期呼び出しをした場合に限る$ aws lambda invoke \ --function-name testCanary \ --qualifier Prod \ --region ap-northeast-1 \ - { "StatusCode": 200, "ExecutedVersion": "3" }CloudWatch
CloudWatchでは、呼び出しに用いられたAliasとVersionごとにメトリクスを取得できる。
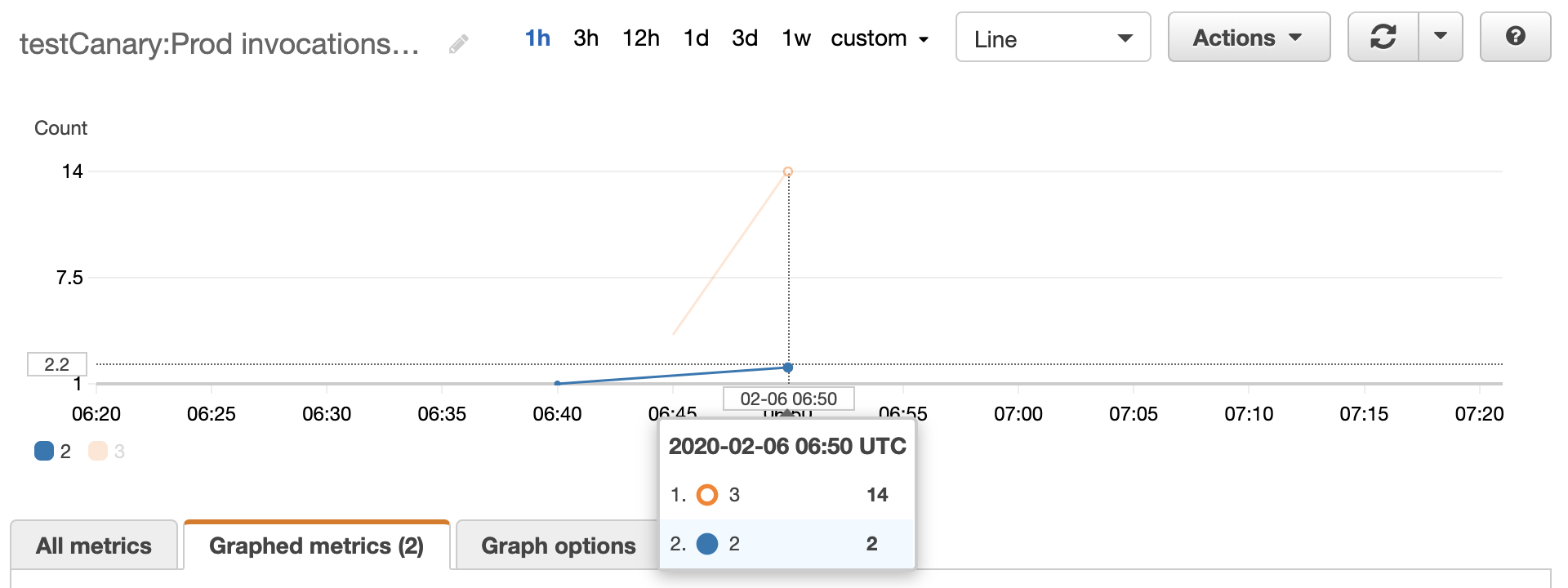
- 投稿日:2020-02-06T15:30:03+09:00
AWSルートアカウントのMFA(2段階認証)用の携帯が手元にない場合、着信1回で取らないと無限ループになる
はまった問題
https://aws.amazon.com/jp/premiumsupport/knowledge-center/lost-broken-mfa/
- AWSルートアカウントの二段階認証番号が昔の電話番号に向けて送られているため、ログインできない状態。新しい電話番号に設定したい
- 上記URLの「unusable~」から専用フォームで問い合わせ、電話が来るのを待つが、いちど不在着信で取れずかけなおすことに
- かけなおすと、カスタマーサポートの自動音声が流れ、AWS関係を問い合わせる番号はなく、とりあえずその他を押す
- AWSがわからない人が出てきていろいろ言われるが何も意味はなくもう一度2に戻る
なぜこうなったのか
おそらく、Amazonのユーザ側のカスタマーサポートが出てきちゃうので何もできなかったんだと思います。
さらに、どうやら日本のカスタマーサポートは中国人の方が非常に多くたまたまその人にあたってしまったのも大きそうです。
英語と日本語でサポート言語が選べますが、日本語の場合対応が遅いので英語のほうが絶対よかったと思いました。
教訓
着信がきたら必ず取れるようにしよう!(消音モードだった)
- 投稿日:2020-02-06T15:15:31+09:00
CloudWatchのログをlocalにdownload
CloudWatchのをlocalにdownloadしたい
get-log-eventsで落とせるとおもったけど、これloopさせないと全部取れないんですね。
download.sh#!/bin/bash log_group_name=$1 log_stream_name=$2 response=`aws logs get-log-events --log-group-name ${log_group_name} --log-stream-name "${log_stream_name}" --start-from-head` next_token=`echo $response | jq -r '.nextForwardToken'` while [ -n "${next_token}" ]; do echo ${response} | jq -r .events[].message response=`aws logs get-log-events --log-group-name ${log_group_name} --log-stream-name "${log_stream_name}" --start-from-head --next-token ${next_token}` next_token=`echo $response | jq -r '.nextForwardToken'` if [[ $(echo ${response} | jq -e '.events == []') == "true" ]]; then break fi done./download.sh /aws/lambda/hoge '2020/00/00/[$LATEST]xxxxxx'注意 lambdaのlog streamは$があるのでシングルクォートで囲む
- 投稿日:2020-02-06T11:20:56+09:00
【AWS】EC2へのMetabaseの導入
以前、Elastic Beanstalkで構築しようとしたのですが、望んだとおりの結果が得られなかったので、自分でEC2へ導入してみようと思いました。
EC2インスタンスの用意
今回は「t3.small」を利用することにしました。
EBSは汎用SSDの10GBにしました。
※ Metabaseはポート3000で起動するので、3000にアクセスできるようにセキュリティーグループの設定をしてください。
※ Metabaseにアクセスする為に、Public IPアドレスを付与してください。
インスタンス生成時の設定 or Elastic IPEC2へDockerをインストールする
yumアップデート
まずは、yumをアップデートします。
yumのアップデートsudo yum update -y
complete!が表示されれば完了です。Dockerインストール
Dockerをインストールします。
Dockerのインストールsudo yum install docker -yDockerの起動
Dockerを起動します。
Docker起動sudo systemctl start docker起動コマンドのが実行できれば、下記のコマンドで起動できているかを確認します。
起動確認コマンドsudo systemctl status docker確認コマンド実行結果● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; disabled; vendor preset: disabled) Active: active (running) since Thu 2020-02-06 00:51:30 UTC; 24s ago実行結果に
Active: active (running)と表示されていれば正常に起動されています。Dockerの自動起動設定
再起動等を行った際に、Dockerを自動で起動するように設定します。
Docker自動起動設定sudo systemctl enable docker下記のような実行結果が表示されていれば、自動起動の設定が完了しています。
自動起動設定結果Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.ユーザーをDockerグループに追加
ec2-user を docker グループに追加すると、sudo を使用せずに Docker コマンドを実行できます。
ユーザー追加sudo usermod -a -G docker ec2-user実行が完了したら、下記のコマンドでDockerコマンドが実行できるか確認してください。
確認用コマンドdocker info実行が成功した場合の結果表示Containers: 0 Running: 0 Paused: 0 Stopped: 0 Images: 0 Server Version: 18.09.9-ce Storage Driver: overlay2 ・ ・ ・確認コマンドが失敗する場合
下記の例のように表示された場合は、実行が失敗しています。
失敗時メッセージGot permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.39/info: dial unix /var/ru n/docker.sock: connect: permission deniedこの場合、Dockerを再起動する必要があります。
下記のコマンドで再起動後、再度確認してください。Docker再起動sudo systemctl restart docker上記のコマンドでも正常に実行できない場合は、インスタンスを再起動してみてください。
Metabaseのインストール
今回は、ローカルファイルシステムを使用して、H2埋め込みデータベースを実行し、アプリケーションのデータを保存する方法にします。
この方法だと、コンテナを削除すると、設定ファイル等がすべて消えてしまうので、本番運用をする際は、RDS等にPostgresSQL等のDBを用意して、アプリケーションデータを保存することが必要です。Metabaseのdocker実行docker run -d -p 3000:3000 --name metabase metabase/metabase起動の確認
EC2のインスタンスのパブリックIPアドレスを確認します。
上記方法で確認したIPアドレスの3000番ポートにブラウザでアクセスします。
http://XX.XXX.xxx.xxx:3000下記のような画面が表示されれば完了です。
Metabaseの初期設定
開始しましょうをクリックします。
個人情報の入力
必要な情報を入力します。
データを追加する
利用するデータベースの情報を追加します。
データ使用の優先度
Metabaseへの動作レポートの送信を行うかを選択する事ができます。
EC2再起動時の設定
コンテナの一覧を表示する
コンテナの情報を表示し、起動するコンテナIDを確認する。
コンテナの一覧を表示docker ps -a実行結果CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 01254c6459fa metabase/metabase "/app/run_metabase.sh" 8 hours ago Up 6 minutes 0.0.0.0:3000->3000/tcp metabaseコンテナの起動
下記のコマンドでコンテナを起動します。
コンテナの起動docker start <CONTAINER ID>コンテナの自動起動設定
起動するコンテナ名を取得します。
コンテナ名の取得docker ps -aコンテナの自動起動設定docker update --restart=always <コンテナ名>下記のコマンドで自動起動の設定を確認できます。
自動起動設定確認コマンドdocker inspect -f "{{.Name}} {{.HostConfig.RestartPolicy.Name}}" $(docker ps -aq) | grep always自動起動の無効化
コンテナの自動起動を無効化docker update --restart=no <コンテナ名>実行ログの取得
コンテナIDを取得し、実行情況を表示します。
コンテナIDの検索方法docker ps -a実行状況の取得docker logs -f -t <コンテナID>



- 投稿日:2020-02-06T08:27:39+09:00
AWS Solution Architect Professional合格レポート
昨日AWS Solution Architect Professionalを受験し、無事合格できましたのでまとめておきます。
合格とは言っても、点数は合格ギリギリなので参考程度に見て下さい。
先日AWS Certified DevOps Engineer - Professionalも一応合格していて、同じくレポート書いてます。
⇛AWS DevOps Professional合格レポート
資格取得状況
資格 取得日 AWS Certified Solutions Architect - Associate (SAA) 2019-03-01 AWS Certified Developer - Associate (DVA) 2019-08-29 AWS Certified SysOps Administrator - Associate (SOA) 2019-09-28 AWS Certified DevOps Engineer - Professional (DOP) 2020-01-18 AWS Certified Solution Architect Professional (SAP) 2020-02-05 ようやく5冠…!前回のDevOpsから20日程度での受験となってます。
AWS勉強して約1年で取得することができました。学習方法
- Advanced Architecting on AWS
- 公式E-ラーニング
- 模擬試験
- Blackbelt
- ユーザーガイド
- Udemy問題集
Advanced Architecting on AWS
会社で枠が残っていたので受験の1週間前に受講。
業務で触ったことがあるサービス以外については浅く広く学習する良い機会でした。ただこれだけで合格するのは難しいと思いますし、BlackBelt読む方がサービスに対しての理解が深まります。
とはいえディスカッションの時間と講師への質問できる環境だったため、とても有意義に過ごすことができました。
公式E-ラーニング
こちらも学習の足がかりとしてはとても便利です。
ただDevOps Proとは違い、一番大事かと言われると優先度は少し下がるかもしれません。模擬試験
結果は70%でこれまで受けた模擬試験で一番高かったです。ここで少し安心してしまったのが良くなかった…
もうPro受ける方々は承知だと思いますが、必ず試験中のスクリーンショットを撮って復習できるようにしておきましょう。
Blackbelt
私は以下のサービスを中心に読みました。
正直これでも足りなかったかなと思っています。DevOps Proを受けた後だったので、Code系やCloudWatch、Systems Manager等のサービスは特に勉強していません。API GatewayやLambdaは読むの忘れてましたが、Dynamoと合わせて出題されることが多いのでカバー必須です。
太字は強いて言えば重要だと思うサービスです。
- AWS Organizations
- AWS Shield
- AWS WAF
- AWS CloudHSM
- Amazon Cognito
- AWS Certificate Manager
- Amazon Kinesis
- Amazon Redshift
- Amazon Route 53
- Amazon CloudFront
- AWS Database Migration Service
- Amazon DynamoDB
- AWS Storage Gateway
- Amazon S3
ユーザーガイド
模擬試験や問題集でわからない部分を確認するために使用していました。
Udemy問題集
前回のDevOpsと同じ人の問題集が良かったのですが、まだ出ていないようだったので、評価が高めのこちらをセールで購入しました。
AWS Certified Solutions Architect Professional Practice Exam
75×4回分が入っているのですが、時間がなく2回分しか解けませんでした。
多分ですが、しっかり4回分解いて復習していれば、合格ラインは超えられるように作られていると思います。ただとにかく文章量が多く2回でも辛かったです。
感想
とにかく範囲が広く、AWS最高難度と言われているだけあります。受験中は自信を持って回答できない問題が多く正直落ちたと思いました。
私自身がDNSや暗号化、認証の知識に疎く、ACMやRoute53、CognitoやAD絡みの問題に非常に苦労しました。この辺はAWSというより一般的なIT知識として勉強しなければならない部分なので、これから受験される方は基礎から勉強してもいいかもしれません。
DDoS関連のサービスは全く出題されなくて少し凹みました。
噂には聞いていましたが、問題の誤訳が多くてびっくりしました。笑っちゃうような誤訳なら許せますが、言っている意味がわからない問題がいくつかあり、足りない英語力で解き直す必要があったのが辛かったです。
まとめ
とにかく難しいので十分に勉強時間をとってから挑みましょう。受験料も高いので。
以下の流れで、特に6を頑張れば合格に近づくはずです。
- E-ラーニングを見る
- 模擬試験を受ける
- 模擬試験の復習
- Udemy問題集を解く
- 解けなかった問題の復習
- 4と5を全問できるまで繰り返す
参考になれば幸いです。
- 投稿日:2020-02-06T08:00:48+09:00
AWS学習 もくじ
まえがき このページはAWSの学習用のメモです。
学習の目的
・AWSの基礎学習
・AWS認定ソリューションアーキテクト-アソシエイト試験の合格
・ハンズオンでAWSの操作方法を学習1.学習した項目
IAM
EC2
VPC
S3(Simple Storage Service)
Route53
RDB
ハンズオン
2.学習方法
Udemy
3.その他
~ Linux学習 ~
参考
- 投稿日:2020-02-06T04:13:57+09:00
Aurora(MySQL互換)で、外部キーが絡んだINSERT/UPDATEによるデッドロックが検知されない問題
何が起きたのか
たまーにproduction環境でデッドロックが発生した
デッドロック発生時のログや各処理ごとで実行されるSQLのログから調査して
デッドロックが発生するクエリは特定できたがstagingやローカルでは再現せず
環境 DB production MySQL互換Aurora staging MySQL development dockerのMySQL 各環境は上記の状態だったため
Aurora独自の何かがあるのでは?と思い検証をしてみることにデッドロック発生後の対処
デッドロック発生時、mysqlコマンドでDBにつないで
原因となるクエリをKILLしてみたが解決せず
リードレプリカをフェイルオーバーさせることで対応した検証開始
デッドロックが起きていたテーブル群
- offers
- offer_child_1
- offer_child_2
- documents
- document_offer_child_2
※わかりやすいようにテーブル名は実際とは変えています
スキーマ
CREATE TABLE offers ( id bigint(8) AUTO_INCREMENT PRIMARY KEY, title text ); CREATE TABLE offer_child_1 ( id bigint(8) AUTO_INCREMENT PRIMARY KEY, title text, offer_id bigint(8), FOREIGN KEY (offer_id) REFERENCES offers(id) ); CREATE TABLE offer_child_2 ( id bigint(8) AUTO_INCREMENT PRIMARY KEY, offer_id bigint(8), FOREIGN KEY (offer_id) REFERENCES offers(id) ); CREATE TABLE documents ( id bigint(8) AUTO_INCREMENT PRIMARY KEY, url text ); CREATE TABLE document_offer_child_2 ( id bigint(8) AUTO_INCREMENT PRIMARY KEY, document_id bigint(8), offer_child_2_id bigint(8), FOREIGN KEY (document_id) REFERENCES documents(id), FOREIGN KEY (offer_child_2_id) REFERENCES offer_child_2(id) );デッドロックが起きていたトランザクションのクエリ
事前に流すクエリ
INSERT INTO offers (title) VALUES (CURRENT_TIMESTAMP); INSERT INTO offer_child_2 (offer_id) VALUES (1); INSERT INTO documents(url) VALUES ('http://example.com');トランザクション
No トランザクション1 トランザクション2 BEGIN;BEGIN;1 UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1;2 SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE;3 INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1);4 INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');なぜデッドロックが起きるのか
InnoDBの行レベルロックには
共有ロック(IS)と排他ロック(IX)の2種類がある
共有ロック(IS)同士では競合は発生しないがそれ以外の組み合わせでは競合(ロック待ち)が発生する
IS IX IS 競合 IX 競合 競合 そして今回のケースでいうと
No.1のUPDATE文は該当のレコードにIXを獲得
No.2のSELECT FOR UPDATE文は該当のレコードIXを獲得
No.3のINSERT文は外部キーの参照先(documentsとoffer_child_2)のレコードにISを獲得
No.4のINSERT文は外部キーの参照先(offers)のレコードにISを獲得
となるため
No.3はNo.2をロック待ち、No.4はNo.1をロック待ちをして
トランザクション1、2間でロックが交錯しデッドロックが発生する各環境での挙動
事前にパラメータグループから
Aurorainnodb_lock_wait_timeout = 10 lock_wait_timeout = 15MySQL(auroraに準拠)autocommit = 0 innodb_lock_wait_timeout = 10 innodb_rollback_on_timeout = 0 innodb_table_locks = 1 lock_wait_timeout = 15に設定しておく
innodb_rollback_on_timeoutとinnodb_table_locksは
Auroraにパラメータグループで設定できないためAuroraでのデフォルト値に準拠
SHOW VARIABLES;で確認可能
autocommitについてはAuroraのデフォルトが0で
デッドロック検知には0がいいらしいのでMySQL側も0に設定してAuroraに合わせるref: https://dev.mysql.com/doc/refman/5.6/ja/innodb-deadlock-detection.html
MySQL互換のAurora(5.7.12)
transaction1mysql> BEGIN; Query OK, 0 rows affected (0.05 sec) mysql> UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; Query OK, 1 row affected (0.03 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1);transaction2mysql> BEGIN; Query OK, 0 rows affected (0.03 sec) mysql> SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; +----+----------+ | id | offer_id | +----+----------+ | 1 | 1 | +----+----------+ 1 row in set (0.09 sec) mysql> INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');
transaction1もtransaction2もタイムアウトせず止まり続け
INSERTのプロセスが残ったままDBのCPUが100%に貼りつくMySQL(5.7.16)(5.7.12がなかったので仕方なく。。。)
transaction1mysql> BEGIN; Query OK, 0 rows affected (0.02 sec) mysql> UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; Query OK, 1 row affected (0.04 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1); Query OK, 1 row affected (0.90 sec)transaction2mysql> BEGIN; Query OK, 0 rows affected (0.03 sec) mysql> SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; +----+----------+ | id | offer_id | +----+----------+ | 1 | 1 | +----+----------+ 1 row in set (0.07 sec) mysql> INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a'); ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
transaction1のINSERT INTO document_offer_child_2...は最初待たされるが
transaction2のINSERT INTO offer_child_1...を実行すると
transaction2は瞬時にdeadlockが検知されてトランザクションがロールバックされて
transaction1の待ちがなくなりINSERTを完了するAuroraの他のパターンのデッドロックでの検知の挙動を検証
※見やすくなるようSQLのみ書いていく 実行順はここまで同様transaction1/2交互
長いので折りたたんだ
全パターンを網羅しようとすると、
4クエリ(=2トランザクション×2クエリ)がそれぞれIS/IXのいずれかだとして
インテンションロックの組み合わせが16パターンさらに
IXのDMLはSELECT FOR UPDATE/UPDATE
ISのDMLはINSERT/SELECT LOCK IN SHARE MODE
とすると、それぞれ2パターンとして
1つのインテンションロックの組み合わせの中でクエリの組み合わせは16パターン
全部で256(=16*16)パターンになるまた、
IXにDELETE文も考慮するとクエリの組み合わせが36パターンになり
全部で576(16*36)パターンになってさすがにつらいので網羅せず
少しずつ条件を変えて検知できないデッドロックに作用してそうなクエリを探す1. transaction1の先発クエリも
SELECT FOR UPDATEにしてみる結果: × デッドロックを検知せず止まり続ける
考察: 先発のUPDATEは関係なさそうtransaction1BEGIN; SELECT * from offers WHERE id = 1 LIMIT 1 FOR UPDATE; INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1);transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');2. transaction2の先発クエリも
UPDATEにしてみる結果: × デッドロックを検知せず止まり続ける
考察: 先発のSELECT FOR UPDATEは関係なさそうtransaction1BEGIN; UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1);transaction2BEGIN; UPDATE offer_child_2 SET offer_id = 1 WHERE id = 1; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');3. transaction1の後発クエリを
SELECT LOCK IN SHARE MODEにしてみる結果: ◯ transaction1はデッドロックを検知してロールバックし、transaction2は正常終了
考察: 後発が両トランザクションINSERTじゃないと検知しないデッドロックにならない?transaction1BEGIN; UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 LOCK IN SHARE MODE;transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');4. transaction2の後発クエリを
SELECT LOCK IN SHARE MODEにしてみる結果: ◯ transaction2はデッドロックを検知してロールバックし、transaction1は正常終了
考察: 3とはtransaction2がロールバックされた、InnoDBの仕様(※1)かtransaction1BEGIN; UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1);transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; SELECT * FROM offers WHERE id = 1 LIMIT 1 LOCK IN SHARE MODE;※1 https://dev.mysql.com/doc/refman/5.6/ja/innodb-deadlock-detection.html
小さいトランザクションを選択してロールバックしようと試みます
とあるので3のパターンではtransaction1が、今回はtransaction2が
小さいと判断されたのだろうここまでで
- transaction1/2いずれも後発が
INSERTの時に検知されないデッドロックになることがわかった- では後発がいずれも
SELECT/UPDATE/DELETEのときはどうだろうか5. transaction1/2の後発クエリを
SELECT LOCK IN SHARE MODEにしてみる結果: ◯ transaction2はデッドロックを検知してロールバックし、transaction1は正常終了
考察: 後発がSELECTだとデッドロック検知してくれるらしいtransaction1BEGIN; UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 LOCK IN SHARE MODE;transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; SELECT * FROM offers WHERE id = 1 LIMIT 1 LOCK IN SHARE MODE;6. transaction1/2の後発クエリを
UPDATEにしてみる結果: ◯ transaction2はデッドロックを検知してロールバックし、transaction1は正常終了
考察: 後発がUPDATEでもデッドロック検知してくれるらしいtransaction1BEGIN; UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; UPDATE offer_child_2 SET offer_id = 1 WHERE id = 1;transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1;7. transaction1/2の後発クエリを
DELETEにしてみる結果: ◯ transaction2はデッドロックを検知してロールバックし、transaction1は正常終了
考察: 後発がDELETEでもデッドロック検知されるINSERTだけがやはり特殊なのかtransaction1BEGIN; UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; DELETE from offer_child_2 WHERE id = 1;transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; DELETE from offers WHERE id = 1;8. transaction1/2の先発クエリを
INSERTにしてみる結果: ◯ transaction2はデッドロックを検知してロールバックし、transaction1は正常終了
考察:INSERTが後発であることに意味があるらしいtransaction1BEGIN; INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1); UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1;transaction2BEGIN; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a'); SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE;結果
Auroraでは、
transaction1/2ともに後発のクエリがINSERTの時に発生するデッドロックが
検知されず止まり続けることがわかった
また、検知されないパターンのデッドロックをMySQLで試すと検知される気になることがあったので追加で検証
- そもそもデッドロックではなく普通に
INSERTがロック待ちした時ならちゃんとタイムアウトするのかUPDATEの外部キー参照時の挙動はINSERTと異なるのかAuroraとMySQLの
INSERTとUPDATEのロック待ちの挙動を検証
長いので折りたたんだ
9.
IX獲得されたレコードを参照するINSERTをするAurora: 待ちが発生 タイムアウトもせず
MySQL: 待ちが発生 タイムアウトもせずtransaction1BEGIN; SELECT * FROM offers WHERE id = 1 LIMIT 1 FOR UPDATE;transaction2BEGIN; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');外部キーを持つレコードへの
UPDATE時の待ちの挙動を検証10. UPDATE対象レコードの外部キーは変更せずリレーションがないカラムを更新する
Aurora: 待ちなしで更新できた
MySQL: 待ちなしで更新できたまず普通にデータ作るINSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');transaction1BEGIN; SELECT * FROM offers WHERE id = 1 LIMIT 1 FOR UPDATE;transaction2-- id確認のSELECT -- SELECT * FROM offer_child_1 WHERE offer_id = 1; BEGIN; UPDATE offer_child_1 SET title = CURRENT_TIMESTAMP WHERE id = 1;11. UPDATE対象レコードの外部キーを変更すると
Aurora: 待ちが発生 タイムアウトもせず
MySQL: 待ちが発生 タイムアウトもせず事前にINSERT INTO offers (title) VALUES (CURRENT_TIMESTAMP);transaction1-- id確認 -- SELECT * FROM offers; BEGIN; SELECT * FROM offers WHERE id = 2 LIMIT 1 FOR UPDATE;transaction2-- id確認のSELECT -- SELECT * FROM offer_child_1 WHERE offer_id = 1; BEGIN; UPDATE offer_child_1 SET offer_id = 2 WHERE id = 1;12. デッドロック発生するクエリの後発クエリを、ロックされているレコードへ外部キーを変更する
UPDATEにするAurora: デッドロック検知されず止まり続ける
MySQL: デッドロックを検知してロールバック事前に流すINSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1); INSERT INTO offer_child_2 (offer_id) VALUES (2);
offer_child_1のid=1は10の検証で、
offersのid=2は11の検証で、
すでに作ったからここでは作らないtransaction1-- id確認 -- SELECT * FROM document_offer_child_2 WHERE offer_child_2_id = 1; BEGIN; SELECT * from offers WHERE id = 2 LIMIT 1 FOR UPDATE; UPDATE document_offer_child_2 SET offer_child_2_id = 2 WHERE id = 1;transaction2-- id確認 -- SELECT * FROM offer_child_1 WHERE offer_id = 1; BEGIN; SELECT * FROM offer_child_2 WHERE id = 2 LIMIT 1 FOR UPDATE; UPDATE offer_child_1 SET offer_id = 2 WHERE id = 1;結果
MySQLでもAuroraでも外部キーの参照先が
IXを取られていると
INSERTとUPDATE(外部キー変更を含む時のみ)はロック待ちの時、タイムアウトしない
そして後発クエリがINSERTだけでなく、UPDATE(外部キー変更を含む時のみ)の場合も
Auroraはデッドロックを検知してくれない(MySQLはデッドロック検知してくれる)さらに2点気になったので追加で検証
ref: https://dev.mysql.com/doc/refman/5.6/ja/innodb-foreign-key-constraints.html
- InnoDBの
INSERT時の挙動は外部キー参照先にISを取るという処理はAuroraも同じだろうか- だったら
IS獲得されたレコードに対する外部キー参照のINSERTは待たずに実行されるよね?あと
ref: https://dev.mysql.com/doc/refman/5.6/ja/innodb-parameters.html#sysvar_innodb_lock_wait_timeout
INSERT時にinnodb_lock_wait_timeoutが効かないってことは参照先をテーブルロックしようとしている可能性もある? ってことでこれらも一応検証してみる
長いので折りたたんだ
13. 親レコードのIS取って、それを参照する
INSERTを書いてみるAurora: 待たずに
INSERTができた
MySQL: 待たずにINSERTができた
考察:INSERT時の外部キー参照先に取るロックはISで間違いなさそうtransaction1BEGIN; SELECT * FROM offers WHERE id = 1 LIMIT 1 LOCK IN SHARE MODE;transaction2BEGIN; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');14.
INSERTしたあと、そのレコードの外部キー参照先のテーブルの別レコードをIXでロックしてみるAurora: 待たずに
SELECTできた
MySQL: 待たずにSELECTできた
考察: つまり参照先がテーブルロックの可能性もないtransaction1BEGIN; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');transaction2BEGIN; SELECT * FROM offers WHERE id = 2 FOR UPDATE;結果
予想通り、かつInnoDBのドキュメント通り外部キーの参照先へのロックは
ISだったここまでの結果をまとめて考察すると
INSERT時は外部キー参照先にはIS(行レベル共有ロック)を取るだけ外部キー変更のないUPDATEであれば外部キー参照先にIS取らないので参照先がロック取られてても待ちなく更新可能- MySQLでもAuroraでも、外部キーの参照先が先にロックが取られているときは
外部キー参照を持つINSERTや外部キーの変更があるUPDATEのロック待ちはタイムアウトしない- そしてAuroraでは後発クエリがそのような
INSERTやUPDATEの時に発生するデッドロックはDBは検知してくれない- MySQLならそのようなデッドロックでも検知してロールバックしてくれる
ということがわかった
MySQL互換Auroraでの
外部キーを持つINSERTや外部キーの変更を行うUPDATEのロック待ちの挙動が危うそうなのでアプリケーションレイヤーでも実装時に以下のようなことに気をつけた方がいいかもしれない
- 今回の事象の解決法としては
transaction2がINSERTの外部キー参照先(offers)を最初にロック取りに行けばデッドロックは起きなくなる
- ロックを取る順番を合わせるっていう基本的なデッドロック対策ですね
- 外部キー参照先の
IS取ればシンプルに今回のデッドロックが解決IXだと同時にINSERTやUPDATEできなくなって同時アクセス時に待ちが発生する- どっちを取るかはケースバイケース
INSERTやUPDATEだけのトランザクションであれば気にする必要はないが他のレコードもロックするような場合は注意が必要- 親レコードを更新して子レコード(外部キー持っている)更新するような処理があると
INSERT/UPDATE側が親をロックするようにする以外に回避策なさそう?- 中間テーブルのような外部キー参照が多いテーブルが多く、そこへの
INSERTや外部キー変更のUPDATEも多く、さらにその参照先もロックを取る処理があるアプリケーションは気をつけて実装しないと検知されないデッドロックで死ぬ可能性が高そう- スループットは落ちるがあえてMySQLを使うと少し安全かもしれない
ちなみにRailsでも共有ロック(
IS)取れるただし、MySQL依存になってちょっと悲しい
Model.lock('LOCK IN SHARE MODE').find(...)ref: https://api.rubyonrails.org/classes/ActiveRecord/Locking/Pessimistic.html
タイムアウトしないとかデッドロック検知しない問題、何か解決法とか知ってる方いたらぜひコメントで教えて頂けると超助かります
※「このパラメータを設定すれば解決するよ」とかいうオチだったら恥ずかしすぎる。。。おまけ編 PostgreSQL互換Auroraでも検証
長いので折りたたんだ
スキーマ
CREATE TABLE offers ( id SERIAL PRIMARY KEY, title text ); CREATE TABLE offer_child_1 ( id SERIAL PRIMARY KEY, title text, offer_id bigint, FOREIGN KEY (offer_id) REFERENCES offers(id) ); CREATE TABLE offer_child_2 ( id SERIAL PRIMARY KEY, offer_id bigint, FOREIGN KEY (offer_id) REFERENCES offers(id) ); CREATE TABLE documents ( id SERIAL PRIMARY KEY, url text ); CREATE TABLE document_offer_child_2 ( id SERIAL PRIMARY KEY, document_id bigint, offer_child_2_id bigint, FOREIGN KEY (document_id) REFERENCES documents(id), FOREIGN KEY (offer_child_2_id) REFERENCES offer_child_2(id) );事前に流すクエリINSERT INTO offers (title) VALUES (CURRENT_TIMESTAMP); INSERT INTO offer_child_2 (offer_id) VALUES (1); INSERT INTO documents(url) VALUES ('http://example.com');15. 最初のデッドロックのパターンを試す
Aurora: transaction2の後発クエリでロック待ちが発生しなかった
Postgres: transaction2の後発クエリでロック待ちが発生しなかった
考察: Postgresは行ロックの種類が多くUPDATEとINSERTが競合しないようだ
ref: https://www.postgresql.jp/document/9.6/html/explicit-locking.html#locking-rowstransaction1BEGIN; UPDATE offers SET title = CURRENT_TIMESTAMP WHERE id = 1; INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1);transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');16. デッドロック再現のため
UPDATEをSELECT FOR UPDATEに変えるAurora: デッドロックを検知した
Postgres: デッドロックを検知したtransaction1BEGIN; SELECT * FROM offers WHERE id = 1 LIMIT 1 FOR UPDATE; INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1);transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 1 LIMIT 1 FOR UPDATE; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');17. 後発クエリを外部キー変更のあるUPDATEにしてみる
データ用意INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a'); INSERT INTO offers (title) VALUES (CURRENT_TIMESTAMP); INSERT INTO document_offer_child_2 (document_id, offer_child_2_id) VALUES (1, 1); INSERT INTO offer_child_2 (offer_id) VALUES (2);Aurora: デッドロックを検知した
Postgres: デッドロックを検知したtransaction1BEGIN; SELECT * FROM offers WHERE id = 2 LIMIT 1 FOR UPDATE; UPDATE document_offer_child_2 SET offer_child_2_id = 2 WHERE id = 1;transaction2BEGIN; SELECT * FROM offer_child_2 WHERE id = 2 LIMIT 1 FOR UPDATE; UPDATE offer_child_1 SET offer_id = 2 WHERE id = 1;18.
SELECT FOR UPDATEへのINSERTの待ちを検証
lock_timeoutを設定したかったがパラメータグループに項目がなく設定できなかったのでコンソールから設定
(これAWS RDSだと設定永続化できないのかな。。。)
postgresの`lock_timeoutはmsecなので3000(=3sec)でAurora: 3秒でロックがタイムアウトした
Postgres: 3秒でロックがタイムアウトしたtransaction1SET lock_timeout = 3000; BEGIN; SELECT * FROM offers WHERE id = 1 LIMIT 1 FOR UPDATE;transaction2SET lock_timeout = 3000; BEGIN; INSERT INTO offer_child_1 (offer_id, title) VALUES (1, 'a');19.
SELECT FOR UPDATEへのUPDATEの待ちを検証Aurora: 3秒でタイムアウトした
Postgres: 3秒でタイムアウトしたtransaction1SET lock_timeout = 3000; BEGIN; SELECT * FROM offers WHERE id = 2 LIMIT 1 FOR UPDATE;transaction2SET lock_timeout = 3000; BEGIN; UPDATE offer_child_1 SET offer_id = 2 WHERE id = 1;(3)結果
Postgresの方がロックのモードが多彩で暗黙的なロックで競合しづらいようなので安心かもしれない
また、Postgres互換のAuroraやPostgresでは
外部キーが絡んだINSERTやUPDATEでのロック待ちはちゃんとタイムアウトするし
デッドロックが検知されない問題も起きなかった結論
パターンとして見落としがあるかもしれないのでこれで完璧とは言えないが
- MySQL互換のAuroraもMySQLも外部キーが絡んだ
INSERTやUPDATEでタイムアウトしないロック待ちが発生する- MySQL互換のAuroraではさらにその
INSERT/UPDATEによるデッドロックが検知されない- Postgres互換のAuroraやPostgresは
INSERT/UPDATEのデッドロック検知されたし
- 外部キーが絡んだ
INSERTやUPDATEによる待ちもちゃんとタイムアウトする- 行ロックの種類が多いのでMySQLよりもそもそも競合しづらい
デッドロック発生しやすさや発生時の挙動など考えて安全度が高そうなのは
Postgres互換Aurora = Postgres > MySQL > MySQL互換Aurora
といった感じかな雑な追記
ふと検証してないことに気づいて
Aurora(MySQL互換)で外部キー参照先がロックされている状態でのDELETEを試したところ
正常にロックタイムアウトされた2トランザクション2クエリでデッドロックを起こすパターンも
後続クエリを外部キーを先にロックされたDELETEにして試したが
両方のトランザクションともロックタイムアウトしたのでちょっと予想外だったけどまぁ問題ない挙動
やはりINSERT/UPDATEだけが異質
- 投稿日:2020-02-06T01:52:57+09:00
syslog受信 → S3保存 してくれるDockerコンテナ お手軽セット
https://github.com/yagrush/docker-td-agent-syslog-to-s3
↑成果物は、こちらへどうぞ!実現したかったこと
syslogをS3に勝手に保存してくれる環境を、簡単に量産できるようにしたい!
作ったもの概要
ポート514にsyslogを送ると S3にgzipで1時間毎に保存してくれるDockerコンテナが、すぐ作れます。
(実際は、Dockerコンテナの中で td-agent が常駐しています)必要なもの
syslogを保存するS3バケット
S3バケットにアクセス権限を持つIAMユーザー
docker,docker-composeが入ったEC2インスタンスAmazon Linux release 2 (Karoo) で動作確認済。
ポート514の受信許可(セキュリティグループの設定)もお忘れなく。→ 必要でしたら こちら(AWS EC2 AmazonLinux2 のdockerホスト用初期設定)もご参照下さい。
使い方
詳細部分は README.md をご参照頂ければと思いますが、
全体的な流れも含めてざっくり説明しますと…
- S3に、syslogを保存するためのバケットを作成。
- そのバケットに書き込む権限を持つIAMユーザーを作成。
- そのIAMユーザーのアクセスキーとシークレットをダウンロードしておく。
- DockerホストとなるEC2インスタンスを作成。
- そのインスタンスがポート514でsyslogを受信できるようセキュリティグループを設定しておく。
- そのインスタンスにSSHで接続。
docker,docker-composeをインストールしてセットアップする。- 本成果物をダウンロードする。(gitとかcurlなどで。)
- 中のディレクトリに
cdする。.env.templateを.envにリネーム。.envを編集する。(S3に接続するための設定を書く。)- (保存間隔やファイル名のカスタムなどは、td-agent.conf をお好みで編集。)
- Dockerイメージをビルドする。
docker-compose build- イメージからコンテナを起動する。
docker-compose up -d- 余裕があれば、動作テストなどしておく。
- syslog送信側端末にて、送信先を上記のインスタンスのポート514に設定!
ミソ
1: .env から S3接続設定を拾って Dockerfile 内で(ビルド中に)使う
今回、S3接続設定を td-agent.conf から外出し(.env)したのですが、これができるまで結構ハマりました・・・
外部ファイルから docker-compose.yml 内で値を拾うことは割とすんなりできたのですが、
環境変数として
- docker-compose.yml 内の environment で渡し、
- Dockerfile 内の ENV で拾う
でビルド中に渡そうとしても、どうにもできず・・・
どうやらその方法では、コンテナが起動した後でないと有効にならないそうでした。
(起動後、コンテナ内のシェルに繋いでenvすると、間違いなく設定されてはいるのですが・・・)で、アンサーはというと
- docker-compose.yml 内の args で渡し、
- Dockerfile 内の ARG で拾う
これで、Dockerfile内で
$HOGE_HOGEで利用可能には、なりました。が・・・2: td-agent.conf 内で使う
しかーし!
今度は、td-agent.conf 内で環境変数として引用${ENV{'HOGE_HOGE'}}できない・・・Dockerfile 内でわざわざ ARG → ENV で拾い直してもダメ・・・
どうやら、今回 td-agent を Docker内のサービス(デーモン)として起動する仕組みにした影響っぽく。
工数的限界もあり、ここはゴリ押しでsedで置換する方法にしました
- 投稿日:2020-02-06T01:00:12+09:00
aws cli S3でよく使うコマンド
aws cli S3でよく使うコマンドについて記載。
#バケットの内容を表示 $aws s3 ls s3://bucket-name/path #バケットを作成 $aws s3 mb s3://bucket-name #バケットを削除(空の場合は削除されない) $aws s3 rb s3://bucket-name #バケットを削除(強制削除) $aws s3 rb s3://bucket-name --force #バケット内のファイルを削除 $aws s3 rm s3://bucket-name/file-name #バケット内のフォルダを削除 $aws s3 rm s3://bucket-name/file-name --recursive #ローカルのファイルをバケットにコピー $aws s3 cp {ファイルパス} s3://bucket-name/path #ローカルのファイルをバケットに移動 $aws s3 mv {ファイルパス} s3://bucket-name/path #バケットをローカルのフォルダと同期(追加・更新のみ) $aws s3 sync {フォルダパス} s3://bucket-name/path #バケットをローカルのフォルダと同期(削除される) $aws s3 sync {フォルダパス} s3://bucket-name/path --delete以上
参考
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-services-s3-commands.html
https://docs.aws.amazon.com/cli/latest/reference/index.html#cli-aws
- 投稿日:2020-02-06T00:44:06+09:00
AWSの10分間チュートリアルをやってみる 3.WordPress ウェブサイトの起動
こんにちは。トリドリといいます。
新卒で入社した会社でJavaを数年やった後、1年ほど前に転職してからはRailsを中心に使用してアプリケーションの開発をしているしがないエンジニアです。今回、AWSの勉強をするために公式の10分間チュートリアルをやってみることにしたので、備忘のために記事に残していこうと思います。
AWSに関しては、1年ほど前転職活動をしていた時期にEC2とRDSを少し触っていた以外ほとんど触ったことが無い初心者です。
(ただし、このときにアカウントを作ったので、12ヶ月の無料枠は切れていました)前回は「Linux 仮想マシンの起動」を行いました。
今回は「WordPress ウェブサイトの起動」をやっていきます。そういえば、昨日EC2を起動した結果、1日目に見た請求ダッシュボードに金額が入ってました。
WordPress ウェブサイトの起動
https://aws.amazon.com/jp/getting-started/tutorials/launch-a-wordpress-website/?trk=gs_card
本日のチュートリアルはEC2にインストールされたWordPressを使用してウェブサイトを起動するという内容です。
今回は概要で新しい用語の説明等は特にありませんので、早速各ステップに進んでいきます。ステップ 1: Amazon EC2 インスタンスを起動する
前回やったとおり、EC2ダッシュボードを開いて[Launch instance]のボタンを押します。
このステップはこれだけです。ステップ 2: インスタンスを設定する
画面は前回も見たAMIを選択するところです。
a.
前回は画面が開いたときから表示されている無料枠の[Amazon Linux AMI]を選択しましたが、今回は左側のメニューにある[AWS Marketplace]を使用してインスタンスを選択します。
AWS Marketplaceではソフトウェアがあらかじめインストールされたイメージを選択することができます。
前回も例に出したノートPCを買う時の話だと、プリインストールされたアプリケーションで選ぶ感じでしょうか。今回はチュートリアルにしたがって、[WordPress powered by BitNami]を選択します。
b.
選択するとイメージの説明と価格表が表示されたダイアログが開きます。
価格表インスタンスタイプごとにインストールされたソフトウェアの価格・EC2のインスタンス自体の価格・合計額が記載されています。
前回使用したQuick Startからだと価格表が表示されることはなかったので、こちらのほうが親切に感じました。確認したら[Continue]ボタンを押します。
c.
インスタンスタイプの選択に進みます。
今回はグレーアウトされているインスタンスタイプが存在します。
グレーアウトされているものは先程の価格表になかったものなので、このAMIでは対応していないということでしょう。チュートリアルに従って[t2.micro]を選択し、今回は[Configure Instance Details]を押下します。
d.
[Configure Instance Details],[Add Storage]と続きますが、今回はこの2つは何も変更せず[Next:]のボタンを押下して[Add Tags]に進みます。
タグとはAWSのリソースにつける自分で定義してつける事ができるラベルで、リソースを分類するのに使用するものです。
チュートリアル内にタグの説明はありませんが、インスタンスを作成する画面上部のリンクからタグについて説明されているユーザーガイドを開くことができます。
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/Using_Tags.htmlチュートリアルでは
Nameというキーに対してWordPressという値でタグを作成しています。
タグの作成後は前回同様、[Review And Launch]に進みます。e.
前回同様、内容を確認して[Launch]ボタンを押します。
f.
今回は、SSHを使ってこのインスタンスにアクセスしないため、前回キーを作成したダイアログで[Proceed without a key pair]を選択します。
選択すると下のチェックボックスの文章がAMIに組み込まれたパスワードがわからないとインスタンスに接続できない旨のメッセージが表示されます。
前述の通り今回はインスタンスに直接接続しないので、チェックを入れ[Launch Instances]を押します。g./h.
前回同様、インスタンスがrunnning状態になるのを待ち、起動したら[IPv4 Public IP]をコピーします。
i.
コピーしたIPにブラウザからアクセスするとWordPressのHello worldページが開きます。
ステップ 3: Web サイトを変更する
インスタンスのシステムログを確認するステップです。
システムログの中にWordPressの管理ページへのログインに必要な情報が出力されているので、それを確認してログインすることでWebサイトを変更できる形になっています。a.
システムログを開くためには、EC2の管理コンソールでインスタンスを選択し、[Actions]->[Instance Setting]->[Get System Log]の順に選択します。
選択するとダイアログでシステムログが表示されます。b.
ここからはWordPressの管理ページへのログインに関する手順です。
システムログから#で囲まれたユーザー名とパスワードを探します。c.
Hello worldページの末尾に
/adminで管理ページを開くことができます。
ログインを求められるので、先程見つけたユーザー名とパスワードを入力しログインします。今回のチュートリアルはここまでです。
次のチュートリアルでもこのインスタンスを使用するために、インスタンスを停止しておきます
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/Stop_Start.htmlまとめ
今回の主な内容は
- AWS Marketplaceを使用してソフトウェアがインストールされたAMIを選択し、インスタンスを作成する
- インスタンスのシステムログを見る
でした。
AWS Marketplaceを使用するのは初めてだったので勉強になりました。
今回WordPressではログインのユーザー名とパスワードがシステムログに出録されていましたが、他のソフトウェアについても同様にシステムログに出力されるものなのか、そうでなければどうやって確認するのかという疑問が湧いたので、別途調べようと思いますそういえば、チュートリアルの内容とは別に、概要のところに高度なチュートリアルがあるのを見つけました
10分間チュートリアルのあとはこれをやってみるのもありですかね
まだ少し先になりそうですが…次回は、「ドメイン名の登録」に進む予定です。

- 投稿日:2020-02-06T00:18:31+09:00
aws cliを複数のプロファイルで使う
aws cliで複数のプロファイルを使う方法について記載
すでにaws cliインストール、デフォルトのプロファイルが設定されている前提。
1.新しいプロファイルを作成する
$aws configure --profile new-user AWS Access Key ID [None]: xxxxxxxxxxxxxx AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxx Default region name [None]: ap-northeast-1 Default output format [None]: jsonDefault output formatについては以下のような感じ、
json – JSON 文字列形式で出力されます。
yaml – YAML 文字列形式で出力されます。(AWS CLI バージョン 2 でのみ利用できます。)
text – 複数行のタブ区切り文字列値の形式で出力されます。これは、grep、sed、または awk などのテキストプロセッサに出力を渡すのに役立ちます。
table – セルの罫線を形成する文字列 +|- を使用して表形式で出力されます。通常、情報は他の形式よりも読みやすい「わかりやすい」形式で表示されますが、プログラムとしては役立ちません。2.プロファイルを指定してコマンドを実行する
$aws s3 ls --profile new-user3.面倒な場合は、環境変数で指定する
$export AWS_DEFAULT_PROFILE=new-user以上
参考
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-chap-configure.html