- 投稿日:2020-02-06T21:49:45+09:00
27歳、未経験です あっ・・・(察し)
はじめに
なんだこのオッサン!?(驚愕)
近年半導体業界が不景気になり業界丸ごとタイタニック並みに沈没しました。
請負先も「クビだクビだクビだ」ということで27歳にしてお仕事がなくなってしまったので
学生時代に興味があったWebエンジニアとして働きたく転職活動を始めました。
インプットした事を忘れないようにする為Qiitaでサボらずアウトプットして行きます。
あっ! 遅れましたがQiita初投稿になります。
今後は生暖かく見守もってください!
本日のアウトプット
目的はprogateで理解できなかったdivタグとfloatの仕組みを理解すること。
divタグ
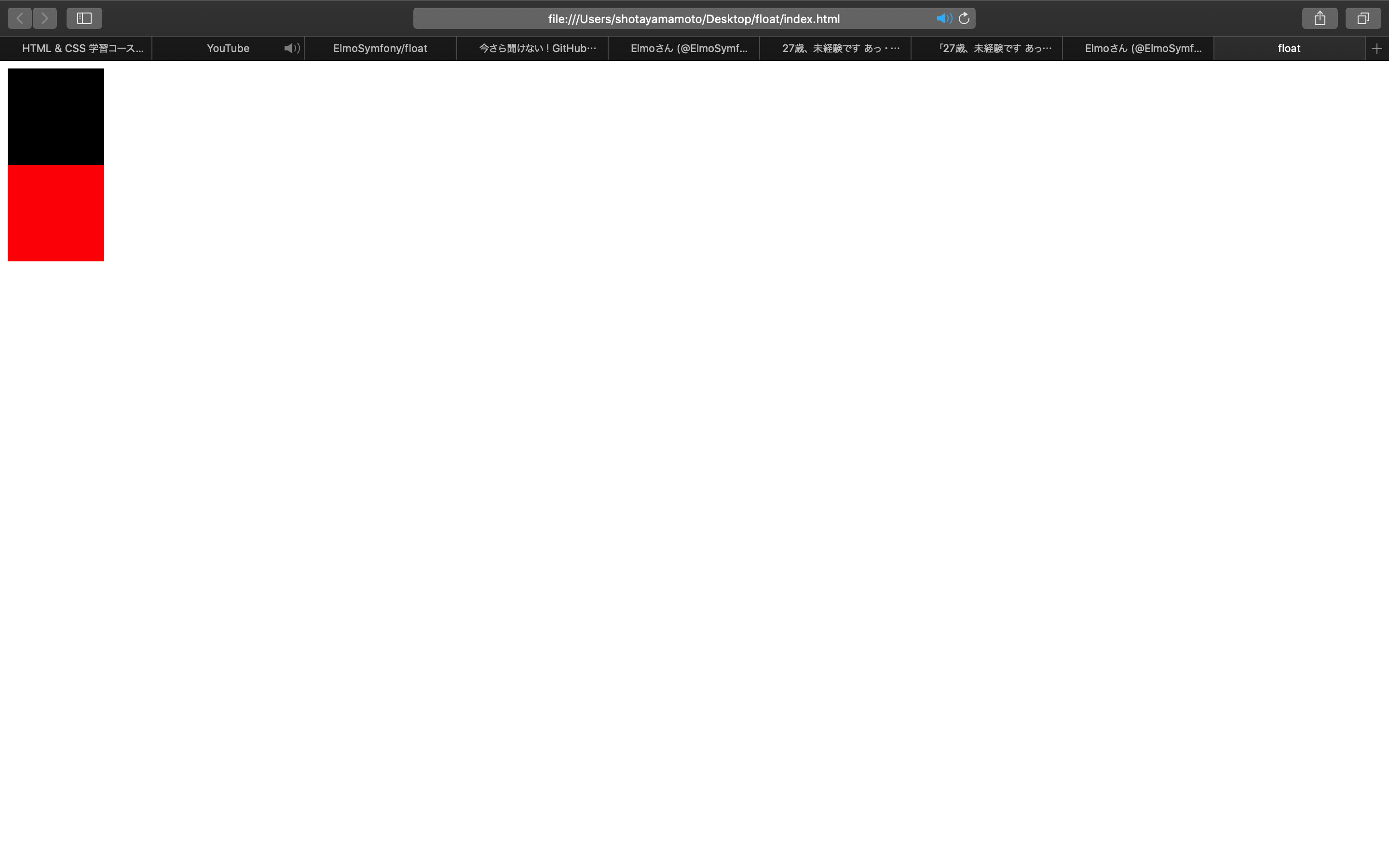
divタグは、ブロック要素であるため表示される要素は縦並びになる。
index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title> float </title> <link rel="stylesheet" href="style.css"> </head> <body> <div class="parent1"></div> <div class="parent2"></div> </body> </html>style.css.parent1{ width: 100px; height: 100px; background-color: black; } .parent2{ width: 100px; height: 100px; background-color: red; }float
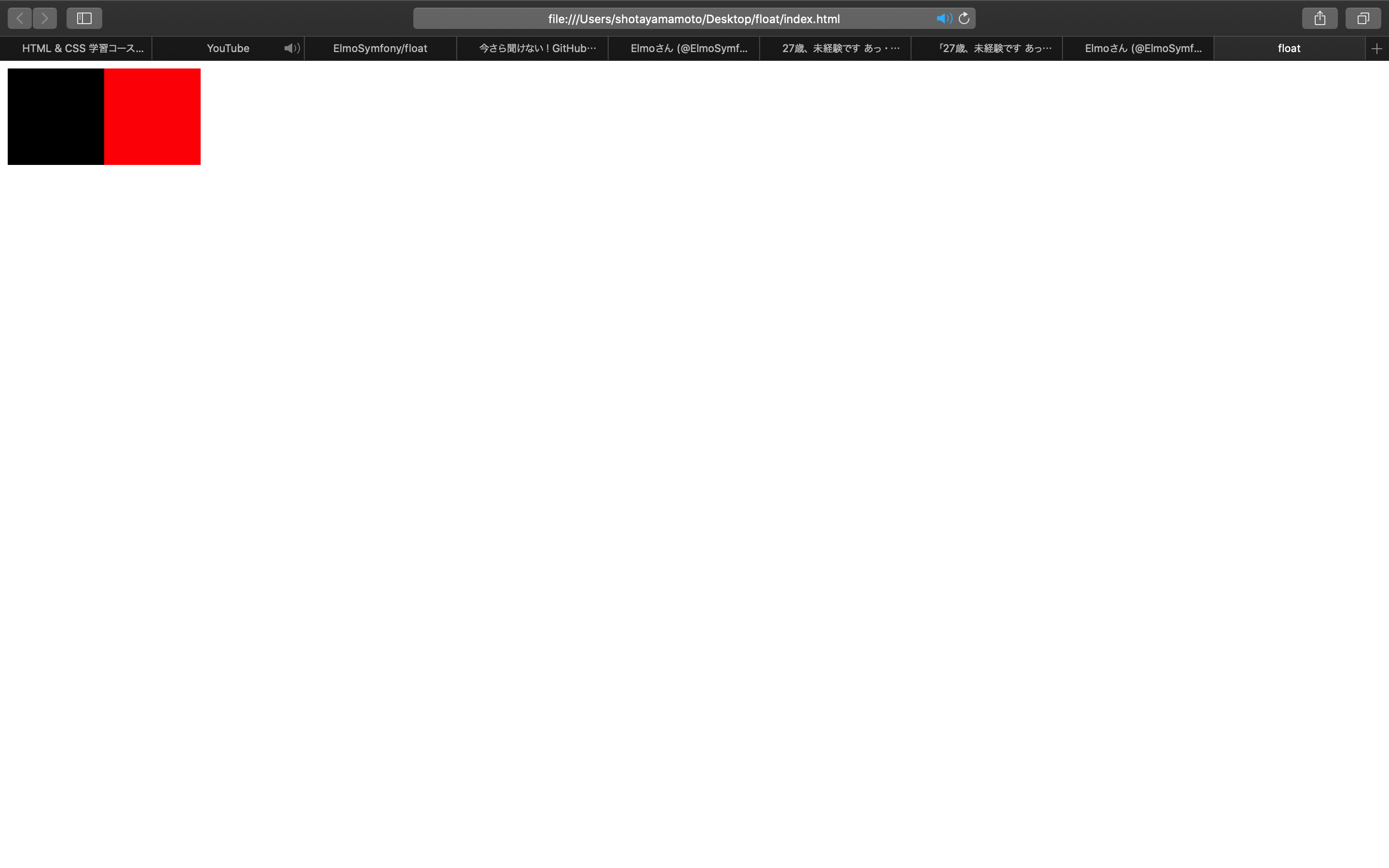
ブロック要素を横並びにする際はfloatを使用する。
今回は横並びに隣り合った状態にしたいのでブロック要素にfloat:leftを使用する。
style.css.parent1{ width: 100px; height: 100px; background-color: black; float: left; } .parent2{ width: 100px; height: 100px; background-color: red; float: left; }ついでに親要素内に子要素も追加し親要素だけfloat:rightを使用してみた。
その結果、子要素は親要素に釣られ一緒に移動する。
index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title> float </title> <link rel="stylesheet" href="style.css"> </head> <body> <div class="parent1"> <div class="child1"></div> </div> <div class="parent2"> <div class="child2"></div> </div> </body> </html>style.css.parent1{ width: 100px; height: 100px; background-color: black; float: right; } .child1{ width: 50px; height: 50px; background-color: blue; } .parent2{ width: 100px; height: 100px; background-color: red; float: right; } .child2{ width: 50px; height: 50px; background-color: yellow; }おわりに
floatが親要素や子要素にどういう挙動をさせているか実際に手を動かす事で理解する事が分かった。
今日はここまで。次はfloatの解除方法が複数あるのでどれを使えば良いかを考えて行きます。

- 投稿日:2020-02-06T21:46:18+09:00
【JavaScript】グループ分けアプリを作って護廷十三隊を分けてみた
はじめに
- 結構な人数で懇親会をしたい
- テーブルが別れている店を予約してしまった
- 同じ部署の人は離れて座ってほしい
こんな条件が揃った時に使うグループ分けアプリを作りました。
試しに最近はまったBLEACHに出てくる護廷十三隊をグループ分けしてみます。(まだ全巻読んでいないので初期メンバーで)デモ
4ステップでグループ分けしていきます
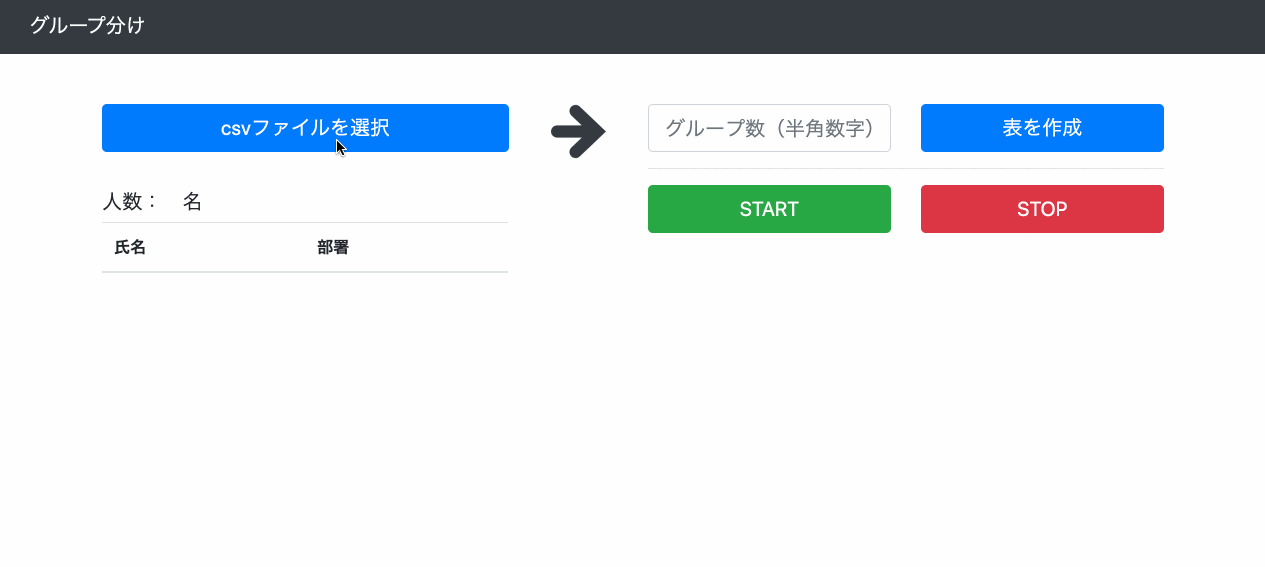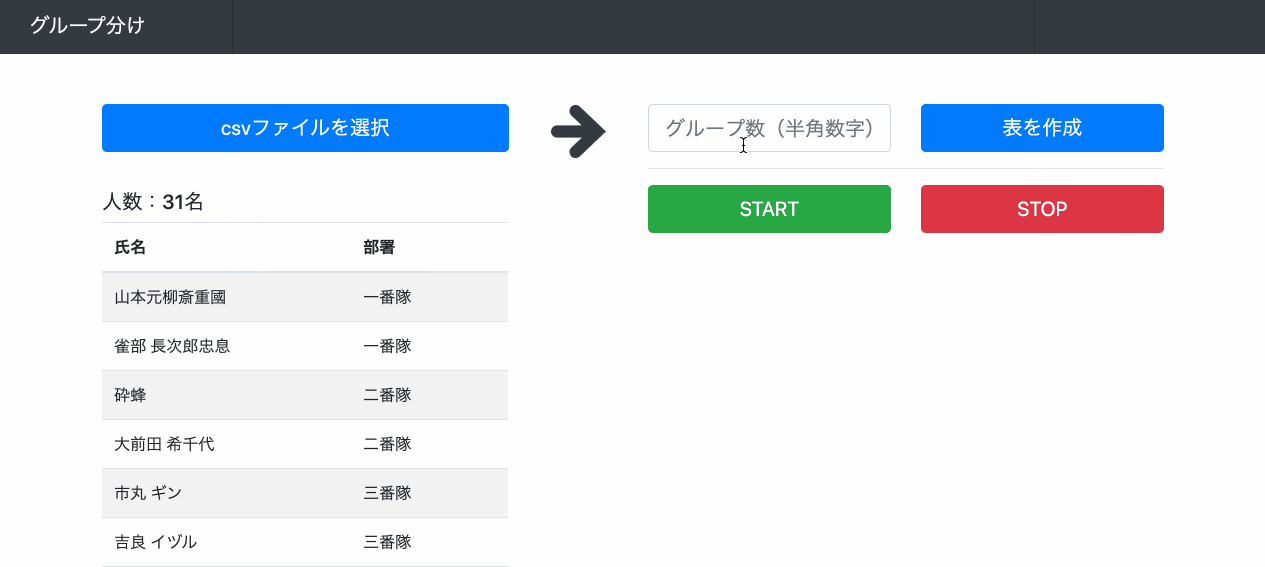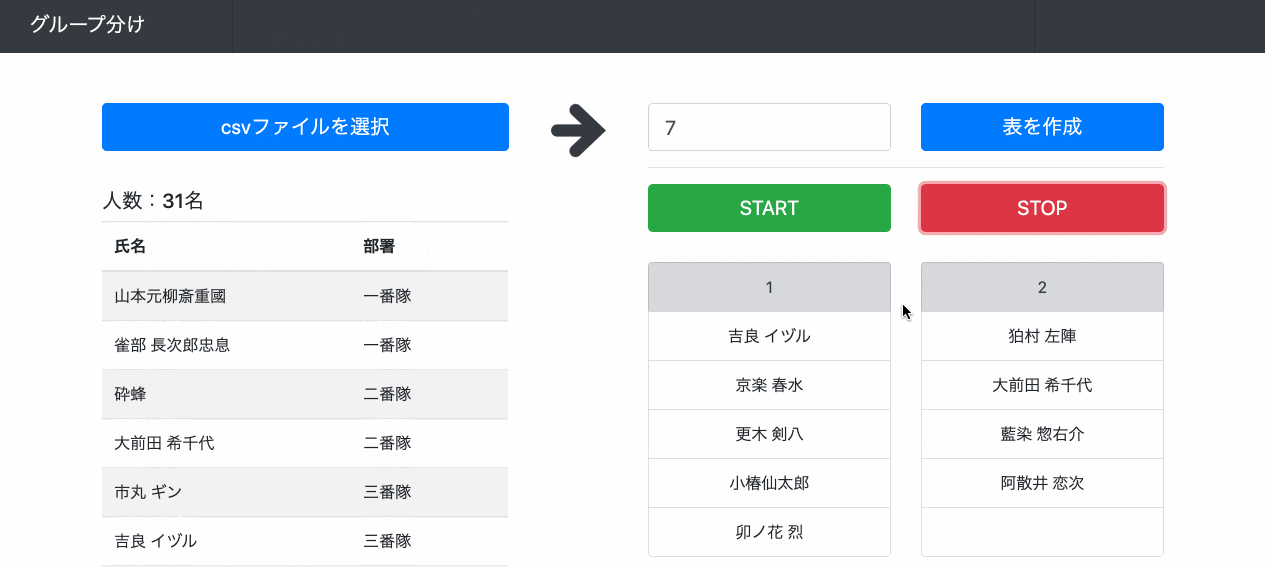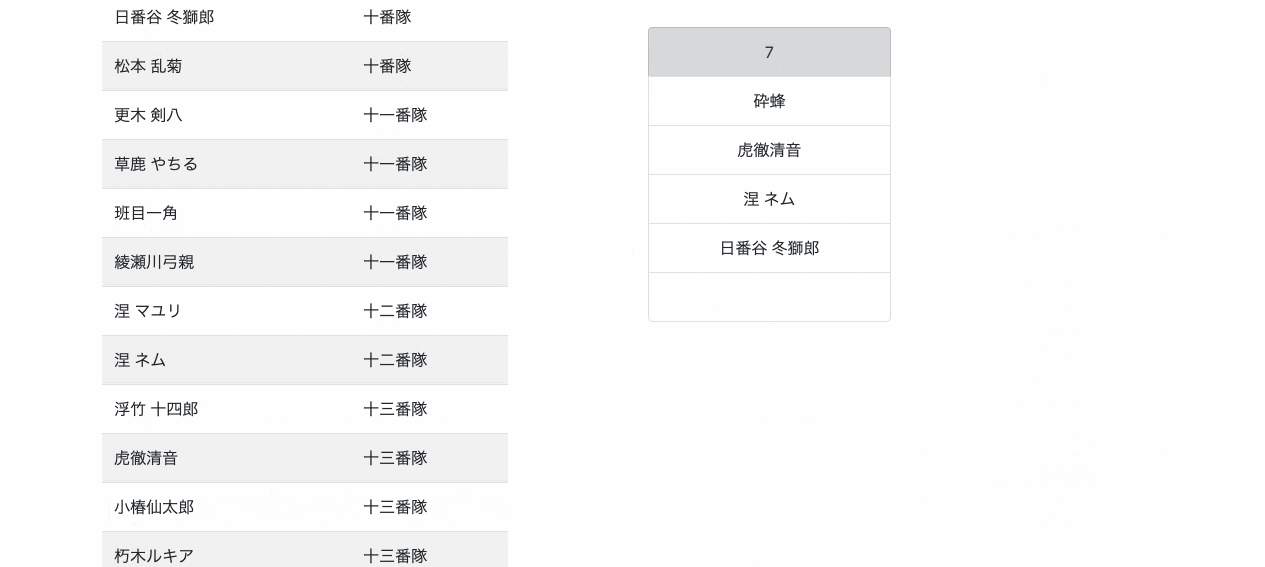
1. 氏名と部署を入れたCSVファイルを読み込む → csvの内容が下に表示される
2. グループ数を入力 + [表を作成]をクリック → グループの数だけ表が作成される
3. [START]をクリック → ビンゴっぽく動く
4. [STOP]をクリック → 各グループに振り分けられる
CSVを読み込んで画面に表示する
こちらの記事を参考に実装しました。
うまく読み取ってくれなかったので<body onLoad='readCsv();'>でページ読み込み時に関数を呼び出しています。
ファイル選択ボタンを他のボタンとデザインを合わせたかったのでinput要素をdisplay:noneにします。index.html<body onload='readCsv();'> <!-- CSV読み込みボタン --> <label> <form name='myform'> csvファイルを選択 <input type='file' name='myfile' style='display:none'> </form> </label> <!-- CSVの内容を表示 --> <h5 id='num'>人数: 名</h5> <table class='table table-striped'> <thead> <tr> <th>氏名</th> <th>部署</th> </tr> </thead> <tbody id='tbody'> </tbody> </table> </body>shuffle.jsfunction readCsv(){ document.forms.myform.myfile.addEventListener( 'change', function(e) { var result = e.target.files[0]; var reader = new FileReader(); reader.readAsText( result ); reader.addEventListener( 'load', function() { var memberArray = reader.result.split('\n'); memberArray.shift(); var table = $('.table').children('tbody'); for(var i = 0; i < memberArray.length; i++){ memberArray[i] = memberArray[i].split(','); table.append('<tr>\ <td>' + memberArray[i][0] + '</td>\ <td>' + memberArray[i][1] + '</td>\ </tr>'); } document.getElementById('num').innerHTML = '人数:' + memberArray.length + '名'; }); }); }グループの数分の表を作る
result-leftとresult-rightという領域を作って、そこに入力したグループの数だけ表を作ります。index.html<input id='group' type='text' placeholder='グループ数(半角数字)'> <button type='submit' onClick='createArea();'>表を作成</button> <div id='result-left'></div> <div id='result-right'></div>shuffle.jsfunction createArea(){ var group = parseInt(document.getElementById('group').value); var row = $('#tbody').children().length; var perGroup = Math.ceil(row / group); for(var i = 0; i < group / 2; i++){ $('#result-left').append('<ul>\ <li>' + (2 * i + 1) +'</li>\ </ul>'); for(var j = 0; j < perGroup; j++){ $('#result-left').children('ul').last().append("<li class='shuffle-area'></li>"); } } for(var i = 0; i < Math.floor(group / 2); i++){ $('#result-right').append('<ul>\ <li>' + 2 * (i + 1) +'</li>\ </ul>'); for(var j = 0; j < perGroup; j++){ $('#result-right').children('ul').last().append("<li class='shuffle-area'></li>"); } } }ビンゴっぽく動かす
こちらの記事を参考にビンゴっぽく動かします。
shuffle-areaというクラス(グループの数だけ表を作るときに<li>に設定したクラス)をもつ要素に値をランダムに入れて動かしてる感を出します。index.html<button type='button' onClick='start();'>START</button>shuffle.jsfunction start(){ var memberArray = []; var row = $('#tbody').children().length; for(var i = 0; i < row; i++){ memberArray.push($('#tbody').find('td').eq(2 * i).text()); } roulette = setInterval(function(){ var random = Math.floor(Math.random() * memberArray.length); var shuffleArea = $('.shuffle-area'); var count = shuffleArea.length; for(var i = 0; i < count; i++){ shuffleArea.eq(i).text(memberArray[(random + i) % count]); } }, 10); }グループを分けて表示する
動くものをとりあえず作りましたが正直改善の余地しかない。
「同じ部署の人は違うグループにする」という条件を満たすまでランダムにグループ分けをし続けます。グループ数ニアイコール同じ部署の人数の時にwhile文めっちゃまわります...。index.html<button type='button' onClick='stop();'>STOP</button>shuffle.jsfunction stop(){ clearInterval(roulette); var status = true; var group = parseInt(document.getElementById('group').value); var memberArray = []; var copyArray = []; var groupArray = new Array(group); var row = $('#tbody').children().length; for(var i = 0; i < row; i++){ var name = $('#tbody').find('td').eq(2 * i).text(); var department = $('#tbody').find('td').eq(2 * i + 1).text().replace(/\r?\n/g, ''); memberArray.push([department, name]); } while(status){ status = false; memberArray = shuffle(memberArray); copyArray = memberArray.concat(); for(var i = 0; i < group; i++){ groupArray[i] = copyArray.splice(0, Math.ceil(copyArray.length / (group - i))); groupArray[i].sort(); } loop: for(var i = 0; i < group; i++){ for(var j = 0; j < groupArray[i].length - 1; j++){ if(groupArray[i][j][0] != "" && groupArray[i][j][0] == groupArray[i][j + 1][0]){ status = true; break loop; } } } } for(var i = 0; i < groupArray.length; i++){ for(var j = 0; j < groupArray[i].length; j++){ $('ul').eq(i).children('.shuffle-area').eq(j).text(groupArray[i][j][1]); } if(j < $('ul').eq(i).children('.shuffle-area').length){ $('ul').eq(i).children('.shuffle-area').eq(j).text(' '); } } } function shuffle(array) { for (let i = 0; i < array.length; i++) { let rand = Math.floor(Math.random() * (i + 1)); [array[i], array[rand]] = [array[rand], array[i]] } return array; }TODO
- グループ分けのアルゴリズムを改良する
- グループ数が同じ部署の人数より少ない時にアラートを出す
- 完成したグループをcsv出力する
GitHub
この記事ではhtmlを部分的に記載しているので全体はこちらに載せています。
https://github.com/rntkym/team-divisionおまけ
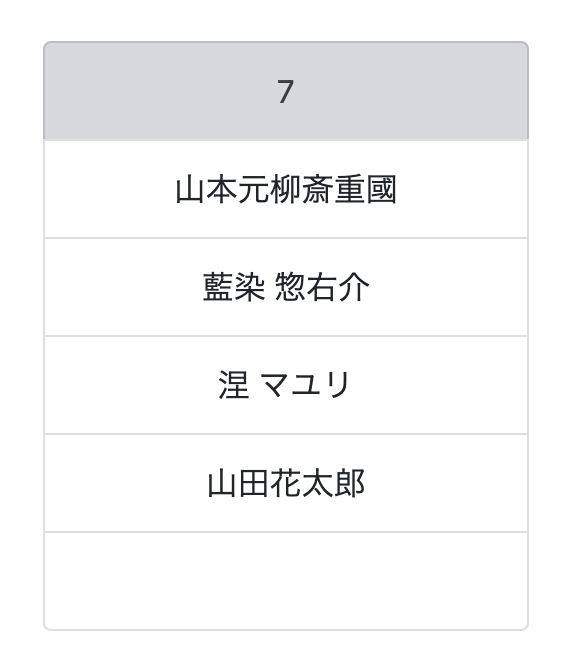
何度かグループ分けをして遊んでたら花太郎が胃痛で死にそうなグループができた
- 投稿日:2020-02-06T21:46:18+09:00
グループ分けアプリを作って護廷十三隊を分けてみた
はじめに
- 結構な人数で懇親会をしたい
- テーブルが別れている店を予約してしまった
- 同じ部署の人は離れて座ってほしい
こんな条件が揃った時に使うグループ分けアプリを作りました。
試しに最近はまったBLEACHに出てくる護廷十三隊をグループ分けしてみます。(まだ全巻読んでいないので初期メンバーで)デモ
4ステップでグループ分けしていきます
1. 氏名と部署を入れたCSVファイルを読み込む → csvの内容が下に表示される
2. グループ数を入力 + [表を作成]をクリック → グループの数だけ表が作成される
3. [START]をクリック → ビンゴっぽく動く
4. [STOP]をクリック → 各グループに振り分けられる
CSVを読み込んで画面に表示する
こちらの記事を参考に実装しました。
うまく読み取ってくれなかったので<body onLoad='readCsv();'>でページ読み込み時に関数を呼び出しています。
ファイル選択ボタンを他のボタンとデザインを合わせたかったのでinput要素をdisplay:noneにします。index.html<body onload='readCsv();'> <!-- CSV読み込みボタン --> <label> <form name='myform'> csvファイルを選択 <input type='file' name='myfile' style='display:none'> </form> </label> <!-- CSVの内容を表示 --> <h5 id='num'>人数: 名</h5> <table class='table table-striped'> <thead> <tr> <th>氏名</th> <th>部署</th> </tr> </thead> <tbody id='tbody'> </tbody> </table> </body>shuffle.jsfunction readCsv(){ document.forms.myform.myfile.addEventListener( 'change', function(e) { var result = e.target.files[0]; var reader = new FileReader(); reader.readAsText( result ); reader.addEventListener( 'load', function() { var memberArray = reader.result.split('\n'); memberArray.shift(); var table = $('.table').children('tbody'); for(var i = 0; i < memberArray.length; i++){ memberArray[i] = memberArray[i].split(','); table.append('<tr>\ <td>' + memberArray[i][0] + '</td>\ <td>' + memberArray[i][1] + '</td>\ </tr>'); } document.getElementById('num').innerHTML = '人数:' + memberArray.length + '名'; }); }); }グループの数分の表を作る
result-leftとresult-rightという領域を作って、そこに入力したグループの数だけ表を作ります。index.html<input id='group' type='text' placeholder='グループ数(半角数字)'> <button type='submit' onClick='createArea();'>表を作成</button> <div id='result-left'></div> <div id='result-right'></div>shuffle.jsfunction createArea(){ var group = parseInt(document.getElementById('group').value); var row = $('#tbody').children().length; var perGroup = Math.ceil(row / group); for(var i = 0; i < group / 2; i++){ $('#result-left').append('<ul>\ <li>' + (2 * i + 1) +'</li>\ </ul>'); for(var j = 0; j < perGroup; j++){ $('#result-left').children('ul').last().append("<li class='shuffle-area'></li>"); } } for(var i = 0; i < Math.floor(group / 2); i++){ $('#result-right').append('<ul>\ <li>' + 2 * (i + 1) +'</li>\ </ul>'); for(var j = 0; j < perGroup; j++){ $('#result-right').children('ul').last().append("<li class='shuffle-area'></li>"); } } }ビンゴっぽく動かす
こちらの記事を参考にビンゴっぽく動かします。
shuffle-areaというクラス(グループの数だけ表を作るときに<li>に設定したクラス)をもつ要素に値をランダムに入れて動かしてる感を出します。index.html<button type='button' onClick='start();'>START</button>shuffle.jsfunction start(){ var memberArray = []; var row = $('#tbody').children().length; for(var i = 0; i < row; i++){ memberArray.push($('#tbody').find('td').eq(2 * i).text()); } roulette = setInterval(function(){ var random = Math.floor(Math.random() * memberArray.length); var shuffleArea = $('.shuffle-area'); var count = shuffleArea.length; for(var i = 0; i < count; i++){ shuffleArea.eq(i).text(memberArray[(random + i) % count]); } }, 10); }グループを分けて表示する
動くものをとりあえず作りましたが正直改善の余地しかない。
「同じ部署の人は違うグループにする」という条件を満たすまでランダムにグループ分けをし続けます。グループ数ニアイコール同じ部署の人数の時にwhile文めっちゃまわります...。index.html<button type='button' onClick='stop();'>STOP</button>shuffle.jsfunction stop(){ clearInterval(roulette); var status = true; var group = parseInt(document.getElementById('group').value); var memberArray = []; var copyArray = []; var groupArray = new Array(group); var row = $('#tbody').children().length; for(var i = 0; i < row; i++){ var name = $('#tbody').find('td').eq(2 * i).text(); var department = $('#tbody').find('td').eq(2 * i + 1).text().replace(/\r?\n/g, ''); memberArray.push([department, name]); } while(status){ status = false; memberArray = shuffle(memberArray); copyArray = memberArray.concat(); for(var i = 0; i < group; i++){ groupArray[i] = copyArray.splice(0, Math.ceil(copyArray.length / (group - i))); groupArray[i].sort(); } loop: for(var i = 0; i < group; i++){ for(var j = 0; j < groupArray[i].length - 1; j++){ if(groupArray[i][j][0] != "" && groupArray[i][j][0] == groupArray[i][j + 1][0]){ status = true; break loop; } } } } for(var i = 0; i < groupArray.length; i++){ for(var j = 0; j < groupArray[i].length; j++){ $('ul').eq(i).children('.shuffle-area').eq(j).text(groupArray[i][j][1]); } if(j < $('ul').eq(i).children('.shuffle-area').length){ $('ul').eq(i).children('.shuffle-area').eq(j).text(' '); } } } function shuffle(array) { for (let i = 0; i < array.length; i++) { let rand = Math.floor(Math.random() * (i + 1)); [array[i], array[rand]] = [array[rand], array[i]] } return array; }TODO
- グループ分けのアルゴリズムを改良する
- グループ数が同じ部署の人数より少ない時にアラートを出す
- 完成したグループをcsv出力する
GitHub
この記事ではhtmlを部分的に記載しているので全体はこちらに載せています。
https://github.com/rntkym/team-divisionおまけ
何度かグループ分けをして遊んでたら花太郎が胃痛で死にそうなグループができた
- 投稿日:2020-02-06T20:13:53+09:00
初心者によるプログラミング学習ログ 231日目
100日チャレンジの231日目
twitterの100日チャレンジ#タグ、#100DaysOfCode実施中です。
すでに100日超えましたが、継続。100日チャレンジは、ぱぺまぺの中ではプログラミングに限らず継続学習のために使っています。
231日目は
おはようございます
— ぱぺまぺ@webエンジニアを目指したい社畜 (@yudapinokio) February 5, 2020
231日目
・udemyで、css+javascript講座
・webサイト部分的模写#早起きチャレンジ#駆け出しエンジニアと繋がりたい#100DaysOfCode
- 投稿日:2020-02-06T19:51:50+09:00
アダルトサイトでも利用OKのHPテンプレート(html)など
超初心者向けにとりあえずHPなど作って公開してみたい人向け。
お金をかけずに自分の力だけではじめられます。HTMLエディターソフト
Homepage Manager
定番なHP作成フリーソフトです。HPテンプレート
ネットマニア
てんぷれの天ぷら
Template Party
アダルト商用利用可のテンプレートです。FTP
FFFTP
作成したサイトをアップロードする際に使う定番なフリーソフトです。
- 投稿日:2020-02-06T18:06:48+09:00
[rails,html]文字省略〜続きを読む実装〜

- 投稿日:2020-02-06T17:52:55+09:00
z-indexでわけがわからなくなった君へ
HTMLとかCSSとかの基本はこれや
・後に記述してるやつほど表にくる
以下みたいにすると、試してないけど、たぶん画面は青くなるんちゃうかなって思うねん
<style> .a, .b { position: fixed top: 0; left: 0; width: 100%; height: 100%; } .a { background-color: red; } .b { background-color: blue; } </style> <div class="a"></div> <div class="b"></div>ようするに、モーダル出したり、画面にカーテンみたいな効果かけたりしたいとき、上に乗りたい要素の後に記述すれば、そもそもz-indexは使う必要ないねん z-index: 999 とか z-index: 9999 とかは不毛や
- 投稿日:2020-02-06T14:54:40+09:00
JavascriptでDOM生成したフォームは別の関数スコープで作成しないと要素を取得できない
選択ボックスの値を取得したり、操作するために使われるgetElementByIdの解説が充実しているサイトは数多くありましたが、基本的にhtmlファイルにベタ打ちで書かれたフォームに対する操作を前提としたものです。
getElementByIdのおさらい
例えば
form.html<form> <select id='musume5'> <option value='001'>紺野</option> <option value='002'>小川</option> <option value='003'>高橋</option> <option value='004'>新垣</option> </select> </form>と言う形でプルダウンリストを作成することが出来るが、以下のjavascriptでリストの中身を取得することが可能である。
form.jsvar elm = document.getElementById('musume5');ここまではどこにでも書かれている。
リストをDOM生成したとき
しかし、リストをJavascriptやJQueryでDOM生成して書かせた際は、同じスコープで全部の作業を一気にやったときにうまくいかなかった。
恐らく関数内の巻き上げとDOMへの値の挿入タイミングの都合でgetElementByIdが値を取得できなかったと思われる。まず、以下のhtmlファイルを用意する。
initialize関数で起動してIDがhello-morning内のdivタグの中にフォームを入力する方針を取る。form.html<!-- 中略 --> <body> <div id='hello-morning'></div> <!-- 中略 --> <script>initialize()</script> <body> <html>うまくいかなかったやり方
form.jsvar initialize = function () { // 中略 insertMusume(); // 中略 }; var insertMusume = function() { var block = $('<div'>) var musumeForm = $('<form>'); var select = $('<select>').attr({ 'id': 'musume5' }); select.appendTo(musumeForm); $('<option>').attr({'value': '001' }).text('紺野').appenTo(select); $('<option>').attr({'value': '002' }).text('小川').appenTo(select); $('<option>').attr({'value': '003' }).text('高橋').appenTo(select); $('<option>').attr({'value': '004' }).text('新垣').appenTo(select); musumeForm.appendTo(block); // ここではクラッシュしないが値が取得できない console.log(document.getElementById('musume5')); return block; }同一関数内でDOM生成及び挿入を行うと、フォームはブラウザに表示されるがgetElementByIdで値を取得できなかった。
ブラウザ上のコンソールでgetElementByIdを実施するときちんと取得できたことから、値の挿入タイミングが合わなかったことが考えられる。そこで、以下のようにやってみるとうまく取得できた。
コード設計時には「DOM生成」と「値取得・処理」は別スコープで行う必要があることが分かった。うまくいったやり方
form.jsvar initialize = function () { // 中略 insertMusume(); // 中略 // ここでなら取得できた console.log(document.getElementById('musume5')); }; var insertMusume = function() { var block = $('<div'>) var musumeForm = $('<form>'); var select = $('<select>').attr({ 'id': 'musume5' }); select.appendTo(musumeForm); $('<option>').attr({'value': '001' }).text('紺野').appenTo(select); $('<option>').attr({'value': '002' }).text('小川').appenTo(select); $('<option>').attr({'value': '003' }).text('高橋').appenTo(select); $('<option>').attr({'value': '004' }).text('新垣').appenTo(select); musumeForm.appendTo(block); return block; }
- 投稿日:2020-02-06T12:27:25+09:00
HTML+CSSコーディングの言語化
はじめに
HTML+CSSコーディングにおける制作者の思考や判断、アプローチ、コード化に至るまでの流れなどを分解し、コードの状態なども含めてそれぞれを短い言葉で言語化しました。
以下のような効果が期待できます。
- HTMLとCSSを使っておこなってきた事を客観視・再認識できる
- 始原的な動機を把握することで、手法を別の視点で捉えられるようになる
- 認識合わせや熟練度確認に利用し、制作時のコミュニケーションを円滑にする
場合によっては、ぼんやりと捉えていたことや、詰まりやすかったポイントなどがハッキリと認識できるようになるかもしれません。
言語化の概要
まずは、全体像が分かる概要図を掲載します。
この記事は、以下のステップと各項目について順に説明するものになります。
前提事項・環境について
言語化するにあたって前提となる考え方や環境について記載します。
- HTMLとCSSの役割
- HTML → データに意味を持たせるためにマークアップした、情報表示の基礎となるもの
- CSS → HTMLでマークアップされた情報を、よりよく伝達するために装飾や機能を持たせるためのもの
- 業務フロー
- コーディングをおこなう以前にデザインやWFなどを作成する
- これらは、Webページという納品物をつくるための「完成予想図」と言える
- 完成予想図は成果物がプロジェクトの目的を達成できるかどうかを事前に検討・確認するためのもの
- 業務上ではコーディングから開始するケースは稀であるため、何らかの「図」や「絵」が存在しているものとする
- コーディングのゴールと目的
- 何らかの「完成予想図」に求められる視覚情報や動きや働きをコードに変換しつくすこと
- 情報や機能などを、Webページとして利用者に提供可能な状態にすること
コーディング行動の流れ
ここから、HTML+CSSコーディングの言語化に関する具体的な説明です。
コーディングを制作者(人間)中心に捉えると、コード化までには一連の流れがある事に気づきます。
最終的にコードを記述するまでの流れを分解すると以下のようになります。
制作者はこれらを一瞬、もしくは短時間で連続的に流れるようにおこなっているため、恐らく普段はこのような事を意識する事は少なく、また、実際には全てが直線的な訳ではありません。
例えば「完成予想図」を確認した直後であれば、頭の中でHTML構造を組み立てながら、CSSの設計のために共通部分を見つけようとするかもしれません。
HTMLコードを記述している時であれば、同時にCSSの実装を考えるでしょうし、CSSコードの記述中にHTMLの修正に移る事もあります。
また、その視野についても、「広い範囲」と「狭い範囲」の両視点を切り替えながら進める事が多く、本来の思考や行動は放射状や螺旋、ジグザグといった形に近くなります。
上記のステップは、こういった行動を分解・細分化し、直線に組み替えたときの基本の流れとなります。以下、このステップに準じて説明を記載します。
【STEP-1】 関心の対象
「関心の対象」とは、制作者が心の焦点をあてたもの、意識したものです。
すべての思考や行動は、対象が定まることから始まります。その対象は、例えば完成予想図を確認した時の大きな面や塊、その中の小さな部品など様々です。ほかにも、既にコード化し終わったものであったり、何らかの補助用classそのもの、あるいは何らかのアニメーションや動きといったものが対象になることもあります。
こういったものを全く意識することなく「文字列を入力し、それから対象を考える」といったことは、少なくとも業務効率を意識している制作者であればおこなわないはずです。ここから先、「対象」と記載しているものは、常に制作者の「関心の対象」を意味します。
【STEP-2】 対象への欲求
対象が定まると、次に「それをどうしたいか」という欲求が発生します。
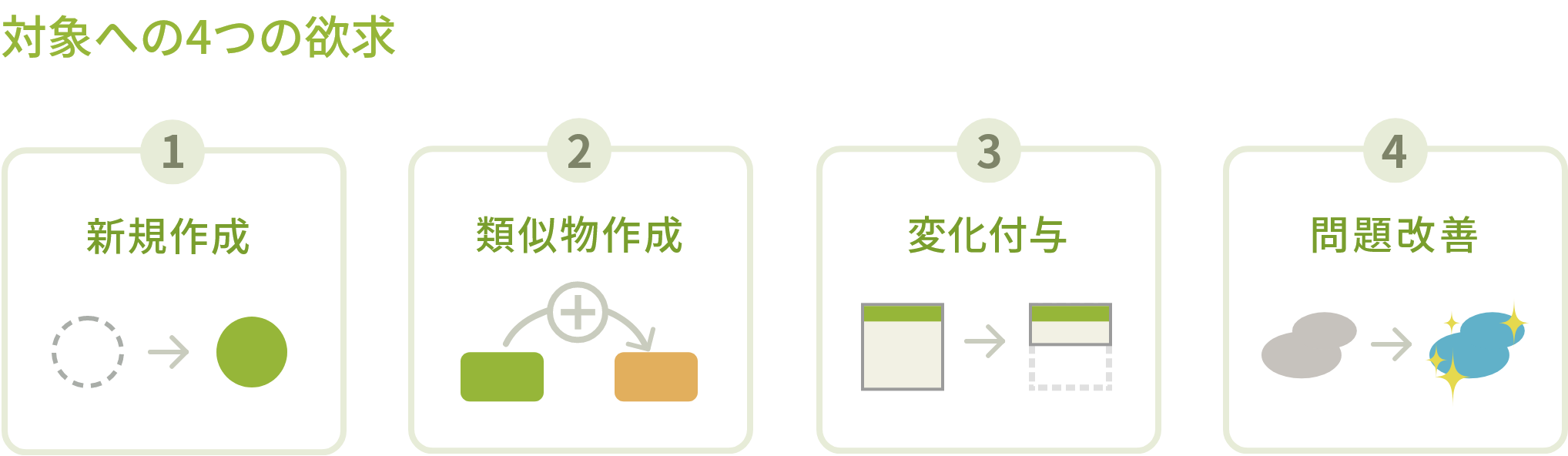
コーディングにおける対象への欲求は、大きく以下の4つに分類できます。
- 1. 新たな部品や役割・働きをつくりたい
- まだコード化されていないものを新たに作成したいという欲求
- 2. 類似した部品や役割・働きをつくりたい
- 既に存在している対象の「似て非なるもの」を新たに作りたいという欲求
- 3. 対象を変化させたい
- 既に存在している対象を何らかの方法によって変化させたいという欲求
- 4. 現状の問題をよりよく改善したい
- 既に存在している対象の問題を修正したり、改善したいという欲求
これらはどれか1つだけの事もあれば複数同時に発生する事もありえます。
例えば、何かを新規作成したいと思ったと同時に、類似したものが必要になると判断した場合や、新たなものを作るには、既存で影響を受ける対象の問題解決が必要。といったようにです。いずれにしても、コード化に向けて次の「確認・想定」に移行します。
【STEP-3】 確認・想定
「対象への欲求」が発生したら、次はそれを実現するために以下の内容を判定・確認・予測します。
以下、それぞれについての詳細説明です。
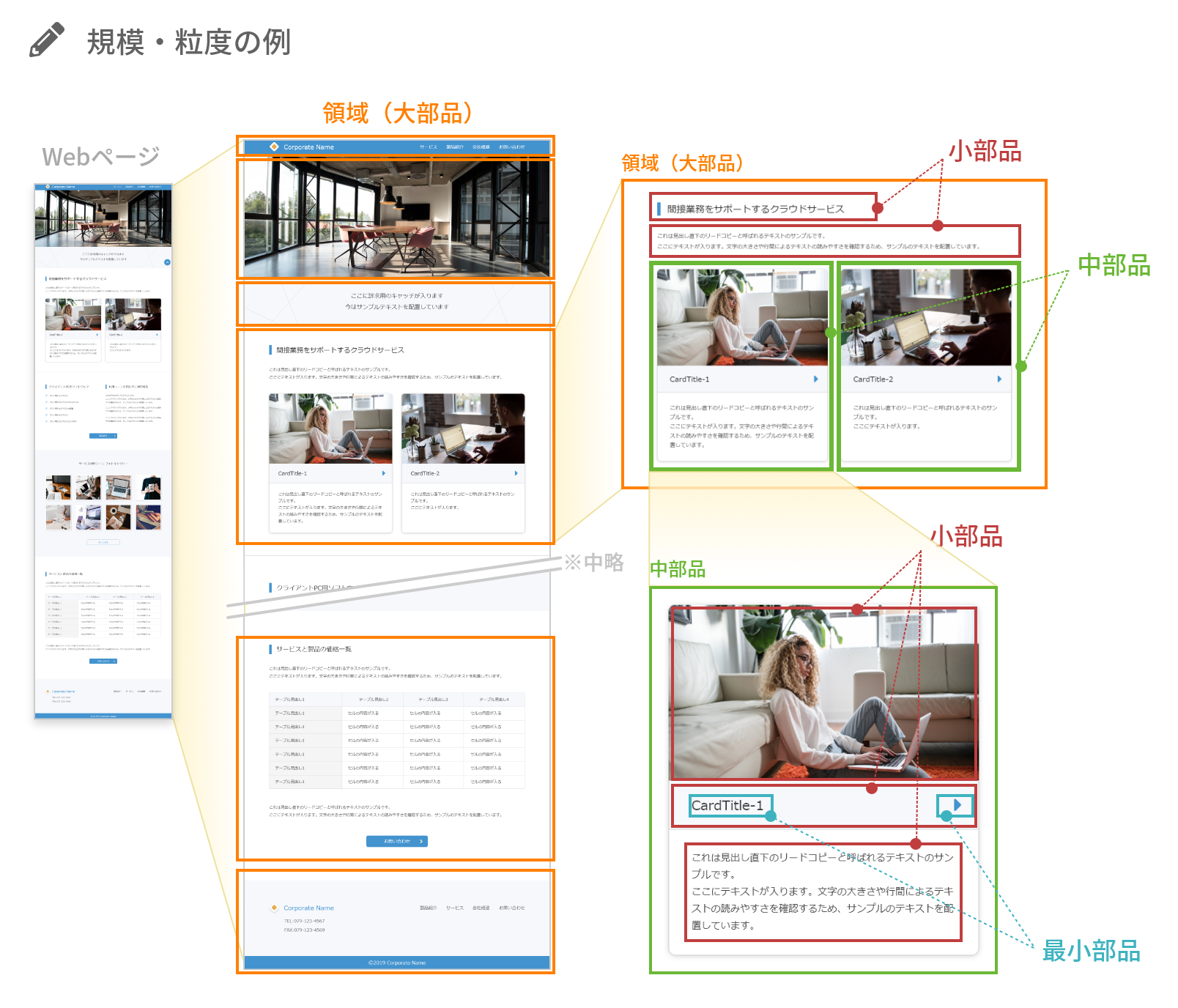
A-1. 規模・粒度
「規模・粒度」は、対象の表示面積や範囲、コードの行数・情報量といった、それそのものの規模感です。
最終の表示が「面」を持つスクリーンである場合、そこに映し出されるものには「面積」や「範囲」といったものが伴います。
制作者は、大きいものなら他への影響、小さいものなら受ける影響があるのを知っており、また、HTMLコードの行数、情報量が必ずしも表示面積に比例するとは限らない事も知っているため、これらを含めた「規模・粒度」を意識しています。HTMLコードの記述前、つまり「完成予想図」の特定箇所に関心を寄せている段階であるなら、その対象をどれくらいのコード量で再現できるかを予測・想定するでしょうし、記述後のHTMLコードが対象の場合は、それはどこで区切られたもので、どんな表示になるのか。といったことを、レンダリング結果と照らし合わせながら確認することになります。
もし既に、規模感を定義したルールを使っているなら、上記の語句や判定・認識は別のものになるかもしれません。
A-2. 構造
「構造」は、HTMLコードのネスト状態を指します。
HTMLには文書構造のほかに、コード自体のネスト構造が存在します。
対象である視覚情報をはじめてコードに置き換えていく時には、CSSを想定しながらHTMLのネスト構造を設計する事になるでしょう。HTMLを記述した後のスタイリング段階では、CSSセレクタの記述のために構造の把握が必要となります。
これらも、HTMLとCSSを扱う制作者であれば自然と判定・認識・予測しているものであり、その状態はいずれか1つ、もしくは複数にあてはまる場合もあります。以下は、コードの状態を言語化したものの説明です。
A-3. CSS読解
「CSS読解」は、現在のCSSのセレクタやプロパティがどのような状態になっているのかを把握することです。
CSS読解の目的は、そのコードを記述したのが自分自身であれば「再度確認」といった意味になるでしょう。
他者が作成したコードの場合、かつ情報が何も無いところからのスタートであれば、影響がありそうな箇所のすべての状況を調査・把握して「仕様のマップ」を頭の中に作成する事になります。
いずれにしても、既存コードの影響や状況把握のための行動で、必要に応じて随時実行することになります。A-4. JS読解
「JS読解」は、現在のJavaScriptのコードがどのような状態になっているのかを把握することです。
JS読解の目的は、JavaScriptのコードが「何に対してどのような影響を与えているか」を把握するためです。
直接的なアニメーションをおこなっているのか、classを追加する事でCSS側で何かを変化させているのか、直接スタイルを付与しているのか。などを確認することになります。
JSコードの作成に関する言語化はおこないませんが、リファクタリングの時などにJSコードが関わっている場合は、必ず確認することになるでしょう。【STEP-4】 コード化のための思考
対象の状況確認や想定が終われば、コード化のために以下のような思考(設計)が必要となります。
このうち上段の2つ(B群)は「【STEP-2】 対象に対する欲求」で挙げた、「類似した部品や役割・働きをつくりたい」と「対象を変化させたい」の2つにそれぞれ対応し、下段の3つ(C群)は共通しておこなう思考内容となります。
以下、1つずつ個別に説明します。
B-1. 類似複製
「類似複製」は、とある部品や役割、働きの「似て非なるもの」が必要となった時に検討する内容です。
Webページやサイトには、類似した部品が多数必要となることも少なくありません。例えば「形状は同じだが色が異なる」「形状のみが少しが異なる」といったケースです。
対象の「バリエーション」が必要な状況であり、どのように実装するのかを検討する事になります。
これらの表示変化は、以下の二つのアプローチによって実現可能です。
別名複製
「別名複製」は、複製元に類似した見栄え・役割・働きのものを新たに作成するために、複製した対象に対して単一の別の英単語や文字列(※多くの場合はシングルクラス)を与え、似て非なるものを作成する方法です。
複製物の名前を、複製元の名前と類似させる事によって、制作者は二つの関連性を予測できるようになりますが、機械からすれば全く別のものになるため、CSSプロパティは同一のものや似たコードが多くなります。HTML例
※似て非なる部品を作成した場合
- 複製元:
<a class="btn-primary">- 複製物:
<a class="btn-secondary">文字列追加
「文字列追加」も類似品を作成する行動です。
複製対象に新たな単語や文字列を追加(※多くの場合はマルチクラス)することによって、対象のCSSプロパティを追加・キャンセル・上書きし、意図した表示を完成させる方法です。対象そのものに直接語句を追加する方法と、親要素や先祖要素に語句を追加して間接的に対象をスタイリングする方法があり、併用するパターンも合わせれば合計3つのパターンがあります。
A. 「直接」のHTML例
.btnが複製元で、複製したものを似て非なる見栄えにする場合。直接btn-largeという文字列を付与している。
- 複製元:
<a class="btn">- 複製物:
<a class="btn btn-large">B. 「間接」のHTML例
.innerがスタイリングの対象の場合。対象の親要素にbox-pattern1という文字列を追加している。
- 複製元:
<div class="box"><div class="inner"> … </div></div>- 複製物:
<div class="box box-pattern1"><div class="inner"> … </div></div>C. 「直接・間接の両方」のHTML例
※
.boxと.innerがスタイリングの対象の場合。HTMLはBと同じ(CSSで目的の状態にしている)
- 複製元:
<div class="box"><div class="inner"> … </div></div>- 複製物:
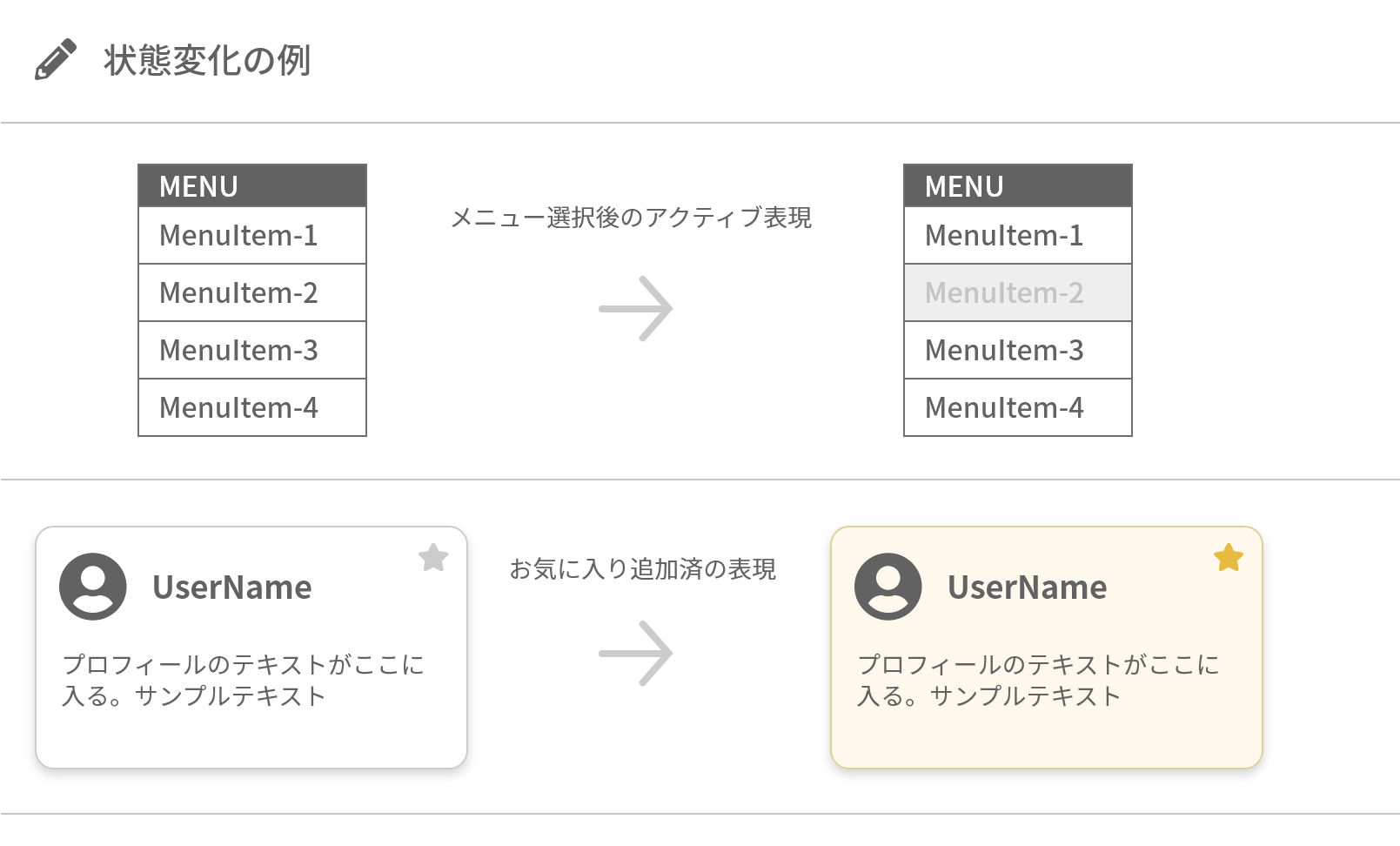
<div class="box box-pattern1"><div class="inner"> … </div></div>B-2. 状態変化
「状態変化」は、対象に何らかの変化を与えたい場合に検討する内容となります。
Webページやサイトは、人の行動(クリックやタップ、スクロールなど)と共に利用されます。
このため、その動作に対する色や形状の変化、アニメーションなど、行動に対する反応も必要とされる事が多いと言えます。※ JavaScriptなどの外部プログラムによって直接対象を操作する場合もありますが、こちらはプログラムの領域となるため、CSSによる変化の場合を対象として説明します。
効果付与
「効果付与」は、目的の対象を変化させるために、対象そのもの、もしくは対象の親や先祖要素に語句を追加する方法です。
アプローチそのものは「類似複製」の「語句追加」と同一であり、パターンも同様に以下の3つがあります。※ これらは静的に追加(記述)することもあれば、JavaScriptなどによって動的に追加する事もあります。A. 「直接」のHTML例
.boxを直接変化させたい場合。直接is-closeという文字列を付与している。
- 変化前:
<div class="box"> … </div>- 変化後:
<div class="box is-close"> … </div>B. 「間接」のHTML例
変化させたい対象が、内部の
pの場合。親要素にis-activeの文字列が付与され、それを起点にセレクタを記述するパターン。
- 変化前:
<div class="text_box"><p>テキスト</p></div>- 変化後:
<div class="text_box is-active"><p>テキスト</p></div>C. 「直接・間接の両方」のHTML例
変化させたい対象が、
.boxと.inner両方の場合。is-fixedの文字列を加え、両方をスタイリング。
- 変化前:
<div class="box"><div class="inner"> … </div></div>- 変化後:
<div class="box is-fixed"><div class="inner"> … </div></div>「効果付与」と「文字列追加」との違い
状態変化の「効果付与」と、類似複製の「文字列追加」は、HTML要素に対する命名のアプローチが同じです。
「効果付与」の欲求は対象に状態変化を与えることであり、「類似複製」の「文字列追加」は、似て非なるものを作成したいという欲求が起点となっています。二つの違いを言い表すと、「表示要素が増える前提であったかどうか」と言えます。
「効果付与」した後のものを、単独かつ別用途で再利用する事になれば「類似複製」とも言えますし、「効果付与」したものにCSSプロパティを書き足していけば、変化に伴うバリエーションを作成した事にもなりえます。
つまり「元々どう望んでいたか」は後でどうとでも変容し、曖昧になりがちで、変容しても画面上にエラーが表示される訳ではありません。どのように使っているのかは、HTML上からは命名から予測するしかなく、実装方法はCSSコードを見る事でしか判断できません。この2つを区分けして制御したりルール化するかどうか。といった事も制作者の意思によるものと言えます。
C-1. 活用方法
「活用方法」とは、その対象を全体の中でどのように扱いたいのか、制作者の意思を指します。
Webページの表示部品は、ページ間で再利用するものや、その場所でしか使用しないもの、その場でしか使用しないと思っていても後々再利用の必要が発生した。などの様々なケースがあります。
このため、その対象を成果物(Webページ・サイト)の全域でどのように活用するのかを定めることが必要になります。HTMLタグそのままの状態とclass属性で名前を与えたものは、どちらも「仕様上は」すべて共用として扱える状態になりますが、制作者がその仕様通りに望んでいるかどうかは別の話です。
HTMLとCSSの仕様は自由度が高く「絶対に表示されない」といった制約が少ないため、制作者の意思による制御が必要となります。C-2. 命名判断
「命名判断」は、対象のHTMLタグに独自の名前を与えるかどうかの判断を指します。
名前を与えると、何も命名しなかった時と比べCSSからその要素を指定するのが容易になり、さらに、その単語は制作者の予測・判断のための「道しるべ」としての役割も兼用することになります。
対象の表示を考える時、「どんな名前を与えるか」の前に「名前を与えるかどうか」を先に判断しており、「無名」の場合は、何らかの判断により「命名しない事を選んだ」という事になります。
C-3. 特定方法
「特定方法」は、CSSのセレクタの記述方法を指します。
最終的なセレクタ記述は様々な意図や意思、複数の影響を踏まえて総合的に決定する事になります。
- 公共的
- 「公共的」なアプローチとは、第一セレクタにその対象を指定することによってCSSの詳細度を低く抑える方法です。命名の法則によって「活用方法」を「一意」に扱うという意図がある場合は、「公共的」な記述をしたとしても「一意」になります。(BEMなどの単語連結規則による命名一意化がこれにあたります)
- 詳細的
- 「詳細的」なアプローチとは、対象のCSSの詳細度を上げるため、もしくは他の要素へのスタイリングとの影響を分離するために、子セレクタや子孫セレクタを利用する方法です。
- 条件的
- 「条件的」なアプローチとは、隣接セレクタや以降のセレクタ、記述の順番などのセレクタ、クラスや属性のマッチなど、HTMLの記述条件をセレクタに利用する方法です。
- 局所的
- 「局所的」なアプローチとは、HTMLのid属性による指定方法です。
- HTMLのid属性の名前は仕様上ページの中に1つと定められていますが、実際のブラウザレンダリングでは複数のid属性を利用していても意図した通りに表示される事も多くあります。 しかし、与えられた役割そのものと、役割違いの状態をソフトウェアが柔軟にレンダリングする事とは別の話といえます。 id属性をCSSのセレクタに使用するかどうかはその環境やプロジェクトのルール次第となります。
【STEP-5】 コードの記述
最終的に物理的なファイルにコードを記述します。
大抵の場合はデータ表示の基礎となるHTMLコードを記述する所からはじまります。Webページとしてスクリーンに表示するにはHTMLとCSSの両方のコードが必要であり、この二つは同時には記述できないため、実際には「確認・想定」と「コード化のための思考」を行き来しながら記述する事になります。
実際にどのようなコードを記述するのかは制作者の役割であり、この記事の目的とは異なるため割愛します。
さいごに
この試みは「CSS設計手法に振り回されない、何か不変的なものは無いのか」という疑問からはじまりました。
そのための方法として選んだのが今回の「コーディングを短い言葉で言い表してみよう」というものです。2019年初頭に完成した原文には用例と思考パターンによる裏付け情報もあります(※こちらはまた機会があれば公開します)そして、これらの情報を背景として構築した「HTML+CSSコーディングの標準化」のノウハウがあるのですが、一連の情報を「Ultimate Coding」と題して、今後順次、情報を公開していく予定です。
最後になりましたが、この記事の内容に対し、仕事として貴重なレビューを下さった次の方々に感謝いたします。
レビュワー(※五十音順)
- 酒井優 @glatyou - Twitter
- 深沢幸治郎 @kojirofukazawa - Twitter
- YAT @yat8823jp - Twitter
以下は、レビュー頂いた内容の一部です。
- 普段やっている事が言語化されている
- 頭の中で起こっている事と遜色なし
- 初学者と読み合わせして反応を見れば、どこで詰まっているかが分かる
- 書き方を変えれば教育用に使えるのでは
- コーディングを公平かつ中立的な視点で捉えたコンテンツ
- (原文の状態では)図が無く、情報がぱっと頭に入ってこない
※ ⇒ これを受け、今回、図を追加して公開クレジット
Ultimate Coding
- 設計・考案/構築/記事投稿
- croco_works - Twitter
- 技術検証/設計パートナー
- wildwest_kazya - Twitter
















- 投稿日:2020-02-06T11:08:16+09:00
Rubyで始めるスクレイピング 〜入門編〜
スクレイピングとは
Webサイトから自分の知りたい情報を抽出すること。
ex) 文章、画像、動画などTL; DR
Qiitaで「ruby」で検索して「いいね順」に並べた検索結果一覧をスクレイピングします。
コードを見ながら説明します。1. まずは前準備。
scraping01.rb# コードのsyntax highlight・補完などをしてくれるgem(無くてもいいけどめっちゃ便利) # https://github.com/janlelis/irbtools require 'irbtools/more' # URLにアクセスした内容をファイルのように扱えるgem require 'open-uri' # スクレイピングのgem require 'nokogiri' # CSV出力するgem require 'csv' url = 'https://qiita.com/search?page=1&q=ruby&sort=like'URLのパラメータの仕組みについて
https://qiita.com/search?page=1&q=ruby&sort=like
?以降がパラメーターです。
パラメータを複数つなげるには&で繋ぎます。今回のURLですと、
pageとqとsortというパラメータがあります。
page=の後に続く値がページ番号になります。Qiitaの場合は、
q=の後に続く値が検索ワードになっています。
試しに、以下のURLを打ってみてください。
https://qiita.com/search?q=アイウエオ
sort=に続く値が並び順になっているようです。
sort=は受け取る値によって並び順が変わるようです。
パラメータ 並び順 like いいね順 created 新着順 rel 関連順 stock ストック順 また、上記に該当しない値の場合は、
関連順になるようです。
https://qiita.com/search?q=ruby&sort=テストトトLet's Parse!!!
scraping02.rb# openブロック内に入る前に変数定義をしておかないと、openブロック内でしか使えないスコープ変数になってしまう為、ここで定義する必要がある。 charset = nil # 「open(url)」でそのサイトの情報を取得。 html = open(url) do |f| # 文字コードはそのサイトの文字コードに合わせる。 charset = f.charset #「.read」でHTML情報を出力 f.read end # html変数に入っている情報はただの文字列です。 html.class #=> String # つまり、HTML要素もただの文字情報として認識されている(文章とHTML要素の区別がなされていない)と分かります。 # なので、HTML要素とそうでない文字列に分解(構文解析「parse」)する必要があります。 # そこで登場するのが、Nokogiriです。 # こんな感じで書きます。 Nokogiri::HTML.parse(構文解析したい文章, URL, 文字コード) # https://www.rubydoc.info/github/sparklemotion/nokogiri/Nokogiri%2FHTML.parse doc = Nokogiri::HTML.parse(html, nil, charset) doc.class #=> Nokogiri::HTML::Document # これでHTML要素とそうでない文字列を分けて扱えるデータになりました。Let's Nokogiri!!!
scraping03.rb# 取得したい情報のHTML要素を「.css」メソッドに渡して取得します。 # 渡すHTML要素は、HTMLにCSSを当てる時のCSSセレクタ(HTMLタグやクラス、ID)を指定する記述方法と同じです。 # 例えば、検索結果一覧から「記事タイトル」を取得するには doc.css('h1.searchResult_itemTitle').text #=> "Markdown記法 チートシートペアプログラミングして気がついた新人プログラマの成長を阻害する悪習プログラミングでよく使う英単語のまとめ【随時更新】非デザイナーエンジニアが一人でWebサービスを作るときに便利なツール32選【まとめ】これ知らないプログラマって損してんなって思う汎用的なツール 100超新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡もう保守されない画面遷移図は嫌なので、UI Flow図を簡単にマークダウンぽく書くエディタ作った翻訳: WebAPI 設計のベストプラクティス開設後3週間で収益10万円を得た個人開発サイトでやったことの全部を公開するエンジニアの情報収集法まとめ" # もちろん結果は、セレクタでヒットするかずを全部持ってきます。 doc.css('h1.searchResult_itemTitle') #=> 10 # 結果を見やすくしてみましょう。 # 「.search」は「.css」のエイリアスメソッド # 「.inner_text」は「text」のエイリアスメソッド titles = doc.search('.searchResult_itemTitle').map{ |node| node.inner_text } # これを応用して、「タイトル」と「タグ」と「本文」を取ってきましょう。 results = [] doc.search('.searchResult_main').each_with_index do |node, i| tags = [] title = node.css('.searchResult_itemTitle').inner_text node.css('.tagList_item').each{ |article_tag| tags << article_tag.inner_text } details = node.css('.searchResult_snippet').inner_text results << [ title, tags, details ] p tags end results.each_with_index do |res, i| puts puts "#{i+1}番目の検索結果" puts "Title: #{res[0]}" puts "Tags: #{res[1]}" puts "Details: #{res[2]}" puts '-----------------------------------------' endLet's Scraping!!!
scraping04.rb# 検索ワードを配列で持ちます。 search_terms = ['ruby', 'php', 'python', 'perl'] results = {} search_terms.each do |search_term| query_hash = [] # 検索結果一覧ページが100ページまでしか無いので1から100にしています。 (1..100).each do |i| # URLはベタがきではなく、「ページ番号」と「検索ワード」に式展開を使い、柔軟にしています。 url = "https://qiita.com/search?page=#{i}&q=#{search_term}&sort=like" charset = nil html = open(url) do |f| charset = f.charset f.read end doc = Nokogiri::HTML.parse(html, nil, charset) # 「.searchResult」にタイトルやタグなどの親クラスで、各記事の情報がぶら下っているので、一度ここを取得し、ここから子クラスの情報を抽出します。 # ここからはRubyというより、CSSセレクタの内容になります。欲しい情報に応じてHTMLタグやクラスを書き換えてください。検証ツールで確認できます。 doc.search('.searchResult').each do |node| tags = [] title = node.css('.searchResult_itemTitle').text node.css('.tagList_item').each{ |article_tag| tags << article_tag.text } details = node.css('.searchResult_snippet').text link = "https://qiita.com/" + node.css('.searchResult_itemTitle').css('a')[0][:href] # [0]が「良いね」の数。[1]は「コメント」の数 stars = node.css('.list-unstyled.list-inline.searchResult_statusList li')[0].text.gsub(" ","") # コメント数が0個の場合は、コメントのHTML要素が出力されない為、[1]のところでNilエラーになります。それを回避する為にアンパサンドを使用します。 comments = node.css('.list-unstyled.list-inline.searchResult_statusList li')[1]&.text&.gsub(" ","") author = node.css('.searchResult_header').css('a')&.text query_hash << { stars: stars, title: title, tags: tags, details: details, link: link, comments: comments, author: author } end # この一連の処理は時間がかかります。ここでputsすることで、処理がどれぐらい進んでいるかを確認しながら待つことができます。 puts "#{search_term} #{i}" end results["#{search_term}"] = query_hash end # resultsというハッシュに入った結果を一元配列で管理し、結果をCSV出力する。 ruby_array, php_array, python_array, perl_array = [], [], [], [] results["ruby"].each do |a| ruby_array << [ a[:stars], a[:title], a[:tags], a[:details], a[:link], a[:comments], a[:author] ] end # CSV.openの引数に、書き出すファイル名を指定します。その際にLinuxコマンドのようにPathで指定すれば任意の場所に保存できます。 CSV.open('qiita_ruby.csv', 'w') do |csv| # ヘッダーの設定 csv << ['stars', 'title', 'tags', 'details', 'link', 'comments', 'author'] ruby_array.each do |r| csv << r end end results["php"].each do |a| php_array << [ a[:stars], a[:title], a[:tags], a[:details], a[:link], a[:comments], a[:author] ] end CSV.open('qiita_php.csv', 'w') do |csv| # ヘッダーの設定 csv << ['stars', 'title', 'tags', 'details', 'link', 'comments', 'author'] php_array.each do |r| csv << r end end results["python"].each do |a| python_array << [ a[:stars], a[:title], a[:tags], a[:details], a[:link], a[:comments], a[:author] ] end CSV.open('Desktop/qiita_python.csv', 'w') do |csv| # ヘッダーの設定 csv << ['stars', 'title', 'tags', 'details', 'link', 'comments', 'author'] python_array.each do |r| csv << r end end results["perl"].each do |a| perl_array << [ a[:stars], a[:title], a[:tags], a[:details], a[:link], a[:comments], a[:author] ] end CSV.open('Desktop/qiita_perl.csv', 'w') do |csv| # ヘッダーの設定 csv << ['stars', 'title', 'tags', 'details', 'link', 'comments', 'author'] perl_array.each do |r| csv << r end endまとめ
- 指定したURLの情報を取得
- 取得した情報を構文解析
- CSSセレクタの記法を使って欲しい情報を抽出
- CSVに吐き出す
こんな感じでスクレイピングできます!!!
コメントや指摘をいただけると幸いです!!!P.S.
rubyのスクレイピングは人気なさそう。。。
やっぱりライブラリや記事・文献の多さから、Pythonが圧倒的に人気っぽそうですよねぇ。。。
https://trends.google.co.jp/trends/explore?q=ruby%20scraping,python%20scraping,php%20scraping,perl%20scraping,javascript%20scraping